TRL documentation
TRL - Transformer Reinforcement Learning

TRL - Transformer Reinforcement Learning
TRL is a full stack library where we provide a set of tools to train transformer language models with methods like Supervised Fine-Tuning (SFT), Group Relative Policy Optimization (GRPO), Direct Preference Optimization (DPO), Reward Modeling, and more. The library is integrated with 🤗 transformers.
You can also explore TRL-related models, datasets, and demos in the TRL Hugging Face organization.
Learn
Learn post-training with TRL and other libraries in 🤗 smol course.
Contents
The documentation is organized into the following sections:
- Getting Started: installation and quickstart guide.
- Conceptual Guides: dataset formats, training FAQ, and understanding logs.
- How-to Guides: reducing memory usage, speeding up training, distributing training, etc.
- Integrations: DeepSpeed, Liger Kernel, PEFT, etc.
- Examples: example overview, community tutorials, etc.
- API: trainers, utils, etc.
Blog posts

Published on January 28, 2025
Open-R1: a fully open reproduction of DeepSeek-R1

Published on July 10, 2024
Preference Optimization for Vision Language Models with TRL

Published on June 12, 2024
Putting RL back in RLHF

Published on September 29, 2023
Finetune Stable Diffusion Models with DDPO via TRL

Published on August 8, 2023
Fine-tune Llama 2 with DPO

Published on April 5, 2023
StackLLaMA: A hands-on guide to train LLaMA with RLHF

Published on March 9, 2023
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
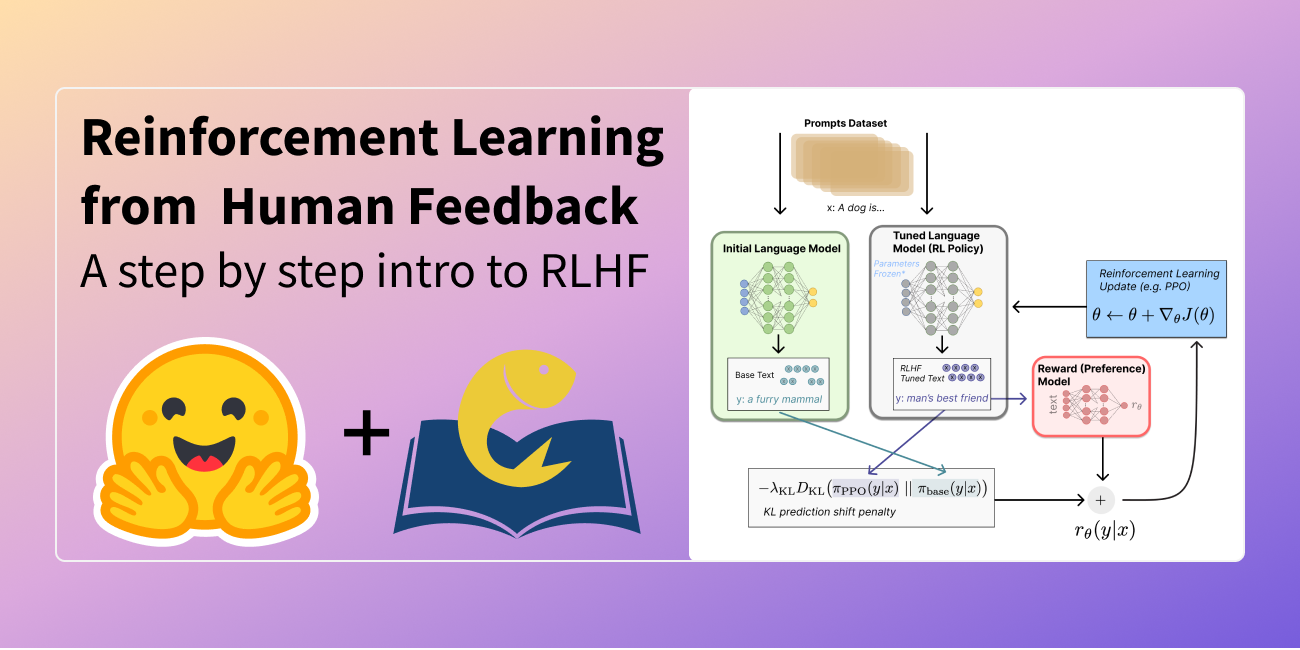
Published on December 9, 2022
Illustrating Reinforcement Learning from Human Feedback