
code
stringlengths 5
1M
| repo_name
stringlengths 5
109
| path
stringlengths 6
208
| language
stringclasses 1
value | license
stringclasses 15
values | size
int64 5
1M
|
|---|---|---|---|---|---|
package com.twitter.scalding.estimation
import cascading.flow.{Flow, FlowStep}
import com.twitter.algebird.Monoid
import org.apache.hadoop.mapred.JobConf
import org.slf4j.LoggerFactory
import scala.util.{Failure, Success}
case class FlowStrategyInfo(
flow: Flow[JobConf],
predecessorSteps: Seq[FlowStep[JobConf]],
step: FlowStep[JobConf]
)
/**
* Trait for estimation some parameters of Job.
* @tparam T
* return type of estimation
*/
trait Estimator[T] {
def estimate(info: FlowStrategyInfo): Option[T]
}
case class FallbackEstimator[T](first: Estimator[T], fallback: Estimator[T]) extends Estimator[T] {
private val LOG = LoggerFactory.getLogger(this.getClass)
override def estimate(info: FlowStrategyInfo): Option[T] =
first.estimate(info).orElse {
LOG.warn(s"$first estimator failed. Falling back to $fallback.")
fallback.estimate(info)
}
}
class FallbackEstimatorMonoid[T] extends Monoid[Estimator[T]] {
override def zero: Estimator[T] = new Estimator[T] {
override def estimate(info: FlowStrategyInfo): Option[T] = None
}
override def plus(l: Estimator[T], r: Estimator[T]): Estimator[T] = FallbackEstimator(l, r)
}
trait HistoryEstimator[T] extends Estimator[T] {
private val LOG = LoggerFactory.getLogger(this.getClass)
def maxHistoryItems(conf: JobConf): Int
def historyService: HistoryService
override def estimate(info: FlowStrategyInfo): Option[T] = {
val conf = info.step.getConfig
historyService.fetchHistory(info, maxHistoryItems(conf)) match {
case Success(history) if history.isEmpty =>
LOG.warn(s"No matching history found for $info")
None
case Success(history) =>
LOG.info(s"${history.length} history entries found for $info")
val estimation = estimate(info, conf, history)
LOG.info(s"$getClass estimate: $estimation")
estimation
case Failure(f) =>
LOG.warn(s"Unable to fetch history in $getClass", f)
None
}
}
protected def estimate(info: FlowStrategyInfo, conf: JobConf, history: Seq[FlowStepHistory]): Option[T]
}
| twitter/scalding | scalding-core/src/main/scala/com/twitter/scalding/estimation/Estimator.scala | Scala | apache-2.0 | 2,108 |
package dreamer.conceptnet
import java.net.URL
import scala.util.parsing.json.JSON
import dreamer.concept._
import Concept._
import Relation._
import util.Util._
private object ConceptNet {
val defaultBaseURL = "http://conceptnet5.media.mit.edu/data/5.2"
val defaultTimeout = 20l
val defaultMinWeight = 1.0
val defaultMaxResults = 50
val specials = Question(What,IsA,Thing) ::
Question(What,IsA,Place) :: Nil
val specialMax = 500
val bannedWords =
// offensive
"prostitute" :: "hooker" :: "whore" ::
"period" :: "breast" :: "pussy" ::
"jew" :: "nigger" ::
"sex" ::
// way too generic
"something" :: "someone" :: "area" ::
"there" :: "this" :: "it" :: "i" ::
Nil
val badPrefixes =
"the " :: "a " :: "any " :: "your " :: "my " :: "on " ::
"in " :: "at " ::
"sex " :: "gay " ::
"one " :: "two " :: "three " :: "four " :: "five " ::
"six " :: "seven " :: "eight " :: "nine " :: "ten " ::
(0 until 9).map(_.toString).toList
def filter(edges: List[Map[String,Any]]): List[Map[String,Any]] = for {
e <- edges
val start = e.get("startLemmas").asInstanceOf[Option[String]]
if start.isEmpty || (!bannedWords.contains(start.get) &&
badPrefixes.find(start.get.startsWith(_)).isEmpty)
val end = e.get("endLemmas").asInstanceOf[Option[String]]
if end.isEmpty || (!bannedWords.contains(end.get) &&
badPrefixes.find(end.get.startsWith(_)).isEmpty)
} yield e
def builtins: (Set[Edge],Set[(String,Concept)]) = (Set(
// Augment conceptnet with a few more builtin concepts
Edge(DreamerGame,IsA,Abstract("/c/en/computer_game")),
Edge(Abstract("/c/en/conceptnet"),IsA,Abstract("/c/en/database"))
), Set(
"dreamer of electric sheep" -> DreamerGame,
"conceptnet" -> Abstract("/c/en/conceptnet"),
"looming" -> Abstract("/c/en/looming"),
"grabbing" -> Abstract("/c/en/grabbing"),
"laughing maniacally" -> Abstract("/c/en/laughing_maniacally"),
"yelling \\"WAKE UP\\"" -> Abstract("/c/en/yelling_wake_up")
))
}
class ConceptNet(
baseURL: String=ConceptNet.defaultBaseURL,
timeout: Long=ConceptNet.defaultTimeout,
minWeight: Double=ConceptNet.defaultMinWeight,
maxResults: Int=ConceptNet.defaultMaxResults)
extends EdgeSource {
type Self = ConceptNet
private var memo: MentalMap = {
val (edges, names) = ConceptNet.builtins
names.foldLeft(edges.foldLeft(MentalMap())(_+_)){ (mind, name_concept) =>
val (name,concept) = name_concept
mind.name(concept, name)
}
}
private var alreadyFetched = Set[URL]()
def nameOf(c: Concept): Option[String] = memo.nameOf(c) orElse (c match {
case Abstract(uri) =>
val url = new URL(baseURL + uri)
fetch(url) foreach (memo += _)
memo.nameOf(c)
case _ => None
})
def named(name: String): Option[Concept] = memo.named(name) orElse {
val url = new URL(baseURL + "/search?text=" + uriEncode(name))
fetch(url) foreach (memo += _)
memo.named(name)
}
def name(c: Concept, name: String): ConceptNet = {
// yuck impure
memo = memo.name(c, name)
this
}
private def getConceptUri[T](c: QFragment[T]) = c match {
case Variable(_) => Some("-")
case Abstract(uri) => Some(uri)
case _ => None
}
private def getRelationUri(r: Relation) = r match {
case IsA => Some("/r/IsA")
case AtLocation => Some("/r/AtLocation")
case HasA => Some("/r/HasA")
case Verb(_) => None
case NextTo(_) => None
case HasState => None
}
private def getRelation(uri: String) = uri match {
case "/r/IsA" => Some(IsA)
case "/r/AtLocation" => Some(AtLocation)
case "/r/HasA" => Some(HasA)
case _ => None
}
private def urlFor(start: String, rel: String, end: String, max: Int): URL = {
val search = baseURL + "/search?" +
"minWeight=" + minWeight.toString +
"&limit=" + max.toString + "&"
val kvs = Array("start" -> start, "rel" -> rel, "end" -> end)
new URL(search + (for ((k,v) <- kvs; if v != "-")
yield k+"="+uriEncode(v)).mkString("&"))
}
private def urlFor[T](q: Question[T]): Option[URL] = {
val Question(start, rel, end) = q
val startUri = getConceptUri(start)
val relUri = getRelationUri(rel)
val endUri = getConceptUri(end)
val max = if (ConceptNet.specials contains q) ConceptNet.specialMax
else maxResults
for (start <- startUri;
rel <- relUri;
end <- endUri)
yield urlFor(start, rel, end, max)
}
private def fetch[T](url: URL): Set[Edge] = {
if (alreadyFetched contains url) Set()
else {
val r = parseResults(fetchURLCached(url))
alreadyFetched += url
r
}
}
private def fetch[T](q: Question[T]): Set[Edge] = urlFor(q) match {
case Some(url) => fetch(url)
case None => Set()
}
// The following functions are gross impure monsters.
private def parseResults[T](json: String): Set[Edge] =
JSON.parseFull(json) match {
case Some(obj) =>
obj.asInstanceOf[Map[String,List[Map[String,Any]]]].get("edges") match {
case Some(edges0) =>
val edges = ConceptNet.filter(edges0)
def nameNode(nodeKey: String, lemmaKey: String) {
for (edge <- edges;
node <- edge.get(nodeKey).asInstanceOf[Option[String]];
lemma <- edge.get(lemmaKey).asInstanceOf[Option[String]]) {
if (memo.named(lemma).isEmpty ||
memo.nameOf(Abstract(node)).isEmpty)
memo = memo.name(Abstract(node), lemma)
}
}
nameNode("start", "startLemmas")
nameNode("end", "endLemmas")
val parsedEdges = (for (edge <- edges;
relStr <- edge.get("rel");
rel <- getRelation(relStr.toString);
start <- edge.get("start");
end <- edge.get("end"))
yield Edge(Abstract(start.toString), rel,
Abstract(end.toString)))
parsedEdges.filter(
_ match {
case Edge(x,_,y) => x != y
case _ => true
}).toSet
case None => Set()
}
case _ => Set()
}
override def ask[T](q: Question[T]): Set[Edge] = {
fetch(q) foreach (memo += _)
memo.ask(q)
}
}
| tcoxon/dreamer | src/dreamer/conceptnet.scala | Scala | mit | 6,516 |
package org.scalaide.ui.internal.actions
import scala.collection.mutable.Set
import org.eclipse.ui.IObjectActionDelegate
import org.eclipse.core.resources.IProject
import scala.collection.mutable.HashSet
import org.eclipse.jface.action.IAction
import org.eclipse.jface.viewers.ISelection
import org.eclipse.jface.viewers.IStructuredSelection
import org.eclipse.core.runtime.IAdaptable
import org.scalaide.util.eclipse.EclipseUtils.RichAdaptable
import org.eclipse.ui.dialogs.ElementListSelectionDialog
import org.eclipse.jface.window.Window
import org.scalaide.core.internal.project.ScalaInstallation
import org.scalaide.core.internal.project.ScalaInstallationChoice
import org.scalaide.util.Utils.WithAsInstanceOfOpt
import org.scalaide.util.eclipse.SWTUtils
import org.eclipse.ui.IWorkbenchWindow
import org.scalaide.core.IScalaPlugin
import org.scalaide.util.internal.SettingConverterUtil
import org.eclipse.ui.IWorkbenchPart
import org.scalaide.util.internal.CompilerUtils.shortString
import scala.tools.nsc.settings.ScalaVersion
import org.scalaide.core.internal.ScalaPlugin
/** Offers to set a Scala Installation (and by consequence project-specific settings) for a
* selection (possibly multiple) of Scala Projects
*/
class ScalaInstallationAction extends IObjectActionDelegate {
var parentWindow: IWorkbenchWindow = null
val currSelected: Set[IProject] = new HashSet[IProject]()
val scalaPlugin = IScalaPlugin()
private def selectionObjectToProject(selectionElement: Object): Option[IProject] = selectionElement match {
case project: IProject => Some(project)
case adaptable: IAdaptable => adaptable.adaptToOpt[IProject]
case _ => None
}
override def setActivePart(action: IAction, targetpart: IWorkbenchPart) = {}
def selectionChanged(action: IAction, select: ISelection) = {
currSelected.clear()
for {
selection <- Option(select) collect { case s: IStructuredSelection => s }
selObject <- selection.toArray
project <- selectionObjectToProject(selObject)
} currSelected.add(project)
if (action != null) {
action.setEnabled(!currSelected.isEmpty)
}
}
// only to be used on resolvable choices, which is the case here
private def getDecoration(sc:ScalaInstallationChoice): String = sc.marker match{
case Left(version) => s"Latest ${shortString(version)} (dynamic)"
case Right(_) =>
val si = ScalaInstallation.resolve(sc)
val name = si.get.getName()
s"Fixed Scala Installation: ${name.getOrElse("")} ${si.get.version.unparse} ${if (name.isEmpty) "(bundled)" else ""}"
}
def labeler = new org.eclipse.jface.viewers.LabelProvider {
override def getText(element: Any): String = PartialFunction.condOpt(element){case si: ScalaInstallationChoice => getDecoration(si)}.getOrElse("")
}
def run(action: IAction): Unit = {
if (!currSelected.isEmpty) {
val chosenScalaInstallation = chooseScalaInstallation()
chosenScalaInstallation foreach { (sic) =>
currSelected foreach {
ScalaPlugin().asScalaProject(_) foreach { (spj) =>
spj.projectSpecificStorage.setValue(SettingConverterUtil.SCALA_DESIRED_INSTALLATION, sic.toString())
}
}
}
}
}
//Ask the user to select a build configuration from the selected project.
private def chooseScalaInstallation(): Option[ScalaInstallationChoice] = {
val dialog = new ElementListSelectionDialog(getShell(), labeler)
def getInstallationChoice: Option[ScalaInstallationChoice] = {
val res = dialog.getResult
if (res != null && !res.isEmpty) res(0).asInstanceOfOpt[ScalaInstallationChoice]
else None
}
val dynamicVersions:List[ScalaInstallationChoice] = List("2.10", "2.11").map((s) => ScalaInstallationChoice(ScalaVersion(s)))
val fixedVersions: List[ScalaInstallationChoice] = ScalaInstallation.availableInstallations.map((si) => ScalaInstallationChoice(si))
dialog.setElements((fixedVersions ++ dynamicVersions).toArray)
dialog.setTitle("Scala Installation Choice")
dialog.setMessage("Select a Scala Installation for your projects")
dialog.setMultipleSelection(false)
val result = dialog.open()
labeler.dispose()
if (result == Window.OK)
getInstallationChoice
else
None
}
private def getShell() = if (parentWindow == null) SWTUtils.getShell else parentWindow.getShell
def init(window: IWorkbenchWindow): Unit = {
parentWindow = window
}
}
| dragos/scala-ide | org.scala-ide.sdt.core/src/org/scalaide/ui/internal/actions/ScalaInstallationAction.scala | Scala | bsd-3-clause | 4,471 |
package org.opendronecontrol
package drone
package video
import java.awt.image.BufferedImage
trait VideoStream {
def start(){}
def stop(){}
def apply() = getFrame()
def getFrame():BufferedImage
def config(key:String, value:Any){}
} | IDMNYU/Creative-Coding-UG-Fall-2014 | Class25/dronestuff/odc-master/odc/src/main/scala/drone/video/VideoStream.scala | Scala | gpl-2.0 | 246 |
/*
* Copyright (C) 2015 Red Bull Media House GmbH <http://www.redbullmediahouse.com> - all rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.rbmhtechnology.eventuate.chaos
import akka.actor._
import com.rbmhtechnology.eventuate._
import com.rbmhtechnology.eventuate.chaos.ChaosActorInterface.HealthCheckResult
import com.rbmhtechnology.eventuate.log.cassandra._
import com.typesafe.config.ConfigFactory
import scala.concurrent.Await
import scala.io.StdIn
import scala.util._
import scala.concurrent.duration._
object ChaosActor extends App with ChaosCommands {
def defaultConfig(seeds: Seq[String]) = ConfigFactory.parseString(
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider"
|akka.remote.enabled-transports = ["akka.remote.netty.tcp"]
|akka.remote.netty.tcp.hostname = "127.0.0.1"
|akka.remote.netty.tcp.port = 2552
|akka.test.single-expect-default = 10s
|akka.loglevel = "ERROR"
|
|eventuate.log.cassandra.contact-points = [${seeds.map(quote).mkString(",")}]
|eventuate.log.cassandra.replication-factor = 3
""".stripMargin)
private def quote(str: String) = "\\"" + str + "\\""
def runChaosActor(seeds: String*): Unit = {
val system = ActorSystem("chaos", defaultConfig(seeds))
val log = system.actorOf(CassandraEventLog.props("chaos"))
val actor = system.actorOf(Props(new ChaosActor(log)))
val interface = system.actorOf(Props(new ChaosActorInterface(actor)))
// -d = daemon mode that does not listen on stdin (i.e. docker instances)
if (args.contains("-d")) {
Await.result(system.whenTerminated, Duration.Inf)
} else {
StdIn.readLine()
system.stop(interface)
system.stop(actor)
system.terminate
}
}
sys.env.get("CASSANDRA_NODES") match {
case Some(nodes) if nodes.nonEmpty =>
runChaosActor(nodes.split(","): _*)
case _ =>
seedAddress() match {
case Failure(err) => err.printStackTrace()
case Success(seed) => runChaosActor(seed.getHostName)
}
}
}
class ChaosActor(val eventLog: ActorRef) extends EventsourcedActor {
val id = "chaos"
// persistent state
var state: Int = 0
// transient state
var failures: Int = 0
override def onCommand: Receive = {
case i: Int => persist(i) {
case Success(i) =>
scheduleCommand()
case Failure(e) =>
failures += 1
println(s"persist failure $failures: ${e.getMessage}")
scheduleCommand()
}
case cmd: ChaosActorInterface.HealthCheck =>
val chaosInterface = sender
persist(cmd) {
case Success(command) =>
chaosInterface ! HealthCheckResult(state, command.requester)
case Failure(e) =>
println(s"health check persist failed: ${e.getMessage}")
}
}
override def onEvent: Receive = {
case i: Int =>
state += i
println(s"counter = $state (recovery = $recovering)")
}
import context.dispatcher
override def preStart(): Unit = {
super.preStart()
scheduleCommand()
}
override def postStop(): Unit = {
schedule.foreach(_.cancel())
super.postStop()
}
private def scheduleCommand(): Unit =
schedule = Some(context.system.scheduler.scheduleOnce(2.seconds, self, 1))
private var schedule: Option[Cancellable] = None
}
| RBMHTechnology/eventuate-chaos | src/main/scala/com/rbmhtechnology/eventuate/chaos/ChaosActor.scala | Scala | apache-2.0 | 3,880 |
package io.shaka.http
import io.shaka.http.Https.{DoNotUseKeyStore, HttpsConfig, TrustServersByTrustStore, UseKeyStore}
import io.shaka.http.Request.GET
import io.shaka.http.Response.respond
import io.shaka.http.Status.OK
import io.shaka.http.TestCerts._
import org.scalatest.{BeforeAndAfterAll, FunSuite}
class SslAuthSpec extends FunSuite with BeforeAndAfterAll {
var server: HttpServer = _
test("Client can connect to server on SSL when the client specifies a certificate"){
val response = Http.http(GET(s"https://127.0.0.1:${server.port}/foo"))(httpsConfig = Some(HttpsConfig(
TrustServersByTrustStore(trustStoreWithServerCert.path, trustStoreWithServerCert.password),
UseKeyStore(keyStoreWithClientCert.path, keyStoreWithClientCert.password)
)))
assert(statusAndBody(response) === (OK, Some("Hello world")))
}
test("Client can connect to server on SSL when the client does not specify a certificate"){
val response: Response = Http.http(GET(s"https://127.0.0.1:${server.port}/foo"))(httpsConfig = Some(HttpsConfig(
TrustServersByTrustStore(trustStoreWithServerCert.path, trustStoreWithServerCert.password),
DoNotUseKeyStore
)))
assert(statusAndBody(response) === (OK, Some("Hello world")))
}
override protected def beforeAll() = {
server = HttpServer.https(
keyStoreConfig = PathAndPassword(keyStoreWithServerCert.path, keyStoreWithServerCert.password)
).handler(_ => respond("Hello world")).start()
}
override protected def afterAll() = {
server.stop()
}
private def statusAndBody(response: Response): (Status, Option[String]) = (response.status, response.entity.map(_.toString))
} | stacycurl/naive-http | src/test/scala/io/shaka/http/SslAuthSpec.scala | Scala | apache-2.0 | 1,683 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.status
import java.io.File
import java.util.{Date, Properties}
import scala.collection.JavaConverters._
import scala.collection.immutable.Map
import scala.reflect.{classTag, ClassTag}
import org.scalatest.BeforeAndAfter
import org.apache.spark._
import org.apache.spark.executor.{ExecutorMetrics, TaskMetrics}
import org.apache.spark.internal.config.Status._
import org.apache.spark.metrics.ExecutorMetricType
import org.apache.spark.resource.ResourceProfile
import org.apache.spark.scheduler._
import org.apache.spark.scheduler.cluster._
import org.apache.spark.status.ListenerEventsTestHelper._
import org.apache.spark.status.api.v1
import org.apache.spark.storage._
import org.apache.spark.tags.ExtendedLevelDBTest
import org.apache.spark.util.Utils
import org.apache.spark.util.kvstore.{InMemoryStore, KVStore}
@ExtendedLevelDBTest
class AppStatusListenerSuite extends SparkFunSuite with BeforeAndAfter {
private val conf = new SparkConf()
.set(LIVE_ENTITY_UPDATE_PERIOD, 0L)
.set(ASYNC_TRACKING_ENABLED, false)
private val twoReplicaMemAndDiskLevel = StorageLevel(true, true, false, true, 2)
private var time: Long = _
private var testDir: File = _
private var store: ElementTrackingStore = _
private var taskIdTracker = -1L
protected def createKVStore: KVStore = KVUtils.open(testDir, getClass().getName())
before {
time = 0L
testDir = Utils.createTempDir()
store = new ElementTrackingStore(createKVStore, conf)
taskIdTracker = -1L
}
after {
store.close()
Utils.deleteRecursively(testDir)
}
test("environment info") {
val listener = new AppStatusListener(store, conf, true)
val details = Map(
"JVM Information" -> Seq(
"Java Version" -> sys.props("java.version"),
"Java Home" -> sys.props("java.home"),
"Scala Version" -> scala.util.Properties.versionString
),
"Spark Properties" -> Seq(
"spark.conf.1" -> "1",
"spark.conf.2" -> "2"
),
"System Properties" -> Seq(
"sys.prop.1" -> "1",
"sys.prop.2" -> "2"
),
"Classpath Entries" -> Seq(
"/jar1" -> "System",
"/jar2" -> "User"
)
)
listener.onEnvironmentUpdate(SparkListenerEnvironmentUpdate(details))
val appEnvKey = classOf[ApplicationEnvironmentInfoWrapper].getName()
check[ApplicationEnvironmentInfoWrapper](appEnvKey) { env =>
val info = env.info
val runtimeInfo = Map(details("JVM Information"): _*)
assert(info.runtime.javaVersion == runtimeInfo("Java Version"))
assert(info.runtime.javaHome == runtimeInfo("Java Home"))
assert(info.runtime.scalaVersion == runtimeInfo("Scala Version"))
assert(info.sparkProperties === details("Spark Properties"))
assert(info.systemProperties === details("System Properties"))
assert(info.classpathEntries === details("Classpath Entries"))
}
}
test("scheduler events") {
val listener = new AppStatusListener(store, conf, true)
listener.onOtherEvent(SparkListenerLogStart("TestSparkVersion"))
// Start the application.
time += 1
listener.onApplicationStart(SparkListenerApplicationStart(
"name",
Some("id"),
time,
"user",
Some("attempt"),
None))
check[ApplicationInfoWrapper]("id") { app =>
assert(app.info.name === "name")
assert(app.info.id === "id")
assert(app.info.attempts.size === 1)
val attempt = app.info.attempts.head
assert(attempt.attemptId === Some("attempt"))
assert(attempt.startTime === new Date(time))
assert(attempt.lastUpdated === new Date(time))
assert(attempt.endTime.getTime() === -1L)
assert(attempt.sparkUser === "user")
assert(!attempt.completed)
assert(attempt.appSparkVersion === "TestSparkVersion")
}
// Start a couple of executors.
time += 1
val execIds = Array("1", "2")
execIds.foreach { id =>
listener.onExecutorAdded(SparkListenerExecutorAdded(time, id,
new ExecutorInfo(s"$id.example.com", 1, Map.empty, Map.empty)))
}
execIds.foreach { id =>
check[ExecutorSummaryWrapper](id) { exec =>
assert(exec.info.id === id)
assert(exec.info.hostPort === s"$id.example.com")
assert(exec.info.isActive)
}
}
// Start a job with 2 stages / 4 tasks each
time += 1
val stages = Seq(
new StageInfo(1, 0, "stage1", 4, Nil, Nil, "details1",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID),
new StageInfo(2, 0, "stage2", 4, Nil, Seq(1), "details2",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID))
val jobProps = new Properties()
jobProps.setProperty(SparkContext.SPARK_JOB_DESCRIPTION, "jobDescription")
jobProps.setProperty(SparkContext.SPARK_JOB_GROUP_ID, "jobGroup")
jobProps.setProperty(SparkContext.SPARK_SCHEDULER_POOL, "schedPool")
listener.onJobStart(SparkListenerJobStart(1, time, stages, jobProps))
check[JobDataWrapper](1) { job =>
assert(job.info.jobId === 1)
assert(job.info.name === stages.last.name)
assert(job.info.description === Some("jobDescription"))
assert(job.info.status === JobExecutionStatus.RUNNING)
assert(job.info.submissionTime === Some(new Date(time)))
assert(job.info.jobGroup === Some("jobGroup"))
}
stages.foreach { info =>
check[StageDataWrapper](key(info)) { stage =>
assert(stage.info.status === v1.StageStatus.PENDING)
assert(stage.jobIds === Set(1))
}
}
// Submit stage 1
time += 1
stages.head.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stages.head, jobProps))
check[JobDataWrapper](1) { job =>
assert(job.info.numActiveStages === 1)
}
check[StageDataWrapper](key(stages.head)) { stage =>
assert(stage.info.status === v1.StageStatus.ACTIVE)
assert(stage.info.submissionTime === Some(new Date(stages.head.submissionTime.get)))
assert(stage.info.numTasks === stages.head.numTasks)
}
// Start tasks from stage 1
time += 1
val s1Tasks = createTasks(4, execIds)
s1Tasks.foreach { task =>
listener.onTaskStart(SparkListenerTaskStart(stages.head.stageId,
stages.head.attemptNumber,
task))
}
assert(store.count(classOf[TaskDataWrapper]) === s1Tasks.size)
check[JobDataWrapper](1) { job =>
assert(job.info.numActiveTasks === s1Tasks.size)
}
check[StageDataWrapper](key(stages.head)) { stage =>
assert(stage.info.numActiveTasks === s1Tasks.size)
assert(stage.info.firstTaskLaunchedTime === Some(new Date(s1Tasks.head.launchTime)))
}
s1Tasks.foreach { task =>
check[TaskDataWrapper](task.taskId) { wrapper =>
assert(wrapper.taskId === task.taskId)
assert(wrapper.stageId === stages.head.stageId)
assert(wrapper.stageAttemptId === stages.head.attemptNumber)
assert(wrapper.index === task.index)
assert(wrapper.attempt === task.attemptNumber)
assert(wrapper.launchTime === task.launchTime)
assert(wrapper.executorId === task.executorId)
assert(wrapper.host === task.host)
assert(wrapper.status === task.status)
assert(wrapper.taskLocality === task.taskLocality.toString())
assert(wrapper.speculative === task.speculative)
}
}
// Send two executor metrics update. Only update one metric to avoid a lot of boilerplate code.
// The tasks are distributed among the two executors, so the executor-level metrics should
// hold half of the cumulative value of the metric being updated.
Seq(1L, 2L).foreach { value =>
s1Tasks.foreach { task =>
val accum = new AccumulableInfo(1L, Some(InternalAccumulator.MEMORY_BYTES_SPILLED),
Some(value), None, true, false, None)
listener.onExecutorMetricsUpdate(SparkListenerExecutorMetricsUpdate(
task.executorId,
Seq((task.taskId, stages.head.stageId, stages.head.attemptNumber, Seq(accum)))))
}
check[StageDataWrapper](key(stages.head)) { stage =>
assert(stage.info.memoryBytesSpilled === s1Tasks.size * value)
}
val execs = store.view(classOf[ExecutorStageSummaryWrapper]).index("stage")
.first(key(stages.head)).last(key(stages.head)).asScala.toSeq
assert(execs.size > 0)
execs.foreach { exec =>
assert(exec.info.memoryBytesSpilled === s1Tasks.size * value / 2)
}
}
// Excluding executor for stage
time += 1
listener.onExecutorExcludedForStage(SparkListenerExecutorExcludedForStage(
time = time,
executorId = execIds.head,
taskFailures = 2,
stageId = stages.head.stageId,
stageAttemptId = stages.head.attemptNumber))
val executorStageSummaryWrappers =
store.view(classOf[ExecutorStageSummaryWrapper]).index("stage")
.first(key(stages.head))
.last(key(stages.head))
.asScala.toSeq
assert(executorStageSummaryWrappers.nonEmpty)
executorStageSummaryWrappers.foreach { exec =>
// only the first executor is expected to be excluded
val expectedExcludedFlag = exec.executorId == execIds.head
assert(exec.info.isBlacklistedForStage === expectedExcludedFlag)
assert(exec.info.isExcludedForStage === expectedExcludedFlag)
}
check[ExecutorSummaryWrapper](execIds.head) { exec =>
assert(exec.info.blacklistedInStages === Set(stages.head.stageId))
assert(exec.info.excludedInStages === Set(stages.head.stageId))
}
// Excluding node for stage
time += 1
listener.onNodeExcludedForStage(SparkListenerNodeExcludedForStage(
time = time,
hostId = "2.example.com", // this is where the second executor is hosted
executorFailures = 1,
stageId = stages.head.stageId,
stageAttemptId = stages.head.attemptNumber))
val executorStageSummaryWrappersForNode =
store.view(classOf[ExecutorStageSummaryWrapper]).index("stage")
.first(key(stages.head))
.last(key(stages.head))
.asScala.toSeq
assert(executorStageSummaryWrappersForNode.nonEmpty)
executorStageSummaryWrappersForNode.foreach { exec =>
// both executor is expected to be excluded
assert(exec.info.isBlacklistedForStage)
assert(exec.info.isExcludedForStage)
}
// Fail one of the tasks, re-start it.
time += 1
s1Tasks.head.markFinished(TaskState.FAILED, time)
listener.onTaskEnd(SparkListenerTaskEnd(stages.head.stageId, stages.head.attemptNumber,
"taskType", TaskResultLost, s1Tasks.head, new ExecutorMetrics, null))
time += 1
val reattempt = newAttempt(s1Tasks.head, nextTaskId())
listener.onTaskStart(SparkListenerTaskStart(stages.head.stageId, stages.head.attemptNumber,
reattempt))
assert(store.count(classOf[TaskDataWrapper]) === s1Tasks.size + 1)
check[JobDataWrapper](1) { job =>
assert(job.info.numFailedTasks === 1)
assert(job.info.numActiveTasks === s1Tasks.size)
}
check[StageDataWrapper](key(stages.head)) { stage =>
assert(stage.info.numFailedTasks === 1)
assert(stage.info.numActiveTasks === s1Tasks.size)
}
check[TaskDataWrapper](s1Tasks.head.taskId) { task =>
assert(task.status === s1Tasks.head.status)
assert(task.errorMessage == Some(TaskResultLost.toErrorString))
}
check[TaskDataWrapper](reattempt.taskId) { task =>
assert(task.index === s1Tasks.head.index)
assert(task.attempt === reattempt.attemptNumber)
}
// Kill one task, restart it.
time += 1
val killed = s1Tasks.drop(1).head
killed.finishTime = time
killed.failed = true
listener.onTaskEnd(SparkListenerTaskEnd(stages.head.stageId, stages.head.attemptNumber,
"taskType", TaskKilled("killed"), killed, new ExecutorMetrics, null))
check[JobDataWrapper](1) { job =>
assert(job.info.numKilledTasks === 1)
assert(job.info.killedTasksSummary === Map("killed" -> 1))
}
check[StageDataWrapper](key(stages.head)) { stage =>
assert(stage.info.numKilledTasks === 1)
assert(stage.info.killedTasksSummary === Map("killed" -> 1))
}
check[TaskDataWrapper](killed.taskId) { task =>
assert(task.index === killed.index)
assert(task.errorMessage === Some("killed"))
}
// Start a new attempt and finish it with TaskCommitDenied, make sure it's handled like a kill.
time += 1
val denied = newAttempt(killed, nextTaskId())
val denyReason = TaskCommitDenied(1, 1, 1)
listener.onTaskStart(SparkListenerTaskStart(stages.head.stageId, stages.head.attemptNumber,
denied))
time += 1
denied.finishTime = time
denied.failed = true
listener.onTaskEnd(SparkListenerTaskEnd(stages.head.stageId, stages.head.attemptNumber,
"taskType", denyReason, denied, new ExecutorMetrics, null))
check[JobDataWrapper](1) { job =>
assert(job.info.numKilledTasks === 2)
assert(job.info.killedTasksSummary === Map("killed" -> 1, denyReason.toErrorString -> 1))
}
check[StageDataWrapper](key(stages.head)) { stage =>
assert(stage.info.numKilledTasks === 2)
assert(stage.info.killedTasksSummary === Map("killed" -> 1, denyReason.toErrorString -> 1))
}
check[TaskDataWrapper](denied.taskId) { task =>
assert(task.index === killed.index)
assert(task.errorMessage === Some(denyReason.toErrorString))
}
// Start a new attempt.
val reattempt2 = newAttempt(denied, nextTaskId())
listener.onTaskStart(SparkListenerTaskStart(stages.head.stageId, stages.head.attemptNumber,
reattempt2))
// Succeed all tasks in stage 1.
val pending = s1Tasks.drop(2) ++ Seq(reattempt, reattempt2)
val s1Metrics = TaskMetrics.empty
s1Metrics.setExecutorCpuTime(2L)
s1Metrics.setExecutorRunTime(4L)
time += 1
pending.foreach { task =>
task.markFinished(TaskState.FINISHED, time)
listener.onTaskEnd(SparkListenerTaskEnd(stages.head.stageId, stages.head.attemptNumber,
"taskType", Success, task, new ExecutorMetrics, s1Metrics))
}
check[JobDataWrapper](1) { job =>
assert(job.info.numFailedTasks === 1)
assert(job.info.numKilledTasks === 2)
assert(job.info.numActiveTasks === 0)
assert(job.info.numCompletedTasks === pending.size)
}
check[StageDataWrapper](key(stages.head)) { stage =>
assert(stage.info.numFailedTasks === 1)
assert(stage.info.numKilledTasks === 2)
assert(stage.info.numActiveTasks === 0)
assert(stage.info.numCompleteTasks === pending.size)
}
pending.foreach { task =>
check[TaskDataWrapper](task.taskId) { wrapper =>
assert(wrapper.errorMessage === None)
assert(wrapper.executorCpuTime === 2L)
assert(wrapper.executorRunTime === 4L)
assert(wrapper.duration === task.duration)
}
}
assert(store.count(classOf[TaskDataWrapper]) === pending.size + 3)
// End stage 1.
time += 1
stages.head.completionTime = Some(time)
listener.onStageCompleted(SparkListenerStageCompleted(stages.head))
check[JobDataWrapper](1) { job =>
assert(job.info.numActiveStages === 0)
assert(job.info.numCompletedStages === 1)
}
check[StageDataWrapper](key(stages.head)) { stage =>
assert(stage.info.status === v1.StageStatus.COMPLETE)
assert(stage.info.numFailedTasks === 1)
assert(stage.info.numActiveTasks === 0)
assert(stage.info.numCompleteTasks === pending.size)
}
check[ExecutorSummaryWrapper](execIds.head) { exec =>
assert(exec.info.blacklistedInStages === Set())
assert(exec.info.excludedInStages === Set())
}
// Submit stage 2.
time += 1
stages.last.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stages.last, jobProps))
check[JobDataWrapper](1) { job =>
assert(job.info.numActiveStages === 1)
}
check[StageDataWrapper](key(stages.last)) { stage =>
assert(stage.info.status === v1.StageStatus.ACTIVE)
assert(stage.info.submissionTime === Some(new Date(stages.last.submissionTime.get)))
}
// Excluding node for stage
time += 1
listener.onNodeExcludedForStage(SparkListenerNodeExcludedForStage(
time = time,
hostId = "1.example.com",
executorFailures = 1,
stageId = stages.last.stageId,
stageAttemptId = stages.last.attemptNumber))
check[ExecutorSummaryWrapper](execIds.head) { exec =>
assert(exec.info.blacklistedInStages === Set(stages.last.stageId))
assert(exec.info.excludedInStages === Set(stages.last.stageId))
}
// Start and fail all tasks of stage 2.
time += 1
val s2Tasks = createTasks(4, execIds)
s2Tasks.foreach { task =>
listener.onTaskStart(SparkListenerTaskStart(stages.last.stageId,
stages.last.attemptNumber,
task))
}
time += 1
s2Tasks.foreach { task =>
task.markFinished(TaskState.FAILED, time)
listener.onTaskEnd(SparkListenerTaskEnd(stages.last.stageId, stages.last.attemptNumber,
"taskType", TaskResultLost, task, new ExecutorMetrics, null))
}
check[JobDataWrapper](1) { job =>
assert(job.info.numFailedTasks === 1 + s2Tasks.size)
assert(job.info.numActiveTasks === 0)
}
check[StageDataWrapper](key(stages.last)) { stage =>
assert(stage.info.numFailedTasks === s2Tasks.size)
assert(stage.info.numActiveTasks === 0)
}
// Fail stage 2.
time += 1
stages.last.completionTime = Some(time)
stages.last.failureReason = Some("uh oh")
listener.onStageCompleted(SparkListenerStageCompleted(stages.last))
check[JobDataWrapper](1) { job =>
assert(job.info.numCompletedStages === 1)
assert(job.info.numFailedStages === 1)
}
check[StageDataWrapper](key(stages.last)) { stage =>
assert(stage.info.status === v1.StageStatus.FAILED)
assert(stage.info.numFailedTasks === s2Tasks.size)
assert(stage.info.numActiveTasks === 0)
assert(stage.info.numCompleteTasks === 0)
assert(stage.info.failureReason === stages.last.failureReason)
}
// - Re-submit stage 2, all tasks, and succeed them and the stage.
val oldS2 = stages.last
val newS2 = new StageInfo(oldS2.stageId, oldS2.attemptNumber + 1, oldS2.name, oldS2.numTasks,
oldS2.rddInfos, oldS2.parentIds, oldS2.details, oldS2.taskMetrics,
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
time += 1
newS2.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(newS2, jobProps))
assert(store.count(classOf[StageDataWrapper]) === 3)
val newS2Tasks = createTasks(4, execIds)
newS2Tasks.foreach { task =>
listener.onTaskStart(SparkListenerTaskStart(newS2.stageId, newS2.attemptNumber, task))
}
time += 1
newS2Tasks.foreach { task =>
task.markFinished(TaskState.FINISHED, time)
listener.onTaskEnd(SparkListenerTaskEnd(newS2.stageId, newS2.attemptNumber, "taskType",
Success, task, new ExecutorMetrics, null))
}
time += 1
newS2.completionTime = Some(time)
listener.onStageCompleted(SparkListenerStageCompleted(newS2))
check[JobDataWrapper](1) { job =>
assert(job.info.numActiveStages === 0)
assert(job.info.numFailedStages === 1)
assert(job.info.numCompletedStages === 2)
}
check[StageDataWrapper](key(newS2)) { stage =>
assert(stage.info.status === v1.StageStatus.COMPLETE)
assert(stage.info.numActiveTasks === 0)
assert(stage.info.numCompleteTasks === newS2Tasks.size)
}
// End job.
time += 1
listener.onJobEnd(SparkListenerJobEnd(1, time, JobSucceeded))
check[JobDataWrapper](1) { job =>
assert(job.info.status === JobExecutionStatus.SUCCEEDED)
}
// Submit a second job that re-uses stage 1 and stage 2. Stage 1 won't be re-run, but
// stage 2 will. In any case, the DAGScheduler creates new info structures that are copies
// of the old stages, so mimic that behavior here. The "new" stage 1 is submitted without
// a submission time, which means it is "skipped", and the stage 2 re-execution should not
// change the stats of the already finished job.
time += 1
val j2Stages = Seq(
new StageInfo(3, 0, "stage1", 4, Nil, Nil, "details1",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID),
new StageInfo(4, 0, "stage2", 4, Nil, Seq(3), "details2",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID))
j2Stages.last.submissionTime = Some(time)
listener.onJobStart(SparkListenerJobStart(2, time, j2Stages, null))
assert(store.count(classOf[JobDataWrapper]) === 2)
listener.onStageSubmitted(SparkListenerStageSubmitted(j2Stages.head, jobProps))
listener.onStageCompleted(SparkListenerStageCompleted(j2Stages.head))
listener.onStageSubmitted(SparkListenerStageSubmitted(j2Stages.last, jobProps))
assert(store.count(classOf[StageDataWrapper]) === 5)
time += 1
val j2s2Tasks = createTasks(4, execIds)
j2s2Tasks.foreach { task =>
listener.onTaskStart(SparkListenerTaskStart(j2Stages.last.stageId,
j2Stages.last.attemptNumber,
task))
}
time += 1
j2s2Tasks.foreach { task =>
task.markFinished(TaskState.FINISHED, time)
listener.onTaskEnd(SparkListenerTaskEnd(j2Stages.last.stageId, j2Stages.last.attemptNumber,
"taskType", Success, task, new ExecutorMetrics, null))
}
time += 1
j2Stages.last.completionTime = Some(time)
listener.onStageCompleted(SparkListenerStageCompleted(j2Stages.last))
time += 1
listener.onJobEnd(SparkListenerJobEnd(2, time, JobSucceeded))
check[JobDataWrapper](1) { job =>
assert(job.info.numCompletedStages === 2)
assert(job.info.numCompletedTasks === s1Tasks.size + s2Tasks.size)
}
check[JobDataWrapper](2) { job =>
assert(job.info.status === JobExecutionStatus.SUCCEEDED)
assert(job.info.numCompletedStages === 1)
assert(job.info.numCompletedTasks === j2s2Tasks.size)
assert(job.info.numSkippedStages === 1)
assert(job.info.numSkippedTasks === s1Tasks.size)
}
// Exclude an executor.
time += 1
listener.onExecutorExcluded(SparkListenerExecutorExcluded(time, "1", 42))
check[ExecutorSummaryWrapper]("1") { exec =>
assert(exec.info.isBlacklisted)
assert(exec.info.isExcluded)
}
time += 1
listener.onExecutorUnexcluded(SparkListenerExecutorUnexcluded(time, "1"))
check[ExecutorSummaryWrapper]("1") { exec =>
assert(!exec.info.isBlacklisted)
assert(!exec.info.isExcluded)
}
// Exclude a node.
time += 1
listener.onNodeExcluded(SparkListenerNodeExcluded(time, "1.example.com", 2))
check[ExecutorSummaryWrapper]("1") { exec =>
assert(exec.info.isBlacklisted)
assert(exec.info.isExcluded)
}
time += 1
listener.onNodeUnexcluded(SparkListenerNodeUnexcluded(time, "1.example.com"))
check[ExecutorSummaryWrapper]("1") { exec =>
assert(!exec.info.isBlacklisted)
assert(!exec.info.isExcluded)
}
// Stop executors.
time += 1
listener.onExecutorRemoved(SparkListenerExecutorRemoved(time, "1", "Test"))
listener.onExecutorRemoved(SparkListenerExecutorRemoved(time, "2", "Test"))
Seq("1", "2").foreach { id =>
check[ExecutorSummaryWrapper](id) { exec =>
assert(exec.info.id === id)
assert(!exec.info.isActive)
}
}
// End the application.
listener.onApplicationEnd(SparkListenerApplicationEnd(42L))
check[ApplicationInfoWrapper]("id") { app =>
assert(app.info.name === "name")
assert(app.info.id === "id")
assert(app.info.attempts.size === 1)
val attempt = app.info.attempts.head
assert(attempt.attemptId === Some("attempt"))
assert(attempt.startTime === new Date(1L))
assert(attempt.lastUpdated === new Date(42L))
assert(attempt.endTime === new Date(42L))
assert(attempt.duration === 41L)
assert(attempt.sparkUser === "user")
assert(attempt.completed)
}
}
test("storage events") {
val listener = new AppStatusListener(store, conf, true)
val maxMemory = 42L
// Register a couple of block managers.
val bm1 = BlockManagerId("1", "1.example.com", 42)
val bm2 = BlockManagerId("2", "2.example.com", 84)
Seq(bm1, bm2).foreach { bm =>
listener.onExecutorAdded(SparkListenerExecutorAdded(1L, bm.executorId,
new ExecutorInfo(bm.host, 1, Map.empty, Map.empty)))
listener.onBlockManagerAdded(SparkListenerBlockManagerAdded(1L, bm, maxMemory))
check[ExecutorSummaryWrapper](bm.executorId) { exec =>
assert(exec.info.maxMemory === maxMemory)
}
}
val rdd1b1 = RddBlock(1, 1, 1L, 2L)
val rdd1b2 = RddBlock(1, 2, 3L, 4L)
val rdd2b1 = RddBlock(2, 1, 5L, 6L)
val level = StorageLevel.MEMORY_AND_DISK
// Submit a stage for the first RDD before it's marked for caching, to make sure later
// the listener picks up the correct storage level.
val rdd1Info = new RDDInfo(rdd1b1.rddId, "rdd1", 2, StorageLevel.NONE, false, Nil)
val stage0 = new StageInfo(0, 0, "stage0", 4, Seq(rdd1Info), Nil, "details0",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage0, new Properties()))
listener.onStageCompleted(SparkListenerStageCompleted(stage0))
assert(store.count(classOf[RDDStorageInfoWrapper]) === 0)
// Submit a stage and make sure the RDDs are recorded.
rdd1Info.storageLevel = level
val rdd2Info = new RDDInfo(rdd2b1.rddId, "rdd2", 1, level, false, Nil)
val stage = new StageInfo(1, 0, "stage1", 4, Seq(rdd1Info, rdd2Info), Nil, "details1",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage, new Properties()))
check[RDDStorageInfoWrapper](rdd1b1.rddId) { wrapper =>
assert(wrapper.info.name === rdd1Info.name)
assert(wrapper.info.numPartitions === rdd1Info.numPartitions)
assert(wrapper.info.storageLevel === rdd1Info.storageLevel.description)
}
// Add partition 1 replicated on two block managers.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, rdd1b1.blockId, level, rdd1b1.memSize, rdd1b1.diskSize)))
check[RDDStorageInfoWrapper](rdd1b1.rddId) { wrapper =>
assert(wrapper.info.numCachedPartitions === 1L)
assert(wrapper.info.memoryUsed === rdd1b1.memSize)
assert(wrapper.info.diskUsed === rdd1b1.diskSize)
assert(wrapper.info.dataDistribution.isDefined)
assert(wrapper.info.dataDistribution.get.size === 1)
val dist = wrapper.info.dataDistribution.get.head
assert(dist.address === bm1.hostPort)
assert(dist.memoryUsed === rdd1b1.memSize)
assert(dist.diskUsed === rdd1b1.diskSize)
assert(dist.memoryRemaining === maxMemory - dist.memoryUsed)
assert(wrapper.info.partitions.isDefined)
assert(wrapper.info.partitions.get.size === 1)
val part = wrapper.info.partitions.get.head
assert(part.blockName === rdd1b1.blockId.name)
assert(part.storageLevel === level.description)
assert(part.memoryUsed === rdd1b1.memSize)
assert(part.diskUsed === rdd1b1.diskSize)
assert(part.executors === Seq(bm1.executorId))
}
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.rddBlocks === 1L)
assert(exec.info.memoryUsed === rdd1b1.memSize)
assert(exec.info.diskUsed === rdd1b1.diskSize)
}
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm2, rdd1b1.blockId, level, rdd1b1.memSize, rdd1b1.diskSize)))
check[RDDStorageInfoWrapper](rdd1b1.rddId) { wrapper =>
assert(wrapper.info.numCachedPartitions === 1L)
assert(wrapper.info.memoryUsed === rdd1b1.memSize * 2)
assert(wrapper.info.diskUsed === rdd1b1.diskSize * 2)
assert(wrapper.info.dataDistribution.get.size === 2L)
assert(wrapper.info.partitions.get.size === 1L)
val dist = wrapper.info.dataDistribution.get.find(_.address == bm2.hostPort).get
assert(dist.memoryUsed === rdd1b1.memSize)
assert(dist.diskUsed === rdd1b1.diskSize)
assert(dist.memoryRemaining === maxMemory - dist.memoryUsed)
val part = wrapper.info.partitions.get(0)
assert(part.memoryUsed === rdd1b1.memSize * 2)
assert(part.diskUsed === rdd1b1.diskSize * 2)
assert(part.executors === Seq(bm1.executorId, bm2.executorId))
assert(part.storageLevel === twoReplicaMemAndDiskLevel.description)
}
check[ExecutorSummaryWrapper](bm2.executorId) { exec =>
assert(exec.info.rddBlocks === 1L)
assert(exec.info.memoryUsed === rdd1b1.memSize)
assert(exec.info.diskUsed === rdd1b1.diskSize)
}
// Add a second partition only to bm 1.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, rdd1b2.blockId, level, rdd1b2.memSize, rdd1b2.diskSize)))
check[RDDStorageInfoWrapper](rdd1b1.rddId) { wrapper =>
assert(wrapper.info.numCachedPartitions === 2L)
assert(wrapper.info.memoryUsed === 2 * rdd1b1.memSize + rdd1b2.memSize)
assert(wrapper.info.diskUsed === 2 * rdd1b1.diskSize + rdd1b2.diskSize)
assert(wrapper.info.dataDistribution.get.size === 2L)
assert(wrapper.info.partitions.get.size === 2L)
val dist = wrapper.info.dataDistribution.get.find(_.address == bm1.hostPort).get
assert(dist.memoryUsed === rdd1b1.memSize + rdd1b2.memSize)
assert(dist.diskUsed === rdd1b1.diskSize + rdd1b2.diskSize)
assert(dist.memoryRemaining === maxMemory - dist.memoryUsed)
val part = wrapper.info.partitions.get.find(_.blockName === rdd1b2.blockId.name).get
assert(part.storageLevel === level.description)
assert(part.memoryUsed === rdd1b2.memSize)
assert(part.diskUsed === rdd1b2.diskSize)
assert(part.executors === Seq(bm1.executorId))
}
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.rddBlocks === 2L)
assert(exec.info.memoryUsed === rdd1b1.memSize + rdd1b2.memSize)
assert(exec.info.diskUsed === rdd1b1.diskSize + rdd1b2.diskSize)
}
// Evict block 1 from memory in bm 1. Note that because of SPARK-29319, the disk size
// is reported as "0" here to avoid double-counting; the current behavior of the block
// manager is to provide the actual disk size of the block.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, rdd1b1.blockId, StorageLevel.DISK_ONLY,
rdd1b1.memSize, 0L)))
check[RDDStorageInfoWrapper](rdd1b1.rddId) { wrapper =>
assert(wrapper.info.numCachedPartitions === 2L)
assert(wrapper.info.memoryUsed === rdd1b1.memSize + rdd1b2.memSize)
assert(wrapper.info.diskUsed === 2 * rdd1b1.diskSize + rdd1b2.diskSize)
assert(wrapper.info.dataDistribution.get.size === 2L)
assert(wrapper.info.partitions.get.size === 2L)
}
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.rddBlocks === 2L)
assert(exec.info.memoryUsed === rdd1b2.memSize)
assert(exec.info.diskUsed === rdd1b1.diskSize + rdd1b2.diskSize)
}
// Remove block 1 from bm 1; note memSize = 0 due to the eviction above.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, rdd1b1.blockId, StorageLevel.NONE, 0, rdd1b1.diskSize)))
check[RDDStorageInfoWrapper](rdd1b1.rddId) { wrapper =>
assert(wrapper.info.numCachedPartitions === 2L)
assert(wrapper.info.memoryUsed === rdd1b1.memSize + rdd1b2.memSize)
assert(wrapper.info.diskUsed === rdd1b1.diskSize + rdd1b2.diskSize)
assert(wrapper.info.dataDistribution.get.size === 2L)
assert(wrapper.info.partitions.get.size === 2L)
val dist = wrapper.info.dataDistribution.get.find(_.address == bm1.hostPort).get
assert(dist.memoryUsed === rdd1b2.memSize)
assert(dist.diskUsed === rdd1b2.diskSize)
assert(dist.memoryRemaining === maxMemory - dist.memoryUsed)
val part = wrapper.info.partitions.get.find(_.blockName === rdd1b1.blockId.name).get
assert(part.storageLevel === level.description)
assert(part.memoryUsed === rdd1b1.memSize)
assert(part.diskUsed === rdd1b1.diskSize)
assert(part.executors === Seq(bm2.executorId))
}
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.rddBlocks === 1L)
assert(exec.info.memoryUsed === rdd1b2.memSize)
assert(exec.info.diskUsed === rdd1b2.diskSize)
}
// Remove block 1 from bm 2. This should leave only block 2's info in the store.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm2, rdd1b1.blockId, StorageLevel.NONE, rdd1b1.memSize, rdd1b1.diskSize)))
check[RDDStorageInfoWrapper](rdd1b1.rddId) { wrapper =>
assert(wrapper.info.numCachedPartitions === 1L)
assert(wrapper.info.memoryUsed === rdd1b2.memSize)
assert(wrapper.info.diskUsed === rdd1b2.diskSize)
assert(wrapper.info.dataDistribution.get.size === 1L)
assert(wrapper.info.partitions.get.size === 1L)
assert(wrapper.info.partitions.get(0).blockName === rdd1b2.blockId.name)
}
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.rddBlocks === 1L)
assert(exec.info.memoryUsed === rdd1b2.memSize)
assert(exec.info.diskUsed === rdd1b2.diskSize)
}
check[ExecutorSummaryWrapper](bm2.executorId) { exec =>
assert(exec.info.rddBlocks === 0L)
assert(exec.info.memoryUsed === 0L)
assert(exec.info.diskUsed === 0L)
}
// Add a block from a different RDD. Verify the executor is updated correctly and also that
// the distribution data for both rdds is updated to match the remaining memory.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, rdd2b1.blockId, level, rdd2b1.memSize, rdd2b1.diskSize)))
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.rddBlocks === 2L)
assert(exec.info.memoryUsed === rdd1b2.memSize + rdd2b1.memSize)
assert(exec.info.diskUsed === rdd1b2.diskSize + rdd2b1.diskSize)
}
check[RDDStorageInfoWrapper](rdd1b2.rddId) { wrapper =>
assert(wrapper.info.dataDistribution.get.size === 1L)
val dist = wrapper.info.dataDistribution.get(0)
assert(dist.memoryRemaining === maxMemory - rdd2b1.memSize - rdd1b2.memSize )
}
check[RDDStorageInfoWrapper](rdd2b1.rddId) { wrapper =>
assert(wrapper.info.dataDistribution.get.size === 1L)
val dist = wrapper.info.dataDistribution.get(0)
assert(dist.memoryUsed === rdd2b1.memSize)
assert(dist.diskUsed === rdd2b1.diskSize)
assert(dist.memoryRemaining === maxMemory - rdd2b1.memSize - rdd1b2.memSize )
}
// Add block1 of rdd1 back to bm 1.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, rdd1b1.blockId, level, rdd1b1.memSize, rdd1b1.diskSize)))
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.rddBlocks === 3L)
assert(exec.info.memoryUsed === rdd1b1.memSize + rdd1b2.memSize + rdd2b1.memSize)
assert(exec.info.diskUsed === rdd1b1.diskSize + rdd1b2.diskSize + rdd2b1.diskSize)
}
// Unpersist RDD1.
listener.onUnpersistRDD(SparkListenerUnpersistRDD(rdd1b1.rddId))
intercept[NoSuchElementException] {
check[RDDStorageInfoWrapper](rdd1b1.rddId) { _ => () }
}
// executor1 now only contains block1 from rdd2.
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.rddBlocks === 1L)
assert(exec.info.memoryUsed === rdd2b1.memSize)
assert(exec.info.diskUsed === rdd2b1.diskSize)
}
// Unpersist RDD2.
listener.onUnpersistRDD(SparkListenerUnpersistRDD(rdd2b1.rddId))
intercept[NoSuchElementException] {
check[RDDStorageInfoWrapper](rdd2b1.rddId) { _ => () }
}
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.rddBlocks === 0L)
assert(exec.info.memoryUsed === 0)
assert(exec.info.diskUsed === 0)
}
// Update a StreamBlock.
val stream1 = StreamBlockId(1, 1L)
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, stream1, level, 1L, 1L)))
check[StreamBlockData](Array(stream1.name, bm1.executorId)) { stream =>
assert(stream.name === stream1.name)
assert(stream.executorId === bm1.executorId)
assert(stream.hostPort === bm1.hostPort)
assert(stream.storageLevel === level.description)
assert(stream.useMemory === level.useMemory)
assert(stream.useDisk === level.useDisk)
assert(stream.deserialized === level.deserialized)
assert(stream.memSize === 1L)
assert(stream.diskSize === 1L)
}
// Drop a StreamBlock.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, stream1, StorageLevel.NONE, 0L, 0L)))
intercept[NoSuchElementException] {
check[StreamBlockData](stream1.name) { _ => () }
}
// Update a BroadcastBlock.
val broadcast1 = BroadcastBlockId(1L)
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, broadcast1, level, 1L, 1L)))
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.memoryUsed === 1L)
assert(exec.info.diskUsed === 1L)
}
// Drop a BroadcastBlock.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, broadcast1, StorageLevel.NONE, 1L, 1L)))
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.memoryUsed === 0)
assert(exec.info.diskUsed === 0)
}
}
test("eviction of old data") {
val testConf = conf.clone()
.set(MAX_RETAINED_JOBS, 2)
.set(MAX_RETAINED_STAGES, 2)
.set(MAX_RETAINED_TASKS_PER_STAGE, 2)
.set(MAX_RETAINED_DEAD_EXECUTORS, 1)
val listener = new AppStatusListener(store, testConf, true)
// Start 3 jobs, all should be kept. Stop one, it should be evicted.
time += 1
listener.onJobStart(SparkListenerJobStart(1, time, Nil, null))
listener.onJobStart(SparkListenerJobStart(2, time, Nil, null))
listener.onJobStart(SparkListenerJobStart(3, time, Nil, null))
assert(store.count(classOf[JobDataWrapper]) === 3)
time += 1
listener.onJobEnd(SparkListenerJobEnd(2, time, JobSucceeded))
assert(store.count(classOf[JobDataWrapper]) === 2)
intercept[NoSuchElementException] {
store.read(classOf[JobDataWrapper], 2)
}
// Start 3 stages, all should be kept. Stop 2 of them, the stopped one with the lowest id should
// be deleted. Start a new attempt of the second stopped one, and verify that the stage graph
// data is not deleted.
time += 1
val stages = Seq(
new StageInfo(1, 0, "stage1", 4, Nil, Nil, "details1",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID),
new StageInfo(2, 0, "stage2", 4, Nil, Nil, "details2",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID),
new StageInfo(3, 0, "stage3", 4, Nil, Nil, "details3",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID))
// Graph data is generated by the job start event, so fire it.
listener.onJobStart(SparkListenerJobStart(4, time, stages, null))
stages.foreach { s =>
time += 1
s.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(s, new Properties()))
}
assert(store.count(classOf[StageDataWrapper]) === 3)
assert(store.count(classOf[RDDOperationGraphWrapper]) === 3)
val dropped = stages.drop(1).head
// Cache some quantiles by calling AppStatusStore.taskSummary(). For quantiles to be
// calculated, we need at least one finished task. The code in AppStatusStore uses
// `executorRunTime` to detect valid tasks, so that metric needs to be updated in the
// task end event.
time += 1
val task = createTasks(1, Array("1")).head
listener.onTaskStart(SparkListenerTaskStart(dropped.stageId, dropped.attemptNumber, task))
time += 1
task.markFinished(TaskState.FINISHED, time)
val metrics = TaskMetrics.empty
metrics.setExecutorRunTime(42L)
listener.onTaskEnd(SparkListenerTaskEnd(dropped.stageId, dropped.attemptNumber,
"taskType", Success, task, new ExecutorMetrics, metrics))
new AppStatusStore(store)
.taskSummary(dropped.stageId, dropped.attemptNumber, Array(0.25d, 0.50d, 0.75d))
assert(store.count(classOf[CachedQuantile], "stage", key(dropped)) === 3)
stages.drop(1).foreach { s =>
time += 1
s.completionTime = Some(time)
listener.onStageCompleted(SparkListenerStageCompleted(s))
}
assert(store.count(classOf[StageDataWrapper]) === 2)
assert(store.count(classOf[RDDOperationGraphWrapper]) === 2)
intercept[NoSuchElementException] {
store.read(classOf[StageDataWrapper], Array(2, 0))
}
assert(store.count(classOf[CachedQuantile], "stage", key(dropped)) === 0)
val attempt2 = new StageInfo(3, 1, "stage3", 4, Nil, Nil, "details3",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
time += 1
attempt2.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(attempt2, new Properties()))
assert(store.count(classOf[StageDataWrapper]) === 2)
assert(store.count(classOf[RDDOperationGraphWrapper]) === 2)
intercept[NoSuchElementException] {
store.read(classOf[StageDataWrapper], Array(2, 0))
}
intercept[NoSuchElementException] {
store.read(classOf[StageDataWrapper], Array(3, 0))
}
store.read(classOf[StageDataWrapper], Array(3, 1))
// Start 2 tasks. Finish the second one.
time += 1
val tasks = createTasks(2, Array("1"))
tasks.foreach { task =>
listener.onTaskStart(SparkListenerTaskStart(attempt2.stageId, attempt2.attemptNumber, task))
}
assert(store.count(classOf[TaskDataWrapper]) === 2)
// Start a 3rd task. The finished tasks should be deleted.
createTasks(1, Array("1")).foreach { task =>
listener.onTaskStart(SparkListenerTaskStart(attempt2.stageId, attempt2.attemptNumber, task))
}
assert(store.count(classOf[TaskDataWrapper]) === 2)
intercept[NoSuchElementException] {
store.read(classOf[TaskDataWrapper], tasks.last.id)
}
// Start a 4th task. The first task should be deleted, even if it's still running.
createTasks(1, Array("1")).foreach { task =>
listener.onTaskStart(SparkListenerTaskStart(attempt2.stageId, attempt2.attemptNumber, task))
}
assert(store.count(classOf[TaskDataWrapper]) === 2)
intercept[NoSuchElementException] {
store.read(classOf[TaskDataWrapper], tasks.head.id)
}
}
test("eviction should respect job completion time") {
val testConf = conf.clone().set(MAX_RETAINED_JOBS, 2)
val listener = new AppStatusListener(store, testConf, true)
// Start job 1 and job 2
time += 1
listener.onJobStart(SparkListenerJobStart(1, time, Nil, null))
time += 1
listener.onJobStart(SparkListenerJobStart(2, time, Nil, null))
// Stop job 2 before job 1
time += 1
listener.onJobEnd(SparkListenerJobEnd(2, time, JobSucceeded))
time += 1
listener.onJobEnd(SparkListenerJobEnd(1, time, JobSucceeded))
// Start job 3 and job 2 should be evicted.
time += 1
listener.onJobStart(SparkListenerJobStart(3, time, Nil, null))
assert(store.count(classOf[JobDataWrapper]) === 2)
intercept[NoSuchElementException] {
store.read(classOf[JobDataWrapper], 2)
}
}
test("eviction should respect stage completion time") {
val testConf = conf.clone().set(MAX_RETAINED_STAGES, 2)
val listener = new AppStatusListener(store, testConf, true)
val stage1 = new StageInfo(1, 0, "stage1", 4, Nil, Nil, "details1",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
val stage2 = new StageInfo(2, 0, "stage2", 4, Nil, Nil, "details2",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
val stage3 = new StageInfo(3, 0, "stage3", 4, Nil, Nil, "details3",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
// Start stage 1 and stage 2
time += 1
stage1.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage1, new Properties()))
time += 1
stage2.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage2, new Properties()))
// Stop stage 2 before stage 1
time += 1
stage2.completionTime = Some(time)
listener.onStageCompleted(SparkListenerStageCompleted(stage2))
time += 1
stage1.completionTime = Some(time)
listener.onStageCompleted(SparkListenerStageCompleted(stage1))
// Start stage 3 and stage 2 should be evicted.
stage3.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage3, new Properties()))
assert(store.count(classOf[StageDataWrapper]) === 2)
intercept[NoSuchElementException] {
store.read(classOf[StageDataWrapper], Array(2, 0))
}
}
test("skipped stages should be evicted before completed stages") {
val testConf = conf.clone().set(MAX_RETAINED_STAGES, 2)
val listener = new AppStatusListener(store, testConf, true)
val stage1 = new StageInfo(1, 0, "stage1", 4, Nil, Nil, "details1",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
val stage2 = new StageInfo(2, 0, "stage2", 4, Nil, Nil, "details2",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
// Sart job 1
time += 1
listener.onJobStart(SparkListenerJobStart(1, time, Seq(stage1, stage2), null))
// Start and stop stage 1
time += 1
stage1.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage1, new Properties()))
time += 1
stage1.completionTime = Some(time)
listener.onStageCompleted(SparkListenerStageCompleted(stage1))
// Stop job 1 and stage 2 will become SKIPPED
time += 1
listener.onJobEnd(SparkListenerJobEnd(1, time, JobSucceeded))
// Submit stage 3 and verify stage 2 is evicted
val stage3 = new StageInfo(3, 0, "stage3", 4, Nil, Nil, "details3",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
time += 1
stage3.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage3, new Properties()))
assert(store.count(classOf[StageDataWrapper]) === 2)
intercept[NoSuchElementException] {
store.read(classOf[StageDataWrapper], Array(2, 0))
}
}
test("eviction should respect task completion time") {
val testConf = conf.clone().set(MAX_RETAINED_TASKS_PER_STAGE, 2)
val listener = new AppStatusListener(store, testConf, true)
val stage1 = new StageInfo(1, 0, "stage1", 4, Nil, Nil, "details1",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
stage1.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage1, new Properties()))
// Start task 1 and task 2
val tasks = createTasks(3, Array("1"))
tasks.take(2).foreach { task =>
listener.onTaskStart(SparkListenerTaskStart(stage1.stageId, stage1.attemptNumber, task))
}
// Stop task 2 before task 1
time += 1
tasks(1).markFinished(TaskState.FINISHED, time)
listener.onTaskEnd(SparkListenerTaskEnd(
stage1.stageId, stage1.attemptNumber, "taskType", Success, tasks(1),
new ExecutorMetrics, null))
time += 1
tasks(0).markFinished(TaskState.FINISHED, time)
listener.onTaskEnd(SparkListenerTaskEnd(
stage1.stageId, stage1.attemptNumber, "taskType", Success, tasks(0),
new ExecutorMetrics, null))
// Start task 3 and task 2 should be evicted.
listener.onTaskStart(SparkListenerTaskStart(stage1.stageId, stage1.attemptNumber, tasks(2)))
assert(store.count(classOf[TaskDataWrapper]) === 2)
intercept[NoSuchElementException] {
store.read(classOf[TaskDataWrapper], tasks(1).id)
}
}
test("lastStageAttempt should fail when the stage doesn't exist") {
val testConf = conf.clone().set(MAX_RETAINED_STAGES, 1)
val listener = new AppStatusListener(store, testConf, true)
val appStore = new AppStatusStore(store)
val stage1 = new StageInfo(1, 0, "stage1", 4, Nil, Nil, "details1",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
val stage2 = new StageInfo(2, 0, "stage2", 4, Nil, Nil, "details2",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
val stage3 = new StageInfo(3, 0, "stage3", 4, Nil, Nil, "details3",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
time += 1
stage1.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage1, new Properties()))
stage1.completionTime = Some(time)
listener.onStageCompleted(SparkListenerStageCompleted(stage1))
// Make stage 3 complete before stage 2 so that stage 3 will be evicted
time += 1
stage3.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage3, new Properties()))
stage3.completionTime = Some(time)
listener.onStageCompleted(SparkListenerStageCompleted(stage3))
time += 1
stage2.submissionTime = Some(time)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage2, new Properties()))
stage2.completionTime = Some(time)
listener.onStageCompleted(SparkListenerStageCompleted(stage2))
assert(appStore.asOption(appStore.lastStageAttempt(1)) === None)
assert(appStore.asOption(appStore.lastStageAttempt(2)).map(_.stageId) === Some(2))
assert(appStore.asOption(appStore.lastStageAttempt(3)) === None)
}
test("SPARK-24415: update metrics for tasks that finish late") {
val listener = new AppStatusListener(store, conf, true)
val stage1 = new StageInfo(1, 0, "stage1", 4, Nil, Nil, "details1",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
val stage2 = new StageInfo(2, 0, "stage2", 4, Nil, Nil, "details2",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
// Start job
listener.onJobStart(SparkListenerJobStart(1, time, Seq(stage1, stage2), null))
// Start 2 stages
listener.onStageSubmitted(SparkListenerStageSubmitted(stage1, new Properties()))
listener.onStageSubmitted(SparkListenerStageSubmitted(stage2, new Properties()))
// Start 2 Tasks
val tasks = createTasks(2, Array("1"))
tasks.foreach { task =>
listener.onTaskStart(SparkListenerTaskStart(stage1.stageId, stage1.attemptNumber, task))
}
// Task 1 Finished
time += 1
tasks(0).markFinished(TaskState.FINISHED, time)
listener.onTaskEnd(SparkListenerTaskEnd(
stage1.stageId, stage1.attemptNumber, "taskType", Success, tasks(0),
new ExecutorMetrics, null))
// Stage 1 Completed
stage1.failureReason = Some("Failed")
listener.onStageCompleted(SparkListenerStageCompleted(stage1))
// Stop job 1
time += 1
listener.onJobEnd(SparkListenerJobEnd(1, time, JobSucceeded))
// Task 2 Killed
time += 1
tasks(1).markFinished(TaskState.FINISHED, time)
listener.onTaskEnd(
SparkListenerTaskEnd(stage1.stageId, stage1.attemptNumber, "taskType",
TaskKilled(reason = "Killed"), tasks(1), new ExecutorMetrics, null))
// Ensure killed task metrics are updated
val allStages = store.view(classOf[StageDataWrapper]).reverse().asScala.map(_.info)
val failedStages = allStages.filter(_.status == v1.StageStatus.FAILED)
assert(failedStages.size == 1)
assert(failedStages.head.numKilledTasks == 1)
assert(failedStages.head.numCompleteTasks == 1)
val allJobs = store.view(classOf[JobDataWrapper]).reverse().asScala.map(_.info)
assert(allJobs.size == 1)
assert(allJobs.head.numKilledTasks == 1)
assert(allJobs.head.numCompletedTasks == 1)
assert(allJobs.head.numActiveStages == 1)
assert(allJobs.head.numFailedStages == 1)
}
Seq(true, false).foreach { live =>
test(s"Total tasks in the executor summary should match total stage tasks (live = $live)") {
val testConf = if (live) {
conf.clone().set(LIVE_ENTITY_UPDATE_PERIOD, Long.MaxValue)
} else {
conf.clone().set(LIVE_ENTITY_UPDATE_PERIOD, -1L)
}
val listener = new AppStatusListener(store, testConf, live)
listener.onExecutorAdded(createExecutorAddedEvent(1))
listener.onExecutorAdded(createExecutorAddedEvent(2))
val stage = new StageInfo(1, 0, "stage", 4, Nil, Nil, "details",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
listener.onJobStart(SparkListenerJobStart(1, time, Seq(stage), null))
listener.onStageSubmitted(SparkListenerStageSubmitted(stage, new Properties()))
val tasks = createTasks(4, Array("1", "2"))
tasks.foreach { task =>
listener.onTaskStart(SparkListenerTaskStart(stage.stageId, stage.attemptNumber, task))
}
time += 1
tasks(0).markFinished(TaskState.FINISHED, time)
listener.onTaskEnd(SparkListenerTaskEnd(stage.stageId, stage.attemptNumber, "taskType",
Success, tasks(0), new ExecutorMetrics, null))
time += 1
tasks(1).markFinished(TaskState.FINISHED, time)
listener.onTaskEnd(SparkListenerTaskEnd(stage.stageId, stage.attemptNumber, "taskType",
Success, tasks(1), new ExecutorMetrics, null))
stage.failureReason = Some("Failed")
listener.onStageCompleted(SparkListenerStageCompleted(stage))
time += 1
listener.onJobEnd(SparkListenerJobEnd(1, time, JobFailed(
new RuntimeException("Bad Executor"))))
time += 1
tasks(2).markFinished(TaskState.FAILED, time)
listener.onTaskEnd(SparkListenerTaskEnd(stage.stageId, stage.attemptNumber, "taskType",
ExecutorLostFailure("1", true, Some("Lost executor")), tasks(2), new ExecutorMetrics,
null))
time += 1
tasks(3).markFinished(TaskState.FAILED, time)
listener.onTaskEnd(SparkListenerTaskEnd(stage.stageId, stage.attemptNumber, "taskType",
ExecutorLostFailure("2", true, Some("Lost executor")), tasks(3), new ExecutorMetrics,
null))
val esummary = store.view(classOf[ExecutorStageSummaryWrapper]).asScala.map(_.info)
esummary.foreach { execSummary =>
assert(execSummary.failedTasks === 1)
assert(execSummary.succeededTasks === 1)
assert(execSummary.killedTasks === 0)
}
val allExecutorSummary = store.view(classOf[ExecutorSummaryWrapper]).asScala.map(_.info)
assert(allExecutorSummary.size === 2)
allExecutorSummary.foreach { allExecSummary =>
assert(allExecSummary.failedTasks === 1)
assert(allExecSummary.activeTasks === 0)
assert(allExecSummary.completedTasks === 1)
}
store.delete(classOf[ExecutorSummaryWrapper], "1")
store.delete(classOf[ExecutorSummaryWrapper], "2")
}
}
test("driver logs") {
val listener = new AppStatusListener(store, conf, true)
val driver = BlockManagerId(SparkContext.DRIVER_IDENTIFIER, "localhost", 42)
listener.onBlockManagerAdded(SparkListenerBlockManagerAdded(time, driver, 42L))
listener.onApplicationStart(SparkListenerApplicationStart(
"name",
Some("id"),
time,
"user",
Some("attempt"),
Some(Map("stdout" -> "file.txt"))))
check[ExecutorSummaryWrapper](SparkContext.DRIVER_IDENTIFIER) { d =>
assert(d.info.executorLogs("stdout") === "file.txt")
}
}
test("executor metrics updates") {
val listener = new AppStatusListener(store, conf, true)
val driver = BlockManagerId(SparkContext.DRIVER_IDENTIFIER, "localhost", 42)
listener.onExecutorAdded(createExecutorAddedEvent(1))
listener.onExecutorAdded(createExecutorAddedEvent(2))
listener.onStageSubmitted(createStageSubmittedEvent(0))
// receive 3 metric updates from each executor with just stage 0 running,
// with different peak updates for each executor
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(0, 1,
Array(4000L, 50L, 20L, 0L, 40L, 0L, 60L, 0L, 70L, 20L, 7500L, 3500L,
6500L, 2500L, 5500L, 1500L)))
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(0, 2,
Array(1500L, 50L, 20L, 0L, 0L, 0L, 20L, 0L, 70L, 0L, 8500L, 3500L,
7500L, 2500L, 6500L, 1500L)))
// exec 1: new stage 0 peaks for metrics at indexes: 2, 4, 6
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(0, 1,
Array(4000L, 50L, 50L, 0L, 50L, 0L, 100L, 0L, 70L, 20L, 8000L, 4000L,
7000L, 3000L, 6000L, 2000L)))
// exec 2: new stage 0 peaks for metrics at indexes: 0, 4, 6
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(0, 2,
Array(2000L, 50L, 10L, 0L, 10L, 0L, 30L, 0L, 70L, 0L, 9000L, 4000L,
8000L, 3000L, 7000L, 2000L)))
// exec 1: new stage 0 peaks for metrics at indexes: 5, 7
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(0, 1,
Array(2000L, 40L, 50L, 0L, 40L, 10L, 90L, 10L, 50L, 0L, 8000L, 3500L,
7000L, 2500L, 6000L, 1500L)))
// exec 2: new stage 0 peaks for metrics at indexes: 0, 5, 6, 7, 8
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(0, 2,
Array(3500L, 50L, 15L, 0L, 10L, 10L, 35L, 10L, 80L, 0L, 8500L, 3500L,
7500L, 2500L, 6500L, 1500L)))
// now start stage 1, one more metric update for each executor, and new
// peaks for some stage 1 metrics (as listed), initialize stage 1 peaks
listener.onStageSubmitted(createStageSubmittedEvent(1))
// exec 1: new stage 0 peaks for metrics at indexes: 0, 3, 7
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(0, 1,
Array(5000L, 30L, 50L, 20L, 30L, 10L, 80L, 30L, 50L, 0L, 5000L, 3000L,
4000L, 2000L, 3000L, 1000L)))
// exec 2: new stage 0 peaks for metrics at indexes: 0, 1, 2, 3, 6, 7, 9
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(0, 2,
Array(7000L, 80L, 50L, 20L, 0L, 10L, 50L, 30L, 10L, 40L, 8000L, 4000L,
7000L, 3000L, 6000L, 2000L)))
// complete stage 0, and 3 more updates for each executor with just
// stage 1 running
listener.onStageCompleted(createStageCompletedEvent(0))
// exec 1: new stage 1 peaks for metrics at indexes: 0, 1, 3
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(1, 1,
Array(6000L, 70L, 20L, 30L, 10L, 0L, 30L, 30L, 30L, 0L, 5000L, 3000L,
4000L, 2000L, 3000L, 1000L)))
// exec 2: new stage 1 peaks for metrics at indexes: 3, 4, 7, 8
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(1, 2,
Array(5500L, 30L, 20L, 40L, 10L, 0L, 30L, 40L, 40L, 20L, 8000L, 5000L,
7000L, 4000L, 6000L, 3000L)))
// exec 1: new stage 1 peaks for metrics at indexes: 0, 4, 5, 7
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(1, 1,
Array(7000L, 70L, 5L, 25L, 60L, 30L, 65L, 55L, 30L, 0L, 3000L, 2500L, 2000L,
1500L, 1000L, 500L)))
// exec 2: new stage 1 peak for metrics at index: 7
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(1, 2,
Array(5500L, 40L, 25L, 30L, 10L, 30L, 35L, 60L, 0L, 20L, 7000L, 3000L,
6000L, 2000L, 5000L, 1000L)))
// exec 1: no new stage 1 peaks
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(1, 1,
Array(5500L, 70L, 15L, 20L, 55L, 20L, 70L, 40L, 20L, 0L, 4000L, 2500L,
3000L, 1500, 2000L, 500L)))
listener.onExecutorRemoved(createExecutorRemovedEvent(1))
// exec 2: new stage 1 peak for metrics at index: 6
listener.onExecutorMetricsUpdate(createExecutorMetricsUpdateEvent(1, 2,
Array(4000L, 20L, 25L, 30L, 10L, 30L, 35L, 60L, 0L, 0L, 7000L, 4000L, 6000L,
3000L, 5000L, 2000L)))
listener.onStageCompleted(createStageCompletedEvent(1))
// expected peak values for each executor
val expectedValues = Map(
"1" -> new ExecutorMetrics(Array(7000L, 70L, 50L, 30L, 60L, 30L, 100L, 55L,
70L, 20L, 8000L, 4000L, 7000L, 3000L, 6000L, 2000L)),
"2" -> new ExecutorMetrics(Array(7000L, 80L, 50L, 40L, 10L, 30L, 50L, 60L,
80L, 40L, 9000L, 5000L, 8000L, 4000L, 7000L, 3000L)))
// check that the stored peak values match the expected values
expectedValues.foreach { case (id, metrics) =>
check[ExecutorSummaryWrapper](id) { exec =>
assert(exec.info.id === id)
exec.info.peakMemoryMetrics match {
case Some(actual) =>
checkExecutorMetrics(metrics, actual)
case _ =>
assert(false)
}
}
}
// check stage level executor metrics
val expectedStageValues = Map(
0 -> StageExecutorMetrics(
new ExecutorMetrics(Array(7000L, 80L, 50L, 20L, 50L, 10L, 100L, 30L,
80L, 40L, 9000L, 4000L, 8000L, 3000L, 7000L, 2000L)),
Map(
"1" -> new ExecutorMetrics(Array(5000L, 50L, 50L, 20L, 50L, 10L, 100L, 30L,
70L, 20L, 8000L, 4000L, 7000L, 3000L, 6000L, 2000L)),
"2" -> new ExecutorMetrics(Array(7000L, 80L, 50L, 20L, 10L, 10L, 50L, 30L,
80L, 40L, 9000L, 4000L, 8000L, 3000L, 7000L, 2000L)))),
1 -> StageExecutorMetrics(
new ExecutorMetrics(Array(7000L, 70L, 25L, 40L, 60L, 30L, 70L, 60L,
40L, 20L, 8000L, 5000L, 7000L, 4000L, 6000L, 3000L)),
Map(
"1" -> new ExecutorMetrics(Array(7000L, 70L, 20L, 30L, 60L, 30L, 70L, 55L,
30L, 0L, 5000L, 3000L, 4000L, 2000L, 3000L, 1000L)),
"2" -> new ExecutorMetrics(Array(5500L, 40L, 25L, 40L, 10L, 30L, 35L, 60L,
40L, 20L, 8000L, 5000L, 7000L, 4000L, 6000L, 3000L)))))
checkStageExecutorMetrics(expectedStageValues)
}
test("stage executor metrics") {
// simulate reading in StageExecutorMetrics events from the history log
val listener = new AppStatusListener(store, conf, false)
val driver = BlockManagerId(SparkContext.DRIVER_IDENTIFIER, "localhost", 42)
listener.onExecutorAdded(createExecutorAddedEvent(1))
listener.onExecutorAdded(createExecutorAddedEvent(2))
listener.onStageSubmitted(createStageSubmittedEvent(0))
listener.onStageSubmitted(createStageSubmittedEvent(1))
listener.onStageExecutorMetrics(SparkListenerStageExecutorMetrics("1", 0, 0,
new ExecutorMetrics(Array(5000L, 50L, 50L, 20L, 50L, 10L, 100L, 30L,
70L, 20L, 8000L, 4000L, 7000L, 3000L, 6000L, 2000L))))
listener.onStageExecutorMetrics(SparkListenerStageExecutorMetrics("2", 0, 0,
new ExecutorMetrics(Array(7000L, 70L, 50L, 20L, 10L, 10L, 50L, 30L, 80L, 40L, 9000L,
4000L, 8000L, 3000L, 7000L, 2000L))))
listener.onStageCompleted(createStageCompletedEvent(0))
// executor 1 is removed before stage 1 has finished, the stage executor metrics
// are logged afterwards and should still be used to update the executor metrics.
listener.onExecutorRemoved(createExecutorRemovedEvent(1))
listener.onStageExecutorMetrics(SparkListenerStageExecutorMetrics("1", 1, 0,
new ExecutorMetrics(Array(7000L, 70L, 50L, 30L, 60L, 30L, 80L, 55L, 50L, 0L, 5000L, 3000L,
4000L, 2000L, 3000L, 1000L))))
listener.onStageExecutorMetrics(SparkListenerStageExecutorMetrics("2", 1, 0,
new ExecutorMetrics(Array(7000L, 80L, 50L, 40L, 10L, 30L, 50L, 60L, 40L, 40L, 8000L, 5000L,
7000L, 4000L, 6000L, 3000L))))
listener.onStageCompleted(createStageCompletedEvent(1))
// expected peak values for each executor
val expectedValues = Map(
"1" -> new ExecutorMetrics(Array(7000L, 70L, 50L, 30L, 60L, 30L, 100L, 55L,
70L, 20L, 8000L, 4000L, 7000L, 3000L, 6000L, 2000L)),
"2" -> new ExecutorMetrics(Array(7000L, 80L, 50L, 40L, 10L, 30L, 50L, 60L,
80L, 40L, 9000L, 5000L, 8000L, 4000L, 7000L, 3000L)))
// check that the stored peak values match the expected values
for ((id, metrics) <- expectedValues) {
check[ExecutorSummaryWrapper](id) { exec =>
assert(exec.info.id === id)
exec.info.peakMemoryMetrics match {
case Some(actual) =>
checkExecutorMetrics(metrics, actual)
case _ =>
assert(false)
}
}
}
// check stage level executor metrics
val expectedStageValues = Map(
0 -> StageExecutorMetrics(
new ExecutorMetrics(Array(7000L, 70L, 50L, 20L, 50L, 10L, 100L, 30L,
80L, 40L, 9000L, 4000L, 8000L, 3000L, 7000L, 2000L)),
Map(
"1" -> new ExecutorMetrics(Array(5000L, 50L, 50L, 20L, 50L, 10L, 100L, 30L,
70L, 20L, 8000L, 4000L, 7000L, 3000L, 6000L, 2000L)),
"2" -> new ExecutorMetrics(Array(7000L, 70L, 50L, 20L, 10L, 10L, 50L, 30L,
80L, 40L, 9000L, 4000L, 8000L, 3000L, 7000L, 2000L)))),
1 -> StageExecutorMetrics(
new ExecutorMetrics(Array(7000L, 80L, 50L, 40L, 60L, 30L, 80L, 60L,
50L, 40L, 8000L, 5000L, 7000L, 4000L, 6000L, 3000L)),
Map(
"1" -> new ExecutorMetrics(Array(7000L, 70L, 50L, 30L, 60L, 30L, 80L, 55L,
50L, 0L, 5000L, 3000L, 4000L, 2000L, 3000L, 1000L)),
"2" -> new ExecutorMetrics(Array(7000L, 80L, 50L, 40L, 10L, 30L, 50L, 60L,
40L, 40L, 8000L, 5000L, 7000L, 4000L, 6000L, 3000L)))))
checkStageExecutorMetrics(expectedStageValues)
}
/** expected stage executor metrics */
private case class StageExecutorMetrics(
peakExecutorMetrics: ExecutorMetrics,
executorMetrics: Map[String, ExecutorMetrics])
private def checkExecutorMetrics(expected: ExecutorMetrics, actual: ExecutorMetrics): Unit = {
ExecutorMetricType.metricToOffset.foreach { metric =>
assert(actual.getMetricValue(metric._1) === expected.getMetricValue(metric._1))
}
}
/** check stage level peak executor metric values, and executor peak values for each stage */
private def checkStageExecutorMetrics(expectedStageValues: Map[Int, StageExecutorMetrics]) = {
// check stage level peak executor metric values for each stage
for ((stageId, expectedMetrics) <- expectedStageValues) {
check[StageDataWrapper](Array(stageId, 0)) { stage =>
stage.info.peakExecutorMetrics match {
case Some(actual) =>
checkExecutorMetrics(expectedMetrics.peakExecutorMetrics, actual)
case None =>
assert(false)
}
}
}
// check peak executor metric values for each stage and executor
val stageExecSummaries = store.view(classOf[ExecutorStageSummaryWrapper]).asScala.toSeq
stageExecSummaries.foreach { exec =>
expectedStageValues.get(exec.stageId) match {
case Some(stageValue) =>
(stageValue.executorMetrics.get(exec.executorId), exec.info.peakMemoryMetrics) match {
case (Some(expected), Some(actual)) =>
checkExecutorMetrics(expected, actual)
case _ =>
assert(false)
}
case None =>
assert(false)
}
}
}
test("storage information on executor lost/down") {
val listener = new AppStatusListener(store, conf, true)
val maxMemory = 42L
// Register a couple of block managers.
val bm1 = BlockManagerId("1", "1.example.com", 42)
val bm2 = BlockManagerId("2", "2.example.com", 84)
Seq(bm1, bm2).foreach { bm =>
listener.onExecutorAdded(SparkListenerExecutorAdded(1L, bm.executorId,
new ExecutorInfo(bm.host, 1, Map.empty, Map.empty)))
listener.onBlockManagerAdded(SparkListenerBlockManagerAdded(1L, bm, maxMemory))
}
val rdd1b1 = RddBlock(1, 1, 1L, 2L)
val rdd1b2 = RddBlock(1, 2, 3L, 4L)
val level = StorageLevel.MEMORY_AND_DISK
// Submit a stage and make sure the RDDs are recorded.
val rdd1Info = new RDDInfo(rdd1b1.rddId, "rdd1", 2, level, false, Nil)
val stage = new StageInfo(1, 0, "stage1", 4, Seq(rdd1Info), Nil, "details1",
resourceProfileId = ResourceProfile.DEFAULT_RESOURCE_PROFILE_ID)
listener.onStageSubmitted(SparkListenerStageSubmitted(stage, new Properties()))
// Add partition 1 replicated on two block managers.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, rdd1b1.blockId, level, rdd1b1.memSize, rdd1b1.diskSize)))
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm2, rdd1b1.blockId, level, rdd1b1.memSize, rdd1b1.diskSize)))
// Add a second partition only to bm 1.
listener.onBlockUpdated(SparkListenerBlockUpdated(
BlockUpdatedInfo(bm1, rdd1b2.blockId, level, rdd1b2.memSize, rdd1b2.diskSize)))
check[RDDStorageInfoWrapper](rdd1b1.rddId) { wrapper =>
assert(wrapper.info.numCachedPartitions === 2L)
assert(wrapper.info.memoryUsed === 2 * rdd1b1.memSize + rdd1b2.memSize)
assert(wrapper.info.diskUsed === 2 * rdd1b1.diskSize + rdd1b2.diskSize)
assert(wrapper.info.dataDistribution.get.size === 2L)
assert(wrapper.info.partitions.get.size === 2L)
val dist = wrapper.info.dataDistribution.get.find(_.address == bm1.hostPort).get
assert(dist.memoryUsed === rdd1b1.memSize + rdd1b2.memSize)
assert(dist.diskUsed === rdd1b1.diskSize + rdd1b2.diskSize)
assert(dist.memoryRemaining === maxMemory - dist.memoryUsed)
val part1 = wrapper.info.partitions.get.find(_.blockName === rdd1b1.blockId.name).get
assert(part1.storageLevel === twoReplicaMemAndDiskLevel.description)
assert(part1.memoryUsed === 2 * rdd1b1.memSize)
assert(part1.diskUsed === 2 * rdd1b1.diskSize)
assert(part1.executors === Seq(bm1.executorId, bm2.executorId))
val part2 = wrapper.info.partitions.get.find(_.blockName === rdd1b2.blockId.name).get
assert(part2.storageLevel === level.description)
assert(part2.memoryUsed === rdd1b2.memSize)
assert(part2.diskUsed === rdd1b2.diskSize)
assert(part2.executors === Seq(bm1.executorId))
}
check[ExecutorSummaryWrapper](bm1.executorId) { exec =>
assert(exec.info.rddBlocks === 2L)
assert(exec.info.memoryUsed === rdd1b1.memSize + rdd1b2.memSize)
assert(exec.info.diskUsed === rdd1b1.diskSize + rdd1b2.diskSize)
}
// Remove Executor 1.
listener.onExecutorRemoved(createExecutorRemovedEvent(1))
// check that partition info now contains only details about what is remaining in bm2
check[RDDStorageInfoWrapper](rdd1b1.rddId) { wrapper =>
assert(wrapper.info.numCachedPartitions === 1L)
assert(wrapper.info.memoryUsed === rdd1b1.memSize)
assert(wrapper.info.diskUsed === rdd1b1.diskSize)
assert(wrapper.info.dataDistribution.get.size === 1L)
assert(wrapper.info.partitions.get.size === 1L)
val dist = wrapper.info.dataDistribution.get.find(_.address == bm2.hostPort).get
assert(dist.memoryUsed === rdd1b1.memSize)
assert(dist.diskUsed === rdd1b1.diskSize)
assert(dist.memoryRemaining === maxMemory - dist.memoryUsed)
val part = wrapper.info.partitions.get.find(_.blockName === rdd1b1.blockId.name).get
assert(part.storageLevel === level.description)
assert(part.memoryUsed === rdd1b1.memSize)
assert(part.diskUsed === rdd1b1.diskSize)
assert(part.executors === Seq(bm2.executorId))
}
// Remove Executor 2.
listener.onExecutorRemoved(createExecutorRemovedEvent(2))
// Check that storage cost is zero as both exec are down
check[RDDStorageInfoWrapper](rdd1b1.rddId) { wrapper =>
assert(wrapper.info.numCachedPartitions === 0)
assert(wrapper.info.memoryUsed === 0)
assert(wrapper.info.diskUsed === 0)
assert(wrapper.info.dataDistribution.isEmpty)
assert(wrapper.info.partitions.get.isEmpty)
}
}
test("clean up used memory when BlockManager added") {
val listener = new AppStatusListener(store, conf, true)
// Add block manager at the first time
val driver = BlockManagerId(SparkContext.DRIVER_IDENTIFIER, "localhost", 42)
listener.onBlockManagerAdded(SparkListenerBlockManagerAdded(
time, driver, 42L, Some(43L), Some(44L)))
// Update the memory metrics
listener.updateExecutorMemoryDiskInfo(
listener.liveExecutors(SparkContext.DRIVER_IDENTIFIER),
StorageLevel.MEMORY_AND_DISK,
10L,
10L
)
// Re-add the same block manager again
listener.onBlockManagerAdded(SparkListenerBlockManagerAdded(
time, driver, 42L, Some(43L), Some(44L)))
check[ExecutorSummaryWrapper](SparkContext.DRIVER_IDENTIFIER) { d =>
val memoryMetrics = d.info.memoryMetrics.get
assert(memoryMetrics.usedOffHeapStorageMemory == 0)
assert(memoryMetrics.usedOnHeapStorageMemory == 0)
}
}
test("SPARK-34877 - check YarnAmInfoEvent is populated correctly") {
def checkInfoPopulated(listener: AppStatusListener,
logUrlMap: Map[String, String], processId: String): Unit = {
val yarnAmInfo = listener.liveMiscellaneousProcess.get(processId)
assert(yarnAmInfo.isDefined)
yarnAmInfo.foreach { info =>
assert(info.processId == processId)
assert(info.isActive)
assert(info.processLogs == logUrlMap)
}
check[ProcessSummaryWrapper](processId) { process =>
assert(process.info.id === processId)
assert(process.info.isActive)
assert(process.info.processLogs == logUrlMap)
}
}
val processId = "yarn-am"
val listener = new AppStatusListener(store, conf, true)
var stdout = "http:yarnAmHost:2453/con1/stdout"
var stderr = "http:yarnAmHost:2453/con2/stderr"
var logUrlMap: Map[String, String] = Map("stdout" -> stdout,
"stderr" -> stderr)
var hostport = "yarnAmHost:2453"
var info = new MiscellaneousProcessDetails(hostport, 1, logUrlMap)
listener.onOtherEvent(SparkListenerMiscellaneousProcessAdded(123678L, processId, info))
checkInfoPopulated(listener, logUrlMap, processId)
// Launch new AM in case of failure
// New container entry will be updated in this scenario
stdout = "http:yarnAmHost:2451/con1/stdout"
stderr = "http:yarnAmHost:2451/con2/stderr"
logUrlMap = Map("stdout" -> stdout,
"stderr" -> stderr)
hostport = "yarnAmHost:2451"
info = new MiscellaneousProcessDetails(hostport, 1, logUrlMap)
listener.onOtherEvent(SparkListenerMiscellaneousProcessAdded(123678L, processId, info))
checkInfoPopulated(listener, logUrlMap, processId)
}
private def key(stage: StageInfo): Array[Int] = Array(stage.stageId, stage.attemptNumber)
private def check[T: ClassTag](key: Any)(fn: T => Unit): Unit = {
val value = store.read(classTag[T].runtimeClass, key).asInstanceOf[T]
fn(value)
}
private def newAttempt(orig: TaskInfo, nextId: Long): TaskInfo = {
// Task reattempts have a different ID, but the same index as the original.
new TaskInfo(nextId, orig.index, orig.attemptNumber + 1, time, orig.executorId,
s"${orig.executorId}.example.com", TaskLocality.PROCESS_LOCAL, orig.speculative)
}
private def createTasks(count: Int, execs: Array[String]): Seq[TaskInfo] = {
(1 to count).map { id =>
val exec = execs(id.toInt % execs.length)
val taskId = nextTaskId()
new TaskInfo(taskId, taskId.toInt, 1, time, exec, s"$exec.example.com",
TaskLocality.PROCESS_LOCAL, id % 2 == 0)
}
}
private def nextTaskId(): Long = {
taskIdTracker += 1
taskIdTracker
}
private case class RddBlock(
rddId: Int,
partId: Int,
memSize: Long,
diskSize: Long) {
def blockId: BlockId = RDDBlockId(rddId, partId)
}
}
class AppStatusListenerWithInMemoryStoreSuite extends AppStatusListenerSuite {
override def createKVStore: KVStore = new InMemoryStore()
}
| nchammas/spark | core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala | Scala | apache-2.0 | 77,116 |
import java.util.{Calendar, Date}
import Common.{Account, Balance}
import util.{Failure, Success, Try}
import scala.util.Try
object Common {
type Amount = BigDecimal
def today = Calendar.getInstance.getTime
sealed trait Currency
case class Balance(amount: Amount = 0)
case class Money(amount: BigDecimal)
case class Position(account: Account, currency: Currency, balance: Money)
case class Address(no: String, street: String, city: String, state: String, zip: String)
case class Customer(id: Int, name: String, address: Address)
sealed trait Account {
def no: String
def name: String
def dateOfOpen: Option[Date]
def dateOfClose: Option[Date]
def balance: Balance
}
case class Lens[O, V] (get: O => V, set: (O, V) => O)
def compose[Outer, Inner, Value](outer: Lens[Outer, Inner], inner: Lens[Inner, Value]) =
Lens[Outer, Value](
get = outer.get andThen inner.get,
set = (obj: Outer, value: Value) => outer.set(obj, inner.set(outer.get(obj), value))
)
}
trait AccountService[Account, Amount, Balance] {
def open(name: String, no: String, openingDate: Option[Date]): Try[Account]
def open(account: Account, closingDate: Option[Date], repo: AccountRepository): Try[Account]
def credit(account: Account, amount: Amount): (AccountRepository => Try[Account])
def debit(account: Account, amount: Amount): (AccountRepository => Try[Account])
def balance(account: Account, amount: Amount): (AccountRepository => Try[Balance])
def transfer(from: Account, to: Account, amount: Amount): (AccountRepository => Try[(Account, Account, Amount)]) = {
for {
a <- debit(from, amount)
b <- credit(to, amount)
} yield (a, b, amount)
}
}
sealed trait Repository [Account, String]
trait AccountRepository extends Repository[Account, String] {
def query(accountNo: String) : Try[Option[Account]]
def store(a: Account) : Try[Account]
def balance(accountNo: String) : Try[Balance]
def openedOn(date: Date): Try[Seq[Account]]
}
import Common._
final case class CheckingAccount private(no: String,
name: String,
dateOfOpen: Option[Date],
dateOfClose: Option[Date],
balance: Balance) extends Account
final case class SavingsAccount private(no: String,
name: String,
dateOfOpen: Option[Date],
dateOfClose: Option[Date],
balance: Balance) extends Account
object Account {
private def closeDataCheck(openDate: Option[Date], closeDate: Option[Date]) : Try[(Date, Option[Date])] = {
val od = openDate.getOrElse(today)
closeDate.map(cd =>
if(cd before od)
Failure(new Exception("CD > OD"))
else
Success(od, closeDate)
).getOrElse(Success(od, closeDate))
}
/*def checkingAccount(no: String,
name: String,
dateOfOpen: Option[Date],
dateOfClose: Option[Date],
balance: Balance) : Try[Account] = {
}*/
}
object Main {
def main(args: Array[String]): Unit = {
val a = Address(no = "B-12", street = "My Street", city = "MyCity", state = "MH", zip = "411043")
val c = Customer(12, "RD", a)
val addressNoLens = Lens[Address, String](
get = _.no,
set = (o, v) => o.copy(no = v)
)
val custAddressLens = Lens[Customer, Address](
get = _.address,
set = (o, v) => o.copy(address = v)
)
val custAddressNoLens = compose(custAddressLens, addressNoLens)
val c1 = custAddressNoLens.set(c, "B675")
println("Existing Customer: " + custAddressNoLens.get(c))
println("Updated Customer : " + custAddressNoLens.get(c1))
}
} | dongarerahul/FunctionalProgrammingInScala | FunctionalReactiveModelling/src/main/scala/Chapter3.scala | Scala | apache-2.0 | 3,934 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.execution
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute, SortOrder}
import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
/**
* Iterates over [[GroupedIterator]]s and returns the cogrouped data, i.e. each record is a
* grouping key with its associated values from all [[GroupedIterator]]s.
* Note: we assume the output of each [[GroupedIterator]] is ordered by the grouping key.
*/
class CoGroupedIterator(
left: Iterator[(InternalRow, Iterator[InternalRow])],
right: Iterator[(InternalRow, Iterator[InternalRow])],
groupingSchema: Seq[Attribute])
extends Iterator[(InternalRow, Iterator[InternalRow], Iterator[InternalRow])] {
private val keyOrdering =
GenerateOrdering.generate(groupingSchema.map(SortOrder(_, Ascending)), groupingSchema)
private var currentLeftData: (InternalRow, Iterator[InternalRow]) = _
private var currentRightData: (InternalRow, Iterator[InternalRow]) = _
override def hasNext: Boolean = {
if (currentLeftData == null && left.hasNext) {
currentLeftData = left.next()
}
if (currentRightData == null && right.hasNext) {
currentRightData = right.next()
}
currentLeftData != null || currentRightData != null
}
override def next(): (InternalRow, Iterator[InternalRow], Iterator[InternalRow]) = {
assert(hasNext)
if (currentLeftData.eq(null)) {
// left is null, right is not null, consume the right data.
rightOnly()
} else if (currentRightData.eq(null)) {
// left is not null, right is null, consume the left data.
leftOnly()
} else if (currentLeftData._1 == currentRightData._1) {
// left and right have the same grouping key, consume both of them.
val result = (currentLeftData._1, currentLeftData._2, currentRightData._2)
currentLeftData = null
currentRightData = null
result
} else {
val compare = keyOrdering.compare(currentLeftData._1, currentRightData._1)
assert(compare != 0)
if (compare < 0) {
// the grouping key of left is smaller, consume the left data.
leftOnly()
} else {
// the grouping key of right is smaller, consume the right data.
rightOnly()
}
}
}
private def leftOnly(): (InternalRow, Iterator[InternalRow], Iterator[InternalRow]) = {
val result = (currentLeftData._1, currentLeftData._2, Iterator.empty)
currentLeftData = null
result
}
private def rightOnly(): (InternalRow, Iterator[InternalRow], Iterator[InternalRow]) = {
val result = (currentRightData._1, Iterator.empty, currentRightData._2)
currentRightData = null
result
}
}
| wangyixiaohuihui/spark2-annotation | sql/core/src/main/scala/org/apache/spark/sql/execution/CoGroupedIterator.scala | Scala | apache-2.0 | 3,642 |
package smarthouse
import akka.http.scaladsl.testkit.ScalatestRouteTest
import de.heikoseeberger.akkahttpcirce.CirceSupport
import smarthouse.restapi.http.HttpService
import smarthouse.restapi.models.UserEntity
import smarthouse.restapi.services.{AuthService, DevicesService, EventsService, UsersService}
import smarthouse.restapi.utils.DatabaseService
import smarthouse.utils.InMemoryPostgresStorage._
import org.scalatest._
import scala.concurrent.duration._
import scala.concurrent.{Await, Future}
import scala.util.Random
trait BaseServiceTest extends WordSpec with Matchers with ScalatestRouteTest with CirceSupport {
dbProcess.getProcessId
private val databaseService = new DatabaseService(jdbcUrl, dbUser, dbPassword)
val usersService = new UsersService(databaseService)
val authService = new AuthService(databaseService)(usersService)
val eventsService = new EventsService(databaseService)
val devicesService = new DevicesService(databaseService)
val httpService = new HttpService(usersService, authService, eventsService, devicesService)
def provisionUsersList(size: Int): Seq[UserEntity] = {
val savedUsers = (1 to size).map { _ =>
UserEntity(Some(Random.nextLong()), Random.nextString(10), Random.nextString(10))
}.map(usersService.createUser)
Await.result(Future.sequence(savedUsers), 10.seconds)
}
def provisionTokensForUsers(usersList: Seq[UserEntity]) = {
val savedTokens = usersList.map(authService.createToken)
Await.result(Future.sequence(savedTokens), 10.seconds)
}
}
| andrewobukhov/smart-house | src/test/scala/smarthouse/BaseServiceTest.scala | Scala | mit | 1,546 |
// Copyright 2014 Foursquare Labs Inc. All Rights Reserved.
package io.fsq.twofishes.indexer.scalding
import com.twitter.scalding._
import com.twitter.scalding.typed.{MultiJoin, TypedSink}
import io.fsq.twofishes.gen._
import io.fsq.twofishes.indexer.util.SpindleSequenceFileSource
import org.apache.hadoop.io.LongWritable
class BaseFeatureMergeIntermediateJob(
name: String,
sources: Seq[String],
merger: (Seq[GeocodeServingFeature]) => GeocodeServingFeature,
args: Args
) extends TwofishesIntermediateJob(name, args) {
val coGroupables =
sources.map(source => getJobOutputsAsTypedPipe[LongWritable, GeocodeServingFeature](Seq(source)).group)
val joined = coGroupables.size match {
case 2 => MultiJoin(coGroupables(0), coGroupables(1))
case 3 => MultiJoin(coGroupables(0), coGroupables(1), coGroupables(2))
case 4 => MultiJoin(coGroupables(0), coGroupables(1), coGroupables(2), coGroupables(3))
case 5 => MultiJoin(coGroupables(0), coGroupables(1), coGroupables(2), coGroupables(3), coGroupables(4))
case 6 =>
MultiJoin(coGroupables(0), coGroupables(1), coGroupables(2), coGroupables(3), coGroupables(4), coGroupables(5))
case 7 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6)
)
case 8 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7)
)
case 9 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8)
)
case 10 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9)
)
case 11 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10)
)
case 12 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11)
)
case 13 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11),
coGroupables(12)
)
case 14 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11),
coGroupables(12),
coGroupables(13)
)
case 15 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11),
coGroupables(12),
coGroupables(13),
coGroupables(14)
)
case 16 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11),
coGroupables(12),
coGroupables(13),
coGroupables(14),
coGroupables(15)
)
case 17 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11),
coGroupables(12),
coGroupables(13),
coGroupables(14),
coGroupables(15),
coGroupables(16)
)
case 18 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11),
coGroupables(12),
coGroupables(13),
coGroupables(14),
coGroupables(15),
coGroupables(16),
coGroupables(17)
)
case 19 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11),
coGroupables(12),
coGroupables(13),
coGroupables(14),
coGroupables(15),
coGroupables(16),
coGroupables(17),
coGroupables(18)
)
case 20 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11),
coGroupables(12),
coGroupables(13),
coGroupables(14),
coGroupables(15),
coGroupables(16),
coGroupables(17),
coGroupables(18),
coGroupables(19)
)
case 21 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11),
coGroupables(12),
coGroupables(13),
coGroupables(14),
coGroupables(15),
coGroupables(16),
coGroupables(17),
coGroupables(18),
coGroupables(19),
coGroupables(20)
)
case 22 =>
MultiJoin(
coGroupables(0),
coGroupables(1),
coGroupables(2),
coGroupables(3),
coGroupables(4),
coGroupables(5),
coGroupables(6),
coGroupables(7),
coGroupables(8),
coGroupables(9),
coGroupables(10),
coGroupables(11),
coGroupables(12),
coGroupables(13),
coGroupables(14),
coGroupables(15),
coGroupables(16),
coGroupables(17),
coGroupables(18),
coGroupables(19),
coGroupables(20),
coGroupables(21)
)
case other: Int =>
throw new IllegalArgumentException(
"Cannot multi-join output from %d jobs (between 2 and 22 supported).".format(other)
)
}
val merged = joined.map({
case (k: LongWritable, t: Product) => {
val features = t.productIterator.toSeq.collect({ case f: GeocodeServingFeature => f })
(k -> merger(features))
}
})
merged.write(
TypedSink[(LongWritable, GeocodeServingFeature)](
SpindleSequenceFileSource[LongWritable, GeocodeServingFeature](outputPath)
)
)
}
| foursquare/fsqio | src/jvm/io/fsq/twofishes/indexer/scalding/BaseFeatureMergeIntermediateJob.scala | Scala | apache-2.0 | 8,208 |
/*
#
# MIT License
#
# Copyright (c) 2016 Saniya Tech Inc.
#
# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and
# associated documentation files (the "Software"), to deal in the Software without restriction,
# including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so,
# subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all copies or substantial
# portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT
# LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
# IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,
# WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
#
#
*/
/* SparkApp.scala */
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Dataset, SparkSession}
object SparkApp {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("Spark App")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
val dataset = spark.range(1, 101, 1, 2)
val avg = dataset.agg("id" -> "avg").head.getAs[Double](0)
spark.stop()
println(s"Spark App average : $avg")
}
}
| saniyatech/spark-app | src/main/scala/SparkApp.scala | Scala | mit | 1,617 |
/**
* © 2019 Refinitiv. All Rights Reserved.
*
* Licensed under the Apache License, Version 2.0 (the “License”); you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
* an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
*
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package cmwell.ctrl.hc
import java.net.InetAddress
import akka.actor._
import akka.cluster.Cluster
import akka.cluster.ClusterEvent._
import akka.pattern.ask
import akka.util.Timeout
import cmwell.ctrl.checkers._
import cmwell.ctrl.commands.{RestartWebserver, StartElasticsearchMaster}
import cmwell.ctrl.config.Config._
import cmwell.ctrl.config.{Config, Jvms}
import cmwell.ctrl.controllers.ZookeeperController
import cmwell.ctrl.ddata.DData
import cmwell.ctrl.server.CommandActor
import cmwell.ctrl.tasks._
import cmwell.ctrl.utils.AlertReporter
import cmwell.util.resource._
import com.typesafe.scalalogging.LazyLogging
import k.grid._
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.duration._
import scala.concurrent.{blocking, Future}
import scala.language.postfixOps
import scala.util.Success
/**
* Created by michael on 12/14/14.
*/
case class NodeJoinRequest(host: String)
trait JoinResponse
case object JoinOk extends JoinResponse
case object JoinBootComponents extends JoinResponse
case object JoinShutdown extends JoinResponse
case object GetClusterStatus
case object GetClusterDetailedStatus
case object GetCassandraStatus
case object GetCassandraDetailedStatus
case object GetElasticsearchStatus
case object GetElasticsearchDetailedStatus
case object GetBgStatus
case object GetWebStatus
case object GetDcStatus
case object GetGcStatus
case class ClusterStatus(members: Set[String],
casStat: ComponentState,
esStat: ComponentState,
wsStat: (Map[String, ComponentState], StatusColor),
bgStat: (Map[String, ComponentState], StatusColor),
zookeeperStat: (Map[String, ComponentState], StatusColor),
kafkaStat: (Map[String, ComponentState], StatusColor),
controlNode: String,
esMasters: Set[String])
case class ClusterStatusDetailed(casStat: Map[String, ComponentState],
esStat: Map[String, ComponentState],
wsStat: Map[String, ComponentState],
bgStat: Map[String, ComponentState],
zkStat: Map[String, ComponentState],
kafkaStat: Map[String, ComponentState],
healthHost: String)
case class RemoveNode(ip: String)
case class RemoveFromDownNodes(ip: String)
case class SetKnownHosts(hosts: Set[String])
case class ReSpawnMasters(downHosts: Set[String])
case object GetActiveNodes
case class ActiveNodes(an: Set[String])
case object CommandReceived
trait UpdateStat
case class UpdateCasStat(ccr: (String, ComponentState)) extends UpdateStat
case class UpdateEsStat(ecr: (String, ComponentState)) extends UpdateStat
case class UpdateWsStat(wcr: (String, ComponentState)) extends UpdateStat
case class UpdateBgStat(bcr: (String, ComponentState)) extends UpdateStat
case class UpdateDcStat(dcr: (String, ComponentState)) extends UpdateStat
case class UpdateZookeeperStat(zkr: (String, ComponentState)) extends UpdateStat
case class UpdateKafkaStat(kafr: (String, ComponentState)) extends UpdateStat
case class UpdateSystemStat(sstat: (String, ComponentState)) extends UpdateStat
case class GcStats(hostName: String, pid: Int, roles: Set[String], timeInGc: Long, amountOfGc: Long, gcInterval: Long)
case class HeakupLatency(hostName: String,
pid: Int,
roles: Set[String],
p25: Long,
p50: Long,
p75: Long,
p90: Long,
p99: Long,
p99_5: Long,
max: Long)
case class UpdateHostName(ip: String, hostName: String)
case class PingGot(message: String)
case object CheckElasticsearchMasterStatus
case object CheckZookeeperStatus
case object CheckForWsCrisis
object HealthActor {
//lazy val ref = Grid.selectSingleton(Singletons.health)
lazy val ref = Grid.serviceRef("HealthActor")
}
class HealthActor extends Actor with LazyLogging with AlertReporter {
implicit val timeout = Timeout(3 seconds)
alert(s"Started health actor on $host", host = Some(host))
val cluster = Cluster(context.system)
override def preStart(): Unit = {
//cluster.subscribe(self, classOf[ClusterDomainEvent])
Grid.subscribeForGridEvents(self)
DData.setPingIp(Config.pingIp)
system.scheduler.schedule(30 seconds, 30 seconds, self, CheckElasticsearchMasterStatus)
system.scheduler.scheduleOnce(5.minutes, self, CheckForWsCrisis)
system.scheduler.scheduleOnce(5.seconds, self, CheckZookeeperStatus)
val downHosts = Grid.allKnownHosts -- Grid.upHosts
log.info(s"Down nodes: $downHosts")
if (downHosts.nonEmpty) {
self ! DownNodesDetected(downHosts)
self ! ReSpawnMasters(downHosts)
}
}
def log = logger
def currentTimestamp: Long = System.currentTimeMillis / 1000
case object CheckIdles
val system = Grid.system
private[this] val casStat = new CassandraGridStatus()
private[this] val esStat = new ElasticsearchGridStatus()
private[this] val wsStat = new WebGridStatus()
private[this] val bgStat = new BgGridStatus()
private[this] val dcStat = new DcGridStatus()
private[this] val zkStat = new ZkGridStatus()
private[this] val kafkaStat = new KafkaGridStatus()
private[this] var hostIps: Map[String, Vector[String]] = Map.empty
private[this] var gcStats: Map[(String, Int), (Set[String], Long, Long)] = Map.empty
private[this] var heakupLatencyStats: Map[(String, Int), (Set[String], Long)] = Map.empty
private[this] var hostNames: Map[String, String] = Map.empty
private[this] val cancellableScheduler = system.scheduler.schedule(30 seconds, 30 seconds) {
self ! CheckIdles
}
override def postStop(): Unit = {
log.info("Health actor unsubscribed")
cluster.unsubscribe(self)
logger.info("HealthActor died. Cancelling the scheduler")
cancellableScheduler.cancel()
}
def getReachableCassandraNode: Future[String] = {
Future {
blocking {
val s = hostIps.keySet ++ hostIps.values.flatten.toSet
CassandraChecker.getReachableHost(s) match {
case Some(host) => host
case None => ""
}
}
}
}
private def isReachable(host: String): Boolean = {
InetAddress.getByName(host).isReachable(3000)
}
private def getCasDetailed = {
val detailedRes = hostIps.map { hip =>
casStat.getState match {
case CassandraOk(m, _, _) => (hip._1, CassandraOk(m.filter(stats => hip._2.contains(stats._1))))
case CassandraDown(gt) => (hip._1, CassandraDown(gt))
case ReportTimeout(gt) => (hip._1, CassandraDown(gt))
}
}
detailedRes
}
override def receive: Receive =
GridReceives.monitoring(sender).orElse {
//case WhoAreYou => sender ! WhoIAm(Grid.me.toString)
case LeaderChanged(leader) => log.info(s"Leader changed: $leader")
case CheckIdles =>
val now = currentTimestamp
if (casStat.getState != null && now - casStat.getState.genTime > idleWaitSeconds) {
log.warn(s"Cass diff: ${now - casStat.getState.genTime}")
self ! UpdateCasStat("", ReportTimeout())
}
esStat.getStatesMap.foreach { estat =>
if (now - estat._2.genTime > idleWaitSeconds) {
log.warn(s"Elastic ${estat._1} diff ${now - estat._2.genTime}")
self ! UpdateEsStat(estat._1 -> ReportTimeout())
}
}
wsStat.getStatesMap.foreach { wstat =>
if (now - wstat._2.genTime > idleWaitSeconds) {
log.warn(s"Web ${wstat._1} diff ${now - wstat._2.genTime}")
self ! UpdateWsStat(wstat._1 -> ReportTimeout())
}
}
bgStat.getStatesMap.foreach {
case (host, cs) =>
if (now - cs.genTime > idleWaitSeconds) {
log.warn(s"bg $host diff ${now - cs.genTime}")
self ! UpdateBgStat(host -> ReportTimeout())
}
}
dcStat.getStatesMap.foreach { dcstat =>
if (now - dcstat._2.genTime > idleWaitSeconds) {
log.warn(s"Dc ${dcstat._1} diff ${now - dcstat._2.genTime}")
self ! UpdateDcStat(dcstat._1 -> ReportTimeout())
}
}
zkStat.getStatesMap.foreach { zkS =>
if (now - zkS._2.genTime > idleWaitSeconds) {
log.warn(s"Zookeeper ${zkS._1} diff ${now - zkS._2.genTime}")
self ! UpdateZookeeperStat(zkS._1 -> ReportTimeout())
}
}
kafkaStat.getStatesMap.foreach { kafS =>
if (now - kafS._2.genTime > idleWaitSeconds) {
log.warn(s"Kafka ${kafS._1} diff ${now - kafS._2.genTime}")
self ! UpdateKafkaStat(kafS._1 -> ReportTimeout())
}
}
case us: UpdateStat =>
logger.debug(s"Received UpdateStat: $us from actor $sender")
//AlertReporter.alert(us)
us match {
case UpdateCasStat(ccr) =>
ccr._2 match {
case co: CassandraOk =>
case _ =>
getReachableCassandraNode.onComplete {
case Success(host) if host != "" => DData.setPingIp(host)
case _ => // do nothing
}
}
casStat.update("", ccr._2)
case UpdateEsStat(ecr) =>
esStat.update(ecr._1, ecr._2)
// ecr._2 match {
// case eState : ElasticsearchState if eState.hasMaster=> {
// val currentMasters = DData.getEsMasters
// if(currentMasters.size == Config.esMasters && !currentMasters.contains(ecr._1)){
// logger.info(s"Stopping Elasticsearch master on ${ecr._1}")
// CommandActor.select(ecr._1) ! StopElasticsearchMaster
// } else {
// DData.addEsMaster(ecr._1)
// }
// }
// case _ => // Do nothing
// }
case UpdateWsStat(wcr) =>
wsStat.update(wcr._1, wcr._2)
case UpdateBgStat(bcr) =>
bgStat.update(bcr._1, bcr._2)
case UpdateDcStat(dcr) =>
dcStat.update(dcr._1, dcr._2)
case UpdateZookeeperStat(zkr) =>
zkStat.update(zkr._1, zkr._2)
case UpdateKafkaStat(kafr) =>
kafkaStat.update(kafr._1, kafr._2)
case UpdateSystemStat(sstat) =>
log.debug(s"received cluster info from ${sstat._1} : ${sstat._2}")
sstat._2 match {
case SystemResponse(ips, shortName, _) =>
hostIps = hostIps.updated(sstat._1, ips)
updateIps(sstat._1, ips)
updateShortName(sstat._1, shortName)
//HealthActor.addKnownNode(sstat._1)
case _ =>
}
}
case GcStats(hostName, pid, roles, timeInGc, amountOfGc, gcInterval) =>
log.debug(s"got gc stats: $hostName $pid")
gcStats = gcStats.updated((hostName, pid), (roles, timeInGc, amountOfGc))
case HeakupLatency(hostName, pid, roles, p25, p50, p75, p90, p99, p99_5, max) =>
log.debug(s"GotHeakupLatencyStats $hostName $pid ${roles.toSeq(1)} $p25 $p50 $p75 $p90 $p99 $p99_5 $max")
heakupLatencyStats = heakupLatencyStats.updated((hostName, pid), (roles, max))
case GetActiveNodes => sender ! ActiveNodes(hostIps.keySet)
case GetClusterStatus =>
sender ! ClusterStatus(
Grid.availableMachines,
casStat.getState,
esStat.getStatesMap.headOption.getOrElse("" -> ElasticsearchDown())._2,
(wsStat.getStatesMap.map(t => (t._1, t._2)), wsStat.getColor),
(bgStat.getStatesMap.map(t => (t._1, t._2)), bgStat.getColor),
(zkStat.getStatesMap.map(t => (t._1, t._2)), zkStat.getColor),
(kafkaStat.getStatesMap.map(t => (t._1, t._2)), kafkaStat.getColor),
Config.listenAddress,
esStat.getStatesMap.filter(_._2.asInstanceOf[ElasticsearchState].hasMaster).keySet
)
case GetCassandraStatus => sender ! casStat.getState
case GetElasticsearchStatus => sender ! esStat.getStatesMap.head._2
case GetWebStatus => sender ! (wsStat.getStatesMap.map(t => (t._1, t._2)), wsStat.getColor)
case GetBgStatus => sender ! (bgStat.getStatesMap.map(t => (t._1, t._2)), bgStat.getColor)
case GetCassandraDetailedStatus =>
sender ! getCasDetailed
case GetElasticsearchDetailedStatus =>
sender ! esStat
case GetClusterDetailedStatus =>
sender ! ClusterStatusDetailed(getCasDetailed,
esStat.getStatesMap,
wsStat.getStatesMap,
bgStat.getStatesMap,
zkStat.getStatesMap,
kafkaStat.getStatesMap,
listenAddress)
case GetGcStatus => sender ! gcStats
case GetDcStatus => sender ! dcStat.getStatesMap
case RemoveFromDownNodes(ip) =>
logger.info(s"Removing $ip from down nodes")
DData.setDownNodes(DData.getDownNodes -- Set(ip))
logger.info(s"down nodes list after removing: ${DData.getDownNodes}")
case msg @ RemoveNode(ip) =>
logger.info(s"received $msg")
sender ! CommandReceived
esStat.remove(ip)
bgStat.remove(ip)
wsStat.remove(ip)
kafkaStat.remove(ip)
zkStat.remove(ip)
hostIps = hostIps.filterNot(_._1 == ip)
gcStats = gcStats.filterNot(_._1._1 == ip)
heakupLatencyStats = heakupLatencyStats.filterNot(_._1._1 == ip)
DData.addDownNode(ip)
logger.info("Sending EndOfGraceTime")
Grid.system.scheduler.scheduleOnce(20.seconds) {
self ! EndOfGraceTime
}
case NodeJoined(host) => {
logger.info(s"Node $host has joined.")
self ! NodesJoinedDetected(Set(host))
}
case NodeLeft(host) => {
logger.info(s"Node $host has left.")
self ! DownNodesDetected(Set(host))
}
case ReSpawnMasters(downHosts) =>
val masters = DData.getEsMasters
val known = DData.getKnownNodes
val upMasters = masters -- downHosts
val upNotMasters = known -- masters -- downHosts
if (upMasters.size < Config.esMasters) {
val numOfDownMasters = Config.esMasters - upMasters.size
upNotMasters.take(numOfDownMasters).foreach { host =>
logger.info(s"Spawning Elasticsearch master on $host")
CommandActor.select(host) ! StartElasticsearchMaster
}
(masters -- upMasters).foreach(DData.removeEsMaster(_))
}
case r: ClusterEvent =>
ClusterState.newState(r)
case NodeJoinRequest(node) =>
log.info(
s"Join request from: $node , current state: ${ClusterState.getCurrentState} , down nodes: ${DData.getDownNodes}"
)
val res = ClusterState.getCurrentState match {
case Stable =>
if (DData.getDownNodes.contains(node)) {
(None, JoinShutdown)
} else {
(Some(NodesJoinedDetected(Set(node))), JoinOk)
}
case DownNodes(nodes) =>
if (nodes.contains(node)) {
(Some(NodesJoinedDetected(Set(node))), JoinBootComponents)
} else if (DData.getDownNodes.contains(node)) {
(None, JoinShutdown)
} else {
(Some(NodesJoinedDetected(Set(node))), JoinOk)
}
}
sender ! res._2
if (res._1.isDefined) self ! res._1.get
log.info(s"Join verdict: $res")
alert(node, res._2)
val fHname =
blocking {
Future {
val addr = InetAddress.getByName(node)
addr.getHostName()
}
}
fHname.map(hostName => self ! UpdateHostName(node, hostName))
case ce: ComponentEvent =>
val hostName = hostNames.get(ce.id)
alert(ce, hostName)
case UpdateHostName(ip, hostName) => hostNames = hostNames.updated(ip, hostName)
case PingGot(message) => log.debug(s"Got: $message")
case str: String => log.info(s"Got: $str")
case CheckElasticsearchMasterStatus => esStat.normalizeMasters()
case CheckZookeeperStatus if ZookeeperUtils.isZkNode =>
ZookeeperController.start
case t: Task => {
t match {
case an @ AddNode(node) =>
implicit val timeout = Timeout(24.hours)
val ar = Grid.create(clazz = classOf[TaskExecutorActor],
name = TaskExecutorActor.name + "AddNode" + System.currentTimeMillis().toString)
val s = sender()
//ar.ask(an)(implicitly[akka.util.Timeout],sender()) - equivalent besides the log print
val f = (ar ? an).mapTo[TaskResult]
f.foreach { ts =>
logger.info(s"Task status is: $ts")
s ! ts
}
case cn @ ClearNode(node) =>
implicit val timeout = Timeout(1.hours)
val included = Grid.jvms(Jvms.CTRL).filterNot(_.host == node)
val ar =
Grid.createSomewhere(white = included,
black = Set.empty[GridJvm],
clazz = classOf[TaskExecutorActor],
name = TaskExecutorActor.name + "ClearNode" + System.currentTimeMillis().toString)
val s = sender()
val f = (ar ? cn).mapTo[TaskResult]
f.foreach { ts =>
logger.info(s"Task status is: $ts")
s ! ts
}
case _ => // do nothing
}
}
case CheckForWsCrisis =>
logger.debug("Checking for web service crisis")
val (greens, notGreens) = wsStat.getStatesMap.partition(_._2.getColor == GreenStatus)
if (greens.size <= 2 && notGreens.size > 0) {
logger.warn(s"web services are not responding, restarting ${notGreens.map(_._1).mkString(", ")}.")
notGreens.foreach(comp => CommandActor.select(comp._1) ! RestartWebserver)
system.scheduler.scheduleOnce(10.minutes, self, CheckForWsCrisis)
} else {
system.scheduler.scheduleOnce(30.seconds, self, CheckForWsCrisis)
}
case message => {
logger.warn(s"unexcpected message $message")
}
}
}
object ZookeeperUtils {
def isZkNode: Boolean = zkServers(Config.listenAddress)
def zkServers = using(scala.io.Source.fromFile(s"${Config.cmwellHome}/conf/zookeeper/zoo.cfg")) { source =>
source.getLines().filter(_.startsWith("server.")).map(_.dropWhile(_ != '=').takeWhile(_ != ':').substring(1)).toSet
}
}
| dudi3001/CM-Well | server/cmwell-controller/src/main/scala/cmwell/ctrl/hc/HealthActor.scala | Scala | apache-2.0 | 19,735 |
package ga
import org.scalatest._
import sGeneticAlgorithm.ga.GA._
import sGeneticAlgorithm.ga._
import sGeneticAlgorithm.utils.SimRandom
class EvolverSpec extends FlatSpec {
val random = new SimRandom(0)
//Create a population with uniform genomes
val pop: Population[Long, Vector[Long]] = (for (i <- 1 to 100) yield {
(for (j <- 1 to 100) yield i.toLong).toVector
}).toVector
// Evaluate the population so that fitness is the average of the values
class FirstEvaluator extends SimpleEvaluator[Long, Vector[Long], Double] {
override def evaluateGenome(g: Genome[Long, Vector[Long]]): EvaluatedGenome[Long, Vector[Long], Double] = {
new EvaluatedGenome[Long, Vector[Long], Double](g, g.sum/g.size)
}
}
val species = Vector(pop)
val animals = Vector(species)
val evaluator = new FirstEvaluator
val evaluatedSpecies = evaluator.evaluate(animals)
val evaluatedPopulation = evaluatedSpecies(0)(0)
"An Evolver" should "evolve the population with crossover only" in {
// First try with no mutation
val numCrossoverPoints = 2
val numChildren = 1
val mutationRate = 0.0
val numInTournament = 2
val replacementRate = 0.5
val crossover = new MultiPointCrossover[Long](random, numCrossoverPoints, numChildren)
val ias = LongAlleleSet(random, 101, 200)
val alleles = (for (i <- 1 to 100) yield ias).toVector
val mutator = AlleleSetMutator[Long](random, alleles, mutationRate)
val tournamentSelector = new TournamentSelector[Long, Vector[Long], Double](random, numInTournament)
val bestSelector = new BestSelector[Long, Vector[Long], Double]
val archiveUpdater = new BestNArchiveUpdater[Long, Vector[Long], Double](20)
val evolver = new CrossoverEvolver(mutator, crossover, tournamentSelector, bestSelector, archiveUpdater, replacementRate)
val nextGeneration = evolver.evolve(evaluatedPopulation, None).pop
// The new population should be the same size as the old
assert(nextGeneration.size == evaluatedPopulation.size)
// About half of the new population from crossover should have two unique values
val distinctValues = nextGeneration.map(_.distinct.size)
val twos = distinctValues.filter(v => v == 2)
val ones = distinctValues.filter(v => v == 1)
assert(twos.size > 45)
// The survivors should have one unique value
assert(ones.size >= 50)
// The average fitness should increase
val nextEvaluated = evaluator.evaluatePopulation(nextGeneration)
val numbers = nextEvaluated.map(_.fitness)
val average = numbers.sum/numbers.size
assert(average > 60)
}
"An Evolver" should "evolve the population with mutation only" in {
// First try with no mutation
val mutationRate = 0.1
val replacementRate = 0.5
val numInTournament = 2
val crossover = new NoCrossover[Long, Vector[Long]]
val ias = LongAlleleSet(random, 101, 200)
val alleles = (for (i <- 1 to 100) yield ias).toVector
val mutator = AlleleSetMutator[Long](random, alleles, mutationRate)
val tournamentSelector = new TournamentSelector[Long, Vector[Long], Double](random, numInTournament)
val bestSelector = new BestSelector[Long, Vector[Long], Double]
val archiveUpdater = new BestNArchiveUpdater[Long, Vector[Long], Double](20)
val evolver = new CrossoverEvolver(mutator, crossover, tournamentSelector, bestSelector, archiveUpdater, replacementRate)
val nextGeneration = evolver.evolve(evaluatedPopulation, None).pop
// The new population should be the same size as the old
assert(nextGeneration.size == evaluatedPopulation.size)
// About half of the new population from crossover should have only one value
val distinctValues = nextGeneration.map(_.distinct.size)
val more = distinctValues.filter(v => v >= 2)
val ones = distinctValues.filter(v => v == 1)
assert(more.size > 45)
// The survivors should have one unique value
assert(ones.size >= 50)
// The average fitness should increase
val nextEvaluated = evaluator.evaluatePopulation(nextGeneration)
val numbers = nextEvaluated.map(_.fitness)
val average = numbers.sum/numbers.size
assert(average > 60)
}
}
| rkewley/sGeneticAlgorithm | src/test/scala/ga/EvolverSpec.scala | Scala | apache-2.0 | 4,196 |
/*
* Copyright 2016 LinkedIn Corp.
*
* Licensed under the Apache License, Version 2.0 (the "License"); you may not
* use this file except in compliance with the License. You may obtain a copy of
* the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
* WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
* License for the specific language governing permissions and limitations under
* the License.
*/
package com.linkedin.drelephant.spark.heuristics
import scala.collection.JavaConverters
import scala.concurrent.duration.Duration
import com.linkedin.drelephant.analysis.{ApplicationType, Severity}
import com.linkedin.drelephant.configurations.heuristic.HeuristicConfigurationData
import com.linkedin.drelephant.spark.data.{SparkApplicationData, SparkLogDerivedData, SparkRestDerivedData}
import com.linkedin.drelephant.spark.fetchers.statusapiv1.{ApplicationInfo, JobData, StageData}
import org.apache.spark.scheduler.SparkListenerEnvironmentUpdate
import org.apache.spark.status.api.v1.StageStatus
import org.scalatest.{FunSpec, Matchers}
class StagesHeuristicTest extends FunSpec with Matchers {
import StagesHeuristicTest._
describe("StagesHeuristic") {
val heuristicConfigurationData = newFakeHeuristicConfigurationData(
Map(
"stage_failure_rate_severity_thresholds" -> "0.2,0.4,0.6,0.8",
"stage_task_failure_rate_severity_thresholds" -> "0.2,0.4,0.6,0.8",
"stage_runtime_minutes_severity_thresholds" -> "15,30,45,60"
)
)
val stagesHeuristic = new StagesHeuristic(heuristicConfigurationData)
val stageDatas = Seq(
newFakeStageData(StageStatus.COMPLETE, 0, numCompleteTasks = 10, numFailedTasks = 0, executorRunTime = Duration("2min").toMillis, "foo"),
newFakeStageData(StageStatus.COMPLETE, 1, numCompleteTasks = 8, numFailedTasks = 2, executorRunTime = Duration("2min").toMillis, "bar"),
newFakeStageData(StageStatus.COMPLETE, 2, numCompleteTasks = 6, numFailedTasks = 4, executorRunTime = Duration("2min").toMillis, "baz"),
newFakeStageData(StageStatus.FAILED, 3, numCompleteTasks = 4, numFailedTasks = 6, executorRunTime = Duration("2min").toMillis, "aaa"),
newFakeStageData(StageStatus.FAILED, 4, numCompleteTasks = 2, numFailedTasks = 8, executorRunTime = Duration("2min").toMillis, "zzz"),
newFakeStageData(StageStatus.COMPLETE, 5, numCompleteTasks = 10, numFailedTasks = 0, executorRunTime = Duration("0min").toMillis, "bbb"),
newFakeStageData(StageStatus.COMPLETE, 6, numCompleteTasks = 10, numFailedTasks = 0, executorRunTime = Duration("30min").toMillis, "ccc"),
newFakeStageData(StageStatus.COMPLETE, 7, numCompleteTasks = 10, numFailedTasks = 0, executorRunTime = Duration("60min").toMillis, "ddd"),
newFakeStageData(StageStatus.COMPLETE, 8, numCompleteTasks = 10, numFailedTasks = 0, executorRunTime = Duration("90min").toMillis, "eee"),
newFakeStageData(StageStatus.COMPLETE, 9, numCompleteTasks = 10, numFailedTasks = 0, executorRunTime = Duration("120min").toMillis, "fff")
)
val appConfigurationProperties = Map("spark.executor.instances" -> "2")
describe(".apply") {
val data = newFakeSparkApplicationData(stageDatas, appConfigurationProperties)
val heuristicResult = stagesHeuristic.apply(data)
val heuristicResultDetails = heuristicResult.getHeuristicResultDetails
it("returns the severity") {
heuristicResult.getSeverity should be(Severity.CRITICAL)
}
it("returns the number of completed stages") {
heuristicResultDetails.get(0).getValue should be("8")
}
it("returns the number of failed stages") {
heuristicResultDetails.get(1).getValue should be("2")
}
it("returns the stage failure rate") {
heuristicResultDetails.get(2).getValue should be("0.200")
}
/*
it("returns the list of stages with high task failure rates") {
heuristicResultDetails.get(3).getValue should be(
s"""|stage 3, attempt 0 (task failure rate: 0.600)
|stage 4, attempt 0 (task failure rate: 0.800)""".stripMargin
)
}
it("returns the list of stages with long runtimes") {
heuristicResultDetails.get(4).getValue should be(
s"""|stage 8, attempt 0 (runtime: 45 min)
|stage 9, attempt 0 (runtime: 1 hr)""".stripMargin
)
}
*/
}
describe(".Evaluator") {
import StagesHeuristic.Evaluator
val data = newFakeSparkApplicationData(stageDatas, appConfigurationProperties)
val evaluator = new Evaluator(stagesHeuristic, data)
it("has the number of completed stages") {
evaluator.numCompletedStages should be(8)
}
it("has the number of failed stages") {
evaluator.numFailedStages should be(2)
}
it("has the stage failure rate") {
evaluator.stageFailureRate should be(Some(0.2D))
}
/*
it("has the list of stages with high task failure rates") {
val stageIdsAndTaskFailureRates =
evaluator.stagesWithHighTaskFailureRates.map { case (stageData, taskFailureRate) => (stageData.stageId, taskFailureRate) }
stageIdsAndTaskFailureRates should contain theSameElementsInOrderAs(Seq((3, 0.6D), (4, 0.8D)))
}
it("has the list of stages with long average executor runtimes") {
val stageIdsAndRuntimes =
evaluator.stagesWithLongAverageExecutorRuntimes.map { case (stageData, runtime) => (stageData.stageId, runtime) }
stageIdsAndRuntimes should contain theSameElementsInOrderAs(
Seq((8, Duration("45min").toMillis), (9, Duration("60min").toMillis))
)
}
*/
it("computes the overall severity") {
evaluator.severity should be(Severity.CRITICAL)
}
}
}
}
object StagesHeuristicTest {
import JavaConverters._
def newFakeHeuristicConfigurationData(params: Map[String, String] = Map.empty): HeuristicConfigurationData =
new HeuristicConfigurationData("heuristic", "class", "view", new ApplicationType("type"), params.asJava)
def newFakeStageData(
status: StageStatus,
stageId: Int,
numCompleteTasks: Int,
numFailedTasks: Int,
executorRunTime: Long,
name: String
): StageData = new StageData(
status,
stageId,
attemptId = 0,
numActiveTasks = numCompleteTasks + numFailedTasks,
numCompleteTasks,
numFailedTasks,
executorRunTime,
inputBytes = 0,
inputRecords = 0,
outputBytes = 0,
outputRecords = 0,
shuffleReadBytes = 0,
shuffleReadRecords = 0,
shuffleWriteBytes = 0,
shuffleWriteRecords = 0,
memoryBytesSpilled = 0,
diskBytesSpilled = 0,
name,
details = "",
schedulingPool = "",
accumulatorUpdates = Seq.empty,
tasks = None,
executorSummary = None
)
def newFakeSparkApplicationData(
stageDatas: Seq[StageData],
appConfigurationProperties: Map[String, String]
): SparkApplicationData = {
val appId = "application_1"
val restDerivedData = SparkRestDerivedData(
new ApplicationInfo(appId, name = "app", Seq.empty),
jobDatas = Seq.empty,
stageDatas,
executorSummaries = Seq.empty
)
val logDerivedData = SparkLogDerivedData(
SparkListenerEnvironmentUpdate(Map("Spark Properties" -> appConfigurationProperties.toSeq))
)
SparkApplicationData(appId, restDerivedData, Some(logDerivedData))
}
}
| bretlowery/dr-elephant-mapr | test/com/linkedin/drelephant/spark/heuristics/StagesHeuristicTest.scala | Scala | apache-2.0 | 7,601 |
package com.twitter.finagle.kestrelx.protocol
import com.twitter.io.Buf
sealed abstract class Response
case class NotFound() extends Response
case class Stored() extends Response
case class Deleted() extends Response
case class Error() extends Response
case class Values(values: Seq[Value]) extends Response
case class Value(key: Buf, value: Buf)
| kristofa/finagle | finagle-kestrelx/src/main/scala/com/twitter/finagle/kestrelx/protocol/Response.scala | Scala | apache-2.0 | 425 |
import java.io.File
import org.apache.commons.vfs2._
object VTest extends App {
import com.intridea.io.vfs.provider.s3.S3FileProvider
import org.apache.commons.vfs2.provider.local.DefaultLocalFileProvider
val bucket: String = {
if (args.length!=1) {
println("Usage: VTest bucketName")
System.exit(-2)
}
args(0)
}
val fsManager: FileSystemManager = {
import java.io.FileInputStream
import java.util.Properties
import com.intridea.io.vfs.provider.s3.S3FileProvider
import org.apache.commons.vfs2.auth.StaticUserAuthenticator
import org.apache.commons.vfs2.impl.DefaultFileSystemConfigBuilder
val config = new Properties()
config.load(new FileInputStream(System.getProperty("user.home") + "/.aws/config")) // same authentication file used by aws-cli
val auth = new StaticUserAuthenticator(null, config.getProperty("aws_access_key_id"), config.getProperty("aws_secret_access_key"))
val opts = S3FileProvider.getDefaultFileSystemOptions
DefaultFileSystemConfigBuilder.getInstance().setUserAuthenticator(opts, auth)
VFS.getManager
}
val s3Utils = new VFileUtils(new S3FileProvider, fsManager)
val localUtils = new VFileUtils(new DefaultLocalFileProvider, fsManager)
val dir: FileObject = try {
s3Utils.resolveFile("s3://vfs-test")
} catch {
case npe: NullPointerException =>
println("Did you provide AWS credentials?")
sys.exit(-1)
}
dir.createFolder()
val dest: FileObject = fsManager.resolveFile(s"s3://$bucket/README.md")
val src: FileObject = fsManager.resolveFile(new File("README.md").getAbsolutePath)
dest.delete() // copyFrom fails if the destination already exists, so try to delete it first
dest.copyFrom(src, Selectors.SELECT_SELF)
}
| mslinn/vfs-s3Test | src/main/scala/VTest.scala | Scala | apache-2.0 | 1,770 |
/*
* Copyright (c) 2013 Oracle and/or its affiliates. All rights reserved.
* DO NOT ALTER OR REMOVE COPYRIGHT NOTICES OR THIS FILE HEADER.
*
* This program is free software: you can redistribute it and/or modify
* it under the terms of the GNU Affero General Public License as
* published by the Free Software Foundation, either version 3 of the
* License, or (at your option) any later version.
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU Affero General Public License for more details.
*
* You should have received a copy of the GNU Affero General Public License
* along with this program. If not, see http://www.gnu.org/licenses/agpl.html.
*
* Please contact Oracle, 500 Oracle Parkway, Redwood Shores, CA 94065 USA
* or visit www.oracle.com if you need additional information or have any
* questions.
*/
package lancet
package advanced
import lancet.api._
import lancet.interpreter._
import lancet.core._
//import ppl.dsl.optila.{Vector,DenseVector,RangeVector}
//import ppl.dsl.optiml.{IndexVectorRange}
import ppl.dsl.optiml.{OptiMLApplication, OptiMLApplicationRunner}
import ppl.delite.framework.DeliteApplication
import ppl.delite.framework.Config
import ppl.dsl.optiml.{OptiMLCodeGenScala,OptiMLExp}
import scala.virtualization.lms.internal.{GenericFatCodegen}
import scala.virtualization.lms.common._
class TestDelite2 extends FileDiffSuite {
val prefix = "test-out/test-delite-2"
def testA1 = withOutFileChecked(prefix+"A1") {
import DeliteRunner._
/*
CURRENT STATUS / STEPS:
- work around issues/conflicts: IfThenElse, compile{x=>}
- using lancet lms codegen with embedded delite objects
- make delite scala codegen generate lancet stuff
- use delite backend codegen. lancet just for decompiling bytecode
TODO:
- need to hook into DeliteCodegen for Base_LMS classes?
- ISSUE: control flow?? need to use DeliteIf, and don't have functions ...
- lancet generates lots of strong effect dependencies (objects, fields, etc): remove!!
- what to do about generic types? require manifests and evaluate then at compile time?
*/
def printxx(x:Any) = { println(x) }
class VectorCompanion {
def rand(n:Int): Vector[Double] = { printxx("Vector$.rand"); new Vector[Double] }
def apply[T:Manifest](xs: T*): Vector[T] = { printxx("Vector$.apply"); new Vector[T] }
}
class Vector[T] {
def t: Vector[T] = { printxx("Vector.t"); this } //new Vector[T] } FIXME: ISSUE WITH OUTER POINTER / Delite conditionals
def isRow: Boolean = { printxx("Vector.isRow"); false }
def sum: T = ???
def max: T = ???
def min: T = ???
def length: Int = ???
}
class UtilCompanion {
def mean(v: Vector[Int]): Int = v.sum / v.length
def max(v: Vector[Int]): Int = v.max
def min(v: Vector[Int]): Int = v.min
def collect(b: Boolean): Unit = { println(b) }
}
val Vector = new VectorCompanion
val Util = new UtilCompanion
def myprog = {
import Util._
val v = Vector.rand(1000)
val vt = v.t
//collect(vt.isRow != v.isRow)
//val vc = v.clone
//collect(vc.cmp(v) == true)
val v2 = Vector(1,2,3,4,5)
//collect(median(v2) == 3)
collect(mean(v2) == 3)
collect(max(v2) == 5)
collect(min(v2) == 1)
printxx("AA")
printxx("BB")
printxx("CC")
42 // need result?
}
val VectorOperatorsRunner = new LancetDeliteRunner
VectorOperatorsRunner.initialize()
VectorOperatorsRunner.traceMethods = false
VectorOperatorsRunner.emitUniqueOpt = true
object Macros extends VectorOperatorsRunner.ClassMacros {
val targets = List(classOf[VectorCompanion],classOf[Vector[_]])
//type Rep[T] = VectorOperatorsRunner.Rep[T]
import VectorOperatorsRunner._ //{Rep,reflect,mtr,infix_relax,eval,VConst,Def}
def rand(self: Rep[VectorCompanion], n: Rep[Int]): Rep[DenseVector[Double]] = {
Console.println("catch vector_rand")
VectorOperatorsRunner.densevector_obj_rand(n)
}
def apply[T](self: Rep[VectorCompanion], xs: Rep[Seq[T]], mf: Rep[Manifest[T]]): Rep[DenseVector[T]] = {
Console.println("catch vector_apply")
implicit val mfT = eval(mf) match {
case VConst(mf: Manifest[T]) => mf
case _ =>
//Console.println("ERROR: non-constant manifest in vector_apply: "+mf+"="+Def.unapply(mf)+" -- assuming Double")
Console.println("ERROR: non-constant manifest in vector_apply -- assuming Double")
manifest[Double].asInstanceOf[Manifest[T]]
}
//implicit val mf = manifest[Int].asInstanceOf[Manifest[T]] //FIXME: generic types
val xs1 = reflect[Seq[T]](xs,".asInstanceOf[Seq[Int]]")(mtr[Seq[Int]].relax) // need cast ...
VectorOperatorsRunner.densevector_obj_fromseq(xs1)
// TODO: generic types are problematic...
// require manifest parameter and try to eval that?
// or use scala reflection?
}
def t[T](self: Rep[DenseVector[T]]): Rep[DenseVector[T]] = {
Console.println("catch vector_t")
implicit val mf = manifest[Int].asInstanceOf[Manifest[T]] //FIXME: generic types
VectorOperatorsRunner.densevector_trans(self)
}
def isRow[T](self: Rep[DenseVector[T]]): Rep[Boolean] = {
Console.println("catch vector_isRow")
implicit val mf = manifest[Int].asInstanceOf[Manifest[T]] //FIXME: generic types
VectorOperatorsRunner.densevector_isrow(self)
}
def length[T](self: Rep[DenseVector[T]]): Rep[Int] = {
Console.println("catch vector_length")
implicit val mf = manifest[Int].asInstanceOf[Manifest[T]] //FIXME: generic types
VectorOperatorsRunner.densevector_length(self)
}
def sum[T](self: Rep[DenseVector[T]]): Rep[T] = {
Console.println("catch vector_sum")
implicit val mf = manifest[Int].asInstanceOf[Manifest[T]] //FIXME: generic types
implicit val af = VectorOperatorsRunner.intArith.asInstanceOf[VectorOperatorsRunner.Arith[T]] //FIXME: generic types
VectorOperatorsRunner.vector_sum(VectorOperatorsRunner.denseVecToInterface(self))
}
def max[T](self: Rep[DenseVector[T]]): Rep[T] = {
Console.println("catch vector_max")
implicit val mf = manifest[Int].asInstanceOf[Manifest[T]] //FIXME: generic types
implicit val af = implicitly[Ordering[Int]].asInstanceOf[Ordering[T]] //FIXME: generic types
implicit val bf = VectorOperatorsRunner.intHasMinMax.asInstanceOf[VectorOperatorsRunner.HasMinMax[T]] //FIXME: generic types
VectorOperatorsRunner.vector_max(VectorOperatorsRunner.denseVecToInterface(self))
}
def min[T](self: Rep[DenseVector[T]]): Rep[T] = {
Console.println("catch vector_min")
implicit val mf = manifest[Int].asInstanceOf[Manifest[T]] //FIXME: generic types
implicit val af = implicitly[Ordering[Int]].asInstanceOf[Ordering[T]] //FIXME: generic types
implicit val bf = VectorOperatorsRunner.intHasMinMax.asInstanceOf[VectorOperatorsRunner.HasMinMax[T]] //FIXME: generic types
VectorOperatorsRunner.vector_min(VectorOperatorsRunner.denseVecToInterface(self))
}
}
VectorOperatorsRunner.install(Macros)
VectorOperatorsRunner.program = x => myprog
// now run stuff....
VectorOperatorsRunner.VConstantPool = scala.collection.immutable.Vector.empty
VectorOperatorsRunner.generateScalaSource("Generated", new java.io.PrintWriter(System.out))
VectorOperatorsRunner.globalDefs.foreach(println)
val cst = VectorOperatorsRunner.VConstantPool
println("constants: "+cst)
//println("*** running execute ***")
//VectorOperatorsRunner.execute(Array())
println("*** running compileAndTest ***")
compileAndTest(VectorOperatorsRunner)
}
} | TiarkRompf/lancet | src/test/scala/lancet/advanced/test2-delite.scala | Scala | agpl-3.0 | 8,088 |
/*******************************************************************************
* Copyright (c) 2015-2018 Skymind, Inc.
*
* This program and the accompanying materials are made available under the
* terms of the Apache License, Version 2.0 which is available at
* https://www.apache.org/licenses/LICENSE-2.0.
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
* WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
* License for the specific language governing permissions and limitations
* under the License.
*
* SPDX-License-Identifier: Apache-2.0
******************************************************************************/
package org.deeplearning4j.scalnet.layers.core
trait WrapperLayer extends Layer {
def underlying: Layer
override def inputShape: List[Int] = underlying.inputShape
override def outputShape: List[Int] = underlying.outputShape
}
| RobAltena/deeplearning4j | scalnet/src/main/scala/org/deeplearning4j/scalnet/layers/core/WrapperLayer.scala | Scala | apache-2.0 | 1,012 |
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
package org.apache.samza.container
import java.util
import org.apache.samza.metrics.{Gauge, ReadableMetricsRegistry, MetricsRegistryMap, MetricsHelper}
class SamzaContainerMetrics(
val source: String = "unknown",
val registry: ReadableMetricsRegistry = new MetricsRegistryMap) extends MetricsHelper {
val commits = newCounter("commit-calls")
val windows = newCounter("window-calls")
val processes = newCounter("process-calls")
val sends = newCounter("send-calls")
val envelopes = newCounter("process-envelopes")
val nullEnvelopes = newCounter("process-null-envelopes")
val chooseNs = newTimer("choose-ns")
val windowNs = newTimer("window-ns")
val processNs = newTimer("process-ns")
val commitNs = newTimer("commit-ns")
val utilization = newGauge("event-loop-utilization", 0.0F)
val taskStoreRestorationMetrics: util.Map[TaskName, Gauge[Long]] = new util.HashMap[TaskName, Gauge[Long]]()
def addStoreRestorationGauge(taskName: TaskName, storeName: String) {
taskStoreRestorationMetrics.put(taskName, newGauge("%s-%s-restore-time" format(taskName.toString, storeName), -1L))
}
/**
* Creates or gets the disk usage gauge for the container and returns it.
*/
def createOrGetDiskUsageGauge(): Gauge[Long] = {
// Despite the name, this function appears to be idempotent. A more defensive approach would be
// to ensure idempotency at this level, e.g. via a CAS operation. Unfortunately, it appears that
// the mechanism to register a Gauge is hidden. An alternative would be to use a mutex to
// set ensure the gauge is created once.
newGauge("disk-usage", 0L)
}
}
| vjagadish/samza-clone | samza-core/src/main/scala/org/apache/samza/container/SamzaContainerMetrics.scala | Scala | apache-2.0 | 2,443 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.hive
import java.util
import org.apache.hadoop.hive.ql.udf.UDAFPercentile
import org.apache.hadoop.hive.serde2.io.DoubleWritable
import org.apache.hadoop.hive.serde2.objectinspector.{ObjectInspector, ObjectInspectorFactory, StructObjectInspector}
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory.ObjectInspectorOptions
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory
import org.apache.hadoop.io.LongWritable
import org.apache.spark.SparkFunSuite
import org.apache.spark.sql.{Row, TestUserClassUDT}
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.expressions.Literal
import org.apache.spark.sql.catalyst.util.{ArrayBasedMapData, GenericArrayData, MapData}
import org.apache.spark.sql.types._
class HiveInspectorSuite extends SparkFunSuite with HiveInspectors {
def unwrap(data: Any, oi: ObjectInspector): Any = {
val unwrapper = unwrapperFor(oi)
unwrapper(data)
}
test("Test wrap SettableStructObjectInspector") {
val udaf = new UDAFPercentile.PercentileLongEvaluator()
udaf.init()
udaf.iterate(new LongWritable(1), 0.1)
udaf.iterate(new LongWritable(1), 0.1)
val state = udaf.terminatePartial()
val soi = ObjectInspectorFactory.getReflectionObjectInspector(
classOf[UDAFPercentile.State],
ObjectInspectorOptions.JAVA).asInstanceOf[StructObjectInspector]
val a = unwrap(state, soi).asInstanceOf[InternalRow]
val dt = new StructType()
.add("counts", MapType(LongType, LongType))
.add("percentiles", ArrayType(DoubleType))
val b = wrap(a, soi, dt).asInstanceOf[UDAFPercentile.State]
val sfCounts = soi.getStructFieldRef("counts")
val sfPercentiles = soi.getStructFieldRef("percentiles")
assert(2 === soi.getStructFieldData(b, sfCounts)
.asInstanceOf[util.Map[LongWritable, LongWritable]]
.get(new LongWritable(1L))
.get())
assert(0.1 === soi.getStructFieldData(b, sfPercentiles)
.asInstanceOf[util.ArrayList[DoubleWritable]]
.get(0)
.get())
}
val data =
Literal(true) ::
Literal(null) ::
Literal(0.asInstanceOf[Byte]) ::
Literal(0.asInstanceOf[Short]) ::
Literal(0) ::
Literal(0.asInstanceOf[Long]) ::
Literal(0.asInstanceOf[Float]) ::
Literal(0.asInstanceOf[Double]) ::
Literal("0") ::
Literal(java.sql.Date.valueOf("2014-09-23")) ::
Literal(Decimal(BigDecimal("123.123"))) ::
Literal(new java.sql.Timestamp(123123)) ::
Literal(Array[Byte](1, 2, 3)) ::
Literal.create(Seq[Int](1, 2, 3), ArrayType(IntegerType)) ::
Literal.create(Map[Int, Int](1 -> 2, 2 -> 1), MapType(IntegerType, IntegerType)) ::
Literal.create(Row(1, 2.0d, 3.0f),
StructType(StructField("c1", IntegerType) ::
StructField("c2", DoubleType) ::
StructField("c3", FloatType) :: Nil)) ::
Nil
val row = data.map(_.eval(null))
val dataTypes = data.map(_.dataType)
def toWritableInspector(dataType: DataType): ObjectInspector = dataType match {
case ArrayType(tpe, _) =>
ObjectInspectorFactory.getStandardListObjectInspector(toWritableInspector(tpe))
case MapType(keyType, valueType, _) =>
ObjectInspectorFactory.getStandardMapObjectInspector(
toWritableInspector(keyType), toWritableInspector(valueType))
case StringType => PrimitiveObjectInspectorFactory.writableStringObjectInspector
case IntegerType => PrimitiveObjectInspectorFactory.writableIntObjectInspector
case DoubleType => PrimitiveObjectInspectorFactory.writableDoubleObjectInspector
case BooleanType => PrimitiveObjectInspectorFactory.writableBooleanObjectInspector
case LongType => PrimitiveObjectInspectorFactory.writableLongObjectInspector
case FloatType => PrimitiveObjectInspectorFactory.writableFloatObjectInspector
case ShortType => PrimitiveObjectInspectorFactory.writableShortObjectInspector
case ByteType => PrimitiveObjectInspectorFactory.writableByteObjectInspector
case NullType => PrimitiveObjectInspectorFactory.writableVoidObjectInspector
case BinaryType => PrimitiveObjectInspectorFactory.writableBinaryObjectInspector
case DateType => PrimitiveObjectInspectorFactory.writableDateObjectInspector
case TimestampType => PrimitiveObjectInspectorFactory.writableTimestampObjectInspector
case DecimalType() => PrimitiveObjectInspectorFactory.writableHiveDecimalObjectInspector
case StructType(fields) =>
ObjectInspectorFactory.getStandardStructObjectInspector(
java.util.Arrays.asList(fields.map(f => f.name) : _*),
java.util.Arrays.asList(fields.map(f => toWritableInspector(f.dataType)) : _*))
}
def checkDataType(dt1: Seq[DataType], dt2: Seq[DataType]): Unit = {
dt1.zip(dt2).foreach { case (dd1, dd2) =>
assert(dd1.getClass === dd2.getClass) // DecimalType doesn't has the default precision info
}
}
def checkValues(row1: Seq[Any], row2: Seq[Any]): Unit = {
row1.zip(row2).foreach { case (r1, r2) =>
checkValue(r1, r2)
}
}
def checkValues(row1: Seq[Any], row2: InternalRow, row2Schema: StructType): Unit = {
row1.zip(row2.toSeq(row2Schema)).foreach { case (r1, r2) =>
checkValue(r1, r2)
}
}
def checkValue(v1: Any, v2: Any): Unit = {
(v1, v2) match {
case (r1: Decimal, r2: Decimal) =>
// Ignore the Decimal precision
assert(r1.compare(r2) === 0)
case (r1: Array[Byte], r2: Array[Byte])
if r1 != null && r2 != null && r1.length == r2.length =>
r1.zip(r2).foreach { case (b1, b2) => assert(b1 === b2) }
// We don't support equality & ordering for map type, so skip it.
case (r1: MapData, r2: MapData) =>
case (r1, r2) => assert(r1 === r2)
}
}
test("oi => datatype => oi") {
val ois = dataTypes.map(toInspector)
checkDataType(ois.map(inspectorToDataType), dataTypes)
checkDataType(dataTypes.map(toWritableInspector).map(inspectorToDataType), dataTypes)
}
test("wrap / unwrap null, constant null and writables") {
val writableOIs = dataTypes.map(toWritableInspector)
val nullRow = data.map(d => null)
checkValues(nullRow, nullRow.zip(writableOIs).zip(dataTypes).map {
case ((d, oi), dt) => unwrap(wrap(d, oi, dt), oi)
})
// struct couldn't be constant, sweep it out
val constantExprs = data.filter(!_.dataType.isInstanceOf[StructType])
val constantTypes = constantExprs.map(_.dataType)
val constantData = constantExprs.map(_.eval())
val constantNullData = constantData.map(_ => null)
val constantWritableOIs = constantExprs.map(e => toWritableInspector(e.dataType))
val constantNullWritableOIs =
constantExprs.map(e => toInspector(Literal.create(null, e.dataType)))
checkValues(constantData, constantData.zip(constantWritableOIs).zip(constantTypes).map {
case ((d, oi), dt) => unwrap(wrap(d, oi, dt), oi)
})
checkValues(constantNullData, constantData.zip(constantNullWritableOIs).zip(constantTypes).map {
case ((d, oi), dt) => unwrap(wrap(d, oi, dt), oi)
})
checkValues(constantNullData, constantNullData.zip(constantWritableOIs).zip(constantTypes).map {
case ((d, oi), dt) => unwrap(wrap(d, oi, dt), oi)
})
}
test("wrap / unwrap primitive writable object inspector") {
val writableOIs = dataTypes.map(toWritableInspector)
checkValues(row, row.zip(writableOIs).zip(dataTypes).map {
case ((data, oi), dt) => unwrap(wrap(data, oi, dt), oi)
})
}
test("wrap / unwrap primitive java object inspector") {
val ois = dataTypes.map(toInspector)
checkValues(row, row.zip(ois).zip(dataTypes).map {
case ((data, oi), dt) => unwrap(wrap(data, oi, dt), oi)
})
}
test("wrap / unwrap UDT Type") {
val dt = new TestUserClassUDT
checkValue(1, unwrap(wrap(1, toInspector(dt), dt), toInspector(dt)))
checkValue(null, unwrap(wrap(null, toInspector(dt), dt), toInspector(dt)))
}
test("wrap / unwrap Struct Type") {
val dt = StructType(dataTypes.zipWithIndex.map {
case (t, idx) => StructField(s"c_$idx", t)
})
val inspector = toInspector(dt)
checkValues(
row,
unwrap(wrap(InternalRow.fromSeq(row), inspector, dt), inspector).asInstanceOf[InternalRow],
dt)
checkValue(null, unwrap(wrap(null, toInspector(dt), dt), toInspector(dt)))
}
test("wrap / unwrap Array Type") {
val dt = ArrayType(dataTypes(0))
val d = new GenericArrayData(Array(row(0), row(0)))
checkValue(d, unwrap(wrap(d, toInspector(dt), dt), toInspector(dt)))
checkValue(null, unwrap(wrap(null, toInspector(dt), dt), toInspector(dt)))
checkValue(d,
unwrap(wrap(d, toInspector(Literal.create(d, dt)), dt), toInspector(Literal.create(d, dt))))
checkValue(d,
unwrap(wrap(null, toInspector(Literal.create(d, dt)), dt),
toInspector(Literal.create(d, dt))))
}
test("wrap / unwrap Map Type") {
val dt = MapType(dataTypes(0), dataTypes(1))
val d = ArrayBasedMapData(Array(row(0)), Array(row(1)))
checkValue(d, unwrap(wrap(d, toInspector(dt), dt), toInspector(dt)))
checkValue(null, unwrap(wrap(null, toInspector(dt), dt), toInspector(dt)))
checkValue(d,
unwrap(wrap(d, toInspector(Literal.create(d, dt)), dt), toInspector(Literal.create(d, dt))))
checkValue(d,
unwrap(wrap(null, toInspector(Literal.create(d, dt)), dt),
toInspector(Literal.create(d, dt))))
}
}
| hvanhovell/spark | sql/hive/src/test/scala/org/apache/spark/sql/hive/HiveInspectorSuite.scala | Scala | apache-2.0 | 10,291 |
/*
* Scala.js (https://www.scala-js.org/)
*
* Copyright EPFL.
*
* Licensed under Apache License 2.0
* (https://www.apache.org/licenses/LICENSE-2.0).
*
* See the NOTICE file distributed with this work for
* additional information regarding copyright ownership.
*/
package org.scalajs.linker.backend.emitter
import scala.collection.mutable
import org.scalajs.ir.ClassKind
import org.scalajs.ir.Names._
import org.scalajs.ir.Trees._
import org.scalajs.ir.Types.Type
import org.scalajs.linker.interface.ModuleKind
import org.scalajs.linker.standard._
import org.scalajs.linker.standard.ModuleSet.ModuleID
import org.scalajs.linker.CollectionsCompat.MutableMapCompatOps
import EmitterNames._
private[emitter] final class KnowledgeGuardian(config: Emitter.Config) {
import KnowledgeGuardian._
private var specialInfo: SpecialInfo = _
private val classes = mutable.Map.empty[ClassName, Class]
/** Returns `true` if *all* caches should be invalidated.
*
* For global properties that are rarely changed and heavily used (such as
* isParentDataAccessed), we do not want to pay the price of the
* dependency graph, in terms of memory consumption and time spent
* maintaining it. It is a better trade-off to invalidate everything in
* the rare events where they do change.
*/
def update(moduleSet: ModuleSet): Boolean = {
val hasInlineableInit = computeHasInlineableInit(moduleSet)
val staticFieldMirrors = computeStaticFieldMirrors(moduleSet)
// Object is optional, because the module splitter might remove everything.
var objectClass: Option[LinkedClass] = None
var classClass: Option[LinkedClass] = None
val hijackedClasses = Iterable.newBuilder[LinkedClass]
// Update classes
for {
module <- moduleSet.modules
linkedClass <- module.classDefs
} {
updateClass(linkedClass, Some(module.id))
}
moduleSet.abstractClasses.foreach(updateClass(_, module = None))
def updateClass(linkedClass: LinkedClass, module: Option[ModuleID]): Unit = {
val className = linkedClass.className
val thisClassHasInlineableInit = hasInlineableInit(className)
val thisClassStaticFieldMirrors =
staticFieldMirrors.getOrElse(className, Map.empty)
classes.get(className).fold[Unit] {
// new class
classes.put(className,
new Class(linkedClass, thisClassHasInlineableInit, thisClassStaticFieldMirrors, module))
} { existingCls =>
existingCls.update(linkedClass, thisClassHasInlineableInit, thisClassStaticFieldMirrors, module)
}
linkedClass.className match {
case ClassClass =>
classClass = Some(linkedClass)
case ObjectClass =>
objectClass = Some(linkedClass)
case name if HijackedClasses(name) =>
hijackedClasses += linkedClass
case _ =>
}
}
// Garbage collection
classes.filterInPlace((_, cls) => cls.testAndResetIsAlive())
val invalidateAll = {
if (specialInfo == null) {
specialInfo = new SpecialInfo(objectClass, classClass, hijackedClasses.result())
false
} else {
specialInfo.update(objectClass, classClass, hijackedClasses.result())
}
}
if (invalidateAll) {
classes.valuesIterator.foreach(_.unregisterAll())
specialInfo.unregisterAll()
}
invalidateAll
}
private def computeHasInlineableInit(moduleSet: ModuleSet): Set[ClassName] = {
val scalaClassDefs = moduleSet.modules
.flatMap(_.classDefs)
.filter(_.kind.isClass)
val classesWithInstantiatedSubclasses = scalaClassDefs
.withFilter(_.hasInstances)
.flatMap(_.superClass)
.map(_.name)
.toSet
def enableInlineableInitFor(classDef: LinkedClass): Boolean = {
/* We can enable inlined init if all of the following apply:
* - It does not have any instantiated subclass
* - It has exactly one constructor
*
* By construction, this is always true for module classes.
*/
!classesWithInstantiatedSubclasses(classDef.className) && {
classDef.methods.count(
x => x.value.flags.namespace == MemberNamespace.Constructor) == 1
}
}
scalaClassDefs
.withFilter(enableInlineableInitFor(_))
.map(_.className)
.toSet
}
private def computeStaticFieldMirrors(
moduleSet: ModuleSet): Map[ClassName, Map[FieldName, List[String]]] = {
if (config.moduleKind != ModuleKind.NoModule) {
Map.empty
} else {
var result = Map.empty[ClassName, Map[FieldName, List[String]]]
for {
module <- moduleSet.modules
export <- module.topLevelExports
} {
export.tree match {
case TopLevelFieldExportDef(_, exportName, FieldIdent(fieldName)) =>
val className = export.owningClass
val mirrors = result.getOrElse(className, Map.empty)
val newExportNames = exportName :: mirrors.getOrElse(fieldName, Nil)
val newMirrors = mirrors.updated(fieldName, newExportNames)
result = result.updated(className, newMirrors)
case _ =>
}
}
result
}
}
abstract class KnowledgeAccessor extends GlobalKnowledge with Invalidatable {
/* In theory, a KnowledgeAccessor should *contain* a GlobalKnowledge, not
* *be* a GlobalKnowledge. We organize it that way to reduce memory
* footprint and pointer indirections.
*/
def isParentDataAccessed: Boolean =
specialInfo.askIsParentDataAccessed(this)
def isClassClassInstantiated: Boolean =
specialInfo.askIsClassClassInstantiated(this)
def isInterface(className: ClassName): Boolean =
classes(className).askIsInterface(this)
def getAllScalaClassFieldDefs(className: ClassName): List[(ClassName, List[AnyFieldDef])] =
classes(className).askAllScalaClassFieldDefs(this)
def hasInlineableInit(className: ClassName): Boolean =
classes(className).askHasInlineableInit(this)
def hasStoredSuperClass(className: ClassName): Boolean =
classes(className).askHasStoredSuperClass(this)
def hasInstances(className: ClassName): Boolean =
classes(className).askHasInstances(this)
def getJSClassCaptureTypes(className: ClassName): Option[List[Type]] =
classes(className).askJSClassCaptureTypes(this)
def getJSNativeLoadSpec(className: ClassName): Option[JSNativeLoadSpec] =
classes(className).askJSNativeLoadSpec(this)
def getJSNativeLoadSpec(className: ClassName, member: MethodName): JSNativeLoadSpec =
classes(className).askJSNativeLoadSpec(this, member)
def getSuperClassOfJSClass(className: ClassName): ClassName =
classes(className).askJSSuperClass(this)
def getJSClassFieldDefs(className: ClassName): List[AnyFieldDef] =
classes(className).askJSClassFieldDefs(this)
def getStaticFieldMirrors(className: ClassName, field: FieldName): List[String] =
classes(className).askStaticFieldMirrors(this, field)
def getModule(className: ClassName): ModuleID =
classes(className).askModule(this)
def methodsInRepresentativeClasses(): List[(MethodName, Set[ClassName])] =
specialInfo.askMethodsInRepresentativeClasses(this)
def methodsInObject(): List[Versioned[MethodDef]] =
specialInfo.askMethodsInObject(this)
def hijackedDescendants(className: ClassName): Set[ClassName] =
specialInfo.askHijackedDescendants(this).getOrElse(className, Set.empty)
def isAncestorOfHijackedClass(className: ClassName): Boolean =
specialInfo.askHijackedDescendants(this).contains(className)
}
private class Class(initClass: LinkedClass,
initHasInlineableInit: Boolean,
initStaticFieldMirrors: Map[FieldName, List[String]],
initModule: Option[ModuleID])
extends Unregisterable {
private val className = initClass.className
private var isAlive: Boolean = true
private var isInterface = computeIsInterface(initClass)
private var hasInlineableInit = initHasInlineableInit
private var hasStoredSuperClass = computeHasStoredSuperClass(initClass)
private var hasInstances = initClass.hasInstances
private var jsClassCaptureTypes = computeJSClassCaptureTypes(initClass)
private var jsNativeLoadSpec = computeJSNativeLoadSpec(initClass)
private var jsNativeMemberLoadSpecs = computeJSNativeMemberLoadSpecs(initClass)
private var superClass = computeSuperClass(initClass)
private var fieldDefs = computeFieldDefs(initClass)
private var staticFieldMirrors = initStaticFieldMirrors
private var module = initModule
private val isInterfaceAskers = mutable.Set.empty[Invalidatable]
private val hasInlineableInitAskers = mutable.Set.empty[Invalidatable]
private val hasStoredSuperClassAskers = mutable.Set.empty[Invalidatable]
private val hasInstancesAskers = mutable.Set.empty[Invalidatable]
private val jsClassCaptureTypesAskers = mutable.Set.empty[Invalidatable]
private val jsNativeLoadSpecAskers = mutable.Set.empty[Invalidatable]
private val jsNativeMemberLoadSpecsAskers = mutable.Set.empty[Invalidatable]
private val superClassAskers = mutable.Set.empty[Invalidatable]
private val fieldDefsAskers = mutable.Set.empty[Invalidatable]
private val staticFieldMirrorsAskers = mutable.Set.empty[Invalidatable]
private val moduleAskers = mutable.Set.empty[Invalidatable]
def update(linkedClass: LinkedClass, newHasInlineableInit: Boolean,
newStaticFieldMirrors: Map[FieldName, List[String]],
newModule: Option[ModuleID]): Unit = {
isAlive = true
val newIsInterface = computeIsInterface(linkedClass)
if (newIsInterface != isInterface) {
isInterface = newIsInterface
invalidateAskers(isInterfaceAskers)
}
if (newHasInlineableInit != hasInlineableInit) {
hasInlineableInit = newHasInlineableInit
invalidateAskers(hasInlineableInitAskers)
}
val newHasStoredSuperClass = computeHasStoredSuperClass(linkedClass)
if (newHasStoredSuperClass != hasStoredSuperClass) {
hasStoredSuperClass = newHasStoredSuperClass
invalidateAskers(hasStoredSuperClassAskers)
}
val newHasInstances = linkedClass.hasInstances
if (newHasInstances != hasInstances) {
hasInstances = newHasInstances
invalidateAskers(hasInstancesAskers)
}
val newJSClassCaptureTypes = computeJSClassCaptureTypes(linkedClass)
if (newJSClassCaptureTypes != jsClassCaptureTypes) {
jsClassCaptureTypes = newJSClassCaptureTypes
invalidateAskers(jsClassCaptureTypesAskers)
}
val newJSNativeLoadSpec = computeJSNativeLoadSpec(linkedClass)
if (newJSNativeLoadSpec != jsNativeLoadSpec) {
jsNativeLoadSpec = newJSNativeLoadSpec
invalidateAskers(jsNativeLoadSpecAskers)
}
val newJSNativeMemberLoadSpecs = computeJSNativeMemberLoadSpecs(linkedClass)
if (newJSNativeMemberLoadSpecs != jsNativeMemberLoadSpecs) {
jsNativeMemberLoadSpecs = newJSNativeMemberLoadSpecs
invalidateAskers(jsNativeMemberLoadSpecsAskers)
}
val newSuperClass = computeSuperClass(linkedClass)
if (newSuperClass != superClass) {
superClass = newSuperClass
invalidateAskers(superClassAskers)
}
val newFieldDefs = computeFieldDefs(linkedClass)
if (newFieldDefs != fieldDefs) {
fieldDefs = newFieldDefs
invalidateAskers(fieldDefsAskers)
}
if (newStaticFieldMirrors != staticFieldMirrors) {
staticFieldMirrors = newStaticFieldMirrors
invalidateAskers(staticFieldMirrorsAskers)
}
if (newModule != module) {
module = newModule
invalidateAskers(moduleAskers)
}
}
private def computeIsInterface(linkedClass: LinkedClass): Boolean =
linkedClass.kind == ClassKind.Interface
private def computeHasStoredSuperClass(linkedClass: LinkedClass): Boolean =
linkedClass.jsSuperClass.isDefined
private def computeJSClassCaptureTypes(linkedClass: LinkedClass): Option[List[Type]] =
linkedClass.jsClassCaptures.map(_.map(_.ptpe))
private def computeJSNativeLoadSpec(linkedClass: LinkedClass): Option[JSNativeLoadSpec] =
linkedClass.jsNativeLoadSpec
private def computeJSNativeMemberLoadSpecs(
linkedClass: LinkedClass): Map[MethodName, JSNativeLoadSpec] = {
if (linkedClass.jsNativeMembers.isEmpty) {
// Fast path
Map.empty
} else {
linkedClass.jsNativeMembers
.map(m => m.name.name -> m.jsNativeLoadSpec)
.toMap
}
}
private def computeSuperClass(linkedClass: LinkedClass): ClassName =
linkedClass.superClass.fold[ClassName](null.asInstanceOf[ClassName])(_.name)
private def computeFieldDefs(linkedClass: LinkedClass): List[AnyFieldDef] =
linkedClass.fields
def testAndResetIsAlive(): Boolean = {
val result = isAlive
isAlive = false
result
}
def askIsInterface(invalidatable: Invalidatable): Boolean = {
invalidatable.registeredTo(this)
isInterfaceAskers += invalidatable
isInterface
}
def askAllScalaClassFieldDefs(
invalidatable: Invalidatable): List[(ClassName, List[AnyFieldDef])] = {
invalidatable.registeredTo(this)
superClassAskers += invalidatable
fieldDefsAskers += invalidatable
val inheritedFieldDefs =
if (superClass == null) Nil
else classes(superClass).askAllScalaClassFieldDefs(invalidatable)
inheritedFieldDefs :+ (className -> fieldDefs)
}
def askHasInlineableInit(invalidatable: Invalidatable): Boolean = {
invalidatable.registeredTo(this)
hasInlineableInitAskers += invalidatable
hasInlineableInit
}
def askHasStoredSuperClass(invalidatable: Invalidatable): Boolean = {
invalidatable.registeredTo(this)
hasStoredSuperClassAskers += invalidatable
hasStoredSuperClass
}
def askHasInstances(invalidatable: Invalidatable): Boolean = {
invalidatable.registeredTo(this)
hasInstancesAskers += invalidatable
hasInstances
}
def askJSClassCaptureTypes(invalidatable: Invalidatable): Option[List[Type]] = {
invalidatable.registeredTo(this)
jsClassCaptureTypesAskers += invalidatable
jsClassCaptureTypes
}
def askJSNativeLoadSpec(invalidatable: Invalidatable): Option[JSNativeLoadSpec] = {
invalidatable.registeredTo(this)
jsNativeLoadSpecAskers += invalidatable
jsNativeLoadSpec
}
def askJSNativeLoadSpec(invalidatable: Invalidatable, member: MethodName): JSNativeLoadSpec = {
invalidatable.registeredTo(this)
jsNativeMemberLoadSpecsAskers += invalidatable
jsNativeMemberLoadSpecs(member)
}
def askJSSuperClass(invalidatable: Invalidatable): ClassName = {
invalidatable.registeredTo(this)
superClassAskers += invalidatable
superClass
}
def askJSClassFieldDefs(invalidatable: Invalidatable): List[AnyFieldDef] = {
invalidatable.registeredTo(this)
fieldDefsAskers += invalidatable
fieldDefs
}
def askStaticFieldMirrors(invalidatable: Invalidatable,
field: FieldName): List[String] = {
invalidatable.registeredTo(this)
staticFieldMirrorsAskers += invalidatable
staticFieldMirrors.getOrElse(field, Nil)
}
def askModule(invalidatable: Invalidatable): ModuleID = {
invalidatable.registeredTo(this)
moduleAskers += invalidatable
module.getOrElse {
throw new AssertionError(
"trying to get module of abstract class " + className.nameString)
}
}
def unregister(invalidatable: Invalidatable): Unit = {
isInterfaceAskers -= invalidatable
hasInlineableInitAskers -= invalidatable
hasStoredSuperClassAskers -= invalidatable
hasInstancesAskers -= invalidatable
jsClassCaptureTypesAskers -= invalidatable
jsNativeLoadSpecAskers -= invalidatable
jsNativeMemberLoadSpecsAskers -= invalidatable
superClassAskers -= invalidatable
fieldDefsAskers -= invalidatable
staticFieldMirrorsAskers -= invalidatable
moduleAskers -= invalidatable
}
/** Call this when we invalidate all caches. */
def unregisterAll(): Unit = {
isInterfaceAskers.clear()
hasInlineableInitAskers.clear()
hasStoredSuperClassAskers.clear()
hasInstancesAskers.clear()
jsClassCaptureTypesAskers.clear()
jsNativeLoadSpecAskers.clear()
jsNativeMemberLoadSpecsAskers.clear()
superClassAskers.clear()
fieldDefsAskers.clear()
staticFieldMirrorsAskers.clear()
moduleAskers.clear()
}
}
private class SpecialInfo(initObjectClass: Option[LinkedClass],
initClassClass: Option[LinkedClass],
initHijackedClasses: Iterable[LinkedClass]) extends Unregisterable {
private var isClassClassInstantiated =
computeIsClassClassInstantiated(initClassClass)
private var isParentDataAccessed =
computeIsParentDataAccessed(initClassClass)
private var methodsInRepresentativeClasses =
computeMethodsInRepresentativeClasses(initObjectClass, initHijackedClasses)
private var methodsInObject =
computeMethodsInObject(initObjectClass)
private var hijackedDescendants =
computeHijackedDescendants(initHijackedClasses)
private val isClassClassInstantiatedAskers = mutable.Set.empty[Invalidatable]
private val methodsInRepresentativeClassesAskers = mutable.Set.empty[Invalidatable]
private val methodsInObjectAskers = mutable.Set.empty[Invalidatable]
def update(objectClass: Option[LinkedClass], classClass: Option[LinkedClass],
hijackedClasses: Iterable[LinkedClass]): Boolean = {
var invalidateAll = false
val newIsClassClassInstantiated = computeIsClassClassInstantiated(classClass)
if (newIsClassClassInstantiated != isClassClassInstantiated) {
isClassClassInstantiated = newIsClassClassInstantiated
invalidateAskers(isClassClassInstantiatedAskers)
}
val newIsParentDataAccessed = computeIsParentDataAccessed(classClass)
if (newIsParentDataAccessed != isParentDataAccessed) {
isParentDataAccessed = newIsParentDataAccessed
invalidateAll = true
}
val newMethodsInRepresentativeClasses =
computeMethodsInRepresentativeClasses(objectClass, hijackedClasses)
if (newMethodsInRepresentativeClasses != methodsInRepresentativeClasses) {
methodsInRepresentativeClasses = newMethodsInRepresentativeClasses
invalidateAskers(methodsInRepresentativeClassesAskers)
}
/* Usage-sites of methodsInObject never cache.
* Therefore, we do not bother comparing (which is expensive), but simply
* invalidate.
*/
methodsInObject = computeMethodsInObject(objectClass)
invalidateAskers(methodsInObjectAskers)
val newHijackedDescendants = computeHijackedDescendants(hijackedClasses)
if (newHijackedDescendants != hijackedDescendants) {
hijackedDescendants = newHijackedDescendants
invalidateAll = true
}
invalidateAll
}
private def computeIsClassClassInstantiated(classClass: Option[LinkedClass]): Boolean =
classClass.exists(_.hasInstances)
private def computeIsParentDataAccessed(classClass: Option[LinkedClass]): Boolean = {
def methodExists(linkedClass: LinkedClass, methodName: MethodName): Boolean = {
linkedClass.methods.exists { m =>
m.value.flags.namespace == MemberNamespace.Public &&
m.value.methodName == methodName
}
}
classClass.exists(methodExists(_, getSuperclassMethodName))
}
private def computeMethodsInRepresentativeClasses(objectClass: Option[LinkedClass],
hijackedClasses: Iterable[LinkedClass]): List[(MethodName, Set[ClassName])] = {
val representativeClasses =
objectClass.iterator ++ hijackedClasses.iterator
val result = mutable.HashMap.empty[MethodName, mutable.Set[ClassName]]
for {
representativeClass <- representativeClasses
method <- representativeClass.methods
if method.value.flags.namespace == MemberNamespace.Public
} {
result.getOrElseUpdate(method.value.methodName, mutable.Set.empty) +=
representativeClass.className
}
result.toList.sortBy(_._1.nameString).map(kv => (kv._1, kv._2.toSet))
}
private def computeMethodsInObject(objectClass: Option[LinkedClass]): List[Versioned[MethodDef]] = {
objectClass.toList.flatMap(
_.methods.filter(_.value.flags.namespace == MemberNamespace.Public))
}
private def computeHijackedDescendants(
hijackedClasses: Iterable[LinkedClass]): Map[ClassName, Set[ClassName]] = {
val pairs = for {
hijackedClass <- hijackedClasses
ancestor <- hijackedClass.ancestors
if ancestor != hijackedClass.className
} yield {
(ancestor, hijackedClass)
}
for {
(ancestor, pairs) <- pairs.groupBy(_._1)
} yield {
(ancestor, pairs.map(_._2.className).toSet)
}
}
def askIsClassClassInstantiated(invalidatable: Invalidatable): Boolean = {
invalidatable.registeredTo(this)
isClassClassInstantiatedAskers += invalidatable
isClassClassInstantiated
}
def askIsParentDataAccessed(invalidatable: Invalidatable): Boolean =
isParentDataAccessed
def askMethodsInRepresentativeClasses(
invalidatable: Invalidatable): List[(MethodName, Set[ClassName])] = {
invalidatable.registeredTo(this)
methodsInRepresentativeClassesAskers += invalidatable
methodsInRepresentativeClasses
}
def askMethodsInObject(invalidatable: Invalidatable): List[Versioned[MethodDef]] = {
invalidatable.registeredTo(this)
methodsInObjectAskers += invalidatable
methodsInObject
}
def askHijackedDescendants(
invalidatable: Invalidatable): Map[ClassName, Set[ClassName]] = {
hijackedDescendants
}
def unregister(invalidatable: Invalidatable): Unit = {
isClassClassInstantiatedAskers -= invalidatable
methodsInRepresentativeClassesAskers -= invalidatable
methodsInObjectAskers -= invalidatable
}
/** Call this when we invalidate all caches. */
def unregisterAll(): Unit = {
isClassClassInstantiatedAskers.clear()
methodsInRepresentativeClassesAskers.clear()
methodsInObjectAskers.clear()
}
}
private def invalidateAskers(askers: mutable.Set[Invalidatable]): Unit = {
/* Calling `invalidate` cause the `Invalidatable` to call `unregister()` in
* this class, which will mutate the `askers` set. Therefore, we cannot
* directly iterate over `askers`, and need to take a snapshot instead.
*/
val snapshot = askers.toSeq
askers.clear()
snapshot.foreach(_.invalidate())
}
}
private[emitter] object KnowledgeGuardian {
private trait Unregisterable {
def unregister(invalidatable: Invalidatable): Unit
}
trait Invalidatable {
private val _registeredTo = mutable.Set.empty[Unregisterable]
private[KnowledgeGuardian] def registeredTo(
unregisterable: Unregisterable): Unit = {
_registeredTo += unregisterable
}
/** To be overridden to perform subclass-specific invalidation.
*
* All overrides should call the default implementation with `super` so
* that this `Invalidatable` is unregistered from the dependency graph.
*/
def invalidate(): Unit = {
_registeredTo.foreach(_.unregister(this))
_registeredTo.clear()
}
}
}
| scala-js/scala-js | linker/shared/src/main/scala/org/scalajs/linker/backend/emitter/KnowledgeGuardian.scala | Scala | apache-2.0 | 23,844 |
import scala.io.Source
import java.io.File
import scala.collection.mutable
object Main {
def main(args:Array[String]) {
val input = Source.fromFile(new File(args(0)))
val parsedLines = for(line <- input.getLines) yield BIParser.parse(line)
val threadsToEntries = entryMap(parsedLines)
for((thread,entries) <- threadsToEntries) {
println(thread.name)
val summaryEntries = Summary.summarise(entries)
summaryEntries.foreach { e =>
println(e.name +" times=" + e.count+" totalTime="+ e.totalTime)
}
println
println
}
}
// Converts stream of timed to threads mapped to Entries for that thread
def entryMap(parsedLines:Iterator[Timed]) = {
var thread :ThreadEntry = null
val threads: mutable.Map[ThreadEntry,List[Entry]] = mutable.Map()
for(e <- parsedLines) {
e match {
case te : ThreadEntry => {
thread = te
threads.put(thread,List())
}
case e : Entry => threads put(thread,e :: threads(thread))
}
}
val inOrder = for((k,v) <- threads) yield (k,v.reverse)
inOrder.toMap
}
} | PaulKeeble/BIProfileSummary | src/main/scala/Main.scala | Scala | gpl-2.0 | 1,212 |
import scala.reflect.macros.blackbox.Context
import language.experimental.macros
object MyAttachment
object Macros {
def impl(c: Context) = {
import c.universe._
import internal._
val ident = updateAttachment(Ident(TermName("bar")), MyAttachment)
assert(attachments(ident).get[MyAttachment.type].isDefined, attachments(ident))
val typed = c.typecheck(ident)
assert(attachments(typed).get[MyAttachment.type].isDefined, attachments(typed))
c.Expr[Int](typed)
}
def foo: Int = macro impl
}
| scala/scala | test/files/pos/attachments-typed-ident/Impls_1.scala | Scala | apache-2.0 | 524 |
/**
* Copyright: Copyright (C) 2016, ATS Advanced Telematic Systems GmbH
* License: MPL-2.0
*/
package org.genivi.sota.data
import cats.{Eq, Show}
import eu.timepit.refined.api.Validate
import com.typesafe.config.ConfigFactory
case class PackageId(name : PackageId.Name,
version: PackageId.Version) {
override def toString(): String = s"PackageId(${name.get}, ${version.get})"
def mkString: String = s"${name.get}-${version.get}"
}
/**
* A (software) package has a notion of id which is shared between the
* core and the resolver.
*/
object PackageId {
import eu.timepit.refined.api.Refined
/**
* A valid package id consists of two refined strings, the first
* being the name of the package and the second being the
* version. See the predicate below for what constitutes as valid.
*
* @see [[https://github.com/fthomas/refined]]
*/
case class ValidName()
case class ValidVersion()
type Name = Refined[String, ValidName]
type Version = Refined[String, ValidVersion]
implicit val validPackageName: Validate.Plain[String, ValidName] =
Validate.fromPredicate(
s => s.length > 0 && s.length <= 100
&& s.forall(c => c.isLetter || c.isDigit || List('-', '+', '.', '_').contains(c)),
s => s"$s: isn't a valid package name (between 1 and 100 character long alpha numeric string)",
ValidName()
)
implicit val validPackageVersion: Validate.Plain[String, ValidVersion] = {
val packageFormat = ConfigFactory.load().getString("packages.versionFormat")
Validate.fromPredicate(
_.matches(packageFormat),
s => s"Invalid version format ($s) valid is: $packageFormat",
ValidVersion()
)
}
/**
* Use the underlying (string) ordering, show and equality for
* package ids.
*/
implicit val PackageIdOrdering: Ordering[PackageId] = new Ordering[PackageId] {
override def compare(id1: PackageId, id2: PackageId): Int =
id1.name.get + id1.version.get compare id2.name.get + id2.version.get
}
implicit val showInstance: Show[PackageId] =
Show.show(id => s"${id.name.get}-${id.version.get}")
implicit val eqInstance: Eq[PackageId] =
Eq.fromUniversalEquals[PackageId]
}
| PDXostc/rvi_sota_server | common-data/src/main/scala/org/genivi/sota/data/PackageId.scala | Scala | mpl-2.0 | 2,252 |
import sbt._
import Keys._
object BuildSettings {
val buildSettings = Defaults.defaultSettings ++ Seq(
organization := "org.scala-lang.macroparadise",
version := "1.0.0",
scalacOptions ++= Seq(),
scalaVersion := "2.11.0-SNAPSHOT",
resolvers += Resolver.sonatypeRepo("snapshots"),
addCompilerPlugin("org.scala-lang.plugins" % "macro-paradise" % "2.0.0-SNAPSHOT" cross CrossVersion.full)
)
}
object MyBuild extends Build {
import BuildSettings._
lazy val root: Project = Project(
"root",
file("."),
settings = buildSettings ++ Seq(
run <<= run in Compile in core
)
) aggregate(macros, core)
lazy val macros: Project = Project(
"macros",
file("macros"),
settings = buildSettings ++ Seq(
libraryDependencies <+= (scalaVersion)("org.scala-lang" % "scala-reflect" % _))
)
lazy val core: Project = Project(
"core",
file("core"),
settings = buildSettings
) dependsOn(macros)
}
| pascohen/ScalaAnnotationsMacro | project/Build.scala | Scala | apache-2.0 | 968 |
package com.socrata.datacoordinator.resources
import com.rojoma.json.v3.util.JsonUtil
import com.socrata.datacoordinator.id.DatasetId
import com.socrata.datacoordinator.service.ServiceUtil._
import com.socrata.datacoordinator.truth.metadata.RollupInfo
import com.socrata.http.server.HttpRequest
import com.socrata.http.server.responses._
import com.socrata.http.server.implicits._
case class DatasetRollupResource(datasetId: DatasetId,
getRollups: DatasetId => Option[Seq[RollupInfo]],
formatDatasetId: DatasetId => String)
extends ErrorHandlingSodaResource(formatDatasetId) {
override val log = org.slf4j.LoggerFactory.getLogger(classOf[DatasetRollupResource])
override def get = { (req: HttpRequest) =>
getRollups(datasetId) match {
case None => notFoundError(datasetId)
case Some(rollups) => OK ~> Write(JsonContentType) { w =>
JsonUtil.writeJson(w, rollups.map { r => r.unanchored })
}}
}
} | socrata-platform/data-coordinator | coordinator/src/main/scala/com/socrata/datacoordinator/resources/DatasetRollupResource.scala | Scala | apache-2.0 | 1,004 |
/**
* User: Aditya Vishwakarma
* Date: 06/11/13
* Time: 4:03 PM
* Note:
*/
import org.specs2._
class Chapter6tests extends Specification {
import Chapter6.State._
def is = s2"""
Test for Vendor Machine
series of (Coin, Turn)*3 $a1"
"""
val machine1 = Machine(true,10, 10)
val machine2 = Machine(false,10, 10)
def a1 = {
val inputs:List[Input] = List.fill(3)(Coin::Turn::Nil).flatten
val t = simulateMachine(inputs)
val (finalMachine,_) = t run machine1
finalMachine mustEqual Machine(true, 7, 13)
}
}
| adityav/fpPractice | src/test/scala/Chapter6tests.scala | Scala | gpl-3.0 | 550 |
package lila.setup
import chess.Clock
import chess.format.FEN
import chess.variant.{ FromPosition, Variant }
import lila.game.{ Game, IdGenerator, Player, Pov, Source }
import lila.lobby.Color
import lila.user.User
final case class ApiAiConfig(
variant: Variant,
clock: Option[Clock.Config],
daysO: Option[Int],
color: Color,
level: Int,
fen: Option[FEN] = None
) extends Config
with Positional {
val strictFen = false
val days = ~daysO
val increment = clock.??(_.increment.roundSeconds)
val time = clock.??(_.limit.roundSeconds / 60)
val timeMode =
if (clock.isDefined) TimeMode.RealTime
else if (daysO.isDefined) TimeMode.Correspondence
else TimeMode.Unlimited
private def game(user: Option[User])(implicit idGenerator: IdGenerator): Fu[Game] =
fenGame { chessGame =>
val perfPicker = lila.game.PerfPicker.mainOrDefault(
chess.Speed(chessGame.clock.map(_.config)),
chessGame.situation.board.variant,
makeDaysPerTurn
)
Game
.make(
chess = chessGame,
whitePlayer = creatorColor.fold(
Player.make(chess.White, user, perfPicker),
Player.make(chess.White, level.some)
),
blackPlayer = creatorColor.fold(
Player.make(chess.Black, level.some),
Player.make(chess.Black, user, perfPicker)
),
mode = chess.Mode.Casual,
source = if (chessGame.board.variant.fromPosition) Source.Position else Source.Ai,
daysPerTurn = makeDaysPerTurn,
pgnImport = None
)
.withUniqueId
}.dmap(_.start)
def pov(user: Option[User])(implicit idGenerator: IdGenerator) = game(user) dmap { Pov(_, creatorColor) }
def autoVariant =
if (variant.standard && fen.exists(!_.initial)) copy(variant = FromPosition)
else this
}
object ApiAiConfig extends BaseConfig {
// lazy val clockLimitSeconds: Set[Int] = Set(0, 15, 30, 45, 60, 90) ++ (2 to 180).view.map(60 *).toSet
def from(
l: Int,
v: Option[String],
cl: Option[Clock.Config],
d: Option[Int],
c: Option[String],
pos: Option[FEN]
) =
new ApiAiConfig(
variant = chess.variant.Variant.orDefault(~v),
clock = cl,
daysO = d,
color = Color.orDefault(~c),
level = l,
fen = pos
).autoVariant
}
| luanlv/lila | modules/setup/src/main/ApiAiConfig.scala | Scala | mit | 2,386 |
package org.talkingpuffin.ui
import java.awt.event.KeyEvent
import javax.swing.{JToolBar, JFrame, SwingUtilities}
import scala.swing.{Action}
import org.talkingpuffin.Session
import org.talkingpuffin.state.{PrefKeys, GlobalPrefs}
import org.talkingpuffin.ui.filter.FiltersDialog
import util.{ToolBarHelpers}
/**
* Status pane tool bar
*/
class StatusToolBar(val session: Session, tweetsProvider: BaseProvider, filtersDialog: FiltersDialog,
val statusPane: StatusPane, showWordFrequencies: => Unit, clearTweets: (Boolean) => Unit,
showMaxColumns: (Boolean) => Unit) extends {
val pane = statusPane
} with JToolBar with ToolBarHelpers {
var tweetDetailPanel: TweetDetailPanel = _
val showFiltersAction = new Action("Filter") {
toolTip = "Set filters for this stream"
mnemonic = KeyEvent.VK_F
def apply = {
filtersDialog.peer.setLocationRelativeTo(SwingUtilities.getAncestorOfClass(classOf[JFrame],
statusPane.peer))
filtersDialog.visible = true
}
}
val clearAction = new Action("Clr") {
toolTip = "Removes all tweets (except filtered-out ones) from the view"
mnemonic = KeyEvent.VK_C
def apply = clearAndOptionallyLoad(false)
}
val clearAllAction = new Action("Clr All") {
toolTip = "Removes all tweets (including filtered-out ones) from the view"
mnemonic = KeyEvent.VK_L
def apply = clearAndOptionallyLoad(true)
}
val loadNewAction = new Action("Load New") {
toolTip = "Loads any new items"
mnemonic = KeyEvent.VK_N
def apply = tweetsProvider.loadContinually()
}
val last200Action = new Action("Load Max") {
toolTip = "Fetches all available (≈800) items"
mnemonic = KeyEvent.VK_A
def apply = tweetsProvider.loadAllAvailable
}
val wordsAction = new Action("Words") {
toolTip = "Shows word frequencies"
mnemonic = KeyEvent.VK_W
def apply = showWordFrequencies
}
val showMinColsAction = new Action("Min") {
toolTip = "Show the minimum number of columns"
mnemonic = KeyEvent.VK_M
def apply = showMaxColumns(false)
}
val showMaxColsAction = new Action("Max") {
toolTip = "Show the maximum number of columns"
mnemonic = KeyEvent.VK_X
def apply = showMaxColumns(true)
}
setFloatable(false)
addComponentsToToolBar
private def addComponentsToToolBar {
aa(showFiltersAction, clearAction, clearAllAction, loadNewAction)
aa(last200Action, wordsAction)
aa(showMinColsAction, showMaxColsAction)
addSeparator
ac(statusPane.dockedButton, (new CommonToolbarButtons).createDetailsButton(tweetDetailPanel))
}
private def clearAndOptionallyLoad(all: Boolean) {
clearTweets(all)
if (GlobalPrefs.isOn(PrefKeys.NEW_AFTER_CLEAR))
tweetsProvider.loadContinually()
}
}
| dcbriccetti/talking-puffin | desktop/src/main/scala/org/talkingpuffin/ui/StatusToolBar.scala | Scala | mit | 2,790 |
package biology.fish
import grizzled.slf4j._
import io.config.ConfigMappings._
import io.config.LarvaConfig
import locals._
import maths.{RandomNumberGenerator}
import org.apache.commons.math3.distribution.NormalDistribution
import com.github.nscala_time.time.Imports._
import physical.GeoCoordinate
import biology._
import biology.swimming._
import utilities.Time
import scala.collection.mutable.ArrayBuffer
import java.util.UUID.randomUUID
class FishFactory(config: LarvaConfig) extends LarvaeFactory with Logging {
val pldDistribution = new PelagicLarvalDuration(config.pelagicLarvalDuration)
val horizontalSwimming = config.swimming match {
case Some(swim) => {
Some(
new HorizontalSwimming(
swim.ability.getOrElse("") match {
case "directed" => Directed
case "undirected" => Undirected
case _ => Passive
},
swim.strategy match {
case "one" => StrategyOne
case "two" => StrategyTwo
case "three" => StrategyThree
},
swim.criticalSwimmingSpeed.getOrElse(0),
swim.inSituSwimmingPotential.getOrElse(1),
swim.endurance.getOrElse(1),
swim.reynoldsEffect.getOrElse(false),
swim.hatchSwimmingSpeed.getOrElse(0)
)
)
}
case None => None
}
val dielMigration = config.dielProbabilities match {
case Some(dvm) => Some(new DielMigration(dvm.depths, dvm.day, dvm.night))
case None => None
}
val ovmMigration = config.ovmProbabilities match {
case Some(ovm) =>
Some(new OntogeneticMigration(config.ovmProbabilities.get))
case None => None
}
val hatchingDistribution = new NormalDistribution(
Time.convertDaysToSeconds(config.ontogeny.hatching),
Constants.SecondsInDay * 0.5
)
val preflexionDistribution = new NormalDistribution(
Time.convertDaysToSeconds(config.ontogeny.preflexion),
Constants.SecondsInDay * 0.5
)
val flexionDistribution = new NormalDistribution(
Time.convertDaysToSeconds(config.ontogeny.flexion),
Constants.SecondsInDay * 0.5
)
val postflexionDistribution = new NormalDistribution(
Time.convertDaysToSeconds(config.ontogeny.postflexion),
Constants.SecondsInDay * 0.5
)
var larvaeCount: Int = 0
def create(site: SpawningLocation, time: LocalDateTime): Larva = {
val pld = pldDistribution.getPld()
// Handles case of demersal eggs
val hatching = hatchingDistribution.sample().toInt
val preflexion = config.ontogeny.preflexion match {
case 0 => 0
case _ => preflexionDistribution.sample().toInt
}
val flexion = flexionDistribution.sample().toInt
val postflexion = postflexionDistribution.sample().toInt
val birthLocation = new GeoCoordinate(
site.location.latitude,
site.location.longitude,
RandomNumberGenerator.get(0, site.location.depth)
)
def getNonSettlementPeriod(): Int = {
val settlement = config.pelagicLarvalDuration.nonSettlementPeriod
if (settlement < pld) {
Time.convertDaysToSeconds(settlement)
} else {
pld
}
}
val nonSettlementPeriod = getNonSettlementPeriod()
val fish = new Fish(
randomUUID.toString(),
pld,
pld,
new Birthplace(site.title, site.reefId, birthLocation),
time,
hatching,
preflexion,
flexion,
postflexion,
ovmMigration,
dielMigration,
horizontalSwimming,
nonSettlementPeriod
)
//info("Just created the fish: " + fish)
fish
}
}
| shawes/zissou | src/main/scala/biology/fish/FishFactory.scala | Scala | mit | 3,605 |
object Version {
val scalaTestVersion = "3.0.1"
val scalacheckVersion = "1.13.4"
val jtsVersion = "1.13"
val proj4jVersion = "0.1.0"
val sprayJsonVersion = "1.3.3"
val dbfVersion = "0.4.0"
}
| jmarin/scale | project/Version.scala | Scala | apache-2.0 | 203 |
package scala.tasty.internal.dotc
package util
import language.implicitConversions
/** Position format in little endian:
* Start: unsigned 26 Bits (works for source files up to 64M)
* End: unsigned 26 Bits
* Point: unsigned 12 Bits relative to start
* NoPosition encoded as -1L (this is a normally invalid position
* because point would lie beyond end.
*/
object Positions {
private val StartEndBits = 26
val StartEndMask: Long = (1L << StartEndBits) - 1
private val SyntheticPointDelta = (1 << (64 - StartEndBits * 2)) - 1
/** The maximal representable offset in a position */
val MaxOffset = StartEndMask
/** Convert offset `x` to an integer by sign extending the original
* field of `StartEndBits` width.
*/
def offsetToInt(x: Int) =
x << (32 - StartEndBits) >> (32 - StartEndBits)
/** A position indicates a range between a start offset and an end offset.
* Positions can be synthetic or source-derived. A source-derived position
* has in addition a point lies somewhere between start and end. The point
* is roughly where the ^ would go if an error was diagnosed at that position.
* All quantities are encoded opaquely in a Long.
*/
class Position(val coords: Long) extends AnyVal {
/** Is this position different from NoPosition? */
def exists = this != NoPosition
/** The start of this position. */
def start: Int = {
assert(exists)
(coords & StartEndMask).toInt
}
/** The end of this position */
def end: Int = {
assert(exists)
((coords >>> StartEndBits) & StartEndMask).toInt
}
/** The point of this position, returns start for synthetic positions */
def point: Int = {
assert(exists)
val poff = pointDelta
if (poff == SyntheticPointDelta) start else start + poff
}
/** The difference between point and start in this position */
def pointDelta =
(coords >>> (StartEndBits * 2)).toInt
def orElse(that: Position) =
if (this.exists) this else that
/** The union of two positions. This is the least range that encloses
* both positions. It is always a synthetic position.
*/
def union(that: Position) =
if (!this.exists) that
else if (!that.exists) this
else Position(this.start min that.start, this.end max that.end, this.point)
/** Does the range of this position contain the one of that position? */
def contains(that: Position): Boolean =
!that.exists || exists && (start <= that.start && end >= that.end)
/** Is this position synthetic? */
def isSynthetic = pointDelta == SyntheticPointDelta
/** Is this position source-derived? */
def isSourceDerived = !isSynthetic
/** A position where all components are shifted by a given `offset`
* relative to this position.
*/
def shift(offset: Int) =
if (exists) fromOffsets(start + offset, end + offset, pointDelta)
else this
/** The zero-extent position with start and end at the point of this position */
def focus = if (exists) Position(point) else NoPosition
/** The zero-extent position with start and end at the start of this position */
def startPos = if (exists) Position(start) else NoPosition
/** The zero-extent position with start and end at the end of this position */
def endPos = if (exists) Position(end) else NoPosition
/** A copy of this position with a different start */
def withStart(start: Int) =
fromOffsets(start, this.end, if (isSynthetic) SyntheticPointDelta else this.point - start)
/** A copy of this position with a different end */
def withEnd(end: Int) = fromOffsets(this.start, end, pointDelta)
/** A copy of this position with a different point */
def withPoint(point: Int) = fromOffsets(this.start, this.end, point - this.start)
/** A synthetic copy of this position */
def toSynthetic = if (isSynthetic) this else Position(start, end)
override def toString = {
val (left, right) = if (isSynthetic) ("<", ">") else ("[", "]")
if (exists)
s"$left$start..${if (point == start) "" else s"$point.."}$end$right"
else
s"${left}no position${right}"
}
}
private def fromOffsets(start: Int, end: Int, pointDelta: Int) = {
//assert(start <= end || start == 1 && end == 0, s"$start..$end")
new Position(
(start & StartEndMask).toLong |
((end & StartEndMask).toLong << StartEndBits) |
(pointDelta.toLong << (StartEndBits * 2)))
}
/** A synthetic position with given start and end */
def Position(start: Int, end: Int): Position = {
val pos = fromOffsets(start, end, SyntheticPointDelta)
assert(pos.isSynthetic)
pos
}
/** A source-derived position with given start, end, and point delta */
def Position(start: Int, end: Int, point: Int): Position = {
val pointDelta = (point - start) max 0
val pos = fromOffsets(start, end, if (pointDelta >= SyntheticPointDelta) 0 else pointDelta)
assert(pos.isSourceDerived)
pos
}
/** A synthetic zero-extent position that starts and ends at given `start`. */
def Position(start: Int): Position = Position(start, start)
/** A sentinel for a non-existing position */
val NoPosition = Position(1, 0)
/** The coordinate of a symbol. This is either an index or
* a zero-range position.
*/
class Coord(val encoding: Int) extends AnyVal {
def isIndex = encoding > 0
def isPosition = encoding <= 0
def toIndex: Int = {
assert(isIndex)
encoding - 1
}
def toPosition = {
assert(isPosition)
if (this == NoCoord) NoPosition else Position(1 - encoding)
}
}
/** An index coordinate */
implicit def indexCoord(n: Int): Coord = new Coord(n + 1)
implicit def positionCoord(pos: Position): Coord =
if (pos.exists) new Coord(-(pos.point + 1))
else NoCoord
/** A sentinel for a missing coordinate */
val NoCoord = new Coord(0)
}
| VladimirNik/tasty | plugin/src/main/scala/scala/tasty/internal/dotc/util/Positions.scala | Scala | bsd-3-clause | 5,982 |
/*
* Copyright 1998-2015 Linux.org.ru
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package ru.org.linux.tag
case class TagInfo(name:String, topicCount:Int, id:Int)
| ymn/lorsource | src/main/scala/ru/org/linux/tag/TagInfo.scala | Scala | apache-2.0 | 708 |
object select {
def either[A](a: => A) = new {
import scala.util.Random
def or[B >: A](b: => B) = if (Random.nextBoolean) a else b
}
}
| grzegorzbalcerek/scala-book-examples | examples/EitherOr5.scala | Scala | mit | 147 |
package swag_pact
package properties
import java.util.UUID
import io.circe.Json
import io.circe.syntax._
import org.scalatest.EitherValues
import org.scalatest.FunSpec
class PropertiesJsonSpec extends FunSpec with EitherValues {
describe("Properties from Json") {
describe("null") {
it("should convert to an unknown property") {
val json = Json.Null
val property = Property.fromJson(json)
assert(property === UnknownProperty(required = Some(false)))
}
}
describe("boolean") {
it("should convert to a boolean property") {
val json = Json.fromBoolean(true)
val property = Property.fromJson(json)
assert(property === BooleanProperty(None))
}
}
describe("number") {
it("should convert an int like number to an int property") {
val json = io.circe.parser.parse("10").right.value
val property = Property.fromJson(json)
assert(property === IntProperty(None))
}
it("should convert a long like number to a long property") {
val json = io.circe.parser.parse("100000000000").right.value
val property = Property.fromJson(json)
assert(property === LongProperty(None))
}
it("should convert a decimal like number to a double property") {
val json = io.circe.parser.parse("10.34").right.value
val property = Property.fromJson(json)
assert(property === DoubleProperty(None))
}
}
describe("string") {
it("should convert to a string property") {
val json = Json.fromString("value")
val property = Property.fromJson(json)
assert(property === StringProperty(None))
}
it("should convert a date string to a date property") {
val json = Json.fromString("2017-01-01")
val property = Property.fromJson(json)
assert(property === DateProperty(None))
}
it("should convert a date time string to a date property") {
val json = Json.fromString("2017-01-01T01:02:03Z")
val property = Property.fromJson(json)
assert(property === DateTimeProperty(None))
}
it("should convert a uuid string to a uuid property") {
val json = UUID.randomUUID().asJson
val property = Property.fromJson(json)
assert(property === UUIDProperty(None))
}
}
describe("array") {
it("should convert an empty array property") {
val json = Json.arr()
val property = Property.fromJson(json)
assert(property === ArrayProperty(UnknownProperty(None), None))
}
it("should convert a non-empty array property") {
val json = Json.arr(Json.fromString(""))
val property = Property.fromJson(json)
assert(property === ArrayProperty(StringProperty(None), None))
}
}
describe("object") {
it("should convert to a object property") {
val json =
Json.obj("key_a" -> Json.fromString("value_a"), "key_b" -> Json.fromString("value_b"))
val property = Property.fromJson(json)
assert(
property === ObjectProperty(Map("key_a" -> StringProperty(None), "key_b" -> StringProperty(None)), None)
)
}
}
}
}
| guymers/swag-pact | core/src/test/scala/swag_pact/properties/PropertiesJsonSpec.scala | Scala | apache-2.0 | 3,252 |
package com.sksamuel.elastic4s.http.search.queries
import com.sksamuel.elastic4s.http.search.queries.term.RegexQueryBodyFn
import com.sksamuel.elastic4s.searches.queries.{RegexQuery, RegexpFlag}
import org.scalatest.{FunSuite, Matchers}
class RegexQueryBodyFnTest extends FunSuite with Matchers {
test("regex query should generate expected json") {
val q = RegexQuery("mysearch", ".*")
.flags(RegexpFlag.AnyString, RegexpFlag.Complement, RegexpFlag.Empty, RegexpFlag.Intersection, RegexpFlag.Interval)
.boost(1.2)
.queryName("myquery")
.maxDeterminedStates(10000)
RegexQueryBodyFn(q).string() shouldBe
"""{"regexp":{"mysearch":{"value":".*","flags":"ANYSTRING|COMPLEMENT|EMPTY|INTERSECTION|INTERVAL","max_determinized_states":10000,"boost":1.2,"_name":"myquery"}}}"""
}
}
| Tecsisa/elastic4s | elastic4s-http/src/test/scala/com/sksamuel/elastic4s/http/search/queries/RegexQueryBodyFnTest.scala | Scala | apache-2.0 | 817 |
package fpinscala.laziness
import Stream._
trait Stream[+A] {
def foldRight[B](z: => B)(f: (A, => B) => B): B = // The arrow `=>` in front of the argument type `B` means that the function `f` takes its second argument by name and may choose not to evaluate it.
this match {
case Cons(h,t) => f(h(), t().foldRight(z)(f)) // If `f` doesn't evaluate its second argument, the recursion never occurs.
case _ => z
}
def exists(p: A => Boolean): Boolean =
foldRight(false)((a, b) => p(a) || b) // Here `b` is the unevaluated recursive step that folds the tail of the stream. If `p(a)` returns `true`, `b` will never be evaluated and the computation terminates early.
@annotation.tailrec
final def find(f: A => Boolean): Option[A] = this match {
case Empty => None
case Cons(h, t) => if (f(h())) Some(h()) else t().find(f)
}
def toList: List[A] = this.foldRight(List.empty[A]) { (a, b) => a :: b }
def take(n: Int): Stream[A] = this match {
case Cons(h, t) if n > 0 => cons(h(), t().take(n - 1))
case _ => Empty
}
def takeWithLoop(n: Int): Stream[A] = {
def loop(s: Stream[A], n: Int): Stream[A] = s match {
case Cons(h, t) if n > 0 => cons(h(), loop(t(), n - 1))
case _ => Empty
}
loop(this, n)
}
def drop(n: Int): Stream[A] = sys.error("todo")
def takeWhile(p: A => Boolean): Stream[A] = this match {
case Cons(h, t) =>
val a: A = h()
if (p(a)) cons(a, t().takeWhile(p))
else Empty
case _ => Empty
}
def takeWhileViaFoldRight(p: A => Boolean): Stream[A] =
this.foldRight(Stream.empty[A]) { (a, b) =>
if (p(a)) cons(a, b)
else empty
}
def forAll(p: A => Boolean): Boolean = foldRight(true){ (a, b) => p(a) && b }
def headOption: Option[A] = this.foldRight(None: Option[A]) { (a, _) => Option(a) }
// 5.7 map, filter, append, flatmap using foldRight. Part of the exercise is
// writing your own function signatures.
def map[B](op: A => B): Stream[B] = this.foldRight(Stream.empty[B]) { (a, b) => cons(op(a), b) }
def flatMap[B](op: A => Stream[B]): Stream[B] = this.foldRight(Stream.empty[B]) { (a, b) => op(a).append(b) }
def append[B >: A](bs: => Stream[B]): Stream[B] = this.foldRight(bs){ (a, b) => cons(a, b) }
def filter(op: A => Boolean): Stream[A] = this.foldRight(Stream.empty[A]) { (a, b) =>
if (op(a)) cons(a, b)
else b
}
def mapViaUnfold[B](f: A => B): Stream[B] =
unfold(this) {
case Empty => None
case Cons(h, t) => Some((f(h()), t()))
}
def takeViaUnfold(n: Int): Stream[A] = unfold((this, n)) {
case (Cons(h, t), x) if x > 0 => Some((h(), (t(), x - 1)))
case _ => None
}
def takeWhileViaUnfold(p: A => Boolean): Stream[A] = unfold(this) {
case Cons(h, t) if p(h()) => Some((h(), t()))
case _ => None
}
def zipWith[B, C](bs: Stream[B])(f: (A, B) => C): Stream[C] = unfold((this, bs)) {
case (Cons(h1, t1), Cons(h2, t2)) => Some(f(h1(), h2()), (t1(), t2()))
case _ => None
}
def zipAllWith[B, C](bs: Stream[B])(f: (Option[A], Option[B]) => C): Stream[C] = unfold(this, bs) {
case (Cons(h1, t1), Cons(h2, t2)) => Some((f(Some(h1()), Some(h2())), (t1(), t2())))
case (Cons(h1, t1), Empty) => Some(f(Some(h1()), None), (t1(), empty[B]))
case (Empty, Cons(h2, t2)) => Some(f(None, Some(h2())), (empty[A], t2()))
case _ => None
}
def zipAll[B](bs: Stream[B]): Stream[(Option[A], Option[B])] = zipAllWith(bs) { (a, b) => (a, b) }
def hasSubsequence[B](s: Stream[B]): Boolean = {
def go(as: Stream[A], bs: Stream[B]): Boolean = {
if (as.startsWith(bs)) true
else as match {
case Cons(_, t) => go(t(), bs)
case _ => false
}
}
go(this, s)
}
def startsWith[B](s: Stream[B]): Boolean =
this.zipAll(s).takeWhile { (a) => a._2.isDefined }.forAll { a => a._1 == a._2 }
def tails1: Stream[Stream[A]] = {
def go(as: Stream[A]): Stream[Stream[A]] = as match {
case Cons(_, t) => cons(t(), go(t()))
case _ => Stream.empty[Stream[A]]
}
cons(this, go(this))
}
def tails2: Stream[Stream[A]] = unfold((this, true)) {
case (s@Cons(_, t), _) => Some((s, (t(), true)))
case (Empty, b) if b => Some(Empty, (Empty, false))
case (Empty, b) if !b => None
}
def tails: Stream[Stream[A]] = unfold(this) {
case s@Cons(_, t) => Some((s, t()))
case Empty => None
}.append(Stream(empty))
def hasSubsequence2[B](bs: Stream[B]): Boolean = this.tails.exists { as => as.startsWith(bs) }
def scanRightSlow[B](z: => B)(f: (A, => B) => B): Stream[B] = this.tails.map { t => t.foldRight(z)(f) }
def scanRight[B](z: => B)(f: (A, => B) => B): Stream[B] = this.foldRight((z, Stream(z))) { (a, p) =>
lazy val p0 = p
val nextFold: B = f(a, p0._1)
val nextStream: Stream[B] = cons(nextFold, p0._2)
(nextFold, nextStream)
}._2
}
case object Empty extends Stream[Nothing]
case class Cons[+A](h: () => A, t: () => Stream[A]) extends Stream[A]
object Stream {
def cons[A](hd: => A, tl: => Stream[A]): Stream[A] = {
lazy val head = hd
lazy val tail = tl
Cons(() => head, () => tail)
}
def empty[A]: Stream[A] = Empty
def apply[A](as: A*): Stream[A] =
if (as.isEmpty) empty
else cons(as.head, apply(as.tail: _*))
val ones: Stream[Int] = Stream.cons(1, ones)
def from(n: Int): Stream[Int] = cons(n, from(n + 1))
def constant[A](a: A): Stream[A] = cons(a, constant(a))
def fibs: Stream[Int] = {
def go(a0: Int, a1: Int): Stream[Int] = cons(a0, go(a1, a0 + a1))
go(0, 1)
}
def unfold[A, S](z: S)(f: S => Option[(A, S)]): Stream[A] = f(z).map { case (a, s) =>
cons(a, unfold(s)(f))
}.getOrElse(Stream.empty[A])
def fibsViaUnfold: Stream[Int] = unfold((0, 1)) { t => Option((t._1, (t._2, t._1 + t._2))) }
def constantViaUnfold[A](a: A): Stream[A] = unfold(()) { _ => Option((a, ())) }
def fromViaUnfold(n: Int): Stream[Int] = unfold(n) { s => Option((s, s + 1)) }
} | lshlyapnikov/fpinscala | exercises/src/main/scala/fpinscala/laziness/Stream.scala | Scala | mit | 6,000 |
/*
* Scala.js (https://www.scala-js.org/)
*
* Copyright EPFL.
*
* Licensed under Apache License 2.0
* (https://www.apache.org/licenses/LICENSE-2.0).
*
* See the NOTICE file distributed with this work for
* additional information regarding copyright ownership.
*/
package org.scalajs.testsuite.javalib.lang
import java.lang.{Short => JShort}
import org.junit.Test
import org.junit.Assert._
import org.scalajs.testsuite.utils.AssertThrows.assertThrows
/** Tests the implementation of the java standard library Short
*/
class ShortTest {
@Test def compareToJavaShort(): Unit = {
def compare(x: Short, y: Short): Int =
new JShort(x).compareTo(new JShort(y))
assertTrue(compare(0.toShort, 5.toShort) < 0)
assertTrue(compare(10.toShort, 9.toShort) > 0)
assertTrue(compare(-2.toShort, -1.toShort) < 0)
assertEquals(0, compare(3.toShort, 3.toShort))
}
@Test def compareTo(): Unit = {
def compare(x: Any, y: Any): Int =
x.asInstanceOf[Comparable[Any]].compareTo(y)
assertTrue(compare(0.toShort, 5.toShort) < 0)
assertTrue(compare(10.toShort, 9.toShort) > 0)
assertTrue(compare(-2.toShort, -1.toShort) < 0)
assertEquals(0, compare(3.toShort, 3.toShort))
}
@Test def toUnsignedInt(): Unit = {
assertEquals(0, JShort.toUnsignedInt(0.toShort))
assertEquals(42, JShort.toUnsignedInt(42.toShort))
assertEquals(65494, JShort.toUnsignedInt(-42.toShort))
assertEquals(32768, JShort.toUnsignedInt(Short.MinValue))
assertEquals(32767, JShort.toUnsignedInt(Short.MaxValue))
}
@Test def toUnsignedLong(): Unit = {
assertEquals(0L, JShort.toUnsignedLong(0.toShort))
assertEquals(42L, JShort.toUnsignedLong(42.toShort))
assertEquals(65494L, JShort.toUnsignedLong(-42.toShort))
assertEquals(32768L, JShort.toUnsignedLong(Short.MinValue))
assertEquals(32767L, JShort.toUnsignedLong(Short.MaxValue))
}
@Test def parseString(): Unit = {
def test(s: String, v: Short): Unit = {
assertEquals(v, JShort.parseShort(s))
assertEquals(v, JShort.valueOf(s).shortValue())
assertEquals(v, new JShort(s).shortValue())
assertEquals(v, JShort.decode(s))
}
test("0", 0)
test("5", 5)
test("127", 127)
test("-100", -100)
test("30000", 30000)
}
@Test def parseStringInvalidThrows(): Unit = {
def test(s: String): Unit = {
assertThrows(classOf[NumberFormatException], JShort.parseShort(s))
assertThrows(classOf[NumberFormatException], JShort.decode(s))
}
test("abc")
test("")
test("60000") // out of range
test("-90000") // out of range
}
@Test def parseStringBase16(): Unit = {
def test(s: String, v: Short): Unit = {
assertEquals(v, JShort.parseShort(s, 16))
assertEquals(v, JShort.valueOf(s, 16).intValue())
assertEquals(v, JShort.decode(IntegerTest.insertAfterSign("0x", s)))
assertEquals(v, JShort.decode(IntegerTest.insertAfterSign("0X", s)))
assertEquals(v, JShort.decode(IntegerTest.insertAfterSign("#", s)))
}
test("0", 0x0)
test("5", 0x5)
test("ff", 0xff)
test("-24", -0x24)
test("3000", 0x3000)
test("-900", -0x900)
}
@Test def decodeStringBase8(): Unit = {
def test(s: String, v: Short): Unit = {
assertEquals(v, JShort.decode(s))
}
test("00", 0)
test("0123", 83)
test("-012", -10)
}
@Test def decodeStringInvalidThrows(): Unit = {
def test(s: String): Unit =
assertThrows(classOf[NumberFormatException], JShort.decode(s))
// sign after another sign or after a base prefix
test("++0")
test("--0")
test("0x+1")
test("0X-1")
test("#-1")
test("0-1")
// empty string after sign or after base prefix
test("")
test("+")
test("-")
test("-0x")
test("+0X")
test("#")
// integer too large
test("0x8000")
test("-0x8001")
test("0100000")
test("-0100001")
}
}
| scala-js/scala-js | test-suite/shared/src/test/scala/org/scalajs/testsuite/javalib/lang/ShortTest.scala | Scala | apache-2.0 | 3,937 |
package models
import play.api.db._
import play.api.Play.current
import anorm._
import anorm.SqlParser._
import java.util.{Date}
import java.security._
import scala.util._
case class User(id: Option[Long] = None, email: String, name: String, password: String)
case class UserEmail(email: String)
case class UserCreateData(
email: String,
nameFirst: String,
nameLast: String,
password: String,
birthday: String,
gender: String,
country: String)
case class AdminAddData(email: String)
object User {
// -- Parsers
/**
* Parse a User from a ResultSet
*/
val simple = {
get[Long]("user.id") ~
get[String]("user.email") ~
get[String]("user.name_first") ~
get[String]("user.name_last") ~
get[String]("user.password") map {
case id~email~name_first~name_last~password =>
User(Some(id), email, s"$name_first $name_last", password)
}
}
val emailOnly = {
get[String]("user.email") map {
case email => UserEmail(email)
}
}
// -- Queries
/**
* Retrieve a User from email.
*
* @param email Email of user in question
*/
def getByEmail(email: String): Option[User] = {
DB.withConnection { implicit connection =>
SQL("select * from user where email = {email}").on(
'email -> email
).as(User.simple.singleOpt)
}
}
/*
* Basically get a user by email, but with the stipulation that they have
* the given container list number. Saves having to query whether or not
* the user found by email has a container list number.
*
* @param email Email of user to return
* @param listNum Container list number of user
*/
def getByEmailWithListNum(email: String, listNum: Long) = {
DB.withConnection { implicit connection =>
SQL(
"""
SELECT * FROM user
WHERE email = {email}
AND container_list_number = {listNum}
"""
).on(
'email -> email,
'listNum -> listNum
).as(User.simple.singleOpt)
}
}
/**
* Retrieve all users.
*/
def getAll: Seq[User] = {
DB.withConnection { implicit connection =>
SQL("select * from user").as(User.simple *)
}
}
/**
* Authenticate a User.
*
* @param email Submitted email value
* @param password Submitted password value
*/
def authenticate(email: String, password: String): Option[User] = {
DB.withConnection { implicit connection =>
SQL(
"""
select * from user where
email = {email} and password = {password}
"""
).on(
'email -> email,
'password -> password
).as(User.simple.singleOpt)
}
}
/**
* Verify that the given email/password pair are valid
*
* @param email Email to verify
* @param password Password to verify
*/
def valid(email: String, password: String): Boolean = {
DB.withConnection { implicit connection =>
val valid = SQL(
"""
SELECT EXISTS(
SELECT u.email,
u.password
FROM user as u
WHERE email = {email}
AND password = {password}
);
"""
).on(
'email -> email,
'password -> password
).as(scalar[Long].single)
(valid == 1)
}
}
/**
* Create a User.
*
* @param user Data required to create a new user
*/
def create(user: UserCreateData) = {
DB.withConnection { implicit connection =>
SQL(
"""
insert into user (
email,
name_first,
name_last,
password,
birthday,
gender,
country
) values (
{email},
{name_first},
{name_last},
{password},
{birthday},
{gender},
{country}
)
"""
).on(
'email -> user.email,
'name_first -> user.nameFirst,
'name_last -> user.nameLast,
'password -> user.password,
'birthday -> user.birthday,
'gender -> user.gender,
'country -> user.country
).executeUpdate()
user
}
}
/*
* retrieve the list number of the user with given email; returns the user's
* list number if found or 0 if not (not very functional, I know)
*
* @param email Email to search for
*/
def getListNum(email: String): Int = {
User.getByEmail(email).map { user =>
DB.withConnection { implicit connection =>
SQL (
"""
SELECT u.container_list_number FROM user as u where u.email = {email}
"""
).on('email -> email).as(scalar[Int].single)
}
}.getOrElse(0)
}
/*
* Get all users with given container list number
*
* @param listNum Container list number to search by
*/
def getByListNum(listNum: Long): List[UserEmail] = {
DB.withConnection { implicit connection =>
val users = SQL (
"""
select u.email
from user as u
where u.container_list_number = {list_num}
AND u.email != "[email protected]"
"""
).on(
'list_num -> listNum
).as(User.emailOnly *)
return users
}
}
/*
* Add an admin, i.e. a user
*/
def addAdmin(admin: String, listNum: Long) = {
DB.withConnection { implicit connection =>
SQL (
"""
insert into user (
email,
name_first,
name_last,
password,
birthday,
gender,
country,
container_list_number
) values (
{email},
"Fake",
"Name",
{password},
"1-2-3",
"O",
"CA",
{listNum}
);
"""
).on(
'email -> admin,
'password -> "",
'listNum -> listNum
).executeUpdate()
}
}
def delete(admin: String) = {
DB.withConnection { implicit connection =>
SQL (
"""
delete from user
where email = {userEmail}
"""
).on(
'userEmail -> admin
).executeUpdate()
}
}
}
| cbsrbiobank/tempmonServer | app/models/User.scala | Scala | bsd-2-clause | 6,222 |
package net.benchmark.akka.http.world
import akka.NotUsed
import akka.http.scaladsl.common.{EntityStreamingSupport, JsonEntityStreamingSupport}
import akka.http.scaladsl.server.Directives._
import akka.stream.scaladsl.Source
import de.heikoseeberger.akkahttpcirce.ErrorAccumulatingCirceSupport._
import scala.concurrent.ExecutionContextExecutor
import scala.util.Try
class UpdateRoute(wr: WorldRepository, sd: ExecutionContextExecutor) {
implicit private val jss: JsonEntityStreamingSupport =
EntityStreamingSupport.json().withParallelMarshalling(5, unordered = true)
private def rand(i: Int): Int = {
val _ = i
java.util.concurrent.ThreadLocalRandom.current().nextInt(10000) + 1
}
private def rand(): Int = {
java.util.concurrent.ThreadLocalRandom.current().nextInt(10000) + 1
}
private def parse(pn: Option[String]): Int = {
pn.fold(Try(1))(s => Try(s.toInt)).getOrElse(1).min(500).max(1)
}
private def source(n: Int): Source[World, NotUsed] = {
val t = if (1 <= n && n < 5) n else 5
Source(1 to n)
.map(rand)
.mapAsync(t)(wr.require)
.mapAsync(t) { w =>
val wn = w.copy(randomNumber = rand())
wr.update(wn).map(_ => wn)(sd)
}
}
def route() = {
path("updates") {
parameter('queries.?) { pn =>
complete(source(parse(pn)))
}
}
}
}
| nbrady-techempower/FrameworkBenchmarks | frameworks/Scala/akka-http/akka-http-slick-postgres/src/main/scala/net/benchmark/akka/http/world/UpdateRoute.scala | Scala | bsd-3-clause | 1,359 |
package gapt.provers.prover9
import java.io.IOException
import gapt.expr._
import gapt.expr.formula.Bottom
import gapt.expr.formula.Neg
import gapt.expr.formula.Or
import gapt.expr.formula.Top
import gapt.expr.formula.fol.FOLAtom
import gapt.expr.formula.fol.FOLFunction
import gapt.expr.formula.fol.FOLVar
import gapt.expr.formula.hol._
import gapt.expr.subst.Substitution
import gapt.expr.util.freeVariables
import gapt.expr.util.syntacticMatching
import gapt.formats.{ InputFile, StringInputFile }
import gapt.formats.ivy.IvyParser
import gapt.formats.ivy.conversion.IvyToResolution
import gapt.formats.prover9.{ Prover9TermParser, Prover9TermParserLadrStyle }
import gapt.proofs._
import gapt.proofs.context.mutable.MutableContext
import gapt.proofs.expansion.ExpansionProof
import gapt.proofs.lk.LKProof
import gapt.proofs.resolution._
import gapt.provers.{ ResolutionProver, renameConstantsToFi }
import gapt.utils.{ ExternalProgram, Maybe, runProcess }
import scala.collection.mutable.ArrayBuffer
object Prover9 extends Prover9( extraCommands = _ => Seq() )
class Prover9( val extraCommands: ( Map[Const, Const] => Seq[String] ) = _ => Seq() ) extends ResolutionProver with ExternalProgram {
override def getResolutionProof( cnf: Iterable[HOLClause] )( implicit ctx: Maybe[MutableContext] ): Option[ResolutionProof] =
renameConstantsToFi.wrap( cnf.toSeq )(
( renaming, cnf: Seq[HOLClause] ) => {
val p9Input = toP9Input( cnf, renaming )
( runProcess.withExitValue( Seq( "prover9" ), p9Input ): @unchecked ) match {
case ( 0, out ) => Some( parseProof( out ) )
case ( 2, _ ) => None
}
} ) map {
mapInputClauses( _ ) { clause =>
cnf.view flatMap { ourClause =>
syntacticMatching( ourClause.toDisjunction, clause.toDisjunction ) map { Subst( Input( ourClause ), _ ) }
} head
}
}
private[prover9] def parseProof( p9Output: String ) = {
val ivy = runProcess( Seq( "prooftrans", "ivy" ), p9Output )
val ivyProof = IvyParser( StringInputFile( ivy ) )
IvyToResolution( ivyProof )
}
private def toP9Input( cnf: Iterable[HOLClause], renaming: Map[Const, Const] ): String = {
val commands = ArrayBuffer[String]()
commands += "set(quiet)" // suppresses noisy output on stderr
commands += "clear(auto_denials)" // prevents prover9 from exiting with error code 2 even though a proof was found
commands ++= extraCommands( renaming )
commands += "formulas(sos)"
commands ++= cnf map toP9Input
commands += "end_of_list"
commands.map( _ + "." + sys.props( "line.separator" ) ).mkString
}
private def renameVars( formula: Expr ): Expr =
Substitution( freeVariables( formula ).
toSeq.zipWithIndex.map {
case ( v, i ) => v -> FOLVar( s"x$i" )
} )( formula )
private def toP9Input( clause: HOLClause ): String = toP9Input( renameVars( clause.toDisjunction ) )
private def toP9Input( expr: Expr ): String = expr match {
case Top() => "$T"
case Bottom() => "$F"
case Neg( a ) => s"-${toP9Input( a )}"
case Or( a, b ) => s"${toP9Input( a )} | ${toP9Input( b )}"
case FOLAtom( f, as ) => toP9Input( f, as )
case FOLFunction( f, as ) => toP9Input( f, as )
case FOLVar( v ) => v
}
private def toP9Input( function: String, args: Seq[Expr] ): String =
if ( args.isEmpty ) function else s"$function(${args.map( toP9Input ).mkString( "," )})"
override val isInstalled: Boolean =
try {
runProcess.withExitValue( Seq( "prover9", "--help" ), "", true )._1 == 1
} catch { case _: IOException => false }
}
object Prover9Importer extends ExternalProgram {
override val isInstalled: Boolean = Prover9 isInstalled
def robinsonProof( p9Output: InputFile ): ResolutionProof = {
// The TPTP prover9 output files can't be read by prooftrans ivy directly...
val fixedP9Output = runProcess(
Seq( "prooftrans" ),
loadExpansionProof.extractFromTSTPCommentsIfNecessary( p9Output ).read )
Prover9 parseProof fixedP9Output
}
private def reconstructEndSequent( p9Output: String ): HOLSequent = {
val lines = p9Output split "\\n" toSeq
val parser = if ( lines contains "set(prolog_style_variables)." )
Prover9TermParser
else
Prover9TermParserLadrStyle
val proof_start = """=+ (PROOF) =+""".r
val proof_end = """=+ (end) of proof =+""".r
val linesInProof = lines dropWhile {
case proof_start( _ ) => false
case _ => true
} drop 1 takeWhile {
case proof_end( _ ) => false
case _ => true
}
val assumption = """(\\d+) ([^#.]+).*\\[assumption\\]\\.""".r
val assumptions = linesInProof collect {
case assumption( id, formula ) => parser parseFormula formula
}
val goal = """(\\d+) ([^#.]+).*\\[goal\\]\\.""".r
val goals = linesInProof collect {
case goal( id, formula ) => parser parseFormula formula
}
assumptions ++: Sequent() :++ goals distinct
}
def robinsonProofWithReconstructedEndSequent( p9Output: InputFile, runFixDerivation: Boolean = true ): ( ResolutionProof, HOLSequent ) = {
val p9Output_ = loadExpansionProof.extractFromTSTPCommentsIfNecessary( p9Output )
val resProof = robinsonProof( p9Output_ )
val endSequent = existentialClosure {
val tptpEndSequent = reconstructEndSequent( p9Output_.read )
if ( containsStrongQuantifier( tptpEndSequent ) ) {
// in this case the prover9 proof contains skolem symbols which we do not try to match
resProof.subProofs.collect { case Input( seq ) => seq.toDisjunction } ++: Sequent()
} else {
formulaToSequent.pos( tptpEndSequent.toDisjunction )
}
}
val fixedResProof = if ( runFixDerivation ) fixDerivation( resProof, endSequent ) else resProof
( fixedResProof, endSequent )
}
def lkProof( p9Output: InputFile ): LKProof =
ResolutionToLKProof( robinsonProofWithReconstructedEndSequent( p9Output )._1 )
def expansionProof( p9Output: InputFile ): ExpansionProof =
ResolutionToExpansionProof( robinsonProofWithReconstructedEndSequent( p9Output )._1 )
} | gapt/gapt | core/src/main/scala/gapt/provers/prover9/prover9.scala | Scala | gpl-3.0 | 6,238 |
package memnets.model
import java.lang.Math._
import memnets.model.impl._
import scala.beans.BeanProperty
trait Goal extends Element with TickFunction {
type T <: AnyRef
def startTick: Int
def startTick_=(tick: Int): Unit
def completedTick: Int
def completedTick_=(tick: Int): Unit
def owner: Goals
def progress: Double
def progress_=(d: Double): Unit
def reward: Int
def reset(): Unit = {
progress = 0.0
startTick = 0
completedTick = 0
}
def tgt: T
def tick(te: Tick, gh: GoalHandler): Unit = {
if (progress < 1.0) {
progress = min(1.0, eval(te))
if (progress > 0.99) {
progress = 1.0
gh.goalOver(this)
}
}
}
def isGood: Boolean = reward > 0
def isCompleted: Boolean = progress >= 1.0
override def toString = s"Goal[tgt: $tgt]"
}
trait YGoal extends Goal {
type T = Y
var linkable: Option[Linkable] = None
@BeanProperty var expected: Double = 1.0
def eval(te: Tick): Double = max(0.0, tgt.act / expected)
}
object Goal {
def apply(tgt: AnyRef, reward: Int = 1, desc: String = EMPTY_STRING)(eval: TickFunction)(
implicit tri: Trial): Goal = {
implicit val gg = tri.lastGoals
val g = new GoalImpl(tgt, eval)
g.desc = desc
g.reward = reward
g
}
}
object YGoal {
def apply(tgt: Y, expected: Double, reward: Int = 1, desc: String = EMPTY_STRING, linkable: Linkable = null)(
implicit tri: Trial): YGoal = {
implicit val gg = tri.lastGoals
val g = new YGoalImpl(tgt)
g.desc = desc
g.expected = expected
g.reward = reward
g
}
}
object OscGoal {
def apply(tgt: Osc, expected: Double, reward: Int = 1, desc: String = EMPTY_STRING)(implicit tri: Trial): YGoal = {
val yg = YGoal(tgt.y, expected, reward, desc)
yg.linkable = Option(tgt)
yg
}
}
| MemoryNetworks/memnets | api/src/main/scala/memnets/model/Goal.scala | Scala | apache-2.0 | 1,817 |
/*
* Copyright 2013 Akiyoshi Sugiki, University of Tsukuba
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package kumoi.shell.vm.store
/**
*
* @author Akiyoshi SUGIKI
*/
object VMVolumeFormat extends Enumeration {
val Raw = Value("raw")
val Bochs = Value("bochs")
val Cloop = Value("cloop")
val Cow = Value("cow")
val Dmg = Value("dmg")
val Iso = Value("iso")
val Qcow = Value("qcow")
val Qcow2 = Value("qcow2")
val Vmdk = Value("vmdk")
val Vpc = Value("vpc")
val None = Value("none")
val Linux = Value("linux")
val Fat16 = Value("fat16")
val Fat32 = Value("fat32")
val LinuxSwap = Value("linux-swap")
val LinuxLvm = Value("linux-lvm")
val LinuxRaid = Value("linux-raid")
val Extended = Value("extended")
}
| axi-sugiki/kumoi | src/kumoi/shell/vm/store/VMVolumeFormat.scala | Scala | apache-2.0 | 1,248 |
/*
* Copyright 2010 Michael Fortin <[email protected]>
*
* Licensed under the Apache License, Version 2.0 (the "License"); you may not use this
* file except in compliance with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software distributed
* under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR
* CONDITIONS OF ANY KIND, either express or implied. See the License for the specific
* language governing permissions and limitations under the License.
*/
package org.brzy.calista.schema
import org.scalatest.junit.JUnitSuite
import org.junit.Test
import org.junit.Assert._
import org.brzy.calista.server.EmbeddedTest
class CountTest extends JUnitSuite with EmbeddedTest {
@Test def countTest() {
sessionManager.doWith {
session =>
val key = StandardFamily("Standard")("count")
key("column5").set("value0")
key("column4").set("value1")
key("column3").set("value2")
key("column2").set("value3")
key("column1").set("value4")
}
sessionManager.doWith {
session =>
val key = StandardFamily("Standard")("count")
val amount = session.count(key)
assertNotNull(amount)
assertEquals(5, amount)
}
}
} | m410/calista | src/test/scala/org/brzy/calista/schema/CountTest.scala | Scala | apache-2.0 | 1,356 |
/*
* Copyright (C) 2016-2019 Lightbend Inc. <https://www.lightbend.com>
*/
package com.lightbend.lagom.maven
import java.io.File
import java.util
import java.util.Collections
import javax.inject.{ Inject, Singleton }
import org.apache.maven.RepositoryUtils
import org.apache.maven.artifact.ArtifactUtils
import org.apache.maven.execution.MavenSession
import org.apache.maven.lifecycle.internal._
import org.apache.maven.model.Plugin
import org.apache.maven.plugin.{ BuildPluginManager, MojoExecution }
import org.apache.maven.project.MavenProject
import org.codehaus.plexus.configuration.PlexusConfiguration
import org.codehaus.plexus.util.StringUtils
import org.codehaus.plexus.util.xml.Xpp3Dom
import org.eclipse.aether.{ DefaultRepositorySystemSession, RepositorySystem }
import org.eclipse.aether.artifact.Artifact
import org.eclipse.aether.collection.CollectRequest
import org.eclipse.aether.graph.Dependency
import org.eclipse.aether.repository.{ WorkspaceReader, WorkspaceRepository }
import org.eclipse.aether.resolution.{ DependencyRequest, DependencyResult }
import scala.collection.JavaConverters._
/**
* Facade in front of maven.
*
* All the hairy stuff goes here.
*/
@Singleton
class MavenFacade @Inject() (repoSystem: RepositorySystem, session: MavenSession,
buildPluginManager: BuildPluginManager, lifecycleExecutionPlanCalculator: LifecycleExecutionPlanCalculator,
logger: MavenLoggerProxy) {
/**
* Resolve the classpath for the given artifact.
*
* @return The classpath.
*/
def resolveArtifact(artifact: Artifact): Seq[Artifact] = {
resolveDependency(new Dependency(artifact, "runtime"))
}
/**
* Resolve the classpath for the given dependency.
*/
def resolveDependency(dependency: Dependency, additionalDependencies: Seq[Dependency] = Nil): Seq[Artifact] = {
val collect = new CollectRequest()
collect.setRoot(dependency)
collect.setRepositories(session.getCurrentProject.getRemoteProjectRepositories)
additionalDependencies.foreach(collect.addDependency)
toDependencies(resolveDependencies(collect)).map(_.getArtifact)
}
/**
* Resolve a project, with additional dependencies added to the project.
*
* @param project The project to resolve.
* @param additionalDependencies The additional dependencies to add.
* @return The resolved project.
*/
def resolveProject(project: MavenProject, additionalDependencies: Seq[Dependency]): Seq[Dependency] = {
// We use a low level API rather than just resolving the project so we can inject our own dev mode dependencies
// The implementation of this is modelled off org.apache.maven.project.DefaultProjectDependenciesResolver
val collect = new CollectRequest()
collect.setRootArtifact(RepositoryUtils.toArtifact(project.getArtifact))
collect.setRequestContext("dev-mode")
collect.setRepositories(project.getRemoteProjectRepositories)
val stereotypes = session.getRepositorySession.getArtifactTypeRegistry
// Add project dependencies
project.getDependencies.asScala.foreach { dep =>
if (!(
StringUtils.isEmpty(dep.getGroupId) ||
StringUtils.isEmpty(dep.getArtifactId) ||
StringUtils.isEmpty(dep.getVersion)
)) {
collect.addDependency(RepositoryUtils.toDependency(dep, stereotypes))
}
}
// Add additional dependencies
additionalDependencies.foreach(collect.addDependency)
val depMngt = project.getDependencyManagement
if (depMngt != null) {
depMngt.getDependencies.asScala.foreach { dep =>
collect.addManagedDependency(RepositoryUtils.toDependency(dep, stereotypes))
}
}
val depResult = resolveDependencies(collect)
// The code below comes from org.apache.maven.project.DefaultProjectBuilder
val artifacts = new util.LinkedHashSet[org.apache.maven.artifact.Artifact]
if (depResult.getRoot != null) {
RepositoryUtils.toArtifacts(artifacts, depResult.getRoot.getChildren, Collections.singletonList(project.getArtifact.getId), null)
val lrm = session.getRepositorySession.getLocalRepositoryManager
artifacts.asScala.foreach { artifact =>
if (!artifact.isResolved) {
val path = lrm.getPathForLocalArtifact(RepositoryUtils.toArtifact(artifact))
artifact.setFile(new File(lrm.getRepository.getBasedir, path))
}
}
}
if (additionalDependencies.isEmpty) {
project.setResolvedArtifacts(artifacts)
project.setArtifacts(artifacts)
}
toDependencies(depResult)
}
private def resolveDependencies(collect: CollectRequest): DependencyResult = {
val depRequest = new DependencyRequest(collect, null)
// Replace the workspace reader with one that will resolve projects that haven't been compiled yet
val repositorySession = new DefaultRepositorySystemSession(session.getRepositorySession)
repositorySession.setWorkspaceReader(new UnbuiltWorkspaceReader(repositorySession.getWorkspaceReader, session))
val collectResult = repoSystem.collectDependencies(repositorySession, collect)
val node = collectResult.getRoot
depRequest.setRoot(node)
repoSystem.resolveDependencies(repositorySession, depRequest)
}
private def toDependencies(depResult: DependencyResult): Seq[Dependency] = {
depResult.getArtifactResults.asScala.map(_.getRequest.getDependencyNode.getDependency)
}
def locateServices: Seq[MavenProject] = {
session.getAllProjects.asScala.filter(isService)
}
private def isService(project: MavenProject): Boolean = {
// If the value is set, return it
isLagomOrPlayService(project).getOrElse {
// Otherwise try and run lagom:configure
if (executeMavenPluginGoal(project, "configure")) {
// Now try and get the value
isLagomOrPlayService(project).getOrElse {
// The value should have been set by lagom:configure, fail
sys.error(s"${LagomKeys.LagomService} not set on project ${project.getArtifactId} after running configure!")
}
} else {
// Lagom plugin not configured, return false
logger.debug(s"Project ${project.getArtifactId} is not a Lagom service because it doesn't have the Lagom plugin")
LagomKeys.LagomService.put(project, false)
LagomKeys.PlayService.put(project, false)
false
}
}
}
private def isLagomOrPlayService(project: MavenProject): Option[Boolean] = {
LagomKeys.LagomService.get(project).flatMap {
case true => Some(true)
case false => LagomKeys.PlayService.get(project)
}
}
/**
* Execute the given Lagom plugin goal on the given project.
*
* @return True if the plugin goal was found and executed
*/
def executeMavenPluginGoal(project: MavenProject, name: String): Boolean = {
getLagomPlugin(project) match {
case Some(plugin) =>
val pluginDescriptor = buildPluginManager.loadPlugin(plugin, project.getRemotePluginRepositories,
session.getRepositorySession)
val mojoDescriptor = Option(pluginDescriptor.getMojo(name)).getOrElse {
sys.error(s"Could not find goal $name on Lagom maven plugin")
}
val mojoExecution = new MojoExecution(mojoDescriptor, "lagom-internal-request", MojoExecution.Source.CLI)
lifecycleExecutionPlanCalculator.setupMojoExecution(session, project, mojoExecution)
switchProject(project) {
buildPluginManager.executeMojo(session, mojoExecution)
true
}
case _ => false
}
}
def executeLifecyclePhase(projects: Seq[MavenProject], phase: String): Unit = {
projects.foreach { project =>
switchProject(project) {
// Calculate an execution plan
val executionPlan = lifecycleExecutionPlanCalculator.calculateExecutionPlan(session, project,
Collections.singletonList(new LifecycleTask(phase)))
// Execute it
executionPlan.asScala.foreach { mojoExecution =>
buildPluginManager.executeMojo(session, mojoExecution.getMojoExecution)
}
}
}
}
private def switchProject[T](project: MavenProject)(block: => T): T = {
val currentProject = session.getCurrentProject
if (currentProject != project) {
try {
session.setCurrentProject(project)
block
} finally {
session.setCurrentProject(currentProject)
}
} else {
block
}
}
/**
* Converts PlexusConfiguration to an Xpp3Dom.
*/
private def plexusConfigurationToXpp3Dom(config: PlexusConfiguration): Xpp3Dom = {
val result = new Xpp3Dom(config.getName)
result.setValue(config.getValue(null))
config.getAttributeNames.foreach { name =>
result.setAttribute(name, config.getAttribute(name))
}
config.getChildren.foreach { child =>
result.addChild(plexusConfigurationToXpp3Dom(child))
}
result
}
private def getLagomPlugin(project: MavenProject): Option[Plugin] = {
Option(project.getPlugin("com.lightbend.lagom:lagom-maven-plugin"))
}
}
/**
* A workspace reader that always resolves to the output directories of projects, even when they aren't built.
*
* The default maven workspace reader will prefer to resolve the jar file if it exists, and will not resolve if the
* project has not yet been compiled.
*/
class UnbuiltWorkspaceReader(delegate: WorkspaceReader, session: MavenSession) extends WorkspaceReader {
override def findVersions(artifact: Artifact): util.List[String] = {
delegate.findVersions(artifact)
}
override def getRepository: WorkspaceRepository = delegate.getRepository
override def findArtifact(artifact: Artifact): File = {
val projectKey = ArtifactUtils.key(artifact.getGroupId, artifact.getArtifactId, artifact.getVersion)
session.getProjectMap.get(projectKey) match {
case null => null
case project =>
artifact.getExtension match {
case "pom" => project.getFile
case "jar" if project.getPackaging == "jar" =>
if (isTestArtifact(artifact)) {
new File(project.getBuild.getTestOutputDirectory)
} else {
new File(project.getBuild.getOutputDirectory)
}
case _ =>
delegate.findArtifact(artifact)
}
}
}
private def isTestArtifact(artifact: Artifact): Boolean = {
("test-jar" == artifact.getProperty("type", "")) ||
("jar" == artifact.getExtension && "tests" == artifact.getClassifier)
}
}
| rstento/lagom | dev/maven-plugin/src/main/scala/com/lightbend/lagom/maven/MavenFacade.scala | Scala | apache-2.0 | 10,553 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.util.collection
import java.util.Comparator
import org.apache.spark.storage.DiskBlockObjectWriter
/**
* A common interface for size-tracking collections of key-value pairs that
*
* - Have an associated partition for each key-value pair.
* - Support a memory-efficient sorted iterator
* - Support a WritablePartitionedIterator for writing the contents directly as bytes.
*/
private[spark] trait WritablePartitionedPairCollection[K, V] {
/**
* Insert a key-value pair with a partition into the collection
*/
def insert(partition: Int, key: K, value: V): Unit
/**
* Iterate through the data in order of partition ID and then the given comparator. This may
* destroy the underlying collection.
*/
def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]])
: Iterator[((Int, K), V)]
/**
* Iterate through the data and write out the elements instead of returning them. Records are
* returned in order of their partition ID and then the given comparator.
* This may destroy the underlying collection.
*/
def destructiveSortedWritablePartitionedIterator(keyComparator: Option[Comparator[K]])
: WritablePartitionedIterator = {
val it = partitionedDestructiveSortedIterator(keyComparator)
new WritablePartitionedIterator {
private[this] var cur = if (it.hasNext) it.next() else null
def writeNext(writer: PairsWriter): Unit = {
writer.write(cur._1._2, cur._2)
cur = if (it.hasNext) it.next() else null
}
def hasNext(): Boolean = cur != null
def nextPartition(): Int = cur._1._1
}
}
}
private[spark] object WritablePartitionedPairCollection {
/**
* A comparator for (Int, K) pairs that orders them by only their partition ID.
*/
def partitionComparator[K]: Comparator[(Int, K)] = (a: (Int, K), b: (Int, K)) => a._1 - b._1
/**
* A comparator for (Int, K) pairs that orders them both by their partition ID and a key ordering.
*/
def partitionKeyComparator[K](keyComparator: Comparator[K]): Comparator[(Int, K)] =
(a: (Int, K), b: (Int, K)) => {
val partitionDiff = a._1 - b._1
if (partitionDiff != 0) {
partitionDiff
} else {
keyComparator.compare(a._2, b._2)
}
}
}
/**
* Iterator that writes elements to a DiskBlockObjectWriter instead of returning them. Each element
* has an associated partition.
*/
private[spark] trait WritablePartitionedIterator {
def writeNext(writer: PairsWriter): Unit
def hasNext(): Boolean
def nextPartition(): Int
}
| pgandhi999/spark | core/src/main/scala/org/apache/spark/util/collection/WritablePartitionedPairCollection.scala | Scala | apache-2.0 | 3,385 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.deploy
import java.io.{File, PrintStream}
import java.lang.reflect.{InvocationTargetException, Modifier, UndeclaredThrowableException}
import java.net.URL
import java.security.PrivilegedExceptionAction
import scala.annotation.tailrec
import scala.collection.mutable.{ArrayBuffer, HashMap, Map}
import scala.util.Properties
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.fs.Path
import org.apache.hadoop.security.UserGroupInformation
import org.apache.ivy.Ivy
import org.apache.ivy.core.LogOptions
import org.apache.ivy.core.module.descriptor._
import org.apache.ivy.core.module.id.{ArtifactId, ModuleId, ModuleRevisionId}
import org.apache.ivy.core.report.ResolveReport
import org.apache.ivy.core.resolve.ResolveOptions
import org.apache.ivy.core.retrieve.RetrieveOptions
import org.apache.ivy.core.settings.IvySettings
import org.apache.ivy.plugins.matcher.GlobPatternMatcher
import org.apache.ivy.plugins.repository.file.FileRepository
import org.apache.ivy.plugins.resolver.{ChainResolver, FileSystemResolver, IBiblioResolver}
import org.apache.spark._
import org.apache.spark.api.r.RUtils
import org.apache.spark.deploy.rest._
import org.apache.spark.launcher.SparkLauncher
import org.apache.spark.util._
/**
* Whether to submit, kill, or request the status of an application.
* The latter two operations are currently supported only for standalone and Mesos cluster modes.
*/
private[deploy] object SparkSubmitAction extends Enumeration {
type SparkSubmitAction = Value
val SUBMIT, KILL, REQUEST_STATUS = Value
}
/**
* Main gateway of launching a Spark application.
*
* This program handles setting up the classpath with relevant Spark dependencies and provides
* a layer over the different cluster managers and deploy modes that Spark supports.
*/
object SparkSubmit extends CommandLineUtils {
// Cluster managers
private val YARN = 1
private val STANDALONE = 2
private val MESOS = 4
private val LOCAL = 8
private val ALL_CLUSTER_MGRS = YARN | STANDALONE | MESOS | LOCAL
// Deploy modes
private val CLIENT = 1
private val CLUSTER = 2
private val ALL_DEPLOY_MODES = CLIENT | CLUSTER
// Special primary resource names that represent shells rather than application jars.
private val SPARK_SHELL = "spark-shell"
private val PYSPARK_SHELL = "pyspark-shell"
private val SPARKR_SHELL = "sparkr-shell"
private val SPARKR_PACKAGE_ARCHIVE = "sparkr.zip"
private val R_PACKAGE_ARCHIVE = "rpkg.zip"
private val CLASS_NOT_FOUND_EXIT_STATUS = 101
// scalastyle:off println
private[spark] def printVersionAndExit(): Unit = {
printStream.println("""Welcome to
____ __
/ __/__ ___ _____/ /__
_\\ \\/ _ \\/ _ `/ __/ '_/
/___/ .__/\\_,_/_/ /_/\\_\\ version %s
/_/
""".format(SPARK_VERSION))
printStream.println("Using Scala %s, %s, %s".format(
Properties.versionString, Properties.javaVmName, Properties.javaVersion))
printStream.println("Branch %s".format(SPARK_BRANCH))
printStream.println("Compiled by user %s on %s".format(SPARK_BUILD_USER, SPARK_BUILD_DATE))
printStream.println("Revision %s".format(SPARK_REVISION))
printStream.println("Url %s".format(SPARK_REPO_URL))
printStream.println("Type --help for more information.")
exitFn(0)
}
// scalastyle:on println
override def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
/**
* Kill an existing submission using the REST protocol. Standalone and Mesos cluster mode only.
*/
private def kill(args: SparkSubmitArguments): Unit = {
new RestSubmissionClient(args.master)
.killSubmission(args.submissionToKill)
}
/**
* Request the status of an existing submission using the REST protocol.
* Standalone and Mesos cluster mode only.
*/
private def requestStatus(args: SparkSubmitArguments): Unit = {
new RestSubmissionClient(args.master)
.requestSubmissionStatus(args.submissionToRequestStatusFor)
}
/**
* Submit the application using the provided parameters.
*
* This runs in two steps. First, we prepare the launch environment by setting up
* the appropriate classpath, system properties, and application arguments for
* running the child main class based on the cluster manager and the deploy mode.
* Second, we use this launch environment to invoke the main method of the child
* main class.
*/
@tailrec
private def submit(args: SparkSubmitArguments): Unit = {
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
})
} catch {
case e: Exception =>
// Hadoop's AuthorizationException suppresses the exception's stack trace, which
// makes the message printed to the output by the JVM not very helpful. Instead,
// detect exceptions with empty stack traces here, and treat them differently.
if (e.getStackTrace().length == 0) {
// scalastyle:off println
printStream.println(s"ERROR: ${e.getClass().getName()}: ${e.getMessage()}")
// scalastyle:on println
exitFn(1)
} else {
throw e
}
}
} else {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
// In standalone cluster mode, there are two submission gateways:
// (1) The traditional RPC gateway using o.a.s.deploy.Client as a wrapper
// (2) The new REST-based gateway introduced in Spark 1.3
// The latter is the default behavior as of Spark 1.3, but Spark submit will fail over
// to use the legacy gateway if the master endpoint turns out to be not a REST server.
if (args.isStandaloneCluster && args.useRest) {
try {
// scalastyle:off println
printStream.println("Running Spark using the REST application submission protocol.")
// scalastyle:on println
doRunMain()
} catch {
// Fail over to use the legacy submission gateway
case e: SubmitRestConnectionException =>
printWarning(s"Master endpoint ${args.master} was not a REST server. " +
"Falling back to legacy submission gateway instead.")
args.useRest = false
submit(args)
}
// In all other modes, just run the main class as prepared
} else {
doRunMain()
}
}
/**
* Prepare the environment for submitting an application.
* This returns a 4-tuple:
* (1) the arguments for the child process,
* (2) a list of classpath entries for the child,
* (3) a map of system properties, and
* (4) the main class for the child
* Exposed for testing.
*/
private[deploy] def prepareSubmitEnvironment(args: SparkSubmitArguments)
: (Seq[String], Seq[String], Map[String, String], String) = {
// Return values
val childArgs = new ArrayBuffer[String]()
val childClasspath = new ArrayBuffer[String]()
val sysProps = new HashMap[String, String]()
var childMainClass = ""
// Set the cluster manager
val clusterManager: Int = args.master match {
case "yarn" => YARN
case "yarn-client" | "yarn-cluster" =>
printWarning(s"Master ${args.master} is deprecated since 2.0." +
" Please use master \\"yarn\\" with specified deploy mode instead.")
YARN
case m if m.startsWith("spark") => STANDALONE
case m if m.startsWith("mesos") => MESOS
case m if m.startsWith("local") => LOCAL
case _ =>
printErrorAndExit("Master must either be yarn or start with spark, mesos, local")
-1
}
// Set the deploy mode; default is client mode
var deployMode: Int = args.deployMode match {
case "client" | null => CLIENT
case "cluster" => CLUSTER
case _ => printErrorAndExit("Deploy mode must be either client or cluster"); -1
}
// Because the deprecated way of specifying "yarn-cluster" and "yarn-client" encapsulate both
// the master and deploy mode, we have some logic to infer the master and deploy mode
// from each other if only one is specified, or exit early if they are at odds.
if (clusterManager == YARN) {
(args.master, args.deployMode) match {
case ("yarn-cluster", null) =>
deployMode = CLUSTER
args.master = "yarn"
case ("yarn-cluster", "client") =>
printErrorAndExit("Client deploy mode is not compatible with master \\"yarn-cluster\\"")
case ("yarn-client", "cluster") =>
printErrorAndExit("Cluster deploy mode is not compatible with master \\"yarn-client\\"")
case (_, mode) =>
args.master = "yarn"
}
// Make sure YARN is included in our build if we're trying to use it
if (!Utils.classIsLoadable("org.apache.spark.deploy.yarn.Client") && !Utils.isTesting) {
printErrorAndExit(
"Could not load YARN classes. " +
"This copy of Spark may not have been compiled with YARN support.")
}
}
// Update args.deployMode if it is null. It will be passed down as a Spark property later.
(args.deployMode, deployMode) match {
case (null, CLIENT) => args.deployMode = "client"
case (null, CLUSTER) => args.deployMode = "cluster"
case _ =>
}
val isYarnCluster = clusterManager == YARN && deployMode == CLUSTER
val isMesosCluster = clusterManager == MESOS && deployMode == CLUSTER
// Resolve maven dependencies if there are any and add classpath to jars. Add them to py-files
// too for packages that include Python code
val exclusions: Seq[String] =
if (!StringUtils.isBlank(args.packagesExclusions)) {
args.packagesExclusions.split(",")
} else {
Nil
}
val resolvedMavenCoordinates = SparkSubmitUtils.resolveMavenCoordinates(args.packages,
Option(args.repositories), Option(args.ivyRepoPath), exclusions = exclusions)
if (!StringUtils.isBlank(resolvedMavenCoordinates)) {
args.jars = mergeFileLists(args.jars, resolvedMavenCoordinates)
if (args.isPython) {
args.pyFiles = mergeFileLists(args.pyFiles, resolvedMavenCoordinates)
}
}
// install any R packages that may have been passed through --jars or --packages.
// Spark Packages may contain R source code inside the jar.
if (args.isR && !StringUtils.isBlank(args.jars)) {
RPackageUtils.checkAndBuildRPackage(args.jars, printStream, args.verbose)
}
// Require all python files to be local, so we can add them to the PYTHONPATH
// In YARN cluster mode, python files are distributed as regular files, which can be non-local.
// In Mesos cluster mode, non-local python files are automatically downloaded by Mesos.
if (args.isPython && !isYarnCluster && !isMesosCluster) {
if (Utils.nonLocalPaths(args.primaryResource).nonEmpty) {
printErrorAndExit(s"Only local python files are supported: ${args.primaryResource}")
}
val nonLocalPyFiles = Utils.nonLocalPaths(args.pyFiles).mkString(",")
if (nonLocalPyFiles.nonEmpty) {
printErrorAndExit(s"Only local additional python files are supported: $nonLocalPyFiles")
}
}
// Require all R files to be local
if (args.isR && !isYarnCluster && !isMesosCluster) {
if (Utils.nonLocalPaths(args.primaryResource).nonEmpty) {
printErrorAndExit(s"Only local R files are supported: ${args.primaryResource}")
}
}
// The following modes are not supported or applicable
(clusterManager, deployMode) match {
case (STANDALONE, CLUSTER) if args.isPython =>
printErrorAndExit("Cluster deploy mode is currently not supported for python " +
"applications on standalone clusters.")
case (STANDALONE, CLUSTER) if args.isR =>
printErrorAndExit("Cluster deploy mode is currently not supported for R " +
"applications on standalone clusters.")
case (LOCAL, CLUSTER) =>
printErrorAndExit("Cluster deploy mode is not compatible with master \\"local\\"")
case (_, CLUSTER) if isShell(args.primaryResource) =>
printErrorAndExit("Cluster deploy mode is not applicable to Spark shells.")
case (_, CLUSTER) if isSqlShell(args.mainClass) =>
printErrorAndExit("Cluster deploy mode is not applicable to Spark SQL shell.")
case (_, CLUSTER) if isThriftServer(args.mainClass) =>
printErrorAndExit("Cluster deploy mode is not applicable to Spark Thrift server.")
case _ =>
}
// If we're running a python app, set the main class to our specific python runner
if (args.isPython && deployMode == CLIENT) {
if (args.primaryResource == PYSPARK_SHELL) {
args.mainClass = "org.apache.spark.api.python.PythonGatewayServer"
} else {
// If a python file is provided, add it to the child arguments and list of files to deploy.
// Usage: PythonAppRunner <main python file> <extra python files> [app arguments]
args.mainClass = "org.apache.spark.deploy.PythonRunner"
args.childArgs = ArrayBuffer(args.primaryResource, args.pyFiles) ++ args.childArgs
if (clusterManager != YARN) {
// The YARN backend distributes the primary file differently, so don't merge it.
args.files = mergeFileLists(args.files, args.primaryResource)
}
}
if (clusterManager != YARN) {
// The YARN backend handles python files differently, so don't merge the lists.
args.files = mergeFileLists(args.files, args.pyFiles)
}
if (args.pyFiles != null) {
sysProps("spark.submit.pyFiles") = args.pyFiles
}
}
// In YARN mode for an R app, add the SparkR package archive and the R package
// archive containing all of the built R libraries to archives so that they can
// be distributed with the job
if (args.isR && clusterManager == YARN) {
val sparkRPackagePath = RUtils.localSparkRPackagePath
if (sparkRPackagePath.isEmpty) {
printErrorAndExit("SPARK_HOME does not exist for R application in YARN mode.")
}
val sparkRPackageFile = new File(sparkRPackagePath.get, SPARKR_PACKAGE_ARCHIVE)
if (!sparkRPackageFile.exists()) {
printErrorAndExit(s"$SPARKR_PACKAGE_ARCHIVE does not exist for R application in YARN mode.")
}
val sparkRPackageURI = Utils.resolveURI(sparkRPackageFile.getAbsolutePath).toString
// Distribute the SparkR package.
// Assigns a symbol link name "sparkr" to the shipped package.
args.archives = mergeFileLists(args.archives, sparkRPackageURI + "#sparkr")
// Distribute the R package archive containing all the built R packages.
if (!RUtils.rPackages.isEmpty) {
val rPackageFile =
RPackageUtils.zipRLibraries(new File(RUtils.rPackages.get), R_PACKAGE_ARCHIVE)
if (!rPackageFile.exists()) {
printErrorAndExit("Failed to zip all the built R packages.")
}
val rPackageURI = Utils.resolveURI(rPackageFile.getAbsolutePath).toString
// Assigns a symbol link name "rpkg" to the shipped package.
args.archives = mergeFileLists(args.archives, rPackageURI + "#rpkg")
}
}
// TODO: Support distributing R packages with standalone cluster
if (args.isR && clusterManager == STANDALONE && !RUtils.rPackages.isEmpty) {
printErrorAndExit("Distributing R packages with standalone cluster is not supported.")
}
// TODO: Support distributing R packages with mesos cluster
if (args.isR && clusterManager == MESOS && !RUtils.rPackages.isEmpty) {
printErrorAndExit("Distributing R packages with mesos cluster is not supported.")
}
// If we're running an R app, set the main class to our specific R runner
if (args.isR && deployMode == CLIENT) {
if (args.primaryResource == SPARKR_SHELL) {
args.mainClass = "org.apache.spark.api.r.RBackend"
} else {
// If an R file is provided, add it to the child arguments and list of files to deploy.
// Usage: RRunner <main R file> [app arguments]
args.mainClass = "org.apache.spark.deploy.RRunner"
args.childArgs = ArrayBuffer(args.primaryResource) ++ args.childArgs
args.files = mergeFileLists(args.files, args.primaryResource)
}
}
if (isYarnCluster && args.isR) {
// In yarn-cluster mode for an R app, add primary resource to files
// that can be distributed with the job
args.files = mergeFileLists(args.files, args.primaryResource)
}
// Special flag to avoid deprecation warnings at the client
sysProps("SPARK_SUBMIT") = "true"
// A list of rules to map each argument to system properties or command-line options in
// each deploy mode; we iterate through these below
val options = List[OptionAssigner](
// All cluster managers
OptionAssigner(args.master, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES, sysProp = "spark.master"),
OptionAssigner(args.deployMode, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES,
sysProp = "spark.submit.deployMode"),
OptionAssigner(args.name, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES, sysProp = "spark.app.name"),
OptionAssigner(args.ivyRepoPath, ALL_CLUSTER_MGRS, CLIENT, sysProp = "spark.jars.ivy"),
OptionAssigner(args.driverMemory, ALL_CLUSTER_MGRS, CLIENT,
sysProp = "spark.driver.memory"),
OptionAssigner(args.driverExtraClassPath, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES,
sysProp = "spark.driver.extraClassPath"),
OptionAssigner(args.driverExtraJavaOptions, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES,
sysProp = "spark.driver.extraJavaOptions"),
OptionAssigner(args.driverExtraLibraryPath, ALL_CLUSTER_MGRS, ALL_DEPLOY_MODES,
sysProp = "spark.driver.extraLibraryPath"),
// Yarn only
OptionAssigner(args.queue, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.queue"),
OptionAssigner(args.numExecutors, YARN, ALL_DEPLOY_MODES,
sysProp = "spark.executor.instances"),
OptionAssigner(args.jars, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.dist.jars"),
OptionAssigner(args.files, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.dist.files"),
OptionAssigner(args.archives, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.dist.archives"),
OptionAssigner(args.principal, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.principal"),
OptionAssigner(args.keytab, YARN, ALL_DEPLOY_MODES, sysProp = "spark.yarn.keytab"),
// Other options
OptionAssigner(args.executorCores, STANDALONE | YARN, ALL_DEPLOY_MODES,
sysProp = "spark.executor.cores"),
OptionAssigner(args.executorMemory, STANDALONE | MESOS | YARN, ALL_DEPLOY_MODES,
sysProp = "spark.executor.memory"),
OptionAssigner(args.totalExecutorCores, STANDALONE | MESOS, ALL_DEPLOY_MODES,
sysProp = "spark.cores.max"),
OptionAssigner(args.files, LOCAL | STANDALONE | MESOS, ALL_DEPLOY_MODES,
sysProp = "spark.files"),
OptionAssigner(args.jars, LOCAL, CLIENT, sysProp = "spark.jars"),
OptionAssigner(args.jars, STANDALONE | MESOS, ALL_DEPLOY_MODES, sysProp = "spark.jars"),
OptionAssigner(args.driverMemory, STANDALONE | MESOS | YARN, CLUSTER,
sysProp = "spark.driver.memory"),
OptionAssigner(args.driverCores, STANDALONE | MESOS | YARN, CLUSTER,
sysProp = "spark.driver.cores"),
OptionAssigner(args.supervise.toString, STANDALONE | MESOS, CLUSTER,
sysProp = "spark.driver.supervise"),
OptionAssigner(args.ivyRepoPath, STANDALONE, CLUSTER, sysProp = "spark.jars.ivy")
)
// In client mode, launch the application main class directly
// In addition, add the main application jar and any added jars (if any) to the classpath
if (deployMode == CLIENT) {
childMainClass = args.mainClass
if (isUserJar(args.primaryResource)) {
childClasspath += args.primaryResource
}
if (args.jars != null) { childClasspath ++= args.jars.split(",") }
if (args.childArgs != null) { childArgs ++= args.childArgs }
}
// Map all arguments to command-line options or system properties for our chosen mode
for (opt <- options) {
if (opt.value != null &&
(deployMode & opt.deployMode) != 0 &&
(clusterManager & opt.clusterManager) != 0) {
if (opt.clOption != null) { childArgs += (opt.clOption, opt.value) }
if (opt.sysProp != null) { sysProps.put(opt.sysProp, opt.value) }
}
}
// Add the application jar automatically so the user doesn't have to call sc.addJar
// For YARN cluster mode, the jar is already distributed on each node as "app.jar"
// For python and R files, the primary resource is already distributed as a regular file
if (!isYarnCluster && !args.isPython && !args.isR) {
var jars = sysProps.get("spark.jars").map(x => x.split(",").toSeq).getOrElse(Seq.empty)
if (isUserJar(args.primaryResource)) {
jars = jars ++ Seq(args.primaryResource)
}
sysProps.put("spark.jars", jars.mkString(","))
}
// In standalone cluster mode, use the REST client to submit the application (Spark 1.3+).
// All Spark parameters are expected to be passed to the client through system properties.
if (args.isStandaloneCluster) {
if (args.useRest) {
childMainClass = "org.apache.spark.deploy.rest.RestSubmissionClient"
childArgs += (args.primaryResource, args.mainClass)
} else {
// In legacy standalone cluster mode, use Client as a wrapper around the user class
childMainClass = "org.apache.spark.deploy.Client"
if (args.supervise) { childArgs += "--supervise" }
Option(args.driverMemory).foreach { m => childArgs += ("--memory", m) }
Option(args.driverCores).foreach { c => childArgs += ("--cores", c) }
childArgs += "launch"
childArgs += (args.master, args.primaryResource, args.mainClass)
}
if (args.childArgs != null) {
childArgs ++= args.childArgs
}
}
// Let YARN know it's a pyspark app, so it distributes needed libraries.
if (clusterManager == YARN) {
if (args.isPython) {
sysProps.put("spark.yarn.isPython", "true")
}
if (args.pyFiles != null) {
sysProps("spark.submit.pyFiles") = args.pyFiles
}
}
// assure a keytab is available from any place in a JVM
if (clusterManager == YARN || clusterManager == LOCAL) {
if (args.principal != null) {
require(args.keytab != null, "Keytab must be specified when principal is specified")
if (!new File(args.keytab).exists()) {
throw new SparkException(s"Keytab file: ${args.keytab} does not exist")
} else {
// Add keytab and principal configurations in sysProps to make them available
// for later use; e.g. in spark sql, the isolated class loader used to talk
// to HiveMetastore will use these settings. They will be set as Java system
// properties and then loaded by SparkConf
sysProps.put("spark.yarn.keytab", args.keytab)
sysProps.put("spark.yarn.principal", args.principal)
UserGroupInformation.loginUserFromKeytab(args.principal, args.keytab)
}
}
}
// In yarn-cluster mode, use yarn.Client as a wrapper around the user class
if (isYarnCluster) {
childMainClass = "org.apache.spark.deploy.yarn.Client"
if (args.isPython) {
childArgs += ("--primary-py-file", args.primaryResource)
childArgs += ("--class", "org.apache.spark.deploy.PythonRunner")
} else if (args.isR) {
val mainFile = new Path(args.primaryResource).getName
childArgs += ("--primary-r-file", mainFile)
childArgs += ("--class", "org.apache.spark.deploy.RRunner")
} else {
if (args.primaryResource != SparkLauncher.NO_RESOURCE) {
childArgs += ("--jar", args.primaryResource)
}
childArgs += ("--class", args.mainClass)
}
if (args.childArgs != null) {
args.childArgs.foreach { arg => childArgs += ("--arg", arg) }
}
}
if (isMesosCluster) {
assert(args.useRest, "Mesos cluster mode is only supported through the REST submission API")
childMainClass = "org.apache.spark.deploy.rest.RestSubmissionClient"
if (args.isPython) {
// Second argument is main class
childArgs += (args.primaryResource, "")
if (args.pyFiles != null) {
sysProps("spark.submit.pyFiles") = args.pyFiles
}
} else if (args.isR) {
// Second argument is main class
childArgs += (args.primaryResource, "")
} else {
childArgs += (args.primaryResource, args.mainClass)
}
if (args.childArgs != null) {
childArgs ++= args.childArgs
}
}
// Load any properties specified through --conf and the default properties file
for ((k, v) <- args.sparkProperties) {
sysProps.getOrElseUpdate(k, v)
}
// Ignore invalid spark.driver.host in cluster modes.
if (deployMode == CLUSTER) {
sysProps -= "spark.driver.host"
}
// Resolve paths in certain spark properties
val pathConfigs = Seq(
"spark.jars",
"spark.files",
"spark.yarn.dist.files",
"spark.yarn.dist.archives",
"spark.yarn.dist.jars")
pathConfigs.foreach { config =>
// Replace old URIs with resolved URIs, if they exist
sysProps.get(config).foreach { oldValue =>
sysProps(config) = Utils.resolveURIs(oldValue)
}
}
// Resolve and format python file paths properly before adding them to the PYTHONPATH.
// The resolving part is redundant in the case of --py-files, but necessary if the user
// explicitly sets `spark.submit.pyFiles` in his/her default properties file.
sysProps.get("spark.submit.pyFiles").foreach { pyFiles =>
val resolvedPyFiles = Utils.resolveURIs(pyFiles)
val formattedPyFiles = if (!isYarnCluster && !isMesosCluster) {
PythonRunner.formatPaths(resolvedPyFiles).mkString(",")
} else {
// Ignoring formatting python path in yarn and mesos cluster mode, these two modes
// support dealing with remote python files, they could distribute and add python files
// locally.
resolvedPyFiles
}
sysProps("spark.submit.pyFiles") = formattedPyFiles
}
(childArgs, childClasspath, sysProps, childMainClass)
}
/**
* Run the main method of the child class using the provided launch environment.
*
* Note that this main class will not be the one provided by the user if we're
* running cluster deploy mode or python applications.
*/
private def runMain(
childArgs: Seq[String],
childClasspath: Seq[String],
sysProps: Map[String, String],
childMainClass: String,
verbose: Boolean): Unit = {
// scalastyle:off println
if (verbose) {
printStream.println(s"Main class:\\n$childMainClass")
printStream.println(s"Arguments:\\n${childArgs.mkString("\\n")}")
printStream.println(s"System properties:\\n${sysProps.mkString("\\n")}")
printStream.println(s"Classpath elements:\\n${childClasspath.mkString("\\n")}")
printStream.println("\\n")
}
// scalastyle:on println
val loader =
if (sysProps.getOrElse("spark.driver.userClassPathFirst", "false").toBoolean) {
new ChildFirstURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
} else {
new MutableURLClassLoader(new Array[URL](0),
Thread.currentThread.getContextClassLoader)
}
Thread.currentThread.setContextClassLoader(loader)
for (jar <- childClasspath) {
addJarToClasspath(jar, loader)
}
for ((key, value) <- sysProps) {
System.setProperty(key, value)
}
var mainClass: Class[_] = null
try {
mainClass = Utils.classForName(childMainClass)
} catch {
case e: ClassNotFoundException =>
e.printStackTrace(printStream)
if (childMainClass.contains("thriftserver")) {
// scalastyle:off println
printStream.println(s"Failed to load main class $childMainClass.")
printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.")
// scalastyle:on println
}
System.exit(CLASS_NOT_FOUND_EXIT_STATUS)
case e: NoClassDefFoundError =>
e.printStackTrace(printStream)
if (e.getMessage.contains("org/apache/hadoop/hive")) {
// scalastyle:off println
printStream.println(s"Failed to load hive class.")
printStream.println("You need to build Spark with -Phive and -Phive-thriftserver.")
// scalastyle:on println
}
System.exit(CLASS_NOT_FOUND_EXIT_STATUS)
}
// SPARK-4170
if (classOf[scala.App].isAssignableFrom(mainClass)) {
printWarning("Subclasses of scala.App may not work correctly. Use a main() method instead.")
}
val mainMethod = mainClass.getMethod("main", new Array[String](0).getClass)
if (!Modifier.isStatic(mainMethod.getModifiers)) {
throw new IllegalStateException("The main method in the given main class must be static")
}
@tailrec
def findCause(t: Throwable): Throwable = t match {
case e: UndeclaredThrowableException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: InvocationTargetException =>
if (e.getCause() != null) findCause(e.getCause()) else e
case e: Throwable =>
e
}
try {
mainMethod.invoke(null, childArgs.toArray)
} catch {
case t: Throwable =>
findCause(t) match {
case SparkUserAppException(exitCode) =>
System.exit(exitCode)
case t: Throwable =>
throw t
}
}
}
private def addJarToClasspath(localJar: String, loader: MutableURLClassLoader) {
val uri = Utils.resolveURI(localJar)
uri.getScheme match {
case "file" | "local" =>
val file = new File(uri.getPath)
if (file.exists()) {
loader.addURL(file.toURI.toURL)
} else {
printWarning(s"Local jar $file does not exist, skipping.")
}
case _ =>
printWarning(s"Skip remote jar $uri.")
}
}
/**
* Return whether the given primary resource represents a user jar.
*/
private[deploy] def isUserJar(res: String): Boolean = {
!isShell(res) && !isPython(res) && !isInternal(res) && !isR(res)
}
/**
* Return whether the given primary resource represents a shell.
*/
private[deploy] def isShell(res: String): Boolean = {
(res == SPARK_SHELL || res == PYSPARK_SHELL || res == SPARKR_SHELL)
}
/**
* Return whether the given main class represents a sql shell.
*/
private[deploy] def isSqlShell(mainClass: String): Boolean = {
mainClass == "org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver"
}
/**
* Return whether the given main class represents a thrift server.
*/
private def isThriftServer(mainClass: String): Boolean = {
mainClass == "org.apache.spark.sql.hive.thriftserver.HiveThriftServer2"
}
/**
* Return whether the given primary resource requires running python.
*/
private[deploy] def isPython(res: String): Boolean = {
res != null && res.endsWith(".py") || res == PYSPARK_SHELL
}
/**
* Return whether the given primary resource requires running R.
*/
private[deploy] def isR(res: String): Boolean = {
res != null && res.endsWith(".R") || res == SPARKR_SHELL
}
private[deploy] def isInternal(res: String): Boolean = {
res == SparkLauncher.NO_RESOURCE
}
/**
* Merge a sequence of comma-separated file lists, some of which may be null to indicate
* no files, into a single comma-separated string.
*/
private def mergeFileLists(lists: String*): String = {
val merged = lists.filterNot(StringUtils.isBlank)
.flatMap(_.split(","))
.mkString(",")
if (merged == "") null else merged
}
}
/** Provides utility functions to be used inside SparkSubmit. */
private[spark] object SparkSubmitUtils {
// Exposed for testing
var printStream = SparkSubmit.printStream
/**
* Represents a Maven Coordinate
* @param groupId the groupId of the coordinate
* @param artifactId the artifactId of the coordinate
* @param version the version of the coordinate
*/
private[deploy] case class MavenCoordinate(groupId: String, artifactId: String, version: String) {
override def toString: String = s"$groupId:$artifactId:$version"
}
/**
* Extracts maven coordinates from a comma-delimited string. Coordinates should be provided
* in the format `groupId:artifactId:version` or `groupId/artifactId:version`.
* @param coordinates Comma-delimited string of maven coordinates
* @return Sequence of Maven coordinates
*/
def extractMavenCoordinates(coordinates: String): Seq[MavenCoordinate] = {
coordinates.split(",").map { p =>
val splits = p.replace("/", ":").split(":")
require(splits.length == 3, s"Provided Maven Coordinates must be in the form " +
s"'groupId:artifactId:version'. The coordinate provided is: $p")
require(splits(0) != null && splits(0).trim.nonEmpty, s"The groupId cannot be null or " +
s"be whitespace. The groupId provided is: ${splits(0)}")
require(splits(1) != null && splits(1).trim.nonEmpty, s"The artifactId cannot be null or " +
s"be whitespace. The artifactId provided is: ${splits(1)}")
require(splits(2) != null && splits(2).trim.nonEmpty, s"The version cannot be null or " +
s"be whitespace. The version provided is: ${splits(2)}")
new MavenCoordinate(splits(0), splits(1), splits(2))
}
}
/** Path of the local Maven cache. */
private[spark] def m2Path: File = {
if (Utils.isTesting) {
// test builds delete the maven cache, and this can cause flakiness
new File("dummy", ".m2" + File.separator + "repository")
} else {
new File(System.getProperty("user.home"), ".m2" + File.separator + "repository")
}
}
/**
* Extracts maven coordinates from a comma-delimited string
* @param remoteRepos Comma-delimited string of remote repositories
* @param ivySettings The Ivy settings for this session
* @return A ChainResolver used by Ivy to search for and resolve dependencies.
*/
def createRepoResolvers(remoteRepos: Option[String], ivySettings: IvySettings): ChainResolver = {
// We need a chain resolver if we want to check multiple repositories
val cr = new ChainResolver
cr.setName("list")
val repositoryList = remoteRepos.getOrElse("")
// add any other remote repositories other than maven central
if (repositoryList.trim.nonEmpty) {
repositoryList.split(",").zipWithIndex.foreach { case (repo, i) =>
val brr: IBiblioResolver = new IBiblioResolver
brr.setM2compatible(true)
brr.setUsepoms(true)
brr.setRoot(repo)
brr.setName(s"repo-${i + 1}")
cr.add(brr)
// scalastyle:off println
printStream.println(s"$repo added as a remote repository with the name: ${brr.getName}")
// scalastyle:on println
}
}
val localM2 = new IBiblioResolver
localM2.setM2compatible(true)
localM2.setRoot(m2Path.toURI.toString)
localM2.setUsepoms(true)
localM2.setName("local-m2-cache")
cr.add(localM2)
val localIvy = new FileSystemResolver
val localIvyRoot = new File(ivySettings.getDefaultIvyUserDir, "local")
localIvy.setLocal(true)
localIvy.setRepository(new FileRepository(localIvyRoot))
val ivyPattern = Seq(localIvyRoot.getAbsolutePath, "[organisation]", "[module]", "[revision]",
"ivys", "ivy.xml").mkString(File.separator)
localIvy.addIvyPattern(ivyPattern)
val artifactPattern = Seq(localIvyRoot.getAbsolutePath, "[organisation]", "[module]",
"[revision]", "[type]s", "[artifact](-[classifier]).[ext]").mkString(File.separator)
localIvy.addArtifactPattern(artifactPattern)
localIvy.setName("local-ivy-cache")
cr.add(localIvy)
// the biblio resolver resolves POM declared dependencies
val br: IBiblioResolver = new IBiblioResolver
br.setM2compatible(true)
br.setUsepoms(true)
br.setName("central")
cr.add(br)
val sp: IBiblioResolver = new IBiblioResolver
sp.setM2compatible(true)
sp.setUsepoms(true)
sp.setRoot("http://dl.bintray.com/spark-packages/maven")
sp.setName("spark-packages")
cr.add(sp)
cr
}
/**
* Output a comma-delimited list of paths for the downloaded jars to be added to the classpath
* (will append to jars in SparkSubmit).
* @param artifacts Sequence of dependencies that were resolved and retrieved
* @param cacheDirectory directory where jars are cached
* @return a comma-delimited list of paths for the dependencies
*/
def resolveDependencyPaths(
artifacts: Array[AnyRef],
cacheDirectory: File): String = {
artifacts.map { artifactInfo =>
val artifact = artifactInfo.asInstanceOf[Artifact].getModuleRevisionId
cacheDirectory.getAbsolutePath + File.separator +
s"${artifact.getOrganisation}_${artifact.getName}-${artifact.getRevision}.jar"
}.mkString(",")
}
/** Adds the given maven coordinates to Ivy's module descriptor. */
def addDependenciesToIvy(
md: DefaultModuleDescriptor,
artifacts: Seq[MavenCoordinate],
ivyConfName: String): Unit = {
artifacts.foreach { mvn =>
val ri = ModuleRevisionId.newInstance(mvn.groupId, mvn.artifactId, mvn.version)
val dd = new DefaultDependencyDescriptor(ri, false, false)
dd.addDependencyConfiguration(ivyConfName, ivyConfName + "(runtime)")
// scalastyle:off println
printStream.println(s"${dd.getDependencyId} added as a dependency")
// scalastyle:on println
md.addDependency(dd)
}
}
/** Add exclusion rules for dependencies already included in the spark-assembly */
def addExclusionRules(
ivySettings: IvySettings,
ivyConfName: String,
md: DefaultModuleDescriptor): Unit = {
// Add scala exclusion rule
md.addExcludeRule(createExclusion("*:scala-library:*", ivySettings, ivyConfName))
// We need to specify each component explicitly, otherwise we miss spark-streaming-kafka-0-8 and
// other spark-streaming utility components. Underscore is there to differentiate between
// spark-streaming_2.1x and spark-streaming-kafka-0-8-assembly_2.1x
val components = Seq("catalyst_", "core_", "graphx_", "hive_", "mllib_", "repl_",
"sql_", "streaming_", "yarn_", "network-common_", "network-shuffle_", "network-yarn_")
components.foreach { comp =>
md.addExcludeRule(createExclusion(s"org.apache.spark:spark-$comp*:*", ivySettings,
ivyConfName))
}
}
/** A nice function to use in tests as well. Values are dummy strings. */
def getModuleDescriptor: DefaultModuleDescriptor = DefaultModuleDescriptor.newDefaultInstance(
ModuleRevisionId.newInstance("org.apache.spark", "spark-submit-parent", "1.0"))
/**
* Resolves any dependencies that were supplied through maven coordinates
* @param coordinates Comma-delimited string of maven coordinates
* @param remoteRepos Comma-delimited string of remote repositories other than maven central
* @param ivyPath The path to the local ivy repository
* @param exclusions Exclusions to apply when resolving transitive dependencies
* @return The comma-delimited path to the jars of the given maven artifacts including their
* transitive dependencies
*/
def resolveMavenCoordinates(
coordinates: String,
remoteRepos: Option[String],
ivyPath: Option[String],
exclusions: Seq[String] = Nil,
isTest: Boolean = false): String = {
if (coordinates == null || coordinates.trim.isEmpty) {
""
} else {
val sysOut = System.out
try {
// To prevent ivy from logging to system out
System.setOut(printStream)
val artifacts = extractMavenCoordinates(coordinates)
// Default configuration name for ivy
val ivyConfName = "default"
// set ivy settings for location of cache
val ivySettings: IvySettings = new IvySettings
// Directories for caching downloads through ivy and storing the jars when maven coordinates
// are supplied to spark-submit
val alternateIvyCache = ivyPath.getOrElse("")
val packagesDirectory: File =
if (alternateIvyCache == null || alternateIvyCache.trim.isEmpty) {
new File(ivySettings.getDefaultIvyUserDir, "jars")
} else {
ivySettings.setDefaultIvyUserDir(new File(alternateIvyCache))
ivySettings.setDefaultCache(new File(alternateIvyCache, "cache"))
new File(alternateIvyCache, "jars")
}
// scalastyle:off println
printStream.println(
s"Ivy Default Cache set to: ${ivySettings.getDefaultCache.getAbsolutePath}")
printStream.println(s"The jars for the packages stored in: $packagesDirectory")
// scalastyle:on println
// create a pattern matcher
ivySettings.addMatcher(new GlobPatternMatcher)
// create the dependency resolvers
val repoResolver = createRepoResolvers(remoteRepos, ivySettings)
ivySettings.addResolver(repoResolver)
ivySettings.setDefaultResolver(repoResolver.getName)
val ivy = Ivy.newInstance(ivySettings)
// Set resolve options to download transitive dependencies as well
val resolveOptions = new ResolveOptions
resolveOptions.setTransitive(true)
val retrieveOptions = new RetrieveOptions
// Turn downloading and logging off for testing
if (isTest) {
resolveOptions.setDownload(false)
resolveOptions.setLog(LogOptions.LOG_QUIET)
retrieveOptions.setLog(LogOptions.LOG_QUIET)
} else {
resolveOptions.setDownload(true)
}
// A Module descriptor must be specified. Entries are dummy strings
val md = getModuleDescriptor
// clear ivy resolution from previous launches. The resolution file is usually at
// ~/.ivy2/org.apache.spark-spark-submit-parent-default.xml. In between runs, this file
// leads to confusion with Ivy when the files can no longer be found at the repository
// declared in that file/
val mdId = md.getModuleRevisionId
val previousResolution = new File(ivySettings.getDefaultCache,
s"${mdId.getOrganisation}-${mdId.getName}-$ivyConfName.xml")
if (previousResolution.exists) previousResolution.delete
md.setDefaultConf(ivyConfName)
// Add exclusion rules for Spark and Scala Library
addExclusionRules(ivySettings, ivyConfName, md)
// add all supplied maven artifacts as dependencies
addDependenciesToIvy(md, artifacts, ivyConfName)
exclusions.foreach { e =>
md.addExcludeRule(createExclusion(e + ":*", ivySettings, ivyConfName))
}
// resolve dependencies
val rr: ResolveReport = ivy.resolve(md, resolveOptions)
if (rr.hasError) {
throw new RuntimeException(rr.getAllProblemMessages.toString)
}
// retrieve all resolved dependencies
ivy.retrieve(rr.getModuleDescriptor.getModuleRevisionId,
packagesDirectory.getAbsolutePath + File.separator +
"[organization]_[artifact]-[revision].[ext]",
retrieveOptions.setConfs(Array(ivyConfName)))
resolveDependencyPaths(rr.getArtifacts.toArray, packagesDirectory)
} finally {
System.setOut(sysOut)
}
}
}
private[deploy] def createExclusion(
coords: String,
ivySettings: IvySettings,
ivyConfName: String): ExcludeRule = {
val c = extractMavenCoordinates(coords)(0)
val id = new ArtifactId(new ModuleId(c.groupId, c.artifactId), "*", "*", "*")
val rule = new DefaultExcludeRule(id, ivySettings.getMatcher("glob"), null)
rule.addConfiguration(ivyConfName)
rule
}
}
/**
* Provides an indirection layer for passing arguments as system properties or flags to
* the user's driver program or to downstream launcher tools.
*/
private case class OptionAssigner(
value: String,
clusterManager: Int,
deployMode: Int,
clOption: String = null,
sysProp: String = null)
| sh-cho/cshSpark | deploy/SparkSubmit.scala | Scala | apache-2.0 | 46,264 |
/*
* Scala.js (https://www.scala-js.org/)
*
* Copyright EPFL.
*
* Licensed under Apache License 2.0
* (https://www.apache.org/licenses/LICENSE-2.0).
*
* See the NOTICE file distributed with this work for
* additional information regarding copyright ownership.
*/
/**
* All doc-comments marked as "MDN" are by Mozilla Contributors,
* distributed under the Creative Commons Attribution-ShareAlike license from
* https://developer.mozilla.org/en-US/docs/Web/Reference/API
*/
package scala.scalajs.js
import scala.scalajs.js
import scala.scalajs.js.annotation._
/**
* The JSON object contains methods for converting values to JavaScript Object
* Notation (JSON) and for converting JSON to values.
*
* MDN
*/
@js.native
@JSGlobal
object JSON extends js.Object {
/**
* Parse a string as JSON, optionally transforming the value produced by parsing.
* @param text The string to parse as JSON. See the JSON object for a
* description of JSON syntax.
* @param reviver If a function, prescribes how the value originally produced
* by parsing is transformed, before being returned.
*
* MDN
*/
def parse(text: String,
reviver: js.Function2[js.Any, js.Any, js.Any] = ???): js.Dynamic = js.native
/**
* Convert a value to JSON, optionally replacing values if a replacer function
* is specified, or optionally including only the specified properties if a
* replacer array is specified.
*
* @param value The value to convert to a JSON string.
* @param replacer If a function, transforms values and properties encountered
* while stringifying; if an array, specifies the set of
* properties included in objects in the final string.
* @param space Causes the resulting string to be pretty-printed.
*
* MDN
*/
def stringify(value: js.Any,
replacer: js.Function2[String, js.Any, js.Any] = ???,
space: js.Any = ???): String = js.native
def stringify(value: js.Any, replacer: js.Array[Any]): String = js.native
def stringify(value: js.Any, replacer: js.Array[Any],
space: js.Any): String = js.native
}
| SebsLittleHelpers/scala-js | library/src/main/scala/scala/scalajs/js/JSON.scala | Scala | apache-2.0 | 2,158 |
package com.seanshubin.schulze.persistence
import java.util.{Collection => JavaCollection, List => JavaList, Map => JavaMap}
import scala.collection.JavaConverters._
import datomic.{Connection, Util, Peer}
import com.seanshubin.schulze.persistence.datomic_util.ScalaAdaptor._
object DatomicUtil {
type Ref = Long
type DatomicRow = JavaList[AnyRef]
type DatomicRows = JavaCollection[DatomicRow]
type DatomicTransaction = AnyRef
type DatomicTransactions = JavaList[DatomicTransaction]
def extractString(row: DatomicRow): String = {
if (row.size != 1) throw new RuntimeException("Expected only a single value in the row")
row.get(0).asInstanceOf[String]
}
def extractLong(row: DatomicRow): Long = {
if (row.size != 1) throw new RuntimeException("Expected only a single value in the row")
row.get(0).asInstanceOf[java.lang.Long]
}
def extractLongFromRows(rows: DatomicRows): Long = {
if (rows.size() != 1) throw new RuntimeException("Expected only a single row")
val row = rows.asScala.iterator.next()
if (row.size() != 1) throw new RuntimeException("Expected only a single value in the row")
row.get(0) match {
case x: java.lang.Long => x
case _ => throw new RuntimeException("Expected a value of type long")
}
}
def rowsToStringSet(rows: DatomicRows): Set[String] = {
rows.asScala.map(extractString).toSet
}
def rowsToLongSet(rows: DatomicRows): Set[Long] = {
rows.asScala.map(extractLong).toSet
}
def rowsToIterable(rows: DatomicRows): Iterable[DatomicRow] = rows.asScala
def transactionsToIterable(transactions: DatomicTransactions): Iterable[DatomicTransaction] = transactions.asScala
def tempId() = Peer.tempid(":db.part/user")
def deleteEntities(connection: Connection, entities: Seq[Long]) {
def retractEntity(id: Long) = Seq(":db.fn/retractEntity", id)
val retractEntityTransactions = entities.map(retractEntity)
transact(connection, retractEntityTransactions).get()
}
}
| SeanShubin/schulze | persistence/src/main/scala/com/seanshubin/schulze/persistence/DatomicUtil.scala | Scala | unlicense | 1,995 |
package org.salgo.geometry.structures
import org.salgo.common.Comparison
case class Point2D(x: Double, y: Double) {
def + (toAdd: Point2D) : Vector2D = {
Vector2D(this.x + toAdd.x, this.y + toAdd.y)
}
def - (subtrahend: Point2D) : Vector2D = {
Vector2D(this.x - subtrahend.x, this.y - subtrahend.y)
}
def toVector : Vector2D = {
Vector2D(this.x, this.y)
}
def distance(other: Point2D) : Double = {
(other - this).magnitude()
}
def isInTriangle(a: Point2D, b: Point2D, c: Point2D, epsilon: Double) : Boolean = {
val epsilonSquare = epsilon * epsilon
if (!this.isInTriangleBoundingBox(a, b, c, epsilon)) false
else if (this.isInTriangleByDotProduct(a, b, c)) true
else if (this.distanceSquarePointToSegment(a, b) <= epsilonSquare) true
else if (this.distanceSquarePointToSegment(b, c) <= epsilonSquare) true
else if (this.distanceSquarePointToSegment(c, a) <= epsilonSquare) true
else false
}
def isInTriangleBoundingBox(a: Point2D, b: Point2D, c: Point2D, epsilon: Double) : Boolean = {
if (this.x < math.min(a.x, math.min(b.x, c.x)) - epsilon) false
else if (this.x > math.max(a.x, math.max(b.x, c.x)) + epsilon) false
else if (this.y < math.min(a.y, math.min(b.y, c.y)) - epsilon) false
else if (this.y > math.max(a.y, math.max(b.y, c.y)) + epsilon) false
else true
}
def isInTriangleByDotProduct(a: Point2D, b: Point2D, c: Point2D) : Boolean = {
val ab = this.side(a, b)
val bc = this.side(b, c)
val ca = this.side(c, a)
(ab > 0 && bc > 0 && ca > 0) || (ab < 0 && bc < 0 && ca < 0)
}
private def side(a: Point2D, b: Point2D) : Double = {
(b.y - a.y) * (this.x - a.x) + (a.x - b.x) * (this.y - a.y)
}
private def distanceSquarePointToSegment(a: Point2D, b: Point2D) : Double = {
val va = a.toVector
val vb = b.toVector
val vThis = this.toVector
val vab = vb - va
val vthisa = vThis - va
val lengthSquareAB = vab scalarProduct vab
val dotProduct = (vthisa scalarProduct vab) / lengthSquareAB
if (dotProduct < 0) {
vthisa scalarProduct vthisa
}
else if (dotProduct <= 1) {
val vathis = va - vThis
(vathis scalarProduct vathis) - (dotProduct * dotProduct) * lengthSquareAB
}
else {
val vthisb = vThis - vb
vthisb scalarProduct vthisb
}
}
}
object Point2D {
def apply(coordinates: (Double, Double)*) : Traversable[Point2D] = {
coordinates.foldLeft(Seq[Point2D]())((seq, c) => seq :+ Point2D(c._1, c._2))
}
def areInClockwiseOrder(p1: Point2D, p2: Point2D, p3: Point2D) : Boolean = {
Comparison.isApproximatelyEqualOrSmaller(this.vectorDeterminantResult(p1, p2, p3), 0d)
}
def areInCounterClockwiseOrder(p1: Point2D, p2: Point2D, p3: Point2D) : Boolean = {
Comparison.isApproximatelyEqualOrGreater(this.vectorDeterminantResult(p1, p2, p3), 0d)
}
def areInCollinearOrder(p1: Point2D, p2: Point2D, p3: Point2D) : Boolean = {
Comparison.isApproximatelyEqual(this.vectorDeterminantResult(p1, p2, p3), 0d)
}
def vectorDeterminantResult(p1: Point2D, p2: Point2D, p3: Point2D) : Double = {
val vector12 = p2 - p1
val vector13 = p3 - p1
vector12.x * vector13.y - vector12.y * vector13.x
}
}
| ascensio/salgo | src/org.salgo/geometry/structures/Point2D.scala | Scala | apache-2.0 | 3,246 |
import sbt._
import sbt.Keys._
import bintray.Plugin._
import bintray.Keys._
object Build extends Build {
val customBintraySettings = bintrayPublishSettings ++ Seq(
packageLabels in bintray := Seq("observable", "try"),
bintrayOrganization in bintray := Some("plasmaconduit"),
repository in bintray := "releases"
)
val root = Project("root", file("."))
.settings(customBintraySettings: _*)
.settings(
name := "try-to-observable",
organization := "com.plasmaconduit",
version := "0.2.0",
scalaVersion := "2.11.2",
licenses += ("MIT", url("http://opensource.org/licenses/MIT")),
scalacOptions += "-feature",
scalacOptions += "-unchecked",
scalacOptions += "-feature",
scalacOptions += "-deprecation",
scalacOptions += "-Xlint",
scalacOptions += "-Xfatal-warnings",
resolvers += "Plasma Conduit Repository" at "http://dl.bintray.com/plasmaconduit/releases",
libraryDependencies += "io.reactivex" % "rxscala_2.11" % "0.23.1"
)
} | plasmaconduit/try-to-observable | project/Build.scala | Scala | mit | 1,149 |
/**
* Swaggy Jenkins
* Jenkins API clients generated from Swagger / Open API specification
*
* The version of the OpenAPI document: 1.1.2-pre.0
* Contact: [email protected]
*
* NOTE: This class is auto generated by OpenAPI Generator (https://openapi-generator.tech).
* https://openapi-generator.tech
* Do not edit the class manually.
*/
package org.openapitools.client.core
import java.util.concurrent.TimeUnit
import akka.actor.{ActorSystem, ExtendedActorSystem, Extension, ExtensionId, ExtensionIdProvider}
import akka.http.scaladsl.model.StatusCodes.CustomStatusCode
import akka.http.scaladsl.model.headers.RawHeader
import com.typesafe.config.Config
import scala.jdk.CollectionConverters._
import scala.concurrent.duration.FiniteDuration
class ApiSettings(config: Config) extends Extension {
def this(system: ExtendedActorSystem) = this(system.settings.config)
private def cfg = config.getConfig("org.openapitools.client.apiRequest")
val alwaysTrustCertificates: Boolean = cfg.getBoolean("trust-certificates")
val defaultHeaders: List[RawHeader] = cfg.getConfig("default-headers").entrySet.asScala.toList.map(c => RawHeader(c.getKey, c.getValue.render))
val connectionTimeout = FiniteDuration(cfg.getDuration("connection-timeout", TimeUnit.MILLISECONDS), TimeUnit.MILLISECONDS)
val compressionEnabled: Boolean = cfg.getBoolean("compression.enabled")
val compressionSizeThreshold: Int = cfg.getBytes("compression.size-threshold").toInt
val customCodes: List[CustomStatusCode] = cfg.getConfigList("custom-codes").asScala.toList.map { c =>
CustomStatusCode(
c.getInt("code"))(
c.getString("reason"),
if (c.hasPath("defaultMessage")) c.getString("defaultMessage") else c.getString("reason"),
c.getBoolean("success"),
if (c.hasPath("allowsEntity")) c.getBoolean("allowsEntity") else true
)
}
}
object ApiSettings extends ExtensionId[ApiSettings] with ExtensionIdProvider {
override def lookup = ApiSettings
override def createExtension(system: ExtendedActorSystem): ApiSettings =
new ApiSettings(system)
// needed to get the type right when used from Java
override def get(system: ActorSystem): ApiSettings = super.get(system)
}
| cliffano/swaggy-jenkins | clients/scala-akka/generated/src/main/scala/org/openapitools/client/core/ApiSettings.scala | Scala | mit | 2,216 |
package breeze.stats
package distributions
import scala.collection.compat._
import breeze.linalg.Axis._1
import breeze.linalg.Counter
import breeze.numerics._
import breeze.optimize.DiffFunction
/*
Copyright 2009 David Hall, Daniel Ramage
Licensed under the Apache License, Version 2.0 (the "License")
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
/**
* A Bernoulli distribution represents a distribution over weighted coin flips
*
* @author dlwh
* @param p the probability of true
*/
case class Bernoulli(p: Double)(implicit rand: RandBasis)
extends DiscreteDistr[Boolean]
with Moments[Double, Double] {
require(p >= 0.0)
require(p <= 1.0)
def probabilityOf(b: Boolean) = if (b) p else (1 - p)
override def draw() = {
rand.uniform.draw() < p
}
override def toString() = "Bernoulli(" + p + ")"
def mean = p
def variance = p * (1 - p)
def mode = I(p >= 0.5)
def entropy = -p * math.log(p) - (1 - p) * math.log1p(-p)
}
object Bernoulli extends ExponentialFamily[Bernoulli, Boolean] with HasConjugatePrior[Bernoulli, Boolean] {
type ConjugatePrior = Beta
val conjugateFamily: Beta.type = Beta
override def predictive(parameter: Beta.Parameter)(implicit basis: RandBasis) = new Polya(Counter(true -> parameter._1, false -> parameter._2))
override def posterior(prior: Beta.Parameter, evidence: IterableOnce[Boolean]) = {
evidence.foldLeft(prior) { (acc, ev) =>
if (ev) acc.copy(_1 = acc._1 + 1)
else acc.copy(_2 = acc._2 + 1)
}
}
type Parameter = Double
case class SufficientStatistic(numYes: Double, n: Double)
extends distributions.SufficientStatistic[SufficientStatistic] {
def *(weight: Double) = SufficientStatistic(numYes * weight, n * weight)
def +(t: SufficientStatistic) = SufficientStatistic(numYes + t.numYes, n + t.n)
}
def emptySufficientStatistic = SufficientStatistic(0, 0)
def sufficientStatisticFor(t: Boolean) = SufficientStatistic(I(t), 1)
def mle(stats: SufficientStatistic) = stats.numYes / stats.n
override def distribution(p: Double)(implicit rand: RandBasis) = new Bernoulli(p)
def likelihoodFunction(stats: SufficientStatistic) = new DiffFunction[Double] {
val SufficientStatistic(yes, num) = stats
val no = num - yes
def calculate(p: Double) = {
import math._
val obj = yes * log(p) + no * log1p(-p)
val grad = yes / p - no / (1 - p)
(-obj, -grad)
}
}
}
| scalanlp/breeze | math/src/main/scala/breeze/stats/distributions/Bernoulli.scala | Scala | apache-2.0 | 2,855 |
package com.github.ldaniels528.trifecta.modules.etl
import java.io.File
import org.slf4j.LoggerFactory
import scala.concurrent.ExecutionContext
import scala.concurrent.duration._
/**
* Story Processor
* @author [email protected]
*/
class StoryProcessor() {
private val logger = LoggerFactory.getLogger(getClass)
def load(configFile: File) = {
logger.info(s"Loading Broadway story config '${configFile.getAbsolutePath}'...")
StoryConfigParser.parse(configFile)
}
def run(configFile: File)(implicit ec: ExecutionContext): Unit = load(configFile) foreach run
/**
* Executes the ETL processing
* @param story the given [[StoryConfig ETL configuration]]
*/
def run(story: StoryConfig)(implicit ec: ExecutionContext) {
logger.info(s"Executing story '${story.id}'...")
story.triggers foreach (_.execute(story))
Thread.sleep(1.seconds.toMillis)
logger.info("*" * 30 + " PROCESS COMPLETED " + "*" * 30)
}
}
| ldaniels528/trifecta | app-modules/etl/src/main/scala/com/github/ldaniels528/trifecta/modules/etl/StoryProcessor.scala | Scala | apache-2.0 | 972 |
package com.sksamuel.elastic4s
import org.scalatest.{ FlatSpec, OneInstancePerTest }
import org.scalatest.mock.MockitoSugar
import ElasticDsl._
/** @author Stephen Samuel */
class PercolateDslTest extends FlatSpec with MockitoSugar with JsonSugar with OneInstancePerTest {
"the percolate dsl" should "should generate json for a register query" in {
val req = register id 2 into "captains" query termQuery("name", "cook") fields { "color" -> "blue" }
req.build.source.toUtf8 should matchJsonResource("/json/percolate/percolate_register.json")
}
it should "should generate fields json for a percolate request" in {
val req = percolate in "captains" doc "name" -> "cook" query { termQuery("color" -> "blue") }
req._doc.string should matchJsonResource("/json/percolate/percolate_request.json")
}
it should "should use raw doc for a percolate request" in {
val req = percolate in "captains" rawDoc { """{ "name": "cook" }""" } query { termQuery("color" -> "blue") }
req._doc.string should matchJsonResource("/json/percolate/percolate_request.json")
}
}
| l15k4/elastic4s | elastic4s-core/src/test/scala/com/sksamuel/elastic4s/PercolateDslTest.scala | Scala | apache-2.0 | 1,089 |
package argonaut
import scala.math.{ Ordering => ScalaOrdering }
import scala.collection.generic.CanBuildFrom
import scala.collection.immutable.{ SortedSet, SortedMap, MapLike }
import scala.util.control.Exception.catching
import scalaz._, std.string._, syntax.either._, syntax.applicative._
import Json._
trait DecodeJson[A] {
/**
* Decode the given hcursor. Alias for `decode`.
*/
def apply(c: HCursor): DecodeResult[A] = decode(c)
/**
* Decode the given hcursor.
*/
def decode(c: HCursor): DecodeResult[A]
/**
* Decode the given acursor.
*/
def tryDecode(c: ACursor): DecodeResult[A] = c.either match {
case -\\/(invalid) => DecodeResult.fail("Attempt to decode value on failed cursor.", invalid.history)
case \\/-(valid) => decode(valid)
}
/**
* Decode the given json.
*/
def decodeJson(j: Json): DecodeResult[A] = decode(j.hcursor)
/**
* Covariant functor.
*/
def map[B](f: A => B): DecodeJson[B] = {
def thisDecode = decode(_)
def thisTryDecode = tryDecode(_)
new DecodeJson[B] {
override def decode(c: HCursor): DecodeResult[B] = {
thisDecode(c).map(f)
}
override def tryDecode(c: ACursor): DecodeResult[B] = {
thisTryDecode(c).map(f)
}
}
}
/**
* Monad.
*/
def flatMap[B](f: A => DecodeJson[B]): DecodeJson[B] = {
def thisDecode = decode(_)
def thisTryDecode = tryDecode(_)
new DecodeJson[B] {
override def decode(c: HCursor): DecodeResult[B] = {
thisDecode(c).flatMap(a => f(a).decode(c))
}
override def tryDecode(c: ACursor): DecodeResult[B] = {
thisTryDecode(c).flatMap(a => f(a).tryDecode(c))
}
}
}
/**
* Build a new DecodeJson codec with the specified name.
*/
def setName(n: String): DecodeJson[A] = {
DecodeJson(c => apply(c).result.fold(
{ case (_, h) => DecodeResult.fail(n, h) },
a => DecodeResult.ok(a)
))
}
/**
* Build a new DecodeJson codec with the specified precondition that f(c) == true.
*/
def validate(f: HCursor => Boolean, message: => String) = {
DecodeJson(c => if (f(c)) apply(c) else DecodeResult.fail[A](message, c.history))
}
/**
* Build a new DecodeJson codec with the precondition that the cursor focus is object with exactly n field.
*/
def validateFields(n: Int) = {
validate(_.focus.obj exists (_.size == n), "Expected json object with exactly [" + n + "] fields.")
}
/**
* Isomorphism to kleisli.
*/
def kleisli: Kleisli[DecodeResult, HCursor, A] = Kleisli(apply(_))
/**
* Combine two decoders.
*/
def &&&[B](x: DecodeJson[B]): DecodeJson[(A, B)] = {
DecodeJson(j => for {
a <- this(j)
b <- x(j)
} yield (a, b))
}
/**
* Choose the first succeeding decoder.
*/
def |||[AA >: A](x: => DecodeJson[AA]): DecodeJson[AA] = {
DecodeJson[AA](c => {
val q = apply(c).map(a => a: AA)
q.result.fold(_ => x(c), _ => q)
})
}
/**
* Run one or another decoder.
*/
def split[B](x: DecodeJson[B]): HCursor \\/ HCursor => DecodeResult[A \\/ B] = {
c => c.fold(a => this(a) map (_.left), a => x(a) map (_.right))
}
/**
* Run two decoders.
*/
def product[B](x: DecodeJson[B]): (HCursor, HCursor) => DecodeResult[(A, B)] = {
case (a1, a2) => for {
a <- this(a1)
b <- x(a2)
} yield (a, b)
}
}
object DecodeJson extends DecodeJsons {
def apply[A](r: HCursor => DecodeResult[A]): DecodeJson[A] = {
new DecodeJson[A] {
def decode(c: HCursor) = r(c)
}
}
def withReattempt[A](r: ACursor => DecodeResult[A]): DecodeJson[A] = {
new DecodeJson[A] {
def decode(c: HCursor): DecodeResult[A] = tryDecode(c.acursor)
override def tryDecode(c: ACursor) = r(c)
}
}
def derive[A]: DecodeJson[A] = macro internal.Macros.materializeDecodeImpl[A]
def of[A: DecodeJson] = implicitly[DecodeJson[A]]
def fromParser[A : DecodeJson, B](parser: A => String \\/ B): DecodeJson[B] =
implicitly[DecodeJson[A]].flatMap(s => DecodeJson(h => DecodeResult.fromDisjunction(parser(s), h.history)))
}
trait DecodeJsons extends GeneratedDecodeJsons {
def optionDecoder[A](k: Json => Option[A], e: String): DecodeJson[A] = {
DecodeJson(a => k(a.focus) match {
case None => DecodeResult.fail(e, a.history)
case Some(w) => DecodeResult.ok(w)
})
}
/**
* Construct a succeeding decoder from the given function.
*/
def decodeArr[A](f: HCursor => A): DecodeJson[A] = DecodeJson(j => DecodeResult.ok(f(j)))
def tryTo[A](f: => A): Option[A] = catching(classOf[IllegalArgumentException]).opt(f)
implicit def HCursorDecodeJson: DecodeJson[HCursor] = decodeArr(q => q)
implicit def JsonDecodeJson: DecodeJson[Json] = decodeArr(j => j.focus)
implicit def CanBuildFromDecodeJson[A, C[_]](implicit e: DecodeJson[A], c: CanBuildFrom[Nothing, A, C[A]]): DecodeJson[C[A]] = {
DecodeJson(a =>
a.downArray.hcursor match {
case None =>
if (a.focus.isArray)
DecodeResult.ok(c.apply.result)
else
DecodeResult.fail("[A]List[A]", a.history)
case Some(hcursor) =>
hcursor.traverseDecode(c.apply)(_.right, (acc, c) =>
c.jdecode[A] map (acc += _)).map(_.result)
})
}
implicit def UnitDecodeJson: DecodeJson[Unit] = {
DecodeJson{a =>
if (a.focus.isNull || a.focus == jEmptyObject || a.focus == jEmptyArray) {
().point[DecodeResult]
} else {
DecodeResult.fail("Unit", a.history)
}
}
}
implicit def StringDecodeJson: DecodeJson[String] = optionDecoder(_.string, "String")
implicit def DoubleDecodeJson: DecodeJson[Double] = {
optionDecoder(x => {
if (x.isNull) {
Some(Double.NaN)
} else {
x.number.map(_.toDouble).orElse(x.string.flatMap(s => tryTo(s.toDouble)))
}
}, "Double")
}
implicit def FloatDecodeJson: DecodeJson[Float] = {
optionDecoder(x => if(x.isNull) Some(Float.NaN) else x.number.map(_.toFloat), "Float")
}
implicit def IntDecodeJson: DecodeJson[Int] = {
optionDecoder(x =>
(x.number map (_.truncateToInt)).orElse(
(x.string flatMap (s => tryTo(s.toInt)))), "Int")
}
implicit def LongDecodeJson: DecodeJson[Long] = {
optionDecoder(x =>
(x.number map (_.truncateToLong)).orElse(
(x.string flatMap (s => tryTo(s.toLong)))), "Long")
}
implicit def ShortDecodeJson: DecodeJson[Short] = {
optionDecoder(x =>
(x.number map (_.truncateToShort)).orElse(
(x.string flatMap (s => tryTo(s.toShort)))), "Short")
}
implicit def ByteDecodeJson: DecodeJson[Byte] = {
optionDecoder(x =>
(x.number map (_.truncateToByte)).orElse(
(x.string flatMap (s => tryTo(s.toByte)))), "Byte")
}
implicit def BigIntDecodeJson: DecodeJson[BigInt] = {
optionDecoder(x =>
(x.number map (_.truncateToBigInt)).orElse(
(x.string flatMap (s => tryTo(BigInt(s))))), "BigInt")
}
implicit def BigDecimalDecodeJson: DecodeJson[BigDecimal] = {
optionDecoder(x =>
(x.number map (_.toBigDecimal)).orElse(
(x.string flatMap (s => tryTo(BigDecimal(s))))), "BigDecimal")
}
implicit def BooleanDecodeJson: DecodeJson[Boolean] = {
optionDecoder(_.bool, "Boolean")
}
implicit def CharDecodeJson: DecodeJson[Char] = {
optionDecoder(_.string flatMap (s => if(s.length == 1) Some(s(0)) else None), "Char")
}
implicit def JDoubleDecodeJson: DecodeJson[java.lang.Double] = {
optionDecoder(_.number map (_.toDouble), "java.lang.Double")
}
implicit def JFloatDecodeJson: DecodeJson[java.lang.Float] = {
optionDecoder(_.number map (_.toFloat), "java.lang.Float")
}
implicit def JIntegerDecodeJson: DecodeJson[java.lang.Integer] = {
optionDecoder(_.number flatMap (s => tryTo(s.truncateToInt)), "java.lang.Integer")
}
implicit def JLongDecodeJson: DecodeJson[java.lang.Long] = {
optionDecoder(_.number flatMap (s => tryTo(s.truncateToLong)), "java.lang.Long")
}
implicit def JShortDecodeJson: DecodeJson[java.lang.Short] = {
optionDecoder(_.number flatMap (s => tryTo(s.truncateToShort)), "java.lang.Short")
}
implicit def JByteDecodeJson: DecodeJson[java.lang.Byte] = {
optionDecoder(_.number flatMap (s => tryTo(s.truncateToByte)), "java.lang.Byte")
}
implicit def JBooleanDecodeJson: DecodeJson[java.lang.Boolean] = {
optionDecoder(_.bool map (q => q), "java.lang.Boolean")
}
implicit def JCharacterDecodeJson: DecodeJson[java.lang.Character] = {
optionDecoder(_.string flatMap (s => if(s.length == 1) Some(s(0)) else None), "java.lang.Character")
}
implicit def OptionDecodeJson[A](implicit e: DecodeJson[A]): DecodeJson[Option[A]] = {
DecodeJson.withReattempt(a => a.success match {
case None => DecodeResult.ok(None)
case Some(valid) => {
if (valid.focus.isNull) {
DecodeResult.ok(None)
} else {
e(valid).option
}
}
})
}
implicit def MaybeDecodeJson[A](implicit e: DecodeJson[A]): DecodeJson[Maybe[A]] = {
implicitly[DecodeJson[Option[A]]].map(Maybe.fromOption)
}
implicit def ScalazEitherDecodeJson[A, B](implicit ea: DecodeJson[A], eb: DecodeJson[B]): DecodeJson[A \\/ B] = {
implicitly[DecodeJson[Either[A, B]]].map(\\/.fromEither(_))
}
implicit def EitherDecodeJson[A, B](implicit ea: DecodeJson[A], eb: DecodeJson[B]): DecodeJson[Either[A, B]] = {
DecodeJson(a => {
val l = (a --\\ "Left").success
val r = (a --\\ "Right").success
(l, r) match {
case (Some(c), None) => ea(c) map (Left(_))
case (None, Some(c)) => eb(c) map (Right(_))
case _ => DecodeResult.fail("[A, B]Either[A, B]", a.history)
}
})
}
implicit def ValidationDecodeJson[A, B](implicit ea: DecodeJson[A], eb: DecodeJson[B]): DecodeJson[Validation[A, B]] = {
DecodeJson(a => {
val l = (a --\\ "Failure").success
val r = (a --\\ "Success").success
(l, r) match {
case (Some(c), None) => ea(c) map (Failure(_))
case (None, Some(c)) => eb(c) map (Success(_))
case _ => DecodeResult.fail("[A, B]Validation[A, B]", a.history)
}
})
}
implicit def MapDecodeJson[M[K, +V] <: Map[K, V], V](implicit e: DecodeJson[V], cbf: CanBuildFrom[Nothing, (String, V), M[String, V]]): DecodeJson[M[String, V]] = {
DecodeJson(a =>
a.fields match {
case None => DecodeResult.fail("[V]Map[String, V]", a.history)
case Some(s) => {
def spin(x: List[JsonField], acc: DecodeResult[Vector[(String, V)]]): DecodeResult[M[String, V]] =
x match {
case Nil =>
acc.map { fields =>
(cbf() ++= fields).result()
}
case h::t =>
val acc0 = for {
m <- acc
v <- a.get(h)(e)
} yield m :+ (h -> v)
if (acc0.isError) spin(Nil, acc0)
else spin(t, acc0)
}
spin(s, DecodeResult.ok(Vector.empty))
}
}
)
}
implicit def SetDecodeJson[A](implicit e: DecodeJson[A]): DecodeJson[Set[A]] = {
implicitly[DecodeJson[List[A]]] map (_.toSet) setName "[A]Set[A]"
}
implicit def IMapDecodeJson[A: DecodeJson: Order]: DecodeJson[String ==>> A] = {
MapDecodeJson[Map, A].map(a => ==>>.fromList(a.toList)) setName "[A]==>>[String, A]"
}
implicit def IListDecodeJson[A: DecodeJson]: DecodeJson[IList[A]] = {
implicitly[DecodeJson[List[A]]] map (IList.fromList) setName "[A]IList[A]"
}
implicit def DListDecodeJson[A: DecodeJson]: DecodeJson[DList[A]] = {
implicitly[DecodeJson[List[A]]] map (DList.fromList(_)) setName "[A]DList[A]"
}
implicit def EphemeralStreamDecodeJson[A: DecodeJson]: DecodeJson[EphemeralStream[A]] = {
implicitly[DecodeJson[List[A]]] map (list => EphemeralStream.apply(list: _*)) setName "[A]EphemeralStream[A]"
}
implicit def ISetDecodeJson[A: DecodeJson: Order]: DecodeJson[ISet[A]] = {
implicitly[DecodeJson[List[A]]] map (ISet.fromList(_)) setName "[A]ISet[A]"
}
implicit def NonEmptyListDecodeJson[A: DecodeJson]: DecodeJson[NonEmptyList[A]] = {
implicitly[DecodeJson[List[A]]] flatMap (l =>
DecodeJson[NonEmptyList[A]](c => std.list.toNel(l) match {
case None => DecodeResult.fail("[A]NonEmptyList[A]", c.history)
case Some(n) => DecodeResult.ok(n)
})
) setName "[A]NonEmptyList[A]"
}
}
| etorreborre/argonaut | src/main/scala/argonaut/DecodeJson.scala | Scala | bsd-3-clause | 12,525 |
package com.zobot.client.packet.definitions.serverbound.login
import com.zobot.client.packet.Packet
case class EncryptionResponse(sharedSecretLength: Int, sharedSecret: Any, verifyTokenLength: Int, verifyToken: Any) extends Packet {
override lazy val packetId = 0x01
override lazy val packetData: Array[Byte] =
fromVarInt(sharedSecretLength) ++
fromAny(sharedSecret) ++
fromVarInt(verifyTokenLength) ++
fromAny(verifyToken)
}
| BecauseNoReason/zobot | src/main/scala/com/zobot/client/packet/definitions/serverbound/login/EncryptionResponse.scala | Scala | mit | 449 |
/* Copyright 2009-2016 EPFL, Lausanne */
import leon.lang._
import leon.annotation._
object SearchLinkedList {
sealed abstract class List
case class Cons(head : BigInt, tail : List) extends List
case class Nil() extends List
def size(list : List) : BigInt = (list match {
case Nil() => BigInt(0)
case Cons(_, xs) => 1 + size(xs)
}) ensuring(_ >= 0)
def contains(list : List, elem : BigInt) : Boolean = (list match {
case Nil() => false
case Cons(x, xs) => x == elem || contains(xs, elem)
})
def firstZero(list : List) : BigInt = (list match {
case Nil() => BigInt(0)
case Cons(x, xs) => if (x == 0) BigInt(0) else firstZero(xs) + 1
}) ensuring (res =>
res >= 0 && (if (contains(list, 0)) {
firstZeroAtPos(list, res)
} else {
res == size(list)
}))
def firstZeroAtPos(list : List, pos : BigInt) : Boolean = {
list match {
case Nil() => false
case Cons(x, xs) => if (pos == BigInt(0)) x == 0 else x != 0 && firstZeroAtPos(xs, pos - 1)
}
}
def goal(list : List, i : BigInt) : Boolean = {
if(firstZero(list) == i) {
if(contains(list, 0)) {
firstZeroAtPos(list, i)
} else {
i == size(list)
}
} else {
true
}
}.holds
}
| regb/leon | src/test/resources/regression/verification/newsolvers/valid/SearchLinkedList.scala | Scala | gpl-3.0 | 1,266 |
object exec{
trait Runner[T]{
def run(t: T): Unit
}
object Runner{
def run[T: Runner](t: T): Unit = implicitly[Runner[T]].run(t)
implicit inline def runImplicitly[T]: Runner[T] = new {
def run(t: T) = List(()).map(x => x).head // <<<
}
}
}
| dotty-staging/dotty | tests/pos/i5793/A.scala | Scala | apache-2.0 | 270 |
def mapper(l: List[AnyRef], f: (AnyRef) => Any) = {
l.map(f(_))
}
println(mapper("a" :: "b" :: Nil,
(x:AnyRef) => x.getClass))
// println(mapper("a" :: "b" :: Nil,
// (x:String) => x.toUpperCase))
println(mapper("a" :: "b" :: Nil,
(x:Any) => x.isInstanceOf[Int]))
println(mapper("a" :: "b" :: Nil,
(x:Any) => x.toString))
| deanwampler/SeductionsOfScalaTutorial | code-examples/mapper.scala | Scala | apache-2.0 | 339 |
package org.jetbrains.sbt.shell
/**
* Created by Roman.Shein on 13.04.2017.
*/
trait CommunicationListener {
def onCommandQueued(command: String): Unit
def onCommandPolled(command: String): Unit
def onCommandFinished(command: String): Unit
}
| ilinum/intellij-scala | src/org/jetbrains/sbt/shell/CommunicationListener.scala | Scala | apache-2.0 | 253 |
package exercises.ch03
object Ex12 {
def reverse[A](as: List[A]): List[A] = List.foldLeft(as, List[A]())((l, a) => Cons(a, l))
def main(args: Array[String]): Unit = {
println(reverse(List()))
println(reverse(List(1)))
println(reverse(List(1,2)))
println(reverse(List(1,2,3)))
println(reverse(List(1,2,3,4)))
// foldLeft(List(1,2,3,4), Nil) ->
// foldLeft(List(2,3,4), Cons(1,Nil))
// foldLeft(List(3,4), Cons(2,Cons(1,Nil))
// foldLeft(List(4), Cons(3,Cons(2,Cons(1,Nil)))
// foldLeft(Nil, Cons(4,Cons(3,Cons(2,Cons(1,Nil))))
// Cons(4,Cons(3,Cons(2,Cons(1,Nil)))
}
}
| VladMinzatu/fpinscala-exercises | src/main/scala/exercises/ch03/Ex12.scala | Scala | mit | 621 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.execution
import java.io.{ByteArrayInputStream, ByteArrayOutputStream, DataInputStream, DataOutputStream}
import java.util.concurrent.atomic.AtomicInteger
import scala.collection.mutable.{ArrayBuffer, ListBuffer}
import org.apache.spark.{broadcast, SparkEnv}
import org.apache.spark.internal.Logging
import org.apache.spark.io.CompressionCodec
import org.apache.spark.rdd.{RDD, RDDOperationScope}
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.catalyst.{CatalystTypeConverters, InternalRow}
import org.apache.spark.sql.catalyst.expressions._
import org.apache.spark.sql.catalyst.plans.QueryPlan
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
import org.apache.spark.sql.catalyst.plans.physical._
import org.apache.spark.sql.catalyst.trees.{BinaryLike, LeafLike, TreeNodeTag, UnaryLike}
import org.apache.spark.sql.errors.QueryExecutionErrors
import org.apache.spark.sql.execution.metric.SQLMetric
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.vectorized.ColumnarBatch
object SparkPlan {
/** The original [[LogicalPlan]] from which this [[SparkPlan]] is converted. */
val LOGICAL_PLAN_TAG = TreeNodeTag[LogicalPlan]("logical_plan")
/** The [[LogicalPlan]] inherited from its ancestor. */
val LOGICAL_PLAN_INHERITED_TAG = TreeNodeTag[LogicalPlan]("logical_plan_inherited")
private val nextPlanId = new AtomicInteger(0)
/** Register a new SparkPlan, returning its SparkPlan ID */
private[execution] def newPlanId(): Int = nextPlanId.getAndIncrement()
}
/**
* The base class for physical operators.
*
* The naming convention is that physical operators end with "Exec" suffix, e.g. [[ProjectExec]].
*/
abstract class SparkPlan extends QueryPlan[SparkPlan] with Logging with Serializable {
@transient final val session = SparkSession.getActiveSession.orNull
protected def sparkContext = session.sparkContext
override def conf: SQLConf = {
if (session != null) {
session.sessionState.conf
} else {
super.conf
}
}
val id: Int = SparkPlan.newPlanId()
/**
* Return true if this stage of the plan supports columnar execution.
*/
def supportsColumnar: Boolean = false
/**
* The exact java types of the columns that are output in columnar processing mode. This
* is a performance optimization for code generation and is optional.
*/
def vectorTypes: Option[Seq[String]] = None
/** Overridden make copy also propagates sqlContext to copied plan. */
override def makeCopy(newArgs: Array[AnyRef]): SparkPlan = {
if (session != null) {
session.withActive(super.makeCopy(newArgs))
} else {
super.makeCopy(newArgs)
}
}
/**
* @return The logical plan this plan is linked to.
*/
def logicalLink: Option[LogicalPlan] =
getTagValue(SparkPlan.LOGICAL_PLAN_TAG)
.orElse(getTagValue(SparkPlan.LOGICAL_PLAN_INHERITED_TAG))
/**
* Set logical plan link recursively if unset.
*/
def setLogicalLink(logicalPlan: LogicalPlan): Unit = {
setLogicalLink(logicalPlan, false)
}
private def setLogicalLink(logicalPlan: LogicalPlan, inherited: Boolean = false): Unit = {
// Stop at a descendant which is the root of a sub-tree transformed from another logical node.
if (inherited && getTagValue(SparkPlan.LOGICAL_PLAN_TAG).isDefined) {
return
}
val tag = if (inherited) {
SparkPlan.LOGICAL_PLAN_INHERITED_TAG
} else {
SparkPlan.LOGICAL_PLAN_TAG
}
setTagValue(tag, logicalPlan)
children.foreach(_.setLogicalLink(logicalPlan, true))
}
/**
* @return All metrics containing metrics of this SparkPlan.
*/
def metrics: Map[String, SQLMetric] = Map.empty
/**
* Resets all the metrics.
*/
def resetMetrics(): Unit = {
metrics.valuesIterator.foreach(_.reset())
children.foreach(_.resetMetrics())
}
/**
* @return [[SQLMetric]] for the `name`.
*/
def longMetric(name: String): SQLMetric = metrics(name)
// TODO: Move to `DistributedPlan`
/**
* Specifies how data is partitioned across different nodes in the cluster.
* Note this method may fail if it is invoked before `EnsureRequirements` is applied
* since `PartitioningCollection` requires all its partitionings to have
* the same number of partitions.
*/
def outputPartitioning: Partitioning = UnknownPartitioning(0) // TODO: WRONG WIDTH!
/**
* Specifies the data distribution requirements of all the children for this operator. By default
* it's [[UnspecifiedDistribution]] for each child, which means each child can have any
* distribution.
*
* If an operator overwrites this method, and specifies distribution requirements(excluding
* [[UnspecifiedDistribution]] and [[BroadcastDistribution]]) for more than one child, Spark
* guarantees that the outputs of these children will have same number of partitions, so that the
* operator can safely zip partitions of these children's result RDDs. Some operators can leverage
* this guarantee to satisfy some interesting requirement, e.g., non-broadcast joins can specify
* HashClusteredDistribution(a,b) for its left child, and specify HashClusteredDistribution(c,d)
* for its right child, then it's guaranteed that left and right child are co-partitioned by
* a,b/c,d, which means tuples of same value are in the partitions of same index, e.g.,
* (a=1,b=2) and (c=1,d=2) are both in the second partition of left and right child.
*/
def requiredChildDistribution: Seq[Distribution] =
Seq.fill(children.size)(UnspecifiedDistribution)
/** Specifies how data is ordered in each partition. */
def outputOrdering: Seq[SortOrder] = Nil
/** Specifies sort order for each partition requirements on the input data for this operator. */
def requiredChildOrdering: Seq[Seq[SortOrder]] = Seq.fill(children.size)(Nil)
/**
* Returns the result of this query as an RDD[InternalRow] by delegating to `doExecute` after
* preparations.
*
* Concrete implementations of SparkPlan should override `doExecute`.
*/
final def execute(): RDD[InternalRow] = executeQuery {
if (isCanonicalizedPlan) {
throw new IllegalStateException("A canonicalized plan is not supposed to be executed.")
}
doExecute()
}
/**
* Returns the result of this query as a broadcast variable by delegating to `doExecuteBroadcast`
* after preparations.
*
* Concrete implementations of SparkPlan should override `doExecuteBroadcast`.
*/
final def executeBroadcast[T](): broadcast.Broadcast[T] = executeQuery {
if (isCanonicalizedPlan) {
throw new IllegalStateException("A canonicalized plan is not supposed to be executed.")
}
doExecuteBroadcast()
}
/**
* Returns the result of this query as an RDD[ColumnarBatch] by delegating to `doColumnarExecute`
* after preparations.
*
* Concrete implementations of SparkPlan should override `doColumnarExecute` if `supportsColumnar`
* returns true.
*/
final def executeColumnar(): RDD[ColumnarBatch] = executeQuery {
if (isCanonicalizedPlan) {
throw new IllegalStateException("A canonicalized plan is not supposed to be executed.")
}
doExecuteColumnar()
}
/**
* Executes a query after preparing the query and adding query plan information to created RDDs
* for visualization.
*/
protected final def executeQuery[T](query: => T): T = {
RDDOperationScope.withScope(sparkContext, nodeName, false, true) {
prepare()
waitForSubqueries()
query
}
}
/**
* List of (uncorrelated scalar subquery, future holding the subquery result) for this plan node.
* This list is populated by [[prepareSubqueries]], which is called in [[prepare]].
*/
@transient
private val runningSubqueries = new ArrayBuffer[ExecSubqueryExpression]
/**
* Finds scalar subquery expressions in this plan node and starts evaluating them.
*/
protected def prepareSubqueries(): Unit = {
expressions.foreach {
_.collect {
case e: ExecSubqueryExpression =>
e.plan.prepare()
runningSubqueries += e
}
}
}
/**
* Blocks the thread until all subqueries finish evaluation and update the results.
*/
protected def waitForSubqueries(): Unit = synchronized {
// fill in the result of subqueries
runningSubqueries.foreach { sub =>
sub.updateResult()
}
runningSubqueries.clear()
}
/**
* Whether the "prepare" method is called.
*/
private var prepared = false
/**
* Prepares this SparkPlan for execution. It's idempotent.
*/
final def prepare(): Unit = {
// doPrepare() may depend on it's children, we should call prepare() on all the children first.
children.foreach(_.prepare())
synchronized {
if (!prepared) {
prepareSubqueries()
doPrepare()
prepared = true
}
}
}
/**
* Overridden by concrete implementations of SparkPlan. It is guaranteed to run before any
* `execute` of SparkPlan. This is helpful if we want to set up some state before executing the
* query, e.g., `BroadcastHashJoin` uses it to broadcast asynchronously.
*
* @note `prepare` method has already walked down the tree, so the implementation doesn't have
* to call children's `prepare` methods.
*
* This will only be called once, protected by `this`.
*/
protected def doPrepare(): Unit = {}
/**
* Produces the result of the query as an `RDD[InternalRow]`
*
* Overridden by concrete implementations of SparkPlan.
*/
protected def doExecute(): RDD[InternalRow]
/**
* Produces the result of the query as a broadcast variable.
*
* Overridden by concrete implementations of SparkPlan.
*/
protected[sql] def doExecuteBroadcast[T](): broadcast.Broadcast[T] = {
throw QueryExecutionErrors.doExecuteBroadcastNotImplementedError(nodeName)
}
/**
* Produces the result of the query as an `RDD[ColumnarBatch]` if [[supportsColumnar]] returns
* true. By convention the executor that creates a ColumnarBatch is responsible for closing it
* when it is no longer needed. This allows input formats to be able to reuse batches if needed.
*/
protected def doExecuteColumnar(): RDD[ColumnarBatch] = {
throw new IllegalStateException(s"Internal Error ${this.getClass} has column support" +
s" mismatch:\\n${this}")
}
/**
* Packing the UnsafeRows into byte array for faster serialization.
* The byte arrays are in the following format:
* [size] [bytes of UnsafeRow] [size] [bytes of UnsafeRow] ... [-1]
*
* UnsafeRow is highly compressible (at least 8 bytes for any column), the byte array is also
* compressed.
*/
private def getByteArrayRdd(
n: Int = -1, takeFromEnd: Boolean = false): RDD[(Long, Array[Byte])] = {
execute().mapPartitionsInternal { iter =>
var count = 0
val buffer = new Array[Byte](4 << 10) // 4K
val codec = CompressionCodec.createCodec(SparkEnv.get.conf)
val bos = new ByteArrayOutputStream()
val out = new DataOutputStream(codec.compressedOutputStream(bos))
if (takeFromEnd && n > 0) {
// To collect n from the last, we should anyway read everything with keeping the n.
// Otherwise, we don't know where is the last from the iterator.
var last: Seq[UnsafeRow] = Seq.empty[UnsafeRow]
val slidingIter = iter.map(_.copy()).sliding(n)
while (slidingIter.hasNext) { last = slidingIter.next().asInstanceOf[Seq[UnsafeRow]] }
var i = 0
count = last.length
while (i < count) {
val row = last(i)
out.writeInt(row.getSizeInBytes)
row.writeToStream(out, buffer)
i += 1
}
} else {
// `iter.hasNext` may produce one row and buffer it, we should only call it when the
// limit is not hit.
while ((n < 0 || count < n) && iter.hasNext) {
val row = iter.next().asInstanceOf[UnsafeRow]
out.writeInt(row.getSizeInBytes)
row.writeToStream(out, buffer)
count += 1
}
}
out.writeInt(-1)
out.flush()
out.close()
Iterator((count, bos.toByteArray))
}
}
/**
* Decodes the byte arrays back to UnsafeRows and put them into buffer.
*/
private def decodeUnsafeRows(bytes: Array[Byte]): Iterator[InternalRow] = {
val nFields = schema.length
val codec = CompressionCodec.createCodec(SparkEnv.get.conf)
val bis = new ByteArrayInputStream(bytes)
val ins = new DataInputStream(codec.compressedInputStream(bis))
new Iterator[InternalRow] {
private var sizeOfNextRow = ins.readInt()
override def hasNext: Boolean = sizeOfNextRow >= 0
override def next(): InternalRow = {
val bs = new Array[Byte](sizeOfNextRow)
ins.readFully(bs)
val row = new UnsafeRow(nFields)
row.pointTo(bs, sizeOfNextRow)
sizeOfNextRow = ins.readInt()
row
}
}
}
/**
* Runs this query returning the result as an array.
*/
def executeCollect(): Array[InternalRow] = {
val byteArrayRdd = getByteArrayRdd()
val results = ArrayBuffer[InternalRow]()
byteArrayRdd.collect().foreach { countAndBytes =>
decodeUnsafeRows(countAndBytes._2).foreach(results.+=)
}
results.toArray
}
private[spark] def executeCollectIterator(): (Long, Iterator[InternalRow]) = {
val countsAndBytes = getByteArrayRdd().collect()
val total = countsAndBytes.map(_._1).sum
val rows = countsAndBytes.iterator.flatMap(countAndBytes => decodeUnsafeRows(countAndBytes._2))
(total, rows)
}
/**
* Runs this query returning the result as an iterator of InternalRow.
*
* @note Triggers multiple jobs (one for each partition).
*/
def executeToIterator(): Iterator[InternalRow] = {
getByteArrayRdd().map(_._2).toLocalIterator.flatMap(decodeUnsafeRows)
}
/**
* Runs this query returning the result as an array, using external Row format.
*/
def executeCollectPublic(): Array[Row] = {
val converter = CatalystTypeConverters.createToScalaConverter(schema)
executeCollect().map(converter(_).asInstanceOf[Row])
}
/**
* Runs this query returning the first `n` rows as an array.
*
* This is modeled after `RDD.take` but never runs any job locally on the driver.
*/
def executeTake(n: Int): Array[InternalRow] = executeTake(n, takeFromEnd = false)
/**
* Runs this query returning the last `n` rows as an array.
*
* This is modeled after `RDD.take` but never runs any job locally on the driver.
*/
def executeTail(n: Int): Array[InternalRow] = executeTake(n, takeFromEnd = true)
private def executeTake(n: Int, takeFromEnd: Boolean): Array[InternalRow] = {
if (n == 0) {
return new Array[InternalRow](0)
}
val childRDD = getByteArrayRdd(n, takeFromEnd)
val buf = if (takeFromEnd) new ListBuffer[InternalRow] else new ArrayBuffer[InternalRow]
val totalParts = childRDD.partitions.length
var partsScanned = 0
while (buf.length < n && partsScanned < totalParts) {
// The number of partitions to try in this iteration. It is ok for this number to be
// greater than totalParts because we actually cap it at totalParts in runJob.
var numPartsToTry = 1L
if (partsScanned > 0) {
// If we didn't find any rows after the previous iteration, quadruple and retry.
// Otherwise, interpolate the number of partitions we need to try, but overestimate
// it by 50%. We also cap the estimation in the end.
val limitScaleUpFactor = Math.max(conf.limitScaleUpFactor, 2)
if (buf.isEmpty) {
numPartsToTry = partsScanned * limitScaleUpFactor
} else {
val left = n - buf.length
// As left > 0, numPartsToTry is always >= 1
numPartsToTry = Math.ceil(1.5 * left * partsScanned / buf.length).toInt
numPartsToTry = Math.min(numPartsToTry, partsScanned * limitScaleUpFactor)
}
}
val parts = partsScanned.until(math.min(partsScanned + numPartsToTry, totalParts).toInt)
val partsToScan = if (takeFromEnd) {
// Reverse partitions to scan. So, if parts was [1, 2, 3] in 200 partitions (0 to 199),
// it becomes [198, 197, 196].
parts.map(p => (totalParts - 1) - p)
} else {
parts
}
val sc = sparkContext
val res = sc.runJob(childRDD, (it: Iterator[(Long, Array[Byte])]) =>
if (it.hasNext) it.next() else (0L, Array.emptyByteArray), partsToScan)
var i = 0
if (takeFromEnd) {
while (buf.length < n && i < res.length) {
val rows = decodeUnsafeRows(res(i)._2)
if (n - buf.length >= res(i)._1) {
buf.prepend(rows.toArray[InternalRow]: _*)
} else {
val dropUntil = res(i)._1 - (n - buf.length)
// Same as Iterator.drop but this only takes a long.
var j: Long = 0L
while (j < dropUntil) { rows.next(); j += 1L}
buf.prepend(rows.toArray[InternalRow]: _*)
}
i += 1
}
} else {
while (buf.length < n && i < res.length) {
val rows = decodeUnsafeRows(res(i)._2)
if (n - buf.length >= res(i)._1) {
buf ++= rows.toArray[InternalRow]
} else {
buf ++= rows.take(n - buf.length).toArray[InternalRow]
}
i += 1
}
}
partsScanned += partsToScan.size
}
buf.toArray
}
/**
* Cleans up the resources used by the physical operator (if any). In general, all the resources
* should be cleaned up when the task finishes but operators like SortMergeJoinExec and LimitExec
* may want eager cleanup to free up tight resources (e.g., memory).
*/
protected[sql] def cleanupResources(): Unit = {
children.foreach(_.cleanupResources())
}
}
trait LeafExecNode extends SparkPlan with LeafLike[SparkPlan] {
override def producedAttributes: AttributeSet = outputSet
override def verboseStringWithOperatorId(): String = {
val argumentString = argString(conf.maxToStringFields)
val outputStr = s"${ExplainUtils.generateFieldString("Output", output)}"
if (argumentString.nonEmpty) {
s"""
|$formattedNodeName
|$outputStr
|Arguments: $argumentString
|""".stripMargin
} else {
s"""
|$formattedNodeName
|$outputStr
|""".stripMargin
}
}
}
object UnaryExecNode {
def unapply(a: Any): Option[(SparkPlan, SparkPlan)] = a match {
case s: SparkPlan if s.children.size == 1 => Some((s, s.children.head))
case _ => None
}
}
trait UnaryExecNode extends SparkPlan with UnaryLike[SparkPlan] {
override def verboseStringWithOperatorId(): String = {
val argumentString = argString(conf.maxToStringFields)
val inputStr = s"${ExplainUtils.generateFieldString("Input", child.output)}"
if (argumentString.nonEmpty) {
s"""
|$formattedNodeName
|$inputStr
|Arguments: $argumentString
|""".stripMargin
} else {
s"""
|$formattedNodeName
|$inputStr
|""".stripMargin
}
}
}
trait BinaryExecNode extends SparkPlan with BinaryLike[SparkPlan] {
override def verboseStringWithOperatorId(): String = {
val argumentString = argString(conf.maxToStringFields)
val leftOutputStr = s"${ExplainUtils.generateFieldString("Left output", left.output)}"
val rightOutputStr = s"${ExplainUtils.generateFieldString("Right output", right.output)}"
if (argumentString.nonEmpty) {
s"""
|$formattedNodeName
|$leftOutputStr
|$rightOutputStr
|Arguments: $argumentString
|""".stripMargin
} else {
s"""
|$formattedNodeName
|$leftOutputStr
|$rightOutputStr
|""".stripMargin
}
}
}
| chuckchen/spark | sql/core/src/main/scala/org/apache/spark/sql/execution/SparkPlan.scala | Scala | apache-2.0 | 20,812 |
package com.socrata.datacoordinator.id
import com.rojoma.json.v3.codec.{DecodeError, JsonDecode, JsonEncode}
import com.rojoma.json.v3.ast.{JValue, JNumber}
class DatasetId(val underlying: Long) extends AnyVal {
override def toString = s"DatasetId($underlying)"
}
object DatasetId {
implicit val jCodec = new JsonDecode[DatasetId] with JsonEncode[DatasetId] {
def encode(datasetId: DatasetId) = JNumber(datasetId.underlying)
def decode(v: JValue): Either[DecodeError, DatasetId] = v match {
case n: JNumber => Right(new DatasetId(n.toLong))
case other => Left(DecodeError.InvalidType(JNumber, other.jsonType))
}
}
val Invalid = new DatasetId(-1)
}
| socrata-platform/data-coordinator | coordinatorlib/src/main/scala/com/socrata/datacoordinator/id/DatasetId.scala | Scala | apache-2.0 | 689 |
package mesosphere.marathon
package raml
import mesosphere.UnitTest
import mesosphere.marathon.core.base.ConstantClock
import mesosphere.marathon.core.condition.Condition
import mesosphere.marathon.core.health.{ MesosCommandHealthCheck, MesosHttpHealthCheck, PortReference }
import mesosphere.marathon.core.instance.Instance
import mesosphere.marathon.core.pod.{ ContainerNetwork, MesosContainer, PodDefinition }
import mesosphere.marathon.core.task.Task
import mesosphere.marathon.core.task.state.NetworkInfoPlaceholder
import mesosphere.marathon.state.{ PathId, Timestamp }
import mesosphere.marathon.stream.Implicits._
import org.apache.mesos.Protos
import scala.concurrent.duration._
class PodStatusConversionTest extends UnitTest {
import PodStatusConversionTest._
"PodStatusConversion" should {
"multiple tasks with multiple container networks convert to proper network status" in {
def fakeContainerNetworks(netmap: Map[String, String]): Seq[Protos.NetworkInfo] = netmap.map { entry =>
val (name, ip) = entry
Protos.NetworkInfo.newBuilder()
.setName(name)
.addIpAddresses(Protos.NetworkInfo.IPAddress.newBuilder().setIpAddress(ip))
.build()
}(collection.breakOut)
val tasksWithNetworks: Seq[Task] = Seq(
fakeTask(fakeContainerNetworks(Map("abc" -> "1.2.3.4", "def" -> "5.6.7.8"))),
fakeTask(fakeContainerNetworks(Map("abc" -> "1.2.3.4", "def" -> "5.6.7.8")))
)
val result: Seq[NetworkStatus] = networkStatuses(tasksWithNetworks)
val expected: Seq[NetworkStatus] = Seq(
NetworkStatus(name = Some("abc"), addresses = Seq("1.2.3.4")),
NetworkStatus(name = Some("def"), addresses = Seq("5.6.7.8"))
)
result.size should be(expected.size)
result.toSet should be(expected.toSet)
}
"multiple tasks with multiple host networks convert to proper network status" in {
def fakeHostNetworks(ips: Seq[String]): Seq[Protos.NetworkInfo] = ips.map { ip =>
Protos.NetworkInfo.newBuilder()
.addIpAddresses(Protos.NetworkInfo.IPAddress.newBuilder().setIpAddress(ip))
.build()
}(collection.breakOut)
val tasksWithNetworks: Seq[Task] = Seq(
fakeTask(fakeHostNetworks(Seq("1.2.3.4", "5.6.7.8"))),
fakeTask(fakeHostNetworks(Seq("1.2.3.4", "5.6.7.8")))
)
val result: Seq[NetworkStatus] = networkStatuses(tasksWithNetworks)
val expected: Seq[NetworkStatus] = Seq(
// host network IPs are consolidated since they are nameless
NetworkStatus(addresses = Seq("1.2.3.4", "5.6.7.8"))
)
result.size should be(expected.size)
result should be(expected)
}
"ephemeral pod launched, no official Mesos status yet" in {
implicit val clock = ConstantClock()
val pod = basicOneContainerPod.copy(version = clock.now())
clock += 1.seconds
val fixture = createdInstance(pod)
val status = PodStatusConversion.podInstanceStatusRamlWriter((pod, fixture.instance))
status.id should be(fixture.instance.instanceId.idString)
status.specReference should be(Option(s"/v2/pods/foo::versions/${pod.version.toOffsetDateTime}"))
status.agentHostname should be(Some("agent1"))
status.status should be(PodInstanceState.Pending)
status.resources should be(Some(PodDefinition.DefaultExecutorResources))
status.containers should be(Seq(
ContainerStatus(
name = "ct1",
status = "TASK_STAGING",
statusSince = fixture.since.toOffsetDateTime,
containerId = Some(fixture.taskIds.head.idString),
endpoints = Seq(
ContainerEndpointStatus(name = "admin", allocatedHostPort = Some(1001)),
ContainerEndpointStatus(name = "web")
),
lastUpdated = fixture.since.toOffsetDateTime,
lastChanged = fixture.since.toOffsetDateTime
)
))
}
"ephemeral pod launched, received STAGING status from Mesos" in {
implicit val clock = ConstantClock()
val pod = basicOneContainerPod.copy(version = clock.now())
clock += 1.seconds
val fixture = stagingInstance(pod)
val status = PodStatusConversion.podInstanceStatusRamlWriter((pod, fixture.instance))
status.id should be(fixture.instance.instanceId.idString)
status.agentHostname should be(Some("agent1"))
status.status should be(PodInstanceState.Staging)
status.resources should be(Some(pod.aggregateResources()))
status.containers should be(Seq(
ContainerStatus(
name = "ct1",
status = "TASK_STAGING",
statusSince = fixture.since.toOffsetDateTime,
containerId = Some(fixture.taskIds.head.idString),
endpoints = Seq(
ContainerEndpointStatus(name = "admin", allocatedHostPort = Some(1001)),
ContainerEndpointStatus(name = "web")
),
resources = pod.container("ct1").map(_.resources),
lastUpdated = fixture.since.toOffsetDateTime,
lastChanged = fixture.since.toOffsetDateTime
)
))
status.networks should be('empty)
}
"ephemeral pod launched, received STARTING status from Mesos" in {
implicit val clock = ConstantClock()
val pod = basicOneContainerPod.copy(version = clock.now())
clock += 1.seconds
val fixture = startingInstance(pod)
val status = PodStatusConversion.podInstanceStatusRamlWriter((pod, fixture.instance))
status.id should be(fixture.instance.instanceId.idString)
status.agentHostname should be(Some("agent1"))
status.status should be(PodInstanceState.Staging)
status.resources should be(Some(pod.aggregateResources()))
status.containers should be(Seq(
ContainerStatus(
name = "ct1",
status = "TASK_STARTING",
statusSince = fixture.since.toOffsetDateTime,
containerId = Some(fixture.taskIds.head.idString),
endpoints = Seq(
ContainerEndpointStatus(name = "admin", allocatedHostPort = Some(1001)),
ContainerEndpointStatus(name = "web")
),
resources = pod.container("ct1").map(_.resources),
lastUpdated = fixture.since.toOffsetDateTime,
lastChanged = fixture.since.toOffsetDateTime
)
))
status.networks.toSet should be(Set(
NetworkStatus(Some("dcos"), Seq("1.2.3.4")),
NetworkStatus(Some("bigdog"), Seq("2.3.4.5"))
))
}
"ephemeral pod launched, received RUNNING status from Mesos, no task endpoint health info" in {
implicit val clock = ConstantClock()
val pod = basicOneContainerPod.copy(version = clock.now())
clock += 1.seconds
val fixture = runningInstance(pod)
val status = PodStatusConversion.podInstanceStatusRamlWriter((pod, fixture.instance))
status.id should be(fixture.instance.instanceId.idString)
status.agentHostname should be(Some("agent1"))
status.status should be(PodInstanceState.Degraded)
status.resources should be(Some(pod.aggregateResources()))
status.containers should be(Seq(
ContainerStatus(
name = "ct1",
status = "TASK_RUNNING",
statusSince = fixture.since.toOffsetDateTime,
containerId = Some(fixture.taskIds.head.idString),
conditions = Seq(
StatusCondition("healthy", fixture.since.toOffsetDateTime, fixture.since.toOffsetDateTime, "false",
Some(PodStatusConversion.HEALTH_UNREPORTED))
),
endpoints = Seq(
ContainerEndpointStatus(name = "admin", allocatedHostPort = Some(1001)),
ContainerEndpointStatus(name = "web")
),
resources = pod.container("ct1").map(_.resources),
lastUpdated = fixture.since.toOffsetDateTime,
lastChanged = fixture.since.toOffsetDateTime
)
))
status.networks.toSet should be(Set(
NetworkStatus(Some("dcos"), Seq("1.2.3.4")),
NetworkStatus(Some("bigdog"), Seq("2.3.4.5"))
))
}
"ephemeral pod launched, received RUNNING status from Mesos, task endpoint health is failing" in {
implicit val clock = ConstantClock()
val pod = basicOneContainerPod.copy(version = clock.now())
clock += 1.seconds
val fixture = runningInstance(pod = pod, maybeHealthy = Some(false)) // task status will say unhealthy
val status = PodStatusConversion.podInstanceStatusRamlWriter((pod, fixture.instance))
status.id should be(fixture.instance.instanceId.idString)
status.agentHostname should be(Some("agent1"))
status.status should be(PodInstanceState.Degraded)
status.resources should be(Some(pod.aggregateResources()))
status.containers should be(Seq(
ContainerStatus(
name = "ct1",
status = "TASK_RUNNING",
statusSince = fixture.since.toOffsetDateTime,
containerId = Some(fixture.taskIds.head.idString),
conditions = Seq(
StatusCondition("healthy", fixture.since.toOffsetDateTime, fixture.since.toOffsetDateTime, "false",
Some(PodStatusConversion.HEALTH_REPORTED))
),
endpoints = Seq(
ContainerEndpointStatus(name = "admin", allocatedHostPort = Some(1001)),
ContainerEndpointStatus(name = "web", healthy = Some(false))
),
resources = pod.container("ct1").map(_.resources),
lastUpdated = fixture.since.toOffsetDateTime,
lastChanged = fixture.since.toOffsetDateTime
)
))
status.networks.toSet should be(Set(
NetworkStatus(Some("dcos"), Seq("1.2.3.4")),
NetworkStatus(Some("bigdog"), Seq("2.3.4.5"))
))
}
"ephemeral pod launched, received RUNNING status from Mesos, task endpoint health looks great" in {
implicit val clock = ConstantClock()
val pod = basicOneContainerPod.copy(version = clock.now())
clock += 1.seconds
val fixture = runningInstance(pod = pod, maybeHealthy = Some(true)) // task status will say healthy
val status = PodStatusConversion.podInstanceStatusRamlWriter((pod, fixture.instance))
status.id should be(fixture.instance.instanceId.idString)
status.agentHostname should be(Some("agent1"))
status.status should be(PodInstanceState.Stable)
status.resources should be(Some(pod.aggregateResources()))
status.containers should be(Seq(
ContainerStatus(
name = "ct1",
status = "TASK_RUNNING",
statusSince = fixture.since.toOffsetDateTime,
containerId = Some(fixture.taskIds.head.idString),
conditions = Seq(
StatusCondition("healthy", fixture.since.toOffsetDateTime, fixture.since.toOffsetDateTime, "true",
Some(PodStatusConversion.HEALTH_REPORTED))
),
endpoints = Seq(
ContainerEndpointStatus(name = "admin", allocatedHostPort = Some(1001)),
ContainerEndpointStatus(name = "web", healthy = Some(true))
),
resources = pod.container("ct1").map(_.resources),
lastUpdated = fixture.since.toOffsetDateTime,
lastChanged = fixture.since.toOffsetDateTime
)
))
status.networks.toSet should be(Set(
NetworkStatus(Some("dcos"), Seq("1.2.3.4")),
NetworkStatus(Some("bigdog"), Seq("2.3.4.5"))
))
}
"ephemeral pod launched, received RUNNING status from Mesos, task command-line health is missing" in {
implicit val clock = ConstantClock()
val pod = withCommandLineHealthChecks(basicOneContainerPod.copy(version = clock.now()))
clock += 1.seconds
val fixture = runningInstance(pod = pod) // mesos task status health is missing
val status = PodStatusConversion.podInstanceStatusRamlWriter((pod, fixture.instance))
status.id should be(fixture.instance.instanceId.idString)
status.agentHostname should be(Some("agent1"))
status.status should be(PodInstanceState.Degraded)
status.resources should be(Some(pod.aggregateResources()))
status.containers should be(Seq(
ContainerStatus(
name = "ct1",
status = "TASK_RUNNING",
statusSince = fixture.since.toOffsetDateTime,
containerId = Some(fixture.taskIds.head.idString),
conditions = Seq(
StatusCondition("healthy", fixture.since.toOffsetDateTime, fixture.since.toOffsetDateTime, "false",
Some(PodStatusConversion.HEALTH_UNREPORTED))
),
endpoints = Seq(
ContainerEndpointStatus(name = "admin", allocatedHostPort = Some(1001)),
ContainerEndpointStatus(name = "web")
),
resources = pod.container("ct1").map(_.resources),
lastUpdated = fixture.since.toOffsetDateTime,
lastChanged = fixture.since.toOffsetDateTime
)
))
status.networks.toSet should be(Set(
NetworkStatus(Some("dcos"), Seq("1.2.3.4")),
NetworkStatus(Some("bigdog"), Seq("2.3.4.5"))
))
}
"ephemeral pod launched, received RUNNING status from Mesos, task command-line health is failing" in {
implicit val clock = ConstantClock()
val pod = withCommandLineHealthChecks(basicOneContainerPod.copy(version = clock.now()))
clock += 1.seconds
val fixture = runningInstance(pod = pod, maybeHealthy = Some(false)) // task status will say unhealthy
val status = PodStatusConversion.podInstanceStatusRamlWriter((pod, fixture.instance))
status.id should be(fixture.instance.instanceId.idString)
status.agentHostname should be(Some("agent1"))
status.status should be(PodInstanceState.Degraded)
status.resources should be(Some(pod.aggregateResources()))
status.containers should be(Seq(
ContainerStatus(
name = "ct1",
status = "TASK_RUNNING",
statusSince = fixture.since.toOffsetDateTime,
containerId = Some(fixture.taskIds.head.idString),
conditions = Seq(
StatusCondition("healthy", fixture.since.toOffsetDateTime, fixture.since.toOffsetDateTime, "false",
Some(PodStatusConversion.HEALTH_REPORTED))
),
endpoints = Seq(
ContainerEndpointStatus(name = "admin", allocatedHostPort = Some(1001)),
ContainerEndpointStatus(name = "web")
),
resources = pod.container("ct1").map(_.resources),
lastUpdated = fixture.since.toOffsetDateTime,
lastChanged = fixture.since.toOffsetDateTime
)
))
status.networks.toSet should be(Set(
NetworkStatus(Some("dcos"), Seq("1.2.3.4")),
NetworkStatus(Some("bigdog"), Seq("2.3.4.5"))
))
}
"ephemeral pod launched, received RUNNING status from Mesos, task command-line health is passing" in {
implicit val clock = ConstantClock()
val pod = withCommandLineHealthChecks(basicOneContainerPod.copy(version = clock.now()))
clock += 1.seconds
val fixture = runningInstance(pod = pod, maybeHealthy = Some(true)) // task status will say healthy
val status = PodStatusConversion.podInstanceStatusRamlWriter((pod, fixture.instance))
status.id should be(fixture.instance.instanceId.idString)
status.agentHostname should be(Some("agent1"))
status.status should be(PodInstanceState.Stable)
status.resources should be(Some(pod.aggregateResources()))
status.containers should be(Seq(
ContainerStatus(
name = "ct1",
status = "TASK_RUNNING",
statusSince = fixture.since.toOffsetDateTime,
containerId = Some(fixture.taskIds.head.idString),
conditions = Seq(
StatusCondition("healthy", fixture.since.toOffsetDateTime, fixture.since.toOffsetDateTime, "true",
Some(PodStatusConversion.HEALTH_REPORTED))
),
endpoints = Seq(
ContainerEndpointStatus(name = "admin", allocatedHostPort = Some(1001)),
ContainerEndpointStatus(name = "web")
),
resources = pod.container("ct1").map(_.resources),
lastUpdated = fixture.since.toOffsetDateTime,
lastChanged = fixture.since.toOffsetDateTime
)
))
status.networks.toSet should be(Set(
NetworkStatus(Some("dcos"), Seq("1.2.3.4")),
NetworkStatus(Some("bigdog"), Seq("2.3.4.5"))
))
}
}
}
object PodStatusConversionTest {
val containerResources = Resources(cpus = 0.01, mem = 100)
val basicOneContainerPod = PodDefinition(
id = PathId("/foo"),
containers = Seq(
MesosContainer(
name = "ct1",
resources = containerResources,
image = Some(Image(kind = ImageType.Docker, id = "busybox")),
endpoints = Seq(
Endpoint(name = "web", containerPort = Some(80)),
Endpoint(name = "admin", containerPort = Some(90), hostPort = Some(0))
),
healthCheck = Some(MesosHttpHealthCheck(portIndex = Some(PortReference("web")), path = Some("/ping")))
)
),
networks = Seq(ContainerNetwork(name = "dcos"), ContainerNetwork("bigdog"))
)
case class InstanceFixture(
since: Timestamp,
agentInfo: Instance.AgentInfo,
taskIds: Seq[Task.Id],
instance: Instance)
def createdInstance(pod: PodDefinition)(implicit clock: ConstantClock): InstanceFixture =
fakeInstance(pod, Condition.Created, Condition.Created)
def stagingInstance(pod: PodDefinition)(implicit clock: ConstantClock): InstanceFixture =
fakeInstance(pod, Condition.Staging, Condition.Staging, Some(Protos.TaskState.TASK_STAGING))
def startingInstance(pod: PodDefinition)(implicit clock: ConstantClock): InstanceFixture =
fakeInstance(pod, Condition.Starting, Condition.Starting, Some(Protos.TaskState.TASK_STARTING),
Some(Map("dcos" -> "1.2.3.4", "bigdog" -> "2.3.4.5")))
def runningInstance(
pod: PodDefinition,
maybeHealthy: Option[Boolean] = None)(implicit clock: ConstantClock): InstanceFixture =
fakeInstance(pod, Condition.Running, Condition.Running, Some(Protos.TaskState.TASK_RUNNING),
Some(Map("dcos" -> "1.2.3.4", "bigdog" -> "2.3.4.5")), maybeHealthy)
def fakeInstance(
pod: PodDefinition,
condition: Condition,
taskStatus: Condition,
maybeTaskState: Option[Protos.TaskState] = None,
maybeNetworks: Option[Map[String, String]] = None,
maybeHealthy: Option[Boolean] = None)(implicit clock: ConstantClock): InstanceFixture = {
val since = clock.now()
val agentInfo = Instance.AgentInfo("agent1", None, Seq.empty)
val instanceId = Instance.Id.forRunSpec(pod.id)
val taskIds = pod.containers.map { container =>
Task.Id.forInstanceId(instanceId, Some(container))
}
val mesosStatus = maybeTaskState.map { taskState =>
val statusProto = Protos.TaskStatus.newBuilder()
.setState(taskState)
.setTaskId(taskIds.head.mesosTaskId)
maybeNetworks.foreach { networks =>
statusProto.setContainerStatus(Protos.ContainerStatus.newBuilder()
.addAllNetworkInfos(networks.map { entry =>
val (networkName, ipAddress) = entry
Protos.NetworkInfo.newBuilder().addIpAddresses(
Protos.NetworkInfo.IPAddress.newBuilder().setIpAddress(ipAddress)
).setName(networkName).build()
}).build()
).build()
}
maybeHealthy.foreach(statusProto.setHealthy)
statusProto.build()
}
val instance: Instance = Instance(
instanceId = instanceId,
agentInfo = agentInfo,
state = Instance.InstanceState(
condition = condition,
since = since,
activeSince = if (condition == Condition.Created) None else Some(since),
healthy = None),
tasksMap = Seq[Task](
Task.LaunchedEphemeral(
taskIds.head,
since,
Task.Status(
stagedAt = since,
startedAt = if (taskStatus == Condition.Created) None else Some(since),
mesosStatus = mesosStatus,
condition = taskStatus,
networkInfo = NetworkInfoPlaceholder(hostPorts = Seq(1001))
)
)
).map(t => t.taskId -> t)(collection.breakOut),
runSpecVersion = pod.version,
unreachableStrategy = state.UnreachableStrategy.default()
)
InstanceFixture(since, agentInfo, taskIds, instance)
} // fakeInstance
def fakeTask(networks: Seq[Protos.NetworkInfo]) = {
val taskId = Task.Id.forRunSpec(PathId.empty)
Task.LaunchedEphemeral(
taskId = taskId,
status = Task.Status(
stagedAt = Timestamp.zero,
mesosStatus = Some(Protos.TaskStatus.newBuilder()
.setTaskId(taskId.mesosTaskId)
.setState(Protos.TaskState.TASK_UNKNOWN)
.setContainerStatus(Protos.ContainerStatus.newBuilder()
.addAllNetworkInfos(networks).build())
.build()),
condition = Condition.Finished,
networkInfo = NetworkInfoPlaceholder()
),
runSpecVersion = Timestamp.zero)
}
def withCommandLineHealthChecks(pod: PodDefinition): PodDefinition = pod.copy(
// swap any endpoint health checks for a command-line health check
containers = basicOneContainerPod.containers.map { ct =>
ct.copy(
healthCheck = Some(MesosCommandHealthCheck(command = state.Command("echo this is a health check command"))))
})
}
| natemurthy/marathon | src/test/scala/mesosphere/marathon/raml/PodStatusConversionTest.scala | Scala | apache-2.0 | 21,541 |
package org.dbpedia.spotlight.db.stem
import org.junit.Assert._
import org.junit.Test
/**
* Tests SnowballStemmer
* @author dav009
*/
class SnowballStemmerTest {
@Test
def englishStemmer(){
val snowballStemmer = new SnowballStemmer("EnglishStemmer")
assertTrue( "buy".equals(snowballStemmer.stem("buying")))
assertTrue( "poni".equals(snowballStemmer.stem("ponies")))
}
}
| Skunnyk/dbpedia-spotlight-model | core/src/test/scala/org/dbpedia/spotlight/db/stem/SnowballStemmerTest.scala | Scala | apache-2.0 | 395 |
/*
* SPDX-License-Identifier: Apache-2.0
*
* Copyright 2015-2021 Andre White.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package io.truthencode.ddo.model.feats
/**
* Created by adarr on 4/9/2017.
*/
trait DamageReductionLevel extends DeityFeatLevel
| adarro/ddo-calc | subprojects/common/ddo-core/src/main/scala/io/truthencode/ddo/model/feats/DamageReductionLevel.scala | Scala | apache-2.0 | 798 |
/*
* SPDX-License-Identifier: Apache-2.0
*
* Copyright 2015-2021 Andre White.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package io.truthencode.ddo.model.feats
import io.truthencode.ddo.model.classes.HeroicCharacterClass
import io.truthencode.ddo.support.requisite.{ClassRequisiteImpl, FeatRequisiteImpl, RequiresAllOfClass}
/**
* Icon Tactical Training.png Tactical Supremacy Passive +8 bonus to Tactics DC's.
*
* Level 16: Fighter
*
* Note: they all stack with each other.
*/
trait TacticalSupremacy
extends FeatRequisiteImpl with ClassRequisiteImpl with Passive with RequiresAllOfClass
with FighterBonusFeat {
self: GeneralFeat =>
override def allOfClass: Seq[(HeroicCharacterClass, Int)] =
List((HeroicCharacterClass.Fighter, 16))
}
| adarro/ddo-calc | subprojects/common/ddo-core/src/main/scala/io/truthencode/ddo/model/feats/TacticalSupremacy.scala | Scala | apache-2.0 | 1,316 |
/*
* Copyright (c) 2014-2020 by The Monix Project Developers.
* See the project homepage at: https://monix.io
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package monix.reactive.subjects
import monix.execution.Ack.{Continue, Stop}
import monix.execution.{Ack, Cancelable}
import monix.reactive.Observable
import monix.reactive.internal.util.PromiseCounter
import monix.reactive.observers.{ConnectableSubscriber, Subscriber}
import monix.execution.atomic.Atomic
import scala.util.control.NonFatal
import scala.annotation.tailrec
import scala.collection.immutable.Queue
import scala.concurrent.Future
/** `ReplaySubject` emits to any observer all of the items that were emitted
* by the source, regardless of when the observer subscribes.
*/
final class ReplaySubject[A] private (initialState: ReplaySubject.State[A]) extends Subject[A, A] { self =>
private[this] val stateRef = Atomic(initialState)
def size: Int =
stateRef.get().subscribers.size
@tailrec
def unsafeSubscribeFn(subscriber: Subscriber[A]): Cancelable = {
def streamOnDone(buffer: Iterable[A], errorThrown: Throwable): Cancelable =
Observable
.fromIterable(buffer)
.unsafeSubscribeFn(new Subscriber[A] {
implicit val scheduler = subscriber.scheduler
def onNext(elem: A) =
subscriber.onNext(elem)
def onError(ex: Throwable) =
subscriber.onError(ex)
def onComplete() =
if (errorThrown != null)
subscriber.onError(errorThrown)
else
subscriber.onComplete()
})
val state = stateRef.get()
val buffer = state.buffer
if (state.isDone) {
// fast path
streamOnDone(buffer, state.errorThrown)
} else {
val c = ConnectableSubscriber(subscriber)
val newState = state.addNewSubscriber(c)
if (stateRef.compareAndSet(state, newState)) {
c.pushFirstAll(buffer)
import subscriber.scheduler
val connecting = c.connect()
connecting.syncOnStopOrFailure(_ => removeSubscriber(c))
Cancelable { () =>
try removeSubscriber(c)
finally connecting.cancel()
}
} else {
// retry
unsafeSubscribeFn(subscriber)
}
}
}
@tailrec
def onNext(elem: A): Future[Ack] = {
val state = stateRef.get()
if (state.isDone) Stop
else {
val newState = state.appendElem(elem)
if (!stateRef.compareAndSet(state, newState)) {
onNext(elem) // retry
} else {
val iterator = state.subscribers.iterator
// counter that's only used when we go async, hence the null
var result: PromiseCounter[Continue.type] = null
while (iterator.hasNext) {
val subscriber = iterator.next()
// using the scheduler defined by each subscriber
import subscriber.scheduler
val ack =
try subscriber.onNext(elem)
catch {
case ex if NonFatal(ex) => Future.failed(ex)
}
// if execution is synchronous, takes the fast-path
if (ack.isCompleted) {
// subscriber canceled or triggered an error? then remove
if (ack != Continue && ack.value.get != Continue.AsSuccess)
removeSubscriber(subscriber)
} else {
// going async, so we've got to count active futures for final Ack
// the counter starts from 1 because zero implies isCompleted
if (result == null) result = PromiseCounter(Continue, 1)
result.acquire()
ack.onComplete {
case Continue.AsSuccess =>
result.countdown()
case _ =>
// subscriber canceled or triggered an error? then remove
removeSubscriber(subscriber)
result.countdown()
}
}
}
// has fast-path for completely synchronous invocation
if (result == null) Continue
else {
result.countdown()
result.future
}
}
}
}
override def onError(ex: Throwable): Unit =
onCompleteOrError(ex)
override def onComplete(): Unit =
onCompleteOrError(null)
@tailrec
private def onCompleteOrError(ex: Throwable): Unit = {
val state = stateRef.get()
if (!state.isDone) {
if (!stateRef.compareAndSet(state, state.markDone(ex)))
onCompleteOrError(ex)
else {
val iterator = state.subscribers.iterator
while (iterator.hasNext) {
val ref = iterator.next()
if (ex != null)
ref.onError(ex)
else
ref.onComplete()
}
}
}
}
@tailrec
private def removeSubscriber(s: ConnectableSubscriber[A]): Unit = {
val state = stateRef.get()
val newState = state.removeSubscriber(s)
if (!stateRef.compareAndSet(state, newState))
removeSubscriber(s)
}
}
object ReplaySubject {
/** Creates an unbounded replay subject. */
def apply[A](initial: A*): ReplaySubject[A] =
create(initial)
/** Creates an unbounded replay subject. */
def create[A](initial: Seq[A]): ReplaySubject[A] =
new ReplaySubject[A](State[A](initial.toVector, 0))
/** Creates a size-bounded replay subject.
*
* In this setting, the ReplaySubject holds at most size items in its
* internal buffer and discards the oldest item.
*
* @param capacity is the maximum size of the internal buffer
*/
def createLimited[A](capacity: Int): ReplaySubject[A] = {
require(capacity > 0, "capacity must be strictly positive")
new ReplaySubject[A](State[A](Queue.empty, capacity))
}
/** Creates a size-bounded replay subject, prepopulated.
*
* In this setting, the ReplaySubject holds at most size items in its
* internal buffer and discards the oldest item.
*
* @param capacity is the maximum size of the internal buffer
* @param initial is an initial sequence of elements to prepopulate the buffer
*/
def createLimited[A](capacity: Int, initial: Seq[A]): ReplaySubject[A] = {
require(capacity > 0, "capacity must be strictly positive")
val elems = initial.takeRight(capacity)
new ReplaySubject[A](State[A](Queue(elems: _*), capacity))
}
/** Internal state for [[monix.reactive.subjects.ReplaySubject]] */
private final case class State[A](
buffer: Seq[A],
capacity: Int,
subscribers: Set[ConnectableSubscriber[A]] = Set.empty[ConnectableSubscriber[A]],
length: Int = 0,
isDone: Boolean = false,
errorThrown: Throwable = null) {
def appendElem(elem: A): State[A] = {
if (capacity == 0)
copy(buffer = buffer :+ elem)
else if (length >= capacity)
copy(buffer = buffer.tail :+ elem)
else
copy(buffer = buffer :+ elem, length = length + 1)
}
def addNewSubscriber(s: ConnectableSubscriber[A]): State[A] =
copy(subscribers = subscribers + s)
def removeSubscriber(toRemove: ConnectableSubscriber[A]): State[A] = {
val newSet = subscribers - toRemove
copy(subscribers = newSet)
}
def markDone(ex: Throwable): State[A] = {
copy(subscribers = Set.empty, isDone = true, errorThrown = ex)
}
}
}
| alexandru/monifu | monix-reactive/shared/src/main/scala/monix/reactive/subjects/ReplaySubject.scala | Scala | apache-2.0 | 7,804 |
package com.twitter.finagle
import com.twitter.conversions.time._
import com.twitter.finagle.stats.InMemoryStatsReceiver
import com.twitter.util.{Future, Await}
import java.net.{UnknownHostException, InetAddress}
import org.junit.runner.RunWith
import org.scalatest.FunSuite
import org.scalatest.junit.JUnitRunner
@RunWith(classOf[JUnitRunner])
class InetResolverTest extends FunSuite {
val statsReceiver = new InMemoryStatsReceiver
val dnsResolver = new DnsResolver(statsReceiver)
def resolveHost(host: String): Future[Seq[InetAddress]] = {
if (host.isEmpty || host.equals("localhost")) dnsResolver(host)
else Future.exception(new UnknownHostException())
}
val resolver = new InetResolver(resolveHost, statsReceiver, None)
test("local address") {
val empty = resolver.bind(":9990")
assert(empty.sample() == Addr.Bound(Address(9990)))
val localhost = resolver.bind("localhost:9990")
assert(localhost.sample() == Addr.Bound(Address(9990)))
}
test("host not found") {
val addr = resolver.bind("no_TLDs_for_old_humans:80")
val f = addr.changes.filter(_ == Addr.Neg).toFuture
assert(Await.result(f) == Addr.Neg)
assert(statsReceiver.counter("failures")() > 0)
}
test("resolution failure") {
val addr = resolver.bind("no_port_number")
val f = addr.changes.filter(_ != Addr.Pending).toFuture
Await.result(f) match {
case Addr.Failed(_) =>
case _ => fail()
}
}
test("partial resolution success") {
val addr = resolver.bind("bad_host_name:100, localhost:80")
val f = addr.changes.filter(_ != Addr.Pending).toFuture
Await.result(f, 10.seconds) match {
case Addr.Bound(b, meta) if meta.isEmpty =>
assert(b.contains(Address("localhost", 80)))
case _ => fail()
}
assert(statsReceiver.counter("successes")() > 0)
assert(statsReceiver.stat("lookup_ms")().size > 0)
}
test("empty host list returns an empty set") {
val addr = resolver.bind("")
val f = addr.changes.filter(_ != Addr.Pending).toFuture
Await.result(f) match {
case Addr.Bound(b, meta) if b.isEmpty =>
case _ => fail()
}
}
test("successful resolution") {
val addr = resolver.bind("localhost:80") // name resolution only, not bound
val f = addr.changes.filter(_ != Addr.Pending).toFuture
Await.result(f) match {
case Addr.Bound(b, meta) if meta.isEmpty =>
assert(b.contains(Address("localhost", 80)))
case _ => fail()
}
assert(statsReceiver.counter("successes")() > 0)
assert(statsReceiver.stat("lookup_ms")().size > 0)
}
}
| adriancole/finagle | finagle-core/src/test/scala/com/twitter/finagle/InetResolverTest.scala | Scala | apache-2.0 | 2,600 |
package chandu0101.scalajs.react.components.demo.components.materialui
import chandu0101.scalajs.react.components.demo.components.CodeExample
import chandu0101.scalajs.react.components.fascades.LatLng
import chandu0101.scalajs.react.components.materialui._
import japgolly.scalajs.react._
import japgolly.scalajs.react.vdom.prefix_<^._
import scala.scalajs.js
object MuiDialogDemo {
val code =
"""
| val actions : js.Array[ReactElement] = js.Array(
| MuiFlatButton(label = "Cancel",secondary = true,onTouchTap = B.handleDialogCancel _)(),
| MuiFlatButton(label = "Submit",secondary = true,onTouchTap = B.handleDialogSubmit _)()
| )
| MuiDialog(title = "Dialog With Actions",
| actions = actions,
| ref = "dialogref")(
| "Dialog example with floating buttons"
| )
|
""".stripMargin
class Backend(t : BackendScope[_,_]) {
def handleDialogCancel(e : ReactEventH) = {
println("Cancel Clicked")
dialogRef(t).get.dismiss()
}
def handleDialogSubmit(e : ReactEventH) = {
println("Submit Clicked")
dialogRef(t).get.dismiss()
}
def openDialog(e : ReactEventH) = {
dialogRef(t).get.show()
}
}
val dialogRef = Ref.toJS[MuiDialogM]("dialogref")
val component = ReactComponentB[Unit]("MuiDialogDemo")
.stateless
.backend(new Backend(_))
.render((P,S,B) => {
val actions : js.Array[ReactElement] = js.Array(
MuiFlatButton(label = "Cancel",secondary = true,onTouchTap = B.handleDialogCancel _)(),
MuiFlatButton(label = "Submit",secondary = true,onTouchTap = B.handleDialogSubmit _)()
)
<.div(
CodeExample(code,"MuiDialog")(
<.div(
MuiDialog(title = "Dialog With Actions",
actions = actions,
ref = "dialogref")(
"Dialog example with floating buttons"
),
MuiRaisedButton(label = "Dialog",onTouchTap = B.openDialog _ )()
)
)
)
}).buildU
def apply() = component()
}
| coreyauger/scalajs-react-components | demo/src/main/scala/chandu0101/scalajs/react/components/demo/components/materialui/MuiDialogDemo.scala | Scala | apache-2.0 | 2,067 |
package org.vaadin.addons.rinne
import com.vaadin.ui.{Alignment, Component, GridLayout}
import org.vaadin.addons.rinne.mixins._
class VGridLayout extends GridLayout with AbstractLayoutMixin
with LayoutSpacingHandlerMixin with LayoutMarginHandlerMixin with LayoutAlignmentHandlerMixin with LayoutClickNotifierMixin {
def add[C <: Component](
component: C = null,
col: Int = -1,
row: Int = -1,
col2: Int = -1,
row2: Int = -1,
alignment: Alignment = null
): C = {
if (col >= 0 && row >= 0 && col2 >= 0 && row2 >= 0)
addComponent(component, col, row, col2, row2)
else if (col >= 0 && row >= 0)
addComponent(component, col, row)
else
addComponent(component)
if (alignment != null) {
setComponentAlignment(component, alignment)
}
component
}
def columns: Int = getColumns
def columns_=(columns: Int): Unit = setColumns(columns)
def rows: Int = getRows
def rows_=(rows: Int): Unit = setRows(rows)
def cursorX: Int = getCursorX
def cursorX_=(cursorX: Int): Unit = setCursorX(cursorX)
def cursorY: Int = getCursorY
def cursorY_=(cursorY: Int): Unit = setCursorY(cursorY)
}
| LukaszByczynski/rinne | src/main/scala/org/vaadin/addons/rinne/VGridLayout.scala | Scala | apache-2.0 | 1,174 |
/*
* Copyright 2021 HM Revenue & Customs
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package controllers.responsiblepeople
import connectors.DataCacheConnector
import controllers.{AmlsBaseController, CommonPlayDependencies}
import forms.{EmptyForm, Form2, InvalidForm, ValidForm}
import javax.inject.Inject
import models.responsiblepeople.{NonUKPassport, ResponsiblePerson}
import play.api.i18n.MessagesApi
import play.api.mvc.{AnyContent, MessagesControllerComponents, Request}
import uk.gov.hmrc.http.cache.client.CacheMap
import utils.{AuthAction, ControllerHelper, RepeatingSection}
import views.html.responsiblepeople.person_non_uk_passport
import scala.concurrent.Future
class PersonNonUKPassportController @Inject()(override val messagesApi: MessagesApi,
val dataCacheConnector: DataCacheConnector,
authAction: AuthAction,
val ds: CommonPlayDependencies,
val cc: MessagesControllerComponents,
person_non_uk_passport: person_non_uk_passport,
implicit val error: views.html.error) extends AmlsBaseController(ds, cc) with RepeatingSection {
def get(index:Int, edit: Boolean = false, flow: Option[String] = None) = authAction.async {
implicit request =>
getData[ResponsiblePerson](request.credId, index) map {
case Some(ResponsiblePerson(Some(personName),_,_,_,_,_,Some(nonUKPassport),_,_,_,_,_,_,_,_,_,_,_,_,_,_,_)) =>
Ok(person_non_uk_passport(Form2[NonUKPassport](nonUKPassport), edit, index, flow, personName.titleName))
case Some(ResponsiblePerson(Some(personName),_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_,_)) =>
Ok(person_non_uk_passport(EmptyForm, edit, index, flow, personName.titleName))
case _ => NotFound(notFoundView)
}
}
def post(index: Int, edit: Boolean = false, flow: Option[String] = None) = authAction.async {
implicit request =>
Form2[NonUKPassport](request.body) match {
case f: InvalidForm => getData[ResponsiblePerson](request.credId, index) map { rp =>
BadRequest(person_non_uk_passport(f, edit, index, flow, ControllerHelper.rpTitleName(rp)))
}
case ValidForm(_, data) => {
for {
result <- fetchAllAndUpdateStrict[ResponsiblePerson](request.credId, index) { (_, rp) =>
rp.nonUKPassport(data)
}
} yield redirectToNextPage(result, index, edit, flow)
} recoverWith {
case _: IndexOutOfBoundsException => Future.successful(NotFound(notFoundView))
}
}
}
private def redirectToNextPage(result: Option[CacheMap], index: Int, edit: Boolean, flow: Option[String])
(implicit request: Request[AnyContent]) = {
(for {
cache <- result
rp <- getData[ResponsiblePerson](cache, index)
} yield (rp.dateOfBirth.isDefined, edit) match {
case (true, true) => Redirect(routes.DetailedAnswersController.get(index, flow))
case (true, false) => Redirect(routes.CountryOfBirthController.get(index, edit, flow))
case(false, _) => Redirect(routes.DateOfBirthController.get(index, edit, flow))
}).getOrElse(NotFound(notFoundView))
}
}
| hmrc/amls-frontend | app/controllers/responsiblepeople/PersonNonUKPassportController.scala | Scala | apache-2.0 | 3,963 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.network.netty
import java.nio.ByteBuffer
import java.util.{HashMap => JHashMap, Map => JMap}
import scala.collection.JavaConverters._
import scala.concurrent.{Future, Promise}
import scala.reflect.ClassTag
import com.codahale.metrics.{Metric, MetricSet}
import org.apache.spark.{SecurityManager, SparkConf}
import org.apache.spark.network._
import org.apache.spark.network.buffer.ManagedBuffer
import org.apache.spark.network.client.{RpcResponseCallback, TransportClientBootstrap, TransportClientFactory}
import org.apache.spark.network.crypto.{AuthClientBootstrap, AuthServerBootstrap}
import org.apache.spark.network.server._
import org.apache.spark.network.shuffle.{BlockFetchingListener, OneForOneBlockFetcher, RetryingBlockFetcher, TempShuffleFileManager}
import org.apache.spark.network.shuffle.protocol.UploadBlock
import org.apache.spark.network.util.JavaUtils
import org.apache.spark.serializer.JavaSerializer
import org.apache.spark.storage.{BlockId, StorageLevel}
import org.apache.spark.util.Utils
/**
* A BlockTransferService that uses Netty to fetch a set of blocks at time.
*/
private[spark] class NettyBlockTransferService(
conf: SparkConf,
securityManager: SecurityManager,
bindAddress: String,
override val hostName: String,
_port: Int,
numCores: Int)
extends BlockTransferService {
// TODO: Don't use Java serialization, use a more cross-version compatible serialization format.
private val serializer = new JavaSerializer(conf)
private val authEnabled = securityManager.isAuthenticationEnabled()
private val transportConf = SparkTransportConf.fromSparkConf(conf, "shuffle", numCores)
private[this] var transportContext: TransportContext = _
private[this] var server: TransportServer = _
private[this] var clientFactory: TransportClientFactory = _
private[this] var appId: String = _
override def init(blockDataManager: BlockDataManager): Unit = {
val rpcHandler = new NettyBlockRpcServer(conf.getAppId, serializer, blockDataManager)
var serverBootstrap: Option[TransportServerBootstrap] = None
var clientBootstrap: Option[TransportClientBootstrap] = None
if (authEnabled) {
serverBootstrap = Some(new AuthServerBootstrap(transportConf, securityManager))
clientBootstrap = Some(new AuthClientBootstrap(transportConf, conf.getAppId, securityManager))
}
transportContext = new TransportContext(transportConf, rpcHandler)
clientFactory = transportContext.createClientFactory(clientBootstrap.toSeq.asJava)
server = createServer(serverBootstrap.toList)
appId = conf.getAppId
logInfo(s"Server created on ${hostName}:${server.getPort}")
}
/** Creates and binds the TransportServer, possibly trying multiple ports. */
private def createServer(bootstraps: List[TransportServerBootstrap]): TransportServer = {
def startService(port: Int): (TransportServer, Int) = {
val server = transportContext.createServer(bindAddress, port, bootstraps.asJava)
(server, server.getPort)
}
Utils.startServiceOnPort(_port, startService, conf, getClass.getName)._1
}
override def shuffleMetrics(): MetricSet = {
require(server != null && clientFactory != null, "NettyBlockTransferServer is not initialized")
new MetricSet {
val allMetrics = new JHashMap[String, Metric]()
override def getMetrics: JMap[String, Metric] = {
allMetrics.putAll(clientFactory.getAllMetrics.getMetrics)
allMetrics.putAll(server.getAllMetrics.getMetrics)
allMetrics
}
}
}
override def fetchBlocks(
host: String,
port: Int,
execId: String,
blockIds: Array[String],
listener: BlockFetchingListener,
tempShuffleFileManager: TempShuffleFileManager): Unit = {
logTrace(s"Fetch blocks from $host:$port (executor id $execId)")
try {
val blockFetchStarter = new RetryingBlockFetcher.BlockFetchStarter {
override def createAndStart(blockIds: Array[String], listener: BlockFetchingListener) {
val client = clientFactory.createClient(host, port)
new OneForOneBlockFetcher(client, appId, execId, blockIds, listener,
transportConf, tempShuffleFileManager).start()
}
}
val maxRetries = transportConf.maxIORetries()
if (maxRetries > 0) {
// Note this Fetcher will correctly handle maxRetries == 0; we avoid it just in case there's
// a bug in this code. We should remove the if statement once we're sure of the stability.
new RetryingBlockFetcher(transportConf, blockFetchStarter, blockIds, listener).start()
} else {
blockFetchStarter.createAndStart(blockIds, listener)
}
} catch {
case e: Exception =>
logError("Exception while beginning fetchBlocks", e)
blockIds.foreach(listener.onBlockFetchFailure(_, e))
}
}
override def port: Int = server.getPort
override def uploadBlock(
hostname: String,
port: Int,
execId: String,
blockId: BlockId,
blockData: ManagedBuffer,
level: StorageLevel,
classTag: ClassTag[_]): Future[Unit] = {
val result = Promise[Unit]()
val client = clientFactory.createClient(hostname, port)
// StorageLevel and ClassTag are serialized as bytes using our JavaSerializer.
// Everything else is encoded using our binary protocol.
val metadata = JavaUtils.bufferToArray(serializer.newInstance().serialize((level, classTag)))
// Convert or copy nio buffer into array in order to serialize it.
val array = JavaUtils.bufferToArray(blockData.nioByteBuffer())
client.sendRpc(new UploadBlock(appId, execId, blockId.name, metadata, array).toByteBuffer,
new RpcResponseCallback {
override def onSuccess(response: ByteBuffer): Unit = {
logTrace(s"Successfully uploaded block $blockId")
result.success((): Unit)
}
override def onFailure(e: Throwable): Unit = {
logError(s"Error while uploading block $blockId", e)
result.failure(e)
}
})
result.future
}
override def close(): Unit = {
if (server != null) {
server.close()
}
if (clientFactory != null) {
clientFactory.close()
}
}
}
| shubhamchopra/spark | core/src/main/scala/org/apache/spark/network/netty/NettyBlockTransferService.scala | Scala | apache-2.0 | 7,073 |
package org.dele.misc
/**
* Created by jiaji on 11/26/2016.
*/
class PH {
}
| new2scala/text-util | misc/src/main/scala/org/dele/misc/PH.scala | Scala | apache-2.0 | 81 |
// Databricks notebook source
// MAGIC %md
// MAGIC # [SDS-2.2-360-in-525-01: Intro to Apache Spark for data Scientists](https://lamastex.github.io/scalable-data-science/360-in-525/2018/01/)
// MAGIC ### [SDS-2.2, Scalable Data Science](https://lamastex.github.io/scalable-data-science/sds/2/2/)
// COMMAND ----------
// MAGIC %md
// MAGIC # Introduction to Spark
// MAGIC ## Spark Essentials: RDDs, Transformations and Actions
// MAGIC
// MAGIC * This introductory notebook describes how to get started running Spark (Scala) code in Notebooks.
// MAGIC * Working with Spark's Resilient Distributed Datasets (RDDs)
// MAGIC * creating RDDs
// MAGIC * performing basic transformations on RDDs
// MAGIC * performing basic actions on RDDs
// MAGIC
// MAGIC **RECOLLECT** from `001_WhySpark` notebook and AJ's videos (did you watch the ones marked *Watch Now*? if NOT we should watch NOW!!! This was last night's "Viewing Home-Work") that *Spark does fault-tolerant, distributed, in-memory computing*
// COMMAND ----------
// MAGIC %md
// MAGIC # Spark Cluster Overview:
// MAGIC ## Driver Program, Cluster Manager and Worker Nodes
// MAGIC
// MAGIC The *driver* does the following:
// MAGIC
// MAGIC 1. connects to a *cluster manager* to allocate resources across applications
// MAGIC * acquire *executors* on cluster nodes
// MAGIC * executor processs run compute tasks and cache data in memory or disk on a *worker node*
// MAGIC * sends *application* (user program built on Spark) to the executors
// MAGIC * sends *tasks* for the executors to run
// MAGIC * task is a unit of work that will be sent to one executor
// MAGIC
// MAGIC 
// MAGIC
// MAGIC See [http://spark.apache.org/docs/latest/cluster-overview.html](http://spark.apache.org/docs/latest/cluster-overview.html) for an overview of the spark cluster.
// COMMAND ----------
// MAGIC %md
// MAGIC ## The Abstraction of Resilient Distributed Dataset (RDD)
// MAGIC
// MAGIC #### RDD is a fault-tolerant collection of elements that can be operated on in parallel
// MAGIC
// MAGIC #### Two types of Operations are possible on an RDD
// MAGIC
// MAGIC * Transformations
// MAGIC * Actions
// MAGIC
// MAGIC **(watch now 2:26)**:
// MAGIC
// MAGIC [](https://www.youtube.com/watch?v=3nreQ1N7Jvk?rel=0&autoplay=1&modestbranding=1&start=1&end=146)
// MAGIC
// MAGIC
// MAGIC ***
// MAGIC
// MAGIC ## Transformations
// MAGIC **(watch now 1:18)**:
// MAGIC
// MAGIC [](https://www.youtube.com/watch?v=360UHWy052k?rel=0&autoplay=1&modestbranding=1)
// MAGIC
// MAGIC ***
// MAGIC
// MAGIC
// MAGIC ## Actions
// MAGIC **(watch now 0:48)**:
// MAGIC
// MAGIC [](https://www.youtube.com/watch?v=F2G4Wbc5ZWQ?rel=0&autoplay=1&modestbranding=1&start=1&end=48)
// MAGIC
// MAGIC ***
// MAGIC
// MAGIC ## Key Points
// MAGIC
// MAGIC * Resilient distributed datasets (RDDs) are the primary abstraction in Spark.
// MAGIC * RDDs are immutable once created:
// MAGIC * can transform it.
// MAGIC * can perform actions on it.
// MAGIC * but cannot change an RDD once you construct it.
// MAGIC * Spark tracks each RDD's lineage information or recipe to enable its efficient recomputation if a machine fails.
// MAGIC * RDDs enable operations on collections of elements in parallel.
// MAGIC * We can construct RDDs by:
// MAGIC * parallelizing Scala collections such as lists or arrays
// MAGIC * by transforming an existing RDD,
// MAGIC * from files in distributed file systems such as (HDFS, S3, etc.).
// MAGIC * We can specify the number of partitions for an RDD
// MAGIC * The more partitions in an RDD, the more opportunities for parallelism
// MAGIC * There are **two types of operations** you can perform on an RDD:
// MAGIC * **transformations** (are lazily evaluated)
// MAGIC * map
// MAGIC * flatMap
// MAGIC * filter
// MAGIC * distinct
// MAGIC * ...
// MAGIC * **actions** (actual evaluation happens)
// MAGIC * count
// MAGIC * reduce
// MAGIC * take
// MAGIC * collect
// MAGIC * takeOrdered
// MAGIC * ...
// MAGIC * Spark transformations enable us to create new RDDs from an existing RDD.
// MAGIC * RDD transformations are lazy evaluations (results are not computed right away)
// MAGIC * Spark remembers the set of transformations that are applied to a base data set (this is the lineage graph of RDD)
// MAGIC * The allows Spark to automatically recover RDDs from failures and slow workers.
// MAGIC * The lineage graph is a recipe for creating a result and it can be optimized before execution.
// MAGIC * A transformed RDD is executed only when an action runs on it.
// MAGIC * You can also persist, or cache, RDDs in memory or on disk (this speeds up iterative ML algorithms that transforms the initial RDD iteratively).
// MAGIC * Here is a great reference URL for working with Spark.
// MAGIC * [The latest Spark programming guide](http://spark.apache.org/docs/latest/programming-guide.html).
// MAGIC
// COMMAND ----------
// MAGIC %md
// MAGIC ## Let us get our hands dirty in Spark implementing these ideas!
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC #### DO NOW
// MAGIC
// MAGIC In your databricks community edition:
// MAGIC
// MAGIC 1. In your `WorkSpace` create a Folder named `scalable-data-science`
// MAGIC 2. *Import* the databricks archive file at the following URL:
// MAGIC * [https://github.com/lamastex/scalable-data-science/raw/master/dbcArchives/2017/parts/xtraResources.dbc](https://github.com/lamastex/scalable-data-science/raw/master/dbcArchives/2017/parts/xtraResources.dbc)
// MAGIC 3. This should open a structure of directories in with path: `/Workspace/scalable-data-science/xtraResources/`
// COMMAND ----------
// MAGIC %md
// MAGIC ### Let us look at the legend and overview of the visual RDD Api by doing the following first:
// MAGIC
// MAGIC
// MAGIC 
// COMMAND ----------
// MAGIC %md
// MAGIC ### Running **Spark**
// MAGIC The variable **sc** allows you to access a Spark Context to run your Spark programs.
// MAGIC Recall ``SparkContext`` is in the Driver Program.
// MAGIC
// MAGIC 
// MAGIC
// MAGIC **NOTE: Do not create the *sc* variable - it is already initialized for you. **
// COMMAND ----------
// MAGIC %md
// MAGIC ### We will do the following next:
// MAGIC
// MAGIC 1. Create an RDD using `sc.parallelize`
// MAGIC * Perform the `collect` action on the RDD and find the number of partitions it is made of using `getNumPartitions` action
// MAGIC * Perform the ``take`` action on the RDD
// MAGIC * Transform the RDD by ``map`` to make another RDD
// MAGIC * Transform the RDD by ``filter`` to make another RDD
// MAGIC * Perform the ``reduce`` action on the RDD
// MAGIC * Transform the RDD by ``flatMap`` to make another RDD
// MAGIC * Create a Pair RDD
// MAGIC * Perform some transformations on a Pair RDD
// MAGIC * Where in the cluster is your computation running?
// MAGIC * Shipping Closures, Broadcast Variables and Accumulator Variables
// MAGIC * Spark Essentials: Summary
// MAGIC * HOMEWORK
// COMMAND ----------
// MAGIC %md
// MAGIC ## Entry Point
// MAGIC
// MAGIC Now we are ready to start programming in Spark!
// MAGIC
// MAGIC Our entry point for Spark 2.x applications is the class `SparkSession`. An instance of this object is already instantiated for us which can be easily demonstrated by running the next cell
// MAGIC
// MAGIC We will need these docs!
// MAGIC
// MAGIC * [RDD Scala Docs](https://spark.apache.org/docs/2.2.0/api/scala/index.html#org.apache.spark.rdd.RDD)
// MAGIC * [RDD Python Docs](https://spark.apache.org/docs/2.2.0/api/python/index.html#org.apache.spark.rdd.RDD)
// MAGIC * [DataFrame Scala Docs](https://spark.apache.org/docs/2.2.0/api/scala/index.html#org.apache.spark.sql.Dataset)
// MAGIC * [DataFrame Python Docs](https://spark.apache.org/docs/latest/api/python/pyspark.sql.html)
// COMMAND ----------
println(spark)
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC NOTE that in Spark 2.0 `SparkSession` is a replacement for the other entry points:
// MAGIC * `SparkContext`, available in our notebook as **sc**.
// MAGIC * `SQLContext`, or more specifically its subclass `HiveContext`, available in our notebook as **sqlContext**.
// COMMAND ----------
println(sc)
println(sqlContext)
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC We will be using the pre-made SparkContext `sc` when learning about RDDs.
// COMMAND ----------
// MAGIC %md
// MAGIC ### 1. Create an RDD using `sc.parallelize`
// MAGIC
// MAGIC First, let us create an RDD of three elements (of integer type ``Int``) from a Scala ``Seq`` (or ``List`` or ``Array``) with two partitions by using the ``parallelize`` method of the available Spark Context ``sc`` as follows:
// COMMAND ----------
val x = sc.parallelize(Array(1, 2, 3), 2) // <Ctrl+Enter> to evaluate this cell (using 2 partitions)
// COMMAND ----------
x. // place the cursor after 'x.' and hit Tab to see the methods available for the RDD x we created
// COMMAND ----------
// MAGIC %md
// MAGIC ### 2. Perform the `collect` action on the RDD and find the number of partitions it is made of using `getNumPartitions` action
// MAGIC
// MAGIC No action has been taken by ``sc.parallelize`` above. To see what is "cooked" by the recipe for RDD ``x`` we need to take an action.
// MAGIC
// MAGIC The simplest is the ``collect`` action which returns all of the elements of the RDD as an ``Array`` to the driver program and displays it.
// MAGIC
// MAGIC *So you have to make sure that all of that data will fit in the driver program if you call ``collect`` action!*
// COMMAND ----------
// MAGIC %md
// MAGIC #### Let us look at the [collect action in detail](/#workspace/scalable-data-science/xtraResources/visualRDDApi/recall/actions/collect) and return here to try out the example codes.
// MAGIC
// MAGIC
// MAGIC 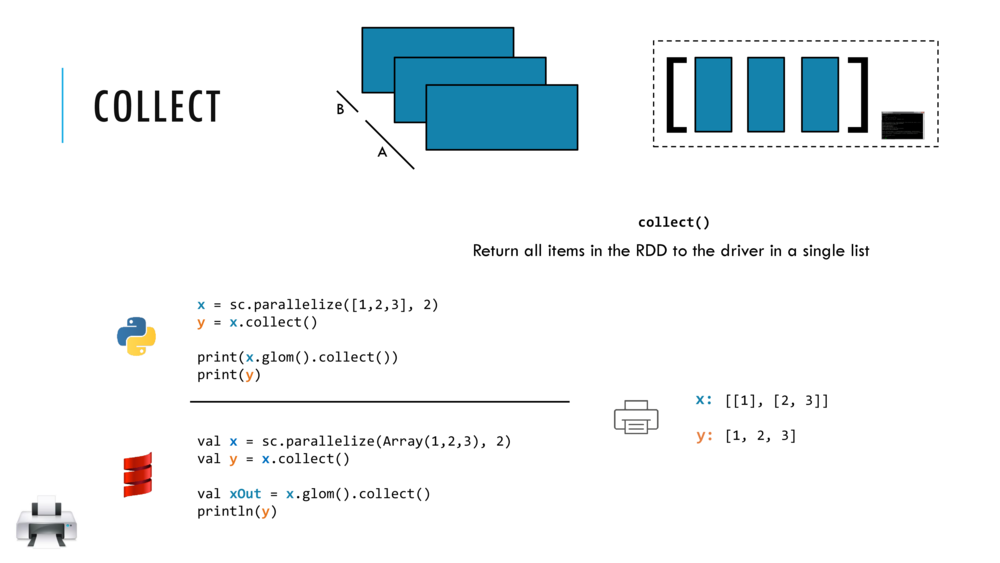
// COMMAND ----------
// MAGIC %md
// MAGIC Let us perform a `collect` action on RDD `x` as follows:
// COMMAND ----------
x.collect() // <Ctrl+Enter> to collect (action) elements of rdd; should be (1, 2, 3)
// COMMAND ----------
// MAGIC %md
// MAGIC *CAUTION:* ``collect`` can crash the driver when called upon an RDD with massively many elements.
// MAGIC So, it is better to use other diplaying actions like ``take`` or ``takeOrdered`` as follows:
// COMMAND ----------
// MAGIC %md
// MAGIC #### Let us look at the [getNumPartitions action in detail](/#workspace/scalable-data-science/xtraResources/visualRDDApi/recall/actions/getNumPartitions) and return here to try out the example codes.
// MAGIC
// MAGIC 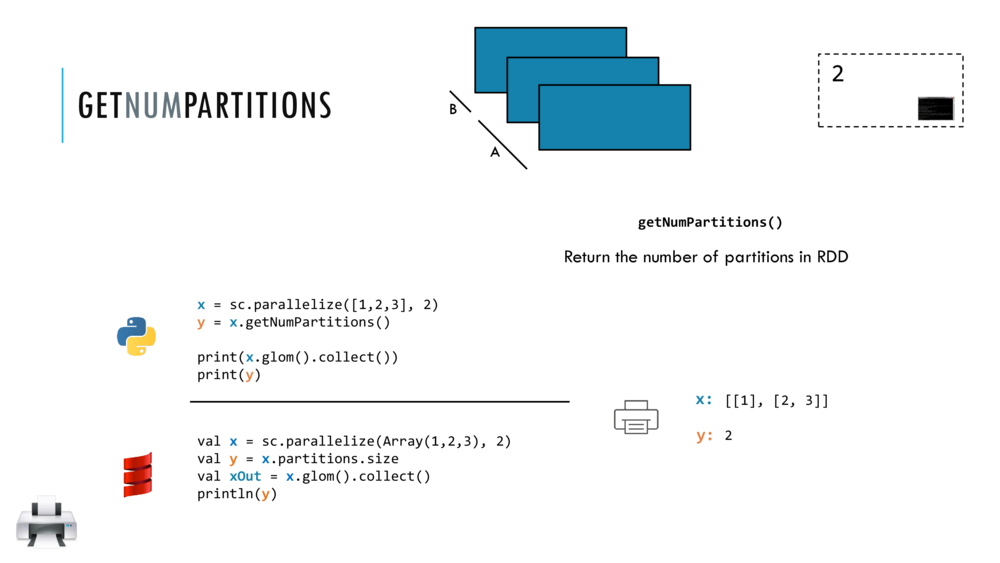
// COMMAND ----------
// <Ctrl+Enter> to evaluate this cell and find the number of partitions in RDD x
x.getNumPartitions
// COMMAND ----------
// MAGIC %md
// MAGIC We can see which elements of the RDD are in which parition by calling `glom()` before `collect()`.
// MAGIC
// MAGIC `glom()` flattens elements of the same partition into an `Array`.
// COMMAND ----------
x.glom().collect() // glom() flattens elements on the same partition
// COMMAND ----------
// MAGIC %md
// MAGIC Thus from the output above, `Array[Array[Int]] = Array(Array(1), Array(2, 3))`, we know that `1` is in one partition while `2` and `3` are in another partition.
// COMMAND ----------
// MAGIC %md
// MAGIC ##### You Try!
// MAGIC Crate an RDD `x` with three elements, 1,2,3, and this time do not specifiy the number of partitions. Then the default number of partitions will be used.
// MAGIC Find out what this is for the cluster you are attached to.
// MAGIC
// MAGIC The default number of partitions for an RDD depends on the cluster this notebook is attached to among others - see [programming-guide](http://spark.apache.org/docs/latest/programming-guide.html).
// COMMAND ----------
val x = sc.parallelize(Seq(1, 2, 3)) // <Shift+Enter> to evaluate this cell (using default number of partitions)
// COMMAND ----------
x.getNumPartitions // <Shift+Enter> to evaluate this cell
// COMMAND ----------
x.glom().collect() // <Ctrl+Enter> to evaluate this cell
// COMMAND ----------
// MAGIC %md
// MAGIC ### 3. Perform the `take` action on the RDD
// MAGIC
// MAGIC The ``.take(n)`` action returns an array with the first ``n`` elements of the RDD.
// COMMAND ----------
x.take(2) // Ctrl+Enter to take two elements from the RDD x
// COMMAND ----------
// MAGIC %md
// MAGIC ##### You Try!
// MAGIC Fill in the parenthes `( )` below in order to `take` just one element from RDD `x`.
// COMMAND ----------
//x.take( ) // uncomment by removing '//' before x in the cell and fill in the parenthesis to take just one element from RDD x and Cntrl+Enter
// COMMAND ----------
// MAGIC %md
// MAGIC ***
// MAGIC
// MAGIC ### 4. Transform the RDD by ``map`` to make another RDD
// MAGIC
// MAGIC The ``map`` transformation returns a new RDD that's formed by passing each element of the source RDD through a function (closure). The closure is automatically passed on to the workers for evaluation (when an action is called later).
// COMMAND ----------
// MAGIC %md
// MAGIC #### Let us look at the [map transformation in detail](/#workspace/scalable-data-science/xtraResources/visualRDDApi/recall/transformations/map) and return here to try out the example codes.
// MAGIC
// MAGIC 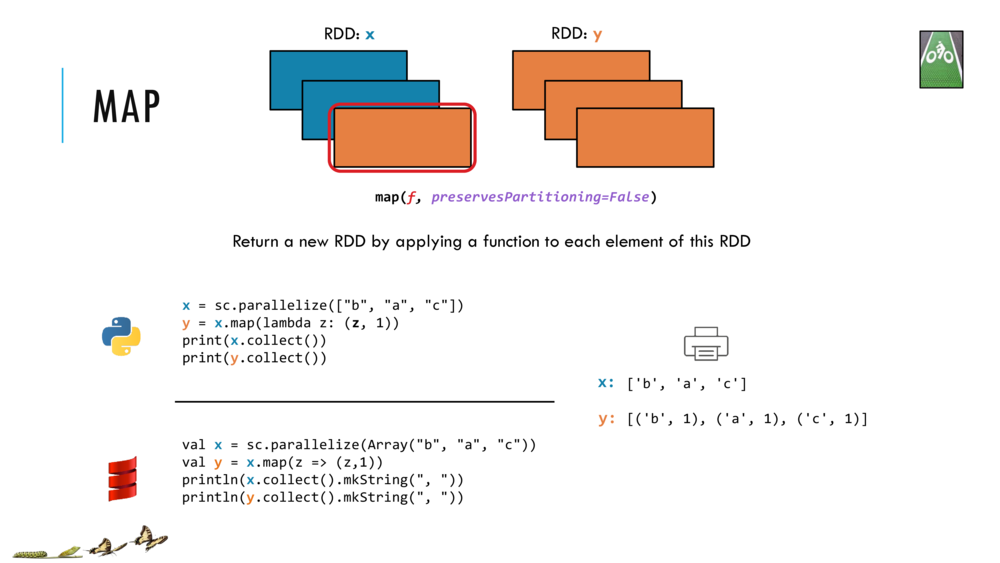
// COMMAND ----------
// Shift+Enter to make RDD x and RDD y that is mapped from x
val x = sc.parallelize(Array("b", "a", "c")) // make RDD x: [b, a, c]
val y = x.map(z => (z,1)) // map x into RDD y: [(b, 1), (a, 1), (c, 1)]
// COMMAND ----------
// Cntrl+Enter to collect and print the two RDDs
println(x.collect().mkString(", "))
println(y.collect().mkString(", "))
// COMMAND ----------
// MAGIC %md
// MAGIC ***
// MAGIC
// MAGIC ### 5. Transform the RDD by ``filter`` to make another RDD
// MAGIC
// MAGIC The ``filter`` transformation returns a new RDD that's formed by selecting those elements of the source RDD on which the function returns ``true``.
// COMMAND ----------
// MAGIC %md
// MAGIC #### Let us look at the [filter transformation in detail](/#workspace/scalable-data-science/xtraResources/visualRDDApi/recall/transformations/filter) and return here to try out the example codes.
// MAGIC
// MAGIC 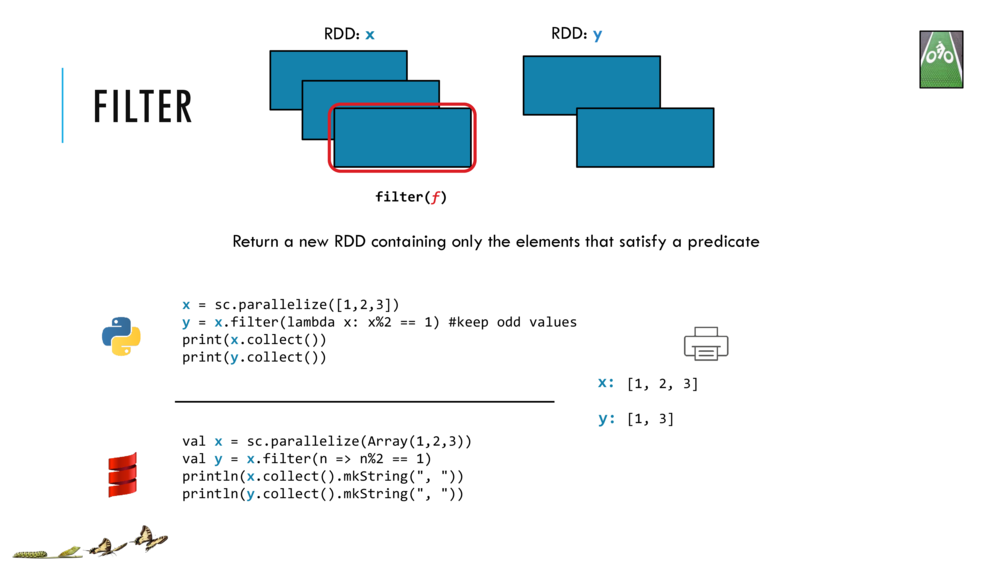
// COMMAND ----------
//Shift+Enter to make RDD x and filter it by (n => n%2 == 1) to make RDD y
val x = sc.parallelize(Array(1,2,3))
// the closure (n => n%2 == 1) in the filter will
// return True if element n in RDD x has remainder 1 when divided by 2 (i.e., if n is odd)
val y = x.filter(n => n%2 == 1)
// COMMAND ----------
// Cntrl+Enter to collect and print the two RDDs
println(x.collect().mkString(", "))
println(y.collect().mkString(", "))
// COMMAND ----------
// MAGIC %md
// MAGIC ***
// MAGIC ### 6. Perform the ``reduce`` action on the RDD
// MAGIC
// MAGIC Reduce aggregates a data set element using a function (closure).
// MAGIC This function takes two arguments and returns one and can often be seen as a binary operator.
// MAGIC This operator has to be commutative and associative so that it can be computed correctly in parallel (where we have little control over the order of the operations!).
// COMMAND ----------
// MAGIC %md
// MAGIC ### Let us look at the [reduce action in detail](/#workspace/scalable-data-science/xtraResources/visualRDDApi/recall/actions/reduce) and return here to try out the example codes.
// MAGIC
// MAGIC 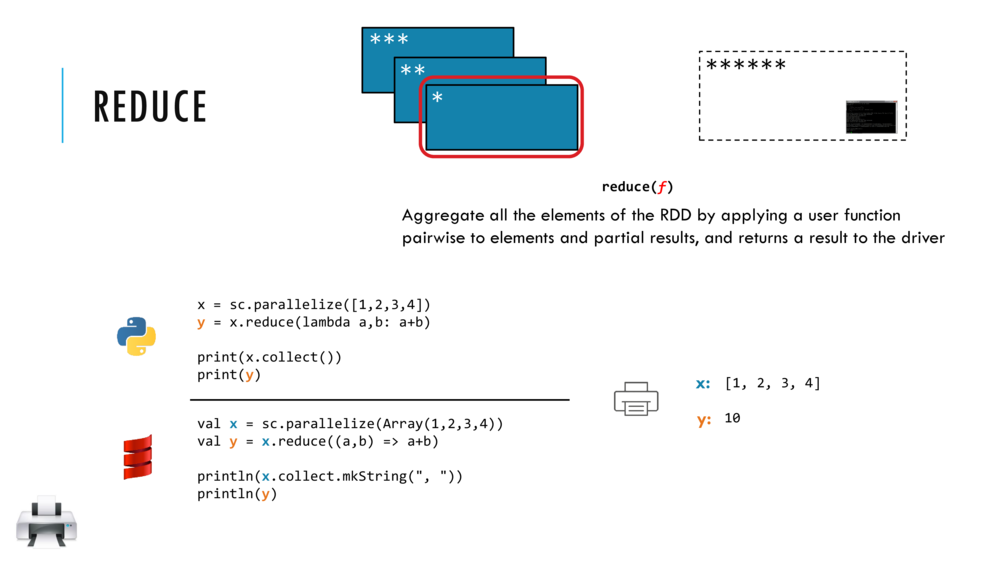
// COMMAND ----------
//Shift+Enter to make RDD x of inteegrs 1,2,3,4 and reduce it to sum
val x = sc.parallelize(Array(1,2,3,4))
val y = x.reduce((a,b) => a+b)
// COMMAND ----------
//Cntrl+Enter to collect and print RDD x and the Int y, sum of x
println(x.collect.mkString(", "))
println(y)
// COMMAND ----------
// MAGIC %md
// MAGIC ### 7. Transform an RDD by ``flatMap`` to make another RDD
// MAGIC
// MAGIC ``flatMap`` is similar to ``map`` but each element from input RDD can be mapped to zero or more output elements.
// MAGIC Therefore your function should return a sequential collection such as an ``Array`` rather than a single element as shown below.
// COMMAND ----------
// MAGIC %md
// MAGIC ### Let us look at the [flatMap transformation in detail](/#workspace/scalable-data-science/xtraResources/visualRDDApi/recall/transformations/flatMap) and return here to try out the example codes.
// MAGIC
// MAGIC 
// COMMAND ----------
//Shift+Enter to make RDD x and flatMap it into RDD by closure (n => Array(n, n*100, 42))
val x = sc.parallelize(Array(1,2,3))
val y = x.flatMap(n => Array(n, n*100, 42))
// COMMAND ----------
//Cntrl+Enter to collect and print RDDs x and y
println(x.collect().mkString(", "))
println(y.collect().mkString(", "))
// COMMAND ----------
// MAGIC %md
// MAGIC ### 8. Create a Pair RDD
// MAGIC
// MAGIC Let's next work with RDD of ``(key,value)`` pairs called a *Pair RDD* or *Key-Value RDD*.
// COMMAND ----------
// Cntrl+Enter to make RDD words and display it by collect
val words = sc.parallelize(Array("a", "b", "a", "a", "b", "b", "a", "a", "a", "b", "b"))
words.collect()
// COMMAND ----------
// MAGIC %md
// MAGIC Let's make a Pair RDD called `wordCountPairRDD` that is made of (key,value) pairs with key=word and value=1 in order to encode each occurrence of each word in the RDD `words`, as follows:
// COMMAND ----------
// Cntrl+Enter to make and collect Pair RDD wordCountPairRDD
val wordCountPairRDD = words.map(s => (s, 1))
wordCountPairRDD.collect()
// COMMAND ----------
// MAGIC %md
// MAGIC ### 9. Perform some transformations on a Pair RDD
// MAGIC
// MAGIC Let's next work with RDD of ``(key,value)`` pairs called a *Pair RDD* or *Key-Value RDD*.
// MAGIC
// MAGIC Now some of the Key-Value transformations that we could perform include the following.
// MAGIC
// MAGIC * **`reduceByKey` transformation**
// MAGIC * which takes an RDD and returns a new RDD of key-value pairs, such that:
// MAGIC * the values for each key are aggregated using the given reduced function
// MAGIC * and the reduce function has to be of the type that takes two values and returns one value.
// MAGIC * **`sortByKey` transformation**
// MAGIC * this returns a new RDD of key-value pairs that's sorted by keys in ascending order
// MAGIC * **`groupByKey` transformation**
// MAGIC * this returns a new RDD consisting of key and iterable-valued pairs.
// MAGIC
// MAGIC Let's see some concrete examples next.
// COMMAND ----------
// MAGIC %md
// MAGIC 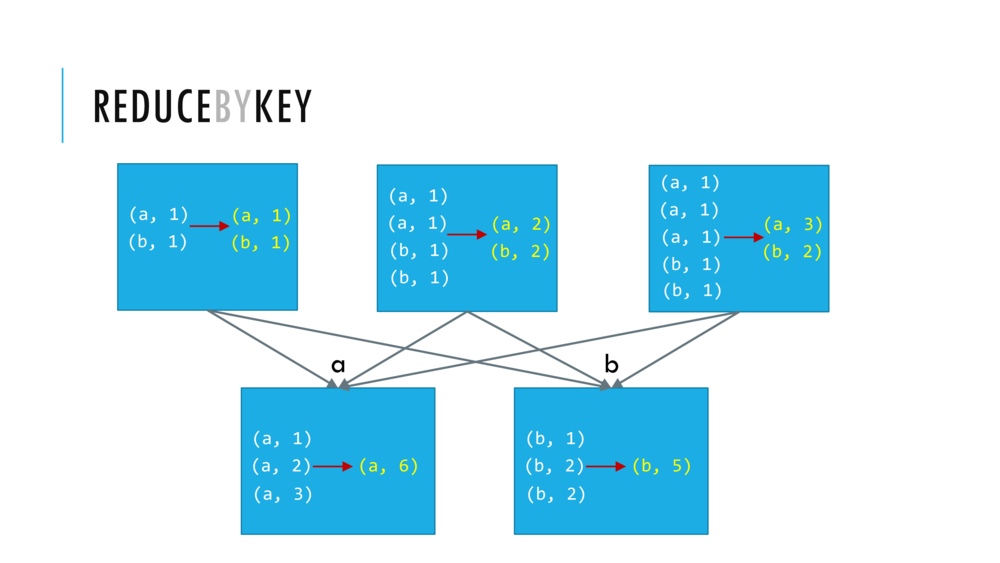
// COMMAND ----------
// Cntrl+Enter to reduceByKey and collect wordcounts RDD
//val wordcounts = wordCountPairRDD.reduceByKey( _ + _ )
val wordcounts = wordCountPairRDD.reduceByKey( (v1,v2) => v1+v2 )
wordcounts.collect()
// COMMAND ----------
// MAGIC %md
// MAGIC Now, let us do just the crucial steps and avoid collecting intermediate RDDs (something we should avoid for large datasets anyways, as they may not fit in the driver program).
// COMMAND ----------
//Cntrl+Enter to make words RDD and do the word count in two lines
val words = sc.parallelize(Array("a", "b", "a", "a", "b", "b", "a", "a", "a", "b", "b"))
val wordcounts = words.map(s => (s, 1)).reduceByKey(_ + _).collect()
// COMMAND ----------
// MAGIC %md
// MAGIC ##### You Try!
// MAGIC You try evaluating `sortByKey()` which will make a new RDD that consists of the elements of the original pair RDD that are sorted by Keys.
// COMMAND ----------
// Shift+Enter and comprehend code
val words = sc.parallelize(Array("a", "b", "a", "a", "b", "b", "a", "a", "a", "b", "b"))
val wordCountPairRDD = words.map(s => (s, 1))
val wordCountPairRDDSortedByKey = wordCountPairRDD.sortByKey()
// COMMAND ----------
wordCountPairRDD.collect() // Shift+Enter and comprehend code
// COMMAND ----------
wordCountPairRDDSortedByKey.collect() // Cntrl+Enter and comprehend code
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC The next key value transformation we will see is `groupByKey`
// MAGIC
// MAGIC When we apply the `groupByKey` transformation to `wordCountPairRDD` we end up with a new RDD that contains two elements.
// MAGIC The first element is the tuple `b` and an iterable `CompactBuffer(1,1,1,1,1)` obtained by grouping the value `1` for each of the five key value pairs `(b,1)`.
// MAGIC Similarly the second element is the key `a` and an iterable `CompactBuffer(1,1,1,1,1,1)` obtained by grouping the value `1` for each of the six key value pairs `(a,1)`.
// MAGIC
// MAGIC *CAUTION*: `groupByKey` can cause a large amount of data movement across the network.
// MAGIC It also can create very large iterables at a worker.
// MAGIC Imagine you have an RDD where you have 1 billion pairs that have the key `a`.
// MAGIC All of the values will have to fit in a single worker if you use group by key.
// MAGIC So instead of a group by key, consider using reduced by key.
// COMMAND ----------
// MAGIC %md
// MAGIC 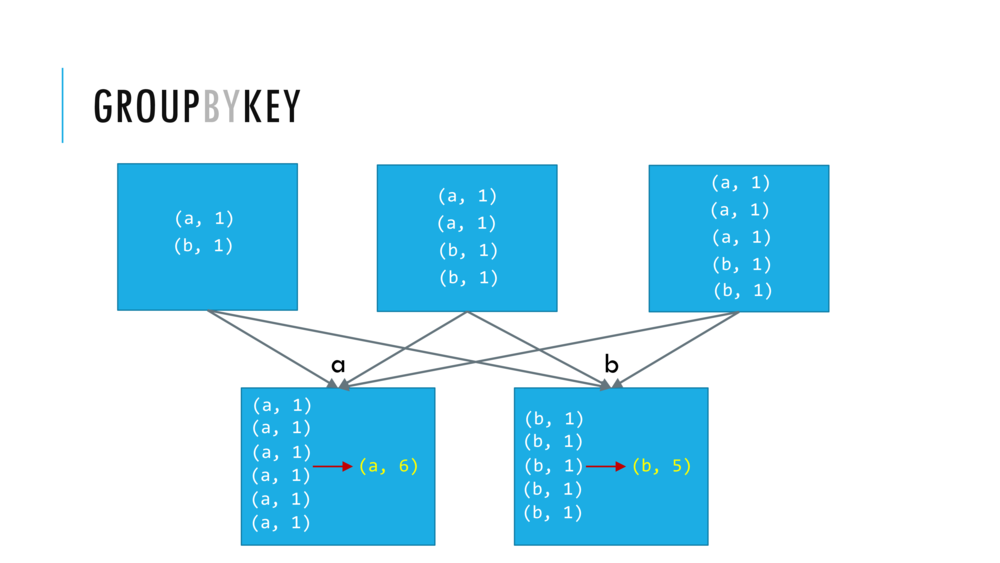
// COMMAND ----------
val wordCountPairRDDGroupByKey = wordCountPairRDD.groupByKey() // <Shift+Enter> CAUTION: this transformation can be very wide!
// COMMAND ----------
wordCountPairRDDGroupByKey.collect() // Cntrl+Enter
// COMMAND ----------
// MAGIC %md
// MAGIC ### 10. Where in the cluster is your computation running?
// COMMAND ----------
val list = 1 to 10
var sum = 0
list.map(x => sum = sum + x)
print(sum)
// COMMAND ----------
val rdd = sc.parallelize(1 to 10)
var sum = 0
// COMMAND ----------
val rdd1 = rdd.map(x => sum = sum + x)
// COMMAND ----------
rdd1.collect()
// COMMAND ----------
val rdd1 = rdd.map(x => {var sum = 0;
sum = sum + x
sum}
)
// COMMAND ----------
rdd1.collect()
// COMMAND ----------
// MAGIC %md
// MAGIC ### 11. Shipping Closures, Broadcast Variables and Accumulator Variables
// MAGIC
// MAGIC #### Closures, Broadcast and Accumulator Variables
// MAGIC **(watch now 2:06)**:
// MAGIC
// MAGIC [](https://www.youtube.com/watch?v=I9Zcr4R35Ao?rel=0&autoplay=1&modestbranding=1)
// MAGIC
// MAGIC
// MAGIC We will use these variables in the sequel.
// MAGIC
// MAGIC #### SUMMARY
// MAGIC Spark automatically creates closures
// MAGIC
// MAGIC * for functions that run on RDDs at workers,
// MAGIC * and for any global variables that are used by those workers
// MAGIC * one closure per worker is sent with every task
// MAGIC * and there's no communication between workers
// MAGIC * closures are one way from the driver to the worker
// MAGIC * any changes that you make to the global variables at the workers
// MAGIC * are not sent to the driver or
// MAGIC * are not sent to other workers.
// MAGIC
// MAGIC
// MAGIC The problem we have is that these closures
// MAGIC
// MAGIC * are automatically created are sent or re-sent with every job
// MAGIC * with a large global variable it gets inefficient to send/resend lots of data to each worker
// MAGIC * we cannot communicate that back to the driver
// MAGIC
// MAGIC
// MAGIC To do this, Spark provides shared variables in two different types.
// MAGIC
// MAGIC * **broadcast variables**
// MAGIC * lets us to efficiently send large read-only values to all of the workers
// MAGIC * these are saved at the workers for use in one or more Spark operations.
// MAGIC * **accumulator variables**
// MAGIC * These allow us to aggregate values from workers back to the driver.
// MAGIC * only the driver can access the value of the accumulator
// MAGIC * for the tasks, the accumulators are basically write-only
// MAGIC
// MAGIC ***
// MAGIC
// MAGIC ### 12. Spark Essentials: Summary
// MAGIC **(watch now: 0:29)**
// MAGIC
// MAGIC [](https://www.youtube.com/watch?v=F50Vty9Ia8Y?rel=0&autoplay=1&modestbranding=1)
// MAGIC
// MAGIC *NOTE:* In databricks cluster, we (the course coordinator/administrators) set the number of workers for you.
// COMMAND ----------
// MAGIC %md
// MAGIC ### 13. HOMEWORK
// MAGIC See the notebook in this folder named `005_RDDsTransformationsActionsHOMEWORK`.
// MAGIC This notebook will give you more examples of the operations above as well as others we will be using later, including:
// MAGIC
// MAGIC * Perform the ``takeOrdered`` action on the RDD
// MAGIC * Transform the RDD by ``distinct`` to make another RDD and
// MAGIC * Doing a bunch of transformations to our RDD and performing an action in a single cell.
// COMMAND ----------
// MAGIC %md
// MAGIC ***
// MAGIC ***
// MAGIC ### Importing Standard Scala and Java libraries
// MAGIC * For other libraries that are not available by default, you can upload other libraries to the Workspace.
// MAGIC * Refer to the **[Libraries](https://docs.databricks.com/user-guide/libraries.html)** guide for more details.
// COMMAND ----------
import scala.math._
val x = min(1, 10)
// COMMAND ----------
import java.util.HashMap
val map = new HashMap[String, Int]()
map.put("a", 1)
map.put("b", 2)
map.put("c", 3)
map.put("d", 4)
map.put("e", 5)
| lamastex/scalable-data-science | db/2/2/360-in-525-01/004_RDDsTransformationsActions.scala | Scala | unlicense | 26,752 |
/*
* Copyright 2019 ACINQ SAS
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package fr.acinq.eclair.api.handlers
import akka.http.scaladsl.server.Route
import com.google.common.net.HostAndPort
import fr.acinq.eclair.api.Service
import fr.acinq.eclair.api.directives.EclairDirectives
import fr.acinq.eclair.api.serde.FormParamExtractors._
import fr.acinq.eclair.io.NodeURI
trait Node {
this: Service with EclairDirectives =>
import fr.acinq.eclair.api.serde.JsonSupport.{formats, marshaller, serialization}
val getInfo: Route = postRequest("getinfo") { implicit t =>
complete(eclairApi.getInfo())
}
val connect: Route = postRequest("connect") { implicit t =>
formFields("uri".as[NodeURI]) { uri =>
complete(eclairApi.connect(Left(uri)))
} ~ formFields(nodeIdFormParam, "host".as[String], "port".as[Int].?) { (nodeId, host, port_opt) =>
complete {
eclairApi.connect(
Left(NodeURI(nodeId, HostAndPort.fromParts(host, port_opt.getOrElse(NodeURI.DEFAULT_PORT))))
)
}
} ~ formFields(nodeIdFormParam) { nodeId =>
complete(eclairApi.connect(Right(nodeId)))
}
}
val disconnect: Route = postRequest("disconnect") { implicit t =>
formFields(nodeIdFormParam) { nodeId =>
complete(eclairApi.disconnect(nodeId))
}
}
val peers: Route = postRequest("peers") { implicit t =>
complete(eclairApi.peers())
}
val audit: Route = postRequest("audit") { implicit t =>
formFields(fromFormParam, toFormParam) { (from, to) =>
complete(eclairApi.audit(from, to))
}
}
val nodeRoutes: Route = getInfo ~ connect ~ disconnect ~ peers ~ audit
}
| ACINQ/eclair | eclair-node/src/main/scala/fr/acinq/eclair/api/handlers/Node.scala | Scala | apache-2.0 | 2,167 |
package org.scalatest.examples.fixture.wordspec.sharing
import java.util.concurrent.ConcurrentHashMap
import org.scalatest.fixture
import DbServer._
import java.util.UUID.randomUUID
object DbServer { // Simulating a database server
type Db = StringBuffer
private val databases = new ConcurrentHashMap[String, Db]
def createDb(name: String): Db = {
val db = new StringBuffer
databases.put(name, db)
db
}
def removeDb(name: String) {
databases.remove(name)
}
}
trait DbFixture { this: fixture.Suite =>
type FixtureParam = Db
// Allow clients to populate the database after
// it is created
def populateDb(db: Db) {}
def withFixture(test: OneArgTest) {
val dbName = randomUUID.toString
val db = createDb(dbName) // create the fixture
try {
populateDb(db) // setup the fixture
withFixture(test.toNoArgTest(db)) // "loan" the fixture to the test
}
finally removeDb(dbName) // clean up the fixture
}
}
class ExampleSpec extends fixture.WordSpec with DbFixture {
override def populateDb(db: Db) { // setup the fixture
db.append("ScalaTest is ")
}
"Testing" should {
"should be easy" in { db =>
db.append("easy!")
assert(db.toString === "ScalaTest is easy!")
}
"should be fun" in { db =>
db.append("fun!")
assert(db.toString === "ScalaTest is fun!")
}
}
// This test doesn't need a Db
"Test code" should {
"should be clear" in { () =>
val buf = new StringBuffer
buf.append("ScalaTest code is ")
buf.append("clear!")
assert(buf.toString === "ScalaTest code is clear!")
}
}
}
| hubertp/scalatest | examples/src/main/scala/org/scalatest/examples/fixture/wordspec/sharing/ExampleSpec.scala | Scala | apache-2.0 | 1,645 |
package mesosphere.marathon
package api
import java.io.{ IOException, InputStream, OutputStream }
import java.net._
import javax.inject.Named
import javax.net.ssl._
import javax.servlet._
import javax.servlet.http.{ HttpServletRequest, HttpServletResponse }
import akka.Done
import com.google.inject.Inject
import mesosphere.chaos.http.HttpConf
import mesosphere.marathon.core.election.ElectionService
import mesosphere.marathon.io.IO
import mesosphere.marathon.stream.Implicits._
import akka.http.scaladsl.model.StatusCodes._
import org.slf4j.LoggerFactory
import scala.annotation.tailrec
import scala.util.{ Failure, Success, Try }
import scala.util.control.NonFatal
/**
* Servlet filter that proxies requests to the leader if we are not the leader.
*/
class LeaderProxyFilter @Inject() (
httpConf: HttpConf,
electionService: ElectionService,
@Named(ModuleNames.HOST_PORT) myHostPort: String,
forwarder: RequestForwarder) extends Filter {
import LeaderProxyFilter._
private[this] val scheme = if (httpConf.disableHttp()) "https" else "http"
@SuppressWarnings(Array("EmptyMethod"))
override def init(filterConfig: FilterConfig): Unit = {}
@SuppressWarnings(Array("EmptyMethod"))
override def destroy(): Unit = {}
private[this] def buildUrl(leaderData: String, request: HttpServletRequest): URL = {
buildUrl(leaderData, request.getRequestURI, Option(request.getQueryString))
}
private[this] def buildUrl(
leaderData: String,
requestURI: String = "",
queryStringOpt: Option[String] = None): URL =
{
queryStringOpt match {
case Some(queryString) => new URL(s"$scheme://$leaderData$requestURI?$queryString")
case None => new URL(s"$scheme://$leaderData$requestURI")
}
}
@tailrec
final def doFilter(
rawRequest: ServletRequest,
rawResponse: ServletResponse,
chain: FilterChain): Unit = {
def waitForConsistentLeadership(): Boolean = {
var retries = 10
var result = false
do {
val weAreLeader = electionService.isLeader
val currentLeaderData = electionService.leaderHostPort
if (weAreLeader || currentLeaderData.exists(_ != myHostPort)) {
log.info("Leadership info is consistent again!")
result = true
retries = 0
} else if (retries >= 0) {
// as long as we are not flagged as elected yet, the leadership transition is still
// taking place and we hold back any requests.
log.info(s"Waiting for consistent leadership state. Are we leader?: $weAreLeader, leader: $currentLeaderData")
sleep()
} else {
log.error(
s"inconsistent leadership state, refusing request for ourselves at $myHostPort. " +
s"Are we leader?: $weAreLeader, leader: $currentLeaderData")
}
retries -= 1
} while (retries >= 0)
result
}
(rawRequest, rawResponse) match {
case (request: HttpServletRequest, response: HttpServletResponse) =>
lazy val leaderDataOpt = electionService.leaderHostPort
if (electionService.isLeader) {
response.addHeader(LeaderProxyFilter.HEADER_MARATHON_LEADER, buildUrl(myHostPort).toString)
chain.doFilter(request, response)
} else if (leaderDataOpt.forall(_ == myHostPort)) { // either not leader or ourselves
log.info(
"Do not proxy to myself. Waiting for consistent leadership state. " +
s"Are we leader?: false, leader: $leaderDataOpt")
if (waitForConsistentLeadership()) {
doFilter(rawRequest, rawResponse, chain)
} else {
response.sendError(ServiceUnavailable.intValue, ERROR_STATUS_NO_CURRENT_LEADER)
}
} else {
try {
leaderDataOpt.foreach { leaderData =>
val url = buildUrl(leaderData, request)
forwarder.forward(url, request, response)
}
} catch {
case NonFatal(e) =>
throw new RuntimeException("while proxying", e)
}
}
case _ =>
throw new IllegalArgumentException(s"expected http request/response but got $rawRequest/$rawResponse")
}
}
protected def sleep(): Unit = {
Thread.sleep(250)
}
}
object LeaderProxyFilter {
private val log = LoggerFactory.getLogger(getClass.getName)
val HEADER_MARATHON_LEADER: String = "X-Marathon-Leader"
val ERROR_STATUS_NO_CURRENT_LEADER: String = "Could not determine the current leader"
}
/**
* Forwards a HttpServletRequest to an URL.
*/
trait RequestForwarder {
def forward(url: URL, request: HttpServletRequest, response: HttpServletResponse): Unit
}
class JavaUrlConnectionRequestForwarder @Inject() (
@Named(JavaUrlConnectionRequestForwarder.NAMED_LEADER_PROXY_SSL_CONTEXT) sslContext: SSLContext,
leaderProxyConf: LeaderProxyConf,
@Named(ModuleNames.HOST_PORT) myHostPort: String)
extends RequestForwarder {
import JavaUrlConnectionRequestForwarder._
private[this] val viaValue: String = s"1.1 $myHostPort"
private lazy val ignoreHostnameVerifier = new javax.net.ssl.HostnameVerifier {
override def verify(hostname: String, sslSession: SSLSession): Boolean = true
}
override def forward(url: URL, request: HttpServletRequest, response: HttpServletResponse): Unit = {
def hasProxyLoop: Boolean = {
Option(request.getHeaders(HEADER_VIA)).exists(_.seq.contains(viaValue))
}
def createAndConfigureConnection(url: URL): HttpURLConnection = {
val connection = url.openConnection() match {
case httpsConnection: HttpsURLConnection =>
httpsConnection.setSSLSocketFactory(sslContext.getSocketFactory)
if (leaderProxyConf.leaderProxySSLIgnoreHostname()) {
httpsConnection.setHostnameVerifier(ignoreHostnameVerifier)
}
httpsConnection
case httpConnection: HttpURLConnection =>
httpConnection
case connection: URLConnection =>
throw new scala.RuntimeException(s"unexpected connection type: ${connection.getClass}")
}
connection.setConnectTimeout(leaderProxyConf.leaderProxyConnectionTimeout())
connection.setReadTimeout(leaderProxyConf.leaderProxyReadTimeout())
connection.setInstanceFollowRedirects(false)
connection
}
def copyRequestHeadersToConnection(leaderConnection: HttpURLConnection, request: HttpServletRequest): Unit = {
// getHeaderNames() and getHeaders() are known to return null, see:
//http://docs.oracle.com/javaee/6/api/javax/servlet/http/HttpServletRequest.html#getHeaders(java.lang.String)
val names = Option(request.getHeaderNames).map(_.seq).getOrElse(Nil)
for {
name <- names
// Reverse proxies commonly filter these headers: connection, host.
//
// The connection header is removed since it may make sense to persist the connection
// for further requests even if this single client will stop using it.
//
// The host header is used to choose the correct virtual host and should be set to the hostname
// of the URL for HTTP 1.1. Thus we do not preserve it, even though Marathon does not care.
if !name.equalsIgnoreCase("host") && !name.equalsIgnoreCase("connection")
headerValues <- Option(request.getHeaders(name))
headerValue <- headerValues.seq
} {
log.debug(s"addRequestProperty $name: $headerValue")
leaderConnection.addRequestProperty(name, headerValue)
}
leaderConnection.addRequestProperty(HEADER_VIA, viaValue)
val forwardedFor = Seq(
Option(request.getHeader(HEADER_FORWARDED_FOR)),
Option(request.getRemoteAddr)
).flatten.mkString(",")
leaderConnection.addRequestProperty(HEADER_FORWARDED_FOR, forwardedFor)
}
def copyRequestBodyToConnection(leaderConnection: HttpURLConnection, request: HttpServletRequest): Unit = {
request.getMethod match {
case "GET" | "HEAD" | "DELETE" =>
leaderConnection.setDoOutput(false)
case _ =>
leaderConnection.setDoOutput(true)
IO.using(request.getInputStream) { requestInput =>
IO.using(leaderConnection.getOutputStream) { proxyOutputStream =>
copy(request.getInputStream, proxyOutputStream)
}
}
}
}
def copyRequestToConnection(leaderConnection: HttpURLConnection, request: HttpServletRequest): Unit = {
leaderConnection.setRequestMethod(request.getMethod)
copyRequestHeadersToConnection(leaderConnection, request)
copyRequestBodyToConnection(leaderConnection, request)
}
def cloneResponseStatusAndHeader(remote: HttpURLConnection, response: HttpServletResponse): Try[Done] = Try {
val status = remote.getResponseCode
response.setStatus(status)
Option(remote.getHeaderFields).foreach { fields =>
// headers and values can both be null :(
fields.foreach {
case (n, v) =>
(Option(n), Option(v)) match {
case (Some(name), Some(values)) =>
values.foreach(value =>
response.addHeader(name, value)
)
case _ => // ignore
}
}
}
response.addHeader(HEADER_VIA, viaValue)
Done
}
def cloneResponseEntity(remote: HttpURLConnection, response: HttpServletResponse): Unit = {
IO.using(response.getOutputStream) { output =>
try {
IO.using(remote.getInputStream) { connectionInput => copy(connectionInput, output) }
} catch {
case e: IOException =>
log.debug("got exception response, this is maybe an error code", e)
IO.using(remote.getErrorStream) { connectionError => copy(connectionError, output) }
}
}
}
log.info(s"Proxying request to ${request.getMethod} $url from $myHostPort")
try {
if (hasProxyLoop) {
log.error("Prevent proxy cycle, rejecting request")
response.sendError(BadGateway.intValue, ERROR_STATUS_LOOP)
} else {
val leaderConnection: HttpURLConnection = createAndConfigureConnection(url)
try {
copyRequestToConnection(leaderConnection, request)
copyConnectionResponse(
response
)(
() => cloneResponseStatusAndHeader(leaderConnection, response),
() => cloneResponseEntity(leaderConnection, response)
)
} catch {
case connException: ConnectException =>
response.sendError(BadGateway.intValue, ERROR_STATUS_CONNECTION_REFUSED)
} finally {
Try(leaderConnection.getInputStream.close())
Try(leaderConnection.getErrorStream.close())
}
}
} finally {
Try(request.getInputStream.close())
Try(response.getOutputStream.close())
}
}
def copy(nullableIn: InputStream, nullableOut: OutputStream): Unit = {
try {
for {
in <- Option(nullableIn)
out <- Option(nullableOut)
} IO.transfer(in, out, close = false)
} catch {
case e: UnknownServiceException =>
log.warn("unexpected unknown service exception", e)
}
}
}
object JavaUrlConnectionRequestForwarder {
private val log = LoggerFactory.getLogger(getClass)
/** Header for proxy loop detection. Simply "Via" is ignored by the URL connection.*/
val HEADER_VIA: String = "X-Marathon-Via"
val ERROR_STATUS_LOOP: String = "Detected proxying loop."
val ERROR_STATUS_CONNECTION_REFUSED: String = "Connection to leader refused."
val ERROR_STATUS_BAD_CONNECTION: String = "Failed to successfully establish a connection to the leader."
val HEADER_FORWARDED_FOR: String = "X-Forwarded-For"
final val NAMED_LEADER_PROXY_SSL_CONTEXT = "JavaUrlConnectionRequestForwarder.SSLContext"
def copyConnectionResponse(response: HttpServletResponse)(
forwardHeaders: () => Try[Done], forwardEntity: () => Unit): Unit = {
forwardHeaders() match {
case Failure(e) =>
// early detection of proxy failure, before we commit the status code to the response stream
log.warn("failed to proxy response headers from leader", e)
response.sendError(BadGateway.intValue, ERROR_STATUS_BAD_CONNECTION)
case Success(_) =>
forwardEntity()
}
}
}
| natemurthy/marathon | src/main/scala/mesosphere/marathon/api/LeaderProxyFilter.scala | Scala | apache-2.0 | 12,427 |
package edu.gemini.model.p1.immutable
import edu.gemini.model.p1.{ mutable => M }
import scala.collection.JavaConverters._
import java.util.UUID
object Investigator {
def apply(m:M.Investigator) = m match {
case pi:M.PrincipalInvestigator => PrincipalInvestigator.apply(pi)
case coi:M.CoInvestigator => CoInvestigator.apply(coi)
}
//val noneID = UUID.randomUUID()
//val none = CoInvestigator(noneID, "None", "", Nil, "", InvestigatorStatus.OTHER, "")
}
sealed trait Investigator {
/**
* Each Investigator has a UUID that can be used as a reference. This value is preserved on copy (unless a new one
* is specified) and on PI/CoI conversion. Investigators constructed from the same mutable instance will have the
* same uuid.
*/
def uuid:UUID
def ref:InvestigatorRef = InvestigatorRef(this)
def firstName: String
def lastName: String
def email: String
def phone: List[String]
def status: InvestigatorStatus
def mutable(n:Namer):M.Investigator
def fullName = firstName + " " + lastName
override def toString = fullName
def toPi: PrincipalInvestigator
def toCoi: CoInvestigator
def isComplete:Boolean =
EmailRegex.findFirstIn(email).isDefined &&
List(firstName, lastName, email).forall(!_.trim.isEmpty) // phone is optional
}
object PrincipalInvestigator extends UuidCache[M.PrincipalInvestigator] {
def apply(m: M.PrincipalInvestigator):PrincipalInvestigator = apply(
uuid(m),
m.getFirstName,
m.getLastName,
m.getPhone.asScala.toList,
m.getEmail,
m.getStatus,
InstitutionAddress(m.getAddress))
def empty = apply(UUID.randomUUID(), "Principal", "Investigator", Nil, "", InvestigatorStatus.PH_D, InstitutionAddress.empty)
}
case class PrincipalInvestigator(
uuid:UUID,
firstName: String,
lastName: String,
phone: List[String],
email: String,
status: InvestigatorStatus,
address: InstitutionAddress) extends Investigator {
def mutable(n:Namer) = {
val m = Factory.createPrincipalInvestigator
m.setId(n.nameOf(this))
m.setFirstName(firstName)
m.setLastName(lastName)
m.getPhone.addAll(phone.asJavaCollection)
m.setEmail(email)
m.setStatus(status)
m.setAddress(address.mutable)
m
}
def toPi = this
def toCoi = CoInvestigator(
uuid,
firstName,
lastName,
phone,
email,
status,
address.institution)
override def isComplete = super.isComplete && address.isComplete
}
object CoInvestigator extends UuidCache[M.CoInvestigator] {
def apply(m: M.CoInvestigator):CoInvestigator = apply(
uuid(m),
m.getFirstName,
m.getLastName,
m.getPhone.asScala.toList,
m.getEmail,
m.getStatus,
m.getInstitution)
def empty = apply(UUID.randomUUID(), "", "", Nil, "", InvestigatorStatus.PH_D, "")
}
case class CoInvestigator(
uuid:UUID,
firstName: String,
lastName: String,
phone: List[String],
email: String,
status: InvestigatorStatus,
institution: String) extends Investigator {
def mutable(n:Namer) = {
val m = Factory.createCoInvestigator
m.setId(n.nameOf(this))
m.setFirstName(firstName)
m.setLastName(lastName)
m.getPhone.addAll(phone.asJavaCollection)
m.setEmail(email)
m.setStatus(status)
m.setInstitution(institution)
m
}
def toPi = PrincipalInvestigator(
uuid,
firstName,
lastName,
phone,
email,
status,
InstitutionAddress.empty.copy(institution = institution))
def toCoi = this
override def isComplete = super.isComplete && (!institution.trim.isEmpty)
} | arturog8m/ocs | bundle/edu.gemini.model.p1/src/main/scala/edu/gemini/model/p1/immutable/Investigator.scala | Scala | bsd-3-clause | 3,604 |
package com.avsystem.scex
package util
import org.slf4j.{Logger, LoggerFactory}
import scala.reflect.{ClassTag, classTag}
/**
* Created: 06-12-2013
* Author: ghik
*/
trait LoggingUtils {
protected case class LazyLogger(underlying: Logger) {
def trace(msg: => String, cause: Throwable = null): Unit = {
if (underlying.isTraceEnabled) {
underlying.trace(msg, cause)
}
}
def debug(msg: => String, cause: Throwable = null): Unit = {
if (underlying.isDebugEnabled) {
underlying.debug(msg, cause)
}
}
def info(msg: => String, cause: Throwable = null): Unit = {
if (underlying.isInfoEnabled) {
underlying.info(msg, cause)
}
}
def warn(msg: => String, cause: Throwable = null): Unit = {
if (underlying.isWarnEnabled) {
underlying.warn(msg, cause)
}
}
def error(msg: => String, cause: Throwable = null): Unit = {
if (underlying.isErrorEnabled) {
underlying.error(msg, cause)
}
}
}
protected def createLogger[T: ClassTag] =
LazyLogger(LoggerFactory.getLogger(classTag[T].runtimeClass))
}
| AVSystem/scex | scex-core/src/main/scala/com/avsystem/scex/util/LoggingUtils.scala | Scala | mit | 1,140 |
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.gearpump.streaming.state.impl
import org.slf4j.Logger
import org.apache.gearpump.Time.MilliSeconds
import org.apache.gearpump.streaming.state.api.{Monoid, MonoidState, Serializer}
import org.apache.gearpump.streaming.state.impl.NonWindowState._
import org.apache.gearpump.util.LogUtil
object NonWindowState {
val LOG: Logger = LogUtil.getLogger(classOf[NonWindowState[_]])
}
/**
* a MonoidState storing non-window state
*/
class NonWindowState[T](monoid: Monoid[T], serializer: Serializer[T])
extends MonoidState[T](monoid) {
override def recover(timestamp: MilliSeconds, bytes: Array[Byte]): Unit = {
serializer.deserialize(bytes).foreach(left = _)
}
override def update(timestamp: MilliSeconds, t: T): Unit = {
updateState(timestamp, t)
}
override def checkpoint(): Array[Byte] = {
val serialized = serializer.serialize(left)
LOG.debug(s"checkpoint time: $checkpointTime; checkpoint value: ($checkpointTime, $left)")
left = monoid.plus(left, right)
right = monoid.zero
serialized
}
}
| manuzhang/incubator-gearpump | streaming/src/main/scala/org/apache/gearpump/streaming/state/impl/NonWindowState.scala | Scala | apache-2.0 | 1,866 |
/* NSC -- new Scala compiler
* Copyright 2005-2015 LAMP/EPFL
* @author Martin Odersky
*/
package scala.tools.nsc.interpreter
import scala.reflect.internal.util.RangePosition
import scala.reflect.io.AbstractFile
import scala.tools.nsc.backend.JavaPlatform
import scala.tools.nsc.util.ClassPath
import scala.tools.nsc.{interactive, Settings}
import scala.tools.nsc.reporters.StoreReporter
import scala.tools.nsc.classpath._
trait PresentationCompilation {
self: IMain =>
/** Typecheck a line of REPL input, suitably wrapped with "interpreter wrapper" objects/classes, with the
* presentation compiler. The result of this method gives access to the typechecked tree and to autocompletion
* suggestions.
*
* The caller is responsible for calling [[PresentationCompileResult#cleanup]] to dispose of the compiler instance.
*/
private[scala] def presentationCompile(line: String): Either[IR.Result, PresentationCompileResult] = {
if (global == null) Left(IR.Error)
else {
// special case for:
//
// scala> 1
// scala> .toInt
//
// and for multi-line input.
val line1 = partialInput + (if (Completion.looksLikeInvocation(line)) { self.mostRecentVar + line } else line)
val compiler = newPresentationCompiler()
val trees = compiler.newUnitParser(line1).parseStats()
val importer = global.mkImporter(compiler)
val request = new Request(line1, trees map (t => importer.importTree(t)), generousImports = true)
val wrappedCode: String = request.ObjectSourceCode(request.handlers)
val unit = compiler.newCompilationUnit(wrappedCode)
import compiler._
val richUnit = new RichCompilationUnit(unit.source)
unitOfFile(richUnit.source.file) = richUnit
enteringTyper(typeCheck(richUnit))
val result = PresentationCompileResult(compiler)(richUnit, request.ObjectSourceCode.preambleLength + line1.length - line.length)
Right(result)
}
}
/** Create an instance of the presentation compiler with a classpath comprising the REPL's configured classpath
* and the classes output by previously compiled REPL lines.
*
* You may directly interact with this compiler from any thread, although you must not access it concurrently
* from multiple threads.
*
* You may downcast the `reporter` to `StoreReporter` to access type errors.
*/
def newPresentationCompiler(): interactive.Global = {
def mergedFlatClasspath = {
val replOutClasspath = ClassPathFactory.newClassPath(replOutput.dir, settings)
AggregateClassPath(replOutClasspath :: global.platform.classPath :: Nil)
}
def copySettings: Settings = {
val s = new Settings(_ => () /* ignores "bad option -nc" errors, etc */)
s.processArguments(global.settings.recreateArgs, processAll = false)
s.YpresentationAnyThread.value = true
s
}
val storeReporter: StoreReporter = new StoreReporter
val interactiveGlobal = new interactive.Global(copySettings, storeReporter) { self =>
override lazy val platform: ThisPlatform = {
new JavaPlatform {
lazy val global: self.type = self
override private[nsc] lazy val classPath: ClassPath = mergedFlatClasspath
}
}
}
new interactiveGlobal.TyperRun()
interactiveGlobal
}
abstract class PresentationCompileResult {
val compiler: scala.tools.nsc.interactive.Global
def unit: compiler.RichCompilationUnit
/** The length of synthetic code the precedes the user written code */
def preambleLength: Int
def cleanup(): Unit = {
compiler.askShutdown()
}
import compiler.CompletionResult
def completionsAt(cursor: Int): CompletionResult = {
val pos = unit.source.position(preambleLength + cursor)
compiler.completionsAt(pos)
}
def typedTreeAt(code: String, selectionStart: Int, selectionEnd: Int): compiler.Tree = {
val start = selectionStart + preambleLength
val end = selectionEnd + preambleLength
val pos = new RangePosition(unit.source, start, start, end)
compiler.typedTreeAt(pos)
}
}
object PresentationCompileResult {
def apply(compiler0: interactive.Global)(unit0: compiler0.RichCompilationUnit, preambleLength0: Int) = new PresentationCompileResult {
override val compiler = compiler0
override def unit = unit0.asInstanceOf[compiler.RichCompilationUnit]
override def preambleLength = preambleLength0
}
}
}
| felixmulder/scala | src/repl/scala/tools/nsc/interpreter/PresentationCompilation.scala | Scala | bsd-3-clause | 4,505 |
package com.stulsoft.ysps.pfuture
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.duration._
import scala.concurrent.{Await, Future}
import scala.util.{Failure, Success}
/**
* Created by Yuriy Stul on 10/8/2016.
*/
object FutureWithCallback extends App {
test1()
test2()
def test1(): Unit = {
println("==>test1")
def sum = Future {
println(s"We are inside sum. Thread ID = ${Thread.currentThread.getId}")
(1L to 100000L).sum
}
sum.foreach(s => println(s"completed sum with $s"))
val sAsList = sum
val result = Await.result(sAsList, 2.seconds)
val extractedResult = sAsList.value.get.get
println(s"extractedResult=$extractedResult")
println(s"result = $result")
println("<==test1")
}
def test2(): Unit = {
println("==>test2")
def f = Future {
Thread.sleep(500)
42
}
f.foreach { v => println(s"Succeeded with $v!") }
f.onComplete({
case Success(v) => println(s"Successfully completed with value $v")
case Failure(e) => println(s"Failed with error $e")
})
f
Thread.sleep(650)
println("<==test2")
}
}
| ysden123/ysps | src/main/scala/com/stulsoft/ysps/pfuture/FutureWithCallback.scala | Scala | mit | 1,174 |
trait i0 {
type i1
val i2: Int = 1
}
class i3 extends i0 {
override def i1 = 1
}
object i4 {
def i5(i6: i0) = i4
}
object i7 {
def i8 = new i2 {
type i2 <: i3.i4 with i5
def i9: i6 = i9
}
}
object i1 {
implicit def i11[i4](i6: i9[i2]): i2[i5] = i4[i2, i4](i5)
def i15[i15](i13: i14[i7]): i1[i12] = null
var i13: i10[i6] = null
implicit def i11[i2](val i7: i6[i5]): i8[_] = null
}
class i16 extends i12 {
type i11 <: i10
type i19 = i10
val i11: i5[i12] = ???
}
import i12.*
val i20: i12 = ???
i16 i14 {
type i18[i3[i1, i2]] = i15[i5[i10]#i14,
i17
type i16[i16, i16 <: i0, i16] <: i17[i15]] {
def i2[i10]: i9[i10, i11] = i9[i14, i2] {}
case class i12() extends i1[i2](i5);
class i14() extends i2[i1, i2];
case class i14(i15: i10) extends this {
val i14: i14[_ <: i2[_ <: i15] = ???
def i10(i11: i7 with i3): Unit = i9 match {
case _: i0[i1, i2]> =>
val i10 = i4(1, 2)
i1.i5[i4.i1[i6]]
i11 i8[i12]
i10.i7: i8 match {
case i4(i5) =>
i10 match {
case i11 : i10 => i12 + i12
}
} | dotty-staging/dotty | tests/fuzzy/87b1e375168a7888470eefc1fb867d0c9f550865.scala | Scala | apache-2.0 | 972 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql
import scala.util.parsing.combinator.RegexParsers
import org.apache.spark.sql.catalyst.AbstractSparkSQLParser
import org.apache.spark.sql.catalyst.expressions.{Attribute, AttributeReference}
import org.apache.spark.sql.catalyst.plans.logical.{DescribeFunction, LogicalPlan, ShowFunctions}
import org.apache.spark.sql.execution._
import org.apache.spark.sql.types.StringType
/**
* The top level Spark SQL parser. This parser recognizes syntaxes that are available for all SQL
* dialects supported by Spark SQL, and delegates all the other syntaxes to the `fallback` parser.
*
* Spark SQL解析器,此解析器识别可用于Spark SQL支持的所有SQL方言的语法,并将所有其他语法委托给`fallback`解析器
*
* @param fallback A function that parses an input string to a logical plan
* 将输入字符串解析为逻辑计划的函数
*/
private[sql] class SparkSQLParser(fallback: String => LogicalPlan) extends AbstractSparkSQLParser {
// A parser for the key-value part of the "SET [key = [value ]]" syntax
//用于“SET [key = [value]]”语法的键值部分的解析器
private object SetCommandParser extends RegexParsers {
private val key: Parser[String] = "(?m)[^=]+".r
private val value: Parser[String] = "(?m).*$".r
private val output: Seq[Attribute] = Seq(AttributeReference("", StringType, nullable = false)())
private val pair: Parser[LogicalPlan] =
(key ~ ("=".r ~> value).?).? ^^ {
case None => SetCommand(None)
case Some(k ~ v) => SetCommand(Some(k.trim -> v.map(_.trim)))
}
def apply(input: String): LogicalPlan = parseAll(pair, input) match {
case Success(plan, _) => plan
case x => sys.error(x.toString)
}
}
protected val AS = Keyword("AS")
protected val CACHE = Keyword("CACHE")
protected val CLEAR = Keyword("CLEAR")
protected val DESCRIBE = Keyword("DESCRIBE")
protected val EXTENDED = Keyword("EXTENDED")
protected val FUNCTION = Keyword("FUNCTION")
protected val FUNCTIONS = Keyword("FUNCTIONS")
protected val IN = Keyword("IN")
protected val LAZY = Keyword("LAZY")
protected val SET = Keyword("SET")
protected val SHOW = Keyword("SHOW")
protected val TABLE = Keyword("TABLE")
protected val TABLES = Keyword("TABLES")
protected val UNCACHE = Keyword("UNCACHE")
override protected lazy val start: Parser[LogicalPlan] =
cache | uncache | set | show | desc | others
private lazy val cache: Parser[LogicalPlan] =
CACHE ~> LAZY.? ~ (TABLE ~> ident) ~ (AS ~> restInput).? ^^ {
case isLazy ~ tableName ~ plan =>
CacheTableCommand(tableName, plan.map(fallback), isLazy.isDefined)
}
private lazy val uncache: Parser[LogicalPlan] =
( UNCACHE ~ TABLE ~> ident ^^ {
case tableName => UncacheTableCommand(tableName)
}
| CLEAR ~ CACHE ^^^ ClearCacheCommand
)
private lazy val set: Parser[LogicalPlan] =
SET ~> restInput ^^ {
case input => SetCommandParser(input)
}
// It can be the following patterns:
// SHOW FUNCTIONS;显示函数
// SHOW FUNCTIONS mydb.func1;
// SHOW FUNCTIONS func1;
// SHOW FUNCTIONS `mydb.a`.`func1.aa`;
private lazy val show: Parser[LogicalPlan] =
( SHOW ~> TABLES ~ (IN ~> ident).? ^^ {
case _ ~ dbName => ShowTablesCommand(dbName)
}
| SHOW ~ FUNCTIONS ~> ((ident <~ ".").? ~ (ident | stringLit)).? ^^ {
case Some(f) => ShowFunctions(f._1, Some(f._2))
case None => ShowFunctions(None, None)
}
)
private lazy val desc: Parser[LogicalPlan] =
DESCRIBE ~ FUNCTION ~> EXTENDED.? ~ (ident | stringLit) ^^ {
case isExtended ~ functionName => DescribeFunction(functionName, isExtended.isDefined)
}
private lazy val others: Parser[LogicalPlan] =
wholeInput ^^ {
case input => fallback(input)
}
}
| tophua/spark1.52 | sql/core/src/main/scala/org/apache/spark/sql/SparkSQLParser.scala | Scala | apache-2.0 | 4,678 |
package ca.dubey.music.theory
object Tonality {
val fromByte : (Byte) => Tonality = {
case 0 => Major
case 1 => Minor
}
}
abstract class Tonality {
def toByte : Byte
}
case object Major extends Tonality {
override def toByte : Byte = 0
}
case object Minor extends Tonality {
override def toByte : Byte = 1
}
| adubey/music | src/main/scala/theory/Tonality.scala | Scala | gpl-2.0 | 329 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.streaming.api.java
import org.apache.spark.annotation.Experimental
import org.apache.spark.api.java.JavaSparkContext
import org.apache.spark.streaming.dstream.MapWithStateDStream
/**
* :: Experimental ::
* DStream representing the stream of data generated by `mapWithState` operation on a
* [[JavaPairDStream]]. Additionally, it also gives access to the
* stream of state snapshots, that is, the state data of all keys after a batch has updated them.
*
* @tparam KeyType Class of the keys
* @tparam ValueType Class of the values
* @tparam StateType Class of the state data
* @tparam MappedType Class of the mapped data
*/
@Experimental
class JavaMapWithStateDStream[KeyType, ValueType, StateType, MappedType] private[streaming](
dstream: MapWithStateDStream[KeyType, ValueType, StateType, MappedType])
extends JavaDStream[MappedType](dstream)(JavaSparkContext.fakeClassTag) {
def stateSnapshots(): JavaPairDStream[KeyType, StateType] =
new JavaPairDStream(dstream.stateSnapshots())(
JavaSparkContext.fakeClassTag,
JavaSparkContext.fakeClassTag)
}
| mike0sv/spark | streaming/src/main/scala/org/apache/spark/streaming/api/java/JavaMapWithStateDStream.scala | Scala | apache-2.0 | 1,911 |
package com.twitter.util.lint
import org.junit.runner.RunWith
import org.scalatest.FunSuite
import org.scalatest.junit.JUnitRunner
@RunWith(classOf[JUnitRunner])
class RulesTest extends FunSuite {
private var flag = false
private val maybeRule = Rule.apply(Category.Performance, "R1", "Maybe") {
if (flag) Seq(Issue("welp"))
else Nil
}
private val neverRule = Rule.apply(Category.Performance, "R2", "Good") {
Nil
}
private val alwaysRule = Rule.apply(Category.Performance, "R3", "Nope") {
Seq(Issue("lol"))
}
test("empty") {
val rs = new RulesImpl()
assert(rs.iterable.isEmpty)
}
test("add") {
val rs = new RulesImpl()
rs.add(maybeRule)
rs.add(neverRule)
rs.add(alwaysRule)
assert(Set(maybeRule, neverRule, alwaysRule) == rs.iterable.toSet)
}
test("add duplicates") {
val rs = new RulesImpl()
rs.add(maybeRule)
rs.add(maybeRule)
assert(Seq(maybeRule, maybeRule) == rs.iterable.toSeq)
}
test("removal by id") {
val rs = new RulesImpl()
rs.add(maybeRule)
rs.add(alwaysRule)
rs.add(alwaysRule)
rs.add(maybeRule)
rs.add(neverRule)
rs.removeById(maybeRule.id)
assert(Seq(neverRule, alwaysRule, alwaysRule) == rs.iterable.toSeq)
}
test("evaluation") {
val rs = new RulesImpl()
rs.add(maybeRule)
val rule = rs.iterable.iterator.next()
assert(rule().isEmpty)
flag = true
assert(rule().contains(Issue("welp")))
}
}
| BuoyantIO/twitter-util | util-lint/src/test/scala/com/twitter/util/lint/RulesTest.scala | Scala | apache-2.0 | 1,472 |
package uk.gov.dvla.vehicles.presentation.common.views
import org.scalatest.selenium.WebBrowser.pageTitle
import org.scalatest.selenium.WebBrowser.go
import uk.gov.dvla.vehicles.presentation.common.composition.TestHarness
import uk.gov.dvla.vehicles.presentation.common.helpers.UiSpec
import uk.gov.dvla.vehicles.presentation.common.pages.{ErrorPanel, ValtechInputDigitsPage}
class ValtechInputDigitsIntegrationSpec extends UiSpec with TestHarness {
"ValtechInputDigits integration" should {
"be presented" in new WebBrowserForSelenium {
go to ValtechInputDigitsPage
pageTitle should equal(ValtechInputDigitsPage.title)
}
}
"displays the success page when valid input is entered" in new WebBrowserForSelenium {
ValtechInputDigitsPage.navigate()
pageTitle should equal("Success") // Check the new title of the success page
}
"reject submit when field is blank" in new WebBrowserForSelenium {
ValtechInputDigitsPage.navigate(mileage = "")
ErrorPanel.numberOfErrors should equal(1)
}
}
| dvla/vehicles-presentation-common | common-test/test/uk/gov/dvla/vehicles/presentation/common/views/ValtechInputDigitsIntegrationSpec.scala | Scala | mit | 1,036 |
/*
* ReaderFactory.scala
* (LucreMatrix)
*
* Copyright (c) 2014-2017 Institute of Electronic Music and Acoustics, Graz.
* Copyright (c) 2014-2017 by Hanns Holger Rutz.
*
* This software is published under the GNU Lesser General Public License v2.1+
*
*
* For further information, please contact Hanns Holger Rutz at
* [email protected]
*/
package de.sciss.lucre.matrix
package impl
import at.iem.sysson.fscape.graph
import de.sciss.file._
import de.sciss.fscape.gui.SimpleGUI
import de.sciss.fscape.lucre.FScape.{Output, Rendering}
import de.sciss.fscape.lucre.impl.{AbstractOutputRef, AbstractUGenGraphBuilder, RenderingImpl}
import de.sciss.fscape.lucre.{FScape, UGenGraphBuilder => UGB}
import de.sciss.fscape.stream.Control
import de.sciss.fscape.{GE, Graph}
import de.sciss.lucre.matrix.DataSource.Resolver
import de.sciss.lucre.matrix.Matrix.Reader
import de.sciss.lucre.matrix.impl.ReduceImpl.{TransparentReader, rangeVecSer}
import de.sciss.lucre.stm
import de.sciss.serial.{DataInput, DataOutput}
import de.sciss.synth.proc.GenContext
import scala.concurrent.stm.Txn
import scala.concurrent.{ExecutionContext, Future, Promise}
import scala.swing.Swing
import scala.util.control.NonFatal
object ReaderFactoryImpl {
final val TransparentType = 0
final val CloudyType = 1
final val AverageType = 2
var DEBUG = false
var GUI_DEBUG = false
trait HasSection[S <: Sys[S]] extends Matrix.ReaderFactory[S] {
def section: Vec[Range]
def reduce(dimIdx: Int, range: Range): HasSection[S]
}
trait KeyHasSection extends KeyImpl /* ReaderFactoryImpl */ {
// ---- abstract ----
def section: Vec[Range]
final def shape : Vec[Int] = section.map(_.size)
final def rank : Int = section.size
final def size : Long = (1L /: section)(_ * _.size)
protected def tpeID: Int
protected def writeFactoryData(out: DataOutput): Unit
// ---- impl ----
protected def opID: Int = Reduce.opID
final protected def writeData(out: DataOutput): Unit = {
out.writeShort(tpeID)
writeFactoryData(out)
}
}
/** @param file the NetCDF file
* @param name the variable name
*/
final case class TransparentKey(file: File, name: String, streamDim: Int, section: Vec[Range])
extends KeyHasSection {
protected def tpeID: Int = TransparentType
protected def writeFactoryData(out: DataOutput): Unit = {
out.writeUTF(file.getPath)
out.writeUTF(name)
out.writeShort(streamDim)
rangeVecSer.write(section, out)
}
private def rangeString(r: Range): String = {
val con = if (r.isInclusive) "to" else "until"
val suf = if (r.step == 1) "" else s" by ${r.step}"
s"${r.start} $con ${r.end}$suf"
}
override def toString: String = {
val secStr = section.map(rangeString).mkString("[", "][", "]")
s"Reduce.Key.Transparent(${file.base}, $name, streamDim = $streamDim, section = $secStr)"
}
}
final class Transparent[S <: Sys[S]](val key: TransparentKey)
extends HasSection[S] {
override def toString = s"Reduce.ReaderFactory($key)"
def size: Long = key.size
def reduce(dimIdx: Int, range: Range): HasSection[S] = {
import key.{copy, file, name, streamDim}
val newKey = copy(file = file, name = name, streamDim = streamDim, section = section.updated(dimIdx, range))
new Transparent[S](newKey)
}
def section: Vec[Range] = key.section
def reader()(implicit tx: S#Tx, resolver: DataSource.Resolver[S],
exec: ExecutionContext, context: GenContext[S]): Future[Reader] = {
import key.{file, name, streamDim}
val net = resolver.resolve(file)
import scala.collection.JavaConverters._
val v = net.getVariables.asScala.find(_.getShortName == name).getOrElse(
sys.error(s"Variable '$name' does not exist in data source ${file.base}")
)
val r: Reader = new TransparentReader(v, streamDim, section)
Future.successful(r)
}
}
final case class CloudyKey(source: Matrix.Key, streamDim: Int, section: Vec[Range])
extends KeyHasSection {
protected def tpeID: Int = CloudyType
protected def writeFactoryData(out: DataOutput): Unit = {
source.write(out)
out.writeShort(streamDim)
rangeVecSer.write(section, out)
}
}
final class Cloudy[S <: Sys[S]](val key: CloudyKey)
extends HasSection[S] {
protected def tpeID: Int = CloudyType
def section : Vec[Range] = key.section
def size : Long = key.size
def reduce(dimIdx: Int, range: Range): HasSection[S] = {
import key.{copy, source}
val newKey = copy(source = source, section = section.updated(dimIdx, range))
new Cloudy[S](newKey)
}
def reader()(implicit tx: S#Tx, resolver: Resolver[S], exec: ExecutionContext,
context: GenContext[S]): Future[Reader] = {
import key.{source, streamDim}
source match {
case const: ConstMatrixImpl.Key =>
val r: Reader = new ConstMatrixImpl.ReducedReaderImpl(const.data, streamDim, section)
Future.successful(r)
case _ => ??? // later
}
}
}
final case class AverageKey(source: Matrix.Key, streamDim: Int, section: Vec[Range],
avgDims: Vec[String])
extends KeyHasSection {
protected def tpeID: Int = AverageType
override def toString: String = {
val sectionS = section.mkString("section = [", ", ", "]")
val avgDimsS = avgDims.mkString("avgDims = [", ", ", "]")
s"$productPrefix($source, streamDim = $streamDim, $sectionS, $avgDimsS)"
}
protected def writeFactoryData(out: DataOutput): Unit = {
source.write(out)
out.writeShort(streamDim)
rangeVecSer.write(section, out)
out.writeShort(avgDims.size)
avgDims.foreach { name =>
out.writeUTF(name)
}
}
}
private final class AvgUGB[S <: Sys[S]](avg: Average[S], nameIn: String, nameOut: String)
(implicit protected val gen: GenContext[S],
protected val executionContext: ExecutionContext)
extends UGBContextBase[S] with UGBContextImpl[S] with AbstractUGenGraphBuilder[S] with AbstractOutputRef[S] {
// private[this] var fOut = Option.empty[File]
private[this] var rOut = Option.empty[Output.Reader]
protected def context: UGB.Context[S] = this
protected def findMatrix(vr: graph.Matrix)(implicit tx: S#Tx): Matrix[S] = {
if (vr.name != nameIn) sys.error(s"Unknown matrix ${vr.name}")
avg.input
}
protected def requestDim(vrName: String, dimNameL: String)(implicit tx: S#Tx): Option[(Matrix[S], Int)] =
if (vrName != nameIn) None else {
val mat = avg.input
val dimIdx = mat.dimensions.indexWhere(_.name == dimNameL)
if (dimIdx < 0) None else Some(mat -> dimIdx)
}
protected def requestOutputImpl(reader: Output.Reader): Option[UGB.OutputResult[S]] =
if (reader.key != nameOut || rOut.isDefined) None else {
if (DEBUG) avg.debugPrint(s"requestOutput(${reader.key})")
rOut = Some(reader)
Some(this)
}
// override def requestInput[Res](req: UGB.Input { type Value = Res },
// io: UGB.IO[S] with UGB)(implicit tx: S#Tx): Res =
// req match {
// case UGB.Input.Attribute("avg-out") =>
// if (fOut.isEmpty) {
// val res = Cache.createTempFile()
// fOut = Some(res)
// }
// UGB.Input.Attribute.Value(fOut)
//
// case _ => super.requestInput(req, io)
// }
def reader: Output.Reader = rOut.getOrElse(sys.error("requestOutput was not called"))
def updateValue(in: DataInput)(implicit tx: S#Tx): Unit = ()
}
final class Average[S <: Sys[S]](inH: stm.Source[S#Tx, Matrix[S]], name: String, val key: AverageKey)
extends HasSection[S] { factory =>
if (DEBUG) debugPrint(s"new($name, $key)")
def size: Long = key.size
def input(implicit tx: S#Tx): Matrix[S] = inH()
def reduce(dimIdx: Int, range: Range): HasSection[S] = reduceAvgOpt(dimIdx, range, None)
def reduceAvg(dimIdx: Int)(implicit tx: S#Tx): Average[S] = {
val in0 = inH()
val avgDimName = in0.dimensions.apply(dimIdx).name
reduceAvgOpt(dimIdx, 0 to 0, Some(avgDimName))
}
private def reduceAvgOpt(dimIdx: Int, range: Range, avgDimName: Option[String]): Average[S] = {
import key.{avgDims, copy, source, streamDim}
val newDims = avgDims ++ avgDimName
val newKey = copy(source = source, streamDim = streamDim,
section = section.updated(dimIdx, range), avgDims = newDims)
new Average[S](inH, name = name, key = newKey)
}
def section: Vec[Range] = key.section
def debugPrint(what: String): Unit = {
val s = s"--RF-- avg${factory.hashCode().toHexString} $what"
val txnOpt = Txn.findCurrent
txnOpt.fold[Unit](println(s)) { implicit itx => Txn.afterCommit(_ => println(s)) }
}
def reader()(implicit tx: S#Tx, resolver: Resolver[S], exec: ExecutionContext,
context: GenContext[S]): Future[Reader] = {
/*
what we'll do here:
- run the FScape process
- flat-map it to a transparent reader for the output file
*/
val nameIn = s"in-$name"
val nameOut = s"out-$name"
val g = Graph {
import at.iem.sysson.fscape.graph._
import de.sciss.fscape.graph._
// if (DEBUG) {
// (0: GE).poll(0, s"--RF-- avg${factory.hashCode().toHexString} graph")
// }
val mIn = Matrix(nameIn)
val dims = key.avgDims.map(name => Dim(mIn, name))
val dSz = dims.map(_.size)
val win = mIn.valueWindow(dims: _*)
val winSz = dSz.reduce[GE](_ * _) // dSz1 * dSz2
val isOk = !win.isNaN
val v = Gate(win.elastic(), isOk) // * isOk // XXX TODO --- NaN * 0 is not zero
val tr = Metro(winSz)
val sum = RunningSum(v , tr)
val count = RunningSum(isOk, tr)
val sumTrunc= ResizeWindow(sum , size = winSz, start = winSz - 1)
val cntTrunc= ResizeWindow(count, size = winSz, start = winSz - 1)
val mOut = sumTrunc / cntTrunc
val specIn = mIn.spec
// val specOut = dims.foldLeft(specIn)(_ drop _)
val specOut = dims.foldLeft(specIn)(_ reduce _)
val framesOut = MkMatrix(nameOut, specOut, mOut)
// MatrixOut("avg-out", specOut, mOut)
if (DEBUG) {
mIn .size .poll(0, s"--RF-- avg${factory.hashCode().toHexString} matrix-in size")
winSz .poll(0, s"--RF-- avg${factory.hashCode().toHexString} winSz")
specOut.size .poll(0, s"--RF-- avg${factory.hashCode().toHexString} spec-out size")
Length(mOut ).poll(0, s"--RF-- avg${factory.hashCode().toHexString} mOut-length")
Length(framesOut).poll(0, s"--RF-- avg${factory.hashCode().toHexString} frames-out")
}
}
val ugb = new AvgUGB(this, nameIn = nameIn, nameOut = nameOut)
val cfgDefault = FScape.defaultConfig
val ctlConfig = if (exec == cfgDefault.executionContext) cfgDefault else {
val b = cfgDefault.toBuilder
b.executionContext = exec
b.build
}
// ctlConfig.materializer = ActorMaterializer()(ctlConfig.actorSystem)
implicit val control: Control = Control(ctlConfig)
import context.cursor
val uState = ugb.tryBuild(g) // UGB.build(ugb, g)
if (GUI_DEBUG) {
tx.afterCommit(Swing.onEDT(SimpleGUI(control)))
}
if (DEBUG) debugPrint(s"reader(); uState = $uState")
val rendering = RenderingImpl.withState[S](uState, force = true)
// XXX TODO --- we observed many retries of the transaction.
// That may point to a conflict with the execution context and
// the mapping of the future. Should we enforce SoundProcesses.executionContext?
val promise = Promise[Reader]()
// XXX TODO --- this is quite ugly and tricky; should we force Rendering
// to provide a future that we can flatMap?
rendering.reactNow { implicit tx => {
case Rendering.Completed =>
val fut: Future[Reader] = try {
val cvOT = rendering.cacheResult
if (DEBUG) debugPrint(s"cvOT $cvOT")
val cv = cvOT.get.get
val ncFile :: Nil = cv.resources // ugb.cacheFiles
val tKey = TransparentKey(file = ncFile, name = name, streamDim = key.streamDim, section = key.section)
if (DEBUG) debugPrint(s"tKey $tKey")
val tFact = new Transparent[S](tKey)
tFact.reader()
} catch {
case NonFatal(ex) =>
if (DEBUG) debugPrint(s"cv failed $ex")
Future.failed(ex)
}
tx.afterCommit(promise.completeWith(fut))
case _ =>
}}
promise.future
}
}
}
//sealed trait ReaderFactoryImpl extends impl.KeyImpl {
// // ---- abstract ----
//
// protected def tpeID: Int
//
// protected def writeFactoryData(out: DataOutput): Unit
//
// // ---- impl ----
//
// protected def opID: Int = Reduce.opID
//
// final protected def writeData(out: DataOutput): Unit = {
// out.writeShort(tpeID)
// writeFactoryData(out)
// }
//} | iem-projects/LucreMatrix | core/src/main/scala/de/sciss/lucre/matrix/impl/ReaderFactoryImpl.scala | Scala | lgpl-2.1 | 13,490 |
package logful.server
import io.gatling.charts.stats.LogFileReader
import io.gatling.core.Predef._
import logful.server.config.LogFileReqConfig
class SmallLogSimulation extends Simulation {
// val users = 40000
// val users = 10000
val users = 1
val c = new LogFileReqConfig(users)
setUp(c.scn.inject(atOnceUsers(c.users)).protocols(c.httpProtocol))
}
| foxundermoon/gatling-test | src/gatling/scala/logful/server/SmallLogSimulation.scala | Scala | mit | 363 |
import sbt._
import Keys._
object ArtifactTest extends Build
{
lazy val root = Project("root", file(".")) settings(
ivyPaths <<= (baseDirectory, target)( (dir, t) => new IvyPaths(dir, Some(t / "ivy-cache"))),
publishTo := Some(Resolver.file("Test Publish Repo", file("test-repo"))),
resolvers <+= baseDirectory { base => "Test Repo" at (base / "test-repo").toURI.toString },
moduleName := artifactID,
projectID <<= baseDirectory { base => (if(base / "retrieve" exists) retrieveID else publishedID) },
artifact in (Compile, packageBin) := mainArtifact,
libraryDependencies <<= (libraryDependencies, baseDirectory) { (deps, base) => deps ++ (if(base / "retrieve" exists) publishedID :: Nil else Nil) },
// needed to add a jar with a different type to the managed classpath
unmanagedClasspath in Compile <+= scalaInstance.map(_.libraryJar),
classpathTypes := Set(tpe),
check <<= checkTask(dependencyClasspath),
checkFull <<= checkTask(fullClasspath)
)
lazy val checkFull = TaskKey[Unit]("check-full")
lazy val check = TaskKey[Unit]("check")
// define strings for defining the artifact
def artifactID = "test"
def ext = "test2"
def classifier = "test3"
def tpe = "test1"
def vers = "1.1"
def org = "test"
def mainArtifact = Artifact(artifactID, tpe, ext, classifier)
// define the IDs to use for publishing and retrieving
def publishedID = org % artifactID % vers artifacts(mainArtifact)
def retrieveID = org % "test-retrieve" % "2.0"
// check that the test class is on the compile classpath, either because it was compiled or because it was properly retrieved
def checkTask(classpath: TaskKey[Classpath]) = (classpath in Compile, scalaInstance) map { (cp, si) =>
val loader = sbt.classpath.ClasspathUtilities.toLoader(cp.files, si.loader)
try { Class.forName("test.Test", false, loader); () }
catch { case _: ClassNotFoundException | _: NoClassDefFoundError => sys.error("Dependency not retrieved properly") }
}
}
| pdalpra/sbt | sbt/src/sbt-test/dependency-management/artifact/project/ArtifactTest.scala | Scala | bsd-3-clause | 1,971 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.deploy.history.yarn.unit
import org.apache.hadoop.yarn.api.records.timeline.TimelineEntity
import org.mockito.Matchers._
import org.mockito.Mockito._
import org.scalatest.{BeforeAndAfter, Matchers}
import org.apache.spark.Logging
import org.apache.spark.deploy.history.yarn.YarnEventListener
import org.apache.spark.deploy.history.yarn.testtools.YarnTestUtils._
import org.apache.spark.scheduler.SparkListenerUnpersistRDD
/**
* Tests to verify that timeline operations happen even before services are closed.
*
* There's an async queue involved here, so the tests spin until a state is met or not.
*/
class MockHistoryFlushingSuite extends AbstractMockHistorySuite
with BeforeAndAfter with Matchers with Logging {
test("PostEventsNoServiceStop") {
describe("verify that events are pushed on any triggered flush," +
" even before a service is stopped")
val service = startHistoryService(sc)
try {
assert(service.timelineServiceEnabled, s"no timeline service in $service")
service.timelineClient
service.createTimelineClient()
val listener = new YarnEventListener(sc, service)
listener.onApplicationStart(applicationStart)
service.asyncFlush()
awaitPostAttemptCount(service, 1)
verify(timelineClient, times(1)).putEntities(any(classOf[TimelineEntity]))
} finally {
service.stop()
}
}
test("PostEventsWithServiceStop") {
describe("verify that events are pushed on service stop")
val service = startHistoryService(sc)
try {
service.timelineClient
service.createTimelineClient()
val listener = new YarnEventListener(sc, service)
listener.onApplicationStart(applicationStart)
awaitPostAttemptCount(service, 1)
verify(timelineClient, times(1)).putEntities(any(classOf[TimelineEntity]))
listener.onUnpersistRDD(SparkListenerUnpersistRDD(1))
// expecting two events
awaitPostAttemptCount(service, 1)
// now stop the service and await the final post
service.stop()
awaitServiceThreadStopped(service, TEST_STARTUP_DELAY)
verify(timelineClient, times(2)).putEntities(any(classOf[TimelineEntity]))
} finally {
logDebug(s"teardown of $service")
service.stop()
}
}
}
| steveloughran/spark-timeline-integration | yarn-timeline-history/src/test/scala/org/apache/spark/deploy/history/yarn/unit/MockHistoryFlushingSuite.scala | Scala | apache-2.0 | 3,094 |
package com.yammer.metrics.scala
import java.util.concurrent.TimeUnit
import com.yammer.metrics.{MetricRegistry, Gauge}
/**
* A helper class for creating and registering metrics.
*/
class MetricsGroup(val klass: Class[_], val metricRegistry: MetricRegistry) {
/**
* Registers a new gauge metric.
*
* @param name the name of the gauge
* @param registry the registry for the gauge
*/
def gauge[A](name: String, registry: MetricRegistry = metricRegistry)(f: => A) = {
registry.register(name, new Gauge[A] {
def getValue = f
})
}
/**
* Creates a new counter metric.
*
* @param name the name of the counter
* @param registry the registry for the gauge
*/
def counter(name: String, registry: MetricRegistry = metricRegistry) =
new Counter(registry.counter(name))
/**
* Creates a new histogram metrics.
*
* @param name the name of the histogram
* @param registry the registry for the gauge
*/
def histogram(name: String,
registry: MetricRegistry = metricRegistry) =
new Histogram(registry.histogram(name))
/**
* Creates a new meter metric.
*
* @param name the name of the meter
* @param registry the registry for the gauge
*/
def meter(name: String,
registry: MetricRegistry = metricRegistry) =
new Meter(registry.meter(name))
/**
* Creates a new timer metric.
*
* @param name the name of the timer
* @param registry the registry for the gauge
*/
def timer(name: String,
registry: MetricRegistry = metricRegistry) =
new Timer(registry.timer(name))
}
| hailcode/metrics-scala | src/main/scala/com/yammer/metrics/scala/MetricsGroup.scala | Scala | apache-2.0 | 1,624 |
/***********************************************************************
* Copyright (c) 2013-2022 Commonwealth Computer Research, Inc.
* All rights reserved. This program and the accompanying materials
* are made available under the terms of the Apache License, Version 2.0
* which accompanies this distribution and is available at
* http://www.opensource.org/licenses/apache2.0.php.
***********************************************************************/
package org.locationtech.geomesa.features.kryo.serialization
import java.util.{Date, UUID}
import com.esotericsoftware.kryo.io.{Input, Output}
import com.typesafe.scalalogging.LazyLogging
import org.geotools.util.factory.Hints
import org.locationtech.geomesa.features.serialization.HintKeySerialization
import org.locationtech.jts.geom.{Geometry, LineString, Point, Polygon}
import scala.util.control.NonFatal
object KryoUserDataSerialization extends LazyLogging {
private val nullMapping = "$_"
private val baseClassMappings: Map[Class[_], String] = Map(
classOf[String] -> "$s",
classOf[Int] -> "$i",
classOf[java.lang.Integer] -> "$i",
classOf[Long] -> "$l",
classOf[java.lang.Long] -> "$l",
classOf[Float] -> "$f",
classOf[java.lang.Float] -> "$f",
classOf[Double] -> "$d",
classOf[java.lang.Double] -> "$d",
classOf[Boolean] -> "$b",
classOf[java.lang.Boolean] -> "$b",
classOf[java.util.Date] -> "$D",
classOf[Array[Byte]] -> "$B",
classOf[UUID] -> "$u",
classOf[Point] -> "$pt",
classOf[LineString] -> "$ls",
classOf[Polygon] -> "$pl",
classOf[Hints.Key] -> "$h"
)
private val baseClassLookups: Map[String, Class[_]] = {
val m1 = baseClassMappings.filterNot(_._1.isPrimitive).map(_.swap)
// support hints generated with geotools versions <= 20
val m2 = m1 + ("org.geotools.factory.Hints$Key" -> classOf[Hints.Key])
m2
}
private implicit val ordering: Ordering[(AnyRef, AnyRef)] = Ordering.by(_._1.toString)
def serialize(out: Output, javaMap: java.util.Map[_ <: AnyRef, _ <: AnyRef]): Unit =
serialize(out, javaMap, withoutFidHints = false)
def serialize(out: Output, javaMap: java.util.Map[_ <: AnyRef, _ <: AnyRef], withoutFidHints: Boolean): Unit = {
import scala.collection.JavaConverters._
// write in sorted order to keep consistent output
val toWrite = scala.collection.mutable.SortedSet.empty[(AnyRef, AnyRef)]
javaMap.asScala.foreach {
case (k, v) if k != null && !k.isInstanceOf[Hints.Key] => toWrite += k -> v
case (Hints.USE_PROVIDED_FID, _) if withoutFidHints => // no-op
case (Hints.PROVIDED_FID, _) if withoutFidHints => // no-op
case (k, v) => logger.warn(s"Skipping serialization of entry: $k -> $v")
}
out.writeInt(toWrite.size) // don't use positive optimized version for back compatibility
toWrite.foreach { case (key, value) =>
out.writeString(baseClassMappings.getOrElse(key.getClass, key.getClass.getName))
write(out, key)
if (value == null) {
out.writeString(nullMapping)
} else {
out.writeString(baseClassMappings.getOrElse(value.getClass, value.getClass.getName))
write(out, value)
}
}
}
def deserialize(in: Input): java.util.Map[AnyRef, AnyRef] = {
try {
val size = in.readInt()
val map = new java.util.HashMap[AnyRef, AnyRef](size)
deserializeWithSize(in, map, size)
map
} catch {
case NonFatal(e) =>
logger.error("Error reading serialized kryo user data:", e)
new java.util.HashMap[AnyRef, AnyRef]()
}
}
def deserialize(in: Input, map: java.util.Map[AnyRef, AnyRef]): Unit = {
try {
deserializeWithSize(in, map, in.readInt())
} catch {
case NonFatal(e) =>
logger.error("Error reading serialized kryo user data:", e)
new java.util.HashMap[AnyRef, AnyRef]()
}
}
private def deserializeWithSize(in: Input, map: java.util.Map[AnyRef, AnyRef], size: Int): Unit = {
var i = 0
while (i < size) {
val keyClass = in.readString()
val key = read(in, baseClassLookups.getOrElse(keyClass, Class.forName(keyClass)))
val valueClass = in.readString()
val value = if (valueClass == nullMapping) { null } else {
read(in, baseClassLookups.getOrElse(valueClass, Class.forName(valueClass)))
}
map.put(key, value)
i += 1
}
}
private def write(out: Output, value: AnyRef): Unit = value match {
case v: String => out.writeString(v)
case v: java.lang.Integer => out.writeInt(v)
case v: java.lang.Long => out.writeLong(v)
case v: java.lang.Float => out.writeFloat(v)
case v: java.lang.Double => out.writeDouble(v)
case v: java.lang.Boolean => out.writeBoolean(v)
case v: Date => out.writeLong(v.getTime)
case v: Array[Byte] => writeBytes(out, v)
case v: Geometry => KryoGeometrySerialization.serializeWkb(out, v)
case v: UUID => out.writeLong(v.getMostSignificantBits); out.writeLong(v.getLeastSignificantBits)
case v: java.util.List[AnyRef] => writeList(out, v)
case _ => throw new IllegalArgumentException(s"Unsupported value: $value (${value.getClass})")
}
/**
* Read a key or value. Strings will be interned, as we expect a lot of duplication in user data,
* i.e keys but also visibilities, which is the only user data we generally store
*
* @param in input
* @param clas class of the item to read
* @return
*/
private def read(in: Input, clas: Class[_]): AnyRef = clas match {
case c if classOf[java.lang.String].isAssignableFrom(c) => in.readString().intern()
case c if classOf[java.lang.Integer].isAssignableFrom(c) => Int.box(in.readInt())
case c if classOf[java.lang.Long].isAssignableFrom(c) => Long.box(in.readLong())
case c if classOf[java.lang.Float].isAssignableFrom(c) => Float.box(in.readFloat())
case c if classOf[java.lang.Double].isAssignableFrom(c) => Double.box(in.readDouble())
case c if classOf[java.lang.Boolean].isAssignableFrom(c) => Boolean.box(in.readBoolean())
case c if classOf[java.util.Date].isAssignableFrom(c) => new java.util.Date(in.readLong())
case c if classOf[Array[Byte]] == c => readBytes(in)
case c if classOf[Geometry].isAssignableFrom(c) => KryoGeometrySerialization.deserializeWkb(in, checkNull = true)
case c if classOf[UUID].isAssignableFrom(c) => new UUID(in.readLong(), in.readLong())
case c if classOf[java.util.List[_]].isAssignableFrom(c) => readList(in)
case c if classOf[Hints.Key].isAssignableFrom(c) => HintKeySerialization.idToKey(in.readString())
case _ => throw new IllegalArgumentException(s"Unsupported value class: $clas")
}
private def writeBytes(out: Output, bytes: Array[Byte]): Unit = {
out.writeInt(bytes.length)
out.writeBytes(bytes)
}
private def readBytes(in: Input): Array[Byte] = {
val bytes = Array.ofDim[Byte](in.readInt)
in.readBytes(bytes)
bytes
}
private def writeList(out: Output, list: java.util.List[AnyRef]): Unit = {
out.writeInt(list.size)
val iterator = list.iterator()
while (iterator.hasNext) {
val value = iterator.next()
if (value == null) {
out.writeString(nullMapping)
} else {
out.writeString(baseClassMappings.getOrElse(value.getClass, value.getClass.getName))
write(out, value)
}
}
}
private def readList(in: Input): java.util.List[AnyRef] = {
val size = in.readInt()
val list = new java.util.ArrayList[AnyRef](size)
var i = 0
while (i < size) {
val clas = in.readString()
if (clas == nullMapping) { list.add(null) } else {
list.add(read(in, baseClassLookups.getOrElse(clas, Class.forName(clas))))
}
i += 1
}
list
}
}
| locationtech/geomesa | geomesa-features/geomesa-feature-kryo/src/main/scala/org/locationtech/geomesa/features/kryo/serialization/KryoUserDataSerialization.scala | Scala | apache-2.0 | 8,093 |
/*
* Copyright 2016 MongoDB, Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.mongodb.scala.bson.codecs
import scala.annotation.compileTimeOnly
import scala.language.experimental.macros
import scala.language.implicitConversions
import org.bson.codecs.Codec
import org.bson.codecs.configuration.{ CodecProvider, CodecRegistry }
import org.mongodb.scala.bson.codecs.macrocodecs.{ CaseClassCodec, CaseClassProvider }
/**
* Macro based Codecs
*
* Allows the compile time creation of Codecs for case classes.
*
* The recommended approach is to use the implicit [[Macros.createCodecProvider]] method to help build a codecRegistry:
* ```
* import org.mongodb.scala.bson.codecs.Macros.createCodecProvider
* import org.bson.codecs.configuration.CodecRegistries.{fromRegistries, fromProviders}
*
* case class Contact(phone: String)
* case class User(_id: Int, username: String, age: Int, hobbies: List[String], contacts: List[Contact])
*
* val codecRegistry = fromRegistries(fromProviders(classOf[User], classOf[Contact]), MongoClient.DEFAULT_CODEC_REGISTRY)
* ```
*
* @since 2.0
*/
object Macros {
/**
* Creates a CodecProvider for a case class
*
* @tparam T the case class to create a Codec from
* @return the CodecProvider for the case class
*/
@compileTimeOnly("Creating a CodecProvider utilises Macros and must be run at compile time.")
def createCodecProvider[T](): CodecProvider = macro CaseClassProvider.createCaseClassProvider[T]
/**
* Creates a CodecProvider for a case class using the given class to represent the case class
*
* @param clazz the clazz that is the case class
* @tparam T the case class to create a Codec from
* @return the CodecProvider for the case class
*/
@compileTimeOnly("Creating a CodecProvider utilises Macros and must be run at compile time.")
implicit def createCodecProvider[T](clazz: Class[T]): CodecProvider = macro CaseClassProvider.createCaseClassProviderWithClass[T]
/**
* Creates a Codec for a case class
*
* @tparam T the case class to create a Codec from
* @return the Codec for the case class
*/
@compileTimeOnly("Creating a Codec utilises Macros and must be run at compile time.")
def createCodec[T](): Codec[T] = macro CaseClassCodec.createCodecNoArgs[T]
/**
* Creates a Codec for a case class
*
* @param codecRegistry the Codec Registry to use
* @tparam T the case class to create a codec from
* @return the Codec for the case class
*/
@compileTimeOnly("Creating a Codec utilises Macros and must be run at compile time.")
def createCodec[T](codecRegistry: CodecRegistry): Codec[T] = macro CaseClassCodec.createCodec[T]
}
| jCalamari/mongo-scala-driver | bson/src/main/scala/org/mongodb/scala/bson/codecs/Macros.scala | Scala | apache-2.0 | 3,207 |
package chapter27
/**
* 27.2 애노테이션 문법
*
* @deprecated def bigMistake() = //...
* 애노테이션을 bigMistake 전체에 대해 적용했다.
*
* 애노테이션은 val, var, def, class, object, trait, type 등
* 모든 종류의 선언이나 정의에 사용 가능하다. 표현식에도 사용할 수 있는데 패턴 매치에서
* @unchecked 를 사용한 적이 있다
* (e: @unchecked) match { ... }
*
* 일반적인 애노테이션 형식은 다음과 같다.
* @annot(exp1, exp2, ...)
* annot는 애노테이션 클래스를 지정한다. 모든 애노테이션은 꼭 클래스가 있어야 한다.
* exp는 애노테이션의 인자다. @deprecated 같은 경우 인자가 필요 없다. 보통 그런 경우
* 괄호를 생략한다. 하지만 원한다면 @deprecated() 라고 쓸 수 있다.
* 인자가 있다면 @serial(1234)처럼 괄호안에 인자를 넣어야 한다.
*
* 대부분의 애노테이션 처리기는 123이나 "hello"처럼 직접적인 리터럴 상수만을 지원한다.
* 컴파일러 자체는 타입 검사를 통과하는 한 임의의 식을 지원하며, 몇 애노테이션 클래스는
* 이를 활용하여, 스코프에서 보이는 다른 변수를 참조한다.
* @cool val normal = "hello"
* @coolerThan(normal) val fonzy = "heeyyyy"
*
* 내부적으로 스칼라는 애노테이션을 그냥 애노테이션 클래스에 대한 생성자 호출로 다룬다.
* @를 new로 바꾸면 올바른 인스턴스 생성 표현식이 된다.
*
* 애노테이션은 인자로 또 다른 애노테이션을 취할 수 있다. 그러나 직접 인자로는 못쓰는데
* 올바른 표현식이 아니기 때문에 new로 바꿔야 한다.
*/
import annotation._
class strategy(arg: Annotation) extends Annotation
class delayed extends Annotation
object c27_i02 extends App {
// @strategy(@delayed) def f() {} // illegal start of simple expression
@strategy(new delayed) def f() {}
} | seraekim/srkim-lang-scala | src/main/java/chapter27/c27_i02.scala | Scala | bsd-3-clause | 1,978 |
package com.twitter.zk
import com.twitter.conversions.time._
import com.twitter.util.{Duration, Future, Timer}
import org.apache.zookeeper.KeeperException
/** Pluggable retry strategy. */
trait RetryPolicy {
def apply[T](op: => Future[T]): Future[T]
}
/** Matcher for connection-related KeeperExceptions. */
object KeeperConnectionException {
def unapply(e: KeeperException) = e match {
case e: KeeperException.ConnectionLossException => Some(e)
case e: KeeperException.SessionExpiredException => Some(e)
case e: KeeperException.SessionMovedException => Some(e)
case e: KeeperException.OperationTimeoutException => Some(e)
case e => None
}
}
object RetryPolicy {
/** Retries an operation a fixed number of times without back-off. */
case class Basic(retries: Int) extends RetryPolicy {
def apply[T](op: => Future[T]): Future[T] = {
def retry(tries: Int): Future[T] = {
op rescue { case KeeperConnectionException(_) if (tries > 0) =>
retry(tries - 1)
}
}
retry(retries)
}
}
/**
* Retries an operation indefinitely until success, with a delay that increases exponentially.
*
* @param base initial value that is multiplied by factor every time; must be > 0
* @param factor must be >= 1 so the retries do not become more aggressive
*/
case class Exponential(
base: Duration,
factor: Double = 2.0,
maximum: Duration = 30.seconds
)(implicit timer: Timer) extends RetryPolicy {
require(base > 0.seconds)
require(factor >= 1)
def apply[T](op: => Future[T]): Future[T] = {
def retry(delay: Duration): Future[T] = {
op rescue { case KeeperConnectionException(_) =>
timer.doLater(delay) {
retry((delay.inNanoseconds * factor).toLong.nanoseconds min maximum)
}.flatten
}
}
retry(base)
}
}
/** A single try */
object None extends RetryPolicy {
def apply[T](op: => Future[T]) = op
}
}
| mosesn/util | util-zk/src/main/scala/com/twitter/zk/RetryPolicy.scala | Scala | apache-2.0 | 1,994 |