

metadata
language:
- en
license: apache-2.0
tags:
- openllama
- 3b
datasets:
- totally-not-an-llm/EverythingLM-data-V3
model-index:
- name: open-llama-3b-v2-elmv3
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 42.06
name: normalized accuracy
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 73.28
name: normalized accuracy
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 27.61
name: accuracy
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 35.54
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.96
name: accuracy
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 3.41
name: accuracy
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=aloobun/open-llama-3b-v2-elmv3
name: Open LLM Leaderboard
Trained on 3 epoch of the EverythingLM data.
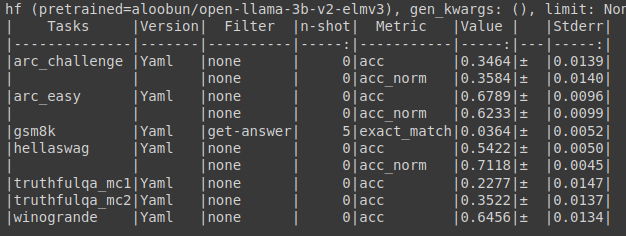
Eval Results :
I like to tweak smaller models than 3B and mix loras, but now I'm trying my hand at finetuning a 3B model. Lets see how it goes.
Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 41.14 |
| AI2 Reasoning Challenge (25-Shot) | 42.06 |
| HellaSwag (10-Shot) | 73.28 |
| MMLU (5-Shot) | 27.61 |
| TruthfulQA (0-shot) | 35.54 |
| Winogrande (5-shot) | 64.96 |
| GSM8k (5-shot) | 3.41 |