|
--- |
|
license: openrail |
|
--- |
|
|
|
# PMC_LLaMA |
|
|
|
To obtain the foundation model in medical field, we propose [MedLLaMA_13B](https://huggingface.co./chaoyi-wu/MedLLaMA_13B) and PMC_LLaMA_13B. |
|
|
|
MedLLaMA_13B is initialized from LLaMA-13B and further pretrained with medical corpus. Despite the expert knowledge gained, it lacks instruction-following ability. |
|
Hereby we construct a instruction-tuning dataset and evaluate the tuned model. |
|
|
|
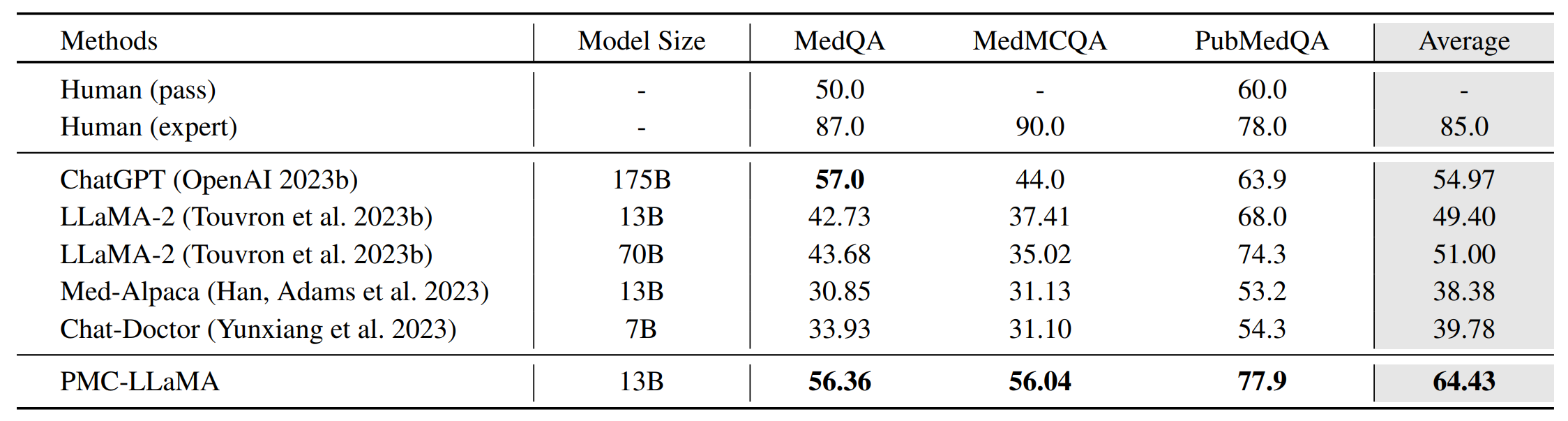
As shown in the table, PMC_LLaMA_13B achieves comparable results to ChatGPT on medical QA benchmarks. |
|
|
|
 |
|
|
|
|
|
## Usage |
|
|
|
```python |
|
import transformers |
|
import torch |
|
|
|
tokenizer = transformers.LlamaTokenizer.from_pretrained('axiong/PMC_LLaMA_13B') |
|
model = transformers.LlamaForCausalLM.from_pretrained('axiong/PMC_LLaMA_13B') |
|
|
|
sentence = 'Hello, doctor' |
|
batch = tokenizer( |
|
sentence, |
|
return_tensors="pt", |
|
add_special_tokens=False |
|
) |
|
with torch.no_grad(): |
|
generated = model.generate( |
|
inputs = batch["input_ids"], |
|
max_length=200, |
|
do_sample=True, |
|
top_k=50 |
|
) |
|
print('model predict: ',tokenizer.decode(generated[0])) |
|
``` |
|
|
|
|
