
Model Card for Model ID
Model Details
줄 단위로 수식이 포함된 글자를 인식 모델입니다.
microsoft TrOCR-large 모델을 기반으로 한국어 + latex 데이터셋 finetuning 했습니다.
줄 단위로 이미지를 crop하는 별도의 detector가 필요합니다.
Uses
Direct Use
from PIL import Image
import glob
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
import torch
import IPython.display as ipd
## 이미지 준비
img_path_list = sorted(glob.glob('images/mathematical_expression_2-*.png'))
img_list = [Image.open(img_path).convert("RGB") for img_path in img_path_list]
## 모델 및 프로세서 준비
model_path = 'TeamUNIVA/23MATHQ_TrOCR-large'
processor = TrOCRProcessor.from_pretrained(model_path)
model = VisionEncoderDecoderModel.from_pretrained(model_path)
model.eval()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
processor.feature_extractor.size = model.config.encoder.image_size
gc = model.generation_config
gc.max_length = 128
gc.early_stopping = True
gc.no_repeat_ngram_size = 3
gc.length_penalty = 2.0
gc.num_beams = 4
gc.eos_token_id = processor.tokenizer.sep_token_id
## TrOCR 추론
pixel_values = processor(img_list, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values.to(model.device), pad_token_id=processor.tokenizer.eos_token_id)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for img,text in zip(img_list, generated_text):
ipd.display(img)
print(text)
Result example
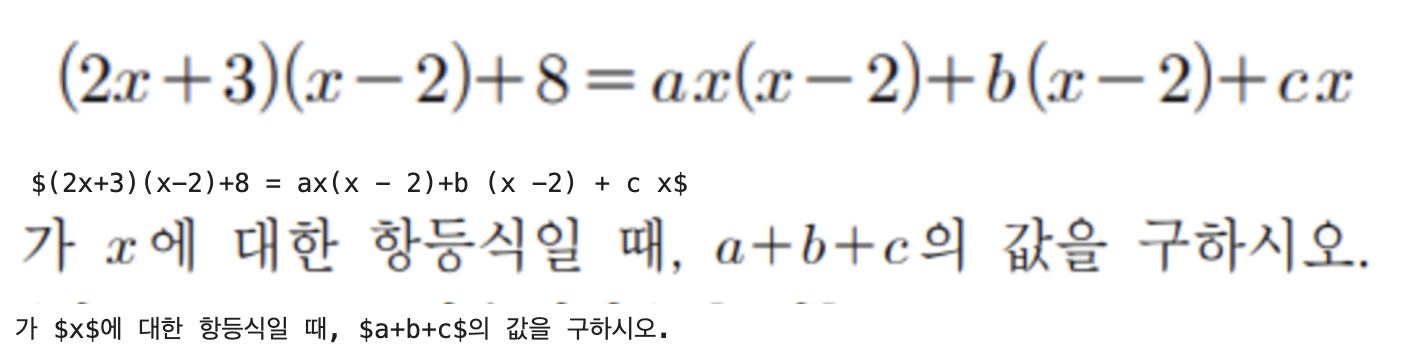
BibTeX entry and citation info
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 7
Inference API (serverless) does not yet support transformers models for this pipeline type.