
Hymba
Collection
A series of Hybrid Small Language Models.
•
2 items
•
Updated
•
28
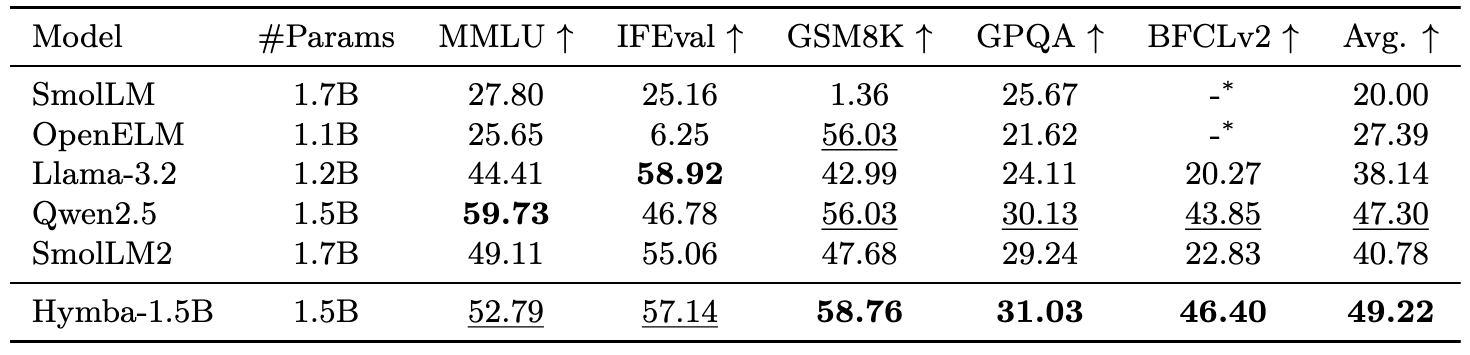
Hymba-1.5B-Instruct is a 1.5B parameter model finetuned from Hymba-1.5B-Base using a combination of open source instruction datasets and internally collected synthetic datasets. This model is finetuned with supervised fine-tuning and direct preference optimization.
Hymba-1.5B-Instruct is capable of many complex and important tasks like math reasoning, function calling, and role playing.
This model is ready for commercial use.
Model Developer: NVIDIA
Model Dates: Hymba-1.5B-Instruct was trained between September 4, 2024 and November 10th, 2024.
License: This model is released under the NVIDIA Open Model License Agreement.
⚡️ We've released a minimal implementation of Hymba on GitHub to help developers understand and implement its design principles in their own models. Check it out! barebones-hymba.
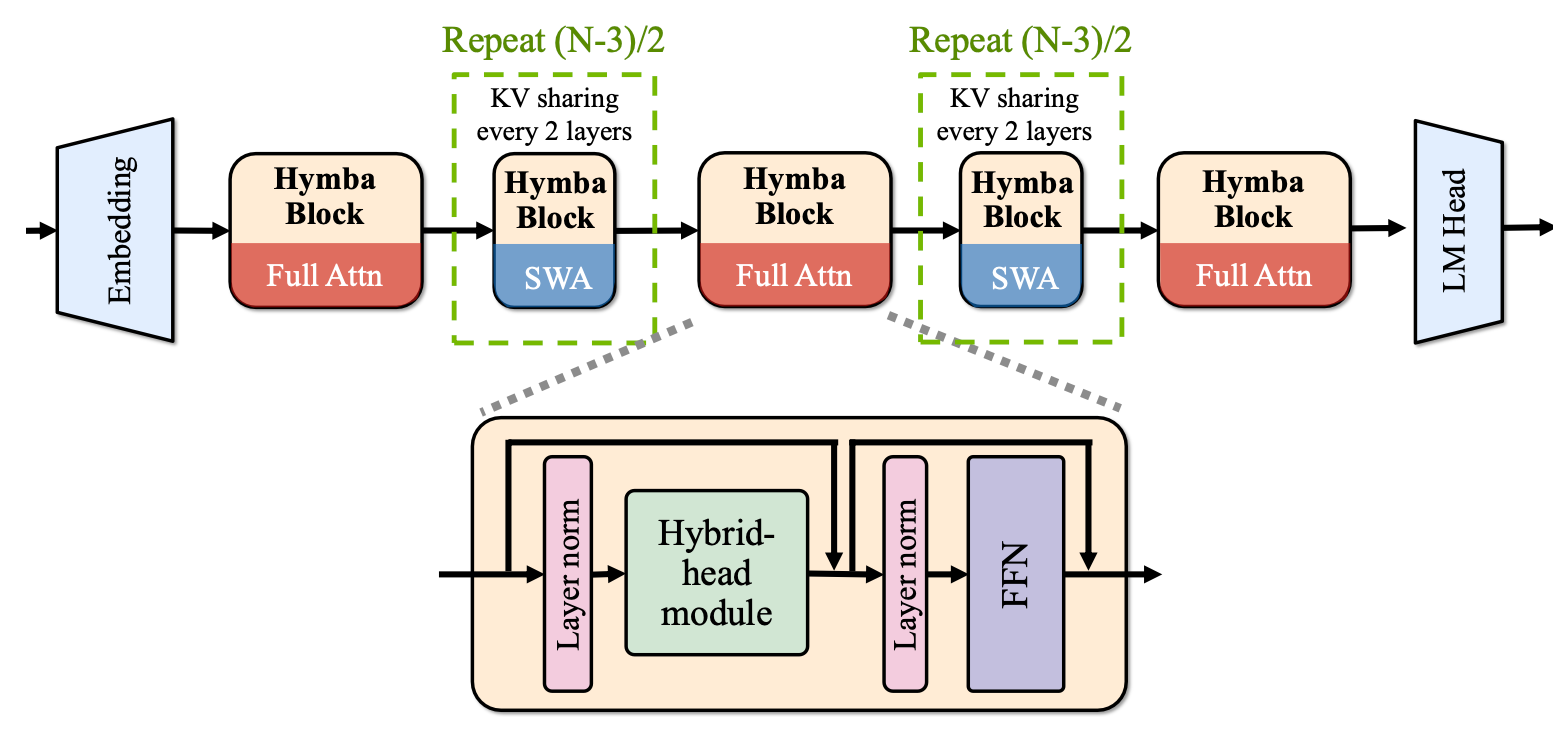
Hymba-1.5B-Instruct has a model embedding size of 1600, 25 attention heads, and an MLP intermediate dimension of 5504, with 32 layers in total, 16 SSM states, 3 full attention layers, the rest are sliding window attention. Unlike the standard Transformer, each attention layer in Hymba has a hybrid combination of standard attention heads and Mamba heads in parallel. Additionally, it uses Grouped-Query Attention (GQA) and Rotary Position Embeddings (RoPE).
Features of this architecture:
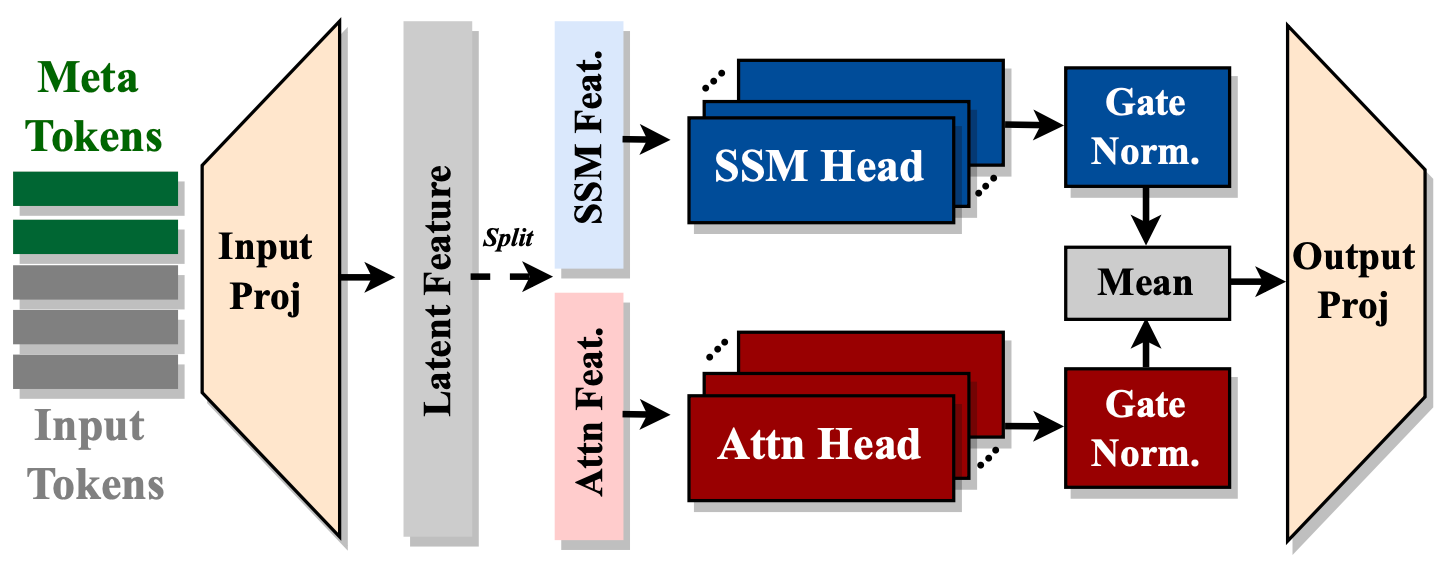
Introduce meta tokens that are prepended to the input sequences and interact with all subsequent tokens, thus storing important information and alleviating the burden of "forced-to-attend" in attention.
Integrate with cross-layer KV sharing and global-local attention to further boost memory and computation efficiency.
Since Hymba-1.5B-Instruct employs FlexAttention, which relies on Pytorch2.5 and other related dependencies, we provide two ways to setup the environment:
setup.sh (support CUDA 12.1/12.4):wget --header="Authorization: Bearer YOUR_HF_TOKEN" https://huggingface.co./nvidia/Hymba-1.5B-Base/resolve/main/setup.sh
bash setup.sh
docker pull ghcr.io/tilmto/hymba:v1
docker run --gpus all -v /home/$USER:/home/$USER -it ghcr.io/tilmto/hymba:v1 bash
After setting up the environment, you can use the following script to chat with our Model
from transformers import AutoModelForCausalLM, AutoTokenizer, StopStringCriteria, StoppingCriteriaList
import torch
# Load the tokenizer and model
repo_name = "nvidia/Hymba-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(repo_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(repo_name, trust_remote_code=True)
model = model.cuda().to(torch.bfloat16)
# Chat with Hymba
prompt = input()
messages = [
{"role": "system", "content": "You are a helpful assistant."}
]
messages.append({"role": "user", "content": prompt})
# Apply chat template
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").to('cuda')
stopping_criteria = StoppingCriteriaList([StopStringCriteria(tokenizer=tokenizer, stop_strings="</s>")])
outputs = model.generate(
tokenized_chat,
max_new_tokens=256,
do_sample=False,
temperature=0.7,
use_cache=True,
stopping_criteria=stopping_criteria
)
input_length = tokenized_chat.shape[1]
response = tokenizer.decode(outputs[0][input_length:], skip_special_tokens=True)
print(f"Model response: {response}")
The prompt template used by Hymba-1.5B-Instruct is as follows, which has been integrated into the tokenizer and can be applied using tokenizer.apply_chat_template:
<extra_id_0>System
{system prompt}
<extra_id_1>User
<tool> ... </tool>
<context> ... </context>
{prompt}
<extra_id_1>Assistant
<toolcall> ... </toolcall>
<extra_id_1>Tool
{tool response}
<extra_id_1>Assistant\n
LMFlow is a complete pipeline for fine-tuning large language models.
The following steps provide an example of how to fine-tune the Hymba-1.5B-Base models using LMFlow.
Using Docker
docker pull ghcr.io/tilmto/hymba:v1
docker run --gpus all -v /home/$USER:/home/$USER -it ghcr.io/tilmto/hymba:v1 bash
Install LMFlow
git clone https://github.com/OptimalScale/LMFlow.git
cd LMFlow
conda create -n lmflow python=3.9 -y
conda activate lmflow
conda install mpi4py
pip install -e .
Fine-tune the model using the following command.
cd LMFlow
bash ./scripts/run_finetune_hymba.sh
With LMFlow, you can also fine-tune the model on your custom dataset. The only thing you need to do is transform your dataset into the LMFlow data format. In addition to full-finetuniing, you can also fine-tune hymba efficiently with DoRA, LoRA, LISA, Flash Attention, and other acceleration techniques. For more details, please refer to the LMFlow for Hymba documentation.
The model was trained on data that contains toxic language, unsafe content, and societal biases originally crawled from the internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts. The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive.
The testing suggests that this model is susceptible to jailbreak attacks. If using this model in a RAG or agentic setting, we recommend strong output validation controls to ensure security and safety risks from user-controlled model outputs are consistent with the intended use cases.
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse. Please report security vulnerabilities or NVIDIA AI Concerns here.
@misc{dong2024hymbahybridheadarchitecturesmall,
title={Hymba: A Hybrid-head Architecture for Small Language Models},
author={Xin Dong and Yonggan Fu and Shizhe Diao and Wonmin Byeon and Zijia Chen and Ameya Sunil Mahabaleshwarkar and Shih-Yang Liu and Matthijs Van Keirsbilck and Min-Hung Chen and Yoshi Suhara and Yingyan Lin and Jan Kautz and Pavlo Molchanov},
year={2024},
eprint={2411.13676},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2411.13676},
}
Base model
nvidia/Hymba-1.5B-Base