
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
sequence | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/509 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/509/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/509/comments | https://api.github.com/repos/huggingface/transformers/issues/509/events | https://github.com/huggingface/transformers/issues/509 | 435,407,887 | MDU6SXNzdWU0MzU0MDc4ODc= | 509 | How to read a checkpoint and continue training? | {
"login": "a-maci",
"id": 23125439,
"node_id": "MDQ6VXNlcjIzMTI1NDM5",
"avatar_url": "https://avatars.githubusercontent.com/u/23125439?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/a-maci",
"html_url": "https://github.com/a-maci",
"followers_url": "https://api.github.com/users/a-maci/followers",
"following_url": "https://api.github.com/users/a-maci/following{/other_user}",
"gists_url": "https://api.github.com/users/a-maci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/a-maci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/a-maci/subscriptions",
"organizations_url": "https://api.github.com/users/a-maci/orgs",
"repos_url": "https://api.github.com/users/a-maci/repos",
"events_url": "https://api.github.com/users/a-maci/events{/privacy}",
"received_events_url": "https://api.github.com/users/a-maci/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, what fine-tuning script and model are you referring to?",
"I would like to know how to restart / continue runs as well.\r\nI would like to fine tune on half data first, checkpoint it. Then restart and continue on the other half of the data.\r\n\r\nLike the `main` function in this finetuning script:\r\nhttps://github.com/huggingface/pytorch-pretrained-BERT/blob/3fc63f126ddf883ba9659f13ec046c3639db7b7e/examples/lm_finetuning/simple_lm_finetuning.py",
"@thomwolf Hi. I was experimenting with run_squad.py on colab. I was able to train and checkpoint the model after every 50 steps. However, for some reason, the notebook crashed and did not resume training. Is there a way to load that checkpoint and resume training from that point onwards? ",
"I am fine-tuning using run_glue.py on bert. Have a checkpoint that I would like to continue from since my run crashed. Also, what happens to the tensorboard event file? For example, if my checkpoint is at iteration 250 (and my checkpoint crashed at 290), will the Tensorboard event file be appended correctly???",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"I think the solution is to change the model name to the checkpoint directory. When using the `run_glue.py` example script I changed the parameter from `--model_name_or_path bert-base-uncased` to `--model_name_or_path ../my-output-dir/checkpoint-1600`",
"> I think the solution is to change the model name to the checkpoint directory. When using the `run_glue.py` example script I changed the parameter from `--model_name_or_path bert-base-uncased` to `--model_name_or_path ../my-output-dir/checkpoint-1600`\r\n\r\nHi, this works but may I know what did you do the OURPUT-DIR? Keeping the same one while \"overwriting\" or starting a new one? Thanks!",
"> I think the solution is to change the model name to the checkpoint directory. When using the `run_glue.py` example script I changed the parameter from `--model_name_or_path bert-base-uncased` to `--model_name_or_path ../my-output-dir/checkpoint-1600`\r\n\r\nHi, I tried this. The following error message shows: \"We assumed '/cluster/home/xiazhi/finetune_results_republican/checkpoint-1500' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.json', 'merges.txt'] but couldn't find such vocabulary files at this path or url.\" But only after all epochs are done will the vocal.json and merges.txt be generated.\r\n",
"@anniezhi I have the same problem. This makes training very difficult; anyone have any ideas re: how to save the tokenizer whenever the checkpoints are saved?",
"@anniezhi I figured it out - if loading from a checkpoint, use the additional argument --tokenizer_name and provide the name of your tokenizer. Here's my helper bash script for reference :\r\n\r\n```\r\n#!/bin/bash\r\nconda activate transformers\r\n\r\ncd \"${HOME}/Desktop\"\r\nrm -rf \"./${1}\"\r\n\r\nTRAIN_FILE=\"/media/b/F:/debiased_archive_200.h5\"\r\n\r\n#Matt login key\r\nwandb login MY_API_KEY\r\n\r\npython bao-ai/training_flows/run_language_custom_modeling.py \\\r\n --output_dir=\"./${1}\" \\\r\n --tokenizer_name=gpt2 \\\r\n --model_name_or_path=\"${2}\" \\\r\n --block_size \"${3}\" \\\r\n --per_device_train_batch_size \"${4}\" \\\r\n --do_train \\\r\n --train_data_file=$TRAIN_FILE\\\r\n```",
"If you're using the latest release (v3.1.0), the tokenizer should be saved as well, so there's no need to use the `--tokenizer_name` anymore.\r\n\r\nFor any version <3.1.0, @apteryxlabs's solution is the way to go!",
"> \r\n\r\nBrowse parameters, resume_from_checkpoint=./\r\n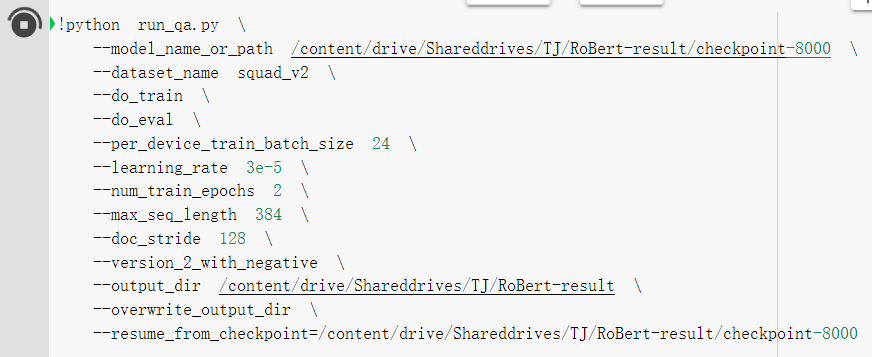\r\nNow, the code runs from checkpoint\r\n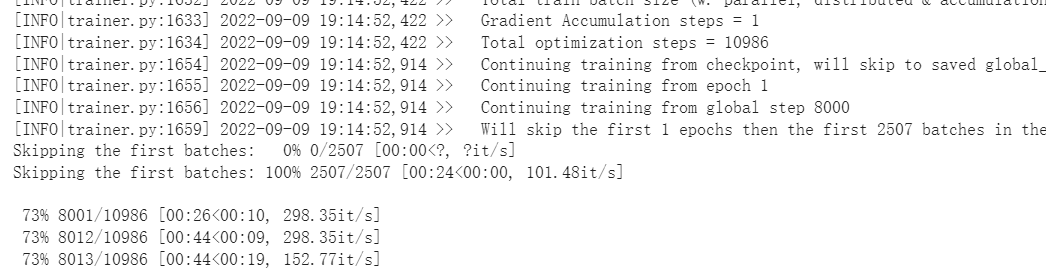\r\n",
"> \r\n\r\nBrowse parameters, resume_from_checkpoint=./\r\n\r\nNow, the code runs from checkpoint\r\n\r\n"
] | 1,555 | 1,662 | 1,571 | NONE | null | I wanted to experiment with longer training schedules. How do I re-start a run from it’s fine-tuned checkpoint? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/509/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/509/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/508 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/508/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/508/comments | https://api.github.com/repos/huggingface/transformers/issues/508/events | https://github.com/huggingface/transformers/pull/508 | 435,037,149 | MDExOlB1bGxSZXF1ZXN0MjcxODk2MzYx | 508 | Fix python syntax in examples/run_gpt2.py | {
"login": "SivilTaram",
"id": 10275209,
"node_id": "MDQ6VXNlcjEwMjc1MjA5",
"avatar_url": "https://avatars.githubusercontent.com/u/10275209?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SivilTaram",
"html_url": "https://github.com/SivilTaram",
"followers_url": "https://api.github.com/users/SivilTaram/followers",
"following_url": "https://api.github.com/users/SivilTaram/following{/other_user}",
"gists_url": "https://api.github.com/users/SivilTaram/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SivilTaram/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SivilTaram/subscriptions",
"organizations_url": "https://api.github.com/users/SivilTaram/orgs",
"repos_url": "https://api.github.com/users/SivilTaram/repos",
"events_url": "https://api.github.com/users/SivilTaram/events{/privacy}",
"received_events_url": "https://api.github.com/users/SivilTaram/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for the PR. This is fixed now."
] | 1,555 | 1,556 | 1,556 | CONTRIBUTOR | null | As the title, we will never reach the code from line 115 to 131 because the space before `if args.unconditional` is not enough. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/508/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/508/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/508",
"html_url": "https://github.com/huggingface/transformers/pull/508",
"diff_url": "https://github.com/huggingface/transformers/pull/508.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/508.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/507 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/507/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/507/comments | https://api.github.com/repos/huggingface/transformers/issues/507/events | https://github.com/huggingface/transformers/issues/507 | 434,994,568 | MDU6SXNzdWU0MzQ5OTQ1Njg= | 507 | GPT-2 FineTuning on Cloze/ ROC | {
"login": "rohuns",
"id": 17604744,
"node_id": "MDQ6VXNlcjE3NjA0NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/17604744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rohuns",
"html_url": "https://github.com/rohuns",
"followers_url": "https://api.github.com/users/rohuns/followers",
"following_url": "https://api.github.com/users/rohuns/following{/other_user}",
"gists_url": "https://api.github.com/users/rohuns/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rohuns/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rohuns/subscriptions",
"organizations_url": "https://api.github.com/users/rohuns/orgs",
"repos_url": "https://api.github.com/users/rohuns/repos",
"events_url": "https://api.github.com/users/rohuns/events{/privacy}",
"received_events_url": "https://api.github.com/users/rohuns/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
}
] | closed | false | null | [] | [
"Hi rohuns, I was wondering what padding value have you used for the lm_labels, since the -1 specified in the docs doesn't work for me on GPT2LMHead model. See #577. ",
"> Hi rohuns, I was wondering what padding value have you used for the lm_labels, since the -1 specified in the docs doesn't work for me on GPT2LMHead model. See #577.\r\n\r\nI had just used -1, can take a look at your stack trace and respond on that chat",
"Also to close this issue it appears others also achieved similar performance on the MC task, more details on the thread issue #468 ",
"> > Hi rohuns, I was wondering what padding value have you used for the lm_labels, since the -1 specified in the docs doesn't work for me on GPT2LMHead model. See #577.\r\n> \r\n> I had just used -1, can take a look at your stack trace and respond on that chat\r\n\r\nYes, please do have a look. Here is a toy example with a hand-coded dataset to prove that the -1 throws an error. It looks like it's a library issue.\r\n[gpt2_simplified.py.zip](https://github.com/huggingface/pytorch-pretrained-BERT/files/3144185/gpt2_simplified.py.zip)\r\n\r\nRegards,\r\nAdrian\r\n"
] | 1,555 | 1,556 | 1,556 | NONE | null | Hi, wrote some code to finetune GPT2 on rocstories using the DoubleHeads model mirroring the GPT1 code. However, I'm only getting performance of 68% on the eval. Was wondering if anyone else had tried it and seen this drop in performance. Thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/507/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/507/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/506 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/506/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/506/comments | https://api.github.com/repos/huggingface/transformers/issues/506/events | https://github.com/huggingface/transformers/pull/506 | 434,515,106 | MDExOlB1bGxSZXF1ZXN0MjcxNDkyNjg0 | 506 | Hubconf | {
"login": "ailzhang",
"id": 5248122,
"node_id": "MDQ6VXNlcjUyNDgxMjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5248122?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ailzhang",
"html_url": "https://github.com/ailzhang",
"followers_url": "https://api.github.com/users/ailzhang/followers",
"following_url": "https://api.github.com/users/ailzhang/following{/other_user}",
"gists_url": "https://api.github.com/users/ailzhang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ailzhang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ailzhang/subscriptions",
"organizations_url": "https://api.github.com/users/ailzhang/orgs",
"repos_url": "https://api.github.com/users/ailzhang/repos",
"events_url": "https://api.github.com/users/ailzhang/events{/privacy}",
"received_events_url": "https://api.github.com/users/ailzhang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @ailzhang,\r\nThis is great! I went through it and it looks good to me.\r\n\r\nI guess we should update the `from_pretrained` method of the other models as well (like [here](https://github.com/huggingface/pytorch-pretrained-BERT/blob/19666dcb3bee3e379f1458e295869957aac8590c/pytorch_pretrained_bert/modeling_openai.py#L420))\r\n\r\nDo you want to have a look at the other models (GPT, GPT-2 and Transformer-XL) and add them to the `hubconf.py` as well ?",
"Hi @thomwolf, thanks for the quick reply! Yea we definitely would like to add GPT and Transformer-XL models in. \r\n\r\nI can definitely add them in this PR myself. Alternatively one thing could be super helpful to us would be someone from your team try out implementing a few models using `torch.hub` interfaces and let us know if you see any bugs/issues from a repo owner perspective :D. Let me know which way you prefer, thanks! \r\n\r\n Another question is about cache dir, pytorch has move to comply with XDG specification about caching dirs(https://github.com/pytorch/pytorch/issues/14693). Detailed logic can be found here https://pytorch.org/docs/master/hub.html#where-are-my-downloaded-models-saved ( I will fix the doc formatting soon :P ) Are you interested in moving to be in the same place? Happy to help on it as well. \r\n",
"@thomwolf Any update on this? ;) Thanks!",
"Hi @ailzhang, sorry for the delay, here are some answers to your questions:\r\n\r\n- `torch.hub`: I can give it a try but the present week is fully packed. I'll see if I can free some time next week. If you want to see it reach `master` faster, I'm also fine with you adding the other models.\r\n\r\nOne question I have here is that the pretrained models cannot really be used without the associated tokenizers. How is this supposed to work with `torch.hub`? Can you give me an example of usage (like the one in the readme for instance)?\r\n\r\n- update to `cache dir`: XDG specification seems nice indeed. If you want to give it a try it would be a lot cleaner than the present caching setting I guess.\r\n\r\nRelated note: we (Sebastian Ruder, Matthew Peters, Swabha Swayamdipta and I) are preparing a [tutorial on Transfer Learning in NLP to be held at NAACL](https://naacl2019.org/program/tutorials). We'll show various frameworks in action. I'll will see if we can include a `torch.hub` example.",
"@thomwolf \r\nNote that there's a tokenizer in hub already. Typically we'd prefer hub only contains models, but in this case we also includes tokenizer as it's a required part. \r\nThere's an example in docstring of BertTokenizer. Is this good enough? \r\n```\r\n >>> sentence = 'Hello, World!'\r\n >>> tokenizer = torch.hub.load('ailzhang/pytorch-pretrained-BERT:hubconf', 'bertTokenizer', 'bert-base-cased', do_basic_tokenize=False, force_reload=False)\r\n >>> toks = tokenizer.tokenize(sentence)\r\n ['Hello', '##,', 'World', '##!']\r\n >>> ids = tokenizer.convert_tokens_to_ids(toks)\r\n [8667, 28136, 1291, 28125]\r\n```\r\nMaybe we can merge this PR first if it looks good? \r\n",
"Oh indeed, I missed the tokenizer.\r\nOk let's go with this PR!"
] | 1,555 | 1,556 | 1,556 | NONE | null | fixes #504
Also add hubconf for bert related tokenizer & models.
There're a few GPT models and transformer models, but would like to send this out to get a review first.
Also there's possibility to unify the cache dir with pytorch one. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/506/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/506/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/506",
"html_url": "https://github.com/huggingface/transformers/pull/506",
"diff_url": "https://github.com/huggingface/transformers/pull/506.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/506.patch",
"merged_at": 1556132361000
} |
https://api.github.com/repos/huggingface/transformers/issues/505 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/505/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/505/comments | https://api.github.com/repos/huggingface/transformers/issues/505/events | https://github.com/huggingface/transformers/issues/505 | 434,489,113 | MDU6SXNzdWU0MzQ0ODkxMTM= | 505 | Generating text with Transformer XL | {
"login": "shashwath94",
"id": 7631779,
"node_id": "MDQ6VXNlcjc2MzE3Nzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/7631779?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shashwath94",
"html_url": "https://github.com/shashwath94",
"followers_url": "https://api.github.com/users/shashwath94/followers",
"following_url": "https://api.github.com/users/shashwath94/following{/other_user}",
"gists_url": "https://api.github.com/users/shashwath94/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shashwath94/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shashwath94/subscriptions",
"organizations_url": "https://api.github.com/users/shashwath94/orgs",
"repos_url": "https://api.github.com/users/shashwath94/repos",
"events_url": "https://api.github.com/users/shashwath94/events{/privacy}",
"received_events_url": "https://api.github.com/users/shashwath94/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Here's an example of text generation, picks second most likely word at each step\r\n\r\n```\r\ntokenizer = TransfoXLTokenizer.from_pretrained('transfo-xl-wt103')\r\nmodel = TransfoXLLMHeadModel.from_pretrained('transfo-xl-wt103')\r\nline = \"Cars were invented in\"\r\nline_tokenized = tokenizer.tokenize(line)\r\nline_indexed = tokenizer.convert_tokens_to_ids(line_tokenized)\r\ntokens_tensor = torch.tensor([line_indexed])\r\ntokens_tensor = tokens_tensor.to(device)\r\n\r\nmax_predictions = 50\r\nmems = None\r\nfor i in range(max_predictions):\r\n predictions, mems = model(tokens_tensor, mems=mems)\r\n predicted_index = torch.topk(predictions[0, -1, :],5)[1][1].item()\r\n predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]\r\n print(predicted_token)\r\n predicted_index = torch.tensor([[predicted_index]]).to(device)\r\n tokens_tensor = torch.cat((tokens_tensor, predicted_index), dim=1)\r\n```\r\nShould produce\r\n\r\n```\r\nBritain\r\nand\r\nAmerica\r\n,\r\nbut\r\nthe\r\nfirst\r\ntwo\r\ncars\r\nhad\r\nto\r\nhave\r\nbeen\r\na\r\n\"\r\nTurbo\r\n```",
"Yeah figured it out. Thanks nevertheless @yaroslavvb !",
"@yaroslavvb I think, there is a bug in the code, you shared \r\n`predicted_index = torch.topk(predictions[0, -1, :],5)[1][1].item()`why is it not `predicted_index = torch.topk(predictions[0, -1, :],5)[1][0].item()` or probably its not a bug \r\n",
"@yaroslavvb Why in the text generation with Transformer-XL there is a loop over the number of predictions requested, like max_predictions? \r\n\r\nGiven a fixed input like line = \"Cars were invented in\", which is 21 characters or 4 words (depending if trained for character output or word output), say, why one cannot generate say the next 21 characters or 4 words directly from the T-XL output all at once? Then generate another set of 21 characters or 4 words again in the next iteration? \r\n\r\nI thought one advantage of the T-XL vs the vanilla Transformer was this ability to predict a whole next sequence without having to loop by adding character by character or word by word at the input? \r\n\r\nIsn't the T-XL trained by computing the loss over the whole input and whole target (label) without looping?\r\nThus why would it be different during text generation? To provide a more accurate context along the prediction by adding the previous prediction one by one?",
"@shashwath94 Could you please post your fix, so that we can learn by example? Thanks. ",
"@gussmith you could do it this way, but empirically the results are very bad. The model loss is trained to maximize probability of \"next token prediction\". What looks like loss over a loss over whole sequence is actually a parallelization trick to compute many \"next token prediction\" losses in a single pass."
] | 1,555 | 1,595 | 1,555 | CONTRIBUTOR | null | Hi everyone,
I am trying to generate text with the pre-trained transformer XL model in a similar way to how we do with the GPT-2 model. But I guess there is a bug in the `sample_sequence` function after I adjusted to the transformer XL architecture. But the generated text is completely random in general and with respect to the context as well.
The core sampling loop looks very similar to the gpt-2 one:
```
with torch.no_grad():
for i in trange(length):
logits, past = model(prev, mems=past)
logits = logits[:, -1, :] / temperature
logits = top_k_logits(logits, k=top_k)
log_probs = F.softmax(logits, dim=-1)
if sample:
prev = torch.multinomial(log_probs, num_samples=1)
else:
_, prev = torch.topk(log_probs, k=1, dim=-1)
output = torch.cat((output, prev), dim=1)
```
What is the bug that I'm missing?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/505/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/505/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/504 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/504/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/504/comments | https://api.github.com/repos/huggingface/transformers/issues/504/events | https://github.com/huggingface/transformers/issues/504 | 434,469,616 | MDU6SXNzdWU0MzQ0Njk2MTY= | 504 | Init BertForTokenClassification from from_pretrained | {
"login": "ailzhang",
"id": 5248122,
"node_id": "MDQ6VXNlcjUyNDgxMjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5248122?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ailzhang",
"html_url": "https://github.com/ailzhang",
"followers_url": "https://api.github.com/users/ailzhang/followers",
"following_url": "https://api.github.com/users/ailzhang/following{/other_user}",
"gists_url": "https://api.github.com/users/ailzhang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ailzhang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ailzhang/subscriptions",
"organizations_url": "https://api.github.com/users/ailzhang/orgs",
"repos_url": "https://api.github.com/users/ailzhang/repos",
"events_url": "https://api.github.com/users/ailzhang/events{/privacy}",
"received_events_url": "https://api.github.com/users/ailzhang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"actually this is related to my current work, I will send a fix along with my PR."
] | 1,555 | 1,556 | 1,556 | NONE | null | ```
model = BertForTokenClassification.from_pretrained('bert-base-uncased', 2)
```
will complain about missing positional arg for `num_labels`.
The root cause is here the function signature should actually be
https://github.com/huggingface/pytorch-pretrained-BERT/blob/19666dcb3bee3e379f1458e295869957aac8590c/pytorch_pretrained_bert/modeling.py#L522
```
def from_pretrained(cls, pretrained_model_name_or_path, *inputs, state_dict=None, cache_dir=None, from_tf=False, **kwargs):
```
But note that the signature above above is actually only supported in py3 not py2. See a similar workaround here: https://github.com/pytorch/pytorch/pull/19247/files#diff-bdb85c31edc2daaad6cdb68c0d19bafbR300 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/504/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/504/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/503 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/503/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/503/comments | https://api.github.com/repos/huggingface/transformers/issues/503/events | https://github.com/huggingface/transformers/pull/503 | 434,376,103 | MDExOlB1bGxSZXF1ZXN0MjcxMzgyMTEz | 503 | Fix possible risks of bpe on special tokens | {
"login": "SivilTaram",
"id": 10275209,
"node_id": "MDQ6VXNlcjEwMjc1MjA5",
"avatar_url": "https://avatars.githubusercontent.com/u/10275209?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SivilTaram",
"html_url": "https://github.com/SivilTaram",
"followers_url": "https://api.github.com/users/SivilTaram/followers",
"following_url": "https://api.github.com/users/SivilTaram/following{/other_user}",
"gists_url": "https://api.github.com/users/SivilTaram/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SivilTaram/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SivilTaram/subscriptions",
"organizations_url": "https://api.github.com/users/SivilTaram/orgs",
"repos_url": "https://api.github.com/users/SivilTaram/repos",
"events_url": "https://api.github.com/users/SivilTaram/events{/privacy}",
"received_events_url": "https://api.github.com/users/SivilTaram/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,555 | 1,560 | 1,560 | CONTRIBUTOR | null | Hi developers !
When I use the openai tokenizer, I find it hard to handle the `special tokens` correctly (my library version is v0.6.1) , even though I have already defined them and told the tokenizer NEVER SPLIT them. It is because all tokens, including the special ones will be processed by BPE. So I add one line for avoiding BPE on special tokens.
But there still are some problems when we use `spacy` as the tokenizer. I will try to add special tokens to the vocabulary of `spacy` and pull another request. Thanks for code review :) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/503/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/503/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/503",
"html_url": "https://github.com/huggingface/transformers/pull/503",
"diff_url": "https://github.com/huggingface/transformers/pull/503.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/503.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/502 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/502/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/502/comments | https://api.github.com/repos/huggingface/transformers/issues/502/events | https://github.com/huggingface/transformers/issues/502 | 434,217,681 | MDU6SXNzdWU0MzQyMTc2ODE= | 502 | How to obtain attention values for each layer | {
"login": "serenaklm",
"id": 34397223,
"node_id": "MDQ6VXNlcjM0Mzk3MjIz",
"avatar_url": "https://avatars.githubusercontent.com/u/34397223?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/serenaklm",
"html_url": "https://github.com/serenaklm",
"followers_url": "https://api.github.com/users/serenaklm/followers",
"following_url": "https://api.github.com/users/serenaklm/following{/other_user}",
"gists_url": "https://api.github.com/users/serenaklm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/serenaklm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/serenaklm/subscriptions",
"organizations_url": "https://api.github.com/users/serenaklm/orgs",
"repos_url": "https://api.github.com/users/serenaklm/repos",
"events_url": "https://api.github.com/users/serenaklm/events{/privacy}",
"received_events_url": "https://api.github.com/users/serenaklm/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Not really.\r\nYou should build a new sub-class of `BertPreTrainedModel` which is identical to `BertModel`but send back self-attention values in addition to the hidden states.\r\n",
"I see. Thank you! ",
"Hi, \r\n\r\nJust to add on. If this is what I would be doing, would it be advisable to fine-tune the weights for the pretrained model? \r\n\r\nRegards",
"Probably.\r\nIt depends on what's your final use-case.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,555 | 1,561 | 1,561 | NONE | null | Hi all,
Please correct me if I am wrong.
From my understanding, The encoded values for each layer (12 of them for base model) would be returned when we run our results through the pre-trained model.
However, I would like to examine the self-attention values for each layer. Is there a way I can extract that out?
Regards | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/502/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/502/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/501 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/501/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/501/comments | https://api.github.com/repos/huggingface/transformers/issues/501/events | https://github.com/huggingface/transformers/issues/501 | 434,200,823 | MDU6SXNzdWU0MzQyMDA4MjM= | 501 | Test a fine-tuned BERT-QA model | {
"login": "wasiahmad",
"id": 17520413,
"node_id": "MDQ6VXNlcjE3NTIwNDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/17520413?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wasiahmad",
"html_url": "https://github.com/wasiahmad",
"followers_url": "https://api.github.com/users/wasiahmad/followers",
"following_url": "https://api.github.com/users/wasiahmad/following{/other_user}",
"gists_url": "https://api.github.com/users/wasiahmad/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wasiahmad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wasiahmad/subscriptions",
"organizations_url": "https://api.github.com/users/wasiahmad/orgs",
"repos_url": "https://api.github.com/users/wasiahmad/repos",
"events_url": "https://api.github.com/users/wasiahmad/events{/privacy}",
"received_events_url": "https://api.github.com/users/wasiahmad/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649053,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Help%20wanted",
"name": "Help wanted",
"color": "008672",
"default": false,
"description": "Extra attention is needed, help appreciated"
}
] | closed | false | null | [] | [
"I noticed the following snippet in the code. (which I have edited to solve my problem)\r\n\r\n if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):\r\n # Save a trained model, configuration and tokenizer\r\n model_to_save = model.module if hasattr(model, 'module') else model # Only save the model it-self\r\n\r\n # If we save using the predefined names, we can load using `from_pretrained`\r\n output_model_file = os.path.join(args.output_dir, WEIGHTS_NAME)\r\n output_config_file = os.path.join(args.output_dir, CONFIG_NAME)\r\n\r\n torch.save(model_to_save.state_dict(), output_model_file)\r\n model_to_save.config.to_json_file(output_config_file)\r\n tokenizer.save_vocabulary(args.output_dir)\r\n\r\n # Load a trained model and vocabulary that you have fine-tuned\r\n model = BertForQuestionAnswering.from_pretrained(args.output_dir)\r\n tokenizer = BertTokenizer.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)\r\n else:\r\n model = BertForQuestionAnswering.from_pretrained(args.bert_model)\r\n\r\n\r\nSo, if we want to load the fine-tuned model only for prediction, need to load it from `args.output_dir`. But the current code loads from `args.bert_model` when we use `squad.py` only for prediction.",
"@wasiahmad tokenizer is not needed at prediction time?\r\n\r\nThanks\r\nMahesh",
"need help in understanding how to get the model trained with SQuAD + my dataset. Once trained, how to use it for actual prediction.\r\n\r\nmodel : BERT Question Answering\r\n",
"@Swathygsb \r\nhttps://github.com/kamalkraj/BERT-SQuAD\r\ninference on bert-squad model",
"> @Swathygsb\r\n> https://github.com/kamalkraj/BERT-SQuAD\r\n> inference on bert-squad model\r\n\r\nthx for your sharing, and there is inference on bert-squad model by tensorflow?\r\n3Q~"
] | 1,555 | 1,569 | 1,555 | NONE | null | I have fine-tuned a BERT-QA model on SQuAD and it produced a `pytorch_model.bin` file. Now, I want to load this fine-tuned model and evaluate on SQuAD. How can I do that? I am using the `run_squad.py` script. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/501/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/501/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/500 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/500/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/500/comments | https://api.github.com/repos/huggingface/transformers/issues/500/events | https://github.com/huggingface/transformers/pull/500 | 434,196,137 | MDExOlB1bGxSZXF1ZXN0MjcxMjM3NTYw | 500 | Updating network handling | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,555 | 1,566 | 1,555 | MEMBER | null | This PR adds:
- a bunch of tests for the models and tokenizers stored on S3 with `--runslow` (download and load one model/tokenizer for each type of model BERT, GPT, GPT-2, Transformer-XL)
- relax network connection checking (fallback on the last downloaded model in the cache when we can't get the last eTag from s3) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/500/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/500/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/500",
"html_url": "https://github.com/huggingface/transformers/pull/500",
"diff_url": "https://github.com/huggingface/transformers/pull/500.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/500.patch",
"merged_at": 1555507335000
} |
https://api.github.com/repos/huggingface/transformers/issues/499 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/499/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/499/comments | https://api.github.com/repos/huggingface/transformers/issues/499/events | https://github.com/huggingface/transformers/issues/499 | 434,182,603 | MDU6SXNzdWU0MzQxODI2MDM= | 499 | error when do python3 run_squad.py | {
"login": "directv00",
"id": 37170991,
"node_id": "MDQ6VXNlcjM3MTcwOTkx",
"avatar_url": "https://avatars.githubusercontent.com/u/37170991?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/directv00",
"html_url": "https://github.com/directv00",
"followers_url": "https://api.github.com/users/directv00/followers",
"following_url": "https://api.github.com/users/directv00/following{/other_user}",
"gists_url": "https://api.github.com/users/directv00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/directv00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/directv00/subscriptions",
"organizations_url": "https://api.github.com/users/directv00/orgs",
"repos_url": "https://api.github.com/users/directv00/repos",
"events_url": "https://api.github.com/users/directv00/events{/privacy}",
"received_events_url": "https://api.github.com/users/directv00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
}
] | closed | false | null | [] | [
"Did you install pytorch-pretrained-bert as indicated in the README?\r\n`pip install pytorch_pretrained_bert`\r\n\r\nYou don't have to convert the checkpoints yourself, there are already converted.\r\n\r\nTry reading the installation and usage sections of the README.",
"Of cause I installed,\r\nMore precisely, error code is slightly changed.\r\n```bash\r\nTraceback (most recent call last):\r\n File \"run_squad.py\", line 37, in <module>\r\n from pytorch_pretrained_bert.file_utils import PYTORCH_PRETRAINED_BERT_CACHE, WEIGHTS_NAME, CONFIG_NAME\r\nImportError: cannot import name WEIGHTS_NAME\r\n```",
"Hmm you are right, the examples are compatible with `master` only now that we have a new token serialization. I guess we'll have to do a new release (0.6.2) today so everybody is on the same page.\r\nLet me do that.",
"Actually, we'll wait for the merge of #506.\r\n\r\nIn the meantime you can install from source and it should work.",
"Oh it's done immediately when I installed from source. Thanks.",
"Ok great.\r\n\r\nJust a side note on writing messages in github: you should add triple-quotes like this: \\``` before and after the command line, errors and code you are pasting. This way it's easier to read.\r\n\r\nEx:\r\n\\```\r\npip install -e .\r\n\\```\r\n\r\nwill display like:\r\n```\r\npip install -e .\r\n```",
"Good point(triple quotes).\r\nI didn't know what to do, but now I have it all.\r\nThanks.",
"> Actually, we'll wait for the merge of #506.\r\n> \r\n> In the meantime you can install from source and it should work.\r\n\r\nhow to \"install from source\"?",
"@YanZhangADS \r\n\r\nYou can install from source with this command below\r\n```\r\ngit clone https://github.com/huggingface/pytorch-pretrained-BERT.git\r\ncd pytorch-pretrained-BERT\r\npython setup.py install\r\n```",
"Same problem with \"ImportError: cannot import name WEIGHTS_NAME\". However, after building **0.6.1** from source, I get: \r\n```\r\nfrom pytorch_pretrained_bert.optimization import BertAdam, warmup_linear\r\n ImportError: cannot import name 'warmup_linear'\r\n```\r\nI don't need the warmup, so I removed the import, but letting you guys know that this is an import error as well. Thanks!",
"Thanks for that @dumitrescustefan, we're working on it in #518.\r\nI'm closing this issue for now as we start to deviate from the original discussion.",
"I just built from source. I'm still getting the same error as in original issue.",
"The version 0.4.0 doesn't give this issue.\r\npip install pytorch_pretrained_bert==0.4.0"
] | 1,555 | 1,580 | 1,556 | NONE | null | Hello,
I am newbie of pytorch-pretrained-Bert.
After successfully converted from init-checkpoint of tensorflow to pytorch bin,
I found an error when I do run_squad.
Guessing I should've included some configuration ahead, could anyone can help?
See below.
```bash
File "run_squad.py", line 37, in <module>
from pytorch_pretrained_bert.file_utils import PYTORCH_PRETRAINED_BERT_CACHE, WEIGHTS_NAME, CONFIG_NAME
ImportError: No module named pytorch_pretrained_bert.file_utils
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/499/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/499/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/498 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/498/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/498/comments | https://api.github.com/repos/huggingface/transformers/issues/498/events | https://github.com/huggingface/transformers/pull/498 | 434,153,484 | MDExOlB1bGxSZXF1ZXN0MjcxMjAzODg4 | 498 | Gpt2 tokenization | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,555 | 1,566 | 1,555 | MEMBER | null | Complete #489 by:
- adding tests on GPT-2 Tokenizer (at last)
- fixing GPT-2 tokenization to work on python 2 as well
- adding `special_tokens` handling logic in GPT-2 tokenizer
- fixing GPT and GPT-2 serialization logic to save special tokens | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/498/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/498/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/498",
"html_url": "https://github.com/huggingface/transformers/pull/498",
"diff_url": "https://github.com/huggingface/transformers/pull/498.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/498.patch",
"merged_at": 1555492002000
} |
https://api.github.com/repos/huggingface/transformers/issues/497 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/497/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/497/comments | https://api.github.com/repos/huggingface/transformers/issues/497/events | https://github.com/huggingface/transformers/issues/497 | 434,028,654 | MDU6SXNzdWU0MzQwMjg2NTQ= | 497 | UnboundLocalError: local variable 'special_tokens_file' referenced before assignment | {
"login": "yaroslavvb",
"id": 23068,
"node_id": "MDQ6VXNlcjIzMDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/23068?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yaroslavvb",
"html_url": "https://github.com/yaroslavvb",
"followers_url": "https://api.github.com/users/yaroslavvb/followers",
"following_url": "https://api.github.com/users/yaroslavvb/following{/other_user}",
"gists_url": "https://api.github.com/users/yaroslavvb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yaroslavvb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yaroslavvb/subscriptions",
"organizations_url": "https://api.github.com/users/yaroslavvb/orgs",
"repos_url": "https://api.github.com/users/yaroslavvb/repos",
"events_url": "https://api.github.com/users/yaroslavvb/events{/privacy}",
"received_events_url": "https://api.github.com/users/yaroslavvb/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Yes, this should be fixed by #498."
] | 1,555 | 1,555 | 1,555 | CONTRIBUTOR | null | Happens during this
```enc = GPT2Tokenizer.from_pretrained('gpt2')```
```
File "example_lambada_prediction_difference.py", line 23, in <module>
enc = GPT2Tokenizer.from_pretrained(model_name)
File "/bflm/pytorch-pretrained-BERT/pytorch_pretrained_bert/tokenization_gpt2.py", line 134, in from_pretrained
if special_tokens_file and 'special_tokens' not in kwargs:
UnboundLocalError: local variable 'special_tokens_file' referenced before assignment
```
Looking at offending file, it looks like there's a path for which `special_tokens_file` is never initialized
https://github.com/huggingface/pytorch-pretrained-BERT/blob/3d78e226e68a5c5d0ef612132b601024c3534e38/pytorch_pretrained_bert/tokenization_gpt2.py#L134 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/497/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/497/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/496 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/496/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/496/comments | https://api.github.com/repos/huggingface/transformers/issues/496/events | https://github.com/huggingface/transformers/pull/496 | 434,011,487 | MDExOlB1bGxSZXF1ZXN0MjcxMDk1Mjgw | 496 | [run_gpt2.py] temperature should be a float, not int | {
"login": "8enmann",
"id": 1021104,
"node_id": "MDQ6VXNlcjEwMjExMDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1021104?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/8enmann",
"html_url": "https://github.com/8enmann",
"followers_url": "https://api.github.com/users/8enmann/followers",
"following_url": "https://api.github.com/users/8enmann/following{/other_user}",
"gists_url": "https://api.github.com/users/8enmann/gists{/gist_id}",
"starred_url": "https://api.github.com/users/8enmann/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/8enmann/subscriptions",
"organizations_url": "https://api.github.com/users/8enmann/orgs",
"repos_url": "https://api.github.com/users/8enmann/repos",
"events_url": "https://api.github.com/users/8enmann/events{/privacy}",
"received_events_url": "https://api.github.com/users/8enmann/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Indeed, thanks @8enmann!"
] | 1,555 | 1,555 | 1,555 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/496/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/496/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/496",
"html_url": "https://github.com/huggingface/transformers/pull/496",
"diff_url": "https://github.com/huggingface/transformers/pull/496.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/496.patch",
"merged_at": 1555492134000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/495 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/495/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/495/comments | https://api.github.com/repos/huggingface/transformers/issues/495/events | https://github.com/huggingface/transformers/pull/495 | 433,929,690 | MDExOlB1bGxSZXF1ZXN0MjcxMDI5MDQx | 495 | Fix gradient overflow issue during attention mask | {
"login": "SudoSharma",
"id": 18308855,
"node_id": "MDQ6VXNlcjE4MzA4ODU1",
"avatar_url": "https://avatars.githubusercontent.com/u/18308855?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SudoSharma",
"html_url": "https://github.com/SudoSharma",
"followers_url": "https://api.github.com/users/SudoSharma/followers",
"following_url": "https://api.github.com/users/SudoSharma/following{/other_user}",
"gists_url": "https://api.github.com/users/SudoSharma/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SudoSharma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SudoSharma/subscriptions",
"organizations_url": "https://api.github.com/users/SudoSharma/orgs",
"repos_url": "https://api.github.com/users/SudoSharma/repos",
"events_url": "https://api.github.com/users/SudoSharma/events{/privacy}",
"received_events_url": "https://api.github.com/users/SudoSharma/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Ok, great, thanks @SudoSharma!",
"While the outputs are the same between 1e10 and 1e4, I shouldn't expect the outputs between fp32 and fp16 to be the same, should I? I get different outputs between the two when doing unconditional/conditional generation with top_k=40 but even with top_k=1. Usually they're the same for a while and then deviate. This is with Apex installed, so using FusedLayerNorm.\r\n\r\nIf I turn on Apex's AMP with `from apex import amp; amp.init()` then they still deviate but after a longer time (I think it makes the attention nn.Softmax use fp32). Have to remove the `model.half()` call when using AMP.\r\n\r\nPerhaps it's not realistic to have the outputs be the same when fp16 errors in the \"past\" tensors are compounding as the sequence gets longer? But it is surprising to see them differ for top_k=1 (deterministic) since only the largest logit affects the output there.\r\n\r\nP.S. For my site it's been enormously helpful to have this PyTorch implementation. @thomwolf Thank you!",
"Hi @AdamDanielKing,\r\nCongratulation on your demo!\r\nAre you using the updated API for apex Amp? (https://nvidia.github.io/apex/amp.html)\r\nAlso, we should discuss this in a new issue? At first, I thought this was related to this PR but I understand it's not, right?",
"@thomwolf You're probably right that a new issue is best. I've created one at #602.\r\n\r\nThanks for pointing out I was using the old Apex API. Switching to the new one unfortunately didn't fix the issue though."
] | 1,555 | 1,557 | 1,555 | CONTRIBUTOR | null | This fix is in reference to issue #382. GPT2 can now be trained in mixed precision, which I've confirmed with testing. I also tested unconditional generation on multiple seeds before and after changing 1e10 to 1e4 and there was no difference. Please let me know if there is anything else I can do to make this pull request better. Thanks for all your work! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/495/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/495/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/495",
"html_url": "https://github.com/huggingface/transformers/pull/495",
"diff_url": "https://github.com/huggingface/transformers/pull/495.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/495.patch",
"merged_at": 1555492237000
} |
https://api.github.com/repos/huggingface/transformers/issues/494 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/494/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/494/comments | https://api.github.com/repos/huggingface/transformers/issues/494/events | https://github.com/huggingface/transformers/pull/494 | 433,917,699 | MDExOlB1bGxSZXF1ZXN0MjcxMDE5NTA3 | 494 | Fix indentation for unconditional generation | {
"login": "SudoSharma",
"id": 18308855,
"node_id": "MDQ6VXNlcjE4MzA4ODU1",
"avatar_url": "https://avatars.githubusercontent.com/u/18308855?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SudoSharma",
"html_url": "https://github.com/SudoSharma",
"followers_url": "https://api.github.com/users/SudoSharma/followers",
"following_url": "https://api.github.com/users/SudoSharma/following{/other_user}",
"gists_url": "https://api.github.com/users/SudoSharma/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SudoSharma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SudoSharma/subscriptions",
"organizations_url": "https://api.github.com/users/SudoSharma/orgs",
"repos_url": "https://api.github.com/users/SudoSharma/repos",
"events_url": "https://api.github.com/users/SudoSharma/events{/privacy}",
"received_events_url": "https://api.github.com/users/SudoSharma/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks!"
] | 1,555 | 1,555 | 1,555 | CONTRIBUTOR | null | Hey guys, there was an issue with the example file for generating unconditional samples. I just fixed the indentation. Let me know if there is anything else I need to do! Thanks for the great work on this repo. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/494/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/494/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/494",
"html_url": "https://github.com/huggingface/transformers/pull/494",
"diff_url": "https://github.com/huggingface/transformers/pull/494.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/494.patch",
"merged_at": 1555492296000
} |
https://api.github.com/repos/huggingface/transformers/issues/493 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/493/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/493/comments | https://api.github.com/repos/huggingface/transformers/issues/493/events | https://github.com/huggingface/transformers/issues/493 | 433,778,597 | MDU6SXNzdWU0MzM3Nzg1OTc= | 493 | how to use extracted features in extract_features.py? | {
"login": "heslowen",
"id": 22348625,
"node_id": "MDQ6VXNlcjIyMzQ4NjI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22348625?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/heslowen",
"html_url": "https://github.com/heslowen",
"followers_url": "https://api.github.com/users/heslowen/followers",
"following_url": "https://api.github.com/users/heslowen/following{/other_user}",
"gists_url": "https://api.github.com/users/heslowen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/heslowen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/heslowen/subscriptions",
"organizations_url": "https://api.github.com/users/heslowen/orgs",
"repos_url": "https://api.github.com/users/heslowen/repos",
"events_url": "https://api.github.com/users/heslowen/events{/privacy}",
"received_events_url": "https://api.github.com/users/heslowen/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Without fine-tuning, BERT features are usually less useful than plain GloVe or wrd2vec indeed.\r\nThey start to be interesting when you fine-tune a classifier on top of BERT.\r\n\r\nSee the recent study by Matthew Peters, Sebastian Ruder, Noah A. Smith ([To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks](https://arxiv.org/abs/1903.05987)) for some practical tips on that.",
"thank you so much~",
"@heslowen could you please share the code for extracting features in order to use them for learning a classifier? Thanks.",
"@joistick11 you can find a demo in extract_features.py",
"Could you please help me?\r\nI was using bert-as-service (https://github.com/hanxiao/bert-as-service) and there is model method `encode`, which accepts list and returns list of the same size, each element containing sentence embedding. All the elements of the same size. \r\n1. When I use extract_features.py, it returns embedding for each recognized symbol in the sentence from the specified layers. I mean, instead of sentence embedding it returns symbols embeddings. How should I use it, for instance, to train an SVM? I am using `bert-base-multilingual-cased`\r\n2. Which layer output should I use? Is it with index `-1`?\r\n\r\nThanks you very much!",
"@joistick11 you want to embed a sentence to a vector?\r\n`all_encoder_layers, pooled_output = model(input_ids, token_type_ids=None, attention_mask=input_mask)` pooled_output may help you.\r\nI have no idea about using these features to train an SVM although I know the theory about SVM.\r\nFor the second question, please refer to thomwolf's answer.\r\nI used the top 4 encoders_layers, but I did not get a better result than using Glove ",
"@heslowen Hello, would you please help me? For a sequence like [cls I have a dog.sep], when I input this to Bert and get the last hidden layer of sequence out, let’s say the output is “vector”, is the vector[0] embedding of cls, vector[1] embedding of I, etc. vector[-1] embedding of sep?",
"@heslowen How did you extract features after training a classifier on top of BERT? I've been trying to do the same, but I'm unable to do so. \r\nDo I first follow run_classifier.py, and then extract the features from tf.Estimator?",
"@rvoak I use pytorch. I did it as the demo in extract_featrues.py. it is easy to do that, you just need to load a tokenizer, a bert model, then tokenize your sentences, and then run the model to get the encoded_layers",
"@RomanShen yes you're right\r\n",
"@heslowen Thanks for your reply!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@heslowen sorry about my english, now i doing embedding for sentence task, i tuned with my corpus with this library, and i received config.json, vocab.txt and model.bin file, but in bert's original doc, can extract feature when load from ckpt tensorflow checkpoint. according to your answer, i must write feature_extraction for torch, that's right ? please help me",
"@hungph-dev-ict Do you mind opening a new issue with your problem? I'll try and help you out.",
"@LysandreJik Thank you for your help, I will find solution for my problem, it's use last hidden layer in bert mechanism, but if you have a better solution, can you help me ?\r\nSo i have more concerns about with my corpus, with this library code, use tokenizer from pretrained BERT model, so I want use only BasicTokenizer. Can you help me ? ",
"How long should the extract_features.py take to complete?\r\n\r\nwhen using 'bert-large-uncased' it takes seconds however it writes a blank file.\r\nwhen using 'bert-base-uncased' its been running for over 30 mins.\r\n\r\nany advice?\r\n\r\nthe code I used:\r\n\r\n!python extract_features.py \\\r\n --input_file data/src_train.txt \\\r\n --output_file data/output1.jsonl \\\r\n --bert_model bert-base-uncased \\\r\n --layers -1\r\n",
"You can look at what the BertForSequenceClassification model [https://github.com/huggingface/transformers/blob/3ba5470eb85464df62f324bea88e20da234c423f/pytorch_pretrained_bert/modeling.py#L867 ](url) does in it’s forward 139.\r\nThe pooled_output obtained from self.bert would seem to be the features you are looking for."
] | 1,555 | 1,576 | 1,562 | NONE | null | I extract features like examples in extarct_features.py. But went I used these features (the last encoded_layers) as word embeddings in a text classification task, I got a worse result than using 300D Glove(any other parameters are the same). I also used these features to compute the cos similarity for each word in sentences, I found that all values were around 0.6. So are these features can be used as Glove or word2vec embeddings? What exactly these features are? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/493/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/493/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/492 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/492/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/492/comments | https://api.github.com/repos/huggingface/transformers/issues/492/events | https://github.com/huggingface/transformers/issues/492 | 433,597,604 | MDU6SXNzdWU0MzM1OTc2MDQ= | 492 | no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight'] | {
"login": "RayXu14",
"id": 22774575,
"node_id": "MDQ6VXNlcjIyNzc0NTc1",
"avatar_url": "https://avatars.githubusercontent.com/u/22774575?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RayXu14",
"html_url": "https://github.com/RayXu14",
"followers_url": "https://api.github.com/users/RayXu14/followers",
"following_url": "https://api.github.com/users/RayXu14/following{/other_user}",
"gists_url": "https://api.github.com/users/RayXu14/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RayXu14/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RayXu14/subscriptions",
"organizations_url": "https://api.github.com/users/RayXu14/orgs",
"repos_url": "https://api.github.com/users/RayXu14/repos",
"events_url": "https://api.github.com/users/RayXu14/events{/privacy}",
"received_events_url": "https://api.github.com/users/RayXu14/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Yes. We are reproducing the behavior of the original optimizer, see [here](https://github.com/google-research/bert/blob/master/optimization.py#L65).",
"thanks~",
"but why?",
"I have the same question, but did this prove to be better? Or is it just to speed up calculations?"
] | 1,555 | 1,613 | 1,555 | NONE | null | what does this means? Whay these three kind no decay? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/492/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/492/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/491 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/491/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/491/comments | https://api.github.com/repos/huggingface/transformers/issues/491/events | https://github.com/huggingface/transformers/issues/491 | 433,550,221 | MDU6SXNzdWU0MzM1NTAyMjE= | 491 | pretrained GPT-2 checkpoint gets only 31% accuracy on Lambada | {
"login": "yaroslavvb",
"id": 23068,
"node_id": "MDQ6VXNlcjIzMDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/23068?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yaroslavvb",
"html_url": "https://github.com/yaroslavvb",
"followers_url": "https://api.github.com/users/yaroslavvb/followers",
"following_url": "https://api.github.com/users/yaroslavvb/following{/other_user}",
"gists_url": "https://api.github.com/users/yaroslavvb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yaroslavvb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yaroslavvb/subscriptions",
"organizations_url": "https://api.github.com/users/yaroslavvb/orgs",
"repos_url": "https://api.github.com/users/yaroslavvb/repos",
"events_url": "https://api.github.com/users/yaroslavvb/events{/privacy}",
"received_events_url": "https://api.github.com/users/yaroslavvb/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
}
] | closed | false | null | [] | [
"Accuracy goes to 31% if I use [stop-word filter](https://github.com/cybertronai/bflm/blob/51908bdd15477a0cedfbd010d489f8d355443b6a/eval_lambada_slow.py#L62), still seems lower than expected ([predictions](https://s3.amazonaws.com/yaroslavvb2/data/lambada_predictions_stopword_filter.txt))\r\n",
"Hi, I doubt it's a problem with the model. Usually the culprit is too find in the pre-processing logic.\r\n\r\nYour dataset seems to be pre-processed but Radford, Wu et al. says they are using a version without preprocessing (end of section 3.3). GPT-2 is likely sensitive to tokenization issues and the like.\r\n\r\nIf you want to check the model it-self, you could try comparing with the predictions of the Tensorflow version on a few lambada completions?",
"Applying [detokenization](https://github.com/cybertronai/bflm/blob/d58a6860451ee2afa3688aff13d104ad74001ebe/eval_lambada_slow.py#L77) raises accuracy to 33.11%\r\n\r\nI spot checked a few errors against TF implementation and they give the same errors, so it seems likely the difference is due to eval protocol, rather than the checkpoint",
"IMHO \"without pre-processing\" means taking the original dataset without modification, which is what I also did here.\r\n\r\nHowever in the original dataset, everything is tokenized. IE \"haven't\" was turned into \"have n't\"\r\nEither way, undoing this tokenization only has a improvement of 2%, so there must be some deeper underlying difference in the way OpenAI did their evaluation.\r\n",
"Indeed. It's not very clear to me what they mean exactly by \"stop-word filter\". It seems like the kind of heuristic that can have a very large impact on the performances.\r\n\r\nMaybe a better filtering is key. I would probably go with a sort of beam-search to compute the probability of having a punctuation/end-of-sentence token after the predicted word and use that to filter the results.",
"I spoke with Alec and turns out for evaluation they got used the \"raw\" lambada corpus which was obtained by finding original sentences in book corpus that matched the tokenized versions in the lambada release. So to to reproduce the numbers we need the \"raw\" corpus https://github.com/openai/gpt-2/issues/131",
"I'm now able to get within 1% of their reported accuracy on GPT2-small. The two missing modifications were:\r\n1. Evaluate on OpenAI's version of lambada which adds extra formatting\r\n2. Evaluate by counting number of times the last BPE token is predicted incorrectly instead of last word, details are in https://github.com/openai/gpt-2/issues/131#issuecomment-497136199"
] | 1,555 | 1,559 | 1,559 | CONTRIBUTOR | null | For some reason I only see 26% accuracy when evaluating on Lambada for GPT-2 checkpoint instead of expected 45.99%
Here's a file of [predictions](https://s3.amazonaws.com/yaroslavvb2/data/lambada_predictions.txt) with sets of 3 lines of the form:
ground truth
predicted last_word
is_counted_as_error
Generated by this [script](https://github.com/cybertronai/bflm/blob/master/eval_lambada_slow.py)
Could this be caused by the way GPT-2 checkpoint was imported into HuggingFace?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/491/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/491/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/490 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/490/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/490/comments | https://api.github.com/repos/huggingface/transformers/issues/490/events | https://github.com/huggingface/transformers/pull/490 | 433,306,374 | MDExOlB1bGxSZXF1ZXN0MjcwNTM1OTk1 | 490 | Clean up GPT and GPT-2 losses computation | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,555 | 1,566 | 1,555 | MEMBER | null | Small clean up of GPT and GPT-2 losses computations.
Also fix an issue with special adding tokens. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/490/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/490/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/490",
"html_url": "https://github.com/huggingface/transformers/pull/490",
"diff_url": "https://github.com/huggingface/transformers/pull/490.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/490.patch",
"merged_at": 1555337691000
} |
https://api.github.com/repos/huggingface/transformers/issues/489 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/489/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/489/comments | https://api.github.com/repos/huggingface/transformers/issues/489/events | https://github.com/huggingface/transformers/pull/489 | 433,198,223 | MDExOlB1bGxSZXF1ZXN0MjcwNDUwNjg4 | 489 | Better serialization for Tokenizer and Config classes (BERT, GPT, GPT-2 and Transformer-XL) | {
"login": "thomwolf",
"id": 7353373,
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomwolf",
"html_url": "https://github.com/thomwolf",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,555 | 1,566 | 1,555 | MEMBER | null | This PR add standardized serialization to all the tokenizers (BERT, GPT, GPT-2, Transformer-XL) through a `tokenizer.save_vocabulary(path)` method.
Also add a serialization method to all the Configuration classes: `Config.to_json_file(file_path)`
Added clean examples for serialization best practices in README and examples.
Also fixes Transformer-XL "split on punctation" bug mentioned in #466. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/489/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/489/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/489",
"html_url": "https://github.com/huggingface/transformers/pull/489",
"diff_url": "https://github.com/huggingface/transformers/pull/489.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/489.patch",
"merged_at": 1555397395000
} |
https://api.github.com/repos/huggingface/transformers/issues/488 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/488/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/488/comments | https://api.github.com/repos/huggingface/transformers/issues/488/events | https://github.com/huggingface/transformers/pull/488 | 433,161,099 | MDExOlB1bGxSZXF1ZXN0MjcwNDIxODM2 | 488 | fixed BertForMultipleChoice model init and forward pass | {
"login": "dhpollack",
"id": 368699,
"node_id": "MDQ6VXNlcjM2ODY5OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/368699?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dhpollack",
"html_url": "https://github.com/dhpollack",
"followers_url": "https://api.github.com/users/dhpollack/followers",
"following_url": "https://api.github.com/users/dhpollack/following{/other_user}",
"gists_url": "https://api.github.com/users/dhpollack/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dhpollack/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dhpollack/subscriptions",
"organizations_url": "https://api.github.com/users/dhpollack/orgs",
"repos_url": "https://api.github.com/users/dhpollack/repos",
"events_url": "https://api.github.com/users/dhpollack/events{/privacy}",
"received_events_url": "https://api.github.com/users/dhpollack/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Indeed, it looks better.\r\nDo you want to have a look and confirm @rodgzilla?",
"@thomwolf any word on this?",
"Oh yes sorry. Looking at it and reading Alec Radford's paper on GPT (section 3.3) again, I think @rodgzilla was actually right in the original implementation.\r\n\r\nSo I guess we should close this PR.\r\n\r\nI still would have been happy to get @rodgzilla input on that.",
"Oh sorry, we should still keep the `token_type_ids` and `attention_mask` `NoneType` fixes.\r\nThese ones are correct!"
] | 1,555 | 1,556 | 1,556 | CONTRIBUTOR | null | the number of choices is not respected because you've hardcoded '1' into the classifier layer. also `token_type_ids` and `attention_mask` will cause an error if `None` because `None` does not have a `view` method. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/488/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/488/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/488",
"html_url": "https://github.com/huggingface/transformers/pull/488",
"diff_url": "https://github.com/huggingface/transformers/pull/488.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/488.patch",
"merged_at": 1556219057000
} |
https://api.github.com/repos/huggingface/transformers/issues/487 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/487/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/487/comments | https://api.github.com/repos/huggingface/transformers/issues/487/events | https://github.com/huggingface/transformers/issues/487 | 432,963,792 | MDU6SXNzdWU0MzI5NjM3OTI= | 487 | BERT multilingual for zero-shot classification | {
"login": "ramild",
"id": 9999944,
"node_id": "MDQ6VXNlcjk5OTk5NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9999944?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ramild",
"html_url": "https://github.com/ramild",
"followers_url": "https://api.github.com/users/ramild/followers",
"following_url": "https://api.github.com/users/ramild/following{/other_user}",
"gists_url": "https://api.github.com/users/ramild/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ramild/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ramild/subscriptions",
"organizations_url": "https://api.github.com/users/ramild/orgs",
"repos_url": "https://api.github.com/users/ramild/repos",
"events_url": "https://api.github.com/users/ramild/events{/privacy}",
"received_events_url": "https://api.github.com/users/ramild/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649053,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Help%20wanted",
"name": "Help wanted",
"color": "008672",
"default": false,
"description": "Extra attention is needed, help appreciated"
},
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"UPD. I tried it with bert-multilingual-cased, but the results are still bad. A number of very simple (text, translated text) give very different probability distributions (the translated versions almost always fall into one major category).\r\n\r\nSpecifiically, **I fine-tune pre-trained bert-multilingual-cased on Russian text classification problem and then make a prediction using the model on an English text** (tried other languages -- nothing works).",
"Hi, my feeling is that this is still an open research problem.\r\n\r\n[Here](https://twitter.com/nlpmattg/status/1091367511117881345) is a recent thread discussing the related problem of fine-tuning BERT on English SQuAD and trying to do QA in another language. Maybe you can get a pre-print from the RecitalAI guys if they haven't published it yet.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,555 | 1,561 | 1,561 | NONE | null | Hi!
I'm interested in solving a classification problem in which I train the model on one language and make the predictions for another one (zero-shot classification).
It is said in the README for the multilingual BERT model (https://github.com/google-research/bert/blob/master/multilingual.md) that:
> For tokenization, we use a 110k shared WordPiece vocabulary. The word counts are weighted the same way as the data, so low-resource languages are upweighted by some factor. We intentionally do not use any marker to denote the input language (so that zero-shot training can work).
But after finetuning the BERT-multilingual-uncased for one language dataset, it absolutely doesn't work for the texts in another languages. Predictions turn out to be inadequate: I tried multiple pairs `(text, the same text translated to another language)` and probability distributions over labels (after apply softmax) were wildly different.
Do you know what can be the cause of the problem? Should I somehow change the tokenization when applying the model to other languages (BPE embeddings are shared, so not sure about this one)? Or should I use multilingual-cased instead of multilingual-uncased (is it possible it can be the source of the problem)? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/487/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/487/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/486 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/486/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/486/comments | https://api.github.com/repos/huggingface/transformers/issues/486/events | https://github.com/huggingface/transformers/issues/486 | 432,884,928 | MDU6SXNzdWU0MzI4ODQ5Mjg= | 486 | Difference between this repo and bert-as-service | {
"login": "tcqiuyu",
"id": 6031166,
"node_id": "MDQ6VXNlcjYwMzExNjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/6031166?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tcqiuyu",
"html_url": "https://github.com/tcqiuyu",
"followers_url": "https://api.github.com/users/tcqiuyu/followers",
"following_url": "https://api.github.com/users/tcqiuyu/following{/other_user}",
"gists_url": "https://api.github.com/users/tcqiuyu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tcqiuyu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tcqiuyu/subscriptions",
"organizations_url": "https://api.github.com/users/tcqiuyu/orgs",
"repos_url": "https://api.github.com/users/tcqiuyu/repos",
"events_url": "https://api.github.com/users/tcqiuyu/events{/privacy}",
"received_events_url": "https://api.github.com/users/tcqiuyu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Yes there are some optimizations. Please take a look here:\r\n\r\nhttps://hanxiao.github.io/2019/01/02/Serving-Google-BERT-in-Production-using-Tensorflow-and-ZeroMQ/#engineering-building-a-scalable-service",
"Hi, there is no specific relation between the present repo (which provides PyTorch implementations of several transformer's models) and bert-as-a-service (which is built on top of BERT TensorFlow implementation AFAICT).\r\n\r\nWe want to keep the code simple in the present repo and don't provide specific optimizations out-of-the-box but if you want to add some of bert-as-a-service optimizations, here are the most straightforward ones:\r\n- use `with torch.no_grad()` to avoid computing gradient during evaluation (should divide memory consumption by two)\r\n- use fp16 code to get another factor of 2, probably the easiest is to use the amp wrapper in NVIDIA's apex library, see the details [here](https://github.com/NVIDIA/apex).",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,555 | 1,561 | 1,561 | NONE | null | Hi,
I wondered if anybody knows the difference between the `BertModel` of this repo and [bert-as-service](https://github.com/hanxiao/bert-as-service).
1. I cannot get the same result between these two even if I use the same checkpoint. pytorch-pretrained-BERT yield a lower acc and slower convergence.
2. The memory usage of `BertModel` seems much higher than bert-as-service. With the same batch-size=32, max_seq_len=100, the bert-as-service will take about 8000MB but `BertModel` will cost more than 16000MB because I got an OOM issue.
Does any one knows the reason behind it? Is there any optimization done for bert-as-service? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/486/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/486/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/485 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/485/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/485/comments | https://api.github.com/repos/huggingface/transformers/issues/485/events | https://github.com/huggingface/transformers/issues/485 | 432,830,533 | MDU6SXNzdWU0MzI4MzA1MzM= | 485 | UnboundLocalError: local variable 'i' referenced before assignment when using fine_tuning code | {
"login": "KavyaGujjala",
"id": 28920687,
"node_id": "MDQ6VXNlcjI4OTIwNjg3",
"avatar_url": "https://avatars.githubusercontent.com/u/28920687?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KavyaGujjala",
"html_url": "https://github.com/KavyaGujjala",
"followers_url": "https://api.github.com/users/KavyaGujjala/followers",
"following_url": "https://api.github.com/users/KavyaGujjala/following{/other_user}",
"gists_url": "https://api.github.com/users/KavyaGujjala/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KavyaGujjala/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KavyaGujjala/subscriptions",
"organizations_url": "https://api.github.com/users/KavyaGujjala/orgs",
"repos_url": "https://api.github.com/users/KavyaGujjala/repos",
"events_url": "https://api.github.com/users/KavyaGujjala/events{/privacy}",
"received_events_url": "https://api.github.com/users/KavyaGujjala/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I found out the issue. The text corpus I was using is just one document. So the code is for two or more documents only?",
"Yes only for multiple documents.\r\nWe have a test now to check that since #478 thanks to @Rocketknight1."
] | 1,555 | 1,555 | 1,555 | NONE | null | Hi @thomwolf
I am using the lm_finetuning codes. Generated training data using generate_pretraining_data.py
When running finetune_on_pregenerated.py . I am getting this error.
logs
python finetune_on_pregenerated.py --pregenerated_data training_1/ --bert_model bert-base-uncased --do_lower_case --output_dir finetuned_lm_1Msents_3epochs/ --epochs 3
Better speed can be achieved with apex installed from https://www.github.com/nvidia/apex.
2019-04-13 09:32:43,014: device: cuda n_gpu: 4, distributed training: False, 16-bits training: False
2019-04-13 09:32:43,361: loading vocabulary file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt from cache at /home/cloud/.pytorch_pretrained_bert/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084
2019-04-13 09:32:43,676: loading archive file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz from cache at /home/cloud/.pytorch_pretrained_bert/9c41111e2de84547a463fd39217199738d1e3deb72d4fec4399e6e241983c6f0.ae3cef932725ca7a30cdcb93fc6e09150a55e2a130ec7af63975a16c153ae2ba
2019-04-13 09:32:43,677: extracting archive file /home/cloud/.pytorch_pretrained_bert/9c41111e2de84547a463fd39217199738d1e3deb72d4fec4399e6e241983c6f0.ae3cef932725ca7a30cdcb93fc6e09150a55e2a130ec7af63975a16c153ae2ba to temp dir /tmp/tmprmsendyc
2019-04-13 09:32:48,700: Model config {
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30522
}
2019-04-13 09:33:17,672: ***** Running training *****
2019-04-13 09:33:17,672: Num examples = 0
2019-04-13 09:33:17,672: Batch size = 32
2019-04-13 09:33:17,672: Num steps = 0
2019-04-13 09:33:17,674: Loading training examples for epoch 0
Training examples: 0it [00:00, ?it/s]
Traceback (most recent call last):
File "finetune_on_pregenerated.py", line 333, in <module>
main()
File "finetune_on_pregenerated.py", line 286, in main
num_data_epochs=num_data_epochs)
File "finetune_on_pregenerated.py", line 101, in __init__
assert i == num_samples - 1 # Assert that the sample count metric was true
UnboundLocalError: local variable 'i' referenced before assignment | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/485/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/485/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/484 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/484/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/484/comments | https://api.github.com/repos/huggingface/transformers/issues/484/events | https://github.com/huggingface/transformers/issues/484 | 432,826,407 | MDU6SXNzdWU0MzI4MjY0MDc= | 484 | KeyError: in convert_tokens_to_ids() | {
"login": "wasiahmad",
"id": 17520413,
"node_id": "MDQ6VXNlcjE3NTIwNDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/17520413?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wasiahmad",
"html_url": "https://github.com/wasiahmad",
"followers_url": "https://api.github.com/users/wasiahmad/followers",
"following_url": "https://api.github.com/users/wasiahmad/following{/other_user}",
"gists_url": "https://api.github.com/users/wasiahmad/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wasiahmad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wasiahmad/subscriptions",
"organizations_url": "https://api.github.com/users/wasiahmad/orgs",
"repos_url": "https://api.github.com/users/wasiahmad/repos",
"events_url": "https://api.github.com/users/wasiahmad/events{/privacy}",
"received_events_url": "https://api.github.com/users/wasiahmad/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
}
] | closed | false | null | [] | [
"Hi @wasiahmad,\r\nThis should actually already been taken care of by the WordPieceTokenizer ([here](https://github.com/huggingface/pytorch-pretrained-BERT/blob/19666dcb3bee3e379f1458e295869957aac8590c/pytorch_pretrained_bert/tokenization.py#L357)).\r\nDo you have a simple example to share so I can try to reproduce the behavior?",
"Hi @thomwolf ,\r\n I alse found the same question when using BertTokenizer class. \r\nCode likes:\r\n```\r\nsent = ['hi', 'mary']\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-cased')\r\nmodel_bert = BertModel.from_pretrained('bert-base-cased')\r\ntokenizer.convert_tokens_to_ids(sent)\r\n```",
"Hi @thomwolf \r\nI didn't record that token for which I encountered that error but that token was not an English word, it was more like a weird symbol which was probably able to bypass WordPieceTokenizer. I was using BERT as a feature extractor for MSMARCO v2 QA dataset when I encountered the error.",
"@congjianluo you should not tokenize the sentence your self but use Bert tokenizer.\r\nPlease follow the usage example in the [readme](https://github.com/huggingface/pytorch-pretrained-BERT#bert).\r\nIn your case:\r\n```python\r\nsent = \"hi mary\"\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-cased')\r\ntokens = tokenizer.tokenize(sent)\r\ntokens_ids = tokenizer.convert_tokens_to_ids(tokens)\r\n```",
"@wasiahmad ok then I'm closing this issue.\r\nFeel free to re-open it if you have a (reproductible) example of such issue."
] | 1,555 | 1,555 | 1,555 | NONE | null | In BertTokenizer's, [convert_tokens_to_ids](https://github.com/huggingface/pytorch-pretrained-BERT/blob/19666dcb3bee3e379f1458e295869957aac8590c/pytorch_pretrained_bert/tokenization.py#L117) function gives KeyError. So, I suggest to modify the **for loop** in the function as follows.
```
for token in tokens:
ids.append(self.vocab.get(token, self.vocab['[UNK]']))
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/484/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/484/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/483 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/483/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/483/comments | https://api.github.com/repos/huggingface/transformers/issues/483/events | https://github.com/huggingface/transformers/issues/483 | 432,747,117 | MDU6SXNzdWU0MzI3NDcxMTc= | 483 | Perplexity number of wikitext-103 on gpt-2 don't match the paper | {
"login": "Akhila-Yerukola",
"id": 4477323,
"node_id": "MDQ6VXNlcjQ0NzczMjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/4477323?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Akhila-Yerukola",
"html_url": "https://github.com/Akhila-Yerukola",
"followers_url": "https://api.github.com/users/Akhila-Yerukola/followers",
"following_url": "https://api.github.com/users/Akhila-Yerukola/following{/other_user}",
"gists_url": "https://api.github.com/users/Akhila-Yerukola/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Akhila-Yerukola/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Akhila-Yerukola/subscriptions",
"organizations_url": "https://api.github.com/users/Akhila-Yerukola/orgs",
"repos_url": "https://api.github.com/users/Akhila-Yerukola/repos",
"events_url": "https://api.github.com/users/Akhila-Yerukola/events{/privacy}",
"received_events_url": "https://api.github.com/users/Akhila-Yerukola/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Are you using context length 256 by chance?\r\n\r\nOn WikiText-2 I see\r\n\r\nI see 29.17378 using context length 1024 and 43.3393707 using context length 256\r\nThis is close to OpenAI report result of 29.41\r\n(although I don't get why it doesn't match it exactly)\r\n",
"@yaroslavvb \r\nNo, I'm using a context length of 1024. \r\n\r\nAlthough, when I evaluate it on wikitext-2, my numbers dont match with yours. Would it be possible for you to share what you've done? I believe that you might have normalized the loss by the number of tokens after the gpt-2 tokenization, and not by the number of tokens originally in wikitext-2. ",
"Here's our loss [computation](https://github.com/cybertronai/bflm/blob/b6ba6d97c9ccdf2b12e104fbdcd0bed25ada7b68/train_gpt2.py#L163)\r\n\r\nWe don't normalize the loss here, just take the average output of `model(batch, lm_labels=batch)` where model is `GPT2LMHeadModel.from_pretrained(args.model_name_or_path)`\r\n\r\nNote wikitext-103 and wikitext-2 have the same test set, so you should get `29.17378` perplexity on either one",
"@Akhila-Yerukola when we tried normalizing by the original token count, our ppl number got much further from the paper.\r\n\r\nI ran `wikitext-2-raw/wiki.train.raw` through the encoder and got 2417793 tokens. Then I split the original on spaces and got 2088678. \r\n```py\r\nmath.exp(math.log(29.41) * 2088678 / 2417793) # 18.56\r\n```\r\nWe got 30.4 ppl unnormalized and 28 after [detokenizing](https://github.com/cybertronai/bflm/blob/master/detokenizer.py), so we're still quite far from 18.56.\r\nAnother possibility is that for evaluation, instead of chunking the dataset and shoving it through, they pass it in 1 token at a time the same way they do for sample generation. This would significantly reduce the loss because the model wouldn't \"forget\" what it was doing at the beginning of each sequence. I'll try this later today.",
"As a quick test, I calculated loss based on only the last 10 tokens of the sequence without changing the chunking. I got test loss of 23.9 and train 24.9.",
"@yaroslavvb @8enmann \r\nI still think the numbers don't match the paper.\r\nThe Table 3 in the paper which contains Zero-shot results on many datasets has a \"SOTA\" row which correspond to the reported perplexity numbers on the test sets of the data sets. (I verified this for wikitext-2 and wikitext-103)\r\nWhen I run [this](https://github.com/cybertronai/bflm/blob/b6ba6d97c9ccdf2b12e104fbdcd0bed25ada7b68/train_gpt2.py) evaluation script, I get ppl of 23.85 on wikitext-2 (not raw), 28.186 on wikitext-103 (not raw), 29.01 on wikitext-103-raw (and wikitext-2-raw). None of these match the reported 117M gpt-2 model (which is the model available) numbers from the paper (29.41 for wikitext-2, 37.5 for wikitext-103)\r\nFrom the looks of it wikitext-103 is way off.",
"You're right, our results are very different from the paper. Perhaps they used the detokenized non-raw version and also for the labels passed -1 for <UNK> tokens, which causes them not to be evaluated for loss. This, combined with the 1 at a time trick I mentioned 2 days ago, could bring PPL down to ~18. However that still leaves a big puzzle as to why the loss they reported on wikitext-103 is so much worse than wikitext-2.",
"Related issue, Lambada numbers also don't match the paper (31% instead of reported 46%) https://github.com/huggingface/pytorch-pretrained-BERT/issues/491",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> @yaroslavvb @8enmann\r\n> When I run [this](https://github.com/cybertronai/bflm/blob/b6ba6d97c9ccdf2b12e104fbdcd0bed25ada7b68/train_gpt2.py) evaluation script, I get ppl of 23.85 on wikitext-2 (not raw), 28.186 on wikitext-103 (not raw), 29.01 on wikitext-103-raw (and wikitext-2-raw). None of these match the reported 117M gpt-2 model (which is the model available) numbers from the paper (29.41 for wikitext-2, 37.5 for wikitext-103)\r\n\r\nIs it possible to know why 0.7 and 0.3? --> 0.7 * exp_average_loss + 0.3 * loss.item()\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"This discussion is old, so this may not be applicable anymore. But I'd like to offer a data point if it's still the case. I tried gpt2 and gpt2-medium on OpenWebText (tokenized with HuggingFace's corresponding tokenizer settings), and I got the ppl about 24 and 18, respectively, whereas the openai version of them is 17 and 13, respectively. This is good enough to say that I probably didn't make any catastrophic mistake, but there still is some gap, which may or may not explain the performance gap on other datasets."
] | 1,555 | 1,592 | 1,567 | NONE | null | Hi,
The reported perplexity number of gpt-2 (117M) on wikitext-103 is 37.5.
However when I use the pre-trained tokenizer for gpt-2 `GPT2Tokenizer` using:
`tokenizer = GPT2Tokenizer.from_pretrained('gpt2')` to tokenize wikitext-103, and then evaluate it using the pre-trained 117M gpt-2 model, I get a ppl of 48.4
Note: I have added newlines instead of EOS tags at the end of each line read. I've also normalized the loss by the number of tokens originally in wikitext-103 as mentioned by Alec Radford at https://github.com/openai/gpt-2/issues/78
Could you please let me know whats wrong here? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/483/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/483/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/482 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/482/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/482/comments | https://api.github.com/repos/huggingface/transformers/issues/482/events | https://github.com/huggingface/transformers/issues/482 | 432,743,293 | MDU6SXNzdWU0MzI3NDMyOTM= | 482 | Suggestion: exception handling for out-of-vocab in pretrained model | {
"login": "sdeva14",
"id": 18130526,
"node_id": "MDQ6VXNlcjE4MTMwNTI2",
"avatar_url": "https://avatars.githubusercontent.com/u/18130526?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sdeva14",
"html_url": "https://github.com/sdeva14",
"followers_url": "https://api.github.com/users/sdeva14/followers",
"following_url": "https://api.github.com/users/sdeva14/following{/other_user}",
"gists_url": "https://api.github.com/users/sdeva14/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sdeva14/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sdeva14/subscriptions",
"organizations_url": "https://api.github.com/users/sdeva14/orgs",
"repos_url": "https://api.github.com/users/sdeva14/repos",
"events_url": "https://api.github.com/users/sdeva14/events{/privacy}",
"received_events_url": "https://api.github.com/users/sdeva14/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
}
] | closed | false | null | [] | [
"Hi Sungho,\r\nThis should already be taken care of by the BertTokenizer which defaults on the `unk` token when a sub-word is not in the vocabulary (see [here](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/pytorch_pretrained_bert/tokenization.py#L372)).\r\nWhat BERT model are you using?\r\nDo you have a simple example you can share so I can try to reproduce the behavior?",
"Hi Tomas,\r\n\r\nIt is really shame to describe, I think it is just my typo problem again :(\r\nPlease ignore this issue.\r\n\r\nYou are absolutely right, there is an exception handling.\r\nJust I loaded a wrong model in the BertModel after tokenizing.\r\n\"bert-base-cased\" in the model part, Instead of \"bert-base-uncased\", which has a smaller vocab size than \"uncased\".\r\n\r\nI am so sorry to waste your time, and appreciate your favor again! :)\r\n\r\nBest\r\nSungho",
"Ok make sense, good to know.\r\nSo there is no problem in the end?",
"Yep, only my embarrassing here :)\r\n\r\nThough there is no performance change, but I believe it is not a problem of pretrained model at all, but \r\n just different application.\r\n\r\nThus, no problem for implementation at all, I appreciate it!",
"Ok, let's close the issue then. Feel free to open a new one if you have other problems.",
"May I know why cased vocabulary is smaller than uncased? "
] | 1,555 | 1,573 | 1,555 | NONE | null | Dear concern,
I appreciate your favor for public implementation.
As you know, all NLP people have an interest in applying your gorgeous model to every NLP problem.
I am writing this to suggest to add exception handling or warning message about out-of-vocabulary when a pretrained model is used.
I had been suffered by an error message for two days with checking every my code, naturally, I had believed it is my programming problem again :)
Then I discovered that it is out-of-vocab problem.
The pretrained BERT model has vocab size 28996, but my dataset with BERT subword tokenizer has more than 30000 vocab.
Then it is an error, when the BERT model meets an index higher than 28996.
If we know the problem, a solution is quite simple, filtering or replacing it to UNK index.
Error messages are caused from somewhat embedding parts in CPU mode, but it was unclear to identify GPU mode, thus other people might be suffered like me.
I know the pretrained model is not designed for application, long documents with unusual vocabulary.
However, I believe many people will appreciate your favor if you add exception handling or warning message.
If you already have recognized the issue, please ignore this message :)
Best
Sungho | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/482/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/482/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/481 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/481/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/481/comments | https://api.github.com/repos/huggingface/transformers/issues/481/events | https://github.com/huggingface/transformers/issues/481 | 432,700,310 | MDU6SXNzdWU0MzI3MDAzMTA= | 481 | BERT does mask-answering or sequence prediction or both??? | {
"login": "bladedsupernova",
"id": 46139490,
"node_id": "MDQ6VXNlcjQ2MTM5NDkw",
"avatar_url": "https://avatars.githubusercontent.com/u/46139490?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bladedsupernova",
"html_url": "https://github.com/bladedsupernova",
"followers_url": "https://api.github.com/users/bladedsupernova/followers",
"following_url": "https://api.github.com/users/bladedsupernova/following{/other_user}",
"gists_url": "https://api.github.com/users/bladedsupernova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bladedsupernova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bladedsupernova/subscriptions",
"organizations_url": "https://api.github.com/users/bladedsupernova/orgs",
"repos_url": "https://api.github.com/users/bladedsupernova/repos",
"events_url": "https://api.github.com/users/bladedsupernova/events{/privacy}",
"received_events_url": "https://api.github.com/users/bladedsupernova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I'm not sure I understand your question.\r\n\r\nBut one thing BERT can do is mask-answering indeed (guessing a word in the middle of a sentence).\r\n\r\nBERT is quite bad at doing sequence prediction at the end of an input because it's not trained on partial sentences.",
"When BERT fills-in a MASK, does it always use a answer it has seen or does it generalize and create never-seen Q-As? Ex. \"The *dog* in the hat, by Dr. Souse the Cat\"",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,555 | 1,561 | 1,561 | NONE | null | I'm working on a exciting project but need to know something fast.
I seen BERT adds a word at the end of your input, like sequence prediction, elongating your input text.
But I read that BERT has been trained at (and is a pro at) filling in the blank word mask, and in fact CANNOT do sequence prediction at the end of one's input (contradiction!!). When BERT adds a fill-in answer where the mask sits, it goes in context.
I want a tool that returns me a similar word in context (the mask ANSWER!!), but the colab tool I tried is not a mask/answer giver, ..it adds words at the endddd of my input lol!!! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/481/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/481/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/480 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/480/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/480/comments | https://api.github.com/repos/huggingface/transformers/issues/480/events | https://github.com/huggingface/transformers/pull/480 | 432,692,428 | MDExOlB1bGxSZXF1ZXN0MjcwMTExMzc3 | 480 | Extend the BertForSequenceClassification docs to mention the special CLS token. | {
"login": "mboyanov",
"id": 1610015,
"node_id": "MDQ6VXNlcjE2MTAwMTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1610015?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mboyanov",
"html_url": "https://github.com/mboyanov",
"followers_url": "https://api.github.com/users/mboyanov/followers",
"following_url": "https://api.github.com/users/mboyanov/following{/other_user}",
"gists_url": "https://api.github.com/users/mboyanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mboyanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mboyanov/subscriptions",
"organizations_url": "https://api.github.com/users/mboyanov/orgs",
"repos_url": "https://api.github.com/users/mboyanov/repos",
"events_url": "https://api.github.com/users/mboyanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/mboyanov/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Ok, let's go for that @mboyanov!",
"Great!"
] | 1,555 | 1,555 | 1,555 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/480/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/480/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/480",
"html_url": "https://github.com/huggingface/transformers/pull/480",
"diff_url": "https://github.com/huggingface/transformers/pull/480.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/480.patch",
"merged_at": 1555318645000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/479 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/479/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/479/comments | https://api.github.com/repos/huggingface/transformers/issues/479/events | https://github.com/huggingface/transformers/issues/479 | 432,688,857 | MDU6SXNzdWU0MzI2ODg4NTc= | 479 | Using GPT2 to implement GLTR | {
"login": "asad1996172",
"id": 19806866,
"node_id": "MDQ6VXNlcjE5ODA2ODY2",
"avatar_url": "https://avatars.githubusercontent.com/u/19806866?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/asad1996172",
"html_url": "https://github.com/asad1996172",
"followers_url": "https://api.github.com/users/asad1996172/followers",
"following_url": "https://api.github.com/users/asad1996172/following{/other_user}",
"gists_url": "https://api.github.com/users/asad1996172/gists{/gist_id}",
"starred_url": "https://api.github.com/users/asad1996172/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/asad1996172/subscriptions",
"organizations_url": "https://api.github.com/users/asad1996172/orgs",
"repos_url": "https://api.github.com/users/asad1996172/repos",
"events_url": "https://api.github.com/users/asad1996172/events{/privacy}",
"received_events_url": "https://api.github.com/users/asad1996172/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"the allen institute tool may help you....it has probabilities of next 10 words for when adding a next word....i think the prorbablities are shown....may just be the 10 words but the git code is available i think so may be what you want.",
"The output of `GPT2LMHeadModel` are logits so you can just apply a softmax (or log-softmax for log probabilities) on them to get probabilities for each token.\r\n\r\nThen if you want to get probabilities for words, you will need to multiply (or add if you used a log-softmax) the probabilities of the sub-words in each word.\r\n\r\nMaybe @sebastianGehrmann you have some additional insights (or plan to release the code of GLTR, it's a great demo!)?",
"Thanks for pinging me @thomwolf. GLTR actually uses this amazing repo in the backend, so you could just use our code in conjunction. \r\n\r\nWe are still working on the docu, but you can find all our code here: https://github.com/HendrikStrobelt/detecting-fake-text ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,555 | 1,561 | 1,561 | NONE | null | How can we use this GPT2 model to create the basic functionality of the GLTR tool?
Like getting probabilities for each word in a sequence.? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/479/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/479/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/478 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/478/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/478/comments | https://api.github.com/repos/huggingface/transformers/issues/478/events | https://github.com/huggingface/transformers/pull/478 | 432,587,116 | MDExOlB1bGxSZXF1ZXN0MjcwMDI4NDcx | 478 | Added a helpful error for users with single-document corpuses | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Looks good to me, thanks @Rocketknight1 "
] | 1,555 | 1,555 | 1,555 | MEMBER | null | This adds the helpful error message suggested in #452 for users trying to do language model fine-tuning with one long document as a corpus, and replaces some of the `randint()` calls with equivalent cleaner `randrange()` ones. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/478/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/478/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/478",
"html_url": "https://github.com/huggingface/transformers/pull/478",
"diff_url": "https://github.com/huggingface/transformers/pull/478.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/478.patch",
"merged_at": 1555318558000
} |
https://api.github.com/repos/huggingface/transformers/issues/477 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/477/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/477/comments | https://api.github.com/repos/huggingface/transformers/issues/477/events | https://github.com/huggingface/transformers/issues/477 | 432,435,797 | MDU6SXNzdWU0MzI0MzU3OTc= | 477 | Getting Sentence level log probabilities using this model | {
"login": "Shashi456",
"id": 18056781,
"node_id": "MDQ6VXNlcjE4MDU2Nzgx",
"avatar_url": "https://avatars.githubusercontent.com/u/18056781?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Shashi456",
"html_url": "https://github.com/Shashi456",
"followers_url": "https://api.github.com/users/Shashi456/followers",
"following_url": "https://api.github.com/users/Shashi456/following{/other_user}",
"gists_url": "https://api.github.com/users/Shashi456/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Shashi456/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shashi456/subscriptions",
"organizations_url": "https://api.github.com/users/Shashi456/orgs",
"repos_url": "https://api.github.com/users/Shashi456/repos",
"events_url": "https://api.github.com/users/Shashi456/events{/privacy}",
"received_events_url": "https://api.github.com/users/Shashi456/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"So p_M(S) is just the output of the model right?\r\n\r\nFor p_u(S), I think the easiest is probably to use the empirical probabilities.\r\n`TransfoXLTokenizer` has a counter to store words frequencies [here](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/pytorch_pretrained_bert/tokenization_transfo_xl.py#L98) which should be populated in the \"pretrained\" tokenizer so I would use and normalize this to get unconditional probabilities for each word and then compute SLOR.",
"@thomwolf So the code would look something like : \r\n```sentence = \"Where is the dog going\"\r\ns_ids = convert_sentence_to_ids(sentence)\r\nconfig = TransfoXLConfig()\r\nmodel = TransfoXLModel(config)\r\nlast_hidden_state, new_mems = model(input_ids)\r\nfor i in sentence : \r\n uni_prob = freq(token)/no_of_tokens\r\n sent_uni_prob * = uni_prob \r\nSLOR = (1/len(sentence))* last_hidden_state - sent_uni_prob \r\n```\r\n\r\nor am i mistaken about the idea that the last_hidden_state is the sentence probability i'm looking for",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"In case someone found this, I found an implementation that seems legit here https://github.com/sgondala/GoogleConceptualCaptioning/commit/981e1b61ca5f84052f6237402319714d7fe70b80."
] | 1,555 | 1,687 | 1,561 | NONE | null | So I was trying to implement the SLOR score, using the transformer-XL, mostly avoiding training. But given the XL model and the sentence, how could i go about getting the sentence level log probability?
Attached is the formula I'm trying to implement.

Thanks a lot for your help.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/477/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/477/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/476 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/476/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/476/comments | https://api.github.com/repos/huggingface/transformers/issues/476/events | https://github.com/huggingface/transformers/issues/476 | 432,372,999 | MDU6SXNzdWU0MzIzNzI5OTk= | 476 | cannot run squad script | {
"login": "jiahuigeng",
"id": 22496073,
"node_id": "MDQ6VXNlcjIyNDk2MDcz",
"avatar_url": "https://avatars.githubusercontent.com/u/22496073?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jiahuigeng",
"html_url": "https://github.com/jiahuigeng",
"followers_url": "https://api.github.com/users/jiahuigeng/followers",
"following_url": "https://api.github.com/users/jiahuigeng/following{/other_user}",
"gists_url": "https://api.github.com/users/jiahuigeng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jiahuigeng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jiahuigeng/subscriptions",
"organizations_url": "https://api.github.com/users/jiahuigeng/orgs",
"repos_url": "https://api.github.com/users/jiahuigeng/repos",
"events_url": "https://api.github.com/users/jiahuigeng/events{/privacy}",
"received_events_url": "https://api.github.com/users/jiahuigeng/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"What hardware are you using?\r\nWhat is your software configuration (versions of python, pytorch, pytorh-pretrained-bert, etc...)?",
"I'm not so sure that this is the same problem that I experienced.\r\n\r\nIf you installed apex, the problem may be related to BertLayerNorm, because BertLayerNorm will use FusedLayerNorm of apex library. Thus, if you disable to use FusedLayerNorm of apex library, then the segmentation fault will disappear.\r\n\r\nThe other solution is that you should reinstall apex. Please refer to https://github.com/NVIDIA/apex/issues/156#issuecomment-465301976.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@cartopy reinstall apex works well thx",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,555 | 1,567 | 1,567 | NONE | null | (g-torch) [bipkg@SVR16173HP380 examples]$ python run_squad.py --bert_model bert-base-uncased --train_file squad/train-v1.1.json --do_train --output_dir exps2
04/12/2019 11:32:03 - INFO - __main__ - device: cuda n_gpu: 1, distributed training: False, 16-bits training: False
04/12/2019 11:32:03 - WARNING - pytorch_pretrained_bert.tokenization - The pre-trained model you are loading is an uncased model but you have set `do_lower_case` to False. We are setting `do_lower_case=True` for you but you may want to check this behavior.
04/12/2019 11:32:05 - INFO - pytorch_pretrained_bert.tokenization - loading vocabulary file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt from cache at /home/bipkg/data/jgeng/Bert/pytorch_pretrained_bert/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084
04/12/2019 11:32:16 - INFO - pytorch_pretrained_bert.modeling - loading archive file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz from cache at /home/bipkg/data/jgeng/Bert/pytorch_pretrained_bert/distributed_-1/9c41111e2de84547a463fd39217199738d1e3deb72d4fec4399e6e241983c6f0.ae3cef932725ca7a30cdcb93fc6e09150a55e2a130ec7af63975a16c153ae2ba
04/12/2019 11:32:16 - INFO - pytorch_pretrained_bert.modeling - extracting archive file /home/bipkg/.pytorch_pretrained_bert/distributed_-1/9c41111e2de84547a463fd39217199738d1e3deb72d4fec4399e6e241983c6f0.ae3cef932725ca7a30cdcb93fc6e09150a55e2a130ec7af63975a16c153ae2ba to temp dir /tmp/tmpj0z3ai2_
04/12/2019 11:32:20 - INFO - pytorch_pretrained_bert.modeling - Model config {
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30522
}
04/12/2019 11:32:25 - INFO - pytorch_pretrained_bert.modeling - Weights of BertForQuestionAnswering not initialized from pretrained model: ['qa_outputs.weight', 'qa_outputs.bias']
04/12/2019 11:32:25 - INFO - pytorch_pretrained_bert.modeling - Weights from pretrained model not used in BertForQuestionAnswering: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias']
04/12/2019 11:32:42 - INFO - __main__ - ***** Running training *****
04/12/2019 11:32:42 - INFO - __main__ - Num orig examples = 87599
04/12/2019 11:32:42 - INFO - __main__ - Num split examples = 88641
04/12/2019 11:32:42 - INFO - __main__ - Batch size = 32
04/12/2019 11:32:42 - INFO - __main__ - Num steps = 8211
Epoch: 0%| | 0/3 [00:00<?, ?it/s]Segmentation fault (core dumped) | 0/2771 [00:00<?, ?it/s]
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/476/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/476/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/475 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/475/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/475/comments | https://api.github.com/repos/huggingface/transformers/issues/475/events | https://github.com/huggingface/transformers/issues/475 | 432,341,853 | MDU6SXNzdWU0MzIzNDE4NTM= | 475 | Non-Determinism Behavior that cannot reproduce result when evaluate on each epoch | {
"login": "Jacob-Ma",
"id": 46578842,
"node_id": "MDQ6VXNlcjQ2NTc4ODQy",
"avatar_url": "https://avatars.githubusercontent.com/u/46578842?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Jacob-Ma",
"html_url": "https://github.com/Jacob-Ma",
"followers_url": "https://api.github.com/users/Jacob-Ma/followers",
"following_url": "https://api.github.com/users/Jacob-Ma/following{/other_user}",
"gists_url": "https://api.github.com/users/Jacob-Ma/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Jacob-Ma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jacob-Ma/subscriptions",
"organizations_url": "https://api.github.com/users/Jacob-Ma/orgs",
"repos_url": "https://api.github.com/users/Jacob-Ma/repos",
"events_url": "https://api.github.com/users/Jacob-Ma/events{/privacy}",
"received_events_url": "https://api.github.com/users/Jacob-Ma/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649053,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Help%20wanted",
"name": "Help wanted",
"color": "008672",
"default": false,
"description": "Extra attention is needed, help appreciated"
},
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
}
] | closed | false | null | [] | [
"There is some non-determinism in cuDNN. Try setting `torch.backends.cudnn.deterministic = True` in your code: with that plus the RNG seeding, you should be able to get deterministic results.",
"Yes go with @Rocketknight1 suggestion.\r\nAlso check that you set model in eval mode to disable the DropOut modules before evaluating.",
"Hi, thank you for you guys reply. \r\nI simplify the model to a simple MNIST problem to check if there are similar phenomena.\r\nI also posted in pytorch/examples github, but no one replies. I found that it seems that it is PyTorch's problem. \r\n\r\nCould you please take a look at these posts?\r\n\r\n[mnist](https://github.com/pytorch/examples/issues/542), in these post, Yes, you are right `torch.backends.cudnn.deterministic = True` could bring some consistency to the result. \r\n\r\nHowever, even though you set `torch.backends.cudnn.deterministic = True`, STILL, when you compare evaluate at each epoch and only make final evaluation gives different results, you could see in this post:\r\n[minis final evaluation VS evaluation each epoch](https://github.com/pytorch/examples/issues/543)\r\n\r\nWhat would you think? Is it indeed pyTorch's problem? I have code attached in the post for your convenience to run. Thank you very much.\r\n\r\n",
"> There is some non-determinism in cuDNN. Try setting `torch.backends.cudnn.deterministic = True` in your code: with that plus the RNG seeding, you should be able to get deterministic results.\r\n\r\nHi, thank you for your reply, when I post this issue, I have searched a lot. In the code I have already set the random seeding like this:\r\n```\r\nuse_cuda = not args.no_cuda and torch.cuda.is_available()\r\n\r\n# set seed\r\nrandom.seed(args.seed)\r\nnp.random.seed(args.seed)\r\ntorch.manual_seed(args.seed)\r\nif use_cuda:\r\n torch.cuda.manual_seed_all(args.seed) # if got GPU also set this seed\r\n```\r\nand also put `torch.backends.cudnn.deterministic = True` at the front of the script. \r\n\r\nBut the behavior is still the same.\r\n\r\nWhat do you think of this mystic difference?\r\nMy this post shows the detail and have code attached to have a try:\r\n[minis final evaluation VS evaluation each epoch](https://github.com/pytorch/examples/issues/543)\r\n",
"> Yes go with @Rocketknight1 suggestion.\r\n> Also check that you set model in eval mode to disable the DropOut modules before evaluating.\r\n\r\nThank you for your reply. \r\nI have checked that, in my original code. \r\nIn train() and test() fuction, I already set model.train() and model.eval() respectively. \r\n\r\nBut the behavior is still the same. \r\nWhat do you think of this mystic difference?\r\n\r\nMy this post shows the detail and have code attached to have a try:\r\n[minis final evaluation VS evaluation each epoch](https://github.com/pytorch/examples/issues/543)",
"This is really a PyTorch/CUDA issue rather than an issue with this repo, but there is more information here: https://pytorch.org/docs/stable/notes/randomness.html\r\n\r\nYou can also try setting `torch.backends.cudnn.benchmark = False`",
"@Rocketknight1 \r\nThank you for your reply. \r\nI also tried to add `torch.backends.cudnn.benchmark=False`, the behavior is still the same as above.\r\nYeah, it seems to be a PyTorch problem. \r\n",
"The #question channel on the PyTorch slack is a good place to get quick answers on these stuff.\r\nPyTorch's forum is also great."
] | 1,555 | 1,556 | 1,556 | NONE | null | I modified the example file `run_classifier.py` a little bit, so that the model could evaluate after each training epoch and save each evaluation results on file. This is good for someone who wants to see how the training epoch number influence the result. It is good to simply set the train_epoch = 50, save a checkpoint model on after each epoch so that you could choose the best model for testing data, based on the evalution results on dev dataset.
The strange phenomena and my question:
(1) even though the seed is correctly set for both Numpy and PyTorch, when evaluating on each step, the result is different from when I only have the final evaluation.
(2) set the training epoch to a different number, say epoch 3 and epoch 10. The intermediate result of epoch 10 on step 3, is different from the epoch 3 results.
(3) In the code I found that `num_train_optimization_steps = int(len(train_examples) / args.train_batch_size / args.gradient_accumulation_steps) * args.num_train_epochs`.
When `args.gradient_accumulation_steps=1, args.num_train_epochs=1`, let's simply it into `num_train_optimization_steps = int(len(train_examples) / args.train_batch_size))`.
I think it should be `num_train_optimization_steps = int((len(train_examples) - 1) / args.train_batch_size) + 1`. If train_examples == 99, train_batch_size=32, it will gives different result. Does it matters in the original code, it is passed into `BertAdam()`?
Could you guys have a try and see what's wrong with my code and what cause the problem?
Thank you very much.
Here is the modified example code and run_script are in the attachment.
### results:
#### [a] should be exactly the same
#### [b] should be exactly the same
=======
epoch 3
final evaluation:
{'eval_loss': 0.7023529836109706, 'eval_accuracy': 0.44, 'train_loss': 0.6765455901622772, 'global_step': 6} ==> [a]
epoch 3
evaluation every epoch:
{'eval_loss': 0.6758423532758441, 'eval_accuracy': 0.6, 'train_loss': 0.8333011567592621, 'global_step': 2}
{'eval_loss': 0.6573205164500645, 'eval_accuracy': 0.58, 'train_loss': 0.7199544608592987, 'global_step': 4}
{'eval_loss': 0.662639707326889, 'eval_accuracy': 0.58, 'train_loss': 0.70155930519104, 'global_step': 6} ==> [a]
epoch 10
final evaluation:
{'eval_loss': 0.8280548453330994, 'eval_accuracy': 0.58, 'train_loss': 0.8153044879436493, 'global_step': 20} ==> [b]
epoch 10
evaluation every epoch:
{'eval_loss': 0.6604576451437814, 'eval_accuracy': 0.58, 'train_loss': 0.8333011567592621, 'global_step': 2}
{'eval_loss': 0.6526826364653451, 'eval_accuracy': 0.58, 'train_loss': 0.8114463090896606, 'global_step': 4}
{'eval_loss': 0.6567909887858799, 'eval_accuracy': 0.58, 'train_loss': 0.6695355176925659, 'global_step': 6} ==> [a]
{'eval_loss': 0.6620746084621975, 'eval_accuracy': 0.62, 'train_loss': 0.6175626814365387, 'global_step': 8}
{'eval_loss': 0.6602040699550084, 'eval_accuracy': 0.52, 'train_loss': 0.5784901082515717, 'global_step': 10}
{'eval_loss': 0.667422890663147, 'eval_accuracy': 0.54, 'train_loss': 0.5177579522132874, 'global_step': 12}
{'eval_loss': 0.6945722614015851, 'eval_accuracy': 0.52, 'train_loss': 0.5649124383926392, 'global_step': 14}
{'eval_loss': 0.7062868390764508, 'eval_accuracy': 0.48, 'train_loss': 0.7067148089408875, 'global_step': 16}
{'eval_loss': 0.7712458883013044, 'eval_accuracy': 0.46, 'train_loss': 0.7441326081752777, 'global_step': 18}
{'eval_loss': 1.5845262237957545, 'eval_accuracy': 0.42, 'train_loss': 1.0378091633319855, 'global_step': 20} ==> [b]
### run the bash script the second time, it is the same as the previous result.
It is deterministic somehow(the result for final evaluation is the same as the final evaluation for the previous run. So as to eval_on_each_epoch), but the difference because of train_epoch num is the same.
epoch 3
final evaluation
{'eval_loss': 0.7023529836109706, 'eval_accuracy': 0.44, 'train_loss': 0.6765455901622772, 'global_step': 6}
epoch 3
evaluation every epoch
{'eval_loss': 0.6758423532758441, 'eval_accuracy': 0.6, 'train_loss': 0.8333011567592621, 'global_step': 2}
{'eval_loss': 0.6573205164500645, 'eval_accuracy': 0.58, 'train_loss': 0.7199544608592987, 'global_step': 4}
{'eval_loss': 0.662639707326889, 'eval_accuracy': 0.58, 'train_loss': 0.70155930519104, 'global_step': 6}
epoch 10
final evaluation
{'eval_loss': 0.8280548453330994, 'eval_accuracy': 0.58, 'train_loss': 0.8153044879436493, 'global_step': 20}
epoch 10
evaluation each step
{'eval_loss': 0.6604576451437814, 'eval_accuracy': 0.58, 'train_loss': 0.8333011567592621, 'global_step': 2}
{'eval_loss': 0.6526826364653451, 'eval_accuracy': 0.58, 'train_loss': 0.8114463090896606, 'global_step': 4}
{'eval_loss': 0.6567909887858799, 'eval_accuracy': 0.58, 'train_loss': 0.6695355176925659, 'global_step': 6}
{'eval_loss': 0.6620746084621975, 'eval_accuracy': 0.62, 'train_loss': 0.6175626814365387, 'global_step': 8}
{'eval_loss': 0.6602040699550084, 'eval_accuracy': 0.52, 'train_loss': 0.5784901082515717, 'global_step': 10}
{'eval_loss': 0.667422890663147, 'eval_accuracy': 0.54, 'train_loss': 0.5177579522132874, 'global_step': 12}
{'eval_loss': 0.6945722614015851, 'eval_accuracy': 0.52, 'train_loss': 0.5649124383926392, 'global_step': 14}
{'eval_loss': 0.7062868390764508, 'eval_accuracy': 0.48, 'train_loss': 0.7067148089408875, 'global_step': 16}
{'eval_loss': 0.7712458883013044, 'eval_accuracy': 0.46, 'train_loss': 0.7441326081752777, 'global_step': 18}
{'eval_loss': 1.5845262237957545, 'eval_accuracy': 0.42, 'train_loss': 1.0378091633319855, 'global_step': 20}
Repeatability is crucial in machine learning, please help with this issue. Thank you very much.
The code sample dataset is here for SST tasks:
[huggingface_bert_issue2.zip](https://github.com/huggingface/pytorch-pretrained-BERT/files/3077188/huggingface_bert_issue2.zip)
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/475/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/475/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/474 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/474/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/474/comments | https://api.github.com/repos/huggingface/transformers/issues/474/events | https://github.com/huggingface/transformers/pull/474 | 432,218,030 | MDExOlB1bGxSZXF1ZXN0MjY5NzMyMTY1 | 474 | Fix tsv read error in Windows | {
"login": "jiesutd",
"id": 9111828,
"node_id": "MDQ6VXNlcjkxMTE4Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/9111828?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jiesutd",
"html_url": "https://github.com/jiesutd",
"followers_url": "https://api.github.com/users/jiesutd/followers",
"following_url": "https://api.github.com/users/jiesutd/following{/other_user}",
"gists_url": "https://api.github.com/users/jiesutd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jiesutd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jiesutd/subscriptions",
"organizations_url": "https://api.github.com/users/jiesutd/orgs",
"repos_url": "https://api.github.com/users/jiesutd/repos",
"events_url": "https://api.github.com/users/jiesutd/events{/privacy}",
"received_events_url": "https://api.github.com/users/jiesutd/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Ok, thanks @jiesutd!"
] | 1,555 | 1,555 | 1,555 | CONTRIBUTOR | null | The initial version suffers from the error of `UnicodeDecodeError: 'charmap' codec can't decode byte 0x90 in position` when loading the `.tsv` filein **Windows** System, as indicated in https://github.com/huggingface/pytorch-pretrained-BERT/issues/52
It is solved by adding `encoding='utf-8'` when reading the `.tsv` file.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/474/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/474/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/474",
"html_url": "https://github.com/huggingface/transformers/pull/474",
"diff_url": "https://github.com/huggingface/transformers/pull/474.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/474.patch",
"merged_at": 1555318609000
} |
https://api.github.com/repos/huggingface/transformers/issues/473 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/473/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/473/comments | https://api.github.com/repos/huggingface/transformers/issues/473/events | https://github.com/huggingface/transformers/issues/473 | 432,162,932 | MDU6SXNzdWU0MzIxNjI5MzI= | 473 | GPT as a Language Model | {
"login": "mdasadul",
"id": 8009589,
"node_id": "MDQ6VXNlcjgwMDk1ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8009589?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mdasadul",
"html_url": "https://github.com/mdasadul",
"followers_url": "https://api.github.com/users/mdasadul/followers",
"following_url": "https://api.github.com/users/mdasadul/following{/other_user}",
"gists_url": "https://api.github.com/users/mdasadul/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mdasadul/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mdasadul/subscriptions",
"organizations_url": "https://api.github.com/users/mdasadul/orgs",
"repos_url": "https://api.github.com/users/mdasadul/repos",
"events_url": "https://api.github.com/users/mdasadul/events{/privacy}",
"received_events_url": "https://api.github.com/users/mdasadul/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Looks good to me. It's perplexity so lower is better.\r\nYou can do a `math.exp(loss.item())` and call you model in a `with torch.no_grad()` context to be a little cleaner.",
"Oh no wait, you need to compare to the shifted inputs:\r\n`loss=model(tensor_input[:-1], lm_labels=tensor_input[1:])`\r\nIt's a causal model, it predicts the next token given the previous ones.",
"I can see inside the ```class OpenAIGPTLMHeadModel(OpenAIGPTPreTrainedModel)``` this shifting is happening \r\n``` if lm_labels is not None:\r\n # Shift so that tokens < n predict n\r\n shift_logits = lm_logits[:, :-1].contiguous()\r\n shift_labels = lm_labels[:, 1:].contiguous()\r\n```\r\n\r\nDo I still need to use \r\n ```loss=model(tensor_input[:-1], lm_labels=tensor_input[1:])```",
"Oh you are right, this has been added now with #404.\r\nSo the way you are doing looks fine to me.\r\nShifting the logics inside the model can a bit dangerous for the people who are used to train a causal model the usual way, I'll add a mention in the README.",
"Thanks for your quick response. I can see there is a minor bug when I am trying to predict with a sentence which has one word. You can re create the error by using my above code.\r\n```\r\nsentence='Learn'\r\nscore(sentence)\r\n```",
"Unfortunately, given the way the model is trained (without using a token indicating the beginning of a sentence), I would say it does not make sense to try to get a score for a sentence with only one word.",
"How can we use this to get the probability of a particular token? So, for instance, let's say we have the following sentence. \r\n\"He was going home\"\r\nand we want to get the probability of \"home\" given the context \"he was going\"\r\nlike in GLTR tool by harvard nlp @thomwolf ",
"@thomwolf If the shifting of the lm_labels matrix isn't necessary (before passing into the model's forward method) because of the internal logit shifting, should the preprocess code for finetuning GPT1 in RocStories be changed? At [https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_openai_gpt.py#L86](url), I believe the continuations are shifted over in lm_labels one relative to input_ids.",
"Oh yes, of course! Do you want to submit a PR on that? Otherwise I'll take of it later.",
"For sure! Will look at it soon.\n\nOn Thu, Apr 25, 2019 at 11:33 PM Thomas Wolf <[email protected]>\nwrote:\n\n> Oh yes, of course! Do you want to submit a PR on that? Otherwise I'll take\n> of it later.\n>\n> —\n> You are receiving this because you commented.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/pytorch-pretrained-BERT/issues/473#issuecomment-486942939>,\n> or mute the thread\n> <https://github.com/notifications/unsubscribe-auth/AC6UQICJ3ROXNOJXROIKYN3PSKO4LANCNFSM4HFJZIVQ>\n> .\n>\n",
"@thomwolf Hey how can I give my own checkpoint files to the model while loading\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Is this score normalized on sentence lenght? And if not, what do I need to change to normalize it? \r\n",
"I'm confused whether the right way to calculate the perplexity for GPT2 is what the OP has done or as per the documentation https://huggingface.co./transformers/perplexity.html? Or both are equivalent for some value of the stride?"
] | 1,555 | 1,623 | 1,563 | NONE | null | I am interested to use GPT as Language Model to assign Language modeling score (Perplexity score) of a sentence. Here is what I am using
```import torch
import math
from pytorch_pretrained_bert import OpenAIGPTTokenizer, OpenAIGPTModel, OpenAIGPTLMHeadModel
# Load pre-trained model (weights)
model = OpenAIGPTLMHeadModel.from_pretrained('openai-gpt')
model.eval()
# Load pre-trained model tokenizer (vocabulary)
tokenizer = OpenAIGPTTokenizer.from_pretrained('openai-gpt')
def score(sentence):
tokenize_input = tokenizer.tokenize(sentence)
tensor_input = torch.tensor([tokenizer.convert_tokens_to_ids(tokenize_input)])
loss=model(tensor_input, lm_labels=tensor_input)
return math.exp(loss)
a=['there is a book on the desk',
'there is a plane on the desk',
'there is a book in the desk']
print([score(i) for i in a])
21.31652459381952, 61.45907380241148, 26.24923942649312
```
Is it the right way to score a sentence ?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/473/reactions",
"total_count": 30,
"+1": 29,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/473/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/472 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/472/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/472/comments | https://api.github.com/repos/huggingface/transformers/issues/472/events | https://github.com/huggingface/transformers/issues/472 | 431,935,327 | MDU6SXNzdWU0MzE5MzUzMjc= | 472 | Compilation terminated | {
"login": "hongkahjun",
"id": 29894605,
"node_id": "MDQ6VXNlcjI5ODk0NjA1",
"avatar_url": "https://avatars.githubusercontent.com/u/29894605?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hongkahjun",
"html_url": "https://github.com/hongkahjun",
"followers_url": "https://api.github.com/users/hongkahjun/followers",
"following_url": "https://api.github.com/users/hongkahjun/following{/other_user}",
"gists_url": "https://api.github.com/users/hongkahjun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hongkahjun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hongkahjun/subscriptions",
"organizations_url": "https://api.github.com/users/hongkahjun/orgs",
"repos_url": "https://api.github.com/users/hongkahjun/repos",
"events_url": "https://api.github.com/users/hongkahjun/events{/privacy}",
"received_events_url": "https://api.github.com/users/hongkahjun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"managed to install it by running \r\n\r\n> sudo apt-get install python3 python-dev"
] | 1,554 | 1,554 | 1,554 | NONE | null | Hi,
I cannot pip install the package. I have
> regex_3/_regex.c:48:10: fatal error: Python.h: No such file or directory
#include "Python.h"
^~~~~~~~~~
compilation terminated.
error: command 'x86_64-linux-gnu-gcc' failed with exit status 1
Might have something to do with CI failure for the new merge. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/472/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/472/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/471 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/471/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/471/comments | https://api.github.com/repos/huggingface/transformers/issues/471/events | https://github.com/huggingface/transformers/issues/471 | 431,881,640 | MDU6SXNzdWU0MzE4ODE2NDA= | 471 | modeling_openai.py bug report | {
"login": "Jonbean",
"id": 10235447,
"node_id": "MDQ6VXNlcjEwMjM1NDQ3",
"avatar_url": "https://avatars.githubusercontent.com/u/10235447?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Jonbean",
"html_url": "https://github.com/Jonbean",
"followers_url": "https://api.github.com/users/Jonbean/followers",
"following_url": "https://api.github.com/users/Jonbean/following{/other_user}",
"gists_url": "https://api.github.com/users/Jonbean/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Jonbean/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jonbean/subscriptions",
"organizations_url": "https://api.github.com/users/Jonbean/orgs",
"repos_url": "https://api.github.com/users/Jonbean/repos",
"events_url": "https://api.github.com/users/Jonbean/events{/privacy}",
"received_events_url": "https://api.github.com/users/Jonbean/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Good catch, I'll fix this."
] | 1,554 | 1,554 | 1,554 | NONE | null | line 651 has a potential bug
``` # Copy word and positional embeddings from the previous weights
self.tokens_embed.weight.data[: self.config.vocab_size, :] = old_embed.weight.data[: self.config.vocab_size, :]
self.tokens_embed.weight.data[-self.config.n_positions :, :] = old_embed.weight.data[-self.config.n_positions :, :]
```
isn't it supposed to be `self.positions_embed ` instead of `self.tokens_embed` ? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/471/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/471/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/470 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/470/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/470/comments | https://api.github.com/repos/huggingface/transformers/issues/470/events | https://github.com/huggingface/transformers/issues/470 | 431,639,901 | MDU6SXNzdWU0MzE2Mzk5MDE= | 470 | how to correctly do classifying? | {
"login": "junchen14",
"id": 19342556,
"node_id": "MDQ6VXNlcjE5MzQyNTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/19342556?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/junchen14",
"html_url": "https://github.com/junchen14",
"followers_url": "https://api.github.com/users/junchen14/followers",
"following_url": "https://api.github.com/users/junchen14/following{/other_user}",
"gists_url": "https://api.github.com/users/junchen14/gists{/gist_id}",
"starred_url": "https://api.github.com/users/junchen14/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/junchen14/subscriptions",
"organizations_url": "https://api.github.com/users/junchen14/orgs",
"repos_url": "https://api.github.com/users/junchen14/repos",
"events_url": "https://api.github.com/users/junchen14/events{/privacy}",
"received_events_url": "https://api.github.com/users/junchen14/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649053,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Help%20wanted",
"name": "Help wanted",
"color": "008672",
"default": false,
"description": "Extra attention is needed, help appreciated"
},
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
},
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"I'm having a similar issue where I run a BERT tutorial by Chris McCormick and receive 65-78% accuracy on training data and 0.0% for test data. Was anyone able to diagnose a result of 0.0%? One theory I have is a division by zero error for very small numbers that are rounded to zero..."
] | 1,554 | 1,568 | 1,560 | NONE | null | when I do the classifying with task cola, the result is like this?
eval_loss = 0.0
global_step = 49173
loss = 0.0
mcc = 0.0
what is my prediction result?
and how should I use the output model????
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/470/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/470/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/469 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/469/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/469/comments | https://api.github.com/repos/huggingface/transformers/issues/469/events | https://github.com/huggingface/transformers/issues/469 | 431,615,901 | MDU6SXNzdWU0MzE2MTU5MDE= | 469 | Why can`t we just use cached pytorch-model without internet | {
"login": "floAlpha",
"id": 21286485,
"node_id": "MDQ6VXNlcjIxMjg2NDg1",
"avatar_url": "https://avatars.githubusercontent.com/u/21286485?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/floAlpha",
"html_url": "https://github.com/floAlpha",
"followers_url": "https://api.github.com/users/floAlpha/followers",
"following_url": "https://api.github.com/users/floAlpha/following{/other_user}",
"gists_url": "https://api.github.com/users/floAlpha/gists{/gist_id}",
"starred_url": "https://api.github.com/users/floAlpha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/floAlpha/subscriptions",
"organizations_url": "https://api.github.com/users/floAlpha/orgs",
"repos_url": "https://api.github.com/users/floAlpha/repos",
"events_url": "https://api.github.com/users/floAlpha/events{/privacy}",
"received_events_url": "https://api.github.com/users/floAlpha/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"First, yes you can. You should be able to download the model(whether use shell command or python downloader) into a specified directory and modify the loading lines. That works for me. \r\nSecond, please be appreciated to these fantastic works huggingface team pulled off. It's not their fault that you don't have stable access, so help yourself.",
"Humm wording apart, maybe we could relax the internet connection check indeed, I'll have a look.",
"Sincerely thank you for your reply, you are the great contributors, I apologize again for my inappropriate expression, mainly because I can`t properly solve the problem till midnight. I just want to make my own suggestion for people encountered this like me, so I opened this issue. Actually I am very grateful for your work, and appreciate the open source community. Best regards!",
"Ok, network connection check has been relaxed in the now merged #500.\r\nIt will be included in the next PyPI release (probably next week).\r\nIn the meantime you can install from `master`.",
"So nice you are,I cannot continue my research without pytorch-pretrained-BERT,Thank you for your Incredible devotion.With my sincere apology.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,581 | 1,561 | NONE | null | Sorry for my Impolite words. I am very appreciate huggingface team for the excellent repo and
my original intention is to provide some suggestion to great repo to help more people like me, forgive me for being rude. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/469/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/469/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/468 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/468/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/468/comments | https://api.github.com/repos/huggingface/transformers/issues/468/events | https://github.com/huggingface/transformers/issues/468 | 431,358,967 | MDU6SXNzdWU0MzEzNTg5Njc= | 468 | GPT-2 fine tunning | {
"login": "Jonbean",
"id": 10235447,
"node_id": "MDQ6VXNlcjEwMjM1NDQ3",
"avatar_url": "https://avatars.githubusercontent.com/u/10235447?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Jonbean",
"html_url": "https://github.com/Jonbean",
"followers_url": "https://api.github.com/users/Jonbean/followers",
"following_url": "https://api.github.com/users/Jonbean/following{/other_user}",
"gists_url": "https://api.github.com/users/Jonbean/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Jonbean/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jonbean/subscriptions",
"organizations_url": "https://api.github.com/users/Jonbean/orgs",
"repos_url": "https://api.github.com/users/Jonbean/repos",
"events_url": "https://api.github.com/users/Jonbean/events{/privacy}",
"received_events_url": "https://api.github.com/users/Jonbean/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"What kind of task are you fine-tuning on? I If it's something like ROCstories task, you need the extra tokens. I think people are doing BERT for up-stream tasks because birectional context gives better results than left-to-right",
"Hi @yaroslavvb, I am mostly focusing on classification tasks(like ROCstories as you mentioned). I just want to confirm that the special tokens used by GPT and GPT2 should be treated the same(add to the end of the vocabulary and feed in along with the original text). \r\n\r\nWe would like to run both BERT and GPT2 which are the two SOTA models, since they shine in different ways. \r\n\r\nI will be happy to submit a pull request if this is a valid extension to the code base or if anyone is interested. ",
"Indeed we should probably add additional embeddings for GPT-2 also.\r\nI'll give it a look, should be pretty easy to add.",
"I just tried implementing the changes suggested in order to make gpt-2 amenable to being finetuned on the Cloze Story Task from ROCStories. However, my eval-accuracy seems to be topping out at 68%. Is this what others are getting?",
"I also want to fine tune gpt-2 for qa and run it on squad. I am new to the field. Should I be following BertForQuestionAnswering and run BERT or SQuAD as a model to do the same for gpt-2? ",
"Hi @rohuns, I met the same situation, the performance of the pre-trained GPT-2 with extra task head is poor on both ROC and sts. I don't truly know the reason. \r\nMy hypothesis is GPT-2 was not trained in the same \"multi-task\" fashion as the GPT1, therefore adding the special token will destroy the model or at least having hard time generating good representation for the sentence for the downstream tasks. \r\nI hope someone can get the fine-tuning work to disprove the above hypothesis. \r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,561 | 1,561 | NONE | null | I wonder if GPT-2 model has some examples of how to do fine tuning like GPT. The DoubleHeadsModel interface of GPT-2 looks similar to GPT. But there's no special token handler for GPT-2 tokenizer. Is that necessary? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/468/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/468/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/467 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/467/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/467/comments | https://api.github.com/repos/huggingface/transformers/issues/467/events | https://github.com/huggingface/transformers/pull/467 | 431,210,818 | MDExOlB1bGxSZXF1ZXN0MjY4OTM2NDAw | 467 | Update README.md | {
"login": "yaroslavvb",
"id": 23068,
"node_id": "MDQ6VXNlcjIzMDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/23068?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yaroslavvb",
"html_url": "https://github.com/yaroslavvb",
"followers_url": "https://api.github.com/users/yaroslavvb/followers",
"following_url": "https://api.github.com/users/yaroslavvb/following{/other_user}",
"gists_url": "https://api.github.com/users/yaroslavvb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yaroslavvb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yaroslavvb/subscriptions",
"organizations_url": "https://api.github.com/users/yaroslavvb/orgs",
"repos_url": "https://api.github.com/users/yaroslavvb/repos",
"events_url": "https://api.github.com/users/yaroslavvb/events{/privacy}",
"received_events_url": "https://api.github.com/users/yaroslavvb/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks Yaroslav!"
] | 1,554 | 1,555 | 1,555 | CONTRIBUTOR | null | Fix for
```> > > > 04/09/2019 21:39:38 - INFO - __main__ - device: cuda n_gpu: 1, distributed training: False, 16-bits training: False
Traceback (most recent call last):
File "/home/ubuntu/pytorch-pretrained-BERT/examples/lm_finetuning/simple_lm_finetuning.py", line 642, in <module>
main()
File "/home/ubuntu/pytorch-pretrained-BERT/examples/lm_finetuning/simple_lm_finetuning.py", line 502, in main
raise ValueError("Training is currently the only implemented execution option. Please set `do_train`.")
ValueError: Training is currently the only implemented execution option. Please set `do_train`.
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/467/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/467/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/467",
"html_url": "https://github.com/huggingface/transformers/pull/467",
"diff_url": "https://github.com/huggingface/transformers/pull/467.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/467.patch",
"merged_at": 1555012404000
} |
https://api.github.com/repos/huggingface/transformers/issues/466 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/466/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/466/comments | https://api.github.com/repos/huggingface/transformers/issues/466/events | https://github.com/huggingface/transformers/issues/466 | 431,172,085 | MDU6SXNzdWU0MzExNzIwODU= | 466 | Mismatch in pre-processed wikitext-103 corpus and using pre-trained tokenizer for TransfoXLLMHeadModel | {
"login": "Akhila-Yerukola",
"id": 4477323,
"node_id": "MDQ6VXNlcjQ0NzczMjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/4477323?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Akhila-Yerukola",
"html_url": "https://github.com/Akhila-Yerukola",
"followers_url": "https://api.github.com/users/Akhila-Yerukola/followers",
"following_url": "https://api.github.com/users/Akhila-Yerukola/following{/other_user}",
"gists_url": "https://api.github.com/users/Akhila-Yerukola/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Akhila-Yerukola/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Akhila-Yerukola/subscriptions",
"organizations_url": "https://api.github.com/users/Akhila-Yerukola/orgs",
"repos_url": "https://api.github.com/users/Akhila-Yerukola/repos",
"events_url": "https://api.github.com/users/Akhila-Yerukola/events{/privacy}",
"received_events_url": "https://api.github.com/users/Akhila-Yerukola/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You are right, thanks for catching this.\r\n\r\nThis behavior is inherited from the BERT Tokenizer but the TransformerXL Tokenizer should behave differently ([this line](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/pytorch_pretrained_bert/tokenization_transfo_xl.py#L316) which split on punctuation is not present in the original tokenizer of Transformer XL [here](https://github.com/kimiyoung/transformer-xl/blob/master/tf/vocabulary.py#L25-L42)).\r\n\r\nI'll check there no other differences, add a test on this and fix this in the next release.",
"@thomwolf Hello thomwolf, first of all very ty for your library. I'm reproducing transformer-xl benchmark performance using hugginface Tokenizer, but I think there is still mismatch. I just want to ask you if its solved.\r\ni would very much appreciated if you reply this :) "
] | 1,554 | 1,637 | 1,555 | NONE | null | In `examples/run_transfo_xl.py`, the pre-processed wikitext-103 corpus is loaded using:
`corpus` = TransfoXLCorpus.from_pretrained(args.model_name)
`
Example of pre-processed batch converted to tokens:
> ['<eos>', '=', 'Homarus', 'gammarus', '=', '<eos>', '<eos>', 'Homarus', 'gammarus', ',', 'known', 'as', 'the', 'European', 'lobster', 'or', 'common', 'lobster', ',', 'is', 'a', 'species', 'of', 'clawed', 'lobster', 'from', 'the', 'eastern', 'Atlantic', 'Ocean', ',', 'Mediterranean', 'Sea', 'and', 'parts', 'of', 'the', 'Black', 'Sea', '.', 'It', 'is', 'closely', 'related', 'to', 'the', 'American', 'lobster', ',', 'H.', 'americanus', '.', 'It', 'may', 'grow', 'to', 'a', 'length', 'of', '60']
Evaluating the TransfoXLLMHeadModel model on this corpus gives a ppl of ~18.
However when I use the pre-trained `TransfoXLTokenizer` for wikitext-103 using:
`tokenizer = TransfoXLTokenizer.from_pretrained('transfo-xl-wt103')`,
there is a mismatch in the tokenizations.
Example of using pre-trained tokenizer to tokenize wikitext-103:
> ['<eos>', '=', 'Homarus', 'gammarus', '=', '<eos>', '<eos>', 'Homarus', 'gammarus', ',', 'known', 'as', 'the', 'European', 'lobster', 'or', 'common', 'lobster', ',', 'is', 'a', 'species', 'of', 'clawed', 'lobster', 'from', 'the', 'eastern', 'Atlantic', 'Ocean', ',', 'Mediterranean', 'Sea', 'and', 'parts', 'of', 'the', 'Black', 'Sea', '.', 'It', 'is', 'closely', 'related', 'to', 'the', 'American', 'lobster', ',', 'H', '.', 'americanus', '.', 'It', 'may', 'grow', 'to', 'a', 'length', 'of']
Here, `H.` is being split, whereas the pre-processed version has it as a single token.
Evaluating the TransfoXLLMHeadModel model on this version of the corpus gives a ppl of ~29.
Could you please help me understand why there is a mismatch?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/466/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/466/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/465 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/465/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/465/comments | https://api.github.com/repos/huggingface/transformers/issues/465/events | https://github.com/huggingface/transformers/issues/465 | 431,026,223 | MDU6SXNzdWU0MzEwMjYyMjM= | 465 | Errors when using Apex | {
"login": "ibeltagy",
"id": 2287797,
"node_id": "MDQ6VXNlcjIyODc3OTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2287797?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ibeltagy",
"html_url": "https://github.com/ibeltagy",
"followers_url": "https://api.github.com/users/ibeltagy/followers",
"following_url": "https://api.github.com/users/ibeltagy/following{/other_user}",
"gists_url": "https://api.github.com/users/ibeltagy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ibeltagy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ibeltagy/subscriptions",
"organizations_url": "https://api.github.com/users/ibeltagy/orgs",
"repos_url": "https://api.github.com/users/ibeltagy/repos",
"events_url": "https://api.github.com/users/ibeltagy/events{/privacy}",
"received_events_url": "https://api.github.com/users/ibeltagy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649053,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Help%20wanted",
"name": "Help wanted",
"color": "008672",
"default": false,
"description": "Extra attention is needed, help appreciated"
},
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Can you try to run it with `CUDA_LAUNCH_BLOCKING=1` so we can see which exact CUDA call fails?\r\nAlso, do you have a simple way for me to try to reproduce this error?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,560 | 1,560 | CONTRIBUTOR | null | Using `pytorch-pretrained-BERT` with `apex` installed breaks with the errors below. I am using it through allennlp, and my environment settings are:
```
ubuntu 16.04
nvidia driver 410.48
4 Titan V gpus
python 3.6.8
cuda 9
pytorch 1.0.1.post2
pytorch-pretrained-bert 0.6.1
```
I also tried python 3.7, cuda 10 and nvidia driver 390 with the same errors.
At training time, the crashes from the first batch with the following error:
```
File "/home/beltagy/miniconda3/lib/python3.7/site-packages/allennlp/modules/text_field_embedders/basic_text_field_embedder.py", line 110, in forward
token_vectors = embedder(*tensors)
File "/home/beltagy/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/lib/python3.7/site-packages/allennlp/modules/token_embedders/bert_token_embedder.py", line 91, in forward
attention_mask=util.combine_initial_dims(input_mask))
File "/home/beltagy/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/lib/python3.7/site-packages/pytorch_pretrained_bert/modeling.py", line 711, in forward
embedding_output = self.embeddings(input_ids, token_type_ids)
File "/home/beltagy/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/lib/python3.7/site-packages/pytorch_pretrained_bert/modeling.py", line 263, in forward
embeddings = self.dropout(embeddings)
File "/home/beltagy/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/lib/python3.7/site-packages/torch/nn/modules/dropout.py", line 58, in forward
return F.dropout(input, self.p, self.training, self.inplace)
File "/home/beltagy/miniconda3/lib/python3.7/site-packages/torch/nn/functional.py", line 749, in dropout
else _VF.dropout(input, p, training))
RuntimeError: cuda runtime error (77) : an illegal memory access was encountered at /opt/conda/conda-bld/pytorch_1549636813070/work/aten/src/THC/THCGeneral.cpp:405
```
At prediction time, it crashes with the following error after exactly 13 batches (even when I shuffle the data or change the batch size)
``` File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/allennlp/modules/text_field_embedders/basic_text_field_embedder.py", line 110, in forward
token_vectors = embedder(*tensors)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/allennlp/modules/token_embedders/bert_token_embedder.py", line 91, in forward
attention_mask=util.combine_initial_dims(input_mask))
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py", line 714, in forward
output_all_encoded_layers=output_all_encoded_layers)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py", line 396, in forward
hidden_states = layer_module(hidden_states, attention_mask)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py", line 381, in forward
attention_output = self.attention(hidden_states, attention_mask)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py", line 339, in forward
self_output = self.self(input_tensor, attention_mask)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py", line 290, in forward
mixed_query_layer = self.query(hidden_states)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/torch/nn/modules/linear.py", line 67, in forward
return F.linear(input, self.weight, self.bias)
File "/home/beltagy/miniconda3/envs/cuda9/lib/python3.6/site-packages/torch/nn/functional.py", line 1354, in linear
output = input.matmul(weight.t())
RuntimeError: cublas runtime error : an internal operation failed at /opt/conda/conda-bld/pytorch_1549628766161/work/aten/src/THC/THCBlas.cu:258
```
Any thoughts what might be wrong, or how I can debug this ? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/465/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/465/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/464 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/464/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/464/comments | https://api.github.com/repos/huggingface/transformers/issues/464/events | https://github.com/huggingface/transformers/issues/464 | 430,879,647 | MDU6SXNzdWU0MzA4Nzk2NDc= | 464 | How to get vocab.txt and bert_config.json as output of fine tuning? | {
"login": "search4mahesh",
"id": 4182331,
"node_id": "MDQ6VXNlcjQxODIzMzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/4182331?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/search4mahesh",
"html_url": "https://github.com/search4mahesh",
"followers_url": "https://api.github.com/users/search4mahesh/followers",
"following_url": "https://api.github.com/users/search4mahesh/following{/other_user}",
"gists_url": "https://api.github.com/users/search4mahesh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/search4mahesh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/search4mahesh/subscriptions",
"organizations_url": "https://api.github.com/users/search4mahesh/orgs",
"repos_url": "https://api.github.com/users/search4mahesh/repos",
"events_url": "https://api.github.com/users/search4mahesh/events{/privacy}",
"received_events_url": "https://api.github.com/users/search4mahesh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You can get `pytorch_model.bin` and `config.json` just as indicated in the examples: https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_classifier.py#L861-L866\r\n\r\nThe vocabulary stays the same, just load the tokenizer as you did for the training (`BertTokenizer.from_pretrained(...)`)",
"Thanks Thomas. I really appreciate it.\r\nOur custom text might have some new words which may not be in original vocab.txt\r\nOriginal vocab.txt contain some unused placeholders. (some 993) out of total 30522\r\nPlease let me know your thoughts on this.\r\nThanks\r\nMahesh",
"Then you should go have a look at https://github.com/huggingface/pytorch-pretrained-BERT/issues/463.\r\nAnd I will close this issue in favor of #463 ;-)"
] | 1,554 | 1,554 | 1,554 | NONE | null | Hi,
I am fine tuning bert on custom data.
As output I am getting only pytorch_model.bin but how to get updated vocab.txt and bert_config.json .
Please suggest.
Thanks
Mahesh | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/464/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/464/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/463 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/463/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/463/comments | https://api.github.com/repos/huggingface/transformers/issues/463/events | https://github.com/huggingface/transformers/issues/463 | 430,716,261 | MDU6SXNzdWU0MzA3MTYyNjE= | 463 | Vocab changes in lm_finetuning in BERT | {
"login": "bhoomit",
"id": 1269954,
"node_id": "MDQ6VXNlcjEyNjk5NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1269954?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhoomit",
"html_url": "https://github.com/bhoomit",
"followers_url": "https://api.github.com/users/bhoomit/followers",
"following_url": "https://api.github.com/users/bhoomit/following{/other_user}",
"gists_url": "https://api.github.com/users/bhoomit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhoomit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhoomit/subscriptions",
"organizations_url": "https://api.github.com/users/bhoomit/orgs",
"repos_url": "https://api.github.com/users/bhoomit/repos",
"events_url": "https://api.github.com/users/bhoomit/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhoomit/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi,\r\nAlso it should produce vocab.txt and bert_config.json along with pytorch_model.bin.\r\nHow you are getting those?",
"We did this for [SciBERT](https://github.com/allenai/scibert), and you might find this discussion useful https://github.com/allenai/scibert/issues/29",
"lm_finetuning produce pytorch_model.bin alone (and not bert_config.json)\r\nwhat do you think @Rocketknight1 ?",
"```\r\nModel name '../../models/bert/' was not found in model name list (bert-base-uncased, \r\nbert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased,\r\nbert-base-multilingual-cased, bert-base-chinese). We assumed '../../models/bert/vocab.txt'\r\nwas a path or url but couldn't find any file associated to this path or url.\r\n```\r\n\r\nYet your fine-tuning script does not produce any such file.",
"The `lm_finetuning` script assumes you're using one of the existing models in the repo, that you're fine-tuning it for a narrower domain in the same language, and that the saved pytorch_model.bin is basically just updated weights for that model - it doesn't support changes in vocab. Altering the vocab and config would probably require more extensive retraining of the model, possibly from scratch, which this repo isn't supporting yet because of the requirement for TPUs to do it quickly enough.\r\n\r\nI can contribute code if @thomwolf thinks it's relevant, but I'm not sure if or how we should be supporting this use-case right now. It might have to wait until we add from-scratch training and TPU support.",
"Hi @Rocketknight1\r\nDoes this mean that the [pytorch_BERT](https://github.com/huggingface/pytorch-pretrained-BERT/) and also the [google_BERT](https://github.com/google-research/bert) implementation do not support *finetuning* with new vocabulary, sentences respectively?\r\n\r\nI would like to train a german model on a domain-specific text: the amount of german words in the multilingual model is relatively small and so I cannot access hidden states for out-of-vocabulary words even when using synonyms generated using [*FastText*](https://radimrehurek.com/gensim/models/fasttext.html), as also those synonyms are out of vocabulary. Is there any suggestion you can give me to alleviate this problem?\r\nI see that [*Issue 405*](https://github.com/huggingface/pytorch-pretrained-BERT/issues/405) has some suggestions together with [*Issue 9*](https://github.com/google-research/bert/issues/9):\r\nCan I really achieve my goal by appending my vocabulary to the end of *vocab.txt* and adjusting the *config.json* accordingly? Do I need to use the [google bert model](https://github.com/google-research/bert) and subsequently [convert_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/pytorch_pretrained_bert/convert_tf_checkpoint_to_pytorch.py) or can I use this repo somehow directly?",
"Hi @gro1m \r\nAny luck with adding vocab to bert_pytorch?",
"\r\n\r\n> Hi @gro1m\r\n> Any luck with adding vocab to bert_pytorch?\r\n\r\nI'm using https://github.com/kwonmha/bert-vocab-builder to build Vocab. Will share experience. ",
"Hi, I am trying to use SciBert, the version with it's own vocab. I am wondering how to point to that vocab.txt file, and not the original. \r\n\r\nEdit\r\n\r\nFound the answer\r\n\r\nhttps://github.com/huggingface/pytorch-transformers/issues/69#issuecomment-443215315\r\n\r\nyou can just do a direct path to it",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@bhoomit \r\nTo achieve BERT level results for Hinglish. would fine-tuning BERT English model with Hinglish data(approx 200 MB) could achieve good results? \r\nor it would be best to train the model from scratch in case of hinglish ? "
] | 1,554 | 1,596 | 1,570 | NONE | null | I want to use lm_finetuning for BERT. A potential issue is vocab_size. Since I'm using Hinglish data (Hindi text written using English Alphabets) there can be new words which are not present in English vocabulary. According to BERT doc...
> If using your own vocabulary, make sure to change vocab_size in bert_config.json. If you use a larger vocabulary without changing this, you will likely get NaNs when training on GPU or TPU due to unchecked out-of-bounds access.
How do I do this? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/463/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/463/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/462 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/462/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/462/comments | https://api.github.com/repos/huggingface/transformers/issues/462/events | https://github.com/huggingface/transformers/pull/462 | 430,713,066 | MDExOlB1bGxSZXF1ZXN0MjY4NTQyMTcx | 462 | fix run_gpt2.py | {
"login": "8enmann",
"id": 1021104,
"node_id": "MDQ6VXNlcjEwMjExMDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1021104?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/8enmann",
"html_url": "https://github.com/8enmann",
"followers_url": "https://api.github.com/users/8enmann/followers",
"following_url": "https://api.github.com/users/8enmann/following{/other_user}",
"gists_url": "https://api.github.com/users/8enmann/gists{/gist_id}",
"starred_url": "https://api.github.com/users/8enmann/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/8enmann/subscriptions",
"organizations_url": "https://api.github.com/users/8enmann/orgs",
"repos_url": "https://api.github.com/users/8enmann/repos",
"events_url": "https://api.github.com/users/8enmann/events{/privacy}",
"received_events_url": "https://api.github.com/users/8enmann/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Fixes #412 ",
"Ok, looks good to me, thanks!"
] | 1,554 | 1,555 | 1,555 | CONTRIBUTOR | null | Before this PR, unconditional sample generation fails silently. Fixing the loop reveals a reference before assignment error. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/462/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/462/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/462",
"html_url": "https://github.com/huggingface/transformers/pull/462",
"diff_url": "https://github.com/huggingface/transformers/pull/462.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/462.patch",
"merged_at": 1555012487000
} |
https://api.github.com/repos/huggingface/transformers/issues/461 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/461/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/461/comments | https://api.github.com/repos/huggingface/transformers/issues/461/events | https://github.com/huggingface/transformers/issues/461 | 430,686,503 | MDU6SXNzdWU0MzA2ODY1MDM= | 461 | Pooler weights not being updated for Multiple Choice models? | {
"login": "meetps",
"id": 6251729,
"node_id": "MDQ6VXNlcjYyNTE3Mjk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6251729?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meetps",
"html_url": "https://github.com/meetps",
"followers_url": "https://api.github.com/users/meetps/followers",
"following_url": "https://api.github.com/users/meetps/following{/other_user}",
"gists_url": "https://api.github.com/users/meetps/gists{/gist_id}",
"starred_url": "https://api.github.com/users/meetps/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/meetps/subscriptions",
"organizations_url": "https://api.github.com/users/meetps/orgs",
"repos_url": "https://api.github.com/users/meetps/repos",
"events_url": "https://api.github.com/users/meetps/events{/privacy}",
"received_events_url": "https://api.github.com/users/meetps/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Indeed this looks like a bug in the `run_swag.py` example.\r\nWhat do you think @rodgzilla?\r\nIsn't the exclusion of the pooler parameters from optimization ([line 392 of `run_swag.py`](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_swag.py#L392)) a typo?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@thomwolf - This surely looks like a bug, should I just send a hotfix and close it?",
"Yes!",
"Fixed in #675."
] | 1,554 | 1,560 | 1,560 | CONTRIBUTOR | null | I'm trying use pretrained BERT to finetune on a multiple choice dataset.
The parameters from `pooler` are excluded from the optimizer params [here](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/pytorch_pretrained_bert/modeling.py#L1044-L1047), however, the MutlipleChoice model does indeed use `pooled_output` (which passes through the `pooler`) [here](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_swag.py#L392).
I wasn't able to find a similar exclusion of `pooler` params from the optimizer in the official repo. I think I'm missing something here. Thanks for your patience. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/461/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/461/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/460 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/460/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/460/comments | https://api.github.com/repos/huggingface/transformers/issues/460/events | https://github.com/huggingface/transformers/issues/460 | 430,584,037 | MDU6SXNzdWU0MzA1ODQwMzc= | 460 | run_classifier on CoLA fails with illegal memory access | {
"login": "prematurelyoptimized",
"id": 13842527,
"node_id": "MDQ6VXNlcjEzODQyNTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/13842527?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/prematurelyoptimized",
"html_url": "https://github.com/prematurelyoptimized",
"followers_url": "https://api.github.com/users/prematurelyoptimized/followers",
"following_url": "https://api.github.com/users/prematurelyoptimized/following{/other_user}",
"gists_url": "https://api.github.com/users/prematurelyoptimized/gists{/gist_id}",
"starred_url": "https://api.github.com/users/prematurelyoptimized/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/prematurelyoptimized/subscriptions",
"organizations_url": "https://api.github.com/users/prematurelyoptimized/orgs",
"repos_url": "https://api.github.com/users/prematurelyoptimized/repos",
"events_url": "https://api.github.com/users/prematurelyoptimized/events{/privacy}",
"received_events_url": "https://api.github.com/users/prematurelyoptimized/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"My guess is that the inputs are either larger than the maximum input size of the model (512) or outside the vocabulary (larger than the vocabulary size).\r\n\r\nDo you think you can try to check this?",
"@ananyahjha93 did the implementation of the additional GLUE tasks. Maybe he has some additional insights on this.",
"@prematurelyoptimized I have not been able to re-create this error with a batch size of 8 on CoLA. I will post an update if I find something on this. In the meantime, is it possible for you to check this code on a different GPU? Also, can you post the version of PyTorch you are using? ",
"My apologies for the delay, I have been out of town.\r\n\r\n@ananyahjha93 Unfortunately, I only have the one GPU for testing. print(torch.__version__) returns 1.1.0a0+be364ac\r\n\r\n@thomwolf I didn't change the tokenizer at all, so it shouldn't be an out-of-vocabulary problem and I didn't change either convert_examples_to_features or _truncate_seq_pair, so it shouldn't be a problem with the input being too long. I can, however, dig in and verify those assumptions.\r\n\r\nUnfortunately, my IT group installed a new NVidia license and now torch reports cuda being unavailable. I should still be able to check the OOV and input overflow problems, but any testing on the GPU I will have to put on hold until we get that issue sorted out.",
"Ok, I am back up and running. Neither I nor my IT folks know what was causing the issue with cuda being unavailable (It was an error 35, indicating a newer runtime than the driver, but it was the same runtime and driver that were working before). In any case, upgrading to CUDA 10.1 and driver version 418.40.04 resolved the unavailability issue after rebuilding the container for the new environment. So now I can start addressing the illegal memory access issue again (sadly, it was not resolved with the driver update)\r\n\r\nI added a validation check before training to ensure that the tokenizer could convert the ids back into tokens and the length of the training samples didn't exceed the maximum length. All the checks passed, so that should rule out OOV and input overflow.\r\n\r\nI also noticed that the illegal memory access in non-deterministic. One example stack is the following:\r\n\r\nTraceback (most recent call last): | 0/1069 [00:00<?, ?it/s]\r\n File \"run_classifier2.py\", line 677, in <module>\r\n main()\r\n File \"run_classifier2.py\", line 580, in main\r\n loss = model(input_ids, segment_ids, input_mask, label_ids)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 970, in forward\r\n _, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 711, in forward\r\n embedding_output = self.embeddings(input_ids, token_type_ids)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 261, in forward\r\n embeddings = words_embeddings + position_embeddings + token_type_embeddings\r\nRuntimeError: CUDA error: an illegal memory access was encountered\r\n\r\nHowever, running the same command immediately afterward gives\r\n\r\nTraceback (most recent call last): | 0/1069 [00:00<?, ?it/s]\r\n File \"run_classifier2.py\", line 677, in <module>\r\n main()\r\n File \"run_classifier2.py\", line 580, in main\r\n loss = model(input_ids, segment_ids, input_mask, label_ids)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 970, in forward\r\n _, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 714, in forward\r\n output_all_encoded_layers=output_all_encoded_layers)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 396, in forward\r\n hidden_states = layer_module(hidden_states, attention_mask)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 382, in forward\r\n intermediate_output = self.intermediate(attention_output)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 354, in forward\r\n hidden_states = self.dense(hidden_states)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/linear.py\", line 67, in forward\r\n return F.linear(input, self.weight, self.bias)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/functional.py\", line 1401, in linear\r\n output = input.matmul(weight.t())\r\nRuntimeError: cublas runtime error : the GPU program failed to execute at /tmp/pip-req-build-k527kqpu/aten/src/THC/THCBlas.cu:259\r\n\r\nAnd then again,\r\n\r\nTraceback (most recent call last):\r\n File \"run_classifier2.py\", line 677, in <module>\r\n main()\r\n File \"run_classifier2.py\", line 580, in main\r\n loss = model(input_ids, segment_ids, input_mask, label_ids)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 970, in forward\r\n _, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 714, in forward\r\n output_all_encoded_layers=output_all_encoded_layers)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 396, in forward\r\n hidden_states = layer_module(hidden_states, attention_mask)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 381, in forward\r\n attention_output = self.attention(hidden_states, attention_mask)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 339, in forward\r\n self_output = self.self(input_tensor, attention_mask)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/pytorch_pretrained_bert/modeling.py\", line 305, in forward\r\n attention_probs = nn.Softmax(dim=-1)(attention_scores)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 491, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/modules/activation.py\", line 877, in forward\r\n return F.softmax(input, self.dim, _stacklevel=5)\r\n File \"/opt/conda/lib/python3.6/site-packages/torch/nn/functional.py\", line 1256, in softmax\r\n ret = input.softmax(dim)\r\nRuntimeError: cuda runtime error (700) : an illegal memory access was encountered at /tmp/pip-req-build-k527kqpu/aten/src/ATen/native/cuda/SoftMax.cu:545\r\n\r\nThis feels like an OOM error, but watching nvidia-smi, the memory usage peaks at only about 800MiB. This doesn't change whether my batch size is 2, 4, 8, or 32, so it looks like the batch size is not the culprit either. The non-determinism could be caused by the kernel running asynchronously, but that shouldn't happen since I'm running with CUDA_LAUNCH_BLOCKING=1.\r\n\r\nLooking at the pytorch source at the lines in the stack traces hasn't been illuminating, so are there some recommended debugging steps at this point?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,561 | 1,561 | NONE | null | I am trying to run the run_classifier.py script against the CoLA task as a smoke test to make sure I have everything installed correctly. However, when I run
`CUDA_LAUNCH_BLOCKING=1 python run_classifier.py --task_name CoLA --do_train --do_eval --do_lower_case --data_dir /workspace/glue/CoLA/ --bert_model bert-base-uncased --max_seq_length128 --train_batch_size 8 --learning_rate 2e-5 --num_train_epochs 3.0 --output_dir /tmp/CoLA`
I get the following stack trace:
`THCudaCheck FAIL file=/tmp/pip-req-build-k527kqpu/aten/src/ATen/native/cuda/Embedding.cu line=340 error=700 : an illegal memory access was encountered
Traceback (most recent call last):
File "run_classifier.py", line 669, in <module>
main()
File "run_classifier.py", line 581, in main
loss.backward()
File "/opt/conda/lib/python3.6/site-packages/torch/tensor.py", line 106, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/opt/conda/lib/python3.6/site-packages/torch/autograd/__init__.py", line 93, in backward
allow_unreachable=True) # allow_unreachable flag
RuntimeError: cuda runtime error (700) : an illegal memory access was encountered at /tmp/pip-req-build-k527kqpu/aten/src/ATen/native/cuda/Embedding.cu:340`
before even a single batch finishes.
I'm running on a Tesla P4 out of NVidia's official pytorch container. I installed pytorch-pretrained-BERT using pip. The only thing that I have changed from the example on the doc page is reducing the batch size from 32 to 8 on account of the P4's lower memory. I wasn't able to check if it works in CPU mode due to [this](https://github.com/huggingface/pytorch-pretrained-BERT/issues/150).
If there is any other useful information that I can provide, let me know. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/460/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/460/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/459 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/459/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/459/comments | https://api.github.com/repos/huggingface/transformers/issues/459/events | https://github.com/huggingface/transformers/issues/459 | 430,525,932 | MDU6SXNzdWU0MzA1MjU5MzI= | 459 | Question about BertForQuestionAnswering model | {
"login": "geekboood",
"id": 23272969,
"node_id": "MDQ6VXNlcjIzMjcyOTY5",
"avatar_url": "https://avatars.githubusercontent.com/u/23272969?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/geekboood",
"html_url": "https://github.com/geekboood",
"followers_url": "https://api.github.com/users/geekboood/followers",
"following_url": "https://api.github.com/users/geekboood/following{/other_user}",
"gists_url": "https://api.github.com/users/geekboood/gists{/gist_id}",
"starred_url": "https://api.github.com/users/geekboood/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/geekboood/subscriptions",
"organizations_url": "https://api.github.com/users/geekboood/orgs",
"repos_url": "https://api.github.com/users/geekboood/repos",
"events_url": "https://api.github.com/users/geekboood/events{/privacy}",
"received_events_url": "https://api.github.com/users/geekboood/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,554 | 1,554 | 1,554 | NONE | null | Hi, I want to train `BertForQuestionAnswering` with my own dataset. I have already taken care of the format of the dataset, however, I encounter some problem when I want to do the inference job. If I am right, the forward output of the model is `start_logits` and `end_logits`. When I use `batchsize=1`, the output shape of both `start_logits` and `end_logits` is `(1, 384)`, with the condition that `max_seq_length=384`.
And the content of the `start_logits` looks like this.
`tensor([[-146.7531, -124.1240, 190.8818, 47.8019, -188.0909, 47.2568,
47.7160, 190.8021, 48.0589, 190.8891, -88.2698, -90.5676,
-86.6798, -85.8938, -83.8673, -86.1693, -149.1830, 190.8824,
48.2365, 47.0692, 48.6216, 47.5917, 190.8883, -88.3360,
-141.6174, -188.1515, -188.1540, -53.4689, 46.8519, -188.1528,
-53.4642, 47.6210, 44.1266, 190.4762, 47.4085, -53.7023,
46.8320, 46.7578, -188.1541, -53.4671, 47.3207, 47.8246,
-188.1536, -53.7048, 46.7347, -188.1540, 45.1644, 47.1797,
-53.7898, 47.3539, 190.8893, 46.2768, 44.3791, 47.1278,
-188.1544, 43.0797, 46.6862, 45.7719, 190.8861, 46.1606,
47.4132, -188.1537, 36.1658, 47.0910, 48.5226, 46.2841,
46.6541, 47.2510, 46.7009, 47.6877, 47.6154, 44.2239,
-187.5396, -53.2560, 47.2695, 46.6610, 48.0983, -169.4403,
-187.6610, 45.5523, 42.2900, -188.1411, 190.2228, 46.8949,
190.8703, 45.7234, 46.2740, 47.1369, -188.1532, -54.4368,
47.4453, 47.8158, 190.8736, 48.5765, 46.3732, 47.6971,
190.8648, 47.9480, 190.8680, 190.8193, 47.7762, 190.8790,
47.3178, 47.6414, 190.8697, 47.4176, 190.8666, 46.2278,
-188.1528, 44.4261, 47.4981, 44.7491, 47.1290, 47.4565,
-53.6217, 47.1531, -188.1532, -53.8363, 190.8584, 190.8332,
47.3138, -181.1877, 47.6136, 190.8501, 189.9186, 47.7481,
190.8734, 46.6971, 47.2033, 47.2970, 46.3130, -188.1545,
46.3114, 46.7054, 46.5795, 190.8862, 46.9812, 47.3662,
47.1590, 45.7121, 47.1540, 46.6390, 47.0824, 46.8635,
47.3509, 47.0953, 46.6325, 190.8554, 46.4527, 45.5026,
25.4061, 190.8870, 46.7979, 47.2999, 45.9724, 47.1344,
46.6824, 190.8658, 47.0369, 46.7866, 190.8427, 47.2813,
46.6452, 47.3353, 46.7846, 190.8449, 47.2189, 45.9533,
-188.1514, 47.8233, 190.8823, 47.5980, 47.1329, 48.1479,
47.0462, 45.7567, 37.7330, 47.4664, 190.8853, 47.6274,
47.3734, 190.8493, 45.9364, 46.3813, 47.6914, 46.7994,
47.1847, 46.3399, 47.4068, 47.3856, 190.8252, 46.8805,
190.8525, 48.3069, 46.0178, 47.0109, 47.4094, 47.7603,
190.8745, 190.8543, 190.8878, 190.8569, 190.8248, 190.8730,
190.8667, 190.8854, 190.8804, 47.4608, 190.8710, 190.8739,
190.8552, 190.8687, 190.8698, 190.8622, 190.8847, 190.8673,
190.8881, 48.5061, 190.8691, 190.8752, 190.8887, 190.8773,
190.8719, 190.8861, 190.8807, 190.8661, 190.8884, 47.6262,
47.9787, 190.8649, 190.8735, 190.8645, 190.8862, 190.8828,
190.8752, 190.8871, 190.8723, 47.5396, 190.8626, 190.8553,
190.8613, 190.8476, 190.8685, 190.8499, 190.8742, 190.8689,
190.8845, 190.8497, 47.2941, 190.8490, 190.8656, 190.8815,
190.8670, 190.8566, 190.8673, 190.8823, 190.8686, 190.8822,
190.8694, 190.8720, 190.8715, 190.8867, 48.3389, 190.8861,
47.6601, 190.8593, 190.8729, 48.1891, 190.8771, 48.9684,
190.8796, 190.8530, 190.8772, 190.8604, 190.8855, 190.8657,
190.8313, 190.8068, 47.2093, 45.8342, 190.8693, 47.0122,
190.8611, 47.9197, 47.5900, 190.8699, 47.1812, 47.0453,
47.8088, 47.3929, 190.8647, 47.4646, 190.8573, 47.6600,
190.8750, 49.9670, 48.0235, 190.8890, 47.1344, 46.9663,
47.8146, 47.5412, 47.8123, 47.0196, 190.8707, -188.1540,
45.6518, -53.6818, 47.1032, -188.1543, 47.6412, 190.8764,
-53.6656, 47.0526, 46.7920, 47.4910, 46.0659, 190.8813,
47.5103, 44.4868, 47.5182, 46.9884, 48.5096, 47.3874,
46.8767, 190.8836, 47.0396, 47.2361, 47.2189, 8.5557,
190.7647, 47.0486, 47.3513, 46.9460, 49.2101, 47.4387,
47.0915, 190.8861, 46.8415, 46.8162, -188.1539, -188.1529,
47.7122, -51.9730, 47.0126, 47.7990, 47.2502, 47.2899,
45.7776, 47.0698, 47.1549, 47.5327, 47.0973, 47.0441,
-52.2246, 47.0743, 46.0908, -141.6221, 47.2081, 47.1517,
47.2605, 47.1618, 47.2170, 47.2807, 47.2537, 47.2298,
47.3016, 47.3111, 47.2860, 47.2685, 47.3075, 47.2483,
47.2479, 47.2315, 47.1936, 47.2113, 47.2494, 47.2810,
47.2674, 47.3000, 47.3290, 47.3196, 47.2996, 47.3611]],
grad_fn=<SqueezeBackward1>)`
Is this behaving normally? Shouldn't it a `(1, 1)` tensor? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/459/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/459/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/458 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/458/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/458/comments | https://api.github.com/repos/huggingface/transformers/issues/458/events | https://github.com/huggingface/transformers/issues/458 | 430,400,523 | MDU6SXNzdWU0MzA0MDA1MjM= | 458 | Suggestion: add warning when using BertForSequenceClassification without special [CLS] token | {
"login": "mboyanov",
"id": 1610015,
"node_id": "MDQ6VXNlcjE2MTAwMTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1610015?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mboyanov",
"html_url": "https://github.com/mboyanov",
"followers_url": "https://api.github.com/users/mboyanov/followers",
"following_url": "https://api.github.com/users/mboyanov/following{/other_user}",
"gists_url": "https://api.github.com/users/mboyanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mboyanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mboyanov/subscriptions",
"organizations_url": "https://api.github.com/users/mboyanov/orgs",
"repos_url": "https://api.github.com/users/mboyanov/repos",
"events_url": "https://api.github.com/users/mboyanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/mboyanov/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
}
] | closed | false | null | [] | [
"I understand the issue but I'm not sure this would be very easy to implement as we would like to keep the model and tokenizer separated one from the other.\r\n\r\nDo you have a solution in mind?\r\n\r\nOtherwise, I'll guess people will have to continue to read the paper before using the model... 😉",
"I totally understand the need for separation between tokenizer and model. \r\nBut, the specific `BertForSequenceClassification` does have the assumption and expects the input to be in a specific form. Even the docs mention \"look at the preprocessing logic\". \r\nI'd suggest extending the documentation for the model - sth like https://github.com/huggingface/pytorch-pretrained-BERT/pull/480"
] | 1,554 | 1,555 | 1,555 | CONTRIBUTOR | null | Thank you for the awesome package!
As I understand it right now, it is the user's responsibility to add the special `CLS` and `SEP` tokens. People who haven't read the paper might miss this detail.
It would be nice to issue a warning in the tokenizer or the model itself if the input is missing these tokens. An alternative is to include it in a more prominent location in the docs.
I understand that the package needs to be flexible so multiple architectures and tokenization procedures can be implemented, so I'm unsure where would be the best place for such a notification.
In short, my suggestion:
# GIVEN
A text sequence without the `CLS` tag
# WHEN
`BertForSequenceClassification` is called
# THEN
A warning is logged
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/458/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/458/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/457 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/457/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/457/comments | https://api.github.com/repos/huggingface/transformers/issues/457/events | https://github.com/huggingface/transformers/issues/457 | 430,289,105 | MDU6SXNzdWU0MzAyODkxMDU= | 457 | Load Biobert pre-trained weights into Bert model with Pytorch bert hugging face run_classifier.py code | {
"login": "sheetalsh456",
"id": 12454534,
"node_id": "MDQ6VXNlcjEyNDU0NTM0",
"avatar_url": "https://avatars.githubusercontent.com/u/12454534?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sheetalsh456",
"html_url": "https://github.com/sheetalsh456",
"followers_url": "https://api.github.com/users/sheetalsh456/followers",
"following_url": "https://api.github.com/users/sheetalsh456/following{/other_user}",
"gists_url": "https://api.github.com/users/sheetalsh456/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sheetalsh456/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sheetalsh456/subscriptions",
"organizations_url": "https://api.github.com/users/sheetalsh456/orgs",
"repos_url": "https://api.github.com/users/sheetalsh456/repos",
"events_url": "https://api.github.com/users/sheetalsh456/events{/privacy}",
"received_events_url": "https://api.github.com/users/sheetalsh456/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Have you tried the solutions discussed in the other issues on this topic:\r\n- https://github.com/huggingface/pytorch-pretrained-BERT/issues/312\r\n- https://github.com/huggingface/pytorch-pretrained-BERT/issues/239",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"> Have you tried the solutions discussed in the other issues on this topic:\r\n> \r\n> * #312\r\n> * #239\r\n\r\nHi @thomwolf ,\r\n\r\nI followed the instructions [here](https://github.com/BaderLab/saber/issues/135#issuecomment-494455933) to convert the checkpoint and then placing the files (pytorch_model.bin, bert_config.json, and vocab.txt) in one folder to compress it. I did not need to ignore any weights as mentioned in any solutions you mentioned above ( #312 or #239 )\r\n\r\nI copied the compressed folder to the home folder of 'pytorch-transformers'. Then I ran the following command from there itself to run the example code (`'examples/run_glue.py'`) on my data.\r\n\r\nThen, I am trying to run the example code given by running the following command,\r\n\r\n`python ./examples/run_glue.py \\ --model_type bert \\ --model_name_or_path biobert.gz \\ --task_name=sts-b \\ --do_train \\ --do_eval \\ --do_lower_case \\ --data_dir=$DIR \\ --max_seq_length 128 \\ --per_gpu_eval_batch_size=8 \\ --per_gpu_train_batch_size=8`\r\n\r\nBut, I get the same error as mentioned in the main discussion:\r\n\r\n`UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte`\r\n\r\nat this location:\r\n\r\n`File \"./examples/run_glue.py\", line 424, in main config = config_class.from_pretrained(args.config_name if args.config_name else args.model_name_or_path, num_labels=num_labels, finetuning_task=args.task_name)`\r\n\r\nCan you please tell what to change.",
"Try to pass the extracted folder of your converted bioBERT model to the `--model_name_or_path` :)\r\n\r\nHere's a short example:\r\n\r\n* Download the *BioBERT v1.1 (+ PubMed 1M)* model (or any other model) from the [bioBERT repo](https://github.com/naver/biobert-pretrained)\r\n* Extract the downloaded file, e.g. with `tar -xzf biobert_v1.1_pubmed.tar.gz`\r\n* Convert the bioBERT model TensorFlow checkpoint to a PyTorch and PyTorch-Transformers compatible one: `pytorch_transformers bert biobert_v1.1_pubmed/model.ckpt-1000000 biobert_v1.1_pubmed/bert_config.json biobert_v1.1_pubmed/pytorch_model.bin`\r\n* Move config `mv biobert_v1.1_pubmed/bert_config.json biobert_v1.1_pubmed/config.json`\r\n\r\nThen pass the folder name to the `--model_name_or_path` argument. You can run this simple script to check, if everything works:\r\n\r\n```python\r\nfrom pytorch_transformers import BertModel\r\nmodel = BertModel.from_pretrained('biobert_v1.1_pubmed')\r\n```",
"How we load a tensor as a pretrained model in bert",
"@stefan-it As per new `transformers-cli` third command would change as follows:\r\n\r\n```bat\r\ntransformers-cli convert --model_type bert \\\r\n--tf_checkpoint biobert_v1.1_pubmed/model.ckpt-1000000 \\\r\n--config biobert_v1.1_pubmed/bert_config.json \\\r\n--pytorch_dump_output biobert_v1.1_pubmed/pytorch_model.bin\r\n```",
"Hello!\r\nJust to complement the @stefan-it instructions in step number 3, it works for me the following code:\r\n\r\n`import os`\r\n`from pytorch_pretrained_bert.convert_tf_checkpoint_to_pytorch import convert_tf_checkpoint_to_pytorch`\r\n`path_bin = 'my_directory/pytorch_model.bin' `\r\n`path_bert = 'my_bert_directory/' `\r\n\r\n`if (not os.path.exists(path_bin)): `\r\n`\tconvert_tf_checkpoint_to_pytorch( `\r\n`\t\tpath_bert + \"biobert_model.ckpt\", `\r\n`\t\tpath_bert + \"bert_config.json\", `\r\n`\t\tpath_bert + \"pytorch_model.bin\" `\r\n`\t\t)`\r\n\r\nMy folder (biobert_v1.0_pmc) was originally 5 files:\r\n3 Tensorflow checkpoint files\r\nA vocab file\r\nA config file\r\n",
"> * Move config `mv biobert_v1.1_pubmed/bert_config.json biobert_v1.1_pubmed/config.json`\r\n\r\nTnank you very much! It did help me!\r\n",
"Thank you every one, this works fine now!",
"Dear all,\r\nThank you very much for the suggestions on how to prepare the model to be used with hugginfaces. I am trying to use huggingfaces BertTokenizer to perform NER on biomedical data with the pre-trained weights. \r\nIt seems to work fine until then point when I want to map annotated tokens to entity labels. I have token ids and prediction ids, but I cannot figure out how/where to get label_list to follow an example of mapping from https://huggingface.co./transformers/usage.html#named-entity-recognition \r\nThank you very much for any help you can provide!\r\nMaria",
"Dear all,\r\nI am a newbie and I don not have so much experience. Does anyone have a full tutorial or code for a regression task, Please share with me! I would greatly appreciate it! Thank you.",
"@stefan-it @nipunsadvilkar Thank you for your solutions."
] | 1,554 | 1,591 | 1,560 | NONE | null | These are the steps I followed to get Biobert working with the existing Bert hugging face pytorch code.
1. I downloaded the pre-trained weights 'biobert_pubmed_pmc.tar.gz' from [the Releases page](https://github.com/naver/biobert-pretrained/releases).
2. I ran this command to convert the tf checkpoint to pytorch model
```
python pytorch-pretrained-BERT/pytorch_pretrained_bert/convert_tf_checkpoint_to_pytorch.py --tf_checkpoint_path="biobert/pubmed_pmc_470k/biobert_model.ckpt.index" --bert_config_file="biobert/pubmed_pmc_470k/bert_config.json" --pytorch_dump_path="biobert/pubmed_pmc_470k/Pytorch/biobert.model"
```
This created a file 'biobert.model' in the specified path.
3. As mentioned in this [link](https://modelzoo.co/model/pytorch-pretrained-bert) , I compressed 'biobert.model' created above and 'biobert/pubmed_pmc_470k/bert_config.json' together into a biobert_model.tar.gz
3. I then ran the run_classifier.py of hugging face bert with the following command, using the tar.gz created above.
```
python pytorch-pretrained-BERT/examples/run_classifier.py --data_dir="Data/" --bert_model="biobert_model.tar.gz" --task_name="qqp" --output_dir="OutputModels/Pretrained/" --do_train --do_eval --do_lower_case
```
I get the error
```
'UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte'
```
in the line
```
tokenizer = BertTokenizer.from_pretrained(args.bert_model, do_lower_case=args.do_lower_case)
```
Am I doing something wrong?
I just wanted to run run_classifier.py code provided by hugging face with biobert pretrained weights in the same way that we run bert with it. Is there a way to do this? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/457/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/457/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/456 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/456/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/456/comments | https://api.github.com/repos/huggingface/transformers/issues/456/events | https://github.com/huggingface/transformers/issues/456 | 430,270,548 | MDU6SXNzdWU0MzAyNzA1NDg= | 456 | max_seq_length for squad | {
"login": "ZhaofengWu",
"id": 11954789,
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhaofengWu",
"html_url": "https://github.com/ZhaofengWu",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Then you're doomed for this answer. There are a possibility to do a sliding window approach but we didn't implemented it in the examples of pytorch-pretrained-bert.\r\nCheck this issue (and the linked TensorFlow issue) for a discussion on this: https://github.com/huggingface/pytorch-pretrained-BERT/issues/89"
] | 1,554 | 1,559 | 1,554 | CONTRIBUTOR | null | The example script for squad sets `--max_seq_length` at 384 as default. However it seems that many paragraphs in squad exceed this length. Then what if the answer to some question lies in the truncated part of the paragraph? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/456/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/456/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/455 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/455/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/455/comments | https://api.github.com/repos/huggingface/transformers/issues/455/events | https://github.com/huggingface/transformers/issues/455 | 430,116,432 | MDU6SXNzdWU0MzAxMTY0MzI= | 455 | LM fine tuning on top of a custom model | {
"login": "ZhaofengWu",
"id": 11954789,
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhaofengWu",
"html_url": "https://github.com/ZhaofengWu",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
}
] | closed | false | null | [] | [
"Not really, I guess we could remove this restriction and just let people point to an arbitrary folder (as we do in the other scripts).\r\nWhat do you think @Rocketknight1?",
"No, that's entirely my bad. We should allow an arbitrary folder!",
"Should I just remove the `choices` argument and allow any string there?",
"Yes, I would go for that!",
"Actually, if you have push access to the repo, do you want to just make that one-line change? I'd have to fork and submit a PR, which seems a bit unnecessary.",
"Indeed, I'll take care of it. I'm on the repo now anyway.",
"is this change applicable and working with run_lm_finetuning.py in 2.x?"
] | 1,554 | 1,573 | 1,554 | CONTRIBUTOR | null | Currently the `finetune_on_pregenerated.py` script allows only fine-tuning on top of one of the five pretrained bert models. However I don't understand why there is such a restriction. I am trying to finetune a LM on top of a custom bert model (mt-dnn). Of course I can just remove the `choices`, but I am wondering if there is some rationale behind this, as none of the other example scripts contains this restriction.
https://github.com/huggingface/pytorch-pretrained-BERT/blob/94980b529fad34f55c5d34c94bae2814db6773a6/examples/lm_finetuning/finetune_on_pregenerated.py#L126-L128 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/455/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/455/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/454 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/454/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/454/comments | https://api.github.com/repos/huggingface/transformers/issues/454/events | https://github.com/huggingface/transformers/issues/454 | 429,755,590 | MDU6SXNzdWU0Mjk3NTU1OTA= | 454 | getting sequence embeddings for pair of sentences | {
"login": "omerarshad",
"id": 16164105,
"node_id": "MDQ6VXNlcjE2MTY0MTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/16164105?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/omerarshad",
"html_url": "https://github.com/omerarshad",
"followers_url": "https://api.github.com/users/omerarshad/followers",
"following_url": "https://api.github.com/users/omerarshad/following{/other_user}",
"gists_url": "https://api.github.com/users/omerarshad/gists{/gist_id}",
"starred_url": "https://api.github.com/users/omerarshad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omerarshad/subscriptions",
"organizations_url": "https://api.github.com/users/omerarshad/orgs",
"repos_url": "https://api.github.com/users/omerarshad/repos",
"events_url": "https://api.github.com/users/omerarshad/events{/privacy}",
"received_events_url": "https://api.github.com/users/omerarshad/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, yes."
] | 1,554 | 1,554 | 1,554 | NONE | null | given [cls] word1 word2 word3 [sep] word1 word2 [sep]
If i get sequence embeddings, will word1 of sentence 1 will have context of word1 of sentence2? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/454/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/454/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/453 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/453/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/453/comments | https://api.github.com/repos/huggingface/transformers/issues/453/events | https://github.com/huggingface/transformers/issues/453 | 429,654,860 | MDU6SXNzdWU0Mjk2NTQ4NjA= | 453 | What‘s op-for-op meaning? | {
"login": "JiahangOK",
"id": 40447174,
"node_id": "MDQ6VXNlcjQwNDQ3MTc0",
"avatar_url": "https://avatars.githubusercontent.com/u/40447174?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JiahangOK",
"html_url": "https://github.com/JiahangOK",
"followers_url": "https://api.github.com/users/JiahangOK/followers",
"following_url": "https://api.github.com/users/JiahangOK/following{/other_user}",
"gists_url": "https://api.github.com/users/JiahangOK/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JiahangOK/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JiahangOK/subscriptions",
"organizations_url": "https://api.github.com/users/JiahangOK/orgs",
"repos_url": "https://api.github.com/users/JiahangOK/repos",
"events_url": "https://api.github.com/users/JiahangOK/events{/privacy}",
"received_events_url": "https://api.github.com/users/JiahangOK/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, it means that the computation graphs of the Tensorflow and PyTorch versions are identical."
] | 1,554 | 1,554 | 1,554 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/453/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/453/timeline | completed | null | null |
|
https://api.github.com/repos/huggingface/transformers/issues/452 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/452/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/452/comments | https://api.github.com/repos/huggingface/transformers/issues/452/events | https://github.com/huggingface/transformers/issues/452 | 429,634,551 | MDU6SXNzdWU0Mjk2MzQ1NTE= | 452 | Pregenerating data requires multiple documents | {
"login": "yanneyanne",
"id": 15113131,
"node_id": "MDQ6VXNlcjE1MTEzMTMx",
"avatar_url": "https://avatars.githubusercontent.com/u/15113131?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yanneyanne",
"html_url": "https://github.com/yanneyanne",
"followers_url": "https://api.github.com/users/yanneyanne/followers",
"following_url": "https://api.github.com/users/yanneyanne/following{/other_user}",
"gists_url": "https://api.github.com/users/yanneyanne/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yanneyanne/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yanneyanne/subscriptions",
"organizations_url": "https://api.github.com/users/yanneyanne/orgs",
"repos_url": "https://api.github.com/users/yanneyanne/repos",
"events_url": "https://api.github.com/users/yanneyanne/events{/privacy}",
"received_events_url": "https://api.github.com/users/yanneyanne/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, I wrote that script! That's a tricky issue, though - what behaviour do you expect when your data is one long text? \r\n\r\nIn the original BERT repo, they used the document breaks to control sampling for the NextSentence task - 'random' next sentences were selected from a different document. I'm not sure there's a \"general\" solution to the case when all the data is a single document, though - people whose data is all one contiguous document will probably have different expectations for how they want that data to be handled (e.g. is it okay to select a 'random' sentence 10 sentences away, or should it be much further? Are 'nearby' sentences too similar?)\r\n\r\nI suppose we could add code to support that with a controllable parameter to stop it sampling random sentences that are too close to the actual sentence, but it might be easier just to throw an error if the data is only one single document and request that the user break it into 'documents' based on whatever structure is in the data, like chapter or page breaks, or in the worst case just add a break every 1,000 lines or something.\r\n\r\nYou're totally right about the f-strings, though. I'll look into updating the README!",
"I'm assuming that the script should just grab any random sentence in the same (only) document. I could see how that particular behavior might not be desired however.\r\n\r\nThe error-throwing idea is good. I ran the script on my mammoth document, only to see empty output after 9 hours (my own fault obviously, but an exception might help similarly sloppy people).",
"Added PR #478 to address this. Unfortunately, it probably still won't resolve your 9 hour problem - the script will only realize there was only one document in the corpus after it's finished reading and tokenizing the whole thing! Still, at least people will get an error message properly explaining the issue and suggesting fixes now.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,560 | 1,560 | NONE | null | The script for pregenerating language modelling data assumes that the training corpus consists of multiple documents (i.e. a single training corpus file where empty lines separate documents). If the training corpus is made up of only one long text, the pregen script produces empty output.
I have a small fix for this locally, which enables pregenerating from a single document. I could create a PR if the empty output is not seen as expected behaviour.
(I can also mention that the **Installation** section of the README states that the repo has been tested with python 3.5+. However, the pregen script uses f-strings, which are a python 3.6 feature.) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/452/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/452/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/451 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/451/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/451/comments | https://api.github.com/repos/huggingface/transformers/issues/451/events | https://github.com/huggingface/transformers/issues/451 | 429,438,737 | MDU6SXNzdWU0Mjk0Mzg3Mzc= | 451 | Help: cannot load pretrain models from .pytorch_pretrained_bert folder | {
"login": "yangliu2",
"id": 3577730,
"node_id": "MDQ6VXNlcjM1Nzc3MzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3577730?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yangliu2",
"html_url": "https://github.com/yangliu2",
"followers_url": "https://api.github.com/users/yangliu2/followers",
"following_url": "https://api.github.com/users/yangliu2/following{/other_user}",
"gists_url": "https://api.github.com/users/yangliu2/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yangliu2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yangliu2/subscriptions",
"organizations_url": "https://api.github.com/users/yangliu2/orgs",
"repos_url": "https://api.github.com/users/yangliu2/repos",
"events_url": "https://api.github.com/users/yangliu2/events{/privacy}",
"received_events_url": "https://api.github.com/users/yangliu2/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"It is likely due to the script is not able to find the vocabulary file. So you should download the vocab first and copy it over. Then when you load the tokenizer you need to specify the path to the vocab. So if you vocab is in \"/tmp/transformer_xl/\" you do:\r\n```python\r\ntokenizer = TransfoXLTokenizer.from_pretrained('/tmp/transformer_xl')\r\n```",
"This works, just not what I expected. I copied over everything in .pytorch_pretrained_bert and though it would load without parameters. Now I have a bunch of file named like this, I have to figure out which model it belongs.\r\n\"12642ff7d0279757d8356bfd86a729d9697018a0c93ad042de1d0d2cc17fd57b.e9704971f27275ec067a00a67e6a5f0b05b4306b3f714a96e9f763d8fb612671\"",
"I will add a section in the readme detailing how to load a model from drive.\r\nBasically, you can just download the models and vocabulary from our S3 following the links at the top of each file (`modeling_transfo_xl.py` and `tokenization_transfo_xl.py` for Transformer-XL) and put them in one directory with the filename also indicated at the top of each file.\r\n\r\nHere is the process in your case:\r\n```bash\r\nmkdir model\r\ncd model\r\nwget -O pytorch_model.bin https://s3.amazonaws.com/models.huggingface.co/bert/transfo-xl-wt103-pytorch_model.bin\r\nwget -O config.json https://s3.amazonaws.com/models.huggingface.co/bert/transfo-xl-wt103-config.json\r\nwget -O vocab.bin https://s3.amazonaws.com/models.huggingface.co/bert/transfo-xl-wt103-vocab.bin\r\n# optional, only if you run the evaluation script run_transfo_xl.py which uses the pre-processed wt103 corpus:\r\n# wget -O corpus.bin https://s3.amazonaws.com/models.huggingface.co/bert/transfo-xl-wt103-corpus.bin\r\n```\r\n\r\nNow just load the model and tokenizer by pointing to this directory:\r\n```python\r\ntokenizer = TransfoXLTokenizer.from_pretrained('./model/')\r\nmodel = TransfoXLModel.from_pretrained('./model/')\r\n```\r\n",
"I'll see if I can relax the requirement on the internet connection in the next release.",
"The network connection check has been relaxed in the now merged #500.\r\nIt will be included in the next PyPI release (probably next week).\r\nIn the meantime you can install from `master`.",
"I have a similar issue with the BERT multilingual cased model: \r\n```\r\nERROR - pytorch_pretrained_bert.modeling - Model name 'bert-base-multilingual-cased' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese). \r\nWe assumed 'https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased.tar.gz' was a path or url but couldn't find any file associated to this path or url. \r\n```\r\nThen I tried to execute the following code block in my Jupyter notebook:\r\n```python\r\nimport requests\r\nurl = \"https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased.tar.gz\"\r\nresponse = requests.get(url, allow_redirects=True, verify=False)\r\n```\r\nI had to set verify to false, because otherwise I get an SSL certificate error. But even now, this does not work, because the site is blocked due to our company security settings, i.e. `response.status_code` returns 403.\r\n\r\nIs there a possibility that you might publish the file in your github repo or that we could load the model from somewhere else?",
"Strange, I can't reproduce this.\r\nI've checked again that every model is public on our S3.\r\nCan you try again?",
"I retried, once using the google tensorflow hub address and once with the Amazon S3 address for the BERT model.\r\nI specified the proxy information like this:\r\n```\r\nproxyDict = { \"http\" : \"http://<proxy-user>:<proxy-password>@<proxy-domain>\",\r\n \"https\" : \"http://<proxy-user>:<proxy-password>@<proxy-domain>\"}\r\n```\r\nwith our company-specific settings for proxy-user, proxy-password and proxy-domain. \r\n\r\nThen I executed the following code:\r\n```python\r\nimport requests\r\nurl_google = \"https://tfhub.dev/google/bert_multi_cased_L-12_H-768_A-12/1\"\r\nurl_amazons3 = \"https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased.tar.gz\"\r\n\r\nresponse_1 = requests.get(url_google, allow_redirects=True, verify=False, proxies = proxyDict)\r\nresponse_2 = requests.get(url_amazons3, allow_redirects=True, verify=False, proxies = proxyDict)\r\n\r\nprint(\"response status code for google address: {}\".format(response_1.status_code))\r\nprint(\"response status code for amazon s3 address: {}\".format(response_2.status_code))\r\n```\r\n\r\nand this is what I got:\r\n```\r\nresponse status code for google address: 200\r\nresponse status code for amazon s3 address: 403\r\n```\r\n\r\nSo unfortunately, it does not seem to work out for me. I might use the convert function you provided, but it would be nicer to be able to load the model directly from the S3.",
"Is it only for this model (`bert-base-multilingual-cased`) or are you blocked from accessing all the pretrained models and tokenizers?",
"I am blocked from accessing all the pretrained models.\r\nI tested it by looping through the values of PRETRAINED_MODEL_ARCHIVE_MAP dictionary and all requests return the status code 403.",
"I haven't tried it yet but maybe torch hub could help (#506)\r\n\r\nCan you try to update to PyTorch 1.1.0 (to get torch.hub) and test this:\r\n```python\r\nimport torch\r\ntokenizer = torch.hub.load('ailzhang/pytorch-pretrained-BERT:hubconf', 'bertTokenizer', 'bert-base-cased', do_basic_tokenize=False, force_reload=False)\r\n```",
"Well, it does not seem to work.\r\nI had to add \r\n```python\r\nimport urllib\r\nproxy_support = urllib.request.ProxyHandler({ \"http\" : \"http://<proxy-user>:<proxy-password>@<proxy-domain>\",\r\n\"https\" : \"http://<proxy-user>:<proxy-password>@<proxy-domain>\"})\r\nopener = urllib.request.build_opener(proxy_support)\r\nurllib.request.install_opener(opener)\r\n```\r\ninto ~/my-virtual-env/lib/site-packages/python3.6/torch/hub.py with my-virtual-env being my pip virtual environment.\r\nThen executing the command you suggested prints the following to the console:\r\n```\r\nDownloading: \"https://github.com/ailzhang/pytorch-pretrained-BERT/archive/hubconf.zip\" to /home/U118693/.cache/torch/hub/hubconf.zip\r\nThe pre-trained model you are loading is a cased model but you have not set `do_lower_case` to False. We are setting `do_lower_case=False` for you but you may want to check this behavior.\r\nModel name 'bert-base-cased' was not found in model name list (bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, bert-base-multilingual-cased, bert-base-chinese). We assumed 'https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt' was a path or url but couldn't find any file associated to this path or url.\r\n```\r\nThere is now a folder ailzhang_pytorch-pretrained-BERT_hubconf in the /home/U118693/.cache/torch/hub/ directory, but there still seems to be issues in finding that bert-cased-vocab.txt file.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,583 | 1,562 | NONE | null | I need to run the package on a machine without internet. Copied over the ".pytorch_pretrained_bert" folder from one machine to another.
Installed anaconda3 and tried to run `tokenizer = TransfoXLTokenizer.from_pretrained('transfo-xl-wt103')`.
Got this error:
`Model name 'transfo-xl-wt103' was not found in model name list (transfo-xl-wt103). We assumed 'transfo-xl-wt103' was a path or url but couldn't find files https://s3.amazonaws.com/models.huggingface.co/bert/transfo-xl-wt103-vocab.bin at this path or url.`
Do I need to copy anything else to the second machine to make it load from the cache folder?
Ubuntu 16.04, pytorch 1.0 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/451/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/451/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/450 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/450/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/450/comments | https://api.github.com/repos/huggingface/transformers/issues/450/events | https://github.com/huggingface/transformers/issues/450 | 429,293,867 | MDU6SXNzdWU0MjkyOTM4Njc= | 450 | Understanding pre-training and fine-tuning | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Maybe a good introduction on the topic are the writings of @sebastianruder:\r\n- http://ruder.io/transfer-learning/\r\n- https://thegradient.pub/nlp-imagenet/\r\n- the ULMFiT paper: http://nlp.fast.ai/classification/2018/05/15/introducting-ulmfit.html\r\n\r\nRegarding your specific question of training a Bert model on a new language, the computing requirements for training BERT are very high. You would probably be better with a version of ULMFiT. There is a huge multilingual initiative on the fast.ai forum that you can check out. One entry point is [here](https://forums.fast.ai/t/language-model-zoo-gorilla/14623).",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,560 | 1,560 | COLLABORATOR | null | I am confused about what these two steps actually do to the model. I would have assumed that pre-training is unsupervised (i.e. no labels) and, thus, the only thing that can be 'learned' is the embedding representations of all tokens. You can then use this pre-trained model (which is an 'empty' model but with pretrained vector representations of tokens) to actually train the whole mode.
However, from the things that I read that is not the case. It's not only the embeddings that are pretrained, but also the whole model. Is that right? How can that be, without labels?
For context: I want to train a Bert model on a new language and I am trying to figure out which steps I have to do to get there. Can I load custom embeddings, and do I then still need to pretrain the rest of the model (but how, which labels?).
I know that my question is quite general, but the difference between pre-training and fine-tuning is not clear to me. Pre-training should be 'done once per language', but then what does the model actually learn? It it simply a seq-to-seq pre-training? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/450/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/450/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/449 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/449/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/449/comments | https://api.github.com/repos/huggingface/transformers/issues/449/events | https://github.com/huggingface/transformers/issues/449 | 429,191,528 | MDU6SXNzdWU0MjkxOTE1Mjg= | 449 | Convert_tf_checkpoint_to_pytorch for bert-joint-baseline | {
"login": "raheja",
"id": 9508410,
"node_id": "MDQ6VXNlcjk1MDg0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/9508410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/raheja",
"html_url": "https://github.com/raheja",
"followers_url": "https://api.github.com/users/raheja/followers",
"following_url": "https://api.github.com/users/raheja/following{/other_user}",
"gists_url": "https://api.github.com/users/raheja/gists{/gist_id}",
"starred_url": "https://api.github.com/users/raheja/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/raheja/subscriptions",
"organizations_url": "https://api.github.com/users/raheja/orgs",
"repos_url": "https://api.github.com/users/raheja/repos",
"events_url": "https://api.github.com/users/raheja/events{/privacy}",
"received_events_url": "https://api.github.com/users/raheja/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649053,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Help%20wanted",
"name": "Help wanted",
"color": "008672",
"default": false,
"description": "Extra attention is needed, help appreciated"
},
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I also encountered a similar problem AttributeError: 'BertForPreTraining' object has no attribute 'crf_loss'\r\n\r\n@thomwolf \r\n\r\nLooking forward to your reply",
"Hi, from my reading of the [Natural Questions model](https://github.com/google-research/language/blob/master/language/question_answering/bert_joint/run_nq.py#L879-L932) it doesn't seems to be directly possible to load this model in the current library (with simple hacks).\r\n\r\nYou will need to define a new sub-class of `BertModel` (e.g. `BertForNaturalQA`) that reproduce the architecture of the TensorFlow model I pointed to. If you use the same name as the TensorFlow variables for the attributes of your PyTorch model you should be able to load the model with the current loading script.\r\n\r\nI don't have time to do this right now but if you want to start opening a PR, I can review it.\r\n\r\nBasically, just add another class after the `BertForQuestionAnswering` class in [`modeling.py`](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/pytorch_pretrained_bert/modeling.py#L1130)",
"Thanks a lot for the reply. Will try this out.\r\n\r\nBest,\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hi @raheja, do you have any updates related to this? I'm trying to do the same and would welcome any hint! ",
"Hi @paulachocron \r\nHaven't been able to try or implement this yet. I am still using the tf version for now. \r\n"
] | 1,554 | 1,562 | 1,560 | NONE | null | Hello,
I know that the format of Squad and Google NQ is different, but is there a way to convert the bert joint model for Natural Questions (https://github.com/google-research/language/tree/master/language/question_answering/bert_joint) to pytorch? I get this error
'BertForPreTraining' object has no attribute 'answer_type_output_bias' | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/449/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/449/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/448 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/448/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/448/comments | https://api.github.com/repos/huggingface/transformers/issues/448/events | https://github.com/huggingface/transformers/issues/448 | 429,145,745 | MDU6SXNzdWU0MjkxNDU3NDU= | 448 | pretrain for chinese dataset | {
"login": "Jason-kid",
"id": 31425629,
"node_id": "MDQ6VXNlcjMxNDI1NjI5",
"avatar_url": "https://avatars.githubusercontent.com/u/31425629?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Jason-kid",
"html_url": "https://github.com/Jason-kid",
"followers_url": "https://api.github.com/users/Jason-kid/followers",
"following_url": "https://api.github.com/users/Jason-kid/following{/other_user}",
"gists_url": "https://api.github.com/users/Jason-kid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Jason-kid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jason-kid/subscriptions",
"organizations_url": "https://api.github.com/users/Jason-kid/orgs",
"repos_url": "https://api.github.com/users/Jason-kid/repos",
"events_url": "https://api.github.com/users/Jason-kid/events{/privacy}",
"received_events_url": "https://api.github.com/users/Jason-kid/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, you should probably turn to the TensorFlow version for pre-training.\r\nThis package is mostly intended to be used for fine-tuning pre-trained models.\r\nAnother option for BERT-like pre-training is to use Facebook's [XLM](https://github.com/facebookresearch/XLM)"
] | 1,554 | 1,557 | 1,554 | NONE | null | Hi , I want to pretrain my model for chinese dataset . can i use my own vocab.txt ?
and what is the format for vocab.txt ? thanks a lot | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/448/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/448/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/447 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/447/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/447/comments | https://api.github.com/repos/huggingface/transformers/issues/447/events | https://github.com/huggingface/transformers/issues/447 | 429,012,525 | MDU6SXNzdWU0MjkwMTI1MjU= | 447 | Dynamic max_seq_length implementation? | {
"login": "zijwang",
"id": 25057983,
"node_id": "MDQ6VXNlcjI1MDU3OTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/25057983?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zijwang",
"html_url": "https://github.com/zijwang",
"followers_url": "https://api.github.com/users/zijwang/followers",
"following_url": "https://api.github.com/users/zijwang/following{/other_user}",
"gists_url": "https://api.github.com/users/zijwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zijwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zijwang/subscriptions",
"organizations_url": "https://api.github.com/users/zijwang/orgs",
"repos_url": "https://api.github.com/users/zijwang/repos",
"events_url": "https://api.github.com/users/zijwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/zijwang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @zijwang , the package doesn't implement any specific batching logic, only tokenizers and models.\r\nYou are supposed to take care of this yourself in your scripts."
] | 1,554 | 1,554 | 1,554 | NONE | null | Does the package support dynamic `max_seq_length`, e.g., if it's None, it will automatically be the maximum length in the mini-batch? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/447/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/447/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/446 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/446/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/446/comments | https://api.github.com/repos/huggingface/transformers/issues/446/events | https://github.com/huggingface/transformers/issues/446 | 428,971,570 | MDU6SXNzdWU0Mjg5NzE1NzA= | 446 | How to select a certain layer as token's representation? | {
"login": "yexing99",
"id": 25463584,
"node_id": "MDQ6VXNlcjI1NDYzNTg0",
"avatar_url": "https://avatars.githubusercontent.com/u/25463584?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yexing99",
"html_url": "https://github.com/yexing99",
"followers_url": "https://api.github.com/users/yexing99/followers",
"following_url": "https://api.github.com/users/yexing99/following{/other_user}",
"gists_url": "https://api.github.com/users/yexing99/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yexing99/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yexing99/subscriptions",
"organizations_url": "https://api.github.com/users/yexing99/orgs",
"repos_url": "https://api.github.com/users/yexing99/repos",
"events_url": "https://api.github.com/users/yexing99/events{/privacy}",
"received_events_url": "https://api.github.com/users/yexing99/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
}
] | closed | false | null | [] | [
"Hi @yexing99,\r\nWhat you need is the `hidden_state`, not the `weights`of the model.\r\nDon't use `model.named_parameters()` but just use the output of the model.\r\nHere is an example: https://github.com/huggingface/pytorch-pretrained-BERT#bert\r\nAnd more details here: https://github.com/huggingface/pytorch-pretrained-BERT#1-bertmodel\r\nYou should do somethings like this to get the BERT features from the second to the last hidden layer if the word `test` is for example the *fifth* word in your sentence (index 4 in the sentence):\r\n```python\r\nencoded_layers, _ = model(tokens_tensor, segments_tensors)\r\nfeatures = [encoded_layer[4] for encoded_layer in encoded_layers[1:]]\r\n```\r\n"
] | 1,554 | 1,554 | 1,554 | NONE | null | My understanding from the paper that each token is represented by a 768-dim vector from the last hidden layer. Is it correct? If so, how can I get the second-to-the last layer's parameter as token representation?
model = BertForTokenClassification.from_pretrained("bert-base-uncased", num_labels=len(tag2idx))
list(model.named_parameters()) gives all weights but how can I know which parameters are from the second to the last layer?
for example, I have a word 'test', how can I get the BERT features from the second to the last hidden layer for the word 'test' in a given sentence? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/446/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/446/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/445 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/445/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/445/comments | https://api.github.com/repos/huggingface/transformers/issues/445/events | https://github.com/huggingface/transformers/pull/445 | 428,837,798 | MDExOlB1bGxSZXF1ZXN0MjY3MTAzMTkx | 445 | Learning rate schedules improvement + extension | {
"login": "lukovnikov",
"id": 1732910,
"node_id": "MDQ6VXNlcjE3MzI5MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/1732910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lukovnikov",
"html_url": "https://github.com/lukovnikov",
"followers_url": "https://api.github.com/users/lukovnikov/followers",
"following_url": "https://api.github.com/users/lukovnikov/following{/other_user}",
"gists_url": "https://api.github.com/users/lukovnikov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lukovnikov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lukovnikov/subscriptions",
"organizations_url": "https://api.github.com/users/lukovnikov/orgs",
"repos_url": "https://api.github.com/users/lukovnikov/repos",
"events_url": "https://api.github.com/users/lukovnikov/events{/privacy}",
"received_events_url": "https://api.github.com/users/lukovnikov/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Sorry for the delay in reviewing this.\r\nThis is a great PR and it looks good to me.\r\nThanks for adding some tests also.\r\nI agree with the (mostly cosmetic) comments from @marpaia.\r\nDo you think you can fix them and then we can merge?",
"Fixed @marpaia 's comments.",
"Awesome @lukovnikov, I think it looks great! Thanks for making this already awesome library even more awesome 💯 ",
"Thanks @lukovnikov!"
] | 1,554 | 1,556 | 1,556 | CONTRIBUTOR | null | re: [PR#389](https://github.com/huggingface/pytorch-pretrained-BERT/pull/389)
- refactored learning rate schedules into objects
- added `WarmupCosineWithHardRestartsSchedule` for cosine schedule with hard restarts
- added `WarmupCosineWithWarmupRestartsSchedule` for cosine schedule with restarts where each restart uses the same warmup slope | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/445/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/445/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/445",
"html_url": "https://github.com/huggingface/transformers/pull/445",
"diff_url": "https://github.com/huggingface/transformers/pull/445.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/445.patch",
"merged_at": 1556008059000
} |
https://api.github.com/repos/huggingface/transformers/issues/444 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/444/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/444/comments | https://api.github.com/repos/huggingface/transformers/issues/444/events | https://github.com/huggingface/transformers/issues/444 | 428,640,724 | MDU6SXNzdWU0Mjg2NDA3MjQ= | 444 | if crf needed when do ner? | {
"login": "alphanlp",
"id": 12368732,
"node_id": "MDQ6VXNlcjEyMzY4NzMy",
"avatar_url": "https://avatars.githubusercontent.com/u/12368732?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alphanlp",
"html_url": "https://github.com/alphanlp",
"followers_url": "https://api.github.com/users/alphanlp/followers",
"following_url": "https://api.github.com/users/alphanlp/following{/other_user}",
"gists_url": "https://api.github.com/users/alphanlp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alphanlp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alphanlp/subscriptions",
"organizations_url": "https://api.github.com/users/alphanlp/orgs",
"repos_url": "https://api.github.com/users/alphanlp/repos",
"events_url": "https://api.github.com/users/alphanlp/events{/privacy}",
"received_events_url": "https://api.github.com/users/alphanlp/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"A CRF gives better NER F1 scores in some cases, but not necessarily in all cases. In the BERT paper, no CRF is used and hence also no CRF in this repository. I'd presume the BERT authors tested both with and without CRF and found that a CRF layer gives no improvement, since using a CRF is kind of the default setting nowadays.",
"Issue #64 is a good reference for discussion on NER.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"This repository have showed how to add a CRF layer on transformers to get a better performance on token classification task.\r\nhttps://github.com/shushanxingzhe/transformers_ner",
"> github.com/shushanxingzhe/transformers_ner\r\n\r\nyour code does not work"
] | 1,554 | 1,652 | 1,560 | NONE | null | If crf needed when do ner? In BertForTokenClassification, just Linear is used to predict tag. If not, why? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/444/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/444/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/443 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/443/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/443/comments | https://api.github.com/repos/huggingface/transformers/issues/443/events | https://github.com/huggingface/transformers/issues/443 | 428,572,223 | MDU6SXNzdWU0Mjg1NzIyMjM= | 443 | How do you train custom corpus with bert? | {
"login": "shadylpstan",
"id": 14815653,
"node_id": "MDQ6VXNlcjE0ODE1NjUz",
"avatar_url": "https://avatars.githubusercontent.com/u/14815653?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shadylpstan",
"html_url": "https://github.com/shadylpstan",
"followers_url": "https://api.github.com/users/shadylpstan/followers",
"following_url": "https://api.github.com/users/shadylpstan/following{/other_user}",
"gists_url": "https://api.github.com/users/shadylpstan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shadylpstan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shadylpstan/subscriptions",
"organizations_url": "https://api.github.com/users/shadylpstan/orgs",
"repos_url": "https://api.github.com/users/shadylpstan/repos",
"events_url": "https://api.github.com/users/shadylpstan/events{/privacy}",
"received_events_url": "https://api.github.com/users/shadylpstan/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Maybe it's a problem of not setting `do_lower_case=False` and using a `cased` model like in #436.\r\nWhich pretrained model are you using?",
"@thomwolf \r\nsorry but this is completely not what I am asking for.\r\nSuppose I have medical data and the names of the medicines and diseases are not in the bert pre-trained corpus. So bert gives me [UNK] token for important medical terms. How can I train it on my custom data?\r\n\r\nUsing lower cased multilingual pre-trained model.\r\n\r\n**PS: Medical data was just an example.** ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hi, I'm also facing similar issue plz let me know if you have found any solution @shadylpstan \r\n",
"> Hi, I'm also facing similar issue plz let me know if you have found any solution @shadylpstan\r\n\r\nI was successful in modifying a couple of bert files and train it using my corpus.\r\nThough it was really a mess doing so because by default bert has a classification model of a certain number of classes.\r\nThe accuracy wasn't good enough. So no idea it is a worth giving it shot from your end."
] | 1,554 | 1,563 | 1,560 | NONE | null | I am using a domain specific dataset for text classification.
But major of my data points are treated with [UNK] token in Bert.
Can I please get help on how to keep my custom corpus tokens? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/443/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/443/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/442 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/442/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/442/comments | https://api.github.com/repos/huggingface/transformers/issues/442/events | https://github.com/huggingface/transformers/issues/442 | 428,418,589 | MDU6SXNzdWU0Mjg0MTg1ODk= | 442 | Unable to incrementally train BERT with custom training | {
"login": "AmrHendy",
"id": 20549448,
"node_id": "MDQ6VXNlcjIwNTQ5NDQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/20549448?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AmrHendy",
"html_url": "https://github.com/AmrHendy",
"followers_url": "https://api.github.com/users/AmrHendy/followers",
"following_url": "https://api.github.com/users/AmrHendy/following{/other_user}",
"gists_url": "https://api.github.com/users/AmrHendy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AmrHendy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AmrHendy/subscriptions",
"organizations_url": "https://api.github.com/users/AmrHendy/orgs",
"repos_url": "https://api.github.com/users/AmrHendy/repos",
"events_url": "https://api.github.com/users/AmrHendy/events{/privacy}",
"received_events_url": "https://api.github.com/users/AmrHendy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,560 | 1,560 | NONE | null | I have trained BERT with custom small training. I am unable to train the same on QQP and then with custom train. Any discussion will be appreciated. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/442/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/442/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/441 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/441/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/441/comments | https://api.github.com/repos/huggingface/transformers/issues/441/events | https://github.com/huggingface/transformers/pull/441 | 428,369,581 | MDExOlB1bGxSZXF1ZXN0MjY2NzUzMzE2 | 441 | Fix bug in run_squad.py | {
"login": "MottoX",
"id": 6220861,
"node_id": "MDQ6VXNlcjYyMjA4NjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6220861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MottoX",
"html_url": "https://github.com/MottoX",
"followers_url": "https://api.github.com/users/MottoX/followers",
"following_url": "https://api.github.com/users/MottoX/following{/other_user}",
"gists_url": "https://api.github.com/users/MottoX/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MottoX/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MottoX/subscriptions",
"organizations_url": "https://api.github.com/users/MottoX/orgs",
"repos_url": "https://api.github.com/users/MottoX/repos",
"events_url": "https://api.github.com/users/MottoX/events{/privacy}",
"received_events_url": "https://api.github.com/users/MottoX/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @MottoX, sorry for the delay on reviewing this.\r\nIt seems to make sense to me.\r\nWhat kind of testing are you referring to? Could you share a bit more about them?",
"Hi, @thomwolf \r\nI was trying to train a BERT-based model on NewsQA, a document-level QA dataset, using `run_squad.py`. I used 384 for max_seq_length and 128 for doc_stride. The model got an extremely bad result. I found there were numerous chunks with start_position and end_position as zeros.\r\nThen I checked the implementation of `run_squad.py` as well as `BertForQuestionAnswering`, which is basically BERT + one fully connected layer. I suspected that such out-of-span chunks are harmful for model to converge. So I modified the script to drop all these out-of-span chunks during training and got an acceptable result. I am sorry that I do not remember the exact numbers before and after doing this.\r\n\r\nI think the reason why the problem is not identified before is that context length (token-level) in SQuAD is not that long, which means the model can still easily converge anyway, with or without out-of-span chunks during training as they are really rare. However, when we have numerous out-of-span chunks in the training set, there will be a problem for model to converge.",
"I looked at the code again, and found it is quite confusing, since chunks with `start_position==0` and `end_position==0` are also used for the cases where we have examples that do not have answer (for version_2_with_negative). So the current fix seems not compatible with this. Now I am not exactly sure whether we need to train the model with those out-of-span chunks. However, from my last experience, there should be a problem when we have too many such out-of-span chunks in the training set and the model is biased to predicting the result on the first token (CLS), despite the fact that `write_predictions` filters out those invalid predictions."
] | 1,554 | 1,556 | 1,556 | CONTRIBUTOR | null | I fired an issue in Google's repo, https://github.com/google-research/bert/issues/540#issue-428344784
After testing, I found it is indeed a bug.
We should not put these chunks with `start_position==0` and `end_position==0` into training set.
Thanks for code review. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/441/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/441/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/441",
"html_url": "https://github.com/huggingface/transformers/pull/441",
"diff_url": "https://github.com/huggingface/transformers/pull/441.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/441.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/440 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/440/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/440/comments | https://api.github.com/repos/huggingface/transformers/issues/440/events | https://github.com/huggingface/transformers/issues/440 | 428,321,828 | MDU6SXNzdWU0MjgzMjE4Mjg= | 440 | How can i use bert for finding word embeddings | {
"login": "gkv91",
"id": 8320832,
"node_id": "MDQ6VXNlcjgzMjA4MzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8320832?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gkv91",
"html_url": "https://github.com/gkv91",
"followers_url": "https://api.github.com/users/gkv91/followers",
"following_url": "https://api.github.com/users/gkv91/following{/other_user}",
"gists_url": "https://api.github.com/users/gkv91/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gkv91/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gkv91/subscriptions",
"organizations_url": "https://api.github.com/users/gkv91/orgs",
"repos_url": "https://api.github.com/users/gkv91/repos",
"events_url": "https://api.github.com/users/gkv91/events{/privacy}",
"received_events_url": "https://api.github.com/users/gkv91/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I extract features like examples in extarct_features.py. But went I used these features(the last encoded_layers) as word embeddings, I got a worse result than using 300D Glove. I also used these features to compute the cos similarity for each word in sentences, I found that all values were around 0.6",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hi. I really need someone's help regarding using the bert model to extract the word embeddings: This script: https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/extract_features.py doesn't exist anymore.\r\n\r\nAny suggestions instead that replaced this script? \r\n"
] | 1,554 | 1,567 | 1,561 | NONE | null | Hi all,
Can I use pre-trained BERT for finding fixed sized word embeddings, like 300D Glove or Word2vec word embeddings?.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/440/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/440/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/439 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/439/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/439/comments | https://api.github.com/repos/huggingface/transformers/issues/439/events | https://github.com/huggingface/transformers/issues/439 | 428,321,776 | MDU6SXNzdWU0MjgzMjE3NzY= | 439 | DistributedDataParallel Not Working | {
"login": "moinnadeem",
"id": 813367,
"node_id": "MDQ6VXNlcjgxMzM2Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/813367?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moinnadeem",
"html_url": "https://github.com/moinnadeem",
"followers_url": "https://api.github.com/users/moinnadeem/followers",
"following_url": "https://api.github.com/users/moinnadeem/following{/other_user}",
"gists_url": "https://api.github.com/users/moinnadeem/gists{/gist_id}",
"starred_url": "https://api.github.com/users/moinnadeem/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moinnadeem/subscriptions",
"organizations_url": "https://api.github.com/users/moinnadeem/orgs",
"repos_url": "https://api.github.com/users/moinnadeem/repos",
"events_url": "https://api.github.com/users/moinnadeem/events{/privacy}",
"received_events_url": "https://api.github.com/users/moinnadeem/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi @moinnadeem,\r\nWhat is the hardware you are using and what is the exact command you are using to run DistributedDataParallel with the PyTorch launch module? ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,560 | 1,560 | NONE | null | Hi, I've been stuck on this for days, so I decided to make an issue.
When I run DistributedDataParallel with the PyTorch launch module, I see that one machine will start training without waiting for the other one to start; this is different than if I run it without the launch module. WIthout the launch module, I am also letting one process have access to multiple GPUs, rather than just one.
I'm following your implementation of DistributedDataParallel in your Medium article: https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/439/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/439/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/438 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/438/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/438/comments | https://api.github.com/repos/huggingface/transformers/issues/438/events | https://github.com/huggingface/transformers/issues/438 | 428,199,727 | MDU6SXNzdWU0MjgxOTk3Mjc= | 438 | convert_tf_checkpoint_to_pytorch 'BertPreTrainingHeads' object has no attribute 'squad' | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @SandeepBhutani,\r\nCan you point me to the script you use for finetuning in Tensorflow?",
"Hi @thomwolf : Thanks for reply. \r\nFine Tuning is done by mentioning do_train=True on run_squad.py (From google bert release github page: [https://github.com/google-research/bert](https://github.com/google-research/bert)) \r\nInternally, it calls `estimator.train(input_fn=train_input_fn, max_steps=num_train_steps)` \r\nFinetuning file was also same train-v1.1.json.. [https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json)\r\nSample header of train file is : \r\n`{\"data\": [{\"title\": \"University_of_Notre_Dame\", \"paragraphs\": [{\"context\": \"Architecturally` \r\n\r\n\r\nFollowing observation in case it is useful:\r\nWhile converting checkpoint of origional uncased bert_model.ckpt following log is printed:\r\n```\r\nLoading TF weight bert/encoder/layer_9/output/LayerNorm/gamma with shape [768]\r\nLoading TF weight bert/encoder/layer_9/output/dense/bias with shape [768]\r\nLoading TF weight bert/encoder/layer_9/output/dense/kernel with shape [3072, 768]\r\nLoading TF weight bert/pooler/dense/bias with shape [768]\r\nLoading TF weight bert/pooler/dense/kernel with shape [768, 768]\r\nLoading TF weight cls/predictions/output_bias with shape [30522]\r\nLoading TF weight cls/predictions/transform/LayerNorm/beta with shape [768]\r\nLoading TF weight cls/predictions/transform/LayerNorm/gamma with shape [768]\r\nLoading TF weight cls/predictions/transform/dense/bias with shape [768]\r\nLoading TF weight cls/predictions/transform/dense/kernel with shape [768, 768]\r\nLoading TF weight cls/seq_relationship/output_bias with shape [2]\r\nLoading TF weight cls/seq_relationship/output_weights with shape [2, 768]\r\nBuilding PyTorch model from configuration: {\r\n```\r\nWhile converting checkpoint after finetuning is done (model.ckpt-9000) following log is printed:\r\n```\r\nLoading TF weight bert/encoder/layer_9/output/dense/kernel/adam_m with shape [3072, 768]\r\nLoading TF weight bert/encoder/layer_9/output/dense/kernel/adam_v with shape [3072, 768]\r\nLoading TF weight bert/pooler/dense/bias with shape [768]\r\nLoading TF weight bert/pooler/dense/kernel with shape [768, 768]\r\nLoading TF weight cls/squad/output_bias with shape [2]\r\nLoading TF weight cls/squad/output_bias/adam_m with shape [2]\r\nLoading TF weight cls/squad/output_bias/adam_v with shape [2]\r\nLoading TF weight cls/squad/output_weights with shape [2, 768]\r\nLoading TF weight cls/squad/output_weights/adam_m with shape [2, 768]\r\nLoading TF weight cls/squad/output_weights/adam_v with shape [2, 768]\r\nLoading TF weight global_step with shape []\r\nBuilding PyTorch model from configuration: {\r\n```\r\n_cls/predictions_ is gone and _cls/squad_ appeared",
"After reading the code of both tensorflow and pytorch version, figured out that tensorflow version is referring squad in create_model, like below (**cls/squad/output_weights**):\r\n```\r\ndef create_model(bert_config, is_training, input_ids, input_mask, segment_ids,\r\n use_one_hot_embeddings):\r\n \"\"\"Creates a classification model.\"\"\"\r\n model = modeling.BertModel(\r\n config=bert_config,\r\n is_training=is_training,\r\n input_ids=input_ids,\r\n input_mask=input_mask,\r\n token_type_ids=segment_ids,\r\n use_one_hot_embeddings=use_one_hot_embeddings)\r\n\r\n final_hidden = model.get_sequence_output()\r\n\r\n final_hidden_shape = modeling.get_shape_list(final_hidden, expected_rank=3)\r\n batch_size = final_hidden_shape[0]\r\n seq_length = final_hidden_shape[1]\r\n hidden_size = final_hidden_shape[2]\r\n\r\n output_weights = tf.get_variable(\r\n \"cls/squad/output_weights\", [2, hidden_size],\r\n initializer=tf.truncated_normal_initializer(stddev=0.02))\r\n\r\n output_bias = tf.get_variable(\r\n \"cls/squad/output_bias\", [2], initializer=tf.zeros_initializer())\r\n```\r\nAny suggestion, what should be tweaked? And where (create_model in tensorflow version should be changed or convert_tf_checkpoint_to_pytorch in pytorch version should be changed?) \r\n\r\nLooks like the definition of pytorch model (BertForPreTraining mentioned in conversion script) is different from tensorflow version, when fine tuned. That is why cls -> squad -> output_bias is not found. Is my understanding correct? If yes, is correct class already available which we can refer while conversion?",
"Hi @thomwolf , \r\nTo make the conversion work, in modeling.py of pytorch version, I have added the class and 1 line of code in BertPreTrainingHeads below. After this conversion is happening. But I am not sure if I have done correct thing (_being a beginner in both tf and pytorch_). \r\nWould you like to validate/correct please. \r\n\r\n\r\n```\r\nclass SandeepSquadClass(nn.Module): ########this class sandeep added\r\n def __init__(self, config, bert_model_embedding_weights): \r\n super(SandeepSquadClass, self).__init__()\r\n self.weight = Variable(torch.ones(2, config.hidden_size), requires_grad=True) \r\n self.bias = Variable(torch.ones(2), requires_grad=True)\r\n \r\n def forward(self):\r\n print(\"What to do?\")\r\n \r\nclass BertPreTrainingHeads(nn.Module):\r\n def __init__(self, config, bert_model_embedding_weights):\r\n super(BertPreTrainingHeads, self).__init__()\r\n self.predictions = BertLMPredictionHead(config, bert_model_embedding_weights)\r\n #sandeep code below 3 apr\r\n self.squad = SandeepSquadClass(config, bert_model_embedding_weights) ###this line sandeep added\r\n self.seq_relationship = nn.Linear(config.hidden_size, 2)\r\n\r\n\r\n```",
"Hi @SandeepBhutani, I pushed a commit to master which should help you do this kind of thing.\r\n\r\nFirst, switch to master by cloning the repo and then follow the following instructions:\r\n\r\nThe `convert_tf_checkpoint_to_pytorch` conversion script is made to create `BertForPretraining` model which is not your use case but you can load another type of model by reproducing the behavior of this script as follows:\r\n\r\n```python\r\nfrom pytorch_pretrained_bert import BertConfig, BertForTokenClassification, load_tf_weights_in_bert\r\n\r\n# Initialise a configuration according to your model\r\nconfig = BertConfig.from_pretrained('bert-XXX-XXX')\r\n\r\n# You will need to load a BertForTokenClassification model\r\nmodel = BertForTokenClassification(config)\r\n\r\n# Load weights from tf checkpoint\r\nload_tf_weights_in_bert(model, tf_checkpoint_path)\r\n\r\n# Save pytorch-model\r\nprint(\"Save PyTorch model to {}\".format(pytorch_dump_path))\r\ntorch.save(model.state_dict(), pytorch_dump_path)\r\n```",
"Thanks @thomwolf ... After following change the checkpoint generated smoothly. \r\n```\r\n #model = BertForPreTraining(config) ##commented this\r\n model = BertForTokenClassification(config, 2) ## Added this\r\n```\r\nLet us give a try to run prediction using new .bin file. Hope the results would be same as using tensorflow version with .ckpt file. \r\nAppreciate 👍 ",
"I downloaded tensorflow checkpoints for domain specific bert model and extracted the zip file into the folder pretrained_bert which contains the following the three files\r\n\r\n- model.ckpt.data-00000-of-00001\r\n- model.ckpt.index\r\n- model.ckpt.meta\r\n\r\nI used the following code to convert tensorflow checkpoints to pytorch\r\n\r\n```\r\nimport torch\r\n\r\nfrom pytorch_transformers.modeling_bert import BertConfig, BertForPreTraining, load_tf_weights_in_bert\r\n\r\n\r\ntf_checkpoint_path=\"pretrained_bert/model.ckpt\"\r\nbert_config_file = \"bert-base-cased-config.json\"\r\npytorch_dump_path=\"pytorch_bert\"\r\n\r\nconfig = BertConfig.from_json_file(bert_config_file)\r\nprint(\"Building PyTorch model from configuration: {}\".format(str(config)))\r\nmodel = BertForPreTraining(config)\r\n\r\n# Load weights from tf checkpoint\r\nload_tf_weights_in_bert(model, config, tf_checkpoint_path)\r\n\r\n# Save pytorch-model\r\nprint(\"Save PyTorch model to {}\".format(pytorch_dump_path))\r\ntorch.save(model.state_dict(), pytorch_dump_path)\r\n```\r\n\r\nI got this error when I ran the above code\r\n\r\n**NotFoundError: Unsuccessful TensorSliceReader constructor: Failed to find any matching files for pretrained_bert/model.ckpt**\r\n\r\nAny help is really appreciated............",
"Seems like the script cannot find your checkpoint. Try giving it the full absolute path to the file.",
"@thomwolf \r\nThanks, I didn't get any error when I gave absolute path of the file. ",
"I was trying to convert my fine tuned model to pytorch using the following command.\r\n\r\n`\r\ntf_checkpoint_path='models/model.ckpt-21'\r\nbert_config_file='PRETRAINED_MODELS/uncased_L-12_H-768_A-12/bert_config.json'\r\npytorch_dump_path='pytorch_models/pytorch_model.bin'\r\n\r\npython convert_bert_original_tf_checkpoint_to_pytorch.py --tf_checkpoint_path=$tf_checkpoint_path --bert_config_file=$bert_config_file --pytorch_dump_path=$pytorch_dump_path `\r\n\r\nThe issue that I face is given below. Any help would be appreciated.\r\n\r\nTraceback (most recent call last):\r\nFile \"convert_bert_original_tf_checkpoint_to_pytorch.py\", line 65, in\r\nargs.pytorch_dump_path)\r\nFile \"convert_bert_original_tf_checkpoint_to_pytorch.py\", line 36, in convert_tf_checkpoint_to_pytorch\r\nload_tf_weights_in_bert(model, config, tf_checkpoint_path)\r\nFile \"/home/cibin/virtual_envs/pytorch/lib/python3.7/site-packages/transformers/modeling_bert.py\", line 98, in load_tf_weights_in_bert\r\npointer = getattr(pointer, 'classifier')\r\nFile \"/home/cibin/virtual_envs/pytorch/lib/python3.7/site-packages/torch/nn/modules/module.py\", line 585, in getattr\r\ntype(self).name, name))\r\nAttributeError: 'BertPreTrainingHeads' object has no attribute 'classifier'",
"**A possible solution if you're copying a SQuAD-fine-tuned Bert from TF to PT**\r\n\r\nIssue: \r\n`AttributeError: 'BertPreTrainingHeads' object has no attribute 'classifier'`\r\n\r\n\r\nIt works for me by doing the following steps:\r\n\r\nStep 1. \r\nIn the script `convert_tf_checkpoint_to_pytorch.py` (or `convert_bert_original_tf_checkpoint_to_pytorch.py`):\r\n\r\n- Replace all `BertForPreTraining `with `BertForQuestionAnswering`.\r\n\r\nStep 2.\r\nOpen the source code file `modeling_bert.py` in your package `site-packages\\transformers`:\r\n\r\n- In the function `load_tf_weights_in_bert`, replace\r\n`elif l[0] == 'squad':`\r\n `pointer = getattr(pointer, 'classifier')`\r\nwith\r\n`elif l[0] == 'squad':`\r\n `pointer = getattr(pointer, 'qa_outputs')`\r\n\r\nIt should work since `qa_outputs` is the attribute name for the output layer of `BertForQuestionAnswering` instead of `classifier`.\r\n\r\nStep 3.\r\nAfter copying, check your pytorch model by evaluating the `dev-v2.0.json` with a script like this:\r\n`python run_squad.py --model_type bert --model_name_or_path MODEL_PATH --do_eval --train_file None --predict_file dev-v2.0.json --max_seq_length 384 --doc_stride 128 --output_dir ./output/ --version_2_with_negative`\r\nwhere `output_dir` should contain a copy of the pytorch model.\r\n\r\nThis will result in an evaluation like this:\r\n`{\r\n \"exact\": 72.99755748336563,\r\n \"f1\": 76.24686988414918,\r\n \"total\": 11873,\r\n \"HasAns_exact\": 72.82388663967612,\r\n \"HasAns_f1\": 79.33182964482165,\r\n \"HasAns_total\": 5928,\r\n \"NoAns_exact\": 73.17073170731707,\r\n \"NoAns_f1\": 73.17073170731707,\r\n \"NoAns_total\": 5945,\r\n \"best_exact\": 74.3619978101575,\r\n \"best_exact_thresh\": -3.6369030475616455,\r\n \"best_f1\": 77.12234803941384,\r\n \"best_f1_thresh\": -3.6369030475616455\r\n}`\r\nfor a `BERT-Base` model.\r\n\r\nHowever, if using `BertForTokenClassification` instead, the model will not be correctly copied since the structures for the classification layer are different. I tried this and got a model that had a f1 score of 10%.",
"AttributeError: 'BertForTokenClassification' object has no attribute 'predict'\r\nHow do I use BERT trained model for prediction?",
"@rashibudati, please take a look at the docs, namely the [Usage](https://huggingface.co./transformers/usage.html#named-entity-recognition) section which shows how to use token classification models.",
"@Hya-cinthus Thank you so much! This saved me a lot of headache! "
] | 1,554 | 1,589 | 1,554 | NONE | null | Trying to convert BERT checkpoints to pytorch checkpoints. It worked for default uncased bert_model.ckpt. However, after we did a custom training of tensorflow version and then tried to convert TF checkpoints to pytorch, it is giving error: 'BertPreTrainingHeads' object has no attribute 'squad'
When printed
```
elif l[0] == 'output_bias' or l[0] == 'beta':
pointer = getattr(pointer, 'bias')
elif l[0] == 'output_weights':
pointer = getattr(pointer, 'weight')
else:
print("--> ", str(l)) ############### printed this
print("==> ", str(pointer)) ################# printed this
pointer = getattr(pointer, l[0])
```
output:
```
--> ['squad']
==> BertPreTrainingHeads(
(predictions): BertLMPredictionHead(
(transform): BertPredictionHeadTransform(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
)
(decoder): Linear(in_features=768, out_features=30522, bias=False)
)
(seq_relationship): Linear(in_features=768, out_features=2, bias=True)
)
```
- Can you please tell us what is happening? Does tensorflow add something during finetuning? Not sure from where squad word got into tensorflow ckpt file.
- And, what needs to be done to fix this?
- Are you planning to fix this and release updated code? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/438/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/438/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/437 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/437/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/437/comments | https://api.github.com/repos/huggingface/transformers/issues/437/events | https://github.com/huggingface/transformers/pull/437 | 428,115,435 | MDExOlB1bGxSZXF1ZXN0MjY2NTU3Nzc5 | 437 | Fix links in README | {
"login": "MottoX",
"id": 6220861,
"node_id": "MDQ6VXNlcjYyMjA4NjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6220861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MottoX",
"html_url": "https://github.com/MottoX",
"followers_url": "https://api.github.com/users/MottoX/followers",
"following_url": "https://api.github.com/users/MottoX/following{/other_user}",
"gists_url": "https://api.github.com/users/MottoX/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MottoX/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MottoX/subscriptions",
"organizations_url": "https://api.github.com/users/MottoX/orgs",
"repos_url": "https://api.github.com/users/MottoX/repos",
"events_url": "https://api.github.com/users/MottoX/events{/privacy}",
"received_events_url": "https://api.github.com/users/MottoX/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,554 | 1,554 | 1,554 | CONTRIBUTOR | null | Fixed two broken links, i.e., _**convert_tf_checkpoint_to_pytorch.py**_ and _**run_squad.py**_.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/437/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/437/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/437",
"html_url": "https://github.com/huggingface/transformers/pull/437",
"diff_url": "https://github.com/huggingface/transformers/pull/437.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/437.patch",
"merged_at": 1554198047000
} |
https://api.github.com/repos/huggingface/transformers/issues/436 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/436/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/436/comments | https://api.github.com/repos/huggingface/transformers/issues/436/events | https://github.com/huggingface/transformers/issues/436 | 427,944,845 | MDU6SXNzdWU0Mjc5NDQ4NDU= | 436 | BertTokenizer.from_pretrained('bert-base-multilingual-cased') does not recognize Korean | {
"login": "chiehminwei",
"id": 2521639,
"node_id": "MDQ6VXNlcjI1MjE2Mzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521639?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chiehminwei",
"html_url": "https://github.com/chiehminwei",
"followers_url": "https://api.github.com/users/chiehminwei/followers",
"following_url": "https://api.github.com/users/chiehminwei/following{/other_user}",
"gists_url": "https://api.github.com/users/chiehminwei/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chiehminwei/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chiehminwei/subscriptions",
"organizations_url": "https://api.github.com/users/chiehminwei/orgs",
"repos_url": "https://api.github.com/users/chiehminwei/repos",
"events_url": "https://api.github.com/users/chiehminwei/events{/privacy}",
"received_events_url": "https://api.github.com/users/chiehminwei/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @icewing1996,\r\nThis comes from the fact that your tokenizer has `do_lower_case=True` but you load an uncased model.\r\n\r\nTry loading the tokenizer like this `tok = BertTokenizer.from_pretrained('bert-base-multilingual-uncased', do_lower_case=False)`.\r\n\r\nThis is actually a common issue and I see Jacob has added [a test](https://github.com/google-research/bert/blob/master/tokenization.py#L28) in the google repo to check the coherence between the lower casing option and the model checkpoint name. I will add a similar test.",
"I used the Korean wiki corpus with the \"do_lower_case = True\" option to create pretrain data.\r\nMost of the data is generated as [UNK] token as followings:\r\n\r\nINFO:tensorflow:next_sentence_labels: 1\r\nINFO:tensorflow:*** Example ***\r\nINFO:tensorflow:tokens: [CLS] gr ##ace [UNK] [MASK] [UNK] [UNK] [UNK] 2 ᄀ ##ᅢ [UNK] [UNK] [UNK] [UNK] gr ##ace - 1 ᄀ ##ᅪ gr ##ace - 2 ᄀ ##ᅡ ( [UNK] e ##ss ##p - 2 a , e ##ss ##p - 2 [MASK] 유전적 [UNK] 220 km [UNK] ᄀ ##ᅥ ##ᄅ ##ᅵ [UNK] [UNK] ᄆ ##ᅧ [UNK] [UNK] [UNK] ᄆ ##ᅧ [UNK] , [UNK] , [UNK] [UNK] [UNK] ##댜 [MASK] [MASK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] . [UNK] [UNK] [UNK] , n ##as ##a , j ##pl , d ##l ##r [UNK] [UNK] [UNK] [MASK] [MASK] [UNK] [MASK] [MASK] [MASK] [MASK] [MASK] [UNK] j ##pl [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] . 2002 [UNK] 3 [UNK] [UNK] [UNK] ᄀ ##ᅵ ##ᄌ ##ᅵ [UNK] [UNK] [UNK] [UNK] [UNK] 2017 [UNK] 10 [UNK] [MASK] ᄀ ##ᅡ [UNK] [UNK] [UNK] . [UNK] [UNK] [UNK] [UNK] [UNK] 5 [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] 15 [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] ᄇ ##ᅩ ##ᄋ ##ᅵ ##ᄌ ##ᅥ [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] . [SEP] [UNK] [MASK] [UNK] 1956 [UNK] [UNK] [UNK] [MASK] [UNK] [UNK] [UNK] [UNK] [UNK] [MASK] ᄀ ##ᅪ [UNK] [UNK] [UNK] [UNK] [UNK] ᄆ ##ᅩ ##ᄃ ##ᅮ 11 [UNK] [UNK] [UNK] [UNK] [MASK] ##졌 [MASK] [MASK] ᄀ ##ᅩ [UNK] [UNK] . [UNK] [UNK] [UNK] 3 [UNK] · [UNK] [MASK] [MASK] ᄀ ##ᅲ ##ᄆ ##ᅩ ᄅ ##ᅩ [UNK] [UNK] [UNK] [UNK] ᄇ ##ᅩ [UNK] [UNK] [UNK] [UNK] ( 人 ) [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] . ᄀ ##ᅳ [MASK] [MASK] ᄀ ##ᅪ [UNK] , [MASK] [MASK] [MASK] [UNK] , [UNK] , ##ᅢ [UNK] [UNK] 착취 [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [MASK] [UNK] . [UNK] ( 任 忠 [UNK] , ? - ? ) [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [MASK] [UNK] [UNK] , [UNK] 토지 [UNK] . [UNK] [MASK] [MASK] [MASK] [MASK] [MASK] [MASK] [MASK] [MASK] [MASK] [MASK] [UNK] [UNK] [UNK] [MASK] [MASK] [UNK] . [UNK] [MASK] [MASK] [UNK] [UNK] ) [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [MASK] [MASK] [UNK] [UNK] [UNK] [UNK] [UNK] , [UNK] , [MASK] [MASK] [UNK] [UNK] [UNK] [UNK] ᄀ ##ᅩ , [UNK] [UNK] [UNK] [UNK] ( [UNK] 1 [MASK] ) [UNK] [UNK] [UNK] [MASK] [UNK] [UNK] [UNK] [UNK] [UNK] [MASK] [UNK] [UNK] . [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] 크라이 경성 ##렘 [MASK] [UNK] [UNK] [UNK] [UNK] 12 [UNK] ᄇ ##ᅮ ##ᄐ ##ᅥ [UNK] [UNK] [UNK] ##ᅡ ##ᄐ ##ᅡ ##ᄂ ##ᅡ [UNK] [UNK] [UNK] [UNK] . [UNK] 1914 [UNK] [UNK] [UNK] ᄀ ##ᅪ [MASK] [MASK] 올리 [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [MASK] [MASK] [MASK] [MASK] [UNK] 1 [UNK] ᄇ ##ᅮ ##ᄐ ##ᅥ [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [MASK] [UNK] . [MASK] [MASK] [UNK] ᄀ ##ᅩ ##ᄌ ##ᅵ ##ᄃ ##ᅩ [UNK] [UNK] [MASK] ᄇ ##ᅡ , [UNK] [UNK] [UNK] [UNK] ᄇ ##ᅩ ##ᄃ ##ᅡ [UNK] [UNK] [UNK] [UNK] ᄅ ##ᅩ ᄂ ##ᅡ ##ᄐ ##ᅡ ##ᄂ ##ᅡ [UNK] [UNK] [MASK] . [MASK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] . [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [SEP]",
"> I'm using the pre-trained multilingual tokenizer to tokenize some Korean texts, but it seems like this tokenizer is unable to recognize any Korean text at all.\r\n> \r\n> For example, when running on all the Universal Dependency Korean treebanks, this tokenizer fails to tokenize (it produces '[UNK]') the following characters. I know some of them are not Korean, but most of them are. More confusingly, when I check the `vocab.txt` file for the [BERT-Base, Multilingual Cased](https://storage.googleapis.com/bert_models/2018_11_23/multi_cased_L-12_H-768_A-12.zip) in the original repo (https://github.com/google-research/bert), it shows that Korean characters (I manually checked for '렬') are in the vocabulary.\r\n> \r\n> This makes me wonder whether there is any bug in the tokenizer provided in this PyTorch repo. I'm considering switching back to the tokenizer in the original code base. Will this create any compatibility issues?\r\n> \r\n> {'燄', '렬', '툇', '촌', '내', '윙', '쌈', '꿇', '톨', '葚', '솟', '힌', '래', '銎', '凊', '컸', '톤', '', '졍', '의', '슭', '옷', '챠', '囒', '뷘', '멤', '싱', '츠', '령', '겸', '댄', '휙', '醗', '돕', '톳', '던', '페', '띔', '짚', '락', '앙', '왜', '핼', '컫', '쿵', '왠', '기', '냇', '칼', '런', '험', '드', '궐', '얄', '찜', '렝', '빈', '후', '싫', '雎', '덕', '틀', '딴', '굶', '뜸', 'ㅑ', '', '손', '펴', '쏠', '튀', '화', '슘', '대', '왕', '잣', '딨', '듈', '뎀', '鑛', '칭', '젝', '뉴', '', '쑤', '작', '묘', '飮', '새', '쑥', '嘈', '캐', '笳', '랩', '', '히', '맵', '냈', '츰', '꿨', '딤', '밑', '낼', '訇', '뀌', '뻑', '혔', '겝', '얹', '랍', '', '옅', '징', '권', '욱', '탭', '', '흩', '벳', '밈', '굴', '연', '엑', '綉', '숯', '무', '셋', '벌', '텃', '클', '쫑', '덟', '쳬', '멎', '칵', '팅', '뜨', '땄', '㎡', '끽', '뿍', '담', '펭', '쉰', '있', '쏘', '탤', '濞', '치', '옵', '잃', '언', '빽', '짠', '넙', '깆', '콤', '러', '픽', '푸', '회', '낍', '스', '쩨', '진', '풋', '횡', '탑', '솝', '딕', '영', '볐', '씹', '뒷', '퀼', '렸', '별', '옇', '얘', '謔', 'Ↄ', '팎', '긋', '뽐', '현', '켠', '룻', '소', '몇', '쨌', '벨', '쩐', '붐', '트', '떴', '', '줌', '꽤', '밭', '쓴', '매', '쳤', '뱃', '콰', '먕', '봤', '', '베', '첩', '년', '짐', '뻤', '괭', '함', '鍝', '도', '폭', '꾸', '뜩', '괞', '닦', '몹', '', '팰', '콕', '떻', '킬', '강', '찡', '궂', '꿉', '빴', '즈', '데', '껑', '엘', '약', '천', '씻', '', '㈜', '롯', '털', '야', '혈', '펀', '', '', '뺐', '繽', '닙', '쪽', '행', '넉', '휩', '퀀', '쇠', '셑', '댑', '얽', '질', '뻬', '', '덥', '骯', '뀔', '룩', '팀', '愙', '괜', '몽', '냐', '씬', '서', '또', '썬', '절', '갱', 'ㅊ', '왼', '펠', '놈', '쯩', '름', '토', '받', '璣', '咧', '츄', '깃', '헬', '잇', '덜', '곡', '것', '겹', '지', '檣', '억', '셀', '픔', '륙', '돈', 'ㅜ', '믈', '멈', '빗', '을', '둘', '탱', '얇', '식', '', '틱', '똑', '줄', '궤', '잼', '착', '廝', '枸', '볏', '샴', '疙', '飈', '', '댁', '날', '킵', '동', '룸', '', '헐', '부', '웬', '램', '윗', '숍', '齲', '빼', '빡', '혐', '뮌', '너', '란', '땠', '개', '이', '끔', '麩', '표', '훈', '간', '바', '옆', '틸', '탄', '살', 'ʈ', '꽂', '벙', '뱅', '닭', '멀', '줍', '✌', '짊', '葯', '쨍', '쥔', '않', '술', '육', '햇', '텁', '뵈', '쿄', '', '웅', '막', '낮', '브', '펼', '색', '갰', '께', '음', '쐬', '숱', '빛', '텝', '젠', '준', '키', '왓', '팝', '순', '떳', '번', '팡', '핫', '팬', '畹', '깍', '슷', '겋', '위', '꺽', '껀', '낸', '숴', '잠', '휴', '訐', '貮', '티', '늪', '깔', '涮', '촐', '좀', '쭐', '턴', '같', '먼', '꾹', '쎌', '충', '땅', '희', '敉', '캠', '넋', '맑', '갇', '凈', '를', '쌌', '잿', '똥', '핵', '올', '윈', '접', '뮤', '귤', '갖', '촘', '웍', '속', '댕', '砒', '謇', '郫', '낄', '죽', '가', '깁', '뷸', '는', '쏜', '뉜', '릉', '쓰', '텼', '환', '皰', '띠', '즙', '자', '톱', '봄', '갠', '쉽', '항', '답', '넣', '옐', '머', '빔', '쬐', '듄', '썰', '로', '칩', '마', '뽂', '숀', '침', '찍', '캘', '노', '뼈', '', '놔', '특', '곁', '챙', '밥', '형', '팠', '섬', '焗', '닉', '관', '쉐', '잡', '슐', '뗏', '획', '추', '욘', '꾼', '좌', '쫀', '나', '킹', '뼛', '은', '랴', '깻', '눈', '욕', '하', '', '찢', '젊', '궁', '총', '놋', '둬', '뮬', '詝', '낭', '얌', '셨', '첫', '柢', '셉', '', '닥', '결', '겪', '', '⅛', '뾰', '뢰', '륨', '좇', '꼐', '옌', '둔', '', '금', '평', '면', '癤', '암', '허', '뱉', '銠', '꿔', '✔', '멘', '겟', '싯', '씁', '림', '볕', '넨', '휠', '☝', '仚', '쟈', '덤', '벅', '즘', '숙', '철', 'ㄹ', '재', '낚', '쉬', '롬', '휘', '렀', '荑', '득', '옮', '렙', '신', '랏', '헉', '푼', '났', '퐁', '쌥', '볶', '밝', '샀', '뽑', '춘', '앓', '곧', '찮', '믿', '늙', '녘', '쌤', '예', '밍', '요', '엣', '딱', '못', '뺨', '렉', '모', '쟁', '퍽', '鬪', '팜', 'ɟ', '틈', '체', '벚', '뛴', '훅', '윤', '짤', '샐', '궈', '댐', '룡', '덧', '깊', '賬', '택', '넬', '흰', '髖', '쁠', '투', '만', '창', '묽', '썼', '', '셩', '僊', '수', '豢', '癥', '삼', '춰', '렁', '퀴', '슛', '쌉', '', '묶', '정', '탓', '얏', '', '버', '쯔', '밉', '챈', '♩', '리', '떨', '료', '했', '잘', '뤄', '붕', '쩌', '탁', '혀', '繙', '껴', '박', '᾽', '뜀', '홉', '팔', '컨', '饃', '釩', '웰', '꼿', '薺', '縕', '깜', '케', '세', '鎰', '褂', '슌', '벵', '꼈', '카', '甍', '檨', '寗', '빵', '찔', '엊', '오', '통', '', '꽝', '니', '첨', '맺', '랑', '헙', '믄', '더', '쳐', '🏼', '옳', '쁨', '鈇', '취', '玕', '럽', '푹', '눠', '제', '디', '벡', '메', '걔', '訄', '滹', '眈', '☎', '물', '갓', '없', '', '송', '뭇', '멸', '빅', '늉', '난', '휼', '흙', '깥', '옥', '쫙', '례', '폰', '맏', '되', '훨', '헝', '짧', '쪼', '▶', '끓', '톡', '흥', '홈', '및', '콘', '빠', '등', '르', '깝', '밟', '펑', '끼', '잭', '와', '넷', '율', '찼', '酃', '균', '뿜', '악', '튈', '률', '', '걱', '과', '퀄', '튜', '끈', '늑', '렐', '쫄', '멋', '―', '탈', '憮', '잉', '醺', '粦', '맣', '큘', '曧', '쿼', '파', '둡', '탕', '抔', '솥', '척', '고', '', '숭', '람', '벗', '잤', 'ௌ', '옻', '叨', '듀', '늘', '염', '늦', '돌', '껏', '귄', '', '봉', '움', '뭄', '낯', '템', '멍', '랜', '', '헌', '샹', '압', '몰', '㎢', '큼', '윽', '', '퀵', '덩', '잊', '眯', '피', '학', '넴', '갬', '녹', '출', '꼴', '', '퍈', '쎄', '굳', '외', '붓', '犂', '슴', '늬', '글', '룬', '탠', '듣', '엿', '칸', '뿌', '갸', '냄', '깡', '괴', '든', '불', '툰', '甪', '箬', '빳', '한', '晳', '킷', '쭉', '둑', '꿍', '쭈', '맙', '鷄', '뜯', '폄', '酩', '퓨', '조', '롤', '프', '뻔', '교', '쿨', '펜', '닯', '', '크', '뀐', '紈', '집', '땡', '놓', '훔', '즌', '헨', '녀', '켤', '따', '', '포', '땐', '랙', '콩', '합', '농', '', '전', '엥', '텄', '', '긍', '', '뮐', '슝', '꽃', '븐', '', '岦', '빤', '찐', '☺', '둥', '랬', '뚤', '깽', '뺏', '목', '슨', '웨', '굵', '칠', '뜻', '려', '산', '끕', '커', '튿', '단', '쌀', '햄', '牾', '켰', '륜', '밤', '골', '익', '흉', '뷔', '랄', '뱀', '숨', '돔', '붙', '찧', '둠', '갔', '럿', '져', 'ʂ', '할', '존', '챌', '늠', '픈', '뷰', '댈', '갑', '컹', '쪄', '맜', '騏', '칡', '餮', '앎', '누', '굿', '幪', '멕', '백', '곤', '싸', '꼬', '헷', '펄', '럴', '饕', '뚫', '芘', 'ᆢ', '젯', '릴', '북', '', '룹', '핀', '옛', '병', '낟', '품', '짱', '겼', '쉴', '앳', '닳', '쾌', '힐', '경', '짓', '델', '酊', '턱', '끌', '횃', '호', '씀', '켯', '‒', '컬', '밋', '인', '향', '렷', '蚺', '몸', '❄', '놀', '탯', '쏭', '왈', '점', '팟', '', '써', '념', '뒬', '혹', '폐', '격', '앨', '본', '듭', '엷', '헴', '루', '콜', '묏', '', '큰', '샛', '았', '돗', '퓌', '장', '깎', '훼', '엾', '맞', '윌', '윷', '졔', '꿰', '쩍', '양', '킨', '', '줬', '왔', '볍', '엌', '샤', '£', '삶', '힘', '꽁', '길', '급', '럭', '엮', '瘩', '땀', '구', '쏟', '몫', '쫌', '✓', '으', '딛', '룰', '놉', '력', '齬', '뒀', '플', '꿩', '확', '졌', 'ㅇ', '㏊', 'ɖ', '넝', '빌', '여', '믹', '삭', '뽕', '뽈', '楂', '킴', '었', '캄', '사', '웠', '청', '뀨', '셈', '말', '넜', '', '맬', '삐', '紜', '챔', '', '논', '쥬', '딧', '쁘', '윔', '들', '뛸', '춧', '좋', '풍', '퓰', '뙤', '흽', '튼', '뮈', '끗', '공', '짖', '볼', '웃', '블', '랫', '뚜', '굉', '묵', '꿀', '톰', '객', '떤', '낙', '찾', '코', '셸', '녔', '원', '넥', '뗀', '펫', '셧', '袥', '羱', '심', '즉', 'ㅎ', '앤', '뜬', '냥', '塍', '쿠', '캔', '숲', '핏', '뭐', '댓', '먹', '얻', '엠', '됨', '띄', '뗄', '봇', '듐', '칫', '두', '롱', '능', '측', '崞', '융', '켓', '딩', '효', '㎝', '거', '샘', '변', '립', '맹', '괄', '쿰', '팸', '판', '앞', 'ㄷ', '밖', '켜', '밌', '', '맸', '', '임', '습', 'Ⓣ', '팽', '뻥', '릭', '높', '성', '짭', '첼', '덫', '슬', '迢', '월', '견', '미', '값', '터', '촉', '근', '옴', '김', '끝', '㎞', '센', '쏴', '呔', '엇', '떡', '뿔', '넛', '승', '섰', '곳', '직', '텅', '륭', '법', '잖', '', '겠', '곽', '용', '죠', '닿', '뭍', '', '생', '액', 'ㅁ', '탬', '뉘', '흡', '썽', '쟝', '♬', '낫', '폼', '층', '곬', '', '칙', '홀', '얕', '낡', '퇴', '臿', '춤', '꿋', '알', '잎', '략', '맡', '', '엔', '뫼', '우', '편', '팥', '였', '蛰', '괘', '鵪', '틴', '뇨', '녕', 'ৌ', '규', '튤', '흘', '', '췄', '딪', '郪', '유', '썹', '럼', '워', '선', '그', '씩', '셜', '떠', '캥', '갚', '뭡', '찰', '겁', '샌', '', '좁', '뇌', '끊', '계', '렘', '협', '밸', '멜', '안', '배', '솜', '귐', '챗', '셔', '꼼', '앗', '친', '꼽', '삿', '시', '각', '잽', '뎠', '울', '필', '', '찬', '쭙', '띤', '솔', '타', '꽹', '축', '밧', '騁', '텨', '완', '봐', '종', '僴', '箚', '발', '딸', '뗐', '깅', '摑', '십', '껄', '큽', '', '욤', '앉', '섯', '놨', '낳', '춥', '굼', '鬢', '독', '첸', '젼', '때', '堈', '錛', 'ɳ', '됩', '테', '죕', '잴', '보', '녁', '뺀', '쯤', '업', '렴', '릿', '懊', '잔', '숫', '웹', '뭉', '컴', '싶', '훌', '흑', '툴', '귓', '닻', '최', '❤', '빚', '겅', '뒹', '벽', '주', '쨋', '읽', '넌', '닮', '싼', '톈', '겨', '쐰', '냅', '듬', '째', '혼', '빻', '꺾', '므', '뚝', '꼭', '琺', '긁', '앵', '웸', '삽', '쥘', '납', '걷', '짰', '넓', '쓸', '걀', '헹', '쾰', '맘', '돋', '콸', '뛰', '걸', '분', 'ㅐ', '챘', '설', '砝', '갯', '룽', '온', '켄', '섭', '쫓', '쌩', '틋', '', '열', '퍼', 'ㅅ', '뒤', '채', '맨', '牘', '샵', '헤', '봅', '곯', '잌', '처', '굽', '극', '촨', '렌', '뎅', '폈', '응', '됐', '비', '차', '랭', '닐', '玷', '증', '섞', '컵', '량', '멩', '瓠', '졸', '녜', '빙', '딘', '썩', '눌', '잰', '뤼', '흠', '梃', '겐', '쑹', '남', '坮', '쩡', '묻', '롭', '췌', '겜', '국', '씨', '씽', '즐', '땟', '많', '덴', '氚', '쇼', '韆', '맴', '깬', '횟', '꺼', '렵', '얼', '반', '낀', '감', '榫', '줘', '죄', '얗', '린', '슈', 'ㅍ', '석', '님', '겉', '방', '벤', '☀', '팍', '꽉', '튕', '뻗', '쩔', '힙', '갈', '역', '듯', '邗', '컥', '牴', '돼', '셍', '붉', '흄', '₴', '', '젖', '달', '황', '홋', '눅', '퀘', '躓', '낱', '찌', '군', '촬', '', '느', '뻘', '눔', '갤', '헛', '입', '혁', '', '엎', '젓', '컷', '몬', '록', '냑', '아', '', '嚨', '애', '릅', '짝', '裋', '짜', '큐', '씌', '덮', '얀', '뜰', '론', '쌍', '앱', '쩝', '눕', '팩', '찹', '혜', '며', '텔', '뮨', '네', '싣', '샷', '곱', '', '빨', '헥', '딜', '옹', '흔', '킥', '태', '뿐', '에', '꾀', '껍', '겔', '끄', '퉁', '렇', '㎍', '닌', '샅', '싹', '', '륵', '縈', '흐', '짙', '뀜', '명', '핸', '', '뻐', '패', '짬', '범', '류', '쿤', '‐', '', '뎌', '될', '뚱', '셰', '쁜', '벼', '밀', '꿈', 'ㅋ', '다', '상', '라', '엽', '鞦', '舀', '닫', '쫘', '운', 'ㄴ', '어', '츌', '긴', '젤', '맥', '캉', '풀', '댔', '읍', '氘', '련', '훗', '쌓', '해', '곰', '뭘', '망', '저', '깨', '건', '당', '뽀', '섹', '활', '샨', '랗', '밴', '릎', '캡', '嫘', '널', '핍', '嘮', '앴', '酆', '', '중', '詼', '책', '엉', '된', 'ㅓ', '켈', '툼', '까', '실', '젭', '랐', '봣', '일', '닷', '초', '콧', '쥐', '렛', '櫾', '핑', '漶', '썸', '광', '넘', '떼', '탐', '곶', '쩜', '적', '쇄', '폴', '맛', '링', '레', '복', '띈', '늄', '텍', '뭔', '닝', '愨', '콥', '꿎', '참', '족', '른', '훑', '읊', '엄', '', '섀', '게', '펙', '삯', '맷', '烺', '검', '귀', '텐', '껌', '멧', '잦', '갗', '민', '찻', '긔', '뽁', '겊', '갉', '', '션', '츨', '릇', '눴', '깐', '껭', '탔', '닛', '문', '홍', '섣', '낌', '냉', '쉼', '撘', '띨', '', '숟'}\r\n\r\nCould you resolve your problem? I have the same problem with 'bert-base-multilingual-cased' on Korean corpus."
] | 1,554 | 1,582 | 1,554 | NONE | null | I'm using the pre-trained multilingual tokenizer to tokenize some Korean texts, but it seems like this tokenizer is unable to recognize any Korean text at all.
For example, when running on all the Universal Dependency Korean treebanks, this tokenizer fails to tokenize (it produces '[UNK]') the following characters. I know some of them are not Korean, but most of them are. More confusingly, when I check the `vocab.txt` file for the [BERT-Base, Multilingual Cased](https://storage.googleapis.com/bert_models/2018_11_23/multi_cased_L-12_H-768_A-12.zip) in the original repo (https://github.com/google-research/bert), it shows that Korean characters (I manually checked for '렬') are in the vocabulary.
This makes me wonder whether there is any bug in the tokenizer provided in this PyTorch repo. I'm considering switching back to the tokenizer in the original code base. Will this create any compatibility issues?
{'燄', '렬', '툇', '촌', '내', '윙', '쌈', '꿇', '톨', '葚', '솟', '힌', '래', '銎', '凊', '컸', '톤', '🙏', '졍', '의', '슭', '옷', '챠', '囒', '뷘', '멤', '싱', '츠', '령', '겸', '댄', '휙', '醗', '돕', '톳', '던', '페', '띔', '짚', '락', '앙', '왜', '핼', '컫', '쿵', '왠', '기', '냇', '칼', '런', '험', '드', '궐', '얄', '찜', '렝', '빈', '후', '싫', '雎', '덕', '틀', '딴', '굶', '뜸', 'ㅑ', '🌹', '손', '펴', '쏠', '튀', '화', '슘', '대', '왕', '잣', '딨', '듈', '뎀', '鑛', '칭', '젝', '뉴', '✋', '쑤', '작', '묘', '飮', '새', '쑥', '嘈', '캐', '笳', '랩', '💖', '히', '맵', '냈', '츰', '꿨', '딤', '밑', '낼', '訇', '뀌', '뻑', '혔', '겝', '얹', '랍', '😘', '옅', '징', '권', '욱', '탭', '🙈', '흩', '벳', '밈', '굴', '연', '엑', '綉', '숯', '무', '셋', '벌', '텃', '클', '쫑', '덟', '쳬', '멎', '칵', '팅', '뜨', '땄', '㎡', '끽', '뿍', '담', '펭', '쉰', '있', '쏘', '탤', '濞', '치', '옵', '잃', '언', '빽', '짠', '넙', '깆', '콤', '러', '픽', '푸', '회', '낍', '스', '쩨', '진', '풋', '횡', '탑', '솝', '딕', '영', '볐', '씹', '뒷', '퀼', '렸', '별', '옇', '얘', '謔', 'Ↄ', '팎', '긋', '뽐', '현', '켠', '룻', '소', '몇', '쨌', '벨', '쩐', '붐', '트', '떴', '😊', '줌', '꽤', '밭', '쓴', '매', '쳤', '뱃', '콰', '먕', '봤', '😜', '베', '첩', '년', '짐', '뻤', '괭', '함', '鍝', '도', '폭', '꾸', '뜩', '괞', '닦', '몹', '👶', '팰', '콕', '떻', '킬', '강', '찡', '궂', '꿉', '빴', '즈', '데', '껑', '엘', '약', '천', '씻', '💚', '㈜', '롯', '털', '야', '혈', '펀', '👑', '😁', '뺐', '繽', '닙', '쪽', '행', '넉', '휩', '퀀', '쇠', '셑', '댑', '얽', '질', '뻬', '🌀', '덥', '骯', '뀔', '룩', '팀', '愙', '괜', '몽', '냐', '씬', '서', '또', '썬', '절', '갱', 'ㅊ', '왼', '펠', '놈', '쯩', '름', '토', '받', '璣', '咧', '츄', '깃', '헬', '잇', '덜', '곡', '것', '겹', '지', '檣', '억', '셀', '픔', '륙', '돈', 'ㅜ', '믈', '멈', '빗', '을', '둘', '탱', '얇', '식', '💙', '틱', '똑', '줄', '궤', '잼', '착', '廝', '枸', '볏', '샴', '疙', '飈', '💟', '댁', '날', '킵', '동', '룸', '😱', '헐', '부', '웬', '램', '윗', '숍', '齲', '빼', '빡', '혐', '뮌', '너', '란', '땠', '개', '이', '끔', '麩', '표', '훈', '간', '바', '옆', '틸', '탄', '살', 'ʈ', '꽂', '벙', '뱅', '닭', '멀', '줍', '✌', '짊', '葯', '쨍', '쥔', '않', '술', '육', '햇', '텁', '뵈', '쿄', '😏', '웅', '막', '낮', '브', '펼', '색', '갰', '께', '음', '쐬', '숱', '빛', '텝', '젠', '준', '키', '왓', '팝', '순', '떳', '번', '팡', '핫', '팬', '畹', '깍', '슷', '겋', '위', '꺽', '껀', '낸', '숴', '잠', '휴', '訐', '貮', '티', '늪', '깔', '涮', '촐', '좀', '쭐', '턴', '같', '먼', '꾹', '쎌', '충', '땅', '희', '敉', '캠', '넋', '맑', '갇', '凈', '를', '쌌', '잿', '똥', '핵', '올', '윈', '접', '뮤', '귤', '갖', '촘', '웍', '속', '댕', '砒', '謇', '郫', '낄', '죽', '가', '깁', '뷸', '는', '쏜', '뉜', '릉', '쓰', '텼', '환', '皰', '띠', '즙', '자', '톱', '봄', '갠', '쉽', '항', '답', '넣', '옐', '머', '빔', '쬐', '듄', '썰', '로', '칩', '마', '뽂', '숀', '침', '찍', '캘', '노', '뼈', '😦', '놔', '특', '곁', '챙', '밥', '형', '팠', '섬', '焗', '닉', '관', '쉐', '잡', '슐', '뗏', '획', '추', '욘', '꾼', '좌', '쫀', '나', '킹', '뼛', '은', '랴', '깻', '눈', '욕', '하', '🌓', '찢', '젊', '궁', '총', '놋', '둬', '뮬', '詝', '낭', '얌', '셨', '첫', '柢', '셉', '🎂', '닥', '결', '겪', '😕', '⅛', '뾰', '뢰', '륨', '좇', '꼐', '옌', '둔', '💜', '금', '평', '면', '癤', '암', '허', '뱉', '銠', '꿔', '✔', '멘', '겟', '싯', '씁', '림', '볕', '넨', '휠', '☝', '仚', '쟈', '덤', '벅', '즘', '숙', '철', 'ㄹ', '재', '낚', '쉬', '롬', '휘', '렀', '荑', '득', '옮', '렙', '신', '랏', '헉', '푼', '났', '퐁', '쌥', '볶', '밝', '샀', '뽑', '춘', '앓', '곧', '찮', '믿', '늙', '녘', '쌤', '예', '밍', '요', '엣', '딱', '못', '뺨', '렉', '모', '쟁', '퍽', '鬪', '팜', 'ɟ', '틈', '체', '벚', '뛴', '훅', '윤', '짤', '샐', '궈', '댐', '룡', '덧', '깊', '賬', '택', '넬', '흰', '髖', '쁠', '투', '만', '창', '묽', '썼', '🍰', '셩', '僊', '수', '豢', '癥', '삼', '춰', '렁', '퀴', '슛', '쌉', '😪', '묶', '정', '탓', '얏', '💏', '버', '쯔', '밉', '챈', '♩', '리', '떨', '료', '했', '잘', '뤄', '붕', '쩌', '탁', '혀', '繙', '껴', '박', '᾽', '뜀', '홉', '팔', '컨', '饃', '釩', '웰', '꼿', '薺', '縕', '깜', '케', '세', '鎰', '褂', '슌', '벵', '꼈', '카', '甍', '檨', '寗', '빵', '찔', '엊', '오', '통', '✨', '꽝', '니', '첨', '맺', '랑', '헙', '믄', '더', '쳐', '🏼', '옳', '쁨', '鈇', '취', '玕', '럽', '푹', '눠', '제', '디', '벡', '메', '걔', '訄', '滹', '眈', '☎', '물', '갓', '없', '😅', '송', '뭇', '멸', '빅', '늉', '난', '휼', '흙', '깥', '옥', '쫙', '례', '폰', '맏', '되', '훨', '헝', '짧', '쪼', '▶', '끓', '톡', '흥', '홈', '및', '콘', '빠', '등', '르', '깝', '밟', '펑', '끼', '잭', '와', '넷', '율', '찼', '酃', '균', '뿜', '악', '튈', '률', '😋', '걱', '과', '퀄', '튜', '끈', '늑', '렐', '쫄', '멋', '―', '탈', '憮', '잉', '醺', '粦', '맣', '큘', '曧', '쿼', '파', '둡', '탕', '抔', '솥', '척', '고', '🎵', '숭', '람', '벗', '잤', 'ௌ', '옻', '叨', '듀', '늘', '염', '늦', '돌', '껏', '귄', '🎄', '봉', '움', '뭄', '낯', '템', '멍', '랜', '💪', '헌', '샹', '압', '몰', '㎢', '큼', '윽', '🌒', '퀵', '덩', '잊', '眯', '피', '학', '넴', '갬', '녹', '출', '꼴', '🌑', '퍈', '쎄', '굳', '외', '붓', '犂', '슴', '늬', '글', '룬', '탠', '듣', '엿', '칸', '뿌', '갸', '냄', '깡', '괴', '든', '불', '툰', '甪', '箬', '빳', '한', '晳', '킷', '쭉', '둑', '꿍', '쭈', '맙', '鷄', '뜯', '폄', '酩', '퓨', '조', '롤', '프', '뻔', '교', '쿨', '펜', '닯', '🍃', '크', '뀐', '紈', '집', '땡', '놓', '훔', '즌', '헨', '녀', '켤', '따', '🍫', '포', '땐', '랙', '콩', '합', '농', '😍', '전', '엥', '텄', '💬', '긍', '😌', '뮐', '슝', '꽃', '븐', '🌼', '岦', '빤', '찐', '☺', '둥', '랬', '뚤', '깽', '뺏', '목', '슨', '웨', '굵', '칠', '뜻', '려', '산', '끕', '커', '튿', '단', '쌀', '햄', '牾', '켰', '륜', '밤', '골', '익', '흉', '뷔', '랄', '뱀', '숨', '돔', '붙', '찧', '둠', '갔', '럿', '져', 'ʂ', '할', '존', '챌', '늠', '픈', '뷰', '댈', '갑', '컹', '쪄', '맜', '騏', '칡', '餮', '앎', '누', '굿', '幪', '멕', '백', '곤', '싸', '꼬', '헷', '펄', '럴', '饕', '뚫', '芘', 'ᆢ', '젯', '릴', '북', '💛', '룹', '핀', '옛', '병', '낟', '품', '짱', '겼', '쉴', '앳', '닳', '쾌', '힐', '경', '짓', '델', '酊', '턱', '끌', '횃', '호', '씀', '켯', '‒', '컬', '밋', '인', '향', '렷', '蚺', '몸', '❄', '놀', '탯', '쏭', '왈', '점', '팟', '😡', '써', '념', '뒬', '혹', '폐', '격', '앨', '본', '듭', '엷', '헴', '루', '콜', '묏', '😒', '큰', '샛', '았', '돗', '퓌', '장', '깎', '훼', '엾', '맞', '윌', '윷', '졔', '꿰', '쩍', '양', '킨', '👏', '줬', '왔', '볍', '엌', '샤', '£', '삶', '힘', '꽁', '길', '급', '럭', '엮', '瘩', '땀', '구', '쏟', '몫', '쫌', '✓', '으', '딛', '룰', '놉', '력', '齬', '뒀', '플', '꿩', '확', '졌', 'ㅇ', '㏊', 'ɖ', '넝', '빌', '여', '믹', '삭', '뽕', '뽈', '楂', '킴', '었', '캄', '사', '웠', '청', '뀨', '셈', '말', '넜', '📚', '맬', '삐', '紜', '챔', '🙊', '논', '쥬', '딧', '쁘', '윔', '들', '뛸', '춧', '좋', '풍', '퓰', '뙤', '흽', '튼', '뮈', '끗', '공', '짖', '볼', '웃', '블', '랫', '뚜', '굉', '묵', '꿀', '톰', '객', '떤', '낙', '찾', '코', '셸', '녔', '원', '넥', '뗀', '펫', '셧', '袥', '羱', '심', '즉', 'ㅎ', '앤', '뜬', '냥', '塍', '쿠', '캔', '숲', '핏', '뭐', '댓', '먹', '얻', '엠', '됨', '띄', '뗄', '봇', '듐', '칫', '두', '롱', '능', '측', '崞', '융', '켓', '딩', '효', '㎝', '거', '샘', '변', '립', '맹', '괄', '쿰', '팸', '판', '앞', 'ㄷ', '밖', '켜', '밌', '💋', '맸', '👪', '임', '습', 'Ⓣ', '팽', '뻥', '릭', '높', '성', '짭', '첼', '덫', '슬', '迢', '월', '견', '미', '값', '터', '촉', '근', '옴', '김', '끝', '㎞', '센', '쏴', '呔', '엇', '떡', '뿔', '넛', '승', '섰', '곳', '직', '텅', '륭', '법', '잖', '😲', '겠', '곽', '용', '죠', '닿', '뭍', '🌔', '생', '액', 'ㅁ', '탬', '뉘', '흡', '썽', '쟝', '♬', '낫', '폼', '층', '곬', '😔', '칙', '홀', '얕', '낡', '퇴', '臿', '춤', '꿋', '알', '잎', '략', '맡', '👼', '엔', '뫼', '우', '편', '팥', '였', '蛰', '괘', '鵪', '틴', '뇨', '녕', 'ৌ', '규', '튤', '흘', '👍', '췄', '딪', '郪', '유', '썹', '럼', '워', '선', '그', '씩', '셜', '떠', '캥', '갚', '뭡', '찰', '겁', '샌', '😳', '좁', '뇌', '끊', '계', '렘', '협', '밸', '멜', '안', '배', '솜', '귐', '챗', '셔', '꼼', '앗', '친', '꼽', '삿', '시', '각', '잽', '뎠', '울', '필', '😀', '찬', '쭙', '띤', '솔', '타', '꽹', '축', '밧', '騁', '텨', '완', '봐', '종', '僴', '箚', '발', '딸', '뗐', '깅', '摑', '십', '껄', '큽', '🐼', '욤', '앉', '섯', '놨', '낳', '춥', '굼', '鬢', '독', '첸', '젼', '때', '堈', '錛', 'ɳ', '됩', '테', '죕', '잴', '보', '녁', '뺀', '쯤', '업', '렴', '릿', '懊', '잔', '숫', '웹', '뭉', '컴', '싶', '훌', '흑', '툴', '귓', '닻', '최', '❤', '빚', '겅', '뒹', '벽', '주', '쨋', '읽', '넌', '닮', '싼', '톈', '겨', '쐰', '냅', '듬', '째', '혼', '빻', '꺾', '므', '뚝', '꼭', '琺', '긁', '앵', '웸', '삽', '쥘', '납', '걷', '짰', '넓', '쓸', '걀', '헹', '쾰', '맘', '돋', '콸', '뛰', '걸', '분', 'ㅐ', '챘', '설', '砝', '갯', '룽', '온', '켄', '섭', '쫓', '쌩', '틋', '😂', '열', '퍼', 'ㅅ', '뒤', '채', '맨', '牘', '샵', '헤', '봅', '곯', '잌', '처', '굽', '극', '촨', '렌', '뎅', '폈', '응', '됐', '비', '차', '랭', '닐', '玷', '증', '섞', '컵', '량', '멩', '瓠', '졸', '녜', '빙', '딘', '썩', '눌', '잰', '뤼', '흠', '梃', '겐', '쑹', '남', '坮', '쩡', '묻', '롭', '췌', '겜', '국', '씨', '씽', '즐', '땟', '많', '덴', '氚', '쇼', '韆', '맴', '깬', '횟', '꺼', '렵', '얼', '반', '낀', '감', '榫', '줘', '죄', '얗', '린', '슈', 'ㅍ', '석', '님', '겉', '방', '벤', '☀', '팍', '꽉', '튕', '뻗', '쩔', '힙', '갈', '역', '듯', '邗', '컥', '牴', '돼', '셍', '붉', '흄', '₴', '💎', '젖', '달', '황', '홋', '눅', '퀘', '躓', '낱', '찌', '군', '촬', '😽', '느', '뻘', '눔', '갤', '헛', '입', '혁', '🌕', '엎', '젓', '컷', '몬', '록', '냑', '아', '🐩', '嚨', '애', '릅', '짝', '裋', '짜', '큐', '씌', '덮', '얀', '뜰', '론', '쌍', '앱', '쩝', '눕', '팩', '찹', '혜', '며', '텔', '뮨', '네', '싣', '샷', '곱', '😉', '빨', '헥', '딜', '옹', '흔', '킥', '태', '뿐', '에', '꾀', '껍', '겔', '끄', '퉁', '렇', '㎍', '닌', '샅', '싹', '📌', '륵', '縈', '흐', '짙', '뀜', '명', '핸', '💕', '뻐', '패', '짬', '범', '류', '쿤', '‐', '🌸', '뎌', '될', '뚱', '셰', '쁜', '벼', '밀', '꿈', 'ㅋ', '다', '상', '라', '엽', '鞦', '舀', '닫', '쫘', '운', 'ㄴ', '어', '츌', '긴', '젤', '맥', '캉', '풀', '댔', '읍', '氘', '련', '훗', '쌓', '해', '곰', '뭘', '망', '저', '깨', '건', '당', '뽀', '섹', '활', '샨', '랗', '밴', '릎', '캡', '嫘', '널', '핍', '嘮', '앴', '酆', '🍷', '중', '詼', '책', '엉', '된', 'ㅓ', '켈', '툼', '까', '실', '젭', '랐', '봣', '일', '닷', '초', '콧', '쥐', '렛', '櫾', '핑', '漶', '썸', '광', '넘', '떼', '탐', '곶', '쩜', '적', '쇄', '폴', '맛', '링', '레', '복', '띈', '늄', '텍', '뭔', '닝', '愨', '콥', '꿎', '참', '족', '른', '훑', '읊', '엄', '😃', '섀', '게', '펙', '삯', '맷', '烺', '검', '귀', '텐', '껌', '멧', '잦', '갗', '민', '찻', '긔', '뽁', '겊', '갉', '😭', '션', '츨', '릇', '눴', '깐', '껭', '탔', '닛', '문', '홍', '섣', '낌', '냉', '쉼', '撘', '띨', '🌈', '숟'} | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/436/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/436/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/435 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/435/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/435/comments | https://api.github.com/repos/huggingface/transformers/issues/435/events | https://github.com/huggingface/transformers/pull/435 | 427,870,022 | MDExOlB1bGxSZXF1ZXN0MjY2MzY5NDAy | 435 | Fixes to the TensorFlow conversion tool | {
"login": "marpaia",
"id": 927168,
"node_id": "MDQ6VXNlcjkyNzE2OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/927168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/marpaia",
"html_url": "https://github.com/marpaia",
"followers_url": "https://api.github.com/users/marpaia/followers",
"following_url": "https://api.github.com/users/marpaia/following{/other_user}",
"gists_url": "https://api.github.com/users/marpaia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/marpaia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/marpaia/subscriptions",
"organizations_url": "https://api.github.com/users/marpaia/orgs",
"repos_url": "https://api.github.com/users/marpaia/repos",
"events_url": "https://api.github.com/users/marpaia/events{/privacy}",
"received_events_url": "https://api.github.com/users/marpaia/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Yes! Thanks @marpaia!"
] | 1,554 | 1,554 | 1,554 | NONE | null | This PR contains a small fix to the script which converts TensorFlow weights to PyTorch weights. The related issues are #50, #306, etc.
Thanks for all of the open source code you've been putting out in this domain, it has been incredibly helpful to me and my team. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/435/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/435/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/435",
"html_url": "https://github.com/huggingface/transformers/pull/435",
"diff_url": "https://github.com/huggingface/transformers/pull/435.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/435.patch",
"merged_at": 1554194501000
} |
https://api.github.com/repos/huggingface/transformers/issues/434 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/434/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/434/comments | https://api.github.com/repos/huggingface/transformers/issues/434/events | https://github.com/huggingface/transformers/issues/434 | 427,743,495 | MDU6SXNzdWU0Mjc3NDM0OTU= | 434 | Model not training at all in Google Colab | {
"login": "nicholasbailey87",
"id": 9570481,
"node_id": "MDQ6VXNlcjk1NzA0ODE=",
"avatar_url": "https://avatars.githubusercontent.com/u/9570481?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nicholasbailey87",
"html_url": "https://github.com/nicholasbailey87",
"followers_url": "https://api.github.com/users/nicholasbailey87/followers",
"following_url": "https://api.github.com/users/nicholasbailey87/following{/other_user}",
"gists_url": "https://api.github.com/users/nicholasbailey87/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nicholasbailey87/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nicholasbailey87/subscriptions",
"organizations_url": "https://api.github.com/users/nicholasbailey87/orgs",
"repos_url": "https://api.github.com/users/nicholasbailey87/repos",
"events_url": "https://api.github.com/users/nicholasbailey87/events{/privacy}",
"received_events_url": "https://api.github.com/users/nicholasbailey87/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649053,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Help%20wanted",
"name": "Help wanted",
"color": "008672",
"default": false,
"description": "Extra attention is needed, help appreciated"
},
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Try train_batch_size =1. Alternatively I propose to finetune with the tensorflow model using colabs TPUs as these have far more memory.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,560 | 1,560 | NONE | null | Hi! Thanks for your help.
I am initiating training in the following way in a Colab notebook with GPU acceleration (with very small train batch size and max seq length to prove I'm not getting out of memory problems!):
!pip install pytorch-pretrained-bert
!rm -rf bert_output
!mkdir bert_output
!python ./pytorch-pretrained-BERT/examples/run_squad.py --bert_model bert-base-multilingual-cased --output_dir bert_output --train_file squad_20_train.json --predict_file squad_20_dev.json --do_train --do_predict --train_batch_size 64 --max_seq_length 64 --version_2_with_negative --fp16
I have cloned the pytorch-pretrained-bert repository and installed the library. I have also installed apex. However, training doesn't even get started - the last thing the verbose logging produces is:
04/01/2019 14:36:45 - INFO - __main__ - tokens: [CLS] When did Bey ##once take a hi ##atus in her career and take control of her management ? [SEP] . Her critically acclaimed fifth studio album , Beyoncé ( 2013 ) , was distinguished from previous releases by its experimental production and exploration of dark ##er themes . [SEP]
04/01/2019 14:36:45 - INFO - __main__ - token_to_orig_map: 20:137 21:138 22:139 23:140 24:141 25:142 26:143 27:143 28:144 29:145 30:145 31:145 32:145 33:146 34:147 35:148 36:149 37:150 38:151 39:152 40:153 41:154 42:155 43:156 44:157 45:158 46:158 47:159 48:159
04/01/2019 14:36:45 - INFO - __main__ - token_is_max_context: 20:True 21:True 22:True 23:True 24:True 25:True 26:True 27:True 28:True 29:True 30:True 31:True 32:True 33:True 34:True 35:True 36:True 37:True 38:True 39:True 40:True 41:True 42:True 43:True 44:True 45:True 46:True 47:True 48:True
04/01/2019 14:36:45 - INFO - __main__ - input_ids: 101 12242 12172 40344 104316 13574 169 11520 26311 10106 10485 13021 10111 13574 12608 10108 10485 17150 136 102 119 13229 108889 87680 22237 13093 10606 117 54106 113 10207 114 117 10134 45233 10188 16741 45906 10155 10474 34176 12116 10111 61326 10108 25100 10165 48462 119 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0
04/01/2019 14:36:45 - INFO - __main__ - input_mask: 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
04/01/2019 14:36:45 - INFO - __main__ - segment_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
04/01/2019 14:36:45 - INFO - __main__ - start_position: 0
04/01/2019 14:36:45 - INFO - __main__ - end_position: 0
04/01/2019 14:36:45 - INFO - __main__ - answer: [CLS]
So, it seems as though the notebook is preprocessing the data OK, but then it hangs here and ultimately terminates the process with a ^C (not from me, but something internal).
Any idea what the problem might be here?
Thanks again!
Nicholas | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/434/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/434/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/433 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/433/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/433/comments | https://api.github.com/repos/huggingface/transformers/issues/433/events | https://github.com/huggingface/transformers/issues/433 | 427,720,799 | MDU6SXNzdWU0Mjc3MjA3OTk= | 433 | how to do the pre training the model form scratch? | {
"login": "SeekPoint",
"id": 18051187,
"node_id": "MDQ6VXNlcjE4MDUxMTg3",
"avatar_url": "https://avatars.githubusercontent.com/u/18051187?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SeekPoint",
"html_url": "https://github.com/SeekPoint",
"followers_url": "https://api.github.com/users/SeekPoint/followers",
"following_url": "https://api.github.com/users/SeekPoint/following{/other_user}",
"gists_url": "https://api.github.com/users/SeekPoint/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SeekPoint/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SeekPoint/subscriptions",
"organizations_url": "https://api.github.com/users/SeekPoint/orgs",
"repos_url": "https://api.github.com/users/SeekPoint/repos",
"events_url": "https://api.github.com/users/SeekPoint/events{/privacy}",
"received_events_url": "https://api.github.com/users/SeekPoint/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"```\r\npython3 examples/lm_finetuning/simple_lm_finetuning.py \r\n--train_corpus sample_text.txt \r\n--bert_model bert-base-uncased \r\n--do_lower_case \r\n--output_dir finetuned_lm/\r\n```\r\nIn addition, you can refer to #385 ",
"Yes let's keep a single issue on this. Closing in favor of #385."
] | 1,554 | 1,554 | 1,554 | NONE | null | for example, use sample_text.txt | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/433/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/433/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/432 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/432/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/432/comments | https://api.github.com/repos/huggingface/transformers/issues/432/events | https://github.com/huggingface/transformers/issues/432 | 427,657,833 | MDU6SXNzdWU0Mjc2NTc4MzM= | 432 | Predictions from BertForSequenceClassification model keep changing across runs | {
"login": "varun-nathan",
"id": 48044871,
"node_id": "MDQ6VXNlcjQ4MDQ0ODcx",
"avatar_url": "https://avatars.githubusercontent.com/u/48044871?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/varun-nathan",
"html_url": "https://github.com/varun-nathan",
"followers_url": "https://api.github.com/users/varun-nathan/followers",
"following_url": "https://api.github.com/users/varun-nathan/following{/other_user}",
"gists_url": "https://api.github.com/users/varun-nathan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/varun-nathan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/varun-nathan/subscriptions",
"organizations_url": "https://api.github.com/users/varun-nathan/orgs",
"repos_url": "https://api.github.com/users/varun-nathan/repos",
"events_url": "https://api.github.com/users/varun-nathan/events{/privacy}",
"received_events_url": "https://api.github.com/users/varun-nathan/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"You probably forgot to deactivate the DropOut modules with `model.eval()`",
"Oh ok, I get it. That's helpful. Thanks!",
"I tried that and now I seem to be getting the same predictions for any input. In other words, the logits don't change with change in input. Not sure why this is happening?",
"Maybe a bug in your code?\r\nIf you can share a simple self-contained example exhibiting the behavior we can have a look.",
"That's unlikely as I tried the same code with other problems and got reasonable results. The problems on which I tried this code include MRPC task, sentiment prediction on IMDB dataset and intent detection on smalltalk data. The results are logical and reasonable.\r\nThe dataset on which I get this behaviour reported above has about 20 examples for each of the 4 intents viz. restaurant_search(0), booking_table(1), greet(2) and thanks(3). So, I was thinking if this could be due to the data having less number of examples. The sequence classifier class is basically bert model + a single hidden layer neural network with output layer as the number of labels. I feel that there's not enough data to train the last (classifier) layer. Here's my test data:\r\ntest_df = pd.DataFrame({'text': [\"hey\", \"indian hotels\"],\r\n 'label': [2, 0]})\r\nI print the logits for each of the 2 test samples which are as follows:\r\ntensor([[ 28.9354, 28.3292, 20.1560, -20.7804]])\r\ntensor([[ 28.9354, 28.3292, 20.1560, -20.7804]])\r\n\r\nThe logits tensor doesn't change for any input text.\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"Hi @varun-nathan, were you ever able to solve this? I'm having a very similar issue with ReformerForSequenceClassification.",
"Hi @varun-nathan and @jstremme, were either of you able to find the issue? I'm experiencing the same thing with ElectraForSequenceClassification!",
"> Hi @varun-nathan and @jstremme, were either of you able to find the issue? I'm experiencing the same thing with ElectraForSequenceClassification!\r\n\r\nHi @mollha, I managed to solve this but can't remember exactly what I did. Did you try `model.eval()`? Also, make sure you are training on more than just a few sample records and using a large enough model in terms of neurons per layer etc. ",
"Thanks! I was already using model.eval(), but my dataset size was too small (around 1000). After increasing to 15000 I am getting much better results.",
"Excellent!"
] | 1,554 | 1,614 | 1,560 | NONE | null | I used the code in run_classifier.py to train a model for intent detection which is a multi-class classification problem. After training the model, when I used it for prediction, I found the predictions to be changing from one run to another. I'm trying to understand the reason for the same and how I can avoid this behavior.
Let's say that model is the fine-tuned sequence classification model. I get different results (logits) every time I run the following:
logits = model1(input_ids, segment_ids, input_mask, labels=None)
Why is that so?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/432/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/432/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/431 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/431/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/431/comments | https://api.github.com/repos/huggingface/transformers/issues/431/events | https://github.com/huggingface/transformers/issues/431 | 427,645,865 | MDU6SXNzdWU0Mjc2NDU4NjU= | 431 | How to fine tune Transformer-XL on own dataset? | {
"login": "Archelunch",
"id": 10900176,
"node_id": "MDQ6VXNlcjEwOTAwMTc2",
"avatar_url": "https://avatars.githubusercontent.com/u/10900176?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Archelunch",
"html_url": "https://github.com/Archelunch",
"followers_url": "https://api.github.com/users/Archelunch/followers",
"following_url": "https://api.github.com/users/Archelunch/following{/other_user}",
"gists_url": "https://api.github.com/users/Archelunch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Archelunch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Archelunch/subscriptions",
"organizations_url": "https://api.github.com/users/Archelunch/orgs",
"repos_url": "https://api.github.com/users/Archelunch/repos",
"events_url": "https://api.github.com/users/Archelunch/events{/privacy}",
"received_events_url": "https://api.github.com/users/Archelunch/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi,\r\nYou can tokenize your data with the Transformer-XL tokenizer and use it to train your model.",
"I understand it. But I want to fine tune pretrained model",
"What is the difference?\r\n\r\nCan you start by trying to do what you would do normally to fine-tune a pytorch model and then if you encounter an issue give the error messages back here so we can help?",
"I found example in readme\r\nAnd my question - can I fine tune model using this script with my own data? \r\n` python run_openai_gpt.py \\\r\n --model_name openai-gpt \\\r\n --do_train \\\r\n --do_eval \\\r\n --train_dataset $ROC_STORIES_DIR/cloze_test_val__spring2016\\ -\\ cloze_test_ALL_val.csv \\\r\n --eval_dataset $ROC_STORIES_DIR/cloze_test_test__spring2016\\ -\\ cloze_test_ALL_test.csv \\\r\n --output_dir ../log \\\r\n --train_batch_size 16 \\ `\r\n\r\nExample for gpt, but I guess it is the same for TransformerXL",
"Hi, you will likely need to adapt this example since Transformer-XL uses memory cells but there is no ready to use example for fine-tuning Transformer-XL in the repo unfortunately (and I don't plan to add one in the near future).\r\n\r\nIf you want to give it a try feel free to ask more specific questions here.\r\n\r\nI would advise to start by reading carefully the author's paper to be sure you have a good understanding of the model. You can also probably start from the authors' own PyTorch training script (which I simplified to make the evaluation script in the present repo).",
"Is it possible to use the transformer with non-tokenized data @thomwolf? I know the Transformer is built for language modeling, but I would like to take advantage of the self-attention aspect of the Transformer's self-attention mechanism to model continuous data, and wonder how doable that sounds to you? ",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,554 | 1,563 | 1,563 | NONE | null | I have my own dataset. What format of data I need to fine tune TransformerXL for text generation? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/431/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/431/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/430 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/430/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/430/comments | https://api.github.com/repos/huggingface/transformers/issues/430/events | https://github.com/huggingface/transformers/pull/430 | 427,305,693 | MDExOlB1bGxSZXF1ZXN0MjY1OTU0MTYy | 430 | Fix typo in example code | {
"login": "MottoX",
"id": 6220861,
"node_id": "MDQ6VXNlcjYyMjA4NjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6220861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MottoX",
"html_url": "https://github.com/MottoX",
"followers_url": "https://api.github.com/users/MottoX/followers",
"following_url": "https://api.github.com/users/MottoX/following{/other_user}",
"gists_url": "https://api.github.com/users/MottoX/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MottoX/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MottoX/subscriptions",
"organizations_url": "https://api.github.com/users/MottoX/orgs",
"repos_url": "https://api.github.com/users/MottoX/repos",
"events_url": "https://api.github.com/users/MottoX/events{/privacy}",
"received_events_url": "https://api.github.com/users/MottoX/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,553 | 1,554 | 1,554 | CONTRIBUTOR | null | Modify 'unambigiously' to 'unambiguously' | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/430/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/430/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/430",
"html_url": "https://github.com/huggingface/transformers/pull/430",
"diff_url": "https://github.com/huggingface/transformers/pull/430.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/430.patch",
"merged_at": 1554194516000
} |
https://api.github.com/repos/huggingface/transformers/issues/429 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/429/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/429/comments | https://api.github.com/repos/huggingface/transformers/issues/429/events | https://github.com/huggingface/transformers/issues/429 | 427,290,740 | MDU6SXNzdWU0MjcyOTA3NDA= | 429 | GPT2Tokenizer <|endoftext|> | {
"login": "latkins",
"id": 1080217,
"node_id": "MDQ6VXNlcjEwODAyMTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1080217?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/latkins",
"html_url": "https://github.com/latkins",
"followers_url": "https://api.github.com/users/latkins/followers",
"following_url": "https://api.github.com/users/latkins/following{/other_user}",
"gists_url": "https://api.github.com/users/latkins/gists{/gist_id}",
"starred_url": "https://api.github.com/users/latkins/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/latkins/subscriptions",
"organizations_url": "https://api.github.com/users/latkins/orgs",
"repos_url": "https://api.github.com/users/latkins/repos",
"events_url": "https://api.github.com/users/latkins/events{/privacy}",
"received_events_url": "https://api.github.com/users/latkins/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
}
] | closed | false | null | [] | [
"`\"<|endoftext|>\"` is a *special token* that is not intended to be feed through the tokenizer but added to the indices list after the tokenization process (see for example the way it is used in the short example [`run_gpt2.py`](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_gpt2.py#L98)).\r\n\r\nIt's common practice to distinguish the way we write *special tokens* for the constrains/behavior of the tokenizers as they (i) become unnecessary complex when we add exception rules for special tokens and (ii) are often designed externally (ex when you use SpaCy's tokenizer). The simplest way to do that is just to add the special tokens after the encoding process like it's done for GPT-2.",
"That makes sense! Is this in the documentation anywhere? I didn't come across it. Regardless, thanks for the clarification.",
"@thomwolf\r\nI think after the new repo migration, you guys made '<|endoftext|>' as first class citizen of GPT2 tokenizer. So now we can just have base inputs with this token and it'd work fine with tokenizer and model, right?",
"Note that in the new version of Transformer, the behavior of the GPT2 tokenizer changed. \r\n\r\n```python\r\ntext = \"<|endoftext|> machine learning using PyTorch and TensorFlow\"\r\ntokenizer_folder = \"gpt2\"\r\ntokenizer = GPT2Tokenizer.from_pretrained(tokenizer_folder)\r\nencoded_ids = tokenizer.encode(text)\r\nprint(encoded_ids)\r\nprint(\"################### when tokenizing the whole sentence ######################\")\r\nprint(encoded_ids)\r\nfor id in encoded_ids:\r\n print(\r\n f\"\"\"id: {id:<7}, original_token: {\"'\" + tokenizer.decoder[id] + \"'\":<10}, ignore_special_token: '{tokenizer.decode(id)}'\"\"\")\r\n# endfor\r\n```\r\n\r\noutput: \r\n```text\r\n################### when tokenizing the whole sentence ######################\r\n[50256, 4572, 4673, 1262, 9485, 15884, 354, 290, 309, 22854, 37535]\r\nid: 50256 , original_token: '<|endoftext|>', ignore_special_token: '<|endoftext|>'\r\nid: 4572 , original_token: 'Ġmachine', ignore_special_token: ' machine'\r\nid: 4673 , original_token: 'Ġlearning', ignore_special_token: ' learning'\r\nid: 1262 , original_token: 'Ġusing' , ignore_special_token: ' using'\r\nid: 9485 , original_token: 'ĠPy' , ignore_special_token: ' Py'\r\nid: 15884 , original_token: 'Tor' , ignore_special_token: 'Tor'\r\nid: 354 , original_token: 'ch' , ignore_special_token: 'ch'\r\nid: 290 , original_token: 'Ġand' , ignore_special_token: ' and'\r\nid: 309 , original_token: 'ĠT' , ignore_special_token: ' T'\r\nid: 22854 , original_token: 'ensor' , ignore_special_token: 'ensor'\r\nid: 37535 , original_token: 'Flow' , ignore_special_token: 'Flow'\r\n```\r\n",
"Please I need your help with the special token <|endoftext|>\nHello to everyone,\n I would like someone to clarify/disaprove the following. I have found a pretrained gpt2 model trained on the Greek language from huggingface named nikokons/gpt2-greek and I want to fine tune it on my custom dataset. My dataset consists of samples of mathematical definitions with related questions written in the Greek language. Let me give some translated examples\n\nDefinition: Two angles are called complementary angles when they sum up to 180 degrees.\nQuestion: What are complementary angles?\n\nDefinition: Two angles are called complementary angles when they sum up to 180 degrees.\nQuestion: How do we call two angles which sum up to 180 degrees?\n\nDefinition: A triangle is called isosceles when it has two sides of equally length.\nQuestion: What is an isosceles triangle?\n\nDefinition: A triangle is called isosceles when it has two sides of equally length.\nQuestion: What do we call a triangle which has two equally in length sides?\n\nNotice that for a Definition I might have multiple questions on my dataset. I want to fine tune the model in order to learn to answer the user’s question by answering to the user with the entire Definition related to the user’s question.\n\nWhat are the steps I should follow?\nFirst fine tune the model to the raw dataset ( I mean the dataset without special tokens) in order to learn the new terminology and then preprocess the dataset in order to add in the beginning and at the ending of each sample the\n|endoftext| token and finetune the model again on the new preprocessed dataset?\n\nthe processed dataset would be like following?\n\n|endoftext| A triangle is called isosceles when it has two sides of equally length. What is an isosceles triangle? |endoftext|\nTwo angles are called complementary angles when they sum up to 180 degrees.\nHow do we call two angles which sum up to 180 degrees?|endoftext|\n\nAlso should I use padding=right when tokenizing the samples?\n\n",
"Hi @redrocket8, thanks for participating on this issue! \r\n\r\nThis is a question best placed in our [forums](https://discuss.huggingface.co/). We try to reserve the github issues for feature requests and bug reports.",
"Ok I will delete it. Thanks"
] | 1,553 | 1,694 | 1,554 | NONE | null | I am confused as to how the GPT2Tokenizer is intended to be used. It looks like `GPT2Tokenizer.encode` doesn't always take the byte pair encoding into account -- is this intentional?
```
from pytorch_pretrained_bert import GPT2Tokenizer
tok = GPT2Tokenizer.from_pretrained("gpt2")
print(tok.encode("<|endoftext|>"))
print(tok.encoder["<|endoftext|>"])
```
Running the above gives:
```
[27, 91, 437, 1659, 5239, 91, 29]
50256
```
I would have (perhaps naively) expected that `tok.encode` gives `[50256]`. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/429/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/429/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/428 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/428/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/428/comments | https://api.github.com/repos/huggingface/transformers/issues/428/events | https://github.com/huggingface/transformers/issues/428 | 427,271,826 | MDU6SXNzdWU0MjcyNzE4MjY= | 428 | Cannot find Synthetic self-training in this repository. | {
"login": "Dogy06",
"id": 27922893,
"node_id": "MDQ6VXNlcjI3OTIyODkz",
"avatar_url": "https://avatars.githubusercontent.com/u/27922893?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dogy06",
"html_url": "https://github.com/Dogy06",
"followers_url": "https://api.github.com/users/Dogy06/followers",
"following_url": "https://api.github.com/users/Dogy06/following{/other_user}",
"gists_url": "https://api.github.com/users/Dogy06/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dogy06/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dogy06/subscriptions",
"organizations_url": "https://api.github.com/users/Dogy06/orgs",
"repos_url": "https://api.github.com/users/Dogy06/repos",
"events_url": "https://api.github.com/users/Dogy06/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dogy06/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, indeed there is no Synthetic self-training in this repository, and the SQuAD leaderboard website actually refers to the Tensorflow repository so I'll close this issue.",
"Will you be adding synthetic self training though?"
] | 1,553 | 1,554 | 1,554 | NONE | null | The SQuAD leader board's (https://rajpurkar.github.io/SQuAD-explorer/) 3rd highest scored model uses 'synthetic self-training'.
There is a PDF explaining it: https://nlp.stanford.edu/seminar/details/jdevlin.pdf?fbclid=IwAR2TBFCJOeZ9cGhxB-z5cJJ17vHN4W25oWsjI8NqJoTEmlYIYEKG7oh4tlY but I have found no such model within this repository.
On the leader board website, it shows me a link to this repository.
Is the synthetic self-training in this repository? (If so, please show me the link to the code)
Is it private? Will it be released?
Thanks,
Dogy06
By the way: I checked both the Pytorch and Tensorflow version of the code., I posted the same issue here:https://github.com/google-research/bert/issues/532 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/428/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/428/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/427 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/427/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/427/comments | https://api.github.com/repos/huggingface/transformers/issues/427/events | https://github.com/huggingface/transformers/pull/427 | 427,247,452 | MDExOlB1bGxSZXF1ZXN0MjY1OTE3NzM2 | 427 | fix sample_doc | {
"login": "jeonsworld",
"id": 37530102,
"node_id": "MDQ6VXNlcjM3NTMwMTAy",
"avatar_url": "https://avatars.githubusercontent.com/u/37530102?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jeonsworld",
"html_url": "https://github.com/jeonsworld",
"followers_url": "https://api.github.com/users/jeonsworld/followers",
"following_url": "https://api.github.com/users/jeonsworld/following{/other_user}",
"gists_url": "https://api.github.com/users/jeonsworld/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jeonsworld/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jeonsworld/subscriptions",
"organizations_url": "https://api.github.com/users/jeonsworld/orgs",
"repos_url": "https://api.github.com/users/jeonsworld/repos",
"events_url": "https://api.github.com/users/jeonsworld/events{/privacy}",
"received_events_url": "https://api.github.com/users/jeonsworld/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Good catch, thanks!",
"Gah. I meant to use `randrange()`, but this fix is equivalent!"
] | 1,553 | 1,555 | 1,554 | CONTRIBUTOR | null | If the value of rand_end is returned from the randint function, the value of sampled_doc_index that matches current_idx is returned from searchsorted.
example:
cumsum_max = {int64} 30
doc_cumsum = {ndarray} [ 5 7 11 19 30]
doc_lengths = {list} <class 'list'>: [5, 2, 4, 8, 11]
if current_idx = 1,
rand_start = 7
rand_end = 35
sentence_index = randint(7, 35) % cumsum_max
if randint return 35, sentence_index becomes 5.
if sentence_index is 5, np.searchsorted returns 1 equal to current_index. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/427/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/427/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/427",
"html_url": "https://github.com/huggingface/transformers/pull/427",
"diff_url": "https://github.com/huggingface/transformers/pull/427.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/427.patch",
"merged_at": 1554283619000
} |
https://api.github.com/repos/huggingface/transformers/issues/426 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/426/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/426/comments | https://api.github.com/repos/huggingface/transformers/issues/426/events | https://github.com/huggingface/transformers/pull/426 | 426,985,414 | MDExOlB1bGxSZXF1ZXN0MjY1NzE0ODgz | 426 | instantiate loss_fct once | {
"login": "Separius",
"id": 519177,
"node_id": "MDQ6VXNlcjUxOTE3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/519177?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Separius",
"html_url": "https://github.com/Separius",
"followers_url": "https://api.github.com/users/Separius/followers",
"following_url": "https://api.github.com/users/Separius/following{/other_user}",
"gists_url": "https://api.github.com/users/Separius/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Separius/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Separius/subscriptions",
"organizations_url": "https://api.github.com/users/Separius/orgs",
"repos_url": "https://api.github.com/users/Separius/repos",
"events_url": "https://api.github.com/users/Separius/events{/privacy}",
"received_events_url": "https://api.github.com/users/Separius/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for the PR but I think it's fine like it is now (slightly easier to read and debug)."
] | 1,553 | 1,554 | 1,554 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/426/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/426/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/426",
"html_url": "https://github.com/huggingface/transformers/pull/426",
"diff_url": "https://github.com/huggingface/transformers/pull/426.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/426.patch",
"merged_at": null
} |
|
https://api.github.com/repos/huggingface/transformers/issues/425 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/425/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/425/comments | https://api.github.com/repos/huggingface/transformers/issues/425/events | https://github.com/huggingface/transformers/pull/425 | 426,865,891 | MDExOlB1bGxSZXF1ZXN0MjY1NjIxMjQ5 | 425 | fix lm_finetuning's link | {
"login": "Separius",
"id": 519177,
"node_id": "MDQ6VXNlcjUxOTE3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/519177?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Separius",
"html_url": "https://github.com/Separius",
"followers_url": "https://api.github.com/users/Separius/followers",
"following_url": "https://api.github.com/users/Separius/following{/other_user}",
"gists_url": "https://api.github.com/users/Separius/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Separius/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Separius/subscriptions",
"organizations_url": "https://api.github.com/users/Separius/orgs",
"repos_url": "https://api.github.com/users/Separius/repos",
"events_url": "https://api.github.com/users/Separius/events{/privacy}",
"received_events_url": "https://api.github.com/users/Separius/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks!"
] | 1,553 | 1,553 | 1,553 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/425/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/425/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/425",
"html_url": "https://github.com/huggingface/transformers/pull/425",
"diff_url": "https://github.com/huggingface/transformers/pull/425.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/425.patch",
"merged_at": 1553847251000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/424 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/424/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/424/comments | https://api.github.com/repos/huggingface/transformers/issues/424/events | https://github.com/huggingface/transformers/issues/424 | 426,651,083 | MDU6SXNzdWU0MjY2NTEwODM= | 424 | Difference between base and large tokenizer? | {
"login": "ZhaofengWu",
"id": 11954789,
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhaofengWu",
"html_url": "https://github.com/ZhaofengWu",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"I haven't looked in the details of the vocabularies for each model.\r\nIf you investigate this question, be sure to share the results here, it may interest others as well!",
"I did a diff on the two vocabulary files and there is no difference. As long as you use the uncased version at least. I haven't investigated others.",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"I can validate @mhattingpete 's research.\r\nI tokenized a big collection of text with the uncased tokenizer from both the base and the large model and both tokenizations are identical."
] | 1,553 | 1,560 | 1,560 | CONTRIBUTOR | null | I understand that a cased tokenizer and an uncased one are surely different because their vocabs are different in casing, but how does a base tokenizer different from a large tokenizer? Does a large tokenizer have a larger vocab? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/424/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/424/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/423 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/423/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/423/comments | https://api.github.com/repos/huggingface/transformers/issues/423/events | https://github.com/huggingface/transformers/pull/423 | 426,614,853 | MDExOlB1bGxSZXF1ZXN0MjY1NDI5MDQx | 423 | making unconditional generation work | {
"login": "dhanajitb",
"id": 19517627,
"node_id": "MDQ6VXNlcjE5NTE3NjI3",
"avatar_url": "https://avatars.githubusercontent.com/u/19517627?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dhanajitb",
"html_url": "https://github.com/dhanajitb",
"followers_url": "https://api.github.com/users/dhanajitb/followers",
"following_url": "https://api.github.com/users/dhanajitb/following{/other_user}",
"gists_url": "https://api.github.com/users/dhanajitb/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dhanajitb/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dhanajitb/subscriptions",
"organizations_url": "https://api.github.com/users/dhanajitb/orgs",
"repos_url": "https://api.github.com/users/dhanajitb/repos",
"events_url": "https://api.github.com/users/dhanajitb/events{/privacy}",
"received_events_url": "https://api.github.com/users/dhanajitb/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi thanks for the PR.\r\nI think we still need to clean up the example a little more indeed.\r\nThese lines should be taken care off:\r\n```python\r\nwhile not args.unconditional:\r\n if not args.unconditional:\r\n```\r\nI will see if I can find time to refactor it next week or you can update your PR if you want to fix this too.",
"I have further cleaned the redundant lines and some conditions.",
"Great, thanks @dhanajitb!"
] | 1,553 | 1,555 | 1,555 | CONTRIBUTOR | null | The unconditional generation works now but if the seed is fixed, the sample is the same every time.
n_samples > 1 will give different samples though.
I am giving the start token as '<|endoftext|>' for the unconditional generation. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/423/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/423/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/423",
"html_url": "https://github.com/huggingface/transformers/pull/423",
"diff_url": "https://github.com/huggingface/transformers/pull/423.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/423.patch",
"merged_at": 1555318914000
} |
https://api.github.com/repos/huggingface/transformers/issues/422 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/422/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/422/comments | https://api.github.com/repos/huggingface/transformers/issues/422/events | https://github.com/huggingface/transformers/issues/422 | 426,611,523 | MDU6SXNzdWU0MjY2MTE1MjM= | 422 | BertForTokenClassification for NER, mask labels | {
"login": "alexyalunin",
"id": 23011284,
"node_id": "MDQ6VXNlcjIzMDExMjg0",
"avatar_url": "https://avatars.githubusercontent.com/u/23011284?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alexyalunin",
"html_url": "https://github.com/alexyalunin",
"followers_url": "https://api.github.com/users/alexyalunin/followers",
"following_url": "https://api.github.com/users/alexyalunin/following{/other_user}",
"gists_url": "https://api.github.com/users/alexyalunin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alexyalunin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexyalunin/subscriptions",
"organizations_url": "https://api.github.com/users/alexyalunin/orgs",
"repos_url": "https://api.github.com/users/alexyalunin/repos",
"events_url": "https://api.github.com/users/alexyalunin/events{/privacy}",
"received_events_url": "https://api.github.com/users/alexyalunin/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Sequence tagging is explained here: https://github.com/huggingface/pytorch-pretrained-BERT/issues/64#issuecomment-443703063",
"Yes, this is the relevant issue on this topic. I'll close this issue in favor of #64."
] | 1,553 | 1,554 | 1,554 | NONE | null | I'm trying to do Named Entity Recognition with BertForTokenClassification.
Say I have 10 words with 10 labels, after WordPiece tokenization I get 15 tokens and I assign them labels, "X" for pieces of words like (##ing).
In the original paper https://arxiv.org/pdf/1810.04805.pdf in 4.3 section is said that we don't make predictions for such pieces or we can simply do not care about them and not take derivatives.
Does this functionality currently exist in BertForTokenClassification or BertModel? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/422/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/422/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/421 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/421/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/421/comments | https://api.github.com/repos/huggingface/transformers/issues/421/events | https://github.com/huggingface/transformers/issues/421 | 426,549,937 | MDU6SXNzdWU0MjY1NDk5Mzc= | 421 | pytorch model to tensorflow checkpoint | {
"login": "KavyaGujjala",
"id": 28920687,
"node_id": "MDQ6VXNlcjI4OTIwNjg3",
"avatar_url": "https://avatars.githubusercontent.com/u/28920687?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KavyaGujjala",
"html_url": "https://github.com/KavyaGujjala",
"followers_url": "https://api.github.com/users/KavyaGujjala/followers",
"following_url": "https://api.github.com/users/KavyaGujjala/following{/other_user}",
"gists_url": "https://api.github.com/users/KavyaGujjala/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KavyaGujjala/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KavyaGujjala/subscriptions",
"organizations_url": "https://api.github.com/users/KavyaGujjala/orgs",
"repos_url": "https://api.github.com/users/KavyaGujjala/repos",
"events_url": "https://api.github.com/users/KavyaGujjala/events{/privacy}",
"received_events_url": "https://api.github.com/users/KavyaGujjala/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi, there is no script to do that currently. I don't plan to add this feature in the short term but I would be happy to welcome a PR on that.",
"A PR for this would be great. It would allow a simple deployment via Han's bert-as-service\r\n https://github.com/hanxiao/bert-as-service/",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,553 | 1,560 | 1,560 | NONE | null | How to convert a pytorch_model.bin to tensorflow checkpoint? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/421/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/421/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/420 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/420/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/420/comments | https://api.github.com/repos/huggingface/transformers/issues/420/events | https://github.com/huggingface/transformers/issues/420 | 426,544,017 | MDU6SXNzdWU0MjY1NDQwMTc= | 420 | Advantage of BertAdam over Adam? | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
}
] | closed | false | null | [] | [
"Some explanation is given here: https://github.com/huggingface/pytorch-pretrained-BERT/blob/694e2117f33d752ae89542e70b84533c52cb9142/README.md#optimizers\r\n\r\n`BertAdam` is a `torch.optimizer` adapted to be closer to the optimizer used in the TensorFlow implementation of Bert. The differences with PyTorch `Adam` optimizer are the following:\r\n\r\n* `BertAdam` implements weight decay fix,\r\n* `BertAdam` doesn't compensate for bias as in the regular `Adam` optimizer.\r\n",
"@stefan-it Thanks for the link. These improvements are not the same as the suggested AdamW improvements, I assume?",
"Yes they are the same. `BertAdam` implements AdamW and in addition doesn't compensate for the bias (I don't know why the Google team decided to do that but that's what they did).\r\n\r\nIn most case we have been using standard Adam with good performances (example by using NVIDIA's apex fusedAdam as optimizer) so you probably shouldn't worry too much about the differences between the two. We've incorporated `BertAdam`mostly to be able to exactly reproduce the behavior of the TensorFlow implementation.",
"@thomwolf Thanks, that explanation really helps. I have been using standard Adam with good results and BertAdam didn't improve that. So in my particular case it may not have been useful.\r\n\r\nClosing this, as my question has been answered.",
"For reference for future visits, recent research suggests that the omission of the bias compensation in BERTAdam is one of the sources of instability in finetuning:\r\n\r\n* [On the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselines](https://www.lsv.uni-saarland.de/wp-content/publications/2020/On_the_Stability_of_Fine-tuning_BERT_preprint.pdf)\r\n* [Revisiting Few-sample BERT Fine-tuning](https://arxiv.org/abs/2006.05987)"
] | 1,553 | 1,594 | 1,554 | COLLABORATOR | null | I have implemented BERT, taking the output of [CLS] and feeding that to a linear layer on top to do regression. I froze the embedding layers of BERT, though. I was using the standard Adam optimizer and did not run into any issues.
When and/or why should one use BERTAdam? And, in a set-up like mine, would you use BERTAdam for BERT, and regular Adam for the rest of the whole model? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/420/reactions",
"total_count": 8,
"+1": 8,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/420/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/419 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/419/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/419/comments | https://api.github.com/repos/huggingface/transformers/issues/419/events | https://github.com/huggingface/transformers/issues/419 | 426,376,347 | MDU6SXNzdWU0MjYzNzYzNDc= | 419 | bug in examples/run_squad.py line 88 & 90 | {
"login": "lbyiuou",
"id": 11863461,
"node_id": "MDQ6VXNlcjExODYzNDYx",
"avatar_url": "https://avatars.githubusercontent.com/u/11863461?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lbyiuou",
"html_url": "https://github.com/lbyiuou",
"followers_url": "https://api.github.com/users/lbyiuou/followers",
"following_url": "https://api.github.com/users/lbyiuou/following{/other_user}",
"gists_url": "https://api.github.com/users/lbyiuou/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lbyiuou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lbyiuou/subscriptions",
"organizations_url": "https://api.github.com/users/lbyiuou/orgs",
"repos_url": "https://api.github.com/users/lbyiuou/repos",
"events_url": "https://api.github.com/users/lbyiuou/events{/privacy}",
"received_events_url": "https://api.github.com/users/lbyiuou/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Indeed, thanks"
] | 1,553 | 1,554 | 1,554 | NONE | null |
if self.start_position:
s += ", end_position: %d" % (self.end_position)
if self.start_position:
s += ", is_impossible: %r" % (self.is_impossible)
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/419/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/419/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/418 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/418/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/418/comments | https://api.github.com/repos/huggingface/transformers/issues/418/events | https://github.com/huggingface/transformers/issues/418 | 426,349,075 | MDU6SXNzdWU0MjYzNDkwNzU= | 418 | can I fine-tuning pretrained gpt2 model on my corpus? | {
"login": "marvinzh",
"id": 6829031,
"node_id": "MDQ6VXNlcjY4MjkwMzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/6829031?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/marvinzh",
"html_url": "https://github.com/marvinzh",
"followers_url": "https://api.github.com/users/marvinzh/followers",
"following_url": "https://api.github.com/users/marvinzh/following{/other_user}",
"gists_url": "https://api.github.com/users/marvinzh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/marvinzh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/marvinzh/subscriptions",
"organizations_url": "https://api.github.com/users/marvinzh/orgs",
"repos_url": "https://api.github.com/users/marvinzh/repos",
"events_url": "https://api.github.com/users/marvinzh/events{/privacy}",
"received_events_url": "https://api.github.com/users/marvinzh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,553 | 1,553 | 1,553 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/418/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/418/timeline | completed | null | null |
|
https://api.github.com/repos/huggingface/transformers/issues/417 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/417/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/417/comments | https://api.github.com/repos/huggingface/transformers/issues/417/events | https://github.com/huggingface/transformers/issues/417 | 426,327,845 | MDU6SXNzdWU0MjYzMjc4NDU= | 417 | Is there any pre-training example code? | {
"login": "tmchojo",
"id": 16629196,
"node_id": "MDQ6VXNlcjE2NjI5MTk2",
"avatar_url": "https://avatars.githubusercontent.com/u/16629196?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tmchojo",
"html_url": "https://github.com/tmchojo",
"followers_url": "https://api.github.com/users/tmchojo/followers",
"following_url": "https://api.github.com/users/tmchojo/following{/other_user}",
"gists_url": "https://api.github.com/users/tmchojo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tmchojo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tmchojo/subscriptions",
"organizations_url": "https://api.github.com/users/tmchojo/orgs",
"repos_url": "https://api.github.com/users/tmchojo/repos",
"events_url": "https://api.github.com/users/tmchojo/events{/privacy}",
"received_events_url": "https://api.github.com/users/tmchojo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @tmchojo there are now several detailed examples [here](https://github.com/huggingface/pytorch-pretrained-BERT/tree/master/examples/lm_finetuning) thanks to @Rocketknight1 and #392 ",
"Thanks.\r\nBut it still needs pre-trained model.\r\nMy data is another domain (not English or Chinese), so I can't use pre-trained model.\r\nDo I have to use [Google's](https://github.com/google-research/bert) to pre-train?",
"I'm also interested in pre-training. Did you make any progress on this, @tmchojo?",
"There is an example provided [here](https://huggingface.co./blog/how-to-train) with colab (this is for pre-training from scratch), however, I'm still trying to figure the continual pre-training and not pretraining from scratch (using a pre-trained model as initial checkpoint). ",
"Hope https://github.com/huggingface/transformers/tree/master/examples/pytorch helps! The language modelling notebook trains a gpt model. This notebook also gives an idea on labelling the dataset for the LM task.\r\n"
] | 1,553 | 1,640 | 1,553 | NONE | null | I want to pre-train BERT with my own data.
[#124](https://github.com/huggingface/pytorch-pretrained-BERT/pull/124), [#170](https://github.com/huggingface/pytorch-pretrained-BERT/issues/170) say the model can pre-training.
But I can't find pre-training example code.
Is there any pre-training example code?
If there is no example code, I wonder [modeling.py](https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/pytorch_pretrained_bert/modeling.py)'s BertForPreTraining is enought to pre-tranining. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/417/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/417/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/416 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/416/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/416/comments | https://api.github.com/repos/huggingface/transformers/issues/416/events | https://github.com/huggingface/transformers/issues/416 | 426,242,746 | MDU6SXNzdWU0MjYyNDI3NDY= | 416 | Distributed Training Gets Stuck | {
"login": "moinnadeem",
"id": 813367,
"node_id": "MDQ6VXNlcjgxMzM2Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/813367?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moinnadeem",
"html_url": "https://github.com/moinnadeem",
"followers_url": "https://api.github.com/users/moinnadeem/followers",
"following_url": "https://api.github.com/users/moinnadeem/following{/other_user}",
"gists_url": "https://api.github.com/users/moinnadeem/gists{/gist_id}",
"starred_url": "https://api.github.com/users/moinnadeem/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moinnadeem/subscriptions",
"organizations_url": "https://api.github.com/users/moinnadeem/orgs",
"repos_url": "https://api.github.com/users/moinnadeem/repos",
"events_url": "https://api.github.com/users/moinnadeem/events{/privacy}",
"received_events_url": "https://api.github.com/users/moinnadeem/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649053,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Help%20wanted",
"name": "Help wanted",
"color": "008672",
"default": false,
"description": "Extra attention is needed, help appreciated"
},
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Hi,\r\nOne possible cause of this behavior may be the way you are freezing your parameters.\r\n\r\nPyTorch's `DistributedDataParallel` is a rather sensitive beast as you can juge by the number of warnings in [its doc](https://pytorch.org/docs/stable/nn.html#torch.nn.parallel.DistributedDataParallel).\r\n\r\nTwo features are especially important to keep in mind:\r\n- *You should never try to change your model’s parameters after wrapping up your model with DistributedDataParallel* or unexpected behaviors can happen, since some parameters’ gradient reduction functions might not get called.\r\n- Another that is probably not important for you but you should be award of: Constructor, forward method, and differentiation of the output (backward pass) are *distributed synchronization point*.\r\n\r\nSo maybe you are freezing your parameters after having wrapped up your model with DistributedDataParallel?",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,553 | 1,560 | 1,560 | NONE | null | Hi,
When I freeze the BERT layers, distributed training works just fine. However, when I unfreeze the BERT layers, the first node continues training, and all other nodes wait on the training step with 100% GPU utilization on the first GPU. Is this expected behavior, or am I doing something wrong?
I'm using PyTorch 1.0.1post2, and 8 GTX 1080 GPUs per machine.
Best,
Moin | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/416/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/416/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/415 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/415/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/415/comments | https://api.github.com/repos/huggingface/transformers/issues/415/events | https://github.com/huggingface/transformers/issues/415 | 426,146,199 | MDU6SXNzdWU0MjYxNDYxOTk= | 415 | For sequence classification, is this model using the wrong token? | {
"login": "CatalinVoss",
"id": 332459,
"node_id": "MDQ6VXNlcjMzMjQ1OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/332459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CatalinVoss",
"html_url": "https://github.com/CatalinVoss",
"followers_url": "https://api.github.com/users/CatalinVoss/followers",
"following_url": "https://api.github.com/users/CatalinVoss/following{/other_user}",
"gists_url": "https://api.github.com/users/CatalinVoss/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CatalinVoss/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CatalinVoss/subscriptions",
"organizations_url": "https://api.github.com/users/CatalinVoss/orgs",
"repos_url": "https://api.github.com/users/CatalinVoss/repos",
"events_url": "https://api.github.com/users/CatalinVoss/events{/privacy}",
"received_events_url": "https://api.github.com/users/CatalinVoss/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Never mind, I think I got confused. Is it that the pooler already takes care of that and encoded_layers represents the pooler output for each attention layer?",
"Hi Catalin, the content of the outputs (`encoded_layers` and `pooled_output`) is detailed in the readme [here](https://github.com/huggingface/pytorch-pretrained-BERT#1-bertmodel) and in the model docstring. `encoded_layers` contains the encoded-hidden-states at the end of each attention block (i.e. 12 full sequences for BERT-base, 24 for BERT-large), each encoded-hidden-state is a torch.FloatTensor of size [batch_size, sequence_length, hidden_size].\r\n\r\nThe Pooler take care of extracting the hidden state of the first token from the encoded hidden state of the full sequence (see [here](https://github.com/huggingface/pytorch-pretrained-BERT/blob/f7c9dc8c998395d2ad9edbf0fd6fa072f03cc667/pytorch_pretrained_bert/modeling.py#L413))"
] | 1,553 | 1,553 | 1,553 | CONTRIBUTOR | null | According to the BERT paper, we want to use the weights for the `[CLS]` token, which – as far as I understand – would be the first hidden output here, not the last?
i.e. shouldn't this be `encoded_layers[0]` below?
https://github.com/huggingface/pytorch-pretrained-BERT/blob/f7c9dc8c998395d2ad9edbf0fd6fa072f03cc667/pytorch_pretrained_bert/modeling.py#L715-L719
@thomwolf Let me know if I'm missing something and if you're concerned about this breaking anything else and I can PR. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/415/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/415/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/414 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/414/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/414/comments | https://api.github.com/repos/huggingface/transformers/issues/414/events | https://github.com/huggingface/transformers/issues/414 | 425,788,102 | MDU6SXNzdWU0MjU3ODgxMDI= | 414 | Help with implementing strides into features for multi-label classifier | {
"login": "alvin-leong",
"id": 33982759,
"node_id": "MDQ6VXNlcjMzOTgyNzU5",
"avatar_url": "https://avatars.githubusercontent.com/u/33982759?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alvin-leong",
"html_url": "https://github.com/alvin-leong",
"followers_url": "https://api.github.com/users/alvin-leong/followers",
"following_url": "https://api.github.com/users/alvin-leong/following{/other_user}",
"gists_url": "https://api.github.com/users/alvin-leong/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alvin-leong/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alvin-leong/subscriptions",
"organizations_url": "https://api.github.com/users/alvin-leong/orgs",
"repos_url": "https://api.github.com/users/alvin-leong/repos",
"events_url": "https://api.github.com/users/alvin-leong/events{/privacy}",
"received_events_url": "https://api.github.com/users/alvin-leong/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649053,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDUz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Help%20wanted",
"name": "Help wanted",
"color": "008672",
"default": false,
"description": "Extra attention is needed, help appreciated"
},
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n",
"@alvin-leong did this make any progress? I am interested in doing something similar for the sequence classifier. ",
"@alvin-leong @maxzzze , just wondering if there is any progress on this? \r\nThanks.",
"No 😞 I ended up implementing several methods to grab different spans of length X (hyperparamter) from all over my documents which have lengths > 512.",
"Thanks @maxzzze . I am doing the same now, and just concerned about the answers from different spans. You may have right answer with low scores and wrong answer with high scores. Finger cross not. Not sure if scores from different spans is comparable?!",
"I modified https://github.com/kyzhouhzau/BERT-NER to implement strides https://github.com/anupamsingh610/bert_ner_stride\r\n\r\nHope it helps :)",
"@alvin-leong Hi, I have you made any progress on this issue? I checked your notebook. What is the problem with that? Is just the train very slow?",
"Hi, we have implemented BERT binary classifier for longer texts [here](https://github.com/mim-solutions/bert_for_longer_texts)."
] | 1,553 | 1,678 | 1,559 | NONE | null | As you might know, BERT has a maximum wordpiece token sequence length of 512.
The SQuAD example actually uses strides to account for this: https://github.com/google-research/bert/issues/27
I want to implement something like what Jacob Devlin described in that post for Kaushal's multi-label BERT classifier: https://medium.com/huggingface/multi-label-text-classification-using-bert-the-mighty-transformer-69714fa3fb3d
What I did was basically just copy and edit a bit the doc_stride functions from the SQuAD example in huggingface into Kaushal's code: https://colab.research.google.com/drive/1aqcIdm2Pn2rvmWHvOSEMUTzw_CNmoseA
However, this is excruciatingly slow, I don't know if it's an issue of stride length?
Also, I'm not sure how to implement the thing about reshaping the combined minibatches and getting predictions from there.
Anyone who has tried to adapt BERT for longer texts, could you please help?
Thanks
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/414/reactions",
"total_count": 11,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 11
} | https://api.github.com/repos/huggingface/transformers/issues/414/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/413 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/413/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/413/comments | https://api.github.com/repos/huggingface/transformers/issues/413/events | https://github.com/huggingface/transformers/issues/413 | 425,665,342 | MDU6SXNzdWU0MjU2NjUzNDI= | 413 | Bert Pretrained model has no modules nor parameters | {
"login": "yousenwang",
"id": 10716228,
"node_id": "MDQ6VXNlcjEwNzE2MjI4",
"avatar_url": "https://avatars.githubusercontent.com/u/10716228?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yousenwang",
"html_url": "https://github.com/yousenwang",
"followers_url": "https://api.github.com/users/yousenwang/followers",
"following_url": "https://api.github.com/users/yousenwang/following{/other_user}",
"gists_url": "https://api.github.com/users/yousenwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yousenwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yousenwang/subscriptions",
"organizations_url": "https://api.github.com/users/yousenwang/orgs",
"repos_url": "https://api.github.com/users/yousenwang/repos",
"events_url": "https://api.github.com/users/yousenwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/yousenwang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,553 | 1,553 | 1,553 | NONE | null | "from pytorch_pretrained_bert.modeling import BertPreTrainedModel
bert_model = BertPreTrainedModel.from_pretrained(pretrained_model_name_or_path='bert-base-uncased')
bert_model.to(device)"
returns:
2019-03-26 21:38:07,404 pytorch_pretrained_bert.modeling INFO loading archive file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz from cache at /home/ubuntu/.pytorch_pretrained_bert/9c41111e2de84547a463fd39217199738d1e3deb72d4fec4399e6e241983c6f0.ae3cef932725ca7a30cdcb93fc6e09150a55e2a130ec7af63975a16c153ae2ba
2019-03-26 21:38:07,405 pytorch_pretrained_bert.modeling INFO extracting archive file /home/ubuntu/.pytorch_pretrained_bert/9c41111e2de84547a463fd39217199738d1e3deb72d4fec4399e6e241983c6f0.ae3cef932725ca7a30cdcb93fc6e09150a55e2a130ec7af63975a16c153ae2ba to temp dir /tmp/tmpkki3a7er
2019-03-26 21:38:11,106 pytorch_pretrained_bert.modeling INFO Model config {
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30522
}
2019-03-26 21:38:11,348 pytorch_pretrained_bert.modeling INFO Weights from pretrained model not used in BertPreTrainedModel: ['bert.embeddings.word_embeddings.weight', 'bert.embeddings.position_embeddings.weight', 'bert.embeddings.token_type_embeddings.weight', 'bert.encoder.layer.0.attention.self.query.weight', 'bert.encoder.layer.0.attention.self.query.bias', 'bert.encoder.layer.0.attention.self.key.weight', 'bert.encoder.layer.0.attention.self.key.bias', 'bert.encoder.layer.0.attention.self.value.weight', 'bert.encoder.layer.0.attention.self.value.bias', 'bert.encoder.layer.0.attention.output.dense.weight', 'bert.encoder.layer.0.attention.output.dense.bias', 'bert.encoder.layer.0.intermediate.dense.weight', 'bert.encoder.layer.0.intermediate.dense.bias', 'bert.encoder.layer.0.output.dense.weight', 'bert.encoder.layer.0.output.dense.bias', 'bert.encoder.layer.1.attention.self.query.weight', 'bert.encoder.layer.1.attention.self.query.bias', 'bert.encoder.layer.1.attention.self.key.weight', 'bert.encoder.layer.1.attention.self.key.bias', 'bert.encoder.layer.1.attention.self.value.weight', 'bert.encoder.layer.1.attention.self.value.bias', 'bert.encoder.layer.1.attention.output.dense.weight', 'bert.encoder.layer.1.attention.output.dense.bias', 'bert.encoder.layer.1.intermediate.dense.weight', 'bert.encoder.layer.1.intermediate.dense.bias', 'bert.encoder.layer.1.output.dense.weight', 'bert.encoder.layer.1.output.dense.bias', 'bert.encoder.layer.2.attention.self.query.weight', 'bert.encoder.layer.2.attention.self.query.bias', 'bert.encoder.layer.2.attention.self.key.weight', 'bert.encoder.layer.2.attention.self.key.bias', 'bert.encoder.layer.2.attention.self.value.weight', 'bert.encoder.layer.2.attention.self.value.bias', 'bert.encoder.layer.2.attention.output.dense.weight', 'bert.encoder.layer.2.attention.output.dense.bias', 'bert.encoder.layer.2.intermediate.dense.weight', 'bert.encoder.layer.2.intermediate.dense.bias', 'bert.encoder.layer.2.output.dense.weight', 'bert.encoder.layer.2.output.dense.bias', 'bert.encoder.layer.3.attention.self.query.weight', 'bert.encoder.layer.3.attention.self.query.bias', 'bert.encoder.layer.3.attention.self.key.weight', 'bert.encoder.layer.3.attention.self.key.bias', 'bert.encoder.layer.3.attention.self.value.weight', 'bert.encoder.layer.3.attention.self.value.bias', 'bert.encoder.layer.3.attention.output.dense.weight', 'bert.encoder.layer.3.attention.output.dense.bias', 'bert.encoder.layer.3.intermediate.dense.weight', 'bert.encoder.layer.3.intermediate.dense.bias', 'bert.encoder.layer.3.output.dense.weight', 'bert.encoder.layer.3.output.dense.bias', 'bert.encoder.layer.4.attention.self.query.weight', 'bert.encoder.layer.4.attention.self.query.bias', 'bert.encoder.layer.4.attention.self.key.weight', 'bert.encoder.layer.4.attention.self.key.bias', 'bert.encoder.layer.4.attention.self.value.weight', 'bert.encoder.layer.4.attention.self.value.bias', 'bert.encoder.layer.4.attention.output.dense.weight', 'bert.encoder.layer.4.attention.output.dense.bias', 'bert.encoder.layer.4.intermediate.dense.weight', 'bert.encoder.layer.4.intermediate.dense.bias', 'bert.encoder.layer.4.output.dense.weight', 'bert.encoder.layer.4.output.dense.bias', 'bert.encoder.layer.5.attention.self.query.weight', 'bert.encoder.layer.5.attention.self.query.bias', 'bert.encoder.layer.5.attention.self.key.weight', 'bert.encoder.layer.5.attention.self.key.bias', 'bert.encoder.layer.5.attention.self.value.weight', 'bert.encoder.layer.5.attention.self.value.bias', 'bert.encoder.layer.5.attention.output.dense.weight', 'bert.encoder.layer.5.attention.output.dense.bias', 'bert.encoder.layer.5.intermediate.dense.weight', 'bert.encoder.layer.5.intermediate.dense.bias', 'bert.encoder.layer.5.output.dense.weight', 'bert.encoder.layer.5.output.dense.bias', 'bert.encoder.layer.6.attention.self.query.weight', 'bert.encoder.layer.6.attention.self.query.bias', 'bert.encoder.layer.6.attention.self.key.weight', 'bert.encoder.layer.6.attention.self.key.bias', 'bert.encoder.layer.6.attention.self.value.weight', 'bert.encoder.layer.6.attention.self.value.bias', 'bert.encoder.layer.6.attention.output.dense.weight', 'bert.encoder.layer.6.attention.output.dense.bias', 'bert.encoder.layer.6.intermediate.dense.weight', 'bert.encoder.layer.6.intermediate.dense.bias', 'bert.encoder.layer.6.output.dense.weight', 'bert.encoder.layer.6.output.dense.bias', 'bert.encoder.layer.7.attention.self.query.weight', 'bert.encoder.layer.7.attention.self.query.bias', 'bert.encoder.layer.7.attention.self.key.weight', 'bert.encoder.layer.7.attention.self.key.bias', 'bert.encoder.layer.7.attention.self.value.weight', 'bert.encoder.layer.7.attention.self.value.bias', 'bert.encoder.layer.7.attention.output.dense.weight', 'bert.encoder.layer.7.attention.output.dense.bias', 'bert.encoder.layer.7.intermediate.dense.weight', 'bert.encoder.layer.7.intermediate.dense.bias', 'bert.encoder.layer.7.output.dense.weight', 'bert.encoder.layer.7.output.dense.bias', 'bert.encoder.layer.8.attention.self.query.weight', 'bert.encoder.layer.8.attention.self.query.bias', 'bert.encoder.layer.8.attention.self.key.weight', 'bert.encoder.layer.8.attention.self.key.bias', 'bert.encoder.layer.8.attention.self.value.weight', 'bert.encoder.layer.8.attention.self.value.bias', 'bert.encoder.layer.8.attention.output.dense.weight', 'bert.encoder.layer.8.attention.output.dense.bias', 'bert.encoder.layer.8.intermediate.dense.weight', 'bert.encoder.layer.8.intermediate.dense.bias', 'bert.encoder.layer.8.output.dense.weight', 'bert.encoder.layer.8.output.dense.bias', 'bert.encoder.layer.9.attention.self.query.weight', 'bert.encoder.layer.9.attention.self.query.bias', 'bert.encoder.layer.9.attention.self.key.weight', 'bert.encoder.layer.9.attention.self.key.bias', 'bert.encoder.layer.9.attention.self.value.weight', 'bert.encoder.layer.9.attention.self.value.bias', 'bert.encoder.layer.9.attention.output.dense.weight', 'bert.encoder.layer.9.attention.output.dense.bias', 'bert.encoder.layer.9.intermediate.dense.weight', 'bert.encoder.layer.9.intermediate.dense.bias', 'bert.encoder.layer.9.output.dense.weight', 'bert.encoder.layer.9.output.dense.bias', 'bert.encoder.layer.10.attention.self.query.weight', 'bert.encoder.layer.10.attention.self.query.bias', 'bert.encoder.layer.10.attention.self.key.weight', 'bert.encoder.layer.10.attention.self.key.bias', 'bert.encoder.layer.10.attention.self.value.weight', 'bert.encoder.layer.10.attention.self.value.bias', 'bert.encoder.layer.10.attention.output.dense.weight', 'bert.encoder.layer.10.attention.output.dense.bias', 'bert.encoder.layer.10.intermediate.dense.weight', 'bert.encoder.layer.10.intermediate.dense.bias', 'bert.encoder.layer.10.output.dense.weight', 'bert.encoder.layer.10.output.dense.bias', 'bert.encoder.layer.11.attention.self.query.weight', 'bert.encoder.layer.11.attention.self.query.bias', 'bert.encoder.layer.11.attention.self.key.weight', 'bert.encoder.layer.11.attention.self.key.bias', 'bert.encoder.layer.11.attention.self.value.weight', 'bert.encoder.layer.11.attention.self.value.bias', 'bert.encoder.layer.11.attention.output.dense.weight', 'bert.encoder.layer.11.attention.output.dense.bias', 'bert.encoder.layer.11.intermediate.dense.weight', 'bert.encoder.layer.11.intermediate.dense.bias', 'bert.encoder.layer.11.output.dense.weight', 'bert.encoder.layer.11.output.dense.bias', 'bert.pooler.dense.weight', 'bert.pooler.dense.bias', 'bert.embeddings.LayerNorm.weight', 'bert.embeddings.LayerNorm.bias', 'bert.encoder.layer.0.attention.output.LayerNorm.weight', 'bert.encoder.layer.0.attention.output.LayerNorm.bias', 'bert.encoder.layer.0.output.LayerNorm.weight', 'bert.encoder.layer.0.output.LayerNorm.bias', 'bert.encoder.layer.1.attention.output.LayerNorm.weight', 'bert.encoder.layer.1.attention.output.LayerNorm.bias', 'bert.encoder.layer.1.output.LayerNorm.weight', 'bert.encoder.layer.1.output.LayerNorm.bias', 'bert.encoder.layer.2.attention.output.LayerNorm.weight', 'bert.encoder.layer.2.attention.output.LayerNorm.bias', 'bert.encoder.layer.2.output.LayerNorm.weight', 'bert.encoder.layer.2.output.LayerNorm.bias', 'bert.encoder.layer.3.attention.output.LayerNorm.weight', 'bert.encoder.layer.3.attention.output.LayerNorm.bias', 'bert.encoder.layer.3.output.LayerNorm.weight', 'bert.encoder.layer.3.output.LayerNorm.bias', 'bert.encoder.layer.4.attention.output.LayerNorm.weight', 'bert.encoder.layer.4.attention.output.LayerNorm.bias', 'bert.encoder.layer.4.output.LayerNorm.weight', 'bert.encoder.layer.4.output.LayerNorm.bias', 'bert.encoder.layer.5.attention.output.LayerNorm.weight', 'bert.encoder.layer.5.attention.output.LayerNorm.bias', 'bert.encoder.layer.5.output.LayerNorm.weight', 'bert.encoder.layer.5.output.LayerNorm.bias', 'bert.encoder.layer.6.attention.output.LayerNorm.weight', 'bert.encoder.layer.6.attention.output.LayerNorm.bias', 'bert.encoder.layer.6.output.LayerNorm.weight', 'bert.encoder.layer.6.output.LayerNorm.bias', 'bert.encoder.layer.7.attention.output.LayerNorm.weight', 'bert.encoder.layer.7.attention.output.LayerNorm.bias', 'bert.encoder.layer.7.output.LayerNorm.weight', 'bert.encoder.layer.7.output.LayerNorm.bias', 'bert.encoder.layer.8.attention.output.LayerNorm.weight', 'bert.encoder.layer.8.attention.output.LayerNorm.bias', 'bert.encoder.layer.8.output.LayerNorm.weight', 'bert.encoder.layer.8.output.LayerNorm.bias', 'bert.encoder.layer.9.attention.output.LayerNorm.weight', 'bert.encoder.layer.9.attention.output.LayerNorm.bias', 'bert.encoder.layer.9.output.LayerNorm.weight', 'bert.encoder.layer.9.output.LayerNorm.bias', 'bert.encoder.layer.10.attention.output.LayerNorm.weight', 'bert.encoder.layer.10.attention.output.LayerNorm.bias', 'bert.encoder.layer.10.output.LayerNorm.weight', 'bert.encoder.layer.10.output.LayerNorm.bias', 'bert.encoder.layer.11.attention.output.LayerNorm.weight', 'bert.encoder.layer.11.attention.output.LayerNorm.bias', 'bert.encoder.layer.11.output.LayerNorm.weight', 'bert.encoder.layer.11.output.LayerNorm.bias']
BertPreTrainedModel()
----
"
#%%
for key, val in bert_model._modules.items():
print(key)
print(val)
#%%
for key, val in bert_model._parameters.items():
print(key)
print(val)
"
returns:
nothing
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/413/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/413/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/412 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/412/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/412/comments | https://api.github.com/repos/huggingface/transformers/issues/412/events | https://github.com/huggingface/transformers/issues/412 | 425,663,361 | MDU6SXNzdWU0MjU2NjMzNjE= | 412 | Possible error in "pytorch-pretrained-BERT/examples/run_gpt2.py" unconditional | {
"login": "brunokinder",
"id": 1786870,
"node_id": "MDQ6VXNlcjE3ODY4NzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/1786870?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brunokinder",
"html_url": "https://github.com/brunokinder",
"followers_url": "https://api.github.com/users/brunokinder/followers",
"following_url": "https://api.github.com/users/brunokinder/following{/other_user}",
"gists_url": "https://api.github.com/users/brunokinder/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brunokinder/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brunokinder/subscriptions",
"organizations_url": "https://api.github.com/users/brunokinder/orgs",
"repos_url": "https://api.github.com/users/brunokinder/repos",
"events_url": "https://api.github.com/users/brunokinder/events{/privacy}",
"received_events_url": "https://api.github.com/users/brunokinder/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This should be fixed by #462."
] | 1,553 | 1,555 | 1,555 | NONE | null | Hello,
First of all thanks for offering us those great NLP implementations.
I think there may be an error in the file pytorch-pretrained-BERT/examples/run_gpt2.py

The way it is implemented if we do unconditional=True nothing happens.
If you fix this line, don't forget to look at too

Thank you.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/412/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/412/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/411 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/411/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/411/comments | https://api.github.com/repos/huggingface/transformers/issues/411/events | https://github.com/huggingface/transformers/issues/411 | 425,415,282 | MDU6SXNzdWU0MjU0MTUyODI= | 411 | Why average the loss when training on multi-GPUs | {
"login": "pkuyym",
"id": 5782283,
"node_id": "MDQ6VXNlcjU3ODIyODM=",
"avatar_url": "https://avatars.githubusercontent.com/u/5782283?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pkuyym",
"html_url": "https://github.com/pkuyym",
"followers_url": "https://api.github.com/users/pkuyym/followers",
"following_url": "https://api.github.com/users/pkuyym/following{/other_user}",
"gists_url": "https://api.github.com/users/pkuyym/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pkuyym/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pkuyym/subscriptions",
"organizations_url": "https://api.github.com/users/pkuyym/orgs",
"repos_url": "https://api.github.com/users/pkuyym/repos",
"events_url": "https://api.github.com/users/pkuyym/events{/privacy}",
"received_events_url": "https://api.github.com/users/pkuyym/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1260952223,
"node_id": "MDU6TGFiZWwxMjYwOTUyMjIz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Discussion",
"name": "Discussion",
"color": "22870e",
"default": false,
"description": "Discussion on a topic (keep it focused or open a new issue though)"
}
] | closed | false | null | [] | [
"Multi-GPU loss returns a tuple of losses with one loss for each GPU.\r\nWe average them to get the full loss. See [this blog post](https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255) for more details."
] | 1,553 | 1,553 | 1,553 | NONE | null | Could anyone help to explain the motivation for this operation?
https://github.com/huggingface/pytorch-pretrained-BERT/blob/master/examples/run_classifier.py#L573-L574 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/411/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/411/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/410 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/410/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/410/comments | https://api.github.com/repos/huggingface/transformers/issues/410/events | https://github.com/huggingface/transformers/issues/410 | 425,411,023 | MDU6SXNzdWU0MjU0MTEwMjM= | 410 | something wrong in example | {
"login": "Wangpeiyi9979",
"id": 42565075,
"node_id": "MDQ6VXNlcjQyNTY1MDc1",
"avatar_url": "https://avatars.githubusercontent.com/u/42565075?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Wangpeiyi9979",
"html_url": "https://github.com/Wangpeiyi9979",
"followers_url": "https://api.github.com/users/Wangpeiyi9979/followers",
"following_url": "https://api.github.com/users/Wangpeiyi9979/following{/other_user}",
"gists_url": "https://api.github.com/users/Wangpeiyi9979/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Wangpeiyi9979/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Wangpeiyi9979/subscriptions",
"organizations_url": "https://api.github.com/users/Wangpeiyi9979/orgs",
"repos_url": "https://api.github.com/users/Wangpeiyi9979/repos",
"events_url": "https://api.github.com/users/Wangpeiyi9979/events{/privacy}",
"received_events_url": "https://api.github.com/users/Wangpeiyi9979/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1108649070,
"node_id": "MDU6TGFiZWwxMTA4NjQ5MDcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Need%20more%20information",
"name": "Need more information",
"color": "d876e3",
"default": false,
"description": "Further information is requested"
},
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] | closed | false | null | [] | [
"Do you have the latest `pytorch-pretrained-bert` ?\r\n```python\r\nimport pytorch_pretrained_bert\r\npytorch_pretrained_bert.__version__\r\n```",
"Thank you so much!!!!!!!",
"This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.\n"
] | 1,553 | 1,559 | 1,559 | NONE | null |

the segmentation is wrong。。 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/410/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/410/timeline | completed | null | null |