Spaces:
Sleeping

Sleeping
Upload 21 files
Browse files- .gitattributes +2 -0
- app.py +670 -347
- history/history_92.34.pkl +3 -0
- history/history_model.pkl +3 -0
- history/history_model_2.pkl +3 -0
- history/history_model_8781.pkl +3 -0
- huggingface-snapshots/Screenshot 2024-11-07 201845.png +0 -0
- huggingface-snapshots/Screenshot 2024-11-07 201937.png +0 -0
- huggingface-snapshots/Screenshot 2024-11-07 201959.png +0 -0
- images/accuracy_loss.png +0 -0
- models/92.34.keras +0 -0
- models/model.keras +3 -0
- models/model_2.keras +3 -0
- models/model_8781.keras +0 -0
- notebook.html +0 -0
- requirements.txt +22 -18
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
models/model_2.keras filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
models/model.keras filter=lfs diff=lfs merge=lfs -text
|
app.py
CHANGED
|
@@ -1,347 +1,670 @@
|
|
| 1 |
-
import marimo
|
| 2 |
-
|
| 3 |
-
__generated_with = "0.9.
|
| 4 |
-
app = marimo.App(width="full")
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
@app.cell(hide_code=True)
|
| 8 |
-
def __(mo):
|
| 9 |
-
mo.md(
|
| 10 |
-
"""
|
| 11 |
-
# Political Ideologies Analysis
|
| 12 |
-
|
| 13 |
-
This project provides a detailed analysis of political ideologies using data from the Huggingface Political Ideologies dataset. The code leverages various data science libraries and visualization tools to map, analyze, and visualize political ideology text data.
|
| 14 |
-
Project Structure
|
| 15 |
-
|
| 16 |
-
This analysis is based on huggingface dataset repository. <br>
|
| 17 |
-
You can visit right [here](https://huggingface.co/datasets/JyotiNayak/political_ideologies)
|
| 18 |
-
"""
|
| 19 |
-
)
|
| 20 |
-
return
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
@app.cell(hide_code=True)
|
| 24 |
-
def __():
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
import
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
|
| 119 |
-
|
| 120 |
-
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
|
| 138 |
-
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
|
| 149 |
-
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
|
| 153 |
-
|
| 154 |
-
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
|
| 158 |
-
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
|
| 162 |
-
|
| 163 |
-
|
| 164 |
-
|
| 165 |
-
|
| 166 |
-
|
| 167 |
-
|
| 168 |
-
|
| 169 |
-
|
| 170 |
-
|
| 171 |
-
|
| 172 |
-
|
| 173 |
-
|
| 174 |
-
|
| 175 |
-
|
| 176 |
-
|
| 177 |
-
|
| 178 |
-
|
| 179 |
-
|
| 180 |
-
|
| 181 |
-
|
| 182 |
-
|
| 183 |
-
|
| 184 |
-
|
| 185 |
-
|
| 186 |
-
|
| 187 |
-
.
|
| 188 |
-
|
| 189 |
-
|
| 190 |
-
|
| 191 |
-
|
| 192 |
-
|
| 193 |
-
|
| 194 |
-
|
| 195 |
-
|
| 196 |
-
|
| 197 |
-
|
| 198 |
-
|
| 199 |
-
|
| 200 |
-
|
| 201 |
-
|
| 202 |
-
|
| 203 |
-
|
| 204 |
-
|
| 205 |
-
|
| 206 |
-
|
| 207 |
-
|
| 208 |
-
|
| 209 |
-
|
| 210 |
-
|
| 211 |
-
|
| 212 |
-
|
| 213 |
-
|
| 214 |
-
|
| 215 |
-
|
| 216 |
-
|
| 217 |
-
|
| 218 |
-
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
|
| 224 |
-
|
| 225 |
-
|
| 226 |
-
|
| 227 |
-
|
| 228 |
-
|
| 229 |
-
|
| 230 |
-
|
| 231 |
-
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
|
| 235 |
-
|
| 236 |
-
|
| 237 |
-
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
|
| 242 |
-
|
| 243 |
-
|
| 244 |
-
|
| 245 |
-
|
| 246 |
-
|
| 247 |
-
|
| 248 |
-
|
| 249 |
-
|
| 250 |
-
|
| 251 |
-
|
| 252 |
-
|
| 253 |
-
|
| 254 |
-
|
| 255 |
-
|
| 256 |
-
|
| 257 |
-
|
| 258 |
-
|
| 259 |
-
|
| 260 |
-
|
| 261 |
-
|
| 262 |
-
|
| 263 |
-
|
| 264 |
-
|
| 265 |
-
|
| 266 |
-
|
| 267 |
-
|
| 268 |
-
|
| 269 |
-
|
| 270 |
-
|
| 271 |
-
|
| 272 |
-
|
| 273 |
-
|
| 274 |
-
|
| 275 |
-
|
| 276 |
-
|
| 277 |
-
|
| 278 |
-
|
| 279 |
-
|
| 280 |
-
|
| 281 |
-
|
| 282 |
-
|
| 283 |
-
|
| 284 |
-
|
| 285 |
-
|
| 286 |
-
|
| 287 |
-
|
| 288 |
-
|
| 289 |
-
|
| 290 |
-
|
| 291 |
-
|
| 292 |
-
|
| 293 |
-
|
| 294 |
-
|
| 295 |
-
|
| 296 |
-
|
| 297 |
-
|
| 298 |
-
|
| 299 |
-
|
| 300 |
-
|
| 301 |
-
|
| 302 |
-
|
| 303 |
-
|
| 304 |
-
|
| 305 |
-
|
| 306 |
-
|
| 307 |
-
|
| 308 |
-
|
| 309 |
-
|
| 310 |
-
|
| 311 |
-
|
| 312 |
-
|
| 313 |
-
|
| 314 |
-
|
| 315 |
-
return
|
| 316 |
-
|
| 317 |
-
|
| 318 |
-
@app.cell(hide_code=True)
|
| 319 |
-
def __(
|
| 320 |
-
|
| 321 |
-
return
|
| 322 |
-
|
| 323 |
-
|
| 324 |
-
@app.cell(hide_code=True)
|
| 325 |
-
def __(
|
| 326 |
-
|
| 327 |
-
|
| 328 |
-
|
| 329 |
-
|
| 330 |
-
|
| 331 |
-
|
| 332 |
-
|
| 333 |
-
|
| 334 |
-
|
| 335 |
-
|
| 336 |
-
|
| 337 |
-
|
| 338 |
-
|
| 339 |
-
|
| 340 |
-
|
| 341 |
-
|
| 342 |
-
|
| 343 |
-
|
| 344 |
-
|
| 345 |
-
|
| 346 |
-
|
| 347 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import marimo
|
| 2 |
+
|
| 3 |
+
__generated_with = "0.9.15"
|
| 4 |
+
app = marimo.App(width="full")
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
@app.cell(hide_code=True)
|
| 8 |
+
def __(mo):
|
| 9 |
+
mo.md(
|
| 10 |
+
"""
|
| 11 |
+
# Political Ideologies Analysis
|
| 12 |
+
|
| 13 |
+
This project provides a detailed analysis of political ideologies using data from the Huggingface Political Ideologies dataset. The code leverages various data science libraries and visualization tools to map, analyze, and visualize political ideology text data.
|
| 14 |
+
Project Structure
|
| 15 |
+
|
| 16 |
+
This analysis is based on huggingface dataset repository. <br>
|
| 17 |
+
You can visit right [here](https://huggingface.co/datasets/JyotiNayak/political_ideologies)
|
| 18 |
+
"""
|
| 19 |
+
)
|
| 20 |
+
return
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
@app.cell(hide_code=True)
|
| 24 |
+
def __(form, mo, try_predict):
|
| 25 |
+
text_classified = 'Please write something'
|
| 26 |
+
if (form.value):
|
| 27 |
+
text_classified = try_predict(form.value)
|
| 28 |
+
mo.vstack([form, mo.md(f"Your Opinion Classified as: **{text_classified}**")])
|
| 29 |
+
return (text_classified,)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
@app.cell(hide_code=True)
|
| 33 |
+
def __():
|
| 34 |
+
import marimo as mo
|
| 35 |
+
import pandas as pd
|
| 36 |
+
import numpy as np
|
| 37 |
+
|
| 38 |
+
import matplotlib.pyplot as plt
|
| 39 |
+
import seaborn as sns
|
| 40 |
+
import altair as alt
|
| 41 |
+
|
| 42 |
+
from gensim.models import Word2Vec
|
| 43 |
+
from sklearn.manifold import TSNE
|
| 44 |
+
from umap import UMAP
|
| 45 |
+
|
| 46 |
+
import tensorflow as tf
|
| 47 |
+
from tensorflow.keras.models import Sequential
|
| 48 |
+
from tensorflow.keras.layers import Embedding, Bidirectional, LSTM, Dense
|
| 49 |
+
|
| 50 |
+
import re
|
| 51 |
+
import string
|
| 52 |
+
|
| 53 |
+
from gensim.models import FastText
|
| 54 |
+
from wordcloud import WordCloud
|
| 55 |
+
from nltk.corpus import stopwords
|
| 56 |
+
from nltk.tokenize import word_tokenize
|
| 57 |
+
from nltk.stem import WordNetLemmatizer
|
| 58 |
+
from nltk.stem.porter import PorterStemmer
|
| 59 |
+
from tensorflow.keras.preprocessing.text import Tokenizer
|
| 60 |
+
from tensorflow.keras.preprocessing.sequence import pad_sequences
|
| 61 |
+
from tensorflow.keras.callbacks import ReduceLROnPlateau, EarlyStopping
|
| 62 |
+
from sklearn.model_selection import train_test_split
|
| 63 |
+
|
| 64 |
+
import nltk
|
| 65 |
+
|
| 66 |
+
mo.md("""
|
| 67 |
+
## 1. Import all libraries needed
|
| 68 |
+
|
| 69 |
+
The initial cells import the necessary libraries for data handling, visualization, and word embedding.
|
| 70 |
+
""")
|
| 71 |
+
return (
|
| 72 |
+
Bidirectional,
|
| 73 |
+
Dense,
|
| 74 |
+
EarlyStopping,
|
| 75 |
+
Embedding,
|
| 76 |
+
FastText,
|
| 77 |
+
LSTM,
|
| 78 |
+
PorterStemmer,
|
| 79 |
+
ReduceLROnPlateau,
|
| 80 |
+
Sequential,
|
| 81 |
+
TSNE,
|
| 82 |
+
Tokenizer,
|
| 83 |
+
UMAP,
|
| 84 |
+
Word2Vec,
|
| 85 |
+
WordCloud,
|
| 86 |
+
WordNetLemmatizer,
|
| 87 |
+
alt,
|
| 88 |
+
mo,
|
| 89 |
+
nltk,
|
| 90 |
+
np,
|
| 91 |
+
pad_sequences,
|
| 92 |
+
pd,
|
| 93 |
+
plt,
|
| 94 |
+
re,
|
| 95 |
+
sns,
|
| 96 |
+
stopwords,
|
| 97 |
+
string,
|
| 98 |
+
tf,
|
| 99 |
+
train_test_split,
|
| 100 |
+
word_tokenize,
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
@app.cell(hide_code=True)
|
| 105 |
+
def __(nltk):
|
| 106 |
+
nltk.download('punkt')
|
| 107 |
+
nltk.download('stopwords')
|
| 108 |
+
nltk.download('wordnet')
|
| 109 |
+
return
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
@app.cell(hide_code=True)
|
| 113 |
+
def __(mo):
|
| 114 |
+
mo.md(
|
| 115 |
+
"""
|
| 116 |
+
Here are the mapped of label and issue type columns.
|
| 117 |
+
|
| 118 |
+
```yaml
|
| 119 |
+
Label Mapping: {'conservative': 0, 'liberal': 1 }
|
| 120 |
+
Issue Type Mapping: {
|
| 121 |
+
'economic': 0, 'environmental': 1,
|
| 122 |
+
'family/gender': 2, 'geo-political and foreign policy': 3,
|
| 123 |
+
'political': 4, 'racial justice and immigration': 5,
|
| 124 |
+
'religious': 6, 'social, health and education': 7
|
| 125 |
+
}
|
| 126 |
+
```
|
| 127 |
+
"""
|
| 128 |
+
)
|
| 129 |
+
return
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
@app.cell(hide_code=True)
|
| 133 |
+
def __(mo, pd):
|
| 134 |
+
df = pd.read_parquet('train.parquet')
|
| 135 |
+
df_val = pd.read_parquet('val.parquet')
|
| 136 |
+
df_test = pd.read_parquet('test.parquet')
|
| 137 |
+
|
| 138 |
+
df = df.drop('__index_level_0__', axis=1)
|
| 139 |
+
|
| 140 |
+
mo.md("""
|
| 141 |
+
## 2. Dataset Loading
|
| 142 |
+
|
| 143 |
+
The dataset files (`train.parquet`, `val.parquet`, and `test.parquet`) are loaded, concatenated, and cleaned to form a single DataFrame (df). Columns are mapped to readable labels for ease of understanding.
|
| 144 |
+
""")
|
| 145 |
+
return df, df_test, df_val
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
@app.cell(hide_code=True)
|
| 149 |
+
def __():
|
| 150 |
+
label_mapping = {
|
| 151 |
+
'conservative': 0,
|
| 152 |
+
'liberal': 1
|
| 153 |
+
}
|
| 154 |
+
|
| 155 |
+
issue_type_mapping = {
|
| 156 |
+
'economic': 0,
|
| 157 |
+
'environmental': 1,
|
| 158 |
+
'family/gender': 2,
|
| 159 |
+
'geo-political and foreign policy': 3,
|
| 160 |
+
'political': 4,
|
| 161 |
+
'racial justice and immigration': 5,
|
| 162 |
+
'religious': 6,
|
| 163 |
+
'social, health and education': 7
|
| 164 |
+
}
|
| 165 |
+
return issue_type_mapping, label_mapping
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
@app.cell
|
| 169 |
+
def __(issue_type_mapping, label_mapping):
|
| 170 |
+
label_mapping_reversed = {v: k for k, v in label_mapping.items()}
|
| 171 |
+
issue_type_mapping_reversed = {v: k for k, v in issue_type_mapping.items()}
|
| 172 |
+
|
| 173 |
+
print(label_mapping_reversed)
|
| 174 |
+
print(issue_type_mapping_reversed)
|
| 175 |
+
return issue_type_mapping_reversed, label_mapping_reversed
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
@app.cell(hide_code=True)
|
| 179 |
+
def __(df, issue_type_mapping_reversed, label_mapping_reversed, mo):
|
| 180 |
+
df['label_text'] = df['label'].replace(label_mapping_reversed)
|
| 181 |
+
df['issue_type_text'] = df['issue_type'].replace(issue_type_mapping_reversed)
|
| 182 |
+
|
| 183 |
+
labels_grouped = df['label_text'].value_counts().rename_axis('label_text').reset_index(name='counts')
|
| 184 |
+
issue_types_grouped = (
|
| 185 |
+
df["issue_type_text"]
|
| 186 |
+
.value_counts()
|
| 187 |
+
.rename_axis("issue_type_text")
|
| 188 |
+
.reset_index(name="counts")
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
mo.md("""
|
| 192 |
+
## 3. Mapping Labels and Issue Types
|
| 193 |
+
|
| 194 |
+
Two dictionaries map labels (conservative and liberal) and issue types (e.g., economic, environmental, etc.) to numerical values for machine learning purposes. Reversed mappings are created to convert numerical labels back into their text form.
|
| 195 |
+
""")
|
| 196 |
+
return issue_types_grouped, labels_grouped
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
@app.cell
|
| 200 |
+
def __(df):
|
| 201 |
+
df.iloc[:, :6].head(7)
|
| 202 |
+
return
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
@app.cell(hide_code=True)
|
| 206 |
+
def __(mo):
|
| 207 |
+
mo.md(
|
| 208 |
+
"""
|
| 209 |
+
## 4. Visualizing Data Distributions
|
| 210 |
+
|
| 211 |
+
Bar plots visualize the proportions of conservative vs. liberal ideologies and the count of different issue types. These provide an overview of the dataset composition.
|
| 212 |
+
"""
|
| 213 |
+
)
|
| 214 |
+
return
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
@app.cell(hide_code=True)
|
| 218 |
+
def __(alt, labels_grouped, mo):
|
| 219 |
+
mo.ui.altair_chart(
|
| 220 |
+
alt.Chart(labels_grouped).mark_bar(
|
| 221 |
+
fill='#4C78A8',
|
| 222 |
+
cursor='pointer',
|
| 223 |
+
).encode(
|
| 224 |
+
x=alt.X('label_text', axis=alt.Axis(labelAngle=0)),
|
| 225 |
+
y='counts:Q'
|
| 226 |
+
)
|
| 227 |
+
)
|
| 228 |
+
return
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
@app.cell(hide_code=True)
|
| 232 |
+
def __(alt, issue_types_grouped, mo):
|
| 233 |
+
mo.ui.altair_chart(
|
| 234 |
+
alt.Chart(issue_types_grouped)
|
| 235 |
+
.mark_bar(
|
| 236 |
+
fill="#4C78A8",
|
| 237 |
+
cursor="pointer",
|
| 238 |
+
)
|
| 239 |
+
.encode(
|
| 240 |
+
x=alt.X(
|
| 241 |
+
"issue_type_text:O",
|
| 242 |
+
axis=alt.Axis(
|
| 243 |
+
labelAngle=-10, labelAlign="center", labelPadding=10
|
| 244 |
+
),
|
| 245 |
+
),
|
| 246 |
+
y="counts:Q",
|
| 247 |
+
)
|
| 248 |
+
)
|
| 249 |
+
return
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
@app.cell(hide_code=True)
|
| 253 |
+
def __(mo):
|
| 254 |
+
mo.md(
|
| 255 |
+
r"""
|
| 256 |
+
## 5. Text Preprocessing
|
| 257 |
+
|
| 258 |
+
Texts preprocessed to remove any ineffective words.
|
| 259 |
+
"""
|
| 260 |
+
)
|
| 261 |
+
return
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
@app.cell(hide_code=True)
|
| 265 |
+
def __(WordCloud, df):
|
| 266 |
+
all_text = ''.join(df['statement'])
|
| 267 |
+
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(all_text)
|
| 268 |
+
return all_text, wordcloud
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
@app.cell(hide_code=True)
|
| 272 |
+
def __(plt, wordcloud):
|
| 273 |
+
plt.figure(figsize=(10, 5))
|
| 274 |
+
plt.imshow(wordcloud, interpolation='bilinear')
|
| 275 |
+
plt.axis='off'
|
| 276 |
+
plt.plot()
|
| 277 |
+
plt.gca()
|
| 278 |
+
return
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
@app.cell(hide_code=True)
|
| 282 |
+
def __(WordNetLemmatizer, stopwords):
|
| 283 |
+
lemmatizer = WordNetLemmatizer()
|
| 284 |
+
stop_words = set(stopwords.words('english'))
|
| 285 |
+
return lemmatizer, stop_words
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
@app.cell(hide_code=True)
|
| 289 |
+
def __(lemmatizer, re, stop_words, word_tokenize):
|
| 290 |
+
# Function for preprocessing text
|
| 291 |
+
def preprocess_text(text):
|
| 292 |
+
# 1. Lowercase the text
|
| 293 |
+
text = text.lower()
|
| 294 |
+
|
| 295 |
+
# 2. Remove punctuation and non-alphabetical characters
|
| 296 |
+
text = re.sub(r'[^a-z\s]', '', text)
|
| 297 |
+
|
| 298 |
+
# 3. Tokenize the text
|
| 299 |
+
tokens = word_tokenize(text)
|
| 300 |
+
|
| 301 |
+
# 4. Remove stopwords and lemmatize each token
|
| 302 |
+
processed_tokens = [lemmatizer.lemmatize(token) for token in tokens if token not in stop_words]
|
| 303 |
+
|
| 304 |
+
return processed_tokens
|
| 305 |
+
return (preprocess_text,)
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
@app.cell(hide_code=True)
|
| 309 |
+
def __(df, df_test, df_val, preprocess_text):
|
| 310 |
+
# Terapkan fungsi preprocessing pada kolom 'statement'
|
| 311 |
+
df['processed_statement'] = df['statement'].apply(preprocess_text)
|
| 312 |
+
df_val['processed_statement'] = df_val['statement'].apply(preprocess_text)
|
| 313 |
+
df_test['processed_statement'] = df_test['statement'].apply(preprocess_text)
|
| 314 |
+
processed_statement = df['processed_statement']
|
| 315 |
+
return (processed_statement,)
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
@app.cell(hide_code=True)
|
| 319 |
+
def __(mo):
|
| 320 |
+
mo.md(r"""## 6. Word Embeddings""")
|
| 321 |
+
return
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
@app.cell(hide_code=True)
|
| 325 |
+
def __(np):
|
| 326 |
+
def get_doc_embedding(tokens, embeddings_model):
|
| 327 |
+
vectors = [embeddings_model.wv[word] for word in tokens if word in embeddings_model.wv]
|
| 328 |
+
if vectors:
|
| 329 |
+
return np.mean(vectors, axis=0)
|
| 330 |
+
else:
|
| 331 |
+
return np.zeros(embeddings_model.vector_size)
|
| 332 |
+
return (get_doc_embedding,)
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
@app.cell(hide_code=True)
|
| 336 |
+
def __(FastText, Word2Vec, processed_statement):
|
| 337 |
+
embedding_models = {
|
| 338 |
+
'fasttext': FastText(sentences=processed_statement, vector_size=100, window=3, min_count=1, seed=0),
|
| 339 |
+
'word2vec': Word2Vec(sentences=processed_statement, vector_size=100, window=3, min_count=1, seed=0)
|
| 340 |
+
}
|
| 341 |
+
return (embedding_models,)
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
@app.cell(hide_code=True)
|
| 345 |
+
def __(mo):
|
| 346 |
+
mo.md(r"""### 6.1 Word Embedding using FastText and Word2Vec""")
|
| 347 |
+
return
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
@app.cell(hide_code=True)
|
| 351 |
+
def __(mo):
|
| 352 |
+
mo.md(
|
| 353 |
+
"""
|
| 354 |
+
#### Dimensionality Reduction using UMAP
|
| 355 |
+
|
| 356 |
+
Embeddings are projected into a 2D space using UMAP for visualization. The embeddings are colored by issue type, showing clusters of similar statements.
|
| 357 |
+
|
| 358 |
+
Interactive scatter plots in Altair show ideology and issue types in 2D space. A brush selection tool allows users to explore specific points and view tooltip information.
|
| 359 |
+
|
| 360 |
+
#### Combined Scatter Plot
|
| 361 |
+
|
| 362 |
+
Combines the two scatter plots into a side-by-side visualization for direct comparison of ideologies vs. issue types.
|
| 363 |
+
Running the Code
|
| 364 |
+
|
| 365 |
+
Run the code using the marimo.App instance. This notebook can also be run as a standalone Python script:
|
| 366 |
+
"""
|
| 367 |
+
)
|
| 368 |
+
return
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
@app.cell(hide_code=True)
|
| 372 |
+
def __(UMAP, alt, df, mo, np):
|
| 373 |
+
def word_embedding_2d(embedding_model, embedding_model_name):
|
| 374 |
+
embeddings_matrix = np.vstack(df[f'embeddings_{embedding_model_name}'].values)
|
| 375 |
+
|
| 376 |
+
umap = UMAP(n_components=2, random_state=42)
|
| 377 |
+
umap_results = umap.fit_transform(embeddings_matrix)
|
| 378 |
+
|
| 379 |
+
df[f'{embedding_model_name}_x'] = umap_results[:, 0]
|
| 380 |
+
df[f'{embedding_model_name}_y'] = umap_results[:, 1]
|
| 381 |
+
|
| 382 |
+
brush = alt.selection_interval()
|
| 383 |
+
size = 350
|
| 384 |
+
|
| 385 |
+
points1 = alt.Chart(df, height=size, width=size).mark_point().encode(
|
| 386 |
+
x=f'{embedding_model_name}_x:Q',
|
| 387 |
+
y=f'{embedding_model_name}_y:Q',
|
| 388 |
+
color=alt.condition(brush, 'label_text', alt.value('grey')),
|
| 389 |
+
tooltip=[f'{embedding_model_name}_x:Q', f'{embedding_model_name}_y:Q', 'statement:N', 'label_text:N']
|
| 390 |
+
).add_params(brush).properties(title='By Political Ideologies')
|
| 391 |
+
|
| 392 |
+
scatter_chart1 = mo.ui.altair_chart(points1)
|
| 393 |
+
|
| 394 |
+
points2 = alt.Chart(df, height=size, width=size).mark_point().encode(
|
| 395 |
+
x=f'{embedding_model_name}_x:Q',
|
| 396 |
+
y=f'{embedding_model_name}_y:Q',
|
| 397 |
+
color=alt.condition(brush, 'issue_type_text', alt.value('grey')),
|
| 398 |
+
tooltip=[f'{embedding_model_name}_x:Q', f'{embedding_model_name}_y:Q', 'statement:N', 'issue_type:N']
|
| 399 |
+
).add_params(brush).properties(title='By Issue Types')
|
| 400 |
+
|
| 401 |
+
scatter_chart2 = mo.ui.altair_chart(points2)
|
| 402 |
+
|
| 403 |
+
combined_chart = (scatter_chart1 | scatter_chart2)
|
| 404 |
+
return combined_chart
|
| 405 |
+
return (word_embedding_2d,)
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
@app.cell(hide_code=True)
|
| 409 |
+
def __(
|
| 410 |
+
df,
|
| 411 |
+
df_test,
|
| 412 |
+
df_val,
|
| 413 |
+
embedding_models,
|
| 414 |
+
get_doc_embedding,
|
| 415 |
+
word_embedding_2d,
|
| 416 |
+
):
|
| 417 |
+
for name, embedding_model in embedding_models.items():
|
| 418 |
+
df['embeddings_' + name] = df['processed_statement'].apply(lambda x: get_doc_embedding(x, embedding_model))
|
| 419 |
+
df_val['embeddings_' + name] = df_val['processed_statement'].apply(lambda x: get_doc_embedding(x, embedding_model))
|
| 420 |
+
df_test['embeddings_' + name] = df_test['processed_statement'].apply(lambda x: get_doc_embedding(x, embedding_model))
|
| 421 |
+
|
| 422 |
+
fasttext_plot = word_embedding_2d(embedding_models['fasttext'], 'fasttext')
|
| 423 |
+
word2vec_plot = word_embedding_2d(embedding_models['word2vec'], 'word2vec')
|
| 424 |
+
|
| 425 |
+
test_embeddings_fasttext = df_test['embeddings_fasttext']
|
| 426 |
+
return (
|
| 427 |
+
embedding_model,
|
| 428 |
+
fasttext_plot,
|
| 429 |
+
name,
|
| 430 |
+
test_embeddings_fasttext,
|
| 431 |
+
word2vec_plot,
|
| 432 |
+
)
|
| 433 |
+
|
| 434 |
+
|
| 435 |
+
@app.cell(hide_code=True)
|
| 436 |
+
def __(fasttext_plot, mo):
|
| 437 |
+
fasttext_table = fasttext_plot.value[['statement', 'label_text', 'issue_type_text']]
|
| 438 |
+
fasttext_chart = mo.vstack([
|
| 439 |
+
fasttext_plot,
|
| 440 |
+
fasttext_table
|
| 441 |
+
])
|
| 442 |
+
return fasttext_chart, fasttext_table
|
| 443 |
+
|
| 444 |
+
|
| 445 |
+
@app.cell(hide_code=True)
|
| 446 |
+
def __(fasttext_plot, mo, word2vec_plot):
|
| 447 |
+
word2vec_table = fasttext_plot.value[['statement', 'label_text', 'issue_type_text']]
|
| 448 |
+
word2vec_chart = mo.vstack([
|
| 449 |
+
word2vec_plot,
|
| 450 |
+
word2vec_table
|
| 451 |
+
])
|
| 452 |
+
return word2vec_chart, word2vec_table
|
| 453 |
+
|
| 454 |
+
|
| 455 |
+
@app.cell(hide_code=True)
|
| 456 |
+
def __(fasttext_chart, mo, word2vec_chart):
|
| 457 |
+
mo.ui.tabs({
|
| 458 |
+
'FastText': fasttext_chart,
|
| 459 |
+
'Word2Vec': word2vec_chart
|
| 460 |
+
})
|
| 461 |
+
return
|
| 462 |
+
|
| 463 |
+
|
| 464 |
+
@app.cell(hide_code=True)
|
| 465 |
+
def __(mo):
|
| 466 |
+
mo.md(
|
| 467 |
+
r"""
|
| 468 |
+
## Data Insights
|
| 469 |
+
|
| 470 |
+
- Ideology Distribution: Visualizes proportions of conservative and liberal ideologies.
|
| 471 |
+
- Issue Types: Bar plot reveals the diversity and frequency of issue types in the dataset.
|
| 472 |
+
- Word Embeddings: Using UMAP for 2D projections helps identify clusters in political statements.
|
| 473 |
+
- Interactive Exploration: Offers detailed, interactive views on ideology vs. issue type distribution.
|
| 474 |
+
|
| 475 |
+
This code provides a thorough analysis pipeline, from data loading to interactive visualizations, enabling an in-depth exploration of political ideologies.
|
| 476 |
+
"""
|
| 477 |
+
)
|
| 478 |
+
return
|
| 479 |
+
|
| 480 |
+
|
| 481 |
+
@app.cell(hide_code=True)
|
| 482 |
+
def __(mo):
|
| 483 |
+
mo.md(
|
| 484 |
+
r"""
|
| 485 |
+
## Building Model
|
| 486 |
+
|
| 487 |
+
```python
|
| 488 |
+
clf_model = Sequential()
|
| 489 |
+
clf_model.add(Bidirectional(tf.keras.layers.GRU(64,
|
| 490 |
+
activation='relu',
|
| 491 |
+
# return_sequences=True,
|
| 492 |
+
input_shape=(sent_length, input_dim),
|
| 493 |
+
kernel_regularizer=tf.keras.regularizers.l2(0.001)))) # L2 regularization
|
| 494 |
+
clf_model.add(tf.keras.layers.Dropout(0.5))
|
| 495 |
+
clf_model.add(Dense(2,
|
| 496 |
+
activation='softmax',
|
| 497 |
+
kernel_regularizer=tf.keras.regularizers.l2(0.001))) # L2 regularization in the Dense layer
|
| 498 |
+
```
|
| 499 |
+
"""
|
| 500 |
+
)
|
| 501 |
+
return
|
| 502 |
+
|
| 503 |
+
|
| 504 |
+
@app.cell(hide_code=True)
|
| 505 |
+
def __(df_test, np, test_embeddings_fasttext):
|
| 506 |
+
# X_train = np.array(df['embeddings_fasttext'].tolist())
|
| 507 |
+
# X_train = X_train.reshape((X_train.shape[0], 1, X_train.shape[1]))
|
| 508 |
+
# y_train = df['label'].values
|
| 509 |
+
|
| 510 |
+
# X_val = np.array(df_val['embeddings_fasttext'].tolist())
|
| 511 |
+
# X_val = X_val.reshape((X_val.shape[0], 1, X_val.shape[1]))
|
| 512 |
+
# y_val = df_val['label'].values
|
| 513 |
+
|
| 514 |
+
X_test = np.array(test_embeddings_fasttext.tolist())
|
| 515 |
+
X_test = X_test.reshape((X_test.shape[0], 1, X_test.shape[1]))
|
| 516 |
+
y_test = df_test['label'].values
|
| 517 |
+
return X_test, y_test
|
| 518 |
+
|
| 519 |
+
|
| 520 |
+
@app.cell(hide_code=True)
|
| 521 |
+
def __():
|
| 522 |
+
# all_tokens = [token for tokens in df['processed_statement'] for token in tokens]
|
| 523 |
+
# vocab_size = len(set(all_tokens))
|
| 524 |
+
# vocab_size
|
| 525 |
+
# input_dim = X_train.shape[1] # Dimensi dari embedding yang digunakan (misalnya 50 atau 100)
|
| 526 |
+
# sent_length = X_train.shape[1] # Ukuran dimensi per embedding
|
| 527 |
+
|
| 528 |
+
# input_dim, sent_length
|
| 529 |
+
return
|
| 530 |
+
|
| 531 |
+
|
| 532 |
+
@app.cell(hide_code=True)
|
| 533 |
+
def __():
|
| 534 |
+
# clf_model = Sequential()
|
| 535 |
+
# clf_model.add(Bidirectional(tf.keras.layers.GRU(64,
|
| 536 |
+
# activation='relu',
|
| 537 |
+
# # return_sequences=True,
|
| 538 |
+
# input_shape=(sent_length, input_dim),
|
| 539 |
+
# kernel_regularizer=tf.keras.regularizers.l2(0.001)))) # L2 regularization
|
| 540 |
+
# clf_model.add(tf.keras.layers.Dropout(0.5))
|
| 541 |
+
# clf_model.add(Dense(2,
|
| 542 |
+
# activation='softmax',
|
| 543 |
+
# kernel_regularizer=tf.keras.regularizers.l2(0.001))) # L2 regularization in the Dense layer
|
| 544 |
+
|
| 545 |
+
# clf_model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
|
| 546 |
+
# clf_model.summary()
|
| 547 |
+
return
|
| 548 |
+
|
| 549 |
+
|
| 550 |
+
@app.cell(hide_code=True)
|
| 551 |
+
def __():
|
| 552 |
+
# lr_scheduler = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=10, min_lr=1e-10)
|
| 553 |
+
|
| 554 |
+
# model_history = clf_model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=100, batch_size=16, verbose=2, callbacks=[lr_scheduler])
|
| 555 |
+
return
|
| 556 |
+
|
| 557 |
+
|
| 558 |
+
@app.cell(hide_code=True)
|
| 559 |
+
def __():
|
| 560 |
+
# clf_model.save('models/model_8781.keras')
|
| 561 |
+
# joblib.dump(model_history, 'history/history_model_8781.pkl')
|
| 562 |
+
return
|
| 563 |
+
|
| 564 |
+
|
| 565 |
+
@app.cell(hide_code=True)
|
| 566 |
+
def __(joblib, tf):
|
| 567 |
+
loaded_model = tf.keras.models.load_model('models/model_8781.keras')
|
| 568 |
+
model_history_loaded = joblib.load('history/history_model_8781.pkl')
|
| 569 |
+
|
| 570 |
+
# loaded_model = clf_model
|
| 571 |
+
# model_history_loaded = model_history
|
| 572 |
+
return loaded_model, model_history_loaded
|
| 573 |
+
|
| 574 |
+
|
| 575 |
+
@app.cell(hide_code=True)
|
| 576 |
+
def __(model_history_loaded, pd):
|
| 577 |
+
history_data = {
|
| 578 |
+
'epoch': range(1, len(model_history_loaded.history['accuracy']) + 1),
|
| 579 |
+
'accuracy': model_history_loaded.history['accuracy'],
|
| 580 |
+
'val_accuracy': model_history_loaded.history['val_accuracy'],
|
| 581 |
+
'loss': model_history_loaded.history['loss'],
|
| 582 |
+
'val_loss': model_history_loaded.history['val_loss']
|
| 583 |
+
}
|
| 584 |
+
|
| 585 |
+
history_df = pd.DataFrame(history_data)
|
| 586 |
+
return history_data, history_df
|
| 587 |
+
|
| 588 |
+
|
| 589 |
+
@app.cell(hide_code=True)
|
| 590 |
+
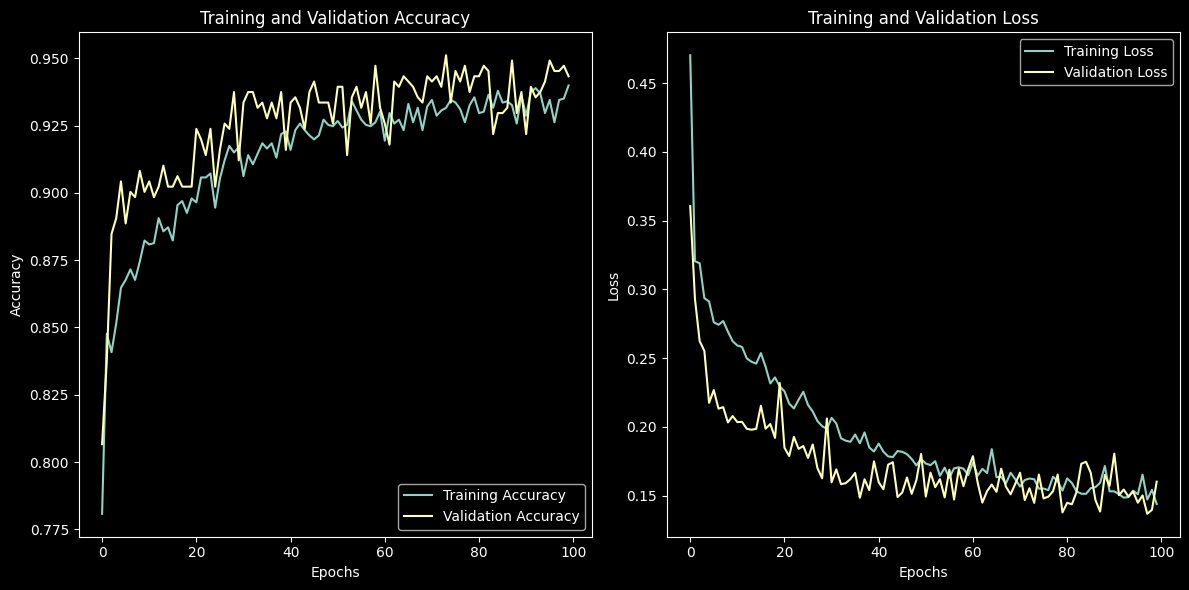
def __(alt, history_df, mo):
|
| 591 |
+
accuracy_chart = alt.Chart(history_df).transform_fold(
|
| 592 |
+
['accuracy', 'val_accuracy'],
|
| 593 |
+
as_=['type', 'accuracy']
|
| 594 |
+
).mark_line().encode(
|
| 595 |
+
x='epoch:Q',
|
| 596 |
+
y='accuracy:Q',
|
| 597 |
+
color='type:N',
|
| 598 |
+
tooltip=['epoch', 'accuracy']
|
| 599 |
+
).properties(title='Training and Validation Accuracy')
|
| 600 |
+
|
| 601 |
+
loss_chart = alt.Chart(history_df).transform_fold(
|
| 602 |
+
['loss', 'val_loss'],
|
| 603 |
+
as_=['type', 'loss']
|
| 604 |
+
).mark_line().encode(
|
| 605 |
+
x='epoch:Q',
|
| 606 |
+
y='loss:Q',
|
| 607 |
+
color='type:N',
|
| 608 |
+
tooltip=['epoch', 'loss']
|
| 609 |
+
).properties(title='Training and Validation Loss')
|
| 610 |
+
|
| 611 |
+
mo.hstack([accuracy_chart | loss_chart])
|
| 612 |
+
return accuracy_chart, loss_chart
|
| 613 |
+
|
| 614 |
+
|
| 615 |
+
@app.cell(hide_code=True)
|
| 616 |
+
def __(X_test, loaded_model, np):
|
| 617 |
+
y_pred = loaded_model.predict(X_test)
|
| 618 |
+
y_pred = np.argmax(y_pred, axis=1)
|
| 619 |
+
return (y_pred,)
|
| 620 |
+
|
| 621 |
+
|
| 622 |
+
@app.cell(hide_code=True)
|
| 623 |
+
def __():
|
| 624 |
+
from sklearn.metrics import accuracy_score, classification_report
|
| 625 |
+
import joblib
|
| 626 |
+
return accuracy_score, classification_report, joblib
|
| 627 |
+
|
| 628 |
+
|
| 629 |
+
@app.cell(hide_code=True)
|
| 630 |
+
def __(accuracy_score, mo, y_pred, y_test):
|
| 631 |
+
mo.md(f"Accuracy score: **{round(accuracy_score(y_test, y_pred) * 100, 2)}**%")
|
| 632 |
+
return
|
| 633 |
+
|
| 634 |
+
|
| 635 |
+
@app.cell(hide_code=True)
|
| 636 |
+
def __(classification_report, mo, y_pred, y_test):
|
| 637 |
+
with mo.redirect_stdout():
|
| 638 |
+
print(classification_report(y_test, y_pred))
|
| 639 |
+
return
|
| 640 |
+
|
| 641 |
+
|
| 642 |
+
@app.cell(hide_code=True)
|
| 643 |
+
def __(embedding_models, get_doc_embedding, loaded_model, preprocess_text):
|
| 644 |
+
def try_predict(text):
|
| 645 |
+
tokenized = preprocess_text(text)
|
| 646 |
+
embedded = get_doc_embedding(tokenized, embedding_models['fasttext'])
|
| 647 |
+
embedded = embedded.reshape(1, 1, -1)
|
| 648 |
+
prediction = loaded_model.predict(embedded)
|
| 649 |
+
predicted_class = prediction.argmax(axis=-1)
|
| 650 |
+
predicted_class = "Progressive" if predicted_class == 1 else "Conservative"
|
| 651 |
+
return predicted_class
|
| 652 |
+
return (try_predict,)
|
| 653 |
+
|
| 654 |
+
|
| 655 |
+
@app.cell(hide_code=True)
|
| 656 |
+
def __():
|
| 657 |
+
def validate(value):
|
| 658 |
+
if len(value.split()) < 15:
|
| 659 |
+
return 'Please enter more than 15 words.'
|
| 660 |
+
return (validate,)
|
| 661 |
+
|
| 662 |
+
|
| 663 |
+
@app.cell(hide_code=True)
|
| 664 |
+
def __(mo, validate):
|
| 665 |
+
form = mo.ui.text_area(placeholder="...").form(validate=validate)
|
| 666 |
+
return (form,)
|
| 667 |
+
|
| 668 |
+
|
| 669 |
+
if __name__ == "__main__":
|
| 670 |
+
app.run()
|
history/history_92.34.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9a777d8961a025255c0652eccee5a9d59873d483af7cd0844b41a8ee56e486d1
|
| 3 |
+
size 8818721
|
history/history_model.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e49e077673ee0bcc77a8bc9d3bd8aaa41483e5a0afb549a214abe68736e7d453
|
| 3 |
+
size 18695238
|
history/history_model_2.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5a13422c9868469d364f08c260817675c1813acfe45233a80672db18cdc515ef
|
| 3 |
+
size 1288318
|
history/history_model_8781.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bcedb7cbde492115908c5e331f3359e56609c81f68bcff8b65246683f591bf75
|
| 3 |
+
size 804042
|
huggingface-snapshots/Screenshot 2024-11-07 201845.png
ADDED
|
huggingface-snapshots/Screenshot 2024-11-07 201937.png
ADDED
|
huggingface-snapshots/Screenshot 2024-11-07 201959.png
ADDED
|
images/accuracy_loss.png
ADDED
|
models/92.34.keras
ADDED
|
Binary file (19.8 kB). View file
|
|
|
models/model.keras
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:21ab37f57ba325e3c5dd85a6f8d98b463b5013a140765e60c8251935872fe178
|
| 3 |
+
size 18691076
|
models/model_2.keras
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:be47c54ab4cc9a31ec47d56fc1c184c693a664303079bef9147d34014011efd9
|
| 3 |
+
size 1284157
|
models/model_8781.keras
ADDED
|
Binary file (799 kB). View file
|
|
|
notebook.html
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
requirements.txt
CHANGED
|
@@ -1,18 +1,22 @@
|
|
| 1 |
-
marimo
|
| 2 |
-
pandas
|
| 3 |
-
numpy
|
| 4 |
-
scipy==1.10.1
|
| 5 |
-
pyarrow
|
| 6 |
-
|
| 7 |
-
matplotlib
|
| 8 |
-
seaborn
|
| 9 |
-
altair
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
marimo==0.9.15
|
| 2 |
+
pandas==1.5.3
|
| 3 |
+
numpy==1.24.2
|
| 4 |
+
scipy==1.10.1
|
| 5 |
+
pyarrow==16.1.0
|
| 6 |
+
|
| 7 |
+
matplotlib==3.7.1
|
| 8 |
+
seaborn==0.12.2
|
| 9 |
+
altair==5.3.10
|
| 10 |
+
|
| 11 |
+
umap-learn==0.5.7
|
| 12 |
+
|
| 13 |
+
gensim==4.3.3
|
| 14 |
+
scikit-learn==0.0.post1
|
| 15 |
+
tensorflow==2.16.1
|
| 16 |
+
wordcloud==1.9.3
|
| 17 |
+
nltk==3.8.1
|
| 18 |
+
|
| 19 |
+
# Or a specific version
|
| 20 |
+
# marimo>=0.9.0
|
| 21 |
+
|
| 22 |
+
# Add other dependencies as needed
|