
id
stringlengths 36
36
| status
stringclasses 1
value | inserted_at
timestamp[us] | updated_at
timestamp[us] | _server_id
stringlengths 36
36
| title
stringlengths 11
142
| authors
stringlengths 3
297
| filename
stringlengths 5
62
| content
stringlengths 2
64.1k
| content_class.responses
sequencelengths 1
1
| content_class.responses.users
sequencelengths 1
1
| content_class.responses.status
sequencelengths 1
1
| content_class.suggestion
sequencelengths 1
4
| content_class.suggestion.agent
null | content_class.suggestion.score
null |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
e5d70009-4e7c-4c3b-bb5a-9fe338b229d1 | completed | 2025-01-16T03:08:53.170791 | 2025-01-19T18:58:44.899654 | d6c31fa9-7f3a-42f2-80a2-1a7ae7f2fccc | BERT 101 - State Of The Art NLP Model Explained | britneymuller | bert-101.md | # BERT 101 🤗 State Of The Art NLP Model Explained
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
## What is BERT?
BERT, short for Bidirectional Encoder Representations from Transformers, is a Machine Learning (ML) model for natural language processing. It was developed in 2018 by researchers at Google AI Language and serves as a swiss army knife solution to 11+ of the most common language tasks, such as sentiment analysis and named entity recognition.
Language has historically been difficult for computers to ‘understand’. Sure, computers can collect, store, and read text inputs but they lack basic language _context_.
So, along came Natural Language Processing (NLP): the field of artificial intelligence aiming for computers to read, analyze, interpret and derive meaning from text and spoken words. This practice combines linguistics, statistics, and Machine Learning to assist computers in ‘understanding’ human language.
Individual NLP tasks have traditionally been solved by individual models created for each specific task. That is, until— BERT!
BERT revolutionized the NLP space by solving for 11+ of the most common NLP tasks (and better than previous models) making it the jack of all NLP trades.
In this guide, you'll learn what BERT is, why it’s different, and how to get started using BERT:
1. [What is BERT used for?](#1-what-is-bert-used-for)
2. [How does BERT work?](#2-how-does-bert-work)
3. [BERT model size & architecture](#3-bert-model-size--architecture)
4. [BERT’s performance on common language tasks](#4-berts-performance-on-common-language-tasks)
5. [Environmental impact of deep learning](#5-enviornmental-impact-of-deep-learning)
6. [The open source power of BERT](#6-the-open-source-power-of-bert)
7. [How to get started using BERT](#7-how-to-get-started-using-bert)
8. [BERT FAQs](#8-bert-faqs)
9. [Conclusion](#9-conclusion)
Let's get started! 🚀
## 1. What is BERT used for?
BERT can be used on a wide variety of language tasks:
- Can determine how positive or negative a movie’s reviews are. [(Sentiment Analysis)](https://huggingface.co./blog/sentiment-analysis-python)
- Helps chatbots answer your questions. [(Question answering)](https://huggingface.co./tasks/question-answering)
- Predicts your text when writing an email (Gmail). [(Text prediction)](https://huggingface.co./tasks/fill-mask)
- Can write an article about any topic with just a few sentence inputs. [(Text generation)](https://huggingface.co./tasks/text-generation)
- Can quickly summarize long legal contracts. [(Summarization)](https://huggingface.co./tasks/summarization)
- Can differentiate words that have multiple meanings (like ‘bank’) based on the surrounding text. (Polysemy resolution)
**There are many more language/NLP tasks + more detail behind each of these.**
***Fun Fact:*** You interact with NLP (and likely BERT) almost every single day!
NLP is behind Google Translate, voice assistants (Alexa, Siri, etc.), chatbots, Google searches, voice-operated GPS, and more. | [
[
"llm",
"transformers",
"research",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"tutorial",
"research"
] | null | null |
7f8a87d1-04d0-417d-beed-386eab5df016 | completed | 2025-01-16T03:08:53.170803 | 2025-01-19T19:06:05.430221 | e1d155de-8231-4454-964e-26b90ac52015 | StackLLaMA: A hands-on guide to train LLaMA with RLHF | edbeeching, kashif, ybelkada, lewtun, lvwerra, nazneen, natolambert | stackllama.md | Models such as [ChatGPT]([https://openai.com/blog/chatgpt](https://openai.com/blog/chatgpt)), [GPT-4]([https://openai.com/research/gpt-4](https://openai.com/research/gpt-4)), and [Claude]([https://www.anthropic.com/index/introducing-claude](https://www.anthropic.com/index/introducing-claude)) are powerful language models that have been fine-tuned using a method called Reinforcement Learning from Human Feedback (RLHF) to be better aligned with how we expect them to behave and would like to use them.
In this blog post, we show all the steps involved in training a [LlaMa model](https://ai.facebook.com/blog/large-language-model-llama-meta-ai) to answer questions on [Stack Exchange](https://stackexchange.com) with RLHF through a combination of:
- Supervised Fine-tuning (SFT)
- Reward / preference modeling (RM)
- Reinforcement Learning from Human Feedback (RLHF)

*From InstructGPT paper: Ouyang, Long, et al. "Training language models to follow instructions with human feedback." arXiv preprint arXiv:2203.02155 (2022).*
By combining these approaches, we are releasing the StackLLaMA model. This model is available on the [🤗 Hub](https://huggingface.co./trl-lib/llama-se-rl-peft) (see [Meta's LLaMA release](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) for the original LLaMA model) and [the entire training pipeline](https://huggingface.co./docs/trl/index) is available as part of the Hugging Face TRL library. To give you a taste of what the model can do, try out the demo below!
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/3.23.0/gradio.js"></script>
<gradio-app theme_mode="light" src="https://trl-lib-stack-llama.hf.space"></gradio-app>
## The LLaMA model
When doing RLHF, it is important to start with a capable model: the RLHF step is only a fine-tuning step to align the model with how we want to interact with it and how we expect it to respond. Therefore, we choose to use the recently introduced and performant [LLaMA models](https://arxiv.org/abs/2302.13971). The LLaMA models are the latest large language models developed by Meta AI. They come in sizes ranging from 7B to 65B parameters and were trained on between 1T and 1.4T tokens, making them very capable. We use the 7B model as the base for all the following steps!
To access the model, use the [form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform) from Meta AI.
## Stack Exchange dataset
Gathering human feedback is a complex and expensive endeavor. In order to bootstrap the process for this example while still building a useful model, we make use of the [StackExchange dataset](https://huggingface.co./datasets/HuggingFaceH4/stack-exchange-preferences). The dataset includes questions and their corresponding answers from the StackExchange platform (including StackOverflow for code and many other topics). It is attractive for this use case because the answers come together with the number of upvotes and a label for the accepted answer.
We follow the approach described in [Askell et al. 2021](https://arxiv.org/abs/2112.00861) and assign each answer a score:
`score = log2 (1 + upvotes) rounded to the nearest integer, plus 1 if the questioner accepted the answer (we assign a score of −1 if the number of upvotes is negative).`
For the reward model, we will always need two answers per question to compare, as we’ll see later. Some questions have dozens of answers, leading to many possible pairs. We sample at most ten answer pairs per question to limit the number of data points per question. Finally, we cleaned up formatting by converting HTML to Markdown to make the model’s outputs more readable. You can find the dataset as well as the processing notebook [here](https://huggingface.co./datasets/lvwerra/stack-exchange-paired).
## Efficient training strategies
Even training the smallest LLaMA model requires an enormous amount of memory. Some quick math: in bf16, every parameter uses 2 bytes (in fp32 4 bytes) in addition to 8 bytes used, e.g., in the Adam optimizer (see the [performance docs](https://huggingface.co./docs/transformers/perf_train_gpu_one#optimizer) in Transformers for more info). So a 7B parameter model would use `(2+8)*7B=70GB` just to fit in memory and would likely need more when you compute intermediate values such as attention scores. So you couldn’t train the model even on a single 80GB A100 like that. You can use some tricks, like more efficient optimizers of half-precision training, to squeeze a bit more into memory, but you’ll run out sooner or later.
Another option is to use Parameter-Efficient Fine-Tuning (PEFT) techniques, such as the [`peft`](https://github.com/huggingface/peft) library, which can perform Low-Rank Adaptation (LoRA) on a model loaded in 8-bit.

*Low-Rank Adaptation of linear layers: extra parameters (in orange) are added next to the frozen layer (in blue), and the resulting encoded hidden states are added together with the hidden states of the frozen layer.*
Loading the model in 8bit reduces the memory footprint drastically since you only need one byte per parameter for the weights (e.g. 7B LlaMa is 7GB in memory). Instead of training the original weights directly, LoRA adds small adapter layers on top of some specific layers (usually the attention layers); thus, the number of trainable parameters is drastically reduced.
In this scenario, a rule of thumb is to allocate ~1.2-1.4GB per billion parameters (depending on the batch size and sequence length) to fit the entire fine-tuning setup. As detailed in the attached blog post above, this enables fine-tuning larger models (up to 50-60B scale models on a NVIDIA A100 80GB) at low cost.
These techniques have enabled fine-tuning large models on consumer devices and Google Colab. Notable demos are fine-tuning `facebook/opt-6.7b` (13GB in `float16` ), and `openai/whisper-large` on Google Colab (15GB GPU RAM). To learn more about using `peft`, refer to our [github repo](https://github.com/huggingface/peft) or the [previous blog post](https://huggingface.co./blog/trl-peft)(https://huggingface.co./blog/trl-peft)) on training 20b parameter models on consumer hardware.
Now we can fit very large models into a single GPU, but the training might still be very slow. The simplest strategy in this scenario is data parallelism: we replicate the same training setup into separate GPUs and pass different batches to each GPU. With this, you can parallelize the forward/backward passes of the model and scale with the number of GPUs.

We use either the `transformers.Trainer` or `accelerate`, which both support data parallelism without any code changes, by simply passing arguments when calling the scripts with `torchrun` or `accelerate launch`. The following runs a training script with 8 GPUs on a single machine with `accelerate` and `torchrun`, respectively.
```bash
accelerate launch --multi_gpu --num_machines 1 --num_processes 8 my_accelerate_script.py
torchrun --nnodes 1 --nproc_per_node 8 my_torch_script.py
```
## Supervised fine-tuning
Before we start training reward models and tuning our model with RL, it helps if the model is already good in the domain we are interested in. In our case, we want it to answer questions, while for other use cases, we might want it to follow instructions, in which case instruction tuning is a great idea. The easiest way to achieve this is by continuing to train the language model with the language modeling objective on texts from the domain or task. The [StackExchange dataset](https://huggingface.co./datasets/HuggingFaceH4/stack-exchange-preferences) is enormous (over 10 million instructions), so we can easily train the language model on a subset of it.
There is nothing special about fine-tuning the model before doing RLHF - it’s just the causal language modeling objective from pretraining that we apply here. To use the data efficiently, we use a technique called packing: instead of having one text per sample in the batch and then padding to either the longest text or the maximal context of the model, we concatenate a lot of texts with a EOS token in between and cut chunks of the context size to fill the batch without any padding.

With this approach the training is much more efficient as each token that is passed through the model is also trained in contrast to padding tokens which are usually masked from the loss. If you don't have much data and are more concerned about occasionally cutting off some tokens that are overflowing the context you can also use a classical data loader.
The packing is handled by the `ConstantLengthDataset` and we can then use the `Trainer` after loading the model with `peft`. First, we load the model in int8, prepare it for training, and then add the LoRA adapters.
```python
# load model in 8bit
model = AutoModelForCausalLM.from_pretrained(
args.model_path,
load_in_8bit=True,
device_map={"": Accelerator().local_process_index}
)
model = prepare_model_for_int8_training(model)
# add LoRA to model
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, lora_config)
```
We train the model for a few thousand steps with the causal language modeling objective and save the model. Since we will tune the model again with different objectives, we merge the adapter weights with the original model weights.
**Disclaimer:** due to LLaMA's license, we release only the adapter weights for this and the model checkpoints in the following sections. You can apply for access to the base model's weights by filling out Meta AI's [form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform) and then converting them to the 🤗 Transformers format by running this [script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py). Note that you'll also need to install 🤗 Transformers from source until the `v4.28` is released.
Now that we have fine-tuned the model for the task, we are ready to train a reward model.
## Reward modeling and human preferences
In principle, we could fine-tune the model using RLHF directly with the human annotations. However, this would require us to send some samples to humans for rating after each optimization iteration. This is expensive and slow due to the number of training samples needed for convergence and the inherent latency of human reading and annotator speed.
A trick that works well instead of direct feedback is training a reward model on human annotations collected before the RL loop. The goal of the reward model is to imitate how a human would rate a text. There are several possible strategies to build a reward model: the most straightforward way would be to predict the annotation (e.g. a rating score or a binary value for “good”/”bad”). In practice, what works better is to predict the ranking of two examples, where the reward model is presented with two candidates \\( (y_k, y_j) \\) for a given prompt \\( x \\) and has to predict which one would be rated higher by a human annotator.
This can be translated into the following loss function:
\\( \operatorname{loss}(\theta)=- E_{\left(x, y_j, y_k\right) \sim D}\left[\log \left(\sigma\left(r_\theta\left(x, y_j\right)-r_\theta\left(x, y_k\right)\right)\right)\right] \\)
where \\( r \\) is the model’s score and \\( y_j \\) is the preferred candidate.
With the StackExchange dataset, we can infer which of the two answers was preferred by the users based on the score. With that information and the loss defined above, we can then modify the `transformers.Trainer` by adding a custom loss function.
```python
class RewardTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
if return_outputs:
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
return loss
```
We utilize a subset of a 100,000 pair of candidates and evaluate on a held-out set of 50,000. With a modest training batch size of 4, we train the LLaMA model using the LoRA `peft` adapter for a single epoch using the Adam optimizer with BF16 precision. Our LoRA configuration is:
```python
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)
```
The training is logged via [Weights & Biases](https://wandb.ai/krasul/huggingface/runs/wmd8rvq6?workspace=user-krasul) and took a few hours on 8-A100 GPUs using the 🤗 research cluster and the model achieves a final **accuracy of 67%**. Although this sounds like a low score, the task is also very hard, even for human annotators.
As detailed in the next section, the resulting adapter can be merged into the frozen model and saved for further downstream use.
## Reinforcement Learning from Human Feedback
With the fine-tuned language model and the reward model at hand, we are now ready to run the RL loop. It follows roughly three steps:
1. Generate responses from prompts
2. Rate the responses with the reward model
3. Run a reinforcement learning policy-optimization step with the ratings

The Query and Response prompts are templated as follows before being tokenized and passed to the model:
```bash
Question: <Query>
Answer: <Response>
```
The same template was used for SFT, RM and RLHF stages.
A common issue with training the language model with RL is that the model can learn to exploit the reward model by generating complete gibberish, which causes the reward model to assign high rewards. To balance this, we add a penalty to the reward: we keep a reference of the model that we don’t train and compare the new model’s generation to the reference one by computing the KL-divergence:
\\( \operatorname{R}(x, y)=\operatorname{r}(x, y)- \beta \operatorname{KL}(x, y) \\)
where \\( r \\) is the reward from the reward model and \\( \operatorname{KL}(x,y) \\) is the KL-divergence between the current policy and the reference model.
Once more, we utilize `peft` for memory-efficient training, which offers an extra advantage in the RLHF context. Here, the reference model and policy share the same base, the SFT model, which we load in 8-bit and freeze during training. We exclusively optimize the policy's LoRA weights using PPO while sharing the base model's weights.
```python
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
question_tensors = batch["input_ids"]
# sample from the policy and generate responses
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
length_sampler=output_length_sampler,
**generation_kwargs,
)
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# Compute sentiment score
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]
# Run PPO step
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
# Log stats to WandB
ppo_trainer.log_stats(stats, batch, rewards)
```
We train for 20 hours on 3x8 A100-80GB GPUs, using the 🤗 research cluster, but you can also get decent results much quicker (e.g. after ~20h on 8 A100 GPUs). All the training statistics of the training run are available on [Weights & Biases](https://wandb.ai/lvwerra/trl/runs/ie2h4q8p).

*Per batch reward at each step during training. The model’s performance plateaus after around 1000 steps.*
So what can the model do after training? Let's have a look!

Although we shouldn't trust its advice on LLaMA matters just, yet, the answer looks coherent and even provides a Google link. Let's have a look and some of the training challenges next.
## Challenges, instabilities and workarounds
Training LLMs with RL is not always plain sailing. The model we demo today is the result of many experiments, failed runs and hyper-parameter sweeps. Even then, the model is far from perfect. Here we will share a few of the observations and headaches we encountered on the way to making this example.
### Higher reward means better performance, right?

*Wow this run must be great, look at that sweet, sweet, reward!*
In general in RL, you want to achieve the highest reward. In RLHF we use a Reward Model, which is imperfect and given the chance, the PPO algorithm will exploit these imperfections. This can manifest itself as sudden increases in reward, however when we look at the text generations from the policy, they mostly contain repetitions of the string ```, as the reward model found the stack exchange answers containing blocks of code usually rank higher than ones without it. Fortunately this issue was observed fairly rarely and in general the KL penalty should counteract such exploits.
### KL is always a positive value, isn’t it?
As we previously mentioned, a KL penalty term is used in order to push the model’s outputs remain close to that of the base policy. In general, KL divergence measures the distances between two distributions and is always a positive quantity. However, in `trl` we use an estimate of the KL which in expectation is equal to the real KL divergence.
\\( KL_{pen}(x,y) = \log \left(\pi_\phi^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right) \\)
Clearly, when a token is sampled from the policy which has a lower probability than the SFT model, this will lead to a negative KL penalty, but on average it will be positive otherwise you wouldn't be properly sampling from the policy. However, some generation strategies can force some tokens to be generated or some tokens can suppressed. For example when generating in batches finished sequences are padded and when setting a minimum length the EOS token is suppressed. The model can assign very high or low probabilities to those tokens which leads to negative KL. As the PPO algorithm optimizes for reward, it will chase after these negative penalties, leading to instabilities.

One needs to be careful when generating the responses and we suggest to always use a simple sampling strategy first before resorting to more sophisticated generation methods.
### Ongoing issues
There are still a number of issues that we need to better understand and resolve. For example, there are occassionally spikes in the loss, which can lead to further instabilities.

As we identify and resolve these issues, we will upstream the changes `trl`, to ensure the community can benefit.
## Conclusion
In this post, we went through the entire training cycle for RLHF, starting with preparing a dataset with human annotations, adapting the language model to the domain, training a reward model, and finally training a model with RL.
By using `peft`, anyone can run our example on a single GPU! If training is too slow, you can use data parallelism with no code changes and scale training by adding more GPUs.
For a real use case, this is just the first step! Once you have a trained model, you must evaluate it and compare it against other models to see how good it is. This can be done by ranking generations of different model versions, similar to how we built the reward dataset.
Once you add the evaluation step, the fun begins: you can start iterating on your dataset and model training setup to see if there are ways to improve the model. You could add other datasets to the mix or apply better filters to the existing one. On the other hand, you could try different model sizes and architecture for the reward model or train for longer.
We are actively improving TRL to make all steps involved in RLHF more accessible and are excited to see the things people build with it! Check out the [issues on GitHub](https://github.com/lvwerra/trl/issues) if you're interested in contributing.
## Citation
```bibtex
@misc {beeching2023stackllama,
author = { Edward Beeching and
Younes Belkada and
Kashif Rasul and
Lewis Tunstall and
Leandro von Werra and
Nazneen Rajani and
Nathan Lambert
},
title = { StackLLaMA: An RL Fine-tuned LLaMA Model for Stack Exchange Question and Answering },
year = 2023,
url = { https://huggingface.co./blog/stackllama },
doi = { 10.57967/hf/0513 },
publisher = { Hugging Face Blog }
}
```
## Acknowledgements
We thank Philipp Schmid for sharing his wonderful [demo](https://huggingface.co./spaces/philschmid/igel-playground) of streaming text generation upon which our demo was based. We also thank Omar Sanseviero and Louis Castricato for giving valuable and detailed feedback on the draft of the blog post. | [
[
"llm",
"implementation",
"tutorial",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"fine_tuning",
"tutorial",
"implementation"
] | null | null |
c88a19d7-c645-40d5-a297-9264ec53d213 | completed | 2025-01-16T03:08:53.170809 | 2025-01-16T03:12:40.426634 | e4403500-5442-4c60-b687-c753e9ee196f | Introducing SafeCoder | jeffboudier, philschmid | safecoder.md | Today we are excited to announce SafeCoder - a code assistant solution built for the enterprise.
The goal of SafeCoder is to unlock software development productivity for the enterprise, with a fully compliant and self-hosted pair programmer. In marketing speak: “your own on-prem GitHub copilot”.
Before we dive deeper, here’s what you need to know:
- SafeCoder is not a model, but a complete end-to-end commercial solution
- SafeCoder is built with security and privacy as core principles - code never leaves the VPC during training or inference
- SafeCoder is designed for self-hosting by the customer on their own infrastructure
- SafeCoder is designed for customers to own their own Code Large Language Model
## Why SafeCoder?
Code assistant solutions built upon LLMs, such as GitHub Copilot, are delivering strong [productivity boosts](https://github.blog/2022-09-07-research-quantifying-github-copilots-impact-on-developer-productivity-and-happiness/). For the enterprise, the ability to tune Code LLMs on the company code base to create proprietary Code LLMs improves reliability and relevance of completions to create another level of productivity boost. For instance, Google internal LLM code assistant reports a completion [acceptance rate of 25-34%](https://ai.googleblog.com/2022/07/ml-enhanced-code-completion-improves.html) by being trained on an internal code base.
However, relying on closed-source Code LLMs to create internal code assistants exposes companies to compliance and security issues. First during training, as fine-tuning a closed-source Code LLM on an internal codebase requires exposing this codebase to a third party. And then during inference, as fine-tuned Code LLMs are likely to “leak” code from their training dataset during inference. To meet compliance requirements, enterprises need to deploy fine-tuned Code LLMs within their own infrastructure - which is not possible with closed source LLMs.
With SafeCoder, Hugging Face will help customers build their own Code LLMs, fine-tuned on their proprietary codebase, using state of the art open models and libraries, without sharing their code with Hugging Face or any other third party. With SafeCoder, Hugging Face delivers a containerized, hardware-accelerated Code LLM inference solution, to be deployed by the customer directly within the Customer secure infrastructure, without code inputs and completions leaving their secure IT environment.
## From StarCoder to SafeCoder
At the core of the SafeCoder solution is the [StarCoder](https://huggingface.co./bigcode/starcoder) family of Code LLMs, created by the [BigCode](https://huggingface.co./bigcode) project, a collaboration between Hugging Face, ServiceNow and the open source community.
The StarCoder models offer unique characteristics ideally suited to enterprise self-hosted solution:
- State of the art code completion results - see benchmarks in the [paper](https://huggingface.co./papers/2305.06161) and [multilingual code evaluation leaderboard](https://huggingface.co./spaces/bigcode/multilingual-code-evals)
- Designed for inference performance: a 15B parameters model with code optimizations, Multi-Query Attention for reduced memory footprint, and Flash Attention to scale to 8,192 tokens context.
- Trained on [the Stack](https://huggingface.co./datasets/bigcode/the-stack), an ethically sourced, open source code dataset containing only commercially permissible licensed code, with a developer opt-out mechanism from the get-go, refined through intensive PII removal and deduplication efforts.
Note: While StarCoder is the inspiration and model powering the initial version of SafeCoder, an important benefit of building a LLM solution upon open source models is that it can adapt to the latest and greatest open source models available. In the future, SafeCoder may offer other similarly commercially permissible open source models built upon ethically sourced and transparent datasets as the base LLM available for fine-tuning.
## Privacy and Security as a Core Principle
For any company, the internal codebase is some of its most important and valuable intellectual property. A core principle of SafeCoder is that the customer internal codebase will never be accessible to any third party (including Hugging Face) during training or inference.
In the initial set up phase of SafeCoder, the Hugging Face team provides containers, scripts and examples to work hand in hand with the customer to select, extract, prepare, duplicate, deidentify internal codebase data into a training dataset to be used in a Hugging Face provided training container configured to the hardware infrastructure available to the customer.
In the deployment phase of SafeCoder, the customer deploys containers provided by Hugging Face on their own infrastructure to expose internal private endpoints within their VPC. These containers are configured to the exact hardware configuration available to the customer, including NVIDIA GPUs, AMD Instinct GPUs, Intel Xeon CPUs, AWS Inferentia2 or Habana Gaudi accelerators.
## Compliance as a Core Principle
As the regulation framework around machine learning models and datasets is still being written across the world, global companies need to make sure the solutions they use minimize legal risks.
Data sources, data governance, management of copyrighted data are just a few of the most important compliance areas to consider. BigScience, the older cousin and inspiration for BigCode, addressed these areas in working groups before they were broadly recognized by the draft AI EU Act, and as a result was [graded as most compliant among Foundational Model Providers in a Stanford CRFM study](https://crfm.stanford.edu/2023/06/15/eu-ai-act.html).
BigCode expanded upon this work by implementing novel techniques for the code domain and building The Stack with compliance as a core principle, such as commercially permissible license filtering, consent mechanisms (developers can [easily find out if their code is present and request to be opted out](https://huggingface.co./spaces/bigcode/in-the-stack) of the dataset), and extensive documentation and tools to inspect the [source data](https://huggingface.co./datasets/bigcode/the-stack-metadata), and dataset improvements (such as [deduplication](https://huggingface.co./blog/dedup) and [PII removal](https://huggingface.co./bigcode/starpii)).
All these efforts translate into legal risk minimization for users of the StarCoder models, and customers of SafeCoder. And for SafeCoder users, these efforts translate into compliance features: when software developers get code completions these suggestions are checked against The Stack, so users know if the suggested code matches existing code in the source dataset, and what the license is. Customers can specify which licenses are preferred and surface those preferences to their users.
## How does it work?
SafeCoder is a complete commercial solution, including service, software and support.
### Training your own SafeCoder model
StarCoder was trained in more than 80 programming languages and offers state of the art performance on [multiple benchmarks](https://huggingface.co./spaces/bigcode/multilingual-code-evals). To offer better code suggestions specifically for a SafeCoder customer, we start the engagement with an optional training phase, where the Hugging Face team works directly with the customer team to guide them through the steps to prepare and build a training code dataset, and to create their own code generation model through fine-tuning, without ever exposing their codebase to third parties or the internet.
The end result is a model that is adapted to the code languages, standards and practices of the customer. Through this process, SafeCoder customers learn the process and build a pipeline for creating and updating their own models, ensuring no vendor lock-in, and keeping control of their AI capabilities.
### Deploying SafeCoder
During the setup phase, SafeCoder customers and Hugging Face design and provision the optimal infrastructure to support the required concurrency to offer a great developer experience. Hugging Face then builds SafeCoder inference containers that are hardware-accelerated and optimized for throughput, to be deployed by the customer on their own infrastructure.
SafeCoder inference supports various hardware to give customers a wide range of options: NVIDIA Ampere GPUs, AMD Instinct GPUs, Habana Gaudi2, AWS Inferentia 2, Intel Xeon Sapphire Rapids CPUs and more.
### Using SafeCoder
Once SafeCoder is deployed and its endpoints are live within the customer VPC, developers can install compatible SafeCoder IDE plugins to get code suggestions as they work. Today, SafeCoder supports popular IDEs, including [VSCode](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode), IntelliJ and with more plugins coming from our partners.
## How can I get SafeCoder?
Today, we are announcing SafeCoder in collaboration with VMware at the VMware Explore conference and making SafeCoder available to VMware enterprise customers. Working with VMware helps ensure the deployment of SafeCoder on customers’ VMware Cloud infrastructure is successful – whichever cloud, on-premises or hybrid infrastructure scenario is preferred by the customer. In addition to utilizing SafeCoder, VMware has published a [reference architecture](https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/docs/vmware-baseline-reference-architecture-for-generative-ai.pdf) with code samples to enable the fastest possible time-to-value when deploying and operating SafeCoder on VMware infrastructure. VMware’s Private AI Reference Architecture makes it easy for organizations to quickly leverage popular open source projects such as ray and kubeflow to deploy AI services adjacent to their private datasets, while working with Hugging Face to ensure that organizations maintain the flexibility to take advantage of the latest and greatest in open-source models. This is all without tradeoffs in total cost of ownership or performance.
“Our collaboration with Hugging Face around SafeCoder fully aligns to VMware’s goal of enabling customer choice of solutions while maintaining privacy and control of their business data. In fact, we have been running SafeCoder internally for months and have seen excellent results. Best of all, our collaboration with Hugging Face is just getting started, and I’m excited to take our solution to our hundreds of thousands of customers worldwide,” says Chris Wolf, Vice President of VMware AI Labs. Learn more about private AI and VMware’s differentiation in this emerging space [here](https://octo.vmware.com/vmware-private-ai-foundation/). | [
[
"llm",
"mlops",
"security",
"deployment"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"mlops",
"security",
"deployment"
] | null | null |
e2169c0b-64d3-413e-8e51-3024a8717f66 | completed | 2025-01-16T03:08:53.170813 | 2025-01-19T18:49:04.030751 | 2be8c7af-3113-44ee-9f03-c01041147421 | What's new in Diffusers? 🎨 | osanseviero | diffusers-2nd-month.md | A month and a half ago we released `diffusers`, a library that provides a modular toolbox for diffusion models across modalities. A couple of weeks later, we released support for Stable Diffusion, a high quality text-to-image model, with a free demo for anyone to try out. Apart from burning lots of GPUs, in the last three weeks the team has decided to add one or two new features to the library that we hope the community enjoys! This blog post gives a high-level overview of the new features in `diffusers` version 0.3! Remember to give a ⭐ to the [GitHub repository](https://github.com/huggingface/diffusers).
- [Image to Image pipelines](#image-to-image-pipeline)
- [Textual Inversion](#textual-inversion)
- [Inpainting](#experimental-inpainting-pipeline)
- [Optimizations for Smaller GPUs](#optimizations-for-smaller-gpus)
- [Run on Mac](#diffusers-in-mac-os)
- [ONNX Exporter](#experimental-onnx-exporter-and-pipeline)
- [New docs](#new-docs)
- [Community](#community)
- [Generate videos with SD latent space](#stable-diffusion-videos)
- [Model Explainability](#diffusers-interpret)
- [Japanese Stable Diffusion](#japanese-stable-diffusion)
- [High quality fine-tuned model](#waifu-diffusion)
- [Cross Attention Control with Stable Diffusion](#cross-attention-control)
- [Reusable seeds](#reusable-seeds)
## Image to Image pipeline
One of the most requested features was to have image to image generation. This pipeline allows you to input an image and a prompt, and it will generate an image based on that!
Let's see some code based on the official Colab [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb).
```python
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
# Download an initial image
# ...
init_image = preprocess(init_img)
prompt = "A fantasy landscape, trending on artstation"
images = pipe(prompt=prompt, init_image=init_image, strength=0.75, guidance_scale=7.5, generator=generator)["sample"]
```
Don't have time for code? No worries, we also created a [Space demo](https://huggingface.co./spaces/huggingface/diffuse-the-rest) where you can try it out directly

## Textual Inversion
Textual Inversion lets you personalize a Stable Diffusion model on your own images with just 3-5 samples. With this tool, you can train a model on a concept, and then share the concept with the rest of the community!

In just a couple of days, the community shared over 200 concepts! Check them out!
* [Organization](https://huggingface.co./sd-concepts-library) with the concepts.
* [Navigator Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion_textual_inversion_library_navigator.ipynb): Browse visually and use over 150 concepts created by the community.
* [Training Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb): Teach Stable Diffusion a new concept and share it with the rest of the community.
* [Inference Colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb): Run Stable Diffusion with the learned concepts.
## Experimental inpainting pipeline
Inpainting allows to provide an image, then select an area in the image (or provide a mask), and use Stable Diffusion to replace the mask. Here is an example:
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/diffusers-2nd-month/inpainting.png" alt="Example inpaint of owl being generated from an initial image and a prompt"/>
</figure>
You can try out a minimal Colab [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb) or check out the code below. A demo is coming soon!
```python
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
).to(device)
images = pipe(
prompt=["a cat sitting on a bench"] * 3,
init_image=init_image,
mask_image=mask_image,
strength=0.75,
guidance_scale=7.5,
generator=None
).images
```
Please note this is experimental, so there is room for improvement.
## Optimizations for smaller GPUs
After some improvements, the diffusion models can take much less VRAM. 🔥 For example, Stable Diffusion only takes 3.2GB! This yields the exact same results at the expense of 10% of speed. Here is how to use these optimizations
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=True
)
pipe = pipe.to("cuda")
pipe.enable_attention_slicing()
```
This is super exciting as this will reduce even more the barrier to use these models!
## Diffusers in Mac OS
🍎 That's right! Another widely requested feature was just released! Read the full instructions in the [official docs](https://huggingface.co./docs/diffusers/optimization/mps) (including performance comparisons, specs, and more).
Using the PyTorch mps device, people with M1/M2 hardware can run inference with Stable Diffusion. 🤯 This requires minimal setup for users, try it out!
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
pipe = pipe.to("mps")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
```
## Experimental ONNX exporter and pipeline
The new experimental pipeline allows users to run Stable Diffusion on any hardware that supports ONNX. Here is an example of how to use it (note that the `onnx` revision is being used)
```python
from diffusers import StableDiffusionOnnxPipeline
pipe = StableDiffusionOnnxPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="onnx",
provider="CPUExecutionProvider",
use_auth_token=True,
)
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
```
Alternatively, you can also convert your SD checkpoints to ONNX directly with the exporter script.
```
python scripts/convert_stable_diffusion_checkpoint_to_onnx.py --model_path="CompVis/stable-diffusion-v1-4" --output_path="./stable_diffusion_onnx"
```
## New docs
All of the previous features are very cool. As maintainers of open-source libraries, we know about the importance of high quality documentation to make it as easy as possible for anyone to try out the library.
💅 Because of this, we did a Docs sprint and we're very excited to do a first release of our [documentation](https://huggingface.co./docs/diffusers/v0.3.0/en/index). This is a first version, so there are many things we plan to add (and contributions are always welcome!).
Some highlights of the docs:
* Techniques for [optimization](https://huggingface.co./docs/diffusers/optimization/fp16)
* The [training overview](https://huggingface.co./docs/diffusers/training/overview)
* A [contributing guide](https://huggingface.co./docs/diffusers/conceptual/contribution)
* In-depth API docs for [schedulers](https://huggingface.co./docs/diffusers/api/schedulers)
* In-depth API docs for [pipelines](https://huggingface.co./docs/diffusers/api/pipelines/overview)
## Community
And while we were doing all of the above, the community did not stay idle! Here are some highlights (although not exhaustive) of what has been done out there
### Stable Diffusion Videos
Create 🔥 videos with Stable Diffusion by exploring the latent space and morphing between text prompts. You can:
* Dream different versions of the same prompt
* Morph between different prompts
The [Stable Diffusion Videos](https://github.com/nateraw/stable-diffusion-videos) tool is pip-installable, comes with a Colab notebook and a Gradio notebook, and is super easy to use!
Here is an example
```python
from stable_diffusion_videos import walk
video_path = walk(['a cat', 'a dog'], [42, 1337], num_steps=3, make_video=True)
```
### Diffusers Interpret
[Diffusers interpret](https://github.com/JoaoLages/diffusers-interpret) is an explainability tool built on top of `diffusers`. It has cool features such as:
* See all the images in the diffusion process
* Analyze how each token in the prompt influences the generation
* Analyze within specified bounding boxes if you want to understand a part of the image

(Image from the tool repository)
```python
# pass pipeline to the explainer class
explainer = StableDiffusionPipelineExplainer(pipe)
# generate an image with `explainer`
prompt = "Corgi with the Eiffel Tower"
output = explainer(
prompt,
num_inference_steps=15
)
output.normalized_token_attributions # (token, attribution_percentage)
#[('corgi', 40),
# ('with', 5),
# ('the', 5),
# ('eiffel', 25),
# ('tower', 25)]
```
### Japanese Stable Diffusion
The name says it all! The goal of JSD was to train a model that also captures information about the culture, identity and unique expressions. It was trained with 100 million images with Japanese captions. You can read more about how the model was trained in the [model card](https://huggingface.co./rinna/japanese-stable-diffusion)
### Waifu Diffusion
[Waifu Diffusion](https://huggingface.co./hakurei/waifu-diffusion) is a fine-tuned SD model for high-quality anime images generation.
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/diffusers-2nd-month/waifu.png" alt="Images of high quality anime"/>
</figure>
(Image from the tool repository)
### Cross Attention Control
[Cross Attention Control](https://github.com/bloc97/CrossAttentionControl) allows fine control of the prompts by modifying the attention maps of the diffusion models. Some cool things you can do:
* Replace a target in the prompt (e.g. replace cat by dog)
* Reduce or increase the importance of words in the prompt (e.g. if you want less attention to be given to "rocks")
* Easily inject styles
And much more! Check out the repo.
### Reusable Seeds
One of the most impressive early demos of Stable Diffusion was the reuse of seeds to tweak images. The idea is to use the seed of an image of interest to generate a new image, with a different prompt. This yields some cool results! Check out the [Colab](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
## Thanks for reading!
I hope you enjoy reading this! Remember to give a Star in our [GitHub Repository](https://github.com/huggingface/diffusers) and join the [Hugging Face Discord Server](https://hf.co/join/discord), where we have a category of channels just for Diffusion models. Over there the latest news in the library are shared!
Feel free to open issues with feature requests and bug reports! Everything that has been achieved couldn't have been done without such an amazing community. | [
[
"computer_vision",
"optimization",
"tools",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"image_generation",
"tools",
"optimization"
] | null | null |
32908790-7e76-4203-ab96-4142f7d282dd | completed | 2025-01-16T03:08:53.170818 | 2025-01-19T18:52:31.757045 | 31a1dd64-f9d3-4521-82bd-ca3c4800f829 | Optimum-NVIDIA Unlocking blazingly fast LLM inference in just 1 line of code | laikh-nvidia, mfuntowicz | optimum-nvidia.md | Large Language Models (LLMs) have revolutionized natural language processing and are increasingly deployed to solve complex problems at scale. Achieving optimal performance with these models is notoriously challenging due to their unique and intense computational demands. Optimized performance of LLMs is incredibly valuable for end users looking for a snappy and responsive experience, as well as for scaled deployments where improved throughput translates to dollars saved.
That's where the [Optimum-NVIDIA](https://github.com/huggingface/optimum-nvidia) inference library comes in. Available on Hugging Face, Optimum-NVIDIA dramatically accelerates LLM inference on the NVIDIA platform through an extremely simple API.
By changing **just a single line of code**, you can unlock up to **28x faster inference and 1,200 tokens/second** on the NVIDIA platform.
Optimum-NVIDIA is the first Hugging Face inference library to benefit from the new `float8` format supported on the NVIDIA Ada Lovelace and Hopper architectures.
FP8, in addition to the advanced compilation capabilities of [NVIDIA TensorRT-LLM software](https://developer.nvidia.com/blog/nvidia-tensorrt-llm-supercharges-large-language-model-inference-on-nvidia-h100-gpus/) software, dramatically accelerates LLM inference.
### How to Run
You can start running LLaMA with blazingly fast inference speeds in just 3 lines of code with a pipeline from Optimum-NVIDIA.
If you already set up a pipeline from Hugging Face’s transformers library to run LLaMA, you just need to modify a single line of code to unlock peak performance!
```diff
- from transformers.pipelines import pipeline
+ from optimum.nvidia.pipelines import pipeline
# everything else is the same as in transformers!
pipe = pipeline('text-generation', 'meta-llama/Llama-2-7b-chat-hf', use_fp8=True)
pipe("Describe a real-world application of AI in sustainable energy.")
```
You can also enable FP8 quantization with a single flag, which allows you to run a bigger model on a single GPU at faster speeds and without sacrificing accuracy.
The flag shown in this example uses a predefined calibration strategy by default, though you can provide your own calibration dataset and customized tokenization to tailor the quantization to your use case.
The pipeline interface is great for getting up and running quickly, but power users who want fine-grained control over setting sampling parameters can use the Model API.
```diff
- from transformers import AutoModelForCausalLM
+ from optimum.nvidia import AutoModelForCausalLM
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-13b-chat-hf", padding_side="left")
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-13b-chat-hf",
+ use_fp8=True,
)
model_inputs = tokenizer(
["How is autonomous vehicle technology transforming the future of transportation and urban planning?"],
return_tensors="pt"
).to("cuda")
generated_ids, generated_length = model.generate(
**model_inputs,
top_k=40,
top_p=0.7,
repetition_penalty=10,
)
tokenizer.batch_decode(generated_ids[0], skip_special_tokens=True)
```
For more details, check out our [documentation](https://github.com/huggingface/optimum-nvidia)
### Performance Evaluation
When evaluating the performance of an LLM, we consider two metrics: First Token Latency and Throughput.
First Token Latency (also known as Time to First Token or prefill latency) measures how long you wait from the time you enter your prompt to the time you begin receiving your output, so this metric can tell you how responsive the model will feel.
Optimum-NVIDIA delivers up to 3.3x faster First Token Latency compared to stock transformers:
<br>
<figure class="image">
<img alt="" src="assets/optimum_nvidia/first_token_latency.svg" />
<figcaption>Figure 1. Time it takes to generate the first token (ms)</figcaption>
</figure>
<br>
Throughput, on the other hand, measures how fast the model can generate tokens and is particularly relevant when you want to batch generations together.
While there are a few ways to calculate throughput, we adopted a standard method to divide the end-to-end latency by the total sequence length, including both input and output tokens summed over all batches.
Optimum-NVIDIA delivers up to 28x better throughput compared to stock transformers:
<br>
<figure class="image">
<img alt="" src="assets/optimum_nvidia/throughput.svg" />
<figcaption>Figure 2. Throughput (token / second)</figcaption>
</figure>
<br>
Initial evaluations of the [recently announced NVIDIA H200 Tensor Core GPU](https://www.nvidia.com/en-us/data-center/h200/) show up to an additional 2x boost in throughput for LLaMA models compared to an NVIDIA H100 Tensor Core GPU.
As H200 GPUs become more readily available, we will share performance data for Optimum-NVIDIA running on them.
### Next steps
Optimum-NVIDIA currently provides peak performance for the LLaMAForCausalLM architecture + task, so any [LLaMA-based model](https://huggingface.co./models?other=llama,llama2), including fine-tuned versions, should work with Optimum-NVIDIA out of the box today.
We are actively expanding support to include other text generation model architectures and tasks, all from within Hugging Face.
We continue to push the boundaries of performance and plan to incorporate cutting-edge optimization techniques like In-Flight Batching to improve throughput when streaming prompts and INT4 quantization to run even bigger models on a single GPU.
Give it a try: we are releasing the [Optimum-NVIDIA repository](https://github.com/huggingface/optimum-nvidia) with instructions on how to get started. Please share your feedback with us! 🤗 | [
[
"llm",
"mlops",
"optimization",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"optimization",
"mlops",
"tools"
] | null | null |
bf512e00-b35b-4d18-8ae8-71e366df4051 | completed | 2025-01-16T03:08:53.170823 | 2025-01-19T19:05:36.952927 | b4f91c67-4010-4b28-a9de-bff13fecd4ef | How to Install and Use the Hugging Face Unity API | dylanebert | unity-api.md | <!-- {authors} -->
The [Hugging Face Unity API](https://github.com/huggingface/unity-api) is an easy-to-use integration of the [Hugging Face Inference API](https://huggingface.co./inference-api), allowing developers to access and use Hugging Face AI models in their Unity projects. In this blog post, we'll walk through the steps to install and use the Hugging Face Unity API.
## Installation
1. Open your Unity project
2. Go to `Window` -> `Package Manager`
3. Click `+` and select `Add Package from git URL`
4. Enter `https://github.com/huggingface/unity-api.git`
5. Once installed, the Unity API wizard should pop up. If not, go to `Window` -> `Hugging Face API Wizard`
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/packagemanager.gif">
</figure>
6. Enter your API key. Your API key can be created in your [Hugging Face account settings](https://huggingface.co./settings/tokens).
7. Test the API key by clicking `Test API key` in the API Wizard.
8. Optionally, change the model endpoints to change which model to use. The model endpoint for any model that supports the inference API can be found by going to the model on the Hugging Face website, clicking `Deploy` -> `Inference API`, and copying the url from the `API_URL` field.
9. Configure advanced settings if desired. For up-to-date information, visit the project repository at `https://github.com/huggingface/unity-api`
10. To see examples of how to use the API, click `Install Examples`. You can now close the API Wizard.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/apiwizard.png">
</figure>
Now that the API is set up, you can make calls from your scripts to the API. Let's look at an example of performing a Sentence Similarity task:
```
using HuggingFace.API;
/* other code */
// Make a call to the API
void Query() {
string inputText = "I'm on my way to the forest.";
string[] candidates = {
"The player is going to the city",
"The player is going to the wilderness",
"The player is wandering aimlessly"
};
HuggingFaceAPI.SentenceSimilarity(inputText, OnSuccess, OnError, candidates);
}
// If successful, handle the result
void OnSuccess(float[] result) {
foreach(float value in result) {
Debug.Log(value);
}
}
// Otherwise, handle the error
void OnError(string error) {
Debug.LogError(error);
}
/* other code */
```
## Supported Tasks and Custom Models
The Hugging Face Unity API also currently supports the following tasks:
- [Conversation](https://huggingface.co./tasks/conversational)
- [Text Generation](https://huggingface.co./tasks/text-generation)
- [Text to Image](https://huggingface.co./tasks/text-to-image)
- [Text Classification](https://huggingface.co./tasks/text-classification)
- [Question Answering](https://huggingface.co./tasks/question-answering)
- [Translation](https://huggingface.co./tasks/translation)
- [Summarization](https://huggingface.co./tasks/summarization)
- [Speech Recognition](https://huggingface.co./tasks/automatic-speech-recognition)
Use the corresponding methods provided by the `HuggingFaceAPI` class to perform these tasks.
To use your own custom model hosted on Hugging Face, change the model endpoint in the API Wizard.
## Usage Tips
1. Keep in mind that the API makes calls asynchronously, and returns a response or error via callbacks.
2. Address slow response times or performance issues by changing model endpoints to lower resource models.
## Conclusion
The Hugging Face Unity API offers a simple way to integrate AI models into your Unity projects. We hope you found this tutorial helpful. If you have any questions or would like to get more involved in using Hugging Face for Games, join the [Hugging Face Discord](https://hf.co/join/discord)! | [
[
"implementation",
"tutorial",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"implementation",
"tutorial",
"integration",
"tools"
] | null | null |
e8f22810-d80b-4c54-9359-2cf62d14bcd2 | completed | 2025-01-16T03:08:53.170828 | 2025-01-16T03:21:38.002539 | a031b75d-c965-4e76-8449-593a47a1e0a3 | Fine-Tuning Gemma Models in Hugging Face | svaibhav, alanwaketan, ybelkada, ArthurZ | gemma-peft.md | We recently announced that [Gemma](https://huggingface.co./blog/gemma), the open weights language model from Google Deepmind, is available for the broader open-source community via Hugging Face. It’s available in 2 billion and 7 billion parameter sizes with pretrained and instruction-tuned flavors. It’s available on Hugging Face, supported in TGI, and easily accessible for deployment and fine-tuning in the Vertex Model Garden and Google Kubernetes Engine.
<div class="flex items-center justify-center">
<img src="/blog/assets/gemma-peft/Gemma-peft.png" alt="Gemma Deploy">
</div>
The Gemma family of models also happens to be well suited for prototyping and experimentation using the free GPU resource available via Colab. In this post we will briefly review how you can do [Parameter Efficient FineTuning (PEFT)](https://huggingface.co./blog/peft) for Gemma models, using the Hugging Face Transformers and PEFT libraries on GPUs and Cloud TPUs for anyone who wants to fine-tune Gemma models on their own dataset.
## Why PEFT?
The default (full weight) training for language models, even for modest sizes, tends to be memory and compute-intensive. On one hand, it can be prohibitive for users relying on openly available compute platforms for learning and experimentation, such as Colab or Kaggle. On the other hand, and even for enterprise users, the cost of adapting these models for different domains is an important metric to optimize. PEFT, or parameter-efficient fine tuning, is a popular technique to accomplish this at low cost.
## PyTorch on GPU and TPU
Gemma models in Hugging Face `transformers` are optimized for both PyTorch and PyTorch/XLA. This enables both TPU and GPU users to access and experiment with Gemma models as needed. Together with the Gemma release, we have also improved the [FSDP](https://engineering.fb.com/2021/07/15/open-source/fsdp/) experience for PyTorch/XLA in Hugging Face. This [FSDP via SPMD](https://github.com/pytorch/xla/issues/6379) integration also allows other Hugging Face models to take advantage of TPU acceleration via PyTorch/XLA. In this post, we will focus on PEFT, and more specifically on Low-Rank Adaptation (LoRA), for Gemma models. For a more comprehensive set of LoRA techniques, we encourage readers to review the [Scaling Down to Scale Up, from Lialin et al.](https://arxiv.org/pdf/2303.15647.pdf) and [this excellent post](https://pytorch.org/blog/finetune-llms/) post by Belkada et al.
## Low-Rank Adaptation for Large Language Models
Low-Rank Adaptation (LoRA) is one of the parameter-efficient fine-tuning techniques for large language models (LLMs). It addresses just a fraction of the total number of model parameters to be fine-tuned, by freezing the original model and only training adapter layers that are decomposed into low-rank matrices. The [PEFT library](https://github.com/huggingface/peft) provides an easy abstraction that allows users to select the model layers where adapter weights should be applied.
```python
from peft import LoraConfig
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
```
In this snippet, we refer to all `nn.Linear` layers as the target layers to be adapted.
In the following example, we will leverage [QLoRA](https://huggingface.co./blog/4bit-transformers-bitsandbytes), from [Dettmers et al.](https://arxiv.org/abs/2305.14314), in order to quantize the base model in 4-bit precision for a more memory efficient fine-tuning protocol. The model can be loaded with QLoRA by first installing the `bitsandbytes` library on your environment, and then passing a `BitsAndBytesConfig` object to `from_pretrained` when loading the model.
## Before we begin
In order to access Gemma model artifacts, users are required to accept [the consent form](https://huggingface.co./google/gemma-7b-it).
Now let’s get started with the implementation.
## Learning to quote
Assuming that you have submitted the consent form, you can access the model artifacts from the [Hugging Face Hub](https://huggingface.co./collections/google/gemma-release-65d5efbccdbb8c4202ec078b).
We start by downloading the model and the tokenizer. We also include a `BitsAndBytesConfig` for weight only quantization.
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "google/gemma-2b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id, token=os.environ['HF_TOKEN'])
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0}, token=os.environ['HF_TOKEN'])
```
Now we test the model before starting the finetuning, using a famous quote:
```python
text = "Quote: Imagination is more"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
The model does a reasonable completion with some extra tokens:
```
Quote: Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world.
-Albert Einstein
I
```
But this is not exactly the format we would love the answer to be. Let’s see if we can use fine-tuning to teach the model to generate the answer in the following format.
```
Quote: Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world.
Author: Albert Einstein
```
To begin with, let's select an English quotes dataset [Abirate/english_quotes](https://huggingface.co./datasets/Abirate/english_quotes).
```python
from datasets import load_dataset
data = load_dataset("Abirate/english_quotes")
data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
```
Now let’s finetune this model using the LoRA config stated above:
```python
import transformers
from trl import SFTTrainer
def formatting_func(example):
text = f"Quote: {example['quote'][0]}\nAuthor: {example['author'][0]}<eos>"
return [text]
trainer = SFTTrainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=2,
max_steps=10,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
optim="paged_adamw_8bit"
),
peft_config=lora_config,
formatting_func=formatting_func,
)
trainer.train()
```
Finally, we are ready to test the model once more with the same prompt we have used earlier:
```python
text = "Quote: Imagination is"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
This time we get the response in the format we like:
```
Quote: Imagination is more important than knowledge. Knowledge is limited. Imagination encircles the world.
Author: Albert Einstein
```
## Accelerate with FSDP via SPMD on TPU
As mentioned earlier, Hugging Face `transformers` now supports PyTorch/XLA’s latest FSDP implementation. This can greatly accelerate the fine-tuning speed. To enable that, one just needs to add a FSDP config to the `transformers.Trainer`:
```python
from transformers import DataCollatorForLanguageModeling, Trainer, TrainingArguments
# Set up the FSDP config. To enable FSDP via SPMD, set xla_fsdp_v2 to True.
fsdp_config = {
"fsdp_transformer_layer_cls_to_wrap": ["GemmaDecoderLayer"],
"xla": True,
"xla_fsdp_v2": True,
"xla_fsdp_grad_ckpt": True
}
# Finally, set up the trainer and train the model.
trainer = Trainer(
model=model,
train_dataset=data,
args=TrainingArguments(
per_device_train_batch_size=64, # This is actually the global batch size for SPMD.
num_train_epochs=100,
max_steps=-1,
output_dir="./output",
optim="adafactor",
logging_steps=1,
dataloader_drop_last = True, # Required for SPMD.
fsdp="full_shard",
fsdp_config=fsdp_config,
),
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.train()
```
## Next Steps
We walked through this simple example adapted from the source notebook to illustrate the LoRA finetuning method applied to Gemma models. The full colab for GPU can be found [here](https://huggingface.co./google/gemma-7b/blob/main/examples/notebook_sft_peft.ipynb), and the full script for TPU can be found [here](https://huggingface.co./google/gemma-7b/blob/main/examples/example_fsdp.py). We are excited about the endless possibilities for research and learning thanks to this recent addition to our open source ecosystem. We encourage users to also visit the [Gemma documentation](https://huggingface.co./docs/transformers/v4.38.0/en/model_doc/gemma), as well as our [launch blog](https://huggingface.co./blog/gemma) for more examples to train, finetune and deploy Gemma models. | [
[
"llm",
"transformers",
"mlops",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"fine_tuning",
"transformers",
"mlops"
] | null | null |
8f58f47c-2afd-4173-8311-53a13f471ecc | completed | 2025-01-16T03:08:53.170833 | 2025-01-19T18:52:45.901121 | 6c75d858-bb98-423a-80d0-864007076fe9 | Faster assisted generation support for Intel Gaudi | haimbarad, neharaste, joeychou | assisted-generation-support-gaudi.md | As model sizes grow, Generative AI implementations require significant inference resources. This not only increases the cost per generation, but also increases the power consumption used to serve such requests.
Inference optimizations for text generation are essential for reducing latency, infrastructure costs, and power consumption. This can lead to an improved user experience and increased efficiency in text generation tasks.
Assisted decoding is a popular method for speeding up text generation. We adapted and optimized it for Intel Gaudi, which delivers similar performance as Nvidia H100 GPUs as shown in [a previous post](https://huggingface.co./blog/bridgetower), while its price is in the same ballpark as Nvidia A100 80GB GPUs. This work is now part of Optimum Habana, which extends various Hugging Face libraries like Transformers and Diffusers so that your AI workflows are fully optimized for Intel Gaudi processors.
## Speculative Sampling - Assisted Decoding
Speculative sampling is a technique used to speed up text generation. It works by generating a draft model that generates K tokens, which are then evaluated in the target model. If the draft model is rejected, the target model is used to generate the next token. This process repeats. By using speculative sampling, we can improve the speed of text generation and achieve similar sampling quality as autoregressive sampling. The technique allows us to specify a draft model when generating text. This method has been shown to provide speedups of about 2x for large transformer-based models. Overall, these techniques can accelerate text generation and improve performance on Intel Gaudi processors.
However, the draft model and target model have different sizes that would be represented in a KV cache, so the challenge is to take advantage of separate optimization strategies simultaneously. For this article, we assume a quantized model and leverage KV caching together with Speculative Sampling. Note that each model has its own KV cache, and the draft model is used to generate K tokens, which are then evaluated in the target model. The target model is used to generate the next token when the draft model is rejected. The draft model is used to generate the next K tokens, and the process repeats.
Note that the authors [2] prove that the target distribution is recovered when performing speculative sampling - this guarantees the same sampling quality as autoregressive sampling on the target itself. Therefore, the situations where not leveraging speculative sampling is not worthwhile have to do with the case where there are not enough savings in the relative size of the draft model or the acceptance rate of the draft model is not high enough to benefit from the smaller size of the draft model.
There is a technique similar to Speculative Sampling, known as Assisted Generation. This was developed independently around the same time [3]. The author integrated this method into Hugging Face Transformers, and the *.generate()* call now has an optional *assistant_model* parameter to enable this method.
## Usage & Experiments
The usage of Assisted Generation is straightforward. An example is provided [here](https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation#run-speculative-sampling-on-gaudi).
As would be expected, the parameter `--assistant_model` is used to specify the draft model. The draft model is used to generate K tokens, which are then evaluated in the target model. The target model is used to generate the next token when the draft model is rejected. The draft model is used to generate the next K tokens, and the process repeats. The acceptance rate of the draft model is partly dependent on the input text. Typically, we have seen speed-ups of about 2x for large transformer-based models.
## Conclusion
Accelerating text generation with Gaudi with assisted generation is now supported and easy to use. This can be used to improve performance on Intel Gaudi processors. The method is based on Speculative Sampling, which has been shown to be effective in improving performance on large transformer-based models.
# References
[1] N. Shazeer, “Fast Transformer Decoding: One Write-Head is All You Need,” Nov. 2019. arXiv:1911.02150.
[2] C. Chen, S. Borgeaud, G. Irving, J.B. Lespiau, L. Sifre, and J. Jumper, “Accelerating Large Language Model Decoding with Speculative Sampling,” Feb. 2023. arXiv:2302.01318.
[3] J. Gante, “Assisted Generation: a new direction toward low-latency text generation,” May 2023, https://huggingface.co./blog/assisted-generation. | [
[
"llm",
"optimization",
"text_generation",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"optimization",
"text_generation",
"efficient_computing"
] | null | null |
77ebe7b9-9753-4fc7-bb9c-8760c2e8be90 | completed | 2025-01-16T03:08:53.170837 | 2025-01-19T18:55:10.651333 | 974f622b-b4cf-4a2f-aa6e-0aacd992d017 | Stable Diffusion with 🧨 Diffusers | valhalla, pcuenq, natolambert, patrickvonplaten | stable_diffusion.md | <a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**Stable Diffusion** 🎨
*...using 🧨 Diffusers*
Stable Diffusion is a text-to-image latent diffusion model created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/).
It is trained on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database.
*LAION-5B* is the largest, freely accessible multi-modal dataset that currently exists.
In this post, we want to show how to use Stable Diffusion with the [🧨 Diffusers library](https://github.com/huggingface/diffusers), explain how the model works and finally dive a bit deeper into how `diffusers` allows
one to customize the image generation pipeline.
**Note**: It is highly recommended to have a basic understanding of how diffusion models work. If diffusion
models are completely new to you, we recommend reading one of the following blog posts:
- [The Annotated Diffusion Model](https://huggingface.co./blog/annotated-diffusion)
- [Getting started with 🧨 Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
Now, let's get started by generating some images 🎨.
## Running Stable Diffusion
### License
Before using the model, you need to accept the model [license](https://huggingface.co./spaces/CompVis/stable-diffusion-license) in order to download and use the weights. **Note: the license does not need to be explicitly accepted through the UI anymore**.
The license is designed to mitigate the potential harmful effects of such a powerful machine learning system.
We request users to **read the license entirely and carefully**. Here we offer a summary:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content,
2. We claim no rights on the outputs you generate, you are free to use them and are accountable for their use which should not go against the provisions set in the license, and
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users.
### Usage
First, you should install `diffusers==0.10.2` to run the following code snippets:
```bash
pip install diffusers==0.10.2 transformers scipy ftfy accelerate
```
In this post we'll use model version [`v1-4`](https://huggingface.co./CompVis/stable-diffusion-v1-4), but you can also use other versions of the model such as 1.5, 2, and 2.1 with minimal code changes.
The Stable Diffusion model can be run in inference with just a couple of lines using the [`StableDiffusionPipeline`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py) pipeline. The pipeline sets up everything you need to generate images from text with
a simple `from_pretrained` function call.
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
```
If a GPU is available, let's move it to one!
```python
pipe.to("cuda")
```
**Note**: If you are limited by GPU memory and have less than 10GB of GPU RAM available, please
make sure to load the `StableDiffusionPipeline` in float16 precision instead of the default
float32 precision as done above.
You can do so by loading the weights from the `fp16` branch and by telling `diffusers` to expect the
weights to be in float16 precision:
```python
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16)
```
To run the pipeline, simply define the prompt and call `pipe`.
```python
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```
The result would look as follows

The previous code will give you a different image every time you run it.
If at some point you get a black image, it may be because the content filter built inside the model might have detected an NSFW result.
If you believe this shouldn't be the case, try tweaking your prompt or using a different seed. In fact, the model predictions include information about whether NSFW was detected for a particular result. Let's see what they look like:
```python
result = pipe(prompt)
print(result)
```
```json
{
'images': [<PIL.Image.Image image mode=RGB size=512x512>],
'nsfw_content_detected': [False]
}
```
If you want deterministic output you can seed a random seed and pass a generator to the pipeline.
Every time you use a generator with the same seed you'll get the same image output.
```python
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```
The result would look as follows

You can change the number of inference steps using the `num_inference_steps` argument.
In general, results are better the more steps you use, however the more steps, the longer the generation takes.
Stable Diffusion works quite well with a relatively small number of steps, so we recommend to use the default number of inference steps of `50`.
If you want faster results you can use a smaller number. If you want potentially higher quality results,
you can use larger numbers.
Let's try out running the pipeline with less denoising steps.
```python
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, num_inference_steps=15, generator=generator).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```

Note how the structure is the same, but there are problems in the astronauts suit and the general form of the horse.
This shows that using only 15 denoising steps has significantly degraded the quality of the generation result. As stated earlier `50` denoising steps is usually sufficient to generate high-quality images.
Besides `num_inference_steps`, we've been using another function argument, called `guidance_scale` in all
previous examples. `guidance_scale` is a way to increase the adherence to the conditional signal that guides the generation (text, in this case) as well as overall sample quality.
It is also known as [classifier-free guidance](https://arxiv.org/abs/2207.12598), which in simple terms forces the generation to better match the prompt potentially at the cost of image quality or diversity.
Values between `7` and `8.5` are usually good choices for Stable Diffusion. By default the pipeline
uses a `guidance_scale` of 7.5.
If you use a very large value the images might look good, but will be less diverse.
You can learn about the technical details of this parameter in [this section](#writing-your-own-inference-pipeline) of the post.
Next, let's see how you can generate several images of the same prompt at once.
First, we'll create an `image_grid` function to help us visualize them nicely in a grid.
```python
from PIL import Image
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
```
We can generate multiple images for the same prompt by simply using a list with the same prompt repeated several times. We'll send the list to the pipeline instead of the string we used before.
```python
num_images = 3
prompt = ["a photograph of an astronaut riding a horse"] * num_images
images = pipe(prompt).images
grid = image_grid(images, rows=1, cols=3)
# you can save the grid with
# grid.save(f"astronaut_rides_horse.png")
```

By default, stable diffusion produces images of `512 × 512` pixels. It's very easy to override the default using the `height` and `width` arguments to create rectangular images in portrait or landscape ratios.
When choosing image sizes, we advise the following:
- Make sure `height` and `width` are both multiples of `8`.
- Going below 512 might result in lower quality images.
- Going over 512 in both directions will repeat image areas (global coherence is lost).
- The best way to create non-square images is to use `512` in one dimension, and a value larger than that in the other one.
Let's run an example:
```python
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt, height=512, width=768).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```

## How does Stable Diffusion work?
Having seen the high-quality images that stable diffusion can produce, let's try to understand
a bit better how the model functions.
Stable Diffusion is based on a particular type of diffusion model called **Latent Diffusion**, proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752).
Generally speaking, diffusion models are machine learning systems that are trained to *denoise* random Gaussian noise step by step, to get to a sample of interest, such as an *image*. For a more detailed overview of how they work, check [this colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb).
Diffusion models have shown to achieve state-of-the-art results for generating image data. But one downside of diffusion models is that the reverse denoising process is slow because of its repeated, sequential nature. In addition, these models consume a lot of memory because they operate in pixel space, which becomes huge when generating high-resolution images. Therefore, it is challenging to train these models and also use them for inference.
<br>
Latent diffusion can reduce the memory and compute complexity by applying the diffusion process over a lower dimensional _latent_ space, instead of using the actual pixel space. This is the key difference between standard diffusion and latent diffusion models: **in latent diffusion the model is trained to generate latent (compressed) representations of the images.**
There are three main components in latent diffusion.
1. An autoencoder (VAE).
2. A [U-Net](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb#scrollTo=wW8o1Wp0zRkq).
3. A text-encoder, *e.g.* [CLIP's Text Encoder](https://huggingface.co./docs/transformers/model_doc/clip#transformers.CLIPTextModel).
**1. The autoencoder (VAE)**
The VAE model has two parts, an encoder and a decoder. The encoder is used to convert the image into a low dimensional latent representation, which will serve as the input to the *U-Net* model.
The decoder, conversely, transforms the latent representation back into an image.
During latent diffusion _training_, the encoder is used to get the latent representations (_latents_) of the images for the forward diffusion process, which applies more and more noise at each step. During _inference_, the denoised latents generated by the reverse diffusion process are converted back into images using the VAE decoder. As we will see during inference we **only need the VAE decoder**.
**2. The U-Net**
The U-Net has an encoder part and a decoder part both comprised of ResNet blocks.
The encoder compresses an image representation into a lower resolution image representation and the decoder decodes the lower resolution image representation back to the original higher resolution image representation that is supposedly less noisy.
More specifically, the U-Net output predicts the noise residual which can be used to compute the predicted denoised image representation.
To prevent the U-Net from losing important information while downsampling, short-cut connections are usually added between the downsampling ResNets of the encoder to the upsampling ResNets of the decoder.
Additionally, the stable diffusion U-Net is able to condition its output on text-embeddings via cross-attention layers. The cross-attention layers are added to both the encoder and decoder part of the U-Net usually between ResNet blocks.
**3. The Text-encoder**
The text-encoder is responsible for transforming the input prompt, *e.g.* "An astronaut riding a horse" into an embedding space that can be understood by the U-Net. It is usually a simple *transformer-based* encoder that maps a sequence of input tokens to a sequence of latent text-embeddings.
Inspired by [Imagen](https://imagen.research.google/), Stable Diffusion does **not** train the text-encoder during training and simply uses an CLIP's already trained text encoder, [CLIPTextModel](https://huggingface.co./docs/transformers/model_doc/clip#transformers.CLIPTextModel).
**Why is latent diffusion fast and efficient?**
Since latent diffusion operates on a low dimensional space, it greatly reduces the memory and compute requirements compared to pixel-space diffusion models. For example, the autoencoder used in Stable Diffusion has a reduction factor of 8. This means that an image of shape `(3, 512, 512)` becomes `(4, 64, 64)` in latent space, which means the spatial compression ratio is `8 × 8 = 64`.
This is why it's possible to generate `512 × 512` images so quickly, even on 16GB Colab GPUs!
**Stable Diffusion during inference**
Putting it all together, let's now take a closer look at how the model works in inference by illustrating the logical flow.
<p align="center">
<img src="https://raw.githubusercontent.com/patrickvonplaten/scientific_images/master/stable_diffusion.png" alt="sd-pipeline" width="500"/>
</p>
The stable diffusion model takes both a latent seed and a text prompt as an input. The latent seed is then used to generate random latent image representations of size \\( 64 \times 64 \\) where as the text prompt is transformed to text embeddings of size \\( 77 \times 768 \\) via CLIP's text encoder.
Next the U-Net iteratively *denoises* the random latent image representations while being conditioned on the text embeddings. The output of the U-Net, being the noise residual, is used to compute a denoised latent image representation via a scheduler algorithm. Many different scheduler algorithms can be used for this computation, each having its pro- and cons. For Stable Diffusion, we recommend using one of:
- [PNDM scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py) (used by default)
- [DDIM scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [K-LMS scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_lms_discrete.py)
Theory on how the scheduler algorithm function is out-of-scope for this notebook, but in short one should remember that they compute the predicted denoised image representation from the previous noise representation and the predicted noise residual.
For more information, we recommend looking into [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364)
The *denoising* process is repeated *ca.* 50 times to step-by-step retrieve better latent image representations.
Once complete, the latent image representation is decoded by the decoder part of the variational auto encoder.
After this brief introduction to Latent and Stable Diffusion, let's see how to make advanced use of 🤗 Hugging Face `diffusers` library!
## Writing your own inference pipeline
Finally, we show how you can create custom diffusion pipelines with `diffusers`.
Writing a custom inference pipeline is an advanced use of the `diffusers` library that can be useful to switch out certain components, such as the VAE or scheduler explained above.
For example, we'll show how to use Stable Diffusion with a different scheduler, namely [Katherine Crowson's](https://github.com/crowsonkb) K-LMS scheduler added in [this PR](https://github.com/huggingface/diffusers/pull/185).
The [pre-trained model](https://huggingface.co./CompVis/stable-diffusion-v1-4/tree/main) includes all the components required to setup a complete diffusion pipeline. They are stored in the following folders:
- `text_encoder`: Stable Diffusion uses CLIP, but other diffusion models may use other encoders such as `BERT`.
- `tokenizer`. It must match the one used by the `text_encoder` model.
- `scheduler`: The scheduling algorithm used to progressively add noise to the image during training.
- `unet`: The model used to generate the latent representation of the input.
- `vae`: Autoencoder module that we'll use to decode latent representations into real images.
We can load the components by referring to the folder they were saved, using the `subfolder` argument to `from_pretrained`.
```python
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
# 1. Load the autoencoder model which will be used to decode the latents into image space.
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
# 2. Load the tokenizer and text encoder to tokenize and encode the text.
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
# 3. The UNet model for generating the latents.
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")
```
Now instead of loading the pre-defined scheduler, we load the [K-LMS scheduler](https://github.com/huggingface/diffusers/blob/71ba8aec55b52a7ba5a1ff1db1265ffdd3c65ea2/src/diffusers/schedulers/scheduling_lms_discrete.py#L26) with some fitting parameters.
```python
from diffusers import LMSDiscreteScheduler
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
```
Next, let's move the models to GPU.
```python
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
```
We now define the parameters we'll use to generate images.
Note that `guidance_scale` is defined analog to the guidance weight `w` of equation (2) in the [Imagen paper](https://arxiv.org/pdf/2205.11487.pdf). `guidance_scale == 1` corresponds to doing no classifier-free guidance. Here we set it to 7.5 as also done previously.
In contrast to the previous examples, we set `num_inference_steps` to 100 to get an even more defined image.
```python
prompt = ["a photograph of an astronaut riding a horse"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 100 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
generator = torch.manual_seed(0) # Seed generator to create the inital latent noise
batch_size = len(prompt)
```
First, we get the `text_embeddings` for the passed prompt.
These embeddings will be used to condition the UNet model and guide the image generation towards something that should resemble the input prompt.
```python
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
```
We'll also get the unconditional text embeddings for classifier-free guidance, which are just the embeddings for the padding token (empty text). They need to have the same shape as the conditional `text_embeddings` (`batch_size` and `seq_length`)
```python
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
```
For classifier-free guidance, we need to do two forward passes: one with the conditioned input (`text_embeddings`), and another with the unconditional embeddings (`uncond_embeddings`). In practice, we can concatenate both into a single batch to avoid doing two forward passes.
```python
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
```
Next, we generate the initial random noise.
```python
latents = torch.randn(
(batch_size, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)
```
If we examine the `latents` at this stage we'll see their shape is `torch.Size([1, 4, 64, 64])`, much smaller than the image we want to generate. The model will transform this latent representation (pure noise) into a `512 × 512` image later on.
Next, we initialize the scheduler with our chosen `num_inference_steps`.
This will compute the `sigmas` and exact time step values to be used during the denoising process.
```python
scheduler.set_timesteps(num_inference_steps)
```
The K-LMS scheduler needs to multiply the `latents` by its `sigma` values. Let's do this here:
```python
latents = latents * scheduler.init_noise_sigma
```
We are ready to write the denoising loop.
```python
from tqdm.auto import tqdm
scheduler.set_timesteps(num_inference_steps)
for t in tqdm(scheduler.timesteps):
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
# predict the noise residual
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sample
```
We now use the `vae` to decode the generated `latents` back into the image.
```python
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
```
And finally, let's convert the image to PIL so we can display or save it.
```python
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
pil_images[0]
```

We've gone from the basic use of Stable Diffusion using 🤗 Hugging Face Diffusers to more advanced uses of the library, and we tried to introduce all the pieces in a modern diffusion system. If you liked this topic and want to learn more, we recommend the following resources:
- Our [Colab notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb).
- The [Getting Started with Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) notebook, that gives a broader overview on Diffusion systems.
- The [Annotated Diffusion Model](https://huggingface.co./blog/annotated-diffusion) blog post.
- Our [code in GitHub](https://github.com/huggingface/diffusers) where we'd be more than happy if you leave a ⭐ if `diffusers` is useful to you!
### Citation:
```
@article{patil2022stable,
author = {Patil, Suraj and Cuenca, Pedro and Lambert, Nathan and von Platen, Patrick},
title = {Stable Diffusion with 🧨 Diffusers},
journal = {Hugging Face Blog},
year = {2022},
note = {[https://huggingface.co./blog/rlhf](https://huggingface.co./blog/stable_diffusion)},
}
``` | [
[
"computer_vision",
"implementation",
"tutorial",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"image_generation",
"implementation",
"tutorial"
] | null | null |
310ff67b-5698-4085-baa3-f9c7581b9df9 | completed | 2025-01-16T03:08:53.170842 | 2025-01-16T15:09:01.051931 | ff092a90-edc8-4253-9a93-d02daaa113dd | An overview of inference solutions on Hugging Face | juliensimon | inference-update.md | Every day, developers and organizations are adopting models hosted on [Hugging Face](https://huggingface.co./models) to turn ideas into proof-of-concept demos, and demos into production-grade applications. For instance, Transformer models have become a popular architecture for a wide range of machine learning (ML) applications, including natural language processing, computer vision, speech, and more. Recently, diffusers have become a popular architecuture for text-to-image or image-to-image generation. Other architectures are popular for other tasks, and we host all of them on the HF Hub!
At Hugging Face, we are obsessed with simplifying ML development and operations without compromising on state-of-the-art quality. In this respect, the ability to test and deploy the latest models with minimal friction is critical, all along the lifecycle of an ML project. Optimizing the cost-performance ratio is equally important, and we'd like to thank our friends at [Intel](https://huggingface.co./intel) for sponsoring our free CPU-based inference solutions. This is another major step in our [partnership](https://huggingface.co./blog/intel). It's also great news for our user community, who can now enjoy the speedup delivered by the [Intel Xeon Ice Lake](https://www.intel.com/content/www/us/en/products/docs/processors/xeon/3rd-gen-xeon-scalable-processors-brief.html) architecture at zero cost.
Now, let's review your inference options with Hugging Face.
## Free Inference Widget
One of my favorite features on the Hugging Face hub is the Inference [Widget](https://huggingface.co./docs/hub/models-widgets). Located on the model page, the Inference Widget lets you upload sample data and predict it in a single click.
Here's a sentence similarity example with the `sentence-transformers/all-MiniLM-L6-v2` [model](https://huggingface.co./sentence-transformers/all-MiniLM-L6-v2):
<kbd>
<img src="assets/116_inference_update/widget.png">
</kbd>
It's the best way to quickly get a sense of what a model does, its output, and how it performs on a few samples from your dataset. The model is loaded on-demand on our servers and unloaded when it's not needed anymore. You don't have to write any code and the feature is free. What's not to love?
## Free Inference API
The [Inference API](https://huggingface.co./docs/api-inference/) is what powers the Inference widget under the hood. With a simple HTTP request, you can load any hub model and predict your data with it in seconds. The model URL and a valid hub token are all you need.
Here's how I can load and predict with the `xlm-roberta-base` [model](https://huggingface.co./xlm-roberta-base) in a single line:
```
curl https://api-inference.huggingface.co/models/xlm-roberta-base \
-X POST \
-d '{"inputs": "The answer to the universe is <mask>."}' \
-H "Authorization: Bearer HF_TOKEN"
```
The Inference API is the simplest way to build a prediction service that you can immediately call from your application during development and tests. No need for a bespoke API, or a model server. In addition, you can instantly switch from one model to the next and compare their performance in your application. And guess what? The Inference API is free to use.
As rate limiting is enforced, we don't recommend using the Inference API for production. Instead, you should consider Inference Endpoints.
## Production with Inference Endpoints
Once you're happy with the performance of your ML model, it's time to deploy it for production. Unfortunately, when leaving the sandbox, everything becomes a concern: security, scaling, monitoring, etc. This is where a lot of ML stumble and sometimes fall.
We built [Inference Endpoints](https://huggingface.co./inference-endpoints) to solve this problem.
In just a few clicks, Inference Endpoints let you deploy any hub model on secure and scalable infrastructure, hosted in your AWS or Azure region of choice. Additional settings include CPU and GPU hosting, built-in auto-scaling, and more. This makes finding the appropriate cost/performance ratio easy, with [pricing](https://huggingface.co./pricing#endpoints) starting as low as $0.06 per hour.
Inference Endpoints support three security levels:
* Public: the endpoint runs in a public Hugging Face subnet, and anyone on the Internet can access it without any authentication.
* Protected: the endpoint runs in a public Hugging Face subnet, and anyone on the Internet with the appropriate Hugging Face token can access it.
* Private: the endpoint runs in a private Hugging Face subnet and is not accessible on the Internet. It's only available through a private connection in your AWS or Azure account. This will satisfy the strictest compliance requirements.
<kbd>
<img src="assets/116_inference_update/endpoints.png">
</kbd>
To learn more about Inference Endpoints, please read this [tutorial](https://huggingface.co./blog/inference-endpoints) and the [documentation](https://huggingface.co./docs/inference-endpoints/).
## Spaces
Finally, Spaces is another production-ready option to deploy your model for inference on top of a simple UI framework (Gradio for instance), and we also support [hardware upgrades](/docs/hub/spaces-gpus) like advanced Intel CPUs and NVIDIA GPUs. There's no better way to demo your models!
<kbd>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/hub/spaces-gpu-settings.png">
</kbd>
To learn more about Spaces, please take a look at the [documentation](https://huggingface.co./docs/hub/spaces) and don't hesitate to browse posts or ask questions in our [forum](https://discuss.huggingface.co/c/spaces/24).
## Getting started
It couldn't be simpler. Just log in to the Hugging Face [hub](https://huggingface.co./) and browse our [models](https://huggingface.co./models). Once you've found one that you like, you can try the Inference Widget directly on the page. Clicking on the "Deploy" button, you'll get auto-generated code to deploy the model on the free Inference API for evaluation, and a direct link to deploy it to production with Inference Endpoints or Spaces.
Please give it a try and let us know what you think. We'd love to read your feedback on the Hugging Face [forum](https://discuss.huggingface.co/).
Thank you for reading! | [
[
"transformers",
"mlops",
"deployment",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"mlops",
"deployment",
"image_generation"
] | null | null |
766dfe33-7a85-40bf-a1b5-1562d4bda46c | completed | 2025-01-16T03:08:53.170847 | 2025-01-16T15:09:43.247466 | 6c42a495-80f9-41ae-a0c3-ddfb589f5c28 | Improving Hugging Face Training Efficiency Through Packing with Flash Attention 2 | RQlee, ArthurZ, achikundu, lwtr, rganti, mayank-mishra | packing-with-FA2.md | Training with packed instruction tuning examples (without padding) is now compatible with Flash Attention 2 in Hugging Face, thanks to a [recent PR](https://github.com/huggingface/transformers/pull/31629) and the new [DataCollatorWithFlattening](https://huggingface.co./docs/transformers/main/en/main_classes/data_collator#transformers.DataCollatorWithFlattening)
It can provide up to 2x improvement in training throughput while maintaining convergence quality. Read on for the details!
## Introduction
Padding input sequences in mini-batches is a usual method to collate inputs during training. However, this introduces inefficiencies because of the irrelevant padding tokens. Packing examples without padding, and using the token position information, is a more efficient alternative. However, previous implementations of packing did not consider example boundaries when using Flash Attention 2, resulting in undesired cross-example attention that reduce quality and convergence.
Hugging Face Transformers now addresses this with a new feature that maintains boundary awareness during packing, alongside the introduction of a new data collator, `DataCollatorWithFlattening`.
By selecting `DataCollatorWithFlattening`, Hugging Face `Trainer` users can now seamlessly concatenate sequences into a single tensor while accounting for sequence boundaries during Flash Attention 2 computations. This is achieved through the `flash_attn_varlen_func`, which calculates the cumulative sequence lengths in each mini-batch (`cu_seqlens`).
The same feature is available to Hugging Face `SFTTrainer` users in the `TRL` library by setting a new flag, `padding_free=True`, when calling the data collator `DataCollatorForCompletionOnlyLM`.
## Up to 2x throughput increase
We see significant improvement in training throughput using this feature with the new `DataCollatorWithFlattening`. The figure below shows the throughput measured in tokens/second during training. In this example, the throughput is the per-GPU average over 8 A100-80 GPU over one epoch of a 20K randomly selected sample from two different instruct tuning datasets, FLAN and OrcaMath.

FLAN has short sequences on average but a large variance in sequence length, so example lengths in each batch may vary widely. This means that padded FLAN batches may incur a significant overhead in unused padding tokens. Training on the FLAN dataset shows a significant benefit using the new `DataCollatorWithFlattening` in terms of increased throughput. We see a 2x throughput increase on the models shown here: llama2-7B, mistral-7B, and granite-8B-code.
OrcaMath has longer examples and a lower variance in example length. As such, the improvement from packing is lower. Our experiments show a 1.4x increase in throughput when training using this form of packing on the OrcaMath dataset across these three models.

Memory usage also improves through packing with the new `DataCollatorWithFlattening`. The following figure shows the peak memory usage of the same three models training on the same two datasets. Peak memory is reduced by 20% on the FLAN dataset, which benefits considerably from packing.
Peak memory reduction is 6% on the OrcaMath dataset with its more homogeneous example lengths.
Packing examples, when it reduces the number of optimization steps, may harm training convergence. The new feature, however, retains the minibatches and, hence, the same number of optimization steps as would be used with padded examples. Thus, there is no impact on train convergence, as we see in the next figure, which shows identical validation loss of the same three models training on the same two datasets, whether the models are trained with packing using the new `DataCollatorWithFlattening` or with padding.

## How it works
Consider a batch of data with a batchsize = 4 where the four sequences are as follows:

After concatenating the examples, the padding-free collator returns the `input_ids`, `labels`, and `position_ids` of each example. Hence, the collator provides, for this batch of data,

The modifications required are lightweight and are limited to providing the `position_ids` to Flash Attention 2.
This relies, however, on the model exposing `position_ids`. As of the time of writing, 14 models expose them and are supported by the solution. Specifically, Llama 2 and 3, Mistral, Mixtral, Granite, DBRX, Falcon, Gemma, OLMo, Phi 1, 2, and 3, phi3, Qwen 2 and 2 MoE, StableLM, and StarCoder 2 are all supported by the solution.
## Getting started
Reaping the benefits of packing with `position_ids` is easy.
If you are using Hugging Face `Trainer` from `Transformers`, only two steps are required:
1) Instantiate the model with Flash Attention 2
2) Use the new `DataCollatorWithFlattening`
If you are using Hugging Face `SFTTrainer` from `TRL` with `DataCollatorForCompletionOnlyLM`, then the two required steps are:
1) Instantiate the model with Flash Attention 2
2) Set `padding_free=True` when calling `DataCollatorForCompletionOnlyLM` as follows:
`collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer, padding_free=True)`
## How to use it
For `Trainer` users, the example below illustrates how to use the new feature.
```Python
# Example using DataCollatorWithFlattening
import torch
# load model as usual
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"instructlab/merlinite-7b-lab",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2"
)
# read dataset as usual
from datasets import load_dataset
train_dataset = load_dataset("json", data_files="path/to/my/dataset")["train"]
# use DataCollatorWithFlattening
from transformers import DataCollatorWithFlattening
data_collator = DataCollatorWithFlattening()
# train
from transformers import TrainingArguments, Trainer
train_args = TrainingArguments(output_dir="/save/path")
trainer = Trainer(
args=train_args,
model=model,
train_dataset=train_dataset,
data_collator=data_collator
)
trainer.train()
```
For `TRL` users, the example below shows how to use the new feature with `SFTTrainer`.
```Python
# SFTTrainer example using DataCollatorForCompletionOnlyLM
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer, DataCollatorForCompletionOnlyLM
dataset = load_dataset("lucasmccabe-lmi/CodeAlpaca-20k", split="train")
model = AutoModelForCausalLM.from_pretrained(
"instructlab/merlinite-7b-lab",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2")
tokenizer = AutoTokenizer.from_pretrained("instructlab/merlinite-7b-lab")
tokenizer.pad_token = tokenizer.eos_token
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"### Question: {example['instruction'][i]}\n ### Answer: {example['output'][i]}"
output_texts.append(text)
return output_texts
response_template = " ### Answer:"
response_template_ids = tokenizer.encode(response_template, add_special_tokens=False)[2:]
collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer, padding_free=True)
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=SFTConfig(
output_dir="./tmp",
gradient_checkpointing=True,
per_device_train_batch_size=8
),
formatting_func=formatting_prompts_func,
data_collator=collator,
)
trainer.train()
```
## Conclusions
Packing instruction tuning examples, instead of padding, is now fully compatible with Flash Attention 2, thanks to a recent PR and the new `DataCollatorWithFlattening`. The method is compatible with models that use `position_ids`. Benefits can be seen in throughput and peak memory usage during training, with no degradation in training convergence. Actual throughput and memory improvement depends on the model and the distribution of example lengths in the training data. Training with data that has a wide variation of example lengths will see the greatest benefit, with respect to padding, by using the `DataCollatorWithFlattening`. The same feature is available to `SFTTrainer` users in the `TRL` library by setting a new flag, `padding_free=True`, when calling `DataCollatorForCompletionOnlyLM`.
For a more detailed analysis, have a look at the paper at https://huggingface.co./papers/2407.09105 | [
[
"llm",
"transformers",
"optimization",
"fine_tuning",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"optimization",
"efficient_computing"
] | null | null |
0548d927-9a3a-4959-9e3a-e0ac98813e58 | completed | 2025-01-16T03:08:53.170852 | 2025-01-19T19:00:39.834864 | 83743ea1-875e-4055-8b41-1fdf768803de | Introducing BERTopic Integration with the Hugging Face Hub | MaartenGr, davanstrien | bertopic.md | [](https://colab.research.google.com/#fileId=https://huggingface.co./spaces/davanstrien/blog_notebooks/blob/main/BERTopic_hub_starter.ipynb)
We are thrilled to announce a significant update to the [BERTopic](https://maartengr.github.io/BERTopic) Python library, expanding its capabilities and further streamlining the workflow for topic modelling enthusiasts and practitioners. BERTopic now supports pushing and pulling trained topic models directly to and from the Hugging Face Hub. This new integration opens up exciting possibilities for leveraging the power of BERTopic in production use cases with ease.
## What is Topic Modelling?
Topic modelling is a method that can help uncover hidden themes or "topics" within a group of documents. By analyzing the words in the documents, we can find patterns and connections that reveal these underlying topics. For example, a document about machine learning is more likely to use words like "gradient" and "embedding" compared to a document about baking bread.
Each document usually covers multiple topics in different proportions. By examining the word statistics, we can identify clusters of related words that represent these topics. This allows us to analyze a set of documents and determine the topics they discuss, as well as the balance of topics within each document. More recently, new approaches to topic modelling have moved beyond using words to using more rich representations such as those offered through Transformer based models.
## What is BERTopic?
BERTopic is a state-of-the-art Python library that simplifies the topic modelling process using various embedding techniques and [c-TF-IDF](https://maartengr.github.io/BERTopic/api/ctfidf.html) to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions.
<figure class="image table text-center m-0 w-full">
<video
alt="BERTopic overview"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/2d1113254a370972470d42e122df150f3551cc07/blog/BERTopic/bertopic_overview.mp4" type="video/mp4">
</video>
</figure>
*An overview of the BERTopic library*
Whilst BERTopic is easy to get started with, it supports a range of advanced approaches to topic modelling including
[guided](https://maartengr.github.io/BERTopic/getting_started/guided/guided.html), [supervised](https://maartengr.github.io/BERTopic/getting_started/supervised/supervised.html), [semi-supervised](https://maartengr.github.io/BERTopic/getting_started/semisupervised/semisupervised.html) and [manual](https://maartengr.github.io/BERTopic/getting_started/manual/manual.html) topic modelling. More recently BERTopic has added support for multi-modal topic models. BERTopic also have a rich set of tools for producing visualizations.
BERTopic provides a powerful tool for users to uncover significant topics within text collections, thereby gaining valuable insights. With BERTopic, users can analyze customer reviews, explore research papers, or categorize news articles with ease, making it an essential tool for anyone looking to extract meaningful information from their text data.
## BERTopic Model Management with the Hugging Face Hub
With the latest integration, BERTopic users can seamlessly push and pull their trained topic models to and from the Hugging Face Hub. This integration marks a significant milestone in simplifying the deployment and management of BERTopic models across different environments.
The process of training and pushing a BERTopic model to the Hub can be done in a few lines
```python
from bertopic import BERTopic
topic_model = BERTopic("english")
topics, probs = topic_model.fit_transform(docs)
topic_model.push_to_hf_hub('davanstrien/transformers_issues_topics')
```
You can then load this model in two lines and use it to predict against new data.
```python
from bertopic import BERTopic
topic_model = BERTopic.load("davanstrien/transformers_issues_topics")
```
By leveraging the power of the Hugging Face Hub, BERTopic users can effortlessly share, version, and collaborate on their topic models. The Hub acts as a central repository, allowing users to store and organize their models, making it easier to deploy models in production, share them with colleagues, or even showcase them to the broader NLP community.
You can use the `libraries` filter on the hub to find BERTopic models.

Once you have found a BERTopic model you are interested in you can use the Hub inference widget to try out the model and see if it might be a good fit for your use case.
Once you have a trained topic model, you can push it to the Hugging Face Hub in one line. Pushing your model to the Hub will automatically create an initial model card for your model, including an overview of the topics created. Below you can see an example of the topics resulting from a [model trained on ArXiv data](https://huggingface.co./MaartenGr/BERTopic_ArXiv).
<details>
<summary>Click here for an overview of all topics.</summary>
| Topic ID | Topic Keywords | Topic Frequency | Label |
| | [
[
"data",
"implementation",
"tutorial",
"tools",
"text_classification",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"integration",
"tools",
"implementation",
"tutorial"
] | null | null |
eb3e8f30-2b22-4af4-85a8-6418b08d7961 | completed | 2025-01-16T03:08:53.170856 | 2025-01-16T15:13:34.958607 | 0a720423-3fb7-4197-90a0-21c70d20705d | Fine-tuning LLMs to 1.58bit: extreme quantization made easy | medmekk, marcsun13, lvwerra, pcuenq, osanseviero, thomwolf | 1_58_llm_extreme_quantization.md | As Large Language Models (LLMs) grow in size and complexity, finding ways to reduce their computational and energy costs has become a critical challenge. One popular solution is quantization, where the precision of parameters is reduced from the standard 16-bit floating-point (FP16) or 32-bit floating-point (FP32) to lower-bit formats like 8-bit or 4-bit. While this approach significantly cuts down on memory usage and speeds up computation, it often comes at the expense of accuracy. Reducing the precision too much can cause models to lose crucial information, resulting in degraded performance.
[BitNet](https://arxiv.org/abs/2402.17764) is a special transformers architecture that represents each parameter with only three values: `(-1, 0, 1)`, offering a extreme quantization of just 1.58 ( \\( log_2(3) \\) ) bits per parameter. However, it requires to train a model from scratch. While the results are impressive, not everybody has the budget to pre-train an LLM. To overcome this limitation, we explored a few tricks that allow fine-tuning an existing model to 1.58 bits! Keep reading to find out how !
## Table of Contents
- [TL;DR](#tldr)
- [What is BitNet in More Depth?](#what-is-bitnet-in-more-depth)
- [Pre-training Results in 1.58b](#pre-training-results-in-158b)
- [Fine-tuning in 1.58b](#fine-tuning-in-158bit)
- [Kernels used & Benchmarks](#kernels-used--benchmarks)
- [Conclusion](#conclusion)
- [Acknowledgements](#acknowledgements)
- [Additional Resources](#additional-resources)
## TL;DR
[BitNet](https://arxiv.org/abs/2402.17764) is an architecture introduced by Microsoft Research that uses extreme quantization, representing each parameter with only three values: -1, 0, and 1. This results in a model that uses just 1.58 bits per parameter, significantly reducing computational and memory requirements.
This architecture uses INT8 addition calculations when performing matrix multiplication, in contrast to LLaMA LLM's FP16 addition and multiplication operations.
<figure style="text-align: center;">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/1.58llm_extreme_quantization/matmulfree.png" alt="The new computation paradigm of BitNet b1.58" style="width: 100%;"/>
<figcaption>The new computation paradigm of BitNet b1.58 (source: BitNet paper https://arxiv.org/abs/2402.17764)</figcaption>
</figure>
This results in a theoretically reduced energy consumption, with BitNet b1.58 saving 71.4 times the arithmetic operations energy for matrix multiplication compared to the Llama baseline.
<figure style="text-align: center;">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/1.58llm_extreme_quantization/energy_consumption.png" alt="Energy consumption of BitNet b1.58 compared to LLaMA" style="width: 100%;"/>
<figcaption>Energy consumption of BitNet b1.58 compared to LLama (source: BitNet paper https://arxiv.org/abs/2402.17764)</figcaption>
</figure>
We have successfully fine-tuned a [Llama3 8B model](https://huggingface.co./meta-llama/Meta-Llama-3-8B-Instruct) using the BitNet architecture, achieving strong performance on downstream tasks. The 8B models we developed are released under the [HF1BitLLM](https://huggingface.co./HF1BitLLM) organization. Two of these models were fine-tuned on 10B tokens with different training setup, while the third was fine-tuned on 100B tokens. Notably, our models surpass the Llama 1 7B model in MMLU benchmarks.
### How to Use with Transformers
To integrate the BitNet architecture into Transformers, we introduced a new quantization method called "bitnet" ([PR](https://github.com/huggingface/transformers/pull/33410)). This method involves replacing the standard Linear layers with specialized BitLinear layers that are compatible with the BitNet architecture, with appropriate dynamic quantization of activations, weight unpacking, and matrix multiplication.
Loading and testing the model in Transformers is incredibly straightforward, there are zero changes to the API:
```python
model = AutoModelForCausalLM.from_pretrained(
"HF1BitLLM/Llama3-8B-1.58-100B-tokens",
device_map="cuda",
torch_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
input_text = "Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?\nAnswer:"
input_ids = tokenizer.encode(input_text, return_tensors="pt").cuda()
output = model.generate(input_ids, max_new_tokens=10)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
```
With this code, everything is managed seamlessly behind the scenes, so there's no need to worry about additional complexities, you just need to install the latest version of transformers.
For a quick test of the model, check out this [notebook](https://colab.research.google.com/drive/1ovmQUOtnYIdvcBkwEE4MzVL1HKfFHdNT?usp=sharing)
## What is BitNet In More Depth?
[BitNet](https://arxiv.org/abs/2402.17764) replaces traditional Linear layers in Multi-Head Attention and Feed-Forward Networks with specialized layers called BitLinear that use ternary precision (or even binary, in the initial version). The BitLinear layers we use in this project quantize the weights using ternary precision (with values of -1, 0, and 1), and we quantize the activations to 8-bit precision. We use a different implementation of BitLinear for training than we do for inference, as we'll see in the next section.
The main obstacle to training in ternary precision is that the weight values are discretized (via the `round()` function) and thus non-differentiable. BitLinear solves this with a nice trick: [STE (Straight Through Estimator)](https://arxiv.org/abs/1903.05662). The STE allows gradients to flow through the non-differentiable rounding operation by approximating its gradient as 1 (treating `round()` as equivalent to the identity function). Another way to view it is that, instead of stopping the gradient at the rounding step, the STE lets the gradient pass through as if the rounding never occurred, enabling weight updates using standard gradient-based optimization techniques.
<figure style="text-align: center;">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/1.58llm_extreme_quantization/bitlinear.png" alt="The architecture of BitNet with BitLinear layers" style="width: 100%"/>
<figcaption>The architecture of BitNet with BitLinear layers (source: BitNet paper https://arxiv.org/pdf/2310.11453)</figcaption>
</figure>
### Training
We train in full precision, but quantize the weights into ternary values as we go, using symmetric per tensor quantization. First, we compute the average of the absolute values of the weight matrix and use this as a scale. We then divide the weights by the scale, round the values, constrain them between -1 and 1, and finally rescale them to continue in full precision.
\\( scale_w = \frac{1}{\frac{1}{nm} \sum_{ij} |W_{ij}|} \\)
\\( W_q = \text{clamp}_{[-1,1]}(\text{round}(W*scale)) \\)
\\( W_{dequantized} = W_q*scale_w \\)
Activations are then quantized to a specified bit-width (8-bit, in our case) using absmax per token quantization (for a comprehensive introduction to quantization methods check out this [post](https://mlabonne.github.io/blog/posts/Introduction_to_Weight_Quantization.html)). This involves scaling the activations into the range `[−128, 127]` for an 8-bit bit-width. The quantization formula is:
\\( scale_x = \frac{127}{|X|_{\text{max}, \, \text{dim}=-1}} \\)
\\( X_q = \text{clamp}_{[-128,127]}(\text{round}(X*scale)) \\)
\\( X_{dequantized} = X_q * scale_x \\)
To make the formulas clearer, here are examples of weight and activation quantization using a 3x3 matrix: | [
[
"llm",
"quantization",
"fine_tuning",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"quantization",
"fine_tuning",
"efficient_computing"
] | null | null |
b2c7c0e2-8d54-4f13-97e8-2a19ec80895f | completed | 2025-01-16T03:08:53.170861 | 2025-01-19T19:01:52.001063 | 346449e8-b96d-4e4d-ba85-a91ed0dc5aec | Graph Classification with Transformers | nan | graphml-classification.md | <div class="blog-metadata">
<small>Published April 14, 2023.</small>
<a target="_blank" class="btn no-underline text-sm mb-5 font-sans" href="https://github.com/huggingface/blog/blob/main/graphml-classification.md">
Update on GitHub
</a>
</div>
<div class="author-card">
<a href="/clefourrier">
<img class="avatar avatar-user" src="https://aeiljuispo.cloudimg.io/v7/https://s3.amazonaws.com/moonup/production/uploads/1644340617257-noauth.png?w=200&h=200&f=face" title="Gravatar">
<div class="bfc">
<code>clefourrier</code>
<span class="fullname">Clémentine Fourrier</span>
</div>
</a>
</div>
In the previous [blog](https://huggingface.co./blog/intro-graphml), we explored some of the theoretical aspects of machine learning on graphs. This one will explore how you can do graph classification using the Transformers library. (You can also follow along by downloading the demo notebook [here](https://github.com/huggingface/blog/blob/main/notebooks/graphml-classification.ipynb)!)
At the moment, the only graph transformer model available in Transformers is Microsoft's [Graphormer](https://arxiv.org/abs/2106.05234), so this is the one we will use here. We are looking forward to seeing what other models people will use and integrate 🤗
## Requirements
To follow this tutorial, you need to have installed `datasets` and `transformers` (version >= 4.27.2), which you can do with `pip install -U datasets transformers`.
## Data
To use graph data, you can either start from your own datasets, or use [those available on the Hub](https://huggingface.co./datasets?task_categories=task_categories:graph-ml&sort=downloads). We'll focus on using already available ones, but feel free to [add your datasets](https://huggingface.co./docs/datasets/upload_dataset)!
### Loading
Loading a graph dataset from the Hub is very easy. Let's load the `ogbg-mohiv` dataset (a baseline from the [Open Graph Benchmark](https://ogb.stanford.edu/) by Stanford), stored in the `OGB` repository:
```python
from datasets import load_dataset
# There is only one split on the hub
dataset = load_dataset("OGB/ogbg-molhiv")
dataset = dataset.shuffle(seed=0)
```
This dataset already has three splits, `train`, `validation`, and `test`, and all these splits contain our 5 columns of interest (`edge_index`, `edge_attr`, `y`, `num_nodes`, `node_feat`), which you can see by doing `print(dataset)`.
If you have other graph libraries, you can use them to plot your graphs and further inspect the dataset. For example, using PyGeometric and matplotlib:
```python
import networkx as nx
import matplotlib.pyplot as plt
# We want to plot the first train graph
graph = dataset["train"][0]
edges = graph["edge_index"]
num_edges = len(edges[0])
num_nodes = graph["num_nodes"]
# Conversion to networkx format
G = nx.Graph()
G.add_nodes_from(range(num_nodes))
G.add_edges_from([(edges[0][i], edges[1][i]) for i in range(num_edges)])
# Plot
nx.draw(G)
```
### Format
On the Hub, graph datasets are mostly stored as lists of graphs (using the `jsonl` format).
A single graph is a dictionary, and here is the expected format for our graph classification datasets:
- `edge_index` contains the indices of nodes in edges, stored as a list containing two parallel lists of edge indices.
- **Type**: list of 2 lists of integers.
- **Example**: a graph containing four nodes (0, 1, 2 and 3) and where connections are 1->2, 1->3 and 3->1 will have `edge_index = [[1, 1, 3], [2, 3, 1]]`. You might notice here that node 0 is not present here, as it is not part of an edge per se. This is why the next attribute is important.
- `num_nodes` indicates the total number of nodes available in the graph (by default, it is assumed that nodes are numbered sequentially).
- **Type**: integer
- **Example**: In our above example, `num_nodes = 4`.
- `y` maps each graph to what we want to predict from it (be it a class, a property value, or several binary label for different tasks).
- **Type**: list of either integers (for multi-class classification), floats (for regression), or lists of ones and zeroes (for binary multi-task classification)
- **Example**: We could predict the graph size (small = 0, medium = 1, big = 2). Here, `y = [0]`.
- `node_feat` contains the available features (if present) for each node of the graph, ordered by node index.
- **Type**: list of lists of integer (Optional)
- **Example**: Our above nodes could have, for example, types (like different atoms in a molecule). This could give `node_feat = [[1], [0], [1], [1]]`.
- `edge_attr` contains the available attributes (if present) for each edge of the graph, following the `edge_index` ordering.
- **Type**: list of lists of integers (Optional)
- **Example**: Our above edges could have, for example, types (like molecular bonds). This could give `edge_attr = [[0], [1], [1]]`.
### Preprocessing
Graph transformer frameworks usually apply specific preprocessing to their datasets to generate added features and properties which help the underlying learning task (classification in our case).
Here, we use Graphormer's default preprocessing, which generates in/out degree information, the shortest path between node matrices, and other properties of interest for the model.
```python
from transformers.models.graphormer.collating_graphormer import preprocess_item, GraphormerDataCollator
dataset_processed = dataset.map(preprocess_item, batched=False)
```
It is also possible to apply this preprocessing on the fly, in the DataCollator's parameters (by setting `on_the_fly_processing` to True): not all datasets are as small as `ogbg-molhiv`, and for large graphs, it might be too costly to store all the preprocessed data beforehand.
## Model
### Loading
Here, we load an existing pretrained model/checkpoint and fine-tune it on our downstream task, which is a binary classification task (hence `num_classes = 2`). We could also fine-tune our model on regression tasks (`num_classes = 1`) or on multi-task classification.
```python
from transformers import GraphormerForGraphClassification
model = GraphormerForGraphClassification.from_pretrained(
"clefourrier/pcqm4mv2_graphormer_base",
num_classes=2, # num_classes for the downstream task
ignore_mismatched_sizes=True,
)
```
Let's look at this in more detail.
Calling the `from_pretrained` method on our model downloads and caches the weights for us. As the number of classes (for prediction) is dataset dependent, we pass the new `num_classes` as well as `ignore_mismatched_sizes` alongside the `model_checkpoint`. This makes sure a custom classification head is created, specific to our task, hence likely different from the original decoder head.
It is also possible to create a new randomly initialized model to train from scratch, either following the known parameters of a given checkpoint or by manually choosing them.
### Training or fine-tuning
To train our model simply, we will use a `Trainer`. To instantiate it, we will need to define the training configuration and the evaluation metric. The most important is the `TrainingArguments`, which is a class that contains all the attributes to customize the training. It requires a folder name, which will be used to save the checkpoints of the model.
```python
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
"graph-classification",
logging_dir="graph-classification",
per_device_train_batch_size=64,
per_device_eval_batch_size=64,
auto_find_batch_size=True, # batch size can be changed automatically to prevent OOMs
gradient_accumulation_steps=10,
dataloader_num_workers=4, #1,
num_train_epochs=20,
evaluation_strategy="epoch",
logging_strategy="epoch",
push_to_hub=False,
)
```
For graph datasets, it is particularly important to play around with batch sizes and gradient accumulation steps to train on enough samples while avoiding out-of-memory errors.
The last argument `push_to_hub` allows the Trainer to push the model to the Hub regularly during training, as each saving step.
```python
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset_processed["train"],
eval_dataset=dataset_processed["validation"],
data_collator=GraphormerDataCollator(),
)
```
In the `Trainer` for graph classification, it is important to pass the specific data collator for the given graph dataset, which will convert individual graphs to batches for training.
```python
train_results = trainer.train()
trainer.push_to_hub()
```
When the model is trained, it can be saved to the hub with all the associated training artefacts using `push_to_hub`.
As this model is quite big, it takes about a day to train/fine-tune for 20 epochs on CPU (IntelCore i7). To go faster, you could use powerful GPUs and parallelization instead, by launching the code either in a Colab notebook or directly on the cluster of your choice.
## Ending note
Now that you know how to use `transformers` to train a graph classification model, we hope you will try to share your favorite graph transformer checkpoints, models, and datasets on the Hub for the rest of the community to use! | [
[
"transformers",
"implementation",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"implementation",
"tutorial"
] | null | null |
009d3452-8564-4138-9beb-a00d4016e633 | completed | 2025-01-16T03:08:53.170866 | 2025-01-16T03:24:10.333148 | 965cc53e-9ef9-474b-9cb3-53ae36e7c8c9 | Hugging Face Teams Up with Protect AI: Enhancing Model Security for the ML Community | mcpotato | protectai.md | [Protect AI](https://protectai.com/) is a company founded with a mission to create a safer AI-powered world. They are developing powerful tools, namely [Guardian](https://protectai.com/guardian), to ensure that the rapid pace of AI innovation can continue without compromising security.
Our decision to partner with Protect AI stems from their [community driven](https://huntr.com/) approach to security, active support of [open source](https://github.com/protectai), and expertise in all things security x AI.
> [!TIP]
> Interested in joining our security partnership / providing scanning information on the Hub? Please get in touch with us over at [email protected].
## Model security refresher
To share models, we serialize weights, configs and other data structures we use to interact with the models, in order to facilitate storage and transport. Some serialization formats are vulnerable to nasty exploits, such as arbitrary code execution (looking at you pickle), making shared models that use those formats potentially dangerous.
As Hugging Face has become a popular platform for model sharing, we’d like to help protect the community from this, hence why we have developed tools like [picklescan](https://github.com/mmaitre314/picklescan) and why we are integrating Guardian in our scanner suite.
Pickle is not the only exploitable format out there, [see for reference](https://github.com/Azure/counterfit/wiki/Abusing-ML-model-file-formats-to-create-malware-on-AI-systems:-A-proof-of-concept) how one can exploit Keras Lambda layers to achieve arbitrary code execution. The good news is that Guardian catches both of these exploits and more in additional file formats – see their [Knowledge Base](https://protectai.com/insights/knowledge-base/) for up to date scanner information.
> [!TIP]
> Read all our documentation on security here: https://huggingface.co./docs/hub/security 🔥
## Integration
While integrating Guardian as a third-party scanner, we have used this as an opportunity to revamp our frontend to display scan results. Here is what it now looks like:
<img class="block" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/hub/third-party-scans-list.png"/>
<img class="block" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/hub/security-scanner-status-banner.png"/>
<img class="block" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/hub/security-scanner-pickle-import-list.png"/>
<em>As you can see here, an additional Pickle button is present when a pickle import scan occurred</em>
As you can see from the screenshot, there's nothing you have to do to benefit from this! All public model repositories will be scanned by Guardian automatically as soon as you push your files to the Hub. Here is an example repository you can check out to see the feature in action: [mcpotato/42-eicar-street](https://huggingface.co./mcpotato/42-eicar-street).
Note that you might not see a scan for your model as of today, as we have over 1 million model repos. It may take us some time to catch up 😅.
In total, we have already scanned hundreds of millions of files, because we believe that empowering the community to share models in a safe and frictionless manner will lead to growth for the whole field. | [
[
"mlops",
"community",
"security",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"security",
"community",
"tools"
] | null | null |
443e0a68-19d7-467a-a266-d5bdf9a4fa99 | completed | 2025-01-16T03:08:53.170870 | 2025-01-16T03:10:54.448086 | 139c0216-470b-4da3-88f7-afb3c940a379 | Welcome Mixtral - a SOTA Mixture of Experts on Hugging Face | lewtun, philschmid, osanseviero, pcuenq, olivierdehaene, lvwerra, ybelkada | mixtral.md | Mixtral 8x7b is an exciting large language model released by Mistral today, which sets a new state-of-the-art for open-access models and outperforms GPT-3.5 across many benchmarks. We’re excited to support the launch with a comprehensive integration of Mixtral in the Hugging Face ecosystem 🔥!
Among the features and integrations being released today, we have:
- [Models on the Hub](https://huggingface.co./models?search=mistralai/Mixtral), with their model cards and licenses (Apache 2.0)
- [🤗 Transformers integration](https://github.com/huggingface/transformers/releases/tag/v4.36.0)
- Integration with Inference Endpoints
- Integration with [Text Generation Inference](https://github.com/huggingface/text-generation-inference) for fast and efficient production-ready inference
- An example of fine-tuning Mixtral on a single GPU with 🤗 TRL.
## Table of Contents
- [What is Mixtral 8x7b](#what-is-mixtral-8x7b)
- [About the name](#about-the-name)
- [Prompt format](#prompt-format)
- [What we don't know](#what-we-dont-know)
- [Demo](#demo)
- [Inference](#inference)
- [Using 🤗 Transformers](#using-🤗-transformers)
- [Using Text Generation Inference](#using-text-generation-inference)
- [Fine-tuning with 🤗 TRL](#fine-tuning-with-🤗-trl)
- [Quantizing Mixtral](#quantizing-mixtral)
- [Load Mixtral with 4-bit quantization](#load-mixtral-with-4-bit-quantization)
- [Load Mixtral with GPTQ](#load-mixtral-with-gptq)
- [Disclaimers and ongoing work](#disclaimers-and-ongoing-work)
- [Additional Resources](#additional-resources)
- [Conclusion](#conclusion)
## What is Mixtral 8x7b?
Mixtral has a similar architecture to Mistral 7B, but comes with a twist: it’s actually 8 “expert” models in one, thanks to a technique called Mixture of Experts (MoE). For transformers models, the way this works is by replacing some Feed-Forward layers with a sparse MoE layer. A MoE layer contains a router network to select which experts process which tokens most efficiently. In the case of Mixtral, two experts are selected for each timestep, which allows the model to decode at the speed of a 12B parameter-dense model, despite containing 4x the number of effective parameters!
For more details on MoEs, see our accompanying blog post: [hf.co/blog/moe](https://huggingface.co./blog/moe)
**Mixtral release TL;DR;**
- Release of base and Instruct versions
- Supports a context length of 32k tokens.
- Outperforms Llama 2 70B and matches or beats GPT3.5 on most benchmarks
- Speaks English, French, German, Spanish, and Italian.
- Good at coding, with 40.2% on HumanEval
- Commercially permissive with an Apache 2.0 license
So how good are the Mixtral models? Here’s an overview of the base model and its performance compared to other open models on the [LLM Leaderboard](https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard) (higher scores are better):
| Model | License | Commercial use? | Pretraining size [tokens] | Leaderboard score ⬇️ |
| | [
[
"llm",
"transformers",
"benchmarks",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"benchmarks",
"integration"
] | null | null |
d5f39db5-85c5-47f4-a9ae-b3765c28ccb1 | completed | 2025-01-16T03:08:53.170875 | 2025-01-16T14:21:28.467005 | d68a4833-9f5d-4af9-b9ae-5b961e810d4c | Director of Machine Learning Insights [Part 2: SaaS Edition] | britneymuller | ml-director-insights-2.md | _If you or your team are interested in building ML solutions faster visit [hf.co/support](https://huggingface.co./support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_2) today!_
👋 Welcome to Part 2 of our Director of Machine Learning Insights [Series]. Check out [Part 1 here.](https://huggingface.co./blog/ml-director-insights)
Directors of Machine Learning have a unique seat at the AI table spanning the perspective of various roles and responsibilities. Their rich knowledge of ML frameworks, engineering, architecture, real-world applications and problem-solving provides deep insights into the current state of ML. For example, one director will note how using new transformers speech technology decreased their team’s error rate by 30% and how simple thinking can help save _a lot_ of computational power.
Ever wonder what directors at Salesforce or ZoomInfo currently think about the state of Machine Learning? What their biggest challenges are? And what they're most excited about? Well, you're about to find out!
In this second SaaS focused installment, you’ll hear from a deep learning for healthcare textbook author who also founded a non-profit for mentoring ML talent, a chess fanatic cybersecurity expert, an entrepreneur whose business was inspired by Barbie’s need to monitor brand reputation after a lead recall, and a seasoned patent and academic paper author who enjoys watching his 4 kids make the same mistakes as his ML models.
🚀 Let’s meet some top Machine Learning Directors in SaaS and hear what they have to say about Machine Learning:
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/67_ml_director_insights/Omar-Rahman.jpeg"></a>
### [Omar Rahman](https://www.linkedin.com/in/omar-rahman-4739713a/) - Director of Machine Learning at [Salesforce](https://www.salesforce.com/)
**Background:** Omar leads a team of Machine Learning and Data Engineers in leveraging ML for defensive security purposes as part of the Cybersecurity team. Previously, Omar has led data science and machine learning engineering teams at Adobe and SAP focusing on bringing intelligent capabilities to marketing cloud and procurement applications. Omar holds a Master’s degree in Electrical Engineering from Arizona State University.
**Fun Fact:** Omar loves to play chess and volunteers his free time to guide and mentor graduate students in AI.
**Salesforce:** World's #1 customer relationship management software.
#### **1. How has ML made a positive impact on SaaS?**
ML has benefited SaaS offerings in many ways.
**a. Improving automation within applications:** For example, a service ticket router using NLP (Natural Language Processing) to understand the context of the service request and routing it to the appropriate team within the organization.
**b. Reduction in code complexity:** Rules-based systems tend to get unwieldy as new rules are added, thereby increasing maintenance costs. For example, An ML-based language translation system is more accurate and robust with much fewer lines of code as compared to previous rules-based systems.
**c. Better forecasting results in cost savings.** Being able to forecast more accurately helps in reducing backorders in the supply chain as well as cost savings due to a reduction in storage costs.
#### **2. What are the biggest ML challenges within SaaS?**
a. Productizing ML applications require a lot more than having a model. Being able to leverage the model for serving results, detecting and adapting to changes in statistics of data, etc. creates significant overhead in deploying and maintaining ML systems.
b. In most large organizations, data is often siloed and not well maintained resulting in significant time spent in consolidating data, pre-processing, data cleaning activities, etc., thereby resulting in a significant amount of time and effort needed to create ML-based applications.
#### **3. What’s a common mistake you see people make trying to integrate ML into SaaS?**
Not focussing enough on the business context and the problem being solved, rather trying to use the latest and greatest algorithms and newly open-sourced libraries. A lot can be achieved by simple traditional ML techniques.
#### **4. What excites you most about the future of ML?**
Generalized artificial intelligence capabilities, if built and managed well, have the capability to transform humanity in more ways than one can imagine. My hope is that we will see great progress in the areas of healthcare and transportation. We already see the benefits of AI in radiology resulting in significant savings in manpower thereby enabling humans to focus on more complex tasks. Self-driving cars and trucks are already transforming the transportation sector.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/67_ml_director_insights/Cao-Danica-Xiao.jpeg"></a>
### [Cao (Danica) Xiao](https://www.linkedin.com/in/caoxiao/) - Senior Director of Machine Learning at [Amplitude](https://amplitude.com/)
**Background:** Cao (Danica) Xiao is the Senior Director and Head of Data Science and Machine Learning at Amplitude. Her team focuses on developing and deploying self-serving machine learning models and products based on multi-sourced user data to solve critical business challenges regarding digital production analytics and optimization. Besides, she is a passionate machine learning researcher with over 95+ papers published in leading CS venues. She is also a technology leader with extensive experience in machine learning roadmap creation, team building, and mentoring.
Prior to Amplitude, Cao (Danica) was the Global Head of Machine Learning in the Analytics Center of Excellence of IQVIA. Before that, she was a research staff member at IBM Research and research lead at MIT-IBM Watson AI Lab. She got her Ph.D. degree in machine learning from the University of Washington, Seattle. Recently, she also co-authored a textbook on deep learning for healthcare and founded a non-profit organization for mentoring machine learning talents.
**Fun Fact:** Cao is a cat-lover and is a mom to two cats: one Singapura girl and one British shorthair boy.
**Amplitude:** A cloud-based product-analytics platform that helps customers build better products.
#### **1. How has ML made a positive impact on SaaS?**
ML plays a game-changing role in turning massive noisy machine-generated or user-generated data into answers to all kinds of business questions including personalization, prediction, recommendation, etc. It impacts a wide spectrum of industry verticals via SaaS.
#### **2. What are the biggest ML challenges within SaaS?**
Lack of data for ML model training that covers a broader range of industry use cases. While being a general solution for all industry verticals, still need to figure out how to handle the vertical-specific needs arising from business, or domain shift issue that affects ML model quality.
#### **3. What’s a common mistake you see people make trying to integrate ML into a SaaS product?**
Not giving users the flexibility to incorporate their business knowledge or other human factors that are critical to business success. For example, for a self-serve product recommendation, it would be great if users could control the diversity of recommended products.
#### **4. What excites you most about the future of ML?**
ML has seen tremendous success. It also evolves rapidly to address the current limitations (e.g., lack of data, domain shift, incorporation of domain knowledge).
More ML technologies will be applied to solve business or customer needs. For example, interpretable ML for users to understand and trust the ML model outputs; counterfactual prediction for users to estimate the alternative outcome should they make a different business decision.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/67_ml_director_insights/Raphael-Cohen.jpeg"></a>
### [Raphael Cohen](https://www.linkedin.com/in/raphael-cohen-63a87779/) - Director of the Machine Learning at [ZoomInfo](https://www.zoominfo.com/)
**Background:** Raphael has a Ph.D. in the field of understanding health records and genetics, has authored 20 academic papers and has 8 patents. Raphael is also a leader in Data Science and Research with a background in NLP, Speech, healthcare, sales, customer journeys, and IT.
**Fun Fact:** Raphael has 4 kids and enjoys seeing them learn and make the same mistakes as some of his ML models.
**ZoomInfo:** Intelligent sales and marketing technology backed by the world's most comprehensive business database.
#### **1. How has ML made a positive impact on SaaS**
Machine Learning has facilitated the transcription of conversational data to help people unlock new insights and understandings. People can now easily view the things they talked about, summarized goals, takeaways, who spoke the most, who asked the best questions, what the next steps are, and more. This is incredibly useful for many interactions like email and video conferencing (which are more common now than ever).
With [Chorus.ai](chorus.ai) we transcribe conversations as they are being recorded in real-time. We use an algorithm called [Wave2Vec](https://arxiv.org/abs/1904.05862) to do this. 🤗 [Hugging Face recently released their own Wave2Vec](https://huggingface.co./docs/transformers/model_doc/wav2vec2) version created for training that we derived a lot of value from. This new generation of transformers speech technology is incredibly powerful, it has decreased our error rate by 30%.
Once we transcribe a conversation we can look into the content - this is where NLP comes in and we rely heavily on [Hugging Face Transformers](https://huggingface.co./docs/transformers/index) to allow us to depict around 20 categories of topics inside recordings and emails; for example, are we talking about pricing, signing a contract, next steps, all of these topics are sent through email or discussed and it’s easy to now extract that info without having to go back through all of your conversations.
This helps make people much better at their jobs.
#### **2. What are the biggest ML challenges within SaaS?**
The biggest challenge is understanding when to make use of ML.
What problems can we solve with ML and which shouldn’t we? A lot of times we have a breakthrough with an ML model but a computationally lighter heuristic model is better suited to solve the problem we have.
This is where a strong AI strategy comes into play. —Understand how you want your final product to work and at what efficiency.
We also have the question of how to get the ML models you’ve built into production with a low environmental/computational footprint? Everyone is struggling with this; how to keep models in production in an efficient way without burning too many resources.
A great example of this was when we moved to the Wav2Vec framework, which required us to break down our conversational audio into 15sec segments that get fed into this huge model. During this, we discovered that we were feeding the model a lot of segments that were pure silence. This is common when someone doesn’t show up or one person is waiting for another to join a meeting.
Just by adding another very light model to tell us when not to send the silent segments into this big complicated ML model, we are able to save a lot of computational power/energy. This is an example of where engineers can think of other easier ways to speed up and save on model production. There’s an opportunity for more engineers to be savvier and better optimize models without burning too many resources.
#### **3. What’s a common mistake you see people make trying to integrate ML into SaaS?**
Is my solution the smartest solution? Is there a better way to break this down and solve it more efficiently?
When we started identifying speakers we went directly with an ML method and this wasn’t as accurate as the video conference provider data.
Since then we learned that the best way to do this is to start with the metadata of who speaks from the conference provider and then overlay that with a smart embedding model. We lost precious time during this learning curve. We shouldn’t have used this large ML solution if we stopped to understand there are other data sources we should invest in that will help us accelerate more efficiently.
Think outside the box and don’t just take something someone built and think I have an idea of how to make this better. Where can we be smarter by understanding the problem better?
#### **4. What excites you most about the future of ML?**
I think we are in the middle of another revolution. For us, seeing our error rates drop by 30% by our Wave2Vec model was amazing. We had been working for years only getting 1% drops at each time and then within 3 months' time we saw such a huge improvement and we know that’s only the beginning.
In academia, bigger and smarter things are happening. These pre-trained models are allowing us to do things we could never imagine before. This is very exciting!
We are also seeing a lot of tech from NLP entering other domains like speech and vision and being able to power them.
Another thing I’m really excited about is generating models! We recently worked with a company called [Bria.ai](https://bria.ai/) and they use these amazing GANs to create images. So you take a stock photo and you can turn it into a different photo by saying “remove glasses”, “add glasses” or “add hair” and it does so perfectly. The idea is that we can use this to generate data. We can take images of people from meetings not smiling and we can make them smile in order to build a data set for smile detection. This will be transformative. You can take 1 image and turn it into 100 images. This will also apply to speech generation which could be a powerful application within the service industry.
#### **Any final thoughts?**
–It’s challenging to put models into production. Believe data science teams need engineering embedded with them. Engineers should be part of the AI team. This will be an important structural pivot in the future.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/67_ml_director_insights/Martin-Ostrovsky.jpeg"></a>
### [Martin Ostrovsky](https://www.linkedin.com/in/martinostrovsky/) Founder/CEO & Machine Learning Director at [Repustate Inc.](https://www.repustate.com/)
**Background:** Martin is passionate about AI, ML, and NLP and is responsible for guiding the strategy and success of all Repustate products by leading the cross-functional team responsible for developing and improving them. He sets the strategy, roadmap, and feature definition for Repustate’s Global Text Analytics API, Sentiment Analysis, Deep Search, and Named Entity Recognition solutions. He has a Bachelor's degree in Computer Science from York University and earned his Master of Business Administration from the Schulich School of Business.
**Fun Fact:** The first application of ML I used was for Barbie toys. My professor at Schulich Business School mentioned that Barbie needed to monitor their brand reputation due to a recall of the toys over concerns of excessive lead in them. Hiring people to manually go through each social post and online article seemed just so inefficient and ineffective to me. So I proposed to create a machine learning algorithm that would monitor what people thought of them from across all social media and online channels. The algorithm worked seamlessly. And that’s how I decided to name my company, Repustate - the “state” of your “repu”tation. 🤖
**Repustate:** A leading provider of text analytics services for enterprise companies.
#### **1. Favorite ML business application?**
My favorite ML application is cybersecurity.
Cybersecurity remains the most critical part for any company (government or non-government) with regard to data. Machine Learning helps identify cyber threats, fight cyber-crime, including cyberbullying, and allows for a faster response to security breaches. ML algorithms quickly analyze the most likely vulnerabilities and potential malware and spyware applications based on user data. They can spot distortion in endpoint entry patterns and identify it as a potential data breach.
#### **2. What is your biggest ML challenge?**
The biggest ML challenge is audio to text transcription in the Arabic Language. There are quite a few systems that can decipher Arabic but they lack accuracy. Arabic is the official language of 26 countries and has 247 million native speakers and 29 million non-native speakers. It is a complex language with a rich vocabulary and many dialects.
The sentiment mining tool needs to read data directly in Arabic if you want accurate insights from Arabic text because otherwise nuances are lost in translations. Translating text to English or any other language can completely change the meaning of words in Arabic, including even the root word. That’s why the algorithm needs to be trained on Arabic datasets and use a dedicated Arabic part-of-speech tagger. Because of these challenges, most companies fail to provide accurate Arabic audio to text translation to date.
#### **3. What’s a common mistake you see people make trying to integrate ML?**
The most common mistake that companies make while trying to integrate ML is insufficient data in their training datasets. Most ML models cannot distinguish between good data and insufficient data. Therefore, training datasets are considered relevant and used as a precedent to determine the results in most cases. This challenge isn’t limited to small- or medium-sized businesses; large enterprises have the same challenge.
No matter what the ML processes are, companies need to ensure that the training datasets are reliable and exhaustive for their desired outcome by incorporating a human element into the early stages of machine learning.
However, companies can create the required foundation for successful machine learning projects with a thorough review of accurate, comprehensive, and constant training data.
#### **4. Where do you see ML having the biggest impact in the next 5-10 years?**
In the next 5-10 years, ML will have the biggest impact on transforming the healthcare sector.
**Networked hospitals and connected care:**
With predictive care, command centers are all set to analyze clinical and location data to monitor supply and demand across healthcare networks in real-time. With ML, healthcare professionals will be able to spot high-risk patients more quickly and efficiently, thus removing bottlenecks in the system. You can check the spread of contractible diseases faster, take better measures to manage epidemics, identify at-risk patients more accurately, especially for genetic diseases, and more.
**Better staff and patient experiences:**
Predictive healthcare networks are expected to reduce wait times, improve staff workflows, and take on the ever-growing administrative burden. By learning from every patient, diagnosis, and procedure, ML is expected to create experiences that adapt to hospital staff as well as the patient. This improves health outcomes and reduces clinician shortages and burnout while enabling the system to be financially sustainable. | [
[
"transformers",
"mlops",
"community",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"optimization",
"efficient_computing",
"transformers"
] | null | null |
46f692d3-fd52-411a-9ac5-19b2bd0f240f | completed | 2025-01-16T03:08:53.170880 | 2025-01-16T03:14:08.872256 | 669c0a7f-0646-43e3-8311-5046f47c7fc9 | Welcome Falcon Mamba: The first strong attention-free 7B model | JingweiZuo, yellowvm, DhiyaEddine, IChahed, ybelkada, Gkunsch | falconmamba.md | In this blog, we will go through the design decisions behind the model, how the model is competitive with respect to other existing SoTA models, and how to use it within the Hugging Face ecosystem.
## First general purpose large-scale pure Mamba model
Transformers, based on the attention mechanism, are the dominant architecture used in all the strongest large language models today. Yet, the attention mechanism is fundamentally limited in processing large sequences due to the increase in compute and memory costs with sequence length. Various alternative architectures, in particular State Space Language Models (SSLMs), tried to address the sequence scaling limitation but fell back in performance compared to SoTA transformers.
With Falcon Mamba, we demonstrate that sequence scaling limitation can indeed be overcome without loss in performance. Falcon Mamba is based on the original Mamba architecture, proposed in [*Mamba: Linear-Time Sequence Modeling with Selective State Spaces*](https://arxiv.org/abs/2312.00752), with the addition of extra RMS normalization layers to ensure stable training at scale. This choice of architecture ensures that Falcon Mamba:
* can process sequences of arbitrary length without any increase in memory storage, in particular, fitting on a single A10 24GB GPU.
* takes a constant amount of time to generate a new token, regardless of the size of the context (see this [section](#hardware-performance))
## Model training
Falcon Mamba was trained with ~ 5500GT of data, mainly composed of RefinedWeb data with addition of high-quality technical data and code data from public sources. We used constant learning rate for the most of the training, followed by a relatively short learning rate decay stage. In this last stage, we also added a small portion of high-quality curated data to further enhance model performance.
## Evaluations
We evaluate our model on all benchmarks of the new leaderboard's version using the `lm-evaluation-harness` package and then normalize the evaluation results with Hugging Face score normalization.
| `model name` |`IFEval`| `BBH` |`MATH LvL5`| `GPQA`| `MUSR`|`MMLU-PRO`|`Average`|
|: | [
[
"llm",
"research",
"benchmarks",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"research",
"efficient_computing",
"benchmarks"
] | null | null |
8f072f96-4ff8-43ef-9433-0c869dc92b18 | completed | 2025-01-16T03:08:53.170885 | 2025-01-19T17:19:46.874664 | d8fc8ce6-39b2-44e5-b0d1-29024f15cf51 | The Annotated Diffusion Model | nielsr, kashif | annotated-diffusion.md | <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/annotated_diffusion.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
In this blog post, we'll take a deeper look into **Denoising Diffusion Probabilistic Models** (also known as DDPMs, diffusion models, score-based generative models or simply [autoencoders](https://benanne.github.io/2022/01/31/diffusion.html)) as researchers have been able to achieve remarkable results with them for (un)conditional image/audio/video generation. Popular examples (at the time of writing) include [GLIDE](https://arxiv.org/abs/2112.10741) and [DALL-E 2](https://openai.com/dall-e-2/) by OpenAI, [Latent Diffusion](https://github.com/CompVis/latent-diffusion) by the University of Heidelberg and [ImageGen](https://imagen.research.google/) by Google Brain.
We'll go over the original DDPM paper by ([Ho et al., 2020](https://arxiv.org/abs/2006.11239)), implementing it step-by-step in PyTorch, based on Phil Wang's [implementation](https://github.com/lucidrains/denoising-diffusion-pytorch) - which itself is based on the [original TensorFlow implementation](https://github.com/hojonathanho/diffusion). Note that the idea of diffusion for generative modeling was actually already introduced in ([Sohl-Dickstein et al., 2015](https://arxiv.org/abs/1503.03585)). However, it took until ([Song et al., 2019](https://arxiv.org/abs/1907.05600)) (at Stanford University), and then ([Ho et al., 2020](https://arxiv.org/abs/2006.11239)) (at Google Brain) who independently improved the approach.
Note that there are [several perspectives](https://twitter.com/sedielem/status/1530894256168222722?s=20&t=mfv4afx1GcNQU5fZklpACw) on diffusion models. Here, we employ the discrete-time (latent variable model) perspective, but be sure to check out the other perspectives as well.
Alright, let's dive in!
```python
from IPython.display import Image
Image(filename='assets/78_annotated-diffusion/ddpm_paper.png')
```
<p align="center">
<img src="assets/78_annotated-diffusion/ddpm_paper.png" width="500" />
</p>
We'll install and import the required libraries first (assuming you have [PyTorch](https://pytorch.org/) installed).
```python
!pip install -q -U einops datasets matplotlib tqdm
import math
from inspect import isfunction
from functools import partial
%matplotlib inline
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
from einops import rearrange, reduce
from einops.layers.torch import Rearrange
import torch
from torch import nn, einsum
import torch.nn.functional as F
```
## What is a diffusion model?
A (denoising) diffusion model isn't that complex if you compare it to other generative models such as Normalizing Flows, GANs or VAEs: they all convert noise from some simple distribution to a data sample. This is also the case here where **a neural network learns to gradually denoise data** starting from pure noise.
In a bit more detail for images, the set-up consists of 2 processes:
* a fixed (or predefined) forward diffusion process \\(q\\) of our choosing, that gradually adds Gaussian noise to an image, until you end up with pure noise
* a learned reverse denoising diffusion process \\(p_\theta\\), where a neural network is trained to gradually denoise an image starting from pure noise, until you end up with an actual image.
<p align="center">
<img src="assets/78_annotated-diffusion/diffusion_figure.png" width="600" />
</p>
Both the forward and reverse process indexed by \\(t\\) happen for some number of finite time steps \\(T\\) (the DDPM authors use \\(T=1000\\)). You start with \\(t=0\\) where you sample a real image \\(\mathbf{x}_0\\) from your data distribution (let's say an image of a cat from ImageNet), and the forward process samples some noise from a Gaussian distribution at each time step \\(t\\), which is added to the image of the previous time step. Given a sufficiently large \\(T\\) and a well behaved schedule for adding noise at each time step, you end up with what is called an [isotropic Gaussian distribution](https://math.stackexchange.com/questions/1991961/gaussian-distribution-is-isotropic) at \\(t=T\\) via a gradual process.
## In more mathematical form
Let's write this down more formally, as ultimately we need a tractable loss function which our neural network needs to optimize.
Let \\(q(\mathbf{x}_0)\\) be the real data distribution, say of "real images". We can sample from this distribution to get an image, \\(\mathbf{x}_0 \sim q(\mathbf{x}_0)\\). We define the forward diffusion process \\(q(\mathbf{x}_t | \mathbf{x}_{t-1})\\) which adds Gaussian noise at each time step \\(t\\), according to a known variance schedule \\(0 < \beta_1 < \beta_2 < ... < \beta_T < 1\\) as
$$
q(\mathbf{x}_t | \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I}).
$$
Recall that a normal distribution (also called Gaussian distribution) is defined by 2 parameters: a mean \\(\mu\\) and a variance \\(\sigma^2 \geq 0\\). Basically, each new (slightly noisier) image at time step \\(t\\) is drawn from a **conditional Gaussian distribution** with \\(\mathbf{\mu}_t = \sqrt{1 - \beta_t} \mathbf{x}_{t-1}\\) and \\(\sigma^2_t = \beta_t\\), which we can do by sampling \\(\mathbf{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\\) and then setting \\(\mathbf{x}_t = \sqrt{1 - \beta_t} \mathbf{x}_{t-1} + \sqrt{\beta_t} \mathbf{\epsilon}\\).
Note that the \\(\beta_t\\) aren't constant at each time step \\(t\\) (hence the subscript) | [
[
"research",
"implementation",
"tutorial",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"image_generation",
"research",
"implementation",
"tutorial"
] | null | null |
84bf8943-c4c1-4fa0-9a28-8572844704c7 | completed | 2025-01-16T03:08:53.170890 | 2025-01-19T18:58:03.816105 | a362b455-cf17-4c5e-aa35-d6f8efbcc8ef | Accelerating PyTorch Transformers with Intel Sapphire Rapids - part 1 | juliensimon | intel-sapphire-rapids.md | About a year ago, we [showed you](https://huggingface.co./blog/accelerating-pytorch) how to distribute the training of Hugging Face transformers on a cluster or third-generation [Intel Xeon Scalable](https://www.intel.com/content/www/us/en/products/details/processors/xeon/scalable.html) CPUs (aka Ice Lake). Recently, Intel has launched the fourth generation of Xeon CPUs, code-named Sapphire Rapids, with exciting new instructions that speed up operations commonly found in deep learning models.
In this post, you will learn how to accelerate a PyTorch training job with a cluster of Sapphire Rapids servers running on AWS. We will use the [Intel oneAPI Collective Communications Library](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html) (CCL) to distribute the job, and the [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX) library to automatically put the new CPU instructions to work. As both libraries are already integrated with the Hugging Face transformers library, we will be able to run our sample scripts out of the box without changing a line of code.
In a follow-up post, we'll look at inference on Sapphire Rapids CPUs and the performance boost that they bring.
## Why You Should Consider Training On CPUs
Training a deep learning (DL) model on Intel Xeon CPUs can be a cost-effective and scalable approach, especially when using techniques such as distributed training and fine-tuning on small and medium datasets.
Xeon CPUs support advanced features such as Advanced Vector Extensions ([AVX-512](https://en.wikipedia.org/wiki/AVX-512)) and Hyper-Threading, which help improve the parallelism and efficiency of DL models. This enables faster training times as well as better utilization of hardware resources.
In addition, Xeon CPUs are generally more affordable and widely available compared to specialized hardware such as GPUs, which are typically required for training large deep learning models. Xeon CPUs can also be easily repurposed for other production tasks, from web servers to databases, making them a versatile and flexible choice for your IT infrastructure.
Finally, cloud users can further reduce the cost of training on Xeon CPUs with spot instances. Spot instances are built from spare compute capacities and sold at a discounted price. They can provide significant cost savings compared to using on-demand instances, sometimes up to 90%. Last but not least, CPU spot instances also are generally easier to procure than GPU instances.
Now, let's look at the new instructions in the Sapphire Rapids architecture.
## Advanced Matrix Extensions: New Instructions for Deep Learning
The Sapphire Rapids architecture introduces the Intel Advanced Matrix Extensions ([AMX](https://en.wikipedia.org/wiki/Advanced_Matrix_Extensions)) to accelerate DL workloads. Using them is as easy as installing the latest version of IPEX. There is no need to change anything in your Hugging Face code.
The AMX instructions accelerate matrix multiplication, an operation central to training DL models on data batches. They support both Brain Floating Point ([BF16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format)) and 8-bit integer (INT8) values, enabling acceleration for different training scenarios.
AMX introduces new 2-dimensional CPU registers, called tile registers. As these registers need to be saved and restored during context switches, they require kernel support: On Linux, you'll need [v5.16](https://discourse.ubuntu.com/t/kinetic-kudu-release-notes/27976) or newer.
Now, let's see how we can build a cluster of Sapphire Rapids CPUs for distributed training.
## Building a Cluster of Sapphire Rapids CPUs
At the time of writing, the simplest way to get your hands on Sapphire Rapids servers is to use the new Amazon EC2 [R7iz](https://aws.amazon.com/ec2/instance-types/r7iz/) instance family. As it's still in preview, you have to [sign up](https://pages.awscloud.com/R7iz-Preview.html) to get access. In addition, virtual servers don't yet support AMX, so we'll use bare metal instances (`r7iz.metal-16xl`, 64 vCPU, 512GB RAM).
To avoid setting up each node in the cluster manually, we will first set up the master node and create a new Amazon Machine Image ([AMI](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html)) from it. Then, we will use this AMI to launch additional nodes.
From a networking perspective, we will need the following setup:
* Open port 22 for ssh access on all instances for setup and debugging.
* Configure [password-less ssh](https://www.redhat.com/sysadmin/passwordless-ssh) from the master instance (the one you'll launch training from) to all other instances (master included). In other words, the ssh public key of the master node must be authorized on all nodes.
* Allow all network traffic inside the cluster, so that distributed training runs unencumbered. AWS provides a safe and convenient way to do this with [security groups](https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html). We just need to create a security group that allows all traffic from instances configured with that same security group and make sure to attach it to all instances in the cluster. Here's how my setup looks.
<kbd>
<img src="assets/124_intel_sapphire_rapids/01.png">
</kbd>
Let's get to work and build the master node of the cluster.
## Setting Up the Master Node
We first create the master node by launching an `r7iz.metal-16xl` instance with an Ubunutu 20.04 AMI (`ami-07cd3e6c4915b2d18`) and the security group we created earlier. This AMI includes Linux v5.15.0, but Intel and AWS have fortunately patched the kernel to add AMX support. Thus, we don't need to upgrade the kernel to v5.16.
Once the instance is running, we ssh to it and check with `lscpu` that AMX are indeed supported. You should see the following in the flags section:
```
amx_bf16 amx_tile amx_int8
```
Then, we install native and Python dependencies.
```
sudo apt-get update
# Install tcmalloc for extra performance (https://github.com/google/tcmalloc)
sudo apt install libgoogle-perftools-dev -y
# Create a virtual environment
sudo apt-get install python3-pip -y
pip install pip --upgrade
export PATH=/home/ubuntu/.local/bin:$PATH
pip install virtualenv
# Activate the virtual environment
virtualenv cluster_env
source cluster_env/bin/activate
# Install PyTorch, IPEX, CCL and Transformers
pip3 install torch==1.13.0 -f https://download.pytorch.org/whl/cpu
pip3 install intel_extension_for_pytorch==1.13.0 -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install oneccl_bind_pt==1.13 -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install transformers==4.24.0
# Clone the transformers repository for its example scripts
git clone https://github.com/huggingface/transformers.git
cd transformers
git checkout v4.24.0
```
Next, we create a new ssh key pair called 'cluster' with `ssh-keygen` and store it at the default location (`~/.ssh`).
Finally, we create a [new AMI](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/creating-an-ami-ebs.html) from this instance.
## Setting Up the Cluster
Once the AMI is ready, we use it to launch 3 additional `r7iz.16xlarge-metal` instances, without forgetting to attach the security group created earlier.
While these instances are starting, we ssh to the master node to complete the network setup. First, we edit the ssh configuration file at `~/.ssh/config` to enable password-less connections from the master to all other nodes, using their private IP address and the key pair created earlier. Here's what my file looks like.
```
Host 172.31.*.*
StrictHostKeyChecking no
Host node1
HostName 172.31.10.251
User ubuntu
IdentityFile ~/.ssh/cluster
Host node2
HostName 172.31.10.189
User ubuntu
IdentityFile ~/.ssh/cluster
Host node3
HostName 172.31.6.15
User ubuntu
IdentityFile ~/.ssh/cluster
```
At this point, we can use `ssh node[1-3]` to connect to any node without any prompt.
On the master node sill, we create a `~/hosts` file with the names of all nodes in the cluster, as defined in the ssh configuration above. We use `localhost` for the master as we will launch the training script there. Here's what my file looks like.
```
localhost
node1
node2
node3
```
The cluster is now ready. Let's start training!
## Launching a Distributed Training Job
In this example, we will fine-tune a [DistilBERT](https://huggingface.co./distilbert-base-uncased) model for question answering on the [SQUAD](https://huggingface.co./datasets/squad) dataset. Feel free to try other examples if you'd like.
```
source ~/cluster_env/bin/activate
cd ~/transformers/examples/pytorch/question-answering
pip3 install -r requirements.txt
```
As a sanity check, we first launch a local training job. Please note several important flags:
* `no_cuda` makes sure the job is ignoring any GPU on this machine,
* `use_ipex` enables the IPEX library and thus the AVX and AMX instructions,
* `bf16` enables BF16 training.
```
export LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc.so"
python run_qa.py --model_name_or_path distilbert-base-uncased \
--dataset_name squad --do_train --do_eval --per_device_train_batch_size 32 \
--num_train_epochs 1 --output_dir /tmp/debug_squad/ \
--use_ipex --bf16 --no_cuda
```
No need to let the job run to completion, We just run for a minute to make sure that all dependencies have been correctly installed. This also gives us a baseline for single-instance training: 1 epoch takes about **26 minutes**. For reference, we clocked the same job on a comparable Ice Lake instance (`c6i.16xlarge`) with the same software setup at **3 hours and 30 minutes** per epoch. That's an **8x speedup**. We can already see how beneficial the new instructions are!
Now, let's distribute the training job on four instances. An `r7iz.16xlarge` instance has 32 physical CPU cores, which we prefer to work with directly instead of using vCPUs (`KMP_HW_SUBSET=1T`). We decide to allocate 24 cores for training (`OMP_NUM_THREADS`) and 2 for CCL communication (`CCL_WORKER_COUNT`), leaving the last 6 threads to the kernel and other processes. The 24 training threads support 2 Python processes (`NUM_PROCESSES_PER_NODE`). Hence, the total number of Python jobs running on the 4-node cluster is 8 (`NUM_PROCESSES`).
```
# Set up environment variables for CCL
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
export MASTER_ADDR=172.31.3.190
export NUM_PROCESSES=8
export NUM_PROCESSES_PER_NODE=2
export CCL_WORKER_COUNT=2
export CCL_WORKER_AFFINITY=auto
export KMP_HW_SUBSET=1T
```
Now, we launch the distributed training job.
```
# Launch distributed training
mpirun -f ~/hosts \
-n $NUM_PROCESSES -ppn $NUM_PROCESSES_PER_NODE \
-genv OMP_NUM_THREADS=24 \
-genv LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc.so" \
python3 run_qa.py \
--model_name_or_path distilbert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 32 \
--num_train_epochs 1 \
--output_dir /tmp/debug_squad/ \
--overwrite_output_dir \
--no_cuda \
--xpu_backend ccl \
--bf16
```
One epoch now takes **7 minutes and 30 seconds**.
Here's what the job looks like. The master node is at the top, and you can see the two training processes running on each one of the other 3 nodes.
<kbd>
<img src="assets/124_intel_sapphire_rapids/02.png">
</kbd>
Perfect linear scaling on 4 nodes would be 6 minutes and 30 seconds (26 minutes divided by 4). We're very close to this ideal value, which shows how scalable this approach is.
## Conclusion
As you can see, training Hugging Face transformers on a cluster of Intel Xeon CPUs is a flexible, scalable, and cost-effective solution, especially if you're working with small or medium-sized models and datasets.
Here are some additional resources to help you get started:
* [Intel IPEX](https://github.com/intel/intel-extension-for-pytorch) on GitHub
* Hugging Face documentation: "[Efficient training on CPU](https://huggingface.co./docs/transformers/perf_train_cpu)" and "[Efficient training on many CPUs](https://huggingface.co./docs/transformers/perf_train_cpu_many)".
If you have questions or feedback, we'd love to read them on the [Hugging Face forum](https://discuss.huggingface.co/).
Thanks for reading! | [
[
"transformers",
"implementation",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"implementation",
"optimization",
"efficient_computing"
] | null | null |
6f4f1340-9fff-4f3a-b37e-b5a6878efa17 | completed | 2025-01-16T03:08:53.170895 | 2025-01-19T19:03:53.729190 | 0618775d-423d-4009-9eee-b7452e0b13e1 | The Hugging Face Hub for Galleries, Libraries, Archives and Museums | davanstrien | hf-hub-glam-guide.md | ### What is the Hugging Face Hub?
Hugging Face aims to make high-quality machine learning accessible to everyone. This goal is pursued in various ways, including developing open-source code libraries such as the widely-used Transformers library, offering [free courses](https://huggingface.co./learn), and providing the Hugging Face Hub.
The [Hugging Face Hub](https://huggingface.co./) is a central repository where people can share and access machine learning models, datasets and demos. The Hub hosts over 190,000 machine learning models, 33,000 datasets and over 100,000 machine learning applications and demos. These models cover a wide range of tasks from pre-trained language models, text, image and audio classification models, object detection models, and a wide range of generative models.
The models, datasets and demos hosted on the Hub span a wide range of domains and languages, with regular community efforts to expand the scope of what is available via the Hub. This blog post intends to offer people working in or with the galleries, libraries, archives and museums (GLAM) sector to understand how they can use — and contribute to — the Hugging Face Hub.
You can read the whole post or jump to the most relevant sections!
- If you don't know what the Hub is, start with: [What is the Hugging Face Hub?](#what-is-the-hugging-face-hub)
- If you want to know how you can find machine learning models on the Hub, start with: [How can you use the Hugging Face Hub: finding relevant models on the Hub](#how-can-you-use-the-hugging-face-hub-finding-relevant-models-on-the-hub)
- If you want to know how you can share GLAM datasets on the Hub, start with [Walkthrough: Adding a GLAM dataset to the Hub?](#walkthrough-adding-a-glam-dataset-to-the-hub)
- If you want to see some examples, check out: [Example uses of the Hugging Face Hub](#example-uses-of-the-hugging-face-hub)
## What can you find on the Hugging Face Hub?
### Models
The Hugging Face Hub provides access to machine learning models covering various tasks and domains. Many machine learning libraries have integrations with the Hugging Face Hub, allowing you to directly use or share models to the Hub via these libraries.
### Datasets
The Hugging Face hub hosts over 30,000 datasets. These datasets cover a range of domains and modalities, including text, image, audio and multi-modal datasets. These datasets are valuable for training and evaluating machine learning models.
### Spaces
Hugging Face [Spaces](https://huggingface.co./docs/hub/spaces) is a platform that allows you to host machine learning demos and applications. These Spaces range from simple demos allowing you to explore the predictions made by a machine learning model to more involved applications.
Spaces make hosting and making your application accessible for others to use much more straightforward. You can use Spaces to host [Gradio](gradio.app/) and [Streamlit](https://streamlit.io/) applications, or you can use Spaces to [custom docker images](https://huggingface.co./docs/hub/spaces-sdks-docker). Using Gradio and Spaces in combination often means you can have an application created and hosted with access for others to use within minutes. You can use Spaces to host a Docker image if you want complete control over your application. There are also Docker templates that can give you quick access to a hosted version of many popular tools, including the [Argailla](https://argilla.io/) and [Label Studio](https://labelstud.io/) annotations tools.
## How can you use the Hugging Face Hub: finding relevant models on the Hub
There are many potential use cases in the GLAM sector where machine learning models can be helpful. Whilst some institutions may have the resources required to train machine learning models from scratch, you can use the Hub to find openly shared models that either already do what you want or are very close to your goal.
As an example, if you are working with a collection of digitized Norwegian documents with minimal metadata. One way to better understand what's in the collection is to use a Named Entity Recognition (NER) model. This model extracts entities from a text, for example, identifying the locations mentioned in a text. Knowing which entities are contained in a text can be a valuable way of better understanding what a document is about.
We can find NER models on the Hub by filtering models by task. In this case, we choose `token-classification`, which is the task which includes named entity recognition models. [This filter](https://huggingface.co./datasets?task_categories=task_categories:token-classification) returns models labelled as doing `token-classification`. Since we are working with Norwegian documents, we may also want to [filter by language](https://huggingface.co./models?pipeline_tag=token-classification&language=no&sort=downloads); this gets us to a smaller set of models we want to explore. Many of these models will also contain a [model widget](https://huggingface.co./saattrupdan/nbailab-base-ner-scandi), allowing us to test the model.

A model widget can quickly show how well a model will likely perform on our data. Once you've found a model that interests you, the Hub provides different ways of using that tool. If you are already familiar with the Transformers library, you can click the use in Transformers button to get a pop-up which shows how to load the model in Transformers.


If you prefer to use a model via an API, clicking the
`deploy` button in a model repository gives you various options for hosting the model behind an API. This can be particularly useful if you want to try out a model on a larger amount of data but need the infrastructure to run models locally.
A similar approach can also be used to find relevant models and datasets
on the Hugging Face Hub.
## Walkthrough: how can you add a GLAM dataset to the Hub?
We can make datasets available via the Hugging Face hub in various ways. I'll walk through an example of adding a CSV dataset to the Hugging Face hub.
<figure class="image table text-center m-0 w-full">
<video
alt="Uploading a file to the Hugging Face Hub"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/hf-hub-glam-guide/Upload%20dataset%20to%20hub.mp4" type="video/mp4">
</video>
</figure>
*Overview of the process of uploading a dataset to the Hub via the browser interface*
For our example, we'll work on making the [On the Books Training Set
](https://cdr.lib.unc.edu/concern/data_sets/6q182v788?locale=en) available via the Hub. This dataset comprises a CSV file containing data that can be used to train a text classification model. Since the CSV format is one of the [supported formats](https://huggingface.co./docs/datasets/upload_dataset#upload-dataset) for uploading data to the Hugging Face Hub, we can share this dataset directly on the Hub without needing to write any code.
### Create a new dataset repository
The first step to uploading a dataset to the Hub is to create a new dataset repository. This can be done by clicking the `New Dataset` button on the dropdown menu in the top right-hand corner of the Hugging Face hub.

Once you have done this you can choose a name for your new dataset repository. You can also create the dataset under a different owner i.e. an organization, and optionally specify a license.

### Upload files
Once you have created a dataset repository you will need to upload the data files. You can do this by clicking on `Add file` under the `Files` tab on the dataset repository.

You can now select the data you wish to upload to the Hub.

You can upload a single file or multiple files using the upload interface. Once you have uploaded your file, you commit your changes to finalize the upload.

### Adding metadata
It is important to add metadata to your dataset repository to make your dataset more discoverable and helpful for others. This will allow others to find your dataset and understand what it contains.
You can edit metadata using the `Metadata UI` editor. This allows you to specify the license, language, tags etc., for the dataset.

It is also very helpful to outline in more detail what your dataset is, how and why it was constructed, and it's strengths and weaknesses. This can be done in a dataset repository by filling out the `README.md` file. This file will serve as a [dataset card](https://huggingface.co./docs/datasets/dataset_card) for your dataset. A dataset card is a semi-structured form of documentation for machine learning datasets that aims to ensure datasets are sufficiently well documented. When you edit the `README.md` file you will be given the option to import a template dataset card. This template will give you helpful prompts for what is useful to include in a dataset card.
*Tip: Writing a good dataset card can be a lot of work. However, you do not need to do all of this work in one go necessarily, and because people can ask questions or make suggestions for datasets hosted on the Hub the processes of documenting datasets can be a collective activity.*
### Datasets preview
Once we've uploaded our dataset to the Hub, we'll get a preview of the dataset. The dataset preview can be a beneficial way of better understanding the dataset.

### Other ways of sharing datasets
You can use many other approaches for sharing datasets on the Hub. The datasets [documentation](https://huggingface.co./docs/datasets/share) will help you better understand what will likely work best for your particular use case.
## Why might Galleries, Libraries, Archives and Museums want to use the Hugging Face hub?
There are many different reasons why institutions want to contribute to
the Hugging Face Hub:
- **Exposure to a new audience**: the Hub has become a central destination for people working in machine learning, AI and related fields. Sharing on the Hub will help expose your collections and work to this audience. This also opens up the opportunity for further collaboration with this audience.
- **Community:** The Hub has many community-oriented features, allowing users and potential users of your material to ask questions and engage with materials you share via the Hub. Sharing trained models and machine learning datasets also allows people to build on each other's work and lowers the barrier to using machine learning in the sector.
- **Diversity of training data:** One of the barriers to the GLAM using machine learning is the availability of relevant data for training and evaluation of machine learning models. Machine learning models that work well on benchmark datasets may not work as well on GLAM organizations' data. Building a community to share domain-specific datasets will ensure machine learning can be more effectively pursued in the GLAM sector.
- **Climate change:** Training machine learning models produces a carbon footprint. The size of this footprint depends on various factors. One way we can collectively reduce this footprint is to share trained models with the community so that people aren't duplicating the same models (and generating more carbon emissions in the process).
## Example uses of the Hugging Face Hub
Individuals and organizations already use the Hugging Face hub to share machine learning models, datasets and demos related to the GLAM sector.
### [BigLAM](https://huggingface.co./biglam)
An initiative developed out of the [BigScience project](https://bigscience.huggingface.co/) is focused on making datasets from GLAM with relevance to machine learning are made more accessible. BigLAM has so far made over 30 datasets related to GLAM available via the Hugging Face hub.
### [Nasjonalbiblioteket AI Lab](https://huggingface.co./NbAiLab)
The AI lab at the National Library of Norway is a very active user of the Hugging Face hub, with ~120 models, 23 datasets and six machine learning demos shared publicly. These models include language models trained on Norwegian texts from the National Library of Norway and Whisper (speech-to-text) models trained on Sámi languages.
### [Smithsonian Institution](https://huggingface.co./Smithsonian)
The Smithsonian shared an application hosted on Hugging Face Spaces, demonstrating two machine learning models trained to identify Amazon fish species. This project aims to empower communities with tools that will allow more accurate measurement of fish species numbers in the Amazon. Making tools such as this available via a Spaces demo further lowers the barrier for people wanting to use these tools.
<html>
<iframe
src="https://smithsonian-amazonian-fish-classifier.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
</html>
[Source](https://huggingface.co./Smithsonian)
## Hub features for Galleries, Libraries, Archives and Museums
The Hub supports many features which help make machine learning more accessible. Some features which may be particularly helpful for GLAM institutions include:
- **Organizations**: you can create an organization on the Hub. This allows you to create a place to share your organization's artefacts.
- **Minting DOIs**: A [DOI](https://www.doi.org/) (Digital Object Identifier) is a persistent digital identifier for an object. DOIs have become essential for creating persistent identifiers for publications, datasets and software. A persistent identifier is often required by journals, conferences or researcher funders when referencing academic outputs. The Hugging Face Hub supports issuing DOIs for models, datasets, and demos shared on the Hub.
- **Usage tracking**: you can view download stats for datasets and models hosted in the Hub monthly or see the total number of downloads over all time. These stats can be a valuable way for institutions to demonstrate their impact.
- **Script-based dataset sharing**: if you already have dataset hosted somewhere, you can still provide access to them via the Hugging Face hub using a [dataset loading script](https://huggingface.co./docs/datasets/dataset_script).
- **Model and dataset gating**: there are circumstances where you want more control over who is accessing models and datasets. The Hugging Face hub supports model and dataset gating, allowing you to add access controls.
## How can I get help using the Hub?
The Hub [docs](https://huggingface.co./docs/hub/index) go into more detail about the various features of the Hugging Face Hub. You can also find more information about [sharing datasets on the Hub](https://huggingface.co./docs/datasets/upload_dataset) and information about [sharing Transformers models to the Hub](https://huggingface.co./docs/transformers/model_sharing).
If you require any assistance while using the Hugging Face Hub, there are several avenues you can explore. You may seek help by utilizing the [discussion forum](https://discuss.huggingface.co/) or through a [Discord](https://discord.com/invite/hugging-face-879548962464493619). | [
[
"transformers",
"data",
"community",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"data",
"community",
"tools"
] | null | null |
1da2d5e2-66f5-495f-9ecd-f699ea3889f5 | completed | 2025-01-16T03:08:53.170900 | 2025-01-19T19:07:14.499148 | 3396fd13-a13d-4c92-b99b-eca82e094048 | Vision Language Models Explained | merve, edbeeching | vlms.md | Vision language models are models that can learn simultaneously from images and texts to tackle many tasks, from visual question answering to image captioning. In this post, we go through the main building blocks of vision language models: have an overview, grasp how they work, figure out how to find the right model, how to use them for inference and how to easily fine-tune them with the new version of [trl](https://github.com/huggingface/trl) released today!
## What is a Vision Language Model?
Vision language models are broadly defined as multimodal models that can learn from images and text. They are a type of generative models that take image and text inputs, and generate text outputs. Large vision language models have good zero-shot capabilities, generalize well, and can work with many types of images, including documents, web pages, and more. The use cases include chatting about images, image recognition via instructions, visual question answering, document understanding, image captioning, and others. Some vision language models can also capture spatial properties in an image. These models can output bounding boxes or segmentation masks when prompted to detect or segment a particular subject, or they can localize different entities or answer questions about their relative or absolute positions. There’s a lot of diversity within the existing set of large vision language models, the data they were trained on, how they encode images, and, thus, their capabilities.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/vlm/visual.jpg" alt="VLM Capabilities" style="width: 90%; height: auto;"><br>
</p>
## Overview of Open-source Vision Language Models
There are many open vision language models on the Hugging Face Hub. Some of the most prominent ones are shown in the table below.
- There are base models, and models fine-tuned for chat that can be used in conversational mode.
- Some of these models have a feature called “grounding” which reduces model hallucinations.
- All models are trained on English unless stated otherwise.
| Model | Permissive License | Model Size | Image Resolution | Additional Capabilities |
| | [
[
"computer_vision",
"tutorial",
"multi_modal",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"multi_modal",
"computer_vision",
"fine_tuning",
"tutorial"
] | null | null |
0d51904e-52b0-49d5-bbc7-888225ed6529 | completed | 2025-01-16T03:08:53.170905 | 2025-01-16T13:38:24.135102 | 8caf46af-8bcb-4d10-8b1b-1add81f78592 | Machine Learning Experts - Sasha Luccioni | britneymuller | sasha-luccioni-interview.md | ## 🤗 Welcome to Machine Learning Experts - Sasha Luccioni
🚀 _If you're interested in learning how ML Experts, like Sasha, can help accelerate your ML roadmap visit: <a href="https://huggingface.co./support?utm_source=blog&utm_medium=blog&utm_campaign=ml_experts&utm_content=sasha_interview_article">hf.co/support.</a>_
Hey friends! Welcome to Machine Learning Experts. I'm your host, Britney Muller and today’s guest is [Sasha Luccioni](https://twitter.com/SashaMTL). Sasha is a Research Scientist at Hugging Face where she works on the ethical and societal impacts of Machine Learning models and datasets.
Sasha is also a co-chair of the Carbon Footprint WG of the [Big Science Workshop](https://bigscience.huggingface.co), on the Board of [WiML](https://wimlworkshop.org), and a founding member of the [Climate Change AI (CCAI)](https://www.climatechange.ai) organization which catalyzes impactful work applying machine learning to the climate crisis.
You’ll hear Sasha talk about how she measures the carbon footprint of an email, how she helped a local soup kitchen leverage the power of ML, and how meaning and creativity fuel her work.
Very excited to introduce this brilliant episode to you! Here’s my conversation with Sasha Luccioni:
<iframe width="100%" style="aspect-ratio: 16 / 9;"src="https://www.youtube.com/embed/AQRkcMr0Zk0" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
*Note: Transcription has been slightly modified/reformatted to deliver the highest-quality reading experience.*
### Thank you so much for joining us today, we are so excited to have you on!
**Sasha:** I'm really excited to be here.
### Diving right in, can you speak to your background and what led you to Hugging Face?
**Sasha:** Yeah, I mean if we go all the way back, I started studying linguistics. I was super into languages and both of my parents were mathematicians. But I thought, I don't want to do math, I want to do language. I started doing NLP, natural language processing, during my undergrad and got super into it.
My Ph.D. was in computer science, but I maintained a linguistic angle. I started out in humanities and then got into computer science. Then after my Ph.D., I spent a couple of years working in applied AI research. My last job was in finance, and then one day I decided that I wanted to do good and socially positive AI research, so I quit my job. I decided that no amount of money was worth working on AI for AI's sake, I wanted to do more. So I spent a couple of years working with Yoshua Bengio, meanwhile working on AI for good projects, AI for climate change projects, and then I was looking for my next role.
I wanted to be in a place that I trusted was doing the right things and going in the right direction. When I met Thom and Clem, I knew that Hugging Face was a place for me and that it would be exactly what I was looking for.
### Love that you wanted to something that felt meaningful!
**Sasha:** Yeah, when I hear people on Sunday evening being like “Monday's tomorrow…” I'm like “Tomorrow's Monday! That's great!” And it's not that I'm a workaholic, I definitely do other stuff, and have a family and everything, but I'm literally excited to go to work to do really cool stuff. Think that's important. I know people can live without it, but I can't.
### What are you most excited about that you're working on now?
**Sasha:** I think the [Big Science](https://bigscience.huggingface.co/) project is definitely super inspiring. For the last couple of years, I've been seeing these large language models, and I was always like, but how do they work? And where's the code, where's their data, and what's going on in there? How are they developed and who was involved? It was all like a black box thing, and I'm so happy that we're finally making it a glass box. And there are so many people involved and so many really interesting perspectives.
And I'm chairing the carbon footprint working group, so we're working on different aspects of environmental impacts and above and beyond just counting CO2 emissions, but other things like the manufacturing costs. At some point, we even consider how much CO2 an email generates, things like that, so we're definitely thinking of different perspectives.
Also about the data, I'm involved in a lot of the data working groups at Big Science, and it's really interesting because typically it’s been like we're gonna get the most data we can, stuff it in a language model and it's gonna be great. And it's gonna learn all this stuff, but what's actually in there, there's so much weird stuff on the internet, and things that you don't necessarily want your model to be seeing. So we're really looking into mindfulness, data curation, and multilingualism as well to make sure that it's not just a hundred percent English or 99% English. So it's such a great initiative, and it makes me excited to be involved.
### Love the idea of evaluating the carbon footprint of an email!?
**Sasha:** Yeah, people did it, depending on the attachment or not, but it was just because we found this article of, I think it was a theoretical physics project and they did that, they did everything. They did video calls, travel commutes, emails, and the actual experiments as well. And they made this pie chart and it was cool because there were 37 categories in the pie chart, and we really wanted to do that. But I don't know if we want to go into that level of detail, but we were going to do a survey and ask participants on average, how many hours did they spend working on Big Science or training in language models and things like that. So we didn’t want just the number of GPU hours for training the model, but also people's implication and participation in the project.
### Can you speak a little bit more about the environmental impact of AI?
**Sasha:** Yeah, it's a topic I got involved in three years ago now. The first article that came out was by [Emma Strubell and her colleagues](https://arxiv.org/pdf/1906.02243.pdf) and they essentially trained a large language model with hyperparameter tuning. So essentially looking at all the different configurations and then the figure they got was like that AI model emitted as much carbon as five cars in their lifetimes. Which includes gas and everything, like the average kind of consumption. And with my colleagues we were like, well that doesn't sound right, it can't be all models, right? And so we really went off the deep end into figuring out what has an impact on emissions, and how we can measure emissions.
So first we just [created this online calculator](https://mlco2.github.io/impact/) where someone could enter what hardware they use, how long they trained for, and where on their location or a cloud computing instance. And then it would give them an estimate of the carbon involved that they admitted. Essentially that was our first attempt, a calculator, and then we helped create a package called code carbon which actually does that in real-time. So it's gonna run in parallel to whatever you're doing training a model and then at the end spit out an estimate of the carbon emissions.
Lately we've been going further and further. I just had an article that I was a co-author on that got accepted, about how to proactively reduce emissions. For example, by anticipating times when servers are not as used as other times, like doing either time delaying or picking the right region because if you train in, I don't know, Australia, it's gonna be a coal-based grid, and so it's gonna be highly polluting. Whereas in Quebec or Montreal where I'm based, it's a hundred percent hydroelectricity. So just by making that choice, you can reduce your emissions by around a hundredfold. And so just small things like that, like above and beyond estimating, we also want people to start reducing their emissions. It's the next step.
### It’s never crossed my mind that geographically where you compute has a different emissions cost.
**Sasha:** Oh yeah, and I'm so into energy grids now. Every time I go somewhere I'm like, so what's the energy coming from? How are you generating it? And so it's really interesting, there are a lot of historical factors and a lot of cultural factors.
For example; France is mostly nuclear, mostly energy, and Canada has a lot of hydroelectric energy. Some places have a lot of wind or tidal, and so it's really interesting just to understand when you turn on a lamp, where that electricity is coming from and at what cost to the environment. Because when I was growing up, I would always turn off the lights, and unplug whatever but not anything more than that. It was just good best practices. You turn off the light when you're not in a room, but after that, you can really go deeper depending on where you live, your energy's coming from different sources. And there is more or less pollution, but we just don't see that we don't see how energy is produced, we just see the light and we're like oh, this is my lamp. So it's really important to start thinking about that.
### It's so easy not to think about that stuff, which I could see being a barrier for machine learning engineers who might not have that general awareness.
**Sasha:** Yeah, exactly. And I mean usually, it's just by habit, right? I think there's a default option when you're using cloud instances, often it's like the closest one to you or the one with the most GPUs available or whatever. There's a default option, and people are like okay, fine, whatever and click the default. It's this nudge theory aspect.
I did a master's in cognitive science and just by changing the default option, you can change people's behavior to an incredible degree. So whether you put apples or chocolate bars near the cash register, or small stuff like that. And so if the default option, all of a sudden was the low carbon one, we could save so many emissions just because people are just like okay, fine, I'm gonna train a model in Montreal, I don't care. It doesn't matter, as long as you have access to the hardware you need, you don't care where it is. But in the long run, it really adds up.
### What are some of the ways that machine learning teams and engineers could be a bit more proactive in aspects like that?
**Sasha:** So I've noticed that a lot of people are really environmentally conscious. Like they'll bike to work or they'll eat less meat and things like that. They'll have this kind of environmental awareness, but then disassociate it from their work because we're not aware of our impact as machine learning researchers or engineers on the environment. And without sharing it necessarily, just starting to measure, for example, carbon emissions. And starting to look at what instances you're picking, if you have a choice. For example, I know that Google Cloud and AWS have started putting low carbon as a little tag so you can pick it because the information is there. And starting to make these little steps, and connecting the dots between environment and tech. These are dots that are not often connected because tech is so like the cloud, it's nice to be distributed, and you don't really see it. And so by grounding it more, you see the impact it can have on the environment.
### That's a great point. And I've listened to a couple talks and podcasts of yours, where you've mentioned how machine learning can be used to help offset the environmental impact of models.
**Sasha:** Yeah, we wrote a paper a couple of years ago that was a cool experience. It's almost a hundred pages, it's called [Tackling Climate Change with Machine Learning](https://dl.acm.org/doi/10.1145/3485128). And there are like 25 authors, but there are all these different sections ranging from electricity to city planning to transportation to forestry and agriculture. We essentially have these chapters of the paper where we talk about the problems that exist. For example, renewable energy is variable in a lot of cases. So if you have solar panels, they won't produce energy at night. That's kind of like a given. And then wind power is dependent on the wind. And so a big challenge in implementing renewable energy is that you have to respond to the demand. You need to be able to give people power at night, even if you're on solar energy. And so typically you have either diesel generators or this backup system that often cancels out the environmental effect, like the emissions that you're saving, but what machine learning can do, you're essentially predicting how much energy will be needed. So based on previous days, based on the temperature, based on events that happen, you can start being like okay, well we're gonna be predicting half an hour out or an hour out or 6 hours or 24 hours. And you can start having different horizons and doing time series prediction.
Then instead of powering up a diesel generator which is cool because you can just power them up, and in a couple of seconds they're up and running. What you can also do is have batteries, but batteries you need to start charging them ahead of time. So say you're six hours out, you start charging your batteries, knowing that either there's a cloud coming or that night's gonna fall, so you need that energy stored ahead. And so there are things that you could do that are proactive that can make a huge difference. And then machine learning is good at that, it’s good at predicting the future, it’s good at finding the right features, and things like that. So that's one of the go-to examples. Another one is remote sensing. So we have a lot of satellite data about the planet and see either deforestation or tracking wildfires. In a lot of cases, you can detect wildfires automatically based on satellite imagery and deploy people right away. Because they're often in remote places that you don't necessarily have people living in. And so there are all these different cases in which machine learning could be super useful. We have the data, we have the need, and so this paper is all about how to get involved and whatever you're good at, whatever you like doing, and how to apply machine learning and use it in the fight against climate change.
### For people listening that are interested in this effort, but perhaps work at an organization where it's not prioritized, what tips do you have to help incentivize teams to prioritize environmental impact?
**Sasha:** So it's always a question of cost and benefit or time, you know, the time that you need to put in. And sometimes people just don't know that there are different tools that exist or approaches. And so if people are interested or even curious to learn about it. I think that's the first up because even when I first started thinking of what I can do, I didn't know that all these things existed. People have been working on this for like a fairly long time using different data science techniques.
For example, we created a website called [climatechange.ai](http://climatechange.ai), and we have interactive summaries that you can read about how climate change can help and detect methane or whatever. And I think that just by sprinkling this knowledge can help trigger some interesting thought processes or discussions. I've participated in several round tables at companies that are not traditionally climate change-oriented but are starting to think about it. And they're like okay well we put a composting bin in the kitchen, or we did this and we did that. So then from the tech side, what can we do? It's really interesting because there are a lot of low-hanging fruits that you just need to learn about. And then it's like oh well, I can do that, I can by default use this cloud computing instance and that's not gonna cost me anything. And you need to change a parameter somewhere.
### What are some of the more common mistakes you see machine learning engineers or teams make when it comes to implementing these improvements?
**Sasha:** Actually, machine learning people or AI people, in general, have this stereotype from other communities that we think AI's gonna solve everything. We just arrived and we're like oh, we're gonna do AI. And it's gonna solve all your problems no matter what you guys have been doing for 50 years, AI's gonna do it. And I haven't seen that attitude that much, but we know what AI can do, we know what machine learning can do, and we have a certain kind of worldview. It's like when you have a hammer, everything's a nail, so it’s kind of something like that. And I participated in a couple of hackathons and just like in general, people want to make stuff or do stuff to fight climate change. It's often like oh, this sounds like a great thing AI can do, and we're gonna do it without thinking of how it's gonna be used or how it's gonna be useful or how it's gonna be. Because it's like yeah, sure, AI can do all this stuff, but then at the end of the day, someone's gonna use it.
For example, if you create something for scanning satellite imagery and detecting wildfire, the information that your model outputs has to be interpretable. Or you need to add that little extra step of sending a new email or whatever it is. Otherwise, we train a model, it's great, it's super accurate, but then at the end of the day, nobody's gonna use it just because it's missing a tiny little connection to the real world or the way that people will use it. And that's not sexy, people are like yeah, whatever, I don't even know how to write a script that sends an email. I don't either. But still, just doing that little extra step, that's so much less technologically complex than what you've done so far. Just adding that little thing will make a big difference and it can be in terms of UI, or it can be in terms of creating an app. It's like the machine learning stuff that's actually crucial for your project to be used.
And I've participated in organizing workshops where people submit ideas that are super great on paper that have great accuracy rates, but then they just stagnate in paper form or article form because you still need to have that next step. I remember this one presentation of a machine learning algorithm that could reduce flight emissions of airplanes by 3 to 7% by calculating the wind speed, etc. Of course, that person should have done a startup or a product or pitched this to Boeing or whatever, otherwise it was just a paper that they published in this workshop that I was organizing, and then that was it. And scientists or engineers don't necessarily have those skills necessary to go see an airplane manufacturer with this thing, but it's frustrating. And at the end of the day, to see these great ideas, this great tech that just fizzles.
### So sad. That's such a great story though and how there are opportunities like that.
**Sasha:** Yeah, and I think scientists, so often, don't necessarily want to make money, they just want to solve problems often. And so you don't necessarily even need to start a startup, you could just talk to someone or pitch this to someone, but you have to get out of your comfort zone. And the academic conferences you go to, you need to go to a networking event in the aviation industry and that's scary, right? And so there are often these barriers between disciplines that I find very sad. I actually like going to a business or random industry networking event because this is where connections can get made, that can make the biggest changes. It's not in the industry-specific conferences because everyone's talking about the same technical style that of course, they're making progress and making innovations. But then if you're the only machine learning expert in a room full of aviation experts, you can do so much. You can spark all these little sparks, and after you're gonna have people reducing emissions of flights.
### That's powerful. Wondering if you could add some more context as to why finding meaning in your work is so important?
**Sasha:** Yeah, there's this concept that my mom read about in some magazine ages ago when I was a kid. It's called [Ikigai](https://en.wikipedia.org/wiki/Ikigai), and it's a Japanese concept, it's like how to find the reason or the meaning of life. It's kind of how to find your place in the universe. And it was like you need to find something that has these four elements. Like what you love doing, what you're good at, what the world needs and then what can be a career. I was always like this is my career, but she was always like no because even if you love doing this, but you can't get paid for it, then it's a hard life as well. And so she always asked me this when I was picking my courses at university or even my degree, she'll always be like okay, well is that aligned with things you love and things you're good at? And some things she'd be like yeah, but you're not good at that though. I mean you could really want to do this, but maybe this is not what you're good at.
So I think that it's always been my driving factor in my career. And I feel that it helps feel that you're useful and you're like a positive force in the world. For example, when I was working at Morgan Stanley, I felt that there were interesting problems like I was doing really well, no questions asked, the salary was amazing. No complaints there, but there was missing this what the world needs aspect that was kind of like this itch I couldn’t scratch essentially. But given this framing, this itchy guy, I was like oh, that's what's missing in my life. And so I think that people in general, not only in machine learning, it's good to think about not only what you're good at, but also what you love doing, what motivates you, why you would get out of bed in the morning and of course having this aspect of what the world needs. And it doesn't have to be like solving world hunger, it can be on a much smaller scale or on a much more conceptual scale.
For example, what I feel like we're doing at Hugging Face is really that machine learning needs more open source code, more model sharing, but not because it's gonna solve any one particular problem, because it can contribute to a spectrum of problems. Anything from reproducibility to compatibility to product, but there's like the world needs this to some extent. And so I think that really helped me converge on Hugging Face as being maybe the world doesn't necessarily need better social networks because a lot of people doing AI research in the context of social media or these big tech companies. Maybe the world doesn't necessarily need that, maybe not right now, maybe what the world needs is something different. And so this kind of four-part framing really helped me find meaning in my career and my life in general, trying to find all these four elements.
### What other examples or applications do you find and see potential meaning in AI machine learning?
**Sasha:** I think that an often overlooked aspect is accessibility and I guess democratization, but like making AI easier for non-specialists. Because can you imagine if I don't know anyone like a journalist or a doctor or any profession you can think of could easily train or use an AI model. Because I feel like yeah, for sure we do AI in medicine and healthcare, but it's from a very AI machine learning angle. But if we had more doctors who were empowered to create more tools or any profession like a baker… I actually have a friend who has a bakery here in Montreal and he was like yeah, well can AI help me make better bread? And I was like probably, yeah. I'm sure that if you do some kind of experimentation and he's like oh, I can install a camera in my oven. And I was like oh yeah, you could do that I guess. I mean we were talking about it and you know, actually, bread is pretty fickle, you need the right humidity, and it actually takes a lot of experimentation and a lot of know-how from ‘boulangers’ [‘bakers’]. And the same thing for croissants, his croissants are so good and he's like yeah, well you need to really know the right butter, etc. And he was like I want to make an AI model that will help bake bread. And I was like I don't even know how to help you start, like where do you start doing that?
So accessibility is such an important part. For example, the internet has become so accessible nowadays. Anyone can navigate, and initially, it was a lot less so I think that AI still has some road to travel in order to become a more accessible and democratic tool.
### And you've talked before about the power of data and how it's not talked about enough.
**Sasha:** Yeah, four or five years ago, I went to Costa Rica with my husband on a trip. We were just looking on a map and then I found this research center that was at the edge of the world. It was like being in the middle of nowhere. We had to take a car on a dirt road, then a first boat then a second boat to get there. And they're in the middle of the jungle and they essentially study the jungle and they have all these camera traps that are automatically activated, that are all over the jungle. And then every couple of days they have to hike from camera to camera to switch out the SD cards. And then they take these SD cards back to the station and then they have a laptop and they have to go through every picture it took. And of course, there are a lot of false positives because of wind or whatever, like an animal moving really fast, so there's literally maybe like 5% of actual good images. And I was like why aren't they using it to track biodiversity? And they'd no, we saw a Jaguar on blah, blah, blah at this location because they have a bunch of them.
Then they would try to track if a Jaguar or another animal got killed, if it had babies, or if it looked injured; like all of these different things. And then I was like, I'm sure a part of that could be automated, at least the filtering process of taking out the images that are essentially not useful, but they had graduate students or whatever doing it. But still, there are so many examples like this domain in all areas. And just having these little tools, I'm not saying that because I think we're not there yet, completely replacing scientists in this kind of task, but just small components that are annoying and time-consuming, then machine learning can help bridge that gap.
### Wow. That is so interesting!
**Sasha:** It's actually really, camera trap data is a really huge part of tracking biodiversity. It's used for birds and other animals. It's used in a lot of cases and actually, there's been Kaggle competitions for the last couple of years around camera trap data. And essentially during the year, they have camera traps in different places like Kenya has a bunch and Tanzania as well. And then at the end of the year, they have this big Kaggle competition of recognizing different species of animals. Then after that they deployed the models, and then they update them every year.
So it's picking up, but there's just a lot of data, as you said. So each ecosystem is unique and so you need a model that's gonna be trained on exactly. You can't take a model from Kenya and make it work in Costa Rica, that's not gonna work. You need data, you need experts to train the model, and so there are a lot of elements that need to converge in order for you to be able to do this. Kind of like AutoTrain, Hugging Face has one, but even simpler where biodiversity researchers in Costa Rica could be like these are my images, help me figure out which ones are good quality and the types of animals that are on them. And they could just drag and drop the images like a web UI or something. And then they had this model that's like, here are the 12 images of Jaguars, this one is injured, this one has a baby, etc.
### Do you have insights for teams that are trying to solve for things like this with machine learning, but just lack the necessary data?
**Sasha:** Yeah, I guess another anecdote, I have a lot of these anecdotes, but at some point we wanted to organize an AI for social good hackathon here in Montreal like three or three or four years ago. And then we were gonna contact all these NGOs, like soup kitchens, homeless shelters in Montreal. And we started going to these places and then we're like okay, where's your data? And they're like, “What data?” I'm like, “Well don't you keep track of how many people you have in your homeless shelter or if they come back,” and they're like “No.” And then they're like, “But on the other hand, we have these problems of either people disappearing and we don't know where they are or people staying for a long time. And then at a certain point we're supposed to not let them stand.” They had a lot of issues, for example, in the food kitchen, they had a lot of wasted food because they had trouble predicting how many people would arrive. And sometimes they're like yeah, we noticed that in October, usually there are fewer people, but we don't really have any data to support that.
So we completely canceled the hackathon, then instead we did, I think we call them data literacy or digital literacy workshops. So essentially we went to these places if they were interested and we gave one or two-hour workshops about how to use a spreadsheet and figure out what they wanted to track. Because sometimes they didn't even know what kind of things they wanted to save or wanted to really have a trace of. So we did a couple of them in some places like we would come back every couple of months and check in. And then a year later we had a couple, especially a food kitchen, we actually managed to make a connection between them, and I don't remember what the company name was anymore, but they essentially did this supply chain management software thing. And so the kitchen was actually able to implement a system where they would track like we got 10 pounds of tomatoes, this many people showed up today, and this is the waste of food we have. Then a year later we were able to do a hackathon to help them reduce food waste.
So that was really cool because we really saw a year and some before they had no trace of anything, they just had intuitions, which were useful, but weren't formal. And then a year later we were able to get data and integrate it into their app, and then they would have a thing saying be careful, your tomatoes are gonna go bad soon because it's been three days since you had them. Or in cases where it's like pasta, it would be six months or a year, and so we implemented a system that would actually give alerts to them. And it was super simple in terms of technology, there was not even much AI in there, but just something that would help them keep track of different categories of food. And so it was a really interesting experience because I realized that yeah, you can come in and be like we're gonna help you do whatever, but if you don't have much data, what are you gonna do?
### Exactly, that's so interesting. That's so amazing that you were able to jump in there and provide that first step; the educational piece of that puzzle to get them set up on something like that.
**Sasha:** Yeah, it's been a while since I organized any hackathons. But I think these community involvement events are really important because they help people learn stuff like we learn that you can't just like barge in and use AI, digital literacy is so much more important and they just never really put the effort into collecting the data, even if they needed it. Or they didn't know what could be done and things like that. So taking this effort or five steps back and helping improve tech skills, generally speaking, is a really useful contribution that people don't really realize is an option, I guess.
### What industries are you most excited to see machine learning be applied to?
**Sasha:** Climate change! Yeah, the environment is kind of my number one. Education has always been something that I've really been interested in and I've kind of always been waiting. I did my Ph.D. in education and AI, like how AI can be used in education. I keep waiting for it to finally hit a certain peak, but I guess there are a lot of contextual elements and stuff like that, but I think AI, machine learning, and education can be used in so many different ways.
For example, what I was working on during my Ph.D. was how to help pick activities, like learning activities and exercises that are best suited for learners. Instead of giving all kids or adults or whatever the same exercise to help them focus on their weak knowledge points, weak skills, and focusing on those. So instead of like a one size fits all approach. And not replacing the teacher, but tutoring more, like okay, you learn a concept in school, and help you work on it. And you have someone figure this one out really fast and they don't need those exercises, but someone else could need more time to practice. And I think that there is so much that can be done, but I still don't see it really being used, but I think it's potentially really impactful.
### All right, so we're going to dive into rapid-fire questions. If you could go back and do one thing differently at the start of your machine learning career, what would it be?
**Sasha:** I would spend more time focusing on math. So as I said, my parents are mathematicians and they would always give me extra math exercises. And they would always be like math is universal, math, math, math. So when you get force-fed things in your childhood, you don't necessarily appreciate them later, and so I was like no, languages. And so for a good part of my university studies, I was like no math, only humanities. And so I feel like if I had been a bit more open from the beginning and realized the potential of math, even in linguistics or a lot of things, I think I would've come to where I'm at much faster than spending three years being like no math, no math.
I remember in grade 12, my final year of high school, my parents made me sign up for a math competition, like an Olympiad and I won it. Then I remember I had a medal and I put it on my mom and I'm like “Now leave me alone, I'm not gonna do any more math in my life.” And she was like “Yeah, yeah.” And then after that, when I was picking my Ph.D. program, she's like “Oh I see there are math classes, eh? because you're doing machine learning, eh?”, and I was like “No,” but yeah, I should have gotten over my initial distaste for math a lot quicker.
### That's so funny, and it’s interesting to hear that because I often hear people say you need to know less and less math, the more advanced some of these ML libraries and programs get.
**Sasha:** Definitely, but I think having a good base, I'm not saying you have to be a super genius, but having this intuition. Like when I was working with Yoshua for example, he's a total math genius and just the facility of interpreting results or understanding behaviors of a machine learning model just because math is so second nature. Whereas for me I have to be like, okay, so I'm gonna write this equation with the loss function. I'm gonna try to understand the consequences, etc., and it's a bit less automatic, but it's a skill that you can develop. It's not necessarily theoretical, it could also be experimental knowledge. But just having this really solid math background helps you get there quicker, you couldn't really skip a few steps.
### That was brilliant. And you can ask your parents for help?
**Sasha:** No, I refuse to ask my parents for help, no way. Plus since they're like theoretical mathematicians, they think machine learning is just for people who aren't good at math and who are lazy or whatever. And so depending on whatever area you're in, there's pure mathematicians, theoretical mathematics, applied mathematicians, there's like statisticians, and there are all these different camps.
And so I remember my little brother also was thinking of going to machine learning, and my dad was like no, stay in theoretical math, that's where all the geniuses are. He was like “No, machine learning is where math goes to die,” and I was like “Dad, I’m here!” And he was like “Well I'd rather your brother stayed in something more refined,” and I was like “That's not fair.”
So yeah, there are a lot of empirical aspects in machine learning, and a lot of trial and error, like you're tuning hyperparameters and you don't really know why. And so I think formal mathematicians, unless there's like a formula, they don't think ML is real or legit.
### So besides maybe a mathematical foundation, what advice would you give to someone looking to get into machine learning?
**Sasha:** I think getting your hands dirty and starting out with I don't know, Jupyter Notebooks or coding exercises, things like that. Especially if you do have specific angles or problems you want to get into or just ideas in general, and so starting to try. I remember I did a summer school in machine learning when I was at the beginning of my Ph.D., I think. And then it was really interesting, but then all these examples were so disconnected. I don't remember what the data was, like cats versus dogs, I don't know, but like, why am I gonna use that? And then they're like part of the exercise was to find something that you want to use, like a classifier essentially to do.
Then I remember I got pictures of flowers or something, and I got super into it. I was like yeah, see, it confuses this flower and that flower because they're kind of similar. I understand I need more images, and I got super into it and that's when it clicked in my head, it's not only this super abstract classification. Or like oh yeah, I remember we were using this data app called [MNIST](https://huggingface.co./datasets/mnist) which is super popular because it's like handwritten digits and they're really small, and the network goes fast. So people use it a lot in the beginning of machine learning courses. And I was like who cares, I don't want to classify digits, like whatever, right? And then when they let us pick our own images, all of a sudden it gets a lot more personal, interesting, and captivating. So I think that if people are stuck in a rut, they can really focus on things that interest them. For example, get some climate change data and start playing around with it and it really makes the process more pleasant.
### I love that, find something that you're interested in.
**Sasha:** Exactly. And one of my favorite projects I worked on was classifying butterflies. We trained neural networks to classify butterflies based on pictures people took and it was so much fun. You learn so much, and then you're also solving a problem that you understand how it's gonna be used, and so it was such a great thing to be involved in. And I wish that everyone had found this kind of interest in the work they do because you really feel like you're making a difference, and it's cool, it's fun and it's interesting, and you want to do more. For example, this project was done in partnership with the Montreal insectarium, which is a museum for insects. And I kept in touch with a lot of these people and then they just renovated the insectarium and they're opening it after like three years of renovation this weekend.
They also invited me and my family to the opening, and I'm so excited to go there. You could actually handle insects, they’re going to have stick bugs, and they're gonna have a big greenhouse where there are butterflies everywhere. And in that greenhouse, I mean you have to install the app, but you can take pictures of butterflies, then it uses our AI network to identify them. And I'm so excited to go there to use the app and to see my kids using it and to see this whole thing. Because of the old version, they would give you this little pamphlet with pictures of butterflies and you have to go find them. I just can't wait to see the difference between that static representation and this actual app that you could use to take pictures of butterflies.
### Oh my gosh. And how cool to see something that you created being used like that.
**Sasha:** Exactly. And even if it's not like fighting climate change, I think it can make a big difference in helping people appreciate nature and biodiversity and taking things from something that's so abstract and two-dimensional to something that you can really get involved in and take pictures of. I think that makes a huge difference in terms of our perception and our connection. It helps you make a connection between yourself and nature, for example.
### So should people be afraid of AI taking over the world?
**Sasha:** I think that we're really far from it. I guess it depends on what you mean by taking over the world, but I think that we should be a lot more mindful of what's going on right now. Instead of thinking to the future and being like oh terminator, whatever, and to kind of be aware of how AI's being used in our phones and our lives, and to be more cognizant of that.
Technology or events in general, we have more influence on them than we think by using Alexa, for example, we're giving agency, we're giving not only material or funds to this technology. And we can also participate in it, for example, oh well I'm gonna opt out of my data being used for whatever if I am using this technology. Or I'm gonna read the fine print and figure out what it is that AI is doing in this case, and being more involved in general.
So I think that people are really seeing AI as a very distant potential mega threat, but it's actually a current threat, but on a different scale. It's like a different perception. It's like instead of thinking of this AGI or whatever, start thinking about the small things in our lives that AI is being used for, and then engage with them. And then there's gonna be less chance that AGI is gonna take over the world if you make the more mindful choices about data sharing, about consent, about using technology in certain ways. Like if you find out that your police force in your city is using facial recognition technology, you can speak up about that. That's part of your rights as a citizen in many places. And so it's by engaging yourself, you can have an influence on the future by engaging in the present.
### What are you interested in right now? It could be anything, a movie, a recipe, a podcast, etc.?
**Sasha:** So during the pandemic, or the lockdowns and stuff like that, I got super into plants. I bought so many plants and now we're preparing a garden with my children. So this is the first time I've done this, we've planted seeds like tomatoes, peppers, and cucumbers. I usually just buy them at the groceries when they're already ready, but this time around I was like, no, I want to teach my kids. But I also want to learn what the whole process is. And so we planted them maybe 10 days ago and they're starting to grow. And we're watering them every day, and I think that this is also part of this process of learning more about nature and the conditions that can help plants thrive and stuff like that. So last summer already, we built not just a square essentially that we fill in with dirt, but this year we're trying to make it better. I want to have several levels and stuff like that, so I'm really looking forward to learning more about growing your own food.
### That is so cool. I feel like that's such a grounding activity.
**Sasha:** Yeah, and it's like the polar opposite of what I do. It's great not doing something on my computer, but just going outside and having dirty fingernails. I remember being like who would want to do gardening, it’s so boring, now I'm super into gardening. I can't wait for the weekend to go gardening.
### Yeah, that's great. There's something so rewarding about creating something that you can see touch, feel, and smell as opposed to pushing pixels.
**Sasha:** Exactly, sometimes you spend a whole day grappling with this program that has bugs in it and it's not working. You're so frustrating, and then you go outside and you're like, but I have cherry tomatoes, it's all good.
### What are some of your favorite machine learning papers?
**Sasha:** My favorite currently, papers by a researcher or by [Abeba Birhane](https://twitter.com/Abebab) who's a researcher in AI ethics. It's like a completely different way of looking at things. So for example, she wrote [a paper](https://arxiv.org/abs/2106.15590) that just got accepted to [FAcct](https://facctconference.org/), which is fairness in ethics conference in AI. Which was about values and how the way we do machine learning research is actually driven by the things that we value and the things that, for example, if I value a network that has high accuracy, for example, performance, I might be less willing to focus on efficiency. So for example, I'll train a model for a long time, just because I want it to be really accurate. Or like if I want to have something new, like this novelty value, I'm not gonna read the literature and see what people have been doing for whatever 10 years, I'm gonna be like I'm gonna reinvent this.
So she and her co-authors write this really interesting paper about the connection between values that are theoretical, like a kind of metaphysical, and the way that they're instantiated in machine learning. And I found that it was really interesting because typically we don't see it that way. Typically it's like oh, well we have to establish state-of-the-art, we have to establish accuracy and do this and that, and then like site-related work, but it's like a checkbox, you just have to do it. And then they think a lot more in-depth about why we're doing this, and then what are some ultra ways of doing things. For example, doing a trade off between efficiency and accuracy, like if you have a model that's slightly less accurate, but that's a lot more efficient and trains faster, that could be a good way of democratizing AI because people need less computational resources to train a model. And so there are all these different connections that they make that I find it really cool.
### Wow, we'll definitely be linking to that paper as well, so people can check that out. Yeah, very cool. Anything else you'd like to share? Maybe things you're working on or that you would like people to know about?
**Sasha:** Yeah, something I'm working on outside of Big Science is on evaluation and how we evaluate models. Well kind of to what Ababa talks about in her paper, but even from just a pure machine learning perspective, what are the different ways that we can evaluate models and compare them on different aspects, I guess. Not only accuracy but efficiency and carbon emissions and things like that. So there's a project that started a month or ago on how to evaluate in a way that's not only performance-driven, but takes into account different aspects essentially. And I think that this has been a really overlooked aspect of machine learning, like people typically just once again and just check off like oh, you have to evaluate this and that and that, and then submit the paper. There are also these interesting trade-offs that we could be doing and things that we could be measuring that we're not.
For example, if you have a data set and you have an average accuracy, is the accuracy the same again in different subsets of the data set, like are there for example, patterns that you can pick up on that will help you improve your model, but also make it fairer? I guess the typical example is like image recognition, does it do the same in different… Well the famous [Gender Shades](http://gendershades.org/) paper about the algorithm did better on white men than African American women, but you could do that about anything. Not only gender and race, but you could do that for images, color or types of objects or angles. Like is it good for images from above or images from street level. There are all these different ways of analyzing accuracy or performance that we haven't really looked at because it's typically more time-consuming. And so we want to make tools to help people delve deeper into the results and understand their models better.
### Where can people find you online?
**Sasha:** I'm on [Twitter @SashaMTL](https://twitter.com/SashaMTL), and that's about it. I have a [website](https://www.sashaluccioni.com/), I don't update it enough, but Twitter I think is the best.
### Perfect. We can link to that too. Sasha, thank you so much for joining me today, this has been so insightful and amazing. I really appreciate it.
**Sasha:** Thanks, Britney.
### Thank you for listening to Machine Learning Experts!
_If you or someone you know is interested in direct access to leading ML experts like Sasha who are ready to help accelerate your ML project, go to <a href="https://huggingface.co./support?utm_source=blog&utm_medium=blog&utm_campaign=ml_experts&utm_content=sasha_interview_article">hf.co/support</a> to learn more._ ❤️ | [
[
"research",
"community"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"research",
"community"
] | null | null |
7c845ab0-b4ac-4680-85f5-4efc16604bf3 | completed | 2025-01-16T03:08:53.170909 | 2025-01-16T14:19:10.356948 | c928aeb1-9463-44cc-83c7-4f68085553a1 | Introducing the Hugging Face Embedding Container for Amazon SageMaker | philschmid, jeffboudier | sagemaker-huggingface-embedding.md | We are excited to announce that the new Hugging Face Embedding Container for Amazon SageMaker is now generally available (GA). AWS customers can now efficiently deploy embedding models on SageMaker to build Generative AI applications, including Retrieval-Augmented Generation (RAG) applications.
In this Blog we will show you how to deploy open Embedding Models, like [Snowflake/snowflake-arctic-embed-l](https://huggingface.co./Snowflake/snowflake-arctic-embed-l), [BAAI/bge-large-en-v1.5](https://huggingface.co./BAAI/bge-large-en-v1.5) or [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co./sentence-transformers/all-MiniLM-L6-v2) to Amazon SageMaker for inference using the new Hugging Face Embedding Container. We will deploy the [Snowflake/snowflake-arctic-embed-m-v1.5](https://huggingface.co./Snowflake/snowflake-arctic-embed-m-v1.5) one of the best open Embedding Models for retrieval - you can check its rankings on the [MTEB Leaderboard](https://huggingface.co./spaces/mteb/leaderboard).
The example covers:
- [1. Setup development environment](#1-setup-development-environment)
- [2. Retrieve the new Hugging Face Embedding Container](#2-retrieve-the-new-hugging-face-embedding-container)
- [3. Deploy Snowflake Arctic to Amazon SageMaker](#3-deploy-snowflake-arctic-to-amazon-sagemaker)
- [4. Run and evaluate Inference performance](#4-run-and-evaluate-inference-performance)
- [5. Delete model and endpoint](#5-delete-model-and-endpoint)
## What is the Hugging Face Embedding Container?
The Hugging Face Embedding Container is a new purpose-built Inference Container to easily deploy Embedding Models in a secure and managed environment. The DLC is powered by [Text Embedding Inference (TEI)](https://github.com/huggingface/text-embeddings-inference) a blazing fast and memory efficient solution for deploying and serving Embedding Models. TEI enables high-performance extraction for the most popular models, including FlagEmbedding, Ember, GTE and E5. TEI implements many features such as:
* No model graph compilation step
* Small docker images and fast boot times
* Token based dynamic batching
* Optimized transformers code for inference using Flash Attention, Candle and cuBLASLt
* Safetensors weight loading
* Production ready (distributed tracing with Open Telemetry, Prometheus metrics)
TEI supports the following model architectures
* BERT/CamemBERT, e.g. [BAAI/bge-large-en-v1.5](https://huggingface.co./BAAI/bge-large-en-v1.5) or [Snowflake/snowflake-arctic-embed-m-v1.5](https://huggingface.co./Snowflake/snowflake-arctic-embed-m-v1.5)
* RoBERTa, [sentence-transformers/all-roberta-large-v1](https://huggingface.co./sentence-transformers/all-roberta-large-v1)
* XLM-RoBERTa, e.g. [sentence-transformers/paraphrase-xlm-r-multilingual-v1](https://huggingface.co./sentence-transformers/paraphrase-xlm-r-multilingual-v1)
* NomicBert, e.g. [jinaai/jina-embeddings-v2-base-en](https://huggingface.co./jinaai/jina-embeddings-v2-base-en)
* JinaBert, e.g. [nomic-ai/nomic-embed-text-v1.5](https://huggingface.co./nomic-ai/nomic-embed-text-v1.5)
Lets get started!
## 1. Setup development environment
We are going to use the `sagemaker` python SDK to deploy Snowflake Arctic to Amazon SageMaker. We need to make sure to have an AWS account configured and the `sagemaker` python SDK installed.
```python
!pip install "sagemaker>=2.221.1" --upgrade --quiet
```
If you are going to use Sagemaker in a local environment, you need access to an IAM Role with the required permissions for Sagemaker. You can find out more about it [here](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html).
```python
import sagemaker
import boto3
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it does not exist
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker session region: {sess.boto_region_name}")
```
## 2. Retrieve the new Hugging Face Embedding Container
Compared to deploying regular Hugging Face models we first need to retrieve the container uri and provide it to our `HuggingFaceModel` model class with a `image_uri` pointing to the image. To retrieve the new Hugging Face Embedding Container in Amazon SageMaker, we can use the `get_huggingface_llm_image_uri` method provided by the `sagemaker` SDK. This method allows us to retrieve the URI for the desired Hugging Face Embedding Container. Important to note is that TEI has 2 different versions for cpu and gpu, so we create a helper function to retrieve the correct image uri based on the instance type.
```python
from sagemaker.huggingface import get_huggingface_llm_image_uri
# retrieve the image uri based on instance type
def get_image_uri(instance_type):
key = "huggingface-tei" if instance_type.startswith("ml.g") or instance_type.startswith("ml.p") else "huggingface-tei-cpu"
return get_huggingface_llm_image_uri(key, version="1.2.3")
```
## 3. Deploy Snowflake Arctic to Amazon SageMaker
To deploy [Snowflake/snowflake-arctic-embed-m-v1.5](https://huggingface.co./Snowflake/snowflake-arctic-embed-m-v1.5) to Amazon SageMaker we create a `HuggingFaceModel` model class and define our endpoint configuration including the `HF_MODEL_ID`, `instance_type` etc. We will use a `c6i.2xlarge` instance type, which has 4 Intel Ice-Lake vCPUs, 8GB of memory and costs around $0.204 per hour.
```python
import json
from sagemaker.huggingface import HuggingFaceModel
# sagemaker config
instance_type = "ml.g5.xlarge"
# Define Model and Endpoint configuration parameter
config = {
'HF_MODEL_ID': "Snowflake/snowflake-arctic-embed-m-v1.5", # model_id from hf.co/models
}
# create HuggingFaceModel with the image uri
emb_model = HuggingFaceModel(
role=role,
image_uri=get_image_uri(instance_type),
env=config
)
```
After we have created the `HuggingFaceModel` we can deploy it to Amazon SageMaker using the `deploy` method. We will deploy the model with the `ml.c6i.2xlarge` instance type.
```python
# Deploy model to an endpoint
# https://sagemaker.readthedocs.io/en/stable/api/inference/model.html#sagemaker.model.Model.deploy
emb = emb_model.deploy(
initial_instance_count=1,
instance_type=instance_type,
)
```
SageMaker will now create our endpoint and deploy the model to it. This can take ~5 minutes.
## 4. Run and evaluate Inference performance
After our endpoint is deployed we can run inference on it. We will use the `predict` method from the `predictor` to run inference on our endpoint.
```python
data = {
"inputs": "the mesmerizing performances of the leads keep the film grounded and keep the audience riveted .",
}
res = emb.predict(data=data)
# print some results
print(f"length of embeddings: {len(res[0])}")
print(f"first 10 elements of embeddings: {res[0][:10]}")
```
Awesome! Now that we can generate embeddings, lets test the performance of our model.
We will send 3,900 requests to our endpoint and use threading with 10 concurrent threads. We will measure the average latency and throughput of our endpoint. We are going to send an input of 256 tokens for a total of ~1 Million tokens. We decided to use 256 tokens as input length to find the right balance between shorter and longer inputs.
Note: When running the load test, the requests are sent from Europe, and the endpoint is deployed in us-east-1. This adds network overhead latency to the requests.
```python
import threading
import time
number_of_threads = 10
number_of_requests = int(3900 // number_of_threads)
print(f"number of threads: {number_of_threads}")
print(f"number of requests per thread: {number_of_requests}")
def send_requests():
for _ in range(number_of_requests):
# input counted at https://huggingface.co./spaces/Xenova/the-tokenizer-playground for 100 tokens
emb.predict(data={"inputs": "Hugging Face is a company and a popular platform in the field of natural language processing (NLP) and machine learning. They are known for their contributions to the development of state-of-the-art models for various NLP tasks and for providing a platform that facilitates the sharing and usage of pre-trained models. One of the key offerings from Hugging Face is the Transformers library, which is an open-source library for working with a variety of pre-trained transformer models, including those for text generation, translation, summarization, question answering, and more. The library is widely used in the research and development of NLP applications and is supported by a large and active community. Hugging Face also provides a model hub where users can discover, share, and download pre-trained models. Additionally, they offer tools and frameworks to make it easier for developers to integrate and use these models in their own projects. The company has played a significant role in advancing the field of NLP and making cutting-edge models more accessible to the broader community. Hugging Face also provides a model hub where users can discover, share, and download pre-trained models. Additionally, they offer tools and frameworks to make it easier for developers and ma"})
# Create multiple threads
threads = [threading.Thread(target=send_requests) for _ in range(number_of_threads) ]
# start all threads
start = time.time()
[t.start() for t in threads]
# wait for all threads to finish
[t.join() for t in threads]
print(f"total time: {round(time.time() - start)} seconds")
```
Sending 3,900 requests or embedding 1 million tokens took around 841 seconds. This means we can run around ~5 requests per second. But keep in mind that includes the network latency from europe to us-east-1. When we inspect the latency of the endpoint through cloudwatch we can see that latency for our Embeddings model is 2s at 10 concurrent requests. This is very impressive for a small & old CPU instance, which cost ~150$ per month. You can deploy the model to a GPU instance to get faster inference times.
_Note: We ran the same test on a `ml.g5.xlarge` with 1x NVIDIA A10G GPU. Embedding 1 million tokens took around 30 seconds. This means we can run around ~130 requests per second. The latency for the endpoint is 4ms at 10 concurrent requests. The `ml.g5.xlarge` costs around $1.408 per hour on Amazon SageMaker._
GPU instances are much faster than CPU instances, but they are also more expensive. If you want to bulk process embeddings, you can use a GPU instance. If you want to run a small endpoint with low costs, you can use a CPU instance. We plan to work on a dedicated benchmark for the Hugging Face Embedding Container in the future.
```python
print(f"https://console.aws.amazon.com/cloudwatch/home?region={sess.boto_region_name}#metricsV2:graph=~(metrics~(~(~'AWS*2fSageMaker~'ModelLatency~'EndpointName~'{emb.endpoint_name}~'VariantName~'AllTraffic))~view~'timeSeries~stacked~false~region~'{sess.boto_region_name}~start~'-PT5M~end~'P0D~stat~'Average~period~30);query=~'*7bAWS*2fSageMaker*2cEndpointName*2cVariantName*7d*20{emb.endpoint_name}")
```

## 5. Delete model and endpoint
To clean up, we can delete the model and endpoint
```python
emb.delete_model()
emb.delete_endpoint()
```
## Conclusion
The new Hugging Face Embedding Container allows you to easily deploy open Embedding Models such as [Snowflake/snowflake-arctic-embed-l](https://huggingface.co./Snowflake/snowflake-arctic-embed-l) to Amazon SageMaker for inference. We walked through setting up the development environment, retrieving the container, deploying the model, and evaluating its inference performance.
With this new container, customers can now easily deploy high-performance embedding models, enabling the creation of sophisticated Generative AI applications with improved efficiency. We are excited to see what you build with the new Hugging Face Embedding Container for Amazon SageMaker. If you have any questions or feedback, please let us know. | [
[
"mlops",
"implementation",
"deployment",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"deployment",
"integration",
"implementation"
] | null | null |
aca4872b-0234-4f50-baca-0f59d3b222be | completed | 2025-01-16T03:08:53.170914 | 2025-01-16T03:17:10.883459 | f8fa529d-45d4-44d3-8a6e-5303c8a5ac2c | Jupyter X Hugging Face | davanstrien, reach-vb, merve | notebooks-hub.md | **We’re excited to announce improved support for Jupyter notebooks hosted on the Hugging Face Hub!**
From serving as an essential learning resource to being a key tool used for model development, Jupyter notebooks have become a key component across many areas of machine learning. Notebooks' interactive and visual nature lets you get feedback quickly as you develop models, datasets, and demos. For many, their first exposure to training machine learning models is via a Jupyter notebook, and many practitioners use notebooks as a critical tool for developing and communicating their work.
Hugging Face is a collaborative Machine Learning platform in which the community has shared over 150,000 models, 25,000 datasets, and 30,000 ML apps. The Hub has model and dataset versioning tools, including model cards and client-side libraries to automate the versioning process. However, only including a model card with hyperparameters is not enough to provide the best reproducibility; this is where notebooks can help. Alongside these models, datasets, and demos, the Hub hosts over 7,000 notebooks. These notebooks often document the development process of a model or a dataset and can provide guidance and tutorials showing how others can use these resources. We’re therefore excited about our improved support for notebook hosting on the Hub.
## What have we changed?
Under the hood, Jupyter notebook files (usually shared with an `ipynb` extension) are JSON files. While viewing these files directly is possible, it's not a format intended to be read by humans. We have now added rendering support for notebooks hosted on the Hub. This means that notebooks will now be displayed in a human-readable format.
<figure>
<img src="/blog/assets/135_notebooks-hub/before_after_notebook_rendering.png" alt="A side-by-side comparison showing a screenshot of a notebook that hasn’t been rendered on the left and a rendered version on the right. The non-rendered image shows part of a JSON file containing notebook cells that are difficult to read. The rendered version shows a notebook hosted on the Hugging Face hub showing the notebook rendered in a human-readable format. The screenshot shows some of the context of the Hugging Face Hub hosting, such as the branch and a window showing the rendered notebook. The rendered notebook has some example Markdown and code snippets showing the notebook output. "/>
<figcaption>Before and after rendering of notebooks hosted on the hub.</figcaption>
</figure>
## Why are we excited to host more notebooks on the Hub?
- Notebooks help document how people can use your models and datasets; sharing notebooks in the same place as your models and datasets makes it easier for others to use the resources you have created and shared on the Hub.
- Many people use the Hub to develop a Machine Learning portfolio. You can now supplement this portfolio with Jupyter Notebooks too.
- Support for one-click direct opening notebooks hosted on the Hub in [Google Colab](https://medium.com/google-colab/hugging-face-notebooks-x-colab-722d91e05e7c), making notebooks on the Hub an even more powerful experience. Look out for future announcements! | [
[
"data",
"implementation",
"community",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"tools",
"integration",
"community",
"implementation"
] | null | null |
436dcecf-eaea-4f8d-a4b5-e38918bab9bb | completed | 2025-01-16T03:08:53.170918 | 2025-01-19T19:14:23.965429 | e1a15ea2-6313-4dee-9c11-81296ec7f2f9 | Fast Inference on Large Language Models: BLOOMZ on Habana Gaudi2 Accelerator | regisss | habana-gaudi-2-bloom.md | This article will show you how to easily deploy large language models with hundreds of billions of parameters like BLOOM on [Habana® Gaudi®2](https://habana.ai/training/gaudi2/) using 🤗 [Optimum Habana](https://huggingface.co./docs/optimum/habana/index), which is the bridge between Gaudi2 and the 🤗 Transformers library. As demonstrated in the benchmark presented in this post, this will enable you to **run inference faster than with any GPU currently available on the market**.
As models get bigger and bigger, deploying them into production to run inference has become increasingly challenging. Both hardware and software have seen a lot of innovations to address these challenges, so let's dive in to see how to efficiently overcome them!
## BLOOMZ
[BLOOM](https://arxiv.org/abs/2211.05100) is a 176-billion-parameter autoregressive model that was trained to complete sequences of text. It can handle 46 different languages and 13 programming languages. Designed and trained as part of the [BigScience](https://bigscience.huggingface.co/) initiative, BLOOM is an open-science project that involved a large number of researchers and engineers all over the world. More recently, another model with the exact same architecture was released: [BLOOMZ](https://arxiv.org/abs/2211.01786), which is a fine-tuned version of BLOOM on several tasks leading to better generalization and zero-shot[^1] capabilities.
Such large models raise new challenges in terms of memory and speed for both [training](https://huggingface.co./blog/bloom-megatron-deepspeed) and [inference](https://huggingface.co./blog/bloom-inference-optimization). Even in 16-bit precision, one instance requires 352 GB to fit! You will probably struggle to find any device with so much memory at the moment, but state-of-the-art hardware like Habana Gaudi2 does make it possible to perform inference on BLOOM and BLOOMZ models with low latencies.
## Habana Gaudi2
[Gaudi2](https://habana.ai/training/gaudi2/) is the second-generation AI hardware accelerator designed by Habana Labs. A single server contains 8 accelerator devices (called Habana Processing Units, or HPUs) with 96GB of memory each, which provides room to make very large models fit in. However, hosting the model is not very interesting if the computation is slow. Fortunately, Gaudi2 shines on that aspect: it differs from GPUs in that its architecture enables the accelerator to perform General Matrix Multiplication (GeMM) and other operations in parallel, which speeds up deep learning workflows. These features make Gaudi2 a great candidate for LLM training and inference.
Habana's SDK, SynapseAI™, supports PyTorch and DeepSpeed for accelerating LLM training and inference. The [SynapseAI graph compiler](https://docs.habana.ai/en/latest/Gaudi_Overview/SynapseAI_Software_Suite.html#graph-compiler-and-runtime) will optimize the execution of the operations accumulated in the graph (e.g. operator fusion, data layout management, parallelization, pipelining and memory management, and graph-level optimizations).
Moreover, support for [HPU graphs](https://docs.habana.ai/en/latest/PyTorch/Inference_on_PyTorch/Inference_Using_HPU_Graphs.html) and [DeepSpeed-inference](https://docs.habana.ai/en/latest/PyTorch/DeepSpeed/Inference_Using_DeepSpeed.html) have just recently been introduced in SynapseAI, and these are well-suited for latency-sensitive applications as shown in our benchmark below.
All these features are integrated into the 🤗 [Optimum Habana](https://github.com/huggingface/optimum-habana) library so that deploying your model on Gaudi is very simple. Check out the quick-start page [here](https://huggingface.co./docs/optimum/habana/quickstart).
If you would like to get access to Gaudi2, go to the [Intel Developer Cloud](https://www.intel.com/content/www/us/en/secure/developer/devcloud/cloud-launchpad.html) and follow [this guide](https://huggingface.co./blog/habana-gaudi-2-benchmark#how-to-get-access-to-gaudi2).
## Benchmarks
In this section, we are going to provide an early benchmark of BLOOMZ on Gaudi2, first-generation Gaudi and Nvidia A100 80GB. Although these devices have quite a lot of memory, the model is so large that a single device is not enough to contain a single instance of BLOOMZ. To solve this issue, we are going to use [DeepSpeed](https://www.deepspeed.ai/), which is a deep learning optimization library that enables many memory and speed improvements to accelerate the model and make it fit the device. In particular, we rely here on [DeepSpeed-inference](https://arxiv.org/abs/2207.00032): it introduces several features such as [model (or pipeline) parallelism](https://huggingface.co./blog/bloom-megatron-deepspeed#pipeline-parallelism) to make the most of the available devices. For Gaudi2, we use [Habana's DeepSpeed fork](https://github.com/HabanaAI/deepspeed) that adds support for HPUs.
### Latency
We measured latencies (batch of one sample) for two different sizes of BLOOMZ, both with multi-billion parameters:
- [176 billion](https://huggingface.co./bigscience/bloomz) parameters
- [7 billion](https://huggingface.co./bigscience/bloomz-7b1) parameters
Runs were performed with DeepSpeed-inference in 16-bit precision with 8 devices and using a [key-value cache](https://huggingface.co./docs/transformers/v4.27.1/en/model_doc/bloom#transformers.BloomForCausalLM.forward.use_cache). Note that while [CUDA graphs](https://developer.nvidia.com/blog/cuda-graphs/) are not currently compatible with model parallelism in DeepSpeed (DeepSpeed v0.8.2, see [here](https://github.com/microsoft/DeepSpeed/blob/v0.8.2/deepspeed/inference/engine.py#L158)), HPU graphs are supported in Habana's DeepSpeed fork. All benchmarks are doing [greedy generation](https://huggingface.co./blog/how-to-generate#greedy-search) of 100 token outputs. The input prompt is:
> "DeepSpeed is a machine learning framework"
which consists of 7 tokens with BLOOM's tokenizer.
The results for inference latency are displayed in the table below (the unit is *seconds*).
| Model | Number of devices | Gaudi2 latency (seconds) | A100-80GB latency (seconds) | First-gen Gaudi latency (seconds) |
|: | [
[
"llm",
"benchmarks",
"optimization",
"deployment"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"deployment",
"optimization",
"benchmarks"
] | null | null |
ea9829c7-35c6-4880-8c0b-5b8ccb4ffd33 | completed | 2025-01-16T03:08:53.170923 | 2025-01-19T19:04:24.009889 | 493d0197-5d28-4910-8fed-b5e87aa50acf | AMD Pervasive AI Developer Contest! | guruprasadmp | amd_pervasive_developer_ai_contest.md | AMD and Hugging Face are actively engaged in helping developers seamlessly deploy cutting-edge AI models on AMD hardware.
This year, AMD takes their commitment one step further by providing developers free, hands-on access to state-of-the-art AMD hardware through their recently announced [Pervasive AI Developer Contest](https://www.hackster.io/contests/amd2023#challengeNav).
This global competition is an incubator of AI innovation, beckoning developers worldwide to create unique AI applications.
Developers can choose from three exciting categories: Generative AI, Robotics AI, and PC AI, each of them entitled to cash prices up to $10,000 USD for winners, with a total of $160,000 USD being given away.
700 AMD platforms are up for grabs to eligible participants.
Don’t miss your chance to receive an AMD Radeon ™ PRO W7900, AMD Kria ™ KR260 Robotics Starter Kit, Ryzen ™ AI powered PC or cloud access to an AMD Instinct ™ MI210 accelerator card.
## AMD + Hugging Face Collaboration
For those focusing on large language model development, Hugging Face and AMD have made significant strides to provide out-of-the-box support on AMD GPUs.
Our combined efforts include the ability to run HF transformer models without the need for code modifications allowing for seamless operation.
On top of native support, additional acceleration tools like ONNX models execution on ROCm-powered GPU, Optimum-Benchmark, DeepSpeed for ROCm-powered GPUs using Transformers, GPTQ, TGI and more are supported.
Additionally, for those applying for the PC AI contest category to develop on AMD Ryzen AI Powered PCs, we are continuously growing our pre-trained model zoo to support a wide variety of models enabling developers to get started in building AI applications swiftly.
## Sign Up Today
We invite you to be innovative, and to contribute to shaping what AI can achieve and we at Hugging Face look forward to the new solutions this contest will bring to light.
To participate, please register over [here](https://www.hackster.io/contests/amd2023#challengeNav) | [
[
"community",
"deployment",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"community",
"robotics",
"deployment",
"tools"
] | null | null |
290c7276-82c8-49af-b816-a8aaafec511f | completed | 2025-01-16T03:08:53.170927 | 2025-01-16T03:24:04.475135 | dff03075-a84d-4c55-adc9-350be5f4ee19 | Exploring simple optimizations for SDXL | sayakpaul, stevhliu | simple_sdxl_optimizations.md | <a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/exploring_simple%20optimizations_for_sdxl.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
[Stable Diffusion XL (SDXL)](https://huggingface.co./papers/2307.01952) is the latest latent diffusion model by Stability AI for generating high-quality super realistic images. It overcomes challenges of previous Stable Diffusion models like getting hands and text right as well as spatially correct compositions. In addition, SDXL is also more context aware and requires fewer words in its prompt to generate better looking images.
However, all of these improvements come at the expense of a significantly larger model. How much larger? The base SDXL model has 3.5B parameters (the UNet, in particular), which is approximately 3x larger than the previous Stable Diffusion model.
To explore how we can optimize SDXL for inference speed and memory use, we ran some tests on an A100 GPU (40 GB). For each inference run, we generate 4 images and repeat it 3 times. While computing the inference latency, we only consider the final iteration out of the 3 iterations.
So if you run SDXL out-of-the-box as is with full precision and use the default attention mechanism, it’ll consume 28GB of memory and take 72.2 seconds!
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0").to("cuda")
pipe.unet.set_default_attn_processor()
```
This isn’t very practical and can slow you down because you’re often generating more than 4 images. And if you don’t have a more powerful GPU, you’ll run into that frustrating out-of-memory error message. So how can we optimize SDXL to increase inference speed and reduce its memory-usage?
In 🤗 Diffusers, we have a bunch of optimization tricks and techniques to help you run memory-intensive models like SDXL and we'll show you how! The two things we’ll focus on are *inference speed* and *memory*.
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
🧠 The techniques discussed in this post are applicable to all the <a href=https://huggingface.co./docs/diffusers/main/en/using-diffusers/pipeline_overview>pipelines</a>.
</div>
## Inference speed
Diffusion is a random process, so there's no guarantee you'll get an image you’ll like. Often times, you’ll need to run inference multiple times and iterate, and that’s why optimizing for speed is crucial. This section focuses on using lower precision weights and incorporating memory-efficient attention and `torch.compile` from PyTorch 2.0 to boost speed and reduce inference time.
### Lower precision
Model weights are stored at a certain *precision* which is expressed as a floating point data type. The standard floating point data type is float32 (fp32), which can accurately represent a wide range of floating numbers. For inference, you often don’t need to be as precise so you should use float16 (fp16) which captures a narrower range of floating numbers. This means fp16 only takes half the amount of memory to store compared to fp32, and is twice as fast because it is easier to calculate. In addition, modern GPU cards have optimized hardware to run fp16 calculations, making it even faster.
With 🤗 Diffusers, you can use fp16 for inference by specifying the `torch.dtype` parameter to convert the weights when the model is loaded:
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.unet.set_default_attn_processor()
```
Compared to a completely unoptimized SDXL pipeline, using fp16 takes 21.7GB of memory and only 14.8 seconds. You’re almost speeding up inference by a full minute!
### Memory-efficient attention
The attention blocks used in transformers modules can be a huge bottleneck, because memory increases _quadratically_ as input sequences get longer. This can quickly take up a ton of memory and leave you with an out-of-memory error message. 😬
Memory-efficient attention algorithms seek to reduce the memory burden of calculating attention, whether it is by exploiting sparsity or tiling. These optimized algorithms used to be mostly available as third-party libraries that needed to be installed separately. But starting with PyTorch 2.0, this is no longer the case. PyTorch 2 introduced [scaled dot product attention (SDPA)](https://pytorch.org/blog/accelerated-diffusers-pt-20/), which offers fused implementations of [Flash Attention](https://huggingface.co./papers/2205.14135), [memory-efficient attention](https://huggingface.co./papers/2112.05682) (xFormers), and a PyTorch implementation in C++. SDPA is probably the easiest way to speed up inference: if you’re using PyTorch ≥ 2.0 with 🤗 Diffusers, it is automatically enabled by default!
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
```
Compared to a completely unoptimized SDXL pipeline, using fp16 and SDPA takes the same amount of memory and the inference time improves to 11.4 seconds. Let’s use this as the new baseline we’ll compare the other optimizations to.
### torch.compile
PyTorch 2.0 also introduced the `torch.compile` API for just-in-time (JIT) compilation of your PyTorch code into more optimized kernels for inference. Unlike other compiler solutions, `torch.compile` requires minimal changes to your existing code and it is as easy as wrapping your model with the function.
With the `mode` parameter, you can optimize for memory overhead or inference speed during compilation, which gives you way more flexibility.
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
Compared to the previous baseline (fp16 + SDPA), wrapping the UNet with `torch.compile` improves inference time to 10.2 seconds.
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
⚠️ The first time you compile a model is slower, but once the model is compiled, all subsequent calls to it are much faster!
</div>
## Model memory footprint
Models today are growing larger and larger, making it a challenge to fit them into memory. This section focuses on how you can reduce the memory footprint of these enormous models so you can run them on consumer GPUs. These techniques include CPU offloading, decoding latents into images over several steps rather than all at once, and using a distilled version of the autoencoder.
### Model CPU offloading
Model offloading saves memory by loading the UNet into the GPU memory while the other components of the diffusion model (text encoders, VAE) are loaded onto the CPU. This way, the UNet can run for multiple iterations on the GPU until it is no longer needed.
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
)
pipe.enable_model_cpu_offload()
```
Compared to the baseline, it now takes 20.2GB of memory which saves you 1.5GB of memory.
### Sequential CPU offloading
Another type of offloading which can save you more memory at the expense of slower inference is sequential CPU offloading. Rather than offloading an entire model - like the UNet - model weights stored in different UNet submodules are offloaded to the CPU and only loaded onto the GPU right before the forward pass. Essentially, you’re only loading parts of the model each time which allows you to save even more memory. The only downside is that it is significantly slower because you’re loading and offloading submodules many times.
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
)
pipe.enable_sequential_cpu_offload()
```
Compared to the baseline, this takes 19.9GB of memory but the inference time increases to 67 seconds.
## Slicing
In SDXL, a variational encoder (VAE) decodes the refined latents (predicted by the UNet) into realistic images. The memory requirement of this step scales with the number of images being predicted (the batch size). Depending on the image resolution and the available GPU VRAM, it can be quite memory-intensive.
This is where “slicing” is useful. The input tensor to be decoded is split into slices and the computation to decode it is completed over several steps. This saves memory and allows larger batch sizes.
```python
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
).to("cuda")
pipe.enable_vae_slicing()
```
With sliced computations, we reduce the memory to 15.4GB. If we add sequential CPU offloading, it is further reduced to 11.45GB which lets you generate 4 images (1024x1024) per prompt. However, with sequential offloading, the inference latency also increases.
## Caching computations
Any text-conditioned image generation model typically uses a text encoder to compute embeddings from the input prompt. SDXL uses *two* text encoders! This contributes quite a bit to the inference latency. However, since these embeddings remain unchanged throughout the reverse diffusion process, we can precompute them and reuse them as we go. This way, after computing the text embeddings, we can remove the text encoders from memory.
First, load the text encoders and their corresponding tokenizers and compute the embeddings from the input prompt:
```python
tokenizers = [tokenizer, tokenizer_2]
text_encoders = [text_encoder, text_encoder_2]
(
prompt_embeds,
negative_prompt_embeds,
pooled_prompt_embeds,
negative_pooled_prompt_embeds
) = encode_prompt(tokenizers, text_encoders, prompt)
```
Next, flush the GPU memory to remove the text encoders:
```jsx
del text_encoder, text_encoder_2, tokenizer, tokenizer_2
flush()
```
Now the embeddings are good to go straight to the SDXL pipeline:
```python
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
text_encoder=None,
text_encoder_2=None,
tokenizer=None,
tokenizer_2=None,
torch_dtype=torch.float16,
).to("cuda")
call_args = dict(
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
pooled_prompt_embeds=pooled_prompt_embeds,
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
num_images_per_prompt=num_images_per_prompt,
num_inference_steps=num_inference_steps,
)
image = pipe(**call_args).images[0]
```
Combined with SDPA and fp16, we can reduce the memory to 21.9GB. Other techniques discussed above for optimizing memory can also be used with cached computations.
## Tiny Autoencoder
As previously mentioned, a VAE decodes latents into images. Naturally, this step is directly bottlenecked by the size of the VAE. So, let’s just use a smaller autoencoder! The [Tiny Autoencoder by `madebyollin`](https://github.com/madebyollin/taesd), available [the Hub](https://huggingface.co./madebyollin/taesdxl) is just 10MB and it is distilled from the original VAE used by SDXL.
```python
from diffusers import AutoencoderTiny
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
)
pipe.vae = AutoencoderTiny.from_pretrained("madebyollin/taesdxl", torch_dtype=torch.float16)
pipe.to("cuda")
```
With this setup, we reduce the memory requirement to 15.6GB while reducing the inference latency at the same time.
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
⚠️ The Tiny Autoencoder can omit some of the more fine-grained details from images, which is why the Tiny AutoEncoder is more appropriate for image previews.
</div>
## Conclusion
To conclude and summarize the savings from our optimizations:
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
⚠️ While profiling GPUs to measure the trade-off between inference latency and memory requirements, it is important to be aware of the hardware being used. The above findings may not translate equally from hardware to hardware. For example, `torch.compile` only seems to benefit modern GPUs, at least for SDXL.
</div>
| **Technique** | **Memory (GB)** | **Inference latency (ms)** |
| | [
[
"computer_vision",
"optimization",
"image_generation",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"optimization",
"image_generation",
"efficient_computing"
] | null | null |
a325f81a-831d-4176-afb6-2e4e228fa67e | completed | 2025-01-16T03:08:53.170932 | 2025-01-16T03:21:20.523059 | d2b0b4f4-bb93-4d6e-8f9e-db5b2da99450 | How to generate text: using different decoding methods for language generation with Transformers | patrickvonplaten | how-to-generate.md | <a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**Note**: Edited on July 2023 with up-to-date references and examples.
## Introduction
In recent years, there has been an increasing interest in open-ended
language generation thanks to the rise of large transformer-based
language models trained on millions of webpages, including OpenAI's [ChatGPT](https://openai.com/blog/chatgpt)
and Meta's [LLaMA](https://ai.meta.com/blog/large-language-model-llama-meta-ai/).
The results on conditioned open-ended language generation are impressive, having shown to
[generalize to new tasks](https://ai.googleblog.com/2021/10/introducing-flan-more-generalizable.html),
[handle code](https://huggingface.co./blog/starcoder),
or [take non-text data as input](https://openai.com/research/whisper).
Besides the improved transformer architecture and massive unsupervised
training data, **better decoding methods** have also played an important
role.
This blog post gives a brief overview of different decoding strategies
and more importantly shows how *you* can implement them with very little
effort using the popular `transformers` library\!
All of the following functionalities can be used for **auto-regressive**
language generation ([here](http://jalammar.github.io/illustrated-gpt2/)
a refresher). In short, *auto-regressive* language generation is based
on the assumption that the probability distribution of a word sequence
can be decomposed into the product of conditional next word
distributions:
$$ P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ ,with } w_{1: 0} = \emptyset, $$
and \\(W_0\\) being the initial *context* word sequence. The length \\(T\\)
of the word sequence is usually determined *on-the-fly* and corresponds
to the timestep \\(t=T\\) the EOS token is generated from \\(P(w_{t} | w_{1: t-1}, W_{0})\\).
We will give a tour of the currently most prominent decoding methods,
mainly *Greedy search*, *Beam search*, and *Sampling*.
Let's quickly install transformers and load the model. We will use GPT2
in PyTorch for demonstration, but the API is 1-to-1 the same for
TensorFlow and JAX.
``` python
!pip install -q transformers
```
``` python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = AutoModelForCausalLM.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id).to(torch_device)
```
## Greedy Search
Greedy search is the simplest decoding method.
It selects the word with the highest probability as
its next word: \\(w_t = argmax_{w}P(w | w_{1:t-1})\\) at each timestep
\\(t\\). The following sketch shows greedy search.
<img src="/blog/assets/02_how-to-generate/greedy_search.png" alt="greedy search" style="margin: auto; display: block;">
Starting from the word \\(\text{"The"},\\) the algorithm greedily chooses
the next word of highest probability \\(\text{"nice"}\\) and so on, so
that the final generated word sequence is \\((\text{"The"}, \text{"nice"}, \text{"woman"})\\)
having an overall probability of \\(0.5 \times 0.4 = 0.2\\) .
In the following we will generate word sequences using GPT2 on the
context \\((\text{"I"}, \text{"enjoy"}, \text{"walking"}, \text{"with"}, \text{"my"}, \text{"cute"}, \text{"dog"})\\). Let's
see how greedy search can be used in `transformers`:
``` python
# encode context the generation is conditioned on
model_inputs = tokenizer('I enjoy walking with my cute dog', return_tensors='pt').to(torch_device)
# generate 40 new tokens
greedy_output = model.generate(**model_inputs, max_new_tokens=40)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
```
```
Output: | [
[
"llm",
"transformers",
"tutorial",
"text_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"text_generation",
"tutorial"
] | null | null |
44ecd27a-5d06-4464-9b99-a8c81fa6cf6a | completed | 2025-01-16T03:08:53.170937 | 2025-01-19T19:06:45.476971 | 68441782-c907-423c-b412-d659f32a8368 | Swift 🧨Diffusers - Fast Stable Diffusion for Mac | pcuenq, reach-vb | fast-mac-diffusers.md | Transform your text into stunning images with ease using Diffusers for Mac, a native app powered by state-of-the-art diffusion models. It leverages a bouquet of SoTA Text-to-Image models contributed by the community to the Hugging Face Hub, and converted to Core ML for blazingly fast performance. Our latest version, 1.1, is now available on the [Mac App Store](https://apps.apple.com/app/diffusers/id1666309574) with significant performance upgrades and user-friendly interface tweaks. It's a solid foundation for future feature updates. Plus, the app is fully open source with a permissive [license](https://github.com/huggingface/swift-coreml-diffusers/blob/main/LICENSE), so you can build on it too! Check out our GitHub repository at https://github.com/huggingface/swift-coreml-diffusers for more information.
<img style="border:none;" alt="Screenshot showing Diffusers for Mac UI" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/fast-mac-diffusers/UI.png" />
## What exactly is 🧨Diffusers for Mac anyway?
The Diffusers app ([App Store](https://apps.apple.com/app/diffusers/id1666309574), [source code](https://github.com/huggingface/swift-coreml-diffusers)) is the Mac counterpart to our [🧨`diffusers` library](https://github.com/huggingface/diffusers). This library is written in Python with PyTorch, and uses a modular design to train and run diffusion models. It supports many different models and tasks, and is highly configurable and well optimized. It runs on Mac, too, using PyTorch's [`mps` accelerator](https://huggingface.co./docs/diffusers/optimization/mps), which is an alternative to `cuda` on Apple Silicon.
Why would you want to run a native Mac app then? There are many reasons:
- It uses Core ML models, instead of the original PyTorch ones. This is important because they allow for [additional optimizations](https://machinelearning.apple.com/research/stable-diffusion-coreml-apple-silicon) relevant to the specifics of Apple hardware, and because Core ML models can run on all the compute devices in your system: the CPU, the GPU and the Neural Engine, _at once_ – the Core ML framework will decide what portions of your model to run on each device to make it as fast as possible. PyTorch's `mps` device cannot use the Neural Engine.
- It's a Mac app! We try to follow Apple's design language and guidelines so it feels at home on your Mac. No need to use the command line, create virtual environments or fix dependencies.
- It's local and private. You don't need credits for online services and won't experience long queues – just generate all the images you want and use them for fun or work. Privacy is guaranteed: your prompts and images are yours to use, and will never leave your computer (unless you choose to share them).
- [It's open source](https://github.com/huggingface/swift-coreml-diffusers), and it uses Swift, Swift UI and the latest languages and technologies for Mac and iOS development. If you are technically inclined, you can use Xcode to extend the code as you like. We welcome your contributions, too!
## Performance Benchmarks
**TL;DR:** Depending on your computer Text-to-Image Generation can be up to **twice as fast** on Diffusers 1.1. ⚡️
We've done a lot of testing on several Macs to determine the best combinations of compute devices that yield optimum performance. For some computers it's best to use the GPU, while others work better when the Neural Engine, or ANE, is engaged.
Come check out our benchmarks. All the combinations use the CPU in addition to either the GPU or the ANE.
| Model name | Benchmark | M1 8 GB | M1 16 GB | M2 24 GB | M1 Max 64 GB |
|: | [
[
"computer_vision",
"implementation",
"tools",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"image_generation",
"implementation",
"tools"
] | null | null |
2fa528ba-3a4d-4df0-9168-d7da67eddd08 | completed | 2025-01-16T03:08:53.170941 | 2025-01-19T17:14:04.097208 | 78f2efc8-2fe2-4161-a83f-9a2b17f18d6d | From OpenAI to Open LLMs with Messages API on Hugging Face | andrewrreed, philschmid, Jofthomas, drbh | tgi-messages-api.md | We are excited to introduce the Messages API to provide OpenAI compatibility with Text Generation Inference (TGI) and Inference Endpoints.
Starting with version 1.4.0, TGI offers an API compatible with the OpenAI Chat Completion API. The new Messages API allows customers and users to transition seamlessly from OpenAI models to open LLMs. The API can be directly used with OpenAI's client libraries or third-party tools, like LangChain or LlamaIndex.
> ##### *"The new Messages API with OpenAI compatibility makes it easy for Ryght's real-time GenAI orchestration platform to switch LLM use cases from OpenAI to open models. Our migration from GPT4 to Mixtral/Llama2 on Inference Endpoints is effortless, and now we have a simplified workflow with more control over our AI solutions." - [Johnny Crupi, CTO](https://www.linkedin.com/in/johncrupi/) at [Ryght](http://www.ryght.ai/?utm_campaign=hf&utm_source=hf_blog)*
The new Messages API is also now available in Inference Endpoints, on both dedicated and serverless flavors. To get you started quickly, we’ve included detailed examples of how to:
- [Create an Inference Endpoint](#create-an-inference-endpoint)
- [Using Inference Endpoints with OpenAI client libraries](#using-inference-endpoints-with-openai-client-libraries)
- [Integrate with LangChain and LlamaIndex](#integrate-with-langchain-and-llamaindex)
**Limitations:** The Messages API does not currently support function calling and will only work for LLMs with a `chat_template` defined in their tokenizer configuration, like in the case of [Mixtral 8x7B Instruct](https://huggingface.co./mistralai/Mixtral-8x7B-Instruct-v0.1/blob/125c431e2ff41a156b9f9076f744d2f35dd6e67a/tokenizer_config.json#L42).
## Create an Inference Endpoint
[Inference Endpoints](https://huggingface.co./docs/inference-endpoints/index) offers a secure, production solution to easily deploy any machine learning model from the Hub on dedicated infrastructure managed by Hugging Face.
In this example, we will deploy [Nous-Hermes-2-Mixtral-8x7B-DPO](https://huggingface.co./NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO), a fine-tuned Mixtral model, to Inference Endpoints using [Text Generation Inference](https://huggingface.co./docs/text-generation-inference/index).
We can deploy the model in just [a few clicks from the UI](https://ui.endpoints.huggingface.co/new?vendor=aws&repository=NousResearch%2FNous-Hermes-2-Mixtral-8x7B-DPO&tgi_max_total_tokens=32000&tgi=true&tgi_max_input_length=1024&task=text-generation&instance_size=2xlarge&tgi_max_batch_prefill_tokens=2048&tgi_max_batch_total_tokens=1024000&no_suggested_compute=true&accelerator=gpu®ion=us-east-1), or take advantage of the `huggingface_hub` Python library to programmatically create and manage Inference Endpoints. We demonstrate the use of the Hub library here.
In our API call shown below, we need to specify the endpoint name and model repository, along with the task of `text-generation`. In this example we use a `protected` type so access to the deployed endpoint will require a valid Hugging Face token. We also need to configure the hardware requirements like vendor, region, accelerator, instance type, and size. You can check out the list of available resource options [using this API call](https://api.endpoints.huggingface.cloud/#get-/v2/provider), and view recommended configurations for select models in our catalog [here](https://ui.endpoints.huggingface.co/catalog).
_Note: You may need to request a quota upgrade by sending an email to [[email protected]](mailto:[email protected])_
```python
from huggingface_hub import create_inference_endpoint
endpoint = create_inference_endpoint(
"nous-hermes-2-mixtral-8x7b-demo",
repository="NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO",
framework="pytorch",
task="text-generation",
accelerator="gpu",
vendor="aws",
region="us-east-1",
type="protected",
instance_type="nvidia-a100",
instance_size="x2",
custom_image={
"health_route": "/health",
"env": {
"MAX_INPUT_LENGTH": "4096",
"MAX_BATCH_PREFILL_TOKENS": "4096",
"MAX_TOTAL_TOKENS": "32000",
"MAX_BATCH_TOTAL_TOKENS": "1024000",
"MODEL_ID": "/repository",
},
"url": "ghcr.io/huggingface/text-generation-inference:sha-1734540", # use this build or newer
},
)
endpoint.wait()
print(endpoint.status)
```
It will take a few minutes for our deployment to spin up. We can use the `.wait()` utility to block the running thread until the endpoint reaches a final "running" state. Once running, we can confirm its status and take it for a spin via the UI Playground:

Great, we now have a working endpoint!
> ##### 💡 When deploying with `huggingface_hub`, your endpoint will scale-to-zero after 15 minutes of idle time by default to optimize cost during periods of inactivity. Check out [the Hub Python Library documentation](https://huggingface.co./docs/huggingface_hub/guides/inference_endpoints) to see all the functionality available for managing your endpoint lifecycle.
## Using Inference Endpoints with OpenAI client libraries
Messages support in TGI makes Inference Endpoints directly compatible with the OpenAI Chat Completion API. This means that any existing scripts that use OpenAI models via the OpenAI client libraries can be directly swapped out to use any open LLM running on a TGI endpoint!
With this seamless transition, you can immediately take advantage of the numerous benefits offered by open models:
- Complete control and transparency over models and data
- No more worrying about rate limits
- The ability to fully customize systems according to your specific needs
Lets see how.
### With the Python client
The example below shows how to make this transition using the [OpenAI Python Library](https://github.com/openai/openai-python). Simply replace the `<ENDPOINT_URL>` with your endpoint URL (be sure to include the `v1/` suffix) and populate the `<HF_API_TOKEN>` field with a valid Hugging Face user token. The `<ENDPOINT_URL>` can be gathered from Inference Endpoints UI, or from the endpoint object we created above with `endpoint.url`.
We can then use the client as usual, passing a list of messages to stream responses from our Inference Endpoint.
```python
from openai import OpenAI
# initialize the client but point it to TGI
client = OpenAI(
base_url="<ENDPOINT_URL>" + "/v1/", # replace with your endpoint url
api_key="<HF_API_TOKEN>", # replace with your token
)
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Why is open-source software important?"},
],
stream=True,
max_tokens=500
)
# iterate and print stream
for message in chat_completion:
print(message.choices[0].delta.content, end="")
```
Behind the scenes, TGI’s Messages API automatically converts the list of messages into the model’s required instruction format using its [chat template](https://huggingface.co./docs/transformers/chat_templating).
> ##### 💡 Certain OpenAI features, like function calling, are not compatible with TGI. Currently, the Messages API supports the following chat completion parameters: `stream`, `max_tokens`, `frequency_penalty`, `logprobs`, `seed`, `temperature`, and `top_p`.
### With the JavaScript client
Here’s the same streaming example above, but using the [OpenAI Javascript/Typescript Library](https://github.com/openai/openai-node).
```js
import OpenAI from "openai";
const openai = new OpenAI({
baseURL: "<ENDPOINT_URL>" + "/v1/", // replace with your endpoint url
apiKey: "<HF_API_TOKEN>", // replace with your token
});
async function main() {
const stream = await openai.chat.completions.create({
model: "tgi",
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Why is open-source software important?" },
],
stream: true,
max_tokens: 500,
});
for await (const chunk of stream) {
process.stdout.write(chunk.choices[0]?.delta?.content || "");
}
}
main();
```
## Integrate with LangChain and LlamaIndex
Now, let’s see how to use this newly created endpoint with your preferred RAG framework.
### How to use with LangChain
To use it in [LangChain](https://python.langchain.com/docs/get_started/introduction), simply create an instance of `ChatOpenAI` and pass your `<ENDPOINT_URL>` and `<HF_API_TOKEN>` as follows:
```python
from langchain_community.chat_models.openai import ChatOpenAI
llm = ChatOpenAI(
model_name="tgi",
openai_api_key="<HF_API_TOKEN>",
openai_api_base="<ENDPOINT_URL>" + "/v1/",
)
llm.invoke("Why is open-source software important?")
```
We’re able to directly leverage the same `ChatOpenAI` class that we would have used with the OpenAI models. This allows all previous code to work with our endpoint by changing just one line of code.
Let’s now use the LLM declared this way in a simple RAG pipeline to answer a question over the contents of a HF blog post.
```python
from langchain_core.runnables import RunnableParallel
from langchain_community.embeddings import HuggingFaceEmbeddings
# Load, chunk and index the contents of the blog
loader = WebBaseLoader(
web_paths=("https://huggingface.co./blog/open-source-llms-as-agents",),
)
docs = loader.load()
# Declare an HF embedding model and vector store
hf_embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-large-en-v1.5")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=hf_embeddings)
# Retrieve and generate using the relevant pieces of context
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| StrOutputParser()
)
rag_chain_with_source = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)
rag_chain_with_source.invoke("According to this article which open-source model is the best for an agent behaviour?")
```
```json
{
"context": [...],
"question": "According to this article which open-source model is the best for an agent behaviour?",
"answer": " According to the article, Mixtral-8x7B is the best open-source model for agent behavior, as it performs well and even beats GPT-3.5. The authors recommend fine-tuning Mixtral for agents to potentially surpass the next challenger, GPT-4.",
}
```
### How to use with LlamaIndex
Similarly, you can also use a TGI endpoint in [LlamaIndex](https://www.llamaindex.ai/). We’ll use the `OpenAILike` class, and instantiate it by configuring some additional arguments (i.e. `is_local`, `is_function_calling_model`, `is_chat_model`, `context_window`). Note that the context window argument should match the value previously set for `MAX_TOTAL_TOKENS` of your endpoint.
```python
from llama_index.llms import OpenAILike
# Instantiate an OpenAILike model
llm = OpenAILike(
model="tgi",
api_key="<HF_API_TOKEN>",
api_base="<ENDPOINT_URL>" + "/v1/",
is_chat_model=True,
is_local=False,
is_function_calling_model=False,
context_window=32000,
)
# Then call it
llm.complete("Why is open-source software important?")
```
We can now use it in a similar RAG pipeline. Keep in mind that the previous choice of `MAX_INPUT_LENGTH` in your Inference Endpoint will directly influence the number of retrieved chunk (`similarity_top_k`) the model can process.
```python
from llama_index import (
ServiceContext,
VectorStoreIndex,
)
from llama_index import download_loader
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index.query_engine import CitationQueryEngine
SimpleWebPageReader = download_loader("SimpleWebPageReader")
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://huggingface.co./blog/open-source-llms-as-agents"]
)
# Load embedding model
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-large-en-v1.5")
# Pass LLM to pipeline
service_context = ServiceContext.from_defaults(embed_model=embed_model, llm=llm)
index = VectorStoreIndex.from_documents(
documents, service_context=service_context, show_progress=True
)
# Query the index
query_engine = CitationQueryEngine.from_args(
index,
similarity_top_k=2,
)
response = query_engine.query(
"According to this article which open-source model is the best for an agent behaviour?"
)
```
```
According to the article, Mixtral-8x7B is the best performing open-source model for an agent behavior [5]. It even beats GPT-3.5 in this task. However, it's worth noting that Mixtral's performance could be further improved with proper fine-tuning for function calling and task planning skills [5].
```
## Cleaning up
After you are done with your endpoint, you can either pause or delete it. This step can be completed via the UI, or programmatically like follows.
```python
# pause our running endpoint
endpoint.pause()
# optionally delete
endpoint.delete()
```
## Conclusion
The new Messages API in Text Generation Inference provides a smooth transition path from OpenAI models to open LLMs. We can’t wait to see what use cases you will power with open LLMs running on TGI!
_See [this notebook](https://github.com/andrewrreed/hf-notebooks/blob/main/tgi-messages-api-demo.ipynb) for a runnable version of the code outlined in the post._ | [
[
"llm",
"mlops",
"tutorial",
"deployment",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"mlops",
"deployment",
"integration"
] | null | null |
42673b12-bc40-4905-929b-94bdf59df12a | completed | 2025-01-16T03:08:53.170946 | 2025-01-19T19:12:47.522657 | ee71108a-fbf6-4b18-ad2b-4932b4ee3f9b | Scaling-up BERT Inference on CPU (Part 1) | mfuntowicz | bert-cpu-scaling-part-1.md | .centered {
display: block;
margin: 0 auto;
}
figure {
text-align: center;
display: table;
max-width: 85%; /* demo; set some amount (px or %) if you can */
margin: 10px auto; /* not needed unless you want centered */
}
</style>
# Scaling up BERT-like model Inference on modern CPU - Part 1
## 1. Context and Motivations
Back in October 2019, my colleague Lysandre Debut published a comprehensive _(at the time)_ [inference performance
benchmarking blog (1)](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2).
Since then, [🤗 transformers (2)](https://github.com/huggingface/transformers) welcomed a tremendous number
of new architectures and thousands of new models were added to the [🤗 hub (3)](https://huggingface.co./models)
which now counts more than 9,000 of them as of first quarter of 2021.
As the NLP landscape keeps trending towards more and more BERT-like models being used in production, it
remains challenging to efficiently deploy and run these architectures at scale.
This is why we recently introduced our [🤗 Inference API](https://api-inference.huggingface.co/docs/python/html/index.html):
to let you focus on building value for your users and customers, rather than digging into all the highly
technical aspects of running such models.
This blog post is the first part of a series which will cover most of the hardware and software optimizations to better
leverage CPUs for BERT model inference.
For this initial blog post, we will cover the hardware part:
- Setting up a baseline - Out of the box results
- Practical & technical considerations when leveraging modern CPUs for CPU-bound tasks
- Core count scaling - Does increasing the number of cores actually give better performance?
- Batch size scaling - Increasing throughput with multiple parallel & independent model instances
We decided to focus on the most famous Transformer model architecture,
[BERT (Delvin & al. 2018) (4)](https://arxiv.org/abs/1810.04805v1). While we focus this blog post on BERT-like
models to keep the article concise, all the described techniques
can be applied to any architecture on the Hugging Face model hub.
In this blog post we will not describe in detail the Transformer architecture - to learn about that I can't
recommend enough the
[Illustrated Transformer blogpost from Jay Alammar (5)](https://jalammar.github.io/illustrated-transformer/).
Today's goals are to give you an idea of where we are from an Open Source perspective using BERT-like
models for inference on PyTorch and TensorFlow, and also what you can easily leverage to speedup inference.
## 2. Benchmarking methodology
When it comes to leveraging BERT-like models from Hugging Face's model hub, there are many knobs which can
be tuned to make things faster.
Also, in order to quantify what "faster" means, we will rely on widely adopted metrics:
- **Latency**: Time it takes for a single execution of the model (i.e. forward call)
- **Throughput**: Number of executions performed in a fixed amount of time
These two metrics will help us understand the benefits and tradeoffs along this blog post.
The benchmarking methodology was reimplemented from scratch in order to integrate the latest features provided by transformers
and also to let the community run and share benchmarks in an __hopefully easier__ way.
The whole framework is now based on [Facebook AI & Research's Hydra configuration library](https://hydra.cc/) allowing us to easily report
and track all the items involved while running the benchmark, hence increasing the overall reproducibility.
You can find the whole structure of the project [here](https://github.com/huggingface/tune)
On the 2021 version, we kept the ability to run inference workloads through PyTorch and Tensorflow as in the
previous blog [(1)](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2) along with their traced counterpart
[TorchScript (6)](https://pytorch.org/docs/stable/jit.html), [Google Accelerated Linear Algebra (XLA) (7)](https://www.tensorflow.org/xla).
Also, we decided to include support for [ONNX Runtime (8)](https://www.onnxruntime.ai/) as it provides many optimizations
specifically targeting transformers based models which makes it a strong candidate to consider when discussing
performance.
Last but not least, this new unified benchmarking environment will allow us to easily run inference for different scenarios
such as [Quantized Models (Zafrir & al.) (9)](https://arxiv.org/abs/1910.06188)
using less precise number representations (`float16`, `int8`, `int4`).
This method known as **quantization** has seen an increased adoption among all major hardware providers.
In the near future, we would like to integrate additional methods we are actively working on at Hugging Face, namely Distillation, Pruning & Sparsificaton.
## 3. Baselines
All the results below were run on [Amazon Web Services (AWS) c5.metal instance](https://aws.amazon.com/ec2/instance-types/c5)
leveraging an Intel Xeon Platinum 8275 CPU (48 cores/96 threads).
The choice of this instance provides all the useful CPU features to speedup Deep Learning workloads such as:
- AVX512 instructions set (_which might not be leveraged out-of-the-box by the various frameworks_)
- Intel Deep Learning Boost (also known as Vector Neural Network Instruction - VNNI) which provides specialized
CPU instructions for running quantized networks (_using int8 data type_)
The choice of using _metal_ instance is to avoid any virtualization issue which can arise when using cloud providers.
This gives us full control of the hardware, especially while targeting the NUMA (Non-Unified Memory Architecture) controller, which
we will cover later in this post.
_The operating system was Ubuntu 20.04 (LTS) and all the experiments were conducted using Hugging Face transformers version 4.5.0, PyTorch 1.8.1 & Google TensorFlow 2.4.0_
## 4. Out of the box results
<br>
<figure class="image">
<img alt="pytorch versus tensorflow out of the box" src="assets/21_bert_cpu_scaling_part_1/imgs/pytorch_vs_tf_oob.svg" />
<figcaption>Figure 1. PyTorch (1.8.1) vs Google TensorFlow (2.4.1) out of the box</figcaption>
</figure>
<br>
<br>
<figure class="image">
<img alt="pytorch versus tensorflow out of the box bigger batch sizes" src="assets/21_bert_cpu_scaling_part_1/imgs/pytorch_vs_tf_oob_big_batch.svg" />
<figcaption>Figure 2. PyTorch (1.8.1) vs Google TensorFlow (2.4.1) out of the box - (Bigger Batch Size)</figcaption>
</figure>
<br>
Straigh to the point, out-of-the-box, PyTorch shows better inference results over TensorFlow for all the configurations tested here.
It is important to note the results out-of-the-box might not reflect the "optimal" setup for both PyTorch and TensorFlow and thus it can look deceiving here.
One possible way to explain such difference between the two frameworks might be the underlying technology to
execute parallel sections within operators.
PyTorch internally uses [OpenMP (10)](https://www.openmp.org/) along with [Intel MKL (now oneDNN) (11)](https://software.intel.com/content/www/us/en/develop/documentation/oneapi-programming-guide/top/api-based-programming/intel-oneapi-deep-neural-network-library-onednn.html) for efficient linear algebra computations whereas TensorFlow relies on Eigen and its own threading implementation.
## 5. Scaling BERT Inference to increase overall throughput on modern CPU
### 5.1. Introduction
There are multiple ways to improve the latency and throughput for tasks such as BERT inference.
Improvements and tuning can be performed at various levels from enabling Operating System features, swapping dependent
libraries with more performant ones, carefully tuning framework properties and, last but not least,
using parallelization logic leveraging all the cores on the CPU(s).
For the remainder of this blog post we will focus on the latter, also known as **Multiple Inference Stream**.
The idea is simple: Allocate **multiple instances** of the same model and assign the execution of each instance to a
**dedicated, non-overlapping subset of the CPU cores** in order to have truly parallel instances.
### 5.2. Cores and Threads on Modern CPUs
On our way towards optimizing CPU inference for better usage of the CPU cores you might have already seen -_at least for the
past 20 years_- modern CPUs specifications report "cores" and "hardware threads" or "physical" and "logical" numbers.
These notions refer to a mechanism called **Simultaneous Multi-Threading** (SMT) or **Hyper-Threading** on Intel's platforms.
To illustrate this, imagine two tasks **A** and **B**, executing in parallel, each on its own software thread.
At some point, there is a high probability these two tasks will have to wait for some resources to be fetched from main memory, SSD, HDD
or even the network.
If the threads are scheduled on different physical cores, with no hyper-threading,
during these periods the core executing the task is in an **Idle** state waiting for the resources to arrive, and effectively doing nothing... and hence not getting fully utilized
Now, with **SMT**, the **two software threads for task A and B** can be scheduled on the same **physical core**,
such that their execution is interleaved on that physical core:
Task A and Task B will execute simultaneously on the physical core and when one task is halted, the other task can still continue execution
on the core thereby increasing the utilization of that core.
<br>
<figure class="image">
<img class="centered" alt="Intel Hyper Threading technology" src="assets/21_bert_cpu_scaling_part_1/imgs/hyper_threading_explained.png" />
<figcaption>Figure 3. Illustration of Intel Hyper Threading technology (SMT)</figcaption>
</figure>
<br>
The figure 3. above simplifies the situation by assuming single core setup. If you want some more details on how SMT works on multi-cores CPUs, please
refer to these two articles with very deep technical explanations of the behavior:
- [Intel® Hyper-Threading Technology - Technical User Guide (12)](http://www.cslab.ece.ntua.gr/courses/advcomparch/2007/material/readings/Intel%20Hyper-Threading%20Technology.pdf)
- [Introduction to Hyper-Threading Technology (13)](https://software.intel.com/content/www/us/en/develop/articles/introduction-to-hyper-threading-technology.html)
Back to our model inference workload... If you think about it, in a perfect world with a fully optimized setup, computations take the majority of time.
In this context, using the logical cores shouldn't bring us any performance benefit because both logical cores (hardware threads) compete for the core’s execution resources.
As a result, the tasks being a majority of general matrix multiplications (_[gemms (14)](https://en.wikipedia.org/wiki/Basic_Linear_Algebra_Subprograms#Level_3)_), they are inherently CPU bounds and **does not benefits** from SMT.
### 5.3. Leveraging Multi-Socket servers and CPU affinity
Nowadays servers bring many cores, some of them even support multi-socket setups (_i.e. multiple CPUs on the motherboard_).
On Linux, the command `lscpu` reports all the specifications and topology of the CPUs present on the system:
```shell
ubuntu@some-ec2-machine:~$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz
Stepping: 7
CPU MHz: 1200.577
CPU max MHz: 3900.0000
CPU min MHz: 1200.0000
BogoMIPS: 6000.00
Virtualization: VT-x
L1d cache: 1.5 MiB
L1i cache: 1.5 MiB
L2 cache: 48 MiB
L3 cache: 71.5 MiB
NUMA node0 CPU(s): 0-23,48-71
NUMA node1 CPU(s): 24-47,72-95
```
In our case we have a machine with **2 sockets**, each socket providing **24 physical cores** with **2 threads per cores** (SMT).
Another interesting characteristic is the notion of **NUMA** node (0, 1) which represents how cores and memory are being
mapped on the system.
Non-Uniform Memory Access (**NUMA**) is the opposite of Uniform Memory Access (**UMA**) where the whole memory pool
is accessible by all the cores through a single unified bus between sockets and the main memory.
**NUMA** on the other hand splits the memory pool and each CPU socket is responsible to address a subset of the memory,
reducing the congestion on the bus.
<br>
<figure class="image">
<img class="centered" alt="Non-Uniform Memory Access and Uniform Memory Access architectures" src="assets/21_bert_cpu_scaling_part_1/imgs/UMA_NUMA.png" />
<figcaption>Figure 5. Difference illustration of UMA and NUMA architectures <a href="https://software.intel.com/content/www/us/en/develop/articles/optimizing-applications-for-numa.html">(source (15))</a></figcaption>
</figure>
<br>
In order to fully utilize the potential of such a beefy machine, we need to ensure our model instances are correctly
dispatched across all the **physical** cores on all sockets along with enforcing memory allocation to be "NUMA-aware".
On Linux, NUMA's process configuration can be tuned through [`numactl`](https://linux.die.net/man/8/numactl) which provides an interface to bind a process to a
set of CPU cores (referred as **Thread Affinity**).
Also, it allows tuning the memory allocation policy, making sure the memory allocated for the process
is as close as possible to the cores' memory pool (referred as **Explicit Memory Allocation Directives**).
_Note: Setting both cores and memory affinities is important here. Having computations done on socket 0 and memory allocated
on socket 1 would ask the system to go over the sockets shared bus to exchange memory, thus leading to an undesired overhead._
### 5.4. Tuning Thread Affinity & Memory Allocation Policy
Now that we have all the knobs required to control the resources' allocation of our model instances we go further and see how to
effectively deploy those and see the impact on latency and throughput.
Let's go gradually to get a sense of what is the impact of each command and parameter.
First, we start by launching our inference model without any tuning, and we observe how the computations are being dispatched on CPU cores (_Left_).
```shell
python3 src/main.py model=bert-base-cased backend.name=pytorch batch_size=1 sequence_length=128
```
Then we specify the core and memory affinity through `numactl` using all the **physical** cores and only a single thread (thread 0) per core (_Right_):
```shell
numactl -C 0-47 -m 0,1 python3 src/main.py model=bert-base-cased backend.name=pytorch batch_size=1 sequence_length=128
```
<br>
<figure class="image">
<img class="centered" alt="htop CPU usage without and with numactl thread affinity set" src="assets/21_bert_cpu_scaling_part_1/imgs/numa_combined.svg" />
<figcaption>Figure 6. Linux htop command side-by-side results without & with Thread Affinity set</figcaption>
</figure>
<br>
As you can see, without any specific tuning, PyTorch and TensorFlow dispatch the work on a single socket, using all the logical cores in that socket (both threads on 24 cores).
Also, as we highlighted earlier, we do not want to leverage the **SMT** feature in our case, so we set the process' thread affinity to target only 1 hardware thread.
_Note, this is specific to this run and can vary depending on individual setups. Hence, it is recommended to check thread affinity settings for each specific use-case._
Let's take sometime from here to highlight what we did with `numactl`:
- `-C 0-47` indicates to `numactl` what is the thread affinity (cores 0 to 47).
- `-m 0,1` indicates to `numactl` to allocate memory on both CPU sockets
If you wonder why we are binding the process to cores [0...47], you need to go back to look at the output of `lscpu`.
From there you will find the section `NUMA node0` and `NUMA node1` which has the form `NUMA node<X> <logical ids>`
In our case, each socket is one NUMA node and there are 2 NUMA nodes.
Each socket or each NUMA node has 24 physical cores and 2 hardware threads per core, so 48 logical cores.
For NUMA node 0, 0-23 are hardware thread 0 and 24-47 are hardware thread 1 on the 24 physical cores in socket 0.
Likewise, for NUMA node 1, 48-71 are hardware thread 0 and 72-95 are hardware thread 1 on the 24 physical cores in socket 1.
As we are targeting just 1 thread per physical core, as explained earlier, we pick only thread 0 on each core and hence logical processors 0-47.
Since we are using both sockets, we need to also bind the memory allocations accordingly (0,1).
_Please note that using both sockets may not always give the best results, particularly for small problem sizes.
The benefit of using compute resources across both sockets might be reduced or even negated by cross-socket communication overhead._
## 6. Core count scaling - Does using more cores actually improve performance?
When thinking about possible ways to improve our model inference performances, the first rational solution might be to
throw some more resources to do the same amount of work.
Through the rest of this blog series, we will refer to this setup as **Core Count Scaling** meaning, only the number
of cores used on the system to achieve the task will vary. This is also often referred as Strong Scaling in the HPC world.
At this stage, you may wonder what is the point of allocating only a subset of the cores rather than throwing
all the horses at the task to achieve minimum latency.
Indeed, depending on the problem-size, throwing more resources to the task might give better results.
It is also possible that for small problems putting more CPU cores at work doesn't improve the final latency.
In order to illustrate this, the figure 6. below takes different problem sizes (`batch_size = 1, sequence length = {32, 128, 512}`)
and reports the latencies with respect to the number of CPU cores used for running
computations for both PyTorch and TensorFlow.
Limiting the number of resources involved in computation is done by limiting the CPU cores involved in
**intra** operations (_**intra** here means inside an operator doing computation, also known as "kernel"_).
This is achieved through the following APIs:
- PyTorch: `torch.set_num_threads(x)`
- TensorFlow: `tf.config.threading.set_intra_op_parallelism_threads(x)`
<br>
<figure class="image">
<img alt="" src="assets/21_bert_cpu_scaling_part_1/imgs/core_count_scaling.svg" />
<figcaption>Figure 7. Latency measurements</figcaption>
</figure>
<br>
As you can see, depending on the problem size, the number of threads involved in the computations has a positive impact
on the latency measurements.
For small-sized problems & medium-sized problems using only one socket would give the best performance.
For large-sized problems, the overhead of the cross-socket communication is covered by the computations cost, thus benefiting from
using all the cores available on the both sockets.
## 7. Multi-Stream Inference - Using multiple instances in parallel
If you're still reading this, you should now be in good shape to set up parallel inference workloads on CPU.
Now, we are going to highlight some possibilities offered by the powerful hardware we have, and tuning the knobs described before,
to scale our inference as linearly as possible.
In the following section we will explore another possible scaling solution **Batch Size Scaling**, but before diving into this, let's
take a look at how we can leverage Linux tools in order to assign Thread Affinity allowing effective model instance parallelism.
Instead of throwing more cores to the task as you would do in the core count scaling setup, now we will be using more model instances.
Each instance will run independently on its own subset of the hardware resources in a truly parallel fashion on a subset of the CPU cores.
### 7.1. How-to allocate multiple independent instances
Let's start simple, if we want to spawn 2 instances, one on each socket with 24 cores assigned:
```shell
numactl -C 0-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=24
numactl -C 24-47 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=24
```
Starting from here, each instance does not share any resource with the other, and everything is operating at maximum efficiency from a
hardware perspective.
The latency measurements are identical to what a single instance would achieve, but throughput is actually 2x higher
as the two instances operate in a truly parallel way.
We can further increase the number of instances, lowering the number of cores assigned for each instance.
Let's run 4 independent instances, each of them effectively bound to 12 CPU cores.
```shell
numactl -C 0-11 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 12-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 24-35 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 36-47 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
```
The outcomes remain the same, our 4 instances are effectively running in a truly parallel manner.
The latency will be slightly higher than the example before (2x less cores being used), but the throughput will be again 2x higher.
### 7.2. Smart dispatching - Allocating different model instances for different problem sizes
One another possibility offered by this setup is to have multiple instances carefully tuned for various problem sizes.
With a smart dispatching approach, one can redirect incoming requests to the right configuration giving the best latency depending on the request workload.
```shell
# Small-sized problems (sequence length <= 32) use only 8 cores (on socket 0 - 8/24 cores used)
numactl -C 0-7 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=32 backend.name=pytorch backend.num_threads=8
# Medium-sized problems (32 > sequence <= 384) use remaining 16 cores (on socket 0 - (8+16)/24 cores used)
numactl -C 8-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=16
# Large sized problems (sequence >= 384) use the entire CPU (on socket 1 - 24/24 cores used)
numactl -C 24-37 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=384 backend.name=pytorch backend.num_threads=24
```
## 8. Batch size scaling - Improving throughput and latency with multiple parallel & independent model instances
One another very interesting direction for scaling up inference is to actually put some more model instances into the pool
along with reducing the actual workload each instance receives proportionally.
This method actually changes both the size of the problem (_batch size_), and the resources involved in the computation (_cores_).
To illustrate, imagine you have a server with `C` CPU cores, and you want to run a workload containing B samples with S tokens.
You can represent this workload as a tensor of shape `[B, S]`, B being the size of the batch and S being the maximum sequence length within the B samples.
For all the instances (`N`), each of them executes on `C / N` cores and would receive a subset of the task `[B / N, S]`.
Each instance doesn't receive the global batch but instead, they all receive a subset of it `[B / N, S]` thus the name **Batch Size Scaling**.
In order to highlight the benefits of such scaling method, the charts below reports both the latencies when scaling up model instances along with the effects on the throughput.
When looking at the results, let's focus on the latency and the throughput aspects:
On one hand, we are taking the maximum latency over the pool of instances to reflect the time it takes to process all the samples in the batch.
Putting it differently, as instances operate in a truly parallel fashion, the time it takes to gather all the batch chunks from all the instances
is driven by the longest time it takes for individual instance in the pool to get their chunk done.
As you can see below on Figure 7., the actual latency gain when increasing the number of instances is really dependent of the problem size.
In all cases, we can find an optimal resource allocation (batch size & number of instances) to minimize our latency but, there is no specific pattern on the number of cores to involve in the computation.
Also, it is important to notice the results might look totally different on another system _(i.e. Operating System, Kernel Version, Framework version, etc.)_
Figure 8. sums up the best multi-instance configuration when targeting minimum latency by taking the minimum over the number of instances involved.
For instance, for `{batch = 8, sequence length = 128}` using 4 instances (each with `{batch = 2}` and 12 cores) gives the best latency measurements.
The Figure 9. reports all the setups minimizing latency for both PyTorch and TensorFlow for various problem-sizes.
_**Spoiler**: There are numerous other optimizations we will discuss in a follow-up blog post which will substantially impact this chart._
<br>
<figure class="image">
<img alt="Batch scaling experiment for PyTorch and Tensorflow" src="assets/21_bert_cpu_scaling_part_1/imgs/batch_scaling_exp.svg" style="width:100%"/>
<figcaption>Figure 8. Max latency evolution with respect to number of instances for a total batch size of 8</figcaption>
</figure>
<br>
<br>
<figure class="image">
<img alt="Optimal number of instance minimizing overall latency for a total batch size of 8" src="assets/21_bert_cpu_scaling_part_1/imgs/batch_size_scaling_latency_optimal_nb_instances.svg" style="width:100%"/>
<figcaption>Figure 9. Optimal number of instance minimizing overall latency for a total batch size of 8</figcaption>
</figure>
<br>
On a second hand, we observe the throughput as the sum of all the model instance executing in parallel.
It allows us to visualize the scalability of the system when adding more and more instances each of them with fewer resources but also proportional workload.
Here, the results show almost linear scalability and thus an optimal hardware usage.
<figure class="image">
<img alt="Batch scaling experiment for PyTorch and Tensorflow" src="assets/21_bert_cpu_scaling_part_1/imgs/batch_scaling_exp_throughput.svg" style="width:100%"/>
<figcaption>Figure 10. Sum throughput with respect to number of instances for a total batch size of 8</figcaption>
</figure>
<br>
## 9. Conclusion
Through this blog post, we covered out-of-box BERT inference performance one can expect for PyTorch and TensorFlow,
from a simple PyPi install and without further tuning.
It is important to highlight results provided here reflects out-of-the-box framework setup hence, they might not provide the absolute best performances.
We decided to not include optimizations as part of this blog post to focus on hardware and efficiency.
Optimizations will be discussed in the second part! 🚀
Then, we covered and detailed the impact, and the importance of setting the thread affinity along with the trade-off between the target problem size, and the number of cores required for achieving the task.
Also, it is important to define **which criteria** _(i.e. latency vs throughput)_ to use when optimizing your deployment as the resulting setups might be totally different.
On a more general note, small problem sizes (_short sequences and/or small batches_) might require much fewer cores to achieve the best possible latency than big problems (_very long sequences and/or big batches_).
It is interesting to cover all these aspects when thinking about the final deployment platform as it might cut the cost of the infrastructure drastically.
For instance, our 48 cores machine charges **4.848\$/h** whereas a smaller instances with only 8 cores lowers the cost to **0.808\$/h**, leading to a **6x cost reduction**.
Last but not least, many of the knobs discussed along this blog post can be automatically tuned through a [launcher script](https://github.com/huggingface/tune/blob/main/launcher.py)
highly inspired from the original script made by Intel and available [here](https://github.com/intel/intel-extension-for-pytorch/blob/master/intel_pytorch_extension_py/launch.py).
The launcher script is able to automatically starts your python process(es) with the correct thread affinity, effectively
splitting resources across instances along with many other performances tips! We will detail many of this tips in the second part 🧐.
In the follow-up blog post, more advanced settings and tuning techniques to decrease model latency even further will be involved, such as:
- Launcher script walk-through
- Tuning the memory allocation library
- Using Linux's Transparent Huge Pages mechanisms
- Using vendor-specific Math/Parallel libraries
Stay tuned! 🤗
## Acknowledgments
- [Omry Yadan](https://github.com/omry) (Facebook FAIR) - Author of [OmegaConf](https://github.com/omry/omegaconf) & [Hydra](https://github.com/facebookresearch/hydra) for all the tips setting up Hydra correctly.
- All Intel & Intel Labs' NLP colleagues - For the ongoing optimizations and research efforts they are putting into transformers and more generally in the NLP field.
- Hugging Face colleagues - For all the comments and improvements in the reviewing process.
## References
1. [Benchmarking Transformers: PyTorch and TensorFlow](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2)
2. [HuggingFace's Transformers: State-of-the-art Natural Language Processing](https://arxiv.org/abs/1910.03771v2)
3. [HuggingFace's Model Hub](https://huggingface.co./models)
4. [BERT - Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin & al. 2018)](https://arxiv.org/abs/1810.04805v1)
5. [Illustrated Transformer blogpost from Jay Alammar](https://jalammar.github.io/illustrated-transformer/)
6. [PyTorch - TorchScript](https://pytorch.org/docs/stable/jit.html)
7. [Google Accelerated Linear Algebra (XLA)](https://www.tensorflow.org/xla)
8. [ONNX Runtime - Optimize and Accelerate Machine Learning Inferencing and Training](https://www.onnxruntime.ai/)
9. [Q8BERT - Quantized 8Bit BERT (Zafrir & al. 2019)](https://arxiv.org/abs/1910.06188)
10. [OpenMP](https://www.openmp.org/)
11. [Intel oneDNN](https://software.intel.com/content/www/us/en/develop/documentation/oneapi-programming-guide/top/api-based-programming/intel-oneapi-deep-neural-network-library-onednn.html)
12. [Intel® Hyper-Threading Technology - Technical User Guide](http://www.cslab.ece.ntua.gr/courses/advcomparch/2007/material/readings/Intel%20Hyper-Threading%20Technology.pdf)
13. [Introduction to Hyper-Threading Technology](https://software.intel.com/content/www/us/en/develop/articles/introduction-to-hyper-threading-technology.html)
14. [BLAS (Basic Linear Algebra Subprogram) - Wikipedia](https://en.wikipedia.org/wiki/Basic_Linear_Algebra_Subprograms#Level_3)
15. [Optimizing Applications for NUMA](https://software.intel.com/content/www/us/en/develop/articles/optimizing-applications-for-numa.html) | [
[
"transformers",
"benchmarks",
"tutorial",
"optimization",
"text_classification",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"optimization",
"efficient_computing",
"benchmarks"
] | null | null |
44b49ae8-8279-4679-a6c8-f1e595dd28b2 | completed | 2025-01-16T03:08:53.170950 | 2025-01-16T15:15:52.812967 | 6d9c4810-0aa5-4e8b-a052-12be88135182 | AI Apps in a Flash with Gradio's Reload Mode | freddyaboulton | gradio-reload.md | In this post, I will show you how you can build a functional AI application quickly with Gradio's reload mode. But before we get to that, I want to explain what reload mode does and why Gradio implements its own auto-reloading logic. If you are already familiar with Gradio and want to get to building, please skip to the third [section](#building-a-document-analyzer-application).
## What Does Reload Mode Do?
To put it simply, it pulls in the latest changes from your source files without restarting the Gradio server. If that does not make sense yet, please continue reading.
Gradio is a popular Python library for creating interactive machine learning apps.
Gradio developers declare their UI layout entirely in Python and add some Python logic that triggers whenever a UI event happens. It's easy to learn if you know basic Python. Check out this [quickstart](https://www.gradio.app/guides/quickstart) if you are not familiar with Gradio yet.
Gradio applications are launched like any other Python script, just run `python app.py` (the file with the Gradio code can be called anything). This will start an HTTP server that renders your app's UI and responds to user actions. If you want to make changes to your app, you stop the server (typically with `Ctrl + C`), edit your source file, and then re-run the script.
Having to stop and relaunch the server can introduce a lot of latency while you are developing your app. It would be better if there was a way to pull in the latest code changes automatically so you can test new ideas instantly.
That's exactly what Gradio's reload mode does. Simply run `gradio app.py` instead of `python app.py` to launch your app in reload mode!
## Why Did Gradio Build Its Own Reloader?
Gradio applications are run with [uvicorn](https://www.uvicorn.org/), an asynchronous server for Python web frameworks. Uvicorn already offers [auto-reloading](https://www.uvicorn.org/) but Gradio implements its own logic for the following reasons:
1. **Faster Reloading**: Uvicorn's auto-reload will shut down the server and spin it back up. This is faster than doing it by hand, but it's too slow for developing a Gradio app. Gradio developers build their UI in Python so they should see how ther UI looks as soon as a change is made. This is standard in the Javascript ecosystem but it's new to Python.
2. **Selective Reloading**: Gradio applications are AI applications. This means they typically load an AI model into memory or connect to a datastore like a vector database. Relaunching the server during development will mean reloading that model or reconnecting to that database, which introduces too much latency between development cycles. To fix this issue, Gradio introduces an `if gr.NO_RELOAD:` code-block that you can use to mark code that should not be reloaded. This is only possible because Gradio implements its own reloading logic.
I will now show you how you can use Gradio reload mode to quickly build an AI App.
## Building a Document Analyzer Application
Our application will allow users to upload pictures of documents and ask questions about them. They will receive answers in natural language. We will use the free [Hugging Face Inference API](https://huggingface.co./docs/huggingface_hub/guides/inference) so you should be able to follow along from your computer. No GPU required!
To get started, let's create a barebones `gr.Interface`. Enter the following code in a file called `app.py` and launch it in reload mode with `gradio app.py`:
```python
import gradio as gr
demo = gr.Interface(lambda x: x, "text", "text")
if __name__ == "__main__":
demo.launch()
```
This creates the following simple UI.

Since I want to let users upload image files along with their questions, I will switch the input component to be a `gr.MultimodalTextbox()`. Notice how the UI updates instantly!

This UI works but, I think it would be better if the input textbox was below the output textbox. I can do this with the `Blocks` API. I'm also customizing the input textbox by adding a placeholder text to guide users.

Now that I'm satisfied with the UI, I will start implementing the logic of the `chat_fn`.
Since I'll be using Hugging Face's Inference API, I will import the `InferenceClient` from the `huggingface_hub` package (it comes pre-installed with Gradio). I'll be using the [`impira/layouylm-document-qa`](https://huggingface.co./impira/layoutlm-document-qa) model to answer the user's question. I will then use the [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co./HuggingFaceH4/zephyr-7b-beta) LLM to provide a response in natural language.
```python
from huggingface_hub import InferenceClient
client = InferenceClient()
def chat_fn(multimodal_message):
question = multimodal_message["text"]
image = multimodal_message["files"][0]
answer = client.document_question_answering(image=image, question=question, model="impira/layoutlm-document-qa")
answer = [{"answer": a.answer, "confidence": a.score} for a in answer]
user_message = {"role": "user", "content": f"Question: {question}, answer: {answer}"}
message = ""
for token in client.chat_completion(messages=[user_message],
max_tokens=200,
stream=True,
model="HuggingFaceH4/zephyr-7b-beta"):
if token.choices[0].finish_reason is not None:
continue
message += token.choices[0].delta.content
yield message
```
Here is our demo in action!

I will also provide a system message so that the LLM keeps answers short and doesn't include the raw confidence scores. To avoid re-instantiating the `InferenceClient` on every change, I will place it inside a no reload code block.
```python
if gr.NO_RELOAD:
client = InferenceClient()
system_message = {
"role": "system",
"content": """
You are a helpful assistant.
You will be given a question and a set of answers along with a confidence score between 0 and 1 for each answer.
You job is to turn this information into a short, coherent response.
For example:
Question: "Who is being invoiced?", answer: {"answer": "John Doe", "confidence": 0.98}
You should respond with something like:
With a high degree of confidence, I can say John Doe is being invoiced.
Question: "What is the invoice total?", answer: [{"answer": "154.08", "confidence": 0.75}, {"answer": "155", "confidence": 0.25}
You should respond with something like:
I believe the invoice total is $154.08 but it can also be $155.
"""}
```
Here is our demo in action now! The system message really helped keep the bot's answers short and free of long decimals.

As a final improvement, I will add a markdown header to the page:

## Conclusion
In this post, I developed a working AI application with Gradio and the Hugging Face Inference API. When I started developing this, I didn't know what the final product would look like so having the UI and server logic reload instanty let me iterate on different ideas very quickly. It took me about an hour to develop this entire app!
If you'd like to see the entire code for this demo, please check out this [space](https://huggingface.co./spaces/freddyaboulton/document-analyzer)! | [
[
"mlops",
"implementation",
"tutorial",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"implementation",
"tutorial",
"tools",
"mlops"
] | null | null |
c7413e14-ea39-4e71-a153-0f29bf9725c2 | completed | 2025-01-16T03:08:53.170955 | 2025-01-19T19:09:03.854027 | d9cc5d6f-5354-4df2-b4a2-4b69f7d1c936 | Building an AI WebTV | jbilcke-hf | ai-webtv.md | The AI WebTV is an experimental demo to showcase the latest advancements in automatic video and music synthesis.
👉 Watch the stream now by going to the [AI WebTV Space](https://huggingface.co./spaces/jbilcke-hf/AI-WebTV).
If you are using a mobile device, you can view the stream from the [Twitch mirror](https://www.twitch.tv/ai_webtv).

## Concept
The motivation for the AI WebTV is to demo videos generated with open-source [text-to-video models](https://huggingface.co./tasks/text-to-video) such as Zeroscope and MusicGen, in an entertaining and accessible way.
You can find those open-source models on the Hugging Face hub:
- For video: [zeroscope_v2_576](https://huggingface.co./cerspense/zeroscope_v2_576w) and [zeroscope_v2_XL](https://huggingface.co./cerspense/zeroscope_v2_XL)
- For music: [musicgen-melody](https://huggingface.co./facebook/musicgen-melody)
The individual video sequences are purposely made to be short, meaning the WebTV should be seen as a tech demo/showreel rather than an actual show (with an art direction or programming).
## Architecture
The AI WebTV works by taking a sequence of [video shot](https://en.wikipedia.org/wiki/Shot_(filmmaking)) prompts and passing them to a [text-to-video model](https://huggingface.co./tasks/text-to-video) to generate a sequence of [takes](https://en.wikipedia.org/wiki/Take).
Additionally, a base theme and idea (written by a human) are passed through a LLM (in this case, ChatGPT), in order to generate a variety of individual prompts for each video clip.
Here's a diagram of the current architecture of the AI WebTV:

## Implementing the pipeline
The WebTV is implemented in NodeJS and TypeScript, and uses various services hosted on Hugging Face.
### The text-to-video model
The central video model is Zeroscope V2, a model based on [ModelScope](https://huggingface.co./damo-vilab/modelscope-damo-text-to-video-synthesis).
Zeroscope is comprised of two parts that can be chained together:
- A first pass with [zeroscope_v2_576](https://huggingface.co./cerspense/zeroscope_v2_576w), to generate a 576x320 video clip
- An optional second pass with [zeroscope_v2_XL](https://huggingface.co./cerspense/zeroscope_v2_XL) to upscale the video to 1024x576
👉 You will need to use the same prompt for both the generation and upscaling.
### Calling the video chain
To make a quick prototype, the WebTV runs Zeroscope from two duplicated Hugging Face Spaces running [Gradio](https://github.com/gradio-app/gradio/), which are called using the [@gradio/client](https://www.npmjs.com/package/@gradio/client) NPM package. You can find the original spaces here:
- [zeroscope-v2](https://huggingface.co./spaces/hysts/zeroscope-v2/tree/main) by @hysts
- [Zeroscope XL](https://huggingface.co./spaces/fffiloni/zeroscope-XL) by @fffiloni
Other spaces deployed by the community can also be found if you [search for Zeroscope on the Hub](https://huggingface.co./spaces?search=zeroscope).
👉 Public Spaces may become overcrowded and paused at any time. If you intend to deploy your own system, please duplicate those Spaces and run them under your own account.
### Using a model hosted on a Space
Spaces using Gradio have the ability to [expose a REST API](https://www.gradio.app/guides/sharing-your-app#api-page), which can then be called from Node using the [@gradio/client](https://www.npmjs.com/package/@gradio/client) module.
Here is an example:
```typescript
import { client } from "@gradio/client"
export const generateVideo = async (prompt: string) => {
const api = await client("*** URL OF THE SPACE ***")
// call the "run()" function with an array of parameters
const { data } = await api.predict("/run", [
prompt,
42, // seed
24, // nbFrames
35 // nbSteps
])
const { orig_name } = data[0][0]
const remoteUrl = `${instance}/file=${orig_name}`
// the file can then be downloaded and stored locally
}
```
### Post-processing
Once an individual take (a video clip) is upscaled, it is then passed to FILM (Frame Interpolation for Large Motion), a frame interpolation algorithm:
- Original links: [website](https://film-net.github.io/), [source code](https://github.com/google-research/frame-interpolation)
- Model on Hugging Face: [/frame-interpolation-film-style](https://huggingface.co./akhaliq/frame-interpolation-film-style)
- A Hugging Face Space you can duplicate: [video_frame_interpolation](https://huggingface.co./spaces/fffiloni/video_frame_interpolation/blob/main/app.py) by @fffiloni
During post-processing, we also add music generated with MusicGen:
- Original links: [website](https://ai.honu.io/papers/musicgen/), [source code](https://github.com/facebookresearch/audiocraft)
- Hugging Face Space you can duplicate: [MusicGen](https://huggingface.co./spaces/facebook/MusicGen)
### Broadcasting the stream
Note: there are multiple tools you can use to create a video stream. The AI WebTV currently uses [FFmpeg](https://ffmpeg.org/documentation.html) to read a playlist made of mp4 videos files and m4a audio files.
Here is an example of creating such a playlist:
```typescript
import { promises as fs } from "fs"
import path from "path"
const allFiles = await fs.readdir("** PATH TO VIDEO FOLDER **")
const allVideos = allFiles
.map(file => path.join(dir, file))
.filter(filePath => filePath.endsWith('.mp4'))
let playlist = 'ffconcat version 1.0\n'
allFilePaths.forEach(filePath => {
playlist += `file '${filePath}'\n`
})
await fs.promises.writeFile("playlist.txt", playlist)
```
This will generate the following playlist content:
```bash
ffconcat version 1.0
file 'video1.mp4'
file 'video2.mp4'
...
```
FFmpeg is then used again to read this playlist and send a [FLV stream](https://en.wikipedia.org/wiki/Flash_Video) to a [RTMP server](https://en.wikipedia.org/wiki/Real-Time_Messaging_Protocol). FLV is an old format but still popular in the world of real-time streaming due to its low latency.
```bash
ffmpeg -y -nostdin \
-re \
-f concat \
-safe 0 -i channel_random.txt -stream_loop -1 \
-loglevel error \
-c:v libx264 -preset veryfast -tune zerolatency \
-shortest \
-f flv rtmp://<SERVER>
```
There are many different configuration options for FFmpeg, for more information in the [official documentation](http://trac.ffmpeg.org/wiki/StreamingGuide).
For the RTMP server, you can find [open-source implementations on GitHub](https://github.com/topics/rtmp-server), such as the [NGINX-RTMP module](https://github.com/arut/nginx-rtmp-module).
The AI WebTV itself uses [node-media-server](https://github.com/illuspas/Node-Media-Server).
💡 You can also directly stream to [one of the Twitch RTMP entrypoints](https://help.twitch.tv/s/twitch-ingest-recommendation?language=en_US). Check out the Twitch documentation for more details.
## Observations and examples
Here are some examples of the generated content.
The first thing we notice is that applying the second pass of Zeroscope XL significantly improves the quality of the image. The impact of frame interpolation is also clearly visible.
### Characters and scene composition
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo4.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo4.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Photorealistic movie of a <strong>llama acting as a programmer, wearing glasses and a hoodie</strong>, intensely <strong>staring at a screen</strong> with lines of code, in a cozy, <strong>dimly lit room</strong>, Canon EOS, ambient lighting, high details, cinematic, trending on artstation</i></figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo5.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo5.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>3D rendered animation showing a group of food characters <strong>forming a pyramid</strong>, with a <strong>banana</strong> standing triumphantly on top. In a city with <strong>cotton candy clouds</strong> and <strong>chocolate road</strong>, Pixar's style, CGI, ambient lighting, direct sunlight, rich color scheme, ultra realistic, cinematic, photorealistic.</i></figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo7.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo7.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Intimate <strong>close-up of a red fox, gazing into the camera with sharp eyes</strong>, ambient lighting creating a high contrast silhouette, IMAX camera, <strong>high detail</strong>, <strong>cinematic effect</strong>, golden hour, film grain.</i></figcaption>
</figure>
### Simulation of dynamic scenes
Something truly fascinating about text-to-video models is their ability to emulate real-life phenomena they have been trained on.
We've seen it with large language models and their ability to synthesize convincing content that mimics human responses, but this takes things to a whole new dimension when applied to video.
A video model predicts the next frames of a scene, which might include objects in motion such as fluids, people, animals, or vehicles. Today, this emulation isn't perfect, but it will be interesting to evaluate future models (trained on larger or specialized datasets, such as animal locomotion) for their accuracy when reproducing physical phenomena, and also their ability to simulate the behavior of agents.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo17.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo17.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Cinematic movie shot of <strong>bees energetically buzzing around a flower</strong>, sun rays illuminating the scene, captured in 4k IMAX with a soft bokeh background.</i></figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo8.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo8.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i><strong>Dynamic footage of a grizzly bear catching a salmon in a rushing river</strong>, ambient lighting highlighting the splashing water, low angle, IMAX camera, 4K movie quality, golden hour, film grain.</i></figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo18.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo18.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Aerial footage of a quiet morning at the coast of California, with <strong>waves gently crashing against the rocky shore</strong>. A startling sunrise illuminates the coast with vibrant colors, captured beautifully with a DJI Phantom 4 Pro. Colors and textures of the landscape come alive under the soft morning light. Film grain, cinematic, imax, movie</i></figcaption>
</figure>
💡 It will be interesting to see these capabilities explored more in the future, for instance by training video models on larger video datasets covering more phenomena.
### Styling and effects
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo0.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo0.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>
<strong>3D rendered video</strong> of a friendly broccoli character wearing a hat, walking in a candy-filled city street with gingerbread houses, under a <strong>bright sun and blue skies</strong>, <strong>Pixar's style</strong>, cinematic, photorealistic, movie, <strong>ambient lighting</strong>, natural lighting, <strong>CGI</strong>, wide-angle view, daytime, ultra realistic.</i>
</figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo2.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo2.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i><strong>Cinematic movie</strong>, shot of an astronaut and a llama at dawn, the mountain landscape bathed in <strong>soft muted colors</strong>, early morning fog, dew glistening on fur, craggy peaks, vintage NASA suit, Canon EOS, high detailed skin, epic composition, high quality, 4K, trending on artstation, beautiful</i>
</figcaption>
</figure>
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="demo1.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/demo1.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Panda and black cat <strong>navigating down the flowing river</strong> in a small boat, Studio Ghibli style > Cinematic, beautiful composition > IMAX <strong>camera panning following the boat</strong> > High quality, cinematic, movie, mist effect, film grain, trending on Artstation</i>
</figcaption>
</figure>
### Failure cases
**Wrong direction:** the model sometimes has trouble with movement and direction. For instance, here the clip seems to be played in reverse. Also the modifier keyword ***green*** was not taken into account.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="fail1.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/fail1.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Movie showing a <strong>green pumpkin</strong> falling into a bed of nails, slow-mo explosion with chunks flying all over, ambient fog adding to the dramatic lighting, filmed with IMAX camera, 8k ultra high definition, high quality, trending on artstation.</i>
</figcaption>
</figure>
**Rendering errors on realistic scenes:** sometimes we can see artifacts such as moving vertical lines or waves. It is unclear what causes this, but it may be due to the combination of keywords used.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="fail2.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/fail2.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Film shot of a captivating flight above the Grand Canyon, ledges and plateaus etched in orange and red. <strong>Deep shadows contrast</strong> with the fiery landscape under the midday sun, shot with DJI Phantom 4 Pro. The camera rotates to capture the vastness, <strong>textures</strong> and colors, in imax quality. Film <strong>grain</strong>, cinematic, movie.</i>
</figcaption>
</figure>
**Text or objects inserted into the image:** the model sometimes injects words from the prompt into the scene, such as "IMAX". Mentioning "Canon EOS" or "Drone footage" in the prompt can also make those objects appear in the video.
In the following example, we notice the word "llama" inserts a llama but also two occurrences of the word llama in flames.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="fail3.mp4"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/156_ai_webtv/fail3.mp4" type="video/mp4">
</video>
<figcaption>Prompt: <i>Movie scene of a <strong>llama</strong> acting as a firefighter, in firefighter uniform, dramatically spraying water at <strong>roaring flames</strong>, amidst a chaotic urban scene, Canon EOS, ambient lighting, high quality, award winning, highly detailed fur, cinematic, trending on artstation.</i>
</figcaption>
</figure>
## Recommendations
Here are some early recommendations that can be made from the previous observations:
### Using video-specific prompt keywords
You may already know that if you don’t prompt a specific aspect of the image with Stable Diffusion, things like the color of clothes or the time of the day might become random, or be assigned a generic value such as a neutral mid-day light.
The same is true for video models: you will want to be specific about things. Examples include camera and character movement, their orientation, speed and direction. You can leave it unspecified for creative purposes (idea generation), but this might not always give you the results you want (e.g., entities animated in reverse).
### Maintaining consistency between scenes
If you plan to create sequences of multiple videos, you will want to make sure you add as many details as possible in each prompt, otherwise you may lose important details from one sequence to another, such as the color.
💡 This will also improve the quality of the image since the prompt is used for the upscaling part with Zeroscope XL.
### Leverage frame interpolation
Frame interpolation is a powerful tool which can repair small rendering errors and turn many defects into features, especially in scenes with a lot of animation, or where a cartoon effect is acceptable. The [FILM algorithm](https://film-net.github.io/) will smoothen out elements of a frame with previous and following events in the video clip.
This works great to displace the background when the camera is panning or rotating, and will also give you creative freedom, such as control over the number of frames after the generation, to make slow-motion effects.
## Future work
We hope you enjoyed watching the AI WebTV stream and that it will inspire you to build more in this space.
As this was a first trial, a lot of things were not the focus of the tech demo: generating longer and more varied sequences, adding audio (sound effects, dialogue), generating and orchestrating complex scenarios, or letting a language model agent have more control over the pipeline.
Some of these ideas may make their way into future updates to the AI WebTV, but we also can’t wait to see what the community of researchers, engineers and builders will come up with! | [
[
"audio",
"implementation",
"image_generation",
"multi_modal"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"image_generation",
"audio",
"multi_modal",
"implementation"
] | null | null |
a64ec70f-20f8-4793-acfe-96c3e681f255 | completed | 2025-01-16T03:08:53.170959 | 2025-01-19T17:18:02.085337 | bace507d-3671-4845-99b3-d0ce175be8f3 | Japanese Stable Diffusion | mshing, keisawada | japanese-stable-diffusion.md | <a target="_blank" href="https://huggingface.co./spaces/rinna/japanese-stable-diffusion" target="_parent"><img src="https://img.shields.io/badge/🤗 Hugging Face-Spaces-blue" alt="Open In Hugging Face Spaces"/></a>
<a target="_blank" href="https://colab.research.google.com/github/rinnakk/japanese-stable-diffusion/blob/master/scripts/txt2img.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
Stable Diffusion, developed by [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/), and [LAION](https://laion.ai/), has generated a great deal of interest due to its ability to generate highly accurate images by simply entering text prompts. Stable Diffusion mainly uses the English subset [LAION2B-en](https://huggingface.co./datasets/laion/laion2B-en) of the [LAION-5B](https://laion.ai/blog/laion-5b/) dataset for its training data and, as a result, requires English text prompts to be entered producing images that tend to be more oriented towards Western culture.
[rinna Co., Ltd](https://rinna.co.jp/). has developed a Japanese-specific text-to-image model named "Japanese Stable Diffusion" by fine-tuning Stable Diffusion on Japanese-captioned images. Japanese Stable Diffusion accepts Japanese text prompts and generates images that reflect the culture of the Japanese-speaking world which may be difficult to express through translation.
In this blog, we will discuss the background of the development of Japanese Stable Diffusion and its learning methodology.
Japanese Stable Diffusion is available on Hugging Face and GitHub. The code is based on [🧨 Diffusers](https://huggingface.co./docs/diffusers/index).
- Hugging Face model card: https://huggingface.co./rinna/japanese-stable-diffusion
- Hugging Face Spaces: https://huggingface.co./spaces/rinna/japanese-stable-diffusion
- GitHub: https://github.com/rinnakk/japanese-stable-diffusion
## Stable Diffusion
Recently diffusion models have been reported to be very effective in artificial synthesis, even more so than GANs (Generative Adversarial Networks) for images. Hugging Face explains how diffusion models work in the following articles:
- [The Annotated Diffusion Model](https://huggingface.co./blog/annotated-diffusion)
- [Getting started with 🧨 Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
Generally, a text-to-image model consists of a text encoder that interprets text and a generative model that generates an image from its output.
Stable Diffusion uses CLIP, the language-image pre-training model from OpenAI, as its text encoder and a latent diffusion model, which is an improved version of the diffusion model, as the generative model. Stable Diffusion was trained mainly on the English subset of LAION-5B and can generate high-performance images simply by entering text prompts. In addition to its high performance, Stable Diffusion is also easy to use with inference running at a computing cost of about 10GB VRAM GPU.
<p align="center">
<img src="https://raw.githubusercontent.com/patrickvonplaten/scientific_images/master/stable_diffusion.png" alt="sd-pipeline" width="300"/>
</p>
*from [Stable Diffusion with 🧨 Diffusers](https://huggingface.co./blog/stable_diffusion)*
## Japanese Stable Diffusion
### Why do we need Japanese Stable Diffusion?
Stable Diffusion is a very powerful text-to-image model not only in terms of quality but also in terms of computational cost. Because Stable Diffusion was trained on an English dataset, it is required to translate non-English prompts to English first. Surprisingly, Stable Diffusion can sometimes generate proper images even when using non-English prompts.
So, why do we need a language-specific Stable Diffusion? The answer is because we want a text-to-image model that can understand Japanese culture, identity, and unique expressions including slang. For example, one of the more common Japanese terms re-interpreted from the English word businessman is "salary man" which we most often imagine as a man wearing a suit. Stable Diffusion cannot understand such Japanese unique words correctly because Japanese is not their target.
<p align="center">
<img src="assets/106_japanese_stable_diffusion/sd.jpeg" alt="salary man of stable diffusion" title="salary man of stable diffusion">
</p>
*"salary man, oil painting" from the original Stable Diffusion*
So, this is why we made a language-specific version of Stable Diffusion. Japanese Stable Diffusion can achieve the following points compared to the original Stable Diffusion.
- Generate Japanese-style images
- Understand Japanese words adapted from English
- Understand Japanese unique onomatope
- Understand Japanese proper noun
### Training Data
We used approximately 100 million images with Japanese captions, including the Japanese subset of [LAION-5B](https://laion.ai/blog/laion-5b/). In addition, to remove low quality samples, we used [japanese-cloob-vit-b-16](https://huggingface.co./rinna/japanese-cloob-vit-b-16) published by rinna Co., Ltd. as a preprocessing step to remove samples whose scores were lower than a certain threshold.
### Training Details
The biggest challenge in making a Japanese-specific text-to-image model is the size of the dataset. Non-English datasets are much smaller than English datasets, and this causes performance degradation in deep learning-based models. The dataset used to train Japanese Stable Diffusion is 1/20th the size of the dataset on which Stable Diffusion is trained. To make a good model with such a small dataset, we fine-tuned the powerful [Stable Diffusion](https://huggingface.co./CompVis/stable-diffusion-v1-4) trained on the English dataset, rather than training a text-to-image model from scratch.
To make a good language-specific text-to-image model, we did not simply fine-tune but applied 2 training stages following the idea of [PITI](https://arxiv.org/abs/2205.12952).
#### 1st stage: Train a Japanese-specific text encoder
In the 1st stage, the latent diffusion model is fixed and we replaced the English text encoder with a Japanese-specific text encoder, which is trained. At this time, our Japanese sentencepiece tokenizer is used as the tokenizer. If the CLIP tokenizer is used as it is, Japanese texts are tokenized bytes, which makes it difficult to learn the token dependency, and the number of tokens becomes unnecessarily large. For example, if we tokenize "サラリーマン 油絵", we get `['ãĤ', 'µ', 'ãĥ©', 'ãĥª', 'ãĥ¼ãĥ', 'ŀ', 'ãĥ³</w>', 'æ', '²', '¹', 'çµ', 'µ</w>']` which are uninterpretable tokens.
```python
from transformers import CLIPTokenizer
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text = "サラリーマン 油絵"
tokens = tokenizer(text, add_special_tokens=False)['input_ids']
print("tokens:", tokenizer.convert_ids_to_tokens(tokens))
# tokens: ['ãĤ', 'µ', 'ãĥ©', 'ãĥª', 'ãĥ¼ãĥ', 'ŀ', 'ãĥ³</w>', 'æ', '²', '¹', 'çµ', 'µ</w>']
print("decoded text:", tokenizer.decode(tokens))
# decoded text: サラリーマン 油絵
```
On the other hand, by using our Japanese tokenizer, the prompt is split into interpretable tokens and the number of tokens is reduced. For example, "サラリーマン 油絵" can be tokenized as `['▁', 'サラリーマン', '▁', '油', '絵']`, which is correctly tokenized in Japanese.
```python
from transformers import T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-stable-diffusion", subfolder="tokenizer", use_auth_token=True)
tokenizer.do_lower_case = True
tokens = tokenizer(text, add_special_tokens=False)['input_ids']
print("tokens:", tokenizer.convert_ids_to_tokens(tokens))
# tokens: ['▁', 'サラリーマン', '▁', '油', '絵']
print("decoded text:", tokenizer.decode(tokens))
# decoded text: サラリーマン 油絵
```
This stage enables the model to understand Japanese prompts but does not still output Japanese-style images because the latent diffusion model has not been changed at all. In other words, the Japanese word "salary man" can be interpreted as the English word "businessman," but the generated result is a businessman with a Western face, as shown below.
<p align="center">
<img src="assets/106_japanese_stable_diffusion/jsd-stage1.jpeg" alt="salary man of japanese stable diffusion at stage 1" title="salary man of japanese stable diffusion at stage 1">
</p>
*"サラリーマン 油絵", which means exactly "salary man, oil painting", from the 1st-stage Japanese Stable Diffusion*
Therefore, in the 2nd stage, we train to output more Japanese-style images.
#### 2nd stage: Fine-tune the text encoder and the latent diffusion model jointly
In the 2nd stage, we will train both the text encoder and the latent diffusion model to generate Japanese-style images. This stage is essential to make the model become a more language-specific model. After this, the model can finally generate a businessman with a Japanese face, as shown in the image below.
<p align="center">
<img src="assets/106_japanese_stable_diffusion/jsd-stage2.jpeg" alt="salary man of japanese stable diffusion" title="salary man of japanese stable diffusion">
</p>
*"サラリーマン 油絵", which means exactly "salary man, oil painting", from the 2nd-stage Japanese Stable Diffusion*
## rinna’s Open Strategy
Numerous research institutes are releasing their research results based on the idea of democratization of AI, aiming for a world where anyone can easily use AI. In particular, recently, pre-trained models with a large number of parameters based on large-scale training data have become the mainstream, and there are concerns about a monopoly of high-performance AI by research institutes with computational resources. Still, fortunately, many pre-trained models have been released and are contributing to the development of AI technology. However, pre-trained models on text often target English, the world's most popular language. For a world in which anyone can easily use AI, we believe that it is desirable to be able to use state-of-the-art AI in languages other than English.
Therefore, rinna Co., Ltd. has released [GPT](https://huggingface.co./rinna/japanese-gpt-1b), [BERT](https://huggingface.co./rinna/japanese-roberta-base), and [CLIP](https://huggingface.co./rinna/japanese-clip-vit-b-16), which are specialized for Japanese, and now have also released [Japanese Stable Diffusion](https://huggingface.co./rinna/japanese-stable-diffusion). By releasing a pre-trained model specialized for Japanese, we hope to make AI that is not biased toward the cultures of the English-speaking world but also incorporates the culture of the Japanese-speaking world. Making it available to everyone will help to democratize an AI that guarantees Japanese cultural identity.
## What’s Next?
Compared to Stable Diffusion, Japanese Stable Diffusion is not as versatile and still has some accuracy issues. However, through the development and release of Japanese Stable Diffusion, we hope to communicate to the research community the importance and potential of language-specific model development.
rinna Co., Ltd. has released GPT and BERT models for Japanese text, and CLIP, CLOOB, and Japanese Stable Diffusion models for Japanese text and images. We will continue to improve these models and next we will consider releasing models based on self-supervised learning specialized for Japanese speech. | [
[
"computer_vision",
"implementation",
"tools",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"image_generation",
"computer_vision",
"implementation",
"tools"
] | null | null |
0e3f54dc-710c-402a-bf43-27865f7570fb | completed | 2025-01-16T03:08:53.170964 | 2025-01-16T14:19:30.960073 | dc79fcc4-a876-4f75-9985-0e8f889f12da | Bamba: Inference-Efficient Hybrid Mamba2 Model | Linsong-C, divykum, tridao, albertgu, rganti, dakshiagrawal, mudhakar, daviswer, mirinflim, aviros, nelsonspbr, tmhoangt, OfirArviv, per, michalshmu, HaochenShen, Minjia, gabegoodhart, Naigang, nickhugs, JRosenkranz, cliuawesome, adhoq26, cyang49, SukritiSharma, anhuong, jaygala, szawad, RTGordon | bamba.md | <p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/bamba/bamba.jpeg" alt="Bamba" width="400" height="400">
</p>
## TL;DR
We introduce **Bamba-9B**, an inference-efficient Hybrid Mamba2 model trained by IBM, Princeton, CMU, and UIUC on **completely open data**. At inference time, the model demonstrates 2.5x throughput improvement and 2x latency speedup compared to standard transformers in vLLM. To foster community experimentation, the model is immediately available to use in `transformers`, `vLLM`, `TRL`, and `llama.cpp`. We also release tuning, training, and extended pretraining recipes with a stateful data loader, and invite the community to further improve this model. Let's overcome the KV-cache bottleneck together!
## Artifacts 📦
1. [Hugging Face Bamba collection](https://huggingface.co./collections/ibm-fms/bamba-674f1388b9bbc98b413c7bab)
2. [GitHub repo with inference, training, and tuning scripts](https://github.com/foundation-model-stack/bamba)
3. [Data loader](https://github.com/foundation-model-stack/fms-fsdp/blob/main/fms_fsdp/utils/dataset_utils.py)
4. [Quantization](https://github.com/foundation-model-stack/fms-model-optimizer)
5. [Auto-pilot for cluster monitoring](https://github.com/IBM/autopilot)
## Motivation 🌟
Transformer models are increasingly used in real-world applications, but they face memory-bandwidth bottlenecks during inference, particularly during per-token decoding in longer context-length models. Techniques like lower precision, layer pruning, and compression can alleviate the problem, but do not address the root cause, which is the increasing amount of memory required by the KV-cache as the context length increases. Emerging architectures such as [Mamba](https://huggingface.co./papers/2312.00752), [Griffin](https://huggingface.co./papers/2402.19427), and [DeltaNet](https://huggingface.co./papers/2406.06484) eliminate this bottleneck by making the KV-cache size constant. The Mamba architecture has gained significant traction in the community in the recent past. For example, [Jamba](https://huggingface.co./papers/2403.19887) and [Samba](https://huggingface.co./papers/2406.07522) interleave Mamba layers with transformer layers and explore the resulting hybrid Mamba models. [Codestral Mamba](https://mistral.ai/news/codestral-mamba/), a pure Mamba2 model, demonstrates state-of-the-art (SOTA) results on coding tasks, while NVIDIA's hybrid Mamba2 model achieves competitive performance across long-context and traditional LLM benchmarks. Recent innovations, like [Falcon Mamba](https://huggingface.co./collections/tiiuae/falconmamba-7b-66b9a580324dd1598b0f6d4a) and [Falcon 3 Mamba](https://huggingface.co./tiiuae/Falcon3-Mamba-7B-Base) achieve SOTA rankings on [Hugging Face leaderboards](https://huggingface.co./spaces/open-llm-leaderboard/open_llm_leaderboard) at the time of their releases.
We introduce Bamba-9B, a hybrid Mamba2 model trained on 2.2T tokens, further validating these emerging architectures. This collaboration between IBM, Princeton, CMU, and UIUC provides full training lineage, model checkpoints, and pretraining code to support reproducibility and experimentation. The training dataset of the released checkpoints does not contain any benchmark-aligned instruction data (except FLAN) to preserve extended pretraining and fine-tuning flexibility. Our aim is to showcase the hybrid Mamba2 architecture's potential by demonstrating strong performance at lower-mid size model scale (7B-10B) and to provide the community with checkpoints that are fully reproducible and trained with open datasets.
To foster community experimentation, we are also releasing a distributed stateless shuffle data loader and enabling hybrid Mamba2 architecture in open-source libraries like `transformers`, `TRL`, `vLLM`, and `llama.cpp`. We hope these efforts advance the adoption of Mamba architectures, alleviate KV-cache bottlenecks, and close the gap with SOTA open-source models.
### Use in transformers 🤗
To use Bamba with transformers, you can use the familiar `AutoModel` classes and the `generate` API. For more details, please follow the instructions outlined in [Bamba GitHub](https://github.com/foundation-model-stack/bamba/).
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("ibm-fms/Bamba-9B")
tokenizer = AutoTokenizer.from_pretrained("ibm-fms/Bamba-9B")
message = ["Mamba is a snake with following properties "]
inputs = tokenizer(message, return_tensors='pt', return_token_type_ids=False)
response = model.generate(**inputs, max_new_tokens=64)
print(tokenizer.batch_decode(response, skip_special_tokens=True)[0])
```
## Evaluations 📊
We divide our evaluations into three parts:
1. Comparison with SoTA transformer models
2. Comparison with transformer models with similar token budget
3. Comparison with other Mamba variants.
> **Evaluation setup ⚙️ 🖥️:**
We rerun all the benchmarks following the setup and scripts [here](https://github.com/foundation-model-stack/bamba/blob/main/evaluation/README.md) for all models except the NVIDIA Mamba2 Hybrid model. We could not run benchmarking for the NVIDIA Mamba2 Hybrid model as the model weights are not in Hugging Face transformers compatible format. Therefore, we report the numbers from the original paper. For the v2 leaderboard results, we perform [normalization](https://huggingface.co./docs/leaderboards/open_llm_leaderboard/normalization) and report the normalized results. In all the evaluations, higher is better except where indicated.
### TL;DR Evals
Bamba-9B demonstrates the competitive performance of hybrid Mamba models compared to transformer models. While it has gaps in math benchmarks and MMLU scores (MMLU, GSM8K, MMLU-PRO, MATH Lvl 5), excluding these benchmarks places its average performance nearly on par with Meta Llama 3.1 8B (44.68 for Llama and 45.53 for Bamba), a model trained on *7x more data*. These gaps can be addressed by (a) extending pretraining with more tokens (MMLU scores steadily improved during training), and (b) incorporating high-quality math data in the pretraining/annealing phases. Future plans include using updated datasets like Olmo2 mix and annealing with benchmark-aligned mixes such as Dolmino mix.
Bamba-9B’s results also alleviate concerns of relatively low scores of NVIDIA’s hybrid Mamba2 model in leaderboard benchmarks. The goal of NVIDIA’s study was to compare architectures under identical conditions. Consistent with their findings, Bamba-9B reaffirms that the hybrid Mamba2 architecture offers performance competitive to transformer models while providing up to 5x inference efficiency.
### Comparison with SoTA transformer models
We compare Bamba-9B with SoTA transformer models of similar size ([Meta Llama 3.1 8B](https://huggingface.co./meta-llama/Llama-3.1-8B), [IBM Granite v3 8B](https://huggingface.co./ibm-granite/granite-3.0-8b-base), [Olmo2 7B](https://huggingface.co./allenai/OLMo-2-1124-7B), and [Gemma 2 9B](https://huggingface.co./google/gemma-2-9b)). We observe that while there are obvious benchmark gaps, it is not clear that these gaps point to deficiencies in the Mamba/Mamba2 based models. In fact, a careful analysis shows that gaps are largely due to the amount of data used for training models and the inclusion of benchmark-aligned instruction datasets during the annealing phase. For example, we had one small scale run that added `metamath` and improved our `GSM8k` score from `36.77` to `60.0`. We will publish detailed analysis and our findings in an upcoming paper.
<details>
<summary>HF OpenLLM v1 leaderboard</summary>
[HF LLM-V1](https://huggingface.co./docs/leaderboards/en/open_llm_leaderboard/archive) \+ OpenbookQA and PIQA:
| Model | Average | MMLU | ARC-C | GSM8K | Hellaswag | OpenbookQA | Piqa | TruthfulQA | Winogrande |
| : | [
[
"llm",
"implementation",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"optimization",
"implementation",
"efficient_computing"
] | null | null |
49fc65bb-8113-4e26-8249-acb1171821f3 | completed | 2025-01-16T03:08:53.170969 | 2025-01-19T17:19:42.739071 | bb82f188-6738-489a-abe6-63563948a71e | The 5 Most Under-Rated Tools on Hugging Face | derek-thomas | unsung-heroes.md | <div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
tl;dr The Hugging Face Hub has a number of tools and integrations that are often overlooked that can make it easier to build many types of AI solutions</div>
The Hugging Face Hub boasts over 850K public models, with ~50k new ones added every month, and that just seems to be
climbing higher and higher. We also offer an Enterprise Hub subscription that
unlocks [compliance](https://huggingface.co./docs/hub/en/storage-regions\#regulatory-and-legal-compliance), [security](https://huggingface.co./docs/hub/en/security\#security),
and [governance](https://huggingface.co./docs/hub/en/enterprise-hub-resource-groups) features, along with additional
compute capacities on inference endpoints for production-level inference and more hardware options for doing demos on
Spaces.
The Hugging Face Hub allows broad usage since you have diverse hardware, and you can run almost anything you want
in [Docker Spaces](https://huggingface.co./docs/hub/en/spaces-sdks-docker). I’ve noticed we have a number of features
that are unsung (listed below). In the process of creating a semantic search application on the Hugging Face hub I took
advantage of all of these features to implement various parts of the solution. While I think the final application
(detailed in this org [reddit-tools-HF](https://huggingface.co./reddit-tools-HF)), is compelling, I'd like to use this example to show how you can apply them to
your own projects.
* [ZeroGPU](#zerogpu) - How can I use a free GPU?
* [Multi-process Docker](#multi-process-docker) - How can I solve 2 (n) problems in 1 space?
* [Gradio API](#gradio-api) - How can I make multiple spaces work together?
* [Webhooks](#webhooks) - How can I trigger events in a space based on the hub changes?
* [Nomic Atlas](#nomic-atlas) - A feature-rich semantic search (visual and text based)
## Use-Case
> An automatically updated, visually enabled, semantic search for a dynamic data source, for free
It’s easy to imagine multiple scenarios where this is useful:
* E-commerce platforms that are looking to handle their many products based on descriptions or reported issues
* Law firms and compliance departments who need to comb through legal documents or regulations
* Researchers who have to keep up with new advances and find relevant papers or articles for their needs
I'll be demonstrating this by using a subreddit as my data source and using the Hub to facilitate the rest. There are a
number of ways to implement this. I could put everything in 1 space, but that would be quite messy. On the other hand, having too
many components in a solution has its own challenges. Ultimately, **I chose a design that allows me to highlight some of
the unsung heroes on the Hub and demonstrate how you can use them effectively**. The architecture is shown in *Figure 1*
and is fully hosted on Hugging Face in the form of spaces, datasets and webhooks. Every feature I'm
using is free for maximum accessibility. As you need to scale your service, you might consider upgrading to the [Enterprise Hub](https://huggingface.co./enterprise).
||
|:--:|
|Figure 1: Project Flow [clickable version here](https://miro.com/app/board/uXjVKnOWQZM=/?share_link_id=183806319042)|
You can see that I'm using [r/bestofredditorupdates](https://www.reddit.com/r/BestofRedditorUpdates/) as my **Data Source**, it has 10-15 new posts a day. I pull from it daily using their API via a [Reddit Application](https://www.reddit.com/prefs/apps) with [PRAW](https://praw.readthedocs.io/en/stable/), and store the results in the **Raw Dataset** ([reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates](https://huggingface.co./datasets/reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates)). Storing new data triggers a [webhook](https://huggingface.co./docs/hub/en/webhooks), which in turn triggers the **Data Processing Space** to take action. The **Data Processing Space** will take the **Raw Dataset** and add columns to it, namely feature embeddings generated by the **Embedding Model Space** and retrieved using a Gradio client. The **Data Processing Space** will then take the processed data and store it in the **Processed Dataset**. It will also build the **Data Explorer** tool. Do note that the data is considered `not-for-all-audiences` due to the data source. More on this in [Ethical Considerations](#ethical-considerations)
| Component | Details | Location | Additional Information |
| : | [
[
"mlops",
"deployment",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"tools",
"mlops",
"integration",
"deployment"
] | null | null |
967ef5d5-751f-4ca0-b4e3-3bada1279081 | completed | 2025-01-16T03:08:53.170973 | 2025-01-16T13:37:22.653774 | 18435b0e-6dd6-4b4f-bf72-9f46c1855794 | Making a web app generator with open ML models | jbilcke-hf | text-to-webapp.md | As more code generation models become publicly available, it is now possible to do text-to-web and even text-to-app in ways that we couldn't imagine before.
This tutorial presents a direct approach to AI web content generation by streaming and rendering the content all in one go.
**Try the live demo here!** → **[Webapp Factory](https://huggingface.co./spaces/jbilcke-hf/webapp-factory-wizardcoder)**

## Using LLM in Node apps
While we usually think of Python for everything related to AI and ML, the web development community relies heavily on JavaScript and Node.
Here are some ways you can use large language models on this platform.
### By running a model locally
Various approaches exist to run LLMs in Javascript, from using [ONNX](https://www.npmjs.com/package/onnxruntime-node) to converting code to [WASM](https://blog.mithrilsecurity.io/porting-tokenizers-to-wasm/) and calling external processes written in other languages.
Some of those techniques are now available as ready-to-use NPM libraries:
- Using AI/ML libraries such as [transformers.js](https://huggingface.co./docs/transformers.js/index) (which supports [code generation](https://huggingface.co./docs/transformers.js/api/models#codegenmodelgenerateargs-codepromiseampltanyampgtcode))
- Using dedicated LLM libraries such as [llama-node](https://github.com/Atome-FE/llama-node) (or [web-llm](https://github.com/mlc-ai/web-llm) for the browser)
- Using Python libraries through a bridge such as [Pythonia](https://www.npmjs.com/package/pythonia)
However, running large language models in such an environment can be pretty resource-intensive, especially if you are not able to use hardware acceleration.
### By using an API
Today, various cloud providers propose commercial APIs to use language models. Here is the current Hugging Face offering:
The free [Inference API](https://huggingface.co./docs/api-inference/index) to allow anyone to use small to medium-sized models from the community.
The more advanced and production-ready [Inference Endpoints API](https://huggingface.co./inference-endpoints) for those who require larger models or custom inference code.
These two APIs can be used from Node using the [Hugging Face Inference API library](https://www.npmjs.com/package/@huggingface/inference) on NPM.
💡 Top performing models generally require a lot of memory (32 Gb, 64 Gb or more) and hardware acceleration to get good latency (see [the benchmarks](https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard)). But we are also seeing a trend of models shrinking in size while keeping relatively good results on some tasks, with requirements as low as 16 Gb or even 8 Gb of memory.
## Architecture
We are going to use NodeJS to create our generative AI web server.
The model will be [WizardCoder-15B](https://huggingface.co./WizardLM/WizardCoder-15B-V1.0) running on the Inference Endpoints API, but feel free to try with another model and stack.
If you are interested in other solutions, here are some pointers to alternative implementations:
- Using the Inference API: [code](https://huggingface.co./spaces/jbilcke-hf/webapp-factory-any-model/tree/main) and [space](https://huggingface.co./spaces/jbilcke-hf/webapp-factory-any-model)
- Using a Python module from Node: [code](https://huggingface.co./spaces/jbilcke-hf/template-node-ctransformers-express/tree/main) and [space](https://huggingface.co./spaces/jbilcke-hf/template-node-ctransformers-express)
- Using llama-node (llama cpp): [code](https://huggingface.co./spaces/jbilcke-hf/webapp-factory-llama-node/tree/main)
## Initializing the project
First, we need to setup a new Node project (you can clone [this template](https://github.com/jbilcke-hf/template-node-express/generate) if you want to).
```html
git clone https://github.com/jbilcke-hf/template-node-express tutorial
cd tutorial
nvm use
npm install
```
Then, we can install the Hugging Face Inference client:
```html
npm install @huggingface/inference
```
And set it up in `src/index.mts``:
```javascript
import { HfInference } from '@huggingface/inference'
// to keep your API token secure, in production you should use something like:
// const hfi = new HfInference(process.env.HF_API_TOKEN)
const hfi = new HfInference('** YOUR TOKEN **')
```
## Configuring the Inference Endpoint
💡 **Note:** If you don't want to pay for an Endpoint instance to do this tutorial, you can skip this step and look at [this free Inference API example](https://huggingface.co./spaces/jbilcke-hf/webapp-factory-any-model/blob/main/src/index.mts) instead. Please, note that this will only work with smaller models, which may not be as powerful.
To deploy a new Endpoint you can go to the [Endpoint creation page](https://ui.endpoints.huggingface.co/new).
You will have to select `WizardCoder` in the **Model Repository** dropdown and make sure that a GPU instance large enough is selected:

Once your endpoint is created, you can copy the URL from [this page](https://ui.endpoints.huggingface.co):

Configure the client to use it:
```javascript
const hf = hfi.endpoint('** URL TO YOUR ENDPOINT **')
```
You can now tell the inference client to use our private endpoint and call our model:
```javascript
const { generated_text } = await hf.textGeneration({
inputs: 'a simple "hello world" html page: <html><body>'
});
```
## Generating the HTML stream
It's now time to return some HTML to the web client when they visit a URL, say `/app`.
We will create and endpoint with Express.js to stream the results from the Hugging Face Inference API.
```javascript
import express from 'express'
import { HfInference } from '@huggingface/inference'
const hfi = new HfInference('** YOUR TOKEN **')
const hf = hfi.endpoint('** URL TO YOUR ENDPOINT **')
const app = express()
```
As we do not have any UI for the moment, the interface will be a simple URL parameter for the prompt:
```javascript
app.get('/', async (req, res) => {
// send the beginning of the page to the browser (the rest will be generated by the AI)
res.write('<html><head></head><body>')
const inputs = `# Task
Generate ${req.query.prompt}
# Out
<html><head></head><body>`
for await (const output of hf.textGenerationStream({
inputs,
parameters: {
max_new_tokens: 1000,
return_full_text: false,
}
})) {
// stream the result to the browser
res.write(output.token.text)
// also print to the console for debugging
process.stdout.write(output.token.text)
}
req.end()
})
app.listen(3000, () => { console.log('server started') })
```
Start your web server:
```bash
npm run start
```
and open `https://localhost:3000?prompt=some%20prompt`. You should see some primitive HTML content after a few moments.
## Tuning the prompt
Each language model reacts differently to prompting. For WizardCoder, simple instructions often work best:
```javascript
const inputs = `# Task
Generate ${req.query.prompt}
# Orders
Write application logic inside a JS <script></script> tag.
Use a central layout to wrap everything in a <div class="flex flex-col items-center">
# Out
<html><head></head><body>`
```
### Using Tailwind
Tailwind is a popular CSS framework for styling content, and WizardCoder is good at it out of the box.
This allows code generation to create styles on the go without having to generate a stylesheet at the beginning or the end of the page (which would make the page feel stuck).
To improve results, we can also guide the model by showing the way (`<body class="p-4 md:p-8">`).
```javascript
const inputs = `# Task
Generate ${req.query.prompt}
# Orders
You must use TailwindCSS utility classes (Tailwind is already injected in the page).
Write application logic inside a JS <script></script> tag.
Use a central layout to wrap everything in a <div class="flex flex-col items-center'>
# Out
<html><head></head><body class="p-4 md:p-8">`
```
### Preventing hallucination
It can be difficult to reliably prevent hallucinations and failures (such as parroting back the whole instructions, or writing “lorem ipsum” placeholder text) on light models dedicated to code generation, compared to larger general-purpose models, but we can try to mitigate it.
You can try to use an imperative tone and repeat the instructions. An efficient way can also be to show the way by giving a part of the output in English:
```javascript
const inputs = `# Task
Generate ${req.query.prompt}
# Orders
Never repeat these instructions, instead write the final code!
You must use TailwindCSS utility classes (Tailwind is already injected in the page)!
Write application logic inside a JS <script></script> tag!
This is not a demo app, so you MUST use English, no Latin! Write in English!
Use a central layout to wrap everything in a <div class="flex flex-col items-center">
# Out
<html><head><title>App</title></head><body class="p-4 md:p-8">`
```
## Adding support for images
We now have a system that can generate HTML, CSS and JS code, but it is prone to hallucinating broken URLs when asked to produce images.
Luckily, we have a lot of options to choose from when it comes to image generation models!
→ The fastest way to get started is to call a Stable Diffusion model using our free [Inference API](https://huggingface.co./docs/api-inference/index) with one of the [public models](https://huggingface.co./spaces/huggingface-projects/diffusers-gallery) available on the hub:
```javascript
app.get('/image', async (req, res) => {
const blob = await hf.textToImage({
inputs: `${req.query.caption}`,
model: 'stabilityai/stable-diffusion-2-1'
})
const buffer = Buffer.from(await blob.arrayBuffer())
res.setHeader('Content-Type', blob.type)
res.setHeader('Content-Length', buffer.length)
res.end(buffer)
})
```
Adding the following line to the prompt was enough to instruct WizardCoder to use our new `/image` endpoint! (you may have to tweak it for other models):
```
To generate images from captions call the /image API: <img src="/image?caption=photo of something in some place" />
```
You can also try to be more specific, for example:
```
Only generate a few images and use descriptive photo captions with at least 10 words!
```

## Adding some UI
[Alpine.js](https://alpinejs.dev/) is a minimalist framework that allows us to create interactive UIs without any setup, build pipeline, JSX processing etc.
Everything is done within the page, making it a great candidate to create the UI of a quick demo.
Here is a static HTML page that you can put in `/public/index.html`:
```html
<html>
<head>
<title>Tutorial</title>
<script defer src="https://cdn.jsdelivr.net/npm/[email protected]/dist/cdn.min.js"></script>
<script src="https://cdn.tailwindcss.com"></script>
</head>
<body>
<div class="flex flex-col space-y-3 p-8" x-data="{ draft: '', prompt: '' }">
<textarea
name="draft"
x-model="draft"
rows="3"
placeholder="Type something.."
class="font-mono"
></textarea>
<button
class="bg-green-300 rounded p-3"
@click="prompt = draft">Generate</button>
<iframe :src="`/app?prompt=${prompt}`"></iframe>
</div>
</body>
</html>
```
To make this work, you will have to make some changes:
```javascript
...
// going to localhost:3000 will load the file from /public/index.html
app.use(express.static('public'))
// we changed this from '/' to '/app'
app.get('/app', async (req, res) => {
...
```
## Optimizing the output
So far we have been generating full sequences of Tailwind utility classes, which are great to give freedom of design to the language model.
But this approach is also very verbose, consuming a large part of our token quota.
To make the output more dense we can use [Daisy UI](https://daisyui.com/docs/use/), a Tailwind plugin which organizes Tailwind utility classes into a design system. The idea is to use shorthand class names for components and utility classes for the rest.
Some language models may not have inner knowledge of Daisy UI as it is a niche library, in that case we can add an [API documentation](https://huggingface.co./spaces/jbilcke-hf/webapp-factory-wizardcoder/blob/main/src/daisy.mts) to the prompt:
```
# DaisyUI docs
## To create a nice layout, wrap each article in:
<article class="prose"></article>
## Use appropriate CSS classes
<button class="btn ..">
<table class="table ..">
<footer class="footer ..">
```
## Going further
The final demo Space includes a [more complete example](https://huggingface.co./spaces/jbilcke-hf/webapp-factory-wizardcoder/blob/main/public/index.html) of user interface.
Here are some ideas to further extend on this concept:
- Test other language models such as [StarCoder](https://huggingface.co./blog/starcoder)
- Generate files and code for intermediary languages (React, Svelte, Vue..)
- Integrate code generation inside an existing framework (eg. NextJS)
- Recover from failed or partial code generation (eg. autofix issues in the JS)
- Connect it to a chatbot plugin (eg. embed tiny webapp iframes in a chat discussion)
 | [
[
"llm",
"implementation",
"tutorial",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"implementation",
"tutorial",
"tools"
] | null | null |
42710a9b-321b-4360-a234-53692e18173d | completed | 2025-01-16T03:08:53.170978 | 2025-01-19T18:47:48.646830 | cfee4a65-ae69-4d10-ab76-854d40fcd4e1 | Hugging Face Reads, Feb. 2021 - Long-range Transformers | VictorSanh | long-range-transformers.md | <img src="/blog/assets/14_long_range_transformers/EfficientTransformerTaxonomy.png" alt="Efficient Transformers taxonomy"/>
<figcaption>Efficient Transformers taxonomy from Efficient Transformers: a Survey by Tay et al.</figcaption>
</figure>
# Hugging Face Reads, Feb. 2021 - Long-range Transformers
Co-written by Teven Le Scao, Patrick Von Platen, Suraj Patil, Yacine Jernite and Victor Sanh.
> Each month, we will choose a topic to focus on, reading a set of four papers recently published on the subject. We will then write a short blog post summarizing their findings and the common trends between them, and questions we had for follow-up work after reading them. The first topic for January 2021 was [Sparsity and Pruning](https://discuss.huggingface.co/t/hugging-face-reads-01-2021-sparsity-and-pruning/3144), in February 2021 we addressed Long-Range Attention in Transformers.
## Introduction
After the rise of large transformer models in 2018 and 2019, two trends have quickly emerged to bring their compute requirements down. First, conditional computation, quantization, distillation, and pruning have unlocked inference of large models in compute-constrained environments; we’ve already touched upon this in part in our [last reading group post](https://discuss.huggingface.co/t/hugging-face-reads-01-2021-sparsity-and-pruning/3144). The research community then moved to reduce the cost of pre-training.
In particular, one issue has been at the center of the efforts: the quadratic cost in memory and time of transformer models with regard to the sequence length. In order to allow efficient training of very large models, 2020 saw an onslaught of papers to address that bottleneck and scale transformers beyond the usual 512- or 1024- sequence lengths that were the default in NLP at the start of the year.
This topic has been a key part of our research discussions from the start, and our own Patrick Von Platen has already dedicated [a 4-part series to Reformer](https://huggingface.co./blog/reformer). In this reading group, rather than trying to cover every approach (there are so many!), we’ll focus on four main ideas:
* Custom attention patterns (with [Longformer](https://arxiv.org/abs/2004.05150))
* Recurrence (with [Compressive Transformer](https://arxiv.org/abs/1911.05507))
* Low-rank approximations (with [Linformer](https://arxiv.org/abs/2006.04768))
* Kernel approximations (with [Performer](https://arxiv.org/abs/2009.14794))
For exhaustive views of the subject, check out [Efficient Transfomers: A Survey](https://arxiv.org/abs/2009.06732) and [Long Range Arena](https://arxiv.org/abs/2011.04006).
## Summaries
### [Longformer - The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
Iz Beltagy, Matthew E. Peters, Arman Cohan
Longformer addresses the memory bottleneck of transformers by replacing conventional self-attention with a combination of windowed/local/sparse (cf. [Sparse Transformers (2019)](https://arxiv.org/abs/1904.10509)) attention and global attention that scales linearly with the sequence length. As opposed to previous long-range transformer models (e.g. [Transformer-XL (2019)](https://arxiv.org/abs/1901.02860), [Reformer (2020)](https://arxiv.org/abs/2001.04451), [Adaptive Attention Span (2019)](https://arxiv.org/abs/1905.07799)), Longformer’s self-attention layer is designed as a drop-in replacement for the standard self-attention, thus making it possible to leverage pre-trained checkpoints for further pre-training and/or fine-tuning on long sequence tasks.
The standard self-attention matrix (Figure a) scales quadratically with the input length:
<figure>
<img src="/blog/assets/14_long_range_transformers/Longformer.png" alt="Longformer attention"/>
<figcaption>Figure taken from Longformer</figcaption>
</figure>
Longformer uses different attention patterns for autoregressive language modeling, encoder pre-training & fine-tuning, and sequence-to-sequence tasks.
* For autoregressive language modeling, the strongest results are obtained by replacing causal self-attention (a la GPT2) with dilated windowed self-attention (Figure c). With \\(n\\) being the sequence length and \\(w\\) being the window length, this attention pattern reduces the memory consumption from \\(n^2\\) to \\(wn\\), which under the assumption that \\(w << n\\), scales linearly with the sequence length.
* For encoder pre-training, Longformer replaces the bi-directional self-attention (a la BERT) with a combination of local windowed and global bi-directional self-attention (Figure d). This reduces the memory consumption from \\(n^2\\) to \\(w n + g n\\) with \\(g\\) being the number of tokens that are attended to globally, which again scales linearly with the sequence length.
* For sequence-to-sequence models, only the encoder layers (a la BART) are replaced with a combination of local and global bi-directional self-attention (Figure d) because for most seq2seq tasks, only the encoder processes very large inputs (e.g. summarization). The memory consumption is thus reduced from \\(n_s^2+ n_s n_t +n_t^2\\) to \\(w n_s +gn_s +n_s n_t +n_t^2\\) with \\(n_s\\) and \\(n_t\\) being the source (encoder input) and target (decoder input) lengths respectively. For Longformer Encoder-Decoder to be efficient, it is assumed that \\(n_s\\) is much bigger than \\(n_t\\).
#### Main findings
* The authors proposed the dilated windowed self-attention (Figure c) and showed that it yields better results on language modeling compared to just windowed/sparse self-attention (Figure b). The window sizes are increased through the layers. This pattern further outperforms previous architectures (such as Transformer-XL, or adaptive span attention) on downstream benchmarks.
* Global attention allows the information to flow through the whole sequence and applying the global attention to task-motivated tokens (such as the tokens of the question in QA, CLS token for sentence classification) leads to stronger performance on downstream tasks. Using this global pattern, Longformer can be successfully applied to document-level NLP tasks in the transfer learning setting.
* Standard pre-trained models can be adapted to long-range inputs by simply replacing the standard self-attention with the long-range self-attention proposed in this paper and then fine-tuning on the downstream task. This avoids costly pre-training specific to long-range inputs.
#### Follow-up questions
* The increasing size (throughout the layers) of the dilated windowed self-attention echoes findings in computer vision on increasing the receptive field of stacked CNN. How do these two findings relate? What are the transposable learnings?
* Longformer’s Encoder-Decoder architecture works well for tasks that do not require a long target length (e.g. summarization). However, how would it work for long-range seq2seq tasks which require a long target length (e.g. document translation, speech recognition, etc.) especially considering the cross-attention layer of encoder-decoder’s models?
* In practice, the sliding window self-attention relies on many indexing operations to ensure a symmetric query-key weights matrix. Those operations are very slow on TPUs which highlights the question of the applicability of such patterns on other hardware.
### [Compressive Transformers for Long-Range Sequence Modelling](https://arxiv.org/abs/1911.05507)
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Timothy P. Lillicrap
[Transformer-XL (2019)](https://arxiv.org/abs/1901.02860) showed that caching previously computed layer activations in a memory can boost performance on language modeling tasks (such as *enwik8*). Instead of just attending the current \\(n\\) input tokens, the model can also attend to the past \\(n_m\\) tokens, with \\(n_m\\) being the memory size of the model. Transformer-XL has a memory complexity of \\(O(n^2+ n n_m)\\), which shows that memory cost can increase significantly for very large \\(n_m\\). Hence, Transformer-XL has to eventually discard past activations from the memory when the number of cached activations gets larger than \\(n_m\\). Compressive Transformer addresses this problem by adding an additional compressed memory to efficiently cache past activations that would have otherwise eventually been discarded. This way the model can learn better long-range sequence dependencies having access to significantly more past activations.
<figure>
<img src="/blog/assets/14_long_range_transformers/CompressiveTransformer.png" alt="Compressive Tranformer recurrence"/>
<figcaption>Figure taken from Compressive Transfomer</figcaption>
</figure>
A compression factor \\(c\\) (equal to 3 in the illustration) is chosen to decide the rate at which past activations are compressed. The authors experiment with different compression functions \\(f_c\\) such as max/mean pooling (parameter-free) and 1D convolution (trainable layer). The compression function is trained with backpropagation through time or local auxiliary compression losses. In addition to the current input of length \\(n\\), the model attends to \\(n_m\\) cached activations in the regular memory and \\(n_{cm}\\) compressed memory activations allowing a long temporal dependency of \\(l × (n_m + c n_{cm})\\), with \\(l\\) being the number of attention layers. This increases Transformer-XL’s range by additional \\(l × c × n_{cm}\\) tokens and the memory cost amounts to \\(O(n^2+ n n_m+ n n_{cm})\\). Experiments are conducted on Reinforcement learning, audio generation, and natural language processing. The authors also introduce a new long-range language modeling benchmark called [PG19](https://huggingface.co./datasets/pg19).
#### Main findings
* Compressive Transformer significantly outperforms the state-of-the-art perplexity on language modeling, namely on the enwik8 and WikiText-103 datasets. In particular, compressed memory plays a crucial role in modeling rare words occurring on long sequences.
* The authors show that the model learns to preserve salient information by increasingly attending the compressed memory instead of the regular memory, which goes against the trend of older memories being accessed less frequently.
* All compression functions (average pooling, max pooling, 1D convolution) yield similar results confirming that memory compression is an effective way to store past information.
#### Follow-up questions
* Compressive Transformer requires a special optimization schedule in which the effective batch size is progressively increased to avoid significant performance degradation for lower learning rates. This effect is not well understood and calls into more analysis.
* The Compressive Transformer has many more hyperparameters compared to a simple model like BERT or GPT2: the compression rate, the compression function and loss, the regular and compressed memory sizes, etc. It is not clear whether those parameters generalize well across different tasks (other than language modeling) or similar to the learning rate, make the training also very brittle.
* It would be interesting to probe the regular memory and compressed memory to analyze what kind of information is memorized through the long sequences. Shedding light on the most salient pieces of information can inform methods such as [Funnel Transformer](https://arxiv.org/abs/2006.03236) which reduces the redundancy in maintaining a full-length token-level sequence.
### [Linformer: Self-Attention with Linear Complexity](https://arxiv.org/abs/2006.04768)
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma
The goal is to reduce the complexity of the self-attention with respect to the sequence length \\(n\\)) from quadratic to linear. This paper makes the observation that the attention matrices are low rank (i.e. they don’t contain \\(n × n\\) worth of information) and explores the possibility of using high-dimensional data compression techniques to build more memory efficient transformers.
The theoretical foundations of the proposed approach are based on the Johnson-Lindenstrauss lemma. Let’s consider \\(m\\)) points in a high-dimensional space. We want to project them to a low-dimensional space while preserving the structure of the dataset (i.e. the mutual distances between points) with a margin of error \\(\varepsilon\\). The Johnson-Lindenstrauss lemma states we can choose a small dimension \\(k \sim 8 \log(m) / \varepsilon^2\\) and find a suitable projection into Rk in polynomial time by simply trying random orthogonal projections.
Linformer projects the sequence length into a smaller dimension by learning a low-rank decomposition of the attention context matrix. The matrix multiplication of the self-attention can be then cleverly re-written such that no matrix of size \\(n × n\\) needs to be ever computed and stored.
Standard transformer:
$$\text{Attention}(Q, K, V) = \text{softmax}(Q * K) * V$$
(n * h) (n * n) (n * h)
Linformer:
$$\text{LinAttention}(Q, K, V) = \text{softmax}(Q * K * W^K) * W^V * V$$
(n * h) (n * d) (d * n) (n * h)
#### Main findings
* The self-attention matrix is low-rank which implies that most of its information can be recovered by its first few highest eigenvalues and can be approximated by a low-rank matrix.
* Lot of works focus on reducing the dimensionality of the hidden states. This paper shows that reducing the sequence length with learned projections can be a strong alternative while shrinking the memory complexity of the self-attention from quadratic to linear.
* Increasing the sequence length doesn’t affect the inference speed (time-clock) of Linformer, when transformers have a linear increase. Moreover, the convergence speed (number of updates) is not impacted by Linformer's self-attention.
<figure>
<img src="/blog/assets/14_long_range_transformers/Linformer.png" alt="Linformer performance"/>
<figcaption>Figure taken from Linformer</figcaption>
</figure>
#### Follow-up questions
* Even though the projections matrices are shared between layers, the approach presented here comes in contrast with the Johnson-Lindenstrauss that states that random orthogonal projections are sufficient (in polynomial time). Would random projections have worked here? This is reminiscent of Reformer which uses random projections in locally sensitive hashing to reduce the memory complexity of the self-attention.
### [Rethinking Attention with Performers](https://arxiv.org/abs/2009.14794)
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, Adrian Weller
The goal is (again!) to reduce the complexity of the self-attention with respect to the sequence length \\(n\\)) from quadratic to linear. In contrast to other papers, the authors note that the sparsity and low-rankness priors of the self-attention may not hold in other modalities (speech, protein sequence modeling). Thus the paper explores methods to reduce the memory burden of the self-attention without any priors on the attention matrix.
The authors observe that if we could perform the matrix multiplication \\(K × V\\) through the softmax ( \\(\text{softmax}(Q × K) × V\\) ), we wouldn’t have to compute the \\(Q x K\\) matrix of size \\(n x n\\) which is the memory bottleneck. They use random feature maps (aka random projections) to approximate the softmax by:
$$\text{softmax}(Q * K) \sim Q’ * K’ = \phi(Q) * \phi(K)$$
, where \\(phi\\) is a non-linear suitable function. And then:
$$\text{Attention}(Q, K, V) \sim \phi(Q) * (\phi(K) * V)$$
Taking inspiration from machine learning papers from the early 2000s, the authors introduce **FAVOR+** (**F**ast **A**ttention **V**ia **O**rthogonal **R**andom positive (**+**) **F**eatures) a procedure to find unbiased or nearly-unbiased estimations of the self-attention matrix, with uniform convergence and low estimation variance.
#### Main findings
* The FAVOR+ procedure can be used to approximate self-attention matrices with high accuracy, without any priors on the form of the attention matrix, making it applicable as a drop-in replacement of standard self-attention and leading to strong performances in multiple applications and modalities.
* The very thorough mathematical investigation of how-to and not-to approximate softmax highlights the relevance of principled methods developed in the early 2000s even in the deep learning era.
* FAVOR+ can also be applied to efficiently model other kernelizable attention mechanisms beyond softmax.
#### Follow-up questions
* Even if the approximation of the attention mechanism is tight, small errors propagate through the transformer layers. This raises the question of the convergence and stability of fine-tuning a pre-trained network with FAVOR+ as an approximation of self-attention.
* The FAVOR+ algorithm is the combination of multiple components. It is not clear which of these components have the most empirical impact on the performance, especially in view of the variety of modalities considered in this work.
## Reading group discussion
The developments in pre-trained transformer-based language models for natural language understanding and generation are impressive. Making these systems efficient for production purposes has become a very active research area. This emphasizes that we still have much to learn and build both on the methodological and practical sides to enable efficient and general deep learning based systems, in particular for applications that require modeling long-range inputs.
The four papers above offer different ways to deal with the quadratic memory complexity of the self-attention mechanism, usually by reducing it to linear complexity. Linformer and Longformer both rely on the observation that the self-attention matrix does not contain \\(n × n\\) worth of information (the attention matrix is low-rank and sparse). Performer gives a principled method to approximate the softmax-attention kernel (and any kernelizable attention mechanisms beyond softmax). Compressive Transformer offers an orthogonal approach to model long range dependencies based on recurrence.
These different inductive biases have implications in terms of computational speed and generalization beyond the training setup. In particular, Linformer and Longformer lead to different trade-offs: Longformer explicitly designs the sparse attention patterns of the self-attention (fixed patterns) while Linformer learns the low-rank matrix factorization of the self-attention matrix. In our experiments, Longformer is less efficient than Linformer, and is currently highly dependent on implementation details. On the other hand, Linformer’s decomposition only works for fixed context length (fixed at training) and cannot generalize to longer sequences without specific adaptation. Moreover, it cannot cache previous activations which can be extremely useful in the generative setup. Interestingly, Performer is conceptually different: it learns to approximate the softmax attention kernel without relying on any sparsity or low-rank assumption. The question of how these inductive biases compare to each other for varying quantities of training data remains.
All these works highlight the importance of long-range inputs modeling in natural language. In the industry, it is common to encounter use-cases such as document translation, document classification or document summarization which require modeling very long sequences in an efficient and robust way. Recently, zero-shot examples priming (a la GPT3) has also emerged as a promising alternative to standard fine-tuning, and increasing the number of priming examples (and thus the context size) steadily increases the performance and robustness. Finally, it is common in other modalities such as speech or protein modeling to encounter long sequences beyond the standard 512 time steps.
Modeling long inputs is not antithetical to modeling short inputs but instead should be thought from the perspective of a continuum from shorter to longer sequences. [Shortformer](https://arxiv.org/abs/2012.15832), Longformer and BERT provide evidence that training the model on short sequences and gradually increasing sequence lengths lead to an accelerated training and stronger downstream performance. This observation is coherent with the intuition that the long-range dependencies acquired when little data is available can rely on spurious correlations instead of robust language understanding. This echoes some experiments Teven Le Scao has run on language modeling: LSTMs are stronger learners in the low data regime compared to transformers and give better perplexities on small-scale language modeling benchmarks such as Penn Treebank.
From a practical point of view, the question of positional embeddings is also a crucial methodological aspect with computational efficiency trade-offs. Relative positional embeddings (introduced in Transformer-XL and used in Compressive Transformers) are appealing because they can easily be extended to yet-unseen sequence lengths, but at the same time, relative positional embeddings are computationally expensive. On the other side, absolute positional embeddings (used in Longformer and Linformer) are less flexible for sequences longer than the ones seen during training, but are computationally more efficient. Interestingly, [Shortformer](https://arxiv.org/abs/2012.15832) introduces a simple alternative by adding the positional information to the queries and keys of the self-attention mechanism instead of adding it to the token embeddings. The method is called position-infused attention and is shown to be very efficient while producing strong results.
## @Hugging Face 🤗: Long-range modeling
The Longformer implementation and the associated open-source checkpoints are available through the Transformers library and the [model hub](https://huggingface.co./models?search=longformer). Performer and Big Bird, which is a long-range model based on sparse attention, are currently in the works as part of our [call for models](https://twitter.com/huggingface/status/1359903233976762368), an effort involving the community in order to promote open-source contributions. We would be pumped to hear from you if you’ve wondered how to contribute to `transformers` but did not know where to start!
For further reading, we recommend checking Patrick Platen’s blog on [Reformer](https://arxiv.org/abs/2001.04451), Teven Le Scao’s post on [Johnson-Lindenstrauss approximation](https://tevenlescao.github.io/blog/fastpages/jupyter/2020/06/18/JL-Lemma-+-Linformer.html), [Efficient Transfomers: A Survey](https://arxiv.org/abs/2009.06732), and [Long Range Arena: A Benchmark for Efficient Transformers](https://arxiv.org/abs/2011.04006).
Next month, we'll cover self-training methods and applications. See you in March! | [
[
"transformers",
"research",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"research",
"efficient_computing",
"optimization"
] | null | null |
360e0a7b-d450-49e8-82f7-d308b2c60b36 | completed | 2025-01-16T03:08:53.170983 | 2025-01-19T18:54:37.268567 | feb0e337-550c-4a99-90e5-e4214aa0d0ee | Llama 2 is here - get it on Hugging Face | philschmid, osanseviero, pcuenq, lewtun | llama2.md | ## Introduction
Llama 2 is a family of state-of-the-art open-access large language models released by Meta today, and we’re excited to fully support the launch with comprehensive integration in Hugging Face. Llama 2 is being released with a very permissive community license and is available for commercial use. The code, pretrained models, and fine-tuned models are all being released today 🔥
We’ve collaborated with Meta to ensure smooth integration into the Hugging Face ecosystem. You can find the 12 open-access models (3 base models & 3 fine-tuned ones with the original Meta checkpoints, plus their corresponding `transformers` models) on the Hub. Among the features and integrations being released, we have:
- [Models on the Hub](https://huggingface.co./meta-llama) with their model cards and license.
- [Transformers integration](https://github.com/huggingface/transformers/releases/tag/v4.31.0)
- Examples to fine-tune the small variants of the model with a single GPU
- Integration with [Text Generation Inference](https://github.com/huggingface/text-generation-inference) for fast and efficient production-ready inference
- Integration with Inference Endpoints
## Table of Contents
- [Why Llama 2?](#why-llama-2)
- [Demo](#demo)
- [Inference](#inference)
- [With Transformers](#using-transformers)
- [With Inference Endpoints](#using-text-generation-inference-and-inference-endpoints)
- [Fine-tuning with PEFT](#fine-tuning-with-peft)
- [How to Prompt Llama 2](#how-to-prompt-llama-2)
- [Additional Resources](#additional-resources)
- [Conclusion](#conclusion)
## Why Llama 2?
The Llama 2 release introduces a family of pretrained and fine-tuned LLMs, ranging in scale from 7B to 70B parameters (7B, 13B, 70B). The pretrained models come with significant improvements over the Llama 1 models, including being trained on 40% more tokens, having a much longer context length (4k tokens 🤯), and using grouped-query attention for fast inference of the 70B model🔥!
However, the most exciting part of this release is the fine-tuned models (Llama 2-Chat), which have been optimized for dialogue applications using [Reinforcement Learning from Human Feedback (RLHF)](https://huggingface.co./blog/rlhf). Across a wide range of helpfulness and safety benchmarks, the Llama 2-Chat models perform better than most open models and achieve comparable performance to ChatGPT according to human evaluations. You can read the paper [here](https://huggingface.co./papers/2307.09288).

_image from [Llama 2: Open Foundation and Fine-Tuned Chat Models](https://scontent-fra3-2.xx.fbcdn.net/v/t39.2365-6/10000000_6495670187160042_4742060979571156424_n.pdf?_nc_cat=104&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=GK8Rh1tm_4IAX8b5yo4&_nc_ht=scontent-fra3-2.xx&oh=00_AfDtg_PRrV6tpy9UmiikeMRuQgk6Rej7bCPOkXZQVmUKAg&oe=64BBD830)_
If you’ve been waiting for an open alternative to closed-source chatbots, Llama 2-Chat is likely your best choice today!
| Model | License | Commercial use? | Pretraining length [tokens] | Leaderboard score |
| | [
[
"llm",
"transformers",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"integration",
"fine_tuning"
] | null | null |
1c18ddfa-894b-44bb-94a1-ed362b3f2757 | completed | 2025-01-16T03:08:53.170987 | 2025-01-19T18:54:10.972719 | d474abdb-bba3-464a-a621-f352f1bcc3d0 | Training CodeParrot 🦜 from Scratch | leandro | codeparrot.md | In this blog post we'll take a look at what it takes to build the technology behind [GitHub CoPilot](https://copilot.github.com/), an application that provides suggestions to programmers as they code. In this step by step guide, we'll learn how to train a large GPT-2 model called CodeParrot 🦜, entirely from scratch. CodeParrot can auto-complete your Python code - give it a spin [here](https://huggingface.co./spaces/lvwerra/codeparrot-generation). Let's get to building it from scratch!

## Creating a Large Dataset of Source Code
The first thing we need is a large training dataset. With the goal to train a Python code generation model, we accessed the GitHub dump available on Google's BigQuery and filtered for all Python files. The result is a 180 GB dataset with 20 million files (available [here](http://hf.co/datasets/transformersbook/codeparrot)). After initial training experiments, we found that the duplicates in the dataset severely impacted the model performance. Further investigating the dataset we found that:
- 0.1% of the unique files make up 15% of all files
- 1% of the unique files make up 35% of all files
- 10% of the unique files make up 66% of all files
You can learn more about our findings in [this Twitter thread](https://twitter.com/lvwerra/status/1458470994146996225). We removed the duplicates and applied the same cleaning heuristics found in the [Codex paper](https://arxiv.org/abs/2107.03374). Codex is the model behind CoPilot and is a GPT-3 model fine-tuned on GitHub code.
The cleaned dataset is still 50GB big and available on the Hugging Face Hub: [codeparrot-clean](http://hf.co/datasets/lvwerra/codeparrot-clean). With that we can setup a new tokenizer and train a model.
## Initializing the Tokenizer and Model
First we need a tokenizer. Let's train one specifically on code so it splits code tokens well. We can take an existing tokenizer (e.g. GPT-2) and directly train it on our own dataset with the `train_new_from_iterator()` method. We then push it to the Hub. Note that we omit imports, arguments parsing and logging from the code examples to keep the code blocks compact. But you'll find the full code including preprocessing and downstream task evaluation [here](https://github.com/huggingface/transformers/tree/master/examples/research_projects/codeparrot).
```Python
# Iterator for Training
def batch_iterator(batch_size=10):
for _ in tqdm(range(0, args.n_examples, batch_size)):
yield [next(iter_dataset)["content"] for _ in range(batch_size)]
# Base tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
base_vocab = list(bytes_to_unicode().values())
# Load dataset
dataset = load_dataset("lvwerra/codeparrot-clean", split="train", streaming=True)
iter_dataset = iter(dataset)
# Training and saving
new_tokenizer = tokenizer.train_new_from_iterator(batch_iterator(),
vocab_size=args.vocab_size,
initial_alphabet=base_vocab)
new_tokenizer.save_pretrained(args.tokenizer_name, push_to_hub=args.push_to_hub)
```
Learn more about tokenizers and how to build them in the [Hugging Face course](https://huggingface.co./course/chapter6/1?fw=pt).
See that inconspicuous `streaming=True` argument? This small change has a big impact: instead of downloading the full (50GB) dataset this will stream individual samples as needed saving a lot of disk space! Checkout the [Hugging Face course](https://huggingface.co./course/chapter5/4?fw=pt
) for more information on streaming.
Now, we initialize a new model. We’ll use the same hyperparameters as GPT-2 large (1.5B parameters) and adjust the embedding layer to fit our new tokenizer also adding some stability tweaks. The `scale_attn_by_layer_idx` flag makes sure we scale the attention by the layer id and `reorder_and_upcast_attn` mainly makes sure that we compute the attention in full precision to avoid numerical issues. We push the freshly initialized model to the same repo as the tokenizer.
```Python
# Load codeparrot tokenizer trained for Python code tokenization
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name)
# Configuration
config_kwargs = {"vocab_size": len(tokenizer),
"scale_attn_by_layer_idx": True,
"reorder_and_upcast_attn": True}
# Load model with config and push to hub
config = AutoConfig.from_pretrained('gpt2-large', **config_kwargs)
model = AutoModelForCausalLM.from_config(config)
model.save_pretrained(args.model_name, push_to_hub=args.push_to_hub)
```
Now that we have an efficient tokenizer and a freshly initialized model we can start with the actual training loop.
## Implementing the Training Loop
We train with the [🤗 Accelerate](https://github.com/huggingface/accelerate) library which allows us to scale the training from our laptop to a multi-GPU machine without changing a single line of code. We just create an accelerator and do some argument housekeeping:
```Python
accelerator = Accelerator()
acc_state = {str(k): str(v) for k, v in accelerator.state.__dict__.items()}
parser = HfArgumentParser(TrainingArguments)
args = parser.parse_args()
args = Namespace(**vars(args), **acc_state)
samples_per_step = accelerator.state.num_processes * args.train_batch_size
set_seed(args.seed)
```
We are now ready to train! Let's use the `huggingface_hub` client library to clone the repository with the new tokenizer and model. We will checkout to a new branch for this experiment. With that setup, we can run many experiments in parallel and in the end we just merge the best one into the main branch.
```Python
# Clone model repository
if accelerator.is_main_process:
hf_repo = Repository(args.save_dir, clone_from=args.model_ckpt)
# Checkout new branch on repo
if accelerator.is_main_process:
hf_repo.git_checkout(run_name, create_branch_ok=True)
```
We can directly load the tokenizer and model from the local repository. Since we are dealing with big models we might want to turn on [gradient checkpointing](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9) to decrease the GPU memory footprint during training.
```Python
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(args.save_dir)
if args.gradient_checkpointing:
model.gradient_checkpointing_enable()
tokenizer = AutoTokenizer.from_pretrained(args.save_dir)
```
Next up is the dataset. We make training simpler with a dataset that yields examples with a fixed context size. To not waste too much data (some samples are too short or too long) we can concatenate many examples with an EOS token and then chunk them.

The more sequences we prepare together, the smaller the fraction of tokens we discard (the grey ones in the previous figure). Since we want to stream the dataset instead of preparing everything in advance we use an `IterableDataset`. The full dataset class looks as follows:
```Python
class ConstantLengthDataset(IterableDataset):
def __init__(
self, tokenizer, dataset, infinite=False, seq_length=1024, num_of_sequences=1024, chars_per_token=3.6
):
self.tokenizer = tokenizer
self.concat_token_id = tokenizer.bos_token_id
self.dataset = dataset
self.seq_length = seq_length
self.input_characters = seq_length * chars_per_token * num_of_sequences
self.epoch = 0
self.infinite = infinite
def __iter__(self):
iterator = iter(self.dataset)
more_examples = True
while more_examples:
buffer, buffer_len = [], 0
while True:
if buffer_len >= self.input_characters:
break
try:
buffer.append(next(iterator)["content"])
buffer_len += len(buffer[-1])
except StopIteration:
if self.infinite:
iterator = iter(self.dataset)
self.epoch += 1
logger.info(f"Dataset epoch: {self.epoch}")
else:
more_examples = False
break
tokenized_inputs = self.tokenizer(buffer, truncation=False)["input_ids"]
all_token_ids = []
for tokenized_input in tokenized_inputs:
all_token_ids.extend(tokenized_input + [self.concat_token_id])
for i in range(0, len(all_token_ids), self.seq_length):
input_ids = all_token_ids[i : i + self.seq_length]
if len(input_ids) == self.seq_length:
yield torch.tensor(input_ids)
```
Texts in the buffer are tokenized in parallel and then concatenated. Chunked samples are then yielded until the buffer is empty and the process starts again. If we set `infinite=True` the dataset iterator restarts at its end.
```Python
def create_dataloaders(args):
ds_kwargs = {"streaming": True}
train_data = load_dataset(args.dataset_name_train, split="train", streaming=True)
train_data = train_data.shuffle(buffer_size=args.shuffle_buffer, seed=args.seed)
valid_data = load_dataset(args.dataset_name_valid, split="train", streaming=True)
train_dataset = ConstantLengthDataset(tokenizer, train_data, infinite=True, seq_length=args.seq_length)
valid_dataset = ConstantLengthDataset(tokenizer, valid_data, infinite=False, seq_length=args.seq_length)
train_dataloader = DataLoader(train_dataset, batch_size=args.train_batch_size)
eval_dataloader = DataLoader(valid_dataset, batch_size=args.valid_batch_size)
return train_dataloader, eval_dataloader
train_dataloader, eval_dataloader = create_dataloaders(args)
```
Before we start training we need to set up the optimizer and learning rate schedule. We don’t want to apply weight decay to biases and LayerNorm weights so we use a helper function to exclude those.
```Python
def get_grouped_params(model, args, no_decay=["bias", "LayerNorm.weight"]):
params_with_wd, params_without_wd = [], []
for n, p in model.named_parameters():
if any(nd in n for nd in no_decay): params_without_wd.append(p)
else: params_with_wd.append(p)
return [{"params": params_with_wd, "weight_decay": args.weight_decay},
{"params": params_without_wd, "weight_decay": 0.0},]
optimizer = AdamW(get_grouped_params(model, args), lr=args.learning_rate)
lr_scheduler = get_scheduler(name=args.lr_scheduler_type, optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,)
```
A big question that remains is how all the data and models will be distributed across several GPUs. This sounds like a complex task but actually only requires a single line of code with 🤗 Accelerate.
```Python
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader)
```
Under the hood it'll use DistributedDataParallel, which means a batch is sent to each GPU worker which has its own copy of the model. There the gradients are computed and then aggregated to update the model on each worker.

We also want to evaluate the model from time to time on the validation set so let’s write a function to do just that. This is done automatically in a distributed fashion and we just need to gather all the losses from the workers. We also want to report the [perplexity](https://huggingface.co./course/chapter7/3#perplexity-for-language-models).
```Python
def evaluate(args):
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(batch, labels=batch)
loss = outputs.loss.repeat(args.valid_batch_size)
losses.append(accelerator.gather(loss))
if args.max_eval_steps > 0 and step >= args.max_eval_steps:
break
loss = torch.mean(torch.cat(losses))
try:
perplexity = torch.exp(loss)
except OverflowError:
perplexity = float("inf")
return loss.item(), perplexity.item()
```
We are now ready to write the main training loop. It will look pretty much like a normal PyTorch training loop. Here and there you can see that we use the accelerator functions rather than native PyTorch. Also, we push the model to the branch after each evaluation.
```Python
# Train model
model.train()
completed_steps = 0
for step, batch in enumerate(train_dataloader, start=1):
loss = model(batch, labels=batch, use_cache=False).loss
loss = loss / args.gradient_accumulation_steps
accelerator.backward(loss)
if step % args.gradient_accumulation_steps == 0:
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
completed_steps += 1
if step % args.save_checkpoint_steps == 0:
eval_loss, perplexity = evaluate(args)
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.save_dir, save_function=accelerator.save)
if accelerator.is_main_process:
hf_repo.push_to_hub(commit_message=f"step {step}")
model.train()
if completed_steps >= args.max_train_steps:
break
```
When we call `wait_for_everyone()` and `unwrap_model()` we make sure that all workers are ready and any model layers that have been added by `prepare()` earlier are removed. We also use gradient accumulation and gradient clipping that are easily implemented. Lastly, after training is complete we run a last evaluation and save the final model and push it to the hub.
```Python
# Evaluate and save the last checkpoint
logger.info("Evaluating and saving model after training")
eval_loss, perplexity = evaluate(args)
log_metrics(step, {"loss/eval": eval_loss, "perplexity": perplexity})
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.save_dir, save_function=accelerator.save)
if accelerator.is_main_process:
hf_repo.push_to_hub(commit_message="final model")
```
Done! That's all the code to train a full GPT-2 model from scratch with as little as 150 lines. We did not show the imports and logs of the scripts to make the code a little bit more compact. Now let's actually train it!
With this code we trained models for our upcoming [book on Transformers and NLP](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/): a [110M](https://hf.co/lvwerra/codeparrot-small) and [1.5B](https://hf.co/lvwerra/codeparrot) parameter GPT-2 model. We used a 16 x A100 GPU machine to train these models for 1 day and 1 week, respectively. Enough time to get a coffee and read a book or two!
## Evaluation
This is still relatively short training time for pretraining but we can already observe good downstream performance as compared to similar models. We evaluated the models on OpenAI's HumanEval benchmark that was introduced in the Codex paper. It measures the performance of code generation models on almost 200 coding challenges.

Note that we trained CodeParrot on roughly 25-30B tokens whereas GPT-neo was trained on 300B tokens and Codex on 300B (GPT-3 checkpoint) + 100B (code) tokens. So you definitely get a good bang for your buck here.
But what is this _pass@k_ metric exactly? Simply put it measures the probability of at least one program passing the unittest of a programming problem given _k_ candidate generations from the model. Naturally, the metric increases with k as more candidates can potentially solve the coding challenge. You can use the metric with `datasets`:
```Python
from datasets import load_metric
code_eval = datasets.load_metric("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a,b): return a*b", "def add(a, b): return a+b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1, 2])
print(pass_at_k)
# -> {'pass@1': 0.5, 'pass@2': 1.0}
```
You can also load OpenAI's HumanEval dataset with `datasets`:
```Python
from datasets import load_dataset
dataset = load_dataset("openai_humaneval")
```
Now let's have a look at what we get after anxiously waiting for so long!
## Results
Let's start slow and check if we can prompt the model to write a function to return the size of a file given its path:
**Prompt:**
```Python
def get_files_size(filename):
```
**Completion:**
```Python
"""
Returns the file size of a file.
:param filepath: The path to the file.
:type filepath: str
:return: The file size.
:rtype: int
"""
return os.path.getsize(filepath)
```
So far so good, but let's take this a step further and try something a bit more interesting. One of the less exciting aspects of building production ready code is writing unittest. Let's see if we can use CodeParrot to do this for us!
**Prompt:**
```Python
def is_even(value):
"""Returns True if value is an even number."""
return value % 2 == 0
# setup unit tests for is_even
import unittest
```
**Completion:**
```Python
class TestIsEven(unittest.TestCase):
"""Tests for is_even function."""
def test_is_even(self):
"""Test is_even function."""
self.assertTrue(is_even(0))
self.assertTrue(is_even(1))
self.assertTrue
```
Although the test condition itself does not look quite right the model has built all the boilerplate code for us. This alone could already be quite useful and save us a couple of minutes time!
But what we really want to do is build better transformer models. Let's use CodeParrot to help us do that:
**Prompt:**
```Python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# build a BERT classifier
```
**Completion:**
```Python
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased')
```
Looking at a few examples is nice but by now you probably want to try it yourself. We prepared a few online demos just for that!
## Demos
You can play with the models in two demos we added to [Hugging Face Spaces](https://huggingface.co./spaces/launch). With the first you can quickly generate code with the model and with the second you can highlight your code with the model to spot bugs!
- [Code Generation](https://hf.co/spaces/lvwerra/codeparrot-generation)
- [Code Highlighting](https://hf.co/spaces/lvwerra/codeparrot-highlighting)
You can also directly use the models from the `transformers` library:
```Python
from transformers import pipeline
pipe = pipeline('text-generation', model='lvwerra/codeparrot')
pipe('def hello_world():')
```
## Summary
In this short blog post we walked through all the steps involved for training a large GPT-2 model called CodeParrot 🦜 for code generation. Using 🤗 Accelerate we built a training script with less than 200 lines of code that we can effortlessly scale across many GPUs. With that you can now train your own GPT-2 model!
This post gives a brief overview of CodeParrot 🦜, but if you are interested in diving deeper into how to pretrain this models, we recommend reading its dedicated chapter in the upcoming [book on Transformers and NLP](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/). This chapter provides many more details around building custom datasets, design considerations when training a new tokenizer, and architecture choice. | [
[
"llm",
"data",
"implementation",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"implementation",
"data",
"tutorial"
] | null | null |
4993197a-622c-418d-8a4e-1759b2dc84e1 | completed | 2025-01-16T03:08:53.170992 | 2025-01-18T14:44:38.208868 | 7cb4802b-037b-4e4d-b6be-aa4a0a5e9c4d | Running IF with 🧨 diffusers on a Free Tier Google Colab | shonenkov, Gugutse, ZeroShot-AI, williamberman, patrickvonplaten, multimodalart | if.md | <a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/deepfloyd_if_free_tier_google_colab.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**TL;DR**: We show how to run one of the most powerful open-source text
to image models **IF** on a free-tier Google Colab with 🧨 diffusers.
You can also explore the capabilities of the model directly in the [Hugging Face Space](https://huggingface.co./spaces/DeepFloyd/IF).
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/diffusers/if/nabla.jpg" alt="if-collage"><br>
<em>Image compressed from official <a href="https://github.com/deep-floyd/IF/blob/release/pics/nabla.jpg">IF GitHub repo</a>.</em>
</p>
## Introduction
IF is a pixel-based text-to-image generation model and was [released in
late April 2023 by DeepFloyd](https://github.com/deep-floyd/IF). The
model architecture is strongly inspired by [Google's closed-sourced
Imagen](https://imagen.research.google/).
IF has two distinct advantages compared to existing text-to-image models
like Stable Diffusion:
- The model operates directly in "pixel space" (*i.e.,* on
uncompressed images) instead of running the denoising process in the
latent space such as [Stable Diffusion](http://hf.co/blog/stable_diffusion).
- The model is trained on outputs of
[T5-XXL](https://huggingface.co./google/t5-v1_1-xxl), a more powerful
text encoder than [CLIP](https://openai.com/research/clip), used by
Stable Diffusion as the text encoder.
As a result, IF is better at generating images with high-frequency
details (*e.g.,* human faces and hands) and is the first open-source
image generation model that can reliably generate images with text.
The downside of operating in pixel space and using a more powerful text
encoder is that IF has a significantly higher amount of parameters. T5,
IF\'s text-to-image UNet, and IF\'s upscaler UNet have 4.5B, 4.3B, and
1.2B parameters respectively. Compared to [Stable Diffusion
2.1](https://huggingface.co./stabilityai/stable-diffusion-2-1)\'s text
encoder and UNet having just 400M and 900M parameters, respectively.
Nevertheless, it is possible to run IF on consumer hardware if one
optimizes the model for low-memory usage. We will show you can do this
with 🧨 diffusers in this blog post.
In 1.), we explain how to use IF for text-to-image generation, and in 2.)
and 3.), we go over IF's image variation and image inpainting
capabilities.
💡 **Note**: We are trading gains in memory by gains in
speed here to make it possible to run IF in a free-tier Google Colab. If
you have access to high-end GPUs such as an A100, we recommend leaving
all model components on GPU for maximum speed, as done in the
[official IF demo](https://huggingface.co./spaces/DeepFloyd/IF).
💡 **Note**: Some of the larger images have been compressed to load faster
in the blog format. When using the official model, they should be even
better quality!
Let\'s dive in 🚀!
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/diffusers/if/meme.png"><br>
<em>IF's text generation capabilities</em>
</p>
## Table of contents
* [Accepting the license](#accepting-the-license)
* [Optimizing IF to run on memory constrained hardware](#optimizing-if-to-run-on-memory-constrained-hardware)
* [Available resources](#available-resources)
* [Install dependencies](#install-dependencies)
* [Text-to-image generation](#1-text-to-image-generation)
* [Image variation](#2-image-variation)
* [Inpainting](#3-inpainting)
## Accepting the license
Before you can use IF, you need to accept its usage conditions. To do so:
- 1. Make sure to have a [Hugging Face account](https://huggingface.co./join) and be logged in
- 2. Accept the license on the model card of [DeepFloyd/IF-I-XL-v1.0](https://huggingface.co./DeepFloyd/IF-I-XL-v1.0). Accepting the license on the stage I model card will auto accept for the other IF models.
- 3. Make sure to login locally. Install `huggingface_hub`
```sh
pip install huggingface_hub --upgrade
```
run the login function in a Python shell
```py
from huggingface_hub import login
login()
```
and enter your [Hugging Face Hub access token](https://huggingface.co./docs/hub/security-tokens#what-are-user-access-tokens).
## Optimizing IF to run on memory constrained hardware
State-of-the-art ML should not just be in the hands of an elite few.
Democratizing ML means making models available to run on more than just
the latest and greatest hardware.
The deep learning community has created world class tools to run
resource intensive models on consumer hardware:
- [🤗 accelerate](https://github.com/huggingface/accelerate) provides
utilities for working with [large models](https://huggingface.co./docs/accelerate/usage_guides/big_modeling).
- [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) makes [8-bit quantization](https://github.com/TimDettmers/bitsandbytes#features) available to all PyTorch models.
- [🤗 safetensors](https://github.com/huggingface/safetensors) not only ensures that save code is executed but also significantly speeds up the loading time of large models.
Diffusers seamlessly integrates the above libraries to allow for a
simple API when optimizing large models.
The free-tier Google Colab is both CPU RAM constrained (13 GB RAM) as
well as GPU VRAM constrained (15 GB RAM for T4), which makes running the
whole >10B IF model challenging!
Let\'s map out the size of IF\'s model components in full float32
precision:
- [T5-XXL Text Encoder](https://huggingface.co./DeepFloyd/IF-I-XL-v1.0/tree/main/text_encoder): 20GB
- [Stage 1 UNet](https://huggingface.co./DeepFloyd/IF-I-XL-v1.0/tree/main/unet): 17.2 GB
- [Stage 2 Super Resolution UNet](https://huggingface.co./DeepFloyd/IF-II-L-v1.0/blob/main/pytorch_model.bin): 2.5 GB
- [Stage 3 Super Resolution Model](https://huggingface.co./stabilityai/stable-diffusion-x4-upscaler): 3.4 GB
There is no way we can run the model in float32 as the T5 and Stage 1
UNet weights are each larger than the available CPU RAM.
In float16, the component sizes are 11GB, 8.6GB, and 1.25GB for T5,
Stage1 and Stage2 UNets, respectively, which is doable for the GPU, but
we're still running into CPU memory overflow errors when loading the T5
(some CPU is occupied by other processes).
Therefore, we lower the precision of T5 even more by using
`bitsandbytes` 8bit quantization, which allows saving the T5 checkpoint
with as little as [8
GB](https://huggingface.co./DeepFloyd/IF-I-XL-v1.0/blob/main/text_encoder/model.8bit.safetensors).
Now that each component fits individually into both CPU and GPU memory,
we need to make sure that components have all the CPU and GPU memory for
themselves when needed.
Diffusers supports modularly loading individual components i.e. we can
load the text encoder without loading the UNet. This modular loading
will ensure that we only load the component we need at a given step in
the pipeline to avoid exhausting the available CPU RAM and GPU VRAM.
Let\'s give it a try 🚀

## Available resources
The free-tier Google Colab comes with around 13 GB CPU RAM:
``` python
!grep MemTotal /proc/meminfo
```
```bash
MemTotal: 13297192 kB
```
And an NVIDIA T4 with 15 GB VRAM:
``` python
!nvidia-smi
```
```bash
Sun Apr 23 23:14:19 2023
+ | [
[
"computer_vision",
"implementation",
"tutorial",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"image_generation",
"implementation",
"tutorial"
] | null | null |
a4ff7daf-55be-4ea9-ae38-9625b695b36b | completed | 2025-01-16T03:08:53.170996 | 2025-01-16T03:24:17.862905 | 6218b210-052c-4b45-8843-844d2785ab10 | Towards Encrypted Large Language Models with FHE | RomanBredehoft, jfrery-zama | encrypted-llm.md | Large Language Models (LLM) have recently been proven as reliable tools for improving productivity in many areas such as programming, content creation, text analysis, web search, and distance learning.
## The Impact of Large Language Models on Users' Privacy
Despite the appeal of LLMs, privacy concerns persist surrounding user queries that are processed by these models. On the one hand, leveraging the power of LLMs is desirable, but on the other hand, there is a risk of leaking sensitive information to the LLM service provider. In some areas, such as healthcare, finance, or law, this privacy risk is a showstopper.
One possible solution to this problem is on-premise deployment, where the LLM owner would deploy their model on the client’s machine. This is however not an optimal solution, as building an LLM may cost millions of dollars ([4.6M$ for GPT3](https://lambdalabs.com/blog/demystifying-gpt-3)) and on-premise deployment runs the risk of leaking the model intellectual property (IP).
Zama believes you can get the best of both worlds: our ambition is to protect both the privacy of the user and the IP of the model. In this blog, you’ll see how to leverage the Hugging Face transformers library and have parts of these models run on encrypted data. The complete code can be found in this [use case example](https://github.com/zama-ai/concrete-ml/tree/17779ca571d20b001caff5792eb11e76fe2c19ba/use_case_examples/llm).
## Fully Homomorphic Encryption (FHE) Can Solve LLM Privacy Challenges
Zama’s solution to the challenges of LLM deployment is to use Fully Homomorphic Encryption (FHE) which enables the execution of functions on encrypted data. It is possible to achieve the goal of protecting the model owner’s IP while still maintaining the privacy of the user's data. This demo shows that an LLM model implemented in FHE maintains the quality of the original model’s predictions. To do this, it’s necessary to adapt the [GPT2](https://huggingface.co./gpt2) implementation from the Hugging Face [transformers library](https://github.com/huggingface/transformers), reworking sections of the inference using Concrete-Python, which enables the conversion of Python functions into their FHE equivalents.

Figure 1 shows the GPT2 architecture which has a repeating structure: a series of multi-head attention (MHA) layers applied successively. Each MHA layer projects the inputs using the model weights, computes the attention mechanism, and re-projects the output of the attention into a new tensor.
In [TFHE](https://www.zama.ai/post/tfhe-deep-dive-part-1), model weights and activations are represented with integers. Nonlinear functions must be implemented with a Programmable Bootstrapping (PBS) operation. PBS implements a table lookup (TLU) operation on encrypted data while also refreshing ciphertexts to allow [arbitrary computation](https://whitepaper.zama.ai/). On the downside, the computation time of PBS dominates the one of linear operations. Leveraging these two types of operations, you can express any sub-part of, or, even the full LLM computation, in FHE.
## Implementation of a LLM layer with FHE
Next, you’ll see how to encrypt a single attention head of the multi-head attention (MHA) block. You can also find an example for the full MHA block in this [use case example](https://github.com/zama-ai/concrete-ml/tree/17779ca571d20b001caff5792eb11e76fe2c19ba/use_case_examples/llm).

Figure 2. shows a simplified overview of the underlying implementation. A client starts the inference locally up to the first layer which has been removed from the shared model. The user encrypts the intermediate operations and sends them to the server. The server applies part of the attention mechanism and the results are then returned to the client who can decrypt them and continue the local inference.
### Quantization
First, in order to perform the model inference on encrypted values, the weights and activations of the model must be quantized and converted to integers. The ideal is to use [post-training quantization](https://docs.zama.ai/concrete-ml/advanced-topics/quantization) which does not require re-training the model. The process is to implement an FHE compatible attention mechanism, use integers and PBS, and then examine the impact on LLM accuracy.
To evaluate the impact of quantization, run the full GPT2 model with a single LLM Head operating over encrypted data. Then, evaluate the accuracy obtained when varying the number of quantization bits for both weights and activations.

This graph shows that 4-bit quantization maintains 96% of the original accuracy. The experiment is done using a data-set of ~80 sentences. The metrics are computed by comparing the logits prediction from the original model against the model with the quantized head model.
### Applying FHE to the Hugging Face GPT2 model
Building upon the transformers library from Hugging Face, rewrite the forward pass of modules that you want to encrypt, in order to include the quantized operators. Build a SingleHeadQGPT2Model instance by first loading a [GPT2LMHeadModel](https://huggingface.co./docs/transformers/model_doc/gpt2#transformers.GPT2LMHeadModel) and then manually replace the first multi-head attention module as following using a [QGPT2SingleHeadAttention](https://github.com/zama-ai/concrete-ml-internal/blob/c291399cb1f2a0655c308c14e2180eb2ffda0ab7/use_case_examples/llm/qgpt2_models.py#L191) module. The complete implementation can be found [here](https://github.com/zama-ai/concrete-ml-internal/blob/c291399cb1f2a0655c308c14e2180eb2ffda0ab7/use_case_examples/llm/qgpt2_models.py).
```python
self.transformer.h[0].attn = QGPT2SingleHeadAttention(config, n_bits=n_bits)
```
The forward pass is then overwritten so that the first head of the multi-head attention mechanism, including the projections made for building the query, keys and value matrices, is performed with FHE-friendly operators. The following QGPT2 module can be found [here](https://github.com/zama-ai/concrete-ml-internal/blob/c291399cb1f2a0655c308c14e2180eb2ffda0ab7/use_case_examples/llm/qgpt2_class.py#L196).
```python
class SingleHeadAttention(QGPT2):
"""Class representing a single attention head implemented with quantization methods."""
def run_numpy(self, q_hidden_states: np.ndarray):
# Convert the input to a DualArray instance
q_x = DualArray(
float_array=self.x_calib,
int_array=q_hidden_states,
quantizer=self.quantizer
)
# Extract the attention base module name
mha_weights_name = f"transformer.h.{self.layer}.attn."
# Extract the query, key and value weight and bias values using the proper indices
head_0_indices = [
list(range(i * self.n_embd, i * self.n_embd + self.head_dim))
for i in range(3)
]
q_qkv_weights = ...
q_qkv_bias = ...
# Apply the first projection in order to extract Q, K and V as a single array
q_qkv = q_x.linear(
weight=q_qkv_weights,
bias=q_qkv_bias,
key=f"attention_qkv_proj_layer_{self.layer}",
)
# Extract the queries, keys and vales
q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}")
q_q, q_k, q_v = q_qkv.enc_split(
3,
axis=-1,
key=f"qkv_split_layer_{self.layer}"
)
# Compute attention mechanism
q_y = self.attention(q_q, q_k, q_v)
return self.finalize(q_y)
```
Other computations in the model remain in floating point, non-encrypted and are expected to be executed by the client on-premise.
Loading pre-trained weights into the GPT2 model modified in this way, you can then call the _generate_ method:
```python
qgpt2_model = SingleHeadQGPT2Model.from_pretrained(
"gpt2_model", n_bits=4, use_cache=False
)
output_ids = qgpt2_model.generate(input_ids)
```
As an example, you can ask the quantized model to complete the phrase ”Cryptography is a”. With sufficient quantization precision when running the model in FHE, the output of the generation is:
“Cryptography is a very important part of the security of your computer”
When quantization precision is too low you will get:
“Cryptography is a great way to learn about the world around you”
### Compilation to FHE
You can now compile the attention head using the following Concrete-ML code:
```python
circuit_head = qgpt2_model.compile(input_ids)
```
Running this, you will see the following print out: “Circuit compiled with 8 bit-width”. This configuration, compatible with FHE, shows the maximum bit-width necessary to perform operations in FHE.
### Complexity
In transformer models, the most computationally intensive operation is the attention mechanism which multiplies the queries, keys, and values. In FHE, the cost is compounded by the specificity of multiplications in the encrypted domain. Furthermore, as the sequence length increases, the number of these challenging multiplications increases quadratically.
For the encrypted head, a sequence of length 6 requires 11,622 PBS operations. This is a first experiment that has not been optimized for performance. While it can run in a matter of seconds, it would require quite a lot of computing power. Fortunately, hardware will improve latency by 1000x to 10000x, making things go from several minutes on CPU to < 100ms on ASIC once they are available in a few years. For more information about these projections, see [this blog post](https://www.zama.ai/post/chatgpt-privacy-with-homomorphic-encryption).
## Conclusion
Large Language Models are great assistance tools in a wide variety of use cases but their implementation raises major issues for user privacy. In this blog, you saw a first step toward having the whole LLM work on encrypted data where the model would run entirely in the cloud while users' privacy would be fully respected.
This step includes the conversion of a specific part in a model like GPT2 to the FHE realm. This implementation leverages the transformers library and allows you to evaluate the impact on the accuracy when part of the model runs on encrypted data. In addition to preserving user privacy, this approach also allows a model owner to keep a major part of their model private. The complete code can be found in this [use case example](https://github.com/zama-ai/concrete-ml/tree/17779ca571d20b001caff5792eb11e76fe2c19ba/use_case_examples/llm).
Zama libraries [Concrete](https://github.com/zama-ai/concrete) and [Concrete-ML](https://github.com/zama-ai/concrete-ml) (Don't forget to star the repos on GitHub ⭐️💛) allow straightforward ML model building and conversion to the FHE equivalent to being able to compute and predict over encrypted data.
Hope you enjoyed this post; feel free to share your thoughts/feedback! | [
[
"llm",
"research",
"security",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"security",
"research",
"efficient_computing"
] | null | null |
724f30eb-ebb1-43bb-a1cc-bc83937a7fae | completed | 2025-01-16T03:08:53.171001 | 2025-01-19T18:55:08.222490 | 2f12d6b8-eace-4063-a4c5-35a235136301 | Code Llama: Llama 2 learns to code | philschmid, osanseviero, pcuenq, lewtun, lvwerra, loubnabnl, ArthurZ, joaogante | codellama.md | ## Introduction
Code Llama is a family of state-of-the-art, open-access versions of [Llama 2](https://huggingface.co./blog/llama2) specialized on code tasks, and we’re excited to release integration in the Hugging Face ecosystem! Code Llama has been released with the same permissive community license as Llama 2 and is available for commercial use.
Today, we’re excited to release:
- Models on the Hub with their model cards and license
- Transformers integration
- Integration with Text Generation Inference for fast and efficient production-ready inference
- Integration with Inference Endpoints
- Integration with VS Code extension
- Code benchmarks
Code LLMs are an exciting development for software engineers because they can boost productivity through code completion in IDEs, take care of repetitive or annoying tasks like writing docstrings, or create unit tests.
## Table of Contents
- [Introduction](#introduction)
- [Table of Contents](#table-of-contents)
- [What’s Code Llama?](#whats-code-llama)
- [How to use Code Llama?](#how-to-use-code-llama)
- [Demo](#demo)
- [Transformers](#transformers)
- [A Note on dtypes](#a-note-on-dtypes)
- [Code Completion](#code-completion)
- [Code Infilling](#code-infilling)
- [Conversational Instructions](#conversational-instructions)
- [4-bit Loading](#4-bit-loading)
- [Using text-generation-inference and Inference Endpoints](#using-text-generation-inference-and-inference-endpoints)
- [Using VS Code extension](#using-vs-code-extension)
- [Evaluation](#evaluation)
- [Additional Resources](#additional-resources)
## What’s Code Llama?
The Code Llama release introduces a family of models of 7, 13, and 34 billion parameters. The base models are initialized from Llama 2 and then trained on 500 billion tokens of code data. Meta fine-tuned those base models for two different flavors: a Python specialist (100 billion additional tokens) and an instruction fine-tuned version, which can understand natural language instructions.
The models show state-of-the-art performance in Python, C++, Java, PHP, C#, TypeScript, and Bash. The 7B and 13B base and instruct variants support infilling based on surrounding content, making them ideal for use as code assistants.
Code Llama was trained on a 16k context window. In addition, the three model variants had additional long-context fine-tuning, allowing them to manage a context window of up to 100,000 tokens.
Increasing Llama 2’s 4k context window to Code Llama’s 16k (that can extrapolate up to 100k) was possible due to recent developments in RoPE scaling. The community found that Llama’s position embeddings can be interpolated linearly or in the frequency domain, which eases the transition to a larger context window through fine-tuning. In the case of Code Llama, the frequency domain scaling is done with a slack: the fine-tuning length is a fraction of the scaled pretrained length, giving the model powerful extrapolation capabilities.

All models were initially trained with 500 billion tokens on a near-deduplicated dataset of publicly available code. The dataset also contains some natural language datasets, such as discussions about code and code snippets. Unfortunately, there is not more information about the dataset.
For the instruction model, they used two datasets: the instruction tuning dataset collected for Llama 2 Chat and a self-instruct dataset. The self-instruct dataset was created by using Llama 2 to create interview programming questions and then using Code Llama to generate unit tests and solutions, which are later evaluated by executing the tests.
## How to use Code Llama?
Code Llama is available in the Hugging Face ecosystem, starting with `transformers` version 4.33.
### Demo
You can easily try the Code Llama Model (13 billion parameters!) in **[this Space](https://huggingface.co./spaces/codellama/codellama-playground)** or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.28.3/gradio.js"> </script>
<gradio-app theme_mode="light" space="codellama/codellama-playground"></gradio-app>
Under the hood, this playground uses Hugging Face's [Text Generation Inference](https://github.com/huggingface/text-generation-inference), the same technology that powers [HuggingChat](https://huggingface.co./chat/), and we'll share more in the following sections.
If you want to try out the bigger instruct-tuned 34B model, it is now available on **HuggingChat**! You can try it out here: [hf.co/chat](https://hf.co/chat). Make sure to specify the Code Llama model. You can also check [this chat-based demo](https://huggingface.co./spaces/codellama/codellama-13b-chat) and duplicate it for your use – it's self-contained, so you can examine the source code and adapt it as you wish!
### Transformers
Starting with `transformers` 4.33, you can use Code Llama and leverage all the tools within the HF ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as `bitsandbytes` (4-bit quantization) and PEFT (parameter efficient fine-tuning)
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
```bash
!pip install --upgrade transformers
```
#### A Note on dtypes
When using models like Code Llama, it's important to take a look at the data types of the models.
* 32-bit floating point (`float32`): PyTorch convention on model initialization is to load models in `float32`, no matter with which precision the model weights were stored. `transformers` also follows this convention for consistency with PyTorch.
* 16-bit Brain floating point (`bfloat16`): Code Llama was trained with this precision, so we recommend using it for further training or fine-tuning.
* 16-bit floating point (`float16`): We recommend running inference using this precision, as it's usually faster than `bfloat16`, and evaluation metrics show no discernible degradation with respect to `bfloat16`. You can also run inference using `bfloat16`, and we recommend you check inference results with both `float16` and `bfloat16` after fine-tuning.
As mentioned above, `transformers` loads weights using `float32` (no matter with which precision the models are stored), so it's important to specify the desired `dtype` when loading the models. If you want to fine-tune Code Llama, it's recommended to use `bfloat16`, as using `float16` can lead to overflows and NaNs. If you run inference, we recommend using `float16` because `bfloat16` can be slower.
#### Code Completion
The 7B and 13B models can be used for text/code completion or infilling. The following code snippet uses the `pipeline` interface to demonstrate text completion. It runs on the free tier of Colab, as long as you select a GPU runtime.
```python
from transformers import AutoTokenizer
import transformers
import torch
tokenizer = AutoTokenizer.from_pretrained("codellama/CodeLlama-7b-hf")
pipeline = transformers.pipeline(
"text-generation",
model="codellama/CodeLlama-7b-hf",
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'def fibonacci(',
do_sample=True,
temperature=0.2,
top_p=0.9,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=100,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
This may produce output like the following:
```python
Result: def fibonacci(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
def fibonacci_memo(n, memo={}):
if n == 0:
return 0
elif n == 1:
return
```
Code Llama is specialized in code understanding, but it's a language model in its own right. You can use the same generation strategy to autocomplete comments or general text.
#### Code Infilling
This is a specialized task particular to code models. The model is trained to generate the code (including comments) that best matches an existing prefix and suffix. This is the strategy typically used by code assistants: they are asked to fill the current cursor position, considering the contents that appear before and after it.
This task is available in the **base** and **instruction** variants of the 7B and 13B models. It is _not_ available for any of the 34B models or the Python versions.
To use this feature successfully, you need to pay close attention to the format used to train the model for this task, as it uses special separators to identify the different parts of the prompt. Fortunately, transformers' `CodeLlamaTokenizer` makes this very easy, as demonstrated below:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "codellama/CodeLlama-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda")
prompt = '''def remove_non_ascii(s: str) -> str:
""" <FILL_ME>
return result
'''
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
output = model.generate(
input_ids,
max_new_tokens=200,
)
output = output[0].to("cpu")
filling = tokenizer.decode(output[input_ids.shape[1]:], skip_special_tokens=True)
print(prompt.replace("<FILL_ME>", filling))
```
```Python
def remove_non_ascii(s: str) -> str:
""" Remove non-ASCII characters from a string.
Args:
s: The string to remove non-ASCII characters from.
Returns:
The string with non-ASCII characters removed.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c
return result
```
Under the hood, the tokenizer [automatically splits by `<FILL_ME>`](https://huggingface.co./docs/transformers/main/model_doc/code_llama#transformers.CodeLlamaTokenizer.fill_token) to create a formatted input string that follows [the original training pattern](https://github.com/facebookresearch/codellama/blob/cb51c14ec761370ba2e2bc351374a79265d0465e/llama/generation.py#L402). This is more robust than preparing the pattern yourself: it avoids pitfalls, such as token glueing, that are very hard to debug.
#### Conversational Instructions
The base model can be used for both completion and infilling, as described. The Code Llama release also includes an instruction fine-tuned model that can be used in conversational interfaces.
To prepare inputs for this task we have to use a prompt template like the one described in our [Llama 2 blog post](https://huggingface.co./blog/llama2#how-to-prompt-llama-2), which we reproduce again here:
```
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]
```
Note that the system prompt is optional - the model will work without it, but you can use it to further configure its behavior or style. For example, if you'd always like to get answers in JavaScript, you could state that here. After the system prompt, you need to provide all the previous interactions in the conversation: what was asked by the user and what was answered by the model. As in the infilling case, you need to pay attention to the delimiters used. The final component of the input must always be a new user instruction, which will be the signal for the model to provide an answer.
The following code snippets demonstrate how the template works in practice.
1. **First user query, no system prompt**
```python
user = 'In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month?'
prompt = f"<s>[INST] {user.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
2. **First user query with system prompt**
```python
system = "Provide answers in JavaScript"
user = "Write a function that computes the set of sums of all contiguous sublists of a given list."
prompt = f"<s>[INST] <<SYS>>\\n{system}\\n<</SYS>>\\n\\n{user}[/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
3. **On-going conversation with previous answers**
The process is the same as in [Llama 2](https://huggingface.co./blog/llama2#how-to-prompt-llama-2). We haven’t used loops or generalized this example code for maximum clarity:
```python
system = "System prompt"
user_1 = "user_prompt_1"
answer_1 = "answer_1"
user_2 = "user_prompt_2"
answer_2 = "answer_2"
user_3 = "user_prompt_3"
prompt = f"<<SYS>>\n{system}\n<</SYS>>\n\n{user_1}"
prompt = f"<s>[INST] {prompt.strip()} [/INST] {answer_1.strip()} </s>"
prompt += f"<s>[INST] {user_2.strip()} [/INST] {answer_2.strip()} </s>"
prompt += f"<s>[INST] {user_3.strip()} [/INST]"
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
```
#### 4-bit Loading
Integration of Code Llama in Transformers means that you get immediate support for advanced features like 4-bit loading. This allows you to run the big 32B parameter models on consumer GPUs like nvidia 3090 cards!
Here's how you can run inference in 4-bit mode:
```Python
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
model_id = "codellama/CodeLlama-34b-hf"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto",
)
prompt = 'def remove_non_ascii(s: str) -> str:\n """ '
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
inputs["input_ids"],
max_new_tokens=200,
do_sample=True,
top_p=0.9,
temperature=0.1,
)
output = output[0].to("cpu")
print(tokenizer.decode(output))
```
### Using text-generation-inference and Inference Endpoints
[Text Generation Inference](https://github.com/huggingface/text-generation-inference) is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
You can try out Text Generation Inference on your own infrastructure, or you can use Hugging Face's [Inference Endpoints](https://huggingface.co./inference-endpoints). To deploy a Codellama 2 model, go to the [model page](https://huggingface.co./codellama) and click on the [Deploy -> Inference Endpoints](https://huggingface.co./codellama/CodeLlama-7b-hf) widget.
- For 7B models, we advise you to select "GPU [medium] - 1x Nvidia A10G".
- For 13B models, we advise you to select "GPU [xlarge] - 1x Nvidia A100".
- For 34B models, we advise you to select "GPU [1xlarge] - 1x Nvidia A100" with `bitsandbytes` quantization enabled or "GPU [2xlarge] - 2x Nvidia A100"
*Note: You might need to request a quota upgrade via email to **[[email protected]](mailto:[email protected])** to access A100s*
You can learn more on how to [Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co./blog/inference-endpoints-llm). The [blog](https://huggingface.co./blog/inference-endpoints-llm) includes information about supported hyperparameters and how to stream your response using Python and Javascript.
### Using VS Code extension
[HF Code Autocomplete](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) is a VS Code extension for testing open source code completion models. The extension was developed as part of [StarCoder project](/blog/starcoder#tools--demos) and was updated to support the medium-sized base model, [Code Llama 13B](/codellama/CodeLlama-13b-hf). Find more [here](https://github.com/huggingface/huggingface-vscode#code-llama) on how to install and run the extension with Code Llama.

## Evaluation
Language models for code are typically benchmarked on datasets such as HumanEval. It consists of programming challenges where the model is presented with a function signature and a docstring and is tasked to complete the function body. The proposed solution is then verified by running a set of predefined unit tests. Finally, a pass rate is reported which describes how many solutions passed all tests. The pass@1 rate describes how often the model generates a passing solution when having one shot whereas pass@10 describes how often at least one solution passes out of 10 proposed candidates.
While HumanEval is a Python benchmark there have been significant efforts to translate it to more programming languages and thus enable a more holistic evaluation. One such approach is [MultiPL-E](https://github.com/nuprl/MultiPL-E) which translates HumanEval to over a dozen languages. We are hosting a [multilingual code leaderboard](https://huggingface.co./spaces/bigcode/multilingual-code-evals) based on it to allow the community to compare models across different languages to evaluate which model fits their use-case best.
| Model | License | Dataset known | Commercial use? | Pretraining length [tokens] | Python | JavaScript | Leaderboard Avg Score |
| | [
[
"llm",
"implementation",
"benchmarks",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"implementation",
"benchmarks",
"integration"
] | null | null |
db1a751d-58dd-482e-a9b0-33c0b263a9b4 | completed | 2025-01-16T03:08:53.171006 | 2025-01-19T19:15:11.859114 | ee8660c2-d368-46ce-a79c-0d3daa53bf60 | Incredibly Fast BLOOM Inference with DeepSpeed and Accelerate | stas, sgugger | bloom-inference-pytorch-scripts.md | This article shows how to get an incredibly fast per token throughput when generating with the 176B parameter [BLOOM model](https://huggingface.co./bigscience/bloom).
As the model needs 352GB in bf16 (bfloat16) weights (`176*2`), the most efficient set-up is 8x80GB A100 GPUs. Also 2x8x40GB A100s or 2x8x48GB A6000 can be used. The main reason for using these GPUs is that at the time of this writing they provide the largest GPU memory, but other GPUs can be used as well. For example, 24x32GB V100s can be used.
Using a single node will typically deliver a fastest throughput since most of the time intra-node GPU linking hardware is faster than inter-node one, but it's not always the case.
If you don't have that much hardware, it's still possible to run BLOOM inference on smaller GPUs, by using CPU or NVMe offload, but of course, the generation time will be much slower.
We are also going to cover the [8bit quantized solutions](https://huggingface.co./blog/hf-bitsandbytes-integration), which require half the GPU memory at the cost of slightly slower throughput. We will discuss [BitsAndBytes](https://github.com/TimDettmers/bitsandbytes) and [Deepspeed-Inference](https://www.deepspeed.ai/tutorials/inference-tutorial/) libraries there.
## Benchmarks
Without any further delay let's show some numbers.
For the sake of consistency, unless stated differently, the benchmarks in this article were all done on the same 8x80GB A100 node w/ 512GB of CPU memory on [Jean Zay HPC](http://www.idris.fr/eng/jean-zay/index.html). The JeanZay HPC users enjoy a very fast IO of about 3GB/s read speed (GPFS). This is important for checkpoint loading time. A slow disc will result in slow loading time. Especially since we are concurrently doing IO in multiple processes.
All benchmarks are doing [greedy generation](https://huggingface.co./blog/how-to-generate#greedy-search) of 100 token outputs:
```
Generate args {'max_length': 100, 'do_sample': False}
```
The input prompt is comprised of just a few tokens. The previous token caching is on as well, as it'd be quite slow to recalculate them all the time.
First, let's have a quick look at how long did it take to get ready to generate - i.e. how long did it take to load and prepare the model:
| project | secs |
| : | [
[
"llm",
"implementation",
"tutorial",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"optimization",
"implementation",
"efficient_computing"
] | null | null |
30f3bcab-e2e9-4a61-99ba-739f698581f1 | completed | 2025-01-16T03:08:53.171010 | 2025-01-16T13:46:26.496192 | f0cf8b67-79ad-4c82-a8f9-1e68b1c101b6 | AI for Game Development: Creating a Farming Game in 5 Days. Part 2 | dylanebert | ml-for-games-2.md | **Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7186551685035085098). Otherwise, if you want the technical details, keep reading!
**Note:** This tutorial is intended for readers who are familiar with Unity development and C#. If you're new to these technologies, check out the [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954) series before continuing.
## Day 2: Game Design
In [Part 1](https://huggingface.co./blog/ml-for-games-1) of this tutorial series, we used **AI for Art Style**. More specifically, we used Stable Diffusion to generate concept art and develop the visual style of our game.
In this part, we'll be using AI for Game Design. In [The Short Version](#the-short-version), I'll talk about how I used ChatGPT as a tool to help develop game ideas. But more importantly, what is actually going on here? Keep reading for background on [Language Models](#language-models) and their broader [Uses in Game Development](#uses-in-game-development).
### The Short Version
The short version is straightforward: ask [ChatGPT](https://chat.openai.com/chat) for advice, and follow its advice at your own discretion. In the case of the farming game, I asked ChatGPT:
> You are a professional game designer, designing a simple farming game. What features are most important to making the farming game fun and engaging?
The answer given includes (summarized):
1. Variety of crops
2. A challenging and rewarding progression system
3. Dynamic and interactive environments
4. Social and multiplayer features
5. A strong and immersive story or theme
Given that I only have 5 days, I decided to [gray-box](https://en.wikipedia.org/wiki/Gray-box_testing) the first two points. You can play the result [here](https://individualkex.itch.io/ml-for-game-dev-2), and view the source code [here](https://github.com/dylanebert/FarmingGame).
I'm not going to go into detail on how I implemented these mechanics, since the focus of this series is how to use AI tools in your own game development process, not how to implement a farming game. Instead, I'll talk about what ChatGPT is (a language model), how these models actually work, and what this means for game development.
### Language Models
ChatGPT, despite being a major breakthrough in adoption, is an iteration on tech that has existed for a while: *language models*.
Language models are a type of AI that are trained to predict the likelihood of a sequence of words. For example, if I were to write "The cat chases the ____", a language model would be trained to predict "mouse". This training process can then be applied to a wide variety of tasks. For example, translation: "the French word for cat is ____". This setup, while successful at some natural language tasks, wasn't anywhere near the level of performance seen today. This is, until the introduction of **transformers**.
**Transformers**, [introduced in 2017](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf), are a neural network architecture that use a self-attention mechanism to predict the entire sequence all at once. This is the tech behind modern language models like ChatGPT. Want to learn more about how they work? Check out our [Introduction to Transformers](https://huggingface.co./course/chapter1/1) course, available free here on Hugging Face.
So why is ChatGPT so successful compared to previous language models? It's impossible to answer this in its entirety, since ChatGPT is not open source. However, one of the reasons is Reinforcement Learning from Human Feedback (RLHF), where human feedback is used to improve the language model. Check out this [blog post](https://huggingface.co./blog/rlhf) for more information on RLHF: how it works, open-source tools for doing it, and its future.
This area of AI is constantly changing, and likely to see an explosion of creativity as it becomes part of the open source community, including in uses for game development. If you're reading this, you're probably ahead of the curve already.
### Uses in Game Development
In [The Short Version](#the-short-version), I talked about how I used ChatGPT to help develop game ideas. There is a lot more you can do with it though, like using it to [code an entire game](https://www.youtube.com/watch?v=YDWvAqKLTLg&ab_channel=AAlex). You can use it for pretty much anything you can think of. Something that might be a bit more helpful is to talk about what it *can't* do.
#### Limitations
ChatGPT often sounds very convincing, while being wrong. Here is an [archive of ChatGPT failures](https://github.com/giuven95/chatgpt-failures). The reason for these is that ChatGPT doesn't *know* what it's talking about the way a human does. It's a very large [Language Model](#language-models) that predicts likely outputs, but doesn't really understand what it's saying. One of my personal favorite examples of these failures (especially relevant to game development) is this explanation of quaternions from [Reddit](https://www.reddit.com/r/Unity3D/comments/zcps1f/eli5_quaternion_by_chatgpt/):
<figure class="image text-center">
<img src="/blog/assets/124_ml-for-games/quaternion.png" alt="ChatGPT Quaternion Explanation">
</figure>
This explanation, while sounding excellent, is completely wrong. This is a great example of why ChatGPT, while very useful, shouldn't be used as a definitive knowledge base.
#### Suggestions
If ChatGPT fails a lot, should you use it? I would argue that it's still extremely useful as a tool, rather than as a replacement. In the example of Game Design, I could have followed up on ChatGPT's answer, and asked it to implement all of its suggestions for me. As I mentioned before, [others have done this](https://www.youtube.com/watch?v=YDWvAqKLTLg&ab_channel=AAlex), and it somewhat works. However, I would suggest using ChatGPT more as a tool for brainstorming and acceleration, rather than as a complete replacement for steps in the development process.
Click [here](https://huggingface.co./blog/ml-for-games-3) to read Part 3, where we use **AI for 3D Assets**. | [
[
"implementation",
"tutorial",
"tools",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"implementation",
"tutorial",
"image_generation",
"tools"
] | null | null |
6f80ba62-e3a8-4842-be9f-9e8d5dc28d71 | completed | 2025-01-16T03:08:53.171015 | 2025-01-16T13:33:50.040916 | 0229ff99-a5d2-4e88-a6ad-dc9510292303 | Introducing The World's Largest Open Multilingual Language Model: BLOOM | bigscience | bloom.md | <a href="https://huggingface.co./bigscience/bloom"><img style="middle" width="950" src="/blog/assets/86_bloom/thumbnail-2.png"></a>
Large language models (LLMs) have made a significant impact on AI research. These powerful, general models can take on a wide variety of new language tasks from a user’s instructions. However, academia, nonprofits and smaller companies' research labs find it difficult to create, study, or even use LLMs as only a few industrial labs with the necessary resources and exclusive rights can fully access them. Today, we release [BLOOM](https://huggingface.co./bigscience/bloom), the first multilingual LLM trained in complete transparency, to change this status quo — the result of the largest collaboration of AI researchers ever involved in a single research project.
With its 176 billion parameters, BLOOM is able to generate text in 46 natural languages and 13 programming languages. For almost all of them, such as Spanish, French and Arabic, BLOOM will be the first language model with over 100B parameters ever created. This is the culmination of a year of work involving over 1000 researchers from 70+ countries and 250+ institutions, leading to a final run of 117 days (March 11 - July 6) training the BLOOM model on the [Jean Zay supercomputer](http://www.idris.fr/eng/info/missions-eng.html) in the south of Paris, France thanks to a compute grant worth an estimated €3M from French research agencies CNRS and GENCI.
Researchers can [now download, run and study BLOOM](https://huggingface.co./bigscience/bloom) to investigate the performance and behavior of recently developed large language models down to their deepest internal operations. More generally, any individual or institution who agrees to the terms of the model’s [Responsible AI License](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) (developed during the BigScience project itself) can use and build upon the model on a local machine or on a cloud provider. In this spirit of collaboration and continuous improvement, we’re also releasing, for the first time, the intermediary checkpoints and optimizer states of the training. Don’t have 8 A100s to play with? An inference API, currently backed by Google’s TPU cloud and a FLAX version of the model, also allows quick tests, prototyping, and lower-scale use. You can already play with it on the Hugging Face Hub.
<img class="mx-auto" style="center" width="950" src="/blog/assets/86_bloom/bloom-examples.jpg"></a>
This is only the beginning. BLOOM’s capabilities will continue to improve as the workshop continues to experiment and tinker with the model. We’ve started work to make it instructable as our earlier effort T0++ was and are slated to add more languages, compress the model into a more usable version with the same level of performance, and use it as a starting point for more complex architectures… All of the experiments researchers and practitioners have always wanted to run, starting with the power of a 100+ billion parameter model, are now possible. BLOOM is the seed of a living family of models that we intend to grow, not just a one-and-done model, and we’re ready to support community efforts to expand it. | [
[
"llm",
"research",
"community",
"text_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"research",
"community",
"text_generation"
] | null | null |
3e1251a5-ede3-4202-8ef6-2f79a3bb54a3 | completed | 2025-01-16T03:08:53.171019 | 2025-01-19T18:55:15.918355 | 3520437e-a75d-4761-9fde-f919a0d7d353 | A failed experiment: Infini-Attention, and why we should keep trying? | neuralink, lvwerra, thomwolf | infini-attention.md | TLDR: Infini-attention's performance gets worse as we increase the number of times we compress the memory, and to the best of our knowledge, [ring attention](https://x.com/Haojun_Zhao14/status/1815419356408336738), [YaRN](https://arxiv.org/abs/2309.00071) and [rope scaling](https://arxiv.org/abs/2309.16039) are still the best ways for extending a pretrained model to longer context length.
## Section 0: Introduction
The context length of language models is one of the central attributes besides the model’s performance. Since the emergence of in-context learning, adding relevant information to the model’s input has become increasingly important. Thus, the context length rapidly increased from paragraphs (512 tokens with BERT/GPT-1) to pages (1024/2048 with GPT-2 and GPT-3 respectively) to books (128k of Claude) all the way to collections of books (1-10M tokens of Gemini). However, extending standard attention to such length remains challenging.
> A small intro to Ring Attention: Ring Attention was first introduced by researchers from UC Berkeley in 2024 [[link]](https://arxiv.org/abs/2310.01889) (to the best of our knowledge). This engineering technique helps overcome memory limitations by performing self-attention and feedforward network computations in a blockwise fashion and distributing sequence dimensions across multiple devices, allowing concurrent computation and communication.
Even with Ring Attention, the number of GPUs required to train a [Llama 3 8B](https://arxiv.org/abs/2407.21783) on a 1-million-token context length with a batch size of 1 is 512 GPUs. As scaling laws have [shown](https://arxiv.org/abs/2001.08361), there is a strong correlation between model size and its downstream performance, which means the bigger the model, the better (of course, both models should be well-trained). So we not only want a 1m context length, but we want a 1m context length on the biggest model (e.g., Llama 3 8B 405B). And there are only a few companies in existence that have the resources to do so.
> Recap on the memory complexity of self-attention
> In standard attention (not-flash-attention), every token attends to every other token in the sequence, resulting in an attention matrix of size [seq_len, seq_len]. For each pair of tokens, we compute an attention score, and as the sequence length (seq_len) increases, the memory and computation requirements grow quadratically: Memory for the attention matrix is O(seq_len^2). For instance, a 10x increase in sequence length results in a 100x increase in memory requirements. Even memory efficient attention methods like Flash Attention still increase linearly with context length and are bottlenecked by single GPU memory, leading to a typical max context far lower than 1M tokens on today's GPUs.
Motivated by this, we explore an alternative approach to standard attention: infini-attention. The paper was released by researchers from Google in April 2024 [[link]](https://arxiv.org/abs/2404.07143). Instead of computing attention scores between every word, Infini-attention divides the sequence into segments, compresses earlier segments into a fixed buffer, and allows the next segment to retrieve memory from the earlier segments while limiting attention scores to words within the current segment. A key advantage is its fixed buffer size upper bounds the total memory usage. It also uses the same query within a segment to access information from both its own segment and the compressed memory, which enables us to cheaply extend the context length for a pretrained model. In theory, we can achieve infinite context length, as it only keeps a single buffer for all the memory of earlier segments. However, in reality compression limits the amount of information which can effectively been stored and the question is thus: how usably is the memory such compressed?
While understanding a new method on paper is relatively easy, actually making it work is often a whole other story, story which is very rarely shared publicly. Motivated by this, we decided to share our experiments and chronicles in reproducing the Infini-attention paper, what motivated us throughout the debugging process (we spent 90% of our time debugging a convergence issue), and how hard it can be to make these things work.
With the release of Llama 3 8B (which has a context length limit of 8k tokens), we sought to extend this length to 1 million tokens without quadratically increasing the memory. In this blog post, we will start by explaining how Infini-attention works. We’ll then outline our reproduction principles and describe our initial small-scale experiment. We discuss the challenges we faced, how we addressed them, and conclude with a summary of our findings and other ideas we explored. If you’re interested in testing our trained checkpoint [[link]](https://huggingface.co./nanotron/llama3-8b-infini-attention), you can find it in the following repo [[link]](https://github.com/huggingface/nanotron/tree/xrsrke/infini_attention_this_actually_works) (note that we currently provide the code as is).
## Section 1: Reproduction Principles
We found the following rules helpful when implementing a new method and use it as guiding principles for a lot of our work:
+ **Principle 1:** Start with the smallest model size that provides good signals, and scale up the experiments once you get good signals.
+ **Principle 2.** Always train a solid baseline to measure progress.
+ **Principle 3.** To determine if a modification improves performance, train two models identically except for the modification being tested.
With these principles in mind, let's dive into how Infini-attention actually works. Understanding the mechanics will be crucial as we move forward with our experiments.
## Section 2: How does Infini-attention works
- Step 1: Split the input sequence into smaller, fixed-size chunks called "segments".
- Step 2: Calculate the standard causal dot-product attention within each segment.
- Step 3: Pull relevant information from the compressive memory using the current segment’s query vector. The retrieval process is defined mathematically as follows:
\\( A_{\text {mem }}=\frac{\sigma(Q) M_{s-1}}{\sigma(Q) z_{s-1}} \\)
+ \\( A_{\text {mem }} \in \mathbb{R}^{N \times d_{\text {value }}} \\) : The retrieved content from memory, representing the long-term context.
+ \\( Q \in \mathbb{R}^{N \times d_{\text {key }}} \\) : The query matrix, where \\( N \\) is the number of queries, and \\( d_{\text {key }} \\) is the dimension of each query.
+ \\( M_{s-1} \in \mathbb{R}^{d_{\text {key }} \times d_{\text {value }}} \\) : The memory matrix from the previous segment, storing key-value pairs.
+ \\( \sigma \\): A nonlinear activation function, specifically element-wise Exponential Linear Unit (ELU) plus 1.
+ \\( z_{s-1} \in \mathbb{R}^{d_{\text {key }}} \\) : A normalization term.
```python
import torch.nn.functional as F
from torch import einsum
from einops import rearrange
def _retrieve_from_memory(query_states, prev_memory, prev_normalization):
...
sigma_query_states = F.elu(query_states) + 1
retrieved_memory = einsum(
sigma_query_states,
prev_memory,
"batch_size n_heads seq_len d_k, batch_size n_heads d_k d_v -> batch_size n_heads seq_len d_v",
)
denominator = einsum(
sigma_query_states,
prev_normalization,
"batch_size n_heads seq_len d_head, batch_size n_heads d_head -> batch_size n_heads seq_len",
)
denominator = rearrange(
denominator,
"batch_size n_heads seq_len -> batch_size n_heads seq_len 1",
)
# NOTE: because normalization is the sum of all the keys, so each word should have the same normalization
retrieved_memory = retrieved_memory / denominator
return retrieved_memory
```
- Step 4: Combine the local context (from the current segment) with the long-term context (retrieved from the compressive memory) to generate the final output. This way, both short-term and long-term contexts can be considered in the attention output.
\\( A=\text{sigmoid}(\beta) \odot A_{\text {mem }}+(1-\text{sigmoid}(\beta)) \odot A_{\text {dot }} \\)
+ \\( A \in \mathbb{R}^{N \times d_{\text {value }}} \\) : The combined attention output.
+ \\( \text{sigmoid}(\beta) \\) : A learnable scalar parameter that controls the trade-off between the long-term memory content \\( A_{\text {mem }} \\) and the local context.
+ \\( A_{\text {dot }} \in \mathbb{R}^{N \times d_{\text {value }}} \\) : The attention output from the current segment using dot-product attention.
+ Step 5: Update the compressive memory by adding the key-value states from the current segment, so this allows us to accumulate the context over time.
\\( M_s \leftarrow M_{s-1}+\sigma(K)^T V \\)
\\( z_s \leftarrow z_{s-1}+\sum_{t=1}^N \sigma\left(K_t\right) \\)
+ \\( M_s \in \mathbb{R}^{d_{\text {key }} \times d_{\text {value }}} \\) : The updated memory matrix for the current segment, incorporating new information.
+ \\( K \in \mathbb{R}^{N \times d_{\text {key }}} \\) : The key matrix for the current segment, representing the new keys to be stored.
+ \\( V \in \mathbb{R}^{N \times d_{\text {value }}} \\) : The value matrix for the current segment, representing the new values associated with the keys.
+ \\( K_t \\) : The \\( t \\)-th key vector in the key matrix.
+ \\( z_s \\) : The updated normalization term for the current segment.
```python
import torch
def _update_memory(prev_memory, prev_normalization, key_states, value_states):
...
sigma_key_states = F.elu(key_states) + 1
if prev_memory is None or prev_normalization is None:
new_value_states = value_states
else:
numerator = einsum(
sigma_key_states,
prev_memory,
"batch_size n_heads seq_len d_k, batch_size n_heads d_k d_v -> batch_size n_heads seq_len d_v",
)
denominator = einsum(
sigma_key_states,
prev_normalization,
"batch_size n_heads seq_len d_k, batch_size n_heads d_k -> batch_size n_heads seq_len",
)
denominator = rearrange(
denominator,
"batch_size n_heads seq_len -> batch_size n_heads seq_len 1",
)
prev_v = numerator / denominator
new_value_states = value_states - prev_v
memory = torch.matmul(sigma_key_states.transpose(-2, -1), new_value_states)
normalization = reduce(
sigma_key_states,
"batch_size n_heads seq_len d_head -> batch_size n_heads d_head",
reduction="sum",
...
)
memory += prev_memory if prev_memory is not None else 0
normalization += prev_normalization if prev_normalization is not None else 0
return memory, normalization
```
+ Step 6: As we move from one segment to the next, we discard the previous segment's attention states and pass along the updated compressed memory to the next segment.
```python
def forward(...):
...
outputs = []
global_weights = F.sigmoid(self.balance_factors)
...
local_weights = 1 - global_weights
memory = None
normalization = None
for segment_hidden_state, segment_sequence_mask in zip(segment_hidden_states, segment_sequence_masks):
attn_outputs = self.forward_with_hidden_states(
hidden_states=segment_hidden_state, sequence_mask=segment_sequence_mask, return_qkv_states=True
)
local_attn_outputs = attn_outputs["attention_output"]
query_states, key_states, value_states = attn_outputs["qkv_states_without_pe"]
q_bs = query_states.shape[0]
q_length = query_states.shape[2]
...
retrieved_memory = _retrieve_from_memory(
query_states, prev_memory=memory, prev_normalization=normalization
)
attention_output = global_weights * retrieved_memory + local_weights * local_attn_outputs
...
output = o_proj(attention_output)
memory, normalization = _update_memory(memory, normalization, key_states, value_states)
outputs.append(output)
outputs = torch.cat(outputs, dim=1) # concat along sequence dimension
...
```
Now that we've got a handle on the theory, time to roll up our sleeves and get into some actual experiments. Let's start small for quick feedback and iterate rapidly.
## Section 3: First experiments on a small scale
Llama 3 8B is quite large so we decided to start with a 200M Llama, pretraining Infini-attention from scratch using Nanotron [[link]](https://github.com/huggingface/nanotron) and the Fineweb dataset [[link]](https://huggingface.co./datasets/HuggingFaceFW/fineweb). Once we obtained good results with the 200M model, we proceeded with continual pretraining on Llama 3 8B. We used a batch size of 2 million tokens, a context length of 256, gradient clipping of 1, and weight decay of 0.1, the first 5,000 iterations were a linear warmup, while the remaining steps were cosine decay, with a learning rate of 3e-5.
**Evaluating using the passkey retrieval task**
The passkey retrieval task was first introduced by researchers from EPFL [[link]](https://arxiv.org/abs/2305.16300). It's a task designed to evaluate a model's ability to retrieve information from long contexts where the location of the information is controllable. The input format for prompting a model is structured as follows:
```There is important info hidden inside a lot of irrelevant text. Find it and memorize them. I will quiz you about the important information there. The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. (repeat x times) The pass key is 9054. Remember it. 9054 is the pass key. The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. (repeat y times) What is the pass key? The pass key is```
We consider the model successful at this task if its output contains the "needle" ("9054" in the above case) and unsuccessful if it does not. In our experiments, we place the needle at various positions within the context, specifically at 0%, 5%, 10%, ..., 95%, and 100% of the total context length (with 0% being the furthest away from the generated tokens). For instance, if the context length is 1024 tokens, placing the needle at 10% means it is located around the 102nd token. At each depth position, we test the model with 10 different samples and calculate the mean success rate.
**First results**
Here are some first results on the small 200M model:

As you can see it somewhat works. If you look at the sample generations, you can see that Infini-attention generates content related to the earlier segment.
Since Infini-attention predicts the first token in the second segment by conditioning on the entire content of the first segment, which it generated as "_grad" for the first token, this provides a good signal. To validate whether this signal is a false positive, we hypothesize that Infini-attention generates content related to its earlier segment because when given "_grad" as the first generated token of the second segment, it consistently generates PyTorch-related tutorials, which happen to relate to its earlier segment. Therefore, we conducted a sanity test where the only input token was "_grad", and it generated [text here]. This suggests it does use the memory, but just doesn’t use it well enough (to retrieve the exact needle or continue the exact content of its earlier segment). The generation:
```
_graduate_education.html
Graduate Education
The Department of Physics and Astronomy offers a program leading to the Master of Science degree in physics. The program is designed to provide students with a broad background in
```
Based on these results, the model appears to in fact use the compressed memory. We decided to scale up our experiments by continually pretraining a Llama 3 8B. Unfortunately, the model failed to pass the needle evaluation when the needle was placed in an earlier segment.
We decided to inspect the balance factors (factor balancing the amount of compressed and not-compressed memory) across all layers. Based on Figure 3a and Figure 3b, we found that about 95% of the weights are centered around 0.5. Recall that for a weight to converge to an ideal range, it depends on two general factors: the step size and the magnitude of the gradients. However, Adam normalizes the gradients to a magnitude of 1 so the question became: are the training hyper-parameters the right ones to allow the finetuning to converge?


## Section 4: Studying convergence?
We decided to simulate how much balance weights would change during training given gradients are in a good range (L2 norm is 0.01), and found that, given the config of the last 8B LLaMA3 fine-tuning experiment, the total of absolute changes in the weight would be 0.03. Since we initialize balance factors at 0 (it doesn’t matter in this case), the weights at the end would be in the range [0 - 0.03, 0 + 0.03] = [-0.03, 0.03].
An educated guess for infinity attention to work well is when global weights spread out in the range 0 and 1 as in the paper. Given the weight above, sigmoid([-0.03, 0.03]) = tensor([0.4992, 0.5008]) (this fits with our previous experiment results that the balance factor is ~0.5). We decided as next step to use a higher learning rate for balance factors (and all other parameters use Llama 3 8B's learning rate), and a larger number of training steps to allow the balance factors to change by at least 4, so that we allow global weights to reach the ideal weights if gradient descent wants (sigmoid(-4) ≈ 0, sigmoid(4) ≈ 1).
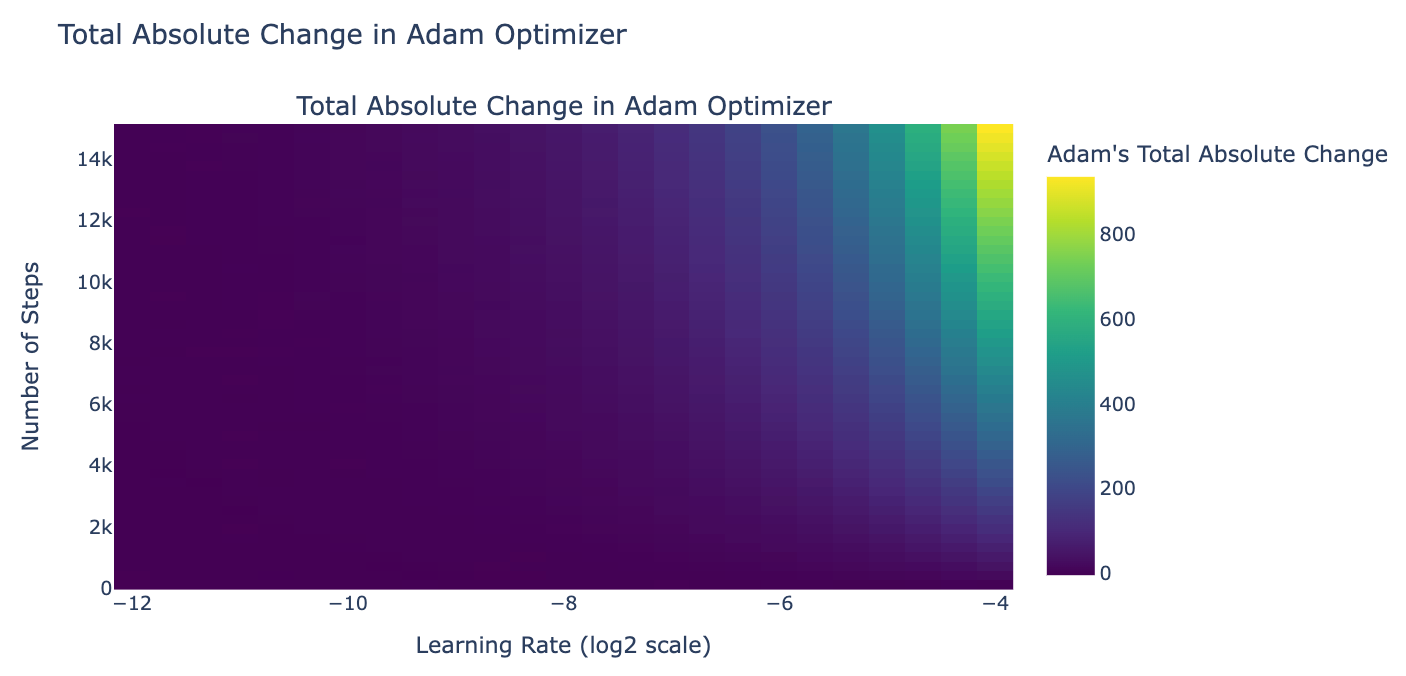
We also note that since the gradients don't always go in the same direction, cancellations occur. This means we should aim for a learning rate and training steps that are significantly larger than the total absolute changes. Recall that the learning rate for Llama 3 8B is 3.0x10^-4, which means if we use this as a global learning rate, the gating cannot converge by any means.
> Conclusion: we decided to go with a global learning rate of 3.0x10^-4 and a gating learning rate of 0.01 which should allows the gating function to converge.
With these hyper-parameters the balance factors in Infini-attention are trainable, but we observed that the 200M llama's loss went NaN after 20B tokens (we tried learning rates from 0.001 to 1.0e-6). We investigated a few generations at the 20B tokens checkpoint (10k training steps) which you can see in Figure 4a. The model now continue the exact content and recall identities (if the memory is knocked out, it generates trash).
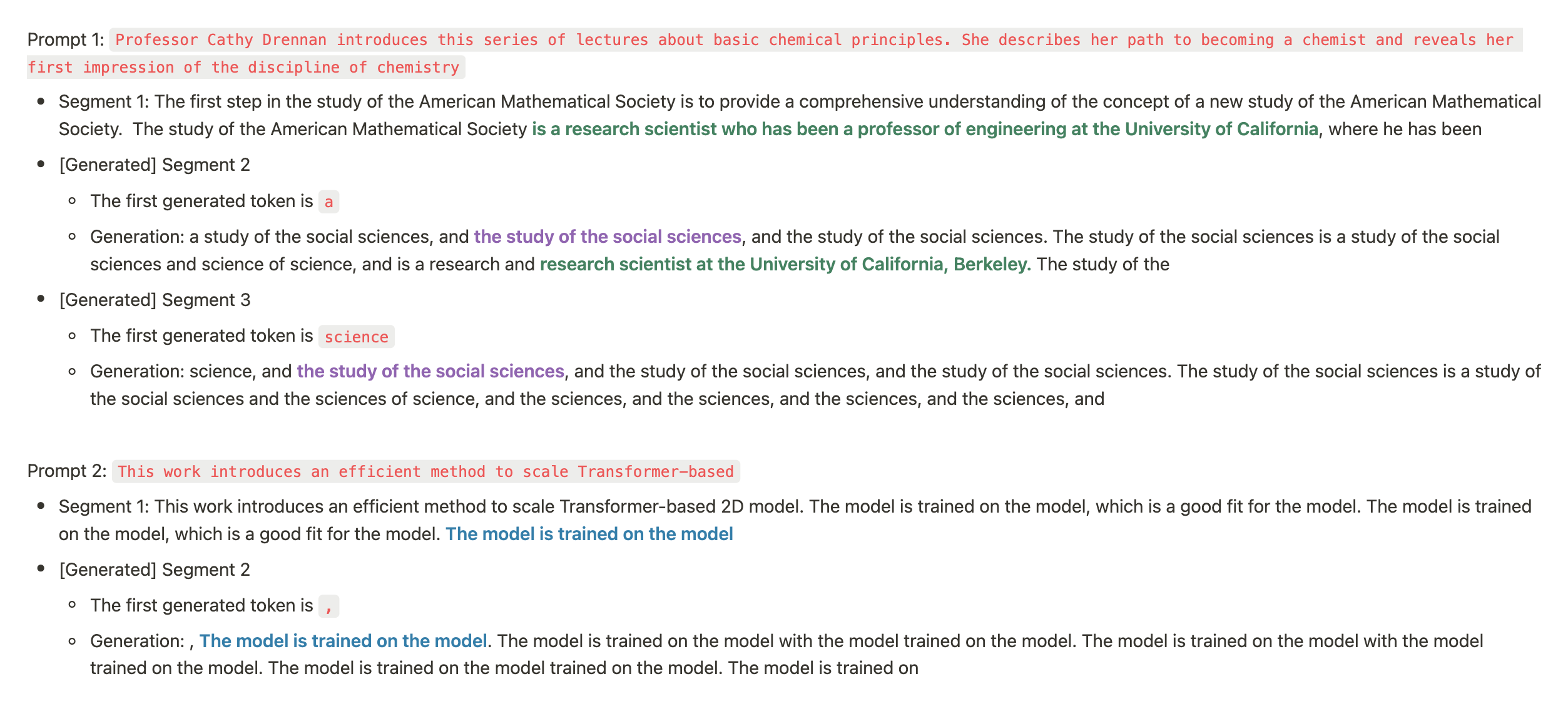

But it is still not able to recall the needle from one segment to the other (it does so reliably within the segment). Needle evaluation fails completely when the needle is placed in the 1st segment (100% success when placed in the 2nd segment, out of 2 segments total). As showed in Figure 4b, we also observed that the balance factors stopped changing after 5,000 steps. While we made some progress, we were not yet out of the woods. The balance factors were still not behaving as we hoped. We decided to dig deeper and make more adjustments.
## Section 5: No weight decay on balance factors
Inspecting in detail the balance factor once again, we saw some progress: approximately 95% of the heads now show a global weight ranging from 0.4 to 0.5, and none of the heads have a global weight greater than 0.6. But the weights still aren't in the ideal range.
We thought of another potential reason: weight decay, which encourages a small L2 norm of balance factors, leading sigmoid values to converge close to zero and factor to center around 0.5.
Yet another potential reason could be that we used too small a rollout. In the 200m experiment, we only used 4 rollouts, and in the 8b experiment, we only used 2 rollouts (8192**2). Using a larger rollout should incentive the model to compress and use the memory well. So we decided to increase the number of rollouts to 16 and use no weight decay. We scaled down the context length to 1024 context length, with 16 rollouts, getting segment lengths of 64.
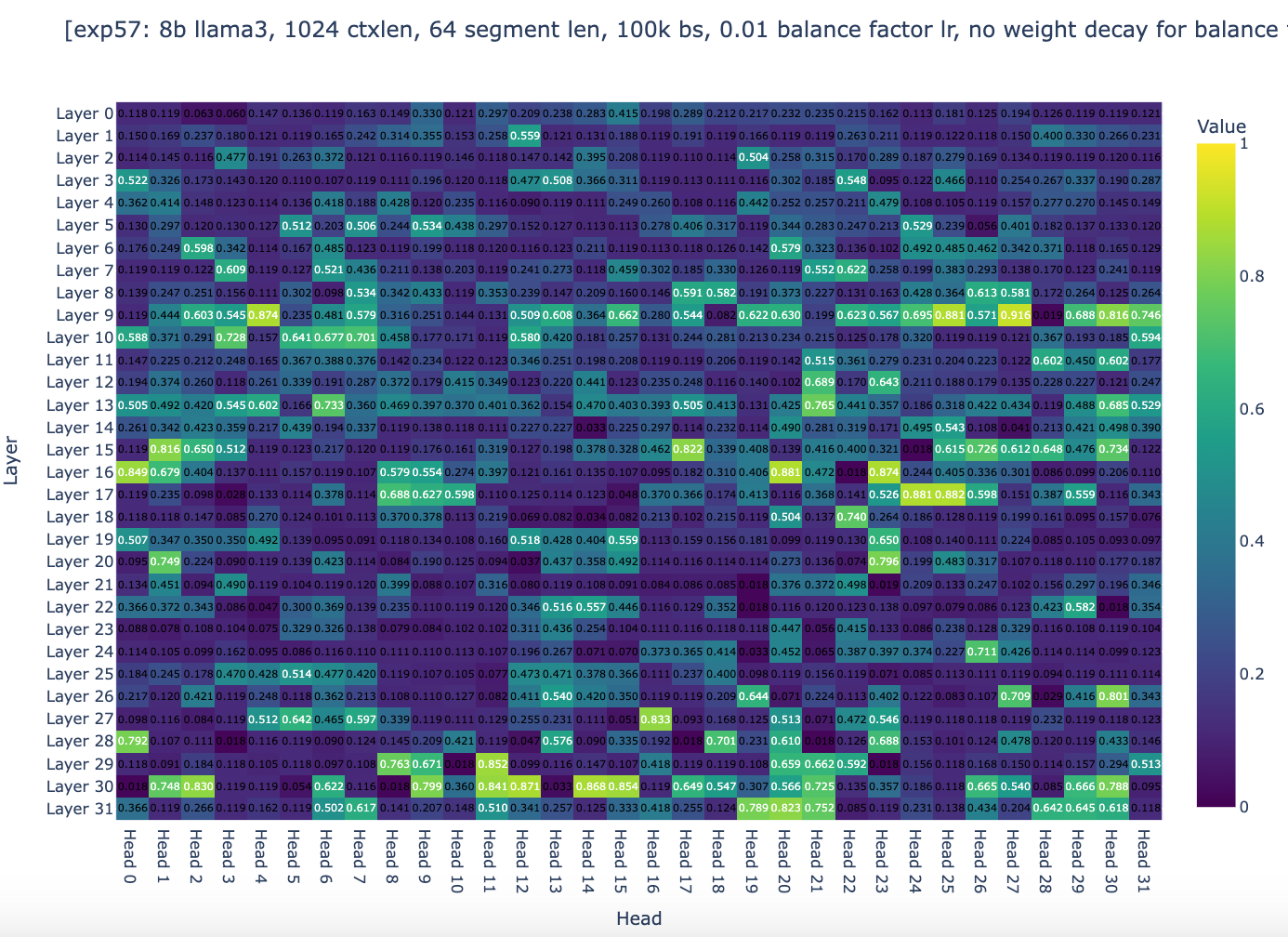
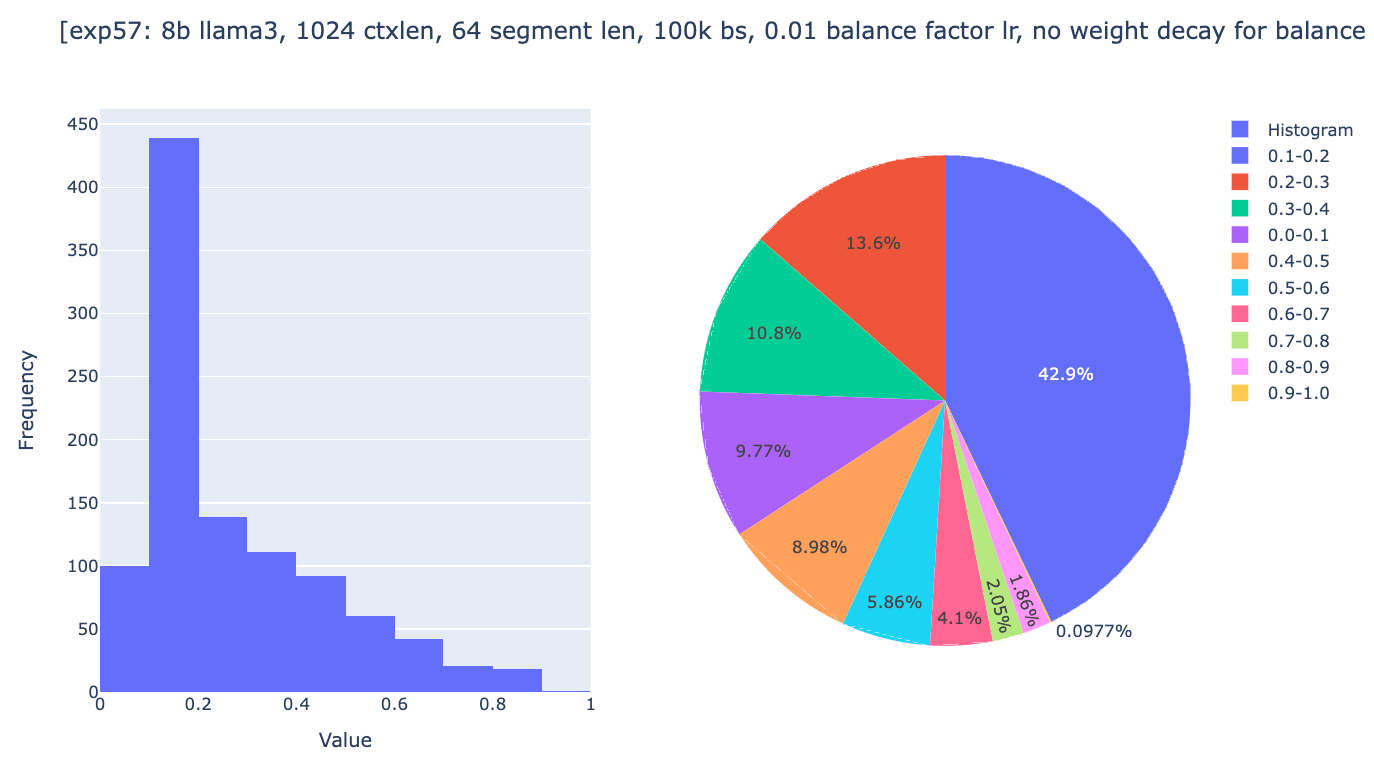
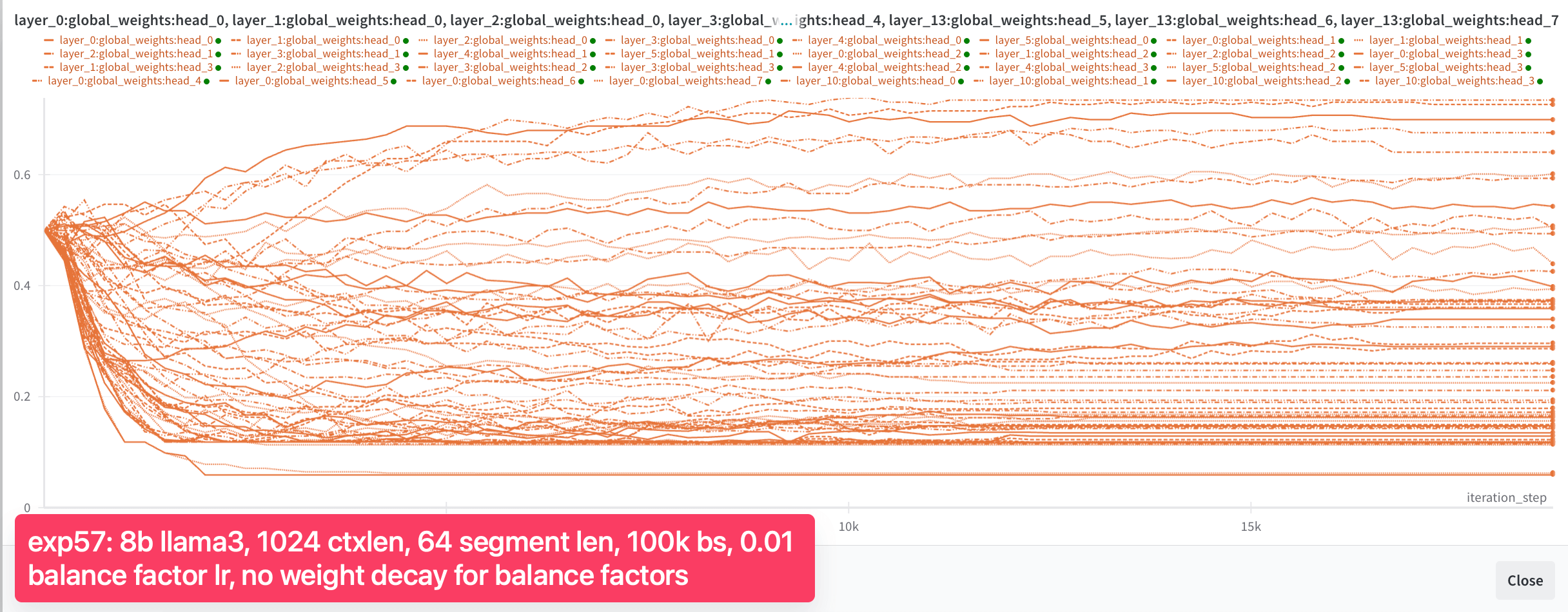
As you can see, global weights are now distributed across the range from 0 to 1, with 10% of heads having a global weight between 0.9 and 1.0, even though after 18k steps, most heads stopped changing their global weights. We were then quite confident that the experiments were setup to allow convergence if the spirits of gradient descent are with us. The only question remaining was whether the general approach of Infini-attention could works well enough.
The following evaluations were run at 1.5B tokens.

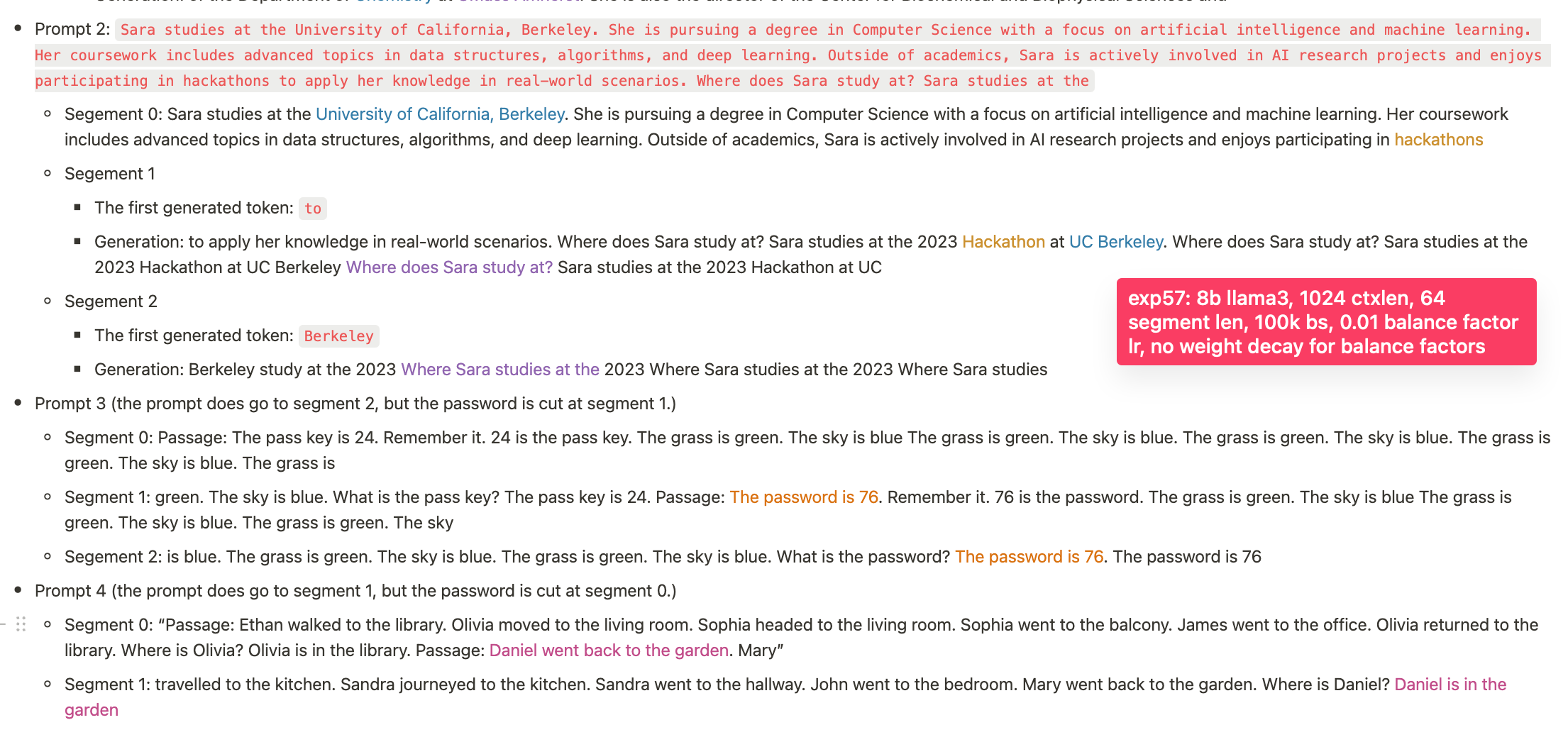
- 0-short: In the prompt 2, it recalls where a person studies (the 8b model yesterday failed at this), but fails at the needle passkey (not comprehensively run yet; will run).
- 1-short
+ Prompt 3: It identifies where a person locates.
+ Prompt 4: It passes the needle pass key
And in this cases, the models continue generating the exact content of earlier segments. (In our previous experiments, the model failed to continue with the exact content of an earlier segment and only generated something approximately related; the new model is thus quite much better already.)
## Section 6: Conclusion
Unfortunately, despite these progress, we found that Infini-attention was not convincing enough in our experiments and in particular not reliable enough. At this stage of our reproduction we are still of the opinion that Ring Attention [[link]](https://x.com/Haojun_Zhao14/status/1815419356408336738), YaRN [[link]](https://arxiv.org/abs/2309.00071) and rope scaling [[link]](https://arxiv.org/abs/2309.16039) are better options for extending a pretrained model to longer context length.
These later technics still come with large resource requirements for very large model sizes (e.g., 400B and beyond). we thus till think that exploring compression techniques or continuing to push the series of experiments we've bee describing in this blog post is of great interest for the community and are are excited to follow and try new techniques that may be developped and overcome some of the limitation of the present work.
**Recaps**
- What it means to train a neural network: give it good data, set up the architecture and training to receive good gradient signals, and allow it to converge.
- Infini-attention's long context performance decreases as the number of times we compresses the memory.
- Gating is important; tweaking the training to allow the gating to converge improves Infini-attention's long context performance (but not good enough).
- Always train a good reference model as a baseline to measure progress.
- There is another bug that messes up the dimensions in the attention output, resulting in a situation where, even though the loss decreases throughout training, the model still can't generate coherent text within its segment length. Lesson learned: Even if you condition the model poorly, gradient descent can still find a way to decrease the loss. However, the model won't work as expected, so always run evaluations.
## Acknowledgements
Thanks to Leandro von Werra and Thomas Wolf for their guidance on the project, and to Tsendsuren Munkhdalai for sharing additional details on the original experiments. We also appreciate Leandro's feedback on the blog post and are grateful to Hugging Face’s science cluster for the compute. | [
[
"llm",
"research",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"research",
"optimization",
"efficient_computing"
] | null | null |
faaa334d-fd38-42e1-9b1c-d9cab9aa5ea3 | completed | 2025-01-16T03:08:53.171024 | 2025-01-16T03:25:16.450397 | c99c326a-ae6f-4d08-95e9-5ae3e4421c1c | The State of Computer Vision at Hugging Face 🤗 | sayakpaul | cv_state.md | At Hugging Face, we pride ourselves on democratizing the field of artificial intelligence together with the community. As a part of that mission, we began focusing our efforts on computer vision over the last year. What started as a [PR for having Vision Transformers (ViT) in 🤗 Transformers](https://github.com/huggingface/transformers/pull/10950) has now grown into something much bigger – 8 core vision tasks, over 3000 models, and over 100 datasets on the Hugging Face Hub.
A lot of exciting things have happened since ViTs joined the Hub. In this blog post, we’ll summarize what went down and what’s coming to support the continuous progress of Computer Vision from the 🤗 ecosystem.
Here is a list of things we’ll cover:
- [Supported vision tasks and Pipelines](#support-for-pipelines)
- [Training your own vision models](#training-your-own-models)
- [Integration with `timm`](#🤗-🤝-timm)
- [Diffusers](#🧨-diffusers)
- [Support for third-party libraries](#support-for-third-party-libraries)
- [Deployment](#deployment)
- and much more!
## Enabling the community: One task at a time 👁
The Hugging Face Hub is home to over 100,000 public models for different tasks such as next-word prediction, mask filling, token classification, sequence classification, and so on. As of today, we support [8 core vision tasks](https://huggingface.co./tasks) providing many model checkpoints:
- Image classification
- Image segmentation
- (Zero-shot) object detection
- Video classification
- Depth estimation
- Image-to-image synthesis
- Unconditional image generation
- Zero-shot image classification
Each of these tasks comes with at least 10 model checkpoints on the Hub for you to explore. Furthermore, we support [tasks](https://huggingface.co./tasks) that lie at the intersection of vision and language such as:
- Image-to-text (image captioning, OCR)
- Text-to-image
- Document question-answering
- Visual question-answering
These tasks entail not only state-of-the-art Transformer-based architectures such as [ViT](https://huggingface.co./docs/transformers/model_doc/vit), [Swin](https://huggingface.co./docs/transformers/model_doc/swin), [DETR](https://huggingface.co./docs/transformers/model_doc/detr) but also *pure convolutional* architectures like [ConvNeXt](https://huggingface.co./docs/transformers/model_doc/convnext), [ResNet](https://huggingface.co./docs/transformers/model_doc/resnet), [RegNet](https://huggingface.co./docs/transformers/model_doc/regnet), and more! Architectures like ResNets are still very much relevant for a myriad of industrial use cases and hence the support of these non-Transformer architectures in 🤗 Transformers.
It’s also important to note that the models on the Hub are not just from the Transformers library but also from other third-party libraries. For example, even though we support tasks like unconditional image generation on the Hub, we don’t have any models supporting that task in Transformers yet (such as [this](https://huggingface.co./ceyda/butterfly_cropped_uniq1K_512)). Supporting all ML tasks, whether they are solved with Transformers or a third-party library is a part of our mission to foster a collaborative open-source Machine Learning ecosystem.
## Support for Pipelines
We developed [Pipelines](https://huggingface.co./docs/transformers/main/en/main_classes/pipelines) to equip practitioners with the tools they need to easily incorporate machine learning into their toolbox. They provide an easy way to perform inference on a given input with respect to a task. We have support for [seven vision tasks](https://huggingface.co./docs/transformers/main/en/main_classes/pipelines#computer-vision) in Pipelines. Here is an example of using Pipelines for depth estimation:
```py
from transformers import pipeline
depth_estimator = pipeline(task="depth-estimation", model="Intel/dpt-large")
output = depth_estimator("http://images.cocodataset.org/val2017/000000039769.jpg")
# This is a tensor with the values being the depth expressed
# in meters for each pixel
output["depth"]
```
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/cv_state/depth_estimation_output.png"/>
</div>
The interface remains the same even for tasks like visual question-answering:
```py
from transformers import pipeline
oracle = pipeline(model="dandelin/vilt-b32-finetuned-vqa")
image_url = "https://huggingface.co./datasets/mishig/sample_images/resolve/main/tiger.jpg"
oracle(question="What's the animal doing?", image=image_url, top_k=1)
# [{'score': 0.778620, 'answer': 'laying down'}]
```
## Training your own models
While being able to use a model for off-the-shelf inference is a great way to get started, fine-tuning is where the community gets the most benefits. This is especially true when your datasets are custom, and you’re not getting good performance out of the pre-trained models.
Transformers provides a [Trainer API](https://huggingface.co./docs/transformers/main_classes/trainer) for everything related to training. Currently, `Trainer` seamlessly supports the following tasks: image classification, image segmentation, video classification, object detection, and depth estimation. Fine-tuning models for other vision tasks are also supported, just not by `Trainer`.
As long as the loss computation is included in a model from Transformers computes loss for a given task, it should be eligible for fine-tuning for the task. If you find issues, please [report](https://github.com/huggingface/transformers/issues) them on GitHub.
**Where do I find the code?**
- [Model documentation](https://huggingface.co./docs/transformers/index#supported-models)
- [Hugging Face notebooks](https://github.com/huggingface/notebooks)
- [Hugging Face example scripts](https://github.com/huggingface/transformers/tree/main/examples)
- [Task pages](https://huggingface.co./tasks)
[Hugging Face example scripts](https://github.com/huggingface/transformers/tree/main/examples) include different [self-supervised pre-training strategies](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining) like [MAE](https://arxiv.org/abs/2111.06377), and [contrastive image-text pre-training strategies](https://github.com/huggingface/transformers/tree/main/examples/pytorch/contrastive-image-text) like [CLIP](https://arxiv.org/abs/2103.00020). These scripts are valuable resources for the research community as well as for practitioners willing to run pre-training from scratch on custom data corpora.
Some tasks are not inherently meant for fine-tuning, though. Examples include zero-shot image classification (such as [CLIP](https://huggingface.co./docs/transformers/main/en/model_doc/clip)), zero-shot object detection (such as [OWL-ViT](https://huggingface.co./docs/transformers/main/en/model_doc/owlvit)), and zero-shot segmentation (such as [CLIPSeg](https://huggingface.co./docs/transformers/model_doc/clipseg)). We’ll revisit these models in this post.
## Integrations with Datasets
[Datasets](https://huggingface.co./docs/datasets) provides easy access to thousands of datasets of different modalities. As mentioned earlier, the Hub has over 100 datasets for computer vision. Some examples worth noting here: [ImageNet-1k](https://huggingface.co./datasets/imagenet-1k), [Scene Parsing](https://huggingface.co./datasets/scene_parse_150), [NYU Depth V2](https://huggingface.co./datasets/sayakpaul/nyu_depth_v2), [COYO-700M](https://huggingface.co./datasets/kakaobrain/coyo-700m), and [LAION-400M](https://huggingface.co./datasets/laion/laion400m). With these datasets being on the Hub, one can easily load them with just two lines of code:
```py
from datasets import load_dataset
dataset = load_dataset("scene_parse_150")
```
Besides these datasets, we provide integration support with augmentation libraries like [albumentations](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) and [Kornia](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb). The community can take advantage of the flexibility and performance of Datasets and powerful augmentation transformations provided by these libraries. In addition to these, we also provide [dedicated data-loading guides](https://huggingface.co./docs/datasets/image_load) for core vision tasks: image classification, image segmentation, object detection, and depth estimation.
## 🤗 🤝 timm
`timm`, also known as [pytorch-image-models](https://github.com/rwightman/pytorch-image-models), is an open-source collection of state-of-the-art PyTorch image models, pre-trained weights, and utility scripts for training, inference, and validation.
We have over 200 models from `timm` on the Hub and more are on the way. Check out the [documentation](https://huggingface.co./docs/timm/index) to know more about this integration.
## 🧨 Diffusers
[Diffusers](https://huggingface.co./docs/diffusers) provides pre-trained vision and audio diffusion models, and serves as a modular toolbox for inference and training. With this library, you can generate plausible images from natural language inputs amongst other creative use cases. Here is an example:
```py
from diffusers import DiffusionPipeline
generator = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
generator.to(“cuda”)
image = generator("An image of a squirrel in Picasso style").images[0]
```
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/cv_state/sd_output.png"/>
</div>
This type of technology can empower a new generation of creative applications and also aid artists coming from different backgrounds. To know more about Diffusers and the different use cases, check out the [official documentation](https://huggingface.co./docs/diffusers).
The literature on Diffusion-based models is developing at a rapid pace which is why we partnered with [Jonathan Whitaker](https://github.com/johnowhitaker) to develop a course on it. The course is free, and you can check it out [here](https://github.com/huggingface/diffusion-models-class).
## Support for third-party libraries
Central to the Hugging Face ecosystem is the [Hugging Face Hub](https://huggingface.co./docs/hub), which lets people collaborate effectively on Machine Learning. As mentioned earlier, we not only support models from 🤗 Transformers on the Hub but also models from other third-party libraries. To this end, we provide [several utilities](https://huggingface.co./docs/hub/models-adding-libraries) so that you can integrate your own library with the Hub. One of the primary advantages of doing this is that it becomes very easy to share artifacts (such as models and datasets) with the community, thereby making it easier for your users to try out your models.
When you have your models hosted on the Hub, you can also [add custom inference widgets](https://github.com/huggingface/api-inference-community) for them. Inference widgets allow users to quickly check out the models. This helps with improving user engagement.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/cv_state/task_widget_generation.png"/>
</div>
## Spaces for computer vision demos
With [Spaces](https://huggingface.co./docs/hub/spaces-overview), one can easily demonstrate their Machine Learning models. Spaces support direct integrations with [Gradio](https://gradio.app/), [Streamlit](https://streamlit.io/), and [Docker](https://www.docker.com/) empowering practitioners to have a great amount of flexibility while showcasing their models. You can bring in your own Machine Learning framework to build a demo with Spaces.
The Gradio library provides several components for building Computer Vision applications on Spaces such as [Video](https://gradio.app/docs/#video), [Gallery](https://gradio.app/docs/#gallery), and [Model3D](https://gradio.app/docs/#model3d). The community has been hard at work building some amazing Computer Vision applications that are powered by Spaces:
- [Generate 3D voxels from a predicted depth map of an input image](https://huggingface.co./spaces/radames/dpt-depth-estimation-3d-voxels)
- [Open vocabulary semantic segmentation](https://huggingface.co./spaces/facebook/ov-seg)
- [Narrate videos by generating captions](https://huggingface.co./spaces/nateraw/lavila)
- [Classify videos from YouTube](https://huggingface.co./spaces/fcakyon/video-classification)
- [Zero-shot video classification](https://huggingface.co./spaces/fcakyon/zero-shot-video-classification)
- [Visual question-answering](https://huggingface.co./spaces/nielsr/vilt-vqa)
- [Use zero-shot image classification to find best captions for an image to generate similar images](https://huggingface.co./spaces/pharma/CLIP-Interrogator)
## 🤗 AutoTrain
[AutoTrain](https://huggingface.co./autotrain) provides a “no-code” solution to train state-of-the-art Machine Learning models for tasks like text classification, text summarization, named entity recognition, and more. For Computer Vision, we currently support [image classification](https://huggingface.co./blog/autotrain-image-classification), but one can expect more task coverage.
AutoTrain also enables [automatic model evaluation](https://huggingface.co./spaces/autoevaluate/model-evaluator). This application allows you to evaluate 🤗 Transformers [models](https://huggingface.co./models?library=transformers&sort=downloads) across a wide variety of [datasets](https://huggingface.co./datasets) on the Hub. The results of your evaluation will be displayed on the [public leaderboards](https://huggingface.co./spaces/autoevaluate/leaderboards). You can check [this blog post](https://huggingface.co./blog/eval-on-the-hub) for more details.
## The technical philosophy
In this section, we wanted to share our philosophy behind adding support for Computer Vision in 🤗 Transformers so that the community is aware of the design choices specific to this area.
Even though Transformers started with NLP, we support multiple modalities today, for example – vision, audio, vision-language, and Reinforcement Learning. For all of these modalities, all the corresponding models from Transformers enjoy some common benefits:
- Easy model download with a single line of code with `from_pretrained()`
- Easy model upload with `push_to_hub()`
- Support for loading huge checkpoints with efficient checkpoint sharding techniques
- Optimization support (with tools like [Optimum](https://huggingface.co./docs/optimum))
- Initialization from model configurations
- Support for both PyTorch and TensorFlow (non-exhaustive)
- and many more
Unlike tokenizers, we have preprocessors (such as [this](https://huggingface.co./docs/transformers/model_doc/vit#transformers.ViTImageProcessor)) that take care of preparing data for the vision models. We have worked hard to ensure the user experience of using a vision model still feels easy and similar:
```py
from transformers import ViTImageProcessor, ViTForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = ViTForImageClassification.from_pretrained("google/vit-base-patch16-224")
inputs = image_processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label])
# Egyptian cat
```
Even for a difficult task like object detection, the user experience doesn’t change very much:
```py
from transformers import AutoImageProcessor, AutoModelForObjectDetection
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("microsoft/conditional-detr-resnet-50")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# convert outputs (bounding boxes and class logits) to COCO API
target_sizes = torch.tensor([image.size[::-1]])
results = image_processor.post_process_object_detection(
outputs, threshold=0.5, target_sizes=target_sizes
)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
```
Leads to:
```bash
Detected remote with confidence 0.833 at location [38.31, 72.1, 177.63, 118.45]
Detected cat with confidence 0.831 at location [9.2, 51.38, 321.13, 469.0]
Detected cat with confidence 0.804 at location [340.3, 16.85, 642.93, 370.95]
Detected remote with confidence 0.683 at location [334.48, 73.49, 366.37, 190.01]
Detected couch with confidence 0.535 at location [0.52, 1.19, 640.35, 475.1]
```
## Zero-shot models for vision
There’s been a surge of models that reformulate core vision tasks like segmentation and detection in interesting ways and introduce even more flexibility. We support a few of those from Transformers:
- [CLIP](https://huggingface.co./docs/transformers/main/en/model_doc/clip) that enables zero-shot image classification with prompts. Given an image, you’d prompt the CLIP model with a natural language query like “an image of {}”. The hope is to get the class label as the answer.
- [OWL-ViT](https://huggingface.co./docs/transformers/main/en/model_doc/owlvit) that allows for language-conditioned zero-shot object detection and image-conditioned one-shot object detection. This means you can detect objects in an image even if the underlying model didn’t learn to detect them during training! You can refer to [this notebook](https://github.com/huggingface/notebooks/tree/main/examples#:~:text=zeroshot_object_detection_with_owlvit.ipynb) to know more.
- [CLIPSeg](https://huggingface.co./docs/transformers/model_doc/clipseg) that supports language-conditioned zero-shot image segmentation and image-conditioned one-shot image segmentation. This means you can segment objects in an image even if the underlying model didn’t learn to segment them during training! You can refer to [this blog post](https://huggingface.co./blog/clipseg-zero-shot) that illustrates this idea. [GroupViT](https://huggingface.co./docs/transformers/model_doc/groupvit) also supports the task of zero-shot segmentation.
- [X-CLIP](https://huggingface.co./docs/transformers/main/en/model_doc/xclip) that showcases zero-shot generalization to videos. Precisely, it supports zero-shot video classification. Check out [this notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/X-CLIP/Zero_shot_classify_a_YouTube_video_with_X_CLIP.ipynb) for more details.
The community can expect to see more zero-shot models for computer vision being supported from 🤗Transformers in the coming days.
## Deployment
As our CTO Julien says - “real artists ship” 🚀
We support the deployment of these vision models through [🤗Inference Endpoints](https://huggingface.co./inference-endpoints). Inference Endpoints integrates directly with compatible models pertaining to image classification, object detection, and image segmentation. For other tasks, you can use the [custom handlers](https://huggingface.co./docs/inference-endpoints/guides/custom_handler). Since we also provide many vision models in TensorFlow from 🤗Transformers for their deployment, we either recommend using the custom handlers or following these resources:
- [Deploying TensorFlow Vision Models in Hugging Face with TF Serving](https://huggingface.co./blog/tf-serving-vision)
- [Deploying 🤗 ViT on Kubernetes with TF Serving](https://huggingface.co./blog/deploy-tfserving-kubernetes)
- [Deploying 🤗 ViT on Vertex AI](https://huggingface.co./blog/deploy-vertex-ai)
- [Deploying ViT with TFX and Vertex AI](https://github.com/deep-diver/mlops-hf-tf-vision-models)
## Conclusion
In this post, we gave you a rundown of the things currently supported from the Hugging Face ecosystem to empower the next generation of Computer Vision applications. We hope you’ll enjoy using these offerings to build reliably and responsibly.
There is a lot to be done, though. Here are some things you can expect to see:
- Direct support of videos from 🤗 Datasets
- Supporting more industry-relevant tasks like image similarity
- Interoperability of the image datasets with TensorFlow
- A course on Computer Vision from the 🤗 community
As always, we welcome your patches, PRs, model checkpoints, datasets, and other contributions! 🤗
*Acknowlegements: Thanks to Omar Sanseviero, Nate Raw, Niels Rogge, Alara Dirik, Amy Roberts, Maria Khalusova, and Lysandre Debut for their rigorous and timely reviews on the blog draft. Thanks to Chunte Lee for creating the blog thumbnail.* | [
[
"computer_vision",
"transformers",
"implementation",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"transformers",
"implementation",
"integration"
] | null | null |
a29adcb1-a8f0-420f-b26c-a6bae11d5e1f | completed | 2025-01-16T03:08:53.171029 | 2025-01-19T19:03:59.342728 | 93efb0fe-6374-4f18-925e-366e2bd6bd62 | Introducing new audio and vision documentation in 🤗 Datasets | stevhliu | datasets-docs-update.md | Open and reproducible datasets are essential for advancing good machine learning. At the same time, datasets have grown tremendously in size as rocket fuel for large language models. In 2020, Hugging Face launched 🤗 Datasets, a library dedicated to:
1. Providing access to standardized datasets with a single line of code.
2. Tools for rapidly and efficiently processing large-scale datasets.
Thanks to the community, we added hundreds of NLP datasets in many languages and dialects during the [Datasets Sprint](https://discuss.huggingface.co/t/open-to-the-community-one-week-team-effort-to-reach-v2-0-of-hf-datasets-library/2176)! 🤗 ❤️
But text datasets are just the beginning. Data is represented in richer formats like 🎵 audio, 📸 images, and even a combination of audio and text or image and text. Models trained on these datasets enable awesome applications like describing what is in an image or answering questions about an image.
<div class="hidden xl:block">
<div style="display: flex; flex-direction: column; align-items: center;">
<iframe src="https://salesforce-blip.hf.space" frameBorder="0" width="1400" height="690" title="Gradio app" class="p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
</div>
</div>
The 🤗 Datasets team has been building tools and features to make working with these dataset types as simple as possible for the best developer experience. We added new documentation along the way to help you learn more about loading and processing audio and image datasets.
## Quickstart
The [Quickstart](https://huggingface.co./docs/datasets/quickstart) is one of the first places new users visit for a TLDR about a library’s features. That’s why we updated the Quickstart to include how you can use 🤗 Datasets to work with audio and image datasets. Choose a dataset modality you want to work with and see an end-to-end example of how to load and process the dataset to get it ready for training with either PyTorch or TensorFlow.
Also new in the Quickstart is the `to_tf_dataset` function which takes care of converting a dataset into a `tf.data.Dataset` like a mama bear taking care of her cubs. This means you don’t have to write any code to shuffle and load batches from your dataset to get it to play nicely with TensorFlow. Once you’ve converted your dataset into a `tf.data.Dataset`, you can train your model with the usual TensorFlow or Keras methods.
Check out the [Quickstart](https://huggingface.co./docs/datasets/quickstart) today to learn how to work with different dataset modalities and try out the new `to_tf_dataset` function!
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="Cards with links to end-to-end examples for how to process audio, vision, and NLP datasets" src="assets/87_datasets-docs-update/quickstart.png" />
<figcaption>Choose your dataset adventure!</figcaption>
</figure>
## Dedicated guides
Each dataset modality has specific nuances on how to load and process them. For example, when you load an audio dataset, the audio signal is automatically decoded and resampled on-the-fly by the `Audio` feature. This is quite different from loading a text dataset!
To make all of the modality-specific documentation more discoverable, there are new dedicated sections with guides focused on showing you how to load and process each modality. If you’re looking for specific information about working with a dataset modality, take a look at these dedicated sections first. Meanwhile, functions that are non-specific and can be used broadly are documented in the General Usage section. Reorganizing the documentation in this way will allow us to better scale to other dataset types we plan to support in the future.
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="An overview of the how-to guides page that displays five new sections of the guides: general usage, audio, vision, text, and dataset repository." src="assets/87_datasets-docs-update/overview.png" />
<figcaption>The guides are organized into sections that cover the most essential aspects of 🤗 Datasets.</figcaption>
</figure>
Check out the [dedicated guides](https://huggingface.co./docs/datasets/how_to) to learn more about loading and processing datasets for different modalities.
## ImageFolder
Typically, 🤗 Datasets users [write a dataset loading script](https://huggingface.co./docs/datasets/dataset_script) to download and generate a dataset with the appropriate `train` and `test` splits. With the `ImageFolder` dataset builder, you don’t need to write any code to download and generate an image dataset. Loading an image dataset for image classification is as simple as ensuring your dataset is organized in a folder like:
```py
folder/train/dog/golden_retriever.png
folder/train/dog/german_shepherd.png
folder/train/dog/chihuahua.png
folder/train/cat/maine_coon.png
folder/train/cat/bengal.png
folder/train/cat/birman.png
```
<figure class="image table text-center m-0 w-full">
<img style="border:none;" alt="A table of images of dogs and their associated label." src="assets/87_datasets-docs-update/good_boi_pics.png" />
<figcaption>Your 🐶 dataset should look something like this once you've uploaded it to the Hub and preview it.</figcaption>
</figure>
Image labels are generated in a `label` column based on the directory name. `ImageFolder` allows you to get started instantly with an image dataset, eliminating the time and effort required to write a dataset loading script.
But wait, it gets even better! If you have a file containing some metadata about your image dataset, `ImageFolder` can be used for other image tasks like image captioning and object detection. For example, object detection datasets commonly have *bounding boxes*, coordinates in an image that identify where an object is. `ImageFolder` can use this file to link the metadata about the bounding box and category for each image to the corresponding images in the folder:
```py
{"file_name": "0001.png", "objects": {"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}}
{"file_name": "0002.png", "objects": {"bbox": [[810.0, 100.0, 57.0, 28.0]], "categories": [1]}}
{"file_name": "0003.png", "objects": {"bbox": [[160.0, 31.0, 248.0, 616.0], [741.0, 68.0, 202.0, 401.0]], "categories": [2, 2]}}
dataset = load_dataset("imagefolder", data_dir="/path/to/folder", split="train")
dataset[0]["objects"]
{"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}
```
You can use `ImageFolder` to load an image dataset for nearly any type of image task if you have a metadata file with the required information. Check out the [ImageFolder](https://huggingface.co./docs/datasets/image_load) guide to learn more.
## What’s next?
Similar to how the first iteration of the 🤗 Datasets library standardized text datasets and made them super easy to download and process, we are very excited to bring this same level of user-friendliness to audio and image datasets. In doing so, we hope it’ll be easier for users to train, build, and evaluate models and applications across all different modalities.
In the coming months, we’ll continue to add new features and tools to support working with audio and image datasets. Word on the 🤗 Hugging Face street is that there’ll be something called `AudioFolder` coming soon! 🤫 While you wait, feel free to take a look at the [audio processing guide](https://huggingface.co./docs/datasets/audio_process) and then get hands-on with an audio dataset like [GigaSpeech](https://huggingface.co./datasets/speechcolab/gigaspeech). | [
[
"computer_vision",
"audio",
"data",
"multi_modal"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"data",
"computer_vision",
"audio",
"multi_modal"
] | null | null |
705c5e96-d025-44b9-8c9a-60c43c1564cc | completed | 2025-01-16T03:08:53.171033 | 2025-01-19T19:15:33.858388 | 834bed13-3042-478a-b8fb-724452e4b877 | 🐶Safetensors audited as really safe and becoming the default | Narsil, stellaathena | safetensors-security-audit.md | [Hugging Face](https://huggingface.co./), in close collaboration with [EleutherAI](https://www.eleuther.ai/) and [Stability AI](https://stability.ai/), has ordered
an external security audit of the `safetensors` library, the results of which allow
all three organizations to move toward making the library the default format
for saved models.
The full results of the security audit, performed by [Trail of Bits](https://www.trailofbits.com/),
can be found here: [Report](https://huggingface.co./datasets/safetensors/trail_of_bits_audit_repot/resolve/main/SOW-TrailofBits-EleutherAI_HuggingFace-v1.2.pdf).
The following blog post explains the origins of the library, why these audit results are important,
and the next steps.
## What is safetensors?
🐶[Safetensors](https://github.com/huggingface/safetensors) is a library
for saving and loading tensors in the most common frameworks (including PyTorch, TensorFlow, JAX, PaddlePaddle, and NumPy).
For a more concrete explanation, we'll use PyTorch.
```python
import torch
from safetensors.torch import load_file, save_file
weights = {"embeddings": torch.zeros((10, 100))}
save_file(weights, "model.safetensors")
weights2 = load_file("model.safetensors")
```
It also has a number of [cool features](https://github.com/huggingface/safetensors#yet-another-format-) compared to other formats, most notably that loading files is _safe_, as we'll see later.
When you're using `transformers`, if `safetensors` is installed, then those files will already
be used preferentially in order to prevent issues, which means that
```
pip install safetensors
```
is likely to be the only thing needed to run `safetensors` files safely.
Going forward and thanks to the validation of the library, `safetensors` will now be installed in `transformers` by
default. The next step is saving models in `safetensors` by default.
We are thrilled to see that the `safetensors` library is already seeing use in the ML ecosystem, including:
- [Civitai](https://civitai.com/)
- [Stable Diffusion Web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
- [dfdx](https://github.com/coreylowman/dfdx)
- [LLaMA.cpp](https://github.com/ggerganov/llama.cpp/blob/e6a46b0ed1884c77267dc70693183e3b7164e0e0/convert.py#L537)
## Why create something new?
The creation of this library was driven by the fact that PyTorch uses `pickle` under
the hood, which is inherently unsafe. (Sources: [1](https://huggingface.co./docs/hub/security-pickle), [2, video](https://www.youtube.com/watch?v=2ethDz9KnLk), [3](https://github.com/pytorch/pytorch/issues/52596))
With pickle, it is possible to write a malicious file posing as a model
that gives full control of a user's computer to an attacker without the user's knowledge,
allowing the attacker to steal all their bitcoins 😓.
While this vulnerability in pickle is widely known in the computer security world (and is acknowledged in the PyTorch [docs](https://pytorch.org/docs/stable/generated/torch.load.html)), it’s not common knowledge in the broader ML community.
Since the Hugging Face Hub is a platform where anyone can upload and share models, it is important to make efforts
to prevent users from getting infected by malware.
We are also taking steps to make sure the existing PyTorch files are not malicious, but the best we can do is flag suspicious-looking files.
Of course, there are other file formats out there, but
none seemed to meet the full set of [ideal requirements](https://github.com/huggingface/safetensors#yet-another-format-) our team identified.
In addition to being safe, `safetensors` allows lazy loading and generally faster loads (around 100x faster on CPU).
Lazy loading means loading only part of a tensor in an efficient manner.
This particular feature enables arbitrary sharding with efficient inference libraries, such as [text-generation-inference](https://github.com/huggingface/text-generation-inference), to load LLMs (such as LLaMA, StarCoder, etc.) on various types of hardware
with maximum efficiency.
Because it loads so fast and is framework agnostic, we can even use the format
to load models from the same file in PyTorch or TensorFlow.
## The security audit
Since `safetensors` main asset is providing safety guarantees, we wanted to make sure
it actually delivered. That's why Hugging Face, EleutherAI, and Stability AI teamed up to get an external
security audit to confirm it.
Important findings:
- No critical security flaw leading to arbitrary code execution was found.
- Some imprecisions in the spec format were detected and fixed.
- Some missing validation allowed [polyglot files](https://en.wikipedia.org/wiki/Polyglot_(computing)), which was fixed.
- Lots of improvements to the test suite were proposed and implemented.
In the name of openness and transparency, all companies agreed to make the report
fully public.
[Full report](https://huggingface.co./datasets/safetensors/trail_of_bits_audit_repot/resolve/main/SOW-TrailofBits-EleutherAI_HuggingFace-v1.2.pdf)
One import thing to note is that the library is written in Rust. This adds
an extra layer of [security](https://doc.rust-lang.org/rustc/exploit-mitigations.html)
coming directly from the language itself.
While it is impossible to
prove the absence of flaws, this is a major step in giving reassurance that `safetensors`
is indeed safe to use.
## Going forward
For Hugging Face, EleutherAI, and Stability AI, the master plan is to shift to using this format by default.
EleutherAI has added support for evaluating models stored as `safetensors` in their LM Evaluation Harness and is working on supporting the format in their GPT-NeoX distributed training library.
Within the `transformers` library we are doing the following:
- Create `safetensors`.
- Verify it works and can deliver on all promises (lazy load for LLMs, single file for all frameworks, faster loads).
- Verify it's safe. (This is today's announcement.)
- Make `safetensors` a core dependency. (This is already done or soon to come.)
- Make `safetensors` the default saving format. This will happen in a few months when we have enough feedback
to make sure it will cause as little disruption as possible and enough users already have the library
to be able to load new models even on relatively old `transformers` versions.
As for `safetensors` itself, we're looking into adding more advanced features for LLM training,
which has its own set of issues with current formats.
Finally, we plan to release a `1.0` in the near future, with the large user base of `transformers` providing the final testing step.
The format and the lib have had very few modifications since their inception,
which is a good sign of stability.
We're glad we can bring ML one step closer to being safe and efficient for all! | [
[
"mlops",
"implementation",
"security",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"security",
"tools",
"implementation"
] | null | null |
39229845-9ac2-4341-87bc-495681862741 | completed | 2025-01-16T03:08:53.171038 | 2025-01-18T14:46:46.236328 | ddd9dce3-f7b2-4e2b-8983-74f9fc564d6d | Sentence Transformers in the Hugging Face Hub | osanseviero, nreimers | sentence-transformers-in-the-hub.md | Over the past few weeks, we've built collaborations with many Open Source frameworks in the machine learning ecosystem. One that gets us particularly excited is Sentence Transformers.
[Sentence Transformers](https://github.com/UKPLab/sentence-transformers) is a framework for sentence, paragraph and image embeddings. This allows to derive semantically meaningful embeddings (1) which is useful for applications such as semantic search or multi-lingual zero shot classification. As part of Sentence Transformers [v2 release](https://github.com/UKPLab/sentence-transformers/releases/tag/v2.0.0), there are a lot of cool new features:
- Sharing your models in the Hub easily.
- Widgets and Inference API for sentence embeddings and sentence similarity.
- Better sentence-embeddings models available ([benchmark](https://www.sbert.net/docs/pretrained_models.html#sentence-embedding-models) and [models](https://huggingface.co./sentence-transformers) in the Hub).
With over 90 pretrained Sentence Transformers models for more than 100 languages in the Hub, anyone can benefit from them and easily use them. Pre-trained models can be loaded and used directly with few lines of code:
```python
from sentence_transformers import SentenceTransformer
sentences = ["Hello World", "Hallo Welt"]
model = SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
But not only this. People will probably want to either demo their models or play with other models easily, so we're happy to announce the release of two new widgets in the Hub! The first one is the `feature-extraction` widget which shows the sentence embedding.
<div><a class="text-xs block mb-3 text-gray-300" href="/sentence-transformers/distilbert-base-nli-max-tokens"><code>sentence-transformers/distilbert-base-nli-max-tokens</code></a> <div class="p-5 shadow-sm rounded-xl bg-white max-w-md"><div class="SVELTE_HYDRATER " data-props="{"apiUrl":"https://api-inference.huggingface.co","model":{"author":"sentence-transformers","autoArchitecture":"AutoModel","branch":"main","cardData":{"pipeline_tag":"feature-extraction","tags":["sentence-transformers","feature-extraction","sentence-similarity","transformers"]},"cardSource":true,"config":{"architectures":["DistilBertModel"],"model_type":"distilbert"},"id":"sentence-transformers/distilbert-base-nli-max-tokens","pipeline_tag":"feature-extraction","library_name":"sentence-transformers","mask_token":"[MASK]","modelId":"sentence-transformers/distilbert-base-nli-max-tokens","private":false,"siblings":[{"rfilename":".gitattributes"},{"rfilename":"README.md"},{"rfilename":"config.json"},{"rfilename":"config_sentence_transformers.json"},{"rfilename":"modules.json"},{"rfilename":"pytorch_model.bin"},{"rfilename":"sentence_bert_config.json"},{"rfilename":"special_tokens_map.json"},{"rfilename":"tokenizer.json"},{"rfilename":"tokenizer_config.json"},{"rfilename":"vocab.txt"},{"rfilename":"1_Pooling/config.json"}],"tags":["pytorch","distilbert","arxiv:1908.10084","sentence-transformers","feature-extraction","sentence-similarity","transformers","pipeline_tag:feature-extraction"],"tag_objs":[{"id":"feature-extraction","label":"Feature Extraction","type":"pipeline_tag"},{"id":"pytorch","label":"PyTorch","type":"library"},{"id":"sentence-transformers","label":"Sentence Transformers","type":"library"},{"id":"transformers","label":"Transformers","type":"library"},{"id":"arxiv:1908.10084","label":"arxiv:1908.10084","type":"arxiv"},{"id":"distilbert","label":"distilbert","type":"other"},{"id":"sentence-similarity","label":"sentence-similarity","type":"other"},{"id":"pipeline_tag:feature-extraction","label":"pipeline_tag:feature-extraction","type":"other"}]},"shouldUpdateUrl":true}" data-target="InferenceWidget"><div class="flex flex-col w-full max-w-full"> <div class="font-semibold flex items-center mb-2"><div class="text-lg flex items-center"><svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" class="-ml-1 mr-1 text-yellow-500" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 24 24"><path d="M11 15H6l7-14v8h5l-7 14v-8z" fill="currentColor"></path></svg>
Hosted inference API</div> <a target="_blank" href="/docs"><svg class="ml-1.5 text-sm text-gray-400 hover:text-black" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M17 22v-8h-4v2h2v6h-3v2h8v-2h-3z" fill="currentColor"></path><path d="M16 8a1.5 1.5 0 1 0 1.5 1.5A1.5 1.5 0 0 0 16 8z" fill="currentColor"></path><path d="M16 30a14 14 0 1 1 14-14a14 14 0 0 1-14 14zm0-26a12 12 0 1 0 12 12A12 12 0 0 0 16 4z" fill="currentColor"></path></svg></a></div> <div class="flex items-center text-sm text-gray-500 mb-1.5"><div class="inline-flex items-center"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" fill="currentColor" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M27 3H5a2 2 0 0 0-2 2v22a2 2 0 0 0 2 2h22a2 2 0 0 0 2-2V5a2 2 0 0 0-2-2zm0 2v4H5V5zm-10 6h10v7H17zm-2 7H5v-7h10zM5 20h10v7H5zm12 7v-7h10v7z"></path></svg> <span>Feature Extraction</span></div> <div class="ml-auto"></div></div> <form><div class="flex h-10"><input class="form-input-alt flex-1 rounded-r-none " placeholder="Your sentence here..." required="" type="text"> <button class="btn-widget w-24 h-10 px-5 rounded-l-none border-l-0 " type="submit">Compute</button></div></form> <div class="mt-1.5"><div class="text-gray-400 text-xs">This model is currently loaded and running on the Inference API.</div> </div> <div class="mt-auto pt-4 flex items-center text-xs text-gray-500"><button class="flex items-center cursor-not-allowed text-gray-300" disabled=""><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32" style="transform: rotate(360deg);"><path d="M31 16l-7 7l-1.41-1.41L28.17 16l-5.58-5.59L24 9l7 7z" fill="currentColor"></path><path d="M1 16l7-7l1.41 1.41L3.83 16l5.58 5.59L8 23l-7-7z" fill="currentColor"></path><path d="M12.419 25.484L17.639 6l1.932.518L14.35 26z" fill="currentColor"></path></svg>
JSON Output</button> <button class="flex items-center ml-auto"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M22 16h2V8h-8v2h6v6z" fill="currentColor"></path><path d="M8 24h8v-2h-6v-6H8v8z" fill="currentColor"></path><path d="M26 28H6a2.002 2.002 0 0 1-2-2V6a2.002 2.002 0 0 1 2-2h20a2.002 2.002 0 0 1 2 2v20a2.002 2.002 0 0 1-2 2zM6 6v20h20.001L26 6z" fill="currentColor"></path></svg>
Maximize</button></div> </div></div></div>
But seeing a bunch of numbers might not be very useful to you (unless you're able to understand the embeddings from a quick look, which would be impressive!). We're also introducing a new widget for a common use case of Sentence Transformers: computing sentence similarity.
<!-- Hackiest hack ever for the draft -->
<div><a class="text-xs block mb-3 text-gray-300" href="/sentence-transformers/paraphrase-MiniLM-L6-v2"><code>sentence-transformers/paraphrase-MiniLM-L6-v2</code></a>
<div class="p-5 shadow-sm rounded-xl bg-white max-w-md"><div class="SVELTE_HYDRATER " data-props="{"apiUrl":"https://api-inference.huggingface.co","model":{"author":"sentence-transformers","autoArchitecture":"AutoModel","branch":"main","cardData":{"tags":["sentence-transformers","sentence-similarity"]},"cardSource":true,"config":{"architectures":["RobertaModel"],"model_type":"roberta"},"pipeline_tag":"sentence-similarity","library_name":"sentence-transformers","mask_token":"<mask>","modelId":"sentence-transformers/paraphrase-MiniLM-L6-v2","private":false,"tags":["pytorch","jax","roberta","sentence-transformers","sentence-similarity"],"tag_objs":[{"id":"sentence-similarity","label":"Sentence Similarity","type":"pipeline_tag"},{"id":"pytorch","label":"PyTorch","type":"library"},{"id":"jax","label":"JAX","type":"library"},{"id":"sentence-transformers","label":"Sentence Transformers","type":"library"},{"id":"roberta","label":"roberta","type":"other"}],"widgetData":[{"source_sentence":"That is a happy person","sentences":["That is a happy dog","That is a very happy person","Today is a sunny day"]}]},"shouldUpdateUrl":false}" data-target="InferenceWidget"><div class="flex flex-col w-full max-w-full
"> <div class="font-semibold flex items-center mb-2"><div class="text-lg flex items-center"><svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" class="-ml-1 mr-1 text-yellow-500" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 24 24"><path d="M11 15H6l7-14v8h5l-7 14v-8z" fill="currentColor"></path></svg>
Hosted inference API</div> <a target="_blank" href="/docs"><svg class="ml-1.5 text-sm text-gray-400 hover:text-black" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M17 22v-8h-4v2h2v6h-3v2h8v-2h-3z" fill="currentColor"></path><path d="M16 8a1.5 1.5 0 1 0 1.5 1.5A1.5 1.5 0 0 0 16 8z" fill="currentColor"></path><path d="M16 30a14 14 0 1 1 14-14a14 14 0 0 1-14 14zm0-26a12 12 0 1 0 12 12A12 12 0 0 0 16 4z" fill="currentColor"></path></svg></a></div> <div class="flex items-center text-sm text-gray-500 mb-1.5"><div class="inline-flex items-center"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" fill="currentColor" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M30 15H17V2h-2v13H2v2h13v13h2V17h13v-2z"></path><path d="M25.586 20L27 21.414L23.414 25L27 28.586L25.586 30l-5-5l5-5z"></path><path d="M11 30H3a1 1 0 0 1-.894-1.447l4-8a1.041 1.041 0 0 1 1.789 0l4 8A1 1 0 0 1 11 30zm-6.382-2h4.764L7 23.236z"></path><path d="M28 12h-6a2.002 2.002 0 0 1-2-2V4a2.002 2.002 0 0 1 2-2h6a2.002 2.002 0 0 1 2 2v6a2.002 2.002 0 0 1-2 2zm-6-8v6h6.001L28 4z"></path><path d="M7 12a5 5 0 1 1 5-5a5.006 5.006 0 0 1-5 5zm0-8a3 3 0 1 0 3 3a3.003 3.003 0 0 0-3-3z"></path></svg> <span>Sentence Similarity</span></div> <div class="ml-auto"></div></div> <form class="flex flex-col space-y-2"><label class="block "> <span class="text-sm text-gray-500">Source Sentence</span> <input class="mt-1.5 form-input-alt block w-full " placeholder="Your sentence here..." type="text"></label> <label class="block "> <span class="text-sm text-gray-500">Sentences to compare to</span> <input class="mt-1.5 form-input-alt block w-full " placeholder="Your sentence here..." type="text"></label> <label class="block "> <input class=" form-input-alt block w-full " placeholder="Your sentence here..." type="text"></label><label class="block "> <input class=" form-input-alt block w-full " placeholder="Your sentence here..." type="text"></label> <button class="btn-widget w-full h-10 px-5" type="submit">Add Sentence</button> <button class="btn-widget w-24 h-10 px-5 " type="submit">Compute</button></form> <div class="mt-1.5"><div class="text-gray-400 text-xs">This model can be loaded on the Inference API on-demand.</div> </div> <div class="mt-auto pt-4 flex items-center text-xs text-gray-500"><button class="flex items-center cursor-not-allowed text-gray-300" disabled=""><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32" style="transform: rotate(360deg);"><path d="M31 16l-7 7l-1.41-1.41L28.17 16l-5.58-5.59L24 9l7 7z" fill="currentColor"></path><path d="M1 16l7-7l1.41 1.41L3.83 16l5.58 5.59L8 23l-7-7z" fill="currentColor"></path><path d="M12.419 25.484L17.639 6l1.932.518L14.35 26z" fill="currentColor"></path></svg>
JSON Output</button> <button class="flex items-center ml-auto"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M22 16h2V8h-8v2h6v6z" fill="currentColor"></path><path d="M8 24h8v-2h-6v-6H8v8z" fill="currentColor"></path><path d="M26 28H6a2.002 2.002 0 0 1-2-2V6a2.002 2.002 0 0 1 2-2h20a2.002 2.002 0 0 1 2 2v20a2.002 2.002 0 0 1-2 2zM6 6v20h20.001L26 6z" fill="currentColor"></path></svg>
Maximize</button></div> </div></div></div>
</div>
Of course, on top of the widgets, we also provide API endpoints in our Inference API that you can use to programmatically call your models!
```python
import json
import requests
API_URL = "https://api-inference.huggingface.co/models/sentence-transformers/paraphrase-MiniLM-L6-v2"
headers = {"Authorization": "Bearer YOUR_TOKEN"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
data = query(
{
"inputs": {
"source_sentence": "That is a happy person",
"sentences": [
"That is a happy dog",
"That is a very happy person",
"Today is a sunny day"
]
}
}
)
```
## Unleashing the Power of Sharing
So why is this powerful? In a matter of minutes, you can share your trained models with the whole community.
```python
from sentence_transformers import SentenceTransformer
# Load or train a model
model.save_to_hub("my_new_model")
```
Now you will have a [repository](https://huggingface.co./osanseviero/my_new_model) in the Hub which hosts your model. A model card was automatically created. It describes the architecture by listing the layers and shows how to use the model with both `Sentence Transformers` and `🤗 Transformers`. You can also try out the widget and use the Inference API straight away!
If this was not exciting enough, your models will also be easily discoverable by [filtering for all](https://huggingface.co./models?filter=sentence-transformers) `Sentence Transformers` models.
## What's next?
Moving forward, we want to make this integration even more useful. In our roadmap, we expect training and evaluation data to be included in the automatically created model card, like is the case in `transformers` from version `v4.8`.
And what's next for you? We're very excited to see your contributions! If you already have a `Sentence Transformer` repo in the Hub, you can now enable the widget and Inference API by changing the model card metadata.
```yaml | [
[
"transformers",
"implementation",
"benchmarks",
"tools",
"text_classification"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"implementation",
"benchmarks",
"tools"
] | null | null |
224fd9de-ee51-4d06-912e-c010aea1c005 | completed | 2025-01-16T03:08:53.171042 | 2025-01-19T18:48:45.543743 | e54fbb0c-774a-494d-9a57-27c266ba92d0 | Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and Speculative Decoding | ofirzaf, echarlaix, imargulis, danielkorat, jmamou, guybd, orenpereg, moshew, Haihao, aayasin, FanZhao | intel-starcoder-quantization.md | ## Introduction
Recently, code generation models have become very popular, especially with the release of state-of-the-art open-source models such as BigCode’s [StarCoder](https://huggingface.co./blog/starcoder) and Meta AI’s [Code Llama](https://ai.meta.com/blog/code-llama-large-language-model-coding). A growing number of works focuses on making Large Language Models (LLMs) more optimized and accessible. In this blog, we are happy to share the latest results of LLM optimization on Intel Xeon focusing on the popular code generation LLM, StarCoder.
The StarCoder Model is a cutting-edge LLM specifically designed for assisting the user with various coding tasks such as code completion, bug fixing, code summarization, and even generating code snippets from natural language descriptions. The StarCoder model is a member of the StarCoder family which includes the StarCoderBase variant as well. These Large Language Models for Code (Code LLMs) are trained on permissively licensed data from GitHub, including over 80 programming languages, Git commits, GitHub issues, and Jupyter notebooks. In this work we show more than 7x inference acceleration of StarCoder-15B model on Intel 4th generation Xeon by integrating 8bit and 4bit quantization with [assisted generation](https://huggingface.co./blog/assisted-generation).
Try out our [demo](https://huggingface.co./spaces/Intel/intel-starcoder-playground) on Hugging Face Spaces that is being run on a 4th Generation Intel Xeon Scalable processor.
<figure class="image table text-center m-0 w-full">
<video
alt="Generating DOI"
style="max-width: 90%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/starcoder-demo.mov" type="video/mp4">
</video>
</figure>
## Step 1: Baseline and Evaluation
We establish our baseline using StarCoder (15B) coupled with PyTorch and [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX). There are several datasets designed to evaluate the quality of automated code completion. In this work, we use the popular [HumanEval](https://huggingface.co./datasets/openai_humaneval) dataset to evaluate the model’s quality and performance. HumanEval consists of 164 programming problems, in the form of a function signature with a docstring and the model completes the function’s code. The average length of the prompt is 139. We measure the quality using Bigcode Evaluation Harness and report the pass@1 metric. We measure model performance by measuring the Time To First Token (TTFT) and Time Per Output Token (TPOT) on the HumanEval test set and report the average TTFT and TPOT.
The 4th generation Intel Xeon processors feature AI infused acceleration known as Intel® Advanced Matrix Extensions (Intel® AMX). Specifically, it has built-in [BFloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format) (BF16) and Int8 GEMM accelerators in every core to accelerate deep learning training and inference workloads. AMX accelerated inference is introduced through PyTorch 2.0 and [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX) in addition to other optimizations for various common operators used in LLM inference (e.g. layer normalization, SoftMax, scaled dot product).
As the starting point we use out-of-the-box optimizations in PyTorch and IPEX to perform inference using a BF16 model. Figure 1 shows the latency of the baseline model and Tables 1 and 2 show its
latency as well as its accuracy.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/latency_baseline_model.png" alt="baseline latency" style="width: 70%; height: auto;"><br>
<em>Figure 1. Latency of the baseline model.</em>
</p>
### LLM Quantization
Text generation in LLMs is performed in an auto-regressive manner thus requiring the entire model to be loaded from memory to the CPU for each new token generation. We find that the bandwidth between the off-chip memory (DRAM) and the CPU poses the biggest bottleneck in the token generation process. Quantization is a popular approach for mitigating this issue. It reduces model size and hence decreases model weights loading time.
In this work we focus on two types of quantization:
1. Weight Only Quantization (WOQ) - the weights of the model being quantized but not the activations while computation is performed in higher precision (e.g. BF16) which requires dequantization.
2. Static Quantization (SQ) - both the weights and the activations are quantized. This quantization process includes pre-calculating the quantization parameters through a calibration step which enables the computation to be executed in lower precision (e.g. INT8). Figure 2 shows the INT8 static quantization computation process.
## Step 2: 8bit Quantization (INT8)
[SmoothQuant](https://huggingface.co./blog/generative-ai-models-on-intel-cpu) is a post training quantization algorithm that is used to quantize LLMs for INT8 with minimal accuracy loss. Static quantization methods were shown to be underperforming on LLMs due to large magnitude outliers found in specific channels of the activations. Since activations are quantized token-wise, static quantization results in either truncated outliers or underflowed low-magnitude activations. SmoothQuant algorithm solves this problem by introducing a pre-quantization phase where additional smoothing scaling factors are applied to both activations and weights which smooths the outliers in the activations and ensures better utilization of the quantization levels.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/int8_diagram.png" alt="INT8 quantization" style="width: 70%; height: auto;"><br>
<em>Figure 2. Computation diagram for INT8 static quantization.</em>
</p>
Using IPEX, we apply SmoothQuant to the StarCoder model. We used the test split of the [MBPP](https://huggingface.co./datasets/nuprl/MultiPL-E) dataset as our calibration dataset and introduced Q8-StarCoder. Our evaluation shows that Q8-StarCoder holds no accuracy loss over the baseline (if fact, there is even a slight improvement). In terms of performance, Q8-StarCoder achieves **~2.19x** speedup in TTFT and **~2.20x** speedup in TPOT. Figure 3 shows the latency (TPOT) of Q8-StarCoder compared to the BF16 baseline model.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/latency_int8_model.png" alt="INT8 latency" style="width: 70%; height: auto;"><br>
<em>Figure 3. Latency speedup of 8-bit quantized model.</em>
</p>
## Step 3: 4bit Quantization (INT4)
Although INT8 decreases the model size by 2x compared to BF16 (8 bits per weight compared to 16 bits), the memory bandwidth is still the largest bottleneck. To further decrease the model’s loading time from the memory, we quantized the model’s weights to 4 bits using WOQ. Note that 4bit WOQ requires dequantization to 16bit before the computation (Figure 4) which means that there is a compute overhead.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/int4_diagram.png" alt="INT4 quantization" style="width: 70%; height: auto;"><br>
<em>Figure 4. Computation diagram for model quantized to INT4.</em>
</p>
Tensor-wise asymmetric Round To Nearest (RTN) quantization, a basic WOQ technique, poses challenges and often results in accuracy reduction, however it was shown in the [literature](https://arxiv.org/pdf/2206.01861.pdf) (Zhewei Yao, 2022) that groupwise quantization of the model’s weights helps in retaining accuracy. To avoid accuracy degradation, we perform 4-bit quantization in groups (e.g. 128) of consequent values along the input channel, with scaling factors calculated per group. We found that groupwise 4bit RTN is sufficient to retain StarCoder’s accuracy on the HumanEval dataset. The 4bit model achieves **3.35x** speedup in TPOT compared to the BF16 baseline (figure 5), however it suffers from expected slowdown of 0.84x in TTFT (Table 1) due to the overhead of dequantizing the 4bit to 16bit before computation.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/latency_int4_model.png" alt="INT4 latency" style="width: 70%; height: auto;"><br>
<em>Figure 5. Latency speedup of 4-bit quantized model.</em>
</p>
## Different Bottlenecks between Generating the First Token and Subsequent Tokens
The initial step of generating the first token, which involves parallel processing of the entire input prompt, demands significant computational resources when the prompt length is high. Computation, therefore, becomes the bottleneck in this stage. Hence, switching from BF16 to INT8 precision for this process improves the performance compared to the baseline (and to 4bit WOQ which involves compute overhead in the form of dequantization). However, starting from the second step, when the system generates the rest of the tokens one by one in an autoregressive manner, the model is loaded from the memory again and again for each new generated token. As a result, the bottleneck becomes memory bandwidth, rather than the number of calculations (FLOPS) performed and therefore INT4 outperforms INT8 and BF16.
## Step 4: Assisted Generation (AG)
Another method to mitigate the high inference latency and alleviate the memory bandwidth bottleneck issue is [Assisted generation](https://huggingface.co./blog/assisted-generation) (AG) which is a practical implementation of [speculative decoding](https://arxiv.org/pdf/2211.17192.pdf). AG mitigates this issue by better balancing memory and computational operations. It relies on the premise that a smaller and faster assistant draft model often generates the same tokens as a larger target model.
AG uses a small, fast draft model to greedily generate K candidate tokens. These output tokens are generated much faster, but some of them may not resemble the output tokens of the original target model. Hence, in the next step, the target model checks the validity of all K candidate tokens in parallel in a single forward pass. This process speeds up the decoding since the latency of parallel decoding of K tokens is smaller than generating K tokens autoregressively.
For accelerating StarCoder, we use [bigcode/tiny_starcoder_py](https://huggingface.co./bigcode/tiny_starcoder_py) as the draft model. This model shares a similar architecture with StarCoder but includes only 164M parameters - **~95x** smaller than StarCoder, and thus much faster. To achieve an even greater speedup, in addition to quantizing the target model, we apply quantization to the draft model as well. We consider both 8bit SmoothQuant and 4bit WOQ quantization for the draft and target models. When evaluating both quantization options for the draft and target models, we found that 8bit SmoothQuant for both models yielded the best results: **~7.30x** speedup in TPOT (Figure 6).
These quantization choices are backed up by the following observations:
1. Draft model quantization: when using 8bit quantized StarCoder with 164M parameters as draft model, the model mostly fits in the CPU cache. As a result, the memory bandwidth bottleneck is alleviated, as token generation occurs without repeatedly reading the target model from off-chip memory for each token. In this case, there is no memory bottleneck, and we see better speedup with StarCoder-164M quantized to 8bit in comparison to StarCoder-164M quantized to 4bit WOQ. We note that 4bit WOQ holds an advantage where memory bandwidth is the bottleneck because of its smaller memory footprint, however 4bit comes with a compute overhead due to the requirement to perform 4bit to 16bit dequantization before the computation.
2. Target model quantization: in assisted generation, the target model processes a sequence of K tokens that were generated by the draft model. Forwarding K tokens at once (in parallel) through the target model instead of applying the “standard” sequential autoregressive processing, shifts the balance from memory bandwidth to compute bottleneck. Therefore, we observed that using an 8bit quantized target model yields higher speedups than using a 4bit model because of the additional compute overhead that stems from dequantization of every single value from 4bit to 16bit.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/174_intel_quantization_starcoder/latency_int8_ag_model.png" alt="IN8 AG" style="width: 70%; height: auto;"><br>
<em>Figure 6. Latency speedup of optimized model.</em>
</p>
| StarCoder | Quantization | Precision | HumanEval (pass@1)| TTFT (ms) | TTFT Speedup | TPOT (ms) | TPOT Speedup |
| | [
[
"llm",
"optimization",
"quantization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"optimization",
"quantization",
"efficient_computing"
] | null | null |
3ff76b10-0583-45a4-9547-446ef9cf5b70 | completed | 2025-01-16T03:08:53.171047 | 2025-01-16T15:16:41.319286 | 32acce30-e3ac-4ebb-827a-47afe23c792c | 'Jack of All Trades, Master of Some, a Multi-Purpose Transformer Agent' | qgallouedec, edbeeching, ClementRomac, thomwolf | jat.md | ## Introduction
We're excited to share Jack of All Trades (JAT), a project that aims to move in the direction of a generalist agent. The project started as an open reproduction of the [Gato](https://huggingface.co./papers/2205.06175) (Reed et al., 2022) work, which proposed to train a Transformer able to perform both vision-and-language and decision-making tasks. We thus started by building an open version of Gato’s dataset. We then trained multi-modal Transformer models on it, introducing several improvements over Gato for handling sequential data and continuous values.
Overall, the project has resulted in:
- The release of a large number of **expert RL agents** on a wide variety of tasks.
- The release of the **JAT dataset**, the first dataset for generalist agent training. It contains hundreds of thousands of expert trajectories collected with the expert agents
- The release of the **JAT model**, a transformer-based agent capable of playing video games, controlling a robot to perform a wide variety of tasks, understanding and executing commands in a simple navigation environment and much more!
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/jat/global_schema.gif" alt="Global schema"/>
## Datasets & expert policies
### The expert policies
RL traditionally involves training policies on single environments. Leveraging these expert policies is a genuine way to build a versatile agent. We selected a wide range of environments, of varying nature and difficulty, including Atari, BabyAI, Meta-World, and MuJoCo. For each of these environments, we train an agent until it reached state-of-the-art performance. (For BabyAI, we use the [BabyAI bot](https://github.com/mila-iqia/babyai) instead). The resulting agents are called expert agents, and have been released on the 🤗 Hub. You'll find a list of all agents in the [JAT dataset card](https://huggingface.co./datasets/jat-project/jat-dataset).
### The JAT dataset
We release the [JAT dataset](https://huggingface.co./datasets/jat-project/jat-dataset), the first dataset for generalist agent training. The JAT dataset contains hundreds of thousands of expert trajectories collected with the above-mentioned expert agents. To use this dataset, simply load it like any other dataset from the 🤗 Hub:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("jat-project/jat-dataset", "metaworld-assembly")
>>> first_episode = dataset["train"][0]
>>> first_episode.keys()
dict_keys(['continuous_observations', 'continuous_actions', 'rewards'])
>>> len(first_episode["rewards"])
500
>>> first_episode["continuous_actions"][0]
[6.459120273590088, 2.2422609329223633, -5.914587020874023, -19.799840927124023]
```
In addition to RL data, we include textual datasets to enable a unique interface for the user. That's why you'll also find subsets for [Wikipedia](https://huggingface.co./datasets/wikipedia), [Oscar](https://huggingface.co./datasets/oscar), [OK-VQA](https://okvqa.allenai.org) and [Conceptual-Captions](https://huggingface.co./datasets/conceptual_captions).
## JAT agent architecture
JAT's architecture is based on a Transformer, using [EleutherAI's GPT-Neo implementation](https://huggingface.co./docs/transformers/model_doc/gpt_neo). JAT's particularity lies in its embedding mechanism, which has been built to intrinsically handle sequential decision tasks. We interleave observation embeddings with action embeddings, along with the corresponding rewards.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/raw/main/blog/jat/model.svg" width="100%" alt="Model">
<figcaption>Architecture of the JAT network. For sequential decision-making tasks, observations and rewards on the one hand, and actions on the other, are encoded and interleaved. The model generates the next embedding autoregressively with a causal mask, and decodes according to expected modality.</figcaption>
</figure>
Each embedding therefore corresponds either to an observation (associated with the reward), or to an action. But how does JAT encode this information? It depends on the type of data. If the data (observation or action) is an image (as is the case for Atari), then JAT uses a CNN. If it's a continuous vector, then JAT uses a linear layer. Finally, if it's a discrete value, JAT uses a linear projection layer. The same principle is used for model output, depending on the type of data to be predicted. Prediction is causal, shifting observations by 1 time step. In this way, the agent must predict the next action from all previous observations and actions.
In addition, we thought it would be fun to train our agent to perform NLP and CV tasks. To do this, we also gave the encoder the option of taking text and image data as input. For text data, we tokenize using GPT-2 tokenization strategy, and for images, we use a [ViT](https://huggingface.co./docs/transformers/model_doc/vit)-type encoder.
Given that the modality of the data can change from one environment to another, how does JAT compute the loss? It computes the loss for each modality separately. For images and continuous values, it uses the MSE loss. For discrete values, it uses the cross-entropy loss. The final loss is the average of the losses for each element of the sequence.
Wait, does that mean we give equal weight to predicting actions and observations? Actually, no, but we'll talk more about that [below](#the-surprising-benefits-of-predicting-observations).
## Experiments and results
We evaluate JAT on all 157 training tasks. We collect 10 episodes and record the total reward. For ease of reading, we aggregate the results by domain.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/raw/main/blog/jat/score_steps.svg" alt="Score evolution" width="100%;">
<figcaption>Aggregated expert normalized scores with 95% Confidence Intervals (CIs) for each RL domain as a function of learning step.</figcaption>
</figure>
If we were to summarize these results in one number, it would be 65.8%, the average performance compared to the JAT expert over the 4 domains. This shows that JAT is capable of mimicking expert performance on a very wide variety of tasks.
Let's go into a little more detail:
- For Atari 57, the agent achieves 14.1% of the expert's score, corresponding to 37.6% of human performance. It exceeds human performance on 21 games.
- For BabyAI, the agent achieves 99.0% of the expert's score, and fails to exceed 50% of the expert on just 1 task.
- For Meta-World, the agent reached 65.5% of the expert.
- For MuJoCo, the agent achieves 84.8% of the expert.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/raw/main/blog/jat/human_normalized_atari_jat_small_250000.svg" alt="Score evolution" width="100%" >
<figcaption>Human normalized scores for the JAT agent on the Atari 57 benchmark.</figcaption>
</figure>
What's most impressive is that JAT achieves this performance using a **single network** for all domains. To take the measure of this performance, let's watch JAT's rendering on a few tasks:
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="jat_hf.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/jat/jat_hf.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
Want to try it out? You can! The [JAT model](https://huggingface.co./jat-project/jat) is available on the 🤗 Hub!
For textual tasks, our model shows rudimentary capabilities, we refer the reader to the [paper](https://huggingface.co./papers/2402.09844) for more details.
### The surprising benefits of predicting observations
When training an RL agent, the primary goal is to maximize future rewards. But what if we also ask the agent to predict what it will observe in the future? Will this additional task help or hinder the learning process?
There are two opposing views on this question. On one hand, learning to predict observations could provide a deeper understanding of the environment, leading to better and faster learning. On the other hand, it could distract the agent from its main goal, resulting in mediocre performance in both observation and action prediction.
To settle this debate, we conducted an experiment using a loss function that combines observation loss and action loss, with a weighting parameter \\( \kappa \\) to balance the two objectives.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/raw/main/blog/jat/kappa_aggregated.svg" width="100%" alt="Kappa Aggregated">
<figcaption>Aggregate measures with 95% CIs for the study on the influence of observation prediction learning for selected tasks. The results presented cover the selected range of κ values and are based on 100 evaluations per task. Optimal \\( \kappa \\) selection can significantly improve agent performance.</figcaption>
</figure>
The results were noteworthy. When \\( \kappa \\) was too high (0.5), the additional objective of predicting observations seemed to hinder the learning process. But when \\( \kappa \\) was lower, the impact on learning was negligible, and the agent's performance was similar to that obtained when observation prediction was not part of the objective.
However, we found a sweet spot around \\( \kappa= 0.005 \\), where learning to predict observations actually improved the agent's learning efficiency.
Our study suggests that adding observation prediction to the learning process can be beneficial, as long as it's balanced correctly. This finding has important implications for the design of such agents, highlighting the potential value of auxiliary objectives in improving learning efficiency.
So, the next time you're training an RL agent, consider asking it to predict what it will observe in the future. It might just lead to better performance and faster learning!
## Conclusions
In this work, we introduced JAT, a multi-purpose transformer agent capable of mastering a wide variety of sequential decision-making tasks, and showing rudimentary capabilities in NLP and CV tasks. For all these tasks, JAT uses a single network. Our contributions include the release of expert RL agents, the JAT dataset, and the JAT model. We hope that this work will inspire future research in the field of generalist agents and contribute to the development of more versatile and capable AI systems.
## What's next? A request for research
We believe that the JAT project has opened up a new direction for research in the field of generalist agents, and we've only just scratched the surface. Here are some ideas for future work:
- **Improving the data**: Although pioneering, the JAT dataset is still in its early stages. The expert trajectories come from only one expert agent per environment which may cause some bias. Although we've done our best to reach state-of-the-art performance, some environments are still challenging. We believe that collecting more data and training more expert agents could help **a lot**.
- **Use offline RL**: The JAT agent is trained using basic Behavioral Cloning. This implies two things: (1) we can't take advantage of sub-optimal trajectories and (2) the JAT agent can't outperform the expert. We've chosen this approach for simplicity, but we believe that using offline RL could **really help** improve the agent's performance, while not being too complex to implement.
- **Unlock the full potential of a smarter multi-task sampling strategy**: Currently, the JAT agent samples data uniformly from all tasks, but this approach may be holding it back. By dynamically adjusting the sampling rate to focus on the most challenging tasks, we can supercharge the agent's learning process and unlock **significant performance gains**.
## Links
- 📄 [Paper](https://huggingface.co./papers/2402.09844)
- 💻 [Source code](https://github.com/huggingface/jat)
- 🗂️ [JAT dataset](https://huggingface.co./datasets/jat-project/jat-dataset)
- 🤖 [JAT model](https://huggingface.co./jat-project/jat)
## Citation
```bibtex
@article{gallouedec2024jack,
title = {{Jack of All Trades, Master of Some, a Multi-Purpose Transformer Agent}},
author = {Gallouédec, Quentin and Beeching, Edward and Romac, Clément and Dellandréa, Emmanuel},
journal = {arXiv preprint arXiv:2402.09844},
year = {2024},
url = {https://arxiv.org/abs/2402.09844}
}
``` | [
[
"transformers",
"data",
"multi_modal",
"robotics"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"multi_modal",
"data",
"robotics"
] | null | null |
e5a96ad4-47f2-4d75-bac4-f75f7d11cd2f | completed | 2025-01-16T03:08:53.171052 | 2025-01-16T03:23:00.619430 | f52594ae-4e7d-4f1e-9676-3a55761c0e42 | Cosmopedia: how to create large-scale synthetic data for pre-training Large Language Models | loubnabnl, anton-l, davanstrien | cosmopedia.md | In this blog post, we outline the challenges and solutions involved in generating a synthetic dataset with billions of tokens to replicate [Phi-1.5](https://arxiv.org/abs/2309.05463), leading to the creation of [Cosmopedia](https://huggingface.co./datasets/HuggingFaceTB/cosmopedia). Synthetic data has become a central topic in Machine Learning. It refers to artificially generated data, for instance by large language models (LLMs), to mimic real-world data.
Traditionally, creating datasets for supervised fine-tuning and instruction-tuning required the costly and time-consuming process of hiring human annotators. This practice entailed significant resources, limiting the development of such datasets to a few key players in the field. However, the landscape has recently changed. We've seen hundreds of high-quality synthetic fine-tuning datasets developed, primarily using GPT-3.5 and GPT-4. The community has also supported this development with numerous publications that guide the process for various domains, and address the associated challenges [[1](https://arxiv.org/abs/2305.14233)][[2](https://arxiv.org/abs/2312.02120)][[3](https://arxiv.org/abs/2402.10176)][[4](https://arxiv.org/abs/2304.12244)][[5](https://huggingface.co./blog/synthetic-data-save-costs)].
<p align="center">
<img src="https://huggingface.co./datasets/HuggingFaceTB/images/resolve/main/cosmopedia/data.png" alt="number of datasets with synthetic tag" style="width: 90%; height: auto;"><br>
<em>Figure 1. Datasets on Hugging Face hub with the tag synthetic.</em>
</p>
However, this is not another blog post on generating synthetic instruction-tuning datasets, a subject the community is already extensively exploring. We focus on scaling from a **few thousand** to **millions** of samples that can be used for **pre-training LLMs from scratch**. This presents a unique set of challenges.
## Why Cosmopedia?
Microsoft pushed this field with their series of Phi models [[6](https://arxiv.org/abs/2306.11644)][[7](https://arxiv.org/abs/2309.05463)][[8](https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/)], which were predominantly trained on synthetic data. They surpassed larger models that were trained much longer on web datasets. [Phi-2](https://huggingface.co./microsoft/phi-2) was downloaded over 617k times in the past month and is among the top 20 most-liked models on the Hugging Face hub.
While the technical reports of the Phi models, such as the [“Textbooks Are All You Need”](https://arxiv.org/abs/2306.11644) paper, shed light on the models’ remarkable performance and creation, they leave out substantial details regarding the curation of their synthetic training datasets. Furthermore, the datasets themselves are not released. This sparks debate among enthusiasts and skeptics alike. Some praise the models' capabilities, while critics argue they may simply be overfitting benchmarks; some of them even label the approach of pre-training models on synthetic data as [« garbage in, garbage out»](https://x.com/Grady_Booch/status/1760042033761378431?s=20). Yet, the idea of having full control over the data generation process and replicating the high-performance of Phi models is intriguing and worth exploring.
This is the motivation for developing [Cosmopedia](https://huggingface.co./datasets/HuggingFaceTB/cosmopedia), which aims to reproduce the training data used for Phi-1.5. In this post we share our initial findings and discuss some plans to improve on the current dataset. We delve into the methodology for creating the dataset, offering an in-depth look at the approach to prompt curation and the technical stack. Cosmopedia is fully open: we release the [code](https://github.com/huggingface/cosmopedia) for our end-to-end pipeline, the [dataset](https://huggingface.co./datasets/HuggingFaceTB/cosmopedia), and a 1B model trained on it called [cosmo-1b](https://huggingface.co./HuggingFaceTB/cosmo-1b). This enables the community to reproduce the results and build upon them.
## Behind the scenes of Cosmopedia’s creation
Besides the lack of information about the creation of the Phi datasets, another downside is that they use proprietary models to generate the data. To address these shortcomings, we introduce Cosmopedia, a dataset of synthetic textbooks, blog posts, stories, posts, and WikiHow articles generated by [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co./mistralai/Mixtral-8x7B-Instruct-v0.1). It contains over 30 million files and 25 billion tokens, making it the largest open synthetic dataset to date.
Heads up: If you are anticipating tales about deploying large-scale generation tasks across hundreds of H100 GPUs, in reality most of the time for Cosmopedia was spent on meticulous prompt engineering.
### Prompts curation
Generating synthetic data might seem straightforward, but maintaining diversity, which is crucial for optimal performance, becomes significantly challenging when scaling up. Therefore, it's essential to curate diverse prompts that cover a wide range of topics and minimize duplicate outputs, as we don’t want to spend compute on generating billions of textbooks only to discard most because they resemble each other closely. Before we launched the generation on hundreds of GPUs, we spent a lot of time iterating on the prompts with tools like [HuggingChat](https://huggingface.co./chat/). In this section, we'll go over the process of creating over 30 million prompts for Cosmopedia, spanning hundreds of topics and achieving less than 1% duplicate content.
Cosmopedia aims to generate a vast quantity of high-quality synthetic data with broad topic coverage. According to the Phi-1.5 [technical report](https://arxiv.org/abs/2309.05463), the authors curated 20,000 topics to produce 20 billion tokens of synthetic textbooks while using samples from web datasets for diversity, stating:
> We carefully selected 20K topics to seed the generation of this new synthetic data. In our generation prompts, we use samples from web datasets for diversity.
>
Assuming an average file length of 1000 tokens, this suggests using approximately 20 million distinct prompts. However, the methodology behind combining topics and web samples for increased diversity remains unclear.
We combine two approaches to build Cosmopedia’s prompts: conditioning on curated sources and conditioning on web data. We refer to the source of the data we condition on as “seed data”.
<p align="center">
<img src="https://huggingface.co./datasets/HuggingFaceTB/images/resolve/main/cosmopedia/piecharts.png" alt="piecharts of data sources" style="width: 90%; height: auto;"><br>
<em>Figure 2. The distribution of data sources for building Cosmopedia prompts (left plot) and the distribution of sources inside the Curated sources category (right plot).</em>
</p>
#### Curated Sources
We use topics from reputable educational sources such as Stanford courses, Khan Academy, OpenStax, and WikiHow. These resources cover many valuable topics for an LLM to learn. For instance, we extracted the outlines of various Stanford courses and constructed prompts that request the model to generate textbooks for individual units within those courses. An example of such a prompt is illustrated in figure 3.
Although this approach yields high-quality content, its main limitation is scalability. We are constrained by the number of resources and the topics available within each source. For example, we can extract only 16,000 unique units from OpenStax and 250,000 from Stanford. Considering our goal of generating 20 billion tokens, we need at least 20 million prompts!
##### Leverage diversity in audience and style
One strategy to increase the variety of generated samples is to leverage the diversity of audience and style: a single topic can be repurposed multiple times by altering the target audience (e.g., young children vs. college students) and the generation style (e.g., academic textbook vs. blog post). However, we discovered that simply modifying the prompt from "Write a detailed course unit for a textbook on 'Why Go To Space?' intended for college students" to "Write a detailed blog post on 'Why Go To Space?'" or "Write a textbook on 'Why Go To Space?' for young children" was insufficient to prevent a high rate of duplicate content. To mitigate this, we emphasized changes in audience and style, providing specific instructions on how the format and content should differ.
Figure 3 illustrates how we adapt a prompt based on the same topic for different audiences.
<p align="center">
<img src="https://huggingface.co./datasets/HuggingFaceTB/images/resolve/main/cosmopedia/textbooks.png" alt="comparison of prompts" style="width: 90%; height: auto;"><br>
<em>Figure 3. Prompts for generating the same textbook for young children vs for professionals and researchers vs for high school students.</em>
</p>
By targeting four different audiences (young children, high school students, college students, researchers) and leveraging three generation styles (textbooks, blog posts, wikiHow articles), we can get up to 12 times the number of prompts. However, we might want to include other topics not covered in these resources, and the small volume of these sources still limits this approach and is very far from the 20+ million prompts we are targeting. That’s when web data comes in handy; what if we were to generate textbooks covering all the web topics? In the next section, we’ll explain how we selected topics and used web data to build millions of prompts.
#### Web data
Using web data to construct prompts proved to be the most scalable, contributing to over 80% of the prompts used in Cosmopedia. We clustered millions of web samples, using a dataset like [RefinedWeb](https://huggingface.co./datasets/tiiuae/falcon-refinedweb), into 145 clusters, and identified the topic of each cluster by providing extracts from 10 random samples and asking Mixtral to find their common topic. More details on this clustering are available in the Technical Stack section.
We inspected the clusters and excluded any deemed of low educational value. Examples of removed content include explicit adult material, celebrity gossip, and obituaries. The full list of the 112 topics retained and those removed can be found [here](https://github.com/huggingface/cosmopedia/blob/dd5cd1f7fcfae255c9cfbe704ba2187965523457/prompts/web_samples/filter_and_classify_clusters.py).
We then built prompts by instructing the model to generate a textbook related to a web sample within the scope of the topic it belongs to based on the clustering. Figure 4 provides an example of a web-based prompt. To enhance diversity and account for any incompleteness in topic labeling, we condition the prompts on the topic only 50% of the time, and change the audience and generation styles, as explained in the previous section. We ultimately built 23 million prompts using this approach. Figure 5 shows the final distribution of seed data, generation formats, and audiences in Cosmopedia.
<p align="center">
<img src="https://huggingface.co./datasets/HuggingFaceTB/images/resolve/main/cosmopedia/web_samples.png" alt="web prompt" style="width: 90%; height: auto;"><br>
<em>Figure 4. Example of a web extract and the associated prompt.</em>
</p>
<p align="center">
<img src="https://huggingface.co./datasets/HuggingFaceTB/images/resolve/main/cosmopedia/histograms.png" alt="histogram" style="width: 90%; height: auto;"><br>
<em>Figure 5. The distribution of seed data, generation format and target audiences in Cosmopedia dataset.</em>
</p>
In addition to random web files, we used samples from AutoMathText, a carefully curated dataset of Mathematical texts with the goal of including more scientific content.
#### Instruction datasets and stories
In our initial assessments of models trained using the generated textbooks, we observed a lack of common sense and fundamental knowledge typical of grade school education. To address this, we created stories incorporating day-to-day knowledge and basic common sense using texts from the [UltraChat](https://huggingface.co./datasets/stingning/ultrachat) and [OpenHermes2.5](https://huggingface.co./datasets/teknium/OpenHermes-2.5) instruction-tuning datasets as seed data for the prompts. These datasets span a broad range of subjects. For instance, from UltraChat, we used the "Questions about the world" subset, which covers 30 meta-concepts about the world. For OpenHermes2.5, another diverse and high-quality instruction-tuning dataset, we omitted sources and categories unsuitable for storytelling, such as glaive-code-assist for programming and camelai for advanced chemistry. Figure 6 shows examples of prompts we used to generate these stories.
<p align="center">
<img src="https://huggingface.co./datasets/HuggingFaceTB/images/resolve/main/cosmopedia/stories.png" alt="stories prompts" style="width: 90%; height: auto;"><br>
<em>Figure 6. Prompts for generating stories from UltraChat and OpenHermes samples for young children vs a general audience vs reddit forums.</em>
</p>
That's the end of our prompt engineering story for building 30+ million diverse prompts that provide content with very few duplicates. The figure below shows the clusters present in Cosmopedia, this distribution resembles the clusters in the web data. You can also find a clickable map from [Nomic](https://www.nomic.ai/) [here](https://atlas.nomic.ai/map/cosmopedia).
<p align="center">
<img src="https://huggingface.co./datasets/HuggingFaceTB/images/resolve/main/cosmopedia/clusters.png" alt="clusters" style="width: 90%; height: auto;"><br>
<em>Figure 7. The clusters of Cosmopedia, annotated using Mixtral.</em>
</p>
You can use the dataset [viewer](https://huggingface.co./datasets/HuggingFaceTB/cosmopedia/viewer/stanford) to investigate the dataset yourself:
<p align="center">
<img src="https://huggingface.co./datasets/HuggingFaceTB/images/resolve/main/cosmopedia/viewer.png" alt="dataset viewer" style="width: 90%; height: auto;"><br>
<em>Figure 8. Cosmopedia's dataset viewer.</em>
</p>
### Technical stack
We release all the code used to build Cosmopedia in: [https://github.com/huggingface/cosmopedia](https://github.com/huggingface/cosmopedia)
In this section we'll highlight the technical stack used for text clustering, text generation at scale and for training cosmo-1b model.
#### Topics clustering
We used [text-clustering](https://github.com/huggingface/text-clustering/) repository to implement the topic clustering for the web data used in Cosmopedia prompts. The plot below illustrates the pipeline for finding and labeling the clusters. We additionally asked Mixtral to give the cluster an educational score out of 10 in the labeling step; this helped us in the topics inspection step. You can find a demo of the web clusters and their scores in this [demo](https://huggingface.co./spaces/HuggingFaceTB/inspect_web_clusters).
<p align="center">
<img src="https://huggingface.co./datasets/HuggingFaceTB/images/resolve/main/cosmopedia/text_clustering.png" alt="text-clustering" style="width: 60%; height: auto;"><br>
<em>Figure 9. The pipleline of text-clustering.</em>
</p>
#### Textbooks generation at scale
We leverage the [llm-swarm](https://github.com/huggingface/llm-swarm) library to generate 25 billion tokens of synthetic content using [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co./mistralai/Mixtral-8x7B-Instruct-v0.1). This is a scalable synthetic data generation tool using local LLMs or inference endpoints on the Hugging Face Hub. It supports [TGI](https://github.com/huggingface/text-generation-inference) and [vLLM](https://github.com/vllm-project/vllm) inference libraries. We deployed Mixtral-8x7B locally on H100 GPUs from the Hugging Face Science cluster with TGI. The total compute time for generating Cosmopedia was over 10k GPU hours.
Here's an example to run generations with Mixtral on 100k Cosmopedia prompts using 2 TGI instances on a Slurm cluster:
```bash
# clone the repo and follow installation requirements
cd llm-swarm
python ./examples/textbooks/generate_synthetic_textbooks.py \
--model mistralai/Mixtral-8x7B-Instruct-v0.1 \
--instances 2 \
--prompts_dataset "HuggingFaceTB/cosmopedia-100k" \
--prompt_column prompt \
--max_samples -1 \
--checkpoint_path "./tests_data" \
--repo_id "HuggingFaceTB/generations_cosmopedia_100k" \
--checkpoint_interval 500
```
You can even track the generations with `wandb` to monitor the throughput and number of generated tokens.
<p align="center">
<img src="https://huggingface.co./datasets/HuggingFaceTB/images/resolve/main/cosmopedia/wandb.png" alt="text-clustering" style="width: 60%; height: auto;"><br>
<em>Figure 10. Wandb plots for an llm-swarm run.</em>
</p>
**Note:**
We used HuggingChat for the initial iterations on the prompts. Then, we generated a few hundred samples for each prompt using `llm-swarm` to spot unusual patterns. For instance, the model used very similar introductory phrases for textbooks and frequently began stories with the same phrases, like "Once upon a time" and "The sun hung low in the sky". Explicitly asking the model to avoid these introductory statements and to be creative fixed the issue; they were still used but less frequently.
#### Benchmark decontamination
Given that we generate synthetic data, there is a possibility of benchmark contamination within the seed samples or the model's training data. To address this, we implement a decontamination pipeline to ensure our dataset is free of any samples from the test benchmarks.
Similar to Phi-1, we identify potentially contaminated samples using a 10-gram overlap. After retrieving the candidates, we employ [`difflib.SequenceMatcher`](https://docs.python.org/3/library/difflib.html) to compare the dataset sample against the benchmark sample. If the ratio of `len(matched_substrings)` to `len(benchmark_sample)` exceeds 0.5, we discard the sample. This decontamination process is applied across all benchmarks evaluated with the Cosmo-1B model, including MMLU, HellaSwag, PIQA, SIQA, Winogrande, OpenBookQA, ARC-Easy, and ARC-Challenge.
We report the number of contaminated samples removed from each dataset split, as well as the number of unique benchmark samples that they correspond to (in brackets):
<div align="center">
| Dataset group | ARC | BoolQ | HellaSwag | PIQA |
| | [
[
"llm",
"data",
"research",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"data",
"research",
"fine_tuning"
] | null | null |
d2ffae61-8edf-4f3e-840d-f6053113d5e4 | completed | 2025-01-16T03:08:53.171056 | 2025-01-19T19:13:24.825447 | d8be851f-a5f3-4430-b6ff-460c6fd0419d | Quanto: a PyTorch quantization backend for Optimum | dacorvo, ybelkada, marcsun13 | quanto-introduction.md | Quantization is a technique to reduce the computational and memory costs of evaluating Deep Learning Models by representing their weights and activations with low-precision data types like 8-bit integer (int8) instead of the usual 32-bit floating point (float32).
Reducing the number of bits means the resulting model requires less memory storage, which is crucial for deploying Large Language Models on consumer devices.
It also enables specific optimizations for lower bitwidth datatypes, such as `int8` or `float8` matrix multiplications on CUDA devices.
Many open-source libraries are available to quantize pytorch Deep Learning Models, each providing very powerful features, yet often restricted to specific model configurations and devices.
Also, although they are based on the same design principles, they are unfortunately often incompatible with one another.
Today, we are excited to introduce [quanto](https://github.com/huggingface/optimum-quanto), a PyTorch quantization backend for [Optimum](https://huggingface.co./docs/optimum/index).
It has been designed with versatility and simplicity in mind:
- all features are available in eager mode (works with non-traceable models),
- quantized models can be placed on any device (including CUDA and MPS),
- automatically inserts quantization and dequantization stubs,
- automatically inserts quantized functional operations,
- automatically inserts quantized modules (see below the list of supported modules),
- provides a seamless workflow from a float model to a dynamic to a static quantized model,
- serialization compatible with PyTorch `weight_only` and 🤗 [Safetensors](https://huggingface.co./docs/safetensors/index),
- accelerated matrix multiplications on CUDA devices (int8-int8, fp16-int4, bf16-int8, bf16-int4),
- supports int2, int4, int8 and float8 weights,
- supports int8 and float8 activations.
Recent quantization methods appear to be focused on quantizing Large Language Models (LLMs), whereas [quanto](https://github.com/huggingface/optimum-quanto) intends to provide extremely simple quantization primitives for simple quantization schemes (linear quantization, per-group quantization) that are adaptable across any modality.
## Quantization workflow
Quanto is available as a pip package.
```sh
pip install optimum-quanto
```
A typical quantization workflow consists of the following steps:
**1. Quantize**
The first step converts a standard float model into a dynamically quantized model.
```python
from optimum.quanto import quantize, qint8
quantize(model, weights=qint8, activations=qint8)
```
At this stage, only the inference of the model is modified to dynamically quantize the weights.
**2. Calibrate (optional if activations are not quantized)**
Quanto supports a calibration mode that allows the recording of the activation ranges while passing representative samples through the quantized model.
```python
from optimum.quanto import Calibration
with Calibration(momentum=0.9):
model(samples)
```
This automatically activates the quantization of the activations in the quantized modules.
**3. Tune, aka Quantization-Aware-Training (optional)**
If the performance of the model degrades too much, one can tune it for a few epochs to recover the float model performance.
```python
import torch
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data).dequantize()
loss = torch.nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
```
**4. Freeze integer weights**
When freezing a model, its float weights are replaced by quantized weights.
```python
from optimum.quanto import freeze
freeze(model)
```
**5. Serialize quantized model**
Quantized models weights can be serialized to a `state_dict`, and saved to a file.
Both `pickle` and `safetensors` (recommended) are supported.
```python
from safetensors.torch import save_file
save_file(model.state_dict(), 'model.safetensors')
```
In order to reload these weights, you also need to store the quantized
models quantization map.
```python
import json
from optimum.quanto import quantization_map
with open('quantization_map.json', w) as f:
json.dump(quantization_map(model))
```
**5. Reload a quantized model**
A serialized quantized model can be reloaded from a `state_dict` and a `quantization_map` using the `requantize` helper.
Note that you need to first instantiate an empty model.
```python
import json
from safetensors.torch import load_file
state_dict = load_file('model.safetensors')
with open('quantization_map.json', r) as f:
quantization_map = json.load(f)
# Create an empty model from your modeling code and requantize it
with torch.device('meta'):
new_model = ...
requantize(new_model, state_dict, quantization_map, device=torch.device('cuda'))
```
Please refer to the [examples](https://github.com/huggingface/optimum-quanto/tree/main/examples) for instantiations of the quantization workflow.
You can also check this [notebook](https://colab.research.google.com/drive/1qB6yXt650WXBWqroyQIegB-yrWKkiwhl?usp=sharing) where we show you how to quantize a BLOOM model with quanto!
## Performance
Below are two graphs evaluating the accuracy of different quantized configurations for [meta-llama/Meta-Llama-3.1-8B](https://huggingface.co./meta-llama/Meta-Llama-3.1-8B).
Note: the first bar in each group always corresponds to the non-quantized model.
<div class="row"><center>
<div class="column">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/quanto-introduction/meta-llama-Meta-Llama-3.1-8B_bf16_Perplexity.png" alt=""meta-llama/Meta-Llama-3.1-8B WikiText perplexity">
</div>
</center>
</div>
These results are obtained without applying any Post-Training-Optimization algorithm like [hqq](https://mobiusml.github.io/hqq_blog/) or [AWQ](https://github.com/mit-han-lab/llm-awq).
The graph below gives the latency per-token measured on an NVIDIA A10 GPU.
<div class="row"><center>
<div class="column">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/quanto-introduction/meta-llama-Meta-Llama-3.1-8B_bf16_Latency__ms_.png" alt="meta-llama/Meta-Llama-3.1-8B Mean latency per token">
</div>
</center>
</div>
Stay tuned for updated results as we are constantly improving [quanto](https://github.com/huggingface/optimum-quanto) with optimizers and optimized kernels.
Please refer to the [quanto benchmarks](https://github.com/huggingface/optimum-quanto/tree/main/bench/) for detailed results for different model architectures and configurations.
## Integration in transformers
Quanto is seamlessly integrated in the Hugging Face [transformers](https://github.com/huggingface/transformers) library. You can quantize any model by passing a `QuantoConfig` to `from_pretrained`!
Currently, you need to use the latest version of [accelerate](https://github.com/huggingface/accelerate) to make sure the integration is fully compatible.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = QuantoConfig(weights="int8")
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config= quantization_config
)
```
You can quantize the weights and/or activations in int8, float8, int4, or int2 by simply passing the correct argument in `QuantoConfig`. The activations can be either in int8 or float8. For float8, you need to have hardware that is compatible with float8 precision, otherwise quanto will silently upcast the weights and activations to torch.float32 or torch.float16 (depending on the original data type of the model) when we perform the matmul (only when the weight is quantized). If you try to use `float8` using MPS devices, `torch` will currently raise an error.
Quanto is device agnostic, meaning you can quantize and run your model regardless if you are on CPU/GPU/ MPS (Apple Silicon).
Quanto is also torch.compile friendly. You can quantize a model with quanto and call `torch.compile` to the model to compile it for faster generation. This feature might not work out of the box if dynamic quantization is involved (i.e., Quantization Aware Training or quantized activations enabled). Make sure to keep `activations=None` when creating your `QuantoConfig` in case you use the transformers integration.
It is also possible to quantize any model, regardless of the modality using quanto! We demonstrate how to quantize `openai/whisper-large-v3` model in int8 using quanto.
```python
from transformers import AutoModelForSpeechSeq2Seq
model_id = "openai/whisper-large-v3"
quanto_config = QuantoConfig(weights="int8")
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="cuda",
quantization_config=quanto_config
)
```
Check out this [notebook](https://colab.research.google.com/drive/16CXfVmtdQvciSh9BopZUDYcmXCDpvgrT?usp=sharing#scrollTo=IHbdLXAg53JL) for a complete tutorial on how to properly use quanto with the transformers integration!
## Contributing to quanto
Contributions to [quanto](https://github.com/huggingface/optimum-quanto) are very much welcomed, especially in the following areas:
- optimized kernels for [quanto](https://github.com/huggingface/optimum-quanto) operations targeting specific devices,
- Post-Training-Quantization optimizers to recover the accuracy lost during quantization,
- helper classes for `transformers` or `diffusers` models. | [
[
"tutorial",
"optimization",
"tools",
"quantization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"quantization",
"optimization",
"tools",
"efficient_computing"
] | null | null |
673cd5a5-61c4-48f3-8e7e-ea21308dba76 | completed | 2025-01-16T03:08:53.171061 | 2025-01-16T03:11:42.057915 | a50274eb-f038-4edb-a15c-32cae050444e | Deploying TensorFlow Vision Models in Hugging Face with TF Serving | sayakpaul | tf-serving-vision.md | <a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/111_tf_serving_vision.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
In the past few months, the Hugging Face team and external contributors
added a variety of vision models in TensorFlow to Transformers. This
list is growing comprehensively and already includes state-of-the-art
pre-trained models like [Vision Transformer](https://huggingface.co./docs/transformers/main/en/model_doc/vit),
[Masked Autoencoders](https://huggingface.co./docs/transformers/model_doc/vit_mae),
[RegNet](https://huggingface.co./docs/transformers/main/en/model_doc/regnet),
[ConvNeXt](https://huggingface.co./docs/transformers/model_doc/convnext),
and many others!
When it comes to deploying TensorFlow models, you have got a variety of
options. Depending on your use case, you may want to expose your model
as an endpoint or package it in an application itself. TensorFlow
provides tools that cater to each of these different scenarios.
In this post, you'll see how to deploy a Vision Transformer (ViT) model (for image classification)
locally using [TensorFlow Serving](https://www.tensorflow.org/tfx/tutorials/serving/rest_simple)
(TF Serving). This will allow developers to expose the model either as a
REST or gRPC endpoint. Moreover, TF Serving supports many
deployment-specific features off-the-shelf such as model warmup,
server-side batching, etc.
To get the complete working code shown throughout this post, refer to
the Colab Notebook shown at the beginning.
## Saving the Model
All TensorFlow models in 🤗 Transformers have a method named
`save_pretrained()`. With it, you can serialize the model weights in
the h5 format as well as in the standalone [SavedModel format](https://www.tensorflow.org/guide/saved_model).
TF Serving needs a model to be present in the SavedModel format. So, let's first
load a Vision Transformer model and save it:
```py
from transformers import TFViTForImageClassification
temp_model_dir = "vit"
ckpt = "google/vit-base-patch16-224"
model = TFViTForImageClassification.from_pretrained(ckpt)
model.save_pretrained(temp_model_dir, saved_model=True)
```
By default, `save_pretrained()` will first create a version directory
inside the path we provide to it. So, the path ultimately becomes:
`{temp_model_dir}/saved_model/{version}`.
We can inspect the serving signature of the SavedModel like so:
```bash
saved_model_cli show --dir {temp_model_dir}/saved_model/1 --tag_set serve --signature_def serving_default
```
This should output:
```bash
The given SavedModel SignatureDef contains the following input(s):
inputs['pixel_values'] tensor_info:
dtype: DT_FLOAT
shape: (-1, -1, -1, -1)
name: serving_default_pixel_values:0
The given SavedModel SignatureDef contains the following output(s):
outputs['logits'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 1000)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predict
```
As can be noticed the model accepts single 4-d inputs (namely
`pixel_values`) which has the following axes: `(batch_size,
num_channels, height, width)`. For this model, the acceptable height
and width are set to 224, and the number of channels is 3. You can verify
this by inspecting the config argument of the model (`model.config`).
The model yields a 1000-d vector of `logits`.
## Model Surgery
Usually, every ML model has certain preprocessing and postprocessing
steps. The ViT model is no exception to this. The major preprocessing
steps include:
- Scaling the image pixel values to [0, 1] range.
- Normalizing the scaled pixel values to [-1, 1].
- Resizing the image so that it has a spatial resolution of (224, 224).
You can confirm these by investigating the image processor associated
with the model:
```py
from transformers import AutoImageProcessor
processor = AutoImageProcessor.from_pretrained(ckpt)
print(processor)
```
This should print:
```bash
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
Since this is an image classification model pre-trained on the
[ImageNet-1k dataset](https://huggingface.co./datasets/imagenet-1k), the model
outputs need to be mapped to the ImageNet-1k classes as the
post-processing step.
To reduce the developers' cognitive load and training-serving skew,
it's often a good idea to ship a model that has most of the
preprocessing and postprocessing steps in built. Therefore, you should
serialize the model as a SavedModel such that the above-mentioned
processing ops get embedded into its computation graph.
### Preprocessing
For preprocessing, image normalization is one of the most essential
components:
```py
def normalize_img(
img, mean=processor.image_mean, std=processor.image_std
):
# Scale to the value range of [0, 1] first and then normalize.
img = img / 255
mean = tf.constant(mean)
std = tf.constant(std)
return (img - mean) / std
```
You also need to resize the image and transpose it so that it has leading
channel dimensions since following the standard format of 🤗
Transformers. The below code snippet shows all the preprocessing steps:
```py
CONCRETE_INPUT = "pixel_values" # Which is what we investigated via the SavedModel CLI.
SIZE = processor.size["height"]
def normalize_img(
img, mean=processor.image_mean, std=processor.image_std
):
# Scale to the value range of [0, 1] first and then normalize.
img = img / 255
mean = tf.constant(mean)
std = tf.constant(std)
return (img - mean) / std
def preprocess(string_input):
decoded_input = tf.io.decode_base64(string_input)
decoded = tf.io.decode_jpeg(decoded_input, channels=3)
resized = tf.image.resize(decoded, size=(SIZE, SIZE))
normalized = normalize_img(resized)
normalized = tf.transpose(
normalized, (2, 0, 1)
) # Since HF models are channel-first.
return normalized
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def preprocess_fn(string_input):
decoded_images = tf.map_fn(
preprocess, string_input, dtype=tf.float32, back_prop=False
)
return {CONCRETE_INPUT: decoded_images}
```
**Note on making the model accept string inputs**:
When dealing with images via REST or gRPC requests the size of the
request payload can easily spiral up depending on the resolution of the
images being passed. This is why it is a good practice to compress them
reliably and then prepare the request payload.
### Postprocessing and Model Export
You're now equipped with the preprocessing operations that you can inject
into the model's existing computation graph. In this section, you'll also
inject the post-processing operations into the graph and export the
model!
```py
def model_exporter(model: tf.keras.Model):
m_call = tf.function(model.call).get_concrete_function(
tf.TensorSpec(
shape=[None, 3, SIZE, SIZE], dtype=tf.float32, name=CONCRETE_INPUT
)
)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def serving_fn(string_input):
labels = tf.constant(list(model.config.id2label.values()), dtype=tf.string)
images = preprocess_fn(string_input)
predictions = m_call(**images)
indices = tf.argmax(predictions.logits, axis=1)
pred_source = tf.gather(params=labels, indices=indices)
probs = tf.nn.softmax(predictions.logits, axis=1)
pred_confidence = tf.reduce_max(probs, axis=1)
return {"label": pred_source, "confidence": pred_confidence}
return serving_fn
```
You can first derive the [concrete function](https://www.tensorflow.org/guide/function)
from the model's forward pass method (`call()`) so the model is nicely compiled
into a graph. After that, you can apply the following steps in order:
1. Pass the inputs through the preprocessing operations.
2. Pass the preprocessing inputs through the derived concrete function.
3. Post-process the outputs and return them in a nicely formatted
dictionary.
Now it's time to export the model!
```py
MODEL_DIR = tempfile.gettempdir()
VERSION = 1
tf.saved_model.save(
model,
os.path.join(MODEL_DIR, str(VERSION)),
signatures={"serving_default": model_exporter(model)},
)
os.environ["MODEL_DIR"] = MODEL_DIR
```
After exporting, let's inspect the model signatures again:
```bash
saved_model_cli show --dir {MODEL_DIR}/1 --tag_set serve --signature_def serving_default
```
```bash
The given SavedModel SignatureDef contains the following input(s):
inputs['string_input'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_string_input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['confidence'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall:0
outputs['label'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
```
You can notice that the model's signature has now changed. Specifically,
the input type is now a string and the model returns two things: a
confidence score and the string label.
Provided you've already installed TF Serving (covered in the Colab
Notebook), you're now ready to deploy this model!
## Deployment with TensorFlow Serving
It just takes a single command to do this:
```bash
nohup tensorflow_model_server \
--rest_api_port=8501 \
--model_name=vit \
--model_base_path=$MODEL_DIR >server.log 2>&1
```
From the above command, the important parameters are:
- `rest_api_port` denotes the port number that TF Serving will use
deploying the REST endpoint of your model. By default, TF Serving
uses the 8500 port for the gRPC endpoint.
- `model_name` specifies the model name (can be anything) that will
used for calling the APIs.
- `model_base_path` denotes the base model path that TF Serving will
use to load the latest version of the model.
(The complete list of supported parameters is
[here](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/model_servers/main.cc).)
And voila! Within minutes, you should be up and running with a deployed
model having two endpoints - REST and gRPC.
## Querying the REST Endpoint
Recall that you exported the model such that it accepts string inputs
encoded with the [base64 format](https://en.wikipedia.org/wiki/Base64). So, to craft the
request payload you can do something like this:
```py
# Get image of a cute cat.
image_path = tf.keras.utils.get_file(
"image.jpg", "http://images.cocodataset.org/val2017/000000039769.jpg"
)
# Read the image from disk as raw bytes and then encode it.
bytes_inputs = tf.io.read_file(image_path)
b64str = base64.urlsafe_b64encode(bytes_inputs.numpy()).decode("utf-8")
# Create the request payload.
data = json.dumps({"signature_name": "serving_default", "instances": [b64str]})
```
TF Serving's request payload format specification for the REST endpoint
is available [here](https://www.tensorflow.org/tfx/serving/api_rest#request_format_2).
Within the `instances` you can pass multiple encoded images. This kind
of endpoints are meant to be consumed for online prediction scenarios.
For inputs having more than a single data point, you would to want to
[enable batching](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/batching/README.md)
to get performance optimization benefits.
Now you can call the API:
```py
headers = {"content-type": "application/json"}
json_response = requests.post(
"http://localhost:8501/v1/models/vit:predict", data=data, headers=headers
)
print(json.loads(json_response.text))
# {'predictions': [{'label': 'Egyptian cat', 'confidence': 0.896659195}]}
```
The REST API is -
`http://localhost:8501/v1/models/vit:predict` following the specification from
[here](https://www.tensorflow.org/tfx/serving/api_rest#predict_api). By default,
this always picks up the latest version of the model. But if you wanted a
specific version you can do: `http://localhost:8501/v1/models/vit/versions/1:predict`.
## Querying the gRPC Endpoint
While REST is quite popular in the API world, many applications often
benefit from gRPC. [This post](https://blog.dreamfactory.com/grpc-vs-rest-how-does-grpc-compare-with-traditional-rest-apis/)
does a good job comparing the two ways of deployment. gRPC is usually
preferred for low-latency, highly scalable, and distributed systems.
There are a couple of steps are. First, you need to open a communication
channel:
```py
import grpc
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
channel = grpc.insecure_channel("localhost:8500")
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
```
Then, create the request payload:
```py
request = predict_pb2.PredictRequest()
request.model_spec.name = "vit"
request.model_spec.signature_name = "serving_default"
request.inputs[serving_input].CopyFrom(tf.make_tensor_proto([b64str]))
```
You can determine the `serving_input` key programmatically like so:
```py
loaded = tf.saved_model.load(f"{MODEL_DIR}/{VERSION}")
serving_input = list(
loaded.signatures["serving_default"].structured_input_signature[1].keys()
)[0]
print("Serving function input:", serving_input)
# Serving function input: string_input
```
Now, you can get some predictions:
```py
grpc_predictions = stub.Predict(request, 10.0) # 10 secs timeout
print(grpc_predictions)
```
```bash
outputs {
key: "confidence"
value {
dtype: DT_FLOAT
tensor_shape {
dim {
size: 1
}
}
float_val: 0.8966591954231262
}
}
outputs {
key: "label"
value {
dtype: DT_STRING
tensor_shape {
dim {
size: 1
}
}
string_val: "Egyptian cat"
}
}
model_spec {
name: "resnet"
version {
value: 1
}
signature_name: "serving_default"
}
```
You can also fetch the key-values of our interest from the above results like so:
```py
grpc_predictions.outputs["label"].string_val, grpc_predictions.outputs[
"confidence"
].float_val
# ([b'Egyptian cat'], [0.8966591954231262])
```
## Wrapping Up
In this post, we learned how to deploy a TensorFlow vision model from
Transformers with TF Serving. While local deployments are great for
weekend projects, we would want to be able to scale these deployments to
serve many users. In the next series of posts, you'll see how to scale up
these deployments with Kubernetes and Vertex AI.
## Additional References
- [gRPC](https://grpc.io/)
- [Practical Machine Learning for Computer Vision](https://www.oreilly.com/library/view/practical-machine-learning/9781098102357/)
- [Faster TensorFlow models in Hugging Face Transformers](https://huggingface.co./blog/tf-serving) | [
[
"computer_vision",
"transformers",
"implementation",
"deployment"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"transformers",
"deployment",
"implementation"
] | null | null |
d4486d47-b739-4b60-a405-57c21f8de706 | completed | 2025-01-16T03:08:53.171066 | 2025-01-18T14:43:50.969731 | 2a5fcbfe-06b2-475f-b4da-b11ddc2bac0e | 'Convert Transformers to ONNX with Hugging Face Optimum' | philschmid | convert-transformers-to-onnx.md | Hundreds of Transformers experiments and models are uploaded to the [Hugging Face Hub](https://huggingface.co./) every single day. Machine learning engineers and students conducting those experiments use a variety of frameworks like PyTorch, TensorFlow/Keras, or others. These models are already used by thousands of companies and form the foundation of AI-powered products.
If you deploy Transformers models in production environments, we recommend exporting them first into a serialized format that can be loaded, optimized, and executed on specialized runtimes and hardware.
In this guide, you'll learn about:
1. [What is ONNX?](#1-what-is-onnx)
2. [What is Hugging Face Optimum?](#2-what-is-hugging-face-optimum)
3. [What Transformers architectures are supported?](#3-what-transformers-architectures-are-supported)
4. [How can I convert a Transformers model (BERT) to ONNX?](#4-how-can-i-convert-a-transformers-model-bert-to-onnx)
5. [What's next?](#5-whats-next)
Let's get started! 🚀 | [
[
"transformers",
"mlops",
"tutorial",
"optimization"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"mlops",
"tutorial",
"optimization"
] | null | null |
72859ce5-ef33-44a2-91f2-a8539fe967d3 | completed | 2025-01-16T03:08:53.171070 | 2025-01-19T17:19:10.185882 | 1ed59f4c-1519-4e91-9836-2fde5b05c8f9 | Simple considerations for simple people building fancy neural networks | VictorSanh | simple-considerations.md | <span class="text-gray-500 text-xs">Photo by [Henry & Co.](https://unsplash.com/@hngstrm?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/s/photos/builder?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)</span>
# 🚧 Simple considerations for simple people building fancy neural networks
As machine learning continues penetrating all aspects of the industry, neural networks have never been so hyped. For instance, models like GPT-3 have been all over social media in the past few weeks and continue to make headlines outside of tech news outlets with fear-mongering titles.

<div class="text-center text-xs text-gray-500">
<a class="text-gray-500" href="https://www.theguardian.com/commentisfree/2020/sep/08/robot-wrote-this-article-gpt-3">An article</a> from The Guardian
</div>
At the same time, deep learning frameworks, tools, and specialized libraries democratize machine learning research by making state-of-the-art research easier to use than ever. It is quite common to see these almost-magical/plug-and-play 5 lines of code that promise (near) state-of-the-art results. Working at [Hugging Face](https://huggingface.co./) 🤗, I admit that I am partially guilty of that. 😅 It can give an inexperienced user the misleading impression that neural networks are now a mature technology while in fact, the field is in constant development.
In reality, **building and training neural networks can often be an extremely frustrating experience**:
* It is sometimes hard to understand if your performance comes from a bug in your model/code or is simply limited by your model’s expressiveness.
* You can make tons of tiny mistakes at every step of the process without realizing at first, and your model will still train and give a decent performance.
**In this post, I will try to highlight a few steps of my mental process when it comes to building and debugging neural networks.** By “debugging”, I mean making sure you align what you have built and what you have in mind. I will also point out things you can look at when you are not sure what your next step should be by listing the typical questions I ask myself.
_A lot of these thoughts stem from my experience doing research in natural language processing but most of these principles can be applied to other fields of machine learning._
## 1. 🙈 Start by putting machine learning aside
It might sound counter-intuitive but the very first step of building a neural network is to **put aside machine learning and simply focus on your data**. Look at the examples, their labels, the diversity of the vocabulary if you are working with text, their length distribution, etc. You should dive into the data to get a first sense of the raw product you are working with and focus on extracting general patterns that a model might be able to catch. Hopefully, by looking at a few hundred examples, you will be able to identify high-level patterns. A few standard questions you can ask yourself:
* Are the labels balanced?
* Are there gold-labels that you do not agree with?
* How were the data obtained? What are the possible sources of noise in this process?
* Are there any preprocessing steps that seem natural (tokenization, URL or hashtag removing, etc.)?
* How diverse are the examples?
* What rule-based algorithm would perform decently on this problem?
It is important to get a **high-level feeling (qualitative) of your dataset along with a fine-grained analysis (quantitative)**. If you are working with a public dataset, someone else might have already dived into the data and reported their analysis (it is quite common in Kaggle competition for instance) so you should absolutely have a look at these!
## 2. 📚 Continue as if you just started machine learning
Once you have a deep and broad understanding of your data, I always recommend **to put yourself in the shoes of your old self when you just started machine learning** and were watching introduction classes from Andrew Ng on Coursera. **Start as simple as possible to get a sense of the difficulty of your task and how well standard baselines would perform.** For instance, if you work with text, standard baselines for binary text classification can include a logistic regression trained on top of word2vec or fastText embeddings. With the current tools, running these baselines is as easy (if not more) as running BERT which can arguably be considered one of the standard tools for many natural language processing problems. If other baselines are available, run (or implement) some of them. It will help you get even more familiar with the data.
As developers, it easy to feel good when building something fancy but it is sometimes hard to rationally justify it if it beats easy baselines by only a few points, so it is central to make sure you have reasonable points of comparisons:
* How would a random predictor perform (especially in classification problems)? Dataset can be unbalanced…
* What would the loss look like for a random predictor?
* What is (are) the best metric(s) to measure progress on my task?
* What are the limits of this metric? If it’s perfect, what can I conclude? What can’t I conclude?
* What is missing in “simple approaches” to reach a perfect score?
* Are there architectures in my neural network toolbox that would be good to model the inductive bias of the data?
## 3. 🦸♀️ Don’t be afraid to look under the hood of these 5-liners templates
Next, you can start building your model based on the insights and understanding you acquired previously. As mentioned earlier, implementing neural networks can quickly become quite tricky: there are many moving parts that work together (the optimizer, the model, the input processing pipeline, etc.), and many small things can go wrong when implementing these parts and connecting them to each other. **The challenge lies in the fact that you can make these mistakes, train a model without it ever crashing, and still get a decent performance…**
Yet, it is a good habit when you think you have finished implementing to **overfit a small batch of examples** (16 for instance). If your implementation is (nearly) correct, your model will be able to overfit and remember these examples by displaying a 0-loss (make sure you remove any form of regularization such as weight decay). If not, it is highly possible that you did something wrong in your implementation. In some rare cases, it means that your model is not expressive enough or lacks capacity. Again, **start with a small-scale model** (fewer layers for instance): you are looking to debug your model so you want a quick feedback loop, not a high performance.
> Pro-tip: in my experience working with pre-trained language models, freezing the embeddings modules to their pre-trained values doesn’t affect much the fine-tuning task performance while considerably speeding up the training.
Some common errors include:
* Wrong indexing… (these are really the worst 😅). Make sure you are gathering tensors along the correct dimensions for instance…
* You forgot to call `model.eval()` in evaluation mode (in PyTorch) or `model.zero\_grad()` to clean the gradients
* Something went wrong in the pre-processing of the inputs
* The loss got wrong arguments (for instance passing probabilities when it expects logits)
* Initialization doesn’t break the symmetry (usually happens when you initialize a whole matrix with a single constant value)
* Some parameters are never called during the forward pass (and thus receive no gradients)
* The learning rate is taking funky values like 0 all the time
* Your inputs are being truncated in a suboptimal way
> Pro-tip: when you work with language, have a serious **look at the outputs of the tokenizers**. I can’t count the number of lost hours I spent trying to reproduce results (and sometimes my own old results) because something went wrong with the tokenization.🤦♂️
Another useful tool is **deep-diving into the training dynamic** and plot (in Tensorboard for instance) the evolution of multiple scalars through training. At the bare minimum, you should look at the dynamic of your loss(es), the parameters, and their gradients.
As the loss decreases, you also want to look at the model’s predictions: either by evaluating on your development set or, my personal favorite, **print a couple of model outputs**. For instance, if you are training a machine translation model, it is quite satisfying to see the generations become more and more convincing through the training. You want to be more specifically careful about overfitting: your training loss continues to decreases while your evaluation loss is aiming at the stars.💫
## 4. 👀 Tune but don’t tune blindly
Once you have everything up and running, you might want to tune your hyperparameters to find the best configuration for your setup. I generally stick with a random grid search as it turns out to be fairly effective in practice.
> Some people report successes using fancy hyperparameter tuning methods such as Bayesian optimization but in my experience, random over a reasonably manually defined grid search is still a tough-to-beat baseline.
Most importantly, there is no point of launching 1000 runs with different hyperparameters (or architecture tweaks like activation functions): **compare a couple of runs with different hyperparameters to get an idea of which hyperparameters have the highest impact** but in general, it is delusional to expect to get your biggest jumps of performance by simply tuning a few values. For instance, if your best performing model is trained with a learning rate of 4e2, there is probably something more fundamental happening inside your neural network and you want to identify and understand this behavior so that you can re-use this knowledge outside of your current specific context.
On average, experts use fewer resources to find better solutions.
To conclude, a piece of general advice that has helped me become better at building neural networks is to **favor (as most as possible) a deep understanding of each component of your neural network instead of blindly (not to say magically) tweak the architecture**. Keep it simple and avoid small tweaks that you can’t reasonably justify even after trying really hard. Obviously, there is the right balance to find between a “trial-and-error” and an “analysis approach” but a lot of these intuitions feel more natural as you accumulate practical experience. **You too are training your internal model.** 🤯
A few related pointers to complete your reading:
* [Reproducibility (in ML) as a vehicle for engineering best practices](https://docs.google.com/presentation/d/1yHLPvPhUs2KGI5ZWo0sU-PKU3GimAk3iTsI38Z-B5Gw/edit#slide=id.p) from Joel Grus
* [Checklist for debugging neural networks](https://towardsdatascience.com/checklist-for-debugging-neural-networks-d8b2a9434f21) from Cecelia Shao
* [How to unit test machine learning code](https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765) from Chase Roberts
* [A recipe for Training Neural Networks](http://karpathy.github.io/2019/04/25/recipe/) from Andrej Karpathy | [
[
"llm",
"implementation",
"optimization"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"implementation",
"optimization"
] | null | null |
d15e998e-8ab4-43c0-9b1b-0b42b951b495 | completed | 2025-01-16T03:08:53.171075 | 2025-01-19T19:00:07.354703 | 82ae44ef-0e6f-4eb4-96a3-e87717a23501 | Using & Mixing Hugging Face Models with Gradio 2.0 | abidlabs | gradio.md | > ##### Cross-posted from the [Gradio blog](https://gradio.app/blog/using-huggingface-models).
The **[Hugging Face Model Hub](https://huggingface.co./models)** has more than 10,000 machine learning models submitted by users. You’ll find all kinds of natural language processing models that, for example, translate between Finnish and English or recognize Chinese speech. More recently, the Hub has expanded to even include models for image classification and audio processing.
Hugging Face has always worked to make models accessible and easy to use. The `transformers` library makes it possible to load a model in a few lines of code. After a model is loaded, it can be used to make predictions on new data programmatically. _But it’s not just programmers that are using machine learning models!_ An increasingly common scenario in machine learning is **demoing models to interdisciplinary teams** or letting **non-programmers use models** (to help discover biases, failure points, etc.).
The **[Gradio library](https://gradio.app/)** lets machine learning developers create demos and GUIs from machine learning models very easily, and share them for free with your collaborators as easily as sharing a Google docs link. Now, we’re excited to share that the Gradio 2.0 library lets you **_load and use almost any Hugging Face model_ _with a GUI_** **_in just 1 line of code_**. Here’s an example:

By default, this uses HuggingFace’s hosted Inference API (you can supply your own API key or use the public access without an API key), or you can also run `pip install transformers` and run the model computations locally if you’d like.
Do you want to customize the demo? You can override any of the default parameters of the [Interface class](https://gradio.app/docs) by passing in your own parameters:

**_But wait, there’s more!_** With 10,000 models already on Model Hub, we see models not just as standalone pieces of code, but as lego pieces that can be **composed and mixed** to create more sophisticated applications and demos.
For example, Gradio lets you load multiple models in _parallel_ (imagine you want to compare 4 different text generation models from Hugging Face to see which one is the best for your use case):

Or put your models in _series_. This makes it easy to build complex applications built from multiple machine learning models. For example, here we can build an application to translate and summarize Finnish news articles in 3 lines of code:

You can even mix multiple models in _series_ compared to each other in _parallel_ (we’ll let you try that yourself!). To try any of this out, just install Gradio (`pip install gradio`) and pick a Hugging Face model you want to try. Start building with Gradio and Hugging Face 🧱⛏️ | [
[
"transformers",
"implementation",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"implementation",
"tools",
"integration"
] | null | null |
d5ffb200-f423-4ddc-aa38-f98e4b17d827 | completed | 2025-01-16T03:08:53.171079 | 2025-01-16T13:46:42.031122 | e0fd75e7-8c11-4d08-ad2e-644060e5f098 | SDXL in 4 steps with Latent Consistency LoRAs | pcuenq, valhalla, SimianLuo, dg845, tyq1024, sayakpaul, multimodalart | lcm_lora.md | [Latent Consistency Models (LCM)](https://huggingface.co./papers/2310.04378) are a way to decrease the number of steps required to generate an image with Stable Diffusion (or SDXL) by _distilling_ the original model into another version that requires fewer steps (4 to 8 instead of the original 25 to 50). Distillation is a type of training procedure that attempts to replicate the outputs from a source model using a new one. The distilled model may be designed to be smaller (that’s the case of [DistilBERT](https://huggingface.co./docs/transformers/model_doc/distilbert) or the recently-released [Distil-Whisper](https://github.com/huggingface/distil-whisper)) or, in this case, require fewer steps to run. It’s usually a lengthy and costly process that requires huge amounts of data, patience, and a few GPUs.
Well, that was the status quo before today!
We are delighted to announce a new method that can essentially make Stable Diffusion and SDXL faster, as if they had been distilled using the LCM process! How does it sound to run _any_ SDXL model in about 1 second instead of 7 on a 3090, or 10x faster on Mac? Read on for details!
## Contents
- [Method Overview](#method-overview)
- [Why does this matter](#why-does-this-matter)
- [Fast Inference with SDXL LCM LoRAs](#fast-inference-with-sdxl-lcm-loras)
- [Quality Comparison](#quality-comparison)
- [Guidance Scale and Negative Prompts](#guidance-scale-and-negative-prompts)
- [Quality vs base SDXL](#quality-vs-base-sdxl)
- [LCM LoRAs with other Models](#lcm-loras-with-other-models)
- [Full Diffusers Integration](#full-diffusers-integration)
- [Benchmarks](#benchmarks)
- [LCM LoRAs and Models Released Today](#lcm-loras-and-models-released-today)
- [Bonus: Combine LCM LoRAs with regular SDXL LoRAs](#bonus-combine-lcm-loras-with-regular-sdxl-loras)
- [How to train LCM LoRAs](#how-to-train-lcm-loras)
- [Resources](#resources)
- [Credits](#credits)
## Method Overview
So, what’s the trick?
For latent consistency distillation, each model needs to be distilled separately. The core idea with LCM LoRA is to train just a small number of adapters, [known as LoRA layers](https://huggingface.co./docs/peft/conceptual_guides/lora), instead of the full model. The resulting LoRAs can then be applied to any fine-tuned version of the model without having to distil them separately. If you are itching to see how this looks in practice, just jump to the [next section](#fast-inference-with-sdxl-lcm-loras) to play with the inference code. If you want to train your own LoRAs, this is the process you’d use:
1. Select an available teacher model from the Hub. For example, you can use [SDXL (base)](https://huggingface.co./stabilityai/stable-diffusion-xl-base-1.0), or any fine-tuned or dreamboothed version you like.
2. [Train a LCM LoRA](#how-to-train-lcm-models-and-loras) on the model. LoRA is a type of performance-efficient fine-tuning, or PEFT, that is much cheaper to accomplish than full model fine-tuning. For additional details on PEFT, please check [this blog post](https://huggingface.co./blog/peft) or [the diffusers LoRA documentation](https://huggingface.co./docs/diffusers/training/lora).
3. Use the LoRA with any SDXL diffusion model and the LCM scheduler; bingo! You get high-quality inference in just a few steps.
For more details on the process, please [download our paper](https://huggingface.co./latent-consistency/lcm-lora-sdxl/resolve/main/LCM-LoRA-Technical-Report.pdf).
## Why does this matter?
Fast inference of Stable Diffusion and SDXL enables new use-cases and workflows. To name a few:
- **Accessibility**: generative tools can be used effectively by more people, even if they don’t have access to the latest hardware.
- **Faster iteration**: get more images and multiple variants in a fraction of the time! This is great for artists and researchers; whether for personal or commercial use.
- Production workloads may be possible on different accelerators, including CPUs.
- Cheaper image generation services.
To gauge the speed difference we are talking about, generating a single 1024x1024 image on an M1 Mac with SDXL (base) takes about a minute. Using the LCM LoRA, we get great results in just ~6s (4 steps). This is an order of magnitude faster, and not having to wait for results is a game-changer. Using a 4090, we get almost instant response (less than 1s). This unlocks the use of SDXL in applications where real-time events are a requirement.
## Fast Inference with SDXL LCM LoRAs
The version of `diffusers` released today makes it very easy to use LCM LoRAs:
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
lcm_lora_id = "latent-consistency/lcm-lora-sdxl"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.load_lora_weights(lcm_lora_id)
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.to(device="cuda", dtype=torch.float16)
prompt = "close-up photography of old man standing in the rain at night, in a street lit by lamps, leica 35mm summilux"
images = pipe(
prompt=prompt,
num_inference_steps=4,
guidance_scale=1,
).images[0]
```
Note how the code:
- Instantiates a standard diffusion pipeline with the SDXL 1.0 base model.
- Applies the LCM LoRA.
- Changes the scheduler to the LCMScheduler, which is the one used in latent consistency models.
- That’s it!
This would result in the following full-resolution image:
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-1.jpg?download=true" alt="SDXL in 4 steps with LCM LoRA"><br>
<em>Image generated with SDXL in 4 steps using an LCM LoRA.</em>
</p>
### Quality Comparison
Let’s see how the number of steps impacts generation quality. The following code will generate images with 1 to 8 total inference steps:
```py
images = []
for steps in range(8):
generator = torch.Generator(device=pipe.device).manual_seed(1337)
image = pipe(
prompt=prompt,
num_inference_steps=steps+1,
guidance_scale=1,
generator=generator,
).images[0]
images.append(image)
```
These are the 8 images displayed in a grid:
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-grid.jpg?download=true" alt="LCM LoRA generations with 1 to 8 steps"><br>
<em>LCM LoRA generations with 1 to 8 steps.</em>
</p>
As expected, using just **1** step produces an approximate shape without discernible features and lacking texture. However, results quickly improve, and they are usually very satisfactory in just 4 to 6 steps. Personally, I find the 8-step image in the previous test to be a bit too saturated and “cartoony” for my taste, so I’d probably choose between the ones with 5 and 6 steps in this example. Generation is so fast that you can create a bunch of different variants using just 4 steps, and then select the ones you like and iterate using a couple more steps and refined prompts as necessary.
### Guidance Scale and Negative Prompts
Note that in the previous examples we used a `guidance_scale` of `1`, which effectively disables it. This works well for most prompts, and it’s fastest, but ignores negative prompts. You can also explore using negative prompts by providing a guidance scale between `1` and `2` – we found that larger values don’t work.
### Quality vs base SDXL
How does this compare against the standard SDXL pipeline, in terms of quality? Let’s see an example!
We can quickly revert our pipeline to a standard SDXL pipeline by unloading the LoRA weights and switching to the default scheduler:
```py
from diffusers import EulerDiscreteScheduler
pipe.unload_lora_weights()
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
```
Then we can run inference as usual for SDXL. We’ll gather results using varying number of steps:
```py
images = []
for steps in (1, 4, 8, 15, 20, 25, 30, 50):
generator = torch.Generator(device=pipe.device).manual_seed(1337)
image = pipe(
prompt=prompt,
num_inference_steps=steps,
generator=generator,
).images[0]
images.append(image)
```
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-sdxl-grid.jpg?download=true" alt="SDXL results for various inference steps"><br>
<em>SDXL pipeline results (same prompt and random seed), using 1, 4, 8, 15, 20, 25, 30, and 50 steps.</em>
</p>
As you can see, images in this example are pretty much useless until ~20 steps (second row), and quality still increases noticeably with more steps. The details in the final image are amazing, but it took 50 steps to get there.
### LCM LoRAs with other models
This technique also works for any other fine-tuned SDXL or Stable Diffusion model. To demonstrate, let's see how to run inference on [`collage-diffusion`](https://huggingface.co./wavymulder/collage-diffusion), a model fine-tuned from [Stable Diffusion v1.5](https://huggingface.co./runwayml/stable-diffusion-v1-5) using Dreambooth.
The code is similar to the one we saw in the previous examples. We load the fine-tuned model, and then the LCM LoRA suitable for Stable Diffusion v1.5.
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "wavymulder/collage-diffusion"
lcm_lora_id = "latent-consistency/lcm-lora-sdv1-5"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.load_lora_weights(lcm_lora_id)
pipe.to(device="cuda", dtype=torch.float16)
prompt = "collage style kid sits looking at the night sky, full of stars"
generator = torch.Generator(device=pipe.device).manual_seed(1337)
images = pipe(
prompt=prompt,
generator=generator,
negative_prompt=negative_prompt,
num_inference_steps=4,
guidance_scale=1,
).images[0]
images
```
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/collage.png?download=true" alt="LCM LoRA technique with a Dreambooth Stable Diffusion v1.5 model, allowing 4-step inference."><br>
<em>LCM LoRA technique with a Dreambooth Stable Diffusion v1.5 model, allowing 4-step inference.</em>
</p>
### Full Diffusers Integration
The integration of LCM in `diffusers` makes it possible to take advantage of many features and workflows that are part of the diffusers toolbox. For example:
- Out of the box `mps` support for Macs with Apple Silicon.
- Memory and performance optimizations like flash attention or `torch.compile()`.
- Additional memory saving strategies for low-RAM environments, including model offload.
- Workflows like ControlNet or image-to-image.
- Training and fine-tuning scripts.
## Benchmarks
This section is not meant to be exhaustive, but illustrative of the generation speed we achieve on various computers. Let us stress again how liberating it is to explore image generation so easily.
| Hardware | SDXL LoRA LCM (4 steps) | SDXL standard (25 steps) |
| | [
[
"computer_vision",
"research",
"optimization",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"image_generation",
"optimization",
"research"
] | null | null |
1fba5914-fa67-4330-895d-91d51631d2f7 | completed | 2025-01-16T03:08:53.171084 | 2025-01-19T18:49:59.660891 | 14af6395-021d-4924-aead-5c4152063663 | Train your ControlNet with diffusers | multimodalart, pcuenq | train-your-controlnet.md | ## Introduction
[ControlNet](https://huggingface.co./blog/controlnet) is a neural network structure that allows fine-grained control of diffusion models by adding extra conditions. The technique debuted with the paper [Adding Conditional Control to Text-to-Image Diffusion Models](https://huggingface.co./papers/2302.05543), and quickly took over the open-source diffusion community author's release of 8 different conditions to control Stable Diffusion v1-5, including pose estimations, depth maps, canny edges, sketches, [and more](https://huggingface.co./lllyasviel).

In this blog post we will go over each step in detail on how we trained the [_Uncanny_ Faces model](#) - a model on face poses based on 3D synthetic faces (the uncanny faces was an unintended consequence actually, stay tuned to see how it came through).
## Getting started with training your ControlNet for Stable Diffusion
Training your own ControlNet requires 3 steps:
1. **Planning your condition**: ControlNet is flexible enough to tame Stable Diffusion towards many tasks. The pre-trained models showcase a wide-range of conditions, and the community has built others, such as conditioning on [pixelated color palettes](https://huggingface.co./thibaud/controlnet-sd21-color-diffusers).
2. **Building your dataset**: Once a condition is decided, it is time to build your dataset. For that, you can either construct a dataset from scratch, or use a sub-set of an existing dataset. You need three columns on your dataset to train the model: a ground truth `image`, a `conditioning_image` and a `prompt`.
3. **Training the model**: Once your dataset is ready, it is time to train the model. This is the easiest part thanks to the [diffusers training script](https://github.com/huggingface/diffusers/tree/main/examples/controlnet). You'll need a GPU with at least 8GB of VRAM.
## 1. Planning your condition
To plan your condition, it is useful to think of two questions:
1. What kind of conditioning do I want to use?
2. Is there an already existing model that can convert 'regular' images into my condition?
For our example, we thought about using a facial landmarks conditioning. Our reasoning was: 1. the general landmarks conditioned ControlNet works well. 2. Facial landmarks are a widespread enough technique, and there are multiple models that calculate facial landmarks on regular pictures 3. Could be fun to tame Stable Diffusion to follow a certain facial landmark or imitate your own facial expression.

## 2. Building your dataset
Okay! So we decided to do a facial landmarks Stable Diffusion conditioning. So, to prepare the dataset we need:
- The ground truth `image`: in this case, images of faces
- The `conditioning_image`: in this case, images where the facial landmarks are visualised
- The `caption`: a caption that describes the images being used
For this project, we decided to go with the `FaceSynthetics` dataset by Microsoft: it is a dataset that contains 100K synthetic faces. Other face research datasets with real faces such as `Celeb-A HQ`, `FFHQ` - but we decided to go with synthetic faces for this project.

The `FaceSynthetics` dataset sounded like a great start: it contains ground truth images of faces, and facial landmarks annotated in the iBUG 68-facial landmarks format, and a segmented image of the face.

Perfect. Right? Unfortunately, not really. Remember the second question in the "planning your condition" step - that we should have models that convert regular images to the conditioning? Turns out there was is no known model that can turn faces into the annotated landmark format of this dataset.

So we decided to follow another path:
- Use the ground truths `image` of faces of the `FaceSynthetics` datase
- Use a known model that can convert any image of a face into the 68-facial landmarks format of iBUG (in our case we used the SOTA model [SPIGA](https://github.com/andresprados/SPIGA))
- Use custom code that converts the facial landmarks into a nice illustrated mask to be used as the `conditioning_image`
- Save that as a [Hugging Face Dataset](https://huggingface.co./docs/datasets/indexx)
[Here you can find](https://huggingface.co./datasets/pcuenq/face_synthetics_spiga) the code used to convert the ground truth images from the `FaceSynthetics` dataset into the illustrated mask and save it as a Hugging Face Dataset.
Now, with the ground truth `image` and the `conditioning_image` on the dataset, we are missing one step: a caption for each image. This step is highly recommended, but you can experiment with empty prompts and report back on your results. As we did not have captions for the `FaceSynthetics` dataset, we ran it through a [BLIP captioning](https://huggingface.co./docs/transformers/model_doc/blip). You can check the code used for captioning all images [here](https://huggingface.co./datasets/multimodalart/facesyntheticsspigacaptioned)
With that, we arrived to our final dataset! The [Face Synthetics SPIGA with captions](https://huggingface.co./datasets/multimodalart/facesyntheticsspigacaptioned) contains a ground truth image, segmentation and a caption for the 100K images of the `FaceSynthetics` dataset. We are ready to train the model!

## 3. Training the model
With our [dataset ready](https://huggingface.co./datasets/multimodalart/facesyntheticsspigacaptioned), it is time to train the model! Even though this was supposed to be the hardest part of the process, with the [diffusers training script](https://github.com/huggingface/diffusers/tree/main/examples/controlnet), it turned out to be the easiest. We used a single A100 rented for US$1.10/h on [LambdaLabs](https://lambdalabs.com).
### Our training experience
We trained the model for 3 epochs (this means that the batch of 100K images were shown to the model 3 times) and a batch size of 4 (each step shows 4 images to the model). This turned out to be excessive and overfit (so it forgot concepts that diverge a bit of a real face, so for example "shrek" or "a cat" in the prompt would not make a shrek or a cat but rather a person, and also started to ignore styles).
With just 1 epoch (so after the model "saw" 100K images), it already converged to following the poses and not overfit. So it worked, but... as we used the face synthetics dataset, the model ended up learning uncanny 3D-looking faces, instead of realistic faces. This makes sense given that we used a synthetic face dataset as opposed to real ones, and can be used for fun/memetic purposes. Here is the [uncannyfaces_25K](https://huggingface.co./multimodalart/uncannyfaces_25K) model.
<iframe src="https://wandb.ai/apolinario/controlnet/reports/ControlNet-Uncanny-Faces-Training--VmlldzozODcxNDY0" style="border:none;height:512px;width:100%"></iframe>
In this interactive table you can play with the dial below to go over how many training steps the model went through and how it affects the training process. At around 15K steps, it already started learning the poses. And it matured around 25K steps. Here
### How did we do the training
All we had to do was, install the dependencies:
```shell
pip install git+https://github.com/huggingface/diffusers.git transformers accelerate xformers==0.0.16 wandb
huggingface-cli login
wandb login
```
And then run the [train_controlnet.py](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/train_controlnet.py) code
```shell
!accelerate launch train_controlnet.py \
--pretrained_model_name_or_path="stabilityai/stable-diffusion-2-1-base" \
--output_dir="model_out" \
--dataset_name=multimodalart/facesyntheticsspigacaptioned \
--conditioning_image_column=spiga_seg \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./face_landmarks1.jpeg" "./face_landmarks2.jpeg" "./face_landmarks3.jpeg" \
--validation_prompt "High-quality close-up dslr photo of man wearing a hat with trees in the background" "Girl smiling, professional dslr photograph, dark background, studio lights, high quality" "Portrait of a clown face, oil on canvas, bittersweet expression" \
--train_batch_size=4 \
--num_train_epochs=3 \
--tracker_project_name="controlnet" \
--enable_xformers_memory_efficient_attention \
--checkpointing_steps=5000 \
--validation_steps=5000 \
--report_to wandb \
--push_to_hub
```
Let's break down some of the settings, and also let's go over some optimisation tips for going as low as 8GB of VRAM for training.
- `pretrained_model_name_or_path`: The Stable Diffusion base model you would like to use (we chose v2-1 here as it can render faces better)
- `output_dir`: The directory you would like your model to be saved
- `dataset_name`: The dataset that will be used for training. In our case [Face Synthetics SPIGA with captions](https://huggingface.co./datasets/multimodalart/facesyntheticsspigacaptioned)
- `conditioning_image_column`: The name of the column in your dataset that contains the conditioning image (in our case `spiga_seg`)
- `image_column`: The name of the colunn in your dataset that contains the ground truth image (in our case `image`)
- `caption_column`: The name of the column in your dataset that contains the caption of tha image (in our case `image_caption`)
- `resolution`: The resolution of both the conditioning and ground truth images (in our case `512x512`)
- `learning_rate`: The learing rate. We found out that `1e-5` worked well for these examples, but you may experiment with different values ranging between `1e-4` and `2e-6`, for example.
- `validation_image`: This is for you to take a sneak peak during training! The validation images will be ran for every amount of `validation_steps` so you can see how your training is going. Insert here a local path to an arbitrary number of conditioning images
- `validation_prompt`: A prompt to be ran togehter with your validation image. Can be anything that can test if your model is training well
- `train_batch_size`: This is the size of the training batch to fit the GPU. We can afford `4` due to having an A100, but if you have a GPU with lower VRAM we recommend bringing this value down to `1`.
- `num_train_epochs`: Each epoch corresponds to how many times the images in the training set will be "seen" by the model. We experimented with 3 epochs, but turns out the best results required just a bit more than 1 epoch, with 3 epochs our model overfit.
- `checkpointing_steps`: Save an intermediary checkpoint every `x` steps (in our case `5000`). Every 5000 steps, an intermediary checkpoint was saved.
- `validation_steps`: Every `x` steps the `validaton_prompt` and the `validation_image` are ran.
- `report_to`: where to report your training to. Here we used Weights and Biases, which gave us [this nice report]().
But reducing the `train_batch_size` from `4` to `1` may not be enough for the training to fit a small GPU, here are some additional parameters to add for each GPU VRAM size:
- `push_to_hub`: a parameter to push the final trained model to the Hugging Face Hub.
### Fitting on a 16GB VRAM GPU
```shell
pip install bitsandbytes
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
```
The combination of a batch size of 1 with 4 gradient accumulation steps is equivalent to using the original batch size of 4 we used in our example. In addition, we enabled gradient checkpointing and 8-bit Adam for additional memory savings.
### Fitting on a 12GB VRAM GPU
```shell
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam
--set_grads_to_none
```
### Fitting on a 8GB VRAM GPU
Please follow [our guide here](https://github.com/huggingface/diffusers/tree/main/examples/controlnet#training-on-an-8-gb-gpu)
## 4. Conclusion!
This experience of training a ControlNet was a lot of fun. We succesfully trained a model that can follow real face poses - however it learned to make uncanny 3D faces instead of real 3D faces because this was the dataset it was trained on, which has its own charm and flare.
Try out our [Hugging Face Space](https://huggingface.co./spaces/pcuenq/uncanny-faces):
<iframe
src="https://pcuenq-uncanny-faces.hf.space"
frameborder="0"
width="100%"
height="1150"
style="border:0"
></iframe>
As for next steps for us - in order to create realistically looking faces, while still not using a real face dataset, one idea is running the entire `FaceSynthetics` dataset through Stable Diffusion Image2Imaage, converting the 3D-looking faces into realistically looking ones, and then trainign another ControlNet.
And stay tuned, as we will have a ControlNet Training event soon! Follow Hugging Face on [Twitter](https://twitter.com/huggingface) or join our [Discord]( http://hf.co/join/discord) to stay up to date on that. | [
[
"computer_vision",
"tutorial",
"image_generation",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"image_generation",
"fine_tuning",
"tutorial"
] | null | null |
67ddaa42-edf7-4450-896c-21d54c93b0e3 | completed | 2025-01-16T03:08:53.171089 | 2025-01-19T18:47:36.110856 | b1ee28d1-3f03-4b48-8957-5a6864dbbb76 | Interactively explore your Huggingface dataset with one line of code | sps44, druzsan, neindochoh, MarkusStoll | scalable-data-inspection.md | The Hugging Face [*datasets* library](https://huggingface.co./docs/datasets/index) not only provides access to more than 70k publicly available datasets, but also offers very convenient data preparation pipelines for custom datasets.
[Renumics Spotlight](https://github.com/Renumics/spotlight) allows you to create **interactive visualizations** to **identify critical clusters** in your data. Because Spotlight understands the data semantics within Hugging Face datasets, you can **[get started with just one line of code](https://renumics.com/docs)**:
```python
import datasets
from renumics import spotlight
ds = datasets.load_dataset('speech_commands', 'v0.01', split='validation')
spotlight.show(ds)
```
<p align="center"><a href="https://github.com/Renumics/spotlight"><img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/speech_commands_vis_s.gif" width="100%"/></a></p>
Spotlight allows to **leverage model results** such as predictions and embeddings to gain a deeper understanding in data segments and model failure modes:
```python
ds_results = datasets.load_dataset('renumics/speech_commands-ast-finetuned-results', 'v0.01', split='validation')
ds = datasets.concatenate_datasets([ds, ds_results], axis=1)
spotlight.show(ds, dtype={'embedding': spotlight.Embedding}, layout=spotlight.layouts.debug_classification(embedding='embedding', inspect={'audio': spotlight.dtypes.audio_dtype}))
```
Data inspection is a very important task in almost all ML development stages, but it can also be very time consuming.
> “Manual inspection of data has probably the highest value-to-prestige ratio of any activity in machine learning.” — Greg Brockman
>
[Spotlight](https://renumics.com/docs) helps you to **make data inspection more scalable** along two dimensions: Setting up and maintaining custom data inspection workflows and finding relevant data samples and clusters to inspect. In the following sections we show some examples based on Hugging Face datasets.
## Spotlight 🤝 Hugging Face datasets
The *datasets* library has several features that makes it an ideal tool for working with ML datasets: It stores tabular data (e.g. metadata, labels) along with unstructured data (e.g. images, audio) in a common Arrows table. *Datasets* also describes important data semantics through features (e.g. images, audio) and additional task-specific metadata.
Spotlight directly works on top of the *datasets* library. This means that there is no need to copy or pre-process the dataset for data visualization and inspection. Spotlight loads the tabular data into memory to allow for efficient, client-side data analytics. Memory-intensive unstructured data samples (e.g. audio, images, video) are loaded lazily on demand. In most cases, data types and label mappings are inferred directly from the dataset. Here, we visualize the CIFAR-100 dataset with one line of code:
```python
ds = datasets.load_dataset('cifar100', split='test')
spotlight.show(ds)
```
In cases where the data types are ambiguous or not specified, the Spotlight API allows to manually assign them:
```python
label_mapping = dict(zip(ds.features['fine_label'].names, range(len(ds.features['fine_label'].names))))
spotlight.show(ds, dtype={'img': spotlight.Image, 'fine_label': spotlight.dtypes.CategoryDType(categories=label_mapping)})
```
## **Leveraging model results for data inspection**
Exploring raw unstructured datasets often yield little insights. Leveraging model results such as predictions or embeddings can help to uncover critical data samples and clusters. Spotlight has several visualization options (e.g. similarity map, confusion matrix) that specifically make use of model results.
We recommend storing your prediction results directly in a Hugging Face dataset. This not only allows you to take advantage of the batch processing capabilities of the datasets library, but also keeps label mappings.
We can use the [*transformers* library](https://huggingface.co./docs/transformers) to compute embeddings and predictions on the CIFAR-100 image classification problem. We install the libraries via pip:
```bash
pip install renumics-spotlight datasets transformers[torch]
```
Now we can compute the enrichment:
```python
import torch
import transformers
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model_name = "Ahmed9275/Vit-Cifar100"
processor = transformers.ViTImageProcessor.from_pretrained(model_name)
cls_model = transformers.ViTForImageClassification.from_pretrained(model_name).to(device)
fe_model = transformers.ViTModel.from_pretrained(model_name).to(device)
def infer(batch):
images = [image.convert("RGB") for image in batch]
inputs = processor(images=images, return_tensors="pt").to(device)
with torch.no_grad():
outputs = cls_model(**inputs)
probs = torch.nn.functional.softmax(outputs.logits, dim=-1).cpu().numpy()
embeddings = fe_model(**inputs).last_hidden_state[:, 0].cpu().numpy()
preds = probs.argmax(axis=-1)
return {"prediction": preds, "embedding": embeddings}
features = datasets.Features({**ds.features, "prediction": ds.features["fine_label"], "embedding": datasets.Sequence(feature=datasets.Value("float32"), length=768)})
ds_enriched = ds.map(infer, input_columns="img", batched=True, batch_size=2, features=features)
```
If you don’t want to perform the full inference run, you can alternatively download pre-computed model results for CIFAR-100 to follow this tutorial:
```python
ds_results = datasets.load_dataset('renumics/spotlight-cifar100-enrichment', split='test')
ds_enriched = datasets.concatenate_datasets([ds, ds_results], axis=1)
```
We can now use the results to interactively explore relevant data samples and clusters in Spotlight:
```python
layout = spotlight.layouts.debug_classification(label='fine_label', embedding='embedding', inspect={'img': spotlight.dtypes.image_dtype})
spotlight.show(ds_enriched, dtype={'embedding': spotlight.Embedding}, layout=layout)
```
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/cifar-100-model-debugging.png" alt="CIFAR-100 model debugging layout example.">
</figure>
## Customizing data inspection workflows
Visualization layouts can be interactively changed, saved and loaded in the GUI: You can select different widget types and configurations. The *Inspector* widget allows to represent multimodal data samples including text, image, audio, video and time series data.
You can also define layouts through the [Python API](https://renumics.com/api/spotlight/). This option is especially useful for building custom data inspection and curation workflows including EDA, model debugging and model monitoring tasks.
In combination with the data issues widget, the Python API offers a great way to integrate the results of existing scripts (e.g. data quality checks or model monitoring) into a scalable data inspection workflow.
## Using Spotlight on the Hugging Face hub
You can use Spotlight directly on your local NLP, audio, CV or multimodal dataset. If you would like to showcase your dataset or model results on the Hugging Face hub, you can use Hugging Face spaces to launch a Spotlight visualization for it.
We have already prepared [example spaces](https://huggingface.co./renumics) for many popular NLP, audio and CV datasets on the hub. You can simply duplicate one of these spaces and specify your dataset in the `HF_DATASET` variable.
You can optionally choose a dataset that contains model results and other configuration options such as splits, subsets or dataset revisions.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/scalable-data-inspection/space_duplication.png" alt="Creating a new dataset visualization with Spotlight by duplicating a Hugging Face space.">
</figure>
## What’s next?
With Spotlight you can create **interactive visualizations** and leverage data enrichments to **identify critical clusters** in your Hugging Face datasets. In this blog, we have seen both an audio ML and a computer vision example.
You can use Spotlight directly to explore and curate your NLP, audio, CV or multimodal dataset:
- Install Spotlight: *pip install renumics-spotlight*
- Check out the [documentation](https://renumics.com/docs) or open an issue on [Github](https://github.com/Renumics/spotlight)
- Join the [Spotlight community](https://discord.gg/VAQdFCU5YD) on Discord
- Follow us on [Twitter](https://twitter.com/renumics) and [LinkedIn](https://www.linkedin.com/company/renumics) | [
[
"audio",
"data",
"implementation",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"data",
"audio",
"implementation",
"tools"
] | null | null |
73f9cb8b-a6fe-41a3-9e35-f1dc9ec1e149 | completed | 2025-01-16T03:08:53.171093 | 2025-01-19T19:12:59.474564 | b59065e9-54bf-4220-a7ef-90585970edfc | ~Don't~ Repeat Yourself | patrickvonplaten | transformers-design-philosophy.md | ##### *Designing open-source libraries for modern machine learning*
## 🤗 Transformers Design Philosophy
*"Don't repeat yourself"*, or **DRY**, is a well-known principle of software development. The principle originates from "The pragmatic programmer", one of the most read books on code design.
The principle's simple message makes obvious sense: Don't rewrite a logic that already exists somewhere else. This ensures the code remains in sync, making it easier to maintain and more robust. Any change to this logical pattern will uniformly affect all of its dependencies.
At first glance, the design of Hugging Face's Transformers library couldn't be more contrary to the DRY principle. Code for the attention mechanism is more or less copied over 50 times into different model files. Sometimes code of the whole BERT model is copied into other model files. We often force new model contributions identical to existing models - besides a small logical tweak - to copy all of the existing code. Why do we do this? Are we just too lazy or overwhelmed to centralize all logical pieces into one place?
No, we are not lazy - it's a very conscious decision not to apply the DRY design principle to the Transformers library. Instead, we decided to adopt a different design principle which we like to call the ***single model file*** policy. The *single model file* policy states that all code necessary for the forward pass of a model is in one and only one file - called the model file. If a reader wants to understand how BERT works for inference, she should only have to look into BERT's `modeling_bert.py` file.
We usually reject any attempt to abstract identical sub-components of different models into a new centralized place. We don't want to have a `attention_layer.py` that includes all possible attention mechanisms. Again why do we do this?
In short the reasons are:
- **1. Transformers is built by and for the open-source community.**
- **2. Our product are models and our customers are users reading or tweaking model code.**
- **3. The field of machine learning evolves extremely fast.**
- **4. Machine Learning models are static.**
### 1. Built by and for the open-source community
Transformers is built to actively incentivize external contributions. A contribution is often either a bug fix or a new model contribution. If a bug is found in one of the model files, we want to make it as easy as possible for the finder to fix it. There is little that is more demotivating than fixing a bug only to see that it caused 100 failures of other models.
Because model code is independent from all other models, it's fairly easy for someone that only understands the one model she is working with to fix it. Similarly, it's easier to add new modeling code and review the corresponding PR if only a single new model file is added. The contributor does not have to figure out how to add new functionality to a centralized attention mechanism without breaking existing models. The reviewer can easily verify that none of the existing models are broken.
### 2. Modeling code is our product
We assume that a significant amount of users of the Transformers library not only read the documentation, but also look into the actual modeling code and potentially modify it. This hypothesis is backed by the Transformers library being forked over 10,000 times and the Transformers paper being cited over a thousand times.
Therefore it is of utmost importance that someone reading Transformers modeling code for the first time can easily understand and potentially adapt it. Providing all the necessary logical components in order in a single modeling file helps a lot to achieve improved readability and adaptability. Additionally, we care a great deal about sensible variable/method naming and prefer expressive/readable code over character-efficient code.
### 3. Machine Learning is evolving at a neck-breaking speed
Research in the field of machine learning, and especially neural networks, evolves extremely fast. A model that was state-of-the-art a year ago might be outdated today. We don't know which attention mechanism, position embedding, or architecture will be the best in a year. Therefore, we cannot define standard logical patterns that apply to all models.
As an example, two years ago, one might have defined BERT's self attention layer as the standard attention layer used by all Transformers models. Logically, a "standard" attention function could have been moved into a central `attention.py` file. But then came attention layers that added relative positional embeddings in each attention layer (T5), multiple different forms of chunked attention (Reformer, Longformer, BigBird), and separate attention mechanism for position and word embeddings (DeBERTa), etc... Every time we would have to have asked ourselves whether the "standard" attention function should be adapted or whether it would have been better to add a new attention function to `attention.py`. But then how do we name it? `attention_with_positional_embd`, `reformer_attention`, `deberta_attention`?
It's dangerous to give logical components of machine learning models general names because the perception of what this component stands for might change or become outdated very quickly. E.g., does chunked attention corresponds to GPTNeo's, Reformer's, or BigBird's chunked attention? Is the attention layer a self-attention layer, a cross-attentional layer, or does it include both? However, if we name attention layers by their model's name, we should directly put the attention function in the corresponding modeling file.
### 4. Machine Learning models are static
The Transformers library is a unified and polished collection of machine learning models that different research teams have created. Every machine learning model is usually accompanied by a paper and its official GitHub repository. Once a machine learning model is published, it is rarely adapted or changed afterward.
Instead, research teams tend to publish a new model built upon previous models but rarely make significant changes to already published code. This is an important realization when deciding on the design principles of the Transformers library.
It means that once a model architecture has been added to Transformers, the fundamental components of the model don't change anymore. Bugs are often found and fixed, methods and variables might be renamed, and the output or input format of the model might be slightly changed, but the model's core components don't change anymore. Consequently, the need to apply global changes to all models in Transformers is significantly reduced, making it less important that every logical pattern only exists once since it's rarely changed.
A second realization is that models do **not** depend on each other in a bidirectional way. More recent published models might depend on existing models, but it's quite obvious that an existing model cannot logically depend on its successor. E.g. T5 is partly built upon BERT and therefore T5's modeling code might logically depend on BERT's modeling code, but BERT cannot logically depend in any way on T5. Thus, it would not be logically sound to refactor BERT's attention function to also work with T5's attention function - someone reading through BERT's attention layer should not have to know anything about T5. Again, this advocates against centralizing components such as the attention layer into modules that all models can access.
On the other hand, the modeling code of successor models can very well logically depend on its predecessor model. E.g., DeBERTa-v2 modeling code does logically depend
to some extent on DeBERTa's modeling code. Maintainability is significantly improved by ensuring the modeling code of DeBERTa-v2 stays in sync with DeBERTa's. Fixing a bug in
DeBERTa should ideally also fix the same bug in DeBERTa-v2. How can we maintain the *single model file* policy while ensuring that successor models stay in sync with their predecessor model?
Now, we explain why we put the asterisk \\( {}^{\textbf{*}} \\) after *"Repeat Yourself"*. We don't blindly copy-paste all existing modeling code even if it looks this way. One of Transformers' core maintainers, [Sylvain Gugger](https://github.com/sgugger), found a great mechanism that respects both the *single file policy* and keeps maintainability cost in bounds. This mechanism, loosely called *"the copying mechanism"*, allows us to mark logical components, such as an attention layer function, with a `# Copied from <predecessor_model>.<function>` statement, which enforces the marked code to be identical to the `<function>` of the `<predecessor_model>`. E.g., this line of over [DeBERTa-v2's class](https://github.com/huggingface/transformers/blob/21decb7731e998d3d208ec33e5b249b0a84c0a02/src/transformers/models/deberta_v2/modeling_deberta_v2.py#L325) enforces the whole class to be identical to [DeBERTa's class](https://github.com/huggingface/transformers/blob/21decb7731e998d3d208ec33e5b249b0a84c0a02/src/transformers/models/deberta/modeling_deberta.py#L336) except for the prefix `DeBERTav2`.
This way, the copying mechanism keeps modeling code very easy to understand while significantly reducing maintenance. If some code is changed in a function of a predecessor model that is referred to by a function of its successor model, there are tools in place that automatically correct the successor model's function.
### Drawbacks
Clearly, there are also drawbacks to the single file policy two of which we quickly want to mention here.
A major goal of Transformers is to provide a unified API for both inference and training for all models so
that a user can quickly switch between different models in her setup. However, ensuring a unified API across
models is much more difficult if modeling files are not allowed to use abstracted logical patterns. We solve
this problem by running **a lot** of tests (*ca.* 20,000 tests are run daily at the time of writing this blog post) to ensure that models follow a consistent API. In this case, the single file policy requires us to be very rigorous when reviewing model and test additions.
Second, there is a lot of research on just a single component of a Machine Learning model. *E.g.*, research
teams investigate new forms of an attention mechanism that would apply to all existing pre-trained models as
has been done in the [Rethinking Attention with Performers](https://arxiv.org/abs/2009.14794). How should
we incorporate such research into the Transformers library? It is indeed problematic. Should we change
all existing models? This would go against points 3. and 4. as written above. Should we add 100+ new modeling
files each prefixed with `Performer...`? This seems absurd. In such a case there is sadly no good solution
and we opt for not integrating the paper into Transformers in this case. If the paper would have gotten
much more traction and included strong pre-trained checkpoints, we would have probably added new modeling
files of the most important models such as `modeling_performer_bert.py`
available.
### Conclusion
All in all, at 🤗 Hugging Face we are convinced that the *single file policy* is the right coding philosophy for Transformers.
What do you think? If you read until here, we would be more than interested in hearing your opinion!
If you would like to leave a comment, please visit the corresponding forum post [here](https://discuss.huggingface.co/t/repeat-yourself-transformers-design-philosophy/16483). | [
[
"transformers",
"research",
"implementation",
"optimization"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"implementation",
"research",
"optimization"
] | null | null |
526381a0-4812-4045-871a-47bfa949bf59 | completed | 2025-01-16T03:08:53.171098 | 2025-01-19T17:17:54.599962 | 7a787c03-3bfb-4bdc-af30-b667a1ed8b5d | Hugging Face partners with TruffleHog to Scan for Secrets | mcpotato | trufflesecurity-partnership.md | We're excited to announce our partnership and integration with Truffle Security, bringing TruffleHog's powerful secret scanning features to our platform as part of [our ongoing commitment to security](https://huggingface.co./blog/2024-security-features).
<img class="block" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/trufflesecurity-partnership/truffle_security_landing_page.png"/>
TruffleHog is an open-source tool that detects and verifies secret leaks in code. With a wide range of detectors for popular SaaS and cloud providers, it scans files and repositories for sensitive information like credentials, tokens, and encryption keys.
Accidentally committing secrets to code repositories can have serious consequences. By scanning repositories for secrets, TruffleHog helps developers catch and remove this sensitive information before it becomes a problem, protecting data and preventing costly security incidents.
To combat secret leakage in public and private repositories, we worked with the TruffleHog team on two different initiatives:
Enhancing our automated scanning pipeline with TruffleHog
Creating a native Hugging Face scanner in TruffleHog
## Enhancing our automated scanning pipeline with TruffleHog
At Hugging Face, we are committed to protecting our users' sensitive information. This is why we've implemented an automated security scanning pipeline that scans all repos and commits. We have extended our automated scanning pipeline to include TruffleHog, which means there are now three types of scans:
- malware scanning: scans for known malware signatures with [ClamAV](https://www.clamav.net/)
- pickle scanning: scans pickle files for malicious executable code with [picklescan](https://github.com/mmaitre314/picklescan)
- secret scanning: scans for passwords, tokens and API keys with [TruffleHog](https://github.com/trufflesecurity/trufflehog)
We run the `trufflehog filesystem` command on every new or modified file on each push to a repository, scanning for potential secrets. If and when a verified secret is detected, we notify the user via email, empowering them to take corrective action.
Verified secrets are the ones that have been confirmed to work for authentication against their respective providers. Note, however, that unverified secrets are not necessarily harmless or invalid: verification can fail due to technical reasons, such as in the case of down time from the provider.
It will always be valuable to run trufflehog on your repositories yourself, even when we do it for you. For instance, you could have rotated the secrets that were leaked and want to make sure they come up as “unverified”, or you’d like to manually check if unverified secrets still pose a threat.
We will eventually migrate to the `trufflehog huggingface` command, the native Hugging Face scanner, once support for LFS lands.
<img class="block" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/hub/token-leak-email-example.png"/>
## TruffleHog Native Hugging Face Scanner
The goal for creating a native Hugging Face scanner in TruffleHog is to empower our users (and the security teams protecting them) to proactively scan their own account data for leaked secrets.
TruffleHog’s new open-source Hugging Face integration can scan models, datasets and Spaces, as well as any relevant PRs or Discussions. The only limitation is TruffleHog will not currently scan files stored in LFS. Their team is looking to address this for all of their `git` sources soon.
To scan all of your, or your organization’s Hugging Face models, datasets, and Spaces for secrets using TruffleHog, run the following command(s):
```sh
# For your user
trufflehog huggingface --user <username>
# For your organization
trufflehog huggingface --org <orgname>
# Or both
trufflehog huggingface --user <username> --org <orgname>
```
You can optionally include the (`--include-discussions`) and PRs (`--include-prs`) flags to scan Hugging Face discussion and PR comments.
If you’d like to scan just one model, dataset or Space, TruffleHog has specific flags for each of those.
```sh
# Scan one model
trufflehog huggingface --model <model_id>
# Scan one dataset
trufflehog huggingface --dataset <dataset_id>
# Scan one Space
trufflehog huggingface --space <space_id>
```
If you need to pass in an authentication token, you can do so using the --token flag or by setting a HUGGINGFACE_TOKEN environment variable.
Here is an example of TruffleHog’s output when run on [mcpotato/42-eicar-street](https://huggingface.co./mcpotato/42-eicar-street):
```
trufflehog huggingface --model mcpotato/42-eicar-street
🐷🔑🐷 TruffleHog. Unearth your secrets. 🐷🔑🐷
2024-09-02T16:39:30+02:00 info-0 trufflehog running source {"source_manager_worker_id": "3KRwu", "with_units": false, "target_count": 0, "source_manager_units_configurable": true}
2024-09-02T16:39:30+02:00 info-0 trufflehog Completed enumeration {"num_models": 1, "num_spaces": 0, "num_datasets": 0}
2024-09-02T16:39:32+02:00 info-0 trufflehog scanning repo {"source_manager_worker_id": "3KRwu", "model": "https://huggingface.co./mcpotato/42-eicar-street.git", "repo": "https://huggingface.co./mcpotato/42-eicar-street.git"}
Found unverified result 🐷🔑❓
Detector Type: HuggingFace
Decoder Type: PLAIN
Raw result: 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
Commit: 9cb322a7c2b4ec7c9f18045f0fa05015b831f256
Email: Luc Georges <[email protected]>
File: token_leak.yml
Line: 1
Link: https://huggingface.co./mcpotato/42-eicar-street/blob/9cb322a7c2b4ec7c9f18045f0fa05015b831f256/token_leak.yml#L1
Repository: https://huggingface.co./mcpotato/42-eicar-street.git
Resource_type: model
Timestamp: 2024-06-17 13:11:50 +0000
2024-09-02T16:39:32+02:00 info-0 trufflehog finished scanning {"chunks": 19, "bytes": 2933, "verified_secrets": 0, "unverified_secrets": 1, "scan_duration": "2.176551292s", "trufflehog_version": "3.81.10"}
```
Kudos to the TruffleHog team for offering such a great tool to make our community safe! Stay tuned for more features as we continue to collaborate to make the Hub more secure for everyone. | [
[
"mlops",
"security",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"security",
"tools",
"integration",
"mlops"
] | null | null |
b843da4c-7c63-4bcd-8da1-1c1504bc5a43 | completed | 2025-01-16T03:08:53.171102 | 2025-01-19T19:05:18.833841 | 19b01e8c-06c8-4956-93b1-2237ebe2950c | Expert Support case study: Bolstering a RAG app with LLM-as-a-Judge | Vinsingh, rajgreen, m-ric | digital-green-llm-judge.md | > [!NOTE] This is a guest blog post authored by [Digital Green](https://huggingface.co./DigiGreen). Digital green is participating in a [CGIAR](https://huggingface.co./CGIAR)-led collaboration to bring agricultural support to smallholder farmers.
There are an estimated 500 million smallholder farmers globally: they play a critical role in global food security. Timely access to accurate information is essential for these farmers to make informed decisions and improve their yields.
An “agricultural extension service” offers technical advice on agriculture to farmers, and also supplies them with the necessary inputs and services to support their agricultural production.
Agriculture extension agents are 300K in India alone, they provide necessary information about improved agriculture practice and help in decision making for the smallholder farmers.
But although their number is impressive, extension workers are not in large enough numbers to cope with all the demand: they interact with farmers at typically in the ratio of 1:1000. Reaching the agriculture extension workers and farmers through partnership and technology remains the key.
Enter project GAIA, a collaborative initiative pioneered by [CGIAR](https://www.cgiar.org/).
It brought together [Hugging Face](https://huggingface.co./) as mentor through the [Expert Support program](https://huggingface.co./support), and [Digital Green](http://digitalgreen.org) as project partner.
GAIA has a lofty goal to bring years of agriculture knowledge in the form of research papers meticulously maintained in [GARDIAN portal](https://gardian.bigdata.cgiar.org/#/) in the hands of the farmers. There are close to 46000 research papers and reports that have agricultural knowledge globally carried over multiple decades across different crops.
[Digital Green](http://www.digitalgreen.org) immediately saw the potential of developing intelligent chatbots powered by Retrieval-Augmented Generation (RAG) on approved, curated information. Thus they decided to develop [Farmer.chat](https://farmerchat.digitalgreen.org/), a chatbot that leverages the capabilities of large language models (LLMs) to deliver personalized and reliable agricultural advice to the farmers and front line extension workers.
Creating such a chatbot for a huge variety of languages, geographies, crops, and use cases, is a gigantic challenge: information disseminated has to be contextual to the local level details about the farm, in the language and tone that farmers can understand and accurate (grounded in trustworthy sources) for farmers to act on it. To evaluate the performance of the system, the CGIAR team and HF expert collaborated to set up a strong evaluation suite, in the form of an LLM-as-a-judge system.
Let’s take a look at how they tackled this challenge!
## System architecture
<p align="center">
<img src="https://miro.medium.com/v2/resize:fit:4800/format:webp/1*L8epmSjWRweoVhQoLlAbuQ.png" alt="System architecture" width=100%>
</p>
The full system uses many components in order to provide chatbot answers grounded in several tools and external knowledge. It has several key elements:
* **Knowledge base:**
* Preprocessing: The first step was to ingest the pdf documents into the Farmer.chat pipeline with the help of APIs maintained by [Scio](https://scio.systems/). The in the knowledge base, topics were auto categorized for relevant geographic areas and semantically grouped together.
* Semantic chunking: the organized files with metadata are processed with sentences similar in meaning grouped together in text chunks. The function uses small-text embedding currently for cosine similarity
* Conversion into VectorDB format: each text chunk is converted into vector representation using an embedding model using which the vector representation is stored in QdrantDB.
* **RAG pipeline:** It is what ensures that the information delivered is grounded in the content and not outside. It consists in two parts:
* Information retrieval: Searching the knowledge base for relevant information that matches the user’s query. This involves calling the vector database API created in knowledge base builder to get necessary text chunks.
* Generation: Using the retrieved information in the text chunks and the user query, the generator calls LLM and generates a human-like response that addresses the user’s needs.
* **User-facing Agent:** The planning agent leverages GPT-4o under the hood.
* Its task is to:
* Understand the user intent
* Based on the user intent and tools description decide what more information is required
* Ask that information from the user till the ask is clear
* Once the ask is clear, call the execution agent
* Get the response form the execution agent and generate response
* The agent runs a ReAct based prompt to think in step by step manner and call the respective tools and analyze the responses. Then it can leverage its tools to answer: Currently, the agent uses the following set of tools:
* Converse more
* RAG QA endpoint
* Video retrieval endpoint
* Weather endpoint
* Crop table
Now this system has many moving parts, and each part has a radical impart on some aspects of performance. So we need to carefully run performance evaluation.
In the last one year, the usage of Farmer.chat has grown to service more than 20k farmers handling over 340k queries. How can we evaluate the performance of the system at this scale?
During weekly brainstorming sessions, Hugging Face hinted to LLM as a judge and provided a link to their notebook [LLM as a Judge](https://huggingface.co./learn/cookbook/en/llm_judge). This resource was discussed in detail, and what followed became a practice that has helped navigating [Farmer.chat](https://farmerchat.digitalgreen.org/)’s development.
## The Power of LLMs-as-Judges
Farmer.Chat employs a sophisticated Retrieval-Augmented Generation (RAG) pipeline to deliver accurate and relevant information to farmers that is grounded in the knowledge base.
The RAG pipeline uses an LLM to retrieve information from a vast knowledge base and then generate a concise and informative response.
But how do we measure the effectiveness of this pipeline?
The difficulty here is that there is no deterministic metric that one could use to rate the quality of an answer, its conciseness, its precision...
That is where *LLM-as-a-judge* technique steps in. The idea is simple: ask an LLM to rate the output on any metric.
The immense advantage is that the metric can be anything: LLM-as-a-Judge is extremely versatile.
For example, you can use it to evaluate the clarity of a prompt as follows:
```
You will be given a user input about agriculture, and your task is to score it on various aspects.
Think step by step and rate the user input on all three following criteria and give a score for each:
1) The intent and ask is clear.
2) The topic is well-specified.
3) The target entity is well-specified, as well as its attributes, for instance "disease resistant" or "high yield".
You should give your scores on an integer scale of 1 to 3, 1 being the worst and 3 the best score.
After creating a score for each three, take the average and round it off to the nearest integer which becomes the final score.
Example:
User input: "tell the benefits of batian coffee variety"
Criterion 1: scores 3, as the intent is clear (about knowing about batian variety of coffee) and the ask is clear (want to summarize the benefits).
Criterion 2: scores 3, the topic is well specified (coffee varieties)
Criterion 3: scores 2, as the entity is clear (batian variety) but not the attributes.
```
As mentioned in [this article that we referred to earlier](https://huggingface.co./learn/cookbook/en/llm_judge), the key to use LLM-as-a-judge is to clearly define the task, the criteria and the integer rating scale.
The research team behind Farmer.Chat leverages the capabilities of LLMs to evaluate several crucial metrics:
* **Prompt Clarity**: This metric evaluates how well users can articulate their questions. LLMs are trained to assess the clarity of user intent, topic specificity, and entity-attribute identification, providing insights into how effectively users can communicate their needs.
* **Question Type**: This metric classifies user questions into different categories based on their cognitive complexity. LLMs analyze the user's query and assign it to one of six categories, such as "remember," "understand," "apply," "analyze," "evaluate," and "create," helping us understand the cognitive demands of user interactions.
* **Answered Queries**: This metric tracks the percentage of questions answered by the chatbot, providing insights into the breadth of the knowledge base and the platform's ability to address a wide range of queries.
* **RAG Accuracy**: This metric assesses the faithfulness and relevance of the information retrieved by the RAG pipeline. The LLM acts as a judge, comparing the retrieved information to the user's query and evaluating whether the response is accurate and relevant.
It empowers us to go beyond simply measuring how many questions a chatbot can answer or how quickly it responds.
Instead, we can delve deeper into the quality of the responses and understand the user experience in a more nuanced way.
For RAG accuracy we use LLM-as-a-judge to evaluate on a binary scale: zero or one.
But the way the task is broken down leads to a well established process that comes up with a score that we tested with human evaluators on roughly 360 questions: LLM answers are found to actually do a great job and have high correlation with human evaluations!
Here is the prompt, which was inspired from the RAGAS library.
```
You are a natural language inference engine. You will be presented with a set of factual statements and context. You are supposed to analyze if each statement is factually correct given the context. You can come up with the scores of 'Yes' (1) and 'No' (0) as verdict.
Use the following rules:
If the statement can be derived from the context, give a score of 1.
If there is no statement and there is no context, give a score of 1.
If the statement can’t be derived from the context, give a score of 0.
If there is no context but there is a statement, give a score of 0.
#### Input :
Context : {context}
Statements : {statements}
```
The context variable above is the input chunks given for generating the answers while statements are the atomic factual statements generated by another LLM call.
This was a very important step as it enables evaluation at scale which is important when dealing with large numbers of documents and queries.
The LLM-as-a-judge at core leads to metrics that act as a compass navigating the various options available for our AI pipeline.
## Results: benchmarking LLMs for RAG
We created a sample dataset of \> 700 user queries randomized across different value chains (crops) and date (months). While this upgrade itself had 11 different versions that evaluated using RAG accuracy and percentage answered, the same approach was used to measure performance of the leading LLMs without any prompt changes in each LLM call. For this experiment, we selected GPT-4-Turbo by OpenAI, Gemini-1.5 in Pro and Flash versions, and Llama-3-70B-Instruct.
| LLM | Faithful | Relevant | Answered * Relevant | Answered * Faithful | Unanswered |
| : | [
[
"llm",
"data",
"implementation",
"community",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"implementation",
"community",
"integration"
] | null | null |
dab75f62-fddc-4c7c-b498-205959597b3b | completed | 2025-01-16T03:08:53.171107 | 2025-01-16T03:13:05.730359 | a3c5e729-f2d0-4e39-979a-c1ebed78be85 | Introducing the SQL Console on Datasets | cfahlgren1 | sql-console.md | 
_Datasets created on Hugging Face Hub each month_
We are very excited to announce that you can now run SQL queries on your datasets directly in the Hugging Face Hub!
## Introducing the SQL Console for Datasets
On every dataset you should see a new **SQL Console** badge. With just one click you can open a SQL Console to query that dataset.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="SQL Console Demo"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/sql_console/Magpie-Ultra-Demo-SQL-Console.mp4" type="video/mp4">
</video>
<figcaption class="text-center text-sm italic">Querying the Magpie-Ultra dataset for excellent, high quality reasoning instructions.</figcaption>
</figure>
All the work is done in the browser and the console comes with a few neat features:
- **100% Local**: The SQL Console is powered by [DuckDB](https://duckdb.org/) WASM, so you can query your dataset without any dependencies.
- **Full DuckDB Syntax**: DuckDB has [full SQL](https://duckdb.org/docs/sql/introduction.html) syntax support, along with many built in functions for regex, lists, JSON, embeddings and more. You'll find DuckDB syntax to be very similar to PostgreSQL.
- **Export Results**: You can export the results of your query to parquet.
- **Shareable**: You can share your query results of public datasets with a link.
## How it works
### Parquet Conversion
Most datasets on Hugging Face are stored in Parquet, a columnar data format that is optimized for performance and storage efficiency. The Dataset Viewer on Hugging Face and the SQL Console load the data directly from the datasets Parquet files. And if the dataset is in another format, the first 5GB is auto-converted to Parquet. You can find more information about the Parquet conversion process in the [Dataset Viewer Parquet API documentation](https://huggingface.co./docs/dataset-viewer/en/parquet).
Using the Parquet files, the SQL Console creates views for you to query based on your dataset splits and configs.
### DuckDB WASM 🦆
[DuckDB WASM](https://duckdb.org/docs/api/wasm/overview.html) is the engine that powers the SQL Console. It is an in-process database engine that runs on Web Assembly in the browser. No server or backend needed.
By running solely in the browser, it gives the user the upmost flexibility to query data as they please without any dependencies. It also makes it really simple to share reproducible results with a simple link.
You may be wondering, _"Will it work for big datasets?"_ and the answer is, "Yes!".
Here's a query of the [OpenCo7/UpVoteWeb](https://huggingface.co./datasets/OpenCo7/UpVoteWeb) dataset which has `12.6M` rows in the Parquet conversion.

You can see we received results for a simple filter query in under 3 seconds.
While queries will take longer based on the size of the dataset and query complexity, you will be surprised about how much you can do with the SQL Console.
As with any technology, there are limitations.
- The SQL Console will work for a lot of queries. However, the memory limit is ~3GB, so it is possible to run out of memory and not be able to process the query (_Tip: try to use filters to reduce the amount of data you are querying along with `LIMIT`_).
- While DuckDB WASM is very powerful, it doesn't have full feature parity with DuckDB. For example, DuckDB WASM does not yet support the [`hf://` protocol to query datasets](https://github.com/duckdb/duckdb-wasm/discussions/1858).
### Example: Converting a dataset from Alpaca to conversations
Now that we've introduced the SQL Console, let's explore a practical example. When fine-tuning a Large Language Model (LLM), you often need to work with different data formats. One particularly popular format is the conversational format, where each row represents a multi-turn dialogue between a user and the model. The SQL Console can help us transform data into this format efficiently. Let's see how we can convert an Alpaca dataset to a conversational format using SQL.
Typically, developers would tackle this task with a Python pre-processing step, but we can show how to use the SQL Console to achieve the same in less than 30 seconds.
<iframe
src="https://huggingface.co./datasets/yahma/alpaca-cleaned/embed/viewer/default/train?sql=--+Convert+Alpaca+format+to+Conversation+format%0AWITH+%0Asource_view+AS+%28%0A++SELECT+*+FROM+train++--+Change+%27train%27+to+your+desired+view+name+here%0A%29%0ASELECT+%0A++%5B%0A++++struct_pack%28%0A++++++%22from%22+%3A%3D+%27user%27%2C%0A++++++%22value%22+%3A%3D+CASE+%0A+++++++++++++++++++WHEN+input+IS+NOT+NULL+AND+input+%21%3D+%27%27+%0A+++++++++++++++++++THEN+instruction+%7C%7C+%27%5Cn%5Cn%27+%7C%7C+input%0A+++++++++++++++++++ELSE+instruction%0A+++++++++++++++++END%0A++++%29%2C%0A++++struct_pack%28%0A++++++%22from%22+%3A%3D+%27assistant%27%2C%0A++++++%22value%22+%3A%3D+output%0A++++%29%0A++%5D+AS+conversation%0AFROM+source_view%0AWHERE+instruction+IS+NOT+NULL+%0AAND+output+IS+NOT+NULL%3B"
frameborder="0"
width="100%"
height="800px"
></iframe>
In the dataset above, click on the **SQL Console** badge to open the SQL Console. You should see the query below automatically populated.
When you are ready, click the **Run Query** button to execute the query.
### SQL
```sql
-- Convert Alpaca format to Conversation format
WITH
source_view AS (
SELECT * FROM train -- Change 'train' to your desired view name here
)
SELECT
[
struct_pack(
"from" := 'user',
"value" := CASE
WHEN input IS NOT NULL AND input != ''
THEN instruction || '\n\n' || input
ELSE instruction
END
),
struct_pack(
"from" := 'assistant',
"value" := output
)
] AS conversation
FROM source_view
WHERE instruction IS NOT NULL
AND output IS NOT NULL;
```
In the query we use the `struct_pack` function to create a new STRUCT row for each conversation.
DuckDB has great documentation on the `STRUCT` [Data Type](https://duckdb.org/docs/sql/data_types/struct.html) and [Functions](https://duckdb.org/docs/sql/functions/struct.html). You'll find many datasets contain columns with JSON data. DuckDB provides functions to easily parse and query these columns.

Once we have the results, we can download them as a Parquet file. You can see what the final output looks like below.
<iframe
src="https://huggingface.co./datasets/cfahlgren1/alpaca-conversational/embed/viewer/default/train"
frameborder="0"
width="100%"
height="560px"
></iframe>
**Try it out!**
As an another example, you can try a SQL Console query for [SkunkworksAI/reasoning-0.01](https://huggingface.co./datasets/SkunkworksAI/reasoning-0.01?sql_console=true&sql=--+Find+instructions+with+more+than+10+reasoning+steps%0Aselect+*+from+train%0Awhere+len%28reasoning_chains%29+%3E+10%0Alimit+100&sql_row=43) to see instructions with more than 10 reasoning steps.
## SQL Snippets
DuckDB has a ton of use cases that we are still exploring. We created a [SQL Snippets](https://huggingface.co./spaces/cfahlgren1/sql-snippets) space to showcase what you can do with the SQL Console.
Here are some really interesting use cases we have found:
- [Filtering a function calling dataset for a specific function with regex](https://x.com/qlhoest/status/1835687940376207651)
- [Finding the most popular base models from open-llm-leaderboard](https://x.com/polinaeterna/status/1834601082862842270)
- [Converting an alpaca dataset to a conversational format](https://x.com/calebfahlgren/status/1834674871688704144)
- [Performing similarity search with embeddings](https://x.com/andrejanysa/status/1834253758152269903)
- [Filtering 50k+ rows from a dataset for the highest quality, reasoning instructions](https://x.com/calebfahlgren/status/1835703284943749301)
Remember, it's one click to download your SQL results as a Parquet file and use for your dataset!
We would love to hear what you think of the SQL Console and if you have any feedback, please comment in this [post!](https://huggingface.co./posts/cfahlgren1/845769119345136)
## Resources
- [DuckDB WASM](https://duckdb.org/docs/api/wasm/overview.html)
- [DuckDB Syntax](https://duckdb.org/docs/sql/introduction.html)
- [DuckDB WASM Paper](https://www.vldb.org/pvldb/vol15/p3574-kohn.pdf)
- [Intro to Parquet Format](https://huggingface.co./blog/cfahlgren1/intro-to-parquet-format)
- [Hugging Face + DuckDB](https://huggingface.co./docs/hub/en/datasets-duckdb)
- [SQL Snippets Space](https://huggingface.co./spaces/cfahlgren1/sql-snippets) | [
[
"data",
"implementation",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"data",
"tools",
"implementation",
"integration"
] | null | null |
8a65fe1a-6ce8-4002-98e2-f76e38236743 | completed | 2025-01-16T03:08:53.171111 | 2025-01-19T19:12:39.715480 | 92fc4a4f-d75c-44ca-b15c-5265115df857 | The Age of Machine Learning As Code Has Arrived | juliensimon | the-age-of-ml-as-code.md | The 2021 edition of the [State of AI Report](https://www.stateof.ai/2021-report-launch.html) came out last week. So did the Kaggle [State of Machine Learning and Data Science Survey](https://www.kaggle.com/c/kaggle-survey-2021). There's much to be learned and discussed in these reports, and a couple of takeaways caught my attention.
> "AI is increasingly being applied to mission critical infrastructure like national electric grids and automated supermarket warehousing calculations during pandemics. However, there are questions about whether the maturity of the industry has caught up with the enormity of its growing deployment."
There's no denying that Machine Learning-powered applications are reaching into every corner of IT. But what does that mean for companies and organizations? How do we build rock-solid Machine Learning workflows? Should we all hire 100 Data Scientists ? Or 100 DevOps engineers?
> "Transformers have emerged as a general purpose architecture for ML. Not just for Natural Language Processing, but also Speech, Computer Vision or even protein structure prediction."
Old timers have learned the hard way that there is [no silver bullet](https://en.wikipedia.org/wiki/No_Silver_Bullet) in IT. Yet, the [Transformer](https://arxiv.org/abs/1706.03762) architecture is indeed very efficient on a wide variety of Machine Learning tasks. But how can we all keep up with the frantic pace of innovation in Machine Learning? Do we really need expert skills to leverage these state of the art models? Or is there a shorter path to creating business value in less time?
Well, here's what I think.
### Machine Learning For The Masses!
Machine Learning is everywhere, or at least it's trying to be. A few years ago, Forbes wrote that "[Software ate the world, now AI is eating Software](https://www.forbes.com/sites/cognitiveworld/2019/08/29/software-ate-the-world-now-ai-is-eating-software/)", but what does this really mean? If it means that Machine Learning models should replace thousands of lines of fossilized legacy code, then I'm all for it. Die, evil business rules, die!
Now, does it mean that Machine Learning will actually replace Software Engineering? There's certainly a lot of fantasizing right now about [AI-generated code](https://www.wired.com/story/ai-latest-trick-writing-computer-code/), and some techniques are certainly interesting, such as [finding bugs and performance issues](https://aws.amazon.com/codeguru). However, not only shouldn't we even consider getting rid of developers, we should work on empowering as many as we can so that Machine Learning becomes just another boring IT workload (and [boring technology is great](http://boringtechnology.club/)). In other words, what we really need is for Software to eat Machine Learning!
### Things are not different this time
For years, I've argued and swashbuckled that decade-old best practices for Software Engineering also apply to Data Science and Machine Learning: versioning, reusability, testability, automation, deployment, monitoring, performance, optimization, etc. I felt alone for a while, and then the Google cavalry unexpectedly showed up:
> "Do machine learning like the great engineer you are, not like the great machine learning expert you aren't." - [Rules of Machine Learning](https://developers.google.com/machine-learning/guides/rules-of-ml), Google
There's no need to reinvent the wheel either. The DevOps movement solved these problems over 10 years ago. Now, the Data Science and Machine Learning community should adopt and adapt these proven tools and processes without delay. This is the only way we'll ever manage to build robust, scalable and repeatable Machine Learning systems in production. If calling it MLOps helps, fine: I won't argue about another buzzword.
It's really high time we stopped considering proof of concepts and sandbox A/B tests as notable achievements. They're merely a small stepping stone toward production, which is the only place where assumptions and business impact can be validated. Every Data Scientist and Machine Learning Engineer should obsess about getting their models in production, as quickly and as often as possible. **An okay production model beats a great sandbox model every time**.
### Infrastructure? So what?
It's 2021. IT infrastructure should no longer stand in the way. Software has devoured it a while ago, abstracting it away with cloud APIs, infrastructure as code, Kubeflow and so on. Yes, even on premises.
The same is quickly happening for Machine Learning infrastructure. According to the Kaggle survey, 75% of respondents use cloud services, and over 45% use an Enterprise ML platform, with Amazon SageMaker, Databricks and Azure ML Studio taking the top 3 spots.
<kbd>
<img src="assets/31_age_of_ml_as_code/01_entreprise_ml.png">
</kbd>
With MLOps, software-defined infrastructure and platforms, it's never been easier to drag all these great ideas out of the sandbox, and to move them to production. To answer my original question, I'm pretty sure you need to hire more ML-savvy Software and DevOps engineers, not more Data Scientists. But deep down inside, you kind of knew that, right?
Now, let's talk about Transformers. | [
[
"transformers",
"data",
"mlops",
"research"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"transformers",
"data",
"research"
] | null | null |
e121e7d0-a6b0-4043-a00e-36085e5821cf | completed | 2025-01-16T03:08:53.171116 | 2025-01-16T14:21:33.566355 | d0671001-76e1-437b-a7c6-00000756655d | Introducing Prodigy-HF: a direct integration with Hugging Face | koaning | prodigy-hf.md | [Prodigy](https://prodi.gy/) is an annotation tool made by [Explosion](https://explosion.ai/), a company well known as the creators of [spaCy](https://spacy.io/). It's a fully scriptable product with a large community around it. The product has many features, including tight integration with spaCy and active learning capabilities. But the main feature of the product is that it is programmatically customizable with Python.
To foster this customisability, Explosion has started releasing [plugins](https://prodi.gy/docs/plugins). These plugins integrate with third-party tools in an open way that encourages users to work on bespoke annotation workflows. However, one customization specifically deserves to be celebrated explicitly. Last week, Explosion introduced [Prodigy-HF](https://github.com/explosion/prodigy-hf), which offers code recipes that directly integrate with the Hugging Face stack. It's been a much-requested feature on the [Prodigy support forum](https://support.prodi.gy/), so we're super excited to have it out there.
## Features
The first main feature is that this plugin allows you to train and re-use Hugging Face models on your annotated data. That means if you've been annotating data in our interface for named entity recognition, you can directly fine-tune BERT models against it.
<figure>
<div style="background-color: #eee; padding-top: 8px; padding-bottom: 8px;">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/prodigy-hf/interface.png" width="100%">
</div>
<figcaption style="text-color: gray; margin-left: auto; margin-right: auto; text-align:center; padding-top: 8px;"><small>What the Prodigy NER interface looks like.</small></figcaption>
</figure>
After installing the plugin you can call the `hf.train.ner` recipe from the command line to train a transformer model directly on your own data.
```
python -m prodigy hf.train.ner fashion-train,eval:fashion-eval path/to/model-out --model "distilbert-base-uncased"
```
This will fine-tune the `distilbert-base-uncased` model for the dataset you've stored in Prodigy and save it to disk. Similarly, this plugin also supports models for text classification via a very similar interface.
```
python -m prodigy hf.train.textcat fashion-train,eval:fashion-eval path/to/model-out --model "distilbert-base-uncased"
```
This offers a lot of flexibility because the tool directly integrates with the `AutoTokenizer` and `AutoModel` classes of Hugging Face transformers. Any transformer model on the hub can be fine-tuned on your own dataset with just a single command. These models will be serialised on disk, which means that you can upload them to the Hugging Face Hub, or re-use them to help you annotate data. This can save a lot of time, especially for NER tasks. To re-use a trained NER model you can use the `hf.correct.ner` recipe.
```
python -m prodigy hf.correct.ner fashion-train path/to/model-out examples.jsonl
```
This will give you a similar interface as before, but now the model predictions will be shown in the interface as well.
### Upload
The second feature, which is equally exciting, is that you can now also publish your annotated datasets on the Hugging Face Hub. This is great if you're interested in sharing datasets that others would like to use.
```
python -m prodigy hf.upload <dataset_name> <username>/<repo_name>
```
We're particularly fond of this upload feature because it encourages collaboration. People can annotate their own datasets independently of each other, but still benefit when they share the data with the wider community.
## More to come
We hope that this direct integration with the Hugging Face ecosystem enables many users to experiment more. The Hugging Face Hub offers _many_ [models](https://huggingface.co./models) for a wide array of tasks as well as a wide array of languages. We really hope that this integration makes it easier to get data annotated, even if you've got a more domain specific and experimental use-case.
More features for this library are on their way, and feel free to reach out on the [Prodigy forum](https://support.prodi.gy/) if you have more questions.
We'd also like to thank the team over at Hugging Face for their feedback on this plugin, specifically @davanstrien, who suggested to add the upload feature. Thanks! | [
[
"data",
"implementation",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"tools",
"integration",
"implementation",
"data"
] | null | null |
94cde224-bf05-457e-bc72-e37653a8d5e1 | completed | 2025-01-16T03:08:53.171120 | 2025-01-19T19:08:35.270025 | 5e284ce5-7096-46ca-b25f-9557cddc53b7 | Universal Image Segmentation with Mask2Former and OneFormer | nielsr, shivi, adirik | mask2former.md | <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
**This guide introduces Mask2Former and OneFormer, 2 state-of-the-art neural networks for image segmentation. The models are now available in [`🤗 transformers`](https://huggingface.co./transformers), an open-source library that offers easy-to-use implementations of state-of-the-art models. Along the way, you'll learn about the difference between the various forms of image segmentation.**
## Image segmentation
Image segmentation is the task of identifying different "segments" in an image, like people or cars. More technically, image segmentation is the task of grouping pixels with different semantics. Refer to the Hugging Face [task page](https://huggingface.co./tasks/image-segmentation) for a brief introduction.
Image segmentation can largely be split into 3 subtasks - instance, semantic and panoptic segmentation - with numerous methods and model architectures to perform each subtask.
- **instance segmentation** is the task of identifying different "instances", like individual people, in an image. Instance segmentation is very similar to object detection, except that we'd like to output a set of binary segmentation masks, rather than bounding boxes, with corresponding class labels. Instances are oftentimes also called "objects" or "things". Note that individual instances may overlap.
- **semantic segmentation** is the task of identifying different "semantic categories", like "person" or "sky" of each pixel in an image. Contrary to instance segmentation, no distinction is made between individual instances of a given semantic category; one just likes to come up with a mask for the "person" category, rather than for the individual people for example. Semantic categories which don't have individual instances, like "sky" or "grass", are oftentimes referred to as "stuff", to make the distinction with "things" (great names, huh?). Note that no overlap between semantic categories is possible, as each pixel belongs to one category.
- **panoptic segmentation**, introduced in 2018 by [Kirillov et al.](https://arxiv.org/abs/1801.00868), aims to unify instance and semantic segmentation, by making models simply identify a set of "segments", each with a corresponding binary mask and class label. Segments can be both "things" or "stuff". Unlike in instance segmentation, no overlap between different segments is possible.
The figure below illustrates the difference between the 3 subtasks (taken from [this blog post](https://www.v7labs.com/blog/panoptic-segmentation-guide)).
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/127_mask2former/semantic_vs_semantic_vs_panoptic.png" alt="drawing" width=500>
</p>
Over the last years, researchers have come up with several architectures that were typically very tailored to either instance, semantic or panoptic segmentation. Instance and panoptic segmentation were typically solved by outputting a set of binary masks + corresponding labels per object instance (very similar to object detection, except that one outputs a binary mask instead of a bounding box per instance). This is oftentimes called "binary mask classification". Semantic segmentation on the other hand was typically solved by making models output a single "segmentation map" with one label per pixel. Hence, semantic segmentation was treated as a "per-pixel classification" problem. Popular semantic segmentation models which adopt this paradigm are [SegFormer](https://huggingface.co./docs/transformers/model_doc/segformer), on which we wrote an extensive [blog post](https://huggingface.co./blog/fine-tune-segformer), and [UPerNet](https://huggingface.co./docs/transformers/main/en/model_doc/upernet).
## Universal image segmentation
Luckily, since around 2020, people started to come up with models that can solve all 3 tasks (instance, semantic and panoptic segmentation) with a unified architecture, using the same paradigm. This started with [DETR](https://huggingface.co./docs/transformers/model_doc/detr), which was the first model that solved panoptic segmentation using a "binary mask classification" paradigm, by treating "things" and "stuff" classes in a unified way. The key innovation was to have a Transformer decoder come up with a set of binary masks + classes in a parallel way. This was then improved in the [MaskFormer](https://huggingface.co./docs/transformers/model_doc/maskformer) paper, which showed that the "binary mask classification" paradigm also works really well for semantic segmentation.
[Mask2Former](https://huggingface.co./docs/transformers/main/model_doc/mask2former) extends this to instance segmentation by further improving the neural network architecture. Hence, we've evolved from separate architectures to what researchers now refer to as "universal image segmentation" architectures, capable of solving any image segmentation task. Interestingly, these universal models all adopt the "mask classification" paradigm, discarding the "per-pixel classification" paradigm entirely. A figure illustrating Mask2Former's architecture is depicted below (taken from the [original paper](https://arxiv.org/abs/2112.01527)).
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/mask2former_architecture.jpg" alt="drawing" width=500>
</p>
In short, an image is first sent through a backbone (which, in the paper could be either [ResNet](https://huggingface.co./docs/transformers/model_doc/resnet) or [Swin Transformer](https://huggingface.co./docs/transformers/model_doc/swin)) to get a list of low-resolution feature maps. Next, these feature maps are enhanced using a pixel decoder module to get high-resolution features. Finally, a Transformer decoder takes in a set of queries and transforms them into a set of binary mask and class predictions, conditioned on the pixel decoder's features.
Note that Mask2Former still needs to be trained on each task separately to obtain state-of-the-art results. This has been improved by the [OneFormer](https://arxiv.org/abs/2211.06220) model, which obtains state-of-the-art performance on all 3 tasks by only training on a panoptic version of the dataset (!), by adding a text encoder to condition the model on either "instance", "semantic" or "panoptic" inputs. This model is also as of today [available in 🤗 transformers](https://huggingface.co./docs/transformers/main/en/model_doc/oneformer). It's even more accurate than Mask2Former, but comes with greater latency due to the additional text encoder. See the figure below for an overview of OneFormer. It leverages either Swin Transformer or the new [DiNAT](https://huggingface.co./docs/transformers/model_doc/dinat) model as backbone.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/oneformer_architecture.png" alt="drawing" width=500>
</p>
## Inference with Mask2Former and OneFormer in Transformers
Usage of Mask2Former and OneFormer is pretty straightforward, and very similar to their predecessor MaskFormer. Let's instantiate a Mask2Former model from the hub trained on the COCO panoptic dataset, along with its processor. Note that the authors released no less than [30 checkpoints](https://huggingface.co./models?other=mask2former) trained on various datasets.
```
from transformers import AutoImageProcessor, Mask2FormerForUniversalSegmentation
processor = AutoImageProcessor.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
model = Mask2FormerForUniversalSegmentation.from_pretrained("facebook/mask2former-swin-base-coco-panoptic")
```
Next, let's load the familiar cats image from the COCO dataset, on which we'll perform inference.
```
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<img src="assets/78_annotated-diffusion/output_cats.jpeg" width="400" />
We prepare the image for the model using the image processor, and forward it through the model.
```
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
```
The model outputs a set of binary masks and corresponding class logits. The raw outputs of Mask2Former can be easily postprocessed using the image processor to get the final instance, semantic or panoptic segmentation predictions:
```
prediction = processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
print(prediction.keys())
```
<div class="output stream stdout">
Output: | [
[
"computer_vision",
"transformers",
"implementation",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"transformers",
"implementation",
"tutorial"
] | null | null |
1ebe6e82-004c-4dff-b6d4-2b54638a951b | completed | 2025-01-16T03:08:53.171125 | 2025-01-19T17:07:21.924414 | 20a83c16-200c-4a36-97c3-582f304edb67 | PatchTSMixer in HuggingFace | ajati, vijaye12, namctin, wmgifford, kashif, nielsr | patchtsmixer.md | <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/patch_tsmixer.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
<!-- #region -->
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/patchtstmixer/first_image.gif" width="640" height="320"/>
</p>
`PatchTSMixer` is a lightweight time-series modeling approach based on the MLP-Mixer architecture. It is proposed in [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://huggingface.co./papers/2306.09364) by IBM Research authors Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong and Jayant Kalagnanam.
For effective mindshare and to promote open-sourcing - IBM Research joins hands with the HuggingFace team to release this model in the Transformers library.
In the [Hugging Face implementation](https://huggingface.co./docs/transformers/main/en/model_doc/patchtsmixer), we provide PatchTSMixer’s capabilities to effortlessly facilitate lightweight mixing across patches, channels, and hidden features for effective multivariate time-series modeling. It also supports various attention mechanisms starting from simple gated attention to more complex self-attention blocks that can be customized accordingly. The model can be pretrained and subsequently used for various downstream tasks such as forecasting, classification, and regression.
`PatchTSMixer` outperforms state-of-the-art MLP and Transformer models in forecasting by a considerable margin of 8-60%. It also outperforms the latest strong benchmarks of Patch-Transformer models (by 1-2%) with a significant reduction in memory and runtime (2-3X). For more details, refer to the [paper](https://arxiv.org/pdf/2306.09364.pdf).
In this blog, we will demonstrate examples of getting started with PatchTSMixer. We will first demonstrate the forecasting capability of `PatchTSMixer` on the Electricity dataset. We will then demonstrate the transfer learning capability of PatchTSMixer by using the model trained on Electricity to do zero-shot forecasting on the `ETTH2` dataset.
<!-- #endregion -->
## PatchTSMixer Quick Overview
#### Skip this section if you are familiar with `PatchTSMixer`!
`PatchTSMixer` splits a given input multivariate time series into a sequence of patches or windows. Subsequently, it passes the series to an embedding layer, which generates a multi-dimensional tensor.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/patchtstmixer/1.gif" width="640" height="360"/>
</p>
The multi-dimensional tensor is subsequently passed to the `PatchTSMixer` backbone, which is composed of a sequence of [MLP Mixer](https://arxiv.org/abs/2105.01601) layers. Each MLP Mixer layer learns inter-patch, intra-patch, and inter-channel correlations through a series of permutation and MLP operations.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/patchtstmixer/2.gif" width="640" height="360"/>
</p>
`PatchTSMixer` also employs residual connections and gated attentions to prioritize important features.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/patchtstmixer/3.gif" width="640" height="360"/>
</p>
Hence, a sequence of MLP Mixer layers creates the following `PatchTSMixer` backbone.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/patchtstmixer/4.png" width="671" height="222"/>
</p>
`PatchTSMixer` has a modular design to seamlessly support masked time series pretraining as well as direct time series forecasting.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/patchtstmixer/5.gif" width="640" height="360"/>
</p>
## Installation
This demo requires Hugging Face [`Transformers`](https://github.com/huggingface/transformers) for the model and the IBM `tsfm` package for auxiliary data pre-processing.
Both can be installed by following the steps below.
1. Install IBM Time Series Foundation Model Repository [`tsfm`](https://github.com/ibm/tsfm).
```
pip install git+https://github.com/IBM/tsfm.git
```
2. Install Hugging Face [`Transformers`](https://github.com/huggingface/transformers#installation)
```
pip install transformers
```
3. Test it with the following commands in a `python` terminal.
```
from transformers import PatchTSMixerConfig
from tsfm_public.toolkit.dataset import ForecastDFDataset
```
## Part 1: Forecasting on Electricity dataset
Here we train a `PatchTSMixer` model directly on the Electricity dataset, and evaluate its performance.
```python
import os
import random
from transformers import (
EarlyStoppingCallback,
PatchTSMixerConfig,
PatchTSMixerForPrediction,
Trainer,
TrainingArguments,
)
import numpy as np
import pandas as pd
import torch
from tsfm_public.toolkit.dataset import ForecastDFDataset
from tsfm_public.toolkit.time_series_preprocessor import TimeSeriesPreprocessor
from tsfm_public.toolkit.util import select_by_index
```
### Set seed
```python
from transformers import set_seed
set_seed(42)
```
### Load and prepare datasets
In the next cell, please adjust the following parameters to suit your application:
- `dataset_path`: path to local .csv file, or web address to a csv file for the data of interest. Data is loaded with pandas, so anything supported by
`pd.read_csv` is supported: (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html).
- `timestamp_column`: column name containing timestamp information, use `None` if there is no such column.
- `id_columns`: List of column names specifying the IDs of different time series. If no ID column exists, use `[]`.
- `forecast_columns`: List of columns to be modeled.
- `context_length`: The amount of historical data used as input to the model. Windows of the input time series data with length equal to
`context_length` will be extracted from the input dataframe. In the case of a multi-time series dataset, the context windows will be created
so that they are contained within a single time series (i.e., a single ID).
- `forecast_horizon`: Number of timestamps to forecast in the future.
- `train_start_index`, `train_end_index`: the start and end indices in the loaded data which delineate the training data.
- `valid_start_index`, `valid_end_index`: the start and end indices in the loaded data which delineate the validation data.
- `test_start_index`, `test_end_index`: the start and end indices in the loaded data which delineate the test data.
- `num_workers`: Number of CPU workers in the PyTorch dataloader.
- `batch_size`: Batch size.
The data is first loaded into a Pandas dataframe and split into training, validation, and test parts. Then the Pandas dataframes are converted to the appropriate PyTorch dataset required for training.
```python
# Download ECL data from https://github.com/zhouhaoyi/Informer2020
dataset_path = "~/Downloads/ECL.csv"
timestamp_column = "date"
id_columns = []
context_length = 512
forecast_horizon = 96
num_workers = 16 # Reduce this if you have low number of CPU cores
batch_size = 64 # Adjust according to GPU memory
```
```python
data = pd.read_csv(
dataset_path,
parse_dates=[timestamp_column],
)
forecast_columns = list(data.columns[1:])
# get split
num_train = int(len(data) * 0.7)
num_test = int(len(data) * 0.2)
num_valid = len(data) - num_train - num_test
border1s = [
0,
num_train - context_length,
len(data) - num_test - context_length,
]
border2s = [num_train, num_train + num_valid, len(data)]
train_start_index = border1s[0] # None indicates beginning of dataset
train_end_index = border2s[0]
# we shift the start of the evaluation period back by context length so that
# the first evaluation timestamp is immediately following the training data
valid_start_index = border1s[1]
valid_end_index = border2s[1]
test_start_index = border1s[2]
test_end_index = border2s[2]
train_data = select_by_index(
data,
id_columns=id_columns,
start_index=train_start_index,
end_index=train_end_index,
)
valid_data = select_by_index(
data,
id_columns=id_columns,
start_index=valid_start_index,
end_index=valid_end_index,
)
test_data = select_by_index(
data,
id_columns=id_columns,
start_index=test_start_index,
end_index=test_end_index,
)
time_series_processor = TimeSeriesPreprocessor(
context_length=context_length,
timestamp_column=timestamp_column,
id_columns=id_columns,
input_columns=forecast_columns,
output_columns=forecast_columns,
scaling=True,
)
time_series_processor.train(train_data)
```
```python
train_dataset = ForecastDFDataset(
time_series_processor.preprocess(train_data),
id_columns=id_columns,
timestamp_column="date",
input_columns=forecast_columns,
output_columns=forecast_columns,
context_length=context_length,
prediction_length=forecast_horizon,
)
valid_dataset = ForecastDFDataset(
time_series_processor.preprocess(valid_data),
id_columns=id_columns,
timestamp_column="date",
input_columns=forecast_columns,
output_columns=forecast_columns,
context_length=context_length,
prediction_length=forecast_horizon,
)
test_dataset = ForecastDFDataset(
time_series_processor.preprocess(test_data),
id_columns=id_columns,
timestamp_column="date",
input_columns=forecast_columns,
output_columns=forecast_columns,
context_length=context_length,
prediction_length=forecast_horizon,
)
```
## Configure the PatchTSMixer model
Next, we instantiate a randomly initialized PatchTSMixer model with a configuration. The settings below control the different hyperparameters related to the architecture.
- `num_input_channels`: the number of input channels (or dimensions) in the time series data. This is
automatically set to the number for forecast columns.
- `context_length`: As described above, the amount of historical data used as input to the model.
- `prediction_length`: This is same as the forecast horizon as described above.
- `patch_length`: The patch length for the `PatchTSMixer` model. It is recommended to choose a value that evenly divides `context_length`.
- `patch_stride`: The stride used when extracting patches from the context window.
- `d_model`: Hidden feature dimension of the model.
- `num_layers`: The number of model layers.
- `dropout`: Dropout probability for all fully connected layers in the encoder.
- `head_dropout`: Dropout probability used in the head of the model.
- `mode`: PatchTSMixer operating mode. "common_channel"/"mix_channel". Common-channel works in channel-independent mode. For pretraining, use "common_channel".
- `scaling`: Per-widow standard scaling. Recommended value: "std".
For full details on the parameters, we refer to the [documentation](https://huggingface.co./docs/transformers/main/en/model_doc/patchtsmixer#transformers.PatchTSMixerConfig).
We recommend that you only adjust the values in the next cell.
```python
patch_length = 8
config = PatchTSMixerConfig(
context_length=context_length,
prediction_length=forecast_horizon,
patch_length=patch_length,
num_input_channels=len(forecast_columns),
patch_stride=patch_length,
d_model=16,
num_layers=8,
expansion_factor=2,
dropout=0.2,
head_dropout=0.2,
mode="common_channel",
scaling="std",
)
model = PatchTSMixerForPrediction(config)
```
## Train model
Next, we can leverage the Hugging Face [Trainer](https://huggingface.co./docs/transformers/main_classes/trainer) class to train the model based on the direct forecasting strategy. We first define the [TrainingArguments](https://huggingface.co./docs/transformers/main_classes/trainer#transformers.TrainingArguments) which lists various hyperparameters regarding training such as the number of epochs, learning rate, and so on.
```python
training_args = TrainingArguments(
output_dir="./checkpoint/patchtsmixer/electricity/pretrain/output/",
overwrite_output_dir=True,
learning_rate=0.001,
num_train_epochs=100, # For a quick test of this notebook, set it to 1
do_eval=True,
evaluation_strategy="epoch",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
dataloader_num_workers=num_workers,
report_to="tensorboard",
save_strategy="epoch",
logging_strategy="epoch",
save_total_limit=3,
logging_dir="./checkpoint/patchtsmixer/electricity/pretrain/logs/", # Make sure to specify a logging directory
load_best_model_at_end=True, # Load the best model when training ends
metric_for_best_model="eval_loss", # Metric to monitor for early stopping
greater_is_better=False, # For loss
label_names=["future_values"],
)
# Create the early stopping callback
early_stopping_callback = EarlyStoppingCallback(
early_stopping_patience=10, # Number of epochs with no improvement after which to stop
early_stopping_threshold=0.0001, # Minimum improvement required to consider as improvement
)
# define trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
callbacks=[early_stopping_callback],
)
# pretrain
trainer.train()
>>> | Epoch | Training Loss | Validation Loss |
| | [
[
"research",
"implementation",
"tutorial",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"research",
"implementation",
"tutorial",
"tools"
] | null | null |
efca23db-56b6-41ac-a964-f0f0537329bd | completed | 2025-01-16T03:08:53.171129 | 2025-01-19T18:59:27.392432 | 60620c60-b6a8-4cad-9e31-fa97dc23b5f7 | Make LLM Fine-tuning 2x faster with Unsloth and 🤗 TRL | danielhanchen | unsloth-trl.md | Pulling your hair out because LLM fine-tuning is taking forever? In this post, we introduce a lightweight tool developed by the community to make LLM fine-tuning go super fast!
Before diving into Unsloth, it may be helpful to read our [QLoRA blog post](https://huggingface.co./blog/4bit-transformers-bitsandbytes), or be familiar with LLM fine-tuning using the 🤗 PEFT library.
## Unsloth - 2x faster, -40% memory usage, 0% accuracy degradation
[Unsloth](https://github.com/unslothai/unsloth) is a lightweight library for faster LLM fine-tuning which is fully compatible with the Hugging Face ecosystem (Hub, transformers, PEFT, TRL). The library is actively developed by the Unsloth team ([Daniel](https://huggingface.co./danielhanchen) and [Michael](https://github.com/shimmyshimmer)) and the open source community. The library supports most NVIDIA GPUs –from GTX 1070 all the way up to H100s–, and can be used with the entire trainer suite from the TRL library (SFTTrainer, DPOTrainer, PPOTrainer). At the time of writing, Unsloth supports the Llama (CodeLlama, Yi, etc) and Mistral architectures.
Unsloth works by overwriting some parts of the modeling code with optimized operations. By manually deriving backpropagation steps and rewriting all Pytorch modules into Triton kernels, Unsloth can both reduce memory usage and make fine-tuning faster. Crucially, accuracy degradation is 0% with respect to normal QLoRA, because no approximations are made in the optimized code.
## Benchmarking
| 1 A100 40GB | Dataset | 🤗 Hugging Face | 🤗 + Flash Attention 2 | 🦥 Unsloth | 🦥 VRAM reduction |
| | [
[
"llm",
"optimization",
"tools",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"fine_tuning",
"optimization",
"tools"
] | null | null |
9247b787-731a-4e72-aef5-5f96a8a52aac | completed | 2025-01-16T03:08:53.171134 | 2025-01-19T19:00:01.189886 | a8031ae0-b554-4f01-aeb6-ac448157851a | Nyströmformer: Approximating self-attention in linear time and memory via the Nyström method | asi | nystromformer.md | <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
## Introduction
Transformers have exhibited remarkable performance on various Natural Language Processing and Computer Vision tasks. Their success can be attributed to the self-attention mechanism, which captures the pairwise interactions between all the tokens in an input. However, the standard self-attention mechanism has a time and memory complexity of \\(O(n^2)\\) (where \\(n\\) is the length of the input sequence), making it expensive to train on long input sequences.
The [Nyströmformer](https://arxiv.org/abs/2102.03902) is one of many efficient Transformer models that approximates standard self-attention with \\(O(n)\\) complexity. Nyströmformer exhibits competitive performance on various downstream NLP and CV tasks while improving upon the efficiency of standard self-attention. The aim of this blog post is to give readers an overview of the Nyström method and how it can be adapted to approximate self-attention.
## Nyström method for matrix approximation
At the heart of Nyströmformer is the Nyström method for matrix approximation. It allows us to approximate a matrix by sampling some of its rows and columns. Let's consider a matrix \\(P^{n \times n}\\), which is expensive to compute in its entirety. So, instead, we approximate it using the Nyström method. We start by sampling \\(m\\) rows and columns from \\(P\\). We can then arrange the sampled rows and columns as follows:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Representing P as a block matrix" src="assets/86_nystromformer/p_block.png"></medium-zoom>
<figcaption>Representing P as a block matrix</figcaption>
</figure>
We now have four submatrices: \\(A_P, B_P, F_P,\\) and \\(C_P\\), with sizes \\(m \times m, m \times (n - m), (n - m) \times m\\) and
\\((n - m) \times (n - m)\\) respectively. The \\(m\\) sampled columns are contained in \\(A_P\\) and \\(F_P\\), whereas the \\(m\\) sampled rows are contained in \\(A_P\\) and \\(B_P\\). So, the entries of \\(A_P, B_P,\\) and \\(F_P\\) are known to us, and we will estimate \\(C_P\\). According to the Nyström method, \\(C_P\\) is given by:
$$C_P = F_P A_P^+ B_P$$
Here, \\(+\\) denotes the Moore-Penrose inverse (or pseudoinverse).
Thus, the Nyström approximation of \\(P, \hat{P}\\) can be written as:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Nyström approximation of P" src="assets/86_nystromformer/p_hat.png"></medium-zoom>
<figcaption>Nyström approximation of P</figcaption>
</figure>
As shown in the second line, \\(\hat{P}\\) can be expressed as a product of three matrices. The reason for doing so will become clear later.
## Can we approximate self-attention with the Nyström method?
Our goal is to ultimately approximate the softmax matrix in standard self attention: S = softmax \\( \frac{QK^T}{\sqrt{d}} \\)
Here, \\(Q\\) and \\(K\\) denote the queries and keys respectively. Following the procedure discussed above, we would sample \\(m\\) rows and columns from \\(S\\), form four submatrices, and obtain \\(\hat{S}\\):
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Nyström approximation of S" src="assets/86_nystromformer/s_hat.png"></medium-zoom>
<figcaption>Nyström approximation of S</figcaption>
</figure>
But, what does it mean to sample a column from \\(S\\)? It means we select one element from each row. Recall how S is calculated: the final operation is a row-wise softmax. To find a single entry in a row, we must access all other entries (for the denominator in softmax). So, sampling one column requires us to know all other columns in the matrix. Therefore, we cannot directly apply the Nyström method to approximate the softmax matrix.
## How can we adapt the Nyström method to approximate self-attention?
Instead of sampling from \\(S\\), the authors propose to sample landmarks (or Nyström points) from queries and keys. We denote the query landmarks and key landmarks as \\(\tilde{Q}\\) and \\(\tilde{K}\\) respectively. \\(\tilde{Q}\\) and \\(\tilde{K}\\) can be used to construct three matrices corresponding to those in the Nyström approximation of \\(S\\). We define the following matrices:
$$\tilde{F} = softmax(\frac{Q\tilde{K}^T}{\sqrt{d}}) \hspace{40pt} \tilde{A} = softmax(\frac{\tilde{Q}\tilde{K}^T}{\sqrt{d}})^+ \hspace{40pt} \tilde{B} = softmax(\frac{\tilde{Q}K^T}{\sqrt{d}})$$
The sizes of \\(\tilde{F}\\), \\(\tilde{A}\\), and \\(\tilde{B}) are \\(n \times m, m \times m,\\) and \\(m \times n\\) respectively.
We replace the three matrices in the Nyström approximation of \\(S\\) with the new matrices we have defined to obtain an alternative Nyström approximation:
$$\begin{aligned}\hat{S} &= \tilde{F} \tilde{A} \tilde{B} \\ &= softmax(\frac{Q\tilde{K}^T}{\sqrt{d}}) softmax(\frac{\tilde{Q}\tilde{K}^T}{\sqrt{d}})^+ softmax(\frac{\tilde{Q}K^T}{\sqrt{d}}) \end{aligned}$$
This is the Nyström approximation of the softmax matrix in the self-attention mechanism. We multiply this matrix with the values ( \\(V\\)) to obtain a linear approximation of self-attention. Note that we never calculated the product \\(QK^T\\), avoiding the \\(O(n^2)\\) complexity.
## How do we select landmarks?
Instead of sampling \\(m\\) rows from \\(Q\\) and \\(K\\), the authors propose to construct \\(\tilde{Q}\\) and \\(\tilde{K}\\)
using segment means. In this procedure, \\(n\\) tokens are grouped into \\(m\\) segments, and the mean of each segment is computed. Ideally, \\(m\\) is much smaller than \\(n\\). According to experiments from the paper, selecting just \\(32\\) or \\(64\\) landmarks produces competetive performance compared to standard self-attention and other efficient attention mechanisms, even for long sequences lengths ( \\(n=4096\\) or \\(8192\\)).
The overall algorithm is summarised by the following figure from the paper:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Efficient self-attention with the Nyström method" src="assets/86_nystromformer/paper_figure.png"></medium-zoom>
<figcaption>Efficient self-attention with the Nyström method</figcaption>
</figure>
The three orange matrices above correspond to the three matrices we constructed using the key and query landmarks. Also, notice that there is a DConv box. This corresponds to a skip connection added to the values using a 1D depthwise convolution.
## How is Nyströmformer implemented?
The original implementation of Nyströmformer can be found [here](https://github.com/mlpen/Nystromformer) and the HuggingFace implementation can be found [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/nystromformer/modeling_nystromformer.py). Let's take a look at a few lines of code (with some comments added) from the HuggingFace implementation. Note that some details such as normalization, attention masking, and depthwise convolution are avoided for simplicity.
```python
key_layer = self.transpose_for_scores(self.key(hidden_states)) # K
value_layer = self.transpose_for_scores(self.value(hidden_states)) # V
query_layer = self.transpose_for_scores(mixed_query_layer) # Q
q_landmarks = query_layer.reshape(
-1,
self.num_attention_heads,
self.num_landmarks,
self.seq_len // self.num_landmarks,
self.attention_head_size,
).mean(dim=-2) # \tilde{Q}
k_landmarks = key_layer.reshape(
-1,
self.num_attention_heads,
self.num_landmarks,
self.seq_len // self.num_landmarks,
self.attention_head_size,
).mean(dim=-2) # \tilde{K}
kernel_1 = torch.nn.functional.softmax(torch.matmul(query_layer, k_landmarks.transpose(-1, -2)), dim=-1) # \tilde{F}
kernel_2 = torch.nn.functional.softmax(torch.matmul(q_landmarks, k_landmarks.transpose(-1, -2)), dim=-1) # \tilde{A} before pseudo-inverse
attention_scores = torch.matmul(q_landmarks, key_layer.transpose(-1, -2)) # \tilde{B} before softmax
kernel_3 = nn.functional.softmax(attention_scores, dim=-1) # \tilde{B}
attention_probs = torch.matmul(kernel_1, self.iterative_inv(kernel_2)) # \tilde{F} * \tilde{A}
new_value_layer = torch.matmul(kernel_3, value_layer) # \tilde{B} * V
context_layer = torch.matmul(attention_probs, new_value_layer) # \tilde{F} * \tilde{A} * \tilde{B} * V
```
## Using Nyströmformer with HuggingFace
Nyströmformer for Masked Language Modeling (MLM) is available on HuggingFace. Currently, there are 4 checkpoints, corresponding to various sequence lengths: [`nystromformer-512`](https://huggingface.co./uw-madison/nystromformer-512), [`nystromformer-1024`](https://huggingface.co./uw-madison/nystromformer-1024), [`nystromformer-2048`](https://huggingface.co./uw-madison/nystromformer-2048), and [`nystromformer-4096`](https://huggingface.co./uw-madison/nystromformer-4096). The number of landmarks, \\(m\\), can be controlled using the `num_landmarks` parameter in the [`NystromformerConfig`](https://huggingface.co./docs/transformers/v4.18.0/en/model_doc/nystromformer#transformers.NystromformerConfig). Let's take a look at a minimal example of Nyströmformer for MLM:
```python
from transformers import AutoTokenizer, NystromformerForMaskedLM
import torch
tokenizer = AutoTokenizer.from_pretrained("uw-madison/nystromformer-512")
model = NystromformerForMaskedLM.from_pretrained("uw-madison/nystromformer-512")
inputs = tokenizer("Paris is the [MASK] of France.", return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# retrieve index of [MASK]
mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
tokenizer.decode(predicted_token_id)
```
<div class="output stream stdout">
Output: | [
[
"transformers",
"research",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"research",
"optimization",
"efficient_computing"
] | null | null |
4eab0e12-858e-41d6-b534-d7bfba658ae4 | completed | 2025-01-16T03:08:53.171139 | 2025-01-16T03:10:01.614395 | ea14a1cf-331c-4233-bf09-b52e7e970afc | 3D Asset Generation: AI for Game Development #3 | dylanebert | ml-for-games-3.md | **Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7190364745495678254). Otherwise, if you want the technical details, keep reading!
**Note:** This tutorial is intended for readers who are familiar with Unity development and C#. If you're new to these technologies, check out the [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954) series before continuing.
## Day 3: 3D Assets
In [Part 2](https://huggingface.co./blog/ml-for-games-2) of this tutorial series, we used **AI for Game Design**. More specifically, we used ChatGPT to brainstorm the design for our game.
In this part, we'll talk about how you can use AI to generate 3D Assets. The short answer is: you can't. That's because text-to-3D isn't at the point it can be practically applied to game development, *yet*. However, that's changing very quickly. Keep reading to learn about [The Current State of Text-to-3D](#the-current-state-of-text-to-3d), [Why It Isn't Useful (yet)](#why-it-isnt-useful-yet), and [The Future of Text-to-3D](#the-future-of-text-to-3d).
### The Current State of Text-to-3D
As discussed in [Part 1](https://huggingface.co./blog/ml-for-games-1), text-to-image tools such as Stable Diffusion are incredibly useful in the game development workflow. However, what about text-to-3D, or generating 3D models from text descriptions? There have been many very recent developments in this area:
- [DreamFusion](https://dreamfusion3d.github.io/) uses 2D diffusion to generate 3D assets.
- [CLIPMatrix](https://arxiv.org/abs/2109.12922) and [CLIP-Mesh-SMPLX](https://github.com/NasirKhalid24/CLIP-Mesh-SMPLX) generate textured meshes directly.
- [CLIP-Forge](https://github.com/autodeskailab/clip-forge) uses language to generate voxel-based models.
- [CLIP-NeRF](https://github.com/cassiePython/CLIPNeRF) drives NeRFs with text and images.
- [Point-E](https://huggingface.co./spaces/openai/point-e) and [Pulsar+CLIP](https://colab.research.google.com/drive/1IvV3HGoNjRoyAKIX-aqSWa-t70PW3nPs) use language to generate 3D point clouds.
- [Dream Textures](https://github.com/carson-katri/dream-textures/releases/tag/0.0.9) uses text-to-image to texture scenes in Blender automatically.
Many of these approaches, excluding CLIPMatrix and CLIP-Mesh-SMPLX, are based on [view synthesis](https://en.wikipedia.org/wiki/View_synthesis), or generating novel views of a subject, as opposed to conventional 3D rendering. This is the idea behind [NeRFs](https://developer.nvidia.com/blog/getting-started-with-nvidia-instant-nerfs/) or Neural Radiance Fields, which use neural networks for view synthesis.
<figure class="image text-center">
<img src="https://developer-blogs.nvidia.com/wp-content/uploads/2022/05/Excavator_NeRF.gif" alt="NeRF">
<figcaption>View synthesis using NeRFs.</figcaption>
</figure>
What does all of this mean if you're a game developer? Currently, nothing. This technology hasn't reached the point that it's useful in game development *yet*. Let's talk about why.
### Why It Isn't Useful (yet)
**Note:** This section is intended for readers who are familiar with conventional 3D rendering techniques, such as [meshes](https://en.wikipedia.org/wiki/Polygon_mesh), [UV mapping](https://en.wikipedia.org/wiki/UV_mapping) and [photogrammetry](https://en.wikipedia.org/wiki/Photogrammetry).
While view synthesis is impressive, the world of 3D runs on meshes, which are not the same as NeRFs. There is, however, [ongoing work on converting NeRFs to meshes](https://github.com/NVlabs/instant-ngp). In practice, this is reminiscient of [photogrammetry](https://en.wikipedia.org/wiki/Photogrammetry), where multiple photos of real-world objects are combined to author 3D assets.
<figure class="image text-center">
<img src="https://github.com/NVlabs/instant-ngp/raw/master/docs/assets_readme/testbed.png" alt="NeRF-to-mesh">
<figcaption>NVlabs instant-ngp, which supports NeRF-to-mesh conversion.</figcaption>
</figure>
The practical use of assets generated using the text-to-NeRF-to-mesh pipeline is limited in a similar way to assets produced using photogrammetry. That is, the resulting mesh is not immediately game-ready, and requires significant work and expertise to become a game-ready asset. In this sense, NeRF-to-mesh may be a useful tool as-is, but doesn't yet reach the transformative potential of text-to-3D.
Since NeRF-to-mesh, like photogrammetry, is currently most suited to creating ultra-high-fidelity assets with significant manual post-processing, it doesn't really make sense for creating a farming game in 5 days. In which case, I decided to just use cubes of different colors to represent the crops in the game.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/cubes.png" alt="Stable Diffusion Demo Space">
</figure>
Things are changing rapidly in this area, though, and there may be a viable solution in the near future. Next, I'll talk about some of the directions text-to-3D may be going.
### The Future of Text-to-3D
While text-to-3D has come a long way recently, there is still a significant gap between where we are now and what could have an impact along the lines of text-to-image. I can only speculate on how this gap will be closed. There are two possible directions that are most apparent:
1. Improvements in NeRF-to-mesh and mesh generation. As we've seen, current generation models are similar to photogrammetry in that they require a lot of work to produce game-ready assets. While this is useful in some scenarios, like creating realistic high-fidelity assets, it's still more time-consuming than making low-poly assets from scratch, especially if you're like me and use an ultra-low-poly art style.
2. New rendering techniques that allow NeRFs to be rendered directly in-engine. While there have been no official announcements, one could speculate that [NVIDIA](https://www.nvidia.com/en-us/omniverse/) and [Google](https://dreamfusion3d.github.io/), among others, may be working on this.
Of course, only time will tell. If you want to keep up with advancements as they come, feel free to follow me on [Twitter](https://twitter.com/dylan_ebert_). If there are new developments I've missed, feel free to reach out!
Click [here](https://huggingface.co./blog/ml-for-games-4) to read Part 4, where we use **AI for 2D Assets**.
#### Attribution
Thanks to Poli [@multimodalart](https://huggingface.co./multimodalart) for providing info on the latest open source text-to-3D. | [
[
"implementation",
"tutorial",
"tools",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"implementation",
"tutorial",
"image_generation",
"tools"
] | null | null |
e675b6c0-5639-4bb0-9b88-b90772fefaf8 | completed | 2025-01-16T03:08:53.171143 | 2025-01-19T17:16:56.684649 | 0dd81474-3b97-4662-953f-44582d7bebbf | Bringing serverless GPU inference to Hugging Face users | philschmid, jeffboudier, rita3ko, nkothariCF | cloudflare-workers-ai.md | <div class="alert alert-warning">
Update (November 2024): The integration is no longer available. Please switch to the Hugging Face Inference API, Inference Endpoints, or other deployment options for your AI model needs.
</div>
Today, we are thrilled to announce the launch of **Deploy on Cloudflare Workers AI**, a new integration on the Hugging Face Hub. Deploy on Cloudflare Workers AI makes using open models as a serverless API easy, powered by state-of-the-art GPUs deployed in Cloudflare edge data centers. Starting today, we are integrating some of the most popular open models on Hugging Face into Cloudflare Workers AI, powered by our production solutions, like [Text Generation Inference](https://github.com/huggingface/text-generation-inference/).
With Deploy on Cloudflare Workers AI, developers can build robust Generative AI applications without managing GPU infrastructure and servers and at a very low operating cost: only pay for the compute you use, not for idle capacity.
## Generative AI for Developers
This new experience expands upon the [strategic partnership we announced last year](https://blog.cloudflare.com/partnering-with-hugging-face-deploying-ai-easier-affordable) to simplify the access and deployment of open Generative AI models. One of the main problems developers and organizations face is the scarcity of GPU availability and the fixed costs of deploying servers to start building. Deploy on Cloudflare Workers AI offers an easy, low-cost solution to these challenges, providing serverless access to popular Hugging Face Models with a [pay-per-request pricing model](https://developers.cloudflare.com/workers-ai/platform/pricing).
Let's take a look at a concrete example. Imagine you develop an RAG Application that gets ~1000 requests per day, with an input of 1k tokens and an output of 100 tokens using Meta Llama 2 7B. The LLM inference production costs would amount to about $1 a day.

"We're excited to bring this integration to life so quickly. Putting the power of Cloudflare's global network of serverless GPUs into the hands of developers, paired with the most popular open source models on Hugging Face, will open the doors to lots of exciting innovation by our community around the world," said John Graham-Cumming, CTO, Cloudflare
## How it works
Using Hugging Face Models on Cloudflare Workers AI is super easy. Below, you will find step-by-step instructions on how to use Hermes 2 Pro on Mistral 7B, the newest model from Nous Research.
You can find all available models in this [Cloudflare Collection](https://huggingface.co./collections/Cloudflare/hf-curated-models-available-on-workers-ai-66036e7ad5064318b3e45db6).
_Note: You need access to a [Cloudflare Account](https://developers.cloudflare.com/fundamentals/setup/find-account-and-zone-ids/) and [API Token](https://dash.cloudflare.com/profile/api-tokens)._
You can find the Deploy on Cloudflare option on all available model pages, including models like Llama, Gemma or Mistral.

Open the “Deploy” menu, and select “Cloudflare Workers AI” - this will open an interface that includes instructions on how to use this model and send requests.
_Note: If the model you want to use does not have a “Cloudflare Workers AI” option, it is currently not supported. We are working on extending the availability of models together with Cloudflare. You can reach out to us at [[email protected]](mailto:[email protected]) with your request._

The integration can currently be used via two options: using the [Workers AI REST API](https://developers.cloudflare.com/workers-ai/get-started/rest-api/) or directly in Workers with the [Cloudflare AI SDK](https://developers.cloudflare.com/workers-ai/get-started/workers-wrangler/#1-create-a-worker-project). Select your preferred option and copy the code into your environment. When using the REST API, you need to make sure the <code>[ACCOUNT_ID](https://developers.cloudflare.com/fundamentals/setup/find-account-and-zone-ids/)</code> and <code>[API_TOKEN](https://dash.cloudflare.com/profile/api-tokens)</code> variables are defined.
That’s it! Now you can start sending requests to Hugging Face Models hosted on Cloudflare Workers AI. Make sure to use the correct prompt & template expected by the model.
## We’re just getting started
We are excited to collaborate with Cloudflare to make AI more accessible to developers. We will work with the Cloudflare team to make more models and experiences available to you! | [
[
"mlops",
"deployment",
"text_generation",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"deployment",
"integration",
"text_generation"
] | null | null |
b37dac5e-e7d8-48e4-9681-38e668887a67 | completed | 2025-01-16T03:08:53.171148 | 2025-01-19T17:20:28.408573 | 5e690cd5-080b-4b04-880c-ff0da0d0c5cb | Welcome Gemma - Google’s new open LLM | philschmid, osanseviero, pcuenq | gemma.md | > [!NOTE] An update to the Gemma models was released two months after this post, see the latest versions [in this collection](https://huggingface.co./collections/google/gemma-release-65d5efbccdbb8c4202ec078b).
Gemma, a new family of state-of-the-art open LLMs, was released today by Google! It's great to see Google reinforcing its commitment to open-source AI, and we’re excited to fully support the launch with comprehensive integration in Hugging Face.
Gemma comes in two sizes: 7B parameters, for efficient deployment and development on consumer-size GPU and TPU and 2B versions for CPU and on-device applications. Both come in base and instruction-tuned variants.
We’ve collaborated with Google to ensure the best integration into the Hugging Face ecosystem. You can find the 4 open-access models (2 base models & 2 fine-tuned ones) on the Hub. Among the features and integrations being released, we have:
- [Models on the Hub](https://huggingface.co./models?search=google/gemma), with their model cards and licenses
- [🤗 Transformers integration](https://github.com/huggingface/transformers/releases/tag/v4.38.0)
- Integration with Google Cloud
- Integration with Inference Endpoints
- An example of fine-tuning Gemma on a single GPU with 🤗 TRL
## Table of contents
- [What is Gemma?](#what-is-gemma)
- [Prompt format](#prompt-format)
- [Exploring the Unknowns](#exploring-the-unknowns)
- [Demo](#demo)
- [Using 🤗 Transformers](#using-🤗-transformers)
- [JAX Weights](#jax-weights)
- [Integration with Google Cloud](#integration-with-google-cloud)
- [Integration with Inference Endpoints](#integration-with-inference-endpoints)
- [Fine-tuning with 🤗 TRL](#fine-tuning-with-🤗-trl)
- [Additional Resources](#additional-resources)
- [Acknowledgments](#acknowledgments)
## What is Gemma?
Gemma is a family of 4 new LLM models by Google based on Gemini. It comes in two sizes: 2B and 7B parameters, each with base (pretrained) and instruction-tuned versions. All the variants can be run on various types of consumer hardware, even without quantization, and have a context length of 8K tokens:
- [gemma-7b](https://huggingface.co./google/gemma-7b): Base 7B model.
- [gemma-7b-it](https://huggingface.co./google/gemma-7b-it): Instruction fine-tuned version of the base 7B model.
- [gemma-2b](https://huggingface.co./google/gemma-2b): Base 2B model.
- [gemma-2b-it](https://huggingface.co./google/gemma-2b-it): Instruction fine-tuned version of the base 2B model.
A month after the original release, Google released a new version of the instruct models. This version has better coding capabilities, factuality, instruction following and multi-turn quality. The model also is less prone to begin its with "Sure,".
- [gemma-1.1-7b-it](https://huggingface.co./google/gemma-1.1-7b-it)
- [gemma-1.1-2b-it](https://huggingface.co./google/gemma-1.1-2b-it)
<div class="flex items-center justify-center">
<img src="/blog/assets/gemma/Gemma-logo-small.png" alt="Gemma logo">
</div>
So, how good are the Gemma models? Here’s an overview of the base models and their performance compared to other open models on the [LLM Leaderboard](https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard) (higher scores are better):
| Model | License | Commercial use? | Pretraining size [tokens] | Leaderboard score ⬇️ |
| | [
[
"llm",
"fine_tuning",
"integration",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"fine_tuning",
"integration",
"efficient_computing"
] | null | null |
fcd6a50f-d6fc-45dc-b467-3c2b5975ef64 | completed | 2025-01-16T03:08:53.171152 | 2025-01-19T17:20:41.591809 | 53a7a063-6426-4dad-877d-0d71a334a187 | Universal Assisted Generation: Faster Decoding with Any Assistant Model | danielkorat, orenpereg, mber, jmamou, joaogante, lewtun, Nadav-Timor, moshew | universal_assisted_generation.md | <em>TL;DR</em>: Many LLMs such as `gemma-2-9b` and `Mixtral-8x22B-Instruct-v0.1` lack a much smaller version to use for [assisted generation](https://huggingface.co./blog/assisted-generation). In this blog post, we present _Universal Assisted Generation_: a method developed by Intel Labs and Hugging Face which extends assisted generation to work with a small language model **from any model family** 🤯. As a result, it is now possible to accelerate inference from _any_ decoder or [Mixture of Experts](https://huggingface.co./blog/moe) model by **1.5x-2.0x** with almost zero overhead 🔥🔥🔥. Let's dive in!
## Introduction
Nowadays, the strongest open weight LLMs typically have billions to hundreds of billions parameters (hello Llama-3.1-405B 👋), and deploying these beasts in production environments poses a range of engineering challenges. One such challenge is that generating text from these large models is _slow_, which has prompted the community to develop a wide range of techniques to accelerate the decoding process. Assisted generation, also known as [speculative decoding](https://arxiv.org/abs/2211.17192), is a very popular and practical approach for accelerating LLM inference without accuracy loss. In this blog post, we take a look at how assisted generation works and share our research to extend it towards _any_ of the [140,000 language models](https://huggingface.co./models?pipeline_tag=text-generation&sort=trending) on the Hugging Face Hub 🚀!
## Assisted Generation
The core idea behind assisted generation involves using a pair of models, referred to as the _target_ and _assistant_ models. The assistant model is a smaller, more efficient version of the target model, for example you can use [`Llama-3.2-1B`](https://huggingface.co./meta-llama/Llama-3.2-1B) as the assistant model for the larger [`Llama-3.1-70b`](https://huggingface.co./meta-llama/Llama-3.1-70b) target model.
Assisted generation is an iterative process. Each cycle, the assistant model generates a sequence of tokens autoregressively, one at a time. The target model then verifies all the assistant tokens in the sequence in a single forward pass. The speedup is achieved by confirming multiple tokens in each forward pass of the target model, rather than producing just one token at a time. For a more detailed explanation, see the original [blog post](https://huggingface.co./blog/assisted-generation). Combined with the recently introduced [Dynamic Speculation](https://huggingface.co./blog/dynamic_speculation_lookahead) strategy, assisted generation accelerates text generation by 1.5x-3x, depending on the task and the models used.
The remarkable speedups offered by assisted generation come with a significant drawback: the target and assistant models must share the same tokenizer, meaning they need to be from the same model family. However, many widely-used models lack smaller versions that are both compact and accurate enough to deliver substantial latency reductions. Based on our experience, meaningful speedups are typically seen when the assistant model is at least 50-100 times smaller than the target one. For instance, [`CodeLlama-13b`](https://huggingface.co./meta-llama/CodeLlama-13b-Instruct-hf) lacks a smaller version, and [`gemma-2-9b`](https://huggingface.co./google/gemma-2-9b) only has a `2b` variant which is still not sufficiently small/fast to achieve significant performance improvements.
## Universal Assisted Generation
In order to mitigate this pain point, Intel Labs, together with our friends at Hugging Face, has developed Universal Assisted Generation (UAG). UAG enables selecting any pair of target and assistant models regardless of their tokenizer. For example, `gemma-2-9b` can be used as the target model, with the tiny [`vicuna-68m`](https://huggingface.co./double7/vicuna-68m) as the assistant.
The main idea behind the method we propose is 2-way tokenizer translations. Once the assistant model completes a generation iteration, the assistant tokens are converted to text, which is then tokenized using the target model's tokenizer to generate target tokens. After the verification step, the target tokens are similarly converted back to the assistant tokens format, which are then appended to the assistant model's context before the next iteration begins.
Since the assistant and target tokenizers use different vocabularies it's necessary to handle the discrepancies between them. To accurately re-encode the newly generated assistant tokens, it’s essential to prepend a context window consisting of several previous tokens. This entire sequence is then re-encoded into the target token format and aligned with the most recent target tokens to pinpoint the exact location where the newly generated tokens should be appended. This process is illustrated in the video below.
<!-- [GIF 1 -- FWD PASS] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 80%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/universal-assisted-generation/method-animation.mov"
></video>
</figure>
While not shown in the video above, token re-encoding from target to assistant follows a similar process. However, mismatched tokens must be discarded from the assistant model's key-value (KV) cache to ensure data integrity.
## Benchmarks
The table below shows the latency improvements observed for target models when paired with assistant models using different tokenizers.
| Target model | Assistant model | Dataset | Task | Speedup |
| | [
[
"llm",
"research",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"optimization",
"efficient_computing",
"research"
] | null | null |
91fdb4f1-84fe-44d8-a16b-f538e5e539ae | completed | 2025-01-16T03:08:53.171157 | 2025-01-19T18:50:44.767494 | 8cb2a6b1-ed13-4ae4-b523-d9875abf956d | Introducing ⚔️ AI vs. AI ⚔️ a deep reinforcement learning multi-agents competition system | CarlCochet, ThomasSimonini | aivsai.md | <div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/thumbnail.png" alt="Thumbnail">
</div>
We’re excited to introduce a new tool we created: **⚔️ AI vs. AI ⚔️, a deep reinforcement learning multi-agents competition system**.
This tool, hosted on [Spaces](https://hf.co/spaces), allows us **to create multi-agent competitions**. It is composed of three elements:
- A *Space* with a matchmaking algorithm that **runs the model fights using a background task**.
- A *Dataset* **containing the results**.
- A *Leaderboard* that gets the **match history results and displays the models’ ELO**.
Then, when a user pushes a trained model to the Hub, **it gets evaluated and ranked against others**. Thanks to that, we can evaluate your agents against other’s agents in a multi-agent setting.
In addition to being a useful tool for hosting multi-agent competitions, we think this tool can also be a **robust evaluation technique in multi-agent settings.** By playing against a lot of policies, your agents are evaluated against a wide range of behaviors. This should give you a good idea of the quality of your policy.
Let’s see how it works with our first competition host: SoccerTwos Challenge.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/soccertwos.gif" alt="SoccerTwos example">
</div>
## How does AI vs. AI works?
AI vs. AI is an open-source tool developed at Hugging Face **to rank the strength of reinforcement learning models in a multi-agent setting**.
The idea is to get a **relative measure of skill rather than an objective one** by making the models play against each other continuously and use the matches results to assess their performance compared to all the other models and consequently get a view of the quality of their policy without requiring classic metrics.
The more agents are submitted for a given task or environment, **the more representative the rating becomes**.
To generate a rating based on match results in a competitive environment, we decided to base the rankings on the [ELO rating system](https://en.wikipedia.org/wiki/Elo_rating_system).
The core concept is that after a match ends, the rating of both players are updated based on the result and the ratings they had before the game. When a user with a high rating beats one with a low ranking, they won't get many points. Likewise, the loser would not lose many points in this case.
Conversely, if a low-rated player wins in an upset against a high-rated player, it will cause a more significant effect on both of their ratings.
In our context, we **kept the system as simple as possible by not adding any alteration to the quantities gained or lost based on the starting ratings of the player**. As such, gain and loss will always be the perfect opposite (+10 / -10, for instance), and the average ELO rating will stay constant at the starting rating. The choice of a 1200 ELO rating start is entirely arbitrary.
If you want to learn more about ELO and see some calculation example, we wrote an explanation in our Deep Reinforcement Learning Course [here](https://huggingface.co./deep-rl-course/unit7/self-play?fw=pt#the-elo-score-to-evaluate-our-agent)
Using this rating, it is possible **to generate matches between models with comparable strengths automatically**. There are several ways you can go about creating a matchmaking system, but here we decided to keep it fairly simple while guaranteeing a minimum amount of diversity in the matchups and also keeping most matches with fairly close opposing ratings.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/aivsai.png" alt="AI vs AI Process">
</div>
Here's how works the algorithm:
1. Gather all the available models on the Hub. New models get a starting rating of 1200, while others keep the rating they have gained/lost through their previous matches.
2. Create a queue from all these models.
3. Pop the first element (model) from the queue, and then pop another random model in this queue from the n models with the closest ratings to the first model.
4. Simulate this match by loading both models in the environment (a Unity executable, for instance) and gathering the results. For this implementation, we sent the results to a Hugging Face Dataset on the Hub.
5. Compute the new rating of both models based on the received result and the ELO formula.
6. Continue popping models two by two and simulating the matches until only one or zero models are in the queue.
7. Save the resulting ratings and go back to step 1
To run this matchmaking process continuously, we use **free Hugging Face Spaces hardware with a Scheduler** to keep running the matchmaking process as a background task.
The Spaces is also used to fetch the ELO ratings of each model that have already been played and, from it display [a leaderboard](https://huggingface.co./spaces/huggingface-projects/AIvsAI-SoccerTwos) **from which everyone can check the progress of the models**.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/leaderboard.png" alt="Leaderboard">
</div>
The process generally uses several Hugging Face Datasets to provide data persistence (here, matches history and model ratings).
Since the process also saves the matches' history, it is possible to see precisely the results of any given model. This can, for instance, allow you to check why your model struggles with another one, most notably using another demo Space to visualize matches like [this one](https://huggingface.co./spaces/unity/ML-Agents-SoccerTwos.).
For now, **this experiment is running with the MLAgent environment SoccerTwos for the Hugging Face Deep RL Course**, however, the process and implementation, in general, are very much **environment agnostic and could be used to evaluate for free a wide range of adversarial multi-agent settings**.
Of course, it is important to remind again that this evaluation is a relative rating between the strengths of the submitted agents, and the ratings by themselves **have no objective meaning contrary to other metrics**. It only represents how good or bad a model performs compared to the other models in the pool. Still, given a large and varied enough pool of models (and enough matches played), this evaluation becomes a very solid way to represent the general performance of a model.
## Our first AI vs. AI challenge experimentation: SoccerTwos Challenge ⚽
This challenge is Unit 7 of our [free Deep Reinforcement Learning Course](https://huggingface.co./deep-rl-course/unit0/introduction). It started on February 1st and will end on April 30th.
If you’re interested, **you don’t need to participate in the course to be able to participate in the competition. You can start here** 👉 https://huggingface.co./deep-rl-course/unit7/introduction
In this Unit, readers learned the basics of multi-agent reinforcement learning (MARL)by training a **2vs2 soccer team.** ⚽
The environment used was made by the [Unity ML-Agents team](https://github.com/Unity-Technologies/ml-agents). The goal is simple: your team needs to score a goal. To do that, they need to beat the opponent's team and collaborate with their teammate.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/soccertwos.gif" alt="SoccerTwos example">
</div>
In addition to the leaderboard, we created a Space demo where people can choose two teams and visualize them playing 👉[https://huggingface.co./spaces/unity/SoccerTwos](https://huggingface.co./spaces/unity/SoccerTwos)
This experimentation is going well since we already have 48 models on the [leaderboard](https://huggingface.co./spaces/huggingface-projects/AIvsAI-SoccerTwos)

We also [created a discord channel called ai-vs-ai-competition](http://hf.co/discord/join) so that people can exchange with others and share advice.
### Conclusion and what’s next?
Since the tool we developed **is environment agnostic**, we want to host more challenges in the future with [PettingZoo](https://pettingzoo.farama.org/) and other multi-agent environments. If you have some environments or challenges you want to do, <a href="mailto:[email protected]">don’t hesitate to reach out to us</a>.
In the future, we will host multiple multi-agent competitions with this tool and environments we created, such as SnowballFight.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_aivsai/snowballfight.gif" alt="Snowballfight gif">
</div>
In addition to being a useful tool for hosting multi-agent competitions, we think that this tool can also be **a robust evaluation technique in multi-agent settings: by playing against a lot of policies, your agents are evaluated against a wide range of behaviors, and you’ll get a good idea of the quality of your policy.**
The best way to keep in touch is to [join our discord server](http://hf.co/discord/join) to exchange with us and with the community.
****************Citation****************
Citation: If you found this useful for your academic work, please consider citing our work, in text:
`Cochet, Simonini, "Introducing AI vs. AI a deep reinforcement learning multi-agents competition system", Hugging Face Blog, 2023.`
BibTeX citation:
```
@article{cochet-simonini2023,
author = {Cochet, Carl and Simonini, Thomas},
title = {Introducing AI vs. AI a deep reinforcement learning multi-agents competition system},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co./blog/aivsai},
}
``` | [
[
"mlops",
"research",
"benchmarks",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"research",
"tools",
"benchmarks",
"mlops"
] | null | null |
3bad4f83-c3cb-4f43-99ea-d1ac8ff6d705 | completed | 2025-01-16T03:08:53.171161 | 2025-01-19T17:17:41.455600 | 844e7c17-377a-4857-885a-ab40d40f70aa | Goodbye cold boot - how we made LoRA Inference 300% faster | raphael-gl | lora-adapters-dynamic-loading.md | tl;dr: We swap the Stable Diffusion LoRA adapters per user request, while keeping the base model warm allowing fast LoRA inference across multiple users. You can experience this by browsing our [LoRA catalogue](https://huggingface.co./models?library=diffusers&other=lora) and playing with the inference widget.

In this blog we will go in detail over how we achieved that.
We've been able to drastically speed up inference in the Hub for public LoRAs based on public Diffusion models. This has allowed us to save compute resources and provide a faster and better user experience.
To perform inference on a given model, there are two steps:
1. Warm up phase - that consists in downloading the model and setting up the service (25s).
2. Then the inference job itself (10s).
With the improvements, we were able to reduce the warm up time from 25s to 3s. We are now able to serve inference for hundreds of distinct LoRAs, with less than 5 A10G GPUs, while the response time to user requests decreased from 35s to 13s.
Let's talk more about how we can leverage some recent features developed in the [Diffusers](https://github.com/huggingface/diffusers/) library to serve many distinct LoRAs in a dynamic fashion with one single service.
## LoRA
LoRA is a fine-tuning technique that belongs to the family of "parameter-efficient" (PEFT) methods, which try to reduce the number of trainable parameters affected by the fine-tuning process. It increases fine-tuning speed while reducing the size of fine-tuned checkpoints.
Instead of fine-tuning the model by performing tiny changes to all its weights, we freeze most of the layers and only train a few specific ones in the attention blocks. Furthermore, we avoid touching the parameters of those layers by adding the product of two smaller matrices to the original weights. Those small matrices are the ones whose weights are updated during the fine-tuning process, and then saved to disk. This means that all of the model original parameters are preserved, and we can load the LoRA weights on top using an adaptation method.
The LoRA name (Low Rank Adaptation) comes from the small matrices we mentioned. For more information about the method, please refer to [this post](https://huggingface.co./blog/lora) or the [original paper](https://arxiv.org/abs/2106.09685).
<div id="diagram"></div>

The diagram above shows two smaller orange matrices that are saved as part of the LoRA adapter. We can later load the LoRA adapter and merge it with the blue base model to obtain the yellow fine-tuned model. Crucially, _unloading_ the adapter is also possible so we can revert back to the original base model at any point.
In other words, the LoRA adapter is like an add-on of a base model that can be added and removed on demand. And because of A and B smaller ranks, it is very light in comparison with the model size. Therefore, loading is much faster than loading the whole base model.
If you look, for example, inside the [Stable Diffusion XL Base 1.0 model repo](https://huggingface.co./stabilityai/stable-diffusion-xl-base-1.0/tree/main), which is widely used as a base model for many LoRA adapters, you can see that its size is around **7 GB**. However, typical LoRA adapters like [this one](https://huggingface.co./minimaxir/sdxl-wrong-lora/) take a mere **24 MB** of space !
There are far less blue base models than there are yellow ones on the Hub. If we can go quickly from the blue to yellow one and vice versa, then we have a way serve many distinct yellow models with only a few distinct blue deployments.
For a more exhaustive presentation on what LoRA is, please refer to the following blog post:[Using LoRA for Efficient Stable Diffusion Fine-Tuning](https://huggingface.co./blog/lora), or refer directly to the [original paper](https://arxiv.org/abs/2106.09685).
## Benefits
We have approximately **2500** distinct public LoRAs on the Hub. The vast majority (**~92%**) of them are LoRAs based on the [Stable Diffusion XL Base 1.0](https://huggingface.co./stabilityai/stable-diffusion-xl-base-1.0) model.
Before this mutualization, this would have meant deploying a dedicated service for all of them (eg. for all the yellow merged matrices in the diagram above); releasing + reserving at least one new GPU. The time to spawn the service and have it ready to serve requests for a specific model is approximately **25s**, then on top of this you have the inference time (**~10s** for a 1024x1024 SDXL inference diffusion with 25 inference steps on an A10G). If an adapter is only occasionally requested, its service gets stopped to free resources preempted by others.
If you were requesting a LoRA that was not so popular, even if it was based on the SDXL model like the vast majority of adapters found on the Hub so far, it would have required **35s** to warm it up and get an answer on the first request (the following ones would have taken the inference time, eg. **10s**).
Now: request time has decreased from 35s to 13s since adapters will use only a few distinct "blue" base models (like 2 significant ones for Diffusion). Even if your adapter is not so popular, there is a good chance that its "blue" service is already warmed up. In other words, there is a good chance that you avoid the 25s warm up time, even if you do not request your model that often. The blue model is already downloaded and ready, all we have to do is unload the previous adapter and load the new one, which takes **3s** as we see [below](#loading-figures).
Overall, this requires less GPUs to serve all distinct models, even though we already had a way to share GPUs between deployments to maximize their compute usage. In a **2min** time frame, there are approximately **10** distinct LoRA weights that are requested. Instead of spawning 10 deployments, and keeping them warm, we simply serve all of them with 1 to 2 GPUs (or more if there is a request burst).
## Implementation
We implemented LoRA mutualization in the Inference API. When a request is performed on a model available in our platform, we first determine whether this is a LoRA or not. We then identify the base model for the LoRA and route the request to a common backend farm, with the ability to serve requests for the said model. Inference requests get served by keeping the base model warm and loading/unloading LoRAs on the fly. This way we can ultimately reuse the same compute resources to serve many distinct models at once.
### LoRA structure
In the Hub, LoRAs can be identified with two attributes:

A LoRA will have a ```base_model``` attribute. This is simply the model which the LoRA was built for and should be applied to when performing inference.
Because LoRAs are not the only models with such an attribute (any duplicated model will have one), a LoRA will also need a ```lora``` tag to be properly identified.
### Loading/Offloading LoRA for Diffusers 🧨
<div class="alert">
<p>
Note that there is a more seemless way to perform the same as what is presented in this section using the <a href="https://github.com/huggingface/peft">peft</a> library. Please refer to <a href="https://huggingface.co./docs/diffusers/main/en/tutorials/using_peft_for_inference">the documentation</a> for more details. The principle remains the same as below (going from/to the blue box to/from the yellow one in the <a href="#diagram">diagram</a> above)
</p>
</div>
</br>
4 functions are used in the Diffusers library to load and unload distinct LoRA weights:
```load_lora_weights``` and ```fuse_lora``` for loading and merging weights with the main layers. Note that merging weights with the main model before performing inference can decrease the inference time by 30%.
```unload_lora_weights``` and ```unfuse_lora``` for unloading.
We provide an example below on how one can leverage the Diffusers library to quickly load several LoRA weights on top of a base model:
```py
import torch
from diffusers import (
AutoencoderKL,
DiffusionPipeline,
)
import time
base = "stabilityai/stable-diffusion-xl-base-1.0"
adapter1 = 'nerijs/pixel-art-xl'
weightname1 = 'pixel-art-xl.safetensors'
adapter2 = 'minimaxir/sdxl-wrong-lora'
weightname2 = None
inputs = "elephant"
kwargs = {}
if torch.cuda.is_available():
kwargs["torch_dtype"] = torch.float16
start = time.time()
# Load VAE compatible with fp16 created by madebyollin
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix",
torch_dtype=torch.float16,
)
kwargs["vae"] = vae
kwargs["variant"] = "fp16"
model = DiffusionPipeline.from_pretrained(
base, **kwargs
)
if torch.cuda.is_available():
model.to("cuda")
elapsed = time.time() - start
print(f"Base model loaded, elapsed {elapsed:.2f} seconds")
def inference(adapter, weightname):
start = time.time()
model.load_lora_weights(adapter, weight_name=weightname)
# Fusing lora weights with the main layers improves inference time by 30 % !
model.fuse_lora()
elapsed = time.time() - start
print(f"LoRA adapter loaded and fused to main model, elapsed {elapsed:.2f} seconds")
start = time.time()
data = model(inputs, num_inference_steps=25).images[0]
elapsed = time.time() - start
print(f"Inference time, elapsed {elapsed:.2f} seconds")
start = time.time()
model.unfuse_lora()
model.unload_lora_weights()
elapsed = time.time() - start
print(f"LoRA adapter unfused/unloaded from base model, elapsed {elapsed:.2f} seconds")
inference(adapter1, weightname1)
inference(adapter2, weightname2)
```
## Loading figures
All numbers below are in seconds:
<table>
<tr>
<th>GPU</th>
<td>T4</td>
<td>A10G</td>
</tr>
<tr>
<th>Base model loading - not cached</th>
<td>20</td>
<td>20</td>
</tr>
<tr>
<th>Base model loading - cached</th>
<td>5.95</td>
<td>4.09</td>
</tr>
<tr>
<th>Adapter 1 loading</th>
<td>3.07</td>
<td>3.46</td>
</tr>
<tr>
<th>Adapter 1 unloading</th>
<td>0.52</td>
<td>0.28</td>
</tr>
<tr>
<th>Adapter 2 loading</th>
<td>1.44</td>
<td>2.71</td>
</tr>
<tr>
<th>Adapter 2 unloading</th>
<td>0.19</td>
<td>0.13</td>
</tr>
<tr>
<th>Inference time</th>
<td>20.7</td>
<td>8.5</td>
</tr>
</table>
With 2 to 4 additional seconds per inference, we can serve many distinct LoRAs. However, on an A10G GPU, the inference time decreases by a lot while the adapters loading time does not change much, so the LoRA's loading/unloading is relatively more expensive.
### Serving requests
To serve inference requests, we use [this open source community image](https://github.com/huggingface/api-inference-community/tree/main/docker_images/diffusers)
You can find the previously described mechanism used in the [TextToImagePipeline](https://github.com/huggingface/api-inference-community/blob/main/docker_images/diffusers/app/pipelines/text_to_image.py) class.
When a LoRA is requested, we'll look at the one that is loaded and change it only if required, then we perform inference as usual. This way, we are able to serve requests for the base model and many distinct adapters.
Below is an example on how you can test and request this image:
```
$ git clone https://github.com/huggingface/api-inference-community.git
$ cd api-inference-community/docker_images/diffusers
$ docker build -t test:1.0 -f Dockerfile .
$ cat > /tmp/env_file <<'EOF'
MODEL_ID=stabilityai/stable-diffusion-xl-base-1.0
TASK=text-to-image
HF_HUB_ENABLE_HF_TRANSFER=1
EOF
$ docker run --gpus all --rm --name test1 --env-file /tmp/env_file_minimal -p 8888:80 -it test:1.0
```
Then in another terminal perform requests to the base model and/or miscellaneous LoRA adapters to be found on the HF Hub.
```
# Request the base model
$ curl 0:8888 -d '{"inputs": "elephant", "parameters": {"num_inference_steps": 20}}' > /tmp/base.jpg
# Request one adapter
$ curl -H 'lora: minimaxir/sdxl-wrong-lora' 0:8888 -d '{"inputs": "elephant", "parameters": {"num_inference_steps": 20}}' > /tmp/adapter1.jpg
# Request another one
$ curl -H 'lora: nerijs/pixel-art-xl' 0:8888 -d '{"inputs": "elephant", "parameters": {"num_inference_steps": 20}}' > /tmp/adapter2.jpg
```
### What about batching ?
Recently a really interesting [paper](https://arxiv.org/abs/2311.03285) came out, that described how to increase the throughput by performing batched inference on LoRA models. In short, all inference requests would be gathered in a batch, the computation related to the common base model would be done all at once, then the remaining adapter-specific products would be computed. We did not implement such a technique (close to the approach adopted in [text-generation-inference](https://github.com/huggingface/text-generation-inference/) for LLMs). Instead, we stuck to single sequential inference requests. The reason is that we observed that batching was not interesting for diffusers: throughput does not increase significantly with batch size. On the simple image generation benchmark we performed, it only increased 25% for a batch size of 8, in exchange for 6 times increased latency! Comparatively, batching is far more interesting for LLMs because you get 8 times the sequential throughput with only a 10% latency increase. This is the reason why we did not implement batching for diffusers.
## Conclusion: **Time**!
Using dynamic LoRA loading, we were able to save compute resources and improve the user experience in the Hub Inference API. Despite the extra time added by the process of unloading the previously loaded adapter and loading the one we're interested in, the fact that the serving process is most often already up and running makes the inference time response on the whole much shorter.
Note that for a LoRA to benefit from this inference optimization on the Hub, it must both be public, non-gated and based on a non-gated public model. Please do let us know if you apply the same method to your deployment! | [
[
"mlops",
"optimization",
"image_generation",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"image_generation",
"optimization",
"mlops",
"efficient_computing"
] | null | null |
e37fd6a0-8735-477a-9f7e-04e38f2eb00a | completed | 2025-01-16T03:08:53.171166 | 2025-01-16T14:20:46.764409 | f9db4b6a-24e1-4742-8c88-55e5ace9ef32 | Data Is Better Together: A Look Back and Forward | davanstrien, davidberenstein1957, sdiazlor | dibt.md | For the past few months, we have been working on the [Data Is Better Together](https://github.com/huggingface/data-is-better-together) initiative. With this collaboration between Hugging Face and Argilla and the support of the open-source ML community, our goal has been to empower the open-source community to create impactful datasets collectively.
Now, we have decided to move forward with the same goal. To provide an overview of our achievements and tasks where everyone can contribute, we organized it into two sections: community efforts and cookbook efforts.
## Community efforts
Our first steps in this initiative focused on the **prompt ranking** project. Our goal was to create a dataset of 10K prompts, both synthetic and human-generated, ranked by quality. The community's response was immediate!
- In a few days, over 385 people joined.
- We released the [DIBT/10k_prompts_ranked](https://huggingface.co./datasets/DIBT/10k_prompts_ranked) dataset intended for prompt ranking tasks or synthetic data generation.
- The dataset was used to build new [models](https://huggingface.co./models?dataset=dataset:DIBT/10k_prompts_ranked), such as SPIN.
Seeing the global support from the community, we recognized that English-centric data alone is insufficient, and there are not enough language-specific benchmarks for open LLMs. So, we created the **Multilingual Prompt Evaluation Project (MPEP)** with the aim of developing a leaderboard for multiple languages. For that, a subset of 500 high-quality prompts from [DIBT/10k_prompts_ranked](https://huggingface.co./datasets/DIBT/10k_prompts_ranked) was selected to be translated into different languages.
- More than 18 language leaders created the spaces for the translations.
- Completed translations for [Dutch](https://huggingface.co./datasets/DIBT/MPEP_DUTCH), [Russian](https://huggingface.co./datasets/DIBT/MPEP_RUSSIAN) or [Spanish](https://huggingface.co./datasets/DIBT/MPEP_SPANISH), with many more efforts working towards complete translations of the prompts.
- The creation of a community of dataset builders on Discord
Going forward, we’ll continue to support community efforts focused on building datasets through tools and documentation.
## Cookbook efforts
As part of [DIBT](https://github.com/huggingface/data-is-better-together), we also created guides and tools that help the community build valuable datasets on their own.
- **Domain Specific dataset**: To bootstrap the creation of more domain-specific datasets for training models, bringing together engineers and domain experts.
- **DPO/ORPO dataset**: To help foster a community of people building more DPO-style datasets for different languages, domains, and tasks.
- **KTO dataset**: To help the community create their own KTO datasets.
## What have we learnt?
- The community is eager to participate in these efforts, and there is excitement about collectively working on datasets.
- There are existing inequalities that must be overcome to ensure comprehensive and inclusive benchmarks. Datasets for certain languages, domains, and tasks are currently underrepresented in the open-source community.
- We have many of the tools needed for the community to effectively collaborate on building valuable datasets.
## How can you get involved?
You can still contribute to the cookbook efforts by following the instructions in the README of the project you're interested in, sharing your datasets and results with the community, or providing new guides and tools for everyone. Your contributions are invaluable in helping us build a robust and comprehensive resource for all.
If you want to be part of it, please join us in the `#data-is-better-together` channel in the [**Hugging Face Discord**](http://hf.co/join/discord) and let us know what you want to build together!
We are looking forward to building better datasets together with you! | [
[
"data",
"research",
"community",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"data",
"community",
"research",
"tools"
] | null | null |
223a148e-7c2a-4a81-a2ed-2885c2d9fae6 | completed | 2025-01-16T03:08:53.171170 | 2025-01-19T19:14:40.193040 | 539f1dc9-be15-4ff3-9390-9e652d0ac33d | Pollen-Vision: Unified interface for Zero-Shot vision models in robotics | apirrone, simheo, PierreRouanet, revellsi | pollen-vision.md | > [!NOTE] This is a guest blog post by the Pollen Robotics team. We are the creators of Reachy, an open-source humanoid robot designed for manipulation in the real world.
<video style="max-width: 100%; margin: auto;" autoplay loop muted playsinline src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/pollen-vision/pollen_vision_intro.mp4"></video>
In the context of autonomous behaviors, the essence of a robot's usability lies in its ability to understand and interact with its environment. This understanding primarily comes from **visual perception**, which enables robots to identify objects, recognize people, navigate spaces, and much more.
We're excited to share the initial launch of our open-source `pollen-vision` library, a first step towards empowering our robots with the autonomy to grasp unknown objects. **This library is a carefully curated collection of vision models chosen for their direct applicability to robotics.** `Pollen-vision` is designed for ease of installation and use, composed of independent modules that can be combined to create a 3D object detection pipeline, getting the position of the objects in 3D space (x, y, z).
We focused on selecting [zero-shot models](https://huggingface.co./tasks/zero-shot-object-detection), eliminating the need for any training, and making these tools instantly usable right out of the box.
Our initial release is focused on 3D object detection—laying the groundwork for tasks like robotic grasping by providing a reliable estimate of objects' spatial coordinates. Currently limited to positioning within a 3D space (not extending to full 6D pose estimation), this functionality establishes a solid foundation for basic robotic manipulation tasks.
## The Core Models of Pollen-Vision
The library encapsulates several key models. We want the models we use to be zero-shot and versatile, allowing a wide range of detectable objects without re-training. The models also have to be “real-time capable”, meaning they should run at least at a few fps on a consumer GPU. The first models we chose are:
- [OWL-VIT](https://huggingface.co./docs/transformers/model_doc/owlvit) (Open World Localization - Vision Transformer, By Google Research): This model performs text-conditioned zero-shot 2D object localization in RGB images. It outputs bounding boxes (like YOLO)
- [Mobile Sam](https://github.com/ChaoningZhang/MobileSAM): A lightweight version of the Segment Anything Model (SAM) by Meta AI. SAM is a zero-shot image segmentation model. It can be prompted with bounding boxes or points.
- [RAM](https://github.com/xinyu1205/recognize-anything) (Recognize Anything Model by OPPO Research Institute): Designed for zero-shot image tagging, RAM can determine the presence of an object in an image based on textual descriptions, laying the groundwork for further analysis.
## Get started in very few lines of code!
Below is an example of how to use pollen-vision to build a simple object detection and segmentation pipeline, taking only images and text as input.
```python
from pollen_vision.vision_models.object_detection import OwlVitWrapper
from pollen_vision.vision_models.object_segmentation import MobileSamWrapper
from pollen_vision.vision_models.utils import Annotator, get_bboxes
owl = OwlVitWrapper()
sam = MobileSamWrapper()
annotator = Annotator()
im = ...
predictions = owl.infer(im, ["paper cups"]) # zero-shot object detection
bboxes = get_bboxes(predictions)
masks = sam.infer(im, bboxes=bboxes) # zero-shot object segmentation
annotated_im = annotator.annotate(im, predictions, masks=masks)
```
<p align="center">
<img width="40%" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/pollen-vision/paper_cups.png">
</p>
OWL-VIT’s inference time depends on the number of prompts provided (i.e., the number of objects to detect). On a Laptop with a RTX 3070 GPU:
```
1 prompt : ~75ms per frame
2 prompts : ~130ms per frame
3 prompts : ~180ms per frame
4 prompts : ~240ms per frame
5 prompts : ~330ms per frame
10 prompts : ~650ms per frame
```
So it is interesting, performance-wise, to only prompt OWL-VIT with objects that we know are in the image. That’s where RAM is useful, as it is fast and provides exactly this information.
## A robotics use case: grasping unknown objects in unconstrained environments
With the object's segmentation mask, we can estimate its (u, v) position in pixel space by computing the centroid of the binary mask. Here, having the segmentation mask is very useful because it allows us to average the depth values inside the mask rather than inside the full bounding box, which also contains a background that would skew the average.
One way to do that is by averaging the u and v coordinates of the non zero pixels in the mask
```python
def get_centroid(mask):
x_center, y_center = np.argwhere(mask == 1).sum(0) / np.count_nonzero(mask)
return int(y_center), int(x_center)
```
We can now bring in depth information in order to estimate the z coordinate of the object. The depth values are already in meters, but the (u, v) coordinates are expressed in pixels. We can get the (x, y, z) position of the centroid of the object in meters using the camera’s intrinsic matrix (K)
```python
def uv_to_xyz(z, u, v, K):
cx = K[0, 2]
cy = K[1, 2]
fx = K[0, 0]
fy = K[1, 1]
x = (u - cx) * z / fx
y = (v - cy) * z / fy
return np.array([x, y, z])
```
We now have an estimation of the 3D position of the object in the camera’s reference frame.
If we know where the camera is positioned relative to the robot’s origin frame, we can perform a simple transformation to get the 3D position of the object in the robot’s frame. This means we can move the end effector of our robot where the object is, **and grasp it** ! 🥳
<video style="max-width: 100%; margin: auto;" autoplay loop muted playsinline src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/pollen-vision/demo.mp4"></video>
## What’s next?
What we presented in this post is a first step towards our goal, which is autonomous grasping of unknown objects in the wild. There are a few issues that still need addressing:
- OWL-Vit does not detect everything every time and can be inconsistent. We are looking for a better option.
- There is no temporal or spatial consistency so far. All is recomputed every frame
- We are currently working on integrating a point tracking solution to enhance the consistency of the detections
- Grasping technique (only front grasp for now) was not the focus of this work. We will be working on different approaches to enhance the grasping capabilities in terms of perception (6D detection) and grasping pose generation.
- Overall speed could be improved
## Try pollen-vision
Wanna try pollen-vision? Check out our [Github repository](https://github.com/pollen-robotics/pollen-vision) ! | [
[
"computer_vision",
"implementation",
"tools",
"robotics"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"robotics",
"tools",
"implementation"
] | null | null |
cbd0dc9b-33cb-4d6f-9dcb-8af73f3e6900 | completed | 2025-01-16T03:08:53.171175 | 2025-01-19T18:47:22.809584 | 83ffb055-b708-4f40-8aaf-029a038c6979 | Using Stable Diffusion with Core ML on Apple Silicon | pcuenq | diffusers-coreml.md | Thanks to Apple engineers, you can now run Stable Diffusion on Apple Silicon using Core ML!
[This Apple repo](https://github.com/apple/ml-stable-diffusion) provides conversion scripts and inference code based on [🧨 Diffusers](https://github.com/huggingface/diffusers), and we love it! To make it as easy as possible for you, we converted the weights ourselves and put the Core ML versions of the models in [the Hugging Face Hub](https://hf.co/apple).
**Update**: some weeks after this post was written we created a native Swift app that you can use to run Stable Diffusion effortlessly on your own hardware. We released [an app in the Mac App Store](https://apps.apple.com/app/diffusers/id1666309574) as well as [the source code to allow other projects to use it](https://github.com/huggingface/swift-coreml-diffusers).
The rest of this post guides you on how to use the converted weights in your own code or convert additional weights yourself.
## Available Checkpoints
The official Stable Diffusion checkpoints are already converted and ready for use:
- Stable Diffusion v1.4: [converted](https://hf.co/apple/coreml-stable-diffusion-v1-4) [original](https://hf.co/CompVis/stable-diffusion-v1-4)
- Stable Diffusion v1.5: [converted](https://hf.co/apple/coreml-stable-diffusion-v1-5) [original](https://hf.co/runwayml/stable-diffusion-v1-5)
- Stable Diffusion v2 base: [converted](https://hf.co/apple/coreml-stable-diffusion-2-base) [original](https://huggingface.co./stabilityai/stable-diffusion-2-base)
- Stable Diffusion v2.1 base: [converted](https://hf.co/apple/coreml-stable-diffusion-2-1-base) [original](https://huggingface.co./stabilityai/stable-diffusion-2-1-base)
Core ML supports all the compute units available in your device: CPU, GPU and Apple's Neural Engine (NE). It's also possible for Core ML to run different portions of the model in different devices to maximize performance.
There are several variants of each model that may yield different performance depending on the hardware you use. We recommend you try them out and stick with the one that works best in your system. Read on for details.
## Notes on Performance
There are several variants per model:
- "Original" attention vs "split_einsum". These are two alternative implementations of the critical attention blocks. `split_einsum` was [previously introduced by Apple](https://machinelearning.apple.com/research/neural-engine-transformers), and is compatible with all the compute units (CPU, GPU and Apple's Neural Engine). `original`, on the other hand, is only compatible with CPU and GPU. Nevertheless, `original` can be faster than `split_einsum` on some devices, so do check it out!
- "ML Packages" vs "Compiled" models. The former is suitable for Python inference, while the `compiled` version is required for Swift code. The `compiled` models in the Hub split the large UNet model weights in several files for compatibility with iOS and iPadOS devices. This corresponds to the [`--chunk-unet` conversion option](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml).
At the time of this writing, we got best results on my MacBook Pro (M1 Max, 32 GPU cores, 64 GB) using the following combination:
- `original` attention.
- `all` compute units (see next section for details).
- macOS Ventura 13.1 Beta 4 (22C5059b).
With these, it took 18s to generate one image with the Core ML version of Stable Diffusion v1.4 🤯.
> **⚠️ Note**
>
> Several improvements to Core ML were introduced in macOS Ventura 13.1, and they are required by Apple's implementation. You may get black images –and much slower times– if you use previous versions of macOS.
Each model repo is organized in a tree structure that provides these different variants:
```
coreml-stable-diffusion-v1-4
├── README.md
├── original
│ ├── compiled
│ └── packages
└── split_einsum
├── compiled
└── packages
```
You can download and use the variant you need as shown below.
## Core ML Inference in Python
### Prerequisites
```bash
pip install huggingface_hub
pip install git+https://github.com/apple/ml-stable-diffusion
```
### Download the Model Checkpoints
To run inference in Python, you have to use one of the versions stored in the `packages` folders, because the compiled ones are only compatible with Swift. You may choose whether you want to use the `original` or `split_einsum` attention styles.
This is how you'd download the `original` attention variant from the Hub:
```Python
from huggingface_hub import snapshot_download
from pathlib import Path
repo_id = "apple/coreml-stable-diffusion-v1-4"
variant = "original/packages"
model_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_"))
snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False)
print(f"Model downloaded at {model_path}")
```
The code above will place the downloaded model snapshot inside a directory called `models`.
### Inference
Once you have downloaded a snapshot of the model, the easiest way to run inference would be to use Apple's Python script.
```shell
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" -i models/coreml-stable-diffusion-v1-4_original_packages -o </path/to/output/image> --compute-unit ALL --seed 93
```
`<output-mlpackages-directory>` should point to the checkpoint you downloaded in the step above, and `--compute-unit` indicates the hardware you want to allow for inference. It must be one of the following options: `ALL`, `CPU_AND_GPU`, `CPU_ONLY`, `CPU_AND_NE`. You may also provide an optional output path, and a seed for reproducibility.
The inference script assumes the original version of the Stable Diffusion model, stored in the Hub as `CompVis/stable-diffusion-v1-4`. If you use another model, you _have_ to specify its Hub id in the inference command-line, using the `--model-version` option. This works both for models already supported, and for custom models you trained or fine-tuned yourself.
For Stable Diffusion 1.5 (Hub id: `runwayml/stable-diffusion-v1-5`):
```shell
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" --compute-unit ALL -o output --seed 93 -i models/coreml-stable-diffusion-v1-5_original_packages --model-version runwayml/stable-diffusion-v1-5
```
For Stable Diffusion 2 base (Hub id: `stabilityai/stable-diffusion-2-base`):
```shell
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" --compute-unit ALL -o output --seed 93 -i models/coreml-stable-diffusion-2-base_original_packages --model-version stabilityai/stable-diffusion-2-base
```
## Core ML inference in Swift
Running inference in Swift is slightly faster than in Python, because the models are already compiled in the `mlmodelc` format. This will be noticeable on app startup when the model is loaded, but shouldn’t be noticeable if you run several generations afterwards.
### Download
To run inference in Swift on your Mac, you need one of the `compiled` checkpoint versions. We recommend you download them locally using Python code similar to the one we showed above, but using one of the `compiled` variants:
```Python
from huggingface_hub import snapshot_download
from pathlib import Path
repo_id = "apple/coreml-stable-diffusion-v1-4"
variant = "original/compiled"
model_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_"))
snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False)
print(f"Model downloaded at {model_path}")
```
### Inference
To run inference, please clone Apple's repo:
```bash
git clone https://github.com/apple/ml-stable-diffusion
cd ml-stable-diffusion
```
And then use Apple's command-line tool using Swift Package Manager's facilities:
```bash
swift run StableDiffusionSample --resource-path models/coreml-stable-diffusion-v1-4_original_compiled --compute-units all "a photo of an astronaut riding a horse on mars"
```
You have to specify in `--resource-path` one of the checkpoints downloaded in the previous step, so please make sure it contains compiled Core ML bundles with the extension `.mlmodelc`. The `--compute-units` has to be one of these values: `all`, `cpuOnly`, `cpuAndGPU`, `cpuAndNeuralEngine`.
For more details, please refer to the [instructions in Apple's repo](https://github.com/apple/ml-stable-diffusion).
## Bring Your own Model
If you have created your own models compatible with Stable Diffusion (for example, if you used Dreambooth, Textual Inversion or fine-tuning), then you have to convert the models yourself. Fortunately, Apple provides a conversion script that allows you to do so.
For this task, we recommend you follow [these instructions](https://github.com/apple/ml-stable-diffusion#converting-models-to-coreml).
## Next Steps
We are really excited about the opportunities this brings and can't wait to see what the community can create from here. Some potential ideas are:
- Native, high-quality apps for Mac, iPhone and iPad.
- Bring additional schedulers to Swift, for even faster inference.
- Additional pipelines and tasks.
- Explore quantization techniques and further optimizations.
Looking forward to seeing what you create! | [
[
"computer_vision",
"implementation",
"tools",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"image_generation",
"implementation",
"tools"
] | null | null |
e9794c9a-8269-4c5e-88ba-573af4e623d0 | completed | 2025-01-16T03:08:53.171179 | 2025-01-19T17:06:38.804404 | 1218648e-fb88-4d15-9b74-576f06e22a0f | Block Sparse Matrices for Smaller and Faster Language Models | madlag | pytorch_block_sparse.md | ## Saving space and time, one zero at a time
In previous [blog](https://medium.com/huggingface/is-the-future-of-neural-networks-sparse-an-introduction-1-n-d03923ecbd70)
[posts](https://medium.com/huggingface/sparse-neural-networks-2-n-gpu-performance-b8bc9ce950fc)
we introduced sparse matrices and what they could do to improve neural networks.
The basic assumption is that full dense layers are often overkill and can be pruned without a significant loss in precision.
In some cases sparse linear layers can even *improve precision or/and generalization*.
The main issue is that currently available code that supports sparse algebra computation is severely lacking efficiency.
We are also [still waiting](https://openai.com/blog/openai-pytorch/) for official PyTorch support.
That's why we ran out of patience and took some time this summer to address this "lacuna".
Today, we are excited to **release the extension [pytorch_block_sparse](https://github.com/huggingface/pytorch_block_sparse)**.
By itself, or even better combined with other methods like
[distillation](https://medium.com/huggingface/distilbert-8cf3380435b5)
and [quantization](https://medium.com/microsoftazure/faster-and-smaller-quantized-nlp-with-hugging-face-and-onnx-runtime-ec5525473bb7),
this library enables **networks** which are both **smaller and faster**,
something Hugging Face considers crucial to let anybody use
neural networks in production at **low cost**, and to **improve the experience** for the end user.
## Usage
The provided `BlockSparseLinear` module is a drop in replacement for `torch.nn.Linear`, and it is trivial to use
it in your models:
```python
# from torch.nn import Linear
from pytorch_block_sparse import BlockSparseLinear
...
# self.fc = nn.Linear(1024, 256)
self.fc = BlockSparseLinear(1024, 256, density=0.1)
```
The extension also provides a `BlockSparseModelPatcher` that allows to modify an existing model "on the fly",
which is shown in this [example notebook](https://github.com/huggingface/pytorch_block_sparse/blob/master/doc/notebooks/ModelSparsification.ipynb).
Such a model can then be trained as usual, without any change in your model source code.
## NVIDIA CUTLASS
This extension is based on the [cutlass tilesparse](https://github.com/YulhwaKim/cutlass_tilesparse) proof of concept by [Yulhwa Kim](https://github.com/YulhwaKim).
It is using **C++ CUDA templates** for block-sparse matrix multiplication
based on **[CUTLASS](https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/)**.
CUTLASS is a collection of CUDA C++ templates for implementing high-performance CUDA kernels.
With CUTLASS, approching cuBLAS performance on custom kernels is possible without resorting to assembly language code.
The latest versions include all the **Ampere Tensor Core primitives**, providing **x10 or more speedups** with a limited loss of precision.
Next versions of pytorch_block_sparse will make use of these primitives,
as block sparsity is 100% compatible with Tensor Cores requirements.
## Performance
At the current stage of the library, the performances for sparse matrices are roughly
two times slower than their cuBLAS optimized dense counterpart, and we are confident
that we can improve this in the future.
This is a huge improvement on PyTorch sparse matrices: their current implementation is an order of magnitude slower
than the dense one.
But the more important point is that the performance gain of using sparse matrices grows with the sparsity,
so a **75% sparse matrix** is roughly **2x** faster than the dense equivalent.
The memory savings are even more significant: for **75% sparsity**, memory consumption is reduced by **4x**
as you would expect.
## Future work
Being able to efficiently train block-sparse linear layers was just the first step.
The sparsity pattern is currenly fixed at initialization, and of course optimizing it during learning will yield large
improvements.
So in future versions, you can expect tools to measure the "usefulness" of parameters to be able to **optimize the sparsity pattern**.
**NVIDIA Ampere 50% sparse pattern** within blocks will probably yield another significant performance gain, just as upgrading
to more recent versions of CUTLASS does.
So, stay tuned for more sparsity goodness in a near future! | [
[
"implementation",
"optimization",
"tools",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"optimization",
"implementation",
"efficient_computing",
"tools"
] | null | null |
c012bb2f-f04d-48cd-a444-8e1a59e53acd | completed | 2025-01-16T03:08:53.171184 | 2025-01-16T03:20:09.440029 | 5988ae9b-c6bf-4ec0-8057-a0e6d54d5fee | Using LoRA for Efficient Stable Diffusion Fine-Tuning | pcuenq, sayakpaul | lora.md | [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) is a novel technique introduced by Microsoft researchers to deal with the problem of fine-tuning large-language models. Powerful models with billions of parameters, such as GPT-3, are prohibitively expensive to fine-tune in order to adapt them to particular tasks or domains. LoRA proposes to freeze pre-trained model weights and inject trainable layers (_rank-decomposition matrices_) in each transformer block. This greatly reduces the number of trainable parameters and GPU memory requirements since gradients don't need to be computed for most model weights. The researchers found that by focusing on the Transformer attention blocks of large-language models, fine-tuning quality with LoRA was on par with full model fine-tuning while being much faster and requiring less compute.
## LoRA for Diffusers 🧨
Even though LoRA was initially proposed for large-language models and demonstrated on transformer blocks, the technique can also be applied elsewhere. In the case of Stable Diffusion fine-tuning, LoRA can be applied to the cross-attention layers that relate the image representations with the prompts that describe them. The details of the following figure (taken from the [Stable Diffusion paper](https://arxiv.org/abs/2112.10752)) are not important, just note that the yellow blocks are the ones in charge of building the relationship between image and text representations.

To the best of our knowledge, Simo Ryu ([`@cloneofsimo`](https://github.com/cloneofsimo)) was the first one to come up with a LoRA implementation adapted to Stable Diffusion. Please, do take a look at [their GitHub project](https://github.com/cloneofsimo/lora) to see examples and lots of interesting discussions and insights.
In order to inject LoRA trainable matrices as deep in the model as in the cross-attention layers, people used to need to hack the source code of [diffusers](https://github.com/huggingface/diffusers) in imaginative (but fragile) ways. If Stable Diffusion has shown us one thing, it is that the community always comes up with ways to bend and adapt the models for creative purposes, and we love that! Providing the flexibility to manipulate the cross-attention layers could be beneficial for many other reasons, such as making it easier to adopt optimization techniques such as [xFormers](https://github.com/facebookresearch/xformers). Other creative projects such as [Prompt-to-Prompt](https://arxiv.org/abs/2208.01626) could do with some easy way to access those layers, so we decided to [provide a general way for users to do it](https://github.com/huggingface/diffusers/pull/1639). We've been testing that _pull request_ since late December, and it officially launched with our [diffusers release yesterday](https://github.com/huggingface/diffusers/releases/tag/v0.12.0).
We've been working with [`@cloneofsimo`](https://github.com/cloneofsimo) to provide LoRA training support in diffusers, for both Dreambooth and full fine-tuning methods! These techniques provide the following benefits:
- Training is much faster, as already discussed.
- Compute requirements are lower. We could create a full fine-tuned model in a 2080 Ti with 11 GB of VRAM!
- **Trained weights are much, much smaller**. Because the original model is frozen and we inject new layers to be trained, we can save the weights for the new layers as a single file that weighs in at ~3 MB in size. This is about _one thousand times smaller_ than the original size of the UNet model!
We are particularly excited about the last point. In order for users to share their awesome fine-tuned or _dreamboothed_ models, they had to share a full copy of the final model. Other users that want to try them out have to download the fine-tuned weights in their favorite UI, adding up to combined massive storage and download costs. As of today, there are about [1,000 Dreambooth models registered in the Dreambooth Concepts Library](https://huggingface.co./sd-dreambooth-library), and probably many more not registered in the library.
With LoRA, it is now possible to publish [a single 3.29 MB file](https://huggingface.co./sayakpaul/sd-model-finetuned-lora-t4/blob/main/pytorch_lora_weights.bin) to allow others to use your fine-tuned model.
_(h/t to [`@mishig25`](https://github.com/mishig25), the first person I heard use **dreamboothing** as a verb in a normal conversation)._
## LoRA fine-tuning
Full model fine-tuning of Stable Diffusion used to be slow and difficult, and that's part of the reason why lighter-weight methods such as Dreambooth or Textual Inversion have become so popular. With LoRA, it is much easier to fine-tune a model on a custom dataset.
Diffusers now provides a [LoRA fine-tuning script](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py) that can run in as low as 11 GB of GPU RAM without resorting to tricks such as 8-bit optimizers. This is how you'd use it to fine-tune a model using [Lambda Labs Pokémon dataset](https://huggingface.co./datasets/lambdalabs/pokemon-blip-captions):
```bash
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="/sddata/finetune/lora/pokemon"
export HUB_MODEL_ID="pokemon-lora"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--dataloader_num_workers=8 \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" --lr_warmup_steps=0 \
--output_dir=${OUTPUT_DIR} \
--push_to_hub \
--hub_model_id=${HUB_MODEL_ID} \
--report_to=wandb \
--checkpointing_steps=500 \
--validation_prompt="Totoro" \
--seed=1337
```
One thing of notice is that the learning rate is `1e-4`, much larger than the usual learning rates for regular fine-tuning (in the order of `~1e-6`, typically). This is a [W&B dashboard](https://wandb.ai/pcuenq/text2image-fine-tune/runs/b4k1w0tn?workspace=user-pcuenq) of the previous run, which took about 5 hours in a 2080 Ti GPU (11 GB of RAM). I did not attempt to optimize the hyperparameters, so feel free to try it out yourself! [Sayak](https://huggingface.co./sayakpaul) did another run on a T4 (16 GB of RAM), here's [his final model](https://huggingface.co./sayakpaul/sd-model-finetuned-lora-t4), and here's [a demo Space that uses it](https://huggingface.co./spaces/pcuenq/lora-pokemon).

For additional details on LoRA support in diffusers, please refer to [our documentation](https://huggingface.co./docs/diffusers/main/en/training/lora) – it will be always kept up to date with the implementation.
## Inference
As we've discussed, one of the major advantages of LoRA is that you get excellent results by training orders of magnitude less weights than the original model size. We designed an inference process that allows loading the additional weights on top of the unmodified Stable Diffusion model weights. Let's see how it works.
First, we'll use the Hub API to automatically determine what was the base model that was used to fine-tune a LoRA model. Starting from [Sayak's model](https://huggingface.co./sayakpaul/sd-model-finetuned-lora-t4), we can use this code:
```Python
from huggingface_hub import model_info
# LoRA weights ~3 MB
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
info = model_info(model_path)
model_base = info.cardData["base_model"]
print(model_base) # CompVis/stable-diffusion-v1-4
```
This snippet will print the model he used for fine-tuning, which is `CompVis/stable-diffusion-v1-4`. In my case, I trained my model starting from version 1.5 of Stable Diffusion, so if you run the same code with [my LoRA model](https://huggingface.co./pcuenq/pokemon-lora) you'll see that the output is `runwayml/stable-diffusion-v1-5`.
The information about the base model is automatically populated by the fine-tuning script we saw in the previous section, if you use the `--push_to_hub` option. This is recorded as a metadata tag in the `README` file of the model's repo, as you can see [here](https://huggingface.co./pcuenq/pokemon-lora/blob/main/README.md).
After we determine the base model we used to fine-tune with LoRA, we load a normal Stable Diffusion pipeline. We'll customize it with the `DPMSolverMultistepScheduler` for very fast inference:
```Python
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
pipe = StableDiffusionPipeline.from_pretrained(model_base, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
```
**And here's where the magic comes**. We load the LoRA weights from the Hub _on top of the regular model weights_, move the pipeline to the cuda device and run inference:
```Python
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
image = pipe("Green pokemon with menacing face", num_inference_steps=25).images[0]
image.save("green_pokemon.png")
```
## Dreamboothing with LoRA
Dreambooth allows you to "teach" new concepts to a Stable Diffusion model. LoRA is compatible with Dreambooth and the process is similar to fine-tuning, with a couple of advantages:
- Training is faster.
- We only need a few images of the subject we want to train (5 or 10 are usually enough).
- We can tweak the text encoder, if we want, for additional fidelity to the subject.
To train Dreambooth with LoRA you need to use [this diffusers script](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora.py). Please, take a look at [the README](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#training-with-low-rank-adaptation-of-large-language-models-lora), [the documentation](https://huggingface.co./docs/diffusers/main/en/training/lora) and [our hyperparameter exploration blog post](https://huggingface.co./blog/dreambooth) for details.
For a quick, cheap and easy way to train your Dreambooth models with LoRA, please [check this Space](https://huggingface.co./spaces/lora-library/LoRA-DreamBooth-Training-UI) by [`hysts`](https://twitter.com/hysts12321). You need to duplicate it and assign a GPU so it runs fast. This process will save you from having to set up your own training environment and you'll be able to train your models in minutes!
## Other Methods
The quest for easy fine-tuning is not new. In addition to Dreambooth, [_textual inversion_](https://huggingface.co./docs/diffusers/main/en/training/text_inversion) is another popular method that attempts to teach new concepts to a trained Stable Diffusion Model. One of the main reasons for using Textual Inversion is that trained weights are also small and easy to share. However, they only work for a single subject (or a small handful of them), whereas LoRA can be used for general-purpose fine-tuning, meaning that it can be adapted to new domains or datasets.
[Pivotal Tuning](https://arxiv.org/abs/2106.05744) is a method that tries to combine Textual Inversion with LoRA. First, you teach the model a new concept using Textual Inversion techniques, obtaining a new token embedding to represent it. Then, you train that token embedding using LoRA to get the best of both worlds.
We haven't explored Pivotal Tuning with LoRA yet. Who's up for the challenge? 🤗 | [
[
"llm",
"tutorial",
"image_generation",
"fine_tuning",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"image_generation",
"fine_tuning",
"efficient_computing"
] | null | null |
e424b0c4-8eca-4804-a324-bbe7c03af284 | completed | 2025-01-16T03:08:53.171189 | 2025-01-16T03:16:35.764876 | 3128ca1a-53f9-460d-84ee-937b8e6e454e | Announcing the 🤗 AI Research Residency Program | douwekiela | ai-residency.md | The 🤗 Research Residency Program is a 9-month opportunity to launch or advance your career in machine learning research 🚀. The goal of the residency is to help you grow into an impactful AI researcher. Residents will work alongside Researchers from our Science Team. Together, you will pick a research problem and then develop new machine learning techniques to solve it in an open & collaborative way, with the hope of ultimately publishing your work and making it visible to a wide audience.
Applicants from all backgrounds are welcome! Ideally, you have some research experience and are excited about our mission to democratize responsible machine learning. The progress of our field has the potential to exacerbate existing disparities in ways that disproportionately hurt the most marginalized people in society — including people of color, people from working-class backgrounds, women, and LGBTQ+ people. These communities must be centered in the work we do as a research community. So we strongly encourage proposals from people whose personal experience reflects these identities.. We encourage applications relating to AI that demonstrate a clear and positive societal impact.
## How to Apply
Since the focus of your work will be on developing Machine Learning techniques, your application should show evidence of programming skills and of prerequisite courses, like calculus or linear algebra, or links to an open-source project that demonstrates programming and mathematical ability.
More importantly, your application needs to present interest in effecting positive change through AI in any number of creative ways. This can stem from a topic that is of particular interest to you and your proposal would capture concrete ways in which machine learning can contribute. Thinking through the entire pipeline, from understanding where ML tools are needed to gathering data and deploying the resulting approach, can help make your project more impactful.
We are actively working to build a culture that values diversity, equity, and inclusivity. We are intentionally building a workplace where people feel respected and supported—regardless of who you are or where you come from. We believe this is foundational to building a great company and community. Hugging Face is an equal opportunity employer and we do not discriminate on the basis of race, religion, color, national origin, gender, sexual orientation, age, marital status, veteran status, or disability status.
[Submit your application here](https://apply.workable.com/huggingface/j/1B77519961).
## FAQs
* **Can I complete the program part-time?**<br>No. The Residency is only offered as a full-time position.
* **I have been out of school for several years. Can I apply?**<br>Yes. We will consider applications from various backgrounds.
* **Can I be enrolled as a student at a university or work for another employer during the residency?**<br>No, the residency can’t be completed simultaneously with any other obligations.
* **Will I receive benefits during the Residency?**<br>Yes, residents are eligible for most benefits, including medical (depending on location).
* **Will I be required to relocate for this residency?**<br>Absolutely not! We are a distributed team and you are welcome to work from wherever you are currently located.
* **Is there a deadline?**<br>Applications close on April 3rd, 2022! | [
[
"research",
"community"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"research",
"community"
] | null | null |
9dfd7785-b1c0-429c-a46a-419b4aa0e9b3 | completed | 2025-01-16T03:08:53.171193 | 2025-01-16T13:33:45.506634 | 4b321d63-33e1-423c-97a5-2a8ca5f3e500 | Hugging Face x LangChain : A new partner package | jofthomas, kkondratenko, efriis | langchain.md | We are thrilled to announce the launch of **`langchain_huggingface`**, a partner package in LangChain jointly maintained by Hugging Face and LangChain. This new Python package is designed to bring the power of the latest development of Hugging Face into LangChain and keep it up to date.
# From the community, for the community
All Hugging Face-related classes in LangChain were coded by the community, and while we thrived on this, over time, some of them became deprecated because of the lack of an insider’s perspective.
By becoming a partner package, we aim to reduce the time it takes to bring new features available in the Hugging Face ecosystem to LangChain's users.
**`langchain-huggingface`** integrates seamlessly with LangChain, providing an efficient and effective way to utilize Hugging Face models within the LangChain ecosystem. This partnership is not just about sharing technology but also about a joint commitment to maintain and continually improve this integration.
## **Getting Started**
Getting started with **`langchain-huggingface`** is straightforward. Here’s how you can install and begin using the [package](https://github.com/langchain-ai/langchain/tree/master/libs/partners/huggingface):
```python
pip install langchain-huggingface
```
Now that the package is installed, let’s have a tour of what’s inside !
## The LLMs
### HuggingFacePipeline
Among `transformers`, the [Pipeline](https://huggingface.co./docs/transformers/main_classes/pipelines) is the most versatile tool in the Hugging Face toolbox. LangChain being designed primarily to address RAG and Agent use cases, the scope of the pipeline here is reduced to the following text-centric tasks: `“text-generation"`, `“text2text-generation"`, `“summarization”`, `“translation”`.
Models can be loaded directly with the `from_model_id` method:
```python
from langchain_huggingface import HuggingFacePipeline
llm = HuggingFacePipeline.from_model_id(
model_id="microsoft/Phi-3-mini-4k-instruct",
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 100,
"top_k": 50,
"temperature": 0.1,
},
)
llm.invoke("Hugging Face is")
```
Or you can also define the pipeline yourself before passing it to the class:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer,pipeline
model_id = "microsoft/Phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
#attn_implementation="flash_attention_2", # if you have an ampere GPU
)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=100, top_k=50, temperature=0.1)
llm = HuggingFacePipeline(pipeline=pipe)
llm.invoke("Hugging Face is")
```
When using this class, the model will be loaded in cache and use your computer’s hardware; thus, you may be limited by the available resources on your computer.
### HuggingFaceEndpoint
There are also two ways to use this class. You can specify the model with the `repo_id` parameter. Those endpoints use the [serverless API](https://huggingface.co./inference-api/serverless), which is particularly beneficial to people using [pro accounts](https://huggingface.co./subscribe/pro) or [enterprise hub](https://huggingface.co./enterprise). Still, regular users can already have access to a fair amount of request by connecting with their HF token in the environment where they are executing the code.
```python
from langchain_huggingface import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(
repo_id="meta-llama/Meta-Llama-3-8B-Instruct",
task="text-generation",
max_new_tokens=100,
do_sample=False,
)
llm.invoke("Hugging Face is")
```
```python
llm = HuggingFaceEndpoint(
endpoint_url="<endpoint_url>",
task="text-generation",
max_new_tokens=1024,
do_sample=False,
)
llm.invoke("Hugging Face is")
```
Under the hood, this class uses the [InferenceClient](https://huggingface.co./docs/huggingface_hub/en/package_reference/inference_client) to be able to serve a wide variety of use-case, serverless API to deployed TGI instances.
### ChatHuggingFace
Every model has its own special tokens with which it works best. Without those tokens added to your prompt, your model will greatly underperform
When going from a list of messages to a completion prompt, there is an attribute that exists in most LLM tokenizers called [chat_template](https://huggingface.co./docs/transformers/chat_templating).
To learn more about chat_template in the different models, visit this [space](https://huggingface.co./spaces/Jofthomas/Chat_template_viewer) I made!
This class is wrapper around the other LLMs. It takes as input a list of messages an then creates the correct completion prompt by using the `tokenizer.apply_chat_template` method.
```python
from langchain_huggingface import ChatHuggingFace, HuggingFaceEndpoint
llm = HuggingFaceEndpoint(
endpoint_url="<endpoint_url>",
task="text-generation",
max_new_tokens=1024,
do_sample=False,
)
llm_engine_hf = ChatHuggingFace(llm=llm)
llm_engine_hf.invoke("Hugging Face is")
```
The code above is equivalent to :
```python
# with mistralai/Mistral-7B-Instruct-v0.2
llm.invoke("<s>[INST] Hugging Face is [/INST]")
# with meta-llama/Meta-Llama-3-8B-Instruct
llm.invoke("""<|begin_of_text|><|start_header_id|>user<|end_header_id|>Hugging Face is<|eot_id|><|start_header_id|>assistant<|end_header_id|>""")
```
## The Embeddings
Hugging Face is filled with very powerful embedding models than you can directly leverage in your pipeline.
First choose your model. One good resource for choosing an embedding model is the [MTEB leaderboard](https://huggingface.co./spaces/mteb/leaderboard).
### HuggingFaceEmbeddings
This class uses [sentence-transformers](https://sbert.net/) embeddings. It computes the embedding locally, hence using your computer resources.
```python
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
model_name = "mixedbread-ai/mxbai-embed-large-v1"
hf_embeddings = HuggingFaceEmbeddings(
model_name=model_name,
)
texts = ["Hello, world!", "How are you?"]
hf_embeddings.embed_documents(texts)
```
### HuggingFaceEndpointEmbeddings
`HuggingFaceEndpointEmbeddings` is very similar to what `HuggingFaceEndpoint` does for the LLM, in the sense that it also uses the InferenceClient under the hood to compute the embeddings.
It can be used with models on the hub, and TEI instances whether they are deployed locally or online.
```python
from langchain_huggingface.embeddings import HuggingFaceEndpointEmbeddings
hf_embeddings = HuggingFaceEndpointEmbeddings(
model= "mixedbread-ai/mxbai-embed-large-v1",
task="feature-extraction",
huggingfacehub_api_token="<HF_TOKEN>",
)
texts = ["Hello, world!", "How are you?"]
hf_embeddings.embed_documents(texts)
```
## Conclusion
We are committed to making **`langchain-huggingface`** better by the day. We will be actively monitoring feedback and issues and working to address them as quickly as possible. We will also be adding new features and functionality and expanding the package to support an even wider range of the community's use cases. We strongly encourage you to try this package and to give your opinion, as it will pave the way for the package's future. | [
[
"llm",
"community",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"integration",
"tools",
"community"
] | null | null |
53087824-e3db-4964-a35c-dc2de5493ddf | completed | 2025-01-16T03:08:53.171198 | 2025-01-16T03:15:21.381963 | 9bce6dcd-9a16-470d-9f2f-2d5640e4bebd | NPHardEval Leaderboard: Unveiling the Reasoning Abilities of Large Language Models through Complexity Classes and Dynamic Updates | lizhouf, wenyueH, hyfrankl, clefourrier | leaderboard-nphardeval.md | We're happy to introduce the [NPHardEval leaderboard](https://huggingface.co./spaces/NPHardEval/NPHardEval-leaderboard), using [NPHardEval](https://arxiv.org/abs/2312.14890), a cutting-edge benchmark developed by researchers from the University of Michigan and Rutgers University.
NPHardEval introduces a dynamic, complexity-based framework for assessing Large Language Models' (LLMs) reasoning abilities. It poses 900 algorithmic questions spanning the NP-Hard complexity class and lower, designed to rigorously test LLMs, and is updated on a monthly basis to prevent overfitting!
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.45.1/gradio.js"> </script>
<gradio-app theme_mode="light" space="NPHardEval/NPHardEval-leaderboard"></gradio-app>
## A Unique Approach to LLM Evaluation
[NPHardEval](https://arxiv.org/abs/2312.14890) stands apart by employing computational complexity classes, offering a quantifiable and robust measure of LLM reasoning skills. The benchmark's tasks mirror real-world decision-making challenges, enhancing its relevance and applicability. Regular monthly updates of the benchmark data points mitigate the risk of model overfitting, ensuring a reliable evaluation.
The major contributions of NPHardEval are new using new benchmarking strategies (proposing an automatic and dynamic benchmark), and introducing a new way to evaluate LLM reasoning.
Regarding benchmarking strategies, NPHardEval uses an **automated mechanism**, both to generate and check questions in the benchmark. Since they are based on algorithmically computable problems, human intervention is not required to determine the correctness of the responses from LLMs. This also allows NPHardEval to be a **dynamic benchmark**: since questions can be automatically generated, the benchmark can be updated on a monthly basis. This monthly-refreshed benchmark helps prevent model overfitting as we can always generate novel questions with varying difficulty levels for evaluation.
The questions themselves use a new system to evaluate LLM Reasoning. The questions in the benchmark are grounded in the computational complexity hierarchy, a well-established concept extensively studied in theoretical computer science. This foundation enables us to leverage existing research to rigorously and quantitatively measure an LLM's logical reasoning extent, by **defining reasoning via complexity classes**. The benchmark also deliberatley excludes numerical computation from the questions, since it is a notoriously difficult task for LLMs. **Focusing on logical questions** allows for a more accurate evaluation of an LLM's pure logical reasoning ability, as numerical questions can obscure this assessment.
## Data Synthesis
NPHardEval uses 100 questions for each of 9 different algorithms, with 10 difficulty levels, resulting in 900 questions across complexity and difficulty. The 9 algorithms, including 3 P, 3 NP-complete, and 3 NP-hard questions, are characterized according to the computing theory. The 900 questions are all synthesized and updated monthly.
<div align="center">
<img src="https://github.com/casmlab/NPHardEval/raw/main/figure/questions_blog.png" alt="Tasks in NPHardEval" style="width:80%">
</div>
More background and insights are available in [these slides](https://docs.google.com/presentation/d/1VYBrCw5BqxuCCwlHeVn_UlhFj6zw04uETJzufw6spA8/edit?usp=sharing).
## Evaluation Metrics
We use two metrics to evaluate the reasoning ability of LLMs: Weighted Accuracy and Failure Rate.
### Weighted Accuracy (WA)
**Weighted Accuracy (WA)** is used to evaluate problem-solving accuracy. This method is applied to each problem, either through comparison with a correct answer or via step-by-step result checking for problems without a singular answer. To reflect comparative accuracy more effectively, we assign weights to different difficulty levels. Each level's weight corresponds to its relative importance or challenge, with higher difficulty levels receiving more weight in a linear progression (for instance, level 1 has weight 1, level 2 has weight 2, and so on).
The formula for Weighted Accuracy is as follows:
<div align="center">
\\( WA = \frac{\sum\limits_{i=1}^{10} (w_i \times A_i)}{\sum\limits_{i=1}^{10} w_i} \\)
</div>
In this equation, \\(w_i\\) represents the weight assigned to difficulty level \\(i\\) (ranging from 1 to 10), and \\(A_i\\) is the accuracy at that level.
### Failure Rate (FR)
Another critical metric we consider is the **Failure Rate (FR)**. This measure helps assess the frequency of unsuccessful outcomes across different problems and difficulty levels. It's particularly useful for identifying instances where an LLM's result does not match the expected output format.
The Failure Rate is calculated by considering the proportion of failed attempts relative to the total number of attempts for each difficulty level. An attempt is counted as failed if the model generates results that cannot be successfully parsed in all endpoint calls. We set the maximum number of tries as 10. For each problem, the Failure Rate is then aggregated across all difficulty levels, considering the total of 10 attempts at each level.
The formal definition of Failure Rate is:
<div align="center">
\\( FR = \frac{\sum\limits_{i=1}^{10} F_i}{100} \\)
</div>
Here, \\( F_i \\) denotes the number of failed attempts at difficulty level \\( i \\).
## Experimentation and Insights
The benchmark includes comprehensive experiments to analyze LLMs across various complexity classes and difficulty levels. It delves into the nuances of LLM performance, providing valuable insights into their reasoning strengths and limitations. In general:
- Closed-source models generally perform better than open-source models, with GPT 4 Turbo performing the best overall.
- Models generally perform better on less-complex questions, i.e. easier complexity classes, while not always linearly decrease on complexity levels. Models such as Claude 2 perform the best on NP-complete (middle-complexity) questions.
- Some open-source models can outperform close-source models on specific questions. Leading open-source models include Yi-34b, Qwen-14b, Phi-2, and Mistral-7b.
<div align="center">
<img src="https://github.com/casmlab/NPHardEval/raw/main/figure/weighted_accuracy_failed.png" alt="Weighted Accuracy and Failure Rate" style="width:80%">
</div>
<div align="center">
<img src="https://github.com/casmlab/NPHardEval/raw/main/figure/zeroshot_heatmap.png" alt="Zeroshot Heatmap" style="width:60%">
</div>
## Reproducing NPHardEval Benchmark results on your machine
To set up the NPHardEval Benchmark, you need to follow a few steps:
1. Environment setup: after cloning the repository to your local machine, install the required python library with `conda`.
```bash
conda create --name llm_reason python==3.10
conda activate llm_reason
git clone https://github.com/casmlab/NPHardEval.git
pip install -r requirements.txt
```
2. Set-up API keys: fetch API keys and change the corresponding entries in `secrets.txt`.
3. Example Commands: evaluate your model with the NPHardEval benchmark!
For example, to use the GPT 4 Turbo model (GPT-4-1106-preview) and the edit distance problem (EDP) for evaluation:
- For its zeroshot experiment, we can use:
```
cd Close/run
python run_p_EDP.py gpt-4-1106-preview
```
- For its fewshot experiment,
```
cd Close/run
python run_p_EDP_few.py gpt-4-1106-preview self
```
We currently support fewshot examples from the same question (self), and may support examples from other questions (other) in the future.
## Join the Conversation
[The NPHardEval leaderboard](https://huggingface.co./spaces/NPHardEval/NPHardEval-leaderboard), [dataset](https://huggingface.co./datasets/NPHardEval/NPHardEval-results) and [code](https://github.com/casmlab/NPHardEval) are available on Github and Hugging Face for community access and contributions.
We'll love to see community contributions and interest on the NPHardEval [GitHub Repository](https://github.com/casmlab/NPHardEval) and [Hugging Face Leaderboard](https://huggingface.co./spaces/NPHardEval/NPHardEval-leaderboard). | [
[
"llm",
"research",
"benchmarks",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"research",
"benchmarks",
"tools"
] | null | null |
00939201-e9f5-46d4-9515-b35cdc009e52 | completed | 2025-01-16T03:08:53.171202 | 2025-01-19T19:12:05.761343 | ead63d19-9e4d-4742-a4d4-b6b4c93d4f82 | Image search with 🤗 datasets | davanstrien | image-search-datasets.md | <a target="_blank" href="https://colab.research.google.com/gist/davanstrien/e2c29fbbed20dc767e5a74e210f4237b/hf_blog_image_search.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
🤗 [`datasets`](https://huggingface.co./docs/datasets/) is a library that makes it easy to access and share datasets. It also makes it easy to process data efficiently -- including working with data which doesn't fit into memory.
When `datasets` was first launched, it was associated mostly with text data. However, recently, `datasets` has added increased support for audio as well as images. In particular, there is now a `datasets` [feature type for images](https://huggingface.co./docs/datasets/package_reference/main_classes.html?highlight=image#datasets.Image). A previous [blog post](https://huggingface.co./blog/fine-tune-vit) showed how `datasets` can be used with 🤗 `transformers` to train an image classification model. In this blog post, we'll see how we can combine `datasets` and a few other libraries to create an image search application.
First, we'll install `datasets`. Since we're going to be working with images, we'll also install [`pillow`](https://pillow.readthedocs.io/en/stable/). We'll also need `sentence_transformers` and `faiss`. We'll introduce those in more detail below. We also install [`rich`](https://github.com/Textualize/rich) - we'll only briefly use it here, but it's a super handy package to have around -- I'd really recommend exploring it further!
``` python
!pip install datasets pillow rich faiss-gpu sentence_transformers
```
To start, let's take a look at the image feature. We can use the wonderful [rich](https://rich.readthedocs.io/) library to poke around python
objects (functions, classes etc.)
``` python
from rich import inspect
import datasets
```
``` python
inspect(datasets.Image, help=True)
```
<pre style="white-space:pre;overflow-x:auto;line-height:normal;font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace"><span style="color: #000080; text-decoration-color: #000080">╭───────────────────────── </span><span style="color: #000080; text-decoration-color: #000080; font-weight: bold"><</span><span style="color: #ff00ff; text-decoration-color: #ff00ff; font-weight: bold">class</span><span style="color: #000000; text-decoration-color: #000000"> </span><span style="color: #008000; text-decoration-color: #008000">'datasets.features.image.Image'</span><span style="color: #000080; text-decoration-color: #000080; font-weight: bold">></span><span style="color: #000080; text-decoration-color: #000080"> ─────────────────────────╮</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #00ffff; text-decoration-color: #00ffff; font-style: italic">class </span><span style="color: #800000; text-decoration-color: #800000; font-weight: bold">Image</span><span style="font-weight: bold">(</span>decode: bool = <span style="color: #00ff00; text-decoration-color: #00ff00; font-style: italic">True</span>, id: Union<span style="font-weight: bold">[</span>str, NoneType<span style="font-weight: bold">]</span> = <span style="color: #800080; text-decoration-color: #800080; font-style: italic">None</span><span style="font-weight: bold">)</span> -> <span style="color: #800080; text-decoration-color: #800080; font-style: italic">None</span>: <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">Image feature to read image data from an image file.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">Input: The Image feature accepts as input:</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">- A :obj:`str`: Absolute path to the image file </span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">(</span><span style="color: #008080; text-decoration-color: #008080">i.e. random access is allowed</span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">)</span><span style="color: #008080; text-decoration-color: #008080">.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">- A :obj:`dict` with the keys:</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080"> - path: String with relative path of the image file to the archive file.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080"> - bytes: Bytes of the image file.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080"> This is useful for archived files with sequential access.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">- An :obj:`np.ndarray`: NumPy array representing an image.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">- A :obj:`PIL.Image.Image`: PIL image object.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">Args:</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080"> decode </span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">(</span><span style="color: #008080; text-decoration-color: #008080">:obj:`bool`, default ``</span><span style="color: #00ff00; text-decoration-color: #00ff00; font-style: italic">True</span><span style="color: #008080; text-decoration-color: #008080">``</span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">)</span><span style="color: #008080; text-decoration-color: #008080">: Whether to decode the image data. If `</span><span style="color: #ff0000; text-decoration-color: #ff0000; font-style: italic">False</span><span style="color: #008080; text-decoration-color: #008080">`,</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080"> returns the underlying dictionary in the format </span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">{</span><span style="color: #008000; text-decoration-color: #008000">"path"</span><span style="color: #008080; text-decoration-color: #008080">: image_path, </span><span style="color: #008000; text-decoration-color: #008000">"bytes"</span><span style="color: #008080; text-decoration-color: #008080">: </span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #008080; text-decoration-color: #008080">image_bytes</span><span style="color: #008080; text-decoration-color: #008080; font-weight: bold">}</span><span style="color: #008080; text-decoration-color: #008080">.</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #808000; text-decoration-color: #808000; font-style: italic">decode</span> = <span style="color: #00ff00; text-decoration-color: #00ff00; font-style: italic">True</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #808000; text-decoration-color: #808000; font-style: italic">dtype</span> = <span style="color: #008000; text-decoration-color: #008000">'PIL.Image.Image'</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #808000; text-decoration-color: #808000; font-style: italic">id</span> = <span style="color: #800080; text-decoration-color: #800080; font-style: italic">None</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">│</span> <span style="color: #808000; text-decoration-color: #808000; font-style: italic">pa_type</span> = <span style="color: #800080; text-decoration-color: #800080; font-weight: bold">StructType</span><span style="font-weight: bold">(</span>struct<span style="font-weight: bold"><</span><span style="color: #ff00ff; text-decoration-color: #ff00ff; font-weight: bold">bytes:</span><span style="color: #000000; text-decoration-color: #000000"> binary, path: string</span><span style="font-weight: bold">>)</span> <span style="color: #000080; text-decoration-color: #000080">│</span>
<span style="color: #000080; text-decoration-color: #000080">╰───────────────────────────────────────────────────────────────────────────────────────────╯</span>
</pre>
We can see there a few different ways in which we can pass in our images. We'll come back to this in a little while.
A really nice feature of the `datasets` library (beyond the functionality for processing data, memory mapping etc.) is that you get
some nice things 'for free'. One of these is the ability to add a [`faiss`](https://github.com/facebookresearch/faiss) index to a dataset. [`faiss`](https://github.com/facebookresearch/faiss) is a ["library for efficient similarity search and clustering of dense
vectors"](https://github.com/facebookresearch/faiss).
The `datasets` [docs](https://huggingface.co./docs/datasets) shows an [example](https://huggingface.co./docs/datasets/faiss_es.html#id1) of using a `faiss` index for text retrieval. In this post we'll see if we can do the same for images.
## The dataset: "Digitised Books - Images identified as Embellishments. c. 1510 - c. 1900"
This is a dataset of images which have been pulled from a collection of digitised books from the British Library. These images come from books across a wide time period and from a broad range of domains. The images were extracted using information contained in the OCR output for each book. As a result, it's known which book the images came from, but not necessarily anything else about that image i.e. what is shown in the image.
Some attempts to help overcome this have included uploading the images to [flickr](https://www.flickr.com/photos/britishlibrary/albums). This allows people to tag the images or put them into various different categories.
There have also been projects to tag the dataset [using machine learning](https://blogs.bl.uk/digital-scholarship/2016/11/sherlocknet-update-millions-of-tags-and-thousands-of-captions-added-to-the-bl-flickr-images.html). This work makes it possible to search by tags, but we might want a 'richer' ability to search. For this particular experiment, we'll work with a subset of the collections which contain "embellishments". This dataset is a bit smaller, so it will be better for experimenting with. We can get the full data from the British Library's data repository: [https://doi.org/10.21250/db17](https://doi.org/10.21250/db17). Since the full dataset is still fairly large, you'll probably want to start with a smaller sample.
## Creating our dataset
Our dataset consists of a folder containing subdirectories inside which are images. This is a fairly standard format for sharing image datasets. Thanks to a recently merged [pull request](https://github.com/huggingface/datasets/pull/2830) we can directly load this dataset using `datasets` `ImageFolder` loader 🤯
```python
from datasets import load_dataset
dataset = load_dataset("imagefolder", data_files="https://zenodo.org/record/6224034/files/embellishments_sample.zip?download=1")
```
Let's see what we get back.
```python
dataset
```
```
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 10000
})
})
```
We can get back a `DatasetDict`, and we have a Dataset with image and label features. Since we don't have any train/validation splits here, let's grab the train part of our dataset. Let's also take a look at one example from our dataset to see what this looks like.
```python
dataset = dataset["train"]
dataset[0]
```
```python
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=358x461 at 0x7F9488DBB090>,
'label': 208}
```
Let's start with the label column. It contains the parent folder for our images. In this case, the label column represents the year of publication for the books from which the images are taken. We can see the mappings for this using `dataset.features`:
```python
dataset.features['label']
```
In this particular dataset, the image filenames also contain some metadata about the book from which the image was taken. There are a few ways we can get this information.
When we look at one example from our dataset that the `image` feature was a `PIL.JpegImagePlugin.JpegImageFile`. Since `PIL.Images` have a filename attribute, one way in which we can grab our filenames is by accessing this.
```python
dataset[0]['image'].filename
```
```python
/root/.cache/huggingface/datasets/downloads/extracted/f324a87ed7bf3a6b83b8a353096fbd9500d6e7956e55c3d96d2b23cc03146582/embellishments_sample/1920/000499442_0_000579_1_[The Ring and the Book etc ]_1920.jpg
```
Since we might want easy access to this information later, let's create a new column to extract the filename. For this, we'll use the `map` method.
```python
dataset = dataset.map(lambda example: {"fname": example['image'].filename.split("/")[-1]})
```
We can look at one example to see what this looks like now.
```python
dataset[0]
```
```python
{'fname': '000499442_0_000579_1_[The Ring and the Book etc ]_1920.jpg',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=358x461 at 0x7F94862A9650>,
'label': 208}
```
We've got our metadata now. Let's see some pictures already! If we access an example and index into the `image` column we'll see our image 😃
``` python
dataset[10]['image']
```
<img src="assets/54_image_search_datasets/dataset_image.jpg" alt="An example image from our dataset">
> **Note** in an [earlier version](https://danielvanstrien.xyz/metadata/deployment/huggingface/ethics/huggingface-datasets/faiss/2022/01/13/image_search.html) of this blog post the steps to download and load the images was much more convoluted. The new ImageFolder loader makes this process much easier 😀 In particular, we don't need to worry about how to load our images since datasets took care of this for us.
## Push all the things to the hub!
<img src="https://i.imgflip.com/613c0r.jpg" alt="Push all the things to the hub">
One of the super awesome things about the 🤗 ecosystem is the Hugging Face Hub. We can use the Hub to access models and datasets. It is often used for sharing work with others, but it can also be a useful tool for work in progress. `datasets` recently added a `push_to_hub` method that allows you to push a dataset to the Hub with minimal fuss. This can be really helpful by allowing you to pass around a dataset with all the transforms etc. already done.
For now, we'll push the dataset to the Hub and keep it private initially.
Depending on where you are running the code, you may need to authenticate. You can either do this using the `huggingface-cli login` command or, if you are running in a notebook, using `notebook_login`
``` python
from huggingface_hub import notebook_login
notebook_login()
```
``` python
dataset.push_to_hub('davanstrien/embellishments-sample', private=True)
```
> **Note**: in a [previous version](https://danielvanstrien.xyz/metadata/deployment/huggingface/ethics/huggingface-datasets/faiss/2022/01/13/image_search.html) of this blog post we had to do a few more steps to ensure images were embedded when using `push_to_hub`. Thanks to [this pull request](https://github.com/huggingface/datasets/pull/3685) we no longer need to worry about these extra steps. We just need to make sure `embed_external_files=True` (which is the default behaviour).
### Switching machines
At this point, we've created a dataset and moved it to the Hub. This means it is possible to pick up the work/dataset elsewhere.
In this particular example, having access to a GPU is important. Using the Hub as a way to pass around our data we could start on a laptop
and pick up the work on Google Colab.
If we move to a new machine, we may need to login again. Once we've done this we can load our dataset
``` python
from datasets import load_dataset
dataset = load_dataset("davanstrien/embellishments-sample", use_auth_token=True)
```
## Creating embeddings 🕸
We now have a dataset with a bunch of images in it. To begin creating our image search app, we need to embed these images. There are various ways to try and do this, but one possible way is to use the CLIP models via the `sentence_transformers` library. The [CLIP model](https://openai.com/blog/clip/) from OpenAI learns a joint representation for both images and text, which is very useful for what we want to do since we want to input text and get back an image.
We can download the model using the `SentenceTransformer` class.
``` python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('clip-ViT-B-32')
```
This model will take as input either an image or some text and return an embedding. We can use the `datasets` `map` method to encode all our images using this model. When we call map, we return a dictionary with the key `embeddings` containing the embeddings returned by the model. We also pass `device='cuda'` when we call the model; this ensures that we're doing the encoding on the GPU.
``` python
ds_with_embeddings = dataset.map(
lambda example: {'embeddings':model.encode(example['image'], device='cuda')}, batched=True, batch_size=32)
```
We can 'save' our work by pushing back to the Hub using
`push_to_hub`.
``` python
ds_with_embeddings.push_to_hub('davanstrien/embellishments-sample', private=True)
```
If we were to move to a different machine, we could grab our work again by loading it from the Hub 😃
``` python
from datasets import load_dataset
ds_with_embeddings = load_dataset("davanstrien/embellishments-sample", use_auth_token=True)
```
We now have a new column which contains the embeddings for our images. We could manually search through these and compare them to some input embedding but datasets has an `add_faiss_index` method. This uses the [faiss](https://github.com/facebookresearch/faiss) library to create an efficient index for searching embeddings. For more background on this library, you can watch this [YouTube video](https://www.youtube.com/embed/sKyvsdEv6rk)
``` python
ds_with_embeddings['train'].add_faiss_index(column='embeddings')
```
```
Dataset({
features: ['fname', 'year', 'path', 'image', 'embeddings'],
num_rows: 10000
})
```
## Image search
> **Note** that these examples were generated from the full version of the dataset so you may get slightly different results.
We now have everything we need to create a simple image search. We can use the same model we used to encode our images to encode some input text. This will act as the prompt we try and find close examples for. Let's start with 'a steam engine'.
``` python
prompt = model.encode("A steam engine")
```
We can use another method from the datasets library `get_nearest_examples` to get images which have an embedding close to our input prompt embedding. We can pass in a number of results we want to get back.
``` python
scores, retrieved_examples = ds_with_embeddings['train'].get_nearest_examples('embeddings', prompt, k=9)
```
We can index into the first example this retrieves:
``` python
retrieved_examples['image'][0]
```
<img src="assets/54_image_search_datasets/search_result.jpg" alt="An image of a factory">
This isn't quite a steam engine, but it's also not a completely weird result. We can plot the other results to see what was returned.
``` python
import matplotlib.pyplot as plt
```
``` python
plt.figure(figsize=(20, 20))
columns = 3
for i in range(9):
image = retrieved_examples['image'][i]
plt.subplot(9 / columns + 1, columns, i + 1)
plt.imshow(image)
```
<img src="assets/54_image_search_datasets/steam_engine_search_results.jpg">
Some of these results look fairly close to our input prompt. We can wrap
this in a function so we can more easily play around with different prompts
``` python
def get_image_from_text(text_prompt, number_to_retrieve=9):
prompt = model.encode(text_prompt)
scores, retrieved_examples = ds_with_embeddings['train'].get_nearest_examples('embeddings', prompt, k=number_to_retrieve)
plt.figure(figsize=(20, 20))
columns = 3
for i in range(9):
image = retrieved_examples['image'][i]
plt.title(text_prompt)
plt.subplot(9 / columns + 1, columns, i + 1)
plt.imshow(image)
```
``` python
get_image_from_text("An illustration of the sun behind a mountain")
```
<img src="assets/54_image_search_datasets/sun_behind_mountain.jpg">
### Trying a bunch of prompts ✨
Now we have a function for getting a few results, we can try a bunch of
different prompts:
- For some of these I'll choose prompts which are a broad 'category' i.e. 'a musical instrument' or 'an animal', others are specific i.e. 'a guitar'.
- Out of interest I also tried a boolean operator: "An illustration of a cat or a dog".
- Finally I tried something a little more abstract: \"an empty abyss\"
``` python
prompts = ["A musical instrument", "A guitar", "An animal", "An illustration of a cat or a dog", "an empty abyss"]
```
``` python
for prompt in prompts:
get_image_from_text(prompt)
```
<img src="assets/54_image_search_datasets/musical_instrument.jpg">
<img src="assets/54_image_search_datasets/guitar.jpg">
<img src="assets/54_image_search_datasets/an_animal.jpg">
<img src="assets/54_image_search_datasets/cat_or_dog.jpg">
<img src="assets/54_image_search_datasets/an_empty_abyss.jpg">
We can see these results aren't always right, but they are usually reasonable. It already seems like this could be useful for searching for the semantic content of an image in this dataset. However we might hold off on sharing this as is...
## Creating a Hugging Face Space? 🤷🏼
One obvious next step for this kind of project is to create a Hugging Face [Space](https://huggingface.co./spaces/launch) demo. This is what I've done for other [models](https://huggingface.co./spaces/BritishLibraryLabs/British-Library-books-genre-classifier-v2).
It was a fairly simple process to get a [Gradio app setup](https://gradio.app/) from the point we got to here. Here is a screenshot of this app:
<img src="assets/54_image_search_datasets/spaces_image_search.jpg" alt="Screenshot of Gradio search app">
However, I'm a little bit vary about making this public straightaway. Looking at the model card for the CLIP model we can look at the primary intended uses:
> ### Primary intended uses
>
> We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
> [source](https://huggingface.co./openai/clip-vit-base-patch32)
This is fairly close to what we are interested in here. Particularly we might be interested in how well the model deals with the kinds of images in our dataset (illustrations from mostly 19th century books). The images in our dataset are (probably) fairly different from the training data. The fact that some of the images also contain text might help CLIP since it displays some [OCR ability](https://openai.com/blog/clip/).
However, looking at the out-of-scope use cases in the model card:
> ### Out-of-Scope Use Cases
>
> Any deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP's performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case > currently potentially harmful. > [source](https://huggingface.co./openai/clip-vit-base-patch32)
suggests that 'deployment' is not a good idea. Whilst the results I got are interesting, I haven't played around with the model enough yet (and haven't done anything more systematic to evaluate its performance and biases) to be confident about 'deploying' it. Another additional consideration is the target dataset itself. The images are drawn from books covering a variety of subjects and time periods. There are plenty of books which represent colonial attitudes and as a result some of the images included may represent certain groups of people in a negative way. This could potentially be a bad combo with a tool which allows any arbitrary text input to be encoded as a prompt.
There may be ways around this issue but this will require a bit more thought.
## Conclusion
Although we don't have a nice demo to show for it, we've seen how we can use `datasets` to:
- load images into the new `Image` feature type
- 'save' our work using `push_to_hub` and use this to move data between machines/sessions
- create a `faiss` index for images that we can use to retrieve images from a text (or image) input. | [
[
"computer_vision",
"data",
"implementation",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"data",
"implementation",
"tutorial"
] | null | null |
37cb04b2-1e0c-45a9-a030-c5a63ca40ce8 | completed | 2025-01-16T03:08:53.171207 | 2025-01-16T03:16:53.228335 | 7bbb116e-9ef1-4b18-8f9d-805787fcd52b | 'Pre-Train BERT with Hugging Face Transformers and Habana Gaudi' | philschmid | pretraining-bert.md | In this Tutorial, you will learn how to pre-train [BERT-base](https://huggingface.co./bert-base-uncased) from scratch using a Habana Gaudi-based [DL1 instance](https://aws.amazon.com/ec2/instance-types/dl1/) on AWS to take advantage of the cost-performance benefits of Gaudi. We will use the Hugging Face [Transformers](https://huggingface.co./docs/transformers), [Optimum Habana](https://huggingface.co./docs/optimum/habana/index) and [Datasets](https://huggingface.co./docs/datasets) libraries to pre-train a BERT-base model using masked-language modeling, one of the two original BERT pre-training tasks. Before we get started, we need to set up the deep learning environment.
<a target="_blank" class="btn no-underline text-sm mb-5 font-sans" href="https://github.com/philschmid/deep-learning-habana-huggingface/blob/master/pre-training/pre-training-bert.ipynb">
View Code
</a>
You will learn how to:
1. [Prepare the dataset](#1-prepare-the-dataset)
2. [Train a Tokenizer](#2-train-a-tokenizer)
3. [Preprocess the dataset](#3-preprocess-the-dataset)
4. [Pre-train BERT on Habana Gaudi](#4-pre-train-bert-on-habana-gaudi)
_Note: Steps 1 to 3 can/should be run on a different instance size since those are CPU intensive tasks._
<figure class="image table text-center m-0 w-full">
<img src="assets/99_pretraining_bert/pre-training.png" alt="Cloud Architecture"/>
</figure>
**Requirements**
Before we start, make sure you have met the following requirements
* AWS Account with quota for [DL1 instance type](https://aws.amazon.com/ec2/instance-types/dl1/)
* [AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html) installed
* AWS IAM user [configured in CLI](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html) with permission to create and manage ec2 instances
**Helpful Resources**
* [Setup Deep Learning environment for Hugging Face Transformers with Habana Gaudi on AWS](https://www.philschmid.de/getting-started-habana-gaudi)
* [Deep Learning setup made easy with EC2 Remote Runner and Habana Gaudi](https://www.philschmid.de/habana-gaudi-ec2-runner)
* [Optimum Habana Documentation](https://huggingface.co./docs/optimum/habana/index)
* [Pre-training script](./scripts/run_mlm.py)
* [Code: pre-training-bert.ipynb](https://github.com/philschmid/deep-learning-habana-huggingface/blob/master/pre-training/pre-training-bert.ipynb)
## What is BERT?
BERT, short for Bidirectional Encoder Representations from Transformers, is a Machine Learning (ML) model for natural language processing. It was developed in 2018 by researchers at Google AI Language and serves as a swiss army knife solution to 11+ of the most common language tasks, such as sentiment analysis and named entity recognition.
Read more about BERT in our [BERT 101 🤗 State Of The Art NLP Model Explained](https://huggingface.co./blog/bert-101) blog.
## What is a Masked Language Modeling (MLM)?
MLM enables/enforces bidirectional learning from text by masking (hiding) a word in a sentence and forcing BERT to bidirectionally use the words on either side of the covered word to predict the masked word.
**Masked Language Modeling Example:**
```bash
“Dang! I’m out fishing and a huge trout just [MASK] my line!”
```
Read more about Masked Language Modeling [here](https://huggingface.co./blog/bert-101). | [
[
"llm",
"transformers",
"tutorial",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"tutorial",
"efficient_computing"
] | null | null |
91443579-a8c5-46de-b6a7-10649148a3c2 | completed | 2025-01-16T03:08:53.171211 | 2025-01-19T18:52:42.890223 | 265ee6f8-50e5-415a-bae6-68700809887d | Memory-efficient Diffusion Transformers with Quanto and Diffusers | sayakpaul, dacorvo | quanto-diffusers.md | Over the past few months, we have seen an emergence in the use of Transformer-based diffusion backbones for high-resolution text-to-image (T2I) generation. These models use the transformer architecture as the building block for the diffusion process, instead of the UNet architecture that was prevalent in many of the initial diffusion models. Thanks to the nature of Transformers, these backbones show good scalability, with models ranging from 0.6B to 8B parameters.
As models become larger, memory requirements increase. The problem intensifies because a diffusion pipeline usually consists of several components: a text encoder, a diffusion backbone, and an image decoder. Furthermore, modern diffusion pipelines use multiple text encoders – for example, there are three in the case of Stable Diffusion 3. It takes 18.765 GB of GPU memory to run SD3 inference using FP16 precision.
These high memory requirements can make it difficult to use these models with consumer GPUs, slowing adoption and making experimentation harder. In this post, we show how to improve the memory efficiency of Transformer-based diffusion pipelines by leveraging Quanto's quantization utilities from the Diffusers library.
### Table of contents
- [Preliminaries](#preliminaries)
- [Quantizing a `DiffusionPipeline` with Quanto](#quantizing-a-diffusionpipeline-with-quanto)
- [Generality of the observations](#generality-of-the-observations)
- [Misc findings](#misc-findings)
- [`bfloat16` as the main compute data-type](#bfloat16-is-usually-better-on-h100)
- [The promise of `qint8`](#the-promise-of-qint8)
- [INT4](#how-about-int4)
- [Bonus - saving and loading Diffusers models in Quanto](#bonus | [
[
"transformers",
"optimization",
"image_generation",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"image_generation",
"optimization",
"efficient_computing"
] | null | null |
64107ddc-1e27-4277-a087-35a1ed6a5b50 | completed | 2025-01-16T03:08:53.171216 | 2025-01-19T18:55:35.760449 | 61f5717c-6461-4ccd-8aca-8f320638bd7f | Public Policy at Hugging Face | irenesolaiman, yjernite, meg, evijit | policy-blog.md | AI Policy at Hugging Face is a multidisciplinary and cross-organizational workstream. Instead of being part of a vertical communications or global affairs organization, our policy work is rooted in the expertise of our many researchers and developers, from [Ethics and Society Regulars](https://huggingface.co./blog/ethics-soc-1) and the legal team to machine learning engineers working on healthcare, art, and evaluations.
What we work on is informed by our Hugging Face community needs and experiences on the Hub. We champion [responsible openness](https://huggingface.co./blog/ethics-soc-3), investing heavily in [ethics-forward research](https://huggingface.co./spaces/society-ethics/about), [transparency mechanisms](https://huggingface.co./blog/model-cards), [platform safeguards](https://huggingface.co./content-guidelines), and translate our lessons to policy.
So what have we shared with policymakers?
## Policy Materials
The following materials reflect what we have found urgent to stress to policymakers at the time of requests for information, and will be updated as materials are published.
- United States of America
- Congressional
- September 2023: [Clement Delangue (CEO) Senate AI Insight Forum Kickoff Statement](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2023_AI%20Insight%20Forum%20Kickoff%20Written%20Statement.pdf)
- June 2023: Clement Delangue (CEO) House Committee on Science, Space, and Technology Testimony
- [Written statement](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2023_HCSST_CongressionalTestimony.pdf)
- View [recorded testimony](https://science.house.gov/2023/6/artificial-intelligence-advancing-innovation-towards-the-national-interest)
- November 2023: [Dr. Margaret Mitchell (Chief Ethics Scientist) Senate Insight Forum Statement](https://www.schumer.senate.gov/imo/media/doc/Margaret%20Mitchell%20-%20Statement.pdf)
- Executive
- September 2024: Response to NIST [RFC on AI 800-1: Managing Misuse Risk for Dual-Use Foundational Models](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2024_AISI_Dual_Use_Foundational_Models_Response.pdf)
- June 2024: Response to NIST [RFC on AI 600-1: Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2024_NIST_GENAI_Response.pdf)
- March 2024: Response to NTIA [RFC on Dual Use Foundation Artificial Intelligence Models with Widely Available Model Weights](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2024_NTIA_Response.pdf)
- February 2024: Response to NIST [RFI Assignments Under Sections 4.1, 4.5 and 11 of the Executive Order Concerning Artificial Intelligence](https://huggingface.co./datasets/huggingface/policy-docs/blob/main/2024_NIST%20RFI%20on%20EO.pdf)
- December 2023: Response to OMB [RFC Agency Use of Artificial Intelligence](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2023_OMB%20EO%20RFC.pdf)
- November 2023: Response to U.S. Copyright Office [Notice of Inquiry on Artificial Intelligence and Copyright](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2023_Copyright_Response.pdf)
- June 2023: Response to NTIA [RFC on AI Accountability](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2023_NTIA_Response.pdf)
- September 2022: Response to NIST [AI Risk Management Framework]](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2022_NIST_RMF_Response.pdf)
- June 2022: Response to NAIRR [Implementing Findings from the National Artificial Intelligence Research Resource Task Force](https://huggingface.co./blog/assets/92_us_national_ai_research_resource/Hugging_Face_NAIRR_RFI_2022.pdf)
- European Union
- January 2024: Response to [Digital Services Act, Transparency Reports](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2024_DSA_Response.pdf)
- July 2023: Comments on the [Proposed AI Act](https://huggingface.co./blog/assets/eu_ai_act_oss/supporting_OS_in_the_AIAct.pdf)
- United Kingdom
- November 2023: Irene Solaiman (Head of Global Policy) [oral evidence to UK Parliament House of Lords transcript](https://committees.parliament.uk/oralevidence/13802/default/)
- September 2023: Response to [UK Parliament: UK Parliament RFI: LLMs](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2023_UK%20Parliament%20RFI%20LLMs.pdf)
- June 2023: Response to [No 10: UK RFI: AI Regulatory Innovation White Paper](https://huggingface.co./datasets/huggingface/policy-docs/resolve/main/2023_UK_RFI_AI_Regulatory_Innovation_White_Paper.pdf) | [
[
"research",
"community",
"security"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"community",
"research",
"security"
] | null | null |
27695837-54fd-46b5-b32d-67035b33998d | completed | 2025-01-16T03:08:53.171220 | 2025-01-19T19:01:36.240722 | d67ff036-04c7-4ea5-b81a-5bfbd8f7f058 | Accelerating PyTorch distributed fine-tuning with Intel technologies | juliensimon | accelerating-pytorch.md | For all their amazing performance, state of the art deep learning models often take a long time to train. In order to speed up training jobs, engineering teams rely on distributed training, a divide-and-conquer technique where clustered servers each keep a copy of the model, train it on a subset of the training set, and exchange results to converge to a final model.
Graphical Processing Units (GPUs) have long been the _de facto_ choice to train deep learning models. However, the rise of transfer learning is changing the game. Models are now rarely trained from scratch on humungous datasets. Instead, they are frequently fine-tuned on specific (and smaller) datasets, in order to build specialized models that are more accurate than the base model for particular tasks. As these training jobs are much shorter, using a CPU-based cluster can prove to be an interesting option that keeps both training time and cost under control.
### What this post is about
In this post, you will learn how to accelerate [PyTorch](https://pytorch.org) training jobs by distributing them on a cluster of Intel Xeon Scalable CPU servers, powered by the Ice Lake architecture and running performance-optimized software libraries. We will build the cluster from scratch using virtual machines, and you should be able to easily replicate the demo on your own infrastructure, either in the cloud or on premise.
Running a text classification job, we will fine-tune a [BERT](https://huggingface.co./bert-base-cased) model on the [MRPC](https://www.microsoft.com/en-us/download/details.aspx?id=52398) dataset (one of the tasks included in the [GLUE](https://gluebenchmark.com/) benchmark). The MRPC dataset contains 5,800 sentence pairs extracted from news sources, with a label telling us whether the two sentences in each pair are semantically equivalent. We picked this dataset for its reasonable training time, and trying other GLUE tasks is just a parameter away.
Once the cluster is up and running, we will run a baseline job on a single server. Then, we will scale it to 2 servers and 4 servers and measure the speed-up.
Along the way, we will cover the following topics:
* Listing the required infrastructure and software building blocks,
* Setting up our cluster,
* Installing dependencies,
* Running a single-node job,
* Running a distributed job.
Let's get to work!
### Using Intel servers
For best performance, we will use Intel servers based on the Ice Lake architecture, which supports hardware features such as Intel AVX-512 and Intel Vector Neural Network Instructions (VNNI). These features accelerate operations typically found in deep learning training and inference. You can learn more about them in this [presentation](https://www.intel.com/content/dam/www/public/us/en/documents/product-overviews/dl-boost-product-overview.pdf) (PDF).
All three major cloud providers offer virtual machines powered by Intel Ice Lake CPUs:
- Amazon Web Services: Amazon EC2 [M6i](https://aws.amazon.com/blogs/aws/new-amazon-ec2-m6i-instances-powered-by-the-latest-generation-intel-xeon-scalable-processors/)
and [C6i](https://aws.amazon.com/blogs/aws/new-amazon-ec2-c6i-instances-powered-by-the-latest-generation-intel-xeon-scalable-processors/) instances.
- Azure: [Dv5/Dsv5-series](https://docs.microsoft.com/en-us/azure/virtual-machines/dv5-dsv5-series), [Ddv5/Ddsv5-series](https://docs.microsoft.com/en-us/azure/virtual-machines/ddv5-ddsv5-series) and [Edv5/Edsv5-series](https://docs.microsoft.com/en-us/azure/virtual-machines/edv5-edsv5-series) virtual machines.
- Google Cloud Platform: [N2](https://cloud.google.com/blog/products/compute/compute-engine-n2-vms-now-available-with-intel-ice-lake) Compute Engine virtual machines.
Of course, you can also use your own servers. If they are based on the Cascade Lake architecture (Ice Lake's predecessor), they're good to go as Cascade Lake also includes AVX-512 and VNNI.
### Using Intel performance libraries
To leverage AVX-512 and VNNI in PyTorch, Intel has designed the [Intel extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch). This software library provides out of the box speedup for training and inference, so we should definitely install it.
When it comes to distributed training, the main performance bottleneck is often networking. Indeed, the different nodes in the cluster need to periodically exchange model state information to stay in sync. As transformers are large models with billions of parameters (sometimes much more), the volume of information is significant, and things only get worse as the number of nodes increase. Thus, it's important to use a communication library optimized for deep learning.
In fact, PyTorch includes the [```torch.distributed```](https://pytorch.org/tutorials/intermediate/dist_tuto.html) package, which supports different communication backends. Here, we'll use the Intel oneAPI Collective Communications Library [(oneCCL)](https://github.com/oneapi-src/oneCCL), an efficient implementation of communication patterns used in deep learning ([all-reduce](https://en.wikipedia.org/wiki/Collective_operation), etc.). You can learn about the performance of oneCCL versus other backends in this PyTorch [blog post](https://pytorch.medium.com/optimizing-dlrm-by-using-pytorch-with-oneccl-backend-9f85b8ef6929).
Now that we're clear on building blocks, let's talk about the overall setup of our training cluster.
### Setting up our cluster
In this demo, I'm using Amazon EC2 instances running Amazon Linux 2 (c6i.16xlarge, 64 vCPUs, 128GB RAM, 25Gbit/s networking). Setup will be different in other environments, but steps should be very similar.
Please keep in mind that you will need 4 identical instances, so you may want to plan for some sort of automation to avoid running the same setup 4 times. Here, I will set up one instance manually, create a new Amazon Machine Image [(AMI)](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html) from this instance, and use this AMI to launch three identical instances.
From a networking perspective, we will need the following setup:
* Open port 22 for ```ssh``` access on all instances for setup and debugging.
* Configure [password-less](https://www.redhat.com/sysadmin/passwordless-ssh) ```ssh``` between the master instance (the one you'll launch training from) and all other instances (__master included__).
* Open all TCP ports on all instances for oneCCL communication inside the cluster. __Please make sure NOT to open these ports to the external world__. AWS provides a convenient way to do this by only allowing connections from instances running a particular [security group](https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html). Here's how my setup looks.
<kbd>
<img src="assets/36_accelerating_pytorch/01_security_group.png">
</kbd>
Now, let's provision the first instance manually. I first create the instance itself, attach the security group above, and add 128GB of storage. To optimize costs, I have launched it as a [spot instance](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-spot-instances.html).
Once the instance is up, I connect to it with ```ssh``` in order to install dependencies.
### Installing dependencies
Here are the steps we will follow:
* Install Intel toolkits,
* Install the Anaconda distribution,
* Create a new ```conda``` environment,
* Install PyTorch and the Intel extension for PyTorch,
* Compile and install oneCCL,
* Install the ```transformers``` library.
It looks like a lot, but there's nothing complicated. Here we go!
__Installing Intel toolkits__
First, we download and install the Intel [OneAPI base toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html?operatingsystem=linux&distributions=webdownload&options=offline) as well as the [AI toolkit](https://www.intel.com/content/www/us/en/developer/tools/oneapi/ai-analytics-toolkit-download.html?operatingsystem=linux&distributions=webdownload&options=offline). You can learn about them on the Intel [website](https://www.intel.com/content/www/us/en/developer/tools/oneapi/toolkits.html#gs.gmojrp).
```
wget https://registrationcenter-download.intel.com/akdlm/irc_nas/18236/l_BaseKit_p_2021.4.0.3422_offline.sh
sudo bash l_BaseKit_p_2021.4.0.3422_offline.sh
wget https://registrationcenter-download.intel.com/akdlm/irc_nas/18235/l_AIKit_p_2021.4.0.1460_offline.sh
sudo bash l_AIKit_p_2021.4.0.1460_offline.sh
```
__Installing Anaconda__
Then, we [download](https://www.anaconda.com/products/individual) and install the Anaconda distribution.
```
wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh
sh Anaconda3-2021.05-Linux-x86_64.sh
```
__Creating a new conda environment__
We log out and log in again to refresh paths. Then, we create a new ```conda``` environment to keep things neat and tidy.
```
yes | conda create -n transformer python=3.7.9 -c anaconda
eval "$(conda shell.bash hook)"
conda activate transformer
yes | conda install pip cmake
```
__Installing PyTorch and the Intel extension for PyTorch__
Next, we install PyTorch 1.9 and the Intel extension toolkit. __Versions must match__.
```
yes | conda install pytorch==1.9.0 cpuonly -c pytorch
pip install torch_ipex==1.9.0 -f https://software.intel.com/ipex-whl-stable
```
__Compiling and installing oneCCL__
Then, we install some native dependencies required to compile oneCCL.
```
sudo yum -y update
sudo yum install -y git cmake3 gcc gcc-c++
```
Next, we clone the oneCCL repository, build the library and install it. __Again, versions must match__.
```
source /opt/intel/oneapi/mkl/latest/env/vars.sh
git clone https://github.com/intel/torch-ccl.git
cd torch-ccl
git checkout ccl_torch1.9
git submodule sync
git submodule update --init --recursive
python setup.py install
cd ..
```
__Installing the transformers library__
Next, we install the ```transformers``` library and dependencies required to run GLUE tasks.
```
pip install transformers datasets
yes | conda install scipy scikit-learn
```
Finally, we clone a fork of the ```transformers```repository containing the example we're going to run.
```
git clone https://github.com/kding1/transformers.git
cd transformers
git checkout dist-sigopt
```
We're done! Let's run a single-node job.
### Launching a single-node job
To get a baseline, let's launch a single-node job running the ```run_glue.py``` script in ```transformers/examples/pytorch/text-classification```. This should work on any of the instances, and it's a good sanity check before proceeding to distributed training.
```
python run_glue.py \
--model_name_or_path bert-base-cased --task_name mrpc \
--do_train --do_eval --max_seq_length 128 \
--per_device_train_batch_size 32 --learning_rate 2e-5 --num_train_epochs 3 \
--output_dir /tmp/mrpc/ --overwrite_output_dir True
```
<kbd>
<img src="assets/36_accelerating_pytorch/02_single_node.png">
</kbd>
This job takes __7 minutes and 46 seconds__. Now, let's set up distributed jobs with oneCCL and speed things up!
### Setting up a distributed job with oneCCL
Three steps are required to run a distributed training job:
* List the nodes of the training cluster,
* Define environment variables,
* Modify the training script.
__Listing the nodes of the training cluster__
On the master instance, in ```transformers/examples/pytorch/text-classification```, we create a text file named ```hostfile```. This file stores the names of the nodes in the cluster (IP addresses would work too). The first line should point to the master instance.
Here's my file:
```
ip-172-31-28-17.ec2.internal
ip-172-31-30-87.ec2.internal
ip-172-31-29-11.ec2.internal
ip-172-31-20-77.ec2.internal
```
__Defining environment variables__
Next, we need to set some environment variables on the master node, most notably its IP address. You can find more information on oneCCL variables in the [documentation](https://oneapi-src.github.io/oneCCL/env-variables.html).
```
for nic in eth0 eib0 hib0 enp94s0f0; do
master_addr=$(ifconfig $nic 2>/dev/null | grep netmask | awk '{print $2}'| cut -f2 -d:)
if [ "$master_addr" ]; then
break
fi
done
export MASTER_ADDR=$master_addr
source /home/ec2-user/anaconda3/envs/transformer/lib/python3.7/site-packages/torch_ccl-1.3.0+43f48a1-py3.7-linux-x86_64.egg/torch_ccl/env/setvars.sh
export LD_LIBRARY_PATH=/home/ec2-user/anaconda3/envs/transformer/lib/python3.7/site-packages/torch_ccl-1.3.0+43f48a1-py3.7-linux-x86_64.egg/:$LD_LIBRARY_PATH
export LD_PRELOAD="${CONDA_PREFIX}/lib/libtcmalloc.so:${CONDA_PREFIX}/lib/libiomp5.so"
export CCL_WORKER_COUNT=4
export CCL_WORKER_AFFINITY="0,1,2,3,32,33,34,35"
export CCL_ATL_TRANSPORT=ofi
export ATL_PROGRESS_MODE=0
```
__Modifying the training script__
The following changes have already been applied to our training script (```run_glue.py```) in order to enable distributed training. You would need to apply similar changes when using your own training code.
* Import the ```torch_ccl```package.
* Receive the address of the master node and the local rank of the node in the cluster.
```
+import torch_ccl
+
import datasets
import numpy as np
from datasets import load_dataset, load_metric
@@ -47,7 +49,7 @@ from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
-check_min_version("4.13.0.dev0")
+# check_min_version("4.13.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
@@ -191,6 +193,17 @@ def main():
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
+ # add local rank for cpu-dist
+ sys.argv.append("--local_rank")
+ sys.argv.append(str(os.environ.get("PMI_RANK", -1)))
+
+ # ccl specific environment variables
+ if "ccl" in sys.argv:
+ os.environ["MASTER_ADDR"] = os.environ.get("MASTER_ADDR", "127.0.0.1")
+ os.environ["MASTER_PORT"] = "29500"
+ os.environ["RANK"] = str(os.environ.get("PMI_RANK", -1))
+ os.environ["WORLD_SIZE"] = str(os.environ.get("PMI_SIZE", -1))
+
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
```
Setup is now complete. Let's scale our training job to 2 nodes and 4 nodes.
### Running a distributed job with oneCCL
On the __master node__, I use ```mpirun```to launch a 2-node job: ```-np``` (number of processes) is set to 2 and ```-ppn``` (process per node) is set to 1. Hence, the first two nodes in ```hostfile``` will be selected.
```
mpirun -f hostfile -np 2 -ppn 1 -genv I_MPI_PIN_DOMAIN=[0xfffffff0] \
-genv OMP_NUM_THREADS=28 python run_glue.py \
--model_name_or_path distilbert-base-uncased --task_name mrpc \
--do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 32 \
--learning_rate 2e-5 --num_train_epochs 3 --output_dir /tmp/mrpc/ \
--overwrite_output_dir True --xpu_backend ccl --no_cuda True
```
Within seconds, a job starts on the first two nodes. The job completes in __4 minutes and 39 seconds__, a __1.7x__ speedup.
<kbd>
<img src="assets/36_accelerating_pytorch/03_two_nodes.png">
</kbd>
Setting ```-np``` to 4 and launching a new job, I now see one process running on each node of the cluster.
<kbd>
<img src="assets/36_accelerating_pytorch/04_four_nodes.png">
</kbd>
Training completes in __2 minutes and 36 seconds__, a __3x__ speedup.
One last thing. Changing ```--task_name``` to ```qqp```, I also ran the Quora Question Pairs GLUE task, which is based on a much larger [dataset](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) (over 400,000 training samples). The fine-tuning times were:
* Single-node: 11 hours 22 minutes,
* 2 nodes: 6 hours and 38 minutes (1.71x),
* 4 nodes: 3 hours and 51 minutes (2.95x).
It looks like the speedup is pretty consistent. Feel free to keep experimenting with different learning rates, batch sizes and oneCCL settings. I'm sure you can go even faster!
### Conclusion
In this post, you've learned how to build a distributed training cluster based on Intel CPUs and performance libraries, and how to use this cluster to speed up fine-tuning jobs. Indeed, transfer learning is putting CPU training back into the game, and you should definitely consider it when designing and building your next deep learning workflows.
Thanks for reading this long post. I hope you found it informative. Feedback and questions are welcome at [email protected]_. Until next time, keep learning!
Julien | [
[
"tutorial",
"optimization",
"fine_tuning",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"fine_tuning",
"efficient_computing",
"optimization"
] | null | null |
b92d906a-5a19-4821-a2f4-a2144c3ccb12 | completed | 2025-01-16T03:08:53.171225 | 2025-01-19T18:46:55.311726 | e8cdce81-7a8c-4cd6-8a78-1ff49b37401f | 'Preference Optimization for Vision Language Models' | qgallouedec, vwxyzjn, merve, kashif | dpo_vlm.md | Training models to understand and predict human preferences can be incredibly complex. Traditional methods, like supervised fine-tuning, often require assigning specific labels to data, which is not cost-efficient, especially for nuanced tasks. Preference optimization is an alternative approach that can simplify this process and yield more accurate results. By focusing on comparing and ranking candidate answers rather than assigning fixed labels, preference optimization allows models to capture the subtleties of human judgment more effectively.
Preference optimization is widely used for fine-tuning language models, but it can also be applied to vision language models (VLM).
We are excited to announce that the **[TRL](https://huggingface.co./docs/trl/index) library now supports direct preference optimization (DPO) for VLMs**. This article will guide you through the process of training VLMs using TRL and DPO.
## Preference dataset
Preference optimization requires data that captures user preferences. In the binary choice setting, each example consists of a prompt, and two candidate answers: one that is chosen and one that is rejected. The model's goal is to learn to predict the chosen answer over the rejected one.
For example, you need to have samples like the following:
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/dpo_vlm/how-many-families.jpg"></img>
<figcaption>Image from <a href="https://huggingface.co./datasets/openbmb/RLAIF-V-Dataset">openbmb/RLAIF-V-Dataset</a></figcaption>
</figure>
**❔ Question**: _How many families?_
- **❌ Rejected:** _The image does not provide any information about families._
- **✅ Chosen:** _The image shows a Union Organization table setup with 18,000 families._
Note that the chosen message is not necessarily correct. For example, the chosen response that says 18,000 families is still wrong, but it's less wrong compared to the rejected response.
For this blog post, we'll be using the [openbmb/RLAIF-V-Dataset](https://huggingface.co./datasets/openbmb/RLAIF-V-Dataset), which includes over 83,000 annotated rows. Let's take a closer look at the dataset:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("openbmb/RLAIF-V-Dataset", split="train[:1%]")
>>> sample = dataset[1]
>>> sample["image"].show()
>>> sample["question"]
'how many families?'
>>> sample["rejected"]
'The image does not provide any information about families.'
>>> sample["chosen"]
'The image shows a Union Organization table setup with 18,000 families.'
```
Our model requires both text and images as input, so the first step is to format the dataset to fit this requirement. The data should be structured to simulate a conversation between a user and an assistant. The user provides a prompt that includes an image and a question, while the assistant responds with an answer. Here's how this formatting is done:
```python
from datasets import features
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics2-8b", do_image_splitting=False)
def format(example):
# Prepare the input for the chat template
prompt = [
{
"role": "user",
"content": [{"type": "image"}, {"type": "text", "text": example["question"]}],
},
]
chosen = [
{
"role": "assistant",
"content": [{"type": "text", "text": example["chosen"]}],
},
]
rejected = [
{
"role": "assistant",
"content": [{"type": "text", "text": example["rejected"]}],
},
]
# Apply the chat template
prompt = processor.apply_chat_template(prompt, tokenize=False)
chosen = processor.apply_chat_template(chosen, tokenize=False)
rejected = processor.apply_chat_template(rejected, tokenize=False)
# Resize the image to ensure it fits within the maximum allowable
# size of the processor to prevent OOM errors.
max_size = processor.image_processor.size["longest_edge"]
example["image"].thumbnail((max_size, max_size))
return {"images": [example["image"]], "prompt": prompt, "chosen": chosen, "rejected": rejected}
# Apply the formatting function to the dataset,
# remove columns to end up with only "images", "prompt", "chosen", "rejected" columns
dataset = dataset.map(format, remove_columns=dataset.column_names)
# Make sure that the images are decoded, it prevents from storing bytes.
# More info here https://github.com/huggingface/blog/pull/2148#discussion_r1667400478
f = dataset.features
f["images"] = features.Sequence(features.Image(decode=True)) # to avoid bytes
dataset = dataset.cast(f)
```
Our dataset is now formatted. Let's have a look at the first example:
```python
>>> dataset[1]
{'images': [<PIL.JpegImagePlugin.JpegImageFile image mode=L size=980x812 at 0x154505570>],
'prompt': 'User:<image>how many families?<end_of_utterance>\n',
'rejected': 'Assistant: The image does not provide any information about families.<end_of_utterance>\n',
'chosen': 'Assistant: The image shows a Union Organization table setup with 18,000 families.<end_of_utterance>\n'}
```
Warm up your GPUs, the dataset is ready for training!
## Training
For the sake of the example, we'll be training the [Idefics2-8b](https://huggingface.co./HuggingFaceM4/idefics2-8b) model, but note that the DPO implementation in TRL supports other models like [Llava 1.5](https://huggingface.co./llava-hf/llava-1.5-7b-hf) and [PaliGemma](https://huggingface.co./google/paligemma-3b-pt-224). More information in Section [Finetuning Llava 1.5, PaliGemma and others](#finetuning-llava-15-paligemma-and-others). Before looking into the training process, we'll first ensure everything fits smoothly into memory.
### How much memory do I need?
I have a GPU with 80GB of VRAM. Is it enough to train my Idefics2-8b model? Here are the calculation steps to get a rough estimate of the memory needed.
Let \\( N \\) be the number of parameters, \\( P \\) the precision. The following components will have to fit together in memory:
- **Model to train**: \\( N \times P \\)
- **Reference model**: the reference model is the same as the model to train, so it also requires \\( N \times P \\)
- **Gradients**: we train the whole model, and each parameter requires a gradient, so it requires \\( N \times P \\)
- **Optimizer states**: we use [AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html), which requires two states per parameter, so it requires \\( 2 \times N \times P \\)
Idefics2-8b has 8 billion parameters, and we use `float32` precision which requires 4 bytes per float. So the total memory required is:
| Component | Calculation | Memory |
| | [
[
"implementation",
"optimization",
"multi_modal",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"multi_modal",
"fine_tuning",
"optimization",
"implementation"
] | null | null |
7756bd40-e7f4-40e9-9c44-9707808b5c42 | completed | 2025-01-16T03:08:53.171229 | 2025-01-19T18:53:21.144563 | f7f9383b-dc37-47c9-b2b6-ddbff152c0de | Federated Learning using Hugging Face and Flower | charlesbvll | fl-with-flower.md | <a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/fl-with-flower.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
This tutorial will show how to leverage Hugging Face to federate the training of language models over multiple clients using [Flower](https://flower.ai/). More specifically, we will fine-tune a pre-trained Transformer model (distilBERT) for sequence classification over a dataset of IMDB ratings. The end goal is to detect if a movie rating is positive or negative.
A notebook is also available [here](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/fl-with-flower.ipynb) but instead of running on multiple separate clients it utilizes the simulation functionality of Flower (using `flwr['simulation']`) in order to emulate a federated setting inside Google Colab (this also means that instead of calling `start_server` we will call `start_simulation`, and that a few other modifications are needed).
## Dependencies
To follow along this tutorial you will need to install the following packages: `datasets`, `evaluate`, `flwr`, `torch`, and `transformers`. This can be done using `pip`:
```sh
pip install datasets evaluate flwr torch transformers
```
## Standard Hugging Face workflow
### Handling the data
To fetch the IMDB dataset, we will use Hugging Face's `datasets` library. We then need to tokenize the data and create `PyTorch` dataloaders, this is all done in the `load_data` function:
```python
import random
import torch
from datasets import load_dataset
from torch.utils.data import DataLoader
from transformers import AutoTokenizer, DataCollatorWithPadding
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
CHECKPOINT = "distilbert-base-uncased"
def load_data():
"""Load IMDB data (training and eval)"""
raw_datasets = load_dataset("imdb")
raw_datasets = raw_datasets.shuffle(seed=42)
# remove unnecessary data split
del raw_datasets["unsupervised"]
tokenizer = AutoTokenizer.from_pretrained(CHECKPOINT)
def tokenize_function(examples):
return tokenizer(examples["text"], truncation=True)
# We will take a small sample in order to reduce the compute time, this is optional
train_population = random.sample(range(len(raw_datasets["train"])), 100)
test_population = random.sample(range(len(raw_datasets["test"])), 100)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets["train"] = tokenized_datasets["train"].select(train_population)
tokenized_datasets["test"] = tokenized_datasets["test"].select(test_population)
tokenized_datasets = tokenized_datasets.remove_columns("text")
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
trainloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
batch_size=32,
collate_fn=data_collator,
)
testloader = DataLoader(
tokenized_datasets["test"], batch_size=32, collate_fn=data_collator
)
return trainloader, testloader
trainloader, testloader = load_data()
```
### Training and testing the model
Once we have a way of creating our trainloader and testloader, we can take care of the training and testing. This is very similar to any `PyTorch` training or testing loop:
```python
from evaluate import load as load_metric
from transformers import AdamW
def train(net, trainloader, epochs):
optimizer = AdamW(net.parameters(), lr=5e-5)
net.train()
for _ in range(epochs):
for batch in trainloader:
batch = {k: v.to(DEVICE) for k, v in batch.items()}
outputs = net(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
def test(net, testloader):
metric = load_metric("accuracy")
loss = 0
net.eval()
for batch in testloader:
batch = {k: v.to(DEVICE) for k, v in batch.items()}
with torch.no_grad():
outputs = net(**batch)
logits = outputs.logits
loss += outputs.loss.item()
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions, references=batch["labels"])
loss /= len(testloader.dataset)
accuracy = metric.compute()["accuracy"]
return loss, accuracy
```
### Creating the model itself
To create the model itself, we will just load the pre-trained distillBERT model using Hugging Face’s `AutoModelForSequenceClassification` :
```python
from transformers import AutoModelForSequenceClassification
net = AutoModelForSequenceClassification.from_pretrained(
CHECKPOINT, num_labels=2
).to(DEVICE)
```
## Federating the example
The idea behind Federated Learning is to train a model between multiple clients and a server without having to share any data. This is done by letting each client train the model locally on its data and send its parameters back to the server, which then aggregates all the clients’ parameters together using a predefined strategy. This process is made very simple by using the [Flower](https://github.com/adap/flower) framework. If you want a more complete overview, be sure to check out this guide: [What is Federated Learning?](https://flower.ai/docs/framework/tutorial-series-what-is-federated-learning.html)
### Creating the IMDBClient
To federate our example to multiple clients, we first need to write our Flower client class (inheriting from `flwr.client.NumPyClient`). This is very easy, as our model is a standard `PyTorch` model:
```python
from collections import OrderedDict
import flwr as fl
class IMDBClient(fl.client.NumPyClient):
def get_parameters(self, config):
return [val.cpu().numpy() for _, val in net.state_dict().items()]
def set_parameters(self, parameters):
params_dict = zip(net.state_dict().keys(), parameters)
state_dict = OrderedDict({k: torch.Tensor(v) for k, v in params_dict})
net.load_state_dict(state_dict, strict=True)
def fit(self, parameters, config):
self.set_parameters(parameters)
print("Training Started...")
train(net, trainloader, epochs=1)
print("Training Finished.")
return self.get_parameters(config={}), len(trainloader), {}
def evaluate(self, parameters, config):
self.set_parameters(parameters)
loss, accuracy = test(net, testloader)
return float(loss), len(testloader), {"accuracy": float(accuracy)}
```
The `get_parameters` function lets the server get the client's parameters. Inversely, the `set_parameters` function allows the server to send its parameters to the client. Finally, the `fit` function trains the model locally for the client, and the `evaluate` function tests the model locally and returns the relevant metrics.
We can now start client instances using:
```python
fl.client.start_numpy_client(
server_address="127.0.0.1:8080",
client=IMDBClient(),
)
```
### Starting the server
Now that we have a way to instantiate clients, we need to create our server in order to aggregate the results. Using Flower, this can be done very easily by first choosing a strategy (here, we are using `FedAvg`, which will define the global weights as the average of all the clients' weights at each round) and then using the `flwr.server.start_server` function:
```python
def weighted_average(metrics):
accuracies = [num_examples * m["accuracy"] for num_examples, m in metrics]
losses = [num_examples * m["loss"] for num_examples, m in metrics]
examples = [num_examples for num_examples, _ in metrics]
return {"accuracy": sum(accuracies) / sum(examples), "loss": sum(losses) / sum(examples)}
# Define strategy
strategy = fl.server.strategy.FedAvg(
fraction_fit=1.0,
fraction_evaluate=1.0,
evaluate_metrics_aggregation_fn=weighted_average,
)
# Start server
fl.server.start_server(
server_address="0.0.0.0:8080",
config=fl.server.ServerConfig(num_rounds=3),
strategy=strategy,
)
```
The `weighted_average` function is there to provide a way to aggregate the metrics distributed amongst the clients (basically this allows us to display a nice average accuracy and loss for every round).
## Putting everything together
If you want to check out everything put together, you should check out the code example we wrote for the Flower repo: [https://github.com/adap/flower/tree/main/examples/quickstart-huggingface](https://github.com/adap/flower/tree/main/examples/quickstart-huggingface).
Of course, this is a very basic example, and a lot can be added or modified, it was just to showcase how simply we could federate a Hugging Face workflow using Flower.
Note that in this example we used `PyTorch`, but we could have very well used `TensorFlow`. | [
[
"transformers",
"tutorial",
"text_classification",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"text_classification",
"tutorial",
"fine_tuning"
] | null | null |
e656dca1-fc4c-43ef-9106-021dcc01ff1a | completed | 2025-01-16T03:08:53.171234 | 2025-01-16T13:35:56.265213 | 9d8af541-9102-493f-88ac-624877a8f0e6 | Introducing the Open FinLLM Leaderboard | QianqianXie1994, jiminHuang, Effoula, yanglet, alejandroll10, Benyou, ldruth, xiangr, Me1oy, ShirleyY, mirageco, blitzionic, clefourrier | leaderboard-finbench.md | *Finding the best LLM models for finance use cases*
The growing complexity of financial language models (LLMs) necessitates evaluations that go beyond general NLP benchmarks. While traditional leaderboards focus on broader NLP tasks like translation or summarization, they often fall short in addressing the specific needs of the finance industry. Financial tasks, such as predicting stock movements, assessing credit risks, and extracting information from financial reports, present unique challenges that require models with specialized skills. This is why we decided to create the [**Open FinLLM Leaderboard**](https://huggingface.co./spaces/TheFinAI/Open-Financial-LLM-Leaderboard).
The [leaderboard](https://huggingface.co./spaces/TheFinAI/Open-Financial-LLM-Leaderboard) provides a **specialized evaluation framework** tailored specifically to the financial sector. We hope it fills this critical gap, by providing a transparent framework that assesses model readiness for real-world use with a one-stop solution. The leaderboard is designed to highlight a model's **financial skill** by focusing on tasks that matter most to finance professionals—such as information extraction from financial documents, market sentiment analysis, and forecasting financial trends.
* **Comprehensive Financial Task Coverage:** The leaderboard evaluates models only on tasks that are directly relevant to finance. These tasks include **information extraction**, **sentiment analysis**, **credit risk scoring**, and **stock movement forecasting**, which are crucial for real-world financial decision-making.
* **Real-World Financial Relevance:** The datasets used for the benchmarks represent real-world challenges faced by the finance industry. This ensures that models are actually assessed on their ability to handle complex financial data, making them suitable for industry applications.
* **Focused Zero-Shot Evaluation:** The leaderboard employs a **zero-shot evaluation** method, testing models on unseen financial tasks without any prior fine-tuning. This approach reveals a model’s ability to generalize and perform well in financial contexts, such as predicting stock price movements or extracting entities from regulatory filings, without being explicitly trained on those tasks.
## Key Features of the Open Financial LLM Leaderboard
* **Diverse Task Categories:** The leaderboard covers tasks across seven categories: Information Extraction (IE), Textual Analysis (TA), Question Answering (QA), Text Generation (TG), Risk Management (RM), Forecasting (FO), and Decision-Making (DM).
* **Evaluation Metrics:** Models are assessed using a variety of metrics, including Accuracy, F1 Score, ROUGE Score, and Matthews Correlation Coefficient (MCC). These metrics provide a multidimensional view of model performance, helping users identify the strengths and weaknesses of each model.
## Supported Tasks and Metric
The **Open Financial LLM Leaderboard (OFLL)** evaluates financial language models across a diverse set of categories that reflect the complex needs of the finance industry. Each category targets specific capabilities, ensuring a comprehensive assessment of model performance in tasks directly relevant to finance.
### Categories
The selection of task categories in OFLL is intentionally designed to capture the full range of capabilities required by financial models. This approach is influenced by both the diverse nature of financial applications and the complexity of the tasks involved in financial language processing.
* **Information Extraction (IE):** The financial sector often requires structured insights from unstructured documents such as regulatory filings, contracts, and earnings reports. Information extraction tasks include **Named Entity Recognition (NER)**, **Relation Extraction**, and **Causal Classification**. These tasks evaluate a model’s ability to identify key financial entities, relationships, and events, which are crucial for downstream applications such as fraud detection or investment strategy.
* **Textual Analysis (TA):** Financial markets are driven by sentiment, opinions, and the interpretation of financial news and reports. Textual analysis tasks such as **Sentiment Analysis**, **News Classification**, and **Hawkish-Dovish Classification** help assess how well a model can interpret market sentiment and textual data, aiding in tasks like investor sentiment analysis and policy interpretation.
* **Question Answering (QA):** This category addresses the ability of models to interpret complex financial queries, particularly those that involve numerical reasoning or domain-specific knowledge. The QA tasks, such as those derived from datasets like **FinQA** and **TATQA**, evaluate a model’s capability to respond to detailed financial questions, which is critical in areas like risk analysis or financial advisory services.
* **Text Generation (TG):** Summarization of complex financial reports and documents is essential for decision-making. Tasks like **ECTSum** and **EDTSum** test models on their ability to generate concise and coherent summaries from lengthy financial texts, which is valuable in generating reports or analyst briefings.
* **Forecasting (FO):** One of the most critical applications in finance is the ability to forecast market movements. Tasks under this category evaluate a model’s ability to predict stock price movements or market trends based on historical data, news, and sentiment. These tasks are central to tasks like portfolio management and trading strategies.
* **Risk Management (RM):** This category focuses on tasks that evaluate a model’s ability to predict and assess financial risks, such as **Credit Scoring**, **Fraud Detection**, and **Financial Distress Identification**. These tasks are fundamental for credit evaluation, risk management, and compliance purposes.
* **Decision-Making (DM):** In finance, making informed decisions based on multiple inputs (e.g., market data, sentiment, and historical trends) is crucial. Decision-making tasks simulate complex financial decisions, such as **Mergers & Acquisitions** and **Stock Trading**, testing the model’s ability to handle multimodal inputs and offer actionable insights.
### Metrics
* **F1-score**, the harmonic mean of precision and recall, offers a balanced evaluation, especially important in cases of class imbalance within the dataset. Both metrics are standard in classification tasks and together give a comprehensive view of the model's capability to discern sentiments in financial language.
* **Accuracy** measures the proportion of correctly classified instances out of all instances, providing a straightforward assessment of overall performance.
* **RMSE** provides a measure of the average deviation between predicted and actual sentiment scores, offering a quantitative insight into the accuracy of the model's predictions.
* **Entity F1 Score (EntityF1)**. This metric assesses the balance between precision and recall specifically for the recognized entities, providing a clear view of the model's effectiveness in identifying relevant financial entities. A high EntityF1 indicates that the model is proficient at both detecting entities and minimizing false positives, making it an essential measure for applications in financial data analysis and automation.
* **Exact Match Accuracy (EmAcc)** measures the proportion of questions for which the model’s answer exactly matches the ground truth, providing a clear indication of the model's effectiveness in understanding and processing numerical information in financial contexts. A high EmAcc reflects a model's capability to deliver precise and reliable answers, crucial for applications that depend on accurate financial data interpretation.
* **ROUGE** (Recall-Oriented Understudy for Gisting Evaluation) is a set of metrics used to assess the quality of summaries by comparing them to reference summaries. It focuses on the overlap of n-grams between the generated summaries and the reference summaries, providing a measure of content coverage and fidelity.
* **BERTScore** utilizes contextual embeddings from the BERT model to evaluate the similarity between generated and reference summaries. By comparing the cosine similarity of the embeddings for each token, BERTScore captures semantic similarity, allowing for a more nuanced evaluation of summary quality.
* **BARTScore** is based on the BART (Bidirectional and Auto-Regressive Transformers) model, which combines the benefits of both autoregressive and autoencoding approaches for text generation. It assesses how well the generated summary aligns with the reference summary in terms of coherence and fluency, providing insights into the overall quality of the extraction process.
* **Matthews Correlation Coefficient (MCC)** takes into account true and false positives and negatives, thereby offering insights into the model's effectiveness in a binary classification context. Together, these metrics ensure a comprehensive assessment of a model's predictive capabilities in the challenging landscape of stock movement forecasting.
* **Sharpe Ratio (SR).** The Sharpe Ratio measures the model's risk-adjusted return, providing insight into how well the model's trading strategies perform relative to the level of risk taken. A higher Sharpe Ratio indicates a more favorable return per unit of risk, making it a critical indicator of the effectiveness and efficiency of the trading strategies generated by the model. This metric enables users to gauge the model’s overall profitability and robustness in various market conditions.
### Individual Tasks
We use 40 tasks on this leaderboard, across these categories:
- **Information Extraction(IE)**: NER, FiNER-ORD, FinRED, SC, CD, FNXL, FSRL
- **Textual Analysis(TA)**: FPB, FiQA-SA, TSA, Headlines, FOMC, FinArg-ACC, FinArg-ARC, MultiFin, MA, MLESG
- **Question Answering(QA)**: FinQA, TATQA, Regulations, ConvFinQA
- **Text Generation(TG)**: ECTSum, EDTSum
- **Risk Management(RM)**: German, Australian, LendingClub, ccf, ccfraud, polish, taiwan, ProtoSeguro, travelinsurance
- **Forecasting(FO)**: BigData22, ACL18, CIKM18
- **Decision-Making(DM)**: FinTrade
- **Spanish**: MultiFin-ES, EFP ,EFPA ,FinanceES, TSA-Spanish
<details><summary><b>Click here for a short explanation of each task</b></summary>
1. **[FPB (Financial PhraseBank Sentiment Classification)](https://huggingface.co./datasets/ChanceFocus/en-fpb) **
**Description:** Sentiment analysis of phrases in financial news and reports, classifying into positive, negative, or neutral categories.
**Metrics:** Accuracy, F1-Score
2. **[FiQA-SA (Sentiment Analysis in Financial Domain)](https://huggingface.co./datasets/ChanceFocus/flare-fiqasa)**
**Description:** Sentiment analysis in financial media (news, social media). Classifies sentiments into positive, negative, and neutral, aiding in market sentiment interpretation.
**Metrics:** F1-Score
3. **[TSA (Sentiment Analysis on Social Media)](https://huggingface.co./datasets/ChanceFocus/flare-fiqasa)**
**Description:** Sentiment classification for financial tweets, reflecting public opinion on market trends. Challenges include informal language and brevity. **Metrics:** F1-Score, RMSE
4. **[Headlines (News Headline Classification)](https://huggingface.co./datasets/ChanceFocus/flare-headlines)**
**Description:** Classification of financial news headlines into sentiment or event categories. Critical for understanding market-moving information.
**Metrics:** AvgF1
5. **[FOMC (Hawkish-Dovish Classification)](https://huggingface.co./datasets/ChanceFocus/flare-fomc)**
**Description:** Classification of FOMC statements as hawkish (favoring higher interest rates) or dovish (favoring lower rates), key for monetary policy predictions.
**Metrics:** F1-Score, Accuracy
6. **[FinArg-ACC (Argument Unit Classification)](https://huggingface.co./datasets/ChanceFocus/flare-finarg-ecc-auc)**
**Description:** Identifies key argument units (claims, evidence) in financial texts, crucial for automated document analysis and transparency.
**Metrics:** F1-Score, Accuracy
7. **[FinArg-ARC (Argument Relation Classification)](https://huggingface.co./datasets/ChanceFocus/flare-finarg-ecc-arc)**
**Description:** Classification of relationships between argument units (support, opposition) in financial documents, helping analysts construct coherent narratives.
**Metrics:** F1-Score, Accuracy
8. **[MultiFin (Multi-Class Sentiment Analysis)](https://huggingface.co./datasets/ChanceFocus/flare-es-multifin)**
**Description:** Classification of diverse financial texts into sentiment categories (bullish, bearish, neutral), valuable for sentiment-driven trading.
**Metrics:** F1-Score, Accuracy
9. **[MA (Deal Completeness Classification)](https://huggingface.co./datasets/ChanceFocus/flare-ma)**
**Description:** Classifies mergers and acquisitions reports as completed, pending, or terminated. Critical for investment and strategy decisions.
**Metrics:** F1-Score, Accuracy
10. **[MLESG (ESG Issue Identification)](https://huggingface.co./datasets/ChanceFocus/flare-mlesg)**
**Description:** Identifies Environmental, Social, and Governance (ESG) issues in financial documents, important for responsible investing.
**Metrics:** F1-Score, Accuracy
11. **[NER (Named Entity Recognition in Financial Texts)](https://huggingface.co./datasets/ChanceFocus/flare-ner)**
**Description:** Identifies and categorizes entities (companies, instruments) in financial documents, essential for information extraction.
**Metrics:** Entity F1-Score
12. **[FINER-ORD (Ordinal Classification in Financial NER)](https://huggingface.co./datasets/ChanceFocus/flare-finer-ord)**
**Description:** Extends NER by classifying entity relevance within financial documents, helping prioritize key information.
**Metrics:** Entity F1-Score
13. **[FinRED (Financial Relation Extraction)](https://huggingface.co./datasets/ChanceFocus/flare-finred)**
**Description:** Extracts relationships (ownership, acquisition) between entities in financial texts, supporting knowledge graph construction.
**Metrics:** F1-Score, Entity F1-Score
14. **[SC (Causal Classification)](https://huggingface.co./datasets/ChanceFocus/flare-causal20-sc)**
**Description:** Classifies causal relationships in financial texts (e.g., "X caused Y"), aiding in market risk assessments.
**Metrics:** F1-Score, Entity F1-Score
15. **[CD (Causal Detection)](https://huggingface.co./datasets/ChanceFocus/flare-cd)**
**Description:** Detects causal relationships in financial texts, helping in risk analysis and investment strategies.
**Metrics:** F1-Score, Entity F1-Score
16. **[FinQA (Numerical Question Answering in Finance)](https://huggingface.co./datasets/ChanceFocus/flare-finqa)**
**Description:** Answers numerical questions from financial documents (e.g., balance sheets), crucial for automated reporting and analysis.
**Metrics:** Exact Match Accuracy (EmAcc)
17. **[TATQA (Table-Based Question Answering)](https://huggingface.co./datasets/ChanceFocus/flare-tatqa)**
**Description:** Extracts information from financial tables (balance sheets, income statements) to answer queries requiring numerical reasoning.
**Metrics:** F1-Score, EmAcc
18. **[ConvFinQA (Multi-Turn QA in Finance)](https://huggingface.co./datasets/ChanceFocus/flare-convfinqa)**
**Description:** Handles multi-turn dialogues in financial question answering, maintaining context throughout the conversation.
**Metrics:** EmAcc
19. **[FNXL (Numeric Labeling)](https://huggingface.co./datasets/ChanceFocus/flare-fnxl)**
**Description:** Labels numeric values in financial documents (e.g., revenue, expenses), aiding in financial data extraction.
**Metrics:** F1-Score, EmAcc
20. **[FSRL (Financial Statement Relation Linking)](https://huggingface.co./datasets/ChanceFocus/flare-fsrl)**
**Description:** Links related information across financial statements (e.g., revenue in income statements and cash flow data).
**Metrics:** F1-Score, EmAcc
21. **[EDTSUM (Extractive Document Summarization)](https://huggingface.co./datasets/ChanceFocus/flare-edtsum)**
**Description:** Summarizes long financial documents, extracting key information for decision-making.
**Metrics:** ROUGE, BERTScore, BARTScore
22. **[ECTSUM (Extractive Content Summarization)](https://huggingface.co./datasets/ChanceFocus/flare-ectsum)**
**Description:** Summarizes financial content, extracting key sentences or phrases from large texts.
**Metrics:** ROUGE, BERTScore, BARTScore
23. **[BigData22 (Stock Movement Prediction)](https://huggingface.co./datasets/TheFinAI/en-forecasting-bigdata)**
**Description:** Predicts stock price movements based on financial news, using textual data to forecast market trends.
**Metrics:** Accuracy, MCC
24. **[ACL18 (Financial News-Based Stock Prediction)](https://huggingface.co./datasets/ChanceFocus/flare-sm-acl)**
**Description:** Predicts stock price movements from news articles, interpreting sentiment and events for short-term forecasts.
**Metrics:** Accuracy, MCC
25. **[CIKM18 (Financial Market Prediction Using News)](https://huggingface.co./datasets/ChanceFocus/flare-sm-cikm)**
**Description:** Predicts broader market movements (indices) from financial news, synthesizing information for market trend forecasts.
**Metrics:** Accuracy, MCC
26. **[German (Credit Scoring in Germany)](https://huggingface.co./datasets/ChanceFocus/flare-german)**
**Description:** Predicts creditworthiness of loan applicants in Germany, important for responsible lending and risk management.
**Metrics:** F1-Score, MCC
27. **[Australian (Credit Scoring in Australia)](https://huggingface.co./datasets/ChanceFocus/flare-australian)**
**Description:** Predicts creditworthiness in the Australian market, considering local economic conditions.
**Metrics:** F1-Score, MCC
28. **[LendingClub (Peer-to-Peer Lending Risk Prediction)](https://huggingface.co./datasets/ChanceFocus/cra-lendingclub)**
**Description:** Predicts loan default risk for peer-to-peer lending, helping lenders manage risk.
**Metrics:** F1-Score, MCC
29. **[ccf (Credit Card Fraud Detection)](https://huggingface.co./datasets/ChanceFocus/cra-ccf)**
**Description:** Identifies fraudulent credit card transactions, ensuring financial security and fraud prevention.
**Metrics:** F1-Score, MCC
30. **[ccfraud (Credit Card Transaction Fraud Detection)](https://huggingface.co./datasets/ChanceFocus/cra-ccfraud)**
**Description:** Detects anomalies in credit card transactions that indicate fraud, while handling imbalanced datasets.
**Metrics:** F1-Score, MCC
31. **[Polish (Credit Risk Prediction in Poland)](https://huggingface.co./datasets/ChanceFocus/cra-polish)**
**Description:** Predicts credit risk for loan applicants in Poland, assessing factors relevant to local economic conditions.
**Metrics:** F1-Score, MCC
32. **[Taiwan (Credit Risk Prediction in Taiwan)](https://huggingface.co./datasets/TheFinAI/cra-taiwan)**
**Description:** Predicts credit risk in the Taiwanese market, helping lenders manage risk in local contexts.
**Metrics:** F1-Score, MCC
33. **[Portoseguro (Claim Analysis in Brazil)](https://huggingface.co./datasets/TheFinAI/en-forecasting-portosegur**
**Description:** Predicts the outcome of insurance claims in Brazil, focusing on auto insurance claims.
**Metrics:** F1-Score, MCC
34. **[Travel Insurance (Claim Prediction)](https://huggingface.co./datasets/TheFinA**
**Description:** Predicts the likelihood of travel insurance claims, helping insurers manage pricing and risk.
**Metrics:** F1-Score, MCC
35. **[MultiFin-ES (Sentiment Analysis in Spanish)](https://huggingface.co./datasets/ChanceFocus/flare-es-multifin)**
**Description:** Classifies sentiment in Spanish-language financial texts (bullish, bearish, neutral).
**Metrics:** F1-Score
36. **[EFP (Financial Phrase Classification in Spanish)](https://huggingface.co./datasets/ChanceFocus/flare-es-efp)**
**Description:** Classifies sentiment or intent in Spanish financial phrases (positive, negative, neutral).
**Metrics:** F1-Score
37. **[EFPA (Argument Classification in Spanish)](https://huggingface.co./datasets/ChanceFocus/flare-es-efpa)**
**Description:** Identifies claims, evidence, and counterarguments in Spanish financial texts.
**Metrics:** F1-Score
38. **[FinanceES (Sentiment Classification in Spanish)](https://huggingface.co./datasets/ChanceFocus/flare-es-financees)**
**Description:** Classifies sentiment in Spanish financial documents, understanding linguistic nuances.
**Metrics:** F1-Score
39. **[TSA-Spanish (Sentiment Analysis in Spanish Tweets)](https://huggingface.co./datasets/TheFinAI/flare-es-tsa)**
**Description:** Sentiment analysis of Spanish tweets, interpreting informal language in real-time market discussions.
**Metrics:** F1-Score
40. **[FinTrade (Stock Trading Simulation)](https://huggingface.co./datasets/TheFinAI/FinTrade_train)**
**Description:** Evaluates models on stock trading simulations, analyzing historical stock prices and financial news to optimize trading outcomes.
**Metrics:** Sharpe Ratio (SR)
</details>
<details><summary><b>Click here for a detailed explanation of each task</b></summary>
This section will document each task within the categories in more detail, explaining the specific datasets, evaluation metrics, and financial relevance.
1. **FPB (Financial PhraseBank Sentiment Classification)**
* **Task Description.** In this task, we evaluate a language model's ability to perform sentiment analysis on financial texts. We employ the Financial PhraseBank dataset1, which consists of annotated phrases extracted from financial news articles and reports. Each phrase is labeled with one of three sentiment categories: positive, negative, or neutral. The dataset provides a nuanced understanding of sentiments expressed in financial contexts, making it essential for applications such as market sentiment analysis and automated trading strategies. The primary objective is to classify each financial phrase accurately according to its sentiment. Example inputs, outputs, and the prompt templates used in this task are detailed in Table 5 and Table 8 in the Appendix.
* **Metric.** Accuracy, F1-score.
2. **FiQA-SA (Sentiment Analysis on FiQA Financial Domain)**
* **Task Description.** The FiQA-SA task evaluates a language model's capability to perform sentiment analysis within the financial domain, particularly focusing on data derived from the FiQA dataset. This dataset includes a diverse collection of financial texts sourced from various media, including news articles, financial reports, and social media posts. The primary objective of the task is to classify sentiments expressed in these texts into distinct categories, such as positive, negative, and neutral. This classification is essential for understanding market sentiment, as it can directly influence investment decisions and strategies. The FiQA-SA task is particularly relevant in today's fast-paced financial environment, where the interpretation of sentiment can lead to timely and informed decision-making.
* **Metrics.** F1 Score.
3. **TSA (Sentiment Analysis on Social Media)**
* **Task Description.** The TSA task focuses on evaluating a model's ability to perform sentiment analysis on tweets related to financial markets. Utilizing a dataset comprised of social media posts, this task seeks to classify sentiments as positive, negative, or neutral. The dynamic nature of social media makes it a rich source of real-time sentiment data, reflecting public opinion on market trends, company news, and economic events. The TSA dataset includes a wide variety of tweets, featuring diverse expressions of sentiment related to financial topics, ranging from stock performance to macroeconomic indicators. Given the brevity and informal nature of tweets, this task presents unique challenges in accurately interpreting sentiment, as context and subtleties can significantly impact meaning. Therefore, effective models must demonstrate robust understanding and analysis of informal language, slang, and sentiment indicators commonly used on social media platforms.
* **Metrics.** F1 Score, RMSE. RMSE provides a measure of the average deviation between predicted and actual sentiment scores, offering a quantitative insight into the accuracy of the model's predictions.
4. **Headlines (News Headline Classification)**
* **Task Description.** The Headlines task involves classifying financial news headlines into various categories, reflecting distinct financial events or sentiment classes. This dataset consists of a rich collection of headlines sourced from reputable financial news outlets, capturing a wide array of topics ranging from corporate earnings reports to market forecasts. The primary objective of this task is to evaluate a model's ability to accurately interpret and categorize brief, context-rich text segments that often drive market movements. Given the succinct nature of headlines, the classification task requires models to quickly grasp the underlying sentiment and relevance of each headline, which can significantly influence investor behavior and market sentiment.
* **Metrics.** Average F1 Score (AvgF1). This metric provides a balanced measure of precision and recall, allowing for a nuanced understanding of the model’s performance in classifying headlines. A high AvgF1 indicates that the model is effectively identifying and categorizing the sentiment and events reflected in the headlines, making it a critical metric for assessing its applicability in real-world financial contexts.
5. **FOMC (Hawkish-Dovish Classification)**
* **Task Description.** The FOMC task evaluates a model's ability to classify statements derived from transcripts of Federal Open Market Committee (FOMC) meetings as either hawkish or dovish. Hawkish statements typically indicate a preference for higher interest rates to curb inflation, while dovish statements suggest a focus on lower rates to stimulate economic growth. This classification is crucial for understanding monetary policy signals that can impact financial markets and investment strategies. The dataset includes a range of statements from FOMC meetings, providing insights into the Federal Reserve's stance on economic conditions, inflation, and employment. Accurately categorizing these statements allows analysts and investors to anticipate market reactions and adjust their strategies accordingly, making this task highly relevant in the context of financial decision-making.
* **Metrics.** F1 Score and Accuracy.
6. **FinArg-ACC (Financial Argument Unit Classification)**
* **Task Description.** The FinArg-ACC task focuses on classifying argument units within financial documents, aiming to identify key components such as main claims, supporting evidence, and counterarguments. This dataset comprises a diverse collection of financial texts, including research reports, investment analyses, and regulatory filings. The primary objective is to assess a model's ability to dissect complex financial narratives into distinct argument units, which is crucial for automated financial document analysis. This task is particularly relevant in the context of increasing regulatory scrutiny and the need for transparency in financial communications, where understanding the structure of arguments can aid in compliance and risk management.
* **Metrics.** F1 Score, Accuracy.
7. **FinArg-ARC (Financial Argument Relation Classification)**
* **Task Description.** The FinArg-ARC task focuses on classifying relationships between different argument units within financial texts. This involves identifying how various claims, evidence, and counterarguments relate to each other, such as support, opposition, or neutrality. The dataset comprises annotated financial documents that highlight argument structures, enabling models to learn the nuances of financial discourse. Understanding these relationships is crucial for constructing coherent narratives and analyses from fragmented data, which can aid financial analysts, investors, and researchers in drawing meaningful insights from complex information. Given the intricate nature of financial arguments, effective models must demonstrate proficiency in discerning subtle distinctions in meaning and context, which are essential for accurate classification.
* **Metrics.** F1 Score, Accuracy
8. **MultiFin (Multi-Class Financial Sentiment Analysis)**
* **Task Description.** The MultiFin task focuses on the classification of sentiments expressed in a diverse array of financial texts into multiple categories, such as bullish, bearish, or neutral. This dataset includes various financial documents, ranging from reports and articles to social media posts, providing a comprehensive view of sentiment across different sources and contexts. The primary objective of this task is to assess a model's ability to accurately discern and categorize sentiments that influence market behavior and investor decisions. Models must demonstrate a robust understanding of contextual clues and varying tones inherent in financial discussions. The MultiFin task is particularly valuable for applications in sentiment-driven trading strategies and market analysis, where precise sentiment classification can lead to more informed investment choices.
* **Metrics.** F1 Score, Accuracy.
9. **MA (Deal Completeness Classification)**
* **Task Description:**
The MA task focuses on classifying mergers and acquisitions (M\&A) reports to determine whether a deal has been completed. This dataset comprises a variety of M\&A announcements sourced from financial news articles, press releases, and corporate filings. The primary objective is to accurately identify the status of each deal—categorized as completed, pending, or terminated—based on the information presented in the reports. This classification is crucial for investment analysts and financial institutions, as understanding the completion status of M\&A deals can significantly influence investment strategies and market reactions. Models must demonstrate a robust understanding of the M\&A landscape and the ability to accurately classify deal statuses based on often complex and evolving narratives.
* **Metrics:**
F1 Score, Accuracy.
10. **MLESG (ESG Issue Identification)**
* **Task Description:**
The MLESG task focuses on identifying Environmental, Social, and Governance (ESG) issues within financial texts. This dataset is specifically designed to capture a variety of texts, including corporate reports, news articles, and regulatory filings, that discuss ESG topics. The primary objective of the task is to evaluate a model's ability to accurately classify and categorize ESG-related content, which is becoming increasingly important in today's investment landscape. Models are tasked with detecting specific ESG issues, such as climate change impacts, social justice initiatives, or corporate governance practices. Models must demonstrate a deep understanding of the language used in these contexts, as well as the ability to discern subtle variations in meaning and intent.
* **Metrics:**
F1 Score, Accuracy.
11. **NER (Named Entity Recognition in Financial Texts)**
* **Task Description:**
The NER task focuses on identifying and classifying named entities within financial documents, such as companies, financial instruments, and individuals. This task utilizes a dataset that includes a diverse range of financial texts, encompassing regulatory filings, earnings reports, and news articles. The primary objective is to accurately recognize entities relevant to the financial domain and categorize them appropriately, which is crucial for information extraction and analysis. Effective named entity recognition enhances the automation of financial analysis processes, allowing stakeholders to quickly gather insights from large volumes of unstructured text.
* **Metrics:**
Entity F1 Score (EntityF1).
12. **FINER-ORD (Ordinal Classification in Financial NER)**
* **Task Description:**
The FINER-ORD task focuses on extending standard Named Entity Recognition (NER) by requiring models to classify entities not only by type but also by their ordinal relevance within financial texts. This dataset comprises a range of financial documents that include reports, articles, and regulatory filings, where entities such as companies, financial instruments, and events are annotated with an additional layer of classification reflecting their importance or priority. The primary objective is to evaluate a model’s ability to discern and categorize entities based on their significance in the context of the surrounding text. For instance, a model might identify a primary entity (e.g., a major corporation) as having a higher relevance compared to secondary entities (e.g., a minor competitor) mentioned in the same document. This capability is essential for prioritizing information and enhancing the efficiency of automated financial analyses, where distinguishing between varying levels of importance can significantly impact decision-making processes.
* **Metrics:**
Entity F1 Score (EntityF1).
13. **FinRED (Financial Relation Extraction from Text)**
* **Task Description:**
The FinRED task focuses on extracting relationships between financial entities mentioned in textual data. This task utilizes a dataset that includes diverse financial documents, such as news articles, reports, and regulatory filings. The primary objective is to identify and classify relationships such as ownership, acquisition, and partnership among various entities, such as companies, financial instruments, and stakeholders. Accurately extracting these relationships is crucial for building comprehensive knowledge graphs and facilitating in-depth financial analysis. The challenge lies in accurately interpreting context, as the relationships often involve nuanced language and implicit connections that require a sophisticated understanding of financial terminology.
* **Metrics:**
F1 Score, Entity F1 Score (EntityF1).
14. **SC (Causal Classification Task in the Financial Domain)**
* **Task Description:**
The SC task focuses on evaluating a language model's ability to classify causal relationships within financial texts. This involves identifying whether one event causes another, which is crucial for understanding dynamics in financial markets. The dataset used for this task encompasses a variety of financial documents, including reports, articles, and regulatory filings, where causal language is often embedded. By examining phrases that express causality—such as "due to," "resulting in," or "leads to"—models must accurately determine the causal links between financial events, trends, or phenomena. This task is particularly relevant for risk assessment, investment strategy formulation, and decision-making processes, as understanding causal relationships can significantly influence evaluations of market conditions and forecasts.
* **Metrics:**
F1 Score, Entity F1 Score (EntityF1).
15. **CD (Causal Detection)**
* **Task Description:**
The CD task focuses on detecting causal relationships within a diverse range of financial texts, including reports, news articles, and social media posts. This task evaluates a model's ability to identify instances where one event influences or causes another, which is crucial for understanding dynamics in financial markets. The dataset comprises annotated examples that explicitly highlight causal links, allowing models to learn from various contexts and expressions of causality. Detecting causality is essential for risk assessment, as it helps analysts understand potential impacts of events on market behavior, investment strategies, and decision-making processes. Models must navigate nuances and subtleties in text to accurately discern causal connections.
* **Metrics:**
F1 Score, Entity F1 Score (EntityF1).
16. **FinQA (Numerical Question Answering in Finance)**
* **Task Description:**
The FinQA task evaluates a model's ability to answer numerical questions based on financial documents, such as balance sheets, income statements, and financial reports. This dataset includes a diverse set of questions that require not only comprehension of the text but also the ability to extract and manipulate numerical data accurately. The primary goal is to assess how well a model can interpret complex financial information and perform necessary calculations to derive answers. The FinQA task is particularly relevant for applications in financial analysis, investment decision-making, and automated reporting, where precise numerical responses are essential for stakeholders.
* **Metrics:**
Exact Match Accuracy (EmAcc)
17. **TATQA (Table-Based Question Answering in Financial Documents)**
* **Task Description:**
The TATQA task focuses on evaluating a model's ability to answer questions that require interpreting and extracting information from tables in financial documents. This dataset is specifically designed to include a variety of financial tables, such as balance sheets, income statements, and cash flow statements, each containing structured data critical for financial analysis. The primary objective of this task is to assess how well models can navigate these tables to provide accurate and relevant answers to questions that often demand numerical reasoning or domain-specific knowledge. Models must demonstrate proficiency in not only locating the correct data but also understanding the relationships between different data points within the context of financial analysis.
* **Metrics:**
F1 Score, Exact Match Accuracy (EmAcc).
18. **ConvFinQA (Multi-Turn Question Answering in Finance)**
* **Task Description:**
The ConvFinQA task focuses on evaluating a model's ability to handle multi-turn question answering in the financial domain. This task simulates real-world scenarios where financial analysts engage in dialogues, asking a series of related questions that build upon previous answers. The dataset includes conversations that reflect common inquiries regarding financial data, market trends, and economic indicators, requiring the model to maintain context and coherence throughout the dialogue. The primary objective is to assess the model's capability to interpret and respond accurately to multi-turn queries, ensuring that it can provide relevant and precise information as the conversation progresses. This task is particularly relevant in financial advisory settings, where analysts must extract insights from complex datasets while engaging with clients or stakeholders.
* **Metrics:**
Exact Match Accuracy (EmAcc).
19. **FNXL (Numeric Labeling in Financial Texts)**
* **Task Description:**
The FNXL task focuses on the identification and categorization of numeric values within financial documents. This involves labeling numbers based on their type (e.g., revenue, profit, expense) and their relevance in the context of the text. The dataset used for this task includes a diverse range of financial reports, statements, and analyses, presenting various numeric expressions that are crucial for understanding financial performance. Accurate numeric labeling is essential for automating financial analysis and ensuring that critical data points are readily accessible for decision-making. Models must demonstrate a robust ability to parse context and semantics to accurately classify numeric information, thereby enhancing the efficiency of financial data processing.
* **Metrics:**
F1 Score, Exact Match Accuracy (EmAcc).
20. **FSRL (Financial Statement Relation Linking)**
* **Task Description:**
The FSRL task focuses on linking related information across different financial statements, such as matching revenue figures from income statements with corresponding cash flow data. This task is crucial for comprehensive financial analysis, enabling models to synthesize data from multiple sources to provide a coherent understanding of a company's financial health. The dataset used for this task includes a variety of financial statements from publicly traded companies, featuring intricate relationships between different financial metrics. Accurate linking of this information is essential for financial analysts and investors who rely on holistic views of financial performance. The task requires models to navigate the complexities of financial terminology and understand the relationships between various financial elements, ensuring they can effectively connect relevant data points.
* **Metrics:**
F1 Score, Exact Match Accuracy (EmAcc).
21. **EDTSUM (Extractive Document Summarization in Finance)**
* **Task Description:**
The EDTSUM task focuses on summarizing lengthy financial documents by extracting the most relevant sentences to create concise and coherent summaries. This task is essential in the financial sector, where professionals often deal with extensive reports, research papers, and regulatory filings. The ability to distill critical information from large volumes of text is crucial for efficient decision-making and information dissemination. The EDTSUM dataset consists of various financial documents, each paired with expert-generated summaries that highlight key insights and data points. Models are evaluated on their capability to identify and select sentences that accurately reflect the main themes and arguments presented in the original documents.
* **Metrics:**
ROUGE, BERTScore, and BARTScore.
22. **ECTSUM (Extractive Content Summarization)**
* **Task Description:**
The ECTSUM task focuses on extractive content summarization within the financial domain, where the objective is to generate concise summaries from extensive financial documents. This task leverages a dataset that includes a variety of financial texts, such as reports, articles, and regulatory filings, each containing critical information relevant to stakeholders. The goal is to evaluate a model’s ability to identify and extract the most salient sentences or phrases that encapsulate the key points of the original text. The ECTSUM task challenges models to demonstrate their understanding of context, relevance, and coherence, ensuring that the extracted summaries accurately represent the main ideas while maintaining readability and clarity.
* **Metrics:**
ROUGE, BERTScore, and BARTScore.
23. **BigData22 (Stock Movement Prediction)**
* **Task Description:**
The BigData22 task focuses on predicting stock price movements based on financial news and reports. This dataset is designed to capture the intricate relationship between market sentiment and stock performance, utilizing a comprehensive collection of news articles, social media posts, and market data. The primary goal of this task is to evaluate a model's ability to accurately forecast whether the price of a specific stock will increase or decrease within a defined time frame. Models must effectively analyze textual data and discern patterns that correlate with market movements.
* **Metrics:**
Accuracy, Matthews Correlation Coefficient (MCC).
24. **ACL18 (Financial News-Based Stock Prediction)**
* **Task Description:**
The ACL18 task focuses on predicting stock movements based on financial news articles and headlines. Utilizing a dataset that includes a variety of news pieces, this task aims to evaluate a model's ability to analyze textual content and forecast whether stock prices will rise or fall in the near term. The dataset encompasses a range of financial news topics, from company announcements to economic indicators, reflecting the complex relationship between news sentiment and market reactions. Models must effectively interpret nuances in language and sentiment that can influence stock performance, ensuring that predictions align with actual market movements.
* **Metrics:**
Accuracy, Matthews Correlation Coefficient (MCC).
25. **CIKM18 (Financial Market Prediction Using News)**
* **Task Description:**
The CIKM18 task focuses on predicting broader market movements, such as stock indices, based on financial news articles. Utilizing a dataset that encompasses a variety of news stories related to market events, this task evaluates a model's ability to synthesize information from multiple sources and make informed predictions about future market trends. The dataset includes articles covering significant financial events, economic indicators, and company news, reflecting the complex interplay between news sentiment and market behavior. The objective of this task is to assess how well a model can analyze the content of financial news and utilize that analysis to forecast market movements.
* **Metrics:**
Accuracy, Matthews Correlation Coefficient (MCC).
26. **German (Credit Scoring in the German Market)**
* **Task Description:**
The German task focuses on evaluating a model's ability to predict creditworthiness among loan applicants within the German market. Utilizing a dataset that encompasses various financial indicators, demographic information, and historical credit data, this task aims to classify applicants as either creditworthy or non-creditworthy. The dataset reflects the unique economic and regulatory conditions of Germany, providing a comprehensive view of the factors influencing credit decisions in this specific market. Given the importance of accurate credit scoring for financial institutions, this task is crucial for minimizing risk and ensuring responsible lending practices. Models must effectively analyze multiple variables to make informed predictions, thereby facilitating better decision-making in loan approvals and risk management.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
27. **Australian (Credit Scoring in the Australian Market)**
* **Task Description:**
The Australian task focuses on predicting creditworthiness among loan applicants within the Australian financial context. This dataset includes a comprehensive array of features derived from various sources, such as financial histories, income levels, and demographic information. The primary objective of this task is to classify applicants as either creditworthy or non-creditworthy, enabling financial institutions to make informed lending decisions. Given the unique economic conditions and regulatory environment in Australia, this task is particularly relevant for understanding the specific factors that influence credit scoring in this market.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
28. **LendingClub (Peer-to-Peer Lending Risk Prediction)**
* **Task Description:**
The LendingClub task focuses on predicting the risk of default for loans issued through the LendingClub platform, a major peer-to-peer lending service. This task utilizes a dataset that includes detailed information about loan applicants, such as credit scores, income levels, employment history, and other financial indicators. The primary objective is to assess the likelihood of loan default, enabling lenders to make informed decisions regarding loan approvals and risk management. The models evaluated in this task must effectively analyze a variety of features, capturing complex relationships within the data to provide reliable risk assessments.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
29. **ccf (Credit Card Fraud Detection)**
* **Task Description:**
The ccf task focuses on identifying fraudulent transactions within a large dataset of credit card operations. This dataset encompasses various transaction features, including transaction amount, time, location, and merchant information, providing a comprehensive view of spending behaviors. The primary objective of the task is to classify transactions as either legitimate or fraudulent, thereby enabling financial institutions to detect and prevent fraudulent activities effectively. Models must navigate the challenges posed by class imbalance, as fraudulent transactions typically represent a small fraction of the overall dataset.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
30. **ccfraud (Credit Card Transaction Fraud Detection)**
* **Task Description:**
The ccfraud task focuses on identifying fraudulent transactions within a dataset of credit card operations. This dataset comprises a large number of transaction records, each labeled as either legitimate or fraudulent. The primary objective is to evaluate a model's capability to accurately distinguish between normal transactions and those that exhibit suspicious behavior indicative of fraud. The ccfraud task presents unique challenges, including the need to handle imbalanced data, as fraudulent transactions typically represent a small fraction of the total dataset. Models must demonstrate proficiency in detecting subtle patterns and anomalies that signify fraudulent activity while minimizing false positives to avoid inconveniencing legitimate customers.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
31. **Polish (Credit Risk Prediction in the Polish Market)**
* **Task Description:**
The Polish task focuses on predicting credit risk for loan applicants within the Polish financial market. Utilizing a comprehensive dataset that includes demographic and financial information about applicants, the task aims to assess the likelihood of default on loans. This prediction is crucial for financial institutions in making informed lending decisions and managing risk effectively. Models must be tailored to account for local factors influencing creditworthiness, such as income levels, employment status, and credit history.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
32. **Taiwan (Credit Risk Prediction in the Taiwanese Market)**
* **Task Description:**
The Taiwan task focuses on predicting credit risk for loan applicants in the Taiwanese market. Utilizing a dataset that encompasses detailed financial and personal information about borrowers, this task aims to assess the likelihood of default based on various factors, including credit history, income, and demographic details. The model's ability to analyze complex patterns within the data and provide reliable predictions is essential in a rapidly evolving financial landscape. Given the unique economic conditions and regulatory environment in Taiwan, this task also emphasizes the importance of local context in risk assessment, requiring models to effectively adapt to specific market characteristics and trends.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
33. **Portoseguro (Claim Analysis in the Brazilian Market)**
* **Task Description:**
The Portoseguro task focuses on analyzing insurance claims within the Brazilian market, specifically for auto insurance. This task leverages a dataset that includes detailed information about various claims, such as the nature of the incident, policyholder details, and claim outcomes. The primary goal is to evaluate a model’s ability to predict the likelihood of a claim being approved or denied based on these factors. By accurately classifying claims, models can help insurance companies streamline their decision-making processes, enhance risk management strategies, and reduce fraudulent activities. Models must consider regional nuances and the specific criteria used in evaluating claims, ensuring that predictions align with local regulations and market practices.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
34. **Travel Insurance (Travel Insurance Claim Prediction)**
* **Task Description:**
The Travel Insurance task focuses on predicting the likelihood of a travel insurance claim being made based on various factors and data points. This dataset includes historical data related to travel insurance policies, claims made, and associated variables such as the type of travel, duration, destination, and demographic information of the insured individuals. The primary objective of this task is to evaluate a model's ability to accurately assess the risk of a claim being filed, which is crucial for insurance companies in determining policy pricing and risk management strategies. By analyzing patterns and trends in the data, models can provide insights into which factors contribute to a higher likelihood of claims, enabling insurers to make informed decisions about underwriting and premium setting.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
35. **MultiFin-ES (Multi-Class Financial Sentiment Analysis in Spanish)**
* **Task Description:**
The MultiFin-ES task focuses on analyzing
* sentiment in Spanish-language financial texts, categorizing sentiments into multiple classes such as bullish, bearish, and neutral. This dataset includes a diverse array of financial documents, including news articles, reports, and social media posts, reflecting various aspects of the financial landscape. The primary objective is to evaluate a model's ability to accurately classify sentiments based on contextual cues, linguistic nuances, and cultural references prevalent in Spanish financial discourse. Models must demonstrate proficiency in processing the subtleties of the Spanish language, including idiomatic expressions and regional variations, to achieve accurate classifications.
* **Metrics:**
F1 Score.
36. **EFP (Financial Phrase Classification in Spanish)**
* **Task Description:**
The EFP task focuses on the classification of financial phrases in Spanish, utilizing a dataset specifically designed for this purpose. This dataset consists of a collection of annotated phrases extracted from Spanish-language financial texts, including news articles, reports, and social media posts. The primary objective is to classify these phrases based on sentiment or intent, categorizing them into relevant classifications such as positive, negative, or neutral. Given the growing importance of the Spanish-speaking market in global finance, accurately interpreting and analyzing sentiment in Spanish financial communications is essential for investors and analysts.
* **Metrics:**
F1 Score.
37. **EFPA (Financial Argument Classification in Spanish)**
* **Task Description:**
The EFPA task focuses on classifying arguments within Spanish financial documents, aiming to identify key components such as claims, evidence, and counterarguments. This dataset encompasses a range of financial texts, including reports, analyses, and regulatory documents, providing a rich resource for understanding argumentative structures in the financial domain. The primary objective is to evaluate a model's ability to accurately categorize different argument units, which is essential for automating the analysis of complex financial narratives. By effectively classifying arguments, stakeholders can gain insights into the reasoning behind financial decisions and the interplay of various factors influencing the market. This task presents unique challenges that require models to demonstrate a deep understanding of both linguistic and domain-specific contexts.
* **Metrics:**
F1 Score.
38. **FinanceES (Financial Sentiment Classification in Spanish)**
* **Task Description:**
The FinanceES task focuses on classifying sentiment within a diverse range of financial documents written in Spanish. This dataset includes news articles, reports, and social media posts, reflecting various financial topics and events. The primary objective is to evaluate a model's ability to accurately identify sentiments as positive, negative, or neutral, thus providing insights into market perceptions in Spanish-speaking regions. Given the cultural and linguistic nuances inherent in the Spanish language, effective sentiment classification requires models to adeptly navigate idiomatic expressions, slang, and context-specific terminology. This task is particularly relevant as financial sentiment analysis expands globally, necessitating robust models that can perform effectively across different languages and cultural contexts.
* **Metrics:**
F1 Score.
39. **TSA-Spanish (Sentiment Analysis in Spanish)**
* **Task Description:**
The TSA-Spanish task focuses on evaluating a model's ability to perform sentiment analysis on tweets and short texts in Spanish related to financial markets. Utilizing a dataset comprised of diverse social media posts, this task aims to classify sentiments as positive, negative, or neutral. The dynamic nature of social media provides a rich source of real-time sentiment data, reflecting public opinion on various financial topics, including stock performance, company announcements, and economic developments. This task presents unique challenges in accurately interpreting sentiment, as context, slang, and regional expressions can significantly influence meaning. Models must demonstrate a robust understanding of the subtleties of the Spanish language, including colloquialisms and varying sentiment indicators commonly used across different Spanish-speaking communities.
* **Metrics:**
F1 Score.
40. **FinTrade (Stock Trading Dataset)**
* **Task Description:**
The FinTrade task evaluates models on their ability to perform stock trading simulations using a specially developed dataset that incorporates historical stock prices, financial news, and sentiment data over a period of one year. This dataset is designed to reflect real-world trading scenarios, providing a comprehensive view of how various factors influence stock performance. The primary objective of this task is to assess the model's capability to make informed trading decisions based on a combination of quantitative and qualitative data, such as market trends and sentiment analysis. By simulating trading activities, models are tasked with generating actionable insights and strategies that maximize profitability while managing risk. The diverse nature of the data, which includes price movements, news events, and sentiment fluctuations, requires models to effectively integrate and analyze multiple data streams to optimize trading outcomes.
* **Metrics:**
Sharpe Ratio (SR).
</details>
## How to Use the Open Financial LLM Leaderboard
When you first visit the OFLL platform, you are greeted by the **main page**, which provides an overview of the leaderboard, including an introduction to the platform's purpose and a link to submit your model for evaluation.
At the top of the main page, you'll see different tabs:
* **LLM Benchmark:** The core page where you evaluate models.
* **Submit here:** A place to submit your own model for automatic evaluation.
* **About:** More details about the benchmarks, evaluation process, and the datasets used.
### Selecting Tasks to Display
To tailor the leaderboard to your specific needs, you can select the financial tasks you want to focus on under the **"Select columns to show"** section. These tasks are divided into several categories, such as:
* **Information Extraction (IE)**
* **Textual Analysis (TA)**
* **Question Answering (QA)**
* **Text Generation (TG)**
* **Risk Management (RM)**
* **Forecasting (FO)**
* **Decision-Making (DM)**
Simply check the box next to the tasks you're interested in. The selected tasks will appear as columns in the evaluation table. If you wish to remove all selections, click the **"Uncheck All"** button to reset the task categories.
### Selecting Models to Display
To further refine the models displayed in the leaderboard, you can use the **"Model types"** and **"Precision"** filters on the right-hand side of the interface, and filter models based on their:
* **Type:** Pretrained, fine-tuned, instruction-tuned, or reinforcement-learning (RL)-tuned.
* **Precision:** float16, bfloat16, or float32.
* **Model Size:** Ranges from \~1.5 billion to 70+ billion parameters.
### Viewing Results in the Task Table
Once you've selected your tasks, the results will populate in the **task table** (see image). This table provides detailed metrics for each model across the tasks you’ve chosen. The performance of each model is displayed under columns labeled **Average IE**, **Average TA**, **Average QA**, and so on, corresponding to the tasks you selected.
### Submitting a Model for Evaluation
If you have a new model that you’d like to evaluate on the leaderboard, the **submission section** allows you to upload your model file. You’ll need to provide:
* **Model name**
* **Revision commit**
* **Model type**
* **Precision**
* **Weight type**
After uploading your model, the leaderboard will **automatically start evaluating** it across the selected tasks, providing real-time feedback on its performance.
## Current Best Models and Surprising Results
Throughout the evaluation process on the Open FinLLM Leaderboard, several models have demonstrated exceptional capabilities across various financial tasks.
As of the latest evaluation:
- **Best model**: GPT-4 and Llama 3.1 have consistently outperformed other models in many tasks, showing high accuracy and robustness in interpreting financial sentiment.
- **Surprising Results**: The **Forecasting(FO)** task, focused on stock movement predictions, showed that smaller models, such as **Llama-3.1-7b, internlm-7b**,often outperformed larger models, for example Llama-3.1-70b, in terms of accuracy and MCC. This suggests that model size does not necessarily correlate with better performance in financial forecasting, especially in tasks where real-time market data and nuanced sentiment analysis are critical. These results highlight the importance of evaluating models based on task-specific performance rather than relying solely on size or general-purpose benchmarks.
## Acknowledgments
We would like to thank our sponsors, including The Linux Foundation, for their generous support in making the Open FinLLM Leaderboard possible. Their contributions have helped us build a platform that serves the financial AI community and advances the evaluation of financial language models.
We also invite the community to participate in this ongoing project by submitting models, datasets, or evaluation tasks. Your involvement is essential in ensuring that the leaderboard remains a comprehensive and evolving tool for benchmarking financial LLMs. Together, we can drive innovation and help develop models better suited for real-world financial applications. | [
[
"llm",
"benchmarks",
"community",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"benchmarks",
"tools"
] | null | null |
404c0665-6de4-4819-bf94-3b86b5ebf995 | completed | 2025-01-16T03:08:53.171238 | 2025-01-19T19:16:16.985867 | e38f9a3b-3334-414f-ba20-c89424e3573a | Hugging Face and IBM partner on watsonx.ai, the next-generation enterprise studio for AI builders | juliensimon | huggingface-and-ibm.md | <kbd>
<img src="assets/144_ibm/01.png">
</kbd>
All hype aside, it's hard to deny the profound impact that AI is having on society and businesses. From startups to enterprises to the public sector, every customer we talk to is busy experimenting with large language models and generative AI, identifying the most promising use cases, and gradually bringing them to production.
The #1 comment we get from customers is that no single model will rule them all. They understand the value of building the best model for each use case to maximize its relevance on company data while optimizing the compute budget. Of course, privacy and intellectual property are also top concerns, and customers want to ensure they maintain complete control.
As AI finds its way into every department and business unit, customers also realize the need to train and deploy many different models. In a large multinational organization, this could mean running hundreds, even thousands, of models at any time. Given the pace of AI innovation, newer and higher-performance model architectures will also lead customers to replace their models quicker than expected, reinforcing the need to train and deploy new models in production quickly and seamlessly.
All of this will only happen with standardization and automation. Organizations can't afford to build models, tools, and infrastructure from scratch for new projects. Fortunately, the last few years have seen some very positive developments:
1. **Model standardization**: the [Transformer](https://arxiv.org/abs/1706.03762) architecture is now the de facto standard for Deep Learning applications like Natural Language Processing, Computer Vision, Audio, Speech, and more. It’s now easier to build tools and workflows that perform well across many use cases.
2. **Pre-trained models**: [hundreds of thousands](https://huggingface.co./models) of pre-trained models are just a click away. You can discover and test them directly on [Hugging Face](https://huggingface.co.) and quickly shortlist the promising ones for your projects.
3. **Open-source libraries**: the Hugging Face [libraries](https://huggingface.co./docs) let you download pre-trained models with a single line of code, and you can start experimenting with your data in minutes. From training to deployment to hardware optimization, customers can rely on a consistent set of community-driven tools that work the same everywhere, from their laptops to their production environment.
In addition, our cloud partnerships let customers use Hugging Face models and libraries at any scale without worrying about provisioning infrastructure and building technical environments. This makes it much easier to get high-quality models out the door at a rapid pace without having to reinvent the wheel.
Following up on our collaboration with AWS on Amazon SageMaker and Microsoft on Azure Machine Learning, we're thrilled to work with none other than IBM on their new AI studio, [watsonx.ai](https://www.ibm.com/products/watsonx-ai). [watsonx.ai](http://watsonx.ai) is the next-generation enterprise studio for AI builders to train, validate, tune, and deploy both traditional ML and new generative AI capabilities, powered by foundation models.
IBM decided that open source should be at the core of watsonx.ai. We couldn't agree more! Built on [RedHat OpenShift](https://www.redhat.com/en/technologies/cloud-computing/openshift), watsonx.ai will be available in the cloud and on-premise. This is excellent news for customers who cannot use the cloud because of strict compliance rules or are more comfortable working with their confidential data on their infrastructure. Until now, these customers often had to build their in-house ML platform. They now have an open-source off-the-shelf alternative deployed and managed using standard DevOps tools.
Under the hood, watsonx.ai also integrates many Hugging Face open-source libraries, such as [transformers](https://github.com/huggingface/transformers) (100k+ GitHub stars!), [accelerate](https://github.com/huggingface/accelerate), [peft](https://github.com/huggingface/peft) and our [Text Generation Inference](https://github.com/huggingface/text-generation-inference) server, to name a few. We're happy to partner with IBM and to collaborate on the watsonx AI and data platform so that Hugging Face customers can work natively with their Hugging Face models and datasets to multiply the impact of AI across businesses.
In addition, IBM has also developed its own collection of Large Language Models, and we will work with their team to open-source them and make them easily available in the Hugging Face Hub.
To learn more, watch Dr. Darío Gil, SVP and Director of IBM Research, and our CEO Clem Delangue, [announce our collaboration](https://youtu.be/FrDnPTPgEmk?t=1077), [walk through the watsonx platform](https://youtu.be/FrDnPTPgEmk?t=283), and present IBM’s [suite of Large Language Models](https://youtu.be/FrDnPTPgEmk?t=586) in an IBM THINK 2023 keynote.
Our joint team is hard at work at the moment. We can't wait to show you what we've been up to! The most iconic of technology companies joining forces with an up-and-coming startup to tackle AI in the Enterprise... who would have thought?
Fascinating times. Stay tuned! | [
[
"llm",
"mlops",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"mlops",
"fine_tuning",
"integration"
] | null | null |
9664a2ab-33c7-4424-a108-e1fd1dddea08 | completed | 2025-01-16T03:08:53.171243 | 2025-01-19T18:50:54.904334 | 22ec02d6-d21a-4b73-a63c-2341d8128e05 | Improving Parquet Dedupe on Hugging Face Hub | yuchenglow, seanses | improve_parquet_dedupe.md | The Xet team at Hugging Face is working on improving the efficiency of the Hub's
storage architecture to make it easier and quicker for users to
store and update data and models. As Hugging Face hosts nearly 11PB of datasets
with Parquet files alone accounting for over 2.2PB of that storage,
optimizing Parquet storage is of pretty high priority.
Most Parquet files are bulk exports from various data analysis pipelines
or databases, often appearing as full snapshots rather than incremental
updates. Data deduplication becomes critical for efficiency when users want to
update their datasets on a regular basis. Only by deduplicating can we store
all versions as compactly as possible, without requiring everything to be uploaded
again on every update. In an ideal case, we should be able to store every version
of a growing dataset with only a little more space than the size of its largest version.
Our default storage algorithm uses byte-level [Content-Defined Chunking (CDC)](https://joshleeb.com/posts/content-defined-chunking.html),
which generally dedupes well over insertions and deletions, but the Parquet layout brings some challenges.
Here we run some experiments to see how some simple modifications behave on
Parquet files, using a 2GB Parquet file with 1,092,000 rows from the
[FineWeb](https://huggingface.co./datasets/HuggingFaceFW/fineweb/tree/main/data/CC-MAIN-2013-20)
dataset and generating visualizations using our [dedupe
estimator](https://github.com/huggingface/dedupe_estimator).
## Background
Parquet tables work by splitting the table into row groups, each with a fixed
number of rows (for instance 1000 rows). Each column within the row group is
then compressed and stored:
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/layout.png" alt="Parquet Layout" width=80%>
</p>
Intuitively, this means that operations which do not mess with the row
grouping, like modifications or appends, should dedupe pretty well. So let's
test this out!
## Append
Here we append 10,000 new rows to the file and compare the results with the
original version. Green represents all deduped blocks, red represents all
new blocks, and shades in between show different levels of deduplication.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/1_append.png" alt="Visualization of dedupe from data appends" width=30%>
</p>
We can see that indeed we are able to dedupe nearly the entire file,
but only with changes seen at the end of the file. The new file is 99.1%
deduped, requiring only 20MB of additional storage. This matches our
intuition pretty well.
## Modification
Given the layout, we would expect that row modifications to be pretty
isolated, but this is apparently not the case. Here we make a small
modification to row 10000, and we see that while most of the file does dedupe,
there are many small regularly spaced sections of new data!
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/2_mod.png" alt="Visualization of dedupe from data modifications" width=30%>
</p>
A quick scan of the [Parquet file
format](https://parquet.apache.org/docs/file-format/metadata/) suggests
that absolute file offsets are part of the Parquet column headers (see the
structures ColumnChunk and ColumnMetaData)! This means that any
modification is likely to rewrite all the Column headers. So while the
data does dedupe well (it is mostly green), we get new bytes in every
column header.
In this case, the new file is only 89% deduped, requiring 230MB of additional
storage.
## Deletion
Here we delete a row from the middle of the file (note: insertion should have
similar behavior). As this reorganizes the entire row group layout (each
row group is 1000 rows), we see that while we dedupe the first half of
the file, the remaining file has completely new blocks.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/3_delete.png" alt="Visualization of dedupe from data deletion" width=30%>
</p>
This is mostly because the Parquet format compresses each column
aggressively. If we turn off compression we are able to dedupe more
aggressively:
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/4_delete_no_compress.png" alt="Visualization of dedupe from data deletion without column compression" width=30%>
</p>
However the file sizes are nearly 2x larger if we store the data
uncompressed.
Is it possible to have the benefit of dedupe and compression at the same
time?
## Content Defined Row Groups
One potential solution is to use not only byte-level CDC, but also apply it at the row level:
we split row groups not based on absolute count (1000 rows), but on a hash of a provided
“Key” column. In other words, I split off a row group whenever the hash of
the key column % [target row count] = 0, with some allowances for a minimum
and a maximum row group size.
I hacked up a quick inefficient experimental demonstration
[here](https://gist.github.com/ylow/db38522fb0ca69bdf1065237222b4d1c).
With this, we are able to efficiently dedupe across compressed Parquet
files even as I delete a row. Here we clearly see a big red block
representing the rewritten row group, followed by a small change for every
column header.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/improve_parquet_dedupe/5_content_defined.png" alt="Visualization of dedupe from data deletion with content defined row groups" width=30%>
</p>
# Optimizing Parquet for Dedupe-ability
Based on these experiments, we could consider improving Parquet file
dedupe-ability in a couple of ways:
1. Use relative offsets instead of absolute offsets for file structure
data. This would make the Parquet structures position independent and
easy to “memcpy” around, although it is an involving file format change that
is probably difficult to do.
2. Support content defined chunking on row groups. The format actually
supports this today as it does not require row groups to be uniformly sized,
so this can be done with minimal blast radius. Only Parquet format writers
would have to be updated.
While we will continue exploring ways to improve Parquet storage performance
(Ex: perhaps we could optionally rewrite Parquet files before uploading?
Strip absolute file offsets on upload and restore on download?), we would
love to work with the Apache Arrow project to see if there is interest in
implementing some of these ideas in the Parquet / Arrow code base.
In the meantime, we are also exploring the behavior of our data dedupe process
on other common filetypes. Please do try our [dedupe
estimator](https://github.com/huggingface/dedupe_estimator) and tell us about
your findings! | [
[
"data",
"optimization",
"tools",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"data",
"optimization",
"efficient_computing",
"tools"
] | null | null |
679afd07-d57d-41b7-a79d-8f12ec83c3c9 | completed | 2025-01-16T03:08:53.171247 | 2025-01-19T17:07:27.283973 | bbf5b00c-bbc3-45d4-9364-81da00cf4b9b | Getting Started with Sentiment Analysis using Python | federicopascual | sentiment-analysis-python.md | <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
Sentiment analysis is the automated process of tagging data according to their sentiment, such as positive, negative and neutral. Sentiment analysis allows companies to analyze data at scale, detect insights and automate processes.
In the past, sentiment analysis used to be limited to researchers, machine learning engineers or data scientists with experience in natural language processing. However, the AI community has built awesome tools to democratize access to machine learning in recent years. Nowadays, you can use sentiment analysis with a few lines of code and no machine learning experience at all! 🤯
In this guide, you'll learn everything to get started with sentiment analysis using Python, including:
1. [What is sentiment analysis?](#1-what-is-sentiment-analysis)
2. [How to use pre-trained sentiment analysis models with Python](#2-how-to-use-pre-trained-sentiment-analysis-models-with-python)
3. [How to build your own sentiment analysis model](#3-building-your-own-sentiment-analysis-model)
4. [How to analyze tweets with sentiment analysis](#4-analyzing-tweets-with-sentiment-analysis-and-python)
Let's get started! 🚀
## 1. What is Sentiment Analysis?
Sentiment analysis is a [natural language processing](https://en.wikipedia.org/wiki/Natural_language_processing) technique that identifies the polarity of a given text. There are different flavors of sentiment analysis, but one of the most widely used techniques labels data into positive, negative and neutral. For example, let's take a look at these tweets mentioning [@VerizonSupport](https://twitter.com/VerizonSupport):
- *"dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over a decade and this is all time low for y’all. i’m talking no internet at all."* → Would be tagged as "Negative".
- *"@verizonsupport ive sent you a dm"* → would be tagged as "Neutral".
- *"thanks to michelle et al at @verizonsupport who helped push my no-show-phone problem along. order canceled successfully and ordered this for pickup today at the apple store in the mall."* → would be tagged as "Positive".
Sentiment analysis allows processing data at scale and in real-time. For example, do you want to analyze thousands of tweets, product reviews or support tickets? Instead of sorting through this data manually, you can use sentiment analysis to automatically understand how people are talking about a specific topic, get insights for data-driven decisions and automate business processes.
Sentiment analysis is used in a wide variety of applications, for example:
- Analyze social media mentions to understand how people are talking about your brand vs your competitors.
- Analyze feedback from surveys and product reviews to quickly get insights into what your customers like and dislike about your product.
- Analyze incoming support tickets in real-time to detect angry customers and act accordingly to prevent churn.
## 2. How to Use Pre-trained Sentiment Analysis Models with Python
Now that we have covered what sentiment analysis is, we are ready to play with some sentiment analysis models! 🎉
On the [Hugging Face Hub](https://huggingface.co./models), we are building the largest collection of models and datasets publicly available in order to democratize machine learning 🚀. In the Hub, you can find more than 27,000 models shared by the AI community with state-of-the-art performances on tasks such as sentiment analysis, object detection, text generation, speech recognition and more. The Hub is free to use and most models have a widget that allows to test them directly on your browser!
There are more than [215 sentiment analysis models](https://huggingface.co./models?pipeline_tag=text-classification&sort=downloads&search=sentiment) publicly available on the Hub and integrating them with Python just takes 5 lines of code:
```python
pip install -q transformers
from transformers import pipeline
sentiment_pipeline = pipeline("sentiment-analysis")
data = ["I love you", "I hate you"]
sentiment_pipeline(data)
```
This code snippet uses the [pipeline class](https://huggingface.co./docs/transformers/main_classes/pipelines) to make predictions from models available in the Hub. It uses the [default model for sentiment analysis](https://huggingface.co./distilbert-base-uncased-finetuned-sst-2-english?text=I+like+you.+I+love+you) to analyze the list of texts `data` and it outputs the following results:
```python
[{'label': 'POSITIVE', 'score': 0.9998},
{'label': 'NEGATIVE', 'score': 0.9991}]
```
You can use a specific sentiment analysis model that is better suited to your language or use case by providing the name of the model. For example, if you want a sentiment analysis model for tweets, you can specify the [model id](https://huggingface.co./finiteautomata/bertweet-base-sentiment-analysis):
```python
specific_model = pipeline(model="finiteautomata/bertweet-base-sentiment-analysis")
specific_model(data)
```
You can test these models with your own data using this [Colab notebook](https://colab.research.google.com/drive/1G4nvWf6NtytiEyiIkYxs03nno5ZupIJn?usp=sharing):
<!-- <div class="flex text-center items-center"> -->
<figure class="flex justify-center w-full">
<iframe width="560" height="315" src="https://www.youtube.com/embed/eN-mbWOKJ7Q" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
</figure>
The following are some popular models for sentiment analysis models available on the Hub that we recommend checking out:
- [Twitter-roberta-base-sentiment](https://huggingface.co./cardiffnlp/twitter-roberta-base-sentiment) is a roBERTa model trained on ~58M tweets and fine-tuned for sentiment analysis. Fine-tuning is the process of taking a pre-trained large language model (e.g. roBERTa in this case) and then tweaking it with additional training data to make it perform a second similar task (e.g. sentiment analysis).
- [Bert-base-multilingual-uncased-sentiment](https://huggingface.co./nlptown/bert-base-multilingual-uncased-sentiment) is a model fine-tuned for sentiment analysis on product reviews in six languages: English, Dutch, German, French, Spanish and Italian.
- [Distilbert-base-uncased-emotion](https://huggingface.co./bhadresh-savani/distilbert-base-uncased-emotion?text=I+feel+a+bit+let+down) is a model fine-tuned for detecting emotions in texts, including sadness, joy, love, anger, fear and surprise.
Are you interested in doing sentiment analysis in languages such as Spanish, French, Italian or German? On the Hub, you will find many models fine-tuned for different use cases and ~28 languages. You can check out the complete list of sentiment analysis models [here](https://huggingface.co./models?pipeline_tag=text-classification&sort=downloads&search=sentiment) and filter at the left according to the language of your interest.
## 3. Building Your Own Sentiment Analysis Model
Using pre-trained models publicly available on the Hub is a great way to get started right away with sentiment analysis. These models use deep learning architectures such as transformers that achieve state-of-the-art performance on sentiment analysis and other machine learning tasks. However, you can fine-tune a model with your own data to further improve the sentiment analysis results and get an extra boost of accuracy in your particular use case.
In this section, we'll go over two approaches on how to fine-tune a model for sentiment analysis with your own data and criteria. The first approach uses the Trainer API from the [🤗Transformers](https://github.com/huggingface/transformers), an open source library with 50K stars and 1K+ contributors and requires a bit more coding and experience. The second approach is a bit easier and more straightforward, it uses [AutoNLP](https://huggingface.co./autonlp), a tool to automatically train, evaluate and deploy state-of-the-art NLP models without code or ML experience.
Let's dive in!
### a. Fine-tuning model with Python
In this tutorial, you'll use the IMDB dataset to fine-tune a DistilBERT model for sentiment analysis.
The [IMDB dataset](https://huggingface.co./datasets/imdb) contains 25,000 movie reviews labeled by sentiment for training a model and 25,000 movie reviews for testing it. [DistilBERT](https://huggingface.co./docs/transformers/model_doc/distilbert) is a smaller, faster and cheaper version of [BERT](https://huggingface.co./docs/transformers/model_doc/bert). It has 40% smaller than BERT and runs 60% faster while preserving over 95% of BERT’s performance. You'll use the IMDB dataset to fine-tune a DistilBERT model that is able to classify whether a movie review is positive or negative. Once you train the model, you will use it to analyze new data! ⚡️
We have [created this notebook](https://colab.research.google.com/drive/1t-NJadXsPTDT6EWIR0PRzpn5o8oMHzp3?usp=sharing) so you can use it through this tutorial in Google Colab.
#### 1. Activate GPU and Install Dependencies
As a first step, let's set up Google Colab to use a GPU (instead of CPU) to train the model much faster. You can do this by going to the menu, clicking on 'Runtime' > 'Change runtime type', and selecting 'GPU' as the Hardware accelerator. Once you do this, you should check if GPU is available on our notebook by running the following code:
```python
import torch
torch.cuda.is_available()
```
Then, install the libraries you will be using in this tutorial:
```python
!pip install datasets transformers huggingface_hub
```
You should also install `git-lfs` to use git in our model repository:
```python
!apt-get install git-lfs
```
#### 2. Preprocess data
You need data to fine-tune DistilBERT for sentiment analysis. So, let's use [🤗Datasets](https://github.com/huggingface/datasets/) library to download and preprocess the IMDB dataset so you can then use this data for training your model:
```python
from datasets import load_dataset
imdb = load_dataset("imdb")
```
IMDB is a huge dataset, so let's create smaller datasets to enable faster training and testing:
```python
small_train_dataset = imdb["train"].shuffle(seed=42).select([i for i in list(range(3000))])
small_test_dataset = imdb["test"].shuffle(seed=42).select([i for i in list(range(300))])
```
To preprocess our data, you will use [DistilBERT tokenizer](https://huggingface.co./docs/transformers/v4.15.0/en/model_doc/distilbert#transformers.DistilBertTokenizer):
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
Next, you will prepare the text inputs for the model for both splits of our dataset (training and test) by using the [map method](https://huggingface.co./docs/datasets/about_map_batch.html):
```python
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True)
tokenized_train = small_train_dataset.map(preprocess_function, batched=True)
tokenized_test = small_test_dataset.map(preprocess_function, batched=True)
```
To speed up training, let's use a data_collator to convert your training samples to PyTorch tensors and concatenate them with the correct amount of [padding](https://huggingface.co./docs/transformers/preprocessing#everything-you-always-wanted-to-know-about-padding-and-truncation):
```python
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
#### 3. Training the model
Now that the preprocessing is done, you can go ahead and train your model 🚀
You will be throwing away the pretraining head of the DistilBERT model and replacing it with a classification head fine-tuned for sentiment analysis. This enables you to transfer the knowledge from DistilBERT to your custom model 🔥
For training, you will be using the [Trainer API](https://huggingface.co./docs/transformers/v4.15.0/en/main_classes/trainer#transformers.Trainer), which is optimized for fine-tuning [Transformers](https://github.com/huggingface/transformers)🤗 models such as DistilBERT, BERT and RoBERTa.
First, let's define DistilBERT as your base model:
```python
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2)
```
Then, let's define the metrics you will be using to evaluate how good is your fine-tuned model ([accuracy and f1 score](https://huggingface.co./metrics)):
```python
import numpy as np
from datasets import load_metric
def compute_metrics(eval_pred):
load_accuracy = load_metric("accuracy")
load_f1 = load_metric("f1")
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
accuracy = load_accuracy.compute(predictions=predictions, references=labels)["accuracy"]
f1 = load_f1.compute(predictions=predictions, references=labels)["f1"]
return {"accuracy": accuracy, "f1": f1}
```
Next, let's login to your [Hugging Face account](https://huggingface.co./join) so you can manage your model repositories. `notebook_login` will launch a widget in your notebook where you'll need to add your [Hugging Face token](https://huggingface.co./settings/token):
```python
from huggingface_hub import notebook_login
notebook_login()
```
You are almost there! Before training our model, you need to define the training arguments and define a Trainer with all the objects you constructed up to this point:
```python
from transformers import TrainingArguments, Trainer
repo_name = "finetuning-sentiment-model-3000-samples"
training_args = TrainingArguments(
output_dir=repo_name,
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
save_strategy="epoch",
push_to_hub=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_test,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
```
Now, it's time to fine-tune the model on the sentiment analysis dataset! 🙌 You just have to call the `train()` method of your Trainer:
```python
trainer.train()
```
And voila! You fine-tuned a DistilBERT model for sentiment analysis! 🎉
Training time depends on the hardware you use and the number of samples in the dataset. In our case, it took almost 10 minutes using a GPU and fine-tuning the model with 3,000 samples. The more samples you use for training your model, the more accurate it will be but training could be significantly slower.
Next, let's compute the evaluation metrics to see how good your model is:
```python
trainer.evaluate()
```
In our case, we got 88% accuracy and 89% f1 score. Quite good for a sentiment analysis model just trained with 3,000 samples!
#### 4. Analyzing new data with the model
Now that you have trained a model for sentiment analysis, let's use it to analyze new data and get 🤖 predictions! This unlocks the power of machine learning; using a model to automatically analyze data at scale, in real-time ⚡️
First, let's upload the model to the Hub:
```python
trainer.push_to_hub()
```
Now that you have pushed the model to the Hub, you can use it [pipeline class](https://huggingface.co./docs/transformers/main_classes/pipelines) to analyze two new movie reviews and see how your model predicts its sentiment with just two lines of code 🤯:
```python
from transformers import pipeline
sentiment_model = pipeline(model="federicopascual/finetuning-sentiment-model-3000-samples")
sentiment_model(["I love this move", "This movie sucks!"])
```
These are the predictions from our model:
```python
[{'label': 'LABEL_1', 'score': 0.9558},
{'label': 'LABEL_0', 'score': 0.9413}]
```
In the IMDB dataset, `Label 1` means positive and `Label 0` is negative. Quite good! 🔥
### b. Training a sentiment model with AutoNLP
[AutoNLP](https://huggingface.co./autonlp) is a tool to train state-of-the-art machine learning models without code. It provides a friendly and easy-to-use user interface, where you can train custom models by simply uploading your data. AutoNLP will automatically fine-tune various pre-trained models with your data, take care of the hyperparameter tuning and find the best model for your use case. All models trained with AutoNLP are deployed and ready for production.
Training a sentiment analysis model using AutoNLP is super easy and it just takes a few clicks 🤯. Let's give it a try!
As a first step, let's get some data! You'll use [Sentiment140](https://huggingface.co./datasets/sentiment140), a popular sentiment analysis dataset that consists of Twitter messages labeled with 3 sentiments: 0 (negative), 2 (neutral), and 4 (positive). The dataset is quite big; it contains 1,600,000 tweets. As you don't need this amount of data to get your feet wet with AutoNLP and train your first models, we have prepared a smaller version of the Sentiment140 dataset with 3,000 samples that you can download from [here](https://cdn-media.huggingface.co/marketing/content/sentiment%20analysis/sentiment-analysis-python/sentiment140-3000samples.csv). This is how the dataset looks like:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment 140 dataset" src="assets/50_sentiment_python/sentiment140-dataset.png"></medium-zoom>
<figcaption>Sentiment 140 dataset</figcaption>
</figure>
Next, let's create a [new project on AutoNLP](https://ui.autonlp.huggingface.co/new) to train 5 candidate models:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Creating a new project on AutoNLP" src="assets/50_sentiment_python/new-project.png"></medium-zoom>
<figcaption>Creating a new project on AutoNLP</figcaption>
</figure>
Then, upload the dataset and map the text column and target columns:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Adding a dataset to AutoNLP" src="assets/50_sentiment_python/add-dataset.png"></medium-zoom>
<figcaption>Adding a dataset to AutoNLP</figcaption>
</figure>
Once you add your dataset, go to the "Trainings" tab and accept the pricing to start training your models. AutoNLP pricing can be as low as $10 per model:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Adding a dataset to AutoNLP" src="assets/50_sentiment_python/trainings.png"></medium-zoom>
<figcaption>Adding a dataset to AutoNLP</figcaption>
</figure>
After a few minutes, AutoNLP has trained all models, showing the performance metrics for all of them:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Adding a dataset to AutoNLP" src="assets/50_sentiment_python/training-success.png"></medium-zoom>
<figcaption>Trained sentiment analysis models by AutoNLP</figcaption>
</figure>
The best model has 77.87% accuracy 🔥 Pretty good for a sentiment analysis model for tweets trained with just 3,000 samples!
All these models are automatically uploaded to the Hub and deployed for production. You can use any of these models to start analyzing new data right away by using the [pipeline class](https://huggingface.co./docs/transformers/main_classes/pipelines) as shown in previous sections of this post.
## 4. Analyzing Tweets with Sentiment Analysis and Python
In this last section, you'll take what you have learned so far in this post and put it into practice with a fun little project: analyzing tweets about NFTs with sentiment analysis!
First, you'll use [Tweepy](https://www.tweepy.org/), an easy-to-use Python library for getting tweets mentioning #NFTs using the [Twitter API](https://developer.twitter.com/en/docs/twitter-api). Then, you will use a sentiment analysis model from the 🤗Hub to analyze these tweets. Finally, you will create some visualizations to explore the results and find some interesting insights.
You can use [this notebook](https://colab.research.google.com/drive/182UbzmSeAFgOiow7WNMxvnz-yO-SJQ0W?usp=sharing) to follow this tutorial. Let’s jump into it!
### 1. Install dependencies
First, let's install all the libraries you will use in this tutorial:
```
!pip install -q transformers tweepy wordcloud matplotlib
```
### 2. Set up Twitter API credentials
Next, you will set up the credentials for interacting with the Twitter API. First, you'll need to sign up for a [developer account on Twitter](https://developer.twitter.com/en/docs/twitter-api/getting-started/getting-access-to-the-twitter-api). Then, you have to create a new project and connect an app to get an API key and token. You can follow this [step-by-step guide](https://developer.twitter.com/en/docs/tutorials/step-by-step-guide-to-making-your-first-request-to-the-twitter-api-v2) to get your credentials.
Once you have the API key and token, let's create a wrapper with Tweepy for interacting with the Twitter API:
```python
import tweepy
# Add Twitter API key and secret
consumer_key = "XXXXXX"
consumer_secret = "XXXXXX"
# Handling authentication with Twitter
auth = tweepy.AppAuthHandler(consumer_key, consumer_secret)
# Create a wrapper for the Twitter API
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)
```
### 3. Search for tweets using Tweepy
At this point, you are ready to start using the Twitter API to collect tweets 🎉. You will use [Tweepy Cursor](https://docs.tweepy.org/en/v3.5.0/cursor_tutorial.html) to extract 1,000 tweets mentioning #NFTs:
```python
# Helper function for handling pagination in our search and handle rate limits
def limit_handled(cursor):
while True:
try:
yield cursor.next()
except tweepy.RateLimitError:
print('Reached rate limite. Sleeping for >15 minutes')
time.sleep(15 * 61)
except StopIteration:
break
# Define the term you will be using for searching tweets
query = '#NFTs'
query = query + ' -filter:retweets'
# Define how many tweets to get from the Twitter API
count = 1000
# Let's search for tweets using Tweepy
search = limit_handled(tweepy.Cursor(api.search,
q=query,
tweet_mode='extended',
lang='en',
result_type="recent").items(count))
```
### 4. Run sentiment analysis on the tweets
Now you can put our new skills to work and run sentiment analysis on your data! 🎉
You will use one of the models available on the Hub fine-tuned for [sentiment analysis of tweets](https://huggingface.co./finiteautomata/bertweet-base-sentiment-analysis). Like in other sections of this post, you will use the [pipeline class](https://huggingface.co./docs/transformers/main_classes/pipelines) to make the predictions with this model:
```python
from transformers import pipeline
# Set up the inference pipeline using a model from the 🤗 Hub
sentiment_analysis = pipeline(model="finiteautomata/bertweet-base-sentiment-analysis")
# Let's run the sentiment analysis on each tweet
tweets = []
for tweet in search:
try:
content = tweet.full_text
sentiment = sentiment_analysis(content)
tweets.append({'tweet': content, 'sentiment': sentiment[0]['label']})
except:
pass
```
### 5. Explore the results of sentiment analysis
How are people talking about NFTs on Twitter? Are they talking mostly positively or negatively? Let's explore the results of the sentiment analysis to find out!
First, let's load the results on a dataframe and see examples of tweets that were labeled for each sentiment:
```python
import pandas as pd
# Load the data in a dataframe
df = pd.DataFrame(tweets)
pd.set_option('display.max_colwidth', None)
# Show a tweet for each sentiment
display(df[df["sentiment"] == 'POS'].head(1))
display(df[df["sentiment"] == 'NEU'].head(1))
display(df[df["sentiment"] == 'NEG'].head(1))
```
Output:
```
Tweet: @NFTGalIery Warm, exquisite and elegant palette of charming beauty Its price is 2401 ETH. \nhttps://t.co/Ej3BfVOAqc\n#NFTs #NFTartists #art #Bitcoin #Crypto #OpenSeaNFT #Ethereum #BTC Sentiment: POS
Tweet: How much our followers made on #Crypto in December:\n#DAPPRadar airdrop — $200\nFree #VPAD tokens — $800\n#GasDAO airdrop — up to $1000\nStarSharks_SSS IDO — $3500\nCeloLaunch IDO — $3000\n12 Binance XMas #NFTs — $360 \nTOTAL PROFIT: $8500+\n\nJoin and earn with us https://t.co/fS30uj6SYx Sentiment: NEU
Tweet: Stupid guy #2\nhttps://t.co/8yKzYjCYIl\n\n#NFT #NFTs #nftcollector #rarible https://t.co/O4V19gMmVk Sentiment: NEG
```
Then, let's see how many tweets you got for each sentiment and visualize these results:
```python
# Let's count the number of tweets by sentiments
sentiment_counts = df.groupby(['sentiment']).size()
print(sentiment_counts)
# Let's visualize the sentiments
fig = plt.figure(figsize=(6,6), dpi=100)
ax = plt.subplot(111)
sentiment_counts.plot.pie(ax=ax, autopct='%1.1f%%', startangle=270, fontsize=12, label="")
```
Interestingly, most of the tweets about NFTs are positive (56.1%) and almost none are negative
(2.0%):
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Sentiment analysis result of NFTs tweets" src="assets/50_sentiment_python/sentiment-result.png"></medium-zoom>
<figcaption>Sentiment analysis result of NFTs tweets</figcaption>
</figure>
Finally, let's see what words stand out for each sentiment by creating a word cloud:
```python
from wordcloud import WordCloud
from wordcloud import STOPWORDS
# Wordcloud with positive tweets
positive_tweets = df['tweet'][df["sentiment"] == 'POS']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
positive_wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white", stopwords = stop_words).generate(str(positive_tweets))
plt.figure()
plt.title("Positive Tweets - Wordcloud")
plt.imshow(positive_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# Wordcloud with negative tweets
negative_tweets = df['tweet'][df["sentiment"] == 'NEG']
stop_words = ["https", "co", "RT"] + list(STOPWORDS)
negative_wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white", stopwords = stop_words).generate(str(negative_tweets))
plt.figure()
plt.title("Negative Tweets - Wordcloud")
plt.imshow(negative_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
```
Some of the words associated with positive tweets include Discord, Ethereum, Join, Mars4 and Shroom:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Word cloud for positive tweets" src="assets/50_sentiment_python/positive-tweets-wordcloud.png"></medium-zoom>
<figcaption>Word cloud for positive tweets</figcaption>
</figure>
In contrast, words associated with negative tweets include: cookies chaos, Solana, and OpenseaNFT:
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Word cloud for negative tweets" src="assets/50_sentiment_python/negative-tweets-wordcloud.png"></medium-zoom>
<figcaption>Word cloud for negative tweets</figcaption>
</figure>
And that is it! With just a few lines of python code, you were able to collect tweets, analyze them with sentiment analysis and create some cool visualizations to analyze the results! Pretty cool, huh?
## 5. Wrapping up
Sentiment analysis with Python has never been easier! Tools such as [🤗Transformers](https://github.com/huggingface/transformers) and the [🤗Hub](https://huggingface.co./models) makes sentiment analysis accessible to all developers. You can use open source, pre-trained models for sentiment analysis in just a few lines of code 🔥
Do you want to train a custom model for sentiment analysis with your own data? Easy peasy! You can fine-tune a model using [Trainer API](https://huggingface.co./docs/transformers/v4.15.0/en/main_classes/trainer#transformers.Trainer) to build on top of large language models and get state-of-the-art results. If you want something even easier, you can use [AutoNLP](https://huggingface.co./autonlp) to train custom machine learning models by simply uploading data.
If you have questions, the Hugging Face community can help answer and/or benefit from, please ask them in the [Hugging Face forum](https://discuss.huggingface.co/). Also, join our [discord server](https://discord.gg/YRAq8fMnUG) to talk with us and with the Hugging Face community. | [
[
"implementation",
"tutorial",
"tools",
"text_classification"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"text_classification",
"implementation",
"tutorial",
"tools"
] | null | null |
34ccec53-1593-4a4a-8079-5e1420b983dc | completed | 2025-01-16T03:08:53.171252 | 2025-01-16T03:20:12.987677 | 65020ea5-bdf1-4ab1-ae45-e273995386ef | Director of Machine Learning Insights | britneymuller | ml-director-insights.md | Few seats at the Machine Learning table span both technical skills, problem solving and business acumen like Directors of Machine Learning
Directors of Machine Learning and/or Data Science are often expected to design ML systems, have deep knowledge of mathematics, familiarity with ML frameworks, rich data architecture understanding, experience applying ML to real-world applications, solid communication skills, and often expected to keep on top of industry developments. A tall order!
<a href="https://huggingface.co./platform?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_1"><img width="100%" style=
"margin:auto" src="/blog/assets/61_ml_director_insights/private-model-hub.png"></a>
For these reasons, we’ve tapped into this unique group of ML Directors for a series of articles highlighting their thoughts on current ML insights and industry trends ranging from Healthcare to Finance, eCommerce, SaaS, Research, Media, and more. For example, one Director will note how ML can be used to reduce empty deadheading truck driving (which occurs ~20% of the time) down to just 19% would cut carbon emissions by ~100,000 Americans. Note: This is back of napkin math, done by an ex-rocket Scientist however, so we’ll take it.
In this first installment, you’ll hear from a researcher (who’s using ground penetrating radar to detect buried landmines), an ex-Rocket Scientist, a Dzongkha fluent amateur gamer (Kuzu = Hello!), an ex-van living Scientist, a high-performance Data Science team coach who’s still very hands-on, a data practitioner who values relationships, family, dogs, and pizza. —All of whom are currently Directors of Machine Learning with rich field insights.
🚀 Let’s meet some top Machine Learning Directors and hear what they have to say about Machine Learning’s impact on their prospective industries:
<img class="mx-auto" style="float: left;" padding="5px" src="/blog/assets/61_ml_director_insights/Archi-Mitra.jpeg"></a>
### [Archi Mitra](https://www.linkedin.com/in/archimitra/) - Director of Machine Learning at [Buzzfeed](https://www.buzzfeed.com/)
**Background:** Bringing balance to the promise of ML for business. People over Process. Strategy over Hope. AI Ethics over AI Profits. Brown New Yorker.
**Fun Fact:** I can speak [Dzongkha](https://en.wikipedia.org/wiki/Dzongkha) (google it!) and am a supporter of [Youth for Seva](https://www.youthforseva.org/Donation).
**Buzzfeed:** An American Internet media, news and entertainment company with a focus on digital media.
#### **1. How has ML made a positive impact on Media?**
_Privacy first personalization for customers:_ Every user is unique and while their long-term interests are stable, their short-term interests are stochastic. They expect their relationship with the Media to reflect this. The combination of advancement in hardware acceleration and Deep Learning for recommendations has unlocked the ability to start deciphering this nuance and serve users with the right content at the right time at the right touchpoint.
_Assistive tools for makers:_ Makers are the limited assets in media and preserving their creative bandwidth by ML driven human-in-the-loop assistive tools have seen an outsized impact. Something as simple as automatically suggesting an appropriate title, image, video, and/or product that can go along with the content they are creating unlocks a collaborative machine-human flywheel.
_Tightened testing:_ In a capital intensive media venture, there is a need to shorten the time between collecting information on what resonates with users and immediately acting on it. With a wide variety of Bayesian techniques and advancements in reinforcement learning, we have been able to drastically reduce not only the time but the cost associated with it.
#### **2. What are the biggest ML challenges within Media?**
_Privacy, editorial voice, and equitable coverage:_ Media is a key pillar in the democratic world now more than ever. ML needs to respect that and operate within constraints that are not strictly considered table stakes in any other domain or industry. Finding a balance between editorially curated content & programming vs ML driven recommendations continues to be a challenge. Another unique challenge to BuzzFeed is we believe that the internet should be free which means we don't track our users like others can.
#### **3. What’s a common mistake you see people make trying to integrate ML into Media?**
Ignoring “the makers” of media: Media is prevalent because it houses a voice that has a deep influence on people. The editors, content creators, writers & makers are the larynx of that voice and the business and building ML that enables them, extends their impact and works in harmony with them is the key ingredient to success.
#### **4. What excites you most about the future of ML?**
Hopefully, small data-driven general-purpose multi-modal multi-task real-time ML systems that create step-function improvements in drug discovery, high precision surgery, climate control systems & immersive metaverse experiences. Realistically, more accessible, low-effort meta-learning techniques for highly accurate text and image generation.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Li-Tan.jpeg"></a>
### [Li Tan](http://linkedin.com/in/iamtanli/) - Director of Machine Learning & AI at [Johnson & Johnson](https://www.jnj.com/)
**Background:** Li is an AI/ML veteran with 15+ years of experience leading high-profile Data Science teams within industry leaders like Johnson & Johnson, Microsoft, and Amazon.
**Fun Fact:** Li continues to be curious, is always learning, and enjoys hands-on programming.
**Johnson & Johnson:** A Multinational corporation that develops medical devices, pharmaceuticals, and consumer packaged goods.
#### **1. How has ML made a positive impact on Pharmaceuticals?**
AI/ML applications have exploded in the pharmaceuticals space the past few years and are making many long-term positive impacts. Pharmaceuticals and healthcare have many use cases that can leverage AI/ML.
Applications range from research, and real-world evidence, to smart manufacturing and quality assurance. The technologies used are also very broad: NLP/NLU, CV, AIIoT, Reinforcement Learning, etc. even things like AlphaFold.
#### **2. What are the biggest ML challenges within Pharmaceuticals?**
The biggest ML challenge within pharma and healthcare is how to ensure equality and diversity in AI applications. For example, how to make sure the training set has good representations of all ethnic groups. Due to the nature of healthcare and pharma, this problem can have a much greater impact compared to applications in some other fields.
#### **3. What’s a common mistake you see people make trying to integrate ML into Pharmaceuticals?**
Wouldn’t say this is necessarily a mistake, but I see many people gravitate toward extreme perspectives when it comes to AI applications in healthcare; either too conservative or too aggressive.
Some people are resistant due to high regulatory requirements. We had to qualify many of our AI applications with strict GxP validation. It may require a fair amount of work, but we believe the effort is worthwhile. On the opposite end of the spectrum, there are many people who think AI/Deep Learning models can outperform humans in many applications and run completely autonomously.
As practitioners, we know that currently, neither is true.
ML models can be incredibly valuable but still make mistakes. So I recommend a more progressive approach. The key is to have a framework that can leverage the power of AI while having goalkeepers in place. [FDA has taken actions](https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-software-medical-device) to regulate how AI/ML should be used in software as a medical device and I believe that’s a positive step forward for our industry.
#### **4. What excites you most about the future of ML?**
The intersections between AI/ML and other hard sciences and technologies. I’m excited to see what’s to come.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Alina-Zare.jpeg"></a>
### [Alina Zare](https://www.linkedin.com/in/alina-zare/) - Director of the Machine Learning & Sensing Laboratory at the [University of Florida](https://faculty.eng.ufl.edu/machine-learning/people/faculty/)
**Background:** Alina Zare teaches and conducts research in the area of machine learning and artificial intelligence as a Professor in the Electrical and Computer Engineering Department at the University of Florida and Director of the Machine Learning and Sensing Lab. Dr. Zare’s research has focused primarily on developing new machine learning algorithms to automatically understand and process data and imagery.
Her research work has included automated plant root phenotyping, sub-pixel hyperspectral image analysis, target detection, and underwater scene understanding using synthetic aperture sonar, LIDAR data analysis, Ground Penetrating Radar analysis, and buried landmine and explosive hazard detection.
**Fun Fact:** Alina is a rower. She joined the crew team in high school, rowed throughout college and grad school, was head coach of the University of Missouri team while she was an assistant professor, and then rowed as a masters rower when she joined the faculty at UF.
**Machine Learning & Sensing Laboratory:** A University of Florida laboratory that develops machine learning methods for autonomously analyzing and understanding sensor data.
#### **1. How has ML made a positive impact on Science**
ML has made a positive impact in a number of ways from helping to automate tedious and/or slow tasks or providing new ways to examine and look at various questions. One example from my work in ML for plant science is that we have developed ML approaches to automate plant root segmentation and characterization in imagery. This task was previously a bottleneck for plant scientists looking at root imagery. By automating this step through ML we can conduct these analyses at a much higher throughput and begin to use this data to investigate plant biology research questions at scale.
#### **2. What are the biggest ML challenges within Scientific research?**
There are many challenges. One example is when using ML for Science research, we have to think carefully through the data collection and curation protocols. In some cases, the protocols we used for non-ML analysis are not appropriate or effective. The quality of the data and how representative it is of what we expect to see in the application can make a huge impact on the performance, reliability, and trustworthiness of an ML-based system.
#### **3. What’s a common mistake you see people make trying to integrate ML into Science?**
Related to the question above, one common mistake is misinterpreting results or performance to be a function of just the ML system and not also considering the data collection, curation, calibration, and normalization protocols.
#### **4. What excites you most about the future of ML?**
There are a lot of really exciting directions. A lot of my research currently is in spaces where we have a huge amount of prior knowledge and empirically derived models. For example, I have ongoing work using ML for forest ecology research. The forestry community has a rich body of prior knowledge and current purely data-driven ML systems are not leveraging. I think hybrid methods that seamlessly blend prior knowledge with ML approaches will be an interesting and exciting path forward.
An example may be understanding how likely two species are to co-occur in an area. Or what species distribution we could expect given certain environmental conditions. These could potentially be used w/ data-driven methods to make predictions in changing conditions.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Nathan-Cahill.jpeg"></a>
### [Nathan Cahill](https://www.linkedin.com/in/nathan-m-cahill/) Ph.D. - Director of Machine Learning at [Xpress Technologies](https://xpresstechfreight.com/)
**Background:** Nathan is a passionate machine learning leader with 7 years of experience in research and development, and three years experience creating business value by shipping ML models to prod. He specializes in finding and strategically prioritizing the business' biggest pain points: unlocking the power of data earlier on in the growth curve.
**Fun Fact:** Before getting into transportation and logistics I was engineering rockets at Northrop Grumman. #RocketScience
**Xpress Technologies:** A digital freight matching technology to connect Shippers, Brokers and Carriers to bring efficiency and automation to the Transportation Industry.
#### **1. How has ML made a positive impact on Logistics/Transportation?**
The transportation industry is incredibly fragmented. The top players in the game have less than 1% market share. As a result, there exist inefficiencies that can be solved by digital solutions.
For example, when you see a semi-truck driving on the road, there is currently a 20% chance that the truck is driving with nothing in the back. Yes, 20% of the miles a tractor-trailer drives are from the last drop off of their previous load to their next pickup. The chances are that there is another truck driving empty (or "deadheading") in the other direction.
With machine learning and optimization this deadhead percent can be reduced significantly, and just taking that number from 20% to 19% percent would cut the equivalent carbon emissions of 100,000 Americans.
Note: the carbon emissions of 100k Americans were my own back of the napkin math.
#### **2. What are the biggest ML challenges within Logistics?**
The big challenge within logistics is due to the fact that the industry is so fragmented: there is no shared pool of data that would allow technology solutions to "see" the big picture. For example a large fraction of brokerage loads, maybe a majority, costs are negotiated on a load by load basis making them highly volatile. This makes pricing a very difficult problem to solve. If the industry became more transparent and shared data more freely, so much more would become possible.
#### **3. What’s a common mistake you see people make trying to integrate ML into Logistics?**
I think that the most common mistake I see is people doing ML and Data Science in a vacuum.
Most ML applications within logistics will significantly change the dynamics of the problem if they are being used so it's important to develop models iteratively with the business and make sure that performance in reality matches what you expect in training.
An example of this is in pricing where if you underprice a lane slightly, your prices may be too competitive which will create an influx of freight on that lane. This, in turn, may cause costs to go up as the brokers struggle to find capacity for those loads, exacerbating the issue.
#### **4. What excites you the most about the future of ML?**
I think the thing that excites me most about ML is the opportunity to make people better at their jobs.
As ML begins to be ubiquitous in business, it will be able to help speed up decisions and automate redundant work. This will accelerate the pace of innovation and create immense economic value. I can’t wait to see what problems we solve in the next 10 years aided by data science and ML!
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Nicolas-Bertagnolli.png"></a>
### [Nicolas Bertagnolli](https://www.linkedin.com/in/nicolas-bertagnolli-058aba81/) - Director of Machine Learning at [BEN](https://ben.productplacement.com/)
**Background:** Nic is a scientist and engineer working to improve human communication through machine learning. He’s spent the last decade applying ML/NLP to solve data problems in the medical space from uncovering novel patterns in cancer genomes to leveraging billions of clinical notes to reduce costs and improve outcomes.
At BEN, Nic innovates intelligent technologies that scale human capabilities to reach people. See his [CV](http://www.nbertagnolli.com/assets/Bertagnolli_CV.pdf), [research](http://www.nbertagnolli.com/), and [Medium articles here](https://nbertagnolli.medium.com/).
**Fun Fact:** Nic lived in a van and traveled around the western United States for three years before starting work at BEN.
**BEN:** An entertainment AI company that places brands inside influencer, streaming, TV, and film content to connect brands with audiences in a way that advertisements cannot.
#### **1. How has ML made a positive impact on Marketing?**
In so many ways! It’s completely changing the landscape. Marketing is a field steeped in tradition based on gut feelings. In the past 20 years, there has been a move to more and more statistically informed marketing decisions but many brands are still relying on the gut instincts of their marketing departments. ML is revolutionizing this. With the ability to analyze data about which advertisements perform well we can make really informed decisions about how and who we market to.
At BEN, ML has really helped us take the guesswork out of a lot of the process when dealing with influencer marketing. Data helps shine a light through the fog of bias and subjectivity so that we can make informed decisions.
That’s just the obvious stuff! ML is also making it possible to make safer marketing decisions for brands. For example, it’s illegal to advertise alcohol to people under the age of 21. Using machine learning we can identify influencers whose audiences are mainly above 21. This scales our ability to help alcohol brands, and also brands who are worried about their image being associated with alcohol.
#### **2. What are the biggest ML challenges within Marketing?**
As with most things in Machine Learning the problems often aren’t really with the models themselves. With tools like [Hugging Face](http://huggingface.co), [torch hub](https://pytorch.org/docs/stable/hub.html), etc. so many great and flexible models are available to work with.
The real challenges have to do with collecting, cleaning, and managing the data. If we want to talk about the hard ML-y bits of the job, some of it comes down to the fact that there is a lot of noise in what people view and enjoy. Understanding things like virality are really really hard.
Understanding what makes a creator/influencer successful over time is really hard. There is a lot of weird preference information buried in some pretty noisy difficult-to-acquire data. These problems come down to having really solid communication between data, ML, and business teams, and building models which augment and collaborate with humans instead of fully automating away their roles.
#### **3. What’s a common mistake you see people make trying to integrate ML into Marketing?**
I don’t think this is exclusive to marketing but prioritizing machine learning and data science over good infrastructure is a big problem I see often. Organizations hear about ML and want to get a piece of the pie so they hire some data scientists only to find out that they don’t have any infrastructure to service their new fancy pants models. A ton of the value of ML is in the infrastructure around the models and if you’ve got trained models but no infrastructure you’re hosed.
One of the really nice things about BEN is we invested heavily in our data infrastructure and built the horse before the cart. Now Data Scientists can build models that get served to our end users quickly instead of having to figure out every step of that pipeline themselves. Invest in data engineering before hiring lots of ML folks.
#### **4. What excites you most about the future of ML?**
There is so much exciting stuff going on. I think the pace and democratization of the field is perhaps what I find most exciting. I remember almost 10 years ago writing my first seq2seq model for language translation. It was hundreds of lines of code, took forever to train and was pretty challenging. Now you can basically build a system to translate any language to any other language in under 100 lines of python code. It’s insane! This trend is most likely to continue and as the ML infrastructure gets better and better it will be easier and easier for people without deep domain expertise to deploy and serve models to other people.
Much like in the beginning of the internet, software developers were few and far between and you needed a skilled team to set up a website. Then things like Django, Rails, etc. came out making website building easy but serving it was hard. We’re kind of at this place where building the models is easy but serving them reliably, monitoring them reliably, etc. is still challenging. I think in the next few years the barrier to entry is going to come WAY down here and basically, any high schooler could deploy a deep transformer to some cloud infrastructure and start serving useful results to the general population. This is really exciting because it means we’ll start to see more and more tangible innovation, much like the explosion of online services. So many cool things!
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Eric-Golinko.jpeg"></a>
### [Eric Golinko](https://www.linkedin.com/in/eric-golinko/) - Director of Machine Learning at [E Source](https://www.esource.com/)
**Background:** Experienced data practitioner and team builder. I’ve worked in many industries across companies of different sizes. I’m a problem solver, by training a mathematician and computer scientist. But, above all, I value relationships, family, dogs, travel and pizza.
**Fun Fact:** Eric adores nachos!
**E Source:** Provides independent market intelligence, consulting, and predictive data science to utilities, major energy users, and other key players in the retail energy marketplace.
#### **1. How has ML made a positive impact on the Energy/Utility industry?**
Access to business insight. Provided a pre-requisite is great data. Utilities have many data relationships within their data portfolio from customers to devices, more specifically, this speaks to monthly billing amounts and enrollment in energy savings programs. Data like that could be stored in a relational database, whereas device or asset data we can think of as the pieces of machinery that make our grid. Bridging those types of data is non-trivial.
In addition, third-party data spatial/gis and weather are extremely important. Through the lens of machine learning, we are able to find and explore features and outcomes that have a real impact.
#### **2. What are the biggest ML challenges within Utilities?**
There is a demystification that needs to happen. What machine learning can do and where it needs to be monitored or could fall short. The utility industry has established ways of operating, machine learning can be perceived as a disruptor. Because of this, departments can be slow to adopt any new technology or paradigm. However, if the practitioner is able to prove results, then results create traction and a larger appetite to adopt. Additional challenges are on-premise data and access to the cloud and infrastructure. It’s a gradual process and has a learning curve that requires patience.
#### **3. What’s a common mistake you see people make trying to integrate ML into Utilities?**
Not unique to utilizes, but moving too fast and neglecting good data quality and simple quality checks. Aside from this machine learning is practiced among many groups in some direct or indirect way. A challenge is integrating best development practices across teams. This also means model tracking and being able to persist experiments and continuous discovery.
#### **4. What excites you most about the future of ML?**
I’ve been doing this for over a decade, and I somehow still feel like a novice. I feel fortunate to have been part of teams where I’d be lucky to be called the average member. My feeling is that the next ten years and beyond will be more focused on data engineering to see even a larger number of use cases covered by machine learning. | [
[
"mlops",
"research",
"community",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"research",
"community",
"tools"
] | null | null |
91b099f8-9bc0-44f4-bdaf-c7dcbf79f5be | completed | 2025-01-16T03:08:53.171256 | 2025-01-16T15:10:12.179593 | 55f8bfa3-38e1-47ad-8729-88454b5c1ede | Introducing the LiveCodeBench Leaderboard - Holistic and Contamination-Free Evaluation of Code LLMs | StringChaos, minimario, tianjunz, xu3kev, kingh0730, FanjiaYan, clefourrier | leaderboard-livecodebench.md | We are excited to introduce the [LiveCodeBench leaderboard](https://huggingface.co./spaces/livecodebench/leaderboard), based on LiveCodeBench, a new benchmark developed by researchers from UC Berkeley, MIT, and Cornell for measuring LLMs’ code generation capabilities.
LiveCodeBench collects coding problems over time from various coding contest platforms, annotating problems with their release dates. Annotations are used to evaluate models on problem sets released in different time windows, allowing an “evaluation over time” strategy that helps detect and prevent contamination. In addition to the usual code generation task, LiveCodeBench also assesses self-repair, test output prediction, and code execution, thus providing a more holistic view of coding capabilities required for the next generation of AI programming agents.
## LiveCodeBench Scenarios and Evaluation
LiveCodeBench problems are curated from coding competition platforms: LeetCode, AtCoder, and CodeForces. These websites periodically host contests containing problems that assess the coding and problem-solving skills of participants. Problems consist of a natural language problem statement along with example input-output examples, and the goal is to write a program that passes a set of hidden tests. Thousands of participants engage in the competitions, which ensures that the problems are vetted for clarity and correctness.
LiveCodeBench uses the collected problems for building its four coding scenarios
- **Code Generation.** The model is given a problem statement, which includes a natural language description and example tests (input-output pairs), and is tasked with generating a correct solution. Evaluation is based on the functional correctness of the generated code, which is determined using a set of test cases.
- **Self Repair.** The model is given a problem statement and generates a candidate program, similar to the code generation scenario above. In case of a mistake, the model is provided with error feedback (either an exception message or a failing test case) and is tasked with generating a fix. Evaluation is performed using the same functional correctness as above.
- **Code Execution.** The model is provided a program snippet consisting of a function (f) along with a test input, and is tasked with predicting the output of the program on the input test case. Evaluation is based on an execution-based correctness metric: the model's output is considered correct if the assertion `assert f(input) == generated_output` passes.
- **Test Output Prediction.** The model is given the problem statement along with a test case input and is tasked with generating the expected output for the input. Tests are generated solely from problem statements, without the need for the function’s implementation, and outputs are evaluated using an exact match checker.
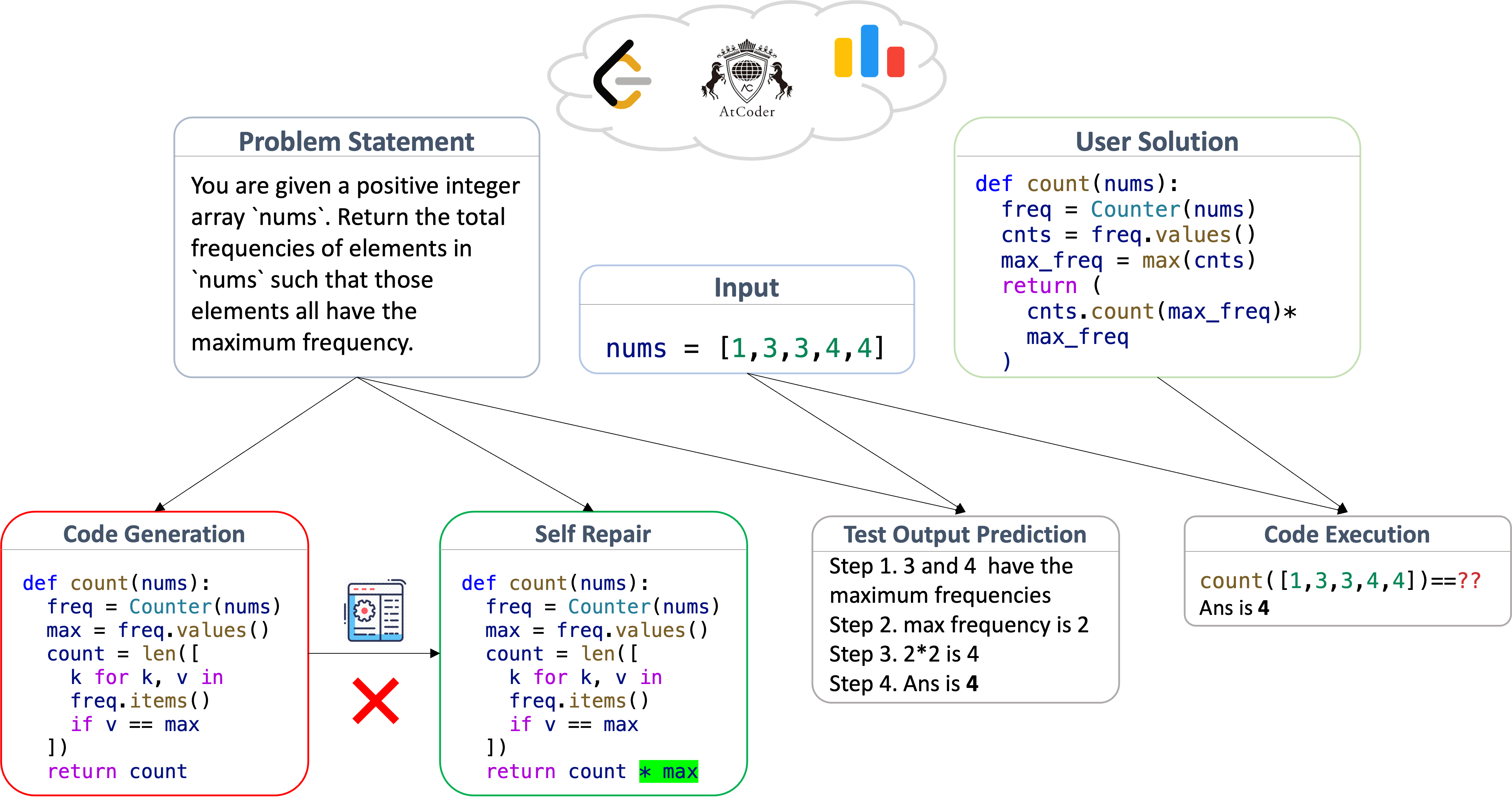
For each scenario, evaluation is performed using the Pass@1 metric. The metric captures the probability of generating a correct answer and is computed using the ratio of the count of correct answers over the count of total attempts, following `Pass@1 = total_correct / total_attempts`.
## Preventing Benchmark Contamination
Contamination is one of the major bottlenecks in current LLM evaluations. Even within LLM coding evaluations, there have been evidential reports of contamination and overfitting on standard benchmarks like HumanEval ([[1]](https://arxiv.org/abs/2403.05530) and [[2]](https://arxiv.org/abs/2311.04850)).
For this reason, we annotate problems with release dates in LiveCodeBench: that way, for new models with a training-cutoff date D, we can compute scores on problems released after D to measure their generalization on unseen problems.
LiveCodeBench formalizes this with a “scrolling over time” feature, that allows you to select problems within a specific time window. You can try it out in the leaderboard above!
## Findings
We find that:
- while model performances are correlated across different scenarios, the relative performances and orderings can vary on the 4 scenarios we use
- `GPT-4-Turbo` is the best-performing model across most scenarios. Furthermore, its margin grows on self-repair tasks, highlighting its capability to take compiler feedback.
- `Claude-3-Opus` overtakes `GPT-4-Turbo` in the test output prediction scenario, highlighting stronger natural language reasoning capabilities.
- `Mistral-Large` performs considerably better on natural language reasoning tasks like test output prediction and code execution.

## How to Submit?
To evaluate your code models on LiveCodeBench, you can follow these steps
1. Environment Setup: You can use conda to create a new environment, and install LiveCodeBench
```
git clone https://github.com/LiveCodeBench/LiveCodeBench.git
cd LiveCodeBench
pip install poetry
poetry install
```
2. For evaluating new Hugging Face models, you can easily evaluate the model using
```
python -m lcb_runner.runner.main --model {model_name} --scenario {scenario_name}
```
for different scenarios. For new model families, we have implemented an extensible framework and you can support new models by modifying `lcb_runner/lm_styles.py` and `lcb_runner/prompts` as described in the [github README](https://github.com/LiveCodeBench/LiveCodeBench).
3. Once you results are generated, you can submit them by filling out [this form](https://forms.gle/h2abvAHh6UnhWzzd9).
## How to contribute
Finally, we are looking for collaborators and suggestions for LiveCodeBench. The [dataset](https://huggingface.co./livecodebench) and [code](https://github.com/LiveCodeBench/LiveCodeBench) are available online, so please reach out by submitting an issue or [mail](mailto:[email protected]). | [
[
"llm",
"research",
"benchmarks",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"research",
"benchmarks",
"tools"
] | null | null |