Aranizer | Arabic Tokenizer
Aranizer is an Arabic PBE-based tokenizer designed for efficient and versatile tokenization.
Features
- Tokenizer Name: Aranizer
- Type: PBE tokenizer
- Vocabulary Size: 86,000
- Total Number of Tokens: 1,301,758
- Fertility Score: 1.691
- It supports Arabic Diacritization
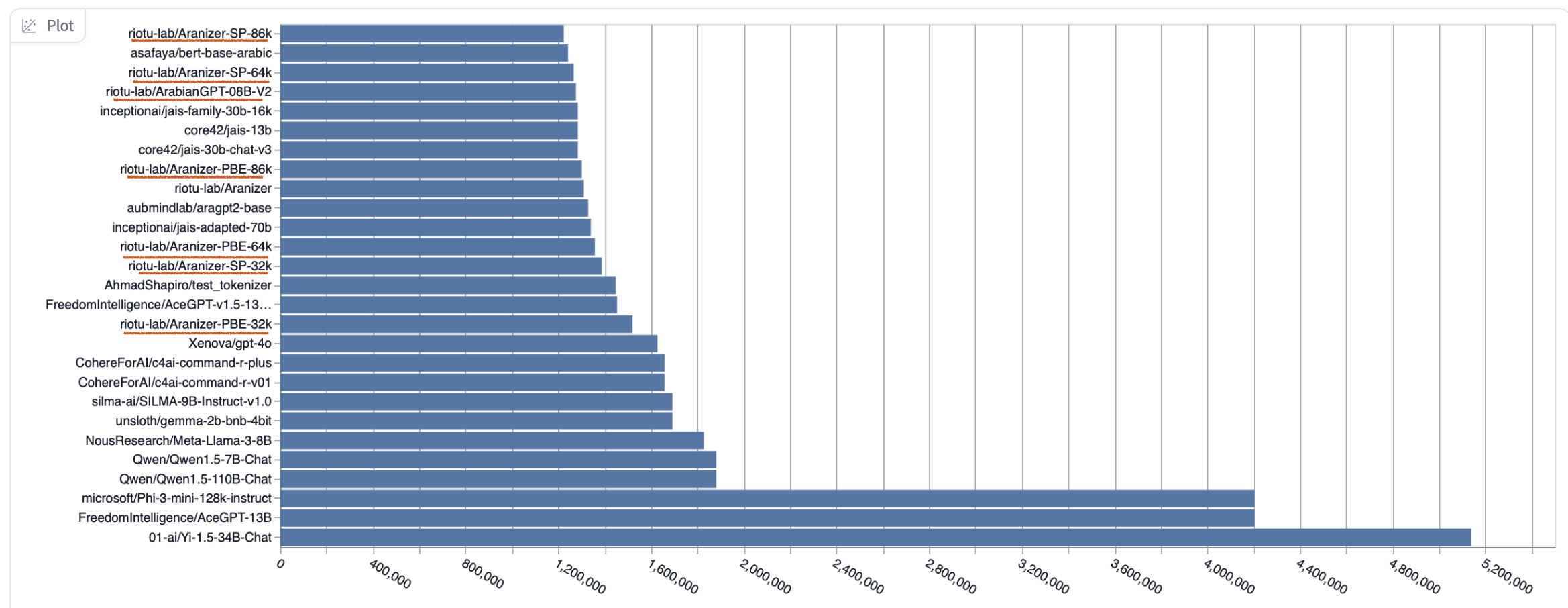
Aranizer Collection Achieved State of the Art Arabic Tokenizer
The Aranizer tokenizer has achieved state-of-the-art results on the Arabic Tokenizers Leaderboard on Hugging Face. Below is a screenshot highlighting this achievement:
How to Use the Aranizer Tokenizer
The Aranizer tokenizer can be easily loaded using the transformers library from Hugging Face. Below is an example of how to load and use the tokenizer in your Python project:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("riotu-lab/Aranizer-PBE-86k")
text = "اكتب النص العربي"
tokens = tokenizer.tokenize(text)
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print("Tokens:", tokens)
print("Token IDs:", token_ids)
## Citation
@article{koubaa2024arabiangpt,
title={ArabianGPT: Native Arabic GPT-based Large Language Model},
author={Koubaa, Anis and Ammar, Adel and Ghouti, Lahouari and Necar, Omer and Sibaee, Serry},
year={2024},
publisher={Preprints}
}
