
DeepSeek MoE Implementation
![]()
Note: This repository contains a modular implementation of the DeepSeek MoE architecture, not trained model weights.
A clean, efficient implementation of DeepSeek's Mixture of Experts (MoE) architecture in PyTorch. This repository provides a simplified version of the architecture described in the DeepSeek paper, focusing on the core innovations that make their MoE approach unique.
This repository is part of a series implementing the key architectural innovations from the DeepSeek paper. See the 'Related Implementations' section for the complete series.
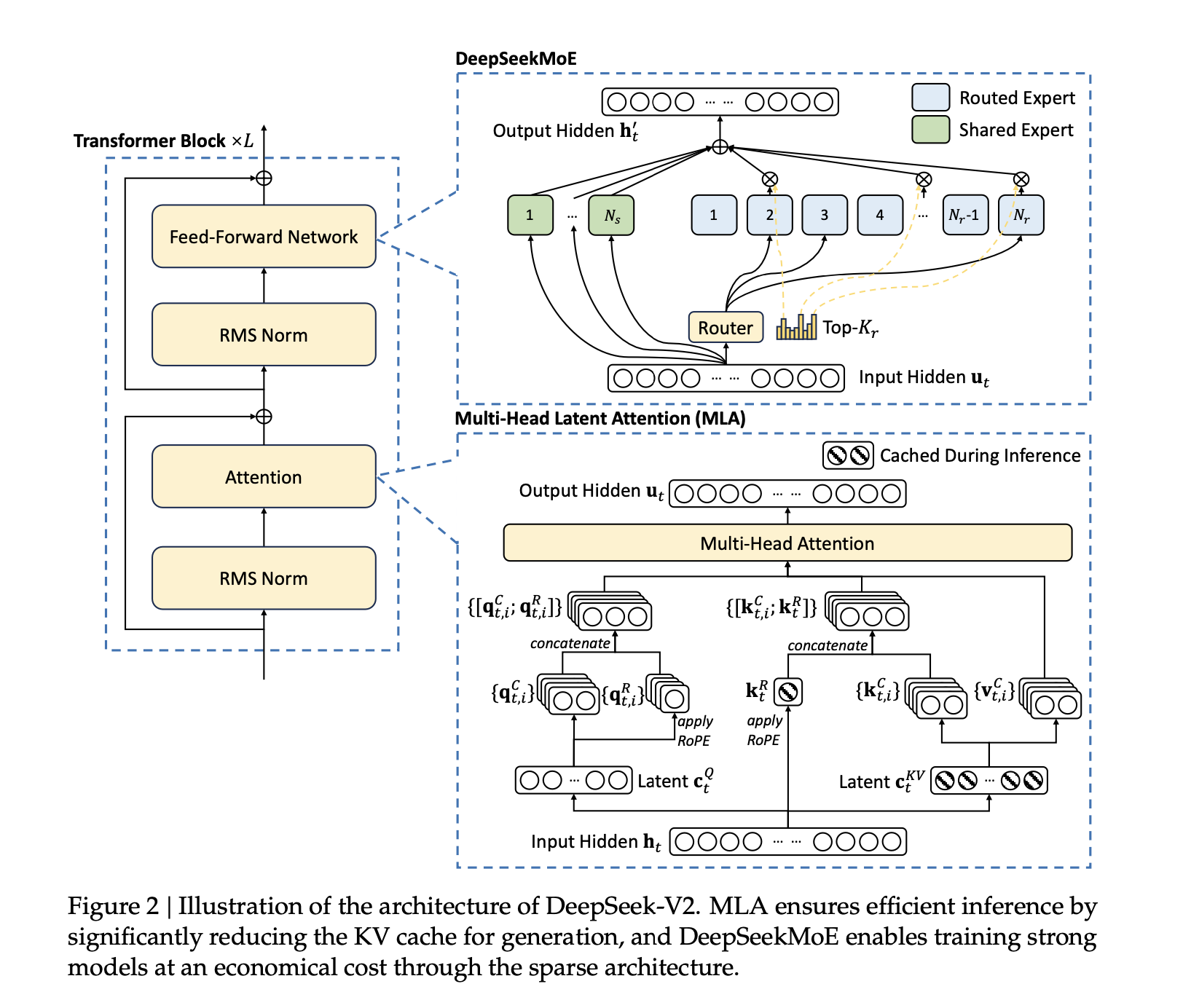
Overview
Mixture of Experts (MoE) architectures enable dramatic scaling of model parameters while maintaining computational efficiency by activating only a subset of parameters for any given input. DeepSeek's approach introduces several key innovations to the MoE architecture that improve performance and efficiency.
Key features of this implementation:
- Hybrid Expert Structure: Combines shared experts (processing all tokens) with routed experts (processing specific tokens)
- Efficient Top-K Routing: Token-to-expert affinity calculation based on dot product similarity
- Multi-Level Load Balancing: Cascading auxiliary losses at expert, device, and communication levels
- Device-Limited Routing: Bounds communication costs in distributed training scenarios
- Token Dropping Strategy: Optimize computation by dropping tokens with low affinities
Quick Start
import torch
from moe import MixtureOfExperts
# Create input tensor
batch_size = 8
seq_length = 16
d_model = 512
inputs = torch.randn(batch_size, seq_length, d_model)
# Create MoE layer
moe = MixtureOfExperts(
d_model=512, # Input dimension
d_expert=1024, # Expert hidden dimension
K=2, # Top-K experts per token
N_s=2, # Number of shared experts
N_r=8, # Number of routed experts
alpha1=0.01, # Expert balance factor
alpha2=0.01, # Device balance factor
alpha3=0.01, # Communication balance factor
D=4, # Number of devices
M=3 # Device limit for routing
)
# Forward pass
outputs, expert_loss, device_loss, commu_loss = moe(inputs)
Architecture Details
For a detailed explanation of the architecture, see architecture.md.
DeepSeek MoE Key Innovations
The DeepSeek MoE architecture introduces several elegant design choices:
Hybrid Expert Structure: Using both shared experts and routed experts with residual connections maintains global information flow while allowing for specialization.
Token-Expert Affinity: Calculating token-to-expert similarity through dot product with expert centroids, similar to attention mechanisms.
Multi-Level Balancing: Cascading auxiliary losses that enforce balance at expert, device, and communication levels, creating a holistic approach to load distribution.
Device-Limited Routing: Constraining each token to experts on at most M devices to bound communication costs.
Implementation Details
The implementation consists of two main classes:
1. Expert
A feed-forward network with two linear transformations and a ReLU activation in between.
Expert(x) = max(0, xW1 + b1)W2 + b2
2. MixtureOfExperts
The main MoE implementation that:
- Combines shared and routed experts
- Calculates token-to-expert affinities
- Applies top-K routing
- Calculates auxiliary balance losses
MoE(x) = x + ∑ Expert^s_i(x) + ∑ gate(x;K)*Expert^r_i(x)
Testing
Unit tests are provided to verify the correct functioning of:
- Expert computations
- MoE routing mechanisms
- Load balancing losses
- Residual connections
Run the tests with:
python -m src.tests.test_moe
Related Implementations
This repository is part of a series implementing the key architectural innovations from the DeepSeek paper:
DeepSeek MoE (This Repository): Implementation of DeepSeek's Mixture of Experts architecture that enables efficient scaling of model parameters.
DeepSeek Multi-head Latent Attention: Implementation of DeepSeek's MLA mechanism for efficient KV cache usage during inference.
Transformer Implementation Tutorial: A detailed tutorial on implementing transformer architecture with explanations of key components.
Together, these implementations cover the core innovations that power DeepSeek's state-of-the-art performance. By combining the MoE architecture with Multi-head Latent Attention, you can build a complete DeepSeek-style model with improved training efficiency and inference performance.
Contributing
Contributions are welcome! Feel free to:
- Report bugs and issues
- Submit pull requests for improvements
- Add additional test cases
- Provide documentation clarifications
Please ensure all tests pass before submitting pull requests.
Citation
If you use this implementation in your research, please cite:
@misc{deepseek-moe-2025,
author = {Jen Wei},
title = {DeepSeek MoE Implementation},
year = {2025},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://huggingface.co./bird-of-paradise/deepseek-moe}}
}
License
This project is licensed under the Apache License 2.0.
Acknowledgements
This implementation is inspired by the DeepSeek paper and other open-source MoE implementations: