Spaces:
Sleeping

Sleeping
Add files for midterm project
Browse files- =0.2.0 +29 -0
- =0.3 +0 -0
- BuildingAChainlitApp.md +312 -0
- Dockerfile +11 -0
- LICENSE +21 -0
- README.md +118 -11
- __pycache__/app.cpython-311.pyc +0 -0
- app.py +112 -0
- chainlit.md +3 -0
- classes/__pycache__/app_state.cpython-311.pyc +0 -0
- classes/app_state.py +81 -0
- images/docchain_img.png +0 -0
- old_app.py +145 -0
- public/custom_styles.css +129 -0
- rag_chain.ipynb +757 -0
- requirements.txt +13 -0
- utilities/__init__.py +0 -0
- utilities/__pycache__/__init__.cpython-311.pyc +0 -0
- utilities/__pycache__/debugger.cpython-311.pyc +0 -0
- utilities/__pycache__/rag_utilities.cpython-311.pyc +0 -0
- utilities/debugger.py +3 -0
- utilities/get_documents.py +33 -0
- utilities/pipeline.py +27 -0
- utilities/rag_utilities.py +109 -0
- utilities/text_utils.py +103 -0
- utilities/vector_database.py +105 -0
- utilities_2/__init__.py +0 -0
- utilities_2/openai_utils/__init__.py +0 -0
- utilities_2/openai_utils/chatmodel.py +45 -0
- utilities_2/openai_utils/embedding.py +60 -0
- utilities_2/openai_utils/prompts.py +78 -0
- utilities_2/text_utils.py +75 -0
- utilities_2/vectordatabase.py +82 -0
=0.2.0
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Requirement already satisfied: langchain_core in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (0.3.1)
|
| 2 |
+
Requirement already satisfied: langchain_openai in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (0.2.0)
|
| 3 |
+
Requirement already satisfied: PyYAML>=5.3 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langchain_core) (6.0)
|
| 4 |
+
Requirement already satisfied: jsonpatch<2.0,>=1.33 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langchain_core) (1.33)
|
| 5 |
+
Requirement already satisfied: langsmith<0.2.0,>=0.1.117 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langchain_core) (0.1.122)
|
| 6 |
+
Requirement already satisfied: packaging<25,>=23.2 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langchain_core) (23.2)
|
| 7 |
+
Requirement already satisfied: pydantic<3.0.0,>=2.5.2 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langchain_core) (2.8.2)
|
| 8 |
+
Requirement already satisfied: tenacity!=8.4.0,<9.0.0,>=8.1.0 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langchain_core) (8.2.2)
|
| 9 |
+
Requirement already satisfied: typing-extensions>=4.7 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langchain_core) (4.12.2)
|
| 10 |
+
Requirement already satisfied: openai<2.0.0,>=1.40.0 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langchain_openai) (1.46.0)
|
| 11 |
+
Requirement already satisfied: tiktoken<1,>=0.7 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langchain_openai) (0.7.0)
|
| 12 |
+
Requirement already satisfied: jsonpointer>=1.9 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from jsonpatch<2.0,>=1.33->langchain_core) (2.1)
|
| 13 |
+
Requirement already satisfied: httpx<1,>=0.23.0 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langsmith<0.2.0,>=0.1.117->langchain_core) (0.24.1)
|
| 14 |
+
Requirement already satisfied: orjson<4.0.0,>=3.9.14 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langsmith<0.2.0,>=0.1.117->langchain_core) (3.10.7)
|
| 15 |
+
Requirement already satisfied: requests<3,>=2 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from langsmith<0.2.0,>=0.1.117->langchain_core) (2.31.0)
|
| 16 |
+
Requirement already satisfied: anyio<5,>=3.5.0 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from openai<2.0.0,>=1.40.0->langchain_openai) (3.5.0)
|
| 17 |
+
Requirement already satisfied: distro<2,>=1.7.0 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from openai<2.0.0,>=1.40.0->langchain_openai) (1.9.0)
|
| 18 |
+
Requirement already satisfied: jiter<1,>=0.4.0 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from openai<2.0.0,>=1.40.0->langchain_openai) (0.5.0)
|
| 19 |
+
Requirement already satisfied: sniffio in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from openai<2.0.0,>=1.40.0->langchain_openai) (1.2.0)
|
| 20 |
+
Requirement already satisfied: tqdm>4 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from openai<2.0.0,>=1.40.0->langchain_openai) (4.65.0)
|
| 21 |
+
Requirement already satisfied: annotated-types>=0.4.0 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from pydantic<3.0.0,>=2.5.2->langchain_core) (0.7.0)
|
| 22 |
+
Requirement already satisfied: pydantic-core==2.20.1 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from pydantic<3.0.0,>=2.5.2->langchain_core) (2.20.1)
|
| 23 |
+
Requirement already satisfied: regex>=2022.1.18 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from tiktoken<1,>=0.7->langchain_openai) (2022.7.9)
|
| 24 |
+
Requirement already satisfied: idna>=2.8 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from anyio<5,>=3.5.0->openai<2.0.0,>=1.40.0->langchain_openai) (3.4)
|
| 25 |
+
Requirement already satisfied: certifi in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from httpx<1,>=0.23.0->langsmith<0.2.0,>=0.1.117->langchain_core) (2023.7.22)
|
| 26 |
+
Requirement already satisfied: httpcore<0.18.0,>=0.15.0 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from httpx<1,>=0.23.0->langsmith<0.2.0,>=0.1.117->langchain_core) (0.17.3)
|
| 27 |
+
Requirement already satisfied: charset-normalizer<4,>=2 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from requests<3,>=2->langsmith<0.2.0,>=0.1.117->langchain_core) (2.0.4)
|
| 28 |
+
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from requests<3,>=2->langsmith<0.2.0,>=0.1.117->langchain_core) (1.26.16)
|
| 29 |
+
Requirement already satisfied: h11<0.15,>=0.13 in /home/rchrdgwr/anaconda3/lib/python3.11/site-packages (from httpcore<0.18.0,>=0.15.0->httpx<1,>=0.23.0->langsmith<0.2.0,>=0.1.117->langchain_core) (0.14.0)
|
=0.3
ADDED
|
File without changes
|
BuildingAChainlitApp.md
ADDED
|
@@ -0,0 +1,312 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Building a Chainlit App
|
| 2 |
+
|
| 3 |
+
What if we want to take our Week 1 Day 2 assignment - [Pythonic RAG](https://github.com/AI-Maker-Space/AIE4/tree/main/Week%201/Day%202) - and bring it out of the notebook?
|
| 4 |
+
|
| 5 |
+
Well - we'll cover exactly that here!
|
| 6 |
+
|
| 7 |
+
## Anatomy of a Chainlit Application
|
| 8 |
+
|
| 9 |
+
[Chainlit](https://docs.chainlit.io/get-started/overview) is a Python package similar to Streamlit that lets users write a backend and a front end in a single (or multiple) Python file(s). It is mainly used for prototyping LLM-based Chat Style Applications - though it is used in production in some settings with 1,000,000s of MAUs (Monthly Active Users).
|
| 10 |
+
|
| 11 |
+
The primary method of customizing and interacting with the Chainlit UI is through a few critical [decorators](https://blog.hubspot.com/website/decorators-in-python).
|
| 12 |
+
|
| 13 |
+
> NOTE: Simply put, the decorators (in Chainlit) are just ways we can "plug-in" to the functionality in Chainlit.
|
| 14 |
+
|
| 15 |
+
We'll be concerning ourselves with three main scopes:
|
| 16 |
+
|
| 17 |
+
1. On application start - when we start the Chainlit application with a command like `chainlit run app.py`
|
| 18 |
+
2. On chat start - when a chat session starts (a user opens the web browser to the address hosting the application)
|
| 19 |
+
3. On message - when the users sends a message through the input text box in the Chainlit UI
|
| 20 |
+
|
| 21 |
+
Let's dig into each scope and see what we're doing!
|
| 22 |
+
|
| 23 |
+
## On Application Start:
|
| 24 |
+
|
| 25 |
+
The first thing you'll notice is that we have the traditional "wall of imports" this is to ensure we have everything we need to run our application.
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
import os
|
| 29 |
+
from typing import List
|
| 30 |
+
from chainlit.types import AskFileResponse
|
| 31 |
+
from utilities_2.text_utils import CharacterTextSplitter, TextFileLoader
|
| 32 |
+
from utilities_2.openai_utils.prompts import (
|
| 33 |
+
UserRolePrompt,
|
| 34 |
+
SystemRolePrompt,
|
| 35 |
+
AssistantRolePrompt,
|
| 36 |
+
)
|
| 37 |
+
from utilities_2.openai_utils.embedding import EmbeddingModel
|
| 38 |
+
from utilities_2.vectordatabase import VectorDatabase
|
| 39 |
+
from utilities_2.openai_utils.chatmodel import ChatOpenAI
|
| 40 |
+
import chainlit as cl
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
Next up, we have some prompt templates. As all sessions will use the same prompt templates without modification, and we don't need these templates to be specific per template - we can set them up here - at the application scope.
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
system_template = """\
|
| 47 |
+
Use the following context to answer a users question. If you cannot find the answer in the context, say you don't know the answer."""
|
| 48 |
+
system_role_prompt = SystemRolePrompt(system_template)
|
| 49 |
+
|
| 50 |
+
user_prompt_template = """\
|
| 51 |
+
Context:
|
| 52 |
+
{context}
|
| 53 |
+
|
| 54 |
+
Question:
|
| 55 |
+
{question}
|
| 56 |
+
"""
|
| 57 |
+
user_role_prompt = UserRolePrompt(user_prompt_template)
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
> NOTE: You'll notice that these are the exact same prompt templates we used from the Pythonic RAG Notebook in Week 1 Day 2!
|
| 61 |
+
|
| 62 |
+
Following that - we can create the Python Class definition for our RAG pipeline - or *chain*, as we'll refer to it in the rest of this walkthrough.
|
| 63 |
+
|
| 64 |
+
Let's look at the definition first:
|
| 65 |
+
|
| 66 |
+
```python
|
| 67 |
+
class RetrievalAugmentedQAPipeline:
|
| 68 |
+
def __init__(self, llm: ChatOpenAI(), vector_db_retriever: VectorDatabase) -> None:
|
| 69 |
+
self.llm = llm
|
| 70 |
+
self.vector_db_retriever = vector_db_retriever
|
| 71 |
+
|
| 72 |
+
async def arun_pipeline(self, user_query: str):
|
| 73 |
+
### RETRIEVAL
|
| 74 |
+
context_list = self.vector_db_retriever.search_by_text(user_query, k=4)
|
| 75 |
+
|
| 76 |
+
context_prompt = ""
|
| 77 |
+
for context in context_list:
|
| 78 |
+
context_prompt += context[0] + "\n"
|
| 79 |
+
|
| 80 |
+
### AUGMENTED
|
| 81 |
+
formatted_system_prompt = system_role_prompt.create_message()
|
| 82 |
+
|
| 83 |
+
formatted_user_prompt = user_role_prompt.create_message(question=user_query, context=context_prompt)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
### GENERATION
|
| 87 |
+
async def generate_response():
|
| 88 |
+
async for chunk in self.llm.astream([formatted_system_prompt, formatted_user_prompt]):
|
| 89 |
+
yield chunk
|
| 90 |
+
|
| 91 |
+
return {"response": generate_response(), "context": context_list}
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
Notice a few things:
|
| 95 |
+
|
| 96 |
+
1. We have modified this `RetrievalAugmentedQAPipeline` from the initial notebook to support streaming.
|
| 97 |
+
2. In essence, our pipeline is *chaining* a few events together:
|
| 98 |
+
1. We take our user query, and chain it into our Vector Database to collect related chunks
|
| 99 |
+
2. We take those contexts and our user's questions and chain them into the prompt templates
|
| 100 |
+
3. We take that prompt template and chain it into our LLM call
|
| 101 |
+
4. We chain the response of the LLM call to the user
|
| 102 |
+
3. We are using a lot of `async` again!
|
| 103 |
+
|
| 104 |
+
Now, we're going to create a helper function for processing uploaded text files.
|
| 105 |
+
|
| 106 |
+
First, we'll instantiate a shared `CharacterTextSplitter`.
|
| 107 |
+
|
| 108 |
+
```python
|
| 109 |
+
text_splitter = CharacterTextSplitter()
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
Now we can define our helper.
|
| 113 |
+
|
| 114 |
+
```python
|
| 115 |
+
def process_text_file(file: AskFileResponse):
|
| 116 |
+
import tempfile
|
| 117 |
+
|
| 118 |
+
with tempfile.NamedTemporaryFile(mode="w", delete=False, suffix=".txt") as temp_file:
|
| 119 |
+
temp_file_path = temp_file.name
|
| 120 |
+
|
| 121 |
+
with open(temp_file_path, "wb") as f:
|
| 122 |
+
f.write(file.content)
|
| 123 |
+
|
| 124 |
+
text_loader = TextFileLoader(temp_file_path)
|
| 125 |
+
documents = text_loader.load_documents()
|
| 126 |
+
texts = text_splitter.split_text(documents)
|
| 127 |
+
return texts
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
Simply put, this downloads the file as a temp file, we load it in with `TextFileLoader` and then split it with our `TextSplitter`, and returns that list of strings!
|
| 131 |
+
|
| 132 |
+
<div style="border: 2px solid white; padding: 10px; border-radius: 5px; background-color: black; padding: 10px;">
|
| 133 |
+
QUESTION #1:
|
| 134 |
+
|
| 135 |
+
Why do we want to support streaming? What about streaming is important, or useful?
|
| 136 |
+
|
| 137 |
+
### ANSWER #1:
|
| 138 |
+
|
| 139 |
+
Streaming is the continuous transmission of the data from the model to the UI. Instead of waiting and batching up the response into a single
|
| 140 |
+
large message, the response is sent in pieces (streams) as it is created.
|
| 141 |
+
|
| 142 |
+
The advantages of streaming:
|
| 143 |
+
- quicker initial response - the user sees the first part of the answer sooner
|
| 144 |
+
- it is easier to identify the results are incorrect and terminate the request
|
| 145 |
+
- it is a more natural mode of communication for humans
|
| 146 |
+
- better handling of large data, not requiring complex caching
|
| 147 |
+
- essential for real time processing
|
| 148 |
+
- humans can only read so fast so its an advantage to get some of the data earlier
|
| 149 |
+
|
| 150 |
+
</div>
|
| 151 |
+
|
| 152 |
+
## On Chat Start:
|
| 153 |
+
|
| 154 |
+
The next scope is where "the magic happens". On Chat Start is when a user begins a chat session. This will happen whenever a user opens a new chat window, or refreshes an existing chat window.
|
| 155 |
+
|
| 156 |
+
You'll see that our code is set-up to immediately show the user a chat box requesting them to upload a file.
|
| 157 |
+
|
| 158 |
+
```python
|
| 159 |
+
while files == None:
|
| 160 |
+
files = await cl.AskFileMessage(
|
| 161 |
+
content="Please upload a Text File file to begin!",
|
| 162 |
+
accept=["text/plain"],
|
| 163 |
+
max_size_mb=2,
|
| 164 |
+
timeout=180,
|
| 165 |
+
).send()
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
Once we've obtained the text file - we'll use our processing helper function to process our text!
|
| 169 |
+
|
| 170 |
+
After we have processed our text file - we'll need to create a `VectorDatabase` and populate it with our processed chunks and their related embeddings!
|
| 171 |
+
|
| 172 |
+
```python
|
| 173 |
+
vector_db = VectorDatabase()
|
| 174 |
+
vector_db = await vector_db.abuild_from_list(texts)
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
Once we have that piece completed - we can create the chain we'll be using to respond to user queries!
|
| 178 |
+
|
| 179 |
+
```python
|
| 180 |
+
retrieval_augmented_qa_pipeline = RetrievalAugmentedQAPipeline(
|
| 181 |
+
vector_db_retriever=vector_db,
|
| 182 |
+
llm=chat_openai
|
| 183 |
+
)
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
Now, we'll save that into our user session!
|
| 187 |
+
|
| 188 |
+
> NOTE: Chainlit has some great documentation about [User Session](https://docs.chainlit.io/concepts/user-session).
|
| 189 |
+
|
| 190 |
+
<div style="border: 2px solid white; padding: 10px; border-radius: 5px; background-color: black; padding: 10px;">
|
| 191 |
+
|
| 192 |
+
### QUESTION #2:
|
| 193 |
+
|
| 194 |
+
Why are we using User Session here? What about Python makes us need to use this? Why not just store everything in a global variable?
|
| 195 |
+
|
| 196 |
+
### ANSWER #2:
|
| 197 |
+
The application hopefully will be run by many people, at the same time. If the data was stored in a global variable
|
| 198 |
+
this would be accessed by everyone using the application. So everytime someone started a new session, the information
|
| 199 |
+
would be overwritten, meaning everyone would basically get the same results. Unless only one person used the system
|
| 200 |
+
at a time.
|
| 201 |
+
|
| 202 |
+
So the goal is to keep each users session information separate from all the other users. The ChainLit User session
|
| 203 |
+
provides the capability of storing each users data separately.
|
| 204 |
+
</div>
|
| 205 |
+
|
| 206 |
+
## On Message
|
| 207 |
+
|
| 208 |
+
First, we load our chain from the user session:
|
| 209 |
+
|
| 210 |
+
```python
|
| 211 |
+
chain = cl.user_session.get("chain")
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
Then, we run the chain on the content of the message - and stream it to the front end - that's it!
|
| 215 |
+
|
| 216 |
+
```python
|
| 217 |
+
msg = cl.Message(content="")
|
| 218 |
+
result = await chain.arun_pipeline(message.content)
|
| 219 |
+
|
| 220 |
+
async for stream_resp in result["response"]:
|
| 221 |
+
await msg.stream_token(stream_resp)
|
| 222 |
+
```
|
| 223 |
+
|
| 224 |
+
## 🎉
|
| 225 |
+
|
| 226 |
+
With that - you've created a Chainlit application that moves our Pythonic RAG notebook to a Chainlit application!
|
| 227 |
+
|
| 228 |
+
## 🚧 CHALLENGE MODE 🚧
|
| 229 |
+
|
| 230 |
+
For an extra challenge - modify the behaviour of your applciation by integrating changes you made to your Pythonic RAG notebook (using new retrieval methods, etc.)
|
| 231 |
+
|
| 232 |
+
If you're still looking for a challenge, or didn't make any modifications to your Pythonic RAG notebook:
|
| 233 |
+
|
| 234 |
+
1) Allow users to upload PDFs (this will require you to build a PDF parser as well)
|
| 235 |
+
2) Modify the VectorStore to leverage [Qdrant](https://python-client.qdrant.tech/)
|
| 236 |
+
|
| 237 |
+
> NOTE: The motivation for these challenges is simple - the beginning of the course is extremely information dense, and people come from all kinds of different technical backgrounds. In order to ensure that all learners are able to engage with the content confidently and comfortably, we want to focus on the basic units of technical competency required. This leads to a situation where some learners, who came in with more robust technical skills, find the introductory material to be too simple - and these open-ended challenges help us do this!
|
| 238 |
+
|
| 239 |
+
## Support pdf documents
|
| 240 |
+
|
| 241 |
+
Code was modified to support pdf documents in the following areas:
|
| 242 |
+
|
| 243 |
+
1) Change to the request for documents in on_chat_start:
|
| 244 |
+
|
| 245 |
+
- changed the message to ask for .txt or .pdf file
|
| 246 |
+
- changed the acceptable file formats so that the pdf documents are included in the select pop up
|
| 247 |
+
|
| 248 |
+
```python
|
| 249 |
+
while not files:
|
| 250 |
+
files = await cl.AskFileMessage(
|
| 251 |
+
content="Please upload a .txt or .pdf file to begin processing!",
|
| 252 |
+
accept=["text/plain", "application/pdf"],
|
| 253 |
+
max_size_mb=2,
|
| 254 |
+
timeout=180,
|
| 255 |
+
).send()
|
| 256 |
+
```
|
| 257 |
+
|
| 258 |
+
2) change process_text_file() function to handle .pdf files
|
| 259 |
+
|
| 260 |
+
- refactor the code to do all file handling in utilities.text_utils
|
| 261 |
+
- app calls process_file, optionally passing in the text splitter function
|
| 262 |
+
- default text splitter function is CharacterTextSplitter
|
| 263 |
+
```python
|
| 264 |
+
texts = process_file(file)
|
| 265 |
+
```
|
| 266 |
+
- load_file() function does the following
|
| 267 |
+
- read the uploaded document into a temporary file
|
| 268 |
+
- identify the file extension
|
| 269 |
+
- process a .txt file as before resulting in the texts list
|
| 270 |
+
- if the file is .pdf use the PyMuPDF library to read each page and extract the text and add it to texts list
|
| 271 |
+
- use the passed in text splitter function to split the documents
|
| 272 |
+
|
| 273 |
+
```python
|
| 274 |
+
def load_file(self, file, text_splitter=CharacterTextSplitter()):
|
| 275 |
+
file_extension = os.path.splitext(file.name)[1].lower()
|
| 276 |
+
with tempfile.NamedTemporaryFile(mode="wb", delete=False, suffix=file_extension) as temp_file:
|
| 277 |
+
self.temp_file_path = temp_file.name
|
| 278 |
+
temp_file.write(file.content)
|
| 279 |
+
|
| 280 |
+
if os.path.isfile(self.temp_file_path):
|
| 281 |
+
if self.temp_file_path.endswith(".txt"):
|
| 282 |
+
self.load_text_file()
|
| 283 |
+
elif self.temp_file_path.endswith(".pdf"):
|
| 284 |
+
self.load_pdf_file()
|
| 285 |
+
else:
|
| 286 |
+
raise ValueError(
|
| 287 |
+
f"Unsupported file type: {self.temp_file_path}"
|
| 288 |
+
)
|
| 289 |
+
return text_splitter.split_text(self.documents)
|
| 290 |
+
else:
|
| 291 |
+
raise ValueError(
|
| 292 |
+
"Not a file"
|
| 293 |
+
)
|
| 294 |
+
|
| 295 |
+
def load_text_file(self):
|
| 296 |
+
with open(self.temp_file_path, "r", encoding=self.encoding) as f:
|
| 297 |
+
self.documents.append(f.read())
|
| 298 |
+
|
| 299 |
+
def load_pdf_file(self):
|
| 300 |
+
|
| 301 |
+
pdf_document = fitz.open(self.temp_file_path)
|
| 302 |
+
for page_num in range(len(pdf_document)):
|
| 303 |
+
page = pdf_document.load_page(page_num)
|
| 304 |
+
text = page.get_text()
|
| 305 |
+
self.documents.append(text)
|
| 306 |
+
```
|
| 307 |
+
|
| 308 |
+
3) Test the handling of .pdf and .txt files
|
| 309 |
+
|
| 310 |
+
Several different .pdf and .txt files were successfully uploaded and processed by the app
|
| 311 |
+
|
| 312 |
+
|
Dockerfile
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.11.9
|
| 2 |
+
RUN useradd -m -u 1000 user
|
| 3 |
+
USER user
|
| 4 |
+
ENV HOME=/home/user \
|
| 5 |
+
PATH=/home/user/.local/bin:$PATH
|
| 6 |
+
WORKDIR $HOME/app
|
| 7 |
+
COPY --chown=user . $HOME/app
|
| 8 |
+
COPY ./requirements.txt ~/app/requirements.txt
|
| 9 |
+
RUN pip install -r requirements.txt
|
| 10 |
+
COPY . .
|
| 11 |
+
CMD ["chainlit", "run", "app.py", "--port", "7860"]
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Richard Gower
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,11 +1,118 @@
|
|
| 1 |
-
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
-
sdk: docker
|
| 7 |
-
pinned: false
|
| 8 |
-
license:
|
| 9 |
-
---
|
| 10 |
-
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: DeployPythonicRAG
|
| 3 |
+
emoji: 📉
|
| 4 |
+
colorFrom: blue
|
| 5 |
+
colorTo: purple
|
| 6 |
+
sdk: docker
|
| 7 |
+
pinned: false
|
| 8 |
+
license: apache-2.0
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# Deploying Pythonic Chat With Your Text File Application
|
| 12 |
+
|
| 13 |
+
In today's breakout rooms, we will be following the processed that you saw during the challenge - for reference, the instructions for that are available [here](https://github.com/AI-Maker-Space/Beyond-ChatGPT/tree/main).
|
| 14 |
+
|
| 15 |
+
Today, we will repeat the same process - but powered by our Pythonic RAG implementation we created last week.
|
| 16 |
+
|
| 17 |
+
You'll notice a few differences in the `app.py` logic - as well as a few changes to the `utilities_2` package to get things working smoothly with Chainlit.
|
| 18 |
+
|
| 19 |
+
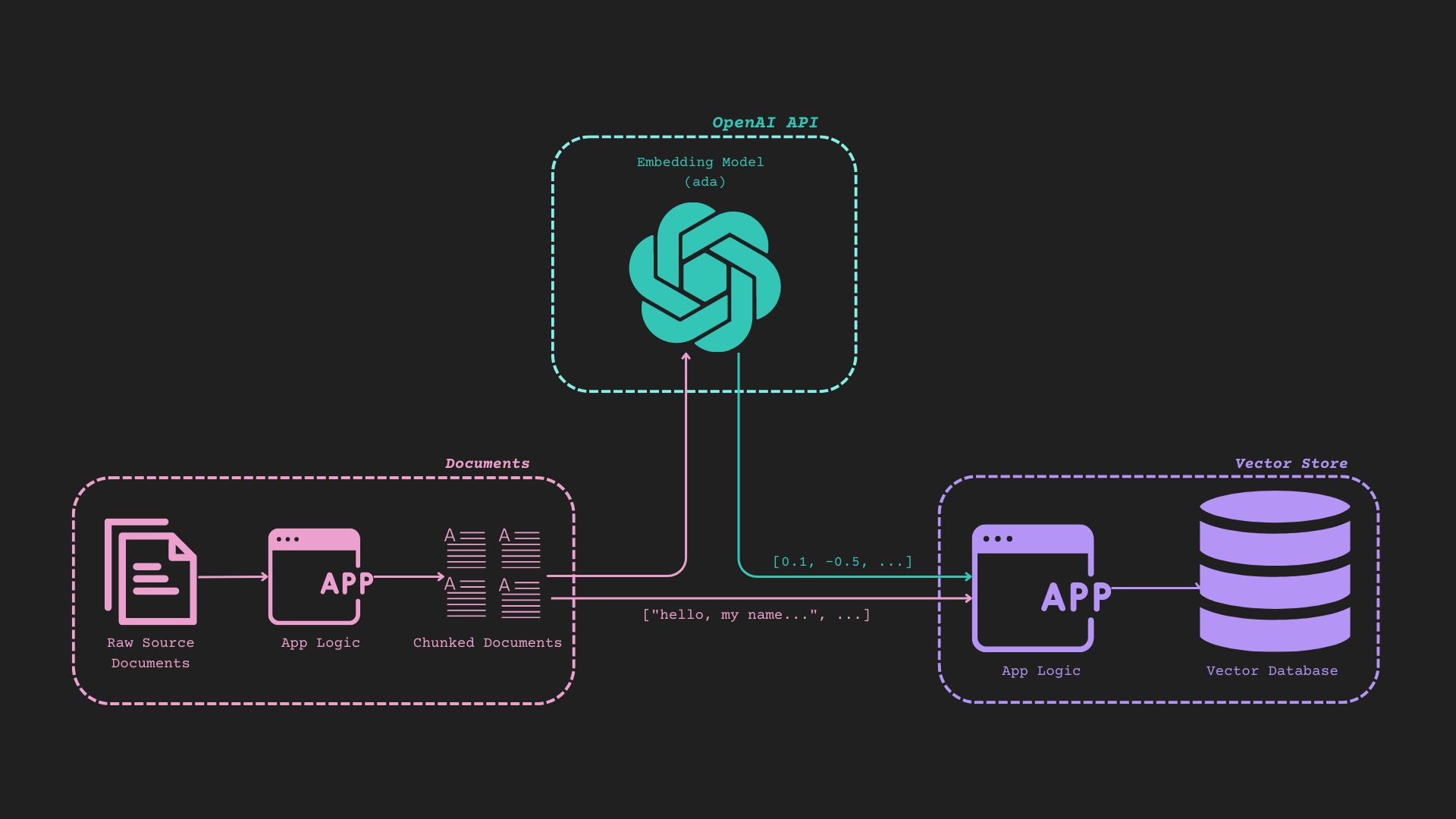
## Reference Diagram (It's Busy, but it works)
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
## Deploying the Application to Hugging Face Space
|
| 24 |
+
|
| 25 |
+
Due to the way the repository is created - it should be straightforward to deploy this to a Hugging Face Space!
|
| 26 |
+
|
| 27 |
+
> NOTE: If you wish to go through the local deployments using `chainlit run app.py` and Docker - please feel free to do so!
|
| 28 |
+
|
| 29 |
+
<details>
|
| 30 |
+
<summary>Creating a Hugging Face Space</summary>
|
| 31 |
+
|
| 32 |
+
1. Navigate to the `Spaces` tab.
|
| 33 |
+
|
| 34 |
+

|
| 35 |
+
|
| 36 |
+
2. Click on `Create new Space`
|
| 37 |
+
|
| 38 |
+

|
| 39 |
+
|
| 40 |
+
3. Create the Space by providing values in the form. Make sure you've selected "Docker" as your Space SDK.
|
| 41 |
+
|
| 42 |
+

|
| 43 |
+
|
| 44 |
+
</details>
|
| 45 |
+
|
| 46 |
+
<details>
|
| 47 |
+
<summary>Adding this Repository to the Newly Created Space</summary>
|
| 48 |
+
|
| 49 |
+
1. Collect the SSH address from the newly created Space.
|
| 50 |
+
|
| 51 |
+

|
| 52 |
+
|
| 53 |
+
> NOTE: The address is the component that starts with `[email protected]:spaces/`.
|
| 54 |
+
|
| 55 |
+
2. Use the command:
|
| 56 |
+
|
| 57 |
+
```bash
|
| 58 |
+
git remote add hf HF_SPACE_SSH_ADDRESS_HERE
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
3. Use the command:
|
| 62 |
+
|
| 63 |
+
```bash
|
| 64 |
+
git pull hf main --no-rebase --allow-unrelated-histories -X ours
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
4. Use the command:
|
| 68 |
+
|
| 69 |
+
```bash
|
| 70 |
+
git add .
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
5. Use the command:
|
| 74 |
+
|
| 75 |
+
```bash
|
| 76 |
+
git commit -m "Deploying Pythonic RAG"
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
6. Use the command:
|
| 80 |
+
|
| 81 |
+
```bash
|
| 82 |
+
git push hf main
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
7. The Space should automatically build as soon as the push is completed!
|
| 86 |
+
|
| 87 |
+
> NOTE: The build will fail before you complete the following steps!
|
| 88 |
+
|
| 89 |
+
</details>
|
| 90 |
+
|
| 91 |
+
<details>
|
| 92 |
+
<summary>Adding OpenAI Secrets to the Space</summary>
|
| 93 |
+
|
| 94 |
+
1. Navigate to your Space settings.
|
| 95 |
+
|
| 96 |
+

|
| 97 |
+
|
| 98 |
+
2. Navigate to `Variables and secrets` on the Settings page and click `New secret`:
|
| 99 |
+
|
| 100 |
+

|
| 101 |
+
|
| 102 |
+
3. In the `Name` field - input `OPENAI_API_KEY` in the `Value (private)` field, put your OpenAI API Key.
|
| 103 |
+
|
| 104 |
+

|
| 105 |
+
|
| 106 |
+
4. The Space will begin rebuilding!
|
| 107 |
+
|
| 108 |
+
</details>
|
| 109 |
+
|
| 110 |
+
## 🎉
|
| 111 |
+
|
| 112 |
+
You just deployed Pythonic RAG!
|
| 113 |
+
|
| 114 |
+
Try uploading a text file and asking some questions!
|
| 115 |
+
|
| 116 |
+
## 🚧CHALLENGE MODE 🚧
|
| 117 |
+
|
| 118 |
+
For more of a challenge, please reference [Building a Chainlit App](./BuildingAChainlitApp.md)!
|
__pycache__/app.cpython-311.pyc
ADDED
|
Binary file (4.66 kB). View file
|
|
|
app.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from dotenv import load_dotenv
|
| 3 |
+
import chainlit as cl
|
| 4 |
+
from langchain_openai import ChatOpenAI
|
| 5 |
+
from langchain.prompts import PromptTemplate
|
| 6 |
+
from utilities.rag_utilities import create_vector_store
|
| 7 |
+
from langchain_core.prompts import ChatPromptTemplate
|
| 8 |
+
from operator import itemgetter
|
| 9 |
+
from langchain.schema.output_parser import StrOutputParser
|
| 10 |
+
from langchain.schema.runnable import RunnablePassthrough
|
| 11 |
+
from classes.app_state import AppState
|
| 12 |
+
|
| 13 |
+
document_urls = [
|
| 14 |
+
"https://www.whitehouse.gov/wp-content/uploads/2022/10/Blueprint-for-an-AI-Bill-of-Rights.pdf",
|
| 15 |
+
"https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf",
|
| 16 |
+
]
|
| 17 |
+
|
| 18 |
+
# Load environment variables from .env file
|
| 19 |
+
load_dotenv()
|
| 20 |
+
|
| 21 |
+
# Get the OpenAI API key from environment variables
|
| 22 |
+
openai_api_key = os.getenv("OPENAI_API_KEY")
|
| 23 |
+
|
| 24 |
+
# Setup our state
|
| 25 |
+
state = AppState()
|
| 26 |
+
state.set_document_urls(document_urls)
|
| 27 |
+
state.set_llm_model("gpt-3.5-turbo")
|
| 28 |
+
state.set_embedding_model("text-embedding-3-small")
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
# Initialize the OpenAI LLM using LangChain
|
| 32 |
+
llm = ChatOpenAI(model=state.llm_model, openai_api_key=openai_api_key)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
qdrant_retriever = create_vector_store(state)
|
| 38 |
+
|
| 39 |
+
system_template = """
|
| 40 |
+
You are an expert at explaining technical documents to people.
|
| 41 |
+
You are provided context below to answer the question.
|
| 42 |
+
Only use the information provided below.
|
| 43 |
+
If they do not ask a question, have a conversation with them and ask them if they have any questions
|
| 44 |
+
If you cannot answer the question with the content below say 'I don't have enough information, sorry'
|
| 45 |
+
The two documents are 'Blueprint for an AI Bill of Rights' and 'Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile'
|
| 46 |
+
"""
|
| 47 |
+
human_template = """
|
| 48 |
+
===
|
| 49 |
+
question:
|
| 50 |
+
{question}
|
| 51 |
+
|
| 52 |
+
===
|
| 53 |
+
context:
|
| 54 |
+
{context}
|
| 55 |
+
===
|
| 56 |
+
"""
|
| 57 |
+
chat_prompt = ChatPromptTemplate.from_messages([
|
| 58 |
+
("system", system_template),
|
| 59 |
+
("human", human_template)
|
| 60 |
+
])
|
| 61 |
+
# create the chain
|
| 62 |
+
openai_chat_model = ChatOpenAI(model="gpt-4o")
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
retrieval_augmented_qa_chain = (
|
| 67 |
+
{"context": itemgetter("question") | qdrant_retriever, "question": itemgetter("question")}
|
| 68 |
+
| RunnablePassthrough.assign(context=itemgetter("context"))
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
| {"response": chat_prompt | openai_chat_model, "context": itemgetter("context")}
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
opening_content = """
|
| 75 |
+
Welcome! I can answer your questions on AI based on the following 2 documents:
|
| 76 |
+
- Blueprint for an AI Bill of Rights
|
| 77 |
+
- Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile
|
| 78 |
+
|
| 79 |
+
What questions do you have for me?
|
| 80 |
+
"""
|
| 81 |
+
|
| 82 |
+
@cl.on_chat_start
|
| 83 |
+
async def on_chat_start():
|
| 84 |
+
|
| 85 |
+
await cl.Message(content=opening_content).send()
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
@cl.on_message
|
| 90 |
+
async def main(message):
|
| 91 |
+
|
| 92 |
+
# formatted_prompt = prompt.format(question=message.content)
|
| 93 |
+
|
| 94 |
+
# Call the LLM with the formatted prompt
|
| 95 |
+
# response = llm.invoke(formatted_prompt)
|
| 96 |
+
#
|
| 97 |
+
response = retrieval_augmented_qa_chain.invoke({"question" : message.content })
|
| 98 |
+
answer_content = response["response"].content
|
| 99 |
+
msg = cl.Message(content="")
|
| 100 |
+
# print(response["response"].content)
|
| 101 |
+
# print(f"Number of found context: {len(response['context'])}")
|
| 102 |
+
for i in range(0, len(answer_content), 50): # Adjust chunk size (e.g., 50 characters)
|
| 103 |
+
chunk = answer_content[i:i+50]
|
| 104 |
+
await msg.stream_token(chunk)
|
| 105 |
+
|
| 106 |
+
# Send the response back to the user
|
| 107 |
+
await msg.send()
|
| 108 |
+
|
| 109 |
+
context_documents = response["context"]
|
| 110 |
+
num_contexts = len(context_documents)
|
| 111 |
+
context_msg = f"Number of found context: {num_contexts}"
|
| 112 |
+
await cl.Message(content=context_msg).send()
|
chainlit.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Welcome to Chat with Your Text File
|
| 2 |
+
|
| 3 |
+
With this application, you can chat with an uploaded text file that is smaller than 2MB!
|
classes/__pycache__/app_state.cpython-311.pyc
ADDED
|
Binary file (4.6 kB). View file
|
|
|
classes/app_state.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class AppState:
|
| 2 |
+
def __init__(self):
|
| 3 |
+
self.debug = False
|
| 4 |
+
self.llm_model = "gpt-3.5-turbo"
|
| 5 |
+
self.embedding_model = "text-embedding-3-small"
|
| 6 |
+
self.chunk_size = 1000
|
| 7 |
+
self.chunk_overlap = 100
|
| 8 |
+
self.document_urls = []
|
| 9 |
+
self.download_folder = "data/"
|
| 10 |
+
self.loaded_documents = []
|
| 11 |
+
self.single_text_documents = []
|
| 12 |
+
self.metadata = []
|
| 13 |
+
self.titles = []
|
| 14 |
+
self.documents = []
|
| 15 |
+
self.combined_document_objects = []
|
| 16 |
+
self.retriever = None
|
| 17 |
+
|
| 18 |
+
self.system_template = "You are a helpful assistant"
|
| 19 |
+
#
|
| 20 |
+
self.user_input = None
|
| 21 |
+
self.retrieved_documents = []
|
| 22 |
+
self.chat_history = []
|
| 23 |
+
self.current_question = None
|
| 24 |
+
|
| 25 |
+
def set_document_urls(self, document_urls):
|
| 26 |
+
self.document_urls = document_urls
|
| 27 |
+
|
| 28 |
+
def set_llm_model(self, llm_model):
|
| 29 |
+
self.llm_model = llm_model
|
| 30 |
+
|
| 31 |
+
def set_embedding_model(self, embedding_model):
|
| 32 |
+
self.embedding_model = embedding_model
|
| 33 |
+
|
| 34 |
+
def set_chunk_size(self, chunk_size):
|
| 35 |
+
self.chunk_size = chunk_size
|
| 36 |
+
|
| 37 |
+
def set_chunk_overlap(self, chunk_overlap):
|
| 38 |
+
self.chunk_overlap = chunk_overlap
|
| 39 |
+
|
| 40 |
+
def set_system_template(self, system_template):
|
| 41 |
+
self.system_template = system_template
|
| 42 |
+
|
| 43 |
+
def add_loaded_document(self, loaded_document):
|
| 44 |
+
self.loaded_documents.append(loaded_document)
|
| 45 |
+
|
| 46 |
+
def add_single_text_documents(self, single_text_document):
|
| 47 |
+
self.single_text_documents.append(single_text_document)
|
| 48 |
+
def add_metadata(self, metadata):
|
| 49 |
+
self.metadata = metadata
|
| 50 |
+
|
| 51 |
+
def add_title(self, title):
|
| 52 |
+
self.titles.append(title)
|
| 53 |
+
def add_document(self, document):
|
| 54 |
+
self.documents.append(document)
|
| 55 |
+
def add_combined_document_objects(self, combined_document_objects):
|
| 56 |
+
self.combined_document_objects = combined_document_objects
|
| 57 |
+
def set_retriever(self, retriever):
|
| 58 |
+
self.retriever = retriever
|
| 59 |
+
#
|
| 60 |
+
# Method to update the user input
|
| 61 |
+
def set_user_input(self, input_text):
|
| 62 |
+
self.user_input = input_text
|
| 63 |
+
|
| 64 |
+
# Method to add a retrieved document
|
| 65 |
+
# def add_document(self, document):
|
| 66 |
+
# print("adding document")
|
| 67 |
+
# print(self)
|
| 68 |
+
# self.retrieved_documents.append(document)
|
| 69 |
+
|
| 70 |
+
# Method to update chat history
|
| 71 |
+
def update_chat_history(self, message):
|
| 72 |
+
self.chat_history.append(message)
|
| 73 |
+
|
| 74 |
+
# Method to get the current state
|
| 75 |
+
def get_state(self):
|
| 76 |
+
return {
|
| 77 |
+
"user_input": self.user_input,
|
| 78 |
+
"retrieved_documents": self.retrieved_documents,
|
| 79 |
+
"chat_history": self.chat_history,
|
| 80 |
+
"current_question": self.current_question
|
| 81 |
+
}
|
images/docchain_img.png
ADDED
|
old_app.py
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from chainlit.types import AskFileResponse
|
| 3 |
+
|
| 4 |
+
from utilities_2.openai_utils.prompts import (
|
| 5 |
+
UserRolePrompt,
|
| 6 |
+
SystemRolePrompt,
|
| 7 |
+
AssistantRolePrompt,
|
| 8 |
+
)
|
| 9 |
+
from utilities_2.openai_utils.embedding import EmbeddingModel
|
| 10 |
+
from utilities_2.vectordatabase import VectorDatabase
|
| 11 |
+
from utilities_2.openai_utils.chatmodel import ChatOpenAI
|
| 12 |
+
import chainlit as cl
|
| 13 |
+
from utilities.text_utils import FileLoader
|
| 14 |
+
from utilities.pipeline import RetrievalAugmentedQAPipeline
|
| 15 |
+
# from utilities.vector_database import QdrantDatabase
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def process_file(file, use_rct):
|
| 19 |
+
fileLoader = FileLoader()
|
| 20 |
+
return fileLoader.load_file(file, use_rct)
|
| 21 |
+
|
| 22 |
+
system_template = """\
|
| 23 |
+
Use the following context to answer a users question.
|
| 24 |
+
If you cannot find the answer in the context, say you don't know the answer.
|
| 25 |
+
The context contains the text from a document. Refer to it as the document not the context.
|
| 26 |
+
"""
|
| 27 |
+
system_role_prompt = SystemRolePrompt(system_template)
|
| 28 |
+
|
| 29 |
+
user_prompt_template = """\
|
| 30 |
+
Context:
|
| 31 |
+
{context}
|
| 32 |
+
|
| 33 |
+
Question:
|
| 34 |
+
{question}
|
| 35 |
+
"""
|
| 36 |
+
user_role_prompt = UserRolePrompt(user_prompt_template)
|
| 37 |
+
|
| 38 |
+
@cl.on_chat_start
|
| 39 |
+
async def on_chat_start():
|
| 40 |
+
# get user inputs
|
| 41 |
+
res = await cl.AskActionMessage(
|
| 42 |
+
content="Do you want to use Qdrant?",
|
| 43 |
+
actions=[
|
| 44 |
+
cl.Action(name="yes", value="yes", label="✅ Yes"),
|
| 45 |
+
cl.Action(name="no", value="no", label="❌ No"),
|
| 46 |
+
],
|
| 47 |
+
).send()
|
| 48 |
+
use_qdrant = False
|
| 49 |
+
use_qdrant_type = "Local"
|
| 50 |
+
if res and res.get("value") == "yes":
|
| 51 |
+
use_qdrant = True
|
| 52 |
+
local_res = await cl.AskActionMessage(
|
| 53 |
+
content="Do you want to use local or cloud?",
|
| 54 |
+
actions=[
|
| 55 |
+
cl.Action(name="Local", value="Local", label="✅ Local"),
|
| 56 |
+
cl.Action(name="Cloud", value="Cloud", label="❌ Cloud"),
|
| 57 |
+
],
|
| 58 |
+
).send()
|
| 59 |
+
if local_res and local_res.get("value") == "Cloud":
|
| 60 |
+
use_qdrant_type = "Cloud"
|
| 61 |
+
use_rct = False
|
| 62 |
+
res = await cl.AskActionMessage(
|
| 63 |
+
content="Do you want to use RecursiveCharacterTextSplitter?",
|
| 64 |
+
actions=[
|
| 65 |
+
cl.Action(name="yes", value="yes", label="✅ Yes"),
|
| 66 |
+
cl.Action(name="no", value="no", label="❌ No"),
|
| 67 |
+
],
|
| 68 |
+
).send()
|
| 69 |
+
if res and res.get("value") == "yes":
|
| 70 |
+
use_rct = True
|
| 71 |
+
|
| 72 |
+
files = None
|
| 73 |
+
# Wait for the user to upload a file
|
| 74 |
+
while not files:
|
| 75 |
+
files = await cl.AskFileMessage(
|
| 76 |
+
content="Please upload a .txt or .pdf file to begin processing!",
|
| 77 |
+
accept=["text/plain", "application/pdf"],
|
| 78 |
+
max_size_mb=2,
|
| 79 |
+
timeout=180,
|
| 80 |
+
).send()
|
| 81 |
+
|
| 82 |
+
file = files[0]
|
| 83 |
+
|
| 84 |
+
msg = cl.Message(
|
| 85 |
+
content=f"Processing `{file.name}`...", disable_human_feedback=True
|
| 86 |
+
)
|
| 87 |
+
await msg.send()
|
| 88 |
+
|
| 89 |
+
texts = process_file(file, use_rct)
|
| 90 |
+
|
| 91 |
+
msg = cl.Message(
|
| 92 |
+
content=f"Resulted in {len(texts)} chunks", disable_human_feedback=True
|
| 93 |
+
)
|
| 94 |
+
await msg.send()
|
| 95 |
+
|
| 96 |
+
# decide if to use the dict vector store of the Qdrant vector store
|
| 97 |
+
|
| 98 |
+
# Create a dict vector store
|
| 99 |
+
if use_qdrant == False:
|
| 100 |
+
vector_db = VectorDatabase()
|
| 101 |
+
vector_db = await vector_db.abuild_from_list(texts)
|
| 102 |
+
else:
|
| 103 |
+
embedding_model = EmbeddingModel(embeddings_model_name= "text-embedding-3-small", dimensions=1000)
|
| 104 |
+
if use_qdrant_type == "Local":
|
| 105 |
+
from utilities.vector_database import QdrantDatabase
|
| 106 |
+
vector_db = QdrantDatabase(
|
| 107 |
+
embedding_model=embedding_model
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
vector_db = await vector_db.abuild_from_list(texts)
|
| 111 |
+
|
| 112 |
+
msg = cl.Message(
|
| 113 |
+
content=f"The Vector store has been created", disable_human_feedback=True
|
| 114 |
+
)
|
| 115 |
+
await msg.send()
|
| 116 |
+
|
| 117 |
+
chat_openai = ChatOpenAI()
|
| 118 |
+
|
| 119 |
+
# Create a chain
|
| 120 |
+
retrieval_augmented_qa_pipeline = RetrievalAugmentedQAPipeline(
|
| 121 |
+
vector_db_retriever=vector_db,
|
| 122 |
+
llm=chat_openai,
|
| 123 |
+
system_role_prompt=system_role_prompt,
|
| 124 |
+
user_role_prompt=user_role_prompt
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
# Let the user know that the system is ready
|
| 128 |
+
msg.content = f"Processing `{file.name}` is complete."
|
| 129 |
+
await msg.update()
|
| 130 |
+
msg.content = f"You can now ask questions about `{file.name}`."
|
| 131 |
+
await msg.update()
|
| 132 |
+
cl.user_session.set("chain", retrieval_augmented_qa_pipeline)
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
@cl.on_message
|
| 136 |
+
async def main(message):
|
| 137 |
+
chain = cl.user_session.get("chain")
|
| 138 |
+
|
| 139 |
+
msg = cl.Message(content="")
|
| 140 |
+
result = await chain.arun_pipeline(message.content)
|
| 141 |
+
|
| 142 |
+
async for stream_resp in result["response"]:
|
| 143 |
+
await msg.stream_token(stream_resp)
|
| 144 |
+
|
| 145 |
+
await msg.send()
|
public/custom_styles.css
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
/* General Styling */
|
| 2 |
+
body {
|
| 3 |
+
background-color: #f0f4f8;
|
| 4 |
+
font-family: 'Poppins', sans-serif;
|
| 5 |
+
color: #333;
|
| 6 |
+
margin: 0;
|
| 7 |
+
padding: 0;
|
| 8 |
+
}
|
| 9 |
+
|
| 10 |
+
/* Container for the main content */
|
| 11 |
+
.container {
|
| 12 |
+
max-width: 1200px;
|
| 13 |
+
margin: 40px auto;
|
| 14 |
+
padding: 20px;
|
| 15 |
+
background-color: #fff;
|
| 16 |
+
box-shadow: 0px 4px 12px rgba(0, 0, 0, 0.1);
|
| 17 |
+
border-radius: 12px;
|
| 18 |
+
}
|
| 19 |
+
|
| 20 |
+
/* Header */
|
| 21 |
+
header {
|
| 22 |
+
background-color: #4b6584;
|
| 23 |
+
color: white;
|
| 24 |
+
text-align: center;
|
| 25 |
+
padding: 20px 0;
|
| 26 |
+
border-radius: 12px 12px 0 0;
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
header h1 {
|
| 30 |
+
margin: 0;
|
| 31 |
+
font-size: 2.5rem;
|
| 32 |
+
font-weight: bold;
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
/* Buttons */
|
| 36 |
+
button {
|
| 37 |
+
background-color: #20bf6b;
|
| 38 |
+
color: white;
|
| 39 |
+
padding: 12px 20px;
|
| 40 |
+
font-size: 1rem;
|
| 41 |
+
font-weight: bold;
|
| 42 |
+
border: none;
|
| 43 |
+
border-radius: 6px;
|
| 44 |
+
cursor: pointer;
|
| 45 |
+
transition: background-color 0.3s ease;
|
| 46 |
+
}
|
| 47 |
+
|
| 48 |
+
button:hover {
|
| 49 |
+
background-color: #26de81;
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
/* Input Fields */
|
| 53 |
+
input, textarea {
|
| 54 |
+
width: 100%;
|
| 55 |
+
padding: 12px;
|
| 56 |
+
margin: 8px 0;
|
| 57 |
+
font-size: 1rem;
|
| 58 |
+
border: 1px solid #ced6e0;
|
| 59 |
+
border-radius: 6px;
|
| 60 |
+
transition: border-color 0.3s ease;
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
input:focus, textarea:focus {
|
| 64 |
+
border-color: #4b7bec;
|
| 65 |
+
outline: none;
|
| 66 |
+
}
|
| 67 |
+
|
| 68 |
+
/* Custom Card Design */
|
| 69 |
+
.card {
|
| 70 |
+
background-color: white;
|
| 71 |
+
border: 1px solid #dcdde1;
|
| 72 |
+
border-radius: 12px;
|
| 73 |
+
padding: 20px;
|
| 74 |
+
margin: 20px 0;
|
| 75 |
+
box-shadow: 0px 4px 8px rgba(0, 0, 0, 0.1);
|
| 76 |
+
transition: transform 0.3s ease, box-shadow 0.3s ease;
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
.card:hover {
|
| 80 |
+
transform: translateY(-5px);
|
| 81 |
+
box-shadow: 0px 6px 16px rgba(0, 0, 0, 0.15);
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
/* Headings inside cards */
|
| 85 |
+
.card h2 {
|
| 86 |
+
font-size: 1.8rem;
|
| 87 |
+
font-weight: bold;
|
| 88 |
+
margin-bottom: 12px;
|
| 89 |
+
color: #34495e;
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
/* Custom Chat Bubbles */
|
| 93 |
+
.chat-bubble {
|
| 94 |
+
background-color: #eaf0f8;
|
| 95 |
+
border-radius: 20px;
|
| 96 |
+
padding: 15px;
|
| 97 |
+
margin: 10px 0;
|
| 98 |
+
max-width: 75%;
|
| 99 |
+
box-shadow: 0px 2px 10px rgba(0, 0, 0, 0.05);
|
| 100 |
+
}
|
| 101 |
+
|
| 102 |
+
.chat-bubble.user {
|
| 103 |
+
background-color: #20bf6b;
|
| 104 |
+
color: white;
|
| 105 |
+
align-self: flex-end;
|
| 106 |
+
}
|
| 107 |
+
|
| 108 |
+
.chat-bubble.bot {
|
| 109 |
+
background-color: #4b6584;
|
| 110 |
+
color: white;
|
| 111 |
+
}
|
| 112 |
+
|
| 113 |
+
/* Footer */
|
| 114 |
+
footer {
|
| 115 |
+
text-align: center;
|
| 116 |
+
padding: 20px 0;
|
| 117 |
+
font-size: 0.9rem;
|
| 118 |
+
color: #7f8c8d;
|
| 119 |
+
}
|
| 120 |
+
|
| 121 |
+
footer a {
|
| 122 |
+
color: #4b7bec;
|
| 123 |
+
text-decoration: none;
|
| 124 |
+
transition: color 0.3s ease;
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
footer a:hover {
|
| 128 |
+
color: #3867d6;
|
| 129 |
+
}
|
rag_chain.ipynb
ADDED
|
@@ -0,0 +1,757 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"AI Engineering Bootcamp Cohort 4 Midterm"
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"cell_type": "markdown",
|
| 12 |
+
"metadata": {},
|
| 13 |
+
"source": [
|
| 14 |
+
"#### Install our key components for RAG etc"
|
| 15 |
+
]
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"cell_type": "code",
|
| 19 |
+
"execution_count": 1,
|
| 20 |
+
"metadata": {},
|
| 21 |
+
"outputs": [
|
| 22 |
+
{
|
| 23 |
+
"name": "stdout",
|
| 24 |
+
"output_type": "stream",
|
| 25 |
+
"text": [
|
| 26 |
+
"Requirement already satisfied: langchain-core==0.2.27 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (0.2.27)\n",
|
| 27 |
+
"Requirement already satisfied: langchain-community==0.2.10 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (0.2.10)\n",
|
| 28 |
+
"Requirement already satisfied: PyYAML>=5.3 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core==0.2.27) (6.0.1)\n",
|
| 29 |
+
"Requirement already satisfied: jsonpatch<2.0,>=1.33 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core==0.2.27) (1.33)\n",
|
| 30 |
+
"Requirement already satisfied: langsmith<0.2.0,>=0.1.75 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core==0.2.27) (0.1.122)\n",
|
| 31 |
+
"Requirement already satisfied: packaging<25,>=23.2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core==0.2.27) (24.1)\n",
|
| 32 |
+
"Requirement already satisfied: pydantic<3,>=1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core==0.2.27) (2.8.2)\n",
|
| 33 |
+
"Requirement already satisfied: tenacity!=8.4.0,<9.0.0,>=8.1.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core==0.2.27) (8.5.0)\n",
|
| 34 |
+
"Requirement already satisfied: typing-extensions>=4.7 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core==0.2.27) (4.11.0)\n",
|
| 35 |
+
"Requirement already satisfied: SQLAlchemy<3,>=1.4 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community==0.2.10) (2.0.32)\n",
|
| 36 |
+
"Requirement already satisfied: aiohttp<4.0.0,>=3.8.3 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community==0.2.10) (3.10.3)\n",
|
| 37 |
+
"Requirement already satisfied: dataclasses-json<0.7,>=0.5.7 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community==0.2.10) (0.5.14)\n",
|
| 38 |
+
"Requirement already satisfied: langchain<0.3.0,>=0.2.9 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community==0.2.10) (0.2.12)\n",
|
| 39 |
+
"Requirement already satisfied: numpy<2,>=1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community==0.2.10) (1.26.4)\n",
|
| 40 |
+
"Requirement already satisfied: requests<3,>=2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community==0.2.10) (2.32.3)\n",
|
| 41 |
+
"Requirement already satisfied: aiohappyeyeballs>=2.3.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community==0.2.10) (2.3.5)\n",
|
| 42 |
+
"Requirement already satisfied: aiosignal>=1.1.2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community==0.2.10) (1.3.1)\n",
|
| 43 |
+
"Requirement already satisfied: attrs>=17.3.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community==0.2.10) (24.2.0)\n",
|
| 44 |
+
"Requirement already satisfied: frozenlist>=1.1.1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community==0.2.10) (1.4.1)\n",
|
| 45 |
+
"Requirement already satisfied: multidict<7.0,>=4.5 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community==0.2.10) (6.0.5)\n",
|
| 46 |
+
"Requirement already satisfied: yarl<2.0,>=1.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community==0.2.10) (1.9.4)\n",
|
| 47 |
+
"Requirement already satisfied: marshmallow<4.0.0,>=3.18.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain-community==0.2.10) (3.21.3)\n",
|
| 48 |
+
"Requirement already satisfied: typing-inspect<1,>=0.4.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain-community==0.2.10) (0.9.0)\n",
|
| 49 |
+
"Requirement already satisfied: jsonpointer>=1.9 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from jsonpatch<2.0,>=1.33->langchain-core==0.2.27) (3.0.0)\n",
|
| 50 |
+
"Requirement already satisfied: langchain-text-splitters<0.3.0,>=0.2.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain<0.3.0,>=0.2.9->langchain-community==0.2.10) (0.2.2)\n",
|
| 51 |
+
"Requirement already satisfied: httpx<1,>=0.23.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langsmith<0.2.0,>=0.1.75->langchain-core==0.2.27) (0.27.0)\n",
|
| 52 |
+
"Requirement already satisfied: orjson<4.0.0,>=3.9.14 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langsmith<0.2.0,>=0.1.75->langchain-core==0.2.27) (3.10.7)\n",
|
| 53 |
+
"Requirement already satisfied: annotated-types>=0.4.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from pydantic<3,>=1->langchain-core==0.2.27) (0.7.0)\n",
|
| 54 |
+
"Requirement already satisfied: pydantic-core==2.20.1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from pydantic<3,>=1->langchain-core==0.2.27) (2.20.1)\n",
|
| 55 |
+
"Requirement already satisfied: charset-normalizer<4,>=2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from requests<3,>=2->langchain-community==0.2.10) (3.3.2)\n",
|
| 56 |
+
"Requirement already satisfied: idna<4,>=2.5 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from requests<3,>=2->langchain-community==0.2.10) (3.7)\n",
|
| 57 |
+
"Requirement already satisfied: urllib3<3,>=1.21.1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from requests<3,>=2->langchain-community==0.2.10) (2.2.2)\n",
|
| 58 |
+
"Requirement already satisfied: certifi>=2017.4.17 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from requests<3,>=2->langchain-community==0.2.10) (2024.8.30)\n",
|
| 59 |
+
"Requirement already satisfied: greenlet!=0.4.17 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from SQLAlchemy<3,>=1.4->langchain-community==0.2.10) (3.0.3)\n",
|
| 60 |
+
"Requirement already satisfied: anyio in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx<1,>=0.23.0->langsmith<0.2.0,>=0.1.75->langchain-core==0.2.27) (3.7.1)\n",
|
| 61 |
+
"Requirement already satisfied: httpcore==1.* in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx<1,>=0.23.0->langsmith<0.2.0,>=0.1.75->langchain-core==0.2.27) (1.0.5)\n",
|
| 62 |
+
"Requirement already satisfied: sniffio in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx<1,>=0.23.0->langsmith<0.2.0,>=0.1.75->langchain-core==0.2.27) (1.3.0)\n",
|
| 63 |
+
"Requirement already satisfied: h11<0.15,>=0.13 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpcore==1.*->httpx<1,>=0.23.0->langsmith<0.2.0,>=0.1.75->langchain-core==0.2.27) (0.14.0)\n",
|
| 64 |
+
"Requirement already satisfied: mypy-extensions>=0.3.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from typing-inspect<1,>=0.4.0->dataclasses-json<0.7,>=0.5.7->langchain-community==0.2.10) (1.0.0)\n",
|
| 65 |
+
"Requirement already satisfied: langchain-experimental==0.0.64 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (0.0.64)\n",
|
| 66 |
+
"Requirement already satisfied: langgraph-checkpoint==1.0.6 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (1.0.6)\n",
|
| 67 |
+
"Requirement already satisfied: langgraph==0.2.16 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (0.2.16)\n",
|
| 68 |
+
"Requirement already satisfied: langchain-qdrant==0.1.3 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (0.1.3)\n",
|
| 69 |
+
"Requirement already satisfied: langchain-community<0.3.0,>=0.2.10 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-experimental==0.0.64) (0.2.10)\n",
|
| 70 |
+
"Requirement already satisfied: langchain-core<0.3.0,>=0.2.27 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-experimental==0.0.64) (0.2.27)\n",
|
| 71 |
+
"Requirement already satisfied: pydantic<3.0.0,>=2.7.4 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-qdrant==0.1.3) (2.8.2)\n",
|
| 72 |
+
"Requirement already satisfied: qdrant-client<2.0.0,>=1.10.1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-qdrant==0.1.3) (1.11.2)\n",
|
| 73 |
+
"Requirement already satisfied: PyYAML>=5.3 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (6.0.1)\n",
|
| 74 |
+
"Requirement already satisfied: SQLAlchemy<3,>=1.4 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (2.0.32)\n",
|
| 75 |
+
"Requirement already satisfied: aiohttp<4.0.0,>=3.8.3 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (3.10.3)\n",
|
| 76 |
+
"Requirement already satisfied: dataclasses-json<0.7,>=0.5.7 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (0.5.14)\n",
|
| 77 |
+
"Requirement already satisfied: langchain<0.3.0,>=0.2.9 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (0.2.12)\n",
|
| 78 |
+
"Requirement already satisfied: langsmith<0.2.0,>=0.1.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (0.1.122)\n",
|
| 79 |
+
"Requirement already satisfied: numpy<2,>=1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (1.26.4)\n",
|
| 80 |
+
"Requirement already satisfied: requests<3,>=2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (2.32.3)\n",
|
| 81 |
+
"Requirement already satisfied: tenacity!=8.4.0,<9.0.0,>=8.1.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (8.5.0)\n",
|
| 82 |
+
"Requirement already satisfied: jsonpatch<2.0,>=1.33 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core<0.3.0,>=0.2.27->langchain-experimental==0.0.64) (1.33)\n",
|
| 83 |
+
"Requirement already satisfied: packaging<25,>=23.2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core<0.3.0,>=0.2.27->langchain-experimental==0.0.64) (24.1)\n",
|
| 84 |
+
"Requirement already satisfied: typing-extensions>=4.7 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core<0.3.0,>=0.2.27->langchain-experimental==0.0.64) (4.11.0)\n",
|
| 85 |
+
"Requirement already satisfied: annotated-types>=0.4.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from pydantic<3.0.0,>=2.7.4->langchain-qdrant==0.1.3) (0.7.0)\n",
|
| 86 |
+
"Requirement already satisfied: pydantic-core==2.20.1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from pydantic<3.0.0,>=2.7.4->langchain-qdrant==0.1.3) (2.20.1)\n",
|
| 87 |
+
"Requirement already satisfied: grpcio>=1.41.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (1.66.1)\n",
|
| 88 |
+
"Requirement already satisfied: grpcio-tools>=1.41.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (1.66.1)\n",
|
| 89 |
+
"Requirement already satisfied: httpx>=0.20.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx[http2]>=0.20.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (0.27.0)\n",
|
| 90 |
+
"Requirement already satisfied: portalocker<3.0.0,>=2.7.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (2.10.1)\n",
|
| 91 |
+
"Requirement already satisfied: urllib3<3,>=1.26.14 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (2.2.2)\n",
|
| 92 |
+
"Requirement already satisfied: aiohappyeyeballs>=2.3.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (2.3.5)\n",
|
| 93 |
+
"Requirement already satisfied: aiosignal>=1.1.2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (1.3.1)\n",
|
| 94 |
+
"Requirement already satisfied: attrs>=17.3.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (24.2.0)\n",
|
| 95 |
+
"Requirement already satisfied: frozenlist>=1.1.1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (1.4.1)\n",
|
| 96 |
+
"Requirement already satisfied: multidict<7.0,>=4.5 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (6.0.5)\n",
|
| 97 |
+
"Requirement already satisfied: yarl<2.0,>=1.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (1.9.4)\n",
|
| 98 |
+
"Requirement already satisfied: marshmallow<4.0.0,>=3.18.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (3.21.3)\n",
|
| 99 |
+
"Requirement already satisfied: typing-inspect<1,>=0.4.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (0.9.0)\n",
|
| 100 |
+
"Requirement already satisfied: protobuf<6.0dev,>=5.26.1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from grpcio-tools>=1.41.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (5.28.0)\n",
|
| 101 |
+
"Requirement already satisfied: setuptools in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from grpcio-tools>=1.41.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (74.0.0)\n",
|
| 102 |
+
"Requirement already satisfied: anyio in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx>=0.20.0->httpx[http2]>=0.20.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (3.7.1)\n",
|
| 103 |
+
"Requirement already satisfied: certifi in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx>=0.20.0->httpx[http2]>=0.20.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (2024.8.30)\n",
|
| 104 |
+
"Requirement already satisfied: httpcore==1.* in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx>=0.20.0->httpx[http2]>=0.20.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (1.0.5)\n",
|
| 105 |
+
"Requirement already satisfied: idna in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx>=0.20.0->httpx[http2]>=0.20.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (3.7)\n",
|
| 106 |
+
"Requirement already satisfied: sniffio in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx>=0.20.0->httpx[http2]>=0.20.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (1.3.0)\n",
|
| 107 |
+
"Requirement already satisfied: h11<0.15,>=0.13 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpcore==1.*->httpx>=0.20.0->httpx[http2]>=0.20.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (0.14.0)\n",
|
| 108 |
+
"Requirement already satisfied: h2<5,>=3 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx[http2]>=0.20.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (4.1.0)\n",
|
| 109 |
+
"Requirement already satisfied: jsonpointer>=1.9 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from jsonpatch<2.0,>=1.33->langchain-core<0.3.0,>=0.2.27->langchain-experimental==0.0.64) (3.0.0)\n",
|
| 110 |
+
"Requirement already satisfied: langchain-text-splitters<0.3.0,>=0.2.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain<0.3.0,>=0.2.9->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (0.2.2)\n",
|
| 111 |
+
"Requirement already satisfied: orjson<4.0.0,>=3.9.14 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langsmith<0.2.0,>=0.1.0->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (3.10.7)\n",
|
| 112 |
+
"Requirement already satisfied: charset-normalizer<4,>=2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from requests<3,>=2->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (3.3.2)\n",
|
| 113 |
+
"Requirement already satisfied: greenlet!=0.4.17 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from SQLAlchemy<3,>=1.4->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (3.0.3)\n",
|
| 114 |
+
"Requirement already satisfied: hyperframe<7,>=6.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from h2<5,>=3->httpx[http2]>=0.20.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (6.0.1)\n",
|
| 115 |
+
"Requirement already satisfied: hpack<5,>=4.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from h2<5,>=3->httpx[http2]>=0.20.0->qdrant-client<2.0.0,>=1.10.1->langchain-qdrant==0.1.3) (4.0.0)\n",
|
| 116 |
+
"Requirement already satisfied: mypy-extensions>=0.3.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from typing-inspect<1,>=0.4.0->dataclasses-json<0.7,>=0.5.7->langchain-community<0.3.0,>=0.2.10->langchain-experimental==0.0.64) (1.0.0)\n",
|
| 117 |
+
"Requirement already satisfied: langchain-openai==0.1.9 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (0.1.9)\n",
|
| 118 |
+
"Requirement already satisfied: langchain-core<0.3,>=0.2.2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-openai==0.1.9) (0.2.27)\n",
|
| 119 |
+
"Requirement already satisfied: openai<2.0.0,>=1.26.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-openai==0.1.9) (1.44.0)\n",
|
| 120 |
+
"Requirement already satisfied: tiktoken<1,>=0.7 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-openai==0.1.9) (0.7.0)\n",
|
| 121 |
+
"Requirement already satisfied: PyYAML>=5.3 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (6.0.1)\n",
|
| 122 |
+
"Requirement already satisfied: jsonpatch<2.0,>=1.33 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (1.33)\n",
|
| 123 |
+
"Requirement already satisfied: langsmith<0.2.0,>=0.1.75 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (0.1.122)\n",
|
| 124 |
+
"Requirement already satisfied: packaging<25,>=23.2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (24.1)\n",
|
| 125 |
+
"Requirement already satisfied: pydantic<3,>=1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (2.8.2)\n",
|
| 126 |
+
"Requirement already satisfied: tenacity!=8.4.0,<9.0.0,>=8.1.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (8.5.0)\n",
|
| 127 |
+
"Requirement already satisfied: typing-extensions>=4.7 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (4.11.0)\n",
|
| 128 |
+
"Requirement already satisfied: anyio<5,>=3.5.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from openai<2.0.0,>=1.26.0->langchain-openai==0.1.9) (3.7.1)\n",
|
| 129 |
+
"Requirement already satisfied: distro<2,>=1.7.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from openai<2.0.0,>=1.26.0->langchain-openai==0.1.9) (1.9.0)\n",
|
| 130 |
+
"Requirement already satisfied: httpx<1,>=0.23.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from openai<2.0.0,>=1.26.0->langchain-openai==0.1.9) (0.27.0)\n",
|
| 131 |
+
"Requirement already satisfied: jiter<1,>=0.4.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from openai<2.0.0,>=1.26.0->langchain-openai==0.1.9) (0.5.0)\n",
|
| 132 |
+
"Requirement already satisfied: sniffio in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from openai<2.0.0,>=1.26.0->langchain-openai==0.1.9) (1.3.0)\n",
|
| 133 |
+
"Requirement already satisfied: tqdm>4 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from openai<2.0.0,>=1.26.0->langchain-openai==0.1.9) (4.66.5)\n",
|
| 134 |
+
"Requirement already satisfied: regex>=2022.1.18 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from tiktoken<1,>=0.7->langchain-openai==0.1.9) (2024.7.24)\n",
|
| 135 |
+
"Requirement already satisfied: requests>=2.26.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from tiktoken<1,>=0.7->langchain-openai==0.1.9) (2.32.3)\n",
|
| 136 |
+
"Requirement already satisfied: idna>=2.8 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from anyio<5,>=3.5.0->openai<2.0.0,>=1.26.0->langchain-openai==0.1.9) (3.7)\n",
|
| 137 |
+
"Requirement already satisfied: certifi in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx<1,>=0.23.0->openai<2.0.0,>=1.26.0->langchain-openai==0.1.9) (2024.8.30)\n",
|
| 138 |
+
"Requirement already satisfied: httpcore==1.* in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpx<1,>=0.23.0->openai<2.0.0,>=1.26.0->langchain-openai==0.1.9) (1.0.5)\n",
|
| 139 |
+
"Requirement already satisfied: h11<0.15,>=0.13 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from httpcore==1.*->httpx<1,>=0.23.0->openai<2.0.0,>=1.26.0->langchain-openai==0.1.9) (0.14.0)\n",
|
| 140 |
+
"Requirement already satisfied: jsonpointer>=1.9 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from jsonpatch<2.0,>=1.33->langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (3.0.0)\n",
|
| 141 |
+
"Requirement already satisfied: orjson<4.0.0,>=3.9.14 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from langsmith<0.2.0,>=0.1.75->langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (3.10.7)\n",
|
| 142 |
+
"Requirement already satisfied: annotated-types>=0.4.0 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from pydantic<3,>=1->langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (0.7.0)\n",
|
| 143 |
+
"Requirement already satisfied: pydantic-core==2.20.1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from pydantic<3,>=1->langchain-core<0.3,>=0.2.2->langchain-openai==0.1.9) (2.20.1)\n",
|
| 144 |
+
"Requirement already satisfied: charset-normalizer<4,>=2 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from requests>=2.26.0->tiktoken<1,>=0.7->langchain-openai==0.1.9) (3.3.2)\n",
|
| 145 |
+
"Requirement already satisfied: urllib3<3,>=1.21.1 in /home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages (from requests>=2.26.0->tiktoken<1,>=0.7->langchain-openai==0.1.9) (2.2.2)\n"
|
| 146 |
+
]
|
| 147 |
+
}
|
| 148 |
+
],
|
| 149 |
+
"source": [
|
| 150 |
+
"!pip install langchain-core==0.2.27 langchain-community==0.2.10\n",
|
| 151 |
+
"!pip install langchain-experimental==0.0.64 langgraph-checkpoint==1.0.6 langgraph==0.2.16 langchain-qdrant==0.1.3\n",
|
| 152 |
+
"!pip install langchain-openai==0.1.9"
|
| 153 |
+
]
|
| 154 |
+
},
|
| 155 |
+
{
|
| 156 |
+
"cell_type": "markdown",
|
| 157 |
+
"metadata": {},
|
| 158 |
+
"source": [
|
| 159 |
+
"#### Install our vector store - Qdrant"
|
| 160 |
+
]
|
| 161 |
+
},
|
| 162 |
+
{
|
| 163 |
+
"cell_type": "code",
|
| 164 |
+
"execution_count": 2,
|
| 165 |
+
"metadata": {},
|
| 166 |
+
"outputs": [
|
| 167 |
+
{
|
| 168 |
+
"ename": "",
|
| 169 |
+
"evalue": "",
|
| 170 |
+
"output_type": "error",
|
| 171 |
+
"traceback": [
|
| 172 |
+
"\u001b[1;31mThe kernel failed to start as the Python Environment 'Python' is no longer available. Consider selecting another kernel or refreshing the list of Python Environments."
|
| 173 |
+
]
|
| 174 |
+
}
|
| 175 |
+
],
|
| 176 |
+
"source": [
|
| 177 |
+
"!pip install -qU qdrant-client"
|
| 178 |
+
]
|
| 179 |
+
},
|
| 180 |
+
{
|
| 181 |
+
"cell_type": "markdown",
|
| 182 |
+
"metadata": {},
|
| 183 |
+
"source": [
|
| 184 |
+
"#### Install supporting utilities"
|
| 185 |
+
]
|
| 186 |
+
},
|
| 187 |
+
{
|
| 188 |
+
"cell_type": "code",
|
| 189 |
+
"execution_count": 3,
|
| 190 |
+
"metadata": {},
|
| 191 |
+
"outputs": [],
|
| 192 |
+
"source": [
|
| 193 |
+
"!pip install -qU tiktoken pymupdf\n",
|
| 194 |
+
"from langchain_community.document_loaders import PyMuPDFLoader"
|
| 195 |
+
]
|
| 196 |
+
},
|
| 197 |
+
{
|
| 198 |
+
"cell_type": "markdown",
|
| 199 |
+
"metadata": {},
|
| 200 |
+
"source": [
|
| 201 |
+
"Environment Variables\n",
|
| 202 |
+
"\n",
|
| 203 |
+
"- get OpenAI API Key - will use some of the OpenAI models"
|
| 204 |
+
]
|
| 205 |
+
},
|
| 206 |
+
{
|
| 207 |
+
"cell_type": "code",
|
| 208 |
+
"execution_count": 4,
|
| 209 |
+
"metadata": {},
|
| 210 |
+
"outputs": [],
|
| 211 |
+
"source": [
|
| 212 |
+
"import os\n",
|
| 213 |
+
"import getpass\n",
|
| 214 |
+
"\n",
|
| 215 |
+
"os.environ[\"OPENAI_API_KEY\"] = getpass.getpass(\"OpenAI API Key:\")"
|
| 216 |
+
]
|
| 217 |
+
},
|
| 218 |
+
{
|
| 219 |
+
"cell_type": "code",
|
| 220 |
+
"execution_count": 60,
|
| 221 |
+
"metadata": {},
|
| 222 |
+
"outputs": [
|
| 223 |
+
{
|
| 224 |
+
"name": "stdout",
|
| 225 |
+
"output_type": "stream",
|
| 226 |
+
"text": [
|
| 227 |
+
"Number of pages in 1: 73\n",
|
| 228 |
+
"Number of pages in 2: 64\n",
|
| 229 |
+
"Title of Document 1: Blueprint for an AI Bill of Rights\n",
|
| 230 |
+
"Title of Document 2: Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile\n",
|
| 231 |
+
"Full metadata for Document 1: {'format': 'PDF 1.6', 'title': 'Blueprint for an AI Bill of Rights', 'author': '', 'subject': '', 'keywords': '', 'creator': 'Adobe Illustrator 26.3 (Macintosh)', 'producer': 'iLovePDF', 'creationDate': \"D:20220920133035-04'00'\", 'modDate': \"D:20221003104118-04'00'\", 'trapped': '', 'encryption': None}\n",
|
| 232 |
+
"Full metadata for Document 2: {'format': 'PDF 1.6', 'title': 'Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile', 'author': 'National Institute of Standards and Technology', 'subject': '', 'keywords': '', 'creator': 'Acrobat PDFMaker 24 for Word', 'producer': 'Adobe PDF Library 24.2.159', 'creationDate': \"D:20240805141702-04'00'\", 'modDate': \"D:20240805143048-04'00'\", 'trapped': '', 'encryption': None}\n",
|
| 233 |
+
"Number of chunks for Document 1: 61\n",
|
| 234 |
+
"Number of chunks for Document 2: 53\n"
|
| 235 |
+
]
|
| 236 |
+
}
|
| 237 |
+
],
|
| 238 |
+
"source": [
|
| 239 |
+
"\n"
|
| 240 |
+
]
|
| 241 |
+
},
|
| 242 |
+
{
|
| 243 |
+
"cell_type": "code",
|
| 244 |
+
"execution_count": 12,
|
| 245 |
+
"metadata": {},
|
| 246 |
+
"outputs": [
|
| 247 |
+
{
|
| 248 |
+
"name": "stdout",
|
| 249 |
+
"output_type": "stream",
|
| 250 |
+
"text": [
|
| 251 |
+
"Number of pages in 1: 73\n",
|
| 252 |
+
"Number of pages in 2: 64\n",
|
| 253 |
+
"Title of Document 1: Blueprint for an AI Bill of Rights\n",
|
| 254 |
+
"Title of Document 2: Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile\n",
|
| 255 |
+
"Full metadata for Document 1: {'format': 'PDF 1.6', 'title': 'Blueprint for an AI Bill of Rights', 'author': '', 'subject': '', 'keywords': '', 'creator': 'Adobe Illustrator 26.3 (Macintosh)', 'producer': 'iLovePDF', 'creationDate': \"D:20220920133035-04'00'\", 'modDate': \"D:20221003104118-04'00'\", 'trapped': '', 'encryption': None}\n",
|
| 256 |
+
"Full metadata for Document 2: {'format': 'PDF 1.6', 'title': 'Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile', 'author': 'National Institute of Standards and Technology', 'subject': '', 'keywords': '', 'creator': 'Acrobat PDFMaker 24 for Word', 'producer': 'Adobe PDF Library 24.2.159', 'creationDate': \"D:20240805141702-04'00'\", 'modDate': \"D:20240805143048-04'00'\", 'trapped': '', 'encryption': None}\n",
|
| 257 |
+
"Number of chunks for Document 1: 61\n",
|
| 258 |
+
"Number of chunks for Document 2: 53\n"
|
| 259 |
+
]
|
| 260 |
+
}
|
| 261 |
+
],
|
| 262 |
+
"source": [
|
| 263 |
+
"from utilities.rag_utilities import create_vector_store\n",
|
| 264 |
+
"\n",
|
| 265 |
+
"qdrant_retriever = create_vector_store()"
|
| 266 |
+
]
|
| 267 |
+
},
|
| 268 |
+
{
|
| 269 |
+
"cell_type": "markdown",
|
| 270 |
+
"metadata": {},
|
| 271 |
+
"source": [
|
| 272 |
+
"Test it"
|
| 273 |
+
]
|
| 274 |
+
},
|
| 275 |
+
{
|
| 276 |
+
"cell_type": "code",
|
| 277 |
+
"execution_count": 13,
|
| 278 |
+
"metadata": {},
|
| 279 |
+
"outputs": [
|
| 280 |
+
{
|
| 281 |
+
"name": "stdout",
|
| 282 |
+
"output_type": "stream",
|
| 283 |
+
"text": [
|
| 284 |
+
"You should be protected from abusive data practices via built-in \n",
|
| 285 |
+
"protections and you should have agency over how data about \n",
|
| 286 |
+
"you is used. You should be protected from violations of privacy through \n",
|
| 287 |
+
"design choices that ensure such protections are included by default, including \n",
|
| 288 |
+
"ensuring that data collection conforms to reasonable expectations and that \n",
|
| 289 |
+
"only data strictly necessary for the specific context is collected. Designers, de\n",
|
| 290 |
+
"velopers, and deployers of automated systems should seek your permission \n",
|
| 291 |
+
"and respect your decisions regarding collection, use, access, transfer, and de\n",
|
| 292 |
+
"letion of your data in appropriate ways and to the greatest extent possible; \n",
|
| 293 |
+
"where not possible, alternative privacy by design safeguards should be used. \n",
|
| 294 |
+
"Systems should not employ user experience and design decisions that obfus\n",
|
| 295 |
+
"cate user choice or burden users with defaults that are privacy invasive. Con\n",
|
| 296 |
+
"sent should only be used to justify collection of data in cases where it can be \n",
|
| 297 |
+
"appropriately and meaningfully given. Any consent requests should be brief, \n",
|
| 298 |
+
"be understandable in plain language, and give you agency over data collection \n",
|
| 299 |
+
"and the specific context of use; current hard-to-understand no\n",
|
| 300 |
+
"tice-and-choice practices for broad uses of data should be changed. Enhanced \n",
|
| 301 |
+
"protections and restrictions for data and inferences related to sensitive do\n",
|
| 302 |
+
"mains, including health, work, education, criminal justice, and finance, and \n",
|
| 303 |
+
"for data pertaining to youth should put you first. In sensitive domains, your \n",
|
| 304 |
+
"data and related inferences should only be used for necessary functions, and \n",
|
| 305 |
+
"you should be protected by ethical review and use prohibitions. You and your \n",
|
| 306 |
+
"communities should be free from unchecked surveillance; surveillance tech\n",
|
| 307 |
+
"nologies should be subject to heightened oversight that includes at least \n",
|
| 308 |
+
"pre-deployment assessment of their potential harms and scope limits to pro\n",
|
| 309 |
+
"tect privacy and civil liberties. Continuous surveillance and monitoring \n",
|
| 310 |
+
"should not be used in education, work, housing, or in other contexts where the \n",
|
| 311 |
+
"use of such surveillance technologies is likely to limit rights, opportunities, or \n",
|
| 312 |
+
"access. Whenever possible, you should have access to reporting that confirms \n",
|
| 313 |
+
"your data decisions have been respected and provides an assessment of the \n",
|
| 314 |
+
"potential impact of surveillance technologies on your rights, opportunities, or \n",
|
| 315 |
+
"access. \n",
|
| 316 |
+
"DATA PRIVACY\n",
|
| 317 |
+
"30\n",
|
| 318 |
+
"{'source': 'Blueprint for an AI Bill of Rights', 'document_id': 'doc1', '_id': 'c7bb1309f85f46c7b5d1c7511523cb10', '_collection_name': 'ffb2f8aece51430086938e04161466e4'}\n",
|
| 319 |
+
"---\n",
|
| 320 |
+
"You should be protected from abusive data practices via built-in \n",
|
| 321 |
+
"protections and you should have agency over how data about \n",
|
| 322 |
+
"you is used. You should be protected from violations of privacy through \n",
|
| 323 |
+
"design choices that ensure such protections are included by default, including \n",
|
| 324 |
+
"ensuring that data collection conforms to reasonable expectations and that \n",
|
| 325 |
+
"only data strictly necessary for the specific context is collected. Designers, de\n",
|
| 326 |
+
"velopers, and deployers of automated systems should seek your permission \n",
|
| 327 |
+
"and respect your decisions regarding collection, use, access, transfer, and de\n",
|
| 328 |
+
"letion of your data in appropriate ways and to the greatest extent possible; \n",
|
| 329 |
+
"where not possible, alternative privacy by design safeguards should be used. \n",
|
| 330 |
+
"Systems should not employ user experience and design decisions that obfus\n",
|
| 331 |
+
"cate user choice or burden users with defaults that are privacy invasive. Con\n",
|
| 332 |
+
"sent should only be used to justify collection of data in cases where it can be \n",
|
| 333 |
+
"appropriately and meaningfully given. Any consent requests should be brief, \n",
|
| 334 |
+
"be understandable in plain language, and give you agency over data collection \n",
|
| 335 |
+
"and the specific context of use; current hard-to-understand no\n",
|
| 336 |
+
"tice-and-choice practices for broad uses of data should be changed. Enhanced \n",
|
| 337 |
+
"protections and restrictions for data and inferences related to sensitive do\n",
|
| 338 |
+
"mains, including health, work, education, criminal justice, and finance, and \n",
|
| 339 |
+
"for data pertaining to youth should put you first. In sensitive domains, your \n",
|
| 340 |
+
"data and related inferences should only be used for necessary functions, and \n",
|
| 341 |
+
"you should be protected by ethical review and use prohibitions. You and your \n",
|
| 342 |
+
"communities should be free from unchecked surveillance; surveillance tech\n",
|
| 343 |
+
"nologies should be subject to heightened oversight that includes at least \n",
|
| 344 |
+
"pre-deployment assessment of their potential harms and scope limits to pro\n",
|
| 345 |
+
"tect privacy and civil liberties. Continuous surveillance and monitoring \n",
|
| 346 |
+
"should not be used in education, work, housing, or in other contexts where the \n",
|
| 347 |
+
"use of such surveillance technologies is likely to limit rights, opportunities, or \n",
|
| 348 |
+
"access. Whenever possible, you should have access to reporting that confirms \n",
|
| 349 |
+
"your data decisions have been respected and provides an assessment of the \n",
|
| 350 |
+
"potential impact of surveillance technologies on your rights, opportunities, or \n",
|
| 351 |
+
"access. \n",
|
| 352 |
+
"DATA PRIVACY\n",
|
| 353 |
+
"30\n",
|
| 354 |
+
"{'source': 'Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile', 'document_id': 'doc2', '_id': '3969630587ab4c199e299edfb92905b5', '_collection_name': 'ffb2f8aece51430086938e04161466e4'}\n",
|
| 355 |
+
"---\n",
|
| 356 |
+
"DATA PRIVACY \n",
|
| 357 |
+
"WHAT SHOULD BE EXPECTED OF AUTOMATED SYSTEMS\n",
|
| 358 |
+
"The expectations for automated systems are meant to serve as a blueprint for the development of additional \n",
|
| 359 |
+
"technical standards and practices that are tailored for particular sectors and contexts. \n",
|
| 360 |
+
"Traditional terms of service—the block of text that the public is accustomed to clicking through when using a web\n",
|
| 361 |
+
"site or digital app—are not an adequate mechanism for protecting privacy. The American public should be protect\n",
|
| 362 |
+
"ed via built-in privacy protections, data minimization, use and collection limitations, and transparency, in addition \n",
|
| 363 |
+
"to being entitled to clear mechanisms to control access to and use of their data—including their metadata—in a \n",
|
| 364 |
+
"proactive, informed, and ongoing way. Any automated system collecting, using, sharing, or storing personal data \n",
|
| 365 |
+
"should meet these expectations. \n",
|
| 366 |
+
"Protect privacy by design and by default \n",
|
| 367 |
+
"Privacy by design and by default. Automated systems should be designed and built with privacy protect\n",
|
| 368 |
+
"ed by default. Privacy risks should be assessed throughout the development life cycle, including privacy risks \n",
|
| 369 |
+
"from reidentification, and appropriate technical and policy mitigation measures should be implemented. This \n",
|
| 370 |
+
"includes potential harms to those who are not users of the automated system, but who may be harmed by \n",
|
| 371 |
+
"inferred data, purposeful privacy violations, or community surveillance or other community harms. Data \n",
|
| 372 |
+
"collection should be minimized and clearly communicated to the people whose data is collected. Data should \n",
|
| 373 |
+
"only be collected or used for the purposes of training or testing machine learning models if such collection and \n",
|
| 374 |
+
"use is legal and consistent with the expectations of the people whose data is collected. User experience \n",
|
| 375 |
+
"research should be conducted to confirm that people understand what data is being collected about them and \n",
|
| 376 |
+
"how it will be used, and that this collection matches their expectations and desires. \n",
|
| 377 |
+
"Data collection and use-case scope limits. Data collection should be limited in scope, with specific, \n",
|
| 378 |
+
"narrow identified goals, to avoid \"mission creep.\" Anticipated data collection should be determined to be \n",
|
| 379 |
+
"strictly necessary to the identified goals and should be minimized as much as possible. Data collected based on \n",
|
| 380 |
+
"these identified goals and for a specific context should not be used in a different context without assessing for \n",
|
| 381 |
+
"new privacy risks and implementing appropriate mitigation measures, which may include express consent. \n",
|
| 382 |
+
"Clear timelines for data retention should be established, with data deleted as soon as possible in accordance \n",
|
| 383 |
+
"with legal or policy-based limitations. Determined data retention timelines should be documented and justi\n",
|
| 384 |
+
"fied. \n",
|
| 385 |
+
"Risk identification and mitigation. Entities that collect, use, share, or store sensitive data should \n",
|
| 386 |
+
"attempt to proactively identify harms and seek to manage them so as to avoid, mitigate, and respond appropri\n",
|
| 387 |
+
"ately to identified risks. Appropriate responses include determining not to process data when the privacy risks \n",
|
| 388 |
+
"outweigh the benefits or implementing measures to mitigate acceptable risks. Appropriate responses do not \n",
|
| 389 |
+
"include sharing or transferring the privacy risks to users via notice or consent requests where users could not \n",
|
| 390 |
+
"reasonably be expected to understand the risks without further support. \n",
|
| 391 |
+
"Privacy-preserving security. Entities creating, using, or governing automated systems should follow \n",
|
| 392 |
+
"privacy and security best practices designed to ensure data and metadata do not leak beyond the specific \n",
|
| 393 |
+
"consented use case. Best practices could include using privacy-enhancing cryptography or other types of \n",
|
| 394 |
+
"privacy-enhancing technologies or fine-grained permissions and access control mechanisms, along with \n",
|
| 395 |
+
"conventional system security protocols. \n",
|
| 396 |
+
"33\n",
|
| 397 |
+
"{'source': 'Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile', 'document_id': 'doc2', '_id': '382b9ef10528494a85b60231a0d0981b', '_collection_name': 'ffb2f8aece51430086938e04161466e4'}\n",
|
| 398 |
+
"---\n",
|
| 399 |
+
"DATA PRIVACY \n",
|
| 400 |
+
"WHAT SHOULD BE EXPECTED OF AUTOMATED SYSTEMS\n",
|
| 401 |
+
"The expectations for automated systems are meant to serve as a blueprint for the development of additional \n",
|
| 402 |
+
"technical standards and practices that are tailored for particular sectors and contexts. \n",
|
| 403 |
+
"Traditional terms of service—the block of text that the public is accustomed to clicking through when using a web\n",
|
| 404 |
+
"site or digital app—are not an adequate mechanism for protecting privacy. The American public should be protect\n",
|
| 405 |
+
"ed via built-in privacy protections, data minimization, use and collection limitations, and transparency, in addition \n",
|
| 406 |
+
"to being entitled to clear mechanisms to control access to and use of their data—including their metadata—in a \n",
|
| 407 |
+
"proactive, informed, and ongoing way. Any automated system collecting, using, sharing, or storing personal data \n",
|
| 408 |
+
"should meet these expectations. \n",
|
| 409 |
+
"Protect privacy by design and by default \n",
|
| 410 |
+
"Privacy by design and by default. Automated systems should be designed and built with privacy protect\n",
|
| 411 |
+
"ed by default. Privacy risks should be assessed throughout the development life cycle, including privacy risks \n",
|
| 412 |
+
"from reidentification, and appropriate technical and policy mitigation measures should be implemented. This \n",
|
| 413 |
+
"includes potential harms to those who are not users of the automated system, but who may be harmed by \n",
|
| 414 |
+
"inferred data, purposeful privacy violations, or community surveillance or other community harms. Data \n",
|
| 415 |
+
"collection should be minimized and clearly communicated to the people whose data is collected. Data should \n",
|
| 416 |
+
"only be collected or used for the purposes of training or testing machine learning models if such collection and \n",
|
| 417 |
+
"use is legal and consistent with the expectations of the people whose data is collected. User experience \n",
|
| 418 |
+
"research should be conducted to confirm that people understand what data is being collected about them and \n",
|
| 419 |
+
"how it will be used, and that this collection matches their expectations and desires. \n",
|
| 420 |
+
"Data collection and use-case scope limits. Data collection should be limited in scope, with specific, \n",
|
| 421 |
+
"narrow identified goals, to avoid \"mission creep.\" Anticipated data collection should be determined to be \n",
|
| 422 |
+
"strictly necessary to the identified goals and should be minimized as much as possible. Data collected based on \n",
|
| 423 |
+
"these identified goals and for a specific context should not be used in a different context without assessing for \n",
|
| 424 |
+
"new privacy risks and implementing appropriate mitigation measures, which may include express consent. \n",
|
| 425 |
+
"Clear timelines for data retention should be established, with data deleted as soon as possible in accordance \n",
|
| 426 |
+
"with legal or policy-based limitations. Determined data retention timelines should be documented and justi\n",
|
| 427 |
+
"fied. \n",
|
| 428 |
+
"Risk identification and mitigation. Entities that collect, use, share, or store sensitive data should \n",
|
| 429 |
+
"attempt to proactively identify harms and seek to manage them so as to avoid, mitigate, and respond appropri\n",
|
| 430 |
+
"ately to identified risks. Appropriate responses include determining not to process data when the privacy risks \n",
|
| 431 |
+
"outweigh the benefits or implementing measures to mitigate acceptable risks. Appropriate responses do not \n",
|
| 432 |
+
"include sharing or transferring the privacy risks to users via notice or consent requests where users could not \n",
|
| 433 |
+
"reasonably be expected to understand the risks without further support. \n",
|
| 434 |
+
"Privacy-preserving security. Entities creating, using, or governing automated systems should follow \n",
|
| 435 |
+
"privacy and security best practices designed to ensure data and metadata do not leak beyond the specific \n",
|
| 436 |
+
"consented use case. Best practices could include using privacy-enhancing cryptography or other types of \n",
|
| 437 |
+
"privacy-enhancing technologies or fine-grained permissions and access control mechanisms, along with \n",
|
| 438 |
+
"conventional system security protocols. \n",
|
| 439 |
+
"33\n",
|
| 440 |
+
"{'source': 'Blueprint for an AI Bill of Rights', 'document_id': 'doc1', '_id': '316b7df2f22c4975ad8621ec0131c8ac', '_collection_name': 'ffb2f8aece51430086938e04161466e4'}\n",
|
| 441 |
+
"---\n"
|
| 442 |
+
]
|
| 443 |
+
},
|
| 444 |
+
{
|
| 445 |
+
"name": "stderr",
|
| 446 |
+
"output_type": "stream",
|
| 447 |
+
"text": [
|
| 448 |
+
"/home/rchrdgwr/anaconda3/envs/llmops-course/lib/python3.11/site-packages/langchain_core/_api/deprecation.py:139: LangChainDeprecationWarning: The method `BaseRetriever.get_relevant_documents` was deprecated in langchain-core 0.1.46 and will be removed in 0.3.0. Use invoke instead.\n",
|
| 449 |
+
" warn_deprecated(\n"
|
| 450 |
+
]
|
| 451 |
+
}
|
| 452 |
+
],
|
| 453 |
+
"source": [
|
| 454 |
+
"query = \"How should you be protected from abusive data practices \"\n",
|
| 455 |
+
"results = qdrant_retriever.get_relevant_documents(query)\n",
|
| 456 |
+
"\n",
|
| 457 |
+
"for result in results:\n",
|
| 458 |
+
" print(result.page_content)\n",
|
| 459 |
+
" print(result.metadata)\n",
|
| 460 |
+
" print(\"---\")\n",
|
| 461 |
+
"\n"
|
| 462 |
+
]
|
| 463 |
+
},
|
| 464 |
+
{
|
| 465 |
+
"cell_type": "code",
|
| 466 |
+
"execution_count": 53,
|
| 467 |
+
"metadata": {},
|
| 468 |
+
"outputs": [
|
| 469 |
+
{
|
| 470 |
+
"name": "stdout",
|
| 471 |
+
"output_type": "stream",
|
| 472 |
+
"text": [
|
| 473 |
+
"ENDNOTES\n",
|
| 474 |
+
"75. See., e.g., Sam Sabin. Digital surveillance in a post-Roe world. Politico. May 5, 2022. https://\n",
|
| 475 |
+
"www.politico.com/newsletters/digital-future-daily/2022/05/05/digital-surveillance-in-a-post-roe\n",
|
| 476 |
+
"world-00030459; Federal Trade Commission. FTC Sues Kochava for Selling Data that Tracks People at\n",
|
| 477 |
+
"Reproductive Health Clinics, Places of Worship, and Other Sensitive Locations. Aug. 29, 2022. https://\n",
|
| 478 |
+
"www.ftc.gov/news-events/news/press-releases/2022/08/ftc-sues-kochava-selling-data-tracks-people\n",
|
| 479 |
+
"reproductive-health-clinics-places-worship-other\n",
|
| 480 |
+
"76. Todd Feathers. This Private Equity Firm Is Amassing Companies That Collect Data on America’s\n",
|
| 481 |
+
"Children. The Markup. Jan. 11, 2022.\n",
|
| 482 |
+
"https://themarkup.org/machine-learning/2022/01/11/this-private-equity-firm-is-amassing-companies\n",
|
| 483 |
+
"that-collect-data-on-americas-children\n",
|
| 484 |
+
"77. Reed Albergotti. Every employee who leaves Apple becomes an ‘associate’: In job databases used by\n",
|
| 485 |
+
"employers to verify resume information, every former Apple employee’s title gets erased and replaced with\n",
|
| 486 |
+
"a generic title. The Washington Post. Feb. 10, 2022.\n",
|
| 487 |
+
"https://www.washingtonpost.com/technology/2022/02/10/apple-associate/\n",
|
| 488 |
+
"78. National Institute of Standards and Technology. Privacy Framework Perspectives and Success\n",
|
| 489 |
+
"Stories. Accessed May 2, 2022.\n",
|
| 490 |
+
"https://www.nist.gov/privacy-framework/getting-started-0/perspectives-and-success-stories\n",
|
| 491 |
+
"79. ACLU of New York. What You Need to Know About New York’s Temporary Ban on Facial\n",
|
| 492 |
+
"Recognition in Schools. Accessed May 2, 2022.\n",
|
| 493 |
+
"https://www.nyclu.org/en/publications/what-you-need-know-about-new-yorks-temporary-ban-facial\n",
|
| 494 |
+
"recognition-schools\n",
|
| 495 |
+
"80. New York State Assembly. Amendment to Education Law. Enacted Dec. 22, 2020.\n",
|
| 496 |
+
"https://nyassembly.gov/leg/?default_fld=&leg_video=&bn=S05140&term=2019&Summary=Y&Text=Y\n",
|
| 497 |
+
"81. U.S Department of Labor. Labor-Management Reporting and Disclosure Act of 1959, As Amended.\n",
|
| 498 |
+
"https://www.dol.gov/agencies/olms/laws/labor-management-reporting-and-disclosure-act (Section\n",
|
| 499 |
+
"203). See also: U.S Department of Labor. Form LM-10. OLMS Fact Sheet, Accessed May 2, 2022. https://\n",
|
| 500 |
+
"www.dol.gov/sites/dolgov/files/OLMS/regs/compliance/LM-10_factsheet.pdf\n",
|
| 501 |
+
"82. See, e.g., Apple. Protecting the User’s Privacy. Accessed May 2, 2022.\n",
|
| 502 |
+
"https://developer.apple.com/documentation/uikit/protecting_the_user_s_privacy; Google Developers.\n",
|
| 503 |
+
"Design for Safety: Android is secure by default and private by design. Accessed May 3, 2022.\n",
|
| 504 |
+
"https://developer.android.com/design-for-safety\n",
|
| 505 |
+
"83. Karen Hao. The coming war on the hidden algorithms that trap people in poverty. MIT Tech Review.\n",
|
| 506 |
+
"Dec. 4, 2020.\n",
|
| 507 |
+
"https://www.technologyreview.com/2020/12/04/1013068/algorithms-create-a-poverty-trap-lawyers\n",
|
| 508 |
+
"fight-back/\n",
|
| 509 |
+
"84. Anjana Samant, Aaron Horowitz, Kath Xu, and Sophie Beiers. Family Surveillance by Algorithm.\n",
|
| 510 |
+
"ACLU. Accessed May 2, 2022.\n",
|
| 511 |
+
"https://www.aclu.org/fact-sheet/family-surveillance-algorithm\n",
|
| 512 |
+
"70\n",
|
| 513 |
+
"{'source': 'Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile', 'document_id': 'doc2', '_id': '4301d9bb14f44d928a3e254b4da4aa18', '_collection_name': '527fdbdd8d4148b48f493df2f8334866'}\n",
|
| 514 |
+
"---\n",
|
| 515 |
+
"ENDNOTES\n",
|
| 516 |
+
"75. See., e.g., Sam Sabin. Digital surveillance in a post-Roe world. Politico. May 5, 2022. https://\n",
|
| 517 |
+
"www.politico.com/newsletters/digital-future-daily/2022/05/05/digital-surveillance-in-a-post-roe\n",
|
| 518 |
+
"world-00030459; Federal Trade Commission. FTC Sues Kochava for Selling Data that Tracks People at\n",
|
| 519 |
+
"Reproductive Health Clinics, Places of Worship, and Other Sensitive Locations. Aug. 29, 2022. https://\n",
|
| 520 |
+
"www.ftc.gov/news-events/news/press-releases/2022/08/ftc-sues-kochava-selling-data-tracks-people\n",
|
| 521 |
+
"reproductive-health-clinics-places-worship-other\n",
|
| 522 |
+
"76. Todd Feathers. This Private Equity Firm Is Amassing Companies That Collect Data on America’s\n",
|
| 523 |
+
"Children. The Markup. Jan. 11, 2022.\n",
|
| 524 |
+
"https://themarkup.org/machine-learning/2022/01/11/this-private-equity-firm-is-amassing-companies\n",
|
| 525 |
+
"that-collect-data-on-americas-children\n",
|
| 526 |
+
"77. Reed Albergotti. Every employee who leaves Apple becomes an ‘associate’: In job databases used by\n",
|
| 527 |
+
"employers to verify resume information, every former Apple employee’s title gets erased and replaced with\n",
|
| 528 |
+
"a generic title. The Washington Post. Feb. 10, 2022.\n",
|
| 529 |
+
"https://www.washingtonpost.com/technology/2022/02/10/apple-associate/\n",
|
| 530 |
+
"78. National Institute of Standards and Technology. Privacy Framework Perspectives and Success\n",
|
| 531 |
+
"Stories. Accessed May 2, 2022.\n",
|
| 532 |
+
"https://www.nist.gov/privacy-framework/getting-started-0/perspectives-and-success-stories\n",
|
| 533 |
+
"79. ACLU of New York. What You Need to Know About New York’s Temporary Ban on Facial\n",
|
| 534 |
+
"Recognition in Schools. Accessed May 2, 2022.\n",
|
| 535 |
+
"https://www.nyclu.org/en/publications/what-you-need-know-about-new-yorks-temporary-ban-facial\n",
|
| 536 |
+
"recognition-schools\n",
|
| 537 |
+
"80. New York State Assembly. Amendment to Education Law. Enacted Dec. 22, 2020.\n",
|
| 538 |
+
"https://nyassembly.gov/leg/?default_fld=&leg_video=&bn=S05140&term=2019&Summary=Y&Text=Y\n",
|
| 539 |
+
"81. U.S Department of Labor. Labor-Management Reporting and Disclosure Act of 1959, As Amended.\n",
|
| 540 |
+
"https://www.dol.gov/agencies/olms/laws/labor-management-reporting-and-disclosure-act (Section\n",
|
| 541 |
+
"203). See also: U.S Department of Labor. Form LM-10. OLMS Fact Sheet, Accessed May 2, 2022. https://\n",
|
| 542 |
+
"www.dol.gov/sites/dolgov/files/OLMS/regs/compliance/LM-10_factsheet.pdf\n",
|
| 543 |
+
"82. See, e.g., Apple. Protecting the User’s Privacy. Accessed May 2, 2022.\n",
|
| 544 |
+
"https://developer.apple.com/documentation/uikit/protecting_the_user_s_privacy; Google Developers.\n",
|
| 545 |
+
"Design for Safety: Android is secure by default and private by design. Accessed May 3, 2022.\n",
|
| 546 |
+
"https://developer.android.com/design-for-safety\n",
|
| 547 |
+
"83. Karen Hao. The coming war on the hidden algorithms that trap people in poverty. MIT Tech Review.\n",
|
| 548 |
+
"Dec. 4, 2020.\n",
|
| 549 |
+
"https://www.technologyreview.com/2020/12/04/1013068/algorithms-create-a-poverty-trap-lawyers\n",
|
| 550 |
+
"fight-back/\n",
|
| 551 |
+
"84. Anjana Samant, Aaron Horowitz, Kath Xu, and Sophie Beiers. Family Surveillance by Algorithm.\n",
|
| 552 |
+
"ACLU. Accessed May 2, 2022.\n",
|
| 553 |
+
"https://www.aclu.org/fact-sheet/family-surveillance-algorithm\n",
|
| 554 |
+
"70\n",
|
| 555 |
+
"{'source': 'Blueprint for an AI Bill of Rights', 'document_id': 'doc1', '_id': '2442bc209b7842858b5a85e83131fd69', '_collection_name': '527fdbdd8d4148b48f493df2f8334866'}\n",
|
| 556 |
+
"---\n",
|
| 557 |
+
"ENDNOTES\n",
|
| 558 |
+
"57. ISO Technical Management Board. ISO/IEC Guide 71:2014. Guide for addressing accessibility in\n",
|
| 559 |
+
"standards. International Standards Organization. 2021. https://www.iso.org/standard/57385.html\n",
|
| 560 |
+
"58. World Wide Web Consortium. Web Content Accessibility Guidelines (WCAG) 2.0. Dec. 11, 2008.\n",
|
| 561 |
+
"https://www.w3.org/TR/WCAG20/\n",
|
| 562 |
+
"59. Reva Schwartz, Apostol Vassilev, Kristen Greene, Lori Perine, and Andrew Bert. NIST Special\n",
|
| 563 |
+
"Publication 1270: Towards a Standard for Identifying and Managing Bias in Artificial Intelligence. The\n",
|
| 564 |
+
"National Institute of Standards and Technology. March, 2022. https://nvlpubs.nist.gov/nistpubs/\n",
|
| 565 |
+
"SpecialPublications/NIST.SP.1270.pdf\n",
|
| 566 |
+
"60. See, e.g., the 2014 Federal Trade Commission report “Data Brokers A Call for Transparency and\n",
|
| 567 |
+
"Accountability”. https://www.ftc.gov/system/files/documents/reports/data-brokers-call-transparency\n",
|
| 568 |
+
"accountability-report-federal-trade-commission-may-2014/140527databrokerreport.pdf\n",
|
| 569 |
+
"61. See, e.g., Nir Kshetri. School surveillance of students via laptops may do more harm than good. The\n",
|
| 570 |
+
"Conversation. Jan. 21, 2022.\n",
|
| 571 |
+
"https://theconversation.com/school-surveillance-of-students-via-laptops-may-do-more-harm-than\n",
|
| 572 |
+
"good-170983; Matt Scherer. Warning: Bossware May be Hazardous to Your Health. Center for Democracy\n",
|
| 573 |
+
"& Technology Report.\n",
|
| 574 |
+
"https://cdt.org/wp-content/uploads/2021/07/2021-07-29-Warning-Bossware-May-Be-Hazardous-To\n",
|
| 575 |
+
"Your-Health-Final.pdf; Human Impact Partners and WWRC. The Public Health Crisis Hidden in Amazon\n",
|
| 576 |
+
"Warehouses. HIP and WWRC report. Jan. 2021.\n",
|
| 577 |
+
"https://humanimpact.org/wp-content/uploads/2021/01/The-Public-Health-Crisis-Hidden-In-Amazon\n",
|
| 578 |
+
"Warehouses-HIP-WWRC-01-21.pdf; Drew Harwell. Contract lawyers face a growing invasion of\n",
|
| 579 |
+
"surveillance programs that monitor their work. The Washington Post. Nov. 11, 2021. https://\n",
|
| 580 |
+
"www.washingtonpost.com/technology/2021/11/11/lawyer-facial-recognition-monitoring/;\n",
|
| 581 |
+
"Virginia Doellgast and Sean O'Brady. Making Call Center Jobs Better: The Relationship between\n",
|
| 582 |
+
"Management Practices and Worker Stress. A Report for the CWA. June 2020. https://\n",
|
| 583 |
+
"hdl.handle.net/1813/74307\n",
|
| 584 |
+
"62. See, e.g., Federal Trade Commission. Data Brokers: A Call for Transparency and Accountability. May\n",
|
| 585 |
+
"2014.\n",
|
| 586 |
+
"https://www.ftc.gov/system/files/documents/reports/data-brokers-call-transparency-accountability\n",
|
| 587 |
+
"report-federal-trade-commission-may-2014/140527databrokerreport.pdf; Cathy O’Neil.\n",
|
| 588 |
+
"Weapons of Math Destruction. Penguin Books. 2017.\n",
|
| 589 |
+
"https://en.wikipedia.org/wiki/Weapons_of_Math_Destruction\n",
|
| 590 |
+
"63. See, e.g., Rachel Levinson-Waldman, Harsha Pandurnga, and Faiza Patel. Social Media Surveillance by\n",
|
| 591 |
+
"the U.S. Government. Brennan Center for Justice. Jan. 7, 2022.\n",
|
| 592 |
+
"https://www.brennancenter.org/our-work/research-reports/social-media-surveillance-us-government;\n",
|
| 593 |
+
"Shoshana Zuboff. The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of\n",
|
| 594 |
+
"Power. Public Affairs. 2019.\n",
|
| 595 |
+
"64. Angela Chen. Why the Future of Life Insurance May Depend on Your Online Presence. The Verge. Feb.\n",
|
| 596 |
+
"7, 2019.\n",
|
| 597 |
+
"https://www.theverge.com/2019/2/7/18211890/social-media-life-insurance-new-york-algorithms-big\n",
|
| 598 |
+
"data-discrimination-online-records\n",
|
| 599 |
+
"68\n",
|
| 600 |
+
"{'source': 'Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile', 'document_id': 'doc2', '_id': 'ce568df861214be999caf4c0dac9d07d', '_collection_name': '527fdbdd8d4148b48f493df2f8334866'}\n",
|
| 601 |
+
"---\n",
|
| 602 |
+
"ENDNOTES\n",
|
| 603 |
+
"57. ISO Technical Management Board. ISO/IEC Guide 71:2014. Guide for addressing accessibility in\n",
|
| 604 |
+
"standards. International Standards Organization. 2021. https://www.iso.org/standard/57385.html\n",
|
| 605 |
+
"58. World Wide Web Consortium. Web Content Accessibility Guidelines (WCAG) 2.0. Dec. 11, 2008.\n",
|
| 606 |
+
"https://www.w3.org/TR/WCAG20/\n",
|
| 607 |
+
"59. Reva Schwartz, Apostol Vassilev, Kristen Greene, Lori Perine, and Andrew Bert. NIST Special\n",
|
| 608 |
+
"Publication 1270: Towards a Standard for Identifying and Managing Bias in Artificial Intelligence. The\n",
|
| 609 |
+
"National Institute of Standards and Technology. March, 2022. https://nvlpubs.nist.gov/nistpubs/\n",
|
| 610 |
+
"SpecialPublications/NIST.SP.1270.pdf\n",
|
| 611 |
+
"60. See, e.g., the 2014 Federal Trade Commission report “Data Brokers A Call for Transparency and\n",
|
| 612 |
+
"Accountability”. https://www.ftc.gov/system/files/documents/reports/data-brokers-call-transparency\n",
|
| 613 |
+
"accountability-report-federal-trade-commission-may-2014/140527databrokerreport.pdf\n",
|
| 614 |
+
"61. See, e.g., Nir Kshetri. School surveillance of students via laptops may do more harm than good. The\n",
|
| 615 |
+
"Conversation. Jan. 21, 2022.\n",
|
| 616 |
+
"https://theconversation.com/school-surveillance-of-students-via-laptops-may-do-more-harm-than\n",
|
| 617 |
+
"good-170983; Matt Scherer. Warning: Bossware May be Hazardous to Your Health. Center for Democracy\n",
|
| 618 |
+
"& Technology Report.\n",
|
| 619 |
+
"https://cdt.org/wp-content/uploads/2021/07/2021-07-29-Warning-Bossware-May-Be-Hazardous-To\n",
|
| 620 |
+
"Your-Health-Final.pdf; Human Impact Partners and WWRC. The Public Health Crisis Hidden in Amazon\n",
|
| 621 |
+
"Warehouses. HIP and WWRC report. Jan. 2021.\n",
|
| 622 |
+
"https://humanimpact.org/wp-content/uploads/2021/01/The-Public-Health-Crisis-Hidden-In-Amazon\n",
|
| 623 |
+
"Warehouses-HIP-WWRC-01-21.pdf; Drew Harwell. Contract lawyers face a growing invasion of\n",
|
| 624 |
+
"surveillance programs that monitor their work. The Washington Post. Nov. 11, 2021. https://\n",
|
| 625 |
+
"www.washingtonpost.com/technology/2021/11/11/lawyer-facial-recognition-monitoring/;\n",
|
| 626 |
+
"Virginia Doellgast and Sean O'Brady. Making Call Center Jobs Better: The Relationship between\n",
|
| 627 |
+
"Management Practices and Worker Stress. A Report for the CWA. June 2020. https://\n",
|
| 628 |
+
"hdl.handle.net/1813/74307\n",
|
| 629 |
+
"62. See, e.g., Federal Trade Commission. Data Brokers: A Call for Transparency and Accountability. May\n",
|
| 630 |
+
"2014.\n",
|
| 631 |
+
"https://www.ftc.gov/system/files/documents/reports/data-brokers-call-transparency-accountability\n",
|
| 632 |
+
"report-federal-trade-commission-may-2014/140527databrokerreport.pdf; Cathy O’Neil.\n",
|
| 633 |
+
"Weapons of Math Destruction. Penguin Books. 2017.\n",
|
| 634 |
+
"https://en.wikipedia.org/wiki/Weapons_of_Math_Destruction\n",
|
| 635 |
+
"63. See, e.g., Rachel Levinson-Waldman, Harsha Pandurnga, and Faiza Patel. Social Media Surveillance by\n",
|
| 636 |
+
"the U.S. Government. Brennan Center for Justice. Jan. 7, 2022.\n",
|
| 637 |
+
"https://www.brennancenter.org/our-work/research-reports/social-media-surveillance-us-government;\n",
|
| 638 |
+
"Shoshana Zuboff. The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of\n",
|
| 639 |
+
"Power. Public Affairs. 2019.\n",
|
| 640 |
+
"64. Angela Chen. Why the Future of Life Insurance May Depend on Your Online Presence. The Verge. Feb.\n",
|
| 641 |
+
"7, 2019.\n",
|
| 642 |
+
"https://www.theverge.com/2019/2/7/18211890/social-media-life-insurance-new-york-algorithms-big\n",
|
| 643 |
+
"data-discrimination-online-records\n",
|
| 644 |
+
"68\n",
|
| 645 |
+
"{'source': 'Blueprint for an AI Bill of Rights', 'document_id': 'doc1', '_id': '0dea504571ec413bbb96e84737f87a19', '_collection_name': '527fdbdd8d4148b48f493df2f8334866'}\n",
|
| 646 |
+
"---\n"
|
| 647 |
+
]
|
| 648 |
+
}
|
| 649 |
+
],
|
| 650 |
+
"source": [
|
| 651 |
+
"query = \"tell me about Karen Hao\"\n",
|
| 652 |
+
"results = qdrant_retriever.get_relevant_documents(query)\n",
|
| 653 |
+
"\n",
|
| 654 |
+
"for result in results:\n",
|
| 655 |
+
" print(result.page_content)\n",
|
| 656 |
+
" print(result.metadata)\n",
|
| 657 |
+
" print(\"---\")"
|
| 658 |
+
]
|
| 659 |
+
},
|
| 660 |
+
{
|
| 661 |
+
"cell_type": "code",
|
| 662 |
+
"execution_count": 17,
|
| 663 |
+
"metadata": {},
|
| 664 |
+
"outputs": [
|
| 665 |
+
{
|
| 666 |
+
"name": "stdout",
|
| 667 |
+
"output_type": "stream",
|
| 668 |
+
"text": [
|
| 669 |
+
"content=\"I don't have enough information, sorry.\" response_metadata={'token_usage': {'completion_tokens': 8, 'prompt_tokens': 112, 'total_tokens': 120, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-4o-2024-05-13', 'system_fingerprint': 'fp_52a7f40b0b', 'finish_reason': 'stop', 'logprobs': None} id='run-511e9c6e-8c54-4ca3-8991-18bb3ba7c744-0' usage_metadata={'input_tokens': 112, 'output_tokens': 8, 'total_tokens': 120}\n"
|
| 670 |
+
]
|
| 671 |
+
}
|
| 672 |
+
],
|
| 673 |
+
"source": [
|
| 674 |
+
"from langchain_core.prompts import ChatPromptTemplate\n",
|
| 675 |
+
"from langchain_openai import ChatOpenAI\n",
|
| 676 |
+
"system_template = \"\"\"\n",
|
| 677 |
+
" You are an expert at explaining technical documents to people.\n",
|
| 678 |
+
" You are provided context below to answer the question.\n",
|
| 679 |
+
" Only use the information provided below.\n",
|
| 680 |
+
" If you cannot answer the question with the content below say 'I don't have enough information, sorry'\n",
|
| 681 |
+
" The two documents are 'Blueprint for an AI Bill of Rights' and 'Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile'\n",
|
| 682 |
+
"\"\"\"\n",
|
| 683 |
+
"human_template = \"\"\" \n",
|
| 684 |
+
"===\n",
|
| 685 |
+
"question:\n",
|
| 686 |
+
"{question}\n",
|
| 687 |
+
"\n",
|
| 688 |
+
"===\n",
|
| 689 |
+
"context:\n",
|
| 690 |
+
"{context}\n",
|
| 691 |
+
"===\n",
|
| 692 |
+
"\"\"\"\n",
|
| 693 |
+
"chat_prompt = ChatPromptTemplate.from_messages([\n",
|
| 694 |
+
" (\"system\", system_template),\n",
|
| 695 |
+
" (\"human\", human_template)\n",
|
| 696 |
+
"])\n",
|
| 697 |
+
"# create the chain\n",
|
| 698 |
+
"openai_chat_model = ChatOpenAI(model=\"gpt-4o\")\n",
|
| 699 |
+
"chain = chat_prompt | openai_chat_model\n",
|
| 700 |
+
"print(chain.invoke({\"question\": \"Can you give me a summary of the 2 documents\", \"context\":\"\"})) # displays \n"
|
| 701 |
+
]
|
| 702 |
+
},
|
| 703 |
+
{
|
| 704 |
+
"cell_type": "code",
|
| 705 |
+
"execution_count": 21,
|
| 706 |
+
"metadata": {},
|
| 707 |
+
"outputs": [
|
| 708 |
+
{
|
| 709 |
+
"name": "stdout",
|
| 710 |
+
"output_type": "stream",
|
| 711 |
+
"text": [
|
| 712 |
+
"{'response': AIMessage(content='The AI Bill of Rights, officially known as the \"Blueprint for an AI Bill of Rights,\" is a set of five principles and associated practices designed to guide the design, use, and deployment of automated systems. Its primary goal is to protect the rights of the American public in the age of artificial intelligence (AI). Developed through extensive consultation with various stakeholders, including impacted communities, industry stakeholders, technology developers, and policymakers, these principles are intended to ensure that AI systems are aligned with democratic values and protect civil rights, civil liberties, and privacy. The Blueprint provides a national values statement and a toolkit that is sector-agnostic, meaning it can be applied across different sectors to inform policy decisions and the technological design process.', response_metadata={'token_usage': {'completion_tokens': 144, 'prompt_tokens': 1848, 'total_tokens': 1992, 'completion_tokens_details': {'reasoning_tokens': 0}}, 'model_name': 'gpt-4o-2024-05-13', 'system_fingerprint': 'fp_52a7f40b0b', 'finish_reason': 'stop', 'logprobs': None}, id='run-eb76dbb2-facd-471e-9752-580bd7f46fc4-0', usage_metadata={'input_tokens': 1848, 'output_tokens': 144, 'total_tokens': 1992}), 'context': [Document(metadata={'source': 'Blueprint for an AI Bill of Rights', 'document_id': 'doc1', '_id': '7bacb7e37ad04ed0881408b49dfa5bd2', '_collection_name': 'ffb2f8aece51430086938e04161466e4'}, page_content='other protected data. Such activities require alternative, compatible safeguards through existing policies that \\ngovern automated systems and AI, such as the Department of Defense (DOD) AI Ethical Principles and \\nResponsible AI Implementation Pathway and the Intelligence Community (IC) AI Ethics Principles and \\nFramework. The implementation of these policies to national security and defense activities can be informed by \\nthe Blueprint for an AI Bill of Rights where feasible. \\nThe Blueprint for an AI Bill of Rights is not intended to, and does not, create any legal right, benefit, or \\ndefense, substantive or procedural, enforceable at law or in equity by any party against the United States, its \\ndepartments, agencies, or entities, its officers, employees, or agents, or any other person, nor does it constitute a \\nwaiver of sovereign immunity. \\nCopyright Information \\nThis document is a work of the United States Government and is in the public domain (see 17 U.S.C. §105). \\n2'), Document(metadata={'source': 'Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile', 'document_id': 'doc2', '_id': '0b5b8214b946430284b040e7e1a8a027', '_collection_name': 'ffb2f8aece51430086938e04161466e4'}, page_content='other protected data. Such activities require alternative, compatible safeguards through existing policies that \\ngovern automated systems and AI, such as the Department of Defense (DOD) AI Ethical Principles and \\nResponsible AI Implementation Pathway and the Intelligence Community (IC) AI Ethics Principles and \\nFramework. The implementation of these policies to national security and defense activities can be informed by \\nthe Blueprint for an AI Bill of Rights where feasible. \\nThe Blueprint for an AI Bill of Rights is not intended to, and does not, create any legal right, benefit, or \\ndefense, substantive or procedural, enforceable at law or in equity by any party against the United States, its \\ndepartments, agencies, or entities, its officers, employees, or agents, or any other person, nor does it constitute a \\nwaiver of sovereign immunity. \\nCopyright Information \\nThis document is a work of the United States Government and is in the public domain (see 17 U.S.C. §105). \\n2'), Document(metadata={'source': 'Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile', 'document_id': 'doc2', '_id': '4d87b814e59541b2ae7ee2d3bd110f96', '_collection_name': 'ffb2f8aece51430086938e04161466e4'}, page_content='ABOUT THIS FRAMEWORK\\xad\\xad\\xad\\xad\\xad\\nThe Blueprint for an AI Bill of Rights is a set of five principles and associated practices to help guide the \\ndesign, use, and deployment of automated systems to protect the rights of the American public in the age of \\nartificial intel-ligence. Developed through extensive consultation with the American public, these principles are \\na blueprint for building and deploying automated systems that are aligned with democratic values and protect \\ncivil rights, civil liberties, and privacy. The Blueprint for an AI Bill of Rights includes this Foreword, the five \\nprinciples, notes on Applying the The Blueprint for an AI Bill of Rights, and a Technical Companion that gives \\nconcrete steps that can be taken by many kinds of organizations—from governments at all levels to companies of \\nall sizes—to uphold these values. Experts from across the private sector, governments, and international \\nconsortia have published principles and frameworks to guide the responsible use of automated systems; this \\nframework provides a national values statement and toolkit that is sector-agnostic to inform building these \\nprotections into policy, practice, or the technological design process. Where existing law or policy—such as \\nsector-specific privacy laws and oversight requirements—do not already provide guidance, the Blueprint for an \\nAI Bill of Rights should be used to inform policy decisions.\\nLISTENING TO THE AMERICAN PUBLIC\\nThe White House Office of Science and Technology Policy has led a year-long process to seek and distill input \\nfrom people across the country—from impacted communities and industry stakeholders to technology develop-\\ners and other experts across fields and sectors, as well as policymakers throughout the Federal government—on \\nthe issue of algorithmic and data-driven harms and potential remedies. Through panel discussions, public listen-\\ning sessions, meetings, a formal request for information, and input to a publicly accessible and widely-publicized \\nemail address, people throughout the United States, public servants across Federal agencies, and members of the \\ninternational community spoke up about both the promises and potential harms of these technologies, and \\nplayed a central role in shaping the Blueprint for an AI Bill of Rights. The core messages gleaned from these \\ndiscussions include that AI has transformative potential to improve Americans’ lives, and that preventing the \\nharms of these technologies is both necessary and achievable. The Appendix includes a full list of public engage-\\nments. \\n4'), Document(metadata={'source': 'Blueprint for an AI Bill of Rights', 'document_id': 'doc1', '_id': 'd1a69baaaf6244b28fc90ebf898a5d92', '_collection_name': 'ffb2f8aece51430086938e04161466e4'}, page_content='ABOUT THIS FRAMEWORK\\xad\\xad\\xad\\xad\\xad\\nThe Blueprint for an AI Bill of Rights is a set of five principles and associated practices to help guide the \\ndesign, use, and deployment of automated systems to protect the rights of the American public in the age of \\nartificial intel-ligence. Developed through extensive consultation with the American public, these principles are \\na blueprint for building and deploying automated systems that are aligned with democratic values and protect \\ncivil rights, civil liberties, and privacy. The Blueprint for an AI Bill of Rights includes this Foreword, the five \\nprinciples, notes on Applying the The Blueprint for an AI Bill of Rights, and a Technical Companion that gives \\nconcrete steps that can be taken by many kinds of organizations—from governments at all levels to companies of \\nall sizes—to uphold these values. Experts from across the private sector, governments, and international \\nconsortia have published principles and frameworks to guide the responsible use of automated systems; this \\nframework provides a national values statement and toolkit that is sector-agnostic to inform building these \\nprotections into policy, practice, or the technological design process. Where existing law or policy—such as \\nsector-specific privacy laws and oversight requirements—do not already provide guidance, the Blueprint for an \\nAI Bill of Rights should be used to inform policy decisions.\\nLISTENING TO THE AMERICAN PUBLIC\\nThe White House Office of Science and Technology Policy has led a year-long process to seek and distill input \\nfrom people across the country—from impacted communities and industry stakeholders to technology develop-\\ners and other experts across fields and sectors, as well as policymakers throughout the Federal government—on \\nthe issue of algorithmic and data-driven harms and potential remedies. Through panel discussions, public listen-\\ning sessions, meetings, a formal request for information, and input to a publicly accessible and widely-publicized \\nemail address, people throughout the United States, public servants across Federal agencies, and members of the \\ninternational community spoke up about both the promises and potential harms of these technologies, and \\nplayed a central role in shaping the Blueprint for an AI Bill of Rights. The core messages gleaned from these \\ndiscussions include that AI has transformative potential to improve Americans’ lives, and that preventing the \\nharms of these technologies is both necessary and achievable. The Appendix includes a full list of public engage-\\nments. \\n4')]}\n",
|
| 713 |
+
"The AI Bill of Rights, officially known as the \"Blueprint for an AI Bill of Rights,\" is a set of five principles and associated practices designed to guide the design, use, and deployment of automated systems. Its primary goal is to protect the rights of the American public in the age of artificial intelligence (AI). Developed through extensive consultation with various stakeholders, including impacted communities, industry stakeholders, technology developers, and policymakers, these principles are intended to ensure that AI systems are aligned with democratic values and protect civil rights, civil liberties, and privacy. The Blueprint provides a national values statement and a toolkit that is sector-agnostic, meaning it can be applied across different sectors to inform policy decisions and the technological design process.\n",
|
| 714 |
+
"Number of found context: 4\n"
|
| 715 |
+
]
|
| 716 |
+
}
|
| 717 |
+
],
|
| 718 |
+
"source": [
|
| 719 |
+
"from operator import itemgetter\n",
|
| 720 |
+
"from langchain.schema.output_parser import StrOutputParser\n",
|
| 721 |
+
"from langchain.schema.runnable import RunnablePassthrough\n",
|
| 722 |
+
"retrieval_augmented_qa_chain = (\n",
|
| 723 |
+
" {\"context\": itemgetter(\"question\") | qdrant_retriever, \"question\": itemgetter(\"question\")}\n",
|
| 724 |
+
" | RunnablePassthrough.assign(context=itemgetter(\"context\"))\n",
|
| 725 |
+
"\n",
|
| 726 |
+
"\n",
|
| 727 |
+
" | {\"response\": chat_prompt | openai_chat_model, \"context\": itemgetter(\"context\")}\n",
|
| 728 |
+
")\n",
|
| 729 |
+
"response = retrieval_augmented_qa_chain.invoke({\"question\" : \"What is the AI Bill of Rights \"})\n",
|
| 730 |
+
"print(response)\n",
|
| 731 |
+
"print(response[\"response\"].content)\n",
|
| 732 |
+
"print(f\"Number of found context: {len(response['context'])}\")"
|
| 733 |
+
]
|
| 734 |
+
}
|
| 735 |
+
],
|
| 736 |
+
"metadata": {
|
| 737 |
+
"kernelspec": {
|
| 738 |
+
"display_name": "llmops-course",
|
| 739 |
+
"language": "python",
|
| 740 |
+
"name": "python3"
|
| 741 |
+
},
|
| 742 |
+
"language_info": {
|
| 743 |
+
"codemirror_mode": {
|
| 744 |
+
"name": "ipython",
|
| 745 |
+
"version": 3
|
| 746 |
+
},
|
| 747 |
+
"file_extension": ".py",
|
| 748 |
+
"mimetype": "text/x-python",
|
| 749 |
+
"name": "python",
|
| 750 |
+
"nbconvert_exporter": "python",
|
| 751 |
+
"pygments_lexer": "ipython3",
|
| 752 |
+
"version": "3.11.9"
|
| 753 |
+
}
|
| 754 |
+
},
|
| 755 |
+
"nbformat": 4,
|
| 756 |
+
"nbformat_minor": 2
|
| 757 |
+
}
|
requirements.txt
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy==1.26.4
|
| 2 |
+
chainlit==0.7.700 # 1.1.402
|
| 3 |
+
openai==1.3.5
|
| 4 |
+
pymupdf==1.24.9
|
| 5 |
+
qdrant-client==1.11.0
|
| 6 |
+
langchain-text-splitters
|
| 7 |
+
langchain-core==0.2.27
|
| 8 |
+
langchain-community==0.2.10
|
| 9 |
+
langchain-experimental==0.0.64
|
| 10 |
+
langgraph-checkpoint==1.0.6
|
| 11 |
+
langgraph==0.2.16
|
| 12 |
+
langchain-qdrant==0.1.3
|
| 13 |
+
langchain-openai==0.1.9
|
utilities/__init__.py
ADDED
|
File without changes
|
utilities/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (176 Bytes). View file
|
|
|
utilities/__pycache__/debugger.cpython-311.pyc
ADDED
|
Binary file (398 Bytes). View file
|
|
|
utilities/__pycache__/rag_utilities.cpython-311.pyc
ADDED
|
Binary file (6.41 kB). View file
|
|
|
utilities/debugger.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def dprint(state, msg):
|
| 2 |
+
if state.debug == True:
|
| 3 |
+
print(msg)
|
utilities/get_documents.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests
|
| 2 |
+
import os
|
| 3 |
+
from langchain.document_loaders import PyMuPDFLoader
|
| 4 |
+
|
| 5 |
+
# Define the URLs for the documents
|
| 6 |
+
url_1 = "https://example.com/Blueprint-for-an-AI-Bill-of-Rights.pdf"
|
| 7 |
+
url_2 = "https://example.com/NIST.AI.600-1.pdf"
|
| 8 |
+
|
| 9 |
+
# Define local file paths for storing the downloaded PDFs
|
| 10 |
+
file_path_1 = "data/Blueprint-for-an-AI-Bill-of-Rights.pdf"
|
| 11 |
+
file_path_2 = "data/NIST.AI.600-1.pdf"
|
| 12 |
+
|
| 13 |
+
# Function to download a file from a URL
|
| 14 |
+
def download_pdf(url, file_path):
|
| 15 |
+
# Check if the file already exists to avoid re-downloading
|
| 16 |
+
if not os.path.exists(file_path):
|
| 17 |
+
print(f"Downloading {file_path} from {url}...")
|
| 18 |
+
response = requests.get(url)
|
| 19 |
+
with open(file_path, 'wb') as f:
|
| 20 |
+
f.write(response.content)
|
| 21 |
+
else:
|
| 22 |
+
print(f"{file_path} already exists, skipping download.")
|
| 23 |
+
|
| 24 |
+
# Download the PDFs from the URLs
|
| 25 |
+
download_pdf(url_1, file_path_1)
|
| 26 |
+
download_pdf(url_2, file_path_2)
|
| 27 |
+
|
| 28 |
+
# Load the PDFs using PyMuPDFLoader
|
| 29 |
+
loader_1 = PyMuPDFLoader(file_path_1)
|
| 30 |
+
documents_1 = loader_1.load()
|
| 31 |
+
|
| 32 |
+
loader_2 = PyMuPDFLoader(file_path_2)
|
| 33 |
+
documents_2 = loader_2.load()
|
utilities/pipeline.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from utilities_2.vectordatabase import VectorDatabase
|
| 2 |
+
|
| 3 |
+
class RetrievalAugmentedQAPipeline:
|
| 4 |
+
def __init__(self, llm, vector_db_retriever: VectorDatabase,
|
| 5 |
+
system_role_prompt, user_role_prompt
|
| 6 |
+
) -> None:
|
| 7 |
+
self.llm = llm
|
| 8 |
+
self.vector_db_retriever = vector_db_retriever
|
| 9 |
+
self.system_role_prompt = system_role_prompt
|
| 10 |
+
self.user_role_prompt = user_role_prompt
|
| 11 |
+
|
| 12 |
+
async def arun_pipeline(self, user_query: str):
|
| 13 |
+
context_list = self.vector_db_retriever.search_by_text(user_query, k=4)
|
| 14 |
+
|
| 15 |
+
context_prompt = ""
|
| 16 |
+
for context in context_list:
|
| 17 |
+
context_prompt += context[0] + "\n"
|
| 18 |
+
|
| 19 |
+
formatted_system_prompt = self.system_role_prompt.create_message()
|
| 20 |
+
|
| 21 |
+
formatted_user_prompt = self.user_role_prompt.create_message(question=user_query, context=context_prompt)
|
| 22 |
+
|
| 23 |
+
async def generate_response():
|
| 24 |
+
async for chunk in self.llm.astream([formatted_system_prompt, formatted_user_prompt]):
|
| 25 |
+
yield chunk
|
| 26 |
+
|
| 27 |
+
return {"response": generate_response(), "context": context_list}
|
utilities/rag_utilities.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
| 2 |
+
from langchain.docstore.document import Document
|
| 3 |
+
from langchain_community.document_loaders import PyMuPDFLoader
|
| 4 |
+
from langchain_community.vectorstores import Qdrant
|
| 5 |
+
from langchain_openai.embeddings import OpenAIEmbeddings
|
| 6 |
+
import fitz
|
| 7 |
+
import io
|
| 8 |
+
import tiktoken
|
| 9 |
+
import requests
|
| 10 |
+
import os
|
| 11 |
+
from utilities.debugger import dprint
|
| 12 |
+
|
| 13 |
+
def tiktoken_len(text):
|
| 14 |
+
tokens = tiktoken.encoding_for_model("gpt-4o").encode(
|
| 15 |
+
text,
|
| 16 |
+
)
|
| 17 |
+
return len(tokens)
|
| 18 |
+
|
| 19 |
+
def download_document(state, url, file_name, download_folder):
|
| 20 |
+
file_path = os.path.join(download_folder, file_name)
|
| 21 |
+
if not os.path.exists(download_folder):
|
| 22 |
+
os.makedirs(download_folder)
|
| 23 |
+
|
| 24 |
+
if not os.path.exists(file_path):
|
| 25 |
+
print(f"Downloading {file_name} from {url}...")
|
| 26 |
+
response = requests.get(url)
|
| 27 |
+
if response.status_code == 200:
|
| 28 |
+
with open(file_path, 'wb') as f:
|
| 29 |
+
f.write(response.content)
|
| 30 |
+
else:
|
| 31 |
+
dprint(state, f"Failed to download document from {url}. Status code: {response.status_code}")
|
| 32 |
+
else:
|
| 33 |
+
dprint(state, f"{file_name} already exists locally.")
|
| 34 |
+
return file_path
|
| 35 |
+
|
| 36 |
+
def get_documents(state):
|
| 37 |
+
for url in state.document_urls:
|
| 38 |
+
dprint(state, f"Downloading and loading document from {url}...")
|
| 39 |
+
file_name = url.split("/")[-1]
|
| 40 |
+
file_path = download_document(state, url, file_name, state.download_folder)
|
| 41 |
+
loader = PyMuPDFLoader(file_path)
|
| 42 |
+
loaded_document = loader.load()
|
| 43 |
+
single_text_document = "\n".join([doc.page_content for doc in loaded_document])
|
| 44 |
+
#state.add_loaded_document(loaded_document) # Append the loaded documents to the list
|
| 45 |
+
#state.add_single_text_document(single_text_document)
|
| 46 |
+
dprint(state, f"Number of pages: {len(loaded_document)}")
|
| 47 |
+
# lets get titles and metadata
|
| 48 |
+
pdf = fitz.open(file_path)
|
| 49 |
+
metadata = pdf.metadata
|
| 50 |
+
title = metadata.get('title', 'Document 1')
|
| 51 |
+
#state.add_metadata(metadata)
|
| 52 |
+
#state.add_title(title)
|
| 53 |
+
document = {
|
| 54 |
+
"url": url,
|
| 55 |
+
"title": title,
|
| 56 |
+
"metadata": metadata,
|
| 57 |
+
"single_text_document": single_text_document,
|
| 58 |
+
}
|
| 59 |
+
state.add_document(document)
|
| 60 |
+
dprint(state, f"Title of Document: {title}")
|
| 61 |
+
dprint(state, f"Full metadata for Document 1: {metadata}")
|
| 62 |
+
pdf.close()
|
| 63 |
+
dprint(state, f"documents: {state.documents}")
|
| 64 |
+
|
| 65 |
+
def create_chunked_documents(state):
|
| 66 |
+
get_documents(state)
|
| 67 |
+
# file_path_1 = "data/Blueprint-for-an-AI-Bill-of-Rights.pdf"
|
| 68 |
+
# file_path_2 = "data/NIST.AI.600-1.pdf"
|
| 69 |
+
# loader = PyMuPDFLoader(file_path_1)
|
| 70 |
+
# documents_1 = loader.load()
|
| 71 |
+
# loader = PyMuPDFLoader(file_path_2)
|
| 72 |
+
# documents_2 = loader.load()
|
| 73 |
+
# print(f"Number of pages in 1: {len(documents_1)}")
|
| 74 |
+
# print(f"Number of pages in 2: {len(documents_2)}")
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
text_splitter = RecursiveCharacterTextSplitter(
|
| 78 |
+
chunk_size=state.chunk_size,
|
| 79 |
+
chunk_overlap=state.chunk_overlap,
|
| 80 |
+
length_function = tiktoken_len,
|
| 81 |
+
)
|
| 82 |
+
combined_document_objects = []
|
| 83 |
+
|
| 84 |
+
dprint(state, "Chunking documents and creating document objects")
|
| 85 |
+
for document in state.documents:
|
| 86 |
+
dprint(state, f"processing documend: {document['title']}")
|
| 87 |
+
text = document["single_text_document"]
|
| 88 |
+
dprint(state, text)
|
| 89 |
+
title = document["title"]
|
| 90 |
+
chunks_document = text_splitter.split_text(text)
|
| 91 |
+
dprint(state, len(chunks_document))
|
| 92 |
+
document_objects = [Document(page_content=chunk, metadata={"source": title, "document_id": "doc1"}) for chunk in chunks_document]
|
| 93 |
+
dprint(state, f"Number of chunks for Document: {len(chunks_document)}")
|
| 94 |
+
combined_document_objects = combined_document_objects + document_objects
|
| 95 |
+
state.add_combined_document_objects(combined_document_objects)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def create_vector_store(state):
|
| 99 |
+
create_chunked_documents(state)
|
| 100 |
+
embedding_model = OpenAIEmbeddings(model=state.embedding_model)
|
| 101 |
+
|
| 102 |
+
qdrant_vectorstore = Qdrant.from_documents(
|
| 103 |
+
documents=state.combined_document_objects,
|
| 104 |
+
embedding=embedding_model,
|
| 105 |
+
location=":memory:"
|
| 106 |
+
)
|
| 107 |
+
qdrant_retriever = qdrant_vectorstore.as_retriever()
|
| 108 |
+
state.set_retriever(qdrant_retriever)
|
| 109 |
+
return qdrant_retriever
|
utilities/text_utils.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
import fitz # pymupdf
|
| 4 |
+
import tempfile
|
| 5 |
+
from utilities_2.text_utils import CharacterTextSplitter
|
| 6 |
+
from langchain_text_splitters import RecursiveCharacterTextSplitter
|
| 7 |
+
|
| 8 |
+
# load the file
|
| 9 |
+
# handle .txt and .pdf
|
| 10 |
+
|
| 11 |
+
class FileLoader:
|
| 12 |
+
|
| 13 |
+
def __init__(self, encoding: str = "utf-8"):
|
| 14 |
+
self.documents = []
|
| 15 |
+
self.encoding = encoding
|
| 16 |
+
self.temp_file_path = ""
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def load_file(self, file, use_rct):
|
| 20 |
+
if use_rct:
|
| 21 |
+
text_splitter=MyRecursiveCharacterTextSplitter()
|
| 22 |
+
else:
|
| 23 |
+
text_splitter=CharacterTextSplitter()
|
| 24 |
+
file_extension = os.path.splitext(file.name)[1].lower()
|
| 25 |
+
|
| 26 |
+
with tempfile.NamedTemporaryFile(mode="wb", delete=False, suffix=file_extension) as temp_file:
|
| 27 |
+
self.temp_file_path = temp_file.name
|
| 28 |
+
temp_file.write(file.content)
|
| 29 |
+
|
| 30 |
+
if os.path.isfile(self.temp_file_path):
|
| 31 |
+
if self.temp_file_path.endswith(".txt"):
|
| 32 |
+
self.load_text_file()
|
| 33 |
+
elif self.temp_file_path.endswith(".pdf"):
|
| 34 |
+
self.load_pdf_file()
|
| 35 |
+
else:
|
| 36 |
+
raise ValueError(
|
| 37 |
+
f"Unsupported file type: {self.temp_file_path}"
|
| 38 |
+
)
|
| 39 |
+
return text_splitter.split_text(self.documents)
|
| 40 |
+
else:
|
| 41 |
+
raise ValueError(
|
| 42 |
+
"Not a file"
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
def load_text_file(self):
|
| 46 |
+
with open(self.temp_file_path, "r", encoding=self.encoding) as f:
|
| 47 |
+
self.documents.append(f.read())
|
| 48 |
+
|
| 49 |
+
def load_pdf_file(self):
|
| 50 |
+
# pymupdf
|
| 51 |
+
pdf_document = fitz.open(self.temp_file_path)
|
| 52 |
+
for page_num in range(len(pdf_document)):
|
| 53 |
+
page = pdf_document.load_page(page_num)
|
| 54 |
+
text = page.get_text()
|
| 55 |
+
self.documents.append(text)
|
| 56 |
+
|
| 57 |
+
class CharacterTextSplitter:
|
| 58 |
+
def __init__(
|
| 59 |
+
self,
|
| 60 |
+
chunk_size: int = 1000,
|
| 61 |
+
chunk_overlap: int = 200,
|
| 62 |
+
):
|
| 63 |
+
assert (
|
| 64 |
+
chunk_size > chunk_overlap
|
| 65 |
+
), "Chunk size must be greater than chunk overlap"
|
| 66 |
+
|
| 67 |
+
self.chunk_size = chunk_size
|
| 68 |
+
self.chunk_overlap = chunk_overlap
|
| 69 |
+
|
| 70 |
+
def split(self, text: str) -> List[str]:
|
| 71 |
+
chunks = []
|
| 72 |
+
for i in range(0, len(text), self.chunk_size - self.chunk_overlap):
|
| 73 |
+
chunks.append(text[i : i + self.chunk_size])
|
| 74 |
+
return chunks
|
| 75 |
+
|
| 76 |
+
def split_text(self, texts: List[str]) -> List[str]:
|
| 77 |
+
chunks = []
|
| 78 |
+
for text in texts:
|
| 79 |
+
chunks.extend(self.split(text))
|
| 80 |
+
return chunks
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class MyRecursiveCharacterTextSplitter:
|
| 85 |
+
# uses langChain.RecursiveCharacterTextSplitter
|
| 86 |
+
def __init__(
|
| 87 |
+
self
|
| 88 |
+
):
|
| 89 |
+
self.RCTS = RecursiveCharacterTextSplitter(
|
| 90 |
+
chunk_size=1000,
|
| 91 |
+
chunk_overlap=20,
|
| 92 |
+
length_function=len,
|
| 93 |
+
separators=["\n\n", "\n", " ", ""]
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
def split_text(self, texts: List[str]) -> List[str]:
|
| 97 |
+
all_chunks = []
|
| 98 |
+
for doc in texts:
|
| 99 |
+
chunks = self.RCTS.split_text(doc)
|
| 100 |
+
all_chunks.extend(chunks)
|
| 101 |
+
return all_chunks
|
| 102 |
+
|
| 103 |
+
|
utilities/vector_database.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from collections import defaultdict
|
| 3 |
+
from typing import List, Tuple, Callable
|
| 4 |
+
from utilities_2.openai_utils.embedding import EmbeddingModel
|
| 5 |
+
import hashlib
|
| 6 |
+
from qdrant_client import QdrantClient
|
| 7 |
+
from qdrant_client.http.models import PointStruct
|
| 8 |
+
from qdrant_client.models import VectorParams
|
| 9 |
+
import uuid
|
| 10 |
+
|
| 11 |
+
def cosine_similarity(vector_a: np.array, vector_b: np.array) -> float:
|
| 12 |
+
"""Computes the cosine similarity between two vectors."""
|
| 13 |
+
dot_product = np.dot(vector_a, vector_b)
|
| 14 |
+
norm_a = np.linalg.norm(vector_a)
|
| 15 |
+
norm_b = np.linalg.norm(vector_b)
|
| 16 |
+
return dot_product / (norm_a * norm_b)
|
| 17 |
+
|
| 18 |
+
class QdrantDatabase:
|
| 19 |
+
def __init__(self, embedding_model=None):
|
| 20 |
+
self.qdrant_client = QdrantClient(location=":memory:")
|
| 21 |
+
self.collection_name = "my_collection"
|
| 22 |
+
self.embedding_model = embedding_model or EmbeddingModel(embeddings_model_name= "text-embedding-3-small", dimensions=1000)
|
| 23 |
+
vector_params = VectorParams(
|
| 24 |
+
size=self.embedding_model.dimensions, # vector size
|
| 25 |
+
distance="Cosine"
|
| 26 |
+
) # distance metric
|
| 27 |
+
self.qdrant_client.create_collection(
|
| 28 |
+
collection_name=self.collection_name,
|
| 29 |
+
vectors_config={"text": vector_params},
|
| 30 |
+
)
|
| 31 |
+
self.vectors = defaultdict(np.array) # Still keeps a local copy if needed
|
| 32 |
+
|
| 33 |
+
def string_to_int_id(self, s: str) -> int:
|
| 34 |
+
return int(hashlib.sha256(s.encode('utf-8')).hexdigest(), 16) % (10**8)
|
| 35 |
+
def get_test_vector(self):
|
| 36 |
+
retrieved_vector = self.qdrant_client.retrieve(
|
| 37 |
+
collection_name="my_collection",
|
| 38 |
+
ids=[self.string_to_int_id("test_key")]
|
| 39 |
+
)
|
| 40 |
+
return retrieved_vector
|
| 41 |
+
def insert(self, key: str, vector: np.array) -> None:
|
| 42 |
+
point_id = str(uuid.uuid4())
|
| 43 |
+
payload = {"text": key}
|
| 44 |
+
|
| 45 |
+
point = PointStruct(
|
| 46 |
+
id=point_id,
|
| 47 |
+
vector={"default": vector.tolist()},
|
| 48 |
+
payload=payload
|
| 49 |
+
)
|
| 50 |
+
print(f"Inserting vector for key: {key}, ID: {point_id}")
|
| 51 |
+
# Insert the vector into Qdrant with the associated document
|
| 52 |
+
self.qdrant_client.upsert(
|
| 53 |
+
collection_name=self.collection_name,
|
| 54 |
+
points=[point] # Qdrant expects a list of PointStruct
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def search(
|
| 59 |
+
self,
|
| 60 |
+
query_vector: np.array,
|
| 61 |
+
k: int=5,
|
| 62 |
+
distance_measure: Callable = cosine_similarity,
|
| 63 |
+
) -> List[Tuple[str, float]]:
|
| 64 |
+
# Perform search in Qdrant
|
| 65 |
+
if isinstance(query_vector, np.ndarray):
|
| 66 |
+
query_vector = query_vector.tolist()
|
| 67 |
+
print(type(query_vector))
|
| 68 |
+
search_results = self.qdrant_client.search(
|
| 69 |
+
collection_name=self.collection_name,
|
| 70 |
+
query_vector=query_vector, # Pass the vector as a list
|
| 71 |
+
limit=k
|
| 72 |
+
)
|
| 73 |
+
return [(result.payload['text'], result.score) for result in search_results]
|
| 74 |
+
|
| 75 |
+
def search_by_text(
|
| 76 |
+
self,
|
| 77 |
+
query_text: str,
|
| 78 |
+
k: int,
|
| 79 |
+
distance_measure: Callable = cosine_similarity,
|
| 80 |
+
return_as_text: bool = False,
|
| 81 |
+
) -> List[Tuple[str, float]]:
|
| 82 |
+
|
| 83 |
+
query_vector = self.embedding_model.get_embedding(query_text)
|
| 84 |
+
results = self.search(query_vector, k, distance_measure)
|
| 85 |
+
return [result[0] for result in results] if return_as_text else results
|
| 86 |
+
|
| 87 |
+
async def abuild_from_list(self, list_of_text: List[str]) -> "QdrantDatabase":
|
| 88 |
+
from qdrant_client.http import models
|
| 89 |
+
embeddings = await self.embedding_model.async_get_embeddings(list_of_text)
|
| 90 |
+
points = [
|
| 91 |
+
models.PointStruct(
|
| 92 |
+
id=str(uuid.uuid4()),
|
| 93 |
+
vector={"text": embedding}, # Should be a named vector as per vector_config
|
| 94 |
+
payload={
|
| 95 |
+
"text": text
|
| 96 |
+
}
|
| 97 |
+
)
|
| 98 |
+
for text, embedding in zip(list_of_text, embeddings)
|
| 99 |
+
]
|
| 100 |
+
self.qdrant_client.upsert(
|
| 101 |
+
collection_name=self.collection_name,
|
| 102 |
+
points=points
|
| 103 |
+
)
|
| 104 |
+
return self
|
| 105 |
+
|
utilities_2/__init__.py
ADDED
|
File without changes
|
utilities_2/openai_utils/__init__.py
ADDED
|
File without changes
|
utilities_2/openai_utils/chatmodel.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from openai import OpenAI, AsyncOpenAI
|
| 2 |
+
from dotenv import load_dotenv
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
load_dotenv()
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class ChatOpenAI:
|
| 9 |
+
def __init__(self, model_name: str = "gpt-4o-mini"):
|
| 10 |
+
self.model_name = model_name
|
| 11 |
+
self.openai_api_key = os.getenv("OPENAI_API_KEY")
|
| 12 |
+
if self.openai_api_key is None:
|
| 13 |
+
raise ValueError("OPENAI_API_KEY is not set")
|
| 14 |
+
|
| 15 |
+
def run(self, messages, text_only: bool = True, **kwargs):
|
| 16 |
+
if not isinstance(messages, list):
|
| 17 |
+
raise ValueError("messages must be a list")
|
| 18 |
+
|
| 19 |
+
client = OpenAI()
|
| 20 |
+
response = client.chat.completions.create(
|
| 21 |
+
model=self.model_name, messages=messages, **kwargs
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
if text_only:
|
| 25 |
+
return response.choices[0].message.content
|
| 26 |
+
|
| 27 |
+
return response
|
| 28 |
+
|
| 29 |
+
async def astream(self, messages, **kwargs):
|
| 30 |
+
if not isinstance(messages, list):
|
| 31 |
+
raise ValueError("messages must be a list")
|
| 32 |
+
|
| 33 |
+
client = AsyncOpenAI()
|
| 34 |
+
|
| 35 |
+
stream = await client.chat.completions.create(
|
| 36 |
+
model=self.model_name,
|
| 37 |
+
messages=messages,
|
| 38 |
+
stream=True,
|
| 39 |
+
**kwargs
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
async for chunk in stream:
|
| 43 |
+
content = chunk.choices[0].delta.content
|
| 44 |
+
if content is not None:
|
| 45 |
+
yield content
|
utilities_2/openai_utils/embedding.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dotenv import load_dotenv
|
| 2 |
+
from openai import AsyncOpenAI, OpenAI
|
| 3 |
+
import openai
|
| 4 |
+
from typing import List
|
| 5 |
+
import os
|
| 6 |
+
import asyncio
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class EmbeddingModel:
|
| 10 |
+
def __init__(self, embeddings_model_name: str = "text-embedding-3-small", dimensions: int = None):
|
| 11 |
+
load_dotenv()
|
| 12 |
+
self.openai_api_key = os.getenv("OPENAI_API_KEY")
|
| 13 |
+
self.async_client = AsyncOpenAI()
|
| 14 |
+
self.client = OpenAI()
|
| 15 |
+
self.dimensions = dimensions
|
| 16 |
+
|
| 17 |
+
if self.openai_api_key is None:
|
| 18 |
+
raise ValueError(
|
| 19 |
+
"OPENAI_API_KEY environment variable is not set. Please set it to your OpenAI API key."
|
| 20 |
+
)
|
| 21 |
+
openai.api_key = self.openai_api_key
|
| 22 |
+
self.embeddings_model_name = embeddings_model_name
|
| 23 |
+
|
| 24 |
+
async def async_get_embeddings(self, list_of_text: List[str]) -> List[List[float]]:
|
| 25 |
+
embedding_response = await self.async_client.embeddings.create(
|
| 26 |
+
input=list_of_text, model=self.embeddings_model_name, dimensions=self.dimensions
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
return [embeddings.embedding for embeddings in embedding_response.data]
|
| 30 |
+
|
| 31 |
+
async def async_get_embedding(self, text: str) -> List[float]:
|
| 32 |
+
embedding = await self.async_client.embeddings.create(
|
| 33 |
+
input=text, model=self.embeddings_model_name, dimensions=self.dimensions
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
return embedding.data[0].embedding
|
| 37 |
+
|
| 38 |
+
def get_embeddings(self, list_of_text: List[str]) -> List[List[float]]:
|
| 39 |
+
embedding_response = self.client.embeddings.create(
|
| 40 |
+
input=list_of_text, model=self.embeddings_model_name, dimensions=self.dimensions
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
return [embeddings.embedding for embeddings in embedding_response.data]
|
| 44 |
+
|
| 45 |
+
def get_embedding(self, text: str) -> List[float]:
|
| 46 |
+
embedding = self.client.embeddings.create(
|
| 47 |
+
input=text, model=self.embeddings_model_name, dimensions=self.dimensions
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
return embedding.data[0].embedding
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
if __name__ == "__main__":
|
| 54 |
+
embedding_model = EmbeddingModel()
|
| 55 |
+
print(asyncio.run(embedding_model.async_get_embedding("Hello, world!")))
|
| 56 |
+
print(
|
| 57 |
+
asyncio.run(
|
| 58 |
+
embedding_model.async_get_embeddings(["Hello, world!", "Goodbye, world!"])
|
| 59 |
+
)
|
| 60 |
+
)
|
utilities_2/openai_utils/prompts.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class BasePrompt:
|
| 5 |
+
def __init__(self, prompt):
|
| 6 |
+
"""
|
| 7 |
+
Initializes the BasePrompt object with a prompt template.
|
| 8 |
+
|
| 9 |
+
:param prompt: A string that can contain placeholders within curly braces
|
| 10 |
+
"""
|
| 11 |
+
self.prompt = prompt
|
| 12 |
+
self._pattern = re.compile(r"\{([^}]+)\}")
|
| 13 |
+
|
| 14 |
+
def format_prompt(self, **kwargs):
|
| 15 |
+
"""
|
| 16 |
+
Formats the prompt string using the keyword arguments provided.
|
| 17 |
+
|
| 18 |
+
:param kwargs: The values to substitute into the prompt string
|
| 19 |
+
:return: The formatted prompt string
|
| 20 |
+
"""
|
| 21 |
+
matches = self._pattern.findall(self.prompt)
|
| 22 |
+
return self.prompt.format(**{match: kwargs.get(match, "") for match in matches})
|
| 23 |
+
|
| 24 |
+
def get_input_variables(self):
|
| 25 |
+
"""
|
| 26 |
+
Gets the list of input variable names from the prompt string.
|
| 27 |
+
|
| 28 |
+
:return: List of input variable names
|
| 29 |
+
"""
|
| 30 |
+
return self._pattern.findall(self.prompt)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class RolePrompt(BasePrompt):
|
| 34 |
+
def __init__(self, prompt, role: str):
|
| 35 |
+
"""
|
| 36 |
+
Initializes the RolePrompt object with a prompt template and a role.
|
| 37 |
+
|
| 38 |
+
:param prompt: A string that can contain placeholders within curly braces
|
| 39 |
+
:param role: The role for the message ('system', 'user', or 'assistant')
|
| 40 |
+
"""
|
| 41 |
+
super().__init__(prompt)
|
| 42 |
+
self.role = role
|
| 43 |
+
|
| 44 |
+
def create_message(self, format=True, **kwargs):
|
| 45 |
+
"""
|
| 46 |
+
Creates a message dictionary with a role and a formatted message.
|
| 47 |
+
|
| 48 |
+
:param kwargs: The values to substitute into the prompt string
|
| 49 |
+
:return: Dictionary containing the role and the formatted message
|
| 50 |
+
"""
|
| 51 |
+
if format:
|
| 52 |
+
return {"role": self.role, "content": self.format_prompt(**kwargs)}
|
| 53 |
+
|
| 54 |
+
return {"role": self.role, "content": self.prompt}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class SystemRolePrompt(RolePrompt):
|
| 58 |
+
def __init__(self, prompt: str):
|
| 59 |
+
super().__init__(prompt, "system")
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class UserRolePrompt(RolePrompt):
|
| 63 |
+
def __init__(self, prompt: str):
|
| 64 |
+
super().__init__(prompt, "user")
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class AssistantRolePrompt(RolePrompt):
|
| 68 |
+
def __init__(self, prompt: str):
|
| 69 |
+
super().__init__(prompt, "assistant")
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
if __name__ == "__main__":
|
| 73 |
+
prompt = BasePrompt("Hello {name}, you are {age} years old")
|
| 74 |
+
print(prompt.format_prompt(name="John", age=30))
|
| 75 |
+
|
| 76 |
+
prompt = SystemRolePrompt("Hello {name}, you are {age} years old")
|
| 77 |
+
print(prompt.create_message(name="John", age=30))
|
| 78 |
+
print(prompt.get_input_variables())
|
utilities_2/text_utils.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
class TextFileLoader:
|
| 5 |
+
def __init__(self, path: str, encoding: str = "utf-8"):
|
| 6 |
+
self.documents = []
|
| 7 |
+
self.path = path
|
| 8 |
+
self.encoding = encoding
|
| 9 |
+
|
| 10 |
+
def load(self):
|
| 11 |
+
if os.path.isdir(self.path):
|
| 12 |
+
self.load_directory()
|
| 13 |
+
elif os.path.isfile(self.path) and self.path.endswith(".txt"):
|
| 14 |
+
self.load_file()
|
| 15 |
+
else:
|
| 16 |
+
raise ValueError(
|
| 17 |
+
"Provided path is neither a valid directory nor a .txt file."
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
def load_file(self):
|
| 21 |
+
with open(self.path, "r", encoding=self.encoding) as f:
|
| 22 |
+
self.documents.append(f.read())
|
| 23 |
+
|
| 24 |
+
def load_directory(self):
|
| 25 |
+
for root, _, files in os.walk(self.path):
|
| 26 |
+
for file in files:
|
| 27 |
+
if file.endswith(".txt"):
|
| 28 |
+
with open(
|
| 29 |
+
os.path.join(root, file), "r", encoding=self.encoding
|
| 30 |
+
) as f:
|
| 31 |
+
self.documents.append(f.read())
|
| 32 |
+
|
| 33 |
+
def load_documents(self):
|
| 34 |
+
self.load()
|
| 35 |
+
return self.documents
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class CharacterTextSplitter:
|
| 39 |
+
def __init__(
|
| 40 |
+
self,
|
| 41 |
+
chunk_size: int = 1000,
|
| 42 |
+
chunk_overlap: int = 200,
|
| 43 |
+
):
|
| 44 |
+
assert (
|
| 45 |
+
chunk_size > chunk_overlap
|
| 46 |
+
), "Chunk size must be greater than chunk overlap"
|
| 47 |
+
|
| 48 |
+
self.chunk_size = chunk_size
|
| 49 |
+
self.chunk_overlap = chunk_overlap
|
| 50 |
+
|
| 51 |
+
def split(self, text: str) -> List[str]:
|
| 52 |
+
chunks = []
|
| 53 |
+
for i in range(0, len(text), self.chunk_size - self.chunk_overlap):
|
| 54 |
+
chunks.append(text[i : i + self.chunk_size])
|
| 55 |
+
return chunks
|
| 56 |
+
|
| 57 |
+
def split_text(self, texts: List[str]) -> List[str]:
|
| 58 |
+
chunks = []
|
| 59 |
+
for text in texts:
|
| 60 |
+
chunks.extend(self.split(text))
|
| 61 |
+
return chunks
|
| 62 |
+
|
| 63 |
+
if __name__ == "__main__":
|
| 64 |
+
loader = TextFileLoader("data/KingLear.txt")
|
| 65 |
+
loader.load()
|
| 66 |
+
splitter = CharacterTextSplitter()
|
| 67 |
+
chunks = splitter.split_text(loader.documents)
|
| 68 |
+
print(len(chunks))
|
| 69 |
+
print(chunks[0])
|
| 70 |
+
print("--------")
|
| 71 |
+
print(chunks[1])
|
| 72 |
+
print("--------")
|
| 73 |
+
print(chunks[-2])
|
| 74 |
+
print("--------")
|
| 75 |
+
print(chunks[-1])
|
utilities_2/vectordatabase.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from collections import defaultdict
|
| 3 |
+
from typing import List, Tuple, Callable
|
| 4 |
+
from utilities_2.openai_utils.embedding import EmbeddingModel
|
| 5 |
+
import asyncio
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def cosine_similarity(vector_a: np.array, vector_b: np.array) -> float:
|
| 9 |
+
"""Computes the cosine similarity between two vectors."""
|
| 10 |
+
dot_product = np.dot(vector_a, vector_b)
|
| 11 |
+
norm_a = np.linalg.norm(vector_a)
|
| 12 |
+
norm_b = np.linalg.norm(vector_b)
|
| 13 |
+
return dot_product / (norm_a * norm_b)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class VectorDatabase:
|
| 17 |
+
def __init__(self, embedding_model: EmbeddingModel = None):
|
| 18 |
+
self.vectors = defaultdict(np.array)
|
| 19 |
+
self.embedding_model = embedding_model or EmbeddingModel()
|
| 20 |
+
|
| 21 |
+
def insert(self, key: str, vector: np.array) -> None:
|
| 22 |
+
self.vectors[key] = vector
|
| 23 |
+
|
| 24 |
+
def search(
|
| 25 |
+
self,
|
| 26 |
+
query_vector: np.array,
|
| 27 |
+
k: int,
|
| 28 |
+
distance_measure: Callable = cosine_similarity,
|
| 29 |
+
) -> List[Tuple[str, float]]:
|
| 30 |
+
scores = [
|
| 31 |
+
(key, distance_measure(query_vector, vector))
|
| 32 |
+
for key, vector in self.vectors.items()
|
| 33 |
+
]
|
| 34 |
+
return sorted(scores, key=lambda x: x[1], reverse=True)[:k]
|
| 35 |
+
|
| 36 |
+
def search_by_text(
|
| 37 |
+
self,
|
| 38 |
+
query_text: str,
|
| 39 |
+
k: int,
|
| 40 |
+
distance_measure: Callable = cosine_similarity,
|
| 41 |
+
return_as_text: bool = False,
|
| 42 |
+
) -> List[Tuple[str, float]]:
|
| 43 |
+
query_vector = self.embedding_model.get_embedding(query_text)
|
| 44 |
+
results = self.search(query_vector, k, distance_measure)
|
| 45 |
+
return [result[0] for result in results] if return_as_text else results
|
| 46 |
+
|
| 47 |
+
def retrieve_from_key(self, key: str) -> np.array:
|
| 48 |
+
return self.vectors.get(key, None)
|
| 49 |
+
|
| 50 |
+
async def abuild_from_list(self, list_of_text: List[str]) -> "VectorDatabase":
|
| 51 |
+
embeddings = await self.embedding_model.async_get_embeddings(list_of_text)
|
| 52 |
+
for text, embedding in zip(list_of_text, embeddings):
|
| 53 |
+
self.insert(text, np.array(embedding))
|
| 54 |
+
return self
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
if __name__ == "__main__":
|
| 59 |
+
list_of_text = [
|
| 60 |
+
"I like to eat broccoli and bananas.",
|
| 61 |
+
"I ate a banana and spinach smoothie for breakfast.",
|
| 62 |
+
"Chinchillas and kittens are cute.",
|
| 63 |
+
"My sister adopted a kitten yesterday.",
|
| 64 |
+
"Look at this cute hamster munching on a piece of broccoli.",
|
| 65 |
+
]
|
| 66 |
+
|
| 67 |
+
vector_db = VectorDatabase()
|
| 68 |
+
vector_db = asyncio.run(vector_db.abuild_from_list(list_of_text))
|
| 69 |
+
k = 2
|
| 70 |
+
|
| 71 |
+
searched_vector = vector_db.search_by_text("I think fruit is awesome!", k=k)
|
| 72 |
+
print(f"Closest {k} vector(s):", searched_vector)
|
| 73 |
+
|
| 74 |
+
retrieved_vector = vector_db.retrieve_from_key(
|
| 75 |
+
"I like to eat broccoli and bananas."
|
| 76 |
+
)
|
| 77 |
+
print("Retrieved vector:", retrieved_vector)
|
| 78 |
+
|
| 79 |
+
relevant_texts = vector_db.search_by_text(
|
| 80 |
+
"I think fruit is awesome!", k=k, return_as_text=True
|
| 81 |
+
)
|
| 82 |
+
print(f"Closest {k} text(s):", relevant_texts)
|