diff --git a/.dockerignore b/.dockerignore
new file mode 100644
index 0000000000000000000000000000000000000000..d600b6c76dd93f7b2472160d42b2797cae50c8e5
--- /dev/null
+++ b/.dockerignore
@@ -0,0 +1,25 @@
+# Logs
+logs
+*.log
+npm-debug.log*
+yarn-debug.log*
+yarn-error.log*
+pnpm-debug.log*
+lerna-debug.log*
+
+node_modules
+dist
+dist-ssr
+*.local
+
+# Editor directories and files
+.vscode/*
+!.vscode/extensions.json
+.idea
+.DS_Store
+*.suo
+*.ntvs*
+*.njsproj
+*.sln
+*.sw?
+
diff --git a/.editorconfig b/.editorconfig
new file mode 100644
index 0000000000000000000000000000000000000000..a78447ebf932f1bb3a5b124b472bea8b3a86f80f
--- /dev/null
+++ b/.editorconfig
@@ -0,0 +1,7 @@
+[*]
+charset = utf-8
+insert_final_newline = true
+end_of_line = lf
+indent_style = space
+indent_size = 2
+max_line_length = 80
\ No newline at end of file
diff --git a/.env.example b/.env.example
new file mode 100644
index 0000000000000000000000000000000000000000..5040bb9f113aa1c22a2aacfbcece438f970ed5be
--- /dev/null
+++ b/.env.example
@@ -0,0 +1,29 @@
+# A comma-separated list of access keys. Example: `ACCESS_KEYS="ABC123,JUD71F,HUWE3"`. Leave blank for unrestricted access.
+ACCESS_KEYS=""
+
+# The timeout in hours for access key validation. Set to 0 to require validation on every page load.
+ACCESS_KEY_TIMEOUT_HOURS="24"
+
+# The default model ID for WebLLM with F16 shaders.
+WEBLLM_DEFAULT_F16_MODEL_ID="Qwen2.5-0.5B-Instruct-q4f16_1-MLC"
+
+# The default model ID for WebLLM with F32 shaders.
+WEBLLM_DEFAULT_F32_MODEL_ID="Qwen2.5-0.5B-Instruct-q4f32_1-MLC"
+
+# The default model ID for Wllama.
+WLLAMA_DEFAULT_MODEL_ID="qwen-2.5-0.5b"
+
+# The base URL for the internal OpenAI compatible API. Example: `INTERNAL_OPENAI_COMPATIBLE_API_BASE_URL="https://api.openai.com/v1"`. Leave blank to disable internal OpenAI compatible API.
+INTERNAL_OPENAI_COMPATIBLE_API_BASE_URL=""
+
+# The access key for the internal OpenAI compatible API.
+INTERNAL_OPENAI_COMPATIBLE_API_KEY=""
+
+# The model for the internal OpenAI compatible API.
+INTERNAL_OPENAI_COMPATIBLE_API_MODEL=""
+
+# The name of the internal OpenAI compatible API, displayed in the UI.
+INTERNAL_OPENAI_COMPATIBLE_API_NAME="Internal API"
+
+# The type of inference to use by default. Options: "browser" (browser-based), "openai" (OpenAI-compatible API), "internal" (internal API).
+DEFAULT_INFERENCE_TYPE="browser"
diff --git a/.github/workflows/on-pull-request-to-main.yml b/.github/workflows/on-pull-request-to-main.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1132d0b744fd9440ba8c00900f02790a3fc0438d
--- /dev/null
+++ b/.github/workflows/on-pull-request-to-main.yml
@@ -0,0 +1,7 @@
+name: On Pull Request To Main
+on:
+ pull_request:
+ branches: ["main"]
+jobs:
+ test-lint-ping:
+ uses: ./.github/workflows/reusable-test-lint-ping.yml
diff --git a/.github/workflows/on-push-to-main.yml b/.github/workflows/on-push-to-main.yml
new file mode 100644
index 0000000000000000000000000000000000000000..cc884e452f5eeeac557e4b92f90ba22cd0a859ae
--- /dev/null
+++ b/.github/workflows/on-push-to-main.yml
@@ -0,0 +1,56 @@
+name: On Push To Main
+on:
+ push:
+ branches: ["main"]
+jobs:
+ test-lint-ping:
+ uses: ./.github/workflows/reusable-test-lint-ping.yml
+ build-and-push-image:
+ needs: [test-lint-ping]
+ name: Publish Docker image to GitHub Packages
+ runs-on: ubuntu-latest
+ env:
+ REGISTRY: ghcr.io
+ IMAGE_NAME: ${{ github.repository }}
+ permissions:
+ contents: read
+ packages: write
+ steps:
+ - name: Checkout repository
+ uses: actions/checkout@v4
+ - name: Log in to the Container registry
+ uses: docker/login-action@v3
+ with:
+ registry: ${{ env.REGISTRY }}
+ username: ${{ github.actor }}
+ password: ${{ secrets.GITHUB_TOKEN }}
+ - name: Extract metadata (tags, labels) for Docker
+ id: meta
+ uses: docker/metadata-action@v5
+ with:
+ images: ${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}
+ - name: Set up Docker Buildx
+ uses: docker/setup-buildx-action@v3
+ - name: Build and push Docker image
+ uses: docker/build-push-action@v6
+ with:
+ context: .
+ push: true
+ tags: ${{ steps.meta.outputs.tags }}
+ labels: ${{ steps.meta.outputs.labels }}
+ platforms: linux/amd64,linux/arm64
+ sync-to-hf:
+ needs: [test-lint-ping]
+ name: Sync to HuggingFace Spaces
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+ with:
+ lfs: true
+ - uses: JacobLinCool/huggingface-sync@v1
+ with:
+ github: ${{ secrets.GITHUB_TOKEN }}
+ user: ${{ vars.HF_SPACE_OWNER }}
+ space: ${{ vars.HF_SPACE_NAME }}
+ token: ${{ secrets.HF_TOKEN }}
+ configuration: "hf-space-config.yml"
diff --git a/.github/workflows/reusable-test-lint-ping.yml b/.github/workflows/reusable-test-lint-ping.yml
new file mode 100644
index 0000000000000000000000000000000000000000..63c8e7c09f4a8598702dd4a30cd4a920d770043d
--- /dev/null
+++ b/.github/workflows/reusable-test-lint-ping.yml
@@ -0,0 +1,25 @@
+on:
+ workflow_call:
+jobs:
+ check-code-quality:
+ name: Check Code Quality
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+ - uses: actions/setup-node@v4
+ with:
+ node-version: 20
+ cache: "npm"
+ - run: npm ci --ignore-scripts
+ - run: npm test
+ - run: npm run lint
+ check-docker-container:
+ needs: [check-code-quality]
+ name: Check Docker Container
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+ - run: docker compose -f docker-compose.production.yml up -d
+ - name: Check if main page is available
+ run: until curl -s -o /dev/null -w "%{http_code}" localhost:7860 | grep 200; do sleep 1; done
+ - run: docker compose -f docker-compose.production.yml down
diff --git a/.github/workflows/update-searxng-docker-image.yml b/.github/workflows/update-searxng-docker-image.yml
new file mode 100644
index 0000000000000000000000000000000000000000..50261a76e8453bc473fa6e487d81a45cebe7cd1a
--- /dev/null
+++ b/.github/workflows/update-searxng-docker-image.yml
@@ -0,0 +1,44 @@
+name: Update SearXNG Docker Image
+
+on:
+ schedule:
+ - cron: "0 14 * * *"
+ workflow_dispatch:
+
+permissions:
+ contents: write
+
+jobs:
+ update-searxng-image:
+ runs-on: ubuntu-latest
+ steps:
+ - name: Checkout code
+ uses: actions/checkout@v4
+ with:
+ token: ${{ secrets.GITHUB_TOKEN }}
+
+ - name: Get latest SearXNG image tag
+ id: get_latest_tag
+ run: |
+ LATEST_TAG=$(curl -s "https://hub.docker.com/v2/repositories/searxng/searxng/tags/?page_size=3&ordering=last_updated" | jq -r '.results[] | select(.name != "latest-build-cache" and .name != "latest") | .name' | head -n 1)
+ echo "LATEST_TAG=${LATEST_TAG}" >> $GITHUB_OUTPUT
+
+ - name: Update Dockerfile
+ run: |
+ sed -i 's|FROM searxng/searxng:.*|FROM searxng/searxng:${{ steps.get_latest_tag.outputs.LATEST_TAG }}|' Dockerfile
+
+ - name: Check for changes
+ id: git_status
+ run: |
+ git diff --exit-code || echo "changes=true" >> $GITHUB_OUTPUT
+
+ - name: Commit and push if changed
+ if: steps.git_status.outputs.changes == 'true'
+ run: |
+ git config --local user.email "github-actions[bot]@users.noreply.github.com"
+ git config --local user.name "github-actions[bot]"
+ git add Dockerfile
+ git commit -m "Update SearXNG Docker image to tag ${{ steps.get_latest_tag.outputs.LATEST_TAG }}"
+ git push
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..f1b26f1ea73cad18af0078381a02bbc532714a0a
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,7 @@
+node_modules
+.DS_Store
+/client/dist
+/server/models
+.vscode
+/vite-build-stats.html
+.env
diff --git a/.npmrc b/.npmrc
new file mode 100644
index 0000000000000000000000000000000000000000..80bcbed90c4f2b3d895d5086dc775e1bd8b32b43
--- /dev/null
+++ b/.npmrc
@@ -0,0 +1 @@
+legacy-peer-deps = true
diff --git a/Dockerfile b/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..3f662e8ea80654912fe5c914a73a972845bc9cf3
--- /dev/null
+++ b/Dockerfile
@@ -0,0 +1,82 @@
+# Use the SearXNG image as the base
+FROM searxng/searxng:2024.10.23-b14d885f2
+
+# Set the default port to 7860 if not provided
+ENV PORT=7860
+
+# Expose the port specified by the PORT environment variable
+EXPOSE $PORT
+
+# Install necessary packages using Alpine's package manager
+RUN apk add --update \
+ nodejs \
+ npm \
+ git \
+ build-base \
+ cmake \
+ ccache
+
+# Set the SearXNG settings folder path
+ARG SEARXNG_SETTINGS_FOLDER=/etc/searxng
+
+# Modify SearXNG configuration:
+# 1. Change output format from HTML to JSON
+# 2. Remove user switching in the entrypoint script
+# 3. Create and set permissions for the settings folder
+RUN sed -i 's/- html/- json/' /usr/local/searxng/searx/settings.yml \
+ && sed -i 's/su-exec searxng:searxng //' /usr/local/searxng/dockerfiles/docker-entrypoint.sh \
+ && mkdir -p ${SEARXNG_SETTINGS_FOLDER} \
+ && chmod 777 ${SEARXNG_SETTINGS_FOLDER}
+
+# Set up user and directory structure
+ARG USERNAME=user
+ARG HOME_DIR=/home/${USERNAME}
+ARG APP_DIR=${HOME_DIR}/app
+
+# Create a non-root user and set up the application directory
+RUN adduser -D -u 1000 ${USERNAME} \
+ && mkdir -p ${APP_DIR} \
+ && chown -R ${USERNAME}:${USERNAME} ${HOME_DIR}
+
+# Switch to the non-root user
+USER ${USERNAME}
+
+# Set the working directory to the application directory
+WORKDIR ${APP_DIR}
+
+# Define environment variables that can be passed to the container during build.
+# This approach allows for dynamic configuration without relying on a `.env` file,
+# which might not be suitable for all deployment scenarios.
+ARG ACCESS_KEYS
+ARG ACCESS_KEY_TIMEOUT_HOURS
+ARG WEBLLM_DEFAULT_F16_MODEL_ID
+ARG WEBLLM_DEFAULT_F32_MODEL_ID
+ARG WLLAMA_DEFAULT_MODEL_ID
+ARG INTERNAL_OPENAI_COMPATIBLE_API_BASE_URL
+ARG INTERNAL_OPENAI_COMPATIBLE_API_KEY
+ARG INTERNAL_OPENAI_COMPATIBLE_API_MODEL
+ARG INTERNAL_OPENAI_COMPATIBLE_API_NAME
+ARG DEFAULT_INFERENCE_TYPE
+
+# Copy package.json, package-lock.json, and .npmrc files
+COPY --chown=${USERNAME}:${USERNAME} ./package.json ./package.json
+COPY --chown=${USERNAME}:${USERNAME} ./package-lock.json ./package-lock.json
+COPY --chown=${USERNAME}:${USERNAME} ./.npmrc ./.npmrc
+
+# Install Node.js dependencies
+RUN npm ci
+
+# Copy the rest of the application files
+COPY --chown=${USERNAME}:${USERNAME} . .
+
+# Configure Git to treat the app directory as safe
+RUN git config --global --add safe.directory ${APP_DIR}
+
+# Build the application
+RUN npm run build
+
+# Set the entrypoint to use a shell
+ENTRYPOINT [ "/bin/sh", "-c" ]
+
+# Run SearXNG in the background and start the Node.js application using PM2
+CMD [ "(/usr/local/searxng/dockerfiles/docker-entrypoint.sh -f > /dev/null 2>&1) & (npx pm2 start ecosystem.config.cjs && npx pm2 logs production-server)" ]
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8663733578ab3a007a39abb748692b0ccb363357
--- /dev/null
+++ b/README.md
@@ -0,0 +1,121 @@
+---
+title: MiniSearch
+emoji: 👌🔍
+colorFrom: yellow
+colorTo: yellow
+sdk: docker
+short_description: Minimalist web-searching app with browser-based AI assistant
+pinned: true
+custom_headers:
+ cross-origin-embedder-policy: require-corp
+ cross-origin-opener-policy: same-origin
+ cross-origin-resource-policy: cross-origin
+---
+
+# MiniSearch
+
+A minimalist web-searching app with an AI assistant that runs directly from your browser.
+
+Live demo: https://felladrin-minisearch.hf.space
+
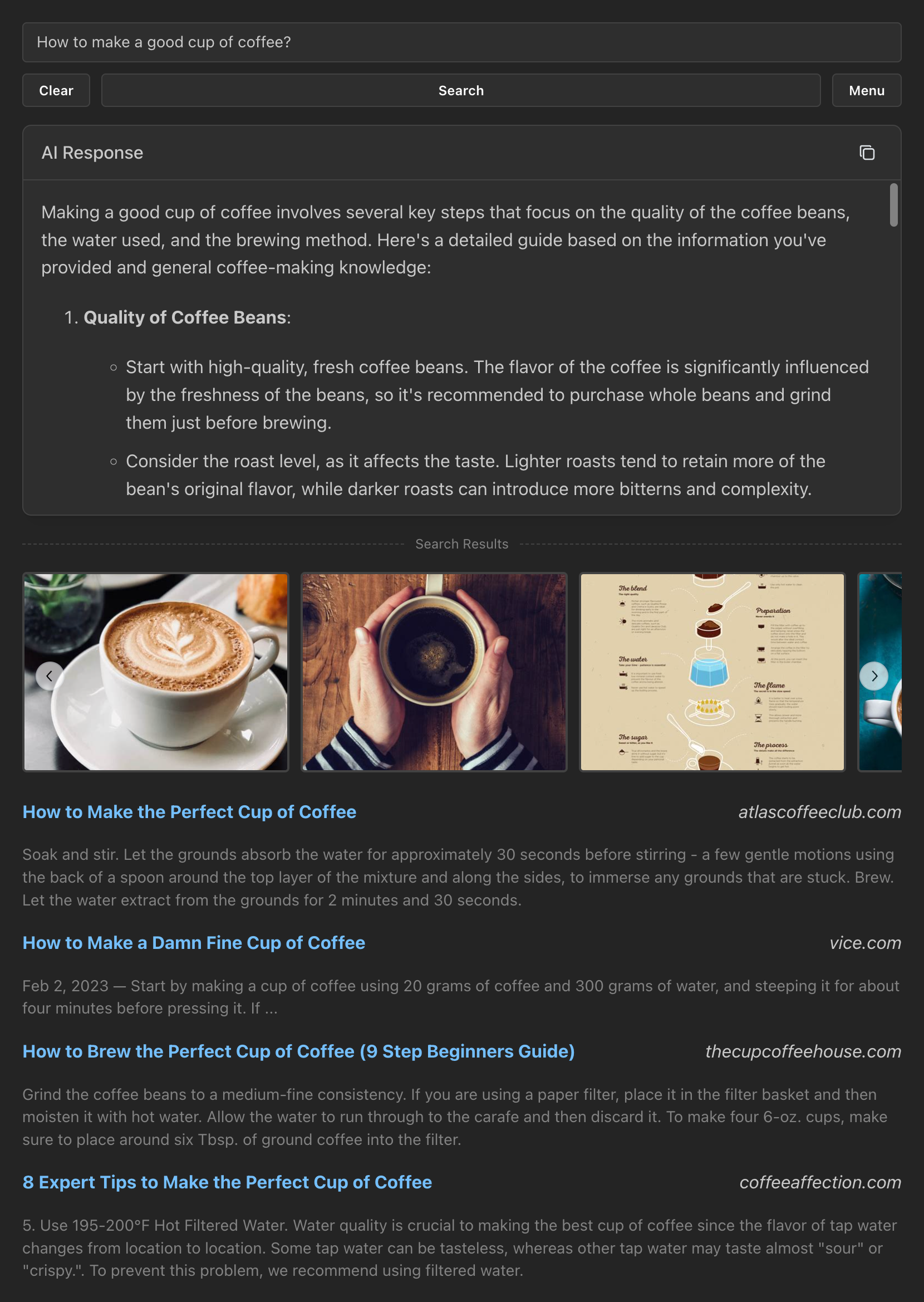
+## Screenshot
+
+
+
+## Features
+
+- **Privacy-focused**: [No tracking, no ads, no data collection](https://docs.searxng.org/own-instance.html#how-does-searxng-protect-privacy)
+- **Easy to use**: Minimalist yet intuitive interface for all users
+- **Cross-platform**: Models run inside the browser, both on desktop and mobile
+- **Integrated**: Search from the browser address bar by setting it as the default search engine
+- **Efficient**: Models are loaded and cached only when needed
+- **Customizable**: Tweakable settings for search results and text generation
+- **Open-source**: [The code is available for inspection and contribution at GitHub](https://github.com/felladrin/MiniSearch)
+
+## Prerequisites
+
+- [Docker](https://docs.docker.com/get-docker/)
+
+## Getting started
+
+There are two ways to get started with MiniSearch. Pick one that suits you best.
+
+**Option 1** - Use [MiniSearch's Docker Image](https://github.com/felladrin/MiniSearch/pkgs/container/minisearch) by running:
+
+```bash
+docker run -p 7860:7860 ghcr.io/felladrin/minisearch:main
+```
+
+**Option 2** - Build from source by [downloading the repository files](https://github.com/felladrin/MiniSearch/archive/refs/heads/main.zip) and running:
+
+```bash
+docker compose -f docker-compose.production.yml up --build
+```
+
+Then, open http://localhost:7860 in your browser and start searching!
+
+## Frequently asked questions
+
+
+ How do I search via the browser's address bar?
+
+ You can set MiniSearch as your browser's address-bar search engine using the pattern http://localhost:7860/?q=%s, in which your search term replaces %s.
+
+
+
+
+ Can I use custom models via OpenAI-Compatible API?
+
+ Yes! For this, open the Menu and change the "AI Processing Location" to Remote server (API). Then configure the Base URL, and optionally set an API Key and a Model to use.
+
+
+
+
+ How do I restrict the access to my MiniSearch instance via password?
+
+ Create a .env file and set a value for ACCESS_KEYS. Then reset the MiniSearch docker container.
+
+
+ For example, if you to set the password to PepperoniPizza, then this is what you should add to your .env:
+ ACCESS_KEYS="PepperoniPizza"
+
+
+ You can find more examples in the .env.example file.
+
+
+
+
+ I want to serve MiniSearch to other users, allowing them to use my own OpenAI-Compatible API key, but without revealing it to them. Is it possible?
+
Yes! In MiniSearch, we call this text-generation feature "Internal OpenAI-Compatible API". To use this it:
+
+
Set up your OpenAI-Compatible API endpoint by configuring the following environment variables in your .env file:
+
+
INTERNAL_OPENAI_COMPATIBLE_API_BASE_URL: The base URL for your API
+
INTERNAL_OPENAI_COMPATIBLE_API_KEY: Your API access key
+
INTERNAL_OPENAI_COMPATIBLE_API_MODEL: The model to use
+
INTERNAL_OPENAI_COMPATIBLE_API_NAME: The name to display in the UI
+
+
+
Restart MiniSearch server.
+
In the MiniSearch menu, select the new option (named as per your INTERNAL_OPENAI_COMPATIBLE_API_NAME setting) from the "AI Processing Location" dropdown.
+
+
+
+
+ How can I contribute to the development of this tool?
+
Fork this repository and clone it. Then, start the development server by running the following command:
+
docker compose up
+
Make your changes, push them to your fork, and open a pull request! All contributions are welcome!
+
+
+
+ Why is MiniSearch built upon SearXNG's Docker Image and using a single image instead of composing it from multiple services?
+
There are a few reasons for this:
+
+
MiniSearch utilizes SearXNG as its meta-search engine.
+
Manual installation of SearXNG is not trivial, so we use the docker image they provide, which has everything set up.
+
SearXNG only provides a Docker Image based on Alpine Linux.
+
The user of the image needs to be customized in a specific way to run on HuggingFace Spaces, where MiniSearch's demo runs.
+
HuggingFace only accepts a single docker image. It doesn't run docker compose or multiple images, unfortunately.