
Vinqw-1B

Introduction
We are excited to introduce Vinqw-1B, a 1-billion-parameter VLM built using the InternViT-300m-448px vision model and the Qwen2.5-0.5B-Instruct large language model. It incorporates a new image processing method we developed and is trained on a newly curated dataset we compiled using Gemini.
Model Architecture
As shown in the figure below, our model adopts the same architecture as other models, following the "ViT-MLP-LLM" paradigm. However, in this new version, we employ a different image processing method developed by us at the pre-processing stage before feeding it into InternViT-300M-448px.
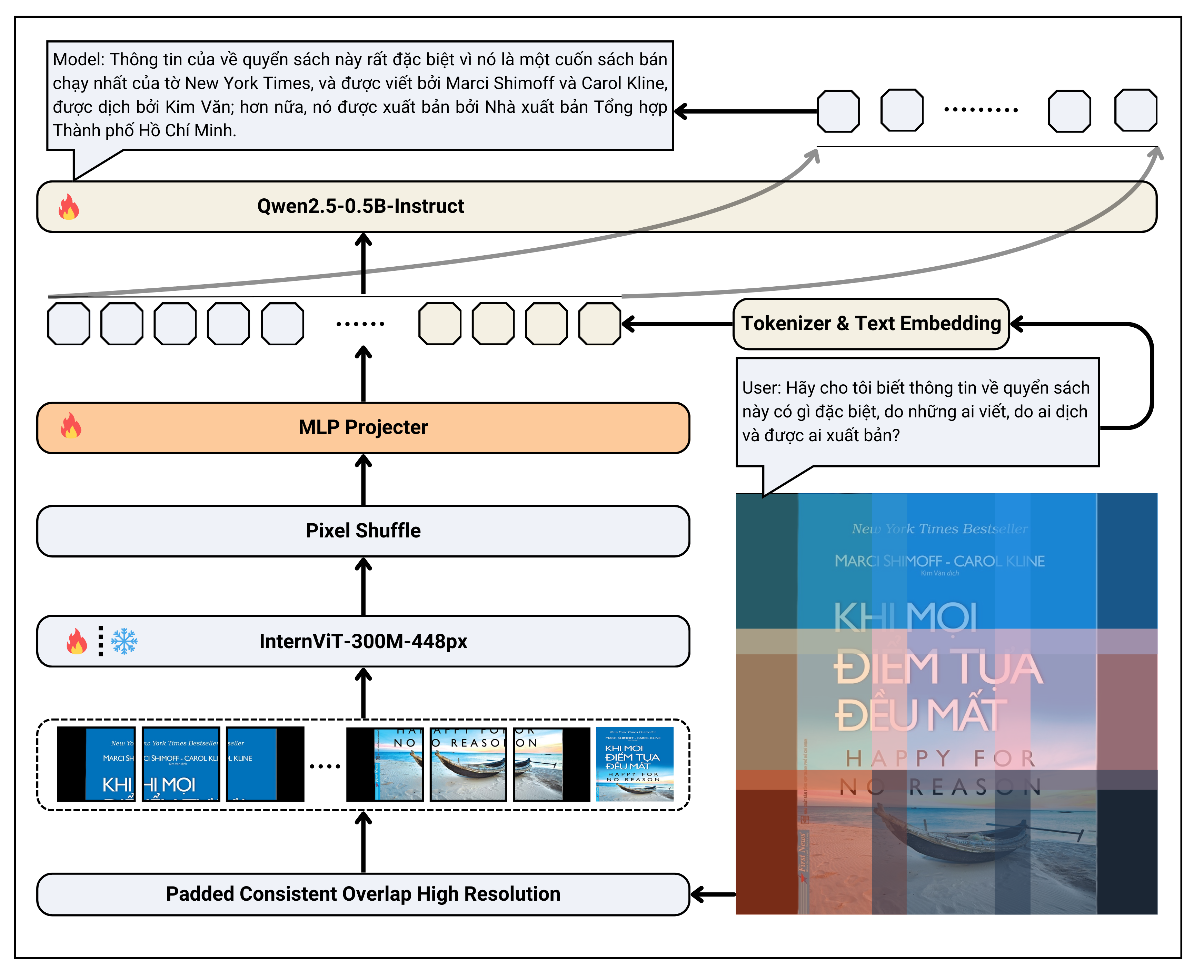
Padded Consistent Overlap High Resolution
Padding images and resizing them with a consistent aspect ratio led us to believe this approach would perform better for text detection, minimizing the likelihood of text being truncated when split into tiles. Additionally, overlapping helps preserve context in cases where text might accidentally be cut right in the middle.

Training details
The pre-training datasets used in this study are: Viet-OCR-VQA, Viet-Doc-VQA, Viet-Doc-VQA-II, Vista
The fine-tuning datasets used in this study is: TD-ViOCR-CPVQA
Benchmarks
We evaluated our method against other approaches, including DHR, and found that our method improved the model's performance by 0.2 points on the CIDEr scale compared to the DHR method.
| Image Processor | Train Dataset | BLEU@1 | BLEU@2 | BLEU@3 | BLEU@4 | avg. BLEU | CIDEr |
|---|---|---|---|---|---|---|---|
| DHR | ORI VQA | 0.3520 | 0.3002 | 0.2609 | 0.2305 | 0.2859 | 1.8069 |
| DHR | CP VQA (ours) | 0.7002 | 0.6429 | 0.5970 | 0.5591 | 0.6248 | 5.1814 |
| PCOHR (ours) | CP VQA (ours) | 0.7174 | 0.6623 | 0.6185 | 0.5826 | 0.6452 | 5.3619 |
We also compared our model with others. Due to hardware limitations, we were unable to train other models on the complex dataset we created. Instead, we used the Gemini Score, employing a "LLM-as-a-judge" evaluation method to calculate the scores between our model and the others.
| Model name | Gemini score |
|---|---|
| Vintern-1B-V2 | 0.7635 |
| Qwen2-VL-2B-Instruct | 0.6334 |
| InternVL2-2B | 0.2790 |
| mblip-mt0-xl-vivqa (ICNLP - VNPT AI) | 0.3387 |
| Lavy | 0.5672 |
| EraX-VL-7B-V1.0 | 0.7681 |
| Vinqw-1B (ours) | 0.7677 |
Also here is some result that we compare from our model with different model.




Quickstart
![]()
Authors
- Thanh Nguyen - [email protected]
- Du Nguyen - [email protected]
- Phuc Dang - [email protected]
- Downloads last month
- 88
Model tree for antphb/Vinqw-1B-v1
Base model
OpenGVLab/InternViT-300M-448px