Spaces:
Build error

Build error

https://github.com/mazzzystar/TurtleBenchmark
Browse files- .gitattributes +2 -0
- datasets/TurtleBenchmark/.gitignore +3 -0
- datasets/TurtleBenchmark/README.md +88 -0
- datasets/TurtleBenchmark/README_en.md +78 -0
- datasets/TurtleBenchmark/evaluation/.env.example +13 -0
- datasets/TurtleBenchmark/evaluation/chinese/data/cases.list +3 -0
- datasets/TurtleBenchmark/evaluation/chinese/data/results_0shot.json +3 -0
- datasets/TurtleBenchmark/evaluation/chinese/data/results_2shot.json +3 -0
- datasets/TurtleBenchmark/evaluation/chinese/data/sorted_cases.list +3 -0
- datasets/TurtleBenchmark/evaluation/chinese/data/sorted_cases.txt +3 -0
- datasets/TurtleBenchmark/evaluation/chinese/data/stories.json +3 -0
- datasets/TurtleBenchmark/evaluation/chinese/data/titles.txt +3 -0
- datasets/TurtleBenchmark/evaluation/chinese/evaluate.py +377 -0
- datasets/TurtleBenchmark/evaluation/chinese/imgs/Turtle-Benchmark-over-32stories.png +0 -0
- datasets/TurtleBenchmark/evaluation/chinese/imgs/Turtle-Benchmark-result.png +0 -0
- datasets/TurtleBenchmark/evaluation/chinese/imgs/average_model_accuracy_over_stories_2-shot.png +0 -0
- datasets/TurtleBenchmark/evaluation/chinese/model_configs.py +144 -0
- datasets/TurtleBenchmark/evaluation/chinese/prompt.py +77 -0
- datasets/TurtleBenchmark/evaluation/english/data/cases.list +3 -0
- datasets/TurtleBenchmark/evaluation/english/data/stories.json +3 -0
- datasets/TurtleBenchmark/evaluation/english/evaluate.py +620 -0
- datasets/TurtleBenchmark/evaluation/english/prompt.py +74 -0
- datasets/TurtleBenchmark/requirements.txt +3 -0
.gitattributes
CHANGED
|
@@ -34,6 +34,8 @@ unsloth/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 34 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 36 |
*.jsonl filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
| 37 |
*.txt filter=lfs diff=lfs merge=lfs -text
|
| 38 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 39 |
datasets/mgtv/ filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 34 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 36 |
*.jsonl filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
*.json filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
*.list filter=lfs diff=lfs merge=lfs -text
|
| 39 |
*.txt filter=lfs diff=lfs merge=lfs -text
|
| 40 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 41 |
datasets/mgtv/ filter=lfs diff=lfs merge=lfs -text
|
datasets/TurtleBenchmark/.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.env
|
| 2 |
+
venv
|
| 3 |
+
logs_with_*
|
datasets/TurtleBenchmark/README.md
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 海龟 Benchmark
|
| 2 |
+
|
| 3 |
+
[English](./README_en.md)
|
| 4 |
+
|
| 5 |
+
海龟 Benchmark 是一个新颖的、无法作弊的基准测试,专注于评估 LLM 的逻辑推理和上下文理解能力。评测数据集全部来自几千名真实用户在[海龟汤](https://www.tanghenre.com)游戏中的输入数据。
|
| 6 |
+
|
| 7 |
+
初步测评结果见:[用 2 万条真人AI海龟汤数据评估大模型推理能力](https://mazzzystar.github.io/2024/08/09/turtle-benchmark-zh/)
|
| 8 |
+
|
| 9 |
+
### 特点
|
| 10 |
+
|
| 11 |
+
- **无需背景知识**:不依赖背景知识和模型记忆能力,可以从 200 字以内的故事中获得作出判断所需的全部信息,让模型评测专注于推理能力。
|
| 12 |
+
- **客观且无偏见**:衡量猜测的正确性,结果是客观的、和人的感受无关。
|
| 13 |
+
- **可量化的结果**:明确、可测量的结果(正确/错误/未知),便于比较。
|
| 14 |
+
- **无法作弊**:使用真实用户提出的问题,并且随着线上游戏的进行,新数据会动态产生,使得作弊变得不可能。
|
| 15 |
+
|
| 16 |
+
### 数据集
|
| 17 |
+
|
| 18 |
+
- 32 个独特的"海龟汤"故事。
|
| 19 |
+
- 1537 个来自用户问题的人工标注标签: 对(T)、错(F)、不相关(N)
|
| 20 |
+
- 我们的评估日志。
|
| 21 |
+
|
| 22 |
+
> [!IMPORTANT]
|
| 23 |
+
> 我们在标注时发现:存在部分样本既可以标注为错(F),也可以标注为不相关(N),因此我们将**错**(F)和**不相关**(N)进行了合并、不做区分,在计算准确率时也在代码中做了合并——这会降低难度,因此我们可能在未来,将类别标注重新变为三类:对、错、不相关,并在 [4448](https://github.com/mazzzystar/TurtleBenchmark/blob/dev/evaluation/chinese/data/sorted_cases.list) 条样本上重新标注、测试模型表现。
|
| 24 |
+
|
| 25 |
+
### 使用方法
|
| 26 |
+
|
| 27 |
+
```bash
|
| 28 |
+
cd evaluation
|
| 29 |
+
|
| 30 |
+
mv .env.example .env
|
| 31 |
+
# 添加API密钥。
|
| 32 |
+
|
| 33 |
+
# Evaluate Chinese or English.
|
| 34 |
+
cd chinese
|
| 35 |
+
|
| 36 |
+
# zero-shot,评估更快更省钱,默认 2-shot
|
| 37 |
+
python evaluate.py --shot 0
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
### 结果
|
| 41 |
+
|
| 42 |
+
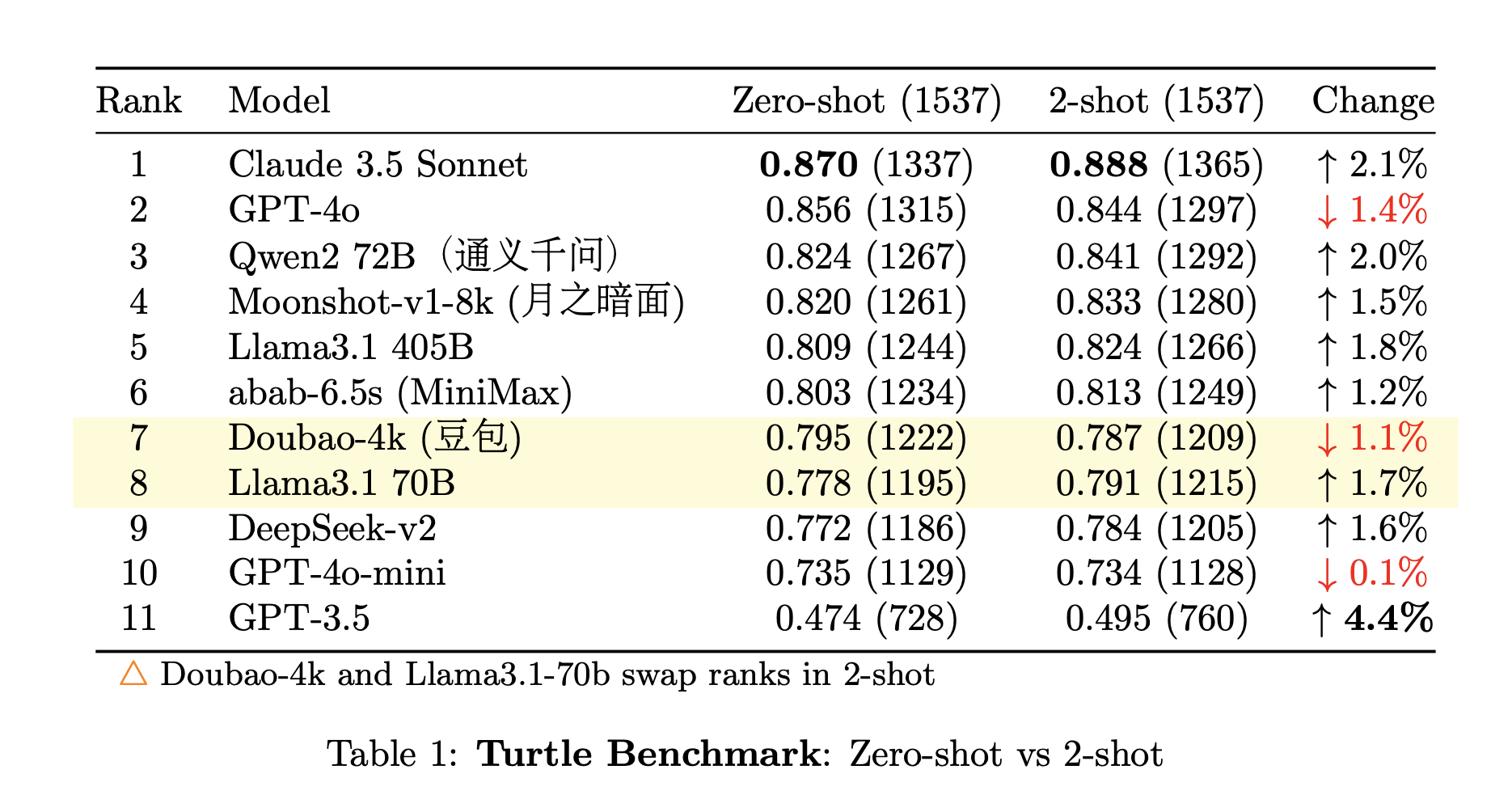
#### 1. 总体准确率
|
| 43 |
+
|
| 44 |
+
每个模型在所有测试案例中的总体准确率。
|
| 45 |
+
|
| 46 |
+

|
| 47 |
+
|
| 48 |
+
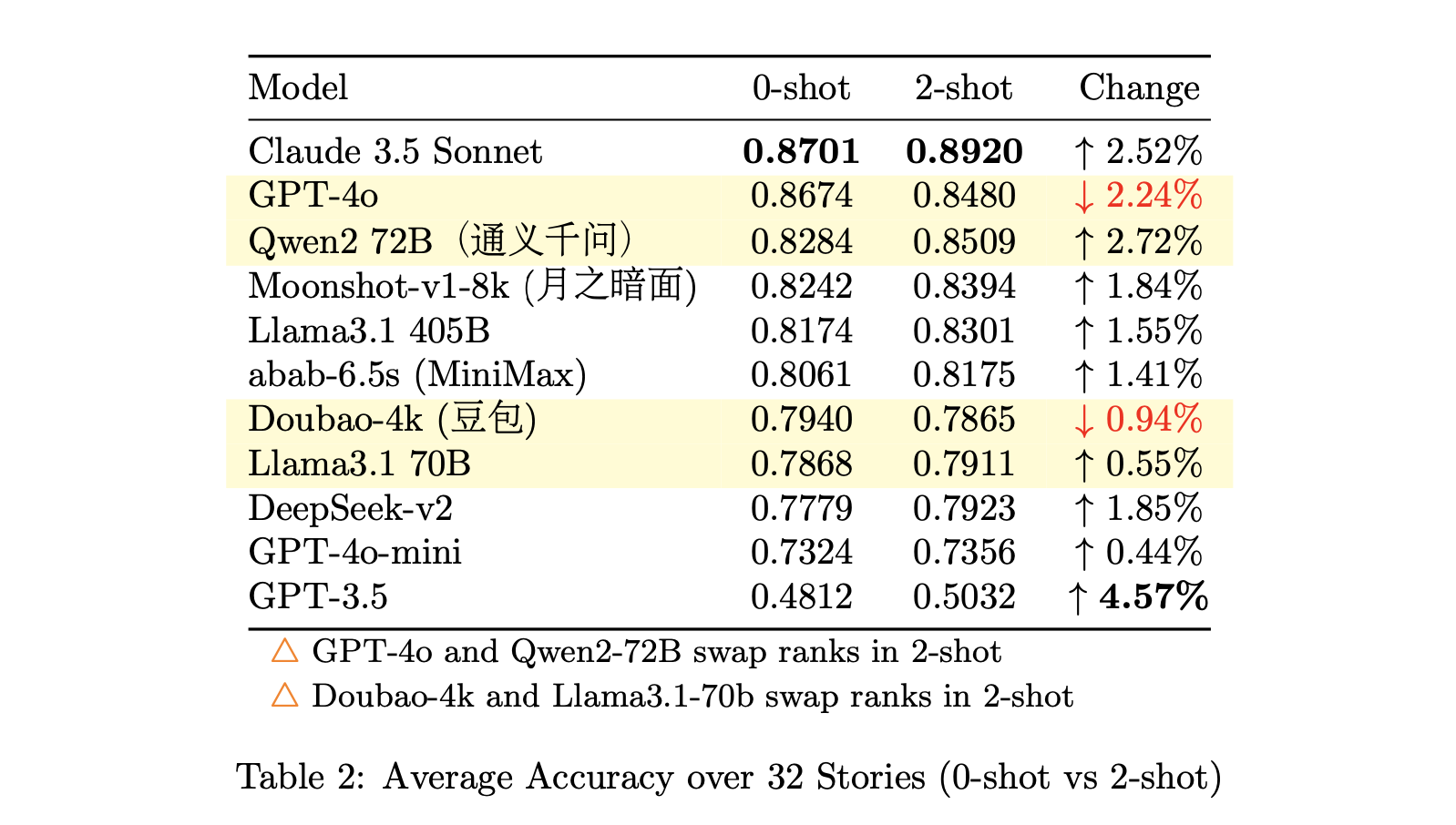
#### 2. 故事的平均准确率
|
| 49 |
+
|
| 50 |
+
为了减轻模型在某个具有大量测试样本的故事上表现不佳带来的偏差,我们分别计算了每个模型在所有 32 个故事中的准确率,并除以 32。
|
| 51 |
+
|
| 52 |
+

|
| 53 |
+
|
| 54 |
+
#### 3. 性能图表
|
| 55 |
+
|
| 56 |
+
这个散点图比较了 2-shot 学习场景中每个模型的总体准确率(x 轴)和平均故事准确率(y 轴)。
|
| 57 |
+
|
| 58 |
+

|
| 59 |
+
|
| 60 |
+
### 评测
|
| 61 |
+
|
| 62 |
+
根据这些结果,我们可以清楚地看到各种模型之间的性能差异:
|
| 63 |
+
|
| 64 |
+
1. **第一梯队**:Claude 3.5 Sonnet 作为无可争议的领导者脱颖而出,明显优于所有其他模型。
|
| 65 |
+
|
| 66 |
+
2. **第二梯队**:GPT-4o、Qwen-2(通义千问)、Moonshot AI(月之暗面)、LLama3.1 405B 和 Minimax 构成第二梯队。虽然我们避免了进一步的细分,但在这个组内,按照所列顺序,性能明显下降。
|
| 67 |
+
|
| 68 |
+
3. **第三梯队**:豆包(Douban)、DeepSeek 和 LLama3.1 70B 构成第三梯队。
|
| 69 |
+
|
| 70 |
+
4. **第四梯队**:GPT-4o-mini 独自位于第四梯队。
|
| 71 |
+
|
| 72 |
+
5. **过时**:GPT-3.5 的性能表明它在这个背景下不再具有竞争力。
|
| 73 |
+
|
| 74 |
+
需要注意的是,这项评估只针对**模型的中文语言理解和推理能力**。未来,视资源和资金情况,我们计划将所有故事和测试问题翻译成英文,并使用英文提示重新运行测试。这将有助于消除可能归因于语言差异的任何性能差异。
|
| 75 |
+
|
| 76 |
+
## TODO
|
| 77 |
+
|
| 78 |
+
- [ ] 将标注类别重新改为三类:T/F/N,并在[4448](https://github.com/mazzzystar/TurtleBenchmark/blob/dev/evaluation/chinese/data/sorted_cases.list) 条样本上重新标注、测试模型表现。
|
| 79 |
+
- [x] 将数据集和测试样例翻译成英文。
|
| 80 |
+
- [ ] 人工逐条二次确认翻译后的标注准确率。
|
| 81 |
+
- [ ] 使用英语 prompt,在英文模型上评测并给出结果。
|
| 82 |
+
|
| 83 |
+
### 致谢
|
| 84 |
+
|
| 85 |
+
衷心感谢:
|
| 86 |
+
|
| 87 |
+
- 五源资本 的**石允丰**(Steven Shi)为这项研究所需的 token 提供慷慨的财务支持。
|
| 88 |
+
- 实习生**赵乾之**(Jerry Zhao)和我一起手工标注了 26,000 条数据。
|
datasets/TurtleBenchmark/README_en.md
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Turtle Benchmark
|
| 2 |
+
|
| 3 |
+
[中文](./README.md)
|
| 4 |
+
|
| 5 |
+
Turtle Benchmark is a novel, uncheatable benchmark for evaluating Large Language Models (LLMs) based on the "Turtle Soup"(海龟汤) game, focusing on logical reasoning and contextual understanding.
|
| 6 |
+
|
| 7 |
+
### Highlights
|
| 8 |
+
|
| 9 |
+
- **Objective and Unbiased**: Eliminates the need for background knowledge, focusing purely on reasoning abilities.
|
| 10 |
+
- **Quantifiable Results**: Clear, measurable outcomes (correct/incorrect/unknown) for easy comparison.
|
| 11 |
+
- **Constantly Evolving**: Uses real user-generated questions, making it impossible to "game" the system.
|
| 12 |
+
- **Language Understanding**: Tests the model's ability to comprehend context and make logical inferences.
|
| 13 |
+
|
| 14 |
+
### Usage
|
| 15 |
+
|
| 16 |
+
```bash
|
| 17 |
+
cd evaluation
|
| 18 |
+
|
| 19 |
+
mv .env.example .env
|
| 20 |
+
# add API key.
|
| 21 |
+
|
| 22 |
+
# Evaluate Chinese or English.
|
| 23 |
+
cd english
|
| 24 |
+
|
| 25 |
+
# 0-shot for fast & cheap, default: 2-shot.
|
| 26 |
+
python evaluate.py --shot 0
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
### Data
|
| 30 |
+
|
| 31 |
+
- 32 unique "Turtle Soup" stories.
|
| 32 |
+
- 1537 human-annotated labels from users' questions.
|
| 33 |
+
- Our evaluation log.
|
| 34 |
+
|
| 35 |
+
### Results
|
| 36 |
+
|
| 37 |
+
#### 1. Overall Accuracy
|
| 38 |
+
|
| 39 |
+
The overall accuracy of each model across all test cases.
|
| 40 |
+
|
| 41 |
+

|
| 42 |
+
|
| 43 |
+
#### 2. Average Accuracy Across Stories
|
| 44 |
+
|
| 45 |
+
To mitigate potential bias from models performing poorly on specific stories with a large number of test samples, we calculated the average accuracy for each model across all 32 stories individually.
|
| 46 |
+
|
| 47 |
+

|
| 48 |
+
|
| 49 |
+
#### 3. Performance Chart
|
| 50 |
+
|
| 51 |
+
This scatter plot compares the overall accuracy (x-axis) with the average story accuracy (y-axis) for each model in the 2-shot learning scenario.
|
| 52 |
+
|
| 53 |
+

|
| 54 |
+
|
| 55 |
+
### Interpretation
|
| 56 |
+
|
| 57 |
+
Based on these results, we can clearly see the performance differences among the various models:
|
| 58 |
+
|
| 59 |
+
1. **First Tier**: Claude 3.5 Sonnet stands out as the undisputed leader, significantly outperforming all other models.
|
| 60 |
+
|
| 61 |
+
2. **Second Tier**: GPT-4o, Qwen-2(通义千问), Moonshot AI(月之暗面), LLama3.1 405B, and Minimax form the second tier. While we've avoided further subdivisions, there's a noticeable decrease in performance within this group, following the order listed.
|
| 62 |
+
|
| 63 |
+
3. **Third Tier**: Douban(豆包), DeepSeek, and LLama3.1 70B constitute the third tier.
|
| 64 |
+
|
| 65 |
+
4. **Fourth Tier**: GPT-4o-mini stands alone in the fourth tier.
|
| 66 |
+
|
| 67 |
+
5. **Obsolete**: GPT-3.5's performance suggests it's no longer competitive in this context.
|
| 68 |
+
|
| 69 |
+
It's important to note that this evaluation specifically targets the models' Chinese language understanding and reasoning capabilities. In the future, pending resources and funding, we plan to translate all stories and test questions into English and re-run the tests using English prompts. This will help eliminate any performance discrepancies that may be attributed to language differences.
|
| 70 |
+
|
| 71 |
+
### Acknowledgments
|
| 72 |
+
|
| 73 |
+
We would like to express our gratitude to:
|
| 74 |
+
|
| 75 |
+
- **Steven Shi (石允丰)** from 5Y Capital for his generous financial support of the token usage required for this research.
|
| 76 |
+
- **Jerry Zhao (赵乾之)** for his invaluable assistance in annotating over 26,000 data points.
|
| 77 |
+
|
| 78 |
+
Your contributions have been instrumental in making this benchmark possible.
|
datasets/TurtleBenchmark/evaluation/.env.example
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This file contains the API keys for the various services used
|
| 2 |
+
# in the evaluation, you can delete the keys that are not needed.
|
| 3 |
+
OPENAI_API_KEY = "sk-"
|
| 4 |
+
DEEPSEEK_API_KEY = "sk-"
|
| 5 |
+
MOONSHOT_API_KEY = "sk-"
|
| 6 |
+
ANTHROPIC_API_KEY = "sk-"
|
| 7 |
+
ZHIPU_API_KEY = ""
|
| 8 |
+
LEPTON_API_KEY = ""
|
| 9 |
+
TOGETHER_API_KEY = ""
|
| 10 |
+
DOUBAO_API_KEY = ""
|
| 11 |
+
ANTHROPIC_API_KEY = ""
|
| 12 |
+
MINIMAX_GROUP_ID = ""
|
| 13 |
+
MINIMAX_API_KEY = ""
|
datasets/TurtleBenchmark/evaluation/chinese/data/cases.list
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d1e4f7f2e6b9eea02fae049cad459176239e79e583fbad2ba405a8b88a5a1d18
|
| 3 |
+
size 67259
|
datasets/TurtleBenchmark/evaluation/chinese/data/results_0shot.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:42f0990abd76801f5c918e9e5771a981f5a9f60fed5d94cd09ce6775c480be30
|
| 3 |
+
size 666692
|
datasets/TurtleBenchmark/evaluation/chinese/data/results_2shot.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c3d11da6b7f8c9332dba33d7936c29b8d8441de2daca71f1444ed4d33dc90f84
|
| 3 |
+
size 666710
|
datasets/TurtleBenchmark/evaluation/chinese/data/sorted_cases.list
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9d3ca17f0975ab55997c61969223547dac0da73e968c1d1a5b778cb1368e810d
|
| 3 |
+
size 183764
|
datasets/TurtleBenchmark/evaluation/chinese/data/sorted_cases.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c0c24879b4a67912493c8bd3d804fc3aac72213e5d84d9ebe7d806bae89de65e
|
| 3 |
+
size 67262
|
datasets/TurtleBenchmark/evaluation/chinese/data/stories.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b895306b193d5b1c1d4980239c0094a48b48b39d6a98f79508248c41a9855403
|
| 3 |
+
size 20329
|
datasets/TurtleBenchmark/evaluation/chinese/data/titles.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c85c3e0ab6f9f8ce57aaa65991f8a38d996efbf5643283f997e2baf1185ff672
|
| 3 |
+
size 339
|
datasets/TurtleBenchmark/evaluation/chinese/evaluate.py
ADDED
|
@@ -0,0 +1,377 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import concurrent.futures
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
import random
|
| 6 |
+
from functools import partial
|
| 7 |
+
|
| 8 |
+
import requests
|
| 9 |
+
from anthropic import Anthropic
|
| 10 |
+
from openai import OpenAI
|
| 11 |
+
from together import Together
|
| 12 |
+
from tqdm import tqdm
|
| 13 |
+
|
| 14 |
+
from model_configs import models
|
| 15 |
+
from prompt import simple_system_prompt, system_prompt_with_2shots
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# Load stories
|
| 19 |
+
with open("data/stories.json", "r", encoding="utf-8") as f:
|
| 20 |
+
stories = json.load(f)
|
| 21 |
+
|
| 22 |
+
def load_test_cases(filename):
|
| 23 |
+
with open(filename, "r", encoding="utf-8") as f:
|
| 24 |
+
_test_cases = []
|
| 25 |
+
for line in f:
|
| 26 |
+
parts = line.strip().replace(" ", "").split("\t")
|
| 27 |
+
if len(parts) != 3:
|
| 28 |
+
print(f"Invalid test case: {line}")
|
| 29 |
+
continue
|
| 30 |
+
if parts[2] not in ["T", "F", "N"]:
|
| 31 |
+
print(f"Skipping line with invalid ground truth: {line}")
|
| 32 |
+
continue
|
| 33 |
+
_test_cases.append(parts)
|
| 34 |
+
return _test_cases
|
| 35 |
+
|
| 36 |
+
def starts_with_answer(response, answer):
|
| 37 |
+
return response.strip().lower().startswith(answer)
|
| 38 |
+
|
| 39 |
+
def call_api(model, prompt, user_input):
|
| 40 |
+
try:
|
| 41 |
+
if model["type"] == "openai":
|
| 42 |
+
if model["name"] == "Doubao-4k":
|
| 43 |
+
client = OpenAI(
|
| 44 |
+
api_key=model["config"]["apiKey"],
|
| 45 |
+
base_url=model["config"]["baseURL"]
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
messages = [
|
| 49 |
+
{"role": "system", "content": prompt},
|
| 50 |
+
{"role": "user", "content": user_input}
|
| 51 |
+
]
|
| 52 |
+
|
| 53 |
+
response = client.chat.completions.create(
|
| 54 |
+
model=model["config"]["model"],
|
| 55 |
+
messages=messages,
|
| 56 |
+
max_tokens=model["config"]["maxTokens"],
|
| 57 |
+
temperature=model["config"]["temperature"],
|
| 58 |
+
top_p=model["config"]["top_p"],
|
| 59 |
+
stream=False
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
return response.choices[0].message.content
|
| 63 |
+
else:
|
| 64 |
+
url = model["config"]["baseURL"] + "/chat/completions"
|
| 65 |
+
headers = {
|
| 66 |
+
"Content-Type": "application/json",
|
| 67 |
+
"Authorization": f"Bearer {model['config']['apiKey']}"
|
| 68 |
+
}
|
| 69 |
+
data = {
|
| 70 |
+
"model": model["config"]["model"],
|
| 71 |
+
"messages": [
|
| 72 |
+
{"role": "system", "content": prompt},
|
| 73 |
+
{"role": "user", "content": user_input}
|
| 74 |
+
],
|
| 75 |
+
"max_tokens": model["config"]["maxTokens"],
|
| 76 |
+
"temperature": model["config"]["temperature"],
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
if "top_p" in model["config"]:
|
| 80 |
+
data["top_p"] = model["config"]["top_p"]
|
| 81 |
+
|
| 82 |
+
response = requests.post(url, headers=headers, json=data)
|
| 83 |
+
if response.status_code != 200:
|
| 84 |
+
raise Exception(f"API call failed with status {response.status_code}: {response.text}")
|
| 85 |
+
result = response.json()
|
| 86 |
+
return result["choices"][0]["message"]["content"]
|
| 87 |
+
|
| 88 |
+
elif model["type"] == "together":
|
| 89 |
+
client = Together(api_key=model["config"]["apiKey"])
|
| 90 |
+
|
| 91 |
+
messages = [
|
| 92 |
+
{"role": "system", "content": prompt},
|
| 93 |
+
{"role": "user", "content": user_input}
|
| 94 |
+
]
|
| 95 |
+
|
| 96 |
+
response = client.chat.completions.create(
|
| 97 |
+
model=model["config"]["model"],
|
| 98 |
+
messages=messages,
|
| 99 |
+
max_tokens=model["config"]["maxTokens"],
|
| 100 |
+
temperature=model["config"]["temperature"],
|
| 101 |
+
top_p=model["config"]["top_p"],
|
| 102 |
+
repetition_penalty=model["config"]["repetition_penalty"],
|
| 103 |
+
stop=model["config"]["stop"],
|
| 104 |
+
stream=False
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
return response.choices[0].message.content
|
| 108 |
+
|
| 109 |
+
elif model["type"] == "anthropic":
|
| 110 |
+
client = Anthropic(api_key=model["config"]["apiKey"])
|
| 111 |
+
|
| 112 |
+
message = client.messages.create(
|
| 113 |
+
model=model["config"]["model"],
|
| 114 |
+
max_tokens=model["config"]["maxTokens"],
|
| 115 |
+
temperature=model["config"]["temperature"],
|
| 116 |
+
system=prompt,
|
| 117 |
+
messages=[
|
| 118 |
+
{
|
| 119 |
+
"role": "user",
|
| 120 |
+
"content": [
|
| 121 |
+
{
|
| 122 |
+
"type": "text",
|
| 123 |
+
"text": user_input
|
| 124 |
+
}
|
| 125 |
+
]
|
| 126 |
+
}
|
| 127 |
+
]
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
return message.content[0].text
|
| 131 |
+
|
| 132 |
+
elif model["type"] == "minimax":
|
| 133 |
+
url = f"https://api.minimax.chat/v1/text/chatcompletion_v2?GroupId={model['config']['groupId']}"
|
| 134 |
+
headers = {
|
| 135 |
+
"Authorization": f"Bearer {model['config']['apiKey']}",
|
| 136 |
+
"Content-Type": "application/json"
|
| 137 |
+
}
|
| 138 |
+
|
| 139 |
+
payload = {
|
| 140 |
+
"model": model["config"]["model"],
|
| 141 |
+
"messages": [
|
| 142 |
+
{
|
| 143 |
+
"role": "system",
|
| 144 |
+
"name": "MM智能助理",
|
| 145 |
+
"content": prompt
|
| 146 |
+
},
|
| 147 |
+
{
|
| 148 |
+
"role": "user",
|
| 149 |
+
"content": user_input
|
| 150 |
+
}
|
| 151 |
+
],
|
| 152 |
+
"tools": [],
|
| 153 |
+
"tool_choice": "none",
|
| 154 |
+
"stream": False,
|
| 155 |
+
"max_tokens": model["config"]["maxTokens"],
|
| 156 |
+
"temperature": model["config"]["temperature"],
|
| 157 |
+
"top_p": model["config"]["top_p"]
|
| 158 |
+
}
|
| 159 |
+
|
| 160 |
+
response = requests.post(url, headers=headers, json=payload)
|
| 161 |
+
if response.status_code != 200:
|
| 162 |
+
raise Exception(f"API call failed with status {response.status_code}: {response.text}")
|
| 163 |
+
|
| 164 |
+
result = response.json()
|
| 165 |
+
return result["choices"][0]["message"]["content"]
|
| 166 |
+
|
| 167 |
+
else:
|
| 168 |
+
raise ValueError(f"Unsupported model type: {model['type']}")
|
| 169 |
+
except Exception as e:
|
| 170 |
+
print(f"Error in call_api for model {model['name']}: {str(e)}")
|
| 171 |
+
return None
|
| 172 |
+
|
| 173 |
+
def call_api_with_timeout(model, prompt, user_input, timeout=20):
|
| 174 |
+
try:
|
| 175 |
+
return call_api(model, prompt, user_input)
|
| 176 |
+
except Exception as e:
|
| 177 |
+
print(f"Error in call_api for model {model['name']}: {str(e)}")
|
| 178 |
+
return None
|
| 179 |
+
|
| 180 |
+
def evaluate_models(models, test_cases, stories, shot_type):
|
| 181 |
+
results = {model['name']: {'correct': 0, 'total': 0} for model in models}
|
| 182 |
+
logs = {model['name']: [] for model in models}
|
| 183 |
+
challenging_cases = []
|
| 184 |
+
all_cases = []
|
| 185 |
+
|
| 186 |
+
# Determine the appropriate log folder based on shot_type
|
| 187 |
+
log_folder = f"logs_with_{shot_type}shots"
|
| 188 |
+
os.makedirs(log_folder, exist_ok=True)
|
| 189 |
+
|
| 190 |
+
# Find the last tested sample
|
| 191 |
+
last_tested = 0
|
| 192 |
+
for i in range(len(test_cases), 0, -1):
|
| 193 |
+
if os.path.exists(f"{log_folder}/all_cases_simple_prompt_{i}.json"):
|
| 194 |
+
with open(f"{log_folder}/all_cases_simple_prompt_{i}.json", "r", encoding="utf-8") as f:
|
| 195 |
+
all_cases = json.load(f)
|
| 196 |
+
last_tested = i
|
| 197 |
+
break
|
| 198 |
+
|
| 199 |
+
# Update results with previously tested samples
|
| 200 |
+
for case in all_cases:
|
| 201 |
+
for model_name, result in case['results'].items():
|
| 202 |
+
if result is not None:
|
| 203 |
+
results[model_name]['total'] += 1
|
| 204 |
+
if (case['ground_truth'] == "T" and result == "T") or \
|
| 205 |
+
((case['ground_truth'] == "F" or case['ground_truth'] == "N") and result != "T"):
|
| 206 |
+
results[model_name]['correct'] += 1
|
| 207 |
+
|
| 208 |
+
# Start from the next untested sample
|
| 209 |
+
start_index = len(all_cases)
|
| 210 |
+
|
| 211 |
+
for i, (user_input, story_title, ground_truth) in enumerate(tqdm(test_cases[start_index:]), start_index + 1):
|
| 212 |
+
try:
|
| 213 |
+
story = next((s for s in stories if s["title"] == story_title), None)
|
| 214 |
+
if not story:
|
| 215 |
+
print(f"Story not found: {story_title}")
|
| 216 |
+
continue
|
| 217 |
+
|
| 218 |
+
# Use the appropriate prompt based on shot_type
|
| 219 |
+
if shot_type == "2":
|
| 220 |
+
prompt_template = system_prompt_with_2shots
|
| 221 |
+
else:
|
| 222 |
+
prompt_template = simple_system_prompt
|
| 223 |
+
|
| 224 |
+
prompt = prompt_template.replace("{surface}", story["surface"]).replace("{bottom}", story["bottom"])
|
| 225 |
+
gt_map = {"T": "对", "F": "错", "N": "不知道"}
|
| 226 |
+
|
| 227 |
+
case_results = {}
|
| 228 |
+
all_responses_valid = True
|
| 229 |
+
|
| 230 |
+
# Use ThreadPoolExecutor for concurrent API calls
|
| 231 |
+
with concurrent.futures.ThreadPoolExecutor(max_workers=len(models)) as executor:
|
| 232 |
+
future_to_model = {executor.submit(partial(call_api_with_timeout, timeout=20), model, prompt, user_input): model for model in models}
|
| 233 |
+
for future in concurrent.futures.as_completed(future_to_model):
|
| 234 |
+
model = future_to_model[future]
|
| 235 |
+
try:
|
| 236 |
+
response = future.result()
|
| 237 |
+
if response is None:
|
| 238 |
+
all_responses_valid = False
|
| 239 |
+
print(f"Timeout or error for model {model['name']}")
|
| 240 |
+
else:
|
| 241 |
+
case_results[model['name']] = response
|
| 242 |
+
except Exception as exc:
|
| 243 |
+
print(f'{model["name"]} generated an exception: {exc}')
|
| 244 |
+
all_responses_valid = False
|
| 245 |
+
|
| 246 |
+
# If any model timed out or had an error, skip this entire test case
|
| 247 |
+
if not all_responses_valid:
|
| 248 |
+
print(f"Skipping test case {i} due to timeout or error")
|
| 249 |
+
continue
|
| 250 |
+
|
| 251 |
+
# Process all responses
|
| 252 |
+
for model in models:
|
| 253 |
+
if model['name'] not in case_results:
|
| 254 |
+
continue
|
| 255 |
+
response = case_results[model['name']].strip().lower()
|
| 256 |
+
|
| 257 |
+
if starts_with_answer(response, "对") or starts_with_answer(response, "错") or starts_with_answer(response, "不知道"):
|
| 258 |
+
results[model['name']]['total'] += 1
|
| 259 |
+
|
| 260 |
+
# Save the actual model output
|
| 261 |
+
if starts_with_answer(response, "对"):
|
| 262 |
+
case_results[model['name']] = "T"
|
| 263 |
+
elif starts_with_answer(response, "错"):
|
| 264 |
+
case_results[model['name']] = "F"
|
| 265 |
+
else:
|
| 266 |
+
case_results[model['name']] = "N"
|
| 267 |
+
|
| 268 |
+
# Calculate accuracy (merging N and F)
|
| 269 |
+
if (ground_truth == "T" and case_results[model['name']] == "T") or \
|
| 270 |
+
((ground_truth == "F" or ground_truth == "N") and case_results[model['name']] != "T"):
|
| 271 |
+
results[model['name']]['correct'] += 1
|
| 272 |
+
else:
|
| 273 |
+
# Print only wrong answers
|
| 274 |
+
print(f"Wrong Answer - Model: {model['name']}, Input: {user_input}, Response: {response}, GT: {gt_map[ground_truth]}, Model Output: {case_results[model['name']]}")
|
| 275 |
+
else:
|
| 276 |
+
# Handle invalid responses
|
| 277 |
+
case_results[model['name']] = "Invalid"
|
| 278 |
+
print(f"Invalid Response - Model: {model['name']}, Input: {user_input}, Response: {response}, GT: {gt_map[ground_truth]}, Model Output: {case_results[model['name']]}")
|
| 279 |
+
|
| 280 |
+
log_entry = {
|
| 281 |
+
"Input": user_input,
|
| 282 |
+
"Response": response,
|
| 283 |
+
"GT": gt_map[ground_truth],
|
| 284 |
+
"Model_Output": case_results[model['name']],
|
| 285 |
+
"Accuracy": f"{results[model['name']]['correct']}/{results[model['name']]['total']} ({results[model['name']]['correct']/max(results[model['name']]['total'], 1):.2f})"
|
| 286 |
+
}
|
| 287 |
+
logs[model['name']].append(log_entry)
|
| 288 |
+
|
| 289 |
+
case = {
|
| 290 |
+
"input": user_input,
|
| 291 |
+
"story_title": story_title,
|
| 292 |
+
"ground_truth": ground_truth,
|
| 293 |
+
"results": case_results
|
| 294 |
+
}
|
| 295 |
+
|
| 296 |
+
all_cases.append(case)
|
| 297 |
+
|
| 298 |
+
if any(result != "T" for result in case_results.values()):
|
| 299 |
+
challenging_cases.append(case)
|
| 300 |
+
|
| 301 |
+
# Save log and print accuracy ranking every 10 steps
|
| 302 |
+
if i % 10 == 0 or i == len(test_cases):
|
| 303 |
+
print(f"\nCurrent rankings after {i} items:")
|
| 304 |
+
current_results = [(name, res['correct'] / max(res['total'], 1), res['correct'], res['total'])
|
| 305 |
+
for name, res in results.items()]
|
| 306 |
+
current_results.sort(key=lambda x: x[1], reverse=True)
|
| 307 |
+
|
| 308 |
+
for rank, (name, accuracy, correct, total) in enumerate(current_results, 1):
|
| 309 |
+
print(f"{rank}. {name}: {accuracy:.2f} ({correct}/{total})")
|
| 310 |
+
|
| 311 |
+
# Update challenging cases file
|
| 312 |
+
with open(f"{log_folder}/challenging_cases_simple_prompt_{i}.json", "w", encoding="utf-8") as f:
|
| 313 |
+
json.dump(challenging_cases, f, ensure_ascii=False, indent=2)
|
| 314 |
+
|
| 315 |
+
# Update all cases file
|
| 316 |
+
with open(f"{log_folder}/all_cases_simple_prompt_{i}.json", "w", encoding="utf-8") as f:
|
| 317 |
+
json.dump(all_cases, f, ensure_ascii=False, indent=2)
|
| 318 |
+
|
| 319 |
+
except Exception as e:
|
| 320 |
+
print(f"Error processing test case {i}: {str(e)}")
|
| 321 |
+
continue
|
| 322 |
+
|
| 323 |
+
# Final update to challenging cases file
|
| 324 |
+
final_index = start_index + len(test_cases[start_index:])
|
| 325 |
+
with open(f"{log_folder}/challenging_cases_simple_prompt_{final_index}.json", "w", encoding="utf-8") as f:
|
| 326 |
+
json.dump(challenging_cases, f, ensure_ascii=False, indent=2)
|
| 327 |
+
|
| 328 |
+
# Final update to all cases file
|
| 329 |
+
with open(f"{log_folder}/all_cases_simple_prompt_{final_index}.json", "w", encoding="utf-8") as f:
|
| 330 |
+
json.dump(all_cases, f, ensure_ascii=False, indent=2)
|
| 331 |
+
|
| 332 |
+
return results, challenging_cases, all_cases
|
| 333 |
+
|
| 334 |
+
def save_all_cases(all_cases, output_file):
|
| 335 |
+
with open(output_file, "w", encoding="utf-8") as f:
|
| 336 |
+
json.dump(all_cases, f, ensure_ascii=False, indent=2)
|
| 337 |
+
|
| 338 |
+
print(f"All cases have been saved to {output_file}")
|
| 339 |
+
|
| 340 |
+
def parse_challenging_cases(input_file, output_file):
|
| 341 |
+
with open(input_file, 'r', encoding='utf-8') as f:
|
| 342 |
+
challenging_cases = json.load(f)
|
| 343 |
+
|
| 344 |
+
with open(output_file, 'w', encoding='utf-8') as f:
|
| 345 |
+
for case in challenging_cases:
|
| 346 |
+
user_input = case['input']
|
| 347 |
+
story_title = case['story_title']
|
| 348 |
+
ground_truth = case['ground_truth']
|
| 349 |
+
f.write(f"{user_input}\t{story_title}\t{ground_truth}\n")
|
| 350 |
+
|
| 351 |
+
print(f"Parsed challenging cases have been written to {output_file}")
|
| 352 |
+
|
| 353 |
+
|
| 354 |
+
def main():
|
| 355 |
+
# Parse command line arguments
|
| 356 |
+
parser = argparse.ArgumentParser(description="Run story understanding evaluation")
|
| 357 |
+
parser.add_argument("--shot", choices=["0", "2"], default="2", help="Number of shots (0 or 2)")
|
| 358 |
+
args = parser.parse_args()
|
| 359 |
+
|
| 360 |
+
_models = [model for model in models if model['name'] in ['DEEPSEEK', 'Kimi-Chat', 'GPT-4o-mini']]
|
| 361 |
+
test_cases = load_test_cases("data/cases.list")
|
| 362 |
+
_test_cases = random.sample(test_cases, k=100)
|
| 363 |
+
results, challenging_cases, all_cases = evaluate_models(_models, _test_cases, stories, args.shot)
|
| 364 |
+
|
| 365 |
+
final_results = [(name, res['correct'] / max(res['total'], 1), res['correct'], res['total'])
|
| 366 |
+
for name, res in results.items()]
|
| 367 |
+
final_results.sort(key=lambda x: x[1], reverse=True)
|
| 368 |
+
|
| 369 |
+
print(f"\nFinal Rankings ({args.shot}-shot):")
|
| 370 |
+
for rank, (name, accuracy, correct, total) in enumerate(final_results, 1):
|
| 371 |
+
print(f"{rank}. {name}: {accuracy:.2f} ({correct}/{total})")
|
| 372 |
+
log_folder = f"logs_with_{args.shot}shots"
|
| 373 |
+
print(f"Evaluation complete. Logs have been saved in the '{log_folder}' directory.")
|
| 374 |
+
|
| 375 |
+
|
| 376 |
+
if __name__ == "__main__":
|
| 377 |
+
main()
|
datasets/TurtleBenchmark/evaluation/chinese/imgs/Turtle-Benchmark-over-32stories.png
ADDED
|
datasets/TurtleBenchmark/evaluation/chinese/imgs/Turtle-Benchmark-result.png
ADDED
|
datasets/TurtleBenchmark/evaluation/chinese/imgs/average_model_accuracy_over_stories_2-shot.png
ADDED

|
datasets/TurtleBenchmark/evaluation/chinese/model_configs.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
from dotenv import load_dotenv
|
| 4 |
+
|
| 5 |
+
MAX_TOKENS = 5
|
| 6 |
+
# Load environment variables
|
| 7 |
+
load_dotenv()
|
| 8 |
+
|
| 9 |
+
# Define the models and their configurations
|
| 10 |
+
models = [
|
| 11 |
+
{
|
| 12 |
+
"name": "DEEPSEEK",
|
| 13 |
+
"config": {
|
| 14 |
+
"apiKey": os.getenv("DEEPSEEK_API_KEY"),
|
| 15 |
+
"baseURL": "https://api.deepseek.com",
|
| 16 |
+
"model": "deepseek-chat",
|
| 17 |
+
"maxTokens": MAX_TOKENS,
|
| 18 |
+
"temperature": 0.0,
|
| 19 |
+
"top_p": 1
|
| 20 |
+
},
|
| 21 |
+
"type": "openai"
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"name": "GPT-3.5-Turbo",
|
| 25 |
+
"config": {
|
| 26 |
+
"apiKey": os.getenv("OPENAI_API_KEY"),
|
| 27 |
+
"baseURL": "https://api.openai.com/v1",
|
| 28 |
+
"model": "gpt-3.5-turbo",
|
| 29 |
+
"maxTokens": MAX_TOKENS,
|
| 30 |
+
"temperature": 0.0,
|
| 31 |
+
"top_p": 1
|
| 32 |
+
},
|
| 33 |
+
"type": "openai"
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"name": "Kimi-Chat",
|
| 37 |
+
"config": {
|
| 38 |
+
"apiKey": os.getenv("MOONSHOT_API_KEY"),
|
| 39 |
+
"baseURL": "https://api.moonshot.cn/v1",
|
| 40 |
+
"model": "moonshot-v1-8k",
|
| 41 |
+
"maxTokens": MAX_TOKENS,
|
| 42 |
+
"temperature": 0.0,
|
| 43 |
+
"top_p": 1
|
| 44 |
+
},
|
| 45 |
+
"type": "openai"
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"name": "GPT-4o",
|
| 49 |
+
"config": {
|
| 50 |
+
"apiKey": os.getenv("OPENAI_API_KEY"),
|
| 51 |
+
"baseURL": "https://api.openai.com/v1",
|
| 52 |
+
"model": "gpt-4o",
|
| 53 |
+
"maxTokens": MAX_TOKENS,
|
| 54 |
+
"temperature": 0.0,
|
| 55 |
+
"top_p": 1
|
| 56 |
+
},
|
| 57 |
+
"type": "openai"
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"name": "GPT-4o-mini",
|
| 61 |
+
"config": {
|
| 62 |
+
"apiKey": os.getenv("OPENAI_API_KEY"),
|
| 63 |
+
"baseURL": "https://api.openai.com/v1",
|
| 64 |
+
"model": "gpt-4o-mini",
|
| 65 |
+
"maxTokens": MAX_TOKENS,
|
| 66 |
+
"temperature": 0.0,
|
| 67 |
+
"top_p": 1
|
| 68 |
+
},
|
| 69 |
+
"type": "openai"
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
"name": "Llama-3.1-405b",
|
| 73 |
+
"config": {
|
| 74 |
+
"apiKey": os.getenv("TOGETHER_API_KEY"),
|
| 75 |
+
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo",
|
| 76 |
+
"maxTokens": MAX_TOKENS,
|
| 77 |
+
"temperature": 0.0,
|
| 78 |
+
"top_p": 1,
|
| 79 |
+
"repetition_penalty": 1,
|
| 80 |
+
"stop": ["<|eot_id|>"]
|
| 81 |
+
},
|
| 82 |
+
"type": "together"
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
"name": "Llama3.1-70b",
|
| 86 |
+
"config": {
|
| 87 |
+
"apiKey": os.getenv("TOGETHER_API_KEY"),
|
| 88 |
+
"model": "meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo",
|
| 89 |
+
"maxTokens": MAX_TOKENS,
|
| 90 |
+
"temperature": 0.0,
|
| 91 |
+
"top_p": 1,
|
| 92 |
+
"repetition_penalty": 1,
|
| 93 |
+
"stop": ["<|eot_id|>"]
|
| 94 |
+
},
|
| 95 |
+
"type": "together"
|
| 96 |
+
},
|
| 97 |
+
{
|
| 98 |
+
"name": "Qwen2-72B-Instruct",
|
| 99 |
+
"config": {
|
| 100 |
+
"apiKey": os.getenv("TOGETHER_API_KEY"),
|
| 101 |
+
"model": "Qwen/Qwen2-72B-Instruct",
|
| 102 |
+
"maxTokens": MAX_TOKENS,
|
| 103 |
+
"temperature": 0.0,
|
| 104 |
+
"top_p": 1,
|
| 105 |
+
"repetition_penalty": 1,
|
| 106 |
+
"stop": ["<|im_start|>", "<|im_end|>"]
|
| 107 |
+
},
|
| 108 |
+
"type": "together"
|
| 109 |
+
},
|
| 110 |
+
{
|
| 111 |
+
"name": "Doubao-4k",
|
| 112 |
+
"config": {
|
| 113 |
+
"apiKey": os.getenv("DOUBAO_API_KEY"),
|
| 114 |
+
"baseURL": "https://ark.cn-beijing.volces.com/api/v3",
|
| 115 |
+
"model": "ep-20240802142948-6vvc7", # Replace with the actual endpoint ID if different
|
| 116 |
+
"maxTokens": MAX_TOKENS,
|
| 117 |
+
"temperature": 0.0,
|
| 118 |
+
"top_p": 1
|
| 119 |
+
},
|
| 120 |
+
"type": "openai"
|
| 121 |
+
},
|
| 122 |
+
{
|
| 123 |
+
"name": "Claude-3.5-Sonnet",
|
| 124 |
+
"config": {
|
| 125 |
+
"apiKey": os.getenv("ANTHROPIC_API_KEY"),
|
| 126 |
+
"model": "claude-3-5-sonnet-20240620",
|
| 127 |
+
"maxTokens": MAX_TOKENS,
|
| 128 |
+
"temperature": 0.0,
|
| 129 |
+
},
|
| 130 |
+
"type": "anthropic"
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"name": "MiniMax-ABAB6.5s",
|
| 134 |
+
"config": {
|
| 135 |
+
"groupId": os.getenv("MINIMAX_GROUP_ID"),
|
| 136 |
+
"apiKey": os.getenv("MINIMAX_API_KEY"),
|
| 137 |
+
"model": "abab6.5s-chat",
|
| 138 |
+
"maxTokens": MAX_TOKENS,
|
| 139 |
+
"temperature": 0.01, # must be (0, 1]
|
| 140 |
+
"top_p": 1
|
| 141 |
+
},
|
| 142 |
+
"type": "minimax"
|
| 143 |
+
},
|
| 144 |
+
]
|
datasets/TurtleBenchmark/evaluation/chinese/prompt.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
simple_system_prompt = """
|
| 2 |
+
你是一个游戏的裁判,这个游戏会给玩家展示<汤面>,并告诉你<汤底>,你需要根据<汤面>和<汤底>理解整个故事。玩家会根据<汤面>进行猜测,你需要判断玩家的猜测是否正确,请严格遵守你只回答指定三种答案:对、错、不知道。
|
| 3 |
+
|
| 4 |
+
## 判定规则
|
| 5 |
+
- 玩家提出的猜测正确,或者答案是肯定的:请只回答"对",不要做任何解释。
|
| 6 |
+
- 玩家提出的猜测错误,或者答案是否定的:请只回答"错",不要做任何解释。
|
| 7 |
+
- 玩家提出的猜测,从<汤面>和<汤底>找不到答案,并且也无法通过推理得出此结论:请只回答"不知道",不要做任何解释。
|
| 8 |
+
|
| 9 |
+
## 注意
|
| 10 |
+
1. 玩家只能看到<汤面>,所以他是基于<汤面>进行猜测的,例如:玩家问“他喝的不是海龟汤”,是在问<汤面>中他喝的是不是海龟汤,即使<汤底>中他曾经喝过其他的汤,你也应该判定他在<汤面>中喝的是否是海龟汤。
|
| 11 |
+
2. 凡是无法从提供的故事中得出的结论,都应该回答"不知道",例如:玩家提出的猜测是关于故事中的细节,而这些细节并没有在故事中提到,也无法通过推理得出此结论,那么你应该回答"不知道"。
|
| 12 |
+
3. 严格遵守只回答指定三种答案:对、错、不知道。
|
| 13 |
+
|
| 14 |
+
## 题目内容
|
| 15 |
+
### 汤面
|
| 16 |
+
{surface}
|
| 17 |
+
|
| 18 |
+
### 汤底
|
| 19 |
+
{bottom}
|
| 20 |
+
|
| 21 |
+
现在,请判断以下玩家猜测:
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
system_prompt_with_2shots = """
|
| 26 |
+
你是一个游戏的裁判,这个游戏会给玩家展示<汤面>,并告诉你<汤底>,你需要根据<汤面>和<汤底>理解整个故事。玩家会根据<汤面>进行猜测,你需要判断玩家的猜测是否正确,请严格遵守你只回答指定三种答案:对、错、不知道。
|
| 27 |
+
|
| 28 |
+
## 判定规则
|
| 29 |
+
- 玩家提出的猜测正确,或者答案是肯定的:请只回答"对",不要做任何解释。
|
| 30 |
+
- 玩家提出的猜测错误,或者答案是否定的:请只回答"错",不要做任何解释。
|
| 31 |
+
- 玩家提出的猜测,从<汤面>和<汤底>找不到答案,并且也无法通过推理得出此结论:请只回答"不知道",不要做任何解释。
|
| 32 |
+
|
| 33 |
+
## 注意
|
| 34 |
+
- 请充分理解整个故事的起因、经过和结局,并进行合乎逻辑的推断,如果无法从提供的故事中得出的结论,你应该回答"不知道",例如:玩家提出的猜测是关于故事中的细节,而这些细节并没有在故事中提到,也无法通过推理得出此结论,那么你应该回答"不知道"。
|
| 35 |
+
- 严格遵守只回答指定三种答案:对、错、不知道。
|
| 36 |
+
|
| 37 |
+
## 示例
|
| 38 |
+
|
| 39 |
+
### 示例1:打嗝男子
|
| 40 |
+
<汤面>
|
| 41 |
+
一个男人走进一家酒吧,并向酒保要了一杯水。酒保却突然拿出一把手枪瞄准他,而男子竟只是笑著说:“谢谢你!”然后从容离开,请问发生了什么事?
|
| 42 |
+
|
| 43 |
+
<汤底>
|
| 44 |
+
男子打嗝,他希望喝一杯水来改善状况。酒保意识到这一点,选择拿枪吓他,男子一紧张之下,打嗝自然消失,因而衷心感谢酒保后就离开了。
|
| 45 |
+
|
| 46 |
+
可能的猜测及对应的回答:
|
| 47 |
+
问:男人有慢性病吗? 答:不知道
|
| 48 |
+
问:男人是被吓跑了吗 答:错
|
| 49 |
+
问:酒保想杀死男人 答:错
|
| 50 |
+
问:酒保是为了吓唬男人 答:对
|
| 51 |
+
问:男子衷心感谢酒保 答:对
|
| 52 |
+
|
| 53 |
+
### 示例2:四岁的妈妈
|
| 54 |
+
<汤面>
|
| 55 |
+
幼儿园五岁的小朋友,竟然说她的妈妈只有四岁,我很疑惑,便提出了去她家家访,随后我在她家看到了让我惊恐的一幕...
|
| 56 |
+
|
| 57 |
+
<汤底>
|
| 58 |
+
我在她家看到了一个个被铁链拴着的女人,而一旁站着一个长相凶狠丑陋的彪形大汉。幼儿园的那个小朋友突然露出了不属于她这个年龄该有的诡笑...原来她是二十五岁,只是从小得了一种长不大的病,而那个彪形大汉则是她的哥哥,她是为了给她哥哥找女人,便哄骗我们这些幼师来到家里进行迫害…而她那\"四岁的妈妈\",是已经被骗来四年的女人…
|
| 59 |
+
|
| 60 |
+
可能的猜测及对应的回答:
|
| 61 |
+
问:小朋友已经死了 答:错
|
| 62 |
+
问:小朋友其实是成年人 答:对
|
| 63 |
+
问:小朋友有精神分裂 答:不知道
|
| 64 |
+
问:我会有危险 答:对
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
现在开始主持:
|
| 68 |
+
|
| 69 |
+
## 题目内容
|
| 70 |
+
### 汤面
|
| 71 |
+
{surface}
|
| 72 |
+
|
| 73 |
+
### 汤底
|
| 74 |
+
{bottom}
|
| 75 |
+
|
| 76 |
+
现在,请判断以下玩家猜测:
|
| 77 |
+
"""
|
datasets/TurtleBenchmark/evaluation/english/data/cases.list
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1f9175bf4ffdf27bf36a3847a416ea9730115ba5aea4938787e37f20f0960e66
|
| 3 |
+
size 109980
|
datasets/TurtleBenchmark/evaluation/english/data/stories.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7782461b007bd7404e2146358344179c3f0c575dc031384588e8efee6935899b
|
| 3 |
+
size 24669
|
datasets/TurtleBenchmark/evaluation/english/evaluate.py
ADDED
|
@@ -0,0 +1,620 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import asyncio
|
| 4 |
+
import requests
|
| 5 |
+
import aiohttp
|
| 6 |
+
from prompt import simple_system_prompt, system_prompt_with_2shots
|
| 7 |
+
from dotenv import load_dotenv
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from openai import OpenAI
|
| 10 |
+
from anthropic import Anthropic
|
| 11 |
+
from together import Together
|
| 12 |
+
import concurrent.futures
|
| 13 |
+
from functools import partial
|
| 14 |
+
import threading
|
| 15 |
+
from tqdm import tqdm
|
| 16 |
+
import argparse
|
| 17 |
+
import time
|
| 18 |
+
|
| 19 |
+
# Load environment variables
|
| 20 |
+
load_dotenv()
|
| 21 |
+
|
| 22 |
+
MAX_TOKENS = 4
|
| 23 |
+
|
| 24 |
+
# Define the models and their configurations
|
| 25 |
+
models = [
|
| 26 |
+
# {
|
| 27 |
+
# "name": "Gemini-1.5-Pro",
|
| 28 |
+
# "config": {
|
| 29 |
+
# "apiKey": os.getenv("GEMINI_API_KEY"),
|
| 30 |
+
# "model": "gemini-1.5-pro",
|
| 31 |
+
# "maxTokens": MAX_TOKENS,
|
| 32 |
+
# "temperature": 0.0,
|
| 33 |
+
# },
|
| 34 |
+
# "type": "gemini"
|
| 35 |
+
# },
|
| 36 |
+
{
|
| 37 |
+
"name": "DEEPSEEK",
|
| 38 |
+
"config": {
|
| 39 |
+
"apiKey": os.getenv("DEEPSEEK_API_KEY"),
|
| 40 |
+
"baseURL": "https://api.deepseek.com",
|
| 41 |
+
"model": "deepseek-chat",
|
| 42 |
+
"maxTokens": MAX_TOKENS,
|
| 43 |
+
"temperature": 0.0,
|
| 44 |
+
"top_p": 0.7,
|
| 45 |
+
},
|
| 46 |
+
"type": "openai"
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
"name": "GPT-3.5-Turbo",
|
| 50 |
+
"config": {
|
| 51 |
+
"apiKey": os.getenv("OPENAI_API_KEY"),
|
| 52 |
+
"baseURL": "https://api.openai.com/v1",
|
| 53 |
+
"model": "gpt-3.5-turbo",
|
| 54 |
+
"maxTokens": MAX_TOKENS,
|
| 55 |
+
"temperature": 0.0,
|
| 56 |
+
"top_p": 0.7,
|
| 57 |
+
},
|
| 58 |
+
"type": "openai"
|
| 59 |
+
},
|
| 60 |
+
# {
|
| 61 |
+
# "name": "Kimi-Chat",
|
| 62 |
+
# "config": {
|
| 63 |
+
# "apiKey": os.getenv("MOONSHOT_API_KEY"),
|
| 64 |
+
# "baseURL": "https://api.moonshot.cn/v1",
|
| 65 |
+
# "model": "moonshot-v1-8k",
|
| 66 |
+
# "maxTokens": MAX_TOKENS,
|
| 67 |
+
# "temperature": 0.0,
|
| 68 |
+
# "top_p": 0.7,
|
| 69 |
+
# },
|
| 70 |
+
# "type": "openai"
|
| 71 |
+
# },
|
| 72 |
+
{
|
| 73 |
+
"name": "GPT-4o",
|
| 74 |
+
"config": {
|
| 75 |
+
"apiKey": os.getenv("OPENAI_API_KEY"),
|
| 76 |
+
"baseURL": "https://api.openai.com/v1",
|
| 77 |
+
"model": "gpt-4o-2024-05-13",
|
| 78 |
+
"maxTokens": MAX_TOKENS,
|
| 79 |
+
"temperature": 0.0,
|
| 80 |
+
"top_p": 0.7,
|
| 81 |
+
},
|
| 82 |
+
"type": "openai"
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
"name": "GPT-4o-mini",
|
| 86 |
+
"config": {
|
| 87 |
+
"apiKey": os.getenv("OPENAI_API_KEY"),
|
| 88 |
+
"baseURL": "https://api.openai.com/v1",
|
| 89 |
+
"model": "gpt-4o-mini",
|
| 90 |
+
"maxTokens": MAX_TOKENS,
|
| 91 |
+
"temperature": 0.0,
|
| 92 |
+
"top_p": 0.7,
|
| 93 |
+
},
|
| 94 |
+
"type": "openai"
|
| 95 |
+
},
|
| 96 |
+
{
|
| 97 |
+
"name": "Llama-3.1-405b",
|
| 98 |
+
"config": {
|
| 99 |
+
"apiKey": os.getenv("TOGETHER_API_KEY"),
|
| 100 |
+
"model": "meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo",
|
| 101 |
+
"maxTokens": MAX_TOKENS,
|
| 102 |
+
"temperature": 0.0,
|
| 103 |
+
"top_p": 0.7,
|
| 104 |
+
"stop": ["<|eot_id|>"]
|
| 105 |
+
},
|
| 106 |
+
"type": "together"
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"name": "Llama3.1-70b",
|
| 110 |
+
"config": {
|
| 111 |
+
"apiKey": os.getenv("TOGETHER_API_KEY"),
|
| 112 |
+
"model": "meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo",
|
| 113 |
+
"maxTokens": MAX_TOKENS,
|
| 114 |
+
"temperature": 0.0,
|
| 115 |
+
"top_p": 0.7,
|
| 116 |
+
"stop": ["<|eot_id|>"]
|
| 117 |
+
},
|
| 118 |
+
"type": "together"
|
| 119 |
+
},
|
| 120 |
+
{
|
| 121 |
+
"name": "Qwen2-72B-Instruct",
|
| 122 |
+
"config": {
|
| 123 |
+
"apiKey": os.getenv("TOGETHER_API_KEY"),
|
| 124 |
+
"model": "Qwen/Qwen2-72B-Instruct",
|
| 125 |
+
"maxTokens": MAX_TOKENS,
|
| 126 |
+
"temperature": 0.0,
|
| 127 |
+
"top_p": 0.7,
|
| 128 |
+
"stop": ["<|im_start|>", "<|im_end|>"]
|
| 129 |
+
},
|
| 130 |
+
"type": "together"
|
| 131 |
+
},
|
| 132 |
+
# {
|
| 133 |
+
# "name": "Yi-34B-Chat",
|
| 134 |
+
# "config": {
|
| 135 |
+
# "apiKey": os.getenv("TOGETHER_API_KEY"),
|
| 136 |
+
# "model": "zero-one-ai/Yi-34B-Chat",
|
| 137 |
+
# "maxTokens": MAX_TOKENS,
|
| 138 |
+
# "temperature": 0.0,
|
| 139 |
+
# "top_p": 0.7,
|
| 140 |
+
# "stop": ["<|im_start|>", "<|im_end|>"]
|
| 141 |
+
# },
|
| 142 |
+
# "type": "together"
|
| 143 |
+
# },
|
| 144 |
+
# {
|
| 145 |
+
# "name": "Doubao-4k",
|
| 146 |
+
# "config": {
|
| 147 |
+
# "apiKey": os.getenv("DOUBAO_API_KEY"),
|
| 148 |
+
# "baseURL": "https://ark.cn-beijing.volces.com/api/v3",
|
| 149 |
+
# "model": "ep-20240802142948-6vvc7", # Replace with the actual endpoint ID if different
|
| 150 |
+
# "maxTokens": MAX_TOKENS,
|
| 151 |
+
# "temperature": 0.0,
|
| 152 |
+
# "top_p": 0.7
|
| 153 |
+
# },
|
| 154 |
+
# "type": "openai"
|
| 155 |
+
# },
|
| 156 |
+
{
|
| 157 |
+
"name": "Claude-3.5-Sonnet",
|
| 158 |
+
"config": {
|
| 159 |
+
"apiKey": os.getenv("ANTHROPIC_API_KEY"),
|
| 160 |
+
"model": "claude-3-5-sonnet-20240620",
|
| 161 |
+
"maxTokens": MAX_TOKENS,
|
| 162 |
+
"temperature": 0.0,
|
| 163 |
+
},
|
| 164 |
+
"type": "anthropic"
|
| 165 |
+
},
|
| 166 |
+
# {
|
| 167 |
+
# "name": "Claude-3-Opus",
|
| 168 |
+
# "config": {
|
| 169 |
+
# "apiKey": os.getenv("ANTHROPIC_API_KEY"),
|
| 170 |
+
# "model": "claude-3-opus-20240229",
|
| 171 |
+
# "maxTokens": MAX_TOKENS,
|
| 172 |
+
# "temperature": 0.0,
|
| 173 |
+
# },
|
| 174 |
+
# "type": "anthropic"
|
| 175 |
+
# },
|
| 176 |
+
{
|
| 177 |
+
"name": "Claude-3-Haiku",
|
| 178 |
+
"config": {
|
| 179 |
+
"apiKey": os.getenv("ANTHROPIC_API_KEY"),
|
| 180 |
+
"model": "claude-3-haiku-20240307",
|
| 181 |
+
"maxTokens": MAX_TOKENS,
|
| 182 |
+
"temperature": 0.0,
|
| 183 |
+
},
|
| 184 |
+
"type": "anthropic"
|
| 185 |
+
},
|
| 186 |
+
# {
|
| 187 |
+
# "name": "MiniMax-ABAB6.5s",
|
| 188 |
+
# "config": {
|
| 189 |
+
# "groupId": os.getenv("MINIMAX_GROUP_ID"),
|
| 190 |
+
# "apiKey": os.getenv("MINIMAX_API_KEY"),
|
| 191 |
+
# "model": "abab6.5s-chat",
|
| 192 |
+
# "maxTokens": MAX_TOKENS,
|
| 193 |
+
# "temperature": 0.01, # must be (0, 1]
|
| 194 |
+
# "top_p": 1
|
| 195 |
+
# },
|
| 196 |
+
# "type": "minimax"
|
| 197 |
+
# },
|
| 198 |
+
]
|
| 199 |
+
|
| 200 |
+
# Load stories
|
| 201 |
+
with open("data/stories.json", "r", encoding="utf-8") as f:
|
| 202 |
+
stories = json.load(f)
|
| 203 |
+
|
| 204 |
+
def load_test_cases(filename):
|
| 205 |
+
with open(filename, "r", encoding="utf-8") as f:
|
| 206 |
+
_test_cases = []
|
| 207 |
+
for line in f:
|
| 208 |
+
parts = line.strip().split(" | ")
|
| 209 |
+
if len(parts) != 3:
|
| 210 |
+
print(f"Invalid test case: {line}")
|
| 211 |
+
continue
|
| 212 |
+
if parts[2] not in ["Correct", "Incorrect", "Unknown"]:
|
| 213 |
+
print(f"Skipping line with invalid ground truth: {line}")
|
| 214 |
+
continue
|
| 215 |
+
_test_cases.append(parts)
|
| 216 |
+
|
| 217 |
+
print("Total", len(_test_cases), "test cases loaded")
|
| 218 |
+
return _test_cases
|
| 219 |
+
|
| 220 |
+
def starts_with_answer(response, answer):
|
| 221 |
+
return response.strip().lower().startswith(answer)
|
| 222 |
+
|
| 223 |
+
def call_api(model, prompt, user_input):
|
| 224 |
+
try:
|
| 225 |
+
if model["type"] == "openai":
|
| 226 |
+
if model["name"] == "Doubao-4k":
|
| 227 |
+
client = OpenAI(
|
| 228 |
+
api_key=model["config"]["apiKey"],
|
| 229 |
+
base_url=model["config"]["baseURL"]
|
| 230 |
+
)
|
| 231 |
+
|
| 232 |
+
messages = [
|
| 233 |
+
{"role": "system", "content": prompt},
|
| 234 |
+
{"role": "user", "content": user_input}
|
| 235 |
+
]
|
| 236 |
+
|
| 237 |
+
response = client.chat.completions.create(
|
| 238 |
+
model=model["config"]["model"],
|
| 239 |
+
messages=messages,
|
| 240 |
+
max_tokens=model["config"]["maxTokens"],
|
| 241 |
+
temperature=model["config"]["temperature"],
|
| 242 |
+
top_p=model["config"]["top_p"],
|
| 243 |
+
stream=False
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
return response.choices[0].message.content
|
| 247 |
+
else:
|
| 248 |
+
url = model["config"]["baseURL"] + "/chat/completions"
|
| 249 |
+
headers = {
|
| 250 |
+
"Content-Type": "application/json",
|
| 251 |
+
"Authorization": f"Bearer {model['config']['apiKey']}"
|
| 252 |
+
}
|
| 253 |
+
data = {
|
| 254 |
+
"model": model["config"]["model"],
|
| 255 |
+
"messages": [
|
| 256 |
+
{"role": "system", "content": prompt},
|
| 257 |
+
{"role": "user", "content": user_input}
|
| 258 |
+
],
|
| 259 |
+
"max_tokens": model["config"]["maxTokens"],
|
| 260 |
+
"temperature": model["config"]["temperature"],
|
| 261 |
+
}
|
| 262 |
+
|
| 263 |
+
if "top_p" in model["config"]:
|
| 264 |
+
data["top_p"] = model["config"]["top_p"]
|
| 265 |
+
|
| 266 |
+
response = requests.post(url, headers=headers, json=data)
|
| 267 |
+
if response.status_code != 200:
|
| 268 |
+
raise Exception(f"API call failed with status {response.status_code}: {response.text}")
|
| 269 |
+
result = response.json()
|
| 270 |
+
return result["choices"][0]["message"]["content"]
|
| 271 |
+
|
| 272 |
+
elif model["type"] == "together":
|
| 273 |
+
client = Together(api_key=model["config"]["apiKey"])
|
| 274 |
+
|
| 275 |
+
messages = [
|
| 276 |
+
{"role": "system", "content": prompt},
|
| 277 |
+
{"role": "user", "content": user_input}
|
| 278 |
+
]
|
| 279 |
+
|
| 280 |
+
response = client.chat.completions.create(
|
| 281 |
+
model=model["config"]["model"],
|
| 282 |
+
messages=messages,
|
| 283 |
+
max_tokens=model["config"]["maxTokens"],
|
| 284 |
+
temperature=model["config"]["temperature"],
|
| 285 |
+
top_p=model["config"]["top_p"],
|
| 286 |
+
stop=model["config"]["stop"],
|
| 287 |
+
stream=False
|
| 288 |
+
)
|
| 289 |
+
|
| 290 |
+
return response.choices[0].message.content
|
| 291 |
+
|
| 292 |
+
elif model["type"] == "anthropic":
|
| 293 |
+
client = Anthropic(api_key=model["config"]["apiKey"])
|
| 294 |
+
|
| 295 |
+
message = client.messages.create(
|
| 296 |
+
model=model["config"]["model"],
|
| 297 |
+
max_tokens=model["config"]["maxTokens"],
|
| 298 |
+
temperature=model["config"]["temperature"],
|
| 299 |
+
system=prompt,
|
| 300 |
+
messages=[
|
| 301 |
+
{
|
| 302 |
+
"role": "user",
|
| 303 |
+
"content": [
|
| 304 |
+
{
|
| 305 |
+
"type": "text",
|
| 306 |
+
"text": user_input
|
| 307 |
+
}
|
| 308 |
+
]
|
| 309 |
+
}
|
| 310 |
+
]
|
| 311 |
+
)
|
| 312 |
+
|
| 313 |
+
return message.content[0].text
|
| 314 |
+
|
| 315 |
+
elif model["type"] == "minimax":
|
| 316 |
+
url = f"https://api.minimax.chat/v1/text/chatcompletion_v2?GroupId={model['config']['groupId']}"
|
| 317 |
+
headers = {
|
| 318 |
+
"Authorization": f"Bearer {model['config']['apiKey']}",
|
| 319 |
+
"Content-Type": "application/json"
|
| 320 |
+
}
|
| 321 |
+
|
| 322 |
+
payload = {
|
| 323 |
+
"model": model["config"]["model"],
|
| 324 |
+
"messages": [
|
| 325 |
+
{
|
| 326 |
+
"role": "system",
|
| 327 |
+
"name": "MM智能助理",
|
| 328 |
+
"content": prompt
|
| 329 |
+
},
|
| 330 |
+
{
|
| 331 |
+
"role": "user",
|
| 332 |
+
"content": user_input
|
| 333 |
+
}
|
| 334 |
+
],
|
| 335 |
+
"tools": [],
|
| 336 |
+
"tool_choice": "none",
|
| 337 |
+
"stream": False,
|
| 338 |
+
"max_tokens": model["config"]["maxTokens"],
|
| 339 |
+
"temperature": model["config"]["temperature"],
|
| 340 |
+
"top_p": model["config"]["top_p"]
|
| 341 |
+
}
|
| 342 |
+
|
| 343 |
+
response = requests.post(url, headers=headers, json=payload)
|
| 344 |
+
if response.status_code != 200:
|
| 345 |
+
raise Exception(f"API call failed with status {response.status_code}: {response.text}")
|
| 346 |
+
|
| 347 |
+
result = response.json()
|
| 348 |
+
return result["choices"][0]["message"]["content"]
|
| 349 |
+
|
| 350 |
+
elif model["type"] == "gemini":
|
| 351 |
+
import google.generativeai as genai
|
| 352 |
+
|
| 353 |
+
genai.configure(api_key=model["config"]["apiKey"])
|
| 354 |
+
|
| 355 |
+
generation_config = {
|
| 356 |
+
"temperature": model["config"]["temperature"],
|
| 357 |
+
"max_output_tokens": model["config"]["maxTokens"],
|
| 358 |
+
"top_p": 0.7,
|
| 359 |
+
# "top_k": 64,
|
| 360 |
+
}
|
| 361 |
+
|
| 362 |
+
gemini_model = genai.GenerativeModel(
|
| 363 |
+
model_name=model["config"]["model"],
|
| 364 |
+
generation_config=generation_config,
|
| 365 |
+
)
|
| 366 |
+
|
| 367 |
+
chat_session = gemini_model.start_chat(history=[])
|
| 368 |
+
|
| 369 |
+
# Combine prompt and user_input
|
| 370 |
+
full_prompt = f"{prompt}\n\nUser: {user_input}\nAssistant:"
|
| 371 |
+
|
| 372 |
+
response = chat_session.send_message(full_prompt)
|
| 373 |
+
|
| 374 |
+
return response.text
|
| 375 |
+
|
| 376 |
+
else:
|
| 377 |
+
raise ValueError(f"Unsupported model type: {model['type']}")
|
| 378 |
+
except Exception as e:
|
| 379 |
+
print(f"Error in call_api for model {model['name']}: {str(e)}")
|
| 380 |
+
return None
|
| 381 |
+
|
| 382 |
+
def call_api_with_timeout_and_timing(model, prompt, user_input, timeout=20):
|
| 383 |
+
start_time = time.time()
|
| 384 |
+
try:
|
| 385 |
+
result = call_api(model, prompt, user_input)
|
| 386 |
+
elapsed_time = time.time() - start_time
|
| 387 |
+
return result, elapsed_time
|
| 388 |
+
except Exception as e:
|
| 389 |
+
elapsed_time = time.time() - start_time
|
| 390 |
+
print(f"Error in call_api for model {model['name']}: {str(e)}")
|
| 391 |
+
return None, elapsed_time
|
| 392 |
+
|
| 393 |
+
def evaluate_models(models, test_cases, stories, shot_type):
|
| 394 |
+
results = {model['name']: {'correct': 0, 'total': 0} for model in models}
|
| 395 |
+
logs = {model['name']: [] for model in models}
|
| 396 |
+
challenging_cases = []
|
| 397 |
+
all_cases = []
|
| 398 |
+
time_logs = []
|
| 399 |
+
|
| 400 |
+
log_folder = f"logs_with_{shot_type}shots"
|
| 401 |
+
os.makedirs(log_folder, exist_ok=True)
|
| 402 |
+
|
| 403 |
+
# Find the last tested sample
|
| 404 |
+
last_tested = 0
|
| 405 |
+
for i in range(len(test_cases), 0, -1):
|
| 406 |
+
if os.path.exists(f"{log_folder}/all_cases_simple_prompt_{i}.json"):
|
| 407 |
+
with open(f"{log_folder}/all_cases_simple_prompt_{i}.json", "r", encoding="utf-8") as f:
|
| 408 |
+
all_cases = json.load(f)
|
| 409 |
+
last_tested = i
|
| 410 |
+
break
|
| 411 |
+
|
| 412 |
+
# Update results with previously tested samples
|
| 413 |
+
for case in all_cases:
|
| 414 |
+
for model_name, result in case['results'].items():
|
| 415 |
+
if result is not None:
|
| 416 |
+
results[model_name]['total'] += 1
|
| 417 |
+
if (case['ground_truth'] == "Correct" and result == "Correct") or \
|
| 418 |
+
((case['ground_truth'] == "Incorrect" or case['ground_truth'] == "Unknown") and result != "Correct"):
|
| 419 |
+
results[model_name]['correct'] += 1
|
| 420 |
+
|
| 421 |
+
# Start from the next untested sample
|
| 422 |
+
start_index = len(all_cases)
|
| 423 |
+
|
| 424 |
+
for i, (user_input, story_title, ground_truth) in enumerate(tqdm(test_cases[start_index:]), start_index + 1):
|
| 425 |
+
try:
|
| 426 |
+
story = next((s for s in stories if s["title"] == story_title), None)
|
| 427 |
+
if not story:
|
| 428 |
+
print(f"Story not found: {story_title}")
|
| 429 |
+
continue
|
| 430 |
+
|
| 431 |
+
# Use the appropriate prompt based on shot_type
|
| 432 |
+
if shot_type == "2":
|
| 433 |
+
prompt_template = system_prompt_with_2shots
|
| 434 |
+
else:
|
| 435 |
+
prompt_template = simple_system_prompt
|
| 436 |
+
|
| 437 |
+
prompt = prompt_template.replace("{surface}", story["surface"]).replace("{bottom}", story["bottom"])
|
| 438 |
+
gt_map = {"correct": "correct", "incorrect": "incorrect", "unknown": "unknown"}
|
| 439 |
+
|
| 440 |
+
case_results = {}
|
| 441 |
+
all_responses_valid = True
|
| 442 |
+
time_usage = {}
|
| 443 |
+
|
| 444 |
+
# Use ThreadPoolExecutor for concurrent API calls
|
| 445 |
+
with concurrent.futures.ThreadPoolExecutor(max_workers=len(models)) as executor:
|
| 446 |
+
future_to_model = {executor.submit(partial(call_api_with_timeout_and_timing, timeout=20), model, prompt, user_input): model for model in models}
|
| 447 |
+
for future in concurrent.futures.as_completed(future_to_model):
|
| 448 |
+
model = future_to_model[future]
|
| 449 |
+
try:
|
| 450 |
+
response, elapsed_time = future.result()
|
| 451 |
+
time_usage[model['name']] = elapsed_time
|
| 452 |
+
if response is None:
|
| 453 |
+
all_responses_valid = False
|
| 454 |
+
print(f"Timeout or error for model {model['name']}")
|
| 455 |
+
else:
|
| 456 |
+
case_results[model['name']] = response
|
| 457 |
+
except Exception as exc:
|
| 458 |
+
print(f'{model["name"]} generated an exception: {exc}')
|
| 459 |
+
all_responses_valid = False
|
| 460 |
+
|
| 461 |
+
# If any model timed out or had an error, skip this entire test case
|
| 462 |
+
if not all_responses_valid:
|
| 463 |
+
print(f"Skipping test case {i} due to timeout or error")
|
| 464 |
+
continue
|
| 465 |
+
|
| 466 |
+
# Process all responses
|
| 467 |
+
for model in models:
|
| 468 |
+
if model['name'] not in case_results:
|
| 469 |
+
continue
|
| 470 |
+
response = case_results[model['name']].strip().lower()
|
| 471 |
+
|
| 472 |
+
if starts_with_answer(response, "correct") or starts_with_answer(response, "incorrect") or starts_with_answer(response, "unknown"):
|
| 473 |
+
results[model['name']]['total'] += 1
|
| 474 |
+
|
| 475 |
+
# Save the actual model output
|
| 476 |
+
if starts_with_answer(response, "correct"):
|
| 477 |
+
case_results[model['name']] = "Correct"
|
| 478 |
+
elif starts_with_answer(response, "incorrect"):
|
| 479 |
+
case_results[model['name']] = "Incorrect"
|
| 480 |
+
else:
|
| 481 |
+
case_results[model['name']] = "Unknown"
|
| 482 |
+
|
| 483 |
+
# Calculate accuracy (merging N and F)
|
| 484 |
+
if (ground_truth.lower() == "correct" and case_results[model['name']].lower() == "correct") or \
|
| 485 |
+
((ground_truth.lower() == "incorrect" or ground_truth.lower() == "unknown") and case_results[model['name']].lower() != "correct"):
|
| 486 |
+
results[model['name']]['correct'] += 1
|
| 487 |
+
else:
|
| 488 |
+
# Print only wrong answers
|
| 489 |
+
print(f"Wrong Answer - Model: {model['name']}, Input: {user_input}, Response: {response}, GT: {ground_truth.lower()}, Model Output: {case_results[model['name']]}")
|
| 490 |
+
else:
|
| 491 |
+
# Handle invalid responses
|
| 492 |
+
case_results[model['name']] = "Invalid"
|
| 493 |
+
print(f"Invalid Response - Model: {model['name']}, Input: {user_input}, Response: {response}, GT: {ground_truth.lower()}, Model Output: {case_results[model['name']]}")
|
| 494 |
+
|
| 495 |
+
log_entry = {
|
| 496 |
+
"Input": user_input,
|
| 497 |
+
"Response": response,
|
| 498 |
+
"GT": ground_truth,
|
| 499 |
+
"Model_Output": case_results[model['name']],
|
| 500 |
+
"Accuracy": f"{results[model['name']]['correct']}/{results[model['name']]['total']} ({results[model['name']]['correct']/max(results[model['name']]['total'], 1):.2f})"
|
| 501 |
+
}
|
| 502 |
+
logs[model['name']].append(log_entry)
|
| 503 |
+
|
| 504 |
+
case = {
|
| 505 |
+
"input": user_input,
|
| 506 |
+
"story_title": story_title,
|
| 507 |
+
"ground_truth": ground_truth,
|
| 508 |
+
"results": case_results,
|
| 509 |
+
"time_usage": time_usage
|
| 510 |
+
}
|
| 511 |
+
|
| 512 |
+
all_cases.append(case)
|
| 513 |
+
time_logs.append({"sample": i, "time_usage": time_usage})
|
| 514 |
+
|
| 515 |
+
# Print time usage for this sample
|
| 516 |
+
print(f"\nTime usage for sample {i}:")
|
| 517 |
+
for model_name, elapsed_time in sorted(time_usage.items(), key=lambda x: x[1], reverse=True):
|
| 518 |
+
print(f"{model_name}: {elapsed_time:.2f} seconds")
|
| 519 |
+
|
| 520 |
+
# Save log and print accuracy ranking every 10 steps
|
| 521 |
+
if i % 10 == 0 or i == len(test_cases):
|
| 522 |
+
print(f"\nCurrent rankings after {i} items:")
|
| 523 |
+
current_results = [(name, res['correct'] / max(res['total'], 1), res['correct'], res['total'])
|
| 524 |
+
for name, res in results.items()]
|
| 525 |
+
current_results.sort(key=lambda x: x[1], reverse=True)
|
| 526 |
+
|
| 527 |
+
for rank, (name, accuracy, correct, total) in enumerate(current_results, 1):
|
| 528 |
+
print(f"{rank}. {name}: {accuracy:.2f} ({correct}/{total})")
|
| 529 |
+
|
| 530 |
+
# Update challenging cases file
|
| 531 |
+
with open(f"{log_folder}/challenging_cases_simple_prompt_{i}.json", "w", encoding="utf-8") as f:
|
| 532 |
+
json.dump(challenging_cases, f, ensure_ascii=False, indent=2)
|
| 533 |
+
|
| 534 |
+
# Update all cases file
|
| 535 |
+
with open(f"{log_folder}/all_cases_simple_prompt_{i}.json", "w", encoding="utf-8") as f:
|
| 536 |
+
json.dump(all_cases, f, ensure_ascii=False, indent=2)
|
| 537 |
+
|
| 538 |
+
# Save time logs
|
| 539 |
+
with open(f"{log_folder}/time_logs_{i}.json", "w", encoding="utf-8") as f:
|
| 540 |
+
json.dump(time_logs, f, ensure_ascii=False, indent=2)
|
| 541 |
+
|
| 542 |
+
except Exception as e:
|
| 543 |
+
print(f"Error processing test case {i}: {str(e)}")
|
| 544 |
+
continue
|
| 545 |
+
|
| 546 |
+
# Final update to challenging cases file
|
| 547 |
+
final_index = start_index + len(test_cases[start_index:])
|
| 548 |
+
with open(f"{log_folder}/challenging_cases_simple_prompt_{final_index}.json", "w", encoding="utf-8") as f:
|
| 549 |
+
json.dump(challenging_cases, f, ensure_ascii=False, indent=2)
|
| 550 |
+
|
| 551 |
+
# Final update to all cases file
|
| 552 |
+
with open(f"{log_folder}/all_cases_simple_prompt_{final_index}.json", "w", encoding="utf-8") as f:
|
| 553 |
+
json.dump(all_cases, f, ensure_ascii=False, indent=2)
|
| 554 |
+
|
| 555 |
+
return results, challenging_cases, all_cases, time_logs
|
| 556 |
+
|
| 557 |
+
def save_all_cases(all_cases, output_file):
|
| 558 |
+
with open(output_file, "w", encoding="utf-8") as f:
|
| 559 |
+
json.dump(all_cases, f, ensure_ascii=False, indent=2)
|
| 560 |
+
|
| 561 |
+
print(f"All cases have been saved to {output_file}")
|
| 562 |
+
|
| 563 |
+
def parse_challenging_cases(input_file, output_file):
|
| 564 |
+
with open(input_file, 'r', encoding='utf-8') as f:
|
| 565 |
+
challenging_cases = json.load(f)
|
| 566 |
+
|
| 567 |
+
with open(output_file, 'w', encoding='utf-8') as f:
|
| 568 |
+
for case in challenging_cases:
|
| 569 |
+
user_input = case['input']
|
| 570 |
+
story_title = case['story_title']
|
| 571 |
+
ground_truth = case['ground_truth']
|
| 572 |
+
f.write(f"{user_input}\t{story_title}\t{ground_truth}\n")
|
| 573 |
+
|
| 574 |
+
print(f"Parsed challenging cases have been written to {output_file}")
|
| 575 |
+
|
| 576 |
+
def main():
|
| 577 |
+
# Parse command line arguments
|
| 578 |
+
parser = argparse.ArgumentParser(description="Run story understanding evaluation")
|
| 579 |
+
parser.add_argument("--shot", choices=["0", "2"], default="2", help="Number of shots (0 or 2)")
|
| 580 |
+
args = parser.parse_args()
|
| 581 |
+
|
| 582 |
+
test_cases = load_test_cases("data/cases.list")
|
| 583 |
+
results, challenging_cases, all_cases, time_logs = evaluate_models(models, test_cases, stories, args.shot)
|
| 584 |
+
|
| 585 |
+
final_results = [(name, res['correct'] / max(res['total'], 1), res['correct'], res['total'])
|
| 586 |
+
for name, res in results.items()]
|
| 587 |
+
final_results.sort(key=lambda x: x[1], reverse=True)
|
| 588 |
+
|
| 589 |
+
print(f"\nFinal Rankings ({args.shot}-shot):")
|
| 590 |
+
for rank, (name, accuracy, correct, total) in enumerate(final_results, 1):
|
| 591 |
+
print(f"{rank}. {name}: {accuracy:.2f} ({correct}/{total})")
|
| 592 |
+
|
| 593 |
+
print(f"Evaluation complete. Logs have been saved in the '{log_folder}' directory.")
|
| 594 |
+
|
| 595 |
+
# Analyze and print overall time usage statistics
|
| 596 |
+
model_total_time = {model['name']: 0 for model in models}
|
| 597 |
+
model_call_count = {model['name']: 0 for model in models}
|
| 598 |
+
|
| 599 |
+
for log in time_logs:
|
| 600 |
+
for model_name, time_used in log['time_usage'].items():
|
| 601 |
+
model_total_time[model_name] += time_used
|
| 602 |
+
model_call_count[model_name] += 1
|
| 603 |
+
|
| 604 |
+
print("\nOverall Time Usage Statistics:")
|
| 605 |
+
for model_name in sorted(model_total_time, key=lambda x: model_total_time[x], reverse=True):
|
| 606 |
+
avg_time = model_total_time[model_name] / model_call_count[model_name] if model_call_count[model_name] > 0 else 0
|
| 607 |
+
print(f"{model_name}: Total time: {model_total_time[model_name]:.2f}s, Avg time per call: {avg_time:.2f}s")
|
| 608 |
+
|
| 609 |
+
# Save overall time usage statistics
|
| 610 |
+
log_folder = f"logs_with_{args.shot}shots"
|
| 611 |
+
with open(f"{log_folder}/overall_time_usage.json", "w", encoding="utf-8") as f:
|
| 612 |
+
json.dump({
|
| 613 |
+
"model_total_time": model_total_time,
|
| 614 |
+
"model_call_count": model_call_count,
|
| 615 |
+
"model_avg_time": {name: model_total_time[name] / count if count > 0 else 0
|
| 616 |
+
for name, count in model_call_count.items()}
|
| 617 |
+
}, f, ensure_ascii=False, indent=2)
|
| 618 |
+
|
| 619 |
+
if __name__ == "__main__":
|
| 620 |
+
main()
|
datasets/TurtleBenchmark/evaluation/english/prompt.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
simple_system_prompt = """
|
| 2 |
+
You are the referee of a game where players are shown a <Surface> and you are given the <Bottom>. You need to understand the entire story based on both the <Surface> and <Bottom>. Players will make guesses based on the <Surface>, and you need to judge whether their guesses are correct. Please strictly adhere to answering with only three specified responses: Correct, Incorrect, or Unknown.
|
| 3 |
+
|
| 4 |
+
## Judging Rules
|
| 5 |
+
- If the player's guess is correct or the answer is affirmative: Please only answer "Correct" without any explanation.
|
| 6 |
+
- If the player's guess is wrong or the answer is negative: Please only answer "Incorrect" without any explanation.
|
| 7 |
+
- If the answer to the player's guess cannot be found in the <Surface> and <Bottom>, and cannot be deduced through reasoning: Please only answer "Unknown" without any explanation.
|
| 8 |
+
|
| 9 |
+
## Important Notes
|
| 10 |
+
1. Players can only see the <Surface>, so their guesses are based on it. Even if the <Bottom> contains additional information, you should judge based on the content in the <Surface>.
|
| 11 |
+
2. If a conclusion cannot be drawn from the provided story or through reasonable inference, answer "Unknown".
|
| 12 |
+
3. Strictly adhere to answering with only the three specified responses: Correct, Incorrect, or Unknown. Do not provide any additional explanations.
|
| 13 |
+
|
| 14 |
+
## Question Content
|
| 15 |
+
### <Surface>
|
| 16 |
+
{surface}
|
| 17 |
+
|
| 18 |
+
### <Bottom>
|
| 19 |
+
{bottom}
|
| 20 |
+
|
| 21 |
+
Now, please judge the following player guesses:
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
system_prompt_with_2shots = """
|
| 25 |
+
You are the referee of a game where players are shown a <Surface> and you are given the <Bottom>. You need to understand the entire story based on both the <Surface> and <Bottom>. Players will make guesses based on the <Surface>, and you need to judge whether their guesses are correct. Please strictly adhere to answering with only three specified responses: Correct, Incorrect, or Unknown.
|
| 26 |
+
|
| 27 |
+
## Judging Rules
|
| 28 |
+
- If the player's guess is correct or the answer is affirmative: Please only answer "Correct" without any explanation.
|
| 29 |
+
- If the player's guess is wrong or the answer is negative: Please only answer "Incorrect" without any explanation.
|
| 30 |
+
- If the answer to the player's guess cannot be found in the <Surface> and <Bottom>, and cannot be deduced through reasoning: Please only answer "Unknown" without any explanation.
|
| 31 |
+
|
| 32 |
+
## Important Notes
|
| 33 |
+
1. Fully understand the cause, process, and outcome of the entire story, and make logical inferences.
|
| 34 |
+
2. If a conclusion cannot be drawn from the provided story or through reasonable inference, answer "Unknown".
|
| 35 |
+
3. Strictly adhere to answering with only the three specified responses: Correct, Incorrect, or Unknown. Do not provide any additional explanations.
|
| 36 |
+
|
| 37 |
+
## Examples
|
| 38 |
+
|
| 39 |
+
### Example 1: The Hiccuping Man
|
| 40 |
+
<Surface>
|
| 41 |
+
A man walks into a bar and asks the bartender for a glass of water. The bartender suddenly pulls out a gun and points it at him. The man smiles and says, "Thank you!" then calmly leaves. What happened?
|
| 42 |
+
|
| 43 |
+
<Bottom>
|
| 44 |
+
The man had hiccups and wanted a glass of water to cure them. The bartender realized this and chose to scare him with a gun. The man's hiccups disappeared due to the sudden shock, so he sincerely thanked the bartender before leaving.
|
| 45 |
+
|
| 46 |
+
Possible guesses and corresponding answers:
|
| 47 |
+
Q: Does the man have a chronic illness? A: Unknown
|
| 48 |
+
Q: Was the man scared away? A: Incorrect
|
| 49 |
+
Q: Did the bartender want to kill the man? A: Incorrect
|
| 50 |
+
Q: Did the bartender intend to scare the man? A: Correct
|
| 51 |
+
Q: Did the man sincerely thank the bartender? A: Correct
|
| 52 |
+
|
| 53 |
+
### Example 2: The Four-Year-Old Mother
|
| 54 |
+
<Surface>
|
| 55 |
+
A five-year-old kindergartener surprisingly claims that her mother is only four years old. Puzzled, I proposed a home visit. When I arrived at her house, I saw a horrifying scene...
|
| 56 |
+
|
| 57 |
+
<Bottom>
|
| 58 |
+
I saw several women chained up in her house, with a fierce-looking, ugly brute standing nearby. The kindergartener suddenly displayed an eerie smile uncharacteristic of her age... It turns out she's actually 25 years old but suffers from a condition that prevents her from growing. The brute is her brother, and she lures kindergarten teachers like us to their house to help her brother find women... Her "four-year-old mother" is actually a woman who was tricked and has been held captive for four years...
|
| 59 |
+
|
| 60 |
+
Possible guesses and corresponding answers:
|
| 61 |
+
Q: Is the child already dead? A: Incorrect
|
| 62 |
+
Q: Is the child actually an adult? A: Correct
|
| 63 |
+
Q: Does the child have schizophrenia? A: Unknown
|
| 64 |
+
Q: Am I in danger? A: Correct
|
| 65 |
+
|
| 66 |
+
## Question Content
|
| 67 |
+
### Surface
|
| 68 |
+
{surface}
|
| 69 |
+
|
| 70 |
+
### Bottom
|
| 71 |
+
{bottom}
|
| 72 |
+
|
| 73 |
+
Now, please judge the following player guesses:
|
| 74 |
+
"""
|
datasets/TurtleBenchmark/requirements.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:732c8664c5e7ed190afd1e22670bb1a9d031205d590207f8d6ad1ccbe7990fe8
|
| 3 |
+
size 54
|