
Taxonomy Classifier
This model is a hierarchical text classifier designed to categorize text into a 7-level taxonomy. It utilizes a chain of models, where the prediction at each level informs the prediction at the subsequent level. This approach reduces the classification space at each step.
Model Details
Model Developers: DEJAN.AI
Model Type: Hierarchical Text Classification
Base Model:
albert/albert-base-v2Taxonomy Structure:
Level Unique Classes 1 21 2 193 3 1350 4 2205 5 1387 6 399 7 50 Model Architecture:
- Level 1: Standard sequence classification using
AlbertForSequenceClassification. - Levels 2-7: Custom architecture (
TaxonomyClassifier) where the ALBERT pooled output is concatenated with a one-hot encoded representation of the predicted ID from the previous level before being fed into a linear classification layer.
- Level 1: Standard sequence classification using
Language(s): English
Library: Transformers
License: link-attribution
Uses
Direct Use
The model is intended for categorizing text into a predefined 7-level taxonomy.
Downstream Uses
Potential applications include:
- Automated content tagging
- Product categorization
- Information organization
Out-of-Scope Use
The model's performance on text outside the domain of the training data or for classifying into taxonomies with different structures is not guaranteed.
Limitations
- Performance is dependent on the quality and coverage of the training data.
- Errors in earlier levels of the hierarchy can propagate to subsequent levels.
- The model's performance on unseen categories is limited.
- The model may exhibit biases present in the training data.
- The reliance on one-hot encoding for parent IDs can lead to high-dimensional input features at deeper levels, potentially impacting training efficiency and performance (especially observed at Level 4).
Training Data
The model was trained on a dataset of 374,521 samples. Each row in the training data represents a full taxonomy path from the root level to a leaf node.
Training Procedure
- Levels: Seven separate models were trained, one for each level of the taxonomy.
- Level 1 Training: Trained as a standard sequence classification task.
- Levels 2-7 Training: Trained with a custom architecture incorporating the predicted parent ID.
- Input Format:
- Level 1: Text response.
- Levels 2-7: Text response concatenated with a one-hot encoded vector of the predicted ID from the previous level.
- Objective Function: CrossEntropyLoss
- Optimizer: AdamW
- Learning Rate: Initially 5e-5, adjusted to 1e-5 for Level 4.
- Training Hyperparameters:
- Epochs: 10
- Validation Split: 0.1
- Validation Frequency: Every 1000 steps
- Batch Size: 38
- Max Sequence Length: 512
- Early Stopping Patience: 3
Evaluation
Validation loss was used as the primary evaluation metric during training. The following validation loss trends were observed:
- Level 1, 2, and 3: Showed a relatively rapid decrease in validation loss during training.
- Level 4: Exhibited a slower decrease in validation loss, potentially due to the significant increase in the dimensionality of the parent ID one-hot encoding and the larger number of unique classes at this level.
Further evaluation on downstream tasks is recommended to assess the model's practical performance.
How to Use
Inference can be performed using the provided Streamlit application.
- Input Text: Enter the text you want to classify.
- Select Checkpoints: Choose the desired checkpoint for each level's model. Checkpoints are saved in the respective
level{n}directories (e.g.,level1/modelorlevel4/level4_step31000). - Run Inference: Click the "Run Inference" button.
The application will output the predicted ID and the corresponding text description for each level of the taxonomy, based on the provided mapping.csv file.
Visualizations
Level 1: Training Loss
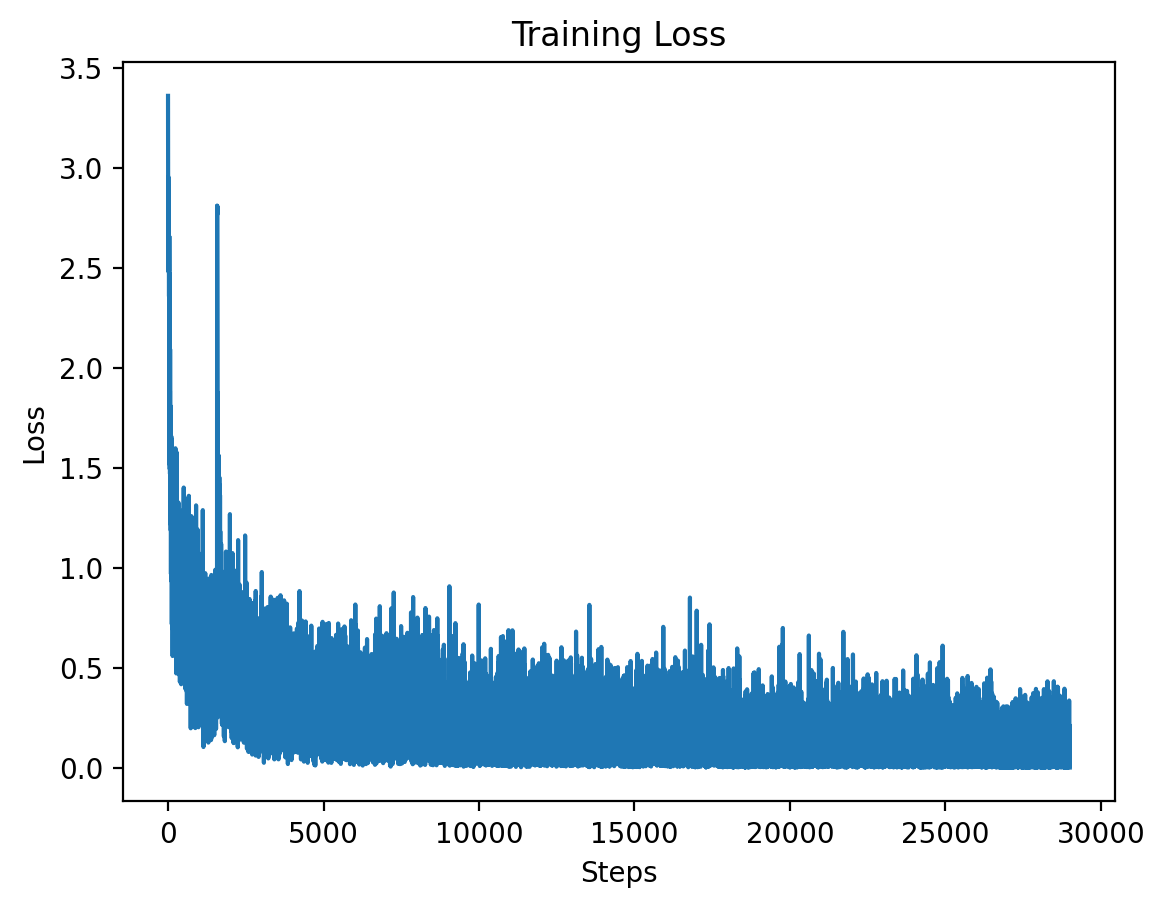 This graph shows the training loss over the steps for Level 1, demonstrating a significant drop in loss during the initial training period.
This graph shows the training loss over the steps for Level 1, demonstrating a significant drop in loss during the initial training period.
Level 1: Validation Loss
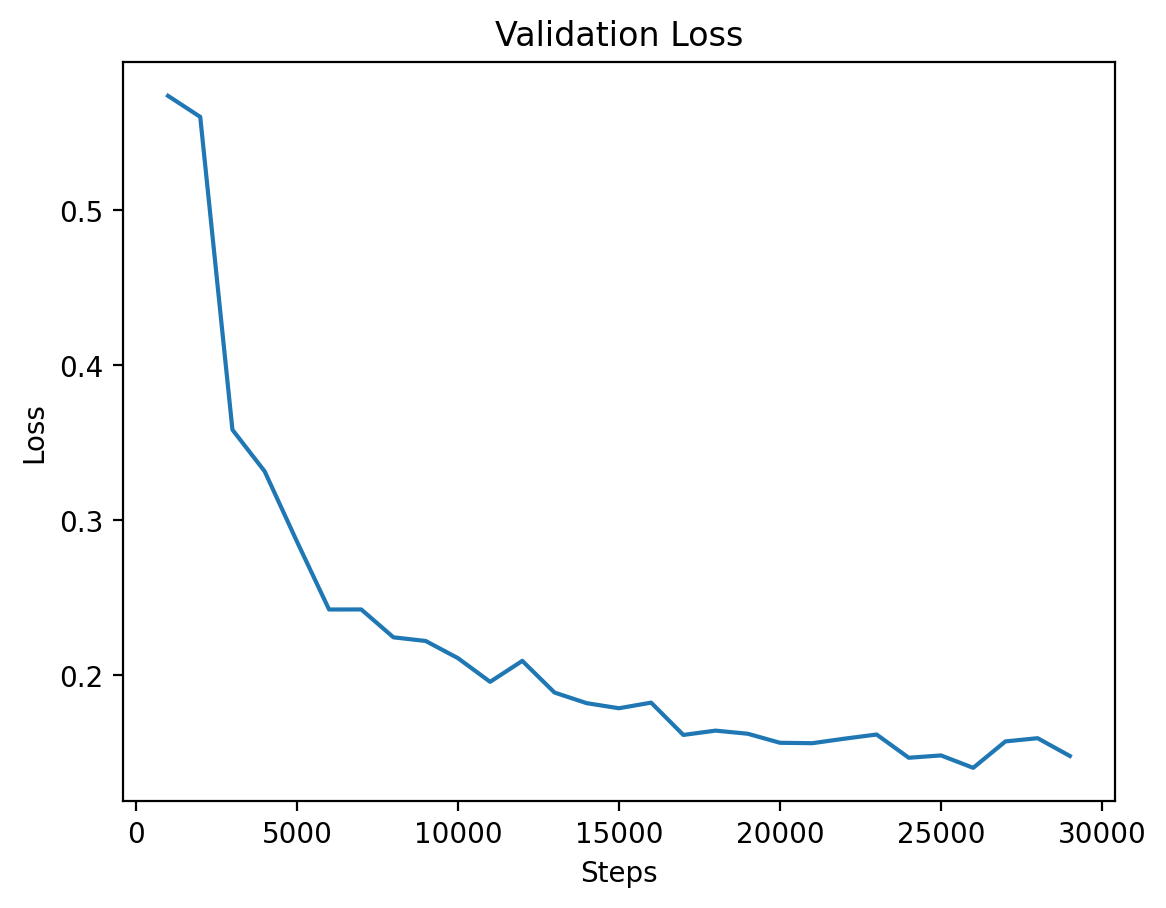 This graph illustrates the validation loss progression over training steps for Level 1, showing steady improvement.
This graph illustrates the validation loss progression over training steps for Level 1, showing steady improvement.
Level 2: Training Loss
 Here we see the training loss for Level 2, which also shows a significant decrease early on in training.
Here we see the training loss for Level 2, which also shows a significant decrease early on in training.
Level 2: Validation Loss
 The validation loss for Level 2 shows consistent reduction as training progresses.
The validation loss for Level 2 shows consistent reduction as training progresses.
Level 3: Training Loss
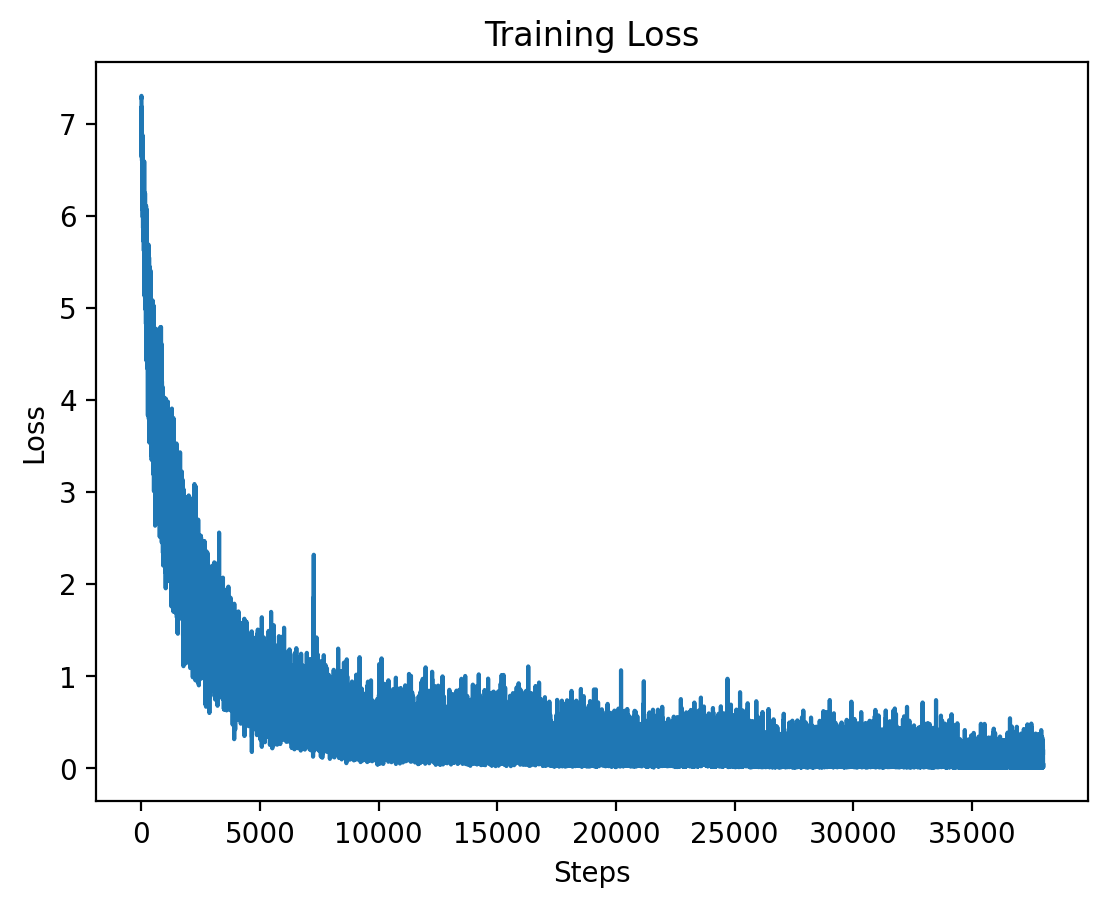 This graph displays the training loss for Level 3, where training stabilizes after an initial drop.
This graph displays the training loss for Level 3, where training stabilizes after an initial drop.
Level 3: Validation Loss
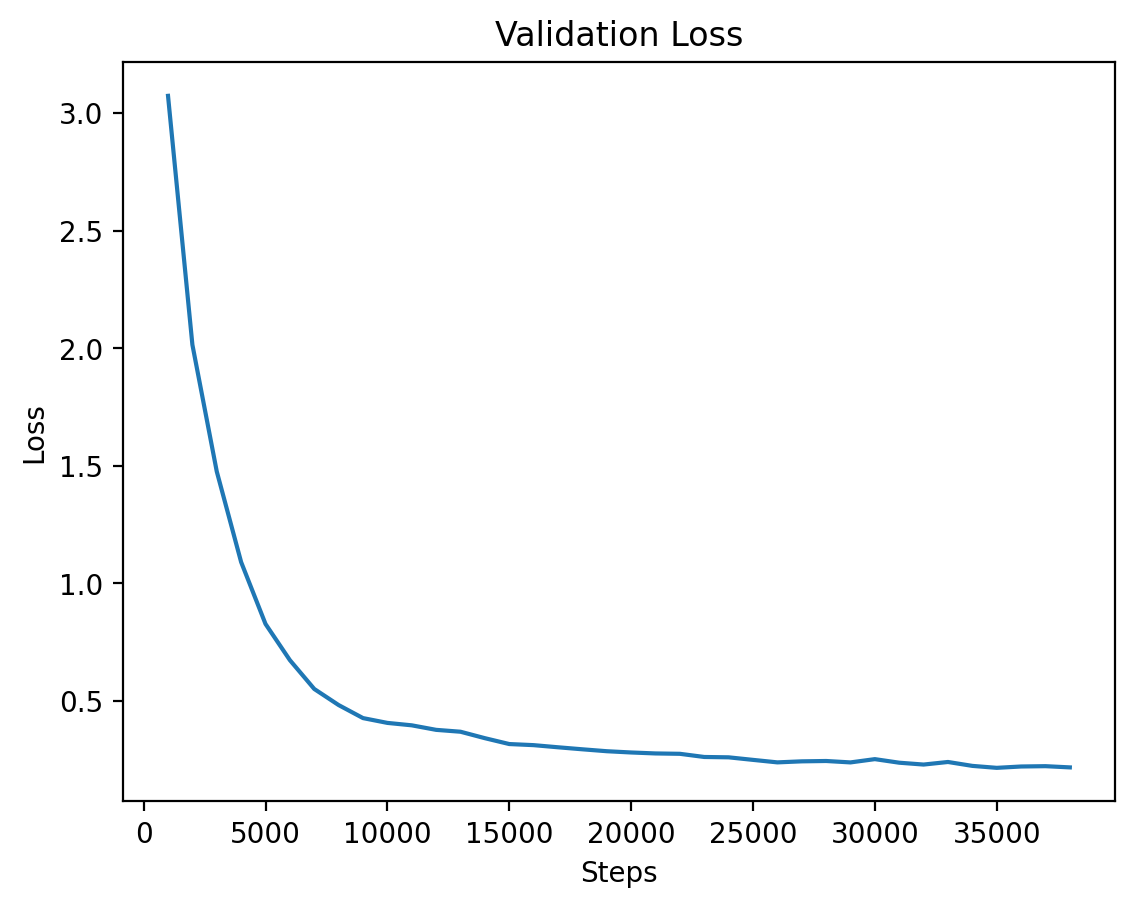 The validation loss for Level 3, demonstrating steady improvements as the model converges.
The validation loss for Level 3, demonstrating steady improvements as the model converges.
Level 4
Level 4: Training Loss
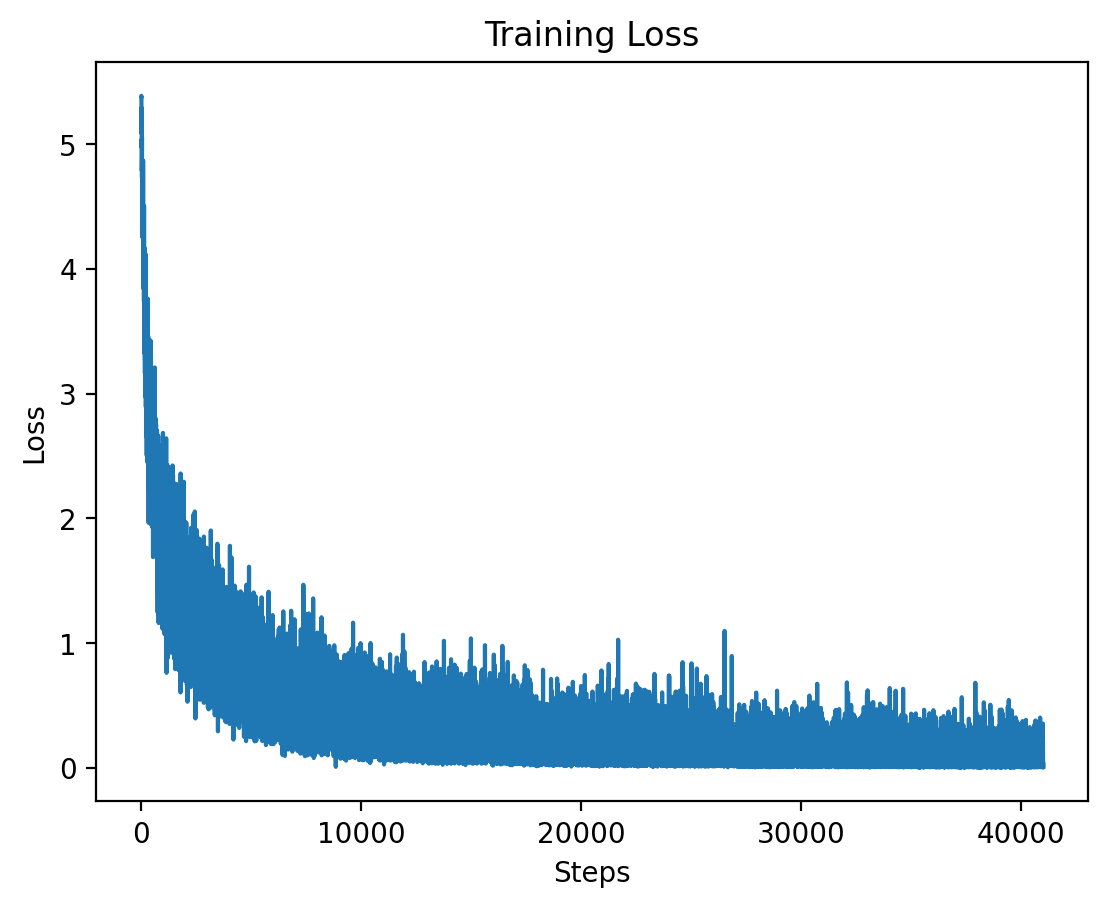
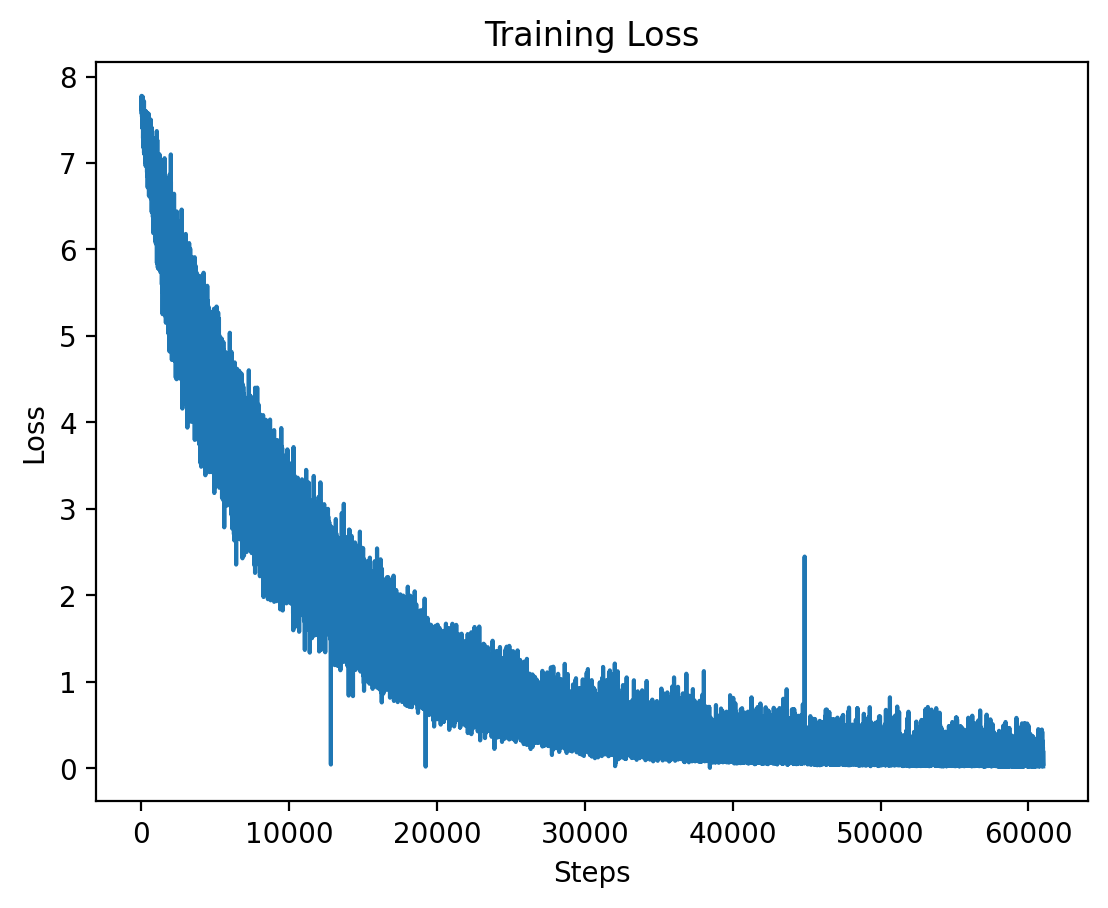 The training loss for Level 4 is plotted here, showing the effects of high-dimensional input features at this level.
The training loss for Level 4 is plotted here, showing the effects of high-dimensional input features at this level.
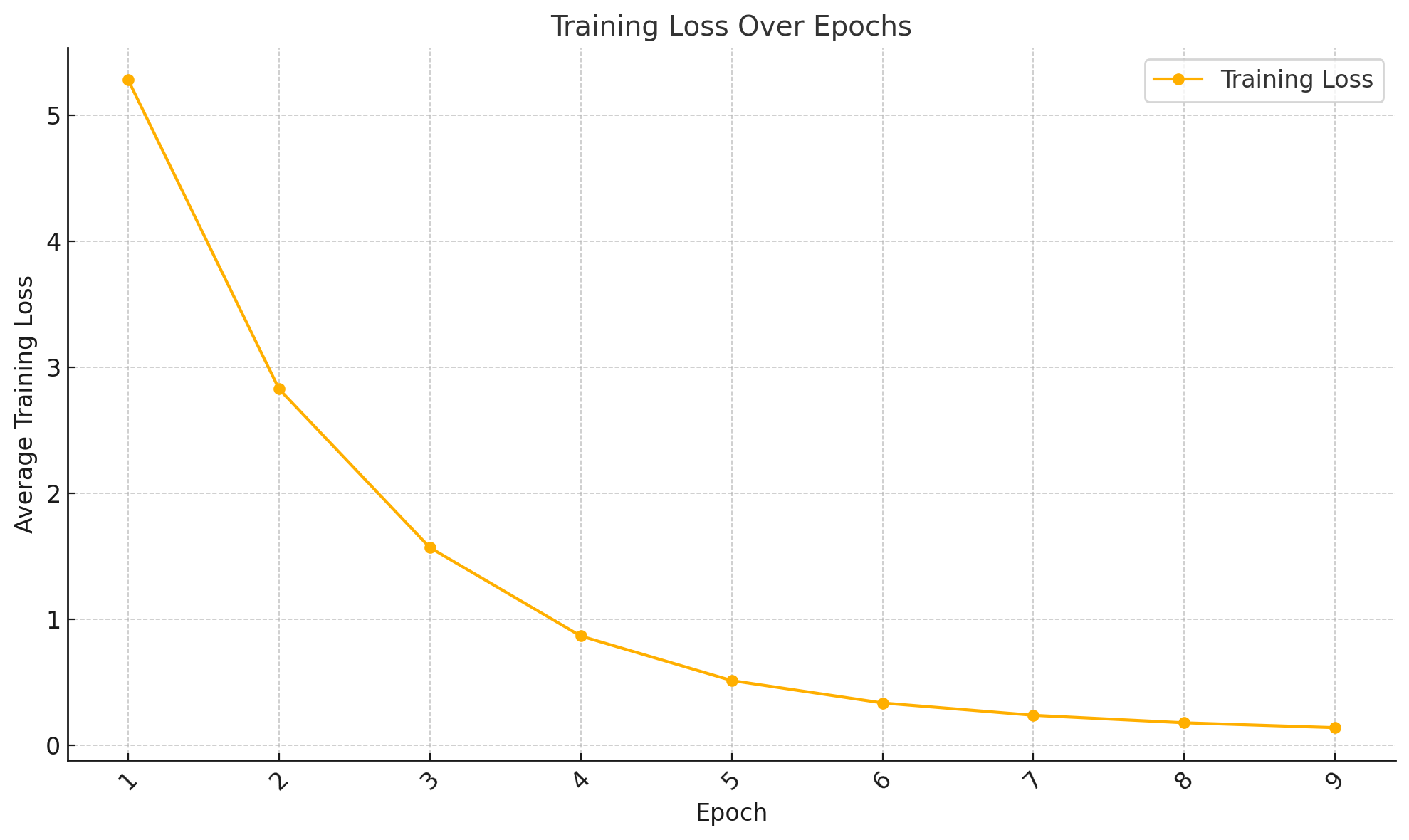
| Epoch | Average Training Loss |
|---|---|
| 1 | 5.2803 |
| 2 | 2.8285 |
| 3 | 1.5707 |
| 4 | 0.8696 |
| 5 | 0.5164 |
| 6 | 0.3384 |
| 7 | 0.2408 |
| 8 | 0.1813 |
| 9 | 0.1426 |
Level 4: Validation Loss
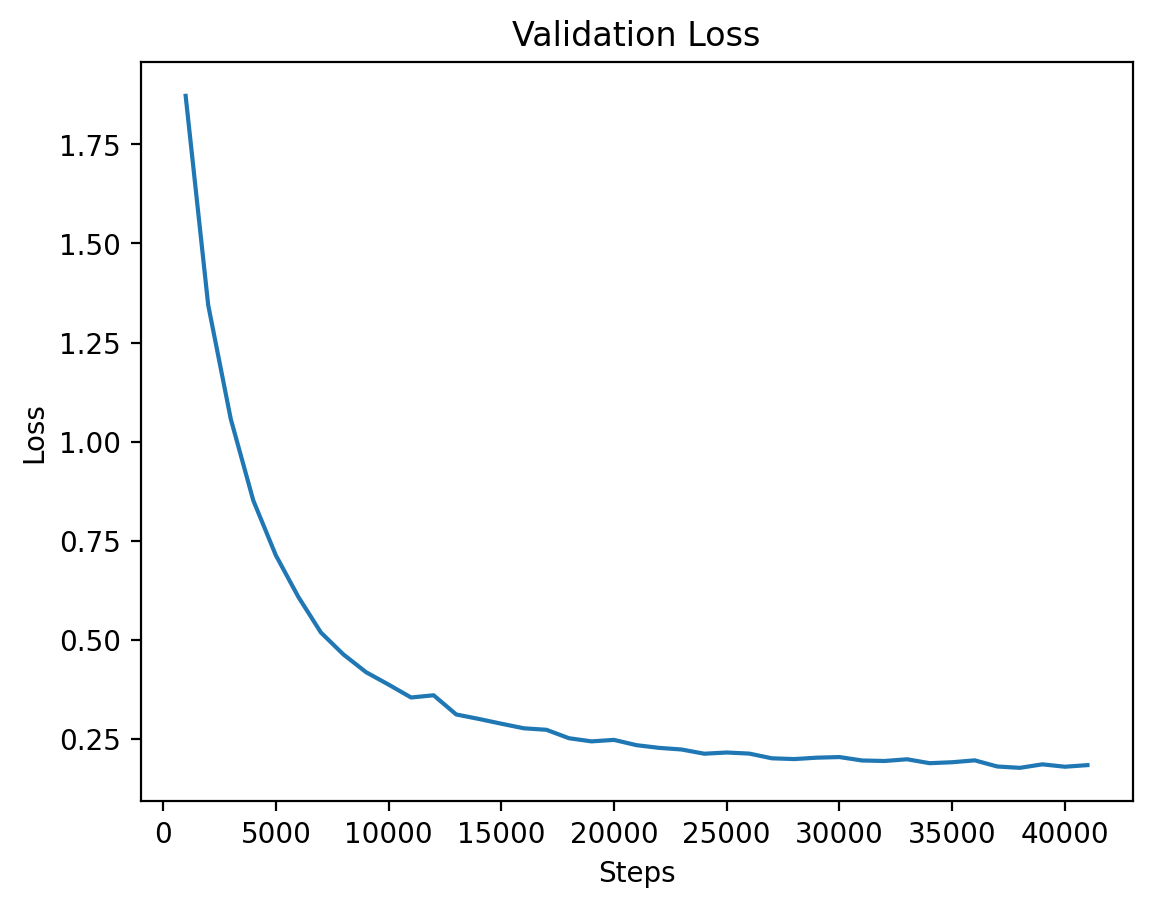
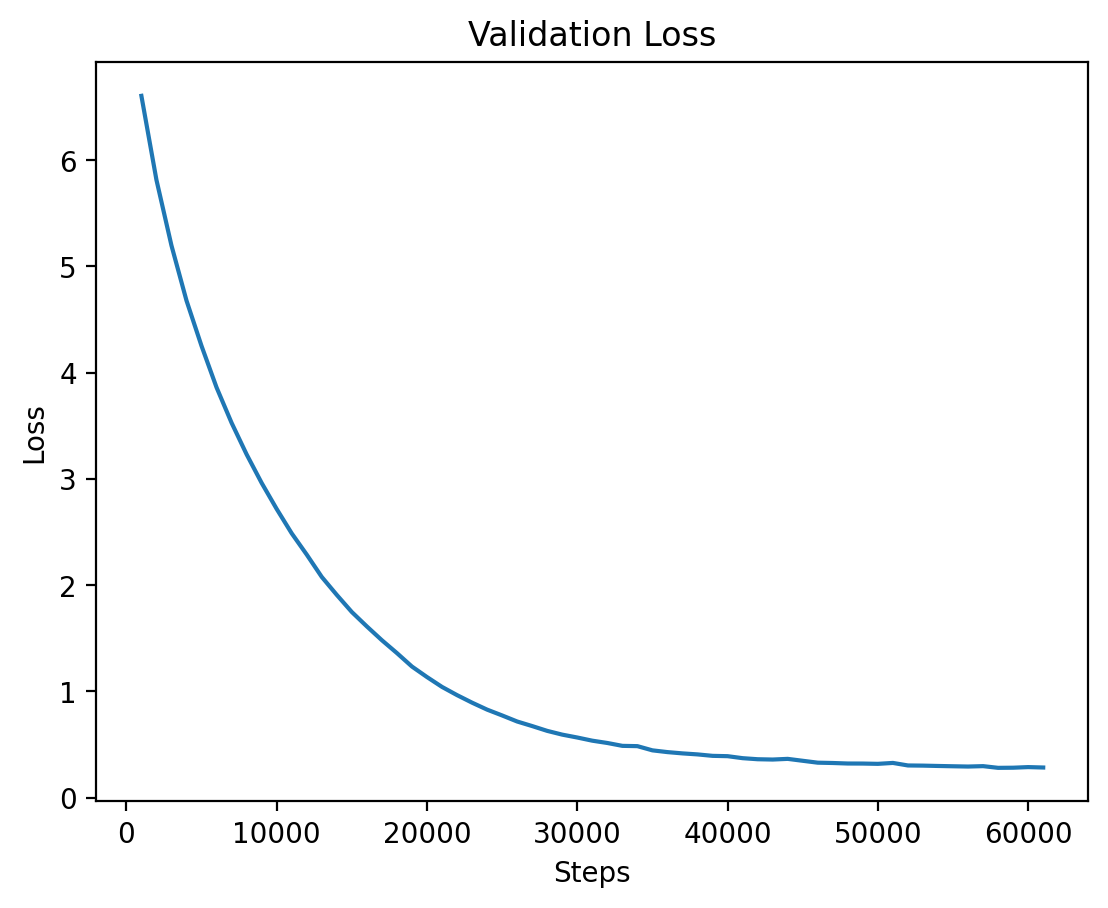 Finally, the validation loss for Level 4 is shown, where training seems to stabilize after a longer period.
Finally, the validation loss for Level 4 is shown, where training seems to stabilize after a longer period.
Level 5
Level 5: Training and Validation Loss
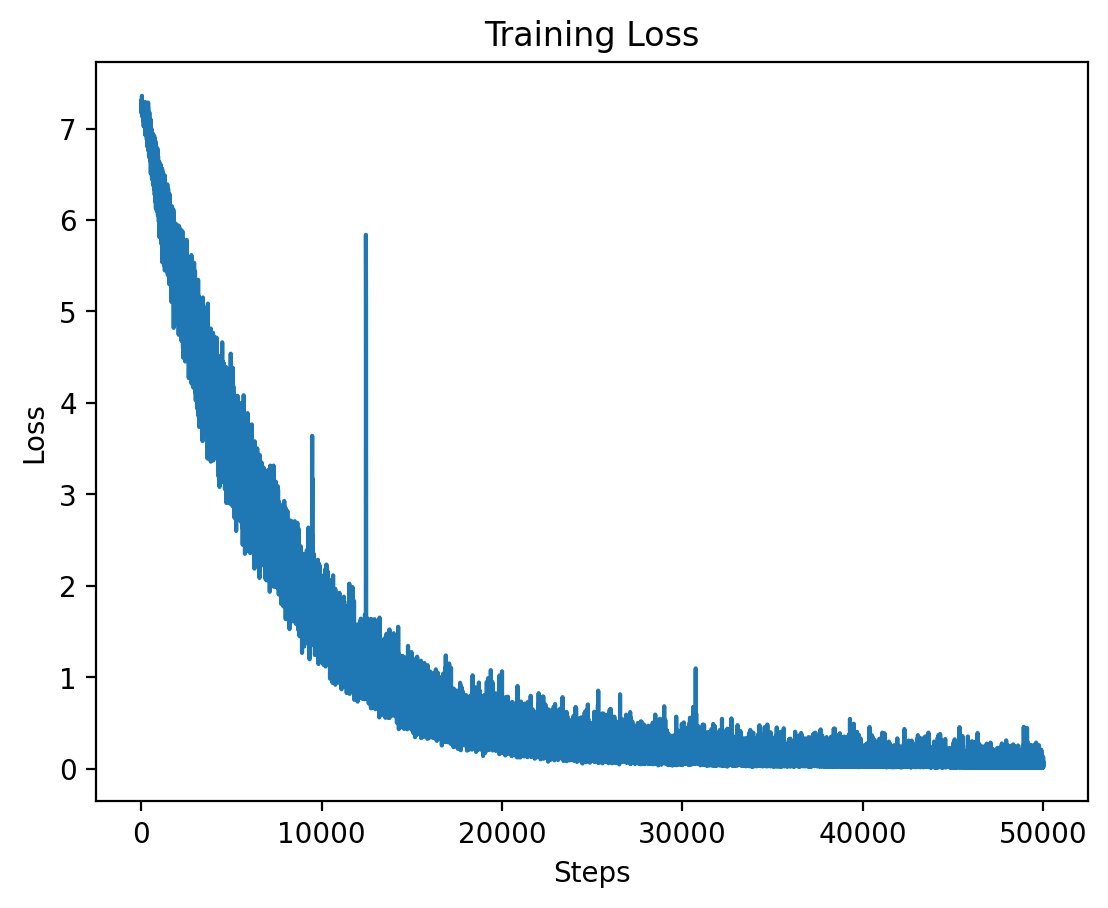 Level 5 training loss.
Level 5 training loss.
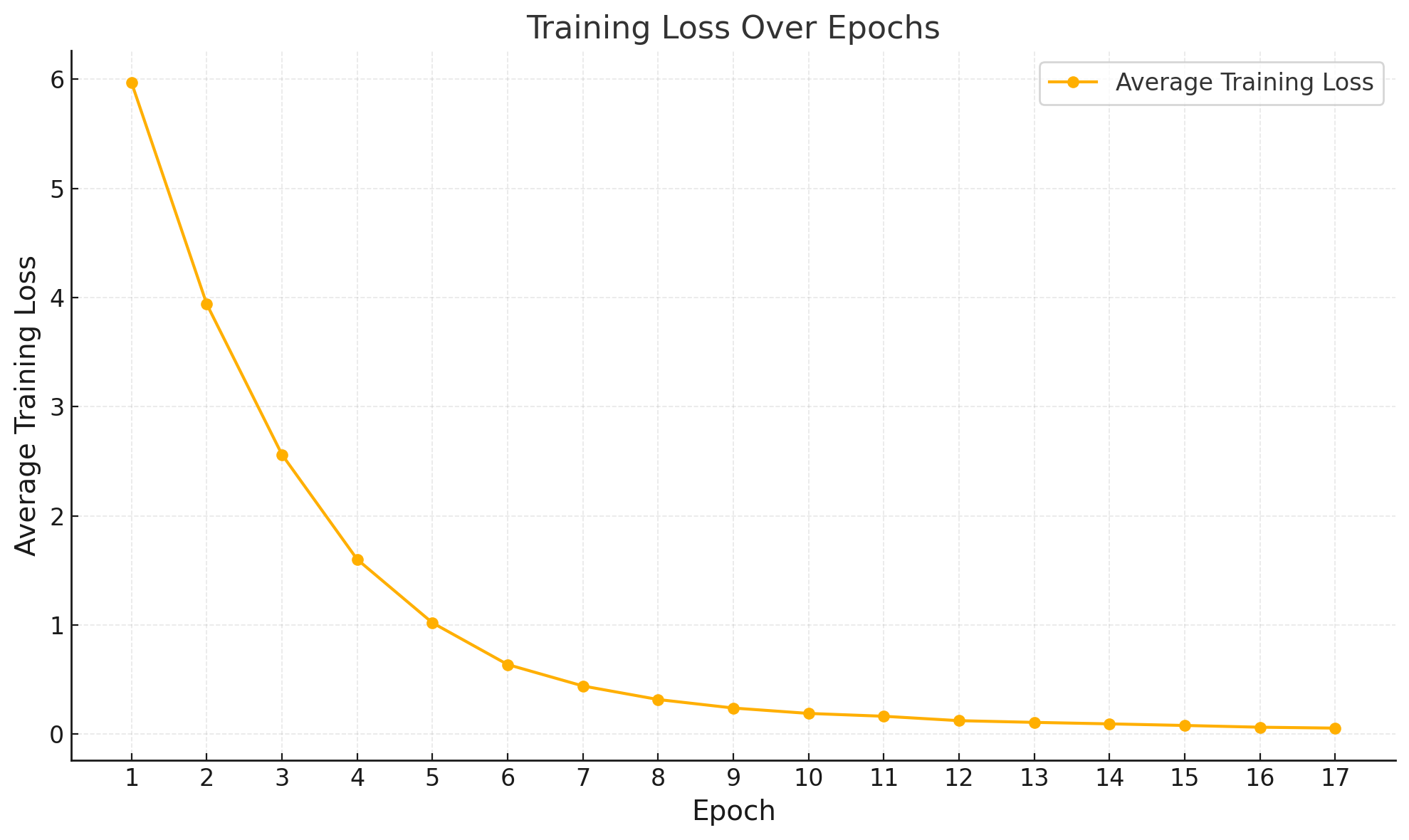 Average training loss / epoch.
Average training loss / epoch.
| Epoch | Average Training Loss |
|---|---|
| 1 | 5.9700 |
| 2 | 3.9396 |
| 3 | 2.5609 |
| 4 | 1.6004 |
| 5 | 1.0196 |
| 6 | 0.6372 |
| 7 | 0.4410 |
| 8 | 0.3169 |
| 9 | 0.2389 |
| 10 | 0.1895 |
| 11 | 0.1635 |
| 12 | 0.1232 |
| 13 | 0.1075 |
| 14 | 0.0939 |
| 15 | 0.0792 |
| 16 | 0.0632 |
| 17 | 0.0549 |
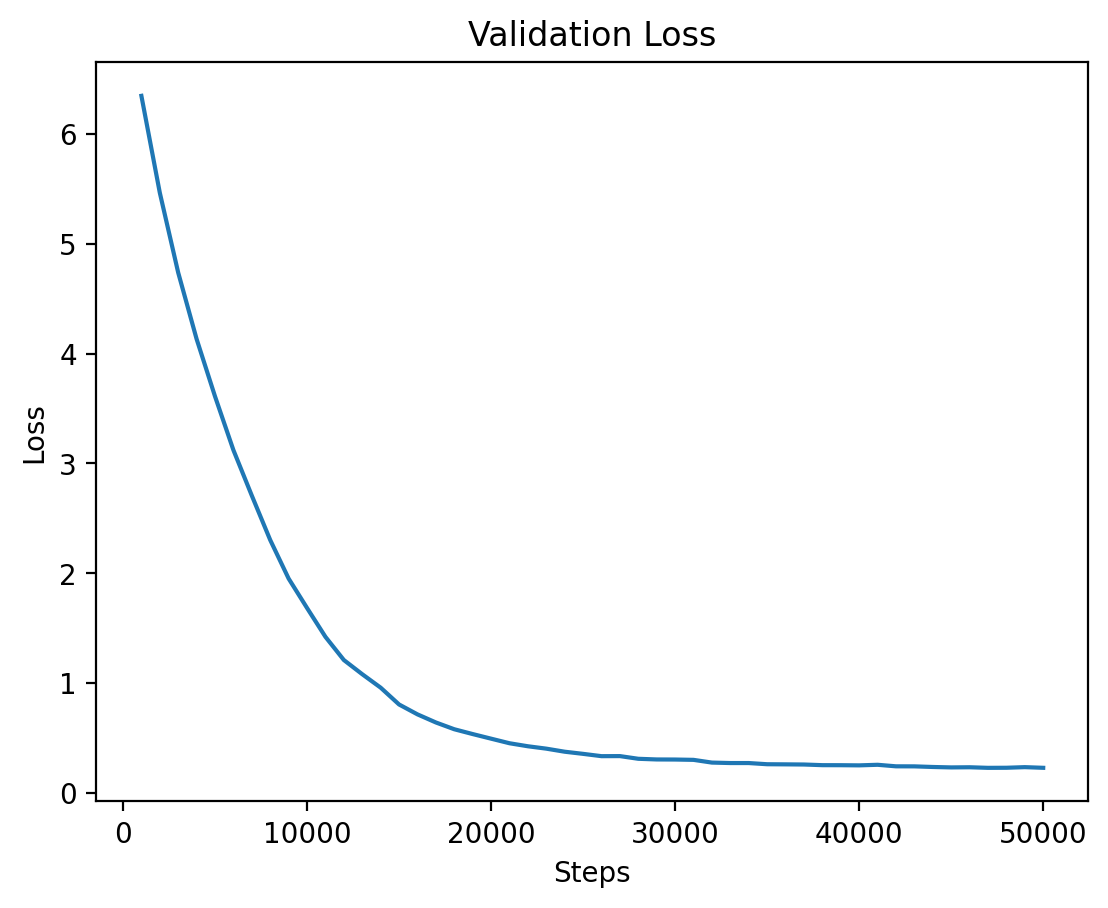 Level 5 validation loss.
Level 5 validation loss.
Level 6
Level 6: Training and Validation Loss
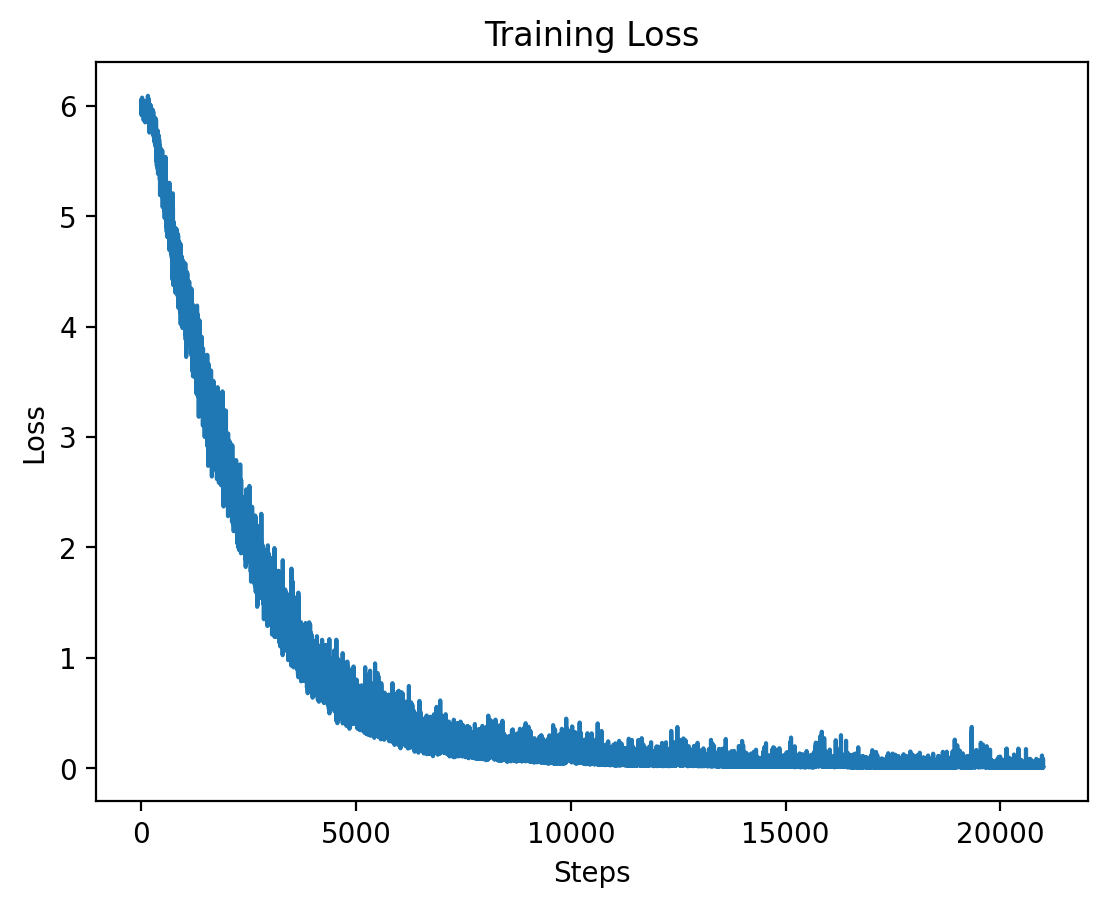
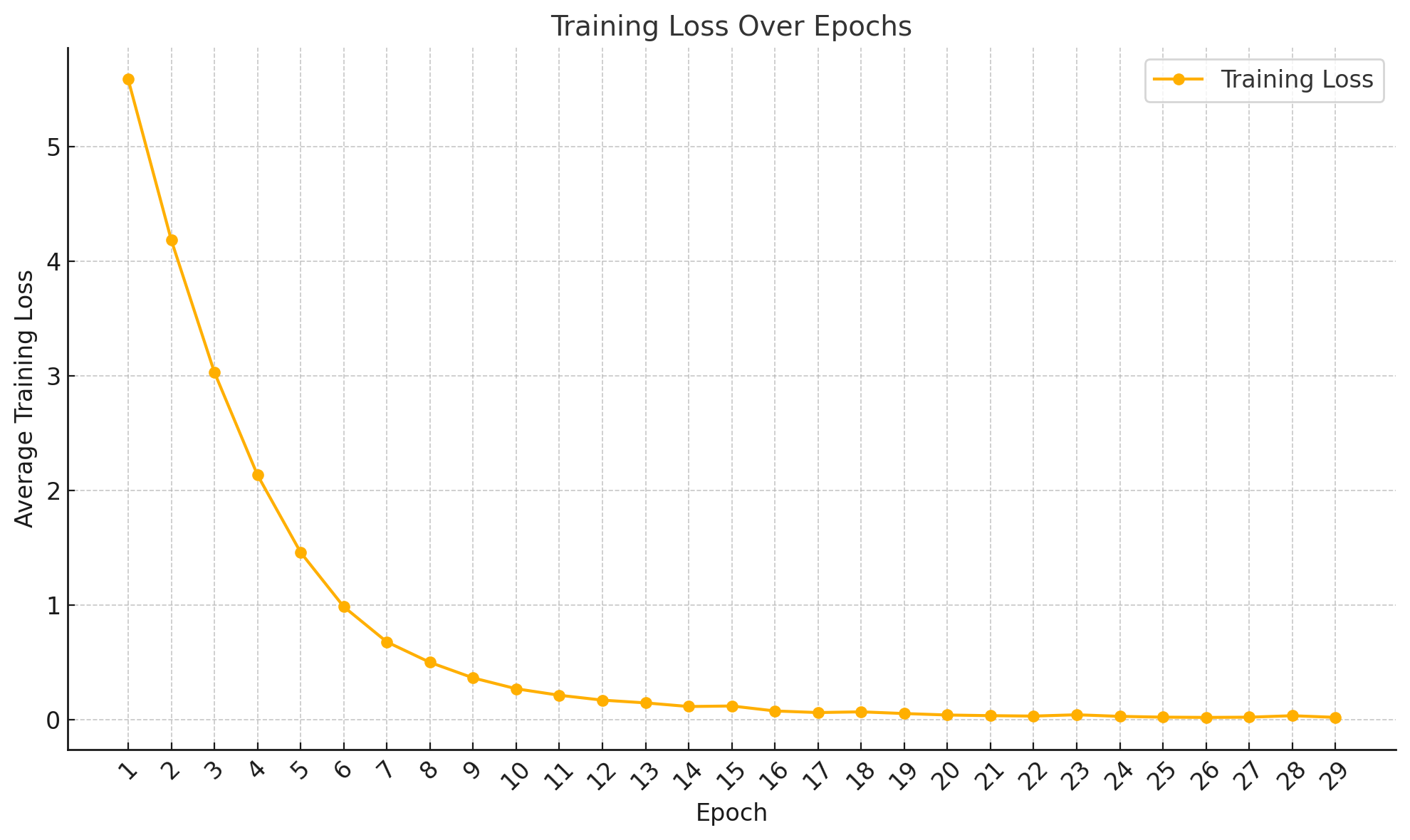
| Epoch | Average Training Loss |
|---|---|
| 1 | 5.5855 |
| 2 | 4.1836 |
| 3 | 3.0299 |
| 4 | 2.1331 |
| 5 | 1.4587 |
| 6 | 0.9847 |
| 7 | 0.6774 |
| 8 | 0.4990 |
| 9 | 0.3637 |
| 10 | 0.2688 |
| 11 | 0.2121 |
| 12 | 0.1697 |
| 13 | 0.1457 |
| 14 | 0.1139 |
| 15 | 0.1186 |
| 16 | 0.0753 |
| 17 | 0.0612 |
| 18 | 0.0676 |
| 19 | 0.0527 |
| 20 | 0.0399 |
| 21 | 0.0342 |
| 22 | 0.0304 |
| 23 | 0.0421 |
| 24 | 0.0280 |
| 25 | 0.0211 |
| 26 | 0.0189 |
| 27 | 0.0207 |
| 28 | 0.0337 |
| 29 | 0.0194 |
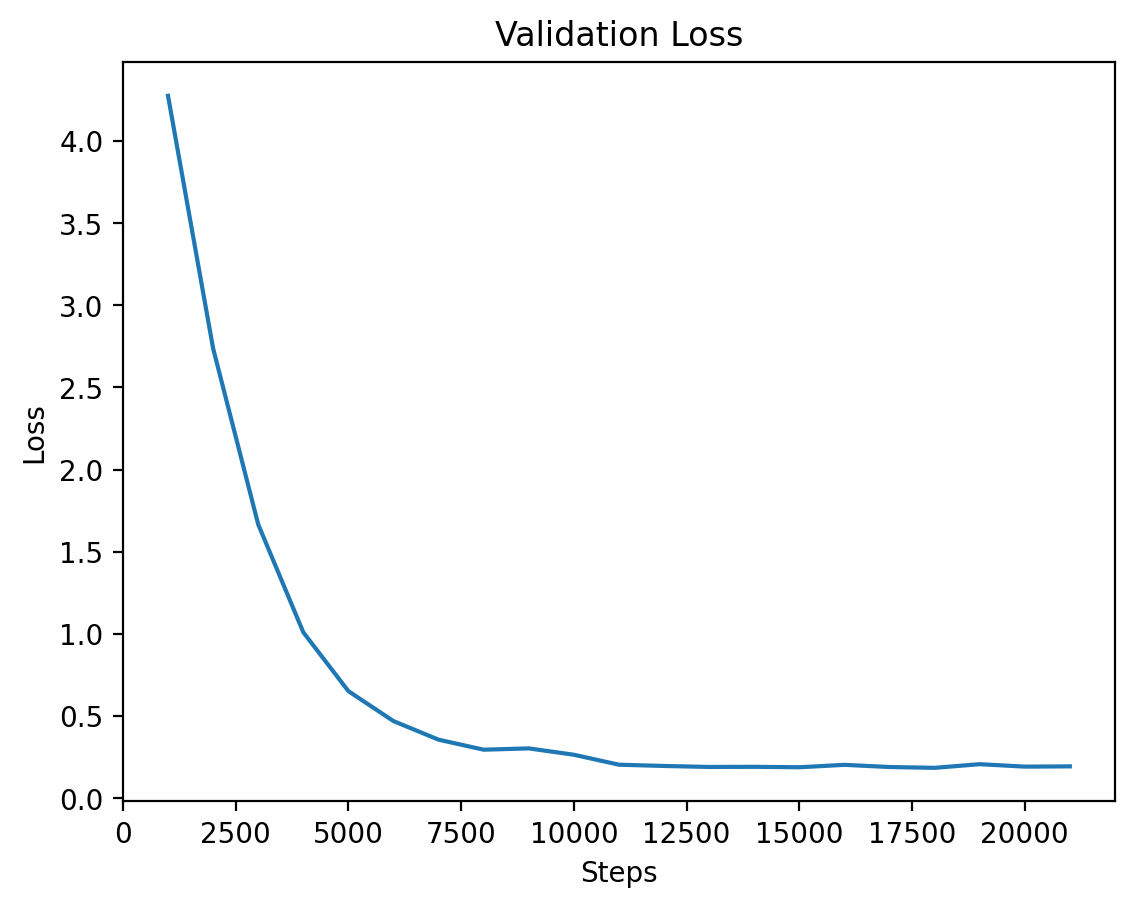
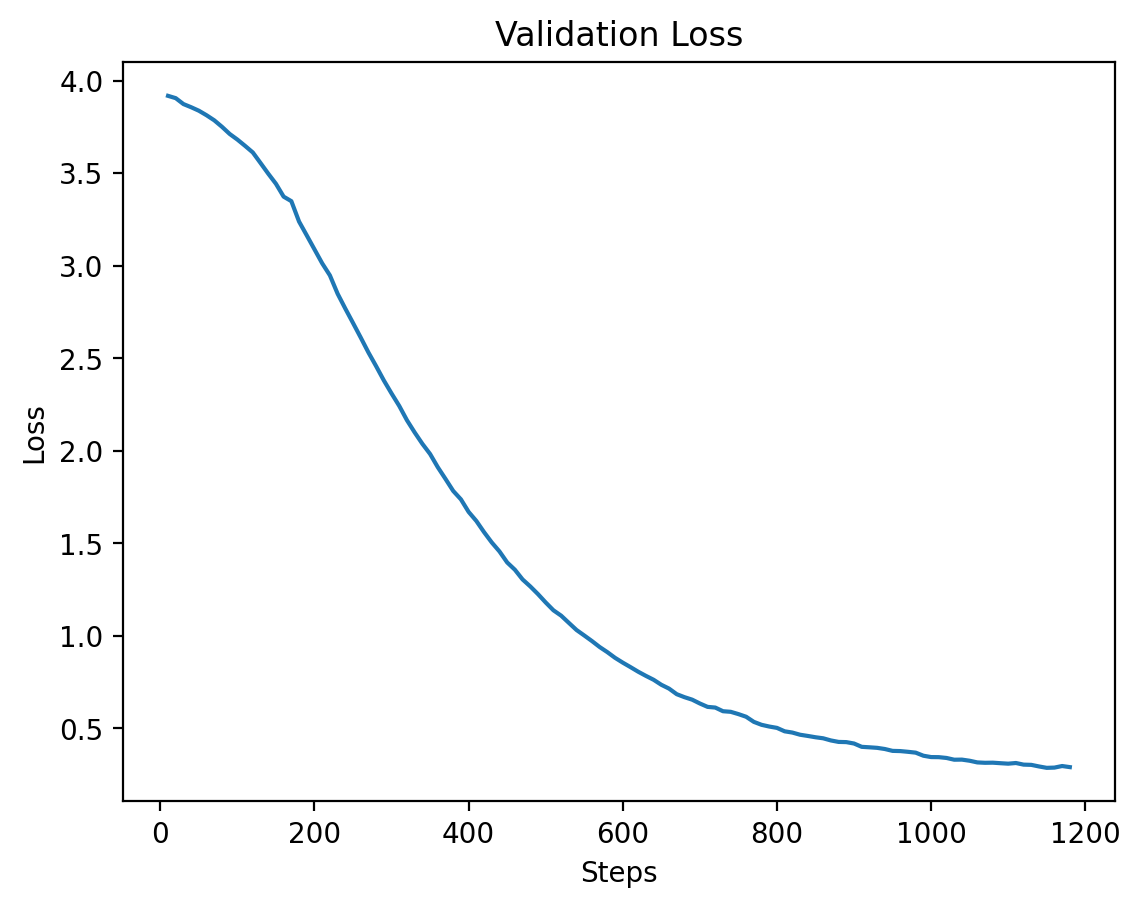
Level 7
Level 7: Training and Validation Loss
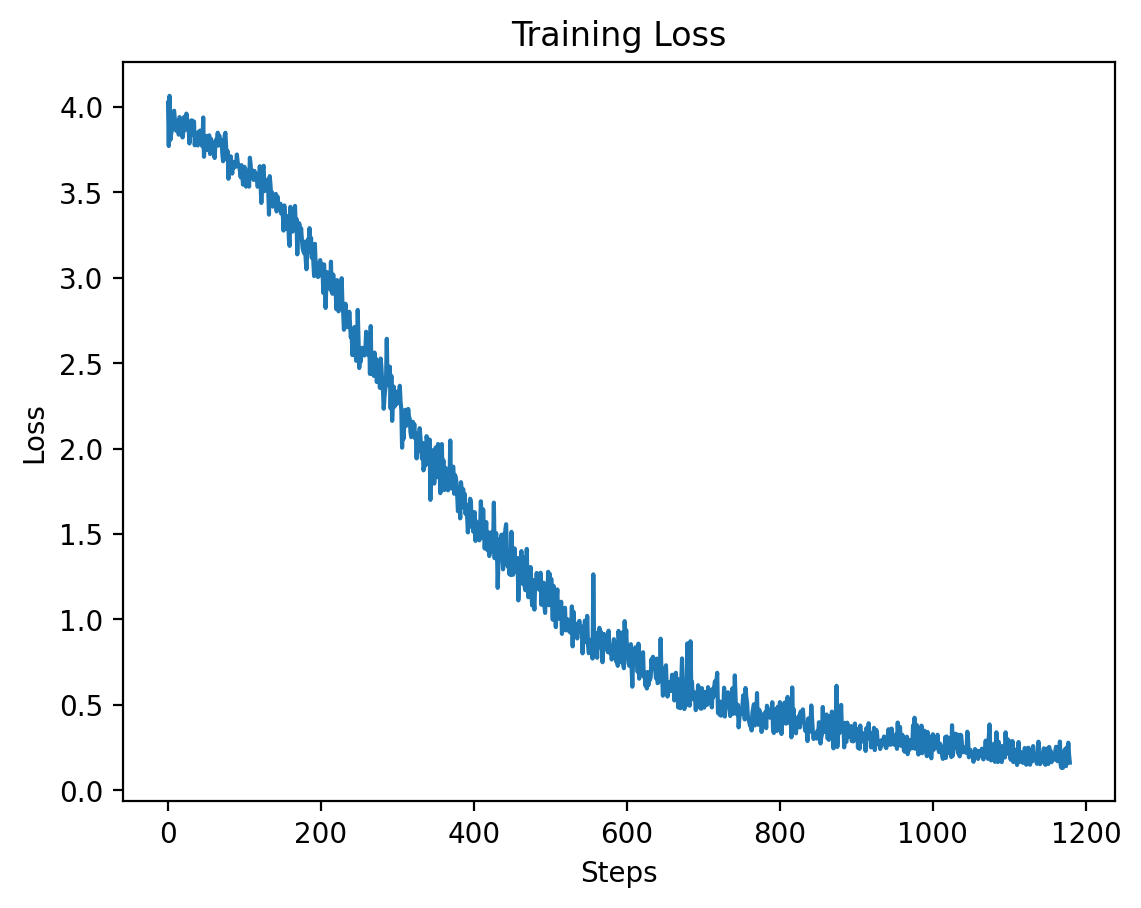
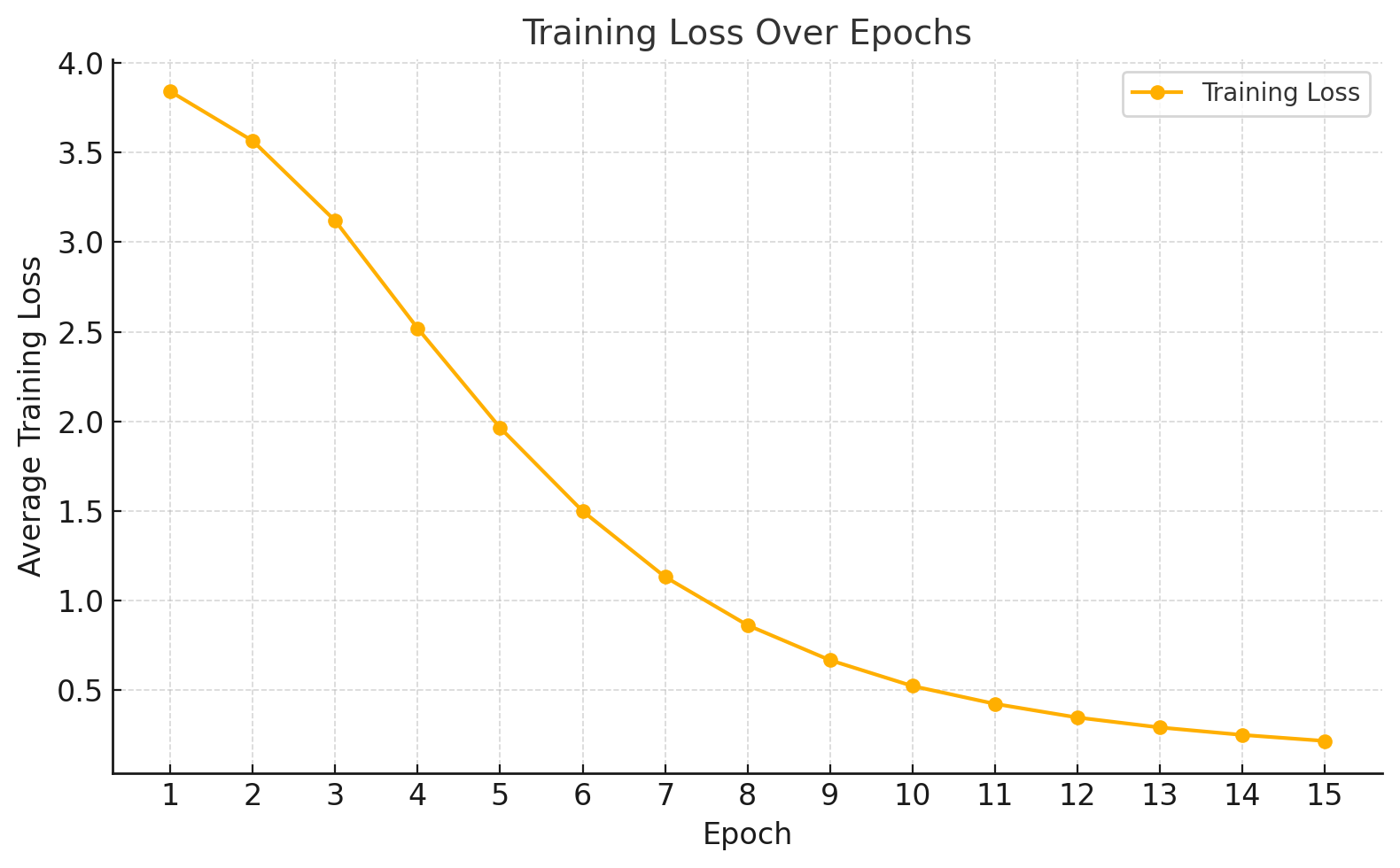
| Epoch | Average Training Loss |
|---|---|
| 1 | 3.8413 |
| 2 | 3.5653 |
| 3 | 3.1193 |
| 4 | 2.5189 |
| 5 | 1.9640 |
| 6 | 1.4992 |
| 7 | 1.1322 |
| 8 | 0.8627 |
| 9 | 0.6674 |
| 10 | 0.5232 |
| 11 | 0.4235 |
| 12 | 0.3473 |
| 13 | 0.2918 |
| 14 | 0.2501 |
| 15 | 0.2166 |
Model tree for dejanseo/ecommerce-taxonomy-classifier
Base model
albert/albert-base-v2