
DeepSeek-V2-Chat-0628
Collection
2 items
•
Updated
GGUF version made with llama.cpp 705b7ec
Original model deepseek-ai/DeepSeek-V2-Chat-0628

Model Download | Evaluation Results | Model Architecture | API Platform | License | Citation
DeepSeek-V2-Chat-0628 is an improved version of DeepSeek-V2-Chat. For model details, please visit DeepSeek-V2 page for more information.
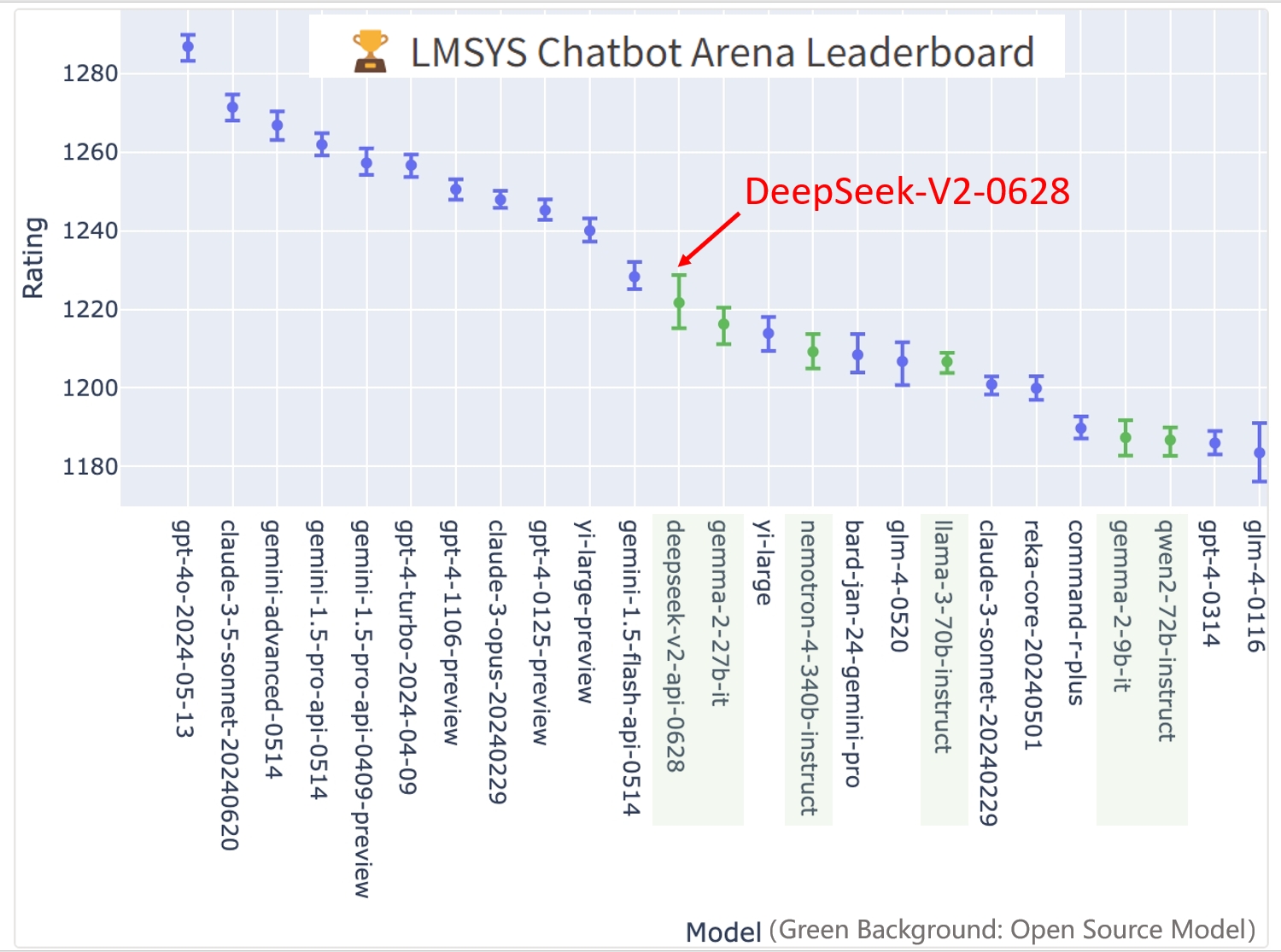
DeepSeek-V2-Chat-0628 has achieved remarkable performance on the LMSYS Chatbot Arena Leaderboard:
Overall Ranking: #11, outperforming all other open-source models.
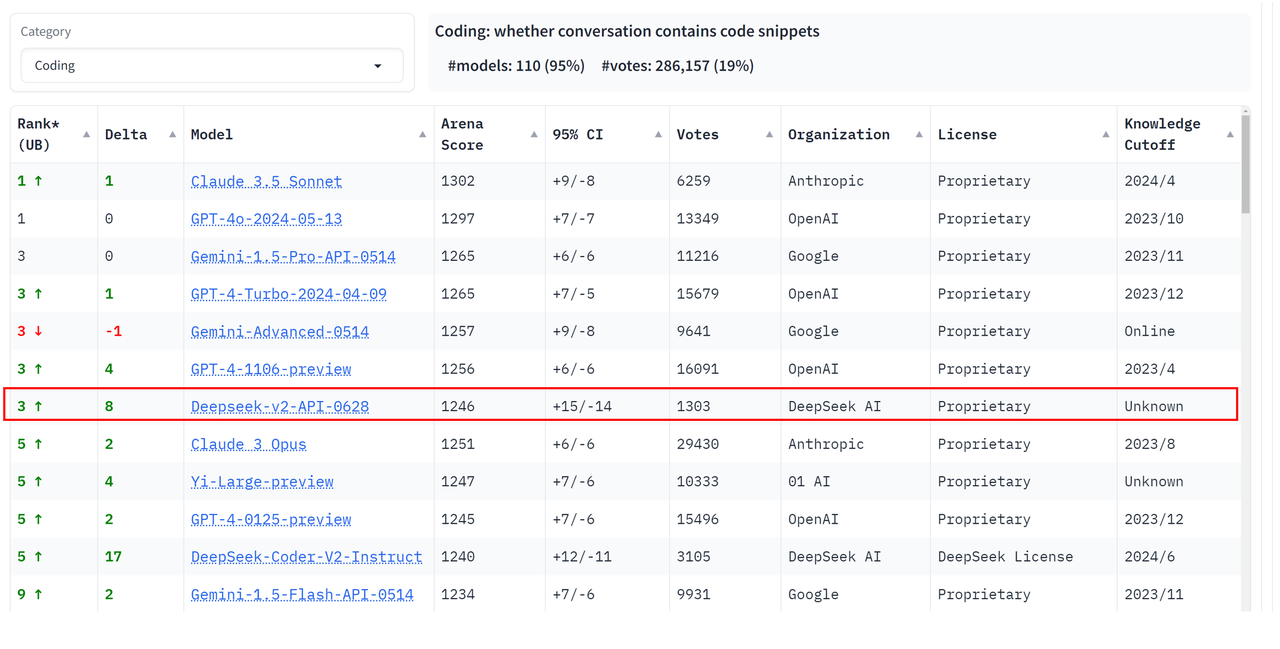
Coding Arena Ranking: #3, showcasing exceptional capabilities in coding tasks.
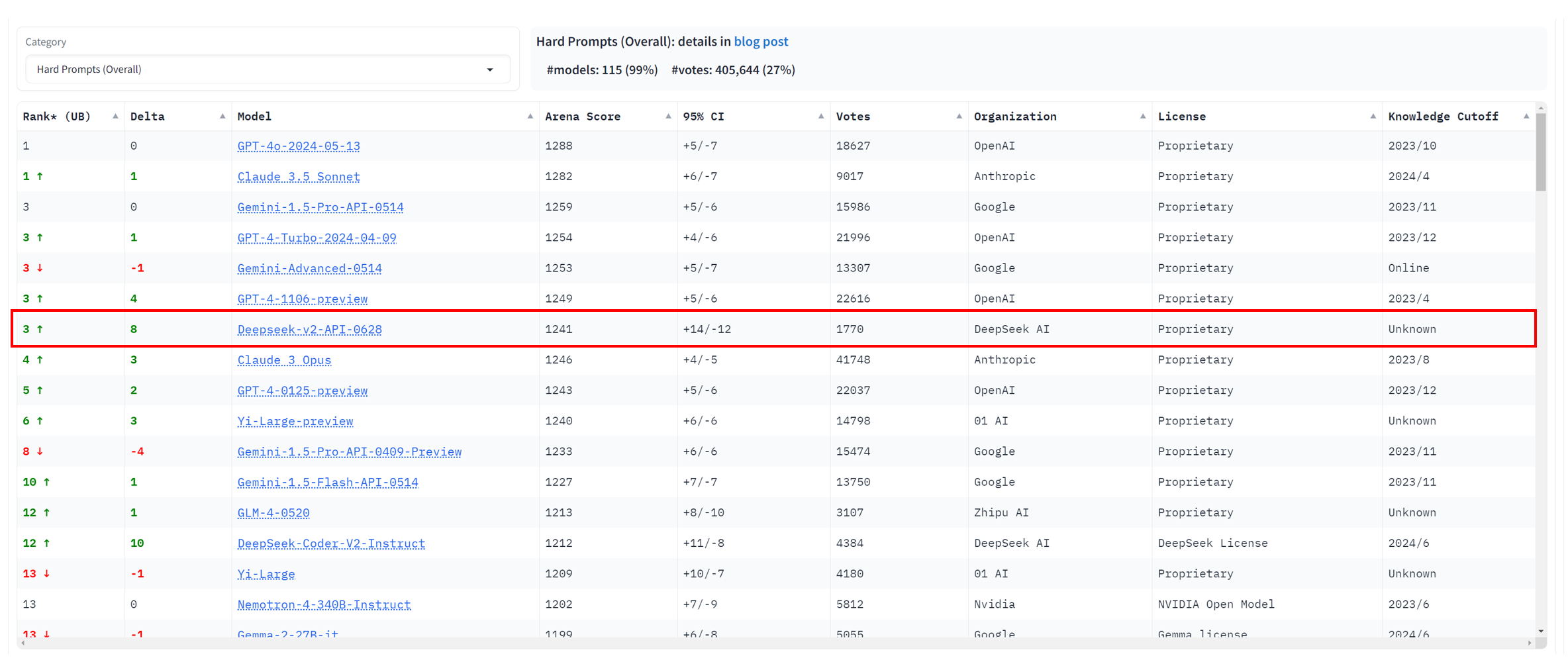
Hard Prompts Arena Ranking: #3, demonstrating strong performance on challenging prompts.
Compared to the previous version DeepSeek-V2-Chat, the new version has made the following improvements:
| Benchmark | DeepSeek-V2-Chat | DeepSeek-V2-Chat-0628 | Improvement |
|---|---|---|---|
| HumanEval | 81.1 | 84.8 | +3.7 |
| MATH | 53.9 | 71.0 | +17.1 |
| BBH | 79.7 | 83.4 | +3.7 |
| IFEval | 63.8 | 77.6 | +13.8 |
| Arena-Hard | 41.6 | 68.3 | +26.7 |
| JSON Output (Internal) | 78 | 85 | +7 |
Furthermore, the instruction following capability in the "system" area has been optimized, significantly enhancing the user experience for immersive translation, RAG, and other tasks.
To utilize DeepSeek-V2-Chat-0628 in BF16 format for inference, 80GB*8 GPUs are required.
You can directly employ Huggingface's Transformers for model inference.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2-Chat-0628"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# `max_memory` should be set based on your devices
max_memory = {i: "75GB" for i in range(8)}
# `device_map` cannot be set to `auto`
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="sequential", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation="eager")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "Write a piece of quicksort code in C++"}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
The complete chat template can be found within tokenizer_config.json located in the huggingface model repository.
Note: The chat template has been updated compared to the previous DeepSeek-V2-Chat version.
An example of chat template is as belows:
<|begin▁of▁sentence|><|User|>{user_message_1}<|Assistant|>{assistant_message_1}<|end▁of▁sentence|><|User|>{user_message_2}<|Assistant|>
You can also add an optional system message:
<|begin▁of▁sentence|>{system_message}
<|User|>{user_message_1}<|Assistant|>{assistant_message_1}<|end▁of▁sentence|><|User|>{user_message_2}<|Assistant|>
To utilize vLLM for model inference, please merge this Pull Request into your vLLM codebase: https://github.com/vllm-project/vllm/pull/4650.
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 8
model_name = "deepseek-ai/DeepSeek-V2-Chat-0628"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "Translate the following content into Chinese directly: DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
This code repository is licensed under the MIT License. The use of DeepSeek-V2 Base/Chat models is subject to the Model License. DeepSeek-V2 series (including Base and Chat) supports commercial use.
@misc{deepseekv2,
title={DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model},
author={DeepSeek-AI},
year={2024},
eprint={2405.04434},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
If you have any questions, please raise an issue or contact us at [email protected].