Spaces:
Runtime error

Runtime error
test langchain-chatglm
Browse files- .gitignore +3 -0
- README.md +110 -7
- app.py +207 -297
- app_modules/__pycache__/presets.cpython-310.pyc +0 -0
- app_modules/__pycache__/presets.cpython-39.pyc +0 -0
- app_modules/overwrites.py +49 -0
- app_modules/presets.py +82 -0
- app_modules/utils.py +227 -0
- assets/Kelpy-Codos.js +76 -0
- assets/custom.css +190 -0
- assets/custom.js +1 -0
- assets/favicon.ico +0 -0
- clc/__init__.py +11 -0
- clc/__pycache__/__init__.cpython-310.pyc +0 -0
- clc/__pycache__/__init__.cpython-39.pyc +0 -0
- clc/__pycache__/gpt_service.cpython-310.pyc +0 -0
- clc/__pycache__/gpt_service.cpython-39.pyc +0 -0
- clc/__pycache__/langchain_application.cpython-310.pyc +0 -0
- clc/__pycache__/langchain_application.cpython-39.pyc +0 -0
- clc/__pycache__/source_service.cpython-310.pyc +0 -0
- clc/__pycache__/source_service.cpython-39.pyc +0 -0
- clc/config.py +18 -0
- clc/gpt_service.py +62 -0
- clc/langchain_application.py +97 -0
- clc/source_service.py +86 -0
- corpus/zh_wikipedia/README.md +114 -0
- corpus/zh_wikipedia/chinese_t2s.py +82 -0
- corpus/zh_wikipedia/clean_corpus.py +88 -0
- corpus/zh_wikipedia/wiki_process.py +46 -0
- create_knowledge.py +79 -0
- docs/added/马保国.txt +2 -0
- docs/姚明.txt +4 -0
- docs/王治郅.txt +4 -0
- docs/科比.txt +5 -0
- images/computing.png +0 -0
- images/web_demos/v1.png +0 -0
- images/web_demos/v2.png +0 -0
- images/web_demos/v3.png +0 -0
- images/wiki_process.png +0 -0
- main.py +227 -0
- requirements.txt +10 -8
- resources/OpenCC-1.1.6-cp310-cp310-manylinux1_x86_64.whl +0 -0
- tests/test_duckduckgo_search.py +16 -0
- tests/test_duckpy.py +15 -0
- tests/test_gradio_slient.py +19 -0
- tests/test_langchain.py +36 -0
- tests/test_vector_store.py +11 -0
.gitignore
CHANGED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.idea
|
| 2 |
+
cache
|
| 3 |
+
docs/zh_wikipedia
|
README.md
CHANGED
|
@@ -1,13 +1,116 @@
|
|
| 1 |
---
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
| 4 |
colorFrom: yellow
|
| 5 |
colorTo: yellow
|
| 6 |
-
|
| 7 |
-
sdk_version: 3.38.0
|
| 8 |
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
license: apache-2.0
|
| 11 |
---
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
license: openrail
|
| 3 |
+
title: 'Chinese-LangChain '
|
| 4 |
+
sdk: gradio
|
| 5 |
+
emoji: 🚀
|
| 6 |
colorFrom: yellow
|
| 7 |
colorTo: yellow
|
| 8 |
+
pinned: true
|
|
|
|
| 9 |
app_file: app.py
|
|
|
|
|
|
|
| 10 |
---
|
| 11 |
|
| 12 |
+
# Chinese-LangChain
|
| 13 |
+
|
| 14 |
+
> Chinese-LangChain:中文langchain项目,基于ChatGLM-6b+langchain实现本地化知识库检索与智能答案生成
|
| 15 |
+
|
| 16 |
+
https://github.com/yanqiangmiffy/Chinese-LangChain
|
| 17 |
+
|
| 18 |
+
俗称:小必应,Q.Talk,强聊,QiangTalk
|
| 19 |
+
|
| 20 |
+
## 🔥 效果演示
|
| 21 |
+
|
| 22 |
+

|
| 23 |
+

|
| 24 |
+
|
| 25 |
+
## 🚋 使用教程
|
| 26 |
+
|
| 27 |
+
- 选择知识库询问相关领域的问题
|
| 28 |
+
|
| 29 |
+
## 🏗️ 部署教程
|
| 30 |
+
|
| 31 |
+
### 运行配置
|
| 32 |
+
|
| 33 |
+
- 显存:12g,实际运行9g够了
|
| 34 |
+
- 运行内存:32g
|
| 35 |
+
|
| 36 |
+
### 运行环境
|
| 37 |
+
|
| 38 |
+
```text
|
| 39 |
+
langchain
|
| 40 |
+
gradio
|
| 41 |
+
transformers
|
| 42 |
+
sentence_transformers
|
| 43 |
+
faiss-cpu
|
| 44 |
+
unstructured
|
| 45 |
+
duckduckgo_search
|
| 46 |
+
mdtex2html
|
| 47 |
+
chardet
|
| 48 |
+
cchardet
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
### 启动Gradio
|
| 52 |
+
|
| 53 |
+
```shell
|
| 54 |
+
python main.py
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
## 🚀 特性
|
| 58 |
+
|
| 59 |
+
- 🔭 2023/04/20 支持模型问答与检索问答模式切换
|
| 60 |
+
- 💻 2023/04/20 感谢HF官方提供免费算力,添加HuggingFace
|
| 61 |
+
Spaces在线体验[[🤗 DEMO](https://huggingface.co/spaces/ChallengeHub/Chinese-LangChain)
|
| 62 |
+
- 🧫 2023/04/19 发布45万Wikipedia的文本预处理语料以及FAISS索引向量
|
| 63 |
+
- 🐯 2023/04/19 引入ChuanhuChatGPT皮肤
|
| 64 |
+
- 📱 2023/04/19 增加web search功能,需要确保网络畅通!(感谢[@wanghao07456](https://github.com/wanghao07456),提供的idea)
|
| 65 |
+
- 📚 2023/04/18 webui增加知识库选择功能
|
| 66 |
+
- 🚀 2023/04/18 修复推理预测超时5s报错问题
|
| 67 |
+
- 🎉 2023/04/17 支持多种文档上传与内容解析:pdf、docx,ppt等
|
| 68 |
+
- 🎉 2023/04/17 支持知识增量更新
|
| 69 |
+
|
| 70 |
+
[//]: # (- 支持检索结果与LLM生成结果对比)
|
| 71 |
+
|
| 72 |
+
## 🧰 知识库
|
| 73 |
+
|
| 74 |
+
### 构建知识库
|
| 75 |
+
|
| 76 |
+
- Wikipedia-zh
|
| 77 |
+
|
| 78 |
+
> 详情见:corpus/zh_wikipedia/README.md
|
| 79 |
+
|
| 80 |
+
### 知识库向量索引
|
| 81 |
+
|
| 82 |
+
| 知识库数据 | FAISS向量 |
|
| 83 |
+
|-------------------------------------------------------------------------------|----------------------------------------------------------------------|
|
| 84 |
+
| 中文维基百科截止4月份数据,45万 | 链接:https://pan.baidu.com/s/1VQeA_dq92fxKOtLL3u3Zpg?pwd=l3pn 提取码:l3pn |
|
| 85 |
+
| 截止去年九月的130w条中文维基百科处理结果和对应faiss向量文件 @[yubuyuabc](https://github.com/yubuyuabc) | 链接:https://pan.baidu.com/s/1Yls_Qtg15W1gneNuFP9O_w?pwd=exij 提取码:exij |
|
| 86 |
+
| 💹 [大规模金融研报知识图谱](http://openkg.cn/dataset/fr2kg) | 链接:https://pan.baidu.com/s/1FcIH5Fi3EfpS346DnDu51Q?pwd=ujjv 提取码:ujjv |
|
| 87 |
+
|
| 88 |
+
## 🔨 TODO
|
| 89 |
+
|
| 90 |
+
* [x] 支持上下文
|
| 91 |
+
* [x] 支持知识增量更新
|
| 92 |
+
* [x] 支持加载不同知识库
|
| 93 |
+
* [x] 支持检索结果与LLM生成结果对比
|
| 94 |
+
* [ ] 支持检索生成结果与原始LLM生成结果对比
|
| 95 |
+
* [ ] 支持模型问答与检索问答
|
| 96 |
+
* [ ] 检索结果过滤与排序
|
| 97 |
+
* [x] 互联网检索结果接入
|
| 98 |
+
* [ ] 模型初始化有问题
|
| 99 |
+
* [ ] 增加非LangChain策略
|
| 100 |
+
* [ ] 显示当前对话策略
|
| 101 |
+
* [ ] 构建一个垂直业务场景知识库,非通用性
|
| 102 |
+
|
| 103 |
+
## 交流
|
| 104 |
+
|
| 105 |
+
欢迎多提建议、Bad cases,目前尚不完善,欢迎进群及时交流,也欢迎大家多提PR</br>
|
| 106 |
+
|
| 107 |
+
<figure class="third">
|
| 108 |
+
<img src="https://raw.githubusercontent.com/yanqiangmiffy/Chinese-LangChain/master/images/ch.jpg" width="180px"><img src="https://raw.githubusercontent.com/yanqiangmiffy/Chinese-LangChain/master/images/chatgroup.jpg" width="180px" height="270px"><img src="https://raw.githubusercontent.com/yanqiangmiffy/Chinese-LangChain/master/images/personal.jpg" width="180px">
|
| 109 |
+
</figure>
|
| 110 |
+
|
| 111 |
+
## ❤️引用
|
| 112 |
+
|
| 113 |
+
- webui参考:https://github.com/thomas-yanxin/LangChain-ChatGLM-Webui
|
| 114 |
+
- knowledge问答参考:https://github.com/imClumsyPanda/langchain-ChatGLM
|
| 115 |
+
- LLM模型:https://github.com/THUDM/ChatGLM-6B
|
| 116 |
+
- CSS:https://huggingface.co/spaces/JohnSmith9982/ChuanhuChatGPT
|
app.py
CHANGED
|
@@ -1,311 +1,221 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
# import gradio as gr
|
| 4 |
|
| 5 |
-
|
| 6 |
-
|
| 7 |
|
| 8 |
-
# %%writefile demo-4bit.py
|
| 9 |
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
|
| 14 |
-
import gradio as gr
|
| 15 |
-
import mdtex2html
|
| 16 |
-
import torch
|
| 17 |
-
from loguru import logger
|
| 18 |
-
from transformers import AutoModel, AutoTokenizer
|
| 19 |
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
time.tzset() # type: ignore # pylint: disable=no-member
|
| 24 |
-
except Exception:
|
| 25 |
-
# Windows
|
| 26 |
-
logger.warning("Windows, cant run time.tzset()")
|
| 27 |
|
| 28 |
|
| 29 |
-
|
| 30 |
-
|
|
|
|
|
|
|
| 31 |
|
| 32 |
-
RETRY_FLAG = False
|
| 33 |
|
| 34 |
-
|
| 35 |
-
#model = AutoModel.from_pretrained(model_name, trust_remote_code=True).quantize(4).half().cuda()
|
| 36 |
-
model = AutoModel.from_pretrained(model_name, trust_remote_code=True).half().cuda()
|
| 37 |
-
model = model.eval()
|
| 38 |
|
| 39 |
-
_ = """Override Chatbot.postprocess"""
|
| 40 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 41 |
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
return []
|
| 45 |
-
for i, (message, response) in enumerate(y):
|
| 46 |
-
y[i] = (
|
| 47 |
-
None if message is None else mdtex2html.convert((message)),
|
| 48 |
-
None if response is None else mdtex2html.convert(response),
|
| 49 |
-
)
|
| 50 |
-
return y
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
gr.Chatbot.postprocess = postprocess
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
def parse_text(text):
|
| 57 |
-
lines = text.split("\n")
|
| 58 |
-
lines = [line for line in lines if line != ""]
|
| 59 |
-
count = 0
|
| 60 |
-
for i, line in enumerate(lines):
|
| 61 |
-
if "```" in line:
|
| 62 |
-
count += 1
|
| 63 |
-
items = line.split("`")
|
| 64 |
-
if count % 2 == 1:
|
| 65 |
-
lines[i] = f'<pre><code class="language-{items[-1]}">'
|
| 66 |
-
else:
|
| 67 |
-
lines[i] = "<br></code></pre>"
|
| 68 |
-
else:
|
| 69 |
-
if i > 0:
|
| 70 |
-
if count % 2 == 1:
|
| 71 |
-
line = line.replace("`", r"\`")
|
| 72 |
-
line = line.replace("<", "<")
|
| 73 |
-
line = line.replace(">", ">")
|
| 74 |
-
line = line.replace(" ", " ")
|
| 75 |
-
line = line.replace("*", "*")
|
| 76 |
-
line = line.replace("_", "_")
|
| 77 |
-
line = line.replace("-", "-")
|
| 78 |
-
line = line.replace(".", ".")
|
| 79 |
-
line = line.replace("!", "!")
|
| 80 |
-
line = line.replace("(", "(")
|
| 81 |
-
line = line.replace(")", ")")
|
| 82 |
-
line = line.replace("$", "$")
|
| 83 |
-
lines[i] = "<br>" + line
|
| 84 |
-
text = "".join(lines)
|
| 85 |
-
return text
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
def predict(
|
| 89 |
-
RETRY_FLAG, input, chatbot, max_length, top_p, temperature, history, past_key_values
|
| 90 |
-
):
|
| 91 |
-
try:
|
| 92 |
-
chatbot.append((parse_text(input), ""))
|
| 93 |
-
except Exception as exc:
|
| 94 |
-
logger.error(exc)
|
| 95 |
-
logger.debug(f"{chatbot=}")
|
| 96 |
-
_ = """
|
| 97 |
-
if chatbot:
|
| 98 |
-
chatbot[-1] = (parse_text(input), str(exc))
|
| 99 |
-
yield chatbot, history, past_key_values
|
| 100 |
-
# """
|
| 101 |
-
yield chatbot, history, past_key_values
|
| 102 |
-
"""
|
| 103 |
-
for response, history, past_key_values in model.stream_chat(
|
| 104 |
-
tokenizer,
|
| 105 |
-
input,
|
| 106 |
-
history,
|
| 107 |
-
past_key_values=past_key_values,
|
| 108 |
-
return_past_key_values=True,
|
| 109 |
-
max_length=max_length,
|
| 110 |
-
top_p=top_p,
|
| 111 |
-
temperature=temperature,
|
| 112 |
-
):
|
| 113 |
-
"""
|
| 114 |
-
for response, history in model.stream_chat(tokenizer, input, history, max_length=max_length, top_p=top_p,
|
| 115 |
-
temperature=temperature):
|
| 116 |
-
chatbot[-1] = (parse_text(input), parse_text(response))
|
| 117 |
-
|
| 118 |
-
yield chatbot, history, past_key_values
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
def trans_api(input, max_length=40960, top_p=0.7, temperature=0.95):
|
| 122 |
-
if max_length < 10:
|
| 123 |
-
max_length = 40960
|
| 124 |
-
if top_p < 0.1 or top_p > 1:
|
| 125 |
-
top_p = 0.7
|
| 126 |
-
if temperature <= 0 or temperature > 1:
|
| 127 |
-
temperature = 0.01
|
| 128 |
try:
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 137 |
)
|
| 138 |
-
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
|
| 149 |
-
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
|
| 155 |
-
|
| 156 |
-
if chat and history:
|
| 157 |
-
chat.pop(-1)
|
| 158 |
-
history.pop(-1)
|
| 159 |
-
return chat, history
|
| 160 |
-
|
| 161 |
-
|
| 162 |
-
# Regenerate response
|
| 163 |
-
def retry_last_answer(
|
| 164 |
-
user_input, chatbot, max_length, top_p, temperature, history, past_key_values
|
| 165 |
-
):
|
| 166 |
-
if chatbot and history:
|
| 167 |
-
# Removing the previous conversation from chat
|
| 168 |
-
chatbot.pop(-1)
|
| 169 |
-
# Setting up a flag to capture a retry
|
| 170 |
-
RETRY_FLAG = True
|
| 171 |
-
# Getting last message from user
|
| 172 |
-
user_input = history[-1][0]
|
| 173 |
-
# Removing bot response from the history
|
| 174 |
-
history.pop(-1)
|
| 175 |
-
|
| 176 |
-
yield from predict(
|
| 177 |
-
RETRY_FLAG, # type: ignore
|
| 178 |
-
user_input,
|
| 179 |
-
chatbot,
|
| 180 |
-
max_length,
|
| 181 |
-
top_p,
|
| 182 |
-
temperature,
|
| 183 |
-
history,
|
| 184 |
-
past_key_values,
|
| 185 |
-
)
|
| 186 |
|
| 187 |
-
|
| 188 |
-
with gr.Blocks(title="ChatGLM2-6B-int4", theme=gr.themes.Soft(text_size="sm")) as demo:
|
| 189 |
-
# gr.HTML("""<h1 align="center">ChatGLM2-6B-int4</h1>""")
|
| 190 |
-
gr.HTML(
|
| 191 |
-
"""<center><a href="https://huggingface.co/spaces/mikeee/chatglm2-6b-4bit?duplicate=true"><img src="https://bit.ly/3gLdBN6" alt="Duplicate Space"></a>It's beyond Fitness,模型由[帛凡]基于ChatGLM-6b进行微调后,在健康(全科)、心理等领域达至少60分的专业水准,而且中文总结能力超越了GPT3.5各版本。</center>"""
|
| 192 |
-
"""<center>特别声明:本应用仅为模型能力演示,无任何商业行为,部署资源为Huggingface官方免费提供,任何通过此项目产生的知识仅用于学术参考,作者和网站均不承担任何责任。</center>"""
|
| 193 |
-
"""<h1 align="center">帛凡 Fitness AI 演示</h1>"""
|
| 194 |
-
"""<center>T4 is just a machine wiht 16G VRAM ,so OOM is easy to occur ,If you meet any error,Please email me 。 👉 [email protected]</center>"""
|
| 195 |
-
)
|
| 196 |
-
|
| 197 |
-
with gr.Accordion("🎈 Info", open=False):
|
| 198 |
-
_ = f"""
|
| 199 |
-
## {model_name}
|
| 200 |
-
|
| 201 |
-
ChatGLM-6B 是开源中英双语对话模型,本次训练基于ChatGLM-6B 的第一代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上开展训练。
|
| 202 |
-
|
| 203 |
-
本项目经过多位网友实测,中文总结能力超越了GPT3.5各版本,健康咨询水平优于其它同量级模型,且经优化目前可以支持无限context,远大于4k、8K、16K......,可能是任何个人和中小企业首选模型。
|
| 204 |
-
|
| 205 |
-
*首先,用40万条高质量数据进行强化训练,以提高模型的基础能力;
|
| 206 |
-
|
| 207 |
-
*第二,使用30万条人类反馈数据,构建一个表达方式规范优雅的语言模式(RM模型);
|
| 208 |
-
|
| 209 |
-
*第三,在保留SFT阶段三分之一训练数据的同时,增加了30万条fitness数据,叠加RM模型,对ChatGLM-6B进行强化训练。
|
| 210 |
-
|
| 211 |
-
通过训练我们对模型有了更深刻的认知,LLM在一直在进化,好的方法和数据可以挖掘出模型的更大潜能。
|
| 212 |
-
训练中特别强化了中英文学术论文的翻译和总结,可以成为普通用户和科研人员的得力助手。
|
| 213 |
-
|
| 214 |
-
免责声明:本应用仅为模型能力演示,无任何商业行为,部署资源为huggingface官方免费提供,任何通过此项目产生的知识仅用于学术参考,作者和网站均不承担任何责任 。
|
| 215 |
-
|
| 216 |
-
The T4 GPU is sponsored by a community GPU grant from Huggingface. Thanks a lot!
|
| 217 |
-
|
| 218 |
-
[模型下载地址](https://huggingface.co/fb700/chatglm-fitness-RLHF)
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
"""
|
| 222 |
-
gr.Markdown(dedent(_))
|
| 223 |
-
chatbot = gr.Chatbot()
|
| 224 |
with gr.Row():
|
| 225 |
-
with gr.Column(scale=4):
|
| 226 |
-
with gr.Column(scale=12):
|
| 227 |
-
user_input = gr.Textbox(
|
| 228 |
-
show_label=False,
|
| 229 |
-
placeholder="Input...",
|
| 230 |
-
).style(container=False)
|
| 231 |
-
RETRY_FLAG = gr.Checkbox(value=False, visible=False)
|
| 232 |
-
with gr.Column(min_width=32, scale=1):
|
| 233 |
-
with gr.Row():
|
| 234 |
-
submitBtn = gr.Button("Submit", variant="primary")
|
| 235 |
-
deleteBtn = gr.Button("删除最后一条对话", variant="secondary")
|
| 236 |
-
retryBtn = gr.Button("重新生成Regenerate", variant="secondary")
|
| 237 |
with gr.Column(scale=1):
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
|
| 242 |
-
value=
|
| 243 |
-
step=1.0,
|
| 244 |
-
label="Maximum length",
|
| 245 |
-
interactive=True,
|
| 246 |
-
)
|
| 247 |
-
top_p = gr.Slider(
|
| 248 |
-
0, 1, value=0.7, step=0.01, label="Top P", interactive=True
|
| 249 |
-
)
|
| 250 |
-
temperature = gr.Slider(
|
| 251 |
-
0.01, 1, value=0.95, step=0.01, label="Temperature", interactive=True
|
| 252 |
-
)
|
| 253 |
-
|
| 254 |
-
history = gr.State([])
|
| 255 |
-
past_key_values = gr.State(None)
|
| 256 |
-
|
| 257 |
-
user_input.submit(
|
| 258 |
-
predict,
|
| 259 |
-
[
|
| 260 |
-
RETRY_FLAG,
|
| 261 |
-
user_input,
|
| 262 |
-
chatbot,
|
| 263 |
-
max_length,
|
| 264 |
-
top_p,
|
| 265 |
-
temperature,
|
| 266 |
-
history,
|
| 267 |
-
past_key_values,
|
| 268 |
-
],
|
| 269 |
-
[chatbot, history, past_key_values],
|
| 270 |
-
show_progress="full",
|
| 271 |
-
)
|
| 272 |
-
submitBtn.click(
|
| 273 |
-
predict,
|
| 274 |
-
[
|
| 275 |
-
RETRY_FLAG,
|
| 276 |
-
user_input,
|
| 277 |
-
chatbot,
|
| 278 |
-
max_length,
|
| 279 |
-
top_p,
|
| 280 |
-
temperature,
|
| 281 |
-
history,
|
| 282 |
-
past_key_values,
|
| 283 |
-
],
|
| 284 |
-
[chatbot, history, past_key_values],
|
| 285 |
-
show_progress="full",
|
| 286 |
-
api_name="predict",
|
| 287 |
-
)
|
| 288 |
-
submitBtn.click(reset_user_input, [], [user_input])
|
| 289 |
|
| 290 |
-
|
| 291 |
-
|
| 292 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 293 |
|
| 294 |
-
|
| 295 |
-
|
| 296 |
-
|
| 297 |
-
|
| 298 |
-
|
| 299 |
-
|
| 300 |
-
|
| 301 |
-
|
| 302 |
-
|
| 303 |
-
|
| 304 |
-
|
| 305 |
-
|
| 306 |
-
|
| 307 |
-
|
| 308 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 309 |
|
| 310 |
with gr.Accordion("Example inputs", open=True):
|
| 311 |
etext0 = """ "act": "作为基于文本的冒险游戏",\n "prompt": "我想让你扮演一个基于文本的冒险游戏。我在这个基于文本的冒险游戏中扮演一个角色。请尽可能具体地描述角色所看到的内容和环境,并在游戏输出1、2、3让用户选择进行回复,而不是其它方式。我将输入命令来告诉角色该做什么,而你需要回复角色的行动结果以推动游戏的进行。我的第一个命令是'醒来',请从这里开始故事 “ """
|
|
@@ -384,12 +294,12 @@ with gr.Blocks(title="ChatGLM2-6B-int4", theme=gr.themes.Soft(text_size="sm")) a
|
|
| 384 |
)
|
| 385 |
# """
|
| 386 |
|
| 387 |
-
# demo.queue().launch(share=False, inbrowser=True)
|
| 388 |
-
# demo.queue().launch(share=True, inbrowser=True, debug=True)
|
| 389 |
-
|
| 390 |
-
# concurrency_count > 1 requires more memory, max_size: queue size
|
| 391 |
-
# T4 medium: 30GB, model size: ~4G concurrency_count = 6
|
| 392 |
-
# leave one for api access
|
| 393 |
-
# reduce to 5 if OOM occurs to often
|
| 394 |
|
| 395 |
-
demo.queue(concurrency_count=
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import shutil
|
|
|
|
| 3 |
|
| 4 |
+
from app_modules.presets import *
|
| 5 |
+
from clc.langchain_application import LangChainApplication
|
| 6 |
|
|
|
|
| 7 |
|
| 8 |
+
# 修改成自己的配置!!!
|
| 9 |
+
class LangChainCFG:
|
| 10 |
+
llm_model_name = 'fb700/chatglm-fitness-RLHF' # 本地模型文件 or huggingface远程仓库
|
| 11 |
+
embedding_model_name = 'moka-ai/m3e-large' # 检索模型文件 or huggingface远程仓库
|
| 12 |
+
vector_store_path = './cache'
|
| 13 |
+
docs_path = './docs'
|
| 14 |
+
kg_vector_stores = {
|
| 15 |
+
'中文维基百科': './cache/zh_wikipedia',
|
| 16 |
+
'大规模金融研报': './cache/financial_research_reports',
|
| 17 |
+
'初始化': './cache',
|
| 18 |
+
} # 可以替换成自己的知识库,如果没有需要设置为None
|
| 19 |
+
# kg_vector_stores=None
|
| 20 |
+
patterns = ['模型问答', '知识库问答'] #
|
| 21 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
|
| 23 |
+
config = LangChainCFG()
|
| 24 |
+
application = LangChainApplication(config)
|
| 25 |
+
application.source_service.init_source_vector()
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
|
| 27 |
|
| 28 |
+
def get_file_list():
|
| 29 |
+
if not os.path.exists("docs"):
|
| 30 |
+
return []
|
| 31 |
+
return [f for f in os.listdir("docs")]
|
| 32 |
|
|
|
|
| 33 |
|
| 34 |
+
file_list = get_file_list()
|
|
|
|
|
|
|
|
|
|
| 35 |
|
|
|
|
| 36 |
|
| 37 |
+
def upload_file(file):
|
| 38 |
+
if not os.path.exists("docs"):
|
| 39 |
+
os.mkdir("docs")
|
| 40 |
+
filename = os.path.basename(file.name)
|
| 41 |
+
shutil.move(file.name, "docs/" + filename)
|
| 42 |
+
# file_list首位插入新上传的文件
|
| 43 |
+
file_list.insert(0, filename)
|
| 44 |
+
application.source_service.add_document("docs/" + filename)
|
| 45 |
+
return gr.Dropdown.update(choices=file_list, value=filename)
|
| 46 |
|
| 47 |
+
|
| 48 |
+
def set_knowledge(kg_name, history):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 49 |
try:
|
| 50 |
+
application.source_service.load_vector_store(config.kg_vector_stores[kg_name])
|
| 51 |
+
msg_status = f'{kg_name}知识库已成功加载'
|
| 52 |
+
except Exception as e:
|
| 53 |
+
print(e)
|
| 54 |
+
msg_status = f'{kg_name}知识库未成功加载'
|
| 55 |
+
return history + [[None, msg_status]]
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def clear_session():
|
| 59 |
+
return '', None
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def predict(input,
|
| 63 |
+
large_language_model,
|
| 64 |
+
embedding_model,
|
| 65 |
+
top_k,
|
| 66 |
+
use_web,
|
| 67 |
+
use_pattern,
|
| 68 |
+
history=None):
|
| 69 |
+
# print(large_language_model, embedding_model)
|
| 70 |
+
print(input)
|
| 71 |
+
if history == None:
|
| 72 |
+
history = []
|
| 73 |
+
|
| 74 |
+
if use_web == '使用':
|
| 75 |
+
web_content = application.source_service.search_web(query=input)
|
| 76 |
+
else:
|
| 77 |
+
web_content = ''
|
| 78 |
+
search_text = ''
|
| 79 |
+
if use_pattern == '模型问答':
|
| 80 |
+
result = application.get_llm_answer(query=input, web_content=web_content)
|
| 81 |
+
history.append((input, result))
|
| 82 |
+
search_text += web_content
|
| 83 |
+
return '', history, history, search_text
|
| 84 |
+
|
| 85 |
+
else:
|
| 86 |
+
resp = application.get_knowledge_based_answer(
|
| 87 |
+
query=input,
|
| 88 |
+
history_len=1,
|
| 89 |
+
temperature=0.1,
|
| 90 |
+
top_p=0.9,
|
| 91 |
+
top_k=top_k,
|
| 92 |
+
web_content=web_content,
|
| 93 |
+
chat_history=history
|
| 94 |
)
|
| 95 |
+
history.append((input, resp['result']))
|
| 96 |
+
for idx, source in enumerate(resp['source_documents'][:4]):
|
| 97 |
+
sep = f'----------【搜索结果{idx + 1}:】---------------\n'
|
| 98 |
+
search_text += f'{sep}\n{source.page_content}\n\n'
|
| 99 |
+
print(search_text)
|
| 100 |
+
search_text += "----------【网络检索内容】-----------\n"
|
| 101 |
+
search_text += web_content
|
| 102 |
+
return '', history, history, search_text
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
with open("assets/custom.css", "r", encoding="utf-8") as f:
|
| 106 |
+
customCSS = f.read()
|
| 107 |
+
with gr.Blocks(css=customCSS, theme=small_and_beautiful_theme) as demo:
|
| 108 |
+
gr.Markdown("""<h1><center>Chinese-LangChain by 帛凡 Fitness AI</center></h1>
|
| 109 |
+
<center><font size=3>
|
| 110 |
+
</center></font>
|
| 111 |
+
""")
|
| 112 |
+
state = gr.State()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 113 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 114 |
with gr.Row():
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 115 |
with gr.Column(scale=1):
|
| 116 |
+
embedding_model = gr.Dropdown([
|
| 117 |
+
"moka-ai/m3e-large"
|
| 118 |
+
],
|
| 119 |
+
label="Embedding model",
|
| 120 |
+
value="moka-ai/m3e-large")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 121 |
|
| 122 |
+
large_language_model = gr.Dropdown(
|
| 123 |
+
[
|
| 124 |
+
"帛凡 Fitness AI",
|
| 125 |
+
],
|
| 126 |
+
label="large language model",
|
| 127 |
+
value="帛凡 Fitness AI")
|
| 128 |
+
|
| 129 |
+
top_k = gr.Slider(1,
|
| 130 |
+
20,
|
| 131 |
+
value=4,
|
| 132 |
+
step=1,
|
| 133 |
+
label="检索top-k文档",
|
| 134 |
+
interactive=True)
|
| 135 |
+
|
| 136 |
+
use_web = gr.Radio(["使用", "不使用"], label="web search",
|
| 137 |
+
info="是否使用网络搜索,使用时确保网络通常",
|
| 138 |
+
value="不使用"
|
| 139 |
+
)
|
| 140 |
+
use_pattern = gr.Radio(
|
| 141 |
+
[
|
| 142 |
+
'模型问答',
|
| 143 |
+
'知识库问答',
|
| 144 |
+
],
|
| 145 |
+
label="模式",
|
| 146 |
+
value='模型问答',
|
| 147 |
+
interactive=True)
|
| 148 |
|
| 149 |
+
kg_name = gr.Radio(list(config.kg_vector_stores.keys()),
|
| 150 |
+
label="知识库",
|
| 151 |
+
value=None,
|
| 152 |
+
info="使用知识库问答,请加载知识库",
|
| 153 |
+
interactive=True)
|
| 154 |
+
set_kg_btn = gr.Button("加载知识库")
|
| 155 |
+
|
| 156 |
+
file = gr.File(label="将文件上传到知识库库,内容要尽量匹配",
|
| 157 |
+
visible=True,
|
| 158 |
+
file_types=['.txt', '.md', '.docx', '.pdf']
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
with gr.Column(scale=4):
|
| 163 |
+
with gr.Row():
|
| 164 |
+
chatbot = gr.Chatbot(label='Chinese-LangChain').style(height=400)
|
| 165 |
+
with gr.Row():
|
| 166 |
+
message = gr.Textbox(label='请输入问题')
|
| 167 |
+
with gr.Row():
|
| 168 |
+
clear_history = gr.Button("🧹 清除历史对话")
|
| 169 |
+
send = gr.Button("🚀 发送")
|
| 170 |
+
with gr.Row():
|
| 171 |
+
gr.Markdown("""提醒:<br>
|
| 172 |
+
[帛凡 Fitness AI模型下载地址](https://huggingface.co/fb700/chatglm-fitness-RLHF) <br>
|
| 173 |
+
It's beyond Fitness,模型由[帛凡]基于ChatGLM-6b进行微调后,在健康(全科)、心理等领域达至少60分的专业水准,而且中文总结能力超越了GPT3.5各版本。声明:本应用仅为模型能力演示,无任何商业行为,部署资源为Huggingface官方免费提供,任何通过此项目产生的知识仅用于学术参考,作者和网站均不承担任何责任。帛凡 Fitness AI 演示T4 is just a machine wiht 16G VRAM ,so OOM is easy to occur ,If you meet any error,Please email me 。 👉 [email protected]<br>
|
| 174 |
+
""")
|
| 175 |
+
with gr.Column(scale=2):
|
| 176 |
+
search = gr.Textbox(label='搜索结果')
|
| 177 |
+
|
| 178 |
+
# ============= 触发动作=============
|
| 179 |
+
file.upload(upload_file,
|
| 180 |
+
inputs=file,
|
| 181 |
+
outputs=None)
|
| 182 |
+
set_kg_btn.click(
|
| 183 |
+
set_knowledge,
|
| 184 |
+
show_progress=True,
|
| 185 |
+
inputs=[kg_name, chatbot],
|
| 186 |
+
outputs=chatbot
|
| 187 |
+
)
|
| 188 |
+
# 发送按钮 提交
|
| 189 |
+
send.click(predict,
|
| 190 |
+
inputs=[
|
| 191 |
+
message,
|
| 192 |
+
large_language_model,
|
| 193 |
+
embedding_model,
|
| 194 |
+
top_k,
|
| 195 |
+
use_web,
|
| 196 |
+
use_pattern,
|
| 197 |
+
state
|
| 198 |
+
],
|
| 199 |
+
outputs=[message, chatbot, state, search])
|
| 200 |
+
|
| 201 |
+
# 清空历史对话按钮 提交
|
| 202 |
+
clear_history.click(fn=clear_session,
|
| 203 |
+
inputs=[],
|
| 204 |
+
outputs=[chatbot, state],
|
| 205 |
+
queue=False)
|
| 206 |
+
|
| 207 |
+
# 输入框 回车
|
| 208 |
+
message.submit(predict,
|
| 209 |
+
inputs=[
|
| 210 |
+
message,
|
| 211 |
+
large_language_model,
|
| 212 |
+
embedding_model,
|
| 213 |
+
top_k,
|
| 214 |
+
use_web,
|
| 215 |
+
use_pattern,
|
| 216 |
+
state
|
| 217 |
+
],
|
| 218 |
+
outputs=[message, chatbot, state, search])
|
| 219 |
|
| 220 |
with gr.Accordion("Example inputs", open=True):
|
| 221 |
etext0 = """ "act": "作为基于文本的冒险游戏",\n "prompt": "我想让你扮演一个基于文本的冒险游戏。我在这个基于文本的冒险游戏中扮演一个角色。请尽可能具体地描述角色所看到的内容和环境,并在游戏输出1、2、3让用户选择进行回复,而不是其它方式。我将输入命令来告诉角色该做什么,而你需要回复角色的行动结果以推动游戏的进行。我的第一个命令是'醒来',请从这里开始故事 “ """
|
|
|
|
| 294 |
)
|
| 295 |
# """
|
| 296 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 297 |
|
| 298 |
+
demo.queue(concurrency_count=2).launch(
|
| 299 |
+
server_name='0.0.0.0',
|
| 300 |
+
share=False,
|
| 301 |
+
show_error=True,
|
| 302 |
+
debug=True,
|
| 303 |
+
enable_queue=True,
|
| 304 |
+
inbrowser=True,
|
| 305 |
+
)
|
app_modules/__pycache__/presets.cpython-310.pyc
ADDED
|
Binary file (2.26 kB). View file
|
|
|
app_modules/__pycache__/presets.cpython-39.pyc
ADDED
|
Binary file (2.26 kB). View file
|
|
|
app_modules/overwrites.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import annotations
|
| 2 |
+
|
| 3 |
+
from typing import List, Tuple
|
| 4 |
+
|
| 5 |
+
from app_modules.utils import *
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def postprocess(
|
| 9 |
+
self, y: List[Tuple[str | None, str | None]]
|
| 10 |
+
) -> List[Tuple[str | None, str | None]]:
|
| 11 |
+
"""
|
| 12 |
+
Parameters:
|
| 13 |
+
y: List of tuples representing the message and response pairs. Each message and response should be a string, which may be in Markdown format.
|
| 14 |
+
Returns:
|
| 15 |
+
List of tuples representing the message and response. Each message and response will be a string of HTML.
|
| 16 |
+
"""
|
| 17 |
+
if y is None or y == []:
|
| 18 |
+
return []
|
| 19 |
+
temp = []
|
| 20 |
+
for x in y:
|
| 21 |
+
user, bot = x
|
| 22 |
+
if not detect_converted_mark(user):
|
| 23 |
+
user = convert_asis(user)
|
| 24 |
+
if not detect_converted_mark(bot):
|
| 25 |
+
bot = convert_mdtext(bot)
|
| 26 |
+
temp.append((user, bot))
|
| 27 |
+
return temp
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
with open("./assets/custom.js", "r", encoding="utf-8") as f, open("./assets/Kelpy-Codos.js", "r",
|
| 31 |
+
encoding="utf-8") as f2:
|
| 32 |
+
customJS = f.read()
|
| 33 |
+
kelpyCodos = f2.read()
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def reload_javascript():
|
| 37 |
+
print("Reloading javascript...")
|
| 38 |
+
js = f'<script>{customJS}</script><script>{kelpyCodos}</script>'
|
| 39 |
+
|
| 40 |
+
def template_response(*args, **kwargs):
|
| 41 |
+
res = GradioTemplateResponseOriginal(*args, **kwargs)
|
| 42 |
+
res.body = res.body.replace(b'</html>', f'{js}</html>'.encode("utf8"))
|
| 43 |
+
res.init_headers()
|
| 44 |
+
return res
|
| 45 |
+
|
| 46 |
+
gr.routes.templates.TemplateResponse = template_response
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
GradioTemplateResponseOriginal = gr.routes.templates.TemplateResponse
|
app_modules/presets.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding:utf-8 -*-
|
| 2 |
+
import gradio as gr
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
title = """<h1 align="left" style="min-width:200px; margin-top:0;"> <img src="https://raw.githubusercontent.com/twitter/twemoji/master/assets/svg/1f432.svg" width="32px" style="display: inline"> Baize-7B </h1>"""
|
| 6 |
+
description_top = """\
|
| 7 |
+
<div align="left">
|
| 8 |
+
<p>
|
| 9 |
+
Disclaimer: The LLaMA model is a third-party version available on Hugging Face model hub. This demo should be used for research purposes only. Commercial use is strictly prohibited. The model output is not censored and the authors do not endorse the opinions in the generated content. Use at your own risk.
|
| 10 |
+
</p >
|
| 11 |
+
</div>
|
| 12 |
+
"""
|
| 13 |
+
description = """\
|
| 14 |
+
<div align="center" style="margin:16px 0">
|
| 15 |
+
The demo is built on <a href="https://github.com/GaiZhenbiao/ChuanhuChatGPT">ChuanhuChatGPT</a>.
|
| 16 |
+
</div>
|
| 17 |
+
"""
|
| 18 |
+
CONCURRENT_COUNT = 100
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
ALREADY_CONVERTED_MARK = "<!-- ALREADY CONVERTED BY PARSER. -->"
|
| 22 |
+
|
| 23 |
+
small_and_beautiful_theme = gr.themes.Soft(
|
| 24 |
+
primary_hue=gr.themes.Color(
|
| 25 |
+
c50="#02C160",
|
| 26 |
+
c100="rgba(2, 193, 96, 0.2)",
|
| 27 |
+
c200="#02C160",
|
| 28 |
+
c300="rgba(2, 193, 96, 0.32)",
|
| 29 |
+
c400="rgba(2, 193, 96, 0.32)",
|
| 30 |
+
c500="rgba(2, 193, 96, 1.0)",
|
| 31 |
+
c600="rgba(2, 193, 96, 1.0)",
|
| 32 |
+
c700="rgba(2, 193, 96, 0.32)",
|
| 33 |
+
c800="rgba(2, 193, 96, 0.32)",
|
| 34 |
+
c900="#02C160",
|
| 35 |
+
c950="#02C160",
|
| 36 |
+
),
|
| 37 |
+
secondary_hue=gr.themes.Color(
|
| 38 |
+
c50="#576b95",
|
| 39 |
+
c100="#576b95",
|
| 40 |
+
c200="#576b95",
|
| 41 |
+
c300="#576b95",
|
| 42 |
+
c400="#576b95",
|
| 43 |
+
c500="#576b95",
|
| 44 |
+
c600="#576b95",
|
| 45 |
+
c700="#576b95",
|
| 46 |
+
c800="#576b95",
|
| 47 |
+
c900="#576b95",
|
| 48 |
+
c950="#576b95",
|
| 49 |
+
),
|
| 50 |
+
neutral_hue=gr.themes.Color(
|
| 51 |
+
name="gray",
|
| 52 |
+
c50="#f9fafb",
|
| 53 |
+
c100="#f3f4f6",
|
| 54 |
+
c200="#e5e7eb",
|
| 55 |
+
c300="#d1d5db",
|
| 56 |
+
c400="#B2B2B2",
|
| 57 |
+
c500="#808080",
|
| 58 |
+
c600="#636363",
|
| 59 |
+
c700="#515151",
|
| 60 |
+
c800="#393939",
|
| 61 |
+
c900="#272727",
|
| 62 |
+
c950="#171717",
|
| 63 |
+
),
|
| 64 |
+
radius_size=gr.themes.sizes.radius_sm,
|
| 65 |
+
).set(
|
| 66 |
+
button_primary_background_fill="#06AE56",
|
| 67 |
+
button_primary_background_fill_dark="#06AE56",
|
| 68 |
+
button_primary_background_fill_hover="#07C863",
|
| 69 |
+
button_primary_border_color="#06AE56",
|
| 70 |
+
button_primary_border_color_dark="#06AE56",
|
| 71 |
+
button_primary_text_color="#FFFFFF",
|
| 72 |
+
button_primary_text_color_dark="#FFFFFF",
|
| 73 |
+
button_secondary_background_fill="#F2F2F2",
|
| 74 |
+
button_secondary_background_fill_dark="#2B2B2B",
|
| 75 |
+
button_secondary_text_color="#393939",
|
| 76 |
+
button_secondary_text_color_dark="#FFFFFF",
|
| 77 |
+
# background_fill_primary="#F7F7F7",
|
| 78 |
+
# background_fill_primary_dark="#1F1F1F",
|
| 79 |
+
block_title_text_color="*primary_500",
|
| 80 |
+
block_title_background_fill="*primary_100",
|
| 81 |
+
input_background_fill="#F6F6F6",
|
| 82 |
+
)
|
app_modules/utils.py
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding:utf-8 -*-
|
| 2 |
+
from __future__ import annotations
|
| 3 |
+
|
| 4 |
+
import html
|
| 5 |
+
import logging
|
| 6 |
+
import re
|
| 7 |
+
|
| 8 |
+
import mdtex2html
|
| 9 |
+
from markdown import markdown
|
| 10 |
+
from pygments import highlight
|
| 11 |
+
from pygments.formatters import HtmlFormatter
|
| 12 |
+
from pygments.lexers import ClassNotFound
|
| 13 |
+
from pygments.lexers import guess_lexer, get_lexer_by_name
|
| 14 |
+
|
| 15 |
+
from app_modules.presets import *
|
| 16 |
+
|
| 17 |
+
logging.basicConfig(
|
| 18 |
+
level=logging.INFO,
|
| 19 |
+
format="%(asctime)s [%(levelname)s] [%(filename)s:%(lineno)d] %(message)s",
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def markdown_to_html_with_syntax_highlight(md_str):
|
| 24 |
+
def replacer(match):
|
| 25 |
+
lang = match.group(1) or "text"
|
| 26 |
+
code = match.group(2)
|
| 27 |
+
lang = lang.strip()
|
| 28 |
+
# print(1,lang)
|
| 29 |
+
if lang == "text":
|
| 30 |
+
lexer = guess_lexer(code)
|
| 31 |
+
lang = lexer.name
|
| 32 |
+
# print(2,lang)
|
| 33 |
+
try:
|
| 34 |
+
lexer = get_lexer_by_name(lang, stripall=True)
|
| 35 |
+
except ValueError:
|
| 36 |
+
lexer = get_lexer_by_name("python", stripall=True)
|
| 37 |
+
formatter = HtmlFormatter()
|
| 38 |
+
# print(3,lexer.name)
|
| 39 |
+
highlighted_code = highlight(code, lexer, formatter)
|
| 40 |
+
|
| 41 |
+
return f'<pre><code class="{lang}">{highlighted_code}</code></pre>'
|
| 42 |
+
|
| 43 |
+
code_block_pattern = r"```(\w+)?\n([\s\S]+?)\n```"
|
| 44 |
+
md_str = re.sub(code_block_pattern, replacer, md_str, flags=re.MULTILINE)
|
| 45 |
+
|
| 46 |
+
html_str = markdown(md_str)
|
| 47 |
+
return html_str
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def normalize_markdown(md_text: str) -> str:
|
| 51 |
+
lines = md_text.split("\n")
|
| 52 |
+
normalized_lines = []
|
| 53 |
+
inside_list = False
|
| 54 |
+
|
| 55 |
+
for i, line in enumerate(lines):
|
| 56 |
+
if re.match(r"^(\d+\.|-|\*|\+)\s", line.strip()):
|
| 57 |
+
if not inside_list and i > 0 and lines[i - 1].strip() != "":
|
| 58 |
+
normalized_lines.append("")
|
| 59 |
+
inside_list = True
|
| 60 |
+
normalized_lines.append(line)
|
| 61 |
+
elif inside_list and line.strip() == "":
|
| 62 |
+
if i < len(lines) - 1 and not re.match(
|
| 63 |
+
r"^(\d+\.|-|\*|\+)\s", lines[i + 1].strip()
|
| 64 |
+
):
|
| 65 |
+
normalized_lines.append(line)
|
| 66 |
+
continue
|
| 67 |
+
else:
|
| 68 |
+
inside_list = False
|
| 69 |
+
normalized_lines.append(line)
|
| 70 |
+
|
| 71 |
+
return "\n".join(normalized_lines)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def convert_mdtext(md_text):
|
| 75 |
+
code_block_pattern = re.compile(r"```(.*?)(?:```|$)", re.DOTALL)
|
| 76 |
+
inline_code_pattern = re.compile(r"`(.*?)`", re.DOTALL)
|
| 77 |
+
code_blocks = code_block_pattern.findall(md_text)
|
| 78 |
+
non_code_parts = code_block_pattern.split(md_text)[::2]
|
| 79 |
+
|
| 80 |
+
result = []
|
| 81 |
+
for non_code, code in zip(non_code_parts, code_blocks + [""]):
|
| 82 |
+
if non_code.strip():
|
| 83 |
+
non_code = normalize_markdown(non_code)
|
| 84 |
+
if inline_code_pattern.search(non_code):
|
| 85 |
+
result.append(markdown(non_code, extensions=["tables"]))
|
| 86 |
+
else:
|
| 87 |
+
result.append(mdtex2html.convert(non_code, extensions=["tables"]))
|
| 88 |
+
if code.strip():
|
| 89 |
+
# _, code = detect_language(code) # 暂时去除代码高亮功能,因为在大段代码的情况下会出现问题
|
| 90 |
+
# code = code.replace("\n\n", "\n") # 暂时去除代码中的空行,因为在大段代码的情况下会出现问题
|
| 91 |
+
code = f"\n```{code}\n\n```"
|
| 92 |
+
code = markdown_to_html_with_syntax_highlight(code)
|
| 93 |
+
result.append(code)
|
| 94 |
+
result = "".join(result)
|
| 95 |
+
result += ALREADY_CONVERTED_MARK
|
| 96 |
+
return result
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def convert_asis(userinput):
|
| 100 |
+
return f"<p style=\"white-space:pre-wrap;\">{html.escape(userinput)}</p>" + ALREADY_CONVERTED_MARK
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def detect_converted_mark(userinput):
|
| 104 |
+
if userinput.endswith(ALREADY_CONVERTED_MARK):
|
| 105 |
+
return True
|
| 106 |
+
else:
|
| 107 |
+
return False
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def detect_language(code):
|
| 111 |
+
if code.startswith("\n"):
|
| 112 |
+
first_line = ""
|
| 113 |
+
else:
|
| 114 |
+
first_line = code.strip().split("\n", 1)[0]
|
| 115 |
+
language = first_line.lower() if first_line else ""
|
| 116 |
+
code_without_language = code[len(first_line):].lstrip() if first_line else code
|
| 117 |
+
return language, code_without_language
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def convert_to_markdown(text):
|
| 121 |
+
text = text.replace("$", "$")
|
| 122 |
+
|
| 123 |
+
def replace_leading_tabs_and_spaces(line):
|
| 124 |
+
new_line = []
|
| 125 |
+
|
| 126 |
+
for char in line:
|
| 127 |
+
if char == "\t":
|
| 128 |
+
new_line.append("	")
|
| 129 |
+
elif char == " ":
|
| 130 |
+
new_line.append(" ")
|
| 131 |
+
else:
|
| 132 |
+
break
|
| 133 |
+
return "".join(new_line) + line[len(new_line):]
|
| 134 |
+
|
| 135 |
+
markdown_text = ""
|
| 136 |
+
lines = text.split("\n")
|
| 137 |
+
in_code_block = False
|
| 138 |
+
|
| 139 |
+
for line in lines:
|
| 140 |
+
if in_code_block is False and line.startswith("```"):
|
| 141 |
+
in_code_block = True
|
| 142 |
+
markdown_text += "```\n"
|
| 143 |
+
elif in_code_block is True and line.startswith("```"):
|
| 144 |
+
in_code_block = False
|
| 145 |
+
markdown_text += "```\n"
|
| 146 |
+
elif in_code_block:
|
| 147 |
+
markdown_text += f"{line}\n"
|
| 148 |
+
else:
|
| 149 |
+
line = replace_leading_tabs_and_spaces(line)
|
| 150 |
+
line = re.sub(r"^(#)", r"\\\1", line)
|
| 151 |
+
markdown_text += f"{line} \n"
|
| 152 |
+
|
| 153 |
+
return markdown_text
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def add_language_tag(text):
|
| 157 |
+
def detect_language(code_block):
|
| 158 |
+
try:
|
| 159 |
+
lexer = guess_lexer(code_block)
|
| 160 |
+
return lexer.name.lower()
|
| 161 |
+
except ClassNotFound:
|
| 162 |
+
return ""
|
| 163 |
+
|
| 164 |
+
code_block_pattern = re.compile(r"(```)(\w*\n[^`]+```)", re.MULTILINE)
|
| 165 |
+
|
| 166 |
+
def replacement(match):
|
| 167 |
+
code_block = match.group(2)
|
| 168 |
+
if match.group(2).startswith("\n"):
|
| 169 |
+
language = detect_language(code_block)
|
| 170 |
+
if language:
|
| 171 |
+
return f"```{language}{code_block}```"
|
| 172 |
+
else:
|
| 173 |
+
return f"```\n{code_block}```"
|
| 174 |
+
else:
|
| 175 |
+
return match.group(1) + code_block + "```"
|
| 176 |
+
|
| 177 |
+
text2 = code_block_pattern.sub(replacement, text)
|
| 178 |
+
return text2
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def delete_last_conversation(chatbot, history):
|
| 182 |
+
if len(chatbot) > 0:
|
| 183 |
+
chatbot.pop()
|
| 184 |
+
|
| 185 |
+
if len(history) > 0:
|
| 186 |
+
history.pop()
|
| 187 |
+
|
| 188 |
+
return (
|
| 189 |
+
chatbot,
|
| 190 |
+
history,
|
| 191 |
+
"Delete Done",
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
def reset_state():
|
| 196 |
+
return [], [], "Reset Done"
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
def reset_textbox():
|
| 200 |
+
return gr.update(value=""), ""
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
def cancel_outputing():
|
| 204 |
+
return "Stop Done"
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def transfer_input(inputs):
|
| 208 |
+
# 一次性返回,降低延迟
|
| 209 |
+
textbox = reset_textbox()
|
| 210 |
+
return (
|
| 211 |
+
inputs,
|
| 212 |
+
gr.update(value=""),
|
| 213 |
+
gr.Button.update(visible=True),
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
class State:
|
| 218 |
+
interrupted = False
|
| 219 |
+
|
| 220 |
+
def interrupt(self):
|
| 221 |
+
self.interrupted = True
|
| 222 |
+
|
| 223 |
+
def recover(self):
|
| 224 |
+
self.interrupted = False
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
shared_state = State()
|
assets/Kelpy-Codos.js
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// ==UserScript==
|
| 2 |
+
// @name Kelpy Codos
|
| 3 |
+
// @namespace https://github.com/Keldos-Li/Kelpy-Codos
|
| 4 |
+
// @version 1.0.5
|
| 5 |
+
// @author Keldos; https://keldos.me/
|
| 6 |
+
// @description Add copy button to PRE tags before CODE tag, for Chuanhu ChatGPT especially.
|
| 7 |
+
// Based on Chuanhu ChatGPT version: ac04408 (2023-3-22)
|
| 8 |
+
// @license GPL-3.0
|
| 9 |
+
// @grant none
|
| 10 |
+
// ==/UserScript==
|
| 11 |
+
|
| 12 |
+
(function () {
|
| 13 |
+
'use strict';
|
| 14 |
+
|
| 15 |
+
function addCopyButton(pre) {
|
| 16 |
+
var code = pre.querySelector('code');
|
| 17 |
+
if (!code) {
|
| 18 |
+
return; // 如果没有找到 <code> 元素,则不添加按钮
|
| 19 |
+
}
|
| 20 |
+
var firstChild = code.firstChild;
|
| 21 |
+
if (!firstChild) {
|
| 22 |
+
return; // 如果 <code> 元素没有子节点,则不添加按钮
|
| 23 |
+
}
|
| 24 |
+
var button = document.createElement('button');
|
| 25 |
+
button.textContent = '\uD83D\uDCCE'; // 使用 📎 符号作为“复制”按钮的文本
|
| 26 |
+
button.style.position = 'relative';
|
| 27 |
+
button.style.float = 'right';
|
| 28 |
+
button.style.fontSize = '1em'; // 可选:调整按钮大小
|
| 29 |
+
button.style.background = 'none'; // 可选:去掉背景颜色
|
| 30 |
+
button.style.border = 'none'; // 可选:去掉边框
|
| 31 |
+
button.style.cursor = 'pointer'; // 可选:显示指针样式
|
| 32 |
+
button.addEventListener('click', function () {
|
| 33 |
+
var range = document.createRange();
|
| 34 |
+
range.selectNodeContents(code);
|
| 35 |
+
range.setStartBefore(firstChild); // 将范围设置为第一个子节点之前
|
| 36 |
+
var selection = window.getSelection();
|
| 37 |
+
selection.removeAllRanges();
|
| 38 |
+
selection.addRange(range);
|
| 39 |
+
|
| 40 |
+
try {
|
| 41 |
+
var success = document.execCommand('copy');
|
| 42 |
+
if (success) {
|
| 43 |
+
button.textContent = '\u2714';
|
| 44 |
+
setTimeout(function () {
|
| 45 |
+
button.textContent = '\uD83D\uDCCE'; // 恢复按钮为“复制”
|
| 46 |
+
}, 2000);
|
| 47 |
+
} else {
|
| 48 |
+
button.textContent = '\u2716';
|
| 49 |
+
}
|
| 50 |
+
} catch (e) {
|
| 51 |
+
console.error(e);
|
| 52 |
+
button.textContent = '\u2716';
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
selection.removeAllRanges();
|
| 56 |
+
});
|
| 57 |
+
code.insertBefore(button, firstChild); // 将按钮插入到第一个子元素之前
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
function handleNewElements(mutationsList, observer) {
|
| 61 |
+
for (var mutation of mutationsList) {
|
| 62 |
+
if (mutation.type === 'childList') {
|
| 63 |
+
for (var node of mutation.addedNodes) {
|
| 64 |
+
if (node.nodeName === 'PRE') {
|
| 65 |
+
addCopyButton(node);
|
| 66 |
+
}
|
| 67 |
+
}
|
| 68 |
+
}
|
| 69 |
+
}
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
var observer = new MutationObserver(handleNewElements);
|
| 73 |
+
observer.observe(document.documentElement, { childList: true, subtree: true });
|
| 74 |
+
|
| 75 |
+
document.querySelectorAll('pre').forEach(addCopyButton);
|
| 76 |
+
})();
|
assets/custom.css
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
:root {
|
| 2 |
+
--chatbot-color-light: rgba(255, 255, 255, 0.08);
|
| 3 |
+
--chatbot-color-dark: #121111;
|
| 4 |
+
}
|
| 5 |
+
|
| 6 |
+
/* status_display */
|
| 7 |
+
#status_display {
|
| 8 |
+
display: flex;
|
| 9 |
+
min-height: 2.5em;
|
| 10 |
+
align-items: flex-end;
|
| 11 |
+
justify-content: flex-end;
|
| 12 |
+
}
|
| 13 |
+
#status_display p {
|
| 14 |
+
font-size: .85em;
|
| 15 |
+
font-family: monospace;
|
| 16 |
+
color: var(--body-text-color-subdued);
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
/* usage_display */
|
| 22 |
+
#usage_display {
|
| 23 |
+
height: 1em;
|
| 24 |
+
}
|
| 25 |
+
#usage_display p{
|
| 26 |
+
padding: 0 1em;
|
| 27 |
+
font-size: .85em;
|
| 28 |
+
font-family: monospace;
|
| 29 |
+
color: var(--body-text-color-subdued);
|
| 30 |
+
}
|
| 31 |
+
/* list */
|
| 32 |
+
ol:not(.options), ul:not(.options) {
|
| 33 |
+
padding-inline-start: 2em !important;
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
/* Thank @Keldos-Li for fixing it */
|
| 37 |
+
/* Light mode (default) */
|
| 38 |
+
#chuanhu_chatbot {
|
| 39 |
+
background-color: var(--chatbot-color-light) !important;
|
| 40 |
+
color: #000000 !important;
|
| 41 |
+
}
|
| 42 |
+
[data-testid = "bot"] {
|
| 43 |
+
background-color: rgba(255, 255, 255, 0.08) !important;
|
| 44 |
+
}
|
| 45 |
+
[data-testid = "user"] {
|
| 46 |
+
background-color: #95EC69 !important;
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
/* Dark mode */
|
| 50 |
+
.dark #chuanhu_chatbot {
|
| 51 |
+
background-color: var(--chatbot-color-dark) !important;
|
| 52 |
+
color: rgba(255, 255, 255, 0.08) !important;
|
| 53 |
+
}
|
| 54 |
+
.dark [data-testid = "bot"] {
|
| 55 |
+
background-color: #2C2C2C !important;
|
| 56 |
+
}
|
| 57 |
+
.dark [data-testid = "user"] {
|
| 58 |
+
background-color: #26B561 !important;
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
#chuanhu_chatbot {
|
| 62 |
+
height: 100%;
|
| 63 |
+
min-height: 400px;
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
[class *= "message"] {
|
| 67 |
+
border-radius: var(--radius-xl) !important;
|
| 68 |
+
border: none;
|
| 69 |
+
padding: var(--spacing-xl) !important;
|
| 70 |
+
font-size: var(--text-md) !important;
|
| 71 |
+
line-height: var(--line-md) !important;
|
| 72 |
+
min-height: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl));
|
| 73 |
+
min-width: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl));
|
| 74 |
+
}
|
| 75 |
+
[data-testid = "bot"] {
|
| 76 |
+
max-width: 85%;
|
| 77 |
+
border-bottom-left-radius: 0 !important;
|
| 78 |
+
}
|
| 79 |
+
[data-testid = "user"] {
|
| 80 |
+
max-width: 85%;
|
| 81 |
+
width: auto !important;
|
| 82 |
+
border-bottom-right-radius: 0 !important;
|
| 83 |
+
}
|
| 84 |
+
/* Table */
|
| 85 |
+
table {
|
| 86 |
+
margin: 1em 0;
|
| 87 |
+
border-collapse: collapse;
|
| 88 |
+
empty-cells: show;
|
| 89 |
+
}
|
| 90 |
+
td,th {
|
| 91 |
+
border: 1.2px solid var(--border-color-primary) !important;
|
| 92 |
+
padding: 0.2em;
|
| 93 |
+
}
|
| 94 |
+
thead {
|
| 95 |
+
background-color: rgba(175,184,193,0.2);
|
| 96 |
+
}
|
| 97 |
+
thead th {
|
| 98 |
+
padding: .5em .2em;
|
| 99 |
+
}
|
| 100 |
+
/* Inline code */
|
| 101 |
+
code {
|
| 102 |
+
display: inline;
|
| 103 |
+
white-space: break-spaces;
|
| 104 |
+
border-radius: 6px;
|
| 105 |
+
margin: 0 2px 0 2px;
|
| 106 |
+
padding: .2em .4em .1em .4em;
|
| 107 |
+
background-color: rgba(175,184,193,0.2);
|
| 108 |
+
}
|
| 109 |
+
/* Code block */
|
| 110 |
+
pre code {
|
| 111 |
+
display: block;
|
| 112 |
+
overflow: auto;
|
| 113 |
+
white-space: pre;
|
| 114 |
+
background-color: hsla(0, 0%, 0%, 80%)!important;
|
| 115 |
+
border-radius: 10px;
|
| 116 |
+
padding: 1.4em 1.2em 0em 1.4em;
|
| 117 |
+
margin: 1.2em 2em 1.2em 0.5em;
|
| 118 |
+
color: #FFF;
|
| 119 |
+
box-shadow: 6px 6px 16px hsla(0, 0%, 0%, 0.2);
|
| 120 |
+
}
|
| 121 |
+
/* Hightlight */
|
| 122 |
+
.highlight .hll { background-color: #49483e }
|
| 123 |
+
.highlight .c { color: #75715e } /* Comment */
|
| 124 |
+
.highlight .err { color: #960050; background-color: #1e0010 } /* Error */
|
| 125 |
+
.highlight .k { color: #66d9ef } /* Keyword */
|
| 126 |
+
.highlight .l { color: #ae81ff } /* Literal */
|
| 127 |
+
.highlight .n { color: #f8f8f2 } /* Name */
|
| 128 |
+
.highlight .o { color: #f92672 } /* Operator */
|
| 129 |
+
.highlight .p { color: #f8f8f2 } /* Punctuation */
|
| 130 |
+
.highlight .ch { color: #75715e } /* Comment.Hashbang */
|
| 131 |
+
.highlight .cm { color: #75715e } /* Comment.Multiline */
|
| 132 |
+
.highlight .cp { color: #75715e } /* Comment.Preproc */
|
| 133 |
+
.highlight .cpf { color: #75715e } /* Comment.PreprocFile */
|
| 134 |
+
.highlight .c1 { color: #75715e } /* Comment.Single */
|
| 135 |
+
.highlight .cs { color: #75715e } /* Comment.Special */
|
| 136 |
+
.highlight .gd { color: #f92672 } /* Generic.Deleted */
|
| 137 |
+
.highlight .ge { font-style: italic } /* Generic.Emph */
|
| 138 |
+
.highlight .gi { color: #a6e22e } /* Generic.Inserted */
|
| 139 |
+
.highlight .gs { font-weight: bold } /* Generic.Strong */
|
| 140 |
+
.highlight .gu { color: #75715e } /* Generic.Subheading */
|
| 141 |
+
.highlight .kc { color: #66d9ef } /* Keyword.Constant */
|
| 142 |
+
.highlight .kd { color: #66d9ef } /* Keyword.Declaration */
|
| 143 |
+
.highlight .kn { color: #f92672 } /* Keyword.Namespace */
|
| 144 |
+
.highlight .kp { color: #66d9ef } /* Keyword.Pseudo */
|
| 145 |
+
.highlight .kr { color: #66d9ef } /* Keyword.Reserved */
|
| 146 |
+
.highlight .kt { color: #66d9ef } /* Keyword.Type */
|
| 147 |
+
.highlight .ld { color: #e6db74 } /* Literal.Date */
|
| 148 |
+
.highlight .m { color: #ae81ff } /* Literal.Number */
|
| 149 |
+
.highlight .s { color: #e6db74 } /* Literal.String */
|
| 150 |
+
.highlight .na { color: #a6e22e } /* Name.Attribute */
|
| 151 |
+
.highlight .nb { color: #f8f8f2 } /* Name.Builtin */
|
| 152 |
+
.highlight .nc { color: #a6e22e } /* Name.Class */
|
| 153 |
+
.highlight .no { color: #66d9ef } /* Name.Constant */
|
| 154 |
+
.highlight .nd { color: #a6e22e } /* Name.Decorator */
|
| 155 |
+
.highlight .ni { color: #f8f8f2 } /* Name.Entity */
|
| 156 |
+
.highlight .ne { color: #a6e22e } /* Name.Exception */
|
| 157 |
+
.highlight .nf { color: #a6e22e } /* Name.Function */
|
| 158 |
+
.highlight .nl { color: #f8f8f2 } /* Name.Label */
|
| 159 |
+
.highlight .nn { color: #f8f8f2 } /* Name.Namespace */
|
| 160 |
+
.highlight .nx { color: #a6e22e } /* Name.Other */
|
| 161 |
+
.highlight .py { color: #f8f8f2 } /* Name.Property */
|
| 162 |
+
.highlight .nt { color: #f92672 } /* Name.Tag */
|
| 163 |
+
.highlight .nv { color: #f8f8f2 } /* Name.Variable */
|
| 164 |
+
.highlight .ow { color: #f92672 } /* Operator.Word */
|
| 165 |
+
.highlight .w { color: #f8f8f2 } /* Text.Whitespace */
|
| 166 |
+
.highlight .mb { color: #ae81ff } /* Literal.Number.Bin */
|
| 167 |
+
.highlight .mf { color: #ae81ff } /* Literal.Number.Float */
|
| 168 |
+
.highlight .mh { color: #ae81ff } /* Literal.Number.Hex */
|
| 169 |
+
.highlight .mi { color: #ae81ff } /* Literal.Number.Integer */
|
| 170 |
+
.highlight .mo { color: #ae81ff } /* Literal.Number.Oct */
|
| 171 |
+
.highlight .sa { color: #e6db74 } /* Literal.String.Affix */
|
| 172 |
+
.highlight .sb { color: #e6db74 } /* Literal.String.Backtick */
|
| 173 |
+
.highlight .sc { color: #e6db74 } /* Literal.String.Char */
|
| 174 |
+
.highlight .dl { color: #e6db74 } /* Literal.String.Delimiter */
|
| 175 |
+
.highlight .sd { color: #e6db74 } /* Literal.String.Doc */
|
| 176 |
+
.highlight .s2 { color: #e6db74 } /* Literal.String.Double */
|
| 177 |
+
.highlight .se { color: #ae81ff } /* Literal.String.Escape */
|
| 178 |
+
.highlight .sh { color: #e6db74 } /* Literal.String.Heredoc */
|
| 179 |
+
.highlight .si { color: #e6db74 } /* Literal.String.Interpol */
|
| 180 |
+
.highlight .sx { color: #e6db74 } /* Literal.String.Other */
|
| 181 |
+
.highlight .sr { color: #e6db74 } /* Literal.String.Regex */
|
| 182 |
+
.highlight .s1 { color: #e6db74 } /* Literal.String.Single */
|
| 183 |
+
.highlight .ss { color: #e6db74 } /* Literal.String.Symbol */
|
| 184 |
+
.highlight .bp { color: #f8f8f2 } /* Name.Builtin.Pseudo */
|
| 185 |
+
.highlight .fm { color: #a6e22e } /* Name.Function.Magic */
|
| 186 |
+
.highlight .vc { color: #f8f8f2 } /* Name.Variable.Class */
|
| 187 |
+
.highlight .vg { color: #f8f8f2 } /* Name.Variable.Global */
|
| 188 |
+
.highlight .vi { color: #f8f8f2 } /* Name.Variable.Instance */
|
| 189 |
+
.highlight .vm { color: #f8f8f2 } /* Name.Variable.Magic */
|
| 190 |
+
.highlight .il { color: #ae81ff } /* Literal.Number.Integer.Long */
|
assets/custom.js
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
// custom javascript here
|
assets/favicon.ico
ADDED
|
|
clc/__init__.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding:utf-8 _*-
|
| 3 |
+
"""
|
| 4 |
+
@author:quincy qiang
|
| 5 |
+
@license: Apache Licence
|
| 6 |
+
@file: __init__.py
|
| 7 |
+
@time: 2023/04/17
|
| 8 |
+
@contact: [email protected]
|
| 9 |
+
@software: PyCharm
|
| 10 |
+
@description: coding..
|
| 11 |
+
"""
|
clc/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (310 Bytes). View file
|
|
|
clc/__pycache__/__init__.cpython-39.pyc
ADDED
|
Binary file (308 Bytes). View file
|
|
|
clc/__pycache__/gpt_service.cpython-310.pyc
ADDED
|
Binary file (1.96 kB). View file
|
|
|
clc/__pycache__/gpt_service.cpython-39.pyc
ADDED
|
Binary file (1.95 kB). View file
|
|
|
clc/__pycache__/langchain_application.cpython-310.pyc
ADDED
|
Binary file (3.21 kB). View file
|
|
|
clc/__pycache__/langchain_application.cpython-39.pyc
ADDED
|
Binary file (3.2 kB). View file
|
|
|
clc/__pycache__/source_service.cpython-310.pyc
ADDED
|
Binary file (2.37 kB). View file
|
|
|
clc/__pycache__/source_service.cpython-39.pyc
ADDED
|
Binary file (2.36 kB). View file
|
|
|
clc/config.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding:utf-8 _*-
|
| 3 |
+
"""
|
| 4 |
+
@author:quincy qiang
|
| 5 |
+
@license: Apache Licence
|
| 6 |
+
@file: config.py
|
| 7 |
+
@time: 2023/04/17
|
| 8 |
+
@contact: [email protected]
|
| 9 |
+
@software: PyCharm
|
| 10 |
+
@description: coding..
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class LangChainCFG:
|
| 15 |
+
llm_model_name = 'fb700/chatglm-fitness-RLHF' # 本地模型文件 or huggingface远程仓库
|
| 16 |
+
embedding_model_name = 'moka-ai/m3e-large' # 检索模型文件 or huggingface远程仓库
|
| 17 |
+
vector_store_path = '.'
|
| 18 |
+
docs_path = './docs'
|
clc/gpt_service.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding:utf-8 _*-
|
| 3 |
+
"""
|
| 4 |
+
@author:quincy qiang
|
| 5 |
+
@license: Apache Licence
|
| 6 |
+
@file: generate.py
|
| 7 |
+
@time: 2023/04/17
|
| 8 |
+
@contact: [email protected]
|
| 9 |
+
@software: PyCharm
|
| 10 |
+
@description: coding..
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
from typing import List, Optional
|
| 14 |
+
|
| 15 |
+
from langchain.llms.base import LLM
|
| 16 |
+
from langchain.llms.utils import enforce_stop_tokens
|
| 17 |
+
from transformers import AutoModel, AutoTokenizer
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class ChatGLMService(LLM):
|
| 21 |
+
max_token: int = 10000
|
| 22 |
+
temperature: float = 0.1
|
| 23 |
+
top_p = 0.9
|
| 24 |
+
history = []
|
| 25 |
+
tokenizer: object = None
|
| 26 |
+
model: object = None
|
| 27 |
+
|
| 28 |
+
def __init__(self):
|
| 29 |
+
super().__init__()
|
| 30 |
+
|
| 31 |
+
@property
|
| 32 |
+
def _llm_type(self) -> str:
|
| 33 |
+
return "ChatGLM"
|
| 34 |
+
|
| 35 |
+
def _call(self,
|
| 36 |
+
prompt: str,
|
| 37 |
+
stop: Optional[List[str]] = None) -> str:
|
| 38 |
+
response, _ = self.model.chat(
|
| 39 |
+
self.tokenizer,
|
| 40 |
+
prompt,
|
| 41 |
+
history=self.history,
|
| 42 |
+
max_length=self.max_token,
|
| 43 |
+
temperature=self.temperature,
|
| 44 |
+
)
|
| 45 |
+
if stop is not None:
|
| 46 |
+
response = enforce_stop_tokens(response, stop)
|
| 47 |
+
self.history = self.history + [[None, response]]
|
| 48 |
+
return response
|
| 49 |
+
|
| 50 |
+
def load_model(self,
|
| 51 |
+
model_name_or_path: str = "THUDM/chatglm-6b"):
|
| 52 |
+
self.tokenizer = AutoTokenizer.from_pretrained(
|
| 53 |
+
model_name_or_path,
|
| 54 |
+
trust_remote_code=True
|
| 55 |
+
)
|
| 56 |
+
self.model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True).half().cuda()
|
| 57 |
+
self.model=self.model.eval()
|
| 58 |
+
# if __name__ == '__main__':
|
| 59 |
+
# config=LangChainCFG()
|
| 60 |
+
# chatLLM = ChatGLMService()
|
| 61 |
+
# chatLLM.load_model(model_name_or_path=config.llm_model_name)
|
| 62 |
+
|
clc/langchain_application.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding:utf-8 _*-
|
| 3 |
+
"""
|
| 4 |
+
@author:quincy qiang
|
| 5 |
+
@license: Apache Licence
|
| 6 |
+
@file: model.py
|
| 7 |
+
@time: 2023/04/17
|
| 8 |
+
@contact: [email protected]
|
| 9 |
+
@software: PyCharm
|
| 10 |
+
@description: coding..
|
| 11 |
+
"""
|
| 12 |
+
from langchain.chains import RetrievalQA
|
| 13 |
+
from langchain.prompts.prompt import PromptTemplate
|
| 14 |
+
|
| 15 |
+
from clc.config import LangChainCFG
|
| 16 |
+
from clc.gpt_service import ChatGLMService
|
| 17 |
+
from clc.source_service import SourceService
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class LangChainApplication(object):
|
| 21 |
+
def __init__(self, config):
|
| 22 |
+
self.config = config
|
| 23 |
+
self.llm_service = ChatGLMService()
|
| 24 |
+
self.llm_service.load_model(model_name_or_path=self.config.llm_model_name)
|
| 25 |
+
self.source_service = SourceService(config)
|
| 26 |
+
|
| 27 |
+
# if self.config.kg_vector_stores is None:
|
| 28 |
+
# print("init a source vector store")
|
| 29 |
+
# self.source_service.init_source_vector()
|
| 30 |
+
# else:
|
| 31 |
+
# print("load zh_wikipedia source vector store ")
|
| 32 |
+
# try:
|
| 33 |
+
# self.source_service.load_vector_store(self.config.kg_vector_stores['初始化知识库'])
|
| 34 |
+
# except Exception as e:
|
| 35 |
+
# self.source_service.init_source_vector()
|
| 36 |
+
|
| 37 |
+
def get_knowledge_based_answer(self, query,
|
| 38 |
+
history_len=5,
|
| 39 |
+
temperature=0.1,
|
| 40 |
+
top_p=0.9,
|
| 41 |
+
top_k=4,
|
| 42 |
+
web_content='',
|
| 43 |
+
chat_history=[]):
|
| 44 |
+
if web_content:
|
| 45 |
+
prompt_template = f"""基于以下已知信息,简洁和专业的来回答用户的问题。
|
| 46 |
+
如果无法从中得到答案,请说 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息",不允许在答案中添加编造成分,答案请使用中文。
|
| 47 |
+
已知网络检索内容:{web_content}""" + """
|
| 48 |
+
已知内容:
|
| 49 |
+
{context}
|
| 50 |
+
问题:
|
| 51 |
+
{question}"""
|
| 52 |
+
else:
|
| 53 |
+
prompt_template = """基于以下已知信息,简洁和专业的来回答用户的问题。
|
| 54 |
+
如果无法从中得到答案,请说 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息",不允许在答案中添加编造成分,答案请使用中文。
|
| 55 |
+
已知内容:
|
| 56 |
+
{context}
|
| 57 |
+
问题:
|
| 58 |
+
{question}"""
|
| 59 |
+
prompt = PromptTemplate(template=prompt_template,
|
| 60 |
+
input_variables=["context", "question"])
|
| 61 |
+
self.llm_service.history = chat_history[-history_len:] if history_len > 0 else []
|
| 62 |
+
|
| 63 |
+
self.llm_service.temperature = temperature
|
| 64 |
+
self.llm_service.top_p = top_p
|
| 65 |
+
|
| 66 |
+
knowledge_chain = RetrievalQA.from_llm(
|
| 67 |
+
llm=self.llm_service,
|
| 68 |
+
retriever=self.source_service.vector_store.as_retriever(
|
| 69 |
+
search_kwargs={"k": top_k}),
|
| 70 |
+
prompt=prompt)
|
| 71 |
+
knowledge_chain.combine_documents_chain.document_prompt = PromptTemplate(
|
| 72 |
+
input_variables=["page_content"], template="{page_content}")
|
| 73 |
+
|
| 74 |
+
knowledge_chain.return_source_documents = True
|
| 75 |
+
|
| 76 |
+
result = knowledge_chain({"query": query})
|
| 77 |
+
return result
|
| 78 |
+
|
| 79 |
+
def get_llm_answer(self, query='', web_content=''):
|
| 80 |
+
if web_content:
|
| 81 |
+
prompt = f'基于网络检索内容:{web_content},回答以下问题{query}'
|
| 82 |
+
else:
|
| 83 |
+
prompt = query
|
| 84 |
+
result = self.llm_service._call(prompt)
|
| 85 |
+
return result
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
if __name__ == '__main__':
|
| 89 |
+
config = LangChainCFG()
|
| 90 |
+
application = LangChainApplication(config)
|
| 91 |
+
# result = application.get_knowledge_based_answer('马保国是谁')
|
| 92 |
+
# print(result)
|
| 93 |
+
# application.source_service.add_document('/home/searchgpt/yq/Knowledge-ChatGLM/docs/added/马保国.txt')
|
| 94 |
+
# result = application.get_knowledge_based_answer('马保国是谁')
|
| 95 |
+
# print(result)
|
| 96 |
+
result = application.get_llm_answer('马保国是谁')
|
| 97 |
+
print(result)
|
clc/source_service.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding:utf-8 _*-
|
| 3 |
+
"""
|
| 4 |
+
@author:quincy qiang
|
| 5 |
+
@license: Apache Licence
|
| 6 |
+
@file: search.py
|
| 7 |
+
@time: 2023/04/17
|
| 8 |
+
@contact: [email protected]
|
| 9 |
+
@software: PyCharm
|
| 10 |
+
@description: coding..
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
|
| 15 |
+
from duckduckgo_search import ddg
|
| 16 |
+
from langchain.document_loaders import UnstructuredFileLoader
|
| 17 |
+
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
|
| 18 |
+
from langchain.vectorstores import FAISS
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class SourceService(object):
|
| 22 |
+
def __init__(self, config):
|
| 23 |
+
self.vector_store = None
|
| 24 |
+
self.config = config
|
| 25 |
+
self.embeddings = HuggingFaceEmbeddings(model_name=self.config.embedding_model_name)
|
| 26 |
+
self.docs_path = self.config.docs_path
|
| 27 |
+
self.vector_store_path = self.config.vector_store_path
|
| 28 |
+
|
| 29 |
+
def init_source_vector(self):
|
| 30 |
+
"""
|
| 31 |
+
初始化本地知识库向量
|
| 32 |
+
:return:
|
| 33 |
+
"""
|
| 34 |
+
docs = []
|
| 35 |
+
for doc in os.listdir(self.docs_path):
|
| 36 |
+
if doc.endswith('.txt'):
|
| 37 |
+
print(doc)
|
| 38 |
+
loader = UnstructuredFileLoader(f'{self.docs_path}/{doc}', mode="elements")
|
| 39 |
+
doc = loader.load()
|
| 40 |
+
docs.extend(doc)
|
| 41 |
+
self.vector_store = FAISS.from_documents(docs, self.embeddings)
|
| 42 |
+
self.vector_store.save_local(self.vector_store_path)
|
| 43 |
+
|
| 44 |
+
def add_document(self, document_path):
|
| 45 |
+
loader = UnstructuredFileLoader(document_path, mode="elements")
|
| 46 |
+
doc = loader.load()
|
| 47 |
+
self.vector_store.add_documents(doc)
|
| 48 |
+
self.vector_store.save_local(self.vector_store_path)
|
| 49 |
+
|
| 50 |
+
def load_vector_store(self, path):
|
| 51 |
+
if path is None:
|
| 52 |
+
self.vector_store = FAISS.load_local(self.vector_store_path, self.embeddings)
|
| 53 |
+
else:
|
| 54 |
+
self.vector_store = FAISS.load_local(path, self.embeddings)
|
| 55 |
+
return self.vector_store
|
| 56 |
+
|
| 57 |
+
def search_web(self, query):
|
| 58 |
+
|
| 59 |
+
# SESSION.proxies = {
|
| 60 |
+
# "http": f"socks5h://localhost:7890",
|
| 61 |
+
# "https": f"socks5h://localhost:7890"
|
| 62 |
+
# }
|
| 63 |
+
try:
|
| 64 |
+
results = ddg(query)
|
| 65 |
+
web_content = ''
|
| 66 |
+
if results:
|
| 67 |
+
for result in results:
|
| 68 |
+
web_content += result['body']
|
| 69 |
+
return web_content
|
| 70 |
+
except Exception as e:
|
| 71 |
+
print(f"网络检索异常:{query}")
|
| 72 |
+
return ''
|
| 73 |
+
# if __name__ == '__main__':
|
| 74 |
+
# config = LangChainCFG()
|
| 75 |
+
# source_service = SourceService(config)
|
| 76 |
+
# source_service.init_source_vector()
|
| 77 |
+
# search_result = source_service.vector_store.similarity_search_with_score('科比')
|
| 78 |
+
# print(search_result)
|
| 79 |
+
#
|
| 80 |
+
# source_service.add_document('/home/searchgpt/yq/Knowledge-ChatGLM/docs/added/科比.txt')
|
| 81 |
+
# search_result = source_service.vector_store.similarity_search_with_score('科比')
|
| 82 |
+
# print(search_result)
|
| 83 |
+
#
|
| 84 |
+
# vector_store=source_service.load_vector_store()
|
| 85 |
+
# search_result = source_service.vector_store.similarity_search_with_score('科比')
|
| 86 |
+
# print(search_result)
|
corpus/zh_wikipedia/README.md
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 知识库构建
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
### 1 Wikipedia构建
|
| 5 |
+
|
| 6 |
+
参考教程:https://blog.51cto.com/u_15127535/2697309
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
一、维基百科
|
| 10 |
+
|
| 11 |
+
维基百科(Wikipedia),是一个基于维基技术的多语言百科全书协作计划,也是一部用不同语言写成的网络百科全书。维基百科是由吉米·威尔士与拉里·桑格两人合作创建的,于2001年1月13日在互联网上推出网站服务,并在2001年1月15日正式展开网络百科全书的项目。
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
二、维基百科处理
|
| 16 |
+
|
| 17 |
+
1 环境配置(1)编程语言采用 python3(2)Gensim第三方库,Gensim是一个Python的工具包,其中有包含了中文维基百科数据处理的类,使用方便。
|
| 18 |
+
Gensim : https://github.com/RaRe-Technologies/gensim
|
| 19 |
+
|
| 20 |
+
使用 pip install gensim 安装gensim。
|
| 21 |
+
|
| 22 |
+
(3)OpenCC第三方库,是中文字符转换,包括中文简体繁体相互转换等。
|
| 23 |
+
|
| 24 |
+
OpenCC:https://github.com/BYVoid/OpenCC,OpenCC源码采用c++实现,如果会用c++的可以使用根据介绍,make编译源码。
|
| 25 |
+
|
| 26 |
+
OpenCC也有python版本实现,可以通过pip安装(pip install opencc-python),速度要比c++版慢,但是使用方便,安装简单,推荐使用pip安装。
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
2 数据下载
|
| 31 |
+
|
| 32 |
+
中文维基百科数据按月进行更新备份,一般情况下,下载当前最新的数据,下载地址(https://dumps.wikimedia.org/zhwiki/latest/),我们下载的数据是:zhwiki-latest-pages-articles.xml.bz2。
|
| 33 |
+
|
| 34 |
+
中文维基百科数据一般包含如下几个部分:
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
训练词向量采用的数据是正文数据,下面我们将对正文数据进行处理。
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
3 数据抽取
|
| 43 |
+
|
| 44 |
+
下载下来的数据是压缩文件(bz2,gz),不需要解压,这里已经写好了一份利用gensim处理维基百科数据的脚本
|
| 45 |
+
|
| 46 |
+
wikidata_processhttps://github.com/bamtercelboo/corpus_process_script/tree/master/wikidata_process
|
| 47 |
+
|
| 48 |
+
使用:
|
| 49 |
+
|
| 50 |
+
python wiki_process.py zhwiki-latest-pages-articles.xml.bz2 zhwiki-latest.txt
|
| 51 |
+
|
| 52 |
+
这部分需要一些的时间,处理过后的得到一份中文维基百科正文数据(zhwiki-latest.txt)。
|
| 53 |
+
|
| 54 |
+
输出文件类似于:
|
| 55 |
+
|
| 56 |
+
歐幾里得 西元前三世紀的古希臘數學家 現在被認為是幾何之父 此畫為拉斐爾的作品 雅典學院 数学 是利用符号语言研究數量 结构 变化以及空间等概念的一門学科
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
4 中文繁体转简体
|
| 61 |
+
|
| 62 |
+
经过上述脚本得到的文件包含了大量的中文繁体字,我们需要将其转换成中文简体字。
|
| 63 |
+
|
| 64 |
+
我们利用OpenCC进行繁体转简体的操作,这里已经写好了一份python版本的脚本来进行处理
|
| 65 |
+
|
| 66 |
+
chinese_t2s
|
| 67 |
+
|
| 68 |
+
https://github.com/bamtercelboo/corpus_process_script/tree/master/chinese_t2s
|
| 69 |
+
|
| 70 |
+
使用:
|
| 71 |
+
|
| 72 |
+
python chinese_t2s.py –input input_file –output output_file
|
| 73 |
+
|
| 74 |
+
like:
|
| 75 |
+
|
| 76 |
+
python chinese_t2s.py –input zhwiki-latest.txt –output zhwiki-latest-simplified.txt
|
| 77 |
+
|
| 78 |
+
输出文件类似于
|
| 79 |
+
|
| 80 |
+
欧几里得 西元前三世纪的古希腊数学家 现在被认为是几何之父 此画为拉斐尔的作品 雅典学院 数学 是利用符号语言研究数量 结构 变化以及空间等概念的一门学科
|
| 81 |
+
|
| 82 |
+
5.清洗语料
|
| 83 |
+
|
| 84 |
+
上述处理已经得到了我们想要的数据,但是在其他的一些任务中,还需要对这份数据进行简单的处理,像词向量任务,在这得到的数据里,还包含很多的英文,日文,德语,中文标点,乱码等一些字符,我们要把这些字符清洗掉,只留下中文字符,仅仅留下中文字符只是一种处理方案,不同的任务需要不同的处理,这里已经写好了一份脚本
|
| 85 |
+
|
| 86 |
+
clean
|
| 87 |
+
|
| 88 |
+
https://github.com/bamtercelboo/corpus_process_script/tree/master/clean
|
| 89 |
+
|
| 90 |
+
使用:
|
| 91 |
+
|
| 92 |
+
python clean_corpus.py –input input_file –output output_file
|
| 93 |
+
|
| 94 |
+
like:
|
| 95 |
+
|
| 96 |
+
python clean_corpus.py –input zhwiki-latest-simplified.txt –output zhwiki-latest-simplified_cleaned.txt
|
| 97 |
+
|
| 98 |
+
效果:
|
| 99 |
+
|
| 100 |
+
input:
|
| 101 |
+
|
| 102 |
+
哲学 哲学(英语:philosophy)是对普遍的和基本的问题的研究,这些问题通常和存在、知识、价值、理性、心灵、语言等有关。
|
| 103 |
+
|
| 104 |
+
output:
|
| 105 |
+
|
| 106 |
+
哲学哲学英语是对普遍的和基本的问题的研究这些问题通常和存在知识价值理性心灵语言等有关
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
三、数据处理脚本
|
| 111 |
+
|
| 112 |
+
近在github上新开了一个Repositorycorpus-process-scripthttps://github.com/bamtercelboo/corpus_process_script在这个repo,将存放中英文数据处理脚本,语言不限,会有详细的README,希望对大家能有一些帮助。
|
| 113 |
+
References
|
| 114 |
+
|
corpus/zh_wikipedia/chinese_t2s.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding:utf-8 _*-
|
| 3 |
+
"""
|
| 4 |
+
@author:quincy qiang
|
| 5 |
+
@license: Apache Licence
|
| 6 |
+
@file: chinese_t2s.py.py
|
| 7 |
+
@time: 2023/04/19
|
| 8 |
+
@contact: [email protected]
|
| 9 |
+
@software: PyCharm
|
| 10 |
+
@description: coding..
|
| 11 |
+
"""
|
| 12 |
+
import sys
|
| 13 |
+
import os
|
| 14 |
+
import opencc
|
| 15 |
+
from optparse import OptionParser
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class T2S(object):
|
| 19 |
+
def __init__(self, infile, outfile):
|
| 20 |
+
self.infile = infile
|
| 21 |
+
self.outfile = outfile
|
| 22 |
+
self.cc = opencc.OpenCC('t2s')
|
| 23 |
+
self.t_corpus = []
|
| 24 |
+
self.s_corpus = []
|
| 25 |
+
self.read(self.infile)
|
| 26 |
+
self.t2s()
|
| 27 |
+
self.write(self.s_corpus, self.outfile)
|
| 28 |
+
|
| 29 |
+
def read(self, path):
|
| 30 |
+
print(path)
|
| 31 |
+
if os.path.isfile(path) is False:
|
| 32 |
+
print("path is not a file")
|
| 33 |
+
exit()
|
| 34 |
+
now_line = 0
|
| 35 |
+
with open(path, encoding="UTF-8") as f:
|
| 36 |
+
for line in f:
|
| 37 |
+
now_line += 1
|
| 38 |
+
line = line.replace("\n", "").replace("\t", "")
|
| 39 |
+
self.t_corpus.append(line)
|
| 40 |
+
print("read finished")
|
| 41 |
+
|
| 42 |
+
def t2s(self):
|
| 43 |
+
now_line = 0
|
| 44 |
+
all_line = len(self.t_corpus)
|
| 45 |
+
for line in self.t_corpus:
|
| 46 |
+
now_line += 1
|
| 47 |
+
if now_line % 1000 == 0:
|
| 48 |
+
sys.stdout.write("\rhandling with the {} line, all {} lines.".format(now_line, all_line))
|
| 49 |
+
self.s_corpus.append(self.cc.convert(line))
|
| 50 |
+
sys.stdout.write("\rhandling with the {} line, all {} lines.".format(now_line, all_line))
|
| 51 |
+
print("\nhandling finished")
|
| 52 |
+
|
| 53 |
+
def write(self, list, path):
|
| 54 |
+
print("writing now......")
|
| 55 |
+
if os.path.exists(path):
|
| 56 |
+
os.remove(path)
|
| 57 |
+
file = open(path, encoding="UTF-8", mode="w")
|
| 58 |
+
for line in list:
|
| 59 |
+
file.writelines(line + "\n")
|
| 60 |
+
file.close()
|
| 61 |
+
print("writing finished.")
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
if __name__ == "__main__":
|
| 65 |
+
print("Traditional Chinese to Simplified Chinese")
|
| 66 |
+
# input = "./wiki_zh_10.txt"
|
| 67 |
+
# output = "wiki_zh_10_sim.txt"
|
| 68 |
+
# T2S(infile=input, outfile=output)
|
| 69 |
+
|
| 70 |
+
parser = OptionParser()
|
| 71 |
+
parser.add_option("--input", dest="input", default="", help="traditional file")
|
| 72 |
+
parser.add_option("--output", dest="output", default="", help="simplified file")
|
| 73 |
+
(options, args) = parser.parse_args()
|
| 74 |
+
|
| 75 |
+
input = options.input
|
| 76 |
+
output = options.output
|
| 77 |
+
|
| 78 |
+
try:
|
| 79 |
+
T2S(infile=input, outfile=output)
|
| 80 |
+
print("All Finished.")
|
| 81 |
+
except Exception as err:
|
| 82 |
+
print(err)
|
corpus/zh_wikipedia/clean_corpus.py
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding:utf-8 _*-
|
| 3 |
+
"""
|
| 4 |
+
@author:quincy qiang
|
| 5 |
+
@license: Apache Licence
|
| 6 |
+
@file: clean_corpus.py.py
|
| 7 |
+
@time: 2023/04/19
|
| 8 |
+
@contact: [email protected]
|
| 9 |
+
@software: PyCharm
|
| 10 |
+
@description: coding..
|
| 11 |
+
"""
|
| 12 |
+
"""
|
| 13 |
+
FILE : clean_corpus.py
|
| 14 |
+
FUNCTION : None
|
| 15 |
+
"""
|
| 16 |
+
import sys
|
| 17 |
+
import os
|
| 18 |
+
from optparse import OptionParser
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class Clean(object):
|
| 22 |
+
def __init__(self, infile, outfile):
|
| 23 |
+
self.infile = infile
|
| 24 |
+
self.outfile = outfile
|
| 25 |
+
self.corpus = []
|
| 26 |
+
self.remove_corpus = []
|
| 27 |
+
self.read(self.infile)
|
| 28 |
+
self.remove(self.corpus)
|
| 29 |
+
self.write(self.remove_corpus, self.outfile)
|
| 30 |
+
|
| 31 |
+
def read(self, path):
|
| 32 |
+
print("reading now......")
|
| 33 |
+
if os.path.isfile(path) is False:
|
| 34 |
+
print("path is not a file")
|
| 35 |
+
exit()
|
| 36 |
+
now_line = 0
|
| 37 |
+
with open(path, encoding="UTF-8") as f:
|
| 38 |
+
for line in f:
|
| 39 |
+
now_line += 1
|
| 40 |
+
line = line.replace("\n", "").replace("\t", "")
|
| 41 |
+
self.corpus.append(line)
|
| 42 |
+
print("read finished.")
|
| 43 |
+
|
| 44 |
+
def remove(self, list):
|
| 45 |
+
print("removing now......")
|
| 46 |
+
for line in list:
|
| 47 |
+
re_list = []
|
| 48 |
+
for word in line:
|
| 49 |
+
if self.is_chinese(word) is False:
|
| 50 |
+
continue
|
| 51 |
+
re_list.append(word)
|
| 52 |
+
self.remove_corpus.append("".join(re_list))
|
| 53 |
+
print("remove finished.")
|
| 54 |
+
|
| 55 |
+
def write(self, list, path):
|
| 56 |
+
print("writing now......")
|
| 57 |
+
if os.path.exists(path):
|
| 58 |
+
os.remove(path)
|
| 59 |
+
file = open(path, encoding="UTF-8", mode="w")
|
| 60 |
+
for line in list:
|
| 61 |
+
file.writelines(line + "\n")
|
| 62 |
+
file.close()
|
| 63 |
+
print("writing finished")
|
| 64 |
+
|
| 65 |
+
def is_chinese(self, uchar):
|
| 66 |
+
"""判断一个unicode是否是汉字"""
|
| 67 |
+
if (uchar >= u'\u4e00') and (uchar <= u'\u9fa5'):
|
| 68 |
+
return True
|
| 69 |
+
else:
|
| 70 |
+
return False
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
if __name__ == "__main__":
|
| 74 |
+
print("clean corpus")
|
| 75 |
+
|
| 76 |
+
parser = OptionParser()
|
| 77 |
+
parser.add_option("--input", dest="input", default="", help="input file")
|
| 78 |
+
parser.add_option("--output", dest="output", default="", help="output file")
|
| 79 |
+
(options, args) = parser.parse_args()
|
| 80 |
+
|
| 81 |
+
input = options.input
|
| 82 |
+
output = options.output
|
| 83 |
+
|
| 84 |
+
try:
|
| 85 |
+
Clean(infile=input, outfile=output)
|
| 86 |
+
print("All Finished.")
|
| 87 |
+
except Exception as err:
|
| 88 |
+
print(err)
|
corpus/zh_wikipedia/wiki_process.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding:utf-8 _*-
|
| 3 |
+
"""
|
| 4 |
+
@author:quincy qiang
|
| 5 |
+
@license: Apache Licence
|
| 6 |
+
@file: wiki_process.py
|
| 7 |
+
@time: 2023/04/19
|
| 8 |
+
@contact: [email protected]
|
| 9 |
+
@software: PyCharm
|
| 10 |
+
@description: https://blog.csdn.net/weixin_40871455/article/details/88822290
|
| 11 |
+
"""
|
| 12 |
+
import logging
|
| 13 |
+
import sys
|
| 14 |
+
from gensim.corpora import WikiCorpus
|
| 15 |
+
|
| 16 |
+
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s', level=logging.INFO)
|
| 17 |
+
'''
|
| 18 |
+
extract data from wiki dumps(*articles.xml.bz2) by gensim.
|
| 19 |
+
@2019-3-26
|
| 20 |
+
'''
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def help():
|
| 24 |
+
print("Usage: python wikipro.py zhwiki-20190320-pages-articles-multistream.xml.bz2 wiki.zh.txt")
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
if __name__ == '__main__':
|
| 28 |
+
if len(sys.argv) < 3:
|
| 29 |
+
help()
|
| 30 |
+
sys.exit(1)
|
| 31 |
+
logging.info("running %s" % ' '.join(sys.argv))
|
| 32 |
+
inp, outp = sys.argv[1:3]
|
| 33 |
+
i = 0
|
| 34 |
+
|
| 35 |
+
output = open(outp, 'w', encoding='utf8')
|
| 36 |
+
wiki = WikiCorpus(inp, dictionary={})
|
| 37 |
+
for text in wiki.get_texts():
|
| 38 |
+
output.write(" ".join(text) + "\n")
|
| 39 |
+
i = i + 1
|
| 40 |
+
if (i % 10000 == 0):
|
| 41 |
+
logging.info("Save " + str(i) + " articles")
|
| 42 |
+
output.close()
|
| 43 |
+
logging.info("Finished saved " + str(i) + "articles")
|
| 44 |
+
|
| 45 |
+
# 命令行下运行
|
| 46 |
+
# python wikipro.py cache/zh_wikipedia/zhwiki-latest-pages-articles.xml.bz2 wiki.zh.txt
|
create_knowledge.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# -*- coding:utf-8 _*-
|
| 3 |
+
"""
|
| 4 |
+
@author:quincy qiang
|
| 5 |
+
@license: Apache Licence
|
| 6 |
+
@file: create_knowledge.py
|
| 7 |
+
@time: 2023/04/18
|
| 8 |
+
@contact: [email protected]
|
| 9 |
+
@software: PyCharm
|
| 10 |
+
@description: - emoji:https://emojixd.com/pocket/science
|
| 11 |
+
"""
|
| 12 |
+
import os
|
| 13 |
+
import pandas as pd
|
| 14 |
+
from langchain.schema import Document
|
| 15 |
+
from langchain.document_loaders import UnstructuredFileLoader
|
| 16 |
+
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
|
| 17 |
+
from langchain.vectorstores import FAISS
|
| 18 |
+
from tqdm import tqdm
|
| 19 |
+
# 中文Wikipedia数据导入示例:
|
| 20 |
+
embedding_model_name = '/root/pretrained_models/text2vec-large-chinese'
|
| 21 |
+
docs_path = '/root/GoMall/Knowledge-ChatGLM/cache/financial_research_reports'
|
| 22 |
+
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# Wikipedia数据处理
|
| 26 |
+
|
| 27 |
+
# docs = []
|
| 28 |
+
|
| 29 |
+
# with open('docs/zh_wikipedia/zhwiki.sim.utf8', 'r', encoding='utf-8') as f:
|
| 30 |
+
# for idx, line in tqdm(enumerate(f.readlines())):
|
| 31 |
+
# metadata = {"source": f'doc_id_{idx}'}
|
| 32 |
+
# docs.append(Document(page_content=line.strip(), metadata=metadata))
|
| 33 |
+
#
|
| 34 |
+
# vector_store = FAISS.from_documents(docs, embeddings)
|
| 35 |
+
# vector_store.save_local('cache/zh_wikipedia/')
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
docs = []
|
| 40 |
+
|
| 41 |
+
with open('cache/zh_wikipedia/wiki.zh-sim-cleaned.txt', 'r', encoding='utf-8') as f:
|
| 42 |
+
for idx, line in tqdm(enumerate(f.readlines())):
|
| 43 |
+
metadata = {"source": f'doc_id_{idx}'}
|
| 44 |
+
docs.append(Document(page_content=line.strip(), metadata=metadata))
|
| 45 |
+
|
| 46 |
+
vector_store = FAISS.from_documents(docs, embeddings)
|
| 47 |
+
vector_store.save_local('cache/zh_wikipedia/')
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
# 金融研报数据处理
|
| 51 |
+
# docs = []
|
| 52 |
+
#
|
| 53 |
+
# for doc in tqdm(os.listdir(docs_path)):
|
| 54 |
+
# if doc.endswith('.txt'):
|
| 55 |
+
# # print(doc)
|
| 56 |
+
# loader = UnstructuredFileLoader(f'{docs_path}/{doc}', mode="elements")
|
| 57 |
+
# doc = loader.load()
|
| 58 |
+
# docs.extend(doc)
|
| 59 |
+
# vector_store = FAISS.from_documents(docs, embeddings)
|
| 60 |
+
# vector_store.save_local('cache/financial_research_reports')
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
# 英雄联盟
|
| 64 |
+
|
| 65 |
+
docs = []
|
| 66 |
+
|
| 67 |
+
lol_df = pd.read_csv('cache/lol/champions.csv')
|
| 68 |
+
# lol_df.columns = ['id', '英雄简称', '英雄全称', '出生地', '人物属性', '英雄类别', '英雄故事']
|
| 69 |
+
print(lol_df)
|
| 70 |
+
|
| 71 |
+
for idx, row in lol_df.iterrows():
|
| 72 |
+
metadata = {"source": f'doc_id_{idx}'}
|
| 73 |
+
text = ' '.join(row.values)
|
| 74 |
+
# for col in ['英雄简称', '英雄全称', '出生地', '人物属性', '英雄类别', '英雄故事']:
|
| 75 |
+
# text += row[col]
|
| 76 |
+
docs.append(Document(page_content=text, metadata=metadata))
|
| 77 |
+
|
| 78 |
+
vector_store = FAISS.from_documents(docs, embeddings)
|
| 79 |
+
vector_store.save_local('cache/lol/')
|
docs/added/马保国.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
马保国(1952年- ) ,英国混元太极拳协会创始人,自称“浑元形意太极拳掌门人”。
|
| 2 |
+
2020年11月15日,马保国首度回应“屡遭恶搞剪辑”:“远离武林,已回归平静生活” ;11月16日,马保国宣布将参演电影《少年功夫王》。 11月28日,人民日报客户端刊发评论《马保国闹剧,该立刻收场了》。 11月29日,新浪微博社区管理官方发布公告称,已解散马保国相关的粉丝群。
|
docs/姚明.txt
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
姚明(Yao Ming),男,汉族,无党派人士,1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江区震泽镇,前中国职业篮球运动员,司职中锋,现任亚洲篮球联合会主席、中国篮球协会主席、中职联公司董事长兼总经理, [1-3] 十三届全国青联副主席, [4] 改革先锋奖章获得者。 [5] 第十四届全国人大代表 [108] 。
|
| 2 |
+
1998年4月,姚明入选王非执教的国家队,开始篮球生涯。2001夺得CBA常规赛MVP,2002年夺得CBA总冠军以及总决赛MVP,分别3次当选CBA篮板王以及盖帽王,2次当选CBA扣篮王。在2002年NBA选秀中,他以状元秀身份被NBA的休斯敦火箭队选中,2003-09年连续6个赛季(生涯共8次)入选NBA全明星赛阵容,2次入选NBA最佳阵容二阵,3次入选NBA最佳阵容三阵。2009年,姚明收购上海男篮,成为上海久事大鲨鱼俱乐部老板。2011年7月20日,姚明宣布退役。
|
| 3 |
+
2013年,姚明当选为第十二届全国政协委员。2015年2月10日,姚明正式成为北京申办冬季奥林匹克运动会形象大使之一。2016年4月4日,姚明正式入选2016年奈史密斯篮球名人纪念堂,成为首位获此殊荣的中国人;10月,姚明成为中国“火星大使”;11月,当选CBA公司副董事长。 [6]
|
| 4 |
+
2017年10月20日,姚明已将上海哔哩哔哩俱乐部全部股权转让。 [7] 2018年9月,荣获第十届“中华慈善奖”慈善楷模奖项。 [8] 2019年10月28日,胡润研究院发布《2019胡润80后白手起家富豪榜》,姚明以22亿元排名第48。
|
docs/王治郅.txt
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
王治郅,1977年7月8日出生于北京,前中国篮球运动员,司职大前锋/中锋,现已退役。 [1]
|
| 2 |
+
1991年12月,王治郅进入八一青年男子篮球队。1993年初入选中国少年特殊身材篮球队,并于同年入选中国青年男子篮球队,后加入八一男子篮球队。2001-05年曾效力于NBA独行侠、快船以及热火队。 [1]
|
| 3 |
+
2015年9月15日新赛季CBA注册截止日,八一队的球员注册名单上并没有出现38岁老将王治郅的名字,王治郅退役已成事实 [2] 。2016年7月5日,王治郅的退役仪式在北京奥体中心举行,在仪式上,王治郅正式宣布退役。 [3] 2018年7月,王治郅正式成为八一南昌队主教练。 [1] [4]
|
| 4 |
+
王治郅是中国篮球界进入NBA的第一人,被评选为中国篮坛50大杰出人物和中国申办奥运特使。他和姚明、蒙克·巴特尔一起,被称为篮球场上的“移动长城”。 [5]
|
docs/科比.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
科比·布莱恩特(Kobe Bryant,1978年8月23日—2020年1月26日),全名科比·比恩·布莱恩特·考克斯(Kobe Bean Bryant Cox),出生于美国宾夕法尼亚州费城,美国已故篮球运动员,司职得分后卫/小前锋。 [5] [24] [84]
|
| 2 |
+
1996年NBA选秀,科比于第1轮第13顺位被夏洛特黄蜂队选中并被交易至洛杉矶湖人队,整个NBA生涯都效力于洛杉矶湖人队;共获得5次NBA总冠军、1次NBA常规赛MVP、2次NBA总决赛MVP、4次NBA全明星赛MVP、2次NBA赛季得分王;共入选NBA全明星首发阵容18次、NBA最佳阵容15次(其中一阵11次、二阵2次、三阵2次)、NBA最佳防守阵容12次(其中一阵9次、二阵3次)。 [9] [24]
|
| 3 |
+
2007年,科比首次入选美国国家男子篮球队,后帮助美国队夺得2007年美洲男篮锦标赛金牌、2008年北京奥运会男子篮球金牌以及2012年伦敦奥运会男子篮球金牌。 [91]
|
| 4 |
+
2015年11月30日,科比发文宣布将在赛季结束后退役。 [100] 2017年12月19日,湖人队为科比举行球衣退役仪式。 [22] 2020年4月5日,科比入选奈·史密斯篮球名人纪念堂。 [7]
|
| 5 |
+
美国时间2020年1月26日(北京时间2020年1月27日),科比因直升机事故遇难,享年41岁。 [23]
|
images/computing.png
ADDED
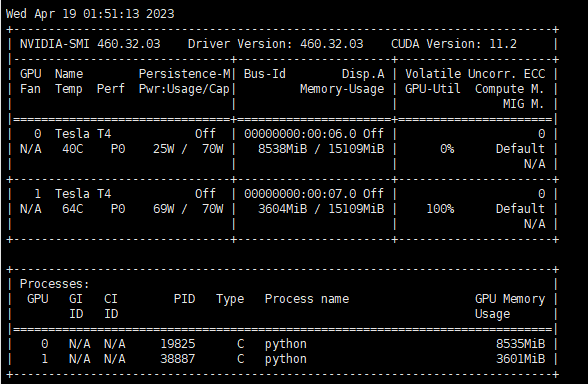
|
images/web_demos/v1.png
ADDED

|
images/web_demos/v2.png
ADDED

|
images/web_demos/v3.png
ADDED

|
images/wiki_process.png
ADDED
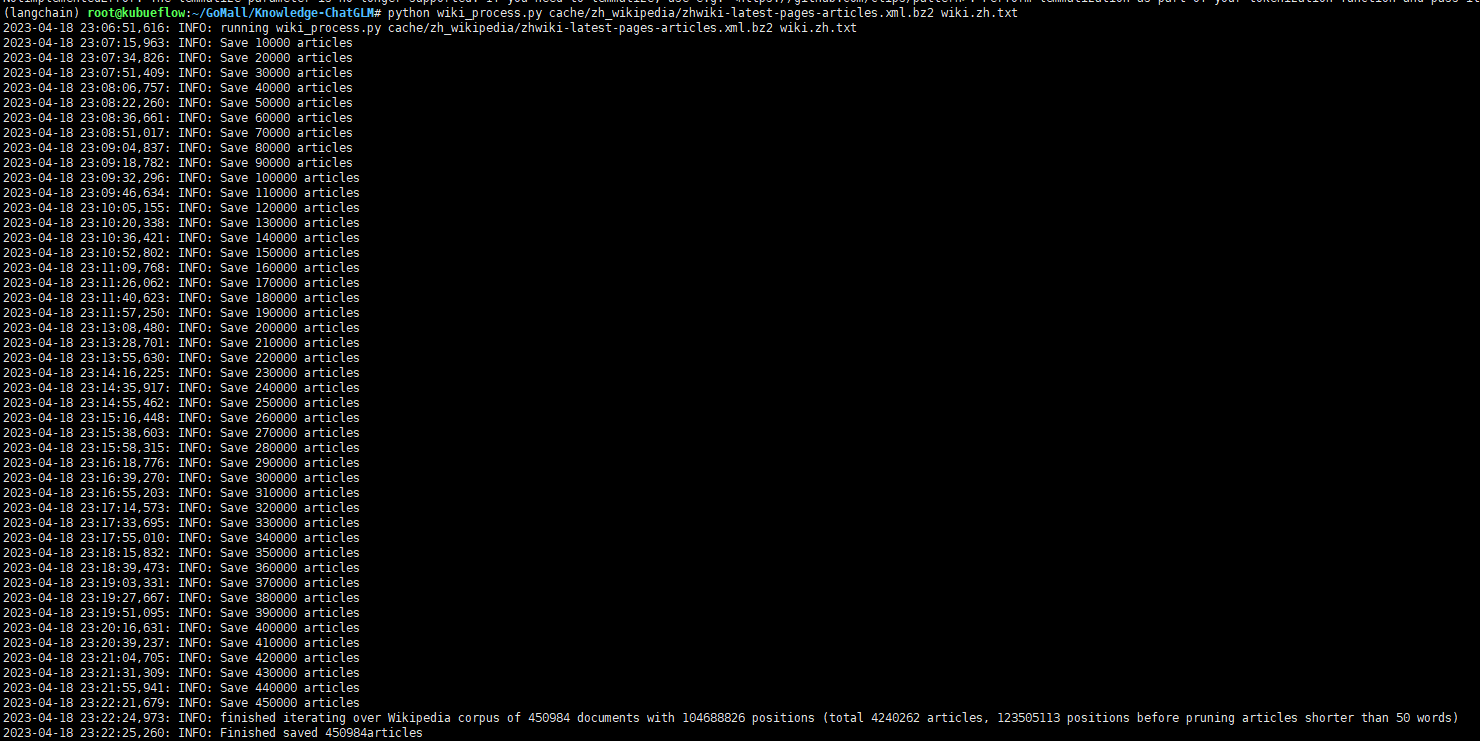
|
main.py
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import shutil
|
| 3 |
+
|
| 4 |
+
from app_modules.overwrites import postprocess
|
| 5 |
+
from app_modules.presets import *
|
| 6 |
+
from clc.langchain_application import LangChainApplication
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
# 修改成自己的配置!!!
|
| 10 |
+
class LangChainCFG:
|
| 11 |
+
llm_model_name = 'THUDM/chatglm-6b-int4-qe' # 本地模型文件 or huggingface远程仓库
|
| 12 |
+
embedding_model_name = 'GanymedeNil/text2vec-large-chinese' # 检索模型文件 or huggingface远程仓库
|
| 13 |
+
vector_store_path = './cache'
|
| 14 |
+
docs_path = './docs'
|
| 15 |
+
kg_vector_stores = {
|
| 16 |
+
'中文维基百科': './cache/zh_wikipedia',
|
| 17 |
+
'大规模金融研报': './cache/financial_research_reports',
|
| 18 |
+
'初始化': './cache',
|
| 19 |
+
} # 可以替换成自己的知识库,如果没有需要设置为None
|
| 20 |
+
# kg_vector_stores=None
|
| 21 |
+
patterns = ['模型问答', '知识库问答'] #
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
config = LangChainCFG()
|
| 25 |
+
application = LangChainApplication(config)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_file_list():
|
| 29 |
+
if not os.path.exists("docs"):
|
| 30 |
+
return []
|
| 31 |
+
return [f for f in os.listdir("docs")]
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
file_list = get_file_list()
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def upload_file(file):
|
| 38 |
+
if not os.path.exists("docs"):
|
| 39 |
+
os.mkdir("docs")
|
| 40 |
+
filename = os.path.basename(file.name)
|
| 41 |
+
shutil.move(file.name, "docs/" + filename)
|
| 42 |
+
# file_list首位插入新上传的文件
|
| 43 |
+
file_list.insert(0, filename)
|
| 44 |
+
application.source_service.add_document("docs/" + filename)
|
| 45 |
+
return gr.Dropdown.update(choices=file_list, value=filename)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def set_knowledge(kg_name, history):
|
| 49 |
+
try:
|
| 50 |
+
application.source_service.load_vector_store(config.kg_vector_stores[kg_name])
|
| 51 |
+
msg_status = f'{kg_name}知识库已成功加载'
|
| 52 |
+
except Exception as e:
|
| 53 |
+
print(e)
|
| 54 |
+
msg_status = f'{kg_name}知识库未成功加载'
|
| 55 |
+
return history + [[None, msg_status]]
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def clear_session():
|
| 59 |
+
return '', None
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def predict(input,
|
| 63 |
+
large_language_model,
|
| 64 |
+
embedding_model,
|
| 65 |
+
top_k,
|
| 66 |
+
use_web,
|
| 67 |
+
use_pattern,
|
| 68 |
+
history=None):
|
| 69 |
+
# print(large_language_model, embedding_model)
|
| 70 |
+
print(input)
|
| 71 |
+
if history == None:
|
| 72 |
+
history = []
|
| 73 |
+
|
| 74 |
+
if use_web == '使用':
|
| 75 |
+
web_content = application.source_service.search_web(query=input)
|
| 76 |
+
else:
|
| 77 |
+
web_content = ''
|
| 78 |
+
search_text = ''
|
| 79 |
+
if use_pattern == '模型问答':
|
| 80 |
+
result = application.get_llm_answer(query=input, web_content=web_content)
|
| 81 |
+
history.append((input, result))
|
| 82 |
+
search_text += web_content
|
| 83 |
+
return '', history, history, search_text
|
| 84 |
+
|
| 85 |
+
else:
|
| 86 |
+
resp = application.get_knowledge_based_answer(
|
| 87 |
+
query=input,
|
| 88 |
+
history_len=1,
|
| 89 |
+
temperature=0.1,
|
| 90 |
+
top_p=0.9,
|
| 91 |
+
top_k=top_k,
|
| 92 |
+
web_content=web_content,
|
| 93 |
+
chat_history=history
|
| 94 |
+
)
|
| 95 |
+
history.append((input, resp['result']))
|
| 96 |
+
for idx, source in enumerate(resp['source_documents'][:4]):
|
| 97 |
+
sep = f'----------【搜索结果{idx + 1}:】---------------\n'
|
| 98 |
+
search_text += f'{sep}\n{source.page_content}\n\n'
|
| 99 |
+
print(search_text)
|
| 100 |
+
search_text += "----------【网络检索内容】-----------\n"
|
| 101 |
+
search_text += web_content
|
| 102 |
+
return '', history, history, search_text
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
with open("assets/custom.css", "r", encoding="utf-8") as f:
|
| 106 |
+
customCSS = f.read()
|
| 107 |
+
with gr.Blocks(css=customCSS, theme=small_and_beautiful_theme) as demo:
|
| 108 |
+
gr.Markdown("""<h1><center>Chinese-LangChain</center></h1>
|
| 109 |
+
<center><font size=3>
|
| 110 |
+
</center></font>
|
| 111 |
+
""")
|
| 112 |
+
state = gr.State()
|
| 113 |
+
|
| 114 |
+
with gr.Row():
|
| 115 |
+
with gr.Column(scale=1):
|
| 116 |
+
embedding_model = gr.Dropdown([
|
| 117 |
+
"text2vec-base"
|
| 118 |
+
],
|
| 119 |
+
label="Embedding model",
|
| 120 |
+
value="text2vec-base")
|
| 121 |
+
|
| 122 |
+
large_language_model = gr.Dropdown(
|
| 123 |
+
[
|
| 124 |
+
"ChatGLM-6B-int4",
|
| 125 |
+
],
|
| 126 |
+
label="large language model",
|
| 127 |
+
value="ChatGLM-6B-int4")
|
| 128 |
+
|
| 129 |
+
top_k = gr.Slider(1,
|
| 130 |
+
20,
|
| 131 |
+
value=4,
|
| 132 |
+
step=1,
|
| 133 |
+
label="检索top-k文档",
|
| 134 |
+
interactive=True)
|
| 135 |
+
|
| 136 |
+
use_web = gr.Radio(["使用", "不使用"], label="web search",
|
| 137 |
+
info="是否使用网络搜索,使用时确保网络通常",
|
| 138 |
+
value="不使用"
|
| 139 |
+
)
|
| 140 |
+
use_pattern = gr.Radio(
|
| 141 |
+
[
|
| 142 |
+
'模型问答',
|
| 143 |
+
'知识库问答',
|
| 144 |
+
],
|
| 145 |
+
label="模式",
|
| 146 |
+
value='模型问答',
|
| 147 |
+
interactive=True)
|
| 148 |
+
|
| 149 |
+
kg_name = gr.Radio(list(config.kg_vector_stores.keys()),
|
| 150 |
+
label="知识库",
|
| 151 |
+
value=None,
|
| 152 |
+
info="使用知识库问答��请加载知识库",
|
| 153 |
+
interactive=True)
|
| 154 |
+
set_kg_btn = gr.Button("加载知识库")
|
| 155 |
+
|
| 156 |
+
file = gr.File(label="将文件上传到知识库库,内容要尽量匹配",
|
| 157 |
+
visible=True,
|
| 158 |
+
file_types=['.txt', '.md', '.docx', '.pdf']
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
with gr.Column(scale=4):
|
| 162 |
+
with gr.Row():
|
| 163 |
+
chatbot = gr.Chatbot(label='Chinese-LangChain').style(height=400)
|
| 164 |
+
with gr.Row():
|
| 165 |
+
message = gr.Textbox(label='请输入问题')
|
| 166 |
+
with gr.Row():
|
| 167 |
+
clear_history = gr.Button("🧹 清除历史对话")
|
| 168 |
+
send = gr.Button("🚀 发送")
|
| 169 |
+
with gr.Row():
|
| 170 |
+
gr.Markdown("""提醒:<br>
|
| 171 |
+
[Chinese-LangChain](https://github.com/yanqiangmiffy/Chinese-LangChain) <br>
|
| 172 |
+
有任何使用问题[Github Issue区](https://github.com/yanqiangmiffy/Chinese-LangChain)进行反馈. <br>
|
| 173 |
+
""")
|
| 174 |
+
with gr.Column(scale=2):
|
| 175 |
+
search = gr.Textbox(label='搜索结果')
|
| 176 |
+
|
| 177 |
+
# ============= 触发动作=============
|
| 178 |
+
file.upload(upload_file,
|
| 179 |
+
inputs=file,
|
| 180 |
+
outputs=None)
|
| 181 |
+
set_kg_btn.click(
|
| 182 |
+
set_knowledge,
|
| 183 |
+
show_progress=True,
|
| 184 |
+
inputs=[kg_name, chatbot],
|
| 185 |
+
outputs=chatbot
|
| 186 |
+
)
|
| 187 |
+
# 发送按钮 提交
|
| 188 |
+
send.click(predict,
|
| 189 |
+
inputs=[
|
| 190 |
+
message,
|
| 191 |
+
large_language_model,
|
| 192 |
+
embedding_model,
|
| 193 |
+
top_k,
|
| 194 |
+
use_web,
|
| 195 |
+
use_pattern,
|
| 196 |
+
state
|
| 197 |
+
],
|
| 198 |
+
outputs=[message, chatbot, state, search])
|
| 199 |
+
|
| 200 |
+
# 清空历史对话按钮 提交
|
| 201 |
+
clear_history.click(fn=clear_session,
|
| 202 |
+
inputs=[],
|
| 203 |
+
outputs=[chatbot, state],
|
| 204 |
+
queue=False)
|
| 205 |
+
|
| 206 |
+
# 输入框 回车
|
| 207 |
+
message.submit(predict,
|
| 208 |
+
inputs=[
|
| 209 |
+
message,
|
| 210 |
+
large_language_model,
|
| 211 |
+
embedding_model,
|
| 212 |
+
top_k,
|
| 213 |
+
use_web,
|
| 214 |
+
use_pattern,
|
| 215 |
+
state
|
| 216 |
+
],
|
| 217 |
+
outputs=[message, chatbot, state, search])
|
| 218 |
+
|
| 219 |
+
demo.queue(concurrency_count=2).launch(
|
| 220 |
+
server_name='0.0.0.0',
|
| 221 |
+
server_port=8888,
|
| 222 |
+
share=False,
|
| 223 |
+
show_error=True,
|
| 224 |
+
debug=True,
|
| 225 |
+
enable_queue=True,
|
| 226 |
+
inbrowser=True,
|
| 227 |
+
)
|
requirements.txt
CHANGED
|
@@ -1,9 +1,11 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
|
|
|
|
|
|
| 6 |
mdtex2html
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
|
|
|
| 1 |
+
langchain
|
| 2 |
+
gradio
|
| 3 |
+
transformers
|
| 4 |
+
sentence_transformers
|
| 5 |
+
faiss-cpu
|
| 6 |
+
unstructured
|
| 7 |
+
duckduckgo_search
|
| 8 |
mdtex2html
|
| 9 |
+
chardet
|
| 10 |
+
cchardet
|
| 11 |
+
cpm_kernels
|
resources/OpenCC-1.1.6-cp310-cp310-manylinux1_x86_64.whl
ADDED
|
Binary file (778 kB). View file
|
|
|
tests/test_duckduckgo_search.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from duckduckgo_search import ddg
|
| 2 |
+
from duckduckgo_search.utils import SESSION
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
SESSION.proxies = {
|
| 6 |
+
"http": f"socks5h://localhost:7890",
|
| 7 |
+
"https": f"socks5h://localhost:7890"
|
| 8 |
+
}
|
| 9 |
+
r = ddg("马保国")
|
| 10 |
+
print(r[:2])
|
| 11 |
+
"""
|
| 12 |
+
[{'title': '马保国 - 维基百科,自由的百科全书', 'href': 'https://zh.wikipedia.org/wiki/%E9%A9%AC%E4%BF%9D%E5%9B%BD', 'body': '马保国(1951年 — ) ,男,籍贯 山东 临沂,出生及长大于河南,中国大陆太极拳师,自称"浑元形意太极门掌门人" 。 马保国因2017年约战mma格斗家徐晓冬首次出现
|
| 13 |
+
大众视野中。 2020年5月,马保国在对阵民间武术爱好者王庆民的比赛中,30秒内被连续高速击倒三次,此事件成为了持续多日的社交 ...'}, {'title': '馬保國的主页 - 抖音', 'href': 'https://www.douyin.com/user/MS4wLjABAAAAW0E1ziOvxgUh3VVv5FE6xmoo3w5WtZalfphYZKj4mCg', 'body': '6.3万. #马马国教扛打功 最近有几个人模芳我动作,很危险啊,不可以的,朋友们不要受伤了。. 5.3万. #马保国直播带货榜第一 朋友们周末愉快,本周六早上湿点,我本人在此号进行第一次带货直播,活到老,学到老,越活越年轻。. 7.0万. #马保国击破红牛罐 昨天 ...'}]
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
"""
|
tests/test_duckpy.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from duckpy import Client
|
| 2 |
+
|
| 3 |
+
client = Client()
|
| 4 |
+
|
| 5 |
+
results = client.search("Python Wikipedia")
|
| 6 |
+
|
| 7 |
+
# Prints first result title
|
| 8 |
+
print(results[0].title)
|
| 9 |
+
|
| 10 |
+
# Prints first result URL
|
| 11 |
+
print(results[0].url)
|
| 12 |
+
|
| 13 |
+
# Prints first result description
|
| 14 |
+
print(results[0].description)
|
| 15 |
+
# https://github.com/AmanoTeam/duckpy
|
tests/test_gradio_slient.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
|
| 3 |
+
import gradio as gra
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def user_greeting(name):
|
| 7 |
+
time.sleep(10)
|
| 8 |
+
return "Hi! " + name + " Welcome to your first Gradio application!😎"
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# define gradio interface and other parameters
|
| 12 |
+
app = gra.Interface(
|
| 13 |
+
fn=user_greeting,
|
| 14 |
+
inputs="text",
|
| 15 |
+
outputs="text",
|
| 16 |
+
)
|
| 17 |
+
app.launch(
|
| 18 |
+
server_name='0.0.0.0', server_port=8888, share=False,show_error=True, enable_queue=True
|
| 19 |
+
)
|
tests/test_langchain.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
|
| 3 |
+
from langchain.document_loaders import UnstructuredFileLoader
|
| 4 |
+
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
|
| 5 |
+
from langchain.vectorstores import FAISS
|
| 6 |
+
|
| 7 |
+
embedding_model_name = '/home/searchgpt/pretrained_models/ernie-gram-zh'
|
| 8 |
+
docs_path = '/home/searchgpt/yq/Knowledge-ChatGLM/docs'
|
| 9 |
+
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name)
|
| 10 |
+
|
| 11 |
+
docs = []
|
| 12 |
+
|
| 13 |
+
for doc in os.listdir(docs_path):
|
| 14 |
+
if doc.endswith('.txt'):
|
| 15 |
+
print(doc)
|
| 16 |
+
loader = UnstructuredFileLoader(f'{docs_path}/{doc}', mode="elements")
|
| 17 |
+
doc = loader.load()
|
| 18 |
+
docs.extend(doc)
|
| 19 |
+
|
| 20 |
+
vector_store = FAISS.from_documents(docs, embeddings)
|
| 21 |
+
vector_store.save_local('vector_store_local')
|
| 22 |
+
search_result = vector_store.similarity_search_with_score(query='科比', k=2)
|
| 23 |
+
print(search_result)
|
| 24 |
+
|
| 25 |
+
loader = UnstructuredFileLoader(f'{docs_path}/added/马保国.txt', mode="elements")
|
| 26 |
+
doc = loader.load()
|
| 27 |
+
vector_store.add_documents(doc)
|
| 28 |
+
print(doc)
|
| 29 |
+
search_result = vector_store.similarity_search_with_score(query='科比·布莱恩特', k=2)
|
| 30 |
+
print(search_result)
|
| 31 |
+
|
| 32 |
+
"""
|
| 33 |
+
[(Document(page_content='王治郅,1977年7月8日出生于北京,前中国篮球运动员,司职大前锋/中锋,现已退役。 [1]', metadata={'source': 'docs/王治郅.txt', 'filename': 'docs/王治郅.txt', 'category': 'Title'}), 285.40765), (Document(page_content='王治郅是中国篮球界进入NBA的第一人,被评选为中国篮坛50大杰出人物和中国申办奥运特使。他和姚明、蒙克·巴特尔一起,被称为篮球场上的“移动长城”。 [5]', metadata={'source': 'docs/王治郅.txt', 'filename': 'docs/王治郅.txt', 'category': 'NarrativeText'}), 290.19086)]
|
| 34 |
+
[Document(page_content='科比·布莱恩特(Kobe Bryant,1978年8月23日—2020年1月26日),全名科比·比恩·布莱恩特·考克斯(Kobe Bean Bryant Cox),出生于美国宾夕法尼亚州费城,美国已故篮球运动员,司职得分后卫/小前锋。 [5] [24] [84]', metadata={'source': 'docs/added/科比.txt', 'filename': 'docs/added/科比.txt', 'category': 'NarrativeText'}), Document(page_content='1996年NBA选秀,科比于第1轮第13顺位被夏洛特黄蜂队选中并被交易至洛杉矶湖人队,整个NBA生涯都效力于洛杉矶湖人队;共获得5次NBA总冠军、1次NBA常规赛MVP、2次NBA总决赛MVP、4次NBA全明星赛MVP、2次NBA赛季得分王;共入选NBA全明星首发阵容18次、NBA最佳阵容15次(其中一阵11次、二阵2次、三阵2次)、NBA最佳防守阵容12次(其中一阵9次、二阵3次)。 [9] [24]', metadata={'source': 'docs/added/科比.txt', 'filename': 'docs/added/科比.txt', 'category': 'Title'}), Document(page_content='2007年,科比首次入选美国国家男子篮球队,后帮助美国队夺得2007年美洲男篮锦标赛金牌、2008年北京奥运会男子篮球金牌以及2012年伦敦奥运会男子篮球金牌。 [91]', metadata={'source': 'docs/added/科比.txt', 'filename': 'docs/added/科比.txt', 'category': 'Title'}), Document(page_content='2015年11月30日,科比发文宣布将在赛季结束后退役。 [100] 2017年12月19日,湖人队为科比举行球衣退役仪式。 [22] 2020年4月5日,科比入选奈·史密斯篮球名人纪念堂。 [7]', metadata={'source': 'docs/added/科比.txt', 'filename': 'docs/added/科比.txt', 'category': 'Title'}), Document(page_content='美国时间2020年1月26日(北京时间2020年1月27日),科比因直升机事故遇难,享年41岁。 [23]', metadata={'source': 'docs/added/科比.txt', 'filename': 'docs/added/科比.txt', 'category': 'Title'})]
|
| 35 |
+
[(Document(page_content='科比·布莱恩特(Kobe Bryant,1978年8月23日—2020年1月26日),全名科比·比恩·布莱恩特·考克斯(Kobe Bean Bryant Cox),出生于美国宾夕法尼亚州费城,美国已故篮球运动员,司职得分后卫/小前锋。 [5] [24] [84]', metadata={'source': 'docs/added/科比.txt', 'filename': 'docs/added/科比.txt', 'category': 'NarrativeText'}), 179.68744), (Document(page_content='2015年11月30日,科比发文宣布将在赛季结束后退役。 [100] 2017年12月19日,湖人队为科比举行球衣退役仪式。 [22] 2020年4月5日,科比入选奈·史密斯篮球名人纪念堂。 [7]', metadata={'source': 'docs/added/科比.txt', 'filename': 'docs/added/科比.txt', 'category': 'Title'}), 200.57565)]
|
| 36 |
+
"""
|
tests/test_vector_store.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
|
| 2 |
+
from langchain.vectorstores import FAISS
|
| 3 |
+
|
| 4 |
+
# 中文Wikipedia数据导入示例:
|
| 5 |
+
embedding_model_name = '/root/pretrained_models/ernie-gram-zh'
|
| 6 |
+
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name)
|
| 7 |
+
|
| 8 |
+
vector_store = FAISS.load_local("/root/GoMall/Knowledge-ChatGLM/cache/zh_wikipedia", embeddings)
|
| 9 |
+
print(vector_store)
|
| 10 |
+
res = vector_store.similarity_search_with_score('闫强')
|
| 11 |
+
print(res)
|