
SmolVLM 256M & 500M
Collection
Collection for models & demos for even smoller SmolVLM release
•
12 items
•
Updated
•
69

SmolVLM-256M is the smallest multimodal model in the world. It accepts arbitrary sequences of image and text inputs to produce text outputs. It's designed for efficiency. SmolVLM can answer questions about images, describe visual content, or transcribe text. Its lightweight architecture makes it suitable for on-device applications while maintaining strong performance on multimodal tasks. It can run inference on one image with under 1GB of GPU RAM.
SmolVLM can be used for inference on multimodal (image + text) tasks where the input comprises text queries along with one or more images. Text and images can be interleaved arbitrarily, enabling tasks like image captioning, visual question answering, and storytelling based on visual content. The model does not support image generation.
To fine-tune SmolVLM on a specific task, you can follow the fine-tuning tutorial.
SmolVLM leverages the lightweight SmolLM2 language model to provide a compact yet powerful multimodal experience. It introduces several changes compared to the larger SmolVLM 2.2B model:
More details about the training and architecture are available in our technical report.
You can use transformers to load, infer and fine-tune SmolVLM.
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Load images
image = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
# Initialize processor and model
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-256M-Instruct")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-256M-Instruct",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager",
).to(DEVICE)
# Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Can you describe this image?"}
]
},
]
# Prepare inputs
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image], return_tensors="pt")
inputs = inputs.to(DEVICE)
# Generate outputs
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])
"""
Assistant: The image depicts a large, historic statue of liberty, located in New York City. The statue is a green, cylindrical structure with a human figure at the top, holding a torch. The statue is situated on a pedestal that resembles the statue of liberty, which is located on a small island in the middle of a body of water. The water surrounding the island is calm, reflecting the blue sky and the statue.
In the background, there are several tall buildings, including the Empire State Building, which is visible in the distance. These buildings are made of glass and steel, and they are positioned in a grid-like pattern, giving them a modern look. The sky is clear, with a few clouds visible, indicating fair weather.
The statue is surrounded by trees, which are green and appear to be healthy. There are also some small structures, possibly houses or buildings, visible in the distance. The overall scene suggests a peaceful and serene environment, typical of a cityscape.
The image is taken during the daytime, likely during the day of the statue's installation. The lighting is bright, casting a strong shadow on the statue and the water, which enhances the visibility of the statue and the surrounding environment.
To summarize, the image captures a significant historical statue of liberty, situated on a small island in the middle of a body of water, surrounded by trees and buildings. The sky is clear, with a few clouds visible, indicating fair weather. The statue is green and cylindrical, with a human figure holding a torch, and is surrounded by trees, indicating a peaceful and well-maintained environment. The overall scene is one of tranquility and historical significance.
"""
We also provide ONNX weights for the model, which you can run with ONNX Runtime as follows:
from transformers import AutoConfig, AutoProcessor
from transformers.image_utils import load_image
import onnxruntime
import numpy as np
# 1. Load models
## Load config and processor
model_id = "HuggingFaceTB/SmolVLM-256M-Instruct"
config = AutoConfig.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
## Load sessions
## !wget https://huggingface.co./HuggingFaceTB/SmolVLM-256M-Instruct/resolve/main/onnx/vision_encoder.onnx
## !wget https://huggingface.co./HuggingFaceTB/SmolVLM-256M-Instruct/resolve/main/onnx/embed_tokens.onnx
## !wget https://huggingface.co./HuggingFaceTB/SmolVLM-256M-Instruct/resolve/main/onnx/decoder_model_merged.onnx
vision_session = onnxruntime.InferenceSession("vision_encoder.onnx")
embed_session = onnxruntime.InferenceSession("embed_tokens.onnx")
decoder_session = onnxruntime.InferenceSession("decoder_model_merged.onnx")
## Set config values
num_key_value_heads = config.text_config.num_key_value_heads
head_dim = config.text_config.head_dim
num_hidden_layers = config.text_config.num_hidden_layers
eos_token_id = config.text_config.eos_token_id
image_token_id = config.image_token_id
# 2. Prepare inputs
## Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "Can you describe this image?"}
]
},
]
## Load image and apply processor
image = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image], return_tensors="np")
## Prepare decoder inputs
batch_size = inputs['input_ids'].shape[0]
past_key_values = {
f'past_key_values.{layer}.{kv}': np.zeros([batch_size, num_key_value_heads, 0, head_dim], dtype=np.float32)
for layer in range(num_hidden_layers)
for kv in ('key', 'value')
}
image_features = None
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
position_ids = np.cumsum(inputs['attention_mask'], axis=-1)
# 3. Generation loop
max_new_tokens = 1024
generated_tokens = np.array([[]], dtype=np.int64)
for i in range(max_new_tokens):
inputs_embeds = embed_session.run(None, {'input_ids': input_ids})[0]
if image_features is None:
## Only compute vision features if not already computed
image_features = vision_session.run(
['image_features'], # List of output names or indices
{
'pixel_values': inputs['pixel_values'],
'pixel_attention_mask': inputs['pixel_attention_mask'].astype(np.bool_)
}
)[0]
## Merge text and vision embeddings
inputs_embeds[inputs['input_ids'] == image_token_id] = image_features.reshape(-1, image_features.shape[-1])
logits, *present_key_values = decoder_session.run(None, dict(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
position_ids=position_ids,
**past_key_values,
))
## Update values for next generation loop
input_ids = logits[:, -1].argmax(-1, keepdims=True)
attention_mask = np.ones_like(input_ids)
position_ids = position_ids[:, -1:] + 1
for j, key in enumerate(past_key_values):
past_key_values[key] = present_key_values[j]
generated_tokens = np.concatenate([generated_tokens, input_ids], axis=-1)
if (input_ids == eos_token_id).all():
break
## (Optional) Streaming
print(processor.decode(input_ids[0]), end='')
print()
# 4. Output result
print(processor.batch_decode(generated_tokens))
Example output:
The image depicts a large, historic statue of Liberty situated on a small island in a body of water. The statue is a green, cylindrical structure with a human figure at the top, which is the actual statue of Liberty. The statue is mounted on a pedestal that is supported by a cylindrical tower. The pedestal is rectangular and appears to be made of stone or a similar material. The statue is surrounded by a large, flat, rectangular area that is likely a base for the statue.
In the background, there is a cityscape with a variety of buildings, including skyscrapers and high-rise buildings. The sky is clear with a gradient of colors, transitioning from a pale blue at the top to a deeper blue at the bottom. The buildings are mostly modern, with a mix of glass and concrete. The buildings are densely packed, with many skyscrapers and high-rise buildings visible.
There are trees and greenery visible on the left side of the image, indicating that the statue is located near a park or a park area. The water in the foreground is calm, with small ripples indicating that the statue is in the water.
The overall scene suggests a peaceful and serene environment, likely a public park or a park area in a city. The statue is likely a representation of liberty, representing the city's commitment to freedom and democracy.
### Analysis and Description:
#### Statue of Liberty:
- **Location**: The statue is located on a small island in a body of water.
- **Statue**: The statue is a green cylindrical structure with a human figure at the top, which is the actual statue of Liberty.
- **Pedestal**: The pedestal is rectangular and supports the statue.
- **Pedestrian**: The pedestal is surrounded by a flat rectangular area.
- **Water**: The water is calm, with small ripples indicating that the statue is in the water.
#### Cityscape:
- **Buildings**: The buildings are modern, with a mix of glass and concrete.
- **Sky**: The sky is clear with a gradient of colors, transitioning from a pale blue at the top to a deeper blue at the bottom.
- **Trees**: There are trees and greenery visible on the left side of the image, indicating that the statue is located near a park or a park area.
#### Environment:
- **Water**: The water is calm, with small ripples indicating that the statue is in the water.
- **Sky**: The sky is clear with a gradient of colors, transitioning from a pale blue at the top to a deeper blue at the bottom.
### Conclusion:
The image depicts a peaceful and serene public park or park area in a city, with the statue of Liberty prominently featured. The cityscape in the background includes modern buildings and a clear sky, suggesting a well-maintained public space.<end_of_utterance>
Precision: For better performance, load and run the model in half-precision (torch.bfloat16) if your hardware supports it.
from transformers import AutoModelForVision2Seq
import torch
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16
).to("cuda")
You can also load SmolVLM with 4/8-bit quantization using bitsandbytes, torchao or Quanto. Refer to this page for other options.
from transformers import AutoModelForVision2Seq, BitsAndBytesConfig
import torch
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
quantization_config=quantization_config,
)
Vision Encoder Efficiency: Adjust the image resolution by setting size={"longest_edge": N*512} when initializing the processor, where N is your desired value. The default N=4 works well, which results in input images of
size 2048×2048. Decreasing N can save GPU memory and is appropriate for lower-resolution images. This is also useful if you want to fine-tune on videos.
SmolVLM is not intended for high-stakes scenarios or critical decision-making processes that affect an individual's well-being or livelihood. The model may produce content that appears factual but may not be accurate. Misuse includes, but is not limited to:
SmolVLM is built upon SigLIP as image encoder and SmolLM2 for text decoder part.
We release the SmolVLM checkpoints under the Apache 2.0 license.
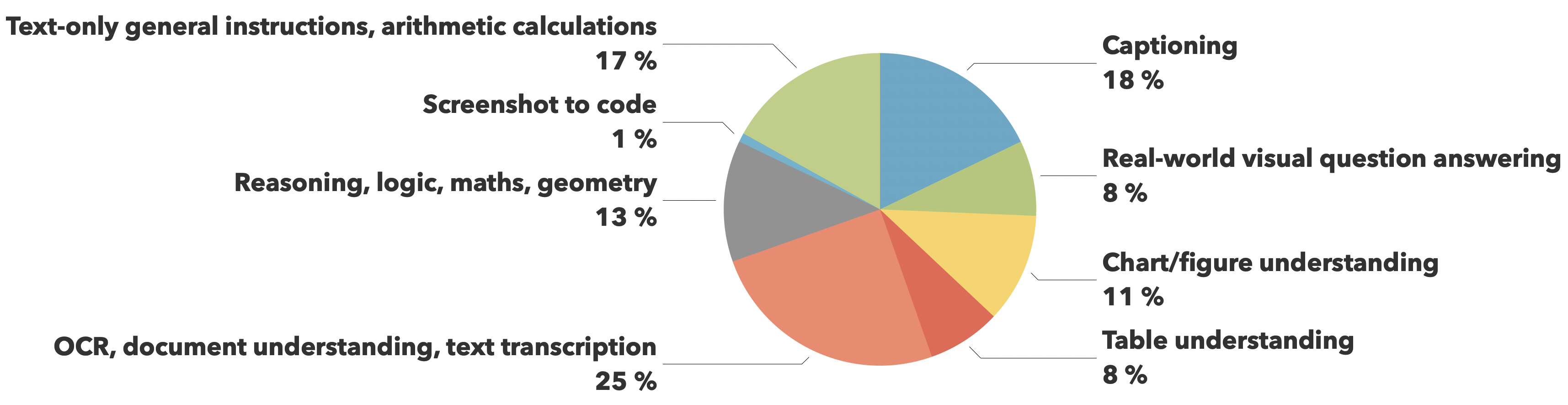
The training data comes from The Cauldron and Docmatix datasets, with emphasis on document understanding (25%) and image captioning (18%), while maintaining balanced coverage across other crucial capabilities like visual reasoning, chart comprehension, and general instruction following.
| Size | Mathvista | MMMU | OCRBench | MMStar | AI2D | ChartQA_Test | Science_QA | TextVQA Val | DocVQA Val |
|---|---|---|---|---|---|---|---|---|---|
| 256M | 35.9 | 28.3 | 52.6 | 34.6 | 47 | 55.8 | 73.6 | 49.9 | 58.3 |
| 500M | 40.1 | 33.7 | 61 | 38.3 | 59.5 | 63.2 | 79.7 | 60.5 | 70.5 |
| 2.2B | 43.9 | 38.3 | 65.5 | 41.8 | 64 | 71.6 | 84.5 | 72.1 | 79.7 |
Base model
HuggingFaceTB/SmolLM2-135M