Spaces:
Running
on
Zero

Running
on
Zero
Commit
•
0a88b62
1
Parent(s):
23ce364
Upload 93 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +37 -35
- README.md +4 -7
- app.py +284 -0
- assets/logo.png +0 -0
- assets/overview_3.png +0 -0
- assets/radar.png +0 -0
- assets/runtime.png +0 -0
- assets/teaser.png +3 -0
- demos/example_000.png +0 -0
- demos/example_001.png +0 -0
- demos/example_002.png +0 -0
- demos/example_003.png +3 -0
- demos/example_list.txt +2 -0
- infer/__init__.py +28 -0
- infer/gif_render.py +55 -0
- infer/image_to_views.py +81 -0
- infer/rembg.py +26 -0
- infer/text_to_image.py +80 -0
- infer/utils.py +77 -0
- infer/views_to_mesh.py +94 -0
- mvd/__init__.py +0 -0
- mvd/hunyuan3d_mvd_lite_pipeline.py +493 -0
- mvd/hunyuan3d_mvd_std_pipeline.py +471 -0
- mvd/utils.py +85 -0
- requirements.txt +22 -0
- scripts/image_to_3d.sh +8 -0
- scripts/image_to_3d_demo.sh +8 -0
- scripts/image_to_3d_fast.sh +6 -0
- scripts/image_to_3d_fast_demo.sh +6 -0
- scripts/text_to_3d.sh +7 -0
- scripts/text_to_3d_demo.sh +7 -0
- scripts/text_to_3d_fast.sh +6 -0
- scripts/text_to_3d_fast_demo.sh +6 -0
- svrm/.DS_Store +0 -0
- svrm/configs/2024-10-24T22-36-18-project.yaml +32 -0
- svrm/configs/svrm.yaml +32 -0
- svrm/ldm/.DS_Store +0 -0
- svrm/ldm/models/svrm.py +263 -0
- svrm/ldm/modules/attention.py +457 -0
- svrm/ldm/modules/encoders/__init__.py +0 -0
- svrm/ldm/modules/encoders/dinov2/__init__.py +0 -0
- svrm/ldm/modules/encoders/dinov2/hub/__init__.py +0 -0
- svrm/ldm/modules/encoders/dinov2/hub/backbones.py +156 -0
- svrm/ldm/modules/encoders/dinov2/hub/utils.py +39 -0
- svrm/ldm/modules/encoders/dinov2/layers/__init__.py +11 -0
- svrm/ldm/modules/encoders/dinov2/layers/attention.py +89 -0
- svrm/ldm/modules/encoders/dinov2/layers/block.py +269 -0
- svrm/ldm/modules/encoders/dinov2/layers/dino_head.py +58 -0
- svrm/ldm/modules/encoders/dinov2/layers/drop_path.py +34 -0
- svrm/ldm/modules/encoders/dinov2/layers/layer_scale.py +27 -0
.gitattributes
CHANGED
|
@@ -1,35 +1,37 @@
|
|
| 1 |
-
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
-
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
-
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
-
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
-
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
-
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
-
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
-
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
-
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
-
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/teaser.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
demos/example_003.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,14 +1,11 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
colorFrom: purple
|
| 5 |
colorTo: red
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 4.42.0
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
---
|
| 13 |
-
|
| 14 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Hunyuan3D-1.0
|
| 3 |
+
emoji: 😻
|
| 4 |
colorFrom: purple
|
| 5 |
colorTo: red
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 4.42.0
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
+
short_description: Text-to-3D and Image-to-3D Generation
|
| 11 |
+
---
|
|
|
|
|
|
|
|
|
app.py
ADDED
|
@@ -0,0 +1,284 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import warnings
|
| 3 |
+
from huggingface_hub import hf_hub_download
|
| 4 |
+
import gradio as gr
|
| 5 |
+
from glob import glob
|
| 6 |
+
import shutil
|
| 7 |
+
import torch
|
| 8 |
+
import numpy as np
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from einops import rearrange
|
| 11 |
+
import argparse
|
| 12 |
+
|
| 13 |
+
# Suppress warnings
|
| 14 |
+
warnings.simplefilter('ignore', category=UserWarning)
|
| 15 |
+
warnings.simplefilter('ignore', category=FutureWarning)
|
| 16 |
+
warnings.simplefilter('ignore', category=DeprecationWarning)
|
| 17 |
+
|
| 18 |
+
def download_models():
|
| 19 |
+
# Create weights directory if it doesn't exist
|
| 20 |
+
os.makedirs("weights", exist_ok=True)
|
| 21 |
+
os.makedirs("weights/hunyuanDiT", exist_ok=True)
|
| 22 |
+
|
| 23 |
+
# Download Hunyuan3D-1 model
|
| 24 |
+
try:
|
| 25 |
+
hf_hub_download(
|
| 26 |
+
repo_id="tencent/Hunyuan3D-1",
|
| 27 |
+
local_dir="./weights",
|
| 28 |
+
resume_download=True
|
| 29 |
+
)
|
| 30 |
+
print("Successfully downloaded Hunyuan3D-1 model")
|
| 31 |
+
except Exception as e:
|
| 32 |
+
print(f"Error downloading Hunyuan3D-1: {e}")
|
| 33 |
+
|
| 34 |
+
# Download HunyuanDiT model
|
| 35 |
+
try:
|
| 36 |
+
hf_hub_download(
|
| 37 |
+
repo_id="Tencent-Hunyuan/HunyuanDiT-v1.1-Diffusers-Distilled",
|
| 38 |
+
local_dir="./weights/hunyuanDiT",
|
| 39 |
+
resume_download=True
|
| 40 |
+
)
|
| 41 |
+
print("Successfully downloaded HunyuanDiT model")
|
| 42 |
+
except Exception as e:
|
| 43 |
+
print(f"Error downloading HunyuanDiT: {e}")
|
| 44 |
+
|
| 45 |
+
# Download models before starting the app
|
| 46 |
+
download_models()
|
| 47 |
+
|
| 48 |
+
# Parse arguments
|
| 49 |
+
parser = argparse.ArgumentParser()
|
| 50 |
+
parser.add_argument("--use_lite", default=False, action="store_true")
|
| 51 |
+
parser.add_argument("--mv23d_cfg_path", default="./svrm/configs/svrm.yaml", type=str)
|
| 52 |
+
parser.add_argument("--mv23d_ckt_path", default="weights/svrm/svrm.safetensors", type=str)
|
| 53 |
+
parser.add_argument("--text2image_path", default="weights/hunyuanDiT", type=str)
|
| 54 |
+
parser.add_argument("--save_memory", default=False, action="store_true")
|
| 55 |
+
parser.add_argument("--device", default="cuda:0", type=str)
|
| 56 |
+
args = parser.parse_args()
|
| 57 |
+
|
| 58 |
+
# Constants
|
| 59 |
+
CONST_PORT = 8080
|
| 60 |
+
CONST_MAX_QUEUE = 1
|
| 61 |
+
CONST_SERVER = '0.0.0.0'
|
| 62 |
+
|
| 63 |
+
CONST_HEADER = '''
|
| 64 |
+
<h2><b>Official 🤗 Gradio Demo</b></h2>
|
| 65 |
+
<h2><a href='https://github.com/tencent/Hunyuan3D-1' target='_blank'>
|
| 66 |
+
<b>Hunyuan3D-1.0: A Unified Framework for Text-to-3D and Image-to-3D Generation</b></a></h2>
|
| 67 |
+
'''
|
| 68 |
+
|
| 69 |
+
# Helper functions
|
| 70 |
+
def get_example_img_list():
|
| 71 |
+
print('Loading example img list ...')
|
| 72 |
+
return sorted(glob('./demos/example_*.png'))
|
| 73 |
+
|
| 74 |
+
def get_example_txt_list():
|
| 75 |
+
print('Loading example txt list ...')
|
| 76 |
+
txt_list = []
|
| 77 |
+
for line in open('./demos/example_list.txt'):
|
| 78 |
+
txt_list.append(line.strip())
|
| 79 |
+
return txt_list
|
| 80 |
+
|
| 81 |
+
example_is = get_example_img_list()
|
| 82 |
+
example_ts = get_example_txt_list()
|
| 83 |
+
|
| 84 |
+
# Import required workers
|
| 85 |
+
from infer import seed_everything, save_gif
|
| 86 |
+
from infer import Text2Image, Removebg, Image2Views, Views2Mesh, GifRenderer
|
| 87 |
+
|
| 88 |
+
# Initialize workers
|
| 89 |
+
worker_xbg = Removebg()
|
| 90 |
+
print(f"loading {args.text2image_path}")
|
| 91 |
+
worker_t2i = Text2Image(
|
| 92 |
+
pretrain=args.text2image_path,
|
| 93 |
+
device=args.device,
|
| 94 |
+
save_memory=args.save_memory
|
| 95 |
+
)
|
| 96 |
+
worker_i2v = Image2Views(
|
| 97 |
+
use_lite=args.use_lite,
|
| 98 |
+
device=args.device
|
| 99 |
+
)
|
| 100 |
+
worker_v23 = Views2Mesh(
|
| 101 |
+
args.mv23d_cfg_path,
|
| 102 |
+
args.mv23d_ckt_path,
|
| 103 |
+
use_lite=args.use_lite,
|
| 104 |
+
device=args.device
|
| 105 |
+
)
|
| 106 |
+
worker_gif = GifRenderer(args.device)
|
| 107 |
+
|
| 108 |
+
# Pipeline stages
|
| 109 |
+
def stage_0_t2i(text, image, seed, step):
|
| 110 |
+
os.makedirs('./outputs/app_output', exist_ok=True)
|
| 111 |
+
exists = set(int(_) for _ in os.listdir('./outputs/app_output') if not _.startswith("."))
|
| 112 |
+
cur_id = min(set(range(30)) - exists) if len(exists) < 30 else 0
|
| 113 |
+
|
| 114 |
+
if os.path.exists(f"./outputs/app_output/{(cur_id + 1) % 30}"):
|
| 115 |
+
shutil.rmtree(f"./outputs/app_output/{(cur_id + 1) % 30}")
|
| 116 |
+
save_folder = f'./outputs/app_output/{cur_id}'
|
| 117 |
+
os.makedirs(save_folder, exist_ok=True)
|
| 118 |
+
|
| 119 |
+
dst = save_folder + '/img.png'
|
| 120 |
+
|
| 121 |
+
if not text:
|
| 122 |
+
if image is None:
|
| 123 |
+
return dst, save_folder
|
| 124 |
+
image.save(dst)
|
| 125 |
+
return dst, save_folder
|
| 126 |
+
|
| 127 |
+
image = worker_t2i(text, seed, step)
|
| 128 |
+
image.save(dst)
|
| 129 |
+
dst = worker_xbg(image, save_folder)
|
| 130 |
+
return dst, save_folder
|
| 131 |
+
|
| 132 |
+
def stage_1_xbg(image, save_folder):
|
| 133 |
+
if isinstance(image, str):
|
| 134 |
+
image = Image.open(image)
|
| 135 |
+
dst = save_folder + '/img_nobg.png'
|
| 136 |
+
rgba = worker_xbg(image)
|
| 137 |
+
rgba.save(dst)
|
| 138 |
+
return dst
|
| 139 |
+
|
| 140 |
+
def stage_2_i2v(image, seed, step, save_folder):
|
| 141 |
+
if isinstance(image, str):
|
| 142 |
+
image = Image.open(image)
|
| 143 |
+
gif_dst = save_folder + '/views.gif'
|
| 144 |
+
res_img, pils = worker_i2v(image, seed, step)
|
| 145 |
+
save_gif(pils, gif_dst)
|
| 146 |
+
views_img, cond_img = res_img[0], res_img[1]
|
| 147 |
+
img_array = np.asarray(views_img, dtype=np.uint8)
|
| 148 |
+
show_img = rearrange(img_array, '(n h) (m w) c -> (n m) h w c', n=3, m=2)
|
| 149 |
+
show_img = show_img[worker_i2v.order, ...]
|
| 150 |
+
show_img = rearrange(show_img, '(n m) h w c -> (n h) (m w) c', n=2, m=3)
|
| 151 |
+
show_img = Image.fromarray(show_img)
|
| 152 |
+
return views_img, cond_img, show_img
|
| 153 |
+
|
| 154 |
+
def stage_3_v23(views_pil, cond_pil, seed, save_folder, target_face_count=30000,
|
| 155 |
+
do_texture_mapping=True, do_render=True):
|
| 156 |
+
do_texture_mapping = do_texture_mapping or do_render
|
| 157 |
+
obj_dst = save_folder + '/mesh_with_colors.obj'
|
| 158 |
+
glb_dst = save_folder + '/mesh.glb'
|
| 159 |
+
worker_v23(
|
| 160 |
+
views_pil,
|
| 161 |
+
cond_pil,
|
| 162 |
+
seed=seed,
|
| 163 |
+
save_folder=save_folder,
|
| 164 |
+
target_face_count=target_face_count,
|
| 165 |
+
do_texture_mapping=do_texture_mapping
|
| 166 |
+
)
|
| 167 |
+
return obj_dst, glb_dst
|
| 168 |
+
|
| 169 |
+
def stage_4_gif(obj_dst, save_folder, do_render_gif=True):
|
| 170 |
+
if not do_render_gif:
|
| 171 |
+
return None
|
| 172 |
+
gif_dst = save_folder + '/output.gif'
|
| 173 |
+
worker_gif(
|
| 174 |
+
save_folder + '/mesh.obj',
|
| 175 |
+
gif_dst_path=gif_dst
|
| 176 |
+
)
|
| 177 |
+
return gif_dst
|
| 178 |
+
|
| 179 |
+
# Gradio Interface
|
| 180 |
+
with gr.Blocks() as demo:
|
| 181 |
+
gr.Markdown(CONST_HEADER)
|
| 182 |
+
|
| 183 |
+
with gr.Row(variant="panel"):
|
| 184 |
+
with gr.Column(scale=2):
|
| 185 |
+
with gr.Tab("Text to 3D"):
|
| 186 |
+
with gr.Column():
|
| 187 |
+
text = gr.TextArea('一只黑白相间的熊猫在白色背景上居中坐着,呈现出卡通风格和可爱氛围。',
|
| 188 |
+
lines=1, max_lines=10, label='Input text')
|
| 189 |
+
with gr.Row():
|
| 190 |
+
textgen_seed = gr.Number(value=0, label="T2I seed", precision=0)
|
| 191 |
+
textgen_step = gr.Number(value=25, label="T2I step", precision=0)
|
| 192 |
+
textgen_SEED = gr.Number(value=0, label="Gen seed", precision=0)
|
| 193 |
+
textgen_STEP = gr.Number(value=50, label="Gen step", precision=0)
|
| 194 |
+
textgen_max_faces = gr.Number(value=90000, label="max number of faces", precision=0)
|
| 195 |
+
|
| 196 |
+
with gr.Row():
|
| 197 |
+
textgen_do_texture_mapping = gr.Checkbox(label="texture mapping", value=False)
|
| 198 |
+
textgen_do_render_gif = gr.Checkbox(label="Render gif", value=False)
|
| 199 |
+
textgen_submit = gr.Button("Generate", variant="primary")
|
| 200 |
+
|
| 201 |
+
gr.Examples(examples=example_ts, inputs=[text], label="Txt examples")
|
| 202 |
+
|
| 203 |
+
with gr.Tab("Image to 3D"):
|
| 204 |
+
with gr.Column():
|
| 205 |
+
input_image = gr.Image(label="Input image", width=256, height=256,
|
| 206 |
+
type="pil", image_mode="RGBA", sources="upload")
|
| 207 |
+
with gr.Row():
|
| 208 |
+
imggen_SEED = gr.Number(value=0, label="Gen seed", precision=0)
|
| 209 |
+
imggen_STEP = gr.Number(value=50, label="Gen step", precision=0)
|
| 210 |
+
imggen_max_faces = gr.Number(value=90000, label="max number of faces", precision=0)
|
| 211 |
+
|
| 212 |
+
with gr.Row():
|
| 213 |
+
imggen_do_texture_mapping = gr.Checkbox(label="texture mapping", value=False)
|
| 214 |
+
imggen_do_render_gif = gr.Checkbox(label="Render gif", value=False)
|
| 215 |
+
imggen_submit = gr.Button("Generate", variant="primary")
|
| 216 |
+
|
| 217 |
+
gr.Examples(examples=example_is, inputs=[input_image], label="Img examples")
|
| 218 |
+
|
| 219 |
+
with gr.Column(scale=3):
|
| 220 |
+
with gr.Tab("rembg image"):
|
| 221 |
+
rem_bg_image = gr.Image(label="No background image", width=256, height=256,
|
| 222 |
+
type="pil", image_mode="RGBA")
|
| 223 |
+
|
| 224 |
+
with gr.Tab("Multi views"):
|
| 225 |
+
result_image = gr.Image(label="Multi views", type="pil")
|
| 226 |
+
with gr.Tab("Obj"):
|
| 227 |
+
result_3dobj = gr.Model3D(label="Output obj")
|
| 228 |
+
with gr.Tab("Glb"):
|
| 229 |
+
result_3dglb = gr.Model3D(label="Output glb")
|
| 230 |
+
with gr.Tab("GIF"):
|
| 231 |
+
result_gif = gr.Image(label="Rendered GIF")
|
| 232 |
+
|
| 233 |
+
# States
|
| 234 |
+
none = gr.State(None)
|
| 235 |
+
save_folder = gr.State()
|
| 236 |
+
cond_image = gr.State()
|
| 237 |
+
views_image = gr.State()
|
| 238 |
+
text_image = gr.State()
|
| 239 |
+
|
| 240 |
+
# Event handlers
|
| 241 |
+
textgen_submit.click(
|
| 242 |
+
fn=stage_0_t2i,
|
| 243 |
+
inputs=[text, none, textgen_seed, textgen_step],
|
| 244 |
+
outputs=[rem_bg_image, save_folder],
|
| 245 |
+
).success(
|
| 246 |
+
fn=stage_2_i2v,
|
| 247 |
+
inputs=[rem_bg_image, textgen_SEED, textgen_STEP, save_folder],
|
| 248 |
+
outputs=[views_image, cond_image, result_image],
|
| 249 |
+
).success(
|
| 250 |
+
fn=stage_3_v23,
|
| 251 |
+
inputs=[views_image, cond_image, textgen_SEED, save_folder, textgen_max_faces,
|
| 252 |
+
textgen_do_texture_mapping, textgen_do_render_gif],
|
| 253 |
+
outputs=[result_3dobj, result_3dglb],
|
| 254 |
+
).success(
|
| 255 |
+
fn=stage_4_gif,
|
| 256 |
+
inputs=[result_3dglb, save_folder, textgen_do_render_gif],
|
| 257 |
+
outputs=[result_gif],
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
imggen_submit.click(
|
| 261 |
+
fn=stage_0_t2i,
|
| 262 |
+
inputs=[none, input_image, textgen_seed, textgen_step],
|
| 263 |
+
outputs=[text_image, save_folder],
|
| 264 |
+
).success(
|
| 265 |
+
fn=stage_1_xbg,
|
| 266 |
+
inputs=[text_image, save_folder],
|
| 267 |
+
outputs=[rem_bg_image],
|
| 268 |
+
).success(
|
| 269 |
+
fn=stage_2_i2v,
|
| 270 |
+
inputs=[rem_bg_image, imggen_SEED, imggen_STEP, save_folder],
|
| 271 |
+
outputs=[views_image, cond_image, result_image],
|
| 272 |
+
).success(
|
| 273 |
+
fn=stage_3_v23,
|
| 274 |
+
inputs=[views_image, cond_image, imggen_SEED, save_folder, imggen_max_faces,
|
| 275 |
+
imggen_do_texture_mapping, imggen_do_render_gif],
|
| 276 |
+
outputs=[result_3dobj, result_3dglb],
|
| 277 |
+
).success(
|
| 278 |
+
fn=stage_4_gif,
|
| 279 |
+
inputs=[result_3dglb, save_folder, imggen_do_render_gif],
|
| 280 |
+
outputs=[result_gif],
|
| 281 |
+
)
|
| 282 |
+
|
| 283 |
+
demo.queue(max_size=CONST_MAX_QUEUE)
|
| 284 |
+
demo.launch(server_name=CONST_SERVER, server_port=CONST_PORT)
|
assets/logo.png
ADDED
|
|
assets/overview_3.png
ADDED
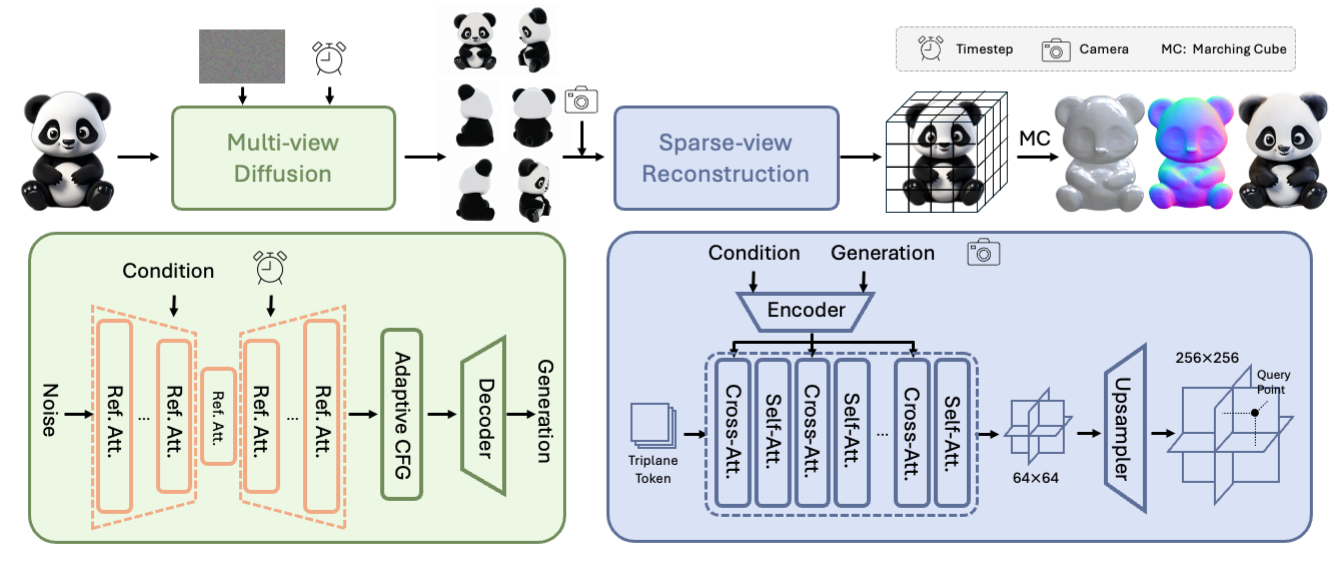
|
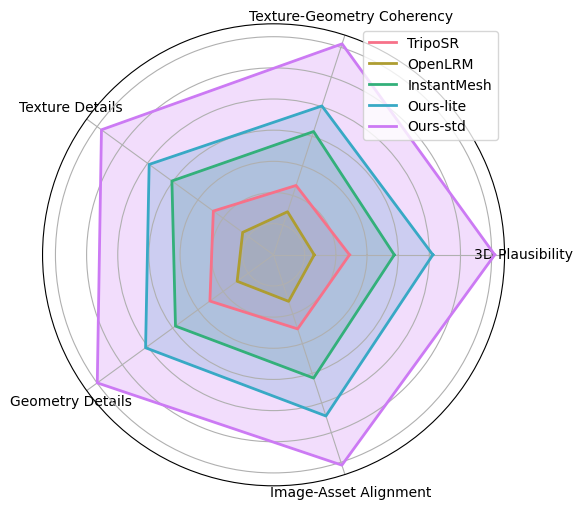
assets/radar.png
ADDED
|
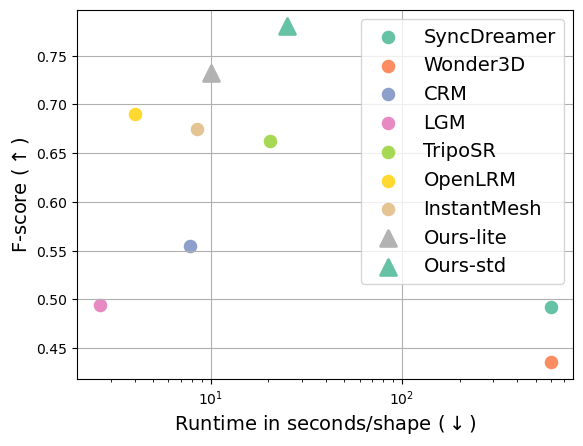
assets/runtime.png
ADDED
|
assets/teaser.png
ADDED

|
Git LFS Details
|
demos/example_000.png
ADDED

|
demos/example_001.png
ADDED

|
demos/example_002.png
ADDED

|
demos/example_003.png
ADDED

|
Git LFS Details
|
demos/example_list.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
a pot of green plants grows in a red flower pot.
|
| 2 |
+
a lovely rabbit eating carrots
|
infer/__init__.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open Source Model Licensed under the Apache License Version 2.0 and Other Licenses of the Third-Party Components therein:
|
| 2 |
+
# The below Model in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2024 THL A29 Limited.
|
| 3 |
+
|
| 4 |
+
# Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved.
|
| 5 |
+
# The below software and/or models in this distribution may have been
|
| 6 |
+
# modified by THL A29 Limited ("Tencent Modifications").
|
| 7 |
+
# All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 8 |
+
|
| 9 |
+
# Hunyuan 3D is licensed under the TENCENT HUNYUAN NON-COMMERCIAL LICENSE AGREEMENT
|
| 10 |
+
# except for the third-party components listed below.
|
| 11 |
+
# Hunyuan 3D does not impose any additional limitations beyond what is outlined
|
| 12 |
+
# in the repsective licenses of these third-party components.
|
| 13 |
+
# Users must comply with all terms and conditions of original licenses of these third-party
|
| 14 |
+
# components and must ensure that the usage of the third party components adheres to
|
| 15 |
+
# all relevant laws and regulations.
|
| 16 |
+
|
| 17 |
+
# For avoidance of doubts, Hunyuan 3D means the large language models and
|
| 18 |
+
# their software and algorithms, including trained model weights, parameters (including
|
| 19 |
+
# optimizer states), machine-learning model code, inference-enabling code, training-enabling code,
|
| 20 |
+
# fine-tuning enabling code and other elements of the foregoing made publicly available
|
| 21 |
+
# by Tencent in accordance with TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT.
|
| 22 |
+
|
| 23 |
+
from .utils import seed_everything, timing_decorator, auto_amp_inference
|
| 24 |
+
from .rembg import Removebg
|
| 25 |
+
from .text_to_image import Text2Image
|
| 26 |
+
from .image_to_views import Image2Views, save_gif
|
| 27 |
+
from .views_to_mesh import Views2Mesh
|
| 28 |
+
from .gif_render import GifRenderer
|
infer/gif_render.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open Source Model Licensed under the Apache License Version 2.0 and Other Licenses of the Third-Party Components therein:
|
| 2 |
+
# The below Model in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2024 THL A29 Limited.
|
| 3 |
+
|
| 4 |
+
# Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved.
|
| 5 |
+
# The below software and/or models in this distribution may have been
|
| 6 |
+
# modified by THL A29 Limited ("Tencent Modifications").
|
| 7 |
+
# All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 8 |
+
|
| 9 |
+
# Hunyuan 3D is licensed under the TENCENT HUNYUAN NON-COMMERCIAL LICENSE AGREEMENT
|
| 10 |
+
# except for the third-party components listed below.
|
| 11 |
+
# Hunyuan 3D does not impose any additional limitations beyond what is outlined
|
| 12 |
+
# in the repsective licenses of these third-party components.
|
| 13 |
+
# Users must comply with all terms and conditions of original licenses of these third-party
|
| 14 |
+
# components and must ensure that the usage of the third party components adheres to
|
| 15 |
+
# all relevant laws and regulations.
|
| 16 |
+
|
| 17 |
+
# For avoidance of doubts, Hunyuan 3D means the large language models and
|
| 18 |
+
# their software and algorithms, including trained model weights, parameters (including
|
| 19 |
+
# optimizer states), machine-learning model code, inference-enabling code, training-enabling code,
|
| 20 |
+
# fine-tuning enabling code and other elements of the foregoing made publicly available
|
| 21 |
+
# by Tencent in accordance with TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT.
|
| 22 |
+
|
| 23 |
+
from svrm.ldm.vis_util import render
|
| 24 |
+
from .utils import seed_everything, timing_decorator
|
| 25 |
+
|
| 26 |
+
class GifRenderer():
|
| 27 |
+
'''
|
| 28 |
+
render frame(s) of mesh using pytorch3d
|
| 29 |
+
'''
|
| 30 |
+
def __init__(self, device="cuda:0"):
|
| 31 |
+
self.device = device
|
| 32 |
+
|
| 33 |
+
@timing_decorator("gif render")
|
| 34 |
+
def __call__(
|
| 35 |
+
self,
|
| 36 |
+
obj_filename,
|
| 37 |
+
elev=0,
|
| 38 |
+
azim=0,
|
| 39 |
+
resolution=512,
|
| 40 |
+
gif_dst_path='',
|
| 41 |
+
n_views=120,
|
| 42 |
+
fps=30,
|
| 43 |
+
rgb=True
|
| 44 |
+
):
|
| 45 |
+
render(
|
| 46 |
+
obj_filename,
|
| 47 |
+
elev=elev,
|
| 48 |
+
azim=azim,
|
| 49 |
+
resolution=resolution,
|
| 50 |
+
gif_dst_path=gif_dst_path,
|
| 51 |
+
n_views=n_views,
|
| 52 |
+
fps=fps,
|
| 53 |
+
device=self.device,
|
| 54 |
+
rgb=rgb
|
| 55 |
+
)
|
infer/image_to_views.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open Source Model Licensed under the Apache License Version 2.0 and Other Licenses of the Third-Party Components therein:
|
| 2 |
+
# The below Model in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2024 THL A29 Limited.
|
| 3 |
+
|
| 4 |
+
# Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved.
|
| 5 |
+
# The below software and/or models in this distribution may have been
|
| 6 |
+
# modified by THL A29 Limited ("Tencent Modifications").
|
| 7 |
+
# All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 8 |
+
|
| 9 |
+
# Hunyuan 3D is licensed under the TENCENT HUNYUAN NON-COMMERCIAL LICENSE AGREEMENT
|
| 10 |
+
# except for the third-party components listed below.
|
| 11 |
+
# Hunyuan 3D does not impose any additional limitations beyond what is outlined
|
| 12 |
+
# in the repsective licenses of these third-party components.
|
| 13 |
+
# Users must comply with all terms and conditions of original licenses of these third-party
|
| 14 |
+
# components and must ensure that the usage of the third party components adheres to
|
| 15 |
+
# all relevant laws and regulations.
|
| 16 |
+
|
| 17 |
+
# For avoidance of doubts, Hunyuan 3D means the large language models and
|
| 18 |
+
# their software and algorithms, including trained model weights, parameters (including
|
| 19 |
+
# optimizer states), machine-learning model code, inference-enabling code, training-enabling code,
|
| 20 |
+
# fine-tuning enabling code and other elements of the foregoing made publicly available
|
| 21 |
+
# by Tencent in accordance with TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT.
|
| 22 |
+
|
| 23 |
+
import os
|
| 24 |
+
import time
|
| 25 |
+
import torch
|
| 26 |
+
import random
|
| 27 |
+
import numpy as np
|
| 28 |
+
from PIL import Image
|
| 29 |
+
from einops import rearrange
|
| 30 |
+
from PIL import Image, ImageSequence
|
| 31 |
+
|
| 32 |
+
from .utils import seed_everything, timing_decorator, auto_amp_inference
|
| 33 |
+
from .utils import get_parameter_number, set_parameter_grad_false
|
| 34 |
+
from mvd.hunyuan3d_mvd_std_pipeline import HunYuan3D_MVD_Std_Pipeline
|
| 35 |
+
from mvd.hunyuan3d_mvd_lite_pipeline import Hunyuan3d_MVD_Lite_Pipeline
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def save_gif(pils, save_path, df=False):
|
| 39 |
+
# save a list of PIL.Image to gif
|
| 40 |
+
spf = 4000 / len(pils)
|
| 41 |
+
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
| 42 |
+
pils[0].save(save_path, format="GIF", save_all=True, append_images=pils[1:], duration=spf, loop=0)
|
| 43 |
+
return save_path
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class Image2Views():
|
| 47 |
+
def __init__(self, device="cuda:0", use_lite=False):
|
| 48 |
+
self.device = device
|
| 49 |
+
if use_lite:
|
| 50 |
+
self.pipe = Hunyuan3d_MVD_Lite_Pipeline.from_pretrained(
|
| 51 |
+
"./weights/mvd_lite",
|
| 52 |
+
torch_dtype = torch.float16,
|
| 53 |
+
use_safetensors = True,
|
| 54 |
+
)
|
| 55 |
+
else:
|
| 56 |
+
self.pipe = HunYuan3D_MVD_Std_Pipeline.from_pretrained(
|
| 57 |
+
"./weights/mvd_std",
|
| 58 |
+
torch_dtype = torch.float16,
|
| 59 |
+
use_safetensors = True,
|
| 60 |
+
)
|
| 61 |
+
self.pipe = self.pipe.to(device)
|
| 62 |
+
self.order = [0, 1, 2, 3, 4, 5] if use_lite else [0, 2, 4, 5, 3, 1]
|
| 63 |
+
set_parameter_grad_false(self.pipe.unet)
|
| 64 |
+
print('image2views unet model', get_parameter_number(self.pipe.unet))
|
| 65 |
+
|
| 66 |
+
@torch.no_grad()
|
| 67 |
+
@timing_decorator("image to views")
|
| 68 |
+
@auto_amp_inference
|
| 69 |
+
def __call__(self, pil_img, seed=0, steps=50, guidance_scale=2.0, guidance_curve=lambda t:2.0):
|
| 70 |
+
seed_everything(seed)
|
| 71 |
+
generator = torch.Generator(device=self.device)
|
| 72 |
+
res_img = self.pipe(pil_img,
|
| 73 |
+
num_inference_steps=steps,
|
| 74 |
+
guidance_scale=guidance_scale,
|
| 75 |
+
guidance_curve=guidance_curve,
|
| 76 |
+
generat=generator).images
|
| 77 |
+
show_image = rearrange(np.asarray(res_img[0], dtype=np.uint8), '(n h) (m w) c -> (n m) h w c', n=3, m=2)
|
| 78 |
+
pils = [res_img[1]]+[Image.fromarray(show_image[idx]) for idx in self.order]
|
| 79 |
+
torch.cuda.empty_cache()
|
| 80 |
+
return res_img, pils
|
| 81 |
+
|
infer/rembg.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from rembg import remove, new_session
|
| 2 |
+
from .utils import timing_decorator
|
| 3 |
+
|
| 4 |
+
class Removebg():
|
| 5 |
+
def __init__(self, name="u2net"):
|
| 6 |
+
'''
|
| 7 |
+
name: rembg
|
| 8 |
+
'''
|
| 9 |
+
self.session = new_session(name)
|
| 10 |
+
|
| 11 |
+
@timing_decorator("remove background")
|
| 12 |
+
def __call__(self, rgb_img, force=False):
|
| 13 |
+
'''
|
| 14 |
+
inputs:
|
| 15 |
+
rgb_img: PIL.Image, with RGB mode expected
|
| 16 |
+
force: bool, input is RGBA mode
|
| 17 |
+
return:
|
| 18 |
+
rgba_img: PIL.Image with RGBA mode
|
| 19 |
+
'''
|
| 20 |
+
if rgb_img.mode == "RGBA":
|
| 21 |
+
if force:
|
| 22 |
+
rgb_img = rgb_img.convert("RGB")
|
| 23 |
+
else:
|
| 24 |
+
return rgb_img
|
| 25 |
+
rgba_img = remove(rgb_img, session=self.session)
|
| 26 |
+
return rgba_img
|
infer/text_to_image.py
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open Source Model Licensed under the Apache License Version 2.0 and Other Licenses of the Third-Party Components therein:
|
| 2 |
+
# The below Model in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2024 THL A29 Limited.
|
| 3 |
+
|
| 4 |
+
# Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved.
|
| 5 |
+
# The below software and/or models in this distribution may have been
|
| 6 |
+
# modified by THL A29 Limited ("Tencent Modifications").
|
| 7 |
+
# All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 8 |
+
|
| 9 |
+
# Hunyuan 3D is licensed under the TENCENT HUNYUAN NON-COMMERCIAL LICENSE AGREEMENT
|
| 10 |
+
# except for the third-party components listed below.
|
| 11 |
+
# Hunyuan 3D does not impose any additional limitations beyond what is outlined
|
| 12 |
+
# in the repsective licenses of these third-party components.
|
| 13 |
+
# Users must comply with all terms and conditions of original licenses of these third-party
|
| 14 |
+
# components and must ensure that the usage of the third party components adheres to
|
| 15 |
+
# all relevant laws and regulations.
|
| 16 |
+
|
| 17 |
+
# For avoidance of doubts, Hunyuan 3D means the large language models and
|
| 18 |
+
# their software and algorithms, including trained model weights, parameters (including
|
| 19 |
+
# optimizer states), machine-learning model code, inference-enabling code, training-enabling code,
|
| 20 |
+
# fine-tuning enabling code and other elements of the foregoing made publicly available
|
| 21 |
+
# by Tencent in accordance with TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT.
|
| 22 |
+
|
| 23 |
+
import torch
|
| 24 |
+
from .utils import seed_everything, timing_decorator, auto_amp_inference
|
| 25 |
+
from .utils import get_parameter_number, set_parameter_grad_false
|
| 26 |
+
from diffusers import HunyuanDiTPipeline, AutoPipelineForText2Image
|
| 27 |
+
|
| 28 |
+
class Text2Image():
|
| 29 |
+
def __init__(self, pretrain="weights/hunyuanDiT", device="cuda:0", save_memory=False):
|
| 30 |
+
'''
|
| 31 |
+
save_memory: if GPU memory is low, can set it
|
| 32 |
+
'''
|
| 33 |
+
self.save_memory = save_memory
|
| 34 |
+
self.device = device
|
| 35 |
+
self.pipe = AutoPipelineForText2Image.from_pretrained(
|
| 36 |
+
pretrain,
|
| 37 |
+
torch_dtype = torch.float16,
|
| 38 |
+
enable_pag = True,
|
| 39 |
+
pag_applied_layers = ["blocks.(16|17|18|19)"]
|
| 40 |
+
)
|
| 41 |
+
set_parameter_grad_false(self.pipe.transformer)
|
| 42 |
+
print('text2image transformer model', get_parameter_number(self.pipe.transformer))
|
| 43 |
+
if not save_memory:
|
| 44 |
+
self.pipe = self.pipe.to(device)
|
| 45 |
+
self.neg_txt = "文本,特写,裁剪,出框,最差质量,低质量,JPEG伪影,PGLY,重复,病态,残缺,多余的手指,变异的手," \
|
| 46 |
+
"画得不好的手,画得不好的脸,变异,畸形,模糊,脱水,糟糕的解剖学,糟糕的比例,多余的肢体,克隆的脸," \
|
| 47 |
+
"毁容,恶心的比例,畸形的肢体,缺失的手臂,缺失的腿,额外的手臂,额外的腿,融合的手指,手指太多,长脖子"
|
| 48 |
+
|
| 49 |
+
@torch.no_grad()
|
| 50 |
+
@timing_decorator('text to image')
|
| 51 |
+
@auto_amp_inference
|
| 52 |
+
def __call__(self, *args, **kwargs):
|
| 53 |
+
if self.save_memory:
|
| 54 |
+
self.pipe = self.pipe.to(self.device)
|
| 55 |
+
torch.cuda.empty_cache()
|
| 56 |
+
res = self.call(*args, **kwargs)
|
| 57 |
+
self.pipe = self.pipe.to("cpu")
|
| 58 |
+
else:
|
| 59 |
+
res = self.call(*args, **kwargs)
|
| 60 |
+
torch.cuda.empty_cache()
|
| 61 |
+
return res
|
| 62 |
+
|
| 63 |
+
def call(self, prompt, seed=0, steps=25):
|
| 64 |
+
'''
|
| 65 |
+
inputs:
|
| 66 |
+
prompr: str
|
| 67 |
+
seed: int
|
| 68 |
+
steps: int
|
| 69 |
+
return:
|
| 70 |
+
rgb: PIL.Image
|
| 71 |
+
'''
|
| 72 |
+
prompt = prompt + ",白色背景,3D风格,最佳质量"
|
| 73 |
+
seed_everything(seed)
|
| 74 |
+
generator = torch.Generator(device=self.device)
|
| 75 |
+
if seed is not None: generator = generator.manual_seed(int(seed))
|
| 76 |
+
rgb = self.pipe(prompt=prompt, negative_prompt=self.neg_txt, num_inference_steps=steps,
|
| 77 |
+
pag_scale=1.3, width=1024, height=1024, generator=generator, return_dict=False)[0][0]
|
| 78 |
+
torch.cuda.empty_cache()
|
| 79 |
+
return rgb
|
| 80 |
+
|
infer/utils.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open Source Model Licensed under the Apache License Version 2.0 and Other Licenses of the Third-Party Components therein:
|
| 2 |
+
# The below Model in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2024 THL A29 Limited.
|
| 3 |
+
|
| 4 |
+
# Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved.
|
| 5 |
+
# The below software and/or models in this distribution may have been
|
| 6 |
+
# modified by THL A29 Limited ("Tencent Modifications").
|
| 7 |
+
# All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 8 |
+
|
| 9 |
+
# Hunyuan 3D is licensed under the TENCENT HUNYUAN NON-COMMERCIAL LICENSE AGREEMENT
|
| 10 |
+
# except for the third-party components listed below.
|
| 11 |
+
# Hunyuan 3D does not impose any additional limitations beyond what is outlined
|
| 12 |
+
# in the repsective licenses of these third-party components.
|
| 13 |
+
# Users must comply with all terms and conditions of original licenses of these third-party
|
| 14 |
+
# components and must ensure that the usage of the third party components adheres to
|
| 15 |
+
# all relevant laws and regulations.
|
| 16 |
+
|
| 17 |
+
# For avoidance of doubts, Hunyuan 3D means the large language models and
|
| 18 |
+
# their software and algorithms, including trained model weights, parameters (including
|
| 19 |
+
# optimizer states), machine-learning model code, inference-enabling code, training-enabling code,
|
| 20 |
+
# fine-tuning enabling code and other elements of the foregoing made publicly available
|
| 21 |
+
# by Tencent in accordance with TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT.
|
| 22 |
+
|
| 23 |
+
import os
|
| 24 |
+
import time
|
| 25 |
+
import random
|
| 26 |
+
import numpy as np
|
| 27 |
+
import torch
|
| 28 |
+
from torch.cuda.amp import autocast, GradScaler
|
| 29 |
+
from functools import wraps
|
| 30 |
+
|
| 31 |
+
def seed_everything(seed):
|
| 32 |
+
'''
|
| 33 |
+
seed everthing
|
| 34 |
+
'''
|
| 35 |
+
random.seed(seed)
|
| 36 |
+
np.random.seed(seed)
|
| 37 |
+
torch.manual_seed(seed)
|
| 38 |
+
os.environ["PL_GLOBAL_SEED"] = str(seed)
|
| 39 |
+
|
| 40 |
+
def timing_decorator(category: str):
|
| 41 |
+
'''
|
| 42 |
+
timing_decorator: record time
|
| 43 |
+
'''
|
| 44 |
+
def decorator(func):
|
| 45 |
+
func.call_count = 0
|
| 46 |
+
@wraps(func)
|
| 47 |
+
def wrapper(*args, **kwargs):
|
| 48 |
+
start_time = time.time()
|
| 49 |
+
result = func(*args, **kwargs)
|
| 50 |
+
end_time = time.time()
|
| 51 |
+
elapsed_time = end_time - start_time
|
| 52 |
+
func.call_count += 1
|
| 53 |
+
print(f"[HunYuan3D]-[{category}], cost time: {elapsed_time:.4f}s") # huiwen
|
| 54 |
+
return result
|
| 55 |
+
return wrapper
|
| 56 |
+
return decorator
|
| 57 |
+
|
| 58 |
+
def auto_amp_inference(func):
|
| 59 |
+
'''
|
| 60 |
+
with torch.cuda.amp.autocast()"
|
| 61 |
+
xxx
|
| 62 |
+
'''
|
| 63 |
+
@wraps(func)
|
| 64 |
+
def wrapper(*args, **kwargs):
|
| 65 |
+
with autocast():
|
| 66 |
+
output = func(*args, **kwargs)
|
| 67 |
+
return output
|
| 68 |
+
return wrapper
|
| 69 |
+
|
| 70 |
+
def get_parameter_number(model):
|
| 71 |
+
total_num = sum(p.numel() for p in model.parameters())
|
| 72 |
+
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
|
| 73 |
+
return {'Total': total_num, 'Trainable': trainable_num}
|
| 74 |
+
|
| 75 |
+
def set_parameter_grad_false(model):
|
| 76 |
+
for p in model.parameters():
|
| 77 |
+
p.requires_grad = False
|
infer/views_to_mesh.py
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open Source Model Licensed under the Apache License Version 2.0 and Other Licenses of the Third-Party Components therein:
|
| 2 |
+
# The below Model in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2024 THL A29 Limited.
|
| 3 |
+
|
| 4 |
+
# Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved.
|
| 5 |
+
# The below software and/or models in this distribution may have been
|
| 6 |
+
# modified by THL A29 Limited ("Tencent Modifications").
|
| 7 |
+
# All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 8 |
+
|
| 9 |
+
# Hunyuan 3D is licensed under the TENCENT HUNYUAN NON-COMMERCIAL LICENSE AGREEMENT
|
| 10 |
+
# except for the third-party components listed below.
|
| 11 |
+
# Hunyuan 3D does not impose any additional limitations beyond what is outlined
|
| 12 |
+
# in the repsective licenses of these third-party components.
|
| 13 |
+
# Users must comply with all terms and conditions of original licenses of these third-party
|
| 14 |
+
# components and must ensure that the usage of the third party components adheres to
|
| 15 |
+
# all relevant laws and regulations.
|
| 16 |
+
|
| 17 |
+
# For avoidance of doubts, Hunyuan 3D means the large language models and
|
| 18 |
+
# their software and algorithms, including trained model weights, parameters (including
|
| 19 |
+
# optimizer states), machine-learning model code, inference-enabling code, training-enabling code,
|
| 20 |
+
# fine-tuning enabling code and other elements of the foregoing made publicly available
|
| 21 |
+
# by Tencent in accordance with TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT.
|
| 22 |
+
|
| 23 |
+
import os
|
| 24 |
+
import time
|
| 25 |
+
import torch
|
| 26 |
+
import random
|
| 27 |
+
import numpy as np
|
| 28 |
+
from PIL import Image
|
| 29 |
+
from einops import rearrange
|
| 30 |
+
from PIL import Image, ImageSequence
|
| 31 |
+
|
| 32 |
+
from .utils import seed_everything, timing_decorator, auto_amp_inference
|
| 33 |
+
from .utils import get_parameter_number, set_parameter_grad_false
|
| 34 |
+
from svrm.predictor import MV23DPredictor
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class Views2Mesh():
|
| 38 |
+
def __init__(self, mv23d_cfg_path, mv23d_ckt_path, device="cuda:0", use_lite=False):
|
| 39 |
+
'''
|
| 40 |
+
mv23d_cfg_path: config yaml file
|
| 41 |
+
mv23d_ckt_path: path to ckpt
|
| 42 |
+
use_lite:
|
| 43 |
+
'''
|
| 44 |
+
self.mv23d_predictor = MV23DPredictor(mv23d_ckt_path, mv23d_cfg_path, device=device)
|
| 45 |
+
self.mv23d_predictor.model.eval()
|
| 46 |
+
self.order = [0, 1, 2, 3, 4, 5] if use_lite else [0, 2, 4, 5, 3, 1]
|
| 47 |
+
set_parameter_grad_false(self.mv23d_predictor.model)
|
| 48 |
+
print('view2mesh model', get_parameter_number(self.mv23d_predictor.model))
|
| 49 |
+
|
| 50 |
+
@torch.no_grad()
|
| 51 |
+
@timing_decorator("views to mesh")
|
| 52 |
+
@auto_amp_inference
|
| 53 |
+
def __call__(
|
| 54 |
+
self,
|
| 55 |
+
views_pil=None,
|
| 56 |
+
cond_pil=None,
|
| 57 |
+
gif_pil=None,
|
| 58 |
+
seed=0,
|
| 59 |
+
target_face_count = 10000,
|
| 60 |
+
do_texture_mapping = True,
|
| 61 |
+
save_folder='./outputs/test'
|
| 62 |
+
):
|
| 63 |
+
'''
|
| 64 |
+
can set views_pil, cond_pil simutaously or set gif_pil only
|
| 65 |
+
seed: int
|
| 66 |
+
target_face_count: int
|
| 67 |
+
save_folder: path to save mesh files
|
| 68 |
+
'''
|
| 69 |
+
save_dir = save_folder
|
| 70 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 71 |
+
|
| 72 |
+
if views_pil is not None and cond_pil is not None:
|
| 73 |
+
show_image = rearrange(np.asarray(views_pil, dtype=np.uint8),
|
| 74 |
+
'(n h) (m w) c -> (n m) h w c', n=3, m=2)
|
| 75 |
+
views = [Image.fromarray(show_image[idx]) for idx in self.order]
|
| 76 |
+
image_list = [cond_pil]+ views
|
| 77 |
+
image_list = [img.convert('RGB') for img in image_list]
|
| 78 |
+
elif gif_pil is not None:
|
| 79 |
+
image_list = [img.convert('RGB') for img in ImageSequence.Iterator(gif_pil)]
|
| 80 |
+
|
| 81 |
+
image_input = image_list[0]
|
| 82 |
+
image_list = image_list[1:] + image_list[:1]
|
| 83 |
+
|
| 84 |
+
seed_everything(seed)
|
| 85 |
+
self.mv23d_predictor.predict(
|
| 86 |
+
image_list,
|
| 87 |
+
save_dir = save_dir,
|
| 88 |
+
image_input = image_input,
|
| 89 |
+
target_face_count = target_face_count,
|
| 90 |
+
do_texture_mapping = do_texture_mapping
|
| 91 |
+
)
|
| 92 |
+
torch.cuda.empty_cache()
|
| 93 |
+
return save_dir
|
| 94 |
+
|
mvd/__init__.py
ADDED
|
File without changes
|
mvd/hunyuan3d_mvd_lite_pipeline.py
ADDED
|
@@ -0,0 +1,493 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open Source Model Licensed under the Apache License Version 2.0 and Other Licenses of the Third-Party Components therein:
|
| 2 |
+
# The below Model in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2024 THL A29 Limited.
|
| 3 |
+
|
| 4 |
+
# Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved.
|
| 5 |
+
# The below software and/or models in this distribution may have been
|
| 6 |
+
# modified by THL A29 Limited ("Tencent Modifications").
|
| 7 |
+
# All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 8 |
+
|
| 9 |
+
# Hunyuan 3D is licensed under the TENCENT HUNYUAN NON-COMMERCIAL LICENSE AGREEMENT
|
| 10 |
+
# except for the third-party components listed below.
|
| 11 |
+
# Hunyuan 3D does not impose any additional limitations beyond what is outlined
|
| 12 |
+
# in the repsective licenses of these third-party components.
|
| 13 |
+
# Users must comply with all terms and conditions of original licenses of these third-party
|
| 14 |
+
# components and must ensure that the usage of the third party components adheres to
|
| 15 |
+
# all relevant laws and regulations.
|
| 16 |
+
|
| 17 |
+
# For avoidance of doubts, Hunyuan 3D means the large language models and
|
| 18 |
+
# their software and algorithms, including trained model weights, parameters (including
|
| 19 |
+
# optimizer states), machine-learning model code, inference-enabling code, training-enabling code,
|
| 20 |
+
# fine-tuning enabling code and other elements of the foregoing made publicly available
|
| 21 |
+
# by Tencent in accordance with TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT.
|
| 22 |
+
|
| 23 |
+
import math
|
| 24 |
+
import numpy
|
| 25 |
+
import torch
|
| 26 |
+
import inspect
|
| 27 |
+
import warnings
|
| 28 |
+
from PIL import Image
|
| 29 |
+
from einops import rearrange
|
| 30 |
+
import torch.nn.functional as F
|
| 31 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 32 |
+
from diffusers.configuration_utils import FrozenDict
|
| 33 |
+
from diffusers.image_processor import VaeImageProcessor
|
| 34 |
+
from typing import Any, Callable, Dict, List, Optional, Union
|
| 35 |
+
from diffusers.models import AutoencoderKL, UNet2DConditionModel
|
| 36 |
+
from diffusers.schedulers import KarrasDiffusionSchedulers
|
| 37 |
+
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
|
| 38 |
+
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
|
| 39 |
+
from diffusers import DDPMScheduler, EulerAncestralDiscreteScheduler, ImagePipelineOutput
|
| 40 |
+
from diffusers.loaders import (
|
| 41 |
+
FromSingleFileMixin,
|
| 42 |
+
LoraLoaderMixin,
|
| 43 |
+
TextualInversionLoaderMixin
|
| 44 |
+
)
|
| 45 |
+
from transformers import (
|
| 46 |
+
CLIPImageProcessor,
|
| 47 |
+
CLIPTextModel,
|
| 48 |
+
CLIPTokenizer,
|
| 49 |
+
CLIPVisionModelWithProjection
|
| 50 |
+
)
|
| 51 |
+
from diffusers.models.attention_processor import (
|
| 52 |
+
Attention,
|
| 53 |
+
AttnProcessor,
|
| 54 |
+
XFormersAttnProcessor,
|
| 55 |
+
AttnProcessor2_0
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
from .utils import to_rgb_image, white_out_background, recenter_img
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
EXAMPLE_DOC_STRING = """
|
| 62 |
+
Examples:
|
| 63 |
+
```py
|
| 64 |
+
>>> import torch
|
| 65 |
+
>>> from here import Hunyuan3d_MVD_Qing_Pipeline
|
| 66 |
+
|
| 67 |
+
>>> pipe = Hunyuan3d_MVD_Qing_Pipeline.from_pretrained(
|
| 68 |
+
... "Tencent-Hunyuan-3D/MVD-Qing", torch_dtype=torch.float16
|
| 69 |
+
... )
|
| 70 |
+
>>> pipe.to("cuda")
|
| 71 |
+
|
| 72 |
+
>>> img = Image.open("demo.png")
|
| 73 |
+
>>> res_img = pipe(img).images[0]
|
| 74 |
+
"""
|
| 75 |
+
|
| 76 |
+
def unscale_latents(latents): return latents / 0.75 + 0.22
|
| 77 |
+
def unscale_image (image ): return image / 0.50 * 0.80
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
|
| 81 |
+
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
|
| 82 |
+
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
|
| 83 |
+
noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
|
| 84 |
+
noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
|
| 85 |
+
return noise_cfg
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class ReferenceOnlyAttnProc(torch.nn.Module):
|
| 90 |
+
# reference attention
|
| 91 |
+
def __init__(self, chained_proc, enabled=False, name=None):
|
| 92 |
+
super().__init__()
|
| 93 |
+
self.enabled = enabled
|
| 94 |
+
self.chained_proc = chained_proc
|
| 95 |
+
self.name = name
|
| 96 |
+
|
| 97 |
+
def __call__(self, attn, hidden_states, encoder_hidden_states=None, attention_mask=None, mode="w", ref_dict=None):
|
| 98 |
+
if encoder_hidden_states is None: encoder_hidden_states = hidden_states
|
| 99 |
+
if self.enabled:
|
| 100 |
+
if mode == 'w':
|
| 101 |
+
ref_dict[self.name] = encoder_hidden_states
|
| 102 |
+
elif mode == 'r':
|
| 103 |
+
encoder_hidden_states = torch.cat([encoder_hidden_states, ref_dict.pop(self.name)], dim=1)
|
| 104 |
+
res = self.chained_proc(attn, hidden_states, encoder_hidden_states, attention_mask)
|
| 105 |
+
return res
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
# class RowWiseAttnProcessor2_0:
|
| 109 |
+
# def __call__(self, attn,
|
| 110 |
+
# hidden_states,
|
| 111 |
+
# encoder_hidden_states=None,
|
| 112 |
+
# attention_mask=None,
|
| 113 |
+
# temb=None,
|
| 114 |
+
# num_views=6,
|
| 115 |
+
# *args,
|
| 116 |
+
# **kwargs):
|
| 117 |
+
# residual = hidden_states
|
| 118 |
+
# if attn.spatial_norm is not None: hidden_states = attn.spatial_norm(hidden_states, temb)
|
| 119 |
+
|
| 120 |
+
# input_ndim = hidden_states.ndim
|
| 121 |
+
# if input_ndim == 4:
|
| 122 |
+
# batch_size, channel, height, width = hidden_states.shape
|
| 123 |
+
# hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
| 124 |
+
|
| 125 |
+
# if encoder_hidden_states is None:
|
| 126 |
+
# batch_size, sequence_length, _ = hidden_states.shape
|
| 127 |
+
# else:
|
| 128 |
+
# batch_size, sequence_length, _ = encoder_hidden_states.shape
|
| 129 |
+
|
| 130 |
+
# if attention_mask is not None:
|
| 131 |
+
# attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
| 132 |
+
# attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
| 133 |
+
# if attn.group_norm is not None: hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
| 134 |
+
|
| 135 |
+
# query = attn.to_q(hidden_states)
|
| 136 |
+
# if encoder_hidden_states is None: encoder_hidden_states = hidden_states
|
| 137 |
+
# elif attn.norm_cross: encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
| 138 |
+
|
| 139 |
+
# # encoder_hidden_states [B, 6hw+hw, C] if ref att
|
| 140 |
+
# key = attn.to_k(encoder_hidden_states) # [B, Vhw+hw, C]
|
| 141 |
+
# value = attn.to_v(encoder_hidden_states) # [B, Vhw+hw, C]
|
| 142 |
+
|
| 143 |
+
# mv_flag = hidden_states.shape[1] < encoder_hidden_states.shape[1] and encoder_hidden_states.shape[1] != 77
|
| 144 |
+
# if mv_flag:
|
| 145 |
+
# target_size = int(math.sqrt(hidden_states.shape[1] // num_views))
|
| 146 |
+
# assert target_size ** 2 * num_views == hidden_states.shape[1]
|
| 147 |
+
|
| 148 |
+
# gen_key = key[:, :num_views*target_size*target_size, :]
|
| 149 |
+
# ref_key = key[:, num_views*target_size*target_size:, :]
|
| 150 |
+
# gen_value = value[:, :num_views*target_size*target_size, :]
|
| 151 |
+
# ref_value = value[:, num_views*target_size*target_size:, :]
|
| 152 |
+
|
| 153 |
+
# # rowwise attention
|
| 154 |
+
# query, gen_key, gen_value = \
|
| 155 |
+
# rearrange( query, "b (v1 h v2 w) c -> (b h) (v1 v2 w) c",
|
| 156 |
+
# v1=num_views//2, v2=2, h=target_size, w=target_size), \
|
| 157 |
+
# rearrange( gen_key, "b (v1 h v2 w) c -> (b h) (v1 v2 w) c",
|
| 158 |
+
# v1=num_views//2, v2=2, h=target_size, w=target_size), \
|
| 159 |
+
# rearrange(gen_value, "b (v1 h v2 w) c -> (b h) (v1 v2 w) c",
|
| 160 |
+
# v1=num_views//2, v2=2, h=target_size, w=target_size)
|
| 161 |
+
|
| 162 |
+
# inner_dim = key.shape[-1]
|
| 163 |
+
# ref_size = int(math.sqrt(ref_key.shape[1]))
|
| 164 |
+
# ref_key_expanded = ref_key.view(batch_size, 1, ref_size * ref_size, inner_dim)
|
| 165 |
+
# ref_key_expanded = ref_key_expanded.expand(-1, target_size, -1, -1).contiguous()
|
| 166 |
+
# ref_key_expanded = ref_key_expanded.view(batch_size * target_size, ref_size * ref_size, inner_dim)
|
| 167 |
+
# key = torch.cat([ gen_key, ref_key_expanded], dim=1)
|
| 168 |
+
|
| 169 |
+
# ref_value_expanded = ref_value.view(batch_size, 1, ref_size * ref_size, inner_dim)
|
| 170 |
+
# ref_value_expanded = ref_value_expanded.expand(-1, target_size, -1, -1).contiguous()
|
| 171 |
+
# ref_value_expanded = ref_value_expanded.view(batch_size * target_size, ref_size * ref_size, inner_dim)
|
| 172 |
+
# value = torch.cat([gen_value, ref_value_expanded], dim=1)
|
| 173 |
+
# h = target_size
|
| 174 |
+
# else:
|
| 175 |
+
# target_size = int(math.sqrt(hidden_states.shape[1]))
|
| 176 |
+
# h = 1
|
| 177 |
+
# num_views = 1
|
| 178 |
+
|
| 179 |
+
# inner_dim = key.shape[-1]
|
| 180 |
+
# head_dim = inner_dim // attn.heads
|
| 181 |
+
|
| 182 |
+
# query = query.view(batch_size * h, -1, attn.heads, head_dim).transpose(1, 2)
|
| 183 |
+
# key = key.view(batch_size * h, -1, attn.heads, head_dim).transpose(1, 2)
|
| 184 |
+
# value = value.view(batch_size * h, -1, attn.heads, head_dim).transpose(1, 2)
|
| 185 |
+
|
| 186 |
+
# hidden_states = F.scaled_dot_product_attention(query, key, value,
|
| 187 |
+
# attn_mask=attention_mask,
|
| 188 |
+
# dropout_p=0.0,
|
| 189 |
+
# is_causal=False)
|
| 190 |
+
# hidden_states = hidden_states.transpose(1, 2).reshape(batch_size * h,
|
| 191 |
+
# -1,
|
| 192 |
+
# attn.heads * head_dim).to(query.dtype)
|
| 193 |
+
# hidden_states = attn.to_out[1](attn.to_out[0](hidden_states))
|
| 194 |
+
|
| 195 |
+
# if mv_flag: hidden_states = rearrange(hidden_states, "(b h) (v1 v2 w) c -> b (v1 h v2 w) c",
|
| 196 |
+
# b=batch_size, v1=num_views//2,
|
| 197 |
+
# v2=2, h=target_size, w=target_size)
|
| 198 |
+
|
| 199 |
+
# if input_ndim == 4:
|
| 200 |
+
# hidden_states = hidden_states.transpose(-1, -2)
|
| 201 |
+
# hidden_states = hidden_states.reshape(batch_size,
|
| 202 |
+
# channel,
|
| 203 |
+
# target_size,
|
| 204 |
+
# target_size)
|
| 205 |
+
# if attn.residual_connection: hidden_states = hidden_states + residual
|
| 206 |
+
# hidden_states = hidden_states / attn.rescale_output_factor
|
| 207 |
+
# return hidden_states
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
class RefOnlyNoisedUNet(torch.nn.Module):
|
| 211 |
+
def __init__(self, unet, train_sched, val_sched):
|
| 212 |
+
super().__init__()
|
| 213 |
+
self.unet = unet
|
| 214 |
+
self.train_sched = train_sched
|
| 215 |
+
self.val_sched = val_sched
|
| 216 |
+
|
| 217 |
+
unet_lora_attn_procs = dict()
|
| 218 |
+
for name, _ in unet.attn_processors.items():
|
| 219 |
+
unet_lora_attn_procs[name] = ReferenceOnlyAttnProc(AttnProcessor2_0(),
|
| 220 |
+
enabled=name.endswith("attn1.processor"),
|
| 221 |
+
name=name)
|
| 222 |
+
unet.set_attn_processor(unet_lora_attn_procs)
|
| 223 |
+
|
| 224 |
+
def __getattr__(self, name: str):
|
| 225 |
+
try:
|
| 226 |
+
return super().__getattr__(name)
|
| 227 |
+
except AttributeError:
|
| 228 |
+
return getattr(self.unet, name)
|
| 229 |
+
|
| 230 |
+
def forward(self, sample, timestep, encoder_hidden_states, *args, cross_attention_kwargs, **kwargs):
|
| 231 |
+
cond_lat = cross_attention_kwargs['cond_lat']
|
| 232 |
+
noise = torch.randn_like(cond_lat)
|
| 233 |
+
if self.training:
|
| 234 |
+
noisy_cond_lat = self.train_sched.add_noise(cond_lat, noise, timestep)
|
| 235 |
+
noisy_cond_lat = self.train_sched.scale_model_input(noisy_cond_lat, timestep)
|
| 236 |
+
else:
|
| 237 |
+
noisy_cond_lat = self.val_sched.add_noise(cond_lat, noise, timestep.reshape(-1))
|
| 238 |
+
noisy_cond_lat = self.val_sched.scale_model_input(noisy_cond_lat, timestep.reshape(-1))
|
| 239 |
+
|
| 240 |
+
ref_dict = {}
|
| 241 |
+
self.unet(noisy_cond_lat,
|
| 242 |
+
timestep,
|
| 243 |
+
encoder_hidden_states,
|
| 244 |
+
*args,
|
| 245 |
+
cross_attention_kwargs=dict(mode="w", ref_dict=ref_dict),
|
| 246 |
+
**kwargs)
|
| 247 |
+
return self.unet(sample,
|
| 248 |
+
timestep,
|
| 249 |
+
encoder_hidden_states,
|
| 250 |
+
*args,
|
| 251 |
+
cross_attention_kwargs=dict(mode="r", ref_dict=ref_dict),
|
| 252 |
+
**kwargs)
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
class Hunyuan3d_MVD_Lite_Pipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, FromSingleFileMixin):
|
| 256 |
+
def __init__(
|
| 257 |
+
self,
|
| 258 |
+
vae: AutoencoderKL,
|
| 259 |
+
text_encoder: CLIPTextModel,
|
| 260 |
+
tokenizer: CLIPTokenizer,
|
| 261 |
+
unet: UNet2DConditionModel,
|
| 262 |
+
scheduler: KarrasDiffusionSchedulers,
|
| 263 |
+
vision_encoder: CLIPVisionModelWithProjection,
|
| 264 |
+
feature_extractor_clip: CLIPImageProcessor,
|
| 265 |
+
feature_extractor_vae: CLIPImageProcessor,
|
| 266 |
+
ramping_coefficients: Optional[list] = None,
|
| 267 |
+
safety_checker=None,
|
| 268 |
+
):
|
| 269 |
+
DiffusionPipeline.__init__(self)
|
| 270 |
+
self.register_modules(
|
| 271 |
+
vae=vae,
|
| 272 |
+
unet=unet,
|
| 273 |
+
tokenizer=tokenizer,
|
| 274 |
+
scheduler=scheduler,
|
| 275 |
+
text_encoder=text_encoder,
|
| 276 |
+
vision_encoder=vision_encoder,
|
| 277 |
+
feature_extractor_vae=feature_extractor_vae,
|
| 278 |
+
feature_extractor_clip=feature_extractor_clip)
|
| 279 |
+
'''
|
| 280 |
+
rewrite the stable diffusion pipeline
|
| 281 |
+
vae: vae
|
| 282 |
+
unet: unet
|
| 283 |
+
tokenizer: tokenizer
|
| 284 |
+
scheduler: scheduler
|
| 285 |
+
text_encoder: text_encoder
|
| 286 |
+
vision_encoder: vision_encoder
|
| 287 |
+
feature_extractor_vae: feature_extractor_vae
|
| 288 |
+
feature_extractor_clip: feature_extractor_clip
|
| 289 |
+
'''
|
| 290 |
+
self.register_to_config(ramping_coefficients=ramping_coefficients)
|
| 291 |
+
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
| 292 |
+
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
|
| 293 |
+
|
| 294 |
+
def prepare_extra_step_kwargs(self, generator, eta):
|
| 295 |
+
extra_step_kwargs = {}
|
| 296 |
+
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
| 297 |
+
if accepts_eta: extra_step_kwargs["eta"] = eta
|
| 298 |
+
|
| 299 |
+
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
| 300 |
+
if accepts_generator: extra_step_kwargs["generator"] = generator
|
| 301 |
+
return extra_step_kwargs
|
| 302 |
+
|
| 303 |
+
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
|
| 304 |
+
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
|
| 305 |
+
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
| 306 |
+
latents = latents * self.scheduler.init_noise_sigma
|
| 307 |
+
return latents
|
| 308 |
+
|
| 309 |
+
@torch.no_grad()
|
| 310 |
+
def _encode_prompt(
|
| 311 |
+
self,
|
| 312 |
+
prompt,
|
| 313 |
+
device,
|
| 314 |
+
num_images_per_prompt,
|
| 315 |
+
do_classifier_free_guidance,
|
| 316 |
+
negative_prompt=None,
|
| 317 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 318 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 319 |
+
lora_scale: Optional[float] = None,
|
| 320 |
+
):
|
| 321 |
+
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
|
| 322 |
+
self._lora_scale = lora_scale
|
| 323 |
+
|
| 324 |
+
if prompt is not None and isinstance(prompt, str):
|
| 325 |
+
batch_size = 1
|
| 326 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 327 |
+
batch_size = len(prompt)
|
| 328 |
+
else:
|
| 329 |
+
batch_size = prompt_embeds.shape[0]
|
| 330 |
+
|
| 331 |
+
if prompt_embeds is None:
|
| 332 |
+
if isinstance(self, TextualInversionLoaderMixin):
|
| 333 |
+
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
|
| 334 |
+
|
| 335 |
+
text_inputs = self.tokenizer(
|
| 336 |
+
prompt,
|
| 337 |
+
padding="max_length",
|
| 338 |
+
max_length=self.tokenizer.model_max_length,
|
| 339 |
+
truncation=True,
|
| 340 |
+
return_tensors="pt",
|
| 341 |
+
)
|
| 342 |
+
text_input_ids = text_inputs.input_ids
|
| 343 |
+
|
| 344 |
+
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
|
| 345 |
+
attention_mask = text_inputs.attention_mask.to(device)
|
| 346 |
+
else:
|
| 347 |
+
attention_mask = None
|
| 348 |
+
|
| 349 |
+
prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)[0]
|
| 350 |
+
|
| 351 |
+
if self.text_encoder is not None:
|
| 352 |
+
prompt_embeds_dtype = self.text_encoder.dtype
|
| 353 |
+
elif self.unet is not None:
|
| 354 |
+
prompt_embeds_dtype = self.unet.dtype
|
| 355 |
+
else:
|
| 356 |
+
prompt_embeds_dtype = prompt_embeds.dtype
|
| 357 |
+
|
| 358 |
+
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
|
| 359 |
+
bs_embed, seq_len, _ = prompt_embeds.shape
|
| 360 |
+
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 361 |
+
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
|
| 362 |
+
|
| 363 |
+
if do_classifier_free_guidance and negative_prompt_embeds is None:
|
| 364 |
+
uncond_tokens: List[str]
|
| 365 |
+
if negative_prompt is None: uncond_tokens = [""] * batch_size
|
| 366 |
+
elif prompt is not None and type(prompt) is not type(negative_prompt): raise TypeError()
|
| 367 |
+
elif isinstance(negative_prompt, str): uncond_tokens = [negative_prompt]
|
| 368 |
+
elif batch_size != len(negative_prompt): raise ValueError()
|
| 369 |
+
else: uncond_tokens = negative_prompt
|
| 370 |
+
if isinstance(self, TextualInversionLoaderMixin):
|
| 371 |
+
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
|
| 372 |
+
|
| 373 |
+
max_length = prompt_embeds.shape[1]
|
| 374 |
+
uncond_input = self.tokenizer(uncond_tokens,
|
| 375 |
+
padding="max_length",
|
| 376 |
+
max_length=max_length,
|
| 377 |
+
truncation=True,
|
| 378 |
+
return_tensors="pt")
|
| 379 |
+
|
| 380 |
+
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
|
| 381 |
+
attention_mask = uncond_input.attention_mask.to(device)
|
| 382 |
+
else:
|
| 383 |
+
attention_mask = None
|
| 384 |
+
|
| 385 |
+
negative_prompt_embeds = self.text_encoder(uncond_input.input_ids.to(device), attention_mask=attention_mask)
|
| 386 |
+
negative_prompt_embeds = negative_prompt_embeds[0]
|
| 387 |
+
|
| 388 |
+
if do_classifier_free_guidance:
|
| 389 |
+
seq_len = negative_prompt_embeds.shape[1]
|
| 390 |
+
negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
|
| 391 |
+
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 392 |
+
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
|
| 393 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
| 394 |
+
|
| 395 |
+
return prompt_embeds
|
| 396 |
+
|
| 397 |
+
@torch.no_grad()
|
| 398 |
+
def encode_condition_image(self, image: torch.Tensor): return self.vae.encode(image).latent_dist.sample()
|
| 399 |
+
|
| 400 |
+
@torch.no_grad()
|
| 401 |
+
def __call__(self, image=None,
|
| 402 |
+
width=640,
|
| 403 |
+
height=960,
|
| 404 |
+
num_inference_steps=75,
|
| 405 |
+
return_dict=True,
|
| 406 |
+
generator=None,
|
| 407 |
+
**kwargs):
|
| 408 |
+
batch_size = 1
|
| 409 |
+
num_images_per_prompt = 1
|
| 410 |
+
output_type = 'pil'
|
| 411 |
+
do_classifier_free_guidance = True
|
| 412 |
+
guidance_rescale = 0.
|
| 413 |
+
if isinstance(self.unet, UNet2DConditionModel):
|
| 414 |
+
self.unet = RefOnlyNoisedUNet(self.unet, None, self.scheduler).eval()
|
| 415 |
+
|
| 416 |
+
cond_image = recenter_img(image)
|
| 417 |
+
cond_image = to_rgb_image(image)
|
| 418 |
+
image = cond_image
|
| 419 |
+
image_1 = self.feature_extractor_vae(images=image, return_tensors="pt").pixel_values
|
| 420 |
+
image_2 = self.feature_extractor_clip(images=image, return_tensors="pt").pixel_values
|
| 421 |
+
image_1 = image_1.to(device=self.vae.device, dtype=self.vae.dtype)
|
| 422 |
+
image_2 = image_2.to(device=self.vae.device, dtype=self.vae.dtype)
|
| 423 |
+
|
| 424 |
+
cond_lat = self.encode_condition_image(image_1)
|
| 425 |
+
negative_lat = self.encode_condition_image(torch.zeros_like(image_1))
|
| 426 |
+
cond_lat = torch.cat([negative_lat, cond_lat])
|
| 427 |
+
cross_attention_kwargs = dict(cond_lat=cond_lat)
|
| 428 |
+
|
| 429 |
+
global_embeds = self.vision_encoder(image_2, output_hidden_states=False).image_embeds.unsqueeze(-2)
|
| 430 |
+
encoder_hidden_states = self._encode_prompt('', self.device, num_images_per_prompt, False)
|
| 431 |
+
ramp = global_embeds.new_tensor(self.config.ramping_coefficients).unsqueeze(-1)
|
| 432 |
+
prompt_embeds = torch.cat([encoder_hidden_states, encoder_hidden_states + global_embeds * ramp])
|
| 433 |
+
|
| 434 |
+
device = self._execution_device
|
| 435 |
+
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
| 436 |
+
timesteps = self.scheduler.timesteps
|
| 437 |
+
num_channels_latents = self.unet.config.in_channels
|
| 438 |
+
latents = self.prepare_latents(batch_size * num_images_per_prompt,
|
| 439 |
+
num_channels_latents,
|
| 440 |
+
height,
|
| 441 |
+
width,
|
| 442 |
+
prompt_embeds.dtype,
|
| 443 |
+
device,
|
| 444 |
+
generator,
|
| 445 |
+
None)
|
| 446 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, 0.0)
|
| 447 |
+
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
| 448 |
+
|
| 449 |
+
# set adaptive cfg
|
| 450 |
+
# the image order is:
|
| 451 |
+
# [0, 60,
|
| 452 |
+
# 120, 180,
|
| 453 |
+
# 240, 300]
|
| 454 |
+
# the cfg is set as 3, 2.5, 2, 1.5
|
| 455 |
+
|
| 456 |
+
tmp_guidance_scale = torch.ones_like(latents)
|
| 457 |
+
tmp_guidance_scale[:, :, :40, :40] = 3
|
| 458 |
+
tmp_guidance_scale[:, :, :40, 40:] = 2.5
|
| 459 |
+
tmp_guidance_scale[:, :, 40:80, :40] = 2
|
| 460 |
+
tmp_guidance_scale[:, :, 40:80, 40:] = 1.5
|
| 461 |
+
tmp_guidance_scale[:, :, 80:120, :40] = 2
|
| 462 |
+
tmp_guidance_scale[:, :, 80:120, 40:] = 2.5
|
| 463 |
+
|
| 464 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 465 |
+
for i, t in enumerate(timesteps):
|
| 466 |
+
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
| 467 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 468 |
+
|
| 469 |
+
noise_pred = self.unet(latent_model_input, t,
|
| 470 |
+
encoder_hidden_states=prompt_embeds,
|
| 471 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 472 |
+
return_dict=False)[0]
|
| 473 |
+
|
| 474 |
+
adaptive_guidance_scale = (2 + 16 * (t / 1000) ** 5) / 3
|
| 475 |
+
if do_classifier_free_guidance:
|
| 476 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 477 |
+
noise_pred = noise_pred_uncond + \
|
| 478 |
+
tmp_guidance_scale * adaptive_guidance_scale * \
|
| 479 |
+
(noise_pred_text - noise_pred_uncond)
|
| 480 |
+
|
| 481 |
+
if do_classifier_free_guidance and guidance_rescale > 0.0:
|
| 482 |
+
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale=guidance_rescale)
|
| 483 |
+
|
| 484 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
| 485 |
+
if i==len(timesteps)-1 or ((i+1)>num_warmup_steps and (i+1)%self.scheduler.order==0):
|
| 486 |
+
progress_bar.update()
|
| 487 |
+
|
| 488 |
+
latents = unscale_latents(latents)
|
| 489 |
+
image = unscale_image(self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0])
|
| 490 |
+
image = self.image_processor.postprocess(image, output_type='pil')[0]
|
| 491 |
+
image = [image, cond_image]
|
| 492 |
+
return ImagePipelineOutput(images=image) if return_dict else (image,)
|
| 493 |
+
|
mvd/hunyuan3d_mvd_std_pipeline.py
ADDED
|
@@ -0,0 +1,471 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open Source Model Licensed under the Apache License Version 2.0 and Other Licenses of the Third-Party Components therein:
|
| 2 |
+
# The below Model in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2024 THL A29 Limited.
|
| 3 |
+
|
| 4 |
+
# Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved.
|
| 5 |
+
# The below software and/or models in this distribution may have been
|
| 6 |
+
# modified by THL A29 Limited ("Tencent Modifications").
|
| 7 |
+
# All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 8 |
+
|
| 9 |
+
# Hunyuan 3D is licensed under the TENCENT HUNYUAN NON-COMMERCIAL LICENSE AGREEMENT
|
| 10 |
+
# except for the third-party components listed below.
|
| 11 |
+
# Hunyuan 3D does not impose any additional limitations beyond what is outlined
|
| 12 |
+
# in the repsective licenses of these third-party components.
|
| 13 |
+
# Users must comply with all terms and conditions of original licenses of these third-party
|
| 14 |
+
# components and must ensure that the usage of the third party components adheres to
|
| 15 |
+
# all relevant laws and regulations.
|
| 16 |
+
|
| 17 |
+
# For avoidance of doubts, Hunyuan 3D means the large language models and
|
| 18 |
+
# their software and algorithms, including trained model weights, parameters (including
|
| 19 |
+
# optimizer states), machine-learning model code, inference-enabling code, training-enabling code,
|
| 20 |
+
# fine-tuning enabling code and other elements of the foregoing made publicly available
|
| 21 |
+
# by Tencent in accordance with TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT.
|
| 22 |
+
|
| 23 |
+
import inspect
|
| 24 |
+
from typing import Any, Dict, Optional
|
| 25 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 26 |
+
|
| 27 |
+
import os
|
| 28 |
+
import torch
|
| 29 |
+
import numpy as np
|
| 30 |
+
from PIL import Image
|
| 31 |
+
|
| 32 |
+
import diffusers
|
| 33 |
+
from diffusers.image_processor import VaeImageProcessor
|
| 34 |
+
from diffusers.utils.import_utils import is_xformers_available
|
| 35 |
+
from diffusers.schedulers import KarrasDiffusionSchedulers
|
| 36 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 37 |
+
from diffusers.utils.import_utils import is_xformers_available
|
| 38 |
+
from diffusers.models.attention_processor import (
|
| 39 |
+
Attention,
|
| 40 |
+
AttnProcessor,
|
| 41 |
+
XFormersAttnProcessor,
|
| 42 |
+
AttnProcessor2_0
|
| 43 |
+
)
|
| 44 |
+
from diffusers import (
|
| 45 |
+
AutoencoderKL,
|
| 46 |
+
DDPMScheduler,
|
| 47 |
+
DiffusionPipeline,
|
| 48 |
+
EulerAncestralDiscreteScheduler,
|
| 49 |
+
UNet2DConditionModel,
|
| 50 |
+
ImagePipelineOutput
|
| 51 |
+
)
|
| 52 |
+
import transformers
|
| 53 |
+
from transformers import (
|
| 54 |
+
CLIPImageProcessor,
|
| 55 |
+
CLIPTextModel,
|
| 56 |
+
CLIPTokenizer,
|
| 57 |
+
CLIPVisionModelWithProjection,
|
| 58 |
+
CLIPTextModelWithProjection
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
from .utils import to_rgb_image, white_out_background, recenter_img
|
| 62 |
+
|
| 63 |
+
EXAMPLE_DOC_STRING = """
|
| 64 |
+
Examples:
|
| 65 |
+
```py
|
| 66 |
+
>>> import torch
|
| 67 |
+
>>> from diffusers import Hunyuan3d_MVD_XL_Pipeline
|
| 68 |
+
|
| 69 |
+
>>> pipe = Hunyuan3d_MVD_XL_Pipeline.from_pretrained(
|
| 70 |
+
... "Tencent-Hunyuan-3D/MVD-XL", torch_dtype=torch.float16
|
| 71 |
+
... )
|
| 72 |
+
>>> pipe.to("cuda")
|
| 73 |
+
|
| 74 |
+
>>> img = Image.open("demo.png")
|
| 75 |
+
>>> res_img = pipe(img).images[0]
|
| 76 |
+
```
|
| 77 |
+
"""
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def scale_latents(latents): return (latents - 0.22) * 0.75
|
| 82 |
+
def unscale_latents(latents): return (latents / 0.75) + 0.22
|
| 83 |
+
def scale_image(image): return (image - 0.5) / 0.5
|
| 84 |
+
def scale_image_2(image): return (image * 0.5) / 0.8
|
| 85 |
+
def unscale_image(image): return (image * 0.5) + 0.5
|
| 86 |
+
def unscale_image_2(image): return (image * 0.8) / 0.5
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
class ReferenceOnlyAttnProc(torch.nn.Module):
|
| 92 |
+
def __init__(self, chained_proc, enabled=False, name=None):
|
| 93 |
+
super().__init__()
|
| 94 |
+
self.enabled = enabled
|
| 95 |
+
self.chained_proc = chained_proc
|
| 96 |
+
self.name = name
|
| 97 |
+
|
| 98 |
+
def __call__(self, attn, hidden_states, encoder_hidden_states=None, attention_mask=None, mode="w", ref_dict=None):
|
| 99 |
+
encoder_hidden_states = hidden_states if encoder_hidden_states is None else encoder_hidden_states
|
| 100 |
+
if self.enabled:
|
| 101 |
+
if mode == 'w': ref_dict[self.name] = encoder_hidden_states
|
| 102 |
+
elif mode == 'r': encoder_hidden_states = torch.cat([encoder_hidden_states, ref_dict.pop(self.name)], dim=1)
|
| 103 |
+
else: raise Exception(f"mode should not be {mode}")
|
| 104 |
+
return self.chained_proc(attn, hidden_states, encoder_hidden_states, attention_mask)
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
class RefOnlyNoisedUNet(torch.nn.Module):
|
| 108 |
+
def __init__(self, unet, scheduler) -> None:
|
| 109 |
+
super().__init__()
|
| 110 |
+
self.unet = unet
|
| 111 |
+
self.scheduler = scheduler
|
| 112 |
+
|
| 113 |
+
unet_attn_procs = dict()
|
| 114 |
+
for name, _ in unet.attn_processors.items():
|
| 115 |
+
if torch.__version__ >= '2.0': default_attn_proc = AttnProcessor2_0()
|
| 116 |
+
elif is_xformers_available(): default_attn_proc = XFormersAttnProcessor()
|
| 117 |
+
else: default_attn_proc = AttnProcessor()
|
| 118 |
+
unet_attn_procs[name] = ReferenceOnlyAttnProc(
|
| 119 |
+
default_attn_proc, enabled=name.endswith("attn1.processor"), name=name
|
| 120 |
+
)
|
| 121 |
+
unet.set_attn_processor(unet_attn_procs)
|
| 122 |
+
|
| 123 |
+
def __getattr__(self, name: str):
|
| 124 |
+
try:
|
| 125 |
+
return super().__getattr__(name)
|
| 126 |
+
except AttributeError:
|
| 127 |
+
return getattr(self.unet, name)
|
| 128 |
+
|
| 129 |
+
def forward(
|
| 130 |
+
self,
|
| 131 |
+
sample: torch.FloatTensor,
|
| 132 |
+
timestep: Union[torch.Tensor, float, int],
|
| 133 |
+
encoder_hidden_states: torch.Tensor,
|
| 134 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 135 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 136 |
+
down_block_res_samples: Optional[Tuple[torch.Tensor]] = None,
|
| 137 |
+
mid_block_res_sample: Optional[Tuple[torch.Tensor]] = None,
|
| 138 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 139 |
+
return_dict: bool = True,
|
| 140 |
+
**kwargs
|
| 141 |
+
):
|
| 142 |
+
|
| 143 |
+
dtype = self.unet.dtype
|
| 144 |
+
|
| 145 |
+
# cond_lat add same level noise
|
| 146 |
+
cond_lat = cross_attention_kwargs['cond_lat']
|
| 147 |
+
noise = torch.randn_like(cond_lat)
|
| 148 |
+
|
| 149 |
+
noisy_cond_lat = self.scheduler.add_noise(cond_lat, noise, timestep.reshape(-1))
|
| 150 |
+
noisy_cond_lat = self.scheduler.scale_model_input(noisy_cond_lat, timestep.reshape(-1))
|
| 151 |
+
|
| 152 |
+
ref_dict = {}
|
| 153 |
+
|
| 154 |
+
_ = self.unet(
|
| 155 |
+
noisy_cond_lat,
|
| 156 |
+
timestep,
|
| 157 |
+
encoder_hidden_states = encoder_hidden_states,
|
| 158 |
+
class_labels = class_labels,
|
| 159 |
+
cross_attention_kwargs = dict(mode="w", ref_dict=ref_dict),
|
| 160 |
+
added_cond_kwargs = added_cond_kwargs,
|
| 161 |
+
return_dict = return_dict,
|
| 162 |
+
**kwargs
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
res = self.unet(
|
| 166 |
+
sample,
|
| 167 |
+
timestep,
|
| 168 |
+
encoder_hidden_states,
|
| 169 |
+
class_labels=class_labels,
|
| 170 |
+
cross_attention_kwargs = dict(mode="r", ref_dict=ref_dict),
|
| 171 |
+
down_block_additional_residuals = [
|
| 172 |
+
sample.to(dtype=dtype) for sample in down_block_res_samples
|
| 173 |
+
] if down_block_res_samples is not None else None,
|
| 174 |
+
mid_block_additional_residual = (
|
| 175 |
+
mid_block_res_sample.to(dtype=dtype)
|
| 176 |
+
if mid_block_res_sample is not None else None),
|
| 177 |
+
added_cond_kwargs = added_cond_kwargs,
|
| 178 |
+
return_dict = return_dict,
|
| 179 |
+
**kwargs
|
| 180 |
+
)
|
| 181 |
+
return res
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
class HunYuan3D_MVD_Std_Pipeline(diffusers.DiffusionPipeline):
|
| 186 |
+
def __init__(
|
| 187 |
+
self,
|
| 188 |
+
vae: AutoencoderKL,
|
| 189 |
+
unet: UNet2DConditionModel,
|
| 190 |
+
scheduler: KarrasDiffusionSchedulers,
|
| 191 |
+
feature_extractor_vae: CLIPImageProcessor,
|
| 192 |
+
vision_processor: CLIPImageProcessor,
|
| 193 |
+
vision_encoder: CLIPVisionModelWithProjection,
|
| 194 |
+
vision_encoder_2: CLIPVisionModelWithProjection,
|
| 195 |
+
ramping_coefficients: Optional[list] = None,
|
| 196 |
+
add_watermarker: Optional[bool] = None,
|
| 197 |
+
safety_checker = None,
|
| 198 |
+
):
|
| 199 |
+
DiffusionPipeline.__init__(self)
|
| 200 |
+
|
| 201 |
+
self.register_modules(
|
| 202 |
+
vae=vae, unet=unet, scheduler=scheduler, safety_checker=None, feature_extractor_vae=feature_extractor_vae,
|
| 203 |
+
vision_processor=vision_processor, vision_encoder=vision_encoder, vision_encoder_2=vision_encoder_2,
|
| 204 |
+
)
|
| 205 |
+
self.register_to_config( ramping_coefficients = ramping_coefficients)
|
| 206 |
+
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
| 207 |
+
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
|
| 208 |
+
self.default_sample_size = self.unet.config.sample_size
|
| 209 |
+
self.watermark = None
|
| 210 |
+
self.prepare_init = False
|
| 211 |
+
|
| 212 |
+
def prepare(self):
|
| 213 |
+
assert isinstance(self.unet, UNet2DConditionModel), "unet should be UNet2DConditionModel"
|
| 214 |
+
self.unet = RefOnlyNoisedUNet(self.unet, self.scheduler).eval()
|
| 215 |
+
self.prepare_init = True
|
| 216 |
+
|
| 217 |
+
def encode_image(self, image: torch.Tensor, scale_factor: bool = False):
|
| 218 |
+
latent = self.vae.encode(image).latent_dist.sample()
|
| 219 |
+
return (latent * self.vae.config.scaling_factor) if scale_factor else latent
|
| 220 |
+
|
| 221 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
|
| 222 |
+
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
|
| 223 |
+
shape = (
|
| 224 |
+
batch_size,
|
| 225 |
+
num_channels_latents,
|
| 226 |
+
int(height) // self.vae_scale_factor,
|
| 227 |
+
int(width) // self.vae_scale_factor,
|
| 228 |
+
)
|
| 229 |
+
if isinstance(generator, list) and len(generator) != batch_size:
|
| 230 |
+
raise ValueError(
|
| 231 |
+
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
| 232 |
+
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
if latents is None:
|
| 236 |
+
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
| 237 |
+
else:
|
| 238 |
+
latents = latents.to(device)
|
| 239 |
+
|
| 240 |
+
# scale the initial noise by the standard deviation required by the scheduler
|
| 241 |
+
latents = latents * self.scheduler.init_noise_sigma
|
| 242 |
+
return latents
|
| 243 |
+
|
| 244 |
+
def _get_add_time_ids(
|
| 245 |
+
self, original_size, crops_coords_top_left, target_size, dtype, text_encoder_projection_dim=None
|
| 246 |
+
):
|
| 247 |
+
add_time_ids = list(original_size + crops_coords_top_left + target_size)
|
| 248 |
+
|
| 249 |
+
passed_add_embed_dim = (
|
| 250 |
+
self.unet.config.addition_time_embed_dim * len(add_time_ids) + text_encoder_projection_dim
|
| 251 |
+
)
|
| 252 |
+
expected_add_embed_dim = self.unet.add_embedding.linear_1.in_features
|
| 253 |
+
|
| 254 |
+
if expected_add_embed_dim != passed_add_embed_dim:
|
| 255 |
+
raise ValueError(
|
| 256 |
+
f"Model expects an added time embedding vector of length {expected_add_embed_dim}, " \
|
| 257 |
+
f"but a vector of {passed_add_embed_dim} was created. The model has an incorrect config." \
|
| 258 |
+
f" Please check `unet.config.time_embedding_type` and `text_encoder_2.config.projection_dim`."
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
add_time_ids = torch.tensor([add_time_ids], dtype=dtype)
|
| 262 |
+
return add_time_ids
|
| 263 |
+
|
| 264 |
+
def prepare_extra_step_kwargs(self, generator, eta):
|
| 265 |
+
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
|
| 266 |
+
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
| 267 |
+
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
| 268 |
+
# and should be between [0, 1]
|
| 269 |
+
|
| 270 |
+
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
| 271 |
+
extra_step_kwargs = {}
|
| 272 |
+
if accepts_eta: extra_step_kwargs["eta"] = eta
|
| 273 |
+
|
| 274 |
+
# check if the scheduler accepts generator
|
| 275 |
+
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
| 276 |
+
if accepts_generator: extra_step_kwargs["generator"] = generator
|
| 277 |
+
return extra_step_kwargs
|
| 278 |
+
|
| 279 |
+
@property
|
| 280 |
+
def guidance_scale(self):
|
| 281 |
+
return self._guidance_scale
|
| 282 |
+
|
| 283 |
+
@property
|
| 284 |
+
def interrupt(self):
|
| 285 |
+
return self._interrupt
|
| 286 |
+
|
| 287 |
+
@property
|
| 288 |
+
def do_classifier_free_guidance(self):
|
| 289 |
+
return self._guidance_scale > 1 and self.unet.config.time_cond_proj_dim is None
|
| 290 |
+
|
| 291 |
+
@torch.no_grad()
|
| 292 |
+
def __call__(
|
| 293 |
+
self,
|
| 294 |
+
image: Image.Image = None,
|
| 295 |
+
guidance_scale = 2.0,
|
| 296 |
+
output_type: Optional[str] = "pil",
|
| 297 |
+
num_inference_steps: int = 50,
|
| 298 |
+
return_dict: bool = True,
|
| 299 |
+
eta: float = 0.0,
|
| 300 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 301 |
+
crops_coords_top_left: Tuple[int, int] = (0, 0),
|
| 302 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 303 |
+
latent: torch.Tensor = None,
|
| 304 |
+
guidance_curve = None,
|
| 305 |
+
**kwargs
|
| 306 |
+
):
|
| 307 |
+
if not self.prepare_init:
|
| 308 |
+
self.prepare()
|
| 309 |
+
|
| 310 |
+
here = dict(device=self.vae.device, dtype=self.vae.dtype)
|
| 311 |
+
|
| 312 |
+
batch_size = 1
|
| 313 |
+
num_images_per_prompt = 1
|
| 314 |
+
width, height = 512 * 2, 512 * 3
|
| 315 |
+
target_size = original_size = (height, width)
|
| 316 |
+
|
| 317 |
+
self._guidance_scale = guidance_scale
|
| 318 |
+
self._cross_attention_kwargs = cross_attention_kwargs
|
| 319 |
+
self._interrupt = False
|
| 320 |
+
|
| 321 |
+
device = self._execution_device
|
| 322 |
+
|
| 323 |
+
# Prepare timesteps
|
| 324 |
+
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
| 325 |
+
timesteps = self.scheduler.timesteps
|
| 326 |
+
|
| 327 |
+
# Prepare latent variables
|
| 328 |
+
num_channels_latents = self.unet.config.in_channels
|
| 329 |
+
latents = self.prepare_latents(
|
| 330 |
+
batch_size * num_images_per_prompt,
|
| 331 |
+
num_channels_latents,
|
| 332 |
+
height,
|
| 333 |
+
width,
|
| 334 |
+
self.vae.dtype,
|
| 335 |
+
device,
|
| 336 |
+
generator,
|
| 337 |
+
latents=latent,
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
# Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 341 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
# Prepare added time ids & embeddings
|
| 345 |
+
text_encoder_projection_dim = 1280
|
| 346 |
+
add_time_ids = self._get_add_time_ids(
|
| 347 |
+
original_size,
|
| 348 |
+
crops_coords_top_left,
|
| 349 |
+
target_size,
|
| 350 |
+
dtype=self.vae.dtype,
|
| 351 |
+
text_encoder_projection_dim=text_encoder_projection_dim,
|
| 352 |
+
)
|
| 353 |
+
negative_add_time_ids = add_time_ids
|
| 354 |
+
|
| 355 |
+
# hw: preprocess
|
| 356 |
+
cond_image = recenter_img(image)
|
| 357 |
+
cond_image = to_rgb_image(image)
|
| 358 |
+
image_vae = self.feature_extractor_vae(images=cond_image, return_tensors="pt").pixel_values.to(**here)
|
| 359 |
+
image_clip = self.vision_processor(images=cond_image, return_tensors="pt").pixel_values.to(**here)
|
| 360 |
+
|
| 361 |
+
# hw: get cond_lat from cond_img using vae
|
| 362 |
+
cond_lat = self.encode_image(image_vae, scale_factor=False)
|
| 363 |
+
negative_lat = self.encode_image(torch.zeros_like(image_vae), scale_factor=False)
|
| 364 |
+
cond_lat = torch.cat([negative_lat, cond_lat])
|
| 365 |
+
|
| 366 |
+
# hw: get visual global embedding using clip
|
| 367 |
+
global_embeds_1 = self.vision_encoder(image_clip, output_hidden_states=False).image_embeds.unsqueeze(-2)
|
| 368 |
+
global_embeds_2 = self.vision_encoder_2(image_clip, output_hidden_states=False).image_embeds.unsqueeze(-2)
|
| 369 |
+
global_embeds = torch.concat([global_embeds_1, global_embeds_2], dim=-1)
|
| 370 |
+
|
| 371 |
+
ramp = global_embeds.new_tensor(self.config.ramping_coefficients).unsqueeze(-1)
|
| 372 |
+
prompt_embeds = self.uc_text_emb.to(**here)
|
| 373 |
+
pooled_prompt_embeds = self.uc_text_emb_2.to(**here)
|
| 374 |
+
|
| 375 |
+
prompt_embeds = prompt_embeds + global_embeds * ramp
|
| 376 |
+
add_text_embeds = pooled_prompt_embeds
|
| 377 |
+
|
| 378 |
+
if self.do_classifier_free_guidance:
|
| 379 |
+
negative_prompt_embeds = torch.zeros_like(prompt_embeds)
|
| 380 |
+
negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
|
| 381 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds], dim=0)
|
| 382 |
+
add_text_embeds = torch.cat([negative_pooled_prompt_embeds, add_text_embeds], dim=0)
|
| 383 |
+
add_time_ids = torch.cat([negative_add_time_ids, add_time_ids], dim=0)
|
| 384 |
+
|
| 385 |
+
prompt_embeds = prompt_embeds.to(device)
|
| 386 |
+
add_text_embeds = add_text_embeds.to(device)
|
| 387 |
+
add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
|
| 388 |
+
|
| 389 |
+
# Denoising loop
|
| 390 |
+
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
|
| 391 |
+
timestep_cond = None
|
| 392 |
+
self._num_timesteps = len(timesteps)
|
| 393 |
+
|
| 394 |
+
if guidance_curve is None:
|
| 395 |
+
guidance_curve = lambda t: guidance_scale
|
| 396 |
+
|
| 397 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 398 |
+
for i, t in enumerate(timesteps):
|
| 399 |
+
if self.interrupt:
|
| 400 |
+
continue
|
| 401 |
+
|
| 402 |
+
# expand the latents if we are doing classifier free guidance
|
| 403 |
+
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
|
| 404 |
+
|
| 405 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 406 |
+
|
| 407 |
+
# predict the noise residual
|
| 408 |
+
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
|
| 409 |
+
|
| 410 |
+
noise_pred = self.unet(
|
| 411 |
+
latent_model_input,
|
| 412 |
+
t,
|
| 413 |
+
encoder_hidden_states=prompt_embeds,
|
| 414 |
+
timestep_cond=timestep_cond,
|
| 415 |
+
cross_attention_kwargs=dict(cond_lat=cond_lat),
|
| 416 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 417 |
+
return_dict=False,
|
| 418 |
+
)[0]
|
| 419 |
+
|
| 420 |
+
# perform guidance
|
| 421 |
+
|
| 422 |
+
# cur_guidance_scale = self.guidance_scale
|
| 423 |
+
cur_guidance_scale = guidance_curve(t) # 1.5 + 2.5 * ((t/1000)**2)
|
| 424 |
+
|
| 425 |
+
if self.do_classifier_free_guidance:
|
| 426 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 427 |
+
noise_pred = noise_pred_uncond + cur_guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 428 |
+
|
| 429 |
+
# cur_guidance_scale_topleft = (cur_guidance_scale - 1.0) * 4 + 1.0
|
| 430 |
+
# noise_pred_top_left = noise_pred_uncond +
|
| 431 |
+
# cur_guidance_scale_topleft * (noise_pred_text - noise_pred_uncond)
|
| 432 |
+
# _, _, h, w = noise_pred.shape
|
| 433 |
+
# noise_pred[:, :, :h//3, :w//2] = noise_pred_top_left[:, :, :h//3, :w//2]
|
| 434 |
+
|
| 435 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 436 |
+
latents_dtype = latents.dtype
|
| 437 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
| 438 |
+
|
| 439 |
+
# call the callback, if provided
|
| 440 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 441 |
+
progress_bar.update()
|
| 442 |
+
|
| 443 |
+
latents = unscale_latents(latents)
|
| 444 |
+
|
| 445 |
+
if output_type=="latent":
|
| 446 |
+
image = latents
|
| 447 |
+
else:
|
| 448 |
+
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
|
| 449 |
+
image = unscale_image(unscale_image_2(image)).clamp(0, 1)
|
| 450 |
+
image = [
|
| 451 |
+
Image.fromarray((image[0]*255+0.5).clamp_(0, 255).permute(1, 2, 0).cpu().numpy().astype("uint8")),
|
| 452 |
+
# self.image_processor.postprocess(image, output_type=output_type)[0],
|
| 453 |
+
cond_image.resize((512, 512))
|
| 454 |
+
]
|
| 455 |
+
|
| 456 |
+
if not return_dict: return (image,)
|
| 457 |
+
return ImagePipelineOutput(images=image)
|
| 458 |
+
|
| 459 |
+
def save_pretrained(self, save_directory):
|
| 460 |
+
# uc_text_emb.pt and uc_text_emb_2.pt are inferenced and saved in advance
|
| 461 |
+
super().save_pretrained(save_directory)
|
| 462 |
+
torch.save(self.uc_text_emb, os.path.join(save_directory, "uc_text_emb.pt"))
|
| 463 |
+
torch.save(self.uc_text_emb_2, os.path.join(save_directory, "uc_text_emb_2.pt"))
|
| 464 |
+
|
| 465 |
+
@classmethod
|
| 466 |
+
def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
|
| 467 |
+
# uc_text_emb.pt and uc_text_emb_2.pt are inferenced and saved in advance
|
| 468 |
+
pipeline = super().from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
|
| 469 |
+
pipeline.uc_text_emb = torch.load(os.path.join(pretrained_model_name_or_path, "uc_text_emb.pt"))
|
| 470 |
+
pipeline.uc_text_emb_2 = torch.load(os.path.join(pretrained_model_name_or_path, "uc_text_emb_2.pt"))
|
| 471 |
+
return pipeline
|
mvd/utils.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open Source Model Licensed under the Apache License Version 2.0 and Other Licenses of the Third-Party Components therein:
|
| 2 |
+
# The below Model in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2024 THL A29 Limited.
|
| 3 |
+
|
| 4 |
+
# Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved.
|
| 5 |
+
# The below software and/or models in this distribution may have been
|
| 6 |
+
# modified by THL A29 Limited ("Tencent Modifications").
|
| 7 |
+
# All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 8 |
+
|
| 9 |
+
# Hunyuan 3D is licensed under the TENCENT HUNYUAN NON-COMMERCIAL LICENSE AGREEMENT
|
| 10 |
+
# except for the third-party components listed below.
|
| 11 |
+
# Hunyuan 3D does not impose any additional limitations beyond what is outlined
|
| 12 |
+
# in the repsective licenses of these third-party components.
|
| 13 |
+
# Users must comply with all terms and conditions of original licenses of these third-party
|
| 14 |
+
# components and must ensure that the usage of the third party components adheres to
|
| 15 |
+
# all relevant laws and regulations.
|
| 16 |
+
|
| 17 |
+
# For avoidance of doubts, Hunyuan 3D means the large language models and
|
| 18 |
+
# their software and algorithms, including trained model weights, parameters (including
|
| 19 |
+
# optimizer states), machine-learning model code, inference-enabling code, training-enabling code,
|
| 20 |
+
# fine-tuning enabling code and other elements of the foregoing made publicly available
|
| 21 |
+
# by Tencent in accordance with TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT.
|
| 22 |
+
|
| 23 |
+
import numpy as np
|
| 24 |
+
from PIL import Image
|
| 25 |
+
|
| 26 |
+
def to_rgb_image(maybe_rgba: Image.Image):
|
| 27 |
+
'''
|
| 28 |
+
convert a PIL.Image to rgb mode with white background
|
| 29 |
+
maybe_rgba: PIL.Image
|
| 30 |
+
return: PIL.Image
|
| 31 |
+
'''
|
| 32 |
+
if maybe_rgba.mode == 'RGB':
|
| 33 |
+
return maybe_rgba
|
| 34 |
+
elif maybe_rgba.mode == 'RGBA':
|
| 35 |
+
rgba = maybe_rgba
|
| 36 |
+
img = np.random.randint(255, 256, size=[rgba.size[1], rgba.size[0], 3], dtype=np.uint8)
|
| 37 |
+
img = Image.fromarray(img, 'RGB')
|
| 38 |
+
img.paste(rgba, mask=rgba.getchannel('A'))
|
| 39 |
+
return img
|
| 40 |
+
else:
|
| 41 |
+
raise ValueError("Unsupported image type.", maybe_rgba.mode)
|
| 42 |
+
|
| 43 |
+
def white_out_background(pil_img, is_gray_fg=True):
|
| 44 |
+
data = pil_img.getdata()
|
| 45 |
+
new_data = []
|
| 46 |
+
# convert fore-ground white to gray
|
| 47 |
+
for r, g, b, a in data:
|
| 48 |
+
if a < 16:
|
| 49 |
+
new_data.append((255, 255, 255, 0)) # back-ground to be black
|
| 50 |
+
else:
|
| 51 |
+
is_white = is_gray_fg and (r>235) and (g>235) and (b>235)
|
| 52 |
+
new_r = 235 if is_white else r
|
| 53 |
+
new_g = 235 if is_white else g
|
| 54 |
+
new_b = 235 if is_white else b
|
| 55 |
+
new_data.append((new_r, new_g, new_b, a))
|
| 56 |
+
pil_img.putdata(new_data)
|
| 57 |
+
return pil_img
|
| 58 |
+
|
| 59 |
+
def recenter_img(img, size=512, color=(255,255,255)):
|
| 60 |
+
img = white_out_background(img)
|
| 61 |
+
mask = np.array(img)[..., 3]
|
| 62 |
+
image = np.array(img)[..., :3]
|
| 63 |
+
|
| 64 |
+
H, W, C = image.shape
|
| 65 |
+
coords = np.nonzero(mask)
|
| 66 |
+
x_min, x_max = coords[0].min(), coords[0].max()
|
| 67 |
+
y_min, y_max = coords[1].min(), coords[1].max()
|
| 68 |
+
h = x_max - x_min
|
| 69 |
+
w = y_max - y_min
|
| 70 |
+
if h == 0 or w == 0: raise ValueError
|
| 71 |
+
roi = image[x_min:x_max, y_min:y_max]
|
| 72 |
+
|
| 73 |
+
border_ratio = 0.15 # 0.2
|
| 74 |
+
pad_h = int(h * border_ratio)
|
| 75 |
+
pad_w = int(w * border_ratio)
|
| 76 |
+
|
| 77 |
+
result_tmp = np.full((h + pad_h, w + pad_w, C), color, dtype=np.uint8)
|
| 78 |
+
result_tmp[pad_h // 2: pad_h // 2 + h, pad_w // 2: pad_w // 2 + w] = roi
|
| 79 |
+
|
| 80 |
+
cur_h, cur_w = result_tmp.shape[:2]
|
| 81 |
+
side = max(cur_h, cur_w)
|
| 82 |
+
result = np.full((side, side, C), color, dtype=np.uint8)
|
| 83 |
+
result[(side-cur_h)//2:(side-cur_h)//2+cur_h, (side-cur_w)//2:(side - cur_w)//2+cur_w,:] = result_tmp
|
| 84 |
+
result = Image.fromarray(result)
|
| 85 |
+
return result.resize((size, size), Image.LANCZOS) if size else result
|
requirements.txt
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
--find-links https://download.pytorch.org/whl/cu118
|
| 2 |
+
torch==2.2.0
|
| 3 |
+
torchvision==0.17.0
|
| 4 |
+
diffusers
|
| 5 |
+
transformers
|
| 6 |
+
rembg
|
| 7 |
+
tqdm
|
| 8 |
+
omegaconf
|
| 9 |
+
matplotlib
|
| 10 |
+
opencv-python
|
| 11 |
+
imageio
|
| 12 |
+
jaxtyping
|
| 13 |
+
einops
|
| 14 |
+
SentencePiece
|
| 15 |
+
accelerate
|
| 16 |
+
trimesh
|
| 17 |
+
PyMCubes
|
| 18 |
+
xatlas
|
| 19 |
+
libigl
|
| 20 |
+
git+https://github.com/facebookresearch/pytorch3d
|
| 21 |
+
git+https://github.com/NVlabs/nvdiffrast
|
| 22 |
+
open3d
|
scripts/image_to_3d.sh
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# image to 3d
|
| 2 |
+
|
| 3 |
+
python main.py \
|
| 4 |
+
--image_prompt ./demos/example_000.png \
|
| 5 |
+
--save_folder ./outputs/test/ \
|
| 6 |
+
--max_faces_num 90000 \
|
| 7 |
+
--do_texture \
|
| 8 |
+
--do_render
|
scripts/image_to_3d_demo.sh
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# image to 3d
|
| 2 |
+
|
| 3 |
+
python main.py \
|
| 4 |
+
--image_prompt ./demos/example_000.png \
|
| 5 |
+
--save_folder ./outputs/test/ \
|
| 6 |
+
--max_faces_num 90000 \
|
| 7 |
+
--do_texture_mapping \
|
| 8 |
+
--do_render
|
scripts/image_to_3d_fast.sh
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# image to 3d fast
|
| 2 |
+
python main.py \
|
| 3 |
+
--image_prompt ./demos/example_000.png \
|
| 4 |
+
--save_folder ./outputs/test/ \
|
| 5 |
+
--max_faces_num 10000 \
|
| 6 |
+
--use_lite
|
scripts/image_to_3d_fast_demo.sh
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# image to 3d fast
|
| 2 |
+
python main.py \
|
| 3 |
+
--image_prompt ./demos/example_000.png \
|
| 4 |
+
--save_folder ./outputs/test/ \
|
| 5 |
+
--max_faces_num 10000 \
|
| 6 |
+
--use_lite
|
scripts/text_to_3d.sh
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# text to 3d fast
|
| 2 |
+
python main.py \
|
| 3 |
+
--text_prompt "a lovely cat" \
|
| 4 |
+
--save_folder ./outputs/test/ \
|
| 5 |
+
--max_faces_num 90000 \
|
| 6 |
+
--do_texture \
|
| 7 |
+
--do_render
|
scripts/text_to_3d_demo.sh
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# text to 3d fast
|
| 2 |
+
python main.py \
|
| 3 |
+
--text_prompt "a lovely rabbit" \
|
| 4 |
+
--save_folder ./outputs/test/ \
|
| 5 |
+
--max_faces_num 90000 \
|
| 6 |
+
--do_texture_mapping \
|
| 7 |
+
--do_render
|
scripts/text_to_3d_fast.sh
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# text to 3d fast
|
| 2 |
+
python main.py \
|
| 3 |
+
--text_prompt "一个广式茶杯" \
|
| 4 |
+
--save_folder ./outputs/test/ \
|
| 5 |
+
--max_faces_num 10000 \
|
| 6 |
+
--use_lite
|
scripts/text_to_3d_fast_demo.sh
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# text to 3d fast
|
| 2 |
+
python main.py \
|
| 3 |
+
--text_prompt "一个广式茶杯" \
|
| 4 |
+
--save_folder ./outputs/test/ \
|
| 5 |
+
--max_faces_num 10000 \
|
| 6 |
+
--use_lite
|
svrm/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
svrm/configs/2024-10-24T22-36-18-project.yaml
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 3.0e-05
|
| 3 |
+
target: svrm.ldm.models.svrm.SVRMModel
|
| 4 |
+
params:
|
| 5 |
+
|
| 6 |
+
img_encoder_config:
|
| 7 |
+
target: svrm.ldm.modules.encoders.dinov2_mod.FrozenDinoV2ImageEmbedder
|
| 8 |
+
params:
|
| 9 |
+
version: dinov2_vitb14
|
| 10 |
+
|
| 11 |
+
img_to_triplane_config:
|
| 12 |
+
target: svrm.ldm.modules.translator.img_to_triplane.ImgToTriplaneModel
|
| 13 |
+
params:
|
| 14 |
+
pos_emb_size: 64
|
| 15 |
+
pos_emb_dim: 1024
|
| 16 |
+
cam_cond_dim: 20
|
| 17 |
+
n_heads: 16
|
| 18 |
+
d_head: 64
|
| 19 |
+
depth: 16
|
| 20 |
+
context_dim: 768
|
| 21 |
+
triplane_dim: 120
|
| 22 |
+
use_fp16: true
|
| 23 |
+
use_bf16: false
|
| 24 |
+
upsample_time: 2
|
| 25 |
+
|
| 26 |
+
render_config:
|
| 27 |
+
target: svrm.ldm.modules.rendering_neus.synthesizer.TriplaneSynthesizer
|
| 28 |
+
params:
|
| 29 |
+
triplane_dim: 120
|
| 30 |
+
samples_per_ray: 128
|
| 31 |
+
|
| 32 |
+
|
svrm/configs/svrm.yaml
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
base_learning_rate: 3.0e-05
|
| 3 |
+
target: svrm.ldm.models.svrm.SVRMModel
|
| 4 |
+
params:
|
| 5 |
+
|
| 6 |
+
img_encoder_config:
|
| 7 |
+
target: svrm.ldm.modules.encoders.dinov2_mod.FrozenDinoV2ImageEmbedder
|
| 8 |
+
params:
|
| 9 |
+
version: dinov2_vitb14
|
| 10 |
+
|
| 11 |
+
img_to_triplane_config:
|
| 12 |
+
target: svrm.ldm.modules.translator.img_to_triplane.ImgToTriplaneModel
|
| 13 |
+
params:
|
| 14 |
+
pos_emb_size: 64
|
| 15 |
+
pos_emb_dim: 1024
|
| 16 |
+
cam_cond_dim: 20
|
| 17 |
+
n_heads: 16
|
| 18 |
+
d_head: 64
|
| 19 |
+
depth: 16
|
| 20 |
+
context_dim: 768
|
| 21 |
+
triplane_dim: 120
|
| 22 |
+
use_fp16: true
|
| 23 |
+
use_bf16: false
|
| 24 |
+
upsample_time: 2
|
| 25 |
+
|
| 26 |
+
render_config:
|
| 27 |
+
target: svrm.ldm.modules.rendering_neus.synthesizer.TriplaneSynthesizer
|
| 28 |
+
params:
|
| 29 |
+
triplane_dim: 120
|
| 30 |
+
samples_per_ray: 128
|
| 31 |
+
|
| 32 |
+
|
svrm/ldm/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
svrm/ldm/models/svrm.py
ADDED
|
@@ -0,0 +1,263 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Open Source Model Licensed under the Apache License Version 2.0 and Other Licenses of the Third-Party Components therein:
|
| 2 |
+
# The below Model in this distribution may have been modified by THL A29 Limited ("Tencent Modifications"). All Tencent Modifications are Copyright (C) 2024 THL A29 Limited.
|
| 3 |
+
|
| 4 |
+
# Copyright (C) 2024 THL A29 Limited, a Tencent company. All rights reserved.
|
| 5 |
+
# The below software and/or models in this distribution may have been
|
| 6 |
+
# modified by THL A29 Limited ("Tencent Modifications").
|
| 7 |
+
# All Tencent Modifications are Copyright (C) THL A29 Limited.
|
| 8 |
+
|
| 9 |
+
# Hunyuan 3D is licensed under the TENCENT HUNYUAN NON-COMMERCIAL LICENSE AGREEMENT
|
| 10 |
+
# except for the third-party components listed below.
|
| 11 |
+
# Hunyuan 3D does not impose any additional limitations beyond what is outlined
|
| 12 |
+
# in the repsective licenses of these third-party components.
|
| 13 |
+
# Users must comply with all terms and conditions of original licenses of these third-party
|
| 14 |
+
# components and must ensure that the usage of the third party components adheres to
|
| 15 |
+
# all relevant laws and regulations.
|
| 16 |
+
|
| 17 |
+
# For avoidance of doubts, Hunyuan 3D means the large language models and
|
| 18 |
+
# their software and algorithms, including trained model weights, parameters (including
|
| 19 |
+
# optimizer states), machine-learning model code, inference-enabling code, training-enabling code,
|
| 20 |
+
# fine-tuning enabling code and other elements of the foregoing made publicly available
|
| 21 |
+
# by Tencent in accordance with TENCENT HUNYUAN COMMUNITY LICENSE AGREEMENT.
|
| 22 |
+
|
| 23 |
+
import os
|
| 24 |
+
import time
|
| 25 |
+
import math
|
| 26 |
+
import cv2
|
| 27 |
+
import numpy as np
|
| 28 |
+
import itertools
|
| 29 |
+
import shutil
|
| 30 |
+
from tqdm import tqdm
|
| 31 |
+
import torch
|
| 32 |
+
import torch.nn.functional as F
|
| 33 |
+
from einops import rearrange
|
| 34 |
+
try:
|
| 35 |
+
import trimesh
|
| 36 |
+
import mcubes
|
| 37 |
+
import xatlas
|
| 38 |
+
import open3d as o3d
|
| 39 |
+
except:
|
| 40 |
+
raise "failed to import 3d libraries "
|
| 41 |
+
|
| 42 |
+
from ..modules.rendering_neus.mesh import Mesh
|
| 43 |
+
from ..modules.rendering_neus.rasterize import NVDiffRasterizerContext
|
| 44 |
+
|
| 45 |
+
from ..utils.ops import scale_tensor
|
| 46 |
+
from ..util import count_params, instantiate_from_config
|
| 47 |
+
from ..vis_util import render
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def unwrap_uv(v_pos, t_pos_idx):
|
| 51 |
+
print("Using xatlas to perform UV unwrapping, may take a while ...")
|
| 52 |
+
atlas = xatlas.Atlas()
|
| 53 |
+
atlas.add_mesh(v_pos, t_pos_idx)
|
| 54 |
+
atlas.generate(xatlas.ChartOptions(), xatlas.PackOptions())
|
| 55 |
+
_, indices, uvs = atlas.get_mesh(0)
|
| 56 |
+
indices = indices.astype(np.int64, casting="same_kind")
|
| 57 |
+
return uvs, indices
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def uv_padding(image, hole_mask, uv_padding_size = 2):
|
| 61 |
+
return cv2.inpaint(
|
| 62 |
+
(image.detach().cpu().numpy() * 255).astype(np.uint8),
|
| 63 |
+
(hole_mask.detach().cpu().numpy() * 255).astype(np.uint8),
|
| 64 |
+
uv_padding_size,
|
| 65 |
+
cv2.INPAINT_TELEA
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
def refine_mesh(vtx_refine, faces_refine):
|
| 69 |
+
mesh = o3d.geometry.TriangleMesh(
|
| 70 |
+
vertices=o3d.utility.Vector3dVector(vtx_refine),
|
| 71 |
+
triangles=o3d.utility.Vector3iVector(faces_refine))
|
| 72 |
+
|
| 73 |
+
mesh = mesh.remove_unreferenced_vertices()
|
| 74 |
+
mesh = mesh.remove_duplicated_triangles()
|
| 75 |
+
mesh = mesh.remove_duplicated_vertices()
|
| 76 |
+
|
| 77 |
+
voxel_size = max(mesh.get_max_bound() - mesh.get_min_bound())
|
| 78 |
+
|
| 79 |
+
mesh = mesh.simplify_vertex_clustering(
|
| 80 |
+
voxel_size=0.007, # 0.005
|
| 81 |
+
contraction=o3d.geometry.SimplificationContraction.Average)
|
| 82 |
+
|
| 83 |
+
mesh = mesh.filter_smooth_simple(number_of_iterations=2)
|
| 84 |
+
|
| 85 |
+
vtx_refine = np.asarray(mesh.vertices).astype(np.float32)
|
| 86 |
+
faces_refine = np.asarray(mesh.triangles)
|
| 87 |
+
return vtx_refine, faces_refine, mesh
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
class SVRMModel(torch.nn.Module):
|
| 91 |
+
def __init__(
|
| 92 |
+
self,
|
| 93 |
+
img_encoder_config,
|
| 94 |
+
img_to_triplane_config,
|
| 95 |
+
render_config,
|
| 96 |
+
device = "cuda:0",
|
| 97 |
+
**kwargs
|
| 98 |
+
):
|
| 99 |
+
super().__init__()
|
| 100 |
+
|
| 101 |
+
self.img_encoder = instantiate_from_config(img_encoder_config).half()
|
| 102 |
+
self.img_to_triplane_decoder = instantiate_from_config(img_to_triplane_config).half()
|
| 103 |
+
self.render = instantiate_from_config(render_config).half()
|
| 104 |
+
self.device = device
|
| 105 |
+
count_params(self, verbose=True)
|
| 106 |
+
|
| 107 |
+
@torch.no_grad()
|
| 108 |
+
def export_mesh_with_uv(
|
| 109 |
+
self,
|
| 110 |
+
data,
|
| 111 |
+
mesh_size: int = 384,
|
| 112 |
+
ctx = None,
|
| 113 |
+
context_type = 'cuda',
|
| 114 |
+
texture_res = 1024,
|
| 115 |
+
target_face_count = 10000,
|
| 116 |
+
do_texture_mapping = True,
|
| 117 |
+
out_dir = 'outputs/test'
|
| 118 |
+
):
|
| 119 |
+
"""
|
| 120 |
+
color_type: 0 for ray texture, 1 for vertices texture
|
| 121 |
+
"""
|
| 122 |
+
st = time.time()
|
| 123 |
+
here = {'device': self.device, 'dtype': torch.float16}
|
| 124 |
+
input_view_image = data["input_view"].to(**here) # [b, m, c, h, w]
|
| 125 |
+
input_view_cam = data["input_view_cam"].to(**here) # [b, m, 20]
|
| 126 |
+
|
| 127 |
+
batch_size, input_view_num, *_ = input_view_image.shape
|
| 128 |
+
assert batch_size == 1, "batch size should be 1"
|
| 129 |
+
|
| 130 |
+
input_view_image = rearrange(input_view_image, 'b m c h w -> (b m) c h w')
|
| 131 |
+
input_view_cam = rearrange(input_view_cam, 'b m d -> (b m) d')
|
| 132 |
+
input_view_feat = self.img_encoder(input_view_image, input_view_cam)
|
| 133 |
+
input_view_feat = rearrange(input_view_feat, '(b m) l d -> b (l m) d', m=input_view_num)
|
| 134 |
+
|
| 135 |
+
# -- decoder
|
| 136 |
+
torch.cuda.empty_cache()
|
| 137 |
+
triplane_gen = self.img_to_triplane_decoder(input_view_feat) # [b, 3, tri_dim, h, w]
|
| 138 |
+
del input_view_feat
|
| 139 |
+
torch.cuda.empty_cache()
|
| 140 |
+
|
| 141 |
+
# --- triplane nerf render
|
| 142 |
+
|
| 143 |
+
cur_triplane = triplane_gen[0:1]
|
| 144 |
+
|
| 145 |
+
aabb = torch.tensor([[-0.6, -0.6, -0.6], [0.6, 0.6, 0.6]]).unsqueeze(0).to(**here)
|
| 146 |
+
grid_out = self.render.forward_grid(planes=cur_triplane, grid_size=mesh_size, aabb=aabb)
|
| 147 |
+
|
| 148 |
+
print(f"=====> LRM forward time: {time.time() - st}")
|
| 149 |
+
st = time.time()
|
| 150 |
+
|
| 151 |
+
vtx, faces = mcubes.marching_cubes(0. - grid_out['sdf'].squeeze(0).squeeze(-1).cpu().float().numpy(), 0)
|
| 152 |
+
|
| 153 |
+
bbox = aabb[0].cpu().numpy()
|
| 154 |
+
vtx = vtx / (mesh_size - 1)
|
| 155 |
+
vtx = vtx * (bbox[1] - bbox[0]) + bbox[0]
|
| 156 |
+
|
| 157 |
+
# refine mesh
|
| 158 |
+
vtx_refine, faces_refine, mesh = refine_mesh(vtx, faces)
|
| 159 |
+
|
| 160 |
+
# reduce faces
|
| 161 |
+
if faces_refine.shape[0] > target_face_count:
|
| 162 |
+
print(f"reduce face: {faces_refine.shape[0]} -> {target_face_count}")
|
| 163 |
+
mesh = o3d.geometry.TriangleMesh(
|
| 164 |
+
vertices = o3d.utility.Vector3dVector(vtx_refine),
|
| 165 |
+
triangles = o3d.utility.Vector3iVector(faces_refine)
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
# Function to simplify mesh using Quadric Error Metric Decimation by Garland and Heckbert
|
| 169 |
+
mesh = mesh.simplify_quadric_decimation(target_face_count, boundary_weight=1.0)
|
| 170 |
+
|
| 171 |
+
mesh = Mesh(
|
| 172 |
+
v_pos = torch.from_numpy(np.asarray(mesh.vertices)).to(self.device),
|
| 173 |
+
t_pos_idx = torch.from_numpy(np.asarray(mesh.triangles)).to(self.device),
|
| 174 |
+
v_rgb = torch.from_numpy(np.asarray(mesh.vertex_colors)).to(self.device)
|
| 175 |
+
)
|
| 176 |
+
vtx_refine = mesh.v_pos.cpu().numpy()
|
| 177 |
+
faces_refine = mesh.t_pos_idx.cpu().numpy()
|
| 178 |
+
|
| 179 |
+
vtx_colors = self.render.forward_points(cur_triplane, torch.tensor(vtx_refine).unsqueeze(0).to(**here))
|
| 180 |
+
vtx_colors = vtx_colors['rgb'].float().squeeze(0).cpu().numpy()
|
| 181 |
+
|
| 182 |
+
color_ratio = 0.8 # increase brightness
|
| 183 |
+
with open(f'{out_dir}/mesh_with_colors.obj', 'w') as fid:
|
| 184 |
+
verts = vtx_refine[:, [1,2,0]]
|
| 185 |
+
for pidx, pp in enumerate(verts):
|
| 186 |
+
color = vtx_colors[pidx]
|
| 187 |
+
color = [color[0]**color_ratio, color[1]**color_ratio, color[2]**color_ratio]
|
| 188 |
+
fid.write('v %f %f %f %f %f %f\n' % (pp[0], pp[1], pp[2], color[0], color[1], color[2]))
|
| 189 |
+
for i, f in enumerate(faces_refine):
|
| 190 |
+
f1 = f + 1
|
| 191 |
+
fid.write('f %d %d %d\n' % (f1[0], f1[1], f1[2]))
|
| 192 |
+
|
| 193 |
+
mesh = trimesh.load_mesh(f'{out_dir}/mesh_with_colors.obj')
|
| 194 |
+
print(f"=====> generate mesh with vertex shading time: {time.time() - st}")
|
| 195 |
+
st = time.time()
|
| 196 |
+
|
| 197 |
+
if not do_texture_mapping:
|
| 198 |
+
shutil.copy(f'{out_dir}/mesh_with_colors.obj', f'{out_dir}/mesh.obj')
|
| 199 |
+
mesh.export(f'{out_dir}/mesh.glb', file_type='glb')
|
| 200 |
+
return None
|
| 201 |
+
|
| 202 |
+
########## export texture ########
|
| 203 |
+
st = time.time()
|
| 204 |
+
|
| 205 |
+
# uv unwrap
|
| 206 |
+
vtx_tex, t_tex_idx = unwrap_uv(vtx_refine, faces_refine)
|
| 207 |
+
vtx_refine = torch.from_numpy(vtx_refine).to(self.device)
|
| 208 |
+
faces_refine = torch.from_numpy(faces_refine).to(self.device)
|
| 209 |
+
t_tex_idx = torch.from_numpy(t_tex_idx).to(self.device)
|
| 210 |
+
uv_clip = torch.from_numpy(vtx_tex * 2.0 - 1.0).to(self.device)
|
| 211 |
+
|
| 212 |
+
# rasterize
|
| 213 |
+
ctx = NVDiffRasterizerContext(context_type, cur_triplane.device) if ctx is None else ctx
|
| 214 |
+
rast = ctx.rasterize_one(
|
| 215 |
+
torch.cat([
|
| 216 |
+
uv_clip,
|
| 217 |
+
torch.zeros_like(uv_clip[..., 0:1]),
|
| 218 |
+
torch.ones_like(uv_clip[..., 0:1])
|
| 219 |
+
], dim=-1),
|
| 220 |
+
t_tex_idx,
|
| 221 |
+
(texture_res, texture_res)
|
| 222 |
+
)[0]
|
| 223 |
+
hole_mask = ~(rast[:, :, 3] > 0)
|
| 224 |
+
|
| 225 |
+
# Interpolate world space position
|
| 226 |
+
gb_pos = ctx.interpolate_one(vtx_refine, rast[None, ...], faces_refine)[0][0]
|
| 227 |
+
with torch.no_grad():
|
| 228 |
+
gb_mask_pos_scale = scale_tensor(gb_pos.unsqueeze(0).view(1, -1, 3), (-1, 1), (-1, 1))
|
| 229 |
+
tex_map = self.render.forward_points(cur_triplane, gb_mask_pos_scale)['rgb']
|
| 230 |
+
tex_map = tex_map.float().squeeze(0) # (0, 1)
|
| 231 |
+
tex_map = tex_map.view((texture_res, texture_res, 3))
|
| 232 |
+
img = uv_padding(tex_map, hole_mask)
|
| 233 |
+
img = ((img/255.0) ** color_ratio) * 255 # increase brightness
|
| 234 |
+
img = img.clip(0, 255).astype(np.uint8)
|
| 235 |
+
|
| 236 |
+
verts = vtx_refine.cpu().numpy()[:, [1,2,0]]
|
| 237 |
+
faces = faces_refine.cpu().numpy()
|
| 238 |
+
|
| 239 |
+
with open(f'{out_dir}/texture.mtl', 'w') as fid:
|
| 240 |
+
fid.write('newmtl material_0\n')
|
| 241 |
+
fid.write("Ka 1.000 1.000 1.000\n")
|
| 242 |
+
fid.write("Kd 1.000 1.000 1.000\n")
|
| 243 |
+
fid.write("Ks 0.000 0.000 0.000\n")
|
| 244 |
+
fid.write("d 1.0\n")
|
| 245 |
+
fid.write("illum 2\n")
|
| 246 |
+
fid.write(f'map_Kd texture.png\n')
|
| 247 |
+
|
| 248 |
+
with open(f'{out_dir}/mesh.obj', 'w') as fid:
|
| 249 |
+
fid.write(f'mtllib texture.mtl\n')
|
| 250 |
+
for pidx, pp in enumerate(verts):
|
| 251 |
+
fid.write('v %f %f %f\n' % (pp[0], pp[1], pp[2]))
|
| 252 |
+
for pidx, pp in enumerate(vtx_tex):
|
| 253 |
+
fid.write('vt %f %f\n' % (pp[0], 1 - pp[1]))
|
| 254 |
+
fid.write('usemtl material_0\n')
|
| 255 |
+
for i, f in enumerate(faces):
|
| 256 |
+
f1 = f + 1
|
| 257 |
+
f2 = t_tex_idx[i] + 1
|
| 258 |
+
fid.write('f %d/%d %d/%d %d/%d\n' % (f1[0], f2[0], f1[1], f2[1], f1[2], f2[2],))
|
| 259 |
+
|
| 260 |
+
cv2.imwrite(f'{out_dir}/texture.png', img[..., [2, 1, 0]])
|
| 261 |
+
mesh = trimesh.load_mesh(f'{out_dir}/mesh.obj')
|
| 262 |
+
mesh.export(f'{out_dir}/mesh.glb', file_type='glb')
|
| 263 |
+
|
svrm/ldm/modules/attention.py
ADDED
|
@@ -0,0 +1,457 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from inspect import isfunction
|
| 2 |
+
import math
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from torch import nn, einsum
|
| 6 |
+
from einops import rearrange, repeat
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
FLASH_IS_AVAILABLE = XFORMERS_IS_AVAILBLE = False
|
| 10 |
+
try:
|
| 11 |
+
from flash_attn import flash_attn_qkvpacked_func, flash_attn_func
|
| 12 |
+
FLASH_IS_AVAILABLE = True
|
| 13 |
+
except:
|
| 14 |
+
try:
|
| 15 |
+
import xformers
|
| 16 |
+
import xformers.ops
|
| 17 |
+
XFORMERS_IS_AVAILBLE = True
|
| 18 |
+
except:
|
| 19 |
+
pass
|
| 20 |
+
|
| 21 |
+
def exists(val):
|
| 22 |
+
return val is not None
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def uniq(arr):
|
| 26 |
+
return{el: True for el in arr}.keys()
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def default(val, d):
|
| 30 |
+
if exists(val):
|
| 31 |
+
return val
|
| 32 |
+
return d() if isfunction(d) else d
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def max_neg_value(t):
|
| 36 |
+
return -torch.finfo(t.dtype).max
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def init_(tensor):
|
| 40 |
+
dim = tensor.shape[-1]
|
| 41 |
+
std = 1 / math.sqrt(dim)
|
| 42 |
+
tensor.uniform_(-std, std)
|
| 43 |
+
return tensor
|
| 44 |
+
|
| 45 |
+
def checkpoint(func, inputs, params, flag):
|
| 46 |
+
"""
|
| 47 |
+
Evaluate a function without caching intermediate activations, allowing for
|
| 48 |
+
reduced memory at the expense of extra compute in the backward pass.
|
| 49 |
+
:param func: the function to evaluate.
|
| 50 |
+
:param inputs: the argument sequence to pass to `func`.
|
| 51 |
+
:param params: a sequence of parameters `func` depends on but does not
|
| 52 |
+
explicitly take as arguments.
|
| 53 |
+
:param flag: if False, disable gradient checkpointing.
|
| 54 |
+
"""
|
| 55 |
+
if flag:
|
| 56 |
+
args = tuple(inputs) + tuple(params)
|
| 57 |
+
return CheckpointFunction.apply(func, len(inputs), *args)
|
| 58 |
+
else:
|
| 59 |
+
return func(*inputs)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class CheckpointFunction(torch.autograd.Function):
|
| 63 |
+
@staticmethod
|
| 64 |
+
def forward(ctx, run_function, length, *args):
|
| 65 |
+
ctx.run_function = run_function
|
| 66 |
+
ctx.input_tensors = list(args[:length])
|
| 67 |
+
ctx.input_params = list(args[length:])
|
| 68 |
+
|
| 69 |
+
with torch.no_grad():
|
| 70 |
+
output_tensors = ctx.run_function(*ctx.input_tensors)
|
| 71 |
+
return output_tensors
|
| 72 |
+
|
| 73 |
+
@staticmethod
|
| 74 |
+
def backward(ctx, *output_grads):
|
| 75 |
+
ctx.input_tensors = [x.detach().requires_grad_(True) for x in ctx.input_tensors]
|
| 76 |
+
with torch.enable_grad():
|
| 77 |
+
# Fixes a bug where the first op in run_function modifies the
|
| 78 |
+
# Tensor storage in place, which is not allowed for detach()'d
|
| 79 |
+
# Tensors.
|
| 80 |
+
shallow_copies = [x.view_as(x) for x in ctx.input_tensors]
|
| 81 |
+
output_tensors = ctx.run_function(*shallow_copies)
|
| 82 |
+
input_grads = torch.autograd.grad(
|
| 83 |
+
output_tensors,
|
| 84 |
+
ctx.input_tensors + ctx.input_params,
|
| 85 |
+
output_grads,
|
| 86 |
+
allow_unused=True,
|
| 87 |
+
)
|
| 88 |
+
del ctx.input_tensors
|
| 89 |
+
del ctx.input_params
|
| 90 |
+
del output_tensors
|
| 91 |
+
return (None, None) + input_grads
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
# feedforward
|
| 95 |
+
class GEGLU(nn.Module):
|
| 96 |
+
def __init__(self, dim_in, dim_out):
|
| 97 |
+
super().__init__()
|
| 98 |
+
self.proj = nn.Linear(dim_in, dim_out * 2)
|
| 99 |
+
|
| 100 |
+
def forward(self, x):
|
| 101 |
+
x, gate = self.proj(x).chunk(2, dim=-1)
|
| 102 |
+
return x * F.gelu(gate)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
class FeedForward(nn.Module):
|
| 106 |
+
def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.):
|
| 107 |
+
super().__init__()
|
| 108 |
+
inner_dim = int(dim * mult)
|
| 109 |
+
dim_out = default(dim_out, dim)
|
| 110 |
+
project_in = nn.Sequential(
|
| 111 |
+
nn.Linear(dim, inner_dim),
|
| 112 |
+
nn.GELU()
|
| 113 |
+
) if not glu else GEGLU(dim, inner_dim)
|
| 114 |
+
|
| 115 |
+
self.net = nn.Sequential(
|
| 116 |
+
project_in,
|
| 117 |
+
nn.Dropout(dropout),
|
| 118 |
+
nn.Linear(inner_dim, dim_out)
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
def forward(self, x):
|
| 122 |
+
return self.net(x)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def zero_module(module):
|
| 126 |
+
"""
|
| 127 |
+
Zero out the parameters of a module and return it.
|
| 128 |
+
"""
|
| 129 |
+
for p in module.parameters():
|
| 130 |
+
p.detach().zero_()
|
| 131 |
+
return module
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
def Normalize(in_channels):
|
| 135 |
+
return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class LinearAttention(nn.Module):
|
| 139 |
+
def __init__(self, dim, heads=4, dim_head=32):
|
| 140 |
+
super().__init__()
|
| 141 |
+
self.heads = heads
|
| 142 |
+
hidden_dim = dim_head * heads
|
| 143 |
+
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias = False)
|
| 144 |
+
self.to_out = nn.Conv2d(hidden_dim, dim, 1)
|
| 145 |
+
|
| 146 |
+
def forward(self, x):
|
| 147 |
+
b, c, h, w = x.shape
|
| 148 |
+
qkv = self.to_qkv(x)
|
| 149 |
+
q, k, v = rearrange(qkv, 'b (qkv heads c) h w -> qkv b heads c (h w)', heads = self.heads, qkv=3)
|
| 150 |
+
k = k.softmax(dim=-1)
|
| 151 |
+
context = torch.einsum('bhdn,bhen->bhde', k, v)
|
| 152 |
+
out = torch.einsum('bhde,bhdn->bhen', context, q)
|
| 153 |
+
out = rearrange(out, 'b heads c (h w) -> b (heads c) h w', heads=self.heads, h=h, w=w)
|
| 154 |
+
return self.to_out(out)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
class SpatialSelfAttention(nn.Module):
|
| 158 |
+
def __init__(self, in_channels):
|
| 159 |
+
super().__init__()
|
| 160 |
+
self.in_channels = in_channels
|
| 161 |
+
|
| 162 |
+
self.norm = Normalize(in_channels)
|
| 163 |
+
self.q = torch.nn.Conv2d(in_channels,
|
| 164 |
+
in_channels,
|
| 165 |
+
kernel_size=1,
|
| 166 |
+
stride=1,
|
| 167 |
+
padding=0)
|
| 168 |
+
self.k = torch.nn.Conv2d(in_channels,
|
| 169 |
+
in_channels,
|
| 170 |
+
kernel_size=1,
|
| 171 |
+
stride=1,
|
| 172 |
+
padding=0)
|
| 173 |
+
self.v = torch.nn.Conv2d(in_channels,
|
| 174 |
+
in_channels,
|
| 175 |
+
kernel_size=1,
|
| 176 |
+
stride=1,
|
| 177 |
+
padding=0)
|
| 178 |
+
self.proj_out = torch.nn.Conv2d(in_channels,
|
| 179 |
+
in_channels,
|
| 180 |
+
kernel_size=1,
|
| 181 |
+
stride=1,
|
| 182 |
+
padding=0)
|
| 183 |
+
|
| 184 |
+
def forward(self, x):
|
| 185 |
+
h_ = x
|
| 186 |
+
h_ = self.norm(h_)
|
| 187 |
+
q = self.q(h_)
|
| 188 |
+
k = self.k(h_)
|
| 189 |
+
v = self.v(h_)
|
| 190 |
+
|
| 191 |
+
# compute attention
|
| 192 |
+
b,c,h,w = q.shape
|
| 193 |
+
q = rearrange(q, 'b c h w -> b (h w) c')
|
| 194 |
+
k = rearrange(k, 'b c h w -> b c (h w)')
|
| 195 |
+
w_ = torch.einsum('bij,bjk->bik', q, k)
|
| 196 |
+
|
| 197 |
+
w_ = w_ * (int(c)**(-0.5))
|
| 198 |
+
w_ = torch.nn.functional.softmax(w_, dim=2)
|
| 199 |
+
|
| 200 |
+
# attend to values
|
| 201 |
+
v = rearrange(v, 'b c h w -> b c (h w)')
|
| 202 |
+
w_ = rearrange(w_, 'b i j -> b j i')
|
| 203 |
+
h_ = torch.einsum('bij,bjk->bik', v, w_)
|
| 204 |
+
h_ = rearrange(h_, 'b c (h w) -> b c h w', h=h)
|
| 205 |
+
h_ = self.proj_out(h_)
|
| 206 |
+
|
| 207 |
+
return x+h_
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
class CrossAttention(nn.Module):
|
| 211 |
+
def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.):
|
| 212 |
+
super().__init__()
|
| 213 |
+
inner_dim = dim_head * heads
|
| 214 |
+
context_dim = default(context_dim, query_dim)
|
| 215 |
+
self.scale = dim_head ** -0.5
|
| 216 |
+
self.heads = heads
|
| 217 |
+
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
|
| 218 |
+
self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
|
| 219 |
+
self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
|
| 220 |
+
|
| 221 |
+
self.to_out = nn.Sequential(
|
| 222 |
+
nn.Linear(inner_dim, query_dim),
|
| 223 |
+
nn.Dropout(dropout)
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
def forward(self, x, context=None, mask=None):
|
| 227 |
+
h = self.heads
|
| 228 |
+
q = self.to_q(x)
|
| 229 |
+
context = default(context, x)
|
| 230 |
+
k = self.to_k(context)
|
| 231 |
+
v = self.to_v(context)
|
| 232 |
+
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
|
| 233 |
+
sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
|
| 234 |
+
if exists(mask):
|
| 235 |
+
mask = rearrange(mask, 'b ... -> b (...)')
|
| 236 |
+
max_neg_value = -torch.finfo(sim.dtype).max
|
| 237 |
+
mask = repeat(mask, 'b j -> (b h) () j', h=h)
|
| 238 |
+
sim.masked_fill_(~mask, max_neg_value)
|
| 239 |
+
# attention, what we cannot get enough of
|
| 240 |
+
attn = sim.softmax(dim=-1)
|
| 241 |
+
out = einsum('b i j, b j d -> b i d', attn, v) # [b*h, n, d]
|
| 242 |
+
out = rearrange(out, '(b h) n d -> b n (h d)', h=h)
|
| 243 |
+
return self.to_out(out)
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
class FlashAttention(nn.Module):
|
| 247 |
+
def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.):
|
| 248 |
+
super().__init__()
|
| 249 |
+
print(f"Setting up {self.__class__.__name__}. Query dim is {query_dim}, context_dim is {context_dim} and using "
|
| 250 |
+
f"{heads} heads.")
|
| 251 |
+
inner_dim = dim_head * heads
|
| 252 |
+
context_dim = default(context_dim, query_dim)
|
| 253 |
+
self.scale = dim_head ** -0.5
|
| 254 |
+
self.heads = heads
|
| 255 |
+
self.dropout = dropout
|
| 256 |
+
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
|
| 257 |
+
self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
|
| 258 |
+
self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
|
| 259 |
+
self.to_out = nn.Sequential(
|
| 260 |
+
nn.Linear(inner_dim, query_dim),
|
| 261 |
+
nn.Dropout(dropout)
|
| 262 |
+
)
|
| 263 |
+
|
| 264 |
+
def forward(self, x, context=None, mask=None):
|
| 265 |
+
context = default(context, x)
|
| 266 |
+
h = self.heads
|
| 267 |
+
dtype = torch.bfloat16 # torch.half
|
| 268 |
+
q = self.to_q(x).to(dtype)
|
| 269 |
+
k = self.to_k(context).to(dtype)
|
| 270 |
+
v = self.to_v(context).to(dtype)
|
| 271 |
+
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b n h d', h=h), (q, k, v)) # q is [b, 3079, 16, 64]
|
| 272 |
+
out = flash_attn_func(q, k, v, dropout_p=self.dropout, softmax_scale=None, causal=False, window_size=(-1, -1)) # out is same shape to q
|
| 273 |
+
out = rearrange(out, 'b n h d -> b n (h d)', h=h)
|
| 274 |
+
return self.to_out(out.float())
|
| 275 |
+
|
| 276 |
+
class MemoryEfficientCrossAttention(nn.Module):
|
| 277 |
+
# https://github.com/MatthieuTPHR/diffusers/blob/d80b531ff8060ec1ea982b65a1b8df70f73aa67c/src/diffusers/models/attention.py#L223
|
| 278 |
+
def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.0):
|
| 279 |
+
super().__init__()
|
| 280 |
+
print(f"Setting up {self.__class__.__name__}. Query dim is {query_dim}, context_dim is {context_dim} and using "
|
| 281 |
+
f"{heads} heads.")
|
| 282 |
+
inner_dim = dim_head * heads
|
| 283 |
+
context_dim = default(context_dim, query_dim)
|
| 284 |
+
|
| 285 |
+
self.heads = heads
|
| 286 |
+
self.dim_head = dim_head
|
| 287 |
+
|
| 288 |
+
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
|
| 289 |
+
self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
|
| 290 |
+
self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
|
| 291 |
+
|
| 292 |
+
self.to_out = nn.Sequential(nn.Linear(inner_dim, query_dim), nn.Dropout(dropout))
|
| 293 |
+
self.attention_op: Optional[Any] = None
|
| 294 |
+
|
| 295 |
+
def forward(self, x, context=None, mask=None):
|
| 296 |
+
q = self.to_q(x)
|
| 297 |
+
context = default(context, x)
|
| 298 |
+
k = self.to_k(context)
|
| 299 |
+
v = self.to_v(context)
|
| 300 |
+
|
| 301 |
+
b, _, _ = q.shape
|
| 302 |
+
q, k, v = map(
|
| 303 |
+
lambda t: t.unsqueeze(3)
|
| 304 |
+
.reshape(b, t.shape[1], self.heads, self.dim_head)
|
| 305 |
+
.permute(0, 2, 1, 3)
|
| 306 |
+
.reshape(b * self.heads, t.shape[1], self.dim_head)
|
| 307 |
+
.contiguous(),
|
| 308 |
+
(q, k, v),
|
| 309 |
+
)
|
| 310 |
+
|
| 311 |
+
# actually compute the attention, what we cannot get enough of
|
| 312 |
+
out = xformers.ops.memory_efficient_attention(q, k, v, attn_bias=None, op=self.attention_op)
|
| 313 |
+
|
| 314 |
+
if exists(mask):
|
| 315 |
+
raise NotImplementedError
|
| 316 |
+
out = (
|
| 317 |
+
out.unsqueeze(0)
|
| 318 |
+
.reshape(b, self.heads, out.shape[1], self.dim_head)
|
| 319 |
+
.permute(0, 2, 1, 3)
|
| 320 |
+
.reshape(b, out.shape[1], self.heads * self.dim_head)
|
| 321 |
+
)
|
| 322 |
+
return self.to_out(out)
|
| 323 |
+
|
| 324 |
+
class BasicTransformerBlock(nn.Module):
|
| 325 |
+
def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True, checkpoint=True,
|
| 326 |
+
disable_self_attn=False):
|
| 327 |
+
super().__init__()
|
| 328 |
+
self.disable_self_attn = disable_self_attn
|
| 329 |
+
self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout,
|
| 330 |
+
context_dim=context_dim if self.disable_self_attn else None) # is a self-attention if not self.disable_self_attn
|
| 331 |
+
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
|
| 332 |
+
self.attn2 = CrossAttention(query_dim=dim, context_dim=context_dim,
|
| 333 |
+
heads=n_heads, dim_head=d_head, dropout=dropout) # is self-attn if context is none
|
| 334 |
+
self.norm1 = Fp32LayerNorm(dim)
|
| 335 |
+
self.norm2 = Fp32LayerNorm(dim)
|
| 336 |
+
self.norm3 = Fp32LayerNorm(dim)
|
| 337 |
+
self.checkpoint = checkpoint
|
| 338 |
+
|
| 339 |
+
def forward(self, x, context=None):
|
| 340 |
+
return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
|
| 341 |
+
|
| 342 |
+
def _forward(self, x, context=None):
|
| 343 |
+
x = self.attn1(self.norm1(x), context=context if self.disable_self_attn else None) + x
|
| 344 |
+
x = self.attn2(self.norm2(x), context=context) + x
|
| 345 |
+
x = self.ff(self.norm3(x)) + x
|
| 346 |
+
return x
|
| 347 |
+
|
| 348 |
+
ATTENTION_MODES = {
|
| 349 |
+
"softmax": CrossAttention, # vanilla attention
|
| 350 |
+
"softmax-xformers": MemoryEfficientCrossAttention,
|
| 351 |
+
"softmax-flash": FlashAttention
|
| 352 |
+
}
|
| 353 |
+
|
| 354 |
+
def modulate(x, shift, scale):
|
| 355 |
+
return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1)
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
class Fp32LayerNorm(nn.LayerNorm):
|
| 359 |
+
def __init__(self, *args, **kwargs):
|
| 360 |
+
super().__init__(*args, **kwargs)
|
| 361 |
+
def forward(self, x):
|
| 362 |
+
return super().forward(x.float()).type(x.dtype)
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
class AdaNorm(nn.Module):
|
| 366 |
+
def __init__(self, dim):
|
| 367 |
+
super().__init__()
|
| 368 |
+
self.adaLN_modulation = nn.Sequential(
|
| 369 |
+
nn.SiLU(),
|
| 370 |
+
nn.Linear(dim, 2 * dim, bias=True)
|
| 371 |
+
)
|
| 372 |
+
self.norm = Fp32LayerNorm(dim, elementwise_affine=False, eps=1e-6)
|
| 373 |
+
|
| 374 |
+
def forward(self, x, c): # x is fp32, c is fp16
|
| 375 |
+
shift, scale = self.adaLN_modulation(c.float()).chunk(2, dim=1) # bf16
|
| 376 |
+
x = modulate(self.norm(x), shift, scale) # fp32
|
| 377 |
+
return x
|
| 378 |
+
|
| 379 |
+
|
| 380 |
+
class BasicTransformerBlockLRM(nn.Module):
|
| 381 |
+
def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True, \
|
| 382 |
+
checkpoint=True):
|
| 383 |
+
super().__init__()
|
| 384 |
+
|
| 385 |
+
attn_mode = "softmax-xformers" if XFORMERS_IS_AVAILBLE else "softmax"
|
| 386 |
+
attn_mode = "softmax-flash" if FLASH_IS_AVAILABLE else attn_mode
|
| 387 |
+
assert attn_mode in ATTENTION_MODES
|
| 388 |
+
attn_cls = ATTENTION_MODES[attn_mode]
|
| 389 |
+
|
| 390 |
+
self.attn1 = attn_cls(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout, \
|
| 391 |
+
context_dim=context_dim) # cross-attn
|
| 392 |
+
self.attn2 = attn_cls(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout, \
|
| 393 |
+
context_dim=None) # self-attn
|
| 394 |
+
|
| 395 |
+
self.norm1 = Fp32LayerNorm(dim)
|
| 396 |
+
self.norm2 = Fp32LayerNorm(dim)
|
| 397 |
+
self.norm3 = Fp32LayerNorm(dim)
|
| 398 |
+
|
| 399 |
+
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
|
| 400 |
+
self.checkpoint = checkpoint
|
| 401 |
+
|
| 402 |
+
def forward(self, x, context=None, cam_emb=None): # (torch.float32, torch.float32, torch.bfloat16)
|
| 403 |
+
return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
|
| 404 |
+
|
| 405 |
+
|
| 406 |
+
def _forward(self, x, context=None, cam_emb=None):
|
| 407 |
+
|
| 408 |
+
x = self.attn1(self.norm1(x), context=context) + x # cross-attn
|
| 409 |
+
x = self.attn2(self.norm2(x), context=None) + x # self-attn
|
| 410 |
+
x = self.ff(self.norm3(x)) + x
|
| 411 |
+
|
| 412 |
+
return x
|
| 413 |
+
|
| 414 |
+
class ImgToTriplaneTransformer(nn.Module):
|
| 415 |
+
"""
|
| 416 |
+
Transformer block for image-like data.
|
| 417 |
+
First, project the input (aka embedding)
|
| 418 |
+
and reshape to b, t, d.
|
| 419 |
+
Then apply standard transformer action.
|
| 420 |
+
Finally, reshape to image
|
| 421 |
+
"""
|
| 422 |
+
def __init__(self, query_dim, n_heads, d_head, depth=1, dropout=0., context_dim=None, triplane_size=64):
|
| 423 |
+
super().__init__()
|
| 424 |
+
|
| 425 |
+
self.transformer_blocks = nn.ModuleList([
|
| 426 |
+
BasicTransformerBlockLRM(query_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
|
| 427 |
+
for d in range(depth)])
|
| 428 |
+
|
| 429 |
+
self.norm = Fp32LayerNorm(query_dim, eps=1e-6)
|
| 430 |
+
|
| 431 |
+
self.initialize_weights()
|
| 432 |
+
|
| 433 |
+
def initialize_weights(self):
|
| 434 |
+
# Initialize transformer layers:
|
| 435 |
+
def _basic_init(module):
|
| 436 |
+
if isinstance(module, nn.Linear):
|
| 437 |
+
torch.nn.init.xavier_uniform_(module.weight)
|
| 438 |
+
if module.bias is not None:
|
| 439 |
+
nn.init.constant_(module.bias, 0)
|
| 440 |
+
elif isinstance(module, nn.LayerNorm):
|
| 441 |
+
if module.bias is not None:
|
| 442 |
+
nn.init.constant_(module.bias, 0)
|
| 443 |
+
if module.weight is not None:
|
| 444 |
+
nn.init.constant_(module.weight, 1.0)
|
| 445 |
+
self.apply(_basic_init)
|
| 446 |
+
|
| 447 |
+
def forward(self, x, context=None, cam_emb=None):
|
| 448 |
+
# note: if no context is given, cross-attention defaults to self-attention
|
| 449 |
+
for block in self.transformer_blocks:
|
| 450 |
+
x = block(x, context=context)
|
| 451 |
+
x = self.norm(x)
|
| 452 |
+
return x
|
| 453 |
+
|
| 454 |
+
|
| 455 |
+
|
| 456 |
+
|
| 457 |
+
|
svrm/ldm/modules/encoders/__init__.py
ADDED
|
File without changes
|
svrm/ldm/modules/encoders/dinov2/__init__.py
ADDED
|
File without changes
|
svrm/ldm/modules/encoders/dinov2/hub/__init__.py
ADDED
|
File without changes
|
svrm/ldm/modules/encoders/dinov2/hub/backbones.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the Apache License, Version 2.0
|
| 4 |
+
# found in the LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
from enum import Enum
|
| 7 |
+
from typing import Union
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
|
| 11 |
+
from .utils import _DINOV2_BASE_URL, _make_dinov2_model_name
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class Weights(Enum):
|
| 15 |
+
LVD142M = "LVD142M"
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def _make_dinov2_model(
|
| 19 |
+
*,
|
| 20 |
+
arch_name: str = "vit_large",
|
| 21 |
+
img_size: int = 518,
|
| 22 |
+
patch_size: int = 14,
|
| 23 |
+
init_values: float = 1.0,
|
| 24 |
+
ffn_layer: str = "mlp",
|
| 25 |
+
block_chunks: int = 0,
|
| 26 |
+
num_register_tokens: int = 0,
|
| 27 |
+
interpolate_antialias: bool = False,
|
| 28 |
+
interpolate_offset: float = 0.1,
|
| 29 |
+
pretrained: bool = True,
|
| 30 |
+
weights: Union[Weights, str] = Weights.LVD142M,
|
| 31 |
+
**kwargs,
|
| 32 |
+
):
|
| 33 |
+
from ..models import vision_transformer as vits
|
| 34 |
+
|
| 35 |
+
if isinstance(weights, str):
|
| 36 |
+
try:
|
| 37 |
+
weights = Weights[weights]
|
| 38 |
+
except KeyError:
|
| 39 |
+
raise AssertionError(f"Unsupported weights: {weights}")
|
| 40 |
+
|
| 41 |
+
model_base_name = _make_dinov2_model_name(arch_name, patch_size)
|
| 42 |
+
vit_kwargs = dict(
|
| 43 |
+
img_size=img_size,
|
| 44 |
+
patch_size=patch_size,
|
| 45 |
+
init_values=init_values,
|
| 46 |
+
ffn_layer=ffn_layer,
|
| 47 |
+
block_chunks=block_chunks,
|
| 48 |
+
num_register_tokens=num_register_tokens,
|
| 49 |
+
interpolate_antialias=interpolate_antialias,
|
| 50 |
+
interpolate_offset=interpolate_offset,
|
| 51 |
+
)
|
| 52 |
+
vit_kwargs.update(**kwargs)
|
| 53 |
+
model = vits.__dict__[arch_name](**vit_kwargs)
|
| 54 |
+
|
| 55 |
+
if pretrained:
|
| 56 |
+
model_full_name = _make_dinov2_model_name(arch_name, patch_size, num_register_tokens)
|
| 57 |
+
url = _DINOV2_BASE_URL + f"/{model_base_name}/{model_full_name}_pretrain.pth"
|
| 58 |
+
state_dict = torch.hub.load_state_dict_from_url(url, map_location="cpu")
|
| 59 |
+
model.load_state_dict(state_dict, strict=True)
|
| 60 |
+
|
| 61 |
+
return model
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def dinov2_vits14(*, pretrained: bool = True, weights: Union[Weights, str] = Weights.LVD142M, **kwargs):
|
| 65 |
+
"""
|
| 66 |
+
DINOv2 ViT-S/14 model (optionally) pretrained on the LVD-142M dataset.
|
| 67 |
+
"""
|
| 68 |
+
return _make_dinov2_model(arch_name="vit_small", pretrained=pretrained, weights=weights, **kwargs)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def dinov2_vitb14(*, pretrained: bool = True, weights: Union[Weights, str] = Weights.LVD142M, **kwargs):
|
| 72 |
+
"""
|
| 73 |
+
DINOv2 ViT-B/14 model (optionally) pretrained on the LVD-142M dataset.
|
| 74 |
+
"""
|
| 75 |
+
return _make_dinov2_model(arch_name="vit_base", pretrained=pretrained, weights=weights, **kwargs)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def dinov2_vitl14(*, pretrained: bool = True, weights: Union[Weights, str] = Weights.LVD142M, **kwargs):
|
| 79 |
+
"""
|
| 80 |
+
DINOv2 ViT-L/14 model (optionally) pretrained on the LVD-142M dataset.
|
| 81 |
+
"""
|
| 82 |
+
return _make_dinov2_model(arch_name="vit_large", pretrained=pretrained, weights=weights, **kwargs)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def dinov2_vitg14(*, pretrained: bool = True, weights: Union[Weights, str] = Weights.LVD142M, **kwargs):
|
| 86 |
+
"""
|
| 87 |
+
DINOv2 ViT-g/14 model (optionally) pretrained on the LVD-142M dataset.
|
| 88 |
+
"""
|
| 89 |
+
return _make_dinov2_model(
|
| 90 |
+
arch_name="vit_giant2",
|
| 91 |
+
ffn_layer="swiglufused",
|
| 92 |
+
weights=weights,
|
| 93 |
+
pretrained=pretrained,
|
| 94 |
+
**kwargs,
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def dinov2_vits14_reg(*, pretrained: bool = True, weights: Union[Weights, str] = Weights.LVD142M, **kwargs):
|
| 99 |
+
"""
|
| 100 |
+
DINOv2 ViT-S/14 model with registers (optionally) pretrained on the LVD-142M dataset.
|
| 101 |
+
"""
|
| 102 |
+
return _make_dinov2_model(
|
| 103 |
+
arch_name="vit_small",
|
| 104 |
+
pretrained=pretrained,
|
| 105 |
+
weights=weights,
|
| 106 |
+
num_register_tokens=4,
|
| 107 |
+
interpolate_antialias=True,
|
| 108 |
+
interpolate_offset=0.0,
|
| 109 |
+
**kwargs,
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def dinov2_vitb14_reg(*, pretrained: bool = True, weights: Union[Weights, str] = Weights.LVD142M, **kwargs):
|
| 114 |
+
"""
|
| 115 |
+
DINOv2 ViT-B/14 model with registers (optionally) pretrained on the LVD-142M dataset.
|
| 116 |
+
"""
|
| 117 |
+
return _make_dinov2_model(
|
| 118 |
+
arch_name="vit_base",
|
| 119 |
+
pretrained=pretrained,
|
| 120 |
+
weights=weights,
|
| 121 |
+
num_register_tokens=4,
|
| 122 |
+
interpolate_antialias=True,
|
| 123 |
+
interpolate_offset=0.0,
|
| 124 |
+
**kwargs,
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def dinov2_vitl14_reg(*, pretrained: bool = True, weights: Union[Weights, str] = Weights.LVD142M, **kwargs):
|
| 129 |
+
"""
|
| 130 |
+
DINOv2 ViT-L/14 model with registers (optionally) pretrained on the LVD-142M dataset.
|
| 131 |
+
"""
|
| 132 |
+
return _make_dinov2_model(
|
| 133 |
+
arch_name="vit_large",
|
| 134 |
+
pretrained=pretrained,
|
| 135 |
+
weights=weights,
|
| 136 |
+
num_register_tokens=4,
|
| 137 |
+
interpolate_antialias=True,
|
| 138 |
+
interpolate_offset=0.0,
|
| 139 |
+
**kwargs,
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def dinov2_vitg14_reg(*, pretrained: bool = True, weights: Union[Weights, str] = Weights.LVD142M, **kwargs):
|
| 144 |
+
"""
|
| 145 |
+
DINOv2 ViT-g/14 model with registers (optionally) pretrained on the LVD-142M dataset.
|
| 146 |
+
"""
|
| 147 |
+
return _make_dinov2_model(
|
| 148 |
+
arch_name="vit_giant2",
|
| 149 |
+
ffn_layer="swiglufused",
|
| 150 |
+
weights=weights,
|
| 151 |
+
pretrained=pretrained,
|
| 152 |
+
num_register_tokens=4,
|
| 153 |
+
interpolate_antialias=True,
|
| 154 |
+
interpolate_offset=0.0,
|
| 155 |
+
**kwargs,
|
| 156 |
+
)
|
svrm/ldm/modules/encoders/dinov2/hub/utils.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the Apache License, Version 2.0
|
| 4 |
+
# found in the LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import itertools
|
| 7 |
+
import math
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
_DINOV2_BASE_URL = "https://dl.fbaipublicfiles.com/dinov2"
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def _make_dinov2_model_name(arch_name: str, patch_size: int, num_register_tokens: int = 0) -> str:
|
| 18 |
+
compact_arch_name = arch_name.replace("_", "")[:4]
|
| 19 |
+
registers_suffix = f"_reg{num_register_tokens}" if num_register_tokens else ""
|
| 20 |
+
return f"dinov2_{compact_arch_name}{patch_size}{registers_suffix}"
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class CenterPadding(nn.Module):
|
| 24 |
+
def __init__(self, multiple):
|
| 25 |
+
super().__init__()
|
| 26 |
+
self.multiple = multiple
|
| 27 |
+
|
| 28 |
+
def _get_pad(self, size):
|
| 29 |
+
new_size = math.ceil(size / self.multiple) * self.multiple
|
| 30 |
+
pad_size = new_size - size
|
| 31 |
+
pad_size_left = pad_size // 2
|
| 32 |
+
pad_size_right = pad_size - pad_size_left
|
| 33 |
+
return pad_size_left, pad_size_right
|
| 34 |
+
|
| 35 |
+
@torch.inference_mode()
|
| 36 |
+
def forward(self, x):
|
| 37 |
+
pads = list(itertools.chain.from_iterable(self._get_pad(m) for m in x.shape[:1:-1]))
|
| 38 |
+
output = F.pad(x, pads)
|
| 39 |
+
return output
|
svrm/ldm/modules/encoders/dinov2/layers/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the Apache License, Version 2.0
|
| 4 |
+
# found in the LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
from .dino_head import DINOHead
|
| 7 |
+
from .mlp import Mlp
|
| 8 |
+
from .patch_embed import PatchEmbed
|
| 9 |
+
from .swiglu_ffn import SwiGLUFFN, SwiGLUFFNFused
|
| 10 |
+
from .block import NestedTensorBlockMod
|
| 11 |
+
from .attention import MemEffAttention
|
svrm/ldm/modules/encoders/dinov2/layers/attention.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the Apache License, Version 2.0
|
| 4 |
+
# found in the LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
# References:
|
| 7 |
+
# https://github.com/facebookresearch/dino/blob/master/vision_transformer.py
|
| 8 |
+
# https://github.com/rwightman/pytorch-image-models/tree/master/timm/models/vision_transformer.py
|
| 9 |
+
|
| 10 |
+
import logging
|
| 11 |
+
import os
|
| 12 |
+
import warnings
|
| 13 |
+
|
| 14 |
+
from torch import Tensor
|
| 15 |
+
from torch import nn
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
logger = logging.getLogger("dinov2")
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
XFORMERS_ENABLED = os.environ.get("XFORMERS_DISABLED") is None
|
| 22 |
+
try:
|
| 23 |
+
if XFORMERS_ENABLED:
|
| 24 |
+
from xformers.ops import memory_efficient_attention, unbind
|
| 25 |
+
|
| 26 |
+
XFORMERS_AVAILABLE = True
|
| 27 |
+
warnings.warn("xFormers is available (Attention)")
|
| 28 |
+
else:
|
| 29 |
+
warnings.warn("xFormers is disabled (Attention)")
|
| 30 |
+
raise ImportError
|
| 31 |
+
except ImportError:
|
| 32 |
+
XFORMERS_AVAILABLE = False
|
| 33 |
+
warnings.warn("xFormers is not available (Attention)")
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class Attention(nn.Module):
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
dim: int,
|
| 40 |
+
num_heads: int = 8,
|
| 41 |
+
qkv_bias: bool = False,
|
| 42 |
+
proj_bias: bool = True,
|
| 43 |
+
attn_drop: float = 0.0,
|
| 44 |
+
proj_drop: float = 0.0,
|
| 45 |
+
) -> None:
|
| 46 |
+
super().__init__()
|
| 47 |
+
self.num_heads = num_heads
|
| 48 |
+
head_dim = dim // num_heads
|
| 49 |
+
self.scale = head_dim**-0.5
|
| 50 |
+
|
| 51 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 52 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 53 |
+
self.proj = nn.Linear(dim, dim, bias=proj_bias)
|
| 54 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 55 |
+
|
| 56 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 57 |
+
B, N, C = x.shape
|
| 58 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 59 |
+
|
| 60 |
+
q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
|
| 61 |
+
attn = q @ k.transpose(-2, -1)
|
| 62 |
+
|
| 63 |
+
attn = attn.softmax(dim=-1)
|
| 64 |
+
attn = self.attn_drop(attn)
|
| 65 |
+
|
| 66 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 67 |
+
x = self.proj(x)
|
| 68 |
+
x = self.proj_drop(x)
|
| 69 |
+
return x
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
class MemEffAttention(Attention):
|
| 73 |
+
def forward(self, x: Tensor, attn_bias=None) -> Tensor:
|
| 74 |
+
if not XFORMERS_AVAILABLE:
|
| 75 |
+
if attn_bias is not None:
|
| 76 |
+
raise AssertionError("xFormers is required for using nested tensors")
|
| 77 |
+
return super().forward(x)
|
| 78 |
+
|
| 79 |
+
B, N, C = x.shape
|
| 80 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads)
|
| 81 |
+
|
| 82 |
+
q, k, v = unbind(qkv, 2)
|
| 83 |
+
|
| 84 |
+
x = memory_efficient_attention(q, k, v, attn_bias=attn_bias)
|
| 85 |
+
x = x.reshape([B, N, C])
|
| 86 |
+
|
| 87 |
+
x = self.proj(x)
|
| 88 |
+
x = self.proj_drop(x)
|
| 89 |
+
return x
|
svrm/ldm/modules/encoders/dinov2/layers/block.py
ADDED
|
@@ -0,0 +1,269 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the Apache License, Version 2.0
|
| 4 |
+
# found in the LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
# References:
|
| 7 |
+
# https://github.com/facebookresearch/dino/blob/master/vision_transformer.py
|
| 8 |
+
# https://github.com/rwightman/pytorch-image-models/tree/master/timm/layers/patch_embed.py
|
| 9 |
+
|
| 10 |
+
import os
|
| 11 |
+
import logging
|
| 12 |
+
import warnings
|
| 13 |
+
from typing import Callable, List, Any, Tuple, Dict
|
| 14 |
+
|
| 15 |
+
import torch
|
| 16 |
+
from torch import nn, Tensor
|
| 17 |
+
|
| 18 |
+
from .attention import Attention, MemEffAttention
|
| 19 |
+
from .drop_path import DropPath
|
| 20 |
+
from .layer_scale import LayerScale
|
| 21 |
+
from .mlp import Mlp
|
| 22 |
+
|
| 23 |
+
from ....attention import AdaNorm
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
logger = logging.getLogger("dinov2")
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
XFORMERS_ENABLED = os.environ.get("XFORMERS_DISABLED") is None
|
| 30 |
+
try:
|
| 31 |
+
if XFORMERS_ENABLED:
|
| 32 |
+
from xformers.ops import fmha, scaled_index_add, index_select_cat
|
| 33 |
+
|
| 34 |
+
XFORMERS_AVAILABLE = True
|
| 35 |
+
warnings.warn("xFormers is available (Block)")
|
| 36 |
+
else:
|
| 37 |
+
warnings.warn("xFormers is disabled (Block)")
|
| 38 |
+
raise ImportError
|
| 39 |
+
except ImportError:
|
| 40 |
+
XFORMERS_AVAILABLE = False
|
| 41 |
+
|
| 42 |
+
warnings.warn("xFormers is not available (Block)")
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class BlockMod(nn.Module):
|
| 46 |
+
'''
|
| 47 |
+
using Modified Block, see below
|
| 48 |
+
'''
|
| 49 |
+
def __init__(
|
| 50 |
+
self,
|
| 51 |
+
dim: int,
|
| 52 |
+
num_heads: int,
|
| 53 |
+
mlp_ratio: float = 4.0,
|
| 54 |
+
qkv_bias: bool = False,
|
| 55 |
+
proj_bias: bool = True,
|
| 56 |
+
ffn_bias: bool = True,
|
| 57 |
+
drop: float = 0.0,
|
| 58 |
+
attn_drop: float = 0.0,
|
| 59 |
+
init_values=None,
|
| 60 |
+
drop_path: float = 0.0,
|
| 61 |
+
act_layer: Callable[..., nn.Module] = nn.GELU,
|
| 62 |
+
norm_layer: Callable[..., nn.Module] = AdaNorm,
|
| 63 |
+
attn_class: Callable[..., nn.Module] = Attention,
|
| 64 |
+
ffn_layer: Callable[..., nn.Module] = Mlp,
|
| 65 |
+
) -> None:
|
| 66 |
+
super().__init__()
|
| 67 |
+
# print(f"biases: qkv: {qkv_bias}, proj: {proj_bias}, ffn: {ffn_bias}")
|
| 68 |
+
self.norm1 = norm_layer(dim)
|
| 69 |
+
self.attn = attn_class(
|
| 70 |
+
dim,
|
| 71 |
+
num_heads=num_heads,
|
| 72 |
+
qkv_bias=qkv_bias,
|
| 73 |
+
proj_bias=proj_bias,
|
| 74 |
+
attn_drop=attn_drop,
|
| 75 |
+
proj_drop=drop,
|
| 76 |
+
)
|
| 77 |
+
self.ls1 = LayerScale(dim, init_values=init_values) if init_values else nn.Identity()
|
| 78 |
+
self.drop_path1 = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 79 |
+
|
| 80 |
+
self.norm2 = norm_layer(dim)
|
| 81 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 82 |
+
self.mlp = ffn_layer(
|
| 83 |
+
in_features=dim,
|
| 84 |
+
hidden_features=mlp_hidden_dim,
|
| 85 |
+
act_layer=act_layer,
|
| 86 |
+
drop=drop,
|
| 87 |
+
bias=ffn_bias,
|
| 88 |
+
)
|
| 89 |
+
self.ls2 = LayerScale(dim, init_values=init_values) if init_values else nn.Identity()
|
| 90 |
+
self.drop_path2 = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 91 |
+
|
| 92 |
+
self.sample_drop_ratio = drop_path
|
| 93 |
+
|
| 94 |
+
def forward(self, x: Tensor, cam_emb: Tensor) -> Tensor:
|
| 95 |
+
def attn_residual_func(x: Tensor, cam_emb: Tensor = None) -> Tensor:
|
| 96 |
+
return self.ls1(self.attn(self.norm1(x, cam_emb)))
|
| 97 |
+
|
| 98 |
+
def ffn_residual_func(x: Tensor, cam_emb: Tensor = None) -> Tensor:
|
| 99 |
+
return self.ls2(self.mlp(self.norm2(x, cam_emb)))
|
| 100 |
+
|
| 101 |
+
if self.training and self.sample_drop_ratio > 0.1:
|
| 102 |
+
# the overhead is compensated only for a drop path rate larger than 0.1
|
| 103 |
+
x = drop_add_residual_stochastic_depth(
|
| 104 |
+
x,
|
| 105 |
+
residual_func=attn_residual_func,
|
| 106 |
+
sample_drop_ratio=self.sample_drop_ratio,
|
| 107 |
+
)
|
| 108 |
+
x = drop_add_residual_stochastic_depth(
|
| 109 |
+
x,
|
| 110 |
+
residual_func=ffn_residual_func,
|
| 111 |
+
sample_drop_ratio=self.sample_drop_ratio,
|
| 112 |
+
)
|
| 113 |
+
elif self.training and self.sample_drop_ratio > 0.0:
|
| 114 |
+
x = x + self.drop_path1(attn_residual_func(x, cam_emb))
|
| 115 |
+
x = x + self.drop_path1(ffn_residual_func(x, cam_emb)) # FIXME: drop_path2
|
| 116 |
+
else:
|
| 117 |
+
x = x + attn_residual_func(x, cam_emb)
|
| 118 |
+
x = x + ffn_residual_func(x, cam_emb)
|
| 119 |
+
return x
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def drop_add_residual_stochastic_depth(
|
| 123 |
+
x: Tensor,
|
| 124 |
+
residual_func: Callable[[Tensor], Tensor],
|
| 125 |
+
sample_drop_ratio: float = 0.0,
|
| 126 |
+
) -> Tensor:
|
| 127 |
+
# drop_add_residual_stochastic_depth_list
|
| 128 |
+
|
| 129 |
+
# 1) extract subset using permutation
|
| 130 |
+
b, n, d = x.shape
|
| 131 |
+
sample_subset_size = max(int(b * (1 - sample_drop_ratio)), 1)
|
| 132 |
+
brange = (torch.randperm(b, device=x.device))[:sample_subset_size]
|
| 133 |
+
x_subset = x[brange]
|
| 134 |
+
|
| 135 |
+
# 2) apply residual_func to get residual
|
| 136 |
+
residual = residual_func(x_subset)
|
| 137 |
+
|
| 138 |
+
x_flat = x.flatten(1)
|
| 139 |
+
residual = residual.flatten(1)
|
| 140 |
+
|
| 141 |
+
residual_scale_factor = b / sample_subset_size
|
| 142 |
+
|
| 143 |
+
# 3) add the residual
|
| 144 |
+
x_plus_residual = torch.index_add(x_flat, 0, brange, residual.to(dtype=x.dtype), alpha=residual_scale_factor)
|
| 145 |
+
return x_plus_residual.view_as(x)
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def get_branges_scales(x, sample_drop_ratio=0.0):
|
| 149 |
+
# get_branges_scales
|
| 150 |
+
b, n, d = x.shape
|
| 151 |
+
sample_subset_size = max(int(b * (1 - sample_drop_ratio)), 1)
|
| 152 |
+
brange = (torch.randperm(b, device=x.device))[:sample_subset_size]
|
| 153 |
+
residual_scale_factor = b / sample_subset_size
|
| 154 |
+
return brange, residual_scale_factor
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def add_residual(x, brange, residual, residual_scale_factor, scaling_vector=None):
|
| 158 |
+
# add residuals
|
| 159 |
+
if scaling_vector is None:
|
| 160 |
+
x_flat = x.flatten(1)
|
| 161 |
+
residual = residual.flatten(1)
|
| 162 |
+
x_plus_residual = torch.index_add(x_flat, 0, brange, residual.to(dtype=x.dtype), alpha=residual_scale_factor)
|
| 163 |
+
else:
|
| 164 |
+
x_plus_residual = scaled_index_add(
|
| 165 |
+
x, brange, residual.to(dtype=x.dtype), scaling=scaling_vector, alpha=residual_scale_factor
|
| 166 |
+
)
|
| 167 |
+
return x_plus_residual
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
attn_bias_cache: Dict[Tuple, Any] = {}
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
def get_attn_bias_and_cat(x_list, branges=None):
|
| 174 |
+
"""
|
| 175 |
+
this will perform the index select, cat the tensors, and provide the attn_bias from cache
|
| 176 |
+
"""
|
| 177 |
+
batch_sizes = [b.shape[0] for b in branges] if branges is not None else [x.shape[0] for x in x_list]
|
| 178 |
+
all_shapes = tuple((b, x.shape[1]) for b, x in zip(batch_sizes, x_list))
|
| 179 |
+
if all_shapes not in attn_bias_cache.keys():
|
| 180 |
+
seqlens = []
|
| 181 |
+
for b, x in zip(batch_sizes, x_list):
|
| 182 |
+
for _ in range(b):
|
| 183 |
+
seqlens.append(x.shape[1])
|
| 184 |
+
attn_bias = fmha.BlockDiagonalMask.from_seqlens(seqlens)
|
| 185 |
+
attn_bias._batch_sizes = batch_sizes
|
| 186 |
+
attn_bias_cache[all_shapes] = attn_bias
|
| 187 |
+
|
| 188 |
+
if branges is not None:
|
| 189 |
+
cat_tensors = index_select_cat([x.flatten(1) for x in x_list], branges).view(1, -1, x_list[0].shape[-1])
|
| 190 |
+
else:
|
| 191 |
+
tensors_bs1 = tuple(x.reshape([1, -1, *x.shape[2:]]) for x in x_list)
|
| 192 |
+
cat_tensors = torch.cat(tensors_bs1, dim=1)
|
| 193 |
+
|
| 194 |
+
return attn_bias_cache[all_shapes], cat_tensors
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
def drop_add_residual_stochastic_list(
|
| 198 |
+
x_list: List[Tensor],
|
| 199 |
+
residual_func: Callable[[Tensor, Any], Tensor],
|
| 200 |
+
sample_drop_ratio: float = 0.0,
|
| 201 |
+
scaling_vector=None,
|
| 202 |
+
) -> Tensor:
|
| 203 |
+
# 1) generate random set of indices for dropping samples in the batch
|
| 204 |
+
branges_scales = [get_branges_scales(x, sample_drop_ratio=sample_drop_ratio) for x in x_list]
|
| 205 |
+
branges = [s[0] for s in branges_scales]
|
| 206 |
+
residual_scale_factors = [s[1] for s in branges_scales]
|
| 207 |
+
|
| 208 |
+
# 2) get attention bias and index+concat the tensors
|
| 209 |
+
attn_bias, x_cat = get_attn_bias_and_cat(x_list, branges)
|
| 210 |
+
|
| 211 |
+
# 3) apply residual_func to get residual, and split the result
|
| 212 |
+
residual_list = attn_bias.split(residual_func(x_cat, attn_bias=attn_bias)) # type: ignore
|
| 213 |
+
|
| 214 |
+
outputs = []
|
| 215 |
+
for x, brange, residual, residual_scale_factor in zip(x_list, branges, residual_list, residual_scale_factors):
|
| 216 |
+
outputs.append(add_residual(x, brange, residual, residual_scale_factor, scaling_vector).view_as(x))
|
| 217 |
+
return outputs
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
class NestedTensorBlockMod(BlockMod):
|
| 221 |
+
def forward_nested(self, x_list: List[Tensor], cam_emb_list: List[Tensor]) -> List[Tensor]:
|
| 222 |
+
"""
|
| 223 |
+
x_list contains a list of tensors to nest together and run
|
| 224 |
+
"""
|
| 225 |
+
assert isinstance(self.attn, MemEffAttention)
|
| 226 |
+
|
| 227 |
+
if self.training and self.sample_drop_ratio > 0.0:
|
| 228 |
+
|
| 229 |
+
def attn_residual_func(x: Tensor, cam_emb: Tensor, attn_bias=None) -> Tensor:
|
| 230 |
+
return self.attn(self.norm1(x, cam_emb), attn_bias=attn_bias)
|
| 231 |
+
|
| 232 |
+
def ffn_residual_func(x: Tensor, cam_emb: Tensor, attn_bias=None) -> Tensor:
|
| 233 |
+
return self.mlp(self.norm2(x, cam_emb))
|
| 234 |
+
|
| 235 |
+
x_list = drop_add_residual_stochastic_list(
|
| 236 |
+
x_list,
|
| 237 |
+
residual_func=attn_residual_func,
|
| 238 |
+
sample_drop_ratio=self.sample_drop_ratio,
|
| 239 |
+
scaling_vector=self.ls1.gamma if isinstance(self.ls1, LayerScale) else None,
|
| 240 |
+
)
|
| 241 |
+
x_list = drop_add_residual_stochastic_list(
|
| 242 |
+
x_list,
|
| 243 |
+
residual_func=ffn_residual_func,
|
| 244 |
+
sample_drop_ratio=self.sample_drop_ratio,
|
| 245 |
+
scaling_vector=self.ls2.gamma if isinstance(self.ls1, LayerScale) else None,
|
| 246 |
+
)
|
| 247 |
+
return x_list
|
| 248 |
+
else:
|
| 249 |
+
|
| 250 |
+
def attn_residual_func(x: Tensor, cam_emb: Tensor, attn_bias=None) -> Tensor:
|
| 251 |
+
return self.ls1(self.attn(self.norm1(x, cam_emb), attn_bias=attn_bias))
|
| 252 |
+
|
| 253 |
+
def ffn_residual_func(x: Tensor, cam_emb: Tensor, attn_bias=None) -> Tensor:
|
| 254 |
+
return self.ls2(self.mlp(self.norm2(x, cam_emb)))
|
| 255 |
+
|
| 256 |
+
attn_bias, x = get_attn_bias_and_cat(x_list)
|
| 257 |
+
x = x + attn_residual_func(x, attn_bias=attn_bias)
|
| 258 |
+
x = x + ffn_residual_func(x)
|
| 259 |
+
return attn_bias.split(x)
|
| 260 |
+
|
| 261 |
+
def forward(self, x_or_x_list, cam_emb_or_cam_emb_list):
|
| 262 |
+
if isinstance(x_or_x_list, Tensor) and isinstance(cam_emb_or_cam_emb_list, Tensor) :
|
| 263 |
+
return super().forward(x_or_x_list, cam_emb_or_cam_emb_list)
|
| 264 |
+
elif isinstance(x_or_x_list, list) and isinstance(cam_emb_or_cam_emb_list, list):
|
| 265 |
+
if not XFORMERS_AVAILABLE:
|
| 266 |
+
raise AssertionError("xFormers is required for using nested tensors")
|
| 267 |
+
return self.forward_nested(x_or_x_list, cam_emb_or_cam_emb_list)
|
| 268 |
+
else:
|
| 269 |
+
raise AssertionError
|
svrm/ldm/modules/encoders/dinov2/layers/dino_head.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the Apache License, Version 2.0
|
| 4 |
+
# found in the LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from torch.nn.init import trunc_normal_
|
| 9 |
+
from torch.nn.utils import weight_norm
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class DINOHead(nn.Module):
|
| 13 |
+
def __init__(
|
| 14 |
+
self,
|
| 15 |
+
in_dim,
|
| 16 |
+
out_dim,
|
| 17 |
+
use_bn=False,
|
| 18 |
+
nlayers=3,
|
| 19 |
+
hidden_dim=2048,
|
| 20 |
+
bottleneck_dim=256,
|
| 21 |
+
mlp_bias=True,
|
| 22 |
+
):
|
| 23 |
+
super().__init__()
|
| 24 |
+
nlayers = max(nlayers, 1)
|
| 25 |
+
self.mlp = _build_mlp(nlayers, in_dim, bottleneck_dim, hidden_dim=hidden_dim, use_bn=use_bn, bias=mlp_bias)
|
| 26 |
+
self.apply(self._init_weights)
|
| 27 |
+
self.last_layer = weight_norm(nn.Linear(bottleneck_dim, out_dim, bias=False))
|
| 28 |
+
self.last_layer.weight_g.data.fill_(1)
|
| 29 |
+
|
| 30 |
+
def _init_weights(self, m):
|
| 31 |
+
if isinstance(m, nn.Linear):
|
| 32 |
+
trunc_normal_(m.weight, std=0.02)
|
| 33 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 34 |
+
nn.init.constant_(m.bias, 0)
|
| 35 |
+
|
| 36 |
+
def forward(self, x):
|
| 37 |
+
x = self.mlp(x)
|
| 38 |
+
eps = 1e-6 if x.dtype == torch.float16 else 1e-12
|
| 39 |
+
x = nn.functional.normalize(x, dim=-1, p=2, eps=eps)
|
| 40 |
+
x = self.last_layer(x)
|
| 41 |
+
return x
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def _build_mlp(nlayers, in_dim, bottleneck_dim, hidden_dim=None, use_bn=False, bias=True):
|
| 45 |
+
if nlayers == 1:
|
| 46 |
+
return nn.Linear(in_dim, bottleneck_dim, bias=bias)
|
| 47 |
+
else:
|
| 48 |
+
layers = [nn.Linear(in_dim, hidden_dim, bias=bias)]
|
| 49 |
+
if use_bn:
|
| 50 |
+
layers.append(nn.BatchNorm1d(hidden_dim))
|
| 51 |
+
layers.append(nn.GELU())
|
| 52 |
+
for _ in range(nlayers - 2):
|
| 53 |
+
layers.append(nn.Linear(hidden_dim, hidden_dim, bias=bias))
|
| 54 |
+
if use_bn:
|
| 55 |
+
layers.append(nn.BatchNorm1d(hidden_dim))
|
| 56 |
+
layers.append(nn.GELU())
|
| 57 |
+
layers.append(nn.Linear(hidden_dim, bottleneck_dim, bias=bias))
|
| 58 |
+
return nn.Sequential(*layers)
|
svrm/ldm/modules/encoders/dinov2/layers/drop_path.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the Apache License, Version 2.0
|
| 4 |
+
# found in the LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
# References:
|
| 7 |
+
# https://github.com/facebookresearch/dino/blob/master/vision_transformer.py
|
| 8 |
+
# https://github.com/rwightman/pytorch-image-models/tree/master/timm/layers/drop.py
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
from torch import nn
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def drop_path(x, drop_prob: float = 0.0, training: bool = False):
|
| 15 |
+
if drop_prob == 0.0 or not training:
|
| 16 |
+
return x
|
| 17 |
+
keep_prob = 1 - drop_prob
|
| 18 |
+
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
|
| 19 |
+
random_tensor = x.new_empty(shape).bernoulli_(keep_prob)
|
| 20 |
+
if keep_prob > 0.0:
|
| 21 |
+
random_tensor.div_(keep_prob)
|
| 22 |
+
output = x * random_tensor
|
| 23 |
+
return output
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class DropPath(nn.Module):
|
| 27 |
+
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
|
| 28 |
+
|
| 29 |
+
def __init__(self, drop_prob=None):
|
| 30 |
+
super(DropPath, self).__init__()
|
| 31 |
+
self.drop_prob = drop_prob
|
| 32 |
+
|
| 33 |
+
def forward(self, x):
|
| 34 |
+
return drop_path(x, self.drop_prob, self.training)
|
svrm/ldm/modules/encoders/dinov2/layers/layer_scale.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
#
|
| 3 |
+
# This source code is licensed under the Apache License, Version 2.0
|
| 4 |
+
# found in the LICENSE file in the root directory of this source tree.
|
| 5 |
+
|
| 6 |
+
# Modified from: https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vision_transformer.py#L103-L110
|
| 7 |
+
|
| 8 |
+
from typing import Union
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
from torch import Tensor
|
| 12 |
+
from torch import nn
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class LayerScale(nn.Module):
|
| 16 |
+
def __init__(
|
| 17 |
+
self,
|
| 18 |
+
dim: int,
|
| 19 |
+
init_values: Union[float, Tensor] = 1e-5,
|
| 20 |
+
inplace: bool = False,
|
| 21 |
+
) -> None:
|
| 22 |
+
super().__init__()
|
| 23 |
+
self.inplace = inplace
|
| 24 |
+
self.gamma = nn.Parameter(init_values * torch.ones(dim))
|
| 25 |
+
|
| 26 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 27 |
+
return x.mul_(self.gamma) if self.inplace else x * self.gamma
|