Spaces:
Running

Running

introduction updates
Browse files- introduction.md +10 -1
- static/img/gatto_cane.png +0 -0
- static/img/image_to_text.png +0 -0
- static/img/text_to_image.png +0 -0
introduction.md
CHANGED
|
@@ -9,7 +9,7 @@ is built upon the pre-trained [Italian BERT](https://huggingface.co/dbmdz/bert-b
|
|
| 9 |
|
| 10 |
In building this project we kept in mind the following principles:
|
| 11 |
|
| 12 |
-
+ **Novel Contributions**: We created
|
| 13 |
+ **Scientific Validity**: Claim are easy, facts are hard. That's why validation is important to assess the real impact of a model. We thoroughly evaluated our models on two tasks and made the validation reproducible for everybody.
|
| 14 |
+ **Broader Outlook**: We always kept in mind which are the possible usages and limitations of this model.
|
| 15 |
|
|
@@ -25,9 +25,18 @@ In this demo, we present two tasks:
|
|
| 25 |
compute the similarity between this string of text with respect to a set of images. The webapp is going to display the images that
|
| 26 |
have the highest similarity with the text query.
|
| 27 |
|
|
|
|
|
|
|
| 28 |
+ *Image to Text*: This task is essentially a zero-shot image classification task. The user is asked for an image and for a set of captions/labels and CLIP
|
| 29 |
is going to compute the similarity between the image and each label. The webapp is going to display a probability distribution over the captions.
|
| 30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
+ *Examples & Applications*: This page showcases some interesting results we got from the model, we believe that there are
|
| 32 |
different applications that can start from here.
|
| 33 |
|
|
|
|
| 9 |
|
| 10 |
In building this project we kept in mind the following principles:
|
| 11 |
|
| 12 |
+
+ **Novel Contributions**: We created an impressive dataset of ~1.4 million Italian image-text pairs (**that we will share with the community**) and, to the best of our knowledge, we trained the best Italian CLIP model currently in existence;
|
| 13 |
+ **Scientific Validity**: Claim are easy, facts are hard. That's why validation is important to assess the real impact of a model. We thoroughly evaluated our models on two tasks and made the validation reproducible for everybody.
|
| 14 |
+ **Broader Outlook**: We always kept in mind which are the possible usages and limitations of this model.
|
| 15 |
|
|
|
|
| 25 |
compute the similarity between this string of text with respect to a set of images. The webapp is going to display the images that
|
| 26 |
have the highest similarity with the text query.
|
| 27 |
|
| 28 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/text_to_image.png" alt="drawing" width="95%"/>
|
| 29 |
+
|
| 30 |
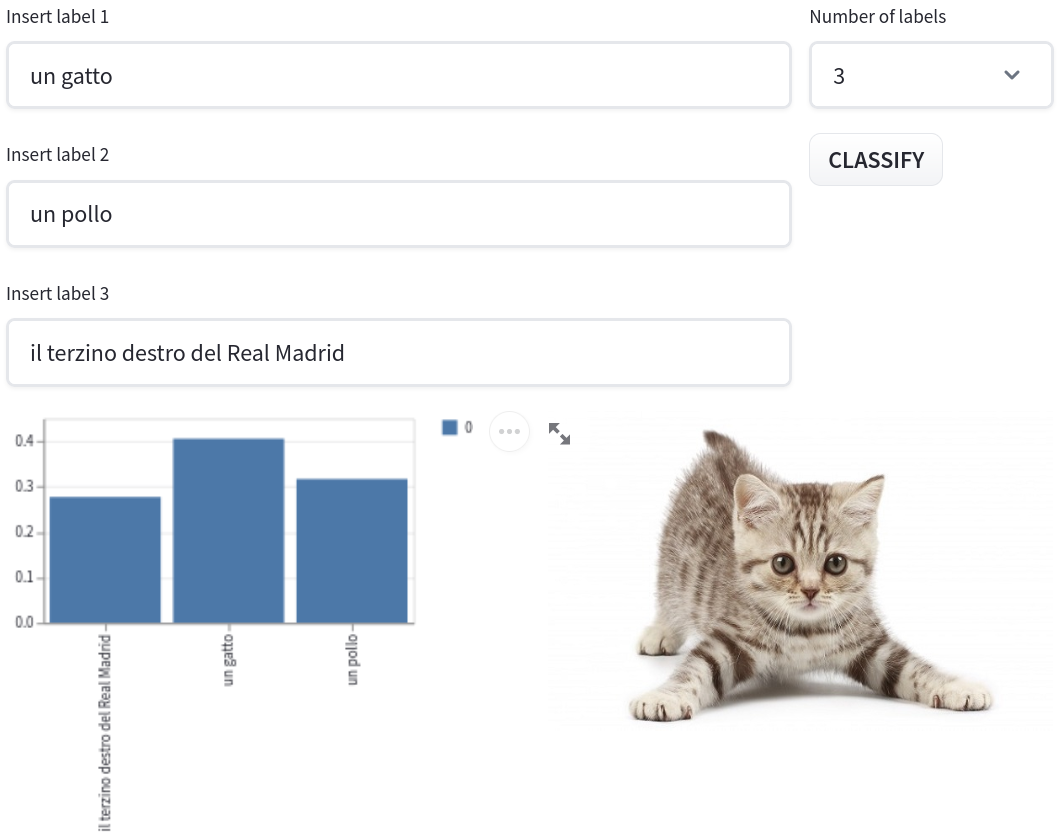
+ *Image to Text*: This task is essentially a zero-shot image classification task. The user is asked for an image and for a set of captions/labels and CLIP
|
| 31 |
is going to compute the similarity between the image and each label. The webapp is going to display a probability distribution over the captions.
|
| 32 |
|
| 33 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/image_to_text.png" alt="drawing" width="95%"/>
|
| 34 |
+
|
| 35 |
+
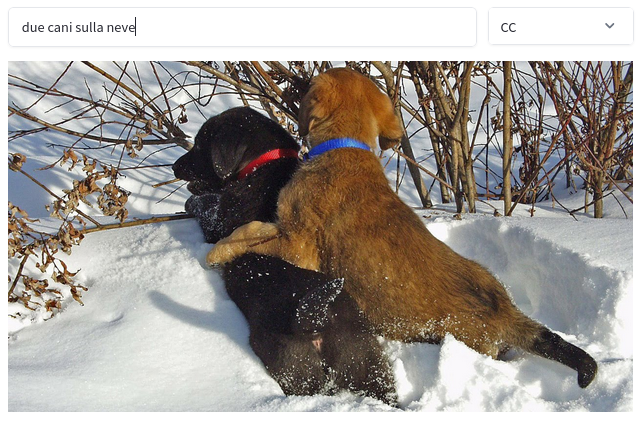
+ *Localization*: This is one of ours **very cool** features and at the best of our knowledge, it is a novel contribution. We can use CLIP
|
| 36 |
+
to find where "something" (like a "cat") is an image. The location of the object is computed by masking different areas of the image and looking at how the similarity to the image description changes.
|
| 37 |
+
|
| 38 |
+
<img src="https://huggingface.co/spaces/clip-italian/clip-italian-demo/raw/main/static/img/gatto_cane.png" alt="drawing" width="95%"/>
|
| 39 |
+
|
| 40 |
+ *Examples & Applications*: This page showcases some interesting results we got from the model, we believe that there are
|
| 41 |
different applications that can start from here.
|
| 42 |
|
static/img/gatto_cane.png
ADDED

|
static/img/image_to_text.png
ADDED
|
static/img/text_to_image.png
ADDED
|