
Architecture
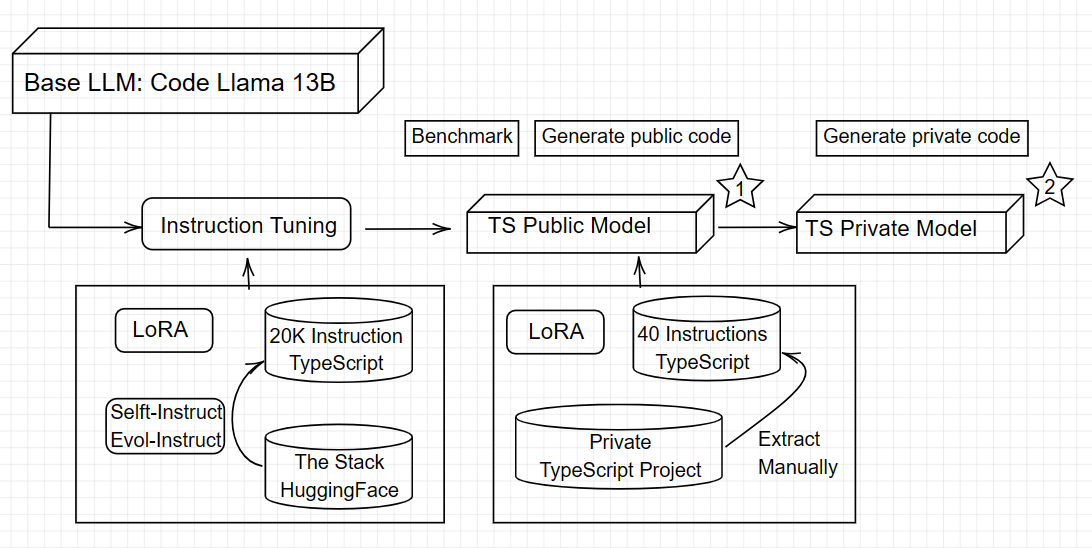
About
This model is a fine-tuned version of codellama/CodeLlama-13b-hf. It achieves the following results on the evaluation set:
- Loss: 0.4268
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 16
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 10
- num_epochs: 1
Training results
| Training Loss | Epoch | Step | Validation Loss |
|---|---|---|---|
| 0.7555 | 0.01 | 1 | 0.7062 |
| 0.7036 | 0.05 | 7 | 0.6673 |
| 0.5422 | 0.1 | 14 | 0.5152 |
| 0.5351 | 0.15 | 21 | 0.4866 |
| 0.495 | 0.2 | 28 | 0.4688 |
| 0.5651 | 0.25 | 35 | 0.4587 |
| 0.5146 | 0.3 | 42 | 0.4486 |
| 0.4955 | 0.35 | 49 | 0.4469 |
| 0.5117 | 0.4 | 56 | 0.4432 |
| 0.5245 | 0.45 | 63 | 0.4410 |
| 0.5003 | 0.5 | 70 | 0.4371 |
| 0.4502 | 0.55 | 77 | 0.4340 |
| 0.527 | 0.6 | 84 | 0.4315 |
| 0.48 | 0.65 | 91 | 0.4305 |
| 0.448 | 0.7 | 98 | 0.4289 |
| 0.5427 | 0.75 | 105 | 0.4289 |
| 0.4715 | 0.8 | 112 | 0.4279 |
| 0.5584 | 0.85 | 119 | 0.4276 |
| 0.4936 | 0.9 | 126 | 0.4267 |
| 0.4788 | 0.95 | 133 | 0.4268 |
| 0.476 | 1.0 | 140 | 0.4268 |
Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.0.1+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
- PEFT 0.6.0
Evaluation
I'm using MultiPL-E benchmark, the same as Code Llmama using in their paper
| Modal | Pass@k | Estimate | Num problems |
|---|---|---|---|
| Code LLama - Instruct 13B | 1 | 39.0% | 159 |
| Our 13B | 1 | 42.4% | 159 |
How to reproduce my evaluation? Just run like the offical document of MultiPL-E: https://nuprl.github.io/MultiPL-E/tutorial.html, change the modal name by my model here: mhhmm/typescript-instruct-20k-v2
This is the code that I ran with Google Colab (using A100 40GB, yes, it requires that much GPU RAM)
If you even have a stronger GPU, increase the --batch-size, or --completion-limit
!pip install --upgrade pip
!pip install aiohttp numpy tqdm pytest datasets torch transformers sentencepiece
!git clone https://github.com/nuprl/MultiPL-E
%cd MultiPL-E
!mkdir typescript
!python3 automodel.py --name mhhmm/typescript-instruct-20k-v2 --root-dataset humaneval --lang ts --temperature 0.2 --batch-size 10 --completion-limit 20 --output-dir-prefix typescript
%cd evaluation/src
!python3 main.py --dir ../../typescript --output-dir ../../typescript --recursive
!python3 pass_k.py ./typescript/*
- Downloads last month
- 7
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.
Model tree for mhhmm/typescript-instruct-20k-v2
Base model
codellama/CodeLlama-13b-hf