Spaces:
Running
on
Zero



A newer version of the Gradio SDK is available:
5.5.0
Text-to-Audio with Latent Diffusion Model
![]()

This is the quicktour for training a text-to-audio model with the popular and powerful generative model: Latent Diffusion Model. Specially, this recipe is also the official implementation of the text-to-audio generation part of our NeurIPS 2023 paper "AUDIT: Audio Editing by Following Instructions with Latent Diffusion Models". You can check the last part of AUDIT demos to see same text-to-audio examples.
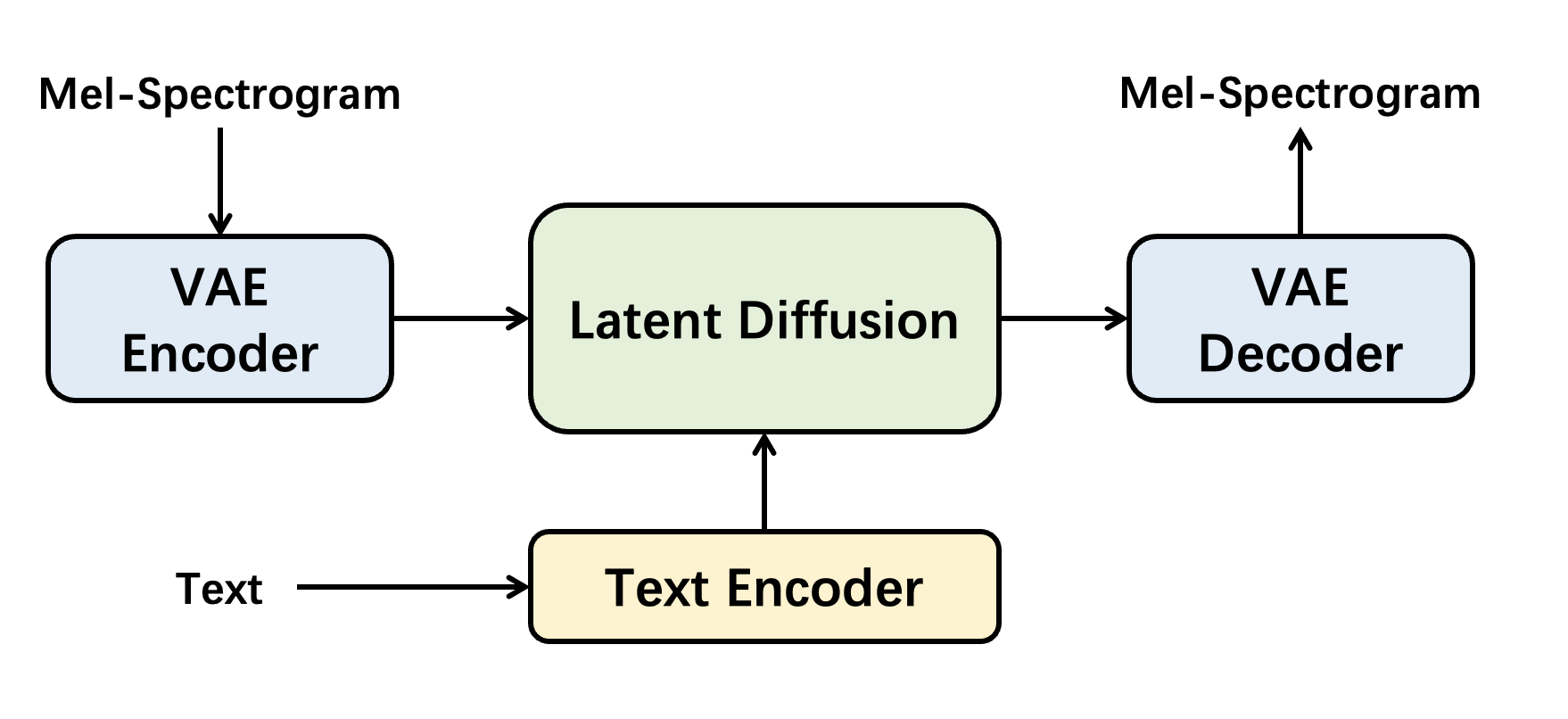
We train this latent diffusion model in two stages:
- In the first stage, we aims to obtain a high-quality VAE (called
AutoencoderKLin Amphion), in order that we can project the input mel-spectrograms to an efficient, low-dimensional latent space. Specially, we train the VAE with GAN loss to improve the reconstruction quality. - In the second stage, we aims to obtain a text-controllable diffusion model (called
AudioLDMin Amphion). We use U-Net architecture diffusion model, and use T5 encoder as text encoder.
There are four stages in total for training the text-to-audio model:
- Data preparation and processing
- Train the VAE model
- Train the latent diffusion model
- Inference
NOTE: You need to run every command of this recipe in the
Amphionroot path:cd Amphion
Overview
# Train the VAE model
sh egs/tta/autoencoderkl/run_train.sh
# Train the latent diffusion model
sh egs/tta/audioldm/run_train.sh
# Inference
sh egs/tta/audioldm/run_inference.sh
1. Data preparation and processing
Dataset Download
We take AudioCaps as an example, AudioCaps is a dataset of around 44K audio-caption pairs, where each audio clip corresponds to a caption with rich semantic information. We have already processed the dataset. You can download the dataset here.
Data Processing
- Download AudioCaps dataset to
[Your path to save tta dataset]and modifypreprocess.processed_dirinegs/tta/.../exp_config.json.
{
"dataset": [
"AudioCaps"
],
"preprocess": {
// Specify the output root path to save the processed data
"processed_dir": "[Your path to save tta dataset]",
...
}
}
The folder structure of your downloaded data should be similar to:
.../[Your path to save tta dataset]
┣ AudioCaps
┃ ┣ wav
┃ ┃ ┣ ---1_cCGK4M_0_10000.wav
┃ ┃ ┣ ---lTs1dxhU_30000_40000.wav
┃ ┃ ┣ ...
Then you may process the data to mel-specgram and save it as
.npyformat. If you use the data we provide, we have processed all the wav data.Generate a json file to save the metadata, the json file is like:
[
{
"Dataset": "AudioCaps",
"Uid": "---1_cCGK4M_0_10000",
"Caption": "Idling car, train blows horn and passes"
},
{
"Dataset": "AudioCaps",
"Uid": "---lTs1dxhU_30000_40000",
"Caption": "A racing vehicle engine is heard passing by"
},
...
]
- Finally, the folder structure is like:
.../[Your path to save tta dataset]
┣ AudioCpas
┃ ┣ wav
┃ ┃ ┣ ---1_cCGK4M_0_10000.wav
┃ ┃ ┣ ---lTs1dxhU_30000_40000.wav
┃ ┃ ┣ ...
┃ ┣ mel
┃ ┃ ┣ ---1_cCGK4M_0_10000.npy
┃ ┃ ┣ ---lTs1dxhU_30000_40000.npy
┃ ┃ ┣ ...
┃ ┣ train.json
┃ ┣ valid.json
┃ ┣ ...
2. Training the VAE Model
The first stage model is a VAE model trained with GAN loss (called AutoencoderKL in Amphion), run the follow commands:
sh egs/tta/autoencoderkl/run_train.sh
3. Training the Latent Diffusion Model
The second stage model is a condition diffusion model with a T5 text encoder (called AudioLDM in Amphion), run the following commands:
sh egs/tta/audioldm/run_train.sh
4. Inference
Now you can generate audio with your pre-trained latent diffusion model, run the following commands and modify the text argument.
sh egs/tta/audioldm/run_inference.sh \
--text "A man is whistling"
Citations
@article{wang2023audit,
title={AUDIT: Audio Editing by Following Instructions with Latent Diffusion Models},
author={Wang, Yuancheng and Ju, Zeqian and Tan, Xu and He, Lei and Wu, Zhizheng and Bian, Jiang and Zhao, Sheng},
journal={NeurIPS 2023},
year={2023}
}
@article{liu2023audioldm,
title={{AudioLDM}: Text-to-Audio Generation with Latent Diffusion Models},
author={Liu, Haohe and Chen, Zehua and Yuan, Yi and Mei, Xinhao and Liu, Xubo and Mandic, Danilo and Wang, Wenwu and Plumbley, Mark D},
journal={Proceedings of the International Conference on Machine Learning},
year={2023}
}