#roleplay #sillytavern #llama3
My GGUF-IQ-Imatrix quants for Sao10K/L3-8B-Stheno-v3.3-32K.
Sao10K with Stheno yet again, now bigger and better than ever!
I recommend checking his page for feedback and support.
Quantization process:
Imatrix data was generated from the FP16-GGUF and conversions directly from the BF16-GGUF.
This is a bit more disk and compute intensive but hopefully avoids any losses during conversion.
To run this model, please use the latest version of KoboldCpp.
If you noticed any issues let me know in the discussions.
General usage:
For 8GB VRAM GPUs, I recommend the Q4_K_M-imat (4.89 BPW) quant for up to 12288 context sizes.
Presets:
Some compatible SillyTavern presets can be found here (Virt's Roleplay Presets).
Check discussions such as this one for other recommendations and samplers.
⇲ Click here to expand/hide information – General chart with relative quant parformances.
Recommended read:
"Which GGUF is right for me? (Opinionated)" by Artefact2
Click the image to view full size.

Personal-support:
I apologize for disrupting your experience.
Eventually I may be able to use a dedicated server for this, but for now hopefully these quants are helpful.
If you want and you are able to...
You can spare some change over here (Ko-fi).
Author-support:
You can support the author at their own page.

Original model card information.
Original card:
Trained with compute from Backyard.ai | Thanks to them and @dynafire for helping me out.
Training Details:
Trained at 8K Context -> Expanded to 32K Context with PoSE training.
Dataset Modifications:
- Further Cleaned up Roleplaying Samples -> Quality Check
- Removed Low Quality Samples from Manual Check -> Increased Baseline Quality Floor
- More Creative Writing Samples -> 2x Samples
- Remade and Refined Detailed Instruct Data
Notes:
- Training run is much less aggressive than previous Stheno versions.
- This model works when tested in bf16 with the same configs as within the file.
- I do not know the effects quantisation has on it.
- Roleplays pretty well. Feels nice in my opinion.
- It has some issues on long context understanding and reasoning. Much better vs rope scaling normally though, so that is a plus.
- Reminder, this isn't a native 32K model. It has it's issues, but it's coherent and working well.
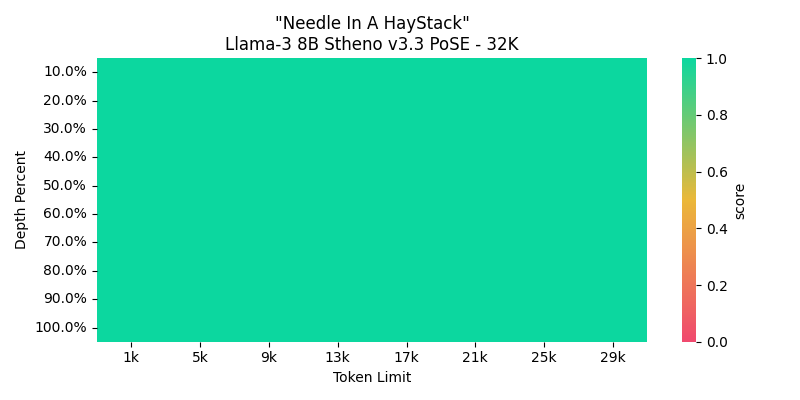
Sanity Check // Needle in a Haystack Results:
- This is not as complex as RULER or NIAN, but it's a basic evaluator. Some improper train examples had Haystack scores ranging from Red to Orange for most of the extended contexts.
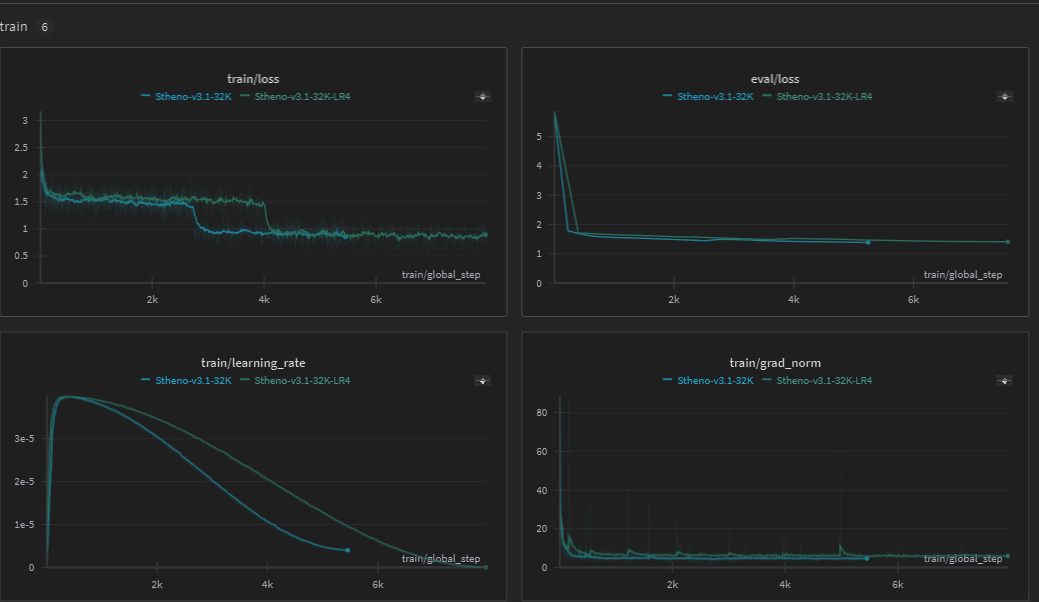
Wandb Run:
Relevant Axolotl Configurations:
-> Taken from winglian/Llama-3-8b-64k-PoSE
- I tried to find my own configs, hours of tinkering but the one he used worked best, so I stuck to it.
- 2M Rope Theta had the best loss results during training compared to other values.
- Leaving it at 500K rope wasn't that much worse, but 4M and 8M Theta made the grad_norm values worsen even if loss drops fast.
- Mixing in Pretraining Data was a PITA. Made it a lot worse with formatting.
- Pretraining / Noise made it worse at Haystack too? It wasn't all Green, Mainly Oranges.
- Improper / Bad Rope Theta shows in Grad_Norm exploding to thousands. It'll drop to low values alright, but it's a scary fast drop even with gradient clipping.
sequence_len: 8192
use_pose: true
pose_max_context_len: 32768
overrides_of_model_config:
rope_theta: 2000000.0
max_position_embeddings: 32768
# peft_use_dora: true
adapter: lora
peft_use_rslora: true
lora_model_dir:
lora_r: 256
lora_alpha: 256
lora_dropout: 0.1
lora_target_linear: true
lora_target_modules:
- gate_proj
- down_proj
- up_proj
- q_proj
- v_proj
- k_proj
- o_proj
warmup_steps: 80
gradient_accumulation_steps: 6
micro_batch_size: 1
num_epochs: 2
optimizer: adamw_bnb_8bit
lr_scheduler: cosine_with_min_lr
learning_rate: 0.00004
lr_scheduler_kwargs:
min_lr: 0.000004
