Spaces:
Running

Running
IC4T
commited on
Commit
·
cfd3735
1
Parent(s):
ab98e06
update
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- app.py +1 -1
- langchain/CITATION.cff +8 -0
- langchain/Dockerfile +48 -0
- langchain/LICENSE +21 -0
- langchain/Makefile +70 -0
- langchain/README.md +93 -0
- langchain/docs/Makefile +21 -0
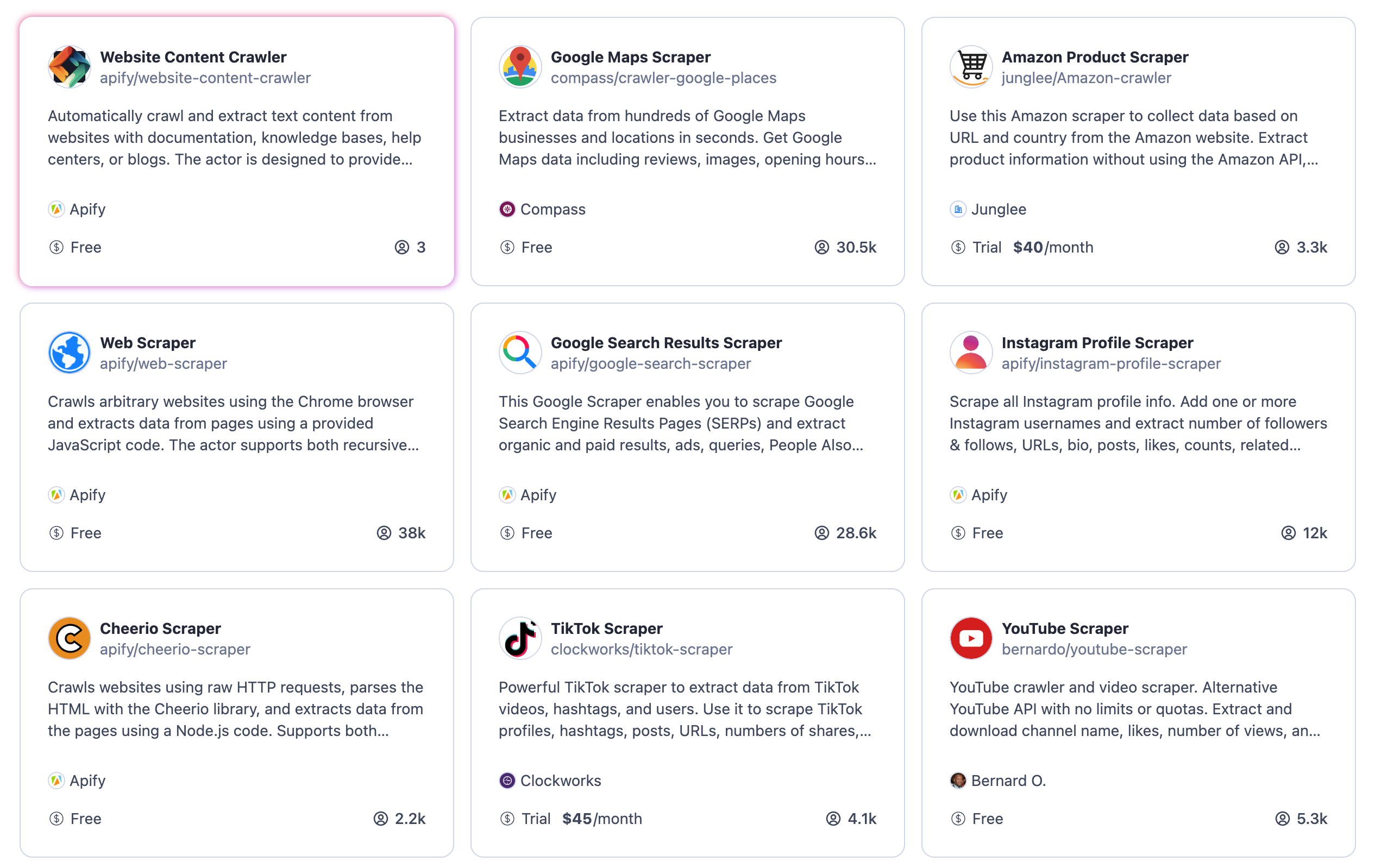
- langchain/docs/_static/ApifyActors.png +0 -0
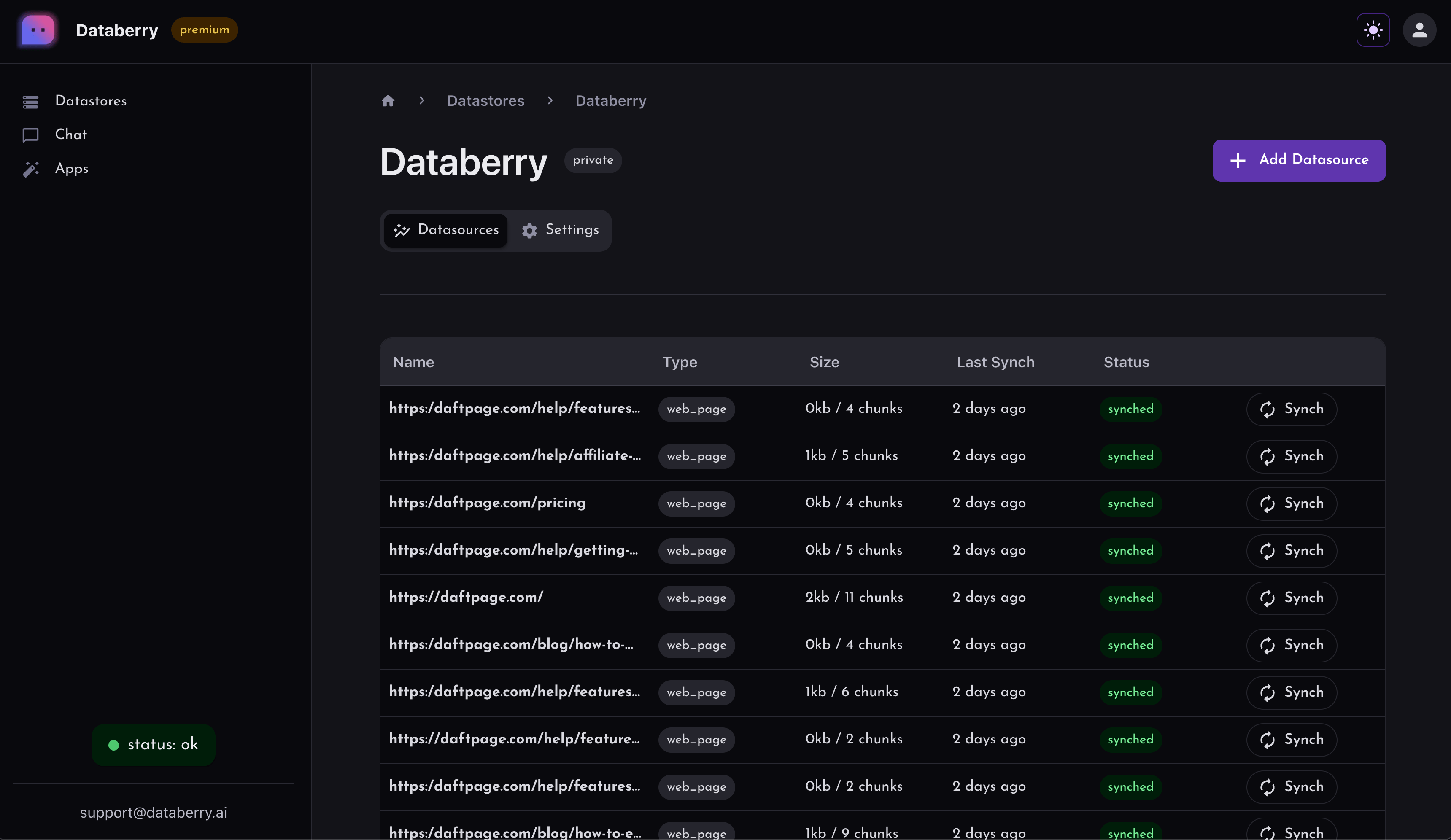
- langchain/docs/_static/DataberryDashboard.png +0 -0
- langchain/docs/_static/HeliconeDashboard.png +0 -0
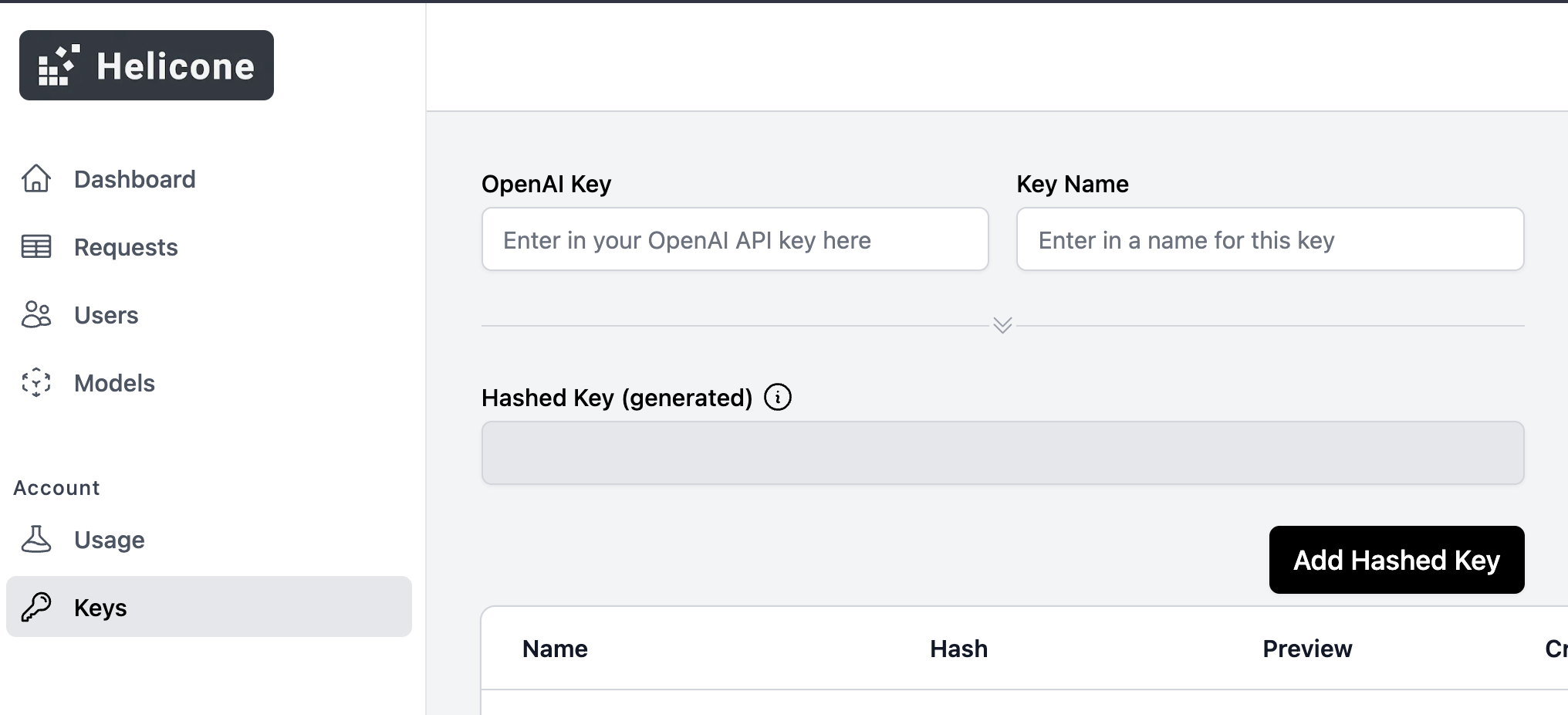
- langchain/docs/_static/HeliconeKeys.png +0 -0
- langchain/docs/_static/css/custom.css +17 -0
- langchain/docs/_static/js/mendablesearch.js +58 -0
- langchain/docs/conf.py +112 -0
- langchain/docs/deployments.md +62 -0
- langchain/docs/ecosystem.rst +29 -0
- langchain/docs/ecosystem/ai21.md +16 -0
- langchain/docs/ecosystem/aim_tracking.ipynb +291 -0
- langchain/docs/ecosystem/analyticdb.md +15 -0
- langchain/docs/ecosystem/anyscale.md +17 -0
- langchain/docs/ecosystem/apify.md +46 -0
- langchain/docs/ecosystem/atlas.md +27 -0
- langchain/docs/ecosystem/bananadev.md +79 -0
- langchain/docs/ecosystem/cerebriumai.md +17 -0
- langchain/docs/ecosystem/chroma.md +20 -0
- langchain/docs/ecosystem/clearml_tracking.ipynb +587 -0
- langchain/docs/ecosystem/cohere.md +25 -0
- langchain/docs/ecosystem/comet_tracking.ipynb +347 -0
- langchain/docs/ecosystem/databerry.md +25 -0
- langchain/docs/ecosystem/deepinfra.md +17 -0
- langchain/docs/ecosystem/deeplake.md +30 -0
- langchain/docs/ecosystem/forefrontai.md +16 -0
- langchain/docs/ecosystem/google_search.md +32 -0
- langchain/docs/ecosystem/google_serper.md +73 -0
- langchain/docs/ecosystem/gooseai.md +23 -0
- langchain/docs/ecosystem/gpt4all.md +48 -0
- langchain/docs/ecosystem/graphsignal.md +44 -0
- langchain/docs/ecosystem/hazy_research.md +19 -0
- langchain/docs/ecosystem/helicone.md +53 -0
- langchain/docs/ecosystem/huggingface.md +69 -0
- langchain/docs/ecosystem/jina.md +18 -0
- langchain/docs/ecosystem/lancedb.md +23 -0
- langchain/docs/ecosystem/llamacpp.md +26 -0
- langchain/docs/ecosystem/metal.md +26 -0
- langchain/docs/ecosystem/milvus.md +20 -0
- langchain/docs/ecosystem/mlflow_tracking.ipynb +172 -0
- langchain/docs/ecosystem/modal.md +66 -0
- langchain/docs/ecosystem/myscale.md +65 -0
- langchain/docs/ecosystem/nlpcloud.md +17 -0
- langchain/docs/ecosystem/openai.md +55 -0
app.py
CHANGED
|
@@ -2,7 +2,7 @@
|
|
| 2 |
# All credit goes to `vnk8071` as I mentioned in the video.
|
| 3 |
# As this code was still in the pull request while I was creating the video, did some modifications so that it works for me locally.
|
| 4 |
import os
|
| 5 |
-
os.system('pip install -e ./langchain')
|
| 6 |
import gradio as gr
|
| 7 |
from dotenv import load_dotenv
|
| 8 |
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
|
|
|
|
| 2 |
# All credit goes to `vnk8071` as I mentioned in the video.
|
| 3 |
# As this code was still in the pull request while I was creating the video, did some modifications so that it works for me locally.
|
| 4 |
import os
|
| 5 |
+
#os.system('pip install -e ./langchain')
|
| 6 |
import gradio as gr
|
| 7 |
from dotenv import load_dotenv
|
| 8 |
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
|
langchain/CITATION.cff
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cff-version: 1.2.0
|
| 2 |
+
message: "If you use this software, please cite it as below."
|
| 3 |
+
authors:
|
| 4 |
+
- family-names: "Chase"
|
| 5 |
+
given-names: "Harrison"
|
| 6 |
+
title: "LangChain"
|
| 7 |
+
date-released: 2022-10-17
|
| 8 |
+
url: "https://github.com/hwchase17/langchain"
|
langchain/Dockerfile
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This is a Dockerfile for running unit tests
|
| 2 |
+
|
| 3 |
+
ARG POETRY_HOME=/opt/poetry
|
| 4 |
+
|
| 5 |
+
# Use the Python base image
|
| 6 |
+
FROM python:3.11.2-bullseye AS builder
|
| 7 |
+
|
| 8 |
+
# Define the version of Poetry to install (default is 1.4.2)
|
| 9 |
+
ARG POETRY_VERSION=1.4.2
|
| 10 |
+
|
| 11 |
+
# Define the directory to install Poetry to (default is /opt/poetry)
|
| 12 |
+
ARG POETRY_HOME
|
| 13 |
+
|
| 14 |
+
# Create a Python virtual environment for Poetry and install it
|
| 15 |
+
RUN python3 -m venv ${POETRY_HOME} && \
|
| 16 |
+
$POETRY_HOME/bin/pip install --upgrade pip && \
|
| 17 |
+
$POETRY_HOME/bin/pip install poetry==${POETRY_VERSION}
|
| 18 |
+
|
| 19 |
+
# Test if Poetry is installed in the expected path
|
| 20 |
+
RUN echo "Poetry version:" && $POETRY_HOME/bin/poetry --version
|
| 21 |
+
|
| 22 |
+
# Set the working directory for the app
|
| 23 |
+
WORKDIR /app
|
| 24 |
+
|
| 25 |
+
# Use a multi-stage build to install dependencies
|
| 26 |
+
FROM builder AS dependencies
|
| 27 |
+
|
| 28 |
+
ARG POETRY_HOME
|
| 29 |
+
|
| 30 |
+
# Copy only the dependency files for installation
|
| 31 |
+
COPY pyproject.toml poetry.lock poetry.toml ./
|
| 32 |
+
|
| 33 |
+
# Install the Poetry dependencies (this layer will be cached as long as the dependencies don't change)
|
| 34 |
+
RUN $POETRY_HOME/bin/poetry install --no-interaction --no-ansi --with test
|
| 35 |
+
|
| 36 |
+
# Use a multi-stage build to run tests
|
| 37 |
+
FROM dependencies AS tests
|
| 38 |
+
|
| 39 |
+
# Copy the rest of the app source code (this layer will be invalidated and rebuilt whenever the source code changes)
|
| 40 |
+
COPY . .
|
| 41 |
+
|
| 42 |
+
RUN /opt/poetry/bin/poetry install --no-interaction --no-ansi --with test
|
| 43 |
+
|
| 44 |
+
# Set the entrypoint to run tests using Poetry
|
| 45 |
+
ENTRYPOINT ["/opt/poetry/bin/poetry", "run", "pytest"]
|
| 46 |
+
|
| 47 |
+
# Set the default command to run all unit tests
|
| 48 |
+
CMD ["tests/unit_tests"]
|
langchain/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) Harrison Chase
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in
|
| 13 |
+
all copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
| 21 |
+
THE SOFTWARE.
|
langchain/Makefile
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.PHONY: all clean format lint test tests test_watch integration_tests docker_tests help extended_tests
|
| 2 |
+
|
| 3 |
+
all: help
|
| 4 |
+
|
| 5 |
+
coverage:
|
| 6 |
+
poetry run pytest --cov \
|
| 7 |
+
--cov-config=.coveragerc \
|
| 8 |
+
--cov-report xml \
|
| 9 |
+
--cov-report term-missing:skip-covered
|
| 10 |
+
|
| 11 |
+
clean: docs_clean
|
| 12 |
+
|
| 13 |
+
docs_build:
|
| 14 |
+
cd docs && poetry run make html
|
| 15 |
+
|
| 16 |
+
docs_clean:
|
| 17 |
+
cd docs && poetry run make clean
|
| 18 |
+
|
| 19 |
+
docs_linkcheck:
|
| 20 |
+
poetry run linkchecker docs/_build/html/index.html
|
| 21 |
+
|
| 22 |
+
format:
|
| 23 |
+
poetry run black .
|
| 24 |
+
poetry run ruff --select I --fix .
|
| 25 |
+
|
| 26 |
+
PYTHON_FILES=.
|
| 27 |
+
lint: PYTHON_FILES=.
|
| 28 |
+
lint_diff: PYTHON_FILES=$(shell git diff --name-only --diff-filter=d master | grep -E '\.py$$')
|
| 29 |
+
|
| 30 |
+
lint lint_diff:
|
| 31 |
+
poetry run mypy $(PYTHON_FILES)
|
| 32 |
+
poetry run black $(PYTHON_FILES) --check
|
| 33 |
+
poetry run ruff .
|
| 34 |
+
|
| 35 |
+
TEST_FILE ?= tests/unit_tests/
|
| 36 |
+
|
| 37 |
+
test:
|
| 38 |
+
poetry run pytest $(TEST_FILE)
|
| 39 |
+
|
| 40 |
+
tests:
|
| 41 |
+
poetry run pytest $(TEST_FILE)
|
| 42 |
+
|
| 43 |
+
extended_tests:
|
| 44 |
+
poetry run pytest --only-extended tests/unit_tests
|
| 45 |
+
|
| 46 |
+
test_watch:
|
| 47 |
+
poetry run ptw --now . -- tests/unit_tests
|
| 48 |
+
|
| 49 |
+
integration_tests:
|
| 50 |
+
poetry run pytest tests/integration_tests
|
| 51 |
+
|
| 52 |
+
docker_tests:
|
| 53 |
+
docker build -t my-langchain-image:test .
|
| 54 |
+
docker run --rm my-langchain-image:test
|
| 55 |
+
|
| 56 |
+
help:
|
| 57 |
+
@echo '----'
|
| 58 |
+
@echo 'coverage - run unit tests and generate coverage report'
|
| 59 |
+
@echo 'docs_build - build the documentation'
|
| 60 |
+
@echo 'docs_clean - clean the documentation build artifacts'
|
| 61 |
+
@echo 'docs_linkcheck - run linkchecker on the documentation'
|
| 62 |
+
@echo 'format - run code formatters'
|
| 63 |
+
@echo 'lint - run linters'
|
| 64 |
+
@echo 'test - run unit tests'
|
| 65 |
+
@echo 'test - run unit tests'
|
| 66 |
+
@echo 'test TEST_FILE=<test_file> - run all tests in file'
|
| 67 |
+
@echo 'extended_tests - run only extended unit tests'
|
| 68 |
+
@echo 'test_watch - run unit tests in watch mode'
|
| 69 |
+
@echo 'integration_tests - run integration tests'
|
| 70 |
+
@echo 'docker_tests - run unit tests in docker'
|
langchain/README.md
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 🦜️🔗 LangChain
|
| 2 |
+
|
| 3 |
+
⚡ Building applications with LLMs through composability ⚡
|
| 4 |
+
|
| 5 |
+
[](https://github.com/hwchase17/langchain/actions/workflows/lint.yml)
|
| 6 |
+
[](https://github.com/hwchase17/langchain/actions/workflows/test.yml)
|
| 7 |
+
[](https://github.com/hwchase17/langchain/actions/workflows/linkcheck.yml)
|
| 8 |
+
[](https://pepy.tech/project/langchain)
|
| 9 |
+
[](https://opensource.org/licenses/MIT)
|
| 10 |
+
[](https://twitter.com/langchainai)
|
| 11 |
+
[](https://discord.gg/6adMQxSpJS)
|
| 12 |
+
[](https://vscode.dev/redirect?url=vscode://ms-vscode-remote.remote-containers/cloneInVolume?url=https://github.com/hwchase17/langchain)
|
| 13 |
+
[](https://codespaces.new/hwchase17/langchain)
|
| 14 |
+
[](https://star-history.com/#hwchase17/langchain)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
Looking for the JS/TS version? Check out [LangChain.js](https://github.com/hwchase17/langchainjs).
|
| 18 |
+
|
| 19 |
+
**Production Support:** As you move your LangChains into production, we'd love to offer more comprehensive support.
|
| 20 |
+
Please fill out [this form](https://forms.gle/57d8AmXBYp8PP8tZA) and we'll set up a dedicated support Slack channel.
|
| 21 |
+
|
| 22 |
+
## Quick Install
|
| 23 |
+
|
| 24 |
+
`pip install langchain`
|
| 25 |
+
or
|
| 26 |
+
`conda install langchain -c conda-forge`
|
| 27 |
+
|
| 28 |
+
## 🤔 What is this?
|
| 29 |
+
|
| 30 |
+
Large language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. However, using these LLMs in isolation is often insufficient for creating a truly powerful app - the real power comes when you can combine them with other sources of computation or knowledge.
|
| 31 |
+
|
| 32 |
+
This library aims to assist in the development of those types of applications. Common examples of these applications include:
|
| 33 |
+
|
| 34 |
+
**❓ Question Answering over specific documents**
|
| 35 |
+
|
| 36 |
+
- [Documentation](https://langchain.readthedocs.io/en/latest/use_cases/question_answering.html)
|
| 37 |
+
- End-to-end Example: [Question Answering over Notion Database](https://github.com/hwchase17/notion-qa)
|
| 38 |
+
|
| 39 |
+
**💬 Chatbots**
|
| 40 |
+
|
| 41 |
+
- [Documentation](https://langchain.readthedocs.io/en/latest/use_cases/chatbots.html)
|
| 42 |
+
- End-to-end Example: [Chat-LangChain](https://github.com/hwchase17/chat-langchain)
|
| 43 |
+
|
| 44 |
+
**🤖 Agents**
|
| 45 |
+
|
| 46 |
+
- [Documentation](https://langchain.readthedocs.io/en/latest/modules/agents.html)
|
| 47 |
+
- End-to-end Example: [GPT+WolframAlpha](https://huggingface.co/spaces/JavaFXpert/Chat-GPT-LangChain)
|
| 48 |
+
|
| 49 |
+
## 📖 Documentation
|
| 50 |
+
|
| 51 |
+
Please see [here](https://langchain.readthedocs.io/en/latest/?) for full documentation on:
|
| 52 |
+
|
| 53 |
+
- Getting started (installation, setting up the environment, simple examples)
|
| 54 |
+
- How-To examples (demos, integrations, helper functions)
|
| 55 |
+
- Reference (full API docs)
|
| 56 |
+
- Resources (high-level explanation of core concepts)
|
| 57 |
+
|
| 58 |
+
## 🚀 What can this help with?
|
| 59 |
+
|
| 60 |
+
There are six main areas that LangChain is designed to help with.
|
| 61 |
+
These are, in increasing order of complexity:
|
| 62 |
+
|
| 63 |
+
**📃 LLMs and Prompts:**
|
| 64 |
+
|
| 65 |
+
This includes prompt management, prompt optimization, a generic interface for all LLMs, and common utilities for working with LLMs.
|
| 66 |
+
|
| 67 |
+
**🔗 Chains:**
|
| 68 |
+
|
| 69 |
+
Chains go beyond a single LLM call and involve sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.
|
| 70 |
+
|
| 71 |
+
**📚 Data Augmented Generation:**
|
| 72 |
+
|
| 73 |
+
Data Augmented Generation involves specific types of chains that first interact with an external data source to fetch data for use in the generation step. Examples include summarization of long pieces of text and question/answering over specific data sources.
|
| 74 |
+
|
| 75 |
+
**🤖 Agents:**
|
| 76 |
+
|
| 77 |
+
Agents involve an LLM making decisions about which Actions to take, taking that Action, seeing an Observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end-to-end agents.
|
| 78 |
+
|
| 79 |
+
**🧠 Memory:**
|
| 80 |
+
|
| 81 |
+
Memory refers to persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.
|
| 82 |
+
|
| 83 |
+
**🧐 Evaluation:**
|
| 84 |
+
|
| 85 |
+
[BETA] Generative models are notoriously hard to evaluate with traditional metrics. One new way of evaluating them is using language models themselves to do the evaluation. LangChain provides some prompts/chains for assisting in this.
|
| 86 |
+
|
| 87 |
+
For more information on these concepts, please see our [full documentation](https://langchain.readthedocs.io/en/latest/).
|
| 88 |
+
|
| 89 |
+
## 💁 Contributing
|
| 90 |
+
|
| 91 |
+
As an open-source project in a rapidly developing field, we are extremely open to contributions, whether it be in the form of a new feature, improved infrastructure, or better documentation.
|
| 92 |
+
|
| 93 |
+
For detailed information on how to contribute, see [here](.github/CONTRIBUTING.md).
|
langchain/docs/Makefile
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Minimal makefile for Sphinx documentation
|
| 2 |
+
#
|
| 3 |
+
|
| 4 |
+
# You can set these variables from the command line, and also
|
| 5 |
+
# from the environment for the first two.
|
| 6 |
+
SPHINXOPTS ?=
|
| 7 |
+
SPHINXBUILD ?= sphinx-build
|
| 8 |
+
SPHINXAUTOBUILD ?= sphinx-autobuild
|
| 9 |
+
SOURCEDIR = .
|
| 10 |
+
BUILDDIR = _build
|
| 11 |
+
|
| 12 |
+
# Put it first so that "make" without argument is like "make help".
|
| 13 |
+
help:
|
| 14 |
+
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
| 15 |
+
|
| 16 |
+
.PHONY: help Makefile
|
| 17 |
+
|
| 18 |
+
# Catch-all target: route all unknown targets to Sphinx using the new
|
| 19 |
+
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
| 20 |
+
%: Makefile
|
| 21 |
+
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
langchain/docs/_static/ApifyActors.png
ADDED
|
langchain/docs/_static/DataberryDashboard.png
ADDED
|
langchain/docs/_static/HeliconeDashboard.png
ADDED

|
langchain/docs/_static/HeliconeKeys.png
ADDED
|
langchain/docs/_static/css/custom.css
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pre {
|
| 2 |
+
white-space: break-spaces;
|
| 3 |
+
}
|
| 4 |
+
|
| 5 |
+
@media (min-width: 1200px) {
|
| 6 |
+
.container,
|
| 7 |
+
.container-lg,
|
| 8 |
+
.container-md,
|
| 9 |
+
.container-sm,
|
| 10 |
+
.container-xl {
|
| 11 |
+
max-width: 2560px !important;
|
| 12 |
+
}
|
| 13 |
+
}
|
| 14 |
+
|
| 15 |
+
#my-component-root *, #headlessui-portal-root * {
|
| 16 |
+
z-index: 1000000000000;
|
| 17 |
+
}
|
langchain/docs/_static/js/mendablesearch.js
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
document.addEventListener('DOMContentLoaded', () => {
|
| 2 |
+
// Load the external dependencies
|
| 3 |
+
function loadScript(src, onLoadCallback) {
|
| 4 |
+
const script = document.createElement('script');
|
| 5 |
+
script.src = src;
|
| 6 |
+
script.onload = onLoadCallback;
|
| 7 |
+
document.head.appendChild(script);
|
| 8 |
+
}
|
| 9 |
+
|
| 10 |
+
function createRootElement() {
|
| 11 |
+
const rootElement = document.createElement('div');
|
| 12 |
+
rootElement.id = 'my-component-root';
|
| 13 |
+
document.body.appendChild(rootElement);
|
| 14 |
+
return rootElement;
|
| 15 |
+
}
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
function initializeMendable() {
|
| 20 |
+
const rootElement = createRootElement();
|
| 21 |
+
const { MendableFloatingButton } = Mendable;
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
const iconSpan1 = React.createElement('span', {
|
| 25 |
+
}, '🦜');
|
| 26 |
+
|
| 27 |
+
const iconSpan2 = React.createElement('span', {
|
| 28 |
+
}, '🔗');
|
| 29 |
+
|
| 30 |
+
const icon = React.createElement('p', {
|
| 31 |
+
style: { color: '#ffffff', fontSize: '22px',width: '48px', height: '48px', margin: '0px', padding: '0px', display: 'flex', alignItems: 'center', justifyContent: 'center', textAlign: 'center' },
|
| 32 |
+
}, [iconSpan1, iconSpan2]);
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
const mendableFloatingButton = React.createElement(
|
| 38 |
+
MendableFloatingButton,
|
| 39 |
+
{
|
| 40 |
+
style: { darkMode: false, accentColor: '#010810' },
|
| 41 |
+
floatingButtonStyle: { color: '#ffffff', backgroundColor: '#010810' },
|
| 42 |
+
anon_key: '82842b36-3ea6-49b2-9fb8-52cfc4bde6bf', // Mendable Search Public ANON key, ok to be public
|
| 43 |
+
messageSettings: {
|
| 44 |
+
openSourcesInNewTab: false,
|
| 45 |
+
},
|
| 46 |
+
icon: icon,
|
| 47 |
+
}
|
| 48 |
+
);
|
| 49 |
+
|
| 50 |
+
ReactDOM.render(mendableFloatingButton, rootElement);
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
loadScript('https://unpkg.com/react@17/umd/react.production.min.js', () => {
|
| 54 |
+
loadScript('https://unpkg.com/react-dom@17/umd/react-dom.production.min.js', () => {
|
| 55 |
+
loadScript('https://unpkg.com/@mendable/[email protected]/dist/umd/mendable.min.js', initializeMendable);
|
| 56 |
+
});
|
| 57 |
+
});
|
| 58 |
+
});
|
langchain/docs/conf.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Configuration file for the Sphinx documentation builder."""
|
| 2 |
+
# Configuration file for the Sphinx documentation builder.
|
| 3 |
+
#
|
| 4 |
+
# This file only contains a selection of the most common options. For a full
|
| 5 |
+
# list see the documentation:
|
| 6 |
+
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
| 7 |
+
|
| 8 |
+
# -- Path setup --------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
# If extensions (or modules to document with autodoc) are in another directory,
|
| 11 |
+
# add these directories to sys.path here. If the directory is relative to the
|
| 12 |
+
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
| 13 |
+
#
|
| 14 |
+
# import os
|
| 15 |
+
# import sys
|
| 16 |
+
# sys.path.insert(0, os.path.abspath('.'))
|
| 17 |
+
|
| 18 |
+
import toml
|
| 19 |
+
|
| 20 |
+
with open("../pyproject.toml") as f:
|
| 21 |
+
data = toml.load(f)
|
| 22 |
+
|
| 23 |
+
# -- Project information -----------------------------------------------------
|
| 24 |
+
|
| 25 |
+
project = "🦜🔗 LangChain"
|
| 26 |
+
copyright = "2023, Harrison Chase"
|
| 27 |
+
author = "Harrison Chase"
|
| 28 |
+
|
| 29 |
+
version = data["tool"]["poetry"]["version"]
|
| 30 |
+
release = version
|
| 31 |
+
|
| 32 |
+
html_title = project + " " + version
|
| 33 |
+
html_last_updated_fmt = "%b %d, %Y"
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# -- General configuration ---------------------------------------------------
|
| 37 |
+
|
| 38 |
+
# Add any Sphinx extension module names here, as strings. They can be
|
| 39 |
+
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
| 40 |
+
# ones.
|
| 41 |
+
extensions = [
|
| 42 |
+
"sphinx.ext.autodoc",
|
| 43 |
+
"sphinx.ext.autodoc.typehints",
|
| 44 |
+
"sphinx.ext.autosummary",
|
| 45 |
+
"sphinx.ext.napoleon",
|
| 46 |
+
"sphinx.ext.viewcode",
|
| 47 |
+
"sphinxcontrib.autodoc_pydantic",
|
| 48 |
+
"myst_nb",
|
| 49 |
+
"sphinx_copybutton",
|
| 50 |
+
"sphinx_panels",
|
| 51 |
+
"IPython.sphinxext.ipython_console_highlighting",
|
| 52 |
+
]
|
| 53 |
+
source_suffix = [".ipynb", ".html", ".md", ".rst"]
|
| 54 |
+
|
| 55 |
+
autodoc_pydantic_model_show_json = False
|
| 56 |
+
autodoc_pydantic_field_list_validators = False
|
| 57 |
+
autodoc_pydantic_config_members = False
|
| 58 |
+
autodoc_pydantic_model_show_config_summary = False
|
| 59 |
+
autodoc_pydantic_model_show_validator_members = False
|
| 60 |
+
autodoc_pydantic_model_show_field_summary = False
|
| 61 |
+
autodoc_pydantic_model_members = False
|
| 62 |
+
autodoc_pydantic_model_undoc_members = False
|
| 63 |
+
# autodoc_typehints = "signature"
|
| 64 |
+
# autodoc_typehints = "description"
|
| 65 |
+
|
| 66 |
+
# Add any paths that contain templates here, relative to this directory.
|
| 67 |
+
templates_path = ["_templates"]
|
| 68 |
+
|
| 69 |
+
# List of patterns, relative to source directory, that match files and
|
| 70 |
+
# directories to ignore when looking for source files.
|
| 71 |
+
# This pattern also affects html_static_path and html_extra_path.
|
| 72 |
+
exclude_patterns = ["_build", "Thumbs.db", ".DS_Store"]
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# -- Options for HTML output -------------------------------------------------
|
| 76 |
+
|
| 77 |
+
# The theme to use for HTML and HTML Help pages. See the documentation for
|
| 78 |
+
# a list of builtin themes.
|
| 79 |
+
#
|
| 80 |
+
html_theme = "sphinx_book_theme"
|
| 81 |
+
|
| 82 |
+
html_theme_options = {
|
| 83 |
+
"path_to_docs": "docs",
|
| 84 |
+
"repository_url": "https://github.com/hwchase17/langchain",
|
| 85 |
+
"use_repository_button": True,
|
| 86 |
+
}
|
| 87 |
+
|
| 88 |
+
html_context = {
|
| 89 |
+
"display_github": True, # Integrate GitHub
|
| 90 |
+
"github_user": "hwchase17", # Username
|
| 91 |
+
"github_repo": "langchain", # Repo name
|
| 92 |
+
"github_version": "master", # Version
|
| 93 |
+
"conf_py_path": "/docs/", # Path in the checkout to the docs root
|
| 94 |
+
}
|
| 95 |
+
|
| 96 |
+
# Add any paths that contain custom static files (such as style sheets) here,
|
| 97 |
+
# relative to this directory. They are copied after the builtin static files,
|
| 98 |
+
# so a file named "default.css" will overwrite the builtin "default.css".
|
| 99 |
+
html_static_path = ["_static"]
|
| 100 |
+
|
| 101 |
+
# These paths are either relative to html_static_path
|
| 102 |
+
# or fully qualified paths (eg. https://...)
|
| 103 |
+
html_css_files = [
|
| 104 |
+
"css/custom.css",
|
| 105 |
+
]
|
| 106 |
+
|
| 107 |
+
html_js_files = [
|
| 108 |
+
"js/mendablesearch.js",
|
| 109 |
+
]
|
| 110 |
+
|
| 111 |
+
nb_execution_mode = "off"
|
| 112 |
+
myst_enable_extensions = ["colon_fence"]
|
langchain/docs/deployments.md
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Deployments
|
| 2 |
+
|
| 3 |
+
So, you've created a really cool chain - now what? How do you deploy it and make it easily shareable with the world?
|
| 4 |
+
|
| 5 |
+
This section covers several options for that. Note that these options are meant for quick deployment of prototypes and demos, not for production systems. If you need help with the deployment of a production system, please contact us directly.
|
| 6 |
+
|
| 7 |
+
What follows is a list of template GitHub repositories designed to be easily forked and modified to use your chain. This list is far from exhaustive, and we are EXTREMELY open to contributions here.
|
| 8 |
+
|
| 9 |
+
## [Streamlit](https://github.com/hwchase17/langchain-streamlit-template)
|
| 10 |
+
|
| 11 |
+
This repo serves as a template for how to deploy a LangChain with Streamlit.
|
| 12 |
+
It implements a chatbot interface.
|
| 13 |
+
It also contains instructions for how to deploy this app on the Streamlit platform.
|
| 14 |
+
|
| 15 |
+
## [Gradio (on Hugging Face)](https://github.com/hwchase17/langchain-gradio-template)
|
| 16 |
+
|
| 17 |
+
This repo serves as a template for how deploy a LangChain with Gradio.
|
| 18 |
+
It implements a chatbot interface, with a "Bring-Your-Own-Token" approach (nice for not wracking up big bills).
|
| 19 |
+
It also contains instructions for how to deploy this app on the Hugging Face platform.
|
| 20 |
+
This is heavily influenced by James Weaver's [excellent examples](https://huggingface.co/JavaFXpert).
|
| 21 |
+
|
| 22 |
+
## [Beam](https://github.com/slai-labs/get-beam/tree/main/examples/langchain-question-answering)
|
| 23 |
+
|
| 24 |
+
This repo serves as a template for how deploy a LangChain with [Beam](https://beam.cloud).
|
| 25 |
+
|
| 26 |
+
It implements a Question Answering app and contains instructions for deploying the app as a serverless REST API.
|
| 27 |
+
|
| 28 |
+
## [Vercel](https://github.com/homanp/vercel-langchain)
|
| 29 |
+
|
| 30 |
+
A minimal example on how to run LangChain on Vercel using Flask.
|
| 31 |
+
|
| 32 |
+
## [Kinsta](https://github.com/kinsta/hello-world-langchain)
|
| 33 |
+
|
| 34 |
+
A minimal example on how to deploy LangChain to [Kinsta](https://kinsta.com) using Flask.
|
| 35 |
+
|
| 36 |
+
## [Fly.io](https://github.com/fly-apps/hello-fly-langchain)
|
| 37 |
+
|
| 38 |
+
A minimal example of how to deploy LangChain to [Fly.io](https://fly.io/) using Flask.
|
| 39 |
+
|
| 40 |
+
## [Digitalocean App Platform](https://github.com/homanp/digitalocean-langchain)
|
| 41 |
+
|
| 42 |
+
A minimal example on how to deploy LangChain to DigitalOcean App Platform.
|
| 43 |
+
|
| 44 |
+
## [Google Cloud Run](https://github.com/homanp/gcp-langchain)
|
| 45 |
+
|
| 46 |
+
A minimal example on how to deploy LangChain to Google Cloud Run.
|
| 47 |
+
|
| 48 |
+
## [SteamShip](https://github.com/steamship-core/steamship-langchain/)
|
| 49 |
+
|
| 50 |
+
This repository contains LangChain adapters for Steamship, enabling LangChain developers to rapidly deploy their apps on Steamship. This includes: production-ready endpoints, horizontal scaling across dependencies, persistent storage of app state, multi-tenancy support, etc.
|
| 51 |
+
|
| 52 |
+
## [Langchain-serve](https://github.com/jina-ai/langchain-serve)
|
| 53 |
+
|
| 54 |
+
This repository allows users to serve local chains and agents as RESTful, gRPC, or WebSocket APIs, thanks to [Jina](https://docs.jina.ai/). Deploy your chains & agents with ease and enjoy independent scaling, serverless and autoscaling APIs, as well as a Streamlit playground on Jina AI Cloud.
|
| 55 |
+
|
| 56 |
+
## [BentoML](https://github.com/ssheng/BentoChain)
|
| 57 |
+
|
| 58 |
+
This repository provides an example of how to deploy a LangChain application with [BentoML](https://github.com/bentoml/BentoML). BentoML is a framework that enables the containerization of machine learning applications as standard OCI images. BentoML also allows for the automatic generation of OpenAPI and gRPC endpoints. With BentoML, you can integrate models from all popular ML frameworks and deploy them as microservices running on the most optimal hardware and scaling independently.
|
| 59 |
+
|
| 60 |
+
## [Databutton](https://databutton.com/home?new-data-app=true)
|
| 61 |
+
|
| 62 |
+
These templates serve as examples of how to build, deploy, and share LangChain applications using Databutton. You can create user interfaces with Streamlit, automate tasks by scheduling Python code, and store files and data in the built-in store. Examples include a Chatbot interface with conversational memory, a Personal search engine, and a starter template for LangChain apps. Deploying and sharing is just one click away.
|
langchain/docs/ecosystem.rst
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
LangChain Ecosystem
|
| 2 |
+
===================
|
| 3 |
+
|
| 4 |
+
Guides for how other companies/products can be used with LangChain
|
| 5 |
+
|
| 6 |
+
Groups
|
| 7 |
+
----------
|
| 8 |
+
|
| 9 |
+
LangChain provides integration with many LLMs and systems:
|
| 10 |
+
|
| 11 |
+
- `LLM Providers <./modules/models/llms/integrations.html>`_
|
| 12 |
+
- `Chat Model Providers <./modules/models/chat/integrations.html>`_
|
| 13 |
+
- `Text Embedding Model Providers <./modules/models/text_embedding.html>`_
|
| 14 |
+
- `Document Loader Integrations <./modules/indexes/document_loaders.html>`_
|
| 15 |
+
- `Text Splitter Integrations <./modules/indexes/text_splitters.html>`_
|
| 16 |
+
- `Vectorstore Providers <./modules/indexes/vectorstores.html>`_
|
| 17 |
+
- `Retriever Providers <./modules/indexes/retrievers.html>`_
|
| 18 |
+
- `Tool Providers <./modules/agents/tools.html>`_
|
| 19 |
+
- `Toolkit Integrations <./modules/agents/toolkits.html>`_
|
| 20 |
+
|
| 21 |
+
Companies / Products
|
| 22 |
+
----------
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
.. toctree::
|
| 26 |
+
:maxdepth: 1
|
| 27 |
+
:glob:
|
| 28 |
+
|
| 29 |
+
ecosystem/*
|
langchain/docs/ecosystem/ai21.md
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# AI21 Labs
|
| 2 |
+
|
| 3 |
+
This page covers how to use the AI21 ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific AI21 wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Get an AI21 api key and set it as an environment variable (`AI21_API_KEY`)
|
| 8 |
+
|
| 9 |
+
## Wrappers
|
| 10 |
+
|
| 11 |
+
### LLM
|
| 12 |
+
|
| 13 |
+
There exists an AI21 LLM wrapper, which you can access with
|
| 14 |
+
```python
|
| 15 |
+
from langchain.llms import AI21
|
| 16 |
+
```
|
langchain/docs/ecosystem/aim_tracking.ipynb
ADDED
|
@@ -0,0 +1,291 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"# Aim\n",
|
| 8 |
+
"\n",
|
| 9 |
+
"Aim makes it super easy to visualize and debug LangChain executions. Aim tracks inputs and outputs of LLMs and tools, as well as actions of agents. \n",
|
| 10 |
+
"\n",
|
| 11 |
+
"With Aim, you can easily debug and examine an individual execution:\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"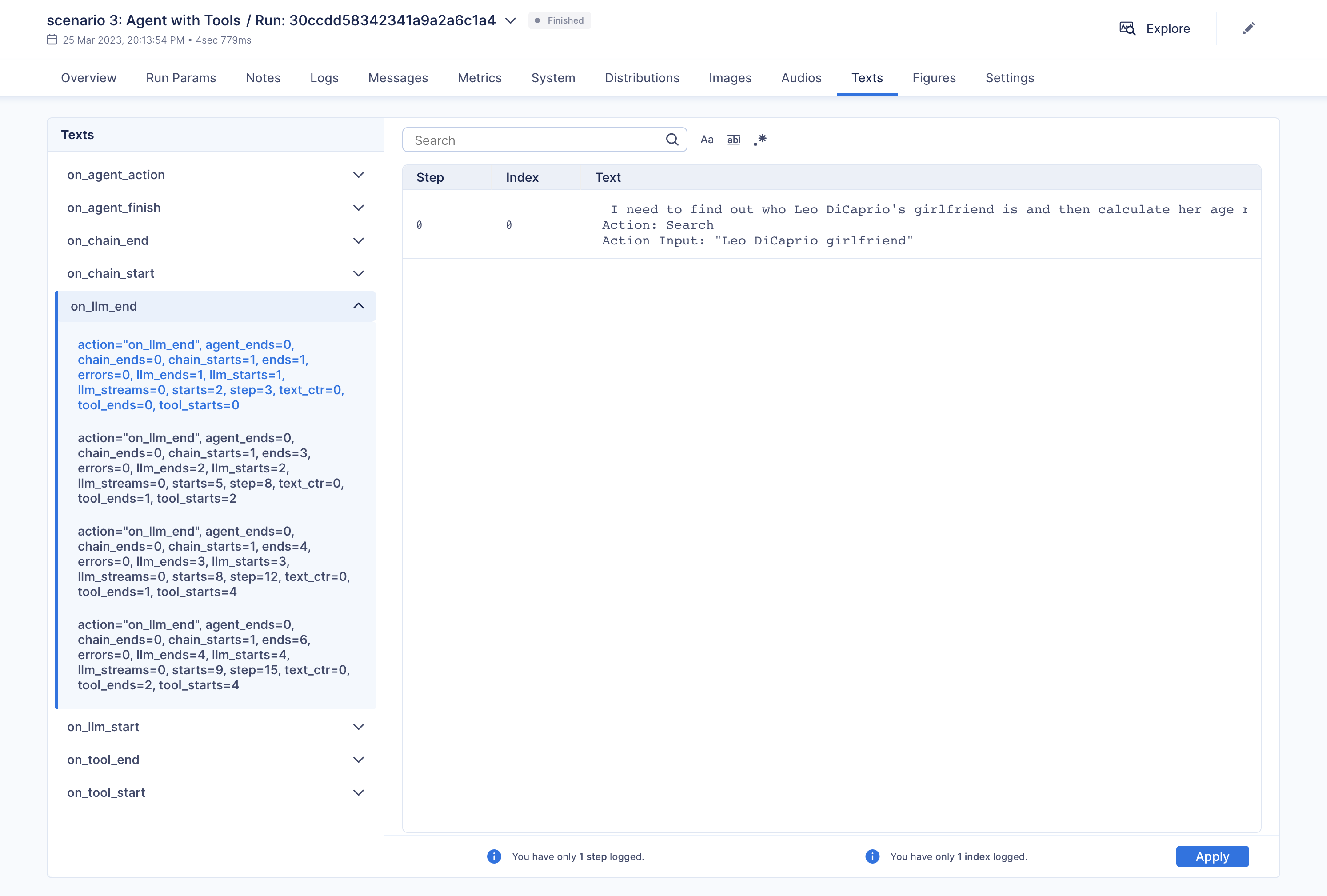\n",
|
| 14 |
+
"\n",
|
| 15 |
+
"Additionally, you have the option to compare multiple executions side by side:\n",
|
| 16 |
+
"\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"\n",
|
| 19 |
+
"Aim is fully open source, [learn more](https://github.com/aimhubio/aim) about Aim on GitHub.\n",
|
| 20 |
+
"\n",
|
| 21 |
+
"Let's move forward and see how to enable and configure Aim callback."
|
| 22 |
+
]
|
| 23 |
+
},
|
| 24 |
+
{
|
| 25 |
+
"cell_type": "markdown",
|
| 26 |
+
"metadata": {},
|
| 27 |
+
"source": [
|
| 28 |
+
"<h3>Tracking LangChain Executions with Aim</h3>"
|
| 29 |
+
]
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
"cell_type": "markdown",
|
| 33 |
+
"metadata": {},
|
| 34 |
+
"source": [
|
| 35 |
+
"In this notebook we will explore three usage scenarios. To start off, we will install the necessary packages and import certain modules. Subsequently, we will configure two environment variables that can be established either within the Python script or through the terminal."
|
| 36 |
+
]
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"cell_type": "code",
|
| 40 |
+
"execution_count": null,
|
| 41 |
+
"metadata": {
|
| 42 |
+
"id": "mf88kuCJhbVu"
|
| 43 |
+
},
|
| 44 |
+
"outputs": [],
|
| 45 |
+
"source": [
|
| 46 |
+
"!pip install aim\n",
|
| 47 |
+
"!pip install langchain\n",
|
| 48 |
+
"!pip install openai\n",
|
| 49 |
+
"!pip install google-search-results"
|
| 50 |
+
]
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"cell_type": "code",
|
| 54 |
+
"execution_count": null,
|
| 55 |
+
"metadata": {
|
| 56 |
+
"id": "g4eTuajwfl6L"
|
| 57 |
+
},
|
| 58 |
+
"outputs": [],
|
| 59 |
+
"source": [
|
| 60 |
+
"import os\n",
|
| 61 |
+
"from datetime import datetime\n",
|
| 62 |
+
"\n",
|
| 63 |
+
"from langchain.llms import OpenAI\n",
|
| 64 |
+
"from langchain.callbacks import AimCallbackHandler, StdOutCallbackHandler"
|
| 65 |
+
]
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"cell_type": "markdown",
|
| 69 |
+
"metadata": {},
|
| 70 |
+
"source": [
|
| 71 |
+
"Our examples use a GPT model as the LLM, and OpenAI offers an API for this purpose. You can obtain the key from the following link: https://platform.openai.com/account/api-keys .\n",
|
| 72 |
+
"\n",
|
| 73 |
+
"We will use the SerpApi to retrieve search results from Google. To acquire the SerpApi key, please go to https://serpapi.com/manage-api-key ."
|
| 74 |
+
]
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"cell_type": "code",
|
| 78 |
+
"execution_count": null,
|
| 79 |
+
"metadata": {
|
| 80 |
+
"id": "T1bSmKd6V2If"
|
| 81 |
+
},
|
| 82 |
+
"outputs": [],
|
| 83 |
+
"source": [
|
| 84 |
+
"os.environ[\"OPENAI_API_KEY\"] = \"...\"\n",
|
| 85 |
+
"os.environ[\"SERPAPI_API_KEY\"] = \"...\""
|
| 86 |
+
]
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"cell_type": "markdown",
|
| 90 |
+
"metadata": {
|
| 91 |
+
"id": "QenUYuBZjIzc"
|
| 92 |
+
},
|
| 93 |
+
"source": [
|
| 94 |
+
"The event methods of `AimCallbackHandler` accept the LangChain module or agent as input and log at least the prompts and generated results, as well as the serialized version of the LangChain module, to the designated Aim run."
|
| 95 |
+
]
|
| 96 |
+
},
|
| 97 |
+
{
|
| 98 |
+
"cell_type": "code",
|
| 99 |
+
"execution_count": null,
|
| 100 |
+
"metadata": {
|
| 101 |
+
"id": "KAz8weWuUeXF"
|
| 102 |
+
},
|
| 103 |
+
"outputs": [],
|
| 104 |
+
"source": [
|
| 105 |
+
"session_group = datetime.now().strftime(\"%m.%d.%Y_%H.%M.%S\")\n",
|
| 106 |
+
"aim_callback = AimCallbackHandler(\n",
|
| 107 |
+
" repo=\".\",\n",
|
| 108 |
+
" experiment_name=\"scenario 1: OpenAI LLM\",\n",
|
| 109 |
+
")\n",
|
| 110 |
+
"\n",
|
| 111 |
+
"callbacks = [StdOutCallbackHandler(), aim_callback]\n",
|
| 112 |
+
"llm = OpenAI(temperature=0, callbacks=callbacks)"
|
| 113 |
+
]
|
| 114 |
+
},
|
| 115 |
+
{
|
| 116 |
+
"cell_type": "markdown",
|
| 117 |
+
"metadata": {
|
| 118 |
+
"id": "b8WfByB4fl6N"
|
| 119 |
+
},
|
| 120 |
+
"source": [
|
| 121 |
+
"The `flush_tracker` function is used to record LangChain assets on Aim. By default, the session is reset rather than being terminated outright."
|
| 122 |
+
]
|
| 123 |
+
},
|
| 124 |
+
{
|
| 125 |
+
"cell_type": "markdown",
|
| 126 |
+
"metadata": {},
|
| 127 |
+
"source": [
|
| 128 |
+
"<h3>Scenario 1</h3> In the first scenario, we will use OpenAI LLM."
|
| 129 |
+
]
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"cell_type": "code",
|
| 133 |
+
"execution_count": null,
|
| 134 |
+
"metadata": {
|
| 135 |
+
"id": "o_VmneyIUyx8"
|
| 136 |
+
},
|
| 137 |
+
"outputs": [],
|
| 138 |
+
"source": [
|
| 139 |
+
"# scenario 1 - LLM\n",
|
| 140 |
+
"llm_result = llm.generate([\"Tell me a joke\", \"Tell me a poem\"] * 3)\n",
|
| 141 |
+
"aim_callback.flush_tracker(\n",
|
| 142 |
+
" langchain_asset=llm,\n",
|
| 143 |
+
" experiment_name=\"scenario 2: Chain with multiple SubChains on multiple generations\",\n",
|
| 144 |
+
")\n"
|
| 145 |
+
]
|
| 146 |
+
},
|
| 147 |
+
{
|
| 148 |
+
"cell_type": "markdown",
|
| 149 |
+
"metadata": {},
|
| 150 |
+
"source": [
|
| 151 |
+
"<h3>Scenario 2</h3> Scenario two involves chaining with multiple SubChains across multiple generations."
|
| 152 |
+
]
|
| 153 |
+
},
|
| 154 |
+
{
|
| 155 |
+
"cell_type": "code",
|
| 156 |
+
"execution_count": null,
|
| 157 |
+
"metadata": {
|
| 158 |
+
"id": "trxslyb1U28Y"
|
| 159 |
+
},
|
| 160 |
+
"outputs": [],
|
| 161 |
+
"source": [
|
| 162 |
+
"from langchain.prompts import PromptTemplate\n",
|
| 163 |
+
"from langchain.chains import LLMChain"
|
| 164 |
+
]
|
| 165 |
+
},
|
| 166 |
+
{
|
| 167 |
+
"cell_type": "code",
|
| 168 |
+
"execution_count": null,
|
| 169 |
+
"metadata": {
|
| 170 |
+
"id": "uauQk10SUzF6"
|
| 171 |
+
},
|
| 172 |
+
"outputs": [],
|
| 173 |
+
"source": [
|
| 174 |
+
"# scenario 2 - Chain\n",
|
| 175 |
+
"template = \"\"\"You are a playwright. Given the title of play, it is your job to write a synopsis for that title.\n",
|
| 176 |
+
"Title: {title}\n",
|
| 177 |
+
"Playwright: This is a synopsis for the above play:\"\"\"\n",
|
| 178 |
+
"prompt_template = PromptTemplate(input_variables=[\"title\"], template=template)\n",
|
| 179 |
+
"synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, callbacks=callbacks)\n",
|
| 180 |
+
"\n",
|
| 181 |
+
"test_prompts = [\n",
|
| 182 |
+
" {\"title\": \"documentary about good video games that push the boundary of game design\"},\n",
|
| 183 |
+
" {\"title\": \"the phenomenon behind the remarkable speed of cheetahs\"},\n",
|
| 184 |
+
" {\"title\": \"the best in class mlops tooling\"},\n",
|
| 185 |
+
"]\n",
|
| 186 |
+
"synopsis_chain.apply(test_prompts)\n",
|
| 187 |
+
"aim_callback.flush_tracker(\n",
|
| 188 |
+
" langchain_asset=synopsis_chain, experiment_name=\"scenario 3: Agent with Tools\"\n",
|
| 189 |
+
")"
|
| 190 |
+
]
|
| 191 |
+
},
|
| 192 |
+
{
|
| 193 |
+
"cell_type": "markdown",
|
| 194 |
+
"metadata": {},
|
| 195 |
+
"source": [
|
| 196 |
+
"<h3>Scenario 3</h3> The third scenario involves an agent with tools."
|
| 197 |
+
]
|
| 198 |
+
},
|
| 199 |
+
{
|
| 200 |
+
"cell_type": "code",
|
| 201 |
+
"execution_count": null,
|
| 202 |
+
"metadata": {
|
| 203 |
+
"id": "_jN73xcPVEpI"
|
| 204 |
+
},
|
| 205 |
+
"outputs": [],
|
| 206 |
+
"source": [
|
| 207 |
+
"from langchain.agents import initialize_agent, load_tools\n",
|
| 208 |
+
"from langchain.agents import AgentType"
|
| 209 |
+
]
|
| 210 |
+
},
|
| 211 |
+
{
|
| 212 |
+
"cell_type": "code",
|
| 213 |
+
"execution_count": null,
|
| 214 |
+
"metadata": {
|
| 215 |
+
"colab": {
|
| 216 |
+
"base_uri": "https://localhost:8080/"
|
| 217 |
+
},
|
| 218 |
+
"id": "Gpq4rk6VT9cu",
|
| 219 |
+
"outputId": "68ae261e-d0a2-4229-83c4-762562263b66"
|
| 220 |
+
},
|
| 221 |
+
"outputs": [
|
| 222 |
+
{
|
| 223 |
+
"name": "stdout",
|
| 224 |
+
"output_type": "stream",
|
| 225 |
+
"text": [
|
| 226 |
+
"\n",
|
| 227 |
+
"\n",
|
| 228 |
+
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
| 229 |
+
"\u001b[32;1m\u001b[1;3m I need to find out who Leo DiCaprio's girlfriend is and then calculate her age raised to the 0.43 power.\n",
|
| 230 |
+
"Action: Search\n",
|
| 231 |
+
"Action Input: \"Leo DiCaprio girlfriend\"\u001b[0m\n",
|
| 232 |
+
"Observation: \u001b[36;1m\u001b[1;3mLeonardo DiCaprio seemed to prove a long-held theory about his love life right after splitting from girlfriend Camila Morrone just months ...\u001b[0m\n",
|
| 233 |
+
"Thought:\u001b[32;1m\u001b[1;3m I need to find out Camila Morrone's age\n",
|
| 234 |
+
"Action: Search\n",
|
| 235 |
+
"Action Input: \"Camila Morrone age\"\u001b[0m\n",
|
| 236 |
+
"Observation: \u001b[36;1m\u001b[1;3m25 years\u001b[0m\n",
|
| 237 |
+
"Thought:\u001b[32;1m\u001b[1;3m I need to calculate 25 raised to the 0.43 power\n",
|
| 238 |
+
"Action: Calculator\n",
|
| 239 |
+
"Action Input: 25^0.43\u001b[0m\n",
|
| 240 |
+
"Observation: \u001b[33;1m\u001b[1;3mAnswer: 3.991298452658078\n",
|
| 241 |
+
"\u001b[0m\n",
|
| 242 |
+
"Thought:\u001b[32;1m\u001b[1;3m I now know the final answer\n",
|
| 243 |
+
"Final Answer: Camila Morrone is Leo DiCaprio's girlfriend and her current age raised to the 0.43 power is 3.991298452658078.\u001b[0m\n",
|
| 244 |
+
"\n",
|
| 245 |
+
"\u001b[1m> Finished chain.\u001b[0m\n"
|
| 246 |
+
]
|
| 247 |
+
}
|
| 248 |
+
],
|
| 249 |
+
"source": [
|
| 250 |
+
"# scenario 3 - Agent with Tools\n",
|
| 251 |
+
"tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm, callbacks=callbacks)\n",
|
| 252 |
+
"agent = initialize_agent(\n",
|
| 253 |
+
" tools,\n",
|
| 254 |
+
" llm,\n",
|
| 255 |
+
" agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,\n",
|
| 256 |
+
" callbacks=callbacks,\n",
|
| 257 |
+
")\n",
|
| 258 |
+
"agent.run(\n",
|
| 259 |
+
" \"Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?\"\n",
|
| 260 |
+
")\n",
|
| 261 |
+
"aim_callback.flush_tracker(langchain_asset=agent, reset=False, finish=True)"
|
| 262 |
+
]
|
| 263 |
+
}
|
| 264 |
+
],
|
| 265 |
+
"metadata": {
|
| 266 |
+
"accelerator": "GPU",
|
| 267 |
+
"colab": {
|
| 268 |
+
"provenance": []
|
| 269 |
+
},
|
| 270 |
+
"gpuClass": "standard",
|
| 271 |
+
"kernelspec": {
|
| 272 |
+
"display_name": "Python 3 (ipykernel)",
|
| 273 |
+
"language": "python",
|
| 274 |
+
"name": "python3"
|
| 275 |
+
},
|
| 276 |
+
"language_info": {
|
| 277 |
+
"codemirror_mode": {
|
| 278 |
+
"name": "ipython",
|
| 279 |
+
"version": 3
|
| 280 |
+
},
|
| 281 |
+
"file_extension": ".py",
|
| 282 |
+
"mimetype": "text/x-python",
|
| 283 |
+
"name": "python",
|
| 284 |
+
"nbconvert_exporter": "python",
|
| 285 |
+
"pygments_lexer": "ipython3",
|
| 286 |
+
"version": "3.9.1"
|
| 287 |
+
}
|
| 288 |
+
},
|
| 289 |
+
"nbformat": 4,
|
| 290 |
+
"nbformat_minor": 1
|
| 291 |
+
}
|
langchain/docs/ecosystem/analyticdb.md
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# AnalyticDB
|
| 2 |
+
|
| 3 |
+
This page covers how to use the AnalyticDB ecosystem within LangChain.
|
| 4 |
+
|
| 5 |
+
### VectorStore
|
| 6 |
+
|
| 7 |
+
There exists a wrapper around AnalyticDB, allowing you to use it as a vectorstore,
|
| 8 |
+
whether for semantic search or example selection.
|
| 9 |
+
|
| 10 |
+
To import this vectorstore:
|
| 11 |
+
```python
|
| 12 |
+
from langchain.vectorstores import AnalyticDB
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
For a more detailed walkthrough of the AnalyticDB wrapper, see [this notebook](../modules/indexes/vectorstores/examples/analyticdb.ipynb)
|
langchain/docs/ecosystem/anyscale.md
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Anyscale
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Anyscale ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Anyscale wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Get an Anyscale Service URL, route and API key and set them as environment variables (`ANYSCALE_SERVICE_URL`,`ANYSCALE_SERVICE_ROUTE`, `ANYSCALE_SERVICE_TOKEN`).
|
| 8 |
+
- Please see [the Anyscale docs](https://docs.anyscale.com/productionize/services-v2/get-started) for more details.
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### LLM
|
| 13 |
+
|
| 14 |
+
There exists an Anyscale LLM wrapper, which you can access with
|
| 15 |
+
```python
|
| 16 |
+
from langchain.llms import Anyscale
|
| 17 |
+
```
|
langchain/docs/ecosystem/apify.md
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Apify
|
| 2 |
+
|
| 3 |
+
This page covers how to use [Apify](https://apify.com) within LangChain.
|
| 4 |
+
|
| 5 |
+
## Overview
|
| 6 |
+
|
| 7 |
+
Apify is a cloud platform for web scraping and data extraction,
|
| 8 |
+
which provides an [ecosystem](https://apify.com/store) of more than a thousand
|
| 9 |
+
ready-made apps called *Actors* for various scraping, crawling, and extraction use cases.
|
| 10 |
+
|
| 11 |
+
[](https://apify.com/store)
|
| 12 |
+
|
| 13 |
+
This integration enables you run Actors on the Apify platform and load their results into LangChain to feed your vector
|
| 14 |
+
indexes with documents and data from the web, e.g. to generate answers from websites with documentation,
|
| 15 |
+
blogs, or knowledge bases.
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
## Installation and Setup
|
| 19 |
+
|
| 20 |
+
- Install the Apify API client for Python with `pip install apify-client`
|
| 21 |
+
- Get your [Apify API token](https://console.apify.com/account/integrations) and either set it as
|
| 22 |
+
an environment variable (`APIFY_API_TOKEN`) or pass it to the `ApifyWrapper` as `apify_api_token` in the constructor.
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## Wrappers
|
| 26 |
+
|
| 27 |
+
### Utility
|
| 28 |
+
|
| 29 |
+
You can use the `ApifyWrapper` to run Actors on the Apify platform.
|
| 30 |
+
|
| 31 |
+
```python
|
| 32 |
+
from langchain.utilities import ApifyWrapper
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
For a more detailed walkthrough of this wrapper, see [this notebook](../modules/agents/tools/examples/apify.ipynb).
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
### Loader
|
| 39 |
+
|
| 40 |
+
You can also use our `ApifyDatasetLoader` to get data from Apify dataset.
|
| 41 |
+
|
| 42 |
+
```python
|
| 43 |
+
from langchain.document_loaders import ApifyDatasetLoader
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
For a more detailed walkthrough of this loader, see [this notebook](../modules/indexes/document_loaders/examples/apify_dataset.ipynb).
|
langchain/docs/ecosystem/atlas.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# AtlasDB
|
| 2 |
+
|
| 3 |
+
This page covers how to use Nomic's Atlas ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Atlas wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install the Python package with `pip install nomic`
|
| 8 |
+
- Nomic is also included in langchains poetry extras `poetry install -E all`
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### VectorStore
|
| 13 |
+
|
| 14 |
+
There exists a wrapper around the Atlas neural database, allowing you to use it as a vectorstore.
|
| 15 |
+
This vectorstore also gives you full access to the underlying AtlasProject object, which will allow you to use the full range of Atlas map interactions, such as bulk tagging and automatic topic modeling.
|
| 16 |
+
Please see [the Atlas docs](https://docs.nomic.ai/atlas_api.html) for more detailed information.
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
To import this vectorstore:
|
| 23 |
+
```python
|
| 24 |
+
from langchain.vectorstores import AtlasDB
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
For a more detailed walkthrough of the AtlasDB wrapper, see [this notebook](../modules/indexes/vectorstores/examples/atlas.ipynb)
|
langchain/docs/ecosystem/bananadev.md
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Banana
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Banana ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Banana wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
|
| 8 |
+
- Install with `pip install banana-dev`
|
| 9 |
+
- Get an Banana api key and set it as an environment variable (`BANANA_API_KEY`)
|
| 10 |
+
|
| 11 |
+
## Define your Banana Template
|
| 12 |
+
|
| 13 |
+
If you want to use an available language model template you can find one [here](https://app.banana.dev/templates/conceptofmind/serverless-template-palmyra-base).
|
| 14 |
+
This template uses the Palmyra-Base model by [Writer](https://writer.com/product/api/).
|
| 15 |
+
You can check out an example Banana repository [here](https://github.com/conceptofmind/serverless-template-palmyra-base).
|
| 16 |
+
|
| 17 |
+
## Build the Banana app
|
| 18 |
+
|
| 19 |
+
Banana Apps must include the "output" key in the return json.
|
| 20 |
+
There is a rigid response structure.
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
# Return the results as a dictionary
|
| 24 |
+
result = {'output': result}
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
An example inference function would be:
|
| 28 |
+
|
| 29 |
+
```python
|
| 30 |
+
def inference(model_inputs:dict) -> dict:
|
| 31 |
+
global model
|
| 32 |
+
global tokenizer
|
| 33 |
+
|
| 34 |
+
# Parse out your arguments
|
| 35 |
+
prompt = model_inputs.get('prompt', None)
|
| 36 |
+
if prompt == None:
|
| 37 |
+
return {'message': "No prompt provided"}
|
| 38 |
+
|
| 39 |
+
# Run the model
|
| 40 |
+
input_ids = tokenizer.encode(prompt, return_tensors='pt').cuda()
|
| 41 |
+
output = model.generate(
|
| 42 |
+
input_ids,
|
| 43 |
+
max_length=100,
|
| 44 |
+
do_sample=True,
|
| 45 |
+
top_k=50,
|
| 46 |
+
top_p=0.95,
|
| 47 |
+
num_return_sequences=1,
|
| 48 |
+
temperature=0.9,
|
| 49 |
+
early_stopping=True,
|
| 50 |
+
no_repeat_ngram_size=3,
|
| 51 |
+
num_beams=5,
|
| 52 |
+
length_penalty=1.5,
|
| 53 |
+
repetition_penalty=1.5,
|
| 54 |
+
bad_words_ids=[[tokenizer.encode(' ', add_prefix_space=True)[0]]]
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
result = tokenizer.decode(output[0], skip_special_tokens=True)
|
| 58 |
+
# Return the results as a dictionary
|
| 59 |
+
result = {'output': result}
|
| 60 |
+
return result
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
You can find a full example of a Banana app [here](https://github.com/conceptofmind/serverless-template-palmyra-base/blob/main/app.py).
|
| 64 |
+
|
| 65 |
+
## Wrappers
|
| 66 |
+
|
| 67 |
+
### LLM
|
| 68 |
+
|
| 69 |
+
There exists an Banana LLM wrapper, which you can access with
|
| 70 |
+
|
| 71 |
+
```python
|
| 72 |
+
from langchain.llms import Banana
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
You need to provide a model key located in the dashboard:
|
| 76 |
+
|
| 77 |
+
```python
|
| 78 |
+
llm = Banana(model_key="YOUR_MODEL_KEY")
|
| 79 |
+
```
|
langchain/docs/ecosystem/cerebriumai.md
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CerebriumAI
|
| 2 |
+
|
| 3 |
+
This page covers how to use the CerebriumAI ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific CerebriumAI wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install with `pip install cerebrium`
|
| 8 |
+
- Get an CerebriumAI api key and set it as an environment variable (`CEREBRIUMAI_API_KEY`)
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### LLM
|
| 13 |
+
|
| 14 |
+
There exists an CerebriumAI LLM wrapper, which you can access with
|
| 15 |
+
```python
|
| 16 |
+
from langchain.llms import CerebriumAI
|
| 17 |
+
```
|
langchain/docs/ecosystem/chroma.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Chroma
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Chroma ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Chroma wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install the Python package with `pip install chromadb`
|
| 8 |
+
## Wrappers
|
| 9 |
+
|
| 10 |
+
### VectorStore
|
| 11 |
+
|
| 12 |
+
There exists a wrapper around Chroma vector databases, allowing you to use it as a vectorstore,
|
| 13 |
+
whether for semantic search or example selection.
|
| 14 |
+
|
| 15 |
+
To import this vectorstore:
|
| 16 |
+
```python
|
| 17 |
+
from langchain.vectorstores import Chroma
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
For a more detailed walkthrough of the Chroma wrapper, see [this notebook](../modules/indexes/vectorstores/getting_started.ipynb)
|
langchain/docs/ecosystem/clearml_tracking.ipynb
ADDED
|
@@ -0,0 +1,587 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"attachments": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# ClearML Integration\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"In order to properly keep track of your langchain experiments and their results, you can enable the ClearML integration. ClearML is an experiment manager that neatly tracks and organizes all your experiment runs.\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"<a target=\"_blank\" href=\"https://colab.research.google.com/github/hwchase17/langchain/blob/master/docs/ecosystem/clearml_tracking.ipynb\">\n",
|
| 13 |
+
" <img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/>\n",
|
| 14 |
+
"</a>"
|
| 15 |
+
]
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"attachments": {},
|
| 19 |
+
"cell_type": "markdown",
|
| 20 |
+
"metadata": {},
|
| 21 |
+
"source": [
|
| 22 |
+
"## Getting API Credentials\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"We'll be using quite some APIs in this notebook, here is a list and where to get them:\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"- ClearML: https://app.clear.ml/settings/workspace-configuration\n",
|
| 27 |
+
"- OpenAI: https://platform.openai.com/account/api-keys\n",
|
| 28 |
+
"- SerpAPI (google search): https://serpapi.com/dashboard"
|
| 29 |
+
]
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
"cell_type": "code",
|
| 33 |
+
"execution_count": 2,
|
| 34 |
+
"metadata": {},
|
| 35 |
+
"outputs": [],
|
| 36 |
+
"source": [
|
| 37 |
+
"import os\n",
|
| 38 |
+
"os.environ[\"CLEARML_API_ACCESS_KEY\"] = \"\"\n",
|
| 39 |
+
"os.environ[\"CLEARML_API_SECRET_KEY\"] = \"\"\n",
|
| 40 |
+
"\n",
|
| 41 |
+
"os.environ[\"OPENAI_API_KEY\"] = \"\"\n",
|
| 42 |
+
"os.environ[\"SERPAPI_API_KEY\"] = \"\""
|
| 43 |
+
]
|
| 44 |
+
},
|
| 45 |
+
{
|
| 46 |
+
"attachments": {},
|
| 47 |
+
"cell_type": "markdown",
|
| 48 |
+
"metadata": {},
|
| 49 |
+
"source": [
|
| 50 |
+
"## Setting Up"
|
| 51 |
+
]
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"cell_type": "code",
|
| 55 |
+
"execution_count": null,
|
| 56 |
+
"metadata": {},
|
| 57 |
+
"outputs": [],
|
| 58 |
+
"source": [
|
| 59 |
+
"!pip install clearml\n",
|
| 60 |
+
"!pip install pandas\n",
|
| 61 |
+
"!pip install textstat\n",
|
| 62 |
+
"!pip install spacy\n",
|
| 63 |
+
"!python -m spacy download en_core_web_sm"
|
| 64 |
+
]
|
| 65 |
+
},
|
| 66 |
+
{
|
| 67 |
+
"cell_type": "code",
|
| 68 |
+
"execution_count": 3,
|
| 69 |
+
"metadata": {},
|
| 70 |
+
"outputs": [
|
| 71 |
+
{
|
| 72 |
+
"name": "stdout",
|
| 73 |
+
"output_type": "stream",
|
| 74 |
+
"text": [
|
| 75 |
+
"The clearml callback is currently in beta and is subject to change based on updates to `langchain`. Please report any issues to https://github.com/allegroai/clearml/issues with the tag `langchain`.\n"
|
| 76 |
+
]
|
| 77 |
+
}
|
| 78 |
+
],
|
| 79 |
+
"source": [
|
| 80 |
+
"from datetime import datetime\n",
|
| 81 |
+
"from langchain.callbacks import ClearMLCallbackHandler, StdOutCallbackHandler\n",
|
| 82 |
+
"from langchain.llms import OpenAI\n",
|
| 83 |
+
"\n",
|
| 84 |
+
"# Setup and use the ClearML Callback\n",
|
| 85 |
+
"clearml_callback = ClearMLCallbackHandler(\n",
|
| 86 |
+
" task_type=\"inference\",\n",
|
| 87 |
+
" project_name=\"langchain_callback_demo\",\n",
|
| 88 |
+
" task_name=\"llm\",\n",
|
| 89 |
+
" tags=[\"test\"],\n",
|
| 90 |
+
" # Change the following parameters based on the amount of detail you want tracked\n",
|
| 91 |
+
" visualize=True,\n",
|
| 92 |
+
" complexity_metrics=True,\n",
|
| 93 |
+
" stream_logs=True\n",
|
| 94 |
+
")\n",
|
| 95 |
+
"callbacks = [StdOutCallbackHandler(), clearml_callback]\n",
|
| 96 |
+
"# Get the OpenAI model ready to go\n",
|
| 97 |
+
"llm = OpenAI(temperature=0, callbacks=callbacks)"
|
| 98 |
+
]
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
"attachments": {},
|
| 102 |
+
"cell_type": "markdown",
|
| 103 |
+
"metadata": {},
|
| 104 |
+
"source": [
|
| 105 |
+
"## Scenario 1: Just an LLM\n",
|
| 106 |
+
"\n",
|
| 107 |
+
"First, let's just run a single LLM a few times and capture the resulting prompt-answer conversation in ClearML"
|
| 108 |
+
]
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"cell_type": "code",
|
| 112 |
+
"execution_count": 5,
|
| 113 |
+
"metadata": {},
|
| 114 |
+
"outputs": [
|
| 115 |
+
{
|
| 116 |
+
"name": "stdout",
|
| 117 |
+
"output_type": "stream",
|
| 118 |
+
"text": [
|
| 119 |
+
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a joke'}\n",
|
| 120 |
+
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a poem'}\n",
|
| 121 |
+
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a joke'}\n",
|
| 122 |
+
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a poem'}\n",
|
| 123 |
+
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a joke'}\n",
|
| 124 |
+
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Tell me a poem'}\n",
|
| 125 |
+
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nQ: What did the fish say when it hit the wall?\\nA: Dam!', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 109.04, 'flesch_kincaid_grade': 1.3, 'smog_index': 0.0, 'coleman_liau_index': -1.24, 'automated_readability_index': 0.3, 'dale_chall_readability_score': 5.5, 'difficult_words': 0, 'linsear_write_formula': 5.5, 'gunning_fog': 5.2, 'text_standard': '5th and 6th grade', 'fernandez_huerta': 133.58, 'szigriszt_pazos': 131.54, 'gutierrez_polini': 62.3, 'crawford': -0.2, 'gulpease_index': 79.8, 'osman': 116.91}\n",
|
| 126 |
+
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nRoses are red,\\nViolets are blue,\\nSugar is sweet,\\nAnd so are you.', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 83.66, 'flesch_kincaid_grade': 4.8, 'smog_index': 0.0, 'coleman_liau_index': 3.23, 'automated_readability_index': 3.9, 'dale_chall_readability_score': 6.71, 'difficult_words': 2, 'linsear_write_formula': 6.5, 'gunning_fog': 8.28, 'text_standard': '6th and 7th grade', 'fernandez_huerta': 115.58, 'szigriszt_pazos': 112.37, 'gutierrez_polini': 54.83, 'crawford': 1.4, 'gulpease_index': 72.1, 'osman': 100.17}\n",
|
| 127 |
+
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nQ: What did the fish say when it hit the wall?\\nA: Dam!', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 109.04, 'flesch_kincaid_grade': 1.3, 'smog_index': 0.0, 'coleman_liau_index': -1.24, 'automated_readability_index': 0.3, 'dale_chall_readability_score': 5.5, 'difficult_words': 0, 'linsear_write_formula': 5.5, 'gunning_fog': 5.2, 'text_standard': '5th and 6th grade', 'fernandez_huerta': 133.58, 'szigriszt_pazos': 131.54, 'gutierrez_polini': 62.3, 'crawford': -0.2, 'gulpease_index': 79.8, 'osman': 116.91}\n",
|
| 128 |
+
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nRoses are red,\\nViolets are blue,\\nSugar is sweet,\\nAnd so are you.', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 83.66, 'flesch_kincaid_grade': 4.8, 'smog_index': 0.0, 'coleman_liau_index': 3.23, 'automated_readability_index': 3.9, 'dale_chall_readability_score': 6.71, 'difficult_words': 2, 'linsear_write_formula': 6.5, 'gunning_fog': 8.28, 'text_standard': '6th and 7th grade', 'fernandez_huerta': 115.58, 'szigriszt_pazos': 112.37, 'gutierrez_polini': 54.83, 'crawford': 1.4, 'gulpease_index': 72.1, 'osman': 100.17}\n",
|
| 129 |
+
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nQ: What did the fish say when it hit the wall?\\nA: Dam!', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 109.04, 'flesch_kincaid_grade': 1.3, 'smog_index': 0.0, 'coleman_liau_index': -1.24, 'automated_readability_index': 0.3, 'dale_chall_readability_score': 5.5, 'difficult_words': 0, 'linsear_write_formula': 5.5, 'gunning_fog': 5.2, 'text_standard': '5th and 6th grade', 'fernandez_huerta': 133.58, 'szigriszt_pazos': 131.54, 'gutierrez_polini': 62.3, 'crawford': -0.2, 'gulpease_index': 79.8, 'osman': 116.91}\n",
|
| 130 |
+
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 24, 'token_usage_completion_tokens': 138, 'token_usage_total_tokens': 162, 'model_name': 'text-davinci-003', 'step': 4, 'starts': 2, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 0, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': '\\n\\nRoses are red,\\nViolets are blue,\\nSugar is sweet,\\nAnd so are you.', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 83.66, 'flesch_kincaid_grade': 4.8, 'smog_index': 0.0, 'coleman_liau_index': 3.23, 'automated_readability_index': 3.9, 'dale_chall_readability_score': 6.71, 'difficult_words': 2, 'linsear_write_formula': 6.5, 'gunning_fog': 8.28, 'text_standard': '6th and 7th grade', 'fernandez_huerta': 115.58, 'szigriszt_pazos': 112.37, 'gutierrez_polini': 54.83, 'crawford': 1.4, 'gulpease_index': 72.1, 'osman': 100.17}\n",
|
| 131 |
+
"{'action_records': action name step starts ends errors text_ctr chain_starts \\\n",
|
| 132 |
+
"0 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
| 133 |
+
"1 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
| 134 |
+
"2 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
| 135 |
+
"3 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
| 136 |
+
"4 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
| 137 |
+
"5 on_llm_start OpenAI 1 1 0 0 0 0 \n",
|
| 138 |
+
"6 on_llm_end NaN 2 1 1 0 0 0 \n",
|
| 139 |
+
"7 on_llm_end NaN 2 1 1 0 0 0 \n",
|
| 140 |
+
"8 on_llm_end NaN 2 1 1 0 0 0 \n",
|
| 141 |
+
"9 on_llm_end NaN 2 1 1 0 0 0 \n",
|
| 142 |
+
"10 on_llm_end NaN 2 1 1 0 0 0 \n",
|
| 143 |
+
"11 on_llm_end NaN 2 1 1 0 0 0 \n",
|
| 144 |
+
"12 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
| 145 |
+
"13 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
| 146 |
+
"14 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
| 147 |
+
"15 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
| 148 |
+
"16 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
| 149 |
+
"17 on_llm_start OpenAI 3 2 1 0 0 0 \n",
|
| 150 |
+
"18 on_llm_end NaN 4 2 2 0 0 0 \n",
|
| 151 |
+
"19 on_llm_end NaN 4 2 2 0 0 0 \n",
|
| 152 |
+
"20 on_llm_end NaN 4 2 2 0 0 0 \n",
|
| 153 |
+
"21 on_llm_end NaN 4 2 2 0 0 0 \n",
|
| 154 |
+
"22 on_llm_end NaN 4 2 2 0 0 0 \n",
|
| 155 |
+
"23 on_llm_end NaN 4 2 2 0 0 0 \n",
|
| 156 |
+
"\n",
|
| 157 |
+
" chain_ends llm_starts ... difficult_words linsear_write_formula \\\n",
|
| 158 |
+
"0 0 1 ... NaN NaN \n",
|
| 159 |
+
"1 0 1 ... NaN NaN \n",
|
| 160 |
+
"2 0 1 ... NaN NaN \n",
|
| 161 |
+
"3 0 1 ... NaN NaN \n",
|
| 162 |
+
"4 0 1 ... NaN NaN \n",
|
| 163 |
+
"5 0 1 ... NaN NaN \n",
|
| 164 |
+
"6 0 1 ... 0.0 5.5 \n",
|
| 165 |
+
"7 0 1 ... 2.0 6.5 \n",
|
| 166 |
+
"8 0 1 ... 0.0 5.5 \n",
|
| 167 |
+
"9 0 1 ... 2.0 6.5 \n",
|
| 168 |
+
"10 0 1 ... 0.0 5.5 \n",
|
| 169 |
+
"11 0 1 ... 2.0 6.5 \n",
|
| 170 |
+
"12 0 2 ... NaN NaN \n",
|
| 171 |
+
"13 0 2 ... NaN NaN \n",
|
| 172 |
+
"14 0 2 ... NaN NaN \n",
|
| 173 |
+
"15 0 2 ... NaN NaN \n",
|
| 174 |
+
"16 0 2 ... NaN NaN \n",
|
| 175 |
+
"17 0 2 ... NaN NaN \n",
|
| 176 |
+
"18 0 2 ... 0.0 5.5 \n",
|
| 177 |
+
"19 0 2 ... 2.0 6.5 \n",
|
| 178 |
+
"20 0 2 ... 0.0 5.5 \n",
|
| 179 |
+
"21 0 2 ... 2.0 6.5 \n",
|
| 180 |
+
"22 0 2 ... 0.0 5.5 \n",
|
| 181 |
+
"23 0 2 ... 2.0 6.5 \n",
|
| 182 |
+
"\n",
|
| 183 |
+
" gunning_fog text_standard fernandez_huerta szigriszt_pazos \\\n",
|
| 184 |
+
"0 NaN NaN NaN NaN \n",
|
| 185 |
+
"1 NaN NaN NaN NaN \n",
|
| 186 |
+
"2 NaN NaN NaN NaN \n",
|
| 187 |
+
"3 NaN NaN NaN NaN \n",
|
| 188 |
+
"4 NaN NaN NaN NaN \n",
|
| 189 |
+
"5 NaN NaN NaN NaN \n",
|
| 190 |
+
"6 5.20 5th and 6th grade 133.58 131.54 \n",
|
| 191 |
+
"7 8.28 6th and 7th grade 115.58 112.37 \n",
|
| 192 |
+
"8 5.20 5th and 6th grade 133.58 131.54 \n",
|
| 193 |
+
"9 8.28 6th and 7th grade 115.58 112.37 \n",
|
| 194 |
+
"10 5.20 5th and 6th grade 133.58 131.54 \n",
|
| 195 |
+
"11 8.28 6th and 7th grade 115.58 112.37 \n",
|
| 196 |
+
"12 NaN NaN NaN NaN \n",
|
| 197 |
+
"13 NaN NaN NaN NaN \n",
|
| 198 |
+
"14 NaN NaN NaN NaN \n",
|
| 199 |
+
"15 NaN NaN NaN NaN \n",
|
| 200 |
+
"16 NaN NaN NaN NaN \n",
|
| 201 |
+
"17 NaN NaN NaN NaN \n",
|
| 202 |
+
"18 5.20 5th and 6th grade 133.58 131.54 \n",
|
| 203 |
+
"19 8.28 6th and 7th grade 115.58 112.37 \n",
|
| 204 |
+
"20 5.20 5th and 6th grade 133.58 131.54 \n",
|
| 205 |
+
"21 8.28 6th and 7th grade 115.58 112.37 \n",
|
| 206 |
+
"22 5.20 5th and 6th grade 133.58 131.54 \n",
|
| 207 |
+
"23 8.28 6th and 7th grade 115.58 112.37 \n",
|
| 208 |
+
"\n",
|
| 209 |
+
" gutierrez_polini crawford gulpease_index osman \n",
|
| 210 |
+
"0 NaN NaN NaN NaN \n",
|
| 211 |
+
"1 NaN NaN NaN NaN \n",
|
| 212 |
+
"2 NaN NaN NaN NaN \n",
|
| 213 |
+
"3 NaN NaN NaN NaN \n",
|
| 214 |
+
"4 NaN NaN NaN NaN \n",
|
| 215 |
+
"5 NaN NaN NaN NaN \n",
|
| 216 |
+
"6 62.30 -0.2 79.8 116.91 \n",
|
| 217 |
+
"7 54.83 1.4 72.1 100.17 \n",
|
| 218 |
+
"8 62.30 -0.2 79.8 116.91 \n",
|
| 219 |
+
"9 54.83 1.4 72.1 100.17 \n",
|
| 220 |
+
"10 62.30 -0.2 79.8 116.91 \n",
|
| 221 |
+
"11 54.83 1.4 72.1 100.17 \n",
|
| 222 |
+
"12 NaN NaN NaN NaN \n",
|
| 223 |
+
"13 NaN NaN NaN NaN \n",
|
| 224 |
+
"14 NaN NaN NaN NaN \n",
|
| 225 |
+
"15 NaN NaN NaN NaN \n",
|
| 226 |
+
"16 NaN NaN NaN NaN \n",
|
| 227 |
+
"17 NaN NaN NaN NaN \n",
|
| 228 |
+
"18 62.30 -0.2 79.8 116.91 \n",
|
| 229 |
+
"19 54.83 1.4 72.1 100.17 \n",
|
| 230 |
+
"20 62.30 -0.2 79.8 116.91 \n",
|
| 231 |
+
"21 54.83 1.4 72.1 100.17 \n",
|
| 232 |
+
"22 62.30 -0.2 79.8 116.91 \n",
|
| 233 |
+
"23 54.83 1.4 72.1 100.17 \n",
|
| 234 |
+
"\n",
|
| 235 |
+
"[24 rows x 39 columns], 'session_analysis': prompt_step prompts name output_step \\\n",
|
| 236 |
+
"0 1 Tell me a joke OpenAI 2 \n",
|
| 237 |
+
"1 1 Tell me a poem OpenAI 2 \n",
|
| 238 |
+
"2 1 Tell me a joke OpenAI 2 \n",
|
| 239 |
+
"3 1 Tell me a poem OpenAI 2 \n",
|
| 240 |
+
"4 1 Tell me a joke OpenAI 2 \n",
|
| 241 |
+
"5 1 Tell me a poem OpenAI 2 \n",
|
| 242 |
+
"6 3 Tell me a joke OpenAI 4 \n",
|
| 243 |
+
"7 3 Tell me a poem OpenAI 4 \n",
|
| 244 |
+
"8 3 Tell me a joke OpenAI 4 \n",
|
| 245 |
+
"9 3 Tell me a poem OpenAI 4 \n",
|
| 246 |
+
"10 3 Tell me a joke OpenAI 4 \n",
|
| 247 |
+
"11 3 Tell me a poem OpenAI 4 \n",
|
| 248 |
+
"\n",
|
| 249 |
+
" output \\\n",
|
| 250 |
+
"0 \\n\\nQ: What did the fish say when it hit the w... \n",
|
| 251 |
+
"1 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
| 252 |
+
"2 \\n\\nQ: What did the fish say when it hit the w... \n",
|
| 253 |
+
"3 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
| 254 |
+
"4 \\n\\nQ: What did the fish say when it hit the w... \n",
|
| 255 |
+
"5 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
| 256 |
+
"6 \\n\\nQ: What did the fish say when it hit the w... \n",
|
| 257 |
+
"7 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
| 258 |
+
"8 \\n\\nQ: What did the fish say when it hit the w... \n",
|
| 259 |
+
"9 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
| 260 |
+
"10 \\n\\nQ: What did the fish say when it hit the w... \n",
|
| 261 |
+
"11 \\n\\nRoses are red,\\nViolets are blue,\\nSugar i... \n",
|
| 262 |
+
"\n",
|
| 263 |
+
" token_usage_total_tokens token_usage_prompt_tokens \\\n",
|
| 264 |
+
"0 162 24 \n",
|
| 265 |
+
"1 162 24 \n",
|
| 266 |
+
"2 162 24 \n",
|
| 267 |
+
"3 162 24 \n",
|
| 268 |
+
"4 162 24 \n",
|
| 269 |
+
"5 162 24 \n",
|
| 270 |
+
"6 162 24 \n",
|
| 271 |
+
"7 162 24 \n",
|
| 272 |
+
"8 162 24 \n",
|
| 273 |
+
"9 162 24 \n",
|
| 274 |
+
"10 162 24 \n",
|
| 275 |
+
"11 162 24 \n",
|
| 276 |
+
"\n",
|
| 277 |
+
" token_usage_completion_tokens flesch_reading_ease flesch_kincaid_grade \\\n",
|
| 278 |
+
"0 138 109.04 1.3 \n",
|
| 279 |
+
"1 138 83.66 4.8 \n",
|
| 280 |
+
"2 138 109.04 1.3 \n",
|
| 281 |
+
"3 138 83.66 4.8 \n",
|
| 282 |
+
"4 138 109.04 1.3 \n",
|
| 283 |
+
"5 138 83.66 4.8 \n",
|
| 284 |
+
"6 138 109.04 1.3 \n",
|
| 285 |
+
"7 138 83.66 4.8 \n",
|
| 286 |
+
"8 138 109.04 1.3 \n",
|
| 287 |
+
"9 138 83.66 4.8 \n",
|
| 288 |
+
"10 138 109.04 1.3 \n",
|
| 289 |
+
"11 138 83.66 4.8 \n",
|
| 290 |
+
"\n",
|
| 291 |
+
" ... difficult_words linsear_write_formula gunning_fog \\\n",
|
| 292 |
+
"0 ... 0 5.5 5.20 \n",
|
| 293 |
+
"1 ... 2 6.5 8.28 \n",
|
| 294 |
+
"2 ... 0 5.5 5.20 \n",
|
| 295 |
+
"3 ... 2 6.5 8.28 \n",
|
| 296 |
+
"4 ... 0 5.5 5.20 \n",
|
| 297 |
+
"5 ... 2 6.5 8.28 \n",
|
| 298 |
+
"6 ... 0 5.5 5.20 \n",
|
| 299 |
+
"7 ... 2 6.5 8.28 \n",
|
| 300 |
+
"8 ... 0 5.5 5.20 \n",
|
| 301 |
+
"9 ... 2 6.5 8.28 \n",
|
| 302 |
+
"10 ... 0 5.5 5.20 \n",
|
| 303 |
+
"11 ... 2 6.5 8.28 \n",
|
| 304 |
+
"\n",
|
| 305 |
+
" text_standard fernandez_huerta szigriszt_pazos gutierrez_polini \\\n",
|
| 306 |
+
"0 5th and 6th grade 133.58 131.54 62.30 \n",
|
| 307 |
+
"1 6th and 7th grade 115.58 112.37 54.83 \n",
|
| 308 |
+
"2 5th and 6th grade 133.58 131.54 62.30 \n",
|
| 309 |
+
"3 6th and 7th grade 115.58 112.37 54.83 \n",
|
| 310 |
+
"4 5th and 6th grade 133.58 131.54 62.30 \n",
|
| 311 |
+
"5 6th and 7th grade 115.58 112.37 54.83 \n",
|
| 312 |
+
"6 5th and 6th grade 133.58 131.54 62.30 \n",
|
| 313 |
+
"7 6th and 7th grade 115.58 112.37 54.83 \n",
|
| 314 |
+
"8 5th and 6th grade 133.58 131.54 62.30 \n",
|
| 315 |
+
"9 6th and 7th grade 115.58 112.37 54.83 \n",
|
| 316 |
+
"10 5th and 6th grade 133.58 131.54 62.30 \n",
|
| 317 |
+
"11 6th and 7th grade 115.58 112.37 54.83 \n",
|
| 318 |
+
"\n",
|
| 319 |
+
" crawford gulpease_index osman \n",
|
| 320 |
+
"0 -0.2 79.8 116.91 \n",
|
| 321 |
+
"1 1.4 72.1 100.17 \n",
|
| 322 |
+
"2 -0.2 79.8 116.91 \n",
|
| 323 |
+
"3 1.4 72.1 100.17 \n",
|
| 324 |
+
"4 -0.2 79.8 116.91 \n",
|
| 325 |
+
"5 1.4 72.1 100.17 \n",
|
| 326 |
+
"6 -0.2 79.8 116.91 \n",
|
| 327 |
+
"7 1.4 72.1 100.17 \n",
|
| 328 |
+
"8 -0.2 79.8 116.91 \n",
|
| 329 |
+
"9 1.4 72.1 100.17 \n",
|
| 330 |
+
"10 -0.2 79.8 116.91 \n",
|
| 331 |
+
"11 1.4 72.1 100.17 \n",
|
| 332 |
+
"\n",
|
| 333 |
+
"[12 rows x 24 columns]}\n",
|
| 334 |
+
"2023-03-29 14:00:25,948 - clearml.Task - INFO - Completed model upload to https://files.clear.ml/langchain_callback_demo/llm.988bd727b0e94a29a3ac0ee526813545/models/simple_sequential\n"
|
| 335 |
+
]
|
| 336 |
+
}
|
| 337 |
+
],
|
| 338 |
+
"source": [
|
| 339 |
+
"# SCENARIO 1 - LLM\n",
|
| 340 |
+
"llm_result = llm.generate([\"Tell me a joke\", \"Tell me a poem\"] * 3)\n",
|
| 341 |
+
"# After every generation run, use flush to make sure all the metrics\n",
|
| 342 |
+
"# prompts and other output are properly saved separately\n",
|
| 343 |
+
"clearml_callback.flush_tracker(langchain_asset=llm, name=\"simple_sequential\")"
|
| 344 |
+
]
|
| 345 |
+
},
|
| 346 |
+
{
|
| 347 |
+
"attachments": {},
|
| 348 |
+
"cell_type": "markdown",
|
| 349 |
+
"metadata": {},
|
| 350 |
+
"source": [
|
| 351 |
+
"At this point you can already go to https://app.clear.ml and take a look at the resulting ClearML Task that was created.\n",
|
| 352 |
+
"\n",
|
| 353 |
+
"Among others, you should see that this notebook is saved along with any git information. The model JSON that contains the used parameters is saved as an artifact, there are also console logs and under the plots section, you'll find tables that represent the flow of the chain.\n",
|
| 354 |
+
"\n",
|
| 355 |
+
"Finally, if you enabled visualizations, these are stored as HTML files under debug samples."
|
| 356 |
+
]
|
| 357 |
+
},
|
| 358 |
+
{
|
| 359 |
+
"attachments": {},
|
| 360 |
+
"cell_type": "markdown",
|
| 361 |
+
"metadata": {},
|
| 362 |
+
"source": [
|
| 363 |
+
"## Scenario 2: Creating an agent with tools\n",
|
| 364 |
+
"\n",
|
| 365 |
+
"To show a more advanced workflow, let's create an agent with access to tools. The way ClearML tracks the results is not different though, only the table will look slightly different as there are other types of actions taken when compared to the earlier, simpler example.\n",
|
| 366 |
+
"\n",
|
| 367 |
+
"You can now also see the use of the `finish=True` keyword, which will fully close the ClearML Task, instead of just resetting the parameters and prompts for a new conversation."
|
| 368 |
+
]
|
| 369 |
+
},
|
| 370 |
+
{
|
| 371 |
+
"cell_type": "code",
|
| 372 |
+
"execution_count": 8,
|
| 373 |
+
"metadata": {},
|
| 374 |
+
"outputs": [
|
| 375 |
+
{
|
| 376 |
+
"name": "stdout",
|
| 377 |
+
"output_type": "stream",
|
| 378 |
+
"text": [
|
| 379 |
+
"\n",
|
| 380 |
+
"\n",
|
| 381 |
+
"\u001b[1m> Entering new AgentExecutor chain...\u001b[0m\n",
|
| 382 |
+
"{'action': 'on_chain_start', 'name': 'AgentExecutor', 'step': 1, 'starts': 1, 'ends': 0, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 0, 'llm_ends': 0, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'input': 'Who is the wife of the person who sang summer of 69?'}\n",
|
| 383 |
+
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 2, 'starts': 2, 'ends': 0, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 1, 'llm_ends': 0, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'prompts': 'Answer the following questions as best you can. You have access to the following tools:\\n\\nSearch: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\\nCalculator: Useful for when you need to answer questions about math.\\n\\nUse the following format:\\n\\nQuestion: the input question you must answer\\nThought: you should always think about what to do\\nAction: the action to take, should be one of [Search, Calculator]\\nAction Input: the input to the action\\nObservation: the result of the action\\n... (this Thought/Action/Action Input/Observation can repeat N times)\\nThought: I now know the final answer\\nFinal Answer: the final answer to the original input question\\n\\nBegin!\\n\\nQuestion: Who is the wife of the person who sang summer of 69?\\nThought:'}\n",
|
| 384 |
+
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 189, 'token_usage_completion_tokens': 34, 'token_usage_total_tokens': 223, 'model_name': 'text-davinci-003', 'step': 3, 'starts': 2, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 1, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 0, 'tool_ends': 0, 'agent_ends': 0, 'text': ' I need to find out who sang summer of 69 and then find out who their wife is.\\nAction: Search\\nAction Input: \"Who sang summer of 69\"', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 91.61, 'flesch_kincaid_grade': 3.8, 'smog_index': 0.0, 'coleman_liau_index': 3.41, 'automated_readability_index': 3.5, 'dale_chall_readability_score': 6.06, 'difficult_words': 2, 'linsear_write_formula': 5.75, 'gunning_fog': 5.4, 'text_standard': '3rd and 4th grade', 'fernandez_huerta': 121.07, 'szigriszt_pazos': 119.5, 'gutierrez_polini': 54.91, 'crawford': 0.9, 'gulpease_index': 72.7, 'osman': 92.16}\n",
|
| 385 |
+
"\u001b[32;1m\u001b[1;3m I need to find out who sang summer of 69 and then find out who their wife is.\n",
|
| 386 |
+
"Action: Search\n",
|
| 387 |
+
"Action Input: \"Who sang summer of 69\"\u001b[0m{'action': 'on_agent_action', 'tool': 'Search', 'tool_input': 'Who sang summer of 69', 'log': ' I need to find out who sang summer of 69 and then find out who their wife is.\\nAction: Search\\nAction Input: \"Who sang summer of 69\"', 'step': 4, 'starts': 3, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 1, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 1, 'tool_ends': 0, 'agent_ends': 0}\n",
|
| 388 |
+
"{'action': 'on_tool_start', 'input_str': 'Who sang summer of 69', 'name': 'Search', 'description': 'A search engine. Useful for when you need to answer questions about current events. Input should be a search query.', 'step': 5, 'starts': 4, 'ends': 1, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 1, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 2, 'tool_ends': 0, 'agent_ends': 0}\n",
|
| 389 |
+
"\n",
|
| 390 |
+
"Observation: \u001b[36;1m\u001b[1;3mBryan Adams - Summer Of 69 (Official Music Video).\u001b[0m\n",
|
| 391 |
+
"Thought:{'action': 'on_tool_end', 'output': 'Bryan Adams - Summer Of 69 (Official Music Video).', 'step': 6, 'starts': 4, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 1, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 2, 'tool_ends': 1, 'agent_ends': 0}\n",
|
| 392 |
+
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 7, 'starts': 5, 'ends': 2, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 1, 'llm_streams': 0, 'tool_starts': 2, 'tool_ends': 1, 'agent_ends': 0, 'prompts': 'Answer the following questions as best you can. You have access to the following tools:\\n\\nSearch: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\\nCalculator: Useful for when you need to answer questions about math.\\n\\nUse the following format:\\n\\nQuestion: the input question you must answer\\nThought: you should always think about what to do\\nAction: the action to take, should be one of [Search, Calculator]\\nAction Input: the input to the action\\nObservation: the result of the action\\n... (this Thought/Action/Action Input/Observation can repeat N times)\\nThought: I now know the final answer\\nFinal Answer: the final answer to the original input question\\n\\nBegin!\\n\\nQuestion: Who is the wife of the person who sang summer of 69?\\nThought: I need to find out who sang summer of 69 and then find out who their wife is.\\nAction: Search\\nAction Input: \"Who sang summer of 69\"\\nObservation: Bryan Adams - Summer Of 69 (Official Music Video).\\nThought:'}\n",
|
| 393 |
+
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 242, 'token_usage_completion_tokens': 28, 'token_usage_total_tokens': 270, 'model_name': 'text-davinci-003', 'step': 8, 'starts': 5, 'ends': 3, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 2, 'tool_ends': 1, 'agent_ends': 0, 'text': ' I need to find out who Bryan Adams is married to.\\nAction: Search\\nAction Input: \"Who is Bryan Adams married to\"', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 94.66, 'flesch_kincaid_grade': 2.7, 'smog_index': 0.0, 'coleman_liau_index': 4.73, 'automated_readability_index': 4.0, 'dale_chall_readability_score': 7.16, 'difficult_words': 2, 'linsear_write_formula': 4.25, 'gunning_fog': 4.2, 'text_standard': '4th and 5th grade', 'fernandez_huerta': 124.13, 'szigriszt_pazos': 119.2, 'gutierrez_polini': 52.26, 'crawford': 0.7, 'gulpease_index': 74.7, 'osman': 84.2}\n",
|
| 394 |
+
"\u001b[32;1m\u001b[1;3m I need to find out who Bryan Adams is married to.\n",
|
| 395 |
+
"Action: Search\n",
|
| 396 |
+
"Action Input: \"Who is Bryan Adams married to\"\u001b[0m{'action': 'on_agent_action', 'tool': 'Search', 'tool_input': 'Who is Bryan Adams married to', 'log': ' I need to find out who Bryan Adams is married to.\\nAction: Search\\nAction Input: \"Who is Bryan Adams married to\"', 'step': 9, 'starts': 6, 'ends': 3, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 3, 'tool_ends': 1, 'agent_ends': 0}\n",
|
| 397 |
+
"{'action': 'on_tool_start', 'input_str': 'Who is Bryan Adams married to', 'name': 'Search', 'description': 'A search engine. Useful for when you need to answer questions about current events. Input should be a search query.', 'step': 10, 'starts': 7, 'ends': 3, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 1, 'agent_ends': 0}\n",
|
| 398 |
+
"\n",
|
| 399 |
+
"Observation: \u001b[36;1m\u001b[1;3mBryan Adams has never married. In the 1990s, he was in a relationship with Danish model Cecilie Thomsen. In 2011, Bryan and Alicia Grimaldi, his ...\u001b[0m\n",
|
| 400 |
+
"Thought:{'action': 'on_tool_end', 'output': 'Bryan Adams has never married. In the 1990s, he was in a relationship with Danish model Cecilie Thomsen. In 2011, Bryan and Alicia Grimaldi, his ...', 'step': 11, 'starts': 7, 'ends': 4, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 2, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 2, 'agent_ends': 0}\n",
|
| 401 |
+
"{'action': 'on_llm_start', 'name': 'OpenAI', 'step': 12, 'starts': 8, 'ends': 4, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 3, 'llm_ends': 2, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 2, 'agent_ends': 0, 'prompts': 'Answer the following questions as best you can. You have access to the following tools:\\n\\nSearch: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.\\nCalculator: Useful for when you need to answer questions about math.\\n\\nUse the following format:\\n\\nQuestion: the input question you must answer\\nThought: you should always think about what to do\\nAction: the action to take, should be one of [Search, Calculator]\\nAction Input: the input to the action\\nObservation: the result of the action\\n... (this Thought/Action/Action Input/Observation can repeat N times)\\nThought: I now know the final answer\\nFinal Answer: the final answer to the original input question\\n\\nBegin!\\n\\nQuestion: Who is the wife of the person who sang summer of 69?\\nThought: I need to find out who sang summer of 69 and then find out who their wife is.\\nAction: Search\\nAction Input: \"Who sang summer of 69\"\\nObservation: Bryan Adams - Summer Of 69 (Official Music Video).\\nThought: I need to find out who Bryan Adams is married to.\\nAction: Search\\nAction Input: \"Who is Bryan Adams married to\"\\nObservation: Bryan Adams has never married. In the 1990s, he was in a relationship with Danish model Cecilie Thomsen. In 2011, Bryan and Alicia Grimaldi, his ...\\nThought:'}\n",
|
| 402 |
+
"{'action': 'on_llm_end', 'token_usage_prompt_tokens': 314, 'token_usage_completion_tokens': 18, 'token_usage_total_tokens': 332, 'model_name': 'text-davinci-003', 'step': 13, 'starts': 8, 'ends': 5, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 3, 'llm_ends': 3, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 2, 'agent_ends': 0, 'text': ' I now know the final answer.\\nFinal Answer: Bryan Adams has never been married.', 'generation_info_finish_reason': 'stop', 'generation_info_logprobs': None, 'flesch_reading_ease': 81.29, 'flesch_kincaid_grade': 3.7, 'smog_index': 0.0, 'coleman_liau_index': 5.75, 'automated_readability_index': 3.9, 'dale_chall_readability_score': 7.37, 'difficult_words': 1, 'linsear_write_formula': 2.5, 'gunning_fog': 2.8, 'text_standard': '3rd and 4th grade', 'fernandez_huerta': 115.7, 'szigriszt_pazos': 110.84, 'gutierrez_polini': 49.79, 'crawford': 0.7, 'gulpease_index': 85.4, 'osman': 83.14}\n",
|
| 403 |
+
"\u001b[32;1m\u001b[1;3m I now know the final answer.\n",
|
| 404 |
+
"Final Answer: Bryan Adams has never been married.\u001b[0m\n",
|
| 405 |
+
"{'action': 'on_agent_finish', 'output': 'Bryan Adams has never been married.', 'log': ' I now know the final answer.\\nFinal Answer: Bryan Adams has never been married.', 'step': 14, 'starts': 8, 'ends': 6, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 0, 'llm_starts': 3, 'llm_ends': 3, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 2, 'agent_ends': 1}\n",
|
| 406 |
+
"\n",
|
| 407 |
+
"\u001b[1m> Finished chain.\u001b[0m\n",
|
| 408 |
+
"{'action': 'on_chain_end', 'outputs': 'Bryan Adams has never been married.', 'step': 15, 'starts': 8, 'ends': 7, 'errors': 0, 'text_ctr': 0, 'chain_starts': 1, 'chain_ends': 1, 'llm_starts': 3, 'llm_ends': 3, 'llm_streams': 0, 'tool_starts': 4, 'tool_ends': 2, 'agent_ends': 1}\n",
|
| 409 |
+
"{'action_records': action name step starts ends errors text_ctr \\\n",
|
| 410 |
+
"0 on_llm_start OpenAI 1 1 0 0 0 \n",
|
| 411 |
+
"1 on_llm_start OpenAI 1 1 0 0 0 \n",
|
| 412 |
+
"2 on_llm_start OpenAI 1 1 0 0 0 \n",
|
| 413 |
+
"3 on_llm_start OpenAI 1 1 0 0 0 \n",
|
| 414 |
+
"4 on_llm_start OpenAI 1 1 0 0 0 \n",
|
| 415 |
+
".. ... ... ... ... ... ... ... \n",
|
| 416 |
+
"66 on_tool_end NaN 11 7 4 0 0 \n",
|
| 417 |
+
"67 on_llm_start OpenAI 12 8 4 0 0 \n",
|
| 418 |
+
"68 on_llm_end NaN 13 8 5 0 0 \n",
|
| 419 |
+
"69 on_agent_finish NaN 14 8 6 0 0 \n",
|
| 420 |
+
"70 on_chain_end NaN 15 8 7 0 0 \n",
|
| 421 |
+
"\n",
|
| 422 |
+
" chain_starts chain_ends llm_starts ... gulpease_index osman input \\\n",
|
| 423 |
+
"0 0 0 1 ... NaN NaN NaN \n",
|
| 424 |
+
"1 0 0 1 ... NaN NaN NaN \n",
|
| 425 |
+
"2 0 0 1 ... NaN NaN NaN \n",
|
| 426 |
+
"3 0 0 1 ... NaN NaN NaN \n",
|
| 427 |
+
"4 0 0 1 ... NaN NaN NaN \n",
|
| 428 |
+
".. ... ... ... ... ... ... ... \n",
|
| 429 |
+
"66 1 0 2 ... NaN NaN NaN \n",
|
| 430 |
+
"67 1 0 3 ... NaN NaN NaN \n",
|
| 431 |
+
"68 1 0 3 ... 85.4 83.14 NaN \n",
|
| 432 |
+
"69 1 0 3 ... NaN NaN NaN \n",
|
| 433 |
+
"70 1 1 3 ... NaN NaN NaN \n",
|
| 434 |
+
"\n",
|
| 435 |
+
" tool tool_input log \\\n",
|
| 436 |
+
"0 NaN NaN NaN \n",
|
| 437 |
+
"1 NaN NaN NaN \n",
|
| 438 |
+
"2 NaN NaN NaN \n",
|
| 439 |
+
"3 NaN NaN NaN \n",
|
| 440 |
+
"4 NaN NaN NaN \n",
|
| 441 |
+
".. ... ... ... \n",
|
| 442 |
+
"66 NaN NaN NaN \n",
|
| 443 |
+
"67 NaN NaN NaN \n",
|
| 444 |
+
"68 NaN NaN NaN \n",
|
| 445 |
+
"69 NaN NaN I now know the final answer.\\nFinal Answer: B... \n",
|
| 446 |
+
"70 NaN NaN NaN \n",
|
| 447 |
+
"\n",
|
| 448 |
+
" input_str description output \\\n",
|
| 449 |
+
"0 NaN NaN NaN \n",
|
| 450 |
+
"1 NaN NaN NaN \n",
|
| 451 |
+
"2 NaN NaN NaN \n",
|
| 452 |
+
"3 NaN NaN NaN \n",
|
| 453 |
+
"4 NaN NaN NaN \n",
|
| 454 |
+
".. ... ... ... \n",
|
| 455 |
+
"66 NaN NaN Bryan Adams has never married. In the 1990s, h... \n",
|
| 456 |
+
"67 NaN NaN NaN \n",
|
| 457 |
+
"68 NaN NaN NaN \n",
|
| 458 |
+
"69 NaN NaN Bryan Adams has never been married. \n",
|
| 459 |
+
"70 NaN NaN NaN \n",
|
| 460 |
+
"\n",
|
| 461 |
+
" outputs \n",
|
| 462 |
+
"0 NaN \n",
|
| 463 |
+
"1 NaN \n",
|
| 464 |
+
"2 NaN \n",
|
| 465 |
+
"3 NaN \n",
|
| 466 |
+
"4 NaN \n",
|
| 467 |
+
".. ... \n",
|
| 468 |
+
"66 NaN \n",
|
| 469 |
+
"67 NaN \n",
|
| 470 |
+
"68 NaN \n",
|
| 471 |
+
"69 NaN \n",
|
| 472 |
+
"70 Bryan Adams has never been married. \n",
|
| 473 |
+
"\n",
|
| 474 |
+
"[71 rows x 47 columns], 'session_analysis': prompt_step prompts name \\\n",
|
| 475 |
+
"0 2 Answer the following questions as best you can... OpenAI \n",
|
| 476 |
+
"1 7 Answer the following questions as best you can... OpenAI \n",
|
| 477 |
+
"2 12 Answer the following questions as best you can... OpenAI \n",
|
| 478 |
+
"\n",
|
| 479 |
+
" output_step output \\\n",
|
| 480 |
+
"0 3 I need to find out who sang summer of 69 and ... \n",
|
| 481 |
+
"1 8 I need to find out who Bryan Adams is married... \n",
|
| 482 |
+
"2 13 I now know the final answer.\\nFinal Answer: B... \n",
|
| 483 |
+
"\n",
|
| 484 |
+
" token_usage_total_tokens token_usage_prompt_tokens \\\n",
|
| 485 |
+
"0 223 189 \n",
|
| 486 |
+
"1 270 242 \n",
|
| 487 |
+
"2 332 314 \n",
|
| 488 |
+
"\n",
|
| 489 |
+
" token_usage_completion_tokens flesch_reading_ease flesch_kincaid_grade \\\n",
|
| 490 |
+
"0 34 91.61 3.8 \n",
|
| 491 |
+
"1 28 94.66 2.7 \n",
|
| 492 |
+
"2 18 81.29 3.7 \n",
|
| 493 |
+
"\n",
|
| 494 |
+
" ... difficult_words linsear_write_formula gunning_fog \\\n",
|
| 495 |
+
"0 ... 2 5.75 5.4 \n",
|
| 496 |
+
"1 ... 2 4.25 4.2 \n",
|
| 497 |
+
"2 ... 1 2.50 2.8 \n",
|
| 498 |
+
"\n",
|
| 499 |
+
" text_standard fernandez_huerta szigriszt_pazos gutierrez_polini \\\n",
|
| 500 |
+
"0 3rd and 4th grade 121.07 119.50 54.91 \n",
|
| 501 |
+
"1 4th and 5th grade 124.13 119.20 52.26 \n",
|
| 502 |
+
"2 3rd and 4th grade 115.70 110.84 49.79 \n",
|
| 503 |
+
"\n",
|
| 504 |
+
" crawford gulpease_index osman \n",
|
| 505 |
+
"0 0.9 72.7 92.16 \n",
|
| 506 |
+
"1 0.7 74.7 84.20 \n",
|
| 507 |
+
"2 0.7 85.4 83.14 \n",
|
| 508 |
+
"\n",
|
| 509 |
+
"[3 rows x 24 columns]}\n"
|
| 510 |
+
]
|
| 511 |
+
},
|
| 512 |
+
{
|
| 513 |
+
"name": "stderr",
|
| 514 |
+
"output_type": "stream",
|
| 515 |
+
"text": [
|
| 516 |
+
"Could not update last created model in Task 988bd727b0e94a29a3ac0ee526813545, Task status 'completed' cannot be updated\n"
|
| 517 |
+
]
|
| 518 |
+
}
|
| 519 |
+
],
|
| 520 |
+
"source": [
|
| 521 |
+
"from langchain.agents import initialize_agent, load_tools\n",
|
| 522 |
+
"from langchain.agents import AgentType\n",
|
| 523 |
+
"\n",
|
| 524 |
+
"# SCENARIO 2 - Agent with Tools\n",
|
| 525 |
+
"tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm, callbacks=callbacks)\n",
|
| 526 |
+
"agent = initialize_agent(\n",
|
| 527 |
+
" tools,\n",
|
| 528 |
+
" llm,\n",
|
| 529 |
+
" agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,\n",
|
| 530 |
+
" callbacks=callbacks,\n",
|
| 531 |
+
")\n",
|
| 532 |
+
"agent.run(\n",
|
| 533 |
+
" \"Who is the wife of the person who sang summer of 69?\"\n",
|
| 534 |
+
")\n",
|
| 535 |
+
"clearml_callback.flush_tracker(langchain_asset=agent, name=\"Agent with Tools\", finish=True)"
|
| 536 |
+
]
|
| 537 |
+
},
|
| 538 |
+
{
|
| 539 |
+
"attachments": {},
|
| 540 |
+
"cell_type": "markdown",
|
| 541 |
+
"metadata": {},
|
| 542 |
+
"source": [
|
| 543 |
+
"## Tips and Next Steps\n",
|
| 544 |
+
"\n",
|
| 545 |
+
"- Make sure you always use a unique `name` argument for the `clearml_callback.flush_tracker` function. If not, the model parameters used for a run will override the previous run!\n",
|
| 546 |
+
"\n",
|
| 547 |
+
"- If you close the ClearML Callback using `clearml_callback.flush_tracker(..., finish=True)` the Callback cannot be used anymore. Make a new one if you want to keep logging.\n",
|
| 548 |
+
"\n",
|
| 549 |
+
"- Check out the rest of the open source ClearML ecosystem, there is a data version manager, a remote execution agent, automated pipelines and much more!\n"
|
| 550 |
+
]
|
| 551 |
+
},
|
| 552 |
+
{
|
| 553 |
+
"cell_type": "code",
|
| 554 |
+
"execution_count": null,
|
| 555 |
+
"metadata": {},
|
| 556 |
+
"outputs": [],
|
| 557 |
+
"source": []
|
| 558 |
+
}
|
| 559 |
+
],
|
| 560 |
+
"metadata": {
|
| 561 |
+
"kernelspec": {
|
| 562 |
+
"display_name": ".venv",
|
| 563 |
+
"language": "python",
|
| 564 |
+
"name": "python3"
|
| 565 |
+
},
|
| 566 |
+
"language_info": {
|
| 567 |
+
"codemirror_mode": {
|
| 568 |
+
"name": "ipython",
|
| 569 |
+
"version": 3
|
| 570 |
+
},
|
| 571 |
+
"file_extension": ".py",
|
| 572 |
+
"mimetype": "text/x-python",
|
| 573 |
+
"name": "python",
|
| 574 |
+
"nbconvert_exporter": "python",
|
| 575 |
+
"pygments_lexer": "ipython3",
|
| 576 |
+
"version": "3.10.9"
|
| 577 |
+
},
|
| 578 |
+
"orig_nbformat": 4,
|
| 579 |
+
"vscode": {
|
| 580 |
+
"interpreter": {
|
| 581 |
+
"hash": "a53ebf4a859167383b364e7e7521d0add3c2dbbdecce4edf676e8c4634ff3fbb"
|
| 582 |
+
}
|
| 583 |
+
}
|
| 584 |
+
},
|
| 585 |
+
"nbformat": 4,
|
| 586 |
+
"nbformat_minor": 2
|
| 587 |
+
}
|
langchain/docs/ecosystem/cohere.md
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Cohere
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Cohere ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Cohere wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install the Python SDK with `pip install cohere`
|
| 8 |
+
- Get an Cohere api key and set it as an environment variable (`COHERE_API_KEY`)
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### LLM
|
| 13 |
+
|
| 14 |
+
There exists an Cohere LLM wrapper, which you can access with
|
| 15 |
+
```python
|
| 16 |
+
from langchain.llms import Cohere
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
### Embeddings
|
| 20 |
+
|
| 21 |
+
There exists an Cohere Embeddings wrapper, which you can access with
|
| 22 |
+
```python
|
| 23 |
+
from langchain.embeddings import CohereEmbeddings
|
| 24 |
+
```
|
| 25 |
+
For a more detailed walkthrough of this, see [this notebook](../modules/models/text_embedding/examples/cohere.ipynb)
|
langchain/docs/ecosystem/comet_tracking.ipynb
ADDED
|
@@ -0,0 +1,347 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"# Comet"
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"cell_type": "markdown",
|
| 12 |
+
"metadata": {},
|
| 13 |
+
"source": [
|
| 14 |
+
""
|
| 15 |
+
]
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"cell_type": "markdown",
|
| 19 |
+
"metadata": {},
|
| 20 |
+
"source": [
|
| 21 |
+
"In this guide we will demonstrate how to track your Langchain Experiments, Evaluation Metrics, and LLM Sessions with [Comet](https://www.comet.com/site/?utm_source=langchain&utm_medium=referral&utm_campaign=comet_notebook). \n",
|
| 22 |
+
"\n",
|
| 23 |
+
"<a target=\"_blank\" href=\"https://colab.research.google.com/github/hwchase17/langchain/blob/master/docs/ecosystem/comet_tracking.ipynb\">\n",
|
| 24 |
+
" <img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/>\n",
|
| 25 |
+
"</a>\n",
|
| 26 |
+
"\n",
|
| 27 |
+
"**Example Project:** [Comet with LangChain](https://www.comet.com/examples/comet-example-langchain/view/b5ZThK6OFdhKWVSP3fDfRtrNF/panels?utm_source=langchain&utm_medium=referral&utm_campaign=comet_notebook)"
|
| 28 |
+
]
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"cell_type": "markdown",
|
| 32 |
+
"metadata": {},
|
| 33 |
+
"source": [
|
| 34 |
+
"<img width=\"1280\" alt=\"comet-langchain\" src=\"https://user-images.githubusercontent.com/7529846/230326720-a9711435-9c6f-4edb-a707-94b67271ab25.png\">\n"
|
| 35 |
+
]
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"cell_type": "markdown",
|
| 39 |
+
"metadata": {},
|
| 40 |
+
"source": [
|
| 41 |
+
"### Install Comet and Dependencies"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "code",
|
| 46 |
+
"execution_count": null,
|
| 47 |
+
"metadata": {},
|
| 48 |
+
"outputs": [],
|
| 49 |
+
"source": [
|
| 50 |
+
"%pip install comet_ml langchain openai google-search-results spacy textstat pandas\n",
|
| 51 |
+
"\n",
|
| 52 |
+
"import sys\n",
|
| 53 |
+
"!{sys.executable} -m spacy download en_core_web_sm"
|
| 54 |
+
]
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"cell_type": "markdown",
|
| 58 |
+
"metadata": {},
|
| 59 |
+
"source": [
|
| 60 |
+
"### Initialize Comet and Set your Credentials"
|
| 61 |
+
]
|
| 62 |
+
},
|
| 63 |
+
{
|
| 64 |
+
"cell_type": "markdown",
|
| 65 |
+
"metadata": {},
|
| 66 |
+
"source": [
|
| 67 |
+
"You can grab your [Comet API Key here](https://www.comet.com/signup?utm_source=langchain&utm_medium=referral&utm_campaign=comet_notebook) or click the link after initializing Comet"
|
| 68 |
+
]
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
"cell_type": "code",
|
| 72 |
+
"execution_count": null,
|
| 73 |
+
"metadata": {},
|
| 74 |
+
"outputs": [],
|
| 75 |
+
"source": [
|
| 76 |
+
"import comet_ml\n",
|
| 77 |
+
"\n",
|
| 78 |
+
"comet_ml.init(project_name=\"comet-example-langchain\")"
|
| 79 |
+
]
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"cell_type": "markdown",
|
| 83 |
+
"metadata": {},
|
| 84 |
+
"source": [
|
| 85 |
+
"### Set OpenAI and SerpAPI credentials"
|
| 86 |
+
]
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"cell_type": "markdown",
|
| 90 |
+
"metadata": {},
|
| 91 |
+
"source": [
|
| 92 |
+
"You will need an [OpenAI API Key](https://platform.openai.com/account/api-keys) and a [SerpAPI API Key](https://serpapi.com/dashboard) to run the following examples"
|
| 93 |
+
]
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"cell_type": "code",
|
| 97 |
+
"execution_count": null,
|
| 98 |
+
"metadata": {},
|
| 99 |
+
"outputs": [],
|
| 100 |
+
"source": [
|
| 101 |
+
"import os\n",
|
| 102 |
+
"\n",
|
| 103 |
+
"os.environ[\"OPENAI_API_KEY\"] = \"...\"\n",
|
| 104 |
+
"#os.environ[\"OPENAI_ORGANIZATION\"] = \"...\"\n",
|
| 105 |
+
"os.environ[\"SERPAPI_API_KEY\"] = \"...\""
|
| 106 |
+
]
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"cell_type": "markdown",
|
| 110 |
+
"metadata": {},
|
| 111 |
+
"source": [
|
| 112 |
+
"### Scenario 1: Using just an LLM"
|
| 113 |
+
]
|
| 114 |
+
},
|
| 115 |
+
{
|
| 116 |
+
"cell_type": "code",
|
| 117 |
+
"execution_count": null,
|
| 118 |
+
"metadata": {},
|
| 119 |
+
"outputs": [],
|
| 120 |
+
"source": [
|
| 121 |
+
"from datetime import datetime\n",
|
| 122 |
+
"\n",
|
| 123 |
+
"from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandler\n",
|
| 124 |
+
"from langchain.llms import OpenAI\n",
|
| 125 |
+
"\n",
|
| 126 |
+
"comet_callback = CometCallbackHandler(\n",
|
| 127 |
+
" project_name=\"comet-example-langchain\",\n",
|
| 128 |
+
" complexity_metrics=True,\n",
|
| 129 |
+
" stream_logs=True,\n",
|
| 130 |
+
" tags=[\"llm\"],\n",
|
| 131 |
+
" visualizations=[\"dep\"],\n",
|
| 132 |
+
")\n",
|
| 133 |
+
"callbacks = [StdOutCallbackHandler(), comet_callback]\n",
|
| 134 |
+
"llm = OpenAI(temperature=0.9, callbacks=callbacks, verbose=True)\n",
|
| 135 |
+
"\n",
|
| 136 |
+
"llm_result = llm.generate([\"Tell me a joke\", \"Tell me a poem\", \"Tell me a fact\"] * 3)\n",
|
| 137 |
+
"print(\"LLM result\", llm_result)\n",
|
| 138 |
+
"comet_callback.flush_tracker(llm, finish=True)"
|
| 139 |
+
]
|
| 140 |
+
},
|
| 141 |
+
{
|
| 142 |
+
"cell_type": "markdown",
|
| 143 |
+
"metadata": {},
|
| 144 |
+
"source": [
|
| 145 |
+
"### Scenario 2: Using an LLM in a Chain"
|
| 146 |
+
]
|
| 147 |
+
},
|
| 148 |
+
{
|
| 149 |
+
"cell_type": "code",
|
| 150 |
+
"execution_count": null,
|
| 151 |
+
"metadata": {},
|
| 152 |
+
"outputs": [],
|
| 153 |
+
"source": [
|
| 154 |
+
"from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandler\n",
|
| 155 |
+
"from langchain.chains import LLMChain\n",
|
| 156 |
+
"from langchain.llms import OpenAI\n",
|
| 157 |
+
"from langchain.prompts import PromptTemplate\n",
|
| 158 |
+
"\n",
|
| 159 |
+
"comet_callback = CometCallbackHandler(\n",
|
| 160 |
+
" complexity_metrics=True,\n",
|
| 161 |
+
" project_name=\"comet-example-langchain\",\n",
|
| 162 |
+
" stream_logs=True,\n",
|
| 163 |
+
" tags=[\"synopsis-chain\"],\n",
|
| 164 |
+
")\n",
|
| 165 |
+
"callbacks = [StdOutCallbackHandler(), comet_callback]\n",
|
| 166 |
+
"llm = OpenAI(temperature=0.9, callbacks=callbacks)\n",
|
| 167 |
+
"\n",
|
| 168 |
+
"template = \"\"\"You are a playwright. Given the title of play, it is your job to write a synopsis for that title.\n",
|
| 169 |
+
"Title: {title}\n",
|
| 170 |
+
"Playwright: This is a synopsis for the above play:\"\"\"\n",
|
| 171 |
+
"prompt_template = PromptTemplate(input_variables=[\"title\"], template=template)\n",
|
| 172 |
+
"synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, callbacks=callbacks)\n",
|
| 173 |
+
"\n",
|
| 174 |
+
"test_prompts = [{\"title\": \"Documentary about Bigfoot in Paris\"}]\n",
|
| 175 |
+
"print(synopsis_chain.apply(test_prompts))\n",
|
| 176 |
+
"comet_callback.flush_tracker(synopsis_chain, finish=True)"
|
| 177 |
+
]
|
| 178 |
+
},
|
| 179 |
+
{
|
| 180 |
+
"cell_type": "markdown",
|
| 181 |
+
"metadata": {},
|
| 182 |
+
"source": [
|
| 183 |
+
"### Scenario 3: Using An Agent with Tools "
|
| 184 |
+
]
|
| 185 |
+
},
|
| 186 |
+
{
|
| 187 |
+
"cell_type": "code",
|
| 188 |
+
"execution_count": null,
|
| 189 |
+
"metadata": {},
|
| 190 |
+
"outputs": [],
|
| 191 |
+
"source": [
|
| 192 |
+
"from langchain.agents import initialize_agent, load_tools\n",
|
| 193 |
+
"from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandler\n",
|
| 194 |
+
"from langchain.llms import OpenAI\n",
|
| 195 |
+
"\n",
|
| 196 |
+
"comet_callback = CometCallbackHandler(\n",
|
| 197 |
+
" project_name=\"comet-example-langchain\",\n",
|
| 198 |
+
" complexity_metrics=True,\n",
|
| 199 |
+
" stream_logs=True,\n",
|
| 200 |
+
" tags=[\"agent\"],\n",
|
| 201 |
+
")\n",
|
| 202 |
+
"callbacks = [StdOutCallbackHandler(), comet_callback]\n",
|
| 203 |
+
"llm = OpenAI(temperature=0.9, callbacks=callbacks)\n",
|
| 204 |
+
"\n",
|
| 205 |
+
"tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm, callbacks=callbacks)\n",
|
| 206 |
+
"agent = initialize_agent(\n",
|
| 207 |
+
" tools,\n",
|
| 208 |
+
" llm,\n",
|
| 209 |
+
" agent=\"zero-shot-react-description\",\n",
|
| 210 |
+
" callbacks=callbacks,\n",
|
| 211 |
+
" verbose=True,\n",
|
| 212 |
+
")\n",
|
| 213 |
+
"agent.run(\n",
|
| 214 |
+
" \"Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?\"\n",
|
| 215 |
+
")\n",
|
| 216 |
+
"comet_callback.flush_tracker(agent, finish=True)"
|
| 217 |
+
]
|
| 218 |
+
},
|
| 219 |
+
{
|
| 220 |
+
"cell_type": "markdown",
|
| 221 |
+
"metadata": {},
|
| 222 |
+
"source": [
|
| 223 |
+
"### Scenario 4: Using Custom Evaluation Metrics"
|
| 224 |
+
]
|
| 225 |
+
},
|
| 226 |
+
{
|
| 227 |
+
"cell_type": "markdown",
|
| 228 |
+
"metadata": {},
|
| 229 |
+
"source": [
|
| 230 |
+
"The `CometCallbackManager` also allows you to define and use Custom Evaluation Metrics to assess generated outputs from your model. Let's take a look at how this works. \n",
|
| 231 |
+
"\n",
|
| 232 |
+
"\n",
|
| 233 |
+
"In the snippet below, we will use the [ROUGE](https://huggingface.co/spaces/evaluate-metric/rouge) metric to evaluate the quality of a generated summary of an input prompt. "
|
| 234 |
+
]
|
| 235 |
+
},
|
| 236 |
+
{
|
| 237 |
+
"cell_type": "code",
|
| 238 |
+
"execution_count": null,
|
| 239 |
+
"metadata": {},
|
| 240 |
+
"outputs": [],
|
| 241 |
+
"source": [
|
| 242 |
+
"%pip install rouge-score"
|
| 243 |
+
]
|
| 244 |
+
},
|
| 245 |
+
{
|
| 246 |
+
"cell_type": "code",
|
| 247 |
+
"execution_count": null,
|
| 248 |
+
"metadata": {},
|
| 249 |
+
"outputs": [],
|
| 250 |
+
"source": [
|
| 251 |
+
"from rouge_score import rouge_scorer\n",
|
| 252 |
+
"\n",
|
| 253 |
+
"from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandler\n",
|
| 254 |
+
"from langchain.chains import LLMChain\n",
|
| 255 |
+
"from langchain.llms import OpenAI\n",
|
| 256 |
+
"from langchain.prompts import PromptTemplate\n",
|
| 257 |
+
"\n",
|
| 258 |
+
"\n",
|
| 259 |
+
"class Rouge:\n",
|
| 260 |
+
" def __init__(self, reference):\n",
|
| 261 |
+
" self.reference = reference\n",
|
| 262 |
+
" self.scorer = rouge_scorer.RougeScorer([\"rougeLsum\"], use_stemmer=True)\n",
|
| 263 |
+
"\n",
|
| 264 |
+
" def compute_metric(self, generation, prompt_idx, gen_idx):\n",
|
| 265 |
+
" prediction = generation.text\n",
|
| 266 |
+
" results = self.scorer.score(target=self.reference, prediction=prediction)\n",
|
| 267 |
+
"\n",
|
| 268 |
+
" return {\n",
|
| 269 |
+
" \"rougeLsum_score\": results[\"rougeLsum\"].fmeasure,\n",
|
| 270 |
+
" \"reference\": self.reference,\n",
|
| 271 |
+
" }\n",
|
| 272 |
+
"\n",
|
| 273 |
+
"\n",
|
| 274 |
+
"reference = \"\"\"\n",
|
| 275 |
+
"The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building.\n",
|
| 276 |
+
"It was the first structure to reach a height of 300 metres.\n",
|
| 277 |
+
"\n",
|
| 278 |
+
"It is now taller than the Chrysler Building in New York City by 5.2 metres (17 ft)\n",
|
| 279 |
+
"Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France .\n",
|
| 280 |
+
"\"\"\"\n",
|
| 281 |
+
"rouge_score = Rouge(reference=reference)\n",
|
| 282 |
+
"\n",
|
| 283 |
+
"template = \"\"\"Given the following article, it is your job to write a summary.\n",
|
| 284 |
+
"Article:\n",
|
| 285 |
+
"{article}\n",
|
| 286 |
+
"Summary: This is the summary for the above article:\"\"\"\n",
|
| 287 |
+
"prompt_template = PromptTemplate(input_variables=[\"article\"], template=template)\n",
|
| 288 |
+
"\n",
|
| 289 |
+
"comet_callback = CometCallbackHandler(\n",
|
| 290 |
+
" project_name=\"comet-example-langchain\",\n",
|
| 291 |
+
" complexity_metrics=False,\n",
|
| 292 |
+
" stream_logs=True,\n",
|
| 293 |
+
" tags=[\"custom_metrics\"],\n",
|
| 294 |
+
" custom_metrics=rouge_score.compute_metric,\n",
|
| 295 |
+
")\n",
|
| 296 |
+
"callbacks = [StdOutCallbackHandler(), comet_callback]\n",
|
| 297 |
+
"llm = OpenAI(temperature=0.9)\n",
|
| 298 |
+
"\n",
|
| 299 |
+
"synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)\n",
|
| 300 |
+
"\n",
|
| 301 |
+
"test_prompts = [\n",
|
| 302 |
+
" {\n",
|
| 303 |
+
" \"article\": \"\"\"\n",
|
| 304 |
+
" The tower is 324 metres (1,063 ft) tall, about the same height as\n",
|
| 305 |
+
" an 81-storey building, and the tallest structure in Paris. Its base is square,\n",
|
| 306 |
+
" measuring 125 metres (410 ft) on each side.\n",
|
| 307 |
+
" During its construction, the Eiffel Tower surpassed the\n",
|
| 308 |
+
" Washington Monument to become the tallest man-made structure in the world,\n",
|
| 309 |
+
" a title it held for 41 years until the Chrysler Building\n",
|
| 310 |
+
" in New York City was finished in 1930.\n",
|
| 311 |
+
"\n",
|
| 312 |
+
" It was the first structure to reach a height of 300 metres.\n",
|
| 313 |
+
" Due to the addition of a broadcasting aerial at the top of the tower in 1957,\n",
|
| 314 |
+
" it is now taller than the Chrysler Building by 5.2 metres (17 ft).\n",
|
| 315 |
+
"\n",
|
| 316 |
+
" Excluding transmitters, the Eiffel Tower is the second tallest\n",
|
| 317 |
+
" free-standing structure in France after the Millau Viaduct.\n",
|
| 318 |
+
" \"\"\"\n",
|
| 319 |
+
" }\n",
|
| 320 |
+
"]\n",
|
| 321 |
+
"print(synopsis_chain.apply(test_prompts, callbacks=callbacks))\n",
|
| 322 |
+
"comet_callback.flush_tracker(synopsis_chain, finish=True)"
|
| 323 |
+
]
|
| 324 |
+
}
|
| 325 |
+
],
|
| 326 |
+
"metadata": {
|
| 327 |
+
"kernelspec": {
|
| 328 |
+
"display_name": "Python 3 (ipykernel)",
|
| 329 |
+
"language": "python",
|
| 330 |
+
"name": "python3"
|
| 331 |
+
},
|
| 332 |
+
"language_info": {
|
| 333 |
+
"codemirror_mode": {
|
| 334 |
+
"name": "ipython",
|
| 335 |
+
"version": 3
|
| 336 |
+
},
|
| 337 |
+
"file_extension": ".py",
|
| 338 |
+
"mimetype": "text/x-python",
|
| 339 |
+
"name": "python",
|
| 340 |
+
"nbconvert_exporter": "python",
|
| 341 |
+
"pygments_lexer": "ipython3",
|
| 342 |
+
"version": "3.9.15"
|
| 343 |
+
}
|
| 344 |
+
},
|
| 345 |
+
"nbformat": 4,
|
| 346 |
+
"nbformat_minor": 2
|
| 347 |
+
}
|
langchain/docs/ecosystem/databerry.md
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Databerry
|
| 2 |
+
|
| 3 |
+
This page covers how to use the [Databerry](https://databerry.ai) within LangChain.
|
| 4 |
+
|
| 5 |
+
## What is Databerry?
|
| 6 |
+
|
| 7 |
+
Databerry is an [open source](https://github.com/gmpetrov/databerry) document retrievial platform that helps to connect your personal data with Large Language Models.
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
## Quick start
|
| 12 |
+
|
| 13 |
+
Retrieving documents stored in Databerry from LangChain is very easy!
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
from langchain.retrievers import DataberryRetriever
|
| 17 |
+
|
| 18 |
+
retriever = DataberryRetriever(
|
| 19 |
+
datastore_url="https://api.databerry.ai/query/clg1xg2h80000l708dymr0fxc",
|
| 20 |
+
# api_key="DATABERRY_API_KEY", # optional if datastore is public
|
| 21 |
+
# top_k=10 # optional
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
docs = retriever.get_relevant_documents("What's Databerry?")
|
| 25 |
+
```
|
langchain/docs/ecosystem/deepinfra.md
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DeepInfra
|
| 2 |
+
|
| 3 |
+
This page covers how to use the DeepInfra ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific DeepInfra wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Get your DeepInfra api key from this link [here](https://deepinfra.com/).
|
| 8 |
+
- Get an DeepInfra api key and set it as an environment variable (`DEEPINFRA_API_TOKEN`)
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### LLM
|
| 13 |
+
|
| 14 |
+
There exists an DeepInfra LLM wrapper, which you can access with
|
| 15 |
+
```python
|
| 16 |
+
from langchain.llms import DeepInfra
|
| 17 |
+
```
|
langchain/docs/ecosystem/deeplake.md
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Deep Lake
|
| 2 |
+
This page covers how to use the Deep Lake ecosystem within LangChain.
|
| 3 |
+
|
| 4 |
+
## Why Deep Lake?
|
| 5 |
+
- More than just a (multi-modal) vector store. You can later use the dataset to fine-tune your own LLM models.
|
| 6 |
+
- Not only stores embeddings, but also the original data with automatic version control.
|
| 7 |
+
- Truly serverless. Doesn't require another service and can be used with major cloud providers (AWS S3, GCS, etc.)
|
| 8 |
+
|
| 9 |
+
## More Resources
|
| 10 |
+
1. [Ultimate Guide to LangChain & Deep Lake: Build ChatGPT to Answer Questions on Your Financial Data](https://www.activeloop.ai/resources/ultimate-guide-to-lang-chain-deep-lake-build-chat-gpt-to-answer-questions-on-your-financial-data/)
|
| 11 |
+
2. [Twitter the-algorithm codebase analysis with Deep Lake](../use_cases/code/twitter-the-algorithm-analysis-deeplake.ipynb)
|
| 12 |
+
3. Here is [whitepaper](https://www.deeplake.ai/whitepaper) and [academic paper](https://arxiv.org/pdf/2209.10785.pdf) for Deep Lake
|
| 13 |
+
4. Here is a set of additional resources available for review: [Deep Lake](https://github.com/activeloopai/deeplake), [Getting Started](https://docs.activeloop.ai/getting-started) and [Tutorials](https://docs.activeloop.ai/hub-tutorials)
|
| 14 |
+
|
| 15 |
+
## Installation and Setup
|
| 16 |
+
- Install the Python package with `pip install deeplake`
|
| 17 |
+
|
| 18 |
+
## Wrappers
|
| 19 |
+
|
| 20 |
+
### VectorStore
|
| 21 |
+
|
| 22 |
+
There exists a wrapper around Deep Lake, a data lake for Deep Learning applications, allowing you to use it as a vector store (for now), whether for semantic search or example selection.
|
| 23 |
+
|
| 24 |
+
To import this vectorstore:
|
| 25 |
+
```python
|
| 26 |
+
from langchain.vectorstores import DeepLake
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
For a more detailed walkthrough of the Deep Lake wrapper, see [this notebook](../modules/indexes/vectorstores/examples/deeplake.ipynb)
|
langchain/docs/ecosystem/forefrontai.md
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ForefrontAI
|
| 2 |
+
|
| 3 |
+
This page covers how to use the ForefrontAI ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific ForefrontAI wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Get an ForefrontAI api key and set it as an environment variable (`FOREFRONTAI_API_KEY`)
|
| 8 |
+
|
| 9 |
+
## Wrappers
|
| 10 |
+
|
| 11 |
+
### LLM
|
| 12 |
+
|
| 13 |
+
There exists an ForefrontAI LLM wrapper, which you can access with
|
| 14 |
+
```python
|
| 15 |
+
from langchain.llms import ForefrontAI
|
| 16 |
+
```
|
langchain/docs/ecosystem/google_search.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Google Search Wrapper
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Google Search API within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to the specific Google Search wrapper.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install requirements with `pip install google-api-python-client`
|
| 8 |
+
- Set up a Custom Search Engine, following [these instructions](https://stackoverflow.com/questions/37083058/programmatically-searching-google-in-python-using-custom-search)
|
| 9 |
+
- Get an API Key and Custom Search Engine ID from the previous step, and set them as environment variables `GOOGLE_API_KEY` and `GOOGLE_CSE_ID` respectively
|
| 10 |
+
|
| 11 |
+
## Wrappers
|
| 12 |
+
|
| 13 |
+
### Utility
|
| 14 |
+
|
| 15 |
+
There exists a GoogleSearchAPIWrapper utility which wraps this API. To import this utility:
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from langchain.utilities import GoogleSearchAPIWrapper
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
For a more detailed walkthrough of this wrapper, see [this notebook](../modules/agents/tools/examples/google_search.ipynb).
|
| 22 |
+
|
| 23 |
+
### Tool
|
| 24 |
+
|
| 25 |
+
You can also easily load this wrapper as a Tool (to use with an Agent).
|
| 26 |
+
You can do this with:
|
| 27 |
+
```python
|
| 28 |
+
from langchain.agents import load_tools
|
| 29 |
+
tools = load_tools(["google-search"])
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
For more information on this, see [this page](../modules/agents/tools/getting_started.md)
|
langchain/docs/ecosystem/google_serper.md
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Google Serper Wrapper
|
| 2 |
+
|
| 3 |
+
This page covers how to use the [Serper](https://serper.dev) Google Search API within LangChain. Serper is a low-cost Google Search API that can be used to add answer box, knowledge graph, and organic results data from Google Search.
|
| 4 |
+
It is broken into two parts: setup, and then references to the specific Google Serper wrapper.
|
| 5 |
+
|
| 6 |
+
## Setup
|
| 7 |
+
- Go to [serper.dev](https://serper.dev) to sign up for a free account
|
| 8 |
+
- Get the api key and set it as an environment variable (`SERPER_API_KEY`)
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### Utility
|
| 13 |
+
|
| 14 |
+
There exists a GoogleSerperAPIWrapper utility which wraps this API. To import this utility:
|
| 15 |
+
|
| 16 |
+
```python
|
| 17 |
+
from langchain.utilities import GoogleSerperAPIWrapper
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
You can use it as part of a Self Ask chain:
|
| 21 |
+
|
| 22 |
+
```python
|
| 23 |
+
from langchain.utilities import GoogleSerperAPIWrapper
|
| 24 |
+
from langchain.llms.openai import OpenAI
|
| 25 |
+
from langchain.agents import initialize_agent, Tool
|
| 26 |
+
from langchain.agents import AgentType
|
| 27 |
+
|
| 28 |
+
import os
|
| 29 |
+
|
| 30 |
+
os.environ["SERPER_API_KEY"] = ""
|
| 31 |
+
os.environ['OPENAI_API_KEY'] = ""
|
| 32 |
+
|
| 33 |
+
llm = OpenAI(temperature=0)
|
| 34 |
+
search = GoogleSerperAPIWrapper()
|
| 35 |
+
tools = [
|
| 36 |
+
Tool(
|
| 37 |
+
name="Intermediate Answer",
|
| 38 |
+
func=search.run,
|
| 39 |
+
description="useful for when you need to ask with search"
|
| 40 |
+
)
|
| 41 |
+
]
|
| 42 |
+
|
| 43 |
+
self_ask_with_search = initialize_agent(tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True)
|
| 44 |
+
self_ask_with_search.run("What is the hometown of the reigning men's U.S. Open champion?")
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
#### Output
|
| 48 |
+
```
|
| 49 |
+
Entering new AgentExecutor chain...
|
| 50 |
+
Yes.
|
| 51 |
+
Follow up: Who is the reigning men's U.S. Open champion?
|
| 52 |
+
Intermediate answer: Current champions Carlos Alcaraz, 2022 men's singles champion.
|
| 53 |
+
Follow up: Where is Carlos Alcaraz from?
|
| 54 |
+
Intermediate answer: El Palmar, Spain
|
| 55 |
+
So the final answer is: El Palmar, Spain
|
| 56 |
+
|
| 57 |
+
> Finished chain.
|
| 58 |
+
|
| 59 |
+
'El Palmar, Spain'
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
For a more detailed walkthrough of this wrapper, see [this notebook](../modules/agents/tools/examples/google_serper.ipynb).
|
| 63 |
+
|
| 64 |
+
### Tool
|
| 65 |
+
|
| 66 |
+
You can also easily load this wrapper as a Tool (to use with an Agent).
|
| 67 |
+
You can do this with:
|
| 68 |
+
```python
|
| 69 |
+
from langchain.agents import load_tools
|
| 70 |
+
tools = load_tools(["google-serper"])
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
For more information on this, see [this page](../modules/agents/tools/getting_started.md)
|
langchain/docs/ecosystem/gooseai.md
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GooseAI
|
| 2 |
+
|
| 3 |
+
This page covers how to use the GooseAI ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific GooseAI wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install the Python SDK with `pip install openai`
|
| 8 |
+
- Get your GooseAI api key from this link [here](https://goose.ai/).
|
| 9 |
+
- Set the environment variable (`GOOSEAI_API_KEY`).
|
| 10 |
+
|
| 11 |
+
```python
|
| 12 |
+
import os
|
| 13 |
+
os.environ["GOOSEAI_API_KEY"] = "YOUR_API_KEY"
|
| 14 |
+
```
|
| 15 |
+
|
| 16 |
+
## Wrappers
|
| 17 |
+
|
| 18 |
+
### LLM
|
| 19 |
+
|
| 20 |
+
There exists an GooseAI LLM wrapper, which you can access with:
|
| 21 |
+
```python
|
| 22 |
+
from langchain.llms import GooseAI
|
| 23 |
+
```
|
langchain/docs/ecosystem/gpt4all.md
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GPT4All
|
| 2 |
+
|
| 3 |
+
This page covers how to use the `GPT4All` wrapper within LangChain. The tutorial is divided into two parts: installation and setup, followed by usage with an example.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
- Install the Python package with `pip install pyllamacpp`
|
| 8 |
+
- Download a [GPT4All model](https://github.com/nomic-ai/pyllamacpp#supported-model) and place it in your desired directory
|
| 9 |
+
|
| 10 |
+
## Usage
|
| 11 |
+
|
| 12 |
+
### GPT4All
|
| 13 |
+
|
| 14 |
+
To use the GPT4All wrapper, you need to provide the path to the pre-trained model file and the model's configuration.
|
| 15 |
+
|
| 16 |
+
```python
|
| 17 |
+
from langchain.llms import GPT4All
|
| 18 |
+
|
| 19 |
+
# Instantiate the model. Callbacks support token-wise streaming
|
| 20 |
+
model = GPT4All(model="./models/gpt4all-model.bin", n_ctx=512, n_threads=8)
|
| 21 |
+
|
| 22 |
+
# Generate text
|
| 23 |
+
response = model("Once upon a time, ")
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
You can also customize the generation parameters, such as n_predict, temp, top_p, top_k, and others.
|
| 27 |
+
|
| 28 |
+
To stream the model's predictions, add in a CallbackManager.
|
| 29 |
+
|
| 30 |
+
```python
|
| 31 |
+
from langchain.llms import GPT4All
|
| 32 |
+
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
|
| 33 |
+
|
| 34 |
+
# There are many CallbackHandlers supported, such as
|
| 35 |
+
# from langchain.callbacks.streamlit import StreamlitCallbackHandler
|
| 36 |
+
|
| 37 |
+
callbacks = [StreamingStdOutCallbackHandler()]
|
| 38 |
+
model = GPT4All(model="./models/gpt4all-model.bin", n_ctx=512, n_threads=8)
|
| 39 |
+
|
| 40 |
+
# Generate text. Tokens are streamed through the callback manager.
|
| 41 |
+
model("Once upon a time, ", callbacks=callbacks)
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
## Model File
|
| 45 |
+
|
| 46 |
+
You can find links to model file downloads in the [pyllamacpp](https://github.com/nomic-ai/pyllamacpp) repository.
|
| 47 |
+
|
| 48 |
+
For a more detailed walkthrough of this, see [this notebook](../modules/models/llms/integrations/gpt4all.ipynb)
|
langchain/docs/ecosystem/graphsignal.md
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Graphsignal
|
| 2 |
+
|
| 3 |
+
This page covers how to use [Graphsignal](https://app.graphsignal.com) to trace and monitor LangChain. Graphsignal enables full visibility into your application. It provides latency breakdowns by chains and tools, exceptions with full context, data monitoring, compute/GPU utilization, OpenAI cost analytics, and more.
|
| 4 |
+
|
| 5 |
+
## Installation and Setup
|
| 6 |
+
|
| 7 |
+
- Install the Python library with `pip install graphsignal`
|
| 8 |
+
- Create free Graphsignal account [here](https://graphsignal.com)
|
| 9 |
+
- Get an API key and set it as an environment variable (`GRAPHSIGNAL_API_KEY`)
|
| 10 |
+
|
| 11 |
+
## Tracing and Monitoring
|
| 12 |
+
|
| 13 |
+
Graphsignal automatically instruments and starts tracing and monitoring chains. Traces and metrics are then available in your [Graphsignal dashboards](https://app.graphsignal.com).
|
| 14 |
+
|
| 15 |
+
Initialize the tracer by providing a deployment name:
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
import graphsignal
|
| 19 |
+
|
| 20 |
+
graphsignal.configure(deployment='my-langchain-app-prod')
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
To additionally trace any function or code, you can use a decorator or a context manager:
|
| 24 |
+
|
| 25 |
+
```python
|
| 26 |
+
@graphsignal.trace_function
|
| 27 |
+
def handle_request():
|
| 28 |
+
chain.run("some initial text")
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
```python
|
| 32 |
+
with graphsignal.start_trace('my-chain'):
|
| 33 |
+
chain.run("some initial text")
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
Optionally, enable profiling to record function-level statistics for each trace.
|
| 37 |
+
|
| 38 |
+
```python
|
| 39 |
+
with graphsignal.start_trace(
|
| 40 |
+
'my-chain', options=graphsignal.TraceOptions(enable_profiling=True)):
|
| 41 |
+
chain.run("some initial text")
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
See the [Quick Start](https://graphsignal.com/docs/guides/quick-start/) guide for complete setup instructions.
|
langchain/docs/ecosystem/hazy_research.md
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Hazy Research
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Hazy Research ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Hazy Research wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- To use the `manifest`, install it with `pip install manifest-ml`
|
| 8 |
+
|
| 9 |
+
## Wrappers
|
| 10 |
+
|
| 11 |
+
### LLM
|
| 12 |
+
|
| 13 |
+
There exists an LLM wrapper around Hazy Research's `manifest` library.
|
| 14 |
+
`manifest` is a python library which is itself a wrapper around many model providers, and adds in caching, history, and more.
|
| 15 |
+
|
| 16 |
+
To use this wrapper:
|
| 17 |
+
```python
|
| 18 |
+
from langchain.llms.manifest import ManifestWrapper
|
| 19 |
+
```
|
langchain/docs/ecosystem/helicone.md
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Helicone
|
| 2 |
+
|
| 3 |
+
This page covers how to use the [Helicone](https://helicone.ai) ecosystem within LangChain.
|
| 4 |
+
|
| 5 |
+
## What is Helicone?
|
| 6 |
+
|
| 7 |
+
Helicone is an [open source](https://github.com/Helicone/helicone) observability platform that proxies your OpenAI traffic and provides you key insights into your spend, latency and usage.
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
## Quick start
|
| 12 |
+
|
| 13 |
+
With your LangChain environment you can just add the following parameter.
|
| 14 |
+
|
| 15 |
+
```bash
|
| 16 |
+
export OPENAI_API_BASE="https://oai.hconeai.com/v1"
|
| 17 |
+
```
|
| 18 |
+
|
| 19 |
+
Now head over to [helicone.ai](https://helicone.ai/onboarding?step=2) to create your account, and add your OpenAI API key within our dashboard to view your logs.
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
## How to enable Helicone caching
|
| 24 |
+
|
| 25 |
+
```python
|
| 26 |
+
from langchain.llms import OpenAI
|
| 27 |
+
import openai
|
| 28 |
+
openai.api_base = "https://oai.hconeai.com/v1"
|
| 29 |
+
|
| 30 |
+
llm = OpenAI(temperature=0.9, headers={"Helicone-Cache-Enabled": "true"})
|
| 31 |
+
text = "What is a helicone?"
|
| 32 |
+
print(llm(text))
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
[Helicone caching docs](https://docs.helicone.ai/advanced-usage/caching)
|
| 36 |
+
|
| 37 |
+
## How to use Helicone custom properties
|
| 38 |
+
|
| 39 |
+
```python
|
| 40 |
+
from langchain.llms import OpenAI
|
| 41 |
+
import openai
|
| 42 |
+
openai.api_base = "https://oai.hconeai.com/v1"
|
| 43 |
+
|
| 44 |
+
llm = OpenAI(temperature=0.9, headers={
|
| 45 |
+
"Helicone-Property-Session": "24",
|
| 46 |
+
"Helicone-Property-Conversation": "support_issue_2",
|
| 47 |
+
"Helicone-Property-App": "mobile",
|
| 48 |
+
})
|
| 49 |
+
text = "What is a helicone?"
|
| 50 |
+
print(llm(text))
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
[Helicone property docs](https://docs.helicone.ai/advanced-usage/custom-properties)
|
langchain/docs/ecosystem/huggingface.md
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Hugging Face
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Hugging Face ecosystem (including the [Hugging Face Hub](https://huggingface.co)) within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Hugging Face wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
|
| 8 |
+
If you want to work with the Hugging Face Hub:
|
| 9 |
+
- Install the Hub client library with `pip install huggingface_hub`
|
| 10 |
+
- Create a Hugging Face account (it's free!)
|
| 11 |
+
- Create an [access token](https://huggingface.co/docs/hub/security-tokens) and set it as an environment variable (`HUGGINGFACEHUB_API_TOKEN`)
|
| 12 |
+
|
| 13 |
+
If you want work with the Hugging Face Python libraries:
|
| 14 |
+
- Install `pip install transformers` for working with models and tokenizers
|
| 15 |
+
- Install `pip install datasets` for working with datasets
|
| 16 |
+
|
| 17 |
+
## Wrappers
|
| 18 |
+
|
| 19 |
+
### LLM
|
| 20 |
+
|
| 21 |
+
There exists two Hugging Face LLM wrappers, one for a local pipeline and one for a model hosted on Hugging Face Hub.
|
| 22 |
+
Note that these wrappers only work for models that support the following tasks: [`text2text-generation`](https://huggingface.co/models?library=transformers&pipeline_tag=text2text-generation&sort=downloads), [`text-generation`](https://huggingface.co/models?library=transformers&pipeline_tag=text-classification&sort=downloads)
|
| 23 |
+
|
| 24 |
+
To use the local pipeline wrapper:
|
| 25 |
+
```python
|
| 26 |
+
from langchain.llms import HuggingFacePipeline
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
To use a the wrapper for a model hosted on Hugging Face Hub:
|
| 30 |
+
```python
|
| 31 |
+
from langchain.llms import HuggingFaceHub
|
| 32 |
+
```
|
| 33 |
+
For a more detailed walkthrough of the Hugging Face Hub wrapper, see [this notebook](../modules/models/llms/integrations/huggingface_hub.ipynb)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
### Embeddings
|
| 37 |
+
|
| 38 |
+
There exists two Hugging Face Embeddings wrappers, one for a local model and one for a model hosted on Hugging Face Hub.
|
| 39 |
+
Note that these wrappers only work for [`sentence-transformers` models](https://huggingface.co/models?library=sentence-transformers&sort=downloads).
|
| 40 |
+
|
| 41 |
+
To use the local pipeline wrapper:
|
| 42 |
+
```python
|
| 43 |
+
from langchain.embeddings import HuggingFaceEmbeddings
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
To use a the wrapper for a model hosted on Hugging Face Hub:
|
| 47 |
+
```python
|
| 48 |
+
from langchain.embeddings import HuggingFaceHubEmbeddings
|
| 49 |
+
```
|
| 50 |
+
For a more detailed walkthrough of this, see [this notebook](../modules/models/text_embedding/examples/huggingfacehub.ipynb)
|
| 51 |
+
|
| 52 |
+
### Tokenizer
|
| 53 |
+
|
| 54 |
+
There are several places you can use tokenizers available through the `transformers` package.
|
| 55 |
+
By default, it is used to count tokens for all LLMs.
|
| 56 |
+
|
| 57 |
+
You can also use it to count tokens when splitting documents with
|
| 58 |
+
```python
|
| 59 |
+
from langchain.text_splitter import CharacterTextSplitter
|
| 60 |
+
CharacterTextSplitter.from_huggingface_tokenizer(...)
|
| 61 |
+
```
|
| 62 |
+
For a more detailed walkthrough of this, see [this notebook](../modules/indexes/text_splitters/examples/huggingface_length_function.ipynb)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
### Datasets
|
| 66 |
+
|
| 67 |
+
The Hugging Face Hub has lots of great [datasets](https://huggingface.co/datasets) that can be used to evaluate your LLM chains.
|
| 68 |
+
|
| 69 |
+
For a detailed walkthrough of how to use them to do so, see [this notebook](../use_cases/evaluation/huggingface_datasets.ipynb)
|
langchain/docs/ecosystem/jina.md
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Jina
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Jina ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Jina wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install the Python SDK with `pip install jina`
|
| 8 |
+
- Get a Jina AI Cloud auth token from [here](https://cloud.jina.ai/settings/tokens) and set it as an environment variable (`JINA_AUTH_TOKEN`)
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### Embeddings
|
| 13 |
+
|
| 14 |
+
There exists a Jina Embeddings wrapper, which you can access with
|
| 15 |
+
```python
|
| 16 |
+
from langchain.embeddings import JinaEmbeddings
|
| 17 |
+
```
|
| 18 |
+
For a more detailed walkthrough of this, see [this notebook](../modules/models/text_embedding/examples/jina.ipynb)
|
langchain/docs/ecosystem/lancedb.md
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# LanceDB
|
| 2 |
+
|
| 3 |
+
This page covers how to use [LanceDB](https://github.com/lancedb/lancedb) within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific LanceDB wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
|
| 8 |
+
- Install the Python SDK with `pip install lancedb`
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### VectorStore
|
| 13 |
+
|
| 14 |
+
There exists a wrapper around LanceDB databases, allowing you to use it as a vectorstore,
|
| 15 |
+
whether for semantic search or example selection.
|
| 16 |
+
|
| 17 |
+
To import this vectorstore:
|
| 18 |
+
|
| 19 |
+
```python
|
| 20 |
+
from langchain.vectorstores import LanceDB
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
For a more detailed walkthrough of the LanceDB wrapper, see [this notebook](../modules/indexes/vectorstores/examples/lancedb.ipynb)
|
langchain/docs/ecosystem/llamacpp.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Llama.cpp
|
| 2 |
+
|
| 3 |
+
This page covers how to use [llama.cpp](https://github.com/ggerganov/llama.cpp) within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Llama-cpp wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install the Python package with `pip install llama-cpp-python`
|
| 8 |
+
- Download one of the [supported models](https://github.com/ggerganov/llama.cpp#description) and convert them to the llama.cpp format per the [instructions](https://github.com/ggerganov/llama.cpp)
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### LLM
|
| 13 |
+
|
| 14 |
+
There exists a LlamaCpp LLM wrapper, which you can access with
|
| 15 |
+
```python
|
| 16 |
+
from langchain.llms import LlamaCpp
|
| 17 |
+
```
|
| 18 |
+
For a more detailed walkthrough of this, see [this notebook](../modules/models/llms/integrations/llamacpp.ipynb)
|
| 19 |
+
|
| 20 |
+
### Embeddings
|
| 21 |
+
|
| 22 |
+
There exists a LlamaCpp Embeddings wrapper, which you can access with
|
| 23 |
+
```python
|
| 24 |
+
from langchain.embeddings import LlamaCppEmbeddings
|
| 25 |
+
```
|
| 26 |
+
For a more detailed walkthrough of this, see [this notebook](../modules/models/text_embedding/examples/llamacpp.ipynb)
|
langchain/docs/ecosystem/metal.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Metal
|
| 2 |
+
|
| 3 |
+
This page covers how to use [Metal](https://getmetal.io) within LangChain.
|
| 4 |
+
|
| 5 |
+
## What is Metal?
|
| 6 |
+
|
| 7 |
+
Metal is a managed retrieval & memory platform built for production. Easily index your data into `Metal` and run semantic search and retrieval on it.
|
| 8 |
+
|
| 9 |
+

|
| 10 |
+
|
| 11 |
+
## Quick start
|
| 12 |
+
|
| 13 |
+
Get started by [creating a Metal account](https://app.getmetal.io/signup).
|
| 14 |
+
|
| 15 |
+
Then, you can easily take advantage of the `MetalRetriever` class to start retrieving your data for semantic search, prompting context, etc. This class takes a `Metal` instance and a dictionary of parameters to pass to the Metal API.
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from langchain.retrievers import MetalRetriever
|
| 19 |
+
from metal_sdk.metal import Metal
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
metal = Metal("API_KEY", "CLIENT_ID", "INDEX_ID");
|
| 23 |
+
retriever = MetalRetriever(metal, params={"limit": 2})
|
| 24 |
+
|
| 25 |
+
docs = retriever.get_relevant_documents("search term")
|
| 26 |
+
```
|
langchain/docs/ecosystem/milvus.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Milvus
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Milvus ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Milvus wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install the Python SDK with `pip install pymilvus`
|
| 8 |
+
## Wrappers
|
| 9 |
+
|
| 10 |
+
### VectorStore
|
| 11 |
+
|
| 12 |
+
There exists a wrapper around Milvus indexes, allowing you to use it as a vectorstore,
|
| 13 |
+
whether for semantic search or example selection.
|
| 14 |
+
|
| 15 |
+
To import this vectorstore:
|
| 16 |
+
```python
|
| 17 |
+
from langchain.vectorstores import Milvus
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
For a more detailed walkthrough of the Miluvs wrapper, see [this notebook](../modules/indexes/vectorstores/examples/milvus.ipynb)
|
langchain/docs/ecosystem/mlflow_tracking.ipynb
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"attachments": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"metadata": {},
|
| 7 |
+
"source": [
|
| 8 |
+
"# MLflow\n",
|
| 9 |
+
"\n",
|
| 10 |
+
"This notebook goes over how to track your LangChain experiments into your MLflow Server"
|
| 11 |
+
]
|
| 12 |
+
},
|
| 13 |
+
{
|
| 14 |
+
"cell_type": "code",
|
| 15 |
+
"execution_count": null,
|
| 16 |
+
"metadata": {},
|
| 17 |
+
"outputs": [],
|
| 18 |
+
"source": [
|
| 19 |
+
"!pip install azureml-mlflow\n",
|
| 20 |
+
"!pip install pandas\n",
|
| 21 |
+
"!pip install textstat\n",
|
| 22 |
+
"!pip install spacy\n",
|
| 23 |
+
"!pip install openai\n",
|
| 24 |
+
"!pip install google-search-results\n",
|
| 25 |
+
"!python -m spacy download en_core_web_sm"
|
| 26 |
+
]
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"cell_type": "code",
|
| 30 |
+
"execution_count": null,
|
| 31 |
+
"metadata": {},
|
| 32 |
+
"outputs": [],
|
| 33 |
+
"source": [
|
| 34 |
+
"import os\n",
|
| 35 |
+
"os.environ[\"MLFLOW_TRACKING_URI\"] = \"\"\n",
|
| 36 |
+
"os.environ[\"OPENAI_API_KEY\"] = \"\"\n",
|
| 37 |
+
"os.environ[\"SERPAPI_API_KEY\"] = \"\"\n"
|
| 38 |
+
]
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"cell_type": "code",
|
| 42 |
+
"execution_count": null,
|
| 43 |
+
"metadata": {},
|
| 44 |
+
"outputs": [],
|
| 45 |
+
"source": [
|
| 46 |
+
"from langchain.callbacks import MlflowCallbackHandler\n",
|
| 47 |
+
"from langchain.llms import OpenAI"
|
| 48 |
+
]
|
| 49 |
+
},
|
| 50 |
+
{
|
| 51 |
+
"cell_type": "code",
|
| 52 |
+
"execution_count": null,
|
| 53 |
+
"metadata": {},
|
| 54 |
+
"outputs": [],
|
| 55 |
+
"source": [
|
| 56 |
+
"\"\"\"Main function.\n",
|
| 57 |
+
"\n",
|
| 58 |
+
"This function is used to try the callback handler.\n",
|
| 59 |
+
"Scenarios:\n",
|
| 60 |
+
"1. OpenAI LLM\n",
|
| 61 |
+
"2. Chain with multiple SubChains on multiple generations\n",
|
| 62 |
+
"3. Agent with Tools\n",
|
| 63 |
+
"\"\"\"\n",
|
| 64 |
+
"mlflow_callback = MlflowCallbackHandler()\n",
|
| 65 |
+
"llm = OpenAI(model_name=\"gpt-3.5-turbo\", temperature=0, callbacks=[mlflow_callback], verbose=True)"
|
| 66 |
+
]
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"cell_type": "code",
|
| 70 |
+
"execution_count": null,
|
| 71 |
+
"metadata": {},
|
| 72 |
+
"outputs": [],
|
| 73 |
+
"source": [
|
| 74 |
+
"# SCENARIO 1 - LLM\n",
|
| 75 |
+
"llm_result = llm.generate([\"Tell me a joke\"])\n",
|
| 76 |
+
"\n",
|
| 77 |
+
"mlflow_callback.flush_tracker(llm)"
|
| 78 |
+
]
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"cell_type": "code",
|
| 82 |
+
"execution_count": null,
|
| 83 |
+
"metadata": {},
|
| 84 |
+
"outputs": [],
|
| 85 |
+
"source": [
|
| 86 |
+
"from langchain.prompts import PromptTemplate\n",
|
| 87 |
+
"from langchain.chains import LLMChain"
|
| 88 |
+
]
|
| 89 |
+
},
|
| 90 |
+
{
|
| 91 |
+
"cell_type": "code",
|
| 92 |
+
"execution_count": null,
|
| 93 |
+
"metadata": {},
|
| 94 |
+
"outputs": [],
|
| 95 |
+
"source": [
|
| 96 |
+
"# SCENARIO 2 - Chain\n",
|
| 97 |
+
"template = \"\"\"You are a playwright. Given the title of play, it is your job to write a synopsis for that title.\n",
|
| 98 |
+
"Title: {title}\n",
|
| 99 |
+
"Playwright: This is a synopsis for the above play:\"\"\"\n",
|
| 100 |
+
"prompt_template = PromptTemplate(input_variables=[\"title\"], template=template)\n",
|
| 101 |
+
"synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, callbacks=[mlflow_callback])\n",
|
| 102 |
+
"\n",
|
| 103 |
+
"test_prompts = [\n",
|
| 104 |
+
" {\n",
|
| 105 |
+
" \"title\": \"documentary about good video games that push the boundary of game design\"\n",
|
| 106 |
+
" },\n",
|
| 107 |
+
"]\n",
|
| 108 |
+
"synopsis_chain.apply(test_prompts)\n",
|
| 109 |
+
"mlflow_callback.flush_tracker(synopsis_chain)"
|
| 110 |
+
]
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"cell_type": "code",
|
| 114 |
+
"execution_count": null,
|
| 115 |
+
"metadata": {
|
| 116 |
+
"id": "_jN73xcPVEpI"
|
| 117 |
+
},
|
| 118 |
+
"outputs": [],
|
| 119 |
+
"source": [
|
| 120 |
+
"from langchain.agents import initialize_agent, load_tools\n",
|
| 121 |
+
"from langchain.agents import AgentType"
|
| 122 |
+
]
|
| 123 |
+
},
|
| 124 |
+
{
|
| 125 |
+
"cell_type": "code",
|
| 126 |
+
"execution_count": null,
|
| 127 |
+
"metadata": {
|
| 128 |
+
"id": "Gpq4rk6VT9cu"
|
| 129 |
+
},
|
| 130 |
+
"outputs": [],
|
| 131 |
+
"source": [
|
| 132 |
+
"# SCENARIO 3 - Agent with Tools\n",
|
| 133 |
+
"tools = load_tools([\"serpapi\", \"llm-math\"], llm=llm, callbacks=[mlflow_callback])\n",
|
| 134 |
+
"agent = initialize_agent(\n",
|
| 135 |
+
" tools,\n",
|
| 136 |
+
" llm,\n",
|
| 137 |
+
" agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,\n",
|
| 138 |
+
" callbacks=[mlflow_callback],\n",
|
| 139 |
+
" verbose=True,\n",
|
| 140 |
+
")\n",
|
| 141 |
+
"agent.run(\n",
|
| 142 |
+
" \"Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?\"\n",
|
| 143 |
+
")\n",
|
| 144 |
+
"mlflow_callback.flush_tracker(agent, finish=True)"
|
| 145 |
+
]
|
| 146 |
+
}
|
| 147 |
+
],
|
| 148 |
+
"metadata": {
|
| 149 |
+
"colab": {
|
| 150 |
+
"provenance": []
|
| 151 |
+
},
|
| 152 |
+
"kernelspec": {
|
| 153 |
+
"display_name": "Python 3 (ipykernel)",
|
| 154 |
+
"language": "python",
|
| 155 |
+
"name": "python3"
|
| 156 |
+
},
|
| 157 |
+
"language_info": {
|
| 158 |
+
"codemirror_mode": {
|
| 159 |
+
"name": "ipython",
|
| 160 |
+
"version": 3
|
| 161 |
+
},
|
| 162 |
+
"file_extension": ".py",
|
| 163 |
+
"mimetype": "text/x-python",
|
| 164 |
+
"name": "python",
|
| 165 |
+
"nbconvert_exporter": "python",
|
| 166 |
+
"pygments_lexer": "ipython3",
|
| 167 |
+
"version": "3.9.16"
|
| 168 |
+
}
|
| 169 |
+
},
|
| 170 |
+
"nbformat": 4,
|
| 171 |
+
"nbformat_minor": 1
|
| 172 |
+
}
|
langchain/docs/ecosystem/modal.md
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modal
|
| 2 |
+
|
| 3 |
+
This page covers how to use the Modal ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific Modal wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install with `pip install modal-client`
|
| 8 |
+
- Run `modal token new`
|
| 9 |
+
|
| 10 |
+
## Define your Modal Functions and Webhooks
|
| 11 |
+
|
| 12 |
+
You must include a prompt. There is a rigid response structure.
|
| 13 |
+
|
| 14 |
+
```python
|
| 15 |
+
class Item(BaseModel):
|
| 16 |
+
prompt: str
|
| 17 |
+
|
| 18 |
+
@stub.webhook(method="POST")
|
| 19 |
+
def my_webhook(item: Item):
|
| 20 |
+
return {"prompt": my_function.call(item.prompt)}
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
An example with GPT2:
|
| 24 |
+
|
| 25 |
+
```python
|
| 26 |
+
from pydantic import BaseModel
|
| 27 |
+
|
| 28 |
+
import modal
|
| 29 |
+
|
| 30 |
+
stub = modal.Stub("example-get-started")
|
| 31 |
+
|
| 32 |
+
volume = modal.SharedVolume().persist("gpt2_model_vol")
|
| 33 |
+
CACHE_PATH = "/root/model_cache"
|
| 34 |
+
|
| 35 |
+
@stub.function(
|
| 36 |
+
gpu="any",
|
| 37 |
+
image=modal.Image.debian_slim().pip_install(
|
| 38 |
+
"tokenizers", "transformers", "torch", "accelerate"
|
| 39 |
+
),
|
| 40 |
+
shared_volumes={CACHE_PATH: volume},
|
| 41 |
+
retries=3,
|
| 42 |
+
)
|
| 43 |
+
def run_gpt2(text: str):
|
| 44 |
+
from transformers import GPT2Tokenizer, GPT2LMHeadModel
|
| 45 |
+
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
|
| 46 |
+
model = GPT2LMHeadModel.from_pretrained('gpt2')
|
| 47 |
+
encoded_input = tokenizer(text, return_tensors='pt').input_ids
|
| 48 |
+
output = model.generate(encoded_input, max_length=50, do_sample=True)
|
| 49 |
+
return tokenizer.decode(output[0], skip_special_tokens=True)
|
| 50 |
+
|
| 51 |
+
class Item(BaseModel):
|
| 52 |
+
prompt: str
|
| 53 |
+
|
| 54 |
+
@stub.webhook(method="POST")
|
| 55 |
+
def get_text(item: Item):
|
| 56 |
+
return {"prompt": run_gpt2.call(item.prompt)}
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
## Wrappers
|
| 60 |
+
|
| 61 |
+
### LLM
|
| 62 |
+
|
| 63 |
+
There exists an Modal LLM wrapper, which you can access with
|
| 64 |
+
```python
|
| 65 |
+
from langchain.llms import Modal
|
| 66 |
+
```
|
langchain/docs/ecosystem/myscale.md
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MyScale
|
| 2 |
+
|
| 3 |
+
This page covers how to use MyScale vector database within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific MyScale wrappers.
|
| 5 |
+
|
| 6 |
+
With MyScale, you can manage both structured and unstructured (vectorized) data, and perform joint queries and analytics on both types of data using SQL. Plus, MyScale's cloud-native OLAP architecture, built on top of ClickHouse, enables lightning-fast data processing even on massive datasets.
|
| 7 |
+
|
| 8 |
+
## Introduction
|
| 9 |
+
|
| 10 |
+
[Overview to MyScale and High performance vector search](https://docs.myscale.com/en/overview/)
|
| 11 |
+
|
| 12 |
+
You can now register on our SaaS and [start a cluster now!](https://docs.myscale.com/en/quickstart/)
|
| 13 |
+
|
| 14 |
+
If you are also interested in how we managed to integrate SQL and vector, please refer to [this document](https://docs.myscale.com/en/vector-reference/) for further syntax reference.
|
| 15 |
+
|
| 16 |
+
We also deliver with live demo on huggingface! Please checkout our [huggingface space](https://huggingface.co/myscale)! They search millions of vector within a blink!
|
| 17 |
+
|
| 18 |
+
## Installation and Setup
|
| 19 |
+
- Install the Python SDK with `pip install clickhouse-connect`
|
| 20 |
+
|
| 21 |
+
### Setting up envrionments
|
| 22 |
+
|
| 23 |
+
There are two ways to set up parameters for myscale index.
|
| 24 |
+
|
| 25 |
+
1. Environment Variables
|
| 26 |
+
|
| 27 |
+
Before you run the app, please set the environment variable with `export`:
|
| 28 |
+
`export MYSCALE_URL='<your-endpoints-url>' MYSCALE_PORT=<your-endpoints-port> MYSCALE_USERNAME=<your-username> MYSCALE_PASSWORD=<your-password> ...`
|
| 29 |
+
|
| 30 |
+
You can easily find your account, password and other info on our SaaS. For details please refer to [this document](https://docs.myscale.com/en/cluster-management/)
|
| 31 |
+
Every attributes under `MyScaleSettings` can be set with prefix `MYSCALE_` and is case insensitive.
|
| 32 |
+
|
| 33 |
+
2. Create `MyScaleSettings` object with parameters
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
```python
|
| 37 |
+
from langchain.vectorstores import MyScale, MyScaleSettings
|
| 38 |
+
config = MyScaleSetting(host="<your-backend-url>", port=8443, ...)
|
| 39 |
+
index = MyScale(embedding_function, config)
|
| 40 |
+
index.add_documents(...)
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
## Wrappers
|
| 44 |
+
supported functions:
|
| 45 |
+
- `add_texts`
|
| 46 |
+
- `add_documents`
|
| 47 |
+
- `from_texts`
|
| 48 |
+
- `from_documents`
|
| 49 |
+
- `similarity_search`
|
| 50 |
+
- `asimilarity_search`
|
| 51 |
+
- `similarity_search_by_vector`
|
| 52 |
+
- `asimilarity_search_by_vector`
|
| 53 |
+
- `similarity_search_with_relevance_scores`
|
| 54 |
+
|
| 55 |
+
### VectorStore
|
| 56 |
+
|
| 57 |
+
There exists a wrapper around MyScale database, allowing you to use it as a vectorstore,
|
| 58 |
+
whether for semantic search or similar example retrieval.
|
| 59 |
+
|
| 60 |
+
To import this vectorstore:
|
| 61 |
+
```python
|
| 62 |
+
from langchain.vectorstores import MyScale
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
For a more detailed walkthrough of the MyScale wrapper, see [this notebook](../modules/indexes/vectorstores/examples/myscale.ipynb)
|
langchain/docs/ecosystem/nlpcloud.md
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# NLPCloud
|
| 2 |
+
|
| 3 |
+
This page covers how to use the NLPCloud ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific NLPCloud wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install the Python SDK with `pip install nlpcloud`
|
| 8 |
+
- Get an NLPCloud api key and set it as an environment variable (`NLPCLOUD_API_KEY`)
|
| 9 |
+
|
| 10 |
+
## Wrappers
|
| 11 |
+
|
| 12 |
+
### LLM
|
| 13 |
+
|
| 14 |
+
There exists an NLPCloud LLM wrapper, which you can access with
|
| 15 |
+
```python
|
| 16 |
+
from langchain.llms import NLPCloud
|
| 17 |
+
```
|
langchain/docs/ecosystem/openai.md
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenAI
|
| 2 |
+
|
| 3 |
+
This page covers how to use the OpenAI ecosystem within LangChain.
|
| 4 |
+
It is broken into two parts: installation and setup, and then references to specific OpenAI wrappers.
|
| 5 |
+
|
| 6 |
+
## Installation and Setup
|
| 7 |
+
- Install the Python SDK with `pip install openai`
|
| 8 |
+
- Get an OpenAI api key and set it as an environment variable (`OPENAI_API_KEY`)
|
| 9 |
+
- If you want to use OpenAI's tokenizer (only available for Python 3.9+), install it with `pip install tiktoken`
|
| 10 |
+
|
| 11 |
+
## Wrappers
|
| 12 |
+
|
| 13 |
+
### LLM
|
| 14 |
+
|
| 15 |
+
There exists an OpenAI LLM wrapper, which you can access with
|
| 16 |
+
```python
|
| 17 |
+
from langchain.llms import OpenAI
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
If you are using a model hosted on Azure, you should use different wrapper for that:
|
| 21 |
+
```python
|
| 22 |
+
from langchain.llms import AzureOpenAI
|
| 23 |
+
```
|
| 24 |
+
For a more detailed walkthrough of the Azure wrapper, see [this notebook](../modules/models/llms/integrations/azure_openai_example.ipynb)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
### Embeddings
|
| 29 |
+
|
| 30 |
+
There exists an OpenAI Embeddings wrapper, which you can access with
|
| 31 |
+
```python
|
| 32 |
+
from langchain.embeddings import OpenAIEmbeddings
|
| 33 |
+
```
|
| 34 |
+
For a more detailed walkthrough of this, see [this notebook](../modules/models/text_embedding/examples/openai.ipynb)
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
### Tokenizer
|
| 38 |
+
|
| 39 |
+
There are several places you can use the `tiktoken` tokenizer. By default, it is used to count tokens
|
| 40 |
+
for OpenAI LLMs.
|
| 41 |
+
|
| 42 |
+
You can also use it to count tokens when splitting documents with
|
| 43 |
+
```python
|
| 44 |
+
from langchain.text_splitter import CharacterTextSplitter
|
| 45 |
+
CharacterTextSplitter.from_tiktoken_encoder(...)
|
| 46 |
+
```
|
| 47 |
+
For a more detailed walkthrough of this, see [this notebook](../modules/indexes/text_splitters/examples/tiktoken.ipynb)
|
| 48 |
+
|
| 49 |
+
### Moderation
|
| 50 |
+
You can also access the OpenAI content moderation endpoint with
|
| 51 |
+
|
| 52 |
+
```python
|
| 53 |
+
from langchain.chains import OpenAIModerationChain
|
| 54 |
+
```
|
| 55 |
+
For a more detailed walkthrough of this, see [this notebook](../modules/chains/examples/moderation.ipynb)
|