|
--- |
|
base_model: m-a-p/OpenCodeInterpreter-DS-6.7B |
|
inference: false |
|
language: |
|
- en |
|
license: apache-2.0 |
|
license_link: https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/main/LICENSE |
|
model_creator: m-a-p |
|
model_name: OpenCodeInterpreter-DS-6.7B |
|
model_type: llama |
|
pipeline_tag: text-generation |
|
tags: |
|
- code |
|
quantized_by: brittlewis12 |
|
--- |
|
|
|
 |
|
|
|
# OpenCodeInterpreter-DS-6.7B GGUF |
|
|
|
|
|
**Original model**: [OpenCodeInterpreter-DS-6.7B](https://huggingface.co./m-a-p/OpenCodeInterpreter-DS-6.7B) |
|
|
|
**Model creator**: [Multimodal Art Projection Research Community](https://huggingface.co./m-a-p) |
|
|
|
This repo contains GGUF format model files for Multimodal Art Projection Research Community (M-A-P)’s OpenCodeInterpreter-DS-6.7B. |
|
|
|
> The introduction of large language models has significantly advanced code generation. However, open-source models often lack the execution capabilities and iterative refinement of advanced systems like the GPT-4 Code Interpreter. To address this, we introduce OpenCodeInterpreter, a family of open-source code systems designed for generating, executing, and iteratively refining code. Supported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter integrates execution and human feedback for dynamic code refinement. Our comprehensive evaluation of OpenCodeInterpreter across key benchmarks such as HumanEval, MBPP, and their enhanced versions from EvalPlus reveals its exceptional performance. Notably, OpenCodeInterpreter-33B achieves an accuracy of 83.2 (76.4) on the average (and plus versions) of HumanEval and MBPP, closely rivaling GPT-4's 84.2 (76.2) and further elevates to 91.6 (84.6) with synthesized human feedback from GPT-4. OpenCodeInterpreter brings the gap between open-source code generation models and proprietary systems like GPT-4 Code Interpreter. |
|
|
|
Learn more on M-A-P’s [Model page](https://opencodeinterpreter.github.io/). |
|
|
|
### What is GGUF? |
|
|
|
GGUF is a file format for representing AI models. It is the third version of the format, introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. |
|
Converted using llama.cpp build 2249 (revision [15499eb](https://github.com/ggerganov/llama.cpp/commit/15499eb94227401bdc8875da6eb85c15d37068f7)) |
|
|
|
### Prompt template |
|
|
|
``` |
|
<|User|> |
|
{{prompt}} |
|
|
|
<|Assistant|> |
|
|
|
``` |
|
|
|
--- |
|
|
|
## Download & run with [cnvrs](https://twitter.com/cnvrsai) on iPhone, iPad, and Mac! |
|
|
|
 |
|
|
|
[cnvrs](https://testflight.apple.com/join/sFWReS7K) is the best app for private, local AI on your device: |
|
- create & save **Characters** with custom system prompts & temperature settings |
|
- download and experiment with any **GGUF model** you can [find on HuggingFace](https://huggingface.co./models?library=gguf)! |
|
- make it your own with custom **Theme colors** |
|
- powered by Metal ⚡️ & [Llama.cpp](https://github.com/ggerganov/llama.cpp), with **haptics** during response streaming! |
|
- **try it out** yourself today, on [Testflight](https://testflight.apple.com/join/sFWReS7K)! |
|
- follow [cnvrs on twitter](https://twitter.com/cnvrsai) to stay up to date |
|
|
|
--- |
|
|
|
## Original Model Evaluation |
|
|
|
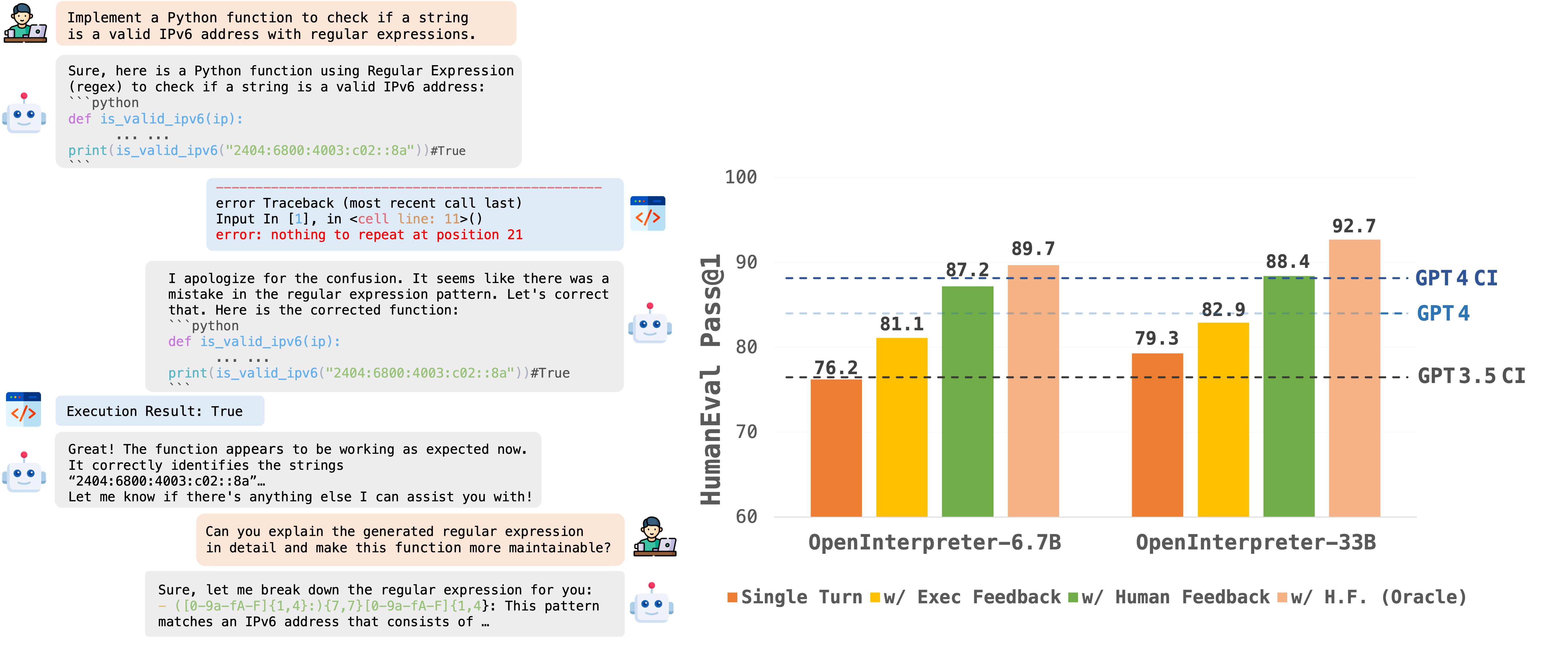
> The study leverages data from the EvalPlus leaderboard, examining OpenCodeInterpreter's performance against benchmarks such as GPT-3.5/4-Turbo, CodeLlama-Python, WizardCoder, Deepseek-Coder, and CodeT5+ across various scales on the HumanEval and MBPP benchmarks and their advanced versions. For multi-turn code generation, the focus shifts to assessing OpenCodeInterpreter's capability in iterative refinement through a two-round limit, considering execution feedback and human feedback scenarios. The experimental setup aims to highlight OpenCodeInterpreter's adaptability and proficiency in code generation, underscored by its achievements in setting new standards in software development tools through iterative feedback and refinement. |
|
|
|
For more detail on evaluation process, see [main results](https://opencodeinterpreter.github.io/#mainresults) & eval code [README](https://github.com/OpenCodeInterpreter/OpenCodeInterpreter/blob/f5bcecc42f84b4b789757daf3af476fcfa8b9d79/evaluation/README.md). |
|
|
|
| Model | HumanEval (+) | MBPP (+) | Average (+) | |
|
|----------------------|---------------|----------|-------------| |
|
| OpenCodeInterpreter-DS-6.7B | 76.2 (72.0) | 73.9 (63.7) | 75.1 (67.9) | |
|
| --> with Execution Feedback | 81.1 (78.7) | 82.7 (72.4) | 81.9 (75.6) | |
|
| --> with Synth. Human Feedback | 87.2 (**86.6**) | 86.2 (74.2) | 86.7 (80.4) | |
|
| --> with Synth. Human Feedback (Oracle) | **89.7 (86.6)** | **87.2 (75.2)** | **88.5 (80.9)** | |
|
| — | — | — | — | |
|
| GPT-4-Turbo | 85.4 (81.7) | 83.0 (70.7) | 84.2 (76.2) | |
|
| --> with Execution Feedback | **88.0 (84.2)** | **92.0 (78.2)** | **90.0 (81.2)** | |
|
| — | — | — | — | |
|
| GPT-3.5-Turbo | 72.6 (65.9) | 81.7 (69.4) | 77.2 (67.7) | |
|
| --> with Execution Feedback | 76.8 (70.7) | 87.0 (73.9) | 81.9 (72.3) | |
|
|
