Unit 4: Going Further with Diffusion Models
Welcome to Unit 4 of the Hugging Face Diffusion Models Course! In this unit, we will look at some of the many improvements and extensions to diffusion models appearing in the latest research. It will be less code-heavy than previous units have been and is designed to give you a jumping-off point for further research.
Start this Unit :rocket:
Here are the steps for this unit:
- Make sure you’ve signed up for this course so that you can be notified when additional units are added to the course.
- Read through the material below for an overview of the different topics covered in this unit.
- Dive deeper into any specific topics with the linked videos and resources.
- Explore the demo notebooks and then read the ‘What Next’ section for some project suggestions.
:loudspeaker: Don’t forget to join Discord, where you can discuss the material and share what you’ve made in the #diffusion-models-class channel.
Table of Contents
Faster Sampling via Distillation
Progressive distillation is a technique for taking an existing diffusion model and using it to train a new version of the model that requires fewer steps for inference. The ‘student’ model is initialized from the weights of the ‘teacher’ model. During training, the teacher model performs two sampling steps and the student model tries to match the resulting prediction in a single step. This process can be repeated multiple times, with the previous iteration’s student model becoming the teacher for the next stage. The result is a model that can produce decent samples in much fewer steps (typically 4 or 8) than the original teacher model. The core mechanism is illustrated in this diagram from the paper that introduced the idea:
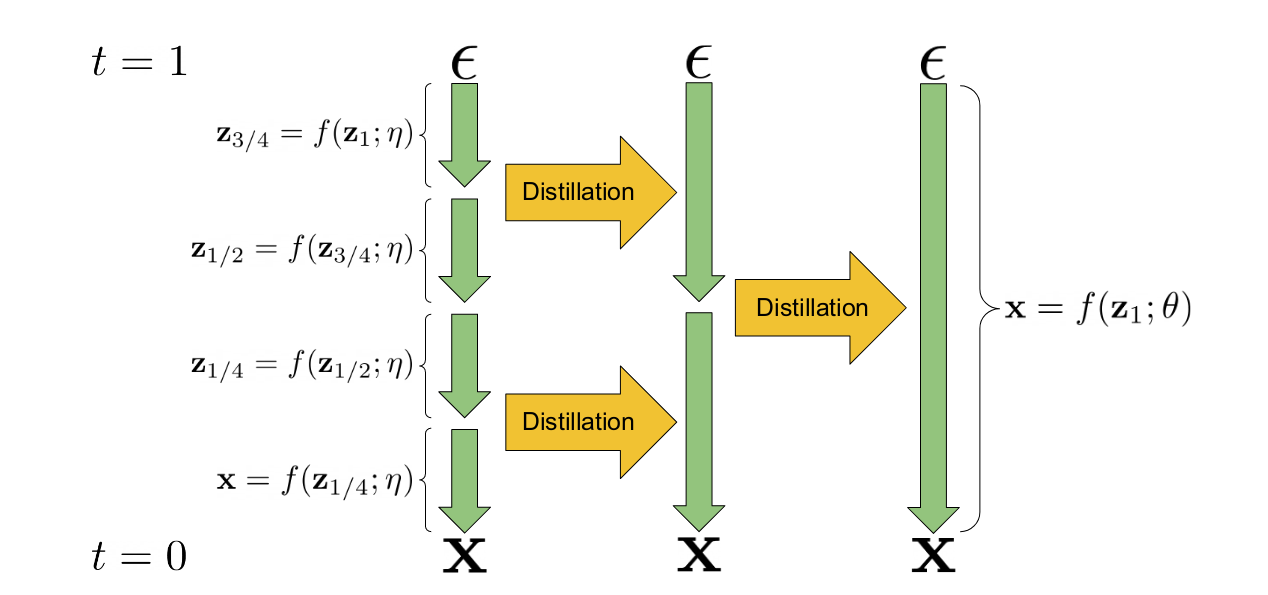
Progressive Distillation illustrated (from the paper)
The idea of using an existing model to ‘teach’ a new model can be extended to create guided models where the classifier-free guidance technique is used by the teacher model and the student model must learn to produce an equivalent output in a single step based on an additional input specifying the targeted guidance scale. This further reduces the number of model evaluations required to produce high-quality samples. This video gives an overview of the approach.
NB: A distilled version of Stable Diffusion can be used here.
Key references:
- Progressive Distillation For Fast Sampling Of Diffusion Models
- On Distillation Of Guided Diffusion Models
Training Improvements
There have been several additional tricks developed to improve diffusion model training. In this section we’ve tried to capture the core ideas from recent papers. There is a constant stream of research coming out with additional improvements, so if you see a paper you feel should be added here please let us know!
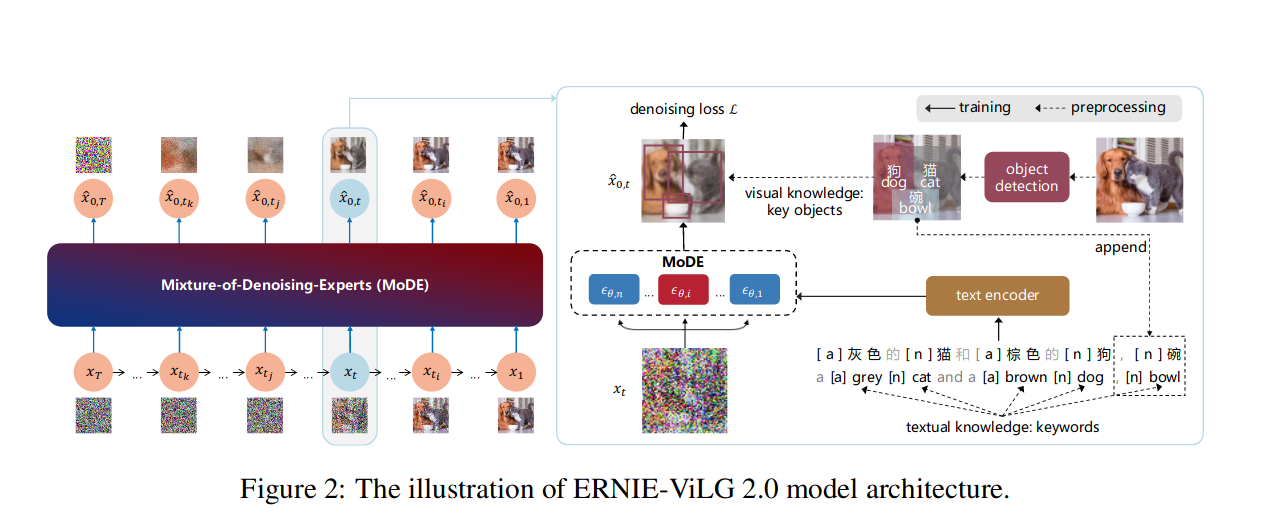 Figure 2 from the ERNIE-ViLG 2.0 paper
Figure 2 from the ERNIE-ViLG 2.0 paper
Key training improvements:
- Tuning the noise schedule, loss weighting and sampling trajectories for more efficient training. An excellent paper exploring some of these design choices is Elucidating the Design Space of Diffusion-Based Generative Models by Karras et al.
- Training on diverse aspect ratios, as described in this video from the course launch event.
- Cascaded diffusion models, training one model at low resolution and then one or more super-res models. Used in DALLE-2, Imagen and more for high-resolution image generation.
- Better conditioning, incorporating rich text embeddings (Imagen uses a large language model called T5) or multiple types of conditioning (eDiffi).
- ‘Knowledge Enhancement’ - incorporating pre-trained image captioning and object detection models into the training process to create more informative captions and produce better performance (ERNIE-ViLG 2.0).
- ‘Mixture of Denoising Experts’ (MoDE) - training different variants of the model (‘experts’) for different noise levels as illustrated in the image above from the ERNIE-ViLG 2.0 paper.
Key references:
- Elucidating the Design Space of Diffusion-Based Generative Models
- eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
- ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts
- Imagen - Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (demo site)
More Control for Generation and Editing
In addition to training improvements, there have been several innovations in the sampling and inference phase, including many approaches that can add new capabilities to existing diffusion models.
 Samples generated by ‘paint-with-words’ (eDiffi)
Samples generated by ‘paint-with-words’ (eDiffi)
The video ‘Editing Images with Diffusion Models’ gives an overview of the different methods being used to edit existing images with diffusion models. The available techniques can be split into four main categories:
1) Add noise and then denoise with a new prompt. This is the idea behind the img2img pipeline, which has been modified and extended in various papers:
- SDEdit and MagicMix build on this idea.
- DDIM inversion (TODO link tutorial) uses the model to ‘reverse’ the sampling trajectory rather than adding random noise, giving more control.
- Null-text Inversion enhances the performance of this kind of approach dramatically by optimizing the unconditional text embeddings used for classifier-free guidance at each step, allowing for extremely high-quality text-based image editing. 2) Extending the ideas in (1) but with a mask to control where the effect is applied:
- Blended Diffusion introduces the basic idea.
- This demo uses an existing segmentation model (CLIPSeg) to create the mask based on a text description.
- DiffEdit is an excellent paper that shows how the diffusion model itself can be used to generate an appropriate mask for editing the image based on text.
- SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model fine-tunes a diffusion model for more accurate mask-guided inpainting. 3) Cross-attention Control: using the cross-attention mechanism in diffusion models to control the spatial location of edits for more fine-grained control:
- Prompt-to-Prompt Image Editing with Cross Attention Control is the key paper that introduced this idea, and the technique has since been applied to Stable Diffusion.
- This idea is also used for ‘paint-with-words’ (eDiffi, shown above). 4) Fine-tune (‘overfit’) on a single image and then generate with the fine-tuned model. The following papers both published variants of this idea at roughly the same time:
- Imagic: Text-Based Real Image Editing with Diffusion Models.
- UniTune: Text-Driven Image Editing by Fine Tuning an Image Generation Model on a Single Image .
The paper InstructPix2Pix: Learning to Follow Image Editing Instructions is notable in that it used some of the image editing techniques described above to build a synthetic dataset of image pairs alongside image edit instructions (generated with GPT3.5) to train a new model capable of editing images based on natural language instructions.
Video
 Still frames from sample videos generated with Imagen Video
Still frames from sample videos generated with Imagen Video
A video can be represented as a sequence of images, and the core ideas of diffusion models can be applied to these sequences. Recent work has focused on finding appropriate architectures (such as ‘3D UNets’ which operate on entire sequences) and on working efficiently with video data. Since high-frame-rate video involves a lot more data than still images, current approaches tend to first generate low-resolution and low-frame-rate video and then apply spatial and temporal super-resolution to produce the final high-quality video outputs.
Key references:
Audio
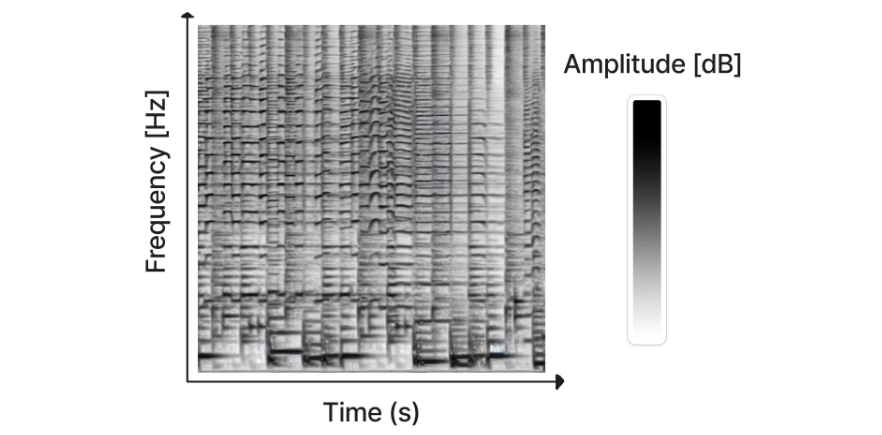
A spectrogram generated with Riffusion (image source)
While there has been some work on generating audio directly using diffusion models (e.g. DiffWave) the most successful approach so far has been to convert the audio signal into something called a spectrogram, which effectively ‘encodes’ the audio as a 2D “image” which can then be used to train the kinds of diffusion models we’re used to using for image generation. The resulting generated spectrograms can then be converted into audio using existing methods. This approach is behind the recently-released Riffusion, which fine-tuned Stable Diffusion to generate spectrograms conditioned on text - try it out here.
The field of audio generation is moving extremely quickly. Over the past week (at the time of writing) there have been at least 5 new advances announced, which are marked with a star in the list below:
Key references:
- DiffWave: A Versatile Diffusion Model for Audio Synthesis
- ‘Riffusion’ (and code)
- *MusicLM by Google generates consistent audio from text and can be conditioned with hummed or whistled melodies.
- RAVE2 - A new version of a Variational Auto-Encoder that will be useful for latent diffusion on audio tasks. This is used in the soon-to-be-announced AudioLDM model.
- *Noise2Music - A diffusion model trained to produce high-quality 30-second clips of audio based on text descriptions.
- *Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models - A diffusion model trained to generate diverse sounds based on text.
- *Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion
New Architectures and Approaches - Towards ‘Iterative Refinement’

Figure 1 from the Cold Diffusion paper
We are slowly moving beyond the original narrow definition of “diffusion” models and towards a more general class of models that perform iterative refinement, where some form of corruption (like the addition of gaussian noise in the forward diffusion process) is gradually reversed to generate samples. The ‘Cold Diffusion’ paper demonstrated that many other types of corruption can be iteratively ‘undone’ to generate images (examples shown above), and recent transformer-based approaches have demonstrated the effectiveness of token replacement or masking as a noising strategy.
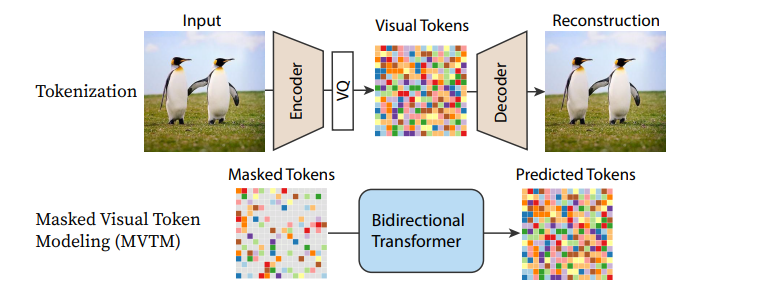
Pipeline from MaskGIT
The UNet architecture at the heart of many current diffusion models is also being replaced with different alternatives, most notably various transformer-based architectures. In Scalable Diffusion Models with Transformers (DiT) a transformer is used in place of the UNet for a fairly standard diffusion model approach, with excellent results. Recurrent Interface Networks applies a novel transformer-based architecture and training strategy in pursuit of additional efficiency. MaskGIT and MUSE use transformer models to work with tokenized representations of images, although the Paella model demonstrates that a UNet can also be applied successfully to these token-based regimes too.
With each new paper, more efficient approaches are being developed, and it may be some time before we see what peak performance looks like on these kinds of iterative refinement tasks. There is much more still to explore!
Key references
- Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise
- Scalable Diffusion Models with Transformers (DiT)
- MaskGIT: Masked Generative Image Transformer
- Muse: Text-To-Image Generation via Masked Generative Transformers
- Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces (Paella)
- Recurrent Interface Networks - A promising new architecture that does well at generating high-resolution images without relying on latent diffusion or super-resolution. See also, simple diffusion: End-to-end diffusion for high-resolution images which highlights the importance of the noise schedule for training at higher resolutions.
Hands-On Notebooks
| Chapter | Colab | Kaggle | Gradient | Studio Lab |
|---|---|---|---|---|
| DDIM Inversion |  |  | ||
| Diffusion for Audio | | |
We’ve covered a LOT of different ideas in this unit, many of which deserve much more detailed follow-on lessons in the future. For now, you can choose two of the many topics via the hands-on notebooks we’ve prepared.
- DDIM Inversion shows how a technique called inversion can be used to edit images using existing diffusion models.
- Diffusion for Audio introduces the idea of spectrograms and shows a minimal example of fine-tuning an audio diffusion model on a specific genre of music.
Where Next?
This is the final unit of this course for now, which means that what comes next is up to you! Remember that you can always ask questions and chat about your projects on the Hugging Face Discord. We look forward to seeing what you create 🤗.
< > Update on GitHub