
Hugging Face TB Research
Enterprise
community
AI & ML interests
Exploring smol models and high quality web and synthetic datasets, generated by LLMs (TB is for Textbook, as inspired by the "Textbooks are all your need" paper)
Recent Activity
Organization Card
HuggingFaceTB
This is the home for smol models (SmolLM & SmolVLM) and high quality pre-training datasets. We released:
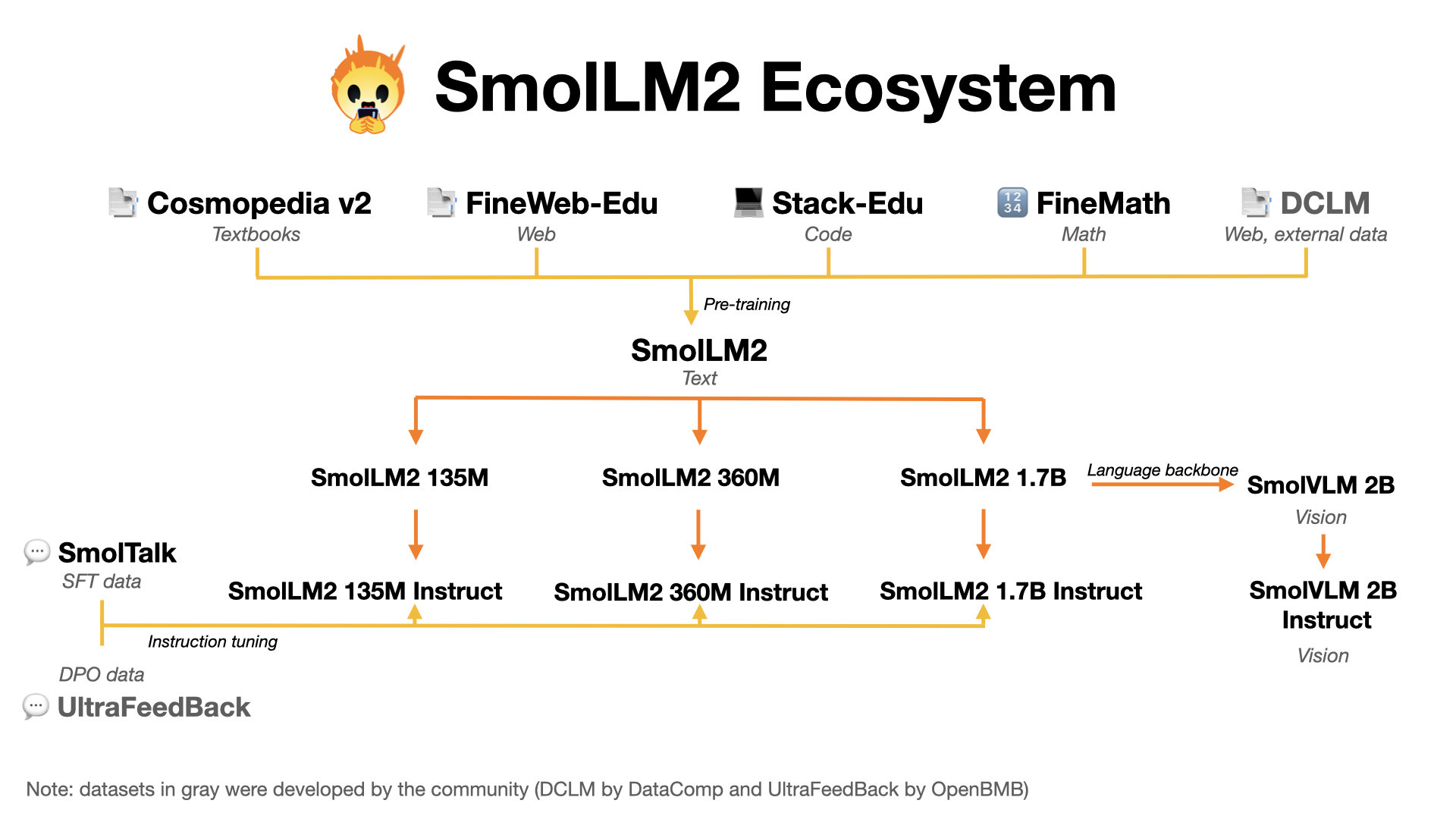
- FineWeb-Edu: a filtered version of FineWeb dataset for educational content, paper available here.
- Cosmopedia: the largest open synthetic dataset, with 25B tokens and 30M samples. It contains synthetic textbooks, blog posts, and stories, posts generated by Mixtral. Blog post available here.
- Smollm-Corpus: the pre-training corpus of SmolLM: Cosmopedia v0.2, FineWeb-Edu dedup and Python-Edu. Blog post available here.
- SmolLM2 models: a series of strong small models in three sizes: 135M, 360M and 1.7B
- SmolVLM: a 2 billion Vision Language Model (VLM) built for on-device inference. It uses SmolLM2-1.7B as a language backbone. Blog post available here.
- FineMath: the best public math pretraining dataset with 50B tokens of mathematical and problem solving data.
News 🗞️
- FineMath: the best public math pretraining dataset with 50B tokens of mathematical and problem solving data https://huggingface.co./datasets/HuggingFaceTB/finemath
Collections
12
spaces
12
Running
on
A100
17
SmolVLM2 XSPFGenerator (VLC prototype)
🎞
Generate video highlights and playlist
Running
15
SmolVLM2 IPhone Waitlist
⏰
sign in to receive news on the iPhone app
Running
on
A100
46
SmolVLM2 HighlightGenerator
🐨
Generate video highlights from uploaded video
Running
on
Zero
41
SmolVLM
📊
Generate text by analyzing images and videos
Running
39
SmolVLM 256M Instruct WebGPU
🐨
Generate descriptions for images using WebGPU technology
Running
31
SmolVLM 500M Instruct WebGPU
💻
models
73
HuggingFaceTB/SmolLM2-360M-intermediate-checkpoints
Updated
HuggingFaceTB/SmolLM2-1.7B-intermediate-checkpoints
Updated
HuggingFaceTB/SmolLM2-135M-intermediate-checkpoints
Updated
•
2
HuggingFaceTB/SmolVLM2-2.2B-Instruct
Image-Text-to-Text
•
Updated
•
51k
•
82
HuggingFaceTB/SmolVLM2-256M-Video-Instruct
Video-Text-to-Text
•
Updated
•
2.4k
•
28
HuggingFaceTB/SmolVLM2-500M-Video-Instruct
Video-Text-to-Text
•
Updated
•
2.99k
•
33
HuggingFaceTB/SmolLM2-1.7B-Instruct-16k
Text Generation
•
Updated
•
1.37k
•
6
HuggingFaceTB/SmolLM2-360M-Instruct
Text Generation
•
Updated
•
725k
•
•
98
HuggingFaceTB/stack-edu-classifier-python
Updated
•
91
•
1
HuggingFaceTB/stack-edu-classifier-cpp
Updated
•
23
datasets
35
HuggingFaceTB/smoltalk
Viewer
•
Updated
•
2.2M
•
7.4k
•
308
HuggingFaceTB/smol-smoltalk
Viewer
•
Updated
•
485k
•
720
•
32
HuggingFaceTB/finemath
Viewer
•
Updated
•
48.3M
•
11.8k
•
286
HuggingFaceTB/everyday-conversations-llama3.1-2k
Viewer
•
Updated
•
2.38k
•
666
•
97
HuggingFaceTB/MagPie-Pro-300k-MT
Viewer
•
Updated
•
300k
•
134
HuggingFaceTB/finemath_contamination_report
Viewer
•
Updated
•
5.33k
•
112
•
1
HuggingFaceTB/math_tasks
Viewer
•
Updated
•
21.3k
•
237
•
1
HuggingFaceTB/MATH
Updated
•
146
•
4
HuggingFaceTB/smollm-corpus
Viewer
•
Updated
•
237M
•
12k
•
301
HuggingFaceTB/instruct-data-basics-smollm-H4
Viewer
•
Updated
•
767
•
175