
repo
stringclasses 856
values | pull_number
int64 3
127k
| instance_id
stringlengths 12
58
| issue_numbers
sequencelengths 1
5
| base_commit
stringlengths 40
40
| patch
stringlengths 67
1.54M
| test_patch
stringlengths 0
107M
| problem_statement
stringlengths 3
307k
| hints_text
stringlengths 0
908k
| created_at
timestamp[s] |
|---|---|---|---|---|---|---|---|---|---|
streamlink/streamlink | 2,825 | streamlink__streamlink-2825 | [
"2823"
] | 3aa41e3e900624a9748f6d4a61d478ffdb3becd2 | diff --git a/src/streamlink/plugins/bloomberg.py b/src/streamlink/plugins/bloomberg.py
--- a/src/streamlink/plugins/bloomberg.py
+++ b/src/streamlink/plugins/bloomberg.py
@@ -32,10 +32,12 @@ class Bloomberg(Plugin):
''', re.VERBOSE)
_live_player_re = re.compile(r'{APP_BUNDLE:"(?P<live_player_url>.+?/app.js)"')
_js_to_json_re = partial(re.compile(r'(\w+):(["\']|\d?\.?\d+,|true|false|\[|{)').sub, r'"\1":\2')
- _video_id_re = re.compile(r'data-bmmr-id=\\"(?P<video_id>.+?)\\"')
_mp4_bitrate_re = re.compile(r'.*_(?P<bitrate>[0-9]+)\.mp4')
- _preload_state_re = re.compile(r'window.__PRELOADED_STATE__\s*=\s*({.*});', re.DOTALL)
- _live_stream_info_re = re.compile(r'12:.*t.exports=({.*})},{}],13:', re.DOTALL)
+ _preload_state_re = re.compile(r'<script>\s*window.__PRELOADED_STATE__\s*=\s*({.+});?\s*</script>')
+ _live_stream_info_module_id_re = re.compile(
+ r'{(?:(?:"[^"]+"|\w+):(?:\d+|"[^"]+"),)*"(?:[^"]*/)?config/livestreams":(\d+)(?:,(?:"[^"]+"|\w+):(?:\d+|"[^"]+"))*}'
+ )
+ _live_stream_info_re = r'],{id}:\[function\(.+var n=({{.+}});r.default=n}},{{"[^"]+":\d+}}],{next}:\['
_live_streams_schema = validate.Schema(
validate.transform(_js_to_json_re),
@@ -75,6 +77,18 @@ class Bloomberg(Plugin):
validate.get("byChannelId"),
)
+ _vod_list_schema = validate.Schema(
+ validate.transform(parse_json),
+ validate.get("video"),
+ validate.get("videoList"),
+ validate.all([
+ validate.Schema({
+ "slug": validate.text,
+ "video": validate.Schema({"bmmrId": validate.text}, validate.get("bmmrId"))
+ })
+ ])
+ )
+
_vod_api_schema = validate.Schema(
{
'secureStreams': validate.all([
@@ -94,6 +108,18 @@ class Bloomberg(Plugin):
validate.transform(lambda x: list(set(x['secureStreams'] + x['streams'] + [x['contentLoc']])))
)
+ _headers = {
+ "authority": "www.bloomberg.com",
+ "upgrade-insecure-requests": "1",
+ "dnt": "1",
+ "accept": ";".join([
+ "text/html,application/xhtml+xml,application/xml",
+ "q=0.9,image/webp,image/apng,*/*",
+ "q=0.8,application/signed-exchange",
+ "v=b3"
+ ])
+ }
+
@classmethod
def can_handle_url(cls, url):
return Bloomberg._url_re.match(url)
@@ -103,65 +129,76 @@ def _get_live_streams(self):
match = self._url_re.match(self.url)
channel = match.group('channel')
- res = self.session.http.get(self.url, headers={
- "authority": "www.bloomberg.com",
- "upgrade-insecure-requests": "1",
- "dnt": "1",
- "accept": ";".join([
- "text/html,application/xhtml+xml,application/xml",
- "q=0.9,image/webp,image/apng,*/*",
- "q=0.8,application/signed-exchange",
- "v=b3"
- ])
- })
+ res = self.session.http.get(self.url, headers=self._headers)
if "Are you a robot?" in res.text:
log.error("Are you a robot?")
+
match = self._preload_state_re.search(res.text)
- if match:
- live_ids = self._channel_list_schema.validate(match.group(1))
- live_id = live_ids.get(channel)
- if live_id:
- log.debug("Found liveId = {0}".format(live_id))
- # Retrieve live player URL
- res = self.session.http.get(self.PLAYER_URL)
- match = self._live_player_re.search(res.text)
- if match is None:
- return []
- live_player_url = update_scheme(self.url, match.group('live_player_url'))
-
- # Extract streams from the live player page
- log.debug("Player URL: {0}".format(live_player_url))
- res = self.session.http.get(live_player_url)
- match = self._live_stream_info_re.search(res.text)
- if match:
- stream_info = self._live_streams_schema.validate(match.group(1))
- data = stream_info.get(live_id, {})
- return data.get('cdns', [])
- else:
- log.error("Could not find liveId for channel '{0}'".format(channel))
-
- return []
+ if match is None:
+ return
+
+ live_ids = self._channel_list_schema.validate(match.group(1))
+ live_id = live_ids.get(channel)
+ if not live_id:
+ log.error("Could not find liveId for channel '{0}'".format(channel))
+ return
+
+ log.debug("Found liveId: {0}".format(live_id))
+ # Retrieve live player URL
+ res = self.session.http.get(self.PLAYER_URL)
+ match = self._live_player_re.search(res.text)
+ if match is None:
+ return
+ live_player_url = update_scheme(self.url, match.group('live_player_url'))
+
+ # Extract streams from the live player page
+ log.debug("Player URL: {0}".format(live_player_url))
+ res = self.session.http.get(live_player_url)
+
+ # Get the ID of the webpack module containing the streams config from another module's dependency list
+ match = self._live_stream_info_module_id_re.search(res.text)
+ if match is None:
+ return
+ webpack_module_id = int(match.group(1))
+ log.debug("Webpack module ID: {0}".format(webpack_module_id))
+
+ # Finally get the streams JSON data from the config/livestreams webpack module
+ regex = re.compile(self._live_stream_info_re.format(id=webpack_module_id, next=webpack_module_id + 1))
+ match = regex.search(res.text)
+ if match is None:
+ return
+ stream_info = self._live_streams_schema.validate(match.group(1))
+ data = stream_info.get(live_id, {})
+
+ return data.get('cdns')
def _get_vod_streams(self):
# Retrieve URL page and search for video ID
- res = self.session.http.get(self.url)
- match = self._video_id_re.search(res.text)
+ res = self.session.http.get(self.url, headers=self._headers)
+
+ match = self._preload_state_re.search(res.text)
if match is None:
- return []
- video_id = match.group('video_id')
+ return
- res = self.session.http.get(self.VOD_API_URL.format(video_id))
+ videos = self._vod_list_schema.validate(match.group(1))
+ video_id = next((v["video"] for v in videos if v["slug"] in self.url), None)
+ if video_id is None:
+ return
+
+ log.debug("Found videoId: {0}".format(video_id))
+ res = self.session.http.get(self.VOD_API_URL.format(video_id), headers=self._headers)
streams = self.session.http.json(res, schema=self._vod_api_schema)
+
return streams
def _get_streams(self):
self.session.http.headers.update({"User-Agent": useragents.CHROME})
if '/news/videos/' in self.url:
# VOD
- streams = self._get_vod_streams()
+ streams = self._get_vod_streams() or []
else:
# Live
- streams = self._get_live_streams()
+ streams = self._get_live_streams() or []
for video_url in streams:
log.debug("Found stream: {0}".format(video_url))
| Unable to play bloomberg with streamlink - unable to parse JSON
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
I am attempting to use streamlink to play bloomberg live. However, I run into an unable to parse JSON error when doing so. I can play other streams fine which makes me think this is a plugin issue.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. I am running this command: streamlink https://www.bloomberg.com/live/us
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
C:\Windows\system32>streamlink https://www.bloomberg.com/live/us -l debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.3.1
[cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin bloomberg for URL https://www.bloomberg.com/live/us
error: Unable to parse JSON: Extra data: line 1 column 16474 (char 16473) ('{"schedule":{"allSchedules":{"us": ...)
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2020-03-11T23:21:10 |
||
streamlink/streamlink | 2,858 | streamlink__streamlink-2858 | [
"2750"
] | 222ab719fbdbf9f388277cda52e39ccdfcd1cacb | diff --git a/src/streamlink/plugins/youtube.py b/src/streamlink/plugins/youtube.py
--- a/src/streamlink/plugins/youtube.py
+++ b/src/streamlink/plugins/youtube.py
@@ -16,75 +16,42 @@
log = logging.getLogger(__name__)
-def parse_stream_map(stream_map):
- if not stream_map:
- return []
-
- return [parse_query(s) for s in stream_map.split(",")]
-
-
-def parse_fmt_list(formatsmap):
- formats = {}
- if not formatsmap:
- return formats
-
- for format in formatsmap.split(","):
- s = format.split("/")
- (w, h) = s[1].split("x")
- formats[int(s[0])] = "{0}p".format(h)
-
- return formats
-
-
_config_schema = validate.Schema(
{
- validate.optional("fmt_list"): validate.all(
- validate.text,
- validate.transform(parse_fmt_list)
- ),
- validate.optional("url_encoded_fmt_stream_map"): validate.all(
- validate.text,
- validate.transform(parse_stream_map),
- [{
- "itag": validate.all(
- validate.text,
- validate.transform(int)
- ),
- "quality": validate.text,
- "url": validate.url(scheme="http"),
- validate.optional("s"): validate.text,
- validate.optional("stereo3d"): validate.all(
- validate.text,
- validate.transform(int),
- validate.transform(bool)
- ),
- }]
- ),
- validate.optional("adaptive_fmts"): validate.all(
- validate.text,
- validate.transform(parse_stream_map),
- [{
- validate.optional("s"): validate.text,
- "type": validate.all(
- validate.text,
- validate.transform(lambda t: t.split(";")[0].split("/")),
- [validate.text, validate.text]
- ),
- "url": validate.all(
- validate.url(scheme="http")
- )
- }]
- ),
- validate.optional("hlsvp"): validate.text,
validate.optional("player_response"): validate.all(
validate.text,
validate.transform(parse_json),
{
validate.optional("streamingData"): {
validate.optional("hlsManifestUrl"): validate.text,
+ validate.optional("formats"): [{
+ "itag": int,
+ validate.optional("url"): validate.text,
+ validate.optional("cipher"): validate.text,
+ "qualityLabel": validate.text
+ }],
+ validate.optional("adaptiveFormats"): [{
+ "itag": int,
+ "mimeType": validate.all(
+ validate.text,
+ validate.transform(
+ lambda t:
+ [t.split(';')[0].split('/')[0], t.split(';')[1].split('=')[1].strip('"')]
+ ),
+ [validate.text, validate.text],
+ ),
+ validate.optional("url"): validate.url(scheme="http"),
+ validate.optional("cipher"): validate.text,
+ validate.optional("qualityLabel"): validate.text,
+ validate.optional("bitrate"): int
+ }]
},
validate.optional("videoDetails"): {
validate.optional("isLive"): validate.transform(bool),
+ validate.optional("isLiveContent"): validate.transform(bool),
+ validate.optional("author"): validate.text,
+ validate.optional("title"): validate.all(validate.text,
+ validate.transform(maybe_decode))
},
validate.optional("playabilityStatus"): {
validate.optional("status"): validate.text,
@@ -93,14 +60,6 @@ def parse_fmt_list(formatsmap):
},
},
),
- validate.optional("live_playback"): validate.transform(bool),
- validate.optional("reason"): validate.all(validate.text, validate.transform(maybe_decode)),
- validate.optional("livestream"): validate.text,
- validate.optional("live_playback"): validate.text,
- validate.optional("author"): validate.all(validate.text,
- validate.transform(maybe_decode)),
- validate.optional("title"): validate.all(validate.text,
- validate.transform(maybe_decode)),
"status": validate.text
}
)
@@ -146,6 +105,7 @@ class YouTube(Plugin):
}
)
+ # There are missing itags
adp_video = {
137: "1080p",
299: "1080p60", # HFR
@@ -155,6 +115,9 @@ class YouTube(Plugin):
315: "2160p60", # HFR
138: "2160p",
302: "720p60", # HFR
+ 135: "480p",
+ 133: "240p",
+ 160: "144p",
}
adp_audio = {
140: 128,
@@ -231,16 +194,15 @@ def get_oembed(self):
self.author = data["author_name"]
self.title = data["title"]
- def _create_adaptive_streams(self, info, streams, protected):
+ def _create_adaptive_streams(self, info, streams):
adaptive_streams = {}
best_audio_itag = None
- # Extract audio streams from the DASH format list
- for stream_info in info.get("adaptive_fmts", []):
- if stream_info.get("s"):
- protected = True
+ # Extract audio streams from the adaptive format list
+ streaming_data = info.get("player_response", {}).get("streamingData", {})
+ for stream_info in streaming_data.get("adaptiveFormats", []):
+ if "url" not in stream_info:
continue
-
stream_params = dict(parse_qsl(stream_info["url"]))
if "itag" not in stream_params:
continue
@@ -248,7 +210,8 @@ def _create_adaptive_streams(self, info, streams, protected):
# extract any high quality streams only available in adaptive formats
adaptive_streams[itag] = stream_info["url"]
- stream_type, stream_format = stream_info["type"]
+ stream_type, stream_format = stream_info["mimeType"]
+
if stream_type == "audio":
stream = HTTPStream(self.session, stream_info["url"])
name = "audio_{0}".format(stream_format)
@@ -272,7 +235,7 @@ def _create_adaptive_streams(self, info, streams, protected):
HTTPStream(self.session, vurl),
HTTPStream(self.session, aurl))
- return streams, protected
+ return streams
def _find_video_id(self, url):
@@ -325,16 +288,16 @@ def _get_stream_info(self, video_id):
res = self.session.http.get(self._video_info_url, params=params)
info_parsed = parse_query(res.content if is_py2 else res.text, name="config", schema=_config_schema)
- if (info_parsed.get("player_response", {}).get("playabilityStatus", {}).get("status") != "OK"
- or info_parsed.get("status") == "fail"):
- reason = (info_parsed.get("player_response", {}).get("playabilityStatus", {}).get("reason")
- or info_parsed.get("reason"))
+ player_response = info_parsed.get("player_response", {})
+ playability_status = player_response.get("playabilityStatus", {})
+ if (playability_status.get("status") != "OK"):
+ reason = playability_status.get("reason")
log.debug("get_video_info - {0}: {1}".format(
count, reason)
)
continue
- self.author = info_parsed.get("author")
- self.title = info_parsed.get("title")
+ self.author = player_response.get("videoDetails", {}).get("author")
+ self.title = player_response.get("videoDetails", {}).get("title")
log.debug("get_video_info - {0}: Found data".format(count))
break
@@ -354,35 +317,34 @@ def _get_streams(self):
log.error("Could not get video info")
return
- if info.get("livestream") == '1' or info.get("live_playback") == '1' \
- or info.get("player_response", {}).get("videoDetails", {}).get("isLive"):
+ if (info.get("player_response", {}).get("videoDetails", {}).get("isLiveContent")
+ or info.get("player_response", {}).get("videoDetails", {}).get("isLive")):
log.debug("This video is live.")
is_live = True
- formats = info.get("fmt_list")
streams = {}
protected = False
- for stream_info in info.get("url_encoded_fmt_stream_map", []):
- if stream_info.get("s"):
- protected = True
- continue
+ if (info.get("player_response", {}).get("streamingData", {}).get("adaptiveFormats", [{}])[0].get("cipher")
+ or info.get("player_response", {}).get("streamingData", {}).get("formats", [{}])[0].get("cipher")):
+ protected = True
+ log.debug("This video may be protected.")
+ for stream_info in info.get("player_response", {}).get("streamingData", {}).get("formats", []):
+ if "url" not in stream_info:
+ continue
stream = HTTPStream(self.session, stream_info["url"])
- name = formats.get(stream_info["itag"]) or stream_info["quality"]
-
- if stream_info.get("stereo3d"):
- name += "_3d"
+ name = stream_info["qualityLabel"]
streams[name] = stream
if not is_live:
- streams, protected = self._create_adaptive_streams(info, streams, protected)
+ streams = self._create_adaptive_streams(info, streams)
- hls_playlist = info.get("hlsvp") or info.get("player_response", {}).get("streamingData", {}).get("hlsManifestUrl")
- if hls_playlist:
+ hls_manifest = info.get("player_response", {}).get("streamingData", {}).get("hlsManifestUrl")
+ if hls_manifest:
try:
hls_streams = HLSStream.parse_variant_playlist(
- self.session, hls_playlist, namekey="pixels"
+ self.session, hls_manifest, namekey="pixels"
)
streams.update(hls_streams)
except IOError as err:
| Youtube plugin not working with some vods
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x ] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
On some vods i get no playable streams found and cant seem to identify why.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. Try to load streamlink https://www.youtube.com/watch?v=FmDUUGOTFCM
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
streamlink https://www.youtube.com/watch?v=jXg93FFZXWk -l debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.3.0
[cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.56.0)
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=jXg93FFZXWk
[plugin.youtube][debug] Video ID from URL
[plugin.youtube][debug] Using video ID: jXg93FFZXWk
[plugin.youtube][debug] get_video_info - 1: Found data
[plugin.youtube][debug] MuxedStream: v 137 a 251 = 1080p
Available streams: audio_mp4, audio_webm, 360p (worst), 720p, 1080p (best)
streamlink https://www.youtube.com/watch?v=FmDUUGOTFCM -l debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.3.0
[cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.56.0)
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=FmDUUGOTFCM
[plugin.youtube][debug] Video ID from URL
[plugin.youtube][debug] Using video ID: FmDUUGOTFCM
[plugin.youtube][debug] get_video_info - 1: Found data
error: No playable streams found on this URL: https://www.youtube.com/watch?v=FmDUUGOTFCM
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| I've faced with similar issue with following link: https://www.youtube.com/watch?v=UhkgggX_-QE&feature=youtu.be
```
streamlink "https://www.youtube.com/watch?v=UhkgggX_-QE&feature=youtu.be" -l debug
[cli][debug] OS: macOS 10.15.2
[cli][debug] Python: 3.8.0
[cli][debug] Streamlink: 1.3.0
[cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.56.0)
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=UhkgggX_-QE&feature=youtu.be
[plugin.youtube][debug] Video ID from URL
[plugin.youtube][debug] Using video ID: UhkgggX_-QE
[plugin.youtube][debug] get_video_info - 1: Found data
error: No playable streams found on this URL: https://www.youtube.com/watch?v=UhkgggX_-QE&feature=youtu.be
```
+1, repro here as well using 1.3.0+19.gad276c4 and video link https://www.youtube.com/watch?v=fCZsk0E-Y5A
Had a chance to poke around at this today. Completely new to the code base and domain so forgive me if this is not a useful observation. I dumped `parse_qsl(res.text)` just following https://github.com/streamlink/streamlink/blob/master/src/streamlink/plugins/youtube.py#L326 and found that the video info response text for each problematic link provided so far has no `fmt_list` or `url_encoded_fmt_stream_map` entries, so the plugin's `_get_streams()` call returns an empty dict.
These same videos all download properly in youtube-dl 2020.01.01 FWIW.
Its getting worse.
E:\tmp2\London>streamlink -l debug https://www.youtube.com/watch?v=c6RpWivuEoY 480p
[cli][debug] OS: Windows 7
[cli][debug] Python: 3.8.0
[cli][debug] Streamlink: 1.3.0
[cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.56.0)
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=c6RpWivuEoY
[plugin.youtube][debug] Video ID from URL
[plugin.youtube][debug] Using video ID: c6RpWivuEoY
[plugin.youtube][debug] get_video_info - 1: Found data
error: No playable streams found on this URL: https://www.youtube.com/watch?v=c6RpWivuEoY
Having the same issue on Manjaro(linux)
$ streamlink https://www.youtube.com/watch?v=RG4IXfTMGSM best -l debug
[cli][debug] OS: Linux-5.4.6-2-MANJARO-x86_64-with-glibc2.2.5
[cli][debug] Python: 3.8.1
[cli][debug] Streamlink: 1.3.0
[cli][debug] Requests(2.22.0), Socks(1.7.0), Websocket(0.57.0)
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=RG4IXfTMGSM
[plugin.youtube][debug] Video ID from URL
[plugin.youtube][debug] Using video ID: RG4IXfTMGSM
[plugin.youtube][debug] get_video_info - 1: Found data
error: No playable streams found on this URL: https://www.youtube.com/watch?v=RG4IXfTMGSM
Same for Raspian :
```streamlink -l debug 'https://www.youtube.com/watch?v=oSmUI3m2kLk' best
[cli][debug] OS: Linux-4.19.42-v7+-armv7l-with-debian-9.9
[cli][debug] Python: 2.7.13
[cli][debug] Streamlink: 1.3.0
[cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=oSmUI3m2kLk
[plugin.youtube][debug] Video ID from URL
[plugin.youtube][debug] Using video ID: oSmUI3m2kLk
[plugin.youtube][debug] get_video_info - 1: Found data
error: No playable streams found on this URL: https://www.youtube.com/watch?v=oSmUI3m2kLk
```
Doesn't work for me either
Verifying, having similar "No playable streams" difficulties. Originally encountered with a 4K video and chalked it up to Google being weird and splitting video and audio at super-high (>=1440p) qualities, but I've also run into this in run-of-the-mill 720p max videos too that don't have strict Content ID protection that would usually spit out the "use youtube-dl instead" fallback message.
same problem on raspbian (I replaced ID with ABC for privacy reasons):
```
[cli][debug] OS: Linux-4.19.93-v7l+-armv7l-with-debian-10.2
[cli][debug] Python: 3.7.3
[cli][debug] Streamlink: 1.3.0
[cli][debug] Requests(2.21.0), Socks(1.6.7), Websocket(0.57.0)
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=ABC
[plugin.youtube][debug] Video ID from URL
[plugin.youtube][debug] Using video ID: ABC
[plugin.youtube][debug] get_video_info - 1: Found data
error: No playable streams found on this URL: https://www.youtube.com/watch?v=ABC
```
Getting the same thing here - Raspbian. Seems any VOD link I try to play fails with "no playable streams" as above.
EDIT: Does seem to be JUST VOD links... as the NASA TV live stream works just fine e.g.
https://www.youtube.com/watch?v=21X5lGlDOfg
Any word from the Streamlink team (@back-to) on this issue? Thanks!
I don't even know if we're going to consider this an issue as livestreams are fine. It's just VODs that don't work so I don't know if anyone will pick this up since we've been moving further and further from VOD support. I don't have time to look at it currently but if anyone wants to investigate feel free to do so.
@gravyboat - I had no idea about the VOD vs Live stream priority - thanks for clarifying that.
Unfortunately although the live stream part of streamlink has historically been my primary use - I've begun using the VOD capability with Youtube quite extensively. I can see that may have been a mistake in view of the priorities for this project.
I'll do my best to dig through the problem and find a solution - but I don't have full faith in my programming capabilities to pull out the solution. Wish me luck!
@Maqken - do you have any luck with any VOD now? The VOD from your original post that WAS working is not working now either.
@phytoporg - do you have any (still) working examples of a VOD video link?
I'm looking for a working VOD so I can compare some additional debug dumps of working vs non-working VOD. Although I am thinking the issue now is something has changed with the youtube API that is now making this an issue will all VOD's with streamlink.
Thanks!
@liamkennedy it was too random so i´m not using it for youtube vods anymore, i´m trying out youtube-dl for the time being and it's working fine. It has the downside that i have to teach my homebrew ui to use it instead of streamlink but it's a nice exercise.
You might want to try older vods, my last experience with youtube vods was that newer vods didn't work and older did. but i suppose that if they are spreading the change backwards eventually none will.
@Maqken thanks for the response. I have tried out some 10-year-old videos on my YT Channel - and the problem is happening with those too - so it does look like it's maybe on all VOD's now.
In my case I have a quite large installed base of users worldwide running as a console application on Raspbian (mostly stretch - but some are still on Jessie) - so there are a few more challenges I have to work out before I could switch to youtube-dl for this. I may very well have to go that route - although my highest priority would be to keep with streamlink and just work out what the fix is.
Thanks again
@liamkennedy Sure no problem. It's mostly just a stance we've had to take against adding new VOD only sites since that kind of defeats the purpose of Streamlink and we were getting a lot of requests for sites that already exist in tools like youtube-dl so I have to make sure to say that it's the main focus so no one comes back to quote this issue going "well you fixed youtube!". All the maintainers have been pretty busy with real life stuff sadly so we've only been hitting more critical issues as of late.
Streamlink just doesn't work for any youtube video anymore.
I just noticed, lot of stuff does not work that connected to youtube. Like playing youtube videos in VLC.
Unless... I did some digging and found this:
https://addons.videolan.org/p/1154080/
or rather this:
https://raw.githubusercontent.com/videolan/vlc/master/share/lua/playlist/youtube.lua
Its fixes the issue for VLC. Maybe there are something in it which helps to fix streamlink aswell. | 2020-04-02T22:43:31 |
|
streamlink/streamlink | 2,871 | streamlink__streamlink-2871 | [
"2444"
] | fdf739d6cdf5e9f249f1b111d2b80d98d080922b | diff --git a/src/streamlink/utils/encoding.py b/src/streamlink/utils/encoding.py
--- a/src/streamlink/utils/encoding.py
+++ b/src/streamlink/utils/encoding.py
@@ -15,7 +15,10 @@ def get_filesystem_encoding():
def maybe_encode(text, encoding="utf8"):
if is_py2:
- return text.encode(encoding)
+ if isinstance(text, unicode):
+ return text.encode(encoding)
+ else:
+ return text
else:
return text
diff --git a/src/streamlink_cli/main.py b/src/streamlink_cli/main.py
--- a/src/streamlink_cli/main.py
+++ b/src/streamlink_cli/main.py
@@ -30,7 +30,7 @@
import streamlink.logger as logger
from .argparser import build_parser
from .compat import stdout, is_win32
-from streamlink.utils.encoding import maybe_encode
+from streamlink.utils.encoding import maybe_decode, get_filesystem_encoding
from .console import ConsoleOutput, ConsoleUserInputRequester
from .constants import CONFIG_FILES, PLUGINS_DIR, STREAM_SYNONYMS, DEFAULT_STREAM_METADATA
from .output import FileOutput, PlayerOutput
@@ -146,7 +146,7 @@ def create_http_server(host=None, port=0):
def create_title(plugin=None):
if args.title and plugin:
title = LazyFormatter.format(
- maybe_encode(args.title),
+ maybe_decode(args.title, get_filesystem_encoding()),
title=lambda: plugin.get_title() or DEFAULT_STREAM_METADATA["title"],
author=lambda: plugin.get_author() or DEFAULT_STREAM_METADATA["author"],
category=lambda: plugin.get_category() or DEFAULT_STREAM_METADATA["category"],
diff --git a/src/streamlink_cli/output.py b/src/streamlink_cli/output.py
--- a/src/streamlink_cli/output.py
+++ b/src/streamlink_cli/output.py
@@ -185,13 +185,13 @@ def _create_arguments(self):
if self.player_name == "vlc":
# see https://wiki.videolan.org/Documentation:Format_String/, allow escaping with \$
self.title = self.title.replace("$", "$$").replace(r'\$$', "$")
- extra_args.extend(["--input-title-format", self.title])
+ extra_args.extend([u"--input-title-format", self.title])
# mpv
if self.player_name == "mpv":
# see https://mpv.io/manual/stable/#property-expansion, allow escaping with \$, respect mpv's $>
self.title = self._mpv_title_escape(self.title)
- extra_args.append("--title={}".format(self.title))
+ extra_args.append(u"--title={}".format(self.title))
# potplayer
if self.player_name == "potplayer":
@@ -209,8 +209,7 @@ def _create_arguments(self):
if is_win32:
eargs = maybe_decode(subprocess.list2cmdline(extra_args))
# do not insert and extra " " when there are no extra_args
- return maybe_encode(u' '.join([cmd] + ([eargs] if eargs else []) + [args]),
- encoding=get_filesystem_encoding())
+ return u' '.join([cmd] + ([eargs] if eargs else []) + [args])
return shlex.split(cmd) + extra_args + shlex.split(args)
def _open(self):
@@ -234,7 +233,8 @@ def _open_call(self):
else:
fargs = subprocess.list2cmdline(args)
log.debug(u"Calling: {0}".format(fargs))
- subprocess.call(args,
+
+ subprocess.call(maybe_encode(args, get_filesystem_encoding()),
stdout=self.stdout,
stderr=self.stderr)
@@ -247,7 +247,8 @@ def _open_subprocess(self):
else:
fargs = subprocess.list2cmdline(args)
log.debug(u"Opening subprocess: {0}".format(fargs))
- self.player = subprocess.Popen(args,
+
+ self.player = subprocess.Popen(maybe_encode(args, get_filesystem_encoding()),
stdin=self.stdin, bufsize=0,
stdout=self.stdout,
stderr=self.stderr)
| diff --git a/tests/__init__.py b/tests/__init__.py
--- a/tests/__init__.py
+++ b/tests/__init__.py
@@ -1,17 +1,29 @@
+import os
import warnings
+import pytest
+
+from streamlink.compat import is_py2, is_py3
+
def catch_warnings(record=False, module=None):
def _catch_warnings_wrapper(f):
def _catch_warnings(*args, **kwargs):
with warnings.catch_warnings(record=True, module=module) as w:
if record:
- return f(*(args + (w, )), **kwargs)
+ return f(*(args + (w,)), **kwargs)
else:
return f(*args, **kwargs)
+
return _catch_warnings
return _catch_warnings_wrapper
-__all__ = ['ignore_warnings']
+windows_only = pytest.mark.skipif(os.name != "nt", reason="test only applicable on Window")
+posix_only = pytest.mark.skipif(os.name != "posix", reason="test only applicable on a POSIX OS")
+py3_only = pytest.mark.skipif(not is_py3, reason="test only applicable for Python 3")
+py2_only = pytest.mark.skipif(not is_py2, reason="test only applicable for Python 2")
+
+
+__all__ = ['catch_warnings', 'windows_only', 'posix_only', 'py2_only', 'py3_only']
diff --git a/tests/test_cli_playerout.py b/tests/test_cli_playerout.py
new file mode 100644
--- /dev/null
+++ b/tests/test_cli_playerout.py
@@ -0,0 +1,71 @@
+# -*- coding: utf-8 -*-
+from streamlink.utils import get_filesystem_encoding
+from streamlink_cli.output import PlayerOutput
+from tests import posix_only, windows_only, py2_only, py3_only
+from tests.mock import patch, ANY
+
+UNICODE_TITLE = u"기타치는소율 with UL섬 "
+
+
+@posix_only
+@patch('subprocess.Popen')
+def test_output_mpv_unicode_title_posix(popen):
+ po = PlayerOutput("mpv", title=UNICODE_TITLE)
+ popen().poll.side_effect = lambda: None
+ po.open()
+ popen.assert_called_with(['mpv', u"--title=" + UNICODE_TITLE, '-'],
+ bufsize=ANY, stderr=ANY, stdout=ANY, stdin=ANY)
+
+
+@posix_only
+@patch('subprocess.Popen')
+def test_output_vlc_unicode_title_posix(popen):
+ po = PlayerOutput("vlc", title=UNICODE_TITLE)
+ popen().poll.side_effect = lambda: None
+ po.open()
+ popen.assert_called_with(['vlc', u'--input-title-format', UNICODE_TITLE, '-'],
+ bufsize=ANY, stderr=ANY, stdout=ANY, stdin=ANY)
+
+
+@py2_only
+@windows_only
+@patch('subprocess.Popen')
+def test_output_mpv_unicode_title_windows_py2(popen):
+ po = PlayerOutput("mpv.exe", title=UNICODE_TITLE)
+ popen().poll.side_effect = lambda: None
+ po.open()
+ popen.assert_called_with("mpv.exe \"--title=" + UNICODE_TITLE.encode(get_filesystem_encoding()) + "\" -",
+ bufsize=ANY, stderr=ANY, stdout=ANY, stdin=ANY)
+
+
+@py2_only
+@windows_only
+@patch('subprocess.Popen')
+def test_output_vlc_unicode_title_windows_py2(popen):
+ po = PlayerOutput("vlc.exe", title=UNICODE_TITLE)
+ popen().poll.side_effect = lambda: None
+ po.open()
+ popen.assert_called_with("vlc.exe --input-title-format \"" + UNICODE_TITLE.encode(get_filesystem_encoding()) + "\" -",
+ bufsize=ANY, stderr=ANY, stdout=ANY, stdin=ANY)
+
+
+@py3_only
+@windows_only
+@patch('subprocess.Popen')
+def test_output_mpv_unicode_title_windows_py3(popen):
+ po = PlayerOutput("mpv.exe", title=UNICODE_TITLE)
+ popen().poll.side_effect = lambda: None
+ po.open()
+ popen.assert_called_with("mpv.exe \"--title=" + UNICODE_TITLE + "\" -",
+ bufsize=ANY, stderr=ANY, stdout=ANY, stdin=ANY)
+
+
+@py3_only
+@windows_only
+@patch('subprocess.Popen')
+def test_output_vlc_unicode_title_windows_py3(popen):
+ po = PlayerOutput("vlc.exe", title=UNICODE_TITLE)
+ popen().poll.side_effect = lambda: None
+ po.open()
+ popen.assert_called_with("vlc.exe --input-title-format \"" + UNICODE_TITLE + "\" -",
+ bufsize=ANY, stderr=ANY, stdout=ANY, stdin=ANY)
diff --git a/tests/test_cmdline_title.py b/tests/test_cmdline_title.py
--- a/tests/test_cmdline_title.py
+++ b/tests/test_cmdline_title.py
@@ -1,7 +1,7 @@
# -*- coding: utf-8 -*-
import unittest
-from streamlink.compat import is_win32, is_py3
+from streamlink.compat import is_win32, is_py3, is_py2
from streamlink.utils import get_filesystem_encoding
from tests.test_cmdline import CommandLineTestCase
@@ -28,6 +28,10 @@ def test_open_player_with_title_mpv(self):
self._test_args(["streamlink", "-p", "/usr/bin/mpv", "--title", "{title}", "http://test.se", "test"],
["/usr/bin/mpv", "--title=Test Title", "-"])
+ def test_unicode_title_2444(self):
+ self._test_args(["streamlink", "-p", "mpv", "-t", "★", "http://test.se", "test"],
+ ["mpv", u'--title=\u2605', "-"])
+
@unittest.skipIf(not is_win32, "test only applicable on Windows")
class TestCommandLineWithTitleWindows(CommandLineTestCase):
@@ -77,7 +81,7 @@ def test_open_player_with_title_pot(self):
passthrough=True
)
- @unittest.skipIf(is_py3, "Encoding is different in Python 2")
+ @unittest.skipUnless(is_py2, "Encoding is different in Python 2")
def test_open_player_with_unicode_author_pot_py2(self):
self._test_args(
["streamlink", "-p", "\"c:\\Program Files\\DAUM\\PotPlayer\\PotPlayerMini64.exe\"",
@@ -88,7 +92,7 @@ def test_open_player_with_unicode_author_pot_py2(self):
passthrough=True
)
- @unittest.skipIf(not is_py3, "Encoding is different in Python 2")
+ @unittest.skipUnless(is_py3, "Encoding is different in Python 3")
def test_open_player_with_unicode_author_pot_py3(self):
self._test_args(
["streamlink", "-p", "\"c:\\Program Files\\DAUM\\PotPlayer\\PotPlayerMini64.exe\"",
@@ -106,3 +110,13 @@ def test_open_player_with_default_title_pot(self):
+ "\"http://test.se/playlist.m3u8\\http://test.se/stream\"",
passthrough=True
)
+
+ @unittest.skipUnless(is_py2, "test only valid for Python 2")
+ def test_unicode_title_2444_py2(self):
+ self._test_args(["streamlink", "-p", "mpv", "-t", u"★".encode(get_filesystem_encoding()), "http://test.se", "test"],
+ "mpv --title=" + u"★".encode(get_filesystem_encoding()) + " -")
+
+ @unittest.skipUnless(is_py3, "test only valid for Python 3")
+ def test_unicode_title_2444_py3(self):
+ self._test_args(["streamlink", "-p", "mpv", "-t", "★", "http://test.se", "test"],
+ "mpv --title=★ -")
| UnicodeDecodeError when opening streams with non-ascii characters in the title
<!--
Thanks for reporting a bug!
USE THE TEMPLATE. Otherwise your bug report may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed bug reports:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Bug Report
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report and I have read the contribution guidelines.
### Description
<!-- Explain the bug as thoroughly as you can. Don't leave out information which is necessary for us to reproduce and debug this issue. -->
When opening a stream with a non-ascii character in the stream title there is a “UnicodeDecodeError” and the stream doesn’t open.
The steam I tried to open had an ‘ö’ in the title, but trying other streams with non-ascii characters gave the same error (tested on random Korean streams). Other streams opened as expected.
### Expected / Actual behavior
<!-- What do you expect to happen, and what is actually happening? -->
Expect: Stream to open.
Actual: It doesn’t.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. Find a stream with a non-ascii title and attempt to open it.
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a bug report!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
OS: macOS 10.14.2
Python: 2.7.14
Streamlink: 1.1.1
Requests(2.21.0), Socks(1.6.7), Websocket(0.47.0)
Found matching plugin twitch for URL twitch.tv/quickybaby
Plugin specific arguments:
--twitch-oauth-token=******** (oauth_token)
--twitch-disable-hosting=True (disable_hosting)
--twitch-disable-ads=True (disable_ads)
Getting live HLS streams for quickybaby
Attempting to authenticate using OAuth token
Successfully logged in as DELETE
[utils.l10n][debug] Language code: en_US
Available streams: audio_only, 160p (worst), 360p, 480p, 720p, 720p60, 1080p60 (best)
Opening stream: 1080p60 (hls)
Starting player: /Applications/mpv.app/Contents/MacOS/mpv
Traceback (most recent call last):
File "/usr/local/bin/streamlink", line 11, in <module>
load_entry_point('streamlink==1.1.1', 'console_scripts', 'streamlink')()
File "/usr/local/lib/python2.7/site-packages/streamlink-1.1.1-py2.7.egg/streamlink_cli/main.py", line 1033, in main
handle_url()
File "/usr/local/lib/python2.7/site-packages/streamlink-1.1.1-py2.7.egg/streamlink_cli/main.py", line 594, in handle_url
handle_stream(plugin, streams, stream_name)
File "/usr/local/lib/python2.7/site-packages/streamlink-1.1.1-py2.7.egg/streamlink_cli/main.py", line 437, in handle_stream
success = output_stream_passthrough(plugin, stream)
File "/usr/local/lib/python2.7/site-packages/streamlink-1.1.1-py2.7.egg/streamlink_cli/main.py", line 262, in output_stream_passthrough
output.open()
File "/usr/local/lib/python2.7/site-packages/streamlink-1.1.1-py2.7.egg/streamlink_cli/output.py", line 24, in open
self._open()
File "/usr/local/lib/python2.7/site-packages/streamlink-1.1.1-py2.7.egg/streamlink_cli/output.py", line 219, in _open
self._open_call()
File "/usr/local/lib/python2.7/site-packages/streamlink-1.1.1-py2.7.egg/streamlink_cli/output.py", line 234, in _open_call
log.debug(u"Calling: {0}".format(fargs))
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 141: ordinal not in range(128)
```
### Additional comments, screenshots, etc.
I can't link to a stream that will give an error as titles always change, but it should be easy enough to find a Korean stream, and they usually have Korean titles.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Hi there.
Noticed this bug on Elementary OS 0.4.1 (based on Ubuntu 16.04.2). It can easily be reproduced by using the title parameter, e.g.
`streamlink -t "★" ((any stream url)) best`
When using Streamlink Twitch GUI, go to Settings > Player > Window title and disable the custom title option as a temporary workaround.
Regards,
Addi
**can't reproduce** on ubuntu 18.10 / python2
---
easiest fix is to use **python3** instead of python2 | 2020-04-07T16:22:01 |
streamlink/streamlink | 2,895 | streamlink__streamlink-2895 | [
"2894"
] | 6773c3fb9c41f3793aab78e40e10eb1b1d19546e | diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -119,25 +119,16 @@
}
)
-
-Segment = namedtuple("Segment", "uri duration title key discontinuity scte35 byterange date map")
+Segment = namedtuple("Segment", "uri duration title key discontinuity ad byterange date map")
LOW_LATENCY_MAX_LIVE_EDGE = 2
-def parse_condition(attr):
- def wrapper(func):
- def method(self, *args, **kwargs):
- if hasattr(self.stream, attr) and getattr(self.stream, attr, False):
- func(self, *args, **kwargs)
- return method
- return wrapper
-
-
class TwitchM3U8Parser(M3U8Parser):
- def __init__(self, base_uri=None, stream=None, **kwargs):
- M3U8Parser.__init__(self, base_uri, **kwargs)
- self.stream = stream
+ def __init__(self, base_uri=None, disable_ads=False, low_latency=False, **kwargs):
+ super(TwitchM3U8Parser, self).__init__(base_uri, **kwargs)
+ self.disable_ads = disable_ads
+ self.low_latency = low_latency
self.has_prefetch_segments = False
def parse(self, *args):
@@ -146,21 +137,16 @@ def parse(self, *args):
return m3u8
- @parse_condition("disable_ads")
- def parse_tag_ext_x_scte35_out(self, value):
- self.state["scte35"] = True
-
- # unsure if this gets used by Twitch
- @parse_condition("disable_ads")
- def parse_tag_ext_x_scte35_out_cont(self, value):
- self.state["scte35"] = True
+ def parse_extinf(self, value):
+ duration, title = super(TwitchM3U8Parser, self).parse_extinf(value)
+ if title and str(title).startswith("Amazon") and self.disable_ads:
+ self.state["ad"] = True
- @parse_condition("disable_ads")
- def parse_tag_ext_x_scte35_in(self, value):
- self.state["scte35"] = False
+ return duration, title
- @parse_condition("low_latency")
def parse_tag_ext_x_twitch_prefetch(self, value):
+ if not self.low_latency:
+ return
self.has_prefetch_segments = True
segments = self.m3u8.segments
if segments:
@@ -173,7 +159,7 @@ def get_segment(self, uri):
map_ = self.state.get("map")
key = self.state.get("key")
discontinuity = self.state.pop("discontinuity", False)
- scte35 = self.state.pop("scte35", None)
+ ad = self.state.pop("ad", False)
return Segment(
uri,
@@ -181,7 +167,7 @@ def get_segment(self, uri):
extinf[1],
key,
discontinuity,
- scte35,
+ ad,
byterange,
date,
map_
@@ -189,17 +175,36 @@ def get_segment(self, uri):
class TwitchHLSStreamWorker(HLSStreamWorker):
+ def __init__(self, *args, **kwargs):
+ self.playlist_reloads = 0
+ super(TwitchHLSStreamWorker, self).__init__(*args, **kwargs)
+
def _reload_playlist(self, text, url):
- return load_hls_playlist(text, url, parser=TwitchM3U8Parser, stream=self.stream)
+ self.playlist_reloads += 1
+ playlist = load_hls_playlist(
+ text,
+ url,
+ parser=TwitchM3U8Parser,
+ disable_ads=self.stream.disable_ads,
+ low_latency=self.stream.low_latency
+ )
+ if (
+ self.stream.disable_ads
+ and self.playlist_reloads == 1
+ and not next((s for s in playlist.segments if not s.ad), False)
+ ):
+ log.info("Waiting for pre-roll ads to finish, be patient")
+
+ return playlist
def _set_playlist_reload_time(self, playlist, sequences):
- if not self.stream.low_latency:
- super(TwitchHLSStreamWorker, self)._set_playlist_reload_time(playlist, sequences)
- else:
+ if self.stream.low_latency and len(sequences) > 0:
self.playlist_reload_time = sequences[-1].segment.duration
+ else:
+ super(TwitchHLSStreamWorker, self)._set_playlist_reload_time(playlist, sequences)
def process_sequences(self, playlist, sequences):
- if self.playlist_sequence < 0 and self.stream.low_latency and not playlist.has_prefetch_segments:
+ if self.stream.low_latency and self.playlist_reloads == 1 and not playlist.has_prefetch_segments:
log.info("This is not a low latency stream")
return super(TwitchHLSStreamWorker, self).process_sequences(playlist, sequences)
@@ -207,38 +212,20 @@ def process_sequences(self, playlist, sequences):
class TwitchHLSStreamWriter(HLSStreamWriter):
def write(self, sequence, *args, **kwargs):
- if self.stream.disable_ads:
- if sequence.segment.scte35 is not None:
- self.reader.ads = sequence.segment.scte35
- if self.reader.ads:
- log.info("Will skip ads beginning with segment {0}".format(sequence.num))
- else:
- log.info("Will stop skipping ads beginning with segment {0}".format(sequence.num))
- if self.reader.ads:
- return
- return HLSStreamWriter.write(self, sequence, *args, **kwargs)
+ if not (self.stream.disable_ads and sequence.segment.ad):
+ return super(TwitchHLSStreamWriter, self).write(sequence, *args, **kwargs)
class TwitchHLSStreamReader(HLSStreamReader):
__worker__ = TwitchHLSStreamWorker
__writer__ = TwitchHLSStreamWriter
- ads = None
class TwitchHLSStream(HLSStream):
def __init__(self, *args, **kwargs):
- HLSStream.__init__(self, *args, **kwargs)
-
- disable_ads = self.session.get_plugin_option("twitch", "disable-ads")
- low_latency = self.session.get_plugin_option("twitch", "low-latency")
-
- if low_latency and disable_ads:
- log.info("Low latency streaming with ad filtering is currently not supported")
- self.session.set_plugin_option("twitch", "low-latency", False)
- low_latency = False
-
- self.disable_ads = disable_ads
- self.low_latency = low_latency
+ super(TwitchHLSStream, self).__init__(*args, **kwargs)
+ self.disable_ads = self.session.get_plugin_option("twitch", "disable-ads")
+ self.low_latency = self.session.get_plugin_option("twitch", "low-latency")
def open(self):
if self.disable_ads:
diff --git a/src/streamlink/stream/hls.py b/src/streamlink/stream/hls.py
--- a/src/streamlink/stream/hls.py
+++ b/src/streamlink/stream/hls.py
@@ -232,21 +232,24 @@ def reload_playlist(self):
sequences = [Sequence(media_sequence + i, s)
for i, s in enumerate(playlist.segments)]
- if sequences:
- self.process_sequences(playlist, sequences)
+ self.process_sequences(playlist, sequences)
def _set_playlist_reload_time(self, playlist, sequences):
self.playlist_reload_time = (playlist.target_duration
- or sequences[-1].segment.duration)
+ or len(sequences) > 0 and sequences[-1].segment.duration)
def process_sequences(self, playlist, sequences):
+ self._set_playlist_reload_time(playlist, sequences)
+
+ if not sequences:
+ return
+
first_sequence, last_sequence = sequences[0], sequences[-1]
if first_sequence.segment.key and first_sequence.segment.key.method != "NONE":
log.debug("Segments in this playlist are encrypted")
self.playlist_changed = ([s.num for s in self.playlist_sequences] != [s.num for s in sequences])
- self._set_playlist_reload_time(playlist, sequences)
self.playlist_sequences = sequences
if not self.playlist_changed:
| diff --git a/tests/plugins/test_twitch.py b/tests/plugins/test_twitch.py
--- a/tests/plugins/test_twitch.py
+++ b/tests/plugins/test_twitch.py
@@ -5,7 +5,7 @@
from streamlink.plugins.twitch import Twitch, TwitchHLSStream
import requests_mock
-from tests.mock import call, patch
+from tests.mock import MagicMock, call, patch
from streamlink.session import Streamlink
from tests.resources import text
@@ -34,22 +34,21 @@ def test_can_handle_url_negative(self):
self.assertFalse(Twitch.can_handle_url(url))
+@patch("streamlink.stream.hls.HLSStreamWorker.wait", MagicMock(return_value=True))
class TestTwitchHLSStream(unittest.TestCase):
url_master = "http://mocked/path/master.m3u8"
url_playlist = "http://mocked/path/playlist.m3u8"
url_segment = "http://mocked/path/stream{0}.ts"
- scte35_out = "#EXT-X-DISCONTINUITY\n#EXT-X-SCTE35-OUT\n"
- scte35_out_cont = "#EXT-X-SCTE35-OUT-CONT\n"
- scte35_in = "#EXT-X-DISCONTINUITY\n#EXT-X-SCTE35-IN\n"
segment = "#EXTINF:1.000,\nstream{0}.ts\n"
+ segment_ad = "#EXTINF:1.000,Amazon|123456789\nstream{0}.ts\n"
prefetch = "#EXT-X-TWITCH-PREFETCH:{0}\n"
def getMasterPlaylist(self):
with text("hls/test_master.m3u8") as pl:
return pl.read()
- def getPlaylist(self, media_sequence, items, prefetch=None):
+ def getPlaylist(self, media_sequence, items, ads=False, prefetch=None):
playlist = """
#EXTM3U
#EXT-X-VERSION:5
@@ -57,11 +56,9 @@ def getPlaylist(self, media_sequence, items, prefetch=None):
#EXT-X-MEDIA-SEQUENCE:{0}
""".format(media_sequence)
+ segment = self.segment if not ads else self.segment_ad
for item in items:
- if type(item) != int:
- playlist += item
- else:
- playlist += self.segment.format(item)
+ playlist += segment.format(item)
for item in prefetch or []:
playlist += self.prefetch.format(self.url_segment.format(item))
@@ -97,117 +94,52 @@ def get_result(self, streams, playlists, **kwargs):
return streamlink, data, mocked
@patch("streamlink.plugins.twitch.log")
- def test_hls_scte35_start_with_end(self, mock_logging):
- streams = ["[{0}]".format(i).encode("ascii") for i in range(12)]
+ def test_hls_disable_ads_preroll(self, mock_logging):
+ streams = ["[{0}]".format(i).encode("ascii") for i in range(6)]
playlists = [
- self.getPlaylist(0, [self.scte35_out, 0, 1, 2, 3]),
- self.getPlaylist(4, [self.scte35_in, 4, 5, 6, 7]),
- self.getPlaylist(8, [8, 9, 10, 11]) + "#EXT-X-ENDLIST\n"
+ self.getPlaylist(0, [0, 1], ads=True),
+ self.getPlaylist(2, [2, 3], ads=True),
+ self.getPlaylist(4, [4, 5]) + "#EXT-X-ENDLIST\n"
]
streamlink, result, mocked = self.get_result(streams, playlists, disable_ads=True)
- expected = b''.join(streams[4:12])
- self.assertEqual(expected, result)
- for i in range(0, 12):
+ self.assertEqual(result, b''.join(streams[4:6]))
+ for i in range(0, 6):
self.assertTrue(mocked[self.url_segment.format(i)].called, i)
mock_logging.info.assert_has_calls([
call("Will skip ad segments"),
- call("Will skip ads beginning with segment 0"),
- call("Will stop skipping ads beginning with segment 4")
+ call("Waiting for pre-roll ads to finish, be patient")
])
+ self.assertEqual(mock_logging.info.call_count, 2)
@patch("streamlink.plugins.twitch.log")
- def test_hls_scte35_no_start(self, mock_logging):
- streams = ["[{0}]".format(i).encode("ascii") for i in range(8)]
+ def test_hls_disable_ads_no_preroll(self, mock_logging):
+ streams = ["[{0}]".format(i).encode("ascii") for i in range(6)]
playlists = [
- self.getPlaylist(0, [0, 1, 2, 3]),
- self.getPlaylist(4, [self.scte35_in, 4, 5, 6, 7]) + "#EXT-X-ENDLIST\n"
+ self.getPlaylist(0, [0, 1]),
+ self.getPlaylist(2, [2, 3], ads=True),
+ self.getPlaylist(4, [4, 5]) + "#EXT-X-ENDLIST\n"
]
streamlink, result, mocked = self.get_result(streams, playlists, disable_ads=True)
- expected = b''.join(streams[0:8])
- self.assertEqual(expected, result)
- for i in range(0, 8):
+ self.assertEqual(result, b''.join(streams[0:2]) + b''.join(streams[4:6]))
+ for i in range(0, 6):
self.assertTrue(mocked[self.url_segment.format(i)].called, i)
mock_logging.info.assert_has_calls([
call("Will skip ad segments")
])
@patch("streamlink.plugins.twitch.log")
- def test_hls_scte35_no_start_with_cont(self, mock_logging):
- streams = ["[{0}]".format(i).encode("ascii") for i in range(8)]
- playlists = [
- self.getPlaylist(0, [self.scte35_out_cont, 0, 1, 2, 3]),
- self.getPlaylist(4, [self.scte35_in, 4, 5, 6, 7]) + "#EXT-X-ENDLIST\n"
- ]
- streamlink, result, mocked = self.get_result(streams, playlists, disable_ads=True)
-
- expected = b''.join(streams[4:8])
- self.assertEqual(expected, result)
- for i in range(0, 8):
- self.assertTrue(mocked[self.url_segment.format(i)].called, i)
- mock_logging.info.assert_has_calls([
- call("Will skip ad segments"),
- call("Will skip ads beginning with segment 0"),
- call("Will stop skipping ads beginning with segment 4")
- ])
-
- @patch("streamlink.plugins.twitch.log")
- def test_hls_scte35_no_end(self, mock_logging):
- streams = ["[{0}]".format(i).encode("ascii") for i in range(12)]
+ def test_hls_no_disable_ads(self, mock_logging):
+ streams = ["[{0}]".format(i).encode("ascii") for i in range(4)]
playlists = [
- self.getPlaylist(0, [0, 1, 2, 3]),
- self.getPlaylist(4, [self.scte35_out, 4, 5, 6, 7]),
- self.getPlaylist(8, [8, 9, 10, 11]) + "#EXT-X-ENDLIST\n"
+ self.getPlaylist(0, [0, 1], ads=True),
+ self.getPlaylist(2, [2, 3]) + "#EXT-X-ENDLIST\n"
]
- streamlink, result, mocked = self.get_result(streams, playlists, disable_ads=True)
+ streamlink, result, mocked = self.get_result(streams, playlists, disable_ads=False)
- expected = b''.join(streams[0:4])
- self.assertEqual(expected, result)
- for i in range(0, 12):
- self.assertTrue(mocked[self.url_segment.format(i)].called, i)
- mock_logging.info.assert_has_calls([
- call("Will skip ad segments"),
- call("Will skip ads beginning with segment 4")
- ])
-
- @patch("streamlink.plugins.twitch.log")
- def test_hls_scte35_in_between(self, mock_logging):
- streams = ["[{0}]".format(i).encode("ascii") for i in range(20)]
- playlists = [
- self.getPlaylist(0, [0, 1, 2, 3]),
- self.getPlaylist(4, [4, 5, self.scte35_out, 6, 7]),
- self.getPlaylist(8, [8, 9, 10, 11]),
- self.getPlaylist(12, [12, 13, self.scte35_in, 14, 15]),
- self.getPlaylist(16, [16, 17, 18, 19]) + "#EXT-X-ENDLIST\n"
- ]
- streamlink, result, mocked = self.get_result(streams, playlists, disable_ads=True)
-
- expected = b''.join(streams[0:6]) + b''.join(streams[14:20])
- self.assertEqual(expected, result)
- for i in range(0, 20):
- self.assertTrue(mocked[self.url_segment.format(i)].called, i)
- mock_logging.info.assert_has_calls([
- call("Will skip ad segments"),
- call("Will skip ads beginning with segment 6"),
- call("Will stop skipping ads beginning with segment 14")
- ])
-
- @patch("streamlink.plugins.twitch.log")
- def test_hls_scte35_no_disable_ads(self, mock_logging):
- streams = ["[{0}]".format(i).encode("ascii") for i in range(20)]
- playlists = [
- self.getPlaylist(0, [0, 1, 2, 3]),
- self.getPlaylist(4, [4, 5, self.scte35_out, 6, 7]),
- self.getPlaylist(8, [8, 9, 10, 11]),
- self.getPlaylist(12, [12, 13, self.scte35_in, 14, 15]),
- self.getPlaylist(16, [16, 17, 18, 19]) + "#EXT-X-ENDLIST\n"
- ]
- streamlink, result, mocked = self.get_result(streams, playlists)
-
- expected = b''.join(streams[0:20])
- self.assertEqual(expected, result)
- for i in range(0, 20):
+ self.assertEqual(result, b''.join(streams[0:4]))
+ for i in range(0, 4):
self.assertTrue(mocked[self.url_segment.format(i)].called, i)
mock_logging.info.assert_has_calls([])
@@ -215,8 +147,8 @@ def test_hls_scte35_no_disable_ads(self, mock_logging):
def test_hls_prefetch(self, mock_logging):
streams = ["[{0}]".format(i).encode("ascii") for i in range(10)]
playlists = [
- self.getPlaylist(0, [0, 1, 2, 3], [4, 5]),
- self.getPlaylist(4, [4, 5, 6, 7], [8, 9]) + "#EXT-X-ENDLIST\n"
+ self.getPlaylist(0, [0, 1, 2, 3], prefetch=[4, 5]),
+ self.getPlaylist(4, [4, 5, 6, 7], prefetch=[8, 9]) + "#EXT-X-ENDLIST\n"
]
streamlink, result, mocked = self.get_result(streams, playlists, low_latency=True)
@@ -237,8 +169,8 @@ def test_hls_prefetch(self, mock_logging):
def test_hls_prefetch_no_low_latency(self, mock_logging):
streams = ["[{0}]".format(i).encode("ascii") for i in range(10)]
playlists = [
- self.getPlaylist(0, [0, 1, 2, 3], [4, 5]),
- self.getPlaylist(4, [4, 5, 6, 7], [8, 9]) + "#EXT-X-ENDLIST\n"
+ self.getPlaylist(0, [0, 1, 2, 3], prefetch=[4, 5]),
+ self.getPlaylist(4, [4, 5, 6, 7], prefetch=[8, 9]) + "#EXT-X-ENDLIST\n"
]
streamlink, result, mocked = self.get_result(streams, playlists)
@@ -253,28 +185,12 @@ def test_hls_prefetch_no_low_latency(self, mock_logging):
self.assertFalse(mocked[self.url_segment.format(i)].called, i)
mock_logging.info.assert_has_calls([])
- @patch("streamlink.plugins.twitch.log")
- def test_hls_no_low_latency_with_disable_ads(self, mock_logging):
- streams = ["[{0}]".format(i).encode("ascii") for i in range(10)]
- playlists = [
- self.getPlaylist(0, [0, 1, 2, 3], [4, 5]),
- self.getPlaylist(4, [4, 5, 6, 7], [8, 9]) + "#EXT-X-ENDLIST\n"
- ]
- streamlink, result, mocked = self.get_result(streams, playlists, low_latency=True, disable_ads=True)
-
- self.assertFalse(streamlink.get_plugin_option("twitch", "low-latency"))
- self.assertTrue(streamlink.get_plugin_option("twitch", "disable-ads"))
-
- mock_logging.info.assert_has_calls([
- call("Low latency streaming with ad filtering is currently not supported")
- ])
-
@patch("streamlink.plugins.twitch.log")
def test_hls_no_low_latency_no_prefetch(self, mock_logging):
streams = ["[{0}]".format(i).encode("ascii") for i in range(10)]
playlists = [
- self.getPlaylist(0, [0, 1, 2, 3], []),
- self.getPlaylist(4, [4, 5, 6, 7], []) + "#EXT-X-ENDLIST\n"
+ self.getPlaylist(0, [0, 1, 2, 3], prefetch=[]),
+ self.getPlaylist(4, [4, 5, 6, 7], prefetch=[]) + "#EXT-X-ENDLIST\n"
]
streamlink, result, mocked = self.get_result(streams, playlists, low_latency=True)
| Twitch streams showing Commercial Break In Progress video
- [x] This is a bug report and I have read the contribution guidelines.
### Description
When launching a Twitch stream you're shown a Commercial Break video before the actual stream starts playing. This behavior started tonight.
### Expected / Actual behavior
The commercial video is expected to be ignored.
### Reproduction steps / Explicit stream URLs to test
Launch a Twitch stream.
### Log output
```
C:\Users\User>streamlink https://www.twitch.tv/esl_csgo best --loglevel debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.3.1
[cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin twitch for URL https://www.twitch.tv/esl_csgo
[plugin.twitch][debug] Getting live HLS streams for esl_csgo
[utils.l10n][debug] Language code: sv_SE
[cli][info] Available streams: audio_only, 160p (worst), 360p, 480p, 720p, 720p60, 1080p60 (best)
[cli][info] Opening stream: 1080p60 (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] First Sequence: 0; Last Sequence: 2
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 0; End Sequence: None
[stream.hls][debug] Adding segment 0 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 1 to queue
[stream.hls][debug] Adding segment 2 to queue
[stream.hls][debug] Download of segment 0 complete
[cli][info] Starting player: "C:\Program Files\VideoLAN\VLC\vlc.exe"
[cli.output][debug] Opening subprocess: "C:\Program Files\VideoLAN\VLC\vlc.exe" --input-title-format https://www.twitch.tv/esl_csgo -
[stream.hls][debug] Download of segment 1 complete
[stream.hls][debug] Download of segment 2 complete
[cli][debug] Writing stream to output
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 3 to queue
[stream.hls][debug] Download of segment 3 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 4 to queue
[stream.hls][debug] Adding segment 5 to queue
[stream.hls][debug] Adding segment 6 to queue
[stream.hls][debug] Download of segment 4 complete
[stream.hls][debug] Download of segment 5 complete
[stream.hls][debug] Download of segment 6 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 7 to queue
[stream.hls][debug] Adding segment 8 to queue
[stream.hls][debug] Download of segment 7 complete
[stream.hls][debug] Download of segment 8 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 9 to queue
[stream.hls][debug] Adding segment 10 to queue
[stream.hls][debug] Adding segment 11 to queue
[stream.hls][debug] Download of segment 9 complete
[stream.hls][debug] Download of segment 10 complete
[stream.hls][debug] Download of segment 11 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 12 to queue
[stream.hls][debug] Adding segment 13 to queue
[stream.hls][debug] Download of segment 12 complete
[stream.hls][debug] Download of segment 13 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 14 to queue
[stream.hls][debug] Adding segment 15 to queue
[stream.hls][debug] Adding segment 16 to queue
[stream.hls][debug] Download of segment 14 complete
[stream.hls][debug] Download of segment 15 complete
[stream.hls][debug] Download of segment 16 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 17 to queue
[stream.hls][debug] Adding segment 18 to queue
[stream.hls][debug] Download of segment 17 complete
[stream.hls][debug] Download of segment 18 complete
[cli][info] Player closed
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[cli][info] Closing currently open stream...
```
[Screenshot](https://i.imgur.com/BbljzTw.png)
| I'm experiencing this and also finding that once the stream loads, the audio is slightly pitched up?
Looks like Twitch has implemented a new embedded ads system again.
In #2372, we've added an HLS segment filter that could detect ad segments between certain HLS tags, so these ads could be ignored in the output stream. These tags however don't seem to exist anymore in the HLS playlist.
**Example HLS playlist**
```
$ curl -s $(streamlink --stream-url twitch.tv/CHANNEL_WITH_PREROLL_ADS best)
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:5
#EXT-X-MEDIA-SEQUENCE:0
#EXT-X-TWITCH-ELAPSED-SECS:12435.691
#EXT-X-TWITCH-TOTAL-SECS:12441.697
#EXT-X-START:TIME-OFFSET=0.000
#EXT-X-DATERANGE:ID="stitched-ad-1586899127-30197999985",CLASS="twitch-stitched-ad",START-DATE="2020-04-14T21:18:47.355Z",DURATION=30.198,X-TV-TWITCH-AD-AD-FORMAT="standard_video_ad",X-TV-TWITCH-AD-LINE-ITEM-ID="1985958650101",X-TV-TWITCH-AD-ORDER-ID="6733488350001",X-TV-TWITCH-AD-ADVERIFICATIONS="eyJ4bWxuczp4c2kiOiJodHRwOi8vd3d3LnczLm9yZy8yMDAxL1hNTFNjaGVtYS1pbnN0YW5jZSIsIlZlcmlmaWNhdGlvbiI6W3sidmVuZG9yIjoibW9hdC5jb20tb21zZGt0d2l0Y2hob3N0ZWRhbWF6b252aWRlbzk2MzM3MTgzODUyOCIsIkphdmFTY3JpcHRSZXNvdXJjZSI6W3siYXBpRnJhbWV3b3JrIjoib21pZCIsImJyb3dzZXJPcHRpb25hbCI6dHJ1ZSwiVVJJIjoiaHR0cHM6Ly96Lm1vYXRhZHMuY29tL29tc2RrdHdpdGNoaG9zdGVkYW1hem9udmlkZW85NjMzNzE4Mzg1MjgvbW9hdHZpZGVvLmpzIn1dLCJWZXJpZmljYXRpb25QYXJhbWV0ZXJzIjoie1wibW9hdENsaWVudExldmVsMVwiOlwiQWR2ZXJ0aXNlcklkXCIsXCJtb2F0Q2xpZW50TGV2ZWwyXCI6XCJPcmRlcklkXCIsXCJtb2F0Q2xpZW50TGV2ZWwzXCI6XCIxOTg1OTU4NjUwMTAxXCIsXCJtb2F0Q2xpZW50TGV2ZWw0XCI6XCI5MzY2MzYwMzczNzJcIn0ifV19",X-TV-TWITCH-AD-POD-LENGTH="1",X-TV-TWITCH-AD-POD-POSITION="0",X-TV-TWITCH-AD-URL="https://example.com",X-TV-TWITCH-AD-ADVERTISER-ID="5122870240601",X-TV-TWITCH-AD-CREATIVE-ID="936636037372",X-TV-TWITCH-AD-ROLL-TYPE="PREROLL",X-TV-TWITCH-AD-LOUDNESS="-52.25",X-TV-TWITCH-AD-CLICK-TRACKING-URL="https://example.com"
#EXT-X-DATERANGE:ID="source-1586899127",CLASS="twitch-stream-source",START-DATE="2020-04-14T21:18:47.355Z",END-ON-NEXT=YES,X-TV-TWITCH-STREAM-SOURCE="Amazon|936636037372"
#EXT-X-DATERANGE:ID="trigger-1586899127",CLASS="twitch-trigger",START-DATE="2020-04-14T21:18:47.355Z",END-ON-NEXT=YES,X-TV-TWITCH-TRIGGER-URL="https://video-weaver.fra06.hls.ttvnw.net/trigger/CoYDN_6IqMMq3EzZ_PnQOxmwPJCAEYO9hUiLdQxb3ry4B_I2ysyYMy3w3YU8vtxg_fvglNcFeiIClmisA-wvu-NocKe8qvVgHsE_wK8-LPA9GXgT2JTC7K8igFFcG7LhIujhNJRMIvIlzLreUFycDTMWwXKKkaDTKvAroAQOnkmzuG2NU5WIElokIoffAvYnt2PP5HJnY-u3hbykV3m6OKyoWm3tv7Xkjperl6VF2SnLZr3luTGw5SRT0eGEhh9xN-37JfLDBgkH7UPVKKtu0d-mnEMew4w5pmOeXdkHxpj5XdZ6ieg1sjV4SYAVpVLM3cl8ak_TcMKtK-Vs-OokBynS3Det9xcOwNfpuHCbcDy9uJTVQ2q2pBgMNvpxCgq-_NqbzAqeIGi8IsWQ9tWMEEaMUisFvqLDtMCLsKVo4KRGpnvFUDYCW6gPe-T78KQc5DjZu6KQ1sg7ibookcusaaVcucUjYmnfyiz1HOo1Ttydx2Lbc9YXn5l6xlYp2ar8-mIdCCmxxGqSEhCBwq1uaVKAx4YDjwt8z8pXGgw2d4n8IFNtbwqPNl4"
#EXT-X-DATERANGE:ID="quartile-1586899127-0",CLASS="twitch-ad-quartile",START-DATE="2020-04-14T21:18:47.355Z",DURATION=2.002,X-TV-TWITCH-AD-QUARTILE="0"
#EXT-X-DISCONTINUITY
#EXT-X-PROGRAM-DATE-TIME:2020-04-14T21:18:47.355Z
#EXTINF:2.002,Amazon|936636037372
https://video-edge-c2ac3c.fra02.abs.hls.ttvnw.net/v1/segment/CsYE2BpUXchZlaHgViGrudxI2Hk4jZ8Ocd7V73x0DJkF6RNF6oIHCbwXaNpft8-UwsZhxFsSHssiThTsi7zSTIxxCyfN2SWYw4WTYVkw9QpYWMXDhH8ikn6hGlIq3nV_UId-L1m9t4KYpA3-qIdCOCD21Mo_XAISGrzUR6oxnU9esS_87pzD-5mBg-_zTqkqEX35Xd81h7OpCUAXE1jmOqaoSkFod4ukLSsOuRDEEVl54dp6igosdgHLehx_L_7b_6jXBWCR7w3YxLn5cAxgFl8wp4aQFcPtiJjtXY-8s-cKAH3CjIbs7JOMsdtHdU24hUp87MdreJ2OEVlzP-yicyP5AgrtJX-KNEmHw-5SoMpvfObwIARJO4bSs91aCZLNgE_aLM-z_LBlypU2um7SGgjCpbzlP37rhy51wSXkCZFGa8_udLjR_YIEKoRYOOtH2QPxfYgPfYwC1DUafBWnaHS34LYAoYsDjQm7y2Zs0FIlTdJb1mgIfbNMYixQagMnh0xGRyJhFkvU-YhSMsN2OrAOytJ0bty_dARDYXePtZXOnTsh-pbGKtnWbSHJ1v8Xgl7YujW3-6dn2QXd5ZbTWKhhh5n0e81FHqeVNDzNuJAIjPKX4SSggMc9fCnoYE82AM4aKJ1miPfJfp7tDa54oSIy9B1lGwQOBUpiAHV1Ts3ZGpXrIBssyYl0ML85vf9zdwb0z874XGIhr9XVXzpWYJVSKOKVaHsmosxxQ7zncUCxLOKIz3_KQBTIzjAWxOnVUT5fh-7U0D-QEhDPebV1GnPnGRdgtXP66QL2Ggyl9-qKt5naNADMvzI.ts
#EXT-X-PROGRAM-DATE-TIME:2020-04-14T21:18:49.356Z
#EXTINF:2.002,Amazon|936636037372
https://video-edge-c2ac3c.fra02.abs.hls.ttvnw.net/v1/segment/CrsDKfGgfAI3X3UdcNvtkqtXIrkZc8jyEiYTmy8VIsFEabq1fqncpfr5L4ETPREoASsONtCK4N7mVM8rIjMQkE06oelq7G2AuOBwmRWn8jniZJf8y1g1kxfTIsE4oYDWi_3-4NxCE9QMmGXLhyqIfZoXmHoqA_hg3ndBohDXF17KauJaQJmugyDuMDyXvNV_NpTsjzACG93oJ3L0DAeT251hNHxD6ljVIe80UvZviV3_6NKqV89fAznDjYLoFTGQJML9MdVxtEVc3uEh4qVwU7-GjuhLL0Rpnu_Sb0a8lNAEysc9N_DaheYv7jz9sOKAS9exIBW3AAIJbfnqT1NxAv7J-Omw-1ZrbO3xqMLYWSDNXsu_rALdR839OVlgChe-CHJljZIaKHuKOLNEKKCCKVgrxAHRuMAsl3jCFPX107dkAdY4kpCBmcydZ4QaP7_cydpENlrFCzuzoNIgtsohQjXRwQIkavZh5WyTfToCwfoOlZqC2cyxQjWtSWw4HB7350hnB3tBL3XJYfKykvHuShuz1jJTJ2nXjK-bR5IO5VsEIvTqh8oKakuI71L6KDIp1Zz5PH4jHmwY1gtzcegSEE_Xvg6i3IuooX6qEsGVoZYaDIZipqY8rYGeWdQslA.ts
#EXT-X-PROGRAM-DATE-TIME:2020-04-14T21:18:51.358Z
#EXTINF:2.002,Amazon|936636037372
https://video-edge-c2ac3c.fra02.abs.hls.ttvnw.net/v1/segment/CrsDgCt3TVmLthbAPpSmkD6uMWeq-T33VEmFJjfxsnS_Au7ZsYbSOyFzxulBYER80OxzCuqs2DXCH7fPExu4Q4yQYLdS_BJjNJFzm7MS3aVV2twwLd8IJTK2q5JseQ1_Z7r5_68hOdh3C0twR22AM9WiySzZyvRHc1Dc_A6VmgDUUR4JF8dF-v_0cUnBo8LaFLc55r2X41xODYt6qIst9LuQEjB69Ey8IeUSBYhYhzztaUKT00x9YffNFUEb3AQuL5Yc2tySq6Px4ZgJUACDlsgRk7cOW3o-hUFyRXfY40W-SnDOAsYW8LbcF_fxHQxr834M0rdNA7Ojzf4udhTDrhCzDoS1H_wDGjZbmTlnW0NNWyD-LGQIHhDpdwoIVnmwOv91R9qayJT2PCGA3aacOKu2zULUAh4UVD81maewSsi_Cs-28UekG2pYxXQz7pgU89vp6FANnXU9qGa7nYN8KBZ2db-kvjFyI4lMIjofDUUml1eZkylprtdpx21UuM9ePgd4PZKpaAnNoI1T7g0BhUZnzxdhKR1d4DHeUdVPp4wOfEAj3KiM0gN7xdMqVIGW78B0NB3my1IFuj9QryYSEBEnZkzyqjGwl9FK8yM5bHcaDOFe3NE2T_KDw4g8sw.ts
```
The "Commerical Break In Progress" video-loop segments are all annotated like this:
`#EXTINF:2.002,Amazon|936636037372`
> the audio is slightly pitched up?
I noticed this as well.
> the audio is slightly pitched up
Which player are you using? VLC? VLC doesn't handle stream discontinuities well. Use a different player if you're using VLC.
Got it! Works fine in MPC.
>
>
> > the audio is slightly pitched up
>
> Which player are you using? VLC? VLC doesn't handle stream discontinuities well. Use a different player if you're using VLC.
I have the same issue with MPC-HC
Also it's lagging for me and i don't think it's my connection. I think the entire video is slightly speed up so it's catching up and then needs time to buffer.
It's happening on all players for me, can't watch any twitch stream as all show "Commercial Break In Progress".
@dCosminn Use MPV. There also can't be any buffering issues, because this new ad system is completely transparent to Streamlink and it's continuing regularly when the real stream data is made available by Twitch. There is a stream discontinuity though, so it's possible that your player is buffering because of the invalid timestamps.
@FractalHippy This has nothing to do with the player you're using, Twitch is simply serving this video data instead of the real stream content. There is nothing that can be done on the client side, just like watching regular TV. All that can be done is ignoring these HLS segments in the stream output or finding a way of making Twitch serve the actual stream data, which is unlikely, as they are in control with the stream access tokens needed for getting the stream data.
What surprises me though is that the Twitch website is showing HLS playlists with normal data. Unfortunately, I don't see anything special in the request data.
Same thing happening here, too. Here's what I'm running:
```
streamlink --twitch-oauth-token <TOKEN> --twitch-disable-ads twitch.tv/parnstarzilean audio_only
```
I even tried and logged in with an account and purchased Turbo for it which supposedly won't show ads, which didn't work either.
What's also weird is, that it also shows ads in `audio_only` streams. 🙄
I figured out how to fix the pitch issue with the audio once the stream loads from the ad break in VLC. You need to disable the audio track under the audio menu and then enable it again. For whatever reason the audio issue only happens on some streams but the ad part happens on all of them.
@dCosminn You can use vlc with the HLS passtrough option. This seems to work fine.
way to go twitch. prime, turbo, and subscriptions still get ads...
Please **don't** post "+1", "same", "me too" or other unrelated stuff. It's **not** useful and just spams the thread.
----
@4dams Authentication is **not** supported anymore since Streamlink's `1.3.0` release and using the parameters doesn't have any effect anymore, as you can read here:
https://github.com/streamlink/streamlink/issues/2680#issuecomment-557605851
Also #2846
----
I'm currently working on a patch that blocks the "Commerical Break In Progress" segments. It's already working but not yet finished. Problem is that it delays the stream launch until the real stream is available, which can take up to half a minute. Should fix any player issues caused by the stream discontinuity though.
> @dCosminn You can use vlc with the HLS passtrough option. This seems to work fine.
FYI Letting VLC handle the stream using `--player-passthrough hls` resolves both the ~~"lagging"/"buffering"~~ stream discontinuity and the audio pitching for me. Everything working as before after an initial 30 seconds or so of "Commercial Break in Progress"
@bastimeyer Thanks a lot for your fast help and for working on this project at this hour! :)
> @4dams Authentication is **not** supported anymore since Streamlink's `1.3.0` release and using the parameters doesn't have any effect anymore, as you can read here:
> [#2680 (comment)](https://github.com/streamlink/streamlink/issues/2680#issuecomment-557605851)
> Also #2846
I just scrolled through the docs and found these options, I thought they were still working.
As for your patch: Is there any way to work around the delay and get to the main video directly? I'm sorry if that's too much to ask yet, I'm not very familiar with all this. 😟
Thanks again!
| 2020-04-14T23:16:25 |
streamlink/streamlink | 2,907 | streamlink__streamlink-2907 | [
"2901"
] | 90c94f8643586af5e9462a71b37fd5225e9e1207 | diff --git a/src/streamlink/plugins/eurocom.py b/src/streamlink/plugins/eurocom.py
deleted file mode 100644
--- a/src/streamlink/plugins/eurocom.py
+++ /dev/null
@@ -1,24 +0,0 @@
-from __future__ import print_function
-import re
-
-from streamlink.plugin import Plugin
-from streamlink.stream import RTMPStream
-
-
-class Eurocom(Plugin):
- url_re = re.compile(r"https?://(?:www\.)?eurocom.bg/live/?")
- file_re = re.compile(r"file:.*?(?P<q>['\"])(?P<url>rtmp://[^\"']+)(?P=q),")
-
- @classmethod
- def can_handle_url(cls, url):
- return cls.url_re.match(url) is not None
-
- def _get_streams(self):
- res = self.session.http.get(self.url)
- m = self.file_re.search(res.text)
- if m:
- stream_url = m.group("url")
- yield "live", RTMPStream(self.session, params={"rtmp": stream_url})
-
-
-__plugin__ = Eurocom
| diff --git a/tests/plugins/test_eurocom.py b/tests/plugins/test_eurocom.py
deleted file mode 100644
--- a/tests/plugins/test_eurocom.py
+++ /dev/null
@@ -1,16 +0,0 @@
-import unittest
-
-from streamlink.plugins.eurocom import Eurocom
-
-
-class TestPluginEurocom(unittest.TestCase):
- def test_can_handle_url(self):
- # should match
- self.assertTrue(Eurocom.can_handle_url("http://eurocom.bg/live"))
- self.assertTrue(Eurocom.can_handle_url("http://eurocom.bg/live/"))
- self.assertTrue(Eurocom.can_handle_url("http://www.eurocom.bg/live/"))
- self.assertTrue(Eurocom.can_handle_url("http://www.eurocom.bg/live"))
-
- # shouldn't match
- self.assertFalse(Eurocom.can_handle_url("http://www.tvcatchup.com/"))
- self.assertFalse(Eurocom.can_handle_url("http://www.youtube.com/"))
| [removal] Eurocom plugin no longer required
## Bug Report
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report and I have read the contribution guidelines.
### Description
When opening the main link, nothing happens.
### Reproduction steps / Explicit stream URLs to test
https://eurocom.bg/live
| They are using a static HLS address now instead of a rtmp stream, which means the plugin can/should be removed now:
```
$ streamlink -l debug https://eurocom.bg/hls/stream.m3u8
[cli][debug] OS: Linux-5.6.0-1-git-x86_64-with-glibc2.2.5
[cli][debug] Python: 3.8.2
[cli][debug] Streamlink: 1.3.1+113.g1b287a6
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.56.0)
[cli][info] Found matching plugin hls for URL https://eurocom.bg/hls/stream.m3u8
[plugin.hls][debug] URL=https://eurocom.bg/hls/stream.m3u8; params={}
[utils.l10n][debug] Language code: en_US
Available streams: live (worst, best)
```
Didn't notice they'd done that, I agree that the plugin is no longer required. | 2020-04-17T09:15:47 |
streamlink/streamlink | 2,911 | streamlink__streamlink-2911 | [
"2904"
] | ed210721fc6eb73d9480ad91194e61d7e85ddda2 | diff --git a/src/streamlink/plugins/tv1channel.py b/src/streamlink/plugins/tv1channel.py
deleted file mode 100644
--- a/src/streamlink/plugins/tv1channel.py
+++ /dev/null
@@ -1,32 +0,0 @@
-import re
-
-from streamlink.plugin import Plugin
-from streamlink.plugin.api import useragents
-from streamlink.plugin.api.utils import itertags
-from streamlink.stream import HLSStream
-
-
-class TV1Channel(Plugin):
- _url_re = re.compile(r'https?://(?:www\.)?tv1channel\.org/(?!play/)(?:index\.php/livetv)?')
-
- @classmethod
- def can_handle_url(cls, url):
- return cls._url_re.match(url) is not None
-
- def _get_streams(self):
- self.session.http.headers.update({'User-Agent': useragents.FIREFOX})
- res = self.session.http.get(self.url)
- for iframe in itertags(res.text, 'iframe'):
- if 'cdn.netbadgers.com' not in iframe.attributes.get('src'):
- continue
-
- res = self.session.http.get(iframe.attributes.get('src'))
- for source in itertags(res.text, 'source'):
- if source.attributes.get('src') and source.attributes.get('src').endswith('.m3u8'):
- return HLSStream.parse_variant_playlist(self.session,
- source.attributes.get('src'))
-
- break
-
-
-__plugin__ = TV1Channel
| diff --git a/tests/plugins/test_tv1channel.py b/tests/plugins/test_tv1channel.py
deleted file mode 100644
--- a/tests/plugins/test_tv1channel.py
+++ /dev/null
@@ -1,15 +0,0 @@
-import unittest
-
-from streamlink.plugins.tv1channel import TV1Channel
-
-
-class TestPluginTV1Channel(unittest.TestCase):
- def test_can_handle_url(self):
- # should match
- self.assertTrue(TV1Channel.can_handle_url("http://tv1channel.org/"))
- self.assertTrue(TV1Channel.can_handle_url("http://tv1channel.org/index.php/livetv"))
-
- # shouldn't match
- self.assertFalse(TV1Channel.can_handle_url("https://local.local"))
- self.assertFalse(TV1Channel.can_handle_url("http://www.tv1channel.org/play/video.php?id=325"))
- self.assertFalse(TV1Channel.can_handle_url("http://www.tv1channel.org/play/video.php?id=340"))
| [bug] Tv1channel plugin no longer works
## Bug Report
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report and I have read the contribution guidelines.
### Reproduction steps / Explicit stream URLs to test
http://tv1channel.org/index.php/livetv fails to open. Stream seems to have moved away to a m3u8 link - either a quick fix or just remove the plugin as it is covered by one of the main plugins.
| This looks like it's a static HLS address, but I'm not sure because of the numbers:
```
$ streamlink -l debug 'https://tv1.cdn.netbadgers.com/bg060/bg061/bg061.m3u8'
[cli][debug] OS: Linux-5.6.0-1-git-x86_64-with-glibc2.2.5
[cli][debug] Python: 3.8.2
[cli][debug] Streamlink: 1.3.1+113.g1b287a6
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.56.0)
[cli][info] Found matching plugin hls for URL https://tv1.cdn.netbadgers.com/bg060/bg061/bg061.m3u8
[plugin.hls][debug] URL=https://tv1.cdn.netbadgers.com/bg060/bg061/bg061.m3u8; params={}
[utils.l10n][debug] Language code: en_US
Available streams: 576p (worst, best)
```
The site you're linking is just embedding an iframe with this URL:
`https://tv1.cdn.netbadgers.com/`
The plugin was apparently built for that, but the content of the embedded site must have changed.
I am a bit dubious about the numbers too, but I'm guessing that's just the 61st livestream they host? Maybe I can check back in X days and if the link is still the same - the plugin can be removed?
@bastimeyer The links should be permanent. I managed to find another hosted channel, so I think this means the Tv1Channel plugin is no longer required.
Example: https://eurofolk.cdn.netbadgers.com/bg040/bg041/bg041.m3u8 | 2020-04-17T09:41:24 |
streamlink/streamlink | 2,912 | streamlink__streamlink-2912 | [
"2902"
] | 6773c3fb9c41f3793aab78e40e10eb1b1d19546e | diff --git a/src/streamlink/plugins/cdnbg.py b/src/streamlink/plugins/cdnbg.py
--- a/src/streamlink/plugins/cdnbg.py
+++ b/src/streamlink/plugins/cdnbg.py
@@ -15,16 +15,15 @@ class CDNBG(Plugin):
url_re = re.compile(r"""
https?://(?:www\.)?(?:
tv\.bnt\.bg/\w+(?:/\w+)?|
- bitelevision\.com/live|
nova\.bg/live|
- kanal3\.bg/live|
bgonair\.bg/tvonline|
- inlife\.bg|
mmtvmusic\.com/live|
mu-vi\.tv/LiveStreams/pages/Live\.aspx|
- videochanel\.bstv\.bg|
live\.bstv\.bg|
- bloombergtv.bg/video
+ bloombergtv.bg/video|
+ armymedia.bg|
+ chernomore.bg|
+ i.cdn.bg/live/
)/?
""", re.VERBOSE)
iframe_re = re.compile(r"iframe .*?src=\"((?:https?(?::|:))?//(?:\w+\.)?cdn.bg/live[^\"]+)\"", re.DOTALL)
@@ -44,23 +43,26 @@ class CDNBG(Plugin):
def can_handle_url(cls, url):
return cls.url_re.match(url) is not None
- def find_iframe(self, res):
- p = urlparse(self.url)
- for url in self.iframe_re.findall(res.text):
- if "googletagmanager" not in url:
- url = url.replace(":", ":")
- if url.startswith("//"):
- return "{0}:{1}".format(p.scheme, url)
+ def find_iframe(self, url):
+ self.session.http.headers.update({"User-Agent": useragents.CHROME})
+ res = self.session.http.get(self.url)
+ p = urlparse(url)
+ for iframe_url in self.iframe_re.findall(res.text):
+ if "googletagmanager" not in iframe_url:
+ log.debug("Found iframe: {0}", iframe_url)
+ iframe_url = iframe_url.replace(":", ":")
+ if iframe_url.startswith("//"):
+ return "{0}:{1}".format(p.scheme, iframe_url)
else:
- return url
+ return iframe_url
def _get_streams(self):
- self.session.http.headers.update({"User-Agent": useragents.CHROME})
- res = self.session.http.get(self.url)
- iframe_url = self.find_iframe(res)
+ if "i.cdn.bg/live/" in self.url:
+ iframe_url = self.url
+ else:
+ iframe_url = self.find_iframe(self.url)
if iframe_url:
- log.debug("Found iframe: {0}", iframe_url)
res = self.session.http.get(iframe_url, headers={"Referer": self.url})
stream_url = update_scheme(self.url, self.stream_schema.validate(res.text))
log.warning("SSL Verification disabled.")
| diff --git a/tests/plugins/test_cdnbg.py b/tests/plugins/test_cdnbg.py
--- a/tests/plugins/test_cdnbg.py
+++ b/tests/plugins/test_cdnbg.py
@@ -1,32 +1,40 @@
-import unittest
+import pytest
from streamlink.plugins.cdnbg import CDNBG
+valid_urls = [
+ ("http://bgonair.bg/tvonline",),
+ ("http://bgonair.bg/tvonline/",),
+ ("http://www.nova.bg/live",),
+ ("http://nova.bg/live",),
+ ("http://tv.bnt.bg/bnt1",),
+ ("http://tv.bnt.bg/bnt2",),
+ ("http://tv.bnt.bg/bnt3",),
+ ("http://tv.bnt.bg/bnt4",),
+ ("https://mmtvmusic.com/live/",),
+ ("http://mu-vi.tv/LiveStreams/pages/Live.aspx",),
+ ("http://live.bstv.bg/",),
+ ("https://www.bloombergtv.bg/video",),
+ ("https://i.cdn.bg/live/xfr3453g0d",)
-class TestPluginCDNBG(unittest.TestCase):
- def test_can_handle_url(self):
- # should match
- self.assertTrue(CDNBG.can_handle_url("http://bgonair.bg/tvonline"))
- self.assertTrue(CDNBG.can_handle_url("http://bgonair.bg/tvonline/"))
- self.assertTrue(CDNBG.can_handle_url("http://bitelevision.com/live"))
- self.assertTrue(CDNBG.can_handle_url("http://www.kanal3.bg/live"))
- self.assertTrue(CDNBG.can_handle_url("http://www.nova.bg/live"))
- self.assertTrue(CDNBG.can_handle_url("http://nova.bg/live"))
- self.assertTrue(CDNBG.can_handle_url("http://tv.bnt.bg/bntworld/"))
- self.assertTrue(CDNBG.can_handle_url("http://tv.bnt.bg/bnt1/hd/"))
- self.assertTrue(CDNBG.can_handle_url("http://tv.bnt.bg/bnt1/hd"))
- self.assertTrue(CDNBG.can_handle_url("http://tv.bnt.bg/bnt1/16x9/"))
- self.assertTrue(CDNBG.can_handle_url("http://tv.bnt.bg/bnt1/16x9"))
- self.assertTrue(CDNBG.can_handle_url("http://tv.bnt.bg/bnt2/16x9/"))
- self.assertTrue(CDNBG.can_handle_url("http://tv.bnt.bg/bnt2/16x9"))
- self.assertTrue(CDNBG.can_handle_url("http://inlife.bg/"))
- self.assertTrue(CDNBG.can_handle_url("https://mmtvmusic.com/live/"))
- self.assertTrue(CDNBG.can_handle_url("http://mu-vi.tv/LiveStreams/pages/Live.aspx"))
- self.assertTrue(CDNBG.can_handle_url("http://videochanel.bstv.bg/"))
- self.assertTrue(CDNBG.can_handle_url("http://live.bstv.bg/"))
- self.assertTrue(CDNBG.can_handle_url("https://www.bloombergtv.bg/video"))
+]
+invalid_urls = [
+ ("http://www.tvcatchup.com/",),
+ ("http://www.youtube.com/",),
+ ("https://www.tvevropa.com",),
+ ("http://www.kanal3.bg/live",),
+ ("http://inlife.bg/",),
+ ("http://videochanel.bstv.bg",),
+ ("http://video.bstv.bg/",),
+ ("http://bitelevision.com/live",)
+]
- # shouldn't match
- self.assertFalse(CDNBG.can_handle_url("http://www.tvcatchup.com/"))
- self.assertFalse(CDNBG.can_handle_url("http://www.youtube.com/"))
- self.assertFalse(CDNBG.can_handle_url("https://www.tvevropa.com"))
+
[email protected](["url"], valid_urls)
+def test_can_handle_url(url):
+ assert CDNBG.can_handle_url(url), "url should be handled"
+
+
[email protected](["url"], invalid_urls)
+def test_can_handle_url_negative(url):
+ assert not CDNBG.can_handle_url(url), "url should not be handled"
| [bug] CDNBG - multiple issues
## Bug Report
1. BITelevision should be removed from the plugin and/or wiki/info pages, as it no longer exists.
2. Inlife.bg shouldn't be listed as supported under CDNbg.
3. Tvbulgare.bg should be listed as supported in inlife.bg's place (latter shares the former's stream)
4. Mu-vi.tv gives an error.
5. CDNBG should cover VTK - the national military channel
6. Kanal3's livestream is not found.
7. CDNBG should cover Cherno More - the regional channel for Varna, Bulgaria.
### Reproduction steps / Explicit stream URLs to test
1. https://bitelevision.com/ is not a thing anymore.
2. Inlife.bg can't be opened and shouldn't be listed - it is a 'media partner' that restreams https://tvbulgare.bg/, which could be put in as a replacement for it.
3. https://tvbulgare.bg/ - No playable streams found.
4. http://mu-vi.tv/LiveStreams/pages/Live.aspx - Error: Unable to open URL.
5. https://www.armymedia.bg/
6. https://kanal3.bg/live
7. https://www.chernomore.bg/
| > gives an error
post a debug log for each of them, as the **plugin issue** template asks you to do
@bastimeyer My bad, here are the logs:
1. https://hastebin.com/oleticofab.md
2. https://hastebin.com/oxosufawad.md
3. https://hastebin.com/piwugiroto.md
4. https://hastebin.com/hotisuqoxu.md
5. https://hastebin.com/inikusovuq.md
6. https://hastebin.com/duwibiyapi.md
7. https://hastebin.com/equyidaloq.md
Edit: Added 6 & 7.
Inlife.bg, tvbulgare.bg and kanal3 are on cdn.netbadgers.com now, so I assume they have a static URL like the other channels in those other issues :)
I cannot get http://mu-vi.tv/LiveStreams/pages/Live.aspx to work in my browser, does it work for you? | 2020-04-17T10:11:07 |
streamlink/streamlink | 2,934 | streamlink__streamlink-2934 | [
"2933"
] | 28a52148513f35893bb43f4529c668ecf995b36b | diff --git a/src/streamlink/plugins/itvplayer.py b/src/streamlink/plugins/itvplayer.py
deleted file mode 100644
--- a/src/streamlink/plugins/itvplayer.py
+++ /dev/null
@@ -1,101 +0,0 @@
-import json
-import logging
-import re
-
-from streamlink.compat import urljoin
-from streamlink.plugin import Plugin
-from streamlink.plugin.api import useragents, validate
-from streamlink.plugin.api.utils import itertags
-from streamlink.stream import HLSStream, RTMPStream
-
-log = logging.getLogger(__name__)
-
-
-class ITVPlayer(Plugin):
- _url_re = re.compile(r"https?://(?:www\.)?itv\.com/hub/(?P<stream>.+)")
- swf_url = "https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf"
- _video_info_schema = validate.Schema({
- "StatusCode": 200,
- "AdditionalInfo": {
- "Message": validate.any(None, validate.text)
- },
- "Playlist": {
- "VideoType": validate.text,
- "Video": {
- "Subtitles": validate.any(None, [{
- "Href": validate.url(),
- }]),
- "Base": validate.url(),
- "MediaFiles": [
- {"Href": validate.text,
- "KeyServiceUrl": validate.any(None, validate.url())}
- ]
- }
- }
- })
-
- @classmethod
- def can_handle_url(cls, url):
- return cls._url_re.match(url) is not None
-
- @property
- def device_info(self):
- return {"user": {},
- "device": {"manufacturer": "Chrome", "model": "66",
- "os": {"name": "Windows", "version": "10", "type": "desktop"}},
- "client": {"version": "4.1", "id": "browser"},
- "variantAvailability": {"featureset": {"min": ["hls", "aes"],
- "max": ["hls", "aes"]},
- "platformTag": "dotcom"}}
-
- def video_info(self):
- page = self.session.http.get(self.url)
- for div in itertags(page.text, 'div'):
- if div.attributes.get("id") == "video":
- return div.attributes
-
- def _get_html5_streams(self, video_info_url):
- video_info = self.video_info()
- res = self.session.http.post(video_info_url,
- data=json.dumps(self.device_info),
- headers={"hmac": video_info.get("data-video-hmac")})
- data = self.session.http.json(res, schema=self._video_info_schema)
-
- log.debug("Video ID info response: {0}".format(data))
-
- stype = data['Playlist']['VideoType']
-
- for media in data['Playlist']['Video']['MediaFiles']:
- url = urljoin(data['Playlist']['Video']['Base'], media['Href'])
- name_fmt = "{pixels}_{bitrate}" if stype == "CATCHUP" else None
- for s in HLSStream.parse_variant_playlist(self.session, url, name_fmt=name_fmt).items():
- yield s
-
- def _get_rtmp_streams(self, video_info_url):
- log.debug("XML data path: {0}".format(video_info_url))
- res = self.session.http.get(video_info_url)
- playlist = self.session.http.xml(res, ignore_ns=True)
- mediafiles = playlist.find(".//Playlist/VideoEntries/Video/MediaFiles")
- playpath = mediafiles.find("./MediaFile/URL")
- return {"live": RTMPStream(self.session, {"rtmp": mediafiles.attrib.get("base"),
- "playpath": playpath.text,
- "live": True,
- "swfVfy": self.swf_url
- })}
-
- def _get_streams(self):
- """
- Find all the streams for the ITV url
- :return: Mapping of quality to stream
- """
- self.session.http.headers.update({"User-Agent": useragents.FIREFOX})
- stream = self._url_re.match(self.url).group("stream")
- video_info = self.video_info()
- video_info_url = video_info.get("data-video-id" if stream.lower() in ("itv", "itv4") else "data-html5-playlist")
- if video_info_url.endswith(".xml"):
- return self._get_rtmp_streams(video_info_url)
- else:
- return self._get_html5_streams(video_info_url)
-
-
-__plugin__ = ITVPlayer
| diff --git a/tests/plugins/test_itvplayer.py b/tests/plugins/test_itvplayer.py
deleted file mode 100644
--- a/tests/plugins/test_itvplayer.py
+++ /dev/null
@@ -1,20 +0,0 @@
-import unittest
-
-from streamlink.plugins.itvplayer import ITVPlayer
-
-
-class TestPluginITVPlayer(unittest.TestCase):
- def test_can_handle_url(self):
- should_match = [
- 'https://www.itv.com/hub/itv',
- 'https://www.itv.com/hub/itv2',
- ]
- for url in should_match:
- self.assertTrue(ITVPlayer.can_handle_url(url))
-
- def test_can_handle_url_negative(self):
- should_not_match = [
- 'https://example.com/index.html',
- ]
- for url in should_not_match:
- self.assertFalse(ITVPlayer.can_handle_url(url))
| itv player fails
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- When using itv player to stream I get the error Error while executing subprocess -->
When using itv player to stream I get the error Error while executing subprocess also error not found
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. .../usr/local/bin/streamlink https://www.itv.com/hub/itv worst --player-external-http --player-external-http-port 23599 -l debug
2. .../usr/local/bin/streamlink https://www.itv.com/hub/itv2 worst --player-external-http --player-external-http-port 23599 -l debug
3. ...
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
/usr/local/bin/streamlink https://www.itv.com/hub/itv worst --player-external-http --player-external-http-port 23599 -l debug
[cli][info] streamlink is running as root! Be careful!
[cli][debug] OS: Linux-4.15.0-50-generic-x86_64-with-Ubuntu-18.04-bionic
[cli][debug] Python: 2.7.17
[cli][debug] Streamlink: 1.3.1
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin itvplayer for URL https://www.itv.com/hub/itv
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Available streams: live (worst, best)
[cli][info] Starting server, access with one of:
[cli][info] http://127.0.0.1:23599/
[cli][info] http://185.247.117.123:23599/
[cli][info] Got HTTP request from VLC/3.0.8 LibVLC/3.0.8
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
[plugin.itvplayer][debug] XML data path: https://mediaplayer.itv.com/flash/playlists/ukonly/itv1.xml
[cli][info] Opening stream: live (rtmp)
[stream.streamprocess][debug] Spawning command: /usr/bin/rtmpdump --flv - --live --playpath itv1static@45475 --rtmp rtmpe://cp532701.live.edgefcs.net/live --swfVfy https://mediaplayer.itv.com/2.19.5%2Bbuild.a23aa62b1e/ITVMediaPlayer.swf
[cli][error] Could not open stream: Error while executing subprocess, error output logged to: /dev/null
^CInterrupted! Exiting...
```
LOG2
/usr/local/bin/streamlink https://www.itv.com/hub/itv2 worst --player-external-http --player-external-http-port 23599 -l debug
[cli][info] streamlink is running as root! Be careful!
[cli][debug] OS: Linux-4.15.0-50-generic-x86_64-with-Ubuntu-18.04-bionic
[cli][debug] Python: 2.7.17
[cli][debug] Streamlink: 1.3.1
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin itvplayer for URL https://www.itv.com/hub/itv2
[plugin.itvplayer][debug] Video ID info response: {'AdditionalInfo': {'Message': None}, 'Playlist': {'VideoType': u'SIMULCAST', 'Video': {'Base': u'https://dotcom-itv2-hls.akamaized.net/hls/live/', 'MediaFiles': [{'Href': u'626380/itvlive/itv2/master.m3u8?hdnea=st=1587839941~exp=1587861541~acl=/*~data=nohubplus~hmac=af7ac8d7952154581bf47d17286d7feb2b3e5d0b42f5e66731a69159e6676473', 'KeyServiceUrl': None}], 'Subtitles': None}}, 'StatusCode': 200}
[utils.l10n][debug] Language code: en_US
[cli][info] Available streams: 615k (worst), 660k, 818k, 880k, 1222k, 1320k, 1526k, 1650k, 1830k, 1980k (best)
[cli][info] Starting server, access with one of:
[cli][info] http://127.0.0.1:23599/
[cli][info] http://185.247.117.123:23599/
[cli][info] Got HTTP request from VLC/3.0.8 LibVLC/3.0.8
[cli][info] Opening stream: 615k (hls)
[stream.hls][debug] Reloading playlist
[cli][error] Could not open stream: Unable to open URL: https://dotcom-itv2-hls.akamaized.net/hls/live/626380/itvlive/itv2/master_Main600.m3u8 (404 Client Error: Not Found for url: https://dotcom-itv2-hls.akamaized.net/hls/live/626380/itvlive/itv2/master_Main600.m3u8)
[plugin.itvplayer][debug] Video ID info response: {'AdditionalInfo': {'Message': None}, 'Playlist': {'VideoType': u'SIMULCAST', 'Video': {'Base': u'https://dotcom-itv2-hls.akamaized.net/hls/live/', 'MediaFiles': [{'Href': u'626380/itvlive/itv2/master.m3u8?hdnea=st=1587839973~exp=1587861573~acl=/*~data=nohubplus~hmac=e537ef1486198e2ff2dba0f0cc85cd35d45577339975ef433418121d8493b02d', 'KeyServiceUrl': None}], 'Subtitles': None}}, 'StatusCode': 200}
[utils.l10n][debug] Language code: en_US
[cli][info] Opening stream: 615k (hls)
[stream.hls][debug] Reloading playlist
[cli][error] Could not open stream: Unable to open URL: https://dotcom-itv2-hls.akamaized.net/hls/live/626380/itvlive/itv2/master_Main600.m3u8 (404 Client Error: Not Found for url: https://dotcom-itv2-hls.akamaized.net/hls/live/626380/itvlive/itv2/master_Main600.m3u8)
[plugin.itvplayer][debug] Video ID info response: {'AdditionalInfo': {'Message': None}, 'Playlist': {'VideoType': u'SIMULCAST', 'Video': {'Base': u'https://dotcom-itv2-hls.akamaized.net/hls/live/', 'MediaFiles': [{'Href': u'626380/itvlive/itv2/master.m3u8?hdnea=st=1587839976~exp=1587861576~acl=/*~data=nohubplus~hmac=cebdac4a123cd01c330c1546575c92814b6b4326770ce2ddb0926fbef604be54', 'KeyServiceUrl': None}], 'Subtitles': None}}, 'StatusCode': 200}
[utils.l10n][debug] Language code: en_US
[cli][info] Opening stream: 615k (hls)
[stream.hls][debug] Reloading playlist
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Unfortunately, the ITV player plugin has been broken for some time now, due to their implementation of DRM on the streams. See:
https://github.com/streamlink/streamlink/issues/2718
https://github.com/streamlink/streamlink/issues/2727
Yep as mkbloke noted they added DRM and we don't circumvent DRM so I'm going to close this one out, we should probably remove the plugin from the next release. | 2020-04-25T20:34:30 |
streamlink/streamlink | 2,958 | streamlink__streamlink-2958 | [
"2751"
] | 3f24fde73086499d1def628033927316a8207a6a | diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -306,9 +306,10 @@ def call(self, path, format="json", schema=None, private=False, **extra_params):
def call_subdomain(self, subdomain, path, format="json", schema=None, **extra_params):
subdomain_buffer = self.subdomain
self.subdomain = subdomain
- response = self.call(path, format=format, schema=schema, **extra_params)
- self.subdomain = subdomain_buffer
- return response
+ try:
+ return self.call(path, format=format, schema=schema, **extra_params)
+ finally:
+ self.subdomain = subdomain_buffer
# Public API calls
| Twitch --retry-streams stop working after internet connection loss and recovery
<!--
Thanks for reporting a bug!
USE THE TEMPLATE. Otherwise your bug report may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed bug reports:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Bug Report
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report and I have read the contribution guidelines.
### Description
<!-- Explain the bug as thoroughly as you can. Don't leave out information which is necessary for us to reproduce and debug this issue. -->
Using the command: ` streamlink -o file --twitch-disable-hosting --retry-streams 5 --loglevel debug twitch.tv/example best` while the streamer is offline, then losing internet connection and reestablishing it, leaves streamlink unable to record the stream when the streamer comes online later on, even though log messages say it's attempting to get live HLS streams.
Forcing close and running command again is necessary.
### Expected / Actual behavior
<!-- What do you expect to happen, and what is actually happening? -->
Expected streamlinks to recognize that the stream went online and start recording, OR close the process despite the "--retry-streams" flag due client internet loss.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. Make sure the twitch streamer to be tested is offline
2. Run ` streamlink -o file --twitch-disable-hosting --retry-streams 5 --loglevel debug twitch.tv/mizkif best`
3. Cut internet connection
4. Wait until timeout error
5. Reestablish internet connection
6. When streamer comes online, streamlink is unable to detect the stream despite log messages attempting to get HLS stream
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a bug report!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
PS C:\1> streamlink -o file --twitch-disable-hosting --retry-streams 5 --loglevel debug twitch.tv/mizkif best
[cli][debug] OS: Windows 7
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.3.0
[cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.56.0)
[cli][info] Found matching plugin twitch for URL twitch.tv/mizkif
[cli][debug] Plugin specific arguments:
[cli][debug] --twitch-disable-hosting=True (disable_hosting)
[plugin.twitch][debug] Getting live HLS streams for mizkif
[plugin.twitch][info] mizkif is hosting erobb221
[plugin.twitch][info] hosting was disabled by command line option
[utils.l10n][debug] Language code: pt_BR
[cli][info] Waiting for streams, retrying every 5.0 second(s)
[plugin.twitch][debug] Getting live HLS streams for mizkif
[cli][error] Unable to open URL: https://tmi.twitch.tv/hosts (HTTPSConnectionPool(host='tmi.twitch.tv', port=443): Read
timed out. (read timeout=20.0))
[plugin.twitch][debug] Getting live HLS streams for mizkif
[cli][error] Unable to open URL: https://tmi.twitch.tv/hosts (HTTPSConnectionPool(host='tmi.twitch.tv', port=443): Max r
etries exceeded with url: /hosts?as3=t&include_logins=1&host=94753024 (Caused by NewConnectionError('<urllib3.connection
.VerifiedHTTPSConnection object at 0x045904F0>: Failed to establish a new connection: [Errno 11004] getaddrinfo failed',
)))
[plugin.twitch][debug] Getting live HLS streams for mizkif
[cli][error] Unable to open URL: https://tmi.twitch.tv/hosts (HTTPSConnectionPool(host='tmi.twitch.tv', port=443): Max r
etries exceeded with url: /hosts?as3=t&include_logins=1&host=94753024 (Caused by NewConnectionError('<urllib3.connection
.VerifiedHTTPSConnection object at 0x04590290>: Failed to establish a new connection: [Errno 11004] getaddrinfo failed',
)))
[plugin.twitch][debug] Getting live HLS streams for mizkif
[plugin.twitch][info] mizkif is hosting erobb221
[plugin.twitch][info] hosting was disabled by command line option
[plugin.twitch][debug] Getting live HLS streams for mizkif
[plugin.twitch][info] mizkif is hosting erobb221
```
### Additional comments, screenshots, etc.
Changing/using a VPN also causes the same issue.
Issue doesn't seem to be channel dependent.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Still same problem on 1.4.1.
```
PS D:\twitch> streamlink -o stream.mp4 --retry-streams 10 --loglevel debug twitch.tv/test115 best
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.4.1
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin twitch for URL twitch.tv/test115
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
[cli][info] Waiting for streams, retrying every 10.0 second(s)
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
[plugin.twitch][debug] Getting live HLS streams for test115
[cli][error] Unable to open URL: https://tmi.twitch.tv/hosts (('Connection aborted.', ConnectionResetError(10054, 'An existing connection was forcibly closed by the remote host', None, 10054, None)))
[plugin.twitch][debug] Getting live HLS streams for test115
[cli][error] Unable to open URL: https://tmi.twitch.tv/hosts (HTTPSConnectionPool(host='tmi.twitch.tv', port=443): Max retries exceeded with url: /hosts?as3=t&include_logins=1&host=94753024 (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x0509CCB0>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed',)))
[plugin.twitch][debug] Getting live HLS streams for test115
[cli][error] Unable to open URL: https://tmi.twitch.tv/hosts (HTTPSConnectionPool(host='tmi.twitch.tv', port=443): Max retries exceeded with url: /hosts?as3=t&include_logins=1&host=94753024 (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x0509C7B0>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed',)))
[plugin.twitch][debug] Getting live HLS streams for test115
[plugin.twitch][debug] Getting live HLS streams for test115
[plugin.twitch][debug] Getting live HLS streams for test115
[plugin.twitch][debug] Getting live HLS streams for test115
```
As TS said, even if the user goes online, a "Getting live HLS streams" will always be shown in streamlink.
Only one difference that I see after reestablishing the connection there is no "[utils.l10n][debug] Language code: en_US" line anymore.
After "Unable to open URL: https://usher.ttvnw.net" streamlink is still able to check, but after some twitch problems streamlink stops working properly.
```
streamlink -o stream.mp4 --retry-streams 1 --loglevel debug twitch.tv/test115 best
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.4.1
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin twitch for URL twitch.tv/test115
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
[cli][info] Waiting for streams, retrying every 1.0 second(s)
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
..... many many same lines
[plugin.twitch][debug] Getting live HLS streams for test115
[cli][error] Unable to open URL: https://usher.ttvnw.net/api/channel/hls/test115.m3u8?player=twitchweb&p=483392&type=any&allow_source=true&allow_audio_only=true&allow_spectre=false&sig=bf787c6a0f739501dacfb68c6384e34b0b37b732&token=%7B%22adblock%22%3Afalse%2C%22authorization%22%3A%7B%22forbidden%22%3Afalse%2C%22reason%22%3A%22%22%7D%2C%22blackout_enabled%22%3Afalse%2C%22channel%22%3A%22test115%22%2C%22channel_id%22%3A195166073%2C%22chansub%22%3A%7B%22restricted_bitrates%22%3A%5B%5D%2C%22view_until%22%3A1924905600%7D%2C%22ci_gb%22%3Afalse%2C%22geoblock_reason%22%3A%22%22%2C%22device_id%22%3Anull%2C%22expires%22%3A1588956923%2C%22extended_history_allowed%22%3Afalse%2C%22game%22%3A%22Just+Chatting%22%2C%22hide_ads%22%3Afalse%2C%22https_required%22%3Afalse%2C%22mature%22%3Afalse%2C%22partner%22%3Afalse%2C%22platform%22%3Anull%2C%22player_type%22%3Anull%2C%22private%22%3A%7B%22allowed_to_view%22%3Atrue%7D%2C%22privileged%22%3Afalse%2C%22server_ads%22%3Atrue%2C%22show_ads%22%3Atrue%2C%22subscriber%22%3Afalse%2C%22turbo%22%3Afalse%2C%22user_id%22%3Anull%2C%22user_ip%22%3A%2278.85.41.135%22%2C%22version%22%3A2%7D&fast_bread=True (('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',)))
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
[plugin.twitch][debug] Getting live HLS streams for test115
[utils.l10n][debug] Language code: en_US
[plugin.twitch][debug] Getting live HLS streams for test115
[cli][error] Unable to open URL: https://tmi.twitch.tv/hosts (HTTPSConnectionPool(host='tmi.twitch.tv', port=443): Read timed out. (read timeout=20.0))
[plugin.twitch][debug] Getting live HLS streams for test115
[cli][error] Unable to open URL: https://tmi.twitch.tv/api/channels/test115/access_token.json (HTTPSConnectionPool(host='tmi.twitch.tv', port=443): Read timed out. (read timeout=20.0))
[plugin.twitch][debug] Getting live HLS streams for test115
[plugin.twitch][debug] Getting live HLS streams for test115
[plugin.twitch][debug] Getting live HLS streams for test115
```
It even drops RAM usage after error appears.

I fixed it for myself. I just added ```break``` in ```except PluginError as err:``` in streamlink_cli\main.py
```
while not streams:
sleep(interval)
try:
streams = fetch_streams(plugin)
except FatalPluginError:
raise
except PluginError as err:
log.error(u"{0}".format(err))
break
if count > 0:
attempts += 1
if attempts >= count:
break
return streams
```
I do not know if this is the correct solution to the problem. But since my streamlink starts in a loop, this solves my problem.
According to my tests, the streamlink stops working only when an error occurs when accessing https://tmi.twitch.tv/. I will test more, but for now I made this:
```
while not streams:
sleep(interval)
try:
streams = fetch_streams(plugin)
except FatalPluginError:
raise
except PluginError as err:
log.error(u"{0}".format(err))
if str(err).find("https://tmi.twitch.tv/") != -1:
break
if count > 0:
attempts += 1
if attempts >= count:
break
return streams
```
I added ```log.debug("{0}".format(str(err)))``` in streamlink\plugins\twitch.py in ```def _access_token``` and there is what I got:
```
[13:28:18,9][cli][debug] OS: Windows 10
[13:28:18,9][cli][debug] Python: 3.6.6
[13:28:18,9][cli][debug] Streamlink: 1.4.1 (retry test)
[13:28:18,9][cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[13:28:18,9][cli][info] Found matching plugin twitch for URL twitch.tv/test115
[13:28:18,9][plugin.twitch][debug] Getting live HLS streams for test115
[13:28:20,41][utils.l10n][debug] Language code: en_US
[13:28:20,546][cli][info] Waiting for streams, retrying every 1.0 second(s)
[13:28:21,547][plugin.twitch][debug] Getting live HLS streams for test115
[13:28:22,22][utils.l10n][debug] Language code: en_US
//INTERNET OFF
[13:28:23,235][plugin.twitch][debug] Getting live HLS streams for test115
[13:28:23,712][utils.l10n][debug] Language code: en_US
[13:28:23,801][cli][error] Unable to open URL: https://usher.ttvnw.net/api/channel/hls/test115.m3u8?player=twitchweb&p=101642&type=any&allow_source=true&allow_audio_only=true&allow_spectre=false&sig=17f6467757b6983024228bcf87603476337c60e0&token=%7B%22adblock%22%3Afalse%2C%22authorization%22%3A%7B%22forbidden%22%3Afalse%2C%22reason%22%3A%22%22%7D%2C%22blackout_enabled%22%3Afalse%2C%22channel%22%3A%22test115%22%2C%22channel_id%22%3A69658351%2C%22chansub%22%3A%7B%22restricted_bitrates%22%3A%5B%5D%2C%22view_until%22%3A1924905600%7D%2C%22ci_gb%22%3Afalse%2C%22geoblock_reason%22%3A%22%22%2C%22device_id%22%3Anull%2C%22expires%22%3A1589021290%2C%22extended_history_allowed%22%3Afalse%2C%22game%22%3A%22%22%2C%22hide_ads%22%3Afalse%2C%22https_required%22%3Afalse%2C%22mature%22%3Afalse%2C%22partner%22%3Afalse%2C%22platform%22%3Anull%2C%22player_type%22%3Anull%2C%22private%22%3A%7B%22allowed_to_view%22%3Atrue%7D%2C%22privileged%22%3Afalse%2C%22server_ads%22%3Atrue%2C%22show_ads%22%3Atrue%2C%22subscriber%22%3Afalse%2C%22turbo%22%3Afalse%2C%22user_id%22%3Anull%2C%22user_ip%22%3A%2278.85.41.135%22%2C%22version%22%3A2%7D&fast_bread=True (('Connection aborted.', ConnectionResetError(10054, 'An existing connection was forcibly closed by the remote host', None, 10054, None)))
[13:28:24,802][plugin.twitch][debug] Getting live HLS streams for test115
[13:28:24,808][cli][error] Unable to open URL: https://tmi.twitch.tv/hosts (HTTPSConnectionPool(host='tmi.twitch.tv', port=443): Max retries exceeded with url: /hosts?as3=t&include_logins=1&host=69658351 (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x049094D0>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed',)))
[13:28:25,808][plugin.twitch][debug] Getting live HLS streams for test115
[13:28:25,810][cli][error] Unable to open URL: https://tmi.twitch.tv/hosts (HTTPSConnectionPool(host='tmi.twitch.tv', port=443): Max retries exceeded with url: /hosts?as3=t&include_logins=1&host=69658351 (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x05374B90>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed',)))
//INTERNET ON
[13:28:32,861][plugin.twitch][debug] Getting live HLS streams for test115
[13:28:34,61][plugin.twitch][debug] Unable to open URL: https://tmi.twitch.tv/api/channels/test115/access_token.json (404 Client Error: Not Found for url: https://tmi.twitch.tv/api/channels/test115/access_token.json?as3=t)
[13:28:35,62][plugin.twitch][debug] Getting live HLS streams for test115
[13:28:35,542][plugin.twitch][debug] Unable to open URL: https://tmi.twitch.tv/api/channels/test115/access_token.json (404 Client Error: Not Found for url: https://tmi.twitch.tv/api/channels/test115/access_token.json?as3=t)
```
So, after reconnecting, we get an error:
```
Unable to open URL: https://tmi.twitch.tv/api/channels/test115/access_token.json (404 Client Error: Not Found for url: https://tmi.twitch.tv/api/channels/test115/access_token.json?as3=t)
```
Link must be https://**api**.twitch.tv/api/channels/test115/access_token.json, but link is https://**tmi**.twitch.tv/api/channels/test115/access_token.json.
So, problem in this in twitch.py:

If ```response = self.call(path, format=format, schema=schema, **extra_params)``` returns an error - next line ```self.subdomain = subdomain_buffer``` not execute. | 2020-05-09T12:33:58 |
|
streamlink/streamlink | 2,969 | streamlink__streamlink-2969 | [
"2970"
] | 76880e46589d2765bf030927169debd295958040 | diff --git a/src/streamlink/plugins/app17.py b/src/streamlink/plugins/app17.py
--- a/src/streamlink/plugins/app17.py
+++ b/src/streamlink/plugins/app17.py
@@ -1,35 +1,49 @@
+import logging
import re
from streamlink.plugin import Plugin
-from streamlink.plugin.api import useragents
+from streamlink.plugin.api import useragents, validate
from streamlink.stream import HLSStream, RTMPStream, HTTPStream
-API_URL = "https://api-dsa.17app.co/api/v1/liveStreams/getLiveStreamInfo"
-
-_url_re = re.compile(r"https://17.live/live/(?P<channel>[^/&?]+)")
-_status_re = re.compile(r'\\"closeBy\\":\\"\\"')
-_rtmp_re = re.compile(r'\\"url\\"\s*:\s*\\"(.+?)\\"')
+log = logging.getLogger(__name__)
class App17(Plugin):
+ _url_re = re.compile(r"https://17.live/live/(?P<channel>[^/&?]+)")
+ API_URL = "https://api-dsa.17app.co/api/v1/lives/{0}/viewers/alive"
+
+ _api_schema = validate.Schema(
+ {
+ "rtmpUrls": [{
+ validate.optional("provider"): validate.any(int, None),
+ "url": validate.url(),
+ }],
+ },
+ validate.get("rtmpUrls"),
+ )
+
@classmethod
def can_handle_url(cls, url):
- return _url_re.match(url)
+ return cls._url_re.match(url) is not None
def _get_streams(self):
- match = _url_re.match(self.url)
+ match = self._url_re.match(self.url)
channel = match.group("channel")
self.session.http.headers.update({'User-Agent': useragents.CHROME, 'Referer': self.url})
- payload = '{"liveStreamID": "%s"}' % (channel)
- res = self.session.http.post(API_URL, data=payload)
- status = _status_re.search(res.text)
- if not status:
- self.logger.info("Stream currently unavailable.")
+ data = '{"liveStreamID":"%s"}' % (channel)
+
+ try:
+ res = self.session.http.post(self.API_URL.format(channel), data=data)
+ res_json = self.session.http.json(res, schema=self._api_schema)
+ log.trace("{0!r}".format(res_json))
+ http_url = res_json[0]["url"]
+ except Exception as e:
+ log.info("Stream currently unavailable.")
+ log.debug(str(e))
return
- http_url = _rtmp_re.search(res.text).group(1)
https_url = http_url.replace("http:", "https:")
yield "live", HTTPStream(self.session, https_url)
@@ -47,11 +61,16 @@ def _get_streams(self):
else:
hls_url = http_url.replace("live-hdl", "live-hls").replace(".flv", ".m3u8")
- s = []
- for s in HLSStream.parse_variant_playlist(self.session, hls_url).items():
- yield s
+ s = HLSStream.parse_variant_playlist(self.session, hls_url)
if not s:
yield "live", HLSStream(self.session, hls_url)
+ else:
+ if len(s) == 1:
+ for _n, _s in s.items():
+ yield "live", _s
+ else:
+ for _s in s.items():
+ yield _s
__plugin__ = App17
| Plugin App17 cannot fetch any stream
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
`Stream currently unavailable.`
The output of the Streamlink is always the same. Even if the streamer is streaming online.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
Paste any URL (e.g., `https://17.live/live/{any stream ID}`) and execute the command.
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
C:\>streamlink https://17.live/live/7000362 -l trace
[22:44:25,408][cli][debug] OS: Windows 10
[22:44:25,409][cli][debug] Python: 3.6.6
[22:44:25,410][cli][debug] Streamlink: 1.4.1
[22:44:25,410][cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[22:44:25,410][cli][info] Found matching plugin app17 for URL https://17.live/live/7000362
[22:44:25,735][plugin.app17][info] Stream currently unavailable.
error: No playable streams found on this URL: https://17.live/live/7000362
```
### Additional comments, screenshots, etc.
[screenshot](https://imgur.com/MFn7K0y)
| 2020-05-12T04:17:40 |
||
streamlink/streamlink | 2,991 | streamlink__streamlink-2991 | [
"2984"
] | 13dd7e67450444870bd4c254f0c1c0cf586979c4 | diff --git a/src/streamlink/plugins/ceskatelevize.py b/src/streamlink/plugins/ceskatelevize.py
--- a/src/streamlink/plugins/ceskatelevize.py
+++ b/src/streamlink/plugins/ceskatelevize.py
@@ -13,89 +13,52 @@
"""
import logging
import re
+import json
from streamlink.plugin import Plugin
from streamlink.plugin.api import useragents, validate
-from streamlink.stream import HLSStream
+from streamlink.stream import HLSStream, DASHStream
from streamlink.exceptions import PluginError
-
-_url_re = re.compile(
- r'http(s)?://([^.]*.)?ceskatelevize.cz'
-)
-_player_re = re.compile(
- r'ivysilani/embed/iFramePlayer[^"]+'
-)
-_hash_re = re.compile(
- r'hash:"([0-9a-z]+)"'
-)
-_playlist_info_re = re.compile(
- r'{"type":"([a-z]+)","id":"([0-9]+)"'
-)
-_playlist_url_schema = validate.Schema({
- validate.optional("streamingProtocol"): validate.text,
- "url": validate.any(
- validate.url(),
- "Error",
- "error_region"
- )
-})
-_playlist_schema = validate.Schema({
- "playlist": [{
- validate.optional("type"): validate.text,
- "streamUrls": {
- "main": validate.url(),
- }
- }]
-})
+from streamlink.compat import html_unescape, quote
log = logging.getLogger(__name__)
-def _find_playlist_info(response):
- """
- Finds playlist info (type, id) in HTTP response.
-
- :param response: Response object.
- :returns: Dictionary with type and id.
- """
- values = {}
- matches = _playlist_info_re.search(response.text)
- if matches:
- values['type'] = matches.group(1)
- values['id'] = matches.group(2)
-
- return values
-
-
-def _find_player_url(response):
- """
- Finds embedded player url in HTTP response.
-
- :param response: Response object.
- :returns: Player url (str).
- """
- url = ''
- matches = _player_re.search(response.text)
- if matches:
- tmp_url = matches.group(0).replace('&', '&')
- if 'hash' not in tmp_url:
- # there's no hash in the URL, try to find it
- matches = _hash_re.search(response.text)
- if matches:
- url = tmp_url + '&hash=' + matches.group(1)
- else:
- url = tmp_url
-
- return 'http://ceskatelevize.cz/' + url
-
-
class Ceskatelevize(Plugin):
ajax_url = 'https://www.ceskatelevize.cz/ivysilani/ajax/get-client-playlist'
+ _url_re = re.compile(
+ r'http(s)?://([^.]*.)?ceskatelevize.cz'
+ )
+ _player_re = re.compile(
+ r'ivysilani/embed/iFramePlayer[^"]+'
+ )
+ _hash_re = re.compile(
+ r'hash:"([0-9a-z]+)"'
+ )
+ _playlist_info_re = re.compile(
+ r'{"type":"([a-z]+)","id":"([0-9]+)"'
+ )
+ _playlist_url_schema = validate.Schema({
+ validate.optional("streamingProtocol"): validate.text,
+ "url": validate.any(
+ validate.url(),
+ "Error",
+ "error_region"
+ )
+ })
+ _playlist_schema = validate.Schema({
+ "playlist": [{
+ validate.optional("type"): validate.text,
+ "streamUrls": {
+ "main": validate.url(),
+ }
+ }]
+ })
@classmethod
def can_handle_url(cls, url):
- return _url_re.match(url)
+ return cls._url_re.match(url)
def _get_streams(self):
self.session.http.headers.update({'User-Agent': useragents.IPAD})
@@ -103,19 +66,26 @@ def _get_streams(self):
log.warning('SSL certificate verification is disabled.')
# fetch requested url and find playlist info
response = self.session.http.get(self.url)
- info = _find_playlist_info(response)
+ info = self._find_playlist_info(response)
if not info:
+ # do next try with new API
+ def _fallback_api(*args, **kwargs):
+ self.api2 = CeskatelevizeAPI2(self.session, self.url, *args, **kwargs)
+ return self.api2._get_streams()
+
# playlist info not found, let's try to find player url
- player_url = _find_player_url(response)
+ player_url = self._find_player_url(response)
if not player_url:
- raise PluginError('Cannot find playlist info or player url!')
+ log.debug('Cannot find playlist info or player url, do next try with new API')
+ return _fallback_api(res=response)
# get player url and try to find playlist info in it
response = self.session.http.get(player_url)
- info = _find_playlist_info(response)
+ info = self._find_playlist_info(response)
if not info:
- raise PluginError('Cannot find playlist info in the player url!')
+ log.debug('Cannot find playlist info in the player url, do next try with new API')
+ return _fallback_api()
log.trace('{0!r}'.format(info))
@@ -136,7 +106,7 @@ def _get_streams(self):
data=data,
headers=headers
)
- json_data = self.session.http.json(response, schema=_playlist_url_schema)
+ json_data = self.session.http.json(response, schema=self._playlist_url_schema)
log.trace('{0!r}'.format(json_data))
if json_data['url'] in ['Error', 'error_region']:
@@ -145,10 +115,154 @@ def _get_streams(self):
# fetch playlist
response = self.session.http.post(json_data['url'])
- json_data = self.session.http.json(response, schema=_playlist_schema)
+ json_data = self.session.http.json(response, schema=self._playlist_schema)
log.trace('{0!r}'.format(json_data))
playlist = json_data['playlist'][0]['streamUrls']['main']
return HLSStream.parse_variant_playlist(self.session, playlist)
+ @classmethod
+ def _find_playlist_info(cls, response):
+ """
+ Finds playlist info (type, id) in HTTP response.
+
+ :param response: Response object.
+ :returns: Dictionary with type and id.
+ """
+ values = {}
+ matches = cls._playlist_info_re.search(response.text)
+ if matches:
+ values['type'] = matches.group(1)
+ values['id'] = matches.group(2)
+
+ return values
+
+ @classmethod
+ def _find_player_url(cls, response):
+ """
+ Finds embedded player url in HTTP response.
+
+ :param response: Response object.
+ :returns: Player url (str).
+ """
+ url = ''
+ matches = cls._player_re.search(response.text)
+ if matches:
+ tmp_url = matches.group(0).replace('&', '&')
+ if 'hash' not in tmp_url:
+ # there's no hash in the URL, try to find it
+ matches = cls._hash_re.search(response.text)
+ if matches:
+ url = tmp_url + '&hash=' + matches.group(1)
+ else:
+ url = tmp_url
+
+ return 'http://ceskatelevize.cz/' + url
+
+
+class CeskatelevizeAPI2(object):
+ _player_api = 'https://playlist.ceskatelevize.cz/'
+ _url_re = re.compile(r'http(s)?://([^.]*.)?ceskatelevize.cz')
+ _playlist_info_re = re.compile(r'{\s*"type":\s*"([a-z]+)",\s*"id":\s*"(\w+)"')
+ _playlist_schema = validate.Schema({
+ "CODE": validate.contains("OK"),
+ "RESULT": {
+ "playlist": [{
+ "streamUrls": {
+ "main": validate.url(),
+ }
+ }]
+ }
+ })
+ _ctcomp_re = re.compile(r'data-ctcomp="Video"\sdata-video-id="(?P<val1>[^"]*)"\sdata-ctcomp-data="(?P<val2>[^"]+)">')
+ _ctcomp_schema = validate.Schema(
+ validate.text,
+ validate.transform(_ctcomp_re.findall),
+ validate.transform(lambda vl: [{"video-id": v[0], "ctcomp-data": json.loads(html_unescape(v[1]))} for v in vl])
+ )
+ _playlist_info_schema = validate.Schema({
+ "type": validate.text,
+ "id": validate.any(validate.text, int),
+ "key": validate.text,
+ "date": validate.text,
+ "requestSource": validate.text,
+ "drm": int,
+ validate.optional("canBePlay"): int,
+ validate.optional("assetId"): validate.text,
+ "quality": validate.text,
+ validate.optional("region"): int
+ })
+
+ def __init__(self, session, url, res=None):
+ self.session = session
+ self.url = url
+ self.response = res
+
+ def _get_streams(self):
+ if self.response is None:
+ infos = self.session.http.get(self.url, schema=self._ctcomp_schema)
+ else:
+ infos = self.session.http.json(self.response, schema=self._ctcomp_schema)
+ if not infos:
+ # playlist infos not found
+ raise PluginError('Cannot find playlist infos!')
+
+ vod_prio = len(infos) == 2
+ for info in infos:
+ try:
+ pl = info['ctcomp-data']['source']['playlist'][0]
+ except KeyError:
+ raise PluginError('Cannot find playlist info!')
+
+ pl = self._playlist_info_schema.validate(pl)
+ if vod_prio and pl['type'] != 'VOD':
+ continue
+
+ log.trace('{0!r}'.format(info))
+ if pl['type'] == 'LIVE':
+ data = {
+ "contentType": "live",
+ "items": [{
+ "id": pl["id"],
+ "assetId": pl["assetId"],
+ "key": pl["key"],
+ "playerType": "dash",
+ "date": pl["date"],
+ "requestSource": pl["requestSource"],
+ "drm": pl["drm"],
+ "quality": pl["quality"],
+ }]
+ }
+ elif pl['type'] == 'VOD':
+ data = {
+ "contentType": "vod",
+ "items": [{
+ "id": pl["id"],
+ "key": pl["key"],
+ "playerType": "dash",
+ "date": pl["date"],
+ "requestSource": pl["requestSource"],
+ "drm": pl["drm"],
+ "canBePlay": pl["canBePlay"],
+ "quality": pl["quality"],
+ "region": pl["region"]
+ }]
+ }
+
+ headers = {
+ "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
+ }
+
+ data = json.dumps(data)
+ response = self.session.http.post(
+ self._player_api,
+ data="data={}".format(quote(data)),
+ headers=headers
+ )
+ json_data = self.session.http.json(response, schema=self._playlist_schema)
+ log.trace('{0!r}'.format(json_data))
+ playlist = json_data['RESULT']['playlist'][0]['streamUrls']['main']
+ for s in DASHStream.parse_manifest(self.session, playlist).items():
+ yield s
+
__plugin__ = Ceskatelevize
| CT Sport with ceskatelevize.py doesn't work
<!--
Thanks for reporting a bug!
USE THE TEMPLATE. Otherwise your bug report may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed bug reports:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Bug Report
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report and I have read the contribution guidelines.
CT Sport with ceskatelevize.py doesn't work.
CT1, CT2, CT24, CT Decko and CT Art are okay, but CT Sport see Description Logfiles
<!-- Explain the bug as thoroughly as you can. Don't leave out information which is necessary for us to reproduce and debug this issue. -->
### Expected / Actual behavior
<!-- What do you expect to happen, and what is actually happening? -->
### Reproduction steps / Explicit stream URLs to test
c:\Streamlink\1_3_1\bin\streamlink.exe https://www.ceskatelevize.cz/sport/zive-vysilani/ best -l trace
or
c:\Streamlink\1_3_1\bin\streamlink.exe https://sport.ceskatelevize.cz/#live best -l trace
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. latest Streamlink Version
2. latest ceskatelevize.py but this Version is two years old
3. ...
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a bug report!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
c:\Streamlink\1_3_1\bin\streamlink.exe https://www.ceskatelevize.cz/sport/zive-vysilani/ best -l trace
[09:22:36,953][cli][debug] OS: Windows 10
[09:22:36,954][cli][debug] Python: 3.6.6
[09:22:36,956][cli][debug] Streamlink: 1.3.1
[09:22:36,957][cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.57.0)
[09:22:36,958][cli][info] Found matching plugin ceskatelevize for URL https://www.ceskatelevize.cz/sport/zive-vysilani/
[09:22:36,958][plugin.ceskatelevize][warning] SSL certificate verification is disabled.
error: Cannot find playlist info in the player url!
```
### Additional comments, screenshots, etc.
But that is not correct.
At the CT Sport Homepage Chrome Network Tools finds a mpd Link.
The mpd Link is not a DRM Link
This Links are at CT1, CT2, CT24 ... too
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2020-05-26T09:29:32 |
||
streamlink/streamlink | 3,000 | streamlink__streamlink-3000 | [
"2996"
] | b024d6f521706badb1154d9fa9850bccc2996e57 | diff --git a/src/streamlink/plugins/reshet.py b/src/streamlink/plugins/reshet.py
deleted file mode 100644
--- a/src/streamlink/plugins/reshet.py
+++ /dev/null
@@ -1,33 +0,0 @@
-from __future__ import print_function
-
-import re
-
-from streamlink.plugin import Plugin
-from streamlink.plugins.brightcove import BrightcovePlayer
-
-
-class Reshet(Plugin):
- url_re = re.compile(r"https?://(?:www\.)?reshet\.tv/(live|item/)")
- video_id_re = re.compile(r'"videoID"\s*:\s*"(\d+)"')
- account_id = "1551111274001"
- live_channel_id = "ref:stream_reshet_live1"
-
- @classmethod
- def can_handle_url(cls, url):
- return cls.url_re.match(url) is not None
-
- def _get_streams(self):
- bp = BrightcovePlayer(self.session, self.account_id)
- m = self.url_re.match(self.url)
- base = m and m.group(1)
- if base == "live":
- return bp.get_streams(self.live_channel_id)
- else:
- res = self.session.http.get(self.url)
- m = self.video_id_re.search(res.text)
- video_id = m and m.group(1)
- if video_id:
- return bp.get_streams(video_id)
-
-
-__plugin__ = Reshet
| diff --git a/tests/plugins/test_reshet.py b/tests/plugins/test_reshet.py
deleted file mode 100644
--- a/tests/plugins/test_reshet.py
+++ /dev/null
@@ -1,26 +0,0 @@
-import unittest
-
-from streamlink.plugins.reshet import Reshet
-
-
-class TestPluginReshet(unittest.TestCase):
- def test_can_handle_url(self):
- should_match = [
- "https://www.reshet.tv/live",
- "http://www.reshet.tv/live",
- "http://reshet.tv/live",
- "https://reshet.tv/live",
- "http://reshet.tv/item/foo/bar123",
- "https://reshet.tv/item/foo/bar123",
- "https://www.reshet.tv/item/foo/bar123",
- "http://www.reshet.tv/item/foo/bar123",
- ]
- for url in should_match:
- self.assertTrue(Reshet.can_handle_url(url))
-
- def test_can_handle_url_negative(self):
- should_not_match = [
- "https://www.youtube.com",
- ]
- for url in should_not_match:
- self.assertFalse(Reshet.can_handle_url(url))
| Plugin 'reshet' changed URL
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
Hi,
"reshet.tv" has changed to "13tv.co.il", making the plugin unuseable.
I suspect there are also changes to the API.
| It would appear that there is a static non geo-IP restricted URL:
```http://reshet-live-il.ctedgecdn.net/13tv-desktop/r13.m3u8```
```
$ streamlink hls://https://reshet-live-il.ctedgecdn.net/13tv-desktop/r13.m3u8 360p
[cli][info] Found matching plugin hls for URL hls://https://reshet-live-il.ctedgecdn.net/13tv-desktop/r13.m3u8
[cli][info] Available streams: 360p (worst), 480p_alt, 480p (best)
[cli][info] Opening stream: 360p (hls)
[cli][info] Starting player: mpv
[cli][info] Player closed
[cli][info] Stream ended
[cli][info] Closing currently open stream...
```
| 2020-05-31T04:53:47 |
streamlink/streamlink | 3,007 | streamlink__streamlink-3007 | [
"3001"
] | 90e634ec17cd7b90f062f25f2b620e50285dd9c0 | diff --git a/src/streamlink/plugins/huya.py b/src/streamlink/plugins/huya.py
--- a/src/streamlink/plugins/huya.py
+++ b/src/streamlink/plugins/huya.py
@@ -8,20 +8,14 @@
HUYA_URL = "http://m.huya.com/%s"
-_url_re = re.compile(r'http(s)?://(www\.)?huya.com/(?P<channel>[^/]+)', re.VERBOSE)
-_hls_re = re.compile(r'^\s*<video\s+id="html5player-video"\s+src="(?P<url>[^"]+)"', re.MULTILINE)
+_url_re = re.compile(r'https?://(www\.)?huya.com/(?P<channel>[^/]+)')
+_hls_re = re.compile(r'liveLineUrl\s*=\s*"(?P<url>[^"]+)"')
_hls_schema = validate.Schema(
- validate.all(
- validate.transform(_hls_re.search),
- validate.any(
- None,
- validate.all(
- validate.get('url'),
- validate.transform(str)
- )
- )
- )
+ validate.transform(_hls_re.search),
+ validate.any(None, validate.get("url")),
+ validate.transform(lambda v: update_scheme("http://", v)),
+ validate.url()
)
@@ -38,7 +32,7 @@ def _get_streams(self):
# Some problem with SSL on huya.com now, do not use https
hls_url = self.session.http.get(HUYA_URL % channel, schema=_hls_schema)
- yield "live", HLSStream(self.session, update_scheme("http://", hls_url))
+ yield "live", HLSStream(self.session, hls_url)
__plugin__ = Huya
| huya.com plugin - error message: Unable to open URL: http://b''/
## Plugin Issue
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
Huya.com plugin suddenly stop working and throws always an error like
`Could not open stream: Unable to open URL: http://b''/ `
It seems the URL of the video cannot be extracted correctly.
### Reproduction steps / Explicit stream URLs to test
1. Go to huya.com and get an ID of active stream
2. Start streamlink recording like streamlink -f -o test.mpg https://www.huya.com/503376 best
### Log output
```
streamlink -f -o test.mpg https://www.huya.com/503376 best
[cli][info] Found matching plugin huya for URL https://www.huya.com/503376
[cli][info] Available streams: live (worst, best)
[cli][info] Opening stream: live (hls)
[cli][error] Try 1/1: Could not open stream <HLSStream("http://b''/")> (Could not open stream: Unable to open URL: http://b''/ (HTTPConnectionPool(host="b''", port=80): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7fe6633a4bb0>: Failed to establish a new connection: [Errno -2] Name or service not known'))))
error: Could not open stream <HLSStream("http://b''/")>, tried 1 times, exiting
```
| 2020-06-04T09:28:34 |
||
streamlink/streamlink | 3,013 | streamlink__streamlink-3013 | [
"3006"
] | 90e634ec17cd7b90f062f25f2b620e50285dd9c0 | diff --git a/src/streamlink/plugins/foxtr.py b/src/streamlink/plugins/foxtr.py
--- a/src/streamlink/plugins/foxtr.py
+++ b/src/streamlink/plugins/foxtr.py
@@ -16,7 +16,7 @@ class FoxTR(Plugin):
foxplay.com.tr/.*)
""", re.VERBOSE)
- playervars_re = re.compile(r"source\s*:\s*\[\s*\{\s*videoSrc\s*:\s*'(.*?)'", re.DOTALL)
+ playervars_re = re.compile(r"source\s*:\s*\[\s*\{\s*videoSrc\s*:\s*(?:mobilecheck\(\)\s*\?\s*)?'([^']+)'")
@classmethod
def can_handle_url(cls, url):
| FOX TR not working anymore
Plugin foxtr.py not working since a few days.
Can someone have a look please?
Greetings
| This issue doesn't meet any of the requirements. Provide them like the issue template said to do.
The command line is giving the following error message:
" [cli][info] Found matching plugin foxtr for URL https://www.fox.com.tr/canli-yayin
error: No playable streams found on this URL: https://www.fox.com.tr/canli-yayin " | 2020-06-05T15:31:23 |
|
streamlink/streamlink | 3,016 | streamlink__streamlink-3016 | [
"3015"
] | ad8113bbb6a9fb0006d7a243418dfe5936e5a1a9 | diff --git a/src/streamlink/plugins/bigo.py b/src/streamlink/plugins/bigo.py
--- a/src/streamlink/plugins/bigo.py
+++ b/src/streamlink/plugins/bigo.py
@@ -1,37 +1,37 @@
-import logging
import re
from streamlink.plugin import Plugin
-from streamlink.plugin.api import useragents
+from streamlink.plugin.api import useragents, validate
from streamlink.stream import HLSStream
-log = logging.getLogger(__name__)
-
class Bigo(Plugin):
- _url_re = re.compile(r"^https?://(?:www\.)?bigo\.tv/[^/]+$")
- _video_re = re.compile(
- r"""videoSrc:\s?["'](?P<url>[^"']+)["']""",
- re.M)
+ _url_re = re.compile(r"https?://(?:www\.)?bigo\.tv/([^/]+)$")
+ _api_url = "https://www.bigo.tv/OInterface/getVideoParam?bigoId={0}"
+
+ _video_info_schema = validate.Schema({
+ "code": 0,
+ "msg": "success",
+ "data": {
+ "videoSrc": validate.any(None, "", validate.url())
+ }
+ })
@classmethod
def can_handle_url(cls, url):
return cls._url_re.match(url) is not None
def _get_streams(self):
- page = self.session.http.get(
- self.url,
+ match = self._url_re.match(self.url)
+ res = self.session.http.get(
+ self._api_url.format(match.group(1)),
allow_redirects=True,
headers={"User-Agent": useragents.IPHONE_6}
)
- videomatch = self._video_re.search(page.text)
- if not videomatch:
- log.error("No playlist found.")
- return
-
- videourl = videomatch.group(1)
- log.debug("URL={0}".format(videourl))
- yield "live", HLSStream(self.session, videourl)
+ data = self.session.http.json(res, schema=self._video_info_schema)
+ videourl = data["data"]["videoSrc"]
+ if videourl:
+ yield "live", HLSStream(self.session, videourl)
__plugin__ = Bigo
| diff --git a/tests/plugins/test_bigo.py b/tests/plugins/test_bigo.py
--- a/tests/plugins/test_bigo.py
+++ b/tests/plugins/test_bigo.py
@@ -5,26 +5,33 @@
class TestPluginBigo(unittest.TestCase):
def test_can_handle_url(self):
- # Correct urls
- self.assertTrue(Bigo.can_handle_url("http://bigo.tv/00000000"))
- self.assertTrue(Bigo.can_handle_url("https://bigo.tv/00000000"))
- self.assertTrue(Bigo.can_handle_url("https://www.bigo.tv/00000000"))
- self.assertTrue(Bigo.can_handle_url("http://www.bigo.tv/00000000"))
- self.assertTrue(Bigo.can_handle_url("http://www.bigo.tv/fancy1234"))
- self.assertTrue(Bigo.can_handle_url("http://www.bigo.tv/abc.123"))
- self.assertTrue(Bigo.can_handle_url("http://www.bigo.tv/000000.00"))
+ should_match = [
+ "http://bigo.tv/00000000",
+ "https://bigo.tv/00000000",
+ "https://www.bigo.tv/00000000",
+ "http://www.bigo.tv/00000000",
+ "http://www.bigo.tv/fancy1234",
+ "http://www.bigo.tv/abc.123",
+ "http://www.bigo.tv/000000.00"
+ ]
+ for url in should_match:
+ self.assertTrue(Bigo.can_handle_url(url), url)
- # Old URLs don't work anymore
- self.assertFalse(Bigo.can_handle_url("http://live.bigo.tv/00000000"))
- self.assertFalse(Bigo.can_handle_url("https://live.bigo.tv/00000000"))
- self.assertFalse(Bigo.can_handle_url("http://www.bigoweb.co/show/00000000"))
- self.assertFalse(Bigo.can_handle_url("https://www.bigoweb.co/show/00000000"))
- self.assertFalse(Bigo.can_handle_url("http://bigoweb.co/show/00000000"))
- self.assertFalse(Bigo.can_handle_url("https://bigoweb.co/show/00000000"))
+ def test_can_handle_url_negative(self):
+ should_not_match = [
+ # Old URLs don't work anymore
+ "http://live.bigo.tv/00000000",
+ "https://live.bigo.tv/00000000",
+ "http://www.bigoweb.co/show/00000000",
+ "https://www.bigoweb.co/show/00000000",
+ "http://bigoweb.co/show/00000000",
+ "https://bigoweb.co/show/00000000"
- # Wrong URL structure
- self.assertFalse(Bigo.can_handle_url("ftp://www.bigo.tv/00000000"))
- self.assertFalse(Bigo.can_handle_url("https://www.bigo.tv/show/00000000"))
- self.assertFalse(Bigo.can_handle_url("http://www.bigo.tv/show/00000000"))
- self.assertFalse(Bigo.can_handle_url("http://bigo.tv/show/00000000"))
- self.assertFalse(Bigo.can_handle_url("https://bigo.tv/show/00000000"))
+ # Wrong URL structure
+ "https://www.bigo.tv/show/00000000",
+ "http://www.bigo.tv/show/00000000",
+ "http://bigo.tv/show/00000000",
+ "https://bigo.tv/show/00000000"
+ ]
+ for url in should_not_match:
+ self.assertFalse(Bigo.can_handle_url(url), url)
| Bigo TV cannot successfully get the videoSrc URL
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
I try to use streamlink to watch the bigo live tv, but the command line pops up the error message as "[plugin.bigo][error] No playlist found."
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. streamlink http://www.bigo.tv/11819287 best &
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
[cli][debug] OS: Linux-5.4.0-33-generic-x86_64-with-glibc2.29
[cli][debug] Python: 3.8.2
[cli][debug] Streamlink: 1.4.1
[cli][debug] Requests(2.22.0), Socks(1.6.7), Websocket(0.53.0)
[cli][info] Found matching plugin bigo for URL http://www.bigo.tv/11819287
[plugin.bigo][error] No playlist found.
error: No playable streams found on this URL: http://www.bigo.tv/11819287
```
### Additional comments, screenshots, etc.
After reviewing the bigo.py in streamlink/plugin, I found that the original method attempts to get the videoSrc in the webpage. However, recently the web page excluded the parameter in the page.
So, here is the alternative
1. Add new API URL.
```
api_url = "http://www.bigo.tv/OInterface/getVideoParam?bigoId="
```
2. Extract bigo_id from self.url.
```
extract_id = self.url.split('/')[-1]
```
3. Use composed url to get the videoSrc.
```
page = self.session.http.get(api_url + extract_id, ...)
```
4. Change the videomatch & videourl.
```
videomatch = page.json()['data']['videoSrc']; videourl = videomatch
```
| If you've got a working solution for a plugin issue, then please submit a pull request with the changes, so it can be reviewed by others. | 2020-06-07T14:35:33 |
streamlink/streamlink | 3,019 | streamlink__streamlink-3019 | [
"2899"
] | 5059d64be20b3cd6adc6374e921382ef2c261978 | diff --git a/src/streamlink/plugins/btv.py b/src/streamlink/plugins/btv.py
--- a/src/streamlink/plugins/btv.py
+++ b/src/streamlink/plugins/btv.py
@@ -1,38 +1,30 @@
-from __future__ import print_function
+import argparse
+import logging
import re
-from streamlink import PluginError
-from streamlink.plugin import Plugin
+from streamlink.plugin import Plugin, PluginArguments, PluginArgument
from streamlink.plugin.api import validate
from streamlink.stream import HLSStream
from streamlink.utils import parse_json
-from streamlink.plugin import PluginArgument, PluginArguments
+
+log = logging.getLogger(__name__)
class BTV(Plugin):
arguments = PluginArguments(
PluginArgument(
"username",
- metavar="USERNAME",
- requires=["password"],
- help="""
- A BTV username required to access any stream.
- """
+ help=argparse.SUPPRESS
),
PluginArgument(
"password",
sensitive=True,
- metavar="PASSWORD",
- help="""
- A BTV account password to use with --btv-username.
- """
+ help=argparse.SUPPRESS
)
)
- url_re = re.compile(r"https?://(?:www\.)?btv\.bg/live/?")
- api_url = "http://www.btv.bg/lbin/global/player_config.php"
- check_login_url = "http://www.btv.bg/lbin/userRegistration/check_user_login.php"
- login_url = "https://www.btv.bg/bin/registration2/login.php?action=login&settings=0"
+ url_re = re.compile(r"https?://(?:www\.)?btvplus\.bg/live/?")
+ api_url = "https://btvplus.bg/lbin/v3/btvplus/player_config.php"
media_id_re = re.compile(r"media_id=(\d+)")
src_re = re.compile(r"src: \"(http.*?)\"")
@@ -55,35 +47,19 @@ class BTV(Plugin):
def can_handle_url(cls, url):
return cls.url_re.match(url) is not None
- def login(self, username, password):
- res = self.session.http.post(self.login_url, data={"username": username, "password": password})
- if "success_logged_in" in res.text:
- return True
- else:
- return False
-
def get_hls_url(self, media_id):
res = self.session.http.get(self.api_url, params=dict(media_id=media_id))
- try:
- return parse_json(res.text, schema=self.api_schema)
- except PluginError:
- return
+ return parse_json(res.text, schema=self.api_schema)
def _get_streams(self):
- if not self.options.get("username") or not self.options.get("password"):
- self.logger.error("BTV requires registration, set the username and password"
- " with --btv-username and --btv-password")
- elif self.login(self.options.get("username"), self.options.get("password")):
- res = self.session.http.get(self.url)
- media_match = self.media_id_re.search(res.text)
- media_id = media_match and media_match.group(1)
- if media_id:
- self.logger.debug("Found media id: {0}", media_id)
- stream_url = self.get_hls_url(media_id)
- if stream_url:
- return HLSStream.parse_variant_playlist(self.session, stream_url)
- else:
- self.logger.error("Login failed, a valid username and password is required")
+ res = self.session.http.get(self.url)
+ media_match = self.media_id_re.search(res.text)
+ media_id = media_match and media_match.group(1)
+ if media_id:
+ log.debug("Found media id: {0}", media_id)
+ stream_url = self.get_hls_url(media_id)
+ if stream_url:
+ return HLSStream.parse_variant_playlist(self.session, stream_url)
__plugin__ = BTV
| diff --git a/tests/plugins/test_btv.py b/tests/plugins/test_btv.py
--- a/tests/plugins/test_btv.py
+++ b/tests/plugins/test_btv.py
@@ -6,9 +6,9 @@
class TestPluginBTV(unittest.TestCase):
def test_can_handle_url(self):
# should match
- self.assertTrue(BTV.can_handle_url("http://btv.bg/live"))
- self.assertTrue(BTV.can_handle_url("http://btv.bg/live/"))
- self.assertTrue(BTV.can_handle_url("http://www.btv.bg/live/"))
+ self.assertTrue(BTV.can_handle_url("http://btvplus.bg/live"))
+ self.assertTrue(BTV.can_handle_url("http://btvplus.bg/live/"))
+ self.assertTrue(BTV.can_handle_url("http://www.btvplus.bg/live/"))
# shouldn't match
self.assertFalse(BTV.can_handle_url("http://www.tvcatchup.com/"))
| [bug] BTV plugin needs updating
## Bug Report
- [x] This is a bug report and I have read the contribution guidelines.
### Description
The location of the BTV livestream has moved to https://btvplus.bg/live/
**Edit**: Livestreaming no longer requires a user to login, so that can be removed from the plugin info page.
### Expected / Actual behavior
Streamlink should be able to handle the link.
### Reproduction steps / Explicit stream URLs to test
1. streamlink https://btvplus.bg/live/ best
2. error: No plugin can handle URL: https://btvplus.bg/live/
| 2020-06-09T17:47:45 |
|
streamlink/streamlink | 3,025 | streamlink__streamlink-3025 | [
"3022"
] | bc3951ac444b351ea27ab66b18a28784530700d4 | diff --git a/src/streamlink_cli/main.py b/src/streamlink_cli/main.py
--- a/src/streamlink_cli/main.py
+++ b/src/streamlink_cli/main.py
@@ -957,7 +957,7 @@ def check_version(force=False):
def setup_logging(stream=sys.stdout, level="info"):
- fmt = ("[{asctime},{msecs:0.0f}]" if level == "trace" else "") + "[{name}][{levelname}] {message}"
+ fmt = ("[{asctime},{msecs:03.0f}]" if level == "trace" else "") + "[{name}][{levelname}] {message}"
logger.basicConfig(stream=stream, level=level,
format=fmt, style="{",
datefmt="%H:%M:%S")
| Two timecode-related features request
I would like to request two minor improvmenets related to timecodes.
1) Make milliseconds value at log with loglevel trace to be three-digit at all time. Now this value is being represented with two or one digit when event happend at the start of second. Please, make it to append zeroes, like 20:20:29,003. At latest version same timecode will be shown as 20:20:29,3.
This change will make log file more easily human-readable.
2) Make streamlink to set time-date of file being written to disk based not on time when script was executed, but based on time-date of last segment provided by server. Each writing of new segment to output file should update time-date of output file to match to time-date of this written segment. So, for example, complete and finished downloading of VOD video should create a file with same time-date as last segment of VOD had.
| > At latest version same timecode will be shown as 20:20:29,3.
This change will make log file more easily human-readable.
it is **300** not **003**,
there is not really a big benefit for showing zeros
it is already readable because there are only 3 digits
> Make streamlink to set time-date of file being written to disk based not on time when script was executed, but based on time-date of last segment provided by server. Each writing of new segment to output file should update time-date of output file to match to time-date of this written segment. So, for example, complete and finished downloading of VOD video should create a file with same time-date as last segment of VOD had.
seems totally out of scope for streamlink | 2020-06-13T11:28:10 |
|
streamlink/streamlink | 3,034 | streamlink__streamlink-3034 | [
"2996"
] | bc3951ac444b351ea27ab66b18a28784530700d4 | diff --git a/src/streamlink/plugins/n13tv.py b/src/streamlink/plugins/n13tv.py
new file mode 100644
--- /dev/null
+++ b/src/streamlink/plugins/n13tv.py
@@ -0,0 +1,147 @@
+import logging
+import re
+
+from streamlink.compat import urljoin, urlunparse
+from streamlink.exceptions import PluginError
+from streamlink.plugin import Plugin
+from streamlink.plugin.api import validate
+from streamlink.stream import HLSStream
+
+log = logging.getLogger(__name__)
+
+
+class N13TV(Plugin):
+ url_re = re.compile(r"https?://(?:www\.)?13tv\.co\.il/(live|.*?/)")
+ api_url = "https://13tv-api.oplayer.io/api/getlink/"
+ main_js_url_re = re.compile(r'type="text/javascript" src="(.*?main\..+\.js)"')
+ user_id_re = re.compile(r'"data-ccid":"(.*?)"')
+ video_name_re = re.compile(r'"videoRef":"(.*?)"')
+ server_addr_re = re.compile(r'(.*[^/])(/.*)')
+ media_file_re = re.compile(r'(.*)(\.[^\.].*)')
+
+ live_schema = validate.Schema(validate.all(
+ [{'Link': validate.url()}],
+ validate.get(0),
+ validate.get('Link')
+ ))
+
+ vod_schema = validate.Schema(validate.all([{
+ 'ShowTitle': validate.text,
+ 'ProtocolType': validate.all(
+ validate.text,
+ validate.transform(lambda x: x.replace("://", ""))
+ ),
+ 'ServerAddress': validate.text,
+ 'MediaRoot': validate.text,
+ 'MediaFile': validate.text,
+ 'Bitrates': validate.text,
+ 'StreamingType': validate.text,
+ 'Token': validate.all(
+ validate.text,
+ validate.transform(lambda x: x.lstrip("?"))
+ )
+ }], validate.get(0)))
+
+ @classmethod
+ def can_handle_url(cls, url):
+ return cls.url_re.match(url) is not None
+
+ def _get_live(self, user_id):
+ res = self.session.http.get(
+ self.api_url,
+ params=dict(
+ userId=user_id,
+ serverType="web",
+ ch=1,
+ cdnName="casttime"
+ )
+ )
+
+ url = self.session.http.json(res, schema=self.live_schema)
+ log.debug("URL={0}".format(url))
+
+ return HLSStream.parse_variant_playlist(self.session, url)
+
+ def _get_vod(self, user_id, video_name):
+ res = self.session.http.get(
+ urljoin(self.api_url, "getVideoByFileName"),
+ params=dict(
+ userId=user_id,
+ videoName=video_name,
+ serverType="web",
+ callback="x"
+ )
+ )
+
+ vod_data = self.session.http.json(res, schema=self.vod_schema)
+
+ if video_name == vod_data['ShowTitle']:
+ host, base_path = self.server_addr_re.search(
+ vod_data['ServerAddress']
+ ).groups()
+ if not host or not base_path:
+ raise PluginError("Could not split 'ServerAddress' components")
+
+ base_file, file_ext = self.media_file_re.search(
+ vod_data['MediaFile']
+ ).groups()
+ if not base_file or not file_ext:
+ raise PluginError("Could not split 'MediaFile' components")
+
+ media_path = "{0}{1}{2}{3}{4}{5}".format(
+ base_path,
+ vod_data['MediaRoot'],
+ base_file,
+ vod_data['Bitrates'],
+ file_ext,
+ vod_data['StreamingType']
+ )
+ log.debug("Media path={0}".format(media_path))
+
+ vod_url = urlunparse((
+ vod_data['ProtocolType'],
+ host,
+ media_path,
+ '',
+ vod_data['Token'],
+ ''
+ ))
+ log.debug("URL={0}".format(vod_url))
+
+ return HLSStream.parse_variant_playlist(self.session, vod_url)
+
+ def _get_streams(self):
+ m = self.url_re.match(self.url)
+ url_type = m and m.group(1)
+ log.debug("URL type={0}".format(url_type))
+
+ res = self.session.http.get(self.url)
+
+ if url_type != "live":
+ m = self.video_name_re.search(res.text)
+ video_name = m and m.group(1)
+ if not video_name:
+ raise PluginError('Could not determine video_name')
+ log.debug("Video name={0}".format(video_name))
+
+ m = self.main_js_url_re.search(res.text)
+ main_js_path = m and m.group(1)
+ if not main_js_path:
+ raise PluginError('Could not determine main_js_path')
+ log.debug("Main JS path={0}".format(main_js_path))
+
+ res = self.session.http.get(urljoin(self.url, main_js_path))
+
+ m = self.user_id_re.search(res.text)
+ user_id = m and m.group(1)
+ if not user_id:
+ raise PluginError('Could not determine user_id')
+ log.debug("User ID={0}".format(user_id))
+
+ if url_type == "live":
+ return self._get_live(user_id)
+ else:
+ return self._get_vod(user_id, video_name)
+
+
+__plugin__ = N13TV
| diff --git a/tests/plugins/test_n13tv.py b/tests/plugins/test_n13tv.py
new file mode 100644
--- /dev/null
+++ b/tests/plugins/test_n13tv.py
@@ -0,0 +1,30 @@
+import unittest
+
+from streamlink.plugins.n13tv import N13TV
+
+
+class TestPluginN13TV(unittest.TestCase):
+ def test_can_handle_url(self):
+ should_match = [
+ "http://13tv.co.il/live",
+ "https://13tv.co.il/live",
+ "http://www.13tv.co.il/live/",
+ "https://www.13tv.co.il/live/",
+ "http://13tv.co.il/item/entertainment/ambush/season-02/episodes/ffuk3-2026112/",
+ "https://13tv.co.il/item/entertainment/ambush/season-02/episodes/ffuk3-2026112/",
+ "http://www.13tv.co.il/item/entertainment/ambush/season-02/episodes/ffuk3-2026112/",
+ "https://www.13tv.co.il/item/entertainment/ambush/season-02/episodes/ffuk3-2026112/"
+ "http://13tv.co.il/item/entertainment/tzhok-mehamatzav/season-01/episodes/vkdoc-2023442/",
+ "https://13tv.co.il/item/entertainment/tzhok-mehamatzav/season-01/episodes/vkdoc-2023442/",
+ "http://www.13tv.co.il/item/entertainment/tzhok-mehamatzav/season-01/episodes/vkdoc-2023442/"
+ "https://www.13tv.co.il/item/entertainment/tzhok-mehamatzav/season-01/episodes/vkdoc-2023442/"
+ ]
+ for url in should_match:
+ self.assertTrue(N13TV.can_handle_url(url))
+
+ def test_can_handle_url_negative(self):
+ should_not_match = [
+ "https://www.youtube.com",
+ ]
+ for url in should_not_match:
+ self.assertFalse(N13TV.can_handle_url(url))
| Plugin 'reshet' changed URL
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
Hi,
"reshet.tv" has changed to "13tv.co.il", making the plugin unuseable.
I suspect there are also changes to the API.
| It would appear that there is a static non geo-IP restricted URL:
```http://reshet-live-il.ctedgecdn.net/13tv-desktop/r13.m3u8```
```
$ streamlink hls://https://reshet-live-il.ctedgecdn.net/13tv-desktop/r13.m3u8 360p
[cli][info] Found matching plugin hls for URL hls://https://reshet-live-il.ctedgecdn.net/13tv-desktop/r13.m3u8
[cli][info] Available streams: 360p (worst), 480p_alt, 480p (best)
[cli][info] Opening stream: 360p (hls)
[cli][info] Starting player: mpv
[cli][info] Player closed
[cli][info] Stream ended
[cli][info] Closing currently open stream...
```
Hi, @yegarti
Could you try my replacement plugin at: https://github.com/mkbloke/streamlink/blob/n13tv-plugin/src/streamlink/plugins/n13tv.py
Select 'Raw', then you can save it and copy into your plugins dir to test. If you can test live and VODs and confirm that all appears to be working OK, that would be great, thanks.
Hi, @mkbloke
Tested the plugin on some videos, worked great for VODs and live.
It failed for short clips, the stream start, I see the first frames and then the stream immediately ends.
For example:
```
> streamlink -l debug https://13tv.co.il/item/mood/survivor/season-04-vip/clips/enbrm-2027273/ best
cli][debug] OS: Linux-5.4.40-1-MANJARO-x86_64-with-glibc2.2.5
[cli][debug] Python: 3.8.3
[cli][debug] Streamlink: 1.4.1+16.g90e634e.dirty
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin n13tv for URL https://13tv.co.il/item/mood/survivor/season-04-vip/clips/enbrm-2027273/
[plugin.n13tv][debug] Main JS path = /wp-content/themes/reshet_tv/build/static/js/main.9f10f8c1.js
[plugin.n13tv][debug] User ID = 45E4A9FB-FCE8-88BF-93CC-3650C39DDF28
[plugin.n13tv][debug] Video name = mood-survivor-season-04-vip-clips-11-part-10-next
[plugin.n13tv][debug] Media file = /media/iiscdn/2020/06/02/mood-survivor-season-04-vip-clips-11-part-10-next_,550,850,1400,.mp4
[plugin.n13tv][debug] VOD URL = https://reshet-vod-il.ctedgecdn.net/reshet-vod/_definst_/amlst:mediaroot/nana10/media/iiscdn/2020/06/02/mood-survivor-season-04-vip-clips-11-part-10-next_,550,850,1400,.mp4/playlist.m3u8?ctoken=c13079014b2fde1b073f1f22e74c808d459f87e99c0b1983beb7aafbca355baa&str=1591344586&exp=1591345786
[utils.l10n][debug] Language code: en_IL
[cli][info] Available streams: 550k (worst), 850k, 1400k (best)
[cli][info] Opening stream: 1400k (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] First Sequence: 0; Last Sequence: 5
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 0; End Sequence: 5
[stream.hls][debug] Adding segment 0 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 1 to queue
[stream.hls][debug] Adding segment 2 to queue
[stream.hls][debug] Adding segment 3 to queue
[stream.hls][debug] Adding segment 4 to queue
[stream.hls][debug] Adding segment 5 to queue
[stream.segmented][debug] Closing worker thread
[stream.hls][debug] Download of segment 0 complete
[cli][info] Starting player: /usr/bin/vlc
[cli.output][debug] Opening subprocess: /usr/bin/vlc --input-title-format https://13tv.co.il/item/mood/survivor/season-04-vip/clips/enbrm-2027273/ -
[stream.hls][debug] Download of segment 1 complete
[stream.hls][debug] Download of segment 2 complete
[stream.hls][debug] Download of segment 3 complete
[cli][debug] Writing stream to output
[stream.hls][debug] Download of segment 4 complete
[stream.hls][debug] Download of segment 5 complete
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[cli][info] Closing currently open stream...
```
Beside this small issue (unimportant one?) it's working great, Thank you.
Hi @yegarti,
Many thanks for testing the plugin and for providing the debug output with the clip. I'm seeing the same thing as you. On the website there are segments 0 to 5 also. I seem to be finding that if I if I use the '-O' option and redirect stdout to a file that I get the whole 54 second clip. It seems to me that perhaps the player is closing before the clip is over. If you save to file can you get the whole clip?
Thanks again.
Hi @mkbloke,
Using '-O' does save the whole clip.
Thanks again for your response. I also seem to find that using the '-O' option and then piping into the player on the command line, e.g. '| vlc -' seems to result in the entire clip being played.
I can only conclude that this is an edge-case bug in streamlink, unless I'm missing something else here. Cheers.
@yegarti @mkbloke
> I can only conclude that this is an edge-case bug in streamlink, unless I'm missing something else here.
not a bug, you can use `--player-no-close`
https://streamlink.github.io/cli.html#cmdoption-player-no-close
Ah! Many thanks, @back-to, for the info on that. Would it be worthwhile putting a log.info() into the plugin as a note to users?
> Would it be worthwhile putting a log.info() into the plugin
No.
Streamlink will send a SIGTERM signal to the player process as soon as the end of the stream has been reached. Depending on the player, it won't wait with the process termination until it has finished decoding and rendering the remaining content. Either do what @back-to said and set the `--player-no-close` Streamlink parameter, or tell your player to ignore SIGTERM (and SIGKILL) signals. In case of VLC, it's the `--no-play-and-exit` parameter and in case of MPV, it's the `--keep-open=<yes|always>` parameter.
I think maybe there are just crossed wires here. I was thinking about a ```log.info()``` message recommending usage of ```--player-no-close``` be used on the command line if necessary by the user, but I think what you're suggesting is to use ```self.set_option()``` within the plugin? If that's the case, I had not realised it from back-to's reply.
Messages on how to use Streamlink don't belong into the log output. I'm also not suggesting to set any kind of output options via plugins, as it's up to the user to decide. I was merely explaining what you can do as a user to make the player stay open after Streamlink as finished reading and writing the stream data.
OK, understood now. Thank you. | 2020-06-18T03:28:37 |
streamlink/streamlink | 3,039 | streamlink__streamlink-3039 | [
"3028"
] | bc3951ac444b351ea27ab66b18a28784530700d4 | diff --git a/src/streamlink/plugins/nicolive.py b/src/streamlink/plugins/nicolive.py
--- a/src/streamlink/plugins/nicolive.py
+++ b/src/streamlink/plugins/nicolive.py
@@ -54,6 +54,8 @@ class NicoLive(Plugin):
stream_reader = None
_ws = None
+ frontend_id = None
+
@classmethod
def can_handle_url(cls, url):
return _url_re.match(url) is not None
@@ -118,10 +120,20 @@ def get_wss_api_url(self):
_log.debug(e)
_log.warning("Failed to extract broadcast id")
+ try:
+ self.frontend_id = extract_text(
+ resp.text, ""frontendId":", ","")
+ except Exception as e:
+ _log.debug(e)
+ _log.warning("Failed to extract frontend id")
+
+ self.wss_api_url = "{0}&frontend_id={1}".format(self.wss_api_url, self.frontend_id)
+
_log.debug("Video page response code: {0}".format(resp.status_code))
_log.trace(u"Video page response body: {0}".format(resp.text))
_log.debug("Got wss_api_url: {0}".format(self.wss_api_url))
_log.debug("Got broadcast_id: {0}".format(self.broadcast_id))
+ _log.debug("Got frontend_id: {0}".format(self.frontend_id))
return self.wss_api_url.startswith("wss://")
@@ -172,33 +184,50 @@ def send_message(self, type_, body):
else:
_log.warning("wss api is not connected.")
- def send_playerversion(self):
- body = {
- "command": "playerversion",
- "params": ["leo"]
- }
- self.send_message("watch", body)
+ def send_no_body_message(self, type_):
+ msg = {"type": type_}
+ msg_json = json.dumps(msg)
+ _log.debug(u"Sending: {0}".format(msg_json))
+ if self._ws and self._ws.sock.connected:
+ self._ws.send(msg_json)
+ else:
+ _log.warning("wss api is not connected.")
- def send_getpermit(self, require_new_stream=True):
+ def send_custom_message(self, msg):
+ msg_json = json.dumps(msg)
+ _log.debug(u"Sending: {0}".format(msg_json))
+ if self._ws and self._ws.sock.connected:
+ self._ws.send(msg_json)
+ else:
+ _log.warning("wss api is not connected.")
+
+ def send_playerversion(self):
body = {
- "command": "getpermit",
- "requirement": {
- "broadcastId": self.broadcast_id,
- "route": "",
+ "type": "startWatching",
+ "data": {
"stream": {
+ "quality": "high",
"protocol": "hls",
- "requireNewStream": require_new_stream,
- "priorStreamQuality": "abr",
- "isLowLatency": True,
- "isChasePlay": False
+ "latency": "high",
+ "chasePlay": False
},
"room": {
- "isCommentable": True,
- "protocol": "webSocket"
- }
+ "protocol": "webSocket",
+ "commentable": True
+ },
+ "reconnect": False
}
}
- self.send_message("watch", body)
+ self.send_custom_message(body)
+
+ def send_getpermit(self, require_new_stream=True):
+ body = {
+ "type": "getAkashic",
+ "data": {
+ "chasePlay": False
+ }
+ }
+ self.send_custom_message(body)
def send_watching(self):
body = {
@@ -208,12 +237,18 @@ def send_watching(self):
self.send_message("watch", body)
def send_pong(self):
- self.send_message("pong", {})
+ self.send_no_body_message("pong")
+ self.send_no_body_message("keepSeat")
def handle_api_message(self, message):
_log.debug(u"Received: {0}".format(message))
message_parsed = json.loads(message)
+ if message_parsed["type"] == "stream":
+ data = message_parsed["data"]
+ self.hls_stream_url = data["uri"]
+ self.is_stream_ready = True
+
if message_parsed["type"] == "watch":
body = message_parsed["body"]
command = body["command"]
| Plugin for Niconico Live doesn't work.
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
NicoNico Live Broadcast will not start playing and will time out.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. install streamlink 1.4.1
2. Play any Niconico live broadcast
ex `$ streamlink live2.nicovideo.jp/watch/lv326495242 best`
3. Time out
`[cli][info] Found matching plugin nicolive for URL live2.nicovideo.jp/watch/lv326495242`
`[plugin.nicolive][error] Waiting for permit timed out.`
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
$ streamlink live2.nicovideo.jp/watch/lv326495242 --loglevel debug
[plugin.nicolive][debug] Restored cookies: nicolivehistory, nicosid
[cli][debug] OS: macOS 10.15.5
[cli][debug] Python: 3.8.3
[cli][debug] Streamlink: 1.4.1
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin nicolive for URL live2.nicovideo.jp/watch/lv326495242
[plugin.nicolive][debug] Getting video page: http://live2.nicovideo.jp/watch/lv326495242
[plugin.nicolive][debug] Video page response code: 200
[plugin.nicolive][debug] Got wss_api_url: wss://a.live2.nicovideo.jp/wsapi/v2/watch/3645917628179?audience_token=29570850150482_3645917628179_1592250299_169bab4af6e54066e9fe092cfabf186910e48bc3
[plugin.nicolive][debug] Got broadcast_id:
[plugin.nicolive][debug] Connecting: wss://a.live2.nicovideo.jp/wsapi/v2/watch/3645917628179?audience_token=29570850150482_3645917628179_1592250299_169bab4af6e54066e9fe092cfabf186910e48bc3
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Sending: {"type": "watch", "body": {"command": "playerversion", "params": ["leo"]}}
[plugin.nicolive][debug] Sending: {"type": "watch", "body": {"command": "getpermit", "requirement": {"broadcastId": "", "route": "", "stream": {"protocol": "hls", "requireNewStream": true, "priorStreamQuality": "abr", "isLowLatency": true, "isChasePlay": false}, "room": {"isCommentable": true, "protocol": "webSocket"}}}}
[plugin.nicolive][debug] Received: {"type":"error","data":{"code":"INVALID_MESSAGE"}}
[plugin.nicolive][debug] Received: {"type":"error","data":{"code":"INVALID_MESSAGE"}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"ping"}
[plugin.nicolive][debug] Sending: {"type": "pong", "body": {}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"serverTime","data":{"currentMs":"2020-06-15T04:45:18.267+09:00"}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"ping"}
[plugin.nicolive][debug] Sending: {"type": "pong", "body": {}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"statistics","data":{"viewers":41753,"comments":16267,"adPoints":65000}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"ping"}
[plugin.nicolive][debug] Sending: {"type": "pong", "body": {}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][error] Waiting for permit timed out.
error: No playable streams found on this URL: live2.nicovideo.jp/watch/lv326495242
```
### Additional comments, screenshots, etc.
There are reports that there was a change in the API specification in late May, but we don't know the details.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Hey guys,
I guess I resolved the new wss api format issue.
1. There is new parameter in wss_api_url, which is frontend_id. I leave the snippet here and example of the new wss_api_url.
```
# frontend_id from webpage
self.frontend_id = extract_text(resp.text, ""frontendId":", ","")
# wss_api_url
wss://a.live2.nicovideo.jp/wsapi/v2/watch/lv326495242/timeshift?audience_token=lv326495242_anonymous-user-30352534264954_1592752486_dc0f7e344c038d2ce3e2c627bc095d72fb4a827c&frontend_id=12
```
2. There is new initial message I found as below:
```
{"type":"startWatching","data":{"stream":{"quality":"high","protocol":"hls","latency":"high","chasePlay":false},"room":{"protocol":"webSocket","commentable":true},"reconnect":false}}
```
3. The m3u8 URI is saved in type "stream" message as following below:
```
Return:
RECEIVED: {"type":"stream","data":{"uri":"https://pa023c07d94.dmc.nico/hlsarchive/ht2_nicolive/nicolive-hamster-lv326495242_main_2c0612eb8f7799ee0bd6a083871f8c80fa5e4ddb94d870ffd747fb7d74800144/master.m3u8?ht2_nicolive=anonymous-user-30352534264954.gcsicpdhrl_qc8d18_1xah805rtldwa","syncUri":"https://pa023c07d94.dmc.nico/hlsarchive/ht2_nicolive/nicolive-hamster-lv326495242_main_2c0612eb8f7799ee0bd6a083871f8c80fa5e4ddb94d870ffd747fb7d74800144/stream_sync.json?ht2_nicolive=anonymous-user-30352534264954.gcsicpdhrl_qc8d18_1xah805rtldwa","quality":"high","availableQualities":["abr","super_high","high","normal","low","super_low"],"protocol":"hls"}}
```
I also found other repository got the same problem. Here is the reference link.
https://github.com/himananiito/livedl/issues/49
Send PR soon~ | 2020-06-20T16:41:41 |
|
streamlink/streamlink | 3,056 | streamlink__streamlink-3056 | [
"2903"
] | 5e5d5e9cab23a223b3e2cf1f44352556b8de78a7 | diff --git a/src/streamlink/plugins/tvnbg.py b/src/streamlink/plugins/tvnbg.py
deleted file mode 100644
--- a/src/streamlink/plugins/tvnbg.py
+++ /dev/null
@@ -1,36 +0,0 @@
-import re
-
-from streamlink.plugin import Plugin
-from streamlink.compat import urljoin
-from streamlink.stream import HLSStream
-
-
-class TVNBG(Plugin):
- url_re = re.compile(r"https?://(?:live\.)?tvn\.bg/(?:live)?")
- iframe_re = re.compile(r'<iframe.*?src="([^"]+)".*?></iframe>')
- src_re = re.compile(r'<source.*?src="([^"]+)".*?/>')
-
- @classmethod
- def can_handle_url(cls, url):
- return cls.url_re.match(url) is not None
-
- def _get_streams(self):
- base_url = self.url
- res = self.session.http.get(self.url)
-
- # Search for the iframe in the page
- iframe_m = self.iframe_re.search(res.text)
- if iframe_m:
- # If the iframe is found, load the embedded page
- base_url = iframe_m.group(1)
- res = self.session.http.get(iframe_m.group(1))
-
- # Search the page (original or embedded) for the stream URL
- src_m = self.src_re.search(res.text)
- if src_m:
- stream_url = urljoin(base_url, src_m.group(1))
- # There is no variant playlist, only a plain HLS Stream
- yield "live", HLSStream(self.session, stream_url)
-
-
-__plugin__ = TVNBG
| diff --git a/tests/plugins/test_tvnbg.py b/tests/plugins/test_tvnbg.py
deleted file mode 100644
--- a/tests/plugins/test_tvnbg.py
+++ /dev/null
@@ -1,19 +0,0 @@
-import unittest
-
-from streamlink.plugins.tvnbg import TVNBG
-
-
-class TestPluginTVNBG(unittest.TestCase):
- def test_can_handle_url(self):
- should_match = [
- 'https://tvn.bg/live/',
- ]
- for url in should_match:
- self.assertTrue(TVNBG.can_handle_url(url))
-
- def test_can_handle_url_negative(self):
- should_not_match = [
- 'https://example.com/index.html',
- ]
- for url in should_not_match:
- self.assertFalse(TVNBG.can_handle_url(url))
| [bug] TVN new links not openable
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report and I have read the contribution guidelines.
### Description
TVN.bg has moved its livestream links and the new ones can't be opened by the plugin.
### Reproduction steps / Explicit stream URLs to test
https://play.tvn.bg/TVNweb/embed.html?realtime=true
| Site uses websockets now. Requires a plugin rewrite.
static URL
`https://play.tvn.bg/TVNweb/index.m3u8`
That static URL is still working and it's not geo-IP blocked. Does this mean the tvnbg plugin should be scheduled for removal, @back-to? Am I right in thinking this plugin is not supporting VODs? It seems that way... | 2020-07-03T10:30:15 |
streamlink/streamlink | 3,061 | streamlink__streamlink-3061 | [
"3028"
] | c443ae3c37ab0bfa846ed9b987642956e2b0d30d | diff --git a/src/streamlink/plugins/nicolive.py b/src/streamlink/plugins/nicolive.py
--- a/src/streamlink/plugins/nicolive.py
+++ b/src/streamlink/plugins/nicolive.py
@@ -108,18 +108,13 @@ def get_wss_api_url(self):
try:
self.wss_api_url = extract_text(
resp.text, ""webSocketUrl":"", """)
+ if not self.wss_api_url:
+ return False
except Exception as e:
_log.debug(e)
_log.debug("Failed to extract wss api url")
return False
- try:
- self.broadcast_id = extract_text(
- resp.text, ""broadcastId":"", """)
- except Exception as e:
- _log.debug(e)
- _log.warning("Failed to extract broadcast id")
-
try:
self.frontend_id = extract_text(
resp.text, ""frontendId":", ","")
@@ -132,7 +127,6 @@ def get_wss_api_url(self):
_log.debug("Video page response code: {0}".format(resp.status_code))
_log.trace(u"Video page response body: {0}".format(resp.text))
_log.debug("Got wss_api_url: {0}".format(self.wss_api_url))
- _log.debug("Got broadcast_id: {0}".format(self.broadcast_id))
_log.debug("Got frontend_id: {0}".format(self.frontend_id))
return self.wss_api_url.startswith("wss://")
| Plugin for Niconico Live doesn't work.
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
NicoNico Live Broadcast will not start playing and will time out.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. install streamlink 1.4.1
2. Play any Niconico live broadcast
ex `$ streamlink live2.nicovideo.jp/watch/lv326495242 best`
3. Time out
`[cli][info] Found matching plugin nicolive for URL live2.nicovideo.jp/watch/lv326495242`
`[plugin.nicolive][error] Waiting for permit timed out.`
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
$ streamlink live2.nicovideo.jp/watch/lv326495242 --loglevel debug
[plugin.nicolive][debug] Restored cookies: nicolivehistory, nicosid
[cli][debug] OS: macOS 10.15.5
[cli][debug] Python: 3.8.3
[cli][debug] Streamlink: 1.4.1
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin nicolive for URL live2.nicovideo.jp/watch/lv326495242
[plugin.nicolive][debug] Getting video page: http://live2.nicovideo.jp/watch/lv326495242
[plugin.nicolive][debug] Video page response code: 200
[plugin.nicolive][debug] Got wss_api_url: wss://a.live2.nicovideo.jp/wsapi/v2/watch/3645917628179?audience_token=29570850150482_3645917628179_1592250299_169bab4af6e54066e9fe092cfabf186910e48bc3
[plugin.nicolive][debug] Got broadcast_id:
[plugin.nicolive][debug] Connecting: wss://a.live2.nicovideo.jp/wsapi/v2/watch/3645917628179?audience_token=29570850150482_3645917628179_1592250299_169bab4af6e54066e9fe092cfabf186910e48bc3
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Sending: {"type": "watch", "body": {"command": "playerversion", "params": ["leo"]}}
[plugin.nicolive][debug] Sending: {"type": "watch", "body": {"command": "getpermit", "requirement": {"broadcastId": "", "route": "", "stream": {"protocol": "hls", "requireNewStream": true, "priorStreamQuality": "abr", "isLowLatency": true, "isChasePlay": false}, "room": {"isCommentable": true, "protocol": "webSocket"}}}}
[plugin.nicolive][debug] Received: {"type":"error","data":{"code":"INVALID_MESSAGE"}}
[plugin.nicolive][debug] Received: {"type":"error","data":{"code":"INVALID_MESSAGE"}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"ping"}
[plugin.nicolive][debug] Sending: {"type": "pong", "body": {}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"serverTime","data":{"currentMs":"2020-06-15T04:45:18.267+09:00"}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"ping"}
[plugin.nicolive][debug] Sending: {"type": "pong", "body": {}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"statistics","data":{"viewers":41753,"comments":16267,"adPoints":65000}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"ping"}
[plugin.nicolive][debug] Sending: {"type": "pong", "body": {}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][error] Waiting for permit timed out.
error: No playable streams found on this URL: live2.nicovideo.jp/watch/lv326495242
```
### Additional comments, screenshots, etc.
There are reports that there was a change in the API specification in late May, but we don't know the details.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Hey guys,
I guess I resolved the new wss api format issue.
1. There is new parameter in wss_api_url, which is frontend_id. I leave the snippet here and example of the new wss_api_url.
```
# frontend_id from webpage
self.frontend_id = extract_text(resp.text, ""frontendId":", ","")
# wss_api_url
wss://a.live2.nicovideo.jp/wsapi/v2/watch/lv326495242/timeshift?audience_token=lv326495242_anonymous-user-30352534264954_1592752486_dc0f7e344c038d2ce3e2c627bc095d72fb4a827c&frontend_id=12
```
2. There is new initial message I found as below:
```
{"type":"startWatching","data":{"stream":{"quality":"high","protocol":"hls","latency":"high","chasePlay":false},"room":{"protocol":"webSocket","commentable":true},"reconnect":false}}
```
3. The m3u8 URI is saved in type "stream" message as following below:
```
Return:
RECEIVED: {"type":"stream","data":{"uri":"https://pa023c07d94.dmc.nico/hlsarchive/ht2_nicolive/nicolive-hamster-lv326495242_main_2c0612eb8f7799ee0bd6a083871f8c80fa5e4ddb94d870ffd747fb7d74800144/master.m3u8?ht2_nicolive=anonymous-user-30352534264954.gcsicpdhrl_qc8d18_1xah805rtldwa","syncUri":"https://pa023c07d94.dmc.nico/hlsarchive/ht2_nicolive/nicolive-hamster-lv326495242_main_2c0612eb8f7799ee0bd6a083871f8c80fa5e4ddb94d870ffd747fb7d74800144/stream_sync.json?ht2_nicolive=anonymous-user-30352534264954.gcsicpdhrl_qc8d18_1xah805rtldwa","quality":"high","availableQualities":["abr","super_high","high","normal","low","super_low"],"protocol":"hls"}}
```
I also found other repository got the same problem. Here is the reference link.
https://github.com/himananiito/livedl/issues/49
Send PR soon~
@wiresp33d Thank you for your work.
I tested it in my environment. It works fine.
Let's keep the issue open until the PR has been reviewed and merged in.
Furthermore, there seems to have been a change in the API.
```
$ streamlink live2.nicovideo.jp/watch/lv326699169 --loglevel debug
[plugin.nicolive][debug] Restored cookies: nicolivehistory, nicosid
[cli][debug] OS: macOS 10.15.5
[cli][debug] Python: 3.8.3
[cli][debug] Streamlink: 1.4.1
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin nicolive for URL live2.nicovideo.jp/watch/lv326699169
[plugin.nicolive][debug] Getting video page: http://live2.nicovideo.jp/watch/lv326699169
[plugin.nicolive][debug] Video page response code: 200
[plugin.nicolive][debug] Got wss_api_url: wss://a.live2.nicovideo.jp/wsapi/v2/watch/4925817882387?audience_token=30541512903109_4925817882387_1593489232_4904ee3bb54aecd7efce343e19f62dfa92fc2487
[plugin.nicolive][debug] Got broadcast_id:
[plugin.nicolive][debug] Connecting: wss://a.live2.nicovideo.jp/wsapi/v2/watch/4925817882387?audience_token=30541512903109_4925817882387_1593489232_4904ee3bb54aecd7efce343e19f62dfa92fc2487
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Sending: {"type": "watch", "body": {"command": "playerversion", "params": ["leo"]}}
[plugin.nicolive][debug] Sending: {"type": "watch", "body": {"command": "getpermit", "requirement": {"broadcastId": "", "route": "", "stream": {"protocol": "hls", "requireNewStream": true, "priorStreamQuality": "abr", "isLowLatency": true, "isChasePlay": false}, "room": {"isCommentable": true, "protocol": "webSocket"}}}}
[plugin.nicolive][debug] Received: {"type":"error","data":{"code":"INVALID_MESSAGE"}}
[plugin.nicolive][debug] Received: {"type":"error","data":{"code":"INVALID_MESSAGE"}}
[plugin.nicolive][debug] Waiting for permit...
.
.
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"ping"}
[plugin.nicolive][debug] Sending: {"type": "pong", "body": {}}
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][debug] Received: {"type":"serverTime","data":{"currentMs":"2020-06-29T12:54:32.944+09:00"}}
[plugin.nicolive][debug] Waiting for permit...
.
.
[plugin.nicolive][debug] Waiting for permit...
[plugin.nicolive][error] Waiting for permit timed out.
error: No playable streams found on this URL: live2.nicovideo.jp/watch/lv326699169
```
Supposedly, "broadcast_id" has been removed.
| 2020-07-05T13:16:38 |
|
streamlink/streamlink | 3,116 | streamlink__streamlink-3116 | [
"3094"
] | 3a57a3ac6211b22843505c53a3466f8719dc3bdf | diff --git a/src/streamlink/plugins/yupptv.py b/src/streamlink/plugins/yupptv.py
--- a/src/streamlink/plugins/yupptv.py
+++ b/src/streamlink/plugins/yupptv.py
@@ -1,7 +1,8 @@
+import argparse
import logging
import re
+import time
-from streamlink import PluginError
from streamlink.plugin import Plugin, PluginArguments, PluginArgument
from streamlink.plugin.api import useragents
from streamlink.stream import HLSStream
@@ -11,62 +12,94 @@
class YuppTV(Plugin):
- _url_re = re.compile(r"""https?://(?:www\.)?yupptv\.com""", re.VERBOSE)
+ _url_re = re.compile(r'https?://(?:www\.)?yupptv\.com')
_m3u8_re = re.compile(r'''['"](http.+\.m3u8.*?)['"]''')
- _login_url = "https://www.yupptv.com/auth/validateSignin"
- _box_logout = "https://www.yupptv.com/auth/confirmLogout"
- _signin_url = "https://www.yupptv.com/signin/"
- _account_url = "https://www.yupptv.com/account/myaccount.aspx"
+ _cookie_expiry = 3600 * 24 * 365
arguments = PluginArguments(
+ PluginArgument("email", help=argparse.SUPPRESS),
+ PluginArgument("password", help=argparse.SUPPRESS),
PluginArgument(
- "email",
- requires=["password"],
- metavar="EMAIL",
- help="Your YuppTV account email"
- ),
+ "boxid",
+ requires=["yuppflixtoken"],
+ sensitive=True,
+ metavar="BOXID",
+ help="""
+ The yupptv.com boxid that's used in the BoxId cookie.
+ Can be used instead of the username/password login process.
+ """),
PluginArgument(
- "password",
+ "yuppflixtoken",
sensitive=True,
- metavar="PASSWORD",
- help="Your YuppTV account password."
- )
+ metavar="YUPPFLIXTOKEN",
+ help="""
+ The yupptv.com yuppflixtoken that's used in the YuppflixToken cookie.
+ Can be used instead of the username/password login process.
+ """),
+ PluginArgument(
+ "purge-credentials",
+ action="store_true",
+ help="""
+ Purge cached YuppTV credentials to initiate a new session
+ and reauthenticate.
+ """),
)
+ def __init__(self, url):
+ super(YuppTV, self).__init__(url)
+ self._authed = (self.session.http.cookies.get("BoxId")
+ and self.session.http.cookies.get("YuppflixToken"))
+
@classmethod
def can_handle_url(cls, url):
return cls._url_re.match(url) is not None
- def login(self, username, password, depth=3):
- if depth == 0:
- log.error("Failed to login to YuppTV")
- raise PluginError("cannot login")
+ def _login_using_box_id_and_yuppflix_token(self, box_id, yuppflix_token):
+ time_now = time.time()
- res = self.session.http.post(
- self._login_url,
- data=dict(user=username, password=password, isMobile=0),
- headers={"Referer": self._signin_url}
+ self.session.http.cookies.set(
+ 'BoxId',
+ box_id,
+ domain='www.yupptv.com',
+ path='/',
+ expires=time_now + self._cookie_expiry,
+ )
+ self.session.http.cookies.set(
+ 'YuppflixToken',
+ yuppflix_token,
+ domain='www.yupptv.com',
+ path='/',
+ expires=time_now + self._cookie_expiry,
)
- data = self.session.http.json(res)
- resp = data['Response']
- if resp["tempBoxid"]:
- # log out on other device
- log.info("Logging out on other device: {0}".format(resp["tempBoxid"]))
- _ = self.session.http.get(self._box_logout, params=dict(boxId=resp["tempBoxid"]))
- return self.login(username, password, depth - 1)
- return resp['errorCode'], resp['statusmsg']
+
+ self.save_cookies()
+ log.info("Successfully set BoxId and YuppflixToken")
def _get_streams(self):
self.session.http.headers.update({"User-Agent": useragents.CHROME})
- if self.get_option("email") and self.get_option("password"):
- error_code, error_msg = self.login(self.get_option("email"), self.get_option("password"))
- if error_code is None:
- log.info("Logged in as {0}".format(self.get_option("email")))
- else:
- log.error("Failed to login: {1} (code: {0})".format(error_code, error_msg))
+ login_box_id = self.get_option("boxid")
+ login_yuppflix_token = self.get_option("yuppflixtoken")
+
+ if self.options.get("purge_credentials"):
+ self.clear_cookies()
+ self._authed = False
+ log.info("All credentials were successfully removed")
+
+ if self._authed:
+ log.debug("Attempting to authenticate using cached cookies")
+ elif not self._authed and login_box_id and login_yuppflix_token:
+ self._login_using_box_id_and_yuppflix_token(
+ login_box_id,
+ login_yuppflix_token,
+ )
+ self._authed = True
page = self.session.http.get(self.url)
+ if self._authed and "btnsignup" in page.text:
+ log.error("This device requires renewed credentials to log in")
+ return
+
match = self._m3u8_re.search(page.text)
if match:
stream_url = match.group(1)
| diff --git a/tests/plugins/test_yupptv.py b/tests/plugins/test_yupptv.py
--- a/tests/plugins/test_yupptv.py
+++ b/tests/plugins/test_yupptv.py
@@ -3,13 +3,20 @@
from streamlink.plugins.yupptv import YuppTV
-class TestPluginZattoo(unittest.TestCase):
+class TestPluginYuppTV(unittest.TestCase):
def test_can_handle_url(self):
- self.assertTrue(YuppTV.can_handle_url('https://www.yupptv.com/channels/etv-telugu/live'))
- self.assertTrue(YuppTV.can_handle_url('https://www.yupptv.com/channels/india-today-news/news/25326023/15-jun-2018'))
-
- def test_can_handle_negative(self):
- # shouldn't match
- self.assertFalse(YuppTV.can_handle_url('https://ewe.de'))
- self.assertFalse(YuppTV.can_handle_url('https://netcologne.de'))
- self.assertFalse(YuppTV.can_handle_url('https://zattoo.com'))
+ should_match = [
+ 'https://www.yupptv.com/channels/etv-telugu/live',
+ 'https://www.yupptv.com/channels/india-today-news/news/25326023/15-jun-2018',
+ ]
+ for url in should_match:
+ self.assertTrue(YuppTV.can_handle_url(url))
+
+ def test_can_handle_url_negative(self):
+ should_not_match = [
+ 'https://ewe.de',
+ 'https://netcologne.de',
+ 'https://zattoo.com',
+ ]
+ for url in should_not_match:
+ self.assertFalse(YuppTV.can_handle_url(url))
| YuppTV - Invalid captcha token
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x ] This is a plugin issue and I have read the contribution guidelines.
<!-- Explain the plugin issue as thoroughly as you can. -->
YuppTV seems to have added some sort of login captcha (looks to be Google's recaptcha) which is preventing logging into the website and getting access to paid/premium streams. Free streams which do not require login still work.
I am willing to provide an account temporarily for anyone that might be interested in fixing this. They will need a UK IP during testing.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. Use relevant Streamlink parameters for premium stream requiring login.
streamlink [email protected] --yupptv-password=password123 --http-no-ssl-verify https://www.yupptv.com/channels/star-plus-uk/live
2. Failed Login and no stream output.
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
**Premium stream requiring login** (Does not work)
C:\Users\*****>streamlink [email protected] --yupptv-password=password123 --http-no-ssl-verify https://www.yupptv.com/channels/star-plus-uk/live --loglevel debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin yupptv for URL https://www.yupptv.com/channels/star-plus-uk/live
[cli][debug] Plugin specific arguments:
[cli][debug] [email protected] (email)
[cli][debug] --yupptv-password=***** (password)
[plugin.yupptv][error] Failed to login: Invalid captcha token (code: 403)
[plugin.yupptv][error] This stream requires you to login
error: No playable streams found on this URL: https://www.yupptv.com/channels/star-plus-uk/live
**Free stream not requiring login** (Does work)
C:\Users\*****>streamlink --http-no-ssl-verify https://www.yupptv.com/channels/aajtak/live best --loglevel debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin yupptv for URL https://www.yupptv.com/channels/aajtak/live
[utils.l10n][debug] Language code: en_GB
[cli][info] Available streams: 216p (worst), 270p, 288p, 396p, 406p (best)
[cli][info] Opening stream: 406p (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] First Sequence: 9065; Last Sequence: 9094
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 9092; End Sequence: None
[stream.hls][debug] Adding segment 9092 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 9093 to queue
[stream.hls][debug] Adding segment 9094 to queue
[cli][info] Starting player: "C:\Program Files\VideoLAN\VLC\vlc.exe"
[stream.hls][debug] Download of segment 9092 complete
[cli.output][debug] Opening subprocess: "C:\Program Files\VideoLAN\VLC\vlc.exe" --input-title-format https://www.yupptv.com/channels/aajtak/live -
[stream.hls][debug] Download of segment 9093 complete
[cli][debug] Writing stream to output
...
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| It *might* be possible to sidestep this by providing the right login cookie to streamlink and passing it via the ```--http-cookie``` parameter on the command line.
The first thing you would need to do is identify the cookie. In Firefox (after logging in to YuppTV in the browser), you can open the debugger with F12, then click the Storage tab. You should look for cookie names that have words like ```sess```, ```session```, ```user```, ```token```, ```auth``` in them under ```yupptv.com``` in the left window pane.
You can click on each cookie to get details in a right window pane. Let's say you find a likely candidate called ```authtoken``` with a value of ```randomstring```. You could then try this:
```streamlink --http-cookie authtoken=randomstring --http-no-ssl-verify https://www.yupptv.com/channels/star-plus-uk/live --loglevel debug```
It's likely that if this works, the token will eventually expire, in which case you will have to renew it by logging in again via the browser and replacing the old ```randomstring``` value with the new one.
Additional tip: if you open the debugger before logging in, then log in and then log out again, while keeping the debugger open, the cookies which are modified will be highlighted briefly in the cookie list window pane, new cookies will appear and deleted cookies will disappear.
Unfortunately, whatever tokens I used I got the same result. I don't know if this is caused by the stream plugin refusing to continue without login parameters on a premium stream or because this method simply wont work.
C:\Users\*****>streamlink --http-cookie 'abc=123' --http-no-ssl-verify https://www.yupptv.com/channels/star-plus-uk/live best --loglevel debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin yupptv for URL https://www.yupptv.com/channels/star-plus-uk/live
[plugin.yupptv][error] This stream requires you to login
error: No playable streams found on this URL: https://www.yupptv.com/channels/star-plus-uk/live
> I don't know if this is caused by the stream plugin refusing to continue without login parameters on a premium stream
The login will only be done if plugin parameters for the email and password are set:
https://github.com/streamlink/streamlink/blob/1.5.0/src/streamlink/plugins/yupptv.py#L62-L67
And the login itself only fetches cookies from the login request, which are then stored on the HTTP session for the next requests:
https://github.com/streamlink/streamlink/blob/1.5.0/src/streamlink/plugins/yupptv.py#L40-L57
This means that you'll have to figure out the cookies yourself or set everything your web browser has set via the [`--http-cookie`](https://streamlink.github.io/cli.html#cmdoption-http-cookie) or [`--http-header`](https://streamlink.github.io/cli.html#cmdoption-http-header) parameters. Note that the plugin performs its login up to three times, until all other devices are logged out, as reported by the site.
Regarding the plugin's login parameters themselves, they are now useless due to the new captcha codes added by the streaming site and thus need to be removed, as there is no way around that for Streamlink.
If someone figures out which exact cookies are needed, a new plugin parameter could be added, similar to #2840.
I've not had any luck tinkering so If anyone is willing to take a look, I can provide a account.
@mytee12, I have some work in progress on this. I'll ping you on here when I have something ready for testing.
Many thanks to @bastimeyer for pointing me to the pixiv plugin. The code was very useful. I mostly just copied and pasted the cookie code with a few modifications, as necessary.
@mytee12, I now have an updated yupptv plugin ready for testing. You can get it from:
https://github.com/mkbloke/streamlink/blob/yupptv-site-change-2020-08/src/streamlink/plugins/yupptv.py
On that page, just select 'Raw', then 'File/Save Page As' in your browser. You can backup the old plugin if you like, although as it doesn't work, there's probably not much point, then copy or move the newly downloaded plugin into your local streamlink plugins directory.
If you could help with testing by following the test regime I'm outlining below, it would very much be appreciated, thanks.
There's no need to report any output if the plugin works as expected, but debug output for tests that don't perform as expected would be very useful.
[Updated to add: include the ```--http-no-ssl-verify``` option to the testing regime command lines below if it's necessary for your system]
Firstly, let's try without authentication:
```streamlink -l debug https://www.yupptv.com/channels/aajtak/live best```
Should play without any errors.
```streamlink -l debug https://www.yupptv.com/channels/star-plus-uk/live best```
Should show:
```
[plugin.yupptv][error] This stream requires you to login
error: No playable streams found on this URL: https://www.yupptv.com/channels/star-plus-uk/live
```
There are two cookies required for login to YuppTV, these are ```BoxId``` and ```YuppflixToken```. As detailed in my post above, you can extract the required values for each of these via the browser. Here are examples of what they should look like:
BoxId ```519a4cdaedee4d53```
YuppflixToken ```YT-8b5fae6b-d794-4beb-431c-36012f3b198f```
When you have the cookie values for a given session, you must leave it logged in within the browser, i.e. do not click 'Logout` on the YuppTV website, otherwise you'll invalidate the credendtials. I'm going to use my example cookie values below, but you should of course replace them with the ones you have obtained from your session.
This updated plugin now caches your cookie values which are used to access YuppTV. That means you only need to specify them once on the command line, unless you need to update them (more on that below).
```streamlink -l debug --yupptv-boxid 519a4cdaedee4d53 --yupptv-yuppflixtoken YT-8b5fae6b-d794-4beb-431c-36012f3b198f https://www.yupptv.com/channels/aajtak/live best```
Should play without any errors.
Now that the credentials are cached and if your YuppTV subscription package allows you to play it (I'm assuming from your original post that it should):
```streamlink -l debug https://www.yupptv.com/channels/star-plus-uk/live best```
Should play using the cached credentials without any errors.
I don't know what subscription you have, but if you can find any content that requires further subscription, then:
```streamlink -l debug https://www.yupptv.com/a-link-to-content-requiring-further-subscription best```
Should in theory show:
```
[plugin.yupptv][debug] Attempting to authenticate using cached cookies
[plugin.yupptv][error] This stream requires a subscription
error: No playable streams found on this URL: https://www.yupptv.com/a-link-to-content-requiring-further-subscription
```
If, when using this updated plugin, you encounter output like:
```
[plugin.yupptv][debug] Attempting to authenticate using cached cookies
[plugin.yupptv][error] This device requires renewed credentials to log in
error: No playable streams found on this URL: https://www.yupptv.com/channels/aajtak/live
```
it means that the cached credentials are no longer considered valid by the YuppTV website. This could be because:
- You have been using the credentials for a long time and the YuppTV website now considers them expired
- You have logged into YuppTV via another device and forced the logout of this session (device)
In that case, you will need to renew the credentials by logging in again with a browser, extracting the new BoxId and YuppflixToken values, then start streamlink with the parameters shown below to update the cached credentials:
```streamlink --yupptv-purge-credentials --yupptv-boxid ```my_new_boxid_value``` --yupptv-yuppflixtoken ```my_new_yuppflixtoken_value``` https://www.yupptv.com/channels/aajtak/live best```
If you just want to remove the cached credentials for the plugin, you can just use:
```streamlink --yupptv-purge-credentials https://www.yupptv.com/channels/aajtak/live```
You can use any YuppTV URL that is recognised by the plugin in the above examples when using the credentials options. If you do not wish to play any content after using the credentials options, just use the URL and do not specify the second command line argument, i.e. the stream quality, as shown in the ```--yupptv-purge-credentials``` example immediately above.
Finally, here's a last note on this updated plugin:
The previous plugin featured the ability to logout other devices, but this plugin can no longer do that. It's a catch-22 situation. If you have logged in via another device and forced logout of other devices, you are invalidating the credentials cached by streamlink for YuppTV access. When you log in via a browser, you first authenticate via the login form, but that involves Google reCAPTCHA, which cannot be done by a streamlink plugin, therefore the plugin cannot authenticate to get to the option of logging out other devices. This means that if you log into YuppTV on another device and force the logout of other devices, you will see:
```
[plugin.yupptv][debug] Attempting to authenticate using cached cookies
[plugin.yupptv][error] This device requires renewed credentials to log in
error: No playable streams found on this URL: https://www.yupptv.com/channels/aajtak/live
```
when you next attempt to use the streamlink plugin and you will have to go through the process of specifying renewed cookie values as detailed above.
Highly appreciate your efforts.
1. Free stream without any cached credentials. Works.
```
C:\Users\*>streamlink -l debug --http-no-ssl-verify https://www.yupptv.com/channels/aajtak/live best
[session][debug] Plugin yupptv is being overridden by C:\Users\*\AppData\Roaming\streamlink\plugins\yupptv.py
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin yupptv for URL https://www.yupptv.com/channels/aajtak/live
[utils.l10n][debug] Language code: en_GB
[cli][info] Available streams: 216p (worst), 270p, 288p, 396p, 406p (best)
[cli][info] Opening stream: 406p (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] First Sequence: 9282; Last Sequence: 9311
...
```
Unfortunately, I am not able to get past the step of using a free stream with the boxid and yuppflixtoken parameters. Here are my steps:
1. Clear credentials.
```
C:\Users\*>streamlink -l debug --http-no-ssl-verify --yupptv-purge-credentials https://www.yupptv.com/channels/aajtak/live
[session][debug] Plugin yupptv is being overridden by C:\Users\*\AppData\Roaming\streamlink\plugins\yupptv.py
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin yupptv for URL https://www.yupptv.com/channels/aajtak/live
[cli][debug] Plugin specific arguments:
[cli][debug] --yupptv-purge-credentials=True (purge_credentials)
[plugin.yupptv][info] All credentials were successfully removed
[utils.l10n][debug] Language code: en_GB
Available streams: 216p (worst), 270p, 288p, 396p, 406p (best)
```
2. Retrieve new boxid and yuppflixtoken from website. Not logging out.
3. Use new tokens with plugin.
```
C:\Users\*>streamlink -l debug --http-no-ssl-verify --yupptv-boxid '****' --yupptv-yuppflixtoken 'YT-****' https://www.yupptv.com/channels/aajtak/live best
[session][debug] Plugin yupptv is being overridden by C:\Users\*\AppData\Roaming\streamlink\plugins\yupptv.py
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin yupptv for URL https://www.yupptv.com/channels/aajtak/live
[cli][debug] Plugin specific arguments:
[cli][debug] --yupptv-boxid=******** (boxid)
[cli][debug] --yupptv-yuppflixtoken=******** (yuppflixtoken)
[plugin.yupptv][debug] Saved cookies: BoxId, YuppflixToken
[plugin.yupptv][info] Successfully set BoxId and YuppflixToken
[plugin.yupptv][error] This device requires renewed credentials to log in
error: No playable streams found on this URL: https://www.yupptv.com/channels/aajtak/live
```
And of course, I get the same result with a premium stream.
I tried many times with new fresh credentials. If I tested the boxid/yuppflixtoken and manually set them in a clean Firefox session, they were active and allowed me to login bypassing the captcha.
Hi @mytee12, many thanks for the feedback.
I have pushed a small change to the plugin, which can again be downloaded from:
https://github.com/mkbloke/streamlink/blob/yupptv-site-change-2020-08/src/streamlink/plugins/yupptv.py
This is a bit of a shot in the dark and based purely on a hunch, but this small modification calls the signin URL, which I notice sets various cookies in its response. It's *possible* some of these could be relevant for somebody with an account that has subscribed packages on YuppTV.
It might be best to start with ```--yupptv-purge-credentials```, then follow the test regime as before. Thanks.
Same result with the new changes sadly.
```
C:\Users\*>streamlink --http-no-ssl-verify -l debug --yupptv-boxid '*' --yupptv-yuppflixtoken '*' https://www.yupptv.com/channels/aajtak/live best
[session][debug] Plugin yupptv is being overridden by C:\Users\*\AppData\Roaming\streamlink\plugins\yupptv.py
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin yupptv for URL https://www.yupptv.com/channels/aajtak/live
[cli][debug] Plugin specific arguments:
[cli][debug] --yupptv-boxid=******** (boxid)
[cli][debug] --yupptv-yuppflixtoken=******** (yuppflixtoken)
[plugin.yupptv][debug] Saved cookies: BoxId, YuppflixToken
[plugin.yupptv][info] Successfully set BoxId and YuppflixToken
[plugin.yupptv][error] This device requires renewed credentials to log in
error: No playable streams found on this URL: https://www.yupptv.com/channels/aajtak/live
```
@mytee12, I think I've got it - I'm an idiot! I managed to reproduce what you're seeing by booting into Windows 10 and testing it there...
I've reverted the last commit to the plugin, so if you can download it again from:
https://github.com/mkbloke/streamlink/blob/yupptv-site-change-2020-08/src/streamlink/plugins/yupptv.py
and go through the testing regime again, it would be much appreciated. This time, you'll note that none of the command lines shown place single quotes around the values specified for the cookie parameters. It turns out, that under Windows, the single quotes are saved as part of the cookie value - doh! I will remember that for the future!
Cheers.
Updated to add: maybe start the testing again with ```--yupptv-purge-credentials```, then add the credentials back during the test regime, but without the single quotes (obviously) this time!
I can confirm that we have lift off! Both free and premium stream are working. Thank you very much @mkbloke
I will update on how long the tokens take to expire for anyone who is interested in knowing.
To clarify for any others, your commands should be like the following, replacing the random strings `342a4cqwedey4d73` and `YT-7h2fae6b-u643-5ctc-483f-11856f3b155p` with the appropriate tokens and the stream link of your choosing e.g.
`streamlink --http-no-ssl-verify -l debug --yupptv-boxid 342a4cqwedey4d73 --yupptv-yuppflixtoken YT-7h2fae6b-u643-5ctc-483f-11856f3b155p https://www.yupptv.com/channels/star-plus-uk/live best`
To get the tokens... use Firefox and log into your YuppTV account, press F12 on your keyboard and go to the _Storage_ tab at the top. You should see the _cookies_ section and go to yupptv.com. Copy the _Value_ of _BoxId_ and _YuppflixToken_ and use them in your streamlink parameters above. Make sure you do not click the logout button on YuppTV website, instead just close it.
That's excellent news. Thanks for the testing, @mytee12.
Just to reiterate, it should only be necessary to use the ```--yupptv-boxid``` and ```--yupptv-yuppflixtoken``` options once while the cookie values remain valid. It should be possible to simply use (with ```--http-no-ssl-verify``` if necessary on your system):
```streamlink https://www.yupptv.com/channels/star-plus-uk/live best```
for as long as you have valid credentials cached. I've updated https://github.com/streamlink/streamlink/issues/3094#issuecomment-672554453 appropriately within this thread, so the info on renewing with: ```--yupptv-purge-credentials```, ```--yupptv-boxid my_new_boxid_value``` and ```--yupptv-yuppflixtoken my_new_yuppflixtoken_value``` also applies, as does using ```--yupptv-purge-credentials``` on its own to clear the cached credentials.
How long do login and stream cookies last? Last time I tried got the account banned but it may be because runit was executing too many times? What's the best way to set up a stream?
> How long do login and stream cookies last?
Try it and see, or wait and see if mytee12 gets back with that information.
> What's the best way to set up a stream?
I'm not quite sure what you mean. With reference to the instructions above, having stored the credentials, you just run streamlink with the URL and stream as command line arguments. You can find the available streams by running streamlink with just the URL argument.
~~I've looked at the ```expires``` values for the cookies I have and it seems to indicate that the cookies are valid for 7 days.~~
>
>
> How long do login and stream cookies last?
>
>
> I've looked at the `expires` values for the cookies I have and it seems to indicate that the cookies are valid for 7 days.
I had to renew my tokens today to check for sure but I used them for 8 days. Checking `BoxId` and `YuppflixToken` in Chrome shows an expiration of 180 days : `2021-02-17T14:20:16.313Z`
>
>
> Last time I tried got the account banned but it may be because runit was executing too many times?
I've been using this addon for over 6 months via [LiveProxy](https://streamlink.github.io/thirdparty.html)
Thanks for coming back on the cookie expiry.
> I've looked at the `expires` values for the cookies I have and it seems to indicate that the cookies are valid for 7 days.
I've retracted that in the post above. I was looking at the wrong thing, so it's incorrect.
> > How long do login and stream cookies last?
>
> > I've looked at the `expires` values for the cookies I have and it seems to indicate that the cookies are valid for 7 days.
>
> I had to renew my tokens today to check for sure but I used them for 8 days. Checking `BoxId` and `YuppflixToken` in Chrome shows an expiration of 180 days : `2021-02-17T14:20:16.313Z`
>
> > Last time I tried got the account banned but it may be because runit was executing too many times?
>
> I've been using this addon for over 6 months via [LiveProxy](https://streamlink.github.io/thirdparty.html)
Thank you. I'll try that. What exactly is the purpose of LiveProxy in this case?
> What exactly is the purpose of LiveProxy in this case?
LiveProxy allows me to essentially have a Streamlink server running in my home network and use Streamlink on devices where installing Streamlink might not be possible or elegant. I currently use an [android](https://www.reddit.com/r/Streamlink/comments/cfno18/guide_streamlink_on_android_termux_vlc/) box I had laying around as a Streamlink server.
It also lets me create a easy to use M3U playlist with Streamlink/Liveproxy urls consisting of YuppTV channels. In my case I use the M3U playlist with an IPTV player app on a Firestick, a much more user friendly experience.
Thanks guys. Really appreciate your hard work!
Folks, do you by any chance experience a similar issue? 1 channel in particular Sony UK HD is throwing 404(i removed token details) error but after I restart the session it starts working
`2020-09-14_21:27:23.34232 [stream.hls][debug] Download of segment 50405 complete
2020-09-14_21:27:29.14064 [stream.hls][debug] Reloading playlist
2020-09-14_21:27:32.23414 [stream.hls][debug] Reloading playlist
2020-09-14_21:27:34.74914 [stream.hls][warning] Failed to reload playlist: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:27:37.75189 [stream.hls][debug] Reloading playlist
2020-09-14_21:27:40.12936 [stream.hls][warning] Failed to reload playlist: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:27:43.13188 [stream.hls][debug] Reloading playlist
2020-09-14_21:27:45.70842 [stream.hls][warning] Failed to reload playlist: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:27:48.71147 [stream.hls][debug] Reloading playlist
2020-09-14_21:27:51.09119 [stream.hls][warning] Failed to reload playlist: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:27:54.09427 [stream.hls][debug] Reloading playlist
2020-09-14_21:27:56.69180 [stream.hls][warning] Failed to reload playlist: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:27:59.69504 [stream.hls][debug] Reloading playlist
2020-09-14_21:28:02.07630 [stream.hls][warning] Failed to reload playlist: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:28:04.02787 [stream.segmented][debug] Closing worker thread
2020-09-14_21:28:04.02789 [stream.segmented][debug] Closing writer thread
2020-09-14_21:28:04.02790 [cli][info] Stream ended
2020-09-14_21:28:04.02790 Interrupted! Exiting...
2020-09-14_21:28:04.02790 [cli][info] Closing currently open stream...
2020-09-14_21:28:04.02791 Failed to load plugin ustvnow:
2020-09-14_21:28:04.02791 File "/usr/lib/python3.7/imp.py", line 234, in load_module
2020-09-14_21:28:04.02792 return load_source(name, filename, file)
2020-09-14_21:28:04.02792 File "/usr/lib/python3.7/imp.py", line 171, in load_source
2020-09-14_21:28:04.02792 module = _load(spec)
2020-09-14_21:28:04.02793 File "<frozen importlib._bootstrap>", line 696, in _load
2020-09-14_21:28:04.02793 File "<frozen importlib._bootstrap>", line 677, in _load_unlocked
2020-09-14_21:28:04.02793 File "<frozen importlib._bootstrap_external>", line 728, in exec_module
2020-09-14_21:28:04.02794 File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
2020-09-14_21:28:04.02794 File "/usr/local/lib/python3.7/dist-packages/streamlink-1.3.1+182.gb3132d7-py3.7.egg/streamlink/plugins/ustvnow.py", line 12, in <module>
2020-09-14_21:28:04.02794 from Crypto.Util.Padding import pad, unpad
2020-09-14_21:28:04.02795 ModuleNotFoundError: No module named 'Crypto.Util.Padding'
2020-09-14_21:28:04.02795
2020-09-14_21:30:02.95929 [plugin.yupptv][debug] Restored cookies: BoxId, YuppflixToken
2020-09-14_21:30:02.96410 [cli][info] streamlink is running as root! Be careful!
2020-09-14_21:30:02.96517 [cli][debug] OS: Linux-4.19.0-10-amd64-x86_64-with-debian-10.5
2020-09-14_21:30:02.96530 [cli][debug] Python: 3.7.3
2020-09-14_21:30:02.96540 [cli][debug] Streamlink: 1.3.1+182.gb3132d7
2020-09-14_21:30:02.96550 [cli][debug] Requests(2.21.0), Socks(1.6.7), Websocket(0.53.0)
2020-09-14_21:30:02.96574 [cli][info] Found matching plugin yupptv for URL https://www.yupptv.com/channels/sony-tv-hd/live
2020-09-14_21:30:02.96585 [cli][debug] Plugin specific arguments:
2020-09-14_21:30:02.96595 [cli][debug] --yupptv-boxid=******** (boxid)
2020-09-14_21:30:02.96605 [cli][debug] --yupptv-yuppflixtoken=******** (yuppflixtoken)
2020-09-14_21:30:02.96621 [plugin.yupptv][debug] Attempting to authenticate using cached cookies
2020-09-14_21:30:04.27101 [utils.l10n][debug] Language code: en_US
2020-09-14_21:30:04.74955 [cli][info] Available streams: 270p (worst), 360p, 540p, 720p (best)
2020-09-14_21:30:04.74990 [cli][info] Starting server, access with one of:
2020-09-14_21:30:04.82587 [cli][info] http://127.0.0.1:11002/
2020-09-14_21:30:10.81929 [cli][info] Got HTTP request from Streamer 20.09
2020-09-14_21:30:10.81948 [cli][info] Opening stream: 720p (hls)
2020-09-14_21:30:10.82009 [stream.hls][debug] Reloading playlist
2020-09-14_21:30:13.33534 [cli][error] Could not open stream: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:30:13.33575 [plugin.yupptv][debug] Attempting to authenticate using cached cookies
2020-09-14_21:30:13.87706 [utils.l10n][debug] Language code: en_US
2020-09-14_21:30:13.95485 [cli][info] Opening stream: 720p (hls)
2020-09-14_21:30:13.95526 [stream.hls][debug] Reloading playlist
2020-09-14_21:30:16.33582 [cli][error] Could not open stream: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:30:16.33613 [plugin.yupptv][debug] Attempting to authenticate using cached cookies
2020-09-14_21:30:17.03601 [utils.l10n][debug] Language code: en_US
2020-09-14_21:30:17.11543 [cli][info] Opening stream: 720p (hls)
2020-09-14_21:30:17.11579 [stream.hls][debug] Reloading playlist
2020-09-14_21:30:19.49311 [cli][error] Could not open stream: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:30:19.49333 [plugin.yupptv][debug] Attempting to authenticate using cached cookies
2020-09-14_21:30:20.03681 [utils.l10n][debug] Language code: en_US
2020-09-14_21:30:20.11409 [cli][info] Opening stream: 720p (hls)
2020-09-14_21:30:20.11448 [stream.hls][debug] Reloading playlist
2020-09-14_21:30:22.59907 [cli][error] Could not open stream: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:30:22.59929 [plugin.yupptv][debug] Attempting to authenticate using cached cookies
2020-09-14_21:30:23.15075 [utils.l10n][debug] Language code: en_US
2020-09-14_21:30:23.22917 [cli][info] Opening stream: 720p (hls)
2020-09-14_21:30:23.22976 [stream.hls][debug] Reloading playlist
2020-09-14_21:30:25.61056 [cli][error] Could not open stream: Unable to open URL: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8? (404 Client Error: Not Found for url: https://yuppmsleuvia1.akamaized.net/hls/live/2017574/sonyukhdhttps/sonyukhdhttps/sonyukhd_2500/chunklist.m3u8?)
2020-09-14_21:30:25.61074 [plugin.yupptv][debug] Attempting to authenticate using cached cookies
2020-09-14_21:30:26.16795 [utils.l10n][debug] Language code: en_US
2020-09-14_21:30:26.24559 [cli][info] Opening stream: 720p (hls)
2020-09-14_21:30:26.24606 [stream.hls][debug] Reloading playlist
`
@limiteddi, can you reformat the above to make it a little more readable, please? I think what you have done (where b=backtick) is specified bbb[content]bbb. If you format it as:
bbb
[content]
bbb
it should be easier to read.
Can you also specify the full command you are using to launch streamlink.
When does this happen - after a short time or a long time? How long?
Does the live stream play in the browser on yupptv.com OK for the same period of time?
I don't have a subscription, so it won't be easy to try and work out why this is happening or if it can be mitigated in streamlink, as a 404 error suggests a remote issue.
@mkbloke
Took me a while to figure out what was happening, but it seems that after 7 days the cache in the file `plugin-cache.json` is automatically purged. However, If I re-set the SAME credentials again they will continue working... I have done this 3 times with the same tokens and the only change is the `expires` in the `plugin-cache.json file` . So it is possibly the expiry date being set in the cache file incorrectly causing the credentials to be purged prematurely?
Prior to trying a stream - plugin-cache.json file:
```
"expires": 1600559413.4241705
"expires": 1600559413.455421
```
Trying to play a stream and YuppTV credentials are purged automatically from plugin-cache.json:
`{}`
```
[plugin.yupptv][error] This stream requires you to login
error: No playable streams found on this URL: https://www.yupptv.com/channels/star-plus-uk/live
```
After setting new credentials, new expiry date with same credentials:
```
"expires": 1601164607.7820444
"expires": 1601164607.8171265
``` | 2020-08-18T01:33:51 |
streamlink/streamlink | 3,126 | streamlink__streamlink-3126 | [
"2341"
] | d3ca4ab8b9f14080f2eaf637f2e12f32ca9a4ac9 | diff --git a/src/streamlink/plugins/huomao.py b/src/streamlink/plugins/huomao.py
--- a/src/streamlink/plugins/huomao.py
+++ b/src/streamlink/plugins/huomao.py
@@ -1,101 +1,198 @@
-"""
-NOTE: Since a documented API is nowhere to be found for Huomao; this plugin
-simply extracts the videos stream_id, stream_url and stream_quality by
-scraping the HTML and JS of one of Huomaos mobile webpages.
-
-When viewing a stream on huomao.com, the base URL references a room_id. This
-room_id is mapped one-to-one to a stream_id which references the actual .m3u8
-file. Both stream_id, stream_url and stream_quality can be found in the
-HTML and JS source of the mobile_page. Since one stream can occur in many
-different qualities, we scrape all stream_url and stream_quality occurrences
-and return each option to the user.
-"""
-
+import hashlib
+import logging
import re
+import time
+from streamlink.compat import bytes
+from streamlink.exceptions import PluginError
from streamlink.plugin import Plugin
+from streamlink.plugin.api import validate
from streamlink.stream import HLSStream
+from streamlink.utils import parse_json
-# URL pattern for recognizing inputed Huomao.tv / Huomao.com URL.
-url_re = re.compile(r"""
- (http(s)?://)?
- (www\.)?
- huomao
- (\.tv|\.com)
- /(?P<room_id>\d+)
-""", re.VERBOSE)
-
-# URL used to retrive the stream_id, stream_url and stream_quality based of
-# a room_id.
-mobile_url = "http://www.huomao.com/mobile/mob_live/{0}"
-
-# Pattern for extracting the stream_id from the mobile_url HTML.
-#
-# Example from HTML:
-# <input id="html_stream" value="efmrCH" type="hidden">
-stream_id_pattern = re.compile(r'id=\"html_stream\" value=\"(?P<stream_id>\w+)\"')
-
-# Pattern for extracting each stream_url and
-# stream_quality_name used for quality naming.
-#
-# Example from HTML:
-# src="http://live-ws-hls.huomaotv.cn/live/<stream_id>_720/playlist.m3u8"
-stream_info_pattern = re.compile(r"""
- (?P<stream_url>(?:[\w\/\.\-:]+)
- \/[^_\"]+(?:_(?P<stream_quality_name>\d+))
- ?/playlist.m3u8)
-""", re.VERBOSE)
+log = logging.getLogger(__name__)
class Huomao(Plugin):
+ magic_val = '6FE26D855E1AEAE090E243EB1AF73685'
+ mobile_url = 'https://m.huomao.com/mobile/mob_live/{0}'
+ live_data_url = 'https://m.huomao.com/swf/live_data'
+ vod_url = 'https://www.huomao.com/video/vreplay/{0}'
+
+ author = None
+ category = None
+ title = None
+
+ url_re = re.compile(r'''
+ (?:https?://)?(?:www\.)?huomao(?:\.tv|\.com)
+ (?P<path>/|/video/v/)
+ (?P<room_id>\d+)
+ ''', re.VERBOSE)
+
+ author_re = re.compile(
+ r'<p class="nickname_live">\s*<span>\s*(.*?)\s*</span>',
+ re.DOTALL,
+ )
+
+ title_re = re.compile(
+ r'<p class="title-name">\s*(.*?)\s*</p>',
+ re.DOTALL,
+ )
+
+ video_id_re = re.compile(r'var stream = "([^"]+)"')
+ video_res_re = re.compile(r'_([\d]+p?)\.m3u8')
+ vod_data_re = re.compile(r'var video = ({.*});')
+
+ _live_data_schema = validate.Schema({
+ 'roomStatus': validate.transform(lambda x: int(x)),
+ 'streamList': [{'list_hls': [{
+ 'url': validate.url(),
+ }]}],
+ })
+
+ _vod_data_schema = validate.Schema({
+ 'title': validate.text,
+ 'username': validate.text,
+ 'vaddress': validate.all(
+ validate.text,
+ validate.transform(parse_json),
+ [{
+ 'url': validate.url(),
+ 'vheight': int,
+ }],
+ ),
+ })
+
@classmethod
- def can_handle_url(self, url):
- return url_re.match(url)
+ def can_handle_url(cls, url):
+ return cls.url_re.match(url) is not None
+
+ def _get_live_streams_data(self, video_id):
+ client_type = 'huomaomobileh5'
+ time_now = str(int(time.time()))
+
+ token_data = "{0}{1}{2}{3}".format(
+ video_id,
+ client_type,
+ time_now,
+ self.magic_val,
+ )
+
+ token = hashlib.md5(bytes(token_data, 'utf-8')).hexdigest()
+ log.debug("Token={0}".format(token))
+
+ post_data = {
+ 'cdns': 1,
+ 'streamtype': 'live',
+ 'VideoIDS': video_id,
+ 'from': client_type,
+ 'time': time_now,
+ 'token': token,
+ }
+ video_data = self.session.http.post(self.live_data_url, data=post_data)
+
+ return self.session.http.json(
+ video_data,
+ schema=self._live_data_schema,
+ )
+
+ def _get_vod_streams(self, vod_id):
+ res = self.session.http.get(self.vod_url.format(vod_id))
+ m = self.vod_data_re.search(res.text)
+ vod_json = m and m.group(1)
+
+ if vod_json is None:
+ raise PluginError("Failed to get VOD data")
+
+ vod_data = parse_json(vod_json, schema=self._vod_data_schema)
+
+ self.author = vod_data['username']
+ self.category = 'VOD'
+ self.title = vod_data['title']
+
+ vod_data = vod_data['vaddress']
- def get_stream_id(self, html):
- """Returns the stream_id contained in the HTML."""
- stream_id = stream_id_pattern.search(html)
+ streams = {}
+ for stream in vod_data:
+ video_res = stream['vheight']
- if not stream_id:
- self.logger.error("Failed to extract stream_id.")
+ if 'p' not in str(video_res):
+ video_res = "{0}p".format(video_res)
- return stream_id.group("stream_id")
+ if video_res in streams:
+ video_res = "{0}_alt".format(video_res)
- def get_stream_info(self, html):
- """
- Returns a nested list of different stream options.
+ streams[video_res] = HLSStream(self.session, stream['url'])
- Each entry in the list will contain a stream_url and stream_quality_name
- for each stream occurrence that was found in the JS.
- """
- stream_info = stream_info_pattern.findall(html)
+ return streams
- if not stream_info:
- self.logger.error("Failed to extract stream_info.")
+ def _get_live_streams(self, room_id):
+ res = self.session.http.get(self.mobile_url.format(room_id))
- # Rename the "" quality to "source" by transforming the tuples to a
- # list and reassigning.
- stream_info_list = []
- for info in stream_info:
- if not info[1]:
- stream_info_list.append([info[0], "source"])
- else:
- stream_info_list.append(list(info))
+ m = self.author_re.search(res.text)
+ if m:
+ self.author = m.group(1)
- return stream_info_list
+ self.category = 'Live'
- def _get_streams(self):
- room_id = url_re.search(self.url).group("room_id")
- html = self.session.http.get(mobile_url.format(room_id))
- stream_id = self.get_stream_id(html.text)
- stream_info = self.get_stream_info(html.text)
+ m = self.title_re.search(res.text)
+ if m:
+ self.title = m.group(1)
+
+ m = self.video_id_re.search(res.text)
+ video_id = m and m.group(1)
+
+ if video_id is None:
+ raise PluginError("Failed to get video ID")
+ else:
+ log.debug("Video ID={0}".format(video_id))
+
+ streams_data = self._get_live_streams_data(video_id)
+
+ if streams_data['roomStatus'] == 0:
+ log.info("This room is currently inactive: {0}".format(room_id))
+ return
+
+ streams_data = streams_data['streamList'][0]['list_hls']
streams = {}
- for info in stream_info:
- if stream_id in info[0]:
- streams[info[1]] = HLSStream(self.session, info[0])
+ for stream in streams_data:
+ m = self.video_res_re.search(stream['url'])
+ video_res = m and m.group(1)
+ if video_res is None:
+ continue
+
+ if 'p' not in video_res:
+ video_res = "{0}p".format(video_res)
+
+ if video_res in streams:
+ video_res = "{0}_alt".format(video_res)
+
+ streams[video_res] = HLSStream(self.session, stream['url'])
return streams
+ def get_author(self):
+ if self.author is not None:
+ return self.author
+
+ def get_category(self):
+ if self.category is not None:
+ return self.category
+
+ def get_title(self):
+ if self.title is not None:
+ return self.title
+
+ def _get_streams(self):
+ path, url_id = self.url_re.search(self.url).groups()
+ log.debug("Path={0}".format(path))
+ log.debug("URL ID={0}".format(url_id))
+
+ if path != '/':
+ return self._get_vod_streams(url_id)
+ else:
+ return self._get_live_streams(url_id)
+
__plugin__ = Huomao
| diff --git a/tests/plugins/test_huomao.py b/tests/plugins/test_huomao.py
--- a/tests/plugins/test_huomao.py
+++ b/tests/plugins/test_huomao.py
@@ -4,85 +4,68 @@
class TestPluginHuomao(unittest.TestCase):
-
- def setUp(self):
-
- # Create a mock source HTML with some example data:
- # room_id = 123456
- # stream_id = 9qsvyF24659
- # stream_url = http://live-ws.huomaotv.cn/live/
- # stream_quality_name = source, 720 and 480
- self.mock_html = """
- <input id="html_stream" value="9qsvyF24659" type="hidden">
- <source src="http://live-ws-hls.huomaotv.cn/live/9qsvyF24659/playlist.m3u8">
- <source src="http://live-ws-hls.huomaotv.cn/live/9qsvyF24659_720/playlist.m3u8">
- <source src="http://live-ws-hls.huomaotv.cn/live/9qsvyF24659_480/playlist.m3u8">
- """
-
- # Create a mock Huomao object.
- self.mock_huomao = Huomao("http://www.huomao.com/123456/")
-
- def tearDown(self):
- self.mock_html = None
- self.mock_huomao = None
-
- def test_get_stream_id(self):
-
- # Assert that the stream_id from is correctly extracted from the mock HTML.
- self.assertEqual(self.mock_huomao.get_stream_id(self.mock_html), "9qsvyF24659")
-
- def test_get_stream_quality(self):
-
- # Assert that the stream_url, stream_quality and stream_quality_name
- # is correctly extracted from the mock HTML.
- self.assertEqual(self.mock_huomao.get_stream_info(self.mock_html), [
- ["http://live-ws-hls.huomaotv.cn/live/9qsvyF24659/playlist.m3u8", "source"],
- ["http://live-ws-hls.huomaotv.cn/live/9qsvyF24659_720/playlist.m3u8", "720"],
- ["http://live-ws-hls.huomaotv.cn/live/9qsvyF24659_480/playlist.m3u8", "480"]
- ])
-
def test_can_handle_url(self):
-
- # Assert that an URL containing the http:// prefix is correctly read.
- self.assertTrue(Huomao.can_handle_url("http://www.huomao.com/123456"))
- self.assertTrue(Huomao.can_handle_url("http://www.huomao.tv/123456"))
- self.assertTrue(Huomao.can_handle_url("http://huomao.com/123456"))
- self.assertTrue(Huomao.can_handle_url("http://huomao.tv/123456"))
-
- # Assert that an URL containing the https:// prefix is correctly read.
- self.assertTrue(Huomao.can_handle_url("https://www.huomao.com/123456"))
- self.assertTrue(Huomao.can_handle_url("https://www.huomao.tv/123456"))
- self.assertTrue(Huomao.can_handle_url("https://huomao.com/123456"))
- self.assertTrue(Huomao.can_handle_url("https://huomao.tv/123456"))
-
- # Assert that an URL without the http(s):// prefix is correctly read.
- self.assertTrue(Huomao.can_handle_url("www.huomao.com/123456"))
- self.assertTrue(Huomao.can_handle_url("www.huomao.tv/123456"))
-
- # Assert that an URL without the www prefix is correctly read.
- self.assertTrue(Huomao.can_handle_url("huomao.com/123456"))
- self.assertTrue(Huomao.can_handle_url("huomao.tv/123456"))
-
- # Assert that an URL without a room_id can't be read.
- self.assertFalse(Huomao.can_handle_url("http://www.huomao.com/"))
- self.assertFalse(Huomao.can_handle_url("http://www.huomao.tv/"))
- self.assertFalse(Huomao.can_handle_url("http://huomao.com/"))
- self.assertFalse(Huomao.can_handle_url("http://huomao.tv/"))
- self.assertFalse(Huomao.can_handle_url("https://www.huomao.com/"))
- self.assertFalse(Huomao.can_handle_url("https://www.huomao.tv/"))
- self.assertFalse(Huomao.can_handle_url("https://huomao.com/"))
- self.assertFalse(Huomao.can_handle_url("https://huomao.tv/"))
- self.assertFalse(Huomao.can_handle_url("www.huomao.com/"))
- self.assertFalse(Huomao.can_handle_url("www.huomao.tv/"))
- self.assertFalse(Huomao.can_handle_url("huomao.tv/"))
- self.assertFalse(Huomao.can_handle_url("huomao.tv/"))
-
- # Assert that an URL without "huomao" can't be read.
- self.assertFalse(Huomao.can_handle_url("http://www.youtube.com/123456"))
- self.assertFalse(Huomao.can_handle_url("http://www.youtube.tv/123456"))
- self.assertFalse(Huomao.can_handle_url("http://youtube.com/123456"))
- self.assertFalse(Huomao.can_handle_url("http://youtube.tv/123456"))
- self.assertFalse(Huomao.can_handle_url("https://www.youtube.com/123456"))
- self.assertFalse(Huomao.can_handle_url("https://www.youtube.tv/123456"))
- self.assertFalse(Huomao.can_handle_url("https://youtube.com/123456"))
- self.assertFalse(Huomao.can_handle_url("https://youtube.tv/123456"))
+ should_match = [
+ # Assert that an URL containing the http:// prefix is correctly read.
+ "http://www.huomao.com/123456",
+ "http://www.huomao.tv/123456",
+ "http://huomao.com/123456",
+ "http://huomao.tv/123456",
+ "http://www.huomao.com/video/v/123456",
+ "http://www.huomao.tv/video/v/123456",
+ "http://huomao.com/video/v/123456",
+ "http://huomao.tv/video/v/123456",
+
+ # Assert that an URL containing the https:// prefix is correctly read.
+ "https://www.huomao.com/123456",
+ "https://www.huomao.tv/123456",
+ "https://huomao.com/123456",
+ "https://huomao.tv/123456",
+ "https://www.huomao.com/video/v/123456",
+ "https://www.huomao.tv/video/v/123456",
+ "https://huomao.com/video/v/123456",
+ "https://huomao.tv/video/v/123456",
+
+ # Assert that an URL without the http(s):// prefix is correctly read.
+ "www.huomao.com/123456",
+ "www.huomao.tv/123456",
+ "www.huomao.com/video/v/123456",
+ "www.huomao.tv/video/v/123456",
+
+ # Assert that an URL without the www prefix is correctly read.
+ "huomao.com/123456",
+ "huomao.tv/123456",
+ "huomao.com/video/v/123456",
+ "huomao.tv/video/v/123456",
+ ]
+ for url in should_match:
+ self.assertTrue(Huomao.can_handle_url(url))
+
+ def test_can_handle_url_negative(self):
+ should_not_match = [
+ # Assert that an URL without a room_id can't be read.
+ "http://www.huomao.com/",
+ "http://www.huomao.tv/",
+ "http://huomao.com/",
+ "http://huomao.tv/",
+ "https://www.huomao.com/",
+ "https://www.huomao.tv/",
+ "https://huomao.com/",
+ "https://huomao.tv/",
+ "www.huomao.com/",
+ "www.huomao.tv/",
+ "huomao.tv/",
+ "huomao.tv/",
+
+ # Assert that an URL without "huomao" can't be read.
+ "http://www.youtube.com/123456",
+ "http://www.youtube.tv/123456",
+ "http://youtube.com/123456",
+ "http://youtube.tv/123456",
+ "https://www.youtube.com/123456",
+ "https://www.youtube.tv/123456",
+ "https://youtube.com/123456",
+ "https://youtube.tv/123456",
+ ]
+ for url in should_not_match:
+ self.assertFalse(Huomao.can_handle_url(url))
| Huomao plugin do not work
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
I tried on two computers but the huomao plugin seems not work,it looks like same as issue#2132,maybe the website updated again.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. https://www.huomao.com/9418
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
[cli][debug] OS: Linux-4.20.7-1.el7.elrepo.x86_64-x86_64-with-centos-7.6.1810-Core
[cli][debug] Python: 2.7.5
[cli][debug] Streamlink: 1.0.0
[cli][debug] Requests(2.21.0), Socks(1.6.7), Websocket(0.55.0)
[cli][info] Found matching plugin huomao for URL https://www.huomao.com/9418
[plugin.huomao][error] Failed to extract stream_info.
error: No playable streams found on this URL: https://www.huomao.com/9418
```
And here is my streamlink version, I think it's the latest version.
```
[root@ live]# pip show streamlink
Name: streamlink
Version: 1.0.0
```
| I took a quick look at a random stream and I think the regex just needs to be updated. The current regex assumes the source url ends in playlist.m3u8, but that was not the case for the one I looked at.
Just go to http://www.huomao.com/mobile/mob_live/<id> for a live stream and search for m3u8 and you can use that as a basis for updating the stream_info_pattern.
How can i use http://www.huomao.com/mobile/mob_live/ for the m3u8?
I want to watch https://www.huomao.com/9755
But get the same error like the first post, thank you
| 2020-08-22T02:45:20 |
streamlink/streamlink | 3,131 | streamlink__streamlink-3131 | [
"3130"
] | 38197fa7fd5b54ddc9f34a2f6bf9873438818495 | diff --git a/src/streamlink/plugins/bloomberg.py b/src/streamlink/plugins/bloomberg.py
--- a/src/streamlink/plugins/bloomberg.py
+++ b/src/streamlink/plugins/bloomberg.py
@@ -37,7 +37,7 @@ class Bloomberg(Plugin):
_live_stream_info_module_id_re = re.compile(
r'{(?:(?:"[^"]+"|\w+):(?:\d+|"[^"]+"),)*"(?:[^"]*/)?config/livestreams":(\d+)(?:,(?:"[^"]+"|\w+):(?:\d+|"[^"]+"))*}'
)
- _live_stream_info_re = r'],{id}:\[function\(.+var n=({{.+}});r.default=n}},{{"[^"]+":\d+}}],{next}:\['
+ _live_stream_info_re = r'],{id}:\[function\(.+var n=({{.+}});r.default=n}},{{}}],{next}:\['
_live_streams_schema = validate.Schema(
validate.transform(_js_to_json_re),
| Unable to play bloomberg with streamlink - No playable streams found on this URL
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [X] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
I am attempting to use streamlink to play bloomberg live. However, when attempting to load the URL https://www.bloomberg.com/live/us I receive an error stating there are no playable streams found on this URL.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. I am running this command: streamlink https://www.bloomberg.com/live/us
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
C:\Windows\system32>streamlink https://www.bloomberg.com/live/us -l debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin bloomberg for URL https://www.bloomberg.com/live/us
[plugin.bloomberg][debug] Found liveId: PHOENIX_US
[plugin.bloomberg][debug] Player URL: https://cdn.gotraffic.net/projector/v0.11.192/app.js
[plugin.bloomberg][debug] Webpack module ID: 203
error: No playable streams found on this URL: https://www.bloomberg.com/live/us
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2020-08-27T14:15:54 |
||
streamlink/streamlink | 3,142 | streamlink__streamlink-3142 | [
"3141"
] | d24467f8dd1195ba04bd15569750bf74a21437e6 | diff --git a/src/streamlink/plugins/sportschau.py b/src/streamlink/plugins/sportschau.py
--- a/src/streamlink/plugins/sportschau.py
+++ b/src/streamlink/plugins/sportschau.py
@@ -1,46 +1,52 @@
-import re
-import json
-
-from streamlink.plugin import Plugin
-from streamlink.stream import HDSStream
-from streamlink.utils import update_scheme
-
-_url_re = re.compile(r"http(s)?://(\w+\.)?sportschau.de/")
-_player_js = re.compile(r"https?://deviceids-medp.wdr.de/ondemand/.*\.js")
-
-
-class sportschau(Plugin):
- @classmethod
- def can_handle_url(cls, url):
- return _url_re.match(url)
-
- def _get_streams(self):
- res = self.session.http.get(self.url)
- match = _player_js.search(res.text)
- if match:
- player_js = match.group(0)
- self.logger.info("Found player js {0}", player_js)
- else:
- self.logger.info("Didn't find player js. Probably this page doesn't contain a video")
- return
-
- res = self.session.http.get(player_js)
-
- jsonp_start = res.text.find('(') + 1
- jsonp_end = res.text.rfind(')')
-
- if jsonp_start <= 0 or jsonp_end <= 0:
- self.logger.info("Couldn't extract json metadata from player.js: {0}", player_js)
- return
-
- json_s = res.text[jsonp_start:jsonp_end]
-
- stream_metadata = json.loads(json_s)
-
- hds_url = stream_metadata['mediaResource']['dflt']['videoURL']
- hds_url = update_scheme(self.url, hds_url)
-
- return HDSStream.parse_manifest(self.session, hds_url).items()
-
-
-__plugin__ = sportschau
+import logging
+import re
+
+from streamlink.plugin import Plugin
+from streamlink.plugin.api import validate
+from streamlink.stream import HLSStream
+from streamlink.utils import parse_json, update_scheme
+
+log = logging.getLogger(__name__)
+
+
+class Sportschau(Plugin):
+ _re_url = re.compile(r"https?://(?:\w+\.)*sportschau.de/")
+
+ _re_player = re.compile(r"https?:(//deviceids-medp.wdr.de/ondemand/\S+\.js)")
+ _re_json = re.compile(r"\$mediaObject.jsonpHelper.storeAndPlay\(({.+})\);?")
+
+ _schema_player = validate.Schema(
+ validate.transform(_re_player.search),
+ validate.any(None, validate.Schema(
+ validate.get(1),
+ validate.transform(lambda url: update_scheme("https:", url))
+ ))
+ )
+ _schema_json = validate.Schema(
+ validate.transform(_re_json.match),
+ validate.get(1),
+ validate.transform(parse_json),
+ validate.get("mediaResource"),
+ validate.get("dflt"),
+ validate.get("videoURL"),
+ validate.transform(lambda url: update_scheme("https:", url))
+ )
+
+ @classmethod
+ def can_handle_url(cls, url):
+ return cls._re_url.match(url) is not None
+
+ def _get_streams(self):
+ player_js = self.session.http.get(self.url, schema=self._schema_player)
+ if not player_js:
+ return
+
+ log.debug("Found player js {0}".format(player_js))
+
+ hls_url = self.session.http.get(player_js, schema=self._schema_json)
+
+ for stream in HLSStream.parse_variant_playlist(self.session, hls_url).items():
+ yield stream
+
+
+__plugin__ = Sportschau
| diff --git a/tests/plugins/test_sportschau.py b/tests/plugins/test_sportschau.py
--- a/tests/plugins/test_sportschau.py
+++ b/tests/plugins/test_sportschau.py
@@ -1,20 +1,20 @@
import unittest
-from streamlink.plugins.sportschau import sportschau
+from streamlink.plugins.sportschau import Sportschau
class TestPluginSportschau(unittest.TestCase):
def test_can_handle_url(self):
should_match = [
'http://www.sportschau.de/wintersport/videostream-livestream---wintersport-im-ersten-242.html',
- 'http://www.sportschau.de/weitere/allgemein/video-kite-surf-world-tour-100.html',
+ 'https://www.sportschau.de/weitere/allgemein/video-kite-surf-world-tour-100.html',
]
for url in should_match:
- self.assertTrue(sportschau.can_handle_url(url))
+ self.assertTrue(Sportschau.can_handle_url(url))
def test_can_handle_url_negative(self):
should_not_match = [
'https://example.com/index.html',
]
for url in should_not_match:
- self.assertFalse(sportschau.can_handle_url(url))
+ self.assertFalse(Sportschau.can_handle_url(url))
| sportschau plugin fails with "Unable to parse manifest XML" error
## Plugin Issue
- [x ] This is a plugin issue and I have read the contribution guidelines.
### Description
streamlink errors out when trying to watch a stream on sportschau.de, e.g. https://www.sportschau.de/tourdefrance/live/videostream-livestream---die--etappe-der-tour-de-france-nach-privas-100.html. It errors out with: "error: Unable to parse manifest XML: syntax error: line 1, column 0 (b'#EXTM3U\n#EXT-X-VERSION:3\n#EXT-X ...)"
### Reproduction steps / Explicit stream URLs to test
1. streamlink "https://www.sportschau.de/tourdefrance/live/videostream-livestream---die--etappe-der-tour-de-france-nach-privas-100.html"
### Log output
```
[14:25:23,464][cli][debug] OS: Linux-5.8.4-x86_64-with-glibc2.2.5
[14:25:23,464][cli][debug] Python: 3.8.5
[14:25:23,464][cli][debug] Streamlink: 1.5.0
[14:25:23,464][cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[14:25:23,465][cli][info] Found matching plugin sportschau for URL https://www.sportschau.de/tourdefrance/live/videostream-livestream---die--etappe-der-tour-de-france-nach-privas-100.html
[14:25:23,734][plugin.sportschau][info] Found player js http://deviceids-medp.wdr.de/ondemand/221/2214170.js
error: Unable to parse manifest XML: syntax error: line 1, column 0 (b'#EXTM3U\n#EXT-X-VERSION:3\n#EXT-X ...)
```
### Additional comments, screenshots, etc.
Not sure that I understand the cause of the error, especially as the problematic part seems truncated. This is what the .m3u file looks like:
```
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-INDEPENDENT-SEGMENTS
#EXT-X-STREAM-INF:BANDWIDTH=5388416,AVERAGE-BANDWIDTH=4048000,CODECS="avc1.640020,mp4a.40.2",RESOLUTION=1280x720,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512/ardevent2_geo/master_3680.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=5388416,AVERAGE-BANDWIDTH=4048000,CODECS="avc1.640020,mp4a.40.2",RESOLUTION=1280x720,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512-b/ardevent2_geo/master_3680.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=2758800,AVERAGE-BANDWIDTH=2085600,CODECS="avc1.4d401f,mp4a.40.2",RESOLUTION=960x540,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512/ardevent2_geo/master_1896.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=2758800,AVERAGE-BANDWIDTH=2085600,CODECS="avc1.4d401f,mp4a.40.2",RESOLUTION=960x540,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512-b/ardevent2_geo/master_1896.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=1614976,AVERAGE-BANDWIDTH=1232000,CODECS="avc1.4d401f,mp4a.40.2",RESOLUTION=640x360,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512/ardevent2_geo/master_1120.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=1614976,AVERAGE-BANDWIDTH=1232000,CODECS="avc1.4d401f,mp4a.40.2",RESOLUTION=640x360,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512-b/ardevent2_geo/master_1120.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=860288,AVERAGE-BANDWIDTH=668800,CODECS="avc1.77.30,mp4a.40.2",RESOLUTION=512x288,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512/ardevent2_geo/master_608.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=860288,AVERAGE-BANDWIDTH=668800,CODECS="avc1.77.30,mp4a.40.2",RESOLUTION=512x288,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512-b/ardevent2_geo/master_608.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=482944,AVERAGE-BANDWIDTH=387200,CODECS="avc1.66.30,mp4a.40.2",RESOLUTION=480x270,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512/ardevent2_geo/master_352.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=482944,AVERAGE-BANDWIDTH=387200,CODECS="avc1.66.30,mp4a.40.2",RESOLUTION=480x270,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512-b/ardevent2_geo/master_352.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=294272,AVERAGE-BANDWIDTH=246400,CODECS="avc1.42c015,mp4a.40.2",RESOLUTION=320x180,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512/ardevent2_geo/master_224.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=294272,AVERAGE-BANDWIDTH=246400,CODECS="avc1.42c015,mp4a.40.2",RESOLUTION=320x180,FRAME-RATE=50.000
https://ardevent2.akamaized.net/hls/live/681512-b/ardevent2_geo/master_224.m3u8
```
| 2020-09-02T13:44:51 |
|
streamlink/streamlink | 3,147 | streamlink__streamlink-3147 | [
"3143"
] | d24467f8dd1195ba04bd15569750bf74a21437e6 | diff --git a/src/streamlink/plugins/raiplay.py b/src/streamlink/plugins/raiplay.py
--- a/src/streamlink/plugins/raiplay.py
+++ b/src/streamlink/plugins/raiplay.py
@@ -1,35 +1,54 @@
-from __future__ import print_function
+import logging
import re
+from streamlink.compat import urlparse, urlunparse
from streamlink.plugin import Plugin
-from streamlink.plugin.api import useragents
from streamlink.plugin.api import validate
from streamlink.stream import HLSStream
+from streamlink.utils import parse_json
+
+
+log = logging.getLogger(__name__)
class RaiPlay(Plugin):
- url_re = re.compile(r"https?://(?:www\.)?raiplay\.it/dirette/(\w+)/?")
- stream_re = re.compile(r"data-video-url.*?=.*?\"([^\"]+)\"")
- stream_schema = validate.Schema(
- validate.all(
- validate.transform(stream_re.search),
- validate.any(
- None,
- validate.all(validate.get(1), validate.url())
- )
- )
+ _re_url = re.compile(r"https?://(?:www\.)?raiplay\.it/dirette/(\w+)/?")
+
+ _re_data = re.compile(r"data-video-json\s*=\s*\"([^\"]+)\"")
+ _schema_data = validate.Schema(
+ validate.transform(_re_data.search),
+ validate.any(None, validate.get(1))
+ )
+ _schema_json = validate.Schema(
+ validate.transform(parse_json),
+ validate.get("video"),
+ validate.get("content_url"),
+ validate.url()
)
@classmethod
def can_handle_url(cls, url):
- return cls.url_re.match(url) is not None
+ return cls._re_url.match(url) is not None
def _get_streams(self):
- channel = self.url_re.match(self.url).group(1)
- self.logger.debug("Found channel: {0}", channel)
- stream_url = self.session.http.get(self.url, schema=self.stream_schema)
- if stream_url:
- return HLSStream.parse_variant_playlist(self.session, stream_url, headers={"User-Agent": useragents.CHROME})
+ json_url = self.session.http.get(self.url, schema=self._schema_data)
+ if not json_url:
+ return
+
+ json_url = urlunparse(urlparse(self.url)._replace(path=json_url))
+ log.debug("Found JSON URL: {0}".format(json_url))
+
+ stream_url = self.session.http.get(json_url, schema=self._schema_json)
+ log.debug("Found stream URL: {0}".format(stream_url))
+
+ res = self.session.http.request("HEAD", stream_url)
+ # status code will be 200 even if geo-blocked, so check the returned content-type
+ if not res or not res.headers or res.headers["Content-Type"] == "video/mp4":
+ log.error("Geo-restricted content")
+ return
+
+ for stream in HLSStream.parse_variant_playlist(self.session, stream_url).items():
+ yield stream
__plugin__ = RaiPlay
| raiplay.it
<!--
Thanks for reporting an issue!
USE THE TEMPLATE. Otherwise your issue may be rejected.
This template should only be used if your issue doesn't match the other more specific ones.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue
Please see the text preview to avoid unnecessary formatting errors.
-->
## Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [ ] This is not a bug report, feature request, or plugin issue/request.
- [ ] I have read the contribution guidelines.
### Description
<!-- Explain the issue as thoroughly as you can. -->
### Expected / Actual behavior
<!-- What do you expect to happen, and what is actually happening? -->
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
https://www.raiplay.it/dirette/rai2
2. ...
3. ...
### Logs
<!--
TEXT LOG OUTPUT IS OPTIONAL for generic issues!
However, depending on the issue, log output can be useful for the developers to understand the problem. It also includes information about your platform. If you don't intend to include log output, please at least provide these platform details.
Thanks!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
~$ streamlink --loglevel debug https://www.raiplay.it/dirette/rai2 best --player ffplay
[cli][debug] OS: Linux-5.4.0-42-generic-x86_64-with-glibc2.29
[cli][debug] Python: 3.8.2
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.22.0), Socks(1.6.7), Websocket(0.53.0)
[cli][info] Found matching plugin raiplay for URL https://www.raiplay.it/dirette/rai2
[plugin.raiplay][debug] Found channel: rai2
error: No playable streams found on this URL: https://www.raiplay.it/dirette/rai2
~$
```
### Additional comments, screenshots, etc.
```
:~$ streamlink --version
streamlink 1.5.0
:~
```
same in windows 10
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| It's not a live stream, it's just VODs.
> It's not a live stream, it's just VODs.
> It's not a live stream, it's just VODs.
I'm sorry You are wrong. Please enter in a browser "https://www.raiplay.it/dirette/rai2" and You will see that you reach live stream just clicking on play botton ( the URL field remain unchanged ! "https://www.raiplay.it/dirette/rai2"
I'm sorry You are wrong. Please enter in a browser "
https://www.raiplay.it/dirette/rai2" and You will see that you reach live
stream just clicking on play botton ( the URL field remain unchanged ! "
https://www.raiplay.it/dirette/rai2".
Just for example:
in web browser address:
"https://www.raiplay.it/dirette/rai2"
... stream playing
using video download helper ... copy address ... insert user agent
then:
ffplay -user_agent "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0)
Gecko/20100101 Firefox/80.0" -i "
https://raidue1-live.akamaized.net/hls/live/598310/raidue1/raidue1/rai2_2400/exp=1599217615~acl=%2fhls%2flive%2f598310%2fraidue1%2f*!%2fhls%2flive%2f598310-b%2fraidue1%2f*!%2f*.key~data=hdntl~hmac=49b0cd0797a4ba799cfb290649c38f6a8fe88c4614224c41008a905217bc2549/chunklist.m3u8?aka_me_session_id=AAAAAAAAAADPH1JfAAAAAJw6HTo7gjvcyNGzLfZMeLFLSx9amXBd+hR0pzbTjDi0l8hGOdkbTy8RvHNoxvp1mhViuL6SMRPt"
play LIVE stream ....
bye for now
On Thu, Sep 3, 2020 at 1:37 AM Forrest <[email protected]> wrote:
> Closed #3143 <https://github.com/streamlink/streamlink/issues/3143>.
>
> —
> You are receiving this because you authored the thread.
> Reply to this email directly, view it on GitHub
> <https://github.com/streamlink/streamlink/issues/3143#event-3722210300>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/AIAGSI42E3SDGVLU3SR4K3DSD3JMXANCNFSM4QTMFHTA>
> .
>
I can't access the video stream itself because it's geo-restricted to Italy. When I visited the URL before, as well as now and did a translation on the title and description it's just a "live" stream of pre-recorded content, and in this case a movie from 2006. That's basically just a bunch of VODs pushed in to a live stream and I don't believe it counts. Please show me a link to live content that is occurring now, not pre-recorded content.
@gravyboat, try: https://www.raiplay.it/dirette/rainews24 for an unrestricted channel. It appears there are URL params on the playlist, but not the individual chunklists:
```
streamlink hls://https://rainews1-live.akamaized.net/hls/live/598326/rainews1/rainews1/rainews_1200/chunklist.m3u8 live
[cli][info] Found matching plugin hls for URL hls://https://rainews1-live.akamaized.net/hls/live/598326/rainews1/rainews1/rainews_1200/chunklist.m3u8
[cli][info] Available streams: live (worst, best)
[cli][info] Opening stream: live (hls)
[cli][info] Starting player: mpv
[cli][info] Player closed
[cli][info] Stream ended
[cli][info] Closing currently open stream...
```
Reopening, since there are a couple of live streams (news channels).
@writetome1
Plugin requests should be as detailed as possible with enough information, so please don't wonder if your thread gets closed if it doesn't meet the requirements. Take a look here:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#plugin-requests
----
> try: [raiplay.it/dirette/rainews24](https://www.raiplay.it/dirette/rainews24) for an unrestricted channel
This one does indeed work with a non-italian IP, but everything else is geo-restricted. It looks like it doesn't make much of a difference though, as you can still make the necessary requests to get to the HLS playlist.
1. Find the DOM element with the `data-video-json` attribute and replace the path segment of the input URL with its value
`https://www.raiplay.it/dirette/rai1` => `https://www.raiplay.it/dirette/rai1.json`
2. Request the video JSON URL, parse it as JSON and find the `video.content_url` value. Optionally replace the HTTP scheme with HTTPS.
`https://mediapolis.rai.it/relinker/relinkerServlet.htm?cont=2606803`
3. That relinker URL will either redirect to the live stream's HLS playlist, or a mp4 file if it's geo-blocked.
Didn't realize and didn't check that we already had a plugin for this site. Relabeling... | 2020-09-04T09:06:42 |
|
streamlink/streamlink | 3,150 | streamlink__streamlink-3150 | [
"3148"
] | d24467f8dd1195ba04bd15569750bf74a21437e6 | diff --git a/src/streamlink/plugins/crunchyroll.py b/src/streamlink/plugins/crunchyroll.py
--- a/src/streamlink/plugins/crunchyroll.py
+++ b/src/streamlink/plugins/crunchyroll.py
@@ -10,7 +10,6 @@
log = logging.getLogger(__name__)
-
STREAM_WEIGHTS = {
"low": 240,
"mid": 420,
@@ -72,7 +71,7 @@ def parse_timestamp(ts):
validate.get("stream_data")
)
_login_schema = validate.Schema({
- "auth": validate.text,
+ "auth": validate.any(validate.text, None),
"expires": validate.all(
validate.text,
validate.transform(parse_timestamp)
@@ -214,9 +213,16 @@ def login(self, username, password):
return login
def authenticate(self):
- data = self._api_call("authenticate", {"auth": self.auth}, schema=_login_schema)
- self.auth = data["auth"]
- self.cache.set("auth", data["auth"], expires_at=data["expires"])
+ try:
+ data = self._api_call("authenticate", {"auth": self.auth}, schema=_login_schema)
+ except CrunchyrollAPIError:
+ self.auth = None
+ self.cache.set("auth", None, expires_at=0)
+ log.warning("Saved credentials have expired")
+ return
+
+ log.debug("Credentials expire at: {}".format(data["expires"]))
+ self.cache.set("auth", self.auth, expires_at=data["expires"])
return data
def get_info(self, media_id, fields=None, schema=None):
@@ -321,7 +327,7 @@ def _get_streams(self):
# The adaptive quality stream sometimes a subset of all the other streams listed, ultra is no included
has_adaptive = any([s[u"quality"] == u"adaptive" for s in info[u"streams"]])
if has_adaptive:
- self.logger.debug(u"Loading streams from adaptive playlist")
+ log.debug(u"Loading streams from adaptive playlist")
for stream in filter(lambda x: x[u"quality"] == u"adaptive", info[u"streams"]):
for q, s in HLSStream.parse_variant_playlist(self.session, stream[u"url"]).items():
# rename the bitrates to low, mid, or high. ultra doesn't seem to appear in the adaptive streams
@@ -361,27 +367,28 @@ def _create_api(self):
locale=locale)
if not self.get_option("session_id"):
- self.logger.debug("Creating session with locale: {0}", locale)
+ log.debug("Creating session with locale: {0}", locale)
api.start_session()
if api.auth:
- self.logger.debug("Using saved credentials")
+ log.debug("Using saved credentials")
login = api.authenticate()
- self.logger.info("Successfully logged in as '{0}'",
- login["user"]["username"] or login["user"]["email"])
- elif self.options.get("username"):
+ if login:
+ log.info("Successfully logged in as '{0}'",
+ login["user"]["username"] or login["user"]["email"])
+ if not api.auth and self.options.get("username"):
try:
- self.logger.debug("Attempting to login using username and password")
+ log.debug("Attempting to login using username and password")
api.login(self.options.get("username"),
self.options.get("password"))
login = api.authenticate()
- self.logger.info("Logged in as '{0}'",
- login["user"]["username"] or login["user"]["email"])
+ log.info("Logged in as '{0}'",
+ login["user"]["username"] or login["user"]["email"])
except CrunchyrollAPIError as err:
raise PluginError(u"Authentication error: {0}".format(err.msg))
- else:
- self.logger.warning(
+ if not api.auth:
+ log.warning(
"No authentication provided, you won't be able to access "
"premium restricted content"
)
| Unable to purge crunchyroll credentials or reauthenticate
## Bug Report
- [x] This is a bug report and I have read the contribution guidelines.
### Description
Once your crunchyroll credentials expire, it seems like you can no longer purge them using --crunchyroll-purge-credentials or reauthenticate (if you delete your existing credentials from appdata).
### Expected / Actual behavior
Earlier, both purge and reauthenticating failed with
```error: Unable to validate API response: Unable to validate key 'auth': Type of None should be 'str' but is 'NoneType'```
Now they fail with:
```
Traceback (most recent call last):
File "runpy.py", line 193, in _run_module_as_main
File "runpy.py", line 85, in _run_code
File "C:\Users\kg\AppData\Local\Streamlink\bin\streamlink.exe\__main__.py", line 18, in <module>
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink_cli\main.py", line 1024, in main
handle_url()
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink_cli\main.py", line 585, in handle_url
streams = fetch_streams(plugin)
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink_cli\main.py", line 465, in fetch_streams
sorting_excludes=args.stream_sorting_excludes)
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\plugin\plugin.py", line 317, in streams
ostreams = self._get_streams()
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 306, in _get_streams
api = self._create_api()
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 369, in _create_api
login = api.authenticate()
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 217, in authenticate
data = self._api_call("authenticate", {"auth": self.auth}, schema=_login_schema)
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 173, in _api_call
raise CrunchyrollAPIError(err_msg, err_code)
streamlink.plugin.crunchyroll.CrunchyrollAPIError: User could not be found.
```
### Reproduction steps / Explicit stream URLs to test
```streamlink https://www.crunchyroll.com/my-teen-romantic-comedy-snafu/episode-9-a-whiff-of-that-fragrance-will-always-bring-memories-of-that-season-796536 best -o oregairu9.mkv```
I have a username and password in my streamlinkrc, and I successfully downloaded an episode from CR about 2 days ago. I'm logged into the CR website right now so I don't think anything is wrong with my account.
### Log output
```
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin crunchyroll for URL https://www.crunchyroll.com/my-teen-romantic-comedy-snafu/episode-9-a-whiff-of-that-fragrance-will-always-bring-memories-of-that-season-796536
[cli][debug] Plugin specific arguments:
[cli][debug] --crunchyroll-username=******** (username)
[cli][debug] --crunchyroll-password=******** (password)
[utils.l10n][debug] Language code: en_US
[plugin.crunchyroll][debug] Creating session with locale: en_US
[plugin.crunchyroll][debug] Session created with ID: c492ba4c706943f73dbf9819a8237465
[plugin.crunchyroll][debug] Using saved credentials
Traceback (most recent call last):
File "runpy.py", line 193, in _run_module_as_main
File "runpy.py", line 85, in _run_code
File "C:\Users\kg\AppData\Local\Streamlink\bin\streamlink.exe\__main__.py", line 18, in <module>
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink_cli\main.py", line 1024, in main
handle_url()
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink_cli\main.py", line 585, in handle_url
streams = fetch_streams(plugin)
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink_cli\main.py", line 465, in fetch_streams
sorting_excludes=args.stream_sorting_excludes)
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\plugin\plugin.py", line 317, in streams
ostreams = self._get_streams()
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 306, in _get_streams
api = self._create_api()
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 369, in _create_api
login = api.authenticate()
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 217, in authenticate
data = self._api_call("authenticate", {"auth": self.auth}, schema=_login_schema)
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 173, in _api_call
raise CrunchyrollAPIError(err_msg, err_code)
streamlink.plugin.crunchyroll.CrunchyrollAPIError: User could not be found.
```
### Additional comments, screenshots, etc.
| 2020-09-04T15:17:15 |
||
streamlink/streamlink | 3,155 | streamlink__streamlink-3155 | [
"3133"
] | c30a59f9a72947cd1a4129d250274149fb1cd847 | diff --git a/src/streamlink/plugins/svtplay.py b/src/streamlink/plugins/svtplay.py
--- a/src/streamlink/plugins/svtplay.py
+++ b/src/streamlink/plugins/svtplay.py
@@ -1,92 +1,148 @@
+import logging
import re
-from streamlink.plugin import Plugin
-from streamlink.plugin.api import StreamMapper, validate
-from streamlink.stream import HLSStream, HDSStream
+from streamlink.compat import urljoin
+from streamlink.plugin import Plugin, PluginArguments, PluginArgument
+from streamlink.plugin.api import validate
+from streamlink.stream import DASHStream, HTTPStream
+from streamlink.stream.ffmpegmux import MuxedStream
-API_URL = "http://www.svt.se/videoplayer-api/video/{0}"
-
-_url_re = re.compile(r"""
- http(s)?://
- (www\.)?
- (?:
- svtplay |
- svtflow |
- oppetarkiv
- )
- .se
-""", re.VERBOSE)
-
-# Regex to match video ID
-_id_re = re.compile(r"""data-video-id=['"](?P<id>[^'"]+)['"]""")
-_old_id_re = re.compile(r"/(?:video|klipp)/(?P<id>[0-9]+)/")
-
-# New video schema used with API call
-_video_schema = validate.Schema(
- {
- "videoReferences": validate.all(
- [{
- "url": validate.text,
- "format": validate.text
- }],
- ),
- },
- validate.get("videoReferences")
-)
-
-# Old video schema
-_old_video_schema = validate.Schema(
- {
- "video": {
- "videoReferences": validate.all(
- [{
- "url": validate.text,
- "playerType": validate.text
- }],
- ),
- }
- },
- validate.get("video"),
- validate.get("videoReferences")
-)
+log = logging.getLogger(__name__)
class SVTPlay(Plugin):
+ api_url = 'https://api.svt.se/videoplayer-api/video/{0}'
+
+ author = None
+ category = None
+ title = None
+
+ url_re = re.compile(r'''
+ https?://(?:www\.)?(?:svtplay|oppetarkiv)\.se
+ (/(kanaler/)?.*)
+ ''', re.VERBOSE)
+
+ latest_episode_url_re = re.compile(r'''
+ class="play_titlepage__latest-video"\s+href="(?P<url>[^"]+)"
+ ''', re.VERBOSE)
+
+ live_id_re = re.compile(r'.*/(?P<live_id>[^?]+)')
+
+ vod_id_re = re.compile(r'''
+ (?:DATA_LAKE\s+=\s+{"content":{"id":|"svtId":|data-video-id=)
+ "(?P<vod_id>[^"]+)"
+ ''', re.VERBOSE)
+
+ _video_schema = validate.Schema({
+ validate.optional('programTitle'): validate.text,
+ validate.optional('episodeTitle'): validate.text,
+ 'videoReferences': [{
+ 'url': validate.url(),
+ 'format': validate.text,
+ }],
+ validate.optional('subtitleReferences'): [{
+ 'url': validate.url(),
+ 'format': validate.text,
+ }],
+ })
+
+ arguments = PluginArguments(
+ PluginArgument(
+ 'mux-subtitles',
+ action='store_true',
+ help="Automatically mux available subtitles in to the output stream.",
+ ),
+ )
+
@classmethod
- def can_handle_url(self, url):
- return _url_re.match(url)
+ def can_handle_url(cls, url):
+ return cls.url_re.match(url) is not None
- def _create_streams(self, stream_type, parser, video):
- try:
- streams = parser(self.session, video["url"])
- return streams.items()
- except IOError as err:
- self.logger.error("Failed to extract {0} streams: {1}",
- stream_type, err)
+ def get_author(self):
+ if self.author is not None:
+ return self.author
- def _get_streams(self):
- # Retrieve URL page and search for new type of video ID
- res = self.session.http.get(self.url)
- match = _id_re.search(res.text)
+ def get_category(self):
+ if self.category is not None:
+ return self.category
- # Use API if match, otherwise resort to old method
- if match:
- vid = match.group("id")
- res = self.session.http.get(API_URL.format(vid))
+ def get_title(self):
+ if self.title is not None:
+ return self.title
- videos = self.session.http.json(res, schema=_video_schema)
- mapper = StreamMapper(cmp=lambda format, video: video["format"] == format)
- mapper.map("hls", self._create_streams, "HLS", HLSStream.parse_variant_playlist)
- mapper.map("hds", self._create_streams, "HDS", HDSStream.parse_manifest)
- else:
- res = self.session.http.get(self.url, params=dict(output="json"))
- videos = self.session.http.json(res, schema=_old_video_schema)
+ def _set_metadata(self, data, category):
+ if 'programTitle' in data:
+ self.author = data['programTitle']
+
+ self.category = category
- mapper = StreamMapper(cmp=lambda type, video: video["playerType"] == type)
- mapper.map("ios", self._create_streams, "HLS", HLSStream.parse_variant_playlist)
- mapper.map("flash", self._create_streams, "HDS", HDSStream.parse_manifest)
+ if 'episodeTitle' in data:
+ self.title = data['episodeTitle']
- return mapper(videos)
+ def _get_live(self, path):
+ match = self.live_id_re.search(path)
+ if match is None:
+ return
+
+ live_id = "ch-{0}".format(match.group('live_id'))
+ log.debug("Live ID={0}".format(live_id))
+
+ res = self.session.http.get(self.api_url.format(live_id))
+ api_data = self.session.http.json(res, schema=self._video_schema)
+
+ self._set_metadata(api_data, 'Live')
+
+ for playlist in api_data['videoReferences']:
+ if playlist['format'] == 'dashhbbtv':
+ for s in DASHStream.parse_manifest(self.session, playlist['url']).items():
+ yield s
+
+ def _get_vod(self):
+ res = self.session.http.get(self.url)
+ match = self.latest_episode_url_re.search(res.text)
+ if match:
+ res = self.session.http.get(
+ urljoin(self.url, match.group('url')),
+ )
+
+ match = self.vod_id_re.search(res.text)
+ if match is None:
+ return
+
+ vod_id = match.group('vod_id')
+ log.debug("VOD ID={0}".format(vod_id))
+
+ res = self.session.http.get(self.api_url.format(vod_id))
+ api_data = self.session.http.json(res, schema=self._video_schema)
+
+ self._set_metadata(api_data, 'VOD')
+
+ substreams = {}
+ if 'subtitleReferences' in api_data:
+ for subtitle in api_data['subtitleReferences']:
+ if subtitle['format'] == 'webvtt':
+ log.debug("Subtitle={0}".format(subtitle['url']))
+ substreams[subtitle['format']] = HTTPStream(
+ self.session,
+ subtitle['url'],
+ )
+
+ for manifest in api_data['videoReferences']:
+ if manifest['format'] == 'dashhbbtv':
+ for q, s in DASHStream.parse_manifest(self.session, manifest['url']).items():
+ if self.get_option('mux_subtitles') and substreams:
+ yield q, MuxedStream(self.session, s, subtitles=substreams)
+ else:
+ yield q, s
+
+ def _get_streams(self):
+ path, live = self.url_re.match(self.url).groups()
+ log.debug("Path={0}".format(path))
+
+ if live:
+ return self._get_live(path)
+ else:
+ return self._get_vod()
__plugin__ = SVTPlay
| diff --git a/tests/plugins/test_svtplay.py b/tests/plugins/test_svtplay.py
--- a/tests/plugins/test_svtplay.py
+++ b/tests/plugins/test_svtplay.py
@@ -6,13 +6,29 @@
class TestPluginSVTPlay(unittest.TestCase):
def test_can_handle_url(self):
should_match = [
- 'https://www.svtplay.se/video/16567350?start=auto',
+ 'https://www.svtplay.se/kanaler/svt1',
+ 'https://www.svtplay.se/kanaler/svt2?start=auto',
+ 'https://www.svtplay.se/kanaler/svtbarn',
+ 'https://www.svtplay.se/kanaler/kunskapskanalen?start=auto',
+ 'https://www.svtplay.se/kanaler/svt24?start=auto',
+ 'https://www.svtplay.se/video/27659457/den-giftbla-floden?start=auto',
+ 'https://www.svtplay.se/video/27794015/100-vaginor',
+ 'https://www.svtplay.se/video/28065172/motet/motet-sasong-1-det-skamtar-du-inte-om',
+ 'https://www.svtplay.se/dokument-inifran-att-radda-ett-barn',
+ 'https://www.oppetarkiv.se/video/1399273/varfor-ar-det-sa-ont-om-q-avsnitt-1-av-5',
+ 'https://www.oppetarkiv.se/video/2781201/karlekens-mirakel',
+ 'https://www.oppetarkiv.se/video/10354325/studio-pop',
+ 'https://www.oppetarkiv.se/video/5792180/studio-pop-david-bowie',
+ 'https://www.oppetarkiv.se/video/2923832/hipp-hipp-sasong-2-avsnitt-3-av-7',
+ 'https://www.oppetarkiv.se/video/3945501/cccp-hockey-cccp-hockey',
]
for url in should_match:
self.assertTrue(SVTPlay.can_handle_url(url))
def test_can_handle_url_negative(self):
should_not_match = [
+ 'http://www.svtflow.se/video/2020285/avsnitt-6',
+ 'https://www.svtflow.se/video/2020285/avsnitt-6',
'https://example.com/index.html',
]
for url in should_not_match:
| Svtplay's Plugin is currently broken
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
The svtplay plugin seems to be broken. Every url I have tested yield the same error. Other Swedish geo-restricted sites work fine.
I'm on the latest streamlink 1.5.0 on Windows 10.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. Go to Svtplay.se with a Swedish Ip, Vpn or Proxy.
2. Pick some show and it's URL
3. Try to stream it with streamlink
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
streamlink https://www.svtplay.se/video/27096341/sportnytt/sportnytt-28-aug-22-00-3
[cli][info] Found matching plugin svtplay for URL https://www.svtplay.se/video/27096341/sportnytt/sportnytt-28-aug-22-00-3
error: Unable to parse JSON: Expecting value: line 1 column 1 (char 0) ('<!DOCTYPE html>\n\n<head>\n <me ...)
```
### Additional comments, screenshots, etc.
Thanks a lot for your support!
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| @kvn1351, I have updated the regex. You can get the whole plugin for testing from:
https://github.com/mkbloke/streamlink/blob/svtplay/src/streamlink/plugins/svtplay.py
Just select raw, then file/save as in your browser to download it.
~~Alternatively, you can just edit your existing plugin to update the regex on line 21 to:~~
~~```_id_re = re.compile(r'DATA_LAKE = {"content":{"id":"(?P<id>[^"]+)"')```~~
If the plugin works for you with that change, I'll create a PR for it. Cheers.
@kvn1351, just to add, if you can test the change against a number of different URLs, that would be very helpful, thanks.
I've just pushed another minor improvement on this plugin, so rather than changing the single line as I mentioned previously, it would be better to download the whole updated plugin from:
https://github.com/mkbloke/streamlink/blob/svtplay/src/streamlink/plugins/svtplay.py
The minor improvement allows the plugin to also pick up the correct video page when given a landing page like:
https://www.svtplay.se/dokument-inifran-att-radda-ett-barn
Cheers.
It still does not work for the direct channel pages like:
https://www.svtplay.se/kanaler/svt1
Worked fine there before so the change they have done also makes this page fail.
Thanks for the report, @DanOscarsson.
I think I'm going to somewhat start from the beginning with this plugin, gathering the possible URLs under svtplay.se and oppetarkiv.se to start with, with a view to removing the support for the 'old' format if I cannot find any URLs where keeping it would be necessary.
I'll likely also drop support for svtflow.se unless I can find any reason for keeping it, as the one URL to content on svtflow.se that I've found with a Google search just results in a redirect to the home page on svtplay.se.
Let me know if I can assist in any way.
Hi all. I've been testing this updated plugin on various URLs for both svtplay.se and oppetarkiv.se sites. It seems to be working, so if anybody would like to test and report back, that would be most welcome.
I've pushed the most recent changes to: https://github.com/mkbloke/streamlink/blob/svtplay/src/streamlink/plugins/svtplay.py
This plugin now supports the ```--title``` option, where data is available, so you can for example use:
```--title '{title} - {author} - {category}'```
You can also multiplex in subtitles for VODs where they are available using the ```--svtplay-mux-subtitles``` option.
Cheers.
Hello!
I can confirm that it works for the following URLs:
- https://www.svtplay.se/kanaler/svt1?start=auto
- https://www.svtplay.se/kanaler/svt2?start=auto
- https://www.svtplay.se/kanaler/kunskapskanalen?start=auto
- https://www.svtplay.se/kanaler/svtbarn?start=auto
- https://www.svtplay.se/kanaler/svt24?start=auto
I have not tested the options though.
Great work!
Thanks for the feedback. | 2020-09-07T14:24:18 |
streamlink/streamlink | 3,173 | streamlink__streamlink-3173 | [
"3170"
] | f09bf6e04cddc78eceb9ded655f716ef3ee4b84f | diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -328,7 +328,7 @@ def streams(self, channel_id, **params):
# Private API calls
def access_token(self, endpoint, asset, **params):
- return self.call("/api/{0}/{1}/access_token".format(endpoint, asset), private=True, **params)
+ return self.call("/api/{0}/{1}/access_token".format(endpoint, asset), private=True, **dict(platform="_", **params))
def hosted_channel(self, **params):
return self.call_subdomain("tmi", "/hosts", format="", **params)
| plugins.twitch: block ads using the same method as uBlock
Implements [uBlock's method](https://github.com/gorhill/uBlock/blob/da7ff2b382c0382e044a4fc2523018a3ea388322/assets/resources/scriptlets.js#L1221-L1225) of blocking ads on twitch. Which basically involves putting the `platform=_` parameter in the `access_token` URLs. Doing that removes ad segments from the stream.
I removed the tests related to removing ad segments since that isn't done anymore. I'm not sure how I'd test the new way of disabling ads so I didn't add any tests.
Also closes #3120 as passthrough should now be compatible with disabling ads.
| # [Codecov](https://codecov.io/gh/streamlink/streamlink/pull/3170?src=pr&el=h1) Report
> Merging [#3170](https://codecov.io/gh/streamlink/streamlink/pull/3170?src=pr&el=desc) into [master](https://codecov.io/gh/streamlink/streamlink/commit/f09bf6e04cddc78eceb9ded655f716ef3ee4b84f?el=desc) will **decrease** coverage by `0.00%`.
> The diff coverage is `0.00%`.
```diff
@@ Coverage Diff @@
## master #3170 +/- ##
==========================================
- Coverage 52.67% 52.66% -0.01%
==========================================
Files 244 244
Lines 15636 15637 +1
==========================================
- Hits 8236 8235 -1
- Misses 7400 7402 +2
```
We've already had the `platform=_` parameter added once and it worked for only a few days until Twitch made further changes.
#2358
~~https://github.com/streamlink/streamlink/issues/2357#issuecomment-474044718 (edit: wrong thread, we've had multiple thread, but I can't find the other one right now)~~
#2368
Then we removed it again:
#2692
Even if this seems to be working right now, I doubt that it will keep working.
If we decide to re-add this request parameter, then the only change should be the parameter itself (#2358), and the `--twitch-disable-ads` logic should not be removed.
It does seem like the parameter isn't a very consistent fix, sorry I didn't see that. I've changed it so the only changes are adding the parameter if the user asks for ads to be disabled.
It really needs to be merged as soon as possible, otherwise the low latency streaming with no ads is unusable.
> adding the parameter if the user asks for ads to be disabled
The `twitch-disable-ads` parameter shouldn't be checked here, because its purpose is to change the HLS client logic. Acquiring an access token and setting the `platform=_` request parameter however should also work when the user is querying the resolved HLS stream URL when setting the `--stream-url` or `--player-passthrough=hls` parameters for example, which means the `platform=_` request parameter should be applied in all cases (see 1bb3f86f3f27c07c07d67a3c01884f654646b5e4). Please fix this, otherwise I'll have to re-apply 1bb3f86f3f27c07c07d67a3c01884f654646b5e4, which I don't want to do because you made this suggestion of (re-)adding the request parameter. Thanks.
> otherwise the low latency streaming with no ads is unusable.
Not true. The LL streaming still works fine when there are preroll ads.
See https://github.com/streamlink/streamlink/issues/3120#issuecomment-691104049
I've submitted #3169 yesterday with a fix for that incorrect info log message, but it hasn't been reviewed yet. Just ignore the incorrect info message for now.
> > adding the parameter if the user asks for ads to be disabled
>
> The `twitch-disable-ads` parameter shouldn't be checked here, because its purpose is to change the HLS client logic. Acquiring an access token and setting the `platform=_` request parameter however should also work when the user is querying the resolved HLS stream URL when setting the `--stream-url` or `--player-passthrough=hls` parameters for example, which means the `platform=_` request parameter should be applied in all cases (see [1bb3f86](https://github.com/streamlink/streamlink/commit/1bb3f86f3f27c07c07d67a3c01884f654646b5e4)). Please fix this, otherwise I'll have to re-apply [1bb3f86](https://github.com/streamlink/streamlink/commit/1bb3f86f3f27c07c07d67a3c01884f654646b5e4), which I don't want to do because you made this suggestion of (re-)adding the request parameter. Thanks.
>
> > otherwise the low latency streaming with no ads is unusable.
>
> Not true. The LL streaming still works fine when there are preroll ads.
> See [#3120 (comment)](https://github.com/streamlink/streamlink/issues/3120#issuecomment-691104049)
> I've submitted #3169 yesterday with a fix for that incorrect info log message, but it hasn't been reviewed yet. Just ignore the incorrect info message for now.
I saw another thread said that it was a player problem, but MPV didn't have this problem with streamlink, why?
Did Twitch change something?
This is unrelated to this PR and shouldn't be discussed here.
I've also answered this plenty of times.
https://github.com/streamlink/streamlink/issues/3165#issuecomment-691366440 | 2020-09-14T09:21:12 |
|
streamlink/streamlink | 3,185 | streamlink__streamlink-3185 | [
"3184"
] | ebc791a4422773466eb36fb507e68e8fb8b82931 | diff --git a/src/streamlink/plugins/tv360.py b/src/streamlink/plugins/tv360.py
--- a/src/streamlink/plugins/tv360.py
+++ b/src/streamlink/plugins/tv360.py
@@ -1,5 +1,3 @@
-from __future__ import print_function
-
import re
from streamlink.plugin import Plugin
@@ -9,11 +7,11 @@
class TV360(Plugin):
url_re = re.compile(r"https?://(?:www.)?tv360.com.tr/canli-yayin")
- hls_re = re.compile(r'''hls.loadSource\(["'](http.*m3u8)["']\)''', re.DOTALL)
+ hls_re = re.compile(r'''src="(http.*m3u8)"''')
hls_schema = validate.Schema(
validate.transform(hls_re.search),
- validate.any(None, validate.all(validate.get(1)))
+ validate.any(None, validate.all(validate.get(1), validate.url()))
)
@classmethod
@@ -21,11 +19,10 @@ def can_handle_url(cls, url):
return cls.url_re.match(url) is not None
def _get_streams(self):
- res = self.session.http.get(self.url)
- hls_url = self.hls_re.search(res.text)
+ hls_url = self.session.http.get(self.url, schema=self.hls_schema)
if hls_url:
- return HLSStream.parse_variant_playlist(self.session, hls_url.group(1))
+ return HLSStream.parse_variant_playlist(self.session, hls_url)
__plugin__ = TV360
| tv360.com.tr no playable stream
## Bug Report
- [x] This is a bug report and I have read the contribution guidelines.
### Description
can't find playable stream.
### Expected / Actual behavior
stream supposed to be found
### Reproduction steps / Explicit stream URLs to test
``` 1. streamlink https://www.tv360.com.tr/canli-yayin ```
### Log output
```
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.8.2
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin tv360 for URL tv360.com.tr/canli-yayin
error: No playable streams found on this URL: tv360.com.tr/canli-yayin
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2020-09-17T22:05:55 |
||
streamlink/streamlink | 3,187 | streamlink__streamlink-3187 | [
"3165"
] | 3a57a3ac6211b22843505c53a3466f8719dc3bdf | diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -17,7 +17,8 @@
from streamlink.stream import (
HTTPStream, HLSStream, FLVPlaylist, extract_flv_header_tags
)
-from streamlink.stream.hls import HLSStreamReader, HLSStreamWriter, HLSStreamWorker
+from streamlink.stream.hls import HLSStreamWorker
+from streamlink.stream.hls_filtered import FilteredHLSStreamWriter, FilteredHLSStreamReader
from streamlink.stream.hls_playlist import M3U8Parser, load as load_hls_playlist
from streamlink.utils.times import hours_minutes_seconds
@@ -199,13 +200,12 @@ def process_sequences(self, playlist, sequences):
return super(TwitchHLSStreamWorker, self).process_sequences(playlist, sequences)
-class TwitchHLSStreamWriter(HLSStreamWriter):
- def write(self, sequence, *args, **kwargs):
- if not (self.stream.disable_ads and sequence.segment.ad):
- return super(TwitchHLSStreamWriter, self).write(sequence, *args, **kwargs)
+class TwitchHLSStreamWriter(FilteredHLSStreamWriter):
+ def should_filter_sequence(self, sequence):
+ return self.stream.disable_ads and sequence.segment.ad
-class TwitchHLSStreamReader(HLSStreamReader):
+class TwitchHLSStreamReader(FilteredHLSStreamReader):
__worker__ = TwitchHLSStreamWorker
__writer__ = TwitchHLSStreamWriter
diff --git a/src/streamlink/stream/hls_filtered.py b/src/streamlink/stream/hls_filtered.py
new file mode 100644
--- /dev/null
+++ b/src/streamlink/stream/hls_filtered.py
@@ -0,0 +1,53 @@
+import logging
+from threading import Event
+
+from .hls import HLSStreamWriter, HLSStreamReader
+
+
+log = logging.getLogger(__name__)
+
+
+class FilteredHLSStreamWriter(HLSStreamWriter):
+ def should_filter_sequence(self, sequence):
+ return False
+
+ def write(self, sequence, *args, **kwargs):
+ if not self.should_filter_sequence(sequence):
+ try:
+ return super(FilteredHLSStreamWriter, self).write(sequence, *args, **kwargs)
+ finally:
+ # unblock reader thread after writing data to the buffer
+ if not self.reader.filter_event.is_set():
+ log.info("Resuming stream output")
+ self.reader.filter_event.set()
+
+ # block reader thread if filtering out segments
+ elif self.reader.filter_event.is_set():
+ log.info("Filtering out segments and pausing stream output")
+ self.reader.filter_event.clear()
+
+
+class FilteredHLSStreamReader(HLSStreamReader):
+ def __init__(self, *args, **kwargs):
+ super(FilteredHLSStreamReader, self).__init__(*args, **kwargs)
+ self.filter_event = Event()
+ self.filter_event.set()
+
+ def read(self, size):
+ while True:
+ try:
+ return super(FilteredHLSStreamReader, self).read(size)
+ except IOError:
+ # wait indefinitely until filtering ends
+ self.filter_event.wait()
+ if self.buffer.closed:
+ return b""
+ # if data is available, try reading again
+ if self.buffer.length > 0:
+ continue
+ # raise if not filtering and no data available
+ raise
+
+ def close(self):
+ super(FilteredHLSStreamReader, self).close()
+ self.filter_event.set()
| diff --git a/tests/streams/test_hls_filtered.py b/tests/streams/test_hls_filtered.py
new file mode 100644
--- /dev/null
+++ b/tests/streams/test_hls_filtered.py
@@ -0,0 +1,263 @@
+import requests_mock
+from tests.mock import MagicMock, call, patch
+import unittest
+
+import itertools
+from textwrap import dedent
+from threading import Event, Thread
+
+from streamlink.session import Streamlink
+from streamlink.stream.hls import HLSStream
+from streamlink.stream.hls_filtered import FilteredHLSStreamWriter, FilteredHLSStreamReader
+
+
+class _TestSubjectFilteredHLSStreamWriter(FilteredHLSStreamWriter):
+ def __init__(self, *args, **kwargs):
+ super(_TestSubjectFilteredHLSStreamWriter, self).__init__(*args, **kwargs)
+ self.write_wait = Event()
+ self.write_done = Event()
+
+ def write(self, *args, **kwargs):
+ # only write once per step
+ self.write_wait.wait()
+ self.write_wait.clear()
+
+ # don't write again during cleanup
+ if self.closed:
+ return
+
+ super(_TestSubjectFilteredHLSStreamWriter, self).write(*args, **kwargs)
+
+ # notify main thread that writing has finished
+ self.write_done.set()
+
+
+class _TestSubjectFilteredHLSReader(FilteredHLSStreamReader):
+ __writer__ = _TestSubjectFilteredHLSStreamWriter
+
+
+class _TestSubjectReadThread(Thread):
+ """
+ Run the reader on a separate thread, so that each read can be controlled from within the main thread
+ """
+ def __init__(self, segments, playlists):
+ Thread.__init__(self)
+ self.daemon = True
+
+ self.mocks = mocks = {}
+ self.mock = requests_mock.Mocker()
+ self.mock.start()
+
+ def addmock(method, url, *args, **kwargs):
+ mocks[url] = method(url, *args, **kwargs)
+
+ addmock(self.mock.get, TestFilteredHLSStream.url_playlist, [{"text": p} for p in playlists])
+ for i, segment in enumerate(segments):
+ addmock(self.mock.get, TestFilteredHLSStream.url_segment.format(i), content=segment)
+
+ session = Streamlink()
+ session.set_option("hls-live-edge", 2)
+ session.set_option("hls-timeout", 0)
+ session.set_option("stream-timeout", 0)
+
+ self.read_wait = Event()
+ self.read_done = Event()
+ self.data = []
+ self.error = None
+
+ self.stream = HLSStream(session, TestFilteredHLSStream.url_playlist)
+ self.reader = _TestSubjectFilteredHLSReader(self.stream)
+ self.reader.open()
+
+ def run(self):
+ while True:
+ # only read once per step
+ self.read_wait.wait()
+ self.read_wait.clear()
+
+ # don't read again during cleanup
+ if self.reader.closed:
+ return
+
+ try:
+ data = self.reader.read(-1)
+ self.data.append(data)
+ except IOError as err:
+ self.error = err
+ return
+ finally:
+ # notify main thread that reading has finished
+ self.read_done.set()
+
+ def cleanup(self):
+ self.reader.close()
+ self.mock.stop()
+ # make sure that write and read threads halts on cleanup
+ self.reader.writer.write_wait.set()
+ self.read_wait.set()
+
+ def await_write(self):
+ writer = self.reader.writer
+ if not writer.closed:
+ # make one write call and wait until write call has finished
+ writer.write_wait.set()
+ writer.write_done.wait()
+ writer.write_done.clear()
+
+ def await_read(self):
+ if not self.reader.closed:
+ # make one read call and wait until read call has finished
+ self.read_wait.set()
+ self.read_done.wait()
+ self.read_done.clear()
+
+
+@patch("streamlink.stream.hls.HLSStreamWorker.wait", MagicMock(return_value=True))
+class TestFilteredHLSStream(unittest.TestCase):
+ url_playlist = "http://mocked/path/playlist.m3u8"
+ url_segment = "http://mocked/path/stream{0}.ts"
+
+ @classmethod
+ def get_segments(cls, num):
+ return ["[{0}]".format(i).encode("ascii") for i in range(num)]
+
+ @classmethod
+ def get_playlist(cls, media_sequence, items, filtered=False, end=False):
+ playlist = dedent("""
+ #EXTM3U
+ #EXT-X-VERSION:5
+ #EXT-X-TARGETDURATION:1
+ #EXT-X-MEDIA-SEQUENCE:{0}
+ """.format(media_sequence))
+
+ for item in items:
+ playlist += "#EXTINF:1.000,{1}\nstream{0}.ts\n".format(item, "filtered" if filtered else "live")
+
+ if end:
+ playlist += "#EXT-X-ENDLIST\n"
+
+ return playlist
+
+ @classmethod
+ def filter_sequence(cls, sequence):
+ return sequence.segment.title == "filtered"
+
+ def subject(self, segments, playlists):
+ thread = _TestSubjectReadThread(segments, playlists)
+ self.addCleanup(thread.cleanup)
+ thread.start()
+
+ return thread, thread.reader, thread.reader.writer
+
+ @patch("streamlink.stream.hls_filtered.FilteredHLSStreamWriter.should_filter_sequence", new=filter_sequence)
+ @patch("streamlink.stream.hls_filtered.log")
+ def test_filtered_logging(self, mock_log):
+ segments = self.get_segments(8)
+ thread, reader, writer = self.subject(segments, [
+ self.get_playlist(0, [0, 1], filtered=True),
+ self.get_playlist(2, [2, 3], filtered=False),
+ self.get_playlist(4, [4, 5], filtered=True),
+ self.get_playlist(6, [6, 7], filtered=False, end=True)
+ ])
+
+ self.assertTrue(reader.filter_event.is_set(), "Doesn't let the reader wait if not filtering")
+
+ for i in range(2):
+ thread.await_write()
+ thread.await_write()
+ self.assertEqual(len(mock_log.info.mock_calls), i * 2 + 1)
+ self.assertEqual(mock_log.info.mock_calls[i * 2 + 0], call("Filtering out segments and pausing stream output"))
+ self.assertFalse(reader.filter_event.is_set(), "Lets the reader wait if filtering")
+
+ thread.await_write()
+ thread.await_write()
+ self.assertEqual(len(mock_log.info.mock_calls), i * 2 + 2)
+ self.assertEqual(mock_log.info.mock_calls[i * 2 + 1], call("Resuming stream output"))
+ self.assertTrue(reader.filter_event.is_set(), "Doesn't let the reader wait if not filtering")
+
+ thread.await_read()
+
+ self.assertEqual(
+ b"".join(thread.data),
+ b"".join(list(itertools.chain(segments[2:4], segments[6:8]))),
+ "Correctly filters out segments"
+ )
+ for i, _ in enumerate(segments):
+ self.assertTrue(thread.mocks[TestFilteredHLSStream.url_segment.format(i)].called, "Downloads all segments")
+
+ # don't patch should_filter_sequence here (it always returns False)
+ def test_not_filtered(self):
+ segments = self.get_segments(2)
+ thread, reader, writer = self.subject(segments, [
+ self.get_playlist(0, [0, 1], filtered=True, end=True)
+ ])
+
+ thread.await_write()
+ thread.await_write()
+ thread.await_read()
+ self.assertEqual(b"".join(thread.data), b"".join(segments[0:2]), "Does not filter by default")
+
+ @patch("streamlink.stream.hls_filtered.FilteredHLSStreamWriter.should_filter_sequence", new=filter_sequence)
+ def test_filtered_timeout(self):
+ segments = self.get_segments(2)
+ thread, reader, writer = self.subject(segments, [
+ self.get_playlist(0, [0, 1], filtered=False, end=True)
+ ])
+
+ thread.await_write()
+ thread.await_read()
+ self.assertEqual(thread.data, segments[0:1], "Has read the first segment")
+
+ # simulate a timeout by having an empty buffer
+ # timeout value is set to 0
+ thread.await_read()
+ self.assertIsInstance(thread.error, IOError, "Raises a timeout error when no data is available to read")
+
+ @patch("streamlink.stream.hls_filtered.FilteredHLSStreamWriter.should_filter_sequence", new=filter_sequence)
+ def test_filtered_no_timeout(self):
+ segments = self.get_segments(4)
+ thread, reader, writer = self.subject(segments, [
+ self.get_playlist(0, [0, 1], filtered=True),
+ self.get_playlist(2, [2, 3], filtered=False, end=True)
+ ])
+
+ self.assertTrue(reader.filter_event.is_set(), "Doesn't let the reader wait if not filtering")
+
+ thread.await_write()
+ thread.await_write()
+ self.assertFalse(reader.filter_event.is_set(), "Lets the reader wait if filtering")
+
+ # make reader read (no data available yet)
+ thread.read_wait.set()
+ # once data becomes available, the reader continues reading
+ thread.await_write()
+ self.assertTrue(reader.filter_event.is_set(), "Reader is not waiting anymore")
+
+ thread.read_done.wait()
+ thread.read_done.clear()
+ self.assertFalse(thread.error, "Doesn't time out when filtering")
+ self.assertEqual(thread.data, segments[2:3], "Reads next available buffer data")
+
+ thread.await_write()
+ thread.await_read()
+ self.assertEqual(thread.data, segments[2:4])
+
+ @patch("streamlink.stream.hls_filtered.FilteredHLSStreamWriter.should_filter_sequence", new=filter_sequence)
+ def test_filtered_closed(self):
+ segments = self.get_segments(2)
+ thread, reader, writer = self.subject(segments, [
+ self.get_playlist(0, [0, 1], filtered=True)
+ ])
+
+ self.assertTrue(reader.filter_event.is_set(), "Doesn't let the reader wait if not filtering")
+ thread.await_write()
+ self.assertFalse(reader.filter_event.is_set(), "Lets the reader wait if filtering")
+
+ # make reader read (no data available yet)
+ thread.read_wait.set()
+
+ # close stream while reader is waiting for filtering to end
+ thread.reader.close()
+ thread.read_done.wait()
+ thread.read_done.clear()
+ self.assertEqual(thread.data, [b""], "Stops reading on stream close")
| Streamlink Crashing after Commercial
<!--
Thanks for reporting a bug!
USE THE TEMPLATE. Otherwise your bug report may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed bug reports:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Bug Report
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report and I have read the contribution guidelines.
### Description
<!-- Explain the bug as thoroughly as you can. Don't leave out information which is necessary for us to reproduce and debug this issue. -->
Streamlink will either crash after a 15 second commercial break or will operate slowly after the 15 second commercial break at startup.
### Expected / Actual behavior
<!-- What do you expect to happen, and what is actually happening? -->
After typing in my streamlink command:
streamlink twitch.tv/xqcow best --hls-live-edge 1 --twitch-low-latency
I should jump right into the live edge of the stream. Instead, I will end up watching a commercial placeholder, and then most of the time crash my VLC media player afterwards. I am currently building an application as well that pipes my streamlink output into FFMPEG, and this pipe will break as well.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. ... Type in the command streamlink twitch.tv/channel_name best --hls-live-edge 1 --twitch-low-latency
2. ... Wait out the new 15 second commercial timeout
3. ... By this point it should have crashed. If it did not then exit VLC media player and try again
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a bug report!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
streamlink twitch.tv/xqcow best --hls-live-edge 1 --twitch-low-latency --loglevel debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin twitch for URL twitch.tv/xqcow
[cli][debug] Plugin specific arguments:
[cli][debug] --twitch-low-latency=True (low_latency)
[plugin.twitch][debug] Getting live HLS streams for xqcow
[utils.l10n][debug] Language code: en_US
[cli][info] Available streams: audio_only, 160p (worst), 360p, 480p, 720p, 720p60, 1080p60 (best)
[cli][info] Opening stream: 1080p60 (hls)
[plugin.twitch][info] Low latency streaming (HLS live edge: 1)
[stream.hls][debug] Reloading playlist
[plugin.twitch][info] This is not a low latency stream
[stream.hls][debug] First Sequence: 0; Last Sequence: 2
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 2; End Sequence: None
[stream.hls][debug] Adding segment 2 to queue
[cli][debug] Pre-buffering 8192 bytes
[cli][info] Starting player: "C:\Program Files\VideoLAN\VLC\vlc.exe"
[cli.output][debug] Opening subprocess: "C:\Program Files\VideoLAN\VLC\vlc.exe" --input-title-format twitch.tv/xqcow -
[stream.hls][debug] Download of segment 2 complete
[cli][debug] Writing stream to output
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 3 to queue
[stream.hls][debug] Download of segment 3 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 4 to queue
[stream.hls][debug] Download of segment 4 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 5 to queue
[stream.hls][debug] Download of segment 5 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 6 to queue
[stream.hls][debug] Download of segment 6 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 7 to queue
[stream.hls][debug] Download of segment 7 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 8 to queue
[stream.hls][debug] Adding segment 9 to queue
[stream.hls][debug] Download of segment 8 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 10 to queue
[cli][info] Player closed
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[cli][info] Closing currently open stream...
### Additional comments, screenshots, etc.
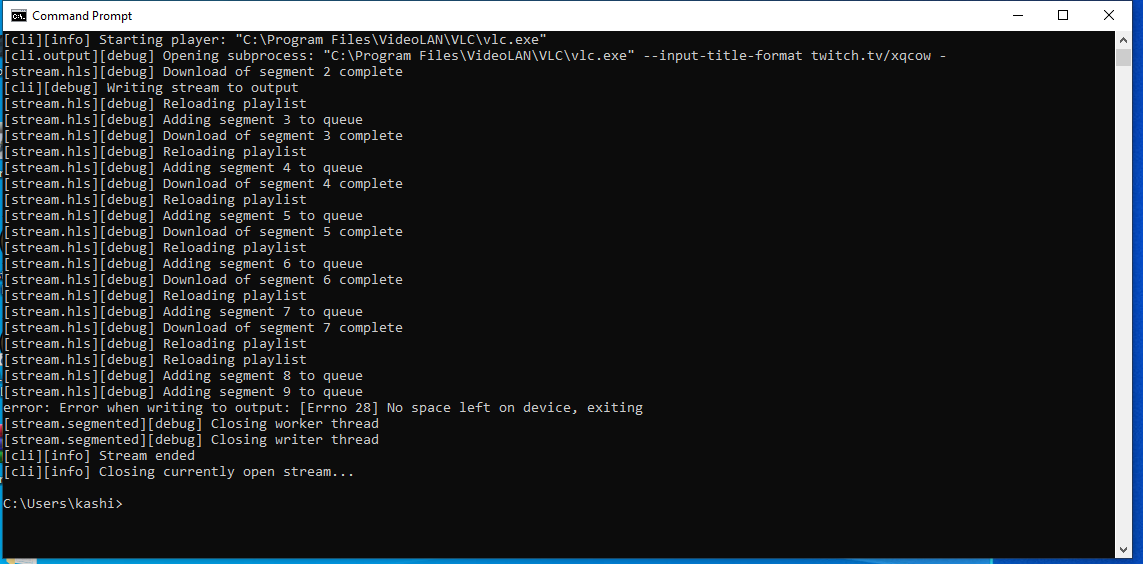
I got the error in the first screenshot once and that's it. All other crashes were due to the log provided above.
Regarding the console image, the execution times used to range from 0.15ms to 0.2ms tops, and now executions times will approach at times 2seconds+. Interestingly enough it always runs great through the commercial. I am not sure if this is any help to the streamlink team but I figured I should provide all the information I possibly could.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Apologies for making this so messy, but I appear to get this [stream.hls][debug] Reloading playlist for each segment that is added, and the segments themselves take extremely long to load compared to segments 1-10 (the ones that are over the commercial). Attached is an image of my console log:
> Streamlink Crashing after Commercial
> [cli][info] Player closed
No, Streamlink is not crashing. Your player is, which will result in Streamlink terminating its process. This is happening due to the discontinuity in Streamlink's output stream when two different streams, namely the ad and the regular stream, get concatenated. This is no issue on their web player, because it's reading an HLS stream directly and can thus react to discontinuities, but Streamlink can't tell the player that there's a discontinuity in a single output stream.
Filter out ads with `--twitch-disable-ads`, if your player can't handle it, or use a different player or try to upgrade it.
#3164
> > Streamlink Crashing after Commercial
> > [cli][info] Player closed
>
> No, Streamlink is not creashing. Your player is, which will result in Streamlink terminating its process. This is happening due to the discontinuity in Streamlink's output stream when two different streams, namely the ad and the regular stream, get concatenated. This is no issue on their web player, because it's reading a HLS directly and can thus react to discontinuities, but Streamlink can't tell the player that there's a discontinuity in a single output stream.
>
> Filter out ads with `--twitch-disable-ads`, if your player can't handle it, or use a different player or try to upgrade it.
>
> #3164
Hello, I use --stream-url to extract the video stream and play it on ffmpeg and potplayer. I have added --twitch-disable-ads but there will still be advertising prompts, and then play normally. If the anchor pushes an advertisement, the video will appear on a blurred screen, and then return to normal after the advertisement ends. I added the --twitch-disable-ads parameter before, but the problem only appeared today.
> I use --stream-url to extract the video stream and play it on ffmpeg and potplayer. I have added --twitch-disable-ads but there will still be advertising
`--stream-url` and `--player-passthrough=hls` **are incompatible** with any parameters which alter Streamlink's HLS client logic, as they simply circumvent Streamlink and just resolve the HLS stream URL for your chosen player to handle it on its own.
See here:
- https://github.com/streamlink/streamlink/issues/3120#issuecomment-676817526
- https://github.com/streamlink/streamlink/issues/3120#issuecomment-676839411
> > 我使用--stream-url提取视频流并在ffmpeg和potplayer上播放。我添加了--twitch-disable-ads,但仍然会有广告
>
> `--stream-url`并且与任何更改Streamlink的HLS客户端逻辑的参数`--player-passthrough=hls` **都不兼容**,因为它们只是绕过Streamlink并只是解析HLS流URL,供您选择的播放器自己处理。
>
> 看这里:
>
> * [#3120(评论)](https://github.com/streamlink/streamlink/issues/3120#issuecomment-676817526)
> * [#3120(评论)](https://github.com/streamlink/streamlink/issues/3120#issuecomment-676839411)
Thank you. Because the problem only appeared today, I thought twitch updated the advertising module again. If I use the -O stream pipeline method, can it be solved?
Please forgive me for not understanding enough how to add player command parameters in streamlink.
> If I use the -O stream pipeline method, can it be solved?
Yes. All output methods except where the resolved HLS stream URL gets returned (`--stream-url`) or where the resolved HLS stream URL gets passed to the player as launch argument (`--player-passthrough`) will work, which includes `--stdout` / `-O`.
> > If I use the -O stream pipeline method, can it be solved?
>
> Yes. All output methods except where the resolved HLS stream URL gets returned (`--stream-url`) or where the resolved HLS stream URL gets passed to the player as launch argument (`--player-passthrough`) will work, which includes `--stdout` / `-O`.
Okay, thank you very much for your answers. I will try it out with pipeline streaming for now. Because I need to use ffmpeg for secondary transcoding, I haven't figured out how to add ffmpeg command parameter information in streamlink.T_T
> > If I use the -O stream pipeline method, can it be solved?
>
> Yes. All output methods except where the resolved HLS stream URL gets returned (`--stream-url`) or where the resolved HLS stream URL gets passed to the player as launch argument (`--player-passthrough`) will work, which includes `--stdout` / `-O`.
Hello, I use the pipeline to record, but it will disconnect when the ad is pushed. I used --player-no-close to block, but it seems to have no effect.The advertisement can be skipped at the beginning, but the advertisement in the middle of the video will cause the streamlink pipeline to stop directly and end the recording.I don't know what changes twtich made today, everything was normal before then.
streamlink --twitch-disable-ads --player-no-close --twitch-disable-hosting $address best -O | ffmpeg -re -i pipe:0 -c:v copy -c:a aac -f flv test.flv
I am using a similar ffmpeg pipe using an example stream:
streamlink twitch.tv/beyondthesummit best --hls-live-edge 1 --twitch-low-latency --twitch-disable-ads -O | ffmpeg -i pipe:0 -r 1 -update 1 <my/image/path.png>
and am noticing that my ffmpeg output .png is ~15 seconds delayed from the actual output on partnered/affiliated streams. The delay occurs whether I have the --twitch-disable-ads flag or not (Beyondthesummit is a 24/7 dota 2 stream where you can look at the clock on the top to measure time differences).
I do NOT have any of these problems on the non-partnered/non-affiliated streams that do not have pre-roll ads, such as when I run a test stream myself.
My guess is that it's ffmpeg itself that is having problems with the new stream, however I am not quite sure why. Perhaps the commercial and stream are encoded differently, which programs such as VLC and ffmpeg seem to mess up and crash on? I am not very experienced at all with streamlink or ffmpeg so I don't know exactly what is going on under the hood
It doesn't work on MPC-HC either (it stops when a commercial starts, then closes after a while).
I don't know what player is supposed to work, since VLC and MPC-HC are by far the most used players on Windows.
> I don't know what player is supposed to work, since VLC and MPC-HC are by far the most used players on Windows.
How does this preclude the player from being a problem? We run in to tons of issues all the times due to players including VLC. I'm watching a stream right now via MPV and it's perfectly fine using `--twitch-low-latency`. I even tested restarting the stream 5 times to get the pre-roll ad, no crashes at all. The debug output is pretty clear that this isn't a problem with Streamlink.
Edit: Unless someone can show me evidence that Streamlink is causing this problem in the next 12 hours I'm going to lock this thread, we go round and round on this every time Twitch enables the pre-roll ads again. If your player can't handle the commercials then go open an issue on their issue tracker.
This is a player issue caused by the way of how Streamlink works, and VLC is especially terrible at it.
All that Streamlink can do is output a single stream. In regards to HLS streams, HLS segments, which are MPEG-TS containers, need to be concatenated to yield a cohesive stream. This is how HLS streaming works. However, when there are two different streams in the same HLS playlist with different encodings, those segments will get concatenated "incorrectly". This is called a stream discontinuity, and since Streamlink's output is just a single stream of concatenated MPEG-TS chunks without any metadata, it is causing some players (or their demuxers/decoders) to crash, as the output is not a correctly encoded stream.
Other players, like MPV for example, are more resilient to this and thus handle it better without crashing.
Players which are reading HLS streams directly, eg. when using Streamlink's --player-passthrough=hls parameter, or also web players, can see the annotated metadata in the HLS playlist and know when a discontinuity happens, so they can simply treat the segments which come after a discontinuity as a new stream to demux/decode, just like when playing the next entry of a regular media playlist.
This means that if your player has issues with this, you will either have to filter out ads, or pass the resolved HLS stream URL through to your player and let it read the HLS stream instead, but then, you will lose all the benefits Streamlink offers, like filtering ads, low latency streaming, customizable live-edge value, buffers, etc.
The only solution that could make Streamlink work with those bad players is implementing an HLS proxy, so that it doesn't output a single stream. Then the player can connect to the proxy and can still access all the metadata that's available, and discontinuities can be handled gracefully if no ads or any other unwanted secondary stream gets filtered out. This is also the solution to the VOD seeking issue, because players reading HLS streams have access to the timing metadata. But implementing an HLS proxy is rather complex, error prone, uncertain, and nobody is willing to do this.
> > I don't know what player is supposed to work, since VLC and MPC-HC are by far the most used players on Windows.
>
> How does this preclude the player from being a problem? We run in to tons of issues all the times due to players including VLC. I'm watching a stream right now via MPV and it's perfectly fine using `--twitch-low-latency`. I even tested restarting the stream 5 times to get the pre-roll ad, no crashes at all. The debug output is pretty clear that this isn't a problem with Streamlink.
>
> Edit: Unless someone can show me evidence that Streamlink is causing this problem in the next 12 hours I'm going to lock this thread, we go round and round on this every time Twitch enables the pre-roll ads again. If your player can't handle the commercials then go open an issue on their issue tracker.
Yes, the problem I currently encounter is not in the pre-advertising, it can be successfully skipped, but if the author plays the ad during the live broadcast, my process will be forced to quit. I currently do not know what command parameters can be added to skip.
> This is a player issue caused by the way of how Streamlink works, and VLC is especially terrible at it.
>
> All that Streamlink can do is output a single stream. In regards to HLS streams, HLS segments, which are MPEG-TS containers, need to be concatenated to yield a cohesive stream. This is how HLS streaming works. However, when there are two different streams in the same HLS playlist with different encodings, those segments will get concatenated "incorrectly". This is called a stream discontinuity, and since Streamlink's output is just a single stream of concatenated MPEG-TS chunks without any metadata, it is causing some players (or their demuxers/decoders) to crash, as the output is not a correctly encoded stream.
>
> Other players, like MPV for example, are more resilient to this and thus handle it better without crashing.
>
> Players which are reading HLS streams directly, eg. when using Streamlink's --player-passthrough=hls parameter, or also web players, can see the annotated metadata in the HLS playlist and know when a discontinuity happens, so they can simply treat the segments which come after a discontinuity as a new stream to demux/decode, just like when playing the next entry of a regular media playlist.
>
> This means that if your player has issues with this, you will either have to filter out ads, or pass the resolved HLS stream URL through to your player and let it read the HLS stream instead, but then, you will lose all the benefits Streamlink offers, like filtering ads, low latency streaming, customizable live-edge value, buffers, etc.
>
> The only solution that could make Streamlink work with those bad players is implementing an HLS proxy, so that it doesn't output a single stream. Then the player can connect to the proxy and can still access all the metadata that's available, and discontinuities can be handled gracefully if no ads or any other unwanted secondary stream gets filtered out. This is also the solution to the VOD seeking issue, because players reading HLS streams have access to the timing metadata. But implementing an HLS proxy is rather complex, error prone, uncertain, and nobody is willing to do this.
I now use streamlink’s pipeline streaming method to skip the 15-second ad prompt, but there is still no way to prevent the anchor from playing ads in the middle of the live broadcast, which will cause my process to crash. (Not sure if it is the problem with streamlink or ffmpeg) Do I need an external command parameter to prevent ads from entering during the live broadcast?
> there is still no way to prevent the anchor from playing ads in the middle of the live broadcast
Post a debug log and the entire command. Ads should be filtered out just fine.
> > there is still no way to prevent the anchor from playing ads in the middle of the live broadcast
>
> Post a debug log and the entire command. Ads should be filtered out just fine.
I intercepted the debug records on two servers, and they had problems at the same time:
[stream.hls][debug] Download of segment 210 complete
[stream.hls][debug] Reloading playlist36kB time=00:06:41.52 bitrate=6156.1kbits/s speed= 1x
[stream.hls][debug] Adding segment 211 to queue
[stream.hls][debug] Adding segment 212 to queue
[stream.hls][debug] Adding segment 213 to queue
[stream.hls][debug] Download of segment 211 complete6:42.03 bitrate=6158.5kbits/s speed= 1x
[stream.hls][debug] Download of segment 212 complete
[stream.hls][debug] Download of segment 213 complete6:42.52 bitrate=6156.5kbits/s speed= 1x
[stream.hls][debug] Reloading playlist28kB time=00:06:46.56 bitrate=6152.2kbits/s speed= 1x
[stream.hls][debug] Adding segment 214 to queue
[stream.hls][debug] Adding segment 215 to queue
[stream.hls][debug] Adding segment 216 to queue
[stream.hls][debug] Reloading playlist41kB time=00:06:51.60 bitrate=6148.8kbits/s speed= 1x
[stream.hls][debug] Adding segment 217 to queue
[stream.hls][debug] Adding segment 218 to queue
[stream.hls][debug] Adding segment 219 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 220 to queue
[stream.hls][debug] Adding segment 221 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 222 to queue
[stream.hls][debug] Adding segment 223 to queue
[stream.hls][debug] Adding segment 224 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 225 to queue
[stream.hls][debug] Adding segment 226 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 227 to queue
[stream.hls][debug] Adding segment 228 to queue
[stream.hls][debug] Adding segment 229 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 230 to queue
[stream.hls][debug] Adding segment 231 to queue
[stream.hls][debug] Adding segment 232 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 233 to queue
[stream.hls][debug] Adding segment 234 to queue
[stream.hls][debug] Adding segment 235 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 236 to queue
[stream.hls][debug] Adding segment 237 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 238 to queue
[stream.hls][debug] Adding segment 239 to queue
[stream.hls][debug] Adding segment 240 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 241 to queue
[stream.hls][debug] Adding segment 242 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 243 to queue
[stream.hls][debug] Adding segment 244 to queue
[stream.hls][debug] Adding segment 245 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 246 to queue
[stream.hls][debug] Adding segment 247 to queue
[stream.hls][debug] Adding segment 248 to queue
error: Error when reading from stream: Read timeout, exiting
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[cli][info] Closing currently open stream...
[flv @ 0x6cca2c0] Failed to update header with correct duration.ate=6148.5kbits/s speed=0.873x
[flv @ 0x6cca2c0] Failed to update header with correct filesize.
frame=24720 fps= 52 q=-1.0 Lsize= 309241kB time=00:06:52.01 bitrate=6148.5kbits/s speed=0.873x
video:301964kB audio:6475kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.260115%
Another server:
[stream.hls][debug] Reloading playlist51kB time=00:03:25.30 bitrate=6146.8kbits/s speed= 1x
[stream.hls][debug] Adding segment 113 to queue
[stream.hls][debug] Adding segment 114 to queue
[stream.hls][debug] Download of segment 113 complete3:25.82 bitrate=6143.6kbits/s speed= 1x
[stream.hls][debug] Download of segment 114 complete
[stream.hls][debug] Reloading playlist81kB time=00:03:30.37 bitrate=6144.1kbits/s speed= 1x
[stream.hls][debug] Adding segment 115 to queue
[stream.hls][debug] Adding segment 116 to queue
[stream.hls][debug] Adding segment 117 to queue
[stream.hls][debug] Adding segment 118 to queue
[stream.hls][debug] Reloading playlist22kB time=00:03:33.89 bitrate=6136.3kbits/s speed= 1x
[stream.hls][debug] Adding segment 119 to queue
[stream.hls][debug] Adding segment 120 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 121 to queue
[stream.hls][debug] Adding segment 122 to queue
[stream.hls][debug] Adding segment 123 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 124 to queue
[stream.hls][debug] Adding segment 125 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 126 to queue
[stream.hls][debug] Adding segment 127 to queue
[stream.hls][debug] Adding segment 128 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 129 to queue
[stream.hls][debug] Adding segment 130 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 131 to queue
[stream.hls][debug] Adding segment 132 to queue
[stream.hls][debug] Adding segment 133 to queue
[stream.hls][debug] Adding segment 134 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 135 to queue
[stream.hls][debug] Adding segment 136 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 137 to queue
[stream.hls][debug] Adding segment 138 to queue
[stream.hls][debug] Adding segment 139 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 140 to queue
[stream.hls][debug] Adding segment 141 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 142 to queue
[stream.hls][debug] Adding segment 143 to queue
[stream.hls][debug] Adding segment 144 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 145 to queue
[stream.hls][debug] Adding segment 146 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 147 to queue
[stream.hls][debug] Adding segment 148 to queue
[stream.hls][debug] Adding segment 149 to queue
[stream.hls][debug] Adding segment 150 to queue
error: Error when reading from stream: Read timeout, exiting
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[cli][info] Closing currently open stream...
[flv @ 0x775f900] Failed to update header with correct duration.ate=6135.7kbits/s speed=0.781x
[flv @ 0x775f900] Failed to update header with correct filesize.
frame=12840 fps= 47 q=-1.0 Lsize= 160310kB time=00:03:34.01 bitrate=6136.3kbits/s speed=0.781x
video:156532kB audio:3361kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.260790%
[aac @ 0x76f9a40] Qavg: 186.999
> > there is still no way to prevent the anchor from playing ads in the middle of the live broadcast
>
> Post a debug log and the entire command. Ads should be filtered out just fine.
This is my streamlink command parameter:
streamlink --player-no-close --http-header "User-Agent=Mozilla/5.0" --twitch-disable-ads https://www.twitch.tv/esl_sc2 best -O --loglevel debug | ffmpeg -re -i pipe:0 -b 8000k -c:v copy -c:a aac -f flv
If you can, I hope you can help me test this address: https://www.twitch.tv/esl_sc2
The comments also confirmed my guess that the anchor will play an advertisement every 15 minutes or so.
When the advertisement does not end, use streamlink to get it again, it will fail.
[cli][info] streamlink is running as root! Be careful!
[cli][debug] OS: Linux-4.14.129-bbrplus-x86_64-with-debian-10.5
[cli][debug] Python: 3.7.3
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.21.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin twitch for URL https://www.twitch.tv/esl_sc2
[cli][debug] Plugin specific arguments:
[cli][debug] --twitch-disable-ads=True (disable_ads)
[plugin.twitch][debug] Getting live HLS streams for esl_sc2
[utils.l10n][debug] Language code: en_US
[cli][info] Available streams: audio_only, 160p (worst), 360p, 480p, 720p, 720p60, 1080p60 (best)
[cli][info] Opening stream: 1080p60 (hls)
[plugin.twitch][info] Will skip ad segments
[stream.hls][debug] Reloading playlist
[plugin.twitch][info] Waiting for pre-roll ads to finish, be patient
[stream.hls][debug] First Sequence: 0; Last Sequence: 2
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 0; End Sequence: None
[stream.hls][debug] Adding segment 0 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 1 to queue
[stream.hls][debug] Adding segment 2 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 3 to queue
[stream.hls][debug] Adding segment 4 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 5 to queue
[stream.hls][debug] Adding segment 6 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 7 to queue
[stream.hls][debug] Adding segment 8 to queue
[stream.hls][debug] Adding segment 9 to queue
[stream.hls][debug] Adding segment 10 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 11 to queue
[stream.hls][debug] Adding segment 12 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 13 to queue
[stream.hls][debug] Adding segment 14 to queue
[stream.hls][debug] Adding segment 15 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 16 to queue
[stream.hls][debug] Adding segment 17 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 18 to queue
[stream.hls][debug] Adding segment 19 to queue
[stream.hls][debug] Adding segment 20 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 21 to queue
[stream.hls][debug] Adding segment 22 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 23 to queue
[stream.hls][debug] Adding segment 24 to queue
[stream.hls][debug] Adding segment 25 to queue
[stream.hls][debug] Adding segment 26 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 27 to queue
[stream.hls][debug] Adding segment 28 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 29 to queue
[stream.hls][debug] Adding segment 30 to queue
[stream.hls][debug] Adding segment 31 to queue
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][error] Try 1/1: Could not open stream <HLSStream('https://video-weaver.lax03.hls.ttvnw.net/v1/playlist/Cs4DuBtotlhEXLRd3q6QJ1QBPGvixmMIWuQD0GyHgUSz350L1sDTZhFzy7quXOWwA7MargkV3ppcn9608KM4NKfUkA5t8yIGerN-lj3A1rQhTqaXVP3HLjDNG07QEpQNQy7fjyT6HhnQsh3RMw2P52SziwGAdz70LX2RICmEdNyXCa5kXhqAHDrLqIPq8iyOUVKu42Up8Z6eO4GZ3u_mnslcRho55BgRh81K8Md0GAEXFwPoeKhz8qQWv3kwRb679ZUuyfx4P_iO6x-TZe-e65F3yRHdDoLR-d_rMAIWxyW6i4Z_Hf2hHXSa1X1aNfTA3HpSuZNvtXcfS96FQ73HAHW7AXl9XqfnremnxsfxzNLrvCZ3yWddXLX9AcgUwJpWJznWu4ZpxNwXrr7_W1Y-afX5eOrORQSych15ZG_HX9-T_DAHP8c2Zyx84T0nJjOdtgZjWRfp1vLuANC5bEF4LQxquVcgMDxN4RU2OtUk_H_hWwhHv2GQHPFOFNBkrrZU9WhdvKCGs5wBiUALbbDk_-2t3-mkEkYce2izCGIYnixzWhki11IhONm3DOEOiMV05Y53jeJuzmIfiSd5cGu2R2tW3eEYPHTlJ9K78cQQuSjGEhA9Q10HbsAk8R4IzXulICYkGgzS741Bv_2eDgui5Xs.m3u8')> (Failed to read data from stream: Read timeout)
error: Could not open stream <HLSStream('https://video-weaver.lax03.hls.ttvnw.net/v1/playlist/Cs4DuBtotlhEXLRd3q6QJ1QBPGvixmMIWuQD0GyHgUSz350L1sDTZhFzy7quXOWwA7MargkV3ppcn9608KM4NKfUkA5t8yIGerN-lj3A1rQhTqaXVP3HLjDNG07QEpQNQy7fjyT6HhnQsh3RMw2P52SziwGAdz70LX2RICmEdNyXCa5kXhqAHDrLqIPq8iyOUVKu42Up8Z6eO4GZ3u_mnslcRho55BgRh81K8Md0GAEXFwPoeKhz8qQWv3kwRb679ZUuyfx4P_iO6x-TZe-e65F3yRHdDoLR-d_rMAIWxyW6i4Z_Hf2hHXSa1X1aNfTA3HpSuZNvtXcfS96FQ73HAHW7AXl9XqfnremnxsfxzNLrvCZ3yWddXLX9AcgUwJpWJznWu4ZpxNwXrr7_W1Y-afX5eOrORQSych15ZG_HX9-T_DAHP8c2Zyx84T0nJjOdtgZjWRfp1vLuANC5bEF4LQxquVcgMDxN4RU2OtUk_H_hWwhHv2GQHPFOFNBkrrZU9WhdvKCGs5wBiUALbbDk_-2t3-mkEkYce2izCGIYnixzWhki11IhONm3DOEOiMV05Y53jeJuzmIfiSd5cGu2R2tW3eEYPHTlJ9K78cQQuSjGEhA9Q10HbsAk8R4IzXulICYkGgzS741Bv_2eDgui5Xs.m3u8')>, tried 1 times, exiting
[cli][info] Closing currently open stream...
pipe:0: Invalid data found when processing input
My ffmpeg version:
built with gcc 8 (Debian 8.3.0-6)
configuration: --enable-gpl --enable-version3 --enable-static --disable-debug --disable-ffplay --disable-indev=sndio --disable-outdev=sndio --cc=gcc --enable-fontconfig --enable-frei0r --enable-gnutls --enable-gmp --enable-libgme --enable-gray --enable-libaom --enable-libfribidi --enable-libass --enable-libvmaf --enable-libfreetype --enable-libmp3lame --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-librubberband --enable-libsoxr --enable-libspeex --enable-libsrt --enable-libvorbis --enable-libopus --enable-libtheora --enable-libvidstab --enable-libvo-amrwbenc --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libdav1d --enable-libxvid --enable-libzvbi --enable-libzimg
Mid-stream ads are annotated the same way pre-roll ads are, and they get filtered out correctly. Just checked again it on your example stream, as it shows ads in short intervals, which is quite handy to debug. Regarding that, there's nothing wrong.
> error: Error when reading from stream: Read timeout, exiting
Well, there you go. You'll of course need to increase the `--hls-timeout` (or `--stream-timeout` fallback) value when filtering out ads, otherwise you'll get timeouts due to the lack of any data returned by the stream reader. This is expected behavior.
We could add a workaround for that though which disables the timeout while filtering out ads, but I'm not sure if it really makes sense and whether it requires some code refactoring.
> Mid-stream ads are annotated the same way pre-roll ads are, and they get filtered out correctly. Just checked again it on your example stream, as it shows ads in short intervals, which is quite handy to debug. Regarding that, there's nothing wrong.
>
> > error: Error when reading from stream: Read timeout, exiting
>
> Well, there you go. You'll of course need to increase the `--hls-timeout` (or `--stream-timeout` fallback) value when filtering out ads, otherwise you'll get timeouts due to the lack of any data returned by the stream reader. This is expected behavior.
>
> We could add a workaround for that though which disables the timeout while filtering out ads, but I'm not sure if it really makes sense and whether it requires some code refactoring.
Thanks, I add --hls-timeout and try again. For setting the timeout period, it should be helpful for the recording process, but if it is a rebroadcast, it will probably be disconnected for a while, right?
> Mid-stream ads are annotated the same way pre-roll ads are, and they get filtered out correctly. Just checked again it on your example stream, as it shows ads in short intervals, which is quite handy to debug. Regarding that, there's nothing wrong.
>
> > error: Error when reading from stream: Read timeout, exiting
>
> Well, there you go. You'll of course need to increase the `--hls-timeout` (or `--stream-timeout` fallback) value when filtering out ads, otherwise you'll get timeouts due to the lack of any data returned by the stream reader. This is expected behavior.
>
> We could add a workaround for that though which disables the timeout while filtering out ads, but I'm not sure if it really makes sense and whether it requires some code refactoring.
Hi, sorry to interrupt again. The problem reappeared, this time I set --stream-timeout 120 for testing, but it still disconnected during midfield. Because it is a live game, there will be a countdown waiting in midfield. I didn’t see any ads when I watched it with the browser. However, the player still fails to obtain the stream, and there is no advertisement fragment in the debug, it is suddenly unable to download.
The game is currently being broadcast live. ( https://www.twitch.tv/esl_sc2 )When the game is over, there will be a short countdown as a rest time, during which the streamlink will be disconnected. But the browser view everything is normal.
streamlink --player-no-close --http-header "User-Agent=Mozilla/5.0" --stream-timeout 120 --twitch-disable-ads https://www.twitch.tv/esl_sc2 best -O --loglevel debug | ffmpeg -re -i pipe:0 -b 8000k -c:v copy -c:a aac -f flv
[stream.hls][debug] Reloading playlist82kB time=00:25:22.97 bitrate=5949.6kbits/s speed= 1x
[stream.hls][debug] Adding segment 770 to queue
[stream.hls][debug] Adding segment 771 to queue
[stream.hls][debug] Adding segment 772 to queue
[stream.hls][debug] Download of segment 770 complete
[stream.hls][debug] Download of segment 771 complete
[stream.hls][debug] Download of segment 772 complete
[stream.hls][debug] Reloading playlist81kB time=00:25:28.02 bitrate=5950.2kbits/s speed= 1x
[stream.hls][debug] Adding segment 773 to queue
[stream.hls][debug] Adding segment 774 to queue
[stream.hls][debug] Adding segment 775 to queue
[stream.hls][debug] Reloading playlist72kB time=00:25:31.05 bitrate=5949.7kbits/s speed= 1x
[stream.hls][debug] Adding segment 776 to queue
[stream.hls][debug] Adding segment 777 to queue
[stream.hls][debug] Adding segment 778 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 779 to queue
[stream.hls][debug] Adding segment 780 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 781 to queue
[stream.hls][debug] Adding segment 782 to queue
[stream.hls][debug] Adding segment 783 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 784 to queue
[stream.hls][debug] Adding segment 785 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 786 to queue
[stream.hls][debug] Adding segment 787 to queue
[stream.hls][debug] Adding segment 788 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 789 to queue
[stream.hls][debug] Adding segment 790 to queue
[stream.hls][debug] Adding segment 791 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 792 to queue
[stream.hls][debug] Adding segment 793 to queue
[stream.hls][debug] Adding segment 794 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 795 to queue
[stream.hls][debug] Adding segment 796 to queue
[stream.hls][debug] Adding segment 797 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 798 to queue
[stream.hls][debug] Adding segment 799 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 800 to queue
[stream.hls][debug] Adding segment 801 to queue
[stream.hls][debug] Adding segment 802 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 803 to queue
[stream.hls][debug] Adding segment 804 to queue
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 805 to queue
[stream.hls][debug] Adding segment 806 to queue
[stream.hls][debug] Adding segment 807 to queue
[stream.hls][debug] Adding segment 808 to queue
error: Error when reading from stream: Read timeout, exiting
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[cli][info] Closing currently open stream...
[flv @ 0x5e34bc0] Failed to update header with correct duration.ate=5949.6kbits/s speed=0.962x
[flv @ 0x5e34bc0] Failed to update header with correct filesize.
frame=91800 fps= 58 q=-1.0 Lsize= 1112298kB time=00:25:31.54 bitrate=5949.5kbits/s speed=0.962x
video:1084914kB audio:24015kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.303856%
[aac @ 0x5e30900] Qavg: 194.405
I can somewhat confirm this, in the sense that I'm using MPC-HC and I don't think it crashes, but it does timeout. This was the behavior that includes my previous comment. It wasn't a player issue, it was the timeout.
I've now tried it running with: --hls-timeout 9500
It doesn't exit now and correctly resumes the stream (but losing what happened during that time it stays paused, so it's not different than the ads screen, functionally).
> Mid-stream ads are annotated the same way pre-roll ads are, and they get filtered out correctly. Just checked again it on your example stream, as it shows ads in short intervals, which is quite handy to debug. Regarding that, there's nothing wrong.
>
> > error: Error when reading from stream: Read timeout, exiting
>
> Well, there you go. You'll of course need to increase the `--hls-timeout` (or `--stream-timeout` fallback) value when filtering out ads, otherwise you'll get timeouts due to the lack of any data returned by the stream reader. This is expected behavior.
>
> We could add a workaround for that though which disables the timeout while filtering out ads, but I'm not sure if it really makes sense and whether it requires some code refactoring.
From my observation, it seems to be different from twitch's patch ads. Because viewing on the browser and APP is normal and there is no pop-up advertisement. But the anchor must have done something that caused the streamlink to be disconnected during the rest of the game.
The picture below is one of them, and the other was not found during the live broadcast. But it also leads to disconnection.
This seems to be different from twitch's ad, because he seems to be playing normally in the background.
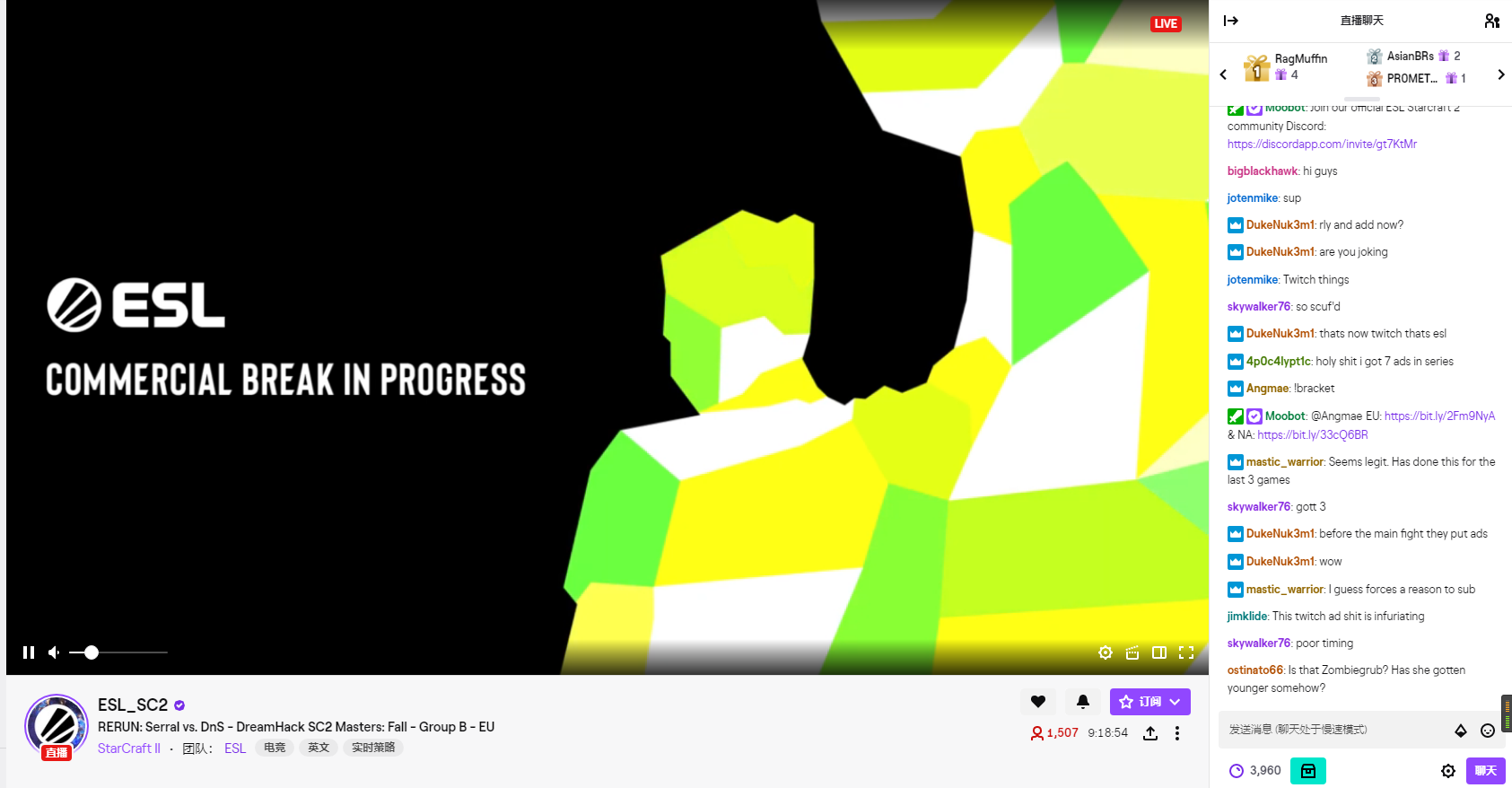
> The picture below is one of them
That is the **content** of their stream while they have triggered an ad on their channel. People see it when they have blocked the overlaying ad system of the web player. This has nothing to do with filtering embedded ads. When the embedded ads are shorter than ESL's "commercial break in progress" screen, you will still see it in the filtered stream.
> But it also leads to disconnection
This only happens if your timeout value is too low (default value is 60). As I've said, we could think about disabling the timeout logic while filtering out HLS segments, as there won't be data to read from the HLSStreamReader in this case, but this hasn't been done yet.
- https://github.com/streamlink/streamlink/blob/master/src/streamlink_cli/main.py#L386
- https://github.com/streamlink/streamlink/blob/master/src/streamlink/buffers.py#L104-L112
- https://github.com/streamlink/streamlink/blob/master/src/streamlink/stream/segmented.py#L206-L207
- https://github.com/streamlink/streamlink/blob/master/src/streamlink/stream/segmented.py#L183-L186
- https://github.com/streamlink/streamlink/blob/master/src/streamlink/stream/hls.py#L333
- https://github.com/streamlink/streamlink/blob/master/src/streamlink/session.py#L73
@bastimeyer So I only need to increase the `--hls-timeout` instead of adding `--player-no-close`?
> > The picture below is one of them
>
> That is the **content** of their stream while they have triggered an ad on their channel. People see it when they have blocked the overlaying ad system of the web player. This has nothing to do with filtering embedded ads. When the embedded ads are shorter than ESL's "commercial break in progress" screen, you will still see it in the filtered stream.
>
> > But it also leads to disconnection
>
> This only happens if your timeout value is too low (default value is 60). As I've said, we could think about disabling the timeout logic while filtering out HLS segments, as there won't be data to read from the HLSStreamReader in this case, but this hasn't been done yet.
>
> * https://github.com/streamlink/streamlink/blob/master/src/streamlink_cli/main.py#L386
> * https://github.com/streamlink/streamlink/blob/master/src/streamlink/buffers.py#L104-L112
> * https://github.com/streamlink/streamlink/blob/master/src/streamlink/stream/segmented.py#L206-L207
> * https://github.com/streamlink/streamlink/blob/master/src/streamlink/stream/segmented.py#L183-L186
> * https://github.com/streamlink/streamlink/blob/master/src/streamlink/stream/hls.py#L333
> * https://github.com/streamlink/streamlink/blob/master/src/streamlink/session.py#L73
I set a parameter of 120, but it seems to have no effect. As my debug shows, it still automatically exits after a period of time. And only this kind of official event channel will have problems, and the personal anchor channel can operate normally.
streamlink --stream-timeout 120 --twitch-low-latency --twitch-disable-ads https://www.twitch.tv/esl_sc2 best -O --loglevel debug | ffmpeg -re -i pipe:0 -b 8000k -c:v copy -c:a aac -f flv
I don’t know if anyone can help me test this address at the same time, it will be disconnected every 15 minutes (or countdown): https://www.twitch.tv/esl_sc2
Thank you very much.
> > I don't know what player is supposed to work, since VLC and MPC-HC are by far the most used players on Windows.
>
> How does this preclude the player from being a problem? We run in to tons of issues all the times due to players including VLC. I'm watching a stream right now via MPV and it's perfectly fine using `--twitch-low-latency`. I even tested restarting the stream 5 times to get the pre-roll ad, no crashes at all. The debug output is pretty clear that this isn't a problem with Streamlink.
>
> Edit: Unless someone can show me evidence that Streamlink is causing this problem in the next 12 hours I'm going to lock this thread, we go round and round on this every time Twitch enables the pre-roll ads again. If your player can't handle the commercials then go open an issue on their issue tracker.
If you have time, please help me test this link address: https://www.twitch.tv/esl_sc2
If the title of the live broadcast room is "rerun", then every 15 minutes or so (there is a set advertising time in the live broadcast room), streamlink will time out and exit because it cannot get the stream clips.
If the current live broadcast is in progress, there will be a midfield countdown after the game is over, during which streamlink will also crash because it cannot get the streaming clips.
I think this is a new way of advertising, which seems to be forcibly cut off the stream transmission and resume it after the advertisement ends. I have added the disable-ads parameter, but it seems to only work at the beginning. And when I watched it with the browser, no ads popped up, but streamlink just couldn't get the data. Thank you.
> I set a parameter of 120
No, you have not, because the default value of 60 of `hls-timeout` still gets applied, as I've shown in the linked source. You will have to set `hls-timeout` instead of `stream-timeout`, as it's only a fallback parameter for different stream implementations, HLS being one of them, nothing more. And increasing the value from 60 to 120 is not enough if the mid-stream ads are longer than 2 minutes. Set it to a higher value to circumvent the stream from timing out.
I've been running the link you've posted for more than 30 minutes now, with additional segment debugging. It had pre-roll ads and several mid-stream ads, and it's working fine when setting the hls-timeout to a higher value like 3600 for example.
There is no need to further spam this thread. We are aware of the issue, even though it's not a bug, and we've shown you a way to work around the issue for now. The suggested fix/improvement still needs to be explored and implemented. Remember that this is a bug tracker and not a support forum.
> > I set a parameter of 120
>
> No, you have not, because the default value of 60 of `hls-timeout` still gets applied, as I've shown in the linked source. You will have to set `hls-timeout` instead of `stream-timeout`, as it's only a fallback parameter for different stream implementations, HLS being one of them, nothing more. And increasing the value from 60 to 120 is not enough if the mid-stream ads are longer than 2 minutes. Set it to a higher value to circumvent the stream from timing out.
>
> I've been running the link you've posted for more than 30 minutes now, with additional segment debugging. It had pre-roll ads and several mid-stream ads, and it's working fine when setting the hls-timeout to a higher value like 3600 for example.
>
> There is no need to further spam this thread. We are aware of the issue, even though it's not a bug, and we've shown you a way to work around the issue for now. The suggested fix/improvement still needs to be explored and implemented. Remember that this is a bug tracker and not a support forum.
Okay, thank you again for your answer, I am sorry for my behavior.
@bastimayer
"Other players, like MPV for example, are more resilient to this and thus handle it better without crashing."
Dunno if I'm having the exact same issue or not, but for me both vlc and mpv are crashing.
Also dunno what exactly reports this error in the output, but it's exactly same for vlc and mpv: "error: Error when reading from stream: Read timeout, exiting"
Might even be more than one issue - at least past couple of days I've had issues with commercials, but also some random crashes have occured when there shouldn't be a commercial break (unless Twitch really wants to force them during prime content).
> both vlc and mpv are crashing
> error: Error when reading from stream: Read timeout, exiting
No, they are not, Streamlink is terminating the player's process and its own due to lack of content when reaching the `hls-timeout` timer (default value of 60 seconds) when filtering out ads, as mentioned above.
https://github.com/streamlink/streamlink/issues/3165#issuecomment-691500807
Ah, my bad. I used --player-no-close, but didn't realize mpv itself closes at end of stream by default. Thanks! | 2020-09-19T17:17:16 |
streamlink/streamlink | 3,188 | streamlink__streamlink-3188 | [
"3136"
] | 7e303c8eafcdf02e39ef02fff8f445cddabf040e | diff --git a/src/streamlink/plugins/mico.py b/src/streamlink/plugins/mico.py
new file mode 100644
--- /dev/null
+++ b/src/streamlink/plugins/mico.py
@@ -0,0 +1,72 @@
+import logging
+import re
+
+from streamlink.plugin import Plugin
+from streamlink.plugin.api import validate
+from streamlink.stream import HLSStream
+from streamlink.utils import parse_json
+from streamlink.utils.url import update_scheme
+
+log = logging.getLogger(__name__)
+
+
+class Mico(Plugin):
+ author = None
+ category = None
+ title = None
+
+ url_re = re.compile(r'https?://(?:www\.)?micous\.com/live/\d+')
+ json_data_re = re.compile(r'win._profile\s*=\s*({.*})')
+
+ _json_data_schema = validate.Schema(
+ validate.transform(json_data_re.search),
+ validate.any(None, validate.all(
+ validate.get(1),
+ validate.transform(parse_json),
+ validate.any(None, validate.all({
+ 'mico_id': int,
+ 'nickname': validate.text,
+ 'h5_url': validate.all(
+ validate.transform(lambda x: update_scheme('http:', x)),
+ validate.url(),
+ ),
+ 'is_live': bool,
+ })),
+ )),
+ )
+
+ @classmethod
+ def can_handle_url(cls, url):
+ return cls.url_re.match(url) is not None
+
+ def get_author(self):
+ if self.author is not None:
+ return self.author
+
+ def get_category(self):
+ if self.category is not None:
+ return self.category
+
+ def get_title(self):
+ if self.title is not None:
+ return self.title
+
+ def _get_streams(self):
+ json_data = self.session.http.get(self.url, schema=self._json_data_schema)
+
+ if not json_data:
+ log.error('Failed to get JSON data')
+ return
+
+ if not json_data['is_live']:
+ log.info('This stream is no longer online')
+ return
+
+ self.author = json_data['mico_id']
+ self.category = 'Live'
+ self.title = json_data['nickname']
+
+ return HLSStream.parse_variant_playlist(self.session, json_data['h5_url'])
+
+
+__plugin__ = Mico
| diff --git a/tests/plugins/test_mico.py b/tests/plugins/test_mico.py
new file mode 100644
--- /dev/null
+++ b/tests/plugins/test_mico.py
@@ -0,0 +1,23 @@
+import unittest
+
+from streamlink.plugins.mico import Mico
+
+
+class TestPluginMico(unittest.TestCase):
+ def test_can_handle_url(self):
+ should_match = [
+ 'http://micous.com/live/73750760',
+ 'http://www.micous.com/live/73750760',
+ 'https://micous.com/live/73750760',
+ 'https://www.micous.com/live/73750760',
+ ]
+ for url in should_match:
+ self.assertTrue(Mico.can_handle_url(url))
+
+ def test_can_handle_url_negative(self):
+ should_not_match = [
+ 'http://www.micous.com/73750760',
+ 'https://example.com/index.html',
+ ]
+ for url in should_not_match:
+ self.assertFalse(Mico.can_handle_url(url))
| MICO LIVE plugin request
<!--
Thanks for requesting a plugin!
USE THE TEMPLATE. Otherwise your plugin request may be rejected.
First, see the contribution guidelines and plugin request requirements:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Plugin requests which fall into the categories we will not implement will be closed immediately.
Also check the list of open and closed plugin requests:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+request%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Request
<!-- Replace [ ] with [x] in order to check the box -->
- [ x] This is a plugin request and I have read the contribution guidelines and plugin request requirements.
### Description
This is a popular live stream app's website which is known as **MICO LIVE** similar to bigo live
<!-- Explain the plugin and site as clearly as you can. What is the site about? Who runs it? What content does it provide? What value does it bring to Streamlink? Etc. -->
### Example stream URLs
<!-- Example URLs for streams are required. Plugin requests which do not have example URLs will be closed. -->
1. https://www.micous.com/live/70314292
2. https://www.micous.com/live/68928340
| 2020-09-20T20:51:17 |
|
streamlink/streamlink | 3,199 | streamlink__streamlink-3199 | [
"2905"
] | 7e303c8eafcdf02e39ef02fff8f445cddabf040e | diff --git a/src/streamlink/plugins/tv999.py b/src/streamlink/plugins/tv999.py
new file mode 100644
--- /dev/null
+++ b/src/streamlink/plugins/tv999.py
@@ -0,0 +1,51 @@
+import logging
+import re
+
+from streamlink.plugin import Plugin
+from streamlink.plugin.api import validate
+from streamlink.stream import HLSStream
+from streamlink.utils.url import update_scheme
+
+log = logging.getLogger(__name__)
+
+
+class TV999(Plugin):
+ url_re = re.compile(r'https?://(?:www\.)?tv999\.bg/live\.html')
+ iframe_re = re.compile(r'<iframe.*src="([^"]+)"')
+ hls_re = re.compile(r'src="([^"]+)"\s+type="application/x-mpegURL"')
+
+ iframe_schema = validate.Schema(
+ validate.transform(iframe_re.search),
+ validate.any(None, validate.all(
+ validate.get(1),
+ validate.url(),
+ )),
+ )
+
+ hls_schema = validate.Schema(
+ validate.transform(hls_re.search),
+ validate.any(None, validate.all(
+ validate.get(1),
+ validate.transform(lambda x: update_scheme('http:', x)),
+ validate.url(),
+ )),
+ )
+
+ @classmethod
+ def can_handle_url(cls, url):
+ return cls.url_re.match(url) is not None
+
+ def _get_streams(self):
+ iframe_url = self.session.http.get(self.url, schema=self.iframe_schema)
+
+ if not iframe_url:
+ log.error('Failed to find IFRAME URL')
+ return
+
+ hls_url = self.session.http.get(iframe_url, schema=self.hls_schema)
+
+ if hls_url:
+ return {'live': HLSStream(self.session, hls_url)}
+
+
+__plugin__ = TV999
| diff --git a/tests/plugins/test_tv999.py b/tests/plugins/test_tv999.py
new file mode 100644
--- /dev/null
+++ b/tests/plugins/test_tv999.py
@@ -0,0 +1,24 @@
+import unittest
+
+from streamlink.plugins.tv999 import TV999
+
+
+class TestPluginTV999(unittest.TestCase):
+ def test_can_handle_url(self):
+ should_match = [
+ 'http://tv999.bg/live.html',
+ 'http://www.tv999.bg/live.html',
+ 'https://tv999.bg/live.html',
+ 'https://www.tv999.bg/live.html',
+ ]
+ for url in should_match:
+ self.assertTrue(TV999.can_handle_url(url))
+
+ def test_can_handle_url_negative(self):
+ should_not_match = [
+ 'http://tv999.bg/',
+ 'https://tv999.bg/live',
+ 'https://example.com/index.html',
+ ]
+ for url in should_not_match:
+ self.assertFalse(TV999.can_handle_url(url))
| [New Plugin] Add TV999
## Plugin Request
- [x] This is a plugin request and I have read the contribution guidelines and plugin request requirements.
### Description
Bulgarian TV channel that mainly features Russian content with Bulgarian subtitles.
### Example stream URLs
http://tv999.bg/live.html
| 2020-09-23T20:17:43 |
|
streamlink/streamlink | 3,202 | streamlink__streamlink-3202 | [
"3197"
] | 4fa902fc93470af30616e29e0fd49692a05ae84c | diff --git a/src/streamlink/plugins/zattoo.py b/src/streamlink/plugins/zattoo.py
--- a/src/streamlink/plugins/zattoo.py
+++ b/src/streamlink/plugins/zattoo.py
@@ -19,6 +19,7 @@
class Zattoo(Plugin):
API_CHANNELS = '{0}/zapi/v2/cached/channels/{1}?details=False'
API_HELLO = '{0}/zapi/session/hello'
+ API_HELLO_V2 = '{0}/zapi/v2/session/hello'
API_HELLO_V3 = '{0}/zapi/v3/session/hello'
API_LOGIN = '{0}/zapi/v2/account/login'
API_LOGIN_V3 = '{0}/zapi/v3/account/login'
@@ -158,18 +159,21 @@ def _hello(self):
# a new session is required for the app_token
self.session.http.cookies = cookiejar_from_dict({})
if self.base_url == 'https://zattoo.com':
- app_token_url = 'https://zattoo.com/int/'
+ app_token_url = 'https://zattoo.com/client/token-2fb69f883fea03d06c68c6e5f21ddaea.json'
elif self.base_url == 'https://www.quantum-tv.com':
app_token_url = 'https://www.quantum-tv.com/token-4d0d61d4ce0bf8d9982171f349d19f34.json'
else:
app_token_url = self.base_url
- res = self.session.http.get(app_token_url)
- match = self._app_token_re.search(res.text)
+ res = self.session.http.get(app_token_url)
if self.base_url == 'https://www.quantum-tv.com':
app_token = self.session.http.json(res)["session_token"]
hello_url = self.API_HELLO_V3.format(self.base_url)
+ elif self.base_url == 'https://zattoo.com':
+ app_token = self.session.http.json(res)['app_tid']
+ hello_url = self.API_HELLO_V2.format(self.base_url)
else:
+ match = self._app_token_re.search(res.text)
app_token = match.group(1)
hello_url = self.API_HELLO.format(self.base_url)
@@ -180,10 +184,17 @@ def _hello(self):
self._session_attributes.set(
'uuid', __uuid, expires=self.TIME_SESSION)
- params = {
- 'client_app_token': app_token,
- 'uuid': __uuid,
- }
+ if self.base_url == 'https://zattoo.com':
+ params = {
+ 'uuid': __uuid,
+ 'app_tid': app_token,
+ 'app_version': '1.0.0'
+ }
+ else:
+ params = {
+ 'client_app_token': app_token,
+ 'uuid': __uuid,
+ }
if self.base_url == 'https://www.quantum-tv.com':
params['app_version'] = '3.2028.3'
| Zattoo (403 Client Error)
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. streamlink -o "RTS Un SD.ts" https://zattoo.com/watch/rts_un 1500k --zattoo-email [email protected] --zattoo-password xxx
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
[plugin.zattoo][debug] Restored cookies: zattoo.session, pzuid, beaker.session.id
[cli][debug] OS: Linux-4.19.0-0.bpo.6-amd64-x86_64-with-debian-9.13
[cli][debug] Python: 3.5.3
[cli][debug] Streamlink: 1.5.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin zattoo for URL https://zattoo.com/watch/rts_un
[cli][debug] Plugin specific arguments:
[cli][debug] --zattoo-email=********@********.******** (email)
[cli][debug] --zattoo-password=******** (password)
[cli][debug] --zattoo-stream-types=['hls'] (stream_types)
[plugin.zattoo][debug] Session control for zattoo.com
[plugin.zattoo][debug] User is not logged in
[plugin.zattoo][debug] _hello ...
error: Unable to open URL: https://zattoo.com/zapi/session/hello (403 Client Error: Forbidden for url: https://zatt
oo.com/zapi/session/hello)
[1] 15604 exit 1 streamlink -o "RTS Un SD.ts" https://zattoo.com/watch/rts_un 1500
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Had the same problem yesterday, Zattoo had changed the hello API.
I changed the following to get it running again:
The following variable changed:
```python
API_HELLO = '{0}/zapi/v2/session/hello'
```
This changed in the hello function:
```python
res_apptid = self.session.http.get('https://zattoo.com/client/token-2fb69f883fea03d06c68c6e5f21ddaea.json')
obj_apptid = json.loads(res_apptid.text)
log.debug(obj_apptid['app_tid'])
params = {
'uuid': __uuid,
'app_tid': obj_apptid['app_tid'],
'app_version': '1.0.0'
}
```
Ok, thank you for the information, on the other hand possible to have the zattoo.py file attached to update it?
Submit a pull request, so it can be reviewed | 2020-09-24T09:28:22 |
|
streamlink/streamlink | 3,205 | streamlink__streamlink-3205 | [
"3201"
] | bbd80a5c6f446652393b525a4a6ae6ed63e4c093 | diff --git a/src/streamlink/plugins/cdnbg.py b/src/streamlink/plugins/cdnbg.py
--- a/src/streamlink/plugins/cdnbg.py
+++ b/src/streamlink/plugins/cdnbg.py
@@ -14,16 +14,14 @@
class CDNBG(Plugin):
url_re = re.compile(r"""
https?://(?:www\.)?(?:
- tv\.bnt\.bg/\w+(?:/\w+)?|
- nova\.bg/live|
+ armymedia\.bg|
bgonair\.bg/tvonline|
- mmtvmusic\.com/live|
- mu-vi\.tv/LiveStreams/pages/Live\.aspx|
+ bloombergtv\.bg/video|
+ (?:tv\.)?bnt\.bg/\w+(?:/\w+)?|
live\.bstv\.bg|
- bloombergtv.bg/video|
- armymedia.bg|
- chernomore.bg|
- i.cdn.bg/live/
+ i\.cdn\.bg/live/|
+ nova\.bg/live|
+ mu-vi\.tv/LiveStreams/pages/Live\.aspx
)/?
""", re.VERBOSE)
iframe_re = re.compile(r"iframe .*?src=\"((?:https?(?::|:))?//(?:\w+\.)?cdn.bg/live[^\"]+)\"", re.DOTALL)
@@ -52,7 +50,7 @@ def find_iframe(self, url):
log.debug("Found iframe: {0}", iframe_url)
iframe_url = iframe_url.replace(":", ":")
if iframe_url.startswith("//"):
- return "{0}:{1}".format(p.scheme, iframe_url)
+ return update_scheme(p.scheme, iframe_url)
else:
return iframe_url
| diff --git a/tests/plugins/test_cdnbg.py b/tests/plugins/test_cdnbg.py
--- a/tests/plugins/test_cdnbg.py
+++ b/tests/plugins/test_cdnbg.py
@@ -1,40 +1,44 @@
-import pytest
+import unittest
from streamlink.plugins.cdnbg import CDNBG
-valid_urls = [
- ("http://bgonair.bg/tvonline",),
- ("http://bgonair.bg/tvonline/",),
- ("http://www.nova.bg/live",),
- ("http://nova.bg/live",),
- ("http://tv.bnt.bg/bnt1",),
- ("http://tv.bnt.bg/bnt2",),
- ("http://tv.bnt.bg/bnt3",),
- ("http://tv.bnt.bg/bnt4",),
- ("https://mmtvmusic.com/live/",),
- ("http://mu-vi.tv/LiveStreams/pages/Live.aspx",),
- ("http://live.bstv.bg/",),
- ("https://www.bloombergtv.bg/video",),
- ("https://i.cdn.bg/live/xfr3453g0d",)
-]
-invalid_urls = [
- ("http://www.tvcatchup.com/",),
- ("http://www.youtube.com/",),
- ("https://www.tvevropa.com",),
- ("http://www.kanal3.bg/live",),
- ("http://inlife.bg/",),
- ("http://videochanel.bstv.bg",),
- ("http://video.bstv.bg/",),
- ("http://bitelevision.com/live",)
-]
+class TestPluginCDNBG(unittest.TestCase):
+ def test_can_handle_url(self):
+ should_match = [
+ 'http://bgonair.bg/tvonline',
+ 'http://bgonair.bg/tvonline/',
+ 'http://www.nova.bg/live',
+ 'http://nova.bg/live',
+ 'http://bnt.bg/live',
+ 'http://bnt.bg/live/bnt1',
+ 'http://bnt.bg/live/bnt2',
+ 'http://bnt.bg/live/bnt3',
+ 'http://bnt.bg/live/bnt4',
+ 'http://tv.bnt.bg/bnt1',
+ 'http://tv.bnt.bg/bnt2',
+ 'http://tv.bnt.bg/bnt3',
+ 'http://tv.bnt.bg/bnt4',
+ 'http://mu-vi.tv/LiveStreams/pages/Live.aspx',
+ 'http://live.bstv.bg/',
+ 'https://www.bloombergtv.bg/video',
+ 'https://i.cdn.bg/live/xfr3453g0d',
+ ]
+ for url in should_match:
+ self.assertTrue(CDNBG.can_handle_url(url))
-
[email protected](["url"], valid_urls)
-def test_can_handle_url(url):
- assert CDNBG.can_handle_url(url), "url should be handled"
-
-
[email protected](["url"], invalid_urls)
-def test_can_handle_url_negative(url):
- assert not CDNBG.can_handle_url(url), "url should not be handled"
+ def test_can_handle_url_negative(self):
+ should_not_match = [
+ 'http://www.tvcatchup.com/',
+ 'http://www.youtube.com/',
+ 'https://www.tvevropa.com',
+ 'http://www.kanal3.bg/live',
+ 'http://inlife.bg/',
+ 'http://videochanel.bstv.bg',
+ 'http://video.bstv.bg/',
+ 'http://bitelevision.com/live',
+ 'http://mmtvmusic.com/live/',
+ 'http://chernomore.bg/',
+ ]
+ for url in should_not_match:
+ self.assertFalse(CDNBG.can_handle_url(url))
| cdnbg can't open new BNT links
## Bug Report
- [x] This is a bug report and I have read the contribution guidelines.
### Description
There have been changes to the bnt.bg live channel links, which have made them unrecognizable by the cdnbg plugin.
**Note:** Streamlink can still open these links, which are now hidden away in a small part of the website and are not protected by an SSL certificate:
```
http://tv.bnt.bg/bnt1
http://tv.bnt.bg/bnt2
http://tv.bnt.bg/bnt3
http://tv.bnt.bg/bnt4
```
**Other plugin issues:**
1. https://mmtvmusic.com/live/ has moved away to another service provider and hence can be deleted from cdnbg. Can't be opened with anything else atm.
2. https://chernomore.bg/ can be removed - the owner of the media group closed down the newspaper and television and converted the website into an information agency.
### Expected / Actual behavior
When I input them through CLI, they should open.
### Reproduction steps / Explicit stream URLs to test
```
streamlink https://bnt.bg/live best
streamlink https://bnt.bg/live/bnt1 best
streamlink https://bnt.bg/live/bnt2 best
streamlink https://bnt.bg/live/bnt3 best
streamlink https://bnt.bg/live/bnt4 best
```
### Log output
```
C:\Users\XXXX> streamlink https://bnt.bg/live/bnt1 best --loglevel debug
[cli][debug] OS: Windows 7
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.6.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
error: No plugin can handle URL: https://bnt.bg/live/bnt1
```
| 2020-09-25T23:52:50 |
|
streamlink/streamlink | 3,207 | streamlink__streamlink-3207 | [
"3198"
] | 21a3067c1790f355849af1d973cf3970262e2eae | diff --git a/src/streamlink/plugins/aljazeeraen.py b/src/streamlink/plugins/aljazeeraen.py
deleted file mode 100644
--- a/src/streamlink/plugins/aljazeeraen.py
+++ /dev/null
@@ -1,39 +0,0 @@
-import re
-
-from streamlink.plugin import Plugin
-from streamlink.plugins.brightcove import BrightcovePlayer
-from streamlink.stream import RTMPStream
-
-
-class AlJazeeraEnglish(Plugin):
- url_re = re.compile(r"https?://(?:\w+\.)?aljazeera\.com")
- account_id = 665003303001
- render_re = re.compile(r'''RenderPagesVideo\((?P<q>['"])(?P<id>\d+)(?P=q)''') # VOD
- video_id_re = re.compile(r'''videoId=(?P<id>\d+)["']''') # Live
-
- @classmethod
- def can_handle_url(cls, url):
- return cls.url_re.match(url) is not None
-
- def _get_streams(self):
- res = self.session.http.get(self.url)
-
- # check two different styles to include the video id in the page
- video_id_m = self.render_re.search(res.text) or self.video_id_re.search(res.text)
- video_id = video_id_m and video_id_m.group("id")
-
- if not video_id:
- self.logger.error("Could not find a video ID on this page")
- return
-
- # Use BrightcovePlayer class to get the streams
- self.logger.debug("Found video ID: {0}", video_id)
- bp = BrightcovePlayer(self.session, self.account_id)
-
- for q, s in bp.get_streams(video_id):
- # RTMP Streams are listed, but they do not appear to work
- if not isinstance(s, RTMPStream):
- yield q, s
-
-
-__plugin__ = AlJazeeraEnglish
| diff --git a/tests/plugins/test_aljazeeraen.py b/tests/plugins/test_aljazeeraen.py
deleted file mode 100644
--- a/tests/plugins/test_aljazeeraen.py
+++ /dev/null
@@ -1,20 +0,0 @@
-import unittest
-
-from streamlink.plugins.aljazeeraen import AlJazeeraEnglish
-
-
-class TestPluginAlJazeeraEnglish(unittest.TestCase):
- def test_can_handle_url(self):
- should_match = [
- 'https://www.aljazeera.com/live/',
- 'https://www.aljazeera.com/programmes/techknow/2017/04/science-sugar-170429141233635.html',
- ]
- for url in should_match:
- self.assertTrue(AlJazeeraEnglish.can_handle_url(url))
-
- def test_can_handle_url_negative(self):
- should_not_match = [
- 'https://example.com/index.html',
- ]
- for url in should_not_match:
- self.assertFalse(AlJazeeraEnglish.can_handle_url(url))
| aljazeera error
[cli][info] Found matching plugin aljazeeraen for URL https://www.aljazeera.com/live/
[plugin.aljazeeraen][error] Could not find a video ID on this page
error: No playable streams found on this URL: https://www.aljazeera.com/live/
| How can I fix this? I like aljazeera news very much through streamlink...
Playlist hasn't changed.
If in doubt, you can find it in browsers network monitor or with Telerik fiddler.
Or you can simply copy it from here and use it as I do.
```
C:\>streamlink https://live-hls-web-aje.getaj.net/AJE/03.m3u8 best
[cli][info] Found matching plugin hls for URL https://live-hls-web-aje.getaj.net/AJE/03.m3u8
[cli][info] Available streams: live (worst, best)
[cli][info] Opening stream: live (hls)
[cli][info] Starting player: C:\P\VLC\vlc.exe
@johnthecracker
This line worked for me here -> streamlink https://live-hls-web-aje.getaj.net/AJE/03.m3u8 best
thx a lot :+1:
You can also use the master index for live:
```
streamlink https://live-hls-web-aje.getaj.net/AJE/index.m3u8
[cli][info] Found matching plugin hls for URL https://live-hls-web-aje.getaj.net/AJE/index.m3u8
Available streams: 240p (worst), 360p, 420p, 540p, 720p, 1080p (best)
```
There's also: https://www.youtube.com/channel/UCNye-wNBqNL5ZzHSJj3l8Bg
@mkbloke Thx a lot :+1: | 2020-09-26T23:19:26 |
streamlink/streamlink | 3,216 | streamlink__streamlink-3216 | [
"2455"
] | 6d5c13c83cb81ba1e2927d917732c8fb967ba5a8 | diff --git a/src/streamlink/plugins/srgssr.py b/src/streamlink/plugins/srgssr.py
deleted file mode 100644
--- a/src/streamlink/plugins/srgssr.py
+++ /dev/null
@@ -1,98 +0,0 @@
-from __future__ import print_function
-
-import re
-
-from streamlink import PluginError
-from streamlink.compat import urlparse, parse_qsl, urlencode, urlunparse
-from streamlink.plugin import Plugin
-from streamlink.plugin.api import validate
-from streamlink.stream import HLSStream
-
-
-class SRGSSR(Plugin):
- url_re = re.compile(r"""https?://(?:www\.)?
- (srf|rts|rsi|rtr)\.ch/
- (?:
- play/tv|
- livestream/player|
- live-streaming|
- sport/direct/(\d+)-
- )""", re.VERBOSE)
- api_url = "http://il.srgssr.ch/integrationlayer/1.0/ue/{site}/video/play/{id}.json"
- token_url = "http://tp.srgssr.ch/akahd/token"
- video_id_re = re.compile(r'urn(?:%3A|:)(srf|rts|rsi|rtr)(?:%3A|:)(?:ais(?:%3A|:))?video(?:%3A|:)([^&"]+)')
- video_id_schema = validate.Schema(validate.transform(video_id_re.search))
- api_schema = validate.Schema(
- {
- "Video":
- {
- "Playlists":
- {
- "Playlist": [{
- "@protocol": validate.text,
- "url": [{"@quality": validate.text, "text": validate.url()}]
- }]
- }
- }
- },
- validate.get("Video"),
- validate.get("Playlists"),
- validate.get("Playlist"))
- token_schema = validate.Schema({"token": {"authparams": validate.text}},
- validate.get("token"),
- validate.get("authparams"))
-
- @classmethod
- def can_handle_url(cls, url):
- return cls.url_re.match(url) is not None
-
- def get_video_id(self):
- parsed = urlparse(self.url)
- qinfo = dict(parse_qsl(parsed.query or parsed.fragment.lstrip("?")))
-
- site, video_id = None, None
- url_m = self.url_re.match(self.url)
-
- # look for the video id in the URL, otherwise find it in the page
- if "tvLiveId" in qinfo:
- video_id = qinfo["tvLiveId"]
- site = url_m.group(1)
- elif url_m.group(2):
- site, video_id = url_m.group(1), url_m.group(2)
- else:
- video_id_m = self.session.http.get(self.url, schema=self.video_id_schema)
- if video_id_m:
- site, video_id = video_id_m.groups()
-
- return site, video_id
-
- def auth_url(self, url):
- parsed = urlparse(url)
- path, _ = parsed.path.rsplit("/", 1)
- token_res = self.session.http.get(self.token_url, params=dict(acl=path + "/*"))
- authparams = self.session.http.json(token_res, schema=self.token_schema)
-
- existing = dict(parse_qsl(parsed.query))
- existing.update(dict(parse_qsl(authparams)))
-
- return urlunparse(parsed._replace(query=urlencode(existing)))
-
- def _get_streams(self):
- site, video_id = self.get_video_id()
-
- if video_id and site:
- self.logger.debug("Found {0} video ID {1}", site, video_id)
-
- try:
- res = self.session.http.get(self.api_url.format(site=site, id=video_id))
- except PluginError:
- return
-
- for stream_info in self.session.http.json(res, schema=self.api_schema):
- for url in stream_info["url"]:
- if stream_info["@protocol"] == "HTTP-HLS":
- for s in HLSStream.parse_variant_playlist(self.session, self.auth_url(url["text"])).items():
- yield s
-
-
-__plugin__ = SRGSSR
| diff --git a/tests/plugins/test_srgssr.py b/tests/plugins/test_srgssr.py
deleted file mode 100644
--- a/tests/plugins/test_srgssr.py
+++ /dev/null
@@ -1,22 +0,0 @@
-import unittest
-
-from streamlink.plugins.srgssr import SRGSSR
-
-
-class TestPluginSRGSSR(unittest.TestCase):
- def test_can_handle_url(self):
- # should match
- self.assertTrue(SRGSSR.can_handle_url("http://srf.ch/play/tv/live"))
- self.assertTrue(SRGSSR.can_handle_url("http://www.rsi.ch/play/tv/live#?tvLiveId=livestream_La1"))
- self.assertTrue(SRGSSR.can_handle_url("http://rsi.ch/play/tv/live?tvLiveId=livestream_La1"))
- self.assertTrue(SRGSSR.can_handle_url("http://www.rtr.ch/play/tv/live"))
- self.assertTrue(SRGSSR.can_handle_url("http://rtr.ch/play/tv/live"))
- self.assertTrue(SRGSSR.can_handle_url("http://rts.ch/play/tv/direct#?tvLiveId=3608506"))
- self.assertTrue(SRGSSR.can_handle_url("http://www.srf.ch/play/tv/live#?tvLiveId=c49c1d64-9f60-0001-1c36-43c288c01a10"))
- self.assertTrue(SRGSSR.can_handle_url("http://www.rts.ch/sport/direct/8328501-tennis-open-daustralie.html"))
- self.assertTrue(SRGSSR.can_handle_url("http://www.rts.ch/play/tv/tennis/video/tennis-open-daustralie?id=8328501"))
-
- # shouldn't match
- self.assertFalse(SRGSSR.can_handle_url("http://www.crunchyroll.com/gintama"))
- self.assertFalse(SRGSSR.can_handle_url("http://www.crunchyroll.es/gintama"))
- self.assertFalse(SRGSSR.can_handle_url("http://www.youtube.com/"))
| RSI.ch new API 2.0
## Plugin Issue
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
RSI.ch now uses a new API to download the Json file containing the streaming information. So the current plugin no longer works. Obviously with Swiss IP.
### Explicit stream URLs to test (Only from Swiss IP)
Live Streaming: https://www.rsi.ch/play/tv/live?tvLiveId=livestream_La1
JSON: https://il.srgssr.ch/integrationlayer/2.0/mediaComposition/byUrn/urn:rsi:video:livestream_La1.json?onlyChapters=true&vector=portalplay
Streaming Data: https://rsila1-euwe.akamaized.net/333fb374-92b8-4a1d-90af-4529f56d683e/rsi1.ism/manifest(format=m3u8-aapl,encryption=cbcs-aapl,filter=nodvr)
### Log output
$ streamlink https://www.rsi.ch/play/tv/live?tvLiveId=livestream_La1 best
[cli][info] Found matching plugin srgssr for URL https://www.rsi.ch/play/tv/live?tvLiveId=livestream_La1
error: Unable to open URL: https://srgssruni12ch-lh.akamaihd.net/i/enc12uni_ch@191527/master.m3u8?hdnts=exp%3D1556873673%7Eacl%3D%2Fi%2Fenc12uni_ch%40191527%2F%2A%7Ehmac%3D82d1c28280c7ad5fe12618106b6600e1593c2acd90bd2db4b9df05a6dbd36f0c (400 Client Error: Bad Request for url: https://srgssruni12ch-lh.akamaihd.net/i/enc12uni_ch@191527/master.m3u8?hdnts=exp%3D1556873673~acl%3D%2Fi%2Fenc12uni_ch%40191527%2F%2A~hmac%3D82d1c28280c7ad5fe12618106b6600e1593c2acd90bd2db4b9df05a6dbd36f0c)
| I rewrote the _srgssr.py_ plugin adapting it to the new API, it acquires the new url correctly.
But now I have this error:
**[stream.hls] [error] Failed to create decryptor: ('Unable to decrypt cipher {0}', 'SAMPLE-AES')**
I do not understand if it is possible to overcome this coding or not, can you help me?
New plugin conde:
```
from __future__ import print_function
import re
from streamlink import PluginError
from streamlink.compat import urlparse, parse_qsl, urlencode, urlunparse
from streamlink.plugin import Plugin
from streamlink.plugin.api import validate
from streamlink.stream import HLSStream
class SRGSSR(Plugin):
url_re = re.compile(r"""https?://(?:www\.)?
(srf|rts|rsi|rtr)\.ch/
(?:
play/tv|
livestream/player|
live-streaming|
sport/direct/(\d+)-
)""", re.VERBOSE)
api_url = "https://il.srgssr.ch/integrationlayer/2.0/mediaComposition/byUrn/urn:{site}:video:{id}.json"
token_url = "http://tp.srgssr.ch/akahd/token"
video_id_re = re.compile(r'urn(?:%3A|:)(srf|rts|rsi|rtr)(?:%3A|:)(?:ais(?:%3A|:))?video(?:%3A|:)([^&"]+)')
video_id_schema = validate.Schema(validate.transform(video_id_re.search))
api_schema = validate.Schema(
{
"Video":
{
"Playlists":
{
"Playlist": [{
"@protocol": validate.text,
"url": [{"@quality": validate.text, "text": validate.url()}]
}]
}
}
},
validate.get("Video"),
validate.get("Playlists"),
validate.get("Playlist"))
token_schema = validate.Schema({"token": {"authparams": validate.text}},
validate.get("token"),
validate.get("authparams"))
@classmethod
def can_handle_url(cls, url):
return cls.url_re.match(url) is not None
def get_video_id(self):
parsed = urlparse(self.url)
qinfo = dict(parse_qsl(parsed.query or parsed.fragment.lstrip("?")))
site, video_id = None, None
url_m = self.url_re.match(self.url)
# look for the video id in the URL, otherwise find it in the page
if "tvLiveId" in qinfo:
video_id = qinfo["tvLiveId"]
site = url_m.group(1)
elif url_m.group(2):
site, video_id = url_m.group(1), url_m.group(2)
else:
video_id_m = self.session.http.get(self.url, schema=self.video_id_schema)
if video_id_m:
site, video_id = video_id_m.groups()
return site, video_id
def auth_url(self, url):
parsed = urlparse(url)
path, _ = parsed.path.rsplit("/", 1)
token_res = self.session.http.get(self.token_url, params=dict(acl=path + "/*"))
authparams = self.session.http.json(token_res, schema=self.token_schema)
existing = dict(parse_qsl(parsed.query))
existing.update(dict(parse_qsl(authparams)))
return urlunparse(parsed._replace(query=urlencode(existing)))
def _get_streams(self):
site, video_id = self.get_video_id()
if video_id and site:
self.logger.debug("Found {0} video ID {1}", site, video_id)
try:
res = self.session.http.get(self.api_url.format(site=site, id=video_id))
except PluginError:
return
data = self.session.http.json(res)
for each in data["chapterList"][0]["resourceList"]:
if each["protocol"] == "HLS":
for s in HLSStream.parse_variant_playlist(self.session, self.auth_url(each["url"])).items():
yield s
__plugin__ = SRGSSR
```
Ok, I just saw that in issues #2155 @back-to said that this type of DRM is not supported. :(
I leave you the decision, or not, to import the new code.
Output with debug loglevel:
> $ streamlink --plugin-dirs="./personalplugin/" https://www.rsi.ch/play/tv/live?tvLiveId=livestream_La1 best --loglevel debug
> [session][debug] Plugin srgssr is being overridden by /personalplugin/srgssr.py
> [cli][debug] OS: macOS 10.14.4
> [cli][debug] Python: 3.6.5
> [cli][debug] Streamlink: 1.1.1
> [cli][debug] Requests(2.21.0), Socks(1.6.7), Websocket(0.48.0)
> [cli][info] Found matching plugin srgssr for URL https://www.rsi.ch/play/tv/live?tvLiveId=livestream_La1
> [plugin.srgssr][debug] Found rsi video ID livestream_La1
> [utils.l10n][debug] Language code: it_IT
> [cli][info] Available streams: 138k (worst), 180p, 272p, 360p, 544p (best)
> [cli][info] Opening stream: 544p (hls)
> [stream.hls][debug] Reloading playlist
> [stream.hls][debug] Segments in this playlist are encrypted
> [stream.hls][debug] First Sequence: 1025469; Last Sequence: 1025477
> [stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 1025475; End Sequence: None
> [stream.hls][debug] Adding segment 1025475 to queue
> [cli][debug] Pre-buffering 8192 bytes
> [stream.hls][debug] Adding segment 1025476 to queue
> [stream.hls][debug] Adding segment 1025477 to queue
> [stream.hls][error] Failed to create decryptor: ('Unable to decrypt cipher {0}', 'SAMPLE-AES')
> [stream.segmented][debug] Closing writer thread
> [stream.segmented][debug] Closing worker thread
> [cli][error] Try 1/1: Could not open stream <HLSStream('https://rsila1-euwe.akamaized.net/333fb374-92b8-4a1d-90af-4529f56d683e/rsi1.ism/QualityLevels(1999600)/Manifest(video,format=m3u8-aapl,filter=nodvr)')> (No data returned from stream)
> error: Could not open stream <HLSStream('https://rsila1-euwe.akamaized.net/333fb374-92b8-4a1d-90af-4529f56d683e/rsi1.ism/QualityLevels(1999600)/Manifest(video,format=m3u8-aapl,filter=nodvr)')>, tried 1 times, exiting
> [cli][info] Closing currently open stream... | 2020-10-01T17:16:34 |
streamlink/streamlink | 3,223 | streamlink__streamlink-3223 | [
"3206"
] | 710787bb58e8b173fbdebfff3f3d6c18af0360a2 | diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -396,6 +396,39 @@ class Twitch(Plugin):
)
)
+ _schema_metadata_empty = validate.transform(lambda _: (None,) * 3)
+ _schema_metadata_channel = validate.Schema(
+ {
+ "stream": validate.any(
+ validate.all(
+ {"channel": {
+ "display_name": validate.text,
+ "game": validate.text,
+ "status": validate.text
+ }},
+ validate.get("channel"),
+ validate.transform(lambda ch: (ch["display_name"], ch["status"], ch["game"]))
+ ),
+ validate.all(None, _schema_metadata_empty)
+ )
+ },
+ validate.get("stream")
+ )
+ _schema_metadata_video = validate.Schema(validate.any(
+ validate.all(
+ {
+ "title": validate.text,
+ "game": validate.text,
+ "channel": validate.all(
+ {"display_name": validate.text},
+ validate.get("display_name")
+ )
+ },
+ validate.transform(lambda data: (data["channel"], data["title"], data["game"]))
+ ),
+ validate.all({}, _schema_metadata_empty)
+ ))
+
@classmethod
def stream_weight(cls, key):
weight = QUALITY_WEIGHTS.get(key)
@@ -410,17 +443,11 @@ def can_handle_url(cls, url):
def _get_metadata(self):
if self.video_id:
- api_res = self.api.videos(self.video_id)
- self.title = api_res["title"]
- self.author = api_res["channel"]["display_name"]
- self.category = api_res["game"]
+ (self.author, self.title, self.category) = self.api.videos(self.video_id, schema=self._schema_metadata_video)
elif self.clip_name:
self._get_clips()
elif self._channel:
- api_res = self.api.streams(self.channel_id)["stream"]["channel"]
- self.title = api_res["status"]
- self.author = api_res["display_name"]
- self.category = api_res["game"]
+ (self.author, self.title, self.category) = self.api.streams(self.channel_id, schema=self._schema_metadata_channel)
def get_title(self):
if self.title is None:
| diff --git a/tests/plugins/test_twitch.py b/tests/plugins/test_twitch.py
--- a/tests/plugins/test_twitch.py
+++ b/tests/plugins/test_twitch.py
@@ -7,6 +7,7 @@
from tests.mock import MagicMock, call, patch
from streamlink import Streamlink
+from streamlink.plugin import PluginError
from streamlink.plugins.twitch import Twitch, TwitchHLSStream
@@ -274,6 +275,81 @@ def test_hls_low_latency_no_prefetch_disable_ads_has_preroll(self, mock_log):
])
+class TestTwitchMetadata(unittest.TestCase):
+ def setUp(self):
+ self.mock = requests_mock.Mocker()
+ self.mock.start()
+
+ def tearDown(self):
+ self.mock.stop()
+
+ def subject(self, url):
+ session = Streamlink()
+ Twitch.bind(session, "tests.plugins.test_twitch")
+ plugin = Twitch(url)
+ return plugin.get_author(), plugin.get_title(), plugin.get_category()
+
+ def subject_channel(self, data=True, failure=False):
+ self.mock.get(
+ "https://api.twitch.tv/kraken/users.json?login=foo",
+ json={"users": [{"_id": 1234}]}
+ )
+ self.mock.get(
+ "https://api.twitch.tv/kraken/streams/1234.json",
+ status_code=200 if not failure else 404,
+ json={"stream": None} if not data else {"stream": {
+ "channel": {
+ "display_name": "channel name",
+ "status": "channel status",
+ "game": "channel game"
+ }
+ }}
+ )
+ return self.subject("https://twitch.tv/foo")
+
+ def subject_video(self, data=True, failure=False):
+ self.mock.get(
+ "https://api.twitch.tv/kraken/videos/1337.json",
+ status_code=200 if not failure else 404,
+ json={} if not data else {
+ "title": "video title",
+ "game": "video game",
+ "channel": {
+ "display_name": "channel name"
+ }
+ }
+ )
+ return self.subject("https://twitch.tv/videos/1337")
+
+ def test_metadata_channel_exists(self):
+ author, title, category = self.subject_channel()
+ self.assertEqual(author, "channel name")
+ self.assertEqual(title, "channel status")
+ self.assertEqual(category, "channel game")
+
+ def test_metadata_channel_missing(self):
+ metadata = self.subject_channel(data=False)
+ self.assertEqual(metadata, (None, None, None))
+
+ def test_metadata_channel_invalid(self):
+ with self.assertRaises(PluginError):
+ self.subject_channel(failure=True)
+
+ def test_metadata_video_exists(self):
+ author, title, category = self.subject_video()
+ self.assertEqual(author, "channel name")
+ self.assertEqual(title, "video title")
+ self.assertEqual(category, "video game")
+
+ def test_metadata_video_missing(self):
+ metadata = self.subject_video(data=False)
+ self.assertEqual(metadata, (None, None, None))
+
+ def test_metadata_video_invalid(self):
+ with self.assertRaises(PluginError):
+ self.subject_video(failure=True)
+
+
@patch("streamlink.plugins.twitch.log")
class TestTwitchReruns(unittest.TestCase):
log_call = call("Reruns were disabled by command line option")
| --title switch with variable arguments prevents Twitch rerun vod from playing
<!--
Thanks for reporting a bug!
USE THE TEMPLATE. Otherwise your bug report may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed bug reports:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Bug Report
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report and I have read the contribution guidelines.
### Description
<!-- Explain the bug as thoroughly as you can. Don't leave out information which is necessary for us to reproduce and debug this issue. --> If you use the --title switch with arguments that contain variables like {author}, {category}, or {title}, streamlink cannot play certain twitch streams (reruns, I think)
### Expected / Actual behavior
<!-- What do you expect to happen, and what is actually happening? -->
I expect streamlink to open the twitch stream in my player of choice and start playing. Instead, I get errors, nothing plays, and streamlink quits.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. Find a twitch channel that is playing reruns, for example: reckful
2. Launch using a command like: streamlink --loglevel debug --verbose-player --player=mpv --title "{author}" twitch.tv/reckful best
3. See log output
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a bug report!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
[azizLIGHT@fractal ~]$ /home/azizLIGHT/Documents/Scripts/streamlink-pip/bin/streamlink --loglevel debug --verbose-player --player=mpv --title "{author}" twitch.tv/reckful best
[cli][debug] OS: Linux-5.4.52-1-MANJARO-x86_64-with-glibc2.2.5
[cli][debug] Python: 3.8.3
[cli][debug] Streamlink: 1.5.0+31.g1913115
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin twitch for URL twitch.tv/reckful
[plugin.twitch][debug] Getting live HLS streams for reckful
[utils.l10n][debug] Language code: en_US
[cli][info] Available streams: audio_only, 160p (worst), 360p, 480p, 720p, 720p60_alt, 720p60 (best)
[cli][info] Opening stream: 720p60 (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] First Sequence: 3689; Last Sequence: 3702
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 3700; End Sequence: None
[stream.hls][debug] Adding segment 3700 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 3701 to queue
[stream.hls][debug] Adding segment 3702 to queue
[stream.hls][debug] Download of segment 3700 complete
[stream.hls][debug] Download of segment 3701 complete
[stream.hls][debug] Download of segment 3702 complete
[cli][info] Closing currently open stream...
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
Traceback (most recent call last):
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/bin/streamlink", line 11, in <module>
load_entry_point('streamlink==1.5.0+31.g1913115', 'console_scripts', 'streamlink')()
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink_cli/main.py", line 1027, in main
handle_url()
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink_cli/main.py", line 602, in handle_url
handle_stream(plugin, streams, stream_name)
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink_cli/main.py", line 455, in handle_stream
success = output_stream(plugin, stream)
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink_cli/main.py", line 316, in output_stream
output = create_output(plugin)
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink_cli/main.py", line 114, in create_output
title = create_title(plugin)
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink_cli/main.py", line 148, in create_title
title = LazyFormatter.format(
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink/utils/lazy_formatter.py", line 22, in format
return string.Formatter().vformat(fmt, (), cls(**lazy_props))
File "/usr/lib/python3.8/string.py", line 167, in vformat
result, _ = self._vformat(format_string, args, kwargs, used_args, 2)
File "/usr/lib/python3.8/string.py", line 207, in _vformat
obj, arg_used = self.get_field(field_name, args, kwargs)
File "/usr/lib/python3.8/string.py", line 272, in get_field
obj = self.get_value(first, args, kwargs)
File "/usr/lib/python3.8/string.py", line 229, in get_value
return kwargs[key]
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink/utils/lazy_formatter.py", line 11, in __getitem__
return value()
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink_cli/main.py", line 151, in <lambda>
author=lambda: plugin.get_author() or DEFAULT_STREAM_METADATA["author"],
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink/plugins/twitch.py", line 422, in get_author
self._get_metadata()
File "/home/azizLIGHT/Documents/Scripts/streamlink-pip/lib/python3.8/site-packages/streamlink/plugins/twitch.py", line 410, in _get_metadata
api_res = self.api.streams(self.channel_id)["stream"]["channel"]
TypeError: 'NoneType' object is not subscriptable
[azizLIGHT@fractal ~]$
```
### Additional comments, screenshots, etc.
Normally I use --title "{author} - {category} - {title} - (\${{video-bitrate}})" in my command, but any of those will cause streamlink to fail when trying to watch reckful stream. It does not seem to do it for regular live twitch channels, maybe it only does it to rerun channels. I am not sure. This was streamlink installed to a venv using [these instructions](https://streamlink.github.io/install.html#virtual-environment)
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Stream launches fine without the --title switch:
`streamlink --player="mpv --keep-open=yes --ontop --autofit=22%" --player-no-close --twitch-disable-ads --twitch-low-latency http://twitch.tv/reckful best`
and also launches fine with the --title switch, IF the arguments are NOT variables:
`streamlink --player="mpv --keep-open=yes --ontop --autofit=22%" --player-no-close --twitch-disable-ads --twitch-low-latency --title="test" http://twitch.tv/reckful best
`
This is because that data is not available from the API where we expect it to be. I'm not sure if this is something we'll consider fixing. @bastimeyer I feel like we discussed this in the past regarding rebroadcasts and that they work differently than a VOD or live stream and we said we wouldn't fix issues with them due to how rare they are, but I can't find the discussion now. Do you remember?
This channel is not "live" (yes, I know why). The Twitch API doesn't return stream data in those cases. That might be a bug with kraken v5, I don't know, but I wouldn't be surprised either, because kraken v5 is really messy, and helix I believe still a shitshow, despite promises of improvements earlier this year.
Streamlink doesn't set the `stream_type` query parameter when requesting streams by channel ID, as documented here:
https://dev.twitch.tv/docs/v5/reference/streams#get-stream-by-user
It doesn't make a difference though, as you can see in the following example:
```bash
LOGIN=reckful
ID=$(curl -s \
-H "Accept: application/vnd.twitchtv.v5+json" \
-H "Client-ID: pwkzresl8kj2rdj6g7bvxl9ys1wly3j" \
"https://api.twitch.tv/kraken/users?login=${LOGIN}" \
| jq -r '.users[0]._id'
)
```
**No `stream_type`**
```bash
curl -s \
-H "Accept: application/vnd.twitchtv.v5+json" \
-H "Client-ID: pwkzresl8kj2rdj6g7bvxl9ys1wly3j" \
"https://api.twitch.tv/kraken/streams/${ID}" \
| jq
```
```json
{
"stream": null
}
```
**With `stream_type=all`**
```bash
curl -s \
-H "Accept: application/vnd.twitchtv.v5+json" \
-H "Client-ID: pwkzresl8kj2rdj6g7bvxl9ys1wly3j" \
"https://api.twitch.tv/kraken/streams/${ID}?stream_type=all" \
| jq
```
```json
{
"stream": null
}
```
This is an issue on the Twitch API and we can't do anything about when they don't provide the correct data. It doesn't mean though that the plugin should raise a `TypeError`. The method for reading the stream's metadata currently doesn't check for missing data and also doesn't use a validation schema. This bug needs to be fixed.
https://github.com/streamlink/streamlink/blame/21a3067c1790f355849af1d973cf3970262e2eae/src/streamlink/plugins/twitch.py#L401-L413
The overall state of the Twitch plugin in regards to the API queries and stuff around that is very much outdated and hasn't been touched in several years. When the `--title` parameter was added two years ago, this should have been implemented way cleaner. When I get the time, I will look into refactoring the plugin's `TwitchAPI`, `UsherService` and overall plugin methods. | 2020-10-04T08:03:27 |
streamlink/streamlink | 3,232 | streamlink__streamlink-3232 | [
"2896",
"2920"
] | 51916b88adadaab4e06ff1bc96a661ad2e5f2da5 | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -7,23 +7,13 @@
import versioneer
+
deps = [
- # Require backport of concurrent.futures on Python 2
- 'futures;python_version<"3.0"',
- # Require singledispatch on Python <3.4
- 'singledispatch;python_version<"3.4"',
"requests>=2.21.0,<3.0",
- 'urllib3[secure]>=1.23;python_version<"3.0"',
"isodate",
"websocket-client",
# Support for SOCKS proxies
"PySocks!=1.5.7,>=1.5.6",
- # win-inet-pton is missing a dependency in PySocks, this has been fixed but not released yet
- # Required due to missing socket.inet_ntop & socket.inet_pton method in Windows Python 2.x
- 'win-inet-pton;python_version<"3.0" and platform_system=="Windows"',
- # shutil.get_terminal_size and which were added in Python 3.3
- 'backports.shutil_which;python_version<"3.3"',
- 'backports.shutil_get_terminal_size;python_version<"3.3"'
]
# for encrypted streams
@@ -76,7 +66,7 @@ def is_wheel_for_windows():
setup(name="streamlink",
version=versioneer.get_version(),
cmdclass=versioneer.get_cmdclass(),
- description="Streamlink is command-line utility that extracts streams "
+ description="Streamlink is a command-line utility that extracts streams "
"from various services and pipes them into a video player of "
"choice.",
long_description=long_description,
@@ -97,7 +87,7 @@ def is_wheel_for_windows():
entry_points=entry_points,
install_requires=deps,
test_suite="tests",
- python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, <4",
+ python_requires=">=3.5, <4",
classifiers=["Development Status :: 5 - Production/Stable",
"License :: OSI Approved :: BSD License",
"Environment :: Console",
@@ -105,11 +95,13 @@ def is_wheel_for_windows():
"Operating System :: POSIX",
"Operating System :: Microsoft :: Windows",
"Operating System :: MacOS",
- "Programming Language :: Python :: 2.7",
+ "Programming Language :: Python :: 3",
+ "Programming Language :: Python :: 3 :: Only",
"Programming Language :: Python :: 3.5",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
"Programming Language :: Python :: 3.8",
+ "Programming Language :: Python :: 3.9",
"Topic :: Internet :: WWW/HTTP",
"Topic :: Multimedia :: Sound/Audio",
"Topic :: Multimedia :: Video",
diff --git a/src/streamlink/session.py b/src/streamlink/session.py
--- a/src/streamlink/session.py
+++ b/src/streamlink/session.py
@@ -3,7 +3,6 @@
import pkgutil
import sys
import traceback
-import warnings
import requests
@@ -52,12 +51,6 @@ class Streamlink(object):
options and log settings."""
def __init__(self, options=None):
- if sys.version_info[0] == 2:
- warnings.warn("Python 2.7 has reached the end of its life. A future version of streamlink will drop "
- "support for Python 2.7. Please upgrade your Python to at least 3.5.",
- category=PythonDeprecatedWarning,
- stacklevel=2)
-
self.http = api.HTTPSession()
self.options = Options({
"hds-live-edge": 10.0,
| Python 2.7 support
## Issue
- [x] This is not a bug report, feature request, or plugin issue/request.
- [x] I have read the contribution guidelines.
### Description
Hi !
This is more of a question and the beginning of a discussion than an issue.
Python 2.7 is not maintained anymore (see: https://github.com/python/devguide/pull/344)
It has been mentioned a few times in the project's issues that Python 2.7 is sometimes problematic.
Last time was only a few days ago (see: https://github.com/streamlink/streamlink/pull/2871#issuecomment-611939149)
I'm really new in this project and I understand that there are historical reasons for a Python 2.7 version of StreamLink but I would like to know if there is a plan on Python 2.7 support.
Maybe some users are still relying on Python 2.7, should they expect an end of support soon?
How many users would be impacted? Is there an easy way to know?
Drop support for EOL Python 2
For #2896.
Minimal version of https://github.com/streamlink/streamlink/pull/2919.
* Don't test or install on Python 2.7
* Remove universal wheel
* Update docs and metadata
| It really comes down to resources. If I could wave a magic wand I'd remove 2.7 support today. We're not going to support it, make code changes for it, or do any work to make Streamlink work with 2.7. The only plan around 2.7 is to stop supporting 2.7. If people are still relying on 2.7 they should expect it to go away at any time as 2.7 was already EoL, we just haven't gotten to it yet.
There is no way to know how many users would be impacted, we don't track stats like that at all within the application but even if it impacted 95% of people I'd still push for removing it.
I understand.
Should we stop testing Python 2.7 then?
see: https://github.com/streamlink/streamlink/blob/master/.github/workflows/main.yml#L23
> we don't track stats like that at all within the application
And I'm grateful for that.
I imagine 99% of the Windows installs are from the installer or a portable version, which use Python 3.5+.
I would imagine a lot of the Linux installs are Python 2.7, because older distros use Python 2.7 by default, same goes for macOS I guess.
@brouxco When someone makes the PR to drop 2.7 support they'll stop testing 2.7, until then it needs to be tested. @beardypig I'm running it on 3.6+ on macOS since it's easy to run both with Brew. I don't think it's something worth worrying about as long as we announce it in the release notes.
Fedora and Ubuntu will be switching to python3 as default python interpreter in a couple of days. Apart from that, all available `streamlink` "system-packages" are based on python3.
The only problem with dropping 2.7 are non-system-package installs via pip/setuptools which were done via the system's default python interpreter on distros shipping with python2 as the default one.
These are the current **default** `/usr/bin/python` versions on various Linux distros and macOS:
- **Arch Linux**
[3.8](https://www.archlinux.org/packages/extra/x86_64/python/)
- **Debian**
- buster (stable): [2.7](https://packages.debian.org/buster/python)
- bullseye (testing): [2.7](https://packages.debian.org/bullseye/python) (release date: [next year](https://en.wikipedia.org/wiki/Debian_version_history#Debian_11_(Bullseye)))
- sid (unstable): [2.7](https://packages.debian.org/sid/python)
https://www.debian.org/doc/packaging-manuals/python-policy/index.html
https://wiki.debian.org/Python/2Removal
- **Fedora**
- fedora 31: [2.7](https://fedoraproject.org/wiki/Changes/Python_means_Python3)
- fedora 32: [3.8](https://fedoraproject.org/wiki/Releases/32/ChangeSet?rd=Releases/32#Python_3.8) (release date: [2020-04-28](https://www.phoronix.com/scan.php?page=news_item&px=Fedora-32-Release-Bug-Delay))
https://fedoraproject.org/wiki/Changes/Python_means_Python3#Python_command
- **Gentoo**
[multiple targets, default is 3.x](https://packages.gentoo.org/packages/dev-lang/python)
- **Linux Mint**
19.3 Tricia: [based on Ubuntu 18.04](https://en.wikipedia.org/wiki/Linux_Mint_version_history#Release_history)
- **openSUSE**
tumbleweed: none / [2.7 - via `python`](https://build.opensuse.org/package/view_file/openSUSE:Factory/python/python-base.spec?expand=1)
leap 15.2: none / [2.7 - via `python`](https://build.opensuse.org/package/view_file/openSUSE:Leap:15.2/python/python-base.spec?expand=1)
- **Solus**
[2.7](https://dev.getsol.us/source/python/browse/master/package.yml)
- **Ubuntu**
- 18.04 LTS: [2.7](https://packages.ubuntu.com/bionic/python/python)
- 19.10: [2.7](https://packages.ubuntu.com/eoan/python/python)
- 20.04 LTS: none / [3.8 - via `python-is-python3`](https://packages.ubuntu.com/focal/python/python-is-python3) (release date: [2020-04-23](https://en.wikipedia.org/wiki/Ubuntu_version_history#Ubuntu_20.04_LTS_(Focal_Fossa)))
https://lists.ubuntu.com/archives/ubuntu-devel/2019-October/040834.html
- **Void Linux**
[2.7](https://github.com/void-linux/void-packages/blob/master/srcpkgs/python/template)
- **macOS**
- catalina: [2.7](https://developer.apple.com/documentation/macos_release_notes/macos_catalina_10_15_release_notes)
> Use of Python 2.7 isn’t recommended as this version is included in macOS for compatibility with legacy software. Future versions of macOS won’t include Python 2.7. Instead, it’s recommended that you run python3 from within Terminal.
- homebrew: [3.7](https://github.com/Homebrew/homebrew-core/blob/master/Formula/python.rb)
https://www.python.org/dev/peps/pep-0394/#history-of-this-pep
Talking about Python: What are the minimal requirements for using version 3, so which version exactly?
Hopefully it is quite a low version like 3.5 as updating Python on a Linux system, 'overwriting' the included version, is a pain in the ass and nearly never works.
We should remove support on July 2nd... :|
Should have also posted this site:
https://python3statement.org/
Also, as a small correction to my earlier post, many distros intentionally leave their `python` package (which provides `/usr/bin/python`) on version 2.7. The user is expected to run python3 explicitly via `/usr/bin/python3`. The python2 "drop" is then done by not having the `python` package installed by default, which is already the case on openSUSE for example. On Ubuntu, they are doing that with the upcoming release and are also providing the `python-is-python3` package, which symlinks `/usr/bin/python` to `/usr/bin/python3`.
----
@malvinas2
https://github.com/streamlink/streamlink/blob/master/.github/workflows/main.yml#L23
Here's the EOL list of the Python3 branches:
https://devguide.python.org/#status-of-python-branches
----
Why that specific date, @beardypig?
@bastimeyer
July 2nd... ==> 2.7 (as we already missed 7th of February, hahaha)
Please see PR https://github.com/streamlink/streamlink/pull/2919.
I have installed python 3.5, but streamlink still thinks that I'm using python 2.7
May I ask what should I do?
(I'm using Ubuntu 20.04)
Thank you very much in advance
@wishfulguy depends how you installed `streamlink`, if you used `pip` you might need to use `pip3`.
@wishfulguy
or in case you clone the git repository replace python by python**3**:
```
# Current user
git clone https://github.com/streamlink/streamlink.git
cd streamlink
python3 setup.py install --user
# System wide
git clone https://github.com/streamlink/streamlink.git
cd streamlink
sudo python3 setup.py install
```
@beardypig Do you want to add the python2-removal branch (or whatever you want to call it) to the repo now? We've said that 1.4.0 was the "last" release with p2 support, so we should start removing python2 now. This parallel branch shouldn't live too long though, otherwise we'll have lots of merge conflicts.
I’m on a Mac and I have limited technical knowledge and zero experience with Python. Trying to get streams running with Streamlink 1.4.1 was painful, I just lacked understanding on what it was that needed to be done, and once I did I had no idea how to go about doing it.
I started off by install Python 3 from phython.org (version 3.8.2), and then ran the easy_install command to update to 1.4.1. This this didn’t work, I pointed Twitch GUI at Python 3 (via “which Python3” command) and still got errors. Googling about, I learnt that I needed to get Streamlink installed to Python 3. Then I hit a brick wall as I couldn’t understand anything that I tried to read on how to do it.
The solution is that “easy_install” is a Python program, and that when you run it you are running the system default 2.7 version of it. I had zero clue that this was the case until by chance I saw that there was a file named “easy_install-3.8” in the Python 3 install folder. With this knowledge, I tried running “sudo easy_install-3.8 -U streamlink”, that installed it in the correct place and now I can watch streams again.
I think with the abandonment of 2.7, you should add some clear steps in the documentation for how to handle this on a Mac. It’s simple if you know what you are dealing with, but as someone who was very much on the outside I had a real hard time with it.
@4AM-Campfire Thanks for the feedback. Homebrew is definitely the way to go in this scenario in terms of ease of use. @bastimeyer maybe we should move Homebrew to be the recommended option as the first entry in the list? Or mark Homebrew as the preferred option somehow? Then it's just an install of Homebrew and installing Streamlink will handle all the deps too.
We should remove the `easy_install` suggestion. It's long been deprecated and shouldn't be used at all. It's also questionable if it'll be available on future macOS versions, as they want to remove the system's default python env from what I remember, which includes setuptools, and which therefore includes easy_install.
- https://setuptools.readthedocs.io/en/latest/easy_install.html
- https://packaging.python.org/discussions/pip-vs-easy-install/
To be honest, I didn't notice that we were still mentioning it in the install docs, let alone having it listed as the first entry. In the [Twitch GUI's install wiki](https://github.com/streamlink/streamlink-twitch-gui/wiki/Installation) (which also includes separate Streamlink instructions), I've explicitly never mentioned it.
@bastimeyer I think we should create a version-2 branch, and do all the changes we want for that there, including removal of Python 2.7. We mentioned before the removal of some deprecated options, etc.
@gravyboat we really should :) We have `easy_install` listed for macOS, but then further down the page we have "Using easy_install is no longer recommended." :) For macOS I'd recommend using homebrew to install Streamlink.
@beardypig Yeah I only ever user Homebrew on my mac, I've never used easy_install for anything Python related.
It's been another month. We've already announced Streamlink's "last py2" release earlier, so we shouldn't drag this out any further and risk having another 1.x release.
Since nobody has pushed the py2 removal forward so far, I guess we should keep it as simple as possible and not create a secondary branch. It's just too much effort keeping track of the changes which will happen simultaneously on the master branch until this gets merged.
Let's remove py2 from the CI runners now, remove everything related to it from setup.py and afterwards strip out all the compatibility stuff and make the remaining code changes. We already have pull requests for that (#2920, #2921).
# [Codecov](https://codecov.io/gh/streamlink/streamlink/pull/2920?src=pr&el=h1) Report
> Merging [#2920](https://codecov.io/gh/streamlink/streamlink/pull/2920?src=pr&el=desc) into [master](https://codecov.io/gh/streamlink/streamlink/commit/6773c3fb9c41f3793aab78e40e10eb1b1d19546e&el=desc) will **decrease** coverage by `0.33%`.
> The diff coverage is `n/a`.
```diff
@@ Coverage Diff @@
## master #2920 +/- ##
==========================================
- Coverage 52.66% 52.33% -0.34%
==========================================
Files 250 250
Lines 15730 15730
==========================================
- Hits 8284 8232 -52
- Misses 7446 7498 +52
```
| 2020-10-07T05:54:09 |
|
streamlink/streamlink | 3,247 | streamlink__streamlink-3247 | [
"3246"
] | 12f6e47280c308c4a945d13a120da6dbf735c5f1 | diff --git a/src/streamlink/plugins/tv3cat.py b/src/streamlink/plugins/tv3cat.py
--- a/src/streamlink/plugins/tv3cat.py
+++ b/src/streamlink/plugins/tv3cat.py
@@ -9,7 +9,7 @@
class TV3Cat(Plugin):
- _url_re = re.compile(r"http://(?:www.)?ccma.cat/tv3/directe/(.+?)/")
+ _url_re = re.compile(r"https?://(?:www\.)?ccma\.cat/tv3/directe/(.+?)/")
_stream_info_url = "http://dinamics.ccma.cat/pvideo/media.jsp" \
"?media=video&version=0s&idint={ident}&profile=pc&desplacament=0"
_media_schema = validate.Schema({
@@ -39,7 +39,6 @@ def _get_streams(self):
return HLSStream.parse_variant_playlist(self.session, stream['url'], name_fmt="{pixels}_{bitrate}")
except PluginError:
log.debug("Failed to get streams for: {0}".format(stream['geo']))
- pass
__plugin__ = TV3Cat
| diff --git a/tests/plugins/test_tv3cat.py b/tests/plugins/test_tv3cat.py
--- a/tests/plugins/test_tv3cat.py
+++ b/tests/plugins/test_tv3cat.py
@@ -6,8 +6,14 @@
class TestPluginTV3Cat(unittest.TestCase):
def test_can_handle_url(self):
should_match = [
+ 'http://ccma.cat/tv3/directe/tv3/',
+ 'http://ccma.cat/tv3/directe/324/',
+ 'https://ccma.cat/tv3/directe/tv3/',
+ 'https://ccma.cat/tv3/directe/324/',
'http://www.ccma.cat/tv3/directe/tv3/',
'http://www.ccma.cat/tv3/directe/324/',
+ 'https://www.ccma.cat/tv3/directe/tv3/',
+ 'https://www.ccma.cat/tv3/directe/324/',
]
for url in should_match:
self.assertTrue(TV3Cat.can_handle_url(url))
| Can't find "tv3cat" plugin
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [ X ] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
A image is worth a thousand words.

### Reproduction steps
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
I've just using the "python3-streamlink" package provided by Fedora 32
Thanks!
| **Feedback/answer (see ticked items):**
As requested in the plugin issue template:
- [ ] Description and/or reproduction steps are insufficiently detailed
- [ ] Streamlink version in use not specified
- [ ] Full ```--loglevel debug``` log output not provided
- [ ] Research of prior issues/fixes appears to be insufficient [1]
Other feedback:
- [ ] Issue is out of scope and/or should be reported/help sought elsewhere
- [ ] Issue appears to unnecessarily duplicate another issue that is open/closed
- [ ] User appears to be using an outdated Streamlink version/plugin [2] [3]
- [x] Other (see below)
- Other: In the future, can you please provide the log output as text, not an image, thanks.
It looks like the URL matching needs a little tweaking and some other small issues with it fixed. For the time being, you can get it to work using the ```http://``` scheme and by appending a ```/``` to the end of the URL you are using:
```
streamlink http://www.ccma.cat/tv3/directe/324/
[cli][info] Found matching plugin tv3cat for URL http://www.ccma.cat/tv3/directe/324/
Available streams: 180p_426k (worst), 360p_646k, 360p_1416k (best)
```
~~Please amend/close your issue accordingly and/or undertake the requested prior research before opening an issue in future.~~
[1] [Search all open/closed issues/pull requests](https://github.com/streamlink/streamlink/issues?q=)
[2] [Install the most recent version of Streamlink](https://streamlink.github.io/install.html)
[3] [Check the master branch for plugin updates](https://github.com/streamlink/streamlink/tree/master/src/streamlink/plugins) | 2020-10-12T21:44:37 |
streamlink/streamlink | 3,268 | streamlink__streamlink-3268 | [
"3263"
] | 51916b88adadaab4e06ff1bc96a661ad2e5f2da5 | diff --git a/src/streamlink/plugins/youtube.py b/src/streamlink/plugins/youtube.py
--- a/src/streamlink/plugins/youtube.py
+++ b/src/streamlink/plugins/youtube.py
@@ -255,6 +255,10 @@ def _find_video_id(self, url):
log.debug("Video ID from currentVideoEndpoint")
return video_id
for x in search_dict(data, 'videoRenderer'):
+ if x.get("viewCountText", {}).get("runs"):
+ if x.get("videoId"):
+ log.debug("Video ID from videoRenderer (live)")
+ return x["videoId"]
for bstyle in search_dict(x.get("badges", {}), "style"):
if bstyle == "BADGE_STYLE_TYPE_LIVE_NOW":
if x.get("videoId"):
@@ -266,8 +270,12 @@ def _find_video_id(self, url):
if link.attributes.get("rel") == "canonical":
canon_link = link.attributes.get("href")
if canon_link != url:
- log.debug("Re-directing to canonical URL: {0}".format(canon_link))
- return self._find_video_id(canon_link)
+ if canon_link.endswith("v=live_stream"):
+ log.debug("The video is not available")
+ break
+ else:
+ log.debug("Re-directing to canonical URL: {0}".format(canon_link))
+ return self._find_video_id(canon_link)
raise PluginError("Could not find a video on this page")
| YouTube live streams not detected from channel page
<!--
Thanks for reporting an issue!
USE THE TEMPLATE. Otherwise your issue may be rejected.
This template should only be used if your issue doesn't match the other more specific ones.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue
Please see the text preview to avoid unnecessary formatting errors.
-->
## Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report.
- [x] I have read the contribution guidelines.
### Description
As of yesterday, Streamlink doesn't detect a YouTube live stream when you put in channel home page as parameter. Tested with several YT channels. A friend of mine started experiencing same issue yesterday as well. Inputting direct video link works, but detecting that video from the channel page is now broken.
### Expected / Actual behavior
<!-- What do you expect to happen, and what is actually happening? -->
Streamlink should find an ID of the live stream and start downloading/streaming it.
Instead no video is found at all.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. Find a YT channel that has a live stream
2. Input: *streamlink.exe https://www.youtube.com/channel/xxxxxxx* (other parameters don't seem to matter)
3. Output: *error: Could not find a video on this page*
### Logs
<!--
TEXT LOG OUTPUT IS OPTIONAL for generic issues!
However, depending on the issue, log output can be useful for the developers to understand the problem. It also includes information about your platform. If you don't intend to include log output, please at least provide these platform details.
Thanks!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
Channel ID removed:
```
streamlink --loglevel debug https://www.youtube.com/channel/xxxxx
[cli][debug] OS: Windows 7
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.6.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/channel/xxxxx
error: Could not find a video on this page
```
### Additional comments, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
|
It works for TRT World.
```
C:\>streamlink.exe --loglevel debug --http-no-ssl-verify --player=ffplay.exe "https://www.youtube.com/embed/live_stream?channel=UC7fWeaHhqgM4Ry-RMpM2YYw"
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.6.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/embed/live_stream?channel=UC7fWeaHhqgM4Ry-RMpM2YYw
[plugin.youtube][debug] Re-directing to canonical URL: https://www.youtube.com/watch?v=CV5Fooi8YJA
[plugin.youtube][debug] Video ID from URL
[plugin.youtube][debug] Using video ID: CV5Fooi8YJA
[plugin.youtube][debug] get_video_info - 1: Found data
[plugin.youtube][debug] This video is live.
[utils.l10n][debug] Language code: en_GB
Available streams: 144p (worst), 240p, 360p, 480p, 720p, 1080p (best)
```
```
C:\>streamlink.exe --loglevel debug --http-no-ssl-verify --player=ffplay.exe "https://www.youtube.com/embed/live_stream?channel=UC7fWeaHhqgM4Ry-RMpM2YYw" 480p
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.6.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/embed/live_stream?channel=UC7fWeaHhqgM4Ry-RMpM2YYw
[plugin.youtube][debug] Re-directing to canonical URL: https://www.youtube.com/watch?v=CV5Fooi8YJA
[plugin.youtube][debug] Video ID from URL
[plugin.youtube][debug] Using video ID: CV5Fooi8YJA
[plugin.youtube][debug] get_video_info - 1: Found data
[plugin.youtube][debug] This video is live.
[utils.l10n][debug] Language code: en_GB
[cli][info] Available streams: 144p (worst), 240p, 360p, 480p, 720p, 1080p (best)
[cli][info] Opening stream: 480p (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] First Sequence: 5216; Last Sequence: 5221
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 5219; End Sequence: None
[stream.hls][debug] Adding segment 5219 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 5220 to queue
[stream.hls][debug] Adding segment 5221 to queue
[stream.hls][debug] Download of segment 5219 complete
[cli][info] Starting player: ffplay.exe
[cli.output][debug] Opening subprocess: ffplay.exe -
[cli][debug] Writing stream to output
[stream.hls][debug] Download of segment 5220 complete
[stream.hls][debug] Download of segment 5221 complete
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 5222 to queue
[stream.hls][debug] Adding segment 5223 to queue
[stream.hls][debug] Download of segment 5222 complete
[stream.hls][debug] Download of segment 5223 complete
```
@johnthecracker
I can confirm it works when you use this type of url: *https://www.youtube.com/embed/live_stream?channel=xxxxx*
I've been using *https://www.youtube.com/channel/xxxxxxx* for weeks and it worked until yesterday.
I too am having this issue. I posted about it in the r/streamlink reddit. I am going to try the embed url, and downgrading to an earlier version | 2020-10-19T09:03:23 |
|
streamlink/streamlink | 3,290 | streamlink__streamlink-3290 | [
"3288"
] | 054b760ce7e9f43451eed08e9f39de440c3e5add | diff --git a/src/streamlink/plugins/bfmtv.py b/src/streamlink/plugins/bfmtv.py
--- a/src/streamlink/plugins/bfmtv.py
+++ b/src/streamlink/plugins/bfmtv.py
@@ -1,45 +1,46 @@
+import logging
import re
from streamlink.plugin import Plugin
from streamlink.plugins.brightcove import BrightcovePlayer
-from streamlink.stream import HLSStream
+
+log = logging.getLogger(__name__)
class BFMTV(Plugin):
_url_re = re.compile(r'https://.+\.(?:bfmtv|01net)\.com')
+ _dailymotion_url = 'https://www.dailymotion.com/embed/video/{}'
_brightcove_video_re = re.compile(
- r'data-holder="video(?P<video_id>[0-9]+)" data-account="(?P<account_id>[0-9]+)"'
- )
- _brightcove_video_alt_re = re.compile(
- r'data-account="(?P<account_id>[0-9]+).*?data-video-id="(?P<video_id>[0-9]+)"',
+ r'accountid="(?P<account_id>[0-9]+).*?videoid="(?P<video_id>[0-9]+)"',
re.DOTALL
)
- _embed_video_url_re = re.compile(
- r"\$YOPLAYER\('liveStitching', {.+?file: '(?P<video_url>[^\"]+?)'.+?}\);",
+ _embed_video_id_re = re.compile(
+ r'<iframe.*?src=".*?/(?P<video_id>\w+)"',
re.DOTALL
)
@classmethod
def can_handle_url(cls, url):
- return BFMTV._url_re.match(url)
+ return cls._url_re.match(url) is not None
def _get_streams(self):
# Retrieve URL page and search for Brightcove video data
res = self.session.http.get(self.url)
- match = self._brightcove_video_re.search(res.text) or self._brightcove_video_alt_re.search(res.text)
+ match = self._brightcove_video_re.search(res.text)
if match is not None:
account_id = match.group('account_id')
+ log.debug(f'Account ID: {account_id}')
video_id = match.group('video_id')
+ log.debug(f'Video ID: {video_id}')
player = BrightcovePlayer(self.session, account_id)
- for stream in player.get_streams(video_id):
- yield stream
+ yield from player.get_streams(video_id)
else:
- # Try to get the stream URL in the page
- match = self._embed_video_url_re.search(res.text)
+ # Try to find the Dailymotion video ID
+ match = self._embed_video_id_re.search(res.text)
if match is not None:
- video_url = match.group('video_url')
- if '.m3u8' in video_url:
- yield from HLSStream.parse_variant_playlist(self.session, video_url).items()
+ video_id = match.group('video_id')
+ log.debug(f'Video ID: {video_id}')
+ yield from self.session.streams(self._dailymotion_url.format(video_id)).items()
__plugin__ = BFMTV
| bfmtv - No playable streams found on this URL
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
There is no playable streams for bfmtv
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
`streamlink https://www.bfmtv.com/en-direct/ best`
or `streamlink https://www.bfmtv.com/paris/en-direct/ best`
or any other channels supported by this plugin
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
streamlink --loglevel debug https://www.bfmtv.com/en-direct/ best
[cli][debug] OS: Linux-5.8.15-201.fc32.x86_64-x86_64-with-glibc2.2.5
[cli][debug] Python: 3.8.6
[cli][debug] Streamlink: 1.7.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin bfmtv for URL https://www.bfmtv.com/en-direct/
error: No playable streams found on this URL: https://www.bfmtv.com/en-direct/
```
### Additional comments, etc.
As a workaround you can use their dailymotion stream: `streamlink https://www.dailymotion.com/embed/video/xgz4t1 best`
| 2020-10-25T20:50:58 |
||
streamlink/streamlink | 3,315 | streamlink__streamlink-3315 | [
"3314"
] | 9384f3df53fdddf87f1b0037963eeb6b7f3c5bf3 | diff --git a/src/streamlink/plugins/vlive.py b/src/streamlink/plugins/vlive.py
--- a/src/streamlink/plugins/vlive.py
+++ b/src/streamlink/plugins/vlive.py
@@ -1,58 +1,106 @@
-import json
import logging
import re
-from streamlink.plugin import Plugin, PluginError
+from streamlink.plugin import Plugin
+from streamlink.plugin.api import validate
from streamlink.stream import HLSStream
+from streamlink.utils import parse_json
log = logging.getLogger(__name__)
class Vlive(Plugin):
- _url_re = re.compile(r"https?://(?:www.)vlive\.tv/video/(\d+)")
- _video_status = re.compile(r'oVideoStatus = (.+)<', re.DOTALL)
- _video_init_url = "https://www.vlive.tv/video/init/view"
+ _url_re = re.compile(r"https://www\.vlive\.tv/(?P<format>video|post)/(?P<id>[0-9\-]+)")
+ _page_info = re.compile(r'window\.__PRELOADED_STATE__\s*=\s*({.*})\s*<', re.DOTALL)
+ _playinfo_url = "https://www.vlive.tv/globalv-web/vam-web/old/v3/live/{0}/playInfo"
+
+ _schema_video = validate.Schema(
+ validate.transform(_page_info.search),
+ validate.any(None, validate.all(
+ validate.get(1),
+ validate.transform(parse_json),
+ validate.any(validate.all(
+ {"postDetail": {"post": {"officialVideo": {
+ "type": str,
+ "videoSeq": int,
+ validate.optional("status"): str,
+ }}}},
+ validate.get("postDetail"),
+ validate.get("post"),
+ validate.get("officialVideo")),
+ validate.all(
+ {"postDetail": {"error": {
+ "errorCode": str,
+ }}},
+ validate.get("postDetail"),
+ validate.get("error")))
+ ))
+ )
+
+ _schema_stream = validate.Schema(
+ validate.transform(parse_json),
+ validate.all(
+ {"result": {"streamList": [{
+ "streamName": str,
+ "serviceUrl": str,
+ }]}},
+ validate.get("result"),
+ validate.get("streamList")
+ )
+ )
@classmethod
def can_handle_url(cls, url):
return cls._url_re.match(url) is not None
- @property
- def video_id(self):
- return self._url_re.match(self.url).group(1)
-
def _get_streams(self):
- vinit_req = self.session.http.get(self._video_init_url,
- params=dict(videoSeq=self.video_id),
- headers=dict(referer=self.url))
- if vinit_req.status_code != 200:
- raise PluginError('Could not get video init page (HTTP Status {})'
- .format(vinit_req.status_code))
-
- video_status_js = self._video_status.search(vinit_req.text)
- if not video_status_js:
- raise PluginError('Could not find video status information!')
-
- video_status = json.loads(video_status_js.group(1))
-
- if video_status['viewType'] == 'vod':
- raise PluginError('VODs are not supported')
+ video_json = self.session.http.get(self.url, headers={"Referer": self.url},
+ schema=self._schema_video)
+ if video_json is None:
+ log.error('Could not parse video page')
+ return
+
+ err = video_json.get('errorCode')
+ if err == 'common_700':
+ log.error('Available only to members of the channel')
+ return
+ elif err == 'common_702':
+ log.error('Vlive+ VODs are not supported')
+ return
+ elif err == 'common_404':
+ log.error('Could not find video page')
+ return
+ elif err is not None:
+ log.error('Unknown error code: {0}'.format(err))
+ return
+
+ if video_json['type'] == 'VOD':
+ log.error('VODs are not supported')
+ return
+
+ url_format, video_id = self._url_re.match(self.url).groups()
+ if url_format == 'post':
+ video_id = str(video_json['videoSeq'])
+
+ video_status = video_json.get('status')
+ if video_status == 'ENDED':
+ log.error('Stream has ended')
+ return
+ elif video_status != 'ON_AIR':
+ log.error('Unknown video status: {0}'.format(video_status))
+ return
+
+ stream_info = self.session.http.get(self._playinfo_url.format(video_id),
+ headers={"Referer": self.url},
+ schema=self._schema_stream)
- if 'liveStreamInfo' not in video_status:
- raise PluginError('Stream is offline')
-
- stream_info = json.loads(video_status['liveStreamInfo'])
-
- streams = dict()
# All "resolutions" have a variant playlist with only one entry, so just combine them
- for i in stream_info['resolutions']:
- res_streams = HLSStream.parse_variant_playlist(self.session, i['cdnUrl'])
+ for i in stream_info:
+ res_streams = HLSStream.parse_variant_playlist(self.session, i['serviceUrl'])
if len(res_streams.values()) > 1:
log.warning('More than one stream in variant playlist, using first entry!')
- streams[i['name']] = res_streams.popitem()[1]
-
- return streams
+ yield i['streamName'], res_streams.popitem()[1]
__plugin__ = Vlive
| diff --git a/tests/plugins/test_vlive.py b/tests/plugins/test_vlive.py
--- a/tests/plugins/test_vlive.py
+++ b/tests/plugins/test_vlive.py
@@ -8,6 +8,7 @@
class TestPluginVlive:
valid_urls = [
("https://www.vlive.tv/video/156824",),
+ ("https://www.vlive.tv/post/0-19740901",)
]
invalid_urls = [
("https://www.vlive.tv/events/2019vheartbeat?lang=en",),
| vlive: plugin is broken
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
VLive.tv plugin is broken due to revising the site. The way to get parameters required for getting stream urls is changed now.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
Example: streamlink https://www.vlive.tv/video/221427 best
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
streamlink -l debug https://www.vlive.tv/video/221427
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.7.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin vlive for URL https://www.vlive.tv/video/221427
error: Could not find video status information!
```
### Additional comments, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2020-11-02T14:38:28 |
|
streamlink/streamlink | 3,338 | streamlink__streamlink-3338 | [
"3336"
] | d0b6598e073c755a2d38470a832e3622ac41f10f | diff --git a/src/streamlink/plugins/mitele.py b/src/streamlink/plugins/mitele.py
--- a/src/streamlink/plugins/mitele.py
+++ b/src/streamlink/plugins/mitele.py
@@ -4,7 +4,8 @@
from streamlink.plugin import Plugin
from streamlink.plugin.api import validate
from streamlink.stream import HLSStream
-from streamlink.utils import parse_json
+from streamlink.utils import parse_json, parse_qsd
+from streamlink.utils.url import update_qsd
log = logging.getLogger(__name__)
@@ -12,40 +13,42 @@
class Mitele(Plugin):
_url_re = re.compile(r"https?://(?:www\.)?mitele\.es/directo/(?P<channel>[\w-]+)")
- pdata_url = "https://indalo.mediaset.es/mmc-player/api/mmc/v1/{channel}/live/html5.json"
- gate_url = "https://gatekeeper.mediaset.es"
+ caronte_url = "https://caronte.mediaset.es/delivery/channel/mmc/{channel}/mtweb"
+ gbx_url = "https://mab.mediaset.es/1.0.0/get?oid=mtmw&eid=%2Fapi%2Fmtmw%2Fv2%2Fgbx%2Fmtweb%2Flive%2Fmmc%2F{channel}"
- error_schema = validate.Schema({
- "code": validate.any(validate.text, int),
- "message": validate.text,
- })
- pdata_schema = validate.Schema(validate.transform(parse_json), validate.any(
- validate.all(
- {
- "locations": [{
- "gcp": validate.text,
- "ogn": validate.any(None, validate.text),
- }],
- },
- validate.get("locations"),
- validate.get(0),
- ),
+ error_schema = validate.Schema({"code": int})
+ caronte_schema = validate.Schema(validate.transform(parse_json), validate.any(
+ {
+ "cerbero": validate.url(),
+ "bbx": str,
+ "dls": [{
+ "lid": validate.all(int, validate.transform(str)),
+ "format": validate.any("hls", "dash", "smooth"),
+ "stream": validate.url(),
+ validate.optional("assetKey"): str,
+ "drm": bool,
+ }],
+ },
error_schema,
))
- gate_schema = validate.Schema(
+ gbx_schema = validate.Schema(
+ validate.transform(parse_json),
+ {"gbx": str},
+ validate.get("gbx")
+ )
+ cerbero_schema = validate.Schema(
validate.transform(parse_json),
validate.any(
- {
- "mimeType": validate.text,
- "stream": validate.url(),
- },
+ validate.all(
+ {"tokens": {str: {"cdn": str}}},
+ validate.get("tokens")
+ ),
error_schema,
)
)
-
- def __init__(self, url):
- super().__init__(url)
- self.session.http.headers.update({"Referer": self.url})
+ token_errors = {
+ 4038: "User has no privileges"
+ }
@classmethod
def can_handle_url(cls, url):
@@ -54,28 +57,37 @@ def can_handle_url(cls, url):
def _get_streams(self):
channel = self._url_re.match(self.url).group("channel")
- pdata = self.session.http.get(self.pdata_url.format(channel=channel),
+ pdata = self.session.http.get(self.caronte_url.format(channel=channel),
acceptable_status=(200, 403, 404),
- schema=self.pdata_schema)
- log.trace("{0!r}".format(pdata))
- if pdata.get("code"):
- log.error("{0} - {1}".format(pdata["code"], pdata["message"]))
+ schema=self.caronte_schema)
+ gbx = self.session.http.get(self.gbx_url.format(channel=channel),
+ schema=self.gbx_schema)
+
+ if "code" in pdata:
+ log.error("error getting pdata: {}".format(pdata["code"]))
return
- gdata = self.session.http.post(self.gate_url,
- acceptable_status=(200, 403, 404),
- data=pdata,
- schema=self.gate_schema)
- log.trace("{0!r}".format(gdata))
- if gdata.get("code"):
- log.error("{0} - {1}".format(gdata["code"], gdata["message"]))
+ tokens = self.session.http.post(pdata["cerbero"],
+ acceptable_status=(200, 403, 404),
+ json={"bbx": pdata["bbx"], "gbx": gbx},
+ headers={"origin": "https://www.mitele.es"},
+ schema=self.cerbero_schema)
+
+ if "code" in tokens:
+ log.error("Could not get stream tokens: {} ({})".format(tokens["code"],
+ self.token_errors.get(tokens["code"], "unknown error")))
return
- log.debug("Stream: {0} ({1})".format(gdata["stream"], gdata.get("mimeType", "n/a")))
- for s in HLSStream.parse_variant_playlist(self.session,
- gdata["stream"],
- name_fmt="{pixels}_{bitrate}").items():
- yield s
+ for stream in pdata["dls"]:
+ if stream["drm"]:
+ log.warning("Stream may be protected by DRM")
+ else:
+ sformat = stream.get("format")
+ log.debug("Stream: {} ({})".format(stream["stream"], sformat or "n/a"))
+ cdn_token = tokens.get(stream["lid"], {}).get("cdn", "")
+ qsd = parse_qsd(cdn_token)
+ if sformat == "hls":
+ yield from HLSStream.parse_variant_playlist(self.session, update_qsd(stream["stream"], qsd)).items()
__plugin__ = Mitele
| Mitele changed
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
Mitele has changed its code.
### Description
Plugin not able to handle the new configuration.
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
[cli][info] Found matching plugin mitele for URL https://mitele.es/directo/telecinco
error: Unable to open URL: https://gatekeeper.mediaset.es (HTTPSConnectionPool(host='gatekeeper.mediaset.es', port=443): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection object at 0x7ff07c967220>: Failed to establish a new connection: [Errno -2] Name or service not known')))
```
### Additional comments, etc.
My english and knowledge are poor, sorry.
| 2020-11-16T19:19:21 |
||
streamlink/streamlink | 3,344 | streamlink__streamlink-3344 | [
"3341"
] | 46edf0d1dcf63be2b89364b8ef18c65310d1a7b5 | diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -285,36 +285,6 @@ def metadata_channel(self, channel_id):
validate.get("stream")
))
- # Private API calls
-
- def access_token(self, endpoint, asset):
- return self.call("/api/{0}/{1}/access_token".format(endpoint, asset), private=True, schema=validate.Schema(
- {
- "token": validate.text,
- "sig": validate.text
- },
- validate.union((
- validate.get("sig"),
- validate.get("token")
- ))
- ))
-
- def token(self, tokenstr):
- return parse_json(tokenstr, schema=validate.Schema(
- {
- "chansub": {
- "restricted_bitrates": validate.all(
- [validate.text],
- validate.filter(
- lambda n: not re.match(r"(.+_)?archives|live|chunked", n)
- )
- )
- }
- },
- validate.get("chansub"),
- validate.get("restricted_bitrates")
- ))
-
def hosted_channel(self, channel_id):
return self.call("/hosts", subdomain="tmi", include_logins=1, host=channel_id, schema=validate.Schema(
{
@@ -337,6 +307,62 @@ def hosted_channel(self, channel_id):
# GraphQL API calls
+ def access_token(self, is_live, channel_or_vod):
+ request = {
+ "operationName": "PlaybackAccessToken",
+ "extensions": {
+ "persistedQuery": {
+ "version": 1,
+ "sha256Hash": "0828119ded1c13477966434e15800ff57ddacf13ba1911c129dc2200705b0712"
+ }
+ },
+ "variables": {
+ "isLive": is_live,
+ "login": channel_or_vod if is_live else "",
+ "isVod": not is_live,
+ "vodID": channel_or_vod if not is_live else "",
+ "playerType": "site"
+ }
+ }
+ subschema = {
+ "value": str,
+ "signature": str,
+ "__typename": "PlaybackAccessToken"
+ }
+ return self.call_gql(request, schema=validate.Schema(
+ {"data": validate.any(
+ validate.all(
+ {"streamPlaybackAccessToken": subschema},
+ validate.get("streamPlaybackAccessToken")
+ ),
+ validate.all(
+ {"videoPlaybackAccessToken": subschema},
+ validate.get("videoPlaybackAccessToken")
+ )
+ )},
+ validate.get("data"),
+ validate.union((
+ validate.get("signature"),
+ validate.get("value")
+ ))
+ ))
+
+ def parse_token(self, tokenstr):
+ return parse_json(tokenstr, schema=validate.Schema(
+ {
+ "chansub": {
+ "restricted_bitrates": validate.all(
+ [str],
+ validate.filter(
+ lambda n: not re.match(r"(.+_)?archives|live|chunked", n)
+ )
+ )
+ }
+ },
+ validate.get("chansub"),
+ validate.get("restricted_bitrates")
+ ))
+
def clips(self, clipname):
query = """{{
clip(slug: "{clipname}") {{
@@ -523,9 +549,9 @@ def _channel_from_login(self, channel):
except PluginError:
raise PluginError("Unable to find channel: {0}".format(channel))
- def _access_token(self, endpoint, asset):
+ def _access_token(self, is_live, channel_or_vod):
try:
- sig, token = self.api.access_token(endpoint, asset)
+ sig, token = self.api.access_token(is_live, channel_or_vod)
except PluginError as err:
if "404 Client Error" in str(err):
raise NoStreamsError(self.url)
@@ -533,7 +559,7 @@ def _access_token(self, endpoint, asset):
raise
try:
- restricted_bitrates = self.api.token(token)
+ restricted_bitrates = self.api.parse_token(token)
except PluginError:
restricted_bitrates = []
@@ -586,14 +612,14 @@ def _get_hls_streams_live(self):
# only get the token once the channel has been resolved
log.debug("Getting live HLS streams for {0}".format(self.channel))
- sig, token, restricted_bitrates = self._access_token("channels", self.channel)
+ sig, token, restricted_bitrates = self._access_token(True, self.channel)
url = self.usher.channel(self.channel, sig=sig, token=token, fast_bread=True)
return self._get_hls_streams(url, restricted_bitrates)
def _get_hls_streams_video(self):
log.debug("Getting video HLS streams for {0}".format(self.channel))
- sig, token, restricted_bitrates = self._access_token("vods", self.video_id)
+ sig, token, restricted_bitrates = self._access_token(False, self.video_id)
url = self.usher.video(self.video_id, nauthsig=sig, nauth=token)
# If the stream is a VOD that is still being recorded, the stream should start at the beginning of the recording
| plugins.twitch: switch access token API request to GQL
As mentioned in #3210, Twitch has begun switching the access token requests on their website to their GQL API a few weeks ago. The transition seems to have been completed by them and no API requests on their old and private `api.twitch.tv/api` API namespace are being made anymore on their website.
Since the old API is still available, the Twitch plugin is still working fine, but once it gets shut down, which can be any time now, it'll break completely. This means we'll have to switch to the GQL API eventually.
I've opened this thread, so this can be monitored and documented, in case Twitch makes further changes.
----
There seem to be two GQL request methods available for the access token acquirement and both return the same response:
1. `PlaybackAccessToken` with the persistedQuery extension (which is a static sha256 of the request, so their servers can use caching when requests are more complicated - variables don't affect the hash):
```json
{
"operationName": "PlaybackAccessToken",
"variables": {
"isLive": true,
"login": "**CHANNELNAME**",
"isVod": false,
"vodID": "",
"playerType": "site"
},
"extensions": {
"persistedQuery": {
"version": 1,
"sha256Hash": "0828119ded1c13477966434e15800ff57ddacf13ba1911c129dc2200705b0712"
}
}
}
```
2. `PlaybackAccessToken_Template`
```json
{
"operationName": "PlaybackAccessToken_Template",
"query": "query PlaybackAccessToken_Template($login: String!, $isLive: Boolean!, $vodID: ID!, $isVod: Boolean!, $playerType: String!) { streamPlaybackAccessToken(channelName: $login, params: {platform: \"web\", playerBackend: \"mediaplayer\", playerType: $playerType}) @include(if: $isLive) { value signature __typename } videoPlaybackAccessToken(id: $vodID, params: {platform: \"web\", playerBackend: \"mediaplayer\", playerType: $playerType}) @include(if: $isVod) { value signature __typename }}",
"variables": {
"isLive": true,
"login": "**CHANNELNAME**",
"isVod": false,
"vodID": "",
"playerType": "site"
}
}
```
Response:
```json
{
"data": {
"streamPlaybackAccessToken": {
"value": "**access-token-string**",
"signature": "**signature-string**",
"__typename": "PlaybackAccessToken"
}
},
"extensions": {
"durationMilliseconds": 63,
"operationName": "PlaybackAccessToken",
"requestID": "**some-random-ID**"
}
}
```
| @bastimeyer Just to address your comment from the other thread. I don't think we should rely on any API endpoint until it's stable. They may also change the naming of the query or the variables which would mean extra work without any benefit. I also have concerns over the fact that it's not actually public. I don't know if this is an error on Twitch's end, or if they aren't updating the documentation. | 2020-11-18T21:47:20 |
|
streamlink/streamlink | 3,358 | streamlink__streamlink-3358 | [
"3357"
] | 3e8fbe63b89dee2d3a2111a88e185be0dbb54b8d | diff --git a/src/streamlink/stream/ffmpegmux.py b/src/streamlink/stream/ffmpegmux.py
--- a/src/streamlink/stream/ffmpegmux.py
+++ b/src/streamlink/stream/ffmpegmux.py
@@ -153,6 +153,9 @@ def read(self, size=-1):
return data
def close(self):
+ if self.closed:
+ return
+
log.debug("Closing ffmpeg thread")
if self.process:
# kill ffmpeg
@@ -161,10 +164,13 @@ def close(self):
# close the streams
for stream in self.streams:
- if hasattr(stream, "close"):
+ if hasattr(stream, "close") and callable(stream.close):
stream.close()
log.debug("Closed all the substreams")
+
if self.close_errorlog:
self.errorlog.close()
self.errorlog = None
+
+ super().close()
| trace logging with ffmpeg - ImportError: sys.meta_path is None, Python is likely shutting down
## Bug Report
- [X] This is a bug report and I have read the contribution guidelines.
### Description
If you use `-l trace` with a FFmpeg Stream, there will be an error when the player is closed or the stream ends.
error might be related to https://github.com/streamlink/streamlink/pull/3273 and `def formatTime`
### Reproduction steps / Explicit stream URLs to test
1. open a muxed ffmpeg video with loglevel trace
2. `streamlink "https://www.youtube.com/watch?v=VaU6GR8OHNU" best -l trace`
3. close the player or wait until the video is over
### Log output
working 9ac40cb075de93dfc90f8f616a649e9cd1ad32eb
```
$ streamlink "https://www.youtube.com/watch?v=VaU6GR8OHNU" -l trace
[16:50:38,702][cli][debug] OS: Linux-5.8.0-29-generic-x86_64-with-glibc2.32
[16:50:38,702][cli][debug] Python: 3.8.6
[16:50:38,702][cli][debug] Streamlink: 1.7.0+20.g9ac40cb
[16:50:38,702][cli][debug] Requests(2.25.0), Socks(1.7.1), Websocket(0.57.0)
[16:50:38,702][cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=VaU6GR8OHNU
[16:50:38,702][plugin.youtube][debug] Video ID from URL
[16:50:38,702][plugin.youtube][debug] Using video ID: VaU6GR8OHNU
[16:50:39,757][plugin.youtube][debug] get_video_info - 1: Found data
[16:50:39,759][plugin.youtube][debug] MuxedStream: v 135 a 251 = 480p
[16:50:39,759][plugin.youtube][debug] MuxedStream: v 133 a 251 = 240p
[16:50:39,759][plugin.youtube][debug] MuxedStream: v 160 a 251 = 144p
[16:50:39,759][cli][info] Available streams: audio_mp4a, audio_opus, 144p (worst), 240p, 360p, 480p (best)
[16:50:39,759][cli][info] Opening stream: 480p (muxed-stream)
[16:50:39,759][stream.ffmpegmux][debug] Opening http substream
[16:50:39,859][stream.ffmpegmux][debug] Opening http substream
[16:50:39,947][stream.ffmpegmux][debug] ffmpeg command: /usr/bin/ffmpeg -nostats -y -i /tmp/ffmpeg-9457-466 -i /tmp/ffmpeg-9457-333 -c:v copy -c:a copy -map 0 -map 1 -f matroska pipe:1
[16:50:39,947][stream.ffmpegmux][debug] Starting copy to pipe: /tmp/ffmpeg-9457-466
[16:50:39,948][stream.ffmpegmux][debug] Starting copy to pipe: /tmp/ffmpeg-9457-333
[16:50:39,950][cli][debug] Pre-buffering 8192 bytes
[16:50:40,002][cli][info] Starting player: /usr/bin/mpv
[16:50:40,002][cli.output][debug] Opening subprocess: /usr/bin/mpv "--title=Christmas Music 2020 🎅 Top Christmas Songs Playlist 2020 🎄 Best Christmas Songs Ever" -
[16:50:40,505][cli][debug] Writing stream to output
[16:50:46,869][cli][info] Player closed
[16:50:46,869][stream.ffmpegmux][debug] Closing ffmpeg thread
[16:50:46,870][stream.ffmpegmux][debug] Pipe copy complete: /tmp/ffmpeg-9457-466
[16:50:46,873][stream.ffmpegmux][error] Pipe copy aborted: /tmp/ffmpeg-9457-333
[16:50:46,954][stream.ffmpegmux][debug] Closed all the substreams
[16:50:46,954][cli][info] Stream ended
[16:50:46,954][cli][info] Closing currently open stream...
[16:50:46,954][stream.ffmpegmux][debug] Closing ffmpeg thread
[16:50:46,954][stream.ffmpegmux][debug] Closed all the substreams
[16:50:46,969][stream.ffmpegmux][debug] Closing ffmpeg thread
[16:50:46,969][stream.ffmpegmux][debug] Closed all the substreams
```
broken 70dc809b8128287f35405ac4279bdea3fa2edddc
```
$ streamlink "https://www.youtube.com/watch?v=VaU6GR8OHNU" -l trace
[16:51:11.763092][cli][debug] OS: Linux-5.8.0-29-generic-x86_64-with-glibc2.32
[16:51:11.763170][cli][debug] Python: 3.8.6
[16:51:11.763193][cli][debug] Streamlink: 1.7.0+21.g70dc809
[16:51:11.763212][cli][debug] Requests(2.25.0), Socks(1.7.1), Websocket(0.57.0)
[16:51:11.763245][cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=VaU6GR8OHNU
[16:51:11.763275][plugin.youtube][debug] Video ID from URL
[16:51:11.763295][plugin.youtube][debug] Using video ID: VaU6GR8OHNU
[16:51:12.669559][plugin.youtube][debug] get_video_info - 1: Found data
[16:51:12.670741][plugin.youtube][debug] MuxedStream: v 135 a 251 = 480p
[16:51:12.670780][plugin.youtube][debug] MuxedStream: v 133 a 251 = 240p
[16:51:12.670804][plugin.youtube][debug] MuxedStream: v 160 a 251 = 144p
[16:51:12.671317][cli][info] Available streams: audio_mp4a, audio_opus, 144p (worst), 240p, 360p, 480p (best)
[16:51:12.671355][cli][info] Opening stream: 480p (muxed-stream)
[16:51:12.671386][stream.ffmpegmux][debug] Opening http substream
[16:51:12.750200][stream.ffmpegmux][debug] Opening http substream
[16:51:12.813040][stream.ffmpegmux][debug] ffmpeg command: /usr/bin/ffmpeg -nostats -y -i /tmp/ffmpeg-9607-784 -i /tmp/ffmpeg-9607-270 -c:v copy -c:a copy -map 0 -map 1 -f matroska pipe:1
[16:51:12.813226][stream.ffmpegmux][debug] Starting copy to pipe: /tmp/ffmpeg-9607-784
[16:51:12.813344][stream.ffmpegmux][debug] Starting copy to pipe: /tmp/ffmpeg-9607-270
[16:51:12.815867][cli][debug] Pre-buffering 8192 bytes
[16:51:12.875782][cli][info] Starting player: /usr/bin/mpv
[16:51:12.876152][cli.output][debug] Opening subprocess: /usr/bin/mpv "--title=Christmas Music 2020 🎅 Top Christmas Songs Playlist 2020 🎄 Best Christmas Songs Ever" -
[16:51:13.378673][cli][debug] Writing stream to output
[16:51:19.777326][cli][info] Player closed
[16:51:19.777459][stream.ffmpegmux][debug] Closing ffmpeg thread
[16:51:19.779916][stream.ffmpegmux][error] Pipe copy aborted: /tmp/ffmpeg-9607-270
[16:51:19.780000][stream.ffmpegmux][error] Pipe copy aborted: /tmp/ffmpeg-9607-784
[16:51:26.824121][stream.ffmpegmux][debug] Closed all the substreams
[16:51:26.824246][cli][info] Stream ended
[16:51:26.824434][cli][info] Closing currently open stream...
[16:51:26.824477][stream.ffmpegmux][debug] Closing ffmpeg thread
[16:51:26.824539][stream.ffmpegmux][debug] Closed all the substreams
--- Logging error ---
Traceback (most recent call last):
File "/usr/lib/python3.8/logging/__init__.py", line 1081, in emit
msg = self.format(record)
File "/usr/lib/python3.8/logging/__init__.py", line 925, in format
return fmt.format(record)
File "venv3/lib/python3.8/site-packages/streamlink/logger.py", line 54, in format
return super().format(record)
File "/usr/lib/python3.8/logging/__init__.py", line 666, in format
record.asctime = self.formatTime(record, self.datefmt)
File "venv3/lib/python3.8/site-packages/streamlink/logger.py", line 41, in formatTime
return tdt.strftime(datefmt or self.default_time_format)
ImportError: sys.meta_path is None, Python is likely shutting down
Call stack:
File "venv3/lib/python3.8/site-packages/streamlink/stream/ffmpegmux.py", line 158, in close
log.debug("Closing ffmpeg thread")
Message: 'Closing ffmpeg thread'
Arguments: ()
--- Logging error ---
Traceback (most recent call last):
File "/usr/lib/python3.8/logging/__init__.py", line 1081, in emit
msg = self.format(record)
File "/usr/lib/python3.8/logging/__init__.py", line 925, in format
return fmt.format(record)
File "venv3/lib/python3.8/site-packages/streamlink/logger.py", line 54, in format
return super().format(record)
File "/usr/lib/python3.8/logging/__init__.py", line 666, in format
record.asctime = self.formatTime(record, self.datefmt)
File "venv3/lib/python3.8/site-packages/streamlink/logger.py", line 41, in formatTime
return tdt.strftime(datefmt or self.default_time_format)
ImportError: sys.meta_path is None, Python is likely shutting down
Call stack:
File "venv3/lib/python3.8/site-packages/streamlink/stream/ffmpegmux.py", line 169, in close
log.debug("Closed all the substreams")
Message: 'Closed all the substreams'
Arguments: ()
```
latest 3e8fbe63b89dee2d3a2111a88e185be0dbb54b8d
```
$ streamlink "https://www.youtube.com/watch?v=VaU6GR8OHNU" -l trace
[16:54:12.507281][cli][debug] OS: Linux-5.8.0-29-generic-x86_64-with-glibc2.32
[16:54:12.507359][cli][debug] Python: 3.8.6
[16:54:12.507383][cli][debug] Streamlink: 1.7.0+78.g3e8fbe6
[16:54:12.507402][cli][debug] Requests(2.25.0), Socks(1.7.1), Websocket(0.57.0)
[16:54:12.507437][cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=VaU6GR8OHNU
[16:54:12.507464][plugin.youtube][debug] Video ID from URL
[16:54:12.507485][plugin.youtube][debug] Using video ID: VaU6GR8OHNU
[16:54:13.673312][plugin.youtube][debug] get_video_info - 1: Found data
[16:54:13.674497][plugin.youtube][debug] MuxedStream: v 135 a 251 = 480p
[16:54:13.674534][plugin.youtube][debug] MuxedStream: v 133 a 251 = 240p
[16:54:13.674558][plugin.youtube][debug] MuxedStream: v 160 a 251 = 144p
[16:54:13.675102][cli][info] Available streams: audio_mp4a, audio_opus, 144p (worst), 240p, 360p, 480p (best)
[16:54:13.675143][cli][info] Opening stream: 480p (muxed-stream)
[16:54:13.675175][stream.ffmpegmux][debug] Opening http substream
[16:54:13.753371][stream.ffmpegmux][debug] Opening http substream
[16:54:13.833386][stream.ffmpegmux][debug] ffmpeg command: /usr/bin/ffmpeg -nostats -y -i /tmp/ffmpeg-9811-893 -i /tmp/ffmpeg-9811-933 -c:v copy -c:a copy -map 0 -map 1 -f matroska pipe:1
[16:54:13.833582][stream.ffmpegmux][debug] Starting copy to pipe: /tmp/ffmpeg-9811-893
[16:54:13.833781][stream.ffmpegmux][debug] Starting copy to pipe: /tmp/ffmpeg-9811-933
[16:54:13.836427][cli][debug] Pre-buffering 8192 bytes
[16:54:13.894765][cli][info] Starting player: /usr/bin/mpv
[16:54:13.895198][cli.output][debug] Opening subprocess: /usr/bin/mpv "--title=Christmas Music 2020 🎅 Top Christmas Songs Playlist 2020 🎄 Best Christmas Songs Ever" -
[16:54:14.398240][cli][debug] Writing stream to output
[16:54:34.826911][cli][info] Player closed
[16:54:34.827058][stream.ffmpegmux][debug] Closing ffmpeg thread
[16:54:34.829721][stream.ffmpegmux][error] Pipe copy aborted: /tmp/ffmpeg-9811-893
[16:54:34.829823][stream.ffmpegmux][error] Pipe copy aborted: /tmp/ffmpeg-9811-933
[16:54:34.941941][stream.ffmpegmux][debug] Closed all the substreams
[16:54:34.942041][cli][info] Stream ended
[16:54:34.942232][cli][info] Closing currently open stream...
[16:54:34.942273][stream.ffmpegmux][debug] Closing ffmpeg thread
[16:54:34.942333][stream.ffmpegmux][debug] Closed all the substreams
--- Logging error ---
Traceback (most recent call last):
File "/usr/lib/python3.8/logging/__init__.py", line 1081, in emit
msg = self.format(record)
File "/usr/lib/python3.8/logging/__init__.py", line 925, in format
return fmt.format(record)
File "venv3/lib/python3.8/site-packages/streamlink/logger.py", line 53, in format
return super().format(record)
File "/usr/lib/python3.8/logging/__init__.py", line 666, in format
record.asctime = self.formatTime(record, self.datefmt)
File "venv3/lib/python3.8/site-packages/streamlink/logger.py", line 40, in formatTime
return tdt.strftime(datefmt or self.default_time_format)
ImportError: sys.meta_path is None, Python is likely shutting down
Call stack:
File "venv3/lib/python3.8/site-packages/streamlink/stream/ffmpegmux.py", line 156, in close
log.debug("Closing ffmpeg thread")
Message: 'Closing ffmpeg thread'
Arguments: ()
--- Logging error ---
Traceback (most recent call last):
File "/usr/lib/python3.8/logging/__init__.py", line 1081, in emit
msg = self.format(record)
File "/usr/lib/python3.8/logging/__init__.py", line 925, in format
return fmt.format(record)
File "venv3/lib/python3.8/site-packages/streamlink/logger.py", line 53, in format
return super().format(record)
File "/usr/lib/python3.8/logging/__init__.py", line 666, in format
record.asctime = self.formatTime(record, self.datefmt)
File "venv3/lib/python3.8/site-packages/streamlink/logger.py", line 40, in formatTime
return tdt.strftime(datefmt or self.default_time_format)
ImportError: sys.meta_path is None, Python is likely shutting down
Call stack:
File "venv3/lib/python3.8/site-packages/streamlink/stream/ffmpegmux.py", line 167, in close
log.debug("Closed all the substreams")
Message: 'Closed all the substreams'
Arguments: ()
```
| The issue is not caused by 70dc809. It's a side-effect of a different issue in the `FFMPEGMuxer` class, which causes `datetime.strftime` that's being used by the logger since 70dc809 to fail.
I think the problem is that `FFMPEGMuxer.close()` gets called twice by `streamlink_cli.main` and the second logging attempt raises the exception:
1. https://github.com/streamlink/streamlink/blob/3e8fbe63b89dee2d3a2111a88e185be0dbb54b8d/src/streamlink_cli/main.py#L384
2. https://github.com/streamlink/streamlink/blob/3e8fbe63b89dee2d3a2111a88e185be0dbb54b8d/src/streamlink_cli/main.py#L1056
`FFMPEGMuxer` inherits from `io.IOBase`, so `close()` should ([call its super method?](https://docs.python.org/3/library/io.html#io.IOBase.close) and) check if it's already closed at the beginning and just return if it's true. That fixes the issue in a simple test here at least.
Btw, is there a reason why the FFMPEG subprocess is killed immediately with a SIGKILL instead of a SIGTERM first and then with a SIGKILL if it doesn't respond after a certain time? The output will probably be corrupted by just SIGKILL-ing its process, which is a problem when writing the output to a file instead of a player's stdin. | 2020-11-22T19:18:50 |
|
streamlink/streamlink | 3,395 | streamlink__streamlink-3395 | [
"3392"
] | 54685731579b6c0c27f36e80e846701e811abc3f | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -80,7 +80,7 @@ def is_wheel_for_windows():
},
author="Streamlink",
# temp until we have a mailing list / global email
- author_email="[email protected]",
+ author_email="[email protected]",
license="Simplified BSD",
packages=find_packages("src"),
package_dir={"": "src"},
| Change `author_email` in setup.py
https://github.com/streamlink/streamlink/blob/08e582580f3411b2de2c368f8b0cc7108264f990/setup.py#L83
@gravyboat
you've registered `[email protected]` a couple of years ago, right? Can this be used instead?
What's the email address of the `streamlink` account on pypi?
https://pypi.org/user/streamlink/
| @bastimeyer Yes `[email protected]` is registered and can be used. I believe @beardypig also has access to this address. I thought I sent you the password as well but maybe not?
For the `streamlink` repo on pypi there is a `streamlink` user that has the same protonmail address, but that user doesn't have direct manage access to the pypi project since it's shared, they're just a maintainer. It was created by @beardypig. Cdrage and I both have owner access. We should get you added on there as well.
> can be used
Open a PR then.
> I thought I sent you the password as well but maybe not?
No, I don't have access to any Streamlink accounts.
> We should get you added on there as well.
Not really important. I've created an acc today though, so if you want to add me, you can. | 2020-12-05T20:27:39 |
|
streamlink/streamlink | 3,421 | streamlink__streamlink-3421 | [
"2950"
] | aa9fc0897c6527c2f27855f496b6380cb898986c | diff --git a/src/streamlink/plugins/schoolism.py b/src/streamlink/plugins/schoolism.py
--- a/src/streamlink/plugins/schoolism.py
+++ b/src/streamlink/plugins/schoolism.py
@@ -17,6 +17,7 @@ class Schoolism(Plugin):
playlist_re = re.compile(r"var allVideos\s*=\s*(\[.*\]);", re.DOTALL)
js_to_json = partial(re.compile(r'(?!<")(\w+):(?!/)').sub, r'"\1":')
fix_brackets = partial(re.compile(r',\s*\}').sub, r'}')
+ fix_colon_in_title = partial(re.compile(r'"title":""(.*?)":(.*?)"').sub, r'"title":"\1:\2"')
playlist_schema = validate.Schema(
validate.transform(playlist_re.search),
validate.any(
@@ -25,6 +26,7 @@ class Schoolism(Plugin):
validate.get(1),
validate.transform(js_to_json),
validate.transform(fix_brackets), # remove invalid ,
+ validate.transform(fix_colon_in_title),
validate.transform(parse_json),
[{
"sources": validate.all([{
| diff --git a/tests/plugins/test_schoolism.py b/tests/plugins/test_schoolism.py
--- a/tests/plugins/test_schoolism.py
+++ b/tests/plugins/test_schoolism.py
@@ -50,3 +50,20 @@ def test_playlist_parse(self):
self.assertIsNotNone(data)
self.assertEqual(2, len(data))
+
+ def test_playlist_parse_colon_in_title(self):
+ colon_in_title = """var allVideos=[
+ {sources:[{type:"application/x-mpegurl",src:"https://d8u31iyce9xic.cloudfront.net/52/1/part1.m3u8?Policy=TOKEN&Signature=TOKEN&Key-Pair-Id=TOKEN",title:"Deconstructed: Drawing People - Lesson 1 - Part 1",playlistTitle:"Part 1",}],},
+ {sources:[{type:"application/x-mpegurl",src:"https://d8u31iyce9xic.cloudfront.net/52/1/part2.m3u8?Policy=TOKEN&Signature=TOKEN&Key-Pair-Id=TOKEN",title:"Deconstructed: Drawing People - Lesson 1 - Part 2",playlistTitle:"Part 2",}],},
+ {sources:[{type:"application/x-mpegurl",src:"https://d8u31iyce9xic.cloudfront.net/52/1/part3.m3u8?Policy=TOKEN&Signature=TOKEN&Key-Pair-Id=TOKEN",title:"Deconstructed: Drawing People - Lesson 1 - Part 3",playlistTitle:"Part 3",}],},
+ {sources:[{type:"application/x-mpegurl",src:"https://d8u31iyce9xic.cloudfront.net/52/1/part4.m3u8?Policy=TOKEN&Signature=TOKEN&Key-Pair-Id=TOKEN",title:"Deconstructed: Drawing People - Lesson 1 - Part 4",playlistTitle:"Part 4",}],},
+ {sources:[{type:"application/x-mpegurl",src:"https://d8u31iyce9xic.cloudfront.net/52/1/part5.m3u8?Policy=TOKEN&Signature=TOKEN&Key-Pair-Id=TOKEN",title:"Deconstructed: Drawing People - Lesson 1 - Part 5",playlistTitle:"Part 5",}],},
+ {sources:[{type:"application/x-mpegurl",src:"https://d8u31iyce9xic.cloudfront.net/52/1/part6.m3u8?Policy=TOKEN&Signature=TOKEN&Key-Pair-Id=TOKEN",title:"Deconstructed: Drawing People - Lesson 1 - Part 6",playlistTitle:"Part 6",}],},
+ {sources:[{type:"application/x-mpegurl",src:"https://d8u31iyce9xic.cloudfront.net/52/1/part7.m3u8?Policy=TOKEN&Signature=TOKEN&Key-Pair-Id=TOKEN",title:"Deconstructed: Drawing People - Lesson 1 - Part 7",playlistTitle:"Part 7",}]}
+ ];
+ """ # noqa: E501
+
+ data = Schoolism.playlist_schema.validate(colon_in_title)
+
+ self.assertIsNotNone(data)
+ self.assertEqual(7, len(data))
| Schoolism Plugin Error with newer streams
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [ X] This is a plugin issue and I have read the contribution guidelines.
### Description
The plugin is working with older streams but not working with newer streams like "Deconstructed: Drawing People"
Description
Schoolism plugin doesnt work with the following
Deconstructed: Drawing People
I'm using streamlink 1.4.1 latest installation
<!-- Explain the plugin issue as thoroughly as you can. -->
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. ... Using Username and password the plugin logs in correctly
2. ... Accessing the path of the course either to stream or to output doesn't work https://www.schoolism.com/watchLesson.php?type=st&id=596
3. ... It throws the following error "Unable to parse JSON" (see log)
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
Using the log i get the following:
C:\Users\PC>streamlink -l debug "https://www.schoolism.com/watchLesson.php?type=
st&id=596" --schoolism-email --schoolism-password --schoolism-part 1
[cli][debug] OS: Windows 7
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.4.1
[cli][debug] Requests(2.23.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin schoolism for URL https://www.schoolism.com/wa
tchLesson.php?type=st&id=596
[cli][debug] Plugin specific arguments:
[cli][debug] --schoolism-email= (email)
[cli][debug] --schoolism-password= (password)
[cli][debug] --schoolism-part=1 (part)
[plugin.schoolism][debug] Logged in to Schoolism as
error: Unable to parse JSON: Expecting ',' delimiter: line 1 column 1053 (char 1
052) ('[{"sources":[{"type":"application/ ...)
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| I can confirm that this is happening on my end as well. I've tested old and new courses URLs and it only happens to this course: "Deconstructed: Drawing People with Viktor Kalvachev"
### Log output
```
> C:\Users\Test\Lesson 1 - Crosshatching\Lesson>streamlink --schoolism-email email --schoolism-password password --schoolism-part 1 -o "1.mp4" "https://www.schoolism.com/watchLesson.php?type=st&id=593" best
> [cli][info] Found matching plugin schoolism for URL https://www.schoolism.com/watchLesson.php?type=st&id=593
> error: Unable to parse JSON: Expecting ',' delimiter: line 1 column 1053 (char 1052) ('[{"sources":[{"type":"application/ ...)
```
Do let me know if I'm not supposed to post here, just wanted to highlight the issue.
I'd like to try and fix this, but I don't have an account. I presume it would also be necessary to have a subscription to see this content. It's possible it could be fixed with help from one or both of you though.
Initially, if you could visit a working video page, right click, select view source, then copy and paste the HTML here (formatted nicely with the GH markup, please), then repeat that on the non-working URL you have identified, then I can perhaps use that to make a fix. Another option, that may or may not be better would be to post the HTML output on a pastebin site like https://pastebin.com/ and just post the links in the issue instead.
I note that the plugin uses a User-Agent string for Safari 8, so it's hard to know if the output will differ enough in other browsers that it matters, but hopefully not. If you're willing to do so, you could install a browser extension that allows you to easily change the user agent string and set it up to use:
```
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/600.7.12 (KHTML, like Gecko) Version/8.0.7 Safari/600.7.12
```
which is what the plugin sends. Cheers.
basically https://github.com/streamlink/streamlink/issues/1683#issuecomment-397264747
I had the same problem so I looked into this issue and found the bug on line 18 in the [schoolism plugin](https://github.com/streamlink/streamlink/blob/master/src/streamlink/plugins/schoolism.py)
Line 18:
```js_to_json = partial(re.compile(r'(?!<")(\w+):(?!/)').sub, r'"\1":')```
Basically a regex sub is used to transform a raw javascript object into python parsable JSON. This breaks for this video because the javascript object in question looks like
```{title: "Deconstructed: Drawing People"}```
which then gets transformed into
```{"title": ""Deconstructed": Drawing People"}```
since the colon inside the string is tripping up the pattern.
Regex patterns can't be created to fix this since the underlying data is nesting. So you need a slightly beefier implementation like [hjson](https://github.com/hjson/hjson) to do this correctly.
Personally I don't know much about the streamlink codebase so maybe this is an issue that's been fixed before in a different plugin? | 2020-12-18T14:31:12 |
streamlink/streamlink | 3,422 | streamlink__streamlink-3422 | [
"3396"
] | 030dbc5f744c05aac4733b2c37bfd771df9b4c00 | diff --git a/src/streamlink/cache.py b/src/streamlink/cache.py
--- a/src/streamlink/cache.py
+++ b/src/streamlink/cache.py
@@ -38,7 +38,7 @@ def _prune(self):
pruned = []
for key, value in self._cache.items():
- expires = value.get("expires", time())
+ expires = value.get("expires", now)
if expires <= now:
pruned.append(key)
@@ -69,10 +69,13 @@ def set(self, key, value, expires=60 * 60 * 24 * 7, expires_at=None):
if self.key_prefix:
key = "{0}:{1}".format(self.key_prefix, key)
- expires += time()
-
- if expires_at:
- expires = mktime(expires_at.timetuple())
+ if expires_at is None:
+ expires += time()
+ else:
+ try:
+ expires = mktime(expires_at.timetuple())
+ except OverflowError:
+ expires = 0
self._cache[key] = dict(value=value, expires=expires)
self._save()
| diff --git a/tests/test_cache.py b/tests/test_cache.py
--- a/tests/test_cache.py
+++ b/tests/test_cache.py
@@ -55,6 +55,11 @@ def test_expired_at_after(self):
self.cache.set("value", 10, expires_at=datetime.datetime.now() + datetime.timedelta(seconds=20))
self.assertEqual(10, self.cache.get("value"))
+ @patch("streamlink.cache.mktime", side_effect=OverflowError)
+ def test_expired_at_raise_overflowerror(self, mock):
+ self.cache.set("value", 10, expires_at=datetime.datetime.now())
+ self.assertEqual(None, self.cache.get("value"))
+
def test_not_expired(self):
self.cache.set("value", 10, expires=20)
self.assertEqual(10, self.cache.get("value"))
| mktime argument out of range when logging in to Crunchyroll after --crunchyroll-purge-credentials
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
Whenver I try to log in to Crunchyroll via streamlink I get an error.
<!-- Explain the plugin issue as thoroughly as you can. -->
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. I enter the command streamlink --crunchyroll-username=xxxx --crunchyroll-password=yyy --crunchyroll-purge-credentials https://www.crunchyroll.com/my/episode/to/watch best and I get it every time
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.6.6
[cli][debug] Streamlink: 1.7.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin crunchyroll for URL https://www.crunchyroll.com/jujutsu-kaisen/episode-10-idle-transfiguration-797874
[cli][debug] Plugin specific arguments:
[cli][debug] [email protected] (username)
[cli][debug] --crunchyroll-password=******** (password)
[cli][debug] --crunchyroll-purge-credentials=True (purge_credentials)
[utils.l10n][debug] Language code: en_US
[plugin.crunchyroll][debug] Creating session with locale: en_US
[plugin.crunchyroll][debug] Session created with ID: 576c3d5d7a83d1dd18217343a6df37ff
[plugin.crunchyroll][debug] Attempting to login using username and password
[plugin.crunchyroll][debug] Credentials expire at: 1969-12-31 08:00:00
Traceback (most recent call last):
File "runpy.py", line 193, in _run_module_as_main
File "runpy.py", line 85, in _run_code
File "C:\Program Files (x86)\Streamlink\bin\streamlink.exe\__main__.py", line 18, in <module>
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink_cli\main.py", line 1029, in main
handle_url()
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink_cli\main.py", line 585, in handle_url
streams = fetch_streams(plugin)
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink_cli\main.py", line 465, in fetch_streams
sorting_excludes=args.stream_sorting_excludes)
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\plugin\plugin.py", line 317, in streams
ostreams = self._get_streams()
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 312, in _get_streams
api = self._create_api()
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 384, in _create_api
login = api.authenticate()
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 225, in authenticate
self.cache.set("auth", self.auth, expires_at=data["expires"])
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\cache.py", line 75, in set
expires = mktime(expires_at.timetuple())
OverflowError: mktime argument out of range
```
### Additional comments, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| As a side note, I was NOT able to reproduce this on Ubuntu 18.04. Logging in to crunchyroll was successful for this
Can confirm I have the same issue on windows - both stable and dev builds and on multiple videos, both those that need credentials and those that don't.
I think it's saving the time stamp for the credential expiry wrong?
Here is my output:
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.8.6
[cli][debug] Streamlink: 1.7.0+115.g83fb57c
[cli][debug] Requests(2.25.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin crunchyroll for URL https://www.crunchyroll.com/en-gb/attack-on-titan/episode-60-the-other-side-of-the-sea-799901
[cli][debug] Plugin specific arguments:
[cli][debug] --crunchyroll-username=*******@******.com (username)
[cli][debug] --crunchyroll-password=************ (password)
[utils.l10n][debug] Language code: en_AU
[plugins.crunchyroll][debug] Device ID: 4c7fa1ba-29ba-485d-af30-d2c8ad9da6d4
[plugins.crunchyroll][debug] Creating session with locale: en_AU
[plugins.crunchyroll][debug] Session created with ID: ec66d76f6abfe0c61472cfb6c9179e53
[plugins.crunchyroll][debug] Using saved credentials
[plugins.crunchyroll][warning] Saved credentials have expired
[plugins.crunchyroll][debug] Attempting to login using username and password
[plugins.crunchyroll][debug] Credentials expire at: 1969-12-31 08:00:00
Traceback (most recent call last):
File "runpy.py", line 194, in _run_module_as_main
File "runpy.py", line 87, in _run_code
File "g:\Video\Streamlink\bin\streamlink.exe\__main__.py", line 18, in <module>
File "g:\Video\Streamlink\pkgs\streamlink_cli\main.py", line 1050, in main
handle_url()
File "g:\Video\Streamlink\pkgs\streamlink_cli\main.py", line 580, in handle_url
streams = fetch_streams(plugin)
File "g:\Video\Streamlink\pkgs\streamlink_cli\main.py", line 459, in fetch_streams
return plugin.streams(stream_types=args.stream_types,
File "g:\Video\Streamlink\pkgs\streamlink\plugin\plugin.py", line 317, in streams
ostreams = self._get_streams()
File "g:\Video\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 305, in _get_streams
api = self._create_api()
File "g:\Video\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 377, in _create_api
login = api.authenticate()
File "g:\Video\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 224, in authenticate
self.cache.set("auth", self.auth, expires_at=data["expires"])
File "g:\Video\Streamlink\pkgs\streamlink\cache.py", line 75, in set
expires = mktime(expires_at.timetuple())
OverflowError: mktime argument out of range
Can also confirm this same problem on windows, this was my output
[cli][info] Found matching plugin crunchyroll for URL https://www.crunchyroll.com/es/attack-on-titan/episode-61-midnight-train-799902
Traceback (most recent call last):
File "runpy.py", line 193, in _run_module_as_main
File "runpy.py", line 85, in _run_code
File "C:\Program Files (x86)\Streamlink\bin\streamlink.exe\__main__.py", line 18, in <module>
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink_cli\main.py", line 1029, in main
handle_url()
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink_cli\main.py", line 585, in handle_url
streams = fetch_streams(plugin)
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink_cli\main.py", line 465, in fetch_streams
sorting_excludes=args.stream_sorting_excludes)
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\plugin\plugin.py", line 317, in streams
ostreams = self._get_streams()
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 312, in _get_streams
api = self._create_api()
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 384, in _create_api
login = api.authenticate()
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\plugins\crunchyroll.py", line 225, in authenticate
self.cache.set("auth", self.auth, expires_at=data["expires"])
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\cache.py", line 75, in set
expires = mktime(expires_at.timetuple())
OverflowError: mktime argument out of range
By the way, I noticed that if I first type in:
` streamlink --crunchyroll-username=xxxx --crunchyroll-password=yyy --crunchyroll-purge-credentials https://www.crunchyroll.com/my/episode/to/watch best`
And then type in the same command WITHOUT specifying username or password via:
` streamlink https://www.crunchyroll.com/my/episode/to/watch best`
Where the url is a Crunchyroll Premium video, I am able to watch it
> Credentials expire at: 1969-12-31 08:00:00
> OverflowError: mktime argument out of range
This looks like a time zone issue when the returned expiration time is `1970-01-01T00:00:00Z` (a UNIX timestamp of 0).
https://github.com/streamlink/streamlink/blob/aa9fc0897c6527c2f27855f496b6380cb898986c/src/streamlink/plugins/crunchyroll.py#L25-L31
> As a side note, I was NOT able to reproduce this on Ubuntu 18.04.
This is indeed only a problem on Windows, as negative timestamps are not supported:
https://stackoverflow.com/a/58203399
To fix this, Streamlink's plugin data cache needs to ignore negative timestamps (before parsing them) or filter out the `OverflowError` on `win32` systems. Also, why doesn't the Crunchyroll plugin use `isodate.parse_datetime` for parsing the ISO8601 strings? | 2020-12-18T16:08:02 |
streamlink/streamlink | 3,424 | streamlink__streamlink-3424 | [
"3416"
] | 9077e2f0597be7fa28cb76b4cb3e50180ba59989 | diff --git a/src/streamlink/plugins/dogan.py b/src/streamlink/plugins/dogan.py
--- a/src/streamlink/plugins/dogan.py
+++ b/src/streamlink/plugins/dogan.py
@@ -14,29 +14,51 @@ class Dogan(Plugin):
Support for the live streams from Doğan Media Group channels
"""
url_re = re.compile(r"""
- https?://(?:www.)?
- (?:teve2.com.tr/(?:canli-yayin|filmler/.*|programlar/.*)|
- kanald.com.tr/.*|
- cnnturk.com/canli-yayin|
- dreamtv.com.tr/canli-yayin|
- dreamturk.com.tr/canli)
+ https?://(?:www\.)?
+ (?:cnnturk\.com/(?:action/embedvideo/.*|canli-yayin|tv-cnn-turk|video/.*)|
+ dreamturk\.com\.tr/(?:canli|canli-yayin-izle|dream-turk-ozel/.*|programlar/.*)|
+ dreamtv\.com\.tr/dream-ozel/.*|
+ kanald\.com\.tr/.*|
+ teve2\.com\.tr/(?:canli-yayin|diziler/.*|embed/.*|filmler/.*|programlar/.*))
""", re.VERBOSE)
- playerctrl_re = re.compile(r'''<div[^>]*?ng-controller=(?P<quote>["'])(?:Live)?PlayerCtrl(?P=quote).*?>''', re.DOTALL)
- data_id_re = re.compile(r'''data-id=(?P<quote>["'])(?P<id>\w+)(?P=quote)''')
- content_id_re = re.compile(r'"content(?:I|i)d", "(\w+)"')
+ playerctrl_re = re.compile(r'''<div\s+id="video-element".*?>''', re.DOTALL)
+ data_id_re = re.compile(r'''data-id=(?P<quote>["'])/?(?P<id>\w+)(?P=quote)''')
+ content_id_re = re.compile(r'"content[Ii]d",\s*"(\w+)"')
item_id_re = re.compile(r"_itemId\s+=\s+'(\w+)';")
- content_api = "/actions/content/media/{id}"
+ content_api = "/actions/media?id={id}"
+ dream_api = "/actions/content/media/{id}"
new_content_api = "/action/media/{id}"
- content_api_schema = validate.Schema({
- "Id": validate.text,
- "Media": {
- "Link": {
- "DefaultServiceUrl": validate.url(),
- validate.optional("ServiceUrl"): validate.any(validate.url(), ""),
- "SecurePath": validate.text,
- }
- }
- })
+ content_api_schema = validate.Schema(
+ {
+ "data": {
+ "id": str,
+ "media": {
+ "link": {
+ validate.optional("defaultServiceUrl"): validate.any(validate.url(), ""),
+ validate.optional("serviceUrl"): validate.any(validate.url(), ""),
+ "securePath": str,
+ },
+ },
+ },
+ },
+ validate.get("data"),
+ validate.get("media"),
+ validate.get("link"),
+ )
+ new_content_api_schema = validate.Schema(
+ {
+ "Media": {
+ "Link": {
+ "ContentId": str,
+ validate.optional("DefaultServiceUrl"): validate.any(validate.url(), ""),
+ validate.optional("ServiceUrl"): validate.any(validate.url(), ""),
+ "SecurePath": str,
+ },
+ },
+ },
+ validate.get("Media"),
+ validate.get("Link"),
+ )
@classmethod
def can_handle_url(cls, url):
@@ -66,19 +88,34 @@ def _get_content_id(self):
log.debug("Found contentId by itemId regex")
return item_id_m.group(1)
- def _get_hls_url(self, content_id):
- # make the api url relative to the current domain
- if "cnnturk" in self.url or "teve2.com.tr" in self.url:
- log.debug("Using new content API url")
- api_url = urljoin(self.url, self.new_content_api.format(id=content_id))
+ def _get_new_content_hls_url(self, content_id, api_url):
+ log.debug("Using new content API url")
+ d = self.session.http.get(urljoin(self.url, api_url.format(id=content_id)))
+ d = self.session.http.json(d, schema=self.new_content_api_schema)
+
+ if d["DefaultServiceUrl"] == "https://www.kanald.com.tr":
+ self.url = d["DefaultServiceUrl"]
+ return self._get_content_hls_url(content_id)
else:
- api_url = urljoin(self.url, self.content_api.format(id=content_id))
+ if d["SecurePath"].startswith("http"):
+ return d["SecurePath"]
+ else:
+ return urljoin((d["ServiceUrl"] or d["DefaultServiceUrl"]), d["SecurePath"])
+
+ def _get_content_hls_url(self, content_id):
+ d = self.session.http.get(urljoin(self.url, self.content_api.format(id=content_id)))
+ d = self.session.http.json(d, schema=self.content_api_schema)
- apires = self.session.http.get(api_url)
+ return urljoin((d["serviceUrl"] or d["defaultServiceUrl"]), d["securePath"])
- stream_data = self.session.http.json(apires, schema=self.content_api_schema)
- d = stream_data["Media"]["Link"]
- return urljoin((d["ServiceUrl"] or d["DefaultServiceUrl"]), d["SecurePath"])
+ def _get_hls_url(self, content_id):
+ # make the api url relative to the current domain
+ if "cnnturk.com" in self.url or "teve2.com.tr" in self.url:
+ return self._get_new_content_hls_url(content_id, self.new_content_api)
+ elif "dreamturk.com.tr" in self.url or "dreamtv.com.tr" in self.url:
+ return self._get_new_content_hls_url(content_id, self.dream_api)
+ else:
+ return self._get_content_hls_url(content_id)
def _get_streams(self):
content_id = self._get_content_id()
| diff --git a/tests/plugins/test_dogan.py b/tests/plugins/test_dogan.py
--- a/tests/plugins/test_dogan.py
+++ b/tests/plugins/test_dogan.py
@@ -6,17 +6,39 @@
class TestPluginDogan(unittest.TestCase):
def test_can_handle_url(self):
should_match = [
+ 'https://www.cnnturk.com/action/embedvideo/',
+ 'https://www.cnnturk.com/action/embedvideo/5fa56d065cf3b018a8dd0bbc',
'https://www.cnnturk.com/canli-yayin',
+ 'https://www.cnnturk.com/tv-cnn-turk/',
+ 'https://www.cnnturk.com/tv-cnn-turk/belgeseller/bir-zamanlar/bir-zamanlar-90lar-belgeseli',
+ 'https://www.cnnturk.com/video/',
+ 'https://www.cnnturk.com/video/turkiye/polis-otomobiliyle-tur-atan-sahisla-ilgili-islem-baslatildi-video',
'https://www.dreamturk.com.tr/canli',
- 'https://www.dreamtv.com.tr/canli-yayin',
+ 'https://www.dreamturk.com.tr/canli-yayin-izle',
+ 'https://www.dreamturk.com.tr/dream-turk-ozel/',
+ 'https://www.dreamturk.com.tr/dream-turk-ozel/radyo-d/ilyas-yalcintas-radyo-dnin-konugu-oldu',
+ 'https://www.dreamturk.com.tr/programlar/',
+ 'https://www.dreamturk.com.tr/programlar/t-rap/bolumler/t-rap-keisan-ozel',
+ 'https://www.dreamtv.com.tr/dream-ozel/',
+ 'https://www.dreamtv.com.tr/dream-ozel/konserler/acik-sahne-dream-ozel',
'https://www.kanald.com.tr/canli-yayin',
+ 'https://www.kanald.com.tr/sadakatsiz/fragmanlar/sadakatsiz-10-bolum-fragmani',
'https://www.teve2.com.tr/canli-yayin',
+ 'https://www.teve2.com.tr/diziler/',
+ 'https://www.teve2.com.tr/diziler/guncel/oyle-bir-gecer-zaman-ki/bolumler/oyle-bir-gecer-zaman-ki-1-bolum',
+ 'https://www.teve2.com.tr/embed/',
+ 'https://www.teve2.com.tr/embed/55f6d5b8402011f264ec7f64',
+ 'https://www.teve2.com.tr/filmler/',
+ 'https://www.teve2.com.tr/filmler/guncel/yasamak-guzel-sey',
+ 'https://www.teve2.com.tr/programlar/',
+ 'https://www.teve2.com.tr/programlar/guncel/kelime-oyunu/bolumler/kelime-oyunu-800-bolum-19-12-2020',
]
for url in should_match:
self.assertTrue(Dogan.can_handle_url(url))
def test_can_handle_url_negative(self):
should_not_match = [
+ 'https://www.dreamtv.com.tr/canli-yayin',
'https://example.com/index.html',
]
for url in should_not_match:
| kanald broken
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
Example link 1 (VOD): https://www.kanald.com.tr/sadakatsiz/fragmanlar/sadakatsiz-10-bolum-fragmani
Example link 2 (Live): https://www.kanald.com.tr/canli-yayin
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
streamlink 'https://www.kanald.com.tr/sadakatsiz/fragmanlar/sadakatsiz-10-bolum-fragmani'
[cli][info] Found matching plugin dogan for URL https://www.kanald.com.tr/sadakatsiz/fragmanlar/sadakatsiz-10-bolum-fragmani
[plugin.dogan][error] Could not find the contentId for this stream
error: No playable streams found on this URL: https://www.kanald.com.tr/sadakatsiz/fragmanlar/sadakatsiz-10-bolum-fragmani
```
### Additional comments, etc.
Thanks in advance
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| I have work in progress on this. I'll just need to validate the changes I've made across all the supported sites for the plugin.
>
>
> I have work in progress on this. I'll just need to validate the changes I've made across all the supported sites for the plugin.
Thank you, I can help with test if you want. | 2020-12-19T22:25:20 |
streamlink/streamlink | 3,457 | streamlink__streamlink-3457 | [
"3455"
] | 468a3f2baf897cd97afbf72fc53e1b50b655a0ec | diff --git a/src/streamlink/plugins/mico.py b/src/streamlink/plugins/mico.py
deleted file mode 100644
--- a/src/streamlink/plugins/mico.py
+++ /dev/null
@@ -1,72 +0,0 @@
-import logging
-import re
-
-from streamlink.plugin import Plugin
-from streamlink.plugin.api import validate
-from streamlink.stream import HLSStream
-from streamlink.utils import parse_json
-from streamlink.utils.url import update_scheme
-
-log = logging.getLogger(__name__)
-
-
-class Mico(Plugin):
- author = None
- category = None
- title = None
-
- url_re = re.compile(r'https?://(?:www\.)?micous\.com/live/\d+')
- json_data_re = re.compile(r'win._profile\s*=\s*({.*})')
-
- _json_data_schema = validate.Schema(
- validate.transform(json_data_re.search),
- validate.any(None, validate.all(
- validate.get(1),
- validate.transform(parse_json),
- validate.any(None, validate.all({
- 'mico_id': int,
- 'nickname': validate.text,
- 'h5_url': validate.all(
- validate.transform(lambda x: update_scheme('http:', x)),
- validate.url(),
- ),
- 'is_live': bool,
- })),
- )),
- )
-
- @classmethod
- def can_handle_url(cls, url):
- return cls.url_re.match(url) is not None
-
- def get_author(self):
- if self.author is not None:
- return self.author
-
- def get_category(self):
- if self.category is not None:
- return self.category
-
- def get_title(self):
- if self.title is not None:
- return self.title
-
- def _get_streams(self):
- json_data = self.session.http.get(self.url, schema=self._json_data_schema)
-
- if not json_data:
- log.error('Failed to get JSON data')
- return
-
- if not json_data['is_live']:
- log.info('This stream is no longer online')
- return
-
- self.author = json_data['mico_id']
- self.category = 'Live'
- self.title = json_data['nickname']
-
- return HLSStream.parse_variant_playlist(self.session, json_data['h5_url'])
-
-
-__plugin__ = Mico
| diff --git a/tests/plugins/test_mico.py b/tests/plugins/test_mico.py
deleted file mode 100644
--- a/tests/plugins/test_mico.py
+++ /dev/null
@@ -1,23 +0,0 @@
-import unittest
-
-from streamlink.plugins.mico import Mico
-
-
-class TestPluginMico(unittest.TestCase):
- def test_can_handle_url(self):
- should_match = [
- 'http://micous.com/live/73750760',
- 'http://www.micous.com/live/73750760',
- 'https://micous.com/live/73750760',
- 'https://www.micous.com/live/73750760',
- ]
- for url in should_match:
- self.assertTrue(Mico.can_handle_url(url))
-
- def test_can_handle_url_negative(self):
- should_not_match = [
- 'http://www.micous.com/73750760',
- 'https://example.com/index.html',
- ]
- for url in should_not_match:
- self.assertFalse(Mico.can_handle_url(url))
| https://www.micous.com/ Site closing webcasts
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [ ] This is a plugin issue and I have read the contribution guidelines.
- [ ] I am using the latest development version from the master branch.
### Description
I was checking the m3u8 codes for Tango Live so that it would benefit people and maybe we can bring plugins but now I have checked and the mico.us plugin does not work because mico.us is no longer working. It looks like it has turned off broadcasting and playback, I guess only broadcasts can be followed through the application and need to be checked.
<!-- Explain the plugin issue as thoroughly as you can. -->
### Reproduction steps / Explicit stream URLs to test
this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. ...https://www.micous.com/
2. ...
3. ...
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
REPLACE THIS TEXT WITH THE LOG OUTPUT
```
### Additional comments, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2020-12-27T15:25:49 |
|
streamlink/streamlink | 3,459 | streamlink__streamlink-3459 | [
"1753"
] | 009bbd82e2e40bc141f85125eeb5e0569f52e750 | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -8,6 +8,7 @@
import versioneer
+data_files = []
deps = [
"requests>=2.21.0,<3.0",
"isodate",
@@ -63,6 +64,19 @@ def is_wheel_for_windows():
entry_points["gui_scripts"] = ["streamlinkw=streamlink_cli.main:main"]
+additional_files = [
+ ("share/man/man1", ["docs/_build/man/streamlink.1"])
+]
+
+for destdir, srcfiles in additional_files:
+ files = []
+ for srcfile in srcfiles:
+ if path.exists(srcfile):
+ files.append(srcfile)
+ if files:
+ data_files.append((destdir, files))
+
+
setup(name="streamlink",
version=versioneer.get_version(),
cmdclass=versioneer.get_cmdclass(),
@@ -85,6 +99,7 @@ def is_wheel_for_windows():
packages=find_packages("src"),
package_dir={"": "src"},
entry_points=entry_points,
+ data_files=data_files,
install_requires=deps,
test_suite="tests",
python_requires=">=3.6, <4",
| No man page with pip install
### Checklist
- [ ] This is a bug report.
- [x] This is a feature request.
- [ ] This is a plugin (improvement) request.
- [x] I have read the contribution guidelines.
### Description
When installing streamlink with pip, no man page gets installed
### Expected / Actual behavior
a man page gets installed during installation of streamlink with pip
### Reproduction steps / Explicit stream URLs to test
1. ``pip install --user streamlink``
2. ``man streamlink``
3. ``No manual entry for streamlink``
4. I get the same results when using ``pip install streamlink``
### Logs
```
[cli][debug] OS: Linux-4.13.0-43-generic-x86_64-with-Ubuntu-17.10-artful
[cli][debug] Python: 3.6.3
[cli][debug] Streamlink: 0.12.1
[cli][debug] Requests(2.18.4), Socks(1.6.7), Websocket(0.47.0)
usage: streamlink [OPTIONS] <URL> [STREAM]
```
| I wouldn't so much call this a bug as a feature request... `pip` packages typically do not install man pages. `pip` doesn't really support it, you can include pre-built man pages, but we would want to generate it at install time. There are 3rd party script that you can use, but they need to be available when you install the package, so must be included.
I tried to do it with `argparse-manpage`, and it doesn't quite work - it could probably be made to work correctly though.
Is it even pip's job to create man pages? If you're using the `--user` parameter, there's no way for pip to install man pages in the `manpath`, as those man paths are usually configured only system-wide and are user independent. And even if pip is used for globally installing packages (which is bad and will result in file conflicts sooner or later), it is not its job to write files in one of the system man paths.
I'd say that the proper distro packages need to be installed for having man pages.
I imagine most distros would _require_ a man page to be accepted, and that's definitely something that should be handled by the package maintainer.
If `pip` did install man pages, they would not work for `--user` (as @bastimeyer said), without updating `$PATH`. System-wide and virtualenv installs would work though.
We could use sphinx to build the man page and include that in the sdist/wheel - actually might be a nice addition (when it works), and it's relatively simple to do :)
I'm not familiar with any Python packages which install man pages via pip and would actually be against it due to packaging standards and this being unexpected behavior. Man pages should be handled by distro packages and have specific requirements based on the distro (take the debian docs for example: https://www.debian.org/doc/debian-policy/#manual-pages).
There has also been discussion on this previously [here](https://github.com/pypa/packaging-problems/issues/72) by members of the pypa team. I don't really think this can of worms is worth opening. How would we handle conflicts where a user installs the package, then installs the pip version? There would be a conflict in management there which could negatively impact the user's system. In addition we provide online documentation and the `--help` option is quite extensive and follows the standards expected for a Python project.
updated this issue to feature request.
just a little FYI, youtube-dl does come with a man page when installed with pip, even when used ``--user``
you can use `streamlink --help` which will get you all commands.
If you need more stuff just use the website https://streamlink.github.io/cli.html
The man page is not really important enough, to get packed with `pip`.
Had another look at it and it should be fairly trivial to add a manpage to the wheels. Let's reopen... | 2020-12-28T12:09:14 |
|
streamlink/streamlink | 3,483 | streamlink__streamlink-3483 | [
"2192"
] | a03f7bfc6932cacfc7a89e62ff509c0be7294f51 | diff --git a/src/streamlink/session.py b/src/streamlink/session.py
--- a/src/streamlink/session.py
+++ b/src/streamlink/session.py
@@ -2,8 +2,11 @@
import pkgutil
from collections import OrderedDict
from functools import lru_cache
+from socket import AF_INET, AF_INET6
import requests
+import requests.packages.urllib3.util.connection as urllib3_connection
+from requests.packages.urllib3.util.connection import allowed_gai_family
from streamlink import __version__, plugins
from streamlink.compat import is_win32
@@ -30,6 +33,9 @@ class Streamlink:
def __init__(self, options=None):
self.http = api.HTTPSession()
self.options = Options({
+ "interface": None,
+ "ipv4": False,
+ "ipv6": False,
"hds-live-edge": 10.0,
"hds-segment-attempts": 3,
"hds-segment-threads": 1,
@@ -83,7 +89,13 @@ def set_option(self, key, value):
**Available options**:
======================== =========================================
- hds-live-edge ( float) Specify the time live HDS
+ interface (str) Set the network interface,
+ default: ``None``
+ ipv4 (bool) Resolve address names to IPv4 only.
+ This option overrides ipv6, default: ``False``
+ ipv6 (bool) Resolve address names to IPv6 only.
+ This option overrides ipv4, default: ``False``
+ hds-live-edge (float) Specify the time live HDS
streams will start from the edge of
stream, default: ``10.0``
@@ -242,7 +254,29 @@ def set_option(self, key, value):
"""
- if key == "http-proxy":
+ if key == "interface":
+ for scheme, adapter in self.http.adapters.items():
+ if scheme not in ("http://", "https://"):
+ continue
+ if not value:
+ adapter.poolmanager.connection_pool_kw.pop("source_address")
+ else:
+ adapter.poolmanager.connection_pool_kw.update(
+ # https://docs.python.org/3/library/socket.html#socket.create_connection
+ source_address=(value, 0)
+ )
+ self.options.set(key, None if not value else value)
+
+ elif key == "ipv4" or key == "ipv6":
+ self.options.set(key, value)
+ if value:
+ self.options.set("ipv6" if key == "ipv4" else "ipv4", False)
+ urllib3_connection.allowed_gai_family = \
+ (lambda: AF_INET) if key == "ipv4" else (lambda: AF_INET6)
+ else:
+ urllib3_connection.allowed_gai_family = allowed_gai_family
+
+ elif key == "http-proxy":
self.http.proxies["http"] = update_scheme("http://", value)
if "https" not in self.http.proxies:
self.http.proxies["https"] = update_scheme("http://", value)
diff --git a/src/streamlink_cli/argparser.py b/src/streamlink_cli/argparser.py
--- a/src/streamlink_cli/argparser.py
+++ b/src/streamlink_cli/argparser.py
@@ -303,6 +303,28 @@ def build_parser():
Default is system locale.
"""
)
+ general.add_argument(
+ "--interface",
+ type=str,
+ metavar="INTERFACE",
+ help="""
+ Set the network interface.
+ """
+ )
+ general.add_argument(
+ "-4", "--ipv4",
+ action="store_true",
+ help="""
+ Resolve address names to IPv4 only. This option overrides :option:`-6`.
+ """
+ )
+ general.add_argument(
+ "-6", "--ipv6",
+ action="store_true",
+ help="""
+ Resolve address names to IPv6 only. This option overrides :option:`-4`.
+ """
+ )
player = parser.add_argument_group("Player options")
player.add_argument(
diff --git a/src/streamlink_cli/main.py b/src/streamlink_cli/main.py
--- a/src/streamlink_cli/main.py
+++ b/src/streamlink_cli/main.py
@@ -751,6 +751,15 @@ def setup_streamlink():
def setup_options():
"""Sets Streamlink options."""
+ if args.interface:
+ streamlink.set_option("interface", args.interface)
+
+ if args.ipv4:
+ streamlink.set_option("ipv4", args.ipv4)
+
+ if args.ipv6:
+ streamlink.set_option("ipv6", args.ipv6)
+
if args.hls_live_edge:
streamlink.set_option("hls-live-edge", args.hls_live_edge)
| diff --git a/tests/test_session.py b/tests/test_session.py
--- a/tests/test_session.py
+++ b/tests/test_session.py
@@ -1,6 +1,9 @@
import os
import unittest
-from unittest.mock import call, patch
+from socket import AF_INET, AF_INET6
+from unittest.mock import Mock, call, patch
+
+from requests.packages.urllib3.util.connection import allowed_gai_family
from streamlink import NoPluginError, Streamlink
from streamlink.plugin.plugin import HIGH_PRIORITY, LOW_PRIORITY
@@ -192,6 +195,66 @@ def test_set_and_get_locale(self):
self.assertEqual(session.localization.language.alpha2, "en")
self.assertEqual(session.localization.language_code, "en_US")
+ @patch("streamlink.session.api")
+ def test_interface(self, mock_api):
+ adapter_http = Mock(poolmanager=Mock(connection_pool_kw={}))
+ adapter_https = Mock(poolmanager=Mock(connection_pool_kw={}))
+ adapter_foo = Mock(poolmanager=Mock(connection_pool_kw={}))
+ mock_api.HTTPSession.return_value = Mock(adapters={
+ "http://": adapter_http,
+ "https://": adapter_https,
+ "foo://": adapter_foo
+ })
+ session = self.subject(load_plugins=False)
+ self.assertEqual(session.get_option("interface"), None)
+
+ session.set_option("interface", "my-interface")
+ self.assertEqual(adapter_http.poolmanager.connection_pool_kw, {"source_address": ("my-interface", 0)})
+ self.assertEqual(adapter_https.poolmanager.connection_pool_kw, {"source_address": ("my-interface", 0)})
+ self.assertEqual(adapter_foo.poolmanager.connection_pool_kw, {})
+ self.assertEqual(session.get_option("interface"), "my-interface")
+
+ session.set_option("interface", None)
+ self.assertEqual(adapter_http.poolmanager.connection_pool_kw, {})
+ self.assertEqual(adapter_https.poolmanager.connection_pool_kw, {})
+ self.assertEqual(adapter_foo.poolmanager.connection_pool_kw, {})
+ self.assertEqual(session.get_option("interface"), None)
+
+ @patch("streamlink.session.urllib3_connection", allowed_gai_family=allowed_gai_family)
+ def test_ipv4_ipv6(self, mock_urllib3_connection):
+ session = self.subject(load_plugins=False)
+ self.assertEqual(session.get_option("ipv4"), False)
+ self.assertEqual(session.get_option("ipv6"), False)
+ self.assertEqual(mock_urllib3_connection.allowed_gai_family, allowed_gai_family)
+
+ session.set_option("ipv4", True)
+ self.assertEqual(session.get_option("ipv4"), True)
+ self.assertEqual(session.get_option("ipv6"), False)
+ self.assertNotEqual(mock_urllib3_connection.allowed_gai_family, allowed_gai_family)
+ self.assertEqual(mock_urllib3_connection.allowed_gai_family(), AF_INET)
+
+ session.set_option("ipv4", False)
+ self.assertEqual(session.get_option("ipv4"), False)
+ self.assertEqual(session.get_option("ipv6"), False)
+ self.assertEqual(mock_urllib3_connection.allowed_gai_family, allowed_gai_family)
+
+ session.set_option("ipv6", True)
+ self.assertEqual(session.get_option("ipv4"), False)
+ self.assertEqual(session.get_option("ipv6"), True)
+ self.assertNotEqual(mock_urllib3_connection.allowed_gai_family, allowed_gai_family)
+ self.assertEqual(mock_urllib3_connection.allowed_gai_family(), AF_INET6)
+
+ session.set_option("ipv6", False)
+ self.assertEqual(session.get_option("ipv4"), False)
+ self.assertEqual(session.get_option("ipv6"), False)
+ self.assertEqual(mock_urllib3_connection.allowed_gai_family, allowed_gai_family)
+
+ session.set_option("ipv4", True)
+ session.set_option("ipv6", False)
+ self.assertEqual(session.get_option("ipv4"), True)
+ self.assertEqual(session.get_option("ipv6"), False)
+ self.assertEqual(mock_urllib3_connection.allowed_gai_family, allowed_gai_family)
+
def test_https_proxy_default(self):
session = self.subject(load_plugins=False)
session.set_option("http-proxy", "http://testproxy.com")
| Specify manually the network interface to use in a multi-homed setup?
## Feature Request
Add the possibility to manually specify the network interface to use. Which can be very useful for multi-homed networks with multiple network interfaces.
### Description
In Streamlink you can specify the proxy to use for streaming. Similar to that it would be also very useful if it would be possible to specify which network interface to use for streaming.
### Expected / Actual behavior
Be able to specify for example "--interface eth1" to use the eth1 interface for streaming.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| https://github.com/requests/toolbelt/blob/master/requests_toolbelt/adapters/source.py
might be useful for this feature
closing,
this feature is not really important for Streamlink. | 2021-01-09T18:15:56 |
streamlink/streamlink | 3,484 | streamlink__streamlink-3484 | [
"3475"
] | 4a75cfd1d2585fb047168f12cb65758920fd1248 | diff --git a/src/streamlink/plugins/turkuvaz.py b/src/streamlink/plugins/turkuvaz.py
--- a/src/streamlink/plugins/turkuvaz.py
+++ b/src/streamlink/plugins/turkuvaz.py
@@ -20,6 +20,10 @@ class Turkuvaz(Plugin):
|
(atv|a2tv|ahaber|aspor|minikago|minikacocuk|anews)\.com\.tr
)/webtv/(?:live-broadcast|canli-yayin)
+ |
+ (ahaber)\.com\.tr/video/canli-yayin
+ |
+ atv\.com\.tr/(a2tv)/canli-yayin
|
sabah\.com\.tr/(apara)/canli-yayin
)""")
@@ -39,7 +43,7 @@ def can_handle_url(cls, url):
def _get_streams(self):
url_m = self._url_re.match(self.url)
- domain = url_m.group(1) or url_m.group(2) or url_m.group(3)
+ domain = url_m.group(1) or url_m.group(2) or url_m.group(3) or url_m.group(4) or url_m.group(5)
# remap the domain to channel
channel = {"atv": "atvhd",
"ahaber": "ahaberhd",
| diff --git a/tests/plugins/test_turkuvaz.py b/tests/plugins/test_turkuvaz.py
--- a/tests/plugins/test_turkuvaz.py
+++ b/tests/plugins/test_turkuvaz.py
@@ -6,8 +6,12 @@
class TestPluginTurkuvaz(unittest.TestCase):
def test_can_handle_url(self):
should_match = [
+ 'http://www.atv.com.tr/a2tv/canli-yayin',
+ 'https://www.atv.com.tr/a2tv/canli-yayin',
'https://www.atv.com.tr/webtv/canli-yayin',
'http://www.a2tv.com.tr/webtv/canli-yayin',
+ 'http://www.ahaber.com.tr/video/canli-yayin',
+ 'https://www.ahaber.com.tr/video/canli-yayin',
'https://www.ahaber.com.tr/webtv/canli-yayin',
'https://www.aspor.com.tr/webtv/canli-yayin',
'http://www.anews.com.tr/webtv/live-broadcast',
| Turkuvaz Plugin missing Streams
Hi,
first of all to be sure installed Streamlink 2.0.0 via Python3 again.
After that tested all streams one by one with the turkuvaz.py
Most of them are working, only 2 of 9 channels missing, "error: No plugin can handle URL"
A2 and A Haber TV:
https://www.atv.com.tr/a2tv/canli-yayin
https://www.ahaber.com.tr/video/canli-yayin
| Probably just needs a regex update. I'll take a look at it tomorrow if nobody else does before. | 2021-01-10T14:57:22 |
streamlink/streamlink | 3,485 | streamlink__streamlink-3485 | [
"3476"
] | 4a75cfd1d2585fb047168f12cb65758920fd1248 | diff --git a/src/streamlink/plugins/dogus.py b/src/streamlink/plugins/dogus.py
--- a/src/streamlink/plugins/dogus.py
+++ b/src/streamlink/plugins/dogus.py
@@ -12,16 +12,15 @@
class Dogus(Plugin):
"""
- Support for live streams from Dogus sites include ntv, ntvspor, and kralmuzik
+ Support for live streams from Dogus sites include ntv, and kralmuzik
"""
- url_re = re.compile(r"""https?://(?:www.)?
+ url_re = re.compile(r"""https?://(?:www\.)?
(?:
- ntv.com.tr/canli-yayin/ntv|
- ntvspor.net/canli-yayin|
- kralmuzik.com.tr/tv/|
- eurostartv.com.tr/canli-izle|
- startv.com.tr/canli-yayin
+ eurostartv\.com\.tr/canli-izle|
+ kralmuzik\.com\.tr/tv/|
+ ntv\.com\.tr/canli-yayin/ntv|
+ startv\.com\.tr/canli-yayin
)/?""", re.VERBOSE)
mobile_url_re = re.compile(r"""(?P<q>["'])(?P<url>(https?:)?//[^'"]*?/live/hls/[^'"]*?\?token=)
(?P<token>[^'"]*?)(?P=q)""", re.VERBOSE)
| diff --git a/tests/plugins/test_dogus.py b/tests/plugins/test_dogus.py
--- a/tests/plugins/test_dogus.py
+++ b/tests/plugins/test_dogus.py
@@ -6,8 +6,9 @@
class TestPluginDogus(unittest.TestCase):
def test_can_handle_url(self):
should_match = [
- 'http://www.ntvspor.net/canli-yayin',
'http://eurostartv.com.tr/canli-izle',
+ 'http://kralmuzik.com.tr/tv/',
+ 'http://ntv.com.tr/canli-yayin/ntv',
'http://startv.com.tr/canli-yayin',
]
for url in should_match:
@@ -16,6 +17,7 @@ def test_can_handle_url(self):
def test_can_handle_url_negative(self):
should_not_match = [
'https://example.com/index.html',
+ 'http://www.ntvspor.net/canli-yayin',
]
for url in should_not_match:
self.assertFalse(Dogus.can_handle_url(url))
| Dogus.py missing stream
https://www.ntvspor.net/ntvspor-canli-yayin
This is normally handled by dogus.py but it seems to be outdated. The other streams are working ok only this one.
| I'll take a look tomorrow.
@Rotarum Make sure to provide all the information required by the template. You didn't here, you didn't on https://github.com/streamlink/streamlink/issues/3477, and you didn't on https://github.com/streamlink/streamlink/issues/3475. You've also been commenting multiple times on closed issues generating unnecessary noise. If this continues I'll have to ban you from the repo in the future. This is an open source project and you're doing less than the bare minimum to help the people trying to fix issues and not contributing in a positive way. | 2021-01-10T18:03:30 |
streamlink/streamlink | 3,505 | streamlink__streamlink-3505 | [
"3504"
] | c5791f75c3f38cdd90090eb88b3ce66de0c56ae5 | diff --git a/src/streamlink/plugins/twitcasting.py b/src/streamlink/plugins/twitcasting.py
--- a/src/streamlink/plugins/twitcasting.py
+++ b/src/streamlink/plugins/twitcasting.py
@@ -1,3 +1,4 @@
+import hashlib
import logging
import re
from threading import Event, Thread
@@ -7,15 +8,25 @@
from streamlink import logger
from streamlink.buffers import RingBuffer
-from streamlink.plugin import Plugin, PluginError
+from streamlink.plugin import Plugin, PluginArgument, PluginArguments, PluginError
from streamlink.plugin.api import useragents, validate
from streamlink.stream.stream import Stream
from streamlink.stream.stream import StreamIO
+from streamlink.utils.url import update_qsd
+
log = logging.getLogger(__name__)
class TwitCasting(Plugin):
+ arguments = PluginArguments(
+ PluginArgument(
+ "password",
+ sensitive=True,
+ metavar="PASSWORD",
+ help="Password for private Twitcasting streams."
+ )
+ )
_url_re = re.compile(r"http(s)?://twitcasting.tv/(?P<channel>[^/]+)", re.VERBOSE)
_STREAM_INFO_URL = "https://twitcasting.tv/streamserver.php?target={channel}&mode=client"
_STREAM_REAL_URL = "{proto}://{host}/ws.app/stream/{movie_id}/fmp4/bd/1/1500?mode={mode}"
@@ -66,6 +77,12 @@ def _get_streams(self):
raise PluginError("No stream available for user {}".format(self.channel))
real_stream_url = self._STREAM_REAL_URL.format(proto=proto, host=host, movie_id=movie_id, mode=mode)
+
+ password = self.options.get("password")
+ if password is not None:
+ password_hash = hashlib.md5(password.encode()).hexdigest()
+ real_stream_url = update_qsd(real_stream_url, {"word": password_hash})
+
log.debug("Real stream url: {}".format(real_stream_url))
return {mode: TwitCastingStream(session=self.session, url=real_stream_url)}
| Support for password-protected TwitCasting streams
## Feature Request
- [x] This is a feature request and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
Using a command line option such as --twitcasting-password, you would be able to retrieve even password-protected TwitCasting streams.
### Expected / Actual behavior
Self-explanatory.
### Additional comments, etc.
Accessing a password-protected stream can be done by sending a POST request to the stream URL containing the form data `password=`.
Possibly of help is youtube-dl's implementation: https://github.com/ytdl-org/youtube-dl/pull/20843/files
For help testing this feature, here is an archived, password-protected stream: https://twitcasting.tv/mttbernardini/movie/3689740
If a live broadcast is needed, you can easily start a livestream from Twitcasting by hovering the blue "Broadcast" button at the top right of the site then clicking "Web broadcasting". Scroll down to set a password then back up to start an audio-only livestream.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2021-01-22T21:03:27 |
||
streamlink/streamlink | 3,508 | streamlink__streamlink-3508 | [
"2502"
] | c5791f75c3f38cdd90090eb88b3ce66de0c56ae5 | diff --git a/src/streamlink/plugins/nimotv.py b/src/streamlink/plugins/nimotv.py
new file mode 100644
--- /dev/null
+++ b/src/streamlink/plugins/nimotv.py
@@ -0,0 +1,97 @@
+import logging
+import re
+
+from streamlink.plugin import Plugin
+from streamlink.plugin.api import useragents, validate
+from streamlink.stream import HLSStream
+from streamlink.utils import parse_json
+
+log = logging.getLogger(__name__)
+
+
+class NimoTV(Plugin):
+ url_re = re.compile(r'https?://(?:www\.)?nimo\.tv/(?P<username>.*)')
+ data_url = 'https://m.nimo.tv/{0}'
+ data_re = re.compile(r'<script>var G_roomBaseInfo = ({.*?});</script>')
+
+ author = None
+ category = None
+ title = None
+
+ data_schema = validate.Schema(
+ validate.transform(data_re.search),
+ validate.any(None, validate.all(
+ validate.get(1),
+ validate.transform(parse_json), {
+ 'title': str,
+ 'nickname': str,
+ 'game': str,
+ 'roomLineInfo': validate.any(None, {
+ 'vCodeLines2': [{
+ 'iBitRate': int,
+ 'vCdns': [{
+ 'vCdnUrls': [{
+ 'smediaUrl': validate.url(),
+ }],
+ }],
+ }],
+ }),
+ },
+ )),
+ )
+
+ video_qualities = {
+ 250: '240p',
+ 500: '360p',
+ 1000: '480p',
+ 2000: '720p',
+ 6000: '1080p',
+ }
+
+ @classmethod
+ def can_handle_url(cls, url):
+ return cls.url_re.match(url) is not None
+
+ def get_author(self):
+ if self.author is not None:
+ return self.author
+
+ def get_category(self):
+ if self.category is not None:
+ return self.category
+
+ def get_title(self):
+ if self.title is not None:
+ return self.title
+
+ def _get_streams(self):
+ m = self.url_re.match(self.url)
+ if m and m.group('username'):
+ username = m.group('username')
+ else:
+ return
+
+ headers = {'User-Agent': useragents.ANDROID}
+ data = self.session.http.get(
+ self.data_url.format(username),
+ headers=headers,
+ schema=self.data_schema,
+ )
+
+ if data is None or data['roomLineInfo'] is None:
+ return
+
+ self.author = data['nickname']
+ self.category = data['game']
+ self.title = data['title']
+
+ for vcl2 in data['roomLineInfo']['vCodeLines2']:
+ q = self.video_qualities[vcl2['iBitRate']]
+ for vcdn in vcl2['vCdns']:
+ for vcdnurl in vcdn['vCdnUrls']:
+ if 'tx.hls.nimo.tv' in vcdnurl['smediaUrl']:
+ log.debug(f"HLS URL={vcdnurl['smediaUrl']} ({q})")
+ yield q, HLSStream(self.session, vcdnurl['smediaUrl'])
+
+
+__plugin__ = NimoTV
| diff --git a/tests/plugins/test_nimotv.py b/tests/plugins/test_nimotv.py
new file mode 100644
--- /dev/null
+++ b/tests/plugins/test_nimotv.py
@@ -0,0 +1,22 @@
+import unittest
+
+from streamlink.plugins.nimotv import NimoTV
+
+
+class TestPluginNimoTV(unittest.TestCase):
+ def test_can_handle_url(self):
+ should_match = [
+ 'http://www.nimo.tv/live/737614',
+ 'https://www.nimo.tv/live/737614',
+ 'http://www.nimo.tv/sanz',
+ 'https://www.nimo.tv/sanz',
+ ]
+ for url in should_match:
+ self.assertTrue(NimoTV.can_handle_url(url))
+
+ def test_can_handle_url_negative(self):
+ should_not_match = [
+ 'https://example.com/index.html',
+ ]
+ for url in should_not_match:
+ self.assertFalse(NimoTV.can_handle_url(url))
| Nimo tv
<!--
Thanks for requesting a plugin!
USE THE TEMPLATE. Otherwise your plugin request may be rejected.
First, see the contribution guidelines and plugin request requirements:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Plugin requests which fall into the categories we will not implement will be closed immediately.
Also check the list of open and closed plugin requests:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+request%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Request
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin request and I have read the contribution guidelines and plugin request requirements.
### Description
<!-- Explain the plugin and site as clearly as you can. What is the site about? Who runs it? What content does it provide? What value does it bring to Streamlink? Etc. -->
### Example stream URLs
<!-- Example URLs for streams are required. Plugin requests which do not have example URLs will be closed. -->
1. http://nimo.tv/
2. https://www.nimo.tv/revo-donkey
3. https://www.nimo.tv/live/106070469
### Additional comments, screenshots, etc.
nimotv is gaming stream app from indonesia, please add this plugin
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2021-01-24T02:47:51 |
|
streamlink/streamlink | 3,514 | streamlink__streamlink-3514 | [
"3513"
] | 7a74e1848d9af9dad9f6fdb8fa4935049efb9a62 | diff --git a/src/streamlink/plugins/bloomberg.py b/src/streamlink/plugins/bloomberg.py
--- a/src/streamlink/plugins/bloomberg.py
+++ b/src/streamlink/plugins/bloomberg.py
@@ -1,111 +1,87 @@
import logging
import re
-from functools import partial
+from urllib.parse import urlparse
from streamlink.plugin import Plugin
from streamlink.plugin.api import useragents, validate
from streamlink.stream import HDSStream, HLSStream, HTTPStream
-from streamlink.utils import parse_json, update_scheme
+from streamlink.utils import parse_json
log = logging.getLogger(__name__)
class Bloomberg(Plugin):
- VOD_API_URL = 'https://www.bloomberg.com/api/embed?id={0}'
- PLAYER_URL = 'https://cdn.gotraffic.net/projector/latest/bplayer.js'
- CHANNEL_MAP = {
- 'audio': 'BBG_RADIO',
- 'live/europe': 'EU',
- 'live/us': 'US',
- 'live/asia': 'ASIA',
- 'live/stream': 'EVENT',
- 'live/emea': 'EMEA_EVENT',
- 'live/asia_stream': 'ASIA_EVENT'
- }
+ LIVE_API_URL = "https://cdn.gotraffic.net/projector/latest/assets/config/config.min.json?v=1"
+ VOD_API_URL = "https://www.bloomberg.com/api/embed?id={0}"
_url_re = re.compile(r'''
https?://(?:www\.)?bloomberg\.com/
(?:
- news/videos/[^/]+/[^/]+|
+ news/videos/[^/]+/[^/]+
+ |
live/(?P<channel>.+)/?
)
-''', re.VERBOSE)
- _live_player_re = re.compile(r'{APP_BUNDLE:"(?P<live_player_url>.+?/app.js)"')
- _js_to_json_re = partial(re.compile(r'(\w+):(["\']|\d?\.?\d+,|true|false|\[|{)').sub, r'"\1":\2')
- _mp4_bitrate_re = re.compile(r'.*_(?P<bitrate>[0-9]+)\.mp4')
- _preload_state_re = re.compile(r'<script>\s*window.__PRELOADED_STATE__\s*=\s*({.+});?\s*</script>')
- _live_stream_info_module_id_re = re.compile(
- r'{(?:(?:"[^"]+"|\w+):(?:\d+|"[^"]+"),)*"(?:[^"]*/)?config/livestreams":(\d+)(?:,(?:"[^"]+"|\w+):(?:\d+|"[^"]+"))*}'
+ ''', re.VERBOSE)
+
+ _re_preload_state = re.compile(r'<script>\s*window.__PRELOADED_STATE__\s*=\s*({.+});?\s*</script>')
+ _re_mp4_bitrate = re.compile(r'.*_(?P<bitrate>[0-9]+)\.mp4')
+
+ _schema_url = validate.all(
+ {"url": validate.url()},
+ validate.get("url")
)
- _live_stream_info_re = r'],{id}:\[function\(.+var n=({{.+}});r.default=n}},{{}}],{next}:\['
- _live_streams_schema = validate.Schema(
- validate.transform(_js_to_json_re),
- validate.transform(lambda x: x.replace(':.', ':0.')),
+ _schema_live_list = validate.Schema(
validate.transform(parse_json),
- validate.Schema({
- validate.text: {
- validate.optional('cdns'): validate.all(
+ validate.get("live"),
+ validate.get("channels"),
+ validate.get("byChannelId"),
+ {
+ str: validate.all({"liveId": str}, validate.get("liveId"))
+ }
+ )
+ _schema_live_streams = validate.Schema(
+ validate.get("livestreams"),
+ {
+ str: {
+ validate.optional("cdns"): validate.all(
[
- validate.Schema(
- {
- 'streams': validate.all([
- validate.Schema(
- {'url': validate.transform(lambda x: re.sub(r'(https?:/)([^/])', r'\1/\2', x))},
- validate.get('url'),
- validate.url()
- )
- ]),
- },
- validate.get('streams')
- )
+ validate.all({"streams": [_schema_url]}, validate.get("streams"))
],
validate.transform(lambda x: [i for y in x for i in y])
)
}
- },
- )
+ }
)
- _channel_list_schema = validate.Schema(
+ _schema_vod_list = validate.Schema(
validate.transform(parse_json),
- {"live": {"channels": {"byChannelId": {
- validate.text: validate.all({"liveId": validate.text}, validate.get("liveId"))
- }}}},
- validate.get("live"),
- validate.get("channels"),
- validate.get("byChannelId"),
- )
-
- _vod_list_schema = validate.Schema(
- validate.transform(parse_json),
- validate.get("video"),
- validate.get("videoList"),
- validate.all([
- validate.Schema({
- "slug": validate.text,
- "video": validate.Schema({"bmmrId": validate.text}, validate.get("bmmrId"))
- })
- ])
+ validate.any(
+ validate.all(
+ {"video": {"videoList": list}},
+ validate.get("video"),
+ validate.get("videoList")
+ ),
+ validate.all(
+ {"quicktakeVideo": {"videoStory": dict}},
+ validate.get("quicktakeVideo"),
+ validate.get("videoStory"),
+ validate.transform(lambda x: [x])
+ )
+ ),
+ [
+ {
+ "slug": str,
+ "video": validate.all({"bmmrId": str}, validate.get("bmmrId"))
+ }
+ ]
)
-
- _vod_api_schema = validate.Schema(
+ _schema_vod_streams = validate.Schema(
{
- 'secureStreams': validate.all([
- validate.Schema(
- {'url': validate.url()},
- validate.get('url')
- )
- ]),
- 'streams': validate.all([
- validate.Schema(
- {'url': validate.url()},
- validate.get('url')
- )
- ]),
- 'contentLoc': validate.url(),
+ "secureStreams": validate.all([_schema_url]),
+ "streams": validate.all([_schema_url])
},
- validate.transform(lambda x: list(set(x['secureStreams'] + x['streams'] + [x['contentLoc']])))
+ validate.transform(lambda x: list(set(x["secureStreams"] + x["streams"])))
)
_headers = {
@@ -124,94 +100,66 @@ class Bloomberg(Plugin):
def can_handle_url(cls, url):
return Bloomberg._url_re.match(url)
- def _get_live_streams(self):
- # Get channel id
- match = self._url_re.match(self.url)
- channel = match.group('channel')
-
+ def _get_live_streams(self, channel):
res = self.session.http.get(self.url, headers=self._headers)
if "Are you a robot?" in res.text:
log.error("Are you a robot?")
- match = self._preload_state_re.search(res.text)
+ match = self._re_preload_state.search(res.text)
if match is None:
return
- live_ids = self._channel_list_schema.validate(match.group(1))
+ live_ids = self._schema_live_list.validate(match.group(1))
live_id = live_ids.get(channel)
if not live_id:
- log.error("Could not find liveId for channel '{0}'".format(channel))
- return
-
- log.debug("Found liveId: {0}".format(live_id))
- # Retrieve live player URL
- res = self.session.http.get(self.PLAYER_URL)
- match = self._live_player_re.search(res.text)
- if match is None:
- return
- live_player_url = update_scheme(self.url, match.group('live_player_url'))
-
- # Extract streams from the live player page
- log.debug("Player URL: {0}".format(live_player_url))
- res = self.session.http.get(live_player_url)
-
- # Get the ID of the webpack module containing the streams config from another module's dependency list
- match = self._live_stream_info_module_id_re.search(res.text)
- if match is None:
+ log.error(f"Could not find liveId for channel '{channel}'")
return
- webpack_module_id = int(match.group(1))
- log.debug("Webpack module ID: {0}".format(webpack_module_id))
- # Finally get the streams JSON data from the config/livestreams webpack module
- regex = re.compile(self._live_stream_info_re.format(id=webpack_module_id, next=webpack_module_id + 1))
- match = regex.search(res.text)
- if match is None:
- return
- stream_info = self._live_streams_schema.validate(match.group(1))
- data = stream_info.get(live_id, {})
+ log.debug(f"Found liveId: {live_id}")
+ res = self.session.http.get(self.LIVE_API_URL)
+ streams = self.session.http.json(res, schema=self._schema_live_streams)
+ data = streams.get(live_id, {})
- return data.get('cdns')
+ return data.get("cdns")
def _get_vod_streams(self):
- # Retrieve URL page and search for video ID
res = self.session.http.get(self.url, headers=self._headers)
- match = self._preload_state_re.search(res.text)
+ match = self._re_preload_state.search(res.text)
if match is None:
return
- videos = self._vod_list_schema.validate(match.group(1))
+ videos = self._schema_vod_list.validate(match.group(1))
video_id = next((v["video"] for v in videos if v["slug"] in self.url), None)
if video_id is None:
return
- log.debug("Found videoId: {0}".format(video_id))
+ log.debug(f"Found videoId: {video_id}")
res = self.session.http.get(self.VOD_API_URL.format(video_id), headers=self._headers)
- streams = self.session.http.json(res, schema=self._vod_api_schema)
+ streams = self.session.http.json(res, schema=self._schema_vod_streams)
return streams
def _get_streams(self):
+ match = self._url_re.match(self.url)
+ channel = match.group("channel")
+
self.session.http.headers.update({"User-Agent": useragents.CHROME})
- if '/news/videos/' in self.url:
- # VOD
- streams = self._get_vod_streams() or []
+ if channel:
+ streams = self._get_live_streams(channel) or []
else:
- # Live
- streams = self._get_live_streams() or []
+ streams = self._get_vod_streams() or []
for video_url in streams:
- log.debug("Found stream: {0}".format(video_url))
- if '.f4m' in video_url:
+ log.debug(f"Found stream: {video_url}")
+ parsed = urlparse(video_url)
+ if parsed.path.endswith(".f4m"):
yield from HDSStream.parse_manifest(self.session, video_url).items()
- elif '.m3u8' in video_url:
+ elif parsed.path.endswith(".m3u8"):
yield from HLSStream.parse_variant_playlist(self.session, video_url).items()
- if '.mp4' in video_url:
- match = self._mp4_bitrate_re.match(video_url)
- if match is not None:
- bitrate = match.group('bitrate') + 'k'
- else:
- bitrate = 'vod'
+ elif parsed.path.endswith(".mp4"):
+ match = self._re_mp4_bitrate.match(video_url)
+ bitrate = "vod" if match is None else f"{match.group('bitrate')}k"
yield bitrate, HTTPStream(self.session, video_url)
| Bloomberg: no playable streams found
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
Bloomberg plugin does not detect playable stream:
```
streamlink https://www.bloomberg.com/live/us -l debug
[cli][debug] OS: macOS 11.0.1
[cli][debug] Python: 3.9.1
[cli][debug] Streamlink: 0+untagged.1.g7a74e18
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin bloomberg for URL https://www.bloomberg.com/live/us
[plugins.bloomberg][debug] Found liveId: PHOENIX_US
error: No playable streams found on this URL: https://www.bloomberg.com/live/us
```
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. Install streamlink from HEAD
2. streamlink https://www.bloomberg.com/live/us [-l debug]
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
Please see the log output above.
### Additional comments, etc.
Thanks!
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2021-01-26T02:33:00 |
||
streamlink/streamlink | 3,518 | streamlink__streamlink-3518 | [
"3517"
] | 7a74e1848d9af9dad9f6fdb8fa4935049efb9a62 | diff --git a/src/streamlink/utils/l10n.py b/src/streamlink/utils/l10n.py
--- a/src/streamlink/utils/l10n.py
+++ b/src/streamlink/utils/l10n.py
@@ -1,6 +1,5 @@
import locale
import logging
-import re
try:
@@ -68,9 +67,19 @@ def __init__(self, alpha2, alpha3, name, bibliographic=None):
def get(cls, language):
try:
if PYCOUNTRY:
- # lookup workaround for alpha_2 language codes
- lang = languages.get(alpha_2=language) if re.match(r"^[a-z]{2}$", language) else languages.lookup(language)
- return Language(lang.alpha_2, lang.alpha_3, lang.name, getattr(lang, "bibliographic", None))
+ lang = (languages.get(alpha_2=language)
+ or languages.get(alpha_3=language)
+ or languages.get(bibliographic=language)
+ or languages.get(name=language))
+ if not lang:
+ raise KeyError(language)
+ return Language(
+ # some languages don't have an alpha_2 code
+ getattr(lang, "alpha_2", ""),
+ lang.alpha_3,
+ lang.name,
+ getattr(lang, "bibliographic", "")
+ )
else:
lang = None
if len(language) == 2:
| diff --git a/tests/test_localization.py b/tests/test_localization.py
--- a/tests/test_localization.py
+++ b/tests/test_localization.py
@@ -109,6 +109,14 @@ def test_language_compare(self):
b = l10n.Language("AA", None, "Test")
self.assertNotEqual(a, b)
+ # issue #3517: language lookups without alpha2 but with alpha3 codes should not raise
+ def test_language_a3_no_a2(self):
+ a = l10n.Localization.get_language("des")
+ self.assertEqual(a.alpha2, "")
+ self.assertEqual(a.alpha3, "des")
+ self.assertEqual(a.name, "Desano")
+ self.assertEqual(a.bibliographic, "")
+
@unittest.skipIf(not ISO639, "iso639+iso3166 modules are required to test iso639+iso3166 Localization")
class TestLocalization(LocalizationTestsMixin, unittest.TestCase):
@@ -131,3 +139,14 @@ def setUp(self):
def test_pycountry(self):
self.assertEqual(True, l10n.PYCOUNTRY)
+
+ # issue #3057: generic "en" lookups via pycountry yield the "En" language, but not "English"
+ def test_language_en(self):
+ english_a = l10n.Localization.get_language("en")
+ english_b = l10n.Localization.get_language("eng")
+ english_c = l10n.Localization.get_language("English")
+ for lang in [english_a, english_b, english_c]:
+ self.assertEqual(lang.alpha2, "en")
+ self.assertEqual(lang.alpha3, "eng")
+ self.assertEqual(lang.name, "English")
+ self.assertEqual(lang.bibliographic, "")
| raise AttributeError with raiplay plugin
## Plugin Issue
- [x] This is a plugin issue and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
I use the `net-misc/streamlink-9999` package (git version) on a stable Gentoo Linux system.
I can successfully use streamlink with the Rainews 24 channel, but it doesn't work with Rai 1, Rai 2 or Rai 3.
### Reproduction steps / Explicit stream URLs to test
1. Run `streamlink https://www.raiplay.it/dirette/rai1`
### Log output
```
$ streamlink --loglevel debug https://www.raiplay.it/dirette/rai1
[cli][debug] OS: Linux-5.4.80-gentoo-r1-2-x86_64-Intel-R-_Core-TM-2_Duo_CPU_E8400_@_3.00GHz-with-glibc2.2.5
[cli][debug] Python: 3.8.7
[cli][debug] Streamlink: 2.0.0+25.g7a74e18
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin raiplay for URL https://www.raiplay.it/dirette/rai1
[plugins.raiplay][debug] Found JSON URL: https://www.raiplay.it/dirette/rai1.json
[plugins.raiplay][debug] Found stream URL: https://mediapolis.rai.it/relinker/relinkerServlet.htm?cont=2606803
[utils.l10n][debug] Language code: en_US
Traceback (most recent call last):
File "/usr/bin/streamlink", line 33, in <module>
sys.exit(load_entry_point('streamlink==2.0.0+25.g7a74e18', 'console_scripts', 'streamlink')())
File "/usr/lib/python3.8/site-packages/streamlink_cli/main.py", line 1052, in main
handle_url()
File "/usr/lib/python3.8/site-packages/streamlink_cli/main.py", line 580, in handle_url
streams = fetch_streams(plugin)
File "/usr/lib/python3.8/site-packages/streamlink_cli/main.py", line 459, in fetch_streams
return plugin.streams(stream_types=args.stream_types,
File "/usr/lib/python3.8/site-packages/streamlink/plugin/plugin.py", line 323, in streams
ostreams = list(ostreams)
File "/usr/lib/python3.8/site-packages/streamlink/plugins/raiplay.py", line 49, in _get_streams
yield from HLSStream.parse_variant_playlist(self.session, stream_url).items()
File "/usr/lib/python3.8/site-packages/streamlink/stream/hls.py", line 494, in parse_variant_playlist
if not default_audio and (media.autoselect and locale.equivalent(language=media.language)):
File "/usr/lib/python3.8/site-packages/streamlink/utils/l10n.py", line 155, in equivalent
equivalent = equivalent and (not language or self.language == self.get_language(language))
File "/usr/lib/python3.8/site-packages/streamlink/utils/l10n.py", line 169, in get_language
return Language.get(language)
File "/usr/lib/python3.8/site-packages/streamlink/utils/l10n.py", line 73, in get
return Language(lang.alpha_2, lang.alpha_3, lang.name, getattr(lang, "bibliographic", None))
File "/usr/lib/python3.8/site-packages/pycountry/db.py", line 19, in __getattr__
raise AttributeError
AttributeError
```
### Additional comments, etc.
I have `dev-python/pycountry-20.7.3`.
I can easily add patches to the `/etc/portage/patches/net-misc/streamlink` directory and then reinstall `streamlink`, but unfortunately I don't know which patch I should apply. Patch from pull #3057 cannot be applied to `net-misc/streamlink-9999` as far as I know.
| Could you please post the content of the HLS playlist?
```bash
curl -sSL "$(streamlink --stream-url 'https://www.raiplay.it/dirette/rai1')"
```
The `HLSStream` is trying to select the right audio stream based on your locale (which is `en_US` according to the log), as the media is annotated with `AUTOSELECT`:
https://github.com/streamlink/streamlink/blob/7a74e1848d9af9dad9f6fdb8fa4935049efb9a62/src/streamlink/stream/hls.py#L494
The reason why it fails is that there's a bug in one of the recent pycountry versions where it looks up generic/unknown language lookups incorrectly and a workaround had to be added in the PR you are referring to. It doesn't catch `AttributeError`s on invalid data though:
https://github.com/streamlink/streamlink/blob/7a74e1848d9af9dad9f6fdb8fa4935049efb9a62/src/streamlink/utils/l10n.py#L71-L73
> I don't know which patch I should apply
There is nothing to apply, because you are already using the latest version.
You can disable pycountry though when building with having `STREAMLINK_USE_PYCOUNTRY` unset:
https://github.com/streamlink/streamlink/blob/7a74e1848d9af9dad9f6fdb8fa4935049efb9a62/setup.py#L28
> Could you please post the content of the HLS playlist?
>
> ```shell
> curl -sSL "$(streamlink --stream-url 'https://www.raiplay.it/dirette/rai1')"
The `curl` command fails because the `streamlink` command fails to produce a valid URL.
```
$ streamlink --stream-url https://www.raiplay.it/dirette/rai1
Traceback (most recent call last):
File "/usr/bin/streamlink", line 33, in <module>
sys.exit(load_entry_point('streamlink==2.0.0+25.g7a74e18', 'console_scripts', 'streamlink')())
File "/usr/lib/python3.8/site-packages/streamlink_cli/main.py", line 1052, in main
handle_url()
File "/usr/lib/python3.8/site-packages/streamlink_cli/main.py", line 580, in handle_url
streams = fetch_streams(plugin)
File "/usr/lib/python3.8/site-packages/streamlink_cli/main.py", line 459, in fetch_streams
return plugin.streams(stream_types=args.stream_types,
File "/usr/lib/python3.8/site-packages/streamlink/plugin/plugin.py", line 323, in streams
ostreams = list(ostreams)
File "/usr/lib/python3.8/site-packages/streamlink/plugins/raiplay.py", line 49, in _get_streams
yield from HLSStream.parse_variant_playlist(self.session, stream_url).items()
File "/usr/lib/python3.8/site-packages/streamlink/stream/hls.py", line 494, in parse_variant_playlist
if not default_audio and (media.autoselect and locale.equivalent(language=media.language)):
File "/usr/lib/python3.8/site-packages/streamlink/utils/l10n.py", line 155, in equivalent
equivalent = equivalent and (not language or self.language == self.get_language(language))
File "/usr/lib/python3.8/site-packages/streamlink/utils/l10n.py", line 169, in get_language
return Language.get(language)
File "/usr/lib/python3.8/site-packages/streamlink/utils/l10n.py", line 73, in get
return Language(lang.alpha_2, lang.alpha_3, lang.name, getattr(lang, "bibliographic", None))
File "/usr/lib/python3.8/site-packages/pycountry/db.py", line 19, in __getattr__
raise AttributeError
AttributeError
```
For comparison, Rainews 24 works instead:
```
$ streamlink --stream-url https://www.raiplay.it/dirette/rainews24
https://streamcdnm24-8e7439fdb1694c8da3a0fd63e4dda518.msvdn.net/rainews1/hls/rainews_2400/chunklist.m3u8?baseuri=%2Frainews1%2Fhls%2F&tstart=0&tend=1611684671&tof=86400&tk2=14c9908814ca5b9318f0f72f000ab1656d2829d3c7842c466b614ddb3a509f3a
```
Can you check it via your webbrowser's dev tools? Go to the network tab, refresh the site and look for the first m3u8 request that their web player will make. That would help me understand why it's raising the AttributeError.
The issue is `getattr(lang, "bibliographic", None)`, but without knowing what `lang` is from the statement above, it's hard to tell why it's raising the error.
there is no `alpha_2` for `LANGUAGE="des"`
```
language=ita
lang=Language(alpha_2='it', alpha_3='ita', name='Italian', scope='I', type='L')
---
language=ita
lang=Language(alpha_2='it', alpha_3='ita', name='Italian', scope='I', type='L')
---
language=V.O
---
language=V.O
---
language=des
lang=Language(alpha_3='des', name='Desano', scope='I', type='L')
Traceback (most recent call last):
...
AttributeError
```
```
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-MEDIA:TYPE=AUDIO,GROUP-ID="aac",LANGUAGE="ita",NAME="Italiano",DEFAULT=YES,AUTOSELECT=YES,URI="itarai1_160/"
#EXT-X-MEDIA:TYPE=AUDIO,GROUP-ID="aac",LANGUAGE="V.O",NAME="Lingua Originale",DEFAULT=NO,AUTOSELECT=YES,URI="engrai1_160/"
#EXT-X-MEDIA:TYPE=AUDIO,GROUP-ID="aac",LANGUAGE="des",NAME="Audiodescrizione",DEFAULT=NO,AUTOSELECT=YES,URI="desrai1_160/"
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=2793078,CODECS="avc1.77.41,mp4a.40.2",RESOLUTION=1024x576,AUDIO="aac"
rai1_2400/chunklist.m3u8
#EXT-X-I-FRAME-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=2793078,CODECS="avc1.77.42",URI="rai1_2400/chunklist.m3u8"
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=2137033,CODECS="avc1.77.31,mp4a.40.2",RESOLUTION=928x522,AUDIO="aac"
rai1_1800/chunklist.m3u8
#EXT-X-I-FRAME-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=2137033,CODECS="avc1.77.42",URI="rai1_1800/chunklist.m3u8"
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=1365331,CODECS="avc1.77.31,mp4a.40.2",RESOLUTION=704x396,AUDIO="aac"
rai1_1200/chunklist.m3u8
#EXT-X-I-FRAME-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=1365331,CODECS="avc1.77.31,mp4a.40.2",URI="rai1_1200/chunklist.m3u8"
```
Replacing `languages.lookup` in favor of multiple `languages.get` calls with specific attributes and raising a `KeyError` if none was found should fix this issue. We shouldn't be using the unknown lookup, as was already suggested in my pycountry bugreport thread, so catching its `AttributeError` is unnecessary.
If one can confirm that this patch is working, I'll open a PR.
```diff
diff --git a/src/streamlink/utils/l10n.py b/src/streamlink/utils/l10n.py
index de2c8892..05113db8 100644
--- a/src/streamlink/utils/l10n.py
+++ b/src/streamlink/utils/l10n.py
@@ -68,8 +68,13 @@ class Language:
def get(cls, language):
try:
if PYCOUNTRY:
- # lookup workaround for alpha_2 language codes
- lang = languages.get(alpha_2=language) if re.match(r"^[a-z]{2}$", language) else languages.lookup(language)
+ lang = languages.get(alpha_2=language) \
+ or languages.get(alpha_3=language) \
+ or languages.get(bibliographic=language) \
+ or languages.get(name=language) \
+ or languages.get(common_name=language)
+ if not lang:
+ raise KeyError(language)
return Language(lang.alpha_2, lang.alpha_3, lang.name, getattr(lang, "bibliographic", None))
else:
lang = None
```
The patch does not work.
lang is not None, it won't raise the KeyError there.
`lang=Language(alpha_3='des', name='Desano', scope='I', type='L')`
`lang.alpha_2` is invalid
```py
Language(alpha_3='des', name='Desano', scope='I', type='L')
-- pycountry.db self._fields --
{'alpha_3': 'des', 'name': 'Desano', 'scope': 'I', 'type': 'L'}
-- pycountry.db key --
alpha_2
```
---
it is also probably `Italian` not `Desano`,
but there is not much we can do about it.
```
LANGUAGE="des",NAME="Audiodescrizione"
```
| 2021-01-27T03:42:49 |
streamlink/streamlink | 3,532 | streamlink__streamlink-3532 | [
"3530"
] | a03f7bfc6932cacfc7a89e62ff509c0be7294f51 | diff --git a/src/streamlink/plugins/tvtoya.py b/src/streamlink/plugins/tvtoya.py
--- a/src/streamlink/plugins/tvtoya.py
+++ b/src/streamlink/plugins/tvtoya.py
@@ -2,7 +2,6 @@
import re
from streamlink.plugin import Plugin
-from streamlink.plugin.api import useragents
from streamlink.stream import HLSStream
from streamlink.utils import update_scheme
@@ -11,7 +10,7 @@
class TVToya(Plugin):
_url_re = re.compile(r"https?://tvtoya.pl/live")
- _playlist_re = re.compile(r'data-stream="([^"]+)"')
+ _playlist_re = re.compile(r'<source src="([^"]+)" type="application/x-mpegURL">')
@classmethod
def can_handle_url(cls, url):
@@ -26,7 +25,6 @@ def _get_streams(self):
return HLSStream.parse_variant_playlist(
self.session,
update_scheme(self.url, playlist_m.group(1)),
- headers={'Referer': self.url, 'User-Agent': useragents.ANDROID}
)
else:
log.debug("Could not find stream data")
| fix plugin tvtoya.py
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [ ] This is a plugin issue and I have read the contribution guidelines.
- [ ] I am using the latest development version from the master branch.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
fix plugin tvtoya http://tvtoya.pl/live
streamlinksrv error No playable streams found on this URL: http://tvtoya.pl/live
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. ...
2. ...
3. ...
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
REPLACE THIS TEXT WITH THE LOG OUTPUT
```
### Additional comments, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| **Feedback/answer (see ticked items):**
* As requested in the issue template:
* - [x] Does not meet requirements for issue or feature/plugin request [[1]] [[2]] [[3]]
* - [x] Description and/or reproduction steps are insufficiently detailed
* - [x] Streamlink version in use not specified
* - [x] Full ```--loglevel debug``` log output not provided
* - [ ] Research of prior issues/fixes appears to be insufficient [[4]]
* Other feedback:
* - [ ] Issue is out of scope and/or should be reported/help sought elsewhere
* - [ ] Issue appears to unnecessarily duplicate another issue that is open/closed
* - [ ] User appears to be using an outdated Streamlink version/plugin [[5]] [[6]]
* - [ ] Use of discussions more appropriate (admin can/will convert to discussion) [[7]]
* - [ ] Other (see below)
* Other: N/A
Please amend/close your issue accordingly and/or undertake the requested prior research before opening an issue in future.
[[1]] [Reporting issues][1]
[[2]] [Feature requests][2]
[[3]] [Plugin requests][3]
[[4]] [Search all open/closed issues/pull requests][4]
[[5]] [Install the most recent version of Streamlink][5]
[[6]] [Check the master branch for plugin updates][6]
[[7]] [Streamlink discussions][7]
[1]: https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#reporting-issues
[2]: https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#feature-requests
[3]: https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#plugin-requests
[4]: https://github.com/streamlink/streamlink/issues?q=
[5]: https://streamlink.github.io/install.html
[6]: https://github.com/streamlink/streamlink/tree/master/src/streamlink/plugins
[7]: https://github.com/streamlink/streamlink/discussions | 2021-02-01T22:23:43 |
|
streamlink/streamlink | 3,559 | streamlink__streamlink-3559 | [
"3558"
] | 6ce20850d574dfcaa75590660ad29e480864265a | diff --git a/src/streamlink/plugins/vtvgo.py b/src/streamlink/plugins/vtvgo.py
--- a/src/streamlink/plugins/vtvgo.py
+++ b/src/streamlink/plugins/vtvgo.py
@@ -1,19 +1,37 @@
import logging
import re
-from streamlink.exceptions import PluginError
from streamlink.plugin import Plugin
+from streamlink.plugin.api import validate
+from streamlink.plugin.api.utils import itertags
from streamlink.stream import HLSStream
+from streamlink.utils import parse_json
log = logging.getLogger(__name__)
class VTVgo(Plugin):
-
AJAX_URL = 'https://vtvgo.vn/ajax-get-stream'
_url_re = re.compile(r'https://vtvgo\.vn/xem-truc-tuyen-kenh-')
- _params_re = re.compile(r'''var\s(?P<key>(?:type_)?id|time|token)\s*=\s*["']?(?P<value>[^"']+)["']?;''')
+ _params_re = re.compile(r'''var\s+(?P<key>(?:type_)?id|time|token)\s*=\s*["']?(?P<value>[^"']+)["']?;''')
+
+ _schema_params = validate.Schema(
+ validate.transform(lambda html: next(tag.text for tag in itertags(html, "script") if "setplayer(" in tag.text)),
+ validate.transform(_params_re.findall),
+ [
+ ("id", int),
+ ("type_id", str),
+ ("time", str),
+ ("token", str)
+ ]
+ )
+ _schema_stream_url = validate.Schema(
+ validate.transform(parse_json),
+ {"stream_url": [validate.url()]},
+ validate.get("stream_url"),
+ validate.get(0)
+ )
@classmethod
def can_handle_url(cls, url):
@@ -25,17 +43,10 @@ def _get_streams(self):
'Referer': self.url,
'X-Requested-With': 'XMLHttpRequest',
})
- res = self.session.http.get(self.url)
-
- params = self._params_re.findall(res.text)
- if not params:
- raise PluginError('No POST data')
- elif len(params) != 4:
- raise PluginError('Not enough POST data: {0!r}'.format(params))
+ params = self.session.http.get(self.url, schema=self._schema_params)
log.trace('{0!r}'.format(params))
- res = self.session.http.post(self.AJAX_URL, data=dict(params))
- hls_url = self.session.http.json(res)['stream_url'][0]
+ hls_url = self.session.http.post(self.AJAX_URL, data=dict(params), schema=self._schema_stream_url)
return HLSStream.parse_variant_playlist(self.session, hls_url)
| vtvgo plugin issue
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
I use this command `streamlink -l trace https://vtvgo.vn/xem-truc-tuyen-kenh-vtv1-1.html best`
And stops with this error
```
[09:47:36.311010][cli][debug] OS: macOS 10.15.7
[09:47:36.311282][cli][debug] Python: 3.9.1
[09:47:36.311364][cli][debug] Streamlink: 2.0.0
[09:47:36.311431][cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(0.57.0)
[09:47:36.311548][cli][info] Found matching plugin vtvgo for URL https://vtvgo.vn/xem-truc-tuyen-kenh-vtv1-1.html
[09:47:37.476177][plugins.vtvgo][trace] <Response [200]>
[09:47:37.476668][plugins.vtvgo][trace] [('id', '1'), ('type_id', '1'), ('time', '1613033257'), ('token', '1613033257.57e947cb0be94a48835ba7219cf4a399'), ('token', 'VTVGO_____VTVGO_____'), ('time', '1613033257')]
Traceback (most recent call last):
File "/usr/local/bin/streamlink", line 33, in <module>
sys.exit(load_entry_point('streamlink==2.0.0', 'console_scripts', 'streamlink')())
File "/usr/local/Cellar/streamlink/2.0.0_1/libexec/lib/python3.9/site-packages/streamlink_cli/main.py", line 1052, in main
handle_url()
File "/usr/local/Cellar/streamlink/2.0.0_1/libexec/lib/python3.9/site-packages/streamlink_cli/main.py", line 580, in handle_url
streams = fetch_streams(plugin)
File "/usr/local/Cellar/streamlink/2.0.0_1/libexec/lib/python3.9/site-packages/streamlink_cli/main.py", line 459, in fetch_streams
return plugin.streams(stream_types=args.stream_types,
File "/usr/local/Cellar/streamlink/2.0.0_1/libexec/lib/python3.9/site-packages/streamlink/plugin/plugin.py", line 317, in streams
ostreams = self._get_streams()
File "/usr/local/Cellar/streamlink/2.0.0_1/libexec/lib/python3.9/site-packages/streamlink/plugins/vtvgo.py", line 38, in _get_streams
hls_url = self.session.http.json(res)['stream_url'][0]
TypeError: list indices must be integers or slices, not str
```
### Additional comments, etc.
I'm not a pro in python, but was able debug this issue.
The plugin expects 4 parameters, but the regex finds 6 parameters on the website.
`[09:47:37.476668][plugins.vtvgo][trace] [('id', '1'), ('type_id', '1'), ('time', '1613033257'), ('token', '1613033257.57e947cb0be94a48835ba7219cf4a399'), ('token', 'VTVGO_____VTVGO_____'), ('time', '1613033257')]`
The last 2 items are redundant and can be removed.
To fix this issue I just added this line to remove the last 2 items.
```diff
params = self._params_re.findall(res.text)
+ del params[-2:]
```
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2021-02-11T14:54:23 |
||
streamlink/streamlink | 3,585 | streamlink__streamlink-3585 | [
"3567"
] | e8f7170adbbb07d50df9de5331a5d2ae3b028893 | diff --git a/src/streamlink/plugins/booyah.py b/src/streamlink/plugins/booyah.py
new file mode 100644
--- /dev/null
+++ b/src/streamlink/plugins/booyah.py
@@ -0,0 +1,153 @@
+import logging
+import re
+from urllib.parse import urljoin
+
+from streamlink.plugin import Plugin
+from streamlink.plugin.api import validate
+from streamlink.stream import HLSStream, HTTPStream
+
+log = logging.getLogger(__name__)
+
+
+class Booyah(Plugin):
+ url_re = re.compile(r'''
+ https?://(?:www\.)?booyah\.live/
+ (?:(?P<type>channels|clips|vods)/)?(?P<id>[^?]+)
+ ''', re.VERBOSE)
+
+ auth_api_url = 'https://booyah.live/api/v3/auths/sessions'
+ vod_api_url = 'https://booyah.live/api/v3/playbacks/{0}'
+ live_api_url = 'https://booyah.live/api/v3/channels/{0}'
+ streams_api_url = 'https://booyah.live/api/v3/channels/{0}/streams'
+
+ auth_schema = validate.Schema({
+ 'expiry_time': int,
+ 'uid': int,
+ })
+
+ vod_schema = validate.Schema({
+ 'user': {
+ 'nickname': str,
+ },
+ 'playback': {
+ 'name': str,
+ 'endpoint_list': [{
+ 'stream_url': validate.url(),
+ 'resolution': validate.all(
+ int,
+ validate.transform(lambda x: f'{x}p'),
+ ),
+ }],
+ },
+ })
+
+ live_schema = validate.Schema({
+ 'user': {
+ 'nickname': str,
+ },
+ 'channel': {
+ 'channel_id': int,
+ 'name': str,
+ 'is_streaming': bool,
+ validate.optional('hostee'): {
+ 'channel_id': int,
+ 'nickname': str,
+ },
+ },
+ })
+
+ streams_schema = validate.Schema({
+ 'stream_addr_list': [{
+ 'resolution': str,
+ 'url_path': str,
+ }],
+ 'mirror_list': [{
+ 'url_domain': validate.url(),
+ }],
+ })
+
+ author = None
+ category = None
+ title = None
+
+ @classmethod
+ def can_handle_url(cls, url):
+ return cls.url_re.match(url) is not None
+
+ def get_author(self):
+ return self.author
+
+ def get_category(self):
+ return self.category
+
+ def get_title(self):
+ return self.title
+
+ def do_auth(self):
+ res = self.session.http.post(self.auth_api_url)
+ self.session.http.json(res, self.auth_schema)
+
+ def get_vod(self, id):
+ res = self.session.http.get(self.vod_api_url.format(id))
+ user_data = self.session.http.json(res, schema=self.vod_schema)
+
+ self.author = user_data['user']['nickname']
+ self.category = 'VOD'
+ self.title = user_data['playback']['name']
+
+ for stream in user_data['playback']['endpoint_list']:
+ if stream['stream_url'].endswith('.mp4'):
+ yield stream['resolution'], HTTPStream(
+ self.session,
+ stream['stream_url'],
+ )
+ else:
+ yield stream['resolution'], HLSStream(
+ self.session,
+ stream['stream_url'],
+ )
+
+ def get_live(self, id):
+ res = self.session.http.get(self.live_api_url.format(id))
+ user_data = self.session.http.json(res, schema=self.live_schema)
+
+ if user_data['channel']['is_streaming']:
+ self.category = 'Live'
+ stream_id = user_data['channel']['channel_id']
+ elif 'hostee' in user_data['channel']:
+ self.category = f'Hosted by {user_data["channel"]["hostee"]["nickname"]}'
+ stream_id = user_data['channel']['hostee']['channel_id']
+ else:
+ log.info('User is offline')
+ return
+
+ self.author = user_data['user']['nickname']
+ self.title = user_data['channel']['name']
+
+ res = self.session.http.get(self.streams_api_url.format(stream_id))
+ streams = self.session.http.json(res, schema=self.streams_schema)
+
+ for stream in streams['stream_addr_list']:
+ if stream['resolution'] != 'Auto':
+ for mirror in streams['mirror_list']:
+ yield stream['resolution'], HLSStream(
+ self.session,
+ urljoin(mirror['url_domain'], stream['url_path']),
+ )
+
+ def _get_streams(self):
+ self.do_auth()
+
+ m = self.url_re.match(self.url)
+ url_data = m.groupdict()
+ log.debug(f'ID={url_data["id"]}')
+
+ if not url_data['type'] or url_data['type'] == 'channels':
+ log.debug('Type=Live')
+ return self.get_live(url_data['id'])
+ else:
+ log.debug('Type=VOD')
+ return self.get_vod(url_data['id'])
+
+
+__plugin__ = Booyah
| diff --git a/tests/plugins/test_booyah.py b/tests/plugins/test_booyah.py
new file mode 100644
--- /dev/null
+++ b/tests/plugins/test_booyah.py
@@ -0,0 +1,32 @@
+from streamlink.plugins.booyah import Booyah
+from tests.plugins import PluginCanHandleUrl
+
+
+class TestPluginCanHandleUrlBooyah(PluginCanHandleUrl):
+ __plugin__ = Booyah
+
+ should_match = [
+ 'http://booyah.live/nancysp',
+ 'https://booyah.live/nancysp',
+ 'http://booyah.live/channels/21755518',
+ 'https://booyah.live/channels/21755518',
+ 'http://booyah.live/clips/13271208573492782667?source=2',
+ 'https://booyah.live/clips/13271208573492782667?source=2',
+ 'http://booyah.live/vods/13865237825203323136?source=2',
+ 'https://booyah.live/vods/13865237825203323136?source=2',
+ 'http://www.booyah.live/nancysp',
+ 'https://www.booyah.live/nancysp',
+ 'http://www.booyah.live/channels/21755518',
+ 'https://www.booyah.live/channels/21755518',
+ 'http://www.booyah.live/clips/13271208573492782667?source=2',
+ 'https://www.booyah.live/clips/13271208573492782667?source=2',
+ 'http://www.booyah.live/vods/13865237825203323136?source=2',
+ 'https://www.booyah.live/vods/13865237825203323136?source=2',
+ ]
+
+ should_not_match = [
+ 'http://booyah.live/',
+ 'https://booyah.live/',
+ 'http://www.booyah.live/',
+ 'https://www.booyah.live/',
+ ]
| Booyah.live
<!--
Thanks for requesting a plugin!
USE THE TEMPLATE. Otherwise your plugin request may be rejected.
First, see the contribution guidelines and plugin request requirements:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Plugin requests which fall into the categories we will not implement will be closed immediately.
Also check the list of open and closed plugin requests:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+request%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Request
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin request and I have read the contribution guidelines and plugin request requirements.
- [x] I am using the latest development version from the master branch.
### Description
<!-- Explain the plugin and site as clearly as you can. What is the site about? Who runs it? What content does it provide? What value does it bring to Streamlink? Etc. -->
Booyah.live is a gaming streaming platfmorm, just like Twitch. It also hosts the official broadcast of the Loading TV channel online.
### Example stream URLs
<!-- Example URLs for streams are required. Plugin requests which do not have example URLs will be closed. -->
1. https://booyah.live/loading52x
2. https://booyah.live/nfa
3. https://booyah.live/levelup
### Additional comments, etc.
No login required, no DRM, no geo-block.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2021-02-26T02:52:12 |
|
streamlink/streamlink | 3,619 | streamlink__streamlink-3619 | [
"3568"
] | cee5ac933de4c487bf9b33c84f46f99fb8c3dd4e | diff --git a/src/streamlink_cli/output.py b/src/streamlink_cli/output.py
--- a/src/streamlink_cli/output.py
+++ b/src/streamlink_cli/output.py
@@ -180,6 +180,11 @@ def _mpv_title_escape(cls, title_string):
def _create_arguments(self):
if self.namedpipe:
filename = self.namedpipe.path
+ if is_win32:
+ if self.player_name == "vlc":
+ filename = f"stream://\\{filename}"
+ elif self.player_name == "mpv":
+ filename = f"file://{filename}"
elif self.filename:
filename = self.filename
elif self.http:
| diff --git a/tests/test_cmdline_player_fifo.py b/tests/test_cmdline_player_fifo.py
new file mode 100644
--- /dev/null
+++ b/tests/test_cmdline_player_fifo.py
@@ -0,0 +1,45 @@
+import unittest
+from unittest.mock import Mock, patch
+
+from streamlink.compat import is_win32
+from tests.test_cmdline import CommandLineTestCase
+
+
[email protected](is_win32, "test only applicable in a POSIX OS")
+@patch("streamlink_cli.main.NamedPipe", Mock(return_value=Mock(path="/tmp/streamlinkpipe")))
+class TestCommandLineWithPlayerFifoPosix(CommandLineTestCase):
+ def test_player_fifo_default(self):
+ self._test_args(
+ ["streamlink", "--player-fifo",
+ "-p", "any-player",
+ "http://test.se", "test"],
+ ["any-player", "/tmp/streamlinkpipe"]
+ )
+
+
[email protected](not is_win32, "test only applicable on Windows")
+@patch("streamlink_cli.main.NamedPipe", Mock(return_value=Mock(path="\\\\.\\pipe\\streamlinkpipe")))
+class TestCommandLineWithPlayerFifoWindows(CommandLineTestCase):
+ def test_player_fifo_default(self):
+ self._test_args(
+ ["streamlink", "--player-fifo",
+ "-p", "any-player.exe",
+ "http://test.se", "test"],
+ "any-player.exe \\\\.\\pipe\\streamlinkpipe"
+ )
+
+ def test_player_fifo_vlc(self):
+ self._test_args(
+ ["streamlink", "--player-fifo",
+ "-p", "C:\\Program Files\\VideoLAN\\vlc.exe",
+ "http://test.se", "test"],
+ "C:\\Program Files\\VideoLAN\\vlc.exe --input-title-format http://test.se stream://\\\\\\.\\pipe\\streamlinkpipe"
+ )
+
+ def test_player_fifo_mpv(self):
+ self._test_args(
+ ["streamlink", "--player-fifo",
+ "-p", "C:\\Program Files\\mpv\\mpv.exe",
+ "http://test.se", "test"],
+ "C:\\Program Files\\mpv\\mpv.exe --force-media-title=http://test.se file://\\\\.\\pipe\\streamlinkpipe"
+ )
| Unable to use --player-fifo with MPV
Streamlink 2.0.0
mpv 0.33.0-76-g93066ff12f Copyright © 2000-2020 mpv/MPlayer/mplayer2 projects
```
streamlink --player-fifo https://www.twitch.tv/channelName best
[cli][info] Found matching plugin twitch for URL https://www.twitch.tv/channelName
[cli][info] Available streams: audio_only, 160p (worst), 360p, 480p, 720p, 720p60, 1080p60 (best)
[cli][info] Opening stream: 1080p60 (hls)
[cli][info] Creating pipe streamlinkpipe-1140
[cli][info] Starting player: "c:\Programs\MPV\mpv.exe"
error: Failed to start player: "c:\Programs\MPV\mpv.exe" (Process exited prematurely)
[cli][info] Closing currently open stream...
```
Works normally without FIFO
| Does it work with VLC?
https://raw.githubusercontent.com/streamlink/streamlink/master/.github/ISSUE_TEMPLATE/bug_report.md
https://streamlink.github.io/cli.html#cmdoption-loglevel
https://streamlink.github.io/cli.html#cmdoption-verbose-player
> Does it work with VLC?
I dont have VLC but I've tried mplayer and it wont work too.
Provided log **IS** a verbose output, it is exactly the same as normal, there is no extra info. It just dies,
> Provided log IS a verbose output, it is exactly the same as normal, there is no extra info. It just dies,
That's not what the command line you have provided above seems to indicate.
> it is exactly the same as normal, there is no extra info. It just dies,
Stop being so immature and dense. Your documentation clearly states MPV works with Named Pipe when in reality it isnt, which is a misleading lie.
```
streamlink --verbose-player https://www.twitch.tv/yuushi_1234 best
[cli][info] Found matching plugin twitch for URL https://www.twitch.tv/yuushi_1234
[cli][info] Available streams: audio_only, 160p (worst), 360p, 480p, 720p60, 1080p60 (best)
[cli][info] Opening stream: 1080p60 (hls)
[cli][info] Starting player: "c:\Programs\MPV\mpv.exe"
[cli][info] Player closed
[cli][info] Stream ended
[cli][info] Closing currently open stream...
streamlink --verbose-player --player-fifo https://www.twitch.tv/yuushi_1234 best
[cli][info] Found matching plugin twitch for URL https://www.twitch.tv/yuushi_1234
[cli][info] Available streams: audio_only, 160p (worst), 360p, 480p, 720p60, 1080p60 (best)
[cli][info] Opening stream: 1080p60 (hls)
[cli][info] Creating pipe streamlinkpipe-9796
[cli][info] Starting player: "c:\Programs\MPV\mpv.exe"
error: Failed to start player: "c:\Programs\MPV\mpv.exe" (Process exited prematurely)
[cli][info] Closing currently open stream...
```
There seems to be an issue with Streamlink's named pipe implementation on Windows. Neither MPV nor VLC is able to read from it. The named pipe implementation is working fine on \*nix.
https://github.com/streamlink/streamlink/blob/164b2579262a72bb291bd641309b703556878332/src/streamlink/utils/named_pipe.py
@Kein This thread was closed and tagged with "does not meet requirements" because you were (still) not able to provide a proper debug log with the necessary details, which the issue template is explicitly asking for. Remember that this is a free open source software project with volunteers working on it in their free time for fun, and the more details you provide, the easier it is for reproducing and fixing bugs. I'm giving you the first and last warning to watch your tone and not harass/insult any maintainers or contributors here.
----
```
$ streamlink -l debug -v --player-fifo -p ./mpv-x86_64-20210214-git-93066ff/mpv.exe twitch.tv/esl_csgo best
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.8.1
[cli][debug] Streamlink: 2.0.0+45.g164b257
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin twitch for URL twitch.tv/esl_csgo
[plugins.twitch][debug] Getting live HLS streams for esl_csgo
[utils.l10n][debug] Language code: en_DE
[cli][info] Available streams: audio_only, 160p (worst), 360p, 480p, 720p, 720p60, 1080p60 (best)
[cli][info] Opening stream: 1080p60 (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] First Sequence: 10328; Last Sequence: 10344
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 10342; End Sequence: None
[stream.hls][debug] Adding segment 10342 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 10343 to queue
[stream.hls][debug] Adding segment 10344 to queue
[stream.hls][debug] Download of segment 10342 complete
[cli][info] Creating pipe streamlinkpipe-1412
[cli][info] Starting player: ./mpv-x86_64-20210214-git-93066ff/mpv.exe
[cli.output][debug] Opening subprocess: ./mpv-x86_64-20210214-git-93066ff/mpv.exe --force-media-title=twitch.tv/esl_csgo \\.\pipe\streamlinkpipe-1412
[stream.hls][debug] Download of segment 10343 complete
[stream.hls][debug] Download of segment 10344 complete
[file] Cannot open file '\\.\pipe\streamlinkpipe-1412': Resource temporarily unavailable
Failed to open \\.\pipe\streamlinkpipe-1412.
Exiting... (Errors when loading file)
error: Failed to start player: ./mpv-x86_64-20210214-git-93066ff/mpv.exe (Process exited prematurely)
[cli][info] Closing currently open stream...
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
```
```
$ streamlink -l debug -v --player-fifo -p /c/Program\ Files/VideoLAN/VLC/vlc.exe twitch.tv/esl_csgo best
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.8.1
[cli][debug] Streamlink: 2.0.0+45.g164b257
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin twitch for URL twitch.tv/esl_csgo
[plugins.twitch][debug] Getting live HLS streams for esl_csgo
[utils.l10n][debug] Language code: en_DE
[cli][info] Available streams: audio_only, 160p (worst), 360p, 480p, 720p, 720p60, 1080p60 (best)
[cli][info] Opening stream: 1080p60 (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] First Sequence: 10535; Last Sequence: 10550
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 10548; End Sequence: None
[stream.hls][debug] Adding segment 10548 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 10549 to queue
[stream.hls][debug] Adding segment 10550 to queue
[stream.hls][debug] Download of segment 10548 complete
[cli][info] Creating pipe streamlinkpipe-6428
[cli][info] Starting player: C:/Program Files/VideoLAN/VLC/vlc.exe
[cli.output][debug] Opening subprocess: C:/Program Files/VideoLAN/VLC/vlc.exe --input-title-format twitch.tv/esl_csgo \\.\pipe\streamlinkpipe-6428
[stream.hls][debug] Download of segment 10549 complete
[stream.hls][debug] Download of segment 10550 complete
[cli][debug] Writing stream to output
[000001407d7b73f0] main libvlc: Running vlc with the default interface. Use 'cvlc' to use vlc without interface.
[000001407f2cf1c0] dvdnav demux error: Could not open \\.\pipe\streamlinkpipe-6428 with libdvdcss.
[000001407f2cf1c0] dvdnav demux error: Can't open \\.\pipe\streamlinkpipe-6428 for reading
[000001407f2cf1c0] dvdnav demux error: vm: failed to open/read the DVD
[000001407f2c74e0] filesystem stream error: cannot open file \\.\pipe\streamlinkpipe-6428 (Invalid argument)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Adding segment 10551 to queue
[stream.hls][debug] Adding segment 10552 to queue
[stream.hls][debug] Adding segment 10553 to queue
[stream.hls][debug] Adding segment 10554 to queue
[stream.hls][debug] Download of segment 10551 complete
[cli][info] Player closed
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[stream.hls][debug] Download of segment 10552 complete
[cli][info] Closing currently open stream...
```
```
$ streamlink -l debug --player-fifo -v -p mpv twitch.tv/esl_csgo best
[cli][debug] OS: Linux-5.11.0-2-git-x86_64-with-glibc2.33
[cli][debug] Python: 3.9.1
[cli][debug] Streamlink: 2.0.0+45.g164b257
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin twitch for URL twitch.tv/esl_csgo
[plugins.twitch][debug] Getting live HLS streams for esl_csgo
[utils.l10n][debug] Language code: en_US
[cli][info] Available streams: audio_only, 160p (worst), 360p, 480p, 720p, 720p60, 1080p60 (best)
[cli][info] Opening stream: 1080p60 (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] First Sequence: 10658; Last Sequence: 10673
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 10671; End Sequence: None
[stream.hls][debug] Adding segment 10671 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 10672 to queue
[stream.hls][debug] Adding segment 10673 to queue
[stream.hls][debug] Download of segment 10671 complete
[cli][info] Creating pipe streamlinkpipe-511177
[cli][info] Starting player: mpv
[cli.output][debug] Opening subprocess: mpv --force-media-title=twitch.tv/esl_csgo --cache=no /tmp/streamlinkpipe-511177
[stream.hls][debug] Download of segment 10672 complete
[stream.hls][debug] Download of segment 10673 complete
[cli][debug] Writing stream to output
(+) Video --vid=1 (h264 1920x1080 59.940fps)
(+) Audio --aid=1 (aac 2ch 48000Hz)
AO: [pulse] 48000Hz stereo 2ch float
VO: [gpu] 1920x1080 yuv420p
Exiting... (Quit)
[cli][info] Player closed
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[cli][info] Closing currently open stream...
```
This should be mentioned on the Documentation page for Players that Named Pipe does not work on Windows.
No, this is a bug and needs to be fixed.
When did last time named pipe work on Windows?
It is not just broken it is super broken. Every time I try to start streamlink with namedpipe, it destroys total OS I/O, any app that uses named pipe slows to a crawl and starts to use 20% of my CPU.
It might not be possible on Windows 10 any more.
> Windows 10, version 1709: Pipes are only supported within an app-container; ie, from one UWP process to another UWP process that's part of the same app. Also, named pipes must use the syntax "\\\\.\pipe\LOCAL\\" for the pipe name.
It doesn't appear that launching `mpv`, or `VLC` via `python` creates those subprocesses in the same App. For example, if you use PowerShell to launch streamlink, then PowerShell is the App that contains streamlink, but the player process will be a separate App.
@Kein as you didn't post the debug logs I cannot tell what version of Windows you are using, but I'm going to assume it's Windows 10, perhaps you can post the output from `winver` to confirm.
@bastimeyer we may need to update the documentation, or disable `--player-fifo` for Windows with a warning.
> You can only use a named pipe to communicate either between two UWP processes that are part of the same app, or between two non-UWP processes. I don't believe NtFsControlFile will work at all in a UWP process
Looks like restriction is applied only to UWP
That does appear to be true. I will continue to investigate. Is there any specific reason that you need to use named pipes @Kein?
I don't understand the question. Is this a bug or a limitation of the platform? If it is a bug that for some reason went unaddressed for 2+ years then it should be fixed, if it is intended limitation then documentation, that was incorrect for 2+ years - should be fixed.
There is no other ways around it.
It used to work, it doesn't any more. An issue has arisen somewhere along the way which has rendered the feature inoperable, I do not know how long it has been broken - you're the first to report it.
This issue will either be fixed or the feature will be removed. I cannot think of a reason why you would _need_ to use named pipes in Windows and I don't think that many users would miss the feature if it were gone. That is why I asked, if you have a reason to use named pipes in Windows then I will put extra effort in to resolving it.
Please remember that this is a non-commercial project, people give their free-time to work on it. Your comments read like you are making demands, I'm sure you didn't mean it that way - but people will be more inclined to help if you're nice.
@beardypig If there's no way around the restriction, we can add a note to the documentation or remove/disable it for win10. The whole NamedPipe class should ideally be split up though if there's a way to fix this, because currently it's checking the OS type on every open/write/close call.
https://docs.microsoft.com/en-us/windows/win32/ipc/named-pipe-security-and-access-rights
> Windows security enables you to control access to named pipes. For more information about security, see Access-Control Model.
> You can specify a security descriptor for a named pipe when you call the CreateNamedPipe function. The security descriptor controls access to both client and server ends of the named pipe.
https://docs.microsoft.com/en-us/windows/win32/api/winbase/nf-winbase-createnamedpipea
> ```
> HANDLE CreateNamedPipeA(
> LPCSTR lpName,
> DWORD dwOpenMode,
> DWORD dwPipeMode,
> DWORD nMaxInstances,
> DWORD nOutBufferSize,
> DWORD nInBufferSize,
> DWORD nDefaultTimeOut,
> LPSECURITY_ATTRIBUTES lpSecurityAttributes
> );
> ```
> `lpSecurityAttributes`
> A pointer to a SECURITY_ATTRIBUTES structure that specifies a security descriptor for the new named pipe and determines whether child processes can inherit the returned handle. If lpSecurityAttributes is NULL, the named pipe gets a default security descriptor and the handle cannot be inherited. The ACLs in the default security descriptor for a named pipe grant full control to the LocalSystem account, administrators, and the creator owner. They also grant read access to members of the Everyone group and the anonymous account.
`lpSecurityAttributes` is currently set to `NULL`/`None`:
https://github.com/streamlink/streamlink/blob/164b2579262a72bb291bd641309b703556878332/src/streamlink/utils/named_pipe.py#L41
I dont have time to test it right now, but I wonder if running streamlink compiled executable (that is how it is distributed via pip on Windows) in Windows 7 compatibility mode can make it work (since python interpreter executable will inherit environment from streamlink.exe). There is something wrong with the pipe python creates, it is possible windows treats it as UWP one, I cant even check its flags via SysInternal's **accesschk** for example. There is simply no access to that pipe even under SYSTEM account.
@Kein You still haven't answered the question Beardypig asked. What is your use case for the named pipe?
Dunno how relevant it will be but here is surface stack snapshot for **explorer.exe** bugged thread after streamlink creates pipe via python which VLC fails to open:
```
ntoskrnl.exe!KeSynchronizeExecution+0x5b66
ntoskrnl.exe!KeWaitForMutexObject+0x1460
ntoskrnl.exe!KeWaitForMutexObject+0x98f
ntoskrnl.exe!KeWaitForMutexObject+0x233
ntoskrnl.exe!ExWaitForRundownProtectionRelease+0x7dd
ntoskrnl.exe!KeWaitForMutexObject+0x3a29
ntoskrnl.exe!KeSynchronizeExecution+0x3140
KERNELBASE.dll!CharNextW+0x2
LINKINFO.dll!DestroyLinkInfo+0x1787
LINKINFO.dll!DestroyLinkInfo+0x1104
windows.storage.dll!SHGetFileInfoW+0x24c8
windows.storage.dll!SHGetFileInfoW+0x1f95
windows.storage.dll!SHGetFileInfoW+0xda1
windows.storage.dll!GetRegDataDrivenCommandWithAssociation+0x529d
windows.storage.dll!GetRegDataDrivenCommandWithAssociation+0x5516
windows.storage.dll!DetermineFolderDestinationParentAppID+0x7ce
windows.storage.dll!DetermineFolderDestinationParentAppID+0x40c
windows.storage.dll!DetermineFolderDestinationParentAppID+0x2e1
windows.storage.dll!CTaskAddDoc_Create+0x1671
windows.storage.dll!CTaskAddDoc_Create+0x14e7
windows.storage.dll!CTaskAddDoc_Create+0xad0
windows.storage.dll!CTaskAddDoc_Create+0x80e
windows.storage.dll!SHGetFolderPathAndSubDirW+0x3211
windows.storage.dll!CShellItemArray_CreateInstance+0x71ac
windows.storage.dll!CShellItemArray_CreateInstance+0x6df1
windows.storage.dll!CShellItemArray_CreateInstance+0x69c4
shcore.dll!DllCanUnloadNow+0x256
ntdll.dll!RtlRegisterWait+0x5b3
ntdll.dll!LdrAccessResource+0x194a
KERNEL32.DLL!BaseThreadInitThunk+0x14
ntdll.dll!RtlUserThreadStart+0x21
```
Interestingly enough the bug only reproducible with VLC, MPV just instant dies and the bug does not happen it seems.
I've tested it with Compatibility mode - it still creates bugged pipe
@Kein You have still not answered the original question. What is your use case for the named pipe? Unless we get an actual reason we're going to remove it since it's pretty pointless on Windows.
@bastimeyer
> If there's no way around the restriction
Here is primitive working example I've tested:
https://jonathonreinhart.com/posts/blog/2012/12/13/named-pipes-between-c-and-python/
it works just fine. After numerous testing I conclude there is something broken about the pipe python creates through winapi (windll).
@beardypig Let's ditch the feature.
fwiw this is the original PR that added named pipe support: https://github.com/chrippa/livestreamer/pull/24
@beardypig Thanks for finding that. Seems more like a limitation of specific players and a very limited use case on Windows devices.
Yeah, I didn't test to see if it was still a limitation with the mplayer forks though. I have tried for quite a while to get it working with VLC but I haven't had much luck yet.
I got it to work with VLC (this was actually reported before in #739).
```
streamlink.exe -v -l debug --player-fifo --player-args "stream://\{playerinput}" twitch.tv/sovietwomble best
```
I haven't managed to get it to work in MPV though, I don't know that MPV supports named pipes in Windows because it treats them as regular files and it would need to do something special... maybe there is an option, but I cannot find it. I suspect it would work with MPlayer, but I haven't tested it yet. This is after I totally rewrote the `NamedPipe` class for Windows using non-blocking overlapping IO calls in an attempt to get it to work... le sigh.
@Kein
> Your documentation clearly states MPV works with Named Pipe when in reality it isnt
Could you point out where it says MPV works with named pipes in the documentation, I couldn't find it. It's so we can fix the docs, we could also add that workaround for VLC (or perhaps implement it, but it's pretty specific; Windows + Named Pipe + VLC > some specific version).
I will test MPV and Mplayer later with generic named pipe where I will feed it byte stream of some video file.
>Could you point out where it says MPV works with named pipes in the documentation
That is incorretly worded question. I never stated that documentation says "MPV works with named pipes on Windows", I said "Documentation states VLC, Mplayer and MPV work with streamlink and named pipes but there are no clearly visible remarks that it is only for Linux/Unix".
Here:
https://streamlink.github.io/players.html
The table just states "Named pipes" and "Yes" for aforementioned players. Windows does have Named Pipes. There are no special platform remarks. Therefore, as an end user, I've assumed "streamlink+selected players" will work with Named Pipes. They dont. A remark is warranted fo whole "Named Pipe" row that Windows platform is an exclusion.
@Kein I literally quoted what you wrote in a previous comment. I also didn't say you did say it worked on Windows, I asked where you it says it works with named pipes because I couldn't remember where it was in the docs.
Anyway, it does work on Windows with MPV - you just need the correct incantation.
```
streamlink.exe -v -l debug --player-fifo -p mpv --player-args "file://{playerinput}" twitch.tv/sovietwomble best
```
----
@bastimeyer
We can update the documentation to include a footnote for VLC and MPV using named pipes on Windows. We could also detect if the user is using named Pipes and Windows and direct them to the documentation notes with an `INFO` log message or something.
The way that Named Pipes have been handled by these players has changed over time, and this has been a frustrating issue to debug...
@beardypig good job finding a solution. :+1:
What we could do instead of adding a note to the docs is change the value of `filename` in `PlayerOutput._create_arguments` depending on the OS and player being used while using a named pipe, so that it automatically sets the right player input argument, and the user doesn't have to change their streamlink command.
The player already gets detected for the `--title` arg, so there shouldn't be any problems here, and regarding the different VLC versions, I don't think we should care about the old versions. [The comment in the linked PR](https://github.com/streamlink/streamlink/pull/739#issuecomment-294462397) says that the issue was found in "both VLC 2.2.4 and VLC 3.0.0", which means it could have also been changed prior to `2.2.4` (which was released mid-2016), but got unnoticed. By the way, the [VLC wiki says](https://wiki.videolan.org/Uncommon_uses/) that named pipes can be read from `fd://nameofpipe`. Not sure where the `stream://nameofpipe` solution of the PR comes from. Are there any version concerns for mpv?
There probably should be a way to specify player args in **streamlinkrc** a-la:
`player="c:\Programs\VLC\vlc.exe args"`
This could be useful here
@bastimeyer we could do it for MPV and VLC as well as adding a generic note in the docs. I didn't want to make it too complicated for such an under utilised feature.
I could not get `fd://nameofpipe` to work in VLC (I think this only applies to POSIX), only `stream://\\\.\pipe\nameofpipe` (nb. there are 3 `\`s instead of the usual 2). I don't know if it worked before in MPV on Windows or it's just that no one ever tried it, I think they it has always required `file://` to work on MPV on Windows.
@Kein this is already possible, you just put `player-args=...` in the config file ([CLI docs](https://streamlink.github.io/cli.html#configuration-file)).
> we could do it for MPV and VLC as well as adding a generic note in the docs.
That is probably the best solution. The whole `Output/PlayerOutput` and `NamedPipe` implementation is unfortunately a bit messy right now and it should probably be refactored a bit before adding more OS- and player-related logic. I can open a PR with a refactor of `NamedPipe` later today that splits up the logic between win32 and \*nix, but there's another issue I've noticed on \*nix systems.
When the `output.open()` call raises an `OSError` in `streamlink_cli.main.output_stream`, eg. when the player set by the user doesn't exist, then the output won't be closed again before `console.error()` gets called, which means that the fifo in the system's tempdir does not get removed. It's not possible to call `output.close()` in the except block though, as the base `Output` class will prevent this, because the output hasn't been successfully opened yet.
```bash
streamlink --player-fifo --player /dev/null URL STREAM
ls /tmp/streamlinkpipe-*
```
> I could not get `fd://nameofpipe` to work in VLC
Ok, I didn't try it myself, just found it in their wiki.
----
https://github.com/streamlink/streamlink/issues/3568#issuecomment-782787642
> twitch.tv/sovietwomble
:+1:
@beardypig
> Is there any specific reason that you need to use named pipes @Kein?
I was investigating latency. Unlike sockets, pipes are are built on top of shared memory segments and have less overhead and in general way faster locally.
https://docs.microsoft.com/en-us/windows/win32/ipc/pipes
@bastimeyer a CLI rewrite is long overdue ;) Actually a lot of things could do with a rewrite...
@Kein was it noticeable? By default STDOUT and STDIN are used to communicate between streamlink and the player process, generally speaking these are pretty fast - I don't know enough about Windows programming to say for sure if they implemented using shared memory or not.
> was it noticeable?
Havent had time to test properly since it was bugged. my current measurements just a few ms which could be margin of error. | 2021-03-14T13:50:02 |
streamlink/streamlink | 3,661 | streamlink__streamlink-3661 | [
"3647"
] | 71b8c5f9baf5de674f224619e2178fca2207f8fa | diff --git a/src/streamlink/plugins/picarto.py b/src/streamlink/plugins/picarto.py
--- a/src/streamlink/plugins/picarto.py
+++ b/src/streamlink/plugins/picarto.py
@@ -1,128 +1,144 @@
-import json
import logging
import re
from streamlink.plugin import Plugin
from streamlink.plugin.api import validate
-from streamlink.stream import HLSStream, RTMPStream
-from streamlink.utils import parse_json
+from streamlink.stream import HLSStream
log = logging.getLogger(__name__)
class Picarto(Plugin):
- CHANNEL_API_URL = "https://api.picarto.tv/v1/channel/name/{channel}"
- VIDEO_API_URL = "https://picarto.tv/process/channel"
- RTMP_URL = "rtmp://{server}:1935/play/"
- RTMP_PLAYPATH = "golive+{channel}?token={token}"
- HLS_URL = "https://{server}/hls/{channel}/index.m3u8?token={token}"
-
- # Regex for all usable URLs
- _url_re = re.compile(r"""
- https?://(?:\w+\.)?picarto\.tv/(?:videopopout/)?([^&?/]+)
- """, re.VERBOSE)
-
- # Regex for VOD extraction
- _vod_re = re.compile(r'''(?<=#vod-player", )(\{.*?\})''')
-
- data_schema = validate.Schema(
- validate.transform(_vod_re.search),
- validate.any(
- None,
- validate.all(
- validate.get(0),
- validate.transform(parse_json),
- {
- "vod": validate.url(),
- }
- )
- )
- )
+ url_re = re.compile(r'''
+ https?://(?:www\.)?picarto\.tv/
+ (?:(?P<po>streampopout|videopopout)/)?
+ (?P<user>[^&?/]+)
+ (?:\?tab=videos&id=(?P<vod_id>\d+))?
+ ''', re.VERBOSE)
+
+ channel_schema = validate.Schema({
+ 'channel': validate.any(None, {
+ 'stream_name': str,
+ 'title': str,
+ 'online': bool,
+ 'private': bool,
+ 'categories': [{'label': str}],
+ }),
+ 'getLoadBalancerUrl': {'origin': str},
+ 'getMultiStreams': validate.any(None, {
+ 'multistream': bool,
+ 'streams': [{
+ 'name': str,
+ 'online': bool,
+ }],
+ }),
+ })
+ vod_schema = validate.Schema({
+ 'data': {
+ 'video': validate.any(None, {
+ 'id': str,
+ 'title': str,
+ 'file_name': str,
+ 'channel': {'name': str},
+ }),
+ },
+ }, validate.get('data'), validate.get('video'))
+
+ HLS_URL = 'https://{origin}.picarto.tv/stream/hls/{file_name}/index.m3u8'
+
+ author = None
+ category = None
+ title = None
@classmethod
def can_handle_url(cls, url):
- return cls._url_re.match(url) is not None
-
- def _create_hls_stream(self, server, channel, token):
- streams = HLSStream.parse_variant_playlist(self.session,
- self.HLS_URL.format(
- server=server,
- channel=channel,
- token=token),
- verify=False)
- if len(streams) > 1:
- log.debug("Multiple HLS streams found")
- return streams
- elif len(streams) == 0:
- log.warning("No HLS streams found when expected")
- return {}
- else:
- # one HLS streams, rename it to live
- return {"live": list(streams.values())[0]}
-
- def _create_flash_stream(self, server, channel, token):
- params = {
- "rtmp": self.RTMP_URL.format(server=server),
- "playpath": self.RTMP_PLAYPATH.format(token=token, channel=channel)
- }
- return RTMPStream(self.session, params=params)
+ return cls.url_re.match(url) is not None
- def _get_vod_stream(self, page):
- data = self.data_schema.validate(page.text)
+ def get_author(self):
+ return self.author
- if data:
- return HLSStream.parse_variant_playlist(self.session, data["vod"])
+ def get_category(self):
+ return self.category
- def _get_streams(self):
- url_channel_name = self._url_re.match(self.url).group(1)
-
- # Handle VODs first, since their "channel name" is different
- if url_channel_name.endswith((".flv", ".mkv")):
- log.debug("Possible VOD stream...")
- page = self.session.http.get(self.url)
- vod_streams = self._get_vod_stream(page)
- if vod_streams:
- yield from vod_streams.items()
- return
- else:
- log.warning("Probably a VOD stream but no VOD found?")
-
- ci = self.session.http.get(self.CHANNEL_API_URL.format(channel=url_channel_name), raise_for_status=False)
-
- if ci.status_code == 404:
- log.error("The channel {0} does not exist".format(url_channel_name))
+ def get_title(self):
+ return self.title
+
+ def get_live(self, username):
+ res = self.session.http.get(f'https://ptvintern.picarto.tv/api/channel/detail/{username}')
+ channel_data = self.session.http.json(res, schema=self.channel_schema)
+ log.trace(f'channel_data={channel_data!r}')
+
+ if not channel_data['channel'] or not channel_data['getMultiStreams']:
+ log.debug('Missing channel or streaming data')
return
- channel_api_json = json.loads(ci.text)
+ if channel_data['channel']['private']:
+ log.info('This is a private stream')
+ return
- if not channel_api_json["online"]:
- log.error("The channel {0} is currently offline".format(url_channel_name))
+ if channel_data['getMultiStreams']['multistream']:
+ msg = 'Found multistream: '
+ i = 1
+ for user in channel_data['getMultiStreams']['streams']:
+ msg += user['name']
+ msg += ' (online)' if user['online'] else ' (offline)'
+ if i < len(channel_data['getMultiStreams']['streams']):
+ msg += ', '
+ i += 1
+ log.info(msg)
+
+ if not channel_data['channel']['online']:
+ log.error('User is not online')
return
- if channel_api_json["private"]:
- log.error("The channel {0} is private, such streams are not yet supported".format(url_channel_name))
+ self.author = username
+ self.category = channel_data['channel']['categories'][0]['label']
+ self.title = channel_data['channel']['title']
+
+ return HLSStream.parse_variant_playlist(self.session,
+ self.HLS_URL.format(file_name=channel_data['channel']['stream_name'],
+ origin=channel_data['getLoadBalancerUrl']['origin']))
+
+ def get_vod(self, vod_id):
+ data = {
+ 'query': (
+ 'query ($videoId: ID!) {\n'
+ ' video(id: $videoId) {\n'
+ ' id\n'
+ ' title\n'
+ ' file_name\n'
+ ' channel {\n'
+ ' name\n'
+ ' }'
+ ' }\n'
+ '}\n'
+ ),
+ 'variables': {'videoId': vod_id},
+ }
+ res = self.session.http.post('https://ptvintern.picarto.tv/ptvapi', json=data)
+ vod_data = self.session.http.json(res, schema=self.vod_schema)
+ log.trace(f'vod_data={vod_data!r}')
+ if not vod_data:
+ log.debug('Missing video data')
return
- server = None
- token = "public"
- channel = channel_api_json["name"]
-
- # Extract preferred edge server and available techs from the undocumented channel API
- channel_server_res = self.session.http.post(self.VIDEO_API_URL, data={"loadbalancinginfo": channel})
- info_json = json.loads(channel_server_res.text)
- pref = info_json["preferedEdge"]
- for i in info_json["edges"]:
- if i["id"] == pref:
- server = i["ep"]
- break
- log.debug("Using load balancing server {0} : {1} for channel {2}".format(pref, server, channel))
-
- for i in info_json["techs"]:
- if i["label"] == "HLS":
- yield from self._create_hls_stream(server, channel, token).items()
- elif i["label"] == "RTMP Flash":
- stream = self._create_flash_stream(server, channel, token)
- yield "live", stream
+ self.author = vod_data['channel']['name']
+ self.category = 'VOD'
+ self.title = vod_data['title']
+ return HLSStream.parse_variant_playlist(self.session,
+ self.HLS_URL.format(file_name=vod_data['file_name'],
+ origin='recording-eu-1'))
+
+ def _get_streams(self):
+ m = self.url_re.match(self.url).groupdict()
+
+ if (m['po'] == 'streampopout' or not m['po']) and m['user'] and not m['vod_id']:
+ log.debug('Type=Live')
+ return self.get_live(m['user'])
+ elif m['po'] == 'videopopout' or (m['user'] and m['vod_id']):
+ log.debug('Type=VOD')
+ vod_id = m['vod_id'] if m['vod_id'] else m['user']
+ return self.get_vod(vod_id)
__plugin__ = Picarto
| diff --git a/tests/plugins/test_picarto.py b/tests/plugins/test_picarto.py
--- a/tests/plugins/test_picarto.py
+++ b/tests/plugins/test_picarto.py
@@ -7,5 +7,8 @@ class TestPluginCanHandleUrlPicarto(PluginCanHandleUrl):
should_match = [
'https://picarto.tv/example',
- 'https://picarto.tv/videopopout/example_2020.00.00.00.00.00_nsfw.mkv',
+ 'https://www.picarto.tv/example',
+ 'https://www.picarto.tv/streampopout/example/public',
+ 'https://www.picarto.tv/videopopout/123456',
+ 'https://www.picarto.tv/example?tab=videos&id=123456',
]
| plugins.picarto: 405 Client Error: Not Allowed for url: https://picarto.tv/process/channel
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Plugin issues describe broken functionality within a plugin's code base, eg. the streaming site has made breaking changes, streams don't get resolved correctly, or authentication has stopped working, etc.
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [ ] I am using the latest development version from the master branch.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. when running the command; # streamlink picarto.tv/<streamname> best
### Log output
<!--
DEBUG LOG OUTPUT IS REQUIRED for a plugin issue!
INCLUDE THE ENTIRE COMMAND LINE and make sure to **remove usernames and passwords**
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
Debug log includes important details about your platform. Don't remove it.
https://streamlink.github.io/latest/cli.html#cmdoption-loglevel
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
[cli][info] Found matching plugin picarto for URL picarto.tv/LukeTUGS
error: Unable to open URL: https://picarto.tv/process/channel (405 Client Error: Not Allowed for url: https://picarto.tv/process/channel)
```
### Additional comments, etc.
Picarto.tv recently updated their API.
Link to their API documents page [https://api.picarto.tv](https://api.picarto.tv)
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Having this issue as well. If I had to guess it has to do with the updated frontend on Picarto.tv
I have work in progress on a rewrite. The live side seems to be working OK, just adding back VOD support.
Have you found a replacement API for extracting the CDN URL? I had a quick stare at the devtools output, but the only place I found the URL was in the body of the main page, plus a fallback hard coded URL in player.js.
For anyone desperate for a quick hack to fix it, using the hard coded fallback ( edge4-us-east.picarto.tv ) seems to work.
Also note that the documented API for channel info has changed URLs slightly:
CHANNEL_API_URL = "https://api.picarto.tv/api/v1/channel/name/{channel}"
@zootboy, I hadn't realised there was documentation! [Edit: I should have gone back and reread the first post...]
With regards to your other post, I'm just following what the web client seems to do. I'm taking the host from the load balancer URL and using that to make a WS connection which returns the data with the streaming URL in it.
I need to get back to this and finish it - I've been sidetracked by other things over the last 2 or 3 days...
| 2021-03-31T16:38:45 |
streamlink/streamlink | 3,662 | streamlink__streamlink-3662 | [
"3660"
] | 6a30ed7524eff2cdb205e024294b187cb660e4e3 | diff --git a/src/streamlink/plugins/bfmtv.py b/src/streamlink/plugins/bfmtv.py
--- a/src/streamlink/plugins/bfmtv.py
+++ b/src/streamlink/plugins/bfmtv.py
@@ -1,8 +1,11 @@
import logging
import re
+from urllib.parse import urljoin, urlparse
from streamlink.plugin import Plugin
+from streamlink.plugin.api.utils import itertags
from streamlink.plugins.brightcove import BrightcovePlayer
+from streamlink.stream import HTTPStream
log = logging.getLogger(__name__)
@@ -22,29 +25,68 @@ class BFMTV(Plugin):
r'<iframe.*?src=".*?/(?P<video_id>\w+)"',
re.DOTALL
)
+ _main_js_url_re = re.compile(r'src="([\w/]+/main\.\w+\.js)"')
+ _js_brightcove_video_re = re.compile(
+ r'i\?\([A-Z]="[^"]+",y="(?P<video_id>[0-9]+).*"data-account"\s*:\s*"(?P<account_id>[0-9]+)',
+ )
@classmethod
def can_handle_url(cls, url):
return cls._url_re.match(url) is not None
def _get_streams(self):
- # Retrieve URL page and search for Brightcove video data
res = self.session.http.get(self.url)
- match = self._brightcove_video_re.search(res.text) or self._brightcove_video_alt_re.search(res.text)
- if match is not None:
- account_id = match.group('account_id')
+
+ m = self._brightcove_video_re.search(res.text) or self._brightcove_video_alt_re.search(res.text)
+ if m:
+ account_id = m.group('account_id')
log.debug(f'Account ID: {account_id}')
- video_id = match.group('video_id')
+ video_id = m.group('video_id')
log.debug(f'Video ID: {video_id}')
player = BrightcovePlayer(self.session, account_id)
yield from player.get_streams(video_id)
- else:
- # Try to find the Dailymotion video ID
- match = self._embed_video_id_re.search(res.text)
- if match is not None:
- video_id = match.group('video_id')
+ return
+
+ # Try to find the Dailymotion video ID
+ m = self._embed_video_id_re.search(res.text)
+ if m:
+ video_id = m.group('video_id')
+ log.debug(f'Video ID: {video_id}')
+ yield from self.session.streams(self._dailymotion_url.format(video_id)).items()
+ return
+
+ # Try the JS for Brightcove video data
+ m = self._main_js_url_re.search(res.text)
+ if m:
+ log.debug(f'JS URL: {urljoin(self.url, m.group(1))}')
+ res = self.session.http.get(urljoin(self.url, m.group(1)))
+ m = self._js_brightcove_video_re.search(res.text)
+ if m:
+ account_id = m.group('account_id')
+ log.debug(f'Account ID: {account_id}')
+ video_id = m.group('video_id')
log.debug(f'Video ID: {video_id}')
- yield from self.session.streams(self._dailymotion_url.format(video_id)).items()
+ player = BrightcovePlayer(self.session, account_id)
+ yield from player.get_streams(video_id)
+ return
+
+ # Audio Live
+ audio_url = None
+ for source in itertags(res.text, 'source'):
+ url = source.attributes.get('src')
+ if url:
+ p_url = urlparse(url)
+ if p_url.path.endswith(('.mp3')):
+ audio_url = url
+
+ # Audio VOD
+ for div in itertags(res.text, 'div'):
+ if div.attributes.get('class') == 'audio-player':
+ audio_url = div.attributes.get('data-media-url')
+
+ if audio_url:
+ yield 'audio', HTTPStream(self.session, audio_url)
+ return
__plugin__ = BFMTV
| plugins.bfmtv: No playable streams found
Hello. for few days, the plugin isn't working anymore
/usr/local/bin/streamlink --loglevel debug https://rmcdecouverte.bfmtv.com/mediaplayer-direct/ best
[cli][info] streamlink is running as root! Be careful!
[cli][debug] OS: Linux-5.8.0-44-generic-x86_64-with-glibc2.29
[cli][debug] Python: 3.8.5
[cli][debug] Streamlink: 2.1.1
[cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.58.0)
[cli][debug] Arguments:
[cli][debug] url=https://rmcdecouverte.bfmtv.com/mediaplayer-direct/
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin bfmtv for URL https://rmcdecouverte.bfmtv.com/mediaplayer-direct/
error: No playable streams found on this URL: https://rmcdecouverte.bfmtv.com/mediaplayer-direct/
| 2021-03-31T20:15:10 |
||
streamlink/streamlink | 3,673 | streamlink__streamlink-3673 | [
"3659"
] | c7bd7ec6099192d2b3c7bed1bbcd472cb8949f95 | diff --git a/src/streamlink/plugins/tvplayer.py b/src/streamlink/plugins/tvplayer.py
deleted file mode 100644
--- a/src/streamlink/plugins/tvplayer.py
+++ /dev/null
@@ -1,141 +0,0 @@
-import logging
-import re
-
-from streamlink.plugin import Plugin, PluginArgument, PluginArguments
-from streamlink.plugin.api import useragents, validate
-from streamlink.stream import HLSStream
-
-log = logging.getLogger(__name__)
-
-
-class TVPlayer(Plugin):
- api_url = "https://v1-streams-elb.tvplayer-cdn.com/api/live/stream/"
- stream_url = "https://live.tvplayer.com/stream-live.php"
- login_url = "https://v1-auth.tvplayer-cdn.com/login?responseType=redirect&redirectUri=https://tvplayer.com/login&lang=en"
- update_url = "https://tvplayer.com/account/update-detail"
- dummy_postcode = "SE1 9LT" # location of ITV HQ in London
-
- url_re = re.compile(r"https?://(?:www\.)?tvplayer\.com/(:?uk/)?(:?watch/?|watch/(.+)?)")
- stream_attrs_re = re.compile(r'data-player-(expiry|key|token|uvid)\s*=\s*"(.*?)"', re.S)
- login_token_re = re.compile(r'input.*?name="_token".*?value="(\w+)"')
- stream_schema = validate.Schema({
- "response": validate.Schema({
- "stream": validate.any(None, validate.text),
- "drm": validate.any(None, validate.text)
- })
- })
- arguments = PluginArguments(
- PluginArgument(
- "email",
- help="The email address used to register with tvplayer.com.",
- metavar="EMAIL",
- requires=["password"]
- ),
- PluginArgument(
- "password",
- sensitive=True,
- help="The password for your tvplayer.com account.",
- metavar="PASSWORD"
- )
- )
-
- @classmethod
- def can_handle_url(cls, url):
- match = TVPlayer.url_re.match(url)
- return match is not None
-
- def __init__(self, url):
- super().__init__(url)
- self.session.http.headers.update({"User-Agent": useragents.CHROME})
-
- def authenticate(self, username, password):
- res = self.session.http.get(self.login_url)
- match = self.login_token_re.search(res.text)
- token = match and match.group(1)
- res2 = self.session.http.post(
- self.login_url,
- data=dict(email=username, password=password, _token=token),
- allow_redirects=False
- )
- # there is a 302 redirect on a successful login
- return res2.status_code == 302
-
- def _get_stream_data(self, expiry, key, token, uvid):
- res = self.session.http.get(
- self.api_url + uvid,
- params=dict(key=key, platform="chrome"),
- headers={
- "Token": token,
- "Token-Expiry": expiry,
- "Uvid": uvid
- }
- )
-
- res_schema = self.session.http.json(res, schema=self.stream_schema)
-
- if res_schema["response"]["stream"] is None:
- res = self.session.http.get(
- self.stream_url,
- params=dict(key=key, platform="chrome"),
- headers={
- "Token": token,
- "Token-Expiry": expiry,
- "Uvid": uvid
- }
- ).json()
- res_schema["response"]["stream"] = res["Streams"]["Adaptive"]
-
- return res_schema
-
- def _get_stream_attrs(self, page):
- stream_attrs = {k.replace("-", "_"): v.strip('"') for k, v in self.stream_attrs_re.findall(page.text)}
-
- log.debug(f"Got stream attributes: {str(stream_attrs)}")
- valid = True
- for a in ("expiry", "key", "token", "uvid"):
- if a not in stream_attrs:
- log.debug(f"Missing '{a}' from stream attributes")
- valid = False
-
- return stream_attrs if valid else {}
-
- def _get_streams(self):
- if self.get_option("email") and self.get_option("password"):
- log.debug("Logging in as {0}".format(self.get_option("email")))
- if not self.authenticate(self.get_option("email"), self.get_option("password")):
- log.warning("Failed to login as {0}".format(self.get_option("email")))
-
- # find the list of channels from the html in the page
- self.url = self.url.replace("https", "http") # https redirects to http
- res = self.session.http.get(self.url)
-
- if "enter your postcode" in res.text:
- log.info(
- f"Setting your postcode to: {self.dummy_postcode}. "
- f"This can be changed in the settings on tvplayer.com"
- )
- res = self.session.http.post(
- self.update_url,
- data=dict(postcode=self.dummy_postcode),
- params=dict(return_url=self.url)
- )
-
- stream_attrs = self._get_stream_attrs(res)
- if stream_attrs:
- stream_data = self._get_stream_data(**stream_attrs)
-
- if stream_data:
- if stream_data["response"]["drm"] is not None:
- log.error("This stream is protected by DRM can cannot be played")
- return
- else:
- return HLSStream.parse_variant_playlist(
- self.session, stream_data["response"]["stream"]
- )
- else:
- if "need to login" in res.text:
- log.error(
- "You need to login using --tvplayer-email/--tvplayer-password to view this stream")
-
-
-__plugin__ = TVPlayer
| diff --git a/tests/plugins/test_tvplayer.py b/tests/plugins/test_tvplayer.py
deleted file mode 100644
--- a/tests/plugins/test_tvplayer.py
+++ /dev/null
@@ -1,143 +0,0 @@
-import unittest
-from unittest.mock import ANY, MagicMock, Mock, call, patch
-
-from streamlink import Streamlink
-from streamlink.plugin.api import HTTPSession
-from streamlink.plugins.tvplayer import TVPlayer
-from streamlink.stream import HLSStream
-from tests.plugins import PluginCanHandleUrl
-
-
-class TestPluginCanHandleUrlTVPlayer(PluginCanHandleUrl):
- __plugin__ = TVPlayer
-
- should_match = [
- "http://tvplayer.com/watch/",
- "http://www.tvplayer.com/watch/",
- "http://tvplayer.com/watch",
- "http://www.tvplayer.com/watch",
- "http://www.tvplayer.com/uk/watch",
- "http://tvplayer.com/watch/dave",
- "http://tvplayer.com/uk/watch/dave",
- "http://www.tvplayer.com/watch/itv",
- "http://www.tvplayer.com/uk/watch/itv",
- "https://www.tvplayer.com/watch/itv",
- "https://www.tvplayer.com/uk/watch/itv",
- "https://tvplayer.com/watch/itv",
- "https://tvplayer.com/uk/watch/itv",
- ]
-
- should_not_match = [
- "http://www.tvplayer.com/"
- ]
-
-
-class TestPluginTVPlayer(unittest.TestCase):
- def setUp(self):
- self.session = Streamlink()
- self.session.http = MagicMock(HTTPSession)
- self.session.http.headers = {}
-
- @patch('streamlink.plugins.tvplayer.TVPlayer._get_stream_data')
- @patch('streamlink.plugins.tvplayer.HLSStream')
- def test_get_streams(self, hlsstream, mock_get_stream_data):
- mock_get_stream_data.return_value = {
- "response": {"stream": "http://test.se/stream1", "drm": None}
- }
-
- page_resp = Mock()
- page_resp.text = """
- <div class="col-xs-12">
- <div id="live-player-root"
- data-player-library="videojs"
- data-player-id="ILWxqLKV91Ql8kF"
- data-player-key="2Pw1Eg0Px3Gy9Jm3Ry8Ar5Bi5Vc5Nk"
- data-player-uvid="139"
- data-player-token="275c808a685a09d6e36d0253ab3765af"
- data-player-expiry="1531958189"
- data-player-poster=""
- data-requested-channel-id="139"
- data-play-button="/assets/tvplayer/images/dist/play-button-epg.svg"
- data-update-url="/now-ajax"
- data-timezone-name="Europe/London"
- data-thumb-link-classes=""
- data-theme-name="tvplayer"
- data-base-entitlements="%5B%22free%22%5D"
- data-has-identity="0"
- data-require-identity-to-watch-free="1"
- data-stream-type="live"
- data-live-route="/watch/%25live_channel_id%25"
- >
- </div>
- </div>
- """
-
- self.session.http.get.return_value = page_resp
- hlsstream.parse_variant_playlist.return_value = {
- "test": HLSStream(self.session, "http://test.se/stream1")
- }
-
- TVPlayer.bind(self.session, "test.tvplayer")
- plugin = TVPlayer("http://tvplayer.com/watch/dave")
-
- streams = plugin.streams()
-
- self.assertTrue("test" in streams)
-
- # test the url is used correctly
- self.session.http.get.assert_called_with(
- "http://tvplayer.com/watch/dave"
- )
- # test that the correct API call is made
- mock_get_stream_data.assert_called_with(
- expiry="1531958189",
- key="2Pw1Eg0Px3Gy9Jm3Ry8Ar5Bi5Vc5Nk",
- token="275c808a685a09d6e36d0253ab3765af",
- uvid="139"
- )
- # test that the correct URL is used for the HLSStream
- hlsstream.parse_variant_playlist.assert_called_with(
- ANY,
- "http://test.se/stream1"
- )
-
- def test_get_invalid_page(self):
- page_resp = Mock()
- page_resp.text = """
- var validate = "foo";
- var resourceId = "1234";
- """
- self.session.http.get.return_value = page_resp
-
- TVPlayer.bind(self.session, "test.tvplayer")
- plugin = TVPlayer("http://tvplayer.com/watch/dave")
-
- streams = plugin.streams()
-
- self.assertEqual({}, streams)
-
- # test the url is used correctly
-
- self.session.http.get.assert_called_with(
- "http://tvplayer.com/watch/dave"
- )
-
- def test_arguments(self):
- from streamlink_cli.main import setup_plugin_args
- session = Streamlink()
- parser = MagicMock()
- group = parser.add_argument_group("Plugin Options").add_argument_group("TVPlayer")
-
- session.plugins = {
- 'tvplayer': TVPlayer
- }
-
- setup_plugin_args(session, parser)
-
- self.assertSequenceEqual(
- group.add_argument.mock_calls,
- [
- call('--tvplayer-email', metavar="EMAIL", help=ANY),
- call('--tvplayer-password', metavar="PASSWORD", help=ANY)
- ],
- )
| plugins.tvplayer: 'Unable to validate result'
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Plugin issues describe broken functionality within a plugin's code base, eg. the streaming site has made breaking changes, streams don't get resolved correctly, or authentication has stopped working, etc.
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
Any URL gives
[cli][info] Found matching plugin tvplayer for URL https://tvplayer.com/uk/watch/channel4
error: Unable to validate JSON: Unable to validate key 'response': Unable to validate result: Key 'stream' not found in {'error': 'Userid header must be provided for DRM streams.'}
### Reproduction steps / Explicit stream URLs to test
https://tvplayer.com/uk/watch/channel4
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. Enter URL
### Log output
<!--
DEBUG LOG OUTPUT IS REQUIRED for a plugin issue!
INCLUDE THE ENTIRE COMMAND LINE and make sure to **remove usernames and passwords**
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
Debug log includes important details about your platform. Don't remove it.
https://streamlink.github.io/latest/cli.html#cmdoption-loglevel
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.8.7
[cli][debug] Streamlink: 2.1.1
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(0.58.0)
[cli][debug] Arguments:
[cli][debug] url=https://tvplayer.com/uk/watch/channel4
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --rtmpdump=C:\Program Files (x86)\Streamlink\rtmpdump\rtmpdump.exe
[cli][debug] --ffmpeg-ffmpeg=C:\Program Files (x86)\Streamlink\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin tvplayer for URL https://tvplayer.com/uk/watch/channel4
[plugins.tvplayer][debug] Got stream attributes: {'key': '2Pw1Eg0Px7Ey9Jm3Ly8Dr5Ci5Vc5Mk', 'uvid': '752', 'token': 'c56ea19685895a44f85ce3e05ac048c2', 'expiry': '1617196874'}
error: Unable to validate JSON: Unable to validate key 'response': Unable to validate result: Key 'stream' not found in {'error': 'Userid header must be provided for DRM streams.'}
```
### Additional comments, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Hmm, that's not good.
https://support-uk.tvplayer.com/hc/en-gb/articles/360018031719-I-can-t-watch-some-channels-on-my-browser-not-supported-
<details><summary>M3U8</summary>
```
#EXTM3U
#EXT-X-VERSION:4
## Created with Unified Streaming Platform(version=1.9.5)
#EXT-X-SESSION-KEY:METHOD=SAMPLE-AES,URI="skd://expressplay_token",KEYFORMAT="com.apple.streamingkeydelivery",KEYFORMATVERSIONS="1"
# AUDIO groups
#EXT-X-MEDIA:TYPE=AUDIO,GROUP-ID="audio-aacl-64",NAME="English",LANGUAGE="en",AUTOSELECT=YES,DEFAULT=YES,CHANNELS="2"
# variants
#EXT-X-STREAM-INF:BANDWIDTH=658000,AVERAGE-BANDWIDTH=598000,CODECS="mp4a.40.2,avc1.64001E",RESOLUTION=640x360,FRAME-RATE=25,AUDIO="audio-aacl-64",CLOSED-CAPTIONS=NONE
bitrate1-audio_track_0_0_eng=64000-video_track=500000.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=1241000,AVERAGE-BANDWIDTH=1128000,CODECS="mp4a.40.2,avc1.64001E",RESOLUTION=768x432,FRAME-RATE=25,AUDIO="audio-aacl-64",CLOSED-CAPTIONS=NONE
bitrate1-audio_track_0_0_eng=64000-video_track=1000000.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=2174000,AVERAGE-BANDWIDTH=1976000,CODECS="mp4a.40.2,avc1.64001F",RESOLUTION=896x504,FRAME-RATE=25,AUDIO="audio-aacl-64",CLOSED-CAPTIONS=NONE
bitrate1-audio_track_0_0_eng=64000-video_track=1800000.m3u8
#EXT-X-STREAM-INF:BANDWIDTH=2990000,AVERAGE-BANDWIDTH=2718000,CODECS="mp4a.40.2,avc1.64001F",RESOLUTION=1024x576,FRAME-RATE=25,AUDIO="audio-aacl-64",CLOSED-CAPTIONS=NONE
bitrate1-audio_track_0_0_eng=64000-video_track=2500000.m3u8
# keyframes
#EXT-X-I-FRAME-STREAM-INF:BANDWIDTH=73000,CODECS="avc1.64001E",RESOLUTION=640x360,URI="keyframes/bitrate1-video_track=500000.m3u8"
#EXT-X-I-FRAME-STREAM-INF:BANDWIDTH=146000,CODECS="avc1.64001E",RESOLUTION=768x432,URI="keyframes/bitrate1-video_track=1000000.m3u8"
#EXT-X-I-FRAME-STREAM-INF:BANDWIDTH=263000,CODECS="avc1.64001F",RESOLUTION=896x504,URI="keyframes/bitrate1-video_track=1800000.m3u8"
#EXT-X-I-FRAME-STREAM-INF:BANDWIDTH=365000,CODECS="avc1.64001F",RESOLUTION=1024x576,URI="keyframes/bitrate1-video_track=2500000.m3u8"
```
</details>
<details><summary>MPD</summary>
```
<?xml version="1.0" encoding="utf-8"?>
<!-- Created with Unified Streaming Platform(version=1.9.5) -->
<MPD
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="urn:mpeg:dash:schema:mpd:2011"
xsi:schemaLocation="urn:mpeg:dash:schema:mpd:2011 http://standards.iso.org/ittf/PubliclyAvailableStandards/MPEG-DASH_schema_files/DASH-MPD.xsd"
xmlns:cenc="urn:mpeg:cenc:2013"
type="dynamic"
availabilityStartTime="1970-01-01T00:00:00Z"
publishTime="2021-03-30T16:39:17.628236Z"
minimumUpdatePeriod="PT2S"
timeShiftBufferDepth="PT30S"
maxSegmentDuration="PT3S"
minBufferTime="PT10S"
profiles="urn:mpeg:dash:profile:isoff-live:2011,urn:com:dashif:dash264">
<Period
id="1"
start="PT0S">
<BaseURL>dash/</BaseURL>
<AdaptationSet
id="1"
group="1"
contentType="audio"
lang="en"
segmentAlignment="true"
audioSamplingRate="48000"
mimeType="audio/mp4"
codecs="mp4a.40.2"
startWithSAP="1">
<AudioChannelConfiguration
schemeIdUri="urn:mpeg:dash:23003:3:audio_channel_configuration:2011"
value="2">
</AudioChannelConfiguration>
<!-- Common Encryption -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
xmlns:cenc="urn:mpeg:cenc:2013"
schemeIdUri="urn:mpeg:dash:mp4protection:2011"
value="cenc"
cenc:default_KID="4963656C-616E-6469-6320-54656C657669">
</ContentProtection>
<!-- PlayReady -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
schemeIdUri="urn:uuid:9A04F079-9840-4286-AB92-E65BE0885F95"
value="MSPR 2.0">
</ContentProtection>
<!-- Widevine -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
schemeIdUri="urn:uuid:EDEF8BA9-79D6-4ACE-A3C8-27DCD51D21ED">
</ContentProtection>
<!-- Marlin -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
schemeIdUri="urn:uuid:5E629AF5-38DA-4063-8977-97FFBD9902D4">
<MarlinContentIds xmlns="urn:marlin:mas:1-0:services:schemas:mpd">
<MarlinContentId>urn:marlin:kid:4963656c616e6469632054656c657669</MarlinContentId>
</MarlinContentIds>
</ContentProtection>
<Role schemeIdUri="urn:mpeg:dash:role:2011" value="main" />
<SegmentTemplate
timescale="48000"
initialization="bitrate1-$RepresentationID$.dash"
media="bitrate1-$RepresentationID$-$Time$.dash">
<!-- 2021-03-30T16:38:35.664000Z / 1617122315 - 2021-03-30T16:39:05.658687Z -->
<SegmentTimeline>
<S t="77621871151872" d="96257" />
<S d="96256" />
<S d="95232" />
<S d="96255" />
<S d="96257" />
<S d="96256" />
<S d="95232" />
<S d="96255" />
<S d="96257" />
<S d="96256" />
<S d="95232" />
<S d="96255" />
<S d="96257" />
<S d="96256" />
<S d="95232" />
</SegmentTimeline>
</SegmentTemplate>
<Representation
id="audio_track_0_0_eng=64000"
bandwidth="64000">
</Representation>
</AdaptationSet>
<AdaptationSet
id="2"
group="2"
contentType="video"
par="16:9"
minBandwidth="500000"
maxBandwidth="2500000"
maxWidth="1024"
maxHeight="576"
segmentAlignment="true"
sar="1:1"
frameRate="25"
mimeType="video/mp4"
startWithSAP="1">
<!-- Common Encryption -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
xmlns:cenc="urn:mpeg:cenc:2013"
schemeIdUri="urn:mpeg:dash:mp4protection:2011"
value="cenc"
cenc:default_KID="4963656C-616E-6469-6320-54656C657669">
</ContentProtection>
<!-- PlayReady -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
schemeIdUri="urn:uuid:9A04F079-9840-4286-AB92-E65BE0885F95"
value="MSPR 2.0">
</ContentProtection>
<!-- Widevine -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
schemeIdUri="urn:uuid:EDEF8BA9-79D6-4ACE-A3C8-27DCD51D21ED">
</ContentProtection>
<!-- Marlin -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
schemeIdUri="urn:uuid:5E629AF5-38DA-4063-8977-97FFBD9902D4">
<MarlinContentIds xmlns="urn:marlin:mas:1-0:services:schemas:mpd">
<MarlinContentId>urn:marlin:kid:4963656c616e6469632054656c657669</MarlinContentId>
</MarlinContentIds>
</ContentProtection>
<Role schemeIdUri="urn:mpeg:dash:role:2011" value="main" />
<SegmentTemplate
timescale="600"
initialization="bitrate1-$RepresentationID$.dash"
media="bitrate1-$RepresentationID$-$Time$.dash">
<!-- 2021-03-30T16:38:37.655000Z / 1617122317 - 2021-03-30T16:39:07.655000Z -->
<SegmentTimeline>
<S t="970273390593" d="1200" r="14" />
</SegmentTimeline>
</SegmentTemplate>
<Representation
id="video_track=500000"
bandwidth="500000"
width="640"
height="360"
codecs="avc1.64001E"
scanType="progressive">
</Representation>
<Representation
id="video_track=1000000"
bandwidth="1000000"
width="768"
height="432"
codecs="avc1.64001E"
scanType="progressive">
</Representation>
<Representation
id="video_track=1800000"
bandwidth="1800000"
width="896"
height="504"
codecs="avc1.64001F"
scanType="progressive">
</Representation>
<Representation
id="video_track=2500000"
bandwidth="2500000"
width="1024"
height="576"
codecs="avc1.64001F"
scanType="progressive">
</Representation>
</AdaptationSet>
<AdaptationSet
id="3"
group="2"
contentType="video"
par="16:9"
minBandwidth="500000"
maxBandwidth="2500000"
maxWidth="1024"
maxHeight="576"
segmentAlignment="true"
sar="1:1"
frameRate="1/2"
mimeType="video/mp4"
startWithSAP="1"
maxPlayoutRate="50"
codingDependency="false">
<!-- Common Encryption -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
xmlns:cenc="urn:mpeg:cenc:2013"
schemeIdUri="urn:mpeg:dash:mp4protection:2011"
value="cenc"
cenc:default_KID="4963656C-616E-6469-6320-54656C657669">
</ContentProtection>
<!-- PlayReady -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
schemeIdUri="urn:uuid:9A04F079-9840-4286-AB92-E65BE0885F95"
value="MSPR 2.0">
</ContentProtection>
<!-- Widevine -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
schemeIdUri="urn:uuid:EDEF8BA9-79D6-4ACE-A3C8-27DCD51D21ED">
</ContentProtection>
<!-- Marlin -->
<ContentProtection
xmlns="urn:mpeg:dash:schema:mpd:2011"
schemeIdUri="urn:uuid:5E629AF5-38DA-4063-8977-97FFBD9902D4">
<MarlinContentIds xmlns="urn:marlin:mas:1-0:services:schemas:mpd">
<MarlinContentId>urn:marlin:kid:4963656c616e6469632054656c657669</MarlinContentId>
</MarlinContentIds>
</ContentProtection>
<EssentialProperty
schemeIdUri="http://dashif.org/guidelines/trickmode"
value="2">
</EssentialProperty>
<Role schemeIdUri="urn:mpeg:dash:role:2011" value="main" />
<SegmentTemplate
timescale="600"
initialization="bitrate1-$RepresentationID$.dash"
media="bitrate1-$RepresentationID$-$Time$.dash">
<!-- 2021-03-30T16:38:37.655000Z / 1617122317 - 2021-03-30T16:39:07.655000Z -->
<SegmentTimeline>
<S t="970273390593" d="1200" r="14" />
</SegmentTimeline>
</SegmentTemplate>
<Representation
id="video_track=500000(mode=trik)"
bandwidth="500000"
width="640"
height="360"
codecs="avc1.64001E"
scanType="progressive">
</Representation>
<Representation
id="video_track=1000000(mode=trik)"
bandwidth="1000000"
width="768"
height="432"
codecs="avc1.64001E"
scanType="progressive">
</Representation>
<Representation
id="video_track=1800000(mode=trik)"
bandwidth="1800000"
width="896"
height="504"
codecs="avc1.64001F"
scanType="progressive">
</Representation>
<Representation
id="video_track=2500000(mode=trik)"
bandwidth="2500000"
width="1024"
height="576"
codecs="avc1.64001F"
scanType="progressive">
</Representation>
</AdaptationSet>
</Period>
<UTCTiming
schemeIdUri="urn:mpeg:dash:utc:http-iso:2014"
value="https://time.akamai.com/?iso" />
</MPD>
```
</details>
| 2021-04-02T16:02:45 |
streamlink/streamlink | 3,677 | streamlink__streamlink-3677 | [
"3676"
] | d568f43c7150bf3d2c7b7c704e91bdf59ae653f9 | diff --git a/src/streamlink/plugins/youtube.py b/src/streamlink/plugins/youtube.py
--- a/src/streamlink/plugins/youtube.py
+++ b/src/streamlink/plugins/youtube.py
@@ -59,7 +59,8 @@
)
_ytdata_re = re.compile(r'ytInitialData\s*=\s*({.*?});', re.DOTALL)
-_url_re = re.compile(r"""(?x)https?://(?:\w+\.)?youtube\.com
+_url_re = re.compile(r"""
+ https?://(?:\w+\.)?youtube\.com
(?:
(?:
/(?:
@@ -83,7 +84,9 @@
/(?:c/)?[^/?]+/live/?$
)
)
-""")
+ |
+ https?://youtu\.be/(?P<video_id_short>[0-9A-z_-]{11})
+""", re.VERBOSE)
class YouTube(Plugin):
@@ -223,9 +226,10 @@ def _create_adaptive_streams(self, info, streams):
def _find_video_id(self, url):
m = _url_re.match(url)
- if m.group("video_id"):
+ video_id = m.group("video_id") or m.group("video_id_short")
+ if video_id:
log.debug("Video ID from URL")
- return m.group("video_id")
+ return video_id
res = self.session.http.get(url)
if urlparse(res.url).netloc == "consent.youtube.com":
| diff --git a/tests/plugins/test_youtube.py b/tests/plugins/test_youtube.py
--- a/tests/plugins/test_youtube.py
+++ b/tests/plugins/test_youtube.py
@@ -22,6 +22,7 @@ class TestPluginCanHandleUrlYouTube(PluginCanHandleUrl):
"https://www.youtube.com/user/EXAMPLE/live",
"https://www.youtube.com/v/aqz-KE-bpKQ",
"https://www.youtube.com/watch?v=aqz-KE-bpKQ",
+ "https://youtu.be/0123456789A",
]
should_not_match = [
@@ -30,6 +31,10 @@ class TestPluginCanHandleUrlYouTube(PluginCanHandleUrl):
"https://www.youtube.com/account",
"https://www.youtube.com/feed/guide_builder",
"https://www.youtube.com/t/terms",
+ "https://youtu.be",
+ "https://youtu.be/",
+ "https://youtu.be/c/CHANNEL",
+ "https://youtu.be/c/CHANNEL/live",
]
| plugins.youtube: error: No plugin can handle URL: https://youtu.be/SebJIjQgdjg
<!--
Hello. for few days, the plugin isn't working anymore
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
for few days, the plugin isn't working anymore getting streams from Youtube channels.
Error: No plugin can handle URL: https://youtu.be/SebJIjQgdjg
### Reproduction steps / Explicit stream URLs to test
1. URL: https://youtu.be/SebJIjQgdjg
### Log output
```
[cli][debug] OS: Linux-3.10.0-1160.11.1.el7.x86_64-x86_64-with-centos-7.9.2009-Core
[cli][debug] Python: 3.6.8
[cli][debug] Streamlink: 2.1.1+3.gd568f43.dirty
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(0.58.0)
[cli][debug] Arguments:
[cli][debug] url=https://youtu.be/SebJIjQgdjg
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --player=/TheCore/web/watchdog/bridge-probe.cgi
[cli][debug] --player-args=eyJmaWx0ZXJzX2NvbXBsZXgiOltdLCJvdXRwdXRzIjpbeyJmb3JtYXRzIjpbeyJ5IjoiNyIsImYiOiJ0aGVjb3JlZWxlbWVudHMifV0sInZpZGVvIjp7Im1hcCI6IjA6diIsInZmIjoiZnBzPWZwcz0yNTpyb3VuZD11cCIsImNvZGVjIjoiZW1wdHkiLCJmaWVsZF9vcmRlciI6InR0In0sImF1ZGlvcyI6W3sibWFwIjoiMDphIiwiY29kZWMiOiJlbXB0eSIsImFmIjoiYXJlc2FtcGxlPTQ4MDAwIn1dfV0sImlucHV0Ijp7InN0cmVhbWxpbmsiOm51bGwsInN0cmVhbWxpbmtfdHdpdGNoLW9hdXRoLXRva2VuIjoiIiwidXJsIjoiKyJ9LCJhbGlhcyI6IiJ9 --overrideurl {filename}
[cli][debug] --player-fifo=True
[cli][debug] --hls-segment-threads=8
[cli][debug] --ringbuffer-size=134217728
[cli][debug] --stream-segment-threads=8
[cli][debug] --ffmpeg-ffmpeg=/usr/local/enctools/bin/ffmpeg
[cli][debug] --http-no-ssl-verify=True
error: No plugin can handle URL: https://youtu.be/SebJIjQgdjg
```
| > error: No plugin can handle URL
This has nothing to do with "plugin broken for a couple of days". The plugin simply doesn't support youtube shorthand links. You need to use youtube's regular video URLs.
The plugin works fine with the latest fix on the master branch. (#3672)
Leaving the issue open for the shorthand link support. | 2021-04-04T12:19:48 |
streamlink/streamlink | 3,698 | streamlink__streamlink-3698 | [
"3589"
] | 1aba04c7d8a124f93226435fc8f0678a81577ae5 | diff --git a/src/streamlink/plugins/euronews.py b/src/streamlink/plugins/euronews.py
--- a/src/streamlink/plugins/euronews.py
+++ b/src/streamlink/plugins/euronews.py
@@ -1,61 +1,52 @@
import re
+from urllib.parse import urlparse
from streamlink.plugin import Plugin
from streamlink.plugin.api import validate
-from streamlink.stream import HLSStream, HTTPStream
-from streamlink.utils.url import update_scheme
+from streamlink.plugin.api.utils import itertags
+from streamlink.stream import HTTPStream
class Euronews(Plugin):
- _url_re = re.compile(r'(?P<scheme>https?)://(?P<subdomain>\w+)\.?euronews.com/(?P<path>live|.*)')
- _re_vod = re.compile(r'<meta\s+property="og:video"\s+content="(http.*?)"\s*/>')
- _live_api_url = "http://{0}.euronews.com/api/watchlive.json"
- _live_schema = validate.Schema({
- "url": validate.url()
- })
- _stream_api_schema = validate.Schema({
- "status": "ok",
- "primary": validate.url(),
- validate.optional("backup"): validate.url()
- })
+ _url_re = re.compile(r'https?://(?:\w+\.)*euronews\.com/')
@classmethod
def can_handle_url(cls, url):
return cls._url_re.match(url)
def _get_vod_stream(self):
- """
- Find the VOD video url
- :return: video url
- """
- res = self.session.http.get(self.url)
- video_urls = self._re_vod.findall(res.text)
- if len(video_urls):
- return dict(vod=HTTPStream(self.session, video_urls[0]))
-
- def _get_live_streams(self, match):
- """
- Get the live stream in a particular language
- :param match:
- :return:
- """
- live_url = self._live_api_url.format(match.get("subdomain"))
- live_res = self.session.http.json(self.session.http.get(live_url), schema=self._live_schema)
-
- api_url = update_scheme("{0}:///".format(match.get("scheme")), live_res["url"])
- api_res = self.session.http.json(self.session.http.get(api_url), schema=self._stream_api_schema)
-
- return HLSStream.parse_variant_playlist(self.session, api_res["primary"])
+ def find_video_url(content):
+ for elem in itertags(content, "meta"):
+ if elem.attributes.get("property") == "og:video":
+ return elem.attributes.get("content")
+
+ video_url = self.session.http.get(self.url, schema=validate.Schema(
+ validate.transform(find_video_url),
+ validate.any(None, validate.url())
+ ))
+
+ if video_url is not None:
+ return dict(vod=HTTPStream(self.session, video_url))
+
+ def _get_live_streams(self):
+ def find_video_id(content):
+ for elem in itertags(content, "div"):
+ if elem.attributes.get("id") == "pfpPlayer" and elem.attributes.get("data-google-src") is not None:
+ return elem.attributes.get("data-video-id")
+
+ video_id = self.session.http.get(self.url, schema=validate.Schema(
+ validate.transform(find_video_id),
+ validate.any(None, str)
+ ))
+
+ if video_id is not None:
+ return self.session.streams(f"https://www.youtube.com/watch?v={video_id}")
def _get_streams(self):
- """
- Find the streams for euronews
- :return:
- """
- match = self._url_re.match(self.url).groupdict()
-
- if match.get("path") == "live":
- return self._get_live_streams(match)
+ parsed = urlparse(self.url)
+
+ if parsed.path == "/live":
+ return self._get_live_streams()
else:
return self._get_vod_stream()
| plugins.euronews: the stream replaced with youtube
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Plugin issues describe broken functionality within a plugin's code base, eg. the streaming site has made breaking changes, streams don't get resolved correctly, or authentication has stopped working, etc.
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
The plugin doesn't work now as the stream on https://www.euronews.com/live is replaced with youtube embedded https://youtu.be/sPgqEHsONK8 . I don't know is it a permanent or a temporary decision. There are cases of moving back. So I don't think the plugin should be removed but rather suspended in some way or temporarily disabled.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
```
streamlink euronews.com/live
```
### Log output
<!--
DEBUG LOG OUTPUT IS REQUIRED for a plugin issue!
INCLUDE THE ENTIRE COMMAND LINE and make sure to **remove usernames and passwords**
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
Debug log includes important details about your platform. Don't remove it.
https://streamlink.github.io/latest/cli.html#cmdoption-loglevel
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
[cli][info] Found matching plugin euronews for URL euronews.com/live
error: Unable to validate JSON: Unable to validate key 'url': Type of None should be 'str' but is 'NoneType'
```
### Additional comments, etc.
You can watch this TV channel on youtube or with streamlink:
```
streamlink youtube.com/EuronewsUSA/live
```
It exists for a long time and the only regret is that resolution reduced from 1080p to 720p.
| Only the live stream has moved to YT, VODs are still hosted on their site, which means the plugin can't be removed. | 2021-04-20T17:35:12 |
|
streamlink/streamlink | 3,725 | streamlink__streamlink-3725 | [
"3726"
] | 28844859aa2cce1e1575991f5bf8aee6f1fbe9b2 | diff --git a/src/streamlink/plugins/bbciplayer.py b/src/streamlink/plugins/bbciplayer.py
--- a/src/streamlink/plugins/bbciplayer.py
+++ b/src/streamlink/plugins/bbciplayer.py
@@ -28,7 +28,7 @@ class BBCiPlayer(Plugin):
""", re.VERBOSE)
mediator_re = re.compile(
r'window\.__IPLAYER_REDUX_STATE__\s*=\s*({.*?});', re.DOTALL)
- state_re = re.compile(r'window.__IPLAYER_REDUX_STATE__\s*=\s*({.*});')
+ state_re = re.compile(r'window.__IPLAYER_REDUX_STATE__\s*=\s*({.*?});</script>')
account_locals_re = re.compile(r'window.bbcAccount.locals\s*=\s*({.*?});')
hash = base64.b64decode(b"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==")
api_url = "https://open.live.bbc.co.uk/mediaselector/6/select/version/2.0/mediaset/" \
| plugins.bbciplayer: Not working
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Plugin issues describe broken functionality within a plugin's code base, eg. the streaming site has made breaking changes, streams don't get resolved correctly, or authentication has stopped working, etc.
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [ x] This is a plugin issue and I have read the contribution guidelines.
- [ x] I am using the latest development version from the master branch.
### Description
If I try to run the plugin, for example with streamlink -p "C:\ProgramData\chocolatey\lib\mpv.install\tools\mpv" --bbciplayer-username="*USERNAME HERE*" --bbciplayer-password="*PASSWORD HERE*" bbc.co.uk/iplayer/live/bbcparliament 288p_dash, I receive the following:
```
error: Unable to parse JSON: Extra data: line 1 column 23991 (char 23990) ('{"navigation":{"items":[{"id":"cha ...)
```
### Reproduction steps / Explicit stream URLs to test
I updated Streamlink to 2.1.0 to try and resolve, but that didn't work.
1. Running using the command posted above
### Additional comments, etc.
It seems to error here: https://github.com/streamlink/streamlink/blob/master/src/streamlink/plugins/bbciplayer.py#L114
I am using Windows 10
I presume it may be an issue with the JSON being returned by BBC iPlayer, as there is a semicolon after a closing bracket?
| 2021-05-14T20:09:35 |
||
streamlink/streamlink | 3,732 | streamlink__streamlink-3732 | [
"3724"
] | 034173da30bd43353de0654a0595d606eac0446c | diff --git a/src/streamlink/plugins/youtube.py b/src/streamlink/plugins/youtube.py
--- a/src/streamlink/plugins/youtube.py
+++ b/src/streamlink/plugins/youtube.py
@@ -286,7 +286,7 @@ def _get_stream_info(self, video_id):
info_parsed = None
for _params in (_params_1, _params_2, _params_3):
count += 1
- params = {"video_id": video_id}
+ params = {"video_id": video_id, "html5": "1"}
params.update(_params)
res = self.session.http.get(self._video_info_url, params=params)
| plugins.youtube Receiving "Unable to open URL: https://youtube.com/get_video_info" when trying to do --retry-streams after a few retry attempts.
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Plugin issues describe broken functionality within a plugin's code base, eg. the streaming site has made breaking changes, streams don't get resolved correctly, or authentication has stopped working, etc.
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
When trying to use the --retry-streams options on a YouTube livestream that has not begun yet, shortly after running it with either 1-20 seconds between when it checks, it will start outputting
`[cli][error] Unable to open URL: https://youtube.com/get_video_info (404 Client Error: Not Found for url: https://www.youtube.com/get_video_info?video_id=yZ7CWjuMCe8&eurl=https%3A%2F%2Fyoutube.googleapis.com%2Fv%2FyZ7CWjuMCe8)`
It used to not do this at all until recently about 2-3 days ago on streamlink 2.0.0 and when it did, I tried updating to the current development build but it is still giving me the same thing.
So I am unable to setup streamlink to record for a stream that I wouldn't be around for since it would give that error even after the stream would start.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. input `streamlink --retry-streams <#> -o <name.ts> <link of a stream that is planned to go live later>`
### Log output
<!--
DEBUG LOG OUTPUT IS REQUIRED for a plugin issue!
INCLUDE THE ENTIRE COMMAND LINE and make sure to **remove usernames and passwords**
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
Debug log includes important details about your platform. Don't remove it.
https://streamlink.github.io/latest/cli.html#cmdoption-loglevel
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.8.7
[cli][debug] Streamlink: 2.1.1+14.g2884485
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(0.59.0)
[cli][debug] Arguments:
[cli][debug] --loglevel=debug
[cli][debug] --rtmpdump=C:\Program Files (x86)\Streamlink\rtmpdump\rtmpdump.exe
[cli][debug] --ffmpeg-ffmpeg=C:\Program Files (x86)\Streamlink\ffmpeg\ffmpeg.exe
```
| > This appears to be a Youtube issue, you can get a 404 on get_video_info if you try to access it too quickly on any URL, not just planned streams or live streams. It appears to be fine if you wait 1 second between requests to get_video_info though.
I've tried 2 seconds and 15 seconds and it still does that. It seems to not do it when I try for 30 seconds, but otherwise it doesn't seem to be possible to do anywhere from 1-15 or 20 seconds for the past 4 days.
So it's just YouTube's side that's causing it to not work with such short intervals?
Is there anything that can be done about it, or something that just can't be worked around?
Edit: I guess the llyyr individual retracted their message...?
I use 5 minutes with --retry-streams and I still get the error sometimes. I've also gotten it when the stream is already live and I've included --retry-streams in the command. This is the only request I make to youtube at that time, its not like I have a lot of streams waiting to go live when the error appears. It used to work fine before so I don't know what happened.
There is some kind of YouTube DDOS protection that kicks in sometimes. There is nothing you can do to stop it. It is on the YouTube server side. All you can do is wait a few days until your IP address is unblocked. It will clear eventually on its own. I have experienced this as well.
Sent from my iPhone
On May 16, 2021, at 1:07 PM, jenlunds ***@***.***> wrote:
I use 5 minutes with --retry-streams and I still get the error sometimes. I've also gotten it when the stream is already live and I've included --retry-streams in the command. This is the only request I make to youtube at that time, its not like I have a lot of streams waiting to go live when the error appears. It used to work fine before so I don't know what happened.
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub<https://github.com/streamlink/streamlink/issues/3724#issuecomment-841845613>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AR6YJPNH4RBUDAJLDWYOPPLTN73UFANCNFSM444XOVKQ>.
It feels too inconsistent to be some kind of DDoS protection.
Seems more like some of their servers are a little screwy from some update that might have been pushed around a week ago. It's affected the RSS of someone I know as well, giving him a lot of 404s recently.
@xanek, does it happen for you 100% of the time, most of the time, occasionally, etc.?
I hit it surprisingly often with streamlink compared to one of my own scripts, and when I was testing with curl. More interesting is that if it gets hit, it continues to be hit for that running instance of streamlink. Stopping and immediately restarting will usually work, even if there's <2 seconds between the failed request of the old instance, and the request from the new instance. I imagine this has to do with requests keeping the connection open, and thus whatever server the youtube proxies forwarded you to continues to be used, so if it is a bad one, it just will not work. I've set `--retry-streams 60` for one test to see if that would be long enough for requests to make a completely new connection, but it seems not.
I've opted for pulling the player_response object from a `script` tag in the watch page as a fallback for my script, disgusting as that is. It's simple enough though, as the script tag that declares it is used solely for the declaration, so there little that needs to be stripped before using it. For now.
> @xanek, does it happen for you 100% of the time, most of the time, occasionally, etc.?
This has been happening ever since a few days ago.
It never happened prior to that and I've been using streamlink for more than half a year already.
This has the same characteristics of what I have experienced. Like I said, it’s definitely some kind of DDOS protection against this URL. Your IP is on a banned list. It will go away on its own after 3/4/5 days or something. There is nothing at all you can do about it as it’s on the server side.
You can tell it’s not a streamlink issue because when this is occurring, the youtube-dl application also exhibits the same issue.
Sent from my iPhone
On May 16, 2021, at 9:26 PM, xanek ***@***.***> wrote:
@xanek<https://github.com/xanek>, does it happen for you 100% of the time, most of the time, occasionally, etc.?
This has been happening ever since a few days ago.
It never happened prior to that and I've been using streamlink for more than half a year already.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub<https://github.com/streamlink/streamlink/issues/3724#issuecomment-841917445>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AR6YJPIIOZZJL7GHMAFS77TTOBWELANCNFSM444XOVKQ>.
> This has the same characteristics of what I have experienced. Like I said, it’s definitely some kind of DDOS protection against this URL. Your IP is on a banned list. It will go away on its own after 3/4/5 days or something. There is nothing at all you can do about it as it’s on the server side. You can tell it’s not a streamlink issue because when this is occurring, the youtube-dl application also exhibits the same issue.
Wouldn't it completely lock me out from using streamlink in general then?
I am able to still use it, just not able to have it retry constantly.
It is not necessarily 100% consistent…so yes this makes sense.
Sent from my iPhone
On May 16, 2021, at 9:31 PM, xanek ***@***.***> wrote:
This has the same characteristics of what I have experienced. Like I said, it’s definitely some kind of DDOS protection against this URL. Your IP is on a banned list. It will go away on its own after 3/4/5 days or something. There is nothing at all you can do about it as it’s on the server side. You can tell it’s not a streamlink issue because when this is occurring, the youtube-dl application also exhibits the same issue.
Wouldn't it completely lock me out from using streamlink in general then?
I am able to still use it, just not able to have it retry constantly.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub<https://github.com/streamlink/streamlink/issues/3724#issuecomment-841918799>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AR6YJPN3VJGERQIGCC3BETTTOBWYZANCNFSM444XOVKQ>.
> It is not necessarily 100% consistent
That would make for some pointless DDoS protection, I must say. Not to mention, at least in my case, it started happening after using streamlink for the first time in almost a week, and I was not exactly spamming downloads with other tools in that time either.
You are correct it's not a streamlink issue though, at least it's not the cause. But if it ends up that this stays an issue for a long while, streamlink devs would probably want to try to figure out some way to mitigate it.
Well the logic of their DDOS protection may indeed be faulty, but unless you are assigned a static IP address from your ISP you have no idea what the person who has your IP before you did was doing.
I have had this happen to me on at least 3 occasions. There is to way to tell what triggered it and there is no way to get around it, except to wait for it to clear out. Trust me.
Sent from my iPhone
On May 16, 2021, at 9:52 PM, Kethsar ***@***.***> wrote:
It is not necessarily 100% consistent
That would make for some pointless DDoS protection, I must say. Not to mention, at least in my case, it started happening after using streamlink for the first time in almost a week, and I was not exactly spamming downloads with other tools in that time either.
You are correct it's not a streamlink issue though, at least it's not the cause. But if it ends up that this stays an issue for a long while, streamlink would probably want to try to figure out some way to mitigate it.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub<https://github.com/streamlink/streamlink/issues/3724#issuecomment-841924154>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AR6YJPM3IPIFBGLGGESVSBDTOBZG5ANCNFSM444XOVKQ>.
> It is not necessarily 100% consistent…so yes this makes sense.
Well I remember the last time I had something similar to where I couldn't even use streamlink at all because of being banned, that I had to use a VPN to get around it.
But even with a VPN right now it is giving me the same message.
is it really DDoS? i tried with youtube-dl and it parse different list of m3u8 contents for an ongoing livestream video.
it's no longer listing webm, mp4 or audio and video only formats.
That is a livestream you checked. Livestreams only have VP9 (webm) if they are using Low Latency mode. Ultra-Low Latency and Normal Latency do not have VP9 as an option. That stream is Normal latency.
Even if it were Low Latency mode, youtube-dl and I think streamlink both grab from the HLS stream playlists, which youtube only provides H264+AAC combined, and thus no audio-only or VP9.
Youtube has again changed the way the stream info is presented. Even the (slightly older) VLC v3.0.9.2 now barfs on most youtube urls.
So would we have to wait for a new update with streamlink or is this something that can't be workaround?
Mpc-be also has issues with the built in parser for youtube... https://sourceforge.net/p/mpcbe/tickets/819/ | 2021-05-19T12:41:55 |
|
streamlink/streamlink | 3,742 | streamlink__streamlink-3742 | [
"3741"
] | f06ae788cef28838c214069267b2226508c67f58 | diff --git a/src/streamlink/plugins/rtpplay.py b/src/streamlink/plugins/rtpplay.py
--- a/src/streamlink/plugins/rtpplay.py
+++ b/src/streamlink/plugins/rtpplay.py
@@ -1,4 +1,5 @@
import re
+from base64 import b64decode
from urllib.parse import unquote
from streamlink.plugin import Plugin
@@ -10,22 +11,38 @@
class RTPPlay(Plugin):
_url_re = re.compile(r"https?://www\.rtp\.pt/play/")
_m3u8_re = re.compile(r"""
- hls:\s*(?:(["'])(?P<string>[^"']+)\1
- |
- decodeURIComponent\((?P<obfuscated>\[.*?])\.join\()
+ hls\s*:\s*(?:
+ (["'])(?P<string>[^"']*)\1
+ |
+ decodeURIComponent\s*\((?P<obfuscated>\[.*?])\.join\(
+ |
+ atob\s*\(\s*decodeURIComponent\s*\((?P<obfuscated_b64>\[.*?])\.join\(
+ )
""", re.VERBOSE)
_schema_hls = validate.Schema(
- validate.transform(_m3u8_re.search),
+ validate.transform(lambda text: next(reversed(list(RTPPlay._m3u8_re.finditer(text))), None)),
validate.any(
None,
validate.all(
validate.get("string"),
- validate.url()
+ str,
+ validate.any(
+ validate.length(0),
+ validate.url()
+ )
),
validate.all(
validate.get("obfuscated"),
+ str,
+ validate.transform(lambda arr: unquote("".join(parse_json(arr)))),
+ validate.url()
+ ),
+ validate.all(
+ validate.get("obfuscated_b64"),
+ str,
validate.transform(lambda arr: unquote("".join(parse_json(arr)))),
+ validate.transform(lambda b64: b64decode(b64).decode("utf-8")),
validate.url()
)
)
@@ -39,9 +56,8 @@ def _get_streams(self):
self.session.http.headers.update({"User-Agent": useragents.CHROME,
"Referer": self.url})
hls_url = self.session.http.get(self.url, schema=self._schema_hls)
- if not hls_url:
- return
- return HLSStream.parse_variant_playlist(self.session, hls_url)
+ if hls_url:
+ return HLSStream.parse_variant_playlist(self.session, hls_url)
__plugin__ = RTPPlay
| diff --git a/tests/plugins/test_rtpplay.py b/tests/plugins/test_rtpplay.py
--- a/tests/plugins/test_rtpplay.py
+++ b/tests/plugins/test_rtpplay.py
@@ -1,5 +1,12 @@
+import unittest
+
+import requests_mock
+
+from streamlink import Streamlink
from streamlink.plugins.rtpplay import RTPPlay
+from streamlink.stream import HLSStream
from tests.plugins import PluginCanHandleUrl
+from tests.resources import text
class TestPluginCanHandleUrlRTPPlay(PluginCanHandleUrl):
@@ -18,3 +25,54 @@ class TestPluginCanHandleUrlRTPPlay(PluginCanHandleUrl):
'https://media.rtp.pt/',
'http://media.rtp.pt/',
]
+
+
+class TestRTPPlay(unittest.TestCase):
+ # all invalid HLS URLs at the beginning need to be ignored ("https://invalid")
+ _content_pre = """
+ /* var player1 = new RTPPlayer({
+ file: {hls : atob( decodeURIComponent(["aHR0c", "HM6Ly", "9pbnZ", "hbGlk"].join("") ) ), dash : foo() } }); */
+ var f = {hls : atob( decodeURIComponent(["aHR0c", "HM6Ly", "9pbnZ", "hbGlk"].join("") ) ), dash: foo() };
+ """
+ # invalid resources sometimes have an empty string as HLS URL
+ _content_invalid = """
+ var f = {hls : ""};
+ """
+ # the actual HLS URL always comes last ("https://valid")
+ _content_valid = """
+ var f = {hls : decodeURIComponent(["https%3","A%2F%2F", "valid"].join("") ), dash: foo() };
+ """
+ _content_valid_b64 = """
+ var f = {hls : atob( decodeURIComponent(["aHR0c", "HM6Ly", "92YWx", "pZA=="].join("") ) ), dash: foo() };
+ """
+
+ @property
+ def playlist(self):
+ with text("hls/test_master.m3u8") as pl:
+ return pl.read()
+
+ def subject(self, url, response):
+ with requests_mock.Mocker() as mock:
+ mock.get(url=url, text=response)
+ mock.get("https://valid", text=self.playlist)
+ mock.get("https://invalid", exc=AssertionError)
+ session = Streamlink()
+ RTPPlay.bind(session, "tests.plugins.test_rtpplay")
+ plugin = RTPPlay(url)
+ return plugin._get_streams()
+
+ def test_empty(self):
+ streams = self.subject("https://www.rtp.pt/play/id/title", "")
+ self.assertEqual(streams, None)
+
+ def test_invalid(self):
+ streams = self.subject("https://www.rtp.pt/play/id/title", self._content_pre + self._content_invalid)
+ self.assertEqual(streams, None)
+
+ def test_valid(self):
+ streams = self.subject("https://www.rtp.pt/play/id/title", self._content_pre + self._content_valid)
+ self.assertIsInstance(next(iter(streams.values())), HLSStream)
+
+ def test_valid_b64(self):
+ streams = self.subject("https://www.rtp.pt/play/id/title", self._content_pre + self._content_valid_b64)
+ self.assertIsInstance(next(iter(streams.values())), HLSStream)
| plugins.rtpplay: Site obfuscated the download URL
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Plugin issues describe broken functionality within a plugin's code base, eg. the streaming site has made breaking changes, streams don't get resolved correctly, or authentication has stopped working, etc.
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [ ] I am using the latest development version from the master branch.
### Description
The RTP site now obfuscating the URL with some function calls. *sigh*
Interpreting the JS leads to working URLs:
```javascript
var f = {hls : atob( decodeURIComponent(["aHR0cHM6Ly","9zdHJlYW1p","bmctdm9kLn","J0cC5wdC9o","bHMvbmFzMi","5zaGFyZS9o","MjY0LzUxMn","gzODQvcDg1","MDEvcDg1MD","FfMV8yMDIx","MDIxMjU1MD","YubXA0L21h","c3Rlci5tM3","U4"].join(""))), dash : atob( decodeURIComponent(["aHR0cHM","6Ly9zdH","JlYW1pb","mctdm9k","LnJ0cC5","wdC9kYX","NoL25hc","zIuc2hh","cmUvaDI","2NC81MT","J4Mzg0L","3A4NTAx","L3A4NTA","xXzFfMj","AyMTAyM","TI1NTA2","Lm1wNC9","tYW5pZm","VzdC5tc","GQ%3D"].join(""))) }
```
```
dash: "https://streaming-vod.rtp.pt/dash/nas2.share/h264/512x384/p8501/p8501_1_202102125506.mp4/manifest.mpd"
hls: "https://streaming-vod.rtp.pt/hls/nas2.share/h264/512x384/p8501/p8501_1_202102125506.mp4/master.m3u8"
```
```javascript
var x1 = decodeURIComponent(["https://cdn-ondemand.rtp.pt/nas2.share/h264/512x384/p5449/preview/p5449_1_201901231263_videoprv.mp4"].join(""));
if ($("#player_prog").length > 0) {
/* var player1 = new RTPPlayer({
file: {hls : atob( decodeURIComponent(["aHR0cHM","6Ly9zdH","JlYW1pb","mctb25k","ZW1hbmQ","ucnRwLn","B0L25hc","zIuc2hh","cmUvaDI","2NC81MT","J4Mzg0L","3AxNTI1","L3AxNTI","1XzFfMj","AyMTA0M","jA1OTk2","L21hc3R","lcnMubT","N1OA%3D","%3D"].join(""))), dash : atob( decodeURIComponent(["aHR0cHM6Ly","9zdHJlYW1p","bmctb25kZW","1hbmQucnRw","LnB0L25hcz","Iuc2hhcmUv","aDI2NC81MT","J4Mzg0L3Ax","NTI1L3AxNT","I1XzFfMjAy","MTA0MjA1OT","k2L21hc3Rl","cnMubXBk"].join(""))) },
seekBarThumbnailsLoc: '//cdn-images.rtp.pt/multimedia/screenshots/p1525/preview/p1525_1_202104205996_preview.vtt', }); */
var f = {hls : atob( decodeURIComponent(["aHR0cH","M6Ly9z","dHJlYW","1pbmct","dm9kLn","J0cC5w","dC9kcm","0tZnBz","L25hcz","Iuc2hh","cmUvaD","I2NC81","MTJ4Mz","g0L3Ax","NTI1L3","AxNTI1","XzFfMj","AyMTA1","MTA2MT","E4Lm1w","NC9tYX","N0ZXIu","bTN1OA","%3D%3D"].join(""))), dash : atob( decodeURIComponent(["aHR0cH","M6Ly9z","dHJlYW","1pbmct","dm9kLn","J0cC5w","dC9kcm","0tZGFz","aC9uYX","MyLnNo","YXJlL2","gyNjQv","NTEyeD","M4NC9w","MTUyNS","9wMTUy","NV8xXz","IwMjEw","NTEwNj","ExOC5t","cDQvbW","FuaWZl","c3QubX","Bk"].join(""))) };
var f = {hls : atob( decodeURIComponent(["aHR0cHM6Ly","9zdHJlYW1p","bmctdm9kLn","J0cC5wdC9o","bHMvbmFzMi","5zaGFyZS9o","MjY0LzUxMn","gzODQvcDg1","MDEvcDg1MD","FfMV8yMDIx","MDIxMjU1MD","YubXA0L21h","c3Rlci5tM3","U4"].join(""))), dash : atob( decodeURIComponent(["aHR0cHM","6Ly9zdH","JlYW1pb","mctdm9k","LnJ0cC5","wdC9kYX","NoL25hc","zIuc2hh","cmUvaDI","2NC81MT","J4Mzg0L","3A4NTAx","L3A4NTA","xXzFfMj","AyMTAyM","TI1NTA2","Lm1wNC9","tYW5pZm","VzdC5tc","GQ%3D"].join(""))) };
var player1 = new RTPPlayer({
id: "player_prog",
fileKey: atob( decodeURIComponent(["L25hczIuc2","hhcmUvaDI2","NC81MTJ4Mz","g0L3A4NTAx","L3A4NTAxXz","FfMjAyMTAy","MTI1NTA2Lm","1wNA%3D%3D"].join(""))),
file: f,
seekBarThumbnailsLoc: '//cdn-images.rtp.pt/multimedia/screenshots/p8501/preview/p8501_1_202102125506_preview.vtt',
adsType: 'dfp',
subadUnit: 'Play',
streamType:"ondemand",
googleCast: true,
drm : false, //extraSettings: { googleCastReceiverAppId:'1A6F2224', skin:'s3', skinAccentColor: '0073FF'},
extraSettings: { googleCastReceiverAppId:'1A6F2224'},
mediaType: "video",
poster: "https://cdn-images.rtp.pt/EPG/imagens/26039_34268_59543.jpg?v=3&w=1170",
modules: [{ name: 'RTPFavIcon', bucket: '1' }],
metadata: {
id: "904282"
}
});
var userPreferences = RTPPLAY.parentalProtection.loadActivatedUserServices(['continue', 'favorite']);
var startPlayer = function() {
if (userPreferences.continue.isActive){
TelemetryRTPPlay.start({player_id:"player_prog",
player_obj: player1,
telemetry_name: "RTPPlay_telemetry_",
key: "524190",
asset_id : "904282",
content_type : "video",
serverTime : 1621633943000,
telemetry_obj : {asset_id : "904282",
content_type : "video",
content_title : "Cidade Despida",
content_episode : "1",
content_date: "2021-01-12",
content_img : "https://cdn-images.rtp.pt/EPG/imagens/26039_34268_59543.jpg?v=3&w=300",
content_url : "https://www.rtp.pt/play/p8501/e524190/cidade-despida",
content_episode_part: "0",
content_episode_lifetime : "2999-12-31",
content_duration : "2830",
content_duration_complete : "2829" ,
content_duration_before : "" }
});
}
```
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. ...
2. ...
3. ...
### Log output
```
$ streamlink -l trace https://www.rtp.pt/play/p8501/cidade-despida --output s1e1.mp4
[22:53:38.592806][cli][debug] OS: Linux-5.12.4-arch1-2-x86_64-with-glibc2.33
[22:53:38.593056][cli][debug] Python: 3.9.5
[22:53:38.593124][cli][debug] Streamlink: 2.1.1
[22:53:38.593220][cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(0.59.0)
[22:53:38.594135][cli][debug] Arguments:
[22:53:38.594264][cli][debug] url=https://www.rtp.pt/play/p8501/cidade-despida
[22:53:38.594370][cli][debug] --loglevel=trace
[22:53:38.594465][cli][debug] --output=s1e1.mp4
[22:53:38.594725][cli][info] Found matching plugin rtpplay for URL https://www.rtp.pt/play/p8501/cidade-despida
error: No playable streams found on this URL: https://www.rtp.pt/play/p8501/cidade-despida
```
### Additional comments, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2021-05-22T07:04:13 |
|
streamlink/streamlink | 3,757 | streamlink__streamlink-3757 | [
"3210"
] | ff95ec387441909df673a14b46f7c5da107d9a9b | diff --git a/src/streamlink/plugins/mediaklikk.py b/src/streamlink/plugins/mediaklikk.py
--- a/src/streamlink/plugins/mediaklikk.py
+++ b/src/streamlink/plugins/mediaklikk.py
@@ -12,7 +12,7 @@
class Mediaklikk(Plugin):
PLAYER_URL = "https://player.mediaklikk.hu/playernew/player.php"
- _url_re = re.compile(r"https?://(?:www\.)?mediaklikk\.hu/[\w\-]+\-elo/?")
+ _url_re = re.compile(r"https?://(?:www\.)?(?:mediaklikk|m4sport)\.hu/(?:[\w\-]+\-)?elo/?")
_id_re = re.compile(r'"streamId":"(\w+)"')
_file_re = re.compile(r'"file":\s*"([\w\./\\=:\-\?]+)"')
| diff --git a/tests/plugins/test_mediaklikk.py b/tests/plugins/test_mediaklikk.py
--- a/tests/plugins/test_mediaklikk.py
+++ b/tests/plugins/test_mediaklikk.py
@@ -10,8 +10,12 @@ class TestPluginCanHandleUrlMediaklikk(PluginCanHandleUrl):
'https://www.mediaklikk.hu/duna-world-radio-elo',
'https://www.mediaklikk.hu/m1-elo',
'https://www.mediaklikk.hu/m2-elo',
+ 'https://m4sport.hu/elo/',
+ 'https://m4sport.hu/elo/?channelId=m4sport+',
+ 'https://m4sport.hu/elo/?showchannel=mtv4plus',
]
should_not_match = [
'https://www.mediaklikk.hu',
+ 'https://m4sport.hu',
]
| Twitch.tv embedded ads (last update: 2021-11-21)
Since we're seeing reports of new changes on Twitch regarding the embedded ads situation (once again), I feel the need of opening a new thread before it gets too messy again with the issues on the issue tracker here. I will update this post once we've got new informations, so that the current state can be found and read easily without digging through issue threads.
----
### Edit 15 (November 2022)
See the new thread:
https://github.com/streamlink/streamlink/issues/4949
### Edit 14 (2021-11-21)
Updated the stream access token request parameter again to reduce the number of preroll and midroll ads. See #4194
[Published in the 3.0.2 release](https://github.com/streamlink/streamlink/releases/tag/3.0.2) (2021-11-25)
### Edit 13 (2021-10-19)
Twitch has made new changes and embedded ads are back again and don't get filtered out correctly. See #4106
### Edit 12 (2021-10-10)
New device ID headers implemented for preventing ads: #4086
### Edit 11 (2021-06-21)
Re-pinning the thread, as it's still relevant.
**If you don't want to see ads on Twitch, or if your player can't handle the stream's discontinuity between the ads and regular content and then crashes (eg. VLC), then set the `--twitch-disable-ads` parameter, which will filter out ads and pre-roll ads and will pause the stream output during that time.**
**CLI documentation:**
https://streamlink.github.io/cli.html#twitch
**Streamlink Twitch GUI**
https://github.com/streamlink/streamlink-twitch-gui/wiki/Embedded-ads
<details>
<summary>Issue changelog</summary>
### Edit 10 (2020-12-23)
Streamlink `2.0.0` has been released yesterday with the workaround from edit 9, but it doesn't seem to be working reliably anymore. Ads can still be filtered out via `--twitch-disable-ads`.
### Edit 9 (2020-11-28)
Added a new access token request workaround in #3373 which again prevents ads from being embedded into the stream. (additional note: the access token requests have been moved to the GQL API already in #3344).
Like usual when there's a new change, you can install Streamlink from the master branch, or wait for the next nightly installer to be built if you're on Windows, or wait for the next release.
### Edit 8 (2020-11-05)
The ad prevention request parameter workaround has stopped working again, as predicted, and the ad "placeholder" screen seems to have been replaced with real ads now :boom:
Filtering out ads via `--twitch-disable-ads` is however still working.
### Edit 7 (2020-10-28)
A new ad prevention has been discovered (#3301) and has been merged into `master` on 2020-10-28.
If you don't want to wait until the next release (`2.0.0` - release date unknown), you can [install Streamlink from the master branch](https://streamlink.github.io/install.html#pypi-package-and-source-code), or apply the small change yourself (cf978c5), or as a Windows user, [wait for the next nightly build of the installer (>= 2020-10-29)](https://github.com/streamlink/streamlink/actions?query=event%3Aschedule+is%3Asuccess+branch%3Amaster).
If you're using the Twitch GUI, you will have to use a debug / pre-release due to other breaking Streamlink changes in regards to the upcoming `2.0.0` release:
streamlink/streamlink-twitch-gui#757
### Edit 6 (2020-10-18)
[`1.7.0`](https://github.com/streamlink/streamlink/releases) has been released on 2020-10-18.
### Edit 5 (2020-10-03)
#3220 has been merged as well, which should prevent the embedded ads again (for now (edit: broken again)).
### Edit 4 (2020-10-03)
#3213 with the new ad filtering implementation has been merged into the master branch. You can install Streamlink from there, [as described in the docs](https://streamlink.github.io/install.html#pypi-package-and-source-code), or if you're on Windows without a Python environment, wait until the [2020-10-04 nightly installer](https://github.com/streamlink/streamlink/actions?query=event%3Aschedule+is%3Asuccess+branch%3Amaster) has been built.
### Edit 3 (2020-10-03)
Removing the `platform=_` parameter again from the stream access token API request once again results in no ads being embedded into the stream. This is a game of cat and mouse at this point, which is ridiculous.
https://github.com/streamlink/streamlink/issues/3210#issuecomment-703022351
### Edit 2 (2020-09-30)
I've opened a pull request (see #3213) with the new filtering implementation. Feedback is highly appreciated, since I still don't get any ads myself and therefore can't verify it.
If you want to test this and give feedback, install it via python-pip like this (more details [in the install docs](https://streamlink.github.io/install.html#pypi-package-and-source-code)), but beware that there will be more changes on that branch. Alternatively, install it in a virtual-env, so that it doesn't interfere with your main install.
```bash
pip install --user 'git+https://github.com/bastimeyer/streamlink.git@plugins/twitch/embedded-ads-2020-09-29'
```
### Edit 1 (2020-09-29)
Twitch has changed the annotated titles of the ads, and Streamlink doesn't expect this and thus can't filter them out. The issue can be fixed with a trivial change ([see post below](https://github.com/streamlink/streamlink/issues/3210#issuecomment-700949045)), but this may introduce other issues in the future. A better filtering approach is being worked on. This trivial change won't prevent embedded ads from happening and only fixes the filtering.
</details>
----
<details>
<summary>Issue triage (old stuff)</summary>
As you can read in the [changelog](https://github.com/streamlink/streamlink/blob/master/CHANGELOG.md), we have recently (re-)added changes in the latest release (1.6.0) to prevent the embedded ads on Twitch from happening. This workaround basically sets the `platform=_` request parameter when acquiring the stream URL and that made Twitch not embed pre-roll and mid-stream ads into the HLS stream. I've already said in #3173 that this probably won't last long, just like last time we had it implemented, and now here we are and it's broken again after Twitch has pushed another set of changes.
Another issue seems to be that the ads themselves are now annotated differently and this breaks the current ad-filtering implementation, which exists in addition to the workaround request parameter. We have gone through multiple iterations here as well, because the way ads were embedded has changed quite a lot.
**It appears though that Twitch is only rolling out new embedded ads in certain regions right now**, because it's not reproducible for me at the time (with a German IP address).
</details>
----
<details>
<summary>Checking the HLS playlist content of the new ads (DONE, thanks for the posts)</summary>
~~Because of that, I'm interested in the content of HLS playlists with embedded ads, so we can debug this. Please share a link to a [Github gist](https://gist.github.com/) post with the playlist content. You can check this by running~~
```bash
curl -s "$(streamlink --stream-url twitch.tv/CHANNEL best)"
```
The content should **NOT** look like this (notice the `EXTINF` tags and their "live" attribute):
```m3u
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:6
#EXT-X-MEDIA-SEQUENCE:1234
#EXT-X-TWITCH-ELAPSED-SECS:1337.000
#EXT-X-TWITCH-TOTAL-SECS:1338.000
#EXT-X-DATERANGE:ID="source-1234567890",CLASS="twitch-stream-source",START-DATE="2020-09-29T00:00:00.000Z",END-ON-NEXT=YES,X-TV-TWITCH-STREAM-SOURCE="live"
#EXT-X-DATERANGE:ID="trigger-1234567890",CLASS="twitch-trigger",START-DATE="2020-09-29T00:00:00.000Z",END-ON-NEXT=YES,X-TV-TWITCH-TRIGGER-URL="https://video-weaver.XXXXX.hls.ttvnw.net/trigger/some-long-base64-string"
#EXT-X-PROGRAM-DATE-TIME:2020-09-29T00:00:00.000Z
#EXTINF:2.000,live
https://video-edge-XXXXXX.XXXXX.abs.hls.ttvnw.net/v1/segment/some-long-base64-string.ts
[... list of remaining segments and program date metadata]
#EXT-X-TWITCH-PREFETCH:https://video-edge-XXXXXX.XXXXX.abs.hls.ttvnw.net/v1/segment/some-long-base64-string.ts
#EXT-X-TWITCH-PREFETCH:https://video-edge-XXXXXX.XXXXX.abs.hls.ttvnw.net/v1/segment/some-long-base64-string.ts
```
</summary>
| On windows 10 you need to directly invoke `curl.exe` in the command otherwise it will run the alias. Your command should look like this: `curl.exe -s "$(streamlink --stream-url twitch.tv/CHANNEL best)"`
https://gist.github.com/fronkr56/75c54414a5aef583bf2326c914e4e1df mine looks slightly different
These are all playlists with regular "live" content. As said, see the `#EXTINF` tags and their title.
Also, a playlist with ads must include tags like [`#EXT-X-DISCONTINUITY`](https://tools.ietf.org/html/draft-pantos-http-live-streaming-23#section-4.3.2.3).
Note that I could not reproduce unless I set Firefox headers.
curl -H "User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:52.0) Gecko/20100101 Firefox/52.0" -s "$(streamlink --stream-url twitch.tv/$CHANNEL best)"
https://gist.github.com/drmthrowaway/99ddc2308ba431e76945e456da837b75
@drmthrowaway
Thank you. I already suspected it, because it's one of the differences between the HTTP requests which `curl` (without params) and Streamlink sends ([Streamlink sets its UA to Firefox by default](https://github.com/streamlink/streamlink/blob/0c22b9a49da58e3655fb8c130ad316b4a5c1e7ac/src/streamlink/plugin/api/http_session.py#L67-L68)).
The [`TwitchM3U8Parser`](https://github.com/streamlink/streamlink/blob/0c22b9a49da58e3655fb8c130ad316b4a5c1e7ac/src/streamlink/plugins/twitch.py#L131-L132) currently only finds ads which are annotated with `Amazon` at the beginning of the segment title. Changing this to `!= "live"` should fix the filtering.
Completely preventing ads however is a different topic.
Btw, I don't know if `title and title != "live"` is the correct solution here, because I'm not sure if this could cause issues with VODs and streams in the future. The VODs I've checked (I have no experience with Twitch's VODs because Streamlink doesn't work well with non-live content and I'm usually not interested in it) currently have empty segment titles, but if Twitch decides to change this, or if I've missed something here, or if regular live streams will have a different annotation in the future for whatever reason, this will break and everything will get detected as an ad incorrectly.
A better fix would be checking for an existing `EXT-X-DATERANGE` tag with an `ID` attribute value beginning with `stitched-ad` and getting its `START-DATE` and `DURATION` attribute values. These attribute values can then be used for properly filtering out segments without reading their titles, because each segment is always annotated with a timestamp and duration.
https://gist.github.com/tp0/f4e6798301fb8361c192e17734a0ca16
Any guess why I would not be seeing the pre-roll ads on 1.4? I do get them on 1.6.
> Any guess why I would not be seeing the pre-roll ads on 1.4? I do get them on 1.6.
I am on 1.5 and I do not even have to wait for the pre-roll ads to finish anymore. Each stream starts immediately.
As usual, Twitch is enabling and disabling embedded ads temporarily for specific events, for testing purposes or whatever their plans are. And that often times regionally, which means not everybody will get embedded ads all the time. [`1.4.0`](https://github.com/streamlink/streamlink/blob/1.4.0/src/streamlink/plugins/twitch.py#L142) had the same filtering logic as [`1.6.0`](https://github.com/streamlink/streamlink/blob/1.6.0/src/streamlink/plugins/twitch.py#L131), so there's no difference here other than the request parameter I mentioned in the issue post which prevents ads (unless it doesn't).
Regarding the better filtering implementation, I have done some work on my local repo and it's working fine so far, but I'm not ready to open a pull request yet. Also because of another PR that needs to be merged first which this work relies on.
Is there a diff/patch available for this that I can try?
As mentioned above, for now, it's just that:
```diff
diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
index 6bdfd452..e17f0475 100644
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -128,7 +128,7 @@ LOW_LATENCY_MAX_LIVE_EDGE = 2
class TwitchM3U8Parser(M3U8Parser):
def parse_extinf(self, value):
duration, title = super(TwitchM3U8Parser, self).parse_extinf(value)
- if title and str(title).startswith("Amazon"):
+ if title and title != "live":
self.state["ad"] = True
return duration, title
```
changing the above ^ does not stop ads for me
Please read the thread. This doesn't prevent/stop ads, this fixes the filtering when having `--twitch-disable-ads` set.
@bastimeyer - I get the feeling Twitch is reading very carfully what people are trying fwiw. The are still using that name or are rotating it.
So I have noticed inconsistencies in the ad skipping, sometimes it skips, sometimes it doesn't. I've been using the same code every time.
"streamlink --loglevel debug --twitch-disable-ads twitch.tv/(insertnamehere) 360p"
EDIT: Never mind it straight up no longer works. What a bummer.
Btw, there's a PR open with the updated filtering logic and I would appreciate it if I could get some more feedback from users getting ads on Twitch, because I don't and can't verify that it's working correctly 100%.
https://github.com/streamlink/streamlink/pull/3213
See the updated OP from yesterday for install instructions, in case you don't know.
And just as a reminder, this doesn't prevent ads, and it is still unknown if there's another workaround for that.
It's been working well on my end - the pre-roll ads have been correctly identified and stream starts when they're over. Fortunately (or unfortunately), over the past day and a half, I've only gotten ONE mid-roll ad, which did get filtered correctly.
FWIW in the last hour or so Twitch has gone full retard wrt ads. Seeing 2minute + prerolls and mid. So while you may not be watching an ad, your player will likely appear hung and eventually timeout.
Was trying to watch the rocket launch on NASA whom have a channel on Twitch. Thankfully they also have other platforms.
Embedded ads should be out for you as well now, just a couple hours ago ads started embedding for me in Germany.
Edit: Using the new uBlock Origin Development version works for me in Chrome though, maybe their fix can be used here as well?
@martinsstuff
This looks like a back-and-forth battle between setting the `platform=_` stream token request parameter and removing it. We've already done it once, and removing it a second time is just ridiculous.
https://github.com/gorhill/uBlock/commit/75c58ec7af969141296371aca2b91bea9ae91a6a#diff-d7616deaf3a39e3f19f8d70d098bfe7aR1337
It seems to work though when I test it on shroud's stream. With `platform=_` => pre-roll, without, no ads.
This requires a decision how/when this parameter should be applied. We can't just add and remove it every couple of days/weeks and play a game of cat and mouse with Twitch.
----
For now, this is the diff to remove the parameter once again:
```diff
diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
index 6bdfd452..a327d405 100644
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -317,7 +317,7 @@ class TwitchAPI(object):
# Private API calls
def access_token(self, endpoint, asset, **params):
- return self.call("/api/{0}/{1}/access_token".format(endpoint, asset), private=True, **dict(platform="_", **params))
+ return self.call("/api/{0}/{1}/access_token".format(endpoint, asset), private=True, **params)
def hosted_channel(self, **params):
return self.call_subdomain("tmi", "/hosts", format="", **params)
```
@bastimeyer What if we simply define a second access token, one with `platform="_"` and one without, then we thread the plugin and whichever one doesn't get hit with pre-roll ads or an error is the one that we use?
That doesn't solve the problem at all, because Twitch can simply make arbitrary changes to their backend and serve embedded ads no matter what parameter+value combination is set or is not set. We don't know why the `platform=_`parameter currently en-/disables embedded ads and why it changes over time. What's for sure though is that `_` is just a placeholder and that the value is meant to differentiate between (official) apps on various platforms because of certain policies, contracts, etc. This system can change any time. And Twitch will also always be able to quickly block workarounds which ad blockers or tools like Streamlink implement.
Also, making multiple requests and loading multiple HLS streams, which first need to be resolved from the master playlists and then parsed and analyzed for embedded ads at the beginning, just slows down the initial stream loading by a lot. That nonsense is not worth the time implementing it, not even remotely close.
What we should do here is not hardcode it, because of the rapid changes, as everyone should know by now. Only applying the request parameter to the `--twitch-disable-ads` Streamlink parameter however doesn't make sense, as the `--twitch-disable-ads` parameter is meant for changing the HLS logic and it should always be possible to set it without affecting the access token acquirement logic. So what are the options here? Add another Streamlink parameter? Parse the request parameters from an env var? I don't know. Or we keep changing the parameter every time Twitch makes new changes and then publish a new release afterwards. Any volunteers for this work? Because I am already annoyed.
Fair points. I commented over in #3220.
Twitch is not as smart as they think they are and I'll leave it at that. Take the target off your back. It could be argued streamlink is doing what it should and leave the implementation of ad handling to another project. Presumably the one embedding streamlink.
The eventual end goal of this will be full drm by them.
Any possible solution to the ads issue in the foreseeable future?
Is there any player out there that can handle the new ad segment filtering? I've tried latest MPV, MPC-HC and VLC and they all freeze and won't resume (or resume after a very long time (couple of minutes) but out of sync / stuttering badly) after the following line:
`[stream.hls_filtered][info] Filtering out segments and pausing stream output`
Streamlink is resuming `Reloading playlist`, `Adding segment x to queue` etc. as normal without errors, but none of the players above seem to be able to resume playback.
What are you talking about? That is the whole point. This is **embedded ad filtering**, and **not an embedded ads workaround**, because **there currently is none**. Read the thread before posting.
If your player has any kind of synchronization issues after the playback resumes, then it's because of the stream discontinuity and the offset in stream timestamps. This can't be avoided, as Twitch simply hasn't served you the necessary data, either when watching an ad, or when filtering it out. Use a player that can handle this properly, like MPV for example. There is nothing that can be done here and I'm sick of repeating myself. If Twitch is embedding ads into the HLS stream, then you'll have to deal with it by either watching it, or filtering it out. And since your player is reading a progressive stream from Streamlink's output, watching ads is more prone to errors, since it's a different stream with different encoding parameters and will thus cause more issues with the player's demuxer and decoder than a simple timestamp offset when filtering out ads.
If it wasn't clear I do understand that it's filtering and not a workaround. I'm also aware that the issue isn't with streamlink but the player, but was simply wondering if there was a known working player with this solution. Neither latest MPV git build or stable version resumes playback (on my end anyway) after the filtering pause, it hard freezes and the process has to be killed manually. But if MPV is supposed to be able to handle it properly I'll look into it, thank you.
My apologies, clearly this wasn't the place to ask.
EDIT:
For anyone else having the same issue and reading this: disabling hardware decoding for MPV seems to have worked for me, but YRMW.
Apparently, ads can be prevented again by adding `player_type=frontpage` to the access token request parameters, as shown here:
https://gist.githubusercontent.com/odensc/764900d841cbdd8aa400796001e189f1/raw/ads.js
That's the current diff if you want to try it out:
```diff
diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
index b534b003..d4bf53ee 100644
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -297,7 +297,7 @@ class TwitchAPI(object):
validate.get("sig"),
validate.get("token")
))
- ))
+ ), player_type="frontpage")
def token(self, tokenstr):
return parse_json(tokenstr, schema=validate.Schema(
```
It's the same situation as the `platform=_` request parameter, and it might get changed quickly again by Twitch if they see it being (ab)used by lots of users, so I don't know if it makes sense hardcoding such a workaround again and having to remove it later on because it's broken and causes other issues.
The header post has been updated again...
I would love to edit the hard code, but How do I access the U Block Orgin script to add that line of code?
Nvm I set my userResourcesLocation to https://gist.githubusercontent.com/odensc/764900d841cbdd8aa400796001e189f1/raw/ads.js
and that seems to work for now. Not sure sometimes twitch ads disappear for a bit and then come back. But if Twitch changes the parameter again how can I check to see what that new parameter is so I can add it?
@bastimeyer I think we're a bit blocked by the remaining Python 3 only stuff, otherwise I'd say we should just do another full release to try and head this off.
Nvm it didnt work lol
hmm well it only works half the time. Not sure why it's inconsistent.
@myhowbou can you stop spamming this thread with unrelated posts? This is about Streamlink, not about any browser related ad blocking stuff. The request parameter is working fine here, and if it doesn't for you in another region or so, then be absolutely clear about that with an example log post. I'm tempted to mark this as offtopic, because I really don't like bloat in such megathreads, and everyone seeing nonsense notifications probably neither.
@gravyboat What do you mean? 2.0.0 is technically ready, as every mandatory change has been merged. Everything else listed in the checklist is optional. I don't see the need of rushing another release right now though just because of this change. The workaround is very simple, and I have provided a diff and also instructions for installing the latest development version, and that should be good for now until we're all confident with publishing the 2.0.0 release in a good shape.
Making another 1.x release would mean that we'd have to branch off from an earlier commit, which doesn't make sense considering that we explicitly chose not to do the py2 removal on a secondary branch (now the situation is in reverse). If that's a problem now, then we should have switched to a different git flow instead of having just one main branch.
@bastimeyer Hmm. Okay sorry. I thought this was a patch for the new twitch thing for Ublock.
I did a pip upgrade and suddenly twitch displays those blank 10 sec moments for ads again? What happened?
@bastimeyer Sorry I should have been clear, I agree with you that the workaround is simple but it was simple last time too when people needed to install the nightly and we still had tons of comments. I do not want to make another 1.x release.
@tarkov2213 You have either not installed the **latest dev** version, or you are using an older version in parallel by accident. As I've said in my previous comment, one should **post a debug log** (with `--twitch-disable-ads` set, so it'll include logs for ad segments) if they think that it's not working correctly, because non-meaningful statements like this without any information at all are a waste of time for every developer, regardless the project.
----
@gravyboat If there's going to be spam or more repetitive questions of people who haven't read anything before posting, then we're going to lock it. This should not make us rush a new release, because there are some changes left which I think should be done/finished first. I hope that's somewhat understandable.
So far, it's been rather tame though. But I also want to mention that due to being the Twitch GUI dev, I've been answering questions left and right each day on various other channels as well, and this gets very annoying over time, especially since I don't get paid for "playing unofficial Twitch support staff" while working on an unrelated project, so I understand that you want to push this and be done with it. But remember that the workaround can stop working at any moment, and if we rush things because of it, it might backfire.
Once again, the current solution for the enduser is very simple, and if some people are unwilling to read or don't understand, or just want to complain, then it's not my problem.
Offtopic:
Interesting, they've moved the HLS request from api.twitch.tv behind graphql
https://i.imgur.com/DteEeoC.png
i put this twitch.py patch and seems to work fine (linux)
no need to push a release
cat & mouse either way
btw, the "commercial break" screen is satisfactory...atleast its not an actual ad
thanks for your work and that "frontpage" discovery lol
Just wanted to add some odd behavior I am observing. I am using the precompiled windows binaries for twitch (latest stable) and am noticing for channels I am subscribed to I am seeing ads. This happens regardless of tier level (I have tier 1-3 subs) and I verified the ads are not being ran by the streamers. I patched in the python above and I am seeing ads for streamers I am subscribed to still (before I was seeing the commercial break screen). I checked streamers that I am not subscribed to and saw ads randomly (5 saw ads 1 did not). If there is any logs you would like me to provide just let me know what you need and how to produce them and I will send them.
@S0und I don't see anything about that on Twitch. They are still using the old private API for the access token. If they had rolled out those changes, then we'd seen tons of posts here, because it'd break the Twitch plugin. It is possible though that this change will come at some point.
----
@Darushin And how exactly do you think Streamlink knows about your subscriptions? Any kind of authentication has been removed from previous Streamlink versions (see https://github.com/streamlink/streamlink/issues/2680#issuecomment-557605851).
https://github.com/streamlink/streamlink/blob/master/CHANGELOG.md
Also, the last stable release is pretty much offtopic at this point since #3301 got merged.
@bastimeyer well excuse me for assuming the package you have in the pip repository would contain important fixes like no ads. uninstalled it and pip installed straight from git+github and the problem is fixed.
If this change was included in the latest stable release, then we wouldn't be discussing it here.
----
I've just noticed that the new ads prevention request parameter is not working on every Twitch channel, unfortunately. It's working fine on most, but on `esl_dota2` for example, you'll still see preroll ads. Not sure why.
In addition to `player_type=frontpage`, it seems that `player_type=dashboard` is another way of preventing embedded ads.
I had to switch from `frontpage` to `embed` yesterday. Seemingly worked for a lot of people, but someone reported ads today even with that.
https://gist.githubusercontent.com/odensc/764900d841cbdd8aa400796001e189f1/raw/ads.js
`dashboard` is also a variant, but i haven't tried it yet.
When mid-roll ads play a mini-player is created so that the viewer can still see the stream whilst ads play. Whilst it's limited to 360p it might be an idea to use this in cases where ads cannot be blocked by streamlink. There's some additional discussion on that here https://gist.github.com/odensc/764900d841cbdd8aa400796001e189f1#gistcomment-3510566
https://gist.github.com/odensc/764900d841cbdd8aa400796001e189f1#gistcomment-3511057
works well for me so far
>
>
> https://gist.github.com/odensc/764900d841cbdd8aa400796001e189f1#gistcomment-3511057
> works well for me so far
how do I go about adding this twitch.py source code?
@dusty-dusty This has nothing to do with Streamlink, it's for uBlock. @f0rmatme why even mention this here? It's completely unrelated to Streamlink.
Today i started to run into embedded ads again from a German ip while using **streamlink-1.7.0_46.g9384f3d**
I confirm the post above.
When I ran a Twitch stream, I got an ad...
Streamlink version: `streamlink 1.7.0+46.g9384f3d`
I have the same problems with this whene i look in to the m3u file i found an intresting domine name on the fist line https://video-weaver.<hosting_location>.hls.ttvnw.net/trigger/<random> when i block this string to a webserver i get no ads in streamlink
That URL is part of an `EXT-X-DATERANGE` tag, and it gets discarded by Streamlink, because it's only looking for those `EXT-X-DATERANGE` tags which indicate advertisement time ranges:
https://github.com/streamlink/streamlink/blob/bc78360c51c95e1052fc387c6e19c071f4a7b5bd/src/streamlink/plugins/twitch.py#L43-L45
If you take a look at the attributes, they look like this:
```
#EXT-X-DATERANGE:ID="trigger-%TIMESTAMP%",CLASS="twitch-trigger",START-DATE="2020-11-05T05:21:33.704Z",END-ON-NEXT=YES,X-TV-TWITCH-TRIGGER-URL="https://video-weaver.%LOCATION%.hls.ttvnw.net/trigger/%LONG_BASE64_STRING%"
```
and the URL is the value of the `X-TV-TWITCH-TRIGGER-URL` attribute, which means it's irrelevant to Streamlink.
The only HTTPS requests which are made by Streamlink are the Twitch API ones, the HLS master playlist, the HLS stream playlist, the regular HLS stream segments and the HLS prefetch segments. There is nothing to block here, and if you're taking about your web browser, then you're at the wrong place here.
I started getting pre and mid roll ADs a couple of day ago while using the fix in the 1.7 streamlink versions. Now I'm using 065cb82794cb80dd5d2abf3f11034ae40e2308df with a german IP and the `twitch-disable-ads` flag, I no longer get mid roll ADs, but I'm pretty sure I get pre roll ADs, cause the stream takes a much longer to open.
--twitch-disable-ads
what do i have to do with it? i use streamlink twitch gui
@cliocaev
Nothing. Just check the checkbox in
Settings -> Streaming -> Advertisements
> I have the same problems with this whene i look in to the m3u file i found an intresting domine name on the fist line https://video-weaver.<hosting_location>.hls.ttvnw.net/trigger/ when i block this string to a webserver i get no ads in streamlink
Sorry to side track the conversation here. I thought this would work, however I just get `There was a network error. Please try again. (Error #2000)` when loading a stream. I think it's because they serve their ads with the same servers as the streams. So you end up blocking both.
Up until last night, I'd been avoiding this issue by using version `1.2.0`. For what ever reason, it is/was innately immune to all these ad changes, including pre-rolls. I don't see any mention of this behavior anywhere here.
`1.2.0` not longer works because of `410 API Gone` error for `/accesss_token.json`. But is it possible to replicate its functionally in a newer version?
@nicolas-martin There is nothing we can do about that, if you google it you can see this is a Twitch error due to a lack of a secure connection. I'm running the same options that the GUI enables via the CLI and I'm not having any problems. If it's still occurring for you try the CLI with `streamlink -l debug --twitch-disable-ads twitch.tv/streamer` for more output.
@tophercullen Nope. Old versions like that are dead and we can't replicate the functionality. The API they used for this was never publicly available, it just happened to be publicly accessible.
Let's stop derailing this thread, it's not a catch all for various Twitch related questions and I'm going to start deleting off-topic comments.
@gravyboat It *wasn't* dead. Thats my point. At a high level, I understand what happened with the API calls included in that version. Yes, certain functions long stopped working when those APIs were disabled. I never expected it to keep working forever. It was a stop gap. However, that doesn't change the fact that it is unaffected by ads.
Now if you're saying you acknowledge it was ad free all this time, know exactly why this is, and are certain that it cannot be replicated in the current API, I can accept that. As I said, I don't see anyone bringing up how legacy code is more functional in this regard.
But the way you have phrased it, it seems like offhandedly ignoring a potential workaround.
Myself, I briefly looked through the code and couldn't tell if the cause of API gone error is relevant or not to why it was still bypassing ads in `1.2.0`. From what I saw, the failing API(s) are still in the current version.
@tophercullen Sorry if my comment wasn't clear. I specifically meant the old API access we cannot replicate. Twitch has had multiple APIs, both public and private, undocumented, but externally accessible. We had to remove the undocumented but externally accessible API back with the 1.3 release due to issues with user login. I had no idea the old release was ad free this entire time as I don't run old releases. If you were logged in via 1.2 and watching streamers you are subscribed to it would make sense as to why you weren't seeing ads. There were a lot of changes we had to make after 1.2 and I'm pretty sure we were using a problematic key at that time as well, it's hard to remember. Without more information about your specific setup I can't say, and even if something was working with that specific release we wouldn't be able to go back to how the Twitch plugin was setup for that release.
Edit: Yeah here is the PR: https://github.com/streamlink/streamlink/issues/2680 it was specifically to address the error you've been seeing. Bastimeyer has a [good comment](https://github.com/streamlink/streamlink/issues/2680#issuecomment-557605851) that sums everything up. Seems like they finally EoL'd the API instead of just saying it was gone for the URL since the message has changed.
@gravyboat Subscription didn't affect the ad status.
I understand completely not running old versions. Literally the only reason I found this out, soon after they started rolling out these changes, one computer was strangely unaffected. Further troubleshooting lead me to find it was the version it was running.
As far as replication, simply uninstalling current streamlink (and twitch-gui) and then installing streamlink 1.2.0 (twitch-gui 1.8.1) replicated the behavior on all computers.
Thanks for the background comment/issue number. Further troubleshooting shows this is indeed likely the root cause of why it worked. There are really two errors I'm seeing in `1.2.0`:
- With Streamlinks clientid: 410 API Gone calling the private api (`/api/access_token`). Most certainly the same issue you linked above
- With Twitch's client-id: 404 client not found calling the public api (`/kraken/users`). Likely indicating its getting passed the private API call, but they changed something in their with their oauth scope or something, and it fails on the public calls.
In either case, `1.2.0` is not functional at a basic level. Switching to twitch's clientid in `1.7.0` does not replicate the ad exempt behavior seen in `1.2.0`
This seems to indicate some magic with tokens returned by twitch's private API was the reason it was being exempted. As this is all on twitch's side, I would now agree with your assessment that the functional behavior cannot be replicated, even juggling clientids.
>
>
> Offtopic:
>
> Interesting, they've moved the HLS request from api.twitch.tv behind graphql
>
> https://i.imgur.com/DteEeoC.png
This just got rolled out today, I think, and the api.twitch.tv/kraken/ portal now gives a "404 Client Error: Not Found for url: https://api.twitch.tv/kraken/user.json?as3=t&oauth_token=secretsymbols0123456789abcdefg" error. We should probably open a separate ticket for this if it breaks the plugin, but I don't think the latest top of git plugin depends on this api at all anymore, as it no longer allows defining the user oauth token since v1.2-ish?
(This is a bit off-topic, but if the oauth token is allowed to be user-defined, then ads do not display on channels a user is subscribed to, which avoids this whole cat-and-mouse game with twitch over blocking embedded ads and doesn't build bad blood between streamlink and twitch. I personally think that blocking embedded ads should not be part of the plugin at all, or we invite twitch's ire, they could even do something as draconic as enabling widevine/EME l3 globally for all streams (instead of just NFL and similar events as they do now) which would mean streamlink is completely useless for twitch from then on due to anti-circumvention laws)
@Lord-Nightmare This behavior was expected. We've known they were switching to GraphQL for a while, and the [V5 API (Kraken)](https://dev.twitch.tv/docs/v5) has been deprecated but somewhat functional for quite a while,
> but I don't think the latest top of git plugin depends on this api at all anymore, as it no longer allows defining the user oauth token since v1.2-ish?
Correct.
Take a look at the comment I linked above from Bastimeyer. We used to let people use their tokens to log in so they wouldn't get ads, we can't do that any more because that endpoint is no longer exposed to us. Twitch has been fine for years with people not watching ads. We aren't doing anything that isn't possible to do in a browser. You don't have to block the ads, feel free to watch them if you want to. I'm not going to watch ads (especially for channels I subscribe to) simply because Twitch took away our ability to log in and I prefer to use a better and more efficient video player than what Twitch offers directly.
Let's please try to keep it very on-topic in this issue, it's already a nightmare notification wise.
Which issue (or other communication means) should I use, if I want to comment on the token thing? (because, as it turns out, the old kraken api did still work and even allowed ads to be avoided if subscribed, with some caveats, until about 12 hours ago. This required using the plugin version 1.1(!) with some fixes from 1.2 backported.)
@Lord-Nightmare For the old login issue from 1.2 with the user token login? The plugin is working fine on the latest Streamlink release, I'm running it right now. If you're on the latest version and getting an error then please open a new issue, don't bump that old one. If this is an issue on an old release there is no need to open an issue as we'll just say upgrade Streamlink then close the issue.
I'm going to lock this thread now, as the past posts have all been off topic. There is nothing to discuss here in terms of embedded ads, because there's currently no workaround known. While writing this post, the master branch is still setting the `player_type=frontpage` access token request parameter. This doesn't make a difference anymore though and it should be removed again.
To explain it again, embedded ads don't occur all the time, and Twitch is in full control over this. If you're not seeing ads for a while and then start seeing them, it doesn't mean that something has changed or that Streamlink's Twitch plugin broke.
What's changed in Streamlink in the past releases in regards to embedded ads on Twitch are just simple request parameter workarounds while acquiring a stream access token. These parameters were used by certain players on Twitch's website to circumvent ads from being embedded into the streams. For example `platform=_`, which made Twitch think that the viewer was on a platform where no ads are being shown, in contrast to `platform=web`, or the most recent workaround with `player_type=frontpage` or `player_type=dashboard`, which made Twitch not embed ads into the streams, as they don't do this on their front page player or on a streamer's dashboard. This however kept working only for a couple of days/weeks until Twitch noticed that behavior among popular browser ad-blockers and applications like Streamlink, so they've changed it and/or ignored those parameters completely.
Applying workarounds in Streamlink is a game of cat and mouse and **there's no solution to this**. If Twitch wants to embed ads into the HLS streams, they can, and you'll have to accept that. The only way of not seeing ads is filtering them out. `--twitch-disable-ads` has seen multiple revisions over the past releases and the most recent one should properly cover all cases now until Twitch stops adding time annotations to the HLS segments or if they change their ad annotation scheme, which could happen, but that would be rather simple to fix.
If your player is having issues with embedded ads, like high-pitched sound or other weird things, you'll have to filter out ads, as the stream-discontinuity with the ads is causing this and the player can't handle differently encoded streams stitched together. The stream-discontinuity while filtering out ads is still a problem, but since it's only a gap in the same stream, this doesn't seem to cause any problems with most modern players / decoders.
----
@nicolas-martin
Anything "video-weaver" related is irrelevant, as I've already explained here
https://github.com/streamlink/streamlink/issues/3210#issuecomment-722152105
And `There was a network error. Please try again. (Error #2000)` is not a Streamlink error message, so you're using a different piece of software and that's off-topic here.
----
@tophercullen @Lord-Nightmare
Regarding older versions of Streamlink, this is completely irrelevant as well, as Twitch has made changes which prevent 3rd party client IDs (eg. Streamlink) or users authenticated with an OAuth token that's tied to a 3rd party client ID (eg. Streamlink) to acquire an access token for watching streams. This happened last November over a period of several weeks with a couple of days still working and then breaking again, multiple times, which made it difficult to make a decision fast. If it has been working for a while again in the past few months while using older versions of Streamlink, then good for you, but the latest version of Streamlink won't be able to revert this, as Twitch will simply break it again.
Read my post from last year here:
https://github.com/streamlink/streamlink/issues/2680#issuecomment-557605851
Streamlink is still using the same private API endpoint for that access token, and it's still working. The public kraken or helix APIs have nothing to do with that. Once Twitch changes the access token API endpoint from their old private API to their new private GQL-based API and shuts down the old private API, then it'll break the Twitch plugin, but so far this hasn't happened yet, otherwise we'd seen a ton of posts already.
While they were only sporadically using the GQL API for the access tokens in the past weeks, this seems to have changed now. I am not sure though if this justifies changing it here yet, as they could still be testing it and make further changes at any time, as it's not a public API endpoint and thus not deemed stable. Comparing the current GQL request with the one mentioned earlier in this thread, there have already been changes in the way the access token is requested. I'm going to open a new issue thread for that later today, so that the status can be checked there.
Commenting here, so people who have subscribed the thread can see it.
There's a new workaround added by #3373 which again prevents ads from being embedded into the stream. I've updated the OP accordingly. | 2021-05-28T12:05:09 |
streamlink/streamlink | 3,762 | streamlink__streamlink-3762 | [
"3761"
] | e747226d2917a611cae9594722434376968fab00 | diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -15,6 +15,7 @@
from streamlink.stream.hls import HLSStreamReader, HLSStreamWorker, HLSStreamWriter
from streamlink.stream.hls_playlist import M3U8, M3U8Parser, load as load_hls_playlist
from streamlink.utils.times import hours_minutes_seconds
+from streamlink.utils.url import update_qsd
log = logging.getLogger(__name__)
@@ -346,47 +347,89 @@ def parse_token(self, tokenstr):
))
def clips(self, clipname):
- query = """{{
- clip(slug: "{clipname}") {{
- broadcaster {{
- displayName
- }}
- title
- game {{
- name
- }}
- videoQualities {{
- quality
- sourceURL
- }}
- }}
- }}""".format(clipname=clipname)
-
- return self.call_gql({"query": query}, schema=validate.Schema(
- {"data": {
- "clip": validate.any(None, validate.all({
- "broadcaster": validate.all({"displayName": validate.text}, validate.get("displayName")),
- "title": validate.text,
- "game": validate.all({"name": validate.text}, validate.get("name")),
- "videoQualities": [validate.all({
- "quality": validate.all(
- validate.text,
- validate.transform(lambda q: "{0}p".format(q))
- ),
- "sourceURL": validate.url()
- }, validate.union((
- validate.get("quality"),
- validate.get("sourceURL")
- )))]
- }, validate.union((
- validate.get("broadcaster"),
- validate.get("title"),
- validate.get("game"),
- validate.get("videoQualities")
- ))))
- }},
- validate.get("data"),
- validate.get("clip")
+ queries = [
+ {
+ "operationName": "VideoAccessToken_Clip",
+ "extensions": {
+ "persistedQuery": {
+ "version": 1,
+ "sha256Hash": "36b89d2507fce29e5ca551df756d27c1cfe079e2609642b4390aa4c35796eb11"
+ }
+ },
+ "variables": {"slug": clipname}
+ },
+ {
+ "operationName": "ClipsView",
+ "extensions": {
+ "persistedQuery": {
+ "version": 1,
+ "sha256Hash": "4480c1dcc2494a17bb6ef64b94a5213a956afb8a45fe314c66b0d04079a93a8f"
+ }
+ },
+ "variables": {"slug": clipname}
+ },
+ {
+ "operationName": "ClipsTitle",
+ "extensions": {
+ "persistedQuery": {
+ "version": 1,
+ "sha256Hash": "f6cca7f2fdfbfc2cecea0c88452500dae569191e58a265f97711f8f2a838f5b4"
+ }
+ },
+ "variables": {"slug": clipname}
+ }
+ ]
+
+ return self.call_gql(queries, schema=validate.Schema(
+ [
+ validate.all(
+ {"data": {
+ "clip": validate.all({
+ "playbackAccessToken": validate.all({
+ "__typename": "PlaybackAccessToken",
+ "signature": str,
+ "value": str
+ }, validate.union((
+ validate.get("signature"),
+ validate.get("value")
+ ))),
+ "videoQualities": [validate.all({
+ "frameRate": validate.any(int, float),
+ "quality": str,
+ "sourceURL": validate.url()
+ }, validate.union((
+ validate.transform(lambda q: f"{q['quality']}p{int(q['frameRate'])}"),
+ validate.get("sourceURL")
+ )))]
+ }, validate.union((
+ validate.get("playbackAccessToken"),
+ validate.get("videoQualities")
+ )))
+ }},
+ validate.get("data"),
+ validate.get("clip")
+ ),
+ validate.all(
+ {"data": {
+ "clip": validate.all({
+ "broadcaster": validate.all({"displayName": str}, validate.get("displayName")),
+ "game": validate.all({"name": str}, validate.get("name"))
+ }, validate.union((
+ validate.get("broadcaster"),
+ validate.get("game")
+ )))
+ }},
+ validate.get("data"),
+ validate.get("clip")
+ ),
+ validate.all(
+ {"data": {
+ "clip": validate.all({"title": str}, validate.get("title"))
+ }},
+ validate.get("data"),
+ validate.get("clip")
+ )
+ ]
))
def stream_metadata(self, channel):
@@ -662,12 +705,12 @@ def _get_hls_streams(self, url, restricted_bitrates, **extra_params):
def _get_clips(self):
try:
- (self.author, self.title, self.category, streams) = self.api.clips(self.clip_name)
+ (((sig, token), streams), (self.author, self.category), self.title) = self.api.clips(self.clip_name)
except (PluginError, TypeError):
return
for quality, stream in streams:
- yield quality, HTTPStream(self.session, stream)
+ yield quality, HTTPStream(self.session, update_qsd(stream, {"sig": sig, "token": token}))
def _get_streams(self):
if self.video_id:
| plugins.twitch: clips 404 - require access token
<!--
Thanks for reporting a bug!
USE THE TEMPLATE. Otherwise your bug report may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Bugs are the result of broken functionality within Streamlink's main code base. Use the plugin issue template if your report is about a broken plugin.
Also check the list of open and closed bug reports:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Bug Report
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a bug report and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
When running streamlink with a twitchclip URL it results in an 404 error
### Expected / Actual behavior
It shouldn't 404
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. run stramlink with a twitch clip URL
2. results in a 404 error
### Log output
<!--
DEBUG LOG OUTPUT IS REQUIRED for a bug report!
INCLUDE THE ENTIRE COMMAND LINE and make sure to **remove usernames and passwords**
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
Debug log includes important details about your platform. Don't remove it.
https://streamlink.github.io/latest/cli.html#cmdoption-loglevel
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.8.2
[cli][debug] Streamlink: 2.1.2+10.ge747226
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(1.0.1)
[cli][debug] Arguments:
[cli][debug] url=https://clips.twitch.tv/GrossRamshacklePheasantPipeHype-vb-LdFjwD-kLo87L
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --rtmpdump=D:\Program Files (x86)\Streamlink\rtmpdump\rtmpdump.exe
[cli][debug] --ffmpeg-ffmpeg=D:\Program Files (x86)\Streamlink\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin twitch for URL https://clips.twitch.tv/GrossRamshacklePheasantPipeHype-vb-LdFjwD-kLo87L
[cli][info] Available streams: 360p (worst), 480p, 720p, 1080p (best)
[cli][info] Opening stream: 1080p (http)
[cli][error] Try 1/1: Could not open stream <HTTPStream('https://production.assets.clips.twitchcdn.net/AT-cm%7C1198016717.mp4')> (Could not open stream: Unable to open URL: https://production.assets.clips.twitchcdn.net/AT-cm%7C1198016717.mp4 (404 Client Error: for url: https://production.assets.clips.twitchcdn.net/AT-cm%7C1198016717.mp4))
error: Could not open stream <HTTPStream('https://production.assets.clips.twitchcdn.net/AT-cm%7C1198016717.mp4')>, tried 1 times, exiting
```
### Additional comments, etc.
Twitch now needs a JWT in the URL for authentication. The page 404 if it isn't present.
The JSON is just plaintext, but urlencoded and has the form:
{"authorization":{"forbidden":false,"reason":""},"clip_uri":"","device_id":str,"expires":int,"user_id":str,"version":2}
The signature appears to be sha1, but I couldn't figure out what exactly that were hashing as nothing I tried resulted in a valid hash.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Clips now seem to require an access token, similar to the live streams and vods.
The access token can be acquired via this GQL query:
```json
[
{
"operationName": "VideoAccessToken_Clip",
"variables": {
"slug": "CLIPNAME"
},
"extensions": {
"persistedQuery": {
"version": 1,
"sha256Hash": "36b89d2507fce29e5ca551df756d27c1cfe079e2609642b4390aa4c35796eb11"
}
}
}
]
``` | 2021-05-30T19:54:39 |
|
streamlink/streamlink | 3,765 | streamlink__streamlink-3765 | [
"3763"
] | e747226d2917a611cae9594722434376968fab00 | diff --git a/src/streamlink/utils/url.py b/src/streamlink/utils/url.py
--- a/src/streamlink/utils/url.py
+++ b/src/streamlink/utils/url.py
@@ -1,24 +1,38 @@
+import re
from collections import OrderedDict
from urllib.parse import parse_qsl, quote_plus, urlencode, urljoin, urlparse, urlunparse
-def update_scheme(current, target):
+_re_uri_implicit_scheme = re.compile(r"""^[a-z0-9][a-z0-9.+-]*://""", re.IGNORECASE)
+
+
+def update_scheme(current: str, target: str) -> str:
"""
- Take the scheme from the current URL and applies it to the
- target URL if the target URL startswith // or is missing a scheme
+ Take the scheme from the current URL and apply it to the
+ target URL if the target URL starts with // or is missing a scheme
:param current: current URL
:param target: target URL
:return: target URL with the current URLs scheme
"""
target_p = urlparse(target)
+
+ if (
+ # target URLs with implicit scheme and netloc including a port: ("http://", "foo.bar:1234") -> "http://foo.bar:1234"
+ # urllib.parse.urlparse has incorrect behavior in py<3.9, so we'll have to use a regex here
+ # py>=3.9: urlparse("127.0.0.1:1234") == ParseResult(scheme='127.0.0.1', netloc='', path='1234', ...)
+ # py<3.9 : urlparse("127.0.0.1:1234") == ParseResult(scheme='', netloc='', path='127.0.0.1:1234', ...)
+ not _re_uri_implicit_scheme.search(target) and not target.startswith("//")
+ # target URLs without scheme and netloc: ("http://", "foo.bar/foo") -> "http://foo.bar/foo"
+ or not target_p.scheme and not target_p.netloc
+ ):
+ return f"{urlparse(current).scheme}://{urlunparse(target_p)}"
+
+ # target URLs without scheme but with netloc: ("http://", "//foo.bar/foo") -> "http://foo.bar/foo"
if not target_p.scheme and target_p.netloc:
- return "{0}:{1}".format(urlparse(current).scheme,
- urlunparse(target_p))
- elif not target_p.scheme and not target_p.netloc:
- return "{0}://{1}".format(urlparse(current).scheme,
- urlunparse(target_p))
- else:
- return target
+ return f"{urlparse(current).scheme}:{urlunparse(target_p)}"
+
+ # target URLs with scheme
+ return target
def url_equal(first, second, ignore_scheme=False, ignore_netloc=False, ignore_path=False, ignore_params=False,
| diff --git a/tests/test_utils_url.py b/tests/test_utils_url.py
--- a/tests/test_utils_url.py
+++ b/tests/test_utils_url.py
@@ -9,6 +9,9 @@ def test_update_scheme():
assert update_scheme("http://other.com/bar", "//example.com/foo") == "http://example.com/foo", "should become http"
assert update_scheme("https://other.com/bar", "http://example.com/foo") == "http://example.com/foo", "should remain http"
assert update_scheme("https://other.com/bar", "example.com/foo") == "https://example.com/foo", "should become https"
+ assert update_scheme("http://", "127.0.0.1:1234/foo") == "http://127.0.0.1:1234/foo", "implicit scheme with IPv4+port"
+ assert update_scheme("http://", "foo.bar:1234/foo") == "http://foo.bar:1234/foo", "implicit scheme with hostname+port"
+ assert update_scheme("http://", "foo.1+2-bar://baz") == "foo.1+2-bar://baz", "correctly parses all kinds of schemes"
def test_url_equal():
| --http[s]-proxy does not properly handle schemeless inputs with port due to urllib behavior change in python 3.9
## Bug Report
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [X] This is a bug report and I have read the contribution guidelines.
- [X] I am using the latest development version from the master branch.
### Description
<!-- Explain the bug as thoroughly as you can. Don't leave out information which is necessary for us to reproduce and debug this issue. -->
While troubleshooting an issue with a project that consumes Streamlink by way of its CLI, I discovered an apparent bug in the interaction between Streamlink and urllib w/r/t how proxy URL inputs are handled - stemming from a behavior change in urllib in Python 3.9.
If the input for `--http[s]-proxy` is provided in host:port or IP:port notation WITHOUT a scheme (e.g. `--http-proxy 127.0.0.1:8050`), the `update_scheme()` function does not actually add a scheme to it under Python 3.9. When the still-schemeless url is then fed to urllib3 for connection setup, it fails with a `ProxySchemeUnknown` exception.
The behavior here appears to be caused by urllib's `urlparse()` function, rather than Streamlink itself, but the intent of the Python developers seems to be that the behavior change is handled by client applications.
Reference:
[44007: urlparse("host:123", "http") inconsistent between 3.8 and 3.9](https://bugs.python.org/issue44007)
which leads to:
[27657: urlparse fails if the path is numeric](https://bugs.python.org/issue27657) as the source of the behavior change
In the latter bug (specifically here: https://bugs.python.org/issue27657#msg371024) it's noted that the behavior change was apparently intentional and consumers of urllib are expected to handle it.
### Expected / Actual behavior
<!-- What do you expect to happen, and what is actually happening? -->
Expected: A scheme-less host:port or ip:port input to a proxy option (e.g. `--http-proxy 127.0.0.1:8050`) should be reformatted by `update_scheme()` to the appropriate format (e.g. `http://127.0.0.1:8050`) before being used as input to urllib3.
Actual: *In Python 3.9* the value is used as-is, and because there is no http/https scheme on the URL, urllib3 throws a `ProxySchemeUnknown` exception. (`Proxy URL had no scheme, should start with http:// or https://`).
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
The observed behavior can be abstracted entirely away from the Streamlink CLI.
In session.py, we have the following (https://github.com/streamlink/streamlink/blob/master/src/streamlink/session.py#L279-L285):
```
elif key == "http-proxy":
self.http.proxies["http"] = update_scheme("http://", value)
if "https" not in self.http.proxies:
self.http.proxies["https"] = update_scheme("http://", value)
elif key == "https-proxy":
self.http.proxies["https"] = update_scheme("https://", value)
```
The `update_scheme()` function should apply the appropriate scheme to the URL, but on *Python 3.9* it does not in the case of a schemeless input with port:
```
Python 3.9.5 (default, May 24 2021, 12:50:35)
[GCC 11.1.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from streamlink import utils
>>> utils.update_scheme("http://", "127.0.0.1:8050")
'127.0.0.1:8050'
>>> utils.update_scheme("https://", "127.0.0.1:8050")
'127.0.0.1:8050'
>>> utils.update_scheme("https://", "localhost:8050")
'localhost:8050'
>>> utils.update_scheme("https://", "localhost")
'https://localhost'
```
Note that the only properly-handled input above was the "schemeless hostname without port" case - any schemeless input _with_ port does not get the expected scheme added.
The root of this issue is actually in urllib, as `update_scheme()` calls `urlparse()` from urllib. In Python 3.8, the `urlparse` call results in the following:
```
Python 3.8.10 (default, May 12 2021, 15:46:43)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from urllib import parse
>>> parse.urlparse('127.0.0.1:8080')
ParseResult(scheme='', netloc='', path='127.0.0.1:8080', params='', query='', fragment='')
```
Whereas in Python 3.9, the folloiwng occurs:
```
Python 3.9.5 (default, May 12 2021, 15:26:36)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from urllib import parse
>>> parse.urlparse('127.0.0.1:8080')
ParseResult(scheme='127.0.0.1', netloc='', path='8080', params='', query='', fragment='')
```
Note in the latter case, urllib returns the IP address in the `scheme` portion of the tuple instead of ... anywhere else (I'm honestly not sure if it should end up in `netloc` or `path`).
### Log output
The consumer of Streamlink which I was troubleshooting (LazyMan) shells out to Streamlink with `--https-proxy 127.0.0.1:<port>` - a schemeless url with port - as seen here: https://github.com/StevensNJD4/LazyMan/blob/master/src/Objects/Streamlink.java#L45
This results in the following output from LM when run on a system with Python 3.9:
```
-----
-----
Streamlink starting...
urlparse was ParseResult(scheme='hlsvariant', netloc='<censored> name_key=bitrate verify=False', params='', query='', fragment='')
got https-proxy 127.0.0.1:8050
urlparse was ParseResult(scheme='127.0.0.1', netloc='', path='8050', params='', query='', fragment='')
output of update_scheme is 127.0.0.1:8050
urlparse was ParseResult(scheme='127.0.0.1', netloc='', path='8050', params='', query='', fragment='')
self.http.proxies['https'] is 127.0.0.1:8050
[cli][debug] OS: Linux-5.12.7-arch1-1-x86_64-with-glibc2.33
[cli][debug] Python: 3.9.5
[cli][debug] Streamlink: 2.1.1
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(0.59.0)
[cli][debug] Arguments:
[cli][debug] url=hlsvariant://<censored> name_key=bitrate verify=False
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --hls-segment-threads=4
[cli][debug] --https-proxy=127.0.0.1:8050
[cli][debug] --http-header=[('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')]
[cli][info] Found matching plugin hls for URL hlsvariant://<censored> name_key=bitrate verify=False
urlparse was ParseResult(scheme='<censored>', params='', query='', fragment='')
[plugins.hls][debug] URL=<censored>; params={'name_key': 'bitrate', 'verify': False}
[utils.l10n][debug] Language code: en_US
[cli][info] Available streams: 670k (worst), 1000k, 1450k, 2140k, 2900k, 4100k, 6600k (best)
[cli][info] Opening stream: 6600k (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Segments in this playlist are encrypted
[stream.hls][debug] First Sequence: 0; Last Sequence: 1970
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 0; End Sequence: 1970
[stream.hls][debug] Adding segment 0 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 1 to queue
[stream.hls][debug] Adding segment 2 to queue
[stream.hls][debug] Adding segment 3 to queue
[stream.hls][debug] Adding segment 4 to queue
[stream.hls][debug] Adding segment 5 to queue
[stream.hls][debug] Adding segment 6 to queue
[stream.hls][debug] Adding segment 7 to queue
[stream.hls][debug] Adding segment 8 to queue
[stream.hls][debug] Adding segment 9 to queue
[stream.hls][debug] Adding segment 10 to queue
[stream.hls][debug] Adding segment 11 to queue
[stream.hls][debug] Adding segment 12 to queue
[stream.hls][debug] Adding segment 13 to queue
[stream.hls][debug] Adding segment 14 to queue
[stream.hls][debug] Adding segment 15 to queue
[stream.hls][debug] Adding segment 16 to queue
[stream.hls][debug] Adding segment 17 to queue
[stream.hls][debug] Adding segment 18 to queue
[stream.hls][debug] Adding segment 19 to queue
[stream.hls][debug] Adding segment 20 to queue
[stream.hls][debug] Adding segment 21 to queue
[stream.hls][error] Failed to create decryptor: Unable to open URL: https://<url snipped> (Proxy URL had no scheme, should start with http:// or https://)
[stream.segmented][debug] Closing writer thread
[stream.segmented][debug] Closing worker thread
[cli][error] Try 1/1: Could not open stream <HLSStream('<censored>', 'http://<url snipped>')> (No data returned from stream)
error: Could not open stream <HLSStream('<censored>', 'http://<url snipped>')>, tried 1 times, exiting
[cli][info] Closing currently open stream...
```
In the above, the notable output is the `Proxy URL had no scheme [...]` error which maps to a `ProxySchemeUnknown` exception from urllib3.
### Additional comments, etc.
| Thanks for the detailed bug report.
> A scheme-less host:port or ip:port input to a proxy option (e.g. `--http-proxy 127.0.0.1:8050`) should be reformatted by `update_scheme()` to the appropriate format (e.g. `http://127.0.0.1:8050`) before being used as input to urllib3.
The problem is that `127.0.0.1:8050` is actually **not** scheme-less and indeed a correct URI with a **scheme** and **path**.
When reading this string as a human being, it is of course clear what is actually meant, but when parsing it as a URI, `127.0.0.1` becomes the scheme and `8050` the path due to the missing `//`, which means Python 3.9 parses it correctly and fixes the incorrect behavior of earlier versions.
----
One way to fix this could be checking whether `^[a-zA-Z][a-zA-Z0-9.+-]*://` matches the input and if not then default to `http://{input}`. | 2021-05-31T14:11:28 |
streamlink/streamlink | 3,768 | streamlink__streamlink-3768 | [
"2365",
"2365"
] | 1ed85fcb24c6436f93c8e7ed9931e0266e7ee696 | diff --git a/src/streamlink/plugin/api/http_session.py b/src/streamlink/plugin/api/http_session.py
--- a/src/streamlink/plugin/api/http_session.py
+++ b/src/streamlink/plugin/api/http_session.py
@@ -1,5 +1,7 @@
import time
+import requests.adapters
+import urllib3
from requests import Session
from streamlink.exceptions import PluginError
@@ -7,16 +9,39 @@
from streamlink.plugin.api import useragents
from streamlink.utils import parse_json, parse_xml
-try:
- from requests.packages import urllib3
+try:
# We tell urllib3 to disable warnings about unverified HTTPS requests,
# because in some plugins we have to do unverified requests intentionally.
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
-except (ImportError, AttributeError):
+except AttributeError:
pass
-__all__ = ["HTTPSession"]
+
+class _HTTPResponse(urllib3.response.HTTPResponse):
+ def __init__(self, *args, **kwargs):
+ # Always enforce content length validation!
+ # This fixes a bug in requests which doesn't raise errors on HTTP responses where
+ # the "Content-Length" header doesn't match the response's body length.
+ # https://github.com/psf/requests/issues/4956#issuecomment-573325001
+ #
+ # Summary:
+ # This bug is related to urllib3.response.HTTPResponse.stream() which calls urllib3.response.HTTPResponse.read() as
+ # a wrapper for http.client.HTTPResponse.read(amt=...), where no http.client.IncompleteRead exception gets raised
+ # due to "backwards compatiblity" of an old bug if a specific amount is attempted to be read on an incomplete response.
+ #
+ # urllib3.response.HTTPResponse.read() however has an additional check implemented via the enforce_content_length
+ # parameter, but it doesn't check by default and requests doesn't set the parameter for enabling it either.
+ #
+ # Fix this by overriding urllib3.response.HTTPResponse's constructor and always setting enforce_content_length to True,
+ # as there is no way to make requests set this parameter on its own.
+ kwargs.update({"enforce_content_length": True})
+ super().__init__(*args, **kwargs)
+
+
+# override all urllib3.response.HTTPResponse references in requests.adapters.HTTPAdapter.send
+urllib3.connectionpool.HTTPConnectionPool.ResponseCls = _HTTPResponse
+requests.adapters.HTTPResponse = _HTTPResponse
def _parse_keyvalue_list(val):
@@ -150,3 +175,6 @@ def request(self, method, url, *args, **kwargs):
res = schema.validate(res.text, name="response text", exception=PluginError)
return res
+
+
+__all__ = ["HTTPSession"]
| How to avoid "Input is not padded or padding is corrupt" error?
<!--
Thanks for reporting a bug!
USE THE TEMPLATE. Otherwise your bug report may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed bug reports:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Bug Report
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report and I have read the contribution guidelines.
### Description
<!-- Explain the bug as thoroughly as you can. Don't leave out information which is necessary for us to reproduce and debug this issue. -->
Sometimes, on streams that involve some kind of decryption, I get a `streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of xxx`
Whenever this happens, streamlink completely stalls until it reaches the timeout value, and then it just quits. This is very frustrating as this is not reproducible, and I have no idea how it is going to happen or when it is going to happen. In some cases, I can be recording the same exact same stream in two different commands running at the same time, and one will quit and the other will keep recording. In the case of downloading a replay of a stream, I can just restart the download and streamlink always gets past the point where it crashed previously with no issue.
What I would like to know is how I can avoid this error. For example if the error comes up, how can I force streamlink to try redownload/redecrypt the segment?
### Expected / Actual behavior
Streamlink downloads the stream with no issues.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
NA. The stream needs to have some sort of encryption. I have received this error across Fox Sports Go streams, ESPN+ streams, and live streams of Turner websites (TNT/TBS).
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a bug report!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
streamlink 'hlsvariant://https://turnerlive.akamaized.net/hls/live/572100/true/aes_slate/de/master.m3u8?hdnts=exp=1553034983~acl=/hls/live/572100/true/*!/hls/live/572100-b/true/*!/hls/live/630682/true/*!/hls/live/630682-b/true/*~id=c5c9ce531e437434c07dc7ff65b0ab94~hmac=112e16086c033e16ffcb3b487ff24f3f4f6626ccc2c57f0be36a60f30d269aee' best -o trutv.ts
[cli][info] Found matching plugin hls for URL hlsvariant://https://turnerlive.akamaized.net/hls/live/572100/true/aes_slate/de/master.m3u8?hdnts=exp=1553034983~acl=/hls/live/572100/true/*!/hls/live/572100-b/true/*!/hls/live/630682/true/*!/hls/live/630682-b/true/*~id=c5c9ce531e437434c07dc7ff65b0ab94~hmac=112e16086c033e16ffcb3b487ff24f3f4f6626ccc2c57f0be36a60f30d269aee
[cli][info] Available streams: 360p_alt2 (worst), 360p_alt, 360p, 480p_alt, 480p, 540p_alt, 540p, 720p_alt, 720p (best)
[cli][info] Opening stream: 720p (hls) [download][trutv.ts] Written 763.8 MB (28m49s @ 424.4 KB/s) Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py", line 917, in _bootstrap_inner
self.run()
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/segmented.py", line 167, in run
self.write(segment, result)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/hls.py", line 140, in write
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/hls.py", line 31, in pkcs7_decode
raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 156
error: Error when reading from stream: Read timeout, exiting
[cli][info] Stream ended
[cli][info] Closing currently open stream...
```
How to avoid "Input is not padded or padding is corrupt" error?
<!--
Thanks for reporting a bug!
USE THE TEMPLATE. Otherwise your bug report may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed bug reports:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Bug Report
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a bug report and I have read the contribution guidelines.
### Description
<!-- Explain the bug as thoroughly as you can. Don't leave out information which is necessary for us to reproduce and debug this issue. -->
Sometimes, on streams that involve some kind of decryption, I get a `streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of xxx`
Whenever this happens, streamlink completely stalls until it reaches the timeout value, and then it just quits. This is very frustrating as this is not reproducible, and I have no idea how it is going to happen or when it is going to happen. In some cases, I can be recording the same exact same stream in two different commands running at the same time, and one will quit and the other will keep recording. In the case of downloading a replay of a stream, I can just restart the download and streamlink always gets past the point where it crashed previously with no issue.
What I would like to know is how I can avoid this error. For example if the error comes up, how can I force streamlink to try redownload/redecrypt the segment?
### Expected / Actual behavior
Streamlink downloads the stream with no issues.
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
NA. The stream needs to have some sort of encryption. I have received this error across Fox Sports Go streams, ESPN+ streams, and live streams of Turner websites (TNT/TBS).
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a bug report!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
streamlink 'hlsvariant://https://turnerlive.akamaized.net/hls/live/572100/true/aes_slate/de/master.m3u8?hdnts=exp=1553034983~acl=/hls/live/572100/true/*!/hls/live/572100-b/true/*!/hls/live/630682/true/*!/hls/live/630682-b/true/*~id=c5c9ce531e437434c07dc7ff65b0ab94~hmac=112e16086c033e16ffcb3b487ff24f3f4f6626ccc2c57f0be36a60f30d269aee' best -o trutv.ts
[cli][info] Found matching plugin hls for URL hlsvariant://https://turnerlive.akamaized.net/hls/live/572100/true/aes_slate/de/master.m3u8?hdnts=exp=1553034983~acl=/hls/live/572100/true/*!/hls/live/572100-b/true/*!/hls/live/630682/true/*!/hls/live/630682-b/true/*~id=c5c9ce531e437434c07dc7ff65b0ab94~hmac=112e16086c033e16ffcb3b487ff24f3f4f6626ccc2c57f0be36a60f30d269aee
[cli][info] Available streams: 360p_alt2 (worst), 360p_alt, 360p, 480p_alt, 480p, 540p_alt, 540p, 720p_alt, 720p (best)
[cli][info] Opening stream: 720p (hls) [download][trutv.ts] Written 763.8 MB (28m49s @ 424.4 KB/s) Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py", line 917, in _bootstrap_inner
self.run()
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/segmented.py", line 167, in run
self.write(segment, result)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/hls.py", line 140, in write
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/hls.py", line 31, in pkcs7_decode
raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 156
error: Error when reading from stream: Read timeout, exiting
[cli][info] Stream ended
[cli][info] Closing currently open stream...
```
| Any chance you can recreate this issue with debug logging enabled (`-l debug`)?
I can try... to be honest the error rate is pretty low (maybe 1 in 25?) and like I said, I have no idea when it's going to show up. I'll just run streamlink on debug from now on though and update if it comes up!
Hey, I just now got back on this... but here's the log:
```
airbears2-10-142-27-169:streams isaac$ streamlink --http-cookie "access_token=eyJhbGciOiJIUzI1NiJ9.eyJpcGlkIjoiaWFwUmVjZWlwdERldmljZTpEZXZpY2U6Nzk0YmFlMTAtYTdjYy0xMWU4LWFmYWYtODMxYTg4NTMxM2Y3OjNlMGY2YWQwLTE4ZTAtNDQzOS04MzYwLWUyODlhYzMyMGZiZiIsImNsaWVudElkIjoiZm94c3BvcnRzZ28tdjEuMC4wIiwicGNfbWF4X3JhdGluZ19tb3ZpZSI6IiIsImNvbnRleHQiOnt9LCJ2ZXJpZmljYXRpb25MZXZlbCI6MCwiZXhwIjoxNTQzMTc5NDQ0LCJ0eXBlIjoiVXNlciIsImlhdCI6MTU0MDU4NzQ0NywidXNlcmlkIjoiMzExMjU2ZTAtZDIzZC00NGVhLWIxMTAtZDdmOWQ1MzcxZmRjLTM1NjQzNS0xZjlmMjdlNDBiOWQzMWVjNTg1M2MyYjk3MmQ0ZjhmYzFiZDNhZDEzIiwidmVyc2lvbiI6InYxLjAiLCJwY19tYXhfcmF0aW5nX3R2IjoiIn0.pME0fTZZSG4YW49EoAW9litm_IciS1mDdKva1Z8z1rQ" --http-cookie "Authorization=eyJraWQiOiJ2MS4wIiwiYWxnIjoiSFMyNTYifQ.eyJpcGlkIjoiaWFwUmVjZWlwdERldmljZTpEZXZpY2U6NGRmNDBhODAtMzhhMS0xMWU5LThhN2UtNTlhOThjYzY4NTg2OmYwMTRjYmNmLWZiNDEtNDE4MC1hMmNkLWM5Mjk5MTAzMDQxYyIsImNsaWVudElkIjoic2Vzc2lvbi1zZXJ2aWNlLXYxLjAiLCJjb250ZXh0Ijp7ImlkIjoiMzZiMmJlNjAtNmRkYi0xMWU5LTk0ODAtMGEzNDBhMmM3MTE0IiwidHlwZSI6IlJFR0lTVEVSRUQiLCJpcF9hZGRyZXNzIjoiMTM2LjE1Mi4xNDMuMjUiLCJkZXZpY2UiOnsiaWQiOiJleUpoYkdjaU9pSklVekkxTmlKOS5leUpwY0dsa0lqb2lhV0Z3VW1WalpXbHdkRVJsZG1salpUcEVaWFpwWTJVNk5HUm1OREJoT0RBdE16aGhNUzB4TVdVNUxUaGhOMlV0TlRsaE9UaGpZelk0TlRnMk9tWXdNVFJqWW1ObUxXWmlOREV0TkRFNE1DMWhNbU5rTFdNNU1qazVNVEF6TURReFl5SXNJbU5zYVdWdWRFbGtJam9pWm05NGMzQnZjblJ6WjI4dGRqRXVNQzR3SWl3aWNHTmZiV0Y0WDNKaGRHbHVaMTl0YjNacFpTSTZJaUlzSW1OdmJuUmxlSFFpT250OUxDSjJaWEpwWm1sallYUnBiMjVNWlhabGJDSTZNQ3dpWlhod0lqb3hOVFUzTXpRME1qZzBMQ0owZVhCbElqb2lWWE5sY2lJc0ltbGhkQ0k2TVRVMU5EYzFNakk0Tnl3aWRYTmxjbWxrSWpvaU16RXhNalUyWlRBdFpESXpaQzAwTkdWaExXSXhNVEF0WkRkbU9XUTFNemN4Wm1SakxUTTFOalF6TlMweFpqbG1NamRsTkRCaU9XUXpNV1ZqTlRnMU0yTXlZamszTW1RMFpqaG1ZekZpWkROaFpERXpJaXdpZG1WeWMybHZiaUk2SW5ZeExqQWlMQ0p3WTE5dFlYaGZjbUYwYVc1blgzUjJJam9pSW4wLjBBSHRjdUdTNlFLQkozbV9OQlBhbTV1cFZuSTRpcFdsUnhKXzFYdU1GMXMiLCJwbGF0Zm9ybSI6IndlYiJ9LCJ1c2VyIjp7ImlkIjoiMzExMjU2ZTAtZDIzZC00NGVhLWIxMTAtZDdmOWQ1MzcxZmRjLTM1NjQzNS0xZjlmMjdlNDBiOWQzMWVjNTg1M2MyYjk3MmQ0ZjhmYzFiZDNhZDEzIiwiaXBpZCI6ImlhcFJlY2VpcHREZXZpY2U6RGV2aWNlOjRkZjQwYTgwLTM4YTEtMTFlOS04YTdlLTU5YTk4Y2M2ODU4NjpmMDE0Y2JjZi1mYjQxLTQxODAtYTJjZC1jOTI5OTEwMzA0MWMiLCJiaWxsaW5nX2xvY2F0aW9uIjp7InR5cGUiOiJaSVBfQ09ERSIsInppcF9jb2RlIjoiMDcwNDAifSwicmVnaXN0cmF0aW9uIjp7ImF1dGhfcHJvdmlkZXIiOiJWZXJpem9uIiwiZW50aXRsZW1lbnRzIjpbImZveGRlcCIsImZiYy1mb3giLCJ5ZXMiLCJmY3MiLCJmczEiLCJmczIiXSwiZXhwaXJlc19vbiI6IjIwMTktMDUtMjFUMDA6MTI6MzQuMDAwKzAwMDAifX0sImdlbmVyYXRlZF9vbiI6IjIwMTktMDUtMDNUMTk6Mzk6NDkuNDQ2KzAwMDAiLCJ1cGRhdGVkX29uIjoiMjAxOS0wNS0wM1QxOTozOTo0OS40NDYrMDAwMCIsImV4cGlyZXNfb24iOiIyMDE5LTA1LTAzVDIzOjM5OjQ5LjQ0NiswMDAwIiwiYXZhaWxhYmxlX2NvbnRlbnQiOnsibmF0aW9uYWwiOnsiY2FsbF9zaWducyI6WyJCR1RFTk8yIiwiQkdURU5PMyIsIkJHVEVOTzQiLCJCSUdURU4iLCJGUzEiLCJGUzIiLCJGWERFUCIsIkZDU0EiLCJGQ1NDIiwiRkNTUCJdfSwiZ2VvIjp7ImxvY2F0aW9uIjp7InR5cGUiOiJaSVBfQ09ERSIsInppcF9jb2RlIjoiOTQ3MjAiLCJjb3VudHJ5X2NvZGUiOiJ1cyJ9LCJyc25fY2hhbm5lbF9ncm91cHMiOlsiIl0sInJzbl9jYWxsX3NpZ25zIjpbIiJdLCJhZmZpbGlhdGVfY2FsbF9zaWducyI6WyJLVFZVIl19LCJob21lIjp7ImxvY2F0aW9uIjp7InR5cGUiOiJaSVBfQ09ERSIsInppcF9jb2RlIjoiMDcwNDAifSwicnNuX2NoYW5uZWxfZ3JvdXBzIjpbInllcyJdLCJyc25fY2FsbF9zaWducyI6WyJZRVMiXSwiYWZmaWxpYXRlX2NhbGxfc2lnbnMiOlsiV05ZVyJdLCJ0ZWFtcyI6W3siaWQiOiJhNTM4ZmZhZi0yODc4LTQ2MDEtOGQ4Yy01OTg1NzNhYTMwMWEiLCJuYW1lIjoiQnJvb2tseW4gTmV0cyIsInNwb3J0IjoiTkJBIn0seyJpZCI6IjM1MDNhZTUxLWJiM2YtNDc3My1hODE4LWIzNWFiYjc3NjJiMyIsIm5hbWUiOiJOZXcgWW9yayBZYW5rZWVzIiwic3BvcnQiOiJNTEIifV19fSwicGFydG5lciI6eyJuYW1lIjoiZm94c3BvcnRzIn19LCJpcEFkZHJlc3MiOiIxMzYuMTUyLjE0My4yNSIsImV4cCI6MTU1NjkyNjc4OSwidHlwZSI6IlVzZXIiLCJ1c2VyaWQiOiIzMTEyNTZlMC1kMjNkLTQ0ZWEtYjExMC1kN2Y5ZDUzNzFmZGMtMzU2NDM1LTFmOWYyN2U0MGI5ZDMxZWM1ODUzYzJiOTcyZDRmOGZjMWJkM2FkMTMiLCJpYXQiOjE1NTY5MTIzODksInZlcnNpb24iOiJ2MS4wIn0.qxPYSK5Kk8u1Eufdlns-k9YZ4npIgVHcZd4L4rI1pVk" --hls-segment-timeout 1000 --hls-timeout 1000 "hlsvariant://http://hlslinear-akc.med2.foxsportsgo.com/hdnts=exp=1556998824~acl=/*~id=311256e0-d23d-44ea-b110-d7f9d5371fdc-356435-1f9f27e40b9d31ec5853c2b972d4f8fc1bd3ad13~hmac=8e7c413013dfec70bab90a3c0d9f5d7b80f074d5a2a70d33da97432074ab03ab/d52f3708ed1c7f367d4012b845a2683b/ls01/foxsports/FOX_SPORTS_2_DUAL_ORIGIN/vod/2019/05/03/73755261/FSG_20190503_FSV_Mainz_05_vs._RB_Leipzig_73755261/master_wired_web_ads.m3u8" best --hls-live-restart -l debug -o mainz.ts
[cli][debug] OS: macOS 10.14.4
[cli][debug] Python: 3.7.0
[cli][debug] Streamlink: 1.0.0
[cli][debug] Requests(2.21.0), Socks(1.6.7), Websocket(0.53.0)
[cli][info] Found matching plugin hls for URL hlsvariant://http://hlslinear-akc.med2.foxsportsgo.com/hdnts=exp=1556998824~acl=/*~id=311256e0-d23d-44ea-b110-d7f9d5371fdc-356435-1f9f27e40b9d31ec5853c2b972d4f8fc1bd3ad13~hmac=8e7c413013dfec70bab90a3c0d9f5d7b80f074d5a2a70d33da97432074ab03ab/d52f3708ed1c7f367d4012b845a2683b/ls01/foxsports/FOX_SPORTS_2_DUAL_ORIGIN/vod/2019/05/03/73755261/FSG_20190503_FSV_Mainz_05_vs._RB_Leipzig_73755261/master_wired_web_ads.m3u8
[plugin.hls][debug] URL=http://hlslinear-akc.med2.foxsportsgo.com/hdnts=exp=1556998824~acl=/*~id=311256e0-d23d-44ea-b110-d7f9d5371fdc-356435-1f9f27e40b9d31ec5853c2b972d4f8fc1bd3ad13~hmac=8e7c413013dfec70bab90a3c0d9f5d7b80f074d5a2a70d33da97432074ab03ab/d52f3708ed1c7f367d4012b845a2683b/ls01/foxsports/FOX_SPORTS_2_DUAL_ORIGIN/vod/2019/05/03/73755261/FSG_20190503_FSV_Mainz_05_vs._RB_Leipzig_73755261/master_wired_web_ads.m3u8; params={}
[utils.l10n][debug] Language code: en_US
[cli][info] Available streams: 224p (worst), 288p, 360p, 504p, 540p, 720p (best)
[cli][info] Opening stream: 720p (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Segments in this playlist are encrypted
[stream.hls][debug] First Sequence: 0; Last Sequence: 1187
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 0; End Sequence: None
[stream.hls][debug] Adding segment 0 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 1 to queue
[stream.hls][debug] Adding segment 2 to queue
[stream.hls][debug] Adding segment 3 to queue
[stream.hls][debug] Adding segment 4 to queue
[stream.hls][debug] Adding segment 5 to queue
[stream.hls][debug] Adding segment 6 to queue
[stream.hls][debug] Adding segment 7 to queue
[stream.hls][debug] Adding segment 8 to queue
[stream.hls][debug] Adding segment 9 to queue
[stream.hls][debug] Adding segment 10 to queue
[stream.hls][debug] Adding segment 11 to queue
[stream.hls][debug] Adding segment 12 to queue
[stream.hls][debug] Adding segment 13 to queue
[stream.hls][debug] Adding segment 14 to queue
[stream.hls][debug] Adding segment 15 to queue
[stream.hls][debug] Adding segment 16 to queue
[stream.hls][debug] Adding segment 17 to queue
[stream.hls][debug] Adding segment 18 to queue
[stream.hls][debug] Adding segment 19 to queue
[stream.hls][debug] Adding segment 20 to queue
[stream.hls][debug] Adding segment 21 to queue
[stream.hls][debug] Download of segment 0 complete
[cli][debug] Checking file output
[stream.hls][debug] Adding segment 22 to queue
File mainz.ts already exists! Overwrite it? [y/N] [stream.hls][debug] Download of segment 1 complete
[stream.hls][debug] Adding segment 23 to queue
[stream.hls][debug] Download of segment 2 complete
...
[download][mainz.ts] Written 1.49 GB (3m55s @ 1.5 MB/s)[stream.hls][debug] Adding segment 727 to queue
[stream.hls][debug] Download of segment 706 complete
[stream.hls][debug] Adding segment 728 to queue
[download][mainz.ts] Written 1.50 GB (3m56s @ 1.4 MB/s) [stream.hls][debug] Download of segment 707 complete
[download][mainz.ts] Written 1.50 GB (3m58s @ 1.6 MB/s)[stream.hls][debug] Adding segment 729 to queue
[stream.hls][debug] Download of segment 708 complete
[stream.hls][debug] Adding segment 730 to queue
[download][mainz.ts] Written 1.50 GB (3m59s @ 1.6 MB/s) [stream.hls][debug] Download of segment 709 complete
[stream.hls][debug] Adding segment 731 to queue
[download][mainz.ts] Written 1.50 GB (4m1s @ 1.7 MB/s) [stream.hls][debug] Download of segment 710 complete
[stream.hls][debug] Adding segment 732 to queue
[download][mainz.ts] Written 1.51 GB (4m2s @ 1.6 MB/s) [stream.hls][debug] Download of segment 711 complete
[stream.hls][debug] Adding segment 733 to queue
[download][mainz.ts] Written 1.51 GB (4m4s @ 1.5 MB/s) [stream.hls][debug] Download of segment 712 complete
[stream.hls][debug] Adding segment 734 to queue
[download][mainz.ts] Written 1.51 GB (4m5s @ 1.5 MB/s) [stream.hls][debug] Download of segment 713 complete
[stream.hls][debug] Adding segment 735 to queue
[download][mainz.ts] Written 1.51 GB (4m6s @ 1.5 MB/s) [stream.hls][debug] Download of segment 714 complete
[stream.hls][debug] Adding segment 736 to queue
[download][mainz.ts] Written 1.51 GB (4m8s @ 1.4 MB/s) [stream.hls][debug] Cutting off 12 bytes of garbage before decrypting
Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py", line 917, in _bootstrap_inner
self.run()
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/segmented.py", line 167, in run
self.write(segment, result)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/hls.py", line 140, in write
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/hls.py", line 31, in pkcs7_decode
raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 225
^C[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
Interrupted! Exiting...
[cli][info] Closing currently open stream...
```
@beardypig just noticed this is the exact same issue as reported here https://github.com/streamlink/streamlink/issues/2631
If it helps. Just got this error again on cnngo. I was trying to save some episodes of a program.
> [cli][debug] OS: Windows 7
> [cli][debug] Python: 3.6.6
> [cli][debug] Streamlink: 1.2.0+22.g6ac9ee0
> [cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.56.0)
> [cli][info] Found matching plugin hls for URL https://phls-vod.cdn.turner.com/cnnngtv/cnn/hls/2019/09/22/urn:ngtv-show:119744/index.m3u8?hdnts=exp=1570445287~acl=/cnnngtv/cnn/hls/2019/*~id=fe3ad43531e3cd8b66ff7118c70b8913~hmac=015a4876ea09d0833904f5bcedd0a06c3bca515a42fa40c1a1d267d39df7094d
> [plugin.hls][debug] URL=https://phls-vod.cdn.turner.com/cnnngtv/cnn/hls/2019/09/22/urn:ngtv-show:119744/index.m3u8?hdnts=exp=1570445287~acl=/cnnngtv/cnn/hls/2019/*~id=fe3ad43531e3cd8b66ff7118c70b8913~hmac=015a4876ea09d0833904f5bcedd0a06c3bca515a42fa40c1a1d267d39df7094d; params={}
> [cli][info] Available streams: 70k (worst), 360p_alt, 360p (best), 540p_alt, 540p, 720p
> [cli][info] Opening stream: 360p (hls)
> [stream.hls][debug] Reloading playlist
> [stream.hls][debug] Segments in this playlist are encrypted
> [stream.hls][debug] First Sequence: 1; Last Sequence: 377
> [stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 1; End Sequence: 377
> [stream.hls][debug] Adding segment 1 to queue
> [cli][debug] Pre-buffering 8192 bytes
> [stream.hls][debug] Adding segment 2 to queue
> [stream.hls][debug] Adding segment 3 to queue
> [stream.hls][debug] Adding segment 4 to queue
> [stream.hls][debug] Adding segment 5 to queue
> [stream.hls][debug] Adding segment 6 to queue
> [stream.hls][debug] Adding segment 7 to queue
> [stream.hls][debug] Adding segment 8 to queue
> [stream.hls][debug] Adding segment 9 to queue
> [stream.hls][debug] Adding segment 10 to queue
> [stream.hls][debug] Adding segment 11 to queue
> [stream.hls][debug] Adding segment 12 to queue
> [stream.hls][debug] Adding segment 13 to queue
> [stream.hls][debug] Adding segment 14 to queue
> [stream.hls][debug] Adding segment 15 to queue
> [stream.hls][debug] Adding segment 16 to queue
> [stream.hls][debug] Adding segment 17 to queue
> [stream.hls][debug] Adding segment 18 to queue
> [stream.hls][debug] Adding segment 19 to queue
> [stream.hls][debug] Adding segment 20 to queue
> [stream.hls][debug] Adding segment 21 to queue
> [stream.hls][debug] Adding segment 22 to queue
> [stream.hls][debug] Download of segment 1 complete
> [cli][debug] Checking file output
> [cli][debug] Writing stream to output
> [stream.hls][debug] Adding segment 23 to queue
> [stream.hls][debug] Download of segment 2 complete
> [stream.hls][debug] Adding segment 24 to queue
> Exception in thread Thread-HLSStreamWriter:
> Traceback (most recent call last):
> File "threading.py", line 916, in _bootstrap_inner
> File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\segmented.py", line 167, in run
> self.write(segment, result)
> File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\hls.py", line 141, in write
> self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
> File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\hls.py", line 31, in pkcs7_decode
> raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
> streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 99
>
> error: Error when reading from stream: Read timeout, exiting
> [stream.segmented][debug] Closing worker thread
> [stream.segmented][debug] Closing writer thread
> [cli][info] Stream ended
> [cli][info] Closing currently open stream...
A couple of streams worked. Another (this one above), didn't. Exactly same platform. This error is very random, but it seems like it may pop up across various different sites.
I'll chime in here and say that I'm seeing the SAME EXACT thing.
Please don't close this as "too difficult to reproduce". This is a CORE FUNCTION of streamlink, and it is not woking. closing as too difficult to reproduce is dodging a major issue.
What streamlink needs to do if it can't (for some reason) download a queued packet is retry the packet. It's what every single player in the world does, why can't streamlink as well?
@sou7611 It's been open for a year, what exactly is your concern of it being closed? The other was closed because it's a duplicate of this issue. Regarding the functionality, if it's so easy to deal with please submit a PR to add the functionality that will address this. These are also on old versions of Streamlink. If it's still happening to you provide debug output and reproduction steps to actually try and solve the problem since based on the tone of your comment it's happening regularly.
An issue that has been reported 4 times in a year is an edge case, if someone wants to work on it they will, otherwise complaining doesn't exactly motivate people to solve a problem that 99.9% of users are not encountering. This is a free open source project, no one is getting paid to work on this, so keep that in mind. People work on whatever aspects they want as little or as much as they want, it's that simple.
Trying to reproduce it to capture said logs. It happens on a wide variety of services but actually capturing it in action, that's another story.
Like a problem with your car not showing up at the mechanics shop, trying to make this happen on purpose is proving challenging.
Somehow it's clearly getting a packet that's not defined, which screws up the decoding, as it's trying to decode data that's null in length.
FWIW, I'd also suggest the following alteration, if it's desired to not call the decrypt if the data is null, that way you know in the logs if it was triggered :
if decrypted_chunk:
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
else:
log.error("Download of segment {0} was zero bytes in length", sequence.num)
Interesting, something is up with padding as well ... there's a function that cuts off garbage at the end (if the packet isn't an even length of 16) but that apparently either doesn't fix, further damages the packet, or it's just bad to begin with:
stream.hls][debug] Cutting off 15 bytes of garbage before decrypting
Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\segmented.py", line 167, in run
self.write(segment, result)
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\hls.py", line 158, in write
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\hls.py", line 34, in pkcs7_decode
raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 38
This also crashes the stream. It may queue more packets, but it never writes anything past this point.
So here's a question ... does anyone know the history behind the padding%16 cutoff? It's been in the code since livestreamer in 2014 :
https://github.com/chrippa/livestreamer/commit/c38a543c726f9b207a80836edb09f9ae696f0871
Near as I can tell, you don't get garbage unless you have a corrupted segment, and since a corrupted segment won't decode, you get a null decrypted_chunk, which then crashes the stream.
So far, this seems to maintain the stream without causing errors :
if garbage_len:
log.error("Segment {0} is damaged with {0} bytes of padded garbage ", sequence.num, garbage_len)
else:
decrypted_chunk = decryptor.decrypt(data)
if decrypted_chunk:
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
else:
log.error("Download of segment {0} was zero bytes in length", sequence.num)
FYI, been running a bunch of repeated capture tests against foxsportsgo, currently the following code block for handling encyrypted chunks seems to be most stable ... this basically just throws out any packet with padded garbage (I've not found a single instance in testing where a packet with padded gargbage truncated to the nearest /16 in size was not corrupted).
decrypted_chunk = 0
if garbage_len:
log.error("Segment {0} is damaged with {0} bytes of padded garbage ", sequence.num, garbage_len)
else:
decrypted_chunk = decryptor.decrypt(data)
if decrypted_chunk:
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
else:
log.error("Download of segment {0} was zero bytes in length", sequence.num)
I currently get this on maybe 1/8 of my download attempts from Crunchyroll with a valid login. Will start running with debug logging enabled, I've seen it three times so far. If I stream the same content again it usually works the next time. The streams are 1080p usually around 1.5GB in total size, if that means anything.
```
[stream.hls][debug] Adding segment 357 to queue
[stream.hls][debug] Download of segment 336 complete
[stream.hls][debug] Adding segment 358 to queue
[stream.hls][debug] Download of segment 337 complete
[stream.hls][debug] Adding segment 359 to queue
[stream.hls][debug] Download of segment 338 complete
[stream.hls][debug] Adding segment 360 to queue
[stream.hls][debug] Download of segment 339 complete
[stream.hls][debug] Adding segment 361 to queue
[stream.hls][debug] Cutting off 8 bytes of garbage before decrypting
error: Error when reading from stream: Read timeout, exiting
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[cli][info] Closing currently open stream...
Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\stream\segmented.py", line 167, in run
self.write(segment, result)
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\stream\hls.py", line 157, in write
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\stream\hls.py", line 34, in pkcs7_decode
raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 196
```
Could you please give #3446 a try and see whether this fixes the input padding issue?
I encountered the exact same bug with the `pluzz` plugin:
```
$ DISPLAY=:0 streamlink --hls-audio-select '*' --ffmpeg-copyts --mux-subtitles https://www.france.tv/france-2/direct.html best
[cli][info] Found matching plugin pluzz for URL https://www.france.tv/france-2/direct.html
[cli][info] Available streams: 144p (worst), 216p, 360p, 540p, 720p (best)
[cli][info] Opening stream: 720p (hls-multi)
[cli][info] Starting player: /usr/bin/vlc
Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "/usr/lib/python3.9/threading.py", line 954, in _bootstrap_inner
self.run()
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/segmented.py", line 189, in run
self.write(segment, result)
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 135, in write
return self._write(sequence, *args, **kwargs)
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 166, in _write
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 33, in pkcs7_decode
raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 187
```
I'll try the patch from #3446 but as the issue does not occur consistently, it's hard to know if the issue is really fixed.
I tried #3446 and the issue still happens:
```
$ DISPLAY=:0 streamlink --hls-audio-select '*' --ffmpeg-copyts --mux-subtitles https://www.france.tv/france-2/direct.html best
[cli][info] Found matching plugin pluzz for URL https://www.france.tv/france-2/direct.html
[cli][info] Available streams: 144p (worst), 216p, 360p, 540p, 720p (best)
[cli][info] Opening stream: 720p (hls-multi)
[cli][info] Starting player: /usr/bin/vlc
[stream.ffmpegmux][error] Pipe copy aborted: /tmp/ffmpeg-355394-340
Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "/usr/lib/python3.9/threading.py", line 954, in _bootstrap_inner
self.run()
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/segmented.py", line 189, in run
self.write(segment, result)
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 124, in write
return self._write(sequence, *args, **kwargs)
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 147, in _write
self.reader.buffer.write(unpad(decrypted_chunk, AES.block_size, style="pkcs7"))
File "/home/adema/.local/lib/python3.9/site-packages/Crypto/Util/Padding.py", line 90, in unpad
raise ValueError("Padding is incorrect.")
ValueError: Padding is incorrect.
```
@bastimeyer I am happy to test anything else you can think of :+1:
If it helps, in the original hls.py. I fixed it completely on my system by
simply commenting out the truncation, and if garbage_len was set, setting
the chunk to a value of 0 prior to checking for garbage. This
basically makes it skip the packet entirely if there's garbage, and keep
going otherwise.
It's a very minimal change, taking advantage of the logic flow already in
place.
The padding error, when it occurs, is triggered by the decryptor.decrypt
command, trying to decrypt a corrupted packet.
Haven't seen any issues at all in captured .ts streams, and it completely
eliminated the padding error.
data = res.content
# If the input data is not a multiple of 16, cut off any garbage
garbage_len = len(data) % 16
#if garbage_len:
# log.debug("Cutting off {0} bytes of garbage "
# "before decrypting", garbage_len)
# decrypted_chunk = decryptor.decrypt(data[:-garbage_len])
decrypted_chunk = 0
if garbage_len:
log.error("Segment {0} is damaged with {0} bytes of padded
garbage ", sequence.num, garbage_len)
else:
decrypted_chunk = decryptor.decrypt(data)
if decrypted_chunk:
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
else:
log.error("Download of segment {0} was zero bytes in
length", sequence.num)
On Thu, Jan 21, 2021 at 2:02 PM Élie ROUDNINSKI <[email protected]>
wrote:
> I tried #3446 <https://github.com/streamlink/streamlink/pull/3446> and
> the issue still happens:
>
> $ DISPLAY=:0 streamlink --hls-audio-select '*' --ffmpeg-copyts --mux-subtitles https://www.france.tv/france-2/direct.html best
>
> [cli][info] Found matching plugin pluzz for URL https://www.france.tv/france-2/direct.html
>
> [cli][info] Available streams: 144p (worst), 216p, 360p, 540p, 720p (best)
>
> [cli][info] Opening stream: 720p (hls-multi)
>
> [cli][info] Starting player: /usr/bin/vlc
>
> [stream.ffmpegmux][error] Pipe copy aborted: /tmp/ffmpeg-355394-340
>
> Exception in thread Thread-HLSStreamWriter:
>
> Traceback (most recent call last):
>
> File "/usr/lib/python3.9/threading.py", line 954, in _bootstrap_inner
>
> self.run()
>
> File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/segmented.py", line 189, in run
>
> self.write(segment, result)
>
> File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 124, in write
>
> return self._write(sequence, *args, **kwargs)
>
> File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 147, in _write
>
> self.reader.buffer.write(unpad(decrypted_chunk, AES.block_size, style="pkcs7"))
>
> File "/home/adema/.local/lib/python3.9/site-packages/Crypto/Util/Padding.py", line 90, in unpad
>
> raise ValueError("Padding is incorrect.")
>
> ValueError: Padding is incorrect.
>
>
> @bastimeyer <https://github.com/bastimeyer> I am happy to test anything
> else you can think of 👍
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/streamlink/streamlink/issues/2365#issuecomment-764867882>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/ABNBVNHSZ4VGA6JA2V4O763S3B25BANCNFSM4G7VONSQ>
> .
>
Would this solution just remove the offending segment from the stream, so those 5, 6, 10, etc. seconds would not be recorded?
I believe so, but I've not seen it cause any issues in recorded video, so
the question is... is that a bad thing?
If we can't record them due to corruption, it may not be an actual loss
with error checks, re-requests, etc.
On Thu, Jan 21, 2021, 5:31 PM ischmidt20 <[email protected]> wrote:
> Would this solution just remove the offending segment from the stream, so
> those 5, 6, 10, etc. segments would not be recorded?
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/streamlink/streamlink/issues/2365#issuecomment-764983399>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/ABNBVNHUSSMSYYLJNHUV6BLS3CTL3ANCNFSM4G7VONSQ>
> .
>
> Would this solution just remove the offending segment from the stream
Yes, it would remove these segments and would thus get rid of the error, but that's not the solution we're looking for here.
> ValueError: Padding is incorrect.
https://github.com/Legrandin/pycryptodome/blob/v3.9.9/lib/Crypto/Util/Padding.py#L87-L90
Is there any other idea floating around that I could try?
I think I may have stumbled across the cause of this (or one of them, anyway): it seems that Python's requests/urllib3 libraries do not signal any kind of error if the server closes the connection mid-way through a file (i.e. it does not verify that it received as many bytes as it should have, using the Content-Length header).
The padding is corrupt because it's not padding, it's arbitrary data where the download was truncated.
urllib3 does have an optional keyword argument enforce_content_length=True that can be specified. However, I can't see any way in requests to get that passed on to urllib3.
This has apparently been reported in psf/requests#4956 years ago but there is no developer response in that issue.
Closing since this is an upstream error.
Though the ultimate code bug is upstream, that doesn't mean it's not a real problem for streamlink users, and a workaround wouldn't bring real value to them.
Let's reopen for visibility. However, it is a bug/issue in Streamlink's dependencies, and unfortunately there's no clean way of fixing this here.
----
https://github.com/psf/requests/issues/4956#issuecomment-573325001
> **The fix**
> I think urllib3 should just make `enforce_content_length=True` by default.
> ...
> If urllib3 makes that change, then Requests can simply bump their minimum required urllib3 version to whatever release includes the change, and be done.
> Failing that, Requests should pass `enforce_content_length=True` explicitly.
- https://github.com/psf/requests/blob/v2.25.1/requests/adapters.py#L394
- https://github.com/urllib3/urllib3/blob/1.26.5/src/urllib3/response.py#L185-L187
Since `requests.adapters.HTTPAdapter.send` doesn't allow for custom parameters to be set for `urllib3.response.HTTPResponse`, this means all that could be done in Streamlink is patching out request's import of urllib3's HTTPResponse. This needs to be done in `streamlink.plugin.api.http_session`. Since I haven't run into this issue yet, I can't test this myself.
Any chance you can recreate this issue with debug logging enabled (`-l debug`)?
I can try... to be honest the error rate is pretty low (maybe 1 in 25?) and like I said, I have no idea when it's going to show up. I'll just run streamlink on debug from now on though and update if it comes up!
Hey, I just now got back on this... but here's the log:
```
airbears2-10-142-27-169:streams isaac$ streamlink --http-cookie "access_token=eyJhbGciOiJIUzI1NiJ9.eyJpcGlkIjoiaWFwUmVjZWlwdERldmljZTpEZXZpY2U6Nzk0YmFlMTAtYTdjYy0xMWU4LWFmYWYtODMxYTg4NTMxM2Y3OjNlMGY2YWQwLTE4ZTAtNDQzOS04MzYwLWUyODlhYzMyMGZiZiIsImNsaWVudElkIjoiZm94c3BvcnRzZ28tdjEuMC4wIiwicGNfbWF4X3JhdGluZ19tb3ZpZSI6IiIsImNvbnRleHQiOnt9LCJ2ZXJpZmljYXRpb25MZXZlbCI6MCwiZXhwIjoxNTQzMTc5NDQ0LCJ0eXBlIjoiVXNlciIsImlhdCI6MTU0MDU4NzQ0NywidXNlcmlkIjoiMzExMjU2ZTAtZDIzZC00NGVhLWIxMTAtZDdmOWQ1MzcxZmRjLTM1NjQzNS0xZjlmMjdlNDBiOWQzMWVjNTg1M2MyYjk3MmQ0ZjhmYzFiZDNhZDEzIiwidmVyc2lvbiI6InYxLjAiLCJwY19tYXhfcmF0aW5nX3R2IjoiIn0.pME0fTZZSG4YW49EoAW9litm_IciS1mDdKva1Z8z1rQ" --http-cookie "Authorization=eyJraWQiOiJ2MS4wIiwiYWxnIjoiSFMyNTYifQ.eyJpcGlkIjoiaWFwUmVjZWlwdERldmljZTpEZXZpY2U6NGRmNDBhODAtMzhhMS0xMWU5LThhN2UtNTlhOThjYzY4NTg2OmYwMTRjYmNmLWZiNDEtNDE4MC1hMmNkLWM5Mjk5MTAzMDQxYyIsImNsaWVudElkIjoic2Vzc2lvbi1zZXJ2aWNlLXYxLjAiLCJjb250ZXh0Ijp7ImlkIjoiMzZiMmJlNjAtNmRkYi0xMWU5LTk0ODAtMGEzNDBhMmM3MTE0IiwidHlwZSI6IlJFR0lTVEVSRUQiLCJpcF9hZGRyZXNzIjoiMTM2LjE1Mi4xNDMuMjUiLCJkZXZpY2UiOnsiaWQiOiJleUpoYkdjaU9pSklVekkxTmlKOS5leUpwY0dsa0lqb2lhV0Z3VW1WalpXbHdkRVJsZG1salpUcEVaWFpwWTJVNk5HUm1OREJoT0RBdE16aGhNUzB4TVdVNUxUaGhOMlV0TlRsaE9UaGpZelk0TlRnMk9tWXdNVFJqWW1ObUxXWmlOREV0TkRFNE1DMWhNbU5rTFdNNU1qazVNVEF6TURReFl5SXNJbU5zYVdWdWRFbGtJam9pWm05NGMzQnZjblJ6WjI4dGRqRXVNQzR3SWl3aWNHTmZiV0Y0WDNKaGRHbHVaMTl0YjNacFpTSTZJaUlzSW1OdmJuUmxlSFFpT250OUxDSjJaWEpwWm1sallYUnBiMjVNWlhabGJDSTZNQ3dpWlhod0lqb3hOVFUzTXpRME1qZzBMQ0owZVhCbElqb2lWWE5sY2lJc0ltbGhkQ0k2TVRVMU5EYzFNakk0Tnl3aWRYTmxjbWxrSWpvaU16RXhNalUyWlRBdFpESXpaQzAwTkdWaExXSXhNVEF0WkRkbU9XUTFNemN4Wm1SakxUTTFOalF6TlMweFpqbG1NamRsTkRCaU9XUXpNV1ZqTlRnMU0yTXlZamszTW1RMFpqaG1ZekZpWkROaFpERXpJaXdpZG1WeWMybHZiaUk2SW5ZeExqQWlMQ0p3WTE5dFlYaGZjbUYwYVc1blgzUjJJam9pSW4wLjBBSHRjdUdTNlFLQkozbV9OQlBhbTV1cFZuSTRpcFdsUnhKXzFYdU1GMXMiLCJwbGF0Zm9ybSI6IndlYiJ9LCJ1c2VyIjp7ImlkIjoiMzExMjU2ZTAtZDIzZC00NGVhLWIxMTAtZDdmOWQ1MzcxZmRjLTM1NjQzNS0xZjlmMjdlNDBiOWQzMWVjNTg1M2MyYjk3MmQ0ZjhmYzFiZDNhZDEzIiwiaXBpZCI6ImlhcFJlY2VpcHREZXZpY2U6RGV2aWNlOjRkZjQwYTgwLTM4YTEtMTFlOS04YTdlLTU5YTk4Y2M2ODU4NjpmMDE0Y2JjZi1mYjQxLTQxODAtYTJjZC1jOTI5OTEwMzA0MWMiLCJiaWxsaW5nX2xvY2F0aW9uIjp7InR5cGUiOiJaSVBfQ09ERSIsInppcF9jb2RlIjoiMDcwNDAifSwicmVnaXN0cmF0aW9uIjp7ImF1dGhfcHJvdmlkZXIiOiJWZXJpem9uIiwiZW50aXRsZW1lbnRzIjpbImZveGRlcCIsImZiYy1mb3giLCJ5ZXMiLCJmY3MiLCJmczEiLCJmczIiXSwiZXhwaXJlc19vbiI6IjIwMTktMDUtMjFUMDA6MTI6MzQuMDAwKzAwMDAifX0sImdlbmVyYXRlZF9vbiI6IjIwMTktMDUtMDNUMTk6Mzk6NDkuNDQ2KzAwMDAiLCJ1cGRhdGVkX29uIjoiMjAxOS0wNS0wM1QxOTozOTo0OS40NDYrMDAwMCIsImV4cGlyZXNfb24iOiIyMDE5LTA1LTAzVDIzOjM5OjQ5LjQ0NiswMDAwIiwiYXZhaWxhYmxlX2NvbnRlbnQiOnsibmF0aW9uYWwiOnsiY2FsbF9zaWducyI6WyJCR1RFTk8yIiwiQkdURU5PMyIsIkJHVEVOTzQiLCJCSUdURU4iLCJGUzEiLCJGUzIiLCJGWERFUCIsIkZDU0EiLCJGQ1NDIiwiRkNTUCJdfSwiZ2VvIjp7ImxvY2F0aW9uIjp7InR5cGUiOiJaSVBfQ09ERSIsInppcF9jb2RlIjoiOTQ3MjAiLCJjb3VudHJ5X2NvZGUiOiJ1cyJ9LCJyc25fY2hhbm5lbF9ncm91cHMiOlsiIl0sInJzbl9jYWxsX3NpZ25zIjpbIiJdLCJhZmZpbGlhdGVfY2FsbF9zaWducyI6WyJLVFZVIl19LCJob21lIjp7ImxvY2F0aW9uIjp7InR5cGUiOiJaSVBfQ09ERSIsInppcF9jb2RlIjoiMDcwNDAifSwicnNuX2NoYW5uZWxfZ3JvdXBzIjpbInllcyJdLCJyc25fY2FsbF9zaWducyI6WyJZRVMiXSwiYWZmaWxpYXRlX2NhbGxfc2lnbnMiOlsiV05ZVyJdLCJ0ZWFtcyI6W3siaWQiOiJhNTM4ZmZhZi0yODc4LTQ2MDEtOGQ4Yy01OTg1NzNhYTMwMWEiLCJuYW1lIjoiQnJvb2tseW4gTmV0cyIsInNwb3J0IjoiTkJBIn0seyJpZCI6IjM1MDNhZTUxLWJiM2YtNDc3My1hODE4LWIzNWFiYjc3NjJiMyIsIm5hbWUiOiJOZXcgWW9yayBZYW5rZWVzIiwic3BvcnQiOiJNTEIifV19fSwicGFydG5lciI6eyJuYW1lIjoiZm94c3BvcnRzIn19LCJpcEFkZHJlc3MiOiIxMzYuMTUyLjE0My4yNSIsImV4cCI6MTU1NjkyNjc4OSwidHlwZSI6IlVzZXIiLCJ1c2VyaWQiOiIzMTEyNTZlMC1kMjNkLTQ0ZWEtYjExMC1kN2Y5ZDUzNzFmZGMtMzU2NDM1LTFmOWYyN2U0MGI5ZDMxZWM1ODUzYzJiOTcyZDRmOGZjMWJkM2FkMTMiLCJpYXQiOjE1NTY5MTIzODksInZlcnNpb24iOiJ2MS4wIn0.qxPYSK5Kk8u1Eufdlns-k9YZ4npIgVHcZd4L4rI1pVk" --hls-segment-timeout 1000 --hls-timeout 1000 "hlsvariant://http://hlslinear-akc.med2.foxsportsgo.com/hdnts=exp=1556998824~acl=/*~id=311256e0-d23d-44ea-b110-d7f9d5371fdc-356435-1f9f27e40b9d31ec5853c2b972d4f8fc1bd3ad13~hmac=8e7c413013dfec70bab90a3c0d9f5d7b80f074d5a2a70d33da97432074ab03ab/d52f3708ed1c7f367d4012b845a2683b/ls01/foxsports/FOX_SPORTS_2_DUAL_ORIGIN/vod/2019/05/03/73755261/FSG_20190503_FSV_Mainz_05_vs._RB_Leipzig_73755261/master_wired_web_ads.m3u8" best --hls-live-restart -l debug -o mainz.ts
[cli][debug] OS: macOS 10.14.4
[cli][debug] Python: 3.7.0
[cli][debug] Streamlink: 1.0.0
[cli][debug] Requests(2.21.0), Socks(1.6.7), Websocket(0.53.0)
[cli][info] Found matching plugin hls for URL hlsvariant://http://hlslinear-akc.med2.foxsportsgo.com/hdnts=exp=1556998824~acl=/*~id=311256e0-d23d-44ea-b110-d7f9d5371fdc-356435-1f9f27e40b9d31ec5853c2b972d4f8fc1bd3ad13~hmac=8e7c413013dfec70bab90a3c0d9f5d7b80f074d5a2a70d33da97432074ab03ab/d52f3708ed1c7f367d4012b845a2683b/ls01/foxsports/FOX_SPORTS_2_DUAL_ORIGIN/vod/2019/05/03/73755261/FSG_20190503_FSV_Mainz_05_vs._RB_Leipzig_73755261/master_wired_web_ads.m3u8
[plugin.hls][debug] URL=http://hlslinear-akc.med2.foxsportsgo.com/hdnts=exp=1556998824~acl=/*~id=311256e0-d23d-44ea-b110-d7f9d5371fdc-356435-1f9f27e40b9d31ec5853c2b972d4f8fc1bd3ad13~hmac=8e7c413013dfec70bab90a3c0d9f5d7b80f074d5a2a70d33da97432074ab03ab/d52f3708ed1c7f367d4012b845a2683b/ls01/foxsports/FOX_SPORTS_2_DUAL_ORIGIN/vod/2019/05/03/73755261/FSG_20190503_FSV_Mainz_05_vs._RB_Leipzig_73755261/master_wired_web_ads.m3u8; params={}
[utils.l10n][debug] Language code: en_US
[cli][info] Available streams: 224p (worst), 288p, 360p, 504p, 540p, 720p (best)
[cli][info] Opening stream: 720p (hls)
[stream.hls][debug] Reloading playlist
[stream.hls][debug] Segments in this playlist are encrypted
[stream.hls][debug] First Sequence: 0; Last Sequence: 1187
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 0; End Sequence: None
[stream.hls][debug] Adding segment 0 to queue
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] Adding segment 1 to queue
[stream.hls][debug] Adding segment 2 to queue
[stream.hls][debug] Adding segment 3 to queue
[stream.hls][debug] Adding segment 4 to queue
[stream.hls][debug] Adding segment 5 to queue
[stream.hls][debug] Adding segment 6 to queue
[stream.hls][debug] Adding segment 7 to queue
[stream.hls][debug] Adding segment 8 to queue
[stream.hls][debug] Adding segment 9 to queue
[stream.hls][debug] Adding segment 10 to queue
[stream.hls][debug] Adding segment 11 to queue
[stream.hls][debug] Adding segment 12 to queue
[stream.hls][debug] Adding segment 13 to queue
[stream.hls][debug] Adding segment 14 to queue
[stream.hls][debug] Adding segment 15 to queue
[stream.hls][debug] Adding segment 16 to queue
[stream.hls][debug] Adding segment 17 to queue
[stream.hls][debug] Adding segment 18 to queue
[stream.hls][debug] Adding segment 19 to queue
[stream.hls][debug] Adding segment 20 to queue
[stream.hls][debug] Adding segment 21 to queue
[stream.hls][debug] Download of segment 0 complete
[cli][debug] Checking file output
[stream.hls][debug] Adding segment 22 to queue
File mainz.ts already exists! Overwrite it? [y/N] [stream.hls][debug] Download of segment 1 complete
[stream.hls][debug] Adding segment 23 to queue
[stream.hls][debug] Download of segment 2 complete
...
[download][mainz.ts] Written 1.49 GB (3m55s @ 1.5 MB/s)[stream.hls][debug] Adding segment 727 to queue
[stream.hls][debug] Download of segment 706 complete
[stream.hls][debug] Adding segment 728 to queue
[download][mainz.ts] Written 1.50 GB (3m56s @ 1.4 MB/s) [stream.hls][debug] Download of segment 707 complete
[download][mainz.ts] Written 1.50 GB (3m58s @ 1.6 MB/s)[stream.hls][debug] Adding segment 729 to queue
[stream.hls][debug] Download of segment 708 complete
[stream.hls][debug] Adding segment 730 to queue
[download][mainz.ts] Written 1.50 GB (3m59s @ 1.6 MB/s) [stream.hls][debug] Download of segment 709 complete
[stream.hls][debug] Adding segment 731 to queue
[download][mainz.ts] Written 1.50 GB (4m1s @ 1.7 MB/s) [stream.hls][debug] Download of segment 710 complete
[stream.hls][debug] Adding segment 732 to queue
[download][mainz.ts] Written 1.51 GB (4m2s @ 1.6 MB/s) [stream.hls][debug] Download of segment 711 complete
[stream.hls][debug] Adding segment 733 to queue
[download][mainz.ts] Written 1.51 GB (4m4s @ 1.5 MB/s) [stream.hls][debug] Download of segment 712 complete
[stream.hls][debug] Adding segment 734 to queue
[download][mainz.ts] Written 1.51 GB (4m5s @ 1.5 MB/s) [stream.hls][debug] Download of segment 713 complete
[stream.hls][debug] Adding segment 735 to queue
[download][mainz.ts] Written 1.51 GB (4m6s @ 1.5 MB/s) [stream.hls][debug] Download of segment 714 complete
[stream.hls][debug] Adding segment 736 to queue
[download][mainz.ts] Written 1.51 GB (4m8s @ 1.4 MB/s) [stream.hls][debug] Cutting off 12 bytes of garbage before decrypting
Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/threading.py", line 917, in _bootstrap_inner
self.run()
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/segmented.py", line 167, in run
self.write(segment, result)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/hls.py", line 140, in write
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/streamlink/stream/hls.py", line 31, in pkcs7_decode
raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 225
^C[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
Interrupted! Exiting...
[cli][info] Closing currently open stream...
```
@beardypig just noticed this is the exact same issue as reported here https://github.com/streamlink/streamlink/issues/2631
If it helps. Just got this error again on cnngo. I was trying to save some episodes of a program.
> [cli][debug] OS: Windows 7
> [cli][debug] Python: 3.6.6
> [cli][debug] Streamlink: 1.2.0+22.g6ac9ee0
> [cli][debug] Requests(2.22.0), Socks(1.7.1), Websocket(0.56.0)
> [cli][info] Found matching plugin hls for URL https://phls-vod.cdn.turner.com/cnnngtv/cnn/hls/2019/09/22/urn:ngtv-show:119744/index.m3u8?hdnts=exp=1570445287~acl=/cnnngtv/cnn/hls/2019/*~id=fe3ad43531e3cd8b66ff7118c70b8913~hmac=015a4876ea09d0833904f5bcedd0a06c3bca515a42fa40c1a1d267d39df7094d
> [plugin.hls][debug] URL=https://phls-vod.cdn.turner.com/cnnngtv/cnn/hls/2019/09/22/urn:ngtv-show:119744/index.m3u8?hdnts=exp=1570445287~acl=/cnnngtv/cnn/hls/2019/*~id=fe3ad43531e3cd8b66ff7118c70b8913~hmac=015a4876ea09d0833904f5bcedd0a06c3bca515a42fa40c1a1d267d39df7094d; params={}
> [cli][info] Available streams: 70k (worst), 360p_alt, 360p (best), 540p_alt, 540p, 720p
> [cli][info] Opening stream: 360p (hls)
> [stream.hls][debug] Reloading playlist
> [stream.hls][debug] Segments in this playlist are encrypted
> [stream.hls][debug] First Sequence: 1; Last Sequence: 377
> [stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 1; End Sequence: 377
> [stream.hls][debug] Adding segment 1 to queue
> [cli][debug] Pre-buffering 8192 bytes
> [stream.hls][debug] Adding segment 2 to queue
> [stream.hls][debug] Adding segment 3 to queue
> [stream.hls][debug] Adding segment 4 to queue
> [stream.hls][debug] Adding segment 5 to queue
> [stream.hls][debug] Adding segment 6 to queue
> [stream.hls][debug] Adding segment 7 to queue
> [stream.hls][debug] Adding segment 8 to queue
> [stream.hls][debug] Adding segment 9 to queue
> [stream.hls][debug] Adding segment 10 to queue
> [stream.hls][debug] Adding segment 11 to queue
> [stream.hls][debug] Adding segment 12 to queue
> [stream.hls][debug] Adding segment 13 to queue
> [stream.hls][debug] Adding segment 14 to queue
> [stream.hls][debug] Adding segment 15 to queue
> [stream.hls][debug] Adding segment 16 to queue
> [stream.hls][debug] Adding segment 17 to queue
> [stream.hls][debug] Adding segment 18 to queue
> [stream.hls][debug] Adding segment 19 to queue
> [stream.hls][debug] Adding segment 20 to queue
> [stream.hls][debug] Adding segment 21 to queue
> [stream.hls][debug] Adding segment 22 to queue
> [stream.hls][debug] Download of segment 1 complete
> [cli][debug] Checking file output
> [cli][debug] Writing stream to output
> [stream.hls][debug] Adding segment 23 to queue
> [stream.hls][debug] Download of segment 2 complete
> [stream.hls][debug] Adding segment 24 to queue
> Exception in thread Thread-HLSStreamWriter:
> Traceback (most recent call last):
> File "threading.py", line 916, in _bootstrap_inner
> File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\segmented.py", line 167, in run
> self.write(segment, result)
> File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\hls.py", line 141, in write
> self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
> File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\hls.py", line 31, in pkcs7_decode
> raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
> streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 99
>
> error: Error when reading from stream: Read timeout, exiting
> [stream.segmented][debug] Closing worker thread
> [stream.segmented][debug] Closing writer thread
> [cli][info] Stream ended
> [cli][info] Closing currently open stream...
A couple of streams worked. Another (this one above), didn't. Exactly same platform. This error is very random, but it seems like it may pop up across various different sites.
I'll chime in here and say that I'm seeing the SAME EXACT thing.
Please don't close this as "too difficult to reproduce". This is a CORE FUNCTION of streamlink, and it is not woking. closing as too difficult to reproduce is dodging a major issue.
What streamlink needs to do if it can't (for some reason) download a queued packet is retry the packet. It's what every single player in the world does, why can't streamlink as well?
@sou7611 It's been open for a year, what exactly is your concern of it being closed? The other was closed because it's a duplicate of this issue. Regarding the functionality, if it's so easy to deal with please submit a PR to add the functionality that will address this. These are also on old versions of Streamlink. If it's still happening to you provide debug output and reproduction steps to actually try and solve the problem since based on the tone of your comment it's happening regularly.
An issue that has been reported 4 times in a year is an edge case, if someone wants to work on it they will, otherwise complaining doesn't exactly motivate people to solve a problem that 99.9% of users are not encountering. This is a free open source project, no one is getting paid to work on this, so keep that in mind. People work on whatever aspects they want as little or as much as they want, it's that simple.
Trying to reproduce it to capture said logs. It happens on a wide variety of services but actually capturing it in action, that's another story.
Like a problem with your car not showing up at the mechanics shop, trying to make this happen on purpose is proving challenging.
Somehow it's clearly getting a packet that's not defined, which screws up the decoding, as it's trying to decode data that's null in length.
FWIW, I'd also suggest the following alteration, if it's desired to not call the decrypt if the data is null, that way you know in the logs if it was triggered :
if decrypted_chunk:
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
else:
log.error("Download of segment {0} was zero bytes in length", sequence.num)
Interesting, something is up with padding as well ... there's a function that cuts off garbage at the end (if the packet isn't an even length of 16) but that apparently either doesn't fix, further damages the packet, or it's just bad to begin with:
stream.hls][debug] Cutting off 15 bytes of garbage before decrypting
Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\segmented.py", line 167, in run
self.write(segment, result)
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\hls.py", line 158, in write
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\hls.py", line 34, in pkcs7_decode
raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 38
This also crashes the stream. It may queue more packets, but it never writes anything past this point.
So here's a question ... does anyone know the history behind the padding%16 cutoff? It's been in the code since livestreamer in 2014 :
https://github.com/chrippa/livestreamer/commit/c38a543c726f9b207a80836edb09f9ae696f0871
Near as I can tell, you don't get garbage unless you have a corrupted segment, and since a corrupted segment won't decode, you get a null decrypted_chunk, which then crashes the stream.
So far, this seems to maintain the stream without causing errors :
if garbage_len:
log.error("Segment {0} is damaged with {0} bytes of padded garbage ", sequence.num, garbage_len)
else:
decrypted_chunk = decryptor.decrypt(data)
if decrypted_chunk:
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
else:
log.error("Download of segment {0} was zero bytes in length", sequence.num)
FYI, been running a bunch of repeated capture tests against foxsportsgo, currently the following code block for handling encyrypted chunks seems to be most stable ... this basically just throws out any packet with padded garbage (I've not found a single instance in testing where a packet with padded gargbage truncated to the nearest /16 in size was not corrupted).
decrypted_chunk = 0
if garbage_len:
log.error("Segment {0} is damaged with {0} bytes of padded garbage ", sequence.num, garbage_len)
else:
decrypted_chunk = decryptor.decrypt(data)
if decrypted_chunk:
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
else:
log.error("Download of segment {0} was zero bytes in length", sequence.num)
I currently get this on maybe 1/8 of my download attempts from Crunchyroll with a valid login. Will start running with debug logging enabled, I've seen it three times so far. If I stream the same content again it usually works the next time. The streams are 1080p usually around 1.5GB in total size, if that means anything.
```
[stream.hls][debug] Adding segment 357 to queue
[stream.hls][debug] Download of segment 336 complete
[stream.hls][debug] Adding segment 358 to queue
[stream.hls][debug] Download of segment 337 complete
[stream.hls][debug] Adding segment 359 to queue
[stream.hls][debug] Download of segment 338 complete
[stream.hls][debug] Adding segment 360 to queue
[stream.hls][debug] Download of segment 339 complete
[stream.hls][debug] Adding segment 361 to queue
[stream.hls][debug] Cutting off 8 bytes of garbage before decrypting
error: Error when reading from stream: Read timeout, exiting
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[cli][info] Closing currently open stream...
Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "threading.py", line 916, in _bootstrap_inner
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\stream\segmented.py", line 167, in run
self.write(segment, result)
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\stream\hls.py", line 157, in write
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
File "C:\Users\kg\AppData\Local\Streamlink\pkgs\streamlink\stream\hls.py", line 34, in pkcs7_decode
raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 196
```
Could you please give #3446 a try and see whether this fixes the input padding issue?
I encountered the exact same bug with the `pluzz` plugin:
```
$ DISPLAY=:0 streamlink --hls-audio-select '*' --ffmpeg-copyts --mux-subtitles https://www.france.tv/france-2/direct.html best
[cli][info] Found matching plugin pluzz for URL https://www.france.tv/france-2/direct.html
[cli][info] Available streams: 144p (worst), 216p, 360p, 540p, 720p (best)
[cli][info] Opening stream: 720p (hls-multi)
[cli][info] Starting player: /usr/bin/vlc
Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "/usr/lib/python3.9/threading.py", line 954, in _bootstrap_inner
self.run()
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/segmented.py", line 189, in run
self.write(segment, result)
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 135, in write
return self._write(sequence, *args, **kwargs)
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 166, in _write
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 33, in pkcs7_decode
raise StreamError("Input is not padded or padding is corrupt, got padding size of {0}".format(val))
streamlink.exceptions.StreamError: Input is not padded or padding is corrupt, got padding size of 187
```
I'll try the patch from #3446 but as the issue does not occur consistently, it's hard to know if the issue is really fixed.
I tried #3446 and the issue still happens:
```
$ DISPLAY=:0 streamlink --hls-audio-select '*' --ffmpeg-copyts --mux-subtitles https://www.france.tv/france-2/direct.html best
[cli][info] Found matching plugin pluzz for URL https://www.france.tv/france-2/direct.html
[cli][info] Available streams: 144p (worst), 216p, 360p, 540p, 720p (best)
[cli][info] Opening stream: 720p (hls-multi)
[cli][info] Starting player: /usr/bin/vlc
[stream.ffmpegmux][error] Pipe copy aborted: /tmp/ffmpeg-355394-340
Exception in thread Thread-HLSStreamWriter:
Traceback (most recent call last):
File "/usr/lib/python3.9/threading.py", line 954, in _bootstrap_inner
self.run()
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/segmented.py", line 189, in run
self.write(segment, result)
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 124, in write
return self._write(sequence, *args, **kwargs)
File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 147, in _write
self.reader.buffer.write(unpad(decrypted_chunk, AES.block_size, style="pkcs7"))
File "/home/adema/.local/lib/python3.9/site-packages/Crypto/Util/Padding.py", line 90, in unpad
raise ValueError("Padding is incorrect.")
ValueError: Padding is incorrect.
```
@bastimeyer I am happy to test anything else you can think of :+1:
If it helps, in the original hls.py. I fixed it completely on my system by
simply commenting out the truncation, and if garbage_len was set, setting
the chunk to a value of 0 prior to checking for garbage. This
basically makes it skip the packet entirely if there's garbage, and keep
going otherwise.
It's a very minimal change, taking advantage of the logic flow already in
place.
The padding error, when it occurs, is triggered by the decryptor.decrypt
command, trying to decrypt a corrupted packet.
Haven't seen any issues at all in captured .ts streams, and it completely
eliminated the padding error.
data = res.content
# If the input data is not a multiple of 16, cut off any garbage
garbage_len = len(data) % 16
#if garbage_len:
# log.debug("Cutting off {0} bytes of garbage "
# "before decrypting", garbage_len)
# decrypted_chunk = decryptor.decrypt(data[:-garbage_len])
decrypted_chunk = 0
if garbage_len:
log.error("Segment {0} is damaged with {0} bytes of padded
garbage ", sequence.num, garbage_len)
else:
decrypted_chunk = decryptor.decrypt(data)
if decrypted_chunk:
self.reader.buffer.write(pkcs7_decode(decrypted_chunk))
else:
log.error("Download of segment {0} was zero bytes in
length", sequence.num)
On Thu, Jan 21, 2021 at 2:02 PM Élie ROUDNINSKI <[email protected]>
wrote:
> I tried #3446 <https://github.com/streamlink/streamlink/pull/3446> and
> the issue still happens:
>
> $ DISPLAY=:0 streamlink --hls-audio-select '*' --ffmpeg-copyts --mux-subtitles https://www.france.tv/france-2/direct.html best
>
> [cli][info] Found matching plugin pluzz for URL https://www.france.tv/france-2/direct.html
>
> [cli][info] Available streams: 144p (worst), 216p, 360p, 540p, 720p (best)
>
> [cli][info] Opening stream: 720p (hls-multi)
>
> [cli][info] Starting player: /usr/bin/vlc
>
> [stream.ffmpegmux][error] Pipe copy aborted: /tmp/ffmpeg-355394-340
>
> Exception in thread Thread-HLSStreamWriter:
>
> Traceback (most recent call last):
>
> File "/usr/lib/python3.9/threading.py", line 954, in _bootstrap_inner
>
> self.run()
>
> File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/segmented.py", line 189, in run
>
> self.write(segment, result)
>
> File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 124, in write
>
> return self._write(sequence, *args, **kwargs)
>
> File "/home/adema/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 147, in _write
>
> self.reader.buffer.write(unpad(decrypted_chunk, AES.block_size, style="pkcs7"))
>
> File "/home/adema/.local/lib/python3.9/site-packages/Crypto/Util/Padding.py", line 90, in unpad
>
> raise ValueError("Padding is incorrect.")
>
> ValueError: Padding is incorrect.
>
>
> @bastimeyer <https://github.com/bastimeyer> I am happy to test anything
> else you can think of 👍
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/streamlink/streamlink/issues/2365#issuecomment-764867882>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/ABNBVNHSZ4VGA6JA2V4O763S3B25BANCNFSM4G7VONSQ>
> .
>
Would this solution just remove the offending segment from the stream, so those 5, 6, 10, etc. seconds would not be recorded?
I believe so, but I've not seen it cause any issues in recorded video, so
the question is... is that a bad thing?
If we can't record them due to corruption, it may not be an actual loss
with error checks, re-requests, etc.
On Thu, Jan 21, 2021, 5:31 PM ischmidt20 <[email protected]> wrote:
> Would this solution just remove the offending segment from the stream, so
> those 5, 6, 10, etc. segments would not be recorded?
>
> —
> You are receiving this because you were mentioned.
> Reply to this email directly, view it on GitHub
> <https://github.com/streamlink/streamlink/issues/2365#issuecomment-764983399>,
> or unsubscribe
> <https://github.com/notifications/unsubscribe-auth/ABNBVNHUSSMSYYLJNHUV6BLS3CTL3ANCNFSM4G7VONSQ>
> .
>
> Would this solution just remove the offending segment from the stream
Yes, it would remove these segments and would thus get rid of the error, but that's not the solution we're looking for here.
> ValueError: Padding is incorrect.
https://github.com/Legrandin/pycryptodome/blob/v3.9.9/lib/Crypto/Util/Padding.py#L87-L90
Is there any other idea floating around that I could try?
I think I may have stumbled across the cause of this (or one of them, anyway): it seems that Python's requests/urllib3 libraries do not signal any kind of error if the server closes the connection mid-way through a file (i.e. it does not verify that it received as many bytes as it should have, using the Content-Length header).
The padding is corrupt because it's not padding, it's arbitrary data where the download was truncated.
urllib3 does have an optional keyword argument enforce_content_length=True that can be specified. However, I can't see any way in requests to get that passed on to urllib3.
This has apparently been reported in psf/requests#4956 years ago but there is no developer response in that issue.
Closing since this is an upstream error.
Though the ultimate code bug is upstream, that doesn't mean it's not a real problem for streamlink users, and a workaround wouldn't bring real value to them.
Let's reopen for visibility. However, it is a bug/issue in Streamlink's dependencies, and unfortunately there's no clean way of fixing this here.
----
https://github.com/psf/requests/issues/4956#issuecomment-573325001
> **The fix**
> I think urllib3 should just make `enforce_content_length=True` by default.
> ...
> If urllib3 makes that change, then Requests can simply bump their minimum required urllib3 version to whatever release includes the change, and be done.
> Failing that, Requests should pass `enforce_content_length=True` explicitly.
- https://github.com/psf/requests/blob/v2.25.1/requests/adapters.py#L394
- https://github.com/urllib3/urllib3/blob/1.26.5/src/urllib3/response.py#L185-L187
Since `requests.adapters.HTTPAdapter.send` doesn't allow for custom parameters to be set for `urllib3.response.HTTPResponse`, this means all that could be done in Streamlink is patching out request's import of urllib3's HTTPResponse. This needs to be done in `streamlink.plugin.api.http_session`. Since I haven't run into this issue yet, I can't test this myself. | 2021-06-02T12:09:39 |
|
streamlink/streamlink | 3,797 | streamlink__streamlink-3797 | [
"3795"
] | 6cdc3ebb141f83c8fe34f2426685443fa1e1b7de | diff --git a/src/streamlink/plugins/youtube.py b/src/streamlink/plugins/youtube.py
--- a/src/streamlink/plugins/youtube.py
+++ b/src/streamlink/plugins/youtube.py
@@ -1,104 +1,47 @@
import logging
import re
-from urllib.parse import parse_qsl, urlparse, urlunparse
+from html import unescape
+from urllib.parse import urlparse, urlunparse
+from streamlink.exceptions import NoStreamsError
from streamlink.plugin import Plugin, PluginError
from streamlink.plugin.api import useragents, validate
-from streamlink.plugin.api.utils import itertags, parse_query
+from streamlink.plugin.api.utils import itertags
from streamlink.stream import HLSStream, HTTPStream
from streamlink.stream.ffmpegmux import MuxedStream
-from streamlink.utils import parse_json, search_dict
+from streamlink.utils import parse_json
log = logging.getLogger(__name__)
-_config_schema = validate.Schema(
- {
- validate.optional("player_response"): validate.all(
- validate.text,
- validate.transform(parse_json),
- {
- validate.optional("streamingData"): {
- validate.optional("hlsManifestUrl"): validate.text,
- validate.optional("formats"): [{
- "itag": int,
- validate.optional("url"): validate.text,
- validate.optional("cipher"): validate.text,
- "qualityLabel": validate.text
- }],
- validate.optional("adaptiveFormats"): [{
- "itag": int,
- "mimeType": validate.all(
- validate.text,
- validate.transform(
- lambda t:
- [t.split(';')[0].split('/')[0], t.split(';')[1].split('=')[1].strip('"')]
- ),
- [validate.text, validate.text],
- ),
- validate.optional("url"): validate.url(scheme="http"),
- validate.optional("cipher"): validate.text,
- validate.optional("signatureCipher"): validate.text,
- validate.optional("qualityLabel"): validate.text,
- validate.optional("bitrate"): int
- }]
- },
- validate.optional("videoDetails"): {
- validate.optional("isLive"): validate.transform(bool),
- validate.optional("author"): validate.text,
- validate.optional("title"): validate.text
- },
- validate.optional("playabilityStatus"): {
- validate.optional("status"): validate.text,
- validate.optional("reason"): validate.text
- },
- },
- ),
- "status": validate.text
- }
-)
-
-_ytdata_re = re.compile(r'ytInitialData\s*=\s*({.*?});', re.DOTALL)
-_url_re = re.compile(r"""
- https?://(?:\w+\.)?youtube\.com
- (?:
- (?:
- /(?:
- watch.+v=
- |
- embed/(?!live_stream)
- |
- v/
- )(?P<video_id>[0-9A-z_-]{11})
- )
- |
+class YouTube(Plugin):
+ _re_url = re.compile(r"""
+ https?://(?:\w+\.)?youtube\.com/
(?:
- /(?:
- (?:user|c(?:hannel)?)/
+ (?:
+ (?:
+ watch\?(?:.*&)*v=
+ |
+ (?P<embed>embed)/(?!live_stream)
+ |
+ v/
+ )(?P<video_id>[0-9A-z_-]{11})
+ )
+ |
+ (?:
+ (?P<embed_live>embed)/live_stream\?channel=[^/?&]+
|
- embed/live_stream\?channel=
- )[^/?&]+
+ (?:c(?:hannel)?/|user/)?[^/?]+/live/?$
+ )
)
|
- (?:
- /(?:c/)?[^/?]+/live/?$
- )
- )
- |
- https?://youtu\.be/(?P<video_id_short>[0-9A-z_-]{11})
-""", re.VERBOSE)
-
+ https?://youtu\.be/(?P<video_id_short>[0-9A-z_-]{11})
+ """, re.VERBOSE)
-class YouTube(Plugin):
- _oembed_url = "https://www.youtube.com/oembed"
- _video_info_url = "https://youtube.com/get_video_info"
+ _re_ytInitialPlayerResponse = re.compile(r"""var\s+ytInitialPlayerResponse\s*=\s*({.*?});\s*var\s+meta\s*=""", re.DOTALL)
+ _re_mime_type = re.compile(r"""^(?P<type>\w+)/(?P<container>\w+); codecs="(?P<codecs>.+)"$""")
- _oembed_schema = validate.Schema(
- {
- "author_name": validate.text,
- "title": validate.text
- }
- )
+ _url_canonical = "https://www.youtube.com/watch?v={video_id}"
# There are missing itags
adp_video = {
@@ -126,29 +69,33 @@ class YouTube(Plugin):
}
def __init__(self, url):
- super().__init__(url)
- parsed = urlparse(self.url)
- if parsed.netloc == 'gaming.youtube.com':
- self.url = urlunparse(parsed._replace(netloc='www.youtube.com'))
+ match = self._re_url.match(url)
+ parsed = urlparse(url)
+
+ if parsed.netloc == "gaming.youtube.com":
+ url = urlunparse(parsed._replace(scheme="https", netloc="www.youtube.com"))
+ elif match.group("video_id_short") is not None:
+ url = self._url_canonical.format(video_id=match.group("video_id_short"))
+ elif match.group("embed") is not None:
+ url = self._url_canonical.format(video_id=match.group("video_id"))
+ else:
+ url = urlunparse(parsed._replace(scheme="https"))
+ super().__init__(url)
+ self._find_canonical_url = match.group("embed_live") is not None
self.author = None
self.title = None
- self.video_id = None
self.session.http.headers.update({'User-Agent': useragents.CHROME})
def get_author(self):
- if self.author is None:
- self.get_oembed
return self.author
def get_title(self):
- if self.title is None:
- self.get_oembed
return self.title
@classmethod
def can_handle_url(cls, url):
- return _url_re.match(url)
+ return cls._re_url.match(url)
@classmethod
def stream_weight(cls, stream):
@@ -167,42 +114,86 @@ def stream_weight(cls, stream):
return weight, group
- @property
- def get_oembed(self):
- if self.video_id is None:
- self.video_id = self._find_video_id(self.url)
-
- params = {
- "url": "https://www.youtube.com/watch?v={0}".format(self.video_id),
- "format": "json"
- }
- res = self.session.http.get(self._oembed_url, params=params)
- data = self.session.http.json(res, schema=self._oembed_schema)
- self.author = data["author_name"]
- self.title = data["title"]
-
- def _create_adaptive_streams(self, info, streams):
+ @classmethod
+ def _get_canonical_url(cls, html):
+ for link in itertags(html, "link"):
+ if link.attributes.get("rel") == "canonical":
+ return link.attributes.get("href")
+
+ @classmethod
+ def _schema_playabilitystatus(cls, data):
+ schema = validate.Schema(
+ {"playabilityStatus": {
+ "status": str,
+ validate.optional("reason"): str
+ }},
+ validate.get("playabilityStatus"),
+ validate.union_get("status", "reason")
+ )
+ return validate.validate(schema, data)
+
+ @classmethod
+ def _schema_videodetails(cls, data):
+ schema = validate.Schema(
+ {"videoDetails": {
+ "videoId": str,
+ "author": str,
+ "title": str,
+ validate.optional("isLiveContent"): validate.transform(bool)
+ }},
+ validate.get("videoDetails"),
+ validate.union_get("videoId", "author", "title", "isLiveContent")
+ )
+ return validate.validate(schema, data)
+
+ @classmethod
+ def _schema_streamingdata(cls, data):
+ schema = validate.Schema(
+ {"streamingData": {
+ validate.optional("hlsManifestUrl"): str,
+ validate.optional("formats"): [validate.all(
+ {
+ "itag": int,
+ "qualityLabel": str,
+ validate.optional("url"): validate.url(scheme="http")
+ },
+ validate.union_get("url", "qualityLabel")
+ )],
+ validate.optional("adaptiveFormats"): [validate.all(
+ {
+ "itag": int,
+ "mimeType": validate.all(
+ str,
+ validate.transform(cls._re_mime_type.search),
+ validate.union_get("type", "codecs"),
+ ),
+ validate.optional("url"): validate.url(scheme="http"),
+ validate.optional("qualityLabel"): str
+ },
+ validate.union_get("url", "qualityLabel", "itag", "mimeType")
+ )]
+ }},
+ validate.get("streamingData"),
+ validate.union_get("hlsManifestUrl", "formats", "adaptiveFormats")
+ )
+ hls_manifest, formats, adaptive_formats = validate.validate(schema, data)
+ return hls_manifest, formats or [], adaptive_formats or []
+
+ def _create_adaptive_streams(self, adaptive_formats):
+ streams = {}
adaptive_streams = {}
best_audio_itag = None
# Extract audio streams from the adaptive format list
- streaming_data = info.get("player_response", {}).get("streamingData", {})
- for stream_info in streaming_data.get("adaptiveFormats", []):
- if "url" not in stream_info:
- continue
- stream_params = dict(parse_qsl(stream_info["url"]))
- if "itag" not in stream_params:
+ for url, label, itag, mimeType in adaptive_formats:
+ if url is None:
continue
- itag = int(stream_params["itag"])
# extract any high quality streams only available in adaptive formats
- adaptive_streams[itag] = stream_info["url"]
-
- stream_type, stream_format = stream_info["mimeType"]
+ adaptive_streams[itag] = url
+ stream_type, stream_codecs = mimeType
if stream_type == "audio":
- stream = HTTPStream(self.session, stream_info["url"])
- name = "audio_{0}".format(stream_format)
- streams[name] = stream
+ streams[f"audio_{stream_codecs}"] = HTTPStream(self.session, url)
# find the best quality audio stream m4a, opus or vorbis
if best_audio_itag is None or self.adp_audio[itag] > self.adp_audio[best_audio_itag]:
@@ -211,151 +202,75 @@ def _create_adaptive_streams(self, info, streams):
if best_audio_itag and adaptive_streams and MuxedStream.is_usable(self.session):
aurl = adaptive_streams[best_audio_itag]
for itag, name in self.adp_video.items():
- if itag in adaptive_streams:
- vurl = adaptive_streams[itag]
- log.debug("MuxedStream: v {video} a {audio} = {name}".format(
- audio=best_audio_itag,
- name=name,
- video=itag,
- ))
- streams[name] = MuxedStream(self.session,
- HTTPStream(self.session, vurl),
- HTTPStream(self.session, aurl))
+ if itag not in adaptive_streams:
+ continue
+ vurl = adaptive_streams[itag]
+ log.debug(f"MuxedStream: v {itag} a {best_audio_itag} = {name}")
+ streams[name] = MuxedStream(
+ self.session,
+ HTTPStream(self.session, vurl),
+ HTTPStream(self.session, aurl)
+ )
return streams
- def _find_video_id(self, url):
- m = _url_re.match(url)
- video_id = m.group("video_id") or m.group("video_id_short")
- if video_id:
- log.debug("Video ID from URL")
- return video_id
-
+ def _get_data(self, url):
res = self.session.http.get(url)
if urlparse(res.url).netloc == "consent.youtube.com":
c_data = {}
for _i in itertags(res.text, "input"):
if _i.attributes.get("type") == "hidden":
- c_data[_i.attributes.get("name")] = _i.attributes.get("value")
+ c_data[_i.attributes.get("name")] = unescape(_i.attributes.get("value"))
log.debug(f"c_data_keys: {', '.join(c_data.keys())}")
res = self.session.http.post("https://consent.youtube.com/s", data=c_data)
- datam = _ytdata_re.search(res.text)
- if datam:
- data = parse_json(datam.group(1))
- # find the videoRenderer object, where there is a LVE NOW badge
- for vid_ep in search_dict(data, 'currentVideoEndpoint'):
- video_id = vid_ep.get("watchEndpoint", {}).get("videoId")
- if video_id:
- log.debug("Video ID from currentVideoEndpoint")
- return video_id
- for x in search_dict(data, 'videoRenderer'):
- if x.get("viewCountText", {}).get("runs"):
- if x.get("videoId"):
- log.debug("Video ID from videoRenderer (live)")
- return x["videoId"]
- for bstyle in search_dict(x.get("badges", {}), "style"):
- if bstyle == "BADGE_STYLE_TYPE_LIVE_NOW":
- if x.get("videoId"):
- log.debug("Video ID from videoRenderer (live)")
- return x["videoId"]
-
- if urlparse(url).path.endswith(("/embed/live_stream", "/live")):
- for link in itertags(res.text, "link"):
- if link.attributes.get("rel") == "canonical":
- canon_link = link.attributes.get("href")
- if canon_link != url:
- if canon_link.endswith("v=live_stream"):
- log.debug("The video is not available")
- break
- else:
- log.debug("Re-directing to canonical URL: {0}".format(canon_link))
- return self._find_video_id(canon_link)
-
- raise PluginError("Could not find a video on this page")
-
- def _get_stream_info(self, video_id):
- # normal
- _params_1 = {"el": "detailpage"}
- # age restricted
- _params_2 = {"el": "embedded"}
- # embedded restricted
- _params_3 = {"eurl": "https://youtube.googleapis.com/v/{0}".format(video_id)}
-
- count = 0
- info_parsed = None
- for _params in (_params_1, _params_2, _params_3):
- count += 1
- params = {"video_id": video_id, "html5": "1"}
- params.update(_params)
-
- res = self.session.http.get(self._video_info_url, params=params)
- info_parsed = parse_query(res.text, name="config", schema=_config_schema)
- player_response = info_parsed.get("player_response", {})
- playability_status = player_response.get("playabilityStatus", {})
- if (playability_status.get("status") != "OK"):
- reason = playability_status.get("reason")
- log.debug("get_video_info - {0}: {1}".format(
- count, reason)
- )
- continue
- self.author = player_response.get("videoDetails", {}).get("author")
- self.title = player_response.get("videoDetails", {}).get("title")
- log.debug("get_video_info - {0}: Found data".format(count))
- break
+ if self._find_canonical_url:
+ self._find_canonical_url = False
+ canonical_url = self._get_canonical_url(res.text)
+ if canonical_url is None:
+ raise NoStreamsError(url)
+ return self._get_data(canonical_url)
- return info_parsed
+ match = re.search(self._re_ytInitialPlayerResponse, res.text)
+ if not match:
+ raise PluginError("Missing initial player response data")
- def _get_streams(self):
- is_live = False
+ return parse_json(match.group(1))
- self.video_id = self._find_video_id(self.url)
- log.debug(f"Using video ID: {self.video_id}")
+ def _get_streams(self):
+ data = self._get_data(self.url)
- info = self._get_stream_info(self.video_id)
- if info and info.get("status") == "fail":
- log.error("Could not get video info: {0}".format(info.get("reason")))
- return
- elif not info:
- log.error("Could not get video info")
+ status, reason = self._schema_playabilitystatus(data)
+ if status != "OK":
+ log.error(f"Could not get video info: {reason}")
return
- if info.get("player_response", {}).get("videoDetails", {}).get("isLive"):
+ video_id, self.author, self.title, is_live = self._schema_videodetails(data)
+ log.debug(f"Using video ID: {video_id}")
+
+ if is_live:
log.debug("This video is live.")
- is_live = True
streams = {}
- protected = False
- if (info.get("player_response", {}).get("streamingData", {}).get("adaptiveFormats", [{}])[0].get("cipher")
- or info.get("player_response", {}).get("streamingData", {}).get("adaptiveFormats", [{}])[0].get("signatureCipher")
- or info.get("player_response", {}).get("streamingData", {}).get("formats", [{}])[0].get("cipher")):
- protected = True
+ hls_manifest, formats, adaptive_formats = self._schema_streamingdata(data)
+
+ protected = next((True for url, *_ in formats + adaptive_formats if url is None), False)
+ if protected:
log.debug("This video may be protected.")
- for stream_info in info.get("player_response", {}).get("streamingData", {}).get("formats", []):
- if "url" not in stream_info:
+ for url, label in formats:
+ if url is None:
continue
- stream = HTTPStream(self.session, stream_info["url"])
- name = stream_info["qualityLabel"]
-
- streams[name] = stream
+ streams[label] = HTTPStream(self.session, url)
if not is_live:
- streams = self._create_adaptive_streams(info, streams)
+ streams.update(self._create_adaptive_streams(adaptive_formats))
- hls_manifest = info.get("player_response", {}).get("streamingData", {}).get("hlsManifestUrl")
if hls_manifest:
- try:
- hls_streams = HLSStream.parse_variant_playlist(
- self.session, hls_manifest, name_key="pixels"
- )
- streams.update(hls_streams)
- except OSError as err:
- log.warning(f"Failed to extract HLS streams: {err}")
+ streams.update(HLSStream.parse_variant_playlist(self.session, hls_manifest, name_key="pixels"))
if not streams and protected:
- raise PluginError("This plugin does not support protected videos, "
- "try youtube-dl instead")
+ raise PluginError("This plugin does not support protected videos, try youtube-dl instead")
return streams
| diff --git a/tests/plugins/test_youtube.py b/tests/plugins/test_youtube.py
--- a/tests/plugins/test_youtube.py
+++ b/tests/plugins/test_youtube.py
@@ -1,6 +1,6 @@
import unittest
-from streamlink.plugins.youtube import YouTube, _url_re
+from streamlink.plugins.youtube import YouTube
from tests.plugins import PluginCanHandleUrl
@@ -9,19 +9,18 @@ class TestPluginCanHandleUrlYouTube(PluginCanHandleUrl):
should_match = [
"https://www.youtube.com/EXAMPLE/live",
- "https://www.youtube.com/c/EXAMPLE",
- "https://www.youtube.com/c/EXAMPLE/",
+ "https://www.youtube.com/EXAMPLE/live/",
"https://www.youtube.com/c/EXAMPLE/live",
"https://www.youtube.com/c/EXAMPLE/live/",
- "https://www.youtube.com/channel/EXAMPLE",
- "https://www.youtube.com/channel/EXAMPLE/",
+ "https://www.youtube.com/channel/EXAMPLE/live",
+ "https://www.youtube.com/channel/EXAMPLE/live/",
+ "https://www.youtube.com/user/EXAMPLE/live",
+ "https://www.youtube.com/user/EXAMPLE/live/",
"https://www.youtube.com/embed/aqz-KE-bpKQ",
"https://www.youtube.com/embed/live_stream?channel=UCNye-wNBqNL5ZzHSJj3l8Bg",
- "https://www.youtube.com/user/EXAMPLE",
- "https://www.youtube.com/user/EXAMPLE/",
- "https://www.youtube.com/user/EXAMPLE/live",
"https://www.youtube.com/v/aqz-KE-bpKQ",
"https://www.youtube.com/watch?v=aqz-KE-bpKQ",
+ "https://www.youtube.com/watch?foo=bar&baz=qux&v=aqz-KE-bpKQ",
"https://youtu.be/0123456789A",
]
@@ -31,6 +30,9 @@ class TestPluginCanHandleUrlYouTube(PluginCanHandleUrl):
"https://www.youtube.com/account",
"https://www.youtube.com/feed/guide_builder",
"https://www.youtube.com/t/terms",
+ "https://www.youtube.com/c/EXAMPLE",
+ "https://www.youtube.com/channel/EXAMPLE",
+ "https://www.youtube.com/user/EXAMPLE",
"https://youtu.be",
"https://youtu.be/",
"https://youtu.be/c/CHANNEL",
@@ -40,7 +42,7 @@ class TestPluginCanHandleUrlYouTube(PluginCanHandleUrl):
class TestPluginYouTube(unittest.TestCase):
def _test_regex(self, url, expected_string, expected_group):
- m = _url_re.match(url)
+ m = YouTube._re_url.match(url)
self.assertIsNotNone(m)
self.assertEqual(expected_string, m.group(expected_group))
| plugins.youtube.py: 404 Intermittent and Repeatable (and related, but not duplicate of 3724 of other 404 issues)
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [X] This is a plugin issue and I have read the contribution guidelines.
- [ ] I am using the latest development version from the master branch. [I apologize, I'm on latest stable, but plugin hasn't been updated in 28 days and we have that installed]
### Description
There have been issues over the past couple of months with YouTube reporting 404s. It's been tricky because it's not always reproducable. We had no problems last two days, and today, half our captures have this problem.
The symptom is no different than 3724 and other previously reported items. The error is the same. Using the simplest execution.
```
ubuntu@ip-XXX-XXX-XXX-XXX:~$ streamlink https://www.youtube.com/watch?v=YertdWavZdk
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=YertdWavZdk
[cli][error] Unable to open URL: https://youtube.com/get_video_info (404 Client Error: Not Found for url: https://www.youtube.com/get_video_info?video_id=YertdWavZdk&html5=1&el=detailpage)
```
However, what we are seeing is similar to what we couldn't narrow down when this occurred a month ago. If you wait 3-5 minutes, or do from different machines, the same call can work, or it can report an error.
From the same machine:
```
ubuntu@ip-XXX-XXX-XXX-XXX:~$ streamlink https://www.youtube.com/watch?v=YertdWavZdk
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=YertdWavZdk
[cli][error] Unable to open URL: https://youtube.com/get_video_info (404 Client Error: Not Found for url: https://www.youtube.com/get_video_info?video_id=YertdWavZdk&html5=1&el=detailpage)
[Note: Paused 10 minutes manually and tried again]
ubuntu@ip-XXX-XXX-XXX-XXX:~$ streamlink https://www.youtube.com/watch?v=YertdWavZdk
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=YertdWavZdk
Available streams: audio_mp4a, audio_opus, 144p (worst), 240p, 360p, 480p (best)
```
If you can test from machines with different IP addresses, you can run the same plain command a few times at the same time, and you'll see about half work, half return the 404.
I'm not sure if I'm missing something on the retry or other recommended fixes (e.g. cookies) but regardless of how complex or simple the query is, we see this intermittent vs. consistent behavior.
Thinking out loud / speculation: a partial rollout of something new in the youtube cluster, a potential change being tested. Just plain don't know. Clearly it's not the plug-in since it behaves some of the time on the same call, but some new behavior (or bug) on YouTube?
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. Run this command on multiple machines (or wait a few minutes in between each call, either works: streamlink `https://www.youtube.com/watch?v=YertdWavZdk` - note you can use any youtube link that was a live stream originally, whether it's not yet live, currently live, or after the stream finishes. URL, have not tested with previously recorded only
### Log output
<!--
DEBUG LOG OUTPUT IS REQUIRED for a plugin issue!
INCLUDE THE ENTIRE COMMAND LINE and make sure to **remove usernames and passwords**
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
Debug log includes important details about your platform. Don't remove it.
https://streamlink.github.io/latest/cli.html#cmdoption-loglevel
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
When the command works / doesn't 404:
```
ubuntu@ip-XXX-XXX-XXX-XXX:~$ streamlink --loglevel debug https://www.youtube.com/watch?v=YertdWavZdk
[cli][debug] OS: Linux-5.4.0-1049-aws-x86_64-with-Ubuntu-18.04-bionic
[cli][debug] Python: 3.6.9
[cli][debug] Streamlink: 2.1.2
[cli][debug] Requests(2.22.0), Socks(1.6.5), Websocket(0.58.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.youtube.com/watch?v=YertdWavZdk
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=YertdWavZdk
[plugins.youtube][debug] Video ID from URL
[plugins.youtube][debug] Using video ID: YertdWavZdk
[plugins.youtube][debug] get_video_info - 1: Found data
[plugins.youtube][debug] MuxedStream: v 135 a 251 = 480p
[plugins.youtube][debug] MuxedStream: v 133 a 251 = 240p
[plugins.youtube][debug] MuxedStream: v 160 a 251 = 144p
Available streams: audio_mp4a, audio_opus, 144p (worst), 240p, 360p, 480p (best)
```
When the command 404s:
```
ubuntu@ip-XXX-XXX-XXX-XXX:~$ streamlink --loglevel debug https://www.youtube.com/watch?v=YertdWavZdk
[cli][debug] OS: Linux-5.4.0-1049-aws-x86_64-with-Ubuntu-18.04-bionic
[cli][debug] Python: 3.6.9
[cli][debug] Streamlink: 2.1.2
[cli][debug] Requests(2.22.0), Socks(1.6.5), Websocket(0.58.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.youtube.com/watch?v=YertdWavZdk
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=YertdWavZdk
[plugins.youtube][debug] Video ID from URL
[plugins.youtube][debug] Using video ID: YertdWavZdk
error: Unable to open URL: https://youtube.com/get_video_info (404 Client Error: Not Found for url: https://www.youtube.com/get_video_info?video_id=YertdWavZdk&html5=1&el=detailpage)
```
Note the two calls above were run on the same machine ~3 minutes apart.
### Additional comments, etc.
I've seen and tried the other suggestions: manually adding a cookie, playing with retries. As best I can tell, this is something on YouTube's end that's now been appearing intermittently for at least 2 months and, in our daily use, has not once been affecting 100% of our calls, which are all structured identically other than the youtube link. Either everything works fine, or half the YouTube calls fail when this appears. Never 100%. In going through our internal Jira, it's always been an intermittent thing.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| Apologies, one key piece. This is NOT a 429 or similar block. We've seen this on First calls to a URL. Also, we can make an identical call via ffmpeg or youtube-dl within seconds to the same URL and neither reports a 429 / block / other countermeasures. Not clear if one or the other or both are compensating for this behind the scenes, but can confirm 100% of the time if we see this intermittent 404, we have not yet encountered any block or restriction on running the exact same youtube URL on the same machine via ytdl / ffmpeg or even manually scraping a stream payload.
@back-to Could the private `/get_video_info` API call be skipped maybe? If I'm not mistaken, the necessary data should already be available in the `ytInitialData` JSON object which is embedded on each video page (I think, not sure). The plugin currently only requests `self.url` and reads the `ytInitialData` data (after returning from the consent dialog) if it can't figure out the video ID from the input URL. That would need to get changed if we need to avoid the private API call.
Apologies, I should have checked the other repos first. 18 days ago, there was an update on the youtube-dl plug-in with the following notes: "youtube.py [youtube] Fix get_video_info request (closes #[29086](https://github.com/ytdl-org/youtube-dl/issues/29086), closes #[29165](https://github.com/ytdl-org/youtube-dl/issues/29165))
This seems to be the age gate, and it appears the plug in now looks for the message about sign in or age gating on get_video_info and falls back to extracting it from` https://youtube.googleapis.com/v/` (function starts around line 1475 - direct link: [https://github.com/ytdl-org/youtube-dl/blob/master/youtube_dl/extractor/youtube.py#L1475](https://github.com/ytdl-org/youtube-dl/blob/master/youtube_dl/extractor/youtube.py#L1475)).
I'd resolve and check in the fix if I could, but afraid I'm a php person and barely competent in writing python (reading I can fake, so the reference on line 1476 appears to be how they resolved, but I could be way off... )...
Does this look right?
I've been working on a complete rewrite of the youtube plugin over the past couple of hours and will submit a PR soon, maybe later today. I will have to split this into multiple commits for reviewing purposes, but I can share a branch on my fork with my current/finished results, so you guys can test it.
As said, the private API calls seem to be unnecessary as it looks like the data is always embedded in the video page via `ytInitialPlayerResponse` (I was looking at the wrong variable name earlier).
To be honest, I haven't really touched the Youtube plugin since I've been working on Streamlink, so I don't know what the edge cases here are as I'm also unfamiliar with Youtube's API and their player data/code, but I haven't found any video/stream types so far which didn't work with my rewrite. Apart from the protected streams of course, which are currently also not supported, but I can't change that.
You can check my rewrite here:
https://github.com/streamlink/streamlink/compare/master...bastimeyer:plugins/youtube/rewrite
Only use this for testing, as it's the first iteration and will probably change again. I will submit a pull request once I've rebased my changes, but that will be later today. I've linked the changes via the branch name and the not commit ID, so I don't have to update my post when something gets changed.
**Install via pip** (install it in a virtualenv)
https://streamlink.github.io/latest/install.html#pypi-package-and-source-code
```bash
$ pip install -U git+https://github.com/bastimeyer/streamlink.git@plugins/youtube/rewrite
```
**Or sideload from here** (use Streamlink's latest **development** version from the master branch)
https://streamlink.github.io/latest/cli.html#sideloading-plugins
```
https://raw.githubusercontent.com/bastimeyer/streamlink/plugins/youtube/rewrite/src/streamlink/plugins/youtube.py
```
@bastimeyer
> streamlink "https://www.youtube.com/channel/UCM39V4aT21lAebPlJToSN2Q/live"
`status` needs an update
https://github.com/bastimeyer/streamlink/blob/1d1fc45703fc30173d1ed62eef1a2415d386507c/src/streamlink/plugins/youtube.py#L120-L123
```
error: Unable to validate result: Unable to validate key 'playabilityStatus': Unable to validate key 'status': 'LIVE_STREAM_OFFLINE' does not equal 'OK' or Unable to validate key 'status': 'LIVE_STREAM_OFFLINE' does not equal 'ERROR' or Unable to validate key 'status': 'LIVE_STREAM_OFFLINE' does not equal ''
```
https://github.com/bastimeyer/streamlink/blob/1d1fc45703fc30173d1ed62eef1a2415d386507c/src/streamlink/plugins/youtube.py#L244
also `if status != "OK":` might be better`
---
urls like `https://www.youtube.com/c/euronews` are currently not supported, not sure if you want to drop it.
> `status` needs an update
Thanks, done.
Also improved the embedded URL handling and fixed the data of the consent dialog which was html-escaped and could redirect to invalid URLs when more than one query params was set (`&`).
Diff here:
https://github.com/bastimeyer/streamlink/compare/1d1fc45..3d2848ae
> `https://www.youtube.com/c/euronews`
Looks like this could be dropped. It's not a video URL and if a channel is live, their live stream can be accessed via `/live` at the end of the URL, eg. `https://www.youtube.com/c/euronews/live`.
I'll take a look at this later and then submit a PR. | 2021-06-17T17:46:30 |
streamlink/streamlink | 3,825 | streamlink__streamlink-3825 | [
"3824"
] | 07029669d58a835bd05029316211343eef78ddf2 | diff --git a/src/streamlink/plugins/mediaklikk.py b/src/streamlink/plugins/mediaklikk.py
--- a/src/streamlink/plugins/mediaklikk.py
+++ b/src/streamlink/plugins/mediaklikk.py
@@ -1,10 +1,12 @@
import logging
import re
+from urllib.parse import unquote, urlparse
-from streamlink.exceptions import PluginError
from streamlink.plugin import Plugin
+from streamlink.plugin.api import validate
from streamlink.stream import HLSStream
-from streamlink.utils.url import update_scheme
+from streamlink.utils import parse_json, update_scheme
+
log = logging.getLogger(__name__)
@@ -12,34 +14,68 @@
class Mediaklikk(Plugin):
PLAYER_URL = "https://player.mediaklikk.hu/playernew/player.php"
- _url_re = re.compile(r"https?://(?:www\.)?(?:mediaklikk|m4sport)\.hu/(?:[\w\-]+\-)?elo/?")
- _id_re = re.compile(r'"streamId":"(\w+)"')
- _file_re = re.compile(r'"file":\s*"([\w\./\\=:\-\?]+)"')
+ _url_re = re.compile(r"https?://(?:www\.)?(?:mediaklikk|m4sport|hirado|petofilive)\.hu/")
+
+ _re_player_manager = re.compile(r"""
+ mtva_player_manager\.player\s*\(\s*
+ document\.getElementById\(\s*"\w+"\s*\)\s*,\s*
+ (?P<json>{.*?})\s*
+ \)\s*;
+ """, re.VERBOSE | re.DOTALL)
+ _re_player_json = re.compile(r"pl\.setup\s*\(\s*(?P<json>{.*?})\s*\)\s*;", re.DOTALL)
@classmethod
def can_handle_url(cls, url):
return cls._url_re.match(url) is not None
def _get_streams(self):
- # get the stream id
- res = self.session.http.get(self.url)
- m = self._id_re.search(res.text)
- if not m:
- raise PluginError("Stream ID could not be extracted.")
-
- # get the m3u8 file url
- params = {
- "video": m.group(1),
+ params = self.session.http.get(self.url, schema=validate.Schema(
+ validate.transform(self._re_player_manager.search),
+ validate.any(None, validate.all(
+ validate.get("json"),
+ validate.transform(parse_json),
+ {
+ "contentId": validate.any(str, int),
+ validate.optional("streamId"): str,
+ validate.optional("idec"): str,
+ validate.optional("token"): str
+ }
+ ))
+ ))
+ if not params:
+ log.error("Could not find player manager data")
+ return
+
+ params.update({
+ "video": (unquote(params.pop("token"))
+ if params.get("token") is not None else
+ params.pop("streamId")),
"noflash": "yes",
- }
- res = self.session.http.get(self.PLAYER_URL, params=params)
- m = self._file_re.search(res.text)
- if m:
- url = update_scheme("https://",
- m.group(1).replace("\\/", "/"))
-
- log.debug("URL={0}".format(url))
- return HLSStream.parse_variant_playlist(self.session, url)
+ "embedded": "0",
+ })
+
+ url_parsed = urlparse(self.url)
+ skip_vods = url_parsed.netloc.endswith("m4sport.hu") and url_parsed.path.startswith("/elo")
+
+ self.session.http.headers.update({"Referer": self.url})
+ playlists = self.session.http.get(self.PLAYER_URL, params=params, schema=validate.Schema(
+ validate.transform(self._re_player_json.search),
+ validate.any(None, validate.all(
+ validate.get("json"),
+ validate.transform(parse_json),
+ {"playlist": [{
+ "file": validate.url(),
+ "type": str
+ }]},
+ validate.get("playlist"),
+ validate.filter(lambda p: p["type"] == "hls"),
+ validate.filter(lambda p: not skip_vods or "vod" not in p["file"]),
+ validate.map(lambda p: update_scheme(self.url, p["file"]))
+ ))
+ ))
+
+ for url in playlists or []:
+ yield from HLSStream.parse_variant_playlist(self.session, url).items()
__plugin__ = Mediaklikk
| diff --git a/tests/plugins/test_mediaklikk.py b/tests/plugins/test_mediaklikk.py
--- a/tests/plugins/test_mediaklikk.py
+++ b/tests/plugins/test_mediaklikk.py
@@ -10,12 +10,12 @@ class TestPluginCanHandleUrlMediaklikk(PluginCanHandleUrl):
'https://www.mediaklikk.hu/duna-world-radio-elo',
'https://www.mediaklikk.hu/m1-elo',
'https://www.mediaklikk.hu/m2-elo',
+ 'https://mediaklikk.hu/video/hirado-2021-06-24-i-adas-6/',
'https://m4sport.hu/elo/',
'https://m4sport.hu/elo/?channelId=m4sport+',
'https://m4sport.hu/elo/?showchannel=mtv4plus',
- ]
-
- should_not_match = [
- 'https://www.mediaklikk.hu',
- 'https://m4sport.hu',
+ 'https://m4sport.hu/euro2020-video/goool2-13-resz',
+ 'https://hirado.hu/videok/',
+ 'https://hirado.hu/videok/nemzeti-sporthirado-2021-06-24-i-adas-2/',
+ 'https://petofilive.hu/video/2021/06/23/the-anahit-klip-limited-edition/',
]
| plugin: support m4sport
Added support for m4sport, during the UEFA championship the page got moved from https://mediaklikk.hu/m4-elo/ to https://m4sport.hu/elo/mtv4live/
| 2021-06-24T18:30:34 |
|
streamlink/streamlink | 3,847 | streamlink__streamlink-3847 | [
"3846"
] | 3995953c49718425db9fafd39a6088a95603dcb4 | diff --git a/src/streamlink/plugins/youtube.py b/src/streamlink/plugins/youtube.py
--- a/src/streamlink/plugins/youtube.py
+++ b/src/streamlink/plugins/youtube.py
@@ -9,7 +9,7 @@
from streamlink.plugin.api.utils import itertags
from streamlink.stream import HLSStream, HTTPStream
from streamlink.stream.ffmpegmux import MuxedStream
-from streamlink.utils import parse_json
+from streamlink.utils import parse_json, search_dict
log = logging.getLogger(__name__)
@@ -29,12 +29,13 @@
|
embed/live_stream\?channel=(?P<embed_live>[^/?&]+)
|
- (?:c(?:hannel)?/|user/)?[^/?]+/live/?$
+ (?:c(?:hannel)?/|user/)?(?P<channel>[^/?]+)(?P<channel_live>/live)?/?$
)
|
https?://youtu\.be/(?P<video_id_short>[\w-]{11})
""", re.VERBOSE))
class YouTube(Plugin):
+ _re_ytInitialData = re.compile(r"""var\s+ytInitialData\s*=\s*({.*?})\s*;\s*</script>""", re.DOTALL)
_re_ytInitialPlayerResponse = re.compile(r"""var\s+ytInitialPlayerResponse\s*=\s*({.*?});\s*var\s+meta\s*=""", re.DOTALL)
_re_mime_type = re.compile(r"""^(?P<type>\w+)/(?P<container>\w+); codecs="(?P<codecs>.+)"$""")
@@ -214,10 +215,11 @@ def _get_res(self, url):
res = self.session.http.post("https://consent.youtube.com/s", data=c_data)
return res
- def _get_data(self, res):
- match = re.search(self._re_ytInitialPlayerResponse, res.text)
+ @staticmethod
+ def _get_data_from_regex(res, regex, descr):
+ match = re.search(regex, res.text)
if not match:
- log.debug("Missing initial player response data")
+ log.debug(f"Missing {descr}")
return
return parse_json(match.group(1))
@@ -265,6 +267,14 @@ def _get_data_from_api(self, res):
)
return parse_json(res.text)
+ @staticmethod
+ def _data_video_id(data):
+ if data:
+ for videoRenderer in search_dict(data, "videoRenderer"):
+ videoId = videoRenderer.get("videoId")
+ if videoId is not None:
+ return videoId
+
def _data_status(self, data):
if not data:
return False
@@ -276,7 +286,17 @@ def _data_status(self, data):
def _get_streams(self):
res = self._get_res(self.url)
- data = self._get_data(res)
+
+ if self.match.group("channel") and not self.match.group("channel_live"):
+ initial = self._get_data_from_regex(res, self._re_ytInitialData, "initial data")
+ video_id = self._data_video_id(initial)
+ if video_id is None:
+ log.error("Could not find videoId on channel page")
+ return
+ self.url = self._url_canonical.format(video_id=video_id)
+ res = self._get_res(self.url)
+
+ data = self._get_data_from_regex(res, self._re_ytInitialPlayerResponse, "initial player response")
if not self._data_status(data):
data = self._get_data_from_api(res)
if not self._data_status(data):
| diff --git a/tests/plugins/test_youtube.py b/tests/plugins/test_youtube.py
--- a/tests/plugins/test_youtube.py
+++ b/tests/plugins/test_youtube.py
@@ -11,14 +11,22 @@ class TestPluginCanHandleUrlYouTube(PluginCanHandleUrl):
__plugin__ = YouTube
should_match = [
- "https://www.youtube.com/EXAMPLE/live",
- "https://www.youtube.com/EXAMPLE/live/",
- "https://www.youtube.com/c/EXAMPLE/live",
- "https://www.youtube.com/c/EXAMPLE/live/",
- "https://www.youtube.com/channel/EXAMPLE/live",
- "https://www.youtube.com/channel/EXAMPLE/live/",
- "https://www.youtube.com/user/EXAMPLE/live",
- "https://www.youtube.com/user/EXAMPLE/live/",
+ "https://www.youtube.com/CHANNELNAME",
+ "https://www.youtube.com/CHANNELNAME/",
+ "https://www.youtube.com/CHANNELNAME/live",
+ "https://www.youtube.com/CHANNELNAME/live/",
+ "https://www.youtube.com/c/CHANNELNAME",
+ "https://www.youtube.com/c/CHANNELNAME/",
+ "https://www.youtube.com/c/CHANNELNAME/live",
+ "https://www.youtube.com/c/CHANNELNAME/live/",
+ "https://www.youtube.com/user/CHANNELNAME",
+ "https://www.youtube.com/user/CHANNELNAME/",
+ "https://www.youtube.com/user/CHANNELNAME/live",
+ "https://www.youtube.com/user/CHANNELNAME/live/",
+ "https://www.youtube.com/channel/CHANNELID",
+ "https://www.youtube.com/channel/CHANNELID/",
+ "https://www.youtube.com/channel/CHANNELID/live",
+ "https://www.youtube.com/channel/CHANNELID/live/",
"https://www.youtube.com/embed/aqz-KE-bpKQ",
"https://www.youtube.com/embed/live_stream?channel=UCNye-wNBqNL5ZzHSJj3l8Bg",
"https://www.youtube.com/v/aqz-KE-bpKQ",
@@ -30,16 +38,13 @@ class TestPluginCanHandleUrlYouTube(PluginCanHandleUrl):
should_not_match = [
"https://accounts.google.com/",
"https://www.youtube.com",
- "https://www.youtube.com/account",
+ "https://www.youtube.com/",
"https://www.youtube.com/feed/guide_builder",
"https://www.youtube.com/t/terms",
- "https://www.youtube.com/c/EXAMPLE",
- "https://www.youtube.com/channel/EXAMPLE",
- "https://www.youtube.com/user/EXAMPLE",
"https://youtu.be",
"https://youtu.be/",
- "https://youtu.be/c/CHANNEL",
- "https://youtu.be/c/CHANNEL/live",
+ "https://youtu.be/c/CHANNELNAME",
+ "https://youtu.be/c/CHANNELNAME/live",
]
| YouTube live stream not detected from channel page
## Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is not a bug report, feature request, or plugin issue/request.
- [x] I have read the contribution guidelines.
- [ ] I am using the latest development version from the master branch.
### Description
Streamlink doesn't detect a YouTube live stream when you put in channel home page as parameter. Tested with several YT channels. If I input direct video link works, but detecting that video from the channel page shows a no plugin error
### Expected / Actual behavior
Streamlink should find an ID of the live stream and start downloading/streaming it. Instead, no plugin error is shown.
### Reproduction steps / Explicit stream URLs to test
Find a YouTube channel that has a live stream
Input: streamlink https://www.youtube.com/c/xxxxxx
Output: error: No plugin can handle URL
### Log output
```
streamlink --loglevel debug https://www.youtube.com/c/xxxxxxx
[cli][debug] OS: Linux-5.4.0-72-generic-x86_64-with-glibc2.29
[cli][debug] Python: 3.8.5
[cli][debug] Streamlink: 2.2.0
[cli][debug] Requests(2.22.0), Socks(1.6.7), Websocket(0.58.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.youtube.com/c/xxxxxxx
[cli][debug] --loglevel=debug
error: No plugin can handle URL: https://www.youtube.com/c/xxxxxxx
```
| See https://github.com/streamlink/streamlink/pull/3797#issuecomment-864443385
Finding a live stream from a channel page is not possible anymore with the removal of the old private API in #3797, even with the fallback API quests added in #3809.
You have to add the `/live` suffix to the URL, otherwise the URL won't match the Youtube plugin, which was an intentional change due to that.
However, as I mentioned in #3797, a URL translation could be added which redirects to `/live` automatically. That is all that can be done. Let me prepare a PR... | 2021-07-04T17:25:28 |
streamlink/streamlink | 3,849 | streamlink__streamlink-3849 | [
"3848"
] | 3995953c49718425db9fafd39a6088a95603dcb4 | diff --git a/src/streamlink/plugins/tv8.py b/src/streamlink/plugins/tv8.py
--- a/src/streamlink/plugins/tv8.py
+++ b/src/streamlink/plugins/tv8.py
@@ -12,23 +12,18 @@
r'https?://www\.tv8\.com\.tr/canli-yayin'
))
class TV8(Plugin):
- _player_schema = validate.Schema(validate.all({
- 'servers': {
- validate.optional('manifest'): validate.url(),
- 'hlsmanifest': validate.url(),
- }},
- validate.get('servers')))
-
- API_URL = 'https://static.personamedia.tv/player/config/tv8.json'
+ _re_hls = re.compile(r"""file\s*:\s*(["'])(?P<hls_url>https?://.*?\.m3u8.*?)\1""")
def get_title(self):
return 'TV8'
def _get_streams(self):
- res = self.session.http.get(self.API_URL)
- data = self.session.http.json(res, schema=self._player_schema)
- log.debug('{0!r}'.format(data))
- return HLSStream.parse_variant_playlist(self.session, data['hlsmanifest'])
+ hls_url = self.session.http.get(self.url, schema=validate.Schema(
+ validate.transform(self._re_hls.search),
+ validate.any(None, validate.get("hls_url"))
+ ))
+ if hls_url is not None:
+ return HLSStream.parse_variant_playlist(self.session, hls_url)
__plugin__ = TV8
| plugins.tv8: doesn't work
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Plugin issues describe broken functionality within a plugin's code base, eg. the streaming site has made breaking changes, streams don't get resolved correctly, or authentication has stopped working, etc.
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace the space character between the square brackets with an x in order to check the boxes -->
- [x] This is a plugin issue and I have read the contribution guidelines.
- [x] I am using the latest development version from the master branch.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
https://www.tv8.com.tr/canli-yayin
### Log output
<!--
DEBUG LOG OUTPUT IS REQUIRED for a plugin issue!
INCLUDE THE ENTIRE COMMAND LINE and make sure to **remove usernames and passwords**
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
Debug log includes important details about your platform. Don't remove it.
https://streamlink.github.io/latest/cli.html#cmdoption-loglevel
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
[cli][debug] OS: Windows
[cli][debug] Python: 3.8.10
[cli][debug] Streamlink: 2.2.0
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(1.1.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.tv8.com.tr/canli-yayin
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --player=mpv.exe
[cli][debug] --rtmpdump=rtmpdump.exe
[cli][debug] --ffmpeg-ffmpeg=ffmpeg.exe
[cli][info] Found matching plugin tv8 for URL https://www.tv8.com.tr/canli-yayin
[plugins.tv8][debug] {'manifest': 'https://tv8.personamedia.tv/tv8', 'hlsmanifest': 'https://tv8.personamedia.tv/tv8hls?fmt=hls'}
[utils.l10n][debug] Language code: tr_TR
error: Unable to open URL: https://tv8.personamedia.tv/tv8hls?fmt=hls (503 Server Error: Service Temporarily Unavailable for url: https://tv8.personamedia.tv/tv8hls?fmt=hls)
```
### Additional comments, etc.
While watching from browser, seeing "https://tv8-tb-live.ercdn.net/tv8-geo/playlist.m3u8" on Network inspector
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
| 2021-07-05T14:13:10 |
||
streamlink/streamlink | 3,880 | streamlink__streamlink-3880 | [
"3868",
"3868"
] | 34b792d139520f2e0a4956f4e59b3f7bcd712087 | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -10,7 +10,10 @@
data_files = []
deps = [
- "requests>=2.26.0,<3.0",
+ # Temporarily set requests to 2.25.1 on Windows to fix issues with randomly failing tests
+ # Don't force an older requests version on non-Windows systems due to packaging reasons
+ "requests>=2.26.0,<3.0 ; platform_system!='Windows'",
+ "requests==2.25.1 ; platform_system=='Windows'",
"isodate",
"websocket-client>=0.58.0",
# Support for SOCKS proxies
| diff --git a/tests/plugins/test_twitch.py b/tests/plugins/test_twitch.py
--- a/tests/plugins/test_twitch.py
+++ b/tests/plugins/test_twitch.py
@@ -5,7 +5,6 @@
import requests_mock
from streamlink import Streamlink
-from streamlink.compat import is_win32
from streamlink.plugin import PluginError
from streamlink.plugins.twitch import Twitch, TwitchHLSStream, TwitchHLSStreamReader, TwitchHLSStreamWriter
from tests.mixins.stream_hls import EventedHLSStreamWriter, Playlist, Segment as _Segment, Tag, TestMixinStreamHLS
@@ -76,7 +75,6 @@ class _TwitchHLSStream(TwitchHLSStream):
__reader__ = _TwitchHLSStreamReader
[email protected](is_win32, "temporarily skip EventedHLSStreamWriter related tests on Windows")
@patch("streamlink.stream.hls.HLSStreamWorker.wait", MagicMock(return_value=True))
class TestTwitchHLSStream(TestMixinStreamHLS, unittest.TestCase):
__stream__ = _TwitchHLSStream
diff --git a/tests/streams/test_hls.py b/tests/streams/test_hls.py
--- a/tests/streams/test_hls.py
+++ b/tests/streams/test_hls.py
@@ -7,7 +7,6 @@
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
-from streamlink.compat import is_win32
from streamlink.session import Streamlink
from streamlink.stream import hls
from tests.mixins.stream_hls import EventedHLSStreamWriter, Playlist, Segment, Tag, TestMixinStreamHLS
@@ -145,7 +144,6 @@ def test_map(self):
self.assertTrue(self.called(map2, once=True), "Downloads second map only once")
[email protected](is_win32, "temporarily skip EventedHLSStreamWriter related tests on Windows")
@patch("streamlink.stream.hls.HLSStreamWorker.wait", Mock(return_value=True))
class TestHLSStreamEncrypted(TestMixinStreamHLS, unittest.TestCase):
__stream__ = EventedHLSStream
diff --git a/tests/streams/test_hls_filtered.py b/tests/streams/test_hls_filtered.py
--- a/tests/streams/test_hls_filtered.py
+++ b/tests/streams/test_hls_filtered.py
@@ -2,7 +2,6 @@
from threading import Event
from unittest.mock import MagicMock, call, patch
-from streamlink.compat import is_win32
from streamlink.stream.hls import HLSStream, HLSStreamReader
from tests.mixins.stream_hls import EventedHLSStreamWriter, Playlist, Segment, TestMixinStreamHLS
@@ -24,7 +23,6 @@ class _TestSubjectHLSStream(HLSStream):
__reader__ = _TestSubjectHLSReader
[email protected](is_win32, "temporarily skip EventedHLSStreamWriter related tests on Windows")
@patch("streamlink.stream.hls.HLSStreamWorker.wait", MagicMock(return_value=True))
class TestFilteredHLSStream(TestMixinStreamHLS, unittest.TestCase):
__stream__ = _TestSubjectHLSStream
| HLS tests randomly failing on Windows due to threading issues
### Checklist
- [X] This is a bug report and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed bug reports](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
This only started happening yesterday, and I still haven't understood why. I'm unable to reproduce this locally and it's only failing in the CI jobs. There haven't been any python or dependency upgrades prior to this, so this must be caused by an upgrade of the Windows CI environment, I think.
https://github.com/streamlink/streamlink/actions
----
For some reason, the following tests (so far) have been randomly failing due to the HLS stream's writer thread not writing the segments correctly. What is weird though is that these tests are supposed to be deterministic with lots of thread locks for writing and reading each segment, so there shouldn't be any timing issues between the threads.
- [`tests/streams/test_hls_filtered.py::TestFilteredHLSStream::test_filtered_closed`](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/streams/test_hls_filtered.py#L133-L167)
- [`tests/streams/test_hls_filtered.py::TestFilteredHLSStream::test_filtered_logging`](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/streams/test_hls_filtered.py#L57-L88)
- [`tests/streams/test_hls.py::TestHLSStreamEncrypted::test_hls_encrypted_aes128_incorrect_padding_length`](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/streams/test_hls.py#L243-L253)
----
Take a look at the [`test_filtered_closed`](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/streams/test_hls_filtered.py#L133-L167) integration test for example, which is the most simple one to understand. It sets up an HLS stream with only two segments which should all get filtered out. Ignore the additional `wait` mock, as it is not important for the issue.
The first assertion checks whether the reader thread's `filter_event` lock is initially set, [which is true](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/src/streamlink/stream/hls.py#L377-L378), as it hasn't begun writing yet.
The next statement is an `await_write()` call, which makes the main thread that runs the test wait until the first `write()` call on the writer thread has finished. Since the first segment gets filtered out, [the reader's `filter_event` should be cleared](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/src/streamlink/stream/hls.py#L172-L175) and the stream output be paused (so that read calls won't time out without data).
For some reason, and I absolutely don't understand why, the next assertion, which checks the state of the `filter_event` lock again, fails. See the log here from my debug branch:
https://github.com/bastimeyer/streamlink/runs/3067746756?check_suite_focus=true#step:6:51
How is this possible when `await_write()` ensures that `write()` on the writer thread has completed?
- https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/mixins/stream_hls.py#L227-L235
- https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/mixins/stream_hls.py#L85-L106
What is going on here?
### Debug log
```text
-
```
HLS tests randomly failing on Windows due to threading issues
### Checklist
- [X] This is a bug report and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed bug reports](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
This only started happening yesterday, and I still haven't understood why. I'm unable to reproduce this locally and it's only failing in the CI jobs. There haven't been any python or dependency upgrades prior to this, so this must be caused by an upgrade of the Windows CI environment, I think.
https://github.com/streamlink/streamlink/actions
----
For some reason, the following tests (so far) have been randomly failing due to the HLS stream's writer thread not writing the segments correctly. What is weird though is that these tests are supposed to be deterministic with lots of thread locks for writing and reading each segment, so there shouldn't be any timing issues between the threads.
- [`tests/streams/test_hls_filtered.py::TestFilteredHLSStream::test_filtered_closed`](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/streams/test_hls_filtered.py#L133-L167)
- [`tests/streams/test_hls_filtered.py::TestFilteredHLSStream::test_filtered_logging`](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/streams/test_hls_filtered.py#L57-L88)
- [`tests/streams/test_hls.py::TestHLSStreamEncrypted::test_hls_encrypted_aes128_incorrect_padding_length`](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/streams/test_hls.py#L243-L253)
----
Take a look at the [`test_filtered_closed`](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/streams/test_hls_filtered.py#L133-L167) integration test for example, which is the most simple one to understand. It sets up an HLS stream with only two segments which should all get filtered out. Ignore the additional `wait` mock, as it is not important for the issue.
The first assertion checks whether the reader thread's `filter_event` lock is initially set, [which is true](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/src/streamlink/stream/hls.py#L377-L378), as it hasn't begun writing yet.
The next statement is an `await_write()` call, which makes the main thread that runs the test wait until the first `write()` call on the writer thread has finished. Since the first segment gets filtered out, [the reader's `filter_event` should be cleared](https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/src/streamlink/stream/hls.py#L172-L175) and the stream output be paused (so that read calls won't time out without data).
For some reason, and I absolutely don't understand why, the next assertion, which checks the state of the `filter_event` lock again, fails. See the log here from my debug branch:
https://github.com/bastimeyer/streamlink/runs/3067746756?check_suite_focus=true#step:6:51
How is this possible when `await_write()` ensures that `write()` on the writer thread has completed?
- https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/mixins/stream_hls.py#L227-L235
- https://github.com/streamlink/streamlink/blob/d04767fa5b812a4e971e454226cecb25b4d975ae/tests/mixins/stream_hls.py#L85-L106
What is going on here?
### Debug log
```text
-
```
| I've been working on this issue for the past couple of days and was able to fix some of the problems with the EventedHLSStreamWriter related tests (and more). There's also some code refactoring of the HLS- and Segmented- classes. I still need to properly rebase my changes before I'm able to submit a PR.
I haven't been able to fully fix the issue yet though, and after already spending more time with debugging this than I would've liked, I'm still terribly confused. As I've said in another PR a couple of days ago, the tests are passing just fine while running the entire test suite, but they fail when running only a subset of the tests, eg. only `tests/streams`. Individual tests are also running just fine.
Just as a brief recap of what the `EventedHLSStreamWriter` class does: it subclasses the `HLSStreamWriter` and waits on each `write()` call for the main thread (which runs the test case) to instruct a write call, so that it can step through the stream write calls individually and make assertions about the HLS stream state. This `await_write()` method on the main thread does have a time limit, in case something goes wrong, so that the test can fail eventually, which means there is a certain time frame where the writer thread needs to make the instructed write call. Same for the main thread which needs to make the `await_write()` call in a certain time frame (the writer thread currently waits indefinitely in this case, but I have fixed this locally).
However, and I absolutely don't understand this, in some cases, the writer thread completely stands still or runs so slowly that it misses some of the time frames and the tests fail, but only when running a subset of all tests. This has nothing to do with thread locks, as this issue occurs when releasing the locks and waking up the writer thread. I have seen this lots of times on my local machine after adding log messages with timestamps all over the code, and I have no explanation for this. It doesn't make sense that there are gaps of several seconds between simple statements or lines of code. I suspect that there is an issue with the way the thread gets woken up.
Take a look at this test branch where I've downgraded requests from 2.26 to 2.25.1:
https://github.com/bastimeyer/streamlink/actions/runs/1056730773
The Windows tests are always passing. I've restarted the CI jobs several times now.
With requests 2.26 and without skipping the tests, at least one of the Windows CI jobs is always failing, every single time.
**This means that there must be an issue with requests-mock and requests 2.26** as we're not doing any real HTTP requests in the tests. And this perfectly makes sense since I've seen random requests-mock responses taking more than 5 seconds, even on my local system, which surely is not right, and this is the cause for the timing window misses in the EventedHLSStreamWriter tests, because either the writer's fetch() method takes too long for some segments to be written or the encryption key takes too long to load to decrypt a segment (or both), which is why the HLS encryption tests fail more often than the other ones.
This further means that even if the tests and test setups get improved and tweaked, there will be no guarantee that this will overall be fixed.
I haven't looked at the code changes of the requests 2.26 release yet, but if one wants to help, please do.
----
We've upgraded requests to `>=2.26.0,<3.0` in #3864 to fix the Windows installer build due to the new dependency tree which needs to be defined explicitly, but what we should actually do is force requests to 2.25.1 on Windows and continue like this until the 2.26 issue with requests-mock is fixed.
I've been working on this issue for the past couple of days and was able to fix some of the problems with the EventedHLSStreamWriter related tests (and more). There's also some code refactoring of the HLS- and Segmented- classes. I still need to properly rebase my changes before I'm able to submit a PR.
I haven't been able to fully fix the issue yet though, and after already spending more time with debugging this than I would've liked, I'm still terribly confused. As I've said in another PR a couple of days ago, the tests are passing just fine while running the entire test suite, but they fail when running only a subset of the tests, eg. only `tests/streams`. Individual tests are also running just fine.
Just as a brief recap of what the `EventedHLSStreamWriter` class does: it subclasses the `HLSStreamWriter` and waits on each `write()` call for the main thread (which runs the test case) to instruct a write call, so that it can step through the stream write calls individually and make assertions about the HLS stream state. This `await_write()` method on the main thread does have a time limit, in case something goes wrong, so that the test can fail eventually, which means there is a certain time frame where the writer thread needs to make the instructed write call. Same for the main thread which needs to make the `await_write()` call in a certain time frame (the writer thread currently waits indefinitely in this case, but I have fixed this locally).
However, and I absolutely don't understand this, in some cases, the writer thread completely stands still or runs so slowly that it misses some of the time frames and the tests fail, but only when running a subset of all tests. This has nothing to do with thread locks, as this issue occurs when releasing the locks and waking up the writer thread. I have seen this lots of times on my local machine after adding log messages with timestamps all over the code, and I have no explanation for this. It doesn't make sense that there are gaps of several seconds between simple statements or lines of code. I suspect that there is an issue with the way the thread gets woken up.
Take a look at this test branch where I've downgraded requests from 2.26 to 2.25.1:
https://github.com/bastimeyer/streamlink/actions/runs/1056730773
The Windows tests are always passing. I've restarted the CI jobs several times now.
With requests 2.26 and without skipping the tests, at least one of the Windows CI jobs is always failing, every single time.
**This means that there must be an issue with requests-mock and requests 2.26** as we're not doing any real HTTP requests in the tests. And this perfectly makes sense since I've seen random requests-mock responses taking more than 5 seconds, even on my local system, which surely is not right, and this is the cause for the timing window misses in the EventedHLSStreamWriter tests, because either the writer's fetch() method takes too long for some segments to be written or the encryption key takes too long to load to decrypt a segment (or both), which is why the HLS encryption tests fail more often than the other ones.
This further means that even if the tests and test setups get improved and tweaked, there will be no guarantee that this will overall be fixed.
I haven't looked at the code changes of the requests 2.26 release yet, but if one wants to help, please do.
----
We've upgraded requests to `>=2.26.0,<3.0` in #3864 to fix the Windows installer build due to the new dependency tree which needs to be defined explicitly, but what we should actually do is force requests to 2.25.1 on Windows and continue like this until the 2.26 issue with requests-mock is fixed. | 2021-07-22T23:00:23 |
streamlink/streamlink | 3,885 | streamlink__streamlink-3885 | [
"3884"
] | 193c5c6eb9147a56df25de160f4d35d6f230733a | diff --git a/src/streamlink/plugins/twitch.py b/src/streamlink/plugins/twitch.py
--- a/src/streamlink/plugins/twitch.py
+++ b/src/streamlink/plugins/twitch.py
@@ -118,6 +118,16 @@ class TwitchHLSStreamReader(HLSStreamReader):
__worker__ = TwitchHLSStreamWorker
__writer__ = TwitchHLSStreamWriter
+ def __init__(self, stream):
+ if stream.disable_ads:
+ log.info("Will skip ad segments")
+ if stream.low_latency:
+ live_edge = max(1, min(LOW_LATENCY_MAX_LIVE_EDGE, stream.session.options.get("hls-live-edge")))
+ stream.session.options.set("hls-live-edge", live_edge)
+ stream.session.options.set("hls-segment-stream-data", True)
+ log.info(f"Low latency streaming (HLS live edge: {live_edge})")
+ super().__init__(stream)
+
class TwitchHLSStream(HLSStream):
__reader__ = TwitchHLSStreamReader
@@ -127,17 +137,6 @@ def __init__(self, *args, **kwargs):
self.disable_ads = self.session.get_plugin_option("twitch", "disable-ads")
self.low_latency = self.session.get_plugin_option("twitch", "low-latency")
- def open(self):
- if self.disable_ads:
- log.info("Will skip ad segments")
- if self.low_latency:
- live_edge = max(1, min(LOW_LATENCY_MAX_LIVE_EDGE, self.session.options.get("hls-live-edge")))
- self.session.options.set("hls-live-edge", live_edge)
- self.session.options.set("hls-segment-stream-data", True)
- log.info("Low latency streaming (HLS live edge: {0})".format(live_edge))
-
- return super().open()
-
@classmethod
def _get_variant_playlist(cls, res):
return load_hls_playlist(res.text, base_uri=res.url)
diff --git a/src/streamlink/stream/hls.py b/src/streamlink/stream/hls.py
--- a/src/streamlink/stream/hls.py
+++ b/src/streamlink/stream/hls.py
@@ -270,7 +270,7 @@ def _playlist_reload_time(self, playlist: M3U8, sequences: List[Sequence]) -> fl
return sequences[-1].segment.duration
if self.playlist_reload_time_override == "live-edge" and sequences:
return sum([s.segment.duration for s in sequences[-max(1, self.live_edge - 1):]])
- if self.playlist_reload_time_override > 0:
+ if type(self.playlist_reload_time_override) is float and self.playlist_reload_time_override > 0:
return self.playlist_reload_time_override
if playlist.target_duration:
return playlist.target_duration
| diff --git a/tests/mixins/stream_hls.py b/tests/mixins/stream_hls.py
--- a/tests/mixins/stream_hls.py
+++ b/tests/mixins/stream_hls.py
@@ -137,7 +137,7 @@ def __init__(self, session: Streamlink, stream: HLSStream, *args, **kwargs):
self.session = session
self.stream = stream
- self.reader = stream.open()
+ self.reader = stream.__reader__(stream)
# ensure that at least one read was attempted before closing the writer thread early
# otherwise, the writer will close the reader's buffer, making it not block on read and yielding empty results
@@ -275,7 +275,7 @@ def get_session(self, options=None, *args, **kwargs):
return Streamlink(options)
# set up HLS responses, create the session and read thread and start it
- def subject(self, playlists, options=None, streamoptions=None, threadoptions=None, *args, **kwargs):
+ def subject(self, playlists, options=None, streamoptions=None, threadoptions=None, start=True, *args, **kwargs):
# filter out tags and duplicate segments between playlist responses while keeping index order
segments_all = [item for playlist in playlists for item in playlist.items if isinstance(item, Segment)]
segments = OrderedDict([(segment.num, segment) for segment in segments_all])
@@ -287,6 +287,12 @@ def subject(self, playlists, options=None, streamoptions=None, threadoptions=Non
self.session = self.get_session(options, *args, **kwargs)
self.stream = self.__stream__(self.session, self.url(playlists[0]), **(streamoptions or {}))
self.thread = self.__readthread__(self.session, self.stream, name=f"ReadThread-{self.id()}", **(threadoptions or {}))
- self.thread.start()
+
+ if start:
+ self.start()
return self.thread, segments
+
+ def start(self):
+ self.thread.reader.open()
+ self.thread.start()
diff --git a/tests/streams/test_hls.py b/tests/streams/test_hls.py
--- a/tests/streams/test_hls.py
+++ b/tests/streams/test_hls.py
@@ -1,5 +1,6 @@
import os
import unittest
+from threading import Event
from unittest.mock import Mock, call, patch
import pytest
@@ -289,11 +290,24 @@ def get_session(self, options=None, reload_time=None, *args, **kwargs):
}))
def subject(self, *args, **kwargs):
- thread, segments = super().subject(*args, **kwargs)
- # wait for the segments to be written, so that we're sure the playlist was parsed
- self.await_write(len(segments))
+ thread, segments = super().subject(start=False, *args, **kwargs)
- return thread.reader.worker.playlist_reload_time
+ # mock the worker thread's _playlist_reload_time method, so that the main thread can wait on its call
+ playlist_reload_time_called = Event()
+ orig_playlist_reload_time = thread.reader.worker._playlist_reload_time
+
+ def mocked_playlist_reload_time(*args, **kwargs):
+ playlist_reload_time_called.set()
+ return orig_playlist_reload_time(*args, **kwargs)
+
+ with patch.object(thread.reader.worker, "_playlist_reload_time", side_effect=mocked_playlist_reload_time):
+ self.start()
+ self.await_write(len(segments))
+
+ if not playlist_reload_time_called.wait(timeout=5): # pragma: no cover
+ raise RuntimeError("Missing _playlist_reload_time() call")
+
+ return thread.reader.worker.playlist_reload_time
def test_hls_playlist_reload_time_default(self):
time = self.subject([Playlist(0, self.segments, end=True, targetduration=6)], reload_time="default")
@@ -303,10 +317,26 @@ def test_hls_playlist_reload_time_segment(self):
time = self.subject([Playlist(0, self.segments, end=True, targetduration=6)], reload_time="segment")
self.assertEqual(time, 3, "segment sets the reload time to the playlist's last segment")
+ def test_hls_playlist_reload_time_segment_no_segments(self):
+ time = self.subject([Playlist(0, [], end=True, targetduration=6)], reload_time="segment")
+ self.assertEqual(time, 6, "segment sets the reload time to the targetduration if no segments are available")
+
+ def test_hls_playlist_reload_time_segment_no_segments_no_targetduration(self):
+ time = self.subject([Playlist(0, [], end=True, targetduration=0)], reload_time="segment")
+ self.assertEqual(time, 15, "sets reload time to 15 seconds when no segments and no targetduration are available")
+
def test_hls_playlist_reload_time_live_edge(self):
time = self.subject([Playlist(0, self.segments, end=True, targetduration=6)], reload_time="live-edge")
self.assertEqual(time, 8, "live-edge sets the reload time to the sum of the number of segments of the live-edge")
+ def test_hls_playlist_reload_time_live_edge_no_segments(self):
+ time = self.subject([Playlist(0, [], end=True, targetduration=6)], reload_time="live-edge")
+ self.assertEqual(time, 6, "live-edge sets the reload time to the targetduration if no segments are available")
+
+ def test_hls_playlist_reload_time_live_edge_no_segments_no_targetduration(self):
+ time = self.subject([Playlist(0, [], end=True, targetduration=0)], reload_time="live-edge")
+ self.assertEqual(time, 15, "sets reload time to 15 seconds when no segments and no targetduration are available")
+
def test_hls_playlist_reload_time_number(self):
time = self.subject([Playlist(0, self.segments, end=True, targetduration=6)], reload_time="4")
self.assertEqual(time, 4, "number values override the reload time")
diff --git a/tests/streams/test_hls_filtered.py b/tests/streams/test_hls_filtered.py
--- a/tests/streams/test_hls_filtered.py
+++ b/tests/streams/test_hls_filtered.py
@@ -132,7 +132,7 @@ def test_filtered_no_timeout(self):
@patch("streamlink.stream.hls.HLSStreamWriter.should_filter_sequence", new=filter_sequence)
def test_filtered_closed(self):
- thread, reader, writer, segments = self.subject([
+ thread, reader, writer, segments = self.subject(start=False, playlists=[
Playlist(0, [SegmentFiltered(0), SegmentFiltered(1)], end=True)
])
@@ -145,6 +145,8 @@ def mocked_wait(*args, **kwargs):
return orig_wait(*args, **kwargs)
with patch.object(reader.filter_event, "wait", side_effect=mocked_wait):
+ self.start()
+
# write first filtered segment and trigger the filter_event's lock
self.assertTrue(reader.filter_event.is_set(), "Doesn't let the reader wait if not filtering")
self.await_write()
| hls.py: Exception in _playlist_reload_time() when hls-playlist-reload-time is "segment" or "live-edge" and sequences is empty
### Checklist
- [X] This is a bug report and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed bug reports](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
An exception of `TypeError: '>' not supported between instances of 'str' and 'int'` occurs here on line 273:
https://github.com/streamlink/streamlink/blob/193c5c6eb9147a56df25de160f4d35d6f230733a/src/streamlink/stream/hls.py#L268-L280
The first 2 `if` statements depend on `sequences` to not be empty, and the third `if` statement makes the assumption that `self.playlist_reload_time_override` is a numeric type.
https://github.com/streamlink/streamlink/blob/193c5c6eb9147a56df25de160f4d35d6f230733a/src/streamlink/stream/hls.py#L229-L232
We can see here `self.playlist_reload_time_override` is only guaranteed to be a numeric type when `hls-playlist-reload-time` is neither `segment` nor `live-edge`.
So when `hls-playlist-reload-time` is either `segment` or `live-edge`, and `sequences` is empty, `self.playlist_reload_time_override` will be a non-numeric type and an exception will occur when trying to do a comparison against an `int` in the third `if` statement.
A fix for this would be to verify `self.playlist_reload_time_override` is a numeric type in the third `if` statement.
```diff
- if self.playlist_reload_time_override > 0:
+ if isinstance(self.playlist_reload_time_override, (float, int)) and self.playlist_reload_time_override > 0:
```
### Debug log
```text
[cli][debug] OS: Linux-5.13.4-arch2-1-x86_64-with-glibc2.33
[cli][debug] Python: 3.9.6
[cli][debug] Streamlink: 2.2.0+46.g193c5c6
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(0.59.0)
[cli][debug] Arguments:
[cli][debug] url=https://hakk.in/crash.m3u8
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --hls-playlist-reload-time=segment
[cli][info] Found matching plugin hls for URL https://hakk.in/crash.m3u8
[plugins.hls][debug] URL=https://hakk.in/crash.m3u8; params={}
[utils.l10n][debug] Language code: en_US
[cli][info] Available streams: live (worst, best)
[cli][info] Opening stream: live (hls)
[stream.hls][debug] Reloading playlist
[cli][debug] Pre-buffering 8192 bytes
Exception in thread Thread-HLSStreamWorker:
Traceback (most recent call last):
File "/usr/lib/python3.9/threading.py", line 973, in _bootstrap_inner
self.run()
File "/home/hakkin/.local/lib/python3.9/site-packages/streamlink/stream/segmented.py", line 84, in run
for segment in self.iter_segments():
File "/home/hakkin/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 325, in iter_segments
self.reload_playlist()
File "/home/hakkin/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 263, in reload_playlist
self.playlist_reload_time = self._playlist_reload_time(playlist, sequences)
File "/home/hakkin/.local/lib/python3.9/site-packages/streamlink/stream/hls.py", line 273, in _playlist_reload_time
if self.playlist_reload_time_override > 0:
TypeError: '>' not supported between instances of 'str' and 'int'
[stream.segmented][debug] Closing worker thread
[stream.segmented][debug] Closing writer thread
[cli][error] Try 1/1: Could not open stream <HLSStream('https://hakk.in/crash.m3u8', None)> (Failed to read data from stream: Read timeout)
error: Could not open stream <HLSStream('https://hakk.in/crash.m3u8', None)>, tried 1 times, exiting
[cli][info] Closing currently open stream...
```
| 2021-07-25T11:11:18 |
|
streamlink/streamlink | 3,887 | streamlink__streamlink-3887 | [
"3886"
] | af29e1c3e183fdf0aa8af89d6c148fdf8f2d10ae | diff --git a/src/streamlink/stream/hls.py b/src/streamlink/stream/hls.py
--- a/src/streamlink/stream/hls.py
+++ b/src/streamlink/stream/hls.py
@@ -217,7 +217,7 @@ def __init__(self, *args, **kwargs):
self.playlist_end: Optional[Sequence.num] = None
self.playlist_sequence: int = -1
self.playlist_sequences: List[Sequence] = []
- self.playlist_reload_time: float = 15
+ self.playlist_reload_time: float = 6
self.playlist_reload_time_override = self.session.options.get("hls-playlist-reload-time")
self.playlist_reload_retries = self.session.options.get("hls-playlist-reload-attempts")
self.live_edge = self.session.options.get("hls-live-edge")
| diff --git a/tests/streams/test_hls.py b/tests/streams/test_hls.py
--- a/tests/streams/test_hls.py
+++ b/tests/streams/test_hls.py
@@ -310,40 +310,40 @@ def mocked_playlist_reload_time(*args, **kwargs):
return thread.reader.worker.playlist_reload_time
def test_hls_playlist_reload_time_default(self):
- time = self.subject([Playlist(0, self.segments, end=True, targetduration=6)], reload_time="default")
- self.assertEqual(time, 6, "default sets the reload time to the playlist's target duration")
+ time = self.subject([Playlist(0, self.segments, end=True, targetduration=4)], reload_time="default")
+ self.assertEqual(time, 4, "default sets the reload time to the playlist's target duration")
def test_hls_playlist_reload_time_segment(self):
- time = self.subject([Playlist(0, self.segments, end=True, targetduration=6)], reload_time="segment")
+ time = self.subject([Playlist(0, self.segments, end=True, targetduration=4)], reload_time="segment")
self.assertEqual(time, 3, "segment sets the reload time to the playlist's last segment")
def test_hls_playlist_reload_time_segment_no_segments(self):
- time = self.subject([Playlist(0, [], end=True, targetduration=6)], reload_time="segment")
- self.assertEqual(time, 6, "segment sets the reload time to the targetduration if no segments are available")
+ time = self.subject([Playlist(0, [], end=True, targetduration=4)], reload_time="segment")
+ self.assertEqual(time, 4, "segment sets the reload time to the targetduration if no segments are available")
def test_hls_playlist_reload_time_segment_no_segments_no_targetduration(self):
time = self.subject([Playlist(0, [], end=True, targetduration=0)], reload_time="segment")
- self.assertEqual(time, 15, "sets reload time to 15 seconds when no segments and no targetduration are available")
+ self.assertEqual(time, 6, "sets reload time to 6 seconds when no segments and no targetduration are available")
def test_hls_playlist_reload_time_live_edge(self):
- time = self.subject([Playlist(0, self.segments, end=True, targetduration=6)], reload_time="live-edge")
+ time = self.subject([Playlist(0, self.segments, end=True, targetduration=4)], reload_time="live-edge")
self.assertEqual(time, 8, "live-edge sets the reload time to the sum of the number of segments of the live-edge")
def test_hls_playlist_reload_time_live_edge_no_segments(self):
- time = self.subject([Playlist(0, [], end=True, targetduration=6)], reload_time="live-edge")
- self.assertEqual(time, 6, "live-edge sets the reload time to the targetduration if no segments are available")
+ time = self.subject([Playlist(0, [], end=True, targetduration=4)], reload_time="live-edge")
+ self.assertEqual(time, 4, "live-edge sets the reload time to the targetduration if no segments are available")
def test_hls_playlist_reload_time_live_edge_no_segments_no_targetduration(self):
time = self.subject([Playlist(0, [], end=True, targetduration=0)], reload_time="live-edge")
- self.assertEqual(time, 15, "sets reload time to 15 seconds when no segments and no targetduration are available")
+ self.assertEqual(time, 6, "sets reload time to 6 seconds when no segments and no targetduration are available")
def test_hls_playlist_reload_time_number(self):
- time = self.subject([Playlist(0, self.segments, end=True, targetduration=6)], reload_time="4")
- self.assertEqual(time, 4, "number values override the reload time")
+ time = self.subject([Playlist(0, self.segments, end=True, targetduration=4)], reload_time="2")
+ self.assertEqual(time, 2, "number values override the reload time")
def test_hls_playlist_reload_time_number_invalid(self):
- time = self.subject([Playlist(0, self.segments, end=True, targetduration=6)], reload_time="0")
- self.assertEqual(time, 6, "invalid number values set the reload time to the playlist's targetduration")
+ time = self.subject([Playlist(0, self.segments, end=True, targetduration=4)], reload_time="0")
+ self.assertEqual(time, 4, "invalid number values set the reload time to the playlist's targetduration")
def test_hls_playlist_reload_time_no_target_duration(self):
time = self.subject([Playlist(0, self.segments, end=True, targetduration=0)], reload_time="default")
@@ -351,7 +351,7 @@ def test_hls_playlist_reload_time_no_target_duration(self):
def test_hls_playlist_reload_time_no_data(self):
time = self.subject([Playlist(0, [], end=True, targetduration=0)], reload_time="default")
- self.assertEqual(time, 15, "sets reload time to 15 seconds when no data is available")
+ self.assertEqual(time, 6, "sets reload time to 6 seconds when no data is available")
@patch('streamlink.stream.hls.FFMPEGMuxer.is_usable', Mock(return_value=True))
| Change default HLS playlist reload time to 6 seconds rather than 15 to meet HLS spec recommendation
### Checklist
- [X] This is a feature request and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin requests](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22feature+request%22)
### Description
The current default playlist reload time for HLS is set to 15 seconds if there is no higher precedent reload time overriding it.
https://github.com/streamlink/streamlink/blob/e2c9032f9e879ca98460fa319e215b32165bd9e1/src/streamlink/stream/hls.py#L220
[It seems like this default has been in place since HLS was originally implemented 9 years ago.](https://github.com/streamlink/streamlink/commit/7909377651f8d85c76d9016b4c7e61d17a7a6d75)
[The current recommended target duration for HLS is 6 seconds](https://developer.apple.com/documentation/http_live_streaming/hls_authoring_specification_for_apple_devices#2969514). I think using this value as the default fallback makes more sense than 15 seconds. With 15 second reload times, it's somewhat likely for segments to expire between playlist reloads if the default reload time is selected for whatever reason.
| The default playlist reload time is derived from the `EXT-X-TARGETDURATION` tag, which is mandatory in every HLS media playlist:
https://datatracker.ietf.org/doc/html/rfc8216#section-4.3.3.1
The value of 15 is the default before the actual reload time gets computed and it's a last resort value when there's no target duration (an invalid HLS media playlist) **and** when there aren't any segments in the playlist. If there are segments in the media playlist and there's no target duration or if it's zero, then the sum of segment durations from the number of segments of the current live edge value is used.
https://github.com/streamlink/streamlink/blob/e2c9032f9e879ca98460fa319e215b32165bd9e1/tests/streams/test_hls.py#L275-L354
There is no need to change this value unless it's somehow important to handle an edge case of an edge case. If you want to change it, then please send a pull request and fix up the test cases with new logical values. | 2021-07-25T20:04:19 |
streamlink/streamlink | 3,920 | streamlink__streamlink-3920 | [
"3919"
] | 6eed23436534df3a558b316d7d495a4021d7a5c7 | diff --git a/src/streamlink/plugin/plugin.py b/src/streamlink/plugin/plugin.py
--- a/src/streamlink/plugin/plugin.py
+++ b/src/streamlink/plugin/plugin.py
@@ -480,7 +480,7 @@ def load_cookies(self):
:return: list of the restored cookie names
"""
if not self.session or not self.cache:
- raise RuntimeError("Cannot loaded cached cookies in unbound plugin")
+ raise RuntimeError("Cannot load cached cookies in unbound plugin")
restored = []
@@ -504,7 +504,7 @@ def clear_cookies(self, cookie_filter=None):
:return: list of the removed cookie names
"""
if not self.session or not self.cache:
- raise RuntimeError("Cannot loaded cached cookies in unbound plugin")
+ raise RuntimeError("Cannot clear cached cookies in unbound plugin")
cookie_filter = cookie_filter or (lambda c: True)
removed = []
| diff --git a/tests/plugins/test_dash.py b/tests/plugins/test_dash.py
--- a/tests/plugins/test_dash.py
+++ b/tests/plugins/test_dash.py
@@ -3,7 +3,7 @@
import pytest
-from streamlink.plugin.plugin import BIT_RATE_WEIGHT_RATIO, LOW_PRIORITY, NORMAL_PRIORITY, NO_PRIORITY, Plugin
+from streamlink.plugin.plugin import BIT_RATE_WEIGHT_RATIO, LOW_PRIORITY, NORMAL_PRIORITY, NO_PRIORITY
from streamlink.plugins.dash import MPEGDASH
from tests.plugins import PluginCanHandleUrl
@@ -26,7 +26,7 @@ class TestPluginCanHandleUrlMPEGDASH(PluginCanHandleUrl):
])
def test_priority(url, priority):
session = Mock()
- Plugin.bind(session, "tests.plugins.test_dash")
+ MPEGDASH.bind(session, "tests.plugins.test_dash")
assert next((matcher.priority for matcher in MPEGDASH.matchers if matcher.pattern.match(url)), NO_PRIORITY) == priority
@@ -41,7 +41,7 @@ def test_stream_weight(self):
@patch("streamlink.stream.DASHStream.parse_manifest")
def test_get_streams_prefix(self, parse_manifest):
session = Mock()
- Plugin.bind(session, "tests.plugins.test_dash")
+ MPEGDASH.bind(session, "tests.plugins.test_dash")
p = MPEGDASH("dash://http://example.com/foo.mpd")
p.streams()
parse_manifest.assert_called_with(session, "http://example.com/foo.mpd")
@@ -49,7 +49,7 @@ def test_get_streams_prefix(self, parse_manifest):
@patch("streamlink.stream.DASHStream.parse_manifest")
def test_get_streams(self, parse_manifest):
session = Mock()
- Plugin.bind(session, "tests.plugins.test_dash")
+ MPEGDASH.bind(session, "tests.plugins.test_dash")
p = MPEGDASH("http://example.com/foo.mpd")
p.streams()
parse_manifest.assert_called_with(session, "http://example.com/foo.mpd")
diff --git a/tests/plugins/test_filmon.py b/tests/plugins/test_filmon.py
--- a/tests/plugins/test_filmon.py
+++ b/tests/plugins/test_filmon.py
@@ -2,7 +2,6 @@
import pytest
-from streamlink.plugin import Plugin
from streamlink.plugins.filmon import Filmon
from tests.plugins import PluginCanHandleUrl
@@ -35,7 +34,7 @@ class TestPluginCanHandleUrlFilmon(PluginCanHandleUrl):
('http://www.filmon.tv/vod/view/10250-0-crime-boss', [None, None, '10250'])
])
def test_match_url(url, expected):
- Plugin.bind(Mock(), "tests.plugins.test_filmon")
+ Filmon.bind(Mock(), "tests.plugins.test_filmon")
plugin = Filmon(url)
assert plugin.match is not None
# expected must return [is_group, channel, vod_id]
diff --git a/tests/plugins/test_qq.py b/tests/plugins/test_qq.py
--- a/tests/plugins/test_qq.py
+++ b/tests/plugins/test_qq.py
@@ -2,7 +2,6 @@
import pytest
-from streamlink.plugin import Plugin
from streamlink.plugins.qq import QQ
from tests.plugins import PluginCanHandleUrl
@@ -31,7 +30,7 @@ class TestPluginCanHandleUrlQQ(PluginCanHandleUrl):
("http://m.live.qq.com/10039165", "room_id", "10039165")
])
def test_match_url(url, group, expected):
- Plugin.bind(Mock(), "tests.plugins.test_qq")
+ QQ.bind(Mock(), "tests.plugins.test_qq")
plugin = QQ(url)
assert plugin.match is not None
assert plugin.match.group(group) == expected
diff --git a/tests/plugins/test_youtube.py b/tests/plugins/test_youtube.py
--- a/tests/plugins/test_youtube.py
+++ b/tests/plugins/test_youtube.py
@@ -2,7 +2,6 @@
import pytest
-from streamlink.plugin import Plugin
from streamlink.plugins.youtube import YouTube
from tests.plugins import PluginCanHandleUrl
@@ -54,7 +53,7 @@ class TestPluginCanHandleUrlYouTube(PluginCanHandleUrl):
("https://www.youtube.com/watch?v=aqz-KE-bpKQ", "video_id", "aqz-KE-bpKQ"),
])
def test_match_url(url, group, expected):
- Plugin.bind(Mock(), "tests.plugins.test_youtube")
+ YouTube.bind(Mock(), "tests.plugins.test_youtube")
plugin = YouTube(url)
assert plugin.match is not None
assert plugin.match.group(group) == expected
@@ -68,5 +67,5 @@ def test_match_url(url, group, expected):
("http://www.youtube.com/watch?v=0123456789A", "https://www.youtube.com/watch?v=0123456789A"),
])
def test_translate_url(url, expected):
- Plugin.bind(Mock(), "tests.plugins.test_youtube")
+ YouTube.bind(Mock(), "tests.plugins.test_youtube")
assert YouTube(url).url == expected
diff --git a/tests/test_plugin.py b/tests/test_plugin.py
--- a/tests/test_plugin.py
+++ b/tests/test_plugin.py
@@ -132,15 +132,21 @@ def test_cookie_store_clear_filter(self):
def test_cookie_load_unbound(self):
plugin = Plugin("http://test.se")
- self.assertRaises(RuntimeError, plugin.load_cookies)
+ with self.assertRaises(RuntimeError) as cm:
+ plugin.load_cookies()
+ self.assertEqual(str(cm.exception), "Cannot load cached cookies in unbound plugin")
def test_cookie_save_unbound(self):
plugin = Plugin("http://test.se")
- self.assertRaises(RuntimeError, plugin.save_cookies)
+ with self.assertRaises(RuntimeError) as cm:
+ plugin.save_cookies()
+ self.assertEqual(str(cm.exception), "Cannot cache cookies in unbound plugin")
def test_cookie_clear_unbound(self):
plugin = Plugin("http://test.se")
- self.assertRaises(RuntimeError, plugin.clear_cookies)
+ with self.assertRaises(RuntimeError) as cm:
+ plugin.clear_cookies()
+ self.assertEqual(str(cm.exception), "Cannot clear cached cookies in unbound plugin")
class TestPluginMatcher(unittest.TestCase):
| Tests are failing on test_cookie_clear_unbound
### Checklist
- [X] This is a bug report and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed bug reports](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
I'm trying to build the package for 2.3.0 on Arch and the tests are failing on test_cookie_clear_unbound. This does look to be an issue with the test itself. I have attached the build log.
[streamlink-2.3.0-1-x86_64-check.log](https://github.com/streamlink/streamlink/files/7001827/streamlink-2.3.0-1-x86_64-check.log)
### Debug log
```text
This issue is on the build process.
```
| The plugin cookie stuff hasn't been touched in three years since it was implemented in #1724:
- https://github.com/streamlink/streamlink/blame/2.3.0/tests/test_plugin.py#L133-L143
- https://github.com/streamlink/streamlink/blame/2.3.0/src/streamlink/plugin/plugin.py#L437-L520
The test checks whether a RuntimeError is being raised when the test plugin is "unbound" and no session object exists on it. Since the test fails, this means that the session object was set somewhere as a class attribute. There are lots of tests which don't have proper setups and pollute the state of certain objects, which means the execution depends on the order of tests being run, which is really bad.
Without having looked at the issue yet, I'm pretty sure that it's caused by some other test calling `Plugin.bind()` instead of calling `SomePluginImplementation.bind()`. Let me see... | 2021-08-17T17:58:43 |
streamlink/streamlink | 3,940 | streamlink__streamlink-3940 | [
"3939"
] | d61d21ff2b17d654aefb8e89c95239374f725a3c | diff --git a/src/streamlink/plugins/euronews.py b/src/streamlink/plugins/euronews.py
--- a/src/streamlink/plugins/euronews.py
+++ b/src/streamlink/plugins/euronews.py
@@ -3,14 +3,17 @@
from streamlink.plugin import Plugin, pluginmatcher
from streamlink.plugin.api import validate
-from streamlink.plugin.api.utils import itertags
-from streamlink.stream import HTTPStream
+from streamlink.plugin.api.utils import itertags, parse_json
+from streamlink.stream import HLSStream, HTTPStream
+from streamlink.utils import update_scheme
@pluginmatcher(re.compile(
- r'https?://(?:\w+\.)*euronews\.com/'
+ r'https?://(?:(?P<subdomain>\w+)\.)?euronews\.com/'
))
class Euronews(Plugin):
+ API_URL = "https://{subdomain}.euronews.com/api/watchlive.json"
+
def _get_vod_stream(self):
def find_video_url(content):
for elem in itertags(content, "meta"):
@@ -39,6 +42,24 @@ def find_video_id(content):
if video_id is not None:
return self.session.streams(f"https://www.youtube.com/watch?v={video_id}")
+ info_url = self.session.http.get(self.API_URL.format(subdomain=self.match.group("subdomain")), schema=validate.Schema(
+ validate.transform(parse_json),
+ {"url": validate.url()},
+ validate.get("url"),
+ validate.transform(lambda url: update_scheme("https://", url))
+ ))
+ hls_url = self.session.http.get(info_url, schema=validate.Schema(
+ validate.transform(parse_json),
+ {
+ "status": "ok",
+ "protocol": "hls",
+ "primary": validate.url()
+ },
+ validate.get("primary")
+ ))
+
+ return HLSStream.parse_variant_playlist(self.session, hls_url)
+
def _get_streams(self):
parsed = urlparse(self.url)
| plugins.euronews: www.euronews.com and ru.euronews.com provide different APIs
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
The main Euronews site has started using the new API some time ago, and the current streamlink's plugin, euronews.py, indeed works correctly with the main site. However, some (?) language specific subdomains, like https://ru.euronews.com/, still use the old API (compare, e.g., the following responses: https://www.euronews.com/api/watchlive.json vs. https://ru.euronews.com/api/watchlive.json).
[This previous version of euronews.py](https://github.com/streamlink/streamlink/blob/fcda5b681422718cc0a95b3de45d3fe2698d8e29/src/streamlink/plugins/euronews.py) works fine with the old API but obviously doesn't support the new one. Would be great if the plugin could support both versions.
### Debug log
```text
[cli][info] Found matching plugin euronews for URL https://ru.euronews.com/live
error: No playable streams found on this URL: https://ru.euronews.com/live
```
| 2021-08-25T16:32:28 |
||
streamlink/streamlink | 3,947 | streamlink__streamlink-3947 | [
"3945"
] | 3668770d608f0fab54d40a46acd6720a97f63775 | diff --git a/src/streamlink/plugins/sportschau.py b/src/streamlink/plugins/sportschau.py
--- a/src/streamlink/plugins/sportschau.py
+++ b/src/streamlink/plugins/sportschau.py
@@ -3,7 +3,7 @@
from streamlink.plugin import Plugin, pluginmatcher
from streamlink.plugin.api import validate
-from streamlink.stream import HLSStream
+from streamlink.stream import HLSStream, HTTPStream
from streamlink.utils import parse_json, update_scheme
log = logging.getLogger(__name__)
@@ -16,33 +16,34 @@ class Sportschau(Plugin):
_re_player = re.compile(r"https?:(//deviceids-medp.wdr.de/ondemand/\S+\.js)")
_re_json = re.compile(r"\$mediaObject.jsonpHelper.storeAndPlay\(({.+})\);?")
- _schema_player = validate.Schema(
- validate.transform(_re_player.search),
- validate.any(None, validate.Schema(
- validate.get(1),
- validate.transform(lambda url: update_scheme("https:", url))
- ))
- )
- _schema_json = validate.Schema(
- validate.transform(_re_json.match),
- validate.get(1),
- validate.transform(parse_json),
- validate.get("mediaResource"),
- validate.get("dflt"),
- validate.get("videoURL"),
- validate.transform(lambda url: update_scheme("https:", url))
- )
-
def _get_streams(self):
- player_js = self.session.http.get(self.url, schema=self._schema_player)
+ player_js = self.session.http.get(self.url, schema=validate.Schema(
+ validate.transform(self._re_player.search),
+ validate.any(None, validate.Schema(
+ validate.get(1),
+ validate.transform(lambda url: update_scheme("https:", url))
+ ))
+ ))
if not player_js:
return
- log.debug("Found player js {0}".format(player_js))
-
- hls_url = self.session.http.get(player_js, schema=self._schema_json)
+ log.debug(f"Found player js {player_js}")
+ data = self.session.http.get(player_js, schema=validate.Schema(
+ validate.transform(self._re_json.match),
+ validate.get(1),
+ validate.transform(parse_json),
+ validate.get("mediaResource"),
+ validate.get("dflt"),
+ {
+ validate.optional("audioURL"): validate.url(),
+ validate.optional("videoURL"): validate.url()
+ }
+ ))
- yield from HLSStream.parse_variant_playlist(self.session, hls_url).items()
+ if data.get("videoURL"):
+ yield from HLSStream.parse_variant_playlist(self.session, update_scheme("https:", data.get("videoURL"))).items()
+ if data.get("audioURL"):
+ yield "audio", HTTPStream(self.session, update_scheme("https:", data.get("audioURL")))
__plugin__ = Sportschau
| sportschau: Does not work with the newly introduced bundesliga livestreams (Konferenz)
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
Does not work with the newly introduced bundesliga livestreams (Konferenz).
e.g. https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html
Neither under windows nor linux. The linux version (Mint 19) was installed with apt-get, maybe is an older version.
Windows version is actual.
### Debug log
```text
Windows:
c:\Users\deiss\Downloads\streamlink>streamlink https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html "best" --loglevel debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.7.9
[cli][debug] Streamlink: 2.1.2
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(1.0.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html
[cli][debug] stream=['best']
[cli][debug] --config=['c:\\Users\\deiss\\Downloads\\streamlink\\\\streamlinkrc']
[cli][debug] --loglevel=debug
[cli][debug] --rtmp-rtmpdump=c:\Users\deiss\Downloads\streamlink\\rtmpdump\rtmpdump.exe
[cli][debug] --ffmpeg-ffmpeg=c:\Users\deiss\Downloads\streamlink\\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin sportschau for URL https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html
[plugins.sportschau][debug] Found player js https://deviceids-medp.wdr.de/ondemand/247/2477304.js
[utils.l10n][debug] Language code: de_DE
error: Unable to open URL: https://b'' (HTTPSConnectionPool(host="b''", port=443): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x000001BAE8276108>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed')))
Linux:
streamlink https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html "best" --loglevel debug
[cli][info] Found matching plugin sportschau for URL https://www.sportschau.de/fussball/bundesliga/audiostream-die-konferenz---bundesliga-live-100.html
[plugin.sportschau][info] Found player js http://deviceids-medp.wdr.de/ondemand/247/2477304.js
Traceback (most recent call last):
File "/usr/bin/streamlink", line 11, in <module>
load_entry_point('streamlink==0.10.0', 'console_scripts', 'streamlink')()
File "/usr/share/streamlink/streamlink_cli/main.py", line 1055, in main
handle_url()
File "/usr/share/streamlink/streamlink_cli/main.py", line 486, in handle_url
streams = fetch_streams(plugin)
File "/usr/share/streamlink/streamlink_cli/main.py", line 398, in fetch_streams
sorting_excludes=args.stream_sorting_excludes)
File "/usr/lib/python3/dist-packages/streamlink/plugin/plugin.py", line 385, in get_streams
return self.streams(*args, **kwargs)
File "/usr/lib/python3/dist-packages/streamlink/plugin/plugin.py", line 288, in streams
ostreams = self._get_streams()
File "/usr/lib/python3/dist-packages/streamlink/plugins/sportschau.py", line 40, in _get_streams
return HDSStream.parse_manifest(self.session, stream_metadata['mediaResource']['dflt']['videoURL']).items()
KeyError: 'videoURL'
Error in sys.excepthook:
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/apport_python_hook.py", line 145, in apport_excepthook
os.O_WRONLY | os.O_CREAT | os.O_EXCL, 0o640), 'wb') as f:
FileNotFoundError: [Errno 2] No such file or directory: '/var/crash/_usr_share_streamlink_streamlink.1000.crash'
Original exception was:
Traceback (most recent call last):
File "/usr/bin/streamlink", line 11, in <module>
load_entry_point('streamlink==0.10.0', 'console_scripts', 'streamlink')()
File "/usr/share/streamlink/streamlink_cli/main.py", line 1055, in main
handle_url()
```
| Both of your Streamlink versions are out of date. That's not the problem here though.
The plugin's validation schema is expecting a `videoURL` property in the JSONP data. The URL you've posted however is not a video stream and it only includes an `audioURL` property instead. | 2021-08-28T00:44:54 |
|
streamlink/streamlink | 3,949 | streamlink__streamlink-3949 | [
"3948"
] | dc27265948a83ff7822f3cea2d6cd585008849cb | diff --git a/src/streamlink/plugins/svtplay.py b/src/streamlink/plugins/svtplay.py
--- a/src/streamlink/plugins/svtplay.py
+++ b/src/streamlink/plugins/svtplay.py
@@ -1,6 +1,6 @@
import logging
import re
-from urllib.parse import urljoin
+from urllib.parse import parse_qsl, urlparse
from streamlink.plugin import Plugin, PluginArgument, PluginArguments, pluginmatcher
from streamlink.plugin.api import validate
@@ -21,16 +21,11 @@ class SVTPlay(Plugin):
title = None
latest_episode_url_re = re.compile(r'''
- class="play_titlepage__latest-video"\s+href="(?P<url>[^"]+)"
+ data-rt="top-area-play-button"\s+href="(?P<url>[^"]+)"
''', re.VERBOSE)
live_id_re = re.compile(r'.*/(?P<live_id>[^?]+)')
- vod_id_re = re.compile(r'''
- (?:DATA_LAKE\s+=\s+{"content":{"id":|"svtId":|data-video-id=)
- "(?P<vod_id>[^"]+)"
- ''', re.VERBOSE)
-
_video_schema = validate.Schema({
validate.optional('programTitle'): validate.text,
validate.optional('episodeTitle'): validate.text,
@@ -87,18 +82,18 @@ def _get_live(self, path):
yield from DASHStream.parse_manifest(self.session, playlist['url']).items()
def _get_vod(self):
- res = self.session.http.get(self.url)
- match = self.latest_episode_url_re.search(res.text)
- if match:
- res = self.session.http.get(
- urljoin(self.url, match.group('url')),
- )
-
- match = self.vod_id_re.search(res.text)
- if match is None:
+ vod_id = self._get_vod_id(self.url)
+
+ if vod_id is None:
+ res = self.session.http.get(self.url)
+ match = self.latest_episode_url_re.search(res.text)
+ if match is None:
+ return
+ vod_id = self._get_vod_id(match.group("url"))
+
+ if vod_id is None:
return
- vod_id = match.group('vod_id')
log.debug("VOD ID={0}".format(vod_id))
res = self.session.http.get(self.api_url.format(vod_id))
@@ -124,6 +119,10 @@ def _get_vod(self):
else:
yield q, s
+ def _get_vod_id(self, url):
+ qs = dict(parse_qsl(urlparse(url).query))
+ return qs.get("id")
+
def _get_streams(self):
path, live = self.match.groups()
log.debug("Path={0}".format(path))
| plugins.svtplay: Cannot resolve playable stream
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
When trying to play for example https://www.svtplay.se/video/32279075/draknastet/draknastet-sasong-1-avsnitt-2?id=KA2BmZD
It does not seem to parse the information correctly anymore to resolve a playable stream. This plugin compared to the one for tv4play is parsing the HTML page in order to resolve where to go if you are on the program page instead of the episode page.
This lookup resolves to nothing anymore:
```
latest_episode_url_re = re.compile(r'''
class="play_titlepage__latest-video"\s+href="(?P<url>[^"]+)"
''', re.VERBOSE)
```
When debugging I find that this https://api.svt.se/video/KA2BmZD resolves the JSON.
```
{
"svtId": "KA2BmZD",
"programVersionId": "1400537-002A",
"contentDuration": 3506,
"blockedForChildren": false,
"live": false,
"programTitle": "Draknästet",
"episodeTitle": "Avsnitt 2",
...
}
```
With the following changes it resolves the video_id correctly from the HTML:
```
latest_episode_vod_id = re.compile(r'''
data-rt="top-area-play-button"\s+href=".*(?:id=)(?P<video_id>[^"]+)"
''', re.VERBOSE)
```
If you are directly on the play page of the site you get the vod_id in the URL as a parameter. So I have refactored to support both.
Now it finds the vod_id and initiates the dash stream worker but it still doesn't run.
I get Exception in thread Thread-DASHStreamWorker and this one seems a little more tricky to figure out.
```
[cli][info] Opening stream: 1080p (dash)
[stream.dash][debug] Opening DASH reader for: 0 (video/mp4)
[stream.dash][debug] Opening DASH reader for: 5 (audio/mp4)
[stream.dash_manifest][debug] Generating segment timeline for static playlist (id=0))
[stream.dash_manifest][debug] Generating segment timeline for static playlist (id=5))
[cli][error] Try 1/1: Could not open stream <Stream()> (Could not open stream: cannot use FFMPEG)
[stream.ffmpegmux][debug] Closing ffmpeg thread
error: Could not open stream <Stream()>, tried 1 times, exiting
[stream.dash][debug] Download of segment: https://svt-vod-8r.akamaized.net/d0/se/20210723/841d135d-fb92-4acb-9dff-898c1db4af30/cmaf-video-avc-1920x1080p25-3089/cmaf-video-avc-1920x1080p25-3089-init.mp4 complete
Exception in thread Thread-DASHStreamWorker:
Traceback (most recent call last):
File "/usr/lib64/python3.9/threading.py", line 973, in _bootstrap_inner
self.run()
File "/usr/local/lib/python3.9/site-packages/streamlink-2.1.2+79.g2b9ca5d.dirty-py3.9.egg/streamlink/stream/segmented.py", line 87, in run
self.writer.put(segment)
File "/usr/local/lib/python3.9/site-packages/streamlink-2.1.2+79.g2b9ca5d.dirty-py3.9.egg/streamlink/stream/segmented.py", line 140, in put
future = self.executor.submit(self.fetch, segment, retries=self.retries)
File "/usr/lib64/python3.9/concurrent/futures/thread.py", line 163, in submit
raise RuntimeError('cannot schedule new futures after '
RuntimeError: cannot schedule new futures after interpreter shutdown
```
### Debug log
```text
[cli][debug] OS: Linux-5.13.12-200.fc34.x86_64-x86_64-with-glibc2.33
[cli][debug] Python: 3.9.6
[cli][debug] Streamlink: 2.3.0
[cli][debug] Requests(2.25.1), Socks(1.7.1), Websocket(0.57.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.svtplay.se/video/32279075/draknastet/draknastet-sasong-1-avsnitt-2?id=KA2BmZD
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --player=mpv
[cli][debug] --verbose-player=True
[cli][debug] --player-passthrough=['hls']
[cli][debug] --hls-segment-threads=2
[cli][info] Found matching plugin svtplay for URL https://www.svtplay.se/video/32279075/draknastet/draknastet-sasong-1-avsnitt-2?id=KA2BmZD
[plugins.svtplay][debug] Path=/
error: No playable streams found on this URL: https://www.svtplay.se/video/32279075/draknastet/draknastet-sasong-1-avsnitt-2?id=KA2BmZD
```
| Oh, LUL. I didn't have ffmpeg installed and you seem to have to have that in order for this plugin to work. Hm, the others work without it so why is this plugin requiring it?
Well, with ffmpeg installed I can confirm that my refactoring worked and it can resolve streams and play correctly again. I guess I will push that part at least and then think about why this plugin requires a dependency the others I use don't. | 2021-08-28T08:50:06 |
|
streamlink/streamlink | 3,952 | streamlink__streamlink-3952 | [
"3944"
] | 87743e631d9de61a63855a9d91a51170ee8587a1 | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -12,6 +12,7 @@
deps = [
"requests>=2.26.0,<3.0",
"isodate",
+ "lxml>=4.6.3",
"websocket-client>=0.58.0",
# Support for SOCKS proxies
"PySocks!=1.5.7,>=1.5.6",
| Add lxml dependency
### Checklist
- [X] This is a feature request and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin requests](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22feature+request%22)
### Description
Streamlink should finally switch to a proper HTML/XML parser for extracting data instead of using cheap regex workarounds which don't work properly. I've already commented on this issue last year:
https://github.com/streamlink/streamlink/issues/3241#issuecomment-706486239
The reason why I'm suggesting this again right now is that I was trying to fix the deutschewelle plugin (https://dw.com) yesterday and ran into issues with the `itertags` utility method, which is based on simple regexes for iterating HTML nodes and their attributes+body. `itertags` for example does not work with nested nodes, which makes adding ridiculous custom regexes necessary. Just take a look at this madness:
https://github.com/streamlink/streamlink/blob/3668770d608f0fab54d40a46acd6720a97f63775/src/streamlink/plugins/deutschewelle.py#L18-L29
With `lxml` (https://lxml.de/), HTML page contents can be parsed and the data extracted via XPath queries and/or the respective API methods. The methods are similar to python's native `xml.etree.ElementTree`, which itself is considered too slow and unsafe in certain cases. I am by no means an expert regarding python's standard library though, so if someone has better insight here, please share. In regards to packaging, this lib is available on basically every packaging system and adding it as a dependency here only has benefits.
I'd suggest that we add `lxml` as a dependency now and start using it for extracting data from HTML documents. The validation schema methods could be improved for this as well. There's also the `parse_xml` utility method, which is currently based on the native module.
Comments?
| 2021-08-28T18:21:30 |
||
streamlink/streamlink | 3,987 | streamlink__streamlink-3987 | [
"3941"
] | fed76bde6cf2b7af1b230e9f1edfd4bcc6fc87f2 | diff --git a/src/streamlink/plugin/plugin.py b/src/streamlink/plugin/plugin.py
--- a/src/streamlink/plugin/plugin.py
+++ b/src/streamlink/plugin/plugin.py
@@ -430,6 +430,13 @@ def stream_weight_only(s):
def _get_streams(self):
raise NotImplementedError
+ def get_metadata(self) -> Dict[str, Optional[str]]:
+ return dict(
+ author=self.get_author(),
+ category=self.get_category(),
+ title=self.get_title()
+ )
+
def get_title(self) -> Optional[str]:
return self.title
diff --git a/src/streamlink_cli/main.py b/src/streamlink_cli/main.py
--- a/src/streamlink_cli/main.py
+++ b/src/streamlink_cli/main.py
@@ -408,7 +408,10 @@ def handle_stream(plugin, streams, stream_name):
# Print JSON representation of the stream
elif args.json:
- console.msg_json(stream)
+ console.msg_json(
+ stream,
+ metadata=plugin.get_metadata()
+ )
elif args.stream_url:
try:
@@ -583,11 +586,20 @@ def handle_url():
err = f"The specified stream(s) '{', '.join(args.stream)}' could not be found"
if args.json:
- console.msg_json(plugin=plugin.module, streams=streams, error=err)
+ console.msg_json(
+ plugin=plugin.module,
+ metadata=plugin.get_metadata(),
+ streams=streams,
+ error=err
+ )
else:
console.exit(f"{err}.\n Available streams: {validstreams}")
elif args.json:
- console.msg_json(plugin=plugin.module, streams=streams)
+ console.msg_json(
+ plugin=plugin.module,
+ metadata=plugin.get_metadata(),
+ streams=streams
+ )
elif args.stream_url:
try:
console.msg(streams[list(streams)[-1]].to_manifest_url())
| diff --git a/tests/test_cli_main.py b/tests/test_cli_main.py
--- a/tests/test_cli_main.py
+++ b/tests/test_cli_main.py
@@ -9,7 +9,6 @@
import streamlink_cli.main
import tests.resources
-from streamlink.plugin.plugin import Plugin
from streamlink.session import Streamlink
from streamlink.stream.stream import Stream
from streamlink_cli.compat import DeprecatedPath, is_win32, stdout
@@ -26,11 +25,7 @@
setup_config_args
)
from streamlink_cli.output import FileOutput, PlayerOutput
-
-
-class FakePlugin(Plugin):
- def _get_streams(self):
- pass # pragma: no cover
+from tests.plugin.testplugin import TestPlugin as FakePlugin
class TestCLIMain(unittest.TestCase):
@@ -107,11 +102,21 @@ class TestCLIMainJsonAndStreamUrl(unittest.TestCase):
def test_handle_stream_with_json_and_stream_url(self, console, args):
stream = Mock()
streams = dict(best=stream)
- plugin = Mock(FakePlugin(""), module="fake", arguments=[], streams=Mock(return_value=streams))
+ plugin = FakePlugin("")
+ plugin.module = "fake"
+ plugin.arguments = []
+ plugin.streams = Mock(return_value=streams)
handle_stream(plugin, streams, "best")
self.assertEqual(console.msg.mock_calls, [])
- self.assertEqual(console.msg_json.mock_calls, [call(stream)])
+ self.assertEqual(console.msg_json.mock_calls, [call(
+ stream,
+ metadata=dict(
+ author="Tѥst Āuƭhǿr",
+ category=None,
+ title="Test Title"
+ )
+ )])
self.assertEqual(console.error.mock_calls, [])
console.msg_json.mock_calls.clear()
@@ -133,12 +138,23 @@ def test_handle_stream_with_json_and_stream_url(self, console, args):
def test_handle_url_with_json_and_stream_url(self, console, args):
stream = Mock()
streams = dict(worst=Mock(), best=stream)
- plugin = Mock(FakePlugin(""), module="fake", arguments=[], streams=Mock(return_value=streams))
+ plugin = FakePlugin("")
+ plugin.module = "fake"
+ plugin.arguments = []
+ plugin.streams = Mock(return_value=streams)
with patch("streamlink_cli.main.streamlink", resolve_url=Mock(return_value=plugin)):
handle_url()
self.assertEqual(console.msg.mock_calls, [])
- self.assertEqual(console.msg_json.mock_calls, [call(plugin="fake", streams=streams)])
+ self.assertEqual(console.msg_json.mock_calls, [call(
+ plugin="fake",
+ metadata=dict(
+ author="Tѥst Āuƭhǿr",
+ category=None,
+ title="Test Title"
+ ),
+ streams=streams
+ )])
self.assertEqual(console.error.mock_calls, [])
console.msg_json.mock_calls.clear()
| cli: add title to json

used as mpv backend :

| After thinking about it again (I only had the diff in mind in my previous comment, sorry), do we want the interpolated `--title` parameter value in the JSON output, or the individual stream metadata properties?
The `--title` parameter is just a utility for formatting the window title of the player launched by Streamlink, which is not useful for JSON data, where individual metadata properties make much more sense.
> After thinking about it again (I only had the diff in mind in my previous comment, sorry), do we want the interpolated `--title` parameter value in the JSON output, or the individual stream metadata properties?
both
> The `--title` parameter is just a utility for formatting the window title of the player launched by Streamlink, which is not useful for JSON data, where individual metadata properties make much more sense.
i have a script that use streamlink as mpv backend instead of youtube-dl for some specific sites like twitch... [$](https://gist.github.com/ChrisK2/8701184fe3ea7701c9cc)
just by typing "mpv %url%"
it run 'streamlink -j url quality' then extract streamurl from the response and passe it to mpv
this is needed so they are no need to call streamlink two times to get the title
What I am saying is that the JSON data should not include the custom `--title` stuff but rather the individual values of the plugin metadata, so one who uses the JSON response can read metadata separately, which is impossible with a single string based on the user's `--title` value. In your case, these single metadata properties can be used and combined for formatting the player window title.
```json
{
"type": "hls",
"url": "https://foo",
"master": "https://bar",
"headers": {},
"metadata": {
"author": ...,
"category": ...,
"title": ...,
}
}
```
i am not sure if this is worth adding right now ;
if user wanted only a specific metadata like the author name he can alwayse call `streamlink -j --title "{author}" %url% best`
if he wanted multiple metadata properties, he probably gonna combine them; so instead of just calling streamlink with the formate he wanted, he gonna need to combine them manually
also this way respect the formate in streamlink config file if i called `streamlink -j %url% best` | 2021-09-03T12:06:44 |
streamlink/streamlink | 3,992 | streamlink__streamlink-3992 | [
"3991"
] | d0878493240b521c3b2682f47a13e8d42b2cb739 | diff --git a/src/streamlink/stream/ffmpegmux.py b/src/streamlink/stream/ffmpegmux.py
--- a/src/streamlink/stream/ffmpegmux.py
+++ b/src/streamlink/stream/ffmpegmux.py
@@ -7,7 +7,7 @@
from streamlink import StreamError
from streamlink.compat import devnull
from streamlink.stream.stream import Stream, StreamIO
-from streamlink.utils import NamedPipe
+from streamlink.utils.named_pipe import NamedPipe, NamedPipeBase
log = logging.getLogger(__name__)
@@ -58,8 +58,8 @@ class FFMPEGMuxer(StreamIO):
DEFAULT_AUDIO_CODEC = "copy"
@staticmethod
- def copy_to_pipe(self, stream, pipe):
- log.debug("Starting copy to pipe: {0}".format(pipe.path))
+ def copy_to_pipe(stream: StreamIO, pipe: NamedPipeBase):
+ log.debug(f"Starting copy to pipe: {pipe.path}")
pipe.open()
while not stream.closed:
try:
@@ -69,13 +69,13 @@ def copy_to_pipe(self, stream, pipe):
else:
break
except OSError:
- log.error("Pipe copy aborted: {0}".format(pipe.path))
- return
+ log.error(f"Pipe copy aborted: {pipe.path}")
+ break
try:
pipe.close()
except OSError: # might fail closing, but that should be ok for the pipe
pass
- log.debug("Pipe copy complete: {0}".format(pipe.path))
+ log.debug(f"Pipe copy complete: {pipe.path}")
def __init__(self, session, *streams, **options):
if not self.is_usable(session):
@@ -86,7 +86,7 @@ def __init__(self, session, *streams, **options):
self.streams = streams
self.pipes = [NamedPipe() for _ in self.streams]
- self.pipe_threads = [threading.Thread(target=self.copy_to_pipe, args=(self, stream, np))
+ self.pipe_threads = [threading.Thread(target=self.copy_to_pipe, args=(stream, np))
for stream, np in
zip(self.streams, self.pipes)]
| stream.ffmpegmux: named pipes don't get cleaned up
### Checklist
- [X] This is a bug report and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed bug reports](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22bug%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
I've already mentioned this in https://github.com/streamlink/streamlink/pull/3709#issue-624558580 where I re-implemented the `NamedPipe` class.
`FFMPEGMuxer` doesn't gracefully close the stream and doesn't clean up the named pipes created for muxing the output stream.
https://github.com/streamlink/streamlink/blame/d0878493240b521c3b2682f47a13e8d42b2cb739/src/streamlink/stream/ffmpegmux.py#L60-L78
```
$ ls /tmp/streamlinkpipe-*
ls: cannot access '/tmp/streamlinkpipe-*': No such file or directory
```
```
$ streamlink -l debug 'https://www.youtube.com/watch?v=xcJtL7QggTI' best
[cli][debug] OS: Linux-5.13.13-1-git-x86_64-with-glibc2.33
[cli][debug] Python: 3.9.6
[cli][debug] Streamlink: 2.3.0+48.gd087849
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(0.58.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.youtube.com/watch?v=xcJtL7QggTI
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --player=mpv
[cli][info] Found matching plugin youtube for URL https://www.youtube.com/watch?v=xcJtL7QggTI
[plugins.youtube][debug] Using video ID: xcJtL7QggTI
[plugins.youtube][debug] MuxedStream: v 137 a 251 = 1080p
[plugins.youtube][debug] MuxedStream: v 135 a 251 = 480p
[plugins.youtube][debug] MuxedStream: v 133 a 251 = 240p
[plugins.youtube][debug] MuxedStream: v 160 a 251 = 144p
[cli][info] Available streams: audio_mp4a, audio_opus, 144p (worst), 240p, 360p, 480p, 720p, 1080p (best)
[cli][info] Opening stream: 1080p (muxed-stream)
[stream.ffmpegmux][debug] Opening http substream
[stream.ffmpegmux][debug] Opening http substream
[utils.named_pipe][info] Creating pipe streamlinkpipe-66128-1-1546
[utils.named_pipe][info] Creating pipe streamlinkpipe-66128-2-2853
[stream.ffmpegmux][debug] ffmpeg command: ffmpeg -nostats -y -i /tmp/streamlinkpipe-66128-1-1546 -i /tmp/streamlinkpipe-66128-2-2853 -c:v copy -c:a copy -map 0 -map 1 -f matroska pipe:1
[stream.ffmpegmux][debug] Starting copy to pipe: /tmp/streamlinkpipe-66128-1-1546
[stream.ffmpegmux][debug] Starting copy to pipe: /tmp/streamlinkpipe-66128-2-2853
[cli][debug] Pre-buffering 8192 bytes
[cli][info] Starting player: mpv
[cli.output][debug] Opening subprocess: mpv --force-media-title=https://www.youtube.com/watch?v=xcJtL7QggTI -
[cli][debug] Writing stream to output
[cli][info] Player closed
[stream.ffmpegmux][debug] Closing ffmpeg thread
[stream.ffmpegmux][error] Pipe copy aborted: /tmp/streamlinkpipe-66128-1-1546
[stream.ffmpegmux][error] Pipe copy aborted: /tmp/streamlinkpipe-66128-2-2853
[stream.ffmpegmux][debug] Closed all the substreams
[cli][info] Stream ended
[cli][info] Closing currently open stream...
```
```
$ ls /tmp/streamlinkpipe-*
/tmp/streamlinkpipe-66128-1-1546 /tmp/streamlinkpipe-66128-2-2853
```
### Debug log
```text
-
```
| 2021-09-04T17:04:50 |
||
streamlink/streamlink | 4,020 | streamlink__streamlink-4020 | [
"4017"
] | fd9e0b137c028a8ea3500da20bce4184902eff70 | diff --git a/src/streamlink/plugins/pluzz.py b/src/streamlink/plugins/pluzz.py
--- a/src/streamlink/plugins/pluzz.py
+++ b/src/streamlink/plugins/pluzz.py
@@ -1,216 +1,132 @@
import logging
import re
-import sys
-import time
+from datetime import datetime
+from urllib.parse import urlparse
-from streamlink.plugin import Plugin, PluginArgument, PluginArguments, pluginmatcher
-from streamlink.plugin.api import validate
-from streamlink.stream import DASHStream, HDSStream, HLSStream, HTTPStream
-from streamlink.stream.ffmpegmux import MuxedStream
+from isodate import LOCAL as LOCALTIMEZONE
+
+from streamlink.plugin import Plugin, PluginError, pluginmatcher
+from streamlink.plugin.api import useragents, validate
+from streamlink.stream import DASHStream, HLSStream
+from streamlink.utils.url import update_qsd
log = logging.getLogger(__name__)
-@pluginmatcher(re.compile(r'''
- https?://(
- (?:www\.)?france\.tv/.+\.html
- |
- www\.(ludo|zouzous)\.fr/heros/[\w-]+
+@pluginmatcher(re.compile(r"""
+ https?://(?:
+ (?:www\.)?france\.tv/
|
- (.+\.)?francetvinfo\.fr
+ (?:.+\.)?francetvinfo\.fr/
)
-''', re.VERBOSE))
+""", re.VERBOSE))
class Pluzz(Plugin):
- GEO_URL = 'http://geo.francetv.fr/ws/edgescape.json'
- API_URL = 'http://sivideo.webservices.francetelevisions.fr/tools/getInfosOeuvre/v2/?idDiffusion={0}'
- TOKEN_URL = 'http://hdfauthftv-a.akamaihd.net/esi/TA?url={0}'
- SWF_PLAYER_URL = 'https://staticftv-a.akamaihd.net/player/bower_components/player_flash/dist/' \
- 'FranceTVNVPVFlashPlayer.akamai-7301b6035a43c4e29b7935c9c36771d2.swf'
-
- _pluzz_video_id_re = re.compile(r'''(?P<q>["']*)videoId(?P=q):\s*["'](?P<video_id>[^"']+)["']''')
- _jeunesse_video_id_re = re.compile(r'playlist: \[{.*?,"identity":"(?P<video_id>.+?)@(?P<catalogue>Ludo|Zouzous)"')
- _sport_video_id_re = re.compile(r'data-video="(?P<video_id>.+?)"')
- _embed_video_id_re = re.compile(r'href="http://videos\.francetv\.fr/video/(?P<video_id>.+?)(?:@.+?)?"')
- _hds_pv_data_re = re.compile(r"~data=.+?!")
- _mp4_bitrate_re = re.compile(r'.*-(?P<bitrate>[0-9]+k)\.mp4')
-
- _geo_schema = validate.Schema({
- 'reponse': {
- 'geo_info': {
- 'country_code': validate.text
- }
- }
- })
-
- _api_schema = validate.Schema({
- 'videos': validate.all(
- [{
- 'format': validate.any(
- None,
- validate.text
- ),
- 'url': validate.any(
- None,
- validate.url(),
- ),
- 'statut': validate.text,
- 'drm': bool,
- 'geoblocage': validate.any(
- None,
- [validate.all(validate.text)]
- ),
- 'plages_ouverture': validate.all(
- [{
- 'debut': validate.any(
- None,
- int
- ),
- 'fin': validate.any(
- None,
- int
- )
- }]
- )
- }]
- ),
- 'subtitles': validate.any(
- [],
- validate.all(
- [{
- 'type': validate.text,
- 'url': validate.url(),
- 'format': validate.text
- }]
- )
- )
- })
-
- _player_schema = validate.Schema({'result': validate.url()})
+ PLAYER_VERSION = "5.51.35"
+ GEO_URL = "https://geoftv-a.akamaihd.net/ws/edgescape.json"
+ API_URL = "https://player.webservices.francetelevisions.fr/v1/videos/{video_id}"
- arguments = PluginArguments(
- PluginArgument("mux-subtitles", is_global=True)
- )
+ _re_ftv_player_videos = re.compile(r"window\.FTVPlayerVideos\s*=\s*(?P<json>\[{.+?}])\s*;\s*(?:$|var)", re.DOTALL)
+ _re_player_load = re.compile(r"""player\.load\s*\(\s*{\s*src\s*:\s*(['"])(?P<video_id>.+?)\1\s*}\s*\)\s*;""")
def _get_streams(self):
+ self.session.http.headers.update({
+ "User-Agent": useragents.CHROME
+ })
+ CHROME_VERSION = re.compile(r"Chrome/(\d+)").search(useragents.CHROME).group(1)
+
# Retrieve geolocation data
- res = self.session.http.get(self.GEO_URL)
- geo = self.session.http.json(res, schema=self._geo_schema)
- country_code = geo['reponse']['geo_info']['country_code']
- log.debug('Country: {0}'.format(country_code))
+ country_code = self.session.http.get(self.GEO_URL, schema=validate.Schema(
+ validate.parse_json(),
+ {"reponse": {"geo_info": {
+ "country_code": str
+ }}},
+ validate.get(("reponse", "geo_info", "country_code"))
+ ))
+ log.debug(f"Country: {country_code}")
# Retrieve URL page and search for video ID
- res = self.session.http.get(self.url)
- if 'france.tv' in self.url:
- match = self._pluzz_video_id_re.search(res.text)
- elif 'ludo.fr' in self.url or 'zouzous.fr' in self.url:
- match = self._jeunesse_video_id_re.search(res.text)
- elif 'sport.francetvinfo.fr' in self.url:
- match = self._sport_video_id_re.search(res.text)
- else:
- match = self._embed_video_id_re.search(res.text)
- if match is None:
+ video_id = None
+ try:
+ video_id = self.session.http.get(self.url, schema=validate.Schema(
+ validate.parse_html(),
+ validate.any(
+ validate.all(
+ validate.xml_xpath_string(".//script[contains(text(),'window.FTVPlayerVideos')][1]/text()"),
+ str,
+ validate.transform(self._re_ftv_player_videos.search),
+ validate.get("json"),
+ validate.parse_json(),
+ [{"videoId": str}],
+ validate.get((0, "videoId"))
+ ),
+ validate.all(
+ validate.xml_xpath_string(".//script[contains(text(),'new Magnetoscope')][1]/text()"),
+ str,
+ validate.transform(self._re_player_load.search),
+ validate.get("video_id")
+ ),
+ validate.all(
+ validate.xml_xpath_string(".//*[@id][contains(@class,'francetv-player-wrapper')][1]/@id"),
+ str
+ ),
+ validate.all(
+ validate.xml_xpath_string(".//*[@data-id][@class='magneto'][1]/@data-id"),
+ str
+ )
+ )
+ ))
+ except PluginError:
+ pass
+ if not video_id:
return
- video_id = match.group('video_id')
- log.debug('Video ID: {0}'.format(video_id))
-
- res = self.session.http.get(self.API_URL.format(video_id))
- videos = self.session.http.json(res, schema=self._api_schema)
- now = time.time()
-
- offline = False
- geolocked = False
- drm = False
- expired = False
-
- streams = []
- for video in videos['videos']:
- log.trace('{0!r}'.format(video))
- video_url = video['url']
-
- # Check whether video format is available
- if video['statut'] != 'ONLINE':
- offline = offline or True
- continue
-
- # Check whether video format is geo-locked
- if video['geoblocage'] is not None and country_code not in video['geoblocage']:
- geolocked = geolocked or True
- continue
-
- # Check whether video is DRM-protected
- if video['drm']:
- drm = drm or True
- continue
-
- # Check whether video format is expired
- available = False
- for interval in video['plages_ouverture']:
- available = (interval['debut'] or 0) <= now <= (interval['fin'] or sys.maxsize)
- if available:
- break
- if not available:
- expired = expired or True
- continue
-
- res = self.session.http.get(self.TOKEN_URL.format(video_url))
- video_url = res.text
-
- if '.mpd' in video_url:
- # Get redirect video URL
- res = self.session.http.get(res.text)
- video_url = res.url
- for bitrate, stream in DASHStream.parse_manifest(self.session,
- video_url).items():
- streams.append((bitrate, stream))
- elif '.f4m' in video_url:
- for bitrate, stream in HDSStream.parse_manifest(self.session,
- video_url,
- is_akamai=True,
- pvswf=self.SWF_PLAYER_URL).items():
- # HDS videos with data in their manifest fragment token
- # doesn't seem to be supported by HDSStream. Ignore such
- # stream (but HDS stream having only the hdntl parameter in
- # their manifest token will be provided)
- pvtoken = stream.request_params['params'].get('pvtoken', '')
- match = self._hds_pv_data_re.search(pvtoken)
- if match is None:
- streams.append((bitrate, stream))
- elif '.m3u8' in video_url:
- for stream in HLSStream.parse_variant_playlist(self.session, video_url).items():
- streams.append(stream)
- # HBB TV streams are not provided anymore by France Televisions
- elif '.mp4' in video_url and '/hbbtv/' not in video_url:
- match = self._mp4_bitrate_re.match(video_url)
- if match is not None:
- bitrate = match.group('bitrate')
- else:
- # Fallback bitrate (seems all France Televisions MP4 videos
- # seem have such bitrate)
- bitrate = '1500k'
- streams.append((bitrate, HTTPStream(self.session, video_url)))
-
- if self.get_option("mux_subtitles") and videos['subtitles'] != []:
- substreams = {}
- for subtitle in videos['subtitles']:
- # TTML subtitles are available but not supported by FFmpeg
- if subtitle['format'] == 'ttml':
- continue
- substreams[subtitle['type']] = HTTPStream(self.session, subtitle['url'])
-
- for quality, stream in streams:
- yield quality, MuxedStream(self.session, stream, subtitles=substreams)
- else:
- for stream in streams:
- yield stream
-
- if offline:
- log.error('Failed to access stream, may be due to offline content')
- if geolocked:
- log.error('Failed to access stream, may be due to geo-restricted content')
- if drm:
- log.error('Failed to access stream, may be due to DRM-protected content')
- if expired:
- log.error('Failed to access stream, may be due to expired content')
+ log.debug(f"Video ID: {video_id}")
+
+ api_url = update_qsd(self.API_URL.format(video_id=video_id), {
+ "country_code": country_code,
+ "w": 1920,
+ "h": 1080,
+ "player_version": self.PLAYER_VERSION,
+ "domain": urlparse(self.url).netloc,
+ "device_type": "mobile",
+ "browser": "chrome",
+ "browser_version": CHROME_VERSION,
+ "os": "ios",
+ "gmt": datetime.now(tz=LOCALTIMEZONE).strftime("%z")
+ })
+ video_format, token_url, url, self.title = self.session.http.get(api_url, schema=validate.Schema(
+ validate.parse_json(),
+ {
+ "video": {
+ "workflow": "token-akamai",
+ "format": validate.any("dash", "hls"),
+ "token": validate.url(),
+ "url": validate.url()
+ },
+ "meta": {
+ "title": str
+ }
+ },
+ validate.union_get(
+ ("video", "format"),
+ ("video", "token"),
+ ("video", "url"),
+ ("meta", "title")
+ )
+ ))
+
+ data_url = update_qsd(token_url, {
+ "url": url
+ })
+ video_url = self.session.http.get(data_url, schema=validate.Schema(
+ validate.parse_json(),
+ {"url": validate.url()},
+ validate.get("url")
+ ))
+
+ if video_format == "dash":
+ yield from DASHStream.parse_manifest(self.session, video_url).items()
+ elif video_format == "hls":
+ yield from HLSStream.parse_variant_playlist(self.session, video_url).items()
__plugin__ = Pluzz
| diff --git a/tests/plugins/test_pluzz.py b/tests/plugins/test_pluzz.py
--- a/tests/plugins/test_pluzz.py
+++ b/tests/plugins/test_pluzz.py
@@ -8,29 +8,12 @@ class TestPluginCanHandleUrlPluzz(PluginCanHandleUrl):
should_match = [
"https://www.france.tv/france-2/direct.html",
"https://www.france.tv/france-3/direct.html",
- "https://www.france.tv/france-3-franche-comte/direct.html",
"https://www.france.tv/france-4/direct.html",
"https://www.france.tv/france-5/direct.html",
- "https://www.france.tv/france-o/direct.html",
"https://www.france.tv/franceinfo/direct.html",
"https://www.france.tv/france-2/journal-20h00/141003-edition-du-lundi-8-mai-2017.html",
- "https://www.france.tv/france-o/underground/saison-1/132187-underground.html",
- "http://www.ludo.fr/heros/the-batman",
- "http://www.ludo.fr/heros/il-etait-une-fois-la-vie",
- "http://www.zouzous.fr/heros/oui-oui",
- "http://www.zouzous.fr/heros/marsupilami-1",
- "http://france3-regions.francetvinfo.fr/bourgogne-franche-comte/tv/direct/franche-comte",
- "http://sport.francetvinfo.fr/roland-garros/direct",
- "http://sport.francetvinfo.fr/roland-garros/live-court-3",
- "http://sport.francetvinfo.fr/roland-garros/andy-murray-gbr-1-andrey-kuznetsov-rus-1er-tour-court"
- + "-philippe-chatrier",
- "https://www.francetvinfo.fr/en-direct/tv.html"
- ]
-
- should_not_match = [
- "http://www.france.tv/",
- "http://pluzz.francetv.fr/",
- "http://www.ludo.fr/",
- "http://www.ludo.fr/jeux",
- "http://www.zouzous.fr/",
+ "https://france3-regions.francetvinfo.fr/bourgogne-franche-comte/tv/direct/franche-comte",
+ "https://www.francetvinfo.fr/en-direct/tv.html",
+ "https://www.francetvinfo.fr/meteo/orages/inondations-dans-le-gard-plus-de-deux-mois-de-pluie-en-quelques-heures-des"
+ + "-degats-mais-pas-de-victime_4771265.html"
]
| plugins.pluzz: doesn't work anymore
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
This plugin stopped working last week. The workflow is the same as current plugin, but API_URL and the json response format have changed, leading to errors and failure to get the streams
I've fixed the code and it's working so far on live streams and on the few vod videos i've checked. I can do a PR if you want, but i won't be able to perform current functionalities coverage evaluation before a long time.
### Debug log
```text
[cli][debug] OS: Linux-5.10.0-8-amd64-x86_64-with-glibc2.31
[cli][debug] Python: 3.9.7
[cli][debug] Streamlink: 2.4.0
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(1.2.1)
[cli][debug] Arguments:
[cli][debug] url=https://www.france.tv/france-3/direct.html
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin pluzz for URL https://www.france.tv/france-3/direct.html
[plugins.pluzz][debug] Country: FR
[plugins.pluzz][debug] Video ID: 29bdf749-7082-4426-a4f3-595cc436aa0d
error: Unable to open URL: http://sivideo.webservices.francetelevisions.fr/tools/getInfosOeuvre/v2/?idDiffusion=29bdf749-7082-4426-a4f3-595cc436aa0d (404 Client Error: Not Found for url: http://sivideo.webservices.francetelevisions.fr/tools/getInfosOeuvre/v2/?idDiffusion=29bdf749-7082-4426-a4f3-595cc436aa0d)
```
| 2021-09-15T06:05:16 |
|
streamlink/streamlink | 4,029 | streamlink__streamlink-4029 | [
"4026",
"4027"
] | 24c59a23103922977991acc28741a323d8efa7a1 | diff --git a/src/streamlink/plugins/artetv.py b/src/streamlink/plugins/artetv.py
--- a/src/streamlink/plugins/artetv.py
+++ b/src/streamlink/plugins/artetv.py
@@ -1,5 +1,3 @@
-"""Plugin for Arte.tv, bi-lingual art and culture channel."""
-
import logging
import re
from operator import itemgetter
@@ -9,25 +7,6 @@
from streamlink.stream import HLSStream
log = logging.getLogger(__name__)
-JSON_VOD_URL = "https://api.arte.tv/api/player/v1/config/{0}/{1}?platform=ARTE_NEXT"
-JSON_LIVE_URL = "https://api.arte.tv/api/player/v1/livestream/{0}"
-
-_video_schema = validate.Schema({
- "videoJsonPlayer": {
- "VSR": validate.any(
- [],
- {
- validate.text: {
- "height": int,
- "mediaType": validate.text,
- "url": validate.text,
- "versionProg": int,
- "versionLibelle": validate.text
- },
- },
- )
- }
-})
@pluginmatcher(re.compile(r"""
@@ -40,34 +19,49 @@
)
""", re.VERBOSE))
class ArteTV(Plugin):
- def _create_stream(self, streams):
- variant, variantname = min([(stream["versionProg"], stream["versionLibelle"]) for stream in streams.values()],
- key=itemgetter(0))
- log.debug(f"Using the '{variantname}' stream variant")
- for sname, stream in streams.items():
- if stream["versionProg"] == variant:
- if stream["mediaType"] == "hls":
- try:
- streams = HLSStream.parse_variant_playlist(self.session, stream["url"])
- yield from streams.items()
- except OSError as err:
- log.warning(f"Failed to extract HLS streams for {sname}/{stream['versionLibelle']}: {err}")
+ API_URL = "https://api.arte.tv/api/player/v2/config/{0}/{1}"
+ API_TOKEN = "MzYyZDYyYmM1Y2Q3ZWRlZWFjMmIyZjZjNTRiMGY4MzY4NzBhOWQ5YjE4MGQ1NGFiODJmOTFlZDQwN2FkOTZjMQ"
def _get_streams(self):
- language = self.match.group('language')
- video_id = self.match.group('video_id')
- if video_id is None:
- json_url = JSON_LIVE_URL.format(language)
- else:
- json_url = JSON_VOD_URL.format(language, video_id)
- res = self.session.http.get(json_url)
- video = self.session.http.json(res, schema=_video_schema)
+ language = self.match.group("language")
+ video_id = self.match.group("video_id")
- if not video["videoJsonPlayer"]["VSR"]:
+ json_url = self.API_URL.format(language, video_id or "LIVE")
+ headers = {
+ "Authorization": f"Bearer {self.API_TOKEN}"
+ }
+ streams, metadata = self.session.http.get(json_url, headers=headers, schema=validate.Schema(
+ validate.parse_json(),
+ {"data": {"attributes": {
+ "streams": validate.any(
+ [],
+ [
+ validate.all(
+ {
+ "url": validate.url(),
+ "slot": int,
+ "protocol": validate.any("HLS", "HLS_NG"),
+ },
+ validate.union_get("slot", "protocol", "url")
+ )
+ ]
+ ),
+ "metadata": {
+ "title": str,
+ "subtitle": validate.any(None, str)
+ }
+ }}},
+ validate.get(("data", "attributes")),
+ validate.union_get("streams", "metadata")
+ ))
+
+ if not streams:
return
- vsr = video["videoJsonPlayer"]["VSR"]
- return self._create_stream(vsr)
+ self.title = f"{metadata['title']} - {metadata['subtitle']}" if metadata["subtitle"] else metadata["title"]
+
+ for slot, protocol, url in sorted(streams, key=itemgetter(0)):
+ return HLSStream.parse_variant_playlist(self.session, url)
__plugin__ = ArteTV
| artetv: de/fr Livestreams aren't playable anymore
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
Since about a week the live channels aren't playable anymore. However VODs working fine.
### Debug log
```text
streamlink https://www.arte.tv/de/live/ worst -l debug
[cli][debug] OS: Linux-5.14.3-arch1-1-x86_64-with-glibc2.33
[cli][debug] Python: 3.9.7
[cli][debug] Streamlink: 2.4.0+17.g24c59a2
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(0.59.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.arte.tv/de/live/
[cli][debug] stream=['worst']
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin artetv for URL https://www.arte.tv/de/live/
error: No playable streams found on this URL: https://www.arte.tv/de/live/
streamlink https://www.arte.tv/fr/direct/ best -l debug
[cli][debug] OS: Linux-5.14.3-arch1-1-x86_64-with-glibc2.33
[cli][debug] Python: 3.9.7
[cli][debug] Streamlink: 2.4.0+17.g24c59a2
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(0.59.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.arte.tv/fr/direct/
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin artetv for URL https://www.arte.tv/fr/direct/
error: No playable streams found on this URL: https://www.arte.tv/fr/direct/
```
plugins.arte: switch to arte.tv v2 API
The Arte.tv V1 API doens't seem to work anymore for live streams (see #4026).
Both web site and mobile app use the V2 API, which requires an authentication token. The one from the website is used here for this fix.
| 2021-09-18T13:47:38 |
||
streamlink/streamlink | 4,048 | streamlink__streamlink-4048 | [
"2993"
] | b37fb31ef864c7a968ab5000a84650782c8c861b | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -65,7 +65,16 @@ def is_wheel_for_windows():
entry_points["gui_scripts"] = ["streamlinkw=streamlink_cli.main:main"]
+# optional data files
additional_files = [
+ # shell completions
+ # requires pre-built completion files via shtab (dev-requirements.txt)
+ # `./script/build-shell-completions.sh`
+ ("share/bash-completion/completions", ["build/shtab/bash/streamlink"]),
+ ("share/zsh/site-functions", ["build/shtab/zsh/_streamlink"]),
+ # man page
+ # requires pre-built man page file via sphinx (docs-requirements.txt)
+ # `make --directory=docs clean man`
("share/man/man1", ["docs/_build/man/streamlink.1"])
]
| Shell tab completion support
## Feature Request
- [x] This is a feature request and I have read the contribution guidelines.
### Description
Streamlink should provide shell completions for all of its parameters. This could either be static and simple, or a bit more sophisticated and dynamic, depending on the allowed parameter values. Completion data for multiple shells, like fish for example, would also be nice.
I've checked a couple of solutions that work in conjunction with `argparse`, so that shell scripts don't have to be written manually and maintained next to the regular parameter definitions. This can be done with [`argcomplete`](https://github.com/kislyuk/argcomplete) for example, but it needs to run before streamlink-cli's own code gets executed and also needs to be added as a dependency (obviously), and I'm not sure if that's desired.
If there's a way to generate shell completion scripts from argparse, then this would be the best solution.
| I've only ever used argcomplete for this. I don't think argparse has anything built in unless it has flown under the radar for quite some time. I'm against adding additional dependencies (such as the js parser as discussed before) since the value added is really low. This actually has some merit to improve functionality so if it doesn't add too much on to the start time of Streamlink or bloat unnecessarily I'd be okay with either argcomplete or something else.
I wonder if it's possible to make it part of the build and include the generated files, without having to include the dependency in the distribution packages.
Everyone hating on the js parser, even though it is pure python and has no transient dependencies, and is useful...
@beardypig My only hate comes from the fact it is unmaintained software. If it was actively being maintained I would have no issue. | 2021-09-25T10:59:37 |
|
streamlink/streamlink | 4,052 | streamlink__streamlink-4052 | [
"4051"
] | c8f0e432368a11a43eaf4bef4bd9882760ae5318 | diff --git a/src/streamlink/plugins/picarto.py b/src/streamlink/plugins/picarto.py
--- a/src/streamlink/plugins/picarto.py
+++ b/src/streamlink/plugins/picarto.py
@@ -1,5 +1,6 @@
import logging
import re
+from urllib.parse import urlparse
from streamlink.plugin import Plugin, pluginmatcher
from streamlink.plugin.api import validate
@@ -15,71 +16,66 @@
(?:\?tab=videos&id=(?P<vod_id>\d+))?
""", re.VERBOSE))
class Picarto(Plugin):
- channel_schema = validate.Schema({
- 'channel': validate.any(None, {
- 'stream_name': str,
- 'title': str,
- 'online': bool,
- 'private': bool,
- 'categories': [{'label': str}],
- }),
- 'getLoadBalancerUrl': {'origin': str},
- 'getMultiStreams': validate.any(None, {
- 'multistream': bool,
- 'streams': [{
- 'name': str,
- 'online': bool,
- }],
- }),
- })
- vod_schema = validate.Schema({
- 'data': {
- 'video': validate.any(None, {
- 'id': str,
- 'title': str,
- 'file_name': str,
- 'channel': {'name': str},
- }),
- },
- }, validate.get('data'), validate.get('video'))
-
- HLS_URL = 'https://{origin}.picarto.tv/stream/hls/{file_name}/index.m3u8'
+ API_URL_LIVE = "https://ptvintern.picarto.tv/api/channel/detail/{username}"
+ API_URL_VOD = "https://ptvintern.picarto.tv/ptvapi"
+ HLS_URL = "https://{netloc}/stream/hls/{file_name}/index.m3u8"
def get_live(self, username):
- res = self.session.http.get(f'https://ptvintern.picarto.tv/api/channel/detail/{username}')
- channel_data = self.session.http.json(res, schema=self.channel_schema)
- log.trace(f'channel_data={channel_data!r}')
+ netloc = self.session.http.get(self.url, schema=validate.Schema(
+ validate.parse_html(),
+ validate.xml_xpath_string(".//script[contains(@src,'/stream/player.js')][1]/@src"),
+ validate.any(None, validate.transform(lambda src: urlparse(src).netloc))
+ ))
+ if not netloc:
+ log.error("Could not find server netloc")
+ return
- if not channel_data['channel'] or not channel_data['getMultiStreams']:
- log.debug('Missing channel or streaming data')
+ channel, multistreams = self.session.http.get(self.API_URL_LIVE.format(username=username), schema=validate.Schema(
+ validate.parse_json(),
+ {
+ "channel": validate.any(None, {
+ "stream_name": str,
+ "title": str,
+ "online": bool,
+ "private": bool,
+ "categories": [{"label": str}],
+ }),
+ "getMultiStreams": validate.any(None, {
+ "multistream": bool,
+ "streams": [{
+ "name": str,
+ "online": bool,
+ }],
+ }),
+ },
+ validate.union_get("channel", "getMultiStreams")
+ ))
+ if not channel or not multistreams:
+ log.debug("Missing channel or streaming data")
return
- if channel_data['channel']['private']:
- log.info('This is a private stream')
+ log.trace(f"netloc={netloc!r}")
+ log.trace(f"channel={channel!r}")
+ log.trace(f"multistreams={multistreams!r}")
+
+ if not channel["online"]:
+ log.error("User is not online")
return
- if channel_data['getMultiStreams']['multistream']:
- msg = 'Found multistream: '
- i = 1
- for user in channel_data['getMultiStreams']['streams']:
- msg += user['name']
- msg += ' (online)' if user['online'] else ' (offline)'
- if i < len(channel_data['getMultiStreams']['streams']):
- msg += ', '
- i += 1
- log.info(msg)
-
- if not channel_data['channel']['online']:
- log.error('User is not online')
+ if channel["private"]:
+ log.info("This is a private stream")
return
self.author = username
- self.category = channel_data['channel']['categories'][0]['label']
- self.title = channel_data['channel']['title']
+ self.category = channel["categories"][0]["label"]
+ self.title = channel["title"]
- return HLSStream.parse_variant_playlist(self.session,
- self.HLS_URL.format(file_name=channel_data['channel']['stream_name'],
- origin=channel_data['getLoadBalancerUrl']['origin']))
+ hls_url = self.HLS_URL.format(
+ netloc=netloc,
+ file_name=channel["stream_name"]
+ )
+
+ return HLSStream.parse_variant_playlist(self.session, hls_url)
def get_vod(self, vod_id):
data = {
@@ -89,6 +85,7 @@ def get_vod(self, vod_id):
' id\n'
' title\n'
' file_name\n'
+ ' video_recording_image_url\n'
' channel {\n'
' name\n'
' }'
@@ -97,19 +94,37 @@ def get_vod(self, vod_id):
),
'variables': {'videoId': vod_id},
}
- res = self.session.http.post('https://ptvintern.picarto.tv/ptvapi', json=data)
- vod_data = self.session.http.json(res, schema=self.vod_schema)
- log.trace(f'vod_data={vod_data!r}')
+ vod_data = self.session.http.post(self.API_URL_VOD, json=data, schema=validate.Schema(
+ validate.parse_json(),
+ {"data": {
+ "video": validate.any(None, {
+ "id": str,
+ "title": str,
+ "file_name": str,
+ "video_recording_image_url": str,
+ "channel": {"name": str},
+ }),
+ }},
+ validate.get(("data", "video"))
+ ))
+
if not vod_data:
- log.debug('Missing video data')
+ log.debug("Missing video data")
return
- self.author = vod_data['channel']['name']
- self.category = 'VOD'
- self.title = vod_data['title']
- return HLSStream.parse_variant_playlist(self.session,
- self.HLS_URL.format(file_name=vod_data['file_name'],
- origin='recording-eu-1'))
+ log.trace(f"vod_data={vod_data!r}")
+
+ self.author = vod_data["channel"]["name"]
+ self.category = "VOD"
+ self.title = vod_data["title"]
+
+ netloc = urlparse(vod_data["video_recording_image_url"]).netloc
+ hls_url = self.HLS_URL.format(
+ netloc=netloc,
+ file_name=vod_data["file_name"]
+ )
+
+ return HLSStream.parse_variant_playlist(self.session, hls_url)
def _get_streams(self):
m = self.match.groupdict()
| plugins.picarto: Unable to validate JSON: Key 'getLoadBalancerUrl' not found
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
Streamlink fails with `error: Unable to validate JSON: Key 'getLoadBalancerUrl' not found in ...` for any Picarto URL, regardless of whether the target livestream is online or not.
### Debug log
```text
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.9.6
[cli][debug] Streamlink: 2.4.0
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(1.1.1)
[cli][debug] Arguments:
[cli][debug] url=https://picarto.tv/Sephive
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin picarto for URL https://picarto.tv/Sephive
[plugins.picarto][debug] Type=Live
error: Unable to validate JSON: Key 'getLoadBalancerUrl' not found in {'channel': {'account_type': 'FREE', 'adult': False, 'avatar': 'https://images.picarto.tv/ptvimages/4/47/471629/avatars/3b903da4e61234afaa49f8d4f0f2a9c0.jpg', 'color': '#1da456', 'columns': 3, 'commissions': False, 'created_at': '2016-10-02 00:31:45', 'enable_subscription': False, 'gaming': False, 'id': 471629, 'name': 'Sephive', 'online': False, 'private': False, 'show_subscriber_count': False, 'title': 'Illustration! (mostly dragons)', 'total_views': 1434, 'verified': False, 'viewers': 0, 'bio': '', 'profile_color': None, 'banned': False, 'redirect': False, 'followers_count': 67, 'subscribers_count': 0, 'videos_count': 0, 'notification': False, 'gifted': False, 'gifted_channel_name': None, 'following': False, 'subscribed': False, 'ubanned': False, 'stream_name': 'golive+Sephive', 'image_thumbnail': 'https://thumb.picarto.tv/thumbnail/Sephive.jpg', 'video_thumbnail': 'https://thumb.picarto.tv/thumbnail/Sephive.mp4', 'banners': [], 'descriptions': [{'id': 1826, 'channel_id': 471629, 'title': '', 'body': 'Follow me on Twitter and FA!\nhttps://twitter.com/SephiveDewlap\nhttp://www.furaffinity.net/user/sephive/', 'image': 'https://images.picarto.tv/ptvimages/4/47/471629/panels/1826_d9406789b0a9688efd7ae264441a7ff65089589e5b99307af1ea36cb5b1ddf08.png', 'url': None, 'button_enabled': 0, 'button_text': '', 'button_link': '', 'position': 0, 'image_link': '', 'background': False, 'shadow': False, 'hide': False, 'icon_id': None, 'created_at': None, 'updated_at': None, 'deleted_at': None, 'image_url': 'https://images.picarto.tv/ptvimages/4/47/471629/panels/1826_d9406789b0a9688efd7ae264441a7ff65089589e5b99307af1ea36cb5b1ddf08.png'}, {'id': 1827, 'channel_id': 471629, 'title': '', 'body': '', 'image': None, 'url': None, 'button_enabled': 0, 'button_text': '', 'button_link': '', 'position': 1, 'image_link': '', 'background': False, 'shadow': False, 'hide': False, 'icon_id': None, 'created_at': None, 'updated_at': None, 'deleted_at': None, 'image_url': 'https://ptvintern.picarto.tv/storage/'}], 'tools': [], 'categories': [{'id': 8, 'name': 'Furry', 'label': 'Furry', 'value': 8, '_id': 8, 'pivot': {'channel_id': 471629, 'category_id': 8}}], 'languages': [{'id': 56, 'name': 'None', 'code': '', 'label': 'None', 'value': 56, '_id': 56, 'image': None, 'pivot': {'channel_id': 471629, 'language_id': 56}}], 'social_medias': [{'id': 13, 'name': 'Homepage', 'icon': 'https://images.picarto.tv/socialmedias/d2bc802bab173a0ae2fdde67.png', 'regex': '', 'created_at': '2021-03-22 23:32:15', 'updated_at': '2021-07-26 09:26:25', 'deleted_at': None, 'pivot': {'channel_id': 471629, 'social_media_id': 13, 'id': 400322, 'link': 'http://www.furaffinity.net/user/sephive/'}}], 'softwares': [{'id': 20, 'name': 'Clip Studio Paint', 'label': 'Clip Studio Paint', 'value': 20, '_id': 20, 'pivot': {'channel_id': 471629, 'software_id': 20}}], 'tags': [], 'user': None}, 'getMultiStreams': {'name': 'Sephive', 'online': False, 'viewers': 0, 'multistream': False, 'streams': [{'id': 471629, 'user_id': 471629, 'name': 'Sephive', 'account_type': 'FREE', 'avatar': 'https://images.picarto.tv/ptvimages/4/47/471629/avatars/3b903da4e61234afaa49f8d4f0f2a9c0.jpg', 'offline_image': None, 'thumbnail_image': 'https://thumb-us-east1.picarto.tv/thumbnail/Sephive.jpg', 'online': False, 'stream_name': 'golive+Sephive', 'color': '#1da456', 'adult': False, 'multistream': False, 'webrtc': False, 'host': False, 'viewers': 0, 'subscription_enabled': False, 'accountType': 'FREE', 'channelId': 471629, 'channelName': 'Sephive', 'nicknameColor': '#1da456', 'offlineImage': None, 'streamName': 'golive+Sephive', 'thumbnailImage': 'https://thumb-us-east1.picarto.tv/thumbnail/Sephive.jpg', 'hosted': False, 'following': False, 'subscription': False}], 'displayName': 'Sephive'}}
```
| I did some quick poking around, and it looks like they just dropped the edge server hostname from the channel detail API response. I don't see any obvious replacements in the new response, so we'll need to find a new way of getting the server hostname. If anyone has any ideas, let me know. The only place I see the hostname showing up is in the HTML of the viewer page, and I'd rather not have to scrape it if there's a more reliable source. | 2021-09-27T08:28:24 |
|
streamlink/streamlink | 4,064 | streamlink__streamlink-4064 | [
"3866"
] | 099e7e4af66f9c4fc62ffe1af522d751f655938d | diff --git a/src/streamlink/plugins/pandalive.py b/src/streamlink/plugins/pandalive.py
new file mode 100644
--- /dev/null
+++ b/src/streamlink/plugins/pandalive.py
@@ -0,0 +1,79 @@
+import logging
+import re
+
+from streamlink.plugin import Plugin, pluginmatcher
+from streamlink.plugin.api import validate
+from streamlink.stream.hls import HLSStream
+
+log = logging.getLogger(__name__)
+
+
+@pluginmatcher(re.compile(
+ r"https?://(?:www\.)?pandalive\.co\.kr/"
+))
+class Pandalive(Plugin):
+ _room_id_re = re.compile(r"roomid\s*=\s*String\.fromCharCode\((.*)\)")
+
+ def _get_streams(self):
+ media_code = self.session.http.get(self.url, schema=validate.Schema(
+ validate.parse_html(),
+ validate.xml_xpath_string(".//script[contains(text(), 'roomid')]/text()"),
+ validate.any(None, validate.all(
+ validate.transform(self._room_id_re.search),
+ validate.any(None, validate.all(
+ validate.get(1),
+ validate.transform(lambda s: "".join(map(lambda c: chr(int(c)), s.split(",")))),
+ )),
+ )),
+ ))
+
+ if not media_code:
+ return
+
+ log.debug(f"Media code: {media_code}")
+
+ json = self.session.http.post(
+ "https://api.pandalive.co.kr/v1/live/play",
+ data={"action": "watch", "mediaCode": media_code},
+ schema=validate.Schema(
+ validate.parse_json(), {
+ validate.optional("media"): {
+ "title": str,
+ "userId": str,
+ "userNick": str,
+ "isPw": bool,
+ "isLive": bool,
+ "liveType": str,
+ },
+ validate.optional("PlayList"): {
+ "hls2": [{
+ "url": validate.url(),
+ }],
+ },
+ "result": bool,
+ "message": str,
+ },
+ )
+ )
+
+ if not json["result"]:
+ log.error(json["message"])
+ return
+
+ if not json["media"]["isLive"]:
+ log.error("The broadcast has ended")
+ return
+
+ if json["media"]["isPw"]:
+ log.error("The broadcast is password protected")
+ return
+
+ log.info(f"Broadcast type: {json['media']['liveType']}")
+
+ self.author = f"{json['media']['userNick']} ({json['media']['userId']})"
+ self.title = f"{json['media']['title']}"
+
+ return HLSStream.parse_variant_playlist(self.session, json["PlayList"]["hls2"][0]["url"])
+
+
+__plugin__ = Pandalive
| diff --git a/tests/plugins/test_pandalive.py b/tests/plugins/test_pandalive.py
new file mode 100644
--- /dev/null
+++ b/tests/plugins/test_pandalive.py
@@ -0,0 +1,17 @@
+from streamlink.plugins.pandalive import Pandalive
+from tests.plugins import PluginCanHandleUrl
+
+
+class TestPluginCanHandleUrlPandalive(PluginCanHandleUrl):
+ __plugin__ = Pandalive
+
+ should_match = [
+ "http://pandalive.co.kr/",
+ "http://pandalive.co.kr/any/path",
+ "http://www.pandalive.co.kr/",
+ "http://www.pandalive.co.kr/any/path",
+ "https://pandalive.co.kr/",
+ "https://pandalive.co.kr/any/path",
+ "https://www.pandalive.co.kr/",
+ "https://www.pandalive.co.kr/any/path",
+ ]
| pandalive.co.kr (not to be confused with panda.tv)
### Checklist
- [X] This is a plugin request and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin requests](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+request%22)
### Description
Pandalive is a Korean live streaming site similar to afreecatv. Previous tickets were closed with "more info required" but was never explained why ticket was rejected.
It has the same name as the panda.tv which is a closed down china site, which in the old ticket others have confused with.
If this ticket gets closed, I hope there would at least be a reason/explanation on why it might be it (like in the previous closed ticket, what exactly is "does not meet requirements"? Seeing that thee list has many possible reasons the plugin might not be added but was never mentioned in the closed ticket.
Thanks
### Input URLs
https://www.pandalive.co.kr/
| Hi, I managed to grab the stream url from the site (apparently the site uses WebSocket to get the stream url)
Demo: https://replit.com/@Trung0246/BowedImperfectZettabyte#main.py
Gist: https://gist.github.com/Trung0246/2676e0180c7d68c0713d96721a206a13

Apparently there's password protected stream but no idea about that yet, beside that anything else I missed?
Also looks like the stream url is ip-dependent so that ip is from repl.it server ip
The reason past requests for this plugin have been closed is because they have not sufficiently met the requirements as set out in the first paragraph of the plugin request advice detailed at: https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#plugin-requests
Also, plugin requests will only be considered if a site meets the 11 requirements also set out there.
I'm unsure what the viewership numbers are for the live streams on the site. There's a person icon with a number next to it in the range of ~10 to ~40, which could be the current number of viewers? There's also a bit on the stream page itself which translates to `cumulative` in English with a number next to it in the hundreds of thousands. I'm not sure what that is, it's probably not a great translation (total number of views for the channel?).
I can't tell you what viewership figures might justify a plugin addition to Streamlink, as it's up to the maintainers and there seems to be no quotable magic figure that I'm aware of.
> Apparently there's password protected stream
When you say `password protected`, do you mean that would require an account and to be signed in to the website? Do these streams require any form of monetary subscription to view? If so, they are unlikely to be supported because they are difficult to maintain.
> When you say `password protected`, do you mean that would require an account and to be signed in to the website? Do these streams require any form of monetary subscription to view? If so, they are unlikely to be supported because they are difficult to maintain.
I'm not really sure which type of password protected stream but by looking at the js code it's seems like you don't even needs to login and only needs the password that are associated with the stream. Needs more investigation of course. | 2021-10-02T04:51:39 |
streamlink/streamlink | 4,075 | streamlink__streamlink-4075 | [
"4074"
] | e38caa19a12363c60be1d73629543b810b6b9c99 | diff --git a/src/streamlink/utils/parse.py b/src/streamlink/utils/parse.py
--- a/src/streamlink/utils/parse.py
+++ b/src/streamlink/utils/parse.py
@@ -76,7 +76,7 @@ def parse_xml(
if isinstance(data, str):
data = bytes(data, "utf8")
if ignore_ns:
- data = re.sub(br"[\t ]xmlns=\"(.+?)\"", b"", data)
+ data = re.sub(br"\s+xmlns=\"(.+?)\"", b"", data)
if invalid_char_entities:
data = re.sub(br"&(?!(?:#(?:[0-9]+|[Xx][0-9A-Fa-f]+)|[A-Za-z0-9]+);)", b"&", data)
| diff --git a/tests/utils/test_parse.py b/tests/utils/test_parse.py
--- a/tests/utils/test_parse.py
+++ b/tests/utils/test_parse.py
@@ -29,12 +29,14 @@ def test_parse_xml_ns_ignore(self):
self.assertEqual(expected.tag, actual.tag)
self.assertEqual(expected.attrib, actual.attrib)
- def test_parse_xml_ns_ignore_tab(self):
- expected = Element("test", {"foo": "bar"})
actual = parse_xml("""<test foo="bar" xmlns="foo:bar"/>""", ignore_ns=True)
self.assertEqual(expected.tag, actual.tag)
self.assertEqual(expected.attrib, actual.attrib)
+ actual = parse_xml("""<test\nfoo="bar"\nxmlns="foo:bar"/>""", ignore_ns=True)
+ self.assertEqual(expected.tag, actual.tag)
+ self.assertEqual(expected.attrib, actual.attrib)
+
def test_parse_xml_ns(self):
expected = Element("{foo:bar}test", {"foo": "bar"})
actual = parse_xml("""<h:test foo="bar" xmlns:h="foo:bar"/>""")
| dash plugin: MPDParsingError: root tag did not match the expected tag: MPD
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [ ] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
The following steps worked until yesterday:
1. Connect to a channel livestream of Teleboy (teleboy.ch) or Zattoo (zattoo.com) with my web browser.
2. Get the .mpd URL link of the livestream.
3. Launch the command "streamlink "mpd-url-link best".
4. The livestream opens up in VLC.
Since today, the command fails.
Here is an example of the .mpd file content which streamlink fails to play: https://pastebin.com/jXD1NY1F
### Debug log
```text
streamlink "https://zh2-0-dash-live.zahs.tv/HD_orf1/m.mpd?z32=MF2WI2LPL5RW6ZDFMNZT2YLBMMTGG43JMQ6TCNSBII4DSMJSIZBTEMJVIQ2EKLJUGEZDORJSGVCDKOBTIE4ECOKEEZWWC6DSMF2GKPJVGAYDAJTNNFXHEYLUMU6TEMJQEZYHEZLGMVZHEZLEL5WGC3THOVQWOZJ5MZZCM43JM46TSX3FG4YDGMJXG5RGIMRVGNSTCMLBGI4GEMZRG5SDQN3DGRSGGYJXGETHK43FOJPWSZB5ORSWYZLCN54TUORYGM4DSMRXEZ3D2MA" best --loglevel debug
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.9.6
[cli][debug] Streamlink: 2.4.0
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(1.2.1)
[cli][debug] Arguments:
[cli][debug] url=https://zh2-0-dash-live.zahs.tv/HD_orf1/m.mpd?z32=MF2WI2LPL5RW6ZDFMNZT2YLBMMTGG43JMQ6TCNSBII4DSMJSIZBTEMJVIQ2EKLJUGEZDORJSGVCDKOBTIE4ECOKEEZWWC6DSMF2GKPJVGAYDAJTNNFXHEYLUMU6TEMJQEZYHEZLGMVZHEZLEL5WGC3THOVQWOZJ5MZZCM43JM46TSX3FG4YDGMJXG5RGIMRVGNSTCMLBGI4GEMZRG5SDQN3DGRSGGYJXGETHK43FOJPWSZB5ORSWYZLCN54TUORYGM4DSMRXEZ3D2MA
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --rtmp-rtmpdump=rtmpdump.exe
[cli][debug] --rtmpdump=C:\Program Files (x86)\Streamlink\rtmpdump\rtmpdump.exe
[cli][debug] --ffmpeg-ffmpeg=C:\Program Files (x86)\Streamlink\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin dash for URL https://zh2-0-dash-live.zahs.tv/HD_orf1/m.mpd?z32=MF2WI2LPL5RW6ZDFMNZT2YLBMMTGG43JMQ6TCNSBII4DSMJSIZBTEMJVIQ2EKLJUGEZDORJSGVCDKOBTIE4ECOKEEZWWC6DSMF2GKPJVGAYDAJTNNFXHEYLUMU6TEMJQEZYHEZLGMVZHEZLEL5WGC3THOVQWOZJ5MZZCM43JM46TSX3FG4YDGMJXG5RGIMRVGNSTCMLBGI4GEMZRG5SDQN3DGRSGGYJXGETHK43FOJPWSZB5ORSWYZLCN54TUORYGM4DSMRXEZ3D2MA
[plugins.dash][debug] Parsing MPD URL: https://zh2-0-dash-live.zahs.tv/HD_orf1/m.mpd?z32=MF2WI2LPL5RW6ZDFMNZT2YLBMMTGG43JMQ6TCNSBII4DSMJSIZBTEMJVIQ2EKLJUGEZDORJSGVCDKOBTIE4ECOKEEZWWC6DSMF2GKPJVGAYDAJTNNFXHEYLUMU6TEMJQEZYHEZLGMVZHEZLEL5WGC3THOVQWOZJ5MZZCM43JM46TSX3FG4YDGMJXG5RGIMRVGNSTCMLBGI4GEMZRG5SDQN3DGRSGGYJXGETHK43FOJPWSZB5ORSWYZLCN54TUORYGM4DSMRXEZ3D2MA
Traceback (most recent call last):
File "runpy.py", line 197, in _run_module_as_main
File "runpy.py", line 87, in _run_code
File "C:\Program Files (x86)\Streamlink\bin\streamlink.exe\__main__.py", line 18, in <module>
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink_cli\main.py", line 1082, in main
handle_url()
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink_cli\main.py", line 576, in handle_url
streams = fetch_streams(plugin)
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink_cli\main.py", line 470, in fetch_streams
return plugin.streams(stream_types=args.stream_types,
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\plugin\plugin.py", line 335, in streams
ostreams = self._get_streams()
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\plugins\dash.py", line 34, in _get_streams
return DASHStream.parse_manifest(self.session, url)
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\dash.py", line 185, in parse_manifest
mpd = MPD(session.http.xml(res, ignore_ns=True), base_url=urlunparse(urlp), url=url)
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\dash_manifest.py", line 224, in __init__
super().__init__(node, root=self, *args, **kwargs)
File "C:\Program Files (x86)\Streamlink\pkgs\streamlink\stream\dash_manifest.py", line 146, in __init__
raise MPDParsingError("root tag did not match the expected tag: {}".format(self.__tag__))
streamlink.stream.dash_manifest.MPDParsingError: root tag did not match the expected tag: MPD
```
| Looks like a bug in the DASH manifest parser / XML parser.
> ```xml
> <MPD xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
> xmlns="urn:mpeg:dash:schema:mpd:2011"
> ...
> ```
The root node's tag value includes the default namespace, which is `{urn:mpeg:dash:schema:mpd:2011}MPD`), and it doesn't match the expected `MPD` string.
https://github.com/streamlink/streamlink/blob/e38caa19a12363c60be1d73629543b810b6b9c99/src/streamlink/stream/dash_manifest.py#L145-L146
There's been some code refactoring in the last couple of weeks and Streamlink also switched to `lxml` for parsing XML (that shouldn't cause an issue though).
In the recently updated [`parse_xml`](https://github.com/streamlink/streamlink/blob/e38caa19a12363c60be1d73629543b810b6b9c99/src/streamlink/utils/parse.py#L78-L79) method (which is called by [`DASHStream.parse_manifest`](https://github.com/streamlink/streamlink/blob/e38caa19a12363c60be1d73629543b810b6b9c99/src/streamlink/stream/dash.py#L185) via `session.http.xml`) its `ignore_ns` parameter is set to True, which means it's supposed to strip off the default namespace attribute. It's possible that this is not working correctly. Let me have a look.
The DASH tests strip off the namespace information from the root node's tag value with custom logic, which is probably the reason why this issue hasn't been caught:
- https://github.com/streamlink/streamlink/blob/e38caa19a12363c60be1d73629543b810b6b9c99/tests/resources/__init__.py#L17-L19
- https://github.com/streamlink/streamlink/blob/e38caa19a12363c60be1d73629543b810b6b9c99/tests/resources/dash/test_1.mpd#L2
- https://github.com/streamlink/streamlink/blob/e38caa19a12363c60be1d73629543b810b6b9c99/tests/stream/test_dash_parser.py#L73-L74
Looks like the issue is the regex for stripping off the default namespace attribute. It's expecting a leading space or tab character, which is not the case in your input manifest, where it's using a new-line character instead. The regex did not get changed though in the recent code refactorings, which means the issue was already present in earlier versions of Streamlink.
https://github.com/streamlink/streamlink/blob/e38caa19a12363c60be1d73629543b810b6b9c99/src/streamlink/utils/parse.py#L79
That should fix it:
```diff
diff --git a/src/streamlink/utils/parse.py b/src/streamlink/utils/parse.py
index 8165a2c3..2a4de948 100644
--- a/src/streamlink/utils/parse.py
+++ b/src/streamlink/utils/parse.py
@@ -76,7 +76,7 @@ def parse_xml(
if isinstance(data, str):
data = bytes(data, "utf8")
if ignore_ns:
- data = re.sub(br"[\t ]xmlns=\"(.+?)\"", b"", data)
+ data = re.sub(br"\s+xmlns=\"(.+?)\"", b"", data)
if invalid_char_entities:
data = re.sub(br"&(?!(?:#(?:[0-9]+|[Xx][0-9A-Fa-f]+)|[A-Za-z0-9]+);)", b"&", data)
```
Can you confirm this? It's parsing the manifest correctly for me.
```
$ streamlink -l debug 'dash://file://./foo'
[cli][debug] OS: Linux-5.14.8-1-git-x86_64-with-glibc2.33
[cli][debug] Python: 3.9.7
[cli][debug] Streamlink: 2.4.0+37.ge38caa1.dirty
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(0.58.0)
[cli][debug] Arguments:
[cli][debug] url=dash://file://./foo
[cli][debug] --loglevel=debug
[cli][debug] --player=mpv
[cli][info] Found matching plugin dash for URL dash://file://./foo
[plugins.dash][debug] Parsing MPD URL: file://./foo
[utils.l10n][debug] Language code: en_US
[stream.dash][debug] Available languages for DASH audio streams: mis, de (using: de)
Available streams: 224p (worst), 288p_alt, 288p, 432p, 720p_alt, 720p (best)
``` | 2021-10-06T21:02:25 |
streamlink/streamlink | 4,119 | streamlink__streamlink-4119 | [
"4118"
] | 6e07f552572fe44aca0d407de269da8682e440aa | diff --git a/src/streamlink/plugins/brightcove.py b/src/streamlink/plugins/brightcove.py
--- a/src/streamlink/plugins/brightcove.py
+++ b/src/streamlink/plugins/brightcove.py
@@ -64,7 +64,7 @@ def get_streams(self, video_id):
)
for source in sources:
- if source.get("type") == "application/vnd.apple.mpegurl":
+ if source.get("type") in ("application/vnd.apple.mpegurl", "application/x-mpegURL"):
yield from HLSStream.parse_variant_playlist(self.session, source.get("src")).items()
elif source.get("container") == "MP4":
| plugins.brightcove: regarding type "application/x-mpegURL"
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
Recent change #4070 to brightcove plugin dropped type "application/x-mpegURL" for HLS playlists. There are several Japanese TV stations that use brightcove to offer the programs, but the type is set to "application/x-mpegURL" thus will not be played after this change.
ex. https://players.brightcove.net/3971130137001/TxOyQoAlL_default/index.html?videoId=6278443298001 (will expire within a week and might be geo-restricted to Japan.)
Would it be possible to add type "application/x-mpegURL" to brightcove plugin?
I'm not thinking of plugin requests because the programs are VODs only.
### Debug log
```text
[cli][debug] OS: macOS 10.12.6
[cli][debug] Python: 3.9.7
[cli][debug] Streamlink: 2.4.0+60.g6e07f55
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(1.2.1)
[cli][debug] Arguments:
[cli][debug] url=https://players.brightcove.net/3971130137001/TxOyQoAlL_default/index.html?videoId=6278443298001
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin brightcove for URL https://players.brightcove.net/3971130137001/TxOyQoAlL_default/index.html?videoId=6278443298001
[plugins.brightcove][debug] Creating player for account 3971130137001 (player_id=TxOyQoAlL_default)
[plugins.brightcove][debug] Finding streams for video: 6278443298001
[plugins.brightcove][debug] Found policy key: BCpkADawqM1F2YPxbuFJzWtohXjxdgDgIJcsnWacQKaAuaf0gyu8yxCQUlca9Dh7V0Uu_8Rt5JUWZTpgcqzD_IT5hRVde8JIR7r1UYR73ne8S9iLSroqTOA2P-jtl2EUw_OrSMAtenvuaXRF
error: No playable streams found on this URL: https://players.brightcove.net/3971130137001/TxOyQoAlL_default/index.html?videoId=6278443298001
With 2.4.0:
[cli][debug] OS: macOS 10.12.6
[cli][debug] Python: 3.9.7
[cli][debug] Streamlink: 2.4.0
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(1.2.1)
[cli][debug] Arguments:
[cli][debug] url=https://players.brightcove.net/3971130137001/TxOyQoAlL_default/index.html?videoId=6278443298001
[cli][debug] --loglevel=debug
[cli][info] Found matching plugin brightcove for URL https://players.brightcove.net/3971130137001/TxOyQoAlL_default/index.html?videoId=6278443298001
[plugins.brightcove][debug] Creating player for account 3971130137001 (player_id=TxOyQoAlL_default)
[plugins.brightcove][debug] Finding streams for video: 6278443298001
[plugins.brightcove][debug] Found policy key: BCpkADawqM1F2YPxbuFJzWtohXjxdgDgIJcsnWacQKaAuaf0gyu8yxCQUlca9Dh7V0Uu_8Rt5JUWZTpgcqzD_IT5hRVde8JIR7r1UYR73ne8S9iLSroqTOA2P-jtl2EUw_OrSMAtenvuaXRF
[utils.l10n][debug] Language code: en_US
[utils.l10n][debug] Language code: en_US
[utils.l10n][debug] Language code: en_US
[stream.hls][debug] Using external audio tracks for stream 270p (language=en, name=en (Main))
[stream.hls][debug] Using external audio tracks for stream 432p (language=en, name=en (Main))
[stream.hls][debug] Using external audio tracks for stream 720p (language=en, name=en (Main))
[stream.hls][debug] Using external audio tracks for stream 1080p (language=en, name=en (Main))
[utils.l10n][debug] Language code: en_US
[stream.hls][debug] Using external audio tracks for stream 270p (language=en, name=en (Main))
[stream.hls][debug] Using external audio tracks for stream 432p (language=en, name=en (Main))
[stream.hls][debug] Using external audio tracks for stream 720p (language=en, name=en (Main))
[stream.hls][debug] Using external audio tracks for stream 1080p (language=en, name=en (Main))
Available streams: 270p_hls, 432p_hls, 720p_hls, 1080p_hls, 270p_alt (worst), 270p, 432p_alt, 432p, 720p_alt, 720p, 1080p_alt, 1080p (best)
```
| Can you apply the following diff and see if it works? The content you've linked is geo-blocked and I can't access it. The reason why "application/x-mpegURL" got removed is that I couldn't see it anywhere in the data I've checked. Previously, there was also the URL-ends-with-m3u8 check, which seemed redundant.
```diff
diff --git a/src/streamlink/plugins/brightcove.py b/src/streamlink/plugins/brightcove.py
index 02321ed9..079a2db9 100644
--- a/src/streamlink/plugins/brightcove.py
+++ b/src/streamlink/plugins/brightcove.py
@@ -64,7 +64,7 @@ class BrightcovePlayer:
)
for source in sources:
- if source.get("type") == "application/vnd.apple.mpegurl":
+ if source.get("type") in ("application/vnd.apple.mpegurl", "application/x-mpegURL"):
yield from HLSStream.parse_variant_playlist(self.session, source.get("src")).items()
elif source.get("container") == "MP4":
```
Thank you for your quick reply. Yes, it worked.
The second test URL https://players.brightcove.net/6093072304001/Ff8ZOjI1z_default/index.html?videoId=6275508909001 in #4070 is returning "application/x-mpegURL", actually. | 2021-10-26T04:46:25 |
|
streamlink/streamlink | 4,120 | streamlink__streamlink-4120 | [
"4094"
] | 77c610393dc0fde2808df1be265e846a9ad10b15 | diff --git a/src/streamlink/session.py b/src/streamlink/session.py
--- a/src/streamlink/session.py
+++ b/src/streamlink/session.py
@@ -230,13 +230,11 @@ def set_option(self, key, value):
else:
urllib3_connection.allowed_gai_family = allowed_gai_family
- elif key == "http-proxy":
+ elif key in ("http-proxy", "https-proxy"):
self.http.proxies["http"] = update_scheme("https://", value, force=False)
- if "https" not in self.http.proxies:
- self.http.proxies["https"] = update_scheme("https://", value, force=False)
-
- elif key == "https-proxy":
- self.http.proxies["https"] = update_scheme("https://", value, force=False)
+ self.http.proxies["https"] = self.http.proxies["http"]
+ if key == "https-proxy":
+ log.info("The https-proxy option has been deprecated in favour of a single http-proxy option")
elif key == "http-cookies":
if isinstance(value, dict):
diff --git a/src/streamlink_cli/argparser.py b/src/streamlink_cli/argparser.py
--- a/src/streamlink_cli/argparser.py
+++ b/src/streamlink_cli/argparser.py
@@ -1162,21 +1162,12 @@ def build_parser():
"--http-proxy",
metavar="HTTP_PROXY",
help="""
- A HTTP proxy to use for all HTTP requests, including WebSocket connections.
- By default this proxy will be used for all HTTPS requests too.
+ A HTTP proxy to use for all HTTP and HTTPS requests, including WebSocket connections.
Example: "http://hostname:port/"
"""
)
- http.add_argument(
- "--https-proxy",
- metavar="HTTPS_PROXY",
- help="""
- A HTTPS capable proxy to use for all HTTPS requests.
-
- Example: "https://hostname:port/"
- """
- )
+ http.add_argument("--https-proxy", help=argparse.SUPPRESS)
http.add_argument(
"--http-cookie",
metavar="KEY=VALUE",
| diff --git a/tests/test_session.py b/tests/test_session.py
--- a/tests/test_session.py
+++ b/tests/test_session.py
@@ -358,21 +358,21 @@ def test_https_proxy_set_first(self):
session.set_option("http-proxy", "http://testproxy.com")
self.assertEqual("http://testproxy.com", session.http.proxies['http'])
- self.assertEqual("https://testhttpsproxy.com", session.http.proxies['https'])
+ self.assertEqual("http://testproxy.com", session.http.proxies['https'])
def test_https_proxy_default_override(self):
session = self.subject(load_plugins=False)
session.set_option("http-proxy", "http://testproxy.com")
session.set_option("https-proxy", "https://testhttpsproxy.com")
- self.assertEqual("http://testproxy.com", session.http.proxies['http'])
+ self.assertEqual("https://testhttpsproxy.com", session.http.proxies['http'])
self.assertEqual("https://testhttpsproxy.com", session.http.proxies['https'])
def test_https_proxy_set_only(self):
session = self.subject(load_plugins=False)
session.set_option("https-proxy", "https://testhttpsproxy.com")
- self.assertFalse("http" in session.http.proxies)
+ self.assertEqual("https://testhttpsproxy.com", session.http.proxies['http'])
self.assertEqual("https://testhttpsproxy.com", session.http.proxies['https'])
def test_http_proxy_socks(self):
@@ -386,5 +386,5 @@ def test_https_proxy_socks(self):
session = self.subject(load_plugins=False)
session.set_option("https-proxy", "socks5://localhost:1234")
- self.assertNotIn("http", session.http.proxies)
+ self.assertEqual("socks5://localhost:1234", session.http.proxies["http"])
self.assertEqual("socks5://localhost:1234", session.http.proxies["https"])
| Drop `https-proxy` option in favor of a single `http-proxy` option
### Checklist
- [X] This is a feature request and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin requests](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22feature+request%22)
### Description
How much sense would it make dropping `https-proxy` in favor of only having the `http-proxy` option?
The reason [why these two options were added](f9ebaa8b33eac95f88d796ae779500f4b00f3c95) is `requests`, which requires proxy configs for each protocol/scheme separately. It also can take scheme+netloc strings as proxy configs, but Streamlink doesn't support setting configs like this via CLI arguments.
- https://github.com/streamlink/streamlink/blame/1a1a3a06a2655f299fd718f5343799ec13ec7ce4/src/streamlink/session.py#L233-L239
- https://docs.python-requests.org/en/latest/user/advanced/#proxies
- https://github.com/psf/requests/blob/v2.26.0/requests/sessions.py#L373-L376
This protocol-specific configuration in `requests` is based on [`urllib.request.getproxies()`](https://docs.python.org/3/library/urllib.request.html#urllib.request.getproxies), which [similar to cURL](https://man.archlinux.org/man/curl.1#ENVIRONMENT) supports the `NO_PROXY`, `HTTP_PROXY`, `HTTPS_PROXY` and `ALL_PROXY` env vars (all-uppercase or all-lowercase), [unless `trust_env` is set to `False`](https://github.com/psf/requests/blob/v2.26.0/requests/sessions.py#L701-L713) (which can be done in Streamlink via the `http-trust-env` option).
Added in 2f76a1b98b7a862fd7a850a5971b7c7a0abb0f36 was the logic for setting the value for `https-proxy` via `http-proxy` when `https-proxy` was not set yet, to make defining proxy configs less redundant and confusing.
But how much sense does it make having a separate option for HTTPS connections? Even though we have just switched to default HTTPS schemes for scheme-less input URLs in #4068, this doesn't mean that every request will be done via HTTPS if a plugin needs to make requests via HTTP for example or if the user has explicitly set the HTTP scheme in the input URL. **This allows for accidental connections via HTTP over the direct connection when only `https-proxy` is set, which is a problem.**
I also don't see any use case for having a configuration which sets one proxy for HTTP and another for HTTPS connections. It doesn't make any sense, especially when almost every connection is made via HTTPS/TLS anyway. [Streamlink CLI also doesn't support setting HTTPS proxies first](https://github.com/streamlink/streamlink/blob/1a1a3a06a2655f299fd718f5343799ec13ec7ce4/src/streamlink_cli/main.py#L707-L711), which makes the is-not-set condition in the Session's `http-proxy` option useless for Streamlink CLI, because it will always be true.
Another point is that every other HTTP option/argument does not have an HTTPS counterpart, which can be confusing for some users.
----
That's why I'd suggest:
- turning `https-proxy` into an alias for `http-proxy` and suppressing the CLI argument
- or dropping `https-proxy` entirely (breaking change)
`requests` would still pick up the env vars if set.
| I don't see any ambiguity between them. There are valid reasons for using an http proxy (non tls/ssl). Example is intercept and injection.
> There are valid reasons for using an http proxy (non tls/ssl).
I am not talking about dropping support for HTTP proxies. Re-read my post again. I am suggesting to only use one single parameter for both types, because having a parameter for each of them allows for accidental direct connections over HTTP if a plugin makes non-TLS HTTP requests and if the user has accidentally only set a proxy for HTTPS.
**`http-proxy` does NOT mean using a HTTP proxy for any kind of network request.** It means using any kind of supported proxy (HTTP, HTTPS, SOCKS, etc) for all non-TLS HTTP requests. Same thing for the `https-proxy` option, which means any kind of supported proxy for all HTTPS requests.
> Example is intercept and injection.
A HTTP proxy doesn't help you with MITM stuff if the underlying connection is encrypted via TLS.
> I am not talking about dropping support for HTTP proxies. Re-read my post again.
I'm aware of what you're talking about, reread what I said. If a plugin is using non-TLS and you expect it not to, that is a bug with the plugin not whether an environment variable or option was set.
> A HTTP proxy doesn't help you with MITM stuff if the underlying connection is encrypted via TLS.
K. In the mean time I'm going to continue doing exactly that which you claim isn't possible. Deal? Regarding the change itself your choice. If you remove the option it's just another patch I cherrypick out.
@h1z1 do you often use two different proxies, or a proxy for https but not http?
@beardypig Depends on the case but in general yes, different proxies, different configs (forward and tunnel). There are cases where the host proxy isn't necessarily wanted to be the same. FWIW I ripped out any mention of http/insecure urls a few years ago. Proxy use in Python is a nightmare.. No sites [that I use/knowof] really broke upstream though. | 2021-10-27T17:43:25 |
streamlink/streamlink | 4,130 | streamlink__streamlink-4130 | [
"4122"
] | bbdb5fc2b670a90f08049ef1795ac59c8733c1dc | diff --git a/src/streamlink/plugins/openrectv.py b/src/streamlink/plugins/openrectv.py
--- a/src/streamlink/plugins/openrectv.py
+++ b/src/streamlink/plugins/openrectv.py
@@ -15,7 +15,8 @@ class OPENRECtv(Plugin):
_stores_re = re.compile(r"window.stores\s*=\s*({.*?});", re.DOTALL | re.MULTILINE)
_config_re = re.compile(r"window.sharedConfig\s*=\s*({.*?});", re.DOTALL | re.MULTILINE)
- api_url = "https://public.openrec.tv/external/api/v5/movies/{id}"
+ movie_info_url = "https://public.openrec.tv/external/api/v5/movies/{id}"
+ subscription_info_url = "https://apiv5.openrec.tv/api/v5/movies/{id}/detail"
login_url = "https://www.openrec.tv/viewapp/v4/mobile/user/login"
_info_schema = validate.Schema({
@@ -23,6 +24,7 @@ class OPENRECtv(Plugin):
validate.optional("title"): validate.text,
validate.optional("movie_type"): validate.text,
validate.optional("onair_status"): validate.any(None, int),
+ validate.optional("public_type"): validate.text,
validate.optional("media"): {
"url": validate.any(None, validate.url()),
"url_public": validate.any(None, validate.url()),
@@ -30,6 +32,17 @@ class OPENRECtv(Plugin):
}
})
+ _subscription_schema = validate.Schema({
+ validate.optional("status"): int,
+ validate.optional("data"): {
+ "items": [{
+ "media": {
+ "url": validate.any(None, validate.url())
+ }
+ }]
+ }
+ })
+
_login_schema = validate.Schema({
validate.optional("error_message"): validate.text,
"status": int,
@@ -68,7 +81,7 @@ def login(self, email, password):
return data["status"] == 0
def _get_movie_data(self):
- url = self.api_url.format(id=self.video_id)
+ url = self.movie_info_url.format(id=self.video_id)
res = self.session.http.get(url, headers={
"access-token": self.session.http.cookies.get("access_token"),
"uuid": self.session.http.cookies.get("uuid")
@@ -81,6 +94,20 @@ def _get_movie_data(self):
else:
log.error("Failed to get video stream: {0}".format(data["message"]))
+ def _get_subscription_movie_data(self):
+ url = self.subscription_info_url.format(id=self.video_id)
+ res = self.session.http.get(url, headers={
+ "access-token": self.session.http.cookies.get("access_token"),
+ "uuid": self.session.http.cookies.get("uuid")
+ })
+ data = self.session.http.json(res, schema=self._subscription_schema)
+
+ if data["status"] == 0:
+ log.debug("Got valid subscription info")
+ return data
+ else:
+ log.error("Failed to get video stream: {0}".format(data["message"]))
+
def get_author(self):
mdata = self._get_movie_data()
if mdata:
@@ -100,8 +127,12 @@ def _get_streams(self):
if mdata:
log.debug("Found video: {0} ({1})".format(mdata["title"], mdata["id"]))
m3u8_file = None
+ # subscription
+ if mdata["public_type"] == "member":
+ subs_data = self._get_subscription_movie_data()
+ m3u8_file = subs_data["data"]["items"][0]["media"]["url"]
# streaming
- if mdata["onair_status"] == 1:
+ elif mdata["onair_status"] == 1:
m3u8_file = mdata["media"]["url_ull"]
# archive
elif mdata["onair_status"] == 2 and mdata["media"]["url_public"] is not None:
| Openrec.tv: cannot get stream from subscription live stream
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
Cannot access to subscription-only live stream.
I tried the channel that I'm subscribed to (premium), or the ones that currently is on free-trial (so everyone can watch), neither worked.
### Debug log
```text
D:\>streamlink --openrectv-email="****" --openrectv-password="****" --loglevel debug --url https:/
/www.openrec.tv/live/lv81d9lm789
[cli][debug] OS: Windows 7
[cli][debug] Python: 3.8.7
[cli][debug] Streamlink: 2.4.0
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(0.58.0)
[cli][debug] Arguments:
[cli][debug] url=https://www.openrec.tv/live/lv81d9lm789
[cli][debug] --loglevel=debug
[cli][debug] --player="D:\Program Files\SMPlayer\mpv\mpv.exe" --cache=yes --demuxer-max-bytes=10000KiB
[cli][debug] --url=https://www.openrec.tv/live/lv81d9lm789
[cli][debug] --rtmpdump=C:\Program Files (x86)\Streamlink\rtmpdump\rtmpdump.exe
[cli][debug] --ffmpeg-ffmpeg=D:\Program Files\!cli\ffmpeg.exe
[cli][debug] --openrectv-email=****
[cli][debug] --openrectv-password=********
[cli][info] Found matching plugin openrectv for URL https://www.openrec.tv/live/lv81d9lm789
[plugins.openrectv][debug] Logged in as ****
[plugins.openrectv][debug] Got valid detail response
[plugins.openrectv][debug] Found video: きどまだSeason2 #16 (lv81d9lm789)
error: No playable streams found on this URL: https://www.openrec.tv/live/lv81d9lm789
```
| Hello @fireattack
Probably I can solve your issue, but I don't subscribe any paid channels, so I can't do the experiment.
So, I would like to know the response of `https://apiv5.openrec.tv/api/v5/movies/lv81d9lm789/detail` when you access `https://www.openrec.tv/live/lv81d9lm789` using DevTools.
In particular, I would like to know `data.items[0].media`.
Please let me know **only whether each value is null or not** because it contains sensitive information.
```json
{
"status": 0,
"data": {
"type": "movie_detail",
"items": [
{
"media": {
"url": "XXX/playlist.m3u8",
"url_source": null,
"url_public": "XXX/public.m3u8",
"url_low_latency": null,
"url_ull": null,
"url_dvr": null,
"url_trailer": null,
"url_audio": "XXX/aac.m3u8",
"url_dvr_audio": null
},
"subs_trial_media": {
"url": null,
"url_low_latency": null,
"url_ull": null,
"url_dvr": null,
"url_audio": null,
"url_dvr_audio": null
},
```
Keep in mind this live is already finished so it's a VOD now. Can't say if it's API return value structure stays the same while live, but it looks like so.
From the look of it, we probably should also try `subs_trial_media` part if the first one fails, so you can still watch trial (which is available for all the users during the live).
Thanks for your time! | 2021-10-31T04:26:38 |
|
streamlink/streamlink | 4,138 | streamlink__streamlink-4138 | [
"4131"
] | c2ce68cf99dc4f81038cde92a70b29c4d4f88327 | diff --git a/src/streamlink/plugins/ltv_lsm_lv.py b/src/streamlink/plugins/ltv_lsm_lv.py
--- a/src/streamlink/plugins/ltv_lsm_lv.py
+++ b/src/streamlink/plugins/ltv_lsm_lv.py
@@ -1,45 +1,128 @@
import logging
import re
-from urllib.parse import urlparse
+from urllib.parse import urlsplit, urlunsplit
from streamlink.plugin import Plugin, pluginmatcher
-from streamlink.plugin.api.utils import itertags
-from streamlink.stream.hls import HLSStream
+from streamlink.plugin.api import validate
+from streamlink.stream.hls import HLSStream, HLSStreamReader, HLSStreamWorker
log = logging.getLogger(__name__)
+def copy_query_url(to, from_):
+ """
+ Replace the query string in one URL with the query string from another URL
+ """
+ return urlunsplit(urlsplit(to)._replace(query=urlsplit(from_).query))
+
+
+class LTVHLSStreamWorker(HLSStreamWorker):
+ def process_sequences(self, playlist, sequences):
+ super().process_sequences(playlist, sequences)
+ # update the segment URLs with the query string from the playlist URL
+ self.playlist_sequences = [
+ sequence._replace(
+ segment=sequence.segment._replace(
+ uri=copy_query_url(sequence.segment.uri, self.stream.url)
+ )
+ )
+ for sequence in self.playlist_sequences
+ ]
+
+
+class LTVHLSStreamReader(HLSStreamReader):
+ __worker__ = LTVHLSStreamWorker
+
+
+class LTVHLSStream(HLSStream):
+ __reader__ = LTVHLSStreamReader
+
+ @classmethod
+ def parse_variant_playlist(cls, *args, **kwargs):
+ streams = super().parse_variant_playlist(*args, **kwargs)
+
+ for stream in streams.values():
+ stream.args["url"] = copy_query_url(stream.args["url"], stream.url_master)
+
+ return streams
+
+
@pluginmatcher(re.compile(
- r"https?://ltv\.lsm\.lv/lv/tieshraide"
+ r"https://ltv\.lsm\.lv/lv/tiesraide"
))
class LtvLsmLv(Plugin):
"""
Support for Latvian live channels streams on ltv.lsm.lv
"""
+
+ def __init__(self, url: str):
+ super().__init__(url)
+ self._json_data_re = re.compile(r'teliaPlayer\((\{.*?\})\);', re.DOTALL)
+
+ self.main_page_schema = validate.Schema(
+ validate.parse_html(),
+ validate.xml_xpath_string(".//iframe[contains(@src, 'ltv.lsm.lv/embed')][1]/@src"),
+ validate.url()
+ )
+
+ self.embed_code_schema = validate.Schema(
+ validate.parse_html(),
+ validate.xml_xpath_string(".//live[1]/@*[name()=':embed-data']"),
+ str,
+ validate.parse_json(),
+ {"source": {"embed_code": str}},
+ validate.get(("source", "embed_code")),
+ validate.parse_html(),
+ validate.xml_xpath_string(".//iframe[@src][1]/@src"),
+ )
+
+ self.player_apicall_schema = validate.Schema(
+ validate.transform(self._json_data_re.search),
+ validate.any(
+ None,
+ validate.all(
+ validate.get(1),
+ validate.transform(lambda s: s.replace("'", '"')),
+ validate.transform(lambda s: re.sub(r",\s*\}", "}", s, flags=re.DOTALL)),
+ validate.parse_json(),
+ {"channel": str},
+ validate.get("channel")
+ )
+ )
+ )
+
+ self.sources_schema = validate.Schema(
+ validate.parse_json(),
+ {
+ "source": {
+ "sources": validate.all(
+ [{"type": str, "src": validate.url()}],
+ validate.filter(lambda src: src["type"] == "application/x-mpegURL"),
+ validate.map(lambda src: src.get("src"))
+ ),
+ }},
+ validate.get(("source", "sources"))
+ )
+
def _get_streams(self):
+ api_url = "https://player.cloudycdn.services/player/ltvlive/channel/{channel_id}/"
+
self.session.http.headers.update({"Referer": self.url})
- iframe_url = None
- res = self.session.http.get(self.url)
- for iframe in itertags(res.text, "iframe"):
- if "embed.lsm.lv" in iframe.attributes.get("src"):
- iframe_url = iframe.attributes.get("src")
- break
-
- if not iframe_url:
- log.error("Could not find player iframe")
- return
-
- log.debug("Found iframe: {0}".format(iframe_url))
- res = self.session.http.get(iframe_url)
- for source in itertags(res.text, "source"):
- if source.attributes.get("src"):
- stream_url = source.attributes.get("src")
- url_path = urlparse(stream_url).path
- if url_path.endswith(".m3u8"):
- yield from HLSStream.parse_variant_playlist(self.session, stream_url).items()
- else:
- log.debug("Not used URL path: {0}".format(url_path))
+ iframe_url = self.session.http.get(self.url, schema=self.main_page_schema)
+ log.debug(f"Found embed iframe: {iframe_url}")
+ player_iframe_url = self.session.http.get(iframe_url, schema=self.embed_code_schema)
+ log.debug(f"Found player iframe: {player_iframe_url}")
+ channel_id = self.session.http.get(player_iframe_url, schema=self.player_apicall_schema)
+ log.debug(f"Found channel ID: {channel_id}")
+
+ stream_sources = self.session.http.post(api_url.format(channel_id=channel_id),
+ data=dict(refer="ltv.lsm.lv",
+ playertype="regular",
+ protocol="hls"),
+ schema=self.sources_schema)
+ for surl in stream_sources:
+ yield from LTVHLSStream.parse_variant_playlist(self.session, surl).items()
__plugin__ = LtvLsmLv
| diff --git a/tests/plugins/test_ltv_lsm_lv.py b/tests/plugins/test_ltv_lsm_lv.py
--- a/tests/plugins/test_ltv_lsm_lv.py
+++ b/tests/plugins/test_ltv_lsm_lv.py
@@ -6,10 +6,10 @@ class TestPluginCanHandleUrlLtvLsmLv(PluginCanHandleUrl):
__plugin__ = LtvLsmLv
should_match = [
- "https://ltv.lsm.lv/lv/tieshraide/example/",
- "http://ltv.lsm.lv/lv/tieshraide/example/",
- "https://ltv.lsm.lv/lv/tieshraide/example/live.123/",
- "http://ltv.lsm.lv/lv/tieshraide/example/live.123/",
+ "https://ltv.lsm.lv/lv/tiesraide/example/",
+ "https://ltv.lsm.lv/lv/tiesraide/example/",
+ "https://ltv.lsm.lv/lv/tiesraide/example/live.123/",
+ "https://ltv.lsm.lv/lv/tiesraide/example/live.123/",
]
should_not_match = [
@@ -21,4 +21,5 @@ class TestPluginCanHandleUrlLtvLsmLv(PluginCanHandleUrl):
"http://ltv.lsm.lv/other-site/",
"https://ltv.lsm.lv/lv/other-site/",
"http://ltv.lsm.lv/lv/other-site/",
+ "https://ltv.lsm.lv/lv/tieshraide/example/",
]
| ltv_lsm_lv.py: Does a typo makes it non-functioning?
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest stable release
### Description
This plugin doesn't work for me on an Enigma2 receiver. When I try to open
#SERVICE 4097:0:1:22B8:446:1:C00000:0:0:0:http%3a//127.0.0.1%3a8088/https%3a//ltv.lsm.lv/lv/tiesraide/ltv1:LTV 1
#DESCRIPTION LTV 1
I get an error message in the debug log (see below). I think this might be caused by a simple typo in the .py file. In line 13 it reads:
r"https?://ltv\.lsm\.lv/lv/tieshraide"
I do think it should rather be 'tiesraide' instead of 'tieshraide' as the actual URLs of the TV stations are:
[https://ltv.lsm.lv/lv/tiesraide/ltv1](url)
[https://ltv.lsm.lv/lv/tiesraide/ltv7](url)
[https://ltv.lsm.lv/lv/tiesraide/visiemltv](url)
### Debug log
```text
root@sf4008:~# /usr/sbin/streamlinksrv manualstart debug
pidfile /var/run/streamlink.pid does not exist. Daemon not running?
[streamlinksrv][info] Sun Oct 31 08:22:04 2021 Server (1.8.2) started
[streamlinksrv][debug] Host: sf4008
[streamlinksrv][debug] Port: 8088
[streamlinksrv][debug] OS: Linux-4.1.20-1.9-armv7l-with-glibc2.4
[streamlinksrv][debug] Python: 2.7.18
[streamlinksrv][info] Streamlink: 1.27.8.0.r1_mod / 2021-10-11
[streamlinksrv][debug] youtube-dl: 2021.06.06
[streamlinksrv][debug] Requests(2.26.0), Socks(1.7.1), Websocket(0.59.0)
[streamlinksrv][error] No plugin can handle URL: https://ltv.lsm.lv/lv/tiesraide/ltv1
[streamlinksrv][debug] Send Offline clip
```
| Looks like the website has been updated and the plugin needs to be updated to support this change. Even updating the URL matching does not fix it because the layout of the page appears to have changed. | 2021-10-31T21:05:00 |
streamlink/streamlink | 4,140 | streamlink__streamlink-4140 | [
"4132"
] | b7747d4e65c1d7c46839f7ddc1ee54f2d12c43c5 | diff --git a/src/streamlink/plugins/picarto.py b/src/streamlink/plugins/picarto.py
--- a/src/streamlink/plugins/picarto.py
+++ b/src/streamlink/plugins/picarto.py
@@ -11,9 +11,15 @@
@pluginmatcher(re.compile(r"""
https?://(?:www\.)?picarto\.tv/
- (?:(?P<po>streampopout|videopopout)/)?
- (?P<user>[^&?/]+)
- (?:\?tab=videos&id=(?P<vod_id>\d+))?
+ (?:
+ streampopout/(?P<po_user>[^/]+)/public
+ |
+ videopopout/(?P<po_vod_id>\d+)
+ |
+ [^/]+/videos/(?P<vod_id>\d+)
+ |
+ (?P<user>[^/?&]+)
+ )$
""", re.VERBOSE))
class Picarto(Plugin):
API_URL_LIVE = "https://ptvintern.picarto.tv/api/channel/detail/{username}"
@@ -129,13 +135,12 @@ def get_vod(self, vod_id):
def _get_streams(self):
m = self.match.groupdict()
- if (m['po'] == 'streampopout' or not m['po']) and m['user'] and not m['vod_id']:
- log.debug('Type=Live')
- return self.get_live(m['user'])
- elif m['po'] == 'videopopout' or (m['user'] and m['vod_id']):
+ if m['po_vod_id'] or m['vod_id']:
log.debug('Type=VOD')
- vod_id = m['vod_id'] if m['vod_id'] else m['user']
- return self.get_vod(vod_id)
+ return self.get_vod(m['po_vod_id'] or m['vod_id'])
+ elif m['po_user'] or m['user']:
+ log.debug('Type=Live')
+ return self.get_live(m['po_user'] or m['user'])
__plugin__ = Picarto
| diff --git a/tests/plugins/test_picarto.py b/tests/plugins/test_picarto.py
--- a/tests/plugins/test_picarto.py
+++ b/tests/plugins/test_picarto.py
@@ -8,7 +8,15 @@ class TestPluginCanHandleUrlPicarto(PluginCanHandleUrl):
should_match = [
'https://picarto.tv/example',
'https://www.picarto.tv/example',
+ 'https://www.picarto.tv/example/videos/123456',
'https://www.picarto.tv/streampopout/example/public',
'https://www.picarto.tv/videopopout/123456',
- 'https://www.picarto.tv/example?tab=videos&id=123456',
+ ]
+
+ should_not_match = [
+ 'https://picarto.tv/',
+ 'https://www.picarto.tv/example/',
+ 'https://www.picarto.tv/example/videos/abc123',
+ 'https://www.picarto.tv/streampopout/example/notpublic',
+ 'https://www.picarto.tv/videopopout/abc123',
]
| plugins.picarto: Plugin fails to open VODS but works just fine on popout player links
### Checklist
- [X] This is a plugin issue and not a different kind of issue
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
Running lateast dev build, The picarto plugin does not seem to want to open Vods.
Attempting to open https://picarto.tv/Grimsby/videos/197524 results in [plugins.picarto][error] User is not online.
But opening https://picarto.tv/videopopout/197524 works just fine.
### Debug log
```text
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.9.7
[cli][debug] Streamlink: 2.4.0+63.gbf269e2
[cli][debug] Requests(2.26.0), Socks(1.7.1), Websocket(1.2.1)
[cli][debug] Arguments:
[cli][debug] url=https://picarto.tv/Grimsby/videos/197524
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --player="C:\mpv\mpv.exe"
[cli][debug] --output=asdd.mkv
[cli][debug] --rtmp-rtmpdump=rtmpdump.exe
[cli][debug] --rtmpdump=C:\Program Files (x86)\Streamlink\rtmpdump\rtmpdump.exe
[cli][debug] --ffmpeg-ffmpeg=C:\Program Files (x86)\Streamlink\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin picarto for URL https://picarto.tv/Grimsby/videos/197524
[plugins.picarto][debug] Type=Live
[plugins.picarto][error] User is not online
```
| It looks like they must have changed things a little bit. Previously it wasn't possible to get a canonical URL anywhere except via the popout link for VoDs. VoDs on profile pages now appear to link via a canonical URL though.
What is happening here is that the current URL logic is identifying the URL as live rather than VoD, so it's going via the method to handle a live stream instead of a VoD. An update to the URL logic should fix it I think.
Edit: I'll put in a PR later today with fix and updated tests
| 2021-11-01T03:56:00 |