
|
|
|
LinTO ASR Arabic Tunisia v0.1
LinTO ASR Arabic Tunisia v0.1 is an Automatic Speech Recognition (ASR) model for the Tunisian dialect, with some capabilities of code-switching when some French or English words are used.
This repository includes two versions of the model and a Language model with ARPA format:
vosk-model: The original, comprehensive model.android-model: A lighter version with a simplified graph, optimized for deployment on Android devices or Raspberry Pi applications.lm_TN_CS.arpa.gz: A language model trained using SRILM on a dataset containing 4.5 million lines of text collected from various sources.
Model Overview
- Model type: Kaldi TDNN
- Language(s): Tunisian Dialect
- Use cases: Automatic Speech Recognition (ASR)
Model Performance
The following table summarizes the performance of the LinTO ASR Arabic Tunisia v0.1 model on various considered test sets:
| Dataset | CER | WER |
|---|---|---|
| Youtube_TNScrapped_V1 | 25.39% |
37.51% |
| TunSwitchCS | 17.72% |
20.51% |
| TunSwitchTO | 11.13% |
22.54% |
| ApprendreLeTunisien | 11.81% |
23.27% |
| TARIC | 10.60% |
16.06% |
| OneStory | 1.53% |
4.47% |
Training code
The model was trained using the following GitHub repository: ASR_train_kaldi_tunisian
Training datasets
The model was trained using the following datasets:
- LinTO DataSet Audio for Arabic Tunisian v0.1: This dataset comprises a collection of Tunisian dialect audio recordings and their annotations for Speech-to-Text (STT) tasks. The data was collected from various sources, including Hugging Face, YouTube, and websites.
- LinTO DataSet Audio for Arabic Tunisian Augmented v0.1: This dataset is an augmented version of the LinTO DataSet Audio for Arabic Tunisian v0.1. The augmentation includes noise reduction and voice conversion.
- TARIC: This dataset consists of Tunisian Arabic speech recordings collected from train stations in Tunisia.
How to use
1. Download the model
You can download the model and its components directly from this repository using one of the following methods:
Method 1: Direct Download via Browser
- Visit the Repository: Navigate to the Hugging Face model page.
- Download as Zip: Click on the "Download" button or the "Code" button (often appearing as a dropdown). Select "Download ZIP" to get the entire repository as a zip file.
Method 2: Using curl command
You can follow the command below:
sudo apt-get install curl
curl -L https://huggingface.co./linagora/linto-asr-ar-tn-0.1/resolve/main/vosk-model.zip --output vosk-model.zip
(or same with android-model.zip instead of vosk-model.zip)
Method 3: Cloning the Repository
You can clone the repository and create a zip file of the contents if needed:
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co./linagora/linto-asr-ar-tn-0.1.git
cd linto-asr-ar-tn-0.1
2. Unzip the model
This can be done in bash:
mkdir dir_for_zip_extract
unzip /path/to/model-name.zip -d dir_for_zip_extract
3. Python code
First, make sure to install the required dependencies:
pip install vosk
Then you can launch the inference script from this repository:
python inference.py <path/to/your/model> <path/to/your/audio/file.wav>
or use such a python code:
from vosk import Model, KaldiRecognizer
import wave
import json
model_dir = "path/to/your/model"
audio_file = "path/to/your/audio/file.wav"
model = Model(model_dir)
with wave.open(audio_file, "rb") as wf:
if wf.getnchannels() != 1 or wf.getsampwidth() != 2 or wf.getcomptype() != "NONE":
raise ValueError("Audio file must be WAV format mono PCM.")
rec = KaldiRecognizer(model, wf.getframerate())
rec.AcceptWaveform(wf.readframes(wf.getnframes()))
res = rec.FinalResult()
transcript = json.loads(res)["text"]
print(f"Transcript: {transcript}")
Example
Here is an example of the transcription capabilities of the model:
Result:
بالدعم هاذايا لي بثتهولو ال berd يعني أحنا حتى ال projet متاعو تقلب حتى sur le plan حتى فال management يا سيد نحنا في تسيير الشريكة يعني تبدل مية و ثمانين درجة ماللي يعني قبل ما تجيه ال berd و بعد ما جاتو ال berd برنامج نخصص لل les startup إسمو
WebRTC Demonstartion
Install required dependencies:
pip install vosk
pip install websockets
If not done, close the repostorory:
git clone https://huggingface.co./linagora/linto-asr-ar-tn-0.1.git
Then call the app.py script:
cd linto-asr-ar-tn-0.1/Demo-WebRTC
python3 app.py <model-path>
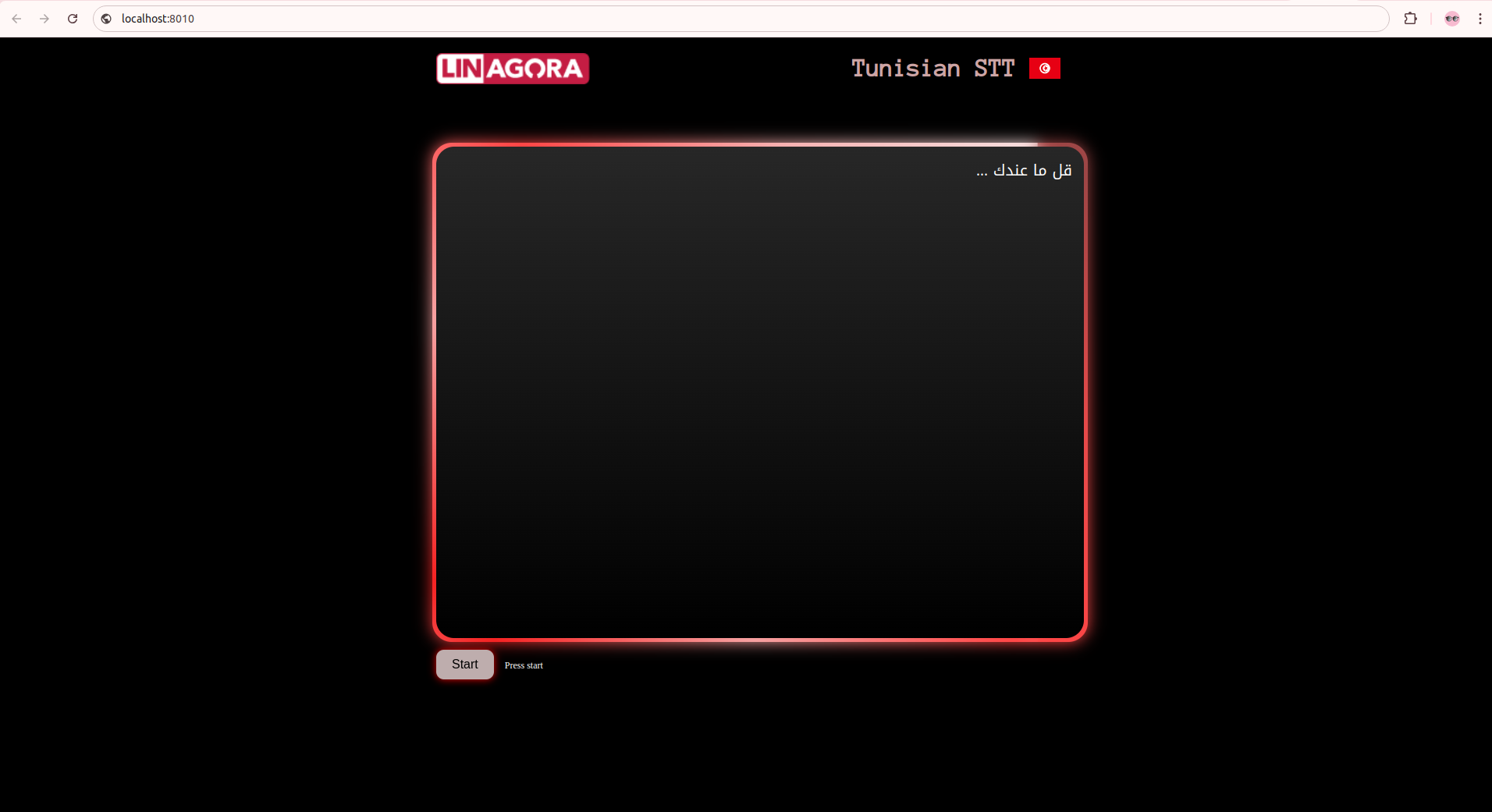
Access the web interface at: localhost:8010 Just start and speak.
Preview of the web app interface:
Citation
@misc{linagora2024Linto-tn,
author = {Hedi Naouara and Jérôme Louradour and Jean-Pierre Lorré and Sarah zribi and Wajdi Ghezaiel},
title = {LinTO ASR AR TN 0.1},
year = {2024},
publisher = {HuggingFace},
journal = {HuggingFace},
howpublished = {\url{https://huggingface.co./linagora/linto-asr-ar-tn-0.1}},
}