
medmac01
commited on
Commit
•
3bd5293
1
Parent(s):
9f5fbfb
Added multilingual_clip module
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .DS_Store +0 -0
- Multilingual_CLIP/HISTORY.md +39 -0
- Multilingual_CLIP/Images/Multilingual-CLIP.png +0 -0
- Multilingual_CLIP/Images/Orange Apple.png +0 -0
- Multilingual_CLIP/Images/Smile.jpg +0 -0
- Multilingual_CLIP/Images/bananas.jpg +0 -0
- Multilingual_CLIP/Images/fruit bowl.jpg +0 -0
- Multilingual_CLIP/Images/green apple.jpg +0 -0
- Multilingual_CLIP/Images/happy person.jpg +0 -0
- Multilingual_CLIP/Images/man on bike.jpg +0 -0
- Multilingual_CLIP/Images/purple apple.png +0 -0
- Multilingual_CLIP/Images/red apple.jpg +0 -0
- Multilingual_CLIP/Images/sad.jpg +0 -0
- Multilingual_CLIP/LICENSE +21 -0
- Multilingual_CLIP/Makefile +3 -0
- Multilingual_CLIP/Model Cards/M-BERT Base 69/Fine-Tune-Languages.md +42 -0
- Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/French-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/German-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/Greek-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/Kannada-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/M-Swedish-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/Russian-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/Spanish-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base 69/README.md +74 -0
- Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Fine-Tune-Languages.md +42 -0
- Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/French-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/German-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/Greek-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/Kannada-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/M-Swedish-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/Russian-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/Spanish-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/README.md +74 -0
- Multilingual_CLIP/Model Cards/M-BERT Distil 40/Fine-Tune-Languages.md +42 -0
- Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/French-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/German-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/Greek-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/Kannada-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/M-Swedish-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/Russian-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/Spanish-Both.png +0 -0
- Multilingual_CLIP/Model Cards/M-BERT Distil 40/README.md +72 -0
- Multilingual_CLIP/Model Cards/Swe-CLIP 2M/README.md +29 -0
- Multilingual_CLIP/Model Cards/Swe-CLIP 500k/README.md +29 -0
- Multilingual_CLIP/Multilingual_CLIP.ipynb +0 -0
- Multilingual_CLIP/README.md +236 -0
- Multilingual_CLIP/inference_example.py +34 -0
- Multilingual_CLIP/larger_mclip.md +60 -0
- Multilingual_CLIP/legacy_get-weights.sh +20 -0
- Multilingual_CLIP/legacy_inference.py +13 -0
.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
Multilingual_CLIP/HISTORY.md
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 1.0.10
|
| 2 |
+
|
| 3 |
+
* it works
|
| 4 |
+
|
| 5 |
+
## 1.0.8
|
| 6 |
+
|
| 7 |
+
* small fix
|
| 8 |
+
|
| 9 |
+
## 1.0.7
|
| 10 |
+
|
| 11 |
+
* small fix
|
| 12 |
+
|
| 13 |
+
## 1.0.6
|
| 14 |
+
|
| 15 |
+
* small fix
|
| 16 |
+
|
| 17 |
+
## 1.0.5
|
| 18 |
+
|
| 19 |
+
* small fix
|
| 20 |
+
|
| 21 |
+
## 1.0.4
|
| 22 |
+
|
| 23 |
+
* small fix
|
| 24 |
+
|
| 25 |
+
## 1.0.3
|
| 26 |
+
|
| 27 |
+
* rename all mentions to multilingual_clip
|
| 28 |
+
|
| 29 |
+
## 1.0.2
|
| 30 |
+
|
| 31 |
+
* Multilingual-clip
|
| 32 |
+
|
| 33 |
+
## 1.0.1
|
| 34 |
+
|
| 35 |
+
* name it m-clip
|
| 36 |
+
|
| 37 |
+
## 1.0.0
|
| 38 |
+
|
| 39 |
+
* first pypi release of multilingual_clip
|
Multilingual_CLIP/Images/Multilingual-CLIP.png
ADDED
|
Multilingual_CLIP/Images/Orange Apple.png
ADDED

|
Multilingual_CLIP/Images/Smile.jpg
ADDED

|
Multilingual_CLIP/Images/bananas.jpg
ADDED

|
Multilingual_CLIP/Images/fruit bowl.jpg
ADDED
|
Multilingual_CLIP/Images/green apple.jpg
ADDED

|
Multilingual_CLIP/Images/happy person.jpg
ADDED

|
Multilingual_CLIP/Images/man on bike.jpg
ADDED

|
Multilingual_CLIP/Images/purple apple.png
ADDED

|
Multilingual_CLIP/Images/red apple.jpg
ADDED

|
Multilingual_CLIP/Images/sad.jpg
ADDED

|
Multilingual_CLIP/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Fredrik Carlsson
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
Multilingual_CLIP/Makefile
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
install: ## [Local development] Upgrade pip, install requirements, install package.
|
| 2 |
+
python -m pip install -U pip
|
| 3 |
+
python -m pip install -e .
|
Multilingual_CLIP/Model Cards/M-BERT Base 69/Fine-Tune-Languages.md
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### List of languages included during CLIP fine-tuning
|
| 2 |
+
|
| 3 |
+
* Albanian
|
| 4 |
+
* Amharic
|
| 5 |
+
* Arabic
|
| 6 |
+
* Azerbaijani
|
| 7 |
+
* Bengali
|
| 8 |
+
* Bulgarian
|
| 9 |
+
* Catalan
|
| 10 |
+
* Chinese (Simplified)
|
| 11 |
+
* Chinese (Traditional)
|
| 12 |
+
* Dutch
|
| 13 |
+
* English
|
| 14 |
+
* Estonian
|
| 15 |
+
* Farsi
|
| 16 |
+
* French
|
| 17 |
+
* Georgian
|
| 18 |
+
* German
|
| 19 |
+
* Greek
|
| 20 |
+
* Hindi
|
| 21 |
+
* Hungarian
|
| 22 |
+
* Icelandic
|
| 23 |
+
* Indonesian
|
| 24 |
+
* Italian
|
| 25 |
+
* Japanese
|
| 26 |
+
* Kazakh
|
| 27 |
+
* Korean
|
| 28 |
+
* Latvian
|
| 29 |
+
* Macedonian
|
| 30 |
+
* Malay
|
| 31 |
+
* Pashto
|
| 32 |
+
* Polish
|
| 33 |
+
* Romanian
|
| 34 |
+
* Russian
|
| 35 |
+
* Slovenian
|
| 36 |
+
* Spanish
|
| 37 |
+
* Swedish
|
| 38 |
+
* Tagalog
|
| 39 |
+
* Thai
|
| 40 |
+
* Turkish
|
| 41 |
+
* Urdu
|
| 42 |
+
* Vietnamese
|
Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/French-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/German-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/Greek-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/Kannada-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/M-Swedish-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/Russian-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base 69/Images/Spanish-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base 69/README.md
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<br />
|
| 2 |
+
<p align="center">
|
| 3 |
+
<h1 align="center">M-BERT Base 69</h1>
|
| 4 |
+
|
| 5 |
+
<p align="center">
|
| 6 |
+
<a href="https://huggingface.co/M-CLIP/M-BERT-Base-69">Huggingface Model</a>
|
| 7 |
+
·
|
| 8 |
+
<a href="https://huggingface.co/bert-base-multilingual-cased">Huggingface Base Model</a>
|
| 9 |
+
</p>
|
| 10 |
+
</p>
|
| 11 |
+
|
| 12 |
+
## Usage
|
| 13 |
+
To use this model along with the original CLIP vision encoder follow the [main page usage instructions](https://github.com/FreddeFrallan/Multilingual-CLIP) to download the additional linear weights.
|
| 14 |
+
Once this is done, you can load and use the model with the following code
|
| 15 |
+
```python
|
| 16 |
+
from multilingual_clip import multilingual_clip
|
| 17 |
+
|
| 18 |
+
model = multilingual_clip.load_model('M-BERT-Base-69')
|
| 19 |
+
embeddings = model(['Älgen är skogens konung!', 'Wie leben Eisbären in der Antarktis?', 'Вы знали, что все белые медведи левши?'])
|
| 20 |
+
print(embeddings.shape)
|
| 21 |
+
# Yields: torch.Size([3, 640])
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
<!-- ABOUT THE PROJECT -->
|
| 25 |
+
## About
|
| 26 |
+
A [bert-base-multilingual](https://huggingface.co/bert-base-multilingual-cased) tuned to match the embedding space for 69 languages, to the embedding space of the CLIP text encoder which accompanies the Res50x4 vision encoder. <br>
|
| 27 |
+
A full list of the 100 languages used during pre-training can be found [here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages), and a list of the 69 languages used during fine-tuning can be found in [SupportedLanguages.md](Fine-Tune-Languages.md).
|
| 28 |
+
|
| 29 |
+
Training data pairs was generated by sampling 40k sentences for each language from the combined descriptions of [GCC](https://ai.google.com/research/ConceptualCaptions/) + [MSCOCO](https://cocodataset.org/#home) + [VizWiz](https://vizwiz.org/tasks-and-datasets/image-captioning/), and translating them into the corresponding language.
|
| 30 |
+
All translation was done using the [AWS translate service](https://aws.amazon.com/translate/), the quality of these translations have currently not been analyzed, but one can assume the quality varies between the 40 languages.
|
| 31 |
+
|
| 32 |
+
<!---
|
| 33 |
+
## Evaluation
|
| 34 |
+
A non-rigorous qualitative evaluation shows that for the languages French, German, Spanish, Russian, Swedish and Greek it seemingly yields respectable results for most instances. The exception being that Greeks are apparently unable to recognize happy persons. <br>
|
| 35 |
+
When testing on Kannada, a language which was included during pre-training but not fine-tuning, it performed close to random
|
| 36 |
+
|
| 37 |
+
<!---
|
| 38 |
+
The qualitative test was organized into two sets of images and their corresponding text descriptions. The texts were manually translated into each different test languages, where the two sets include the following images:
|
| 39 |
+
#### Set Nr 1
|
| 40 |
+
* A man on a motorcycle
|
| 41 |
+
* A green apple
|
| 42 |
+
* A bowl of fruits
|
| 43 |
+
* A bunch of bananas hanging from a tree
|
| 44 |
+
* A happy person laughing/smiling
|
| 45 |
+
* A sad person crying
|
| 46 |
+
#### Set Nr 2
|
| 47 |
+
The second set included only images of fruits, and non-realistic photoshopped images, in an attempt to increase the difficulty.
|
| 48 |
+
* A green apple
|
| 49 |
+
* A red apple
|
| 50 |
+
* A purple apple (photoshopped)
|
| 51 |
+
* A orange apple (photoshopped)
|
| 52 |
+
* A bowl of fruits
|
| 53 |
+
* A bunch of bananas hanging from a tree
|
| 54 |
+
|
| 55 |
+
<!---
|
| 56 |
+
### Results
|
| 57 |
+
The results depicted below are formatted so that each <b>column</b> represents the Softmax prediction over all the texts given the corresponding image. The images and matchings texts are ordered identically, hence a perfect solution would have 100 across the diagonal.
|
| 58 |
+
|
| 59 |
+
<!---
|
| 60 |
+
#### French
|
| 61 |
+

|
| 62 |
+
#### German
|
| 63 |
+

|
| 64 |
+
#### Spanish
|
| 65 |
+

|
| 66 |
+
#### Russian
|
| 67 |
+

|
| 68 |
+
#### Swedish
|
| 69 |
+

|
| 70 |
+
#### Greek
|
| 71 |
+

|
| 72 |
+
#### Kannada
|
| 73 |
+
Kannada was <b>not included</b> in the 40 fine-tuning languages, but included during language modelling pre-training
|
| 74 |
+

|
Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Fine-Tune-Languages.md
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### List of languages included during CLIP fine-tuning
|
| 2 |
+
|
| 3 |
+
* Albanian
|
| 4 |
+
* Amharic
|
| 5 |
+
* Arabic
|
| 6 |
+
* Azerbaijani
|
| 7 |
+
* Bengali
|
| 8 |
+
* Bulgarian
|
| 9 |
+
* Catalan
|
| 10 |
+
* Chinese (Simplified)
|
| 11 |
+
* Chinese (Traditional)
|
| 12 |
+
* Dutch
|
| 13 |
+
* English
|
| 14 |
+
* Estonian
|
| 15 |
+
* Farsi
|
| 16 |
+
* French
|
| 17 |
+
* Georgian
|
| 18 |
+
* German
|
| 19 |
+
* Greek
|
| 20 |
+
* Hindi
|
| 21 |
+
* Hungarian
|
| 22 |
+
* Icelandic
|
| 23 |
+
* Indonesian
|
| 24 |
+
* Italian
|
| 25 |
+
* Japanese
|
| 26 |
+
* Kazakh
|
| 27 |
+
* Korean
|
| 28 |
+
* Latvian
|
| 29 |
+
* Macedonian
|
| 30 |
+
* Malay
|
| 31 |
+
* Pashto
|
| 32 |
+
* Polish
|
| 33 |
+
* Romanian
|
| 34 |
+
* Russian
|
| 35 |
+
* Slovenian
|
| 36 |
+
* Spanish
|
| 37 |
+
* Swedish
|
| 38 |
+
* Tagalog
|
| 39 |
+
* Thai
|
| 40 |
+
* Turkish
|
| 41 |
+
* Urdu
|
| 42 |
+
* Vietnamese
|
Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/French-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/German-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/Greek-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/Kannada-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/M-Swedish-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/Russian-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/Images/Spanish-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Base ViT-B/README.md
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<br />
|
| 2 |
+
<p align="center">
|
| 3 |
+
<h1 align="center">M-BERT Base ViT-B</h1>
|
| 4 |
+
|
| 5 |
+
<p align="center">
|
| 6 |
+
<a href="https://huggingface.co/M-CLIP/M-BERT-Base-ViT-B">Huggingface Model</a>
|
| 7 |
+
·
|
| 8 |
+
<a href="https://huggingface.co/bert-base-multilingual-cased">Huggingface Base Model</a>
|
| 9 |
+
</p>
|
| 10 |
+
</p>
|
| 11 |
+
|
| 12 |
+
## Usage
|
| 13 |
+
To use this model along with the original CLIP vision encoder follow the [main page usage instructions](https://github.com/FreddeFrallan/Multilingual-CLIP) to download the additional linear weights.
|
| 14 |
+
Once this is done, you can load and use the model with the following code
|
| 15 |
+
```python
|
| 16 |
+
from multilingual_clip import multilingual_clip
|
| 17 |
+
|
| 18 |
+
model = multilingual_clip.load_model('M-BERT-Base-ViT-B')
|
| 19 |
+
embeddings = model(['Älgen är skogens konung!', 'Wie leben Eisbären in der Antarktis?', 'Вы знали, что все белые медведи левши?'])
|
| 20 |
+
print(embeddings.shape)
|
| 21 |
+
# Yields: torch.Size([3, 640])
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
<!-- ABOUT THE PROJECT -->
|
| 25 |
+
## About
|
| 26 |
+
A [bert-base-multilingual](https://huggingface.co/bert-base-multilingual-cased) tuned to match the embedding space for 69 languages, to the embedding space of the CLIP text encoder which accompanies the Res50x4 vision encoder. <br>
|
| 27 |
+
A full list of the 100 languages used during pre-training can be found [here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages), and a list of the 69 languages used during fine-tuning can be found in [SupportedLanguages.md](Fine-Tune-Languages.md).
|
| 28 |
+
|
| 29 |
+
Training data pairs was generated by sampling 40k sentences for each language from the combined descriptions of [GCC](https://ai.google.com/research/ConceptualCaptions/) + [MSCOCO](https://cocodataset.org/#home) + [VizWiz](https://vizwiz.org/tasks-and-datasets/image-captioning/), and translating them into the corresponding language.
|
| 30 |
+
All translation was done using the [AWS translate service](https://aws.amazon.com/translate/), the quality of these translations have currently not been analyzed, but one can assume the quality varies between the 40 languages.
|
| 31 |
+
|
| 32 |
+
<!---
|
| 33 |
+
## Evaluation
|
| 34 |
+
A non-rigorous qualitative evaluation shows that for the languages French, German, Spanish, Russian, Swedish and Greek it seemingly yields respectable results for most instances. The exception being that Greeks are apparently unable to recognize happy persons. <br>
|
| 35 |
+
When testing on Kannada, a language which was included during pre-training but not fine-tuning, it performed close to random
|
| 36 |
+
|
| 37 |
+
<!---
|
| 38 |
+
The qualitative test was organized into two sets of images and their corresponding text descriptions. The texts were manually translated into each different test languages, where the two sets include the following images:
|
| 39 |
+
#### Set Nr 1
|
| 40 |
+
* A man on a motorcycle
|
| 41 |
+
* A green apple
|
| 42 |
+
* A bowl of fruits
|
| 43 |
+
* A bunch of bananas hanging from a tree
|
| 44 |
+
* A happy person laughing/smiling
|
| 45 |
+
* A sad person crying
|
| 46 |
+
#### Set Nr 2
|
| 47 |
+
The second set included only images of fruits, and non-realistic photoshopped images, in an attempt to increase the difficulty.
|
| 48 |
+
* A green apple
|
| 49 |
+
* A red apple
|
| 50 |
+
* A purple apple (photoshopped)
|
| 51 |
+
* A orange apple (photoshopped)
|
| 52 |
+
* A bowl of fruits
|
| 53 |
+
* A bunch of bananas hanging from a tree
|
| 54 |
+
|
| 55 |
+
<!---
|
| 56 |
+
### Results
|
| 57 |
+
The results depicted below are formatted so that each <b>column</b> represents the Softmax prediction over all the texts given the corresponding image. The images and matchings texts are ordered identically, hence a perfect solution would have 100 across the diagonal.
|
| 58 |
+
|
| 59 |
+
<!---
|
| 60 |
+
#### French
|
| 61 |
+

|
| 62 |
+
#### German
|
| 63 |
+

|
| 64 |
+
#### Spanish
|
| 65 |
+

|
| 66 |
+
#### Russian
|
| 67 |
+

|
| 68 |
+
#### Swedish
|
| 69 |
+

|
| 70 |
+
#### Greek
|
| 71 |
+

|
| 72 |
+
#### Kannada
|
| 73 |
+
Kannada was <b>not included</b> in the 40 fine-tuning languages, but included during language modelling pre-training
|
| 74 |
+

|
Multilingual_CLIP/Model Cards/M-BERT Distil 40/Fine-Tune-Languages.md
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### List of languages included during CLIP fine-tuning
|
| 2 |
+
|
| 3 |
+
* Albanian
|
| 4 |
+
* Amharic
|
| 5 |
+
* Arabic
|
| 6 |
+
* Azerbaijani
|
| 7 |
+
* Bengali
|
| 8 |
+
* Bulgarian
|
| 9 |
+
* Catalan
|
| 10 |
+
* Chinese (Simplified)
|
| 11 |
+
* Chinese (Traditional)
|
| 12 |
+
* Dutch
|
| 13 |
+
* English
|
| 14 |
+
* Estonian
|
| 15 |
+
* Farsi
|
| 16 |
+
* French
|
| 17 |
+
* Georgian
|
| 18 |
+
* German
|
| 19 |
+
* Greek
|
| 20 |
+
* Hindi
|
| 21 |
+
* Hungarian
|
| 22 |
+
* Icelandic
|
| 23 |
+
* Indonesian
|
| 24 |
+
* Italian
|
| 25 |
+
* Japanese
|
| 26 |
+
* Kazakh
|
| 27 |
+
* Korean
|
| 28 |
+
* Latvian
|
| 29 |
+
* Macedonian
|
| 30 |
+
* Malay
|
| 31 |
+
* Pashto
|
| 32 |
+
* Polish
|
| 33 |
+
* Romanian
|
| 34 |
+
* Russian
|
| 35 |
+
* Slovenian
|
| 36 |
+
* Spanish
|
| 37 |
+
* Swedish
|
| 38 |
+
* Tagalog
|
| 39 |
+
* Thai
|
| 40 |
+
* Turkish
|
| 41 |
+
* Urdu
|
| 42 |
+
* Vietnamese
|
Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/French-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/German-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/Greek-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/Kannada-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/M-Swedish-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/Russian-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Distil 40/Images/Spanish-Both.png
ADDED

|
Multilingual_CLIP/Model Cards/M-BERT Distil 40/README.md
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<br />
|
| 2 |
+
<p align="center">
|
| 3 |
+
<h1 align="center">M-BERT Distil 40</h1>
|
| 4 |
+
|
| 5 |
+
<p align="center">
|
| 6 |
+
<a href="https://huggingface.co/M-CLIP/M-BERT-Distil-40">Huggingface Model</a>
|
| 7 |
+
·
|
| 8 |
+
<a href="https://huggingface.co/distilbert-base-multilingual-cased">Huggingface Base Model</a>
|
| 9 |
+
</p>
|
| 10 |
+
</p>
|
| 11 |
+
|
| 12 |
+
## Usage
|
| 13 |
+
To use this model along with the original CLIP vision encoder follow the [main page usage instructions](https://github.com/FreddeFrallan/Multilingual-CLIP) to download the additional linear weights.
|
| 14 |
+
Once this is done, you can load and use the model with the following code
|
| 15 |
+
```python
|
| 16 |
+
from multilingual_clip import multilingual_clip
|
| 17 |
+
|
| 18 |
+
model = multilingual_clip.load_model('M-BERT-Distil-40')
|
| 19 |
+
embeddings = model(['Älgen är skogens konung!', 'Wie leben Eisbären in der Antarktis?', 'Вы знали, что все белые медведи левши?'])
|
| 20 |
+
print(embeddings.shape)
|
| 21 |
+
# Yields: torch.Size([3, 640])
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
<!-- ABOUT THE PROJECT -->
|
| 25 |
+
## About
|
| 26 |
+
A [distilbert-base-multilingual](https://huggingface.co/distilbert-base-multilingual-cased) tuned to match the embedding space for 40 languages, to the embedding space of the CLIP text encoder which accompanies the Res50x4 vision encoder. <br>
|
| 27 |
+
A full list of the 100 languages used during pre-training can be found [here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages), and a list of the 40 languages used during fine-tuning can be found in [SupportedLanguages.md](Fine-Tune-Languages.md).
|
| 28 |
+
|
| 29 |
+
Training data pairs was generated by sampling 40k sentences for each language from the combined descriptions of [GCC](https://ai.google.com/research/ConceptualCaptions/) + [MSCOCO](https://cocodataset.org/#home) + [VizWiz](https://vizwiz.org/tasks-and-datasets/image-captioning/), and translating them into the corresponding language.
|
| 30 |
+
All translation was done using the [AWS translate service](https://aws.amazon.com/translate/), the quality of these translations have currently not been analyzed, but one can assume the quality varies between the 40 languages.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## Evaluation
|
| 34 |
+
A non-rigorous qualitative evaluation shows that for the languages French, German, Spanish, Russian, Swedish and Greek it seemingly yields respectable results for most instances. The exception being that Greeks are apparently unable to recognize happy persons. <br>
|
| 35 |
+
When testing on Kannada, a language which was included during pre-training but not fine-tuning, it performed close to random
|
| 36 |
+
|
| 37 |
+
The qualitative test was organized into two sets of images and their corresponding text descriptions. The texts were manually translated into each different test languages, where the two sets include the following images:
|
| 38 |
+
#### Set Nr 1
|
| 39 |
+
* A man on a motorcycle
|
| 40 |
+
* A green apple
|
| 41 |
+
* A bowl of fruits
|
| 42 |
+
* A bunch of bananas hanging from a tree
|
| 43 |
+
* A happy person laughing/smiling
|
| 44 |
+
* A sad person crying
|
| 45 |
+
#### Set Nr 2
|
| 46 |
+
The second set included only images of fruits, and non-realistic photoshopped images, in an attempt to increase the difficulty.
|
| 47 |
+
* A green apple
|
| 48 |
+
* A red apple
|
| 49 |
+
* A purple apple (photoshopped)
|
| 50 |
+
* A orange apple (photoshopped)
|
| 51 |
+
* A bowl of fruits
|
| 52 |
+
* A bunch of bananas hanging from a tree
|
| 53 |
+
|
| 54 |
+
### Results
|
| 55 |
+
The results depicted below are formatted so that each <b>column</b> represents the Softmax prediction over all the texts given the corresponding image. The images and matchings texts are ordered identically, hence a perfect solution would have 100 across the diagonal.
|
| 56 |
+
|
| 57 |
+
#### French
|
| 58 |
+

|
| 59 |
+
#### German
|
| 60 |
+

|
| 61 |
+
#### Spanish
|
| 62 |
+

|
| 63 |
+
#### Russian
|
| 64 |
+

|
| 65 |
+
#### Swedish
|
| 66 |
+

|
| 67 |
+
#### Greek
|
| 68 |
+

|
| 69 |
+
#### Kannada
|
| 70 |
+
Kannada was <b>not included</b> in the 40 fine-tuning languages, but included during language modelling pre-training
|
| 71 |
+

|
| 72 |
+
|
Multilingual_CLIP/Model Cards/Swe-CLIP 2M/README.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<br />
|
| 2 |
+
<p align="center">
|
| 3 |
+
<h1 align="center">Swe-CLIP 2M</h1>
|
| 4 |
+
|
| 5 |
+
<p align="center">
|
| 6 |
+
<a href="https://huggingface.co/M-CLIP/Swedish-2M">Huggingface Model</a>
|
| 7 |
+
·
|
| 8 |
+
<a href="https://huggingface.co/KB/bert-base-swedish-cased">Huggingface Base Model</a>
|
| 9 |
+
</p>
|
| 10 |
+
</p>
|
| 11 |
+
|
| 12 |
+
## Usage
|
| 13 |
+
To use this model along with the original CLIP vision encoder follow the [main page usage instructions](https://github.com/FreddeFrallan/Multilingual-CLIP) to download the additional linear weights.
|
| 14 |
+
Once this is done, you can load and use the model with the following code
|
| 15 |
+
```python
|
| 16 |
+
from multilingual_clip import multilingual_clip
|
| 17 |
+
|
| 18 |
+
model = multilingual_clip.load_model('Swe-CLIP-2M')
|
| 19 |
+
embeddings = model(['Älgen är skogens konung!', 'Alla isbjörnar är vänsterhänta'])
|
| 20 |
+
print(embeddings.shape)
|
| 21 |
+
# Yields: torch.Size([2, 640])
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
<!-- ABOUT THE PROJECT -->
|
| 25 |
+
## About
|
| 26 |
+
A [KB/Bert-Swedish-Cased](https://huggingface.co/KB/bert-base-swedish-cased) tuned to match the embedding space of the CLIP text encoder which accompanies the Res50x4 vision encoder. <br>
|
| 27 |
+
|
| 28 |
+
Training data pairs was generated by sampling 2 Million sentences from the combined descriptions of [GCC](https://ai.google.com/research/ConceptualCaptions/) + [MSCOCO](https://cocodataset.org/#home) + [VizWiz](https://vizwiz.org/tasks-and-datasets/image-captioning/), and translating them into Swedish.
|
| 29 |
+
All translation was done using the [Huggingface Opus Model](https://huggingface.co/Helsinki-NLP/opus-mt-en-sv), which seemingly procudes higher quality translations than relying on the [AWS translate service](https://aws.amazon.com/translate/).
|
Multilingual_CLIP/Model Cards/Swe-CLIP 500k/README.md
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<br />
|
| 2 |
+
<p align="center">
|
| 3 |
+
<h1 align="center">Swe-CLIP 500k</h1>
|
| 4 |
+
|
| 5 |
+
<p align="center">
|
| 6 |
+
<a href="https://huggingface.co/M-CLIP/Swedish-500k">Huggingface Model</a>
|
| 7 |
+
·
|
| 8 |
+
<a href="https://huggingface.co/KB/bert-base-swedish-cased">Huggingface Base Model</a>
|
| 9 |
+
</p>
|
| 10 |
+
</p>
|
| 11 |
+
|
| 12 |
+
## Usage
|
| 13 |
+
To use this model along with the original CLIP vision encoder follow the [main page usage instructions](https://github.com/FreddeFrallan/Multilingual-CLIP) to download the additional linear weights.
|
| 14 |
+
Once this is done, you can load and use the model with the following code
|
| 15 |
+
```python
|
| 16 |
+
from multilingual_clip import multilingual_clip
|
| 17 |
+
|
| 18 |
+
model = multilingual_clip.load_model('Swe-CLIP-500k')
|
| 19 |
+
embeddings = model(['Älgen är skogens konung!', 'Alla isbjörnar är vänsterhänta'])
|
| 20 |
+
print(embeddings.shape)
|
| 21 |
+
# Yields: torch.Size([2, 640])
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
<!-- ABOUT THE PROJECT -->
|
| 25 |
+
## About
|
| 26 |
+
A [KB/Bert-Swedish-Cased](https://huggingface.co/KB/bert-base-swedish-cased) tuned to match the embedding space of the CLIP text encoder which accompanies the Res50x4 vision encoder. <br>
|
| 27 |
+
|
| 28 |
+
Training data pairs was generated by sampling 500k sentences from the combined descriptions of [GCC](https://ai.google.com/research/ConceptualCaptions/) + [MSCOCO](https://cocodataset.org/#home) + [VizWiz](https://vizwiz.org/tasks-and-datasets/image-captioning/), and translating them into Swedish.
|
| 29 |
+
All translation was done using the [Huggingface Opus Model](https://huggingface.co/Helsinki-NLP/opus-mt-en-sv), which seemingly procudes higher quality translations than relying on the [AWS translate service](https://aws.amazon.com/translate/).
|
Multilingual_CLIP/Multilingual_CLIP.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
Multilingual_CLIP/README.md
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<br />
|
| 2 |
+
<p align="center">
|
| 3 |
+
<h1 align="center">Multilingual-CLIP</h1>
|
| 4 |
+
<h3 align="center">OpenAI CLIP text encoders for any language</h3>
|
| 5 |
+
|
| 6 |
+
<p align="center">
|
| 7 |
+
<a href="https://rom1504.github.io/clip-retrieval/?back=https%3A%2F%2Fknn5.laion.ai&index=laion_400m&useMclip=true">Live Demo</a>
|
| 8 |
+
·
|
| 9 |
+
<a href="https://huggingface.co/M-CLIP">Pre-trained Models</a>
|
| 10 |
+
·
|
| 11 |
+
<a href="https://github.com/FreddeFrallan/Contrastive-Tension/issues">Report Bug</a>
|
| 12 |
+
</p>
|
| 13 |
+
</p>
|
| 14 |
+
|
| 15 |
+
[](https://colab.research.google.com/github/FreddeFrallan/Multilingual-CLIP/blob/master/Multilingual_CLIP.ipynb)
|
| 16 |
+
[](https://pypi.python.org/pypi/multilingual-clip)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
<!-- ABOUT THE PROJECT -->
|
| 20 |
+
## Overview
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
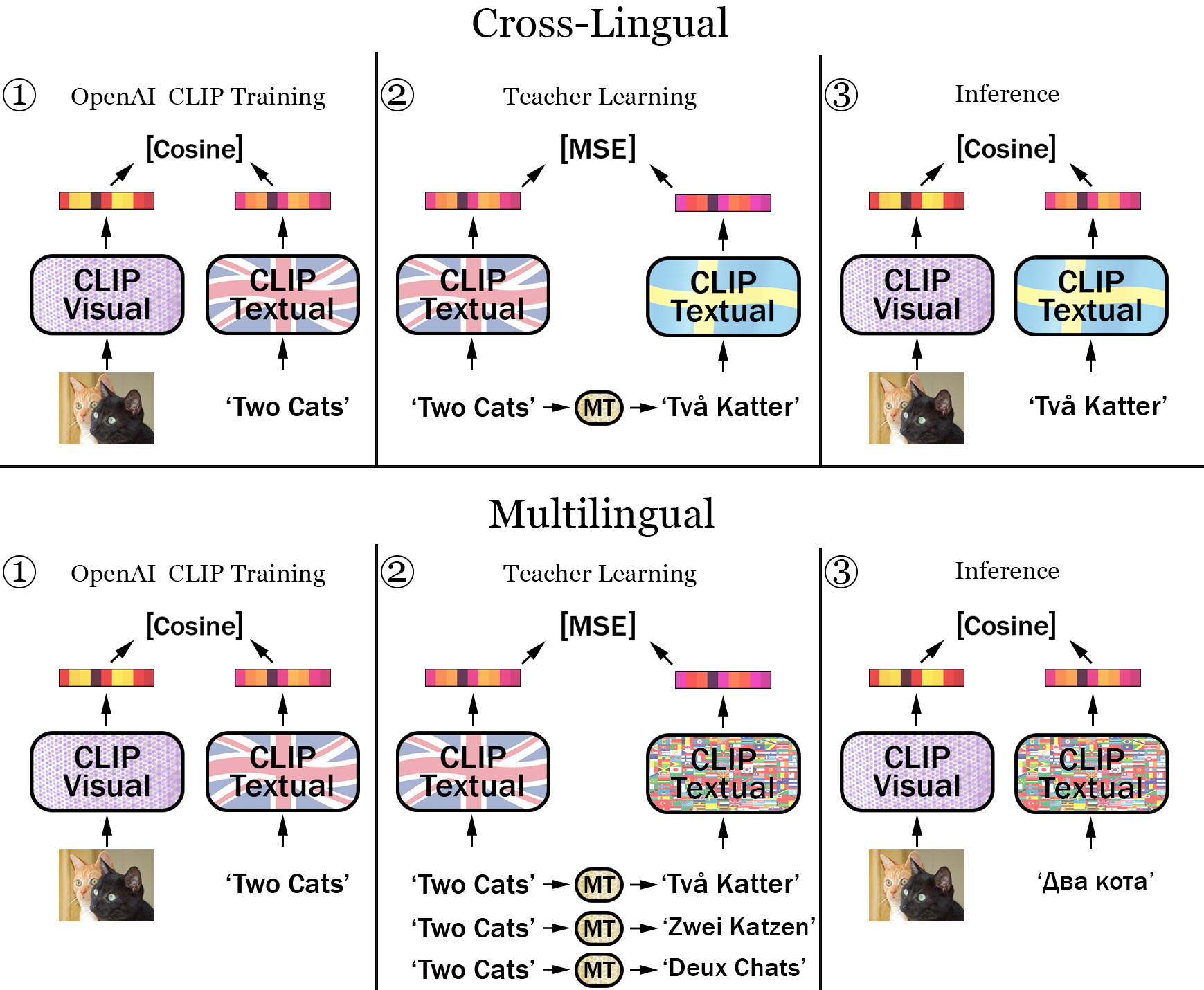
[OpenAI](https://openai.com/) recently released the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) in which they present the CLIP (Contrastive Language–Image Pre-training) model. This model is trained to connect text and images, by matching their corresponding vector representations using a contrastive learning objective.
|
| 24 |
+
CLIP consists of two separate models, a visual encoder and a text encoder. These were trained on a wooping 400 Million images and corresponding captions.
|
| 25 |
+
OpenAI has since released a set of their smaller CLIP models, which can be found on the [official CLIP Github](https://github.com/openai/CLIP).
|
| 26 |
+
|
| 27 |
+
## Demo
|
| 28 |
+
A live demonstration of multilingual Text-Image retrieval using M-CLIP can be found [here!](https://rom1504.github.io/clip-retrieval/?back=https%3A%2F%2Fknn5.laion.ai&index=laion_400m&useMclip=true) This demo was created by [Rom1504](https://github.com/rom1504), and it allows you to search the LAION-400M dataset in various languages using M-CLIP.
|
| 29 |
+
|
| 30 |
+
#### This repository contains
|
| 31 |
+
* Pre-trained CLIP-Text encoders for multiple languages
|
| 32 |
+
* Pytorch & Tensorflow inference code
|
| 33 |
+
* Tensorflow training code
|
| 34 |
+
|
| 35 |
+
### Requirements
|
| 36 |
+
While it is possible that other versions works equally fine, we have worked with the following:
|
| 37 |
+
|
| 38 |
+
* Python = 3.6.9
|
| 39 |
+
* Transformers = 4.8.1
|
| 40 |
+
|
| 41 |
+
## Install
|
| 42 |
+
|
| 43 |
+
`pip install multilingual-clip torch`
|
| 44 |
+
|
| 45 |
+
You can also choose to `pip install tensorflow` instead of torch.
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
## Inference Usage
|
| 49 |
+
|
| 50 |
+
Inference code for Tensorflow is also available in [inference_example.py](https://github.com/FreddeFrallan/Multilingual-CLIP/blob/main/inference_example.py)
|
| 51 |
+
|
| 52 |
+
```python
|
| 53 |
+
from multilingual_clip import pt_multilingual_clip
|
| 54 |
+
import transformers
|
| 55 |
+
|
| 56 |
+
texts = [
|
| 57 |
+
'Three blind horses listening to Mozart.',
|
| 58 |
+
'Älgen är skogens konung!',
|
| 59 |
+
'Wie leben Eisbären in der Antarktis?',
|
| 60 |
+
'Вы знали, что все белые медведи левши?'
|
| 61 |
+
]
|
| 62 |
+
model_name = 'M-CLIP/XLM-Roberta-Large-Vit-L-14'
|
| 63 |
+
|
| 64 |
+
# Load Model & Tokenizer
|
| 65 |
+
model = pt_multilingual_clip.MultilingualCLIP.from_pretrained(model_name)
|
| 66 |
+
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
|
| 67 |
+
|
| 68 |
+
embeddings = model.forward(texts, tokenizer)
|
| 69 |
+
print(embeddings.shape)
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
## Install for development
|
| 73 |
+
|
| 74 |
+
Setup a virtualenv:
|
| 75 |
+
|
| 76 |
+
```
|
| 77 |
+
python3 -m venv .env
|
| 78 |
+
source .env/bin/activate
|
| 79 |
+
pip install -e .
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
## Pre-trained Models
|
| 83 |
+
Every text encoder is a [Huggingface](https://huggingface.co/) available transformer, with an additional linear layer on top. For more information of a specific model, click the Model Name to see its model card.
|
| 84 |
+
<br>
|
| 85 |
+
<br>
|
| 86 |
+
|
| 87 |
+
| Name |Model Base|Vision Model | Vision Dimensions | Pre-trained Languages | #Parameters|
|
| 88 |
+
| ----------------------------------|:-----: |:-----: |:-----: |:-----: | :-----: |
|
| 89 |
+
| [LABSE Vit-L/14](https://huggingface.co/M-CLIP/LABSE-Vit-L-14)| [LaBSE](https://huggingface.co/sentence-transformers/LaBSE)| [OpenAI ViT-L/14](https://github.com/openai/CLIP) | 768 | [109 Languages](https://arxiv.org/pdf/2007.01852.pdf) | 110 M|
|
| 90 |
+
| [XLM-R Large Vit-B/32](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-B-32)| [XLM-Roberta-Large](https://huggingface.co/xlm-roberta-large)| [OpenAI ViT-B/32](https://github.com/openai/CLIP) | 512 | [100 Languages](https://github.com/facebookresearch/fairseq/tree/main/examples/xlmr#Introduction) | 344 M|
|
| 91 |
+
| [XLM-R Large Vit-L/14](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-L-14)| [XLM-Roberta-Large](https://huggingface.co/xlm-roberta-large)| [OpenAI ViT-L/14](https://github.com/openai/CLIP) | 768 | [100 Languages](https://github.com/facebookresearch/fairseq/tree/main/examples/xlmr#Introduction)| 344 M|
|
| 92 |
+
| [XLM-R Large Vit-B/16+](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-B-16Plus)| [XLM-Roberta-Large](https://huggingface.co/xlm-roberta-large)| [Open CLIP ViT-B-16-plus-240](https://github.com/mlfoundations/open_clip) | 640 | [100 Languages](https://github.com/facebookresearch/fairseq/tree/main/examples/xlmr#Introduction)| 344 M|
|
| 93 |
+
|
| 94 |
+
### Validation & Training Curves
|
| 95 |
+
Following is a table of the <b>Txt2Img @10-Recal</b> for the humanly tanslated [MS-COCO testset](https://arxiv.org/abs/2109.07622).
|
| 96 |
+
|
| 97 |
+
| Name | En | De | Es | Fr | Zh | It | Pl | Ko | Ru | Tr | Jp |
|
| 98 |
+
| ----------------------------------|:-----: |:-----: |:-----: |:-----: | :-----: |:-----: |:-----: |:-----: |:-----: |:-----: |:-----: |
|
| 99 |
+
| [OpenAI CLIP Vit-B/32](https://github.com/openai/CLIP)| 90.3 | - | - | - | - | - | - | - | - | - | - |
|
| 100 |
+
| [OpenAI CLIP Vit-L/14](https://github.com/openai/CLIP)| 91.8 | - | - | - | - | - | - | - | - | - | - |
|
| 101 |
+
| [OpenCLIP ViT-B-16+-](https://github.com/openai/CLIP)| 94.3 | - | - | - | - | - | - | - | - | - | - |
|
| 102 |
+
| [LABSE Vit-L/14](https://huggingface.co/M-CLIP/LABSE-Vit-L-14)| 91.6 | 89.6 | 89.5 | 89.9 | 88.9 | 90.1 | 89.8 | 80.8 | 85.5 | 89.8 | 73.9 |
|
| 103 |
+
| [XLM-R Large Vit-B/32](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-B-32)| 91.8 | 88.7 | 89.1 | 89.4 | 89.3 | 89.8| 91.4 | 82.1 | 86.1 | 88.8 | 81.0 |
|
| 104 |
+
| [XLM-R Vit-L/14](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-L-14)| 92.4 | 90.6 | 91.0 | 90.0 | 89.7 | 91.1 | 91.3 | 85.2 | 85.8 | 90.3 | 81.9 |
|
| 105 |
+
| [XLM-R Large Vit-B/16+](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-B-16Plus)| <b>95.0</b> | <b>93.0</b> | <b>93.6</b> | <b>93.1</b> | <b>94.0</b> | <b>93.1</b> | <b>94.4</b> | <b>89.0</b> | <b>90.0</b> | <b>93.0</b> | <b>84.2</b> |
|
| 106 |
+
|
| 107 |
+
The training curves for these models are available at this [Weights and Biases Report](https://wandb.ai/freddefrallan/M-CLIP/reports/M-CLIP-2-6-2022--VmlldzoyMTE1MjU1/edit?firstReport&runsetFilter), the results for other non-succesfull and ongoing experiments can be found in the [Weights and Biases Project](https://wandb.ai/freddefrallan/M-CLIP?workspace=user-freddefrallan).
|
| 108 |
+
|
| 109 |
+
## Legacy Usage and Models
|
| 110 |
+
Older versions of M-CLIP had the linear weights stored separately from Huggingface. Whilst the new models have them directly incorporated in the Huggingface repository. More information about these older models can be found in this section.
|
| 111 |
+
|
| 112 |
+
<details>
|
| 113 |
+
<summary>Click for more information</summary>
|
| 114 |
+
|
| 115 |
+
##### Download CLIP Model
|
| 116 |
+
```bash
|
| 117 |
+
$ conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
|
| 118 |
+
$ pip install ftfy regex tqdm
|
| 119 |
+
$ pip install git+https://github.com/openai/CLIP.git
|
| 120 |
+
```
|
| 121 |
+
Replace `cudatoolkit=11.0` above with the appropriate CUDA version on your machine or `cpuonly` when installing on a machine without a GPU.
|
| 122 |
+
For more information please see the official [CLIP repostitory](https://github.com/openai/CLIP).
|
| 123 |
+
##### Download Linear Weights
|
| 124 |
+
```bash
|
| 125 |
+
# Linear Model Weights
|
| 126 |
+
$ bash legacy_get-weights.sh
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
### Inference
|
| 130 |
+
```python
|
| 131 |
+
from multilingual_clip import multilingual_clip
|
| 132 |
+
|
| 133 |
+
print(multilingual_clip.AVAILABLE_MODELS.keys())
|
| 134 |
+
|
| 135 |
+
model = multilingual_clip.load_model('M-BERT-Distil-40')
|
| 136 |
+
|
| 137 |
+
embeddings = model(['Älgen är skogens konung!', 'Wie leben Eisbären in der Antarktis?', 'Вы знали, что все белые медведи левши?'])
|
| 138 |
+
print(embeddings.shape)
|
| 139 |
+
# Yields: torch.Size([3, 640])
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
<!--- For a more elaborative example see this [Google Colab](https://colab.research.google.com/github/FreddeFrallan/Multilingual-CLIP/blob/master/Multilingual_CLIP.ipynb). --->
|
| 143 |
+
|
| 144 |
+
For a more elaborate example, comparing the textual embeddings to the CLIP image embeddings see this [colab notebook](https://colab.research.google.com/github/FreddeFrallan/Multilingual-CLIP/blob/master/Multilingual_CLIP.ipynb).
|
| 145 |
+
|
| 146 |
+
<!-- GETTING STARTED -->
|
| 147 |
+
## Legacy Pre-trained Models
|
| 148 |
+
Every text encoder is a [Huggingface](https://huggingface.co/) available transformer, with an additional linear layer on top. Neither of the models have been extensively tested, but for more information and qualitative test results for a specific model, click the Model Name to see its model card.
|
| 149 |
+
<br>
|
| 150 |
+
<br>
|
| 151 |
+
<b>*** Make sure to update to the most recent version of the repostitory when downloading a new model, and re-run the shell script to download the Linear Weights. *** </b>
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
| Name |Model Base|Vision Model | Pre-trained Languages | Target Languages | #Parameters|
|
| 155 |
+
| ----------------------------------|:-----: |:-----: |:-----: |:-----: |:-----: |
|
| 156 |
+
|**Multilingual** ||
|
| 157 |
+
| [M-BERT Distil 40](https://github.com/FreddeFrallan/Multilingual-CLIP/tree/main/Model%20Cards/M-BERT%20Distil%2040) | [M-BERT Distil](https://huggingface.co/bert-base-multilingual-uncased)| RN50x4 | [101 Languages](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages) | [40 Languages](https://github.com/FreddeFrallan/Multilingual-CLIP/blob/main/Model%20Cards/M-BERT%20Distil%2040/Fine-Tune-Languages.md) | 66 M|
|
| 158 |
+
| [M-BERT Base 69](https://github.com/FreddeFrallan/Multilingual-CLIP/tree/main/Model%20Cards/M-BERT%20Base%2069) | [M-BERT Base](https://huggingface.co/bert-base-multilingual-uncased)|RN50x4 | [101 Languages](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages) | 68 Languages | 110 M|
|
| 159 |
+
| [M-BERT Base ViT-B](https://github.com/FreddeFrallan/Multilingual-CLIP/tree/main/Model%20Cards/M-BERT%20Base%20ViT-B) | [M-BERT Base](https://huggingface.co/bert-base-multilingual-uncased)|ViT-B/32 | [101 Languages](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages) | 68 Languages | 110 M|
|
| 160 |
+
|**Monolingual** ||
|
| 161 |
+
|[Swe-CLIP 500k](https://github.com/FreddeFrallan/Multilingual-CLIP/tree/main/Model%20Cards/Swe-CLIP%20500k)| [KB-BERT](https://huggingface.co/KB/bert-base-swedish-cased)| RN50x4 | Swedish | Swedish | 110 M|
|
| 162 |
+
|[Swe-CLIP 2M](https://github.com/FreddeFrallan/Multilingual-CLIP/tree/main/Model%20Cards/Swe-CLIP%202M)| [KB-BERT](https://huggingface.co/KB/bert-base-swedish-cased)| RN50x4 | Swedish | Swedish | 110 M|
|
| 163 |
+
|
| 164 |
+
</details>
|
| 165 |
+
|
| 166 |
+
## Training a new model
|
| 167 |
+
[This folder](https://github.com/FreddeFrallan/Multilingual-CLIP/tree/main/multilingual_clip/TeacherLearning) contains the code used for training the above models. If you wsh to train your own model you must do the following things:
|
| 168 |
+
|
| 169 |
+
* Prepare a set of translated sentence pairs from English -> Your Language(s)
|
| 170 |
+
* Compute regular CLIP-Text embeddings for the English sentences.
|
| 171 |
+
* Edit [Training.py](https://github.com/FreddeFrallan/Multilingual-CLIP/blob/main/multilingual_clip/TeacherLearning/Training.py) to load your data.
|
| 172 |
+
* Train a new CLIP-Text encoder via Teacher Learning
|
| 173 |
+
|
| 174 |
+
### Pre-computed CLIP Embeddings & Translaton Data
|
| 175 |
+
[This Google Drive folder](https://drive.google.com/drive/folders/1I9a7naSZubUATWzLFv61DQMWyFlF7wR5?usp=sharing) contains both pre-computed CLIP-Text Embeddings for a large porton of the the image captions of [GCC](https://ai.google.com/research/ConceptualCaptions/) + [MSCOCO](https://cocodataset.org/#home) + [VizWiz](https://vizwiz.org/tasks-and-datasets/image-captioning/).
|
| 176 |
+
|
| 177 |
+
The Google Drive folder also contains the translation data used to train the currently available models.
|
| 178 |
+
Good Luck
|
| 179 |
+
|
| 180 |
+
## Contribution
|
| 181 |
+
If you have trained a CLIP Text encoder specific to your language, or another model covering a language not supported here, Please feel free to contact us and we will either upload your model and credit you, or simply link to your already uploaded model.
|
| 182 |
+
|
| 183 |
+
<!-- CONTACT -->
|
| 184 |
+
## Contact
|
| 185 |
+
If you have questions regarding the code or otherwise related to this Github page, please open an [issue](https://github.com/FreddeFrallan/Contrastive-Tension/issues).
|
| 186 |
+
|
| 187 |
+
For other purposes, feel free to contact me directly at: [email protected]
|
| 188 |
+
|
| 189 |
+
<!-- ACKNOWLEDGEMENTS -->
|
| 190 |
+
## Acknowledgements
|
| 191 |
+
* [Stability.ai](https://stability.ai/) for providing much appreciated compute during training.
|
| 192 |
+
* [CLIP](https://openai.com/blog/clip/)
|
| 193 |
+
* [OpenAI](https://openai.com/)
|
| 194 |
+
* [Huggingface](https://huggingface.co/)
|
| 195 |
+
* [Best Readme Template](https://github.com/othneildrew/Best-README-Template)
|
| 196 |
+
* ["Two Cats" Image by pl1602](https://search.creativecommons.org/photos/8dfd802b-58e5-4cc5-889d-96abba540de1)
|
| 197 |
+
|
| 198 |
+
<!-- LICENSE -->
|
| 199 |
+
## License
|
| 200 |
+
Distributed under the MIT License. See `LICENSE` for more information.
|
| 201 |
+
|
| 202 |
+
<!-- CITATION -->
|
| 203 |
+
## Citing
|
| 204 |
+
If you found this repository useful, please consider citing:
|
| 205 |
+
|
| 206 |
+
```bibtex
|
| 207 |
+
@InProceedings{carlsson-EtAl:2022:LREC,
|
| 208 |
+
author = {Carlsson, Fredrik and Eisen, Philipp and Rekathati, Faton and Sahlgren, Magnus},
|
| 209 |
+
title = {Cross-lingual and Multilingual CLIP},
|
| 210 |
+
booktitle = {Proceedings of the Language Resources and Evaluation Conference},
|
| 211 |
+
month = {June},
|
| 212 |
+
year = {2022},
|
| 213 |
+
address = {Marseille, France},
|
| 214 |
+
publisher = {European Language Resources Association},
|
| 215 |
+
pages = {6848--6854},
|
| 216 |
+
abstract = {The long-standing endeavor of relating the textual and the visual domain recently underwent a pivotal breakthrough, as OpenAI released CLIP. This model distinguishes how well an English text corresponds with a given image with unprecedented accuracy. Trained via a contrastive learning objective over a huge dataset of 400M of images and captions, it is a work that is not easily replicated, especially for low resource languages. Capitalizing on the modularization of the CLIP architecture, we propose to use cross-lingual teacher learning to re-train the textual encoder for various non-English languages. Our method requires no image data and relies entirely on machine translation which removes the need for data in the target language. We find that our method can efficiently train a new textual encoder with relatively low computational cost, whilst still outperforming previous baselines on multilingual image-text retrieval.},
|
| 217 |
+
url = {https://aclanthology.org/2022.lrec-1.739}
|
| 218 |
+
}
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
<!-- MARKDOWN LINKS & IMAGES -->
|
| 223 |
+
<!-- https://www.markdownguide.org/basic-syntax/#reference-style-links -->
|
| 224 |
+
[contributors-shield]: https://img.shields.io/github/contributors/othneildrew/Best-README-Template.svg?style=for-the-badge
|
| 225 |
+
[contributors-url]: https://github.com/othneildrew/Best-README-Template/graphs/contributors
|
| 226 |
+
[forks-shield]: https://img.shields.io/github/forks/othneildrew/Best-README-Template.svg?style=for-the-badge
|
| 227 |
+
[forks-url]: https://github.com/othneildrew/Best-README-Template/network/members
|
| 228 |
+
[stars-shield]: https://img.shields.io/github/stars/othneildrew/Best-README-Template.svg?style=for-the-badge
|
| 229 |
+
[stars-url]: https://github.com/othneildrew/Best-README-Template/stargazers
|
| 230 |
+
[issues-shield]: https://img.shields.io/github/issues/othneildrew/Best-README-Template.svg?style=for-the-badge
|
| 231 |
+
[issues-url]: https://github.com/othneildrew/Best-README-Template/issues
|
| 232 |
+
[license-shield]: https://img.shields.io/github/license/othneildrew/Best-README-Template.svg?style=for-the-badge
|
| 233 |
+
[license-url]: https://github.com/othneildrew/Best-README-Template/blob/master/LICENSE.txt
|
| 234 |
+
[linkedin-shield]: https://img.shields.io/badge/-LinkedIn-black.svg?style=for-the-badge&logo=linkedin&colorB=555
|
| 235 |
+
[linkedin-url]: https://linkedin.com/in/othneildrew
|
| 236 |
+
[product-screenshot]: images/screenshot.png
|
Multilingual_CLIP/inference_example.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import transformers
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def tf_example(texts, model_name='M-CLIP/XLM-Roberta-Large-Vit-L-14'):
|
| 5 |
+
from multilingual_clip import tf_multilingual_clip
|
| 6 |
+
|
| 7 |
+
model = tf_multilingual_clip.MultiLingualCLIP.from_pretrained(model_name)
|
| 8 |
+
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
|
| 9 |
+
|
| 10 |
+
inData = tokenizer.batch_encode_plus(texts, return_tensors='tf', padding=True)
|
| 11 |
+
embeddings = model(inData)
|
| 12 |
+
print(embeddings.shape)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def pt_example(texts, model_name='M-CLIP/XLM-Roberta-Large-Vit-L-14'):
|
| 16 |
+
from multilingual_clip import pt_multilingual_clip
|
| 17 |
+
|
| 18 |
+
model = pt_multilingual_clip.MultilingualCLIP.from_pretrained(model_name)
|
| 19 |
+
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
|
| 20 |
+
|
| 21 |
+
embeddings = model.forward(texts, tokenizer)
|
| 22 |
+
print(embeddings.shape)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
if __name__ == '__main__':
|
| 26 |
+
exampleTexts = [
|
| 27 |
+
'Three blind horses listening to Mozart.',
|
| 28 |
+
'Älgen är skogens konung!',
|
| 29 |
+
'Wie leben Eisbären in der Antarktis?',
|
| 30 |
+
'Вы знали, что все белые медведи левши?'
|
| 31 |
+
]
|
| 32 |
+
|
| 33 |
+
# tf_example(exampleTexts)
|
| 34 |
+
pt_example(exampleTexts)
|
Multilingual_CLIP/larger_mclip.md
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Multilingual CLIP 2/6-2022
|
| 2 |
+
|
| 3 |
+
## Overview
|
| 4 |
+
Recently, OpenAI released some of their [bigger CLIP models](https://github.com/openai/CLIP/blob/main/model-card.md). Additionally, [OpenCLIP](https://github.com/mlfoundations/open_clip) is continuing to provide their large models, which have proven to match or even outperform the OpenAI models.
|
| 5 |
+
|
| 6 |
+
Thanks to the compute provided by [Stability.ai](https://stability.ai/) and [laion.ai](https://laion.ai/), we are now happy to announce that we provide multilingual text encoders for these models!
|
| 7 |
+
Along with:
|
| 8 |
+
- Updated Inference & Training Code
|
| 9 |
+
- The Corresponding Machine Translated Image Caption Dataset
|
| 10 |
+
- PyPi package installer
|
| 11 |
+
|
| 12 |
+
<br>
|
| 13 |
+
|
| 14 |
+
None of the M-CLIP models have been extensivly evaluated, but testing them on Txt2Img retrieval on the humanly translated MS-COCO dataset, we see the following **R@10** results:
|
| 15 |
+
| Name | En | De | Es | Fr | Zh | It | Pl | Ko | Ru | Tr | Jp |
|
| 16 |
+
| ----------------------------------|:-----: |:-----: |:-----: |:-----: | :-----: |:-----: |:-----: |:-----: |:-----: |:-----: |:-----: |
|
| 17 |
+
| [OpenAI CLIP Vit-B/32](https://github.com/openai/CLIP)| 90.3 | - | - | - | - | - | - | - | - | - | - |
|
| 18 |
+
| [OpenAI CLIP Vit-L/14](https://github.com/openai/CLIP)| 91.8 | - | - | - | - | - | - | - | - | - | - |
|
| 19 |
+
| [OpenCLIP ViT-B-16+-](https://github.com/openai/CLIP)| 94.3 | - | - | - | - | - | - | - | - | - | - |
|
| 20 |
+
| [LABSE Vit-L/14](https://huggingface.co/M-CLIP/LABSE-Vit-L-14)| 91.6 | 89.6 | 89.5 | 89.9 | 88.9 | 90.1 | 89.8 | 80.8 | 85.5 | 89.8 | 73.9 |
|
| 21 |
+
| [XLM-R Large Vit-B/32](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-B-32)| 91.8 | 88.7 | 89.1 | 89.4 | 89.3 | 89.8| 91.4 | 82.1 | 86.1 | 88.8 | 81.0 |
|
| 22 |
+
| [XLM-R Vit-L/14](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-L-14)| 92.4 | 90.6 | 91.0 | 90.0 | 89.7 | 91.1 | 91.3 | 85.2 | 85.8 | 90.3 | 81.9 |
|
| 23 |
+
| [XLM-R Large Vit-B/16+](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-B-16Plus)| <b>95.0</b> | <b>93.0</b> | <b>93.6</b> | <b>93.1</b> | <b>94.0</b> | <b>93.1</b> | <b>94.4</b> | <b>89.0</b> | <b>90.0</b> | <b>93.0</b> | <b>84.2</b> |
|
| 24 |
+
|
| 25 |
+
To our surprise, using M-CLIP with XLM-RoBerta Large outperforms the original English models for English. Exactly why this is the case reamins to be determined, and we plan to followup up with more extensive testing.
|
| 26 |
+
|
| 27 |
+
The ViT-L/14 model is integrated into clip retrieval, you can test the retrieval capabilities of this multilingual encoder [there](https://rom1504.github.io/clip-retrieval/?useMclip=true&query=%E9%BB%84%E8%89%B2%E3%81%84%E7%8C%AB). This is a search over 5 billion of clip embeddings of laion5B dataset implemented with an efficient knn index.
|
| 28 |
+
|
| 29 |
+
The training curves for these models can be found at the [Weights and Biases report](https://wandb.ai/freddefrallan/M-CLIP/reports/M-CLIP-2-6-2022--VmlldzoyMTE1MjU1/edit?firstReport&runsetFilter)
|
| 30 |
+
|
| 31 |
+
## Training Data & Machine Translation
|
| 32 |
+
English image captions were taken from the Vit-L filtered captions of the datasets: [CC3M+CC12M+SBU](https://github.com/salesforce/BLIP#pre-training-datasets-download), which are provided by the BLIP repository.
|
| 33 |
+
|
| 34 |
+
From these 14 million captions we sampled 7 million captions, divided them into 48 equally sized buckets, and translated each bucket into one of the [48 target languages](https://github.com/FreddeFrallan/Multilingual-CLIP/blob/main/translation/data/fine_tune_languages.csv). This means that after translation we still end up with a total of 7 million captions. Where 7M/48 = 145,833 of them are in for example Dutch.
|
| 35 |
+
The machine-translated captions are available at [Huggingface](https://huggingface.co/datasets/M-CLIP/ImageCaptions-7M-Translations).
|
| 36 |
+
|
| 37 |
+
Each translation was performed with the corresponding Opus model. For more information see the [machine translation instructions](https://github.com/FreddeFrallan/Multilingual-CLIP/tree/main/translation).
|
| 38 |
+
|
| 39 |
+
It should be noted that only translated captions were used during training. Meaning that none of the original English captions were included. This entails that all the English (and other languages not included in the 49 target languages) results are due to transfer learning.
|
| 40 |
+
|
| 41 |
+
## Training Details
|
| 42 |
+
All released models used in essence the same hyperparameters. These detail are available at [Weights and Biases project](https://wandb.ai/freddefrallan/M-CLIP?workspace=user-freddefrallan).
|
| 43 |
+
|
| 44 |
+
Following is a short list of some of the shared hyperparameters:
|
| 45 |
+
- Batch size of 2048 samples.
|
| 46 |
+
- Adam Optimizer with a target learning rate of 10^-5, with a linear warmup schedule for 1k update steps.
|
| 47 |
+
- 5000 randomly sampled validation samples
|
| 48 |
+
|
| 49 |
+
All models were allowed to train until the validation MSE loss had converged. For most models this took about 24 hours, using 8 Nvidia A-100 GPUs. No early stopping was performed in regard to the Image-Text retrieval tasks.
|
| 50 |
+
|
| 51 |
+
## Additional Experiments
|
| 52 |
+
In addition to the released models, we also performed some experiments that yielded negative or unsubstantial results. The training curves and specific settings for most of these additional experiments can be found at the [Weights and Biases project](https://wandb.ai/freddefrallan/M-CLIP?workspace=user-freddefrallan).
|
| 53 |
+
|
| 54 |
+
Following is a summary of things we tried:
|
| 55 |
+
|
| 56 |
+
- Optimizing the Cosine-Similarity instead of minimizing the mean-squared error: **No noticeable performance difference**.
|
| 57 |
+
- MBERT-BASE as encoder: **Worse performance than LaBSE**
|
| 58 |
+
- USE-CML: **Worse performance than LaBSE**
|
| 59 |
+
- Adding additional TanH layer to the XLM-R Large: **No substantial performance difference, although it achieved slightly faster learning at the start.**
|
| 60 |
+
- Using first *([CLS]?)* token as sentence embedding, instead of mean-pooling for XLM-R Large: **Significantly worse performance. *(Perhaps due to the lack of Next-Sentence Prediction task in the RoBerta pre-training?)***
|
Multilingual_CLIP/legacy_get-weights.sh
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#
|
| 2 |
+
|
| 3 |
+
OUTPATH=$PWD/data/weights
|
| 4 |
+
|
| 5 |
+
mkdir -p $OUTPATH
|
| 6 |
+
|
| 7 |
+
URLSWECLIP=https://www.dropbox.com/s/s77xw5308jeljlp/Swedish-500k%20Linear%20Weights.pkl
|
| 8 |
+
wget -c "${URLSWECLIP}" -P $OUTPATH
|
| 9 |
+
|
| 10 |
+
URLSWECLIP2M=https://www.dropbox.com/s/82c54rsvlry3kwh/Swedish-2M%20Linear%20Weights.pkl
|
| 11 |
+
wget -c "${URLSWECLIP2M}" -P $OUTPATH
|
| 12 |
+
|
| 13 |
+
URLMCLIP=https://www.dropbox.com/s/oihqzctnty5e9kk/M-BERT%20Distil%2040%20Linear%20Weights.pkl
|
| 14 |
+
wget -c "${URLMCLIP}" -P $OUTPATH
|
| 15 |
+
|
| 16 |
+
URLMCLIPBASE=https://www.dropbox.com/s/y4pycinv0eapeb3/M-BERT-Base-69%20Linear%20Weights.pkl
|
| 17 |
+
wget -c "${URLMCLIPBASE}" -P $OUTPATH
|
| 18 |
+
|
| 19 |
+
URLMCLIPBASEVIT=https://www.dropbox.com/s/2oxu7hw0y9fwdqs/M-BERT-Base-69-ViT%20Linear%20Weights.pkl
|
| 20 |
+
wget -c "${URLMCLIPBASEVIT}" -P $OUTPATH
|
Multilingual_CLIP/legacy_inference.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from multilingual_clip.legacy_multilingual_clip import MultilingualClip
|
| 2 |
+
|
| 3 |
+
model_path = 'M-CLIP/Swedish-500k'
|
| 4 |
+
tok_path = 'M-CLIP/Swedish-500k'
|
| 5 |
+
head_weight_path = 'data/weights/Swe-CLIP Linear Weights.pkl'
|
| 6 |
+
|
| 7 |
+
sweclip_args = {'model_name': model_path,
|
| 8 |
+
'tokenizer_name': tok_path,
|
| 9 |
+
'head_path': head_weight_path}
|
| 10 |
+
|
| 11 |
+
sweclip = MultilingualClip(**sweclip_args)
|
| 12 |
+
|
| 13 |
+
print(sweclip('test'))
|