
Added chat_template
#1
by
shizhediao2
- opened
- README.md +62 -158
- added_tokens.json +0 -3
- config.json +14 -14
- generation_config.json +2 -1
- images/instruct_performance.png +0 -0
- images/performance1.png +0 -0
- images/performance2.png +0 -0
- instruct_performance.png +0 -0
- tokenizer.model → model-00001-of-00002.safetensors +2 -2
- model.safetensors → model-00002-of-00002.safetensors +2 -2
- model.safetensors.index.json +618 -0
- modeling_hymba.py +137 -177
- setup.sh +0 -44
- special_tokens_map.json +0 -30
- tokenizer.json +0 -0
- tokenizer_config.json +0 -52
README.md
CHANGED
|
@@ -1,201 +1,105 @@
|
|
| 1 |
---
|
| 2 |
-
|
| 3 |
-
- nvidia/Hymba-1.5B-Base
|
| 4 |
-
library_name: transformers
|
| 5 |
-
license: other
|
| 6 |
-
license_name: nvidia-open-model-license
|
| 7 |
-
license_link: https://developer.download.nvidia.com/licenses/nvidia-open-model-license-agreement-june-2024.pdf
|
| 8 |
-
pipeline_tag: text-generation
|
| 9 |
---
|
|
|
|
| 10 |
|
| 11 |
-
#
|
| 12 |
|
| 13 |
-
|
| 14 |
-
💾 <a href="https://github.com/NVlabs/hymba">Github</a>   |    📄 <a href="https://arxiv.org/abs/2411.13676">Paper</a> |    📜 <a href="https://developer.nvidia.com/blog/hymba-hybrid-head-architecture-boosts-small-language-model-performance/">Blog</a>  
|
| 15 |
-
</p>
|
| 16 |
|
| 17 |
-
## Model Overview
|
| 18 |
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
Hymba-1.5B-Instruct is capable of many complex and important tasks like math reasoning, function calling, and role playing.
|
| 23 |
-
|
| 24 |
-
This model is ready for commercial use.
|
| 25 |
-
|
| 26 |
-
**Model Developer:** NVIDIA
|
| 27 |
-
|
| 28 |
-
**Model Dates:** Hymba-1.5B-Instruct was trained between September 4, 2024 and November 10th, 2024.
|
| 29 |
-
|
| 30 |
-
**License:**
|
| 31 |
-
This model is released under the [NVIDIA Open Model License Agreement](https://developer.download.nvidia.com/licenses/nvidia-open-model-license-agreement-june-2024.pdf).
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
## Model Architecture
|
| 35 |
-
|
| 36 |
-
> ⚡️ We've released a minimal implementation of Hymba on GitHub to help developers understand and implement its design principles in their own models. Check it out! [barebones-hymba](https://github.com/NVlabs/hymba/tree/main/barebones_hymba).
|
| 37 |
-
>
|
| 38 |
-
|
| 39 |
-
Hymba-1.5B-Instruct has a model embedding size of 1600, 25 attention heads, and an MLP intermediate dimension of 5504, with 32 layers in total, 16 SSM states, 3 full attention layers, the rest are sliding window attention. Unlike the standard Transformer, each attention layer in Hymba has a hybrid combination of standard attention heads and Mamba heads in parallel. Additionally, it uses Grouped-Query Attention (GQA) and Rotary Position Embeddings (RoPE).
|
| 40 |
-
|
| 41 |
-
Features of this architecture:
|
| 42 |
-
|
| 43 |
-
- Fuse attention heads and SSM heads within the same layer, offering parallel and complementary processing of the same inputs.
|
| 44 |
|
| 45 |
<div align="center">
|
| 46 |
<img src="https://huggingface.co/nvidia/Hymba-1.5B-Instruct/resolve/main/images/module.png" alt="Hymba Module" width="600">
|
| 47 |
</div>
|
| 48 |
|
| 49 |
-
- Introduce meta tokens that are prepended to the input sequences and interact with all subsequent tokens, thus storing important information and alleviating the burden of "forced-to-attend" in attention
|
| 50 |
|
| 51 |
-
- Integrate with cross-layer KV sharing and global-local attention to further boost memory and computation efficiency
|
| 52 |
|
| 53 |
<div align="center">
|
| 54 |
<img src="https://huggingface.co/nvidia/Hymba-1.5B-Instruct/resolve/main/images/macro_arch.png" alt="Hymba Model" width="600">
|
| 55 |
</div>
|
| 56 |
|
| 57 |
|
| 58 |
-
## Performance Highlights
|
| 59 |
-
|
| 60 |
-
- Hymba-1.5B-Instruct outperforms popular small language models and achieves the highest average performance across all tasks.
|
| 61 |
-
|
| 62 |
|
| 63 |
<div align="center">
|
| 64 |
-
<img src="https://huggingface.co/nvidia/Hymba-1.5B-Instruct/resolve/main/images/
|
| 65 |
</div>
|
| 66 |
|
| 67 |
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
### Step 1: Environment Setup
|
| 71 |
-
|
| 72 |
-
Since Hymba-1.5B-Instruct employs [FlexAttention](https://pytorch.org/blog/flexattention/), which relies on Pytorch2.5 and other related dependencies, we provide two ways to setup the environment:
|
| 73 |
|
| 74 |
-
- **[Local install]** Install the related packages using our provided `setup.sh` (support CUDA 12.1/12.4):
|
| 75 |
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
```
|
| 80 |
|
| 81 |
-
- **[Docker]** A docker image is provided with all of Hymba's dependencies installed. You can download our docker image and start a container using the following commands:
|
| 82 |
-
```
|
| 83 |
-
docker pull ghcr.io/tilmto/hymba:v1
|
| 84 |
-
docker run --gpus all -v /home/$USER:/home/$USER -it ghcr.io/tilmto/hymba:v1 bash
|
| 85 |
-
```
|
| 86 |
|
|
|
|
| 87 |
|
| 88 |
-
|
| 89 |
-
After setting up the environment, you can use the following script to chat with our Model
|
| 90 |
|
| 91 |
-
|
| 92 |
-
from transformers import AutoModelForCausalLM, AutoTokenizer, StopStringCriteria, StoppingCriteriaList
|
| 93 |
-
import torch
|
| 94 |
|
| 95 |
-
|
| 96 |
-
repo_name = "nvidia/Hymba-1.5B-Instruct"
|
| 97 |
-
|
| 98 |
-
tokenizer = AutoTokenizer.from_pretrained(repo_name, trust_remote_code=True)
|
| 99 |
-
model = AutoModelForCausalLM.from_pretrained(repo_name, trust_remote_code=True)
|
| 100 |
-
model = model.cuda().to(torch.bfloat16)
|
| 101 |
-
|
| 102 |
-
# Chat with Hymba
|
| 103 |
-
prompt = input()
|
| 104 |
-
|
| 105 |
-
messages = [
|
| 106 |
-
{"role": "system", "content": "You are a helpful assistant."}
|
| 107 |
-
]
|
| 108 |
-
messages.append({"role": "user", "content": prompt})
|
| 109 |
-
|
| 110 |
-
# Apply chat template
|
| 111 |
-
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to('cuda')
|
| 112 |
-
stopping_criteria = StoppingCriteriaList([StopStringCriteria(tokenizer=tokenizer, stop_strings="</s>")])
|
| 113 |
-
outputs = model.generate(
|
| 114 |
-
tokenized_chat,
|
| 115 |
-
max_new_tokens=256,
|
| 116 |
-
do_sample=False,
|
| 117 |
-
temperature=0.7,
|
| 118 |
-
use_cache=True,
|
| 119 |
-
stopping_criteria=stopping_criteria
|
| 120 |
-
)
|
| 121 |
-
input_length = tokenized_chat.shape[1]
|
| 122 |
-
response = tokenizer.decode(outputs[0][input_length:], skip_special_tokens=True)
|
| 123 |
-
|
| 124 |
-
print(f"Model response: {response}")
|
| 125 |
|
|
|
|
|
|
|
|
|
|
| 126 |
```
|
| 127 |
|
| 128 |
-
|
| 129 |
|
| 130 |
```
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
<extra_id_1>User
|
| 135 |
-
<tool> ... </tool>
|
| 136 |
-
<context> ... </context>
|
| 137 |
-
{prompt}
|
| 138 |
-
<extra_id_1>Assistant
|
| 139 |
-
<toolcall> ... </toolcall>
|
| 140 |
-
<extra_id_1>Tool
|
| 141 |
-
{tool response}
|
| 142 |
-
<extra_id_1>Assistant\n
|
| 143 |
```
|
| 144 |
|
|
|
|
| 145 |
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
|
| 149 |
-
[LMFlow](https://github.com/OptimalScale/LMFlow) is a complete pipeline for fine-tuning large language models.
|
| 150 |
-
The following steps provide an example of how to fine-tune the `Hymba-1.5B-Base` models using LMFlow.
|
| 151 |
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
```
|
| 155 |
-
docker pull ghcr.io/tilmto/hymba:v1
|
| 156 |
-
docker run --gpus all -v /home/$USER:/home/$USER -it ghcr.io/tilmto/hymba:v1 bash
|
| 157 |
-
```
|
| 158 |
-
2. Install LMFlow
|
| 159 |
-
|
| 160 |
-
```
|
| 161 |
-
git clone https://github.com/OptimalScale/LMFlow.git
|
| 162 |
-
cd LMFlow
|
| 163 |
-
conda create -n lmflow python=3.9 -y
|
| 164 |
-
conda activate lmflow
|
| 165 |
-
conda install mpi4py
|
| 166 |
-
pip install -e .
|
| 167 |
-
```
|
| 168 |
-
|
| 169 |
-
3. Fine-tune the model using the following command.
|
| 170 |
-
|
| 171 |
-
```
|
| 172 |
-
cd LMFlow
|
| 173 |
-
bash ./scripts/run_finetune_hymba.sh
|
| 174 |
-
```
|
| 175 |
-
|
| 176 |
-
With LMFlow, you can also fine-tune the model on your custom dataset. The only thing you need to do is transform your dataset into the [LMFlow data format](https://optimalscale.github.io/LMFlow/examples/DATASETS.html).
|
| 177 |
-
In addition to full-finetuniing, you can also fine-tune hymba efficiently with [DoRA](https://arxiv.org/html/2402.09353v4), [LoRA](https://github.com/OptimalScale/LMFlow?tab=readme-ov-file#lora), [LISA](https://github.com/OptimalScale/LMFlow?tab=readme-ov-file#lisa), [Flash Attention](https://github.com/OptimalScale/LMFlow/blob/main/readme/flash_attn2.md), and other acceleration techniques.
|
| 178 |
-
For more details, please refer to the [LMFlow for Hymba](https://github.com/OptimalScale/LMFlow/tree/main/experimental/Hymba) documentation.
|
| 179 |
-
|
| 180 |
-
## Limitations
|
| 181 |
-
The model was trained on data that contains toxic language, unsafe content, and societal biases originally crawled from the internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts. The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive.
|
| 182 |
-
|
| 183 |
-
The testing suggests that this model is susceptible to jailbreak attacks. If using this model in a RAG or agentic setting, we recommend strong output validation controls to ensure security and safety risks from user-controlled model outputs are consistent with the intended use cases.
|
| 184 |
|
| 185 |
-
|
| 186 |
-
|
| 187 |
-
|
|
|
|
| 188 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 189 |
|
| 190 |
-
## Citation
|
| 191 |
-
```
|
| 192 |
-
@misc{dong2024hymbahybridheadarchitecturesmall,
|
| 193 |
-
title={Hymba: A Hybrid-head Architecture for Small Language Models},
|
| 194 |
-
author={Xin Dong and Yonggan Fu and Shizhe Diao and Wonmin Byeon and Zijia Chen and Ameya Sunil Mahabaleshwarkar and Shih-Yang Liu and Matthijs Van Keirsbilck and Min-Hung Chen and Yoshi Suhara and Yingyan Lin and Jan Kautz and Pavlo Molchanov},
|
| 195 |
-
year={2024},
|
| 196 |
-
eprint={2411.13676},
|
| 197 |
-
archivePrefix={arXiv},
|
| 198 |
-
primaryClass={cs.CL},
|
| 199 |
-
url={https://arxiv.org/abs/2411.13676},
|
| 200 |
-
}
|
| 201 |
```
|
|
|
|
| 1 |
---
|
| 2 |
+
{}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
| 4 |
+
# Hymba: A Hybrid-head Architecture for Small Language Models
|
| 5 |
|
| 6 |
+
[[Slide](https://docs.google.com/presentation/d/1uidqBfDy8a149yE1-AKtNnPm1qwa01hp8sOj3_KAoMI/edit#slide=id.g2f73b22dcb8_0_1017)][Technical Report] **!!! This huggingface repo is still under development.**
|
| 7 |
|
| 8 |
+
Developed by Deep Learning Efficiency Research (DLER) team at NVIDIA Research.
|
|
|
|
|
|
|
| 9 |
|
|
|
|
| 10 |
|
| 11 |
+
## Hymba: A Novel LM Architecture
|
| 12 |
+
- Fuse attention heads and SSM heads within the same layer, offering parallel and complementary processing of the same inputs
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
|
| 14 |
<div align="center">
|
| 15 |
<img src="https://huggingface.co/nvidia/Hymba-1.5B-Instruct/resolve/main/images/module.png" alt="Hymba Module" width="600">
|
| 16 |
</div>
|
| 17 |
|
| 18 |
+
- Introduce meta tokens that are prepended to the input sequences and interact with all subsequent tokens, thus storing important information and alleviating the burden of "forced-to-attend" in attention
|
| 19 |
|
| 20 |
+
- Integrate with cross-layer KV sharing and global-local attention to further boost memory and computation efficiency
|
| 21 |
|
| 22 |
<div align="center">
|
| 23 |
<img src="https://huggingface.co/nvidia/Hymba-1.5B-Instruct/resolve/main/images/macro_arch.png" alt="Hymba Model" width="600">
|
| 24 |
</div>
|
| 25 |
|
| 26 |
|
| 27 |
+
## Hymba: Performance Highlights
|
| 28 |
+
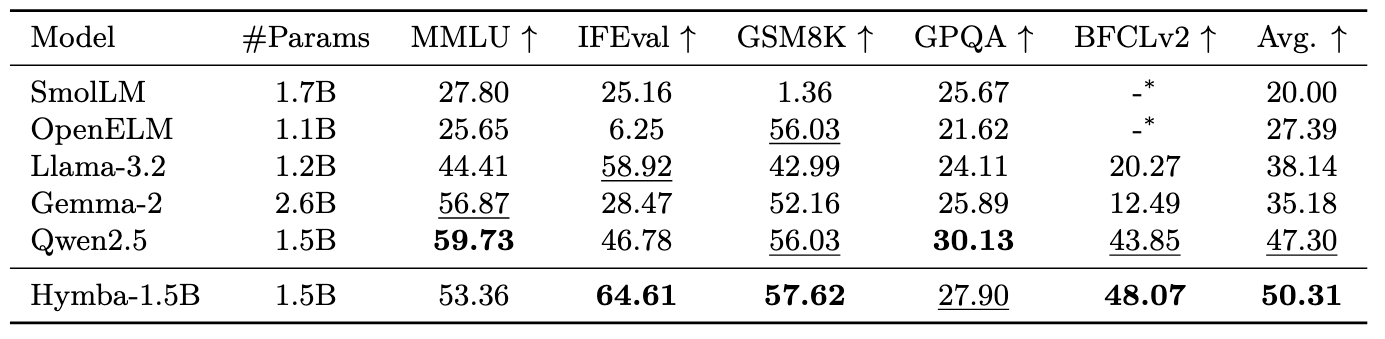
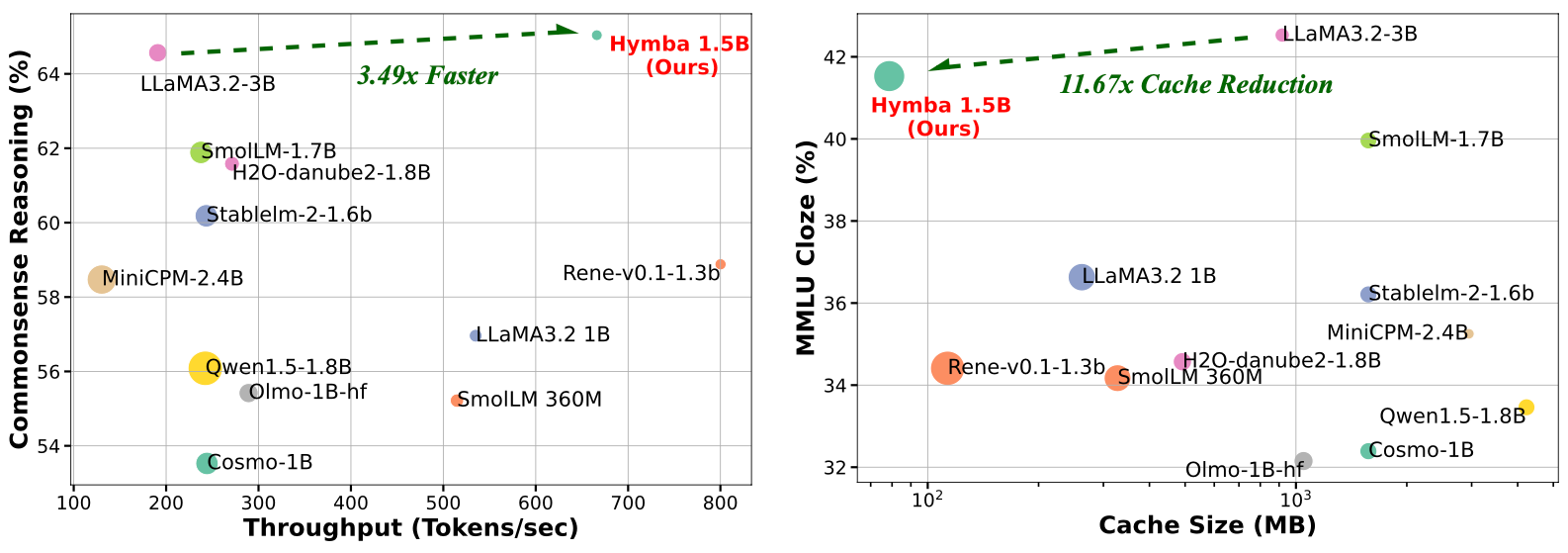
- [Hymba-1.5B-Base](https://huggingface.co/nvidia/Hymba-1.5B): Outperform all sub-2B public models, e.g., matching Llama 3.2 3B’s commonsense reasoning accuracy, being 3.49× faster, and reducing cache size by 11.7×
|
|
|
|
|
|
|
| 29 |
|
| 30 |
<div align="center">
|
| 31 |
+
<img src="https://huggingface.co/nvidia/Hymba-1.5B-Instruct/resolve/main/images/performance1.png" alt="Compare with SoTA Small LMs" width="600">
|
| 32 |
</div>
|
| 33 |
|
| 34 |
|
| 35 |
+
- Hymba-1.5B-Instruct: Outperform SOTA small LMs.
|
|
|
|
|
|
|
|
|
|
|
|
|
| 36 |
|
|
|
|
| 37 |
|
| 38 |
+
<div align="center">
|
| 39 |
+
<img src="https://huggingface.co/nvidia/Hymba-1.5B-Instruct/resolve/main/images/instruct_performance.png" alt="Compare with SoTA Small LMs" width="600">
|
| 40 |
+
</div>
|
|
|
|
| 41 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 42 |
|
| 43 |
+
## Hymba-1.5B-Instruct: Model Usage
|
| 44 |
|
| 45 |
+
We release our Hymba-1.5B-Instruct model and offer the instructions to use our model as follows.
|
|
|
|
| 46 |
|
| 47 |
+
### Step 1: Environment Setup
|
|
|
|
|
|
|
| 48 |
|
| 49 |
+
Since our model employs [FlexAttention](https://pytorch.org/blog/flexattention/), which relies on Pytorch2.5 and other related dependencies, we provide three ways to set up the environment:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
+
- **[Pip]** Install the related packages using our provided `requirement.txt`:
|
| 52 |
+
```
|
| 53 |
+
pip install -r https://huggingface.co/nvidia/Hymba-1.5B-Instruct/resolve/main/requirements.txt
|
| 54 |
```
|
| 55 |
|
| 56 |
+
- **[Docker]** We have prepared a docker image with all of Hymba's dependencies installed. You can download our docker image and start a container using the following commands:
|
| 57 |
|
| 58 |
```
|
| 59 |
+
wget http://10.137.9.244:8000/hymba_docker.tar
|
| 60 |
+
docker load -i hymba.tar
|
| 61 |
+
docker run --security-opt seccomp=unconfined --gpus all -v /home/$USER:/home/$USER -it hymba:v1 bash
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 62 |
```
|
| 63 |
|
| 64 |
+
- **[Internal Only]** If you are an internal user from NVIDIA and are using the ORD cluster, you can use our prepared `sqsh` file to apply for an interactive node:
|
| 65 |
|
| 66 |
+
```
|
| 67 |
+
srun -A nvr_lpr_llm --partition interactive --time 4:00:00 --gpus 8 --container-image /lustre/fsw/portfolios/nvr/users/yongganf/docker/megatron_py25.sqsh --container-mounts=$HOME:/home,/lustre:/lustre --pty bash
|
| 68 |
+
```
|
|
|
|
|
|
|
| 69 |
|
| 70 |
+
### Step 2: Chat with Hymba
|
| 71 |
+
After setting up the environment, you can use the following script to chat with our Model
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 72 |
|
| 73 |
+
```
|
| 74 |
+
from transformers import LlamaTokenizer, AutoModelForCausalLM, AutoTokenizer, AutoModel
|
| 75 |
+
from huggingface_hub import login
|
| 76 |
+
import torch
|
| 77 |
|
| 78 |
+
login()
|
| 79 |
+
|
| 80 |
+
# Load LLaMA2's tokenizer
|
| 81 |
+
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b")
|
| 82 |
+
|
| 83 |
+
# Load Hymba-1.5B
|
| 84 |
+
model = AutoModelForCausalLM.from_pretrained("nvidia/Hymba-1.5B-Instruct", trust_remote_code=True).cuda().to(torch.bfloat16)
|
| 85 |
+
|
| 86 |
+
# Chat with our model
|
| 87 |
+
def chat_with_model(prompt, model, tokenizer, max_length=64):
|
| 88 |
+
inputs = tokenizer(prompt, return_tensors="pt").to('cuda')
|
| 89 |
+
outputs = model.generate(inputs.input_ids, max_length=max_length, do_sample=False, temperature=0.7, use_cache=True)
|
| 90 |
+
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 91 |
+
return response
|
| 92 |
+
|
| 93 |
+
print("Chat with the model (type 'exit' to quit):")
|
| 94 |
+
while True:
|
| 95 |
+
print("User:")
|
| 96 |
+
prompt = input()
|
| 97 |
+
if prompt.lower() == "exit":
|
| 98 |
+
break
|
| 99 |
+
|
| 100 |
+
# Get the model's response
|
| 101 |
+
response = chat_with_model(prompt, model, tokenizer)
|
| 102 |
+
|
| 103 |
+
print(f"Model: {response}")
|
| 104 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 105 |
```
|
added_tokens.json
DELETED
|
@@ -1,3 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"[PAD]": 32000
|
| 3 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
config.json
CHANGED
|
@@ -15,6 +15,14 @@
|
|
| 15 |
"conv_dim": {
|
| 16 |
"0": 3200,
|
| 17 |
"1": 3200,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18 |
"10": 3200,
|
| 19 |
"11": 3200,
|
| 20 |
"12": 3200,
|
|
@@ -25,7 +33,6 @@
|
|
| 25 |
"17": 3200,
|
| 26 |
"18": 3200,
|
| 27 |
"19": 3200,
|
| 28 |
-
"2": 3200,
|
| 29 |
"20": 3200,
|
| 30 |
"21": 3200,
|
| 31 |
"22": 3200,
|
|
@@ -36,15 +43,8 @@
|
|
| 36 |
"27": 3200,
|
| 37 |
"28": 3200,
|
| 38 |
"29": 3200,
|
| 39 |
-
"3": 3200,
|
| 40 |
"30": 3200,
|
| 41 |
-
"31": 3200
|
| 42 |
-
"4": 3200,
|
| 43 |
-
"5": 3200,
|
| 44 |
-
"6": 3200,
|
| 45 |
-
"7": 3200,
|
| 46 |
-
"8": 3200,
|
| 47 |
-
"9": 3200
|
| 48 |
},
|
| 49 |
"eos_token_id": 2,
|
| 50 |
"global_attn_idx": [
|
|
@@ -160,7 +160,7 @@
|
|
| 160 |
"mamba_expand": 2,
|
| 161 |
"mamba_inner_layernorms": true,
|
| 162 |
"mamba_proj_bias": false,
|
| 163 |
-
"max_position_embeddings":
|
| 164 |
"memory_tokens_interspersed_every": 0,
|
| 165 |
"mlp_hidden_act": "silu",
|
| 166 |
"model_type": "hymba",
|
|
@@ -171,18 +171,18 @@
|
|
| 171 |
"num_key_value_heads": 5,
|
| 172 |
"num_mamba": 1,
|
| 173 |
"num_memory_tokens": 128,
|
| 174 |
-
"orig_max_position_embeddings":
|
| 175 |
"output_router_logits": false,
|
| 176 |
"pad_token_id": 0,
|
| 177 |
"rms_norm_eps": 1e-06,
|
| 178 |
"rope": true,
|
| 179 |
"rope_theta": 10000.0,
|
| 180 |
-
"rope_type":
|
| 181 |
"router_aux_loss_coef": 0.001,
|
| 182 |
-
"seq_length":
|
| 183 |
"sliding_window": 1024,
|
| 184 |
"tie_word_embeddings": true,
|
| 185 |
-
"torch_dtype": "
|
| 186 |
"transformers_version": "4.44.0",
|
| 187 |
"use_cache": false,
|
| 188 |
"use_mamba_kernels": true,
|
|
|
|
| 15 |
"conv_dim": {
|
| 16 |
"0": 3200,
|
| 17 |
"1": 3200,
|
| 18 |
+
"2": 3200,
|
| 19 |
+
"3": 3200,
|
| 20 |
+
"4": 3200,
|
| 21 |
+
"5": 3200,
|
| 22 |
+
"6": 3200,
|
| 23 |
+
"7": 3200,
|
| 24 |
+
"8": 3200,
|
| 25 |
+
"9": 3200,
|
| 26 |
"10": 3200,
|
| 27 |
"11": 3200,
|
| 28 |
"12": 3200,
|
|
|
|
| 33 |
"17": 3200,
|
| 34 |
"18": 3200,
|
| 35 |
"19": 3200,
|
|
|
|
| 36 |
"20": 3200,
|
| 37 |
"21": 3200,
|
| 38 |
"22": 3200,
|
|
|
|
| 43 |
"27": 3200,
|
| 44 |
"28": 3200,
|
| 45 |
"29": 3200,
|
|
|
|
| 46 |
"30": 3200,
|
| 47 |
+
"31": 3200
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 48 |
},
|
| 49 |
"eos_token_id": 2,
|
| 50 |
"global_attn_idx": [
|
|
|
|
| 160 |
"mamba_expand": 2,
|
| 161 |
"mamba_inner_layernorms": true,
|
| 162 |
"mamba_proj_bias": false,
|
| 163 |
+
"max_position_embeddings": 1024,
|
| 164 |
"memory_tokens_interspersed_every": 0,
|
| 165 |
"mlp_hidden_act": "silu",
|
| 166 |
"model_type": "hymba",
|
|
|
|
| 171 |
"num_key_value_heads": 5,
|
| 172 |
"num_mamba": 1,
|
| 173 |
"num_memory_tokens": 128,
|
| 174 |
+
"orig_max_position_embeddings": null,
|
| 175 |
"output_router_logits": false,
|
| 176 |
"pad_token_id": 0,
|
| 177 |
"rms_norm_eps": 1e-06,
|
| 178 |
"rope": true,
|
| 179 |
"rope_theta": 10000.0,
|
| 180 |
+
"rope_type": null,
|
| 181 |
"router_aux_loss_coef": 0.001,
|
| 182 |
+
"seq_length": 1024,
|
| 183 |
"sliding_window": 1024,
|
| 184 |
"tie_word_embeddings": true,
|
| 185 |
+
"torch_dtype": "float32",
|
| 186 |
"transformers_version": "4.44.0",
|
| 187 |
"use_cache": false,
|
| 188 |
"use_mamba_kernels": true,
|
generation_config.json
CHANGED
|
@@ -4,5 +4,6 @@
|
|
| 4 |
"eos_token_id": 2,
|
| 5 |
"pad_token_id": 0,
|
| 6 |
"transformers_version": "4.44.0",
|
| 7 |
-
"use_cache": false
|
|
|
|
| 8 |
}
|
|
|
|
| 4 |
"eos_token_id": 2,
|
| 5 |
"pad_token_id": 0,
|
| 6 |
"transformers_version": "4.44.0",
|
| 7 |
+
"use_cache": false,
|
| 8 |
+
"chat_template": "{{'<extra_id_0>System'}}{% for message in messages %}{% if message['role'] == 'system' %}{{'\n' + message['content'].strip()}}{% if tools or contexts %}{{'\n'}}{% endif %}{% endif %}{% endfor %}{% if tools %}{% for tool in tools %}{{ '\n<tool> ' + tool|tojson + ' </tool>' }}{% endfor %}{% endif %}{% if contexts %}{% if tools %}{{'\n'}}{% endif %}{% for context in contexts %}{{ '\n<context> ' + context.strip() + ' </context>' }}{% endfor %}{% endif %}{{'\n\n'}}{% for message in messages %}{% if message['role'] == 'user' %}{{ '<extra_id_1>User\n' + message['content'].strip() + '\n' }}{% elif message['role'] == 'assistant' %}{{ '<extra_id_1>Assistant\n' + message['content'].strip() + '\n' }}{% elif message['role'] == 'tool' %}{{ '<extra_id_1>Tool\n' + message['content'].strip() + '\n' }}{% endif %}{% endfor %}{%- if add_generation_prompt %}{{'<extra_id_1>Assistant\n'}}{%- endif %}"
|
| 9 |
}
|
images/instruct_performance.png
CHANGED

|
|
images/performance1.png
ADDED

|
images/performance2.png
ADDED
|
instruct_performance.png
DELETED
|
Binary file (97.9 kB)
|
|
|
tokenizer.model → model-00001-of-00002.safetensors
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7f01b19a43514af19def4c812a1d453dfd66f5c1b0be9674090a5bf37b699fc1
|
| 3 |
+
size 4988876320
|
model.safetensors → model-00002-of-00002.safetensors
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b11f9bec9246d8dc80612bb4e9d20f58b5744ca90ffae8944fffa0658789fde8
|
| 3 |
+
size 1102383712
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,618 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 6091191296
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"model.embed_tokens.weight": "model-00001-of-00002.safetensors",
|
| 7 |
+
"model.final_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 9 |
+
"model.layers.0.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 10 |
+
"model.layers.0.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 11 |
+
"model.layers.0.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 12 |
+
"model.layers.0.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 13 |
+
"model.layers.0.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 14 |
+
"model.layers.0.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 15 |
+
"model.layers.0.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 16 |
+
"model.layers.0.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 17 |
+
"model.layers.0.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 18 |
+
"model.layers.0.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 19 |
+
"model.layers.0.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 20 |
+
"model.layers.0.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 21 |
+
"model.layers.0.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 22 |
+
"model.layers.0.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 23 |
+
"model.layers.0.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 24 |
+
"model.layers.0.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 25 |
+
"model.layers.0.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 26 |
+
"model.layers.0.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 27 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 28 |
+
"model.layers.1.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 29 |
+
"model.layers.1.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 30 |
+
"model.layers.1.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 31 |
+
"model.layers.1.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 32 |
+
"model.layers.1.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 33 |
+
"model.layers.1.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 34 |
+
"model.layers.1.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 35 |
+
"model.layers.1.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 36 |
+
"model.layers.1.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 37 |
+
"model.layers.1.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 38 |
+
"model.layers.1.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 39 |
+
"model.layers.1.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 40 |
+
"model.layers.1.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 41 |
+
"model.layers.1.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 42 |
+
"model.layers.1.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 43 |
+
"model.layers.1.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 44 |
+
"model.layers.1.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 45 |
+
"model.layers.1.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 46 |
+
"model.layers.10.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 47 |
+
"model.layers.10.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 48 |
+
"model.layers.10.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 49 |
+
"model.layers.10.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 50 |
+
"model.layers.10.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 51 |
+
"model.layers.10.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 52 |
+
"model.layers.10.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 53 |
+
"model.layers.10.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 54 |
+
"model.layers.10.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 55 |
+
"model.layers.10.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 56 |
+
"model.layers.10.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 57 |
+
"model.layers.10.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 58 |
+
"model.layers.10.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 59 |
+
"model.layers.10.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 60 |
+
"model.layers.10.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 61 |
+
"model.layers.10.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 62 |
+
"model.layers.10.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 63 |
+
"model.layers.10.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 64 |
+
"model.layers.10.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 65 |
+
"model.layers.11.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 66 |
+
"model.layers.11.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 67 |
+
"model.layers.11.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 68 |
+
"model.layers.11.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 69 |
+
"model.layers.11.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 70 |
+
"model.layers.11.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 71 |
+
"model.layers.11.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 72 |
+
"model.layers.11.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 73 |
+
"model.layers.11.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 74 |
+
"model.layers.11.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 75 |
+
"model.layers.11.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 76 |
+
"model.layers.11.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 77 |
+
"model.layers.11.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 78 |
+
"model.layers.11.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 79 |
+
"model.layers.11.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 80 |
+
"model.layers.11.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 81 |
+
"model.layers.11.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 82 |
+
"model.layers.11.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 83 |
+
"model.layers.11.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 84 |
+
"model.layers.12.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 85 |
+
"model.layers.12.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 86 |
+
"model.layers.12.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 87 |
+
"model.layers.12.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 88 |
+
"model.layers.12.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 89 |
+
"model.layers.12.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 90 |
+
"model.layers.12.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 91 |
+
"model.layers.12.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 92 |
+
"model.layers.12.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 93 |
+
"model.layers.12.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 94 |
+
"model.layers.12.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 95 |
+
"model.layers.12.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 96 |
+
"model.layers.12.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 97 |
+
"model.layers.12.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 98 |
+
"model.layers.12.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 99 |
+
"model.layers.12.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 100 |
+
"model.layers.12.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 101 |
+
"model.layers.12.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 102 |
+
"model.layers.12.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 103 |
+
"model.layers.13.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 104 |
+
"model.layers.13.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 105 |
+
"model.layers.13.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 106 |
+
"model.layers.13.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 107 |
+
"model.layers.13.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 108 |
+
"model.layers.13.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 109 |
+
"model.layers.13.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 110 |
+
"model.layers.13.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 111 |
+
"model.layers.13.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 112 |
+
"model.layers.13.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 113 |
+
"model.layers.13.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 114 |
+
"model.layers.13.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 115 |
+
"model.layers.13.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 116 |
+
"model.layers.13.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 117 |
+
"model.layers.13.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 118 |
+
"model.layers.13.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 119 |
+
"model.layers.13.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 120 |
+
"model.layers.13.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 121 |
+
"model.layers.13.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 122 |
+
"model.layers.14.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 123 |
+
"model.layers.14.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 124 |
+
"model.layers.14.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 125 |
+
"model.layers.14.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 126 |
+
"model.layers.14.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 127 |
+
"model.layers.14.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 128 |
+
"model.layers.14.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 129 |
+
"model.layers.14.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 130 |
+
"model.layers.14.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 131 |
+
"model.layers.14.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 132 |
+
"model.layers.14.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 133 |
+
"model.layers.14.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 134 |
+
"model.layers.14.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 135 |
+
"model.layers.14.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 136 |
+
"model.layers.14.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 137 |
+
"model.layers.14.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 138 |
+
"model.layers.14.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 139 |
+
"model.layers.14.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 140 |
+
"model.layers.14.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 141 |
+
"model.layers.15.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 142 |
+
"model.layers.15.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 143 |
+
"model.layers.15.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 144 |
+
"model.layers.15.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 145 |
+
"model.layers.15.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 146 |
+
"model.layers.15.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 147 |
+
"model.layers.15.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 148 |
+
"model.layers.15.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 149 |
+
"model.layers.15.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 150 |
+
"model.layers.15.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 151 |
+
"model.layers.15.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 152 |
+
"model.layers.15.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 153 |
+
"model.layers.15.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 154 |
+
"model.layers.15.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 155 |
+
"model.layers.15.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 156 |
+
"model.layers.15.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 157 |
+
"model.layers.15.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 158 |
+
"model.layers.15.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 159 |
+
"model.layers.15.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 160 |
+
"model.layers.16.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 161 |
+
"model.layers.16.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 162 |
+
"model.layers.16.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 163 |
+
"model.layers.16.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 164 |
+
"model.layers.16.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 165 |
+
"model.layers.16.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 166 |
+
"model.layers.16.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 167 |
+
"model.layers.16.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 168 |
+
"model.layers.16.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 169 |
+
"model.layers.16.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 170 |
+
"model.layers.16.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 171 |
+
"model.layers.16.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 172 |
+
"model.layers.16.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 173 |
+
"model.layers.16.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 174 |
+
"model.layers.16.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 175 |
+
"model.layers.16.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 176 |
+
"model.layers.16.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 177 |
+
"model.layers.16.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 178 |
+
"model.layers.16.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 179 |
+
"model.layers.17.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 180 |
+
"model.layers.17.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 181 |
+
"model.layers.17.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 182 |
+
"model.layers.17.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 183 |
+
"model.layers.17.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 184 |
+
"model.layers.17.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 185 |
+
"model.layers.17.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 186 |
+
"model.layers.17.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 187 |
+
"model.layers.17.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 188 |
+
"model.layers.17.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 189 |
+
"model.layers.17.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 190 |
+
"model.layers.17.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 191 |
+
"model.layers.17.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 192 |
+
"model.layers.17.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 193 |
+
"model.layers.17.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 194 |
+
"model.layers.17.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 195 |
+
"model.layers.17.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 196 |
+
"model.layers.17.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 197 |
+
"model.layers.17.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 198 |
+
"model.layers.18.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 199 |
+
"model.layers.18.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 200 |
+
"model.layers.18.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 201 |
+
"model.layers.18.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 202 |
+
"model.layers.18.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 203 |
+
"model.layers.18.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 204 |
+
"model.layers.18.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 205 |
+
"model.layers.18.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 206 |
+
"model.layers.18.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 207 |
+
"model.layers.18.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 208 |
+
"model.layers.18.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 209 |
+
"model.layers.18.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 210 |
+
"model.layers.18.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 211 |
+
"model.layers.18.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 212 |
+
"model.layers.18.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 213 |
+
"model.layers.18.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 214 |
+
"model.layers.18.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 215 |
+
"model.layers.18.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 216 |
+
"model.layers.18.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 217 |
+
"model.layers.19.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 218 |
+
"model.layers.19.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 219 |
+
"model.layers.19.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 220 |
+
"model.layers.19.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 221 |
+
"model.layers.19.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 222 |
+
"model.layers.19.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 223 |
+
"model.layers.19.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 224 |
+
"model.layers.19.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 225 |
+
"model.layers.19.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 226 |
+
"model.layers.19.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 227 |
+
"model.layers.19.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 228 |
+
"model.layers.19.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 229 |
+
"model.layers.19.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 230 |
+
"model.layers.19.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 231 |
+
"model.layers.19.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 232 |
+
"model.layers.19.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 233 |
+
"model.layers.19.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 234 |
+
"model.layers.19.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 235 |
+
"model.layers.19.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 236 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 237 |
+
"model.layers.2.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 238 |
+
"model.layers.2.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 239 |
+
"model.layers.2.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 240 |
+
"model.layers.2.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 241 |
+
"model.layers.2.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 242 |
+
"model.layers.2.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 243 |
+
"model.layers.2.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 244 |
+
"model.layers.2.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 245 |
+
"model.layers.2.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 246 |
+
"model.layers.2.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 247 |
+
"model.layers.2.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 248 |
+
"model.layers.2.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 249 |
+
"model.layers.2.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 250 |
+
"model.layers.2.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 251 |
+
"model.layers.2.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 252 |
+
"model.layers.2.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 253 |
+
"model.layers.2.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 254 |
+
"model.layers.2.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 255 |
+
"model.layers.20.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 256 |
+
"model.layers.20.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 257 |
+
"model.layers.20.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 258 |
+
"model.layers.20.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 259 |
+
"model.layers.20.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 260 |
+
"model.layers.20.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 261 |
+
"model.layers.20.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 262 |
+
"model.layers.20.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 263 |
+
"model.layers.20.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 264 |
+
"model.layers.20.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 265 |
+
"model.layers.20.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 266 |
+
"model.layers.20.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 267 |
+
"model.layers.20.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 268 |
+
"model.layers.20.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 269 |
+
"model.layers.20.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 270 |
+
"model.layers.20.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 271 |
+
"model.layers.20.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 272 |
+
"model.layers.20.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 273 |
+
"model.layers.20.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 274 |
+
"model.layers.21.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 275 |
+
"model.layers.21.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 276 |
+
"model.layers.21.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 277 |
+
"model.layers.21.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 278 |
+
"model.layers.21.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 279 |
+
"model.layers.21.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 280 |
+
"model.layers.21.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 281 |
+
"model.layers.21.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 282 |
+
"model.layers.21.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 283 |
+
"model.layers.21.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 284 |
+
"model.layers.21.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 285 |
+
"model.layers.21.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 286 |
+
"model.layers.21.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 287 |
+
"model.layers.21.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 288 |
+
"model.layers.21.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 289 |
+
"model.layers.21.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 290 |
+
"model.layers.21.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 291 |
+
"model.layers.21.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 292 |
+
"model.layers.21.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 293 |
+
"model.layers.22.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 294 |
+
"model.layers.22.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 295 |
+
"model.layers.22.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 296 |
+
"model.layers.22.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 297 |
+
"model.layers.22.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 298 |
+
"model.layers.22.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 299 |
+
"model.layers.22.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 300 |
+
"model.layers.22.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 301 |
+
"model.layers.22.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 302 |
+
"model.layers.22.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 303 |
+
"model.layers.22.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 304 |
+
"model.layers.22.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 305 |
+
"model.layers.22.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 306 |
+
"model.layers.22.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 307 |
+
"model.layers.22.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 308 |
+
"model.layers.22.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 309 |
+
"model.layers.22.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 310 |
+
"model.layers.22.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 311 |
+
"model.layers.22.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 312 |
+
"model.layers.23.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 313 |
+
"model.layers.23.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 314 |
+
"model.layers.23.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 315 |
+
"model.layers.23.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 316 |
+
"model.layers.23.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 317 |
+
"model.layers.23.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 318 |
+
"model.layers.23.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 319 |
+
"model.layers.23.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 320 |
+
"model.layers.23.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 321 |
+
"model.layers.23.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 322 |
+
"model.layers.23.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 323 |
+
"model.layers.23.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 324 |
+
"model.layers.23.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 325 |
+
"model.layers.23.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 326 |
+
"model.layers.23.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 327 |
+
"model.layers.23.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 328 |
+
"model.layers.23.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 329 |
+
"model.layers.23.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 330 |
+
"model.layers.23.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 331 |
+
"model.layers.24.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 332 |
+
"model.layers.24.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 333 |
+
"model.layers.24.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 334 |
+
"model.layers.24.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 335 |
+
"model.layers.24.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 336 |
+
"model.layers.24.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 337 |
+
"model.layers.24.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 338 |
+
"model.layers.24.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 339 |
+
"model.layers.24.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 340 |
+
"model.layers.24.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 341 |
+
"model.layers.24.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 342 |
+
"model.layers.24.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 343 |
+
"model.layers.24.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 344 |
+
"model.layers.24.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 345 |
+
"model.layers.24.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 346 |
+
"model.layers.24.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 347 |
+
"model.layers.24.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 348 |
+
"model.layers.24.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 349 |
+
"model.layers.24.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 350 |
+
"model.layers.25.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 351 |
+
"model.layers.25.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 352 |
+
"model.layers.25.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 353 |
+
"model.layers.25.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 354 |
+
"model.layers.25.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 355 |
+
"model.layers.25.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 356 |
+
"model.layers.25.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 357 |
+
"model.layers.25.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 358 |
+
"model.layers.25.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 359 |
+
"model.layers.25.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 360 |
+
"model.layers.25.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 361 |
+
"model.layers.25.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 362 |
+
"model.layers.25.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 363 |
+
"model.layers.25.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 364 |
+
"model.layers.25.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 365 |
+
"model.layers.25.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 366 |
+
"model.layers.25.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 367 |
+
"model.layers.25.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 368 |
+
"model.layers.25.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 369 |
+
"model.layers.26.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 370 |
+
"model.layers.26.mamba.A_log.0": "model-00002-of-00002.safetensors",
|
| 371 |
+
"model.layers.26.mamba.B_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 372 |
+
"model.layers.26.mamba.C_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 373 |
+
"model.layers.26.mamba.D.0": "model-00002-of-00002.safetensors",
|
| 374 |
+
"model.layers.26.mamba.conv1d.bias": "model-00002-of-00002.safetensors",
|
| 375 |
+
"model.layers.26.mamba.conv1d.weight": "model-00002-of-00002.safetensors",
|
| 376 |
+
"model.layers.26.mamba.dt_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 377 |
+
"model.layers.26.mamba.dt_proj.0.bias": "model-00002-of-00002.safetensors",
|
| 378 |
+
"model.layers.26.mamba.dt_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 379 |
+
"model.layers.26.mamba.in_proj.weight": "model-00002-of-00002.safetensors",
|
| 380 |
+
"model.layers.26.mamba.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 381 |
+
"model.layers.26.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 382 |
+
"model.layers.26.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 383 |
+
"model.layers.26.mamba.x_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 384 |
+
"model.layers.26.moe.experts.0.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 385 |
+
"model.layers.26.moe.experts.0.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 386 |
+
"model.layers.26.moe.experts.0.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 387 |
+
"model.layers.26.pre_moe_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 388 |
+
"model.layers.27.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 389 |
+
"model.layers.27.mamba.A_log.0": "model-00002-of-00002.safetensors",
|
| 390 |
+
"model.layers.27.mamba.B_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 391 |
+
"model.layers.27.mamba.C_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 392 |
+
"model.layers.27.mamba.D.0": "model-00002-of-00002.safetensors",
|
| 393 |
+
"model.layers.27.mamba.conv1d.bias": "model-00002-of-00002.safetensors",
|
| 394 |
+
"model.layers.27.mamba.conv1d.weight": "model-00002-of-00002.safetensors",
|
| 395 |
+
"model.layers.27.mamba.dt_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 396 |
+
"model.layers.27.mamba.dt_proj.0.bias": "model-00002-of-00002.safetensors",
|
| 397 |
+
"model.layers.27.mamba.dt_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 398 |
+
"model.layers.27.mamba.in_proj.weight": "model-00002-of-00002.safetensors",
|
| 399 |
+
"model.layers.27.mamba.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 400 |
+
"model.layers.27.mamba.pre_avg_layernorm1.weight": "model-00002-of-00002.safetensors",
|
| 401 |
+
"model.layers.27.mamba.pre_avg_layernorm2.weight": "model-00002-of-00002.safetensors",
|
| 402 |
+
"model.layers.27.mamba.x_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 403 |
+
"model.layers.27.moe.experts.0.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 404 |
+
"model.layers.27.moe.experts.0.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 405 |
+
"model.layers.27.moe.experts.0.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 406 |
+
"model.layers.27.pre_moe_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 407 |
+
"model.layers.28.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 408 |
+
"model.layers.28.mamba.A_log.0": "model-00002-of-00002.safetensors",
|
| 409 |
+
"model.layers.28.mamba.B_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 410 |
+
"model.layers.28.mamba.C_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 411 |
+
"model.layers.28.mamba.D.0": "model-00002-of-00002.safetensors",
|
| 412 |
+
"model.layers.28.mamba.conv1d.bias": "model-00002-of-00002.safetensors",
|
| 413 |
+
"model.layers.28.mamba.conv1d.weight": "model-00002-of-00002.safetensors",
|
| 414 |
+
"model.layers.28.mamba.dt_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 415 |
+
"model.layers.28.mamba.dt_proj.0.bias": "model-00002-of-00002.safetensors",
|
| 416 |
+
"model.layers.28.mamba.dt_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 417 |
+
"model.layers.28.mamba.in_proj.weight": "model-00002-of-00002.safetensors",
|
| 418 |
+
"model.layers.28.mamba.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 419 |
+
"model.layers.28.mamba.pre_avg_layernorm1.weight": "model-00002-of-00002.safetensors",
|
| 420 |
+
"model.layers.28.mamba.pre_avg_layernorm2.weight": "model-00002-of-00002.safetensors",
|
| 421 |
+
"model.layers.28.mamba.x_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 422 |
+
"model.layers.28.moe.experts.0.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 423 |
+
"model.layers.28.moe.experts.0.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 424 |
+
"model.layers.28.moe.experts.0.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 425 |
+
"model.layers.28.pre_moe_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 426 |
+
"model.layers.29.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 427 |
+
"model.layers.29.mamba.A_log.0": "model-00002-of-00002.safetensors",
|
| 428 |
+
"model.layers.29.mamba.B_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 429 |
+
"model.layers.29.mamba.C_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 430 |
+
"model.layers.29.mamba.D.0": "model-00002-of-00002.safetensors",
|
| 431 |
+
"model.layers.29.mamba.conv1d.bias": "model-00002-of-00002.safetensors",
|
| 432 |
+
"model.layers.29.mamba.conv1d.weight": "model-00002-of-00002.safetensors",
|
| 433 |
+
"model.layers.29.mamba.dt_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 434 |
+
"model.layers.29.mamba.dt_proj.0.bias": "model-00002-of-00002.safetensors",
|
| 435 |
+
"model.layers.29.mamba.dt_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 436 |
+
"model.layers.29.mamba.in_proj.weight": "model-00002-of-00002.safetensors",
|
| 437 |
+
"model.layers.29.mamba.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 438 |
+
"model.layers.29.mamba.pre_avg_layernorm1.weight": "model-00002-of-00002.safetensors",
|
| 439 |
+
"model.layers.29.mamba.pre_avg_layernorm2.weight": "model-00002-of-00002.safetensors",
|
| 440 |
+
"model.layers.29.mamba.x_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 441 |
+
"model.layers.29.moe.experts.0.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 442 |
+
"model.layers.29.moe.experts.0.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 443 |
+
"model.layers.29.moe.experts.0.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 444 |
+
"model.layers.29.pre_moe_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 445 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 446 |
+
"model.layers.3.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 447 |
+
"model.layers.3.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 448 |
+
"model.layers.3.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 449 |
+
"model.layers.3.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 450 |
+
"model.layers.3.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 451 |
+
"model.layers.3.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 452 |
+
"model.layers.3.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 453 |
+
"model.layers.3.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 454 |
+
"model.layers.3.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 455 |
+
"model.layers.3.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 456 |
+
"model.layers.3.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 457 |
+
"model.layers.3.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 458 |
+
"model.layers.3.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 459 |
+
"model.layers.3.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 460 |
+
"model.layers.3.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 461 |
+
"model.layers.3.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 462 |
+
"model.layers.3.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 463 |
+
"model.layers.3.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 464 |
+
"model.layers.30.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 465 |
+
"model.layers.30.mamba.A_log.0": "model-00002-of-00002.safetensors",
|
| 466 |
+
"model.layers.30.mamba.B_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 467 |
+
"model.layers.30.mamba.C_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 468 |
+
"model.layers.30.mamba.D.0": "model-00002-of-00002.safetensors",
|
| 469 |
+
"model.layers.30.mamba.conv1d.bias": "model-00002-of-00002.safetensors",
|
| 470 |
+
"model.layers.30.mamba.conv1d.weight": "model-00002-of-00002.safetensors",
|
| 471 |
+
"model.layers.30.mamba.dt_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 472 |
+
"model.layers.30.mamba.dt_proj.0.bias": "model-00002-of-00002.safetensors",
|
| 473 |
+
"model.layers.30.mamba.dt_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 474 |
+
"model.layers.30.mamba.in_proj.weight": "model-00002-of-00002.safetensors",
|
| 475 |
+
"model.layers.30.mamba.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 476 |
+
"model.layers.30.mamba.pre_avg_layernorm1.weight": "model-00002-of-00002.safetensors",
|
| 477 |
+
"model.layers.30.mamba.pre_avg_layernorm2.weight": "model-00002-of-00002.safetensors",
|
| 478 |
+
"model.layers.30.mamba.x_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 479 |
+
"model.layers.30.moe.experts.0.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 480 |
+
"model.layers.30.moe.experts.0.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 481 |
+
"model.layers.30.moe.experts.0.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 482 |
+
"model.layers.30.pre_moe_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 483 |
+
"model.layers.31.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 484 |
+
"model.layers.31.mamba.A_log.0": "model-00002-of-00002.safetensors",
|
| 485 |
+
"model.layers.31.mamba.B_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 486 |
+
"model.layers.31.mamba.C_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 487 |
+
"model.layers.31.mamba.D.0": "model-00002-of-00002.safetensors",
|
| 488 |
+
"model.layers.31.mamba.conv1d.bias": "model-00002-of-00002.safetensors",
|
| 489 |
+
"model.layers.31.mamba.conv1d.weight": "model-00002-of-00002.safetensors",
|
| 490 |
+
"model.layers.31.mamba.dt_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 491 |
+
"model.layers.31.mamba.dt_proj.0.bias": "model-00002-of-00002.safetensors",
|
| 492 |
+
"model.layers.31.mamba.dt_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 493 |
+
"model.layers.31.mamba.in_proj.weight": "model-00002-of-00002.safetensors",
|
| 494 |
+
"model.layers.31.mamba.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 495 |
+
"model.layers.31.mamba.pre_avg_layernorm1.weight": "model-00002-of-00002.safetensors",
|
| 496 |
+
"model.layers.31.mamba.pre_avg_layernorm2.weight": "model-00002-of-00002.safetensors",
|
| 497 |
+
"model.layers.31.mamba.x_proj.0.weight": "model-00002-of-00002.safetensors",
|
| 498 |
+
"model.layers.31.moe.experts.0.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 499 |
+
"model.layers.31.moe.experts.0.gate_proj.weight": "model-00002-of-00002.safetensors",
|
| 500 |
+
"model.layers.31.moe.experts.0.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 501 |
+
"model.layers.31.pre_moe_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 502 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 503 |
+
"model.layers.4.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 504 |
+
"model.layers.4.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 505 |
+
"model.layers.4.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 506 |
+
"model.layers.4.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 507 |
+
"model.layers.4.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 508 |
+
"model.layers.4.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 509 |
+
"model.layers.4.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 510 |
+
"model.layers.4.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 511 |
+
"model.layers.4.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 512 |
+
"model.layers.4.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 513 |
+
"model.layers.4.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 514 |
+
"model.layers.4.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 515 |
+
"model.layers.4.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 516 |
+
"model.layers.4.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 517 |
+
"model.layers.4.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 518 |
+
"model.layers.4.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 519 |
+
"model.layers.4.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 520 |
+
"model.layers.4.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 521 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 522 |
+
"model.layers.5.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 523 |
+
"model.layers.5.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 524 |
+
"model.layers.5.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 525 |
+
"model.layers.5.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 526 |
+
"model.layers.5.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 527 |
+
"model.layers.5.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 528 |
+
"model.layers.5.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 529 |
+
"model.layers.5.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 530 |
+
"model.layers.5.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 531 |
+
"model.layers.5.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 532 |
+
"model.layers.5.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 533 |
+
"model.layers.5.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 534 |
+
"model.layers.5.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 535 |
+
"model.layers.5.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 536 |
+
"model.layers.5.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 537 |
+
"model.layers.5.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 538 |
+
"model.layers.5.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 539 |
+
"model.layers.5.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 540 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 541 |
+
"model.layers.6.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 542 |
+
"model.layers.6.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 543 |
+
"model.layers.6.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 544 |
+
"model.layers.6.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 545 |
+
"model.layers.6.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 546 |
+
"model.layers.6.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 547 |
+
"model.layers.6.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 548 |
+
"model.layers.6.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 549 |
+
"model.layers.6.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 550 |
+
"model.layers.6.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 551 |
+
"model.layers.6.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 552 |
+
"model.layers.6.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 553 |
+
"model.layers.6.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 554 |
+
"model.layers.6.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 555 |
+
"model.layers.6.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 556 |
+
"model.layers.6.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 557 |
+
"model.layers.6.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 558 |
+
"model.layers.6.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 559 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 560 |
+
"model.layers.7.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 561 |
+
"model.layers.7.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 562 |
+
"model.layers.7.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 563 |
+
"model.layers.7.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 564 |
+
"model.layers.7.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 565 |
+
"model.layers.7.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 566 |
+
"model.layers.7.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 567 |
+
"model.layers.7.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 568 |
+
"model.layers.7.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 569 |
+
"model.layers.7.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 570 |
+
"model.layers.7.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 571 |
+
"model.layers.7.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 572 |
+
"model.layers.7.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 573 |
+
"model.layers.7.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 574 |
+
"model.layers.7.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 575 |
+
"model.layers.7.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 576 |
+
"model.layers.7.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 577 |
+
"model.layers.7.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 578 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 579 |
+
"model.layers.8.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 580 |
+
"model.layers.8.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 581 |
+
"model.layers.8.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 582 |
+
"model.layers.8.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 583 |
+
"model.layers.8.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 584 |
+
"model.layers.8.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 585 |
+
"model.layers.8.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 586 |
+
"model.layers.8.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 587 |
+
"model.layers.8.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 588 |
+
"model.layers.8.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 589 |
+
"model.layers.8.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 590 |
+
"model.layers.8.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 591 |
+
"model.layers.8.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 592 |
+
"model.layers.8.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 593 |
+
"model.layers.8.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 594 |
+
"model.layers.8.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 595 |
+
"model.layers.8.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 596 |
+
"model.layers.8.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 597 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 598 |
+
"model.layers.9.mamba.A_log.0": "model-00001-of-00002.safetensors",
|
| 599 |
+
"model.layers.9.mamba.B_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 600 |
+
"model.layers.9.mamba.C_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 601 |
+
"model.layers.9.mamba.D.0": "model-00001-of-00002.safetensors",
|
| 602 |
+
"model.layers.9.mamba.conv1d.bias": "model-00001-of-00002.safetensors",
|
| 603 |
+
"model.layers.9.mamba.conv1d.weight": "model-00001-of-00002.safetensors",
|
| 604 |
+
"model.layers.9.mamba.dt_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 605 |
+
"model.layers.9.mamba.dt_proj.0.bias": "model-00001-of-00002.safetensors",
|
| 606 |
+
"model.layers.9.mamba.dt_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 607 |
+
"model.layers.9.mamba.in_proj.weight": "model-00001-of-00002.safetensors",
|
| 608 |
+
"model.layers.9.mamba.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 609 |
+
"model.layers.9.mamba.pre_avg_layernorm1.weight": "model-00001-of-00002.safetensors",
|
| 610 |
+
"model.layers.9.mamba.pre_avg_layernorm2.weight": "model-00001-of-00002.safetensors",
|
| 611 |
+
"model.layers.9.mamba.x_proj.0.weight": "model-00001-of-00002.safetensors",
|
| 612 |
+
"model.layers.9.moe.experts.0.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 613 |
+
"model.layers.9.moe.experts.0.gate_proj.weight": "model-00001-of-00002.safetensors",
|
| 614 |
+
"model.layers.9.moe.experts.0.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 615 |
+
"model.layers.9.pre_moe_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 616 |
+
"model.memory_tokens": "model-00001-of-00002.safetensors"
|
| 617 |
+
}
|
| 618 |
+
}
|
modeling_hymba.py
CHANGED
|
@@ -39,13 +39,16 @@ from .configuration_hymba import HymbaConfig
|
|
| 39 |
from torch.utils.checkpoint import checkpoint
|
| 40 |
|
| 41 |
|
| 42 |
-
|
| 43 |
-
from flash_attn
|
|
|
|
| 44 |
|
| 45 |
-
_flash_supports_window_size = "window_size" in list(inspect.signature(flash_attn_func).parameters)
|
| 46 |
|
| 47 |
-
from einops import rearrange, repeat, reduce, pack, unpack
|
| 48 |
-
from einops.layers.torch import Rearrange
|
|
|
|
|
|
|
| 49 |
|
| 50 |
|
| 51 |
if is_torch_fx_available():
|
|
@@ -396,7 +399,7 @@ class HybridMambaAttentionDynamicCache(DynamicCache):
|
|
| 396 |
|
| 397 |
if has_mamba_state:
|
| 398 |
if hasattr(config, 'conv_dim'):
|
| 399 |
-
conv_dim = config.conv_dim[
|
| 400 |
else:
|
| 401 |
conv_dim = intermediate_size
|
| 402 |
self.conv_states += [
|
|
@@ -543,14 +546,6 @@ class HymbaAttention(nn.Module):
|
|
| 543 |
|
| 544 |
if self.config.rope:
|
| 545 |
self._init_rope()
|
| 546 |
-
|
| 547 |
-
|
| 548 |
-
def set_rope(self, rope_type, orig_max_position_embeddings, max_position_embeddings):
|
| 549 |
-
self.config.rope_type = rope_type
|
| 550 |
-
self.config.orig_max_position_embeddings = orig_max_position_embeddings
|
| 551 |
-
self.config.max_position_embeddings = max_position_embeddings
|
| 552 |
-
|
| 553 |
-
self._init_rope()
|
| 554 |
|
| 555 |
|
| 556 |
def _init_rope(self):
|
|
@@ -1233,7 +1228,7 @@ class HymbaFlexAttention(HymbaFlashAttention2):
|
|
| 1233 |
|
| 1234 |
self.attn_mask = or_masks(attn_mask, register_mask)
|
| 1235 |
|
| 1236 |
-
self.block_mask = create_block_mask(self.attn_mask, B=None, H=None, Q_LEN=qk_length, KV_LEN=qk_length)
|
| 1237 |
|
| 1238 |
self.flex_attention = torch.compile(flex_attention)
|
| 1239 |
|
|
@@ -1523,7 +1518,7 @@ class HymbaBlock(nn.Module):
|
|
| 1523 |
num_ssm_param = 1
|
| 1524 |
|
| 1525 |
if not hasattr(config, 'conv_dim'):
|
| 1526 |
-
config.conv_dim = {
|
| 1527 |
|
| 1528 |
self.conv1d = nn.Conv1d(
|
| 1529 |
in_channels=self.intermediate_size,
|
|
@@ -1534,7 +1529,7 @@ class HymbaBlock(nn.Module):
|
|
| 1534 |
padding=self.conv_kernel_size - 1
|
| 1535 |
)
|
| 1536 |
|
| 1537 |
-
config.conv_dim[
|
| 1538 |
|
| 1539 |
self.x_proj = nn.ModuleList([nn.Linear(self.intermediate_size, self.time_step_rank + self.ssm_state_size * 2, bias=False) for _ in range(num_ssm_param)])
|
| 1540 |
self.dt_proj = nn.ModuleList([nn.Linear(self.time_step_rank, self.intermediate_size, bias=True) for _ in range(num_ssm_param)])
|
|
@@ -1579,133 +1574,145 @@ class HymbaBlock(nn.Module):
|
|
| 1579 |
def cuda_kernels_forward(self, hidden_states: torch.Tensor, cache_params: HybridMambaAttentionDynamicCache = None, attention_mask=None, position_ids=None, kv_last_layer=None, use_cache=False, use_swa=False):
|
| 1580 |
projected_states = self.in_proj(hidden_states).transpose(1, 2) ## (bs, latent_dim, seq_len)
|
| 1581 |
|
| 1582 |
-
|
| 1583 |
-
|
| 1584 |
-
|
| 1585 |
-
|
| 1586 |
-
|
| 1587 |
-
|
| 1588 |
-
|
| 1589 |
-
|
| 1590 |
-
|
| 1591 |
-
|
| 1592 |
-
|
| 1593 |
-
|
| 1594 |
-
|
| 1595 |
-
|
| 1596 |
-
|
| 1597 |
-
|
| 1598 |
-
|
| 1599 |
-
|
| 1600 |
|
| 1601 |
-
if self.reuse_kv:
|
| 1602 |
-
query_states, hidden_states = hidden_states.tensor_split((self.attn_hidden_size,), dim=1)
|
| 1603 |
-
query_states = query_states.transpose(1,2)
|
| 1604 |
else:
|
| 1605 |
-
|
| 1606 |
-
|
| 1607 |
-
|
| 1608 |
-
|
| 1609 |
-
|
| 1610 |
-
|
| 1611 |
-
|
| 1612 |
-
|
| 1613 |
-
|
| 1614 |
-
cache_params.conv_states[self.layer_idx],
|
| 1615 |
-
conv_weights,
|
| 1616 |
-
self.conv1d.bias,
|
| 1617 |
-
self.activation,
|
| 1618 |
)
|
| 1619 |
-
hidden_states = hidden_states.unsqueeze(-1)
|
| 1620 |
|
| 1621 |
-
|
| 1622 |
-
else:
|
| 1623 |
-
if cache_params is not None:
|
| 1624 |
-
conv_states = nn.functional.pad(
|
| 1625 |
-
hidden_states, (self.conv_kernel_size - hidden_states.shape[-1], 0)
|
| 1626 |
-
)
|
| 1627 |
|
| 1628 |
-
|
| 1629 |
|
| 1630 |
-
|
| 1631 |
-
|
| 1632 |
-
|
| 1633 |
-
|
| 1634 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1635 |
|
| 1636 |
-
|
| 1637 |
-
|
| 1638 |
-
|
| 1639 |
-
|
| 1640 |
-
|
| 1641 |
-
|
| 1642 |
-
attn_outputs, attn_key_value = self.self_attn(attention_mask=attention_mask, position_ids=position_ids, query_states=query_states, kv_last_layer=kv_last_layer, use_swa=use_swa, use_cache=use_cache, past_key_value=cache_params)
|
| 1643 |
-
else:
|
| 1644 |
-
attn_outputs, attn_key_value = self.self_attn(attention_mask=attention_mask, position_ids=position_ids, query_states=query_states, key_states=key_states, value_states=value_states, use_swa=use_swa, use_cache=use_cache, past_key_value=cache_params)
|
| 1645 |
|
| 1646 |
-
|
| 1647 |
-
index = 0
|
| 1648 |
-
ssm_parameters = self.x_proj[index](hidden_states.transpose(1, 2))
|
| 1649 |
-
time_step, B, C = torch.split(
|
| 1650 |
-
ssm_parameters, [self.time_step_rank, self.ssm_state_size, self.ssm_state_size], dim=-1
|
| 1651 |
-
)
|
| 1652 |
-
time_step, B, C = self._apply_layernorms(time_step, B, C)
|
| 1653 |
|
| 1654 |
-
|
| 1655 |
-
|
| 1656 |
-
|
| 1657 |
-
|
| 1658 |
-
|
| 1659 |
-
|
| 1660 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1661 |
|
| 1662 |
-
|
| 1663 |
-
|
| 1664 |
-
|
| 1665 |
-
|
| 1666 |
-
|
| 1667 |
-
A = -torch.exp(self.A_log[index].float())
|
| 1668 |
-
|
| 1669 |
-
time_proj_bias = time_proj_bias.float() if time_proj_bias is not None else None
|
| 1670 |
-
if use_precomputed_states:
|
| 1671 |
-
scan_outputs = selective_state_update(
|
| 1672 |
-
cache_params.ssm_states[self.layer_idx],
|
| 1673 |
-
hidden_states[..., 0],
|
| 1674 |
-
discrete_time_step[..., 0],
|
| 1675 |
-
A,
|
| 1676 |
-
B[:, 0],
|
| 1677 |
-
C[:, 0],
|
| 1678 |
-
self.D[index],
|
| 1679 |
-
gate[..., 0],
|
| 1680 |
-
time_proj_bias,
|
| 1681 |
-
dt_softplus=True,
|
| 1682 |
-
).unsqueeze(-1)
|
| 1683 |
-
else:
|
| 1684 |
-
outputs = selective_scan_fn(
|
| 1685 |
-
hidden_states,
|
| 1686 |
-
discrete_time_step,
|
| 1687 |
-
A,
|
| 1688 |
-
B.transpose(1, 2),
|
| 1689 |
-
C.transpose(1, 2),
|
| 1690 |
-
self.D[index].float(),
|
| 1691 |
-
z=gate,
|
| 1692 |
-
delta_bias=time_proj_bias,
|
| 1693 |
-
delta_softplus=True,
|
| 1694 |
-
return_last_state=True,
|
| 1695 |
)
|
| 1696 |
-
|
| 1697 |
-
|
| 1698 |
-
|
|
|
|
|
|
|
| 1699 |
else:
|
| 1700 |
-
|
|
|
|
|
|
|
| 1701 |
|
| 1702 |
-
if
|
| 1703 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1704 |
|
| 1705 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1706 |
|
| 1707 |
-
|
| 1708 |
-
|
| 1709 |
|
| 1710 |
return contextualized_states, attn_key_value
|
| 1711 |
|
|
@@ -2025,49 +2032,6 @@ class HymbaPreTrainedModel(PreTrainedModel):
|
|
| 2025 |
|
| 2026 |
|
| 2027 |
|
| 2028 |
-
def shift_zeros_to_front(attention_mask, hidden_states, position_ids):
|
| 2029 |
-
"""
|
| 2030 |
-
Move all zero entries in 'attention_mask' to the front of the sequence
|
| 2031 |
-
and reorder 'hidden_states' accordingly, preserving the order of zeros
|
| 2032 |
-
and the order of ones.
|
| 2033 |
-
|
| 2034 |
-
Args:
|
| 2035 |
-
attention_mask: (batch_size, seq_len), values in {0, 1}.
|
| 2036 |
-
hidden_states: (batch_size, seq_len, dim).
|
| 2037 |
-
|
| 2038 |
-
Returns:
|
| 2039 |
-
shifted_mask: (batch_size, seq_len) with zeros at the front.
|
| 2040 |
-
shifted_states: (batch_size, seq_len, dim) reordered accordingly.
|
| 2041 |
-
"""
|
| 2042 |
-
B, L = attention_mask.shape
|
| 2043 |
-
D = hidden_states.shape[-1]
|
| 2044 |
-
|
| 2045 |
-
shifted_mask = torch.empty_like(attention_mask)
|
| 2046 |
-
shifted_states = torch.empty_like(hidden_states)
|
| 2047 |
-
shifted_position_ids = torch.empty_like(position_ids)
|
| 2048 |
-
|
| 2049 |
-
# Process each batch row independently
|
| 2050 |
-
for b in range(B):
|
| 2051 |
-
row_mask = attention_mask[b] # (seq_len,)
|
| 2052 |
-
row_states = hidden_states[b] # (seq_len, dim)
|
| 2053 |
-
row_pos = position_ids[b] # (seq_len,)
|
| 2054 |
-
|
| 2055 |
-
# Find positions of zeros and ones
|
| 2056 |
-
zero_indices = torch.where(row_mask == 0)[0]
|
| 2057 |
-
one_indices = torch.where(row_mask == 1)[0]
|
| 2058 |
-
|
| 2059 |
-
# Concatenate zero indices (in order) then one indices
|
| 2060 |
-
new_order = torch.cat([zero_indices, one_indices], dim=0)
|
| 2061 |
-
|
| 2062 |
-
# Reorder mask and states
|
| 2063 |
-
shifted_mask[b] = row_mask[new_order]
|
| 2064 |
-
shifted_states[b] = row_states[new_order]
|
| 2065 |
-
shifted_position_ids[b] = row_pos[new_order]
|
| 2066 |
-
|
| 2067 |
-
return shifted_mask, shifted_states, shifted_position_ids
|
| 2068 |
-
|
| 2069 |
-
|
| 2070 |
-
|
| 2071 |
HYMBA_INPUTS_DOCSTRING = r"""
|
| 2072 |
Args: To be added later. Please refer to the forward function.
|
| 2073 |
"""
|
|
@@ -2236,11 +2200,7 @@ class HymbaModel(HymbaPreTrainedModel):
|
|
| 2236 |
|
| 2237 |
if position_ids is not None and position_ids.shape[1] != inputs_embeds.shape[1]:
|
| 2238 |
position_ids = torch.arange(inputs_embeds.shape[1], device=inputs_embeds.device).unsqueeze(0)
|
| 2239 |
-
|
| 2240 |
-
## Handle paddings: Shift all padding tokens to the beginning of the sequence
|
| 2241 |
-
if inputs_embeds.shape[1] > 1 and attention_mask is not None and (attention_mask == 0).any():
|
| 2242 |
-
attention_mask, inputs_embeds, position_ids = shift_zeros_to_front(attention_mask, inputs_embeds, position_ids)
|
| 2243 |
-
|
| 2244 |
attention_mask_raw = attention_mask
|
| 2245 |
|
| 2246 |
if attention_mask is not None and self._attn_implementation == "flash_attention_2" and use_cache:
|
|
|
|
| 39 |
from torch.utils.checkpoint import checkpoint
|
| 40 |
|
| 41 |
|
| 42 |
+
try:
|
| 43 |
+
from flash_attn import flash_attn_func, flash_attn_varlen_func
|
| 44 |
+
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
|
| 45 |
|
| 46 |
+
_flash_supports_window_size = "window_size" in list(inspect.signature(flash_attn_func).parameters)
|
| 47 |
|
| 48 |
+
from einops import rearrange, repeat, reduce, pack, unpack
|
| 49 |
+
from einops.layers.torch import Rearrange
|
| 50 |
+
except ImportError:
|
| 51 |
+
pass
|
| 52 |
|
| 53 |
|
| 54 |
if is_torch_fx_available():
|
|
|
|
| 399 |
|
| 400 |
if has_mamba_state:
|
| 401 |
if hasattr(config, 'conv_dim'):
|
| 402 |
+
conv_dim = config.conv_dim[i]
|
| 403 |
else:
|
| 404 |
conv_dim = intermediate_size
|
| 405 |
self.conv_states += [
|
|
|
|
| 546 |
|
| 547 |
if self.config.rope:
|
| 548 |
self._init_rope()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 549 |
|
| 550 |
|
| 551 |
def _init_rope(self):
|
|
|
|
| 1228 |
|
| 1229 |
self.attn_mask = or_masks(attn_mask, register_mask)
|
| 1230 |
|
| 1231 |
+
self.block_mask = create_block_mask(self.attn_mask, B=None, H=None, Q_LEN=qk_length, KV_LEN=qk_length, _compile=True)
|
| 1232 |
|
| 1233 |
self.flex_attention = torch.compile(flex_attention)
|
| 1234 |
|
|
|
|
| 1518 |
num_ssm_param = 1
|
| 1519 |
|
| 1520 |
if not hasattr(config, 'conv_dim'):
|
| 1521 |
+
config.conv_dim = {i:0 for i in range(config.num_hidden_layers)}
|
| 1522 |
|
| 1523 |
self.conv1d = nn.Conv1d(
|
| 1524 |
in_channels=self.intermediate_size,
|
|
|
|
| 1529 |
padding=self.conv_kernel_size - 1
|
| 1530 |
)
|
| 1531 |
|
| 1532 |
+
config.conv_dim[self.layer_idx] = self.intermediate_size
|
| 1533 |
|
| 1534 |
self.x_proj = nn.ModuleList([nn.Linear(self.intermediate_size, self.time_step_rank + self.ssm_state_size * 2, bias=False) for _ in range(num_ssm_param)])
|
| 1535 |
self.dt_proj = nn.ModuleList([nn.Linear(self.time_step_rank, self.intermediate_size, bias=True) for _ in range(num_ssm_param)])
|
|
|
|
| 1574 |
def cuda_kernels_forward(self, hidden_states: torch.Tensor, cache_params: HybridMambaAttentionDynamicCache = None, attention_mask=None, position_ids=None, kv_last_layer=None, use_cache=False, use_swa=False):
|
| 1575 |
projected_states = self.in_proj(hidden_states).transpose(1, 2) ## (bs, latent_dim, seq_len)
|
| 1576 |
|
| 1577 |
+
if (
|
| 1578 |
+
self.training and cache_params is None and not self.apply_inner_layernorms
|
| 1579 |
+
): # Doesn't support outputting the states -> used for training
|
| 1580 |
+
contextualized_states = mamba_inner_fn(
|
| 1581 |
+
projected_states,
|
| 1582 |
+
self.conv1d.weight,
|
| 1583 |
+
self.conv1d.bias if self.use_conv_bias else None,
|
| 1584 |
+
self.x_proj.weight,
|
| 1585 |
+
self.dt_proj.weight,
|
| 1586 |
+
self.out_proj.weight,
|
| 1587 |
+
self.out_proj.bias.float() if self.use_bias else None,
|
| 1588 |
+
-torch.exp(self.A_log.float()),
|
| 1589 |
+
None, # input-dependent B
|
| 1590 |
+
None, # input-dependent C
|
| 1591 |
+
self.D.float(),
|
| 1592 |
+
delta_bias=self.dt_proj.bias.float(),
|
| 1593 |
+
delta_softplus=True,
|
| 1594 |
+
)
|
| 1595 |
|
|
|
|
|
|
|
|
|
|
| 1596 |
else:
|
| 1597 |
+
batch_size, seq_len, _ = hidden_states.shape
|
| 1598 |
+
use_precomputed_states = (
|
| 1599 |
+
cache_params is not None
|
| 1600 |
+
and cache_params.has_previous_state
|
| 1601 |
+
and seq_len == 1
|
| 1602 |
+
and cache_params.conv_states[self.layer_idx].shape[0]
|
| 1603 |
+
== cache_params.ssm_states[self.layer_idx].shape[0]
|
| 1604 |
+
== batch_size
|
| 1605 |
+
and use_cache
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1606 |
)
|
|
|
|
| 1607 |
|
| 1608 |
+
hidden_states, gate = projected_states.tensor_split((self.latent_dim,), dim=1)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1609 |
|
| 1610 |
+
conv_weights = self.conv1d.weight.view(self.conv1d.weight.size(0), self.conv1d.weight.size(2))
|
| 1611 |
|
| 1612 |
+
if self.reuse_kv:
|
| 1613 |
+
query_states, hidden_states = hidden_states.tensor_split((self.attn_hidden_size,), dim=1)
|
| 1614 |
+
query_states = query_states.transpose(1,2)
|
| 1615 |
+
else:
|
| 1616 |
+
query_states, key_states, value_states, hidden_states = hidden_states.tensor_split((self.attn_hidden_size, self.attn_hidden_size + self.k_hidden_size, self.attn_hidden_size + self.k_hidden_size + self.v_hidden_size), dim=1)
|
| 1617 |
+
|
| 1618 |
+
query_states = query_states.transpose(1,2)
|
| 1619 |
+
key_states = key_states.transpose(1,2)
|
| 1620 |
+
value_states = value_states.transpose(1,2)
|
| 1621 |
+
|
| 1622 |
+
if use_precomputed_states:
|
| 1623 |
+
hidden_states = causal_conv1d_update(
|
| 1624 |
+
hidden_states.squeeze(-1),
|
| 1625 |
+
cache_params.conv_states[self.layer_idx],
|
| 1626 |
+
conv_weights,
|
| 1627 |
+
self.conv1d.bias,
|
| 1628 |
+
self.activation,
|
| 1629 |
+
)
|
| 1630 |
+
hidden_states = hidden_states.unsqueeze(-1)
|
| 1631 |
|
| 1632 |
+
cache_params.mamba_past_length[self.layer_idx] += seq_len
|
| 1633 |
+
else:
|
| 1634 |
+
if cache_params is not None:
|
| 1635 |
+
conv_states = nn.functional.pad(
|
| 1636 |
+
hidden_states, (self.conv_kernel_size - hidden_states.shape[-1], 0)
|
| 1637 |
+
)
|
|
|
|
|
|
|
|
|
|
| 1638 |
|
| 1639 |
+
cache_params.conv_states[self.layer_idx].copy_(conv_states)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1640 |
|
| 1641 |
+
cache_params.mamba_past_length[self.layer_idx] += seq_len
|
| 1642 |
+
|
| 1643 |
+
hidden_states = causal_conv1d_fn(
|
| 1644 |
+
hidden_states, conv_weights, self.conv1d.bias, activation=self.activation
|
| 1645 |
+
)
|
| 1646 |
+
|
| 1647 |
+
if self.reuse_kv:
|
| 1648 |
+
assert kv_last_layer is not None
|
| 1649 |
+
attn_outputs, attn_key_value = self.self_attn(attention_mask=attention_mask, position_ids=position_ids, query_states=query_states, kv_last_layer=kv_last_layer, use_swa=use_swa, use_cache=use_cache, past_key_value=cache_params)
|
| 1650 |
+
else:
|
| 1651 |
+
attn_outputs, attn_key_value = self.self_attn(attention_mask=attention_mask, position_ids=position_ids, query_states=query_states, key_states=key_states, value_states=value_states, use_swa=use_swa, use_cache=use_cache, past_key_value=cache_params)
|
| 1652 |
|
| 1653 |
+
## Mamba head
|
| 1654 |
+
index = 0
|
| 1655 |
+
ssm_parameters = self.x_proj[index](hidden_states.transpose(1, 2))
|
| 1656 |
+
time_step, B, C = torch.split(
|
| 1657 |
+
ssm_parameters, [self.time_step_rank, self.ssm_state_size, self.ssm_state_size], dim=-1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1658 |
)
|
| 1659 |
+
time_step, B, C = self._apply_layernorms(time_step, B, C)
|
| 1660 |
+
|
| 1661 |
+
if hasattr(self.dt_proj[index], "base_layer"):
|
| 1662 |
+
time_proj_bias = self.dt_proj[index].base_layer.bias
|
| 1663 |
+
self.dt_proj[index].base_layer.bias = None
|
| 1664 |
else:
|
| 1665 |
+
time_proj_bias = self.dt_proj[index].bias
|
| 1666 |
+
self.dt_proj[index].bias = None
|
| 1667 |
+
discrete_time_step = self.dt_proj[index](time_step).transpose(1, 2) # [batch, intermediate_size, seq_len]
|
| 1668 |
|
| 1669 |
+
if hasattr(self.dt_proj[index], "base_layer"):
|
| 1670 |
+
self.dt_proj[index].base_layer.bias = time_proj_bias
|
| 1671 |
+
else:
|
| 1672 |
+
self.dt_proj[index].bias = time_proj_bias
|
| 1673 |
+
|
| 1674 |
+
A = -torch.exp(self.A_log[index].float())
|
| 1675 |
+
|
| 1676 |
+
time_proj_bias = time_proj_bias.float() if time_proj_bias is not None else None
|
| 1677 |
+
if use_precomputed_states:
|
| 1678 |
+
scan_outputs = selective_state_update(
|
| 1679 |
+
cache_params.ssm_states[self.layer_idx],
|
| 1680 |
+
hidden_states[..., 0],
|
| 1681 |
+
discrete_time_step[..., 0],
|
| 1682 |
+
A,
|
| 1683 |
+
B[:, 0],
|
| 1684 |
+
C[:, 0],
|
| 1685 |
+
self.D[index],
|
| 1686 |
+
gate[..., 0],
|
| 1687 |
+
time_proj_bias,
|
| 1688 |
+
dt_softplus=True,
|
| 1689 |
+
).unsqueeze(-1)
|
| 1690 |
+
else:
|
| 1691 |
+
outputs = selective_scan_fn(
|
| 1692 |
+
hidden_states,
|
| 1693 |
+
discrete_time_step,
|
| 1694 |
+
A,
|
| 1695 |
+
B.transpose(1, 2),
|
| 1696 |
+
C.transpose(1, 2),
|
| 1697 |
+
self.D[index].float(),
|
| 1698 |
+
z=gate,
|
| 1699 |
+
delta_bias=time_proj_bias,
|
| 1700 |
+
delta_softplus=True,
|
| 1701 |
+
return_last_state=True,
|
| 1702 |
+
)
|
| 1703 |
|
| 1704 |
+
if len(outputs) == 3:
|
| 1705 |
+
scan_outputs, ssm_state, _ = outputs
|
| 1706 |
+
else:
|
| 1707 |
+
scan_outputs, ssm_state = outputs
|
| 1708 |
+
|
| 1709 |
+
if ssm_state is not None and cache_params is not None:
|
| 1710 |
+
cache_params.ssm_states[self.layer_idx].copy_(ssm_state)
|
| 1711 |
+
|
| 1712 |
+
scan_outputs = scan_outputs.transpose(1, 2)
|
| 1713 |
|
| 1714 |
+
hidden_states = (self.pre_avg_layernorm1(attn_outputs) + self.pre_avg_layernorm2(scan_outputs)) / 2
|
| 1715 |
+
contextualized_states = self.out_proj(hidden_states)
|
| 1716 |
|
| 1717 |
return contextualized_states, attn_key_value
|
| 1718 |
|
|
|
|
| 2032 |
|
| 2033 |
|
| 2034 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2035 |
HYMBA_INPUTS_DOCSTRING = r"""
|
| 2036 |
Args: To be added later. Please refer to the forward function.
|
| 2037 |
"""
|
|
|
|
| 2200 |
|
| 2201 |
if position_ids is not None and position_ids.shape[1] != inputs_embeds.shape[1]:
|
| 2202 |
position_ids = torch.arange(inputs_embeds.shape[1], device=inputs_embeds.device).unsqueeze(0)
|
| 2203 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2204 |
attention_mask_raw = attention_mask
|
| 2205 |
|
| 2206 |
if attention_mask is not None and self._attn_implementation == "flash_attention_2" and use_cache:
|
setup.sh
DELETED
|
@@ -1,44 +0,0 @@
|
|
| 1 |
-
#!/bin/bash
|
| 2 |
-
|
| 3 |
-
# Prompt user to specify CUDA version
|
| 4 |
-
read -p "Enter CUDA version (12.1 or 12.4): " cuda_version
|
| 5 |
-
|
| 6 |
-
# Verify CUDA version input
|
| 7 |
-
if [[ "$cuda_version" != "12.1" && "$cuda_version" != "12.4" ]]; then
|
| 8 |
-
echo "Invalid CUDA version specified. Please choose either 12.1 or 12.4."
|
| 9 |
-
exit 1
|
| 10 |
-
fi
|
| 11 |
-
|
| 12 |
-
# Install PyTorch with the specified CUDA version
|
| 13 |
-
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=$cuda_version -c pytorch -c nvidia
|
| 14 |
-
|
| 15 |
-
# Install other packages
|
| 16 |
-
pip install --upgrade transformers
|
| 17 |
-
pip install tiktoken
|
| 18 |
-
pip install sentencepiece
|
| 19 |
-
pip install protobuf
|
| 20 |
-
pip install ninja einops triton packaging
|
| 21 |
-
|
| 22 |
-
# Clone and install Mamba
|
| 23 |
-
git clone https://github.com/state-spaces/mamba.git
|
| 24 |
-
cd mamba
|
| 25 |
-
pip install -e .
|
| 26 |
-
cd ..
|
| 27 |
-
|
| 28 |
-
# Clone and install causal-conv1d with specified CUDA version
|
| 29 |
-
git clone https://github.com/Dao-AILab/causal-conv1d.git
|
| 30 |
-
cd causal-conv1d
|
| 31 |
-
export CUDA_HOME=/usr/local/cuda-$cuda_version
|
| 32 |
-
TORCH_CUDA_ARCH_LIST="7.0;7.5;8.0;8.6;8.9;9.0" python setup.py install
|
| 33 |
-
cd ..
|
| 34 |
-
|
| 35 |
-
# Clone and install attention-gym
|
| 36 |
-
git clone https://github.com/pytorch-labs/attention-gym.git
|
| 37 |
-
cd attention-gym
|
| 38 |
-
pip install .
|
| 39 |
-
cd ..
|
| 40 |
-
|
| 41 |
-
# Install Flash Attention
|
| 42 |
-
pip install flash_attn
|
| 43 |
-
|
| 44 |
-
echo "Installation completed with CUDA $cuda_version."
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
special_tokens_map.json
DELETED
|
@@ -1,30 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"bos_token": {
|
| 3 |
-
"content": "<s>",
|
| 4 |
-
"lstrip": false,
|
| 5 |
-
"normalized": false,
|
| 6 |
-
"rstrip": false,
|
| 7 |
-
"single_word": false
|
| 8 |
-
},
|
| 9 |
-
"eos_token": {
|
| 10 |
-
"content": "</s>",
|
| 11 |
-
"lstrip": false,
|
| 12 |
-
"normalized": false,
|
| 13 |
-
"rstrip": false,
|
| 14 |
-
"single_word": false
|
| 15 |
-
},
|
| 16 |
-
"pad_token": {
|
| 17 |
-
"content": "[PAD]",
|
| 18 |
-
"lstrip": false,
|
| 19 |
-
"normalized": false,
|
| 20 |
-
"rstrip": false,
|
| 21 |
-
"single_word": false
|
| 22 |
-
},
|
| 23 |
-
"unk_token": {
|
| 24 |
-
"content": "<unk>",
|
| 25 |
-
"lstrip": false,
|
| 26 |
-
"normalized": false,
|
| 27 |
-
"rstrip": false,
|
| 28 |
-
"single_word": false
|
| 29 |
-
}
|
| 30 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
tokenizer.json
DELETED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
DELETED
|
@@ -1,52 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"add_bos_token": true,
|
| 3 |
-
"add_eos_token": false,
|
| 4 |
-
"add_prefix_space": true,
|
| 5 |
-
"added_tokens_decoder": {
|
| 6 |
-
"0": {
|
| 7 |
-
"content": "<unk>",
|
| 8 |
-
"lstrip": false,
|
| 9 |
-
"normalized": false,
|
| 10 |
-
"rstrip": false,
|
| 11 |
-
"single_word": false,
|
| 12 |
-
"special": true
|
| 13 |
-
},
|
| 14 |
-
"1": {
|
| 15 |
-
"content": "<s>",
|
| 16 |
-
"lstrip": false,
|
| 17 |
-
"normalized": false,
|
| 18 |
-
"rstrip": false,
|
| 19 |
-
"single_word": false,
|
| 20 |
-
"special": true
|
| 21 |
-
},
|
| 22 |
-
"2": {
|
| 23 |
-
"content": "</s>",
|
| 24 |
-
"lstrip": false,
|
| 25 |
-
"normalized": false,
|
| 26 |
-
"rstrip": false,
|
| 27 |
-
"single_word": false,
|
| 28 |
-
"special": true
|
| 29 |
-
},
|
| 30 |
-
"32000": {
|
| 31 |
-
"content": "[PAD]",
|
| 32 |
-
"lstrip": false,
|
| 33 |
-
"normalized": false,
|
| 34 |
-
"rstrip": false,
|
| 35 |
-
"single_word": false,
|
| 36 |
-
"special": true
|
| 37 |
-
}
|
| 38 |
-
},
|
| 39 |
-
"bos_token": "<s>",
|
| 40 |
-
"chat_template": "{{'<extra_id_0>System'}}{% for message in messages %}{% if message['role'] == 'system' %}{{'\n' + message['content'].strip()}}{% if tools or contexts %}{{'\n'}}{% endif %}{% endif %}{% endfor %}{% if tools %}{% for tool in tools %}{{ '\n<tool> ' + tool|tojson + ' </tool>' }}{% endfor %}{% endif %}{% if contexts %}{% if tools %}{{'\n'}}{% endif %}{% for context in contexts %}{{ '\n<context> ' + context.strip() + ' </context>' }}{% endfor %}{% endif %}{{'\n\n'}}{% for message in messages %}{% if message['role'] == 'user' %}{{ '<extra_id_1>User\n' + message['content'].strip() + '\n' }}{% elif message['role'] == 'assistant' %}{{ '<extra_id_1>Assistant\n' + message['content'].strip() + '\n' }}{% elif message['role'] == 'tool' %}{{ '<extra_id_1>Tool\n' + message['content'].strip() + '\n' }}{% endif %}{% endfor %}{%- if add_generation_prompt %}{{'<extra_id_1>Assistant\n'}}{%- endif %}",
|
| 41 |
-
"clean_up_tokenization_spaces": false,
|
| 42 |
-
"eos_token": "</s>",
|
| 43 |
-
"legacy": true,
|
| 44 |
-
"model_max_length": 1000000000000000019884624838656,
|
| 45 |
-
"pad_token": "[PAD]",
|
| 46 |
-
"padding_side": "left",
|
| 47 |
-
"sp_model_kwargs": {},
|
| 48 |
-
"spaces_between_special_tokens": false,
|
| 49 |
-
"tokenizer_class": "LlamaTokenizer",
|
| 50 |
-
"unk_token": "<unk>",
|
| 51 |
-
"use_default_system_prompt": false
|
| 52 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|