Spaces:
Runtime error

Runtime error
first push
Browse files- README.md +16 -12
- app.py +127 -0
- images/tight@1920x_transparent.png +0 -0
- requirements.txt +5 -0
README.md
CHANGED
|
@@ -1,12 +1,16 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Transformer Interpret Streamlit App
|
| 2 |
+
|
| 3 |
+
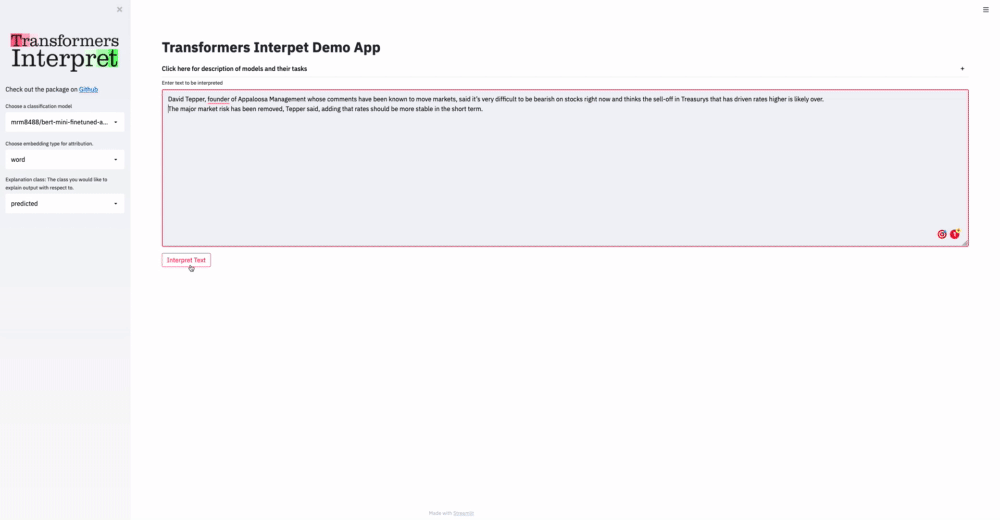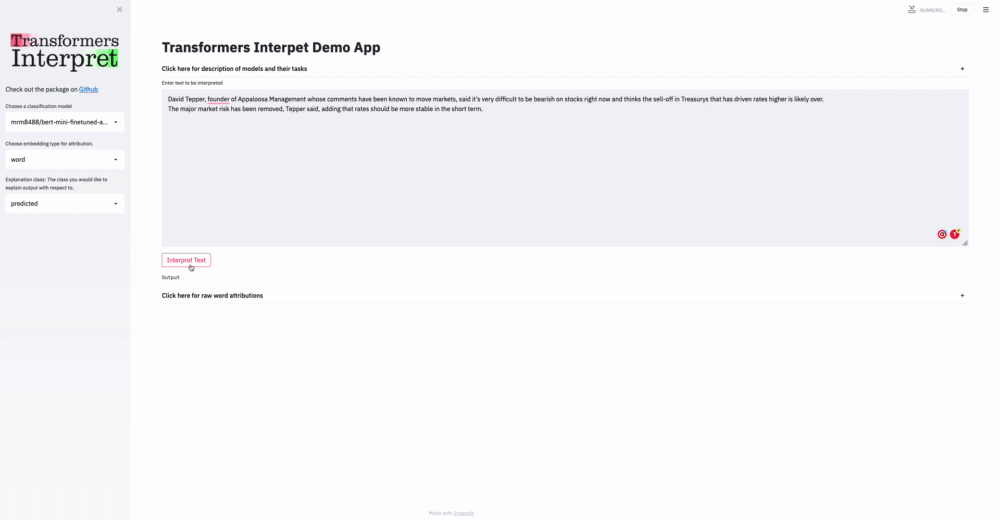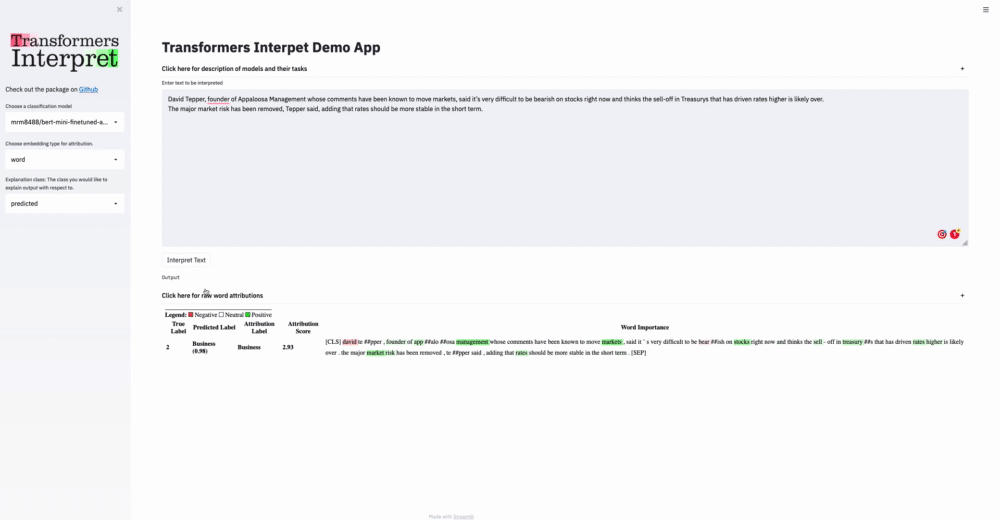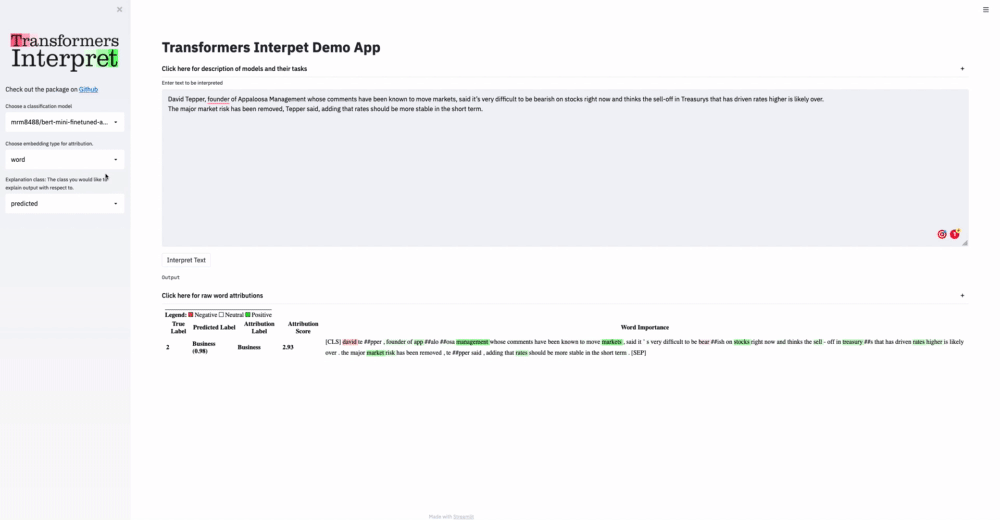
|
| 4 |
+
|
| 5 |
+
- Simple streamlit app to demonstrate some of the features of [Transformers Interpret](https://github.com/cdpierse/transformers-interpret).
|
| 6 |
+
- View the word attributions of 7+ text classification HuggingFace Transformer models.
|
| 7 |
+
- View the attributions w.r.t to any class/label in a model.
|
| 8 |
+
- View attributions w.r.t to both word and position embeddings for a model
|
| 9 |
+
## Install
|
| 10 |
+
|
| 11 |
+
`pip install -r requirements.txt `
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
## Run
|
| 15 |
+
|
| 16 |
+
`streamlit run app.py`
|
app.py
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import asyncio
|
| 2 |
+
import gc
|
| 3 |
+
import logging
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import psutil
|
| 8 |
+
import streamlit as st
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from streamlit import components
|
| 11 |
+
from streamlit.caching import clear_cache
|
| 12 |
+
from transformers import AutoModelForSequenceClassification, AutoTokenizer
|
| 13 |
+
from transformers_interpret import SequenceClassificationExplainer
|
| 14 |
+
|
| 15 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 16 |
+
logging.basicConfig(
|
| 17 |
+
format="%(asctime)s : %(levelname)s : %(message)s", level=logging.INFO
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def print_memory_usage():
|
| 22 |
+
logging.info(f"RAM memory % used: {psutil.virtual_memory()[2]}")
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
@st.cache(allow_output_mutation=True, suppress_st_warning=True, max_entries=1)
|
| 26 |
+
def load_model(model_name):
|
| 27 |
+
return (
|
| 28 |
+
AutoModelForSequenceClassification.from_pretrained(model_name),
|
| 29 |
+
AutoTokenizer.from_pretrained(model_name),
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def main():
|
| 34 |
+
|
| 35 |
+
st.title("Transformers Interpet Demo App")
|
| 36 |
+
|
| 37 |
+
image = Image.open("./images/tight@1920x_transparent.png")
|
| 38 |
+
st.sidebar.image(image, use_column_width=True)
|
| 39 |
+
st.sidebar.markdown(
|
| 40 |
+
"Check out the package on [Github](https://github.com/cdpierse/transformers-interpret)"
|
| 41 |
+
)
|
| 42 |
+
st.info(
|
| 43 |
+
"Due to limited resources only low memory models are available. Run this [app locally](https://github.com/cdpierse/transformers-interpret-streamlit) to run the full selection of available models. "
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
# uncomment the options below to test out the app with a variety of classification models.
|
| 47 |
+
models = {
|
| 48 |
+
# "textattack/distilbert-base-uncased-rotten-tomatoes": "",
|
| 49 |
+
# "textattack/bert-base-uncased-rotten-tomatoes": "",
|
| 50 |
+
# "textattack/roberta-base-rotten-tomatoes": "",
|
| 51 |
+
# "mrm8488/bert-mini-finetuned-age_news-classification": "BERT-Mini finetuned on AG News dataset. Predicts news class (sports/tech/business/world) of text.",
|
| 52 |
+
# "nateraw/bert-base-uncased-ag-news": "BERT finetuned on AG News dataset. Predicts news class (sports/tech/business/world) of text.",
|
| 53 |
+
"distilbert-base-uncased-finetuned-sst-2-english": "DistilBERT model finetuned on SST-2 sentiment analysis task. Predicts positive/negative sentiment.",
|
| 54 |
+
# "ProsusAI/finbert": "BERT model finetuned to predict sentiment of financial text. Finetuned on Financial PhraseBank data. Predicts positive/negative/neutral.",
|
| 55 |
+
"sampathkethineedi/industry-classification": "DistilBERT Model to classify a business description into one of 62 industry tags.",
|
| 56 |
+
"MoritzLaurer/policy-distilbert-7d": "DistilBERT model finetuned to classify text into one of seven political categories.",
|
| 57 |
+
# # "MoritzLaurer/covid-policy-roberta-21": "(Under active development ) RoBERTA model finetuned to identify COVID policy measure classes ",
|
| 58 |
+
# "mrm8488/bert-tiny-finetuned-sms-spam-detection": "Tiny bert model finetuned for spam detection. 0 == not spam, 1 == spam",
|
| 59 |
+
}
|
| 60 |
+
model_name = st.sidebar.selectbox(
|
| 61 |
+
"Choose a classification model", list(models.keys())
|
| 62 |
+
)
|
| 63 |
+
model, tokenizer = load_model(model_name)
|
| 64 |
+
if model_name.startswith("textattack/"):
|
| 65 |
+
model.config.id2label = {0: "NEGATIVE (0) ", 1: "POSITIVE (1)"}
|
| 66 |
+
model.eval()
|
| 67 |
+
cls_explainer = SequenceClassificationExplainer(model=model, tokenizer=tokenizer)
|
| 68 |
+
if cls_explainer.accepts_position_ids:
|
| 69 |
+
emb_type_name = st.sidebar.selectbox(
|
| 70 |
+
"Choose embedding type for attribution.", ["word", "position"]
|
| 71 |
+
)
|
| 72 |
+
if emb_type_name == "word":
|
| 73 |
+
emb_type_num = 0
|
| 74 |
+
if emb_type_name == "position":
|
| 75 |
+
emb_type_num = 1
|
| 76 |
+
else:
|
| 77 |
+
emb_type_num = 0
|
| 78 |
+
|
| 79 |
+
explanation_classes = ["predicted"] + list(model.config.label2id.keys())
|
| 80 |
+
explanation_class_choice = st.sidebar.selectbox(
|
| 81 |
+
"Explanation class: The class you would like to explain output with respect to.",
|
| 82 |
+
explanation_classes,
|
| 83 |
+
)
|
| 84 |
+
my_expander = st.beta_expander(
|
| 85 |
+
"Click here for description of models and their tasks"
|
| 86 |
+
)
|
| 87 |
+
with my_expander:
|
| 88 |
+
st.json(models)
|
| 89 |
+
|
| 90 |
+
# st.info("Max char limit of 350 (memory management)")
|
| 91 |
+
text = st.text_area(
|
| 92 |
+
"Enter text to be interpreted",
|
| 93 |
+
"I like you, I love you",
|
| 94 |
+
height=400,
|
| 95 |
+
max_chars=850,
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
if st.button("Interpret Text"):
|
| 99 |
+
print_memory_usage()
|
| 100 |
+
|
| 101 |
+
st.text("Output")
|
| 102 |
+
with st.spinner("Interpreting your text (This may take some time)"):
|
| 103 |
+
if explanation_class_choice != "predicted":
|
| 104 |
+
word_attributions = cls_explainer(
|
| 105 |
+
text,
|
| 106 |
+
class_name=explanation_class_choice,
|
| 107 |
+
embedding_type=emb_type_num,
|
| 108 |
+
internal_batch_size=2,
|
| 109 |
+
)
|
| 110 |
+
else:
|
| 111 |
+
word_attributions = cls_explainer(
|
| 112 |
+
text, embedding_type=emb_type_num, internal_batch_size=2
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
if word_attributions:
|
| 116 |
+
word_attributions_expander = st.beta_expander(
|
| 117 |
+
"Click here for raw word attributions"
|
| 118 |
+
)
|
| 119 |
+
with word_attributions_expander:
|
| 120 |
+
st.json(word_attributions)
|
| 121 |
+
components.v1.html(
|
| 122 |
+
cls_explainer.visualize()._repr_html_(), scrolling=True, height=350
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
if __name__ == "__main__":
|
| 127 |
+
main()
|
images/tight@1920x_transparent.png
ADDED
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
streamlit==0.82.0
|
| 2 |
+
transformers_interpret==0.5.1
|
| 3 |
+
pandas==1.0.3
|
| 4 |
+
transformers==4.3.2
|
| 5 |
+
psutil==5.7.0
|