
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.32B
| node_id
stringlengths 18
32
| number
int64 1
4.75k
| title
stringlengths 1
276
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
null | comments
sequence | created_at
int64 1,587B
1,659B
| updated_at
int64 1,587B
1,659B
| closed_at
null 1,587B
1,659B
⌀ | author_association
stringclasses 3
values | active_lock_reason
null | draft
bool 2
classes | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
nullclasses 3
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/4748 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4748/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4748/comments | https://api.github.com/repos/huggingface/datasets/issues/4748/events | https://github.com/huggingface/datasets/pull/4748 | 1,318,874,913 | PR_kwDODunzps48JTEb | 4,748 | Add image classification processing guide | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4748). All of your documentation changes will be reflected on that endpoint."
] | 1,658,880,671,000 | 1,658,881,072,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4748",
"html_url": "https://github.com/huggingface/datasets/pull/4748",
"diff_url": "https://github.com/huggingface/datasets/pull/4748.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4748.patch",
"merged_at": null
} | This PR follows up on #4710 to separate the object detection and image classification guides. It expands a little more on the original guide to include a more complete example of loading and transforming a whole dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4748/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4748/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4747 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4747/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4747/comments | https://api.github.com/repos/huggingface/datasets/issues/4747/events | https://github.com/huggingface/datasets/pull/4747 | 1,318,586,932 | PR_kwDODunzps48IWKj | 4,747 | Shard parquet in `download_and_prepare` | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4747). All of your documentation changes will be reflected on that endpoint."
] | 1,658,858,701,000 | 1,658,859,098,000 | null | MEMBER | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4747",
"html_url": "https://github.com/huggingface/datasets/pull/4747",
"diff_url": "https://github.com/huggingface/datasets/pull/4747.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4747.patch",
"merged_at": null
} | Following https://github.com/huggingface/datasets/pull/4724 (needs to be merged first)
It's good practice to shard parquet files to enable parallelism with spark/dask/etc.
I added the `max_shard_size` parameter to `download_and_prepare` (default to 500MB for parquet, and None for arrow).
```python
from datasets import *
cache_dir = "s3://..."
builder = load_dataset_builder("squad", cache_dir=cache_dir)
builder.download_and_prepare(file_format="parquet", max_shard_size="5MB")
```
### Implementation details
The examples are written to a parquet file until `ParquetWriter._num_bytes > max_shard_size`. When this happens, a new writer is instantiated to start writing the next shard. At the end, all the shards are renamed to include the total number of shards in their names: `{builder.name}-{split}-{shard_id:05d}-of-{num_shards:05d}.parquet`
TODO:
- [ ] docstrings
- [ ] docs
- [x] tests
cc @severo | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4747/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4747/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4746 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4746/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4746/comments | https://api.github.com/repos/huggingface/datasets/issues/4746/events | https://github.com/huggingface/datasets/issues/4746 | 1,318,486,599 | I_kwDODunzps5OloJH | 4,746 | Dataset Viewer issue for yanekyuk/wikikey | {
"login": "ai-ashok",
"id": 91247690,
"node_id": "MDQ6VXNlcjkxMjQ3Njkw",
"avatar_url": "https://avatars.githubusercontent.com/u/91247690?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ai-ashok",
"html_url": "https://github.com/ai-ashok",
"followers_url": "https://api.github.com/users/ai-ashok/followers",
"following_url": "https://api.github.com/users/ai-ashok/following{/other_user}",
"gists_url": "https://api.github.com/users/ai-ashok/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ai-ashok/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ai-ashok/subscriptions",
"organizations_url": "https://api.github.com/users/ai-ashok/orgs",
"repos_url": "https://api.github.com/users/ai-ashok/repos",
"events_url": "https://api.github.com/users/ai-ashok/events{/privacy}",
"received_events_url": "https://api.github.com/users/ai-ashok/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | open | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"The dataset is empty, as far as I can tell: there are no files in the repository at https://huggingface.co./datasets/yanekyuk/wikikey/tree/main\r\n\r\nMaybe the viewer can display a better message for empty datasets"
] | 1,658,852,716,000 | 1,658,858,857,000 | null | NONE | null | null | null | ### Link
_No response_
### Description
_No response_
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4746/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4746/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4745 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4745/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4745/comments | https://api.github.com/repos/huggingface/datasets/issues/4745/events | https://github.com/huggingface/datasets/issues/4745 | 1,318,016,655 | I_kwDODunzps5Oj1aP | 4,745 | Allow `list_datasets` to include private datasets | {
"login": "ola13",
"id": 1528523,
"node_id": "MDQ6VXNlcjE1Mjg1MjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1528523?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ola13",
"html_url": "https://github.com/ola13",
"followers_url": "https://api.github.com/users/ola13/followers",
"following_url": "https://api.github.com/users/ola13/following{/other_user}",
"gists_url": "https://api.github.com/users/ola13/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ola13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ola13/subscriptions",
"organizations_url": "https://api.github.com/users/ola13/orgs",
"repos_url": "https://api.github.com/users/ola13/repos",
"events_url": "https://api.github.com/users/ola13/events{/privacy}",
"received_events_url": "https://api.github.com/users/ola13/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"Thanks for opening this issue :)\r\n\r\nIf it can help, I think you can already use `huggingface_hub` to achieve this:\r\n```python\r\n>>> from huggingface_hub import HfApi\r\n>>> [ds_info.id for ds_info in HfApi().list_datasets(use_auth_token=token) if ds_info.private]\r\n['bigscience/xxxx', 'bigscience-catalogue-data/xxxxxxx', ... ]\r\n```\r\n\r\n---------\r\n\r\nThough the latest versions of `huggingface_hub` that contain this feature are not available on python 3.6, so maybe we should first drop support for python 3.6 (see #4460) to update `list_datasets` in `datasets` as well (or we would have to copy/paste some `huggingface_hub` code)",
"Great, thanks @lhoestq the workaround works! I think it would be intuitive to have the support directly in `datasets` but it makes sense to wait given that the workaround exists :)",
"i also think that going forward we should replace more and more implementations inside datasets with the corresponding ones from `huggingface_hub` (same as we're doing in `transformers`)"
] | 1,658,830,568,000 | 1,658,836,765,000 | null | NONE | null | null | null | I am working with a large collection of private datasets, it would be convenient for me to be able to list them.
I would envision extending the convention of using `use_auth_token` keyword argument to `list_datasets` function, then calling:
```
list_datasets(use_auth_token="my_token")
```
would return the list of all datasets I have permissions to view, including private ones. The only current alternative I see is to use the hub website to manually obtain the list of dataset names - this is in the context of BigScience where respective private spaces contain hundreds of datasets, so not very convenient to list manually. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4745/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4745/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4744 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4744/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4744/comments | https://api.github.com/repos/huggingface/datasets/issues/4744/events | https://github.com/huggingface/datasets/issues/4744 | 1,317,822,345 | I_kwDODunzps5OjF-J | 4,744 | Remove instructions to generate dummy data from our docs | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"Note that for me personally, conceptually all the dummy data (even for \"canonical\" datasets) should be superseded by `datasets-server`, which performs some kind of CI/CD of datasets (including the canonical ones)",
"I totally agree: next step should be rethinking if dummy data makes sense for canonical datasets (once we have datasets-server) and eventually remove it.\r\n\r\nBut for now, we could at least start by removing the indication to generate dummy data from our docs."
] | 1,658,820,778,000 | 1,658,823,453,000 | null | MEMBER | null | null | null | In our docs, we indicate to generate the dummy data: https://huggingface.co./docs/datasets/dataset_script#testing-data-and-checksum-metadata
However:
- dummy data makes sense only for datasets in our GitHub repo: so that we can test their loading with our CI
- for datasets on the Hub:
- they do not pass any CI test requiring dummy data
- there are no instructions on how they can test their dataset locally using the dummy data
- the generation of the dummy data assumes our GitHub directory structure:
- the dummy data will be generated under `./datasets/<dataset_name>/dummy` even if locally there is no `./datasets` directory (which is the usual case). See issue:
- #4742
CC: @stevhliu | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4744/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4744/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4743/comments | https://api.github.com/repos/huggingface/datasets/issues/4743/events | https://github.com/huggingface/datasets/pull/4743 | 1,317,362,561 | PR_kwDODunzps48EUFs | 4,743 | Update map docs | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4743). All of your documentation changes will be reflected on that endpoint."
] | 1,658,782,775,000 | 1,658,783,163,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4743",
"html_url": "https://github.com/huggingface/datasets/pull/4743",
"diff_url": "https://github.com/huggingface/datasets/pull/4743.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4743.patch",
"merged_at": null
} | This PR updates the `map` docs for processing text to include `return_tensors="np"` to make it run faster (see #4676). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4743/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4743/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4742 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4742/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4742/comments | https://api.github.com/repos/huggingface/datasets/issues/4742/events | https://github.com/huggingface/datasets/issues/4742 | 1,317,260,663 | I_kwDODunzps5Og813 | 4,742 | Dummy data nowhere to be found | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi @BramVanroy, thanks for reporting.\r\n\r\nFirst of all, please note that you do not need the dummy data: this was the case when we were adding datasets to the `datasets` library (on this GitHub repo), so that we could test the correct loading of all datasets with our CI. However, this is no longer the case for datasets on the Hub.\r\n- We should definitely update our docs.\r\n\r\nSecond, the dummy data is generated locally:\r\n- in your case, the dummy data will be generated inside the directory: `./datasets/hebban-reviews/dummy`\r\n- please note the preceding `./datasets` directory: the reason for this is that the command to generate the dummy data was specifically created for our `datasets` library, and therefore assumes our directory structure: commands are run from the root directory of our GitHub repo, and datasets scripts are under `./datasets` \r\n\r\n\r\n ",
"I have opened an Issue to update the instructions on dummy data generation:\r\n- #4744"
] | 1,658,776,722,000 | 1,658,820,827,000 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
To finalize my dataset, I wanted to create dummy data as per the guide and I ran
```shell
datasets-cli dummy_data datasets/hebban-reviews --auto_generate
```
where hebban-reviews is [this repo](https://huggingface.co./datasets/BramVanroy/hebban-reviews). And even though the scripts runs and shows a message at the end that it succeeded, I cannot find the dummy data anywhere. Where is it?
## Expected results
To see the dummy data in the datasets' folder or in the folder where I ran the command.
## Actual results
I see the following message but I cannot find the dummy data anywhere.
```
Dummy data generation done and dummy data test succeeded for config 'filtered''.
Automatic dummy data generation succeeded for all configs of '.\datasets\hebban-reviews\'
```
## Environment info
- `datasets` version: 2.4.1.dev0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.8
- PyArrow version: 8.0.0
- Pandas version: 1.4.3
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4742/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4742/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4741 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4741/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4741/comments | https://api.github.com/repos/huggingface/datasets/issues/4741/events | https://github.com/huggingface/datasets/pull/4741 | 1,316,621,272 | PR_kwDODunzps48B2fl | 4,741 | Fix to dict conversion of `DatasetInfo`/`Features` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,745,687,000 | 1,658,753,436,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4741",
"html_url": "https://github.com/huggingface/datasets/pull/4741",
"diff_url": "https://github.com/huggingface/datasets/pull/4741.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4741.patch",
"merged_at": 1658752673000
} | Fix #4681 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4741/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4741/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4740 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4740/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4740/comments | https://api.github.com/repos/huggingface/datasets/issues/4740/events | https://github.com/huggingface/datasets/pull/4740 | 1,316,478,007 | PR_kwDODunzps48BX5l | 4,740 | Fix multiprocessing in map_nested | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4740). All of your documentation changes will be reflected on that endpoint.",
"@lhoestq as a workaround to preserve previous behavior, the parameter `multiprocessing_min_length=16` is passed from `download` to `map_nested`, so that multiprocessing is only used if at least 16 files to be downloaded.\r\n\r\nNote that there is a small breaking change (I think previously it was unintended behavior, so that I have fixed it):\r\n- Before (with default `num_proc=16`) if there were 16 files to be downloaded, multiprocessing was not used\r\n- Now (with default `num_proc=16`) if there are 16 files to be downloaded, multiprocessing is used",
"Thanks for the workaround !"
] | 1,658,738,659,000 | 1,658,860,880,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4740",
"html_url": "https://github.com/huggingface/datasets/pull/4740",
"diff_url": "https://github.com/huggingface/datasets/pull/4740.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4740.patch",
"merged_at": null
} | As previously discussed:
Before, multiprocessing was not used in `map_nested` if `num_proc` was greater than or equal to `len(iterable)`.
- Multiprocessing was not used e.g. when passing `num_proc=20` but having 19 files to download
- As by default, `DownloadManager` sets `num_proc=16`, before multiprocessing was only used when `len(iterable)>16` by default
Now, if `num_proc` is greater than or equal to ``len(iterable)``, `num_proc` is set to ``len(iterable)`` and multiprocessing is used.
- We pass the variable `multiprocessing_min_length=16`, so that multiprocessing is only used if at least 16 files to be downloaded
- ~As by default, `DownloadManager` sets `num_proc=16`, now multiprocessing is used when `len(iterable)>1` by default~
See discussion below.
~After having had to fix some tests (87602ac), I am wondering:~
- ~do we want to have multiprocessing by default?~
- ~please note that `DownloadManager.download` sets `num_proc=16` by default~
- ~or would it be better to ask the user to set it explicitly if they want multiprocessing (and default to `num_proc=1`)?~
Fix #4636.
CC: @nateraw | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4740/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4740/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4739 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4739/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4739/comments | https://api.github.com/repos/huggingface/datasets/issues/4739/events | https://github.com/huggingface/datasets/pull/4739 | 1,316,400,915 | PR_kwDODunzps48BHdE | 4,739 | Deprecate metrics | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4739). All of your documentation changes will be reflected on that endpoint.",
"I mark this as Draft because the deprecated version number needs being updated after the latest release.",
"Perhaps now is the time to also update the `inspect_metric` from `evaluate` with the changes introduced in https://github.com/huggingface/datasets/pull/4433 (cc @lvwerra) ",
"What do you think of including what changes users have to do to switch to `evaluate` in the warning message ?\r\n(basically replace `datasets.load_metric` by `evaluate.load`)\r\n\r\nI think it can help users migrate to `evaluate` and silence the warnings"
] | 1,658,734,555,000 | 1,658,869,190,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4739",
"html_url": "https://github.com/huggingface/datasets/pull/4739",
"diff_url": "https://github.com/huggingface/datasets/pull/4739.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4739.patch",
"merged_at": null
} | Deprecate metrics:
- deprecate public functions: `load_metric`, `list_metrics` and `inspect_metric`: docstring and warning
- test deprecation warnings are issues
- deprecate metrics in all docs
- remove mentions to metrics in docs and README
- deprecate internal functions/classes
Maybe we should also stop testing metrics? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4739/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4739/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4738/comments | https://api.github.com/repos/huggingface/datasets/issues/4738/events | https://github.com/huggingface/datasets/pull/4738 | 1,315,222,166 | PR_kwDODunzps479hq4 | 4,738 | Use CI unit/integration tests | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I think this PR can be merged. Willing to see it in action.\r\n\r\nCC: @lhoestq "
] | 1,658,508,480,000 | 1,658,866,762,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4738",
"html_url": "https://github.com/huggingface/datasets/pull/4738",
"diff_url": "https://github.com/huggingface/datasets/pull/4738.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4738.patch",
"merged_at": 1658866025000
} | This PR:
- Implements separate unit/integration tests
- A fail in integration tests does not cancel the rest of the jobs
- We should implement more robust integration tests: work in progress in a subsequent PR
- For the moment, test involving network requests are marked as integration: to be evolved | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4738/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4738/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4737 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4737/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4737/comments | https://api.github.com/repos/huggingface/datasets/issues/4737/events | https://github.com/huggingface/datasets/issues/4737 | 1,315,011,004 | I_kwDODunzps5OYXm8 | 4,737 | Download error on scene_parse_150 | {
"login": "juliensimon",
"id": 3436143,
"node_id": "MDQ6VXNlcjM0MzYxNDM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3436143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/juliensimon",
"html_url": "https://github.com/juliensimon",
"followers_url": "https://api.github.com/users/juliensimon/followers",
"following_url": "https://api.github.com/users/juliensimon/following{/other_user}",
"gists_url": "https://api.github.com/users/juliensimon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/juliensimon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/juliensimon/subscriptions",
"organizations_url": "https://api.github.com/users/juliensimon/orgs",
"repos_url": "https://api.github.com/users/juliensimon/repos",
"events_url": "https://api.github.com/users/juliensimon/events{/privacy}",
"received_events_url": "https://api.github.com/users/juliensimon/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi! The server with the data seems to be down. I've reported this issue (https://github.com/CSAILVision/sceneparsing/issues/34) in the dataset repo. "
] | 1,658,496,508,000 | 1,658,500,151,000 | null | NONE | null | null | null | ```
from datasets import load_dataset
dataset = load_dataset("scene_parse_150", "scene_parsing")
FileNotFoundError: Couldn't find file at http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4737/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4737/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4736/comments | https://api.github.com/repos/huggingface/datasets/issues/4736/events | https://github.com/huggingface/datasets/issues/4736 | 1,314,931,996 | I_kwDODunzps5OYEUc | 4,736 | Dataset Viewer issue for deepklarity/huggingface-spaces-dataset | {
"login": "dk-crazydiv",
"id": 47515542,
"node_id": "MDQ6VXNlcjQ3NTE1NTQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47515542?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dk-crazydiv",
"html_url": "https://github.com/dk-crazydiv",
"followers_url": "https://api.github.com/users/dk-crazydiv/followers",
"following_url": "https://api.github.com/users/dk-crazydiv/following{/other_user}",
"gists_url": "https://api.github.com/users/dk-crazydiv/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dk-crazydiv/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dk-crazydiv/subscriptions",
"organizations_url": "https://api.github.com/users/dk-crazydiv/orgs",
"repos_url": "https://api.github.com/users/dk-crazydiv/repos",
"events_url": "https://api.github.com/users/dk-crazydiv/events{/privacy}",
"received_events_url": "https://api.github.com/users/dk-crazydiv/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Thanks for reporting. You're right, workers were under-provisioned due to a manual error, and the job queue was full. It's fixed now."
] | 1,658,492,058,000 | 1,658,497,598,000 | null | NONE | null | null | null | ### Link
https://huggingface.co./datasets/deepklarity/huggingface-spaces-dataset/viewer/deepklarity--huggingface-spaces-dataset/train
### Description
Hi Team,
I'm getting the following error on a uploaded dataset. I'm getting the same status for a couple of hours now. The dataset size is `<1MB` and the format is csv, so I'm not sure if it's supposed to take this much time or not.
```
Status code: 400
Exception: Status400Error
Message: The split is being processed. Retry later.
```
Is there any explicit step to be taken to get the viewer to work?
### Owner
Yes | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4736/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4736/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4735 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4735/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4735/comments | https://api.github.com/repos/huggingface/datasets/issues/4735/events | https://github.com/huggingface/datasets/pull/4735 | 1,314,501,641 | PR_kwDODunzps477CuP | 4,735 | Pin rouge_score test dependency | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,474,301,000 | 1,658,476,694,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4735",
"html_url": "https://github.com/huggingface/datasets/pull/4735",
"diff_url": "https://github.com/huggingface/datasets/pull/4735.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4735.patch",
"merged_at": 1658475918000
} | Temporarily pin `rouge_score` (to avoid latest version 0.7.0) until the issue is fixed.
Fix #4734 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4735/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4735/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4734 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4734/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4734/comments | https://api.github.com/repos/huggingface/datasets/issues/4734/events | https://github.com/huggingface/datasets/issues/4734 | 1,314,495,382 | I_kwDODunzps5OWZuW | 4,734 | Package rouge-score cannot be imported | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"We have added a comment on an existing issue opened in their repo: https://github.com/google-research/google-research/issues/1212#issuecomment-1192267130\r\n- https://github.com/google-research/google-research/issues/1212"
] | 1,658,474,105,000 | 1,658,475,919,000 | null | MEMBER | null | null | null | ## Describe the bug
After the today release of `rouge_score-0.0.7` it seems no longer importable. Our CI fails: https://github.com/huggingface/datasets/runs/7463218591?check_suite_focus=true
```
FAILED tests/test_dataset_common.py::LocalDatasetTest::test_builder_class_bigbench
FAILED tests/test_dataset_common.py::LocalDatasetTest::test_builder_configs_bigbench
FAILED tests/test_dataset_common.py::LocalDatasetTest::test_load_dataset_bigbench
FAILED tests/test_metric_common.py::LocalMetricTest::test_load_metric_rouge
```
with errors:
```
> from rouge_score import rouge_scorer
E ModuleNotFoundError: No module named 'rouge_score'
```
```
E ImportError: To be able to use rouge, you need to install the following dependency: rouge_score.
E Please install it using 'pip install rouge_score' for instance'
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4734/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4734/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4733 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4733/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4733/comments | https://api.github.com/repos/huggingface/datasets/issues/4733/events | https://github.com/huggingface/datasets/issues/4733 | 1,314,479,616 | I_kwDODunzps5OWV4A | 4,733 | rouge metric | {
"login": "asking28",
"id": 29248466,
"node_id": "MDQ6VXNlcjI5MjQ4NDY2",
"avatar_url": "https://avatars.githubusercontent.com/u/29248466?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/asking28",
"html_url": "https://github.com/asking28",
"followers_url": "https://api.github.com/users/asking28/followers",
"following_url": "https://api.github.com/users/asking28/following{/other_user}",
"gists_url": "https://api.github.com/users/asking28/gists{/gist_id}",
"starred_url": "https://api.github.com/users/asking28/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/asking28/subscriptions",
"organizations_url": "https://api.github.com/users/asking28/orgs",
"repos_url": "https://api.github.com/users/asking28/repos",
"events_url": "https://api.github.com/users/asking28/events{/privacy}",
"received_events_url": "https://api.github.com/users/asking28/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Fixed by:\r\n- #4735"
] | 1,658,473,611,000 | 1,658,480,882,000 | null | NONE | null | null | null | ## Describe the bug
A clear and concise description of what the bug is.
Loading Rouge metric gives error after latest rouge-score==0.0.7 release.
Downgrading rougemetric==0.0.4 works fine.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
```
## Expected results
A clear and concise description of the expected results.
from rouge_score import rouge_scorer, scoring
should run
## Actual results
Specify the actual results or traceback.
File "/root/.cache/huggingface/modules/datasets_modules/metrics/rouge/0ffdb60f436bdb8884d5e4d608d53dbe108e82dac4f494a66f80ef3f647c104f/rouge.py", line 21, in <module>
from rouge_score import rouge_scorer, scoring
ImportError: cannot import name 'rouge_scorer' from 'rouge_score' (unknown location)
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Linux
- Python version:3.9
- PyArrow version:
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4733/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4733/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4732 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4732/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4732/comments | https://api.github.com/repos/huggingface/datasets/issues/4732/events | https://github.com/huggingface/datasets/issues/4732 | 1,314,371,566 | I_kwDODunzps5OV7fu | 4,732 | Document better that loading a dataset passing its name does not use the local script | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [
"Thanks for the feedback!\r\n\r\nI think since this issue is closely related to loading, I can add a clearer explanation under [Load > local loading script](https://huggingface.co./docs/datasets/main/en/loading#local-loading-script).",
"That makes sense but I think having a line about it under https://huggingface.co./docs/datasets/installation#source the \"source\" header here would be useful. My mental model of `pip install -e .` does not include the fact that the source files aren't actually being used. "
] | 1,658,470,051,000 | 1,658,777,132,000 | null | MEMBER | null | null | null | As reported by @TrentBrick here https://github.com/huggingface/datasets/issues/4725#issuecomment-1191858596, it could be more clear that loading a dataset by passing its name does not use the (modified) local script of it.
What he did:
- he installed `datasets` from source
- he modified locally `datasets/the_pile/the_pile.py` loading script
- he tried to load it but using `load_dataset("the_pile")` instead of `load_dataset("datasets/the_pile")`
- as explained here https://github.com/huggingface/datasets/issues/4725#issuecomment-1191040245:
- the former does not use the local script, but instead it downloads a copy of `the_pile.py` from our GitHub, caches it locally (inside `~/.cache/huggingface/modules`) and uses that.
He suggests adding a more clear explanation about this. He suggests adding it maybe in [Installation > source](https://huggingface.co./docs/datasets/installation))
CC: @stevhliu | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4732/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4732/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4731 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4731/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4731/comments | https://api.github.com/repos/huggingface/datasets/issues/4731/events | https://github.com/huggingface/datasets/pull/4731 | 1,313,773,348 | PR_kwDODunzps474dlZ | 4,731 | docs: ✏️ fix TranslationVariableLanguages example | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,435,741,000 | 1,658,473,260,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4731",
"html_url": "https://github.com/huggingface/datasets/pull/4731",
"diff_url": "https://github.com/huggingface/datasets/pull/4731.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4731.patch",
"merged_at": 1658472522000
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4731/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4731/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4730/comments | https://api.github.com/repos/huggingface/datasets/issues/4730/events | https://github.com/huggingface/datasets/issues/4730 | 1,313,421,263 | I_kwDODunzps5OSTfP | 4,730 | Loading imagenet-1k validation split takes much more RAM than expected | {
"login": "fxmarty",
"id": 9808326,
"node_id": "MDQ6VXNlcjk4MDgzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fxmarty",
"html_url": "https://github.com/fxmarty",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https://api.github.com/users/fxmarty/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fxmarty/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fxmarty/subscriptions",
"organizations_url": "https://api.github.com/users/fxmarty/orgs",
"repos_url": "https://api.github.com/users/fxmarty/repos",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"received_events_url": "https://api.github.com/users/fxmarty/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"My bad, `482 * 418 * 50000 * 3 / 1000000 = 30221 MB` ( https://stackoverflow.com/a/42979315 ).\r\n\r\nMeanwhile `256 * 256 * 50000 * 3 / 1000000 = 9830 MB`. We are loading the non-cropped images and that is why we take so much RAM."
] | 1,658,416,446,000 | 1,658,421,664,000 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
Loading into memory the validation split of imagenet-1k takes much more RAM than expected. Assuming ImageNet-1k is 150 GB, split is 50000 validation images and 1,281,167 train images, I would expect only about 6 GB loaded in RAM.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("imagenet-1k", split="validation")
print(dataset)
"""prints
Dataset({
features: ['image', 'label'],
num_rows: 50000
})
"""
pipe_inputs = dataset["image"]
# and wait :-)
```
## Expected results
Use only < 10 GB RAM when loading the images.
## Actual results

```
Using custom data configuration default
Reusing dataset imagenet-1k (/home/fxmarty/.cache/huggingface/datasets/imagenet-1k/default/1.0.0/a1e9bfc56c3a7350165007d1176b15e9128fcaf9ab972147840529aed3ae52bc)
Killed
```
## Environment info
- `datasets` version: 2.3.3.dev0
- Platform: Linux-5.15.0-41-generic-x86_64-with-glibc2.35
- Python version: 3.9.12
- PyArrow version: 7.0.0
- Pandas version: 1.3.5
- datasets commit: 4e4222f1b6362c2788aec0dd2cd8cede6dd17b80
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4730/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4730/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4729 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4729/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4729/comments | https://api.github.com/repos/huggingface/datasets/issues/4729/events | https://github.com/huggingface/datasets/pull/4729 | 1,313,374,015 | PR_kwDODunzps473GmR | 4,729 | Refactor Hub tests | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,414,593,000 | 1,658,502,589,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4729",
"html_url": "https://github.com/huggingface/datasets/pull/4729",
"diff_url": "https://github.com/huggingface/datasets/pull/4729.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4729.patch",
"merged_at": 1658501789000
} | This PR refactors `test_upstream_hub` by removing unittests and using the following pytest Hub fixtures:
- `ci_hub_config`
- `set_ci_hub_access_token`: to replace setUp/tearDown
- `temporary_repo` context manager: to replace `try... finally`
- `cleanup_repo`: to delete repo accidentally created if one of the tests fails
This is a preliminary work done to manage unit/integration tests separately. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4729/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4729/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4728 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4728/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4728/comments | https://api.github.com/repos/huggingface/datasets/issues/4728/events | https://github.com/huggingface/datasets/issues/4728 | 1,312,897,454 | I_kwDODunzps5OQTmu | 4,728 | load_dataset gives "403" error when using Financial Phrasebank | {
"login": "rohitvincent",
"id": 2209134,
"node_id": "MDQ6VXNlcjIyMDkxMzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2209134?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rohitvincent",
"html_url": "https://github.com/rohitvincent",
"followers_url": "https://api.github.com/users/rohitvincent/followers",
"following_url": "https://api.github.com/users/rohitvincent/following{/other_user}",
"gists_url": "https://api.github.com/users/rohitvincent/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rohitvincent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rohitvincent/subscriptions",
"organizations_url": "https://api.github.com/users/rohitvincent/orgs",
"repos_url": "https://api.github.com/users/rohitvincent/repos",
"events_url": "https://api.github.com/users/rohitvincent/events{/privacy}",
"received_events_url": "https://api.github.com/users/rohitvincent/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hi @rohitvincent, thanks for reporting.\r\n\r\nUnfortunately I'm not able to reproduce your issue:\r\n```python\r\nIn [2]: from datasets import load_dataset, DownloadMode\r\n ...: load_dataset(path='financial_phrasebank',name='sentences_allagree', download_mode=\"force_redownload\")\r\nDownloading builder script: 6.04kB [00:00, 2.87MB/s] \r\nDownloading metadata: 13.7kB [00:00, 7.24MB/s] \r\nDownloading and preparing dataset financial_phrasebank/sentences_allagree (download: 665.91 KiB, generated: 296.26 KiB, post-processed: Unknown size, total: 962.17 KiB) to .../.cache/huggingface/datasets/financial_phrasebank/sentences_allagree/1.0.0/550bde12e6c30e2674da973a55f57edde5181d53f5a5a34c1531c53f93b7e141...\r\nDownloading data: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 682k/682k [00:00<00:00, 7.66MB/s]\r\nDataset financial_phrasebank downloaded and prepared to .../.cache/huggingface/datasets/financial_phrasebank/sentences_allagree/1.0.0/550bde12e6c30e2674da973a55f57edde5181d53f5a5a34c1531c53f93b7e141. Subsequent calls will reuse this data.\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 918.80it/s]\r\nOut[2]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['sentence', 'label'],\r\n num_rows: 2264\r\n })\r\n})\r\n```\r\n\r\nAre you able to access the link? https://www.researchgate.net/profile/Pekka-Malo/publication/251231364_FinancialPhraseBank-v10/data/0c96051eee4fb1d56e000000/FinancialPhraseBank-v10.zip",
"Yes was able to download from the link manually. But still, get the same error when I use load_dataset."
] | 1,658,393,012,000 | 1,658,478,333,000 | null | NONE | null | null | null | I tried both codes below to download the financial phrasebank dataset (https://huggingface.co./datasets/financial_phrasebank) with the sentences_allagree subset. However, the code gives a 403 error when executed from multiple machines locally or on the cloud.
```
from datasets import load_dataset, DownloadMode
load_dataset(path='financial_phrasebank',name='sentences_allagree',download_mode=DownloadMode.FORCE_REDOWNLOAD)
```
```
from datasets import load_dataset, DownloadMode
load_dataset(path='financial_phrasebank',name='sentences_allagree')
```
**Error**
ConnectionError: Couldn't reach https://www.researchgate.net/profile/Pekka_Malo/publication/251231364_FinancialPhraseBank-v10/data/0c96051eee4fb1d56e000000/FinancialPhraseBank-v10.zip (error 403)
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4728/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4728/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4727/comments | https://api.github.com/repos/huggingface/datasets/issues/4727/events | https://github.com/huggingface/datasets/issues/4727 | 1,312,645,391 | I_kwDODunzps5OPWEP | 4,727 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"login": "thenerd31",
"id": 53668030,
"node_id": "MDQ6VXNlcjUzNjY4MDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thenerd31",
"html_url": "https://github.com/thenerd31",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "https://api.github.com/users/thenerd31/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thenerd31/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thenerd31/subscriptions",
"organizations_url": "https://api.github.com/users/thenerd31/orgs",
"repos_url": "https://api.github.com/users/thenerd31/repos",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"received_events_url": "https://api.github.com/users/thenerd31/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"The preview is working OK:\r\n\r\n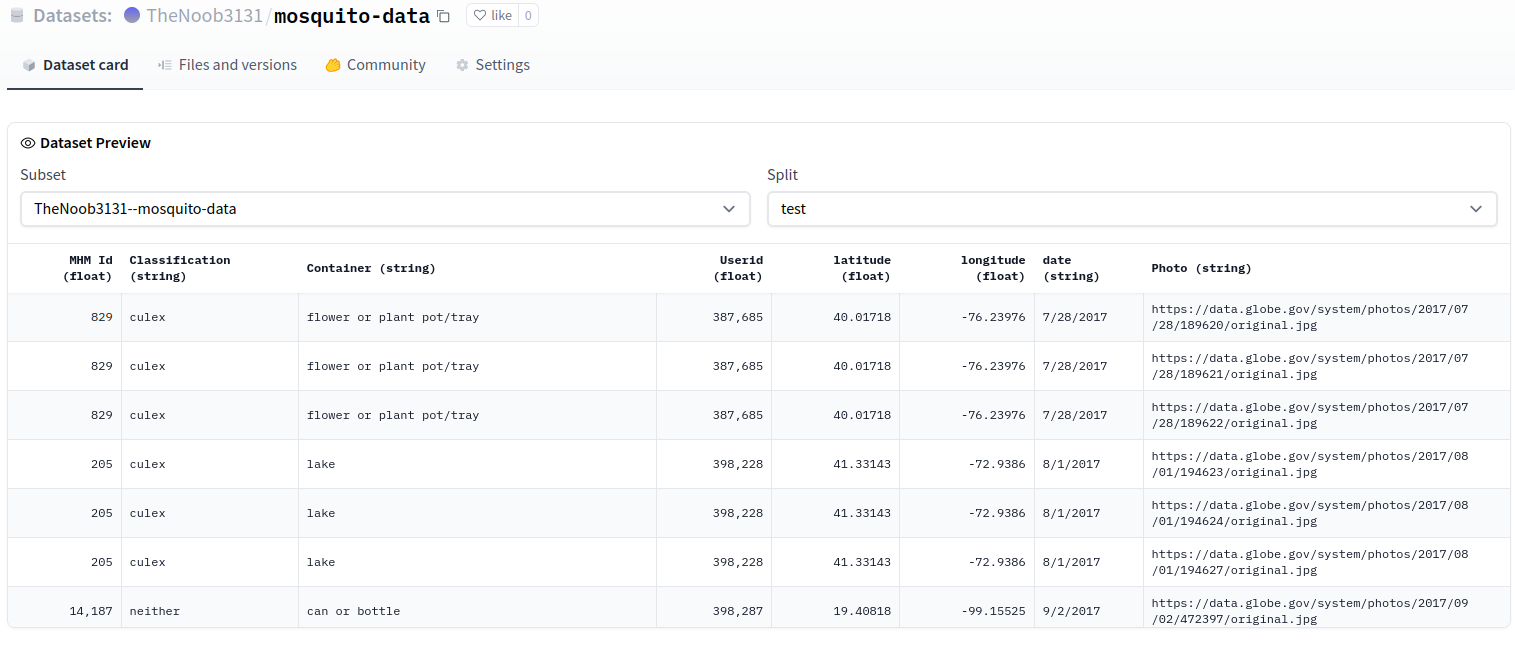\r\n\r\n"
] | 1,658,381,088,000 | 1,658,389,916,000 | null | NONE | null | null | null | ### Link
https://huggingface.co./datasets/TheNoob3131/mosquito-data/viewer/TheNoob3131--mosquito-data/test
### Description
Dataset preview not showing with large files. Says 'split cache is empty' even though there are train and test splits.
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4727/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4727/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4726 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4726/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4726/comments | https://api.github.com/repos/huggingface/datasets/issues/4726/events | https://github.com/huggingface/datasets/pull/4726 | 1,312,082,175 | PR_kwDODunzps47ykPI | 4,726 | Fix broken link to the Hub | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,357,847,000 | 1,658,413,998,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4726",
"html_url": "https://github.com/huggingface/datasets/pull/4726",
"diff_url": "https://github.com/huggingface/datasets/pull/4726.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4726.patch",
"merged_at": 1658390454000
} | The Markdown link fails to render if it is in the same line as the `<span>`. This PR implements @mishig25's fix by using `<a href=" ">` instead.
 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4726/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4726/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4725/comments | https://api.github.com/repos/huggingface/datasets/issues/4725/events | https://github.com/huggingface/datasets/issues/4725 | 1,311,907,096 | I_kwDODunzps5OMh0Y | 4,725 | the_pile datasets URL broken. | {
"login": "TrentBrick",
"id": 12433427,
"node_id": "MDQ6VXNlcjEyNDMzNDI3",
"avatar_url": "https://avatars.githubusercontent.com/u/12433427?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TrentBrick",
"html_url": "https://github.com/TrentBrick",
"followers_url": "https://api.github.com/users/TrentBrick/followers",
"following_url": "https://api.github.com/users/TrentBrick/following{/other_user}",
"gists_url": "https://api.github.com/users/TrentBrick/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TrentBrick/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TrentBrick/subscriptions",
"organizations_url": "https://api.github.com/users/TrentBrick/orgs",
"repos_url": "https://api.github.com/users/TrentBrick/repos",
"events_url": "https://api.github.com/users/TrentBrick/events{/privacy}",
"received_events_url": "https://api.github.com/users/TrentBrick/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Thanks for reporting, @TrentBrick. We are addressing the change with their data host server.\r\n\r\nOn the meantime, if you would like to work with your fixed local copy of the_pile script, you should use:\r\n```python\r\nload_dataset(\"path/to/your/local/the_pile/the_pile.py\",...\r\n```\r\ninstead of just `load_dataset(\"the_pile\",...`.\r\n\r\nThe latter downloads a copy of `the_pile.py` from our GitHub, caches it locally (inside `~/.cache/huggingface/modules`) and uses that.",
"@TrentBrick, I have checked the URLs and both hosts work, the original (https://the-eye.eu/) and the mirror (https://mystic.the-eye.eu/). See e.g.:\r\n- https://mystic.the-eye.eu/public/AI/pile/\r\n- https://mystic.the-eye.eu/public/AI/pile_preliminary_components/\r\n\r\nPlease, let me know if you still find any issue loading this dataset by using current server URLs.",
"Great this is working now. Re the download from GitHub... I'm sure thought went into doing this but could it be made more clear maybe here? https://huggingface.co./docs/datasets/installation for example under installing from source? I spent over an hour questioning my sanity as I kept trying to edit this file, uninstall and reinstall the repo, git reset to previous versions of the file etc.",
"Thanks for the quick reply and help too\r\n",
"Thanks @TrentBrick for the suggestion about improving our docs: we should definitely do this if you find they are not clear enough.\r\n\r\nCurrently, our docs explain how to load a dataset from a local loading script here: [Load > Local loading script](https://huggingface.co./docs/datasets/loading#local-loading-script)\r\n\r\nI've opened an issue here:\r\n- #4732\r\n\r\nFeel free to comment on it any additional explanation/suggestion/requirement related to this problem."
] | 1,658,350,650,000 | 1,658,470,186,000 | null | NONE | null | null | null | https://github.com/huggingface/datasets/pull/3627 changed the Eleuther AI Pile dataset URL from https://the-eye.eu/ to https://mystic.the-eye.eu/ but the latter is now broken and the former works again.
Note that when I git clone the repo and use `pip install -e .` and then edit the URL back the codebase doesn't seem to use this edit so the mystic URL is also cached somewhere else that I can't find? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4725/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4725/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4724/comments | https://api.github.com/repos/huggingface/datasets/issues/4724/events | https://github.com/huggingface/datasets/pull/4724 | 1,311,127,404 | PR_kwDODunzps47vLrP | 4,724 | Download and prepare as Parquet for cloud storage | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4724). All of your documentation changes will be reflected on that endpoint."
] | 1,658,324,342,000 | 1,658,769,419,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4724",
"html_url": "https://github.com/huggingface/datasets/pull/4724",
"diff_url": "https://github.com/huggingface/datasets/pull/4724.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4724.patch",
"merged_at": null
} | Download a dataset as Parquet in a cloud storage can be useful for streaming mode and to use with spark/dask/ray.
This PR adds support for `fsspec` URIs like `s3://...`, `gcs://...` etc. and ads the `file_format` to save as parquet instead of arrow:
```python
from datasets import *
cache_dir = "s3://..."
builder = load_dataset_builder("crime_and_punish", cache_dir=cache_dir)
builder.download_and_prepare(file_format="parquet")
```
credentials to cloud storage can be passed using the `storage_options` argument in `load_dataset_builder`
For consistency with the BeamBasedBuilder, I name the parquet files `{builder.name}-{split}-xxxxx-of-xxxxx.parquet`. I think this is fine since we'll need to implement parquet sharding after this PR, so that a dataset can be used efficiently with dask for example.
TODO:
- [x] docs
- [x] tests | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4724/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4724/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4723 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4723/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4723/comments | https://api.github.com/repos/huggingface/datasets/issues/4723/events | https://github.com/huggingface/datasets/pull/4723 | 1,310,970,604 | PR_kwDODunzps47uoSj | 4,723 | Refactor conftest fixtures | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,319,322,000 | 1,658,414,231,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4723",
"html_url": "https://github.com/huggingface/datasets/pull/4723",
"diff_url": "https://github.com/huggingface/datasets/pull/4723.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4723.patch",
"merged_at": 1658413458000
} | Previously, fixture modules `hub_fixtures` and `s3_fixtures`:
- were both at the root test directory
- were imported using `import *`
- as a side effect, the modules `os` and `pytest` were imported from `s3_fixtures` into `conftest`
This PR:
- puts both fixture modules in a dedicated directory `fixtures`
- renames both to: `fixtures.hub` and `fixtures.s3`
- imports them into `conftest` as plugins, using the `pytest_plugins`: this avoids the `import *`
- additionally creates a new fixture module `fixtures.files` with all file-related fixtures | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4723/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4723/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4722/comments | https://api.github.com/repos/huggingface/datasets/issues/4722/events | https://github.com/huggingface/datasets/pull/4722 | 1,310,785,916 | PR_kwDODunzps47t_HJ | 4,722 | Docs: Fix same-page haslinks | {
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"repos_url": "https://api.github.com/users/mishig25/repos",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,311,477,000 | 1,658,336,553,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4722",
"html_url": "https://github.com/huggingface/datasets/pull/4722",
"diff_url": "https://github.com/huggingface/datasets/pull/4722.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4722.patch",
"merged_at": 1658335776000
} | `href="/docs/datasets/quickstart#audio"` implicitly goes to `href="/docs/datasets/{$LATEST_STABLE_VERSION}/quickstart#audio"`. Therefore, https://huggingface.co./docs/datasets/quickstart#audio #audio hashlink does not work since the new docs were not added to v2.3.2 (LATEST_STABLE_VERSION)
to preserve the version, it should be just `href="#audio"`, which will implicilty go to curren_page + #audio element | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4722/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4722/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4721 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4721/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4721/comments | https://api.github.com/repos/huggingface/datasets/issues/4721/events | https://github.com/huggingface/datasets/issues/4721 | 1,310,253,552 | I_kwDODunzps5OGOHw | 4,721 | PyArrow Dataset error when calling `load_dataset` | {
"login": "piraka9011",
"id": 16828657,
"node_id": "MDQ6VXNlcjE2ODI4NjU3",
"avatar_url": "https://avatars.githubusercontent.com/u/16828657?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/piraka9011",
"html_url": "https://github.com/piraka9011",
"followers_url": "https://api.github.com/users/piraka9011/followers",
"following_url": "https://api.github.com/users/piraka9011/following{/other_user}",
"gists_url": "https://api.github.com/users/piraka9011/gists{/gist_id}",
"starred_url": "https://api.github.com/users/piraka9011/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/piraka9011/subscriptions",
"organizations_url": "https://api.github.com/users/piraka9011/orgs",
"repos_url": "https://api.github.com/users/piraka9011/repos",
"events_url": "https://api.github.com/users/piraka9011/events{/privacy}",
"received_events_url": "https://api.github.com/users/piraka9011/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi ! It looks like a bug in `pyarrow`. If you manage to end up with only one chunk per parquet file it should workaround this issue.\r\n\r\nTo achieve that you can try to lower the value of `max_shard_size` and also don't use `map` before `push_to_hub`.\r\n\r\nDo you have a minimum reproducible example that we can share with the Arrow team for further debugging ?",
"> If you manage to end up with only one chunk per parquet file it should workaround this issue.\r\n\r\nYup, I did not encounter this bug when I was testing my script with a slice of <1000 samples for my dataset.\r\n\r\n> Do you have a minimum reproducible example...\r\n\r\nNot sure if I can get more minimal than the script I shared above. Are you asking for a sample json file?\r\nJust generate a random manifest list, I can add that to the above script if that's what you mean?\r\n",
"Actually this is probably linked to this open issue: https://issues.apache.org/jira/browse/ARROW-5030.\r\n\r\nsetting `max_shard_size=\"2GB\"` should do the job (or `max_shard_size=\"1GB\"` if you want to be on the safe side, especially given that there can be some variance in the shard sizes if the dataset is not evenly distributed)"
] | 1,658,279,763,000 | 1,658,499,107,000 | null | NONE | null | null | null | ## Describe the bug
I am fine tuning a wav2vec2 model following the script here using my own dataset: https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
Loading my Audio dataset from the hub which was originally generated from disk results in the following PyArrow error:
```sh
File "/home/ubuntu/w2v2/run_speech_recognition_ctc.py", line 227, in main
raw_datasets = load_dataset(
File "/home/ubuntu/.virtualenvs/meval/lib/python3.8/site-packages/datasets/load.py", line 1679, in load_dataset
builder_instance.download_and_prepare(
File "/home/ubuntu/.virtualenvs/meval/lib/python3.8/site-packages/datasets/builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "/home/ubuntu/.virtualenvs/meval/lib/python3.8/site-packages/datasets/builder.py", line 793, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/ubuntu/.virtualenvs/meval/lib/python3.8/site-packages/datasets/builder.py", line 1268, in _prepare_split
for key, table in logging.tqdm(
File "/home/ubuntu/.virtualenvs/meval/lib/python3.8/site-packages/tqdm/std.py", line 1195, in __iter__
for obj in iterable:
File "/home/ubuntu/.virtualenvs/meval/lib/python3.8/site-packages/datasets/packaged_modules/parquet/parquet.py", line 68, in _generate_tables
for batch_idx, record_batch in enumerate(
File "pyarrow/_parquet.pyx", line 1309, in iter_batches
File "pyarrow/error.pxi", line 121, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Nested data conversions not implemented for chunked array outputs
```
## Steps to reproduce the bug
I created a dataset from a JSON lines manifest of `audio_filepath`, `text`, and `duration`.
When creating the dataset, I do something like this:
```python
import json
from datasets import Dataset, Audio
# manifest_lines is a list of dicts w/ "audio_filepath", "duration", and "text
for line in manifest_lines:
line = line.strip()
if line:
line_dict = json.loads(line)
manifest_dict["audio"].append(f"{root_path}/{line_dict['audio_filepath']}")
manifest_dict["duration"].append(line_dict["duration"])
manifest_dict["transcription"].append(line_dict["text"])
# Create a HF dataset
dataset = Dataset.from_dict(manifest_dict).cast_column(
"audio", Audio(sampling_rate=16_000),
)
# From the docs for saving to disk
# https://huggingface.co./docs/datasets/v2.3.2/en/package_reference/main_classes#datasets.Dataset.save_to_disk
def read_audio_file(example):
with open(example["audio"]["path"], "rb") as f:
return {"audio": {"bytes": f.read()}}
dataset = dataset.map(read_audio_file, num_proc=70)
dataset.save_to_disk(f"/audio-data/hf/{artifact_name}")
dataset.push_to_hub(f"{org-name}/{artifact_name}", max_shard_size="5GB", private=True)
```
Then when I call `load_dataset()` in my training script, with the same dataset I generated above, and download from the huggingface hub I get the above stack trace.
I am able to load the dataset fine if I use `load_from_disk()`.
## Expected results
`load_dataset()` should behave just like `load_from_disk()` and not cause any errors.
## Actual results
See above
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
I am using the `huggingface/transformers-pytorch-gpu:latest` image
- `datasets` version: 2.3.0
- Platform: Docker/Ubuntu 20.04
- Python version: 3.8
- PyArrow version: 8.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4721/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4721/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4720 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4720/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4720/comments | https://api.github.com/repos/huggingface/datasets/issues/4720/events | https://github.com/huggingface/datasets/issues/4720 | 1,309,980,195 | I_kwDODunzps5OFLYj | 4,720 | Dataset Viewer issue for shamikbose89/lancaster_newsbooks | {
"login": "shamikbose",
"id": 50837285,
"node_id": "MDQ6VXNlcjUwODM3Mjg1",
"avatar_url": "https://avatars.githubusercontent.com/u/50837285?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shamikbose",
"html_url": "https://github.com/shamikbose",
"followers_url": "https://api.github.com/users/shamikbose/followers",
"following_url": "https://api.github.com/users/shamikbose/following{/other_user}",
"gists_url": "https://api.github.com/users/shamikbose/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shamikbose/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shamikbose/subscriptions",
"organizations_url": "https://api.github.com/users/shamikbose/orgs",
"repos_url": "https://api.github.com/users/shamikbose/repos",
"events_url": "https://api.github.com/users/shamikbose/events{/privacy}",
"received_events_url": "https://api.github.com/users/shamikbose/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"It seems like the list of splits could not be obtained:\r\n\r\n```python\r\n>>> from datasets import get_dataset_split_names\r\n>>> get_dataset_split_names(\"shamikbose89/lancaster_newsbooks\", \"default\")\r\nUsing custom data configuration default\r\nTraceback (most recent call last):\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 354, in get_dataset_config_info\r\n for split_generator in builder._split_generators(\r\n File \"/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/shamikbose89--lancaster_newsbooks/2d1c63d269bf7b9342accce0a95960b1710ab4bc774248878bd80eb96c1afaf7/lancaster_newsbooks.py\", line 73, in _split_generators\r\n data_dir = dl_manager.download_and_extract(_URL)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 916, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 879, in extract\r\n urlpaths = map_nested(self._extract, path_or_paths, map_tuple=True)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 348, in map_nested\r\n return function(data_struct)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 884, in _extract\r\n protocol = _get_extraction_protocol(urlpath, use_auth_token=self.download_config.use_auth_token)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 388, in _get_extraction_protocol\r\n return _get_extraction_protocol_with_magic_number(f)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 354, in _get_extraction_protocol_with_magic_number\r\n f.seek(0)\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/fsspec/implementations/http.py\", line 684, in seek\r\n raise ValueError(\"Cannot seek streaming HTTP file\")\r\nValueError: Cannot seek streaming HTTP file\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 404, in get_dataset_split_names\r\n info = get_dataset_config_info(\r\n File \"/home/slesage/hf/datasets-server/services/worker/.venv/lib/python3.9/site-packages/datasets/inspect.py\", line 359, in get_dataset_config_info\r\n raise SplitsNotFoundError(\"The split names could not be parsed from the dataset config.\") from err\r\ndatasets.inspect.SplitsNotFoundError: The split names could not be parsed from the dataset config.\r\n```\r\n\r\nping @huggingface/datasets ",
"Oh, I removed the 'split' key from `kwargs`. I put it back in, but there's still the same error",
"It looks like the data host doesn't support http range requests, which is necessary to glob inside a ZIP archive in streaming mode. Can you try hosting the dataset elsewhere ? Or download each file separately from https://ota.bodleian.ox.ac.uk/repository/xmlui/handle/20.500.12024/2531 ?",
"@lhoestq Thanks! That seems to have solved it. I can get the splits with the `get_dataset_split_names()` function. The dataset viewer is still not loading properly, though. The new error is\r\n```\r\nStatus code: 400\r\nException: BadZipFile\r\nMessage: File is not a zip file\r\n```\r\n\r\nPS. The dataset loads properly and can be accessed"
] | 1,658,260,807,000 | 1,658,336,762,000 | null | NONE | null | null | null | ### Link
https://huggingface.co./datasets/shamikbose89/lancaster_newsbooks
### Description
Status code: 400
Exception: ValueError
Message: Cannot seek streaming HTTP file
I am able to use the dataset loading script locally and it also runs when I'm using the one from the hub, but the viewer still doesn't load
### Owner
Yes | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4720/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4720/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4719/comments | https://api.github.com/repos/huggingface/datasets/issues/4719/events | https://github.com/huggingface/datasets/issues/4719 | 1,309,854,492 | I_kwDODunzps5OEssc | 4,719 | Issue loading TheNoob3131/mosquito-data dataset | {
"login": "thenerd31",
"id": 53668030,
"node_id": "MDQ6VXNlcjUzNjY4MDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thenerd31",
"html_url": "https://github.com/thenerd31",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "https://api.github.com/users/thenerd31/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thenerd31/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thenerd31/subscriptions",
"organizations_url": "https://api.github.com/users/thenerd31/orgs",
"repos_url": "https://api.github.com/users/thenerd31/repos",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"received_events_url": "https://api.github.com/users/thenerd31/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I am also getting a ValueError: 'Couldn't cast' at the bottom. Is this because of some delimiter issue? My dataset is on the Huggingface Hub. If you could look at it, that would be greatly appreciated.",
"Hi @thenerd31, thanks for reporting.\r\n\r\nPlease note that your issue is not caused by the Hugging Face Datasets library, but it has to do with the specific implementation of your dataset on the Hub.\r\n\r\nTherefore, I'm transferring this discussion to your own dataset Community tab: https://huggingface.co./datasets/TheNoob3131/mosquito-data/discussions/1"
] | 1,658,252,857,000 | 1,658,299,617,000 | null | NONE | null | null | null | 
So my dataset is public in the Huggingface Hub, but when I try to load it using the load_dataset command, it shows that it is downloading the files, but throws a ValueError. When I went to my directory to see if the files were downloaded, the folder was blank.
Here is the error below:
ValueError Traceback (most recent call last)
Input In [8], in <cell line: 3>()
1 from datasets import load_dataset
----> 3 dataset = load_dataset("TheNoob3131/mosquito-data", split="train")
File ~\Anaconda3\lib\site-packages\datasets\load.py:1679, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1676 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
1678 # Download and prepare data
-> 1679 builder_instance.download_and_prepare(
1680 download_config=download_config,
1681 download_mode=download_mode,
1682 ignore_verifications=ignore_verifications,
1683 try_from_hf_gcs=try_from_hf_gcs,
1684 use_auth_token=use_auth_token,
1685 )
1687 # Build dataset for splits
1688 keep_in_memory = (
1689 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
1690 )
Is the dataset in the wrong format or is there some security permission that I should enable? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4719/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4719/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4718 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4718/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4718/comments | https://api.github.com/repos/huggingface/datasets/issues/4718/events | https://github.com/huggingface/datasets/pull/4718 | 1,309,520,453 | PR_kwDODunzps47prWR | 4,718 | Make Extractor accept Path as input | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,237,106,000 | 1,658,497,347,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4718",
"html_url": "https://github.com/huggingface/datasets/pull/4718",
"diff_url": "https://github.com/huggingface/datasets/pull/4718.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4718.patch",
"merged_at": 1658496583000
} | This PR:
- Makes `Extractor` accept instance of `Path` as input
- Removes unnecessary castings of `Path` to `str` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4718/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4718/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4717 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4717/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4717/comments | https://api.github.com/repos/huggingface/datasets/issues/4717/events | https://github.com/huggingface/datasets/issues/4717 | 1,309,512,483 | I_kwDODunzps5ODZMj | 4,717 | Dataset Viewer issue for LawalAfeez/englishreview-ds-mini | {
"login": "lawalAfeez820",
"id": 69974956,
"node_id": "MDQ6VXNlcjY5OTc0OTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/69974956?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lawalAfeez820",
"html_url": "https://github.com/lawalAfeez820",
"followers_url": "https://api.github.com/users/lawalAfeez820/followers",
"following_url": "https://api.github.com/users/lawalAfeez820/following{/other_user}",
"gists_url": "https://api.github.com/users/lawalAfeez820/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lawalAfeez820/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lawalAfeez820/subscriptions",
"organizations_url": "https://api.github.com/users/lawalAfeez820/orgs",
"repos_url": "https://api.github.com/users/lawalAfeez820/repos",
"events_url": "https://api.github.com/users/lawalAfeez820/events{/privacy}",
"received_events_url": "https://api.github.com/users/lawalAfeez820/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"It's currently working, as far as I understand\r\n\r\nhttps://huggingface.co./datasets/LawalAfeez/englishreview-ds-mini/viewer/LawalAfeez--englishreview-ds-mini/train\r\n\r\n<img width=\"1556\" alt=\"Capture d’écran 2022-07-19 à 09 24 01\" src=\"https://user-images.githubusercontent.com/1676121/179761130-2d7980b9-c0f6-4093-8b1d-f0a3872fef3f.png\">\r\n\r\n---\r\n\r\nWhat was your issue?"
] | 1,658,236,779,000 | 1,658,305,977,000 | null | NONE | null | null | null | ### Link
_No response_
### Description
Unable to view the split data
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4717/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4717/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4716/comments | https://api.github.com/repos/huggingface/datasets/issues/4716/events | https://github.com/huggingface/datasets/pull/4716 | 1,309,455,838 | PR_kwDODunzps47pdbh | 4,716 | Support "tags" yaml tag | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"IMO `DatasetMetadata` shouldn't crash with attributes that it doesn't know, btw",
"Yea this PR is mostly to have a validation that this field contains a list of strings.\r\n\r\nRegarding unknown fields, the tagging app currently returns an error if a field is unknown using the `DatasetMetadata`. We can change that though"
] | 1,658,234,071,000 | 1,658,324,690,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4716",
"html_url": "https://github.com/huggingface/datasets/pull/4716",
"diff_url": "https://github.com/huggingface/datasets/pull/4716.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4716.patch",
"merged_at": 1658323916000
} | Added the "tags" YAML tag, so that users can specify data domain/topics keywords for dataset search | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4716/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4716/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4715/comments | https://api.github.com/repos/huggingface/datasets/issues/4715/events | https://github.com/huggingface/datasets/pull/4715 | 1,309,405,980 | PR_kwDODunzps47pSui | 4,715 | Fix POS tags | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"CI failures are about missing content in the dataset cards or bad tags, and this is unrelated to this PR. Merging :)"
] | 1,658,231,574,000 | 1,658,235,274,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4715",
"html_url": "https://github.com/huggingface/datasets/pull/4715",
"diff_url": "https://github.com/huggingface/datasets/pull/4715.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4715.patch",
"merged_at": 1658234475000
} | We're now using `part-of-speech` and not `part-of-speech-tagging`, see discussion here: https://github.com/huggingface/datasets/commit/114c09aff2fa1519597b46fbcd5a8e0c0d3ae020#r78794777 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4715/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4715/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4714 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4714/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4714/comments | https://api.github.com/repos/huggingface/datasets/issues/4714/events | https://github.com/huggingface/datasets/pull/4714 | 1,309,265,682 | PR_kwDODunzps47o0YG | 4,714 | Fix named split sorting and remove unnecessary casting | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"hahaha what a timing, I added my comment right after you merged x)\r\n\r\nyou can ignore my (nit), it's fine",
"Sorry, just too sync... :sweat_smile: "
] | 1,658,224,108,000 | 1,658,482,785,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4714",
"html_url": "https://github.com/huggingface/datasets/pull/4714",
"diff_url": "https://github.com/huggingface/datasets/pull/4714.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4714.patch",
"merged_at": 1658481057000
} | This PR:
- makes `NamedSplit` sortable: so that `sorted()` can be called on them
- removes unnecessary `sorted()` on `dict.keys()`: `dict_keys` view is already like a `set`
- removes unnecessary casting of `NamedSplit` to `str` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4714/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4714/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4713/comments | https://api.github.com/repos/huggingface/datasets/issues/4713/events | https://github.com/huggingface/datasets/pull/4713 | 1,309,184,756 | PR_kwDODunzps47ojC1 | 4,713 | Document installation of sox OS dependency for audio | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,220,155,000 | 1,658,391,419,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4713",
"html_url": "https://github.com/huggingface/datasets/pull/4713",
"diff_url": "https://github.com/huggingface/datasets/pull/4713.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4713.patch",
"merged_at": 1658390655000
} | The `sox` OS package needs being installed manually using the distribution package manager.
This PR adds this explanation to the docs. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4713/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4713/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4712 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4712/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4712/comments | https://api.github.com/repos/huggingface/datasets/issues/4712/events | https://github.com/huggingface/datasets/pull/4712 | 1,309,177,302 | PR_kwDODunzps47ohdr | 4,712 | Highlight non-commercial license in amazon_reviews_multi dataset card | {
"login": "sbroadhurst-hf",
"id": 108879611,
"node_id": "U_kgDOBn1e-w",
"avatar_url": "https://avatars.githubusercontent.com/u/108879611?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sbroadhurst-hf",
"html_url": "https://github.com/sbroadhurst-hf",
"followers_url": "https://api.github.com/users/sbroadhurst-hf/followers",
"following_url": "https://api.github.com/users/sbroadhurst-hf/following{/other_user}",
"gists_url": "https://api.github.com/users/sbroadhurst-hf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sbroadhurst-hf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sbroadhurst-hf/subscriptions",
"organizations_url": "https://api.github.com/users/sbroadhurst-hf/orgs",
"repos_url": "https://api.github.com/users/sbroadhurst-hf/repos",
"events_url": "https://api.github.com/users/sbroadhurst-hf/events{/privacy}",
"received_events_url": "https://api.github.com/users/sbroadhurst-hf/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_4712). All of your documentation changes will be reflected on that endpoint."
] | 1,658,219,780,000 | 1,658,753,859,000 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4712",
"html_url": "https://github.com/huggingface/datasets/pull/4712",
"diff_url": "https://github.com/huggingface/datasets/pull/4712.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4712.patch",
"merged_at": null
} | Highlight that the licence granted by Amazon only covers non-commercial research use. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4712/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4712/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4711 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4711/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4711/comments | https://api.github.com/repos/huggingface/datasets/issues/4711/events | https://github.com/huggingface/datasets/issues/4711 | 1,309,138,570 | I_kwDODunzps5OB96K | 4,711 | Document how to create a dataset loading script for audio/vision | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892861,
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation",
"name": "documentation",
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation"
}
] | open | false | null | [] | null | [] | 1,658,217,820,000 | 1,658,217,820,000 | null | MEMBER | null | null | null | Currently, in our docs for Audio/Vision/Text, we explain how to:
- Load data
- Process data
However we only explain how to *Create a dataset loading script* for text data.
I think it would be useful that we add the same for Audio/Vision as these have some specificities different from Text.
See, for example:
- #4697
CC: @stevhliu
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4711/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4711/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4710 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4710/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4710/comments | https://api.github.com/repos/huggingface/datasets/issues/4710/events | https://github.com/huggingface/datasets/pull/4710 | 1,308,958,525 | PR_kwDODunzps47ny0L | 4,710 | Add object detection processing tutorial | {
"login": "nateraw",
"id": 32437151,
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nateraw",
"html_url": "https://github.com/nateraw",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"repos_url": "https://api.github.com/users/nateraw/repos",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Great idea! Now that we have more than one task, it makes sense to separate image classification and object detection so it'll be easier for users to follow.",
"@lhoestq do we want to do that in this PR, or should we merge it and let @stevhliu reorganize separately? "
] | 1,658,204,626,000 | 1,658,434,235,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4710",
"html_url": "https://github.com/huggingface/datasets/pull/4710",
"diff_url": "https://github.com/huggingface/datasets/pull/4710.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4710.patch",
"merged_at": 1658433402000
} | The following adds a quick guide on how to process object detection datasets with `albumentations`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4710/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4710/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4709/comments | https://api.github.com/repos/huggingface/datasets/issues/4709/events | https://github.com/huggingface/datasets/issues/4709 | 1,308,633,093 | I_kwDODunzps5OACgF | 4,709 | WMT21 & WMT22 | {
"login": "Muennighoff",
"id": 62820084,
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Muennighoff",
"html_url": "https://github.com/Muennighoff",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_url": "https://api.github.com/users/Muennighoff/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Muennighoff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Muennighoff/subscriptions",
"organizations_url": "https://api.github.com/users/Muennighoff/orgs",
"repos_url": "https://api.github.com/users/Muennighoff/repos",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"received_events_url": "https://api.github.com/users/Muennighoff/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"Hi ! That would be awesome to have them indeed, thanks for opening this issue\r\n\r\nI just added you to the WMT org on the HF Hub if you're interested in adding those datasets.\r\n\r\nFeel free to create a dataset repository for each dataset and upload the data files there :) preferably in ZIP archives instead of TAR archives (the current WMT scripts don't support streaming TAR archives, so it would break the dataset preview). We've also had issues with the `statmt.org` host (data unavailable, slow download speed), that's why I think it's better if we re-host the files on the Hub.\r\n\r\n`wmt21` (and wmt22) can be added in this GitHub repository I think, for consistency with the previous ones.\r\nTo add it, you can copy paste the code of the previous one (e.g. wmt19), and add the new data:\r\n- in wmt_utils.py, add the new data subsets. You need to provide the download URLs, as well as the target and source languages\r\n- in wmt21.py (renamed from wmt19.py), you can specify the subsets that WMT21 uses (i.e. the one you just added)\r\n- in wmt_utils.py, define the python function that must be used to parse the subsets you added. To do so, you must go in `_generate_examples` and chose the proper `sub_generator` based on the subset name. For example, the `paracrawl_v3` subset uses the `_parse_tmx` function:\r\n\r\nhttps://github.com/huggingface/datasets/blob/ede72d3f9796339701ec59899c7c31d2427046fb/datasets/wmt19/wmt_utils.py#L834-L835\r\n\r\nHopefully the data is in a format that is already supported and there's no need to write a new `_parse_*` function for the new subsets. Let me know if you have questions or if I can help :)"
] | 1,658,178,333,000 | 1,658,225,264,000 | null | NONE | null | null | null | ## Adding a Dataset
- **Name:** WMT21 & WMT22
- **Description:** We are going to have three tracks: two small tasks and a large task.
The small tracks evaluate translation between fairly related languages and English (all pairs). The large track uses 101 languages.
- **Paper:** /
- **Data:** https://statmt.org/wmt21/large-scale-multilingual-translation-task.html https://statmt.org/wmt22/large-scale-multilingual-translation-task.html
- **Motivation:** Many more languages than previous WMT versions - Could be very high impact
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/main/ADD_NEW_DATASET.md).
I could also tackle this. I saw the existing logic for WMT models is a bit complex (datasets are stored on the wmt account & retrieved in separate wmt datasets afaict). How long do you think it would take me? @lhoestq
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4709/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4709/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4708/comments | https://api.github.com/repos/huggingface/datasets/issues/4708/events | https://github.com/huggingface/datasets/pull/4708 | 1,308,279,700 | PR_kwDODunzps47lewm | 4,708 | Fix require torchaudio and refactor test requirements | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,165,068,000 | 1,658,471,456,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4708",
"html_url": "https://github.com/huggingface/datasets/pull/4708",
"diff_url": "https://github.com/huggingface/datasets/pull/4708.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4708.patch",
"merged_at": 1658470691000
} | Currently there is a bug in `require_torchaudio` (indeed it is requiring `sox` instead):
```python
def require_torchaudio(test_case):
if find_spec("sox") is None:
...
```
The bug was introduced by:
- #3685
- Commit: https://github.com/huggingface/datasets/pull/3685/commits/b5a3e7122d49c4dcc9333b1d8d18a833fc04b940
which moved
```python
require_sndfile = pytest.mark.skipif(
# In Windows and OS X, soundfile installs sndfile
(sys.platform != "linux" and find_spec("soundfile") is None)
# In Linux, soundfile throws RuntimeError if sndfile not installed with distribution package manager
or (sys.platform == "linux" and find_library("sndfile") is None),
reason="Test requires 'sndfile': `pip install soundfile`; "
"Linux requires sndfile installed with distribution package manager, e.g.: `sudo apt-get install libsndfile1`",
)
require_sox = pytest.mark.skipif(
find_library("sox") is None,
reason="Test requires 'sox'; only available in non-Windows, e.g.: `sudo apt-get install sox`",
)
require_torchaudio = pytest.mark.skipif(find_spec("torchaudio") is None, reason="Test requires 'torchaudio'")
```
to
```python
def require_sndfile(test_case):
"""
Decorator marking a test that requires soundfile.
These tests are skipped when soundfile isn't installed.
"""
if (sys.platform != "linux" and find_spec("soundfile") is None) or (
sys.platform == "linux" and find_library("sndfile") is None
):
test_case = unittest.skip(
"test requires 'sndfile': `pip install soundfile`; "
"Linux requires sndfile installed with distribution package manager, e.g.: `sudo apt-get install libsndfile1`",
)(test_case)
return test_case
def require_sox(test_case):
"""
Decorator marking a test that requires sox.
These tests are skipped when sox isn't installed.
"""
if find_library("sox") is None:
return unittest.skip("test requires 'sox'; only available in non-Windows, e.g.: `sudo apt-get install sox`")(
test_case
)
return test_case
def require_torchaudio(test_case):
"""
Decorator marking a test that requires torchaudio.
These tests are skipped when torchaudio isn't installed.
"""
if find_spec("sox") is None:
return unittest.skip("test requires 'torchaudio'")(test_case)
return test_case
```
This PR;
- fixes the bug in `require_torchaudio`
- refactors the test requirements back to using `pytest` instead of `unittest`
- the text in `pytest.skipif` `reason` can be used if needed in a test body: `require_torchaudio.kwargs["reason"]` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4708/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4708/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4707/comments | https://api.github.com/repos/huggingface/datasets/issues/4707/events | https://github.com/huggingface/datasets/issues/4707 | 1,308,251,405 | I_kwDODunzps5N-lUN | 4,707 | Dataset Viewer issue for TheNoob3131/mosquito-data | {
"login": "thenerd31",
"id": 53668030,
"node_id": "MDQ6VXNlcjUzNjY4MDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/53668030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thenerd31",
"html_url": "https://github.com/thenerd31",
"followers_url": "https://api.github.com/users/thenerd31/followers",
"following_url": "https://api.github.com/users/thenerd31/following{/other_user}",
"gists_url": "https://api.github.com/users/thenerd31/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thenerd31/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thenerd31/subscriptions",
"organizations_url": "https://api.github.com/users/thenerd31/orgs",
"repos_url": "https://api.github.com/users/thenerd31/repos",
"events_url": "https://api.github.com/users/thenerd31/events{/privacy}",
"received_events_url": "https://api.github.com/users/thenerd31/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"Thanks for reporting. I refreshed the dataset viewer and it now works as expected.\r\n\r\nhttps://huggingface.co./datasets/TheNoob3131/mosquito-data\r\n\r\n<img width=\"1135\" alt=\"Capture d’écran 2022-07-18 à 13 15 22\" src=\"https://user-images.githubusercontent.com/1676121/179566497-e47f1a27-fd84-4a8d-9d7f-2e0f2da803df.png\">\r\n\r\nWe will investigate why it occurred in the first place\r\n",
"By chance, could you provide some details about the operations done on the dataset: was it private? gated?",
"Yes, it was a private dataset, and when I made it public, the Dataset Preview did not work. \r\n\r\nHowever, now when I make the dataset private, it says that the Dataset Preview has been disabled. Why is this?",
"Thanks for the details. For now, the dataset viewer is always disabled on private datasets (see https://huggingface.co./docs/hub/datasets-viewer for more details)",
"Hi, it was working fine for a few hours, but then I can't see the dataset viewer again (public dataset). Why is this still happening?\r\nIt's the same error too:\r\n\r\n",
"OK? This is a bug, thanks for help spotting and reproducing it (it occurs when a dataset is switched to private, then to public). We will be working on it, meanwhile, I've restored the dataset viewer manually again."
] | 1,658,164,039,000 | 1,658,173,486,000 | null | NONE | null | null | null | ### Link
_No response_
### Description
Getting this error when trying to view dataset preview:
Message: 401, message='Unauthorized', url=URL('https://huggingface.co./datasets/TheNoob3131/mosquito-data/resolve/8aceebd6c4a359d216d10ef020868bd9e8c986dd/0_Africa_train.csv')
### Owner
_No response_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4707/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4707/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4706 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4706/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4706/comments | https://api.github.com/repos/huggingface/datasets/issues/4706/events | https://github.com/huggingface/datasets/pull/4706 | 1,308,198,454 | PR_kwDODunzps47lNBg | 4,706 | Fix empty examples in xtreme dataset for bucc18 config | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I guess the report link is this instead: https://huggingface.co./datasets/xtreme/discussions/1"
] | 1,658,161,366,000 | 1,658,212,874,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4706",
"html_url": "https://github.com/huggingface/datasets/pull/4706",
"diff_url": "https://github.com/huggingface/datasets/pull/4706.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4706.patch",
"merged_at": 1658212157000
} | As reported in https://huggingface.co./muibk, there are empty examples in xtreme/bucc18.de
I applied your fix @mustaszewski
I also used a dict to make the dataset generation much faster | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4706/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4706/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4705/comments | https://api.github.com/repos/huggingface/datasets/issues/4705/events | https://github.com/huggingface/datasets/pull/4705 | 1,308,161,794 | PR_kwDODunzps47lFDo | 4,705 | Fix crd3 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,159,624,000 | 1,658,423,924,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4705",
"html_url": "https://github.com/huggingface/datasets/pull/4705",
"diff_url": "https://github.com/huggingface/datasets/pull/4705.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4705.patch",
"merged_at": 1658423190000
} | As reported in https://huggingface.co./datasets/crd3/discussions/1#62cc377073b2512b81662794, each split of the dataset was containing the same data. This issues comes from a bug in the dataset script
I fixed it and also uploaded the data to hf.co to make the dataset work in streaming mode | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4705/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4705/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4704 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4704/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4704/comments | https://api.github.com/repos/huggingface/datasets/issues/4704/events | https://github.com/huggingface/datasets/pull/4704 | 1,308,147,876 | PR_kwDODunzps47lCFt | 4,704 | Skip tests only for lz4/zstd params if not installed | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,158,900,000 | 1,658,235,751,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4704",
"html_url": "https://github.com/huggingface/datasets/pull/4704",
"diff_url": "https://github.com/huggingface/datasets/pull/4704.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4704.patch",
"merged_at": 1658234958000
} | Currently, if `zstandard` or `lz4` are not installed, `test_compression_filesystems` and `test_streaming_dl_manager_extract_all_supported_single_file_compression_types` are skipped for all compression format parameters.
This PR fixes these tests, so that if `zstandard` or `lz4` are not installed, the tests are skipped only for the corresponding compression parameters (`zstd` or `lz4`), whereas the tests are not skipped for all the other compression parameters (`gzip`, `xz` and `bz2`).
Related to:
- #4688 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4704/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4704/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4703/comments | https://api.github.com/repos/huggingface/datasets/issues/4703/events | https://github.com/huggingface/datasets/pull/4703 | 1,307,844,097 | PR_kwDODunzps47kABf | 4,703 | Make cast in `from_pandas` more robust | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,145,349,000 | 1,658,488,662,000 | null | CONTRIBUTOR | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4703",
"html_url": "https://github.com/huggingface/datasets/pull/4703",
"diff_url": "https://github.com/huggingface/datasets/pull/4703.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4703.patch",
"merged_at": 1658487924000
} | Make the cast in `from_pandas` more robust (as it was done for the packaged modules in https://github.com/huggingface/datasets/pull/4364)
This should be useful in situations like [this one](https://discuss.huggingface.co/t/loading-custom-audio-dataset-and-fine-tuning-model/8836/4). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4703/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4703/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4702 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4702/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4702/comments | https://api.github.com/repos/huggingface/datasets/issues/4702/events | https://github.com/huggingface/datasets/issues/4702 | 1,307,793,811 | I_kwDODunzps5N81mT | 4,702 | Domain specific dataset discovery on the Hugging Face hub | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/users/davanstrien/followers",
"following_url": "https://api.github.com/users/davanstrien/following{/other_user}",
"gists_url": "https://api.github.com/users/davanstrien/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davanstrien/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davanstrien/subscriptions",
"organizations_url": "https://api.github.com/users/davanstrien/orgs",
"repos_url": "https://api.github.com/users/davanstrien/repos",
"events_url": "https://api.github.com/users/davanstrien/events{/privacy}",
"received_events_url": "https://api.github.com/users/davanstrien/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"Hi! I added a link to this issue in our internal request for adding keywords/topics to the Hub, which is identical to the `topic tags` solution. The `collections` solution seems too complex (as you point out). Regarding the `domain tags` solution, we primarily focus on machine learning, so I'm not sure if it's a good idea to make our current taxonomy more complex.",
"> Hi! I added a link to this issue in our internal request for adding keywords/topics to the Hub, which is identical to the `topic tags` solution. The `collections` solution seems too complex (as you point out). Regarding the `domain tags` solution, we primarily focus on machine learning, so I'm not sure if it's a good idea to make our current taxonomy more complex.\r\n\r\nThanks, for letting me know. Will you allow the topic tags to be user-generated or only chosen from a list?",
"Thanks for opening this issue @davanstrien.\r\n\r\nAs we discussed last week, the tag approach would be in principle the simpler to be implemented, either the domain tag (with closed vocabulary: more reliable but also more rigid), or the topic tag (with open vocabulary: more flexible for user needs)",
"Hi @davanstrien If i remember correctly this was also discussed inside a hf.co Discussion, would you be able to link it here too?\r\n\r\n(where i suggested using `tags: - foo - bar` IIRC.\r\n\r\nThanks a ton!",
"> Hi @davanstrien If i remember correctly this was also discussed inside a hf.co Discussion, would you be able to link it here too?\r\n> \r\n> (where i suggested using `tags: - foo - bar` IIRC.\r\n> \r\n> Thanks a ton!\r\n\r\nThis doesn't ring a bell - I did a quick search of https://discuss.huggingface.co but didn't find anything. \r\n\r\nThe `tags: ` approach sounds like a good option for this. It would be especially nice if these could suggest existing tags, but this probably won't be easily possible through the current interface. \r\n",
"I opened a PR to add \"tags\" to the YAML validator:\r\nhttps://github.com/huggingface/datasets/pull/4716\r\n\r\nI also added \"tags\" to the [tagging app](https://huggingface.co./spaces/huggingface/datasets-tagging), with suggestions like \"bio\" or \"newspapers\"",
"Thanks @lhoestq for the initiative.\r\n \r\nJust one question: are \"tags\" already supported on the Hub? \r\n\r\nI think they aren't. Thus, the Hub should support them so that they are properly displayed.",
"I think they're not displayed, but at least it should enable users to filter by tag in using `huggingface_hub` or using the appropriate query params on the website (not sure if it's possible yet though)",
"> I think they're not displayed, but at least it should enable users to filter by tag in using `huggingface_hub` or using the appropriate query params on the website (not sure if it's possible yet though)\r\n\r\nI think this would already be a helpful start. I'm happy to try this out with the datasets added to https://huggingface.co./organizations/biglam and use the `huggingface_hub` to filter those datasets using the tags. "
] | 1,658,142,843,000 | 1,658,243,891,000 | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
## The problem
The datasets hub currently has `8,239` datasets. These datasets span a wide range of different modalities and tasks (currently with a bias towards textual data).
There are various ways of identifying datasets that may be relevant for a particular use case:
- searching
- various filters
Currently, however, there isn't an easy way to identify datasets belonging to a specific domain. For example, I want to browse machine learning datasets related to 'social science' or 'climate change research'.
The ability to identify datasets relating to a specific domain has come up in discussions around the [BigLA](https://github.com/bigscience-workshop/lam/) datasets hackathon https://github.com/bigscience-workshop/lam/discussions/31#discussioncomment-3123610. As part of the hackathon, we're currently collecting datasets related to Libraries, Archives and Museums and making them available via the hub. We currently do this under a Hugging Face organization (https://huggingface.co./biglam). However, going forward, I can see some of these datasets being migrated to sit under an organization that is the custodian of the dataset (for example, a national library the data was originally from). At this point, it becomes more difficult to quickly identify datasets from this domain without relying on search.
This is also related to some existing issues on Github related to metadata on the hub:
- https://github.com/huggingface/datasets/issues/3625
- https://github.com/huggingface/datasets/issues/3877
**Describe the solution you'd like**
### Some possible solutions that may help with this:
#### Enable domain tags (from a controlled vocabulary)
- This would add metadata field to the YAML for the domain a dataset relates to
- Advantages:
- the list is controlled, allowing it to be more easily integrated into the datasets tag app (https://huggingface.co./space/huggingface/datasets-tagging)
- the controlled vocabulary could align with an existing controlled vocabulary
- this additional metadata can be used to perform filtering by domain
- disadvantages
- choosing the best controlled vocab may be difficult
- there are many datasets that are likely to fit into the 'machine learning' domain (i.e. there is a long tail of datasets that aren't in more 'generic' machine learning domain
#### Enable topic tags (user-generated)
Enable 'free form' topic tags for datasets and models. This would be closer to GitHub's repository topics which can be chosen from a controlled list (https://github.com/topics/) but can also be more user/org specific. This could potentially be useful for organizations to also manage their own models and datasets as the number they hold in their org grows. For example, they may create 'topic tags' for a specific project, so it's clearer which datasets /models are related to that project.
#### Collections
This solution would likely be the biggest shift and may require significant changes in the hub fronted. Collections could work in several different ways but would include:
Users can curate particular datasets, models, spaces, etc., into a collection. For example, they may create a collection of 'historic newspapers suitable for training language models'. These collections would not be mutually exclusive, i.e. a dataset can belong to zero, one or many collections. Collections can also potentially be nested under other collections.
This is fairly common on other data reposotiores for example the following collections:
<img width="293" alt="Screenshot 2022-07-18 at 11 50 44" src="https://user-images.githubusercontent.com/8995957/179496445-963ed122-5e26-4574-96e8-41081bce3e2b.png">
all belong under a higher level collection (https://bl.iro.bl.uk/collections/353c908d-b495-4413-b047-87236d2573e3?locale=en).
There are different models one could use for how these collections could be created:
- only within an org
- for any dataset/model
- the owner or a dataset/model has to agree to be added to a collection
- a collection owner can have people suggest additions to their collection
- other models....
These collections could be thematic, related to particular training approaches, curate models with particular inference properties etc. Whilst some of these features may duplicate current/or future tag filters on the hub, they offer the advantage of being flexible and not having to predict what users will want to do upfront.
There is also potential for automating the creation of these collections based on existing metadata. For example, one could collect models trained on a collection of datasets so for example, if we had a collection of 'historic newspapers suitable for training language models' that contained 30 datasets, we could create another collection 'historic newspaper language models' that takes any model on the hub whose metadata says it used one or more of those 30 datasets.
There is also the option of exploring ML approaches to suggest models/datasets may be relevant to a particular collection.
This approach is likely to be quite difficult to implement well and would require significant thought. There is also likely to be a benefit in doing quite a bit of upfront work in curating useful collections to demonstrate the benefits of collections.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
It is possible to collate this information externally, i.e. one could link back to the relevant models/datasets from an external platform.
**Additional context**
Add any other context about the feature request here.
I'm cc'ing others involved in the BigLAM hackathon who may also have thoughts @cakiki @clancyoftheoverflow @albertvillanova | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4702/reactions",
"total_count": 2,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4702/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/4701 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4701/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4701/comments | https://api.github.com/repos/huggingface/datasets/issues/4701/events | https://github.com/huggingface/datasets/pull/4701 | 1,307,689,625 | PR_kwDODunzps47jeE9 | 4,701 | Added more information in the README about contributors of the Arabic Speech Corpus | {
"login": "nawarhalabi",
"id": 2845798,
"node_id": "MDQ6VXNlcjI4NDU3OTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2845798?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nawarhalabi",
"html_url": "https://github.com/nawarhalabi",
"followers_url": "https://api.github.com/users/nawarhalabi/followers",
"following_url": "https://api.github.com/users/nawarhalabi/following{/other_user}",
"gists_url": "https://api.github.com/users/nawarhalabi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nawarhalabi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nawarhalabi/subscriptions",
"organizations_url": "https://api.github.com/users/nawarhalabi/orgs",
"repos_url": "https://api.github.com/users/nawarhalabi/repos",
"events_url": "https://api.github.com/users/nawarhalabi/events{/privacy}",
"received_events_url": "https://api.github.com/users/nawarhalabi/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,658,137,683,000 | 1,658,212,646,000 | null | NONE | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4701",
"html_url": "https://github.com/huggingface/datasets/pull/4701",
"diff_url": "https://github.com/huggingface/datasets/pull/4701.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4701.patch",
"merged_at": null
} | Added more information in the README about contributors and encouraged reading the thesis for more infos | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4701/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4701/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/4700 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4700/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4700/comments | https://api.github.com/repos/huggingface/datasets/issues/4700/events | https://github.com/huggingface/datasets/pull/4700 | 1,307,599,161 | PR_kwDODunzps47jKNx | 4,700 | Support extract lz4 compressed data files | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,658,133,691,000 | 1,658,155,439,000 | null | MEMBER | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4700",
"html_url": "https://github.com/huggingface/datasets/pull/4700",
"diff_url": "https://github.com/huggingface/datasets/pull/4700.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4700.patch",
"merged_at": 1658154707000
} | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/4700/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/4700/timeline | null | null | true |
End of preview. Expand
in Dataset Viewer.
No dataset card yet
New: Create and edit this dataset card directly on the website!
Contribute a Dataset Card- Downloads last month
- 9