Spaces:
Running
on
L40S

Running
on
L40S
Migrated from GitHub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -0
- LICENSE +202 -0
- ORIGINAL_README.md +171 -0
- assets/DiffuEraser_pipeline.png +0 -0
- diffueraser/diffueraser.py +432 -0
- diffueraser/pipeline_diffueraser.py +1349 -0
- examples/example1/mask.mp4 +0 -0
- examples/example1/video.mp4 +0 -0
- examples/example2/mask.mp4 +3 -0
- examples/example2/video.mp4 +0 -0
- examples/example3/mask.mp4 +0 -0
- examples/example3/video.mp4 +3 -0
- libs/brushnet_CA.py +939 -0
- libs/transformer_temporal.py +375 -0
- libs/unet_2d_blocks.py +0 -0
- libs/unet_2d_condition.py +1359 -0
- libs/unet_3d_blocks.py +2463 -0
- libs/unet_motion_model.py +975 -0
- propainter/RAFT/__init__.py +2 -0
- propainter/RAFT/corr.py +111 -0
- propainter/RAFT/datasets.py +235 -0
- propainter/RAFT/demo.py +79 -0
- propainter/RAFT/extractor.py +267 -0
- propainter/RAFT/raft.py +146 -0
- propainter/RAFT/update.py +139 -0
- propainter/RAFT/utils/__init__.py +2 -0
- propainter/RAFT/utils/augmentor.py +246 -0
- propainter/RAFT/utils/flow_viz.py +132 -0
- propainter/RAFT/utils/flow_viz_pt.py +118 -0
- propainter/RAFT/utils/frame_utils.py +137 -0
- propainter/RAFT/utils/utils.py +82 -0
- propainter/core/dataset.py +232 -0
- propainter/core/dist.py +47 -0
- propainter/core/loss.py +180 -0
- propainter/core/lr_scheduler.py +112 -0
- propainter/core/metrics.py +571 -0
- propainter/core/prefetch_dataloader.py +125 -0
- propainter/core/trainer.py +509 -0
- propainter/core/trainer_flow_w_edge.py +380 -0
- propainter/core/utils.py +371 -0
- propainter/inference.py +520 -0
- propainter/model/__init__.py +1 -0
- propainter/model/canny/canny_filter.py +256 -0
- propainter/model/canny/filter.py +288 -0
- propainter/model/canny/gaussian.py +116 -0
- propainter/model/canny/kernels.py +690 -0
- propainter/model/canny/sobel.py +263 -0
- propainter/model/misc.py +131 -0
- propainter/model/modules/base_module.py +131 -0
- propainter/model/modules/deformconv.py +54 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
examples/example2/mask.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
examples/example3/video.mp4 filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
Apache License
|
| 3 |
+
Version 2.0, January 2004
|
| 4 |
+
http://www.apache.org/licenses/
|
| 5 |
+
|
| 6 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 7 |
+
|
| 8 |
+
1. Definitions.
|
| 9 |
+
|
| 10 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 11 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 12 |
+
|
| 13 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 14 |
+
the copyright owner that is granting the License.
|
| 15 |
+
|
| 16 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 17 |
+
other entities that control, are controlled by, or are under common
|
| 18 |
+
control with that entity. For the purposes of this definition,
|
| 19 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 20 |
+
direction or management of such entity, whether by contract or
|
| 21 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 22 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 23 |
+
|
| 24 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 25 |
+
exercising permissions granted by this License.
|
| 26 |
+
|
| 27 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 28 |
+
including but not limited to software source code, documentation
|
| 29 |
+
source, and configuration files.
|
| 30 |
+
|
| 31 |
+
"Object" form shall mean any form resulting from mechanical
|
| 32 |
+
transformation or translation of a Source form, including but
|
| 33 |
+
not limited to compiled object code, generated documentation,
|
| 34 |
+
and conversions to other media types.
|
| 35 |
+
|
| 36 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 37 |
+
Object form, made available under the License, as indicated by a
|
| 38 |
+
copyright notice that is included in or attached to the work
|
| 39 |
+
(an example is provided in the Appendix below).
|
| 40 |
+
|
| 41 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 42 |
+
form, that is based on (or derived from) the Work and for which the
|
| 43 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 44 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 45 |
+
of this License, Derivative Works shall not include works that remain
|
| 46 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 47 |
+
the Work and Derivative Works thereof.
|
| 48 |
+
|
| 49 |
+
"Contribution" shall mean any work of authorship, including
|
| 50 |
+
the original version of the Work and any modifications or additions
|
| 51 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 52 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 53 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 54 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 55 |
+
means any form of electronic, verbal, or written communication sent
|
| 56 |
+
to the Licensor or its representatives, including but not limited to
|
| 57 |
+
communication on electronic mailing lists, source code control systems,
|
| 58 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 59 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 60 |
+
excluding communication that is conspicuously marked or otherwise
|
| 61 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 62 |
+
|
| 63 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 64 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 65 |
+
subsequently incorporated within the Work.
|
| 66 |
+
|
| 67 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 68 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 69 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 70 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 71 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 72 |
+
Work and such Derivative Works in Source or Object form.
|
| 73 |
+
|
| 74 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 75 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 76 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 77 |
+
(except as stated in this section) patent license to make, have made,
|
| 78 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 79 |
+
where such license applies only to those patent claims licensable
|
| 80 |
+
by such Contributor that are necessarily infringed by their
|
| 81 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 82 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 83 |
+
institute patent litigation against any entity (including a
|
| 84 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 85 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 86 |
+
or contributory patent infringement, then any patent licenses
|
| 87 |
+
granted to You under this License for that Work shall terminate
|
| 88 |
+
as of the date such litigation is filed.
|
| 89 |
+
|
| 90 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 91 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 92 |
+
modifications, and in Source or Object form, provided that You
|
| 93 |
+
meet the following conditions:
|
| 94 |
+
|
| 95 |
+
(a) You must give any other recipients of the Work or
|
| 96 |
+
Derivative Works a copy of this License; and
|
| 97 |
+
|
| 98 |
+
(b) You must cause any modified files to carry prominent notices
|
| 99 |
+
stating that You changed the files; and
|
| 100 |
+
|
| 101 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 102 |
+
that You distribute, all copyright, patent, trademark, and
|
| 103 |
+
attribution notices from the Source form of the Work,
|
| 104 |
+
excluding those notices that do not pertain to any part of
|
| 105 |
+
the Derivative Works; and
|
| 106 |
+
|
| 107 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 108 |
+
distribution, then any Derivative Works that You distribute must
|
| 109 |
+
include a readable copy of the attribution notices contained
|
| 110 |
+
within such NOTICE file, excluding those notices that do not
|
| 111 |
+
pertain to any part of the Derivative Works, in at least one
|
| 112 |
+
of the following places: within a NOTICE text file distributed
|
| 113 |
+
as part of the Derivative Works; within the Source form or
|
| 114 |
+
documentation, if provided along with the Derivative Works; or,
|
| 115 |
+
within a display generated by the Derivative Works, if and
|
| 116 |
+
wherever such third-party notices normally appear. The contents
|
| 117 |
+
of the NOTICE file are for informational purposes only and
|
| 118 |
+
do not modify the License. You may add Your own attribution
|
| 119 |
+
notices within Derivative Works that You distribute, alongside
|
| 120 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 121 |
+
that such additional attribution notices cannot be construed
|
| 122 |
+
as modifying the License.
|
| 123 |
+
|
| 124 |
+
You may add Your own copyright statement to Your modifications and
|
| 125 |
+
may provide additional or different license terms and conditions
|
| 126 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 127 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 128 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 129 |
+
the conditions stated in this License.
|
| 130 |
+
|
| 131 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 132 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 133 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 134 |
+
this License, without any additional terms or conditions.
|
| 135 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 136 |
+
the terms of any separate license agreement you may have executed
|
| 137 |
+
with Licensor regarding such Contributions.
|
| 138 |
+
|
| 139 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 140 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 141 |
+
except as required for reasonable and customary use in describing the
|
| 142 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 143 |
+
|
| 144 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 145 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 146 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 147 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 148 |
+
implied, including, without limitation, any warranties or conditions
|
| 149 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 150 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 151 |
+
appropriateness of using or redistributing the Work and assume any
|
| 152 |
+
risks associated with Your exercise of permissions under this License.
|
| 153 |
+
|
| 154 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 155 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 156 |
+
unless required by applicable law (such as deliberate and grossly
|
| 157 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 158 |
+
liable to You for damages, including any direct, indirect, special,
|
| 159 |
+
incidental, or consequential damages of any character arising as a
|
| 160 |
+
result of this License or out of the use or inability to use the
|
| 161 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 162 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 163 |
+
other commercial damages or losses), even if such Contributor
|
| 164 |
+
has been advised of the possibility of such damages.
|
| 165 |
+
|
| 166 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 167 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 168 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 169 |
+
or other liability obligations and/or rights consistent with this
|
| 170 |
+
License. However, in accepting such obligations, You may act only
|
| 171 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 172 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 173 |
+
defend, and hold each Contributor harmless for any liability
|
| 174 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 175 |
+
of your accepting any such warranty or additional liability.
|
| 176 |
+
|
| 177 |
+
END OF TERMS AND CONDITIONS
|
| 178 |
+
|
| 179 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 180 |
+
|
| 181 |
+
To apply the Apache License to your work, attach the following
|
| 182 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 183 |
+
replaced with your own identifying information. (Don't include
|
| 184 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 185 |
+
comment syntax for the file format. We also recommend that a
|
| 186 |
+
file or class name and description of purpose be included on the
|
| 187 |
+
same "printed page" as the copyright notice for easier
|
| 188 |
+
identification within third-party archives.
|
| 189 |
+
|
| 190 |
+
Copyright [yyyy] [name of copyright owner]
|
| 191 |
+
|
| 192 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 193 |
+
you may not use this file except in compliance with the License.
|
| 194 |
+
You may obtain a copy of the License at
|
| 195 |
+
|
| 196 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 197 |
+
|
| 198 |
+
Unless required by applicable law or agreed to in writing, software
|
| 199 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 200 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 201 |
+
See the License for the specific language governing permissions and
|
| 202 |
+
limitations under the License.
|
ORIGINAL_README.md
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
|
| 3 |
+
<h1>DiffuEraser: A Diffusion Model for Video Inpainting</h1>
|
| 4 |
+
|
| 5 |
+
<div>
|
| 6 |
+
Xiaowen Li 
|
| 7 |
+
Haolan Xue 
|
| 8 |
+
Peiran Ren 
|
| 9 |
+
Liefeng Bo
|
| 10 |
+
</div>
|
| 11 |
+
<div>
|
| 12 |
+
Tongyi Lab, Alibaba Group 
|
| 13 |
+
</div>
|
| 14 |
+
|
| 15 |
+
<div>
|
| 16 |
+
<strong>TECHNICAL REPORT</strong>
|
| 17 |
+
</div>
|
| 18 |
+
|
| 19 |
+
<div>
|
| 20 |
+
<h4 align="center">
|
| 21 |
+
<a href="https://lixiaowen-xw.github.io/DiffuEraser-page" target='_blank'>
|
| 22 |
+
<img src="https://img.shields.io/badge/%F0%9F%8C%B1-Project%20Page-blue">
|
| 23 |
+
</a>
|
| 24 |
+
<a href="https://arxiv.org/abs/2501.10018" target='_blank'>
|
| 25 |
+
<img src="https://img.shields.io/badge/arXiv-2501.10018-B31B1B.svg">
|
| 26 |
+
</a>
|
| 27 |
+
</h4>
|
| 28 |
+
</div>
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
</div>
|
| 34 |
+
|
| 35 |
+
DiffuEraser is a diffusion model for video inpainting, which outperforms state-of-the-art model Propainter in both content completeness and temporal consistency while maintaining acceptable efficiency.
|
| 36 |
+
|
| 37 |
+
---
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
## Update Log
|
| 41 |
+
- *2025.01.20*: Release inference code.
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
## TODO
|
| 45 |
+
- [ ] Release training code.
|
| 46 |
+
- [ ] Release HuggingFace/ModelScope demo.
|
| 47 |
+
- [ ] Release gradio demo.
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
## Results
|
| 51 |
+
More results will be displayed on the project page.
|
| 52 |
+
|
| 53 |
+
https://github.com/user-attachments/assets/b59d0b88-4186-4531-8698-adf6e62058f8
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
## Method Overview
|
| 59 |
+
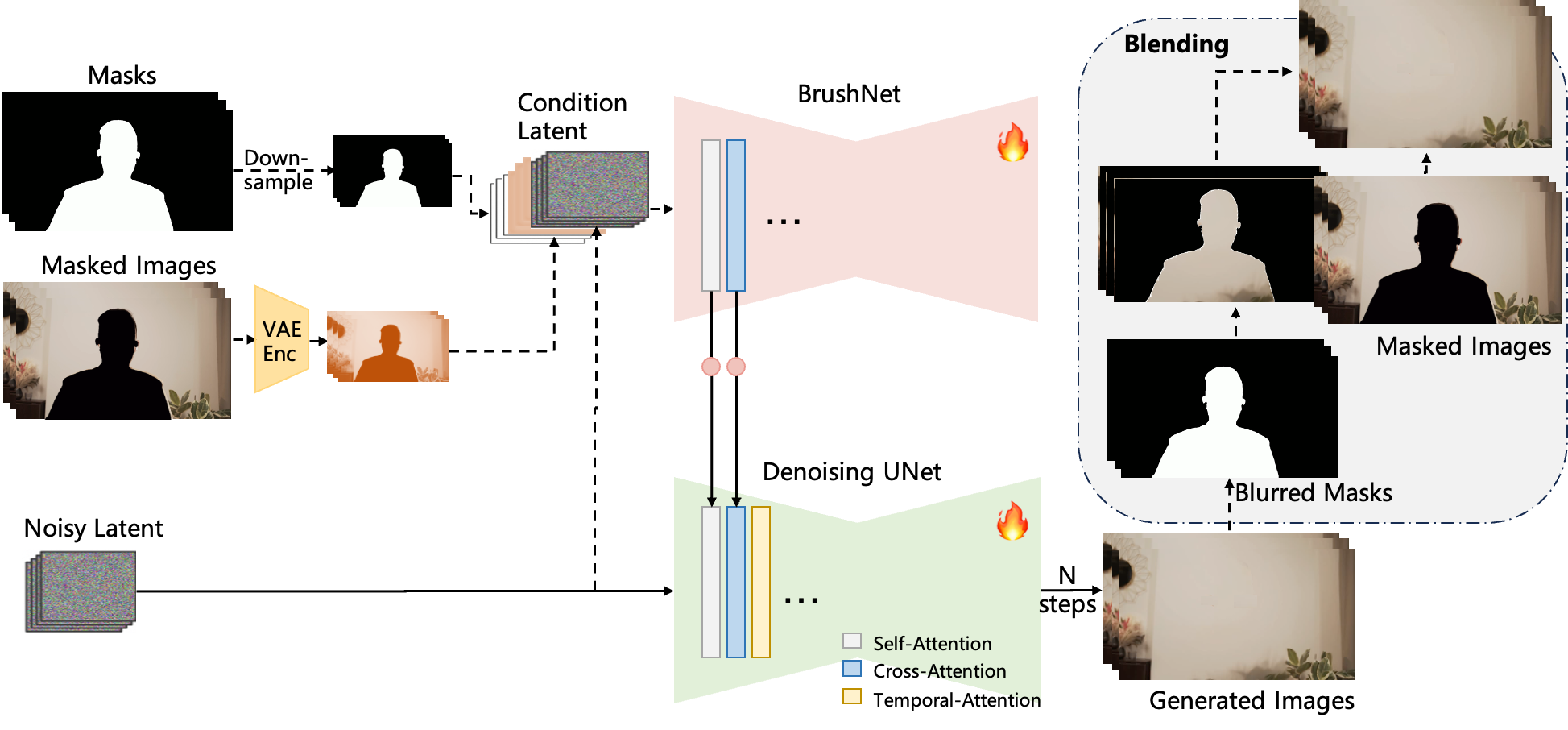
Our network is inspired by [BrushNet](https://github.com/TencentARC/BrushNet) and [Animatediff](https://github.com/guoyww/AnimateDiff). The architecture comprises the primary `denoising UNet` and an auxiliary `BrushNet branch`. Features extracted by BrushNet branch are integrated into the denoising UNet layer by layer after a zero convolution block. The denoising UNet performs the denoising process to generate the final output. To enhance temporal consistency, `temporal attention` mechanisms are incorporated following both self-attention and cross-attention layers. After denoising, the generated images are blended with the input masked images using blurred masks.
|
| 60 |
+
|
| 61 |
+

|
| 62 |
+
|
| 63 |
+
We incorporate `prior` information to provide initialization and weak conditioning, which helps mitigate noisy artifacts and suppress hallucinations.
|
| 64 |
+
Additionally, to improve temporal consistency during long-sequence inference, we expand the `temporal receptive fields` of both the prior model and DiffuEraser, and further enhance consistency by leveraging the temporal smoothing capabilities of Video Diffusion Models. Please read the paper for details.
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
## Getting Started
|
| 68 |
+
|
| 69 |
+
#### Installation
|
| 70 |
+
|
| 71 |
+
1. Clone Repo
|
| 72 |
+
|
| 73 |
+
```bash
|
| 74 |
+
git clone https://github.com/lixiaowen-xw/DiffuEraser.git
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
2. Create Conda Environment and Install Dependencies
|
| 78 |
+
|
| 79 |
+
```bash
|
| 80 |
+
# create new anaconda env
|
| 81 |
+
conda create -n diffueraser python=3.9.19
|
| 82 |
+
conda activate diffueraser
|
| 83 |
+
# install python dependencies
|
| 84 |
+
pip install -r requirements.txt
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
#### Prepare pretrained models
|
| 88 |
+
Weights will be placed under the `./weights` directory.
|
| 89 |
+
1. Download our pretrained models from [Hugging Face](https://huggingface.co/lixiaowen/diffuEraser) or [ModelScope](https://www.modelscope.cn/xingzi/diffuEraser.git) to the `weights` folder.
|
| 90 |
+
2. Download pretrained weight of based models and other components:
|
| 91 |
+
- [stable-diffusion-v1-5](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5) . The full folder size is over 30 GB. If you want to save storage space, you can download only the necessary files: feature_extractor, model_index.json, safety_checker, scheduler, text_encoder, and tokenizer,about 4GB.
|
| 92 |
+
- [PCM_Weights](https://huggingface.co/wangfuyun/PCM_Weights)
|
| 93 |
+
- [propainter](https://github.com/sczhou/ProPainter/releases/tag/v0.1.0)
|
| 94 |
+
- [sd-vae-ft-mse](https://huggingface.co/stabilityai/sd-vae-ft-mse)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
The directory structure will be arranged as:
|
| 98 |
+
```
|
| 99 |
+
weights
|
| 100 |
+
|- diffuEraser
|
| 101 |
+
|-brushnet
|
| 102 |
+
|-unet_main
|
| 103 |
+
|- stable-diffusion-v1-5
|
| 104 |
+
|-feature_extractor
|
| 105 |
+
|-...
|
| 106 |
+
|- PCM_Weights
|
| 107 |
+
|-sd15
|
| 108 |
+
|- propainter
|
| 109 |
+
|-ProPainter.pth
|
| 110 |
+
|-raft-things.pth
|
| 111 |
+
|-recurrent_flow_completion.pth
|
| 112 |
+
|- sd-vae-ft-mse
|
| 113 |
+
|-diffusion_pytorch_model.bin
|
| 114 |
+
|-...
|
| 115 |
+
|- README.md
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
#### Main Inference
|
| 119 |
+
We provide some examples in the [`examples`](./examples) folder.
|
| 120 |
+
Run the following commands to try it out:
|
| 121 |
+
```shell
|
| 122 |
+
cd DiffuEraser
|
| 123 |
+
python run_diffueraser.py
|
| 124 |
+
```
|
| 125 |
+
The results will be saved in the `results` folder.
|
| 126 |
+
To test your own videos, please replace the `input_video` and `input_mask` in run_diffueraser.py . The first inference may take a long time.
|
| 127 |
+
|
| 128 |
+
The `frame rate` of input_video and input_mask needs to be consistent. We currently only support `mp4 video` as input intead of split frames, you can convert frames to video using ffmepg:
|
| 129 |
+
```shell
|
| 130 |
+
ffmpeg -i image%03d.jpg -c:v libx264 -r 25 output.mp4
|
| 131 |
+
```
|
| 132 |
+
Notice: Do not convert the frame rate of mask video if it is not consitent with that of the input video, which would lead to errors due to misalignment.
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
Blow shows the estimated GPU memory requirements and inference time for different resolution:
|
| 136 |
+
|
| 137 |
+
| Resolution | Gpu Memeory | Inference Time(250f(~10s), L20) |
|
| 138 |
+
| :--------- | :---------: | :-----------------------------: |
|
| 139 |
+
| 1280 x 720 | 33G | 314s |
|
| 140 |
+
| 960 x 540 | 20G | 175s |
|
| 141 |
+
| 640 x 360 | 12G | 92s |
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
## Citation
|
| 145 |
+
|
| 146 |
+
If you find our repo useful for your research, please consider citing our paper:
|
| 147 |
+
|
| 148 |
+
```bibtex
|
| 149 |
+
@misc{li2025diffueraserdiffusionmodelvideo,
|
| 150 |
+
title={DiffuEraser: A Diffusion Model for Video Inpainting},
|
| 151 |
+
author={Xiaowen Li and Haolan Xue and Peiran Ren and Liefeng Bo},
|
| 152 |
+
year={2025},
|
| 153 |
+
eprint={2501.10018},
|
| 154 |
+
archivePrefix={arXiv},
|
| 155 |
+
primaryClass={cs.CV},
|
| 156 |
+
url={https://arxiv.org/abs/2501.10018},
|
| 157 |
+
}
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
## License
|
| 162 |
+
This repository uses [Propainter](https://github.com/sczhou/ProPainter) as the prior model. Users must comply with [Propainter's license](https://github.com/sczhou/ProPainter/blob/main/LICENSE) when using this code. Or you can use other model to replace it.
|
| 163 |
+
|
| 164 |
+
This project is licensed under the [Apache License Version 2.0](./LICENSE) except for the third-party components listed below.
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
## Acknowledgement
|
| 168 |
+
|
| 169 |
+
This code is based on [BrushNet](https://github.com/TencentARC/BrushNet), [Propainter](https://github.com/sczhou/ProPainter) and [Animatediff](https://github.com/guoyww/AnimateDiff). The example videos come from [Pexels](https://www.pexels.com/), [DAVIS](https://davischallenge.org/), [SA-V](https://ai.meta.com/datasets/segment-anything-video) and [DanceTrack](https://dancetrack.github.io/). Thanks for their awesome works.
|
| 170 |
+
|
| 171 |
+
|
assets/DiffuEraser_pipeline.png
ADDED
|
diffueraser/diffueraser.py
ADDED
|
@@ -0,0 +1,432 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gc
|
| 2 |
+
import copy
|
| 3 |
+
import cv2
|
| 4 |
+
import os
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
import torchvision
|
| 8 |
+
from einops import repeat
|
| 9 |
+
from PIL import Image, ImageFilter
|
| 10 |
+
from diffusers import (
|
| 11 |
+
AutoencoderKL,
|
| 12 |
+
DDPMScheduler,
|
| 13 |
+
UniPCMultistepScheduler,
|
| 14 |
+
LCMScheduler,
|
| 15 |
+
)
|
| 16 |
+
from diffusers.schedulers import TCDScheduler
|
| 17 |
+
from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
|
| 18 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 19 |
+
from transformers import AutoTokenizer, PretrainedConfig
|
| 20 |
+
|
| 21 |
+
from libs.unet_motion_model import MotionAdapter, UNetMotionModel
|
| 22 |
+
from libs.brushnet_CA import BrushNetModel
|
| 23 |
+
from libs.unet_2d_condition import UNet2DConditionModel
|
| 24 |
+
from diffueraser.pipeline_diffueraser import StableDiffusionDiffuEraserPipeline
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
checkpoints = {
|
| 28 |
+
"2-Step": ["pcm_{}_smallcfg_2step_converted.safetensors", 2, 0.0],
|
| 29 |
+
"4-Step": ["pcm_{}_smallcfg_4step_converted.safetensors", 4, 0.0],
|
| 30 |
+
"8-Step": ["pcm_{}_smallcfg_8step_converted.safetensors", 8, 0.0],
|
| 31 |
+
"16-Step": ["pcm_{}_smallcfg_16step_converted.safetensors", 16, 0.0],
|
| 32 |
+
"Normal CFG 4-Step": ["pcm_{}_normalcfg_4step_converted.safetensors", 4, 7.5],
|
| 33 |
+
"Normal CFG 8-Step": ["pcm_{}_normalcfg_8step_converted.safetensors", 8, 7.5],
|
| 34 |
+
"Normal CFG 16-Step": ["pcm_{}_normalcfg_16step_converted.safetensors", 16, 7.5],
|
| 35 |
+
"LCM-Like LoRA": [
|
| 36 |
+
"pcm_{}_lcmlike_lora_converted.safetensors",
|
| 37 |
+
4,
|
| 38 |
+
0.0,
|
| 39 |
+
],
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str, revision: str):
|
| 43 |
+
text_encoder_config = PretrainedConfig.from_pretrained(
|
| 44 |
+
pretrained_model_name_or_path,
|
| 45 |
+
subfolder="text_encoder",
|
| 46 |
+
revision=revision,
|
| 47 |
+
)
|
| 48 |
+
model_class = text_encoder_config.architectures[0]
|
| 49 |
+
|
| 50 |
+
if model_class == "CLIPTextModel":
|
| 51 |
+
from transformers import CLIPTextModel
|
| 52 |
+
|
| 53 |
+
return CLIPTextModel
|
| 54 |
+
elif model_class == "RobertaSeriesModelWithTransformation":
|
| 55 |
+
from diffusers.pipelines.alt_diffusion.modeling_roberta_series import RobertaSeriesModelWithTransformation
|
| 56 |
+
|
| 57 |
+
return RobertaSeriesModelWithTransformation
|
| 58 |
+
else:
|
| 59 |
+
raise ValueError(f"{model_class} is not supported.")
|
| 60 |
+
|
| 61 |
+
def resize_frames(frames, size=None):
|
| 62 |
+
if size is not None:
|
| 63 |
+
out_size = size
|
| 64 |
+
process_size = (out_size[0]-out_size[0]%8, out_size[1]-out_size[1]%8)
|
| 65 |
+
frames = [f.resize(process_size) for f in frames]
|
| 66 |
+
else:
|
| 67 |
+
out_size = frames[0].size
|
| 68 |
+
process_size = (out_size[0]-out_size[0]%8, out_size[1]-out_size[1]%8)
|
| 69 |
+
if not out_size == process_size:
|
| 70 |
+
frames = [f.resize(process_size) for f in frames]
|
| 71 |
+
|
| 72 |
+
return frames
|
| 73 |
+
|
| 74 |
+
def read_mask(validation_mask, fps, n_total_frames, img_size, mask_dilation_iter, frames):
|
| 75 |
+
cap = cv2.VideoCapture(validation_mask)
|
| 76 |
+
if not cap.isOpened():
|
| 77 |
+
print("Error: Could not open mask video.")
|
| 78 |
+
exit()
|
| 79 |
+
mask_fps = cap.get(cv2.CAP_PROP_FPS)
|
| 80 |
+
if mask_fps != fps:
|
| 81 |
+
cap.release()
|
| 82 |
+
raise ValueError("The frame rate of all input videos needs to be consistent.")
|
| 83 |
+
|
| 84 |
+
masks = []
|
| 85 |
+
masked_images = []
|
| 86 |
+
idx = 0
|
| 87 |
+
while True:
|
| 88 |
+
ret, frame = cap.read()
|
| 89 |
+
if not ret:
|
| 90 |
+
break
|
| 91 |
+
if(idx >= n_total_frames):
|
| 92 |
+
break
|
| 93 |
+
mask = Image.fromarray(frame[...,::-1]).convert('L')
|
| 94 |
+
if mask.size != img_size:
|
| 95 |
+
mask = mask.resize(img_size, Image.NEAREST)
|
| 96 |
+
mask = np.asarray(mask)
|
| 97 |
+
m = np.array(mask > 0).astype(np.uint8)
|
| 98 |
+
m = cv2.erode(m,
|
| 99 |
+
cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)),
|
| 100 |
+
iterations=1)
|
| 101 |
+
m = cv2.dilate(m,
|
| 102 |
+
cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)),
|
| 103 |
+
iterations=mask_dilation_iter)
|
| 104 |
+
|
| 105 |
+
mask = Image.fromarray(m * 255)
|
| 106 |
+
masks.append(mask)
|
| 107 |
+
|
| 108 |
+
masked_image = np.array(frames[idx])*(1-(np.array(mask)[:,:,np.newaxis].astype(np.float32)/255))
|
| 109 |
+
masked_image = Image.fromarray(masked_image.astype(np.uint8))
|
| 110 |
+
masked_images.append(masked_image)
|
| 111 |
+
|
| 112 |
+
idx += 1
|
| 113 |
+
cap.release()
|
| 114 |
+
|
| 115 |
+
return masks, masked_images
|
| 116 |
+
|
| 117 |
+
def read_priori(priori, fps, n_total_frames, img_size):
|
| 118 |
+
cap = cv2.VideoCapture(priori)
|
| 119 |
+
if not cap.isOpened():
|
| 120 |
+
print("Error: Could not open video.")
|
| 121 |
+
exit()
|
| 122 |
+
priori_fps = cap.get(cv2.CAP_PROP_FPS)
|
| 123 |
+
if priori_fps != fps:
|
| 124 |
+
cap.release()
|
| 125 |
+
raise ValueError("The frame rate of all input videos needs to be consistent.")
|
| 126 |
+
|
| 127 |
+
prioris=[]
|
| 128 |
+
idx = 0
|
| 129 |
+
while True:
|
| 130 |
+
ret, frame = cap.read()
|
| 131 |
+
if not ret:
|
| 132 |
+
break
|
| 133 |
+
if(idx >= n_total_frames):
|
| 134 |
+
break
|
| 135 |
+
img = Image.fromarray(frame[...,::-1])
|
| 136 |
+
if img.size != img_size:
|
| 137 |
+
img = img.resize(img_size)
|
| 138 |
+
prioris.append(img)
|
| 139 |
+
idx += 1
|
| 140 |
+
cap.release()
|
| 141 |
+
|
| 142 |
+
os.remove(priori) # remove priori
|
| 143 |
+
|
| 144 |
+
return prioris
|
| 145 |
+
|
| 146 |
+
def read_video(validation_image, video_length, nframes, max_img_size):
|
| 147 |
+
vframes, aframes, info = torchvision.io.read_video(filename=validation_image, pts_unit='sec', end_pts=video_length) # RGB
|
| 148 |
+
fps = info['video_fps']
|
| 149 |
+
n_total_frames = int(video_length * fps)
|
| 150 |
+
n_clip = int(np.ceil(n_total_frames/nframes))
|
| 151 |
+
|
| 152 |
+
frames = list(vframes.numpy())[:n_total_frames]
|
| 153 |
+
frames = [Image.fromarray(f) for f in frames]
|
| 154 |
+
max_size = max(frames[0].size)
|
| 155 |
+
if(max_size<256):
|
| 156 |
+
raise ValueError("The resolution of the uploaded video must be larger than 256x256.")
|
| 157 |
+
if(max_size>4096):
|
| 158 |
+
raise ValueError("The resolution of the uploaded video must be smaller than 4096x4096.")
|
| 159 |
+
if max_size>max_img_size:
|
| 160 |
+
ratio = max_size/max_img_size
|
| 161 |
+
ratio_size = (int(frames[0].size[0]/ratio),int(frames[0].size[1]/ratio))
|
| 162 |
+
img_size = (ratio_size[0]-ratio_size[0]%8, ratio_size[1]-ratio_size[1]%8)
|
| 163 |
+
resize_flag=True
|
| 164 |
+
elif (frames[0].size[0]%8==0) and (frames[0].size[1]%8==0):
|
| 165 |
+
img_size = frames[0].size
|
| 166 |
+
resize_flag=False
|
| 167 |
+
else:
|
| 168 |
+
ratio_size = frames[0].size
|
| 169 |
+
img_size = (ratio_size[0]-ratio_size[0]%8, ratio_size[1]-ratio_size[1]%8)
|
| 170 |
+
resize_flag=True
|
| 171 |
+
if resize_flag:
|
| 172 |
+
frames = resize_frames(frames, img_size)
|
| 173 |
+
img_size = frames[0].size
|
| 174 |
+
|
| 175 |
+
return frames, fps, img_size, n_clip, n_total_frames
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
class DiffuEraser:
|
| 179 |
+
def __init__(
|
| 180 |
+
self, device, base_model_path, vae_path, diffueraser_path, revision=None,
|
| 181 |
+
ckpt="Normal CFG 4-Step", mode="sd15", loaded=None):
|
| 182 |
+
self.device = device
|
| 183 |
+
|
| 184 |
+
## load model
|
| 185 |
+
self.vae = AutoencoderKL.from_pretrained(vae_path)
|
| 186 |
+
self.noise_scheduler = DDPMScheduler.from_pretrained(base_model_path,
|
| 187 |
+
subfolder="scheduler",
|
| 188 |
+
prediction_type="v_prediction",
|
| 189 |
+
timestep_spacing="trailing",
|
| 190 |
+
rescale_betas_zero_snr=True
|
| 191 |
+
)
|
| 192 |
+
self.tokenizer = AutoTokenizer.from_pretrained(
|
| 193 |
+
base_model_path,
|
| 194 |
+
subfolder="tokenizer",
|
| 195 |
+
use_fast=False,
|
| 196 |
+
)
|
| 197 |
+
text_encoder_cls = import_model_class_from_model_name_or_path(base_model_path,revision)
|
| 198 |
+
self.text_encoder = text_encoder_cls.from_pretrained(
|
| 199 |
+
base_model_path, subfolder="text_encoder"
|
| 200 |
+
)
|
| 201 |
+
self.brushnet = BrushNetModel.from_pretrained(diffueraser_path, subfolder="brushnet")
|
| 202 |
+
self.unet_main = UNetMotionModel.from_pretrained(
|
| 203 |
+
diffueraser_path, subfolder="unet_main",
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
## set pipeline
|
| 207 |
+
self.pipeline = StableDiffusionDiffuEraserPipeline.from_pretrained(
|
| 208 |
+
base_model_path,
|
| 209 |
+
vae=self.vae,
|
| 210 |
+
text_encoder=self.text_encoder,
|
| 211 |
+
tokenizer=self.tokenizer,
|
| 212 |
+
unet=self.unet_main,
|
| 213 |
+
brushnet=self.brushnet
|
| 214 |
+
).to(self.device, torch.float16)
|
| 215 |
+
self.pipeline.scheduler = UniPCMultistepScheduler.from_config(self.pipeline.scheduler.config)
|
| 216 |
+
self.pipeline.set_progress_bar_config(disable=True)
|
| 217 |
+
|
| 218 |
+
self.noise_scheduler = UniPCMultistepScheduler.from_config(self.pipeline.scheduler.config)
|
| 219 |
+
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
| 220 |
+
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
|
| 221 |
+
|
| 222 |
+
## use PCM
|
| 223 |
+
self.ckpt = ckpt
|
| 224 |
+
PCM_ckpts = checkpoints[ckpt][0].format(mode)
|
| 225 |
+
self.guidance_scale = checkpoints[ckpt][2]
|
| 226 |
+
if loaded != (ckpt + mode):
|
| 227 |
+
self.pipeline.load_lora_weights(
|
| 228 |
+
"weights/PCM_Weights", weight_name=PCM_ckpts, subfolder=mode
|
| 229 |
+
)
|
| 230 |
+
loaded = ckpt + mode
|
| 231 |
+
|
| 232 |
+
if ckpt == "LCM-Like LoRA":
|
| 233 |
+
self.pipeline.scheduler = LCMScheduler()
|
| 234 |
+
else:
|
| 235 |
+
self.pipeline.scheduler = TCDScheduler(
|
| 236 |
+
num_train_timesteps=1000,
|
| 237 |
+
beta_start=0.00085,
|
| 238 |
+
beta_end=0.012,
|
| 239 |
+
beta_schedule="scaled_linear",
|
| 240 |
+
timestep_spacing="trailing",
|
| 241 |
+
)
|
| 242 |
+
self.num_inference_steps = checkpoints[ckpt][1]
|
| 243 |
+
self.guidance_scale = 0
|
| 244 |
+
|
| 245 |
+
def forward(self, validation_image, validation_mask, priori, output_path,
|
| 246 |
+
max_img_size = 1280, video_length=2, mask_dilation_iter=4,
|
| 247 |
+
nframes=22, seed=None, revision = None, guidance_scale=None, blended=True):
|
| 248 |
+
validation_prompt = "" #
|
| 249 |
+
guidance_scale_final = self.guidance_scale if guidance_scale==None else guidance_scale
|
| 250 |
+
|
| 251 |
+
if (max_img_size<256 or max_img_size>1920):
|
| 252 |
+
raise ValueError("The max_img_size must be larger than 256, smaller than 1920.")
|
| 253 |
+
|
| 254 |
+
################ read input video ################
|
| 255 |
+
frames, fps, img_size, n_clip, n_total_frames = read_video(validation_image, video_length, nframes, max_img_size)
|
| 256 |
+
video_len = len(frames)
|
| 257 |
+
|
| 258 |
+
################ read mask ################
|
| 259 |
+
validation_masks_input, validation_images_input = read_mask(validation_mask, fps, video_len, img_size, mask_dilation_iter, frames)
|
| 260 |
+
|
| 261 |
+
################ read priori ################
|
| 262 |
+
prioris = read_priori(priori, fps, n_total_frames, img_size)
|
| 263 |
+
|
| 264 |
+
## recheck
|
| 265 |
+
n_total_frames = min(min(len(frames), len(validation_masks_input)), len(prioris))
|
| 266 |
+
if(n_total_frames<22):
|
| 267 |
+
raise ValueError("The effective video duration is too short. Please make sure that the number of frames of video, mask, and priori is at least greater than 22 frames.")
|
| 268 |
+
validation_masks_input = validation_masks_input[:n_total_frames]
|
| 269 |
+
validation_images_input = validation_images_input[:n_total_frames]
|
| 270 |
+
frames = frames[:n_total_frames]
|
| 271 |
+
prioris = prioris[:n_total_frames]
|
| 272 |
+
|
| 273 |
+
prioris = resize_frames(prioris)
|
| 274 |
+
validation_masks_input = resize_frames(validation_masks_input)
|
| 275 |
+
validation_images_input = resize_frames(validation_images_input)
|
| 276 |
+
resized_frames = resize_frames(frames)
|
| 277 |
+
|
| 278 |
+
##############################################
|
| 279 |
+
# DiffuEraser inference
|
| 280 |
+
##############################################
|
| 281 |
+
print("DiffuEraser inference...")
|
| 282 |
+
if seed is None:
|
| 283 |
+
generator = None
|
| 284 |
+
else:
|
| 285 |
+
generator = torch.Generator(device=self.device).manual_seed(seed)
|
| 286 |
+
|
| 287 |
+
## random noise
|
| 288 |
+
real_video_length = len(validation_images_input)
|
| 289 |
+
tar_width, tar_height = validation_images_input[0].size
|
| 290 |
+
shape = (
|
| 291 |
+
nframes,
|
| 292 |
+
4,
|
| 293 |
+
tar_height//8,
|
| 294 |
+
tar_width//8
|
| 295 |
+
)
|
| 296 |
+
if self.text_encoder is not None:
|
| 297 |
+
prompt_embeds_dtype = self.text_encoder.dtype
|
| 298 |
+
elif self.unet_main is not None:
|
| 299 |
+
prompt_embeds_dtype = self.unet_main.dtype
|
| 300 |
+
else:
|
| 301 |
+
prompt_embeds_dtype = torch.float16
|
| 302 |
+
noise_pre = randn_tensor(shape, device=torch.device(self.device), dtype=prompt_embeds_dtype, generator=generator)
|
| 303 |
+
noise = repeat(noise_pre, "t c h w->(repeat t) c h w", repeat=n_clip)[:real_video_length,...]
|
| 304 |
+
|
| 305 |
+
################ prepare priori ################
|
| 306 |
+
images_preprocessed = []
|
| 307 |
+
for image in prioris:
|
| 308 |
+
image = self.image_processor.preprocess(image, height=tar_height, width=tar_width).to(dtype=torch.float32)
|
| 309 |
+
image = image.to(device=torch.device(self.device), dtype=torch.float16)
|
| 310 |
+
images_preprocessed.append(image)
|
| 311 |
+
pixel_values = torch.cat(images_preprocessed)
|
| 312 |
+
|
| 313 |
+
with torch.no_grad():
|
| 314 |
+
pixel_values = pixel_values.to(dtype=torch.float16)
|
| 315 |
+
latents = []
|
| 316 |
+
num=4
|
| 317 |
+
for i in range(0, pixel_values.shape[0], num):
|
| 318 |
+
latents.append(self.vae.encode(pixel_values[i : i + num]).latent_dist.sample())
|
| 319 |
+
latents = torch.cat(latents, dim=0)
|
| 320 |
+
latents = latents * self.vae.config.scaling_factor #[(b f), c1, h, w], c1=4
|
| 321 |
+
torch.cuda.empty_cache()
|
| 322 |
+
timesteps = torch.tensor([0], device=self.device)
|
| 323 |
+
timesteps = timesteps.long()
|
| 324 |
+
|
| 325 |
+
validation_masks_input_ori = copy.deepcopy(validation_masks_input)
|
| 326 |
+
resized_frames_ori = copy.deepcopy(resized_frames)
|
| 327 |
+
################ Pre-inference ################
|
| 328 |
+
if n_total_frames > nframes*2: ## do pre-inference only when number of input frames is larger than nframes*2
|
| 329 |
+
## sample
|
| 330 |
+
step = n_total_frames / nframes
|
| 331 |
+
sample_index = [int(i * step) for i in range(nframes)]
|
| 332 |
+
sample_index = sample_index[:22]
|
| 333 |
+
validation_masks_input_pre = [validation_masks_input[i] for i in sample_index]
|
| 334 |
+
validation_images_input_pre = [validation_images_input[i] for i in sample_index]
|
| 335 |
+
latents_pre = torch.stack([latents[i] for i in sample_index])
|
| 336 |
+
|
| 337 |
+
## add proiri
|
| 338 |
+
noisy_latents_pre = self.noise_scheduler.add_noise(latents_pre, noise_pre, timesteps)
|
| 339 |
+
latents_pre = noisy_latents_pre
|
| 340 |
+
|
| 341 |
+
with torch.no_grad():
|
| 342 |
+
latents_pre_out = self.pipeline(
|
| 343 |
+
num_frames=nframes,
|
| 344 |
+
prompt=validation_prompt,
|
| 345 |
+
images=validation_images_input_pre,
|
| 346 |
+
masks=validation_masks_input_pre,
|
| 347 |
+
num_inference_steps=self.num_inference_steps,
|
| 348 |
+
generator=generator,
|
| 349 |
+
guidance_scale=guidance_scale_final,
|
| 350 |
+
latents=latents_pre,
|
| 351 |
+
).latents
|
| 352 |
+
torch.cuda.empty_cache()
|
| 353 |
+
|
| 354 |
+
def decode_latents(latents, weight_dtype):
|
| 355 |
+
latents = 1 / self.vae.config.scaling_factor * latents
|
| 356 |
+
video = []
|
| 357 |
+
for t in range(latents.shape[0]):
|
| 358 |
+
video.append(self.vae.decode(latents[t:t+1, ...].to(weight_dtype)).sample)
|
| 359 |
+
video = torch.concat(video, dim=0)
|
| 360 |
+
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
|
| 361 |
+
video = video.float()
|
| 362 |
+
return video
|
| 363 |
+
with torch.no_grad():
|
| 364 |
+
video_tensor_temp = decode_latents(latents_pre_out, weight_dtype=torch.float16)
|
| 365 |
+
images_pre_out = self.image_processor.postprocess(video_tensor_temp, output_type="pil")
|
| 366 |
+
torch.cuda.empty_cache()
|
| 367 |
+
|
| 368 |
+
## replace input frames with updated frames
|
| 369 |
+
black_image = Image.new('L', validation_masks_input[0].size, color=0)
|
| 370 |
+
for i,index in enumerate(sample_index):
|
| 371 |
+
latents[index] = latents_pre_out[i]
|
| 372 |
+
validation_masks_input[index] = black_image
|
| 373 |
+
validation_images_input[index] = images_pre_out[i]
|
| 374 |
+
resized_frames[index] = images_pre_out[i]
|
| 375 |
+
else:
|
| 376 |
+
latents_pre_out=None
|
| 377 |
+
sample_index=None
|
| 378 |
+
gc.collect()
|
| 379 |
+
torch.cuda.empty_cache()
|
| 380 |
+
|
| 381 |
+
################ Frame-by-frame inference ################
|
| 382 |
+
## add priori
|
| 383 |
+
noisy_latents = self.noise_scheduler.add_noise(latents, noise, timesteps)
|
| 384 |
+
latents = noisy_latents
|
| 385 |
+
with torch.no_grad():
|
| 386 |
+
images = self.pipeline(
|
| 387 |
+
num_frames=nframes,
|
| 388 |
+
prompt=validation_prompt,
|
| 389 |
+
images=validation_images_input,
|
| 390 |
+
masks=validation_masks_input,
|
| 391 |
+
num_inference_steps=self.num_inference_steps,
|
| 392 |
+
generator=generator,
|
| 393 |
+
guidance_scale=guidance_scale_final,
|
| 394 |
+
latents=latents,
|
| 395 |
+
).frames
|
| 396 |
+
images = images[:real_video_length]
|
| 397 |
+
|
| 398 |
+
gc.collect()
|
| 399 |
+
torch.cuda.empty_cache()
|
| 400 |
+
|
| 401 |
+
################ Compose ################
|
| 402 |
+
binary_masks = validation_masks_input_ori
|
| 403 |
+
mask_blurreds = []
|
| 404 |
+
if blended:
|
| 405 |
+
# blur, you can adjust the parameters for better performance
|
| 406 |
+
for i in range(len(binary_masks)):
|
| 407 |
+
mask_blurred = cv2.GaussianBlur(np.array(binary_masks[i]), (21, 21), 0)/255.
|
| 408 |
+
binary_mask = 1-(1-np.array(binary_masks[i])/255.) * (1-mask_blurred)
|
| 409 |
+
mask_blurreds.append(Image.fromarray((binary_mask*255).astype(np.uint8)))
|
| 410 |
+
binary_masks = mask_blurreds
|
| 411 |
+
|
| 412 |
+
comp_frames = []
|
| 413 |
+
for i in range(len(images)):
|
| 414 |
+
mask = np.expand_dims(np.array(binary_masks[i]),2).repeat(3, axis=2).astype(np.float32)/255.
|
| 415 |
+
img = (np.array(images[i]).astype(np.uint8) * mask \
|
| 416 |
+
+ np.array(resized_frames_ori[i]).astype(np.uint8) * (1 - mask)).astype(np.uint8)
|
| 417 |
+
comp_frames.append(Image.fromarray(img))
|
| 418 |
+
|
| 419 |
+
default_fps = fps
|
| 420 |
+
writer = cv2.VideoWriter(output_path, cv2.VideoWriter_fourcc(*"mp4v"),
|
| 421 |
+
default_fps, comp_frames[0].size)
|
| 422 |
+
for f in range(real_video_length):
|
| 423 |
+
img = np.array(comp_frames[f]).astype(np.uint8)
|
| 424 |
+
writer.write(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
|
| 425 |
+
writer.release()
|
| 426 |
+
################################
|
| 427 |
+
|
| 428 |
+
return output_path
|
| 429 |
+
|
| 430 |
+
|
| 431 |
+
|
| 432 |
+
|
diffueraser/pipeline_diffueraser.py
ADDED
|
@@ -0,0 +1,1349 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import inspect
|
| 2 |
+
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
|
| 3 |
+
import numpy as np
|
| 4 |
+
import PIL.Image
|
| 5 |
+
from einops import rearrange, repeat
|
| 6 |
+
from dataclasses import dataclass
|
| 7 |
+
import copy
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection
|
| 11 |
+
|
| 12 |
+
from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
|
| 13 |
+
from diffusers.loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
| 14 |
+
from diffusers.models import AutoencoderKL, ImageProjection
|
| 15 |
+
from diffusers.models.lora import adjust_lora_scale_text_encoder
|
| 16 |
+
from diffusers.schedulers import KarrasDiffusionSchedulers
|
| 17 |
+
from diffusers.utils import (
|
| 18 |
+
USE_PEFT_BACKEND,
|
| 19 |
+
deprecate,
|
| 20 |
+
logging,
|
| 21 |
+
replace_example_docstring,
|
| 22 |
+
scale_lora_layers,
|
| 23 |
+
unscale_lora_layers,
|
| 24 |
+
BaseOutput
|
| 25 |
+
)
|
| 26 |
+
from diffusers.utils.torch_utils import is_compiled_module, is_torch_version, randn_tensor
|
| 27 |
+
from diffusers.pipelines.pipeline_utils import DiffusionPipeline, StableDiffusionMixin
|
| 28 |
+
from diffusers.pipelines.stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
| 29 |
+
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
| 30 |
+
from diffusers import (
|
| 31 |
+
AutoencoderKL,
|
| 32 |
+
DDPMScheduler,
|
| 33 |
+
UniPCMultistepScheduler,
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
from libs.unet_2d_condition import UNet2DConditionModel
|
| 37 |
+
from libs.brushnet_CA import BrushNetModel
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 41 |
+
|
| 42 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.retrieve_timesteps
|
| 43 |
+
def retrieve_timesteps(
|
| 44 |
+
scheduler,
|
| 45 |
+
num_inference_steps: Optional[int] = None,
|
| 46 |
+
device: Optional[Union[str, torch.device]] = None,
|
| 47 |
+
timesteps: Optional[List[int]] = None,
|
| 48 |
+
**kwargs,
|
| 49 |
+
):
|
| 50 |
+
"""
|
| 51 |
+
Calls the scheduler's `set_timesteps` method and retrieves timesteps from the scheduler after the call. Handles
|
| 52 |
+
custom timesteps. Any kwargs will be supplied to `scheduler.set_timesteps`.
|
| 53 |
+
|
| 54 |
+
Args:
|
| 55 |
+
scheduler (`SchedulerMixin`):
|
| 56 |
+
The scheduler to get timesteps from.
|
| 57 |
+
num_inference_steps (`int`):
|
| 58 |
+
The number of diffusion steps used when generating samples with a pre-trained model. If used,
|
| 59 |
+
`timesteps` must be `None`.
|
| 60 |
+
device (`str` or `torch.device`, *optional*):
|
| 61 |
+
The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
|
| 62 |
+
timesteps (`List[int]`, *optional*):
|
| 63 |
+
Custom timesteps used to support arbitrary spacing between timesteps. If `None`, then the default
|
| 64 |
+
timestep spacing strategy of the scheduler is used. If `timesteps` is passed, `num_inference_steps`
|
| 65 |
+
must be `None`.
|
| 66 |
+
|
| 67 |
+
Returns:
|
| 68 |
+
`Tuple[torch.Tensor, int]`: A tuple where the first element is the timestep schedule from the scheduler and the
|
| 69 |
+
second element is the number of inference steps.
|
| 70 |
+
"""
|
| 71 |
+
if timesteps is not None:
|
| 72 |
+
accepts_timesteps = "timesteps" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
|
| 73 |
+
if not accepts_timesteps:
|
| 74 |
+
raise ValueError(
|
| 75 |
+
f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
|
| 76 |
+
f" timestep schedules. Please check whether you are using the correct scheduler."
|
| 77 |
+
)
|
| 78 |
+
scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
|
| 79 |
+
timesteps = scheduler.timesteps
|
| 80 |
+
num_inference_steps = len(timesteps)
|
| 81 |
+
else:
|
| 82 |
+
scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)
|
| 83 |
+
timesteps = scheduler.timesteps
|
| 84 |
+
return timesteps, num_inference_steps
|
| 85 |
+
|
| 86 |
+
def get_frames_context_swap(total_frames=192, overlap=4, num_frames_per_clip=24):
|
| 87 |
+
if total_frames<num_frames_per_clip:
|
| 88 |
+
num_frames_per_clip = total_frames
|
| 89 |
+
context_list = []
|
| 90 |
+
context_list_swap = []
|
| 91 |
+
for i in range(1, 2): # i=1
|
| 92 |
+
sample_interval = np.array(range(0,total_frames,i))
|
| 93 |
+
n = len(sample_interval)
|
| 94 |
+
if n>num_frames_per_clip:
|
| 95 |
+
## [0,num_frames_per_clip-1], [num_frames_per_clip, 2*num_frames_per_clip-1]....
|
| 96 |
+
for k in range(0,n-num_frames_per_clip,num_frames_per_clip-overlap):
|
| 97 |
+
context_list.append(sample_interval[k:k+num_frames_per_clip])
|
| 98 |
+
if k+num_frames_per_clip < n and i==1:
|
| 99 |
+
context_list.append(sample_interval[n-num_frames_per_clip:n])
|
| 100 |
+
context_list_swap.append(sample_interval[0:num_frames_per_clip])
|
| 101 |
+
for k in range(num_frames_per_clip//2, n-num_frames_per_clip, num_frames_per_clip-overlap):
|
| 102 |
+
context_list_swap.append(sample_interval[k:k+num_frames_per_clip])
|
| 103 |
+
if k+num_frames_per_clip < n and i==1:
|
| 104 |
+
context_list_swap.append(sample_interval[n-num_frames_per_clip:n])
|
| 105 |
+
if n==num_frames_per_clip:
|
| 106 |
+
context_list.append(sample_interval[n-num_frames_per_clip:n])
|
| 107 |
+
context_list_swap.append(sample_interval[n-num_frames_per_clip:n])
|
| 108 |
+
return context_list, context_list_swap
|
| 109 |
+
|
| 110 |
+
@dataclass
|
| 111 |
+
class DiffuEraserPipelineOutput(BaseOutput):
|
| 112 |
+
frames: Union[torch.Tensor, np.ndarray]
|
| 113 |
+
latents: Union[torch.Tensor, np.ndarray]
|
| 114 |
+
|
| 115 |
+
class StableDiffusionDiffuEraserPipeline(
|
| 116 |
+
DiffusionPipeline,
|
| 117 |
+
StableDiffusionMixin,
|
| 118 |
+
TextualInversionLoaderMixin,
|
| 119 |
+
LoraLoaderMixin,
|
| 120 |
+
IPAdapterMixin,
|
| 121 |
+
FromSingleFileMixin,
|
| 122 |
+
):
|
| 123 |
+
r"""
|
| 124 |
+
Pipeline for video inpainting using Video Diffusion Model with BrushNet guidance.
|
| 125 |
+
|
| 126 |
+
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
|
| 127 |
+
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
|
| 128 |
+
|
| 129 |
+
The pipeline also inherits the following loading methods:
|
| 130 |
+
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
|
| 131 |
+
- [`~loaders.LoraLoaderMixin.load_lora_weights`] for loading LoRA weights
|
| 132 |
+
- [`~loaders.LoraLoaderMixin.save_lora_weights`] for saving LoRA weights
|
| 133 |
+
- [`~loaders.FromSingleFileMixin.from_single_file`] for loading `.ckpt` files
|
| 134 |
+
- [`~loaders.IPAdapterMixin.load_ip_adapter`] for loading IP Adapters
|
| 135 |
+
|
| 136 |
+
Args:
|
| 137 |
+
vae ([`AutoencoderKL`]):
|
| 138 |
+
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
|
| 139 |
+
text_encoder ([`~transformers.CLIPTextModel`]):
|
| 140 |
+
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
|
| 141 |
+
tokenizer ([`~transformers.CLIPTokenizer`]):
|
| 142 |
+
A `CLIPTokenizer` to tokenize text.
|
| 143 |
+
unet ([`UNet2DConditionModel`]):
|
| 144 |
+
A `UNet2DConditionModel` to denoise the encoded image latents.
|
| 145 |
+
brushnet ([`BrushNetModel`]`):
|
| 146 |
+
Provides additional conditioning to the `unet` during the denoising process.
|
| 147 |
+
scheduler ([`SchedulerMixin`]):
|
| 148 |
+
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
|
| 149 |
+
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
|
| 150 |
+
safety_checker ([`StableDiffusionSafetyChecker`]):
|
| 151 |
+
Classification module that estimates whether generated images could be considered offensive or harmful.
|
| 152 |
+
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
|
| 153 |
+
about a model's potential harms.
|
| 154 |
+
feature_extractor ([`~transformers.CLIPImageProcessor`]):
|
| 155 |
+
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
|
| 156 |
+
"""
|
| 157 |
+
|
| 158 |
+
model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
|
| 159 |
+
_optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
|
| 160 |
+
_exclude_from_cpu_offload = ["safety_checker"]
|
| 161 |
+
_callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds"]
|
| 162 |
+
|
| 163 |
+
def __init__(
|
| 164 |
+
self,
|
| 165 |
+
vae: AutoencoderKL,
|
| 166 |
+
text_encoder: CLIPTextModel,
|
| 167 |
+
tokenizer: CLIPTokenizer,
|
| 168 |
+
unet: UNet2DConditionModel,
|
| 169 |
+
brushnet: BrushNetModel,
|
| 170 |
+
scheduler: KarrasDiffusionSchedulers,
|
| 171 |
+
safety_checker: StableDiffusionSafetyChecker,
|
| 172 |
+
feature_extractor: CLIPImageProcessor,
|
| 173 |
+
image_encoder: CLIPVisionModelWithProjection = None,
|
| 174 |
+
requires_safety_checker: bool = True,
|
| 175 |
+
):
|
| 176 |
+
super().__init__()
|
| 177 |
+
|
| 178 |
+
if safety_checker is None and requires_safety_checker:
|
| 179 |
+
logger.warning(
|
| 180 |
+
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
|
| 181 |
+
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
|
| 182 |
+
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
|
| 183 |
+
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
|
| 184 |
+
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
|
| 185 |
+
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
if safety_checker is not None and feature_extractor is None:
|
| 189 |
+
raise ValueError(
|
| 190 |
+
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
|
| 191 |
+
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
self.register_modules(
|
| 195 |
+
vae=vae,
|
| 196 |
+
text_encoder=text_encoder,
|
| 197 |
+
tokenizer=tokenizer,
|
| 198 |
+
unet=unet,
|
| 199 |
+
brushnet=brushnet,
|
| 200 |
+
scheduler=scheduler,
|
| 201 |
+
safety_checker=safety_checker,
|
| 202 |
+
feature_extractor=feature_extractor,
|
| 203 |
+
image_encoder=image_encoder,
|
| 204 |
+
)
|
| 205 |
+
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
| 206 |
+
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
|
| 207 |
+
self.register_to_config(requires_safety_checker=requires_safety_checker)
|
| 208 |
+
|
| 209 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
|
| 210 |
+
def _encode_prompt(
|
| 211 |
+
self,
|
| 212 |
+
prompt,
|
| 213 |
+
device,
|
| 214 |
+
num_images_per_prompt,
|
| 215 |
+
do_classifier_free_guidance,
|
| 216 |
+
negative_prompt=None,
|
| 217 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 218 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 219 |
+
lora_scale: Optional[float] = None,
|
| 220 |
+
**kwargs,
|
| 221 |
+
):
|
| 222 |
+
deprecation_message = "`_encode_prompt()` is deprecated and it will be removed in a future version. Use `encode_prompt()` instead. Also, be aware that the output format changed from a concatenated tensor to a tuple."
|
| 223 |
+
deprecate("_encode_prompt()", "1.0.0", deprecation_message, standard_warn=False)
|
| 224 |
+
|
| 225 |
+
prompt_embeds_tuple = self.encode_prompt(
|
| 226 |
+
prompt=prompt,
|
| 227 |
+
device=device,
|
| 228 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 229 |
+
do_classifier_free_guidance=do_classifier_free_guidance,
|
| 230 |
+
negative_prompt=negative_prompt,
|
| 231 |
+
prompt_embeds=prompt_embeds,
|
| 232 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 233 |
+
lora_scale=lora_scale,
|
| 234 |
+
**kwargs,
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
# concatenate for backwards comp
|
| 238 |
+
prompt_embeds = torch.cat([prompt_embeds_tuple[1], prompt_embeds_tuple[0]])
|
| 239 |
+
|
| 240 |
+
return prompt_embeds
|
| 241 |
+
|
| 242 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_prompt
|
| 243 |
+
def encode_prompt(
|
| 244 |
+
self,
|
| 245 |
+
prompt,
|
| 246 |
+
device,
|
| 247 |
+
num_images_per_prompt,
|
| 248 |
+
do_classifier_free_guidance,
|
| 249 |
+
negative_prompt=None,
|
| 250 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 251 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 252 |
+
lora_scale: Optional[float] = None,
|
| 253 |
+
clip_skip: Optional[int] = None,
|
| 254 |
+
):
|
| 255 |
+
r"""
|
| 256 |
+
Encodes the prompt into text encoder hidden states.
|
| 257 |
+
|
| 258 |
+
Args:
|
| 259 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 260 |
+
prompt to be encoded
|
| 261 |
+
device: (`torch.device`):
|
| 262 |
+
torch device
|
| 263 |
+
num_images_per_prompt (`int`):
|
| 264 |
+
number of images that should be generated per prompt
|
| 265 |
+
do_classifier_free_guidance (`bool`):
|
| 266 |
+
whether to use classifier free guidance or not
|
| 267 |
+
negative_prompt (`str` or `List[str]`, *optional*):
|
| 268 |
+
The prompt or prompts not to guide the image generation. If not defined, one has to pass
|
| 269 |
+
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
|
| 270 |
+
less than `1`).
|
| 271 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 272 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
|
| 273 |
+
provided, text embeddings will be generated from `prompt` input argument.
|
| 274 |
+
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 275 |
+
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
| 276 |
+
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
| 277 |
+
argument.
|
| 278 |
+
lora_scale (`float`, *optional*):
|
| 279 |
+
A LoRA scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
|
| 280 |
+
clip_skip (`int`, *optional*):
|
| 281 |
+
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
|
| 282 |
+
the output of the pre-final layer will be used for computing the prompt embeddings.
|
| 283 |
+
"""
|
| 284 |
+
# set lora scale so that monkey patched LoRA
|
| 285 |
+
# function of text encoder can correctly access it
|
| 286 |
+
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
|
| 287 |
+
self._lora_scale = lora_scale
|
| 288 |
+
|
| 289 |
+
# dynamically adjust the LoRA scale
|
| 290 |
+
if not USE_PEFT_BACKEND:
|
| 291 |
+
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
|
| 292 |
+
else:
|
| 293 |
+
scale_lora_layers(self.text_encoder, lora_scale)
|
| 294 |
+
|
| 295 |
+
if prompt is not None and isinstance(prompt, str):
|
| 296 |
+
batch_size = 1
|
| 297 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 298 |
+
batch_size = len(prompt)
|
| 299 |
+
else:
|
| 300 |
+
batch_size = prompt_embeds.shape[0]
|
| 301 |
+
|
| 302 |
+
if prompt_embeds is None:
|
| 303 |
+
# textual inversion: process multi-vector tokens if necessary
|
| 304 |
+
if isinstance(self, TextualInversionLoaderMixin):
|
| 305 |
+
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
|
| 306 |
+
|
| 307 |
+
text_inputs = self.tokenizer(
|
| 308 |
+
prompt,
|
| 309 |
+
padding="max_length",
|
| 310 |
+
max_length=self.tokenizer.model_max_length,
|
| 311 |
+
truncation=True,
|
| 312 |
+
return_tensors="pt",
|
| 313 |
+
)
|
| 314 |
+
text_input_ids = text_inputs.input_ids
|
| 315 |
+
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
| 316 |
+
|
| 317 |
+
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
|
| 318 |
+
text_input_ids, untruncated_ids
|
| 319 |
+
):
|
| 320 |
+
removed_text = self.tokenizer.batch_decode(
|
| 321 |
+
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
|
| 322 |
+
)
|
| 323 |
+
logger.warning(
|
| 324 |
+
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
| 325 |
+
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
| 326 |
+
)
|
| 327 |
+
|
| 328 |
+
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
|
| 329 |
+
attention_mask = text_inputs.attention_mask.to(device)
|
| 330 |
+
else:
|
| 331 |
+
attention_mask = None
|
| 332 |
+
|
| 333 |
+
if clip_skip is None:
|
| 334 |
+
prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)
|
| 335 |
+
prompt_embeds = prompt_embeds[0]
|
| 336 |
+
else:
|
| 337 |
+
prompt_embeds = self.text_encoder(
|
| 338 |
+
text_input_ids.to(device), attention_mask=attention_mask, output_hidden_states=True
|
| 339 |
+
)
|
| 340 |
+
# Access the `hidden_states` first, that contains a tuple of
|
| 341 |
+
# all the hidden states from the encoder layers. Then index into
|
| 342 |
+
# the tuple to access the hidden states from the desired layer.
|
| 343 |
+
prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
|
| 344 |
+
# We also need to apply the final LayerNorm here to not mess with the
|
| 345 |
+
# representations. The `last_hidden_states` that we typically use for
|
| 346 |
+
# obtaining the final prompt representations passes through the LayerNorm
|
| 347 |
+
# layer.
|
| 348 |
+
prompt_embeds = self.text_encoder.text_model.final_layer_norm(prompt_embeds)
|
| 349 |
+
|
| 350 |
+
if self.text_encoder is not None:
|
| 351 |
+
prompt_embeds_dtype = self.text_encoder.dtype
|
| 352 |
+
elif self.unet is not None:
|
| 353 |
+
prompt_embeds_dtype = self.unet.dtype
|
| 354 |
+
else:
|
| 355 |
+
prompt_embeds_dtype = prompt_embeds.dtype
|
| 356 |
+
|
| 357 |
+
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
|
| 358 |
+
|
| 359 |
+
bs_embed, seq_len, _ = prompt_embeds.shape
|
| 360 |
+
# duplicate text embeddings for each generation per prompt, using mps friendly method
|
| 361 |
+
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 362 |
+
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
|
| 363 |
+
|
| 364 |
+
# get unconditional embeddings for classifier free guidance
|
| 365 |
+
if do_classifier_free_guidance and negative_prompt_embeds is None:
|
| 366 |
+
uncond_tokens: List[str]
|
| 367 |
+
if negative_prompt is None:
|
| 368 |
+
uncond_tokens = [""] * batch_size
|
| 369 |
+
elif prompt is not None and type(prompt) is not type(negative_prompt):
|
| 370 |
+
raise TypeError(
|
| 371 |
+
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
| 372 |
+
f" {type(prompt)}."
|
| 373 |
+
)
|
| 374 |
+
elif isinstance(negative_prompt, str):
|
| 375 |
+
uncond_tokens = [negative_prompt]
|
| 376 |
+
elif batch_size != len(negative_prompt):
|
| 377 |
+
raise ValueError(
|
| 378 |
+
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
| 379 |
+
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
| 380 |
+
" the batch size of `prompt`."
|
| 381 |
+
)
|
| 382 |
+
else:
|
| 383 |
+
uncond_tokens = negative_prompt
|
| 384 |
+
|
| 385 |
+
# textual inversion: process multi-vector tokens if necessary
|
| 386 |
+
if isinstance(self, TextualInversionLoaderMixin):
|
| 387 |
+
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
|
| 388 |
+
|
| 389 |
+
max_length = prompt_embeds.shape[1]
|
| 390 |
+
uncond_input = self.tokenizer(
|
| 391 |
+
uncond_tokens,
|
| 392 |
+
padding="max_length",
|
| 393 |
+
max_length=max_length,
|
| 394 |
+
truncation=True,
|
| 395 |
+
return_tensors="pt",
|
| 396 |
+
)
|
| 397 |
+
|
| 398 |
+
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
|
| 399 |
+
attention_mask = uncond_input.attention_mask.to(device)
|
| 400 |
+
else:
|
| 401 |
+
attention_mask = None
|
| 402 |
+
|
| 403 |
+
negative_prompt_embeds = self.text_encoder(
|
| 404 |
+
uncond_input.input_ids.to(device),
|
| 405 |
+
attention_mask=attention_mask,
|
| 406 |
+
)
|
| 407 |
+
negative_prompt_embeds = negative_prompt_embeds[0]
|
| 408 |
+
|
| 409 |
+
if do_classifier_free_guidance:
|
| 410 |
+
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
| 411 |
+
seq_len = negative_prompt_embeds.shape[1]
|
| 412 |
+
|
| 413 |
+
negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
|
| 414 |
+
|
| 415 |
+
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
| 416 |
+
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
|
| 417 |
+
|
| 418 |
+
if isinstance(self, LoraLoaderMixin) and USE_PEFT_BACKEND:
|
| 419 |
+
# Retrieve the original scale by scaling back the LoRA layers
|
| 420 |
+
unscale_lora_layers(self.text_encoder, lora_scale)
|
| 421 |
+
|
| 422 |
+
return prompt_embeds, negative_prompt_embeds
|
| 423 |
+
|
| 424 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_image
|
| 425 |
+
def encode_image(self, image, device, num_images_per_prompt, output_hidden_states=None):
|
| 426 |
+
dtype = next(self.image_encoder.parameters()).dtype
|
| 427 |
+
|
| 428 |
+
if not isinstance(image, torch.Tensor):
|
| 429 |
+
image = self.feature_extractor(image, return_tensors="pt").pixel_values
|
| 430 |
+
|
| 431 |
+
image = image.to(device=device, dtype=dtype)
|
| 432 |
+
if output_hidden_states:
|
| 433 |
+
image_enc_hidden_states = self.image_encoder(image, output_hidden_states=True).hidden_states[-2]
|
| 434 |
+
image_enc_hidden_states = image_enc_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
| 435 |
+
uncond_image_enc_hidden_states = self.image_encoder(
|
| 436 |
+
torch.zeros_like(image), output_hidden_states=True
|
| 437 |
+
).hidden_states[-2]
|
| 438 |
+
uncond_image_enc_hidden_states = uncond_image_enc_hidden_states.repeat_interleave(
|
| 439 |
+
num_images_per_prompt, dim=0
|
| 440 |
+
)
|
| 441 |
+
return image_enc_hidden_states, uncond_image_enc_hidden_states
|
| 442 |
+
else:
|
| 443 |
+
image_embeds = self.image_encoder(image).image_embeds
|
| 444 |
+
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
| 445 |
+
uncond_image_embeds = torch.zeros_like(image_embeds)
|
| 446 |
+
|
| 447 |
+
return image_embeds, uncond_image_embeds
|
| 448 |
+
|
| 449 |
+
def decode_latents(self, latents, weight_dtype):
|
| 450 |
+
latents = 1 / self.vae.config.scaling_factor * latents
|
| 451 |
+
video = []
|
| 452 |
+
for t in range(latents.shape[0]):
|
| 453 |
+
video.append(self.vae.decode(latents[t:t+1, ...].to(weight_dtype)).sample)
|
| 454 |
+
video = torch.concat(video, dim=0)
|
| 455 |
+
|
| 456 |
+
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
|
| 457 |
+
video = video.float()
|
| 458 |
+
return video
|
| 459 |
+
|
| 460 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_ip_adapter_image_embeds
|
| 461 |
+
def prepare_ip_adapter_image_embeds(
|
| 462 |
+
self, ip_adapter_image, ip_adapter_image_embeds, device, num_images_per_prompt, do_classifier_free_guidance
|
| 463 |
+
):
|
| 464 |
+
if ip_adapter_image_embeds is None:
|
| 465 |
+
if not isinstance(ip_adapter_image, list):
|
| 466 |
+
ip_adapter_image = [ip_adapter_image]
|
| 467 |
+
|
| 468 |
+
if len(ip_adapter_image) != len(self.unet.encoder_hid_proj.image_projection_layers):
|
| 469 |
+
raise ValueError(
|
| 470 |
+
f"`ip_adapter_image` must have same length as the number of IP Adapters. Got {len(ip_adapter_image)} images and {len(self.unet.encoder_hid_proj.image_projection_layers)} IP Adapters."
|
| 471 |
+
)
|
| 472 |
+
|
| 473 |
+
image_embeds = []
|
| 474 |
+
for single_ip_adapter_image, image_proj_layer in zip(
|
| 475 |
+
ip_adapter_image, self.unet.encoder_hid_proj.image_projection_layers
|
| 476 |
+
):
|
| 477 |
+
output_hidden_state = not isinstance(image_proj_layer, ImageProjection)
|
| 478 |
+
single_image_embeds, single_negative_image_embeds = self.encode_image(
|
| 479 |
+
single_ip_adapter_image, device, 1, output_hidden_state
|
| 480 |
+
)
|
| 481 |
+
single_image_embeds = torch.stack([single_image_embeds] * num_images_per_prompt, dim=0)
|
| 482 |
+
single_negative_image_embeds = torch.stack(
|
| 483 |
+
[single_negative_image_embeds] * num_images_per_prompt, dim=0
|
| 484 |
+
)
|
| 485 |
+
|
| 486 |
+
if do_classifier_free_guidance:
|
| 487 |
+
single_image_embeds = torch.cat([single_negative_image_embeds, single_image_embeds])
|
| 488 |
+
single_image_embeds = single_image_embeds.to(device)
|
| 489 |
+
|
| 490 |
+
image_embeds.append(single_image_embeds)
|
| 491 |
+
else:
|
| 492 |
+
repeat_dims = [1]
|
| 493 |
+
image_embeds = []
|
| 494 |
+
for single_image_embeds in ip_adapter_image_embeds:
|
| 495 |
+
if do_classifier_free_guidance:
|
| 496 |
+
single_negative_image_embeds, single_image_embeds = single_image_embeds.chunk(2)
|
| 497 |
+
single_image_embeds = single_image_embeds.repeat(
|
| 498 |
+
num_images_per_prompt, *(repeat_dims * len(single_image_embeds.shape[1:]))
|
| 499 |
+
)
|
| 500 |
+
single_negative_image_embeds = single_negative_image_embeds.repeat(
|
| 501 |
+
num_images_per_prompt, *(repeat_dims * len(single_negative_image_embeds.shape[1:]))
|
| 502 |
+
)
|
| 503 |
+
single_image_embeds = torch.cat([single_negative_image_embeds, single_image_embeds])
|
| 504 |
+
else:
|
| 505 |
+
single_image_embeds = single_image_embeds.repeat(
|
| 506 |
+
num_images_per_prompt, *(repeat_dims * len(single_image_embeds.shape[1:]))
|
| 507 |
+
)
|
| 508 |
+
image_embeds.append(single_image_embeds)
|
| 509 |
+
|
| 510 |
+
return image_embeds
|
| 511 |
+
|
| 512 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
|
| 513 |
+
def run_safety_checker(self, image, device, dtype):
|
| 514 |
+
if self.safety_checker is None:
|
| 515 |
+
has_nsfw_concept = None
|
| 516 |
+
else:
|
| 517 |
+
if torch.is_tensor(image):
|
| 518 |
+
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
|
| 519 |
+
else:
|
| 520 |
+
feature_extractor_input = self.image_processor.numpy_to_pil(image)
|
| 521 |
+
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
|
| 522 |
+
image, has_nsfw_concept = self.safety_checker(
|
| 523 |
+
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
|
| 524 |
+
)
|
| 525 |
+
return image, has_nsfw_concept
|
| 526 |
+
|
| 527 |
+
# Copied from diffusers.pipelines.text_to_video_synthesis/pipeline_text_to_video_synth.TextToVideoSDPipeline.decode_latents
|
| 528 |
+
def decode_latents(self, latents, weight_dtype):
|
| 529 |
+
latents = 1 / self.vae.config.scaling_factor * latents
|
| 530 |
+
video = []
|
| 531 |
+
for t in range(latents.shape[0]):
|
| 532 |
+
video.append(self.vae.decode(latents[t:t+1, ...].to(weight_dtype)).sample)
|
| 533 |
+
video = torch.concat(video, dim=0)
|
| 534 |
+
|
| 535 |
+
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
|
| 536 |
+
video = video.float()
|
| 537 |
+
return video
|
| 538 |
+
|
| 539 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
|
| 540 |
+
def prepare_extra_step_kwargs(self, generator, eta):
|
| 541 |
+
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
|
| 542 |
+
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
| 543 |
+
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
| 544 |
+
# and should be between [0, 1]
|
| 545 |
+
|
| 546 |
+
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
| 547 |
+
extra_step_kwargs = {}
|
| 548 |
+
if accepts_eta:
|
| 549 |
+
extra_step_kwargs["eta"] = eta
|
| 550 |
+
|
| 551 |
+
# check if the scheduler accepts generator
|
| 552 |
+
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
| 553 |
+
if accepts_generator:
|
| 554 |
+
extra_step_kwargs["generator"] = generator
|
| 555 |
+
return extra_step_kwargs
|
| 556 |
+
|
| 557 |
+
def check_inputs(
|
| 558 |
+
self,
|
| 559 |
+
prompt,
|
| 560 |
+
images,
|
| 561 |
+
masks,
|
| 562 |
+
callback_steps,
|
| 563 |
+
negative_prompt=None,
|
| 564 |
+
prompt_embeds=None,
|
| 565 |
+
negative_prompt_embeds=None,
|
| 566 |
+
ip_adapter_image=None,
|
| 567 |
+
ip_adapter_image_embeds=None,
|
| 568 |
+
brushnet_conditioning_scale=1.0,
|
| 569 |
+
control_guidance_start=0.0,
|
| 570 |
+
control_guidance_end=1.0,
|
| 571 |
+
callback_on_step_end_tensor_inputs=None,
|
| 572 |
+
):
|
| 573 |
+
if callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0):
|
| 574 |
+
raise ValueError(
|
| 575 |
+
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
|
| 576 |
+
f" {type(callback_steps)}."
|
| 577 |
+
)
|
| 578 |
+
|
| 579 |
+
if callback_on_step_end_tensor_inputs is not None and not all(
|
| 580 |
+
k in self._callback_tensor_inputs for k in callback_on_step_end_tensor_inputs
|
| 581 |
+
):
|
| 582 |
+
raise ValueError(
|
| 583 |
+
f"`callback_on_step_end_tensor_inputs` has to be in {self._callback_tensor_inputs}, but found {[k for k in callback_on_step_end_tensor_inputs if k not in self._callback_tensor_inputs]}"
|
| 584 |
+
)
|
| 585 |
+
|
| 586 |
+
if prompt is not None and prompt_embeds is not None:
|
| 587 |
+
raise ValueError(
|
| 588 |
+
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
|
| 589 |
+
" only forward one of the two."
|
| 590 |
+
)
|
| 591 |
+
elif prompt is None and prompt_embeds is None:
|
| 592 |
+
raise ValueError(
|
| 593 |
+
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
|
| 594 |
+
)
|
| 595 |
+
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
|
| 596 |
+
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
| 597 |
+
|
| 598 |
+
if negative_prompt is not None and negative_prompt_embeds is not None:
|
| 599 |
+
raise ValueError(
|
| 600 |
+
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
|
| 601 |
+
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
|
| 602 |
+
)
|
| 603 |
+
|
| 604 |
+
if prompt_embeds is not None and negative_prompt_embeds is not None:
|
| 605 |
+
if prompt_embeds.shape != negative_prompt_embeds.shape:
|
| 606 |
+
raise ValueError(
|
| 607 |
+
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
|
| 608 |
+
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
|
| 609 |
+
f" {negative_prompt_embeds.shape}."
|
| 610 |
+
)
|
| 611 |
+
|
| 612 |
+
# Check `image`
|
| 613 |
+
is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
|
| 614 |
+
self.brushnet, torch._dynamo.eval_frame.OptimizedModule
|
| 615 |
+
)
|
| 616 |
+
if (
|
| 617 |
+
isinstance(self.brushnet, BrushNetModel)
|
| 618 |
+
or is_compiled
|
| 619 |
+
and isinstance(self.brushnet._orig_mod, BrushNetModel)
|
| 620 |
+
):
|
| 621 |
+
self.check_image(images, masks, prompt, prompt_embeds)
|
| 622 |
+
else:
|
| 623 |
+
assert False
|
| 624 |
+
|
| 625 |
+
# Check `brushnet_conditioning_scale`
|
| 626 |
+
if (
|
| 627 |
+
isinstance(self.brushnet, BrushNetModel)
|
| 628 |
+
or is_compiled
|
| 629 |
+
and isinstance(self.brushnet._orig_mod, BrushNetModel)
|
| 630 |
+
):
|
| 631 |
+
if not isinstance(brushnet_conditioning_scale, float):
|
| 632 |
+
raise TypeError("For single brushnet: `brushnet_conditioning_scale` must be type `float`.")
|
| 633 |
+
else:
|
| 634 |
+
assert False
|
| 635 |
+
|
| 636 |
+
if not isinstance(control_guidance_start, (tuple, list)):
|
| 637 |
+
control_guidance_start = [control_guidance_start]
|
| 638 |
+
|
| 639 |
+
if not isinstance(control_guidance_end, (tuple, list)):
|
| 640 |
+
control_guidance_end = [control_guidance_end]
|
| 641 |
+
|
| 642 |
+
if len(control_guidance_start) != len(control_guidance_end):
|
| 643 |
+
raise ValueError(
|
| 644 |
+
f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
|
| 645 |
+
)
|
| 646 |
+
|
| 647 |
+
for start, end in zip(control_guidance_start, control_guidance_end):
|
| 648 |
+
if start >= end:
|
| 649 |
+
raise ValueError(
|
| 650 |
+
f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
|
| 651 |
+
)
|
| 652 |
+
if start < 0.0:
|
| 653 |
+
raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
|
| 654 |
+
if end > 1.0:
|
| 655 |
+
raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
|
| 656 |
+
|
| 657 |
+
if ip_adapter_image is not None and ip_adapter_image_embeds is not None:
|
| 658 |
+
raise ValueError(
|
| 659 |
+
"Provide either `ip_adapter_image` or `ip_adapter_image_embeds`. Cannot leave both `ip_adapter_image` and `ip_adapter_image_embeds` defined."
|
| 660 |
+
)
|
| 661 |
+
|
| 662 |
+
if ip_adapter_image_embeds is not None:
|
| 663 |
+
if not isinstance(ip_adapter_image_embeds, list):
|
| 664 |
+
raise ValueError(
|
| 665 |
+
f"`ip_adapter_image_embeds` has to be of type `list` but is {type(ip_adapter_image_embeds)}"
|
| 666 |
+
)
|
| 667 |
+
elif ip_adapter_image_embeds[0].ndim not in [3, 4]:
|
| 668 |
+
raise ValueError(
|
| 669 |
+
f"`ip_adapter_image_embeds` has to be a list of 3D or 4D tensors but is {ip_adapter_image_embeds[0].ndim}D"
|
| 670 |
+
)
|
| 671 |
+
|
| 672 |
+
def check_image(self, images, masks, prompt, prompt_embeds):
|
| 673 |
+
for image in images:
|
| 674 |
+
image_is_pil = isinstance(image, PIL.Image.Image)
|
| 675 |
+
image_is_tensor = isinstance(image, torch.Tensor)
|
| 676 |
+
image_is_np = isinstance(image, np.ndarray)
|
| 677 |
+
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
|
| 678 |
+
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
|
| 679 |
+
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
|
| 680 |
+
|
| 681 |
+
if (
|
| 682 |
+
not image_is_pil
|
| 683 |
+
and not image_is_tensor
|
| 684 |
+
and not image_is_np
|
| 685 |
+
and not image_is_pil_list
|
| 686 |
+
and not image_is_tensor_list
|
| 687 |
+
and not image_is_np_list
|
| 688 |
+
):
|
| 689 |
+
raise TypeError(
|
| 690 |
+
f"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(image)}"
|
| 691 |
+
)
|
| 692 |
+
for mask in masks:
|
| 693 |
+
mask_is_pil = isinstance(mask, PIL.Image.Image)
|
| 694 |
+
mask_is_tensor = isinstance(mask, torch.Tensor)
|
| 695 |
+
mask_is_np = isinstance(mask, np.ndarray)
|
| 696 |
+
mask_is_pil_list = isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image)
|
| 697 |
+
mask_is_tensor_list = isinstance(mask, list) and isinstance(mask[0], torch.Tensor)
|
| 698 |
+
mask_is_np_list = isinstance(mask, list) and isinstance(mask[0], np.ndarray)
|
| 699 |
+
|
| 700 |
+
if (
|
| 701 |
+
not mask_is_pil
|
| 702 |
+
and not mask_is_tensor
|
| 703 |
+
and not mask_is_np
|
| 704 |
+
and not mask_is_pil_list
|
| 705 |
+
and not mask_is_tensor_list
|
| 706 |
+
and not mask_is_np_list
|
| 707 |
+
):
|
| 708 |
+
raise TypeError(
|
| 709 |
+
f"mask must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors, but is {type(mask)}"
|
| 710 |
+
)
|
| 711 |
+
|
| 712 |
+
if image_is_pil:
|
| 713 |
+
image_batch_size = 1
|
| 714 |
+
else:
|
| 715 |
+
image_batch_size = len(image)
|
| 716 |
+
|
| 717 |
+
if prompt is not None and isinstance(prompt, str):
|
| 718 |
+
prompt_batch_size = 1
|
| 719 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 720 |
+
prompt_batch_size = len(prompt)
|
| 721 |
+
elif prompt_embeds is not None:
|
| 722 |
+
prompt_batch_size = prompt_embeds.shape[0]
|
| 723 |
+
|
| 724 |
+
if image_batch_size != 1 and image_batch_size != prompt_batch_size:
|
| 725 |
+
raise ValueError(
|
| 726 |
+
f"If image batch size is not 1, image batch size must be same as prompt batch size. image batch size: {image_batch_size}, prompt batch size: {prompt_batch_size}"
|
| 727 |
+
)
|
| 728 |
+
|
| 729 |
+
def prepare_image(
|
| 730 |
+
self,
|
| 731 |
+
images,
|
| 732 |
+
width,
|
| 733 |
+
height,
|
| 734 |
+
batch_size,
|
| 735 |
+
num_images_per_prompt,
|
| 736 |
+
device,
|
| 737 |
+
dtype,
|
| 738 |
+
do_classifier_free_guidance=False,
|
| 739 |
+
guess_mode=False,
|
| 740 |
+
):
|
| 741 |
+
images_new = []
|
| 742 |
+
for image in images:
|
| 743 |
+
image = self.image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
|
| 744 |
+
image_batch_size = image.shape[0]
|
| 745 |
+
|
| 746 |
+
if image_batch_size == 1:
|
| 747 |
+
repeat_by = batch_size
|
| 748 |
+
else:
|
| 749 |
+
# image batch size is the same as prompt batch size
|
| 750 |
+
repeat_by = num_images_per_prompt
|
| 751 |
+
|
| 752 |
+
image = image.repeat_interleave(repeat_by, dim=0)
|
| 753 |
+
|
| 754 |
+
image = image.to(device=device, dtype=dtype)
|
| 755 |
+
|
| 756 |
+
# if do_classifier_free_guidance and not guess_mode:
|
| 757 |
+
# image = torch.cat([image] * 2)
|
| 758 |
+
images_new.append(image)
|
| 759 |
+
|
| 760 |
+
return images_new
|
| 761 |
+
|
| 762 |
+
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
|
| 763 |
+
def prepare_latents(self, batch_size, num_channels_latents, num_frames, height, width, dtype, device, generator, latents=None):
|
| 764 |
+
# shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
|
| 765 |
+
#b,c,n,h,w
|
| 766 |
+
shape = (
|
| 767 |
+
batch_size,
|
| 768 |
+
num_channels_latents,
|
| 769 |
+
num_frames,
|
| 770 |
+
height // self.vae_scale_factor,
|
| 771 |
+
width // self.vae_scale_factor
|
| 772 |
+
)
|
| 773 |
+
if isinstance(generator, list) and len(generator) != batch_size:
|
| 774 |
+
raise ValueError(
|
| 775 |
+
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
| 776 |
+
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
| 777 |
+
)
|
| 778 |
+
|
| 779 |
+
if latents is None:
|
| 780 |
+
# noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
| 781 |
+
noise = rearrange(randn_tensor(shape, generator=generator, device=device, dtype=dtype), "b c t h w -> (b t) c h w")
|
| 782 |
+
else:
|
| 783 |
+
noise = latents.to(device)
|
| 784 |
+
|
| 785 |
+
# scale the initial noise by the standard deviation required by the scheduler
|
| 786 |
+
latents = noise * self.scheduler.init_noise_sigma
|
| 787 |
+
return latents, noise
|
| 788 |
+
|
| 789 |
+
@staticmethod
|
| 790 |
+
def temp_blend(a, b, overlap):
|
| 791 |
+
factor = torch.arange(overlap).to(b.device).view(overlap, 1, 1, 1) / (overlap - 1)
|
| 792 |
+
a[:overlap, ...] = (1 - factor) * a[:overlap, ...] + factor * b[:overlap, ...]
|
| 793 |
+
a[overlap:, ...] = b[overlap:, ...]
|
| 794 |
+
return a
|
| 795 |
+
|
| 796 |
+
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
| 797 |
+
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
| 798 |
+
"""
|
| 799 |
+
See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
|
| 800 |
+
|
| 801 |
+
Args:
|
| 802 |
+
timesteps (`torch.Tensor`):
|
| 803 |
+
generate embedding vectors at these timesteps
|
| 804 |
+
embedding_dim (`int`, *optional*, defaults to 512):
|
| 805 |
+
dimension of the embeddings to generate
|
| 806 |
+
dtype:
|
| 807 |
+
data type of the generated embeddings
|
| 808 |
+
|
| 809 |
+
Returns:
|
| 810 |
+
`torch.FloatTensor`: Embedding vectors with shape `(len(timesteps), embedding_dim)`
|
| 811 |
+
"""
|
| 812 |
+
assert len(w.shape) == 1
|
| 813 |
+
w = w * 1000.0
|
| 814 |
+
|
| 815 |
+
half_dim = embedding_dim // 2
|
| 816 |
+
emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
|
| 817 |
+
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
|
| 818 |
+
emb = w.to(dtype)[:, None] * emb[None, :]
|
| 819 |
+
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
|
| 820 |
+
if embedding_dim % 2 == 1: # zero pad
|
| 821 |
+
emb = torch.nn.functional.pad(emb, (0, 1))
|
| 822 |
+
assert emb.shape == (w.shape[0], embedding_dim)
|
| 823 |
+
return emb
|
| 824 |
+
|
| 825 |
+
@property
|
| 826 |
+
def guidance_scale(self):
|
| 827 |
+
return self._guidance_scale
|
| 828 |
+
|
| 829 |
+
@property
|
| 830 |
+
def clip_skip(self):
|
| 831 |
+
return self._clip_skip
|
| 832 |
+
|
| 833 |
+
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
| 834 |
+
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
| 835 |
+
# corresponds to doing no classifier free guidance.
|
| 836 |
+
@property
|
| 837 |
+
def do_classifier_free_guidance(self):
|
| 838 |
+
return self._guidance_scale > 1 and self.unet.config.time_cond_proj_dim is None
|
| 839 |
+
|
| 840 |
+
@property
|
| 841 |
+
def cross_attention_kwargs(self):
|
| 842 |
+
return self._cross_attention_kwargs
|
| 843 |
+
|
| 844 |
+
@property
|
| 845 |
+
def num_timesteps(self):
|
| 846 |
+
return self._num_timesteps
|
| 847 |
+
|
| 848 |
+
# based on BrushNet: https://github.com/TencentARC/BrushNet/blob/main/src/diffusers/pipelines/brushnet/pipeline_brushnet.py
|
| 849 |
+
@torch.no_grad()
|
| 850 |
+
def __call__(
|
| 851 |
+
self,
|
| 852 |
+
num_frames: Optional[int] = 24,
|
| 853 |
+
prompt: Union[str, List[str]] = None,
|
| 854 |
+
images: PipelineImageInput = None, ##masked images
|
| 855 |
+
masks: PipelineImageInput = None,
|
| 856 |
+
height: Optional[int] = None,
|
| 857 |
+
width: Optional[int] = None,
|
| 858 |
+
num_inference_steps: int = 50,
|
| 859 |
+
timesteps: List[int] = None,
|
| 860 |
+
guidance_scale: float = 7.5,
|
| 861 |
+
negative_prompt: Optional[Union[str, List[str]]] = None,
|
| 862 |
+
num_images_per_prompt: Optional[int] = 1,
|
| 863 |
+
eta: float = 0.0,
|
| 864 |
+
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
| 865 |
+
latents: Optional[torch.FloatTensor] = None,
|
| 866 |
+
prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 867 |
+
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
| 868 |
+
ip_adapter_image: Optional[PipelineImageInput] = None,
|
| 869 |
+
ip_adapter_image_embeds: Optional[List[torch.FloatTensor]] = None,
|
| 870 |
+
output_type: Optional[str] = "pil",
|
| 871 |
+
return_dict: bool = True,
|
| 872 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 873 |
+
brushnet_conditioning_scale: Union[float, List[float]] = 1.0,
|
| 874 |
+
guess_mode: bool = False,
|
| 875 |
+
control_guidance_start: Union[float, List[float]] = 0.0,
|
| 876 |
+
control_guidance_end: Union[float, List[float]] = 1.0,
|
| 877 |
+
clip_skip: Optional[int] = None,
|
| 878 |
+
callback_on_step_end: Optional[Callable[[int, int, Dict], None]] = None,
|
| 879 |
+
callback_on_step_end_tensor_inputs: List[str] = ["latents"],
|
| 880 |
+
**kwargs,
|
| 881 |
+
):
|
| 882 |
+
r"""
|
| 883 |
+
The call function to the pipeline for generation.
|
| 884 |
+
|
| 885 |
+
Args:
|
| 886 |
+
prompt (`str` or `List[str]`, *optional*):
|
| 887 |
+
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
|
| 888 |
+
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
|
| 889 |
+
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
|
| 890 |
+
The BrushNet branch input condition to provide guidance to the `unet` for generation.
|
| 891 |
+
mask (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
|
| 892 |
+
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
|
| 893 |
+
The BrushNet branch input condition to provide guidance to the `unet` for generation.
|
| 894 |
+
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 895 |
+
The height in pixels of the generated image.
|
| 896 |
+
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
|
| 897 |
+
The width in pixels of the generated image.
|
| 898 |
+
num_inference_steps (`int`, *optional*, defaults to 50):
|
| 899 |
+
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
| 900 |
+
expense of slower inference.
|
| 901 |
+
timesteps (`List[int]`, *optional*):
|
| 902 |
+
Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
|
| 903 |
+
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
|
| 904 |
+
passed will be used. Must be in descending order.
|
| 905 |
+
guidance_scale (`float`, *optional*, defaults to 7.5):
|
| 906 |
+
A higher guidance scale value encourages the model to generate images closely linked to the text
|
| 907 |
+
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
|
| 908 |
+
negative_prompt (`str` or `List[str]`, *optional*):
|
| 909 |
+
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
|
| 910 |
+
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
|
| 911 |
+
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
| 912 |
+
The number of images to generate per prompt.
|
| 913 |
+
eta (`float`, *optional*, defaults to 0.0):
|
| 914 |
+
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
|
| 915 |
+
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
|
| 916 |
+
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
| 917 |
+
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
|
| 918 |
+
generation deterministic.
|
| 919 |
+
latents (`torch.FloatTensor`, *optional*):
|
| 920 |
+
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
|
| 921 |
+
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
| 922 |
+
tensor is generated by sampling using the supplied random `generator`.
|
| 923 |
+
prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 924 |
+
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
|
| 925 |
+
provided, text embeddings are generated from the `prompt` input argument.
|
| 926 |
+
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
| 927 |
+
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
|
| 928 |
+
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
|
| 929 |
+
ip_adapter_image: (`PipelineImageInput`, *optional*): Optional image input to work with IP Adapters.
|
| 930 |
+
ip_adapter_image_embeds (`List[torch.FloatTensor]`, *optional*):
|
| 931 |
+
Pre-generated image embeddings for IP-Adapter. It should be a list of length same as number of IP-adapters.
|
| 932 |
+
Each element should be a tensor of shape `(batch_size, num_images, emb_dim)`. It should contain the negative image embedding
|
| 933 |
+
if `do_classifier_free_guidance` is set to `True`.
|
| 934 |
+
If not provided, embeddings are computed from the `ip_adapter_image` input argument.
|
| 935 |
+
output_type (`str`, *optional*, defaults to `"pil"`):
|
| 936 |
+
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
|
| 937 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 938 |
+
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
|
| 939 |
+
plain tuple.
|
| 940 |
+
callback (`Callable`, *optional*):
|
| 941 |
+
A function that calls every `callback_steps` steps during inference. The function is called with the
|
| 942 |
+
following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
|
| 943 |
+
callback_steps (`int`, *optional*, defaults to 1):
|
| 944 |
+
The frequency at which the `callback` function is called. If not specified, the callback is called at
|
| 945 |
+
every step.
|
| 946 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 947 |
+
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
|
| 948 |
+
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 949 |
+
brushnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
|
| 950 |
+
The outputs of the BrushNet are multiplied by `brushnet_conditioning_scale` before they are added
|
| 951 |
+
to the residual in the original `unet`. If multiple BrushNets are specified in `init`, you can set
|
| 952 |
+
the corresponding scale as a list.
|
| 953 |
+
guess_mode (`bool`, *optional*, defaults to `False`):
|
| 954 |
+
The BrushNet encoder tries to recognize the content of the input image even if you remove all
|
| 955 |
+
prompts. A `guidance_scale` value between 3.0 and 5.0 is recommended.
|
| 956 |
+
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
|
| 957 |
+
The percentage of total steps at which the BrushNet starts applying.
|
| 958 |
+
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
|
| 959 |
+
The percentage of total steps at which the BrushNet stops applying.
|
| 960 |
+
clip_skip (`int`, *optional*):
|
| 961 |
+
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
|
| 962 |
+
the output of the pre-final layer will be used for computing the prompt embeddings.
|
| 963 |
+
callback_on_step_end (`Callable`, *optional*):
|
| 964 |
+
A function that calls at the end of each denoising steps during the inference. The function is called
|
| 965 |
+
with the following arguments: `callback_on_step_end(self: DiffusionPipeline, step: int, timestep: int,
|
| 966 |
+
callback_kwargs: Dict)`. `callback_kwargs` will include a list of all tensors as specified by
|
| 967 |
+
`callback_on_step_end_tensor_inputs`.
|
| 968 |
+
callback_on_step_end_tensor_inputs (`List`, *optional*):
|
| 969 |
+
The list of tensor inputs for the `callback_on_step_end` function. The tensors specified in the list
|
| 970 |
+
will be passed as `callback_kwargs` argument. You will only be able to include variables listed in the
|
| 971 |
+
`._callback_tensor_inputs` attribute of your pipeine class.
|
| 972 |
+
|
| 973 |
+
Examples:
|
| 974 |
+
|
| 975 |
+
Returns:
|
| 976 |
+
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
|
| 977 |
+
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
|
| 978 |
+
otherwise a `tuple` is returned where the first element is a list with the generated images and the
|
| 979 |
+
second element is a list of `bool`s indicating whether the corresponding generated image contains
|
| 980 |
+
"not-safe-for-work" (nsfw) content.
|
| 981 |
+
"""
|
| 982 |
+
|
| 983 |
+
callback = kwargs.pop("callback", None)
|
| 984 |
+
callback_steps = kwargs.pop("callback_steps", None)
|
| 985 |
+
|
| 986 |
+
if callback is not None:
|
| 987 |
+
deprecate(
|
| 988 |
+
"callback",
|
| 989 |
+
"1.0.0",
|
| 990 |
+
"Passing `callback` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
|
| 991 |
+
)
|
| 992 |
+
if callback_steps is not None:
|
| 993 |
+
deprecate(
|
| 994 |
+
"callback_steps",
|
| 995 |
+
"1.0.0",
|
| 996 |
+
"Passing `callback_steps` as an input argument to `__call__` is deprecated, consider using `callback_on_step_end`",
|
| 997 |
+
)
|
| 998 |
+
|
| 999 |
+
brushnet = self.brushnet._orig_mod if is_compiled_module(self.brushnet) else self.brushnet
|
| 1000 |
+
|
| 1001 |
+
# align format for control guidance
|
| 1002 |
+
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
|
| 1003 |
+
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
|
| 1004 |
+
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
|
| 1005 |
+
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
|
| 1006 |
+
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
|
| 1007 |
+
control_guidance_start, control_guidance_end = (
|
| 1008 |
+
[control_guidance_start],
|
| 1009 |
+
[control_guidance_end],
|
| 1010 |
+
)
|
| 1011 |
+
|
| 1012 |
+
# 1. Check inputs. Raise error if not correct
|
| 1013 |
+
self.check_inputs(
|
| 1014 |
+
prompt,
|
| 1015 |
+
images,
|
| 1016 |
+
masks,
|
| 1017 |
+
callback_steps,
|
| 1018 |
+
negative_prompt,
|
| 1019 |
+
prompt_embeds,
|
| 1020 |
+
negative_prompt_embeds,
|
| 1021 |
+
ip_adapter_image,
|
| 1022 |
+
ip_adapter_image_embeds,
|
| 1023 |
+
brushnet_conditioning_scale,
|
| 1024 |
+
control_guidance_start,
|
| 1025 |
+
control_guidance_end,
|
| 1026 |
+
callback_on_step_end_tensor_inputs,
|
| 1027 |
+
)
|
| 1028 |
+
|
| 1029 |
+
self._guidance_scale = guidance_scale
|
| 1030 |
+
self._clip_skip = clip_skip
|
| 1031 |
+
self._cross_attention_kwargs = cross_attention_kwargs
|
| 1032 |
+
|
| 1033 |
+
# 2. Define call parameters
|
| 1034 |
+
if prompt is not None and isinstance(prompt, str):
|
| 1035 |
+
batch_size = 1
|
| 1036 |
+
elif prompt is not None and isinstance(prompt, list):
|
| 1037 |
+
batch_size = len(prompt)
|
| 1038 |
+
else:
|
| 1039 |
+
batch_size = prompt_embeds.shape[0]
|
| 1040 |
+
|
| 1041 |
+
device = self._execution_device
|
| 1042 |
+
|
| 1043 |
+
global_pool_conditions = (
|
| 1044 |
+
brushnet.config.global_pool_conditions
|
| 1045 |
+
if isinstance(brushnet, BrushNetModel)
|
| 1046 |
+
else brushnet.nets[0].config.global_pool_conditions
|
| 1047 |
+
)
|
| 1048 |
+
guess_mode = guess_mode or global_pool_conditions
|
| 1049 |
+
video_length = len(images)
|
| 1050 |
+
|
| 1051 |
+
# 3. Encode input prompt
|
| 1052 |
+
text_encoder_lora_scale = (
|
| 1053 |
+
self.cross_attention_kwargs.get("scale", None) if self.cross_attention_kwargs is not None else None
|
| 1054 |
+
)
|
| 1055 |
+
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
|
| 1056 |
+
prompt,
|
| 1057 |
+
device,
|
| 1058 |
+
num_images_per_prompt,
|
| 1059 |
+
self.do_classifier_free_guidance,
|
| 1060 |
+
negative_prompt,
|
| 1061 |
+
prompt_embeds=prompt_embeds,
|
| 1062 |
+
negative_prompt_embeds=negative_prompt_embeds,
|
| 1063 |
+
lora_scale=text_encoder_lora_scale,
|
| 1064 |
+
clip_skip=self.clip_skip,
|
| 1065 |
+
)
|
| 1066 |
+
# For classifier free guidance, we need to do two forward passes.
|
| 1067 |
+
# Here we concatenate the unconditional and text embeddings into a single batch
|
| 1068 |
+
# to avoid doing two forward passes
|
| 1069 |
+
if self.do_classifier_free_guidance:
|
| 1070 |
+
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
| 1071 |
+
|
| 1072 |
+
if ip_adapter_image is not None or ip_adapter_image_embeds is not None:
|
| 1073 |
+
image_embeds = self.prepare_ip_adapter_image_embeds(
|
| 1074 |
+
ip_adapter_image,
|
| 1075 |
+
ip_adapter_image_embeds,
|
| 1076 |
+
device,
|
| 1077 |
+
batch_size * num_images_per_prompt,
|
| 1078 |
+
self.do_classifier_free_guidance,
|
| 1079 |
+
)
|
| 1080 |
+
|
| 1081 |
+
# 4. Prepare image
|
| 1082 |
+
if isinstance(brushnet, BrushNetModel):
|
| 1083 |
+
images = self.prepare_image(
|
| 1084 |
+
images=images,
|
| 1085 |
+
width=width,
|
| 1086 |
+
height=height,
|
| 1087 |
+
batch_size=batch_size * num_images_per_prompt,
|
| 1088 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 1089 |
+
device=device,
|
| 1090 |
+
dtype=brushnet.dtype,
|
| 1091 |
+
do_classifier_free_guidance=self.do_classifier_free_guidance,
|
| 1092 |
+
guess_mode=guess_mode,
|
| 1093 |
+
)
|
| 1094 |
+
original_masks = self.prepare_image(
|
| 1095 |
+
images=masks,
|
| 1096 |
+
width=width,
|
| 1097 |
+
height=height,
|
| 1098 |
+
batch_size=batch_size * num_images_per_prompt,
|
| 1099 |
+
num_images_per_prompt=num_images_per_prompt,
|
| 1100 |
+
device=device,
|
| 1101 |
+
dtype=brushnet.dtype,
|
| 1102 |
+
do_classifier_free_guidance=self.do_classifier_free_guidance,
|
| 1103 |
+
guess_mode=guess_mode,
|
| 1104 |
+
)
|
| 1105 |
+
original_masks_new = []
|
| 1106 |
+
for original_mask in original_masks:
|
| 1107 |
+
original_mask=(original_mask.sum(1)[:,None,:,:] < 0).to(images[0].dtype)
|
| 1108 |
+
original_masks_new.append(original_mask)
|
| 1109 |
+
original_masks = original_masks_new
|
| 1110 |
+
|
| 1111 |
+
height, width = images[0].shape[-2:]
|
| 1112 |
+
else:
|
| 1113 |
+
assert False
|
| 1114 |
+
|
| 1115 |
+
# 5. Prepare timesteps
|
| 1116 |
+
timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
|
| 1117 |
+
self._num_timesteps = len(timesteps)
|
| 1118 |
+
|
| 1119 |
+
# 6. Prepare latent variables
|
| 1120 |
+
num_channels_latents = self.unet.config.in_channels
|
| 1121 |
+
latents, noise = self.prepare_latents(
|
| 1122 |
+
batch_size * num_images_per_prompt,
|
| 1123 |
+
num_channels_latents,
|
| 1124 |
+
num_frames,
|
| 1125 |
+
height,
|
| 1126 |
+
width,
|
| 1127 |
+
prompt_embeds.dtype,
|
| 1128 |
+
device,
|
| 1129 |
+
generator,
|
| 1130 |
+
latents,
|
| 1131 |
+
)
|
| 1132 |
+
|
| 1133 |
+
# 6.1 prepare condition latents
|
| 1134 |
+
images = torch.cat(images)
|
| 1135 |
+
images = images.to(dtype=images[0].dtype)
|
| 1136 |
+
conditioning_latents = []
|
| 1137 |
+
num=4
|
| 1138 |
+
for i in range(0, images.shape[0], num):
|
| 1139 |
+
conditioning_latents.append(self.vae.encode(images[i : i + num]).latent_dist.sample())
|
| 1140 |
+
conditioning_latents = torch.cat(conditioning_latents, dim=0)
|
| 1141 |
+
|
| 1142 |
+
conditioning_latents = conditioning_latents * self.vae.config.scaling_factor #[(f c h w],c2=4
|
| 1143 |
+
|
| 1144 |
+
original_masks = torch.cat(original_masks)
|
| 1145 |
+
masks = torch.nn.functional.interpolate(
|
| 1146 |
+
original_masks,
|
| 1147 |
+
size=(
|
| 1148 |
+
latents.shape[-2],
|
| 1149 |
+
latents.shape[-1]
|
| 1150 |
+
)
|
| 1151 |
+
) ##[ f c h w],c=1
|
| 1152 |
+
|
| 1153 |
+
conditioning_latents=torch.concat([conditioning_latents,masks],1)
|
| 1154 |
+
|
| 1155 |
+
# 6.5 Optionally get Guidance Scale Embedding
|
| 1156 |
+
timestep_cond = None
|
| 1157 |
+
if self.unet.config.time_cond_proj_dim is not None:
|
| 1158 |
+
guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
|
| 1159 |
+
timestep_cond = self.get_guidance_scale_embedding(
|
| 1160 |
+
guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
|
| 1161 |
+
).to(device=device, dtype=latents.dtype)
|
| 1162 |
+
|
| 1163 |
+
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
| 1164 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 1165 |
+
|
| 1166 |
+
# 7.1 Add image embeds for IP-Adapter
|
| 1167 |
+
added_cond_kwargs = (
|
| 1168 |
+
{"image_embeds": image_embeds}
|
| 1169 |
+
if ip_adapter_image is not None or ip_adapter_image_embeds is not None
|
| 1170 |
+
else None
|
| 1171 |
+
)
|
| 1172 |
+
|
| 1173 |
+
# 7.2 Create tensor stating which brushnets to keep
|
| 1174 |
+
brushnet_keep = []
|
| 1175 |
+
for i in range(len(timesteps)):
|
| 1176 |
+
keeps = [
|
| 1177 |
+
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
|
| 1178 |
+
for s, e in zip(control_guidance_start, control_guidance_end)
|
| 1179 |
+
]
|
| 1180 |
+
brushnet_keep.append(keeps[0] if isinstance(brushnet, BrushNetModel) else keeps)
|
| 1181 |
+
|
| 1182 |
+
|
| 1183 |
+
overlap = num_frames//4
|
| 1184 |
+
context_list, context_list_swap = get_frames_context_swap(video_length, overlap=overlap, num_frames_per_clip=num_frames)
|
| 1185 |
+
scheduler_status = [copy.deepcopy(self.scheduler.__dict__)] * len(context_list)
|
| 1186 |
+
scheduler_status_swap = [copy.deepcopy(self.scheduler.__dict__)] * len(context_list_swap)
|
| 1187 |
+
count = torch.zeros_like(latents)
|
| 1188 |
+
value = torch.zeros_like(latents)
|
| 1189 |
+
|
| 1190 |
+
|
| 1191 |
+
# 8. Denoising loop
|
| 1192 |
+
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
| 1193 |
+
is_unet_compiled = is_compiled_module(self.unet)
|
| 1194 |
+
is_brushnet_compiled = is_compiled_module(self.brushnet)
|
| 1195 |
+
is_torch_higher_equal_2_1 = is_torch_version(">=", "2.1")
|
| 1196 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 1197 |
+
for i, t in enumerate(timesteps):
|
| 1198 |
+
|
| 1199 |
+
count.zero_()
|
| 1200 |
+
value.zero_()
|
| 1201 |
+
## swap
|
| 1202 |
+
if (i%2==1):
|
| 1203 |
+
context_list_choose = context_list_swap
|
| 1204 |
+
scheduler_status_choose = scheduler_status_swap
|
| 1205 |
+
else:
|
| 1206 |
+
context_list_choose = context_list
|
| 1207 |
+
scheduler_status_choose = scheduler_status
|
| 1208 |
+
|
| 1209 |
+
|
| 1210 |
+
for j, context in enumerate(context_list_choose):
|
| 1211 |
+
self.scheduler.__dict__.update(scheduler_status_choose[j])
|
| 1212 |
+
|
| 1213 |
+
latents_j = latents[context, :, :, :]
|
| 1214 |
+
|
| 1215 |
+
# Relevant thread:
|
| 1216 |
+
# https://dev-discuss.pytorch.org/t/cudagraphs-in-pytorch-2-0/1428
|
| 1217 |
+
if (is_unet_compiled and is_brushnet_compiled) and is_torch_higher_equal_2_1:
|
| 1218 |
+
torch._inductor.cudagraph_mark_step_begin()
|
| 1219 |
+
# expand the latents if we are doing classifier free guidance
|
| 1220 |
+
latent_model_input = torch.cat([latents_j] * 2) if self.do_classifier_free_guidance else latents_j
|
| 1221 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 1222 |
+
|
| 1223 |
+
# brushnet(s) inference
|
| 1224 |
+
if guess_mode and self.do_classifier_free_guidance:
|
| 1225 |
+
# Infer BrushNet only for the conditional batch.
|
| 1226 |
+
control_model_input = latents_j
|
| 1227 |
+
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
|
| 1228 |
+
brushnet_prompt_embeds = prompt_embeds.chunk(2)[1]
|
| 1229 |
+
brushnet_prompt_embeds = rearrange(repeat(brushnet_prompt_embeds, "b c d -> b t c d", t=num_frames), 'b t c d -> (b t) c d')
|
| 1230 |
+
else:
|
| 1231 |
+
control_model_input = latent_model_input
|
| 1232 |
+
brushnet_prompt_embeds = prompt_embeds
|
| 1233 |
+
if self.do_classifier_free_guidance:
|
| 1234 |
+
neg_brushnet_prompt_embeds, brushnet_prompt_embeds = brushnet_prompt_embeds.chunk(2)
|
| 1235 |
+
brushnet_prompt_embeds = rearrange(repeat(brushnet_prompt_embeds, "b c d -> b t c d", t=num_frames), 'b t c d -> (b t) c d')
|
| 1236 |
+
neg_brushnet_prompt_embeds = rearrange(repeat(neg_brushnet_prompt_embeds, "b c d -> b t c d", t=num_frames), 'b t c d -> (b t) c d')
|
| 1237 |
+
brushnet_prompt_embeds = torch.cat([neg_brushnet_prompt_embeds, brushnet_prompt_embeds])
|
| 1238 |
+
else:
|
| 1239 |
+
brushnet_prompt_embeds = rearrange(repeat(brushnet_prompt_embeds, "b c d -> b t c d", t=num_frames), 'b t c d -> (b t) c d')
|
| 1240 |
+
|
| 1241 |
+
if isinstance(brushnet_keep[i], list):
|
| 1242 |
+
cond_scale = [c * s for c, s in zip(brushnet_conditioning_scale, brushnet_keep[i])]
|
| 1243 |
+
else:
|
| 1244 |
+
brushnet_cond_scale = brushnet_conditioning_scale
|
| 1245 |
+
if isinstance(brushnet_cond_scale, list):
|
| 1246 |
+
brushnet_cond_scale = brushnet_cond_scale[0]
|
| 1247 |
+
cond_scale = brushnet_cond_scale * brushnet_keep[i]
|
| 1248 |
+
|
| 1249 |
+
|
| 1250 |
+
down_block_res_samples, mid_block_res_sample, up_block_res_samples = self.brushnet(
|
| 1251 |
+
control_model_input,
|
| 1252 |
+
t,
|
| 1253 |
+
encoder_hidden_states=brushnet_prompt_embeds,
|
| 1254 |
+
brushnet_cond=torch.cat([conditioning_latents[context, :, :, :]]*2) if self.do_classifier_free_guidance else conditioning_latents[context, :, :, :],
|
| 1255 |
+
conditioning_scale=cond_scale,
|
| 1256 |
+
guess_mode=guess_mode,
|
| 1257 |
+
return_dict=False,
|
| 1258 |
+
)
|
| 1259 |
+
|
| 1260 |
+
if guess_mode and self.do_classifier_free_guidance:
|
| 1261 |
+
# Infered BrushNet only for the conditional batch.
|
| 1262 |
+
# To apply the output of BrushNet to both the unconditional and conditional batches,
|
| 1263 |
+
# add 0 to the unconditional batch to keep it unchanged.
|
| 1264 |
+
down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
|
| 1265 |
+
mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
|
| 1266 |
+
up_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in up_block_res_samples]
|
| 1267 |
+
|
| 1268 |
+
# predict the noise residual
|
| 1269 |
+
noise_pred = self.unet(
|
| 1270 |
+
latent_model_input,
|
| 1271 |
+
t,
|
| 1272 |
+
encoder_hidden_states=prompt_embeds,
|
| 1273 |
+
timestep_cond=timestep_cond,
|
| 1274 |
+
cross_attention_kwargs=self.cross_attention_kwargs,
|
| 1275 |
+
down_block_add_samples=down_block_res_samples,
|
| 1276 |
+
mid_block_add_sample=mid_block_res_sample,
|
| 1277 |
+
up_block_add_samples=up_block_res_samples,
|
| 1278 |
+
added_cond_kwargs=added_cond_kwargs,
|
| 1279 |
+
return_dict=False,
|
| 1280 |
+
num_frames=num_frames,
|
| 1281 |
+
)[0]
|
| 1282 |
+
|
| 1283 |
+
# perform guidance
|
| 1284 |
+
if self.do_classifier_free_guidance:
|
| 1285 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 1286 |
+
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 1287 |
+
|
| 1288 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 1289 |
+
latents_j = self.scheduler.step(noise_pred, t, latents_j, **extra_step_kwargs, return_dict=False)[0]
|
| 1290 |
+
|
| 1291 |
+
count[context, ...] += 1
|
| 1292 |
+
|
| 1293 |
+
if j==0:
|
| 1294 |
+
value[context, ...] += latents_j
|
| 1295 |
+
else:
|
| 1296 |
+
overlap_index_list = [index for index, value in enumerate(count[context, 0, 0, 0]) if value > 1]
|
| 1297 |
+
overlap_cur = len(overlap_index_list)
|
| 1298 |
+
ratio_next = torch.linspace(0, 1, overlap_cur+2)[1:-1]
|
| 1299 |
+
ratio_pre = 1-ratio_next
|
| 1300 |
+
for i_overlap in overlap_index_list:
|
| 1301 |
+
value[context[i_overlap], ...] = value[context[i_overlap], ...]*ratio_pre[i_overlap] + latents_j[i_overlap, ...]*ratio_next[i_overlap]
|
| 1302 |
+
value[context[i_overlap:num_frames], ...] = latents_j[i_overlap:num_frames, ...]
|
| 1303 |
+
|
| 1304 |
+
latents = value.clone()
|
| 1305 |
+
|
| 1306 |
+
if callback_on_step_end is not None:
|
| 1307 |
+
callback_kwargs = {}
|
| 1308 |
+
for k in callback_on_step_end_tensor_inputs:
|
| 1309 |
+
callback_kwargs[k] = locals()[k]
|
| 1310 |
+
callback_outputs = callback_on_step_end(self, i, t, callback_kwargs)
|
| 1311 |
+
|
| 1312 |
+
latents = callback_outputs.pop("latents", latents)
|
| 1313 |
+
prompt_embeds = callback_outputs.pop("prompt_embeds", prompt_embeds)
|
| 1314 |
+
negative_prompt_embeds = callback_outputs.pop("negative_prompt_embeds", negative_prompt_embeds)
|
| 1315 |
+
|
| 1316 |
+
# call the callback, if provided
|
| 1317 |
+
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
| 1318 |
+
progress_bar.update()
|
| 1319 |
+
if callback is not None and i % callback_steps == 0:
|
| 1320 |
+
step_idx = i // getattr(self.scheduler, "order", 1)
|
| 1321 |
+
callback(step_idx, t, latents)
|
| 1322 |
+
|
| 1323 |
+
|
| 1324 |
+
# If we do sequential model offloading, let's offload unet and brushnet
|
| 1325 |
+
# manually for max memory savings
|
| 1326 |
+
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
|
| 1327 |
+
self.unet.to("cpu")
|
| 1328 |
+
self.brushnet.to("cpu")
|
| 1329 |
+
torch.cuda.empty_cache()
|
| 1330 |
+
|
| 1331 |
+
if output_type == "latent":
|
| 1332 |
+
image = latents
|
| 1333 |
+
has_nsfw_concept = None
|
| 1334 |
+
return DiffuEraserPipelineOutput(frames=image, nsfw_content_detected=has_nsfw_concept)
|
| 1335 |
+
|
| 1336 |
+
video_tensor = self.decode_latents(latents, weight_dtype=prompt_embeds.dtype)
|
| 1337 |
+
|
| 1338 |
+
if output_type == "pt":
|
| 1339 |
+
video = video_tensor
|
| 1340 |
+
else:
|
| 1341 |
+
video = self.image_processor.postprocess(video_tensor, output_type=output_type)
|
| 1342 |
+
|
| 1343 |
+
# Offload all models
|
| 1344 |
+
self.maybe_free_model_hooks()
|
| 1345 |
+
|
| 1346 |
+
if not return_dict:
|
| 1347 |
+
return (video, has_nsfw_concept)
|
| 1348 |
+
|
| 1349 |
+
return DiffuEraserPipelineOutput(frames=video, latents=latents)
|
examples/example1/mask.mp4
ADDED
|
Binary file (716 kB). View file
|
|
|
examples/example1/video.mp4
ADDED
|
Binary file (672 kB). View file
|
|
|
examples/example2/mask.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:39849531b31960ee023cd33caf402afd4a4c1402276ba8afa04b7888feb52c3f
|
| 3 |
+
size 1249680
|
examples/example2/video.mp4
ADDED
|
Binary file (684 kB). View file
|
|
|
examples/example3/mask.mp4
ADDED
|
Binary file (142 kB). View file
|
|
|
examples/example3/video.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b21c936a305f80ed6707bad621712b24bd1e7a69f82ec7cdd949b18fd1a7fd56
|
| 3 |
+
size 5657081
|
libs/brushnet_CA.py
ADDED
|
@@ -0,0 +1,939 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
from torch.nn import functional as F
|
| 7 |
+
|
| 8 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 9 |
+
from diffusers.utils import BaseOutput, logging
|
| 10 |
+
from diffusers.models.attention_processor import (
|
| 11 |
+
ADDED_KV_ATTENTION_PROCESSORS,
|
| 12 |
+
CROSS_ATTENTION_PROCESSORS,
|
| 13 |
+
AttentionProcessor,
|
| 14 |
+
AttnAddedKVProcessor,
|
| 15 |
+
AttnProcessor,
|
| 16 |
+
)
|
| 17 |
+
from diffusers.models.embeddings import TextImageProjection, TextImageTimeEmbedding, TextTimeEmbedding, TimestepEmbedding, Timesteps
|
| 18 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 19 |
+
from .unet_2d_blocks import (
|
| 20 |
+
CrossAttnDownBlock2D,
|
| 21 |
+
DownBlock2D,
|
| 22 |
+
UNetMidBlock2D,
|
| 23 |
+
UNetMidBlock2DCrossAttn,
|
| 24 |
+
get_down_block,
|
| 25 |
+
get_mid_block,
|
| 26 |
+
get_up_block,
|
| 27 |
+
MidBlock2D
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
# from diffusers.models.unets.unet_2d_condition import UNet2DConditionModel
|
| 31 |
+
from libs.unet_2d_condition import UNet2DConditionModel
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
@dataclass
|
| 38 |
+
class BrushNetOutput(BaseOutput):
|
| 39 |
+
"""
|
| 40 |
+
The output of [`BrushNetModel`].
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
up_block_res_samples (`tuple[torch.Tensor]`):
|
| 44 |
+
A tuple of upsample activations at different resolutions for each upsampling block. Each tensor should
|
| 45 |
+
be of shape `(batch_size, channel * resolution, height //resolution, width // resolution)`. Output can be
|
| 46 |
+
used to condition the original UNet's upsampling activations.
|
| 47 |
+
down_block_res_samples (`tuple[torch.Tensor]`):
|
| 48 |
+
A tuple of downsample activations at different resolutions for each downsampling block. Each tensor should
|
| 49 |
+
be of shape `(batch_size, channel * resolution, height //resolution, width // resolution)`. Output can be
|
| 50 |
+
used to condition the original UNet's downsampling activations.
|
| 51 |
+
mid_down_block_re_sample (`torch.Tensor`):
|
| 52 |
+
The activation of the midde block (the lowest sample resolution). Each tensor should be of shape
|
| 53 |
+
`(batch_size, channel * lowest_resolution, height // lowest_resolution, width // lowest_resolution)`.
|
| 54 |
+
Output can be used to condition the original UNet's middle block activation.
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
up_block_res_samples: Tuple[torch.Tensor]
|
| 58 |
+
down_block_res_samples: Tuple[torch.Tensor]
|
| 59 |
+
mid_block_res_sample: torch.Tensor
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class BrushNetModel(ModelMixin, ConfigMixin):
|
| 63 |
+
"""
|
| 64 |
+
A BrushNet model.
|
| 65 |
+
|
| 66 |
+
Args:
|
| 67 |
+
in_channels (`int`, defaults to 4):
|
| 68 |
+
The number of channels in the input sample.
|
| 69 |
+
flip_sin_to_cos (`bool`, defaults to `True`):
|
| 70 |
+
Whether to flip the sin to cos in the time embedding.
|
| 71 |
+
freq_shift (`int`, defaults to 0):
|
| 72 |
+
The frequency shift to apply to the time embedding.
|
| 73 |
+
down_block_types (`tuple[str]`, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
|
| 74 |
+
The tuple of downsample blocks to use.
|
| 75 |
+
mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
|
| 76 |
+
Block type for middle of UNet, it can be one of `UNetMidBlock2DCrossAttn`, `UNetMidBlock2D`, or
|
| 77 |
+
`UNetMidBlock2DSimpleCrossAttn`. If `None`, the mid block layer is skipped.
|
| 78 |
+
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D")`):
|
| 79 |
+
The tuple of upsample blocks to use.
|
| 80 |
+
only_cross_attention (`Union[bool, Tuple[bool]]`, defaults to `False`):
|
| 81 |
+
block_out_channels (`tuple[int]`, defaults to `(320, 640, 1280, 1280)`):
|
| 82 |
+
The tuple of output channels for each block.
|
| 83 |
+
layers_per_block (`int`, defaults to 2):
|
| 84 |
+
The number of layers per block.
|
| 85 |
+
downsample_padding (`int`, defaults to 1):
|
| 86 |
+
The padding to use for the downsampling convolution.
|
| 87 |
+
mid_block_scale_factor (`float`, defaults to 1):
|
| 88 |
+
The scale factor to use for the mid block.
|
| 89 |
+
act_fn (`str`, defaults to "silu"):
|
| 90 |
+
The activation function to use.
|
| 91 |
+
norm_num_groups (`int`, *optional*, defaults to 32):
|
| 92 |
+
The number of groups to use for the normalization. If None, normalization and activation layers is skipped
|
| 93 |
+
in post-processing.
|
| 94 |
+
norm_eps (`float`, defaults to 1e-5):
|
| 95 |
+
The epsilon to use for the normalization.
|
| 96 |
+
cross_attention_dim (`int`, defaults to 1280):
|
| 97 |
+
The dimension of the cross attention features.
|
| 98 |
+
transformer_layers_per_block (`int` or `Tuple[int]`, *optional*, defaults to 1):
|
| 99 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
|
| 100 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 101 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 102 |
+
encoder_hid_dim (`int`, *optional*, defaults to None):
|
| 103 |
+
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
| 104 |
+
dimension to `cross_attention_dim`.
|
| 105 |
+
encoder_hid_dim_type (`str`, *optional*, defaults to `None`):
|
| 106 |
+
If given, the `encoder_hidden_states` and potentially other embeddings are down-projected to text
|
| 107 |
+
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
| 108 |
+
attention_head_dim (`Union[int, Tuple[int]]`, defaults to 8):
|
| 109 |
+
The dimension of the attention heads.
|
| 110 |
+
use_linear_projection (`bool`, defaults to `False`):
|
| 111 |
+
class_embed_type (`str`, *optional*, defaults to `None`):
|
| 112 |
+
The type of class embedding to use which is ultimately summed with the time embeddings. Choose from None,
|
| 113 |
+
`"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
|
| 114 |
+
addition_embed_type (`str`, *optional*, defaults to `None`):
|
| 115 |
+
Configures an optional embedding which will be summed with the time embeddings. Choose from `None` or
|
| 116 |
+
"text". "text" will use the `TextTimeEmbedding` layer.
|
| 117 |
+
num_class_embeds (`int`, *optional*, defaults to 0):
|
| 118 |
+
Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
|
| 119 |
+
class conditioning with `class_embed_type` equal to `None`.
|
| 120 |
+
upcast_attention (`bool`, defaults to `False`):
|
| 121 |
+
resnet_time_scale_shift (`str`, defaults to `"default"`):
|
| 122 |
+
Time scale shift config for ResNet blocks (see `ResnetBlock2D`). Choose from `default` or `scale_shift`.
|
| 123 |
+
projection_class_embeddings_input_dim (`int`, *optional*, defaults to `None`):
|
| 124 |
+
The dimension of the `class_labels` input when `class_embed_type="projection"`. Required when
|
| 125 |
+
`class_embed_type="projection"`.
|
| 126 |
+
brushnet_conditioning_channel_order (`str`, defaults to `"rgb"`):
|
| 127 |
+
The channel order of conditional image. Will convert to `rgb` if it's `bgr`.
|
| 128 |
+
conditioning_embedding_out_channels (`tuple[int]`, *optional*, defaults to `(16, 32, 96, 256)`):
|
| 129 |
+
The tuple of output channel for each block in the `conditioning_embedding` layer.
|
| 130 |
+
global_pool_conditions (`bool`, defaults to `False`):
|
| 131 |
+
TODO(Patrick) - unused parameter.
|
| 132 |
+
addition_embed_type_num_heads (`int`, defaults to 64):
|
| 133 |
+
The number of heads to use for the `TextTimeEmbedding` layer.
|
| 134 |
+
"""
|
| 135 |
+
|
| 136 |
+
_supports_gradient_checkpointing = True
|
| 137 |
+
|
| 138 |
+
@register_to_config
|
| 139 |
+
def __init__(
|
| 140 |
+
self,
|
| 141 |
+
in_channels: int = 4,
|
| 142 |
+
conditioning_channels: int = 5,
|
| 143 |
+
flip_sin_to_cos: bool = True,
|
| 144 |
+
freq_shift: int = 0,
|
| 145 |
+
down_block_types: Tuple[str, ...] = (
|
| 146 |
+
"CrossAttnDownBlock2D",
|
| 147 |
+
"CrossAttnDownBlock2D",
|
| 148 |
+
"CrossAttnDownBlock2D",
|
| 149 |
+
"DownBlock2D",
|
| 150 |
+
),
|
| 151 |
+
mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
|
| 152 |
+
up_block_types: Tuple[str, ...] = (
|
| 153 |
+
"UpBlock2D",
|
| 154 |
+
"CrossAttnUpBlock2D",
|
| 155 |
+
"CrossAttnUpBlock2D",
|
| 156 |
+
"CrossAttnUpBlock2D",
|
| 157 |
+
),
|
| 158 |
+
only_cross_attention: Union[bool, Tuple[bool]] = False,
|
| 159 |
+
block_out_channels: Tuple[int, ...] = (320, 640, 1280, 1280),
|
| 160 |
+
layers_per_block: int = 2,
|
| 161 |
+
downsample_padding: int = 1,
|
| 162 |
+
mid_block_scale_factor: float = 1,
|
| 163 |
+
act_fn: str = "silu",
|
| 164 |
+
norm_num_groups: Optional[int] = 32,
|
| 165 |
+
norm_eps: float = 1e-5,
|
| 166 |
+
cross_attention_dim: int = 1280,
|
| 167 |
+
transformer_layers_per_block: Union[int, Tuple[int, ...]] = 1,
|
| 168 |
+
encoder_hid_dim: Optional[int] = None,
|
| 169 |
+
encoder_hid_dim_type: Optional[str] = None,
|
| 170 |
+
attention_head_dim: Union[int, Tuple[int, ...]] = 8,
|
| 171 |
+
num_attention_heads: Optional[Union[int, Tuple[int, ...]]] = None,
|
| 172 |
+
use_linear_projection: bool = False,
|
| 173 |
+
class_embed_type: Optional[str] = None,
|
| 174 |
+
addition_embed_type: Optional[str] = None,
|
| 175 |
+
addition_time_embed_dim: Optional[int] = None,
|
| 176 |
+
num_class_embeds: Optional[int] = None,
|
| 177 |
+
upcast_attention: bool = False,
|
| 178 |
+
resnet_time_scale_shift: str = "default",
|
| 179 |
+
projection_class_embeddings_input_dim: Optional[int] = None,
|
| 180 |
+
brushnet_conditioning_channel_order: str = "rgb",
|
| 181 |
+
conditioning_embedding_out_channels: Optional[Tuple[int, ...]] = (16, 32, 96, 256),
|
| 182 |
+
global_pool_conditions: bool = False,
|
| 183 |
+
addition_embed_type_num_heads: int = 64,
|
| 184 |
+
):
|
| 185 |
+
super().__init__()
|
| 186 |
+
|
| 187 |
+
# If `num_attention_heads` is not defined (which is the case for most models)
|
| 188 |
+
# it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
|
| 189 |
+
# The reason for this behavior is to correct for incorrectly named variables that were introduced
|
| 190 |
+
# when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
|
| 191 |
+
# Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
|
| 192 |
+
# which is why we correct for the naming here.
|
| 193 |
+
num_attention_heads = num_attention_heads or attention_head_dim
|
| 194 |
+
|
| 195 |
+
# Check inputs
|
| 196 |
+
if len(down_block_types) != len(up_block_types):
|
| 197 |
+
raise ValueError(
|
| 198 |
+
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
|
| 199 |
+
)
|
| 200 |
+
|
| 201 |
+
if len(block_out_channels) != len(down_block_types):
|
| 202 |
+
raise ValueError(
|
| 203 |
+
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
|
| 207 |
+
raise ValueError(
|
| 208 |
+
f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
|
| 212 |
+
raise ValueError(
|
| 213 |
+
f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
if isinstance(transformer_layers_per_block, int):
|
| 217 |
+
transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
|
| 218 |
+
|
| 219 |
+
# input
|
| 220 |
+
conv_in_kernel = 3
|
| 221 |
+
conv_in_padding = (conv_in_kernel - 1) // 2
|
| 222 |
+
self.conv_in_condition = nn.Conv2d(
|
| 223 |
+
in_channels+conditioning_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
# time
|
| 227 |
+
time_embed_dim = block_out_channels[0] * 4
|
| 228 |
+
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
| 229 |
+
timestep_input_dim = block_out_channels[0]
|
| 230 |
+
self.time_embedding = TimestepEmbedding(
|
| 231 |
+
timestep_input_dim,
|
| 232 |
+
time_embed_dim,
|
| 233 |
+
act_fn=act_fn,
|
| 234 |
+
)
|
| 235 |
+
|
| 236 |
+
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
| 237 |
+
encoder_hid_dim_type = "text_proj"
|
| 238 |
+
self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
|
| 239 |
+
logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
|
| 240 |
+
|
| 241 |
+
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
| 242 |
+
raise ValueError(
|
| 243 |
+
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
if encoder_hid_dim_type == "text_proj":
|
| 247 |
+
self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
|
| 248 |
+
elif encoder_hid_dim_type == "text_image_proj":
|
| 249 |
+
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 250 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 251 |
+
# case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
|
| 252 |
+
self.encoder_hid_proj = TextImageProjection(
|
| 253 |
+
text_embed_dim=encoder_hid_dim,
|
| 254 |
+
image_embed_dim=cross_attention_dim,
|
| 255 |
+
cross_attention_dim=cross_attention_dim,
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
elif encoder_hid_dim_type is not None:
|
| 259 |
+
raise ValueError(
|
| 260 |
+
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
| 261 |
+
)
|
| 262 |
+
else:
|
| 263 |
+
self.encoder_hid_proj = None
|
| 264 |
+
|
| 265 |
+
# class embedding
|
| 266 |
+
if class_embed_type is None and num_class_embeds is not None:
|
| 267 |
+
self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
|
| 268 |
+
elif class_embed_type == "timestep":
|
| 269 |
+
self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
|
| 270 |
+
elif class_embed_type == "identity":
|
| 271 |
+
self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
|
| 272 |
+
elif class_embed_type == "projection":
|
| 273 |
+
if projection_class_embeddings_input_dim is None:
|
| 274 |
+
raise ValueError(
|
| 275 |
+
"`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
|
| 276 |
+
)
|
| 277 |
+
# The projection `class_embed_type` is the same as the timestep `class_embed_type` except
|
| 278 |
+
# 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
|
| 279 |
+
# 2. it projects from an arbitrary input dimension.
|
| 280 |
+
#
|
| 281 |
+
# Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
|
| 282 |
+
# When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
|
| 283 |
+
# As a result, `TimestepEmbedding` can be passed arbitrary vectors.
|
| 284 |
+
self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 285 |
+
else:
|
| 286 |
+
self.class_embedding = None
|
| 287 |
+
|
| 288 |
+
if addition_embed_type == "text":
|
| 289 |
+
if encoder_hid_dim is not None:
|
| 290 |
+
text_time_embedding_from_dim = encoder_hid_dim
|
| 291 |
+
else:
|
| 292 |
+
text_time_embedding_from_dim = cross_attention_dim
|
| 293 |
+
|
| 294 |
+
self.add_embedding = TextTimeEmbedding(
|
| 295 |
+
text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
|
| 296 |
+
)
|
| 297 |
+
elif addition_embed_type == "text_image":
|
| 298 |
+
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 299 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 300 |
+
# case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
|
| 301 |
+
self.add_embedding = TextImageTimeEmbedding(
|
| 302 |
+
text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
|
| 303 |
+
)
|
| 304 |
+
elif addition_embed_type == "text_time":
|
| 305 |
+
self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
|
| 306 |
+
self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 307 |
+
|
| 308 |
+
elif addition_embed_type is not None:
|
| 309 |
+
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
|
| 310 |
+
|
| 311 |
+
self.down_blocks = nn.ModuleList([])
|
| 312 |
+
self.brushnet_down_blocks = nn.ModuleList([])
|
| 313 |
+
|
| 314 |
+
if isinstance(only_cross_attention, bool):
|
| 315 |
+
only_cross_attention = [only_cross_attention] * len(down_block_types)
|
| 316 |
+
|
| 317 |
+
if isinstance(attention_head_dim, int):
|
| 318 |
+
attention_head_dim = (attention_head_dim,) * len(down_block_types)
|
| 319 |
+
|
| 320 |
+
if isinstance(num_attention_heads, int):
|
| 321 |
+
num_attention_heads = (num_attention_heads,) * len(down_block_types)
|
| 322 |
+
|
| 323 |
+
# down
|
| 324 |
+
output_channel = block_out_channels[0]
|
| 325 |
+
|
| 326 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 327 |
+
brushnet_block = zero_module(brushnet_block)
|
| 328 |
+
self.brushnet_down_blocks.append(brushnet_block) #零卷积
|
| 329 |
+
|
| 330 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 331 |
+
input_channel = output_channel
|
| 332 |
+
output_channel = block_out_channels[i]
|
| 333 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 334 |
+
|
| 335 |
+
down_block = get_down_block(
|
| 336 |
+
down_block_type,
|
| 337 |
+
num_layers=layers_per_block,
|
| 338 |
+
transformer_layers_per_block=transformer_layers_per_block[i],
|
| 339 |
+
in_channels=input_channel,
|
| 340 |
+
out_channels=output_channel,
|
| 341 |
+
temb_channels=time_embed_dim,
|
| 342 |
+
add_downsample=not is_final_block,
|
| 343 |
+
resnet_eps=norm_eps,
|
| 344 |
+
resnet_act_fn=act_fn,
|
| 345 |
+
resnet_groups=norm_num_groups,
|
| 346 |
+
cross_attention_dim=cross_attention_dim,
|
| 347 |
+
num_attention_heads=num_attention_heads[i],
|
| 348 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 349 |
+
downsample_padding=downsample_padding,
|
| 350 |
+
use_linear_projection=use_linear_projection,
|
| 351 |
+
only_cross_attention=only_cross_attention[i],
|
| 352 |
+
upcast_attention=upcast_attention,
|
| 353 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 354 |
+
)
|
| 355 |
+
self.down_blocks.append(down_block)
|
| 356 |
+
|
| 357 |
+
for _ in range(layers_per_block):
|
| 358 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 359 |
+
brushnet_block = zero_module(brushnet_block)
|
| 360 |
+
self.brushnet_down_blocks.append(brushnet_block) #零卷积
|
| 361 |
+
|
| 362 |
+
if not is_final_block:
|
| 363 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 364 |
+
brushnet_block = zero_module(brushnet_block)
|
| 365 |
+
self.brushnet_down_blocks.append(brushnet_block)
|
| 366 |
+
|
| 367 |
+
# mid
|
| 368 |
+
mid_block_channel = block_out_channels[-1]
|
| 369 |
+
|
| 370 |
+
brushnet_block = nn.Conv2d(mid_block_channel, mid_block_channel, kernel_size=1)
|
| 371 |
+
brushnet_block = zero_module(brushnet_block)
|
| 372 |
+
self.brushnet_mid_block = brushnet_block
|
| 373 |
+
|
| 374 |
+
self.mid_block = get_mid_block(
|
| 375 |
+
mid_block_type,
|
| 376 |
+
transformer_layers_per_block=transformer_layers_per_block[-1],
|
| 377 |
+
in_channels=mid_block_channel,
|
| 378 |
+
temb_channels=time_embed_dim,
|
| 379 |
+
resnet_eps=norm_eps,
|
| 380 |
+
resnet_act_fn=act_fn,
|
| 381 |
+
output_scale_factor=mid_block_scale_factor,
|
| 382 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 383 |
+
cross_attention_dim=cross_attention_dim,
|
| 384 |
+
num_attention_heads=num_attention_heads[-1],
|
| 385 |
+
resnet_groups=norm_num_groups,
|
| 386 |
+
use_linear_projection=use_linear_projection,
|
| 387 |
+
upcast_attention=upcast_attention,
|
| 388 |
+
)
|
| 389 |
+
|
| 390 |
+
# count how many layers upsample the images
|
| 391 |
+
self.num_upsamplers = 0
|
| 392 |
+
|
| 393 |
+
# up
|
| 394 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 395 |
+
reversed_num_attention_heads = list(reversed(num_attention_heads))
|
| 396 |
+
reversed_transformer_layers_per_block = (list(reversed(transformer_layers_per_block)))
|
| 397 |
+
only_cross_attention = list(reversed(only_cross_attention))
|
| 398 |
+
|
| 399 |
+
output_channel = reversed_block_out_channels[0]
|
| 400 |
+
|
| 401 |
+
self.up_blocks = nn.ModuleList([])
|
| 402 |
+
self.brushnet_up_blocks = nn.ModuleList([])
|
| 403 |
+
|
| 404 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 405 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 406 |
+
|
| 407 |
+
prev_output_channel = output_channel
|
| 408 |
+
output_channel = reversed_block_out_channels[i]
|
| 409 |
+
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
| 410 |
+
|
| 411 |
+
# add upsample block for all BUT final layer
|
| 412 |
+
if not is_final_block:
|
| 413 |
+
add_upsample = True
|
| 414 |
+
self.num_upsamplers += 1
|
| 415 |
+
else:
|
| 416 |
+
add_upsample = False
|
| 417 |
+
|
| 418 |
+
up_block = get_up_block(
|
| 419 |
+
up_block_type,
|
| 420 |
+
num_layers=layers_per_block+1,
|
| 421 |
+
transformer_layers_per_block=reversed_transformer_layers_per_block[i],
|
| 422 |
+
in_channels=input_channel,
|
| 423 |
+
out_channels=output_channel,
|
| 424 |
+
prev_output_channel=prev_output_channel,
|
| 425 |
+
temb_channels=time_embed_dim,
|
| 426 |
+
add_upsample=add_upsample,
|
| 427 |
+
resnet_eps=norm_eps,
|
| 428 |
+
resnet_act_fn=act_fn,
|
| 429 |
+
resolution_idx=i,
|
| 430 |
+
resnet_groups=norm_num_groups,
|
| 431 |
+
cross_attention_dim=cross_attention_dim,
|
| 432 |
+
num_attention_heads=reversed_num_attention_heads[i],
|
| 433 |
+
use_linear_projection=use_linear_projection,
|
| 434 |
+
only_cross_attention=only_cross_attention[i],
|
| 435 |
+
upcast_attention=upcast_attention,
|
| 436 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 437 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 438 |
+
)
|
| 439 |
+
self.up_blocks.append(up_block)
|
| 440 |
+
prev_output_channel = output_channel
|
| 441 |
+
|
| 442 |
+
for _ in range(layers_per_block+1):
|
| 443 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 444 |
+
brushnet_block = zero_module(brushnet_block)
|
| 445 |
+
self.brushnet_up_blocks.append(brushnet_block)
|
| 446 |
+
|
| 447 |
+
if not is_final_block:
|
| 448 |
+
brushnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
|
| 449 |
+
brushnet_block = zero_module(brushnet_block)
|
| 450 |
+
self.brushnet_up_blocks.append(brushnet_block)
|
| 451 |
+
|
| 452 |
+
|
| 453 |
+
@classmethod
|
| 454 |
+
def from_unet(
|
| 455 |
+
cls,
|
| 456 |
+
unet: UNet2DConditionModel,
|
| 457 |
+
brushnet_conditioning_channel_order: str = "rgb",
|
| 458 |
+
conditioning_embedding_out_channels: Optional[Tuple[int, ...]] = (16, 32, 96, 256),
|
| 459 |
+
load_weights_from_unet: bool = True,
|
| 460 |
+
conditioning_channels: int = 5,
|
| 461 |
+
):
|
| 462 |
+
r"""
|
| 463 |
+
Instantiate a [`BrushNetModel`] from [`UNet2DConditionModel`].
|
| 464 |
+
|
| 465 |
+
Parameters:
|
| 466 |
+
unet (`UNet2DConditionModel`):
|
| 467 |
+
The UNet model weights to copy to the [`BrushNetModel`]. All configuration options are also copied
|
| 468 |
+
where applicable.
|
| 469 |
+
"""
|
| 470 |
+
transformer_layers_per_block = (
|
| 471 |
+
unet.config.transformer_layers_per_block if "transformer_layers_per_block" in unet.config else 1
|
| 472 |
+
)
|
| 473 |
+
encoder_hid_dim = unet.config.encoder_hid_dim if "encoder_hid_dim" in unet.config else None
|
| 474 |
+
encoder_hid_dim_type = unet.config.encoder_hid_dim_type if "encoder_hid_dim_type" in unet.config else None
|
| 475 |
+
addition_embed_type = unet.config.addition_embed_type if "addition_embed_type" in unet.config else None
|
| 476 |
+
addition_time_embed_dim = (
|
| 477 |
+
unet.config.addition_time_embed_dim if "addition_time_embed_dim" in unet.config else None
|
| 478 |
+
)
|
| 479 |
+
|
| 480 |
+
brushnet = cls(
|
| 481 |
+
in_channels=unet.config.in_channels,
|
| 482 |
+
conditioning_channels=conditioning_channels,
|
| 483 |
+
flip_sin_to_cos=unet.config.flip_sin_to_cos,
|
| 484 |
+
freq_shift=unet.config.freq_shift,
|
| 485 |
+
# down_block_types=['DownBlock2D','DownBlock2D','DownBlock2D','DownBlock2D'],
|
| 486 |
+
down_block_types=[
|
| 487 |
+
"CrossAttnDownBlock2D",
|
| 488 |
+
"CrossAttnDownBlock2D",
|
| 489 |
+
"CrossAttnDownBlock2D",
|
| 490 |
+
"DownBlock2D",
|
| 491 |
+
],
|
| 492 |
+
# mid_block_type='MidBlock2D',
|
| 493 |
+
mid_block_type="UNetMidBlock2DCrossAttn",
|
| 494 |
+
# up_block_types=['UpBlock2D','UpBlock2D','UpBlock2D','UpBlock2D'],
|
| 495 |
+
up_block_types=["UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"],
|
| 496 |
+
only_cross_attention=unet.config.only_cross_attention,
|
| 497 |
+
block_out_channels=unet.config.block_out_channels,
|
| 498 |
+
layers_per_block=unet.config.layers_per_block,
|
| 499 |
+
downsample_padding=unet.config.downsample_padding,
|
| 500 |
+
mid_block_scale_factor=unet.config.mid_block_scale_factor,
|
| 501 |
+
act_fn=unet.config.act_fn,
|
| 502 |
+
norm_num_groups=unet.config.norm_num_groups,
|
| 503 |
+
norm_eps=unet.config.norm_eps,
|
| 504 |
+
cross_attention_dim=unet.config.cross_attention_dim,
|
| 505 |
+
transformer_layers_per_block=transformer_layers_per_block,
|
| 506 |
+
encoder_hid_dim=encoder_hid_dim,
|
| 507 |
+
encoder_hid_dim_type=encoder_hid_dim_type,
|
| 508 |
+
attention_head_dim=unet.config.attention_head_dim,
|
| 509 |
+
num_attention_heads=unet.config.num_attention_heads,
|
| 510 |
+
use_linear_projection=unet.config.use_linear_projection,
|
| 511 |
+
class_embed_type=unet.config.class_embed_type,
|
| 512 |
+
addition_embed_type=addition_embed_type,
|
| 513 |
+
addition_time_embed_dim=addition_time_embed_dim,
|
| 514 |
+
num_class_embeds=unet.config.num_class_embeds,
|
| 515 |
+
upcast_attention=unet.config.upcast_attention,
|
| 516 |
+
resnet_time_scale_shift=unet.config.resnet_time_scale_shift,
|
| 517 |
+
projection_class_embeddings_input_dim=unet.config.projection_class_embeddings_input_dim,
|
| 518 |
+
brushnet_conditioning_channel_order=brushnet_conditioning_channel_order,
|
| 519 |
+
conditioning_embedding_out_channels=conditioning_embedding_out_channels,
|
| 520 |
+
)
|
| 521 |
+
|
| 522 |
+
if load_weights_from_unet:
|
| 523 |
+
conv_in_condition_weight=torch.zeros_like(brushnet.conv_in_condition.weight)
|
| 524 |
+
conv_in_condition_weight[:,:4,...]=unet.conv_in.weight
|
| 525 |
+
conv_in_condition_weight[:,4:8,...]=unet.conv_in.weight
|
| 526 |
+
brushnet.conv_in_condition.weight=torch.nn.Parameter(conv_in_condition_weight)
|
| 527 |
+
brushnet.conv_in_condition.bias=unet.conv_in.bias
|
| 528 |
+
|
| 529 |
+
brushnet.time_proj.load_state_dict(unet.time_proj.state_dict())
|
| 530 |
+
brushnet.time_embedding.load_state_dict(unet.time_embedding.state_dict())
|
| 531 |
+
|
| 532 |
+
if brushnet.class_embedding:
|
| 533 |
+
brushnet.class_embedding.load_state_dict(unet.class_embedding.state_dict())
|
| 534 |
+
|
| 535 |
+
brushnet.down_blocks.load_state_dict(unet.down_blocks.state_dict(),strict=False)
|
| 536 |
+
brushnet.mid_block.load_state_dict(unet.mid_block.state_dict(),strict=False)
|
| 537 |
+
brushnet.up_blocks.load_state_dict(unet.up_blocks.state_dict(),strict=False)
|
| 538 |
+
|
| 539 |
+
return brushnet
|
| 540 |
+
|
| 541 |
+
@property
|
| 542 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.attn_processors
|
| 543 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 544 |
+
r"""
|
| 545 |
+
Returns:
|
| 546 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 547 |
+
indexed by its weight name.
|
| 548 |
+
"""
|
| 549 |
+
# set recursively
|
| 550 |
+
processors = {}
|
| 551 |
+
|
| 552 |
+
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
| 553 |
+
if hasattr(module, "get_processor"):
|
| 554 |
+
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
|
| 555 |
+
|
| 556 |
+
for sub_name, child in module.named_children():
|
| 557 |
+
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
| 558 |
+
|
| 559 |
+
return processors
|
| 560 |
+
|
| 561 |
+
for name, module in self.named_children():
|
| 562 |
+
fn_recursive_add_processors(name, module, processors)
|
| 563 |
+
|
| 564 |
+
return processors
|
| 565 |
+
|
| 566 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_attn_processor
|
| 567 |
+
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
| 568 |
+
r"""
|
| 569 |
+
Sets the attention processor to use to compute attention.
|
| 570 |
+
|
| 571 |
+
Parameters:
|
| 572 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 573 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 574 |
+
for **all** `Attention` layers.
|
| 575 |
+
|
| 576 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 577 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 578 |
+
|
| 579 |
+
"""
|
| 580 |
+
count = len(self.attn_processors.keys())
|
| 581 |
+
|
| 582 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 583 |
+
raise ValueError(
|
| 584 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 585 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 586 |
+
)
|
| 587 |
+
|
| 588 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 589 |
+
if hasattr(module, "set_processor"):
|
| 590 |
+
if not isinstance(processor, dict):
|
| 591 |
+
module.set_processor(processor)
|
| 592 |
+
else:
|
| 593 |
+
module.set_processor(processor.pop(f"{name}.processor"))
|
| 594 |
+
|
| 595 |
+
for sub_name, child in module.named_children():
|
| 596 |
+
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
| 597 |
+
|
| 598 |
+
for name, module in self.named_children():
|
| 599 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 600 |
+
|
| 601 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
|
| 602 |
+
def set_default_attn_processor(self):
|
| 603 |
+
"""
|
| 604 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 605 |
+
"""
|
| 606 |
+
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 607 |
+
processor = AttnAddedKVProcessor()
|
| 608 |
+
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 609 |
+
processor = AttnProcessor()
|
| 610 |
+
else:
|
| 611 |
+
raise ValueError(
|
| 612 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 613 |
+
)
|
| 614 |
+
|
| 615 |
+
self.set_attn_processor(processor)
|
| 616 |
+
|
| 617 |
+
# Copied from diffusers.models.unets.unet_2d_condition.UNet2DConditionModel.set_attention_slice
|
| 618 |
+
def set_attention_slice(self, slice_size: Union[str, int, List[int]]) -> None:
|
| 619 |
+
r"""
|
| 620 |
+
Enable sliced attention computation.
|
| 621 |
+
|
| 622 |
+
When this option is enabled, the attention module splits the input tensor in slices to compute attention in
|
| 623 |
+
several steps. This is useful for saving some memory in exchange for a small decrease in speed.
|
| 624 |
+
|
| 625 |
+
Args:
|
| 626 |
+
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
|
| 627 |
+
When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
|
| 628 |
+
`"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
|
| 629 |
+
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
|
| 630 |
+
must be a multiple of `slice_size`.
|
| 631 |
+
"""
|
| 632 |
+
sliceable_head_dims = []
|
| 633 |
+
|
| 634 |
+
def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
|
| 635 |
+
if hasattr(module, "set_attention_slice"):
|
| 636 |
+
sliceable_head_dims.append(module.sliceable_head_dim)
|
| 637 |
+
|
| 638 |
+
for child in module.children():
|
| 639 |
+
fn_recursive_retrieve_sliceable_dims(child)
|
| 640 |
+
|
| 641 |
+
# retrieve number of attention layers
|
| 642 |
+
for module in self.children():
|
| 643 |
+
fn_recursive_retrieve_sliceable_dims(module)
|
| 644 |
+
|
| 645 |
+
num_sliceable_layers = len(sliceable_head_dims)
|
| 646 |
+
|
| 647 |
+
if slice_size == "auto":
|
| 648 |
+
# half the attention head size is usually a good trade-off between
|
| 649 |
+
# speed and memory
|
| 650 |
+
slice_size = [dim // 2 for dim in sliceable_head_dims]
|
| 651 |
+
elif slice_size == "max":
|
| 652 |
+
# make smallest slice possible
|
| 653 |
+
slice_size = num_sliceable_layers * [1]
|
| 654 |
+
|
| 655 |
+
slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
|
| 656 |
+
|
| 657 |
+
if len(slice_size) != len(sliceable_head_dims):
|
| 658 |
+
raise ValueError(
|
| 659 |
+
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
|
| 660 |
+
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
|
| 661 |
+
)
|
| 662 |
+
|
| 663 |
+
for i in range(len(slice_size)):
|
| 664 |
+
size = slice_size[i]
|
| 665 |
+
dim = sliceable_head_dims[i]
|
| 666 |
+
if size is not None and size > dim:
|
| 667 |
+
raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
|
| 668 |
+
|
| 669 |
+
# Recursively walk through all the children.
|
| 670 |
+
# Any children which exposes the set_attention_slice method
|
| 671 |
+
# gets the message
|
| 672 |
+
def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
|
| 673 |
+
if hasattr(module, "set_attention_slice"):
|
| 674 |
+
module.set_attention_slice(slice_size.pop())
|
| 675 |
+
|
| 676 |
+
for child in module.children():
|
| 677 |
+
fn_recursive_set_attention_slice(child, slice_size)
|
| 678 |
+
|
| 679 |
+
reversed_slice_size = list(reversed(slice_size))
|
| 680 |
+
for module in self.children():
|
| 681 |
+
fn_recursive_set_attention_slice(module, reversed_slice_size)
|
| 682 |
+
|
| 683 |
+
def _set_gradient_checkpointing(self, module, value: bool = False) -> None:
|
| 684 |
+
if isinstance(module, (CrossAttnDownBlock2D, DownBlock2D)):
|
| 685 |
+
module.gradient_checkpointing = value
|
| 686 |
+
|
| 687 |
+
def forward(
|
| 688 |
+
self,
|
| 689 |
+
sample: torch.FloatTensor,
|
| 690 |
+
timestep: Union[torch.Tensor, float, int],
|
| 691 |
+
encoder_hidden_states: torch.Tensor,
|
| 692 |
+
brushnet_cond: torch.FloatTensor,
|
| 693 |
+
conditioning_scale: float = 1.0,
|
| 694 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 695 |
+
timestep_cond: Optional[torch.Tensor] = None,
|
| 696 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 697 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 698 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 699 |
+
guess_mode: bool = False,
|
| 700 |
+
return_dict: bool = True,
|
| 701 |
+
) -> Union[BrushNetOutput, Tuple[Tuple[torch.FloatTensor, ...], torch.FloatTensor]]:
|
| 702 |
+
"""
|
| 703 |
+
The [`BrushNetModel`] forward method.
|
| 704 |
+
|
| 705 |
+
Args:
|
| 706 |
+
sample (`torch.FloatTensor`):
|
| 707 |
+
The noisy input tensor.
|
| 708 |
+
timestep (`Union[torch.Tensor, float, int]`):
|
| 709 |
+
The number of timesteps to denoise an input.
|
| 710 |
+
encoder_hidden_states (`torch.Tensor`):
|
| 711 |
+
The encoder hidden states.
|
| 712 |
+
brushnet_cond (`torch.FloatTensor`):
|
| 713 |
+
The conditional input tensor of shape `(batch_size, sequence_length, hidden_size)`.
|
| 714 |
+
conditioning_scale (`float`, defaults to `1.0`):
|
| 715 |
+
The scale factor for BrushNet outputs.
|
| 716 |
+
class_labels (`torch.Tensor`, *optional*, defaults to `None`):
|
| 717 |
+
Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
|
| 718 |
+
timestep_cond (`torch.Tensor`, *optional*, defaults to `None`):
|
| 719 |
+
Additional conditional embeddings for timestep. If provided, the embeddings will be summed with the
|
| 720 |
+
timestep_embedding passed through the `self.time_embedding` layer to obtain the final timestep
|
| 721 |
+
embeddings.
|
| 722 |
+
attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
|
| 723 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 724 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 725 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 726 |
+
added_cond_kwargs (`dict`):
|
| 727 |
+
Additional conditions for the Stable Diffusion XL UNet.
|
| 728 |
+
cross_attention_kwargs (`dict[str]`, *optional*, defaults to `None`):
|
| 729 |
+
A kwargs dictionary that if specified is passed along to the `AttnProcessor`.
|
| 730 |
+
guess_mode (`bool`, defaults to `False`):
|
| 731 |
+
In this mode, the BrushNet encoder tries its best to recognize the input content of the input even if
|
| 732 |
+
you remove all prompts. A `guidance_scale` between 3.0 and 5.0 is recommended.
|
| 733 |
+
return_dict (`bool`, defaults to `True`):
|
| 734 |
+
Whether or not to return a [`~models.brushnet.BrushNetOutput`] instead of a plain tuple.
|
| 735 |
+
|
| 736 |
+
Returns:
|
| 737 |
+
[`~models.brushnet.BrushNetOutput`] **or** `tuple`:
|
| 738 |
+
If `return_dict` is `True`, a [`~models.brushnet.BrushNetOutput`] is returned, otherwise a tuple is
|
| 739 |
+
returned where the first element is the sample tensor.
|
| 740 |
+
"""
|
| 741 |
+
# check channel order
|
| 742 |
+
channel_order = self.config.brushnet_conditioning_channel_order
|
| 743 |
+
|
| 744 |
+
if channel_order == "rgb":
|
| 745 |
+
# in rgb order by default
|
| 746 |
+
...
|
| 747 |
+
elif channel_order == "bgr":
|
| 748 |
+
brushnet_cond = torch.flip(brushnet_cond, dims=[1])
|
| 749 |
+
else:
|
| 750 |
+
raise ValueError(f"unknown `brushnet_conditioning_channel_order`: {channel_order}")
|
| 751 |
+
|
| 752 |
+
# prepare attention_mask
|
| 753 |
+
if attention_mask is not None:
|
| 754 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 755 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 756 |
+
|
| 757 |
+
# 1. time
|
| 758 |
+
timesteps = timestep
|
| 759 |
+
if not torch.is_tensor(timesteps):
|
| 760 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 761 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 762 |
+
is_mps = sample.device.type == "mps"
|
| 763 |
+
if isinstance(timestep, float):
|
| 764 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 765 |
+
else:
|
| 766 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 767 |
+
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
| 768 |
+
elif len(timesteps.shape) == 0:
|
| 769 |
+
timesteps = timesteps[None].to(sample.device)
|
| 770 |
+
|
| 771 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 772 |
+
timesteps = timesteps.expand(sample.shape[0])
|
| 773 |
+
|
| 774 |
+
t_emb = self.time_proj(timesteps)
|
| 775 |
+
|
| 776 |
+
# timesteps does not contain any weights and will always return f32 tensors
|
| 777 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 778 |
+
# there might be better ways to encapsulate this.
|
| 779 |
+
t_emb = t_emb.to(dtype=sample.dtype)
|
| 780 |
+
|
| 781 |
+
emb = self.time_embedding(t_emb, timestep_cond)
|
| 782 |
+
aug_emb = None
|
| 783 |
+
|
| 784 |
+
if self.class_embedding is not None:
|
| 785 |
+
if class_labels is None:
|
| 786 |
+
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
| 787 |
+
|
| 788 |
+
if self.config.class_embed_type == "timestep":
|
| 789 |
+
class_labels = self.time_proj(class_labels)
|
| 790 |
+
|
| 791 |
+
class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
|
| 792 |
+
emb = emb + class_emb
|
| 793 |
+
|
| 794 |
+
if self.config.addition_embed_type is not None:
|
| 795 |
+
if self.config.addition_embed_type == "text":
|
| 796 |
+
aug_emb = self.add_embedding(encoder_hidden_states)
|
| 797 |
+
|
| 798 |
+
elif self.config.addition_embed_type == "text_time":
|
| 799 |
+
if "text_embeds" not in added_cond_kwargs:
|
| 800 |
+
raise ValueError(
|
| 801 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
|
| 802 |
+
)
|
| 803 |
+
text_embeds = added_cond_kwargs.get("text_embeds")
|
| 804 |
+
if "time_ids" not in added_cond_kwargs:
|
| 805 |
+
raise ValueError(
|
| 806 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
|
| 807 |
+
)
|
| 808 |
+
time_ids = added_cond_kwargs.get("time_ids")
|
| 809 |
+
time_embeds = self.add_time_proj(time_ids.flatten())
|
| 810 |
+
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
|
| 811 |
+
|
| 812 |
+
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
|
| 813 |
+
add_embeds = add_embeds.to(emb.dtype)
|
| 814 |
+
aug_emb = self.add_embedding(add_embeds)
|
| 815 |
+
|
| 816 |
+
emb = emb + aug_emb if aug_emb is not None else emb
|
| 817 |
+
|
| 818 |
+
# 2. pre-process
|
| 819 |
+
brushnet_cond=torch.concat([sample,brushnet_cond],1)
|
| 820 |
+
sample = self.conv_in_condition(brushnet_cond)
|
| 821 |
+
|
| 822 |
+
|
| 823 |
+
# 3. down
|
| 824 |
+
down_block_res_samples = (sample,)
|
| 825 |
+
for downsample_block in self.down_blocks:
|
| 826 |
+
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
| 827 |
+
sample, res_samples = downsample_block(
|
| 828 |
+
hidden_states=sample,
|
| 829 |
+
temb=emb,
|
| 830 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 831 |
+
attention_mask=attention_mask,
|
| 832 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 833 |
+
)
|
| 834 |
+
else:
|
| 835 |
+
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
| 836 |
+
|
| 837 |
+
down_block_res_samples += res_samples
|
| 838 |
+
|
| 839 |
+
# 4. PaintingNet down blocks
|
| 840 |
+
brushnet_down_block_res_samples = ()
|
| 841 |
+
for down_block_res_sample, brushnet_down_block in zip(down_block_res_samples, self.brushnet_down_blocks):
|
| 842 |
+
down_block_res_sample = brushnet_down_block(down_block_res_sample)
|
| 843 |
+
brushnet_down_block_res_samples = brushnet_down_block_res_samples + (down_block_res_sample,)
|
| 844 |
+
|
| 845 |
+
# 5. mid
|
| 846 |
+
if self.mid_block is not None:
|
| 847 |
+
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
|
| 848 |
+
sample = self.mid_block(
|
| 849 |
+
sample,
|
| 850 |
+
emb,
|
| 851 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 852 |
+
attention_mask=attention_mask,
|
| 853 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 854 |
+
)
|
| 855 |
+
else:
|
| 856 |
+
sample = self.mid_block(sample, emb)
|
| 857 |
+
|
| 858 |
+
# 6. BrushNet mid blocks
|
| 859 |
+
brushnet_mid_block_res_sample = self.brushnet_mid_block(sample)
|
| 860 |
+
|
| 861 |
+
|
| 862 |
+
# 7. up
|
| 863 |
+
up_block_res_samples = ()
|
| 864 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 865 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 866 |
+
|
| 867 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
| 868 |
+
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
| 869 |
+
|
| 870 |
+
# if we have not reached the final block and need to forward the
|
| 871 |
+
# upsample size, we do it here
|
| 872 |
+
if not is_final_block:
|
| 873 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 874 |
+
|
| 875 |
+
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
| 876 |
+
sample, up_res_samples = upsample_block(
|
| 877 |
+
hidden_states=sample,
|
| 878 |
+
temb=emb,
|
| 879 |
+
res_hidden_states_tuple=res_samples,
|
| 880 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 881 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 882 |
+
upsample_size=upsample_size,
|
| 883 |
+
attention_mask=attention_mask,
|
| 884 |
+
return_res_samples=True
|
| 885 |
+
)
|
| 886 |
+
else:
|
| 887 |
+
sample, up_res_samples = upsample_block(
|
| 888 |
+
hidden_states=sample,
|
| 889 |
+
temb=emb,
|
| 890 |
+
res_hidden_states_tuple=res_samples,
|
| 891 |
+
upsample_size=upsample_size,
|
| 892 |
+
return_res_samples=True
|
| 893 |
+
)
|
| 894 |
+
|
| 895 |
+
up_block_res_samples += up_res_samples
|
| 896 |
+
|
| 897 |
+
# 8. BrushNet up blocks
|
| 898 |
+
brushnet_up_block_res_samples = ()
|
| 899 |
+
for up_block_res_sample, brushnet_up_block in zip(up_block_res_samples, self.brushnet_up_blocks):
|
| 900 |
+
up_block_res_sample = brushnet_up_block(up_block_res_sample)
|
| 901 |
+
brushnet_up_block_res_samples = brushnet_up_block_res_samples + (up_block_res_sample,)
|
| 902 |
+
|
| 903 |
+
# 6. scaling
|
| 904 |
+
if guess_mode and not self.config.global_pool_conditions:
|
| 905 |
+
scales = torch.logspace(-1, 0, len(brushnet_down_block_res_samples) + 1 + len(brushnet_up_block_res_samples), device=sample.device) # 0.1 to 1.0
|
| 906 |
+
scales = scales * conditioning_scale
|
| 907 |
+
|
| 908 |
+
brushnet_down_block_res_samples = [sample * scale for sample, scale in zip(brushnet_down_block_res_samples, scales[:len(brushnet_down_block_res_samples)])]
|
| 909 |
+
brushnet_mid_block_res_sample = brushnet_mid_block_res_sample * scales[len(brushnet_down_block_res_samples)]
|
| 910 |
+
brushnet_up_block_res_samples = [sample * scale for sample, scale in zip(brushnet_up_block_res_samples, scales[len(brushnet_down_block_res_samples)+1:])]
|
| 911 |
+
else:
|
| 912 |
+
brushnet_down_block_res_samples = [sample * conditioning_scale for sample in brushnet_down_block_res_samples]
|
| 913 |
+
brushnet_mid_block_res_sample = brushnet_mid_block_res_sample * conditioning_scale
|
| 914 |
+
brushnet_up_block_res_samples = [sample * conditioning_scale for sample in brushnet_up_block_res_samples]
|
| 915 |
+
|
| 916 |
+
|
| 917 |
+
if self.config.global_pool_conditions:
|
| 918 |
+
brushnet_down_block_res_samples = [
|
| 919 |
+
torch.mean(sample, dim=(2, 3), keepdim=True) for sample in brushnet_down_block_res_samples
|
| 920 |
+
]
|
| 921 |
+
brushnet_mid_block_res_sample = torch.mean(brushnet_mid_block_res_sample, dim=(2, 3), keepdim=True)
|
| 922 |
+
brushnet_up_block_res_samples = [
|
| 923 |
+
torch.mean(sample, dim=(2, 3), keepdim=True) for sample in brushnet_up_block_res_samples
|
| 924 |
+
]
|
| 925 |
+
|
| 926 |
+
if not return_dict:
|
| 927 |
+
return (brushnet_down_block_res_samples, brushnet_mid_block_res_sample, brushnet_up_block_res_samples)
|
| 928 |
+
|
| 929 |
+
return BrushNetOutput(
|
| 930 |
+
down_block_res_samples=brushnet_down_block_res_samples,
|
| 931 |
+
mid_block_res_sample=brushnet_mid_block_res_sample,
|
| 932 |
+
up_block_res_samples=brushnet_up_block_res_samples
|
| 933 |
+
)
|
| 934 |
+
|
| 935 |
+
|
| 936 |
+
def zero_module(module):
|
| 937 |
+
for p in module.parameters():
|
| 938 |
+
nn.init.zeros_(p)
|
| 939 |
+
return module
|
libs/transformer_temporal.py
ADDED
|
@@ -0,0 +1,375 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from dataclasses import dataclass
|
| 15 |
+
from typing import Any, Dict, Optional
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
from torch import nn
|
| 19 |
+
|
| 20 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 21 |
+
from diffusers.utils import BaseOutput
|
| 22 |
+
from diffusers.models.attention import BasicTransformerBlock, TemporalBasicTransformerBlock
|
| 23 |
+
from diffusers.models.embeddings import TimestepEmbedding, Timesteps
|
| 24 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 25 |
+
from diffusers.models.resnet import AlphaBlender
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
@dataclass
|
| 29 |
+
class TransformerTemporalModelOutput(BaseOutput):
|
| 30 |
+
"""
|
| 31 |
+
The output of [`TransformerTemporalModel`].
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
sample (`torch.FloatTensor` of shape `(batch_size x num_frames, num_channels, height, width)`):
|
| 35 |
+
The hidden states output conditioned on `encoder_hidden_states` input.
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
sample: torch.FloatTensor
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class TransformerTemporalModel(ModelMixin, ConfigMixin):
|
| 42 |
+
"""
|
| 43 |
+
A Transformer model for video-like data.
|
| 44 |
+
|
| 45 |
+
Parameters:
|
| 46 |
+
num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
|
| 47 |
+
attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
|
| 48 |
+
in_channels (`int`, *optional*):
|
| 49 |
+
The number of channels in the input and output (specify if the input is **continuous**).
|
| 50 |
+
num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
|
| 51 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 52 |
+
cross_attention_dim (`int`, *optional*): The number of `encoder_hidden_states` dimensions to use.
|
| 53 |
+
attention_bias (`bool`, *optional*):
|
| 54 |
+
Configure if the `TransformerBlock` attention should contain a bias parameter.
|
| 55 |
+
sample_size (`int`, *optional*): The width of the latent images (specify if the input is **discrete**).
|
| 56 |
+
This is fixed during training since it is used to learn a number of position embeddings.
|
| 57 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`):
|
| 58 |
+
Activation function to use in feed-forward. See `diffusers.models.activations.get_activation` for supported
|
| 59 |
+
activation functions.
|
| 60 |
+
norm_elementwise_affine (`bool`, *optional*):
|
| 61 |
+
Configure if the `TransformerBlock` should use learnable elementwise affine parameters for normalization.
|
| 62 |
+
double_self_attention (`bool`, *optional*):
|
| 63 |
+
Configure if each `TransformerBlock` should contain two self-attention layers.
|
| 64 |
+
positional_embeddings: (`str`, *optional*):
|
| 65 |
+
The type of positional embeddings to apply to the sequence input before passing use.
|
| 66 |
+
num_positional_embeddings: (`int`, *optional*):
|
| 67 |
+
The maximum length of the sequence over which to apply positional embeddings.
|
| 68 |
+
"""
|
| 69 |
+
|
| 70 |
+
@register_to_config
|
| 71 |
+
def __init__(
|
| 72 |
+
self,
|
| 73 |
+
num_attention_heads: int = 16,
|
| 74 |
+
attention_head_dim: int = 88,
|
| 75 |
+
in_channels: Optional[int] = None,
|
| 76 |
+
out_channels: Optional[int] = None,
|
| 77 |
+
num_layers: int = 1,
|
| 78 |
+
dropout: float = 0.0,
|
| 79 |
+
norm_num_groups: int = 32,
|
| 80 |
+
cross_attention_dim: Optional[int] = None,
|
| 81 |
+
attention_bias: bool = False,
|
| 82 |
+
sample_size: Optional[int] = None,
|
| 83 |
+
activation_fn: str = "geglu",
|
| 84 |
+
norm_elementwise_affine: bool = True,
|
| 85 |
+
double_self_attention: bool = True,
|
| 86 |
+
positional_embeddings: Optional[str] = None,
|
| 87 |
+
num_positional_embeddings: Optional[int] = None,
|
| 88 |
+
):
|
| 89 |
+
super().__init__()
|
| 90 |
+
self.num_attention_heads = num_attention_heads
|
| 91 |
+
self.attention_head_dim = attention_head_dim
|
| 92 |
+
inner_dim = num_attention_heads * attention_head_dim
|
| 93 |
+
|
| 94 |
+
self.in_channels = in_channels
|
| 95 |
+
|
| 96 |
+
self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
|
| 97 |
+
self.proj_in = nn.Linear(in_channels, inner_dim)
|
| 98 |
+
|
| 99 |
+
# 3. Define transformers blocks
|
| 100 |
+
self.transformer_blocks = nn.ModuleList(
|
| 101 |
+
[
|
| 102 |
+
BasicTransformerBlock(
|
| 103 |
+
inner_dim,
|
| 104 |
+
num_attention_heads,
|
| 105 |
+
attention_head_dim,
|
| 106 |
+
dropout=dropout,
|
| 107 |
+
cross_attention_dim=cross_attention_dim,
|
| 108 |
+
activation_fn=activation_fn,
|
| 109 |
+
attention_bias=attention_bias,
|
| 110 |
+
double_self_attention=double_self_attention,
|
| 111 |
+
norm_elementwise_affine=norm_elementwise_affine,
|
| 112 |
+
positional_embeddings=positional_embeddings,
|
| 113 |
+
num_positional_embeddings=num_positional_embeddings,
|
| 114 |
+
)
|
| 115 |
+
for d in range(num_layers)
|
| 116 |
+
]
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
self.proj_out = nn.Linear(inner_dim, in_channels)
|
| 120 |
+
|
| 121 |
+
def forward(
|
| 122 |
+
self,
|
| 123 |
+
hidden_states: torch.FloatTensor,
|
| 124 |
+
timestep: Optional[torch.LongTensor] = None,
|
| 125 |
+
num_frames: int = 1,
|
| 126 |
+
encoder_hidden_states: Optional[torch.LongTensor] = None,
|
| 127 |
+
class_labels: torch.LongTensor = None,
|
| 128 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 129 |
+
) -> TransformerTemporalModelOutput:
|
| 130 |
+
"""
|
| 131 |
+
The [`TransformerTemporal`] forward method.
|
| 132 |
+
|
| 133 |
+
Args:
|
| 134 |
+
hidden_states (`torch.LongTensor` of shape `(batch size, num latent pixels)` if discrete, `torch.FloatTensor` of shape `(batch size, channel, height, width)` if continuous):
|
| 135 |
+
Input hidden_states.
|
| 136 |
+
encoder_hidden_states ( `torch.LongTensor` of shape `(batch size, encoder_hidden_states dim)`, *optional*):
|
| 137 |
+
Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
|
| 138 |
+
self-attention.
|
| 139 |
+
timestep ( `torch.LongTensor`, *optional*):
|
| 140 |
+
Used to indicate denoising step. Optional timestep to be applied as an embedding in `AdaLayerNorm`.
|
| 141 |
+
class_labels ( `torch.LongTensor` of shape `(batch size, num classes)`, *optional*):
|
| 142 |
+
Used to indicate class labels conditioning. Optional class labels to be applied as an embedding in
|
| 143 |
+
`AdaLayerZeroNorm`.
|
| 144 |
+
num_frames (`int`, *optional*, defaults to 1):
|
| 145 |
+
The number of frames to be processed per batch. This is used to reshape the hidden states.
|
| 146 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 147 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 148 |
+
`self.processor` in
|
| 149 |
+
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 150 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 151 |
+
Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
|
| 152 |
+
tuple.
|
| 153 |
+
|
| 154 |
+
Returns:
|
| 155 |
+
[`~models.transformer_temporal.TransformerTemporalModelOutput`] or `tuple`:
|
| 156 |
+
If `return_dict` is True, an [`~models.transformer_temporal.TransformerTemporalModelOutput`] is
|
| 157 |
+
returned, otherwise a `tuple` where the first element is the sample tensor.
|
| 158 |
+
"""
|
| 159 |
+
# 1. Input
|
| 160 |
+
batch_frames, channel, height, width = hidden_states.shape
|
| 161 |
+
batch_size = batch_frames // num_frames
|
| 162 |
+
|
| 163 |
+
residual = hidden_states
|
| 164 |
+
|
| 165 |
+
hidden_states = hidden_states[None, :].reshape(batch_size, num_frames, channel, height, width)
|
| 166 |
+
hidden_states = hidden_states.permute(0, 2, 1, 3, 4)
|
| 167 |
+
|
| 168 |
+
hidden_states = self.norm(hidden_states)
|
| 169 |
+
hidden_states = hidden_states.permute(0, 3, 4, 2, 1).reshape(batch_size * height * width, num_frames, channel)
|
| 170 |
+
|
| 171 |
+
hidden_states = self.proj_in(hidden_states)
|
| 172 |
+
|
| 173 |
+
# 2. Blocks
|
| 174 |
+
for block in self.transformer_blocks:
|
| 175 |
+
hidden_states = block(
|
| 176 |
+
hidden_states,
|
| 177 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 178 |
+
timestep=timestep,
|
| 179 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 180 |
+
class_labels=class_labels,
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
# 3. Output
|
| 184 |
+
hidden_states = self.proj_out(hidden_states)
|
| 185 |
+
hidden_states = (
|
| 186 |
+
hidden_states[None, None, :]
|
| 187 |
+
.reshape(batch_size, height, width, num_frames, channel)
|
| 188 |
+
.permute(0, 3, 4, 1, 2)
|
| 189 |
+
.contiguous()
|
| 190 |
+
)
|
| 191 |
+
hidden_states = hidden_states.reshape(batch_frames, channel, height, width)
|
| 192 |
+
|
| 193 |
+
output = hidden_states + residual
|
| 194 |
+
|
| 195 |
+
return output
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
class TransformerSpatioTemporalModel(nn.Module):
|
| 199 |
+
"""
|
| 200 |
+
A Transformer model for video-like data.
|
| 201 |
+
|
| 202 |
+
Parameters:
|
| 203 |
+
num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
|
| 204 |
+
attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
|
| 205 |
+
in_channels (`int`, *optional*):
|
| 206 |
+
The number of channels in the input and output (specify if the input is **continuous**).
|
| 207 |
+
out_channels (`int`, *optional*):
|
| 208 |
+
The number of channels in the output (specify if the input is **continuous**).
|
| 209 |
+
num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
|
| 210 |
+
cross_attention_dim (`int`, *optional*): The number of `encoder_hidden_states` dimensions to use.
|
| 211 |
+
"""
|
| 212 |
+
|
| 213 |
+
def __init__(
|
| 214 |
+
self,
|
| 215 |
+
num_attention_heads: int = 16,
|
| 216 |
+
attention_head_dim: int = 88,
|
| 217 |
+
in_channels: int = 320,
|
| 218 |
+
out_channels: Optional[int] = None,
|
| 219 |
+
num_layers: int = 1,
|
| 220 |
+
cross_attention_dim: Optional[int] = None,
|
| 221 |
+
):
|
| 222 |
+
super().__init__()
|
| 223 |
+
self.num_attention_heads = num_attention_heads
|
| 224 |
+
self.attention_head_dim = attention_head_dim
|
| 225 |
+
|
| 226 |
+
inner_dim = num_attention_heads * attention_head_dim
|
| 227 |
+
self.inner_dim = inner_dim
|
| 228 |
+
|
| 229 |
+
# 2. Define input layers
|
| 230 |
+
self.in_channels = in_channels
|
| 231 |
+
self.norm = torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6)
|
| 232 |
+
self.proj_in = nn.Linear(in_channels, inner_dim)
|
| 233 |
+
|
| 234 |
+
# 3. Define transformers blocks
|
| 235 |
+
self.transformer_blocks = nn.ModuleList(
|
| 236 |
+
[
|
| 237 |
+
BasicTransformerBlock(
|
| 238 |
+
inner_dim,
|
| 239 |
+
num_attention_heads,
|
| 240 |
+
attention_head_dim,
|
| 241 |
+
cross_attention_dim=cross_attention_dim,
|
| 242 |
+
)
|
| 243 |
+
for d in range(num_layers)
|
| 244 |
+
]
|
| 245 |
+
)
|
| 246 |
+
|
| 247 |
+
time_mix_inner_dim = inner_dim
|
| 248 |
+
self.temporal_transformer_blocks = nn.ModuleList(
|
| 249 |
+
[
|
| 250 |
+
TemporalBasicTransformerBlock(
|
| 251 |
+
inner_dim,
|
| 252 |
+
time_mix_inner_dim,
|
| 253 |
+
num_attention_heads,
|
| 254 |
+
attention_head_dim,
|
| 255 |
+
cross_attention_dim=cross_attention_dim,
|
| 256 |
+
)
|
| 257 |
+
for _ in range(num_layers)
|
| 258 |
+
]
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
time_embed_dim = in_channels * 4
|
| 262 |
+
self.time_pos_embed = TimestepEmbedding(in_channels, time_embed_dim, out_dim=in_channels)
|
| 263 |
+
self.time_proj = Timesteps(in_channels, True, 0)
|
| 264 |
+
self.time_mixer = AlphaBlender(alpha=0.5, merge_strategy="learned_with_images")
|
| 265 |
+
|
| 266 |
+
# 4. Define output layers
|
| 267 |
+
self.out_channels = in_channels if out_channels is None else out_channels
|
| 268 |
+
# TODO: should use out_channels for continuous projections
|
| 269 |
+
self.proj_out = nn.Linear(inner_dim, in_channels)
|
| 270 |
+
|
| 271 |
+
self.gradient_checkpointing = False
|
| 272 |
+
|
| 273 |
+
def forward(
|
| 274 |
+
self,
|
| 275 |
+
hidden_states: torch.Tensor,
|
| 276 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 277 |
+
image_only_indicator: Optional[torch.Tensor] = None,
|
| 278 |
+
return_dict: bool = True,
|
| 279 |
+
):
|
| 280 |
+
"""
|
| 281 |
+
Args:
|
| 282 |
+
hidden_states (`torch.FloatTensor` of shape `(batch size, channel, height, width)`):
|
| 283 |
+
Input hidden_states.
|
| 284 |
+
num_frames (`int`):
|
| 285 |
+
The number of frames to be processed per batch. This is used to reshape the hidden states.
|
| 286 |
+
encoder_hidden_states ( `torch.LongTensor` of shape `(batch size, encoder_hidden_states dim)`, *optional*):
|
| 287 |
+
Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
|
| 288 |
+
self-attention.
|
| 289 |
+
image_only_indicator (`torch.LongTensor` of shape `(batch size, num_frames)`, *optional*):
|
| 290 |
+
A tensor indicating whether the input contains only images. 1 indicates that the input contains only
|
| 291 |
+
images, 0 indicates that the input contains video frames.
|
| 292 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 293 |
+
Whether or not to return a [`~models.transformer_temporal.TransformerTemporalModelOutput`] instead of a plain
|
| 294 |
+
tuple.
|
| 295 |
+
|
| 296 |
+
Returns:
|
| 297 |
+
[`~models.transformer_temporal.TransformerTemporalModelOutput`] or `tuple`:
|
| 298 |
+
If `return_dict` is True, an [`~models.transformer_temporal.TransformerTemporalModelOutput`] is
|
| 299 |
+
returned, otherwise a `tuple` where the first element is the sample tensor.
|
| 300 |
+
"""
|
| 301 |
+
# 1. Input
|
| 302 |
+
batch_frames, _, height, width = hidden_states.shape
|
| 303 |
+
num_frames = image_only_indicator.shape[-1]
|
| 304 |
+
batch_size = batch_frames // num_frames
|
| 305 |
+
|
| 306 |
+
time_context = encoder_hidden_states
|
| 307 |
+
time_context_first_timestep = time_context[None, :].reshape(
|
| 308 |
+
batch_size, num_frames, -1, time_context.shape[-1]
|
| 309 |
+
)[:, 0]
|
| 310 |
+
time_context = time_context_first_timestep[None, :].broadcast_to(
|
| 311 |
+
height * width, batch_size, 1, time_context.shape[-1]
|
| 312 |
+
)
|
| 313 |
+
time_context = time_context.reshape(height * width * batch_size, 1, time_context.shape[-1])
|
| 314 |
+
|
| 315 |
+
residual = hidden_states
|
| 316 |
+
|
| 317 |
+
hidden_states = self.norm(hidden_states)
|
| 318 |
+
inner_dim = hidden_states.shape[1]
|
| 319 |
+
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch_frames, height * width, inner_dim)
|
| 320 |
+
hidden_states = self.proj_in(hidden_states)
|
| 321 |
+
|
| 322 |
+
num_frames_emb = torch.arange(num_frames, device=hidden_states.device)
|
| 323 |
+
num_frames_emb = num_frames_emb.repeat(batch_size, 1)
|
| 324 |
+
num_frames_emb = num_frames_emb.reshape(-1)
|
| 325 |
+
t_emb = self.time_proj(num_frames_emb)
|
| 326 |
+
|
| 327 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 328 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 329 |
+
# there might be better ways to encapsulate this.
|
| 330 |
+
t_emb = t_emb.to(dtype=hidden_states.dtype)
|
| 331 |
+
|
| 332 |
+
emb = self.time_pos_embed(t_emb)
|
| 333 |
+
emb = emb[:, None, :]
|
| 334 |
+
|
| 335 |
+
# 2. Blocks
|
| 336 |
+
for block, temporal_block in zip(self.transformer_blocks, self.temporal_transformer_blocks):
|
| 337 |
+
if self.training and self.gradient_checkpointing:
|
| 338 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 339 |
+
block,
|
| 340 |
+
hidden_states,
|
| 341 |
+
None,
|
| 342 |
+
encoder_hidden_states,
|
| 343 |
+
None,
|
| 344 |
+
use_reentrant=False,
|
| 345 |
+
)
|
| 346 |
+
else:
|
| 347 |
+
hidden_states = block(
|
| 348 |
+
hidden_states,
|
| 349 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
hidden_states_mix = hidden_states
|
| 353 |
+
hidden_states_mix = hidden_states_mix + emb
|
| 354 |
+
|
| 355 |
+
hidden_states_mix = temporal_block(
|
| 356 |
+
hidden_states_mix,
|
| 357 |
+
num_frames=num_frames,
|
| 358 |
+
encoder_hidden_states=time_context,
|
| 359 |
+
)
|
| 360 |
+
hidden_states = self.time_mixer(
|
| 361 |
+
x_spatial=hidden_states,
|
| 362 |
+
x_temporal=hidden_states_mix,
|
| 363 |
+
image_only_indicator=image_only_indicator,
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
# 3. Output
|
| 367 |
+
hidden_states = self.proj_out(hidden_states)
|
| 368 |
+
hidden_states = hidden_states.reshape(batch_frames, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
|
| 369 |
+
|
| 370 |
+
output = hidden_states + residual
|
| 371 |
+
|
| 372 |
+
if not return_dict:
|
| 373 |
+
return (output,)
|
| 374 |
+
|
| 375 |
+
return TransformerTemporalModelOutput(sample=output)
|
libs/unet_2d_blocks.py
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
libs/unet_2d_condition.py
ADDED
|
@@ -0,0 +1,1359 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from dataclasses import dataclass
|
| 15 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
import torch.nn as nn
|
| 19 |
+
import torch.utils.checkpoint
|
| 20 |
+
|
| 21 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 22 |
+
from diffusers.loaders import PeftAdapterMixin, UNet2DConditionLoadersMixin
|
| 23 |
+
from diffusers.utils import USE_PEFT_BACKEND, BaseOutput, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
| 24 |
+
from diffusers.models.activations import get_activation
|
| 25 |
+
from diffusers.models.attention_processor import (
|
| 26 |
+
ADDED_KV_ATTENTION_PROCESSORS,
|
| 27 |
+
CROSS_ATTENTION_PROCESSORS,
|
| 28 |
+
Attention,
|
| 29 |
+
AttentionProcessor,
|
| 30 |
+
AttnAddedKVProcessor,
|
| 31 |
+
AttnProcessor,
|
| 32 |
+
)
|
| 33 |
+
from diffusers.models.embeddings import (
|
| 34 |
+
GaussianFourierProjection,
|
| 35 |
+
GLIGENTextBoundingboxProjection,
|
| 36 |
+
ImageHintTimeEmbedding,
|
| 37 |
+
ImageProjection,
|
| 38 |
+
ImageTimeEmbedding,
|
| 39 |
+
TextImageProjection,
|
| 40 |
+
TextImageTimeEmbedding,
|
| 41 |
+
TextTimeEmbedding,
|
| 42 |
+
TimestepEmbedding,
|
| 43 |
+
Timesteps,
|
| 44 |
+
)
|
| 45 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 46 |
+
from .unet_2d_blocks import (
|
| 47 |
+
get_down_block,
|
| 48 |
+
get_mid_block,
|
| 49 |
+
get_up_block,
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
@dataclass
|
| 57 |
+
class UNet2DConditionOutput(BaseOutput):
|
| 58 |
+
"""
|
| 59 |
+
The output of [`UNet2DConditionModel`].
|
| 60 |
+
|
| 61 |
+
Args:
|
| 62 |
+
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 63 |
+
The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
|
| 64 |
+
"""
|
| 65 |
+
|
| 66 |
+
sample: torch.FloatTensor = None
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin, PeftAdapterMixin):
|
| 70 |
+
r"""
|
| 71 |
+
A conditional 2D UNet model that takes a noisy sample, conditional state, and a timestep and returns a sample
|
| 72 |
+
shaped output.
|
| 73 |
+
|
| 74 |
+
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
|
| 75 |
+
for all models (such as downloading or saving).
|
| 76 |
+
|
| 77 |
+
Parameters:
|
| 78 |
+
sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
|
| 79 |
+
Height and width of input/output sample.
|
| 80 |
+
in_channels (`int`, *optional*, defaults to 4): Number of channels in the input sample.
|
| 81 |
+
out_channels (`int`, *optional*, defaults to 4): Number of channels in the output.
|
| 82 |
+
center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
|
| 83 |
+
flip_sin_to_cos (`bool`, *optional*, defaults to `False`):
|
| 84 |
+
Whether to flip the sin to cos in the time embedding.
|
| 85 |
+
freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
|
| 86 |
+
down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
|
| 87 |
+
The tuple of downsample blocks to use.
|
| 88 |
+
mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
|
| 89 |
+
Block type for middle of UNet, it can be one of `UNetMidBlock2DCrossAttn`, `UNetMidBlock2D`, or
|
| 90 |
+
`UNetMidBlock2DSimpleCrossAttn`. If `None`, the mid block layer is skipped.
|
| 91 |
+
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D")`):
|
| 92 |
+
The tuple of upsample blocks to use.
|
| 93 |
+
only_cross_attention(`bool` or `Tuple[bool]`, *optional*, default to `False`):
|
| 94 |
+
Whether to include self-attention in the basic transformer blocks, see
|
| 95 |
+
[`~models.attention.BasicTransformerBlock`].
|
| 96 |
+
block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
|
| 97 |
+
The tuple of output channels for each block.
|
| 98 |
+
layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
|
| 99 |
+
downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
|
| 100 |
+
mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
|
| 101 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 102 |
+
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
| 103 |
+
norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
|
| 104 |
+
If `None`, normalization and activation layers is skipped in post-processing.
|
| 105 |
+
norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
|
| 106 |
+
cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
|
| 107 |
+
The dimension of the cross attention features.
|
| 108 |
+
transformer_layers_per_block (`int`, `Tuple[int]`, or `Tuple[Tuple]` , *optional*, defaults to 1):
|
| 109 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
|
| 110 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 111 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 112 |
+
reverse_transformer_layers_per_block : (`Tuple[Tuple]`, *optional*, defaults to None):
|
| 113 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`], in the upsampling
|
| 114 |
+
blocks of the U-Net. Only relevant if `transformer_layers_per_block` is of type `Tuple[Tuple]` and for
|
| 115 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 116 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 117 |
+
encoder_hid_dim (`int`, *optional*, defaults to None):
|
| 118 |
+
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
| 119 |
+
dimension to `cross_attention_dim`.
|
| 120 |
+
encoder_hid_dim_type (`str`, *optional*, defaults to `None`):
|
| 121 |
+
If given, the `encoder_hidden_states` and potentially other embeddings are down-projected to text
|
| 122 |
+
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
| 123 |
+
attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
|
| 124 |
+
num_attention_heads (`int`, *optional*):
|
| 125 |
+
The number of attention heads. If not defined, defaults to `attention_head_dim`
|
| 126 |
+
resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
|
| 127 |
+
for ResNet blocks (see [`~models.resnet.ResnetBlock2D`]). Choose from `default` or `scale_shift`.
|
| 128 |
+
class_embed_type (`str`, *optional*, defaults to `None`):
|
| 129 |
+
The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
|
| 130 |
+
`"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
|
| 131 |
+
addition_embed_type (`str`, *optional*, defaults to `None`):
|
| 132 |
+
Configures an optional embedding which will be summed with the time embeddings. Choose from `None` or
|
| 133 |
+
"text". "text" will use the `TextTimeEmbedding` layer.
|
| 134 |
+
addition_time_embed_dim: (`int`, *optional*, defaults to `None`):
|
| 135 |
+
Dimension for the timestep embeddings.
|
| 136 |
+
num_class_embeds (`int`, *optional*, defaults to `None`):
|
| 137 |
+
Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
|
| 138 |
+
class conditioning with `class_embed_type` equal to `None`.
|
| 139 |
+
time_embedding_type (`str`, *optional*, defaults to `positional`):
|
| 140 |
+
The type of position embedding to use for timesteps. Choose from `positional` or `fourier`.
|
| 141 |
+
time_embedding_dim (`int`, *optional*, defaults to `None`):
|
| 142 |
+
An optional override for the dimension of the projected time embedding.
|
| 143 |
+
time_embedding_act_fn (`str`, *optional*, defaults to `None`):
|
| 144 |
+
Optional activation function to use only once on the time embeddings before they are passed to the rest of
|
| 145 |
+
the UNet. Choose from `silu`, `mish`, `gelu`, and `swish`.
|
| 146 |
+
timestep_post_act (`str`, *optional*, defaults to `None`):
|
| 147 |
+
The second activation function to use in timestep embedding. Choose from `silu`, `mish` and `gelu`.
|
| 148 |
+
time_cond_proj_dim (`int`, *optional*, defaults to `None`):
|
| 149 |
+
The dimension of `cond_proj` layer in the timestep embedding.
|
| 150 |
+
conv_in_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_in` layer. conv_out_kernel (`int`,
|
| 151 |
+
*optional*, default to `3`): The kernel size of `conv_out` layer. projection_class_embeddings_input_dim (`int`,
|
| 152 |
+
*optional*): The dimension of the `class_labels` input when
|
| 153 |
+
`class_embed_type="projection"`. Required when `class_embed_type="projection"`.
|
| 154 |
+
class_embeddings_concat (`bool`, *optional*, defaults to `False`): Whether to concatenate the time
|
| 155 |
+
embeddings with the class embeddings.
|
| 156 |
+
mid_block_only_cross_attention (`bool`, *optional*, defaults to `None`):
|
| 157 |
+
Whether to use cross attention with the mid block when using the `UNetMidBlock2DSimpleCrossAttn`. If
|
| 158 |
+
`only_cross_attention` is given as a single boolean and `mid_block_only_cross_attention` is `None`, the
|
| 159 |
+
`only_cross_attention` value is used as the value for `mid_block_only_cross_attention`. Default to `False`
|
| 160 |
+
otherwise.
|
| 161 |
+
"""
|
| 162 |
+
|
| 163 |
+
_supports_gradient_checkpointing = True
|
| 164 |
+
|
| 165 |
+
@register_to_config
|
| 166 |
+
def __init__(
|
| 167 |
+
self,
|
| 168 |
+
sample_size: Optional[int] = None,
|
| 169 |
+
in_channels: int = 4,
|
| 170 |
+
out_channels: int = 4,
|
| 171 |
+
center_input_sample: bool = False,
|
| 172 |
+
flip_sin_to_cos: bool = True,
|
| 173 |
+
freq_shift: int = 0,
|
| 174 |
+
down_block_types: Tuple[str] = (
|
| 175 |
+
"CrossAttnDownBlock2D",
|
| 176 |
+
"CrossAttnDownBlock2D",
|
| 177 |
+
"CrossAttnDownBlock2D",
|
| 178 |
+
"DownBlock2D",
|
| 179 |
+
),
|
| 180 |
+
mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
|
| 181 |
+
up_block_types: Tuple[str] = ("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
|
| 182 |
+
only_cross_attention: Union[bool, Tuple[bool]] = False,
|
| 183 |
+
block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
|
| 184 |
+
layers_per_block: Union[int, Tuple[int]] = 2,
|
| 185 |
+
downsample_padding: int = 1,
|
| 186 |
+
mid_block_scale_factor: float = 1,
|
| 187 |
+
dropout: float = 0.0,
|
| 188 |
+
act_fn: str = "silu",
|
| 189 |
+
norm_num_groups: Optional[int] = 32,
|
| 190 |
+
norm_eps: float = 1e-5,
|
| 191 |
+
cross_attention_dim: Union[int, Tuple[int]] = 1280,
|
| 192 |
+
transformer_layers_per_block: Union[int, Tuple[int], Tuple[Tuple]] = 1,
|
| 193 |
+
reverse_transformer_layers_per_block: Optional[Tuple[Tuple[int]]] = None,
|
| 194 |
+
encoder_hid_dim: Optional[int] = None,
|
| 195 |
+
encoder_hid_dim_type: Optional[str] = None,
|
| 196 |
+
attention_head_dim: Union[int, Tuple[int]] = 8,
|
| 197 |
+
num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
|
| 198 |
+
dual_cross_attention: bool = False,
|
| 199 |
+
use_linear_projection: bool = False,
|
| 200 |
+
class_embed_type: Optional[str] = None,
|
| 201 |
+
addition_embed_type: Optional[str] = None,
|
| 202 |
+
addition_time_embed_dim: Optional[int] = None,
|
| 203 |
+
num_class_embeds: Optional[int] = None,
|
| 204 |
+
upcast_attention: bool = False,
|
| 205 |
+
resnet_time_scale_shift: str = "default",
|
| 206 |
+
resnet_skip_time_act: bool = False,
|
| 207 |
+
resnet_out_scale_factor: float = 1.0,
|
| 208 |
+
time_embedding_type: str = "positional",
|
| 209 |
+
time_embedding_dim: Optional[int] = None,
|
| 210 |
+
time_embedding_act_fn: Optional[str] = None,
|
| 211 |
+
timestep_post_act: Optional[str] = None,
|
| 212 |
+
time_cond_proj_dim: Optional[int] = None,
|
| 213 |
+
conv_in_kernel: int = 3,
|
| 214 |
+
conv_out_kernel: int = 3,
|
| 215 |
+
projection_class_embeddings_input_dim: Optional[int] = None,
|
| 216 |
+
attention_type: str = "default",
|
| 217 |
+
class_embeddings_concat: bool = False,
|
| 218 |
+
mid_block_only_cross_attention: Optional[bool] = None,
|
| 219 |
+
cross_attention_norm: Optional[str] = None,
|
| 220 |
+
addition_embed_type_num_heads: int = 64,
|
| 221 |
+
):
|
| 222 |
+
super().__init__()
|
| 223 |
+
|
| 224 |
+
self.sample_size = sample_size
|
| 225 |
+
|
| 226 |
+
if num_attention_heads is not None:
|
| 227 |
+
raise ValueError(
|
| 228 |
+
"At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
# If `num_attention_heads` is not defined (which is the case for most models)
|
| 232 |
+
# it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
|
| 233 |
+
# The reason for this behavior is to correct for incorrectly named variables that were introduced
|
| 234 |
+
# when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
|
| 235 |
+
# Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
|
| 236 |
+
# which is why we correct for the naming here.
|
| 237 |
+
num_attention_heads = num_attention_heads or attention_head_dim
|
| 238 |
+
|
| 239 |
+
# Check inputs
|
| 240 |
+
self._check_config(
|
| 241 |
+
down_block_types=down_block_types,
|
| 242 |
+
up_block_types=up_block_types,
|
| 243 |
+
only_cross_attention=only_cross_attention,
|
| 244 |
+
block_out_channels=block_out_channels,
|
| 245 |
+
layers_per_block=layers_per_block,
|
| 246 |
+
cross_attention_dim=cross_attention_dim,
|
| 247 |
+
transformer_layers_per_block=transformer_layers_per_block,
|
| 248 |
+
reverse_transformer_layers_per_block=reverse_transformer_layers_per_block,
|
| 249 |
+
attention_head_dim=attention_head_dim,
|
| 250 |
+
num_attention_heads=num_attention_heads,
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
# input
|
| 254 |
+
conv_in_padding = (conv_in_kernel - 1) // 2
|
| 255 |
+
self.conv_in = nn.Conv2d(
|
| 256 |
+
in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
# time
|
| 260 |
+
time_embed_dim, timestep_input_dim = self._set_time_proj(
|
| 261 |
+
time_embedding_type,
|
| 262 |
+
block_out_channels=block_out_channels,
|
| 263 |
+
flip_sin_to_cos=flip_sin_to_cos,
|
| 264 |
+
freq_shift=freq_shift,
|
| 265 |
+
time_embedding_dim=time_embedding_dim,
|
| 266 |
+
)
|
| 267 |
+
|
| 268 |
+
self.time_embedding = TimestepEmbedding(
|
| 269 |
+
timestep_input_dim,
|
| 270 |
+
time_embed_dim,
|
| 271 |
+
act_fn=act_fn,
|
| 272 |
+
post_act_fn=timestep_post_act,
|
| 273 |
+
cond_proj_dim=time_cond_proj_dim,
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
self._set_encoder_hid_proj(
|
| 277 |
+
encoder_hid_dim_type,
|
| 278 |
+
cross_attention_dim=cross_attention_dim,
|
| 279 |
+
encoder_hid_dim=encoder_hid_dim,
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
# class embedding
|
| 283 |
+
self._set_class_embedding(
|
| 284 |
+
class_embed_type,
|
| 285 |
+
act_fn=act_fn,
|
| 286 |
+
num_class_embeds=num_class_embeds,
|
| 287 |
+
projection_class_embeddings_input_dim=projection_class_embeddings_input_dim,
|
| 288 |
+
time_embed_dim=time_embed_dim,
|
| 289 |
+
timestep_input_dim=timestep_input_dim,
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
self._set_add_embedding(
|
| 293 |
+
addition_embed_type,
|
| 294 |
+
addition_embed_type_num_heads=addition_embed_type_num_heads,
|
| 295 |
+
addition_time_embed_dim=addition_time_embed_dim,
|
| 296 |
+
cross_attention_dim=cross_attention_dim,
|
| 297 |
+
encoder_hid_dim=encoder_hid_dim,
|
| 298 |
+
flip_sin_to_cos=flip_sin_to_cos,
|
| 299 |
+
freq_shift=freq_shift,
|
| 300 |
+
projection_class_embeddings_input_dim=projection_class_embeddings_input_dim,
|
| 301 |
+
time_embed_dim=time_embed_dim,
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
if time_embedding_act_fn is None:
|
| 305 |
+
self.time_embed_act = None
|
| 306 |
+
else:
|
| 307 |
+
self.time_embed_act = get_activation(time_embedding_act_fn)
|
| 308 |
+
|
| 309 |
+
self.down_blocks = nn.ModuleList([])
|
| 310 |
+
self.up_blocks = nn.ModuleList([])
|
| 311 |
+
|
| 312 |
+
if isinstance(only_cross_attention, bool):
|
| 313 |
+
if mid_block_only_cross_attention is None:
|
| 314 |
+
mid_block_only_cross_attention = only_cross_attention
|
| 315 |
+
|
| 316 |
+
only_cross_attention = [only_cross_attention] * len(down_block_types)
|
| 317 |
+
|
| 318 |
+
if mid_block_only_cross_attention is None:
|
| 319 |
+
mid_block_only_cross_attention = False
|
| 320 |
+
|
| 321 |
+
if isinstance(num_attention_heads, int):
|
| 322 |
+
num_attention_heads = (num_attention_heads,) * len(down_block_types)
|
| 323 |
+
|
| 324 |
+
if isinstance(attention_head_dim, int):
|
| 325 |
+
attention_head_dim = (attention_head_dim,) * len(down_block_types)
|
| 326 |
+
|
| 327 |
+
if isinstance(cross_attention_dim, int):
|
| 328 |
+
cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
|
| 329 |
+
|
| 330 |
+
if isinstance(layers_per_block, int):
|
| 331 |
+
layers_per_block = [layers_per_block] * len(down_block_types)
|
| 332 |
+
|
| 333 |
+
if isinstance(transformer_layers_per_block, int):
|
| 334 |
+
transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
|
| 335 |
+
|
| 336 |
+
if class_embeddings_concat:
|
| 337 |
+
# The time embeddings are concatenated with the class embeddings. The dimension of the
|
| 338 |
+
# time embeddings passed to the down, middle, and up blocks is twice the dimension of the
|
| 339 |
+
# regular time embeddings
|
| 340 |
+
blocks_time_embed_dim = time_embed_dim * 2
|
| 341 |
+
else:
|
| 342 |
+
blocks_time_embed_dim = time_embed_dim
|
| 343 |
+
|
| 344 |
+
# down
|
| 345 |
+
output_channel = block_out_channels[0]
|
| 346 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 347 |
+
input_channel = output_channel
|
| 348 |
+
output_channel = block_out_channels[i]
|
| 349 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 350 |
+
|
| 351 |
+
down_block = get_down_block(
|
| 352 |
+
down_block_type,
|
| 353 |
+
num_layers=layers_per_block[i],
|
| 354 |
+
transformer_layers_per_block=transformer_layers_per_block[i],
|
| 355 |
+
in_channels=input_channel,
|
| 356 |
+
out_channels=output_channel,
|
| 357 |
+
temb_channels=blocks_time_embed_dim,
|
| 358 |
+
add_downsample=not is_final_block,
|
| 359 |
+
resnet_eps=norm_eps,
|
| 360 |
+
resnet_act_fn=act_fn,
|
| 361 |
+
resnet_groups=norm_num_groups,
|
| 362 |
+
cross_attention_dim=cross_attention_dim[i],
|
| 363 |
+
num_attention_heads=num_attention_heads[i],
|
| 364 |
+
downsample_padding=downsample_padding,
|
| 365 |
+
dual_cross_attention=dual_cross_attention,
|
| 366 |
+
use_linear_projection=use_linear_projection,
|
| 367 |
+
only_cross_attention=only_cross_attention[i],
|
| 368 |
+
upcast_attention=upcast_attention,
|
| 369 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 370 |
+
attention_type=attention_type,
|
| 371 |
+
resnet_skip_time_act=resnet_skip_time_act,
|
| 372 |
+
resnet_out_scale_factor=resnet_out_scale_factor,
|
| 373 |
+
cross_attention_norm=cross_attention_norm,
|
| 374 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 375 |
+
dropout=dropout,
|
| 376 |
+
)
|
| 377 |
+
self.down_blocks.append(down_block)
|
| 378 |
+
|
| 379 |
+
# mid
|
| 380 |
+
self.mid_block = get_mid_block(
|
| 381 |
+
mid_block_type,
|
| 382 |
+
temb_channels=blocks_time_embed_dim,
|
| 383 |
+
in_channels=block_out_channels[-1],
|
| 384 |
+
resnet_eps=norm_eps,
|
| 385 |
+
resnet_act_fn=act_fn,
|
| 386 |
+
resnet_groups=norm_num_groups,
|
| 387 |
+
output_scale_factor=mid_block_scale_factor,
|
| 388 |
+
transformer_layers_per_block=transformer_layers_per_block[-1],
|
| 389 |
+
num_attention_heads=num_attention_heads[-1],
|
| 390 |
+
cross_attention_dim=cross_attention_dim[-1],
|
| 391 |
+
dual_cross_attention=dual_cross_attention,
|
| 392 |
+
use_linear_projection=use_linear_projection,
|
| 393 |
+
mid_block_only_cross_attention=mid_block_only_cross_attention,
|
| 394 |
+
upcast_attention=upcast_attention,
|
| 395 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 396 |
+
attention_type=attention_type,
|
| 397 |
+
resnet_skip_time_act=resnet_skip_time_act,
|
| 398 |
+
cross_attention_norm=cross_attention_norm,
|
| 399 |
+
attention_head_dim=attention_head_dim[-1],
|
| 400 |
+
dropout=dropout,
|
| 401 |
+
)
|
| 402 |
+
|
| 403 |
+
# count how many layers upsample the images
|
| 404 |
+
self.num_upsamplers = 0
|
| 405 |
+
|
| 406 |
+
# up
|
| 407 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 408 |
+
reversed_num_attention_heads = list(reversed(num_attention_heads))
|
| 409 |
+
reversed_layers_per_block = list(reversed(layers_per_block))
|
| 410 |
+
reversed_cross_attention_dim = list(reversed(cross_attention_dim))
|
| 411 |
+
reversed_transformer_layers_per_block = (
|
| 412 |
+
list(reversed(transformer_layers_per_block))
|
| 413 |
+
if reverse_transformer_layers_per_block is None
|
| 414 |
+
else reverse_transformer_layers_per_block
|
| 415 |
+
)
|
| 416 |
+
only_cross_attention = list(reversed(only_cross_attention))
|
| 417 |
+
|
| 418 |
+
output_channel = reversed_block_out_channels[0]
|
| 419 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 420 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 421 |
+
|
| 422 |
+
prev_output_channel = output_channel
|
| 423 |
+
output_channel = reversed_block_out_channels[i]
|
| 424 |
+
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
| 425 |
+
|
| 426 |
+
# add upsample block for all BUT final layer
|
| 427 |
+
if not is_final_block:
|
| 428 |
+
add_upsample = True
|
| 429 |
+
self.num_upsamplers += 1
|
| 430 |
+
else:
|
| 431 |
+
add_upsample = False
|
| 432 |
+
|
| 433 |
+
up_block = get_up_block(
|
| 434 |
+
up_block_type,
|
| 435 |
+
num_layers=reversed_layers_per_block[i] + 1,
|
| 436 |
+
transformer_layers_per_block=reversed_transformer_layers_per_block[i],
|
| 437 |
+
in_channels=input_channel,
|
| 438 |
+
out_channels=output_channel,
|
| 439 |
+
prev_output_channel=prev_output_channel,
|
| 440 |
+
temb_channels=blocks_time_embed_dim,
|
| 441 |
+
add_upsample=add_upsample,
|
| 442 |
+
resnet_eps=norm_eps,
|
| 443 |
+
resnet_act_fn=act_fn,
|
| 444 |
+
resolution_idx=i,
|
| 445 |
+
resnet_groups=norm_num_groups,
|
| 446 |
+
cross_attention_dim=reversed_cross_attention_dim[i],
|
| 447 |
+
num_attention_heads=reversed_num_attention_heads[i],
|
| 448 |
+
dual_cross_attention=dual_cross_attention,
|
| 449 |
+
use_linear_projection=use_linear_projection,
|
| 450 |
+
only_cross_attention=only_cross_attention[i],
|
| 451 |
+
upcast_attention=upcast_attention,
|
| 452 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 453 |
+
attention_type=attention_type,
|
| 454 |
+
resnet_skip_time_act=resnet_skip_time_act,
|
| 455 |
+
resnet_out_scale_factor=resnet_out_scale_factor,
|
| 456 |
+
cross_attention_norm=cross_attention_norm,
|
| 457 |
+
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
|
| 458 |
+
dropout=dropout,
|
| 459 |
+
)
|
| 460 |
+
self.up_blocks.append(up_block)
|
| 461 |
+
prev_output_channel = output_channel
|
| 462 |
+
|
| 463 |
+
# out
|
| 464 |
+
if norm_num_groups is not None:
|
| 465 |
+
self.conv_norm_out = nn.GroupNorm(
|
| 466 |
+
num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
|
| 467 |
+
)
|
| 468 |
+
|
| 469 |
+
self.conv_act = get_activation(act_fn)
|
| 470 |
+
|
| 471 |
+
else:
|
| 472 |
+
self.conv_norm_out = None
|
| 473 |
+
self.conv_act = None
|
| 474 |
+
|
| 475 |
+
conv_out_padding = (conv_out_kernel - 1) // 2
|
| 476 |
+
self.conv_out = nn.Conv2d(
|
| 477 |
+
block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
|
| 478 |
+
)
|
| 479 |
+
|
| 480 |
+
self._set_pos_net_if_use_gligen(attention_type=attention_type, cross_attention_dim=cross_attention_dim)
|
| 481 |
+
|
| 482 |
+
def _check_config(
|
| 483 |
+
self,
|
| 484 |
+
down_block_types: Tuple[str],
|
| 485 |
+
up_block_types: Tuple[str],
|
| 486 |
+
only_cross_attention: Union[bool, Tuple[bool]],
|
| 487 |
+
block_out_channels: Tuple[int],
|
| 488 |
+
layers_per_block: Union[int, Tuple[int]],
|
| 489 |
+
cross_attention_dim: Union[int, Tuple[int]],
|
| 490 |
+
transformer_layers_per_block: Union[int, Tuple[int], Tuple[Tuple[int]]],
|
| 491 |
+
reverse_transformer_layers_per_block: bool,
|
| 492 |
+
attention_head_dim: int,
|
| 493 |
+
num_attention_heads: Optional[Union[int, Tuple[int]]],
|
| 494 |
+
):
|
| 495 |
+
if len(down_block_types) != len(up_block_types):
|
| 496 |
+
raise ValueError(
|
| 497 |
+
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
|
| 498 |
+
)
|
| 499 |
+
|
| 500 |
+
if len(block_out_channels) != len(down_block_types):
|
| 501 |
+
raise ValueError(
|
| 502 |
+
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
|
| 503 |
+
)
|
| 504 |
+
|
| 505 |
+
if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
|
| 506 |
+
raise ValueError(
|
| 507 |
+
f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
|
| 508 |
+
)
|
| 509 |
+
|
| 510 |
+
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
|
| 511 |
+
raise ValueError(
|
| 512 |
+
f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
|
| 513 |
+
)
|
| 514 |
+
|
| 515 |
+
if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
|
| 516 |
+
raise ValueError(
|
| 517 |
+
f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
|
| 518 |
+
)
|
| 519 |
+
|
| 520 |
+
if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
|
| 521 |
+
raise ValueError(
|
| 522 |
+
f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
|
| 523 |
+
)
|
| 524 |
+
|
| 525 |
+
if not isinstance(layers_per_block, int) and len(layers_per_block) != len(down_block_types):
|
| 526 |
+
raise ValueError(
|
| 527 |
+
f"Must provide the same number of `layers_per_block` as `down_block_types`. `layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
|
| 528 |
+
)
|
| 529 |
+
if isinstance(transformer_layers_per_block, list) and reverse_transformer_layers_per_block is None:
|
| 530 |
+
for layer_number_per_block in transformer_layers_per_block:
|
| 531 |
+
if isinstance(layer_number_per_block, list):
|
| 532 |
+
raise ValueError("Must provide 'reverse_transformer_layers_per_block` if using asymmetrical UNet.")
|
| 533 |
+
|
| 534 |
+
def _set_time_proj(
|
| 535 |
+
self,
|
| 536 |
+
time_embedding_type: str,
|
| 537 |
+
block_out_channels: int,
|
| 538 |
+
flip_sin_to_cos: bool,
|
| 539 |
+
freq_shift: float,
|
| 540 |
+
time_embedding_dim: int,
|
| 541 |
+
) -> Tuple[int, int]:
|
| 542 |
+
if time_embedding_type == "fourier":
|
| 543 |
+
time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
|
| 544 |
+
if time_embed_dim % 2 != 0:
|
| 545 |
+
raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
|
| 546 |
+
self.time_proj = GaussianFourierProjection(
|
| 547 |
+
time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
|
| 548 |
+
)
|
| 549 |
+
timestep_input_dim = time_embed_dim
|
| 550 |
+
elif time_embedding_type == "positional":
|
| 551 |
+
time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
|
| 552 |
+
|
| 553 |
+
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
| 554 |
+
timestep_input_dim = block_out_channels[0]
|
| 555 |
+
else:
|
| 556 |
+
raise ValueError(
|
| 557 |
+
f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
|
| 558 |
+
)
|
| 559 |
+
|
| 560 |
+
return time_embed_dim, timestep_input_dim
|
| 561 |
+
|
| 562 |
+
def _set_encoder_hid_proj(
|
| 563 |
+
self,
|
| 564 |
+
encoder_hid_dim_type: Optional[str],
|
| 565 |
+
cross_attention_dim: Union[int, Tuple[int]],
|
| 566 |
+
encoder_hid_dim: Optional[int],
|
| 567 |
+
):
|
| 568 |
+
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
| 569 |
+
encoder_hid_dim_type = "text_proj"
|
| 570 |
+
self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
|
| 571 |
+
logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
|
| 572 |
+
|
| 573 |
+
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
| 574 |
+
raise ValueError(
|
| 575 |
+
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
| 576 |
+
)
|
| 577 |
+
|
| 578 |
+
if encoder_hid_dim_type == "text_proj":
|
| 579 |
+
self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
|
| 580 |
+
elif encoder_hid_dim_type == "text_image_proj":
|
| 581 |
+
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 582 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 583 |
+
# case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
|
| 584 |
+
self.encoder_hid_proj = TextImageProjection(
|
| 585 |
+
text_embed_dim=encoder_hid_dim,
|
| 586 |
+
image_embed_dim=cross_attention_dim,
|
| 587 |
+
cross_attention_dim=cross_attention_dim,
|
| 588 |
+
)
|
| 589 |
+
elif encoder_hid_dim_type == "image_proj":
|
| 590 |
+
# Kandinsky 2.2
|
| 591 |
+
self.encoder_hid_proj = ImageProjection(
|
| 592 |
+
image_embed_dim=encoder_hid_dim,
|
| 593 |
+
cross_attention_dim=cross_attention_dim,
|
| 594 |
+
)
|
| 595 |
+
elif encoder_hid_dim_type is not None:
|
| 596 |
+
raise ValueError(
|
| 597 |
+
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
| 598 |
+
)
|
| 599 |
+
else:
|
| 600 |
+
self.encoder_hid_proj = None
|
| 601 |
+
|
| 602 |
+
def _set_class_embedding(
|
| 603 |
+
self,
|
| 604 |
+
class_embed_type: Optional[str],
|
| 605 |
+
act_fn: str,
|
| 606 |
+
num_class_embeds: Optional[int],
|
| 607 |
+
projection_class_embeddings_input_dim: Optional[int],
|
| 608 |
+
time_embed_dim: int,
|
| 609 |
+
timestep_input_dim: int,
|
| 610 |
+
):
|
| 611 |
+
if class_embed_type is None and num_class_embeds is not None:
|
| 612 |
+
self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
|
| 613 |
+
elif class_embed_type == "timestep":
|
| 614 |
+
self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim, act_fn=act_fn)
|
| 615 |
+
elif class_embed_type == "identity":
|
| 616 |
+
self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
|
| 617 |
+
elif class_embed_type == "projection":
|
| 618 |
+
if projection_class_embeddings_input_dim is None:
|
| 619 |
+
raise ValueError(
|
| 620 |
+
"`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
|
| 621 |
+
)
|
| 622 |
+
# The projection `class_embed_type` is the same as the timestep `class_embed_type` except
|
| 623 |
+
# 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
|
| 624 |
+
# 2. it projects from an arbitrary input dimension.
|
| 625 |
+
#
|
| 626 |
+
# Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
|
| 627 |
+
# When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
|
| 628 |
+
# As a result, `TimestepEmbedding` can be passed arbitrary vectors.
|
| 629 |
+
self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 630 |
+
elif class_embed_type == "simple_projection":
|
| 631 |
+
if projection_class_embeddings_input_dim is None:
|
| 632 |
+
raise ValueError(
|
| 633 |
+
"`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
|
| 634 |
+
)
|
| 635 |
+
self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
|
| 636 |
+
else:
|
| 637 |
+
self.class_embedding = None
|
| 638 |
+
|
| 639 |
+
def _set_add_embedding(
|
| 640 |
+
self,
|
| 641 |
+
addition_embed_type: str,
|
| 642 |
+
addition_embed_type_num_heads: int,
|
| 643 |
+
addition_time_embed_dim: Optional[int],
|
| 644 |
+
flip_sin_to_cos: bool,
|
| 645 |
+
freq_shift: float,
|
| 646 |
+
cross_attention_dim: Optional[int],
|
| 647 |
+
encoder_hid_dim: Optional[int],
|
| 648 |
+
projection_class_embeddings_input_dim: Optional[int],
|
| 649 |
+
time_embed_dim: int,
|
| 650 |
+
):
|
| 651 |
+
if addition_embed_type == "text":
|
| 652 |
+
if encoder_hid_dim is not None:
|
| 653 |
+
text_time_embedding_from_dim = encoder_hid_dim
|
| 654 |
+
else:
|
| 655 |
+
text_time_embedding_from_dim = cross_attention_dim
|
| 656 |
+
|
| 657 |
+
self.add_embedding = TextTimeEmbedding(
|
| 658 |
+
text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
|
| 659 |
+
)
|
| 660 |
+
elif addition_embed_type == "text_image":
|
| 661 |
+
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 662 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 663 |
+
# case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
|
| 664 |
+
self.add_embedding = TextImageTimeEmbedding(
|
| 665 |
+
text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
|
| 666 |
+
)
|
| 667 |
+
elif addition_embed_type == "text_time":
|
| 668 |
+
self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
|
| 669 |
+
self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
|
| 670 |
+
elif addition_embed_type == "image":
|
| 671 |
+
# Kandinsky 2.2
|
| 672 |
+
self.add_embedding = ImageTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
|
| 673 |
+
elif addition_embed_type == "image_hint":
|
| 674 |
+
# Kandinsky 2.2 ControlNet
|
| 675 |
+
self.add_embedding = ImageHintTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
|
| 676 |
+
elif addition_embed_type is not None:
|
| 677 |
+
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
|
| 678 |
+
|
| 679 |
+
def _set_pos_net_if_use_gligen(self, attention_type: str, cross_attention_dim: int):
|
| 680 |
+
if attention_type in ["gated", "gated-text-image"]:
|
| 681 |
+
positive_len = 768
|
| 682 |
+
if isinstance(cross_attention_dim, int):
|
| 683 |
+
positive_len = cross_attention_dim
|
| 684 |
+
elif isinstance(cross_attention_dim, tuple) or isinstance(cross_attention_dim, list):
|
| 685 |
+
positive_len = cross_attention_dim[0]
|
| 686 |
+
|
| 687 |
+
feature_type = "text-only" if attention_type == "gated" else "text-image"
|
| 688 |
+
self.position_net = GLIGENTextBoundingboxProjection(
|
| 689 |
+
positive_len=positive_len, out_dim=cross_attention_dim, feature_type=feature_type
|
| 690 |
+
)
|
| 691 |
+
|
| 692 |
+
@property
|
| 693 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 694 |
+
r"""
|
| 695 |
+
Returns:
|
| 696 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 697 |
+
indexed by its weight name.
|
| 698 |
+
"""
|
| 699 |
+
# set recursively
|
| 700 |
+
processors = {}
|
| 701 |
+
|
| 702 |
+
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
| 703 |
+
if hasattr(module, "get_processor"):
|
| 704 |
+
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
|
| 705 |
+
|
| 706 |
+
for sub_name, child in module.named_children():
|
| 707 |
+
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
| 708 |
+
|
| 709 |
+
return processors
|
| 710 |
+
|
| 711 |
+
for name, module in self.named_children():
|
| 712 |
+
fn_recursive_add_processors(name, module, processors)
|
| 713 |
+
|
| 714 |
+
return processors
|
| 715 |
+
|
| 716 |
+
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
| 717 |
+
r"""
|
| 718 |
+
Sets the attention processor to use to compute attention.
|
| 719 |
+
|
| 720 |
+
Parameters:
|
| 721 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 722 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 723 |
+
for **all** `Attention` layers.
|
| 724 |
+
|
| 725 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 726 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 727 |
+
|
| 728 |
+
"""
|
| 729 |
+
count = len(self.attn_processors.keys())
|
| 730 |
+
|
| 731 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 732 |
+
raise ValueError(
|
| 733 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 734 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 735 |
+
)
|
| 736 |
+
|
| 737 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 738 |
+
if hasattr(module, "set_processor"):
|
| 739 |
+
if not isinstance(processor, dict):
|
| 740 |
+
module.set_processor(processor)
|
| 741 |
+
else:
|
| 742 |
+
module.set_processor(processor.pop(f"{name}.processor"))
|
| 743 |
+
|
| 744 |
+
for sub_name, child in module.named_children():
|
| 745 |
+
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
| 746 |
+
|
| 747 |
+
for name, module in self.named_children():
|
| 748 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 749 |
+
|
| 750 |
+
def set_default_attn_processor(self):
|
| 751 |
+
"""
|
| 752 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 753 |
+
"""
|
| 754 |
+
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 755 |
+
processor = AttnAddedKVProcessor()
|
| 756 |
+
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 757 |
+
processor = AttnProcessor()
|
| 758 |
+
else:
|
| 759 |
+
raise ValueError(
|
| 760 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 761 |
+
)
|
| 762 |
+
|
| 763 |
+
self.set_attn_processor(processor)
|
| 764 |
+
|
| 765 |
+
def set_attention_slice(self, slice_size: Union[str, int, List[int]] = "auto"):
|
| 766 |
+
r"""
|
| 767 |
+
Enable sliced attention computation.
|
| 768 |
+
|
| 769 |
+
When this option is enabled, the attention module splits the input tensor in slices to compute attention in
|
| 770 |
+
several steps. This is useful for saving some memory in exchange for a small decrease in speed.
|
| 771 |
+
|
| 772 |
+
Args:
|
| 773 |
+
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
|
| 774 |
+
When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
|
| 775 |
+
`"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
|
| 776 |
+
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
|
| 777 |
+
must be a multiple of `slice_size`.
|
| 778 |
+
"""
|
| 779 |
+
sliceable_head_dims = []
|
| 780 |
+
|
| 781 |
+
def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
|
| 782 |
+
if hasattr(module, "set_attention_slice"):
|
| 783 |
+
sliceable_head_dims.append(module.sliceable_head_dim)
|
| 784 |
+
|
| 785 |
+
for child in module.children():
|
| 786 |
+
fn_recursive_retrieve_sliceable_dims(child)
|
| 787 |
+
|
| 788 |
+
# retrieve number of attention layers
|
| 789 |
+
for module in self.children():
|
| 790 |
+
fn_recursive_retrieve_sliceable_dims(module)
|
| 791 |
+
|
| 792 |
+
num_sliceable_layers = len(sliceable_head_dims)
|
| 793 |
+
|
| 794 |
+
if slice_size == "auto":
|
| 795 |
+
# half the attention head size is usually a good trade-off between
|
| 796 |
+
# speed and memory
|
| 797 |
+
slice_size = [dim // 2 for dim in sliceable_head_dims]
|
| 798 |
+
elif slice_size == "max":
|
| 799 |
+
# make smallest slice possible
|
| 800 |
+
slice_size = num_sliceable_layers * [1]
|
| 801 |
+
|
| 802 |
+
slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
|
| 803 |
+
|
| 804 |
+
if len(slice_size) != len(sliceable_head_dims):
|
| 805 |
+
raise ValueError(
|
| 806 |
+
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
|
| 807 |
+
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
|
| 808 |
+
)
|
| 809 |
+
|
| 810 |
+
for i in range(len(slice_size)):
|
| 811 |
+
size = slice_size[i]
|
| 812 |
+
dim = sliceable_head_dims[i]
|
| 813 |
+
if size is not None and size > dim:
|
| 814 |
+
raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
|
| 815 |
+
|
| 816 |
+
# Recursively walk through all the children.
|
| 817 |
+
# Any children which exposes the set_attention_slice method
|
| 818 |
+
# gets the message
|
| 819 |
+
def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
|
| 820 |
+
if hasattr(module, "set_attention_slice"):
|
| 821 |
+
module.set_attention_slice(slice_size.pop())
|
| 822 |
+
|
| 823 |
+
for child in module.children():
|
| 824 |
+
fn_recursive_set_attention_slice(child, slice_size)
|
| 825 |
+
|
| 826 |
+
reversed_slice_size = list(reversed(slice_size))
|
| 827 |
+
for module in self.children():
|
| 828 |
+
fn_recursive_set_attention_slice(module, reversed_slice_size)
|
| 829 |
+
|
| 830 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 831 |
+
if hasattr(module, "gradient_checkpointing"):
|
| 832 |
+
module.gradient_checkpointing = value
|
| 833 |
+
|
| 834 |
+
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float):
|
| 835 |
+
r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
|
| 836 |
+
|
| 837 |
+
The suffixes after the scaling factors represent the stage blocks where they are being applied.
|
| 838 |
+
|
| 839 |
+
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of values that
|
| 840 |
+
are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
|
| 841 |
+
|
| 842 |
+
Args:
|
| 843 |
+
s1 (`float`):
|
| 844 |
+
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
|
| 845 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 846 |
+
s2 (`float`):
|
| 847 |
+
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
|
| 848 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 849 |
+
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
|
| 850 |
+
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
|
| 851 |
+
"""
|
| 852 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 853 |
+
setattr(upsample_block, "s1", s1)
|
| 854 |
+
setattr(upsample_block, "s2", s2)
|
| 855 |
+
setattr(upsample_block, "b1", b1)
|
| 856 |
+
setattr(upsample_block, "b2", b2)
|
| 857 |
+
|
| 858 |
+
def disable_freeu(self):
|
| 859 |
+
"""Disables the FreeU mechanism."""
|
| 860 |
+
freeu_keys = {"s1", "s2", "b1", "b2"}
|
| 861 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 862 |
+
for k in freeu_keys:
|
| 863 |
+
if hasattr(upsample_block, k) or getattr(upsample_block, k, None) is not None:
|
| 864 |
+
setattr(upsample_block, k, None)
|
| 865 |
+
|
| 866 |
+
def fuse_qkv_projections(self):
|
| 867 |
+
"""
|
| 868 |
+
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
| 869 |
+
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
| 870 |
+
|
| 871 |
+
<Tip warning={true}>
|
| 872 |
+
|
| 873 |
+
This API is 🧪 experimental.
|
| 874 |
+
|
| 875 |
+
</Tip>
|
| 876 |
+
"""
|
| 877 |
+
self.original_attn_processors = None
|
| 878 |
+
|
| 879 |
+
for _, attn_processor in self.attn_processors.items():
|
| 880 |
+
if "Added" in str(attn_processor.__class__.__name__):
|
| 881 |
+
raise ValueError("`fuse_qkv_projections()` is not supported for models having added KV projections.")
|
| 882 |
+
|
| 883 |
+
self.original_attn_processors = self.attn_processors
|
| 884 |
+
|
| 885 |
+
for module in self.modules():
|
| 886 |
+
if isinstance(module, Attention):
|
| 887 |
+
module.fuse_projections(fuse=True)
|
| 888 |
+
|
| 889 |
+
def unfuse_qkv_projections(self):
|
| 890 |
+
"""Disables the fused QKV projection if enabled.
|
| 891 |
+
|
| 892 |
+
<Tip warning={true}>
|
| 893 |
+
|
| 894 |
+
This API is 🧪 experimental.
|
| 895 |
+
|
| 896 |
+
</Tip>
|
| 897 |
+
|
| 898 |
+
"""
|
| 899 |
+
if self.original_attn_processors is not None:
|
| 900 |
+
self.set_attn_processor(self.original_attn_processors)
|
| 901 |
+
|
| 902 |
+
def unload_lora(self):
|
| 903 |
+
"""Unloads LoRA weights."""
|
| 904 |
+
deprecate(
|
| 905 |
+
"unload_lora",
|
| 906 |
+
"0.28.0",
|
| 907 |
+
"Calling `unload_lora()` is deprecated and will be removed in a future version. Please install `peft` and then call `disable_adapters().",
|
| 908 |
+
)
|
| 909 |
+
for module in self.modules():
|
| 910 |
+
if hasattr(module, "set_lora_layer"):
|
| 911 |
+
module.set_lora_layer(None)
|
| 912 |
+
|
| 913 |
+
def get_time_embed(
|
| 914 |
+
self, sample: torch.Tensor, timestep: Union[torch.Tensor, float, int]
|
| 915 |
+
) -> Optional[torch.Tensor]:
|
| 916 |
+
timesteps = timestep
|
| 917 |
+
if not torch.is_tensor(timesteps):
|
| 918 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 919 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 920 |
+
is_mps = sample.device.type == "mps"
|
| 921 |
+
if isinstance(timestep, float):
|
| 922 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 923 |
+
else:
|
| 924 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 925 |
+
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
| 926 |
+
elif len(timesteps.shape) == 0:
|
| 927 |
+
timesteps = timesteps[None].to(sample.device)
|
| 928 |
+
|
| 929 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 930 |
+
timesteps = timesteps.expand(sample.shape[0])
|
| 931 |
+
|
| 932 |
+
t_emb = self.time_proj(timesteps)
|
| 933 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 934 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 935 |
+
# there might be better ways to encapsulate this.
|
| 936 |
+
t_emb = t_emb.to(dtype=sample.dtype)
|
| 937 |
+
return t_emb
|
| 938 |
+
|
| 939 |
+
def get_class_embed(self, sample: torch.Tensor, class_labels: Optional[torch.Tensor]) -> Optional[torch.Tensor]:
|
| 940 |
+
class_emb = None
|
| 941 |
+
if self.class_embedding is not None:
|
| 942 |
+
if class_labels is None:
|
| 943 |
+
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
| 944 |
+
|
| 945 |
+
if self.config.class_embed_type == "timestep":
|
| 946 |
+
class_labels = self.time_proj(class_labels)
|
| 947 |
+
|
| 948 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 949 |
+
# there might be better ways to encapsulate this.
|
| 950 |
+
class_labels = class_labels.to(dtype=sample.dtype)
|
| 951 |
+
|
| 952 |
+
class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
|
| 953 |
+
return class_emb
|
| 954 |
+
|
| 955 |
+
def get_aug_embed(
|
| 956 |
+
self, emb: torch.Tensor, encoder_hidden_states: torch.Tensor, added_cond_kwargs: Dict[str, Any]
|
| 957 |
+
) -> Optional[torch.Tensor]:
|
| 958 |
+
aug_emb = None
|
| 959 |
+
if self.config.addition_embed_type == "text":
|
| 960 |
+
aug_emb = self.add_embedding(encoder_hidden_states)
|
| 961 |
+
elif self.config.addition_embed_type == "text_image":
|
| 962 |
+
# Kandinsky 2.1 - style
|
| 963 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 964 |
+
raise ValueError(
|
| 965 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 966 |
+
)
|
| 967 |
+
|
| 968 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 969 |
+
text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
|
| 970 |
+
aug_emb = self.add_embedding(text_embs, image_embs)
|
| 971 |
+
elif self.config.addition_embed_type == "text_time":
|
| 972 |
+
# SDXL - style
|
| 973 |
+
if "text_embeds" not in added_cond_kwargs:
|
| 974 |
+
raise ValueError(
|
| 975 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
|
| 976 |
+
)
|
| 977 |
+
text_embeds = added_cond_kwargs.get("text_embeds")
|
| 978 |
+
if "time_ids" not in added_cond_kwargs:
|
| 979 |
+
raise ValueError(
|
| 980 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
|
| 981 |
+
)
|
| 982 |
+
time_ids = added_cond_kwargs.get("time_ids")
|
| 983 |
+
time_embeds = self.add_time_proj(time_ids.flatten())
|
| 984 |
+
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
|
| 985 |
+
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
|
| 986 |
+
add_embeds = add_embeds.to(emb.dtype)
|
| 987 |
+
aug_emb = self.add_embedding(add_embeds)
|
| 988 |
+
elif self.config.addition_embed_type == "image":
|
| 989 |
+
# Kandinsky 2.2 - style
|
| 990 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 991 |
+
raise ValueError(
|
| 992 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 993 |
+
)
|
| 994 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 995 |
+
aug_emb = self.add_embedding(image_embs)
|
| 996 |
+
elif self.config.addition_embed_type == "image_hint":
|
| 997 |
+
# Kandinsky 2.2 - style
|
| 998 |
+
if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
|
| 999 |
+
raise ValueError(
|
| 1000 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
|
| 1001 |
+
)
|
| 1002 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 1003 |
+
hint = added_cond_kwargs.get("hint")
|
| 1004 |
+
aug_emb = self.add_embedding(image_embs, hint)
|
| 1005 |
+
return aug_emb
|
| 1006 |
+
|
| 1007 |
+
def process_encoder_hidden_states(
|
| 1008 |
+
self, encoder_hidden_states: torch.Tensor, added_cond_kwargs: Dict[str, Any]
|
| 1009 |
+
) -> torch.Tensor:
|
| 1010 |
+
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
|
| 1011 |
+
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
|
| 1012 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
|
| 1013 |
+
# Kadinsky 2.1 - style
|
| 1014 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1015 |
+
raise ValueError(
|
| 1016 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1017 |
+
)
|
| 1018 |
+
|
| 1019 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1020 |
+
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
|
| 1021 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
|
| 1022 |
+
# Kandinsky 2.2 - style
|
| 1023 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1024 |
+
raise ValueError(
|
| 1025 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1026 |
+
)
|
| 1027 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1028 |
+
encoder_hidden_states = self.encoder_hid_proj(image_embeds)
|
| 1029 |
+
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "ip_image_proj":
|
| 1030 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1031 |
+
raise ValueError(
|
| 1032 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'ip_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1033 |
+
)
|
| 1034 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1035 |
+
image_embeds = self.encoder_hid_proj(image_embeds)
|
| 1036 |
+
encoder_hidden_states = (encoder_hidden_states, image_embeds)
|
| 1037 |
+
return encoder_hidden_states
|
| 1038 |
+
|
| 1039 |
+
def forward(
|
| 1040 |
+
self,
|
| 1041 |
+
sample: torch.FloatTensor,
|
| 1042 |
+
timestep: Union[torch.Tensor, float, int],
|
| 1043 |
+
encoder_hidden_states: torch.Tensor,
|
| 1044 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 1045 |
+
timestep_cond: Optional[torch.Tensor] = None,
|
| 1046 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1047 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 1048 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 1049 |
+
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 1050 |
+
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
| 1051 |
+
down_intrablock_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 1052 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 1053 |
+
return_dict: bool = True,
|
| 1054 |
+
down_block_add_samples: Optional[Tuple[torch.Tensor]] = None,
|
| 1055 |
+
mid_block_add_sample: Optional[Tuple[torch.Tensor]] = None,
|
| 1056 |
+
up_block_add_samples: Optional[Tuple[torch.Tensor]] = None,
|
| 1057 |
+
features_adapter: Optional[torch.Tensor] = None,
|
| 1058 |
+
) -> Union[UNet2DConditionOutput, Tuple]:
|
| 1059 |
+
r"""
|
| 1060 |
+
The [`UNet2DConditionModel`] forward method.
|
| 1061 |
+
|
| 1062 |
+
Args:
|
| 1063 |
+
sample (`torch.FloatTensor`):
|
| 1064 |
+
The noisy input tensor with the following shape `(batch, channel, height, width)`.
|
| 1065 |
+
timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
|
| 1066 |
+
encoder_hidden_states (`torch.FloatTensor`):
|
| 1067 |
+
The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
|
| 1068 |
+
class_labels (`torch.Tensor`, *optional*, defaults to `None`):
|
| 1069 |
+
Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
|
| 1070 |
+
timestep_cond: (`torch.Tensor`, *optional*, defaults to `None`):
|
| 1071 |
+
Conditional embeddings for timestep. If provided, the embeddings will be summed with the samples passed
|
| 1072 |
+
through the `self.time_embedding` layer to obtain the timestep embeddings.
|
| 1073 |
+
attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
|
| 1074 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 1075 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 1076 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 1077 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 1078 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 1079 |
+
`self.processor` in
|
| 1080 |
+
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 1081 |
+
added_cond_kwargs: (`dict`, *optional*):
|
| 1082 |
+
A kwargs dictionary containing additional embeddings that if specified are added to the embeddings that
|
| 1083 |
+
are passed along to the UNet blocks.
|
| 1084 |
+
down_block_additional_residuals: (`tuple` of `torch.Tensor`, *optional*):
|
| 1085 |
+
A tuple of tensors that if specified are added to the residuals of down unet blocks.
|
| 1086 |
+
mid_block_additional_residual: (`torch.Tensor`, *optional*):
|
| 1087 |
+
A tensor that if specified is added to the residual of the middle unet block.
|
| 1088 |
+
encoder_attention_mask (`torch.Tensor`):
|
| 1089 |
+
A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
|
| 1090 |
+
`True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
|
| 1091 |
+
which adds large negative values to the attention scores corresponding to "discard" tokens.
|
| 1092 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 1093 |
+
Whether or not to return a [`~models.unets.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
|
| 1094 |
+
tuple.
|
| 1095 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 1096 |
+
A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
|
| 1097 |
+
added_cond_kwargs: (`dict`, *optional*):
|
| 1098 |
+
A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
|
| 1099 |
+
are passed along to the UNet blocks.
|
| 1100 |
+
down_block_additional_residuals (`tuple` of `torch.Tensor`, *optional*):
|
| 1101 |
+
additional residuals to be added to UNet long skip connections from down blocks to up blocks for
|
| 1102 |
+
example from ControlNet side model(s)
|
| 1103 |
+
mid_block_additional_residual (`torch.Tensor`, *optional*):
|
| 1104 |
+
additional residual to be added to UNet mid block output, for example from ControlNet side model
|
| 1105 |
+
down_intrablock_additional_residuals (`tuple` of `torch.Tensor`, *optional*):
|
| 1106 |
+
additional residuals to be added within UNet down blocks, for example from T2I-Adapter side model(s)
|
| 1107 |
+
features_adapter (`torch.FloatTensor`, *optional*):
|
| 1108 |
+
(batch, channels, num_frames, height, width) adapter features tensor
|
| 1109 |
+
|
| 1110 |
+
Returns:
|
| 1111 |
+
[`~models.unets.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
| 1112 |
+
If `return_dict` is True, an [`~models.unets.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
|
| 1113 |
+
a `tuple` is returned where the first element is the sample tensor.
|
| 1114 |
+
"""
|
| 1115 |
+
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
| 1116 |
+
# The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
|
| 1117 |
+
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
| 1118 |
+
# on the fly if necessary.
|
| 1119 |
+
default_overall_up_factor = 2**self.num_upsamplers
|
| 1120 |
+
|
| 1121 |
+
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
| 1122 |
+
forward_upsample_size = False
|
| 1123 |
+
upsample_size = None
|
| 1124 |
+
|
| 1125 |
+
for dim in sample.shape[-2:]:
|
| 1126 |
+
if dim % default_overall_up_factor != 0:
|
| 1127 |
+
# Forward upsample size to force interpolation output size.
|
| 1128 |
+
forward_upsample_size = True
|
| 1129 |
+
break
|
| 1130 |
+
|
| 1131 |
+
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension
|
| 1132 |
+
# expects mask of shape:
|
| 1133 |
+
# [batch, key_tokens]
|
| 1134 |
+
# adds singleton query_tokens dimension:
|
| 1135 |
+
# [batch, 1, key_tokens]
|
| 1136 |
+
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
| 1137 |
+
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
| 1138 |
+
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
| 1139 |
+
if attention_mask is not None:
|
| 1140 |
+
# assume that mask is expressed as:
|
| 1141 |
+
# (1 = keep, 0 = discard)
|
| 1142 |
+
# convert mask into a bias that can be added to attention scores:
|
| 1143 |
+
# (keep = +0, discard = -10000.0)
|
| 1144 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 1145 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 1146 |
+
|
| 1147 |
+
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
| 1148 |
+
if encoder_attention_mask is not None:
|
| 1149 |
+
encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
|
| 1150 |
+
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
| 1151 |
+
|
| 1152 |
+
# 0. center input if necessary
|
| 1153 |
+
if self.config.center_input_sample:
|
| 1154 |
+
sample = 2 * sample - 1.0
|
| 1155 |
+
|
| 1156 |
+
# 1. time
|
| 1157 |
+
t_emb = self.get_time_embed(sample=sample, timestep=timestep)
|
| 1158 |
+
emb = self.time_embedding(t_emb, timestep_cond)
|
| 1159 |
+
aug_emb = None
|
| 1160 |
+
|
| 1161 |
+
class_emb = self.get_class_embed(sample=sample, class_labels=class_labels)
|
| 1162 |
+
if class_emb is not None:
|
| 1163 |
+
if self.config.class_embeddings_concat:
|
| 1164 |
+
emb = torch.cat([emb, class_emb], dim=-1)
|
| 1165 |
+
else:
|
| 1166 |
+
emb = emb + class_emb
|
| 1167 |
+
|
| 1168 |
+
aug_emb = self.get_aug_embed(
|
| 1169 |
+
emb=emb, encoder_hidden_states=encoder_hidden_states, added_cond_kwargs=added_cond_kwargs
|
| 1170 |
+
)
|
| 1171 |
+
if self.config.addition_embed_type == "image_hint":
|
| 1172 |
+
aug_emb, hint = aug_emb
|
| 1173 |
+
sample = torch.cat([sample, hint], dim=1)
|
| 1174 |
+
|
| 1175 |
+
emb = emb + aug_emb if aug_emb is not None else emb
|
| 1176 |
+
|
| 1177 |
+
if self.time_embed_act is not None:
|
| 1178 |
+
emb = self.time_embed_act(emb)
|
| 1179 |
+
|
| 1180 |
+
encoder_hidden_states = self.process_encoder_hidden_states(
|
| 1181 |
+
encoder_hidden_states=encoder_hidden_states, added_cond_kwargs=added_cond_kwargs
|
| 1182 |
+
)
|
| 1183 |
+
|
| 1184 |
+
# 2. pre-process
|
| 1185 |
+
sample = self.conv_in(sample)
|
| 1186 |
+
|
| 1187 |
+
# 2.5 GLIGEN position net
|
| 1188 |
+
if cross_attention_kwargs is not None and cross_attention_kwargs.get("gligen", None) is not None:
|
| 1189 |
+
cross_attention_kwargs = cross_attention_kwargs.copy()
|
| 1190 |
+
gligen_args = cross_attention_kwargs.pop("gligen")
|
| 1191 |
+
cross_attention_kwargs["gligen"] = {"objs": self.position_net(**gligen_args)}
|
| 1192 |
+
|
| 1193 |
+
# 3. down
|
| 1194 |
+
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
|
| 1195 |
+
if USE_PEFT_BACKEND:
|
| 1196 |
+
# weight the lora layers by setting `lora_scale` for each PEFT layer
|
| 1197 |
+
scale_lora_layers(self, lora_scale)
|
| 1198 |
+
|
| 1199 |
+
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
|
| 1200 |
+
# using new arg down_intrablock_additional_residuals for T2I-Adapters, to distinguish from controlnets
|
| 1201 |
+
is_adapter = down_intrablock_additional_residuals is not None
|
| 1202 |
+
# maintain backward compatibility for legacy usage, where
|
| 1203 |
+
# T2I-Adapter and ControlNet both use down_block_additional_residuals arg
|
| 1204 |
+
# but can only use one or the other
|
| 1205 |
+
is_brushnet = down_block_add_samples is not None and mid_block_add_sample is not None and up_block_add_samples is not None
|
| 1206 |
+
if not is_adapter and mid_block_additional_residual is None and down_block_additional_residuals is not None:
|
| 1207 |
+
deprecate(
|
| 1208 |
+
"T2I should not use down_block_additional_residuals",
|
| 1209 |
+
"1.3.0",
|
| 1210 |
+
"Passing intrablock residual connections with `down_block_additional_residuals` is deprecated \
|
| 1211 |
+
and will be removed in diffusers 1.3.0. `down_block_additional_residuals` should only be used \
|
| 1212 |
+
for ControlNet. Please make sure use `down_intrablock_additional_residuals` instead. ",
|
| 1213 |
+
standard_warn=False,
|
| 1214 |
+
)
|
| 1215 |
+
down_intrablock_additional_residuals = down_block_additional_residuals
|
| 1216 |
+
is_adapter = True
|
| 1217 |
+
|
| 1218 |
+
down_block_res_samples = (sample,)
|
| 1219 |
+
|
| 1220 |
+
if is_brushnet:
|
| 1221 |
+
sample = sample + down_block_add_samples.pop(0)
|
| 1222 |
+
|
| 1223 |
+
adapter_idx = 0
|
| 1224 |
+
for downsample_block in self.down_blocks:
|
| 1225 |
+
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
| 1226 |
+
# For t2i-adapter CrossAttnDownBlock2D
|
| 1227 |
+
additional_residuals = {}
|
| 1228 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 1229 |
+
additional_residuals["additional_residuals"] = down_intrablock_additional_residuals.pop(0)
|
| 1230 |
+
|
| 1231 |
+
if is_brushnet and len(down_block_add_samples)>0:
|
| 1232 |
+
additional_residuals["down_block_add_samples"] = [down_block_add_samples.pop(0)
|
| 1233 |
+
for _ in range(len(downsample_block.resnets)+(downsample_block.downsamplers !=None))]
|
| 1234 |
+
|
| 1235 |
+
sample, res_samples = downsample_block(
|
| 1236 |
+
hidden_states=sample,
|
| 1237 |
+
temb=emb,
|
| 1238 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1239 |
+
attention_mask=attention_mask,
|
| 1240 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1241 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1242 |
+
**additional_residuals,
|
| 1243 |
+
)
|
| 1244 |
+
else:
|
| 1245 |
+
additional_residuals = {}
|
| 1246 |
+
if is_brushnet and len(down_block_add_samples)>0:
|
| 1247 |
+
additional_residuals["down_block_add_samples"] = [down_block_add_samples.pop(0)
|
| 1248 |
+
for _ in range(len(downsample_block.resnets)+(downsample_block.downsamplers !=None))]
|
| 1249 |
+
|
| 1250 |
+
sample, res_samples = downsample_block(hidden_states=sample, temb=emb, scale=lora_scale, **additional_residuals)
|
| 1251 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 1252 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 1253 |
+
|
| 1254 |
+
if features_adapter is not None:
|
| 1255 |
+
sample += features_adapter[adapter_idx]
|
| 1256 |
+
adapter_idx += 1
|
| 1257 |
+
|
| 1258 |
+
down_block_res_samples += res_samples
|
| 1259 |
+
|
| 1260 |
+
if features_adapter is not None:
|
| 1261 |
+
assert len(features_adapter) == adapter_idx, "Wrong features_adapter"
|
| 1262 |
+
|
| 1263 |
+
if is_controlnet:
|
| 1264 |
+
new_down_block_res_samples = ()
|
| 1265 |
+
|
| 1266 |
+
for down_block_res_sample, down_block_additional_residual in zip(
|
| 1267 |
+
down_block_res_samples, down_block_additional_residuals
|
| 1268 |
+
):
|
| 1269 |
+
down_block_res_sample = down_block_res_sample + down_block_additional_residual
|
| 1270 |
+
new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
|
| 1271 |
+
|
| 1272 |
+
down_block_res_samples = new_down_block_res_samples
|
| 1273 |
+
|
| 1274 |
+
# 4. mid
|
| 1275 |
+
if self.mid_block is not None:
|
| 1276 |
+
if hasattr(self.mid_block, "has_cross_attention") and self.mid_block.has_cross_attention:
|
| 1277 |
+
sample = self.mid_block(
|
| 1278 |
+
sample,
|
| 1279 |
+
emb,
|
| 1280 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1281 |
+
attention_mask=attention_mask,
|
| 1282 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1283 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1284 |
+
)
|
| 1285 |
+
else:
|
| 1286 |
+
sample = self.mid_block(sample, emb)
|
| 1287 |
+
|
| 1288 |
+
# To support T2I-Adapter-XL
|
| 1289 |
+
if (
|
| 1290 |
+
is_adapter
|
| 1291 |
+
and len(down_intrablock_additional_residuals) > 0
|
| 1292 |
+
and sample.shape == down_intrablock_additional_residuals[0].shape
|
| 1293 |
+
):
|
| 1294 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 1295 |
+
|
| 1296 |
+
if is_controlnet:
|
| 1297 |
+
sample = sample + mid_block_additional_residual
|
| 1298 |
+
|
| 1299 |
+
if is_brushnet:
|
| 1300 |
+
sample = sample + mid_block_add_sample
|
| 1301 |
+
|
| 1302 |
+
# 5. up
|
| 1303 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 1304 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 1305 |
+
|
| 1306 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
| 1307 |
+
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
| 1308 |
+
|
| 1309 |
+
# if we have not reached the final block and need to forward the
|
| 1310 |
+
# upsample size, we do it here
|
| 1311 |
+
if not is_final_block and forward_upsample_size:
|
| 1312 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 1313 |
+
|
| 1314 |
+
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
| 1315 |
+
additional_residuals = {}
|
| 1316 |
+
if is_brushnet and len(up_block_add_samples)>0:
|
| 1317 |
+
additional_residuals["up_block_add_samples"] = [up_block_add_samples.pop(0)
|
| 1318 |
+
for _ in range(len(upsample_block.resnets)+(upsample_block.upsamplers !=None))]
|
| 1319 |
+
|
| 1320 |
+
sample = upsample_block(
|
| 1321 |
+
hidden_states=sample,
|
| 1322 |
+
temb=emb,
|
| 1323 |
+
res_hidden_states_tuple=res_samples,
|
| 1324 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1325 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1326 |
+
upsample_size=upsample_size,
|
| 1327 |
+
attention_mask=attention_mask,
|
| 1328 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1329 |
+
**additional_residuals,
|
| 1330 |
+
)
|
| 1331 |
+
else:
|
| 1332 |
+
additional_residuals = {}
|
| 1333 |
+
if is_brushnet and len(up_block_add_samples)>0:
|
| 1334 |
+
additional_residuals["up_block_add_samples"] = [up_block_add_samples.pop(0)
|
| 1335 |
+
for _ in range(len(upsample_block.resnets)+(upsample_block.upsamplers !=None))]
|
| 1336 |
+
|
| 1337 |
+
sample = upsample_block(
|
| 1338 |
+
hidden_states=sample,
|
| 1339 |
+
temb=emb,
|
| 1340 |
+
res_hidden_states_tuple=res_samples,
|
| 1341 |
+
upsample_size=upsample_size,
|
| 1342 |
+
scale=lora_scale,
|
| 1343 |
+
**additional_residuals,
|
| 1344 |
+
)
|
| 1345 |
+
|
| 1346 |
+
# 6. post-process
|
| 1347 |
+
if self.conv_norm_out:
|
| 1348 |
+
sample = self.conv_norm_out(sample)
|
| 1349 |
+
sample = self.conv_act(sample)
|
| 1350 |
+
sample = self.conv_out(sample)
|
| 1351 |
+
|
| 1352 |
+
if USE_PEFT_BACKEND:
|
| 1353 |
+
# remove `lora_scale` from each PEFT layer
|
| 1354 |
+
unscale_lora_layers(self, lora_scale)
|
| 1355 |
+
|
| 1356 |
+
if not return_dict:
|
| 1357 |
+
return (sample,)
|
| 1358 |
+
|
| 1359 |
+
return UNet2DConditionOutput(sample=sample)
|
libs/unet_3d_blocks.py
ADDED
|
@@ -0,0 +1,2463 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
from typing import Any, Dict, Optional, Tuple, Union
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
from torch import nn
|
| 19 |
+
|
| 20 |
+
from diffusers.utils import is_torch_version
|
| 21 |
+
from diffusers.utils.torch_utils import apply_freeu
|
| 22 |
+
from diffusers.models.attention import Attention
|
| 23 |
+
from diffusers.models.transformers.dual_transformer_2d import DualTransformer2DModel
|
| 24 |
+
from diffusers.models.resnet import (
|
| 25 |
+
Downsample2D,
|
| 26 |
+
ResnetBlock2D,
|
| 27 |
+
SpatioTemporalResBlock,
|
| 28 |
+
TemporalConvLayer,
|
| 29 |
+
Upsample2D,
|
| 30 |
+
)
|
| 31 |
+
from diffusers.models.transformers.transformer_2d import Transformer2DModel
|
| 32 |
+
from diffusers.models.transformers.transformer_temporal import (
|
| 33 |
+
TransformerSpatioTemporalModel,
|
| 34 |
+
)
|
| 35 |
+
from libs.transformer_temporal import TransformerTemporalModel
|
| 36 |
+
|
| 37 |
+
def get_down_block(
|
| 38 |
+
down_block_type: str,
|
| 39 |
+
num_layers: int,
|
| 40 |
+
in_channels: int,
|
| 41 |
+
out_channels: int,
|
| 42 |
+
temb_channels: int,
|
| 43 |
+
add_downsample: bool,
|
| 44 |
+
resnet_eps: float,
|
| 45 |
+
resnet_act_fn: str,
|
| 46 |
+
num_attention_heads: int,
|
| 47 |
+
resnet_groups: Optional[int] = None,
|
| 48 |
+
cross_attention_dim: Optional[int] = None,
|
| 49 |
+
downsample_padding: Optional[int] = None,
|
| 50 |
+
dual_cross_attention: bool = False,
|
| 51 |
+
use_linear_projection: bool = True,
|
| 52 |
+
only_cross_attention: bool = False,
|
| 53 |
+
upcast_attention: bool = False,
|
| 54 |
+
resnet_time_scale_shift: str = "default",
|
| 55 |
+
temporal_num_attention_heads: int = 8,
|
| 56 |
+
temporal_max_seq_length: int = 32,
|
| 57 |
+
transformer_layers_per_block: int = 1,
|
| 58 |
+
) -> Union[
|
| 59 |
+
"DownBlock3D",
|
| 60 |
+
"CrossAttnDownBlock3D",
|
| 61 |
+
"DownBlockMotion",
|
| 62 |
+
"CrossAttnDownBlockMotion",
|
| 63 |
+
"DownBlockSpatioTemporal",
|
| 64 |
+
"CrossAttnDownBlockSpatioTemporal",
|
| 65 |
+
]:
|
| 66 |
+
if down_block_type == "DownBlock3D":
|
| 67 |
+
return DownBlock3D(
|
| 68 |
+
num_layers=num_layers,
|
| 69 |
+
in_channels=in_channels,
|
| 70 |
+
out_channels=out_channels,
|
| 71 |
+
temb_channels=temb_channels,
|
| 72 |
+
add_downsample=add_downsample,
|
| 73 |
+
resnet_eps=resnet_eps,
|
| 74 |
+
resnet_act_fn=resnet_act_fn,
|
| 75 |
+
resnet_groups=resnet_groups,
|
| 76 |
+
downsample_padding=downsample_padding,
|
| 77 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 78 |
+
)
|
| 79 |
+
elif down_block_type == "CrossAttnDownBlock3D":
|
| 80 |
+
if cross_attention_dim is None:
|
| 81 |
+
raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlock3D")
|
| 82 |
+
return CrossAttnDownBlock3D(
|
| 83 |
+
num_layers=num_layers,
|
| 84 |
+
in_channels=in_channels,
|
| 85 |
+
out_channels=out_channels,
|
| 86 |
+
temb_channels=temb_channels,
|
| 87 |
+
add_downsample=add_downsample,
|
| 88 |
+
resnet_eps=resnet_eps,
|
| 89 |
+
resnet_act_fn=resnet_act_fn,
|
| 90 |
+
resnet_groups=resnet_groups,
|
| 91 |
+
downsample_padding=downsample_padding,
|
| 92 |
+
cross_attention_dim=cross_attention_dim,
|
| 93 |
+
num_attention_heads=num_attention_heads,
|
| 94 |
+
dual_cross_attention=dual_cross_attention,
|
| 95 |
+
use_linear_projection=use_linear_projection,
|
| 96 |
+
only_cross_attention=only_cross_attention,
|
| 97 |
+
upcast_attention=upcast_attention,
|
| 98 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 99 |
+
)
|
| 100 |
+
if down_block_type == "DownBlockMotion":
|
| 101 |
+
return DownBlockMotion(
|
| 102 |
+
num_layers=num_layers,
|
| 103 |
+
in_channels=in_channels,
|
| 104 |
+
out_channels=out_channels,
|
| 105 |
+
temb_channels=temb_channels,
|
| 106 |
+
add_downsample=add_downsample,
|
| 107 |
+
resnet_eps=resnet_eps,
|
| 108 |
+
resnet_act_fn=resnet_act_fn,
|
| 109 |
+
resnet_groups=resnet_groups,
|
| 110 |
+
downsample_padding=downsample_padding,
|
| 111 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 112 |
+
temporal_num_attention_heads=temporal_num_attention_heads,
|
| 113 |
+
temporal_max_seq_length=temporal_max_seq_length,
|
| 114 |
+
)
|
| 115 |
+
elif down_block_type == "CrossAttnDownBlockMotion":
|
| 116 |
+
if cross_attention_dim is None:
|
| 117 |
+
raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlockMotion")
|
| 118 |
+
return CrossAttnDownBlockMotion(
|
| 119 |
+
num_layers=num_layers,
|
| 120 |
+
in_channels=in_channels,
|
| 121 |
+
out_channels=out_channels,
|
| 122 |
+
temb_channels=temb_channels,
|
| 123 |
+
add_downsample=add_downsample,
|
| 124 |
+
resnet_eps=resnet_eps,
|
| 125 |
+
resnet_act_fn=resnet_act_fn,
|
| 126 |
+
resnet_groups=resnet_groups,
|
| 127 |
+
downsample_padding=downsample_padding,
|
| 128 |
+
cross_attention_dim=cross_attention_dim,
|
| 129 |
+
num_attention_heads=num_attention_heads,
|
| 130 |
+
dual_cross_attention=dual_cross_attention,
|
| 131 |
+
use_linear_projection=use_linear_projection,
|
| 132 |
+
only_cross_attention=only_cross_attention,
|
| 133 |
+
upcast_attention=upcast_attention,
|
| 134 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 135 |
+
temporal_num_attention_heads=temporal_num_attention_heads,
|
| 136 |
+
temporal_max_seq_length=temporal_max_seq_length,
|
| 137 |
+
)
|
| 138 |
+
elif down_block_type == "DownBlockSpatioTemporal":
|
| 139 |
+
# added for SDV
|
| 140 |
+
return DownBlockSpatioTemporal(
|
| 141 |
+
num_layers=num_layers,
|
| 142 |
+
in_channels=in_channels,
|
| 143 |
+
out_channels=out_channels,
|
| 144 |
+
temb_channels=temb_channels,
|
| 145 |
+
add_downsample=add_downsample,
|
| 146 |
+
)
|
| 147 |
+
elif down_block_type == "CrossAttnDownBlockSpatioTemporal":
|
| 148 |
+
# added for SDV
|
| 149 |
+
if cross_attention_dim is None:
|
| 150 |
+
raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlockSpatioTemporal")
|
| 151 |
+
return CrossAttnDownBlockSpatioTemporal(
|
| 152 |
+
in_channels=in_channels,
|
| 153 |
+
out_channels=out_channels,
|
| 154 |
+
temb_channels=temb_channels,
|
| 155 |
+
num_layers=num_layers,
|
| 156 |
+
transformer_layers_per_block=transformer_layers_per_block,
|
| 157 |
+
add_downsample=add_downsample,
|
| 158 |
+
cross_attention_dim=cross_attention_dim,
|
| 159 |
+
num_attention_heads=num_attention_heads,
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
raise ValueError(f"{down_block_type} does not exist.")
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
def get_up_block(
|
| 166 |
+
up_block_type: str,
|
| 167 |
+
num_layers: int,
|
| 168 |
+
in_channels: int,
|
| 169 |
+
out_channels: int,
|
| 170 |
+
prev_output_channel: int,
|
| 171 |
+
temb_channels: int,
|
| 172 |
+
add_upsample: bool,
|
| 173 |
+
resnet_eps: float,
|
| 174 |
+
resnet_act_fn: str,
|
| 175 |
+
num_attention_heads: int,
|
| 176 |
+
resolution_idx: Optional[int] = None,
|
| 177 |
+
resnet_groups: Optional[int] = None,
|
| 178 |
+
cross_attention_dim: Optional[int] = None,
|
| 179 |
+
dual_cross_attention: bool = False,
|
| 180 |
+
use_linear_projection: bool = True,
|
| 181 |
+
only_cross_attention: bool = False,
|
| 182 |
+
upcast_attention: bool = False,
|
| 183 |
+
resnet_time_scale_shift: str = "default",
|
| 184 |
+
temporal_num_attention_heads: int = 8,
|
| 185 |
+
temporal_cross_attention_dim: Optional[int] = None,
|
| 186 |
+
temporal_max_seq_length: int = 32,
|
| 187 |
+
transformer_layers_per_block: int = 1,
|
| 188 |
+
dropout: float = 0.0,
|
| 189 |
+
) -> Union[
|
| 190 |
+
"UpBlock3D",
|
| 191 |
+
"CrossAttnUpBlock3D",
|
| 192 |
+
"UpBlockMotion",
|
| 193 |
+
"CrossAttnUpBlockMotion",
|
| 194 |
+
"UpBlockSpatioTemporal",
|
| 195 |
+
"CrossAttnUpBlockSpatioTemporal",
|
| 196 |
+
]:
|
| 197 |
+
if up_block_type == "UpBlock3D":
|
| 198 |
+
return UpBlock3D(
|
| 199 |
+
num_layers=num_layers,
|
| 200 |
+
in_channels=in_channels,
|
| 201 |
+
out_channels=out_channels,
|
| 202 |
+
prev_output_channel=prev_output_channel,
|
| 203 |
+
temb_channels=temb_channels,
|
| 204 |
+
add_upsample=add_upsample,
|
| 205 |
+
resnet_eps=resnet_eps,
|
| 206 |
+
resnet_act_fn=resnet_act_fn,
|
| 207 |
+
resnet_groups=resnet_groups,
|
| 208 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 209 |
+
resolution_idx=resolution_idx,
|
| 210 |
+
)
|
| 211 |
+
elif up_block_type == "CrossAttnUpBlock3D":
|
| 212 |
+
if cross_attention_dim is None:
|
| 213 |
+
raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock3D")
|
| 214 |
+
return CrossAttnUpBlock3D(
|
| 215 |
+
num_layers=num_layers,
|
| 216 |
+
in_channels=in_channels,
|
| 217 |
+
out_channels=out_channels,
|
| 218 |
+
prev_output_channel=prev_output_channel,
|
| 219 |
+
temb_channels=temb_channels,
|
| 220 |
+
add_upsample=add_upsample,
|
| 221 |
+
resnet_eps=resnet_eps,
|
| 222 |
+
resnet_act_fn=resnet_act_fn,
|
| 223 |
+
resnet_groups=resnet_groups,
|
| 224 |
+
cross_attention_dim=cross_attention_dim,
|
| 225 |
+
num_attention_heads=num_attention_heads,
|
| 226 |
+
dual_cross_attention=dual_cross_attention,
|
| 227 |
+
use_linear_projection=use_linear_projection,
|
| 228 |
+
only_cross_attention=only_cross_attention,
|
| 229 |
+
upcast_attention=upcast_attention,
|
| 230 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 231 |
+
resolution_idx=resolution_idx,
|
| 232 |
+
)
|
| 233 |
+
if up_block_type == "UpBlockMotion":
|
| 234 |
+
return UpBlockMotion(
|
| 235 |
+
num_layers=num_layers,
|
| 236 |
+
in_channels=in_channels,
|
| 237 |
+
out_channels=out_channels,
|
| 238 |
+
prev_output_channel=prev_output_channel,
|
| 239 |
+
temb_channels=temb_channels,
|
| 240 |
+
add_upsample=add_upsample,
|
| 241 |
+
resnet_eps=resnet_eps,
|
| 242 |
+
resnet_act_fn=resnet_act_fn,
|
| 243 |
+
resnet_groups=resnet_groups,
|
| 244 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 245 |
+
resolution_idx=resolution_idx,
|
| 246 |
+
temporal_num_attention_heads=temporal_num_attention_heads,
|
| 247 |
+
temporal_max_seq_length=temporal_max_seq_length,
|
| 248 |
+
)
|
| 249 |
+
elif up_block_type == "CrossAttnUpBlockMotion":
|
| 250 |
+
if cross_attention_dim is None:
|
| 251 |
+
raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlockMotion")
|
| 252 |
+
return CrossAttnUpBlockMotion(
|
| 253 |
+
num_layers=num_layers,
|
| 254 |
+
in_channels=in_channels,
|
| 255 |
+
out_channels=out_channels,
|
| 256 |
+
prev_output_channel=prev_output_channel,
|
| 257 |
+
temb_channels=temb_channels,
|
| 258 |
+
add_upsample=add_upsample,
|
| 259 |
+
resnet_eps=resnet_eps,
|
| 260 |
+
resnet_act_fn=resnet_act_fn,
|
| 261 |
+
resnet_groups=resnet_groups,
|
| 262 |
+
cross_attention_dim=cross_attention_dim,
|
| 263 |
+
num_attention_heads=num_attention_heads,
|
| 264 |
+
dual_cross_attention=dual_cross_attention,
|
| 265 |
+
use_linear_projection=use_linear_projection,
|
| 266 |
+
only_cross_attention=only_cross_attention,
|
| 267 |
+
upcast_attention=upcast_attention,
|
| 268 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 269 |
+
resolution_idx=resolution_idx,
|
| 270 |
+
temporal_num_attention_heads=temporal_num_attention_heads,
|
| 271 |
+
temporal_max_seq_length=temporal_max_seq_length,
|
| 272 |
+
)
|
| 273 |
+
elif up_block_type == "UpBlockSpatioTemporal":
|
| 274 |
+
# added for SDV
|
| 275 |
+
return UpBlockSpatioTemporal(
|
| 276 |
+
num_layers=num_layers,
|
| 277 |
+
in_channels=in_channels,
|
| 278 |
+
out_channels=out_channels,
|
| 279 |
+
prev_output_channel=prev_output_channel,
|
| 280 |
+
temb_channels=temb_channels,
|
| 281 |
+
resolution_idx=resolution_idx,
|
| 282 |
+
add_upsample=add_upsample,
|
| 283 |
+
)
|
| 284 |
+
elif up_block_type == "CrossAttnUpBlockSpatioTemporal":
|
| 285 |
+
# added for SDV
|
| 286 |
+
if cross_attention_dim is None:
|
| 287 |
+
raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlockSpatioTemporal")
|
| 288 |
+
return CrossAttnUpBlockSpatioTemporal(
|
| 289 |
+
in_channels=in_channels,
|
| 290 |
+
out_channels=out_channels,
|
| 291 |
+
prev_output_channel=prev_output_channel,
|
| 292 |
+
temb_channels=temb_channels,
|
| 293 |
+
num_layers=num_layers,
|
| 294 |
+
transformer_layers_per_block=transformer_layers_per_block,
|
| 295 |
+
add_upsample=add_upsample,
|
| 296 |
+
cross_attention_dim=cross_attention_dim,
|
| 297 |
+
num_attention_heads=num_attention_heads,
|
| 298 |
+
resolution_idx=resolution_idx,
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
raise ValueError(f"{up_block_type} does not exist.")
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
class UNetMidBlock3DCrossAttn(nn.Module):
|
| 305 |
+
def __init__(
|
| 306 |
+
self,
|
| 307 |
+
in_channels: int,
|
| 308 |
+
temb_channels: int,
|
| 309 |
+
dropout: float = 0.0,
|
| 310 |
+
num_layers: int = 1,
|
| 311 |
+
resnet_eps: float = 1e-6,
|
| 312 |
+
resnet_time_scale_shift: str = "default",
|
| 313 |
+
resnet_act_fn: str = "swish",
|
| 314 |
+
resnet_groups: int = 32,
|
| 315 |
+
resnet_pre_norm: bool = True,
|
| 316 |
+
num_attention_heads: int = 1,
|
| 317 |
+
output_scale_factor: float = 1.0,
|
| 318 |
+
cross_attention_dim: int = 1280,
|
| 319 |
+
dual_cross_attention: bool = False,
|
| 320 |
+
use_linear_projection: bool = True,
|
| 321 |
+
upcast_attention: bool = False,
|
| 322 |
+
):
|
| 323 |
+
super().__init__()
|
| 324 |
+
|
| 325 |
+
self.has_cross_attention = True
|
| 326 |
+
self.num_attention_heads = num_attention_heads
|
| 327 |
+
resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
|
| 328 |
+
|
| 329 |
+
# there is always at least one resnet
|
| 330 |
+
resnets = [
|
| 331 |
+
ResnetBlock2D(
|
| 332 |
+
in_channels=in_channels,
|
| 333 |
+
out_channels=in_channels,
|
| 334 |
+
temb_channels=temb_channels,
|
| 335 |
+
eps=resnet_eps,
|
| 336 |
+
groups=resnet_groups,
|
| 337 |
+
dropout=dropout,
|
| 338 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 339 |
+
non_linearity=resnet_act_fn,
|
| 340 |
+
output_scale_factor=output_scale_factor,
|
| 341 |
+
pre_norm=resnet_pre_norm,
|
| 342 |
+
)
|
| 343 |
+
]
|
| 344 |
+
temp_convs = [
|
| 345 |
+
TemporalConvLayer(
|
| 346 |
+
in_channels,
|
| 347 |
+
in_channels,
|
| 348 |
+
dropout=0.1,
|
| 349 |
+
norm_num_groups=resnet_groups,
|
| 350 |
+
)
|
| 351 |
+
]
|
| 352 |
+
attentions = []
|
| 353 |
+
temp_attentions = []
|
| 354 |
+
|
| 355 |
+
for _ in range(num_layers):
|
| 356 |
+
attentions.append(
|
| 357 |
+
Transformer2DModel(
|
| 358 |
+
in_channels // num_attention_heads,
|
| 359 |
+
num_attention_heads,
|
| 360 |
+
in_channels=in_channels,
|
| 361 |
+
num_layers=1,
|
| 362 |
+
cross_attention_dim=cross_attention_dim,
|
| 363 |
+
norm_num_groups=resnet_groups,
|
| 364 |
+
use_linear_projection=use_linear_projection,
|
| 365 |
+
upcast_attention=upcast_attention,
|
| 366 |
+
)
|
| 367 |
+
)
|
| 368 |
+
temp_attentions.append(
|
| 369 |
+
TransformerTemporalModel(
|
| 370 |
+
in_channels // num_attention_heads,
|
| 371 |
+
num_attention_heads,
|
| 372 |
+
in_channels=in_channels,
|
| 373 |
+
num_layers=1,
|
| 374 |
+
cross_attention_dim=cross_attention_dim,
|
| 375 |
+
norm_num_groups=resnet_groups,
|
| 376 |
+
)
|
| 377 |
+
)
|
| 378 |
+
resnets.append(
|
| 379 |
+
ResnetBlock2D(
|
| 380 |
+
in_channels=in_channels,
|
| 381 |
+
out_channels=in_channels,
|
| 382 |
+
temb_channels=temb_channels,
|
| 383 |
+
eps=resnet_eps,
|
| 384 |
+
groups=resnet_groups,
|
| 385 |
+
dropout=dropout,
|
| 386 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 387 |
+
non_linearity=resnet_act_fn,
|
| 388 |
+
output_scale_factor=output_scale_factor,
|
| 389 |
+
pre_norm=resnet_pre_norm,
|
| 390 |
+
)
|
| 391 |
+
)
|
| 392 |
+
temp_convs.append(
|
| 393 |
+
TemporalConvLayer(
|
| 394 |
+
in_channels,
|
| 395 |
+
in_channels,
|
| 396 |
+
dropout=0.1,
|
| 397 |
+
norm_num_groups=resnet_groups,
|
| 398 |
+
)
|
| 399 |
+
)
|
| 400 |
+
|
| 401 |
+
self.resnets = nn.ModuleList(resnets)
|
| 402 |
+
self.temp_convs = nn.ModuleList(temp_convs)
|
| 403 |
+
self.attentions = nn.ModuleList(attentions)
|
| 404 |
+
self.temp_attentions = nn.ModuleList(temp_attentions)
|
| 405 |
+
|
| 406 |
+
def forward(
|
| 407 |
+
self,
|
| 408 |
+
hidden_states: torch.FloatTensor,
|
| 409 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 410 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 411 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 412 |
+
num_frames: int = 1,
|
| 413 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 414 |
+
) -> torch.FloatTensor:
|
| 415 |
+
hidden_states = self.resnets[0](hidden_states, temb)
|
| 416 |
+
hidden_states = self.temp_convs[0](hidden_states, num_frames=num_frames)
|
| 417 |
+
for attn, temp_attn, resnet, temp_conv in zip(
|
| 418 |
+
self.attentions, self.temp_attentions, self.resnets[1:], self.temp_convs[1:]
|
| 419 |
+
):
|
| 420 |
+
hidden_states = attn(
|
| 421 |
+
hidden_states,
|
| 422 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 423 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 424 |
+
return_dict=False,
|
| 425 |
+
)[0]
|
| 426 |
+
hidden_states = temp_attn(
|
| 427 |
+
hidden_states,
|
| 428 |
+
num_frames=num_frames,
|
| 429 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 430 |
+
return_dict=False,
|
| 431 |
+
)[0]
|
| 432 |
+
hidden_states = resnet(hidden_states, temb)
|
| 433 |
+
hidden_states = temp_conv(hidden_states, num_frames=num_frames)
|
| 434 |
+
|
| 435 |
+
return hidden_states
|
| 436 |
+
|
| 437 |
+
|
| 438 |
+
class CrossAttnDownBlock3D(nn.Module):
|
| 439 |
+
def __init__(
|
| 440 |
+
self,
|
| 441 |
+
in_channels: int,
|
| 442 |
+
out_channels: int,
|
| 443 |
+
temb_channels: int,
|
| 444 |
+
dropout: float = 0.0,
|
| 445 |
+
num_layers: int = 1,
|
| 446 |
+
resnet_eps: float = 1e-6,
|
| 447 |
+
resnet_time_scale_shift: str = "default",
|
| 448 |
+
resnet_act_fn: str = "swish",
|
| 449 |
+
resnet_groups: int = 32,
|
| 450 |
+
resnet_pre_norm: bool = True,
|
| 451 |
+
num_attention_heads: int = 1,
|
| 452 |
+
cross_attention_dim: int = 1280,
|
| 453 |
+
output_scale_factor: float = 1.0,
|
| 454 |
+
downsample_padding: int = 1,
|
| 455 |
+
add_downsample: bool = True,
|
| 456 |
+
dual_cross_attention: bool = False,
|
| 457 |
+
use_linear_projection: bool = False,
|
| 458 |
+
only_cross_attention: bool = False,
|
| 459 |
+
upcast_attention: bool = False,
|
| 460 |
+
):
|
| 461 |
+
super().__init__()
|
| 462 |
+
resnets = []
|
| 463 |
+
attentions = []
|
| 464 |
+
temp_attentions = []
|
| 465 |
+
temp_convs = []
|
| 466 |
+
|
| 467 |
+
self.has_cross_attention = True
|
| 468 |
+
self.num_attention_heads = num_attention_heads
|
| 469 |
+
|
| 470 |
+
for i in range(num_layers):
|
| 471 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 472 |
+
resnets.append(
|
| 473 |
+
ResnetBlock2D(
|
| 474 |
+
in_channels=in_channels,
|
| 475 |
+
out_channels=out_channels,
|
| 476 |
+
temb_channels=temb_channels,
|
| 477 |
+
eps=resnet_eps,
|
| 478 |
+
groups=resnet_groups,
|
| 479 |
+
dropout=dropout,
|
| 480 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 481 |
+
non_linearity=resnet_act_fn,
|
| 482 |
+
output_scale_factor=output_scale_factor,
|
| 483 |
+
pre_norm=resnet_pre_norm,
|
| 484 |
+
)
|
| 485 |
+
)
|
| 486 |
+
temp_convs.append(
|
| 487 |
+
TemporalConvLayer(
|
| 488 |
+
out_channels,
|
| 489 |
+
out_channels,
|
| 490 |
+
dropout=0.1,
|
| 491 |
+
norm_num_groups=resnet_groups,
|
| 492 |
+
)
|
| 493 |
+
)
|
| 494 |
+
attentions.append(
|
| 495 |
+
Transformer2DModel(
|
| 496 |
+
out_channels // num_attention_heads,
|
| 497 |
+
num_attention_heads,
|
| 498 |
+
in_channels=out_channels,
|
| 499 |
+
num_layers=1,
|
| 500 |
+
cross_attention_dim=cross_attention_dim,
|
| 501 |
+
norm_num_groups=resnet_groups,
|
| 502 |
+
use_linear_projection=use_linear_projection,
|
| 503 |
+
only_cross_attention=only_cross_attention,
|
| 504 |
+
upcast_attention=upcast_attention,
|
| 505 |
+
)
|
| 506 |
+
)
|
| 507 |
+
temp_attentions.append(
|
| 508 |
+
TransformerTemporalModel(
|
| 509 |
+
out_channels // num_attention_heads,
|
| 510 |
+
num_attention_heads,
|
| 511 |
+
in_channels=out_channels,
|
| 512 |
+
num_layers=1,
|
| 513 |
+
cross_attention_dim=cross_attention_dim,
|
| 514 |
+
norm_num_groups=resnet_groups,
|
| 515 |
+
)
|
| 516 |
+
)
|
| 517 |
+
self.resnets = nn.ModuleList(resnets)
|
| 518 |
+
self.temp_convs = nn.ModuleList(temp_convs)
|
| 519 |
+
self.attentions = nn.ModuleList(attentions)
|
| 520 |
+
self.temp_attentions = nn.ModuleList(temp_attentions)
|
| 521 |
+
|
| 522 |
+
if add_downsample:
|
| 523 |
+
self.downsamplers = nn.ModuleList(
|
| 524 |
+
[
|
| 525 |
+
Downsample2D(
|
| 526 |
+
out_channels,
|
| 527 |
+
use_conv=True,
|
| 528 |
+
out_channels=out_channels,
|
| 529 |
+
padding=downsample_padding,
|
| 530 |
+
name="op",
|
| 531 |
+
)
|
| 532 |
+
]
|
| 533 |
+
)
|
| 534 |
+
else:
|
| 535 |
+
self.downsamplers = None
|
| 536 |
+
|
| 537 |
+
self.gradient_checkpointing = False
|
| 538 |
+
|
| 539 |
+
def forward(
|
| 540 |
+
self,
|
| 541 |
+
hidden_states: torch.FloatTensor,
|
| 542 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 543 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 544 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 545 |
+
num_frames: int = 1,
|
| 546 |
+
cross_attention_kwargs: Dict[str, Any] = None,
|
| 547 |
+
) -> Union[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
|
| 548 |
+
# TODO(Patrick, William) - attention mask is not used
|
| 549 |
+
output_states = ()
|
| 550 |
+
|
| 551 |
+
for resnet, temp_conv, attn, temp_attn in zip(
|
| 552 |
+
self.resnets, self.temp_convs, self.attentions, self.temp_attentions
|
| 553 |
+
):
|
| 554 |
+
hidden_states = resnet(hidden_states, temb)
|
| 555 |
+
hidden_states = temp_conv(hidden_states, num_frames=num_frames)
|
| 556 |
+
hidden_states = attn(
|
| 557 |
+
hidden_states,
|
| 558 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 559 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 560 |
+
return_dict=False,
|
| 561 |
+
)[0]
|
| 562 |
+
hidden_states = temp_attn(
|
| 563 |
+
hidden_states,
|
| 564 |
+
num_frames=num_frames,
|
| 565 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 566 |
+
return_dict=False,
|
| 567 |
+
)[0]
|
| 568 |
+
|
| 569 |
+
output_states += (hidden_states,)
|
| 570 |
+
|
| 571 |
+
if self.downsamplers is not None:
|
| 572 |
+
for downsampler in self.downsamplers:
|
| 573 |
+
hidden_states = downsampler(hidden_states)
|
| 574 |
+
|
| 575 |
+
output_states += (hidden_states,)
|
| 576 |
+
|
| 577 |
+
return hidden_states, output_states
|
| 578 |
+
|
| 579 |
+
|
| 580 |
+
class DownBlock3D(nn.Module):
|
| 581 |
+
def __init__(
|
| 582 |
+
self,
|
| 583 |
+
in_channels: int,
|
| 584 |
+
out_channels: int,
|
| 585 |
+
temb_channels: int,
|
| 586 |
+
dropout: float = 0.0,
|
| 587 |
+
num_layers: int = 1,
|
| 588 |
+
resnet_eps: float = 1e-6,
|
| 589 |
+
resnet_time_scale_shift: str = "default",
|
| 590 |
+
resnet_act_fn: str = "swish",
|
| 591 |
+
resnet_groups: int = 32,
|
| 592 |
+
resnet_pre_norm: bool = True,
|
| 593 |
+
output_scale_factor: float = 1.0,
|
| 594 |
+
add_downsample: bool = True,
|
| 595 |
+
downsample_padding: int = 1,
|
| 596 |
+
):
|
| 597 |
+
super().__init__()
|
| 598 |
+
resnets = []
|
| 599 |
+
temp_convs = []
|
| 600 |
+
|
| 601 |
+
for i in range(num_layers):
|
| 602 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 603 |
+
resnets.append(
|
| 604 |
+
ResnetBlock2D(
|
| 605 |
+
in_channels=in_channels,
|
| 606 |
+
out_channels=out_channels,
|
| 607 |
+
temb_channels=temb_channels,
|
| 608 |
+
eps=resnet_eps,
|
| 609 |
+
groups=resnet_groups,
|
| 610 |
+
dropout=dropout,
|
| 611 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 612 |
+
non_linearity=resnet_act_fn,
|
| 613 |
+
output_scale_factor=output_scale_factor,
|
| 614 |
+
pre_norm=resnet_pre_norm,
|
| 615 |
+
)
|
| 616 |
+
)
|
| 617 |
+
temp_convs.append(
|
| 618 |
+
TemporalConvLayer(
|
| 619 |
+
out_channels,
|
| 620 |
+
out_channels,
|
| 621 |
+
dropout=0.1,
|
| 622 |
+
norm_num_groups=resnet_groups,
|
| 623 |
+
)
|
| 624 |
+
)
|
| 625 |
+
|
| 626 |
+
self.resnets = nn.ModuleList(resnets)
|
| 627 |
+
self.temp_convs = nn.ModuleList(temp_convs)
|
| 628 |
+
|
| 629 |
+
if add_downsample:
|
| 630 |
+
self.downsamplers = nn.ModuleList(
|
| 631 |
+
[
|
| 632 |
+
Downsample2D(
|
| 633 |
+
out_channels,
|
| 634 |
+
use_conv=True,
|
| 635 |
+
out_channels=out_channels,
|
| 636 |
+
padding=downsample_padding,
|
| 637 |
+
name="op",
|
| 638 |
+
)
|
| 639 |
+
]
|
| 640 |
+
)
|
| 641 |
+
else:
|
| 642 |
+
self.downsamplers = None
|
| 643 |
+
|
| 644 |
+
self.gradient_checkpointing = False
|
| 645 |
+
|
| 646 |
+
def forward(
|
| 647 |
+
self,
|
| 648 |
+
hidden_states: torch.FloatTensor,
|
| 649 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 650 |
+
num_frames: int = 1,
|
| 651 |
+
) -> Union[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
|
| 652 |
+
output_states = ()
|
| 653 |
+
|
| 654 |
+
for resnet, temp_conv in zip(self.resnets, self.temp_convs):
|
| 655 |
+
hidden_states = resnet(hidden_states, temb)
|
| 656 |
+
hidden_states = temp_conv(hidden_states, num_frames=num_frames)
|
| 657 |
+
|
| 658 |
+
output_states += (hidden_states,)
|
| 659 |
+
|
| 660 |
+
if self.downsamplers is not None:
|
| 661 |
+
for downsampler in self.downsamplers:
|
| 662 |
+
hidden_states = downsampler(hidden_states)
|
| 663 |
+
|
| 664 |
+
output_states += (hidden_states,)
|
| 665 |
+
|
| 666 |
+
return hidden_states, output_states
|
| 667 |
+
|
| 668 |
+
|
| 669 |
+
class CrossAttnUpBlock3D(nn.Module):
|
| 670 |
+
def __init__(
|
| 671 |
+
self,
|
| 672 |
+
in_channels: int,
|
| 673 |
+
out_channels: int,
|
| 674 |
+
prev_output_channel: int,
|
| 675 |
+
temb_channels: int,
|
| 676 |
+
dropout: float = 0.0,
|
| 677 |
+
num_layers: int = 1,
|
| 678 |
+
resnet_eps: float = 1e-6,
|
| 679 |
+
resnet_time_scale_shift: str = "default",
|
| 680 |
+
resnet_act_fn: str = "swish",
|
| 681 |
+
resnet_groups: int = 32,
|
| 682 |
+
resnet_pre_norm: bool = True,
|
| 683 |
+
num_attention_heads: int = 1,
|
| 684 |
+
cross_attention_dim: int = 1280,
|
| 685 |
+
output_scale_factor: float = 1.0,
|
| 686 |
+
add_upsample: bool = True,
|
| 687 |
+
dual_cross_attention: bool = False,
|
| 688 |
+
use_linear_projection: bool = False,
|
| 689 |
+
only_cross_attention: bool = False,
|
| 690 |
+
upcast_attention: bool = False,
|
| 691 |
+
resolution_idx: Optional[int] = None,
|
| 692 |
+
):
|
| 693 |
+
super().__init__()
|
| 694 |
+
resnets = []
|
| 695 |
+
temp_convs = []
|
| 696 |
+
attentions = []
|
| 697 |
+
temp_attentions = []
|
| 698 |
+
|
| 699 |
+
self.has_cross_attention = True
|
| 700 |
+
self.num_attention_heads = num_attention_heads
|
| 701 |
+
|
| 702 |
+
for i in range(num_layers):
|
| 703 |
+
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
|
| 704 |
+
resnet_in_channels = prev_output_channel if i == 0 else out_channels
|
| 705 |
+
|
| 706 |
+
resnets.append(
|
| 707 |
+
ResnetBlock2D(
|
| 708 |
+
in_channels=resnet_in_channels + res_skip_channels,
|
| 709 |
+
out_channels=out_channels,
|
| 710 |
+
temb_channels=temb_channels,
|
| 711 |
+
eps=resnet_eps,
|
| 712 |
+
groups=resnet_groups,
|
| 713 |
+
dropout=dropout,
|
| 714 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 715 |
+
non_linearity=resnet_act_fn,
|
| 716 |
+
output_scale_factor=output_scale_factor,
|
| 717 |
+
pre_norm=resnet_pre_norm,
|
| 718 |
+
)
|
| 719 |
+
)
|
| 720 |
+
temp_convs.append(
|
| 721 |
+
TemporalConvLayer(
|
| 722 |
+
out_channels,
|
| 723 |
+
out_channels,
|
| 724 |
+
dropout=0.1,
|
| 725 |
+
norm_num_groups=resnet_groups,
|
| 726 |
+
)
|
| 727 |
+
)
|
| 728 |
+
attentions.append(
|
| 729 |
+
Transformer2DModel(
|
| 730 |
+
out_channels // num_attention_heads,
|
| 731 |
+
num_attention_heads,
|
| 732 |
+
in_channels=out_channels,
|
| 733 |
+
num_layers=1,
|
| 734 |
+
cross_attention_dim=cross_attention_dim,
|
| 735 |
+
norm_num_groups=resnet_groups,
|
| 736 |
+
use_linear_projection=use_linear_projection,
|
| 737 |
+
only_cross_attention=only_cross_attention,
|
| 738 |
+
upcast_attention=upcast_attention,
|
| 739 |
+
)
|
| 740 |
+
)
|
| 741 |
+
temp_attentions.append(
|
| 742 |
+
TransformerTemporalModel(
|
| 743 |
+
out_channels // num_attention_heads,
|
| 744 |
+
num_attention_heads,
|
| 745 |
+
in_channels=out_channels,
|
| 746 |
+
num_layers=1,
|
| 747 |
+
cross_attention_dim=cross_attention_dim,
|
| 748 |
+
norm_num_groups=resnet_groups,
|
| 749 |
+
)
|
| 750 |
+
)
|
| 751 |
+
self.resnets = nn.ModuleList(resnets)
|
| 752 |
+
self.temp_convs = nn.ModuleList(temp_convs)
|
| 753 |
+
self.attentions = nn.ModuleList(attentions)
|
| 754 |
+
self.temp_attentions = nn.ModuleList(temp_attentions)
|
| 755 |
+
|
| 756 |
+
if add_upsample:
|
| 757 |
+
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
|
| 758 |
+
else:
|
| 759 |
+
self.upsamplers = None
|
| 760 |
+
|
| 761 |
+
self.gradient_checkpointing = False
|
| 762 |
+
self.resolution_idx = resolution_idx
|
| 763 |
+
|
| 764 |
+
def forward(
|
| 765 |
+
self,
|
| 766 |
+
hidden_states: torch.FloatTensor,
|
| 767 |
+
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
|
| 768 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 769 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 770 |
+
upsample_size: Optional[int] = None,
|
| 771 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 772 |
+
num_frames: int = 1,
|
| 773 |
+
cross_attention_kwargs: Dict[str, Any] = None,
|
| 774 |
+
) -> torch.FloatTensor:
|
| 775 |
+
is_freeu_enabled = (
|
| 776 |
+
getattr(self, "s1", None)
|
| 777 |
+
and getattr(self, "s2", None)
|
| 778 |
+
and getattr(self, "b1", None)
|
| 779 |
+
and getattr(self, "b2", None)
|
| 780 |
+
)
|
| 781 |
+
|
| 782 |
+
# TODO(Patrick, William) - attention mask is not used
|
| 783 |
+
for resnet, temp_conv, attn, temp_attn in zip(
|
| 784 |
+
self.resnets, self.temp_convs, self.attentions, self.temp_attentions
|
| 785 |
+
):
|
| 786 |
+
# pop res hidden states
|
| 787 |
+
res_hidden_states = res_hidden_states_tuple[-1]
|
| 788 |
+
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
|
| 789 |
+
|
| 790 |
+
# FreeU: Only operate on the first two stages
|
| 791 |
+
if is_freeu_enabled:
|
| 792 |
+
hidden_states, res_hidden_states = apply_freeu(
|
| 793 |
+
self.resolution_idx,
|
| 794 |
+
hidden_states,
|
| 795 |
+
res_hidden_states,
|
| 796 |
+
s1=self.s1,
|
| 797 |
+
s2=self.s2,
|
| 798 |
+
b1=self.b1,
|
| 799 |
+
b2=self.b2,
|
| 800 |
+
)
|
| 801 |
+
|
| 802 |
+
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
|
| 803 |
+
|
| 804 |
+
hidden_states = resnet(hidden_states, temb)
|
| 805 |
+
hidden_states = temp_conv(hidden_states, num_frames=num_frames)
|
| 806 |
+
hidden_states = attn(
|
| 807 |
+
hidden_states,
|
| 808 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 809 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 810 |
+
return_dict=False,
|
| 811 |
+
)[0]
|
| 812 |
+
hidden_states = temp_attn(
|
| 813 |
+
hidden_states,
|
| 814 |
+
num_frames=num_frames,
|
| 815 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 816 |
+
return_dict=False,
|
| 817 |
+
)[0]
|
| 818 |
+
|
| 819 |
+
if self.upsamplers is not None:
|
| 820 |
+
for upsampler in self.upsamplers:
|
| 821 |
+
hidden_states = upsampler(hidden_states, upsample_size)
|
| 822 |
+
|
| 823 |
+
return hidden_states
|
| 824 |
+
|
| 825 |
+
|
| 826 |
+
class UpBlock3D(nn.Module):
|
| 827 |
+
def __init__(
|
| 828 |
+
self,
|
| 829 |
+
in_channels: int,
|
| 830 |
+
prev_output_channel: int,
|
| 831 |
+
out_channels: int,
|
| 832 |
+
temb_channels: int,
|
| 833 |
+
dropout: float = 0.0,
|
| 834 |
+
num_layers: int = 1,
|
| 835 |
+
resnet_eps: float = 1e-6,
|
| 836 |
+
resnet_time_scale_shift: str = "default",
|
| 837 |
+
resnet_act_fn: str = "swish",
|
| 838 |
+
resnet_groups: int = 32,
|
| 839 |
+
resnet_pre_norm: bool = True,
|
| 840 |
+
output_scale_factor: float = 1.0,
|
| 841 |
+
add_upsample: bool = True,
|
| 842 |
+
resolution_idx: Optional[int] = None,
|
| 843 |
+
):
|
| 844 |
+
super().__init__()
|
| 845 |
+
resnets = []
|
| 846 |
+
temp_convs = []
|
| 847 |
+
|
| 848 |
+
for i in range(num_layers):
|
| 849 |
+
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
|
| 850 |
+
resnet_in_channels = prev_output_channel if i == 0 else out_channels
|
| 851 |
+
|
| 852 |
+
resnets.append(
|
| 853 |
+
ResnetBlock2D(
|
| 854 |
+
in_channels=resnet_in_channels + res_skip_channels,
|
| 855 |
+
out_channels=out_channels,
|
| 856 |
+
temb_channels=temb_channels,
|
| 857 |
+
eps=resnet_eps,
|
| 858 |
+
groups=resnet_groups,
|
| 859 |
+
dropout=dropout,
|
| 860 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 861 |
+
non_linearity=resnet_act_fn,
|
| 862 |
+
output_scale_factor=output_scale_factor,
|
| 863 |
+
pre_norm=resnet_pre_norm,
|
| 864 |
+
)
|
| 865 |
+
)
|
| 866 |
+
temp_convs.append(
|
| 867 |
+
TemporalConvLayer(
|
| 868 |
+
out_channels,
|
| 869 |
+
out_channels,
|
| 870 |
+
dropout=0.1,
|
| 871 |
+
norm_num_groups=resnet_groups,
|
| 872 |
+
)
|
| 873 |
+
)
|
| 874 |
+
|
| 875 |
+
self.resnets = nn.ModuleList(resnets)
|
| 876 |
+
self.temp_convs = nn.ModuleList(temp_convs)
|
| 877 |
+
|
| 878 |
+
if add_upsample:
|
| 879 |
+
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
|
| 880 |
+
else:
|
| 881 |
+
self.upsamplers = None
|
| 882 |
+
|
| 883 |
+
self.gradient_checkpointing = False
|
| 884 |
+
self.resolution_idx = resolution_idx
|
| 885 |
+
|
| 886 |
+
def forward(
|
| 887 |
+
self,
|
| 888 |
+
hidden_states: torch.FloatTensor,
|
| 889 |
+
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
|
| 890 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 891 |
+
upsample_size: Optional[int] = None,
|
| 892 |
+
num_frames: int = 1,
|
| 893 |
+
) -> torch.FloatTensor:
|
| 894 |
+
is_freeu_enabled = (
|
| 895 |
+
getattr(self, "s1", None)
|
| 896 |
+
and getattr(self, "s2", None)
|
| 897 |
+
and getattr(self, "b1", None)
|
| 898 |
+
and getattr(self, "b2", None)
|
| 899 |
+
)
|
| 900 |
+
for resnet, temp_conv in zip(self.resnets, self.temp_convs):
|
| 901 |
+
# pop res hidden states
|
| 902 |
+
res_hidden_states = res_hidden_states_tuple[-1]
|
| 903 |
+
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
|
| 904 |
+
|
| 905 |
+
# FreeU: Only operate on the first two stages
|
| 906 |
+
if is_freeu_enabled:
|
| 907 |
+
hidden_states, res_hidden_states = apply_freeu(
|
| 908 |
+
self.resolution_idx,
|
| 909 |
+
hidden_states,
|
| 910 |
+
res_hidden_states,
|
| 911 |
+
s1=self.s1,
|
| 912 |
+
s2=self.s2,
|
| 913 |
+
b1=self.b1,
|
| 914 |
+
b2=self.b2,
|
| 915 |
+
)
|
| 916 |
+
|
| 917 |
+
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
|
| 918 |
+
|
| 919 |
+
hidden_states = resnet(hidden_states, temb)
|
| 920 |
+
hidden_states = temp_conv(hidden_states, num_frames=num_frames)
|
| 921 |
+
|
| 922 |
+
if self.upsamplers is not None:
|
| 923 |
+
for upsampler in self.upsamplers:
|
| 924 |
+
hidden_states = upsampler(hidden_states, upsample_size)
|
| 925 |
+
|
| 926 |
+
return hidden_states
|
| 927 |
+
|
| 928 |
+
|
| 929 |
+
class DownBlockMotion(nn.Module):
|
| 930 |
+
def __init__(
|
| 931 |
+
self,
|
| 932 |
+
in_channels: int,
|
| 933 |
+
out_channels: int,
|
| 934 |
+
temb_channels: int,
|
| 935 |
+
dropout: float = 0.0,
|
| 936 |
+
num_layers: int = 1,
|
| 937 |
+
resnet_eps: float = 1e-6,
|
| 938 |
+
resnet_time_scale_shift: str = "default",
|
| 939 |
+
resnet_act_fn: str = "swish",
|
| 940 |
+
resnet_groups: int = 32,
|
| 941 |
+
resnet_pre_norm: bool = True,
|
| 942 |
+
output_scale_factor: float = 1.0,
|
| 943 |
+
add_downsample: bool = True,
|
| 944 |
+
downsample_padding: int = 1,
|
| 945 |
+
temporal_num_attention_heads: int = 1,
|
| 946 |
+
temporal_cross_attention_dim: Optional[int] = None,
|
| 947 |
+
temporal_max_seq_length: int = 32,
|
| 948 |
+
):
|
| 949 |
+
super().__init__()
|
| 950 |
+
resnets = []
|
| 951 |
+
motion_modules = []
|
| 952 |
+
|
| 953 |
+
for i in range(num_layers):
|
| 954 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 955 |
+
resnets.append(
|
| 956 |
+
ResnetBlock2D(
|
| 957 |
+
in_channels=in_channels,
|
| 958 |
+
out_channels=out_channels,
|
| 959 |
+
temb_channels=temb_channels,
|
| 960 |
+
eps=resnet_eps,
|
| 961 |
+
groups=resnet_groups,
|
| 962 |
+
dropout=dropout,
|
| 963 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 964 |
+
non_linearity=resnet_act_fn,
|
| 965 |
+
output_scale_factor=output_scale_factor,
|
| 966 |
+
pre_norm=resnet_pre_norm,
|
| 967 |
+
)
|
| 968 |
+
)
|
| 969 |
+
motion_modules.append(
|
| 970 |
+
TransformerTemporalModel(
|
| 971 |
+
num_attention_heads=temporal_num_attention_heads,
|
| 972 |
+
in_channels=out_channels,
|
| 973 |
+
norm_num_groups=resnet_groups,
|
| 974 |
+
cross_attention_dim=temporal_cross_attention_dim,
|
| 975 |
+
attention_bias=False,
|
| 976 |
+
activation_fn="geglu",
|
| 977 |
+
positional_embeddings="sinusoidal",
|
| 978 |
+
num_positional_embeddings=temporal_max_seq_length,
|
| 979 |
+
attention_head_dim=out_channels // temporal_num_attention_heads,
|
| 980 |
+
)
|
| 981 |
+
)
|
| 982 |
+
|
| 983 |
+
self.resnets = nn.ModuleList(resnets)
|
| 984 |
+
self.motion_modules = nn.ModuleList(motion_modules)
|
| 985 |
+
|
| 986 |
+
if add_downsample:
|
| 987 |
+
self.downsamplers = nn.ModuleList(
|
| 988 |
+
[
|
| 989 |
+
Downsample2D(
|
| 990 |
+
out_channels,
|
| 991 |
+
use_conv=True,
|
| 992 |
+
out_channels=out_channels,
|
| 993 |
+
padding=downsample_padding,
|
| 994 |
+
name="op",
|
| 995 |
+
)
|
| 996 |
+
]
|
| 997 |
+
)
|
| 998 |
+
else:
|
| 999 |
+
self.downsamplers = None
|
| 1000 |
+
|
| 1001 |
+
self.gradient_checkpointing = False
|
| 1002 |
+
|
| 1003 |
+
def forward(
|
| 1004 |
+
self,
|
| 1005 |
+
hidden_states: torch.FloatTensor,
|
| 1006 |
+
down_block_add_samples: Optional[torch.FloatTensor] = None,
|
| 1007 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 1008 |
+
scale: float = 1.0,
|
| 1009 |
+
num_frames: int = 1,
|
| 1010 |
+
) -> Union[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
|
| 1011 |
+
output_states = ()
|
| 1012 |
+
|
| 1013 |
+
blocks = zip(self.resnets, self.motion_modules)
|
| 1014 |
+
for resnet, motion_module in blocks:
|
| 1015 |
+
if self.training and self.gradient_checkpointing:
|
| 1016 |
+
|
| 1017 |
+
def create_custom_forward(module, return_dict=None):
|
| 1018 |
+
def custom_forward(*inputs):
|
| 1019 |
+
if return_dict is not None:
|
| 1020 |
+
return module(*inputs, return_dict=return_dict)
|
| 1021 |
+
else:
|
| 1022 |
+
return module(*inputs)
|
| 1023 |
+
|
| 1024 |
+
return custom_forward
|
| 1025 |
+
|
| 1026 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 1027 |
+
|
| 1028 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1029 |
+
create_custom_forward(resnet),
|
| 1030 |
+
hidden_states,
|
| 1031 |
+
temb,
|
| 1032 |
+
**ckpt_kwargs,
|
| 1033 |
+
)
|
| 1034 |
+
|
| 1035 |
+
if down_block_add_samples is not None:
|
| 1036 |
+
hidden_states = hidden_states + down_block_add_samples.pop(0)
|
| 1037 |
+
|
| 1038 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1039 |
+
create_custom_forward(motion_module),
|
| 1040 |
+
hidden_states.requires_grad_(),
|
| 1041 |
+
temb,
|
| 1042 |
+
num_frames,
|
| 1043 |
+
**ckpt_kwargs,
|
| 1044 |
+
)
|
| 1045 |
+
|
| 1046 |
+
else:
|
| 1047 |
+
hidden_states = resnet(hidden_states, temb, scale=scale)
|
| 1048 |
+
if down_block_add_samples is not None:
|
| 1049 |
+
hidden_states = hidden_states + down_block_add_samples.pop(0)
|
| 1050 |
+
hidden_states = motion_module(hidden_states, num_frames=num_frames)
|
| 1051 |
+
|
| 1052 |
+
output_states = output_states + (hidden_states,)
|
| 1053 |
+
|
| 1054 |
+
if self.downsamplers is not None:
|
| 1055 |
+
for downsampler in self.downsamplers:
|
| 1056 |
+
hidden_states = downsampler(hidden_states, scale=scale)
|
| 1057 |
+
|
| 1058 |
+
if down_block_add_samples is not None:
|
| 1059 |
+
hidden_states = hidden_states + down_block_add_samples.pop(0)
|
| 1060 |
+
|
| 1061 |
+
output_states = output_states + (hidden_states,)
|
| 1062 |
+
|
| 1063 |
+
return hidden_states, output_states
|
| 1064 |
+
|
| 1065 |
+
|
| 1066 |
+
class CrossAttnDownBlockMotion(nn.Module):
|
| 1067 |
+
def __init__(
|
| 1068 |
+
self,
|
| 1069 |
+
in_channels: int,
|
| 1070 |
+
out_channels: int,
|
| 1071 |
+
temb_channels: int,
|
| 1072 |
+
dropout: float = 0.0,
|
| 1073 |
+
num_layers: int = 1,
|
| 1074 |
+
transformer_layers_per_block: int = 1,
|
| 1075 |
+
resnet_eps: float = 1e-6,
|
| 1076 |
+
resnet_time_scale_shift: str = "default",
|
| 1077 |
+
resnet_act_fn: str = "swish",
|
| 1078 |
+
resnet_groups: int = 32,
|
| 1079 |
+
resnet_pre_norm: bool = True,
|
| 1080 |
+
num_attention_heads: int = 1,
|
| 1081 |
+
cross_attention_dim: int = 1280,
|
| 1082 |
+
output_scale_factor: float = 1.0,
|
| 1083 |
+
downsample_padding: int = 1,
|
| 1084 |
+
add_downsample: bool = True,
|
| 1085 |
+
dual_cross_attention: bool = False,
|
| 1086 |
+
use_linear_projection: bool = False,
|
| 1087 |
+
only_cross_attention: bool = False,
|
| 1088 |
+
upcast_attention: bool = False,
|
| 1089 |
+
attention_type: str = "default",
|
| 1090 |
+
temporal_cross_attention_dim: Optional[int] = None,
|
| 1091 |
+
temporal_num_attention_heads: int = 8,
|
| 1092 |
+
temporal_max_seq_length: int = 32,
|
| 1093 |
+
):
|
| 1094 |
+
super().__init__()
|
| 1095 |
+
resnets = []
|
| 1096 |
+
attentions = []
|
| 1097 |
+
motion_modules = []
|
| 1098 |
+
|
| 1099 |
+
self.has_cross_attention = True
|
| 1100 |
+
self.num_attention_heads = num_attention_heads
|
| 1101 |
+
|
| 1102 |
+
for i in range(num_layers):
|
| 1103 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 1104 |
+
resnets.append(
|
| 1105 |
+
ResnetBlock2D(
|
| 1106 |
+
in_channels=in_channels,
|
| 1107 |
+
out_channels=out_channels,
|
| 1108 |
+
temb_channels=temb_channels,
|
| 1109 |
+
eps=resnet_eps,
|
| 1110 |
+
groups=resnet_groups,
|
| 1111 |
+
dropout=dropout,
|
| 1112 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 1113 |
+
non_linearity=resnet_act_fn,
|
| 1114 |
+
output_scale_factor=output_scale_factor,
|
| 1115 |
+
pre_norm=resnet_pre_norm,
|
| 1116 |
+
)
|
| 1117 |
+
)
|
| 1118 |
+
|
| 1119 |
+
if not dual_cross_attention:
|
| 1120 |
+
attentions.append(
|
| 1121 |
+
Transformer2DModel(
|
| 1122 |
+
num_attention_heads,
|
| 1123 |
+
out_channels // num_attention_heads,
|
| 1124 |
+
in_channels=out_channels,
|
| 1125 |
+
num_layers=transformer_layers_per_block,
|
| 1126 |
+
cross_attention_dim=cross_attention_dim,
|
| 1127 |
+
norm_num_groups=resnet_groups,
|
| 1128 |
+
use_linear_projection=use_linear_projection,
|
| 1129 |
+
only_cross_attention=only_cross_attention,
|
| 1130 |
+
upcast_attention=upcast_attention,
|
| 1131 |
+
attention_type=attention_type,
|
| 1132 |
+
)
|
| 1133 |
+
)
|
| 1134 |
+
else:
|
| 1135 |
+
attentions.append(
|
| 1136 |
+
DualTransformer2DModel(
|
| 1137 |
+
num_attention_heads,
|
| 1138 |
+
out_channels // num_attention_heads,
|
| 1139 |
+
in_channels=out_channels,
|
| 1140 |
+
num_layers=1,
|
| 1141 |
+
cross_attention_dim=cross_attention_dim,
|
| 1142 |
+
norm_num_groups=resnet_groups,
|
| 1143 |
+
)
|
| 1144 |
+
)
|
| 1145 |
+
|
| 1146 |
+
motion_modules.append(
|
| 1147 |
+
TransformerTemporalModel(
|
| 1148 |
+
num_attention_heads=temporal_num_attention_heads,
|
| 1149 |
+
in_channels=out_channels,
|
| 1150 |
+
norm_num_groups=resnet_groups,
|
| 1151 |
+
cross_attention_dim=temporal_cross_attention_dim,
|
| 1152 |
+
attention_bias=False,
|
| 1153 |
+
activation_fn="geglu",
|
| 1154 |
+
positional_embeddings="sinusoidal",
|
| 1155 |
+
num_positional_embeddings=temporal_max_seq_length,
|
| 1156 |
+
attention_head_dim=out_channels // temporal_num_attention_heads,
|
| 1157 |
+
)
|
| 1158 |
+
)
|
| 1159 |
+
|
| 1160 |
+
self.attentions = nn.ModuleList(attentions)
|
| 1161 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1162 |
+
self.motion_modules = nn.ModuleList(motion_modules)
|
| 1163 |
+
|
| 1164 |
+
if add_downsample:
|
| 1165 |
+
self.downsamplers = nn.ModuleList(
|
| 1166 |
+
[
|
| 1167 |
+
Downsample2D(
|
| 1168 |
+
out_channels,
|
| 1169 |
+
use_conv=True,
|
| 1170 |
+
out_channels=out_channels,
|
| 1171 |
+
padding=downsample_padding,
|
| 1172 |
+
name="op",
|
| 1173 |
+
)
|
| 1174 |
+
]
|
| 1175 |
+
)
|
| 1176 |
+
else:
|
| 1177 |
+
self.downsamplers = None
|
| 1178 |
+
|
| 1179 |
+
self.gradient_checkpointing = False
|
| 1180 |
+
|
| 1181 |
+
def forward(
|
| 1182 |
+
self,
|
| 1183 |
+
hidden_states: torch.FloatTensor,
|
| 1184 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 1185 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 1186 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1187 |
+
num_frames: int = 1,
|
| 1188 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 1189 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 1190 |
+
additional_residuals: Optional[torch.FloatTensor] = None,
|
| 1191 |
+
down_block_add_samples: Optional[torch.FloatTensor] = None,
|
| 1192 |
+
):
|
| 1193 |
+
output_states = ()
|
| 1194 |
+
|
| 1195 |
+
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
|
| 1196 |
+
|
| 1197 |
+
blocks = list(zip(self.resnets, self.attentions, self.motion_modules))
|
| 1198 |
+
for i, (resnet, attn, motion_module) in enumerate(blocks):
|
| 1199 |
+
if self.training and self.gradient_checkpointing:
|
| 1200 |
+
|
| 1201 |
+
def create_custom_forward(module, return_dict=None):
|
| 1202 |
+
def custom_forward(*inputs):
|
| 1203 |
+
if return_dict is not None:
|
| 1204 |
+
return module(*inputs, return_dict=return_dict)
|
| 1205 |
+
else:
|
| 1206 |
+
return module(*inputs)
|
| 1207 |
+
|
| 1208 |
+
return custom_forward
|
| 1209 |
+
|
| 1210 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 1211 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1212 |
+
create_custom_forward(resnet),
|
| 1213 |
+
hidden_states,
|
| 1214 |
+
temb,
|
| 1215 |
+
**ckpt_kwargs,
|
| 1216 |
+
)
|
| 1217 |
+
hidden_states = attn(
|
| 1218 |
+
hidden_states,
|
| 1219 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1220 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1221 |
+
attention_mask=attention_mask,
|
| 1222 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1223 |
+
return_dict=False,
|
| 1224 |
+
)[0]
|
| 1225 |
+
# apply additional residuals to the output of the last pair of resnet and attention blocks
|
| 1226 |
+
if i == len(blocks) - 1 and additional_residuals is not None:
|
| 1227 |
+
hidden_states = hidden_states + additional_residuals
|
| 1228 |
+
if down_block_add_samples is not None:
|
| 1229 |
+
hidden_states = hidden_states + down_block_add_samples.pop(0)
|
| 1230 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1231 |
+
create_custom_forward(motion_module),
|
| 1232 |
+
hidden_states.requires_grad_(),
|
| 1233 |
+
temb,
|
| 1234 |
+
num_frames,
|
| 1235 |
+
**ckpt_kwargs,
|
| 1236 |
+
)
|
| 1237 |
+
else:
|
| 1238 |
+
hidden_states = resnet(hidden_states, temb, scale=lora_scale)
|
| 1239 |
+
hidden_states = attn(
|
| 1240 |
+
hidden_states,
|
| 1241 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1242 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1243 |
+
attention_mask=attention_mask,
|
| 1244 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1245 |
+
return_dict=False,
|
| 1246 |
+
)[0]
|
| 1247 |
+
# apply additional residuals to the output of the last pair of resnet and attention blocks
|
| 1248 |
+
if i == len(blocks) - 1 and additional_residuals is not None:
|
| 1249 |
+
hidden_states = hidden_states + additional_residuals
|
| 1250 |
+
if down_block_add_samples is not None:
|
| 1251 |
+
hidden_states = hidden_states + down_block_add_samples.pop(0)
|
| 1252 |
+
hidden_states = motion_module(
|
| 1253 |
+
hidden_states,
|
| 1254 |
+
num_frames=num_frames,
|
| 1255 |
+
)
|
| 1256 |
+
|
| 1257 |
+
# # apply additional residuals to the output of the last pair of resnet and attention blocks
|
| 1258 |
+
# if i == len(blocks) - 1 and additional_residuals is not None:
|
| 1259 |
+
# hidden_states = hidden_states + additional_residuals
|
| 1260 |
+
|
| 1261 |
+
output_states = output_states + (hidden_states,)
|
| 1262 |
+
|
| 1263 |
+
if self.downsamplers is not None:
|
| 1264 |
+
for downsampler in self.downsamplers:
|
| 1265 |
+
hidden_states = downsampler(hidden_states, scale=lora_scale)
|
| 1266 |
+
|
| 1267 |
+
if down_block_add_samples is not None:
|
| 1268 |
+
hidden_states = hidden_states + down_block_add_samples.pop(0)
|
| 1269 |
+
|
| 1270 |
+
output_states = output_states + (hidden_states,)
|
| 1271 |
+
|
| 1272 |
+
return hidden_states, output_states
|
| 1273 |
+
|
| 1274 |
+
|
| 1275 |
+
class CrossAttnUpBlockMotion(nn.Module):
|
| 1276 |
+
def __init__(
|
| 1277 |
+
self,
|
| 1278 |
+
in_channels: int,
|
| 1279 |
+
out_channels: int,
|
| 1280 |
+
prev_output_channel: int,
|
| 1281 |
+
temb_channels: int,
|
| 1282 |
+
resolution_idx: Optional[int] = None,
|
| 1283 |
+
dropout: float = 0.0,
|
| 1284 |
+
num_layers: int = 1,
|
| 1285 |
+
transformer_layers_per_block: int = 1,
|
| 1286 |
+
resnet_eps: float = 1e-6,
|
| 1287 |
+
resnet_time_scale_shift: str = "default",
|
| 1288 |
+
resnet_act_fn: str = "swish",
|
| 1289 |
+
resnet_groups: int = 32,
|
| 1290 |
+
resnet_pre_norm: bool = True,
|
| 1291 |
+
num_attention_heads: int = 1,
|
| 1292 |
+
cross_attention_dim: int = 1280,
|
| 1293 |
+
output_scale_factor: float = 1.0,
|
| 1294 |
+
add_upsample: bool = True,
|
| 1295 |
+
dual_cross_attention: bool = False,
|
| 1296 |
+
use_linear_projection: bool = False,
|
| 1297 |
+
only_cross_attention: bool = False,
|
| 1298 |
+
upcast_attention: bool = False,
|
| 1299 |
+
attention_type: str = "default",
|
| 1300 |
+
temporal_cross_attention_dim: Optional[int] = None,
|
| 1301 |
+
temporal_num_attention_heads: int = 8,
|
| 1302 |
+
temporal_max_seq_length: int = 32,
|
| 1303 |
+
):
|
| 1304 |
+
super().__init__()
|
| 1305 |
+
resnets = []
|
| 1306 |
+
attentions = []
|
| 1307 |
+
motion_modules = []
|
| 1308 |
+
|
| 1309 |
+
self.has_cross_attention = True
|
| 1310 |
+
self.num_attention_heads = num_attention_heads
|
| 1311 |
+
|
| 1312 |
+
for i in range(num_layers):
|
| 1313 |
+
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
|
| 1314 |
+
resnet_in_channels = prev_output_channel if i == 0 else out_channels
|
| 1315 |
+
|
| 1316 |
+
resnets.append(
|
| 1317 |
+
ResnetBlock2D(
|
| 1318 |
+
in_channels=resnet_in_channels + res_skip_channels,
|
| 1319 |
+
out_channels=out_channels,
|
| 1320 |
+
temb_channels=temb_channels,
|
| 1321 |
+
eps=resnet_eps,
|
| 1322 |
+
groups=resnet_groups,
|
| 1323 |
+
dropout=dropout,
|
| 1324 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 1325 |
+
non_linearity=resnet_act_fn,
|
| 1326 |
+
output_scale_factor=output_scale_factor,
|
| 1327 |
+
pre_norm=resnet_pre_norm,
|
| 1328 |
+
)
|
| 1329 |
+
)
|
| 1330 |
+
|
| 1331 |
+
if not dual_cross_attention:
|
| 1332 |
+
attentions.append(
|
| 1333 |
+
Transformer2DModel(
|
| 1334 |
+
num_attention_heads,
|
| 1335 |
+
out_channels // num_attention_heads,
|
| 1336 |
+
in_channels=out_channels,
|
| 1337 |
+
num_layers=transformer_layers_per_block,
|
| 1338 |
+
cross_attention_dim=cross_attention_dim,
|
| 1339 |
+
norm_num_groups=resnet_groups,
|
| 1340 |
+
use_linear_projection=use_linear_projection,
|
| 1341 |
+
only_cross_attention=only_cross_attention,
|
| 1342 |
+
upcast_attention=upcast_attention,
|
| 1343 |
+
attention_type=attention_type,
|
| 1344 |
+
)
|
| 1345 |
+
)
|
| 1346 |
+
else:
|
| 1347 |
+
attentions.append(
|
| 1348 |
+
DualTransformer2DModel(
|
| 1349 |
+
num_attention_heads,
|
| 1350 |
+
out_channels // num_attention_heads,
|
| 1351 |
+
in_channels=out_channels,
|
| 1352 |
+
num_layers=1,
|
| 1353 |
+
cross_attention_dim=cross_attention_dim,
|
| 1354 |
+
norm_num_groups=resnet_groups,
|
| 1355 |
+
)
|
| 1356 |
+
)
|
| 1357 |
+
motion_modules.append(
|
| 1358 |
+
TransformerTemporalModel(
|
| 1359 |
+
num_attention_heads=temporal_num_attention_heads,
|
| 1360 |
+
in_channels=out_channels,
|
| 1361 |
+
norm_num_groups=resnet_groups,
|
| 1362 |
+
cross_attention_dim=temporal_cross_attention_dim,
|
| 1363 |
+
attention_bias=False,
|
| 1364 |
+
activation_fn="geglu",
|
| 1365 |
+
positional_embeddings="sinusoidal",
|
| 1366 |
+
num_positional_embeddings=temporal_max_seq_length,
|
| 1367 |
+
attention_head_dim=out_channels // temporal_num_attention_heads,
|
| 1368 |
+
)
|
| 1369 |
+
)
|
| 1370 |
+
|
| 1371 |
+
self.attentions = nn.ModuleList(attentions)
|
| 1372 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1373 |
+
self.motion_modules = nn.ModuleList(motion_modules)
|
| 1374 |
+
|
| 1375 |
+
if add_upsample:
|
| 1376 |
+
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
|
| 1377 |
+
else:
|
| 1378 |
+
self.upsamplers = None
|
| 1379 |
+
|
| 1380 |
+
self.gradient_checkpointing = False
|
| 1381 |
+
self.resolution_idx = resolution_idx
|
| 1382 |
+
|
| 1383 |
+
def forward(
|
| 1384 |
+
self,
|
| 1385 |
+
hidden_states: torch.FloatTensor,
|
| 1386 |
+
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
|
| 1387 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 1388 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 1389 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 1390 |
+
upsample_size: Optional[int] = None,
|
| 1391 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1392 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 1393 |
+
num_frames: int = 1,
|
| 1394 |
+
up_block_add_samples: Optional[torch.FloatTensor] = None,
|
| 1395 |
+
) -> torch.FloatTensor:
|
| 1396 |
+
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
|
| 1397 |
+
is_freeu_enabled = (
|
| 1398 |
+
getattr(self, "s1", None)
|
| 1399 |
+
and getattr(self, "s2", None)
|
| 1400 |
+
and getattr(self, "b1", None)
|
| 1401 |
+
and getattr(self, "b2", None)
|
| 1402 |
+
)
|
| 1403 |
+
|
| 1404 |
+
blocks = zip(self.resnets, self.attentions, self.motion_modules)
|
| 1405 |
+
for resnet, attn, motion_module in blocks:
|
| 1406 |
+
# pop res hidden states
|
| 1407 |
+
res_hidden_states = res_hidden_states_tuple[-1]
|
| 1408 |
+
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
|
| 1409 |
+
|
| 1410 |
+
# FreeU: Only operate on the first two stages
|
| 1411 |
+
if is_freeu_enabled:
|
| 1412 |
+
hidden_states, res_hidden_states = apply_freeu(
|
| 1413 |
+
self.resolution_idx,
|
| 1414 |
+
hidden_states,
|
| 1415 |
+
res_hidden_states,
|
| 1416 |
+
s1=self.s1,
|
| 1417 |
+
s2=self.s2,
|
| 1418 |
+
b1=self.b1,
|
| 1419 |
+
b2=self.b2,
|
| 1420 |
+
)
|
| 1421 |
+
|
| 1422 |
+
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
|
| 1423 |
+
|
| 1424 |
+
if self.training and self.gradient_checkpointing:
|
| 1425 |
+
|
| 1426 |
+
def create_custom_forward(module, return_dict=None):
|
| 1427 |
+
def custom_forward(*inputs):
|
| 1428 |
+
if return_dict is not None:
|
| 1429 |
+
return module(*inputs, return_dict=return_dict)
|
| 1430 |
+
else:
|
| 1431 |
+
return module(*inputs)
|
| 1432 |
+
|
| 1433 |
+
return custom_forward
|
| 1434 |
+
|
| 1435 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 1436 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1437 |
+
create_custom_forward(resnet),
|
| 1438 |
+
hidden_states,
|
| 1439 |
+
temb,
|
| 1440 |
+
**ckpt_kwargs,
|
| 1441 |
+
)
|
| 1442 |
+
hidden_states = attn(
|
| 1443 |
+
hidden_states,
|
| 1444 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1445 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1446 |
+
attention_mask=attention_mask,
|
| 1447 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1448 |
+
return_dict=False,
|
| 1449 |
+
)[0]
|
| 1450 |
+
if up_block_add_samples is not None:
|
| 1451 |
+
hidden_states = hidden_states + up_block_add_samples.pop(0)
|
| 1452 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1453 |
+
create_custom_forward(motion_module),
|
| 1454 |
+
hidden_states.requires_grad_(),
|
| 1455 |
+
temb,
|
| 1456 |
+
num_frames,
|
| 1457 |
+
**ckpt_kwargs,
|
| 1458 |
+
)
|
| 1459 |
+
else:
|
| 1460 |
+
hidden_states = resnet(hidden_states, temb, scale=lora_scale)
|
| 1461 |
+
hidden_states = attn(
|
| 1462 |
+
hidden_states,
|
| 1463 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1464 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1465 |
+
attention_mask=attention_mask,
|
| 1466 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1467 |
+
return_dict=False,
|
| 1468 |
+
)[0]
|
| 1469 |
+
if up_block_add_samples is not None:
|
| 1470 |
+
hidden_states = hidden_states + up_block_add_samples.pop(0)
|
| 1471 |
+
hidden_states = motion_module(
|
| 1472 |
+
hidden_states,
|
| 1473 |
+
num_frames=num_frames,
|
| 1474 |
+
)
|
| 1475 |
+
|
| 1476 |
+
if self.upsamplers is not None:
|
| 1477 |
+
for upsampler in self.upsamplers:
|
| 1478 |
+
hidden_states = upsampler(hidden_states, upsample_size, scale=lora_scale)
|
| 1479 |
+
if up_block_add_samples is not None:
|
| 1480 |
+
hidden_states = hidden_states + up_block_add_samples.pop(0)
|
| 1481 |
+
|
| 1482 |
+
return hidden_states
|
| 1483 |
+
|
| 1484 |
+
|
| 1485 |
+
class UpBlockMotion(nn.Module):
|
| 1486 |
+
def __init__(
|
| 1487 |
+
self,
|
| 1488 |
+
in_channels: int,
|
| 1489 |
+
prev_output_channel: int,
|
| 1490 |
+
out_channels: int,
|
| 1491 |
+
temb_channels: int,
|
| 1492 |
+
resolution_idx: Optional[int] = None,
|
| 1493 |
+
dropout: float = 0.0,
|
| 1494 |
+
num_layers: int = 1,
|
| 1495 |
+
resnet_eps: float = 1e-6,
|
| 1496 |
+
resnet_time_scale_shift: str = "default",
|
| 1497 |
+
resnet_act_fn: str = "swish",
|
| 1498 |
+
resnet_groups: int = 32,
|
| 1499 |
+
resnet_pre_norm: bool = True,
|
| 1500 |
+
output_scale_factor: float = 1.0,
|
| 1501 |
+
add_upsample: bool = True,
|
| 1502 |
+
temporal_norm_num_groups: int = 32,
|
| 1503 |
+
temporal_cross_attention_dim: Optional[int] = None,
|
| 1504 |
+
temporal_num_attention_heads: int = 8,
|
| 1505 |
+
temporal_max_seq_length: int = 32,
|
| 1506 |
+
):
|
| 1507 |
+
super().__init__()
|
| 1508 |
+
resnets = []
|
| 1509 |
+
motion_modules = []
|
| 1510 |
+
|
| 1511 |
+
for i in range(num_layers):
|
| 1512 |
+
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
|
| 1513 |
+
resnet_in_channels = prev_output_channel if i == 0 else out_channels
|
| 1514 |
+
|
| 1515 |
+
resnets.append(
|
| 1516 |
+
ResnetBlock2D(
|
| 1517 |
+
in_channels=resnet_in_channels + res_skip_channels,
|
| 1518 |
+
out_channels=out_channels,
|
| 1519 |
+
temb_channels=temb_channels,
|
| 1520 |
+
eps=resnet_eps,
|
| 1521 |
+
groups=resnet_groups,
|
| 1522 |
+
dropout=dropout,
|
| 1523 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 1524 |
+
non_linearity=resnet_act_fn,
|
| 1525 |
+
output_scale_factor=output_scale_factor,
|
| 1526 |
+
pre_norm=resnet_pre_norm,
|
| 1527 |
+
)
|
| 1528 |
+
)
|
| 1529 |
+
|
| 1530 |
+
motion_modules.append(
|
| 1531 |
+
TransformerTemporalModel(
|
| 1532 |
+
num_attention_heads=temporal_num_attention_heads,
|
| 1533 |
+
in_channels=out_channels,
|
| 1534 |
+
norm_num_groups=temporal_norm_num_groups,
|
| 1535 |
+
cross_attention_dim=temporal_cross_attention_dim,
|
| 1536 |
+
attention_bias=False,
|
| 1537 |
+
activation_fn="geglu",
|
| 1538 |
+
positional_embeddings="sinusoidal",
|
| 1539 |
+
num_positional_embeddings=temporal_max_seq_length,
|
| 1540 |
+
attention_head_dim=out_channels // temporal_num_attention_heads,
|
| 1541 |
+
)
|
| 1542 |
+
)
|
| 1543 |
+
|
| 1544 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1545 |
+
self.motion_modules = nn.ModuleList(motion_modules)
|
| 1546 |
+
|
| 1547 |
+
if add_upsample:
|
| 1548 |
+
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
|
| 1549 |
+
else:
|
| 1550 |
+
self.upsamplers = None
|
| 1551 |
+
|
| 1552 |
+
self.gradient_checkpointing = False
|
| 1553 |
+
self.resolution_idx = resolution_idx
|
| 1554 |
+
|
| 1555 |
+
def forward(
|
| 1556 |
+
self,
|
| 1557 |
+
hidden_states: torch.FloatTensor,
|
| 1558 |
+
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
|
| 1559 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 1560 |
+
upsample_size=None,
|
| 1561 |
+
scale: float = 1.0,
|
| 1562 |
+
num_frames: int = 1,
|
| 1563 |
+
up_block_add_samples: Optional[torch.FloatTensor] = None,
|
| 1564 |
+
) -> torch.FloatTensor:
|
| 1565 |
+
is_freeu_enabled = (
|
| 1566 |
+
getattr(self, "s1", None)
|
| 1567 |
+
and getattr(self, "s2", None)
|
| 1568 |
+
and getattr(self, "b1", None)
|
| 1569 |
+
and getattr(self, "b2", None)
|
| 1570 |
+
)
|
| 1571 |
+
|
| 1572 |
+
blocks = zip(self.resnets, self.motion_modules)
|
| 1573 |
+
|
| 1574 |
+
for resnet, motion_module in blocks:
|
| 1575 |
+
# pop res hidden states
|
| 1576 |
+
res_hidden_states = res_hidden_states_tuple[-1]
|
| 1577 |
+
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
|
| 1578 |
+
|
| 1579 |
+
# FreeU: Only operate on the first two stages
|
| 1580 |
+
if is_freeu_enabled:
|
| 1581 |
+
hidden_states, res_hidden_states = apply_freeu(
|
| 1582 |
+
self.resolution_idx,
|
| 1583 |
+
hidden_states,
|
| 1584 |
+
res_hidden_states,
|
| 1585 |
+
s1=self.s1,
|
| 1586 |
+
s2=self.s2,
|
| 1587 |
+
b1=self.b1,
|
| 1588 |
+
b2=self.b2,
|
| 1589 |
+
)
|
| 1590 |
+
|
| 1591 |
+
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
|
| 1592 |
+
|
| 1593 |
+
if self.training and self.gradient_checkpointing:
|
| 1594 |
+
|
| 1595 |
+
def create_custom_forward(module):
|
| 1596 |
+
def custom_forward(*inputs):
|
| 1597 |
+
return module(*inputs)
|
| 1598 |
+
|
| 1599 |
+
return custom_forward
|
| 1600 |
+
|
| 1601 |
+
if is_torch_version(">=", "1.11.0"):
|
| 1602 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1603 |
+
create_custom_forward(resnet),
|
| 1604 |
+
hidden_states,
|
| 1605 |
+
temb,
|
| 1606 |
+
use_reentrant=False,
|
| 1607 |
+
)
|
| 1608 |
+
else:
|
| 1609 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1610 |
+
create_custom_forward(resnet), hidden_states, temb
|
| 1611 |
+
)
|
| 1612 |
+
|
| 1613 |
+
if up_block_add_samples is not None:
|
| 1614 |
+
hidden_states = hidden_states + up_block_add_samples.pop(0)
|
| 1615 |
+
|
| 1616 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1617 |
+
create_custom_forward(motion_module),
|
| 1618 |
+
hidden_states.requires_grad_(),
|
| 1619 |
+
temb,
|
| 1620 |
+
num_frames,
|
| 1621 |
+
use_reentrant=False,
|
| 1622 |
+
)
|
| 1623 |
+
else:
|
| 1624 |
+
hidden_states = resnet(hidden_states, temb, scale=scale)
|
| 1625 |
+
if up_block_add_samples is not None:
|
| 1626 |
+
hidden_states = hidden_states + up_block_add_samples.pop(0)
|
| 1627 |
+
hidden_states = motion_module(hidden_states, num_frames=num_frames)
|
| 1628 |
+
|
| 1629 |
+
if self.upsamplers is not None:
|
| 1630 |
+
for upsampler in self.upsamplers:
|
| 1631 |
+
hidden_states = upsampler(hidden_states, upsample_size, scale=scale)
|
| 1632 |
+
|
| 1633 |
+
if up_block_add_samples is not None:
|
| 1634 |
+
hidden_states = hidden_states + up_block_add_samples.pop(0)
|
| 1635 |
+
|
| 1636 |
+
return hidden_states
|
| 1637 |
+
|
| 1638 |
+
|
| 1639 |
+
class UNetMidBlockCrossAttnMotion(nn.Module):
|
| 1640 |
+
def __init__(
|
| 1641 |
+
self,
|
| 1642 |
+
in_channels: int,
|
| 1643 |
+
temb_channels: int,
|
| 1644 |
+
dropout: float = 0.0,
|
| 1645 |
+
num_layers: int = 1,
|
| 1646 |
+
transformer_layers_per_block: int = 1,
|
| 1647 |
+
resnet_eps: float = 1e-6,
|
| 1648 |
+
resnet_time_scale_shift: str = "default",
|
| 1649 |
+
resnet_act_fn: str = "swish",
|
| 1650 |
+
resnet_groups: int = 32,
|
| 1651 |
+
resnet_pre_norm: bool = True,
|
| 1652 |
+
num_attention_heads: int = 1,
|
| 1653 |
+
output_scale_factor: float = 1.0,
|
| 1654 |
+
cross_attention_dim: int = 1280,
|
| 1655 |
+
dual_cross_attention: float = False,
|
| 1656 |
+
use_linear_projection: float = False,
|
| 1657 |
+
upcast_attention: float = False,
|
| 1658 |
+
attention_type: str = "default",
|
| 1659 |
+
temporal_num_attention_heads: int = 1,
|
| 1660 |
+
temporal_cross_attention_dim: Optional[int] = None,
|
| 1661 |
+
temporal_max_seq_length: int = 32,
|
| 1662 |
+
):
|
| 1663 |
+
super().__init__()
|
| 1664 |
+
|
| 1665 |
+
self.has_cross_attention = True
|
| 1666 |
+
self.num_attention_heads = num_attention_heads
|
| 1667 |
+
resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
|
| 1668 |
+
|
| 1669 |
+
# there is always at least one resnet
|
| 1670 |
+
resnets = [
|
| 1671 |
+
ResnetBlock2D(
|
| 1672 |
+
in_channels=in_channels,
|
| 1673 |
+
out_channels=in_channels,
|
| 1674 |
+
temb_channels=temb_channels,
|
| 1675 |
+
eps=resnet_eps,
|
| 1676 |
+
groups=resnet_groups,
|
| 1677 |
+
dropout=dropout,
|
| 1678 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 1679 |
+
non_linearity=resnet_act_fn,
|
| 1680 |
+
output_scale_factor=output_scale_factor,
|
| 1681 |
+
pre_norm=resnet_pre_norm,
|
| 1682 |
+
)
|
| 1683 |
+
]
|
| 1684 |
+
attentions = []
|
| 1685 |
+
motion_modules = []
|
| 1686 |
+
|
| 1687 |
+
for _ in range(num_layers):
|
| 1688 |
+
if not dual_cross_attention:
|
| 1689 |
+
attentions.append(
|
| 1690 |
+
Transformer2DModel(
|
| 1691 |
+
num_attention_heads,
|
| 1692 |
+
in_channels // num_attention_heads,
|
| 1693 |
+
in_channels=in_channels,
|
| 1694 |
+
num_layers=transformer_layers_per_block,
|
| 1695 |
+
cross_attention_dim=cross_attention_dim,
|
| 1696 |
+
norm_num_groups=resnet_groups,
|
| 1697 |
+
use_linear_projection=use_linear_projection,
|
| 1698 |
+
upcast_attention=upcast_attention,
|
| 1699 |
+
attention_type=attention_type,
|
| 1700 |
+
)
|
| 1701 |
+
)
|
| 1702 |
+
else:
|
| 1703 |
+
attentions.append(
|
| 1704 |
+
DualTransformer2DModel(
|
| 1705 |
+
num_attention_heads,
|
| 1706 |
+
in_channels // num_attention_heads,
|
| 1707 |
+
in_channels=in_channels,
|
| 1708 |
+
num_layers=1,
|
| 1709 |
+
cross_attention_dim=cross_attention_dim,
|
| 1710 |
+
norm_num_groups=resnet_groups,
|
| 1711 |
+
)
|
| 1712 |
+
)
|
| 1713 |
+
resnets.append(
|
| 1714 |
+
ResnetBlock2D(
|
| 1715 |
+
in_channels=in_channels,
|
| 1716 |
+
out_channels=in_channels,
|
| 1717 |
+
temb_channels=temb_channels,
|
| 1718 |
+
eps=resnet_eps,
|
| 1719 |
+
groups=resnet_groups,
|
| 1720 |
+
dropout=dropout,
|
| 1721 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 1722 |
+
non_linearity=resnet_act_fn,
|
| 1723 |
+
output_scale_factor=output_scale_factor,
|
| 1724 |
+
pre_norm=resnet_pre_norm,
|
| 1725 |
+
)
|
| 1726 |
+
)
|
| 1727 |
+
motion_modules.append(
|
| 1728 |
+
TransformerTemporalModel(
|
| 1729 |
+
num_attention_heads=temporal_num_attention_heads,
|
| 1730 |
+
attention_head_dim=in_channels // temporal_num_attention_heads,
|
| 1731 |
+
in_channels=in_channels,
|
| 1732 |
+
norm_num_groups=resnet_groups,
|
| 1733 |
+
cross_attention_dim=temporal_cross_attention_dim,
|
| 1734 |
+
attention_bias=False,
|
| 1735 |
+
positional_embeddings="sinusoidal",
|
| 1736 |
+
num_positional_embeddings=temporal_max_seq_length,
|
| 1737 |
+
activation_fn="geglu",
|
| 1738 |
+
)
|
| 1739 |
+
)
|
| 1740 |
+
|
| 1741 |
+
self.attentions = nn.ModuleList(attentions)
|
| 1742 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1743 |
+
self.motion_modules = nn.ModuleList(motion_modules)
|
| 1744 |
+
|
| 1745 |
+
self.gradient_checkpointing = False
|
| 1746 |
+
|
| 1747 |
+
def forward(
|
| 1748 |
+
self,
|
| 1749 |
+
hidden_states: torch.FloatTensor,
|
| 1750 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 1751 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 1752 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1753 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 1754 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 1755 |
+
num_frames: int = 1,
|
| 1756 |
+
mid_block_add_sample: Optional[Tuple[torch.Tensor]] = None,
|
| 1757 |
+
) -> torch.FloatTensor:
|
| 1758 |
+
lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
|
| 1759 |
+
hidden_states = self.resnets[0](hidden_states, temb, scale=lora_scale)
|
| 1760 |
+
|
| 1761 |
+
blocks = zip(self.attentions, self.resnets[1:], self.motion_modules)
|
| 1762 |
+
for attn, resnet, motion_module in blocks:
|
| 1763 |
+
if self.training and self.gradient_checkpointing:
|
| 1764 |
+
|
| 1765 |
+
def create_custom_forward(module, return_dict=None):
|
| 1766 |
+
def custom_forward(*inputs):
|
| 1767 |
+
if return_dict is not None:
|
| 1768 |
+
return module(*inputs, return_dict=return_dict)
|
| 1769 |
+
else:
|
| 1770 |
+
return module(*inputs)
|
| 1771 |
+
|
| 1772 |
+
return custom_forward
|
| 1773 |
+
|
| 1774 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 1775 |
+
hidden_states = attn(
|
| 1776 |
+
hidden_states,
|
| 1777 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1778 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1779 |
+
attention_mask=attention_mask,
|
| 1780 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1781 |
+
return_dict=False,
|
| 1782 |
+
)[0]
|
| 1783 |
+
##########
|
| 1784 |
+
hidden_states = resnet(hidden_states, temb, scale=lora_scale)
|
| 1785 |
+
if mid_block_add_sample is not None:
|
| 1786 |
+
hidden_states = hidden_states + mid_block_add_sample
|
| 1787 |
+
################################################################
|
| 1788 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1789 |
+
create_custom_forward(motion_module),
|
| 1790 |
+
hidden_states.requires_grad_(),
|
| 1791 |
+
temb,
|
| 1792 |
+
num_frames,
|
| 1793 |
+
**ckpt_kwargs,
|
| 1794 |
+
)
|
| 1795 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1796 |
+
create_custom_forward(resnet),
|
| 1797 |
+
hidden_states,
|
| 1798 |
+
temb,
|
| 1799 |
+
**ckpt_kwargs,
|
| 1800 |
+
)
|
| 1801 |
+
else:
|
| 1802 |
+
hidden_states = attn(
|
| 1803 |
+
hidden_states,
|
| 1804 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1805 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1806 |
+
attention_mask=attention_mask,
|
| 1807 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1808 |
+
return_dict=False,
|
| 1809 |
+
)[0]
|
| 1810 |
+
##########
|
| 1811 |
+
hidden_states = resnet(hidden_states, temb, scale=lora_scale)
|
| 1812 |
+
if mid_block_add_sample is not None:
|
| 1813 |
+
hidden_states = hidden_states + mid_block_add_sample
|
| 1814 |
+
################################################################
|
| 1815 |
+
hidden_states = motion_module(
|
| 1816 |
+
hidden_states,
|
| 1817 |
+
num_frames=num_frames,
|
| 1818 |
+
)
|
| 1819 |
+
hidden_states = resnet(hidden_states, temb, scale=lora_scale)
|
| 1820 |
+
|
| 1821 |
+
return hidden_states
|
| 1822 |
+
|
| 1823 |
+
|
| 1824 |
+
class MidBlockTemporalDecoder(nn.Module):
|
| 1825 |
+
def __init__(
|
| 1826 |
+
self,
|
| 1827 |
+
in_channels: int,
|
| 1828 |
+
out_channels: int,
|
| 1829 |
+
attention_head_dim: int = 512,
|
| 1830 |
+
num_layers: int = 1,
|
| 1831 |
+
upcast_attention: bool = False,
|
| 1832 |
+
):
|
| 1833 |
+
super().__init__()
|
| 1834 |
+
|
| 1835 |
+
resnets = []
|
| 1836 |
+
attentions = []
|
| 1837 |
+
for i in range(num_layers):
|
| 1838 |
+
input_channels = in_channels if i == 0 else out_channels
|
| 1839 |
+
resnets.append(
|
| 1840 |
+
SpatioTemporalResBlock(
|
| 1841 |
+
in_channels=input_channels,
|
| 1842 |
+
out_channels=out_channels,
|
| 1843 |
+
temb_channels=None,
|
| 1844 |
+
eps=1e-6,
|
| 1845 |
+
temporal_eps=1e-5,
|
| 1846 |
+
merge_factor=0.0,
|
| 1847 |
+
merge_strategy="learned",
|
| 1848 |
+
switch_spatial_to_temporal_mix=True,
|
| 1849 |
+
)
|
| 1850 |
+
)
|
| 1851 |
+
|
| 1852 |
+
attentions.append(
|
| 1853 |
+
Attention(
|
| 1854 |
+
query_dim=in_channels,
|
| 1855 |
+
heads=in_channels // attention_head_dim,
|
| 1856 |
+
dim_head=attention_head_dim,
|
| 1857 |
+
eps=1e-6,
|
| 1858 |
+
upcast_attention=upcast_attention,
|
| 1859 |
+
norm_num_groups=32,
|
| 1860 |
+
bias=True,
|
| 1861 |
+
residual_connection=True,
|
| 1862 |
+
)
|
| 1863 |
+
)
|
| 1864 |
+
|
| 1865 |
+
self.attentions = nn.ModuleList(attentions)
|
| 1866 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1867 |
+
|
| 1868 |
+
def forward(
|
| 1869 |
+
self,
|
| 1870 |
+
hidden_states: torch.FloatTensor,
|
| 1871 |
+
image_only_indicator: torch.FloatTensor,
|
| 1872 |
+
):
|
| 1873 |
+
hidden_states = self.resnets[0](
|
| 1874 |
+
hidden_states,
|
| 1875 |
+
image_only_indicator=image_only_indicator,
|
| 1876 |
+
)
|
| 1877 |
+
for resnet, attn in zip(self.resnets[1:], self.attentions):
|
| 1878 |
+
hidden_states = attn(hidden_states)
|
| 1879 |
+
hidden_states = resnet(
|
| 1880 |
+
hidden_states,
|
| 1881 |
+
image_only_indicator=image_only_indicator,
|
| 1882 |
+
)
|
| 1883 |
+
|
| 1884 |
+
return hidden_states
|
| 1885 |
+
|
| 1886 |
+
|
| 1887 |
+
class UpBlockTemporalDecoder(nn.Module):
|
| 1888 |
+
def __init__(
|
| 1889 |
+
self,
|
| 1890 |
+
in_channels: int,
|
| 1891 |
+
out_channels: int,
|
| 1892 |
+
num_layers: int = 1,
|
| 1893 |
+
add_upsample: bool = True,
|
| 1894 |
+
):
|
| 1895 |
+
super().__init__()
|
| 1896 |
+
resnets = []
|
| 1897 |
+
for i in range(num_layers):
|
| 1898 |
+
input_channels = in_channels if i == 0 else out_channels
|
| 1899 |
+
|
| 1900 |
+
resnets.append(
|
| 1901 |
+
SpatioTemporalResBlock(
|
| 1902 |
+
in_channels=input_channels,
|
| 1903 |
+
out_channels=out_channels,
|
| 1904 |
+
temb_channels=None,
|
| 1905 |
+
eps=1e-6,
|
| 1906 |
+
temporal_eps=1e-5,
|
| 1907 |
+
merge_factor=0.0,
|
| 1908 |
+
merge_strategy="learned",
|
| 1909 |
+
switch_spatial_to_temporal_mix=True,
|
| 1910 |
+
)
|
| 1911 |
+
)
|
| 1912 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1913 |
+
|
| 1914 |
+
if add_upsample:
|
| 1915 |
+
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
|
| 1916 |
+
else:
|
| 1917 |
+
self.upsamplers = None
|
| 1918 |
+
|
| 1919 |
+
def forward(
|
| 1920 |
+
self,
|
| 1921 |
+
hidden_states: torch.FloatTensor,
|
| 1922 |
+
image_only_indicator: torch.FloatTensor,
|
| 1923 |
+
) -> torch.FloatTensor:
|
| 1924 |
+
for resnet in self.resnets:
|
| 1925 |
+
hidden_states = resnet(
|
| 1926 |
+
hidden_states,
|
| 1927 |
+
image_only_indicator=image_only_indicator,
|
| 1928 |
+
)
|
| 1929 |
+
|
| 1930 |
+
if self.upsamplers is not None:
|
| 1931 |
+
for upsampler in self.upsamplers:
|
| 1932 |
+
hidden_states = upsampler(hidden_states)
|
| 1933 |
+
|
| 1934 |
+
return hidden_states
|
| 1935 |
+
|
| 1936 |
+
|
| 1937 |
+
class UNetMidBlockSpatioTemporal(nn.Module):
|
| 1938 |
+
def __init__(
|
| 1939 |
+
self,
|
| 1940 |
+
in_channels: int,
|
| 1941 |
+
temb_channels: int,
|
| 1942 |
+
num_layers: int = 1,
|
| 1943 |
+
transformer_layers_per_block: Union[int, Tuple[int]] = 1,
|
| 1944 |
+
num_attention_heads: int = 1,
|
| 1945 |
+
cross_attention_dim: int = 1280,
|
| 1946 |
+
):
|
| 1947 |
+
super().__init__()
|
| 1948 |
+
|
| 1949 |
+
self.has_cross_attention = True
|
| 1950 |
+
self.num_attention_heads = num_attention_heads
|
| 1951 |
+
|
| 1952 |
+
# support for variable transformer layers per block
|
| 1953 |
+
if isinstance(transformer_layers_per_block, int):
|
| 1954 |
+
transformer_layers_per_block = [transformer_layers_per_block] * num_layers
|
| 1955 |
+
|
| 1956 |
+
# there is always at least one resnet
|
| 1957 |
+
resnets = [
|
| 1958 |
+
SpatioTemporalResBlock(
|
| 1959 |
+
in_channels=in_channels,
|
| 1960 |
+
out_channels=in_channels,
|
| 1961 |
+
temb_channels=temb_channels,
|
| 1962 |
+
eps=1e-5,
|
| 1963 |
+
)
|
| 1964 |
+
]
|
| 1965 |
+
attentions = []
|
| 1966 |
+
|
| 1967 |
+
for i in range(num_layers):
|
| 1968 |
+
attentions.append(
|
| 1969 |
+
TransformerSpatioTemporalModel(
|
| 1970 |
+
num_attention_heads,
|
| 1971 |
+
in_channels // num_attention_heads,
|
| 1972 |
+
in_channels=in_channels,
|
| 1973 |
+
num_layers=transformer_layers_per_block[i],
|
| 1974 |
+
cross_attention_dim=cross_attention_dim,
|
| 1975 |
+
)
|
| 1976 |
+
)
|
| 1977 |
+
|
| 1978 |
+
resnets.append(
|
| 1979 |
+
SpatioTemporalResBlock(
|
| 1980 |
+
in_channels=in_channels,
|
| 1981 |
+
out_channels=in_channels,
|
| 1982 |
+
temb_channels=temb_channels,
|
| 1983 |
+
eps=1e-5,
|
| 1984 |
+
)
|
| 1985 |
+
)
|
| 1986 |
+
|
| 1987 |
+
self.attentions = nn.ModuleList(attentions)
|
| 1988 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1989 |
+
|
| 1990 |
+
self.gradient_checkpointing = False
|
| 1991 |
+
|
| 1992 |
+
def forward(
|
| 1993 |
+
self,
|
| 1994 |
+
hidden_states: torch.FloatTensor,
|
| 1995 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 1996 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 1997 |
+
image_only_indicator: Optional[torch.Tensor] = None,
|
| 1998 |
+
) -> torch.FloatTensor:
|
| 1999 |
+
hidden_states = self.resnets[0](
|
| 2000 |
+
hidden_states,
|
| 2001 |
+
temb,
|
| 2002 |
+
image_only_indicator=image_only_indicator,
|
| 2003 |
+
)
|
| 2004 |
+
|
| 2005 |
+
for attn, resnet in zip(self.attentions, self.resnets[1:]):
|
| 2006 |
+
if self.training and self.gradient_checkpointing: # TODO
|
| 2007 |
+
|
| 2008 |
+
def create_custom_forward(module, return_dict=None):
|
| 2009 |
+
def custom_forward(*inputs):
|
| 2010 |
+
if return_dict is not None:
|
| 2011 |
+
return module(*inputs, return_dict=return_dict)
|
| 2012 |
+
else:
|
| 2013 |
+
return module(*inputs)
|
| 2014 |
+
|
| 2015 |
+
return custom_forward
|
| 2016 |
+
|
| 2017 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 2018 |
+
hidden_states = attn(
|
| 2019 |
+
hidden_states,
|
| 2020 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 2021 |
+
image_only_indicator=image_only_indicator,
|
| 2022 |
+
return_dict=False,
|
| 2023 |
+
)[0]
|
| 2024 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 2025 |
+
create_custom_forward(resnet),
|
| 2026 |
+
hidden_states,
|
| 2027 |
+
temb,
|
| 2028 |
+
image_only_indicator,
|
| 2029 |
+
**ckpt_kwargs,
|
| 2030 |
+
)
|
| 2031 |
+
else:
|
| 2032 |
+
hidden_states = attn(
|
| 2033 |
+
hidden_states,
|
| 2034 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 2035 |
+
image_only_indicator=image_only_indicator,
|
| 2036 |
+
return_dict=False,
|
| 2037 |
+
)[0]
|
| 2038 |
+
hidden_states = resnet(
|
| 2039 |
+
hidden_states,
|
| 2040 |
+
temb,
|
| 2041 |
+
image_only_indicator=image_only_indicator,
|
| 2042 |
+
)
|
| 2043 |
+
|
| 2044 |
+
return hidden_states
|
| 2045 |
+
|
| 2046 |
+
|
| 2047 |
+
class DownBlockSpatioTemporal(nn.Module):
|
| 2048 |
+
def __init__(
|
| 2049 |
+
self,
|
| 2050 |
+
in_channels: int,
|
| 2051 |
+
out_channels: int,
|
| 2052 |
+
temb_channels: int,
|
| 2053 |
+
num_layers: int = 1,
|
| 2054 |
+
add_downsample: bool = True,
|
| 2055 |
+
):
|
| 2056 |
+
super().__init__()
|
| 2057 |
+
resnets = []
|
| 2058 |
+
|
| 2059 |
+
for i in range(num_layers):
|
| 2060 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 2061 |
+
resnets.append(
|
| 2062 |
+
SpatioTemporalResBlock(
|
| 2063 |
+
in_channels=in_channels,
|
| 2064 |
+
out_channels=out_channels,
|
| 2065 |
+
temb_channels=temb_channels,
|
| 2066 |
+
eps=1e-5,
|
| 2067 |
+
)
|
| 2068 |
+
)
|
| 2069 |
+
|
| 2070 |
+
self.resnets = nn.ModuleList(resnets)
|
| 2071 |
+
|
| 2072 |
+
if add_downsample:
|
| 2073 |
+
self.downsamplers = nn.ModuleList(
|
| 2074 |
+
[
|
| 2075 |
+
Downsample2D(
|
| 2076 |
+
out_channels,
|
| 2077 |
+
use_conv=True,
|
| 2078 |
+
out_channels=out_channels,
|
| 2079 |
+
name="op",
|
| 2080 |
+
)
|
| 2081 |
+
]
|
| 2082 |
+
)
|
| 2083 |
+
else:
|
| 2084 |
+
self.downsamplers = None
|
| 2085 |
+
|
| 2086 |
+
self.gradient_checkpointing = False
|
| 2087 |
+
|
| 2088 |
+
def forward(
|
| 2089 |
+
self,
|
| 2090 |
+
hidden_states: torch.FloatTensor,
|
| 2091 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 2092 |
+
image_only_indicator: Optional[torch.Tensor] = None,
|
| 2093 |
+
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
|
| 2094 |
+
output_states = ()
|
| 2095 |
+
for resnet in self.resnets:
|
| 2096 |
+
if self.training and self.gradient_checkpointing:
|
| 2097 |
+
|
| 2098 |
+
def create_custom_forward(module):
|
| 2099 |
+
def custom_forward(*inputs):
|
| 2100 |
+
return module(*inputs)
|
| 2101 |
+
|
| 2102 |
+
return custom_forward
|
| 2103 |
+
|
| 2104 |
+
if is_torch_version(">=", "1.11.0"):
|
| 2105 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 2106 |
+
create_custom_forward(resnet),
|
| 2107 |
+
hidden_states,
|
| 2108 |
+
temb,
|
| 2109 |
+
image_only_indicator,
|
| 2110 |
+
use_reentrant=False,
|
| 2111 |
+
)
|
| 2112 |
+
else:
|
| 2113 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 2114 |
+
create_custom_forward(resnet),
|
| 2115 |
+
hidden_states,
|
| 2116 |
+
temb,
|
| 2117 |
+
image_only_indicator,
|
| 2118 |
+
)
|
| 2119 |
+
else:
|
| 2120 |
+
hidden_states = resnet(
|
| 2121 |
+
hidden_states,
|
| 2122 |
+
temb,
|
| 2123 |
+
image_only_indicator=image_only_indicator,
|
| 2124 |
+
)
|
| 2125 |
+
|
| 2126 |
+
output_states = output_states + (hidden_states,)
|
| 2127 |
+
|
| 2128 |
+
if self.downsamplers is not None:
|
| 2129 |
+
for downsampler in self.downsamplers:
|
| 2130 |
+
hidden_states = downsampler(hidden_states)
|
| 2131 |
+
|
| 2132 |
+
output_states = output_states + (hidden_states,)
|
| 2133 |
+
|
| 2134 |
+
return hidden_states, output_states
|
| 2135 |
+
|
| 2136 |
+
|
| 2137 |
+
class CrossAttnDownBlockSpatioTemporal(nn.Module):
|
| 2138 |
+
def __init__(
|
| 2139 |
+
self,
|
| 2140 |
+
in_channels: int,
|
| 2141 |
+
out_channels: int,
|
| 2142 |
+
temb_channels: int,
|
| 2143 |
+
num_layers: int = 1,
|
| 2144 |
+
transformer_layers_per_block: Union[int, Tuple[int]] = 1,
|
| 2145 |
+
num_attention_heads: int = 1,
|
| 2146 |
+
cross_attention_dim: int = 1280,
|
| 2147 |
+
add_downsample: bool = True,
|
| 2148 |
+
):
|
| 2149 |
+
super().__init__()
|
| 2150 |
+
resnets = []
|
| 2151 |
+
attentions = []
|
| 2152 |
+
|
| 2153 |
+
self.has_cross_attention = True
|
| 2154 |
+
self.num_attention_heads = num_attention_heads
|
| 2155 |
+
if isinstance(transformer_layers_per_block, int):
|
| 2156 |
+
transformer_layers_per_block = [transformer_layers_per_block] * num_layers
|
| 2157 |
+
|
| 2158 |
+
for i in range(num_layers):
|
| 2159 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 2160 |
+
resnets.append(
|
| 2161 |
+
SpatioTemporalResBlock(
|
| 2162 |
+
in_channels=in_channels,
|
| 2163 |
+
out_channels=out_channels,
|
| 2164 |
+
temb_channels=temb_channels,
|
| 2165 |
+
eps=1e-6,
|
| 2166 |
+
)
|
| 2167 |
+
)
|
| 2168 |
+
attentions.append(
|
| 2169 |
+
TransformerSpatioTemporalModel(
|
| 2170 |
+
num_attention_heads,
|
| 2171 |
+
out_channels // num_attention_heads,
|
| 2172 |
+
in_channels=out_channels,
|
| 2173 |
+
num_layers=transformer_layers_per_block[i],
|
| 2174 |
+
cross_attention_dim=cross_attention_dim,
|
| 2175 |
+
)
|
| 2176 |
+
)
|
| 2177 |
+
|
| 2178 |
+
self.attentions = nn.ModuleList(attentions)
|
| 2179 |
+
self.resnets = nn.ModuleList(resnets)
|
| 2180 |
+
|
| 2181 |
+
if add_downsample:
|
| 2182 |
+
self.downsamplers = nn.ModuleList(
|
| 2183 |
+
[
|
| 2184 |
+
Downsample2D(
|
| 2185 |
+
out_channels,
|
| 2186 |
+
use_conv=True,
|
| 2187 |
+
out_channels=out_channels,
|
| 2188 |
+
padding=1,
|
| 2189 |
+
name="op",
|
| 2190 |
+
)
|
| 2191 |
+
]
|
| 2192 |
+
)
|
| 2193 |
+
else:
|
| 2194 |
+
self.downsamplers = None
|
| 2195 |
+
|
| 2196 |
+
self.gradient_checkpointing = False
|
| 2197 |
+
|
| 2198 |
+
def forward(
|
| 2199 |
+
self,
|
| 2200 |
+
hidden_states: torch.FloatTensor,
|
| 2201 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 2202 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 2203 |
+
image_only_indicator: Optional[torch.Tensor] = None,
|
| 2204 |
+
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
|
| 2205 |
+
output_states = ()
|
| 2206 |
+
|
| 2207 |
+
blocks = list(zip(self.resnets, self.attentions))
|
| 2208 |
+
for resnet, attn in blocks:
|
| 2209 |
+
if self.training and self.gradient_checkpointing: # TODO
|
| 2210 |
+
|
| 2211 |
+
def create_custom_forward(module, return_dict=None):
|
| 2212 |
+
def custom_forward(*inputs):
|
| 2213 |
+
if return_dict is not None:
|
| 2214 |
+
return module(*inputs, return_dict=return_dict)
|
| 2215 |
+
else:
|
| 2216 |
+
return module(*inputs)
|
| 2217 |
+
|
| 2218 |
+
return custom_forward
|
| 2219 |
+
|
| 2220 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 2221 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 2222 |
+
create_custom_forward(resnet),
|
| 2223 |
+
hidden_states,
|
| 2224 |
+
temb,
|
| 2225 |
+
image_only_indicator,
|
| 2226 |
+
**ckpt_kwargs,
|
| 2227 |
+
)
|
| 2228 |
+
|
| 2229 |
+
hidden_states = attn(
|
| 2230 |
+
hidden_states,
|
| 2231 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 2232 |
+
image_only_indicator=image_only_indicator,
|
| 2233 |
+
return_dict=False,
|
| 2234 |
+
)[0]
|
| 2235 |
+
else:
|
| 2236 |
+
hidden_states = resnet(
|
| 2237 |
+
hidden_states,
|
| 2238 |
+
temb,
|
| 2239 |
+
image_only_indicator=image_only_indicator,
|
| 2240 |
+
)
|
| 2241 |
+
hidden_states = attn(
|
| 2242 |
+
hidden_states,
|
| 2243 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 2244 |
+
image_only_indicator=image_only_indicator,
|
| 2245 |
+
return_dict=False,
|
| 2246 |
+
)[0]
|
| 2247 |
+
|
| 2248 |
+
output_states = output_states + (hidden_states,)
|
| 2249 |
+
|
| 2250 |
+
if self.downsamplers is not None:
|
| 2251 |
+
for downsampler in self.downsamplers:
|
| 2252 |
+
hidden_states = downsampler(hidden_states)
|
| 2253 |
+
|
| 2254 |
+
output_states = output_states + (hidden_states,)
|
| 2255 |
+
|
| 2256 |
+
return hidden_states, output_states
|
| 2257 |
+
|
| 2258 |
+
|
| 2259 |
+
class UpBlockSpatioTemporal(nn.Module):
|
| 2260 |
+
def __init__(
|
| 2261 |
+
self,
|
| 2262 |
+
in_channels: int,
|
| 2263 |
+
prev_output_channel: int,
|
| 2264 |
+
out_channels: int,
|
| 2265 |
+
temb_channels: int,
|
| 2266 |
+
resolution_idx: Optional[int] = None,
|
| 2267 |
+
num_layers: int = 1,
|
| 2268 |
+
resnet_eps: float = 1e-6,
|
| 2269 |
+
add_upsample: bool = True,
|
| 2270 |
+
):
|
| 2271 |
+
super().__init__()
|
| 2272 |
+
resnets = []
|
| 2273 |
+
|
| 2274 |
+
for i in range(num_layers):
|
| 2275 |
+
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
|
| 2276 |
+
resnet_in_channels = prev_output_channel if i == 0 else out_channels
|
| 2277 |
+
|
| 2278 |
+
resnets.append(
|
| 2279 |
+
SpatioTemporalResBlock(
|
| 2280 |
+
in_channels=resnet_in_channels + res_skip_channels,
|
| 2281 |
+
out_channels=out_channels,
|
| 2282 |
+
temb_channels=temb_channels,
|
| 2283 |
+
eps=resnet_eps,
|
| 2284 |
+
)
|
| 2285 |
+
)
|
| 2286 |
+
|
| 2287 |
+
self.resnets = nn.ModuleList(resnets)
|
| 2288 |
+
|
| 2289 |
+
if add_upsample:
|
| 2290 |
+
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
|
| 2291 |
+
else:
|
| 2292 |
+
self.upsamplers = None
|
| 2293 |
+
|
| 2294 |
+
self.gradient_checkpointing = False
|
| 2295 |
+
self.resolution_idx = resolution_idx
|
| 2296 |
+
|
| 2297 |
+
def forward(
|
| 2298 |
+
self,
|
| 2299 |
+
hidden_states: torch.FloatTensor,
|
| 2300 |
+
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
|
| 2301 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 2302 |
+
image_only_indicator: Optional[torch.Tensor] = None,
|
| 2303 |
+
) -> torch.FloatTensor:
|
| 2304 |
+
for resnet in self.resnets:
|
| 2305 |
+
# pop res hidden states
|
| 2306 |
+
res_hidden_states = res_hidden_states_tuple[-1]
|
| 2307 |
+
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
|
| 2308 |
+
|
| 2309 |
+
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
|
| 2310 |
+
|
| 2311 |
+
if self.training and self.gradient_checkpointing:
|
| 2312 |
+
|
| 2313 |
+
def create_custom_forward(module):
|
| 2314 |
+
def custom_forward(*inputs):
|
| 2315 |
+
return module(*inputs)
|
| 2316 |
+
|
| 2317 |
+
return custom_forward
|
| 2318 |
+
|
| 2319 |
+
if is_torch_version(">=", "1.11.0"):
|
| 2320 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 2321 |
+
create_custom_forward(resnet),
|
| 2322 |
+
hidden_states,
|
| 2323 |
+
temb,
|
| 2324 |
+
image_only_indicator,
|
| 2325 |
+
use_reentrant=False,
|
| 2326 |
+
)
|
| 2327 |
+
else:
|
| 2328 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 2329 |
+
create_custom_forward(resnet),
|
| 2330 |
+
hidden_states,
|
| 2331 |
+
temb,
|
| 2332 |
+
image_only_indicator,
|
| 2333 |
+
)
|
| 2334 |
+
else:
|
| 2335 |
+
hidden_states = resnet(
|
| 2336 |
+
hidden_states,
|
| 2337 |
+
temb,
|
| 2338 |
+
image_only_indicator=image_only_indicator,
|
| 2339 |
+
)
|
| 2340 |
+
|
| 2341 |
+
if self.upsamplers is not None:
|
| 2342 |
+
for upsampler in self.upsamplers:
|
| 2343 |
+
hidden_states = upsampler(hidden_states)
|
| 2344 |
+
|
| 2345 |
+
return hidden_states
|
| 2346 |
+
|
| 2347 |
+
|
| 2348 |
+
class CrossAttnUpBlockSpatioTemporal(nn.Module):
|
| 2349 |
+
def __init__(
|
| 2350 |
+
self,
|
| 2351 |
+
in_channels: int,
|
| 2352 |
+
out_channels: int,
|
| 2353 |
+
prev_output_channel: int,
|
| 2354 |
+
temb_channels: int,
|
| 2355 |
+
resolution_idx: Optional[int] = None,
|
| 2356 |
+
num_layers: int = 1,
|
| 2357 |
+
transformer_layers_per_block: Union[int, Tuple[int]] = 1,
|
| 2358 |
+
resnet_eps: float = 1e-6,
|
| 2359 |
+
num_attention_heads: int = 1,
|
| 2360 |
+
cross_attention_dim: int = 1280,
|
| 2361 |
+
add_upsample: bool = True,
|
| 2362 |
+
):
|
| 2363 |
+
super().__init__()
|
| 2364 |
+
resnets = []
|
| 2365 |
+
attentions = []
|
| 2366 |
+
|
| 2367 |
+
self.has_cross_attention = True
|
| 2368 |
+
self.num_attention_heads = num_attention_heads
|
| 2369 |
+
|
| 2370 |
+
if isinstance(transformer_layers_per_block, int):
|
| 2371 |
+
transformer_layers_per_block = [transformer_layers_per_block] * num_layers
|
| 2372 |
+
|
| 2373 |
+
for i in range(num_layers):
|
| 2374 |
+
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
|
| 2375 |
+
resnet_in_channels = prev_output_channel if i == 0 else out_channels
|
| 2376 |
+
|
| 2377 |
+
resnets.append(
|
| 2378 |
+
SpatioTemporalResBlock(
|
| 2379 |
+
in_channels=resnet_in_channels + res_skip_channels,
|
| 2380 |
+
out_channels=out_channels,
|
| 2381 |
+
temb_channels=temb_channels,
|
| 2382 |
+
eps=resnet_eps,
|
| 2383 |
+
)
|
| 2384 |
+
)
|
| 2385 |
+
attentions.append(
|
| 2386 |
+
TransformerSpatioTemporalModel(
|
| 2387 |
+
num_attention_heads,
|
| 2388 |
+
out_channels // num_attention_heads,
|
| 2389 |
+
in_channels=out_channels,
|
| 2390 |
+
num_layers=transformer_layers_per_block[i],
|
| 2391 |
+
cross_attention_dim=cross_attention_dim,
|
| 2392 |
+
)
|
| 2393 |
+
)
|
| 2394 |
+
|
| 2395 |
+
self.attentions = nn.ModuleList(attentions)
|
| 2396 |
+
self.resnets = nn.ModuleList(resnets)
|
| 2397 |
+
|
| 2398 |
+
if add_upsample:
|
| 2399 |
+
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
|
| 2400 |
+
else:
|
| 2401 |
+
self.upsamplers = None
|
| 2402 |
+
|
| 2403 |
+
self.gradient_checkpointing = False
|
| 2404 |
+
self.resolution_idx = resolution_idx
|
| 2405 |
+
|
| 2406 |
+
def forward(
|
| 2407 |
+
self,
|
| 2408 |
+
hidden_states: torch.FloatTensor,
|
| 2409 |
+
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
|
| 2410 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 2411 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 2412 |
+
image_only_indicator: Optional[torch.Tensor] = None,
|
| 2413 |
+
) -> torch.FloatTensor:
|
| 2414 |
+
for resnet, attn in zip(self.resnets, self.attentions):
|
| 2415 |
+
# pop res hidden states
|
| 2416 |
+
res_hidden_states = res_hidden_states_tuple[-1]
|
| 2417 |
+
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
|
| 2418 |
+
|
| 2419 |
+
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
|
| 2420 |
+
|
| 2421 |
+
if self.training and self.gradient_checkpointing: # TODO
|
| 2422 |
+
|
| 2423 |
+
def create_custom_forward(module, return_dict=None):
|
| 2424 |
+
def custom_forward(*inputs):
|
| 2425 |
+
if return_dict is not None:
|
| 2426 |
+
return module(*inputs, return_dict=return_dict)
|
| 2427 |
+
else:
|
| 2428 |
+
return module(*inputs)
|
| 2429 |
+
|
| 2430 |
+
return custom_forward
|
| 2431 |
+
|
| 2432 |
+
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 2433 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 2434 |
+
create_custom_forward(resnet),
|
| 2435 |
+
hidden_states,
|
| 2436 |
+
temb,
|
| 2437 |
+
image_only_indicator,
|
| 2438 |
+
**ckpt_kwargs,
|
| 2439 |
+
)
|
| 2440 |
+
hidden_states = attn(
|
| 2441 |
+
hidden_states,
|
| 2442 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 2443 |
+
image_only_indicator=image_only_indicator,
|
| 2444 |
+
return_dict=False,
|
| 2445 |
+
)[0]
|
| 2446 |
+
else:
|
| 2447 |
+
hidden_states = resnet(
|
| 2448 |
+
hidden_states,
|
| 2449 |
+
temb,
|
| 2450 |
+
image_only_indicator=image_only_indicator,
|
| 2451 |
+
)
|
| 2452 |
+
hidden_states = attn(
|
| 2453 |
+
hidden_states,
|
| 2454 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 2455 |
+
image_only_indicator=image_only_indicator,
|
| 2456 |
+
return_dict=False,
|
| 2457 |
+
)[0]
|
| 2458 |
+
|
| 2459 |
+
if self.upsamplers is not None:
|
| 2460 |
+
for upsampler in self.upsamplers:
|
| 2461 |
+
hidden_states = upsampler(hidden_states)
|
| 2462 |
+
|
| 2463 |
+
return hidden_states
|
libs/unet_motion_model.py
ADDED
|
@@ -0,0 +1,975 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from typing import Any, Dict, Optional, Tuple, Union
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
import torch.nn as nn
|
| 18 |
+
import torch.utils.checkpoint
|
| 19 |
+
|
| 20 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 21 |
+
from diffusers.loaders import UNet2DConditionLoadersMixin
|
| 22 |
+
from diffusers.utils import logging, deprecate
|
| 23 |
+
from diffusers.models.attention_processor import (
|
| 24 |
+
ADDED_KV_ATTENTION_PROCESSORS,
|
| 25 |
+
CROSS_ATTENTION_PROCESSORS,
|
| 26 |
+
AttentionProcessor,
|
| 27 |
+
AttnAddedKVProcessor,
|
| 28 |
+
AttnProcessor,
|
| 29 |
+
)
|
| 30 |
+
# from diffusers.models.controlnet import ControlNetConditioningEmbedding
|
| 31 |
+
from diffusers.models.embeddings import TimestepEmbedding, Timesteps
|
| 32 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 33 |
+
from diffusers.models.transformers.transformer_temporal import TransformerTemporalModel
|
| 34 |
+
from diffusers.models.unets.unet_2d_blocks import UNetMidBlock2DCrossAttn
|
| 35 |
+
from .unet_2d_condition import UNet2DConditionModel
|
| 36 |
+
from .unet_3d_blocks import (
|
| 37 |
+
CrossAttnDownBlockMotion,
|
| 38 |
+
CrossAttnUpBlockMotion,
|
| 39 |
+
DownBlockMotion,
|
| 40 |
+
UNetMidBlockCrossAttnMotion,
|
| 41 |
+
UpBlockMotion,
|
| 42 |
+
get_down_block,
|
| 43 |
+
get_up_block,
|
| 44 |
+
)
|
| 45 |
+
from diffusers.models.unets.unet_3d_condition import UNet3DConditionOutput
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class MotionModules(nn.Module):
|
| 52 |
+
def __init__(
|
| 53 |
+
self,
|
| 54 |
+
in_channels: int,
|
| 55 |
+
layers_per_block: int = 2,
|
| 56 |
+
num_attention_heads: int = 8,
|
| 57 |
+
attention_bias: bool = False,
|
| 58 |
+
cross_attention_dim: Optional[int] = None,
|
| 59 |
+
activation_fn: str = "geglu",
|
| 60 |
+
norm_num_groups: int = 32,
|
| 61 |
+
max_seq_length: int = 32,
|
| 62 |
+
):
|
| 63 |
+
super().__init__()
|
| 64 |
+
self.motion_modules = nn.ModuleList([])
|
| 65 |
+
|
| 66 |
+
for i in range(layers_per_block):
|
| 67 |
+
self.motion_modules.append(
|
| 68 |
+
TransformerTemporalModel(
|
| 69 |
+
in_channels=in_channels,
|
| 70 |
+
norm_num_groups=norm_num_groups,
|
| 71 |
+
cross_attention_dim=cross_attention_dim,
|
| 72 |
+
activation_fn=activation_fn,
|
| 73 |
+
attention_bias=attention_bias,
|
| 74 |
+
num_attention_heads=num_attention_heads,
|
| 75 |
+
attention_head_dim=in_channels // num_attention_heads,
|
| 76 |
+
positional_embeddings="sinusoidal",
|
| 77 |
+
num_positional_embeddings=max_seq_length,
|
| 78 |
+
)
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class MotionAdapter(ModelMixin, ConfigMixin):
|
| 83 |
+
@register_to_config
|
| 84 |
+
def __init__(
|
| 85 |
+
self,
|
| 86 |
+
block_out_channels: Tuple[int, ...] = (320, 640, 1280, 1280),
|
| 87 |
+
motion_layers_per_block: int = 2,
|
| 88 |
+
motion_mid_block_layers_per_block: int = 1,
|
| 89 |
+
motion_num_attention_heads: int = 8,
|
| 90 |
+
motion_norm_num_groups: int = 32,
|
| 91 |
+
motion_max_seq_length: int = 32,
|
| 92 |
+
use_motion_mid_block: bool = True,
|
| 93 |
+
):
|
| 94 |
+
"""Container to store AnimateDiff Motion Modules
|
| 95 |
+
|
| 96 |
+
Args:
|
| 97 |
+
block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
|
| 98 |
+
The tuple of output channels for each UNet block.
|
| 99 |
+
motion_layers_per_block (`int`, *optional*, defaults to 2):
|
| 100 |
+
The number of motion layers per UNet block.
|
| 101 |
+
motion_mid_block_layers_per_block (`int`, *optional*, defaults to 1):
|
| 102 |
+
The number of motion layers in the middle UNet block.
|
| 103 |
+
motion_num_attention_heads (`int`, *optional*, defaults to 8):
|
| 104 |
+
The number of heads to use in each attention layer of the motion module.
|
| 105 |
+
motion_norm_num_groups (`int`, *optional*, defaults to 32):
|
| 106 |
+
The number of groups to use in each group normalization layer of the motion module.
|
| 107 |
+
motion_max_seq_length (`int`, *optional*, defaults to 32):
|
| 108 |
+
The maximum sequence length to use in the motion module.
|
| 109 |
+
use_motion_mid_block (`bool`, *optional*, defaults to True):
|
| 110 |
+
Whether to use a motion module in the middle of the UNet.
|
| 111 |
+
"""
|
| 112 |
+
|
| 113 |
+
super().__init__()
|
| 114 |
+
down_blocks = []
|
| 115 |
+
up_blocks = []
|
| 116 |
+
|
| 117 |
+
for i, channel in enumerate(block_out_channels):
|
| 118 |
+
output_channel = block_out_channels[i]
|
| 119 |
+
down_blocks.append(
|
| 120 |
+
MotionModules(
|
| 121 |
+
in_channels=output_channel,
|
| 122 |
+
norm_num_groups=motion_norm_num_groups,
|
| 123 |
+
cross_attention_dim=None,
|
| 124 |
+
activation_fn="geglu",
|
| 125 |
+
attention_bias=False,
|
| 126 |
+
num_attention_heads=motion_num_attention_heads,
|
| 127 |
+
max_seq_length=motion_max_seq_length,
|
| 128 |
+
layers_per_block=motion_layers_per_block,
|
| 129 |
+
)
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
if use_motion_mid_block:
|
| 133 |
+
self.mid_block = MotionModules(
|
| 134 |
+
in_channels=block_out_channels[-1],
|
| 135 |
+
norm_num_groups=motion_norm_num_groups,
|
| 136 |
+
cross_attention_dim=None,
|
| 137 |
+
activation_fn="geglu",
|
| 138 |
+
attention_bias=False,
|
| 139 |
+
num_attention_heads=motion_num_attention_heads,
|
| 140 |
+
layers_per_block=motion_mid_block_layers_per_block,
|
| 141 |
+
max_seq_length=motion_max_seq_length,
|
| 142 |
+
)
|
| 143 |
+
else:
|
| 144 |
+
self.mid_block = None
|
| 145 |
+
|
| 146 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 147 |
+
output_channel = reversed_block_out_channels[0]
|
| 148 |
+
for i, channel in enumerate(reversed_block_out_channels):
|
| 149 |
+
output_channel = reversed_block_out_channels[i]
|
| 150 |
+
up_blocks.append(
|
| 151 |
+
MotionModules(
|
| 152 |
+
in_channels=output_channel,
|
| 153 |
+
norm_num_groups=motion_norm_num_groups,
|
| 154 |
+
cross_attention_dim=None,
|
| 155 |
+
activation_fn="geglu",
|
| 156 |
+
attention_bias=False,
|
| 157 |
+
num_attention_heads=motion_num_attention_heads,
|
| 158 |
+
max_seq_length=motion_max_seq_length,
|
| 159 |
+
layers_per_block=motion_layers_per_block + 1,
|
| 160 |
+
)
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
self.down_blocks = nn.ModuleList(down_blocks)
|
| 164 |
+
self.up_blocks = nn.ModuleList(up_blocks)
|
| 165 |
+
|
| 166 |
+
def forward(self, sample):
|
| 167 |
+
pass
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
class UNetMotionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
|
| 171 |
+
r"""
|
| 172 |
+
A modified conditional 2D UNet model that takes a noisy sample, conditional state, and a timestep and returns a
|
| 173 |
+
sample shaped output.
|
| 174 |
+
|
| 175 |
+
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
|
| 176 |
+
for all models (such as downloading or saving).
|
| 177 |
+
"""
|
| 178 |
+
|
| 179 |
+
_supports_gradient_checkpointing = True
|
| 180 |
+
|
| 181 |
+
@register_to_config
|
| 182 |
+
def __init__(
|
| 183 |
+
self,
|
| 184 |
+
sample_size: Optional[int] = None,
|
| 185 |
+
in_channels: int = 4,
|
| 186 |
+
conditioning_channels: int = 3,
|
| 187 |
+
out_channels: int = 4,
|
| 188 |
+
down_block_types: Tuple[str, ...] = (
|
| 189 |
+
"CrossAttnDownBlockMotion",
|
| 190 |
+
"CrossAttnDownBlockMotion",
|
| 191 |
+
"CrossAttnDownBlockMotion",
|
| 192 |
+
"DownBlockMotion",
|
| 193 |
+
),
|
| 194 |
+
mid_block_type: Optional[str] = "UNetMidBlockCrossAttnMotion",
|
| 195 |
+
up_block_types: Tuple[str, ...] = (
|
| 196 |
+
"UpBlockMotion",
|
| 197 |
+
"CrossAttnUpBlockMotion",
|
| 198 |
+
"CrossAttnUpBlockMotion",
|
| 199 |
+
"CrossAttnUpBlockMotion",
|
| 200 |
+
),
|
| 201 |
+
block_out_channels: Tuple[int, ...] = (320, 640, 1280, 1280),
|
| 202 |
+
layers_per_block: int = 2,
|
| 203 |
+
downsample_padding: int = 1,
|
| 204 |
+
mid_block_scale_factor: float = 1,
|
| 205 |
+
act_fn: str = "silu",
|
| 206 |
+
norm_num_groups: int = 32,
|
| 207 |
+
norm_eps: float = 1e-5,
|
| 208 |
+
cross_attention_dim: int = 1280,
|
| 209 |
+
use_linear_projection: bool = False,
|
| 210 |
+
num_attention_heads: Union[int, Tuple[int, ...]] = 8,
|
| 211 |
+
motion_max_seq_length: int = 32,
|
| 212 |
+
motion_num_attention_heads: int = 8,
|
| 213 |
+
use_motion_mid_block: int = True,
|
| 214 |
+
encoder_hid_dim: Optional[int] = None,
|
| 215 |
+
encoder_hid_dim_type: Optional[str] = None,
|
| 216 |
+
conditioning_embedding_out_channels: Optional[Tuple[int]] = (16, 32, 96, 256),
|
| 217 |
+
):
|
| 218 |
+
super().__init__()
|
| 219 |
+
|
| 220 |
+
self.sample_size = sample_size
|
| 221 |
+
|
| 222 |
+
# Check inputs
|
| 223 |
+
if len(down_block_types) != len(up_block_types):
|
| 224 |
+
raise ValueError(
|
| 225 |
+
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
if len(block_out_channels) != len(down_block_types):
|
| 229 |
+
raise ValueError(
|
| 230 |
+
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
|
| 234 |
+
raise ValueError(
|
| 235 |
+
f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
|
| 236 |
+
)
|
| 237 |
+
|
| 238 |
+
# input
|
| 239 |
+
conv_in_kernel = 3
|
| 240 |
+
conv_out_kernel = 3
|
| 241 |
+
conv_in_padding = (conv_in_kernel - 1) // 2
|
| 242 |
+
self.conv_in = nn.Conv2d(
|
| 243 |
+
in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
# time
|
| 247 |
+
time_embed_dim = block_out_channels[0] * 4
|
| 248 |
+
self.time_proj = Timesteps(block_out_channels[0], True, 0)
|
| 249 |
+
timestep_input_dim = block_out_channels[0]
|
| 250 |
+
|
| 251 |
+
self.time_embedding = TimestepEmbedding(
|
| 252 |
+
timestep_input_dim,
|
| 253 |
+
time_embed_dim,
|
| 254 |
+
act_fn=act_fn,
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
if encoder_hid_dim_type is None:
|
| 258 |
+
self.encoder_hid_proj = None
|
| 259 |
+
|
| 260 |
+
# control net conditioning embedding
|
| 261 |
+
# self.controlnet_cond_embedding = ControlNetConditioningEmbedding(
|
| 262 |
+
# conditioning_embedding_channels=block_out_channels[0],
|
| 263 |
+
# block_out_channels=conditioning_embedding_out_channels,
|
| 264 |
+
# conditioning_channels=conditioning_channels,
|
| 265 |
+
# )
|
| 266 |
+
|
| 267 |
+
# class embedding
|
| 268 |
+
self.down_blocks = nn.ModuleList([])
|
| 269 |
+
self.up_blocks = nn.ModuleList([])
|
| 270 |
+
|
| 271 |
+
if isinstance(num_attention_heads, int):
|
| 272 |
+
num_attention_heads = (num_attention_heads,) * len(down_block_types)
|
| 273 |
+
|
| 274 |
+
# down
|
| 275 |
+
output_channel = block_out_channels[0]
|
| 276 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 277 |
+
input_channel = output_channel
|
| 278 |
+
output_channel = block_out_channels[i]
|
| 279 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 280 |
+
|
| 281 |
+
down_block = get_down_block(
|
| 282 |
+
down_block_type,
|
| 283 |
+
num_layers=layers_per_block,
|
| 284 |
+
in_channels=input_channel,
|
| 285 |
+
out_channels=output_channel,
|
| 286 |
+
temb_channels=time_embed_dim,
|
| 287 |
+
add_downsample=not is_final_block,
|
| 288 |
+
resnet_eps=norm_eps,
|
| 289 |
+
resnet_act_fn=act_fn,
|
| 290 |
+
resnet_groups=norm_num_groups,
|
| 291 |
+
cross_attention_dim=cross_attention_dim,
|
| 292 |
+
num_attention_heads=num_attention_heads[i],
|
| 293 |
+
downsample_padding=downsample_padding,
|
| 294 |
+
use_linear_projection=use_linear_projection,
|
| 295 |
+
dual_cross_attention=False,
|
| 296 |
+
temporal_num_attention_heads=motion_num_attention_heads,
|
| 297 |
+
temporal_max_seq_length=motion_max_seq_length,
|
| 298 |
+
)
|
| 299 |
+
self.down_blocks.append(down_block)
|
| 300 |
+
|
| 301 |
+
# mid
|
| 302 |
+
if use_motion_mid_block:
|
| 303 |
+
self.mid_block = UNetMidBlockCrossAttnMotion(
|
| 304 |
+
in_channels=block_out_channels[-1],
|
| 305 |
+
temb_channels=time_embed_dim,
|
| 306 |
+
resnet_eps=norm_eps,
|
| 307 |
+
resnet_act_fn=act_fn,
|
| 308 |
+
output_scale_factor=mid_block_scale_factor,
|
| 309 |
+
cross_attention_dim=cross_attention_dim,
|
| 310 |
+
num_attention_heads=num_attention_heads[-1],
|
| 311 |
+
resnet_groups=norm_num_groups,
|
| 312 |
+
dual_cross_attention=False,
|
| 313 |
+
temporal_num_attention_heads=motion_num_attention_heads,
|
| 314 |
+
temporal_max_seq_length=motion_max_seq_length,
|
| 315 |
+
)
|
| 316 |
+
|
| 317 |
+
else:
|
| 318 |
+
self.mid_block = UNetMidBlock2DCrossAttn(
|
| 319 |
+
in_channels=block_out_channels[-1],
|
| 320 |
+
temb_channels=time_embed_dim,
|
| 321 |
+
resnet_eps=norm_eps,
|
| 322 |
+
resnet_act_fn=act_fn,
|
| 323 |
+
output_scale_factor=mid_block_scale_factor,
|
| 324 |
+
cross_attention_dim=cross_attention_dim,
|
| 325 |
+
num_attention_heads=num_attention_heads[-1],
|
| 326 |
+
resnet_groups=norm_num_groups,
|
| 327 |
+
dual_cross_attention=False,
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
# count how many layers upsample the images
|
| 331 |
+
self.num_upsamplers = 0
|
| 332 |
+
|
| 333 |
+
# up
|
| 334 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 335 |
+
reversed_num_attention_heads = list(reversed(num_attention_heads))
|
| 336 |
+
|
| 337 |
+
output_channel = reversed_block_out_channels[0]
|
| 338 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 339 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 340 |
+
|
| 341 |
+
prev_output_channel = output_channel
|
| 342 |
+
output_channel = reversed_block_out_channels[i]
|
| 343 |
+
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
| 344 |
+
|
| 345 |
+
# add upsample block for all BUT final layer
|
| 346 |
+
if not is_final_block:
|
| 347 |
+
add_upsample = True
|
| 348 |
+
self.num_upsamplers += 1
|
| 349 |
+
else:
|
| 350 |
+
add_upsample = False
|
| 351 |
+
|
| 352 |
+
up_block = get_up_block(
|
| 353 |
+
up_block_type,
|
| 354 |
+
num_layers=layers_per_block + 1,
|
| 355 |
+
in_channels=input_channel,
|
| 356 |
+
out_channels=output_channel,
|
| 357 |
+
prev_output_channel=prev_output_channel,
|
| 358 |
+
temb_channels=time_embed_dim,
|
| 359 |
+
add_upsample=add_upsample,
|
| 360 |
+
resnet_eps=norm_eps,
|
| 361 |
+
resnet_act_fn=act_fn,
|
| 362 |
+
resnet_groups=norm_num_groups,
|
| 363 |
+
cross_attention_dim=cross_attention_dim,
|
| 364 |
+
num_attention_heads=reversed_num_attention_heads[i],
|
| 365 |
+
dual_cross_attention=False,
|
| 366 |
+
resolution_idx=i,
|
| 367 |
+
use_linear_projection=use_linear_projection,
|
| 368 |
+
temporal_num_attention_heads=motion_num_attention_heads,
|
| 369 |
+
temporal_max_seq_length=motion_max_seq_length,
|
| 370 |
+
)
|
| 371 |
+
self.up_blocks.append(up_block)
|
| 372 |
+
prev_output_channel = output_channel
|
| 373 |
+
|
| 374 |
+
# out
|
| 375 |
+
if norm_num_groups is not None:
|
| 376 |
+
self.conv_norm_out = nn.GroupNorm(
|
| 377 |
+
num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
|
| 378 |
+
)
|
| 379 |
+
self.conv_act = nn.SiLU()
|
| 380 |
+
else:
|
| 381 |
+
self.conv_norm_out = None
|
| 382 |
+
self.conv_act = None
|
| 383 |
+
|
| 384 |
+
conv_out_padding = (conv_out_kernel - 1) // 2
|
| 385 |
+
self.conv_out = nn.Conv2d(
|
| 386 |
+
block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
|
| 387 |
+
)
|
| 388 |
+
|
| 389 |
+
@classmethod
|
| 390 |
+
def from_unet2d(
|
| 391 |
+
cls,
|
| 392 |
+
unet: UNet2DConditionModel,
|
| 393 |
+
motion_adapter: Optional[MotionAdapter] = None,
|
| 394 |
+
load_weights: bool = True,
|
| 395 |
+
):
|
| 396 |
+
has_motion_adapter = motion_adapter is not None
|
| 397 |
+
|
| 398 |
+
# based on https://github.com/guoyww/AnimateDiff/blob/895f3220c06318ea0760131ec70408b466c49333/animatediff/models/unet.py#L459
|
| 399 |
+
config = unet.config
|
| 400 |
+
config["_class_name"] = cls.__name__
|
| 401 |
+
|
| 402 |
+
down_blocks = []
|
| 403 |
+
for down_blocks_type in config["down_block_types"]:
|
| 404 |
+
if "CrossAttn" in down_blocks_type:
|
| 405 |
+
down_blocks.append("CrossAttnDownBlockMotion")
|
| 406 |
+
else:
|
| 407 |
+
down_blocks.append("DownBlockMotion")
|
| 408 |
+
config["down_block_types"] = down_blocks
|
| 409 |
+
|
| 410 |
+
up_blocks = []
|
| 411 |
+
for down_blocks_type in config["up_block_types"]:
|
| 412 |
+
if "CrossAttn" in down_blocks_type:
|
| 413 |
+
up_blocks.append("CrossAttnUpBlockMotion")
|
| 414 |
+
else:
|
| 415 |
+
up_blocks.append("UpBlockMotion")
|
| 416 |
+
|
| 417 |
+
config["up_block_types"] = up_blocks
|
| 418 |
+
|
| 419 |
+
if has_motion_adapter:
|
| 420 |
+
config["motion_num_attention_heads"] = motion_adapter.config["motion_num_attention_heads"]
|
| 421 |
+
config["motion_max_seq_length"] = motion_adapter.config["motion_max_seq_length"]
|
| 422 |
+
config["use_motion_mid_block"] = motion_adapter.config["use_motion_mid_block"]
|
| 423 |
+
|
| 424 |
+
# Need this for backwards compatibility with UNet2DConditionModel checkpoints
|
| 425 |
+
if not config.get("num_attention_heads"):
|
| 426 |
+
config["num_attention_heads"] = config["attention_head_dim"]
|
| 427 |
+
|
| 428 |
+
model = cls.from_config(config)
|
| 429 |
+
|
| 430 |
+
if not load_weights:
|
| 431 |
+
return model
|
| 432 |
+
|
| 433 |
+
model.conv_in.load_state_dict(unet.conv_in.state_dict())
|
| 434 |
+
model.time_proj.load_state_dict(unet.time_proj.state_dict())
|
| 435 |
+
model.time_embedding.load_state_dict(unet.time_embedding.state_dict())
|
| 436 |
+
# model.controlnet_cond_embedding.load_state_dict(unet.controlnet_cond_embedding.state_dict()) # pose guider
|
| 437 |
+
|
| 438 |
+
for i, down_block in enumerate(unet.down_blocks):
|
| 439 |
+
model.down_blocks[i].resnets.load_state_dict(down_block.resnets.state_dict())
|
| 440 |
+
if hasattr(model.down_blocks[i], "attentions"):
|
| 441 |
+
model.down_blocks[i].attentions.load_state_dict(down_block.attentions.state_dict())
|
| 442 |
+
if model.down_blocks[i].downsamplers:
|
| 443 |
+
model.down_blocks[i].downsamplers.load_state_dict(down_block.downsamplers.state_dict())
|
| 444 |
+
|
| 445 |
+
for i, up_block in enumerate(unet.up_blocks):
|
| 446 |
+
model.up_blocks[i].resnets.load_state_dict(up_block.resnets.state_dict())
|
| 447 |
+
if hasattr(model.up_blocks[i], "attentions"):
|
| 448 |
+
model.up_blocks[i].attentions.load_state_dict(up_block.attentions.state_dict())
|
| 449 |
+
if model.up_blocks[i].upsamplers:
|
| 450 |
+
model.up_blocks[i].upsamplers.load_state_dict(up_block.upsamplers.state_dict())
|
| 451 |
+
|
| 452 |
+
model.mid_block.resnets.load_state_dict(unet.mid_block.resnets.state_dict())
|
| 453 |
+
model.mid_block.attentions.load_state_dict(unet.mid_block.attentions.state_dict())
|
| 454 |
+
|
| 455 |
+
if unet.conv_norm_out is not None:
|
| 456 |
+
model.conv_norm_out.load_state_dict(unet.conv_norm_out.state_dict())
|
| 457 |
+
if unet.conv_act is not None:
|
| 458 |
+
model.conv_act.load_state_dict(unet.conv_act.state_dict())
|
| 459 |
+
model.conv_out.load_state_dict(unet.conv_out.state_dict())
|
| 460 |
+
|
| 461 |
+
if has_motion_adapter:
|
| 462 |
+
model.load_motion_modules(motion_adapter)
|
| 463 |
+
|
| 464 |
+
# ensure that the Motion UNet is the same dtype as the UNet2DConditionModel
|
| 465 |
+
model.to(unet.dtype)
|
| 466 |
+
|
| 467 |
+
return model
|
| 468 |
+
|
| 469 |
+
def freeze_unet2d_params(self) -> None:
|
| 470 |
+
"""Freeze the weights of just the UNet2DConditionModel, and leave the motion modules
|
| 471 |
+
unfrozen for fine tuning.
|
| 472 |
+
"""
|
| 473 |
+
# Freeze everything
|
| 474 |
+
for param in self.parameters():
|
| 475 |
+
param.requires_grad = False
|
| 476 |
+
|
| 477 |
+
# Unfreeze Motion Modules
|
| 478 |
+
for down_block in self.down_blocks:
|
| 479 |
+
motion_modules = down_block.motion_modules
|
| 480 |
+
for param in motion_modules.parameters():
|
| 481 |
+
param.requires_grad = True
|
| 482 |
+
|
| 483 |
+
for up_block in self.up_blocks:
|
| 484 |
+
motion_modules = up_block.motion_modules
|
| 485 |
+
for param in motion_modules.parameters():
|
| 486 |
+
param.requires_grad = True
|
| 487 |
+
|
| 488 |
+
if hasattr(self.mid_block, "motion_modules"):
|
| 489 |
+
motion_modules = self.mid_block.motion_modules
|
| 490 |
+
for param in motion_modules.parameters():
|
| 491 |
+
param.requires_grad = True
|
| 492 |
+
|
| 493 |
+
def load_motion_modules(self, motion_adapter: Optional[MotionAdapter]) -> None:
|
| 494 |
+
for i, down_block in enumerate(motion_adapter.down_blocks):
|
| 495 |
+
self.down_blocks[i].motion_modules.load_state_dict(down_block.motion_modules.state_dict())
|
| 496 |
+
for i, up_block in enumerate(motion_adapter.up_blocks):
|
| 497 |
+
self.up_blocks[i].motion_modules.load_state_dict(up_block.motion_modules.state_dict())
|
| 498 |
+
|
| 499 |
+
# to support older motion modules that don't have a mid_block
|
| 500 |
+
if hasattr(self.mid_block, "motion_modules"):
|
| 501 |
+
self.mid_block.motion_modules.load_state_dict(motion_adapter.mid_block.motion_modules.state_dict())
|
| 502 |
+
|
| 503 |
+
def save_motion_modules(
|
| 504 |
+
self,
|
| 505 |
+
save_directory: str,
|
| 506 |
+
is_main_process: bool = True,
|
| 507 |
+
safe_serialization: bool = True,
|
| 508 |
+
variant: Optional[str] = None,
|
| 509 |
+
push_to_hub: bool = False,
|
| 510 |
+
**kwargs,
|
| 511 |
+
) -> None:
|
| 512 |
+
state_dict = self.state_dict()
|
| 513 |
+
|
| 514 |
+
# Extract all motion modules
|
| 515 |
+
motion_state_dict = {}
|
| 516 |
+
for k, v in state_dict.items():
|
| 517 |
+
if "motion_modules" in k:
|
| 518 |
+
motion_state_dict[k] = v
|
| 519 |
+
|
| 520 |
+
adapter = MotionAdapter(
|
| 521 |
+
block_out_channels=self.config["block_out_channels"],
|
| 522 |
+
motion_layers_per_block=self.config["layers_per_block"],
|
| 523 |
+
motion_norm_num_groups=self.config["norm_num_groups"],
|
| 524 |
+
motion_num_attention_heads=self.config["motion_num_attention_heads"],
|
| 525 |
+
motion_max_seq_length=self.config["motion_max_seq_length"],
|
| 526 |
+
use_motion_mid_block=self.config["use_motion_mid_block"],
|
| 527 |
+
)
|
| 528 |
+
adapter.load_state_dict(motion_state_dict)
|
| 529 |
+
adapter.save_pretrained(
|
| 530 |
+
save_directory=save_directory,
|
| 531 |
+
is_main_process=is_main_process,
|
| 532 |
+
safe_serialization=safe_serialization,
|
| 533 |
+
variant=variant,
|
| 534 |
+
push_to_hub=push_to_hub,
|
| 535 |
+
**kwargs,
|
| 536 |
+
)
|
| 537 |
+
|
| 538 |
+
@property
|
| 539 |
+
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.attn_processors
|
| 540 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 541 |
+
r"""
|
| 542 |
+
Returns:
|
| 543 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 544 |
+
indexed by its weight name.
|
| 545 |
+
"""
|
| 546 |
+
# set recursively
|
| 547 |
+
processors = {}
|
| 548 |
+
|
| 549 |
+
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
| 550 |
+
if hasattr(module, "get_processor"):
|
| 551 |
+
processors[f"{name}.processor"] = module.get_processor(return_deprecated_lora=True)
|
| 552 |
+
|
| 553 |
+
for sub_name, child in module.named_children():
|
| 554 |
+
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
| 555 |
+
|
| 556 |
+
return processors
|
| 557 |
+
|
| 558 |
+
for name, module in self.named_children():
|
| 559 |
+
fn_recursive_add_processors(name, module, processors)
|
| 560 |
+
|
| 561 |
+
return processors
|
| 562 |
+
|
| 563 |
+
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attn_processor
|
| 564 |
+
def set_attn_processor(
|
| 565 |
+
self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]], _remove_lora=False
|
| 566 |
+
):
|
| 567 |
+
r"""
|
| 568 |
+
Sets the attention processor to use to compute attention.
|
| 569 |
+
|
| 570 |
+
Parameters:
|
| 571 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 572 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 573 |
+
for **all** `Attention` layers.
|
| 574 |
+
|
| 575 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 576 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 577 |
+
|
| 578 |
+
"""
|
| 579 |
+
count = len(self.attn_processors.keys())
|
| 580 |
+
|
| 581 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 582 |
+
raise ValueError(
|
| 583 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 584 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 585 |
+
)
|
| 586 |
+
|
| 587 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 588 |
+
if hasattr(module, "set_processor"):
|
| 589 |
+
if not isinstance(processor, dict):
|
| 590 |
+
module.set_processor(processor, _remove_lora=_remove_lora)
|
| 591 |
+
else:
|
| 592 |
+
module.set_processor(processor.pop(f"{name}.processor"), _remove_lora=_remove_lora)
|
| 593 |
+
|
| 594 |
+
for sub_name, child in module.named_children():
|
| 595 |
+
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
| 596 |
+
|
| 597 |
+
for name, module in self.named_children():
|
| 598 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 599 |
+
|
| 600 |
+
# Copied from diffusers.models.unet_3d_condition.UNet3DConditionModel.enable_forward_chunking
|
| 601 |
+
def enable_forward_chunking(self, chunk_size: Optional[int] = None, dim: int = 0) -> None:
|
| 602 |
+
"""
|
| 603 |
+
Sets the attention processor to use [feed forward
|
| 604 |
+
chunking](https://huggingface.co/blog/reformer#2-chunked-feed-forward-layers).
|
| 605 |
+
|
| 606 |
+
Parameters:
|
| 607 |
+
chunk_size (`int`, *optional*):
|
| 608 |
+
The chunk size of the feed-forward layers. If not specified, will run feed-forward layer individually
|
| 609 |
+
over each tensor of dim=`dim`.
|
| 610 |
+
dim (`int`, *optional*, defaults to `0`):
|
| 611 |
+
The dimension over which the feed-forward computation should be chunked. Choose between dim=0 (batch)
|
| 612 |
+
or dim=1 (sequence length).
|
| 613 |
+
"""
|
| 614 |
+
if dim not in [0, 1]:
|
| 615 |
+
raise ValueError(f"Make sure to set `dim` to either 0 or 1, not {dim}")
|
| 616 |
+
|
| 617 |
+
# By default chunk size is 1
|
| 618 |
+
chunk_size = chunk_size or 1
|
| 619 |
+
|
| 620 |
+
def fn_recursive_feed_forward(module: torch.nn.Module, chunk_size: int, dim: int):
|
| 621 |
+
if hasattr(module, "set_chunk_feed_forward"):
|
| 622 |
+
module.set_chunk_feed_forward(chunk_size=chunk_size, dim=dim)
|
| 623 |
+
|
| 624 |
+
for child in module.children():
|
| 625 |
+
fn_recursive_feed_forward(child, chunk_size, dim)
|
| 626 |
+
|
| 627 |
+
for module in self.children():
|
| 628 |
+
fn_recursive_feed_forward(module, chunk_size, dim)
|
| 629 |
+
|
| 630 |
+
# Copied from diffusers.models.unet_3d_condition.UNet3DConditionModel.disable_forward_chunking
|
| 631 |
+
def disable_forward_chunking(self) -> None:
|
| 632 |
+
def fn_recursive_feed_forward(module: torch.nn.Module, chunk_size: int, dim: int):
|
| 633 |
+
if hasattr(module, "set_chunk_feed_forward"):
|
| 634 |
+
module.set_chunk_feed_forward(chunk_size=chunk_size, dim=dim)
|
| 635 |
+
|
| 636 |
+
for child in module.children():
|
| 637 |
+
fn_recursive_feed_forward(child, chunk_size, dim)
|
| 638 |
+
|
| 639 |
+
for module in self.children():
|
| 640 |
+
fn_recursive_feed_forward(module, None, 0)
|
| 641 |
+
|
| 642 |
+
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
|
| 643 |
+
def set_default_attn_processor(self) -> None:
|
| 644 |
+
"""
|
| 645 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 646 |
+
"""
|
| 647 |
+
if all(proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 648 |
+
processor = AttnAddedKVProcessor()
|
| 649 |
+
elif all(proc.__class__ in CROSS_ATTENTION_PROCESSORS for proc in self.attn_processors.values()):
|
| 650 |
+
processor = AttnProcessor()
|
| 651 |
+
else:
|
| 652 |
+
raise ValueError(
|
| 653 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 654 |
+
)
|
| 655 |
+
|
| 656 |
+
self.set_attn_processor(processor, _remove_lora=True)
|
| 657 |
+
|
| 658 |
+
def _set_gradient_checkpointing(self, module, value: bool = False) -> None:
|
| 659 |
+
if isinstance(module, (CrossAttnDownBlockMotion, DownBlockMotion, CrossAttnUpBlockMotion, UpBlockMotion)):
|
| 660 |
+
module.gradient_checkpointing = value
|
| 661 |
+
|
| 662 |
+
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.enable_freeu
|
| 663 |
+
def enable_freeu(self, s1: float, s2: float, b1: float, b2: float) -> None:
|
| 664 |
+
r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
|
| 665 |
+
|
| 666 |
+
The suffixes after the scaling factors represent the stage blocks where they are being applied.
|
| 667 |
+
|
| 668 |
+
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of values that
|
| 669 |
+
are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
|
| 670 |
+
|
| 671 |
+
Args:
|
| 672 |
+
s1 (`float`):
|
| 673 |
+
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
|
| 674 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 675 |
+
s2 (`float`):
|
| 676 |
+
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
|
| 677 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 678 |
+
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
|
| 679 |
+
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
|
| 680 |
+
"""
|
| 681 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 682 |
+
setattr(upsample_block, "s1", s1)
|
| 683 |
+
setattr(upsample_block, "s2", s2)
|
| 684 |
+
setattr(upsample_block, "b1", b1)
|
| 685 |
+
setattr(upsample_block, "b2", b2)
|
| 686 |
+
|
| 687 |
+
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.disable_freeu
|
| 688 |
+
def disable_freeu(self) -> None:
|
| 689 |
+
"""Disables the FreeU mechanism."""
|
| 690 |
+
freeu_keys = {"s1", "s2", "b1", "b2"}
|
| 691 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 692 |
+
for k in freeu_keys:
|
| 693 |
+
if hasattr(upsample_block, k) or getattr(upsample_block, k, None) is not None:
|
| 694 |
+
setattr(upsample_block, k, None)
|
| 695 |
+
|
| 696 |
+
def forward(
|
| 697 |
+
self,
|
| 698 |
+
sample: torch.FloatTensor,
|
| 699 |
+
timestep: Union[torch.Tensor, float, int],
|
| 700 |
+
encoder_hidden_states: torch.Tensor,
|
| 701 |
+
# controlnet_cond: torch.FloatTensor,
|
| 702 |
+
timestep_cond: Optional[torch.Tensor] = None,
|
| 703 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 704 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 705 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 706 |
+
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 707 |
+
down_intrablock_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 708 |
+
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
| 709 |
+
return_dict: bool = True,
|
| 710 |
+
num_frames: int = 24,
|
| 711 |
+
down_block_add_samples: Optional[Tuple[torch.Tensor]] = None,
|
| 712 |
+
mid_block_add_sample: Optional[Tuple[torch.Tensor]] = None,
|
| 713 |
+
up_block_add_samples: Optional[Tuple[torch.Tensor]] = None,
|
| 714 |
+
) -> Union[UNet3DConditionOutput, Tuple[torch.Tensor]]:
|
| 715 |
+
r"""
|
| 716 |
+
The [`UNetMotionModel`] forward method.
|
| 717 |
+
|
| 718 |
+
Args:
|
| 719 |
+
sample (`torch.FloatTensor`):
|
| 720 |
+
The noisy input tensor with the following shape `(batch * num_frames, channel, height, width`.
|
| 721 |
+
timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
|
| 722 |
+
encoder_hidden_states (`torch.FloatTensor`):
|
| 723 |
+
The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
|
| 724 |
+
timestep_cond: (`torch.Tensor`, *optional*, defaults to `None`):
|
| 725 |
+
Conditional embeddings for timestep. If provided, the embeddings will be summed with the samples passed
|
| 726 |
+
through the `self.time_embedding` layer to obtain the timestep embeddings.
|
| 727 |
+
attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
|
| 728 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 729 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 730 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 731 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 732 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 733 |
+
`self.processor` in
|
| 734 |
+
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 735 |
+
down_block_additional_residuals: (`tuple` of `torch.Tensor`, *optional*):
|
| 736 |
+
A tuple of tensors that if specified are added to the residuals of down unet blocks.
|
| 737 |
+
mid_block_additional_residual: (`torch.Tensor`, *optional*):
|
| 738 |
+
A tensor that if specified is added to the residual of the middle unet block.
|
| 739 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 740 |
+
Whether or not to return a [`~models.unet_3d_condition.UNet3DConditionOutput`] instead of a plain
|
| 741 |
+
tuple.
|
| 742 |
+
|
| 743 |
+
Returns:
|
| 744 |
+
[`~models.unet_3d_condition.UNet3DConditionOutput`] or `tuple`:
|
| 745 |
+
If `return_dict` is True, an [`~models.unet_3d_condition.UNet3DConditionOutput`] is returned, otherwise
|
| 746 |
+
a `tuple` is returned where the first element is the sample tensor.
|
| 747 |
+
"""
|
| 748 |
+
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
| 749 |
+
# The overall upsampling factor is equal to 2 ** (# num of upsampling layears).
|
| 750 |
+
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
| 751 |
+
# on the fly if necessary.
|
| 752 |
+
default_overall_up_factor = 2**self.num_upsamplers
|
| 753 |
+
|
| 754 |
+
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
| 755 |
+
forward_upsample_size = False
|
| 756 |
+
upsample_size = None
|
| 757 |
+
|
| 758 |
+
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
| 759 |
+
logger.info("Forward upsample size to force interpolation output size.")
|
| 760 |
+
forward_upsample_size = True
|
| 761 |
+
|
| 762 |
+
# prepare attention_mask
|
| 763 |
+
if attention_mask is not None:
|
| 764 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 765 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 766 |
+
|
| 767 |
+
# 1. time
|
| 768 |
+
timesteps = timestep
|
| 769 |
+
if not torch.is_tensor(timesteps):
|
| 770 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 771 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 772 |
+
is_mps = sample.device.type == "mps"
|
| 773 |
+
if isinstance(timestep, float):
|
| 774 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 775 |
+
else:
|
| 776 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 777 |
+
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
| 778 |
+
elif len(timesteps.shape) == 0:
|
| 779 |
+
timesteps = timesteps[None].to(sample.device)
|
| 780 |
+
|
| 781 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 782 |
+
timesteps = timesteps.expand(sample.shape[0] // num_frames)
|
| 783 |
+
|
| 784 |
+
t_emb = self.time_proj(timesteps)
|
| 785 |
+
|
| 786 |
+
# timesteps does not contain any weights and will always return f32 tensors
|
| 787 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 788 |
+
# there might be better ways to encapsulate this.
|
| 789 |
+
t_emb = t_emb.to(dtype=self.dtype)
|
| 790 |
+
|
| 791 |
+
emb = self.time_embedding(t_emb, timestep_cond)
|
| 792 |
+
emb = emb.repeat_interleave(repeats=num_frames, dim=0)
|
| 793 |
+
|
| 794 |
+
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "ip_image_proj":
|
| 795 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 796 |
+
raise ValueError(
|
| 797 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'ip_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 798 |
+
)
|
| 799 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 800 |
+
image_embeds = self.encoder_hid_proj(image_embeds).to(encoder_hidden_states.dtype)
|
| 801 |
+
encoder_hidden_states = torch.cat([encoder_hidden_states, image_embeds], dim=1)
|
| 802 |
+
|
| 803 |
+
encoder_hidden_states = encoder_hidden_states.repeat_interleave(repeats=num_frames, dim=0)
|
| 804 |
+
|
| 805 |
+
# 2. pre-process
|
| 806 |
+
# sample = sample.permute(0, 2, 1, 3, 4).reshape((sample.shape[0] * num_frames, -1) + sample.shape[3:])
|
| 807 |
+
# N*T C H W
|
| 808 |
+
sample = self.conv_in(sample)
|
| 809 |
+
# controlnet_cond = self.controlnet_cond_embedding(controlnet_cond)
|
| 810 |
+
# sample += controlnet_cond
|
| 811 |
+
|
| 812 |
+
# 3. down
|
| 813 |
+
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
|
| 814 |
+
# using new arg down_intrablock_additional_residuals for T2I-Adapters, to distinguish from controlnets
|
| 815 |
+
is_adapter = down_intrablock_additional_residuals is not None
|
| 816 |
+
# maintain backward compatibility for legacy usage, where
|
| 817 |
+
# T2I-Adapter and ControlNet both use down_block_additional_residuals arg
|
| 818 |
+
# but can only use one or the other
|
| 819 |
+
is_brushnet = down_block_add_samples is not None and mid_block_add_sample is not None and up_block_add_samples is not None
|
| 820 |
+
if not is_adapter and mid_block_additional_residual is None and down_block_additional_residuals is not None:
|
| 821 |
+
deprecate(
|
| 822 |
+
"T2I should not use down_block_additional_residuals",
|
| 823 |
+
"1.3.0",
|
| 824 |
+
"Passing intrablock residual connections with `down_block_additional_residuals` is deprecated \
|
| 825 |
+
and will be removed in diffusers 1.3.0. `down_block_additional_residuals` should only be used \
|
| 826 |
+
for ControlNet. Please make sure use `down_intrablock_additional_residuals` instead. ",
|
| 827 |
+
standard_warn=False,
|
| 828 |
+
)
|
| 829 |
+
down_intrablock_additional_residuals = down_block_additional_residuals
|
| 830 |
+
is_adapter = True
|
| 831 |
+
|
| 832 |
+
down_block_res_samples = (sample,)
|
| 833 |
+
if is_brushnet:
|
| 834 |
+
sample = sample + down_block_add_samples.pop(0)
|
| 835 |
+
|
| 836 |
+
for downsample_block in self.down_blocks:
|
| 837 |
+
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
| 838 |
+
# For t2i-adapter CrossAttnDownBlock2D
|
| 839 |
+
additional_residuals = {}
|
| 840 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 841 |
+
additional_residuals["additional_residuals"] = down_intrablock_additional_residuals.pop(0)
|
| 842 |
+
if is_brushnet and len(down_block_add_samples)>0:
|
| 843 |
+
additional_residuals["down_block_add_samples"] = [down_block_add_samples.pop(0)
|
| 844 |
+
for _ in range(len(downsample_block.resnets)+(downsample_block.downsamplers !=None))]
|
| 845 |
+
|
| 846 |
+
sample, res_samples = downsample_block(
|
| 847 |
+
hidden_states=sample,
|
| 848 |
+
temb=emb,
|
| 849 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 850 |
+
attention_mask=attention_mask,
|
| 851 |
+
num_frames=num_frames,
|
| 852 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 853 |
+
**additional_residuals,
|
| 854 |
+
)
|
| 855 |
+
else:
|
| 856 |
+
additional_residuals = {}
|
| 857 |
+
if is_brushnet and len(down_block_add_samples)>0:
|
| 858 |
+
additional_residuals["down_block_add_samples"] = [down_block_add_samples.pop(0)
|
| 859 |
+
for _ in range(len(downsample_block.resnets)+(downsample_block.downsamplers !=None))]
|
| 860 |
+
sample, res_samples = downsample_block(hidden_states=sample, temb=emb, num_frames=num_frames, **additional_residuals,)
|
| 861 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 862 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 863 |
+
|
| 864 |
+
down_block_res_samples += res_samples
|
| 865 |
+
|
| 866 |
+
if is_controlnet:
|
| 867 |
+
new_down_block_res_samples = ()
|
| 868 |
+
|
| 869 |
+
for down_block_res_sample, down_block_additional_residual in zip(
|
| 870 |
+
down_block_res_samples, down_block_additional_residuals
|
| 871 |
+
):
|
| 872 |
+
down_block_res_sample = down_block_res_sample + down_block_additional_residual
|
| 873 |
+
new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
|
| 874 |
+
|
| 875 |
+
down_block_res_samples = new_down_block_res_samples
|
| 876 |
+
|
| 877 |
+
if down_block_additional_residuals is not None:
|
| 878 |
+
new_down_block_res_samples = ()
|
| 879 |
+
|
| 880 |
+
for down_block_res_sample, down_block_additional_residual in zip(
|
| 881 |
+
down_block_res_samples, down_block_additional_residuals
|
| 882 |
+
):
|
| 883 |
+
down_block_res_sample = down_block_res_sample + down_block_additional_residual
|
| 884 |
+
new_down_block_res_samples += (down_block_res_sample,)
|
| 885 |
+
|
| 886 |
+
down_block_res_samples = new_down_block_res_samples
|
| 887 |
+
|
| 888 |
+
# 4. mid
|
| 889 |
+
if self.mid_block is not None:
|
| 890 |
+
# To support older versions of motion modules that don't have a mid_block
|
| 891 |
+
if hasattr(self.mid_block, "motion_modules"):
|
| 892 |
+
sample = self.mid_block(
|
| 893 |
+
sample,
|
| 894 |
+
emb,
|
| 895 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 896 |
+
attention_mask=attention_mask,
|
| 897 |
+
num_frames=num_frames,
|
| 898 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 899 |
+
mid_block_add_sample=mid_block_add_sample,
|
| 900 |
+
)
|
| 901 |
+
else:
|
| 902 |
+
sample = self.mid_block(
|
| 903 |
+
sample,
|
| 904 |
+
emb,
|
| 905 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 906 |
+
attention_mask=attention_mask,
|
| 907 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 908 |
+
mid_block_add_sample=mid_block_add_sample,
|
| 909 |
+
)
|
| 910 |
+
|
| 911 |
+
if is_controlnet:
|
| 912 |
+
sample = sample + mid_block_additional_residual
|
| 913 |
+
|
| 914 |
+
# if is_brushnet:
|
| 915 |
+
# sample = sample + mid_block_add_sample
|
| 916 |
+
|
| 917 |
+
if mid_block_additional_residual is not None:
|
| 918 |
+
sample = sample + mid_block_additional_residual
|
| 919 |
+
|
| 920 |
+
# 5. up
|
| 921 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 922 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 923 |
+
|
| 924 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
| 925 |
+
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
| 926 |
+
|
| 927 |
+
# if we have not reached the final block and need to forward the
|
| 928 |
+
# upsample size, we do it here
|
| 929 |
+
if not is_final_block and forward_upsample_size:
|
| 930 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 931 |
+
|
| 932 |
+
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
| 933 |
+
additional_residuals = {}
|
| 934 |
+
if is_brushnet and len(up_block_add_samples)>0:
|
| 935 |
+
additional_residuals["up_block_add_samples"] = [up_block_add_samples.pop(0)
|
| 936 |
+
for _ in range(len(upsample_block.resnets)+(upsample_block.upsamplers !=None))]
|
| 937 |
+
sample = upsample_block(
|
| 938 |
+
hidden_states=sample,
|
| 939 |
+
temb=emb,
|
| 940 |
+
res_hidden_states_tuple=res_samples,
|
| 941 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 942 |
+
upsample_size=upsample_size,
|
| 943 |
+
attention_mask=attention_mask,
|
| 944 |
+
num_frames=num_frames,
|
| 945 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 946 |
+
**additional_residuals,
|
| 947 |
+
)
|
| 948 |
+
else:
|
| 949 |
+
additional_residuals = {}
|
| 950 |
+
if is_brushnet and len(up_block_add_samples)>0:
|
| 951 |
+
additional_residuals["up_block_add_samples"] = [up_block_add_samples.pop(0)
|
| 952 |
+
for _ in range(len(upsample_block.resnets)+(upsample_block.upsamplers !=None))]
|
| 953 |
+
sample = upsample_block(
|
| 954 |
+
hidden_states=sample,
|
| 955 |
+
temb=emb,
|
| 956 |
+
res_hidden_states_tuple=res_samples,
|
| 957 |
+
upsample_size=upsample_size,
|
| 958 |
+
num_frames=num_frames,
|
| 959 |
+
**additional_residuals,
|
| 960 |
+
)
|
| 961 |
+
|
| 962 |
+
# 6. post-process
|
| 963 |
+
if self.conv_norm_out:
|
| 964 |
+
sample = self.conv_norm_out(sample)
|
| 965 |
+
sample = self.conv_act(sample)
|
| 966 |
+
|
| 967 |
+
sample = self.conv_out(sample)
|
| 968 |
+
|
| 969 |
+
# reshape to (batch, framerate, channel, width, height)
|
| 970 |
+
# sample = sample[None, :].reshape((-1, num_frames) + sample.shape[1:])
|
| 971 |
+
|
| 972 |
+
if not return_dict:
|
| 973 |
+
return (sample,)
|
| 974 |
+
|
| 975 |
+
return UNet3DConditionOutput(sample=sample)
|
propainter/RAFT/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# from .demo import RAFT_infer
|
| 2 |
+
from .raft import RAFT
|
propainter/RAFT/corr.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
from .utils.utils import bilinear_sampler, coords_grid
|
| 4 |
+
|
| 5 |
+
try:
|
| 6 |
+
import alt_cuda_corr
|
| 7 |
+
except:
|
| 8 |
+
# alt_cuda_corr is not compiled
|
| 9 |
+
pass
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class CorrBlock:
|
| 13 |
+
def __init__(self, fmap1, fmap2, num_levels=4, radius=4):
|
| 14 |
+
self.num_levels = num_levels
|
| 15 |
+
self.radius = radius
|
| 16 |
+
self.corr_pyramid = []
|
| 17 |
+
|
| 18 |
+
# all pairs correlation
|
| 19 |
+
corr = CorrBlock.corr(fmap1, fmap2)
|
| 20 |
+
|
| 21 |
+
batch, h1, w1, dim, h2, w2 = corr.shape
|
| 22 |
+
corr = corr.reshape(batch*h1*w1, dim, h2, w2)
|
| 23 |
+
|
| 24 |
+
self.corr_pyramid.append(corr)
|
| 25 |
+
for i in range(self.num_levels-1):
|
| 26 |
+
corr = F.avg_pool2d(corr, 2, stride=2)
|
| 27 |
+
self.corr_pyramid.append(corr)
|
| 28 |
+
|
| 29 |
+
def __call__(self, coords):
|
| 30 |
+
r = self.radius
|
| 31 |
+
coords = coords.permute(0, 2, 3, 1)
|
| 32 |
+
batch, h1, w1, _ = coords.shape
|
| 33 |
+
|
| 34 |
+
out_pyramid = []
|
| 35 |
+
for i in range(self.num_levels):
|
| 36 |
+
corr = self.corr_pyramid[i]
|
| 37 |
+
dx = torch.linspace(-r, r, 2*r+1)
|
| 38 |
+
dy = torch.linspace(-r, r, 2*r+1)
|
| 39 |
+
delta = torch.stack(torch.meshgrid(dy, dx), axis=-1).to(coords.device)
|
| 40 |
+
|
| 41 |
+
centroid_lvl = coords.reshape(batch*h1*w1, 1, 1, 2) / 2**i
|
| 42 |
+
delta_lvl = delta.view(1, 2*r+1, 2*r+1, 2)
|
| 43 |
+
coords_lvl = centroid_lvl + delta_lvl
|
| 44 |
+
|
| 45 |
+
corr = bilinear_sampler(corr, coords_lvl)
|
| 46 |
+
corr = corr.view(batch, h1, w1, -1)
|
| 47 |
+
out_pyramid.append(corr)
|
| 48 |
+
|
| 49 |
+
out = torch.cat(out_pyramid, dim=-1)
|
| 50 |
+
return out.permute(0, 3, 1, 2).contiguous().float()
|
| 51 |
+
|
| 52 |
+
@staticmethod
|
| 53 |
+
def corr(fmap1, fmap2):
|
| 54 |
+
batch, dim, ht, wd = fmap1.shape
|
| 55 |
+
fmap1 = fmap1.view(batch, dim, ht*wd)
|
| 56 |
+
fmap2 = fmap2.view(batch, dim, ht*wd)
|
| 57 |
+
|
| 58 |
+
corr = torch.matmul(fmap1.transpose(1,2), fmap2)
|
| 59 |
+
corr = corr.view(batch, ht, wd, 1, ht, wd)
|
| 60 |
+
return corr / torch.sqrt(torch.tensor(dim).float())
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class CorrLayer(torch.autograd.Function):
|
| 64 |
+
@staticmethod
|
| 65 |
+
def forward(ctx, fmap1, fmap2, coords, r):
|
| 66 |
+
fmap1 = fmap1.contiguous()
|
| 67 |
+
fmap2 = fmap2.contiguous()
|
| 68 |
+
coords = coords.contiguous()
|
| 69 |
+
ctx.save_for_backward(fmap1, fmap2, coords)
|
| 70 |
+
ctx.r = r
|
| 71 |
+
corr, = correlation_cudaz.forward(fmap1, fmap2, coords, ctx.r)
|
| 72 |
+
return corr
|
| 73 |
+
|
| 74 |
+
@staticmethod
|
| 75 |
+
def backward(ctx, grad_corr):
|
| 76 |
+
fmap1, fmap2, coords = ctx.saved_tensors
|
| 77 |
+
grad_corr = grad_corr.contiguous()
|
| 78 |
+
fmap1_grad, fmap2_grad, coords_grad = \
|
| 79 |
+
correlation_cudaz.backward(fmap1, fmap2, coords, grad_corr, ctx.r)
|
| 80 |
+
return fmap1_grad, fmap2_grad, coords_grad, None
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
class AlternateCorrBlock:
|
| 84 |
+
def __init__(self, fmap1, fmap2, num_levels=4, radius=4):
|
| 85 |
+
self.num_levels = num_levels
|
| 86 |
+
self.radius = radius
|
| 87 |
+
|
| 88 |
+
self.pyramid = [(fmap1, fmap2)]
|
| 89 |
+
for i in range(self.num_levels):
|
| 90 |
+
fmap1 = F.avg_pool2d(fmap1, 2, stride=2)
|
| 91 |
+
fmap2 = F.avg_pool2d(fmap2, 2, stride=2)
|
| 92 |
+
self.pyramid.append((fmap1, fmap2))
|
| 93 |
+
|
| 94 |
+
def __call__(self, coords):
|
| 95 |
+
|
| 96 |
+
coords = coords.permute(0, 2, 3, 1)
|
| 97 |
+
B, H, W, _ = coords.shape
|
| 98 |
+
|
| 99 |
+
corr_list = []
|
| 100 |
+
for i in range(self.num_levels):
|
| 101 |
+
r = self.radius
|
| 102 |
+
fmap1_i = self.pyramid[0][0].permute(0, 2, 3, 1)
|
| 103 |
+
fmap2_i = self.pyramid[i][1].permute(0, 2, 3, 1)
|
| 104 |
+
|
| 105 |
+
coords_i = (coords / 2**i).reshape(B, 1, H, W, 2).contiguous()
|
| 106 |
+
corr = alt_cuda_corr(fmap1_i, fmap2_i, coords_i, r)
|
| 107 |
+
corr_list.append(corr.squeeze(1))
|
| 108 |
+
|
| 109 |
+
corr = torch.stack(corr_list, dim=1)
|
| 110 |
+
corr = corr.reshape(B, -1, H, W)
|
| 111 |
+
return corr / 16.0
|
propainter/RAFT/datasets.py
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Data loading based on https://github.com/NVIDIA/flownet2-pytorch
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
import torch.utils.data as data
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import math
|
| 10 |
+
import random
|
| 11 |
+
from glob import glob
|
| 12 |
+
import os.path as osp
|
| 13 |
+
|
| 14 |
+
from utils import frame_utils
|
| 15 |
+
from utils.augmentor import FlowAugmentor, SparseFlowAugmentor
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class FlowDataset(data.Dataset):
|
| 19 |
+
def __init__(self, aug_params=None, sparse=False):
|
| 20 |
+
self.augmentor = None
|
| 21 |
+
self.sparse = sparse
|
| 22 |
+
if aug_params is not None:
|
| 23 |
+
if sparse:
|
| 24 |
+
self.augmentor = SparseFlowAugmentor(**aug_params)
|
| 25 |
+
else:
|
| 26 |
+
self.augmentor = FlowAugmentor(**aug_params)
|
| 27 |
+
|
| 28 |
+
self.is_test = False
|
| 29 |
+
self.init_seed = False
|
| 30 |
+
self.flow_list = []
|
| 31 |
+
self.image_list = []
|
| 32 |
+
self.extra_info = []
|
| 33 |
+
|
| 34 |
+
def __getitem__(self, index):
|
| 35 |
+
|
| 36 |
+
if self.is_test:
|
| 37 |
+
img1 = frame_utils.read_gen(self.image_list[index][0])
|
| 38 |
+
img2 = frame_utils.read_gen(self.image_list[index][1])
|
| 39 |
+
img1 = np.array(img1).astype(np.uint8)[..., :3]
|
| 40 |
+
img2 = np.array(img2).astype(np.uint8)[..., :3]
|
| 41 |
+
img1 = torch.from_numpy(img1).permute(2, 0, 1).float()
|
| 42 |
+
img2 = torch.from_numpy(img2).permute(2, 0, 1).float()
|
| 43 |
+
return img1, img2, self.extra_info[index]
|
| 44 |
+
|
| 45 |
+
if not self.init_seed:
|
| 46 |
+
worker_info = torch.utils.data.get_worker_info()
|
| 47 |
+
if worker_info is not None:
|
| 48 |
+
torch.manual_seed(worker_info.id)
|
| 49 |
+
np.random.seed(worker_info.id)
|
| 50 |
+
random.seed(worker_info.id)
|
| 51 |
+
self.init_seed = True
|
| 52 |
+
|
| 53 |
+
index = index % len(self.image_list)
|
| 54 |
+
valid = None
|
| 55 |
+
if self.sparse:
|
| 56 |
+
flow, valid = frame_utils.readFlowKITTI(self.flow_list[index])
|
| 57 |
+
else:
|
| 58 |
+
flow = frame_utils.read_gen(self.flow_list[index])
|
| 59 |
+
|
| 60 |
+
img1 = frame_utils.read_gen(self.image_list[index][0])
|
| 61 |
+
img2 = frame_utils.read_gen(self.image_list[index][1])
|
| 62 |
+
|
| 63 |
+
flow = np.array(flow).astype(np.float32)
|
| 64 |
+
img1 = np.array(img1).astype(np.uint8)
|
| 65 |
+
img2 = np.array(img2).astype(np.uint8)
|
| 66 |
+
|
| 67 |
+
# grayscale images
|
| 68 |
+
if len(img1.shape) == 2:
|
| 69 |
+
img1 = np.tile(img1[...,None], (1, 1, 3))
|
| 70 |
+
img2 = np.tile(img2[...,None], (1, 1, 3))
|
| 71 |
+
else:
|
| 72 |
+
img1 = img1[..., :3]
|
| 73 |
+
img2 = img2[..., :3]
|
| 74 |
+
|
| 75 |
+
if self.augmentor is not None:
|
| 76 |
+
if self.sparse:
|
| 77 |
+
img1, img2, flow, valid = self.augmentor(img1, img2, flow, valid)
|
| 78 |
+
else:
|
| 79 |
+
img1, img2, flow = self.augmentor(img1, img2, flow)
|
| 80 |
+
|
| 81 |
+
img1 = torch.from_numpy(img1).permute(2, 0, 1).float()
|
| 82 |
+
img2 = torch.from_numpy(img2).permute(2, 0, 1).float()
|
| 83 |
+
flow = torch.from_numpy(flow).permute(2, 0, 1).float()
|
| 84 |
+
|
| 85 |
+
if valid is not None:
|
| 86 |
+
valid = torch.from_numpy(valid)
|
| 87 |
+
else:
|
| 88 |
+
valid = (flow[0].abs() < 1000) & (flow[1].abs() < 1000)
|
| 89 |
+
|
| 90 |
+
return img1, img2, flow, valid.float()
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def __rmul__(self, v):
|
| 94 |
+
self.flow_list = v * self.flow_list
|
| 95 |
+
self.image_list = v * self.image_list
|
| 96 |
+
return self
|
| 97 |
+
|
| 98 |
+
def __len__(self):
|
| 99 |
+
return len(self.image_list)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
class MpiSintel(FlowDataset):
|
| 103 |
+
def __init__(self, aug_params=None, split='training', root='datasets/Sintel', dstype='clean'):
|
| 104 |
+
super(MpiSintel, self).__init__(aug_params)
|
| 105 |
+
flow_root = osp.join(root, split, 'flow')
|
| 106 |
+
image_root = osp.join(root, split, dstype)
|
| 107 |
+
|
| 108 |
+
if split == 'test':
|
| 109 |
+
self.is_test = True
|
| 110 |
+
|
| 111 |
+
for scene in os.listdir(image_root):
|
| 112 |
+
image_list = sorted(glob(osp.join(image_root, scene, '*.png')))
|
| 113 |
+
for i in range(len(image_list)-1):
|
| 114 |
+
self.image_list += [ [image_list[i], image_list[i+1]] ]
|
| 115 |
+
self.extra_info += [ (scene, i) ] # scene and frame_id
|
| 116 |
+
|
| 117 |
+
if split != 'test':
|
| 118 |
+
self.flow_list += sorted(glob(osp.join(flow_root, scene, '*.flo')))
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class FlyingChairs(FlowDataset):
|
| 122 |
+
def __init__(self, aug_params=None, split='train', root='datasets/FlyingChairs_release/data'):
|
| 123 |
+
super(FlyingChairs, self).__init__(aug_params)
|
| 124 |
+
|
| 125 |
+
images = sorted(glob(osp.join(root, '*.ppm')))
|
| 126 |
+
flows = sorted(glob(osp.join(root, '*.flo')))
|
| 127 |
+
assert (len(images)//2 == len(flows))
|
| 128 |
+
|
| 129 |
+
split_list = np.loadtxt('chairs_split.txt', dtype=np.int32)
|
| 130 |
+
for i in range(len(flows)):
|
| 131 |
+
xid = split_list[i]
|
| 132 |
+
if (split=='training' and xid==1) or (split=='validation' and xid==2):
|
| 133 |
+
self.flow_list += [ flows[i] ]
|
| 134 |
+
self.image_list += [ [images[2*i], images[2*i+1]] ]
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
class FlyingThings3D(FlowDataset):
|
| 138 |
+
def __init__(self, aug_params=None, root='datasets/FlyingThings3D', dstype='frames_cleanpass'):
|
| 139 |
+
super(FlyingThings3D, self).__init__(aug_params)
|
| 140 |
+
|
| 141 |
+
for cam in ['left']:
|
| 142 |
+
for direction in ['into_future', 'into_past']:
|
| 143 |
+
image_dirs = sorted(glob(osp.join(root, dstype, 'TRAIN/*/*')))
|
| 144 |
+
image_dirs = sorted([osp.join(f, cam) for f in image_dirs])
|
| 145 |
+
|
| 146 |
+
flow_dirs = sorted(glob(osp.join(root, 'optical_flow/TRAIN/*/*')))
|
| 147 |
+
flow_dirs = sorted([osp.join(f, direction, cam) for f in flow_dirs])
|
| 148 |
+
|
| 149 |
+
for idir, fdir in zip(image_dirs, flow_dirs):
|
| 150 |
+
images = sorted(glob(osp.join(idir, '*.png')) )
|
| 151 |
+
flows = sorted(glob(osp.join(fdir, '*.pfm')) )
|
| 152 |
+
for i in range(len(flows)-1):
|
| 153 |
+
if direction == 'into_future':
|
| 154 |
+
self.image_list += [ [images[i], images[i+1]] ]
|
| 155 |
+
self.flow_list += [ flows[i] ]
|
| 156 |
+
elif direction == 'into_past':
|
| 157 |
+
self.image_list += [ [images[i+1], images[i]] ]
|
| 158 |
+
self.flow_list += [ flows[i+1] ]
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
class KITTI(FlowDataset):
|
| 162 |
+
def __init__(self, aug_params=None, split='training', root='datasets/KITTI'):
|
| 163 |
+
super(KITTI, self).__init__(aug_params, sparse=True)
|
| 164 |
+
if split == 'testing':
|
| 165 |
+
self.is_test = True
|
| 166 |
+
|
| 167 |
+
root = osp.join(root, split)
|
| 168 |
+
images1 = sorted(glob(osp.join(root, 'image_2/*_10.png')))
|
| 169 |
+
images2 = sorted(glob(osp.join(root, 'image_2/*_11.png')))
|
| 170 |
+
|
| 171 |
+
for img1, img2 in zip(images1, images2):
|
| 172 |
+
frame_id = img1.split('/')[-1]
|
| 173 |
+
self.extra_info += [ [frame_id] ]
|
| 174 |
+
self.image_list += [ [img1, img2] ]
|
| 175 |
+
|
| 176 |
+
if split == 'training':
|
| 177 |
+
self.flow_list = sorted(glob(osp.join(root, 'flow_occ/*_10.png')))
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
class HD1K(FlowDataset):
|
| 181 |
+
def __init__(self, aug_params=None, root='datasets/HD1k'):
|
| 182 |
+
super(HD1K, self).__init__(aug_params, sparse=True)
|
| 183 |
+
|
| 184 |
+
seq_ix = 0
|
| 185 |
+
while 1:
|
| 186 |
+
flows = sorted(glob(os.path.join(root, 'hd1k_flow_gt', 'flow_occ/%06d_*.png' % seq_ix)))
|
| 187 |
+
images = sorted(glob(os.path.join(root, 'hd1k_input', 'image_2/%06d_*.png' % seq_ix)))
|
| 188 |
+
|
| 189 |
+
if len(flows) == 0:
|
| 190 |
+
break
|
| 191 |
+
|
| 192 |
+
for i in range(len(flows)-1):
|
| 193 |
+
self.flow_list += [flows[i]]
|
| 194 |
+
self.image_list += [ [images[i], images[i+1]] ]
|
| 195 |
+
|
| 196 |
+
seq_ix += 1
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
def fetch_dataloader(args, TRAIN_DS='C+T+K+S+H'):
|
| 200 |
+
""" Create the data loader for the corresponding trainign set """
|
| 201 |
+
|
| 202 |
+
if args.stage == 'chairs':
|
| 203 |
+
aug_params = {'crop_size': args.image_size, 'min_scale': -0.1, 'max_scale': 1.0, 'do_flip': True}
|
| 204 |
+
train_dataset = FlyingChairs(aug_params, split='training')
|
| 205 |
+
|
| 206 |
+
elif args.stage == 'things':
|
| 207 |
+
aug_params = {'crop_size': args.image_size, 'min_scale': -0.4, 'max_scale': 0.8, 'do_flip': True}
|
| 208 |
+
clean_dataset = FlyingThings3D(aug_params, dstype='frames_cleanpass')
|
| 209 |
+
final_dataset = FlyingThings3D(aug_params, dstype='frames_finalpass')
|
| 210 |
+
train_dataset = clean_dataset + final_dataset
|
| 211 |
+
|
| 212 |
+
elif args.stage == 'sintel':
|
| 213 |
+
aug_params = {'crop_size': args.image_size, 'min_scale': -0.2, 'max_scale': 0.6, 'do_flip': True}
|
| 214 |
+
things = FlyingThings3D(aug_params, dstype='frames_cleanpass')
|
| 215 |
+
sintel_clean = MpiSintel(aug_params, split='training', dstype='clean')
|
| 216 |
+
sintel_final = MpiSintel(aug_params, split='training', dstype='final')
|
| 217 |
+
|
| 218 |
+
if TRAIN_DS == 'C+T+K+S+H':
|
| 219 |
+
kitti = KITTI({'crop_size': args.image_size, 'min_scale': -0.3, 'max_scale': 0.5, 'do_flip': True})
|
| 220 |
+
hd1k = HD1K({'crop_size': args.image_size, 'min_scale': -0.5, 'max_scale': 0.2, 'do_flip': True})
|
| 221 |
+
train_dataset = 100*sintel_clean + 100*sintel_final + 200*kitti + 5*hd1k + things
|
| 222 |
+
|
| 223 |
+
elif TRAIN_DS == 'C+T+K/S':
|
| 224 |
+
train_dataset = 100*sintel_clean + 100*sintel_final + things
|
| 225 |
+
|
| 226 |
+
elif args.stage == 'kitti':
|
| 227 |
+
aug_params = {'crop_size': args.image_size, 'min_scale': -0.2, 'max_scale': 0.4, 'do_flip': False}
|
| 228 |
+
train_dataset = KITTI(aug_params, split='training')
|
| 229 |
+
|
| 230 |
+
train_loader = data.DataLoader(train_dataset, batch_size=args.batch_size,
|
| 231 |
+
pin_memory=False, shuffle=True, num_workers=4, drop_last=True)
|
| 232 |
+
|
| 233 |
+
print('Training with %d image pairs' % len(train_dataset))
|
| 234 |
+
return train_loader
|
| 235 |
+
|
propainter/RAFT/demo.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import argparse
|
| 3 |
+
import os
|
| 4 |
+
import cv2
|
| 5 |
+
import glob
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
from PIL import Image
|
| 9 |
+
|
| 10 |
+
from .raft import RAFT
|
| 11 |
+
from .utils import flow_viz
|
| 12 |
+
from .utils.utils import InputPadder
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
DEVICE = 'cuda'
|
| 17 |
+
|
| 18 |
+
def load_image(imfile):
|
| 19 |
+
img = np.array(Image.open(imfile)).astype(np.uint8)
|
| 20 |
+
img = torch.from_numpy(img).permute(2, 0, 1).float()
|
| 21 |
+
return img
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def load_image_list(image_files):
|
| 25 |
+
images = []
|
| 26 |
+
for imfile in sorted(image_files):
|
| 27 |
+
images.append(load_image(imfile))
|
| 28 |
+
|
| 29 |
+
images = torch.stack(images, dim=0)
|
| 30 |
+
images = images.to(DEVICE)
|
| 31 |
+
|
| 32 |
+
padder = InputPadder(images.shape)
|
| 33 |
+
return padder.pad(images)[0]
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def viz(img, flo):
|
| 37 |
+
img = img[0].permute(1,2,0).cpu().numpy()
|
| 38 |
+
flo = flo[0].permute(1,2,0).cpu().numpy()
|
| 39 |
+
|
| 40 |
+
# map flow to rgb image
|
| 41 |
+
flo = flow_viz.flow_to_image(flo)
|
| 42 |
+
# img_flo = np.concatenate([img, flo], axis=0)
|
| 43 |
+
img_flo = flo
|
| 44 |
+
|
| 45 |
+
cv2.imwrite('/home/chengao/test/flow.png', img_flo[:, :, [2,1,0]])
|
| 46 |
+
# cv2.imshow('image', img_flo[:, :, [2,1,0]]/255.0)
|
| 47 |
+
# cv2.waitKey()
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def demo(args):
|
| 51 |
+
model = torch.nn.DataParallel(RAFT(args))
|
| 52 |
+
model.load_state_dict(torch.load(args.model))
|
| 53 |
+
|
| 54 |
+
model = model.module
|
| 55 |
+
model.to(DEVICE)
|
| 56 |
+
model.eval()
|
| 57 |
+
|
| 58 |
+
with torch.no_grad():
|
| 59 |
+
images = glob.glob(os.path.join(args.path, '*.png')) + \
|
| 60 |
+
glob.glob(os.path.join(args.path, '*.jpg'))
|
| 61 |
+
|
| 62 |
+
images = load_image_list(images)
|
| 63 |
+
for i in range(images.shape[0]-1):
|
| 64 |
+
image1 = images[i,None]
|
| 65 |
+
image2 = images[i+1,None]
|
| 66 |
+
|
| 67 |
+
flow_low, flow_up = model(image1, image2, iters=20, test_mode=True)
|
| 68 |
+
viz(image1, flow_up)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def RAFT_infer(args):
|
| 72 |
+
model = torch.nn.DataParallel(RAFT(args))
|
| 73 |
+
model.load_state_dict(torch.load(args.model))
|
| 74 |
+
|
| 75 |
+
model = model.module
|
| 76 |
+
model.to(DEVICE)
|
| 77 |
+
model.eval()
|
| 78 |
+
|
| 79 |
+
return model
|
propainter/RAFT/extractor.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class ResidualBlock(nn.Module):
|
| 7 |
+
def __init__(self, in_planes, planes, norm_fn='group', stride=1):
|
| 8 |
+
super(ResidualBlock, self).__init__()
|
| 9 |
+
|
| 10 |
+
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, padding=1, stride=stride)
|
| 11 |
+
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1)
|
| 12 |
+
self.relu = nn.ReLU(inplace=True)
|
| 13 |
+
|
| 14 |
+
num_groups = planes // 8
|
| 15 |
+
|
| 16 |
+
if norm_fn == 'group':
|
| 17 |
+
self.norm1 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 18 |
+
self.norm2 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 19 |
+
if not stride == 1:
|
| 20 |
+
self.norm3 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 21 |
+
|
| 22 |
+
elif norm_fn == 'batch':
|
| 23 |
+
self.norm1 = nn.BatchNorm2d(planes)
|
| 24 |
+
self.norm2 = nn.BatchNorm2d(planes)
|
| 25 |
+
if not stride == 1:
|
| 26 |
+
self.norm3 = nn.BatchNorm2d(planes)
|
| 27 |
+
|
| 28 |
+
elif norm_fn == 'instance':
|
| 29 |
+
self.norm1 = nn.InstanceNorm2d(planes)
|
| 30 |
+
self.norm2 = nn.InstanceNorm2d(planes)
|
| 31 |
+
if not stride == 1:
|
| 32 |
+
self.norm3 = nn.InstanceNorm2d(planes)
|
| 33 |
+
|
| 34 |
+
elif norm_fn == 'none':
|
| 35 |
+
self.norm1 = nn.Sequential()
|
| 36 |
+
self.norm2 = nn.Sequential()
|
| 37 |
+
if not stride == 1:
|
| 38 |
+
self.norm3 = nn.Sequential()
|
| 39 |
+
|
| 40 |
+
if stride == 1:
|
| 41 |
+
self.downsample = None
|
| 42 |
+
|
| 43 |
+
else:
|
| 44 |
+
self.downsample = nn.Sequential(
|
| 45 |
+
nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride), self.norm3)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def forward(self, x):
|
| 49 |
+
y = x
|
| 50 |
+
y = self.relu(self.norm1(self.conv1(y)))
|
| 51 |
+
y = self.relu(self.norm2(self.conv2(y)))
|
| 52 |
+
|
| 53 |
+
if self.downsample is not None:
|
| 54 |
+
x = self.downsample(x)
|
| 55 |
+
|
| 56 |
+
return self.relu(x+y)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class BottleneckBlock(nn.Module):
|
| 61 |
+
def __init__(self, in_planes, planes, norm_fn='group', stride=1):
|
| 62 |
+
super(BottleneckBlock, self).__init__()
|
| 63 |
+
|
| 64 |
+
self.conv1 = nn.Conv2d(in_planes, planes//4, kernel_size=1, padding=0)
|
| 65 |
+
self.conv2 = nn.Conv2d(planes//4, planes//4, kernel_size=3, padding=1, stride=stride)
|
| 66 |
+
self.conv3 = nn.Conv2d(planes//4, planes, kernel_size=1, padding=0)
|
| 67 |
+
self.relu = nn.ReLU(inplace=True)
|
| 68 |
+
|
| 69 |
+
num_groups = planes // 8
|
| 70 |
+
|
| 71 |
+
if norm_fn == 'group':
|
| 72 |
+
self.norm1 = nn.GroupNorm(num_groups=num_groups, num_channels=planes//4)
|
| 73 |
+
self.norm2 = nn.GroupNorm(num_groups=num_groups, num_channels=planes//4)
|
| 74 |
+
self.norm3 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 75 |
+
if not stride == 1:
|
| 76 |
+
self.norm4 = nn.GroupNorm(num_groups=num_groups, num_channels=planes)
|
| 77 |
+
|
| 78 |
+
elif norm_fn == 'batch':
|
| 79 |
+
self.norm1 = nn.BatchNorm2d(planes//4)
|
| 80 |
+
self.norm2 = nn.BatchNorm2d(planes//4)
|
| 81 |
+
self.norm3 = nn.BatchNorm2d(planes)
|
| 82 |
+
if not stride == 1:
|
| 83 |
+
self.norm4 = nn.BatchNorm2d(planes)
|
| 84 |
+
|
| 85 |
+
elif norm_fn == 'instance':
|
| 86 |
+
self.norm1 = nn.InstanceNorm2d(planes//4)
|
| 87 |
+
self.norm2 = nn.InstanceNorm2d(planes//4)
|
| 88 |
+
self.norm3 = nn.InstanceNorm2d(planes)
|
| 89 |
+
if not stride == 1:
|
| 90 |
+
self.norm4 = nn.InstanceNorm2d(planes)
|
| 91 |
+
|
| 92 |
+
elif norm_fn == 'none':
|
| 93 |
+
self.norm1 = nn.Sequential()
|
| 94 |
+
self.norm2 = nn.Sequential()
|
| 95 |
+
self.norm3 = nn.Sequential()
|
| 96 |
+
if not stride == 1:
|
| 97 |
+
self.norm4 = nn.Sequential()
|
| 98 |
+
|
| 99 |
+
if stride == 1:
|
| 100 |
+
self.downsample = None
|
| 101 |
+
|
| 102 |
+
else:
|
| 103 |
+
self.downsample = nn.Sequential(
|
| 104 |
+
nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride), self.norm4)
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def forward(self, x):
|
| 108 |
+
y = x
|
| 109 |
+
y = self.relu(self.norm1(self.conv1(y)))
|
| 110 |
+
y = self.relu(self.norm2(self.conv2(y)))
|
| 111 |
+
y = self.relu(self.norm3(self.conv3(y)))
|
| 112 |
+
|
| 113 |
+
if self.downsample is not None:
|
| 114 |
+
x = self.downsample(x)
|
| 115 |
+
|
| 116 |
+
return self.relu(x+y)
|
| 117 |
+
|
| 118 |
+
class BasicEncoder(nn.Module):
|
| 119 |
+
def __init__(self, output_dim=128, norm_fn='batch', dropout=0.0):
|
| 120 |
+
super(BasicEncoder, self).__init__()
|
| 121 |
+
self.norm_fn = norm_fn
|
| 122 |
+
|
| 123 |
+
if self.norm_fn == 'group':
|
| 124 |
+
self.norm1 = nn.GroupNorm(num_groups=8, num_channels=64)
|
| 125 |
+
|
| 126 |
+
elif self.norm_fn == 'batch':
|
| 127 |
+
self.norm1 = nn.BatchNorm2d(64)
|
| 128 |
+
|
| 129 |
+
elif self.norm_fn == 'instance':
|
| 130 |
+
self.norm1 = nn.InstanceNorm2d(64)
|
| 131 |
+
|
| 132 |
+
elif self.norm_fn == 'none':
|
| 133 |
+
self.norm1 = nn.Sequential()
|
| 134 |
+
|
| 135 |
+
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
|
| 136 |
+
self.relu1 = nn.ReLU(inplace=True)
|
| 137 |
+
|
| 138 |
+
self.in_planes = 64
|
| 139 |
+
self.layer1 = self._make_layer(64, stride=1)
|
| 140 |
+
self.layer2 = self._make_layer(96, stride=2)
|
| 141 |
+
self.layer3 = self._make_layer(128, stride=2)
|
| 142 |
+
|
| 143 |
+
# output convolution
|
| 144 |
+
self.conv2 = nn.Conv2d(128, output_dim, kernel_size=1)
|
| 145 |
+
|
| 146 |
+
self.dropout = None
|
| 147 |
+
if dropout > 0:
|
| 148 |
+
self.dropout = nn.Dropout2d(p=dropout)
|
| 149 |
+
|
| 150 |
+
for m in self.modules():
|
| 151 |
+
if isinstance(m, nn.Conv2d):
|
| 152 |
+
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
|
| 153 |
+
elif isinstance(m, (nn.BatchNorm2d, nn.InstanceNorm2d, nn.GroupNorm)):
|
| 154 |
+
if m.weight is not None:
|
| 155 |
+
nn.init.constant_(m.weight, 1)
|
| 156 |
+
if m.bias is not None:
|
| 157 |
+
nn.init.constant_(m.bias, 0)
|
| 158 |
+
|
| 159 |
+
def _make_layer(self, dim, stride=1):
|
| 160 |
+
layer1 = ResidualBlock(self.in_planes, dim, self.norm_fn, stride=stride)
|
| 161 |
+
layer2 = ResidualBlock(dim, dim, self.norm_fn, stride=1)
|
| 162 |
+
layers = (layer1, layer2)
|
| 163 |
+
|
| 164 |
+
self.in_planes = dim
|
| 165 |
+
return nn.Sequential(*layers)
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
def forward(self, x):
|
| 169 |
+
|
| 170 |
+
# if input is list, combine batch dimension
|
| 171 |
+
is_list = isinstance(x, tuple) or isinstance(x, list)
|
| 172 |
+
if is_list:
|
| 173 |
+
batch_dim = x[0].shape[0]
|
| 174 |
+
x = torch.cat(x, dim=0)
|
| 175 |
+
|
| 176 |
+
x = self.conv1(x)
|
| 177 |
+
x = self.norm1(x)
|
| 178 |
+
x = self.relu1(x)
|
| 179 |
+
|
| 180 |
+
x = self.layer1(x)
|
| 181 |
+
x = self.layer2(x)
|
| 182 |
+
x = self.layer3(x)
|
| 183 |
+
|
| 184 |
+
x = self.conv2(x)
|
| 185 |
+
|
| 186 |
+
if self.training and self.dropout is not None:
|
| 187 |
+
x = self.dropout(x)
|
| 188 |
+
|
| 189 |
+
if is_list:
|
| 190 |
+
x = torch.split(x, [batch_dim, batch_dim], dim=0)
|
| 191 |
+
|
| 192 |
+
return x
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
class SmallEncoder(nn.Module):
|
| 196 |
+
def __init__(self, output_dim=128, norm_fn='batch', dropout=0.0):
|
| 197 |
+
super(SmallEncoder, self).__init__()
|
| 198 |
+
self.norm_fn = norm_fn
|
| 199 |
+
|
| 200 |
+
if self.norm_fn == 'group':
|
| 201 |
+
self.norm1 = nn.GroupNorm(num_groups=8, num_channels=32)
|
| 202 |
+
|
| 203 |
+
elif self.norm_fn == 'batch':
|
| 204 |
+
self.norm1 = nn.BatchNorm2d(32)
|
| 205 |
+
|
| 206 |
+
elif self.norm_fn == 'instance':
|
| 207 |
+
self.norm1 = nn.InstanceNorm2d(32)
|
| 208 |
+
|
| 209 |
+
elif self.norm_fn == 'none':
|
| 210 |
+
self.norm1 = nn.Sequential()
|
| 211 |
+
|
| 212 |
+
self.conv1 = nn.Conv2d(3, 32, kernel_size=7, stride=2, padding=3)
|
| 213 |
+
self.relu1 = nn.ReLU(inplace=True)
|
| 214 |
+
|
| 215 |
+
self.in_planes = 32
|
| 216 |
+
self.layer1 = self._make_layer(32, stride=1)
|
| 217 |
+
self.layer2 = self._make_layer(64, stride=2)
|
| 218 |
+
self.layer3 = self._make_layer(96, stride=2)
|
| 219 |
+
|
| 220 |
+
self.dropout = None
|
| 221 |
+
if dropout > 0:
|
| 222 |
+
self.dropout = nn.Dropout2d(p=dropout)
|
| 223 |
+
|
| 224 |
+
self.conv2 = nn.Conv2d(96, output_dim, kernel_size=1)
|
| 225 |
+
|
| 226 |
+
for m in self.modules():
|
| 227 |
+
if isinstance(m, nn.Conv2d):
|
| 228 |
+
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
|
| 229 |
+
elif isinstance(m, (nn.BatchNorm2d, nn.InstanceNorm2d, nn.GroupNorm)):
|
| 230 |
+
if m.weight is not None:
|
| 231 |
+
nn.init.constant_(m.weight, 1)
|
| 232 |
+
if m.bias is not None:
|
| 233 |
+
nn.init.constant_(m.bias, 0)
|
| 234 |
+
|
| 235 |
+
def _make_layer(self, dim, stride=1):
|
| 236 |
+
layer1 = BottleneckBlock(self.in_planes, dim, self.norm_fn, stride=stride)
|
| 237 |
+
layer2 = BottleneckBlock(dim, dim, self.norm_fn, stride=1)
|
| 238 |
+
layers = (layer1, layer2)
|
| 239 |
+
|
| 240 |
+
self.in_planes = dim
|
| 241 |
+
return nn.Sequential(*layers)
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
def forward(self, x):
|
| 245 |
+
|
| 246 |
+
# if input is list, combine batch dimension
|
| 247 |
+
is_list = isinstance(x, tuple) or isinstance(x, list)
|
| 248 |
+
if is_list:
|
| 249 |
+
batch_dim = x[0].shape[0]
|
| 250 |
+
x = torch.cat(x, dim=0)
|
| 251 |
+
|
| 252 |
+
x = self.conv1(x)
|
| 253 |
+
x = self.norm1(x)
|
| 254 |
+
x = self.relu1(x)
|
| 255 |
+
|
| 256 |
+
x = self.layer1(x)
|
| 257 |
+
x = self.layer2(x)
|
| 258 |
+
x = self.layer3(x)
|
| 259 |
+
x = self.conv2(x)
|
| 260 |
+
|
| 261 |
+
if self.training and self.dropout is not None:
|
| 262 |
+
x = self.dropout(x)
|
| 263 |
+
|
| 264 |
+
if is_list:
|
| 265 |
+
x = torch.split(x, [batch_dim, batch_dim], dim=0)
|
| 266 |
+
|
| 267 |
+
return x
|
propainter/RAFT/raft.py
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
|
| 6 |
+
from .update import BasicUpdateBlock, SmallUpdateBlock
|
| 7 |
+
from .extractor import BasicEncoder, SmallEncoder
|
| 8 |
+
from .corr import CorrBlock, AlternateCorrBlock
|
| 9 |
+
from .utils.utils import bilinear_sampler, coords_grid, upflow8
|
| 10 |
+
|
| 11 |
+
try:
|
| 12 |
+
autocast = torch.cuda.amp.autocast
|
| 13 |
+
except:
|
| 14 |
+
# dummy autocast for PyTorch < 1.6
|
| 15 |
+
class autocast:
|
| 16 |
+
def __init__(self, enabled):
|
| 17 |
+
pass
|
| 18 |
+
def __enter__(self):
|
| 19 |
+
pass
|
| 20 |
+
def __exit__(self, *args):
|
| 21 |
+
pass
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class RAFT(nn.Module):
|
| 25 |
+
def __init__(self, args):
|
| 26 |
+
super(RAFT, self).__init__()
|
| 27 |
+
self.args = args
|
| 28 |
+
|
| 29 |
+
if args.small:
|
| 30 |
+
self.hidden_dim = hdim = 96
|
| 31 |
+
self.context_dim = cdim = 64
|
| 32 |
+
args.corr_levels = 4
|
| 33 |
+
args.corr_radius = 3
|
| 34 |
+
|
| 35 |
+
else:
|
| 36 |
+
self.hidden_dim = hdim = 128
|
| 37 |
+
self.context_dim = cdim = 128
|
| 38 |
+
args.corr_levels = 4
|
| 39 |
+
args.corr_radius = 4
|
| 40 |
+
|
| 41 |
+
if 'dropout' not in args._get_kwargs():
|
| 42 |
+
args.dropout = 0
|
| 43 |
+
|
| 44 |
+
if 'alternate_corr' not in args._get_kwargs():
|
| 45 |
+
args.alternate_corr = False
|
| 46 |
+
|
| 47 |
+
# feature network, context network, and update block
|
| 48 |
+
if args.small:
|
| 49 |
+
self.fnet = SmallEncoder(output_dim=128, norm_fn='instance', dropout=args.dropout)
|
| 50 |
+
self.cnet = SmallEncoder(output_dim=hdim+cdim, norm_fn='none', dropout=args.dropout)
|
| 51 |
+
self.update_block = SmallUpdateBlock(self.args, hidden_dim=hdim)
|
| 52 |
+
|
| 53 |
+
else:
|
| 54 |
+
self.fnet = BasicEncoder(output_dim=256, norm_fn='instance', dropout=args.dropout)
|
| 55 |
+
self.cnet = BasicEncoder(output_dim=hdim+cdim, norm_fn='batch', dropout=args.dropout)
|
| 56 |
+
self.update_block = BasicUpdateBlock(self.args, hidden_dim=hdim)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def freeze_bn(self):
|
| 60 |
+
for m in self.modules():
|
| 61 |
+
if isinstance(m, nn.BatchNorm2d):
|
| 62 |
+
m.eval()
|
| 63 |
+
|
| 64 |
+
def initialize_flow(self, img):
|
| 65 |
+
""" Flow is represented as difference between two coordinate grids flow = coords1 - coords0"""
|
| 66 |
+
N, C, H, W = img.shape
|
| 67 |
+
coords0 = coords_grid(N, H//8, W//8).to(img.device)
|
| 68 |
+
coords1 = coords_grid(N, H//8, W//8).to(img.device)
|
| 69 |
+
|
| 70 |
+
# optical flow computed as difference: flow = coords1 - coords0
|
| 71 |
+
return coords0, coords1
|
| 72 |
+
|
| 73 |
+
def upsample_flow(self, flow, mask):
|
| 74 |
+
""" Upsample flow field [H/8, W/8, 2] -> [H, W, 2] using convex combination """
|
| 75 |
+
N, _, H, W = flow.shape
|
| 76 |
+
mask = mask.view(N, 1, 9, 8, 8, H, W)
|
| 77 |
+
mask = torch.softmax(mask, dim=2)
|
| 78 |
+
|
| 79 |
+
up_flow = F.unfold(8 * flow, [3,3], padding=1)
|
| 80 |
+
up_flow = up_flow.view(N, 2, 9, 1, 1, H, W)
|
| 81 |
+
|
| 82 |
+
up_flow = torch.sum(mask * up_flow, dim=2)
|
| 83 |
+
up_flow = up_flow.permute(0, 1, 4, 2, 5, 3)
|
| 84 |
+
return up_flow.reshape(N, 2, 8*H, 8*W)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def forward(self, image1, image2, iters=12, flow_init=None, test_mode=True):
|
| 88 |
+
""" Estimate optical flow between pair of frames """
|
| 89 |
+
|
| 90 |
+
# image1 = 2 * (image1 / 255.0) - 1.0
|
| 91 |
+
# image2 = 2 * (image2 / 255.0) - 1.0
|
| 92 |
+
|
| 93 |
+
image1 = image1.contiguous()
|
| 94 |
+
image2 = image2.contiguous()
|
| 95 |
+
|
| 96 |
+
hdim = self.hidden_dim
|
| 97 |
+
cdim = self.context_dim
|
| 98 |
+
|
| 99 |
+
# run the feature network
|
| 100 |
+
with autocast(enabled=self.args.mixed_precision):
|
| 101 |
+
fmap1, fmap2 = self.fnet([image1, image2])
|
| 102 |
+
|
| 103 |
+
fmap1 = fmap1.float()
|
| 104 |
+
fmap2 = fmap2.float()
|
| 105 |
+
|
| 106 |
+
if self.args.alternate_corr:
|
| 107 |
+
corr_fn = AlternateCorrBlock(fmap1, fmap2, radius=self.args.corr_radius)
|
| 108 |
+
else:
|
| 109 |
+
corr_fn = CorrBlock(fmap1, fmap2, radius=self.args.corr_radius)
|
| 110 |
+
|
| 111 |
+
# run the context network
|
| 112 |
+
with autocast(enabled=self.args.mixed_precision):
|
| 113 |
+
cnet = self.cnet(image1)
|
| 114 |
+
net, inp = torch.split(cnet, [hdim, cdim], dim=1)
|
| 115 |
+
net = torch.tanh(net)
|
| 116 |
+
inp = torch.relu(inp)
|
| 117 |
+
|
| 118 |
+
coords0, coords1 = self.initialize_flow(image1)
|
| 119 |
+
|
| 120 |
+
if flow_init is not None:
|
| 121 |
+
coords1 = coords1 + flow_init
|
| 122 |
+
|
| 123 |
+
flow_predictions = []
|
| 124 |
+
for itr in range(iters):
|
| 125 |
+
coords1 = coords1.detach()
|
| 126 |
+
corr = corr_fn(coords1) # index correlation volume
|
| 127 |
+
|
| 128 |
+
flow = coords1 - coords0
|
| 129 |
+
with autocast(enabled=self.args.mixed_precision):
|
| 130 |
+
net, up_mask, delta_flow = self.update_block(net, inp, corr, flow)
|
| 131 |
+
|
| 132 |
+
# F(t+1) = F(t) + \Delta(t)
|
| 133 |
+
coords1 = coords1 + delta_flow
|
| 134 |
+
|
| 135 |
+
# upsample predictions
|
| 136 |
+
if up_mask is None:
|
| 137 |
+
flow_up = upflow8(coords1 - coords0)
|
| 138 |
+
else:
|
| 139 |
+
flow_up = self.upsample_flow(coords1 - coords0, up_mask)
|
| 140 |
+
|
| 141 |
+
flow_predictions.append(flow_up)
|
| 142 |
+
|
| 143 |
+
if test_mode:
|
| 144 |
+
return coords1 - coords0, flow_up
|
| 145 |
+
|
| 146 |
+
return flow_predictions
|
propainter/RAFT/update.py
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class FlowHead(nn.Module):
|
| 7 |
+
def __init__(self, input_dim=128, hidden_dim=256):
|
| 8 |
+
super(FlowHead, self).__init__()
|
| 9 |
+
self.conv1 = nn.Conv2d(input_dim, hidden_dim, 3, padding=1)
|
| 10 |
+
self.conv2 = nn.Conv2d(hidden_dim, 2, 3, padding=1)
|
| 11 |
+
self.relu = nn.ReLU(inplace=True)
|
| 12 |
+
|
| 13 |
+
def forward(self, x):
|
| 14 |
+
return self.conv2(self.relu(self.conv1(x)))
|
| 15 |
+
|
| 16 |
+
class ConvGRU(nn.Module):
|
| 17 |
+
def __init__(self, hidden_dim=128, input_dim=192+128):
|
| 18 |
+
super(ConvGRU, self).__init__()
|
| 19 |
+
self.convz = nn.Conv2d(hidden_dim+input_dim, hidden_dim, 3, padding=1)
|
| 20 |
+
self.convr = nn.Conv2d(hidden_dim+input_dim, hidden_dim, 3, padding=1)
|
| 21 |
+
self.convq = nn.Conv2d(hidden_dim+input_dim, hidden_dim, 3, padding=1)
|
| 22 |
+
|
| 23 |
+
def forward(self, h, x):
|
| 24 |
+
hx = torch.cat([h, x], dim=1)
|
| 25 |
+
|
| 26 |
+
z = torch.sigmoid(self.convz(hx))
|
| 27 |
+
r = torch.sigmoid(self.convr(hx))
|
| 28 |
+
q = torch.tanh(self.convq(torch.cat([r*h, x], dim=1)))
|
| 29 |
+
|
| 30 |
+
h = (1-z) * h + z * q
|
| 31 |
+
return h
|
| 32 |
+
|
| 33 |
+
class SepConvGRU(nn.Module):
|
| 34 |
+
def __init__(self, hidden_dim=128, input_dim=192+128):
|
| 35 |
+
super(SepConvGRU, self).__init__()
|
| 36 |
+
self.convz1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
|
| 37 |
+
self.convr1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
|
| 38 |
+
self.convq1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
|
| 39 |
+
|
| 40 |
+
self.convz2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
|
| 41 |
+
self.convr2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
|
| 42 |
+
self.convq2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def forward(self, h, x):
|
| 46 |
+
# horizontal
|
| 47 |
+
hx = torch.cat([h, x], dim=1)
|
| 48 |
+
z = torch.sigmoid(self.convz1(hx))
|
| 49 |
+
r = torch.sigmoid(self.convr1(hx))
|
| 50 |
+
q = torch.tanh(self.convq1(torch.cat([r*h, x], dim=1)))
|
| 51 |
+
h = (1-z) * h + z * q
|
| 52 |
+
|
| 53 |
+
# vertical
|
| 54 |
+
hx = torch.cat([h, x], dim=1)
|
| 55 |
+
z = torch.sigmoid(self.convz2(hx))
|
| 56 |
+
r = torch.sigmoid(self.convr2(hx))
|
| 57 |
+
q = torch.tanh(self.convq2(torch.cat([r*h, x], dim=1)))
|
| 58 |
+
h = (1-z) * h + z * q
|
| 59 |
+
|
| 60 |
+
return h
|
| 61 |
+
|
| 62 |
+
class SmallMotionEncoder(nn.Module):
|
| 63 |
+
def __init__(self, args):
|
| 64 |
+
super(SmallMotionEncoder, self).__init__()
|
| 65 |
+
cor_planes = args.corr_levels * (2*args.corr_radius + 1)**2
|
| 66 |
+
self.convc1 = nn.Conv2d(cor_planes, 96, 1, padding=0)
|
| 67 |
+
self.convf1 = nn.Conv2d(2, 64, 7, padding=3)
|
| 68 |
+
self.convf2 = nn.Conv2d(64, 32, 3, padding=1)
|
| 69 |
+
self.conv = nn.Conv2d(128, 80, 3, padding=1)
|
| 70 |
+
|
| 71 |
+
def forward(self, flow, corr):
|
| 72 |
+
cor = F.relu(self.convc1(corr))
|
| 73 |
+
flo = F.relu(self.convf1(flow))
|
| 74 |
+
flo = F.relu(self.convf2(flo))
|
| 75 |
+
cor_flo = torch.cat([cor, flo], dim=1)
|
| 76 |
+
out = F.relu(self.conv(cor_flo))
|
| 77 |
+
return torch.cat([out, flow], dim=1)
|
| 78 |
+
|
| 79 |
+
class BasicMotionEncoder(nn.Module):
|
| 80 |
+
def __init__(self, args):
|
| 81 |
+
super(BasicMotionEncoder, self).__init__()
|
| 82 |
+
cor_planes = args.corr_levels * (2*args.corr_radius + 1)**2
|
| 83 |
+
self.convc1 = nn.Conv2d(cor_planes, 256, 1, padding=0)
|
| 84 |
+
self.convc2 = nn.Conv2d(256, 192, 3, padding=1)
|
| 85 |
+
self.convf1 = nn.Conv2d(2, 128, 7, padding=3)
|
| 86 |
+
self.convf2 = nn.Conv2d(128, 64, 3, padding=1)
|
| 87 |
+
self.conv = nn.Conv2d(64+192, 128-2, 3, padding=1)
|
| 88 |
+
|
| 89 |
+
def forward(self, flow, corr):
|
| 90 |
+
cor = F.relu(self.convc1(corr))
|
| 91 |
+
cor = F.relu(self.convc2(cor))
|
| 92 |
+
flo = F.relu(self.convf1(flow))
|
| 93 |
+
flo = F.relu(self.convf2(flo))
|
| 94 |
+
|
| 95 |
+
cor_flo = torch.cat([cor, flo], dim=1)
|
| 96 |
+
out = F.relu(self.conv(cor_flo))
|
| 97 |
+
return torch.cat([out, flow], dim=1)
|
| 98 |
+
|
| 99 |
+
class SmallUpdateBlock(nn.Module):
|
| 100 |
+
def __init__(self, args, hidden_dim=96):
|
| 101 |
+
super(SmallUpdateBlock, self).__init__()
|
| 102 |
+
self.encoder = SmallMotionEncoder(args)
|
| 103 |
+
self.gru = ConvGRU(hidden_dim=hidden_dim, input_dim=82+64)
|
| 104 |
+
self.flow_head = FlowHead(hidden_dim, hidden_dim=128)
|
| 105 |
+
|
| 106 |
+
def forward(self, net, inp, corr, flow):
|
| 107 |
+
motion_features = self.encoder(flow, corr)
|
| 108 |
+
inp = torch.cat([inp, motion_features], dim=1)
|
| 109 |
+
net = self.gru(net, inp)
|
| 110 |
+
delta_flow = self.flow_head(net)
|
| 111 |
+
|
| 112 |
+
return net, None, delta_flow
|
| 113 |
+
|
| 114 |
+
class BasicUpdateBlock(nn.Module):
|
| 115 |
+
def __init__(self, args, hidden_dim=128, input_dim=128):
|
| 116 |
+
super(BasicUpdateBlock, self).__init__()
|
| 117 |
+
self.args = args
|
| 118 |
+
self.encoder = BasicMotionEncoder(args)
|
| 119 |
+
self.gru = SepConvGRU(hidden_dim=hidden_dim, input_dim=128+hidden_dim)
|
| 120 |
+
self.flow_head = FlowHead(hidden_dim, hidden_dim=256)
|
| 121 |
+
|
| 122 |
+
self.mask = nn.Sequential(
|
| 123 |
+
nn.Conv2d(128, 256, 3, padding=1),
|
| 124 |
+
nn.ReLU(inplace=True),
|
| 125 |
+
nn.Conv2d(256, 64*9, 1, padding=0))
|
| 126 |
+
|
| 127 |
+
def forward(self, net, inp, corr, flow, upsample=True):
|
| 128 |
+
motion_features = self.encoder(flow, corr)
|
| 129 |
+
inp = torch.cat([inp, motion_features], dim=1)
|
| 130 |
+
|
| 131 |
+
net = self.gru(net, inp)
|
| 132 |
+
delta_flow = self.flow_head(net)
|
| 133 |
+
|
| 134 |
+
# scale mask to balence gradients
|
| 135 |
+
mask = .25 * self.mask(net)
|
| 136 |
+
return net, mask, delta_flow
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
|
propainter/RAFT/utils/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .flow_viz import flow_to_image
|
| 2 |
+
from .frame_utils import writeFlow
|
propainter/RAFT/utils/augmentor.py
ADDED
|
@@ -0,0 +1,246 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import random
|
| 3 |
+
import math
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
import cv2
|
| 7 |
+
cv2.setNumThreads(0)
|
| 8 |
+
cv2.ocl.setUseOpenCL(False)
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
from torchvision.transforms import ColorJitter
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class FlowAugmentor:
|
| 16 |
+
def __init__(self, crop_size, min_scale=-0.2, max_scale=0.5, do_flip=True):
|
| 17 |
+
|
| 18 |
+
# spatial augmentation params
|
| 19 |
+
self.crop_size = crop_size
|
| 20 |
+
self.min_scale = min_scale
|
| 21 |
+
self.max_scale = max_scale
|
| 22 |
+
self.spatial_aug_prob = 0.8
|
| 23 |
+
self.stretch_prob = 0.8
|
| 24 |
+
self.max_stretch = 0.2
|
| 25 |
+
|
| 26 |
+
# flip augmentation params
|
| 27 |
+
self.do_flip = do_flip
|
| 28 |
+
self.h_flip_prob = 0.5
|
| 29 |
+
self.v_flip_prob = 0.1
|
| 30 |
+
|
| 31 |
+
# photometric augmentation params
|
| 32 |
+
self.photo_aug = ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4, hue=0.5/3.14)
|
| 33 |
+
self.asymmetric_color_aug_prob = 0.2
|
| 34 |
+
self.eraser_aug_prob = 0.5
|
| 35 |
+
|
| 36 |
+
def color_transform(self, img1, img2):
|
| 37 |
+
""" Photometric augmentation """
|
| 38 |
+
|
| 39 |
+
# asymmetric
|
| 40 |
+
if np.random.rand() < self.asymmetric_color_aug_prob:
|
| 41 |
+
img1 = np.array(self.photo_aug(Image.fromarray(img1)), dtype=np.uint8)
|
| 42 |
+
img2 = np.array(self.photo_aug(Image.fromarray(img2)), dtype=np.uint8)
|
| 43 |
+
|
| 44 |
+
# symmetric
|
| 45 |
+
else:
|
| 46 |
+
image_stack = np.concatenate([img1, img2], axis=0)
|
| 47 |
+
image_stack = np.array(self.photo_aug(Image.fromarray(image_stack)), dtype=np.uint8)
|
| 48 |
+
img1, img2 = np.split(image_stack, 2, axis=0)
|
| 49 |
+
|
| 50 |
+
return img1, img2
|
| 51 |
+
|
| 52 |
+
def eraser_transform(self, img1, img2, bounds=[50, 100]):
|
| 53 |
+
""" Occlusion augmentation """
|
| 54 |
+
|
| 55 |
+
ht, wd = img1.shape[:2]
|
| 56 |
+
if np.random.rand() < self.eraser_aug_prob:
|
| 57 |
+
mean_color = np.mean(img2.reshape(-1, 3), axis=0)
|
| 58 |
+
for _ in range(np.random.randint(1, 3)):
|
| 59 |
+
x0 = np.random.randint(0, wd)
|
| 60 |
+
y0 = np.random.randint(0, ht)
|
| 61 |
+
dx = np.random.randint(bounds[0], bounds[1])
|
| 62 |
+
dy = np.random.randint(bounds[0], bounds[1])
|
| 63 |
+
img2[y0:y0+dy, x0:x0+dx, :] = mean_color
|
| 64 |
+
|
| 65 |
+
return img1, img2
|
| 66 |
+
|
| 67 |
+
def spatial_transform(self, img1, img2, flow):
|
| 68 |
+
# randomly sample scale
|
| 69 |
+
ht, wd = img1.shape[:2]
|
| 70 |
+
min_scale = np.maximum(
|
| 71 |
+
(self.crop_size[0] + 8) / float(ht),
|
| 72 |
+
(self.crop_size[1] + 8) / float(wd))
|
| 73 |
+
|
| 74 |
+
scale = 2 ** np.random.uniform(self.min_scale, self.max_scale)
|
| 75 |
+
scale_x = scale
|
| 76 |
+
scale_y = scale
|
| 77 |
+
if np.random.rand() < self.stretch_prob:
|
| 78 |
+
scale_x *= 2 ** np.random.uniform(-self.max_stretch, self.max_stretch)
|
| 79 |
+
scale_y *= 2 ** np.random.uniform(-self.max_stretch, self.max_stretch)
|
| 80 |
+
|
| 81 |
+
scale_x = np.clip(scale_x, min_scale, None)
|
| 82 |
+
scale_y = np.clip(scale_y, min_scale, None)
|
| 83 |
+
|
| 84 |
+
if np.random.rand() < self.spatial_aug_prob:
|
| 85 |
+
# rescale the images
|
| 86 |
+
img1 = cv2.resize(img1, None, fx=scale_x, fy=scale_y, interpolation=cv2.INTER_LINEAR)
|
| 87 |
+
img2 = cv2.resize(img2, None, fx=scale_x, fy=scale_y, interpolation=cv2.INTER_LINEAR)
|
| 88 |
+
flow = cv2.resize(flow, None, fx=scale_x, fy=scale_y, interpolation=cv2.INTER_LINEAR)
|
| 89 |
+
flow = flow * [scale_x, scale_y]
|
| 90 |
+
|
| 91 |
+
if self.do_flip:
|
| 92 |
+
if np.random.rand() < self.h_flip_prob: # h-flip
|
| 93 |
+
img1 = img1[:, ::-1]
|
| 94 |
+
img2 = img2[:, ::-1]
|
| 95 |
+
flow = flow[:, ::-1] * [-1.0, 1.0]
|
| 96 |
+
|
| 97 |
+
if np.random.rand() < self.v_flip_prob: # v-flip
|
| 98 |
+
img1 = img1[::-1, :]
|
| 99 |
+
img2 = img2[::-1, :]
|
| 100 |
+
flow = flow[::-1, :] * [1.0, -1.0]
|
| 101 |
+
|
| 102 |
+
y0 = np.random.randint(0, img1.shape[0] - self.crop_size[0])
|
| 103 |
+
x0 = np.random.randint(0, img1.shape[1] - self.crop_size[1])
|
| 104 |
+
|
| 105 |
+
img1 = img1[y0:y0+self.crop_size[0], x0:x0+self.crop_size[1]]
|
| 106 |
+
img2 = img2[y0:y0+self.crop_size[0], x0:x0+self.crop_size[1]]
|
| 107 |
+
flow = flow[y0:y0+self.crop_size[0], x0:x0+self.crop_size[1]]
|
| 108 |
+
|
| 109 |
+
return img1, img2, flow
|
| 110 |
+
|
| 111 |
+
def __call__(self, img1, img2, flow):
|
| 112 |
+
img1, img2 = self.color_transform(img1, img2)
|
| 113 |
+
img1, img2 = self.eraser_transform(img1, img2)
|
| 114 |
+
img1, img2, flow = self.spatial_transform(img1, img2, flow)
|
| 115 |
+
|
| 116 |
+
img1 = np.ascontiguousarray(img1)
|
| 117 |
+
img2 = np.ascontiguousarray(img2)
|
| 118 |
+
flow = np.ascontiguousarray(flow)
|
| 119 |
+
|
| 120 |
+
return img1, img2, flow
|
| 121 |
+
|
| 122 |
+
class SparseFlowAugmentor:
|
| 123 |
+
def __init__(self, crop_size, min_scale=-0.2, max_scale=0.5, do_flip=False):
|
| 124 |
+
# spatial augmentation params
|
| 125 |
+
self.crop_size = crop_size
|
| 126 |
+
self.min_scale = min_scale
|
| 127 |
+
self.max_scale = max_scale
|
| 128 |
+
self.spatial_aug_prob = 0.8
|
| 129 |
+
self.stretch_prob = 0.8
|
| 130 |
+
self.max_stretch = 0.2
|
| 131 |
+
|
| 132 |
+
# flip augmentation params
|
| 133 |
+
self.do_flip = do_flip
|
| 134 |
+
self.h_flip_prob = 0.5
|
| 135 |
+
self.v_flip_prob = 0.1
|
| 136 |
+
|
| 137 |
+
# photometric augmentation params
|
| 138 |
+
self.photo_aug = ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.3/3.14)
|
| 139 |
+
self.asymmetric_color_aug_prob = 0.2
|
| 140 |
+
self.eraser_aug_prob = 0.5
|
| 141 |
+
|
| 142 |
+
def color_transform(self, img1, img2):
|
| 143 |
+
image_stack = np.concatenate([img1, img2], axis=0)
|
| 144 |
+
image_stack = np.array(self.photo_aug(Image.fromarray(image_stack)), dtype=np.uint8)
|
| 145 |
+
img1, img2 = np.split(image_stack, 2, axis=0)
|
| 146 |
+
return img1, img2
|
| 147 |
+
|
| 148 |
+
def eraser_transform(self, img1, img2):
|
| 149 |
+
ht, wd = img1.shape[:2]
|
| 150 |
+
if np.random.rand() < self.eraser_aug_prob:
|
| 151 |
+
mean_color = np.mean(img2.reshape(-1, 3), axis=0)
|
| 152 |
+
for _ in range(np.random.randint(1, 3)):
|
| 153 |
+
x0 = np.random.randint(0, wd)
|
| 154 |
+
y0 = np.random.randint(0, ht)
|
| 155 |
+
dx = np.random.randint(50, 100)
|
| 156 |
+
dy = np.random.randint(50, 100)
|
| 157 |
+
img2[y0:y0+dy, x0:x0+dx, :] = mean_color
|
| 158 |
+
|
| 159 |
+
return img1, img2
|
| 160 |
+
|
| 161 |
+
def resize_sparse_flow_map(self, flow, valid, fx=1.0, fy=1.0):
|
| 162 |
+
ht, wd = flow.shape[:2]
|
| 163 |
+
coords = np.meshgrid(np.arange(wd), np.arange(ht))
|
| 164 |
+
coords = np.stack(coords, axis=-1)
|
| 165 |
+
|
| 166 |
+
coords = coords.reshape(-1, 2).astype(np.float32)
|
| 167 |
+
flow = flow.reshape(-1, 2).astype(np.float32)
|
| 168 |
+
valid = valid.reshape(-1).astype(np.float32)
|
| 169 |
+
|
| 170 |
+
coords0 = coords[valid>=1]
|
| 171 |
+
flow0 = flow[valid>=1]
|
| 172 |
+
|
| 173 |
+
ht1 = int(round(ht * fy))
|
| 174 |
+
wd1 = int(round(wd * fx))
|
| 175 |
+
|
| 176 |
+
coords1 = coords0 * [fx, fy]
|
| 177 |
+
flow1 = flow0 * [fx, fy]
|
| 178 |
+
|
| 179 |
+
xx = np.round(coords1[:,0]).astype(np.int32)
|
| 180 |
+
yy = np.round(coords1[:,1]).astype(np.int32)
|
| 181 |
+
|
| 182 |
+
v = (xx > 0) & (xx < wd1) & (yy > 0) & (yy < ht1)
|
| 183 |
+
xx = xx[v]
|
| 184 |
+
yy = yy[v]
|
| 185 |
+
flow1 = flow1[v]
|
| 186 |
+
|
| 187 |
+
flow_img = np.zeros([ht1, wd1, 2], dtype=np.float32)
|
| 188 |
+
valid_img = np.zeros([ht1, wd1], dtype=np.int32)
|
| 189 |
+
|
| 190 |
+
flow_img[yy, xx] = flow1
|
| 191 |
+
valid_img[yy, xx] = 1
|
| 192 |
+
|
| 193 |
+
return flow_img, valid_img
|
| 194 |
+
|
| 195 |
+
def spatial_transform(self, img1, img2, flow, valid):
|
| 196 |
+
# randomly sample scale
|
| 197 |
+
|
| 198 |
+
ht, wd = img1.shape[:2]
|
| 199 |
+
min_scale = np.maximum(
|
| 200 |
+
(self.crop_size[0] + 1) / float(ht),
|
| 201 |
+
(self.crop_size[1] + 1) / float(wd))
|
| 202 |
+
|
| 203 |
+
scale = 2 ** np.random.uniform(self.min_scale, self.max_scale)
|
| 204 |
+
scale_x = np.clip(scale, min_scale, None)
|
| 205 |
+
scale_y = np.clip(scale, min_scale, None)
|
| 206 |
+
|
| 207 |
+
if np.random.rand() < self.spatial_aug_prob:
|
| 208 |
+
# rescale the images
|
| 209 |
+
img1 = cv2.resize(img1, None, fx=scale_x, fy=scale_y, interpolation=cv2.INTER_LINEAR)
|
| 210 |
+
img2 = cv2.resize(img2, None, fx=scale_x, fy=scale_y, interpolation=cv2.INTER_LINEAR)
|
| 211 |
+
flow, valid = self.resize_sparse_flow_map(flow, valid, fx=scale_x, fy=scale_y)
|
| 212 |
+
|
| 213 |
+
if self.do_flip:
|
| 214 |
+
if np.random.rand() < 0.5: # h-flip
|
| 215 |
+
img1 = img1[:, ::-1]
|
| 216 |
+
img2 = img2[:, ::-1]
|
| 217 |
+
flow = flow[:, ::-1] * [-1.0, 1.0]
|
| 218 |
+
valid = valid[:, ::-1]
|
| 219 |
+
|
| 220 |
+
margin_y = 20
|
| 221 |
+
margin_x = 50
|
| 222 |
+
|
| 223 |
+
y0 = np.random.randint(0, img1.shape[0] - self.crop_size[0] + margin_y)
|
| 224 |
+
x0 = np.random.randint(-margin_x, img1.shape[1] - self.crop_size[1] + margin_x)
|
| 225 |
+
|
| 226 |
+
y0 = np.clip(y0, 0, img1.shape[0] - self.crop_size[0])
|
| 227 |
+
x0 = np.clip(x0, 0, img1.shape[1] - self.crop_size[1])
|
| 228 |
+
|
| 229 |
+
img1 = img1[y0:y0+self.crop_size[0], x0:x0+self.crop_size[1]]
|
| 230 |
+
img2 = img2[y0:y0+self.crop_size[0], x0:x0+self.crop_size[1]]
|
| 231 |
+
flow = flow[y0:y0+self.crop_size[0], x0:x0+self.crop_size[1]]
|
| 232 |
+
valid = valid[y0:y0+self.crop_size[0], x0:x0+self.crop_size[1]]
|
| 233 |
+
return img1, img2, flow, valid
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def __call__(self, img1, img2, flow, valid):
|
| 237 |
+
img1, img2 = self.color_transform(img1, img2)
|
| 238 |
+
img1, img2 = self.eraser_transform(img1, img2)
|
| 239 |
+
img1, img2, flow, valid = self.spatial_transform(img1, img2, flow, valid)
|
| 240 |
+
|
| 241 |
+
img1 = np.ascontiguousarray(img1)
|
| 242 |
+
img2 = np.ascontiguousarray(img2)
|
| 243 |
+
flow = np.ascontiguousarray(flow)
|
| 244 |
+
valid = np.ascontiguousarray(valid)
|
| 245 |
+
|
| 246 |
+
return img1, img2, flow, valid
|
propainter/RAFT/utils/flow_viz.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Flow visualization code used from https://github.com/tomrunia/OpticalFlow_Visualization
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
# MIT License
|
| 5 |
+
#
|
| 6 |
+
# Copyright (c) 2018 Tom Runia
|
| 7 |
+
#
|
| 8 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 9 |
+
# of this software and associated documentation files (the "Software"), to deal
|
| 10 |
+
# in the Software without restriction, including without limitation the rights
|
| 11 |
+
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 12 |
+
# copies of the Software, and to permit persons to whom the Software is
|
| 13 |
+
# furnished to do so, subject to conditions.
|
| 14 |
+
#
|
| 15 |
+
# Author: Tom Runia
|
| 16 |
+
# Date Created: 2018-08-03
|
| 17 |
+
|
| 18 |
+
import numpy as np
|
| 19 |
+
|
| 20 |
+
def make_colorwheel():
|
| 21 |
+
"""
|
| 22 |
+
Generates a color wheel for optical flow visualization as presented in:
|
| 23 |
+
Baker et al. "A Database and Evaluation Methodology for Optical Flow" (ICCV, 2007)
|
| 24 |
+
URL: http://vision.middlebury.edu/flow/flowEval-iccv07.pdf
|
| 25 |
+
|
| 26 |
+
Code follows the original C++ source code of Daniel Scharstein.
|
| 27 |
+
Code follows the the Matlab source code of Deqing Sun.
|
| 28 |
+
|
| 29 |
+
Returns:
|
| 30 |
+
np.ndarray: Color wheel
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
RY = 15
|
| 34 |
+
YG = 6
|
| 35 |
+
GC = 4
|
| 36 |
+
CB = 11
|
| 37 |
+
BM = 13
|
| 38 |
+
MR = 6
|
| 39 |
+
|
| 40 |
+
ncols = RY + YG + GC + CB + BM + MR
|
| 41 |
+
colorwheel = np.zeros((ncols, 3))
|
| 42 |
+
col = 0
|
| 43 |
+
|
| 44 |
+
# RY
|
| 45 |
+
colorwheel[0:RY, 0] = 255
|
| 46 |
+
colorwheel[0:RY, 1] = np.floor(255*np.arange(0,RY)/RY)
|
| 47 |
+
col = col+RY
|
| 48 |
+
# YG
|
| 49 |
+
colorwheel[col:col+YG, 0] = 255 - np.floor(255*np.arange(0,YG)/YG)
|
| 50 |
+
colorwheel[col:col+YG, 1] = 255
|
| 51 |
+
col = col+YG
|
| 52 |
+
# GC
|
| 53 |
+
colorwheel[col:col+GC, 1] = 255
|
| 54 |
+
colorwheel[col:col+GC, 2] = np.floor(255*np.arange(0,GC)/GC)
|
| 55 |
+
col = col+GC
|
| 56 |
+
# CB
|
| 57 |
+
colorwheel[col:col+CB, 1] = 255 - np.floor(255*np.arange(CB)/CB)
|
| 58 |
+
colorwheel[col:col+CB, 2] = 255
|
| 59 |
+
col = col+CB
|
| 60 |
+
# BM
|
| 61 |
+
colorwheel[col:col+BM, 2] = 255
|
| 62 |
+
colorwheel[col:col+BM, 0] = np.floor(255*np.arange(0,BM)/BM)
|
| 63 |
+
col = col+BM
|
| 64 |
+
# MR
|
| 65 |
+
colorwheel[col:col+MR, 2] = 255 - np.floor(255*np.arange(MR)/MR)
|
| 66 |
+
colorwheel[col:col+MR, 0] = 255
|
| 67 |
+
return colorwheel
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def flow_uv_to_colors(u, v, convert_to_bgr=False):
|
| 71 |
+
"""
|
| 72 |
+
Applies the flow color wheel to (possibly clipped) flow components u and v.
|
| 73 |
+
|
| 74 |
+
According to the C++ source code of Daniel Scharstein
|
| 75 |
+
According to the Matlab source code of Deqing Sun
|
| 76 |
+
|
| 77 |
+
Args:
|
| 78 |
+
u (np.ndarray): Input horizontal flow of shape [H,W]
|
| 79 |
+
v (np.ndarray): Input vertical flow of shape [H,W]
|
| 80 |
+
convert_to_bgr (bool, optional): Convert output image to BGR. Defaults to False.
|
| 81 |
+
|
| 82 |
+
Returns:
|
| 83 |
+
np.ndarray: Flow visualization image of shape [H,W,3]
|
| 84 |
+
"""
|
| 85 |
+
flow_image = np.zeros((u.shape[0], u.shape[1], 3), np.uint8)
|
| 86 |
+
colorwheel = make_colorwheel() # shape [55x3]
|
| 87 |
+
ncols = colorwheel.shape[0]
|
| 88 |
+
rad = np.sqrt(np.square(u) + np.square(v))
|
| 89 |
+
a = np.arctan2(-v, -u)/np.pi
|
| 90 |
+
fk = (a+1) / 2*(ncols-1)
|
| 91 |
+
k0 = np.floor(fk).astype(np.int32)
|
| 92 |
+
k1 = k0 + 1
|
| 93 |
+
k1[k1 == ncols] = 0
|
| 94 |
+
f = fk - k0
|
| 95 |
+
for i in range(colorwheel.shape[1]):
|
| 96 |
+
tmp = colorwheel[:,i]
|
| 97 |
+
col0 = tmp[k0] / 255.0
|
| 98 |
+
col1 = tmp[k1] / 255.0
|
| 99 |
+
col = (1-f)*col0 + f*col1
|
| 100 |
+
idx = (rad <= 1)
|
| 101 |
+
col[idx] = 1 - rad[idx] * (1-col[idx])
|
| 102 |
+
col[~idx] = col[~idx] * 0.75 # out of range
|
| 103 |
+
# Note the 2-i => BGR instead of RGB
|
| 104 |
+
ch_idx = 2-i if convert_to_bgr else i
|
| 105 |
+
flow_image[:,:,ch_idx] = np.floor(255 * col)
|
| 106 |
+
return flow_image
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def flow_to_image(flow_uv, clip_flow=None, convert_to_bgr=False):
|
| 110 |
+
"""
|
| 111 |
+
Expects a two dimensional flow image of shape.
|
| 112 |
+
|
| 113 |
+
Args:
|
| 114 |
+
flow_uv (np.ndarray): Flow UV image of shape [H,W,2]
|
| 115 |
+
clip_flow (float, optional): Clip maximum of flow values. Defaults to None.
|
| 116 |
+
convert_to_bgr (bool, optional): Convert output image to BGR. Defaults to False.
|
| 117 |
+
|
| 118 |
+
Returns:
|
| 119 |
+
np.ndarray: Flow visualization image of shape [H,W,3]
|
| 120 |
+
"""
|
| 121 |
+
assert flow_uv.ndim == 3, 'input flow must have three dimensions'
|
| 122 |
+
assert flow_uv.shape[2] == 2, 'input flow must have shape [H,W,2]'
|
| 123 |
+
if clip_flow is not None:
|
| 124 |
+
flow_uv = np.clip(flow_uv, 0, clip_flow)
|
| 125 |
+
u = flow_uv[:,:,0]
|
| 126 |
+
v = flow_uv[:,:,1]
|
| 127 |
+
rad = np.sqrt(np.square(u) + np.square(v))
|
| 128 |
+
rad_max = np.max(rad)
|
| 129 |
+
epsilon = 1e-5
|
| 130 |
+
u = u / (rad_max + epsilon)
|
| 131 |
+
v = v / (rad_max + epsilon)
|
| 132 |
+
return flow_uv_to_colors(u, v, convert_to_bgr)
|
propainter/RAFT/utils/flow_viz_pt.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Flow visualization code adapted from https://github.com/tomrunia/OpticalFlow_Visualization
|
| 2 |
+
import torch
|
| 3 |
+
torch.pi = torch.acos(torch.zeros(1)).item() * 2 # which is 3.1415927410125732
|
| 4 |
+
|
| 5 |
+
@torch.no_grad()
|
| 6 |
+
def flow_to_image(flow: torch.Tensor) -> torch.Tensor:
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
Converts a flow to an RGB image.
|
| 10 |
+
|
| 11 |
+
Args:
|
| 12 |
+
flow (Tensor): Flow of shape (N, 2, H, W) or (2, H, W) and dtype torch.float.
|
| 13 |
+
|
| 14 |
+
Returns:
|
| 15 |
+
img (Tensor): Image Tensor of dtype uint8 where each color corresponds
|
| 16 |
+
to a given flow direction. Shape is (N, 3, H, W) or (3, H, W) depending on the input.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
if flow.dtype != torch.float:
|
| 20 |
+
raise ValueError(f"Flow should be of dtype torch.float, got {flow.dtype}.")
|
| 21 |
+
|
| 22 |
+
orig_shape = flow.shape
|
| 23 |
+
if flow.ndim == 3:
|
| 24 |
+
flow = flow[None] # Add batch dim
|
| 25 |
+
|
| 26 |
+
if flow.ndim != 4 or flow.shape[1] != 2:
|
| 27 |
+
raise ValueError(f"Input flow should have shape (2, H, W) or (N, 2, H, W), got {orig_shape}.")
|
| 28 |
+
|
| 29 |
+
max_norm = torch.sum(flow**2, dim=1).sqrt().max()
|
| 30 |
+
epsilon = torch.finfo((flow).dtype).eps
|
| 31 |
+
normalized_flow = flow / (max_norm + epsilon)
|
| 32 |
+
img = _normalized_flow_to_image(normalized_flow)
|
| 33 |
+
|
| 34 |
+
if len(orig_shape) == 3:
|
| 35 |
+
img = img[0] # Remove batch dim
|
| 36 |
+
return img
|
| 37 |
+
|
| 38 |
+
@torch.no_grad()
|
| 39 |
+
def _normalized_flow_to_image(normalized_flow: torch.Tensor) -> torch.Tensor:
|
| 40 |
+
|
| 41 |
+
"""
|
| 42 |
+
Converts a batch of normalized flow to an RGB image.
|
| 43 |
+
|
| 44 |
+
Args:
|
| 45 |
+
normalized_flow (torch.Tensor): Normalized flow tensor of shape (N, 2, H, W)
|
| 46 |
+
Returns:
|
| 47 |
+
img (Tensor(N, 3, H, W)): Flow visualization image of dtype uint8.
|
| 48 |
+
"""
|
| 49 |
+
|
| 50 |
+
N, _, H, W = normalized_flow.shape
|
| 51 |
+
device = normalized_flow.device
|
| 52 |
+
flow_image = torch.zeros((N, 3, H, W), dtype=torch.uint8, device=device)
|
| 53 |
+
colorwheel = _make_colorwheel().to(device) # shape [55x3]
|
| 54 |
+
num_cols = colorwheel.shape[0]
|
| 55 |
+
norm = torch.sum(normalized_flow**2, dim=1).sqrt()
|
| 56 |
+
a = torch.atan2(-normalized_flow[:, 1, :, :], -normalized_flow[:, 0, :, :]) / torch.pi
|
| 57 |
+
fk = (a + 1) / 2 * (num_cols - 1)
|
| 58 |
+
k0 = torch.floor(fk).to(torch.long)
|
| 59 |
+
k1 = k0 + 1
|
| 60 |
+
k1[k1 == num_cols] = 0
|
| 61 |
+
f = fk - k0
|
| 62 |
+
|
| 63 |
+
for c in range(colorwheel.shape[1]):
|
| 64 |
+
tmp = colorwheel[:, c]
|
| 65 |
+
col0 = tmp[k0] / 255.0
|
| 66 |
+
col1 = tmp[k1] / 255.0
|
| 67 |
+
col = (1 - f) * col0 + f * col1
|
| 68 |
+
col = 1 - norm * (1 - col)
|
| 69 |
+
flow_image[:, c, :, :] = torch.floor(255. * col)
|
| 70 |
+
return flow_image
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
@torch.no_grad()
|
| 74 |
+
def _make_colorwheel() -> torch.Tensor:
|
| 75 |
+
"""
|
| 76 |
+
Generates a color wheel for optical flow visualization as presented in:
|
| 77 |
+
Baker et al. "A Database and Evaluation Methodology for Optical Flow" (ICCV, 2007)
|
| 78 |
+
URL: http://vision.middlebury.edu/flow/flowEval-iccv07.pdf.
|
| 79 |
+
|
| 80 |
+
Returns:
|
| 81 |
+
colorwheel (Tensor[55, 3]): Colorwheel Tensor.
|
| 82 |
+
"""
|
| 83 |
+
|
| 84 |
+
RY = 15
|
| 85 |
+
YG = 6
|
| 86 |
+
GC = 4
|
| 87 |
+
CB = 11
|
| 88 |
+
BM = 13
|
| 89 |
+
MR = 6
|
| 90 |
+
|
| 91 |
+
ncols = RY + YG + GC + CB + BM + MR
|
| 92 |
+
colorwheel = torch.zeros((ncols, 3))
|
| 93 |
+
col = 0
|
| 94 |
+
|
| 95 |
+
# RY
|
| 96 |
+
colorwheel[0:RY, 0] = 255
|
| 97 |
+
colorwheel[0:RY, 1] = torch.floor(255. * torch.arange(0., RY) / RY)
|
| 98 |
+
col = col + RY
|
| 99 |
+
# YG
|
| 100 |
+
colorwheel[col : col + YG, 0] = 255 - torch.floor(255. * torch.arange(0., YG) / YG)
|
| 101 |
+
colorwheel[col : col + YG, 1] = 255
|
| 102 |
+
col = col + YG
|
| 103 |
+
# GC
|
| 104 |
+
colorwheel[col : col + GC, 1] = 255
|
| 105 |
+
colorwheel[col : col + GC, 2] = torch.floor(255. * torch.arange(0., GC) / GC)
|
| 106 |
+
col = col + GC
|
| 107 |
+
# CB
|
| 108 |
+
colorwheel[col : col + CB, 1] = 255 - torch.floor(255. * torch.arange(CB) / CB)
|
| 109 |
+
colorwheel[col : col + CB, 2] = 255
|
| 110 |
+
col = col + CB
|
| 111 |
+
# BM
|
| 112 |
+
colorwheel[col : col + BM, 2] = 255
|
| 113 |
+
colorwheel[col : col + BM, 0] = torch.floor(255. * torch.arange(0., BM) / BM)
|
| 114 |
+
col = col + BM
|
| 115 |
+
# MR
|
| 116 |
+
colorwheel[col : col + MR, 2] = 255 - torch.floor(255. * torch.arange(MR) / MR)
|
| 117 |
+
colorwheel[col : col + MR, 0] = 255
|
| 118 |
+
return colorwheel
|
propainter/RAFT/utils/frame_utils.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from PIL import Image
|
| 3 |
+
from os.path import *
|
| 4 |
+
import re
|
| 5 |
+
|
| 6 |
+
import cv2
|
| 7 |
+
cv2.setNumThreads(0)
|
| 8 |
+
cv2.ocl.setUseOpenCL(False)
|
| 9 |
+
|
| 10 |
+
TAG_CHAR = np.array([202021.25], np.float32)
|
| 11 |
+
|
| 12 |
+
def readFlow(fn):
|
| 13 |
+
""" Read .flo file in Middlebury format"""
|
| 14 |
+
# Code adapted from:
|
| 15 |
+
# http://stackoverflow.com/questions/28013200/reading-middlebury-flow-files-with-python-bytes-array-numpy
|
| 16 |
+
|
| 17 |
+
# WARNING: this will work on little-endian architectures (eg Intel x86) only!
|
| 18 |
+
# print 'fn = %s'%(fn)
|
| 19 |
+
with open(fn, 'rb') as f:
|
| 20 |
+
magic = np.fromfile(f, np.float32, count=1)
|
| 21 |
+
if 202021.25 != magic:
|
| 22 |
+
print('Magic number incorrect. Invalid .flo file')
|
| 23 |
+
return None
|
| 24 |
+
else:
|
| 25 |
+
w = np.fromfile(f, np.int32, count=1)
|
| 26 |
+
h = np.fromfile(f, np.int32, count=1)
|
| 27 |
+
# print 'Reading %d x %d flo file\n' % (w, h)
|
| 28 |
+
data = np.fromfile(f, np.float32, count=2*int(w)*int(h))
|
| 29 |
+
# Reshape data into 3D array (columns, rows, bands)
|
| 30 |
+
# The reshape here is for visualization, the original code is (w,h,2)
|
| 31 |
+
return np.resize(data, (int(h), int(w), 2))
|
| 32 |
+
|
| 33 |
+
def readPFM(file):
|
| 34 |
+
file = open(file, 'rb')
|
| 35 |
+
|
| 36 |
+
color = None
|
| 37 |
+
width = None
|
| 38 |
+
height = None
|
| 39 |
+
scale = None
|
| 40 |
+
endian = None
|
| 41 |
+
|
| 42 |
+
header = file.readline().rstrip()
|
| 43 |
+
if header == b'PF':
|
| 44 |
+
color = True
|
| 45 |
+
elif header == b'Pf':
|
| 46 |
+
color = False
|
| 47 |
+
else:
|
| 48 |
+
raise Exception('Not a PFM file.')
|
| 49 |
+
|
| 50 |
+
dim_match = re.match(rb'^(\d+)\s(\d+)\s$', file.readline())
|
| 51 |
+
if dim_match:
|
| 52 |
+
width, height = map(int, dim_match.groups())
|
| 53 |
+
else:
|
| 54 |
+
raise Exception('Malformed PFM header.')
|
| 55 |
+
|
| 56 |
+
scale = float(file.readline().rstrip())
|
| 57 |
+
if scale < 0: # little-endian
|
| 58 |
+
endian = '<'
|
| 59 |
+
scale = -scale
|
| 60 |
+
else:
|
| 61 |
+
endian = '>' # big-endian
|
| 62 |
+
|
| 63 |
+
data = np.fromfile(file, endian + 'f')
|
| 64 |
+
shape = (height, width, 3) if color else (height, width)
|
| 65 |
+
|
| 66 |
+
data = np.reshape(data, shape)
|
| 67 |
+
data = np.flipud(data)
|
| 68 |
+
return data
|
| 69 |
+
|
| 70 |
+
def writeFlow(filename,uv,v=None):
|
| 71 |
+
""" Write optical flow to file.
|
| 72 |
+
|
| 73 |
+
If v is None, uv is assumed to contain both u and v channels,
|
| 74 |
+
stacked in depth.
|
| 75 |
+
Original code by Deqing Sun, adapted from Daniel Scharstein.
|
| 76 |
+
"""
|
| 77 |
+
nBands = 2
|
| 78 |
+
|
| 79 |
+
if v is None:
|
| 80 |
+
assert(uv.ndim == 3)
|
| 81 |
+
assert(uv.shape[2] == 2)
|
| 82 |
+
u = uv[:,:,0]
|
| 83 |
+
v = uv[:,:,1]
|
| 84 |
+
else:
|
| 85 |
+
u = uv
|
| 86 |
+
|
| 87 |
+
assert(u.shape == v.shape)
|
| 88 |
+
height,width = u.shape
|
| 89 |
+
f = open(filename,'wb')
|
| 90 |
+
# write the header
|
| 91 |
+
f.write(TAG_CHAR)
|
| 92 |
+
np.array(width).astype(np.int32).tofile(f)
|
| 93 |
+
np.array(height).astype(np.int32).tofile(f)
|
| 94 |
+
# arrange into matrix form
|
| 95 |
+
tmp = np.zeros((height, width*nBands))
|
| 96 |
+
tmp[:,np.arange(width)*2] = u
|
| 97 |
+
tmp[:,np.arange(width)*2 + 1] = v
|
| 98 |
+
tmp.astype(np.float32).tofile(f)
|
| 99 |
+
f.close()
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def readFlowKITTI(filename):
|
| 103 |
+
flow = cv2.imread(filename, cv2.IMREAD_ANYDEPTH|cv2.IMREAD_COLOR)
|
| 104 |
+
flow = flow[:,:,::-1].astype(np.float32)
|
| 105 |
+
flow, valid = flow[:, :, :2], flow[:, :, 2]
|
| 106 |
+
flow = (flow - 2**15) / 64.0
|
| 107 |
+
return flow, valid
|
| 108 |
+
|
| 109 |
+
def readDispKITTI(filename):
|
| 110 |
+
disp = cv2.imread(filename, cv2.IMREAD_ANYDEPTH) / 256.0
|
| 111 |
+
valid = disp > 0.0
|
| 112 |
+
flow = np.stack([-disp, np.zeros_like(disp)], -1)
|
| 113 |
+
return flow, valid
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def writeFlowKITTI(filename, uv):
|
| 117 |
+
uv = 64.0 * uv + 2**15
|
| 118 |
+
valid = np.ones([uv.shape[0], uv.shape[1], 1])
|
| 119 |
+
uv = np.concatenate([uv, valid], axis=-1).astype(np.uint16)
|
| 120 |
+
cv2.imwrite(filename, uv[..., ::-1])
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def read_gen(file_name, pil=False):
|
| 124 |
+
ext = splitext(file_name)[-1]
|
| 125 |
+
if ext == '.png' or ext == '.jpeg' or ext == '.ppm' or ext == '.jpg':
|
| 126 |
+
return Image.open(file_name)
|
| 127 |
+
elif ext == '.bin' or ext == '.raw':
|
| 128 |
+
return np.load(file_name)
|
| 129 |
+
elif ext == '.flo':
|
| 130 |
+
return readFlow(file_name).astype(np.float32)
|
| 131 |
+
elif ext == '.pfm':
|
| 132 |
+
flow = readPFM(file_name).astype(np.float32)
|
| 133 |
+
if len(flow.shape) == 2:
|
| 134 |
+
return flow
|
| 135 |
+
else:
|
| 136 |
+
return flow[:, :, :-1]
|
| 137 |
+
return []
|
propainter/RAFT/utils/utils.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
import numpy as np
|
| 4 |
+
from scipy import interpolate
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class InputPadder:
|
| 8 |
+
""" Pads images such that dimensions are divisible by 8 """
|
| 9 |
+
def __init__(self, dims, mode='sintel'):
|
| 10 |
+
self.ht, self.wd = dims[-2:]
|
| 11 |
+
pad_ht = (((self.ht // 8) + 1) * 8 - self.ht) % 8
|
| 12 |
+
pad_wd = (((self.wd // 8) + 1) * 8 - self.wd) % 8
|
| 13 |
+
if mode == 'sintel':
|
| 14 |
+
self._pad = [pad_wd//2, pad_wd - pad_wd//2, pad_ht//2, pad_ht - pad_ht//2]
|
| 15 |
+
else:
|
| 16 |
+
self._pad = [pad_wd//2, pad_wd - pad_wd//2, 0, pad_ht]
|
| 17 |
+
|
| 18 |
+
def pad(self, *inputs):
|
| 19 |
+
return [F.pad(x, self._pad, mode='replicate') for x in inputs]
|
| 20 |
+
|
| 21 |
+
def unpad(self,x):
|
| 22 |
+
ht, wd = x.shape[-2:]
|
| 23 |
+
c = [self._pad[2], ht-self._pad[3], self._pad[0], wd-self._pad[1]]
|
| 24 |
+
return x[..., c[0]:c[1], c[2]:c[3]]
|
| 25 |
+
|
| 26 |
+
def forward_interpolate(flow):
|
| 27 |
+
flow = flow.detach().cpu().numpy()
|
| 28 |
+
dx, dy = flow[0], flow[1]
|
| 29 |
+
|
| 30 |
+
ht, wd = dx.shape
|
| 31 |
+
x0, y0 = np.meshgrid(np.arange(wd), np.arange(ht))
|
| 32 |
+
|
| 33 |
+
x1 = x0 + dx
|
| 34 |
+
y1 = y0 + dy
|
| 35 |
+
|
| 36 |
+
x1 = x1.reshape(-1)
|
| 37 |
+
y1 = y1.reshape(-1)
|
| 38 |
+
dx = dx.reshape(-1)
|
| 39 |
+
dy = dy.reshape(-1)
|
| 40 |
+
|
| 41 |
+
valid = (x1 > 0) & (x1 < wd) & (y1 > 0) & (y1 < ht)
|
| 42 |
+
x1 = x1[valid]
|
| 43 |
+
y1 = y1[valid]
|
| 44 |
+
dx = dx[valid]
|
| 45 |
+
dy = dy[valid]
|
| 46 |
+
|
| 47 |
+
flow_x = interpolate.griddata(
|
| 48 |
+
(x1, y1), dx, (x0, y0), method='nearest', fill_value=0)
|
| 49 |
+
|
| 50 |
+
flow_y = interpolate.griddata(
|
| 51 |
+
(x1, y1), dy, (x0, y0), method='nearest', fill_value=0)
|
| 52 |
+
|
| 53 |
+
flow = np.stack([flow_x, flow_y], axis=0)
|
| 54 |
+
return torch.from_numpy(flow).float()
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def bilinear_sampler(img, coords, mode='bilinear', mask=False):
|
| 58 |
+
""" Wrapper for grid_sample, uses pixel coordinates """
|
| 59 |
+
H, W = img.shape[-2:]
|
| 60 |
+
xgrid, ygrid = coords.split([1,1], dim=-1)
|
| 61 |
+
xgrid = 2*xgrid/(W-1) - 1
|
| 62 |
+
ygrid = 2*ygrid/(H-1) - 1
|
| 63 |
+
|
| 64 |
+
grid = torch.cat([xgrid, ygrid], dim=-1)
|
| 65 |
+
img = F.grid_sample(img, grid, align_corners=True)
|
| 66 |
+
|
| 67 |
+
if mask:
|
| 68 |
+
mask = (xgrid > -1) & (ygrid > -1) & (xgrid < 1) & (ygrid < 1)
|
| 69 |
+
return img, mask.float()
|
| 70 |
+
|
| 71 |
+
return img
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def coords_grid(batch, ht, wd):
|
| 75 |
+
coords = torch.meshgrid(torch.arange(ht), torch.arange(wd))
|
| 76 |
+
coords = torch.stack(coords[::-1], dim=0).float()
|
| 77 |
+
return coords[None].repeat(batch, 1, 1, 1)
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def upflow8(flow, mode='bilinear'):
|
| 81 |
+
new_size = (8 * flow.shape[2], 8 * flow.shape[3])
|
| 82 |
+
return 8 * F.interpolate(flow, size=new_size, mode=mode, align_corners=True)
|
propainter/core/dataset.py
ADDED
|
@@ -0,0 +1,232 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import random
|
| 4 |
+
|
| 5 |
+
import cv2
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torchvision.transforms as transforms
|
| 11 |
+
|
| 12 |
+
from utils.file_client import FileClient
|
| 13 |
+
from utils.img_util import imfrombytes
|
| 14 |
+
from utils.flow_util import resize_flow, flowread
|
| 15 |
+
from core.utils import (create_random_shape_with_random_motion, Stack,
|
| 16 |
+
ToTorchFormatTensor, GroupRandomHorizontalFlip,GroupRandomHorizontalFlowFlip)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class TrainDataset(torch.utils.data.Dataset):
|
| 20 |
+
def __init__(self, args: dict):
|
| 21 |
+
self.args = args
|
| 22 |
+
self.video_root = args['video_root']
|
| 23 |
+
self.flow_root = args['flow_root']
|
| 24 |
+
self.num_local_frames = args['num_local_frames']
|
| 25 |
+
self.num_ref_frames = args['num_ref_frames']
|
| 26 |
+
self.size = self.w, self.h = (args['w'], args['h'])
|
| 27 |
+
|
| 28 |
+
self.load_flow = args['load_flow']
|
| 29 |
+
if self.load_flow:
|
| 30 |
+
assert os.path.exists(self.flow_root)
|
| 31 |
+
|
| 32 |
+
json_path = os.path.join('./datasets', args['name'], 'train.json')
|
| 33 |
+
|
| 34 |
+
with open(json_path, 'r') as f:
|
| 35 |
+
self.video_train_dict = json.load(f)
|
| 36 |
+
self.video_names = sorted(list(self.video_train_dict.keys()))
|
| 37 |
+
|
| 38 |
+
# self.video_names = sorted(os.listdir(self.video_root))
|
| 39 |
+
self.video_dict = {}
|
| 40 |
+
self.frame_dict = {}
|
| 41 |
+
|
| 42 |
+
for v in self.video_names:
|
| 43 |
+
frame_list = sorted(os.listdir(os.path.join(self.video_root, v)))
|
| 44 |
+
v_len = len(frame_list)
|
| 45 |
+
if v_len > self.num_local_frames + self.num_ref_frames:
|
| 46 |
+
self.video_dict[v] = v_len
|
| 47 |
+
self.frame_dict[v] = frame_list
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
self.video_names = list(self.video_dict.keys()) # update names
|
| 51 |
+
|
| 52 |
+
self._to_tensors = transforms.Compose([
|
| 53 |
+
Stack(),
|
| 54 |
+
ToTorchFormatTensor(),
|
| 55 |
+
])
|
| 56 |
+
self.file_client = FileClient('disk')
|
| 57 |
+
|
| 58 |
+
def __len__(self):
|
| 59 |
+
return len(self.video_names)
|
| 60 |
+
|
| 61 |
+
def _sample_index(self, length, sample_length, num_ref_frame=3):
|
| 62 |
+
complete_idx_set = list(range(length))
|
| 63 |
+
pivot = random.randint(0, length - sample_length)
|
| 64 |
+
local_idx = complete_idx_set[pivot:pivot + sample_length]
|
| 65 |
+
remain_idx = list(set(complete_idx_set) - set(local_idx))
|
| 66 |
+
ref_index = sorted(random.sample(remain_idx, num_ref_frame))
|
| 67 |
+
|
| 68 |
+
return local_idx + ref_index
|
| 69 |
+
|
| 70 |
+
def __getitem__(self, index):
|
| 71 |
+
video_name = self.video_names[index]
|
| 72 |
+
# create masks
|
| 73 |
+
all_masks = create_random_shape_with_random_motion(
|
| 74 |
+
self.video_dict[video_name], imageHeight=self.h, imageWidth=self.w)
|
| 75 |
+
|
| 76 |
+
# create sample index
|
| 77 |
+
selected_index = self._sample_index(self.video_dict[video_name],
|
| 78 |
+
self.num_local_frames,
|
| 79 |
+
self.num_ref_frames)
|
| 80 |
+
|
| 81 |
+
# read video frames
|
| 82 |
+
frames = []
|
| 83 |
+
masks = []
|
| 84 |
+
flows_f, flows_b = [], []
|
| 85 |
+
for idx in selected_index:
|
| 86 |
+
frame_list = self.frame_dict[video_name]
|
| 87 |
+
img_path = os.path.join(self.video_root, video_name, frame_list[idx])
|
| 88 |
+
img_bytes = self.file_client.get(img_path, 'img')
|
| 89 |
+
img = imfrombytes(img_bytes, float32=False)
|
| 90 |
+
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
| 91 |
+
img = cv2.resize(img, self.size, interpolation=cv2.INTER_LINEAR)
|
| 92 |
+
img = Image.fromarray(img)
|
| 93 |
+
|
| 94 |
+
frames.append(img)
|
| 95 |
+
masks.append(all_masks[idx])
|
| 96 |
+
|
| 97 |
+
if len(frames) <= self.num_local_frames-1 and self.load_flow:
|
| 98 |
+
current_n = frame_list[idx][:-4]
|
| 99 |
+
next_n = frame_list[idx+1][:-4]
|
| 100 |
+
flow_f_path = os.path.join(self.flow_root, video_name, f'{current_n}_{next_n}_f.flo')
|
| 101 |
+
flow_b_path = os.path.join(self.flow_root, video_name, f'{next_n}_{current_n}_b.flo')
|
| 102 |
+
flow_f = flowread(flow_f_path, quantize=False)
|
| 103 |
+
flow_b = flowread(flow_b_path, quantize=False)
|
| 104 |
+
flow_f = resize_flow(flow_f, self.h, self.w)
|
| 105 |
+
flow_b = resize_flow(flow_b, self.h, self.w)
|
| 106 |
+
flows_f.append(flow_f)
|
| 107 |
+
flows_b.append(flow_b)
|
| 108 |
+
|
| 109 |
+
if len(frames) == self.num_local_frames: # random reverse
|
| 110 |
+
if random.random() < 0.5:
|
| 111 |
+
frames.reverse()
|
| 112 |
+
masks.reverse()
|
| 113 |
+
if self.load_flow:
|
| 114 |
+
flows_f.reverse()
|
| 115 |
+
flows_b.reverse()
|
| 116 |
+
flows_ = flows_f
|
| 117 |
+
flows_f = flows_b
|
| 118 |
+
flows_b = flows_
|
| 119 |
+
|
| 120 |
+
if self.load_flow:
|
| 121 |
+
frames, flows_f, flows_b = GroupRandomHorizontalFlowFlip()(frames, flows_f, flows_b)
|
| 122 |
+
else:
|
| 123 |
+
frames = GroupRandomHorizontalFlip()(frames)
|
| 124 |
+
|
| 125 |
+
# normalizate, to tensors
|
| 126 |
+
frame_tensors = self._to_tensors(frames) * 2.0 - 1.0
|
| 127 |
+
mask_tensors = self._to_tensors(masks)
|
| 128 |
+
if self.load_flow:
|
| 129 |
+
flows_f = np.stack(flows_f, axis=-1) # H W 2 T-1
|
| 130 |
+
flows_b = np.stack(flows_b, axis=-1)
|
| 131 |
+
flows_f = torch.from_numpy(flows_f).permute(3, 2, 0, 1).contiguous().float()
|
| 132 |
+
flows_b = torch.from_numpy(flows_b).permute(3, 2, 0, 1).contiguous().float()
|
| 133 |
+
|
| 134 |
+
# img [-1,1] mask [0,1]
|
| 135 |
+
if self.load_flow:
|
| 136 |
+
return frame_tensors, mask_tensors, flows_f, flows_b, video_name
|
| 137 |
+
else:
|
| 138 |
+
return frame_tensors, mask_tensors, 'None', 'None', video_name
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class TestDataset(torch.utils.data.Dataset):
|
| 142 |
+
def __init__(self, args):
|
| 143 |
+
self.args = args
|
| 144 |
+
self.size = self.w, self.h = args['size']
|
| 145 |
+
|
| 146 |
+
self.video_root = args['video_root']
|
| 147 |
+
self.mask_root = args['mask_root']
|
| 148 |
+
self.flow_root = args['flow_root']
|
| 149 |
+
|
| 150 |
+
self.load_flow = args['load_flow']
|
| 151 |
+
if self.load_flow:
|
| 152 |
+
assert os.path.exists(self.flow_root)
|
| 153 |
+
self.video_names = sorted(os.listdir(self.mask_root))
|
| 154 |
+
|
| 155 |
+
self.video_dict = {}
|
| 156 |
+
self.frame_dict = {}
|
| 157 |
+
|
| 158 |
+
for v in self.video_names:
|
| 159 |
+
frame_list = sorted(os.listdir(os.path.join(self.video_root, v)))
|
| 160 |
+
v_len = len(frame_list)
|
| 161 |
+
self.video_dict[v] = v_len
|
| 162 |
+
self.frame_dict[v] = frame_list
|
| 163 |
+
|
| 164 |
+
self._to_tensors = transforms.Compose([
|
| 165 |
+
Stack(),
|
| 166 |
+
ToTorchFormatTensor(),
|
| 167 |
+
])
|
| 168 |
+
self.file_client = FileClient('disk')
|
| 169 |
+
|
| 170 |
+
def __len__(self):
|
| 171 |
+
return len(self.video_names)
|
| 172 |
+
|
| 173 |
+
def __getitem__(self, index):
|
| 174 |
+
video_name = self.video_names[index]
|
| 175 |
+
selected_index = list(range(self.video_dict[video_name]))
|
| 176 |
+
|
| 177 |
+
# read video frames
|
| 178 |
+
frames = []
|
| 179 |
+
masks = []
|
| 180 |
+
flows_f, flows_b = [], []
|
| 181 |
+
for idx in selected_index:
|
| 182 |
+
frame_list = self.frame_dict[video_name]
|
| 183 |
+
frame_path = os.path.join(self.video_root, video_name, frame_list[idx])
|
| 184 |
+
|
| 185 |
+
img_bytes = self.file_client.get(frame_path, 'input')
|
| 186 |
+
img = imfrombytes(img_bytes, float32=False)
|
| 187 |
+
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
| 188 |
+
img = cv2.resize(img, self.size, interpolation=cv2.INTER_LINEAR)
|
| 189 |
+
img = Image.fromarray(img)
|
| 190 |
+
|
| 191 |
+
frames.append(img)
|
| 192 |
+
|
| 193 |
+
mask_path = os.path.join(self.mask_root, video_name, str(idx).zfill(5) + '.png')
|
| 194 |
+
mask = Image.open(mask_path).resize(self.size, Image.NEAREST).convert('L')
|
| 195 |
+
|
| 196 |
+
# origin: 0 indicates missing. now: 1 indicates missing
|
| 197 |
+
mask = np.asarray(mask)
|
| 198 |
+
m = np.array(mask > 0).astype(np.uint8)
|
| 199 |
+
|
| 200 |
+
m = cv2.dilate(m,
|
| 201 |
+
cv2.getStructuringElement(cv2.MORPH_CROSS, (3, 3)),
|
| 202 |
+
iterations=4)
|
| 203 |
+
mask = Image.fromarray(m * 255)
|
| 204 |
+
masks.append(mask)
|
| 205 |
+
|
| 206 |
+
if len(frames) <= len(selected_index)-1 and self.load_flow:
|
| 207 |
+
current_n = frame_list[idx][:-4]
|
| 208 |
+
next_n = frame_list[idx+1][:-4]
|
| 209 |
+
flow_f_path = os.path.join(self.flow_root, video_name, f'{current_n}_{next_n}_f.flo')
|
| 210 |
+
flow_b_path = os.path.join(self.flow_root, video_name, f'{next_n}_{current_n}_b.flo')
|
| 211 |
+
flow_f = flowread(flow_f_path, quantize=False)
|
| 212 |
+
flow_b = flowread(flow_b_path, quantize=False)
|
| 213 |
+
flow_f = resize_flow(flow_f, self.h, self.w)
|
| 214 |
+
flow_b = resize_flow(flow_b, self.h, self.w)
|
| 215 |
+
flows_f.append(flow_f)
|
| 216 |
+
flows_b.append(flow_b)
|
| 217 |
+
|
| 218 |
+
# normalizate, to tensors
|
| 219 |
+
frames_PIL = [np.array(f).astype(np.uint8) for f in frames]
|
| 220 |
+
frame_tensors = self._to_tensors(frames) * 2.0 - 1.0
|
| 221 |
+
mask_tensors = self._to_tensors(masks)
|
| 222 |
+
|
| 223 |
+
if self.load_flow:
|
| 224 |
+
flows_f = np.stack(flows_f, axis=-1) # H W 2 T-1
|
| 225 |
+
flows_b = np.stack(flows_b, axis=-1)
|
| 226 |
+
flows_f = torch.from_numpy(flows_f).permute(3, 2, 0, 1).contiguous().float()
|
| 227 |
+
flows_b = torch.from_numpy(flows_b).permute(3, 2, 0, 1).contiguous().float()
|
| 228 |
+
|
| 229 |
+
if self.load_flow:
|
| 230 |
+
return frame_tensors, mask_tensors, flows_f, flows_b, video_name, frames_PIL
|
| 231 |
+
else:
|
| 232 |
+
return frame_tensors, mask_tensors, 'None', 'None', video_name
|
propainter/core/dist.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def get_world_size():
|
| 6 |
+
"""Find OMPI world size without calling mpi functions
|
| 7 |
+
:rtype: int
|
| 8 |
+
"""
|
| 9 |
+
if os.environ.get('PMI_SIZE') is not None:
|
| 10 |
+
return int(os.environ.get('PMI_SIZE') or 1)
|
| 11 |
+
elif os.environ.get('OMPI_COMM_WORLD_SIZE') is not None:
|
| 12 |
+
return int(os.environ.get('OMPI_COMM_WORLD_SIZE') or 1)
|
| 13 |
+
else:
|
| 14 |
+
return torch.cuda.device_count()
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def get_global_rank():
|
| 18 |
+
"""Find OMPI world rank without calling mpi functions
|
| 19 |
+
:rtype: int
|
| 20 |
+
"""
|
| 21 |
+
if os.environ.get('PMI_RANK') is not None:
|
| 22 |
+
return int(os.environ.get('PMI_RANK') or 0)
|
| 23 |
+
elif os.environ.get('OMPI_COMM_WORLD_RANK') is not None:
|
| 24 |
+
return int(os.environ.get('OMPI_COMM_WORLD_RANK') or 0)
|
| 25 |
+
else:
|
| 26 |
+
return 0
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_local_rank():
|
| 30 |
+
"""Find OMPI local rank without calling mpi functions
|
| 31 |
+
:rtype: int
|
| 32 |
+
"""
|
| 33 |
+
if os.environ.get('MPI_LOCALRANKID') is not None:
|
| 34 |
+
return int(os.environ.get('MPI_LOCALRANKID') or 0)
|
| 35 |
+
elif os.environ.get('OMPI_COMM_WORLD_LOCAL_RANK') is not None:
|
| 36 |
+
return int(os.environ.get('OMPI_COMM_WORLD_LOCAL_RANK') or 0)
|
| 37 |
+
else:
|
| 38 |
+
return 0
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def get_master_ip():
|
| 42 |
+
if os.environ.get('AZ_BATCH_MASTER_NODE') is not None:
|
| 43 |
+
return os.environ.get('AZ_BATCH_MASTER_NODE').split(':')[0]
|
| 44 |
+
elif os.environ.get('AZ_BATCHAI_MPI_MASTER_NODE') is not None:
|
| 45 |
+
return os.environ.get('AZ_BATCHAI_MPI_MASTER_NODE')
|
| 46 |
+
else:
|
| 47 |
+
return "127.0.0.1"
|
propainter/core/loss.py
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import lpips
|
| 4 |
+
from model.vgg_arch import VGGFeatureExtractor
|
| 5 |
+
|
| 6 |
+
class PerceptualLoss(nn.Module):
|
| 7 |
+
"""Perceptual loss with commonly used style loss.
|
| 8 |
+
|
| 9 |
+
Args:
|
| 10 |
+
layer_weights (dict): The weight for each layer of vgg feature.
|
| 11 |
+
Here is an example: {'conv5_4': 1.}, which means the conv5_4
|
| 12 |
+
feature layer (before relu5_4) will be extracted with weight
|
| 13 |
+
1.0 in calculting losses.
|
| 14 |
+
vgg_type (str): The type of vgg network used as feature extractor.
|
| 15 |
+
Default: 'vgg19'.
|
| 16 |
+
use_input_norm (bool): If True, normalize the input image in vgg.
|
| 17 |
+
Default: True.
|
| 18 |
+
range_norm (bool): If True, norm images with range [-1, 1] to [0, 1].
|
| 19 |
+
Default: False.
|
| 20 |
+
perceptual_weight (float): If `perceptual_weight > 0`, the perceptual
|
| 21 |
+
loss will be calculated and the loss will multiplied by the
|
| 22 |
+
weight. Default: 1.0.
|
| 23 |
+
style_weight (float): If `style_weight > 0`, the style loss will be
|
| 24 |
+
calculated and the loss will multiplied by the weight.
|
| 25 |
+
Default: 0.
|
| 26 |
+
criterion (str): Criterion used for perceptual loss. Default: 'l1'.
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
def __init__(self,
|
| 30 |
+
layer_weights,
|
| 31 |
+
vgg_type='vgg19',
|
| 32 |
+
use_input_norm=True,
|
| 33 |
+
range_norm=False,
|
| 34 |
+
perceptual_weight=1.0,
|
| 35 |
+
style_weight=0.,
|
| 36 |
+
criterion='l1'):
|
| 37 |
+
super(PerceptualLoss, self).__init__()
|
| 38 |
+
self.perceptual_weight = perceptual_weight
|
| 39 |
+
self.style_weight = style_weight
|
| 40 |
+
self.layer_weights = layer_weights
|
| 41 |
+
self.vgg = VGGFeatureExtractor(
|
| 42 |
+
layer_name_list=list(layer_weights.keys()),
|
| 43 |
+
vgg_type=vgg_type,
|
| 44 |
+
use_input_norm=use_input_norm,
|
| 45 |
+
range_norm=range_norm)
|
| 46 |
+
|
| 47 |
+
self.criterion_type = criterion
|
| 48 |
+
if self.criterion_type == 'l1':
|
| 49 |
+
self.criterion = torch.nn.L1Loss()
|
| 50 |
+
elif self.criterion_type == 'l2':
|
| 51 |
+
self.criterion = torch.nn.L2loss()
|
| 52 |
+
elif self.criterion_type == 'mse':
|
| 53 |
+
self.criterion = torch.nn.MSELoss(reduction='mean')
|
| 54 |
+
elif self.criterion_type == 'fro':
|
| 55 |
+
self.criterion = None
|
| 56 |
+
else:
|
| 57 |
+
raise NotImplementedError(f'{criterion} criterion has not been supported.')
|
| 58 |
+
|
| 59 |
+
def forward(self, x, gt):
|
| 60 |
+
"""Forward function.
|
| 61 |
+
|
| 62 |
+
Args:
|
| 63 |
+
x (Tensor): Input tensor with shape (n, c, h, w).
|
| 64 |
+
gt (Tensor): Ground-truth tensor with shape (n, c, h, w).
|
| 65 |
+
|
| 66 |
+
Returns:
|
| 67 |
+
Tensor: Forward results.
|
| 68 |
+
"""
|
| 69 |
+
# extract vgg features
|
| 70 |
+
x_features = self.vgg(x)
|
| 71 |
+
gt_features = self.vgg(gt.detach())
|
| 72 |
+
|
| 73 |
+
# calculate perceptual loss
|
| 74 |
+
if self.perceptual_weight > 0:
|
| 75 |
+
percep_loss = 0
|
| 76 |
+
for k in x_features.keys():
|
| 77 |
+
if self.criterion_type == 'fro':
|
| 78 |
+
percep_loss += torch.norm(x_features[k] - gt_features[k], p='fro') * self.layer_weights[k]
|
| 79 |
+
else:
|
| 80 |
+
percep_loss += self.criterion(x_features[k], gt_features[k]) * self.layer_weights[k]
|
| 81 |
+
percep_loss *= self.perceptual_weight
|
| 82 |
+
else:
|
| 83 |
+
percep_loss = None
|
| 84 |
+
|
| 85 |
+
# calculate style loss
|
| 86 |
+
if self.style_weight > 0:
|
| 87 |
+
style_loss = 0
|
| 88 |
+
for k in x_features.keys():
|
| 89 |
+
if self.criterion_type == 'fro':
|
| 90 |
+
style_loss += torch.norm(
|
| 91 |
+
self._gram_mat(x_features[k]) - self._gram_mat(gt_features[k]), p='fro') * self.layer_weights[k]
|
| 92 |
+
else:
|
| 93 |
+
style_loss += self.criterion(self._gram_mat(x_features[k]), self._gram_mat(
|
| 94 |
+
gt_features[k])) * self.layer_weights[k]
|
| 95 |
+
style_loss *= self.style_weight
|
| 96 |
+
else:
|
| 97 |
+
style_loss = None
|
| 98 |
+
|
| 99 |
+
return percep_loss, style_loss
|
| 100 |
+
|
| 101 |
+
def _gram_mat(self, x):
|
| 102 |
+
"""Calculate Gram matrix.
|
| 103 |
+
|
| 104 |
+
Args:
|
| 105 |
+
x (torch.Tensor): Tensor with shape of (n, c, h, w).
|
| 106 |
+
|
| 107 |
+
Returns:
|
| 108 |
+
torch.Tensor: Gram matrix.
|
| 109 |
+
"""
|
| 110 |
+
n, c, h, w = x.size()
|
| 111 |
+
features = x.view(n, c, w * h)
|
| 112 |
+
features_t = features.transpose(1, 2)
|
| 113 |
+
gram = features.bmm(features_t) / (c * h * w)
|
| 114 |
+
return gram
|
| 115 |
+
|
| 116 |
+
class LPIPSLoss(nn.Module):
|
| 117 |
+
def __init__(self,
|
| 118 |
+
loss_weight=1.0,
|
| 119 |
+
use_input_norm=True,
|
| 120 |
+
range_norm=False,):
|
| 121 |
+
super(LPIPSLoss, self).__init__()
|
| 122 |
+
self.perceptual = lpips.LPIPS(net="vgg", spatial=False).eval()
|
| 123 |
+
self.loss_weight = loss_weight
|
| 124 |
+
self.use_input_norm = use_input_norm
|
| 125 |
+
self.range_norm = range_norm
|
| 126 |
+
|
| 127 |
+
if self.use_input_norm:
|
| 128 |
+
# the mean is for image with range [0, 1]
|
| 129 |
+
self.register_buffer('mean', torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1))
|
| 130 |
+
# the std is for image with range [0, 1]
|
| 131 |
+
self.register_buffer('std', torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1))
|
| 132 |
+
|
| 133 |
+
def forward(self, pred, target):
|
| 134 |
+
if self.range_norm:
|
| 135 |
+
pred = (pred + 1) / 2
|
| 136 |
+
target = (target + 1) / 2
|
| 137 |
+
if self.use_input_norm:
|
| 138 |
+
pred = (pred - self.mean) / self.std
|
| 139 |
+
target = (target - self.mean) / self.std
|
| 140 |
+
lpips_loss = self.perceptual(target.contiguous(), pred.contiguous())
|
| 141 |
+
return self.loss_weight * lpips_loss.mean(), None
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
class AdversarialLoss(nn.Module):
|
| 145 |
+
r"""
|
| 146 |
+
Adversarial loss
|
| 147 |
+
https://arxiv.org/abs/1711.10337
|
| 148 |
+
"""
|
| 149 |
+
def __init__(self,
|
| 150 |
+
type='nsgan',
|
| 151 |
+
target_real_label=1.0,
|
| 152 |
+
target_fake_label=0.0):
|
| 153 |
+
r"""
|
| 154 |
+
type = nsgan | lsgan | hinge
|
| 155 |
+
"""
|
| 156 |
+
super(AdversarialLoss, self).__init__()
|
| 157 |
+
self.type = type
|
| 158 |
+
self.register_buffer('real_label', torch.tensor(target_real_label))
|
| 159 |
+
self.register_buffer('fake_label', torch.tensor(target_fake_label))
|
| 160 |
+
|
| 161 |
+
if type == 'nsgan':
|
| 162 |
+
self.criterion = nn.BCELoss()
|
| 163 |
+
elif type == 'lsgan':
|
| 164 |
+
self.criterion = nn.MSELoss()
|
| 165 |
+
elif type == 'hinge':
|
| 166 |
+
self.criterion = nn.ReLU()
|
| 167 |
+
|
| 168 |
+
def __call__(self, outputs, is_real, is_disc=None):
|
| 169 |
+
if self.type == 'hinge':
|
| 170 |
+
if is_disc:
|
| 171 |
+
if is_real:
|
| 172 |
+
outputs = -outputs
|
| 173 |
+
return self.criterion(1 + outputs).mean()
|
| 174 |
+
else:
|
| 175 |
+
return (-outputs).mean()
|
| 176 |
+
else:
|
| 177 |
+
labels = (self.real_label
|
| 178 |
+
if is_real else self.fake_label).expand_as(outputs)
|
| 179 |
+
loss = self.criterion(outputs, labels)
|
| 180 |
+
return loss
|
propainter/core/lr_scheduler.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
LR scheduler from BasicSR https://github.com/xinntao/BasicSR
|
| 3 |
+
"""
|
| 4 |
+
import math
|
| 5 |
+
from collections import Counter
|
| 6 |
+
from torch.optim.lr_scheduler import _LRScheduler
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class MultiStepRestartLR(_LRScheduler):
|
| 10 |
+
""" MultiStep with restarts learning rate scheme.
|
| 11 |
+
Args:
|
| 12 |
+
optimizer (torch.nn.optimizer): Torch optimizer.
|
| 13 |
+
milestones (list): Iterations that will decrease learning rate.
|
| 14 |
+
gamma (float): Decrease ratio. Default: 0.1.
|
| 15 |
+
restarts (list): Restart iterations. Default: [0].
|
| 16 |
+
restart_weights (list): Restart weights at each restart iteration.
|
| 17 |
+
Default: [1].
|
| 18 |
+
last_epoch (int): Used in _LRScheduler. Default: -1.
|
| 19 |
+
"""
|
| 20 |
+
def __init__(self,
|
| 21 |
+
optimizer,
|
| 22 |
+
milestones,
|
| 23 |
+
gamma=0.1,
|
| 24 |
+
restarts=(0, ),
|
| 25 |
+
restart_weights=(1, ),
|
| 26 |
+
last_epoch=-1):
|
| 27 |
+
self.milestones = Counter(milestones)
|
| 28 |
+
self.gamma = gamma
|
| 29 |
+
self.restarts = restarts
|
| 30 |
+
self.restart_weights = restart_weights
|
| 31 |
+
assert len(self.restarts) == len(
|
| 32 |
+
self.restart_weights), 'restarts and their weights do not match.'
|
| 33 |
+
super(MultiStepRestartLR, self).__init__(optimizer, last_epoch)
|
| 34 |
+
|
| 35 |
+
def get_lr(self):
|
| 36 |
+
if self.last_epoch in self.restarts:
|
| 37 |
+
weight = self.restart_weights[self.restarts.index(self.last_epoch)]
|
| 38 |
+
return [
|
| 39 |
+
group['initial_lr'] * weight
|
| 40 |
+
for group in self.optimizer.param_groups
|
| 41 |
+
]
|
| 42 |
+
if self.last_epoch not in self.milestones:
|
| 43 |
+
return [group['lr'] for group in self.optimizer.param_groups]
|
| 44 |
+
return [
|
| 45 |
+
group['lr'] * self.gamma**self.milestones[self.last_epoch]
|
| 46 |
+
for group in self.optimizer.param_groups
|
| 47 |
+
]
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def get_position_from_periods(iteration, cumulative_period):
|
| 51 |
+
"""Get the position from a period list.
|
| 52 |
+
It will return the index of the right-closest number in the period list.
|
| 53 |
+
For example, the cumulative_period = [100, 200, 300, 400],
|
| 54 |
+
if iteration == 50, return 0;
|
| 55 |
+
if iteration == 210, return 2;
|
| 56 |
+
if iteration == 300, return 2.
|
| 57 |
+
Args:
|
| 58 |
+
iteration (int): Current iteration.
|
| 59 |
+
cumulative_period (list[int]): Cumulative period list.
|
| 60 |
+
Returns:
|
| 61 |
+
int: The position of the right-closest number in the period list.
|
| 62 |
+
"""
|
| 63 |
+
for i, period in enumerate(cumulative_period):
|
| 64 |
+
if iteration <= period:
|
| 65 |
+
return i
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class CosineAnnealingRestartLR(_LRScheduler):
|
| 69 |
+
""" Cosine annealing with restarts learning rate scheme.
|
| 70 |
+
An example of config:
|
| 71 |
+
periods = [10, 10, 10, 10]
|
| 72 |
+
restart_weights = [1, 0.5, 0.5, 0.5]
|
| 73 |
+
eta_min=1e-7
|
| 74 |
+
It has four cycles, each has 10 iterations. At 10th, 20th, 30th, the
|
| 75 |
+
scheduler will restart with the weights in restart_weights.
|
| 76 |
+
Args:
|
| 77 |
+
optimizer (torch.nn.optimizer): Torch optimizer.
|
| 78 |
+
periods (list): Period for each cosine anneling cycle.
|
| 79 |
+
restart_weights (list): Restart weights at each restart iteration.
|
| 80 |
+
Default: [1].
|
| 81 |
+
eta_min (float): The mimimum lr. Default: 0.
|
| 82 |
+
last_epoch (int): Used in _LRScheduler. Default: -1.
|
| 83 |
+
"""
|
| 84 |
+
def __init__(self,
|
| 85 |
+
optimizer,
|
| 86 |
+
periods,
|
| 87 |
+
restart_weights=(1, ),
|
| 88 |
+
eta_min=1e-7,
|
| 89 |
+
last_epoch=-1):
|
| 90 |
+
self.periods = periods
|
| 91 |
+
self.restart_weights = restart_weights
|
| 92 |
+
self.eta_min = eta_min
|
| 93 |
+
assert (len(self.periods) == len(self.restart_weights)
|
| 94 |
+
), 'periods and restart_weights should have the same length.'
|
| 95 |
+
self.cumulative_period = [
|
| 96 |
+
sum(self.periods[0:i + 1]) for i in range(0, len(self.periods))
|
| 97 |
+
]
|
| 98 |
+
super(CosineAnnealingRestartLR, self).__init__(optimizer, last_epoch)
|
| 99 |
+
|
| 100 |
+
def get_lr(self):
|
| 101 |
+
idx = get_position_from_periods(self.last_epoch,
|
| 102 |
+
self.cumulative_period)
|
| 103 |
+
current_weight = self.restart_weights[idx]
|
| 104 |
+
nearest_restart = 0 if idx == 0 else self.cumulative_period[idx - 1]
|
| 105 |
+
current_period = self.periods[idx]
|
| 106 |
+
|
| 107 |
+
return [
|
| 108 |
+
self.eta_min + current_weight * 0.5 * (base_lr - self.eta_min) *
|
| 109 |
+
(1 + math.cos(math.pi * (
|
| 110 |
+
(self.last_epoch - nearest_restart) / current_period)))
|
| 111 |
+
for base_lr in self.base_lrs
|
| 112 |
+
]
|
propainter/core/metrics.py
ADDED
|
@@ -0,0 +1,571 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
# from skimage import measure
|
| 3 |
+
from skimage.metrics import structural_similarity as compare_ssim
|
| 4 |
+
from scipy import linalg
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
|
| 10 |
+
from propainter.core.utils import to_tensors
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def calculate_epe(flow1, flow2):
|
| 14 |
+
"""Calculate End point errors."""
|
| 15 |
+
|
| 16 |
+
epe = torch.sum((flow1 - flow2)**2, dim=1).sqrt()
|
| 17 |
+
epe = epe.view(-1)
|
| 18 |
+
return epe.mean().item()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def calculate_psnr(img1, img2):
|
| 22 |
+
"""Calculate PSNR (Peak Signal-to-Noise Ratio).
|
| 23 |
+
Ref: https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio
|
| 24 |
+
Args:
|
| 25 |
+
img1 (ndarray): Images with range [0, 255].
|
| 26 |
+
img2 (ndarray): Images with range [0, 255].
|
| 27 |
+
Returns:
|
| 28 |
+
float: psnr result.
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
assert img1.shape == img2.shape, \
|
| 32 |
+
(f'Image shapes are differnet: {img1.shape}, {img2.shape}.')
|
| 33 |
+
|
| 34 |
+
mse = np.mean((img1 - img2)**2)
|
| 35 |
+
if mse == 0:
|
| 36 |
+
return float('inf')
|
| 37 |
+
return 20. * np.log10(255. / np.sqrt(mse))
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def calc_psnr_and_ssim(img1, img2):
|
| 41 |
+
"""Calculate PSNR and SSIM for images.
|
| 42 |
+
img1: ndarray, range [0, 255]
|
| 43 |
+
img2: ndarray, range [0, 255]
|
| 44 |
+
"""
|
| 45 |
+
img1 = img1.astype(np.float64)
|
| 46 |
+
img2 = img2.astype(np.float64)
|
| 47 |
+
|
| 48 |
+
psnr = calculate_psnr(img1, img2)
|
| 49 |
+
ssim = compare_ssim(img1,
|
| 50 |
+
img2,
|
| 51 |
+
data_range=255,
|
| 52 |
+
multichannel=True,
|
| 53 |
+
win_size=65,
|
| 54 |
+
channel_axis=2)
|
| 55 |
+
|
| 56 |
+
return psnr, ssim
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
###########################
|
| 60 |
+
# I3D models
|
| 61 |
+
###########################
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def init_i3d_model(i3d_model_path):
|
| 65 |
+
print(f"[Loading I3D model from {i3d_model_path} for FID score ..]")
|
| 66 |
+
i3d_model = InceptionI3d(400, in_channels=3, final_endpoint='Logits')
|
| 67 |
+
i3d_model.load_state_dict(torch.load(i3d_model_path))
|
| 68 |
+
i3d_model.to(torch.device('cuda:0'))
|
| 69 |
+
return i3d_model
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def calculate_i3d_activations(video1, video2, i3d_model, device):
|
| 73 |
+
"""Calculate VFID metric.
|
| 74 |
+
video1: list[PIL.Image]
|
| 75 |
+
video2: list[PIL.Image]
|
| 76 |
+
"""
|
| 77 |
+
video1 = to_tensors()(video1).unsqueeze(0).to(device)
|
| 78 |
+
video2 = to_tensors()(video2).unsqueeze(0).to(device)
|
| 79 |
+
video1_activations = get_i3d_activations(
|
| 80 |
+
video1, i3d_model).cpu().numpy().flatten()
|
| 81 |
+
video2_activations = get_i3d_activations(
|
| 82 |
+
video2, i3d_model).cpu().numpy().flatten()
|
| 83 |
+
|
| 84 |
+
return video1_activations, video2_activations
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def calculate_vfid(real_activations, fake_activations):
|
| 88 |
+
"""
|
| 89 |
+
Given two distribution of features, compute the FID score between them
|
| 90 |
+
Params:
|
| 91 |
+
real_activations: list[ndarray]
|
| 92 |
+
fake_activations: list[ndarray]
|
| 93 |
+
"""
|
| 94 |
+
m1 = np.mean(real_activations, axis=0)
|
| 95 |
+
m2 = np.mean(fake_activations, axis=0)
|
| 96 |
+
s1 = np.cov(real_activations, rowvar=False)
|
| 97 |
+
s2 = np.cov(fake_activations, rowvar=False)
|
| 98 |
+
return calculate_frechet_distance(m1, s1, m2, s2)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def calculate_frechet_distance(mu1, sigma1, mu2, sigma2, eps=1e-6):
|
| 102 |
+
"""Numpy implementation of the Frechet Distance.
|
| 103 |
+
The Frechet distance between two multivariate Gaussians X_1 ~ N(mu_1, C_1)
|
| 104 |
+
and X_2 ~ N(mu_2, C_2) is
|
| 105 |
+
d^2 = ||mu_1 - mu_2||^2 + Tr(C_1 + C_2 - 2*sqrt(C_1*C_2)).
|
| 106 |
+
Stable version by Dougal J. Sutherland.
|
| 107 |
+
Params:
|
| 108 |
+
-- mu1 : Numpy array containing the activations of a layer of the
|
| 109 |
+
inception net (like returned by the function 'get_predictions')
|
| 110 |
+
for generated samples.
|
| 111 |
+
-- mu2 : The sample mean over activations, precalculated on an
|
| 112 |
+
representive data set.
|
| 113 |
+
-- sigma1: The covariance matrix over activations for generated samples.
|
| 114 |
+
-- sigma2: The covariance matrix over activations, precalculated on an
|
| 115 |
+
representive data set.
|
| 116 |
+
Returns:
|
| 117 |
+
-- : The Frechet Distance.
|
| 118 |
+
"""
|
| 119 |
+
|
| 120 |
+
mu1 = np.atleast_1d(mu1)
|
| 121 |
+
mu2 = np.atleast_1d(mu2)
|
| 122 |
+
|
| 123 |
+
sigma1 = np.atleast_2d(sigma1)
|
| 124 |
+
sigma2 = np.atleast_2d(sigma2)
|
| 125 |
+
|
| 126 |
+
assert mu1.shape == mu2.shape, \
|
| 127 |
+
'Training and test mean vectors have different lengths'
|
| 128 |
+
assert sigma1.shape == sigma2.shape, \
|
| 129 |
+
'Training and test covariances have different dimensions'
|
| 130 |
+
|
| 131 |
+
diff = mu1 - mu2
|
| 132 |
+
|
| 133 |
+
# Product might be almost singular
|
| 134 |
+
covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
|
| 135 |
+
if not np.isfinite(covmean).all():
|
| 136 |
+
msg = ('fid calculation produces singular product; '
|
| 137 |
+
'adding %s to diagonal of cov estimates') % eps
|
| 138 |
+
print(msg)
|
| 139 |
+
offset = np.eye(sigma1.shape[0]) * eps
|
| 140 |
+
covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
|
| 141 |
+
|
| 142 |
+
# Numerical error might give slight imaginary component
|
| 143 |
+
if np.iscomplexobj(covmean):
|
| 144 |
+
if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
|
| 145 |
+
m = np.max(np.abs(covmean.imag))
|
| 146 |
+
raise ValueError('Imaginary component {}'.format(m))
|
| 147 |
+
covmean = covmean.real
|
| 148 |
+
|
| 149 |
+
tr_covmean = np.trace(covmean)
|
| 150 |
+
|
| 151 |
+
return (diff.dot(diff) + np.trace(sigma1) + # NOQA
|
| 152 |
+
np.trace(sigma2) - 2 * tr_covmean)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def get_i3d_activations(batched_video,
|
| 156 |
+
i3d_model,
|
| 157 |
+
target_endpoint='Logits',
|
| 158 |
+
flatten=True,
|
| 159 |
+
grad_enabled=False):
|
| 160 |
+
"""
|
| 161 |
+
Get features from i3d model and flatten them to 1d feature,
|
| 162 |
+
valid target endpoints are defined in InceptionI3d.VALID_ENDPOINTS
|
| 163 |
+
VALID_ENDPOINTS = (
|
| 164 |
+
'Conv3d_1a_7x7',
|
| 165 |
+
'MaxPool3d_2a_3x3',
|
| 166 |
+
'Conv3d_2b_1x1',
|
| 167 |
+
'Conv3d_2c_3x3',
|
| 168 |
+
'MaxPool3d_3a_3x3',
|
| 169 |
+
'Mixed_3b',
|
| 170 |
+
'Mixed_3c',
|
| 171 |
+
'MaxPool3d_4a_3x3',
|
| 172 |
+
'Mixed_4b',
|
| 173 |
+
'Mixed_4c',
|
| 174 |
+
'Mixed_4d',
|
| 175 |
+
'Mixed_4e',
|
| 176 |
+
'Mixed_4f',
|
| 177 |
+
'MaxPool3d_5a_2x2',
|
| 178 |
+
'Mixed_5b',
|
| 179 |
+
'Mixed_5c',
|
| 180 |
+
'Logits',
|
| 181 |
+
'Predictions',
|
| 182 |
+
)
|
| 183 |
+
"""
|
| 184 |
+
with torch.set_grad_enabled(grad_enabled):
|
| 185 |
+
feat = i3d_model.extract_features(batched_video.transpose(1, 2),
|
| 186 |
+
target_endpoint)
|
| 187 |
+
if flatten:
|
| 188 |
+
feat = feat.view(feat.size(0), -1)
|
| 189 |
+
|
| 190 |
+
return feat
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
# This code is from https://github.com/piergiaj/pytorch-i3d/blob/master/pytorch_i3d.py
|
| 194 |
+
# I only fix flake8 errors and do some cleaning here
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
class MaxPool3dSamePadding(nn.MaxPool3d):
|
| 198 |
+
def compute_pad(self, dim, s):
|
| 199 |
+
if s % self.stride[dim] == 0:
|
| 200 |
+
return max(self.kernel_size[dim] - self.stride[dim], 0)
|
| 201 |
+
else:
|
| 202 |
+
return max(self.kernel_size[dim] - (s % self.stride[dim]), 0)
|
| 203 |
+
|
| 204 |
+
def forward(self, x):
|
| 205 |
+
# compute 'same' padding
|
| 206 |
+
(batch, channel, t, h, w) = x.size()
|
| 207 |
+
pad_t = self.compute_pad(0, t)
|
| 208 |
+
pad_h = self.compute_pad(1, h)
|
| 209 |
+
pad_w = self.compute_pad(2, w)
|
| 210 |
+
|
| 211 |
+
pad_t_f = pad_t // 2
|
| 212 |
+
pad_t_b = pad_t - pad_t_f
|
| 213 |
+
pad_h_f = pad_h // 2
|
| 214 |
+
pad_h_b = pad_h - pad_h_f
|
| 215 |
+
pad_w_f = pad_w // 2
|
| 216 |
+
pad_w_b = pad_w - pad_w_f
|
| 217 |
+
|
| 218 |
+
pad = (pad_w_f, pad_w_b, pad_h_f, pad_h_b, pad_t_f, pad_t_b)
|
| 219 |
+
x = F.pad(x, pad)
|
| 220 |
+
return super(MaxPool3dSamePadding, self).forward(x)
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
class Unit3D(nn.Module):
|
| 224 |
+
def __init__(self,
|
| 225 |
+
in_channels,
|
| 226 |
+
output_channels,
|
| 227 |
+
kernel_shape=(1, 1, 1),
|
| 228 |
+
stride=(1, 1, 1),
|
| 229 |
+
padding=0,
|
| 230 |
+
activation_fn=F.relu,
|
| 231 |
+
use_batch_norm=True,
|
| 232 |
+
use_bias=False,
|
| 233 |
+
name='unit_3d'):
|
| 234 |
+
"""Initializes Unit3D module."""
|
| 235 |
+
super(Unit3D, self).__init__()
|
| 236 |
+
|
| 237 |
+
self._output_channels = output_channels
|
| 238 |
+
self._kernel_shape = kernel_shape
|
| 239 |
+
self._stride = stride
|
| 240 |
+
self._use_batch_norm = use_batch_norm
|
| 241 |
+
self._activation_fn = activation_fn
|
| 242 |
+
self._use_bias = use_bias
|
| 243 |
+
self.name = name
|
| 244 |
+
self.padding = padding
|
| 245 |
+
|
| 246 |
+
self.conv3d = nn.Conv3d(
|
| 247 |
+
in_channels=in_channels,
|
| 248 |
+
out_channels=self._output_channels,
|
| 249 |
+
kernel_size=self._kernel_shape,
|
| 250 |
+
stride=self._stride,
|
| 251 |
+
padding=0, # we always want padding to be 0 here. We will
|
| 252 |
+
# dynamically pad based on input size in forward function
|
| 253 |
+
bias=self._use_bias)
|
| 254 |
+
|
| 255 |
+
if self._use_batch_norm:
|
| 256 |
+
self.bn = nn.BatchNorm3d(self._output_channels,
|
| 257 |
+
eps=0.001,
|
| 258 |
+
momentum=0.01)
|
| 259 |
+
|
| 260 |
+
def compute_pad(self, dim, s):
|
| 261 |
+
if s % self._stride[dim] == 0:
|
| 262 |
+
return max(self._kernel_shape[dim] - self._stride[dim], 0)
|
| 263 |
+
else:
|
| 264 |
+
return max(self._kernel_shape[dim] - (s % self._stride[dim]), 0)
|
| 265 |
+
|
| 266 |
+
def forward(self, x):
|
| 267 |
+
# compute 'same' padding
|
| 268 |
+
(batch, channel, t, h, w) = x.size()
|
| 269 |
+
pad_t = self.compute_pad(0, t)
|
| 270 |
+
pad_h = self.compute_pad(1, h)
|
| 271 |
+
pad_w = self.compute_pad(2, w)
|
| 272 |
+
|
| 273 |
+
pad_t_f = pad_t // 2
|
| 274 |
+
pad_t_b = pad_t - pad_t_f
|
| 275 |
+
pad_h_f = pad_h // 2
|
| 276 |
+
pad_h_b = pad_h - pad_h_f
|
| 277 |
+
pad_w_f = pad_w // 2
|
| 278 |
+
pad_w_b = pad_w - pad_w_f
|
| 279 |
+
|
| 280 |
+
pad = (pad_w_f, pad_w_b, pad_h_f, pad_h_b, pad_t_f, pad_t_b)
|
| 281 |
+
x = F.pad(x, pad)
|
| 282 |
+
|
| 283 |
+
x = self.conv3d(x)
|
| 284 |
+
if self._use_batch_norm:
|
| 285 |
+
x = self.bn(x)
|
| 286 |
+
if self._activation_fn is not None:
|
| 287 |
+
x = self._activation_fn(x)
|
| 288 |
+
return x
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
class InceptionModule(nn.Module):
|
| 292 |
+
def __init__(self, in_channels, out_channels, name):
|
| 293 |
+
super(InceptionModule, self).__init__()
|
| 294 |
+
|
| 295 |
+
self.b0 = Unit3D(in_channels=in_channels,
|
| 296 |
+
output_channels=out_channels[0],
|
| 297 |
+
kernel_shape=[1, 1, 1],
|
| 298 |
+
padding=0,
|
| 299 |
+
name=name + '/Branch_0/Conv3d_0a_1x1')
|
| 300 |
+
self.b1a = Unit3D(in_channels=in_channels,
|
| 301 |
+
output_channels=out_channels[1],
|
| 302 |
+
kernel_shape=[1, 1, 1],
|
| 303 |
+
padding=0,
|
| 304 |
+
name=name + '/Branch_1/Conv3d_0a_1x1')
|
| 305 |
+
self.b1b = Unit3D(in_channels=out_channels[1],
|
| 306 |
+
output_channels=out_channels[2],
|
| 307 |
+
kernel_shape=[3, 3, 3],
|
| 308 |
+
name=name + '/Branch_1/Conv3d_0b_3x3')
|
| 309 |
+
self.b2a = Unit3D(in_channels=in_channels,
|
| 310 |
+
output_channels=out_channels[3],
|
| 311 |
+
kernel_shape=[1, 1, 1],
|
| 312 |
+
padding=0,
|
| 313 |
+
name=name + '/Branch_2/Conv3d_0a_1x1')
|
| 314 |
+
self.b2b = Unit3D(in_channels=out_channels[3],
|
| 315 |
+
output_channels=out_channels[4],
|
| 316 |
+
kernel_shape=[3, 3, 3],
|
| 317 |
+
name=name + '/Branch_2/Conv3d_0b_3x3')
|
| 318 |
+
self.b3a = MaxPool3dSamePadding(kernel_size=[3, 3, 3],
|
| 319 |
+
stride=(1, 1, 1),
|
| 320 |
+
padding=0)
|
| 321 |
+
self.b3b = Unit3D(in_channels=in_channels,
|
| 322 |
+
output_channels=out_channels[5],
|
| 323 |
+
kernel_shape=[1, 1, 1],
|
| 324 |
+
padding=0,
|
| 325 |
+
name=name + '/Branch_3/Conv3d_0b_1x1')
|
| 326 |
+
self.name = name
|
| 327 |
+
|
| 328 |
+
def forward(self, x):
|
| 329 |
+
b0 = self.b0(x)
|
| 330 |
+
b1 = self.b1b(self.b1a(x))
|
| 331 |
+
b2 = self.b2b(self.b2a(x))
|
| 332 |
+
b3 = self.b3b(self.b3a(x))
|
| 333 |
+
return torch.cat([b0, b1, b2, b3], dim=1)
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
class InceptionI3d(nn.Module):
|
| 337 |
+
"""Inception-v1 I3D architecture.
|
| 338 |
+
The model is introduced in:
|
| 339 |
+
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
|
| 340 |
+
Joao Carreira, Andrew Zisserman
|
| 341 |
+
https://arxiv.org/pdf/1705.07750v1.pdf.
|
| 342 |
+
See also the Inception architecture, introduced in:
|
| 343 |
+
Going deeper with convolutions
|
| 344 |
+
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed,
|
| 345 |
+
Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich.
|
| 346 |
+
http://arxiv.org/pdf/1409.4842v1.pdf.
|
| 347 |
+
"""
|
| 348 |
+
|
| 349 |
+
# Endpoints of the model in order. During construction, all the endpoints up
|
| 350 |
+
# to a designated `final_endpoint` are returned in a dictionary as the
|
| 351 |
+
# second return value.
|
| 352 |
+
VALID_ENDPOINTS = (
|
| 353 |
+
'Conv3d_1a_7x7',
|
| 354 |
+
'MaxPool3d_2a_3x3',
|
| 355 |
+
'Conv3d_2b_1x1',
|
| 356 |
+
'Conv3d_2c_3x3',
|
| 357 |
+
'MaxPool3d_3a_3x3',
|
| 358 |
+
'Mixed_3b',
|
| 359 |
+
'Mixed_3c',
|
| 360 |
+
'MaxPool3d_4a_3x3',
|
| 361 |
+
'Mixed_4b',
|
| 362 |
+
'Mixed_4c',
|
| 363 |
+
'Mixed_4d',
|
| 364 |
+
'Mixed_4e',
|
| 365 |
+
'Mixed_4f',
|
| 366 |
+
'MaxPool3d_5a_2x2',
|
| 367 |
+
'Mixed_5b',
|
| 368 |
+
'Mixed_5c',
|
| 369 |
+
'Logits',
|
| 370 |
+
'Predictions',
|
| 371 |
+
)
|
| 372 |
+
|
| 373 |
+
def __init__(self,
|
| 374 |
+
num_classes=400,
|
| 375 |
+
spatial_squeeze=True,
|
| 376 |
+
final_endpoint='Logits',
|
| 377 |
+
name='inception_i3d',
|
| 378 |
+
in_channels=3,
|
| 379 |
+
dropout_keep_prob=0.5):
|
| 380 |
+
"""Initializes I3D model instance.
|
| 381 |
+
Args:
|
| 382 |
+
num_classes: The number of outputs in the logit layer (default 400, which
|
| 383 |
+
matches the Kinetics dataset).
|
| 384 |
+
spatial_squeeze: Whether to squeeze the spatial dimensions for the logits
|
| 385 |
+
before returning (default True).
|
| 386 |
+
final_endpoint: The model contains many possible endpoints.
|
| 387 |
+
`final_endpoint` specifies the last endpoint for the model to be built
|
| 388 |
+
up to. In addition to the output at `final_endpoint`, all the outputs
|
| 389 |
+
at endpoints up to `final_endpoint` will also be returned, in a
|
| 390 |
+
dictionary. `final_endpoint` must be one of
|
| 391 |
+
InceptionI3d.VALID_ENDPOINTS (default 'Logits').
|
| 392 |
+
name: A string (optional). The name of this module.
|
| 393 |
+
Raises:
|
| 394 |
+
ValueError: if `final_endpoint` is not recognized.
|
| 395 |
+
"""
|
| 396 |
+
|
| 397 |
+
if final_endpoint not in self.VALID_ENDPOINTS:
|
| 398 |
+
raise ValueError('Unknown final endpoint %s' % final_endpoint)
|
| 399 |
+
|
| 400 |
+
super(InceptionI3d, self).__init__()
|
| 401 |
+
self._num_classes = num_classes
|
| 402 |
+
self._spatial_squeeze = spatial_squeeze
|
| 403 |
+
self._final_endpoint = final_endpoint
|
| 404 |
+
self.logits = None
|
| 405 |
+
|
| 406 |
+
if self._final_endpoint not in self.VALID_ENDPOINTS:
|
| 407 |
+
raise ValueError('Unknown final endpoint %s' %
|
| 408 |
+
self._final_endpoint)
|
| 409 |
+
|
| 410 |
+
self.end_points = {}
|
| 411 |
+
end_point = 'Conv3d_1a_7x7'
|
| 412 |
+
self.end_points[end_point] = Unit3D(in_channels=in_channels,
|
| 413 |
+
output_channels=64,
|
| 414 |
+
kernel_shape=[7, 7, 7],
|
| 415 |
+
stride=(2, 2, 2),
|
| 416 |
+
padding=(3, 3, 3),
|
| 417 |
+
name=name + end_point)
|
| 418 |
+
if self._final_endpoint == end_point:
|
| 419 |
+
return
|
| 420 |
+
|
| 421 |
+
end_point = 'MaxPool3d_2a_3x3'
|
| 422 |
+
self.end_points[end_point] = MaxPool3dSamePadding(
|
| 423 |
+
kernel_size=[1, 3, 3], stride=(1, 2, 2), padding=0)
|
| 424 |
+
if self._final_endpoint == end_point:
|
| 425 |
+
return
|
| 426 |
+
|
| 427 |
+
end_point = 'Conv3d_2b_1x1'
|
| 428 |
+
self.end_points[end_point] = Unit3D(in_channels=64,
|
| 429 |
+
output_channels=64,
|
| 430 |
+
kernel_shape=[1, 1, 1],
|
| 431 |
+
padding=0,
|
| 432 |
+
name=name + end_point)
|
| 433 |
+
if self._final_endpoint == end_point:
|
| 434 |
+
return
|
| 435 |
+
|
| 436 |
+
end_point = 'Conv3d_2c_3x3'
|
| 437 |
+
self.end_points[end_point] = Unit3D(in_channels=64,
|
| 438 |
+
output_channels=192,
|
| 439 |
+
kernel_shape=[3, 3, 3],
|
| 440 |
+
padding=1,
|
| 441 |
+
name=name + end_point)
|
| 442 |
+
if self._final_endpoint == end_point:
|
| 443 |
+
return
|
| 444 |
+
|
| 445 |
+
end_point = 'MaxPool3d_3a_3x3'
|
| 446 |
+
self.end_points[end_point] = MaxPool3dSamePadding(
|
| 447 |
+
kernel_size=[1, 3, 3], stride=(1, 2, 2), padding=0)
|
| 448 |
+
if self._final_endpoint == end_point:
|
| 449 |
+
return
|
| 450 |
+
|
| 451 |
+
end_point = 'Mixed_3b'
|
| 452 |
+
self.end_points[end_point] = InceptionModule(192,
|
| 453 |
+
[64, 96, 128, 16, 32, 32],
|
| 454 |
+
name + end_point)
|
| 455 |
+
if self._final_endpoint == end_point:
|
| 456 |
+
return
|
| 457 |
+
|
| 458 |
+
end_point = 'Mixed_3c'
|
| 459 |
+
self.end_points[end_point] = InceptionModule(
|
| 460 |
+
256, [128, 128, 192, 32, 96, 64], name + end_point)
|
| 461 |
+
if self._final_endpoint == end_point:
|
| 462 |
+
return
|
| 463 |
+
|
| 464 |
+
end_point = 'MaxPool3d_4a_3x3'
|
| 465 |
+
self.end_points[end_point] = MaxPool3dSamePadding(
|
| 466 |
+
kernel_size=[3, 3, 3], stride=(2, 2, 2), padding=0)
|
| 467 |
+
if self._final_endpoint == end_point:
|
| 468 |
+
return
|
| 469 |
+
|
| 470 |
+
end_point = 'Mixed_4b'
|
| 471 |
+
self.end_points[end_point] = InceptionModule(
|
| 472 |
+
128 + 192 + 96 + 64, [192, 96, 208, 16, 48, 64], name + end_point)
|
| 473 |
+
if self._final_endpoint == end_point:
|
| 474 |
+
return
|
| 475 |
+
|
| 476 |
+
end_point = 'Mixed_4c'
|
| 477 |
+
self.end_points[end_point] = InceptionModule(
|
| 478 |
+
192 + 208 + 48 + 64, [160, 112, 224, 24, 64, 64], name + end_point)
|
| 479 |
+
if self._final_endpoint == end_point:
|
| 480 |
+
return
|
| 481 |
+
|
| 482 |
+
end_point = 'Mixed_4d'
|
| 483 |
+
self.end_points[end_point] = InceptionModule(
|
| 484 |
+
160 + 224 + 64 + 64, [128, 128, 256, 24, 64, 64], name + end_point)
|
| 485 |
+
if self._final_endpoint == end_point:
|
| 486 |
+
return
|
| 487 |
+
|
| 488 |
+
end_point = 'Mixed_4e'
|
| 489 |
+
self.end_points[end_point] = InceptionModule(
|
| 490 |
+
128 + 256 + 64 + 64, [112, 144, 288, 32, 64, 64], name + end_point)
|
| 491 |
+
if self._final_endpoint == end_point:
|
| 492 |
+
return
|
| 493 |
+
|
| 494 |
+
end_point = 'Mixed_4f'
|
| 495 |
+
self.end_points[end_point] = InceptionModule(
|
| 496 |
+
112 + 288 + 64 + 64, [256, 160, 320, 32, 128, 128],
|
| 497 |
+
name + end_point)
|
| 498 |
+
if self._final_endpoint == end_point:
|
| 499 |
+
return
|
| 500 |
+
|
| 501 |
+
end_point = 'MaxPool3d_5a_2x2'
|
| 502 |
+
self.end_points[end_point] = MaxPool3dSamePadding(
|
| 503 |
+
kernel_size=[2, 2, 2], stride=(2, 2, 2), padding=0)
|
| 504 |
+
if self._final_endpoint == end_point:
|
| 505 |
+
return
|
| 506 |
+
|
| 507 |
+
end_point = 'Mixed_5b'
|
| 508 |
+
self.end_points[end_point] = InceptionModule(
|
| 509 |
+
256 + 320 + 128 + 128, [256, 160, 320, 32, 128, 128],
|
| 510 |
+
name + end_point)
|
| 511 |
+
if self._final_endpoint == end_point:
|
| 512 |
+
return
|
| 513 |
+
|
| 514 |
+
end_point = 'Mixed_5c'
|
| 515 |
+
self.end_points[end_point] = InceptionModule(
|
| 516 |
+
256 + 320 + 128 + 128, [384, 192, 384, 48, 128, 128],
|
| 517 |
+
name + end_point)
|
| 518 |
+
if self._final_endpoint == end_point:
|
| 519 |
+
return
|
| 520 |
+
|
| 521 |
+
end_point = 'Logits'
|
| 522 |
+
self.avg_pool = nn.AvgPool3d(kernel_size=[2, 7, 7], stride=(1, 1, 1))
|
| 523 |
+
self.dropout = nn.Dropout(dropout_keep_prob)
|
| 524 |
+
self.logits = Unit3D(in_channels=384 + 384 + 128 + 128,
|
| 525 |
+
output_channels=self._num_classes,
|
| 526 |
+
kernel_shape=[1, 1, 1],
|
| 527 |
+
padding=0,
|
| 528 |
+
activation_fn=None,
|
| 529 |
+
use_batch_norm=False,
|
| 530 |
+
use_bias=True,
|
| 531 |
+
name='logits')
|
| 532 |
+
|
| 533 |
+
self.build()
|
| 534 |
+
|
| 535 |
+
def replace_logits(self, num_classes):
|
| 536 |
+
self._num_classes = num_classes
|
| 537 |
+
self.logits = Unit3D(in_channels=384 + 384 + 128 + 128,
|
| 538 |
+
output_channels=self._num_classes,
|
| 539 |
+
kernel_shape=[1, 1, 1],
|
| 540 |
+
padding=0,
|
| 541 |
+
activation_fn=None,
|
| 542 |
+
use_batch_norm=False,
|
| 543 |
+
use_bias=True,
|
| 544 |
+
name='logits')
|
| 545 |
+
|
| 546 |
+
def build(self):
|
| 547 |
+
for k in self.end_points.keys():
|
| 548 |
+
self.add_module(k, self.end_points[k])
|
| 549 |
+
|
| 550 |
+
def forward(self, x):
|
| 551 |
+
for end_point in self.VALID_ENDPOINTS:
|
| 552 |
+
if end_point in self.end_points:
|
| 553 |
+
x = self._modules[end_point](
|
| 554 |
+
x) # use _modules to work with dataparallel
|
| 555 |
+
|
| 556 |
+
x = self.logits(self.dropout(self.avg_pool(x)))
|
| 557 |
+
if self._spatial_squeeze:
|
| 558 |
+
logits = x.squeeze(3).squeeze(3)
|
| 559 |
+
# logits is batch X time X classes, which is what we want to work with
|
| 560 |
+
return logits
|
| 561 |
+
|
| 562 |
+
def extract_features(self, x, target_endpoint='Logits'):
|
| 563 |
+
for end_point in self.VALID_ENDPOINTS:
|
| 564 |
+
if end_point in self.end_points:
|
| 565 |
+
x = self._modules[end_point](x)
|
| 566 |
+
if end_point == target_endpoint:
|
| 567 |
+
break
|
| 568 |
+
if target_endpoint == 'Logits':
|
| 569 |
+
return x.mean(4).mean(3).mean(2)
|
| 570 |
+
else:
|
| 571 |
+
return x
|
propainter/core/prefetch_dataloader.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import queue as Queue
|
| 2 |
+
import threading
|
| 3 |
+
import torch
|
| 4 |
+
from torch.utils.data import DataLoader
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class PrefetchGenerator(threading.Thread):
|
| 8 |
+
"""A general prefetch generator.
|
| 9 |
+
|
| 10 |
+
Ref:
|
| 11 |
+
https://stackoverflow.com/questions/7323664/python-generator-pre-fetch
|
| 12 |
+
|
| 13 |
+
Args:
|
| 14 |
+
generator: Python generator.
|
| 15 |
+
num_prefetch_queue (int): Number of prefetch queue.
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
def __init__(self, generator, num_prefetch_queue):
|
| 19 |
+
threading.Thread.__init__(self)
|
| 20 |
+
self.queue = Queue.Queue(num_prefetch_queue)
|
| 21 |
+
self.generator = generator
|
| 22 |
+
self.daemon = True
|
| 23 |
+
self.start()
|
| 24 |
+
|
| 25 |
+
def run(self):
|
| 26 |
+
for item in self.generator:
|
| 27 |
+
self.queue.put(item)
|
| 28 |
+
self.queue.put(None)
|
| 29 |
+
|
| 30 |
+
def __next__(self):
|
| 31 |
+
next_item = self.queue.get()
|
| 32 |
+
if next_item is None:
|
| 33 |
+
raise StopIteration
|
| 34 |
+
return next_item
|
| 35 |
+
|
| 36 |
+
def __iter__(self):
|
| 37 |
+
return self
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class PrefetchDataLoader(DataLoader):
|
| 41 |
+
"""Prefetch version of dataloader.
|
| 42 |
+
|
| 43 |
+
Ref:
|
| 44 |
+
https://github.com/IgorSusmelj/pytorch-styleguide/issues/5#
|
| 45 |
+
|
| 46 |
+
TODO:
|
| 47 |
+
Need to test on single gpu and ddp (multi-gpu). There is a known issue in
|
| 48 |
+
ddp.
|
| 49 |
+
|
| 50 |
+
Args:
|
| 51 |
+
num_prefetch_queue (int): Number of prefetch queue.
|
| 52 |
+
kwargs (dict): Other arguments for dataloader.
|
| 53 |
+
"""
|
| 54 |
+
|
| 55 |
+
def __init__(self, num_prefetch_queue, **kwargs):
|
| 56 |
+
self.num_prefetch_queue = num_prefetch_queue
|
| 57 |
+
super(PrefetchDataLoader, self).__init__(**kwargs)
|
| 58 |
+
|
| 59 |
+
def __iter__(self):
|
| 60 |
+
return PrefetchGenerator(super().__iter__(), self.num_prefetch_queue)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class CPUPrefetcher():
|
| 64 |
+
"""CPU prefetcher.
|
| 65 |
+
|
| 66 |
+
Args:
|
| 67 |
+
loader: Dataloader.
|
| 68 |
+
"""
|
| 69 |
+
|
| 70 |
+
def __init__(self, loader):
|
| 71 |
+
self.ori_loader = loader
|
| 72 |
+
self.loader = iter(loader)
|
| 73 |
+
|
| 74 |
+
def next(self):
|
| 75 |
+
try:
|
| 76 |
+
return next(self.loader)
|
| 77 |
+
except StopIteration:
|
| 78 |
+
return None
|
| 79 |
+
|
| 80 |
+
def reset(self):
|
| 81 |
+
self.loader = iter(self.ori_loader)
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class CUDAPrefetcher():
|
| 85 |
+
"""CUDA prefetcher.
|
| 86 |
+
|
| 87 |
+
Ref:
|
| 88 |
+
https://github.com/NVIDIA/apex/issues/304#
|
| 89 |
+
|
| 90 |
+
It may consums more GPU memory.
|
| 91 |
+
|
| 92 |
+
Args:
|
| 93 |
+
loader: Dataloader.
|
| 94 |
+
opt (dict): Options.
|
| 95 |
+
"""
|
| 96 |
+
|
| 97 |
+
def __init__(self, loader, opt):
|
| 98 |
+
self.ori_loader = loader
|
| 99 |
+
self.loader = iter(loader)
|
| 100 |
+
self.opt = opt
|
| 101 |
+
self.stream = torch.cuda.Stream()
|
| 102 |
+
self.device = torch.device('cuda' if opt['num_gpu'] != 0 else 'cpu')
|
| 103 |
+
self.preload()
|
| 104 |
+
|
| 105 |
+
def preload(self):
|
| 106 |
+
try:
|
| 107 |
+
self.batch = next(self.loader) # self.batch is a dict
|
| 108 |
+
except StopIteration:
|
| 109 |
+
self.batch = None
|
| 110 |
+
return None
|
| 111 |
+
# put tensors to gpu
|
| 112 |
+
with torch.cuda.stream(self.stream):
|
| 113 |
+
for k, v in self.batch.items():
|
| 114 |
+
if torch.is_tensor(v):
|
| 115 |
+
self.batch[k] = self.batch[k].to(device=self.device, non_blocking=True)
|
| 116 |
+
|
| 117 |
+
def next(self):
|
| 118 |
+
torch.cuda.current_stream().wait_stream(self.stream)
|
| 119 |
+
batch = self.batch
|
| 120 |
+
self.preload()
|
| 121 |
+
return batch
|
| 122 |
+
|
| 123 |
+
def reset(self):
|
| 124 |
+
self.loader = iter(self.ori_loader)
|
| 125 |
+
self.preload()
|
propainter/core/trainer.py
ADDED
|
@@ -0,0 +1,509 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import glob
|
| 3 |
+
import logging
|
| 4 |
+
import importlib
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
from core.prefetch_dataloader import PrefetchDataLoader, CPUPrefetcher
|
| 11 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 12 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 13 |
+
import torchvision
|
| 14 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 15 |
+
|
| 16 |
+
from core.lr_scheduler import MultiStepRestartLR, CosineAnnealingRestartLR
|
| 17 |
+
from core.loss import AdversarialLoss, PerceptualLoss, LPIPSLoss
|
| 18 |
+
from core.dataset import TrainDataset
|
| 19 |
+
|
| 20 |
+
from model.modules.flow_comp_raft import RAFT_bi, FlowLoss, EdgeLoss
|
| 21 |
+
from model.recurrent_flow_completion import RecurrentFlowCompleteNet
|
| 22 |
+
|
| 23 |
+
from RAFT.utils.flow_viz_pt import flow_to_image
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class Trainer:
|
| 27 |
+
def __init__(self, config):
|
| 28 |
+
self.config = config
|
| 29 |
+
self.epoch = 0
|
| 30 |
+
self.iteration = 0
|
| 31 |
+
self.num_local_frames = config['train_data_loader']['num_local_frames']
|
| 32 |
+
self.num_ref_frames = config['train_data_loader']['num_ref_frames']
|
| 33 |
+
|
| 34 |
+
# setup data set and data loader
|
| 35 |
+
self.train_dataset = TrainDataset(config['train_data_loader'])
|
| 36 |
+
|
| 37 |
+
self.train_sampler = None
|
| 38 |
+
self.train_args = config['trainer']
|
| 39 |
+
if config['distributed']:
|
| 40 |
+
self.train_sampler = DistributedSampler(
|
| 41 |
+
self.train_dataset,
|
| 42 |
+
num_replicas=config['world_size'],
|
| 43 |
+
rank=config['global_rank'])
|
| 44 |
+
|
| 45 |
+
dataloader_args = dict(
|
| 46 |
+
dataset=self.train_dataset,
|
| 47 |
+
batch_size=self.train_args['batch_size'] // config['world_size'],
|
| 48 |
+
shuffle=(self.train_sampler is None),
|
| 49 |
+
num_workers=self.train_args['num_workers'],
|
| 50 |
+
sampler=self.train_sampler,
|
| 51 |
+
drop_last=True)
|
| 52 |
+
|
| 53 |
+
self.train_loader = PrefetchDataLoader(self.train_args['num_prefetch_queue'], **dataloader_args)
|
| 54 |
+
self.prefetcher = CPUPrefetcher(self.train_loader)
|
| 55 |
+
|
| 56 |
+
# set loss functions
|
| 57 |
+
self.adversarial_loss = AdversarialLoss(type=self.config['losses']['GAN_LOSS'])
|
| 58 |
+
self.adversarial_loss = self.adversarial_loss.to(self.config['device'])
|
| 59 |
+
self.l1_loss = nn.L1Loss()
|
| 60 |
+
# self.perc_loss = PerceptualLoss(
|
| 61 |
+
# layer_weights={'conv3_4': 0.25, 'conv4_4': 0.25, 'conv5_4': 0.5},
|
| 62 |
+
# use_input_norm=True,
|
| 63 |
+
# range_norm=True,
|
| 64 |
+
# criterion='l1'
|
| 65 |
+
# ).to(self.config['device'])
|
| 66 |
+
|
| 67 |
+
if self.config['losses']['perceptual_weight'] > 0:
|
| 68 |
+
self.perc_loss = LPIPSLoss(use_input_norm=True, range_norm=True).to(self.config['device'])
|
| 69 |
+
|
| 70 |
+
# self.flow_comp_loss = FlowCompletionLoss().to(self.config['device'])
|
| 71 |
+
# self.flow_comp_loss = FlowCompletionLoss(self.config['device'])
|
| 72 |
+
|
| 73 |
+
# set raft
|
| 74 |
+
self.fix_raft = RAFT_bi(device = self.config['device'])
|
| 75 |
+
self.fix_flow_complete = RecurrentFlowCompleteNet('weights/recurrent_flow_completion.pth')
|
| 76 |
+
for p in self.fix_flow_complete.parameters():
|
| 77 |
+
p.requires_grad = False
|
| 78 |
+
self.fix_flow_complete.to(self.config['device'])
|
| 79 |
+
self.fix_flow_complete.eval()
|
| 80 |
+
|
| 81 |
+
# self.flow_loss = FlowLoss()
|
| 82 |
+
|
| 83 |
+
# setup models including generator and discriminator
|
| 84 |
+
net = importlib.import_module('model.' + config['model']['net'])
|
| 85 |
+
self.netG = net.InpaintGenerator()
|
| 86 |
+
# print(self.netG)
|
| 87 |
+
self.netG = self.netG.to(self.config['device'])
|
| 88 |
+
if not self.config['model'].get('no_dis', False):
|
| 89 |
+
if self.config['model'].get('dis_2d', False):
|
| 90 |
+
self.netD = net.Discriminator_2D(
|
| 91 |
+
in_channels=3,
|
| 92 |
+
use_sigmoid=config['losses']['GAN_LOSS'] != 'hinge')
|
| 93 |
+
else:
|
| 94 |
+
self.netD = net.Discriminator(
|
| 95 |
+
in_channels=3,
|
| 96 |
+
use_sigmoid=config['losses']['GAN_LOSS'] != 'hinge')
|
| 97 |
+
self.netD = self.netD.to(self.config['device'])
|
| 98 |
+
|
| 99 |
+
self.interp_mode = self.config['model']['interp_mode']
|
| 100 |
+
# setup optimizers and schedulers
|
| 101 |
+
self.setup_optimizers()
|
| 102 |
+
self.setup_schedulers()
|
| 103 |
+
self.load()
|
| 104 |
+
|
| 105 |
+
if config['distributed']:
|
| 106 |
+
self.netG = DDP(self.netG,
|
| 107 |
+
device_ids=[self.config['local_rank']],
|
| 108 |
+
output_device=self.config['local_rank'],
|
| 109 |
+
broadcast_buffers=True,
|
| 110 |
+
find_unused_parameters=True)
|
| 111 |
+
if not self.config['model']['no_dis']:
|
| 112 |
+
self.netD = DDP(self.netD,
|
| 113 |
+
device_ids=[self.config['local_rank']],
|
| 114 |
+
output_device=self.config['local_rank'],
|
| 115 |
+
broadcast_buffers=True,
|
| 116 |
+
find_unused_parameters=False)
|
| 117 |
+
|
| 118 |
+
# set summary writer
|
| 119 |
+
self.dis_writer = None
|
| 120 |
+
self.gen_writer = None
|
| 121 |
+
self.summary = {}
|
| 122 |
+
if self.config['global_rank'] == 0 or (not config['distributed']):
|
| 123 |
+
if not self.config['model']['no_dis']:
|
| 124 |
+
self.dis_writer = SummaryWriter(
|
| 125 |
+
os.path.join(config['save_dir'], 'dis'))
|
| 126 |
+
self.gen_writer = SummaryWriter(
|
| 127 |
+
os.path.join(config['save_dir'], 'gen'))
|
| 128 |
+
|
| 129 |
+
def setup_optimizers(self):
|
| 130 |
+
"""Set up optimizers."""
|
| 131 |
+
backbone_params = []
|
| 132 |
+
for name, param in self.netG.named_parameters():
|
| 133 |
+
if param.requires_grad:
|
| 134 |
+
backbone_params.append(param)
|
| 135 |
+
else:
|
| 136 |
+
print(f'Params {name} will not be optimized.')
|
| 137 |
+
|
| 138 |
+
optim_params = [
|
| 139 |
+
{
|
| 140 |
+
'params': backbone_params,
|
| 141 |
+
'lr': self.config['trainer']['lr']
|
| 142 |
+
},
|
| 143 |
+
]
|
| 144 |
+
|
| 145 |
+
self.optimG = torch.optim.Adam(optim_params,
|
| 146 |
+
betas=(self.config['trainer']['beta1'],
|
| 147 |
+
self.config['trainer']['beta2']))
|
| 148 |
+
|
| 149 |
+
if not self.config['model']['no_dis']:
|
| 150 |
+
self.optimD = torch.optim.Adam(
|
| 151 |
+
self.netD.parameters(),
|
| 152 |
+
lr=self.config['trainer']['lr'],
|
| 153 |
+
betas=(self.config['trainer']['beta1'],
|
| 154 |
+
self.config['trainer']['beta2']))
|
| 155 |
+
|
| 156 |
+
def setup_schedulers(self):
|
| 157 |
+
"""Set up schedulers."""
|
| 158 |
+
scheduler_opt = self.config['trainer']['scheduler']
|
| 159 |
+
scheduler_type = scheduler_opt.pop('type')
|
| 160 |
+
|
| 161 |
+
if scheduler_type in ['MultiStepLR', 'MultiStepRestartLR']:
|
| 162 |
+
self.scheG = MultiStepRestartLR(
|
| 163 |
+
self.optimG,
|
| 164 |
+
milestones=scheduler_opt['milestones'],
|
| 165 |
+
gamma=scheduler_opt['gamma'])
|
| 166 |
+
if not self.config['model']['no_dis']:
|
| 167 |
+
self.scheD = MultiStepRestartLR(
|
| 168 |
+
self.optimD,
|
| 169 |
+
milestones=scheduler_opt['milestones'],
|
| 170 |
+
gamma=scheduler_opt['gamma'])
|
| 171 |
+
elif scheduler_type == 'CosineAnnealingRestartLR':
|
| 172 |
+
self.scheG = CosineAnnealingRestartLR(
|
| 173 |
+
self.optimG,
|
| 174 |
+
periods=scheduler_opt['periods'],
|
| 175 |
+
restart_weights=scheduler_opt['restart_weights'],
|
| 176 |
+
eta_min=scheduler_opt['eta_min'])
|
| 177 |
+
if not self.config['model']['no_dis']:
|
| 178 |
+
self.scheD = CosineAnnealingRestartLR(
|
| 179 |
+
self.optimD,
|
| 180 |
+
periods=scheduler_opt['periods'],
|
| 181 |
+
restart_weights=scheduler_opt['restart_weights'],
|
| 182 |
+
eta_min=scheduler_opt['eta_min'])
|
| 183 |
+
else:
|
| 184 |
+
raise NotImplementedError(
|
| 185 |
+
f'Scheduler {scheduler_type} is not implemented yet.')
|
| 186 |
+
|
| 187 |
+
def update_learning_rate(self):
|
| 188 |
+
"""Update learning rate."""
|
| 189 |
+
self.scheG.step()
|
| 190 |
+
if not self.config['model']['no_dis']:
|
| 191 |
+
self.scheD.step()
|
| 192 |
+
|
| 193 |
+
def get_lr(self):
|
| 194 |
+
"""Get current learning rate."""
|
| 195 |
+
return self.optimG.param_groups[0]['lr']
|
| 196 |
+
|
| 197 |
+
def add_summary(self, writer, name, val):
|
| 198 |
+
"""Add tensorboard summary."""
|
| 199 |
+
if name not in self.summary:
|
| 200 |
+
self.summary[name] = 0
|
| 201 |
+
self.summary[name] += val
|
| 202 |
+
n = self.train_args['log_freq']
|
| 203 |
+
if writer is not None and self.iteration % n == 0:
|
| 204 |
+
writer.add_scalar(name, self.summary[name] / n, self.iteration)
|
| 205 |
+
self.summary[name] = 0
|
| 206 |
+
|
| 207 |
+
def load(self):
|
| 208 |
+
"""Load netG (and netD)."""
|
| 209 |
+
# get the latest checkpoint
|
| 210 |
+
model_path = self.config['save_dir']
|
| 211 |
+
# TODO: add resume name
|
| 212 |
+
if os.path.isfile(os.path.join(model_path, 'latest.ckpt')):
|
| 213 |
+
latest_epoch = open(os.path.join(model_path, 'latest.ckpt'),
|
| 214 |
+
'r').read().splitlines()[-1]
|
| 215 |
+
else:
|
| 216 |
+
ckpts = [
|
| 217 |
+
os.path.basename(i).split('.pth')[0]
|
| 218 |
+
for i in glob.glob(os.path.join(model_path, '*.pth'))
|
| 219 |
+
]
|
| 220 |
+
ckpts.sort()
|
| 221 |
+
latest_epoch = ckpts[-1][4:] if len(ckpts) > 0 else None
|
| 222 |
+
|
| 223 |
+
if latest_epoch is not None:
|
| 224 |
+
gen_path = os.path.join(model_path,
|
| 225 |
+
f'gen_{int(latest_epoch):06d}.pth')
|
| 226 |
+
dis_path = os.path.join(model_path,
|
| 227 |
+
f'dis_{int(latest_epoch):06d}.pth')
|
| 228 |
+
opt_path = os.path.join(model_path,
|
| 229 |
+
f'opt_{int(latest_epoch):06d}.pth')
|
| 230 |
+
|
| 231 |
+
if self.config['global_rank'] == 0:
|
| 232 |
+
print(f'Loading model from {gen_path}...')
|
| 233 |
+
dataG = torch.load(gen_path, map_location=self.config['device'])
|
| 234 |
+
self.netG.load_state_dict(dataG)
|
| 235 |
+
if not self.config['model']['no_dis'] and self.config['model']['load_d']:
|
| 236 |
+
dataD = torch.load(dis_path, map_location=self.config['device'])
|
| 237 |
+
self.netD.load_state_dict(dataD)
|
| 238 |
+
|
| 239 |
+
data_opt = torch.load(opt_path, map_location=self.config['device'])
|
| 240 |
+
self.optimG.load_state_dict(data_opt['optimG'])
|
| 241 |
+
# self.scheG.load_state_dict(data_opt['scheG'])
|
| 242 |
+
if not self.config['model']['no_dis'] and self.config['model']['load_d']:
|
| 243 |
+
self.optimD.load_state_dict(data_opt['optimD'])
|
| 244 |
+
# self.scheD.load_state_dict(data_opt['scheD'])
|
| 245 |
+
self.epoch = data_opt['epoch']
|
| 246 |
+
self.iteration = data_opt['iteration']
|
| 247 |
+
else:
|
| 248 |
+
gen_path = self.config['trainer'].get('gen_path', None)
|
| 249 |
+
dis_path = self.config['trainer'].get('dis_path', None)
|
| 250 |
+
opt_path = self.config['trainer'].get('opt_path', None)
|
| 251 |
+
if gen_path is not None:
|
| 252 |
+
if self.config['global_rank'] == 0:
|
| 253 |
+
print(f'Loading Gen-Net from {gen_path}...')
|
| 254 |
+
dataG = torch.load(gen_path, map_location=self.config['device'])
|
| 255 |
+
self.netG.load_state_dict(dataG)
|
| 256 |
+
|
| 257 |
+
if dis_path is not None and not self.config['model']['no_dis'] and self.config['model']['load_d']:
|
| 258 |
+
if self.config['global_rank'] == 0:
|
| 259 |
+
print(f'Loading Dis-Net from {dis_path}...')
|
| 260 |
+
dataD = torch.load(dis_path, map_location=self.config['device'])
|
| 261 |
+
self.netD.load_state_dict(dataD)
|
| 262 |
+
if opt_path is not None:
|
| 263 |
+
data_opt = torch.load(opt_path, map_location=self.config['device'])
|
| 264 |
+
self.optimG.load_state_dict(data_opt['optimG'])
|
| 265 |
+
self.scheG.load_state_dict(data_opt['scheG'])
|
| 266 |
+
if not self.config['model']['no_dis'] and self.config['model']['load_d']:
|
| 267 |
+
self.optimD.load_state_dict(data_opt['optimD'])
|
| 268 |
+
self.scheD.load_state_dict(data_opt['scheD'])
|
| 269 |
+
else:
|
| 270 |
+
if self.config['global_rank'] == 0:
|
| 271 |
+
print('Warnning: There is no trained model found.'
|
| 272 |
+
'An initialized model will be used.')
|
| 273 |
+
|
| 274 |
+
def save(self, it):
|
| 275 |
+
"""Save parameters every eval_epoch"""
|
| 276 |
+
if self.config['global_rank'] == 0:
|
| 277 |
+
# configure path
|
| 278 |
+
gen_path = os.path.join(self.config['save_dir'],
|
| 279 |
+
f'gen_{it:06d}.pth')
|
| 280 |
+
dis_path = os.path.join(self.config['save_dir'],
|
| 281 |
+
f'dis_{it:06d}.pth')
|
| 282 |
+
opt_path = os.path.join(self.config['save_dir'],
|
| 283 |
+
f'opt_{it:06d}.pth')
|
| 284 |
+
print(f'\nsaving model to {gen_path} ...')
|
| 285 |
+
|
| 286 |
+
# remove .module for saving
|
| 287 |
+
if isinstance(self.netG, torch.nn.DataParallel) or isinstance(self.netG, DDP):
|
| 288 |
+
netG = self.netG.module
|
| 289 |
+
if not self.config['model']['no_dis']:
|
| 290 |
+
netD = self.netD.module
|
| 291 |
+
else:
|
| 292 |
+
netG = self.netG
|
| 293 |
+
if not self.config['model']['no_dis']:
|
| 294 |
+
netD = self.netD
|
| 295 |
+
|
| 296 |
+
# save checkpoints
|
| 297 |
+
torch.save(netG.state_dict(), gen_path)
|
| 298 |
+
if not self.config['model']['no_dis']:
|
| 299 |
+
torch.save(netD.state_dict(), dis_path)
|
| 300 |
+
torch.save(
|
| 301 |
+
{
|
| 302 |
+
'epoch': self.epoch,
|
| 303 |
+
'iteration': self.iteration,
|
| 304 |
+
'optimG': self.optimG.state_dict(),
|
| 305 |
+
'optimD': self.optimD.state_dict(),
|
| 306 |
+
'scheG': self.scheG.state_dict(),
|
| 307 |
+
'scheD': self.scheD.state_dict()
|
| 308 |
+
}, opt_path)
|
| 309 |
+
else:
|
| 310 |
+
torch.save(
|
| 311 |
+
{
|
| 312 |
+
'epoch': self.epoch,
|
| 313 |
+
'iteration': self.iteration,
|
| 314 |
+
'optimG': self.optimG.state_dict(),
|
| 315 |
+
'scheG': self.scheG.state_dict()
|
| 316 |
+
}, opt_path)
|
| 317 |
+
|
| 318 |
+
latest_path = os.path.join(self.config['save_dir'], 'latest.ckpt')
|
| 319 |
+
os.system(f"echo {it:06d} > {latest_path}")
|
| 320 |
+
|
| 321 |
+
def train(self):
|
| 322 |
+
"""training entry"""
|
| 323 |
+
pbar = range(int(self.train_args['iterations']))
|
| 324 |
+
if self.config['global_rank'] == 0:
|
| 325 |
+
pbar = tqdm(pbar,
|
| 326 |
+
initial=self.iteration,
|
| 327 |
+
dynamic_ncols=True,
|
| 328 |
+
smoothing=0.01)
|
| 329 |
+
|
| 330 |
+
os.makedirs('logs', exist_ok=True)
|
| 331 |
+
|
| 332 |
+
logging.basicConfig(
|
| 333 |
+
level=logging.INFO,
|
| 334 |
+
format="%(asctime)s %(filename)s[line:%(lineno)d]"
|
| 335 |
+
"%(levelname)s %(message)s",
|
| 336 |
+
datefmt="%a, %d %b %Y %H:%M:%S",
|
| 337 |
+
filename=f"logs/{self.config['save_dir'].split('/')[-1]}.log",
|
| 338 |
+
filemode='w')
|
| 339 |
+
|
| 340 |
+
while True:
|
| 341 |
+
self.epoch += 1
|
| 342 |
+
self.prefetcher.reset()
|
| 343 |
+
if self.config['distributed']:
|
| 344 |
+
self.train_sampler.set_epoch(self.epoch)
|
| 345 |
+
self._train_epoch(pbar)
|
| 346 |
+
if self.iteration > self.train_args['iterations']:
|
| 347 |
+
break
|
| 348 |
+
print('\nEnd training....')
|
| 349 |
+
|
| 350 |
+
def _train_epoch(self, pbar):
|
| 351 |
+
"""Process input and calculate loss every training epoch"""
|
| 352 |
+
device = self.config['device']
|
| 353 |
+
train_data = self.prefetcher.next()
|
| 354 |
+
while train_data is not None:
|
| 355 |
+
self.iteration += 1
|
| 356 |
+
frames, masks, flows_f, flows_b, _ = train_data
|
| 357 |
+
frames, masks = frames.to(device), masks.to(device).float()
|
| 358 |
+
l_t = self.num_local_frames
|
| 359 |
+
b, t, c, h, w = frames.size()
|
| 360 |
+
gt_local_frames = frames[:, :l_t, ...]
|
| 361 |
+
local_masks = masks[:, :l_t, ...].contiguous()
|
| 362 |
+
|
| 363 |
+
masked_frames = frames * (1 - masks)
|
| 364 |
+
masked_local_frames = masked_frames[:, :l_t, ...]
|
| 365 |
+
# get gt optical flow
|
| 366 |
+
if flows_f[0] == 'None' or flows_b[0] == 'None':
|
| 367 |
+
gt_flows_bi = self.fix_raft(gt_local_frames)
|
| 368 |
+
else:
|
| 369 |
+
gt_flows_bi = (flows_f.to(device), flows_b.to(device))
|
| 370 |
+
|
| 371 |
+
# ---- complete flow ----
|
| 372 |
+
pred_flows_bi, _ = self.fix_flow_complete.forward_bidirect_flow(gt_flows_bi, local_masks)
|
| 373 |
+
pred_flows_bi = self.fix_flow_complete.combine_flow(gt_flows_bi, pred_flows_bi, local_masks)
|
| 374 |
+
# pred_flows_bi = gt_flows_bi
|
| 375 |
+
|
| 376 |
+
# ---- image propagation ----
|
| 377 |
+
prop_imgs, updated_local_masks = self.netG.module.img_propagation(masked_local_frames, pred_flows_bi, local_masks, interpolation=self.interp_mode)
|
| 378 |
+
updated_masks = masks.clone()
|
| 379 |
+
updated_masks[:, :l_t, ...] = updated_local_masks.view(b, l_t, 1, h, w)
|
| 380 |
+
updated_frames = masked_frames.clone()
|
| 381 |
+
prop_local_frames = gt_local_frames * (1-local_masks) + prop_imgs.view(b, l_t, 3, h, w) * local_masks # merge
|
| 382 |
+
updated_frames[:, :l_t, ...] = prop_local_frames
|
| 383 |
+
|
| 384 |
+
# ---- feature propagation + Transformer ----
|
| 385 |
+
pred_imgs = self.netG(updated_frames, pred_flows_bi, masks, updated_masks, l_t)
|
| 386 |
+
pred_imgs = pred_imgs.view(b, -1, c, h, w)
|
| 387 |
+
|
| 388 |
+
# get the local frames
|
| 389 |
+
pred_local_frames = pred_imgs[:, :l_t, ...]
|
| 390 |
+
comp_local_frames = gt_local_frames * (1. - local_masks) + pred_local_frames * local_masks
|
| 391 |
+
comp_imgs = frames * (1. - masks) + pred_imgs * masks
|
| 392 |
+
|
| 393 |
+
gen_loss = 0
|
| 394 |
+
dis_loss = 0
|
| 395 |
+
# optimize net_g
|
| 396 |
+
if not self.config['model']['no_dis']:
|
| 397 |
+
for p in self.netD.parameters():
|
| 398 |
+
p.requires_grad = False
|
| 399 |
+
|
| 400 |
+
self.optimG.zero_grad()
|
| 401 |
+
|
| 402 |
+
# generator l1 loss
|
| 403 |
+
hole_loss = self.l1_loss(pred_imgs * masks, frames * masks)
|
| 404 |
+
hole_loss = hole_loss / torch.mean(masks) * self.config['losses']['hole_weight']
|
| 405 |
+
gen_loss += hole_loss
|
| 406 |
+
self.add_summary(self.gen_writer, 'loss/hole_loss', hole_loss.item())
|
| 407 |
+
|
| 408 |
+
valid_loss = self.l1_loss(pred_imgs * (1 - masks), frames * (1 - masks))
|
| 409 |
+
valid_loss = valid_loss / torch.mean(1-masks) * self.config['losses']['valid_weight']
|
| 410 |
+
gen_loss += valid_loss
|
| 411 |
+
self.add_summary(self.gen_writer, 'loss/valid_loss', valid_loss.item())
|
| 412 |
+
|
| 413 |
+
# perceptual loss
|
| 414 |
+
if self.config['losses']['perceptual_weight'] > 0:
|
| 415 |
+
perc_loss = self.perc_loss(pred_imgs.view(-1,3,h,w), frames.view(-1,3,h,w))[0] * self.config['losses']['perceptual_weight']
|
| 416 |
+
gen_loss += perc_loss
|
| 417 |
+
self.add_summary(self.gen_writer, 'loss/perc_loss', perc_loss.item())
|
| 418 |
+
|
| 419 |
+
# gan loss
|
| 420 |
+
if not self.config['model']['no_dis']:
|
| 421 |
+
# generator adversarial loss
|
| 422 |
+
gen_clip = self.netD(comp_imgs)
|
| 423 |
+
gan_loss = self.adversarial_loss(gen_clip, True, False)
|
| 424 |
+
gan_loss = gan_loss * self.config['losses']['adversarial_weight']
|
| 425 |
+
gen_loss += gan_loss
|
| 426 |
+
self.add_summary(self.gen_writer, 'loss/gan_loss', gan_loss.item())
|
| 427 |
+
gen_loss.backward()
|
| 428 |
+
self.optimG.step()
|
| 429 |
+
|
| 430 |
+
if not self.config['model']['no_dis']:
|
| 431 |
+
# optimize net_d
|
| 432 |
+
for p in self.netD.parameters():
|
| 433 |
+
p.requires_grad = True
|
| 434 |
+
self.optimD.zero_grad()
|
| 435 |
+
|
| 436 |
+
# discriminator adversarial loss
|
| 437 |
+
real_clip = self.netD(frames)
|
| 438 |
+
fake_clip = self.netD(comp_imgs.detach())
|
| 439 |
+
dis_real_loss = self.adversarial_loss(real_clip, True, True)
|
| 440 |
+
dis_fake_loss = self.adversarial_loss(fake_clip, False, True)
|
| 441 |
+
dis_loss += (dis_real_loss + dis_fake_loss) / 2
|
| 442 |
+
self.add_summary(self.dis_writer, 'loss/dis_vid_real', dis_real_loss.item())
|
| 443 |
+
self.add_summary(self.dis_writer, 'loss/dis_vid_fake', dis_fake_loss.item())
|
| 444 |
+
dis_loss.backward()
|
| 445 |
+
self.optimD.step()
|
| 446 |
+
|
| 447 |
+
self.update_learning_rate()
|
| 448 |
+
|
| 449 |
+
# write image to tensorboard
|
| 450 |
+
if self.iteration % 200 == 0:
|
| 451 |
+
# img to cpu
|
| 452 |
+
t = 0
|
| 453 |
+
gt_local_frames_cpu = ((gt_local_frames.view(b,-1,3,h,w) + 1)/2.0).cpu()
|
| 454 |
+
masked_local_frames = ((masked_local_frames.view(b,-1,3,h,w) + 1)/2.0).cpu()
|
| 455 |
+
prop_local_frames_cpu = ((prop_local_frames.view(b,-1,3,h,w) + 1)/2.0).cpu()
|
| 456 |
+
pred_local_frames_cpu = ((pred_local_frames.view(b,-1,3,h,w) + 1)/2.0).cpu()
|
| 457 |
+
img_results = torch.cat([masked_local_frames[0][t], gt_local_frames_cpu[0][t],
|
| 458 |
+
prop_local_frames_cpu[0][t], pred_local_frames_cpu[0][t]], 1)
|
| 459 |
+
img_results = torchvision.utils.make_grid(img_results, nrow=1, normalize=True)
|
| 460 |
+
if self.gen_writer is not None:
|
| 461 |
+
self.gen_writer.add_image(f'img/img:inp-gt-res-{t}', img_results, self.iteration)
|
| 462 |
+
|
| 463 |
+
t = 5
|
| 464 |
+
if masked_local_frames.shape[1] > 5:
|
| 465 |
+
img_results = torch.cat([masked_local_frames[0][t], gt_local_frames_cpu[0][t],
|
| 466 |
+
prop_local_frames_cpu[0][t], pred_local_frames_cpu[0][t]], 1)
|
| 467 |
+
img_results = torchvision.utils.make_grid(img_results, nrow=1, normalize=True)
|
| 468 |
+
if self.gen_writer is not None:
|
| 469 |
+
self.gen_writer.add_image(f'img/img:inp-gt-res-{t}', img_results, self.iteration)
|
| 470 |
+
|
| 471 |
+
# flow to cpu
|
| 472 |
+
gt_flows_forward_cpu = flow_to_image(gt_flows_bi[0][0]).cpu()
|
| 473 |
+
masked_flows_forward_cpu = (gt_flows_forward_cpu[0] * (1-local_masks[0][0].cpu())).to(gt_flows_forward_cpu)
|
| 474 |
+
pred_flows_forward_cpu = flow_to_image(pred_flows_bi[0][0]).cpu()
|
| 475 |
+
|
| 476 |
+
flow_results = torch.cat([gt_flows_forward_cpu[0], masked_flows_forward_cpu, pred_flows_forward_cpu[0]], 1)
|
| 477 |
+
if self.gen_writer is not None:
|
| 478 |
+
self.gen_writer.add_image('img/flow:gt-pred', flow_results, self.iteration)
|
| 479 |
+
|
| 480 |
+
# console logs
|
| 481 |
+
if self.config['global_rank'] == 0:
|
| 482 |
+
pbar.update(1)
|
| 483 |
+
if not self.config['model']['no_dis']:
|
| 484 |
+
pbar.set_description((f"d: {dis_loss.item():.3f}; "
|
| 485 |
+
f"hole: {hole_loss.item():.3f}; "
|
| 486 |
+
f"valid: {valid_loss.item():.3f}"))
|
| 487 |
+
else:
|
| 488 |
+
pbar.set_description((f"hole: {hole_loss.item():.3f}; "
|
| 489 |
+
f"valid: {valid_loss.item():.3f}"))
|
| 490 |
+
|
| 491 |
+
if self.iteration % self.train_args['log_freq'] == 0:
|
| 492 |
+
if not self.config['model']['no_dis']:
|
| 493 |
+
logging.info(f"[Iter {self.iteration}] "
|
| 494 |
+
f"d: {dis_loss.item():.4f}; "
|
| 495 |
+
f"hole: {hole_loss.item():.4f}; "
|
| 496 |
+
f"valid: {valid_loss.item():.4f}")
|
| 497 |
+
else:
|
| 498 |
+
logging.info(f"[Iter {self.iteration}] "
|
| 499 |
+
f"hole: {hole_loss.item():.4f}; "
|
| 500 |
+
f"valid: {valid_loss.item():.4f}")
|
| 501 |
+
|
| 502 |
+
# saving models
|
| 503 |
+
if self.iteration % self.train_args['save_freq'] == 0:
|
| 504 |
+
self.save(int(self.iteration))
|
| 505 |
+
|
| 506 |
+
if self.iteration > self.train_args['iterations']:
|
| 507 |
+
break
|
| 508 |
+
|
| 509 |
+
train_data = self.prefetcher.next()
|
propainter/core/trainer_flow_w_edge.py
ADDED
|
@@ -0,0 +1,380 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import glob
|
| 3 |
+
import logging
|
| 4 |
+
import importlib
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
from core.prefetch_dataloader import PrefetchDataLoader, CPUPrefetcher
|
| 11 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 12 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 13 |
+
|
| 14 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 15 |
+
|
| 16 |
+
from core.lr_scheduler import MultiStepRestartLR, CosineAnnealingRestartLR
|
| 17 |
+
from core.dataset import TrainDataset
|
| 18 |
+
|
| 19 |
+
from model.modules.flow_comp_raft import RAFT_bi, FlowLoss, EdgeLoss
|
| 20 |
+
|
| 21 |
+
# from skimage.feature import canny
|
| 22 |
+
from model.canny.canny_filter import Canny
|
| 23 |
+
from RAFT.utils.flow_viz_pt import flow_to_image
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class Trainer:
|
| 27 |
+
def __init__(self, config):
|
| 28 |
+
self.config = config
|
| 29 |
+
self.epoch = 0
|
| 30 |
+
self.iteration = 0
|
| 31 |
+
self.num_local_frames = config['train_data_loader']['num_local_frames']
|
| 32 |
+
self.num_ref_frames = config['train_data_loader']['num_ref_frames']
|
| 33 |
+
|
| 34 |
+
# setup data set and data loader
|
| 35 |
+
self.train_dataset = TrainDataset(config['train_data_loader'])
|
| 36 |
+
|
| 37 |
+
self.train_sampler = None
|
| 38 |
+
self.train_args = config['trainer']
|
| 39 |
+
if config['distributed']:
|
| 40 |
+
self.train_sampler = DistributedSampler(
|
| 41 |
+
self.train_dataset,
|
| 42 |
+
num_replicas=config['world_size'],
|
| 43 |
+
rank=config['global_rank'])
|
| 44 |
+
|
| 45 |
+
dataloader_args = dict(
|
| 46 |
+
dataset=self.train_dataset,
|
| 47 |
+
batch_size=self.train_args['batch_size'] // config['world_size'],
|
| 48 |
+
shuffle=(self.train_sampler is None),
|
| 49 |
+
num_workers=self.train_args['num_workers'],
|
| 50 |
+
sampler=self.train_sampler,
|
| 51 |
+
drop_last=True)
|
| 52 |
+
|
| 53 |
+
self.train_loader = PrefetchDataLoader(self.train_args['num_prefetch_queue'], **dataloader_args)
|
| 54 |
+
self.prefetcher = CPUPrefetcher(self.train_loader)
|
| 55 |
+
|
| 56 |
+
# set raft
|
| 57 |
+
self.fix_raft = RAFT_bi(device = self.config['device'])
|
| 58 |
+
self.flow_loss = FlowLoss()
|
| 59 |
+
self.edge_loss = EdgeLoss()
|
| 60 |
+
self.canny = Canny(sigma=(2,2), low_threshold=0.1, high_threshold=0.2)
|
| 61 |
+
|
| 62 |
+
# setup models including generator and discriminator
|
| 63 |
+
net = importlib.import_module('model.' + config['model']['net'])
|
| 64 |
+
self.netG = net.RecurrentFlowCompleteNet()
|
| 65 |
+
# print(self.netG)
|
| 66 |
+
self.netG = self.netG.to(self.config['device'])
|
| 67 |
+
|
| 68 |
+
# setup optimizers and schedulers
|
| 69 |
+
self.setup_optimizers()
|
| 70 |
+
self.setup_schedulers()
|
| 71 |
+
self.load()
|
| 72 |
+
|
| 73 |
+
if config['distributed']:
|
| 74 |
+
self.netG = DDP(self.netG,
|
| 75 |
+
device_ids=[self.config['local_rank']],
|
| 76 |
+
output_device=self.config['local_rank'],
|
| 77 |
+
broadcast_buffers=True,
|
| 78 |
+
find_unused_parameters=True)
|
| 79 |
+
|
| 80 |
+
# set summary writer
|
| 81 |
+
self.dis_writer = None
|
| 82 |
+
self.gen_writer = None
|
| 83 |
+
self.summary = {}
|
| 84 |
+
if self.config['global_rank'] == 0 or (not config['distributed']):
|
| 85 |
+
self.gen_writer = SummaryWriter(
|
| 86 |
+
os.path.join(config['save_dir'], 'gen'))
|
| 87 |
+
|
| 88 |
+
def setup_optimizers(self):
|
| 89 |
+
"""Set up optimizers."""
|
| 90 |
+
backbone_params = []
|
| 91 |
+
for name, param in self.netG.named_parameters():
|
| 92 |
+
if param.requires_grad:
|
| 93 |
+
backbone_params.append(param)
|
| 94 |
+
else:
|
| 95 |
+
print(f'Params {name} will not be optimized.')
|
| 96 |
+
|
| 97 |
+
optim_params = [
|
| 98 |
+
{
|
| 99 |
+
'params': backbone_params,
|
| 100 |
+
'lr': self.config['trainer']['lr']
|
| 101 |
+
},
|
| 102 |
+
]
|
| 103 |
+
|
| 104 |
+
self.optimG = torch.optim.Adam(optim_params,
|
| 105 |
+
betas=(self.config['trainer']['beta1'],
|
| 106 |
+
self.config['trainer']['beta2']))
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def setup_schedulers(self):
|
| 110 |
+
"""Set up schedulers."""
|
| 111 |
+
scheduler_opt = self.config['trainer']['scheduler']
|
| 112 |
+
scheduler_type = scheduler_opt.pop('type')
|
| 113 |
+
|
| 114 |
+
if scheduler_type in ['MultiStepLR', 'MultiStepRestartLR']:
|
| 115 |
+
self.scheG = MultiStepRestartLR(
|
| 116 |
+
self.optimG,
|
| 117 |
+
milestones=scheduler_opt['milestones'],
|
| 118 |
+
gamma=scheduler_opt['gamma'])
|
| 119 |
+
elif scheduler_type == 'CosineAnnealingRestartLR':
|
| 120 |
+
self.scheG = CosineAnnealingRestartLR(
|
| 121 |
+
self.optimG,
|
| 122 |
+
periods=scheduler_opt['periods'],
|
| 123 |
+
restart_weights=scheduler_opt['restart_weights'])
|
| 124 |
+
else:
|
| 125 |
+
raise NotImplementedError(
|
| 126 |
+
f'Scheduler {scheduler_type} is not implemented yet.')
|
| 127 |
+
|
| 128 |
+
def update_learning_rate(self):
|
| 129 |
+
"""Update learning rate."""
|
| 130 |
+
self.scheG.step()
|
| 131 |
+
|
| 132 |
+
def get_lr(self):
|
| 133 |
+
"""Get current learning rate."""
|
| 134 |
+
return self.optimG.param_groups[0]['lr']
|
| 135 |
+
|
| 136 |
+
def add_summary(self, writer, name, val):
|
| 137 |
+
"""Add tensorboard summary."""
|
| 138 |
+
if name not in self.summary:
|
| 139 |
+
self.summary[name] = 0
|
| 140 |
+
self.summary[name] += val
|
| 141 |
+
n = self.train_args['log_freq']
|
| 142 |
+
if writer is not None and self.iteration % n == 0:
|
| 143 |
+
writer.add_scalar(name, self.summary[name] / n, self.iteration)
|
| 144 |
+
self.summary[name] = 0
|
| 145 |
+
|
| 146 |
+
def load(self):
|
| 147 |
+
"""Load netG."""
|
| 148 |
+
# get the latest checkpoint
|
| 149 |
+
model_path = self.config['save_dir']
|
| 150 |
+
if os.path.isfile(os.path.join(model_path, 'latest.ckpt')):
|
| 151 |
+
latest_epoch = open(os.path.join(model_path, 'latest.ckpt'),
|
| 152 |
+
'r').read().splitlines()[-1]
|
| 153 |
+
else:
|
| 154 |
+
ckpts = [
|
| 155 |
+
os.path.basename(i).split('.pth')[0]
|
| 156 |
+
for i in glob.glob(os.path.join(model_path, '*.pth'))
|
| 157 |
+
]
|
| 158 |
+
ckpts.sort()
|
| 159 |
+
latest_epoch = ckpts[-1][4:] if len(ckpts) > 0 else None
|
| 160 |
+
|
| 161 |
+
if latest_epoch is not None:
|
| 162 |
+
gen_path = os.path.join(model_path, f'gen_{int(latest_epoch):06d}.pth')
|
| 163 |
+
opt_path = os.path.join(model_path,f'opt_{int(latest_epoch):06d}.pth')
|
| 164 |
+
|
| 165 |
+
if self.config['global_rank'] == 0:
|
| 166 |
+
print(f'Loading model from {gen_path}...')
|
| 167 |
+
dataG = torch.load(gen_path, map_location=self.config['device'])
|
| 168 |
+
self.netG.load_state_dict(dataG)
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
data_opt = torch.load(opt_path, map_location=self.config['device'])
|
| 172 |
+
self.optimG.load_state_dict(data_opt['optimG'])
|
| 173 |
+
self.scheG.load_state_dict(data_opt['scheG'])
|
| 174 |
+
|
| 175 |
+
self.epoch = data_opt['epoch']
|
| 176 |
+
self.iteration = data_opt['iteration']
|
| 177 |
+
|
| 178 |
+
else:
|
| 179 |
+
if self.config['global_rank'] == 0:
|
| 180 |
+
print('Warnning: There is no trained model found.'
|
| 181 |
+
'An initialized model will be used.')
|
| 182 |
+
|
| 183 |
+
def save(self, it):
|
| 184 |
+
"""Save parameters every eval_epoch"""
|
| 185 |
+
if self.config['global_rank'] == 0:
|
| 186 |
+
# configure path
|
| 187 |
+
gen_path = os.path.join(self.config['save_dir'],
|
| 188 |
+
f'gen_{it:06d}.pth')
|
| 189 |
+
opt_path = os.path.join(self.config['save_dir'],
|
| 190 |
+
f'opt_{it:06d}.pth')
|
| 191 |
+
print(f'\nsaving model to {gen_path} ...')
|
| 192 |
+
|
| 193 |
+
# remove .module for saving
|
| 194 |
+
if isinstance(self.netG, torch.nn.DataParallel) or isinstance(self.netG, DDP):
|
| 195 |
+
netG = self.netG.module
|
| 196 |
+
else:
|
| 197 |
+
netG = self.netG
|
| 198 |
+
|
| 199 |
+
# save checkpoints
|
| 200 |
+
torch.save(netG.state_dict(), gen_path)
|
| 201 |
+
torch.save(
|
| 202 |
+
{
|
| 203 |
+
'epoch': self.epoch,
|
| 204 |
+
'iteration': self.iteration,
|
| 205 |
+
'optimG': self.optimG.state_dict(),
|
| 206 |
+
'scheG': self.scheG.state_dict()
|
| 207 |
+
}, opt_path)
|
| 208 |
+
|
| 209 |
+
latest_path = os.path.join(self.config['save_dir'], 'latest.ckpt')
|
| 210 |
+
os.system(f"echo {it:06d} > {latest_path}")
|
| 211 |
+
|
| 212 |
+
def train(self):
|
| 213 |
+
"""training entry"""
|
| 214 |
+
pbar = range(int(self.train_args['iterations']))
|
| 215 |
+
if self.config['global_rank'] == 0:
|
| 216 |
+
pbar = tqdm(pbar,
|
| 217 |
+
initial=self.iteration,
|
| 218 |
+
dynamic_ncols=True,
|
| 219 |
+
smoothing=0.01)
|
| 220 |
+
|
| 221 |
+
os.makedirs('logs', exist_ok=True)
|
| 222 |
+
|
| 223 |
+
logging.basicConfig(
|
| 224 |
+
level=logging.INFO,
|
| 225 |
+
format="%(asctime)s %(filename)s[line:%(lineno)d]"
|
| 226 |
+
"%(levelname)s %(message)s",
|
| 227 |
+
datefmt="%a, %d %b %Y %H:%M:%S",
|
| 228 |
+
filename=f"logs/{self.config['save_dir'].split('/')[-1]}.log",
|
| 229 |
+
filemode='w')
|
| 230 |
+
|
| 231 |
+
while True:
|
| 232 |
+
self.epoch += 1
|
| 233 |
+
self.prefetcher.reset()
|
| 234 |
+
if self.config['distributed']:
|
| 235 |
+
self.train_sampler.set_epoch(self.epoch)
|
| 236 |
+
self._train_epoch(pbar)
|
| 237 |
+
if self.iteration > self.train_args['iterations']:
|
| 238 |
+
break
|
| 239 |
+
print('\nEnd training....')
|
| 240 |
+
|
| 241 |
+
# def get_edges(self, flows): # fgvc
|
| 242 |
+
# # (b, t, 2, H, W)
|
| 243 |
+
# b, t, _, h, w = flows.shape
|
| 244 |
+
# flows = flows.view(-1, 2, h, w)
|
| 245 |
+
# flows_list = flows.permute(0, 2, 3, 1).cpu().numpy()
|
| 246 |
+
# edges = []
|
| 247 |
+
# for f in list(flows_list):
|
| 248 |
+
# flows_gray = (f[:, :, 0] ** 2 + f[:, :, 1] ** 2) ** 0.5
|
| 249 |
+
# if flows_gray.max() < 1:
|
| 250 |
+
# flows_gray = flows_gray*0
|
| 251 |
+
# else:
|
| 252 |
+
# flows_gray = flows_gray / flows_gray.max()
|
| 253 |
+
|
| 254 |
+
# edge = canny(flows_gray, sigma=2, low_threshold=0.1, high_threshold=0.2) # fgvc
|
| 255 |
+
# edge = torch.from_numpy(edge).view(1, 1, h, w).float()
|
| 256 |
+
# edges.append(edge)
|
| 257 |
+
# edges = torch.stack(edges, dim=0).to(self.config['device'])
|
| 258 |
+
# edges = edges.view(b, t, 1, h, w)
|
| 259 |
+
# return edges
|
| 260 |
+
|
| 261 |
+
def get_edges(self, flows):
|
| 262 |
+
# (b, t, 2, H, W)
|
| 263 |
+
b, t, _, h, w = flows.shape
|
| 264 |
+
flows = flows.view(-1, 2, h, w)
|
| 265 |
+
flows_gray = (flows[:, 0, None] ** 2 + flows[:, 1, None] ** 2) ** 0.5
|
| 266 |
+
if flows_gray.max() < 1:
|
| 267 |
+
flows_gray = flows_gray*0
|
| 268 |
+
else:
|
| 269 |
+
flows_gray = flows_gray / flows_gray.max()
|
| 270 |
+
|
| 271 |
+
magnitude, edges = self.canny(flows_gray.float())
|
| 272 |
+
edges = edges.view(b, t, 1, h, w)
|
| 273 |
+
return edges
|
| 274 |
+
|
| 275 |
+
def _train_epoch(self, pbar):
|
| 276 |
+
"""Process input and calculate loss every training epoch"""
|
| 277 |
+
device = self.config['device']
|
| 278 |
+
train_data = self.prefetcher.next()
|
| 279 |
+
while train_data is not None:
|
| 280 |
+
self.iteration += 1
|
| 281 |
+
frames, masks, flows_f, flows_b, _ = train_data
|
| 282 |
+
frames, masks = frames.to(device), masks.to(device)
|
| 283 |
+
masks = masks.float()
|
| 284 |
+
|
| 285 |
+
l_t = self.num_local_frames
|
| 286 |
+
b, t, c, h, w = frames.size()
|
| 287 |
+
gt_local_frames = frames[:, :l_t, ...]
|
| 288 |
+
local_masks = masks[:, :l_t, ...].contiguous()
|
| 289 |
+
|
| 290 |
+
# get gt optical flow
|
| 291 |
+
if flows_f[0] == 'None' or flows_b[0] == 'None':
|
| 292 |
+
gt_flows_bi = self.fix_raft(gt_local_frames)
|
| 293 |
+
else:
|
| 294 |
+
gt_flows_bi = (flows_f.to(device), flows_b.to(device))
|
| 295 |
+
|
| 296 |
+
# get gt edge
|
| 297 |
+
gt_edges_forward = self.get_edges(gt_flows_bi[0])
|
| 298 |
+
gt_edges_backward = self.get_edges(gt_flows_bi[1])
|
| 299 |
+
gt_edges_bi = [gt_edges_forward, gt_edges_backward]
|
| 300 |
+
|
| 301 |
+
# complete flow
|
| 302 |
+
pred_flows_bi, pred_edges_bi = self.netG.module.forward_bidirect_flow(gt_flows_bi, local_masks)
|
| 303 |
+
|
| 304 |
+
# optimize net_g
|
| 305 |
+
self.optimG.zero_grad()
|
| 306 |
+
|
| 307 |
+
# compulte flow_loss
|
| 308 |
+
flow_loss, warp_loss = self.flow_loss(pred_flows_bi, gt_flows_bi, local_masks, gt_local_frames)
|
| 309 |
+
flow_loss = flow_loss * self.config['losses']['flow_weight']
|
| 310 |
+
warp_loss = warp_loss * 0.01
|
| 311 |
+
self.add_summary(self.gen_writer, 'loss/flow_loss', flow_loss.item())
|
| 312 |
+
self.add_summary(self.gen_writer, 'loss/warp_loss', warp_loss.item())
|
| 313 |
+
|
| 314 |
+
# compute edge loss
|
| 315 |
+
edge_loss = self.edge_loss(pred_edges_bi, gt_edges_bi, local_masks)
|
| 316 |
+
edge_loss = edge_loss*1.0
|
| 317 |
+
self.add_summary(self.gen_writer, 'loss/edge_loss', edge_loss.item())
|
| 318 |
+
|
| 319 |
+
loss = flow_loss + warp_loss + edge_loss
|
| 320 |
+
loss.backward()
|
| 321 |
+
self.optimG.step()
|
| 322 |
+
self.update_learning_rate()
|
| 323 |
+
|
| 324 |
+
# write image to tensorboard
|
| 325 |
+
# if self.iteration % 200 == 0:
|
| 326 |
+
if self.iteration % 200 == 0 and self.gen_writer is not None:
|
| 327 |
+
t = 5
|
| 328 |
+
# forward to cpu
|
| 329 |
+
gt_flows_forward_cpu = flow_to_image(gt_flows_bi[0][0]).cpu()
|
| 330 |
+
masked_flows_forward_cpu = (gt_flows_forward_cpu[t] * (1-local_masks[0][t].cpu())).to(gt_flows_forward_cpu)
|
| 331 |
+
pred_flows_forward_cpu = flow_to_image(pred_flows_bi[0][0]).cpu()
|
| 332 |
+
|
| 333 |
+
flow_results = torch.cat([gt_flows_forward_cpu[t], masked_flows_forward_cpu, pred_flows_forward_cpu[t]], 1)
|
| 334 |
+
self.gen_writer.add_image('img/flow-f:gt-pred', flow_results, self.iteration)
|
| 335 |
+
|
| 336 |
+
# backward to cpu
|
| 337 |
+
gt_flows_backward_cpu = flow_to_image(gt_flows_bi[1][0]).cpu()
|
| 338 |
+
masked_flows_backward_cpu = (gt_flows_backward_cpu[t] * (1-local_masks[0][t+1].cpu())).to(gt_flows_backward_cpu)
|
| 339 |
+
pred_flows_backward_cpu = flow_to_image(pred_flows_bi[1][0]).cpu()
|
| 340 |
+
|
| 341 |
+
flow_results = torch.cat([gt_flows_backward_cpu[t], masked_flows_backward_cpu, pred_flows_backward_cpu[t]], 1)
|
| 342 |
+
self.gen_writer.add_image('img/flow-b:gt-pred', flow_results, self.iteration)
|
| 343 |
+
|
| 344 |
+
# TODO: show edge
|
| 345 |
+
# forward
|
| 346 |
+
gt_edges_forward_cpu = gt_edges_bi[0][0].cpu()
|
| 347 |
+
masked_edges_forward_cpu = (gt_edges_forward_cpu[t] * (1-local_masks[0][t].cpu())).to(gt_edges_forward_cpu)
|
| 348 |
+
pred_edges_forward_cpu = pred_edges_bi[0][0].cpu()
|
| 349 |
+
|
| 350 |
+
edge_results = torch.cat([gt_edges_forward_cpu[t], masked_edges_forward_cpu, pred_edges_forward_cpu[t]], 1)
|
| 351 |
+
self.gen_writer.add_image('img/edge-f:gt-pred', edge_results, self.iteration)
|
| 352 |
+
# backward
|
| 353 |
+
gt_edges_backward_cpu = gt_edges_bi[1][0].cpu()
|
| 354 |
+
masked_edges_backward_cpu = (gt_edges_backward_cpu[t] * (1-local_masks[0][t+1].cpu())).to(gt_edges_backward_cpu)
|
| 355 |
+
pred_edges_backward_cpu = pred_edges_bi[1][0].cpu()
|
| 356 |
+
|
| 357 |
+
edge_results = torch.cat([gt_edges_backward_cpu[t], masked_edges_backward_cpu, pred_edges_backward_cpu[t]], 1)
|
| 358 |
+
self.gen_writer.add_image('img/edge-b:gt-pred', edge_results, self.iteration)
|
| 359 |
+
|
| 360 |
+
# console logs
|
| 361 |
+
if self.config['global_rank'] == 0:
|
| 362 |
+
pbar.update(1)
|
| 363 |
+
pbar.set_description((f"flow: {flow_loss.item():.3f}; "
|
| 364 |
+
f"warp: {warp_loss.item():.3f}; "
|
| 365 |
+
f"edge: {edge_loss.item():.3f}; "
|
| 366 |
+
f"lr: {self.get_lr()}"))
|
| 367 |
+
|
| 368 |
+
if self.iteration % self.train_args['log_freq'] == 0:
|
| 369 |
+
logging.info(f"[Iter {self.iteration}] "
|
| 370 |
+
f"flow: {flow_loss.item():.4f}; "
|
| 371 |
+
f"warp: {warp_loss.item():.4f}")
|
| 372 |
+
|
| 373 |
+
# saving models
|
| 374 |
+
if self.iteration % self.train_args['save_freq'] == 0:
|
| 375 |
+
self.save(int(self.iteration))
|
| 376 |
+
|
| 377 |
+
if self.iteration > self.train_args['iterations']:
|
| 378 |
+
break
|
| 379 |
+
|
| 380 |
+
train_data = self.prefetcher.next()
|
propainter/core/utils.py
ADDED
|
@@ -0,0 +1,371 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import io
|
| 3 |
+
import cv2
|
| 4 |
+
import random
|
| 5 |
+
import numpy as np
|
| 6 |
+
from PIL import Image, ImageOps
|
| 7 |
+
import zipfile
|
| 8 |
+
import math
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import matplotlib
|
| 12 |
+
import matplotlib.patches as patches
|
| 13 |
+
from matplotlib.path import Path
|
| 14 |
+
from matplotlib import pyplot as plt
|
| 15 |
+
from torchvision import transforms
|
| 16 |
+
|
| 17 |
+
# matplotlib.use('agg')
|
| 18 |
+
|
| 19 |
+
# ###########################################################################
|
| 20 |
+
# Directory IO
|
| 21 |
+
# ###########################################################################
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def read_dirnames_under_root(root_dir):
|
| 25 |
+
dirnames = [
|
| 26 |
+
name for i, name in enumerate(sorted(os.listdir(root_dir)))
|
| 27 |
+
if os.path.isdir(os.path.join(root_dir, name))
|
| 28 |
+
]
|
| 29 |
+
print(f'Reading directories under {root_dir}, num: {len(dirnames)}')
|
| 30 |
+
return dirnames
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class TrainZipReader(object):
|
| 34 |
+
file_dict = dict()
|
| 35 |
+
|
| 36 |
+
def __init__(self):
|
| 37 |
+
super(TrainZipReader, self).__init__()
|
| 38 |
+
|
| 39 |
+
@staticmethod
|
| 40 |
+
def build_file_dict(path):
|
| 41 |
+
file_dict = TrainZipReader.file_dict
|
| 42 |
+
if path in file_dict:
|
| 43 |
+
return file_dict[path]
|
| 44 |
+
else:
|
| 45 |
+
file_handle = zipfile.ZipFile(path, 'r')
|
| 46 |
+
file_dict[path] = file_handle
|
| 47 |
+
return file_dict[path]
|
| 48 |
+
|
| 49 |
+
@staticmethod
|
| 50 |
+
def imread(path, idx):
|
| 51 |
+
zfile = TrainZipReader.build_file_dict(path)
|
| 52 |
+
filelist = zfile.namelist()
|
| 53 |
+
filelist.sort()
|
| 54 |
+
data = zfile.read(filelist[idx])
|
| 55 |
+
#
|
| 56 |
+
im = Image.open(io.BytesIO(data))
|
| 57 |
+
return im
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class TestZipReader(object):
|
| 61 |
+
file_dict = dict()
|
| 62 |
+
|
| 63 |
+
def __init__(self):
|
| 64 |
+
super(TestZipReader, self).__init__()
|
| 65 |
+
|
| 66 |
+
@staticmethod
|
| 67 |
+
def build_file_dict(path):
|
| 68 |
+
file_dict = TestZipReader.file_dict
|
| 69 |
+
if path in file_dict:
|
| 70 |
+
return file_dict[path]
|
| 71 |
+
else:
|
| 72 |
+
file_handle = zipfile.ZipFile(path, 'r')
|
| 73 |
+
file_dict[path] = file_handle
|
| 74 |
+
return file_dict[path]
|
| 75 |
+
|
| 76 |
+
@staticmethod
|
| 77 |
+
def imread(path, idx):
|
| 78 |
+
zfile = TestZipReader.build_file_dict(path)
|
| 79 |
+
filelist = zfile.namelist()
|
| 80 |
+
filelist.sort()
|
| 81 |
+
data = zfile.read(filelist[idx])
|
| 82 |
+
file_bytes = np.asarray(bytearray(data), dtype=np.uint8)
|
| 83 |
+
im = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR)
|
| 84 |
+
im = Image.fromarray(cv2.cvtColor(im, cv2.COLOR_BGR2RGB))
|
| 85 |
+
# im = Image.open(io.BytesIO(data))
|
| 86 |
+
return im
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
# ###########################################################################
|
| 90 |
+
# Data augmentation
|
| 91 |
+
# ###########################################################################
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def to_tensors():
|
| 95 |
+
return transforms.Compose([Stack(), ToTorchFormatTensor()])
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
class GroupRandomHorizontalFlowFlip(object):
|
| 99 |
+
"""Randomly horizontally flips the given PIL.Image with a probability of 0.5
|
| 100 |
+
"""
|
| 101 |
+
def __call__(self, img_group, flowF_group, flowB_group):
|
| 102 |
+
v = random.random()
|
| 103 |
+
if v < 0.5:
|
| 104 |
+
ret_img = [
|
| 105 |
+
img.transpose(Image.FLIP_LEFT_RIGHT) for img in img_group
|
| 106 |
+
]
|
| 107 |
+
ret_flowF = [ff[:, ::-1] * [-1.0, 1.0] for ff in flowF_group]
|
| 108 |
+
ret_flowB = [fb[:, ::-1] * [-1.0, 1.0] for fb in flowB_group]
|
| 109 |
+
return ret_img, ret_flowF, ret_flowB
|
| 110 |
+
else:
|
| 111 |
+
return img_group, flowF_group, flowB_group
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
class GroupRandomHorizontalFlip(object):
|
| 115 |
+
"""Randomly horizontally flips the given PIL.Image with a probability of 0.5
|
| 116 |
+
"""
|
| 117 |
+
def __call__(self, img_group, is_flow=False):
|
| 118 |
+
v = random.random()
|
| 119 |
+
if v < 0.5:
|
| 120 |
+
ret = [img.transpose(Image.FLIP_LEFT_RIGHT) for img in img_group]
|
| 121 |
+
if is_flow:
|
| 122 |
+
for i in range(0, len(ret), 2):
|
| 123 |
+
# invert flow pixel values when flipping
|
| 124 |
+
ret[i] = ImageOps.invert(ret[i])
|
| 125 |
+
return ret
|
| 126 |
+
else:
|
| 127 |
+
return img_group
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
class Stack(object):
|
| 131 |
+
def __init__(self, roll=False):
|
| 132 |
+
self.roll = roll
|
| 133 |
+
|
| 134 |
+
def __call__(self, img_group):
|
| 135 |
+
mode = img_group[0].mode
|
| 136 |
+
if mode == '1':
|
| 137 |
+
img_group = [img.convert('L') for img in img_group]
|
| 138 |
+
mode = 'L'
|
| 139 |
+
if mode == 'L':
|
| 140 |
+
return np.stack([np.expand_dims(x, 2) for x in img_group], axis=2)
|
| 141 |
+
elif mode == 'RGB':
|
| 142 |
+
if self.roll:
|
| 143 |
+
return np.stack([np.array(x)[:, :, ::-1] for x in img_group],
|
| 144 |
+
axis=2)
|
| 145 |
+
else:
|
| 146 |
+
return np.stack(img_group, axis=2)
|
| 147 |
+
else:
|
| 148 |
+
raise NotImplementedError(f"Image mode {mode}")
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
class ToTorchFormatTensor(object):
|
| 152 |
+
""" Converts a PIL.Image (RGB) or numpy.ndarray (H x W x C) in the range [0, 255]
|
| 153 |
+
to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0] """
|
| 154 |
+
def __init__(self, div=True):
|
| 155 |
+
self.div = div
|
| 156 |
+
|
| 157 |
+
def __call__(self, pic):
|
| 158 |
+
if isinstance(pic, np.ndarray):
|
| 159 |
+
# numpy img: [L, C, H, W]
|
| 160 |
+
img = torch.from_numpy(pic).permute(2, 3, 0, 1).contiguous()
|
| 161 |
+
else:
|
| 162 |
+
# handle PIL Image
|
| 163 |
+
img = torch.ByteTensor(torch.ByteStorage.from_buffer(
|
| 164 |
+
pic.tobytes()))
|
| 165 |
+
img = img.view(pic.size[1], pic.size[0], len(pic.mode))
|
| 166 |
+
# put it from HWC to CHW format
|
| 167 |
+
# yikes, this transpose takes 80% of the loading time/CPU
|
| 168 |
+
img = img.transpose(0, 1).transpose(0, 2).contiguous()
|
| 169 |
+
img = img.float().div(255) if self.div else img.float()
|
| 170 |
+
return img
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
# ###########################################################################
|
| 174 |
+
# Create masks with random shape
|
| 175 |
+
# ###########################################################################
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
def create_random_shape_with_random_motion(video_length,
|
| 179 |
+
imageHeight=240,
|
| 180 |
+
imageWidth=432):
|
| 181 |
+
# get a random shape
|
| 182 |
+
height = random.randint(imageHeight // 3, imageHeight - 1)
|
| 183 |
+
width = random.randint(imageWidth // 3, imageWidth - 1)
|
| 184 |
+
edge_num = random.randint(6, 8)
|
| 185 |
+
ratio = random.randint(6, 8) / 10
|
| 186 |
+
|
| 187 |
+
region = get_random_shape(edge_num=edge_num,
|
| 188 |
+
ratio=ratio,
|
| 189 |
+
height=height,
|
| 190 |
+
width=width)
|
| 191 |
+
region_width, region_height = region.size
|
| 192 |
+
# get random position
|
| 193 |
+
x, y = random.randint(0, imageHeight - region_height), random.randint(
|
| 194 |
+
0, imageWidth - region_width)
|
| 195 |
+
velocity = get_random_velocity(max_speed=3)
|
| 196 |
+
m = Image.fromarray(np.zeros((imageHeight, imageWidth)).astype(np.uint8))
|
| 197 |
+
m.paste(region, (y, x, y + region.size[0], x + region.size[1]))
|
| 198 |
+
masks = [m.convert('L')]
|
| 199 |
+
# return fixed masks
|
| 200 |
+
if random.uniform(0, 1) > 0.5:
|
| 201 |
+
return masks * video_length
|
| 202 |
+
# return moving masks
|
| 203 |
+
for _ in range(video_length - 1):
|
| 204 |
+
x, y, velocity = random_move_control_points(x,
|
| 205 |
+
y,
|
| 206 |
+
imageHeight,
|
| 207 |
+
imageWidth,
|
| 208 |
+
velocity,
|
| 209 |
+
region.size,
|
| 210 |
+
maxLineAcceleration=(3,
|
| 211 |
+
0.5),
|
| 212 |
+
maxInitSpeed=3)
|
| 213 |
+
m = Image.fromarray(
|
| 214 |
+
np.zeros((imageHeight, imageWidth)).astype(np.uint8))
|
| 215 |
+
m.paste(region, (y, x, y + region.size[0], x + region.size[1]))
|
| 216 |
+
masks.append(m.convert('L'))
|
| 217 |
+
return masks
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def create_random_shape_with_random_motion_zoom_rotation(video_length, zoomin=0.9, zoomout=1.1, rotmin=1, rotmax=10, imageHeight=240, imageWidth=432):
|
| 221 |
+
# get a random shape
|
| 222 |
+
assert zoomin < 1, "Zoom-in parameter must be smaller than 1"
|
| 223 |
+
assert zoomout > 1, "Zoom-out parameter must be larger than 1"
|
| 224 |
+
assert rotmin < rotmax, "Minimum value of rotation must be smaller than maximun value !"
|
| 225 |
+
height = random.randint(imageHeight//3, imageHeight-1)
|
| 226 |
+
width = random.randint(imageWidth//3, imageWidth-1)
|
| 227 |
+
edge_num = random.randint(6, 8)
|
| 228 |
+
ratio = random.randint(6, 8)/10
|
| 229 |
+
region = get_random_shape(
|
| 230 |
+
edge_num=edge_num, ratio=ratio, height=height, width=width)
|
| 231 |
+
region_width, region_height = region.size
|
| 232 |
+
# get random position
|
| 233 |
+
x, y = random.randint(
|
| 234 |
+
0, imageHeight-region_height), random.randint(0, imageWidth-region_width)
|
| 235 |
+
velocity = get_random_velocity(max_speed=3)
|
| 236 |
+
m = Image.fromarray(np.zeros((imageHeight, imageWidth)).astype(np.uint8))
|
| 237 |
+
m.paste(region, (y, x, y+region.size[0], x+region.size[1]))
|
| 238 |
+
masks = [m.convert('L')]
|
| 239 |
+
# return fixed masks
|
| 240 |
+
if random.uniform(0, 1) > 0.5:
|
| 241 |
+
return masks*video_length # -> directly copy all the base masks
|
| 242 |
+
# return moving masks
|
| 243 |
+
for _ in range(video_length-1):
|
| 244 |
+
x, y, velocity = random_move_control_points(
|
| 245 |
+
x, y, imageHeight, imageWidth, velocity, region.size, maxLineAcceleration=(3, 0.5), maxInitSpeed=3)
|
| 246 |
+
m = Image.fromarray(
|
| 247 |
+
np.zeros((imageHeight, imageWidth)).astype(np.uint8))
|
| 248 |
+
### add by kaidong, to simulate zoon-in, zoom-out and rotation
|
| 249 |
+
extra_transform = random.uniform(0, 1)
|
| 250 |
+
# zoom in and zoom out
|
| 251 |
+
if extra_transform > 0.75:
|
| 252 |
+
resize_coefficient = random.uniform(zoomin, zoomout)
|
| 253 |
+
region = region.resize((math.ceil(region_width * resize_coefficient), math.ceil(region_height * resize_coefficient)), Image.NEAREST)
|
| 254 |
+
m.paste(region, (y, x, y + region.size[0], x + region.size[1]))
|
| 255 |
+
region_width, region_height = region.size
|
| 256 |
+
# rotation
|
| 257 |
+
elif extra_transform > 0.5:
|
| 258 |
+
m.paste(region, (y, x, y + region.size[0], x + region.size[1]))
|
| 259 |
+
m = m.rotate(random.randint(rotmin, rotmax))
|
| 260 |
+
# region_width, region_height = region.size
|
| 261 |
+
### end
|
| 262 |
+
else:
|
| 263 |
+
m.paste(region, (y, x, y+region.size[0], x+region.size[1]))
|
| 264 |
+
masks.append(m.convert('L'))
|
| 265 |
+
return masks
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
def get_random_shape(edge_num=9, ratio=0.7, width=432, height=240):
|
| 269 |
+
'''
|
| 270 |
+
There is the initial point and 3 points per cubic bezier curve.
|
| 271 |
+
Thus, the curve will only pass though n points, which will be the sharp edges.
|
| 272 |
+
The other 2 modify the shape of the bezier curve.
|
| 273 |
+
edge_num, Number of possibly sharp edges
|
| 274 |
+
points_num, number of points in the Path
|
| 275 |
+
ratio, (0, 1) magnitude of the perturbation from the unit circle,
|
| 276 |
+
'''
|
| 277 |
+
points_num = edge_num*3 + 1
|
| 278 |
+
angles = np.linspace(0, 2*np.pi, points_num)
|
| 279 |
+
codes = np.full(points_num, Path.CURVE4)
|
| 280 |
+
codes[0] = Path.MOVETO
|
| 281 |
+
# Using this instead of Path.CLOSEPOLY avoids an innecessary straight line
|
| 282 |
+
verts = np.stack((np.cos(angles), np.sin(angles))).T * \
|
| 283 |
+
(2*ratio*np.random.random(points_num)+1-ratio)[:, None]
|
| 284 |
+
verts[-1, :] = verts[0, :]
|
| 285 |
+
path = Path(verts, codes)
|
| 286 |
+
# draw paths into images
|
| 287 |
+
fig = plt.figure()
|
| 288 |
+
ax = fig.add_subplot(111)
|
| 289 |
+
patch = patches.PathPatch(path, facecolor='black', lw=2)
|
| 290 |
+
ax.add_patch(patch)
|
| 291 |
+
ax.set_xlim(np.min(verts)*1.1, np.max(verts)*1.1)
|
| 292 |
+
ax.set_ylim(np.min(verts)*1.1, np.max(verts)*1.1)
|
| 293 |
+
ax.axis('off') # removes the axis to leave only the shape
|
| 294 |
+
fig.canvas.draw()
|
| 295 |
+
# convert plt images into numpy images
|
| 296 |
+
data = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)
|
| 297 |
+
data = data.reshape((fig.canvas.get_width_height()[::-1] + (3,)))
|
| 298 |
+
plt.close(fig)
|
| 299 |
+
# postprocess
|
| 300 |
+
data = cv2.resize(data, (width, height))[:, :, 0]
|
| 301 |
+
data = (1 - np.array(data > 0).astype(np.uint8))*255
|
| 302 |
+
corrdinates = np.where(data > 0)
|
| 303 |
+
xmin, xmax, ymin, ymax = np.min(corrdinates[0]), np.max(
|
| 304 |
+
corrdinates[0]), np.min(corrdinates[1]), np.max(corrdinates[1])
|
| 305 |
+
region = Image.fromarray(data).crop((ymin, xmin, ymax, xmax))
|
| 306 |
+
return region
|
| 307 |
+
|
| 308 |
+
|
| 309 |
+
def random_accelerate(velocity, maxAcceleration, dist='uniform'):
|
| 310 |
+
speed, angle = velocity
|
| 311 |
+
d_speed, d_angle = maxAcceleration
|
| 312 |
+
if dist == 'uniform':
|
| 313 |
+
speed += np.random.uniform(-d_speed, d_speed)
|
| 314 |
+
angle += np.random.uniform(-d_angle, d_angle)
|
| 315 |
+
elif dist == 'guassian':
|
| 316 |
+
speed += np.random.normal(0, d_speed / 2)
|
| 317 |
+
angle += np.random.normal(0, d_angle / 2)
|
| 318 |
+
else:
|
| 319 |
+
raise NotImplementedError(
|
| 320 |
+
f'Distribution type {dist} is not supported.')
|
| 321 |
+
return (speed, angle)
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
def get_random_velocity(max_speed=3, dist='uniform'):
|
| 325 |
+
if dist == 'uniform':
|
| 326 |
+
speed = np.random.uniform(max_speed)
|
| 327 |
+
elif dist == 'guassian':
|
| 328 |
+
speed = np.abs(np.random.normal(0, max_speed / 2))
|
| 329 |
+
else:
|
| 330 |
+
raise NotImplementedError(
|
| 331 |
+
f'Distribution type {dist} is not supported.')
|
| 332 |
+
angle = np.random.uniform(0, 2 * np.pi)
|
| 333 |
+
return (speed, angle)
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
def random_move_control_points(X,
|
| 337 |
+
Y,
|
| 338 |
+
imageHeight,
|
| 339 |
+
imageWidth,
|
| 340 |
+
lineVelocity,
|
| 341 |
+
region_size,
|
| 342 |
+
maxLineAcceleration=(3, 0.5),
|
| 343 |
+
maxInitSpeed=3):
|
| 344 |
+
region_width, region_height = region_size
|
| 345 |
+
speed, angle = lineVelocity
|
| 346 |
+
X += int(speed * np.cos(angle))
|
| 347 |
+
Y += int(speed * np.sin(angle))
|
| 348 |
+
lineVelocity = random_accelerate(lineVelocity,
|
| 349 |
+
maxLineAcceleration,
|
| 350 |
+
dist='guassian')
|
| 351 |
+
if ((X > imageHeight - region_height) or (X < 0)
|
| 352 |
+
or (Y > imageWidth - region_width) or (Y < 0)):
|
| 353 |
+
lineVelocity = get_random_velocity(maxInitSpeed, dist='guassian')
|
| 354 |
+
new_X = np.clip(X, 0, imageHeight - region_height)
|
| 355 |
+
new_Y = np.clip(Y, 0, imageWidth - region_width)
|
| 356 |
+
return new_X, new_Y, lineVelocity
|
| 357 |
+
|
| 358 |
+
|
| 359 |
+
if __name__ == '__main__':
|
| 360 |
+
|
| 361 |
+
trials = 10
|
| 362 |
+
for _ in range(trials):
|
| 363 |
+
video_length = 10
|
| 364 |
+
# The returned masks are either stationary (50%) or moving (50%)
|
| 365 |
+
masks = create_random_shape_with_random_motion(video_length,
|
| 366 |
+
imageHeight=240,
|
| 367 |
+
imageWidth=432)
|
| 368 |
+
|
| 369 |
+
for m in masks:
|
| 370 |
+
cv2.imshow('mask', np.array(m))
|
| 371 |
+
cv2.waitKey(500)
|
propainter/inference.py
ADDED
|
@@ -0,0 +1,520 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
import os
|
| 3 |
+
import cv2
|
| 4 |
+
import numpy as np
|
| 5 |
+
import scipy.ndimage
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
import torch
|
| 9 |
+
import torchvision
|
| 10 |
+
import gc
|
| 11 |
+
|
| 12 |
+
try:
|
| 13 |
+
from model.modules.flow_comp_raft import RAFT_bi
|
| 14 |
+
from model.recurrent_flow_completion import RecurrentFlowCompleteNet
|
| 15 |
+
from model.propainter import InpaintGenerator
|
| 16 |
+
from utils.download_util import load_file_from_url
|
| 17 |
+
from core.utils import to_tensors
|
| 18 |
+
from model.misc import get_device
|
| 19 |
+
except:
|
| 20 |
+
from propainter.model.modules.flow_comp_raft import RAFT_bi
|
| 21 |
+
from propainter.model.recurrent_flow_completion import RecurrentFlowCompleteNet
|
| 22 |
+
from propainter.model.propainter import InpaintGenerator
|
| 23 |
+
from propainter.utils.download_util import load_file_from_url
|
| 24 |
+
from propainter.core.utils import to_tensors
|
| 25 |
+
from propainter.model.misc import get_device
|
| 26 |
+
|
| 27 |
+
import warnings
|
| 28 |
+
warnings.filterwarnings("ignore")
|
| 29 |
+
|
| 30 |
+
pretrain_model_url = 'https://github.com/sczhou/ProPainter/releases/download/v0.1.0/'
|
| 31 |
+
MaxSideThresh = 960
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
# resize frames
|
| 35 |
+
def resize_frames(frames, size=None):
|
| 36 |
+
if size is not None:
|
| 37 |
+
out_size = size
|
| 38 |
+
process_size = (out_size[0]-out_size[0]%8, out_size[1]-out_size[1]%8)
|
| 39 |
+
frames = [f.resize(process_size) for f in frames]
|
| 40 |
+
else:
|
| 41 |
+
out_size = frames[0].size
|
| 42 |
+
process_size = (out_size[0]-out_size[0]%8, out_size[1]-out_size[1]%8)
|
| 43 |
+
if not out_size == process_size:
|
| 44 |
+
frames = [f.resize(process_size) for f in frames]
|
| 45 |
+
|
| 46 |
+
return frames, process_size, out_size
|
| 47 |
+
|
| 48 |
+
# read frames from video
|
| 49 |
+
def read_frame_from_videos(frame_root, video_length):
|
| 50 |
+
if frame_root.endswith(('mp4', 'mov', 'avi', 'MP4', 'MOV', 'AVI')): # input video path
|
| 51 |
+
video_name = os.path.basename(frame_root)[:-4]
|
| 52 |
+
vframes, aframes, info = torchvision.io.read_video(filename=frame_root, pts_unit='sec', end_pts=video_length) # RGB
|
| 53 |
+
frames = list(vframes.numpy())
|
| 54 |
+
frames = [Image.fromarray(f) for f in frames]
|
| 55 |
+
fps = info['video_fps']
|
| 56 |
+
nframes = len(frames)
|
| 57 |
+
else:
|
| 58 |
+
video_name = os.path.basename(frame_root)
|
| 59 |
+
frames = []
|
| 60 |
+
fr_lst = sorted(os.listdir(frame_root))
|
| 61 |
+
for fr in fr_lst:
|
| 62 |
+
frame = cv2.imread(os.path.join(frame_root, fr))
|
| 63 |
+
frame = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
|
| 64 |
+
frames.append(frame)
|
| 65 |
+
fps = None
|
| 66 |
+
nframes = len(frames)
|
| 67 |
+
size = frames[0].size
|
| 68 |
+
|
| 69 |
+
return frames, fps, size, video_name, nframes
|
| 70 |
+
|
| 71 |
+
def binary_mask(mask, th=0.1):
|
| 72 |
+
mask[mask>th] = 1
|
| 73 |
+
mask[mask<=th] = 0
|
| 74 |
+
return mask
|
| 75 |
+
|
| 76 |
+
# read frame-wise masks
|
| 77 |
+
def read_mask(mpath, frames_len, size, flow_mask_dilates=8, mask_dilates=5):
|
| 78 |
+
masks_img = []
|
| 79 |
+
masks_dilated = []
|
| 80 |
+
flow_masks = []
|
| 81 |
+
|
| 82 |
+
if mpath.endswith(('jpg', 'jpeg', 'png', 'JPG', 'JPEG', 'PNG')): # input single img path
|
| 83 |
+
masks_img = [Image.open(mpath)]
|
| 84 |
+
elif mpath.endswith(('mp4', 'mov', 'avi', 'MP4', 'MOV', 'AVI')): # input video path
|
| 85 |
+
cap = cv2.VideoCapture(mpath)
|
| 86 |
+
if not cap.isOpened():
|
| 87 |
+
print("Error: Could not open video.")
|
| 88 |
+
exit()
|
| 89 |
+
idx = 0
|
| 90 |
+
while True:
|
| 91 |
+
ret, frame = cap.read()
|
| 92 |
+
if not ret:
|
| 93 |
+
break
|
| 94 |
+
if(idx >= frames_len):
|
| 95 |
+
break
|
| 96 |
+
masks_img.append(Image.fromarray(frame))
|
| 97 |
+
idx += 1
|
| 98 |
+
cap.release()
|
| 99 |
+
else:
|
| 100 |
+
mnames = sorted(os.listdir(mpath))
|
| 101 |
+
for mp in mnames:
|
| 102 |
+
masks_img.append(Image.open(os.path.join(mpath, mp)))
|
| 103 |
+
# print(mp)
|
| 104 |
+
|
| 105 |
+
for mask_img in masks_img:
|
| 106 |
+
if size is not None:
|
| 107 |
+
mask_img = mask_img.resize(size, Image.NEAREST)
|
| 108 |
+
mask_img = np.array(mask_img.convert('L'))
|
| 109 |
+
|
| 110 |
+
# Dilate 8 pixel so that all known pixel is trustworthy
|
| 111 |
+
if flow_mask_dilates > 0:
|
| 112 |
+
flow_mask_img = scipy.ndimage.binary_dilation(mask_img, iterations=flow_mask_dilates).astype(np.uint8)
|
| 113 |
+
else:
|
| 114 |
+
flow_mask_img = binary_mask(mask_img).astype(np.uint8)
|
| 115 |
+
# Close the small holes inside the foreground objects
|
| 116 |
+
# flow_mask_img = cv2.morphologyEx(flow_mask_img, cv2.MORPH_CLOSE, np.ones((21, 21),np.uint8)).astype(bool)
|
| 117 |
+
# flow_mask_img = scipy.ndimage.binary_fill_holes(flow_mask_img).astype(np.uint8)
|
| 118 |
+
flow_masks.append(Image.fromarray(flow_mask_img * 255))
|
| 119 |
+
|
| 120 |
+
if mask_dilates > 0:
|
| 121 |
+
mask_img = scipy.ndimage.binary_dilation(mask_img, iterations=mask_dilates).astype(np.uint8)
|
| 122 |
+
else:
|
| 123 |
+
mask_img = binary_mask(mask_img).astype(np.uint8)
|
| 124 |
+
masks_dilated.append(Image.fromarray(mask_img * 255))
|
| 125 |
+
|
| 126 |
+
if len(masks_img) == 1:
|
| 127 |
+
flow_masks = flow_masks * frames_len
|
| 128 |
+
masks_dilated = masks_dilated * frames_len
|
| 129 |
+
|
| 130 |
+
return flow_masks, masks_dilated
|
| 131 |
+
|
| 132 |
+
def get_ref_index(mid_neighbor_id, neighbor_ids, length, ref_stride=10, ref_num=-1):
|
| 133 |
+
ref_index = []
|
| 134 |
+
if ref_num == -1:
|
| 135 |
+
for i in range(0, length, ref_stride):
|
| 136 |
+
if i not in neighbor_ids:
|
| 137 |
+
ref_index.append(i)
|
| 138 |
+
else:
|
| 139 |
+
start_idx = max(0, mid_neighbor_id - ref_stride * (ref_num // 2))
|
| 140 |
+
end_idx = min(length, mid_neighbor_id + ref_stride * (ref_num // 2))
|
| 141 |
+
for i in range(start_idx, end_idx, ref_stride):
|
| 142 |
+
if i not in neighbor_ids:
|
| 143 |
+
if len(ref_index) > ref_num:
|
| 144 |
+
break
|
| 145 |
+
ref_index.append(i)
|
| 146 |
+
return ref_index
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
class Propainter:
|
| 150 |
+
def __init__(
|
| 151 |
+
self, propainter_model_dir, device):
|
| 152 |
+
self.device = device
|
| 153 |
+
##############################################
|
| 154 |
+
# set up RAFT and flow competition model
|
| 155 |
+
##############################################
|
| 156 |
+
ckpt_path = load_file_from_url(url=os.path.join(pretrain_model_url, 'raft-things.pth'),
|
| 157 |
+
model_dir=propainter_model_dir, progress=True, file_name=None)
|
| 158 |
+
self.fix_raft = RAFT_bi(ckpt_path, device)
|
| 159 |
+
|
| 160 |
+
ckpt_path = load_file_from_url(url=os.path.join(pretrain_model_url, 'recurrent_flow_completion.pth'),
|
| 161 |
+
model_dir=propainter_model_dir, progress=True, file_name=None)
|
| 162 |
+
self.fix_flow_complete = RecurrentFlowCompleteNet(ckpt_path)
|
| 163 |
+
for p in self.fix_flow_complete.parameters():
|
| 164 |
+
p.requires_grad = False
|
| 165 |
+
self.fix_flow_complete.to(device)
|
| 166 |
+
self.fix_flow_complete.eval()
|
| 167 |
+
|
| 168 |
+
##############################################
|
| 169 |
+
# set up ProPainter model
|
| 170 |
+
##############################################
|
| 171 |
+
ckpt_path = load_file_from_url(url=os.path.join(pretrain_model_url, 'ProPainter.pth'),
|
| 172 |
+
model_dir=propainter_model_dir, progress=True, file_name=None)
|
| 173 |
+
self.model = InpaintGenerator(model_path=ckpt_path).to(device)
|
| 174 |
+
self.model.eval()
|
| 175 |
+
def forward(self, video, mask, output_path, resize_ratio=0.6, video_length=2, height=-1, width=-1,
|
| 176 |
+
mask_dilation=4, ref_stride=10, neighbor_length=10, subvideo_length=80,
|
| 177 |
+
raft_iter=20, save_fps=24, save_frames=False, fp16=True):
|
| 178 |
+
|
| 179 |
+
# Use fp16 precision during inference to reduce running memory cost
|
| 180 |
+
use_half = True if fp16 else False
|
| 181 |
+
if self.device == torch.device('cpu'):
|
| 182 |
+
use_half = False
|
| 183 |
+
|
| 184 |
+
################ read input video ################
|
| 185 |
+
frames, fps, size, video_name, nframes = read_frame_from_videos(video, video_length)
|
| 186 |
+
frames = frames[:nframes]
|
| 187 |
+
if not width == -1 and not height == -1:
|
| 188 |
+
size = (width, height)
|
| 189 |
+
|
| 190 |
+
longer_edge = max(size[0], size[1])
|
| 191 |
+
if(longer_edge > MaxSideThresh):
|
| 192 |
+
scale = MaxSideThresh / longer_edge
|
| 193 |
+
resize_ratio = resize_ratio * scale
|
| 194 |
+
if not resize_ratio == 1.0:
|
| 195 |
+
size = (int(resize_ratio * size[0]), int(resize_ratio * size[1]))
|
| 196 |
+
|
| 197 |
+
frames, size, out_size = resize_frames(frames, size)
|
| 198 |
+
fps = save_fps if fps is None else fps
|
| 199 |
+
|
| 200 |
+
################ read mask ################
|
| 201 |
+
frames_len = len(frames)
|
| 202 |
+
flow_masks, masks_dilated = read_mask(mask, frames_len, size,
|
| 203 |
+
flow_mask_dilates=mask_dilation,
|
| 204 |
+
mask_dilates=mask_dilation)
|
| 205 |
+
flow_masks = flow_masks[:nframes]
|
| 206 |
+
masks_dilated = masks_dilated[:nframes]
|
| 207 |
+
w, h = size
|
| 208 |
+
|
| 209 |
+
################ adjust input ################
|
| 210 |
+
frames_len = min(len(frames), len(masks_dilated))
|
| 211 |
+
frames = frames[:frames_len]
|
| 212 |
+
flow_masks = flow_masks[:frames_len]
|
| 213 |
+
masks_dilated = masks_dilated[:frames_len]
|
| 214 |
+
|
| 215 |
+
ori_frames_inp = [np.array(f).astype(np.uint8) for f in frames]
|
| 216 |
+
frames = to_tensors()(frames).unsqueeze(0) * 2 - 1
|
| 217 |
+
flow_masks = to_tensors()(flow_masks).unsqueeze(0)
|
| 218 |
+
masks_dilated = to_tensors()(masks_dilated).unsqueeze(0)
|
| 219 |
+
frames, flow_masks, masks_dilated = frames.to(self.device), flow_masks.to(self.device), masks_dilated.to(self.device)
|
| 220 |
+
|
| 221 |
+
##############################################
|
| 222 |
+
# ProPainter inference
|
| 223 |
+
##############################################
|
| 224 |
+
video_length = frames.size(1)
|
| 225 |
+
print(f'Priori generating: [{video_length} frames]...')
|
| 226 |
+
with torch.no_grad():
|
| 227 |
+
# ---- compute flow ----
|
| 228 |
+
new_longer_edge = max(frames.size(-1), frames.size(-2))
|
| 229 |
+
if new_longer_edge <= 640:
|
| 230 |
+
short_clip_len = 12
|
| 231 |
+
elif new_longer_edge <= 720:
|
| 232 |
+
short_clip_len = 8
|
| 233 |
+
elif new_longer_edge <= 1280:
|
| 234 |
+
short_clip_len = 4
|
| 235 |
+
else:
|
| 236 |
+
short_clip_len = 2
|
| 237 |
+
|
| 238 |
+
# use fp32 for RAFT
|
| 239 |
+
if frames.size(1) > short_clip_len:
|
| 240 |
+
gt_flows_f_list, gt_flows_b_list = [], []
|
| 241 |
+
for f in range(0, video_length, short_clip_len):
|
| 242 |
+
end_f = min(video_length, f + short_clip_len)
|
| 243 |
+
if f == 0:
|
| 244 |
+
flows_f, flows_b = self.fix_raft(frames[:,f:end_f], iters=raft_iter)
|
| 245 |
+
else:
|
| 246 |
+
flows_f, flows_b = self.fix_raft(frames[:,f-1:end_f], iters=raft_iter)
|
| 247 |
+
|
| 248 |
+
gt_flows_f_list.append(flows_f)
|
| 249 |
+
gt_flows_b_list.append(flows_b)
|
| 250 |
+
torch.cuda.empty_cache()
|
| 251 |
+
|
| 252 |
+
gt_flows_f = torch.cat(gt_flows_f_list, dim=1)
|
| 253 |
+
gt_flows_b = torch.cat(gt_flows_b_list, dim=1)
|
| 254 |
+
gt_flows_bi = (gt_flows_f, gt_flows_b)
|
| 255 |
+
else:
|
| 256 |
+
gt_flows_bi = self.fix_raft(frames, iters=raft_iter)
|
| 257 |
+
torch.cuda.empty_cache()
|
| 258 |
+
torch.cuda.empty_cache()
|
| 259 |
+
gc.collect()
|
| 260 |
+
|
| 261 |
+
if use_half:
|
| 262 |
+
frames, flow_masks, masks_dilated = frames.half(), flow_masks.half(), masks_dilated.half()
|
| 263 |
+
gt_flows_bi = (gt_flows_bi[0].half(), gt_flows_bi[1].half())
|
| 264 |
+
self.fix_flow_complete = self.fix_flow_complete.half()
|
| 265 |
+
self.model = self.model.half()
|
| 266 |
+
|
| 267 |
+
# ---- complete flow ----
|
| 268 |
+
flow_length = gt_flows_bi[0].size(1)
|
| 269 |
+
if flow_length > subvideo_length:
|
| 270 |
+
pred_flows_f, pred_flows_b = [], []
|
| 271 |
+
pad_len = 5
|
| 272 |
+
for f in range(0, flow_length, subvideo_length):
|
| 273 |
+
s_f = max(0, f - pad_len)
|
| 274 |
+
e_f = min(flow_length, f + subvideo_length + pad_len)
|
| 275 |
+
pad_len_s = max(0, f) - s_f
|
| 276 |
+
pad_len_e = e_f - min(flow_length, f + subvideo_length)
|
| 277 |
+
pred_flows_bi_sub, _ = self.fix_flow_complete.forward_bidirect_flow(
|
| 278 |
+
(gt_flows_bi[0][:, s_f:e_f], gt_flows_bi[1][:, s_f:e_f]),
|
| 279 |
+
flow_masks[:, s_f:e_f+1])
|
| 280 |
+
pred_flows_bi_sub = self.fix_flow_complete.combine_flow(
|
| 281 |
+
(gt_flows_bi[0][:, s_f:e_f], gt_flows_bi[1][:, s_f:e_f]),
|
| 282 |
+
pred_flows_bi_sub,
|
| 283 |
+
flow_masks[:, s_f:e_f+1])
|
| 284 |
+
|
| 285 |
+
pred_flows_f.append(pred_flows_bi_sub[0][:, pad_len_s:e_f-s_f-pad_len_e])
|
| 286 |
+
pred_flows_b.append(pred_flows_bi_sub[1][:, pad_len_s:e_f-s_f-pad_len_e])
|
| 287 |
+
torch.cuda.empty_cache()
|
| 288 |
+
|
| 289 |
+
pred_flows_f = torch.cat(pred_flows_f, dim=1)
|
| 290 |
+
pred_flows_b = torch.cat(pred_flows_b, dim=1)
|
| 291 |
+
pred_flows_bi = (pred_flows_f, pred_flows_b)
|
| 292 |
+
else:
|
| 293 |
+
pred_flows_bi, _ = self.fix_flow_complete.forward_bidirect_flow(gt_flows_bi, flow_masks)
|
| 294 |
+
pred_flows_bi = self.fix_flow_complete.combine_flow(gt_flows_bi, pred_flows_bi, flow_masks)
|
| 295 |
+
torch.cuda.empty_cache()
|
| 296 |
+
torch.cuda.empty_cache()
|
| 297 |
+
gc.collect()
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
masks_dilated_ori = masks_dilated.clone()
|
| 301 |
+
# ---- Pre-propagation ----
|
| 302 |
+
subvideo_length_img_prop = min(100, subvideo_length) # ensure a minimum of 100 frames for image propagation
|
| 303 |
+
if(len(frames[0]))>subvideo_length_img_prop: # perform propagation only when length of frames is larger than subvideo_length_img_prop
|
| 304 |
+
sample_rate = len(frames[0])//(subvideo_length_img_prop//2)
|
| 305 |
+
index_sample = list(range(0, len(frames[0]), sample_rate))
|
| 306 |
+
sample_frames = torch.stack([frames[0][i].to(torch.float32) for i in index_sample]).unsqueeze(0) # use fp32 for RAFT
|
| 307 |
+
sample_masks_dilated = torch.stack([masks_dilated[0][i] for i in index_sample]).unsqueeze(0)
|
| 308 |
+
sample_flow_masks = torch.stack([flow_masks[0][i] for i in index_sample]).unsqueeze(0)
|
| 309 |
+
|
| 310 |
+
## recompute flow for sampled frames
|
| 311 |
+
# use fp32 for RAFT
|
| 312 |
+
sample_video_length = sample_frames.size(1)
|
| 313 |
+
if sample_frames.size(1) > short_clip_len:
|
| 314 |
+
gt_flows_f_list, gt_flows_b_list = [], []
|
| 315 |
+
for f in range(0, sample_video_length, short_clip_len):
|
| 316 |
+
end_f = min(sample_video_length, f + short_clip_len)
|
| 317 |
+
if f == 0:
|
| 318 |
+
flows_f, flows_b = self.fix_raft(sample_frames[:,f:end_f], iters=raft_iter)
|
| 319 |
+
else:
|
| 320 |
+
flows_f, flows_b = self.fix_raft(sample_frames[:,f-1:end_f], iters=raft_iter)
|
| 321 |
+
|
| 322 |
+
gt_flows_f_list.append(flows_f)
|
| 323 |
+
gt_flows_b_list.append(flows_b)
|
| 324 |
+
torch.cuda.empty_cache()
|
| 325 |
+
|
| 326 |
+
gt_flows_f = torch.cat(gt_flows_f_list, dim=1)
|
| 327 |
+
gt_flows_b = torch.cat(gt_flows_b_list, dim=1)
|
| 328 |
+
sample_gt_flows_bi = (gt_flows_f, gt_flows_b)
|
| 329 |
+
else:
|
| 330 |
+
sample_gt_flows_bi = self.fix_raft(sample_frames, iters=raft_iter)
|
| 331 |
+
torch.cuda.empty_cache()
|
| 332 |
+
torch.cuda.empty_cache()
|
| 333 |
+
gc.collect()
|
| 334 |
+
|
| 335 |
+
if use_half:
|
| 336 |
+
sample_frames, sample_flow_masks, sample_masks_dilated = sample_frames.half(), sample_flow_masks.half(), sample_masks_dilated.half()
|
| 337 |
+
sample_gt_flows_bi = (sample_gt_flows_bi[0].half(), sample_gt_flows_bi[1].half())
|
| 338 |
+
|
| 339 |
+
# ---- complete flow ----
|
| 340 |
+
flow_length = sample_gt_flows_bi[0].size(1)
|
| 341 |
+
if flow_length > subvideo_length:
|
| 342 |
+
pred_flows_f, pred_flows_b = [], []
|
| 343 |
+
pad_len = 5
|
| 344 |
+
for f in range(0, flow_length, subvideo_length):
|
| 345 |
+
s_f = max(0, f - pad_len)
|
| 346 |
+
e_f = min(flow_length, f + subvideo_length + pad_len)
|
| 347 |
+
pad_len_s = max(0, f) - s_f
|
| 348 |
+
pad_len_e = e_f - min(flow_length, f + subvideo_length)
|
| 349 |
+
pred_flows_bi_sub, _ = self.fix_flow_complete.forward_bidirect_flow(
|
| 350 |
+
(sample_gt_flows_bi[0][:, s_f:e_f], sample_gt_flows_bi[1][:, s_f:e_f]),
|
| 351 |
+
sample_flow_masks[:, s_f:e_f+1])
|
| 352 |
+
pred_flows_bi_sub = self.fix_flow_complete.combine_flow(
|
| 353 |
+
(sample_gt_flows_bi[0][:, s_f:e_f], sample_gt_flows_bi[1][:, s_f:e_f]),
|
| 354 |
+
pred_flows_bi_sub,
|
| 355 |
+
sample_flow_masks[:, s_f:e_f+1])
|
| 356 |
+
|
| 357 |
+
pred_flows_f.append(pred_flows_bi_sub[0][:, pad_len_s:e_f-s_f-pad_len_e])
|
| 358 |
+
pred_flows_b.append(pred_flows_bi_sub[1][:, pad_len_s:e_f-s_f-pad_len_e])
|
| 359 |
+
torch.cuda.empty_cache()
|
| 360 |
+
|
| 361 |
+
pred_flows_f = torch.cat(pred_flows_f, dim=1)
|
| 362 |
+
pred_flows_b = torch.cat(pred_flows_b, dim=1)
|
| 363 |
+
sample_pred_flows_bi = (pred_flows_f, pred_flows_b)
|
| 364 |
+
else:
|
| 365 |
+
sample_pred_flows_bi, _ = self.fix_flow_complete.forward_bidirect_flow(sample_gt_flows_bi, sample_flow_masks)
|
| 366 |
+
sample_pred_flows_bi = self.fix_flow_complete.combine_flow(sample_gt_flows_bi, sample_pred_flows_bi, sample_flow_masks)
|
| 367 |
+
torch.cuda.empty_cache()
|
| 368 |
+
torch.cuda.empty_cache()
|
| 369 |
+
gc.collect()
|
| 370 |
+
|
| 371 |
+
masked_frames = sample_frames * (1 - sample_masks_dilated)
|
| 372 |
+
|
| 373 |
+
if sample_video_length > subvideo_length_img_prop:
|
| 374 |
+
updated_frames, updated_masks = [], []
|
| 375 |
+
pad_len = 10
|
| 376 |
+
for f in range(0, sample_video_length, subvideo_length_img_prop):
|
| 377 |
+
s_f = max(0, f - pad_len)
|
| 378 |
+
e_f = min(sample_video_length, f + subvideo_length_img_prop + pad_len)
|
| 379 |
+
pad_len_s = max(0, f) - s_f
|
| 380 |
+
pad_len_e = e_f - min(sample_video_length, f + subvideo_length_img_prop)
|
| 381 |
+
|
| 382 |
+
b, t, _, _, _ = sample_masks_dilated[:, s_f:e_f].size()
|
| 383 |
+
pred_flows_bi_sub = (sample_pred_flows_bi[0][:, s_f:e_f-1], sample_pred_flows_bi[1][:, s_f:e_f-1])
|
| 384 |
+
prop_imgs_sub, updated_local_masks_sub = self.model.img_propagation(masked_frames[:, s_f:e_f],
|
| 385 |
+
pred_flows_bi_sub,
|
| 386 |
+
sample_masks_dilated[:, s_f:e_f],
|
| 387 |
+
'nearest')
|
| 388 |
+
updated_frames_sub = sample_frames[:, s_f:e_f] * (1 - sample_masks_dilated[:, s_f:e_f]) + \
|
| 389 |
+
prop_imgs_sub.view(b, t, 3, h, w) * sample_masks_dilated[:, s_f:e_f]
|
| 390 |
+
updated_masks_sub = updated_local_masks_sub.view(b, t, 1, h, w)
|
| 391 |
+
|
| 392 |
+
updated_frames.append(updated_frames_sub[:, pad_len_s:e_f-s_f-pad_len_e])
|
| 393 |
+
updated_masks.append(updated_masks_sub[:, pad_len_s:e_f-s_f-pad_len_e])
|
| 394 |
+
torch.cuda.empty_cache()
|
| 395 |
+
|
| 396 |
+
updated_frames = torch.cat(updated_frames, dim=1)
|
| 397 |
+
updated_masks = torch.cat(updated_masks, dim=1)
|
| 398 |
+
else:
|
| 399 |
+
b, t, _, _, _ = sample_masks_dilated.size()
|
| 400 |
+
prop_imgs, updated_local_masks = self.model.img_propagation(masked_frames, sample_pred_flows_bi, sample_masks_dilated, 'nearest')
|
| 401 |
+
updated_frames = sample_frames * (1 - sample_masks_dilated) + prop_imgs.view(b, t, 3, h, w) * sample_masks_dilated
|
| 402 |
+
updated_masks = updated_local_masks.view(b, t, 1, h, w)
|
| 403 |
+
torch.cuda.empty_cache()
|
| 404 |
+
|
| 405 |
+
## replace input frames/masks with updated frames/masks
|
| 406 |
+
for i,index in enumerate(index_sample):
|
| 407 |
+
frames[0][index] = updated_frames[0][i]
|
| 408 |
+
masks_dilated[0][index] = updated_masks[0][i]
|
| 409 |
+
|
| 410 |
+
|
| 411 |
+
# ---- frame-by-frame image propagation ----
|
| 412 |
+
masked_frames = frames * (1 - masks_dilated)
|
| 413 |
+
subvideo_length_img_prop = min(100, subvideo_length) # ensure a minimum of 100 frames for image propagation
|
| 414 |
+
if video_length > subvideo_length_img_prop:
|
| 415 |
+
updated_frames, updated_masks = [], []
|
| 416 |
+
pad_len = 10
|
| 417 |
+
for f in range(0, video_length, subvideo_length_img_prop):
|
| 418 |
+
s_f = max(0, f - pad_len)
|
| 419 |
+
e_f = min(video_length, f + subvideo_length_img_prop + pad_len)
|
| 420 |
+
pad_len_s = max(0, f) - s_f
|
| 421 |
+
pad_len_e = e_f - min(video_length, f + subvideo_length_img_prop)
|
| 422 |
+
|
| 423 |
+
b, t, _, _, _ = masks_dilated[:, s_f:e_f].size()
|
| 424 |
+
pred_flows_bi_sub = (pred_flows_bi[0][:, s_f:e_f-1], pred_flows_bi[1][:, s_f:e_f-1])
|
| 425 |
+
prop_imgs_sub, updated_local_masks_sub = self.model.img_propagation(masked_frames[:, s_f:e_f],
|
| 426 |
+
pred_flows_bi_sub,
|
| 427 |
+
masks_dilated[:, s_f:e_f],
|
| 428 |
+
'nearest')
|
| 429 |
+
updated_frames_sub = frames[:, s_f:e_f] * (1 - masks_dilated[:, s_f:e_f]) + \
|
| 430 |
+
prop_imgs_sub.view(b, t, 3, h, w) * masks_dilated[:, s_f:e_f]
|
| 431 |
+
updated_masks_sub = updated_local_masks_sub.view(b, t, 1, h, w)
|
| 432 |
+
|
| 433 |
+
updated_frames.append(updated_frames_sub[:, pad_len_s:e_f-s_f-pad_len_e])
|
| 434 |
+
updated_masks.append(updated_masks_sub[:, pad_len_s:e_f-s_f-pad_len_e])
|
| 435 |
+
torch.cuda.empty_cache()
|
| 436 |
+
|
| 437 |
+
updated_frames = torch.cat(updated_frames, dim=1)
|
| 438 |
+
updated_masks = torch.cat(updated_masks, dim=1)
|
| 439 |
+
else:
|
| 440 |
+
b, t, _, _, _ = masks_dilated.size()
|
| 441 |
+
prop_imgs, updated_local_masks = self.model.img_propagation(masked_frames, pred_flows_bi, masks_dilated, 'nearest')
|
| 442 |
+
updated_frames = frames * (1 - masks_dilated) + prop_imgs.view(b, t, 3, h, w) * masks_dilated
|
| 443 |
+
updated_masks = updated_local_masks.view(b, t, 1, h, w)
|
| 444 |
+
torch.cuda.empty_cache()
|
| 445 |
+
|
| 446 |
+
comp_frames = [None] * video_length
|
| 447 |
+
|
| 448 |
+
neighbor_stride = neighbor_length // 2
|
| 449 |
+
if video_length > subvideo_length:
|
| 450 |
+
ref_num = subvideo_length // ref_stride
|
| 451 |
+
else:
|
| 452 |
+
ref_num = -1
|
| 453 |
+
|
| 454 |
+
torch.cuda.empty_cache()
|
| 455 |
+
# ---- feature propagation + transformer ----
|
| 456 |
+
for f in tqdm(range(0, video_length, neighbor_stride)):
|
| 457 |
+
neighbor_ids = [
|
| 458 |
+
i for i in range(max(0, f - neighbor_stride),
|
| 459 |
+
min(video_length, f + neighbor_stride + 1))
|
| 460 |
+
]
|
| 461 |
+
ref_ids = get_ref_index(f, neighbor_ids, video_length, ref_stride, ref_num)
|
| 462 |
+
selected_imgs = updated_frames[:, neighbor_ids + ref_ids, :, :, :]
|
| 463 |
+
selected_masks = masks_dilated[:, neighbor_ids + ref_ids, :, :, :]
|
| 464 |
+
selected_update_masks = updated_masks[:, neighbor_ids + ref_ids, :, :, :]
|
| 465 |
+
selected_pred_flows_bi = (pred_flows_bi[0][:, neighbor_ids[:-1], :, :, :], pred_flows_bi[1][:, neighbor_ids[:-1], :, :, :])
|
| 466 |
+
|
| 467 |
+
with torch.no_grad():
|
| 468 |
+
# 1.0 indicates mask
|
| 469 |
+
l_t = len(neighbor_ids)
|
| 470 |
+
|
| 471 |
+
# pred_img = selected_imgs # results of image propagation
|
| 472 |
+
pred_img = self.model(selected_imgs, selected_pred_flows_bi, selected_masks, selected_update_masks, l_t)
|
| 473 |
+
pred_img = pred_img.view(-1, 3, h, w)
|
| 474 |
+
|
| 475 |
+
## compose with input frames
|
| 476 |
+
pred_img = (pred_img + 1) / 2
|
| 477 |
+
pred_img = pred_img.cpu().permute(0, 2, 3, 1).numpy() * 255
|
| 478 |
+
binary_masks = masks_dilated_ori[0, neighbor_ids, :, :, :].cpu().permute(
|
| 479 |
+
0, 2, 3, 1).numpy().astype(np.uint8) # use original mask
|
| 480 |
+
for i in range(len(neighbor_ids)):
|
| 481 |
+
idx = neighbor_ids[i]
|
| 482 |
+
img = np.array(pred_img[i]).astype(np.uint8) * binary_masks[i] \
|
| 483 |
+
+ ori_frames_inp[idx] * (1 - binary_masks[i])
|
| 484 |
+
if comp_frames[idx] is None:
|
| 485 |
+
comp_frames[idx] = img
|
| 486 |
+
else:
|
| 487 |
+
comp_frames[idx] = comp_frames[idx].astype(np.float32) * 0.5 + img.astype(np.float32) * 0.5
|
| 488 |
+
|
| 489 |
+
comp_frames[idx] = comp_frames[idx].astype(np.uint8)
|
| 490 |
+
|
| 491 |
+
torch.cuda.empty_cache()
|
| 492 |
+
|
| 493 |
+
##save composed video##
|
| 494 |
+
comp_frames = [cv2.resize(f, out_size) for f in comp_frames]
|
| 495 |
+
writer = cv2.VideoWriter(output_path, cv2.VideoWriter_fourcc(*"mp4v"),
|
| 496 |
+
fps, (comp_frames[0].shape[1],comp_frames[0].shape[0]))
|
| 497 |
+
for f in range(video_length):
|
| 498 |
+
frame = comp_frames[f].astype(np.uint8)
|
| 499 |
+
writer.write(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
|
| 500 |
+
writer.release()
|
| 501 |
+
|
| 502 |
+
torch.cuda.empty_cache()
|
| 503 |
+
|
| 504 |
+
return output_path
|
| 505 |
+
|
| 506 |
+
|
| 507 |
+
|
| 508 |
+
if __name__ == '__main__':
|
| 509 |
+
|
| 510 |
+
device = get_device()
|
| 511 |
+
propainter_model_dir = "weights/propainter"
|
| 512 |
+
propainter = Propainter(propainter_model_dir, device=device)
|
| 513 |
+
|
| 514 |
+
video = "examples/example1/video.mp4"
|
| 515 |
+
mask = "examples/example1/mask.mp4"
|
| 516 |
+
output = "results/priori.mp4"
|
| 517 |
+
res = propainter.forward(video, mask, output)
|
| 518 |
+
|
| 519 |
+
|
| 520 |
+
|
propainter/model/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
propainter/model/canny/canny_filter.py
ADDED
|
@@ -0,0 +1,256 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from typing import Tuple
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
from .gaussian import gaussian_blur2d
|
| 9 |
+
from .kernels import get_canny_nms_kernel, get_hysteresis_kernel
|
| 10 |
+
from .sobel import spatial_gradient
|
| 11 |
+
|
| 12 |
+
def rgb_to_grayscale(image, rgb_weights = None):
|
| 13 |
+
if len(image.shape) < 3 or image.shape[-3] != 3:
|
| 14 |
+
raise ValueError(f"Input size must have a shape of (*, 3, H, W). Got {image.shape}")
|
| 15 |
+
|
| 16 |
+
if rgb_weights is None:
|
| 17 |
+
# 8 bit images
|
| 18 |
+
if image.dtype == torch.uint8:
|
| 19 |
+
rgb_weights = torch.tensor([76, 150, 29], device=image.device, dtype=torch.uint8)
|
| 20 |
+
# floating point images
|
| 21 |
+
elif image.dtype in (torch.float16, torch.float32, torch.float64):
|
| 22 |
+
rgb_weights = torch.tensor([0.299, 0.587, 0.114], device=image.device, dtype=image.dtype)
|
| 23 |
+
else:
|
| 24 |
+
raise TypeError(f"Unknown data type: {image.dtype}")
|
| 25 |
+
else:
|
| 26 |
+
# is tensor that we make sure is in the same device/dtype
|
| 27 |
+
rgb_weights = rgb_weights.to(image)
|
| 28 |
+
|
| 29 |
+
# unpack the color image channels with RGB order
|
| 30 |
+
r = image[..., 0:1, :, :]
|
| 31 |
+
g = image[..., 1:2, :, :]
|
| 32 |
+
b = image[..., 2:3, :, :]
|
| 33 |
+
|
| 34 |
+
w_r, w_g, w_b = rgb_weights.unbind()
|
| 35 |
+
return w_r * r + w_g * g + w_b * b
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def canny(
|
| 39 |
+
input: torch.Tensor,
|
| 40 |
+
low_threshold: float = 0.1,
|
| 41 |
+
high_threshold: float = 0.2,
|
| 42 |
+
kernel_size: Tuple[int, int] = (5, 5),
|
| 43 |
+
sigma: Tuple[float, float] = (1, 1),
|
| 44 |
+
hysteresis: bool = True,
|
| 45 |
+
eps: float = 1e-6,
|
| 46 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 47 |
+
r"""Find edges of the input image and filters them using the Canny algorithm.
|
| 48 |
+
|
| 49 |
+
.. image:: _static/img/canny.png
|
| 50 |
+
|
| 51 |
+
Args:
|
| 52 |
+
input: input image tensor with shape :math:`(B,C,H,W)`.
|
| 53 |
+
low_threshold: lower threshold for the hysteresis procedure.
|
| 54 |
+
high_threshold: upper threshold for the hysteresis procedure.
|
| 55 |
+
kernel_size: the size of the kernel for the gaussian blur.
|
| 56 |
+
sigma: the standard deviation of the kernel for the gaussian blur.
|
| 57 |
+
hysteresis: if True, applies the hysteresis edge tracking.
|
| 58 |
+
Otherwise, the edges are divided between weak (0.5) and strong (1) edges.
|
| 59 |
+
eps: regularization number to avoid NaN during backprop.
|
| 60 |
+
|
| 61 |
+
Returns:
|
| 62 |
+
- the canny edge magnitudes map, shape of :math:`(B,1,H,W)`.
|
| 63 |
+
- the canny edge detection filtered by thresholds and hysteresis, shape of :math:`(B,1,H,W)`.
|
| 64 |
+
|
| 65 |
+
.. note::
|
| 66 |
+
See a working example `here <https://kornia-tutorials.readthedocs.io/en/latest/
|
| 67 |
+
canny.html>`__.
|
| 68 |
+
|
| 69 |
+
Example:
|
| 70 |
+
>>> input = torch.rand(5, 3, 4, 4)
|
| 71 |
+
>>> magnitude, edges = canny(input) # 5x3x4x4
|
| 72 |
+
>>> magnitude.shape
|
| 73 |
+
torch.Size([5, 1, 4, 4])
|
| 74 |
+
>>> edges.shape
|
| 75 |
+
torch.Size([5, 1, 4, 4])
|
| 76 |
+
"""
|
| 77 |
+
if not isinstance(input, torch.Tensor):
|
| 78 |
+
raise TypeError(f"Input type is not a torch.Tensor. Got {type(input)}")
|
| 79 |
+
|
| 80 |
+
if not len(input.shape) == 4:
|
| 81 |
+
raise ValueError(f"Invalid input shape, we expect BxCxHxW. Got: {input.shape}")
|
| 82 |
+
|
| 83 |
+
if low_threshold > high_threshold:
|
| 84 |
+
raise ValueError(
|
| 85 |
+
"Invalid input thresholds. low_threshold should be smaller than the high_threshold. Got: {}>{}".format(
|
| 86 |
+
low_threshold, high_threshold
|
| 87 |
+
)
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
if low_threshold < 0 and low_threshold > 1:
|
| 91 |
+
raise ValueError(f"Invalid input threshold. low_threshold should be in range (0,1). Got: {low_threshold}")
|
| 92 |
+
|
| 93 |
+
if high_threshold < 0 and high_threshold > 1:
|
| 94 |
+
raise ValueError(f"Invalid input threshold. high_threshold should be in range (0,1). Got: {high_threshold}")
|
| 95 |
+
|
| 96 |
+
device: torch.device = input.device
|
| 97 |
+
dtype: torch.dtype = input.dtype
|
| 98 |
+
|
| 99 |
+
# To Grayscale
|
| 100 |
+
if input.shape[1] == 3:
|
| 101 |
+
input = rgb_to_grayscale(input)
|
| 102 |
+
|
| 103 |
+
# Gaussian filter
|
| 104 |
+
blurred: torch.Tensor = gaussian_blur2d(input, kernel_size, sigma)
|
| 105 |
+
|
| 106 |
+
# Compute the gradients
|
| 107 |
+
gradients: torch.Tensor = spatial_gradient(blurred, normalized=False)
|
| 108 |
+
|
| 109 |
+
# Unpack the edges
|
| 110 |
+
gx: torch.Tensor = gradients[:, :, 0]
|
| 111 |
+
gy: torch.Tensor = gradients[:, :, 1]
|
| 112 |
+
|
| 113 |
+
# Compute gradient magnitude and angle
|
| 114 |
+
magnitude: torch.Tensor = torch.sqrt(gx * gx + gy * gy + eps)
|
| 115 |
+
angle: torch.Tensor = torch.atan2(gy, gx)
|
| 116 |
+
|
| 117 |
+
# Radians to Degrees
|
| 118 |
+
angle = 180.0 * angle / math.pi
|
| 119 |
+
|
| 120 |
+
# Round angle to the nearest 45 degree
|
| 121 |
+
angle = torch.round(angle / 45) * 45
|
| 122 |
+
|
| 123 |
+
# Non-maximal suppression
|
| 124 |
+
nms_kernels: torch.Tensor = get_canny_nms_kernel(device, dtype)
|
| 125 |
+
nms_magnitude: torch.Tensor = F.conv2d(magnitude, nms_kernels, padding=nms_kernels.shape[-1] // 2)
|
| 126 |
+
|
| 127 |
+
# Get the indices for both directions
|
| 128 |
+
positive_idx: torch.Tensor = (angle / 45) % 8
|
| 129 |
+
positive_idx = positive_idx.long()
|
| 130 |
+
|
| 131 |
+
negative_idx: torch.Tensor = ((angle / 45) + 4) % 8
|
| 132 |
+
negative_idx = negative_idx.long()
|
| 133 |
+
|
| 134 |
+
# Apply the non-maximum suppression to the different directions
|
| 135 |
+
channel_select_filtered_positive: torch.Tensor = torch.gather(nms_magnitude, 1, positive_idx)
|
| 136 |
+
channel_select_filtered_negative: torch.Tensor = torch.gather(nms_magnitude, 1, negative_idx)
|
| 137 |
+
|
| 138 |
+
channel_select_filtered: torch.Tensor = torch.stack(
|
| 139 |
+
[channel_select_filtered_positive, channel_select_filtered_negative], 1
|
| 140 |
+
)
|
| 141 |
+
|
| 142 |
+
is_max: torch.Tensor = channel_select_filtered.min(dim=1)[0] > 0.0
|
| 143 |
+
|
| 144 |
+
magnitude = magnitude * is_max
|
| 145 |
+
|
| 146 |
+
# Threshold
|
| 147 |
+
edges: torch.Tensor = F.threshold(magnitude, low_threshold, 0.0)
|
| 148 |
+
|
| 149 |
+
low: torch.Tensor = magnitude > low_threshold
|
| 150 |
+
high: torch.Tensor = magnitude > high_threshold
|
| 151 |
+
|
| 152 |
+
edges = low * 0.5 + high * 0.5
|
| 153 |
+
edges = edges.to(dtype)
|
| 154 |
+
|
| 155 |
+
# Hysteresis
|
| 156 |
+
if hysteresis:
|
| 157 |
+
edges_old: torch.Tensor = -torch.ones(edges.shape, device=edges.device, dtype=dtype)
|
| 158 |
+
hysteresis_kernels: torch.Tensor = get_hysteresis_kernel(device, dtype)
|
| 159 |
+
|
| 160 |
+
while ((edges_old - edges).abs() != 0).any():
|
| 161 |
+
weak: torch.Tensor = (edges == 0.5).float()
|
| 162 |
+
strong: torch.Tensor = (edges == 1).float()
|
| 163 |
+
|
| 164 |
+
hysteresis_magnitude: torch.Tensor = F.conv2d(
|
| 165 |
+
edges, hysteresis_kernels, padding=hysteresis_kernels.shape[-1] // 2
|
| 166 |
+
)
|
| 167 |
+
hysteresis_magnitude = (hysteresis_magnitude == 1).any(1, keepdim=True).to(dtype)
|
| 168 |
+
hysteresis_magnitude = hysteresis_magnitude * weak + strong
|
| 169 |
+
|
| 170 |
+
edges_old = edges.clone()
|
| 171 |
+
edges = hysteresis_magnitude + (hysteresis_magnitude == 0) * weak * 0.5
|
| 172 |
+
|
| 173 |
+
edges = hysteresis_magnitude
|
| 174 |
+
|
| 175 |
+
return magnitude, edges
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
class Canny(nn.Module):
|
| 179 |
+
r"""Module that finds edges of the input image and filters them using the Canny algorithm.
|
| 180 |
+
|
| 181 |
+
Args:
|
| 182 |
+
input: input image tensor with shape :math:`(B,C,H,W)`.
|
| 183 |
+
low_threshold: lower threshold for the hysteresis procedure.
|
| 184 |
+
high_threshold: upper threshold for the hysteresis procedure.
|
| 185 |
+
kernel_size: the size of the kernel for the gaussian blur.
|
| 186 |
+
sigma: the standard deviation of the kernel for the gaussian blur.
|
| 187 |
+
hysteresis: if True, applies the hysteresis edge tracking.
|
| 188 |
+
Otherwise, the edges are divided between weak (0.5) and strong (1) edges.
|
| 189 |
+
eps: regularization number to avoid NaN during backprop.
|
| 190 |
+
|
| 191 |
+
Returns:
|
| 192 |
+
- the canny edge magnitudes map, shape of :math:`(B,1,H,W)`.
|
| 193 |
+
- the canny edge detection filtered by thresholds and hysteresis, shape of :math:`(B,1,H,W)`.
|
| 194 |
+
|
| 195 |
+
Example:
|
| 196 |
+
>>> input = torch.rand(5, 3, 4, 4)
|
| 197 |
+
>>> magnitude, edges = Canny()(input) # 5x3x4x4
|
| 198 |
+
>>> magnitude.shape
|
| 199 |
+
torch.Size([5, 1, 4, 4])
|
| 200 |
+
>>> edges.shape
|
| 201 |
+
torch.Size([5, 1, 4, 4])
|
| 202 |
+
"""
|
| 203 |
+
|
| 204 |
+
def __init__(
|
| 205 |
+
self,
|
| 206 |
+
low_threshold: float = 0.1,
|
| 207 |
+
high_threshold: float = 0.2,
|
| 208 |
+
kernel_size: Tuple[int, int] = (5, 5),
|
| 209 |
+
sigma: Tuple[float, float] = (1, 1),
|
| 210 |
+
hysteresis: bool = True,
|
| 211 |
+
eps: float = 1e-6,
|
| 212 |
+
) -> None:
|
| 213 |
+
super().__init__()
|
| 214 |
+
|
| 215 |
+
if low_threshold > high_threshold:
|
| 216 |
+
raise ValueError(
|
| 217 |
+
"Invalid input thresholds. low_threshold should be\
|
| 218 |
+
smaller than the high_threshold. Got: {}>{}".format(
|
| 219 |
+
low_threshold, high_threshold
|
| 220 |
+
)
|
| 221 |
+
)
|
| 222 |
+
|
| 223 |
+
if low_threshold < 0 or low_threshold > 1:
|
| 224 |
+
raise ValueError(f"Invalid input threshold. low_threshold should be in range (0,1). Got: {low_threshold}")
|
| 225 |
+
|
| 226 |
+
if high_threshold < 0 or high_threshold > 1:
|
| 227 |
+
raise ValueError(f"Invalid input threshold. high_threshold should be in range (0,1). Got: {high_threshold}")
|
| 228 |
+
|
| 229 |
+
# Gaussian blur parameters
|
| 230 |
+
self.kernel_size = kernel_size
|
| 231 |
+
self.sigma = sigma
|
| 232 |
+
|
| 233 |
+
# Double threshold
|
| 234 |
+
self.low_threshold = low_threshold
|
| 235 |
+
self.high_threshold = high_threshold
|
| 236 |
+
|
| 237 |
+
# Hysteresis
|
| 238 |
+
self.hysteresis = hysteresis
|
| 239 |
+
|
| 240 |
+
self.eps: float = eps
|
| 241 |
+
|
| 242 |
+
def __repr__(self) -> str:
|
| 243 |
+
return ''.join(
|
| 244 |
+
(
|
| 245 |
+
f'{type(self).__name__}(',
|
| 246 |
+
', '.join(
|
| 247 |
+
f'{name}={getattr(self, name)}' for name in sorted(self.__dict__) if not name.startswith('_')
|
| 248 |
+
),
|
| 249 |
+
')',
|
| 250 |
+
)
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
def forward(self, input: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 254 |
+
return canny(
|
| 255 |
+
input, self.low_threshold, self.high_threshold, self.kernel_size, self.sigma, self.hysteresis, self.eps
|
| 256 |
+
)
|
propainter/model/canny/filter.py
ADDED
|
@@ -0,0 +1,288 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
|
| 6 |
+
from .kernels import normalize_kernel2d
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def _compute_padding(kernel_size: List[int]) -> List[int]:
|
| 10 |
+
"""Compute padding tuple."""
|
| 11 |
+
# 4 or 6 ints: (padding_left, padding_right,padding_top,padding_bottom)
|
| 12 |
+
# https://pytorch.org/docs/stable/nn.html#torch.nn.functional.pad
|
| 13 |
+
if len(kernel_size) < 2:
|
| 14 |
+
raise AssertionError(kernel_size)
|
| 15 |
+
computed = [k - 1 for k in kernel_size]
|
| 16 |
+
|
| 17 |
+
# for even kernels we need to do asymmetric padding :(
|
| 18 |
+
out_padding = 2 * len(kernel_size) * [0]
|
| 19 |
+
|
| 20 |
+
for i in range(len(kernel_size)):
|
| 21 |
+
computed_tmp = computed[-(i + 1)]
|
| 22 |
+
|
| 23 |
+
pad_front = computed_tmp // 2
|
| 24 |
+
pad_rear = computed_tmp - pad_front
|
| 25 |
+
|
| 26 |
+
out_padding[2 * i + 0] = pad_front
|
| 27 |
+
out_padding[2 * i + 1] = pad_rear
|
| 28 |
+
|
| 29 |
+
return out_padding
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def filter2d(
|
| 33 |
+
input: torch.Tensor,
|
| 34 |
+
kernel: torch.Tensor,
|
| 35 |
+
border_type: str = 'reflect',
|
| 36 |
+
normalized: bool = False,
|
| 37 |
+
padding: str = 'same',
|
| 38 |
+
) -> torch.Tensor:
|
| 39 |
+
r"""Convolve a tensor with a 2d kernel.
|
| 40 |
+
|
| 41 |
+
The function applies a given kernel to a tensor. The kernel is applied
|
| 42 |
+
independently at each depth channel of the tensor. Before applying the
|
| 43 |
+
kernel, the function applies padding according to the specified mode so
|
| 44 |
+
that the output remains in the same shape.
|
| 45 |
+
|
| 46 |
+
Args:
|
| 47 |
+
input: the input tensor with shape of
|
| 48 |
+
:math:`(B, C, H, W)`.
|
| 49 |
+
kernel: the kernel to be convolved with the input
|
| 50 |
+
tensor. The kernel shape must be :math:`(1, kH, kW)` or :math:`(B, kH, kW)`.
|
| 51 |
+
border_type: the padding mode to be applied before convolving.
|
| 52 |
+
The expected modes are: ``'constant'``, ``'reflect'``,
|
| 53 |
+
``'replicate'`` or ``'circular'``.
|
| 54 |
+
normalized: If True, kernel will be L1 normalized.
|
| 55 |
+
padding: This defines the type of padding.
|
| 56 |
+
2 modes available ``'same'`` or ``'valid'``.
|
| 57 |
+
|
| 58 |
+
Return:
|
| 59 |
+
torch.Tensor: the convolved tensor of same size and numbers of channels
|
| 60 |
+
as the input with shape :math:`(B, C, H, W)`.
|
| 61 |
+
|
| 62 |
+
Example:
|
| 63 |
+
>>> input = torch.tensor([[[
|
| 64 |
+
... [0., 0., 0., 0., 0.],
|
| 65 |
+
... [0., 0., 0., 0., 0.],
|
| 66 |
+
... [0., 0., 5., 0., 0.],
|
| 67 |
+
... [0., 0., 0., 0., 0.],
|
| 68 |
+
... [0., 0., 0., 0., 0.],]]])
|
| 69 |
+
>>> kernel = torch.ones(1, 3, 3)
|
| 70 |
+
>>> filter2d(input, kernel, padding='same')
|
| 71 |
+
tensor([[[[0., 0., 0., 0., 0.],
|
| 72 |
+
[0., 5., 5., 5., 0.],
|
| 73 |
+
[0., 5., 5., 5., 0.],
|
| 74 |
+
[0., 5., 5., 5., 0.],
|
| 75 |
+
[0., 0., 0., 0., 0.]]]])
|
| 76 |
+
"""
|
| 77 |
+
if not isinstance(input, torch.Tensor):
|
| 78 |
+
raise TypeError(f"Input input is not torch.Tensor. Got {type(input)}")
|
| 79 |
+
|
| 80 |
+
if not isinstance(kernel, torch.Tensor):
|
| 81 |
+
raise TypeError(f"Input kernel is not torch.Tensor. Got {type(kernel)}")
|
| 82 |
+
|
| 83 |
+
if not isinstance(border_type, str):
|
| 84 |
+
raise TypeError(f"Input border_type is not string. Got {type(border_type)}")
|
| 85 |
+
|
| 86 |
+
if border_type not in ['constant', 'reflect', 'replicate', 'circular']:
|
| 87 |
+
raise ValueError(
|
| 88 |
+
f"Invalid border type, we expect 'constant', \
|
| 89 |
+
'reflect', 'replicate', 'circular'. Got:{border_type}"
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
if not isinstance(padding, str):
|
| 93 |
+
raise TypeError(f"Input padding is not string. Got {type(padding)}")
|
| 94 |
+
|
| 95 |
+
if padding not in ['valid', 'same']:
|
| 96 |
+
raise ValueError(f"Invalid padding mode, we expect 'valid' or 'same'. Got: {padding}")
|
| 97 |
+
|
| 98 |
+
if not len(input.shape) == 4:
|
| 99 |
+
raise ValueError(f"Invalid input shape, we expect BxCxHxW. Got: {input.shape}")
|
| 100 |
+
|
| 101 |
+
if (not len(kernel.shape) == 3) and not ((kernel.shape[0] == 0) or (kernel.shape[0] == input.shape[0])):
|
| 102 |
+
raise ValueError(f"Invalid kernel shape, we expect 1xHxW or BxHxW. Got: {kernel.shape}")
|
| 103 |
+
|
| 104 |
+
# prepare kernel
|
| 105 |
+
b, c, h, w = input.shape
|
| 106 |
+
tmp_kernel: torch.Tensor = kernel.unsqueeze(1).to(input)
|
| 107 |
+
|
| 108 |
+
if normalized:
|
| 109 |
+
tmp_kernel = normalize_kernel2d(tmp_kernel)
|
| 110 |
+
|
| 111 |
+
tmp_kernel = tmp_kernel.expand(-1, c, -1, -1)
|
| 112 |
+
|
| 113 |
+
height, width = tmp_kernel.shape[-2:]
|
| 114 |
+
|
| 115 |
+
# pad the input tensor
|
| 116 |
+
if padding == 'same':
|
| 117 |
+
padding_shape: List[int] = _compute_padding([height, width])
|
| 118 |
+
input = F.pad(input, padding_shape, mode=border_type)
|
| 119 |
+
|
| 120 |
+
# kernel and input tensor reshape to align element-wise or batch-wise params
|
| 121 |
+
tmp_kernel = tmp_kernel.reshape(-1, 1, height, width)
|
| 122 |
+
input = input.view(-1, tmp_kernel.size(0), input.size(-2), input.size(-1))
|
| 123 |
+
|
| 124 |
+
# convolve the tensor with the kernel.
|
| 125 |
+
output = F.conv2d(input, tmp_kernel, groups=tmp_kernel.size(0), padding=0, stride=1)
|
| 126 |
+
|
| 127 |
+
if padding == 'same':
|
| 128 |
+
out = output.view(b, c, h, w)
|
| 129 |
+
else:
|
| 130 |
+
out = output.view(b, c, h - height + 1, w - width + 1)
|
| 131 |
+
|
| 132 |
+
return out
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def filter2d_separable(
|
| 136 |
+
input: torch.Tensor,
|
| 137 |
+
kernel_x: torch.Tensor,
|
| 138 |
+
kernel_y: torch.Tensor,
|
| 139 |
+
border_type: str = 'reflect',
|
| 140 |
+
normalized: bool = False,
|
| 141 |
+
padding: str = 'same',
|
| 142 |
+
) -> torch.Tensor:
|
| 143 |
+
r"""Convolve a tensor with two 1d kernels, in x and y directions.
|
| 144 |
+
|
| 145 |
+
The function applies a given kernel to a tensor. The kernel is applied
|
| 146 |
+
independently at each depth channel of the tensor. Before applying the
|
| 147 |
+
kernel, the function applies padding according to the specified mode so
|
| 148 |
+
that the output remains in the same shape.
|
| 149 |
+
|
| 150 |
+
Args:
|
| 151 |
+
input: the input tensor with shape of
|
| 152 |
+
:math:`(B, C, H, W)`.
|
| 153 |
+
kernel_x: the kernel to be convolved with the input
|
| 154 |
+
tensor. The kernel shape must be :math:`(1, kW)` or :math:`(B, kW)`.
|
| 155 |
+
kernel_y: the kernel to be convolved with the input
|
| 156 |
+
tensor. The kernel shape must be :math:`(1, kH)` or :math:`(B, kH)`.
|
| 157 |
+
border_type: the padding mode to be applied before convolving.
|
| 158 |
+
The expected modes are: ``'constant'``, ``'reflect'``,
|
| 159 |
+
``'replicate'`` or ``'circular'``.
|
| 160 |
+
normalized: If True, kernel will be L1 normalized.
|
| 161 |
+
padding: This defines the type of padding.
|
| 162 |
+
2 modes available ``'same'`` or ``'valid'``.
|
| 163 |
+
|
| 164 |
+
Return:
|
| 165 |
+
torch.Tensor: the convolved tensor of same size and numbers of channels
|
| 166 |
+
as the input with shape :math:`(B, C, H, W)`.
|
| 167 |
+
|
| 168 |
+
Example:
|
| 169 |
+
>>> input = torch.tensor([[[
|
| 170 |
+
... [0., 0., 0., 0., 0.],
|
| 171 |
+
... [0., 0., 0., 0., 0.],
|
| 172 |
+
... [0., 0., 5., 0., 0.],
|
| 173 |
+
... [0., 0., 0., 0., 0.],
|
| 174 |
+
... [0., 0., 0., 0., 0.],]]])
|
| 175 |
+
>>> kernel = torch.ones(1, 3)
|
| 176 |
+
|
| 177 |
+
>>> filter2d_separable(input, kernel, kernel, padding='same')
|
| 178 |
+
tensor([[[[0., 0., 0., 0., 0.],
|
| 179 |
+
[0., 5., 5., 5., 0.],
|
| 180 |
+
[0., 5., 5., 5., 0.],
|
| 181 |
+
[0., 5., 5., 5., 0.],
|
| 182 |
+
[0., 0., 0., 0., 0.]]]])
|
| 183 |
+
"""
|
| 184 |
+
out_x = filter2d(input, kernel_x.unsqueeze(0), border_type, normalized, padding)
|
| 185 |
+
out = filter2d(out_x, kernel_y.unsqueeze(-1), border_type, normalized, padding)
|
| 186 |
+
return out
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
def filter3d(
|
| 190 |
+
input: torch.Tensor, kernel: torch.Tensor, border_type: str = 'replicate', normalized: bool = False
|
| 191 |
+
) -> torch.Tensor:
|
| 192 |
+
r"""Convolve a tensor with a 3d kernel.
|
| 193 |
+
|
| 194 |
+
The function applies a given kernel to a tensor. The kernel is applied
|
| 195 |
+
independently at each depth channel of the tensor. Before applying the
|
| 196 |
+
kernel, the function applies padding according to the specified mode so
|
| 197 |
+
that the output remains in the same shape.
|
| 198 |
+
|
| 199 |
+
Args:
|
| 200 |
+
input: the input tensor with shape of
|
| 201 |
+
:math:`(B, C, D, H, W)`.
|
| 202 |
+
kernel: the kernel to be convolved with the input
|
| 203 |
+
tensor. The kernel shape must be :math:`(1, kD, kH, kW)` or :math:`(B, kD, kH, kW)`.
|
| 204 |
+
border_type: the padding mode to be applied before convolving.
|
| 205 |
+
The expected modes are: ``'constant'``,
|
| 206 |
+
``'replicate'`` or ``'circular'``.
|
| 207 |
+
normalized: If True, kernel will be L1 normalized.
|
| 208 |
+
|
| 209 |
+
Return:
|
| 210 |
+
the convolved tensor of same size and numbers of channels
|
| 211 |
+
as the input with shape :math:`(B, C, D, H, W)`.
|
| 212 |
+
|
| 213 |
+
Example:
|
| 214 |
+
>>> input = torch.tensor([[[
|
| 215 |
+
... [[0., 0., 0., 0., 0.],
|
| 216 |
+
... [0., 0., 0., 0., 0.],
|
| 217 |
+
... [0., 0., 0., 0., 0.],
|
| 218 |
+
... [0., 0., 0., 0., 0.],
|
| 219 |
+
... [0., 0., 0., 0., 0.]],
|
| 220 |
+
... [[0., 0., 0., 0., 0.],
|
| 221 |
+
... [0., 0., 0., 0., 0.],
|
| 222 |
+
... [0., 0., 5., 0., 0.],
|
| 223 |
+
... [0., 0., 0., 0., 0.],
|
| 224 |
+
... [0., 0., 0., 0., 0.]],
|
| 225 |
+
... [[0., 0., 0., 0., 0.],
|
| 226 |
+
... [0., 0., 0., 0., 0.],
|
| 227 |
+
... [0., 0., 0., 0., 0.],
|
| 228 |
+
... [0., 0., 0., 0., 0.],
|
| 229 |
+
... [0., 0., 0., 0., 0.]]
|
| 230 |
+
... ]]])
|
| 231 |
+
>>> kernel = torch.ones(1, 3, 3, 3)
|
| 232 |
+
>>> filter3d(input, kernel)
|
| 233 |
+
tensor([[[[[0., 0., 0., 0., 0.],
|
| 234 |
+
[0., 5., 5., 5., 0.],
|
| 235 |
+
[0., 5., 5., 5., 0.],
|
| 236 |
+
[0., 5., 5., 5., 0.],
|
| 237 |
+
[0., 0., 0., 0., 0.]],
|
| 238 |
+
<BLANKLINE>
|
| 239 |
+
[[0., 0., 0., 0., 0.],
|
| 240 |
+
[0., 5., 5., 5., 0.],
|
| 241 |
+
[0., 5., 5., 5., 0.],
|
| 242 |
+
[0., 5., 5., 5., 0.],
|
| 243 |
+
[0., 0., 0., 0., 0.]],
|
| 244 |
+
<BLANKLINE>
|
| 245 |
+
[[0., 0., 0., 0., 0.],
|
| 246 |
+
[0., 5., 5., 5., 0.],
|
| 247 |
+
[0., 5., 5., 5., 0.],
|
| 248 |
+
[0., 5., 5., 5., 0.],
|
| 249 |
+
[0., 0., 0., 0., 0.]]]]])
|
| 250 |
+
"""
|
| 251 |
+
if not isinstance(input, torch.Tensor):
|
| 252 |
+
raise TypeError(f"Input border_type is not torch.Tensor. Got {type(input)}")
|
| 253 |
+
|
| 254 |
+
if not isinstance(kernel, torch.Tensor):
|
| 255 |
+
raise TypeError(f"Input border_type is not torch.Tensor. Got {type(kernel)}")
|
| 256 |
+
|
| 257 |
+
if not isinstance(border_type, str):
|
| 258 |
+
raise TypeError(f"Input border_type is not string. Got {type(kernel)}")
|
| 259 |
+
|
| 260 |
+
if not len(input.shape) == 5:
|
| 261 |
+
raise ValueError(f"Invalid input shape, we expect BxCxDxHxW. Got: {input.shape}")
|
| 262 |
+
|
| 263 |
+
if not len(kernel.shape) == 4 and kernel.shape[0] != 1:
|
| 264 |
+
raise ValueError(f"Invalid kernel shape, we expect 1xDxHxW. Got: {kernel.shape}")
|
| 265 |
+
|
| 266 |
+
# prepare kernel
|
| 267 |
+
b, c, d, h, w = input.shape
|
| 268 |
+
tmp_kernel: torch.Tensor = kernel.unsqueeze(1).to(input)
|
| 269 |
+
|
| 270 |
+
if normalized:
|
| 271 |
+
bk, dk, hk, wk = kernel.shape
|
| 272 |
+
tmp_kernel = normalize_kernel2d(tmp_kernel.view(bk, dk, hk * wk)).view_as(tmp_kernel)
|
| 273 |
+
|
| 274 |
+
tmp_kernel = tmp_kernel.expand(-1, c, -1, -1, -1)
|
| 275 |
+
|
| 276 |
+
# pad the input tensor
|
| 277 |
+
depth, height, width = tmp_kernel.shape[-3:]
|
| 278 |
+
padding_shape: List[int] = _compute_padding([depth, height, width])
|
| 279 |
+
input_pad: torch.Tensor = F.pad(input, padding_shape, mode=border_type)
|
| 280 |
+
|
| 281 |
+
# kernel and input tensor reshape to align element-wise or batch-wise params
|
| 282 |
+
tmp_kernel = tmp_kernel.reshape(-1, 1, depth, height, width)
|
| 283 |
+
input_pad = input_pad.view(-1, tmp_kernel.size(0), input_pad.size(-3), input_pad.size(-2), input_pad.size(-1))
|
| 284 |
+
|
| 285 |
+
# convolve the tensor with the kernel.
|
| 286 |
+
output = F.conv3d(input_pad, tmp_kernel, groups=tmp_kernel.size(0), padding=0, stride=1)
|
| 287 |
+
|
| 288 |
+
return output.view(b, c, d, h, w)
|
propainter/model/canny/gaussian.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Tuple
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
|
| 6 |
+
from .filter import filter2d, filter2d_separable
|
| 7 |
+
from .kernels import get_gaussian_kernel1d, get_gaussian_kernel2d
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def gaussian_blur2d(
|
| 11 |
+
input: torch.Tensor,
|
| 12 |
+
kernel_size: Tuple[int, int],
|
| 13 |
+
sigma: Tuple[float, float],
|
| 14 |
+
border_type: str = 'reflect',
|
| 15 |
+
separable: bool = True,
|
| 16 |
+
) -> torch.Tensor:
|
| 17 |
+
r"""Create an operator that blurs a tensor using a Gaussian filter.
|
| 18 |
+
|
| 19 |
+
.. image:: _static/img/gaussian_blur2d.png
|
| 20 |
+
|
| 21 |
+
The operator smooths the given tensor with a gaussian kernel by convolving
|
| 22 |
+
it to each channel. It supports batched operation.
|
| 23 |
+
|
| 24 |
+
Arguments:
|
| 25 |
+
input: the input tensor with shape :math:`(B,C,H,W)`.
|
| 26 |
+
kernel_size: the size of the kernel.
|
| 27 |
+
sigma: the standard deviation of the kernel.
|
| 28 |
+
border_type: the padding mode to be applied before convolving.
|
| 29 |
+
The expected modes are: ``'constant'``, ``'reflect'``,
|
| 30 |
+
``'replicate'`` or ``'circular'``. Default: ``'reflect'``.
|
| 31 |
+
separable: run as composition of two 1d-convolutions.
|
| 32 |
+
|
| 33 |
+
Returns:
|
| 34 |
+
the blurred tensor with shape :math:`(B, C, H, W)`.
|
| 35 |
+
|
| 36 |
+
.. note::
|
| 37 |
+
See a working example `here <https://kornia-tutorials.readthedocs.io/en/latest/
|
| 38 |
+
gaussian_blur.html>`__.
|
| 39 |
+
|
| 40 |
+
Examples:
|
| 41 |
+
>>> input = torch.rand(2, 4, 5, 5)
|
| 42 |
+
>>> output = gaussian_blur2d(input, (3, 3), (1.5, 1.5))
|
| 43 |
+
>>> output.shape
|
| 44 |
+
torch.Size([2, 4, 5, 5])
|
| 45 |
+
"""
|
| 46 |
+
if separable:
|
| 47 |
+
kernel_x: torch.Tensor = get_gaussian_kernel1d(kernel_size[1], sigma[1])
|
| 48 |
+
kernel_y: torch.Tensor = get_gaussian_kernel1d(kernel_size[0], sigma[0])
|
| 49 |
+
out = filter2d_separable(input, kernel_x[None], kernel_y[None], border_type)
|
| 50 |
+
else:
|
| 51 |
+
kernel: torch.Tensor = get_gaussian_kernel2d(kernel_size, sigma)
|
| 52 |
+
out = filter2d(input, kernel[None], border_type)
|
| 53 |
+
return out
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class GaussianBlur2d(nn.Module):
|
| 57 |
+
r"""Create an operator that blurs a tensor using a Gaussian filter.
|
| 58 |
+
|
| 59 |
+
The operator smooths the given tensor with a gaussian kernel by convolving
|
| 60 |
+
it to each channel. It supports batched operation.
|
| 61 |
+
|
| 62 |
+
Arguments:
|
| 63 |
+
kernel_size: the size of the kernel.
|
| 64 |
+
sigma: the standard deviation of the kernel.
|
| 65 |
+
border_type: the padding mode to be applied before convolving.
|
| 66 |
+
The expected modes are: ``'constant'``, ``'reflect'``,
|
| 67 |
+
``'replicate'`` or ``'circular'``. Default: ``'reflect'``.
|
| 68 |
+
separable: run as composition of two 1d-convolutions.
|
| 69 |
+
|
| 70 |
+
Returns:
|
| 71 |
+
the blurred tensor.
|
| 72 |
+
|
| 73 |
+
Shape:
|
| 74 |
+
- Input: :math:`(B, C, H, W)`
|
| 75 |
+
- Output: :math:`(B, C, H, W)`
|
| 76 |
+
|
| 77 |
+
Examples::
|
| 78 |
+
|
| 79 |
+
>>> input = torch.rand(2, 4, 5, 5)
|
| 80 |
+
>>> gauss = GaussianBlur2d((3, 3), (1.5, 1.5))
|
| 81 |
+
>>> output = gauss(input) # 2x4x5x5
|
| 82 |
+
>>> output.shape
|
| 83 |
+
torch.Size([2, 4, 5, 5])
|
| 84 |
+
"""
|
| 85 |
+
|
| 86 |
+
def __init__(
|
| 87 |
+
self,
|
| 88 |
+
kernel_size: Tuple[int, int],
|
| 89 |
+
sigma: Tuple[float, float],
|
| 90 |
+
border_type: str = 'reflect',
|
| 91 |
+
separable: bool = True,
|
| 92 |
+
) -> None:
|
| 93 |
+
super().__init__()
|
| 94 |
+
self.kernel_size: Tuple[int, int] = kernel_size
|
| 95 |
+
self.sigma: Tuple[float, float] = sigma
|
| 96 |
+
self.border_type = border_type
|
| 97 |
+
self.separable = separable
|
| 98 |
+
|
| 99 |
+
def __repr__(self) -> str:
|
| 100 |
+
return (
|
| 101 |
+
self.__class__.__name__
|
| 102 |
+
+ '(kernel_size='
|
| 103 |
+
+ str(self.kernel_size)
|
| 104 |
+
+ ', '
|
| 105 |
+
+ 'sigma='
|
| 106 |
+
+ str(self.sigma)
|
| 107 |
+
+ ', '
|
| 108 |
+
+ 'border_type='
|
| 109 |
+
+ self.border_type
|
| 110 |
+
+ 'separable='
|
| 111 |
+
+ str(self.separable)
|
| 112 |
+
+ ')'
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
def forward(self, input: torch.Tensor) -> torch.Tensor:
|
| 116 |
+
return gaussian_blur2d(input, self.kernel_size, self.sigma, self.border_type, self.separable)
|
propainter/model/canny/kernels.py
ADDED
|
@@ -0,0 +1,690 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from math import sqrt
|
| 3 |
+
from typing import List, Optional, Tuple
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def normalize_kernel2d(input: torch.Tensor) -> torch.Tensor:
|
| 9 |
+
r"""Normalize both derivative and smoothing kernel."""
|
| 10 |
+
if len(input.size()) < 2:
|
| 11 |
+
raise TypeError(f"input should be at least 2D tensor. Got {input.size()}")
|
| 12 |
+
norm: torch.Tensor = input.abs().sum(dim=-1).sum(dim=-1)
|
| 13 |
+
return input / (norm.unsqueeze(-1).unsqueeze(-1))
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def gaussian(window_size: int, sigma: float) -> torch.Tensor:
|
| 17 |
+
device, dtype = None, None
|
| 18 |
+
if isinstance(sigma, torch.Tensor):
|
| 19 |
+
device, dtype = sigma.device, sigma.dtype
|
| 20 |
+
x = torch.arange(window_size, device=device, dtype=dtype) - window_size // 2
|
| 21 |
+
if window_size % 2 == 0:
|
| 22 |
+
x = x + 0.5
|
| 23 |
+
|
| 24 |
+
gauss = torch.exp((-x.pow(2.0) / (2 * sigma**2)).float())
|
| 25 |
+
return gauss / gauss.sum()
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def gaussian_discrete_erf(window_size: int, sigma) -> torch.Tensor:
|
| 29 |
+
r"""Discrete Gaussian by interpolating the error function.
|
| 30 |
+
|
| 31 |
+
Adapted from:
|
| 32 |
+
https://github.com/Project-MONAI/MONAI/blob/master/monai/networks/layers/convutils.py
|
| 33 |
+
"""
|
| 34 |
+
device = sigma.device if isinstance(sigma, torch.Tensor) else None
|
| 35 |
+
sigma = torch.as_tensor(sigma, dtype=torch.float, device=device)
|
| 36 |
+
x = torch.arange(window_size).float() - window_size // 2
|
| 37 |
+
t = 0.70710678 / torch.abs(sigma)
|
| 38 |
+
gauss = 0.5 * ((t * (x + 0.5)).erf() - (t * (x - 0.5)).erf())
|
| 39 |
+
gauss = gauss.clamp(min=0)
|
| 40 |
+
return gauss / gauss.sum()
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def _modified_bessel_0(x: torch.Tensor) -> torch.Tensor:
|
| 44 |
+
r"""Adapted from:
|
| 45 |
+
|
| 46 |
+
https://github.com/Project-MONAI/MONAI/blob/master/monai/networks/layers/convutils.py
|
| 47 |
+
"""
|
| 48 |
+
if torch.abs(x) < 3.75:
|
| 49 |
+
y = (x / 3.75) * (x / 3.75)
|
| 50 |
+
return 1.0 + y * (
|
| 51 |
+
3.5156229 + y * (3.0899424 + y * (1.2067492 + y * (0.2659732 + y * (0.360768e-1 + y * 0.45813e-2))))
|
| 52 |
+
)
|
| 53 |
+
ax = torch.abs(x)
|
| 54 |
+
y = 3.75 / ax
|
| 55 |
+
ans = 0.916281e-2 + y * (-0.2057706e-1 + y * (0.2635537e-1 + y * (-0.1647633e-1 + y * 0.392377e-2)))
|
| 56 |
+
coef = 0.39894228 + y * (0.1328592e-1 + y * (0.225319e-2 + y * (-0.157565e-2 + y * ans)))
|
| 57 |
+
return (torch.exp(ax) / torch.sqrt(ax)) * coef
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def _modified_bessel_1(x: torch.Tensor) -> torch.Tensor:
|
| 61 |
+
r"""adapted from:
|
| 62 |
+
|
| 63 |
+
https://github.com/Project-MONAI/MONAI/blob/master/monai/networks/layers/convutils.py
|
| 64 |
+
"""
|
| 65 |
+
if torch.abs(x) < 3.75:
|
| 66 |
+
y = (x / 3.75) * (x / 3.75)
|
| 67 |
+
ans = 0.51498869 + y * (0.15084934 + y * (0.2658733e-1 + y * (0.301532e-2 + y * 0.32411e-3)))
|
| 68 |
+
return torch.abs(x) * (0.5 + y * (0.87890594 + y * ans))
|
| 69 |
+
ax = torch.abs(x)
|
| 70 |
+
y = 3.75 / ax
|
| 71 |
+
ans = 0.2282967e-1 + y * (-0.2895312e-1 + y * (0.1787654e-1 - y * 0.420059e-2))
|
| 72 |
+
ans = 0.39894228 + y * (-0.3988024e-1 + y * (-0.362018e-2 + y * (0.163801e-2 + y * (-0.1031555e-1 + y * ans))))
|
| 73 |
+
ans = ans * torch.exp(ax) / torch.sqrt(ax)
|
| 74 |
+
return -ans if x < 0.0 else ans
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def _modified_bessel_i(n: int, x: torch.Tensor) -> torch.Tensor:
|
| 78 |
+
r"""adapted from:
|
| 79 |
+
|
| 80 |
+
https://github.com/Project-MONAI/MONAI/blob/master/monai/networks/layers/convutils.py
|
| 81 |
+
"""
|
| 82 |
+
if n < 2:
|
| 83 |
+
raise ValueError("n must be greater than 1.")
|
| 84 |
+
if x == 0.0:
|
| 85 |
+
return x
|
| 86 |
+
device = x.device
|
| 87 |
+
tox = 2.0 / torch.abs(x)
|
| 88 |
+
ans = torch.tensor(0.0, device=device)
|
| 89 |
+
bip = torch.tensor(0.0, device=device)
|
| 90 |
+
bi = torch.tensor(1.0, device=device)
|
| 91 |
+
m = int(2 * (n + int(sqrt(40.0 * n))))
|
| 92 |
+
for j in range(m, 0, -1):
|
| 93 |
+
bim = bip + float(j) * tox * bi
|
| 94 |
+
bip = bi
|
| 95 |
+
bi = bim
|
| 96 |
+
if abs(bi) > 1.0e10:
|
| 97 |
+
ans = ans * 1.0e-10
|
| 98 |
+
bi = bi * 1.0e-10
|
| 99 |
+
bip = bip * 1.0e-10
|
| 100 |
+
if j == n:
|
| 101 |
+
ans = bip
|
| 102 |
+
ans = ans * _modified_bessel_0(x) / bi
|
| 103 |
+
return -ans if x < 0.0 and (n % 2) == 1 else ans
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def gaussian_discrete(window_size, sigma) -> torch.Tensor:
|
| 107 |
+
r"""Discrete Gaussian kernel based on the modified Bessel functions.
|
| 108 |
+
|
| 109 |
+
Adapted from:
|
| 110 |
+
https://github.com/Project-MONAI/MONAI/blob/master/monai/networks/layers/convutils.py
|
| 111 |
+
"""
|
| 112 |
+
device = sigma.device if isinstance(sigma, torch.Tensor) else None
|
| 113 |
+
sigma = torch.as_tensor(sigma, dtype=torch.float, device=device)
|
| 114 |
+
sigma2 = sigma * sigma
|
| 115 |
+
tail = int(window_size // 2)
|
| 116 |
+
out_pos: List[Optional[torch.Tensor]] = [None] * (tail + 1)
|
| 117 |
+
out_pos[0] = _modified_bessel_0(sigma2)
|
| 118 |
+
out_pos[1] = _modified_bessel_1(sigma2)
|
| 119 |
+
for k in range(2, len(out_pos)):
|
| 120 |
+
out_pos[k] = _modified_bessel_i(k, sigma2)
|
| 121 |
+
out = out_pos[:0:-1]
|
| 122 |
+
out.extend(out_pos)
|
| 123 |
+
out = torch.stack(out) * torch.exp(sigma2) # type: ignore
|
| 124 |
+
return out / out.sum() # type: ignore
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def laplacian_1d(window_size) -> torch.Tensor:
|
| 128 |
+
r"""One could also use the Laplacian of Gaussian formula to design the filter."""
|
| 129 |
+
|
| 130 |
+
filter_1d = torch.ones(window_size)
|
| 131 |
+
filter_1d[window_size // 2] = 1 - window_size
|
| 132 |
+
laplacian_1d: torch.Tensor = filter_1d
|
| 133 |
+
return laplacian_1d
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def get_box_kernel2d(kernel_size: Tuple[int, int]) -> torch.Tensor:
|
| 137 |
+
r"""Utility function that returns a box filter."""
|
| 138 |
+
kx: float = float(kernel_size[0])
|
| 139 |
+
ky: float = float(kernel_size[1])
|
| 140 |
+
scale: torch.Tensor = torch.tensor(1.0) / torch.tensor([kx * ky])
|
| 141 |
+
tmp_kernel: torch.Tensor = torch.ones(1, kernel_size[0], kernel_size[1])
|
| 142 |
+
return scale.to(tmp_kernel.dtype) * tmp_kernel
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def get_binary_kernel2d(window_size: Tuple[int, int]) -> torch.Tensor:
|
| 146 |
+
r"""Create a binary kernel to extract the patches.
|
| 147 |
+
|
| 148 |
+
If the window size is HxW will create a (H*W)xHxW kernel.
|
| 149 |
+
"""
|
| 150 |
+
window_range: int = window_size[0] * window_size[1]
|
| 151 |
+
kernel: torch.Tensor = torch.zeros(window_range, window_range)
|
| 152 |
+
for i in range(window_range):
|
| 153 |
+
kernel[i, i] += 1.0
|
| 154 |
+
return kernel.view(window_range, 1, window_size[0], window_size[1])
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def get_sobel_kernel_3x3() -> torch.Tensor:
|
| 158 |
+
"""Utility function that returns a sobel kernel of 3x3."""
|
| 159 |
+
return torch.tensor([[-1.0, 0.0, 1.0], [-2.0, 0.0, 2.0], [-1.0, 0.0, 1.0]])
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def get_sobel_kernel_5x5_2nd_order() -> torch.Tensor:
|
| 163 |
+
"""Utility function that returns a 2nd order sobel kernel of 5x5."""
|
| 164 |
+
return torch.tensor(
|
| 165 |
+
[
|
| 166 |
+
[-1.0, 0.0, 2.0, 0.0, -1.0],
|
| 167 |
+
[-4.0, 0.0, 8.0, 0.0, -4.0],
|
| 168 |
+
[-6.0, 0.0, 12.0, 0.0, -6.0],
|
| 169 |
+
[-4.0, 0.0, 8.0, 0.0, -4.0],
|
| 170 |
+
[-1.0, 0.0, 2.0, 0.0, -1.0],
|
| 171 |
+
]
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def _get_sobel_kernel_5x5_2nd_order_xy() -> torch.Tensor:
|
| 176 |
+
"""Utility function that returns a 2nd order sobel kernel of 5x5."""
|
| 177 |
+
return torch.tensor(
|
| 178 |
+
[
|
| 179 |
+
[-1.0, -2.0, 0.0, 2.0, 1.0],
|
| 180 |
+
[-2.0, -4.0, 0.0, 4.0, 2.0],
|
| 181 |
+
[0.0, 0.0, 0.0, 0.0, 0.0],
|
| 182 |
+
[2.0, 4.0, 0.0, -4.0, -2.0],
|
| 183 |
+
[1.0, 2.0, 0.0, -2.0, -1.0],
|
| 184 |
+
]
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def get_diff_kernel_3x3() -> torch.Tensor:
|
| 189 |
+
"""Utility function that returns a first order derivative kernel of 3x3."""
|
| 190 |
+
return torch.tensor([[-0.0, 0.0, 0.0], [-1.0, 0.0, 1.0], [-0.0, 0.0, 0.0]])
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
def get_diff_kernel3d(device=torch.device('cpu'), dtype=torch.float) -> torch.Tensor:
|
| 194 |
+
"""Utility function that returns a first order derivative kernel of 3x3x3."""
|
| 195 |
+
kernel: torch.Tensor = torch.tensor(
|
| 196 |
+
[
|
| 197 |
+
[
|
| 198 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 199 |
+
[[0.0, 0.0, 0.0], [-0.5, 0.0, 0.5], [0.0, 0.0, 0.0]],
|
| 200 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 201 |
+
],
|
| 202 |
+
[
|
| 203 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 204 |
+
[[0.0, -0.5, 0.0], [0.0, 0.0, 0.0], [0.0, 0.5, 0.0]],
|
| 205 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 206 |
+
],
|
| 207 |
+
[
|
| 208 |
+
[[0.0, 0.0, 0.0], [0.0, -0.5, 0.0], [0.0, 0.0, 0.0]],
|
| 209 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 210 |
+
[[0.0, 0.0, 0.0], [0.0, 0.5, 0.0], [0.0, 0.0, 0.0]],
|
| 211 |
+
],
|
| 212 |
+
],
|
| 213 |
+
device=device,
|
| 214 |
+
dtype=dtype,
|
| 215 |
+
)
|
| 216 |
+
return kernel.unsqueeze(1)
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
def get_diff_kernel3d_2nd_order(device=torch.device('cpu'), dtype=torch.float) -> torch.Tensor:
|
| 220 |
+
"""Utility function that returns a first order derivative kernel of 3x3x3."""
|
| 221 |
+
kernel: torch.Tensor = torch.tensor(
|
| 222 |
+
[
|
| 223 |
+
[
|
| 224 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 225 |
+
[[0.0, 0.0, 0.0], [1.0, -2.0, 1.0], [0.0, 0.0, 0.0]],
|
| 226 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 227 |
+
],
|
| 228 |
+
[
|
| 229 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 230 |
+
[[0.0, 1.0, 0.0], [0.0, -2.0, 0.0], [0.0, 1.0, 0.0]],
|
| 231 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 232 |
+
],
|
| 233 |
+
[
|
| 234 |
+
[[0.0, 0.0, 0.0], [0.0, 1.0, 0.0], [0.0, 0.0, 0.0]],
|
| 235 |
+
[[0.0, 0.0, 0.0], [0.0, -2.0, 0.0], [0.0, 0.0, 0.0]],
|
| 236 |
+
[[0.0, 0.0, 0.0], [0.0, 1.0, 0.0], [0.0, 0.0, 0.0]],
|
| 237 |
+
],
|
| 238 |
+
[
|
| 239 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 240 |
+
[[1.0, 0.0, -1.0], [0.0, 0.0, 0.0], [-1.0, 0.0, 1.0]],
|
| 241 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 242 |
+
],
|
| 243 |
+
[
|
| 244 |
+
[[0.0, 1.0, 0.0], [0.0, 0.0, 0.0], [0.0, -1.0, 0.0]],
|
| 245 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 246 |
+
[[0.0, -1.0, 0.0], [0.0, 0.0, 0.0], [0.0, 1.0, 0.0]],
|
| 247 |
+
],
|
| 248 |
+
[
|
| 249 |
+
[[0.0, 0.0, 0.0], [1.0, 0.0, -1.0], [0.0, 0.0, 0.0]],
|
| 250 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 251 |
+
[[0.0, 0.0, 0.0], [-1.0, 0.0, 1.0], [0.0, 0.0, 0.0]],
|
| 252 |
+
],
|
| 253 |
+
],
|
| 254 |
+
device=device,
|
| 255 |
+
dtype=dtype,
|
| 256 |
+
)
|
| 257 |
+
return kernel.unsqueeze(1)
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
def get_sobel_kernel2d() -> torch.Tensor:
|
| 261 |
+
kernel_x: torch.Tensor = get_sobel_kernel_3x3()
|
| 262 |
+
kernel_y: torch.Tensor = kernel_x.transpose(0, 1)
|
| 263 |
+
return torch.stack([kernel_x, kernel_y])
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def get_diff_kernel2d() -> torch.Tensor:
|
| 267 |
+
kernel_x: torch.Tensor = get_diff_kernel_3x3()
|
| 268 |
+
kernel_y: torch.Tensor = kernel_x.transpose(0, 1)
|
| 269 |
+
return torch.stack([kernel_x, kernel_y])
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def get_sobel_kernel2d_2nd_order() -> torch.Tensor:
|
| 273 |
+
gxx: torch.Tensor = get_sobel_kernel_5x5_2nd_order()
|
| 274 |
+
gyy: torch.Tensor = gxx.transpose(0, 1)
|
| 275 |
+
gxy: torch.Tensor = _get_sobel_kernel_5x5_2nd_order_xy()
|
| 276 |
+
return torch.stack([gxx, gxy, gyy])
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
def get_diff_kernel2d_2nd_order() -> torch.Tensor:
|
| 280 |
+
gxx: torch.Tensor = torch.tensor([[0.0, 0.0, 0.0], [1.0, -2.0, 1.0], [0.0, 0.0, 0.0]])
|
| 281 |
+
gyy: torch.Tensor = gxx.transpose(0, 1)
|
| 282 |
+
gxy: torch.Tensor = torch.tensor([[-1.0, 0.0, 1.0], [0.0, 0.0, 0.0], [1.0, 0.0, -1.0]])
|
| 283 |
+
return torch.stack([gxx, gxy, gyy])
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
def get_spatial_gradient_kernel2d(mode: str, order: int) -> torch.Tensor:
|
| 287 |
+
r"""Function that returns kernel for 1st or 2nd order image gradients, using one of the following operators:
|
| 288 |
+
|
| 289 |
+
sobel, diff.
|
| 290 |
+
"""
|
| 291 |
+
if mode not in ['sobel', 'diff']:
|
| 292 |
+
raise TypeError(
|
| 293 |
+
"mode should be either sobel\
|
| 294 |
+
or diff. Got {}".format(
|
| 295 |
+
mode
|
| 296 |
+
)
|
| 297 |
+
)
|
| 298 |
+
if order not in [1, 2]:
|
| 299 |
+
raise TypeError(
|
| 300 |
+
"order should be either 1 or 2\
|
| 301 |
+
Got {}".format(
|
| 302 |
+
order
|
| 303 |
+
)
|
| 304 |
+
)
|
| 305 |
+
if mode == 'sobel' and order == 1:
|
| 306 |
+
kernel: torch.Tensor = get_sobel_kernel2d()
|
| 307 |
+
elif mode == 'sobel' and order == 2:
|
| 308 |
+
kernel = get_sobel_kernel2d_2nd_order()
|
| 309 |
+
elif mode == 'diff' and order == 1:
|
| 310 |
+
kernel = get_diff_kernel2d()
|
| 311 |
+
elif mode == 'diff' and order == 2:
|
| 312 |
+
kernel = get_diff_kernel2d_2nd_order()
|
| 313 |
+
else:
|
| 314 |
+
raise NotImplementedError("")
|
| 315 |
+
return kernel
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
def get_spatial_gradient_kernel3d(mode: str, order: int, device=torch.device('cpu'), dtype=torch.float) -> torch.Tensor:
|
| 319 |
+
r"""Function that returns kernel for 1st or 2nd order scale pyramid gradients, using one of the following
|
| 320 |
+
operators: sobel, diff."""
|
| 321 |
+
if mode not in ['sobel', 'diff']:
|
| 322 |
+
raise TypeError(
|
| 323 |
+
"mode should be either sobel\
|
| 324 |
+
or diff. Got {}".format(
|
| 325 |
+
mode
|
| 326 |
+
)
|
| 327 |
+
)
|
| 328 |
+
if order not in [1, 2]:
|
| 329 |
+
raise TypeError(
|
| 330 |
+
"order should be either 1 or 2\
|
| 331 |
+
Got {}".format(
|
| 332 |
+
order
|
| 333 |
+
)
|
| 334 |
+
)
|
| 335 |
+
if mode == 'sobel':
|
| 336 |
+
raise NotImplementedError("Sobel kernel for 3d gradient is not implemented yet")
|
| 337 |
+
if mode == 'diff' and order == 1:
|
| 338 |
+
kernel = get_diff_kernel3d(device, dtype)
|
| 339 |
+
elif mode == 'diff' and order == 2:
|
| 340 |
+
kernel = get_diff_kernel3d_2nd_order(device, dtype)
|
| 341 |
+
else:
|
| 342 |
+
raise NotImplementedError("")
|
| 343 |
+
return kernel
|
| 344 |
+
|
| 345 |
+
|
| 346 |
+
def get_gaussian_kernel1d(kernel_size: int, sigma: float, force_even: bool = False) -> torch.Tensor:
|
| 347 |
+
r"""Function that returns Gaussian filter coefficients.
|
| 348 |
+
|
| 349 |
+
Args:
|
| 350 |
+
kernel_size: filter size. It should be odd and positive.
|
| 351 |
+
sigma: gaussian standard deviation.
|
| 352 |
+
force_even: overrides requirement for odd kernel size.
|
| 353 |
+
|
| 354 |
+
Returns:
|
| 355 |
+
1D tensor with gaussian filter coefficients.
|
| 356 |
+
|
| 357 |
+
Shape:
|
| 358 |
+
- Output: :math:`(\text{kernel_size})`
|
| 359 |
+
|
| 360 |
+
Examples:
|
| 361 |
+
|
| 362 |
+
>>> get_gaussian_kernel1d(3, 2.5)
|
| 363 |
+
tensor([0.3243, 0.3513, 0.3243])
|
| 364 |
+
|
| 365 |
+
>>> get_gaussian_kernel1d(5, 1.5)
|
| 366 |
+
tensor([0.1201, 0.2339, 0.2921, 0.2339, 0.1201])
|
| 367 |
+
"""
|
| 368 |
+
if not isinstance(kernel_size, int) or ((kernel_size % 2 == 0) and not force_even) or (kernel_size <= 0):
|
| 369 |
+
raise TypeError("kernel_size must be an odd positive integer. " "Got {}".format(kernel_size))
|
| 370 |
+
window_1d: torch.Tensor = gaussian(kernel_size, sigma)
|
| 371 |
+
return window_1d
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
def get_gaussian_discrete_kernel1d(kernel_size: int, sigma: float, force_even: bool = False) -> torch.Tensor:
|
| 375 |
+
r"""Function that returns Gaussian filter coefficients based on the modified Bessel functions. Adapted from:
|
| 376 |
+
https://github.com/Project-MONAI/MONAI/blob/master/monai/networks/layers/convutils.py.
|
| 377 |
+
|
| 378 |
+
Args:
|
| 379 |
+
kernel_size: filter size. It should be odd and positive.
|
| 380 |
+
sigma: gaussian standard deviation.
|
| 381 |
+
force_even: overrides requirement for odd kernel size.
|
| 382 |
+
|
| 383 |
+
Returns:
|
| 384 |
+
1D tensor with gaussian filter coefficients.
|
| 385 |
+
|
| 386 |
+
Shape:
|
| 387 |
+
- Output: :math:`(\text{kernel_size})`
|
| 388 |
+
|
| 389 |
+
Examples:
|
| 390 |
+
|
| 391 |
+
>>> get_gaussian_discrete_kernel1d(3, 2.5)
|
| 392 |
+
tensor([0.3235, 0.3531, 0.3235])
|
| 393 |
+
|
| 394 |
+
>>> get_gaussian_discrete_kernel1d(5, 1.5)
|
| 395 |
+
tensor([0.1096, 0.2323, 0.3161, 0.2323, 0.1096])
|
| 396 |
+
"""
|
| 397 |
+
if not isinstance(kernel_size, int) or ((kernel_size % 2 == 0) and not force_even) or (kernel_size <= 0):
|
| 398 |
+
raise TypeError("kernel_size must be an odd positive integer. " "Got {}".format(kernel_size))
|
| 399 |
+
window_1d = gaussian_discrete(kernel_size, sigma)
|
| 400 |
+
return window_1d
|
| 401 |
+
|
| 402 |
+
|
| 403 |
+
def get_gaussian_erf_kernel1d(kernel_size: int, sigma: float, force_even: bool = False) -> torch.Tensor:
|
| 404 |
+
r"""Function that returns Gaussian filter coefficients by interpolating the error function, adapted from:
|
| 405 |
+
https://github.com/Project-MONAI/MONAI/blob/master/monai/networks/layers/convutils.py.
|
| 406 |
+
|
| 407 |
+
Args:
|
| 408 |
+
kernel_size: filter size. It should be odd and positive.
|
| 409 |
+
sigma: gaussian standard deviation.
|
| 410 |
+
force_even: overrides requirement for odd kernel size.
|
| 411 |
+
|
| 412 |
+
Returns:
|
| 413 |
+
1D tensor with gaussian filter coefficients.
|
| 414 |
+
|
| 415 |
+
Shape:
|
| 416 |
+
- Output: :math:`(\text{kernel_size})`
|
| 417 |
+
|
| 418 |
+
Examples:
|
| 419 |
+
|
| 420 |
+
>>> get_gaussian_erf_kernel1d(3, 2.5)
|
| 421 |
+
tensor([0.3245, 0.3511, 0.3245])
|
| 422 |
+
|
| 423 |
+
>>> get_gaussian_erf_kernel1d(5, 1.5)
|
| 424 |
+
tensor([0.1226, 0.2331, 0.2887, 0.2331, 0.1226])
|
| 425 |
+
"""
|
| 426 |
+
if not isinstance(kernel_size, int) or ((kernel_size % 2 == 0) and not force_even) or (kernel_size <= 0):
|
| 427 |
+
raise TypeError("kernel_size must be an odd positive integer. " "Got {}".format(kernel_size))
|
| 428 |
+
window_1d = gaussian_discrete_erf(kernel_size, sigma)
|
| 429 |
+
return window_1d
|
| 430 |
+
|
| 431 |
+
|
| 432 |
+
def get_gaussian_kernel2d(
|
| 433 |
+
kernel_size: Tuple[int, int], sigma: Tuple[float, float], force_even: bool = False
|
| 434 |
+
) -> torch.Tensor:
|
| 435 |
+
r"""Function that returns Gaussian filter matrix coefficients.
|
| 436 |
+
|
| 437 |
+
Args:
|
| 438 |
+
kernel_size: filter sizes in the x and y direction.
|
| 439 |
+
Sizes should be odd and positive.
|
| 440 |
+
sigma: gaussian standard deviation in the x and y
|
| 441 |
+
direction.
|
| 442 |
+
force_even: overrides requirement for odd kernel size.
|
| 443 |
+
|
| 444 |
+
Returns:
|
| 445 |
+
2D tensor with gaussian filter matrix coefficients.
|
| 446 |
+
|
| 447 |
+
Shape:
|
| 448 |
+
- Output: :math:`(\text{kernel_size}_x, \text{kernel_size}_y)`
|
| 449 |
+
|
| 450 |
+
Examples:
|
| 451 |
+
>>> get_gaussian_kernel2d((3, 3), (1.5, 1.5))
|
| 452 |
+
tensor([[0.0947, 0.1183, 0.0947],
|
| 453 |
+
[0.1183, 0.1478, 0.1183],
|
| 454 |
+
[0.0947, 0.1183, 0.0947]])
|
| 455 |
+
>>> get_gaussian_kernel2d((3, 5), (1.5, 1.5))
|
| 456 |
+
tensor([[0.0370, 0.0720, 0.0899, 0.0720, 0.0370],
|
| 457 |
+
[0.0462, 0.0899, 0.1123, 0.0899, 0.0462],
|
| 458 |
+
[0.0370, 0.0720, 0.0899, 0.0720, 0.0370]])
|
| 459 |
+
"""
|
| 460 |
+
if not isinstance(kernel_size, tuple) or len(kernel_size) != 2:
|
| 461 |
+
raise TypeError(f"kernel_size must be a tuple of length two. Got {kernel_size}")
|
| 462 |
+
if not isinstance(sigma, tuple) or len(sigma) != 2:
|
| 463 |
+
raise TypeError(f"sigma must be a tuple of length two. Got {sigma}")
|
| 464 |
+
ksize_x, ksize_y = kernel_size
|
| 465 |
+
sigma_x, sigma_y = sigma
|
| 466 |
+
kernel_x: torch.Tensor = get_gaussian_kernel1d(ksize_x, sigma_x, force_even)
|
| 467 |
+
kernel_y: torch.Tensor = get_gaussian_kernel1d(ksize_y, sigma_y, force_even)
|
| 468 |
+
kernel_2d: torch.Tensor = torch.matmul(kernel_x.unsqueeze(-1), kernel_y.unsqueeze(-1).t())
|
| 469 |
+
return kernel_2d
|
| 470 |
+
|
| 471 |
+
|
| 472 |
+
def get_laplacian_kernel1d(kernel_size: int) -> torch.Tensor:
|
| 473 |
+
r"""Function that returns the coefficients of a 1D Laplacian filter.
|
| 474 |
+
|
| 475 |
+
Args:
|
| 476 |
+
kernel_size: filter size. It should be odd and positive.
|
| 477 |
+
|
| 478 |
+
Returns:
|
| 479 |
+
1D tensor with laplacian filter coefficients.
|
| 480 |
+
|
| 481 |
+
Shape:
|
| 482 |
+
- Output: math:`(\text{kernel_size})`
|
| 483 |
+
|
| 484 |
+
Examples:
|
| 485 |
+
>>> get_laplacian_kernel1d(3)
|
| 486 |
+
tensor([ 1., -2., 1.])
|
| 487 |
+
>>> get_laplacian_kernel1d(5)
|
| 488 |
+
tensor([ 1., 1., -4., 1., 1.])
|
| 489 |
+
"""
|
| 490 |
+
if not isinstance(kernel_size, int) or kernel_size % 2 == 0 or kernel_size <= 0:
|
| 491 |
+
raise TypeError(f"ksize must be an odd positive integer. Got {kernel_size}")
|
| 492 |
+
window_1d: torch.Tensor = laplacian_1d(kernel_size)
|
| 493 |
+
return window_1d
|
| 494 |
+
|
| 495 |
+
|
| 496 |
+
def get_laplacian_kernel2d(kernel_size: int) -> torch.Tensor:
|
| 497 |
+
r"""Function that returns Gaussian filter matrix coefficients.
|
| 498 |
+
|
| 499 |
+
Args:
|
| 500 |
+
kernel_size: filter size should be odd.
|
| 501 |
+
|
| 502 |
+
Returns:
|
| 503 |
+
2D tensor with laplacian filter matrix coefficients.
|
| 504 |
+
|
| 505 |
+
Shape:
|
| 506 |
+
- Output: :math:`(\text{kernel_size}_x, \text{kernel_size}_y)`
|
| 507 |
+
|
| 508 |
+
Examples:
|
| 509 |
+
>>> get_laplacian_kernel2d(3)
|
| 510 |
+
tensor([[ 1., 1., 1.],
|
| 511 |
+
[ 1., -8., 1.],
|
| 512 |
+
[ 1., 1., 1.]])
|
| 513 |
+
>>> get_laplacian_kernel2d(5)
|
| 514 |
+
tensor([[ 1., 1., 1., 1., 1.],
|
| 515 |
+
[ 1., 1., 1., 1., 1.],
|
| 516 |
+
[ 1., 1., -24., 1., 1.],
|
| 517 |
+
[ 1., 1., 1., 1., 1.],
|
| 518 |
+
[ 1., 1., 1., 1., 1.]])
|
| 519 |
+
"""
|
| 520 |
+
if not isinstance(kernel_size, int) or kernel_size % 2 == 0 or kernel_size <= 0:
|
| 521 |
+
raise TypeError(f"ksize must be an odd positive integer. Got {kernel_size}")
|
| 522 |
+
|
| 523 |
+
kernel = torch.ones((kernel_size, kernel_size))
|
| 524 |
+
mid = kernel_size // 2
|
| 525 |
+
kernel[mid, mid] = 1 - kernel_size**2
|
| 526 |
+
kernel_2d: torch.Tensor = kernel
|
| 527 |
+
return kernel_2d
|
| 528 |
+
|
| 529 |
+
|
| 530 |
+
def get_pascal_kernel_2d(kernel_size: int, norm: bool = True) -> torch.Tensor:
|
| 531 |
+
"""Generate pascal filter kernel by kernel size.
|
| 532 |
+
|
| 533 |
+
Args:
|
| 534 |
+
kernel_size: height and width of the kernel.
|
| 535 |
+
norm: if to normalize the kernel or not. Default: True.
|
| 536 |
+
|
| 537 |
+
Returns:
|
| 538 |
+
kernel shaped as :math:`(kernel_size, kernel_size)`
|
| 539 |
+
|
| 540 |
+
Examples:
|
| 541 |
+
>>> get_pascal_kernel_2d(1)
|
| 542 |
+
tensor([[1.]])
|
| 543 |
+
>>> get_pascal_kernel_2d(4)
|
| 544 |
+
tensor([[0.0156, 0.0469, 0.0469, 0.0156],
|
| 545 |
+
[0.0469, 0.1406, 0.1406, 0.0469],
|
| 546 |
+
[0.0469, 0.1406, 0.1406, 0.0469],
|
| 547 |
+
[0.0156, 0.0469, 0.0469, 0.0156]])
|
| 548 |
+
>>> get_pascal_kernel_2d(4, norm=False)
|
| 549 |
+
tensor([[1., 3., 3., 1.],
|
| 550 |
+
[3., 9., 9., 3.],
|
| 551 |
+
[3., 9., 9., 3.],
|
| 552 |
+
[1., 3., 3., 1.]])
|
| 553 |
+
"""
|
| 554 |
+
a = get_pascal_kernel_1d(kernel_size)
|
| 555 |
+
|
| 556 |
+
filt = a[:, None] * a[None, :]
|
| 557 |
+
if norm:
|
| 558 |
+
filt = filt / torch.sum(filt)
|
| 559 |
+
return filt
|
| 560 |
+
|
| 561 |
+
|
| 562 |
+
def get_pascal_kernel_1d(kernel_size: int, norm: bool = False) -> torch.Tensor:
|
| 563 |
+
"""Generate Yang Hui triangle (Pascal's triangle) by a given number.
|
| 564 |
+
|
| 565 |
+
Args:
|
| 566 |
+
kernel_size: height and width of the kernel.
|
| 567 |
+
norm: if to normalize the kernel or not. Default: False.
|
| 568 |
+
|
| 569 |
+
Returns:
|
| 570 |
+
kernel shaped as :math:`(kernel_size,)`
|
| 571 |
+
|
| 572 |
+
Examples:
|
| 573 |
+
>>> get_pascal_kernel_1d(1)
|
| 574 |
+
tensor([1.])
|
| 575 |
+
>>> get_pascal_kernel_1d(2)
|
| 576 |
+
tensor([1., 1.])
|
| 577 |
+
>>> get_pascal_kernel_1d(3)
|
| 578 |
+
tensor([1., 2., 1.])
|
| 579 |
+
>>> get_pascal_kernel_1d(4)
|
| 580 |
+
tensor([1., 3., 3., 1.])
|
| 581 |
+
>>> get_pascal_kernel_1d(5)
|
| 582 |
+
tensor([1., 4., 6., 4., 1.])
|
| 583 |
+
>>> get_pascal_kernel_1d(6)
|
| 584 |
+
tensor([ 1., 5., 10., 10., 5., 1.])
|
| 585 |
+
"""
|
| 586 |
+
pre: List[float] = []
|
| 587 |
+
cur: List[float] = []
|
| 588 |
+
for i in range(kernel_size):
|
| 589 |
+
cur = [1.0] * (i + 1)
|
| 590 |
+
|
| 591 |
+
for j in range(1, i // 2 + 1):
|
| 592 |
+
value = pre[j - 1] + pre[j]
|
| 593 |
+
cur[j] = value
|
| 594 |
+
if i != 2 * j:
|
| 595 |
+
cur[-j - 1] = value
|
| 596 |
+
pre = cur
|
| 597 |
+
|
| 598 |
+
out = torch.as_tensor(cur)
|
| 599 |
+
if norm:
|
| 600 |
+
out = out / torch.sum(out)
|
| 601 |
+
return out
|
| 602 |
+
|
| 603 |
+
|
| 604 |
+
def get_canny_nms_kernel(device=torch.device('cpu'), dtype=torch.float) -> torch.Tensor:
|
| 605 |
+
"""Utility function that returns 3x3 kernels for the Canny Non-maximal suppression."""
|
| 606 |
+
kernel: torch.Tensor = torch.tensor(
|
| 607 |
+
[
|
| 608 |
+
[[0.0, 0.0, 0.0], [0.0, 1.0, -1.0], [0.0, 0.0, 0.0]],
|
| 609 |
+
[[0.0, 0.0, 0.0], [0.0, 1.0, 0.0], [0.0, 0.0, -1.0]],
|
| 610 |
+
[[0.0, 0.0, 0.0], [0.0, 1.0, 0.0], [0.0, -1.0, 0.0]],
|
| 611 |
+
[[0.0, 0.0, 0.0], [0.0, 1.0, 0.0], [-1.0, 0.0, 0.0]],
|
| 612 |
+
[[0.0, 0.0, 0.0], [-1.0, 1.0, 0.0], [0.0, 0.0, 0.0]],
|
| 613 |
+
[[-1.0, 0.0, 0.0], [0.0, 1.0, 0.0], [0.0, 0.0, 0.0]],
|
| 614 |
+
[[0.0, -1.0, 0.0], [0.0, 1.0, 0.0], [0.0, 0.0, 0.0]],
|
| 615 |
+
[[0.0, 0.0, -1.0], [0.0, 1.0, 0.0], [0.0, 0.0, 0.0]],
|
| 616 |
+
],
|
| 617 |
+
device=device,
|
| 618 |
+
dtype=dtype,
|
| 619 |
+
)
|
| 620 |
+
return kernel.unsqueeze(1)
|
| 621 |
+
|
| 622 |
+
|
| 623 |
+
def get_hysteresis_kernel(device=torch.device('cpu'), dtype=torch.float) -> torch.Tensor:
|
| 624 |
+
"""Utility function that returns the 3x3 kernels for the Canny hysteresis."""
|
| 625 |
+
kernel: torch.Tensor = torch.tensor(
|
| 626 |
+
[
|
| 627 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 1.0], [0.0, 0.0, 0.0]],
|
| 628 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 1.0]],
|
| 629 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 1.0, 0.0]],
|
| 630 |
+
[[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [1.0, 0.0, 0.0]],
|
| 631 |
+
[[0.0, 0.0, 0.0], [1.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 632 |
+
[[1.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 633 |
+
[[0.0, 1.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 634 |
+
[[0.0, 0.0, 1.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]],
|
| 635 |
+
],
|
| 636 |
+
device=device,
|
| 637 |
+
dtype=dtype,
|
| 638 |
+
)
|
| 639 |
+
return kernel.unsqueeze(1)
|
| 640 |
+
|
| 641 |
+
|
| 642 |
+
def get_hanning_kernel1d(kernel_size: int, device=torch.device('cpu'), dtype=torch.float) -> torch.Tensor:
|
| 643 |
+
r"""Returns Hanning (also known as Hann) kernel, used in signal processing and KCF tracker.
|
| 644 |
+
|
| 645 |
+
.. math:: w(n) = 0.5 - 0.5cos\\left(\\frac{2\\pi{n}}{M-1}\\right)
|
| 646 |
+
\\qquad 0 \\leq n \\leq M-1
|
| 647 |
+
|
| 648 |
+
See further in numpy docs https://numpy.org/doc/stable/reference/generated/numpy.hanning.html
|
| 649 |
+
|
| 650 |
+
Args:
|
| 651 |
+
kernel_size: The size the of the kernel. It should be positive.
|
| 652 |
+
|
| 653 |
+
Returns:
|
| 654 |
+
1D tensor with Hanning filter coefficients.
|
| 655 |
+
.. math:: w(n) = 0.5 - 0.5cos\\left(\\frac{2\\pi{n}}{M-1}\\right)
|
| 656 |
+
|
| 657 |
+
Shape:
|
| 658 |
+
- Output: math:`(\text{kernel_size})`
|
| 659 |
+
|
| 660 |
+
Examples:
|
| 661 |
+
>>> get_hanning_kernel1d(4)
|
| 662 |
+
tensor([0.0000, 0.7500, 0.7500, 0.0000])
|
| 663 |
+
"""
|
| 664 |
+
if not isinstance(kernel_size, int) or kernel_size <= 2:
|
| 665 |
+
raise TypeError(f"ksize must be an positive integer > 2. Got {kernel_size}")
|
| 666 |
+
|
| 667 |
+
x: torch.Tensor = torch.arange(kernel_size, device=device, dtype=dtype)
|
| 668 |
+
x = 0.5 - 0.5 * torch.cos(2.0 * math.pi * x / float(kernel_size - 1))
|
| 669 |
+
return x
|
| 670 |
+
|
| 671 |
+
|
| 672 |
+
def get_hanning_kernel2d(kernel_size: Tuple[int, int], device=torch.device('cpu'), dtype=torch.float) -> torch.Tensor:
|
| 673 |
+
r"""Returns 2d Hanning kernel, used in signal processing and KCF tracker.
|
| 674 |
+
|
| 675 |
+
Args:
|
| 676 |
+
kernel_size: The size of the kernel for the filter. It should be positive.
|
| 677 |
+
|
| 678 |
+
Returns:
|
| 679 |
+
2D tensor with Hanning filter coefficients.
|
| 680 |
+
.. math:: w(n) = 0.5 - 0.5cos\\left(\\frac{2\\pi{n}}{M-1}\\right)
|
| 681 |
+
|
| 682 |
+
Shape:
|
| 683 |
+
- Output: math:`(\text{kernel_size[0], kernel_size[1]})`
|
| 684 |
+
"""
|
| 685 |
+
if kernel_size[0] <= 2 or kernel_size[1] <= 2:
|
| 686 |
+
raise TypeError(f"ksize must be an tuple of positive integers > 2. Got {kernel_size}")
|
| 687 |
+
ky: torch.Tensor = get_hanning_kernel1d(kernel_size[0], device, dtype)[None].T
|
| 688 |
+
kx: torch.Tensor = get_hanning_kernel1d(kernel_size[1], device, dtype)[None]
|
| 689 |
+
kernel2d = ky @ kx
|
| 690 |
+
return kernel2d
|
propainter/model/canny/sobel.py
ADDED
|
@@ -0,0 +1,263 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
from .kernels import get_spatial_gradient_kernel2d, get_spatial_gradient_kernel3d, normalize_kernel2d
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def spatial_gradient(input: torch.Tensor, mode: str = 'sobel', order: int = 1, normalized: bool = True) -> torch.Tensor:
|
| 9 |
+
r"""Compute the first order image derivative in both x and y using a Sobel operator.
|
| 10 |
+
|
| 11 |
+
.. image:: _static/img/spatial_gradient.png
|
| 12 |
+
|
| 13 |
+
Args:
|
| 14 |
+
input: input image tensor with shape :math:`(B, C, H, W)`.
|
| 15 |
+
mode: derivatives modality, can be: `sobel` or `diff`.
|
| 16 |
+
order: the order of the derivatives.
|
| 17 |
+
normalized: whether the output is normalized.
|
| 18 |
+
|
| 19 |
+
Return:
|
| 20 |
+
the derivatives of the input feature map. with shape :math:`(B, C, 2, H, W)`.
|
| 21 |
+
|
| 22 |
+
.. note::
|
| 23 |
+
See a working example `here <https://kornia-tutorials.readthedocs.io/en/latest/
|
| 24 |
+
filtering_edges.html>`__.
|
| 25 |
+
|
| 26 |
+
Examples:
|
| 27 |
+
>>> input = torch.rand(1, 3, 4, 4)
|
| 28 |
+
>>> output = spatial_gradient(input) # 1x3x2x4x4
|
| 29 |
+
>>> output.shape
|
| 30 |
+
torch.Size([1, 3, 2, 4, 4])
|
| 31 |
+
"""
|
| 32 |
+
if not isinstance(input, torch.Tensor):
|
| 33 |
+
raise TypeError(f"Input type is not a torch.Tensor. Got {type(input)}")
|
| 34 |
+
|
| 35 |
+
if not len(input.shape) == 4:
|
| 36 |
+
raise ValueError(f"Invalid input shape, we expect BxCxHxW. Got: {input.shape}")
|
| 37 |
+
# allocate kernel
|
| 38 |
+
kernel: torch.Tensor = get_spatial_gradient_kernel2d(mode, order)
|
| 39 |
+
if normalized:
|
| 40 |
+
kernel = normalize_kernel2d(kernel)
|
| 41 |
+
|
| 42 |
+
# prepare kernel
|
| 43 |
+
b, c, h, w = input.shape
|
| 44 |
+
tmp_kernel: torch.Tensor = kernel.to(input).detach()
|
| 45 |
+
tmp_kernel = tmp_kernel.unsqueeze(1).unsqueeze(1)
|
| 46 |
+
|
| 47 |
+
# convolve input tensor with sobel kernel
|
| 48 |
+
kernel_flip: torch.Tensor = tmp_kernel.flip(-3)
|
| 49 |
+
|
| 50 |
+
# Pad with "replicate for spatial dims, but with zeros for channel
|
| 51 |
+
spatial_pad = [kernel.size(1) // 2, kernel.size(1) // 2, kernel.size(2) // 2, kernel.size(2) // 2]
|
| 52 |
+
out_channels: int = 3 if order == 2 else 2
|
| 53 |
+
padded_inp: torch.Tensor = F.pad(input.reshape(b * c, 1, h, w), spatial_pad, 'replicate')[:, :, None]
|
| 54 |
+
|
| 55 |
+
return F.conv3d(padded_inp, kernel_flip, padding=0).view(b, c, out_channels, h, w)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def spatial_gradient3d(input: torch.Tensor, mode: str = 'diff', order: int = 1) -> torch.Tensor:
|
| 59 |
+
r"""Compute the first and second order volume derivative in x, y and d using a diff operator.
|
| 60 |
+
|
| 61 |
+
Args:
|
| 62 |
+
input: input features tensor with shape :math:`(B, C, D, H, W)`.
|
| 63 |
+
mode: derivatives modality, can be: `sobel` or `diff`.
|
| 64 |
+
order: the order of the derivatives.
|
| 65 |
+
|
| 66 |
+
Return:
|
| 67 |
+
the spatial gradients of the input feature map with shape math:`(B, C, 3, D, H, W)`
|
| 68 |
+
or :math:`(B, C, 6, D, H, W)`.
|
| 69 |
+
|
| 70 |
+
Examples:
|
| 71 |
+
>>> input = torch.rand(1, 4, 2, 4, 4)
|
| 72 |
+
>>> output = spatial_gradient3d(input)
|
| 73 |
+
>>> output.shape
|
| 74 |
+
torch.Size([1, 4, 3, 2, 4, 4])
|
| 75 |
+
"""
|
| 76 |
+
if not isinstance(input, torch.Tensor):
|
| 77 |
+
raise TypeError(f"Input type is not a torch.Tensor. Got {type(input)}")
|
| 78 |
+
|
| 79 |
+
if not len(input.shape) == 5:
|
| 80 |
+
raise ValueError(f"Invalid input shape, we expect BxCxDxHxW. Got: {input.shape}")
|
| 81 |
+
b, c, d, h, w = input.shape
|
| 82 |
+
dev = input.device
|
| 83 |
+
dtype = input.dtype
|
| 84 |
+
if (mode == 'diff') and (order == 1):
|
| 85 |
+
# we go for the special case implementation due to conv3d bad speed
|
| 86 |
+
x: torch.Tensor = F.pad(input, 6 * [1], 'replicate')
|
| 87 |
+
center = slice(1, -1)
|
| 88 |
+
left = slice(0, -2)
|
| 89 |
+
right = slice(2, None)
|
| 90 |
+
out = torch.empty(b, c, 3, d, h, w, device=dev, dtype=dtype)
|
| 91 |
+
out[..., 0, :, :, :] = x[..., center, center, right] - x[..., center, center, left]
|
| 92 |
+
out[..., 1, :, :, :] = x[..., center, right, center] - x[..., center, left, center]
|
| 93 |
+
out[..., 2, :, :, :] = x[..., right, center, center] - x[..., left, center, center]
|
| 94 |
+
out = 0.5 * out
|
| 95 |
+
else:
|
| 96 |
+
# prepare kernel
|
| 97 |
+
# allocate kernel
|
| 98 |
+
kernel: torch.Tensor = get_spatial_gradient_kernel3d(mode, order)
|
| 99 |
+
|
| 100 |
+
tmp_kernel: torch.Tensor = kernel.to(input).detach()
|
| 101 |
+
tmp_kernel = tmp_kernel.repeat(c, 1, 1, 1, 1)
|
| 102 |
+
|
| 103 |
+
# convolve input tensor with grad kernel
|
| 104 |
+
kernel_flip: torch.Tensor = tmp_kernel.flip(-3)
|
| 105 |
+
|
| 106 |
+
# Pad with "replicate for spatial dims, but with zeros for channel
|
| 107 |
+
spatial_pad = [
|
| 108 |
+
kernel.size(2) // 2,
|
| 109 |
+
kernel.size(2) // 2,
|
| 110 |
+
kernel.size(3) // 2,
|
| 111 |
+
kernel.size(3) // 2,
|
| 112 |
+
kernel.size(4) // 2,
|
| 113 |
+
kernel.size(4) // 2,
|
| 114 |
+
]
|
| 115 |
+
out_ch: int = 6 if order == 2 else 3
|
| 116 |
+
out = F.conv3d(F.pad(input, spatial_pad, 'replicate'), kernel_flip, padding=0, groups=c).view(
|
| 117 |
+
b, c, out_ch, d, h, w
|
| 118 |
+
)
|
| 119 |
+
return out
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def sobel(input: torch.Tensor, normalized: bool = True, eps: float = 1e-6) -> torch.Tensor:
|
| 123 |
+
r"""Compute the Sobel operator and returns the magnitude per channel.
|
| 124 |
+
|
| 125 |
+
.. image:: _static/img/sobel.png
|
| 126 |
+
|
| 127 |
+
Args:
|
| 128 |
+
input: the input image with shape :math:`(B,C,H,W)`.
|
| 129 |
+
normalized: if True, L1 norm of the kernel is set to 1.
|
| 130 |
+
eps: regularization number to avoid NaN during backprop.
|
| 131 |
+
|
| 132 |
+
Return:
|
| 133 |
+
the sobel edge gradient magnitudes map with shape :math:`(B,C,H,W)`.
|
| 134 |
+
|
| 135 |
+
.. note::
|
| 136 |
+
See a working example `here <https://kornia-tutorials.readthedocs.io/en/latest/
|
| 137 |
+
filtering_edges.html>`__.
|
| 138 |
+
|
| 139 |
+
Example:
|
| 140 |
+
>>> input = torch.rand(1, 3, 4, 4)
|
| 141 |
+
>>> output = sobel(input) # 1x3x4x4
|
| 142 |
+
>>> output.shape
|
| 143 |
+
torch.Size([1, 3, 4, 4])
|
| 144 |
+
"""
|
| 145 |
+
if not isinstance(input, torch.Tensor):
|
| 146 |
+
raise TypeError(f"Input type is not a torch.Tensor. Got {type(input)}")
|
| 147 |
+
|
| 148 |
+
if not len(input.shape) == 4:
|
| 149 |
+
raise ValueError(f"Invalid input shape, we expect BxCxHxW. Got: {input.shape}")
|
| 150 |
+
|
| 151 |
+
# comput the x/y gradients
|
| 152 |
+
edges: torch.Tensor = spatial_gradient(input, normalized=normalized)
|
| 153 |
+
|
| 154 |
+
# unpack the edges
|
| 155 |
+
gx: torch.Tensor = edges[:, :, 0]
|
| 156 |
+
gy: torch.Tensor = edges[:, :, 1]
|
| 157 |
+
|
| 158 |
+
# compute gradient maginitude
|
| 159 |
+
magnitude: torch.Tensor = torch.sqrt(gx * gx + gy * gy + eps)
|
| 160 |
+
|
| 161 |
+
return magnitude
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
class SpatialGradient(nn.Module):
|
| 165 |
+
r"""Compute the first order image derivative in both x and y using a Sobel operator.
|
| 166 |
+
|
| 167 |
+
Args:
|
| 168 |
+
mode: derivatives modality, can be: `sobel` or `diff`.
|
| 169 |
+
order: the order of the derivatives.
|
| 170 |
+
normalized: whether the output is normalized.
|
| 171 |
+
|
| 172 |
+
Return:
|
| 173 |
+
the sobel edges of the input feature map.
|
| 174 |
+
|
| 175 |
+
Shape:
|
| 176 |
+
- Input: :math:`(B, C, H, W)`
|
| 177 |
+
- Output: :math:`(B, C, 2, H, W)`
|
| 178 |
+
|
| 179 |
+
Examples:
|
| 180 |
+
>>> input = torch.rand(1, 3, 4, 4)
|
| 181 |
+
>>> output = SpatialGradient()(input) # 1x3x2x4x4
|
| 182 |
+
"""
|
| 183 |
+
|
| 184 |
+
def __init__(self, mode: str = 'sobel', order: int = 1, normalized: bool = True) -> None:
|
| 185 |
+
super().__init__()
|
| 186 |
+
self.normalized: bool = normalized
|
| 187 |
+
self.order: int = order
|
| 188 |
+
self.mode: str = mode
|
| 189 |
+
|
| 190 |
+
def __repr__(self) -> str:
|
| 191 |
+
return (
|
| 192 |
+
self.__class__.__name__ + '('
|
| 193 |
+
'order=' + str(self.order) + ', ' + 'normalized=' + str(self.normalized) + ', ' + 'mode=' + self.mode + ')'
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
def forward(self, input: torch.Tensor) -> torch.Tensor:
|
| 197 |
+
return spatial_gradient(input, self.mode, self.order, self.normalized)
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
class SpatialGradient3d(nn.Module):
|
| 201 |
+
r"""Compute the first and second order volume derivative in x, y and d using a diff operator.
|
| 202 |
+
|
| 203 |
+
Args:
|
| 204 |
+
mode: derivatives modality, can be: `sobel` or `diff`.
|
| 205 |
+
order: the order of the derivatives.
|
| 206 |
+
|
| 207 |
+
Return:
|
| 208 |
+
the spatial gradients of the input feature map.
|
| 209 |
+
|
| 210 |
+
Shape:
|
| 211 |
+
- Input: :math:`(B, C, D, H, W)`. D, H, W are spatial dimensions, gradient is calculated w.r.t to them.
|
| 212 |
+
- Output: :math:`(B, C, 3, D, H, W)` or :math:`(B, C, 6, D, H, W)`
|
| 213 |
+
|
| 214 |
+
Examples:
|
| 215 |
+
>>> input = torch.rand(1, 4, 2, 4, 4)
|
| 216 |
+
>>> output = SpatialGradient3d()(input)
|
| 217 |
+
>>> output.shape
|
| 218 |
+
torch.Size([1, 4, 3, 2, 4, 4])
|
| 219 |
+
"""
|
| 220 |
+
|
| 221 |
+
def __init__(self, mode: str = 'diff', order: int = 1) -> None:
|
| 222 |
+
super().__init__()
|
| 223 |
+
self.order: int = order
|
| 224 |
+
self.mode: str = mode
|
| 225 |
+
self.kernel = get_spatial_gradient_kernel3d(mode, order)
|
| 226 |
+
return
|
| 227 |
+
|
| 228 |
+
def __repr__(self) -> str:
|
| 229 |
+
return self.__class__.__name__ + '(' 'order=' + str(self.order) + ', ' + 'mode=' + self.mode + ')'
|
| 230 |
+
|
| 231 |
+
def forward(self, input: torch.Tensor) -> torch.Tensor: # type: ignore
|
| 232 |
+
return spatial_gradient3d(input, self.mode, self.order)
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
class Sobel(nn.Module):
|
| 236 |
+
r"""Compute the Sobel operator and returns the magnitude per channel.
|
| 237 |
+
|
| 238 |
+
Args:
|
| 239 |
+
normalized: if True, L1 norm of the kernel is set to 1.
|
| 240 |
+
eps: regularization number to avoid NaN during backprop.
|
| 241 |
+
|
| 242 |
+
Return:
|
| 243 |
+
the sobel edge gradient magnitudes map.
|
| 244 |
+
|
| 245 |
+
Shape:
|
| 246 |
+
- Input: :math:`(B, C, H, W)`
|
| 247 |
+
- Output: :math:`(B, C, H, W)`
|
| 248 |
+
|
| 249 |
+
Examples:
|
| 250 |
+
>>> input = torch.rand(1, 3, 4, 4)
|
| 251 |
+
>>> output = Sobel()(input) # 1x3x4x4
|
| 252 |
+
"""
|
| 253 |
+
|
| 254 |
+
def __init__(self, normalized: bool = True, eps: float = 1e-6) -> None:
|
| 255 |
+
super().__init__()
|
| 256 |
+
self.normalized: bool = normalized
|
| 257 |
+
self.eps: float = eps
|
| 258 |
+
|
| 259 |
+
def __repr__(self) -> str:
|
| 260 |
+
return self.__class__.__name__ + '(' 'normalized=' + str(self.normalized) + ')'
|
| 261 |
+
|
| 262 |
+
def forward(self, input: torch.Tensor) -> torch.Tensor:
|
| 263 |
+
return sobel(input, self.normalized, self.eps)
|
propainter/model/misc.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import re
|
| 3 |
+
import random
|
| 4 |
+
import time
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import logging
|
| 8 |
+
import numpy as np
|
| 9 |
+
from os import path as osp
|
| 10 |
+
|
| 11 |
+
def constant_init(module, val, bias=0):
|
| 12 |
+
if hasattr(module, 'weight') and module.weight is not None:
|
| 13 |
+
nn.init.constant_(module.weight, val)
|
| 14 |
+
if hasattr(module, 'bias') and module.bias is not None:
|
| 15 |
+
nn.init.constant_(module.bias, bias)
|
| 16 |
+
|
| 17 |
+
initialized_logger = {}
|
| 18 |
+
def get_root_logger(logger_name='basicsr', log_level=logging.INFO, log_file=None):
|
| 19 |
+
"""Get the root logger.
|
| 20 |
+
The logger will be initialized if it has not been initialized. By default a
|
| 21 |
+
StreamHandler will be added. If `log_file` is specified, a FileHandler will
|
| 22 |
+
also be added.
|
| 23 |
+
Args:
|
| 24 |
+
logger_name (str): root logger name. Default: 'basicsr'.
|
| 25 |
+
log_file (str | None): The log filename. If specified, a FileHandler
|
| 26 |
+
will be added to the root logger.
|
| 27 |
+
log_level (int): The root logger level. Note that only the process of
|
| 28 |
+
rank 0 is affected, while other processes will set the level to
|
| 29 |
+
"Error" and be silent most of the time.
|
| 30 |
+
Returns:
|
| 31 |
+
logging.Logger: The root logger.
|
| 32 |
+
"""
|
| 33 |
+
logger = logging.getLogger(logger_name)
|
| 34 |
+
# if the logger has been initialized, just return it
|
| 35 |
+
if logger_name in initialized_logger:
|
| 36 |
+
return logger
|
| 37 |
+
|
| 38 |
+
format_str = '%(asctime)s %(levelname)s: %(message)s'
|
| 39 |
+
stream_handler = logging.StreamHandler()
|
| 40 |
+
stream_handler.setFormatter(logging.Formatter(format_str))
|
| 41 |
+
logger.addHandler(stream_handler)
|
| 42 |
+
logger.propagate = False
|
| 43 |
+
|
| 44 |
+
if log_file is not None:
|
| 45 |
+
logger.setLevel(log_level)
|
| 46 |
+
# add file handler
|
| 47 |
+
# file_handler = logging.FileHandler(log_file, 'w')
|
| 48 |
+
file_handler = logging.FileHandler(log_file, 'a') #Shangchen: keep the previous log
|
| 49 |
+
file_handler.setFormatter(logging.Formatter(format_str))
|
| 50 |
+
file_handler.setLevel(log_level)
|
| 51 |
+
logger.addHandler(file_handler)
|
| 52 |
+
initialized_logger[logger_name] = True
|
| 53 |
+
return logger
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
IS_HIGH_VERSION = [int(m) for m in list(re.findall(r"^([0-9]+)\.([0-9]+)\.([0-9]+)([^0-9][a-zA-Z0-9]*)?(\+git.*)?$",\
|
| 57 |
+
torch.__version__)[0][:3])] >= [1, 12, 0]
|
| 58 |
+
|
| 59 |
+
def gpu_is_available():
|
| 60 |
+
if IS_HIGH_VERSION:
|
| 61 |
+
if torch.backends.mps.is_available():
|
| 62 |
+
return True
|
| 63 |
+
return True if torch.cuda.is_available() and torch.backends.cudnn.is_available() else False
|
| 64 |
+
|
| 65 |
+
def get_device(gpu_id=None):
|
| 66 |
+
if gpu_id is None:
|
| 67 |
+
gpu_str = ''
|
| 68 |
+
elif isinstance(gpu_id, int):
|
| 69 |
+
gpu_str = f':{gpu_id}'
|
| 70 |
+
else:
|
| 71 |
+
raise TypeError('Input should be int value.')
|
| 72 |
+
|
| 73 |
+
if IS_HIGH_VERSION:
|
| 74 |
+
if torch.backends.mps.is_available():
|
| 75 |
+
return torch.device('mps'+gpu_str)
|
| 76 |
+
return torch.device('cuda'+gpu_str if torch.cuda.is_available() and torch.backends.cudnn.is_available() else 'cpu')
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def set_random_seed(seed):
|
| 80 |
+
"""Set random seeds."""
|
| 81 |
+
random.seed(seed)
|
| 82 |
+
np.random.seed(seed)
|
| 83 |
+
torch.manual_seed(seed)
|
| 84 |
+
torch.cuda.manual_seed(seed)
|
| 85 |
+
torch.cuda.manual_seed_all(seed)
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def get_time_str():
|
| 89 |
+
return time.strftime('%Y%m%d_%H%M%S', time.localtime())
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def scandir(dir_path, suffix=None, recursive=False, full_path=False):
|
| 93 |
+
"""Scan a directory to find the interested files.
|
| 94 |
+
|
| 95 |
+
Args:
|
| 96 |
+
dir_path (str): Path of the directory.
|
| 97 |
+
suffix (str | tuple(str), optional): File suffix that we are
|
| 98 |
+
interested in. Default: None.
|
| 99 |
+
recursive (bool, optional): If set to True, recursively scan the
|
| 100 |
+
directory. Default: False.
|
| 101 |
+
full_path (bool, optional): If set to True, include the dir_path.
|
| 102 |
+
Default: False.
|
| 103 |
+
|
| 104 |
+
Returns:
|
| 105 |
+
A generator for all the interested files with relative pathes.
|
| 106 |
+
"""
|
| 107 |
+
|
| 108 |
+
if (suffix is not None) and not isinstance(suffix, (str, tuple)):
|
| 109 |
+
raise TypeError('"suffix" must be a string or tuple of strings')
|
| 110 |
+
|
| 111 |
+
root = dir_path
|
| 112 |
+
|
| 113 |
+
def _scandir(dir_path, suffix, recursive):
|
| 114 |
+
for entry in os.scandir(dir_path):
|
| 115 |
+
if not entry.name.startswith('.') and entry.is_file():
|
| 116 |
+
if full_path:
|
| 117 |
+
return_path = entry.path
|
| 118 |
+
else:
|
| 119 |
+
return_path = osp.relpath(entry.path, root)
|
| 120 |
+
|
| 121 |
+
if suffix is None:
|
| 122 |
+
yield return_path
|
| 123 |
+
elif return_path.endswith(suffix):
|
| 124 |
+
yield return_path
|
| 125 |
+
else:
|
| 126 |
+
if recursive:
|
| 127 |
+
yield from _scandir(entry.path, suffix=suffix, recursive=recursive)
|
| 128 |
+
else:
|
| 129 |
+
continue
|
| 130 |
+
|
| 131 |
+
return _scandir(dir_path, suffix=suffix, recursive=recursive)
|
propainter/model/modules/base_module.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
from functools import reduce
|
| 6 |
+
|
| 7 |
+
class BaseNetwork(nn.Module):
|
| 8 |
+
def __init__(self):
|
| 9 |
+
super(BaseNetwork, self).__init__()
|
| 10 |
+
|
| 11 |
+
def print_network(self):
|
| 12 |
+
if isinstance(self, list):
|
| 13 |
+
self = self[0]
|
| 14 |
+
num_params = 0
|
| 15 |
+
for param in self.parameters():
|
| 16 |
+
num_params += param.numel()
|
| 17 |
+
print(
|
| 18 |
+
'Network [%s] was created. Total number of parameters: %.1f million. '
|
| 19 |
+
'To see the architecture, do print(network).' %
|
| 20 |
+
(type(self).__name__, num_params / 1000000))
|
| 21 |
+
|
| 22 |
+
def init_weights(self, init_type='normal', gain=0.02):
|
| 23 |
+
'''
|
| 24 |
+
initialize network's weights
|
| 25 |
+
init_type: normal | xavier | kaiming | orthogonal
|
| 26 |
+
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/9451e70673400885567d08a9e97ade2524c700d0/models/networks.py#L39
|
| 27 |
+
'''
|
| 28 |
+
def init_func(m):
|
| 29 |
+
classname = m.__class__.__name__
|
| 30 |
+
if classname.find('InstanceNorm2d') != -1:
|
| 31 |
+
if hasattr(m, 'weight') and m.weight is not None:
|
| 32 |
+
nn.init.constant_(m.weight.data, 1.0)
|
| 33 |
+
if hasattr(m, 'bias') and m.bias is not None:
|
| 34 |
+
nn.init.constant_(m.bias.data, 0.0)
|
| 35 |
+
elif hasattr(m, 'weight') and (classname.find('Conv') != -1
|
| 36 |
+
or classname.find('Linear') != -1):
|
| 37 |
+
if init_type == 'normal':
|
| 38 |
+
nn.init.normal_(m.weight.data, 0.0, gain)
|
| 39 |
+
elif init_type == 'xavier':
|
| 40 |
+
nn.init.xavier_normal_(m.weight.data, gain=gain)
|
| 41 |
+
elif init_type == 'xavier_uniform':
|
| 42 |
+
nn.init.xavier_uniform_(m.weight.data, gain=1.0)
|
| 43 |
+
elif init_type == 'kaiming':
|
| 44 |
+
nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
|
| 45 |
+
elif init_type == 'orthogonal':
|
| 46 |
+
nn.init.orthogonal_(m.weight.data, gain=gain)
|
| 47 |
+
elif init_type == 'none': # uses pytorch's default init method
|
| 48 |
+
m.reset_parameters()
|
| 49 |
+
else:
|
| 50 |
+
raise NotImplementedError(
|
| 51 |
+
'initialization method [%s] is not implemented' %
|
| 52 |
+
init_type)
|
| 53 |
+
if hasattr(m, 'bias') and m.bias is not None:
|
| 54 |
+
nn.init.constant_(m.bias.data, 0.0)
|
| 55 |
+
|
| 56 |
+
self.apply(init_func)
|
| 57 |
+
|
| 58 |
+
# propagate to children
|
| 59 |
+
for m in self.children():
|
| 60 |
+
if hasattr(m, 'init_weights'):
|
| 61 |
+
m.init_weights(init_type, gain)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class Vec2Feat(nn.Module):
|
| 65 |
+
def __init__(self, channel, hidden, kernel_size, stride, padding):
|
| 66 |
+
super(Vec2Feat, self).__init__()
|
| 67 |
+
self.relu = nn.LeakyReLU(0.2, inplace=True)
|
| 68 |
+
c_out = reduce((lambda x, y: x * y), kernel_size) * channel
|
| 69 |
+
self.embedding = nn.Linear(hidden, c_out)
|
| 70 |
+
self.kernel_size = kernel_size
|
| 71 |
+
self.stride = stride
|
| 72 |
+
self.padding = padding
|
| 73 |
+
self.bias_conv = nn.Conv2d(channel,
|
| 74 |
+
channel,
|
| 75 |
+
kernel_size=3,
|
| 76 |
+
stride=1,
|
| 77 |
+
padding=1)
|
| 78 |
+
|
| 79 |
+
def forward(self, x, t, output_size):
|
| 80 |
+
b_, _, _, _, c_ = x.shape
|
| 81 |
+
x = x.view(b_, -1, c_)
|
| 82 |
+
feat = self.embedding(x)
|
| 83 |
+
b, _, c = feat.size()
|
| 84 |
+
feat = feat.view(b * t, -1, c).permute(0, 2, 1)
|
| 85 |
+
feat = F.fold(feat,
|
| 86 |
+
output_size=output_size,
|
| 87 |
+
kernel_size=self.kernel_size,
|
| 88 |
+
stride=self.stride,
|
| 89 |
+
padding=self.padding)
|
| 90 |
+
feat = self.bias_conv(feat)
|
| 91 |
+
return feat
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
class FusionFeedForward(nn.Module):
|
| 95 |
+
def __init__(self, dim, hidden_dim=1960, t2t_params=None):
|
| 96 |
+
super(FusionFeedForward, self).__init__()
|
| 97 |
+
# We set hidden_dim as a default to 1960
|
| 98 |
+
self.fc1 = nn.Sequential(nn.Linear(dim, hidden_dim))
|
| 99 |
+
self.fc2 = nn.Sequential(nn.GELU(), nn.Linear(hidden_dim, dim))
|
| 100 |
+
assert t2t_params is not None
|
| 101 |
+
self.t2t_params = t2t_params
|
| 102 |
+
self.kernel_shape = reduce((lambda x, y: x * y), t2t_params['kernel_size']) # 49
|
| 103 |
+
|
| 104 |
+
def forward(self, x, output_size):
|
| 105 |
+
n_vecs = 1
|
| 106 |
+
for i, d in enumerate(self.t2t_params['kernel_size']):
|
| 107 |
+
n_vecs *= int((output_size[i] + 2 * self.t2t_params['padding'][i] -
|
| 108 |
+
(d - 1) - 1) / self.t2t_params['stride'][i] + 1)
|
| 109 |
+
|
| 110 |
+
x = self.fc1(x)
|
| 111 |
+
b, n, c = x.size()
|
| 112 |
+
normalizer = x.new_ones(b, n, self.kernel_shape).view(-1, n_vecs, self.kernel_shape).permute(0, 2, 1)
|
| 113 |
+
normalizer = F.fold(normalizer,
|
| 114 |
+
output_size=output_size,
|
| 115 |
+
kernel_size=self.t2t_params['kernel_size'],
|
| 116 |
+
padding=self.t2t_params['padding'],
|
| 117 |
+
stride=self.t2t_params['stride'])
|
| 118 |
+
|
| 119 |
+
x = F.fold(x.view(-1, n_vecs, c).permute(0, 2, 1),
|
| 120 |
+
output_size=output_size,
|
| 121 |
+
kernel_size=self.t2t_params['kernel_size'],
|
| 122 |
+
padding=self.t2t_params['padding'],
|
| 123 |
+
stride=self.t2t_params['stride'])
|
| 124 |
+
|
| 125 |
+
x = F.unfold(x / normalizer,
|
| 126 |
+
kernel_size=self.t2t_params['kernel_size'],
|
| 127 |
+
padding=self.t2t_params['padding'],
|
| 128 |
+
stride=self.t2t_params['stride']).permute(
|
| 129 |
+
0, 2, 1).contiguous().view(b, n, c)
|
| 130 |
+
x = self.fc2(x)
|
| 131 |
+
return x
|
propainter/model/modules/deformconv.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.nn import init as init
|
| 4 |
+
from torch.nn.modules.utils import _pair, _single
|
| 5 |
+
import math
|
| 6 |
+
|
| 7 |
+
class ModulatedDeformConv2d(nn.Module):
|
| 8 |
+
def __init__(self,
|
| 9 |
+
in_channels,
|
| 10 |
+
out_channels,
|
| 11 |
+
kernel_size,
|
| 12 |
+
stride=1,
|
| 13 |
+
padding=0,
|
| 14 |
+
dilation=1,
|
| 15 |
+
groups=1,
|
| 16 |
+
deform_groups=1,
|
| 17 |
+
bias=True):
|
| 18 |
+
super(ModulatedDeformConv2d, self).__init__()
|
| 19 |
+
|
| 20 |
+
self.in_channels = in_channels
|
| 21 |
+
self.out_channels = out_channels
|
| 22 |
+
self.kernel_size = _pair(kernel_size)
|
| 23 |
+
self.stride = stride
|
| 24 |
+
self.padding = padding
|
| 25 |
+
self.dilation = dilation
|
| 26 |
+
self.groups = groups
|
| 27 |
+
self.deform_groups = deform_groups
|
| 28 |
+
self.with_bias = bias
|
| 29 |
+
# enable compatibility with nn.Conv2d
|
| 30 |
+
self.transposed = False
|
| 31 |
+
self.output_padding = _single(0)
|
| 32 |
+
|
| 33 |
+
self.weight = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, *self.kernel_size))
|
| 34 |
+
if bias:
|
| 35 |
+
self.bias = nn.Parameter(torch.Tensor(out_channels))
|
| 36 |
+
else:
|
| 37 |
+
self.register_parameter('bias', None)
|
| 38 |
+
self.init_weights()
|
| 39 |
+
|
| 40 |
+
def init_weights(self):
|
| 41 |
+
n = self.in_channels
|
| 42 |
+
for k in self.kernel_size:
|
| 43 |
+
n *= k
|
| 44 |
+
stdv = 1. / math.sqrt(n)
|
| 45 |
+
self.weight.data.uniform_(-stdv, stdv)
|
| 46 |
+
if self.bias is not None:
|
| 47 |
+
self.bias.data.zero_()
|
| 48 |
+
|
| 49 |
+
if hasattr(self, 'conv_offset'):
|
| 50 |
+
self.conv_offset.weight.data.zero_()
|
| 51 |
+
self.conv_offset.bias.data.zero_()
|
| 52 |
+
|
| 53 |
+
def forward(self, x, offset, mask):
|
| 54 |
+
pass
|