


Commit
•
5a510e7
1
Parent(s):
20bf7e1
Upload folder using huggingface_hub
Browse files- .github/workflows/static-check.yaml +26 -0
- .gitignore +170 -0
- .pre-commit-config.yaml +17 -0
- .pylintrc +633 -0
- README.md +209 -12
- assets/framework.png +0 -0
- assets/framework_1.jpg +0 -0
- assets/framework_2.jpg +0 -0
- assets/wechat.jpeg +0 -0
- configs/inference/.gitkeep +0 -0
- configs/inference/default.yaml +90 -0
- configs/unet/unet.yaml +44 -0
- hallo/__init__.py +0 -0
- hallo/animate/__init__.py +0 -0
- hallo/animate/face_animate.py +442 -0
- hallo/animate/face_animate_static.py +481 -0
- hallo/datasets/__init__.py +0 -0
- hallo/datasets/audio_processor.py +172 -0
- hallo/datasets/image_processor.py +201 -0
- hallo/datasets/mask_image.py +154 -0
- hallo/datasets/talk_video.py +312 -0
- hallo/models/__init__.py +0 -0
- hallo/models/attention.py +921 -0
- hallo/models/audio_proj.py +124 -0
- hallo/models/face_locator.py +113 -0
- hallo/models/image_proj.py +76 -0
- hallo/models/motion_module.py +608 -0
- hallo/models/mutual_self_attention.py +496 -0
- hallo/models/resnet.py +435 -0
- hallo/models/transformer_2d.py +431 -0
- hallo/models/transformer_3d.py +257 -0
- hallo/models/unet_2d_blocks.py +1343 -0
- hallo/models/unet_2d_condition.py +1432 -0
- hallo/models/unet_3d.py +839 -0
- hallo/models/unet_3d_blocks.py +1401 -0
- hallo/models/wav2vec.py +209 -0
- hallo/utils/__init__.py +0 -0
- hallo/utils/util.py +616 -0
- requirements.txt +30 -0
- scripts/inference.py +372 -0
- setup.py +55 -0
.github/workflows/static-check.yaml
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Pylint
|
| 2 |
+
|
| 3 |
+
on: [push, pull_request]
|
| 4 |
+
|
| 5 |
+
jobs:
|
| 6 |
+
static-check:
|
| 7 |
+
runs-on: ${{ matrix.os }}
|
| 8 |
+
strategy:
|
| 9 |
+
matrix:
|
| 10 |
+
os: [ubuntu-22.04]
|
| 11 |
+
python-version: ["3.10"]
|
| 12 |
+
steps:
|
| 13 |
+
- uses: actions/checkout@v3
|
| 14 |
+
- name: Set up Python ${{ matrix.python-version }}
|
| 15 |
+
uses: actions/setup-python@v3
|
| 16 |
+
with:
|
| 17 |
+
python-version: ${{ matrix.python-version }}
|
| 18 |
+
- name: Install dependencies
|
| 19 |
+
run: |
|
| 20 |
+
python -m pip install --upgrade pylint
|
| 21 |
+
python -m pip install --upgrade isort
|
| 22 |
+
python -m pip install -r requirements.txt
|
| 23 |
+
- name: Analysing the code with pylint
|
| 24 |
+
run: |
|
| 25 |
+
isort $(git ls-files '*.py') --check-only --diff
|
| 26 |
+
pylint $(git ls-files '*.py')
|
.gitignore
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# running cache
|
| 2 |
+
mlruns/
|
| 3 |
+
|
| 4 |
+
# Test directories
|
| 5 |
+
test_data/
|
| 6 |
+
pretrained_models/
|
| 7 |
+
|
| 8 |
+
# Poetry project
|
| 9 |
+
poetry.lock
|
| 10 |
+
|
| 11 |
+
# Byte-compiled / optimized / DLL files
|
| 12 |
+
__pycache__/
|
| 13 |
+
*.py[cod]
|
| 14 |
+
*$py.class
|
| 15 |
+
|
| 16 |
+
# C extensions
|
| 17 |
+
*.so
|
| 18 |
+
|
| 19 |
+
# Distribution / packaging
|
| 20 |
+
.Python
|
| 21 |
+
build/
|
| 22 |
+
develop-eggs/
|
| 23 |
+
dist/
|
| 24 |
+
downloads/
|
| 25 |
+
eggs/
|
| 26 |
+
.eggs/
|
| 27 |
+
lib/
|
| 28 |
+
lib64/
|
| 29 |
+
parts/
|
| 30 |
+
sdist/
|
| 31 |
+
var/
|
| 32 |
+
wheels/
|
| 33 |
+
share/python-wheels/
|
| 34 |
+
*.egg-info/
|
| 35 |
+
.installed.cfg
|
| 36 |
+
*.egg
|
| 37 |
+
MANIFEST
|
| 38 |
+
|
| 39 |
+
# PyInstaller
|
| 40 |
+
# Usually these files are written by a python script from a template
|
| 41 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 42 |
+
*.manifest
|
| 43 |
+
*.spec
|
| 44 |
+
|
| 45 |
+
# Installer logs
|
| 46 |
+
pip-log.txt
|
| 47 |
+
pip-delete-this-directory.txt
|
| 48 |
+
|
| 49 |
+
# Unit test / coverage reports
|
| 50 |
+
htmlcov/
|
| 51 |
+
.tox/
|
| 52 |
+
.nox/
|
| 53 |
+
.coverage
|
| 54 |
+
.coverage.*
|
| 55 |
+
.cache
|
| 56 |
+
nosetests.xml
|
| 57 |
+
coverage.xml
|
| 58 |
+
*.cover
|
| 59 |
+
*.py,cover
|
| 60 |
+
.hypothesis/
|
| 61 |
+
.pytest_cache/
|
| 62 |
+
cover/
|
| 63 |
+
|
| 64 |
+
# Translations
|
| 65 |
+
*.mo
|
| 66 |
+
*.pot
|
| 67 |
+
|
| 68 |
+
# Django stuff:
|
| 69 |
+
*.log
|
| 70 |
+
local_settings.py
|
| 71 |
+
db.sqlite3
|
| 72 |
+
db.sqlite3-journal
|
| 73 |
+
|
| 74 |
+
# Flask stuff:
|
| 75 |
+
instance/
|
| 76 |
+
.webassets-cache
|
| 77 |
+
|
| 78 |
+
# Scrapy stuff:
|
| 79 |
+
.scrapy
|
| 80 |
+
|
| 81 |
+
# Sphinx documentation
|
| 82 |
+
docs/_build/
|
| 83 |
+
|
| 84 |
+
# PyBuilder
|
| 85 |
+
.pybuilder/
|
| 86 |
+
target/
|
| 87 |
+
|
| 88 |
+
# Jupyter Notebook
|
| 89 |
+
.ipynb_checkpoints
|
| 90 |
+
|
| 91 |
+
# IPython
|
| 92 |
+
profile_default/
|
| 93 |
+
ipython_config.py
|
| 94 |
+
|
| 95 |
+
# pyenv
|
| 96 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 97 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 98 |
+
# .python-version
|
| 99 |
+
|
| 100 |
+
# pipenv
|
| 101 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 102 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 103 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 104 |
+
# install all needed dependencies.
|
| 105 |
+
#Pipfile.lock
|
| 106 |
+
|
| 107 |
+
# poetry
|
| 108 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 109 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 110 |
+
# commonly ignored for libraries.
|
| 111 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 112 |
+
#poetry.lock
|
| 113 |
+
|
| 114 |
+
# pdm
|
| 115 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 116 |
+
#pdm.lock
|
| 117 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 118 |
+
# in version control.
|
| 119 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 120 |
+
.pdm.toml
|
| 121 |
+
|
| 122 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 123 |
+
__pypackages__/
|
| 124 |
+
|
| 125 |
+
# Celery stuff
|
| 126 |
+
celerybeat-schedule
|
| 127 |
+
celerybeat.pid
|
| 128 |
+
|
| 129 |
+
# SageMath parsed files
|
| 130 |
+
*.sage.py
|
| 131 |
+
|
| 132 |
+
# Environments
|
| 133 |
+
.env
|
| 134 |
+
.venv
|
| 135 |
+
env/
|
| 136 |
+
venv/
|
| 137 |
+
ENV/
|
| 138 |
+
env.bak/
|
| 139 |
+
venv.bak/
|
| 140 |
+
|
| 141 |
+
# Spyder project settings
|
| 142 |
+
.spyderproject
|
| 143 |
+
.spyproject
|
| 144 |
+
|
| 145 |
+
# Rope project settings
|
| 146 |
+
.ropeproject
|
| 147 |
+
|
| 148 |
+
# mkdocs documentation
|
| 149 |
+
/site
|
| 150 |
+
|
| 151 |
+
# mypy
|
| 152 |
+
.mypy_cache/
|
| 153 |
+
.dmypy.json
|
| 154 |
+
dmypy.json
|
| 155 |
+
|
| 156 |
+
# Pyre type checker
|
| 157 |
+
.pyre/
|
| 158 |
+
|
| 159 |
+
# pytype static type analyzer
|
| 160 |
+
.pytype/
|
| 161 |
+
|
| 162 |
+
# Cython debug symbols
|
| 163 |
+
cython_debug/
|
| 164 |
+
|
| 165 |
+
# IDE
|
| 166 |
+
.idea/
|
| 167 |
+
.vscode/
|
| 168 |
+
data
|
| 169 |
+
pretrained_models
|
| 170 |
+
test_data
|
.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
repos:
|
| 2 |
+
- repo: local
|
| 3 |
+
hooks:
|
| 4 |
+
- id: isort
|
| 5 |
+
name: isort
|
| 6 |
+
language: system
|
| 7 |
+
types: [python]
|
| 8 |
+
pass_filenames: false
|
| 9 |
+
entry: isort
|
| 10 |
+
args: ["."]
|
| 11 |
+
- id: pylint
|
| 12 |
+
name: pylint
|
| 13 |
+
language: system
|
| 14 |
+
types: [python]
|
| 15 |
+
pass_filenames: false
|
| 16 |
+
entry: pylint
|
| 17 |
+
args: ["**/*.py"]
|
.pylintrc
ADDED
|
@@ -0,0 +1,633 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[MAIN]
|
| 2 |
+
|
| 3 |
+
# Analyse import fallback blocks. This can be used to support both Python 2 and
|
| 4 |
+
# 3 compatible code, which means that the block might have code that exists
|
| 5 |
+
# only in one or another interpreter, leading to false positives when analysed.
|
| 6 |
+
analyse-fallback-blocks=no
|
| 7 |
+
|
| 8 |
+
# Clear in-memory caches upon conclusion of linting. Useful if running pylint
|
| 9 |
+
# in a server-like mode.
|
| 10 |
+
clear-cache-post-run=no
|
| 11 |
+
|
| 12 |
+
# Load and enable all available extensions. Use --list-extensions to see a list
|
| 13 |
+
# all available extensions.
|
| 14 |
+
#enable-all-extensions=
|
| 15 |
+
|
| 16 |
+
# In error mode, messages with a category besides ERROR or FATAL are
|
| 17 |
+
# suppressed, and no reports are done by default. Error mode is compatible with
|
| 18 |
+
# disabling specific errors.
|
| 19 |
+
#errors-only=
|
| 20 |
+
|
| 21 |
+
# Always return a 0 (non-error) status code, even if lint errors are found.
|
| 22 |
+
# This is primarily useful in continuous integration scripts.
|
| 23 |
+
#exit-zero=
|
| 24 |
+
|
| 25 |
+
# A comma-separated list of package or module names from where C extensions may
|
| 26 |
+
# be loaded. Extensions are loading into the active Python interpreter and may
|
| 27 |
+
# run arbitrary code.
|
| 28 |
+
extension-pkg-allow-list=
|
| 29 |
+
|
| 30 |
+
# A comma-separated list of package or module names from where C extensions may
|
| 31 |
+
# be loaded. Extensions are loading into the active Python interpreter and may
|
| 32 |
+
# run arbitrary code. (This is an alternative name to extension-pkg-allow-list
|
| 33 |
+
# for backward compatibility.)
|
| 34 |
+
extension-pkg-whitelist=cv2
|
| 35 |
+
|
| 36 |
+
# Return non-zero exit code if any of these messages/categories are detected,
|
| 37 |
+
# even if score is above --fail-under value. Syntax same as enable. Messages
|
| 38 |
+
# specified are enabled, while categories only check already-enabled messages.
|
| 39 |
+
fail-on=
|
| 40 |
+
|
| 41 |
+
# Specify a score threshold under which the program will exit with error.
|
| 42 |
+
fail-under=10
|
| 43 |
+
|
| 44 |
+
# Interpret the stdin as a python script, whose filename needs to be passed as
|
| 45 |
+
# the module_or_package argument.
|
| 46 |
+
#from-stdin=
|
| 47 |
+
|
| 48 |
+
# Files or directories to be skipped. They should be base names, not paths.
|
| 49 |
+
ignore=CVS
|
| 50 |
+
|
| 51 |
+
# Add files or directories matching the regular expressions patterns to the
|
| 52 |
+
# ignore-list. The regex matches against paths and can be in Posix or Windows
|
| 53 |
+
# format. Because '\\' represents the directory delimiter on Windows systems,
|
| 54 |
+
# it can't be used as an escape character.
|
| 55 |
+
ignore-paths=
|
| 56 |
+
|
| 57 |
+
# Files or directories matching the regular expression patterns are skipped.
|
| 58 |
+
# The regex matches against base names, not paths. The default value ignores
|
| 59 |
+
# Emacs file locks
|
| 60 |
+
ignore-patterns=^\.#
|
| 61 |
+
|
| 62 |
+
# List of module names for which member attributes should not be checked
|
| 63 |
+
# (useful for modules/projects where namespaces are manipulated during runtime
|
| 64 |
+
# and thus existing member attributes cannot be deduced by static analysis). It
|
| 65 |
+
# supports qualified module names, as well as Unix pattern matching.
|
| 66 |
+
ignored-modules=cv2
|
| 67 |
+
|
| 68 |
+
# Python code to execute, usually for sys.path manipulation such as
|
| 69 |
+
# pygtk.require().
|
| 70 |
+
init-hook='import sys; sys.path.append(".")'
|
| 71 |
+
|
| 72 |
+
# Use multiple processes to speed up Pylint. Specifying 0 will auto-detect the
|
| 73 |
+
# number of processors available to use, and will cap the count on Windows to
|
| 74 |
+
# avoid hangs.
|
| 75 |
+
jobs=1
|
| 76 |
+
|
| 77 |
+
# Control the amount of potential inferred values when inferring a single
|
| 78 |
+
# object. This can help the performance when dealing with large functions or
|
| 79 |
+
# complex, nested conditions.
|
| 80 |
+
limit-inference-results=100
|
| 81 |
+
|
| 82 |
+
# List of plugins (as comma separated values of python module names) to load,
|
| 83 |
+
# usually to register additional checkers.
|
| 84 |
+
load-plugins=
|
| 85 |
+
|
| 86 |
+
# Pickle collected data for later comparisons.
|
| 87 |
+
persistent=yes
|
| 88 |
+
|
| 89 |
+
# Minimum Python version to use for version dependent checks. Will default to
|
| 90 |
+
# the version used to run pylint.
|
| 91 |
+
py-version=3.10
|
| 92 |
+
|
| 93 |
+
# Discover python modules and packages in the file system subtree.
|
| 94 |
+
recursive=no
|
| 95 |
+
|
| 96 |
+
# Add paths to the list of the source roots. Supports globbing patterns. The
|
| 97 |
+
# source root is an absolute path or a path relative to the current working
|
| 98 |
+
# directory used to determine a package namespace for modules located under the
|
| 99 |
+
# source root.
|
| 100 |
+
source-roots=
|
| 101 |
+
|
| 102 |
+
# When enabled, pylint would attempt to guess common misconfiguration and emit
|
| 103 |
+
# user-friendly hints instead of false-positive error messages.
|
| 104 |
+
suggestion-mode=yes
|
| 105 |
+
|
| 106 |
+
# Allow loading of arbitrary C extensions. Extensions are imported into the
|
| 107 |
+
# active Python interpreter and may run arbitrary code.
|
| 108 |
+
unsafe-load-any-extension=no
|
| 109 |
+
|
| 110 |
+
# In verbose mode, extra non-checker-related info will be displayed.
|
| 111 |
+
#verbose=
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
[BASIC]
|
| 115 |
+
|
| 116 |
+
# Naming style matching correct argument names.
|
| 117 |
+
argument-naming-style=snake_case
|
| 118 |
+
|
| 119 |
+
# Regular expression matching correct argument names. Overrides argument-
|
| 120 |
+
# naming-style. If left empty, argument names will be checked with the set
|
| 121 |
+
# naming style.
|
| 122 |
+
#argument-rgx=
|
| 123 |
+
|
| 124 |
+
# Naming style matching correct attribute names.
|
| 125 |
+
attr-naming-style=snake_case
|
| 126 |
+
|
| 127 |
+
# Regular expression matching correct attribute names. Overrides attr-naming-
|
| 128 |
+
# style. If left empty, attribute names will be checked with the set naming
|
| 129 |
+
# style.
|
| 130 |
+
#attr-rgx=
|
| 131 |
+
|
| 132 |
+
# Bad variable names which should always be refused, separated by a comma.
|
| 133 |
+
bad-names=foo,
|
| 134 |
+
bar,
|
| 135 |
+
baz,
|
| 136 |
+
toto,
|
| 137 |
+
tutu,
|
| 138 |
+
tata
|
| 139 |
+
|
| 140 |
+
# Bad variable names regexes, separated by a comma. If names match any regex,
|
| 141 |
+
# they will always be refused
|
| 142 |
+
bad-names-rgxs=
|
| 143 |
+
|
| 144 |
+
# Naming style matching correct class attribute names.
|
| 145 |
+
class-attribute-naming-style=any
|
| 146 |
+
|
| 147 |
+
# Regular expression matching correct class attribute names. Overrides class-
|
| 148 |
+
# attribute-naming-style. If left empty, class attribute names will be checked
|
| 149 |
+
# with the set naming style.
|
| 150 |
+
#class-attribute-rgx=
|
| 151 |
+
|
| 152 |
+
# Naming style matching correct class constant names.
|
| 153 |
+
class-const-naming-style=UPPER_CASE
|
| 154 |
+
|
| 155 |
+
# Regular expression matching correct class constant names. Overrides class-
|
| 156 |
+
# const-naming-style. If left empty, class constant names will be checked with
|
| 157 |
+
# the set naming style.
|
| 158 |
+
#class-const-rgx=
|
| 159 |
+
|
| 160 |
+
# Naming style matching correct class names.
|
| 161 |
+
class-naming-style=PascalCase
|
| 162 |
+
|
| 163 |
+
# Regular expression matching correct class names. Overrides class-naming-
|
| 164 |
+
# style. If left empty, class names will be checked with the set naming style.
|
| 165 |
+
#class-rgx=
|
| 166 |
+
|
| 167 |
+
# Naming style matching correct constant names.
|
| 168 |
+
const-naming-style=UPPER_CASE
|
| 169 |
+
|
| 170 |
+
# Regular expression matching correct constant names. Overrides const-naming-
|
| 171 |
+
# style. If left empty, constant names will be checked with the set naming
|
| 172 |
+
# style.
|
| 173 |
+
#const-rgx=
|
| 174 |
+
|
| 175 |
+
# Minimum line length for functions/classes that require docstrings, shorter
|
| 176 |
+
# ones are exempt.
|
| 177 |
+
docstring-min-length=-1
|
| 178 |
+
|
| 179 |
+
# Naming style matching correct function names.
|
| 180 |
+
function-naming-style=snake_case
|
| 181 |
+
|
| 182 |
+
# Regular expression matching correct function names. Overrides function-
|
| 183 |
+
# naming-style. If left empty, function names will be checked with the set
|
| 184 |
+
# naming style.
|
| 185 |
+
#function-rgx=
|
| 186 |
+
|
| 187 |
+
# Good variable names which should always be accepted, separated by a comma.
|
| 188 |
+
good-names=i,
|
| 189 |
+
j,
|
| 190 |
+
k,
|
| 191 |
+
ex,
|
| 192 |
+
Run,
|
| 193 |
+
_
|
| 194 |
+
|
| 195 |
+
# Good variable names regexes, separated by a comma. If names match any regex,
|
| 196 |
+
# they will always be accepted
|
| 197 |
+
good-names-rgxs=
|
| 198 |
+
|
| 199 |
+
# Include a hint for the correct naming format with invalid-name.
|
| 200 |
+
include-naming-hint=no
|
| 201 |
+
|
| 202 |
+
# Naming style matching correct inline iteration names.
|
| 203 |
+
inlinevar-naming-style=any
|
| 204 |
+
|
| 205 |
+
# Regular expression matching correct inline iteration names. Overrides
|
| 206 |
+
# inlinevar-naming-style. If left empty, inline iteration names will be checked
|
| 207 |
+
# with the set naming style.
|
| 208 |
+
#inlinevar-rgx=
|
| 209 |
+
|
| 210 |
+
# Naming style matching correct method names.
|
| 211 |
+
method-naming-style=snake_case
|
| 212 |
+
|
| 213 |
+
# Regular expression matching correct method names. Overrides method-naming-
|
| 214 |
+
# style. If left empty, method names will be checked with the set naming style.
|
| 215 |
+
#method-rgx=
|
| 216 |
+
|
| 217 |
+
# Naming style matching correct module names.
|
| 218 |
+
module-naming-style=snake_case
|
| 219 |
+
|
| 220 |
+
# Regular expression matching correct module names. Overrides module-naming-
|
| 221 |
+
# style. If left empty, module names will be checked with the set naming style.
|
| 222 |
+
#module-rgx=
|
| 223 |
+
|
| 224 |
+
# Colon-delimited sets of names that determine each other's naming style when
|
| 225 |
+
# the name regexes allow several styles.
|
| 226 |
+
name-group=
|
| 227 |
+
|
| 228 |
+
# Regular expression which should only match function or class names that do
|
| 229 |
+
# not require a docstring.
|
| 230 |
+
no-docstring-rgx=^_
|
| 231 |
+
|
| 232 |
+
# List of decorators that produce properties, such as abc.abstractproperty. Add
|
| 233 |
+
# to this list to register other decorators that produce valid properties.
|
| 234 |
+
# These decorators are taken in consideration only for invalid-name.
|
| 235 |
+
property-classes=abc.abstractproperty
|
| 236 |
+
|
| 237 |
+
# Regular expression matching correct type alias names. If left empty, type
|
| 238 |
+
# alias names will be checked with the set naming style.
|
| 239 |
+
#typealias-rgx=
|
| 240 |
+
|
| 241 |
+
# Regular expression matching correct type variable names. If left empty, type
|
| 242 |
+
# variable names will be checked with the set naming style.
|
| 243 |
+
#typevar-rgx=
|
| 244 |
+
|
| 245 |
+
# Naming style matching correct variable names.
|
| 246 |
+
variable-naming-style=snake_case
|
| 247 |
+
|
| 248 |
+
# Regular expression matching correct variable names. Overrides variable-
|
| 249 |
+
# naming-style. If left empty, variable names will be checked with the set
|
| 250 |
+
# naming style.
|
| 251 |
+
variable-rgx=(_?[a-z][A-Za-z0-9]{0,30})|([A-Z0-9]{1,30})
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
[CLASSES]
|
| 255 |
+
|
| 256 |
+
# Warn about protected attribute access inside special methods
|
| 257 |
+
check-protected-access-in-special-methods=no
|
| 258 |
+
|
| 259 |
+
# List of method names used to declare (i.e. assign) instance attributes.
|
| 260 |
+
defining-attr-methods=__init__,
|
| 261 |
+
__new__,
|
| 262 |
+
setUp,
|
| 263 |
+
asyncSetUp,
|
| 264 |
+
__post_init__
|
| 265 |
+
|
| 266 |
+
# List of member names, which should be excluded from the protected access
|
| 267 |
+
# warning.
|
| 268 |
+
exclude-protected=_asdict,_fields,_replace,_source,_make,os._exit
|
| 269 |
+
|
| 270 |
+
# List of valid names for the first argument in a class method.
|
| 271 |
+
valid-classmethod-first-arg=cls
|
| 272 |
+
|
| 273 |
+
# List of valid names for the first argument in a metaclass class method.
|
| 274 |
+
valid-metaclass-classmethod-first-arg=mcs
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
[DESIGN]
|
| 278 |
+
|
| 279 |
+
# List of regular expressions of class ancestor names to ignore when counting
|
| 280 |
+
# public methods (see R0903)
|
| 281 |
+
exclude-too-few-public-methods=
|
| 282 |
+
|
| 283 |
+
# List of qualified class names to ignore when counting class parents (see
|
| 284 |
+
# R0901)
|
| 285 |
+
ignored-parents=
|
| 286 |
+
|
| 287 |
+
# Maximum number of arguments for function / method.
|
| 288 |
+
max-args=7
|
| 289 |
+
|
| 290 |
+
# Maximum number of attributes for a class (see R0902).
|
| 291 |
+
max-attributes=20
|
| 292 |
+
|
| 293 |
+
# Maximum number of boolean expressions in an if statement (see R0916).
|
| 294 |
+
max-bool-expr=5
|
| 295 |
+
|
| 296 |
+
# Maximum number of branch for function / method body.
|
| 297 |
+
max-branches=12
|
| 298 |
+
|
| 299 |
+
# Maximum number of locals for function / method body.
|
| 300 |
+
max-locals=15
|
| 301 |
+
|
| 302 |
+
# Maximum number of parents for a class (see R0901).
|
| 303 |
+
max-parents=7
|
| 304 |
+
|
| 305 |
+
# Maximum number of public methods for a class (see R0904).
|
| 306 |
+
max-public-methods=20
|
| 307 |
+
|
| 308 |
+
# Maximum number of return / yield for function / method body.
|
| 309 |
+
max-returns=6
|
| 310 |
+
|
| 311 |
+
# Maximum number of statements in function / method body.
|
| 312 |
+
max-statements=300
|
| 313 |
+
|
| 314 |
+
# Minimum number of public methods for a class (see R0903).
|
| 315 |
+
min-public-methods=1
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
[EXCEPTIONS]
|
| 319 |
+
|
| 320 |
+
# Exceptions that will emit a warning when caught.
|
| 321 |
+
overgeneral-exceptions=builtins.BaseException,builtins.Exception
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
[FORMAT]
|
| 325 |
+
|
| 326 |
+
# Expected format of line ending, e.g. empty (any line ending), LF or CRLF.
|
| 327 |
+
expected-line-ending-format=
|
| 328 |
+
|
| 329 |
+
# Regexp for a line that is allowed to be longer than the limit.
|
| 330 |
+
ignore-long-lines=^\s*(# )?<?https?://\S+>?$
|
| 331 |
+
|
| 332 |
+
# Number of spaces of indent required inside a hanging or continued line.
|
| 333 |
+
indent-after-paren=4
|
| 334 |
+
|
| 335 |
+
# String used as indentation unit. This is usually " " (4 spaces) or "\t" (1
|
| 336 |
+
# tab).
|
| 337 |
+
indent-string=' '
|
| 338 |
+
|
| 339 |
+
# Maximum number of characters on a single line.
|
| 340 |
+
max-line-length=150
|
| 341 |
+
|
| 342 |
+
# Maximum number of lines in a module.
|
| 343 |
+
max-module-lines=2000
|
| 344 |
+
|
| 345 |
+
# Allow the body of a class to be on the same line as the declaration if body
|
| 346 |
+
# contains single statement.
|
| 347 |
+
single-line-class-stmt=no
|
| 348 |
+
|
| 349 |
+
# Allow the body of an if to be on the same line as the test if there is no
|
| 350 |
+
# else.
|
| 351 |
+
single-line-if-stmt=no
|
| 352 |
+
|
| 353 |
+
|
| 354 |
+
[IMPORTS]
|
| 355 |
+
|
| 356 |
+
# List of modules that can be imported at any level, not just the top level
|
| 357 |
+
# one.
|
| 358 |
+
allow-any-import-level=
|
| 359 |
+
|
| 360 |
+
# Allow explicit reexports by alias from a package __init__.
|
| 361 |
+
allow-reexport-from-package=no
|
| 362 |
+
|
| 363 |
+
# Allow wildcard imports from modules that define __all__.
|
| 364 |
+
allow-wildcard-with-all=no
|
| 365 |
+
|
| 366 |
+
# Deprecated modules which should not be used, separated by a comma.
|
| 367 |
+
deprecated-modules=
|
| 368 |
+
|
| 369 |
+
# Output a graph (.gv or any supported image format) of external dependencies
|
| 370 |
+
# to the given file (report RP0402 must not be disabled).
|
| 371 |
+
ext-import-graph=
|
| 372 |
+
|
| 373 |
+
# Output a graph (.gv or any supported image format) of all (i.e. internal and
|
| 374 |
+
# external) dependencies to the given file (report RP0402 must not be
|
| 375 |
+
# disabled).
|
| 376 |
+
import-graph=
|
| 377 |
+
|
| 378 |
+
# Output a graph (.gv or any supported image format) of internal dependencies
|
| 379 |
+
# to the given file (report RP0402 must not be disabled).
|
| 380 |
+
int-import-graph=
|
| 381 |
+
|
| 382 |
+
# Force import order to recognize a module as part of the standard
|
| 383 |
+
# compatibility libraries.
|
| 384 |
+
known-standard-library=
|
| 385 |
+
|
| 386 |
+
# Force import order to recognize a module as part of a third party library.
|
| 387 |
+
known-third-party=enchant
|
| 388 |
+
|
| 389 |
+
# Couples of modules and preferred modules, separated by a comma.
|
| 390 |
+
preferred-modules=
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
[LOGGING]
|
| 394 |
+
|
| 395 |
+
# The type of string formatting that logging methods do. `old` means using %
|
| 396 |
+
# formatting, `new` is for `{}` formatting.
|
| 397 |
+
logging-format-style=old
|
| 398 |
+
|
| 399 |
+
# Logging modules to check that the string format arguments are in logging
|
| 400 |
+
# function parameter format.
|
| 401 |
+
logging-modules=logging
|
| 402 |
+
|
| 403 |
+
|
| 404 |
+
[MESSAGES CONTROL]
|
| 405 |
+
|
| 406 |
+
# Only show warnings with the listed confidence levels. Leave empty to show
|
| 407 |
+
# all. Valid levels: HIGH, CONTROL_FLOW, INFERENCE, INFERENCE_FAILURE,
|
| 408 |
+
# UNDEFINED.
|
| 409 |
+
confidence=HIGH,
|
| 410 |
+
CONTROL_FLOW,
|
| 411 |
+
INFERENCE,
|
| 412 |
+
INFERENCE_FAILURE,
|
| 413 |
+
UNDEFINED
|
| 414 |
+
|
| 415 |
+
# Disable the message, report, category or checker with the given id(s). You
|
| 416 |
+
# can either give multiple identifiers separated by comma (,) or put this
|
| 417 |
+
# option multiple times (only on the command line, not in the configuration
|
| 418 |
+
# file where it should appear only once). You can also use "--disable=all" to
|
| 419 |
+
# disable everything first and then re-enable specific checks. For example, if
|
| 420 |
+
# you want to run only the similarities checker, you can use "--disable=all
|
| 421 |
+
# --enable=similarities". If you want to run only the classes checker, but have
|
| 422 |
+
# no Warning level messages displayed, use "--disable=all --enable=classes
|
| 423 |
+
# --disable=W".
|
| 424 |
+
disable=too-many-arguments,
|
| 425 |
+
too-many-locals,
|
| 426 |
+
too-many-branches,
|
| 427 |
+
protected-access
|
| 428 |
+
|
| 429 |
+
|
| 430 |
+
# Enable the message, report, category or checker with the given id(s). You can
|
| 431 |
+
# either give multiple identifier separated by comma (,) or put this option
|
| 432 |
+
# multiple time (only on the command line, not in the configuration file where
|
| 433 |
+
# it should appear only once). See also the "--disable" option for examples.
|
| 434 |
+
enable=
|
| 435 |
+
|
| 436 |
+
|
| 437 |
+
[METHOD_ARGS]
|
| 438 |
+
|
| 439 |
+
# List of qualified names (i.e., library.method) which require a timeout
|
| 440 |
+
# parameter e.g. 'requests.api.get,requests.api.post'
|
| 441 |
+
timeout-methods=requests.api.delete,requests.api.get,requests.api.head,requests.api.options,requests.api.patch,requests.api.post,requests.api.put,requests.api.request
|
| 442 |
+
|
| 443 |
+
|
| 444 |
+
[MISCELLANEOUS]
|
| 445 |
+
|
| 446 |
+
# List of note tags to take in consideration, separated by a comma.
|
| 447 |
+
notes=FIXME,
|
| 448 |
+
XXX
|
| 449 |
+
|
| 450 |
+
# Regular expression of note tags to take in consideration.
|
| 451 |
+
notes-rgx=
|
| 452 |
+
|
| 453 |
+
|
| 454 |
+
[REFACTORING]
|
| 455 |
+
|
| 456 |
+
# Maximum number of nested blocks for function / method body
|
| 457 |
+
max-nested-blocks=5
|
| 458 |
+
|
| 459 |
+
# Complete name of functions that never returns. When checking for
|
| 460 |
+
# inconsistent-return-statements if a never returning function is called then
|
| 461 |
+
# it will be considered as an explicit return statement and no message will be
|
| 462 |
+
# printed.
|
| 463 |
+
never-returning-functions=sys.exit,argparse.parse_error
|
| 464 |
+
|
| 465 |
+
# Let 'consider-using-join' be raised when the separator to join on would be
|
| 466 |
+
# non-empty (resulting in expected fixes of the type: ``"- " + " -
|
| 467 |
+
# ".join(items)``)
|
| 468 |
+
# suggest-join-with-non-empty-separator=yes
|
| 469 |
+
|
| 470 |
+
|
| 471 |
+
[REPORTS]
|
| 472 |
+
|
| 473 |
+
# Python expression which should return a score less than or equal to 10. You
|
| 474 |
+
# have access to the variables 'fatal', 'error', 'warning', 'refactor',
|
| 475 |
+
# 'convention', and 'info' which contain the number of messages in each
|
| 476 |
+
# category, as well as 'statement' which is the total number of statements
|
| 477 |
+
# analyzed. This score is used by the global evaluation report (RP0004).
|
| 478 |
+
evaluation=max(0, 0 if fatal else 10.0 - ((float(5 * error + warning + refactor + convention) / statement) * 10))
|
| 479 |
+
|
| 480 |
+
# Template used to display messages. This is a python new-style format string
|
| 481 |
+
# used to format the message information. See doc for all details.
|
| 482 |
+
msg-template=
|
| 483 |
+
|
| 484 |
+
# Set the output format. Available formats are: text, parseable, colorized,
|
| 485 |
+
# json2 (improved json format), json (old json format) and msvs (visual
|
| 486 |
+
# studio). You can also give a reporter class, e.g.
|
| 487 |
+
# mypackage.mymodule.MyReporterClass.
|
| 488 |
+
#output-format=
|
| 489 |
+
|
| 490 |
+
# Tells whether to display a full report or only the messages.
|
| 491 |
+
reports=no
|
| 492 |
+
|
| 493 |
+
# Activate the evaluation score.
|
| 494 |
+
score=yes
|
| 495 |
+
|
| 496 |
+
|
| 497 |
+
[SIMILARITIES]
|
| 498 |
+
|
| 499 |
+
# Comments are removed from the similarity computation
|
| 500 |
+
ignore-comments=yes
|
| 501 |
+
|
| 502 |
+
# Docstrings are removed from the similarity computation
|
| 503 |
+
ignore-docstrings=yes
|
| 504 |
+
|
| 505 |
+
# Imports are removed from the similarity computation
|
| 506 |
+
ignore-imports=yes
|
| 507 |
+
|
| 508 |
+
# Signatures are removed from the similarity computation
|
| 509 |
+
ignore-signatures=yes
|
| 510 |
+
|
| 511 |
+
# Minimum lines number of a similarity.
|
| 512 |
+
min-similarity-lines=4
|
| 513 |
+
|
| 514 |
+
|
| 515 |
+
[SPELLING]
|
| 516 |
+
|
| 517 |
+
# Limits count of emitted suggestions for spelling mistakes.
|
| 518 |
+
max-spelling-suggestions=4
|
| 519 |
+
|
| 520 |
+
# Spelling dictionary name. No available dictionaries : You need to install
|
| 521 |
+
# both the python package and the system dependency for enchant to work.
|
| 522 |
+
spelling-dict=
|
| 523 |
+
|
| 524 |
+
# List of comma separated words that should be considered directives if they
|
| 525 |
+
# appear at the beginning of a comment and should not be checked.
|
| 526 |
+
spelling-ignore-comment-directives=fmt: on,fmt: off,noqa:,noqa,nosec,isort:skip,mypy:
|
| 527 |
+
|
| 528 |
+
# List of comma separated words that should not be checked.
|
| 529 |
+
spelling-ignore-words=
|
| 530 |
+
|
| 531 |
+
# A path to a file that contains the private dictionary; one word per line.
|
| 532 |
+
spelling-private-dict-file=
|
| 533 |
+
|
| 534 |
+
# Tells whether to store unknown words to the private dictionary (see the
|
| 535 |
+
# --spelling-private-dict-file option) instead of raising a message.
|
| 536 |
+
spelling-store-unknown-words=no
|
| 537 |
+
|
| 538 |
+
|
| 539 |
+
[STRING]
|
| 540 |
+
|
| 541 |
+
# This flag controls whether inconsistent-quotes generates a warning when the
|
| 542 |
+
# character used as a quote delimiter is used inconsistently within a module.
|
| 543 |
+
check-quote-consistency=no
|
| 544 |
+
|
| 545 |
+
# This flag controls whether the implicit-str-concat should generate a warning
|
| 546 |
+
# on implicit string concatenation in sequences defined over several lines.
|
| 547 |
+
check-str-concat-over-line-jumps=no
|
| 548 |
+
|
| 549 |
+
|
| 550 |
+
[TYPECHECK]
|
| 551 |
+
|
| 552 |
+
# List of decorators that produce context managers, such as
|
| 553 |
+
# contextlib.contextmanager. Add to this list to register other decorators that
|
| 554 |
+
# produce valid context managers.
|
| 555 |
+
contextmanager-decorators=contextlib.contextmanager
|
| 556 |
+
|
| 557 |
+
# List of members which are set dynamically and missed by pylint inference
|
| 558 |
+
# system, and so shouldn't trigger E1101 when accessed. Python regular
|
| 559 |
+
# expressions are accepted.
|
| 560 |
+
generated-members=
|
| 561 |
+
|
| 562 |
+
# Tells whether to warn about missing members when the owner of the attribute
|
| 563 |
+
# is inferred to be None.
|
| 564 |
+
ignore-none=yes
|
| 565 |
+
|
| 566 |
+
# This flag controls whether pylint should warn about no-member and similar
|
| 567 |
+
# checks whenever an opaque object is returned when inferring. The inference
|
| 568 |
+
# can return multiple potential results while evaluating a Python object, but
|
| 569 |
+
# some branches might not be evaluated, which results in partial inference. In
|
| 570 |
+
# that case, it might be useful to still emit no-member and other checks for
|
| 571 |
+
# the rest of the inferred objects.
|
| 572 |
+
ignore-on-opaque-inference=yes
|
| 573 |
+
|
| 574 |
+
# List of symbolic message names to ignore for Mixin members.
|
| 575 |
+
ignored-checks-for-mixins=no-member,
|
| 576 |
+
not-async-context-manager,
|
| 577 |
+
not-context-manager,
|
| 578 |
+
attribute-defined-outside-init
|
| 579 |
+
|
| 580 |
+
# List of class names for which member attributes should not be checked (useful
|
| 581 |
+
# for classes with dynamically set attributes). This supports the use of
|
| 582 |
+
# qualified names.
|
| 583 |
+
ignored-classes=optparse.Values,thread._local,_thread._local,argparse.Namespace
|
| 584 |
+
|
| 585 |
+
# Show a hint with possible names when a member name was not found. The aspect
|
| 586 |
+
# of finding the hint is based on edit distance.
|
| 587 |
+
missing-member-hint=yes
|
| 588 |
+
|
| 589 |
+
# The minimum edit distance a name should have in order to be considered a
|
| 590 |
+
# similar match for a missing member name.
|
| 591 |
+
missing-member-hint-distance=1
|
| 592 |
+
|
| 593 |
+
# The total number of similar names that should be taken in consideration when
|
| 594 |
+
# showing a hint for a missing member.
|
| 595 |
+
missing-member-max-choices=1
|
| 596 |
+
|
| 597 |
+
# Regex pattern to define which classes are considered mixins.
|
| 598 |
+
mixin-class-rgx=.*[Mm]ixin
|
| 599 |
+
|
| 600 |
+
# List of decorators that change the signature of a decorated function.
|
| 601 |
+
signature-mutators=
|
| 602 |
+
|
| 603 |
+
|
| 604 |
+
[VARIABLES]
|
| 605 |
+
|
| 606 |
+
# List of additional names supposed to be defined in builtins. Remember that
|
| 607 |
+
# you should avoid defining new builtins when possible.
|
| 608 |
+
additional-builtins=
|
| 609 |
+
|
| 610 |
+
# Tells whether unused global variables should be treated as a violation.
|
| 611 |
+
allow-global-unused-variables=yes
|
| 612 |
+
|
| 613 |
+
# List of names allowed to shadow builtins
|
| 614 |
+
allowed-redefined-builtins=
|
| 615 |
+
|
| 616 |
+
# List of strings which can identify a callback function by name. A callback
|
| 617 |
+
# name must start or end with one of those strings.
|
| 618 |
+
callbacks=cb_,
|
| 619 |
+
_cb
|
| 620 |
+
|
| 621 |
+
# A regular expression matching the name of dummy variables (i.e. expected to
|
| 622 |
+
# not be used).
|
| 623 |
+
dummy-variables-rgx=_+$|(_[a-zA-Z0-9_]*[a-zA-Z0-9]+?$)|dummy|^ignored_|^unused_
|
| 624 |
+
|
| 625 |
+
# Argument names that match this expression will be ignored.
|
| 626 |
+
ignored-argument-names=_.*|^ignored_|^unused_
|
| 627 |
+
|
| 628 |
+
# Tells whether we should check for unused import in __init__ files.
|
| 629 |
+
init-import=no
|
| 630 |
+
|
| 631 |
+
# List of qualified module names which can have objects that can redefine
|
| 632 |
+
# builtins.
|
| 633 |
+
redefining-builtins-modules=six.moves,past.builtins,future.builtins,builtins,io
|
README.md
CHANGED
|
@@ -1,12 +1,209 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<h1 align='Center'>Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation</h1>
|
| 2 |
+
|
| 3 |
+
<div align='Center'>
|
| 4 |
+
<a href='https://github.com/xumingw' target='_blank'>Mingwang Xu</a><sup>1*</sup> 
|
| 5 |
+
<a href='https://github.com/crystallee-ai' target='_blank'>Hui Li</a><sup>1*</sup> 
|
| 6 |
+
<a href='https://github.com/subazinga' target='_blank'>Qingkun Su</a><sup>1*</sup> 
|
| 7 |
+
<a href='https://github.com/NinoNeumann' target='_blank'>Hanlin Shang</a><sup>1</sup> 
|
| 8 |
+
<a href='https://github.com/AricGamma' target='_blank'>Liwei Zhang</a><sup>1</sup> 
|
| 9 |
+
<a href='https://github.com/cnexah' target='_blank'>Ce Liu</a><sup>3</sup> 
|
| 10 |
+
</div>
|
| 11 |
+
<div align='center'>
|
| 12 |
+
<a href='https://jingdongwang2017.github.io/' target='_blank'>Jingdong Wang</a><sup>2</sup> 
|
| 13 |
+
<a href='https://yoyo000.github.io/' target='_blank'>Yao Yao</a><sup>4</sup> 
|
| 14 |
+
<a href='https://sites.google.com/site/zhusiyucs/home' target='_blank'>Siyu Zhu</a><sup>1</sup> 
|
| 15 |
+
</div>
|
| 16 |
+
|
| 17 |
+
<div align='Center'>
|
| 18 |
+
<sup>1</sup>Fudan University  <sup>2</sup>Baidu Inc  <sup>3</sup>ETH Zurich  <sup>4</sup>Nanjing University
|
| 19 |
+
</div>
|
| 20 |
+
|
| 21 |
+
<br>
|
| 22 |
+
<div align='Center'>
|
| 23 |
+
<a href='https://github.com/fudan-generative-vision/hallo'><img src='https://img.shields.io/github/stars/fudan-generative-vision/hallo?style=social'></a>
|
| 24 |
+
<a href='https://fudan-generative-vision.github.io/hallo/#/'><img src='https://img.shields.io/badge/Project-HomePage-Green'></a>
|
| 25 |
+
<a href='https://arxiv.org/pdf/2406.08801'><img src='https://img.shields.io/badge/Paper-Arxiv-red'></a>
|
| 26 |
+
<a href='https://huggingface.co/fudan-generative-ai/hallo'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HuggingFace-Model-yellow'></a>
|
| 27 |
+
<a href='assets/wechat.jpeg'><img src='https://badges.aleen42.com/src/wechat.svg'></a>
|
| 28 |
+
</div>
|
| 29 |
+
|
| 30 |
+
<br>
|
| 31 |
+
|
| 32 |
+
# Showcase
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
https://github.com/fudan-generative-vision/hallo/assets/17402682/294e78ef-c60d-4c32-8e3c-7f8d6934c6bd
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# Framework
|
| 39 |
+
|
| 40 |
+

|
| 41 |
+

|
| 42 |
+
|
| 43 |
+
# News
|
| 44 |
+
|
| 45 |
+
- **`2024/06/15`**: 🎉🎉🎉 Release the first version on [GitHub](https://github.com/fudan-generative-vision/hallo).
|
| 46 |
+
- **`2024/06/15`**: ✨✨✨ Release some images and audios for inference testing on [Huggingface](https://huggingface.co/datasets/fudan-generative-ai/hallo_inference_samples).
|
| 47 |
+
|
| 48 |
+
# Installation
|
| 49 |
+
|
| 50 |
+
- System requirement: Ubuntu 20.04/Ubuntu 22.04, Cuda 12.1
|
| 51 |
+
- Tested GPUs: A100
|
| 52 |
+
|
| 53 |
+
Create conda environment:
|
| 54 |
+
|
| 55 |
+
```bash
|
| 56 |
+
conda create -n hallo python=3.10
|
| 57 |
+
conda activate hallo
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
Install packages with `pip`
|
| 61 |
+
|
| 62 |
+
```bash
|
| 63 |
+
pip install -r requirements.txt
|
| 64 |
+
pip install .
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
Besides, ffmpeg is also need:
|
| 68 |
+
```bash
|
| 69 |
+
apt-get install ffmpeg
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
# Inference
|
| 73 |
+
|
| 74 |
+
The inference entrypoint script is `scripts/inference.py`. Before testing your cases, there are two preparations need to be completed:
|
| 75 |
+
|
| 76 |
+
1. [Download all required pretrained models](#download-pretrained-models).
|
| 77 |
+
2. [Run inference](#run-inference).
|
| 78 |
+
|
| 79 |
+
## Download pretrained models
|
| 80 |
+
|
| 81 |
+
You can easily get all pretrained models required by inference from our [HuggingFace repo](https://huggingface.co/fudan-generative-ai/hallo).
|
| 82 |
+
|
| 83 |
+
Clone the the pretrained models into `${PROJECT_ROOT}/pretrained_models` directory by cmd below:
|
| 84 |
+
|
| 85 |
+
```shell
|
| 86 |
+
git lfs install
|
| 87 |
+
git clone https://huggingface.co/fudan-generative-ai/hallo pretrained_models
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
Or you can download them separately from their source repo:
|
| 91 |
+
|
| 92 |
+
- [hallo](https://huggingface.co/fudan-generative-ai/hallo/tree/main/hallo): Our checkpoints consist of denoising UNet, face locator, image & audio proj.
|
| 93 |
+
- [audio_separator](https://huggingface.co/huangjackson/Kim_Vocal_2): Kim\_Vocal\_2 MDX-Net vocal removal model by [KimberleyJensen](https://github.com/KimberleyJensen). (_Thanks to runwayml_)
|
| 94 |
+
- [insightface](https://github.com/deepinsight/insightface/tree/master/python-package#model-zoo): 2D and 3D Face Analysis placed into `pretrained_models/face_analysis/models/`. (_Thanks to deepinsight_)
|
| 95 |
+
- [face landmarker](https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/1/face_landmarker.task): Face detection & mesh model from [mediapipe](https://ai.google.dev/edge/mediapipe/solutions/vision/face_landmarker#models) placed into `pretrained_models/face_analysis/models`.
|
| 96 |
+
- [motion module](https://github.com/guoyww/AnimateDiff/blob/main/README.md#202309-animatediff-v2): motion module from [AnimateDiff](https://github.com/guoyww/AnimateDiff). (_Thanks to guoyww_).
|
| 97 |
+
- [sd-vae-ft-mse](https://huggingface.co/stabilityai/sd-vae-ft-mse): Weights are intended to be used with the diffusers library. (_Thanks to stablilityai_)
|
| 98 |
+
- [StableDiffusion V1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5): Initialized and fine-tuned from Stable-Diffusion-v1-2. (_Thanks to runwayml_)
|
| 99 |
+
- [wav2vec](https://huggingface.co/facebook/wav2vec2-base-960h): wav audio to vector model from [Facebook](https://huggingface.co/facebook/wav2vec2-base-960h).
|
| 100 |
+
|
| 101 |
+
Finally, these pretrained models should be organized as follows:
|
| 102 |
+
|
| 103 |
+
```text
|
| 104 |
+
./pretrained_models/
|
| 105 |
+
|-- audio_separator/
|
| 106 |
+
| `-- Kim_Vocal_2.onnx
|
| 107 |
+
|-- face_analysis/
|
| 108 |
+
| `-- models/
|
| 109 |
+
| |-- face_landmarker_v2_with_blendshapes.task # face landmarker model from mediapipe
|
| 110 |
+
| |-- 1k3d68.onnx
|
| 111 |
+
| |-- 2d106det.onnx
|
| 112 |
+
| |-- genderage.onnx
|
| 113 |
+
| |-- glintr100.onnx
|
| 114 |
+
| `-- scrfd_10g_bnkps.onnx
|
| 115 |
+
|-- motion_module/
|
| 116 |
+
| `-- mm_sd_v15_v2.ckpt
|
| 117 |
+
|-- sd-vae-ft-mse/
|
| 118 |
+
| |-- config.json
|
| 119 |
+
| `-- diffusion_pytorch_model.safetensors
|
| 120 |
+
|-- stable-diffusion-v1-5/
|
| 121 |
+
| |-- feature_extractor/
|
| 122 |
+
| | `-- preprocessor_config.json
|
| 123 |
+
| |-- model_index.json
|
| 124 |
+
| |-- unet/
|
| 125 |
+
| | |-- config.json
|
| 126 |
+
| | `-- diffusion_pytorch_model.safetensors
|
| 127 |
+
| `-- v1-inference.yaml
|
| 128 |
+
`-- wav2vec/
|
| 129 |
+
|-- wav2vec2-base-960h/
|
| 130 |
+
| |-- config.json
|
| 131 |
+
| |-- feature_extractor_config.json
|
| 132 |
+
| |-- model.safetensors
|
| 133 |
+
| |-- preprocessor_config.json
|
| 134 |
+
| |-- special_tokens_map.json
|
| 135 |
+
| |-- tokenizer_config.json
|
| 136 |
+
| `-- vocab.json
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
## Run inference
|
| 140 |
+
|
| 141 |
+
Simply to run the `scripts/inference.py` and pass `source_image` and `driving_audio` as input:
|
| 142 |
+
|
| 143 |
+
```bash
|
| 144 |
+
python scripts/inference.py --source_image your_image.png --driving_audio your_audio.wav
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
Animation results will be saved as `${PROJECT_ROOT}/.cache/output.mp4` by default. You can pass `--output` to specify the output file name.
|
| 148 |
+
|
| 149 |
+
For more options:
|
| 150 |
+
|
| 151 |
+
```shell
|
| 152 |
+
usage: inference.py [-h] [-c CONFIG] [--source_image SOURCE_IMAGE] [--driving_audio DRIVING_AUDIO] [--output OUTPUT] [--pose_weight POSE_WEIGHT]
|
| 153 |
+
[--face_weight FACE_WEIGHT] [--lip_weight LIP_WEIGHT] [--face_expand_ratio FACE_EXPAND_RATIO]
|
| 154 |
+
|
| 155 |
+
options:
|
| 156 |
+
-h, --help show this help message and exit
|
| 157 |
+
-c CONFIG, --config CONFIG
|
| 158 |
+
--source_image SOURCE_IMAGE
|
| 159 |
+
source image
|
| 160 |
+
--driving_audio DRIVING_AUDIO
|
| 161 |
+
driving audio
|
| 162 |
+
--output OUTPUT output video file name
|
| 163 |
+
--pose_weight POSE_WEIGHT
|
| 164 |
+
weight of pose
|
| 165 |
+
--face_weight FACE_WEIGHT
|
| 166 |
+
weight of face
|
| 167 |
+
--lip_weight LIP_WEIGHT
|
| 168 |
+
weight of lip
|
| 169 |
+
--face_expand_ratio FACE_EXPAND_RATIO
|
| 170 |
+
face region
|
| 171 |
+
```
|
| 172 |
+
|
| 173 |
+
# Roadmap
|
| 174 |
+
|
| 175 |
+
| Status | Milestone | ETA |
|
| 176 |
+
| :----: | :---------------------------------------------------------------------------------------------------- | :--------: |
|
| 177 |
+
| ✅ | **[Inference source code meet everyone on GitHub](https://github.com/fudan-generative-vision/hallo)** | 2024-06-15 |
|
| 178 |
+
| ✅ | **[Pretrained models on Huggingface](https://huggingface.co/fudan-generative-ai/hallo)** | 2024-06-15 |
|
| 179 |
+
| 🚀🚀🚀 | **[Traning: data preparation and training scripts]()** | 2024-06-25 |
|
| 180 |
+
|
| 181 |
+
# Citation
|
| 182 |
+
|
| 183 |
+
If you find our work useful for your research, please consider citing the paper:
|
| 184 |
+
|
| 185 |
+
```
|
| 186 |
+
@misc{xu2024hallo,
|
| 187 |
+
title={Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation},
|
| 188 |
+
author={Mingwang Xu and Hui Li and Qingkun Su and Hanlin Shang and Liwei Zhang and Ce Liu and Jingdong Wang and Yao Yao and Siyu zhu},
|
| 189 |
+
year={2024},
|
| 190 |
+
eprint={2406.08801},
|
| 191 |
+
archivePrefix={arXiv},
|
| 192 |
+
primaryClass={cs.CV}
|
| 193 |
+
}
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
# Opportunities available
|
| 197 |
+
|
| 198 |
+
Multiple research positions are open at the **Generative Vision Lab, Fudan University**! Include:
|
| 199 |
+
|
| 200 |
+
- Research assistant
|
| 201 |
+
- Postdoctoral researcher
|
| 202 |
+
- PhD candidate
|
| 203 |
+
- Master students
|
| 204 |
+
|
| 205 |
+
Interested individuals are encouraged to contact us at [[email protected]](mailto://[email protected]) for further information.
|
| 206 |
+
|
| 207 |
+
# Social Risks and Mitigations
|
| 208 |
+
|
| 209 |
+
The development of portrait image animation technologies driven by audio inputs poses social risks, such as the ethical implications of creating realistic portraits that could be misused for deepfakes. To mitigate these risks, it is crucial to establish ethical guidelines and responsible use practices. Privacy and consent concerns also arise from using individuals' images and voices. Addressing these involves transparent data usage policies, informed consent, and safeguarding privacy rights. By addressing these risks and implementing mitigations, the research aims to ensure the responsible and ethical development of this technology.
|
assets/framework.png
ADDED

|
assets/framework_1.jpg
ADDED

|
assets/framework_2.jpg
ADDED
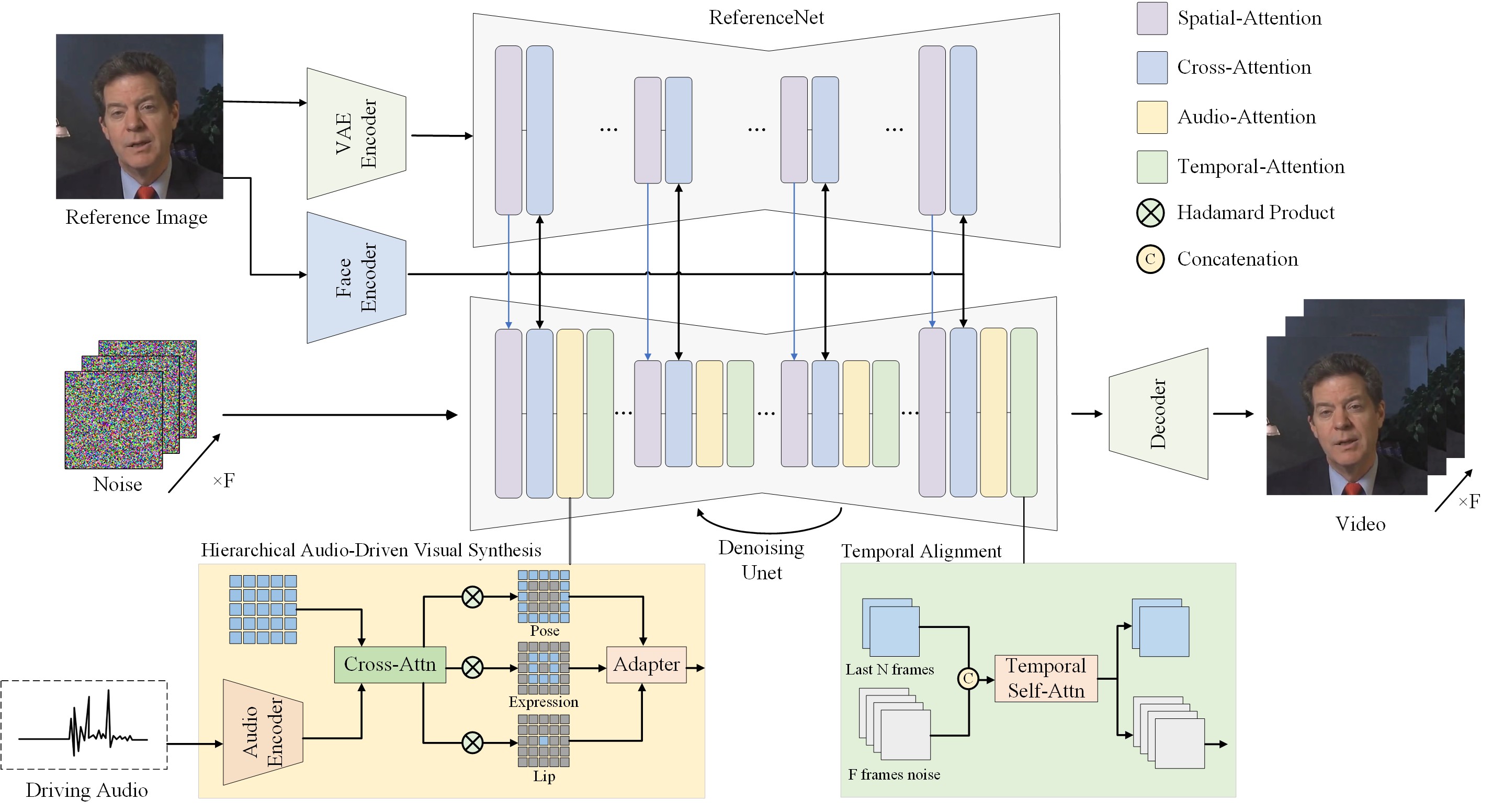
|
assets/wechat.jpeg
ADDED

|
configs/inference/.gitkeep
ADDED
|
File without changes
|
configs/inference/default.yaml
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
source_image: ./default.png
|
| 2 |
+
driving_audio: default.wav
|
| 3 |
+
|
| 4 |
+
weight_dtype: fp16
|
| 5 |
+
|
| 6 |
+
data:
|
| 7 |
+
n_motion_frames: 2
|
| 8 |
+
n_sample_frames: 16
|
| 9 |
+
source_image:
|
| 10 |
+
width: 512
|
| 11 |
+
height: 512
|
| 12 |
+
driving_audio:
|
| 13 |
+
sample_rate: 16000
|
| 14 |
+
export_video:
|
| 15 |
+
fps: 25
|
| 16 |
+
|
| 17 |
+
inference_steps: 40
|
| 18 |
+
cfg_scale: 3.5
|
| 19 |
+
|
| 20 |
+
audio_ckpt_dir: ./pretrained_models/hallo
|
| 21 |
+
|
| 22 |
+
base_model_path: ./pretrained_models/stable-diffusion-v1-5
|
| 23 |
+
|
| 24 |
+
motion_module_path: ./pretrained_models/motion_module/mm_sd_v15_v2.ckpt
|
| 25 |
+
|
| 26 |
+
face_analysis:
|
| 27 |
+
model_path: ./pretrained_models/face_analysis
|
| 28 |
+
|
| 29 |
+
wav2vec:
|
| 30 |
+
model_path: ./pretrained_models/wav2vec/wav2vec2-base-960h
|
| 31 |
+
features: all
|
| 32 |
+
|
| 33 |
+
audio_separator:
|
| 34 |
+
model_path: ./pretrained_models/audio_separator/Kim_Vocal_2.onnx
|
| 35 |
+
|
| 36 |
+
vae:
|
| 37 |
+
model_path: ./pretrained_models/sd-vae-ft-mse
|
| 38 |
+
|
| 39 |
+
save_path: ./.cache
|
| 40 |
+
|
| 41 |
+
face_expand_ratio: 1.1
|
| 42 |
+
pose_weight: 1.1
|
| 43 |
+
face_weight: 1.1
|
| 44 |
+
lip_weight: 1.1
|
| 45 |
+
|
| 46 |
+
unet_additional_kwargs:
|
| 47 |
+
use_inflated_groupnorm: true
|
| 48 |
+
unet_use_cross_frame_attention: false
|
| 49 |
+
unet_use_temporal_attention: false
|
| 50 |
+
use_motion_module: true
|
| 51 |
+
use_audio_module: true
|
| 52 |
+
motion_module_resolutions:
|
| 53 |
+
- 1
|
| 54 |
+
- 2
|
| 55 |
+
- 4
|
| 56 |
+
- 8
|
| 57 |
+
motion_module_mid_block: true
|
| 58 |
+
motion_module_decoder_only: false
|
| 59 |
+
motion_module_type: Vanilla
|
| 60 |
+
motion_module_kwargs:
|
| 61 |
+
num_attention_heads: 8
|
| 62 |
+
num_transformer_block: 1
|
| 63 |
+
attention_block_types:
|
| 64 |
+
- Temporal_Self
|
| 65 |
+
- Temporal_Self
|
| 66 |
+
temporal_position_encoding: true
|
| 67 |
+
temporal_position_encoding_max_len: 32
|
| 68 |
+
temporal_attention_dim_div: 1
|
| 69 |
+
audio_attention_dim: 768
|
| 70 |
+
stack_enable_blocks_name:
|
| 71 |
+
- "up"
|
| 72 |
+
- "down"
|
| 73 |
+
- "mid"
|
| 74 |
+
stack_enable_blocks_depth: [0,1,2,3]
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
enable_zero_snr: true
|
| 78 |
+
|
| 79 |
+
noise_scheduler_kwargs:
|
| 80 |
+
beta_start: 0.00085
|
| 81 |
+
beta_end: 0.012
|
| 82 |
+
beta_schedule: "linear"
|
| 83 |
+
clip_sample: false
|
| 84 |
+
steps_offset: 1
|
| 85 |
+
### Zero-SNR params
|
| 86 |
+
prediction_type: "v_prediction"
|
| 87 |
+
rescale_betas_zero_snr: True
|
| 88 |
+
timestep_spacing: "trailing"
|
| 89 |
+
|
| 90 |
+
sampler: DDIM
|
configs/unet/unet.yaml
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
unet_additional_kwargs:
|
| 2 |
+
use_inflated_groupnorm: true
|
| 3 |
+
unet_use_cross_frame_attention: false
|
| 4 |
+
unet_use_temporal_attention: false
|
| 5 |
+
use_motion_module: true
|
| 6 |
+
use_audio_module: true
|
| 7 |
+
motion_module_resolutions:
|
| 8 |
+
- 1
|
| 9 |
+
- 2
|
| 10 |
+
- 4
|
| 11 |
+
- 8
|
| 12 |
+
motion_module_mid_block: true
|
| 13 |
+
motion_module_decoder_only: false
|
| 14 |
+
motion_module_type: Vanilla
|
| 15 |
+
motion_module_kwargs:
|
| 16 |
+
num_attention_heads: 8
|
| 17 |
+
num_transformer_block: 1
|
| 18 |
+
attention_block_types:
|
| 19 |
+
- Temporal_Self
|
| 20 |
+
- Temporal_Self
|
| 21 |
+
temporal_position_encoding: true
|
| 22 |
+
temporal_position_encoding_max_len: 32
|
| 23 |
+
temporal_attention_dim_div: 1
|
| 24 |
+
audio_attention_dim: 768
|
| 25 |
+
stack_enable_blocks_name:
|
| 26 |
+
- "up"
|
| 27 |
+
- "down"
|
| 28 |
+
- "mid"
|
| 29 |
+
stack_enable_blocks_depth: [0,1,2,3]
|
| 30 |
+
|
| 31 |
+
enable_zero_snr: true
|
| 32 |
+
|
| 33 |
+
noise_scheduler_kwargs:
|
| 34 |
+
beta_start: 0.00085
|
| 35 |
+
beta_end: 0.012
|
| 36 |
+
beta_schedule: "linear"
|
| 37 |
+
clip_sample: false
|
| 38 |
+
steps_offset: 1
|
| 39 |
+
### Zero-SNR params
|
| 40 |
+
prediction_type: "v_prediction"
|
| 41 |
+
rescale_betas_zero_snr: True
|
| 42 |
+
timestep_spacing: "trailing"
|
| 43 |
+
|
| 44 |
+
sampler: DDIM
|
hallo/__init__.py
ADDED
|
File without changes
|
hallo/animate/__init__.py
ADDED
|
File without changes
|
hallo/animate/face_animate.py
ADDED
|
@@ -0,0 +1,442 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
"""
|
| 3 |
+
This module is responsible for animating faces in videos using a combination of deep learning techniques.
|
| 4 |
+
It provides a pipeline for generating face animations by processing video frames and extracting face features.
|
| 5 |
+
The module utilizes various schedulers and utilities for efficient face animation and supports different types
|
| 6 |
+
of latents for more control over the animation process.
|
| 7 |
+
|
| 8 |
+
Functions and Classes:
|
| 9 |
+
- FaceAnimatePipeline: A class that extends the DiffusionPipeline class from the diffusers library to handle face animation tasks.
|
| 10 |
+
- __init__: Initializes the pipeline with the necessary components (VAE, UNets, face locator, etc.).
|
| 11 |
+
- prepare_latents: Generates or loads latents for the animation process, scaling them according to the scheduler's requirements.
|
| 12 |
+
- prepare_extra_step_kwargs: Prepares extra keyword arguments for the scheduler step, ensuring compatibility with different schedulers.
|
| 13 |
+
- decode_latents: Decodes the latents into video frames, ready for animation.
|
| 14 |
+
|
| 15 |
+
Usage:
|
| 16 |
+
- Import the necessary packages and classes.
|
| 17 |
+
- Create a FaceAnimatePipeline instance with the required components.
|
| 18 |
+
- Prepare the latents for the animation process.
|
| 19 |
+
- Use the pipeline to generate the animated video.
|
| 20 |
+
|
| 21 |
+
Note:
|
| 22 |
+
- This module is designed to work with the diffusers library, which provides the underlying framework for face animation using deep learning.
|
| 23 |
+
- The module is intended for research and development purposes, and further optimization and customization may be required for specific use cases.
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
import inspect
|
| 27 |
+
from dataclasses import dataclass
|
| 28 |
+
from typing import Callable, List, Optional, Union
|
| 29 |
+
|
| 30 |
+
import numpy as np
|
| 31 |
+
import torch
|
| 32 |
+
from diffusers import (DDIMScheduler, DiffusionPipeline,
|
| 33 |
+
DPMSolverMultistepScheduler,
|
| 34 |
+
EulerAncestralDiscreteScheduler, EulerDiscreteScheduler,
|
| 35 |
+
LMSDiscreteScheduler, PNDMScheduler)
|
| 36 |
+
from diffusers.image_processor import VaeImageProcessor
|
| 37 |
+
from diffusers.utils import BaseOutput
|
| 38 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 39 |
+
from einops import rearrange, repeat
|
| 40 |
+
from tqdm import tqdm
|
| 41 |
+
|
| 42 |
+
from hallo.models.mutual_self_attention import ReferenceAttentionControl
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
@dataclass
|
| 46 |
+
class FaceAnimatePipelineOutput(BaseOutput):
|
| 47 |
+
"""
|
| 48 |
+
FaceAnimatePipelineOutput is a custom class that inherits from BaseOutput and represents the output of the FaceAnimatePipeline.
|
| 49 |
+
|
| 50 |
+
Attributes:
|
| 51 |
+
videos (Union[torch.Tensor, np.ndarray]): A tensor or numpy array containing the generated video frames.
|
| 52 |
+
|
| 53 |
+
Methods:
|
| 54 |
+
__init__(self, videos: Union[torch.Tensor, np.ndarray]): Initializes the FaceAnimatePipelineOutput object with the generated video frames.
|
| 55 |
+
"""
|
| 56 |
+
videos: Union[torch.Tensor, np.ndarray]
|
| 57 |
+
|
| 58 |
+
class FaceAnimatePipeline(DiffusionPipeline):
|
| 59 |
+
"""
|
| 60 |
+
FaceAnimatePipeline is a custom DiffusionPipeline for animating faces.
|
| 61 |
+
|
| 62 |
+
It inherits from the DiffusionPipeline class and is used to animate faces by
|
| 63 |
+
utilizing a variational autoencoder (VAE), a reference UNet, a denoising UNet,
|
| 64 |
+
a face locator, and an image processor. The pipeline is responsible for generating
|
| 65 |
+
and animating face latents, and decoding the latents to produce the final video output.
|
| 66 |
+
|
| 67 |
+
Attributes:
|
| 68 |
+
vae (VaeImageProcessor): Variational autoencoder for processing images.
|
| 69 |
+
reference_unet (nn.Module): Reference UNet for mutual self-attention.
|
| 70 |
+
denoising_unet (nn.Module): Denoising UNet for image denoising.
|
| 71 |
+
face_locator (nn.Module): Face locator for detecting and cropping faces.
|
| 72 |
+
image_proj (nn.Module): Image projector for processing images.
|
| 73 |
+
scheduler (Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler,
|
| 74 |
+
EulerDiscreteScheduler, EulerAncestralDiscreteScheduler,
|
| 75 |
+
DPMSolverMultistepScheduler]): Diffusion scheduler for
|
| 76 |
+
controlling the noise level.
|
| 77 |
+
|
| 78 |
+
Methods:
|
| 79 |
+
__init__(self, vae, reference_unet, denoising_unet, face_locator,
|
| 80 |
+
image_proj, scheduler): Initializes the FaceAnimatePipeline
|
| 81 |
+
with the given components and scheduler.
|
| 82 |
+
prepare_latents(self, batch_size, num_channels_latents, width, height,
|
| 83 |
+
video_length, dtype, device, generator=None, latents=None):
|
| 84 |
+
Prepares the initial latents for video generation.
|
| 85 |
+
prepare_extra_step_kwargs(self, generator, eta): Prepares extra keyword
|
| 86 |
+
arguments for the scheduler step.
|
| 87 |
+
decode_latents(self, latents): Decodes the latents to produce the final
|
| 88 |
+
video output.
|
| 89 |
+
"""
|
| 90 |
+
def __init__(
|
| 91 |
+
self,
|
| 92 |
+
vae,
|
| 93 |
+
reference_unet,
|
| 94 |
+
denoising_unet,
|
| 95 |
+
face_locator,
|
| 96 |
+
image_proj,
|
| 97 |
+
scheduler: Union[
|
| 98 |
+
DDIMScheduler,
|
| 99 |
+
PNDMScheduler,
|
| 100 |
+
LMSDiscreteScheduler,
|
| 101 |
+
EulerDiscreteScheduler,
|
| 102 |
+
EulerAncestralDiscreteScheduler,
|
| 103 |
+
DPMSolverMultistepScheduler,
|
| 104 |
+
],
|
| 105 |
+
) -> None:
|
| 106 |
+
super().__init__()
|
| 107 |
+
|
| 108 |
+
self.register_modules(
|
| 109 |
+
vae=vae,
|
| 110 |
+
reference_unet=reference_unet,
|
| 111 |
+
denoising_unet=denoising_unet,
|
| 112 |
+
face_locator=face_locator,
|
| 113 |
+
scheduler=scheduler,
|
| 114 |
+
image_proj=image_proj,
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
self.vae_scale_factor: int = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
| 118 |
+
|
| 119 |
+
self.ref_image_processor = VaeImageProcessor(
|
| 120 |
+
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True,
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
@property
|
| 124 |
+
def _execution_device(self):
|
| 125 |
+
if self.device != torch.device("meta") or not hasattr(self.unet, "_hf_hook"):
|
| 126 |
+
return self.device
|
| 127 |
+
for module in self.unet.modules():
|
| 128 |
+
if (
|
| 129 |
+
hasattr(module, "_hf_hook")
|
| 130 |
+
and hasattr(module._hf_hook, "execution_device")
|
| 131 |
+
and module._hf_hook.execution_device is not None
|
| 132 |
+
):
|
| 133 |
+
return torch.device(module._hf_hook.execution_device)
|
| 134 |
+
return self.device
|
| 135 |
+
|
| 136 |
+
def prepare_latents(
|
| 137 |
+
self,
|
| 138 |
+
batch_size: int, # Number of videos to generate in parallel
|
| 139 |
+
num_channels_latents: int, # Number of channels in the latents
|
| 140 |
+
width: int, # Width of the video frame
|
| 141 |
+
height: int, # Height of the video frame
|
| 142 |
+
video_length: int, # Length of the video in frames
|
| 143 |
+
dtype: torch.dtype, # Data type of the latents
|
| 144 |
+
device: torch.device, # Device to store the latents on
|
| 145 |
+
generator: Optional[torch.Generator] = None, # Random number generator for reproducibility
|
| 146 |
+
latents: Optional[torch.Tensor] = None # Pre-generated latents (optional)
|
| 147 |
+
):
|
| 148 |
+
"""
|
| 149 |
+
Prepares the initial latents for video generation.
|
| 150 |
+
|
| 151 |
+
Args:
|
| 152 |
+
batch_size (int): Number of videos to generate in parallel.
|
| 153 |
+
num_channels_latents (int): Number of channels in the latents.
|
| 154 |
+
width (int): Width of the video frame.
|
| 155 |
+
height (int): Height of the video frame.
|
| 156 |
+
video_length (int): Length of the video in frames.
|
| 157 |
+
dtype (torch.dtype): Data type of the latents.
|
| 158 |
+
device (torch.device): Device to store the latents on.
|
| 159 |
+
generator (Optional[torch.Generator]): Random number generator for reproducibility.
|
| 160 |
+
latents (Optional[torch.Tensor]): Pre-generated latents (optional).
|
| 161 |
+
|
| 162 |
+
Returns:
|
| 163 |
+
latents (torch.Tensor): Tensor of shape (batch_size, num_channels_latents, width, height)
|
| 164 |
+
containing the initial latents for video generation.
|
| 165 |
+
"""
|
| 166 |
+
shape = (
|
| 167 |
+
batch_size,
|
| 168 |
+
num_channels_latents,
|
| 169 |
+
video_length,
|
| 170 |
+
height // self.vae_scale_factor,
|
| 171 |
+
width // self.vae_scale_factor,
|
| 172 |
+
)
|
| 173 |
+
if isinstance(generator, list) and len(generator) != batch_size:
|
| 174 |
+
raise ValueError(
|
| 175 |
+
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
| 176 |
+
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
| 177 |
+
)
|
| 178 |
+
|
| 179 |
+
if latents is None:
|
| 180 |
+
latents = randn_tensor(
|
| 181 |
+
shape, generator=generator, device=device, dtype=dtype
|
| 182 |
+
)
|
| 183 |
+
else:
|
| 184 |
+
latents = latents.to(device)
|
| 185 |
+
|
| 186 |
+
# scale the initial noise by the standard deviation required by the scheduler
|
| 187 |
+
latents = latents * self.scheduler.init_noise_sigma
|
| 188 |
+
return latents
|
| 189 |
+
|
| 190 |
+
def prepare_extra_step_kwargs(self, generator, eta):
|
| 191 |
+
"""
|
| 192 |
+
Prepares extra keyword arguments for the scheduler step.
|
| 193 |
+
|
| 194 |
+
Args:
|
| 195 |
+
generator (Optional[torch.Generator]): Random number generator for reproducibility.
|
| 196 |
+
eta (float): The eta (η) parameter used with the DDIMScheduler.
|
| 197 |
+
It corresponds to η in the DDIM paper (https://arxiv.org/abs/2010.02502) and should be between [0, 1].
|
| 198 |
+
|
| 199 |
+
Returns:
|
| 200 |
+
dict: A dictionary containing the extra keyword arguments for the scheduler step.
|
| 201 |
+
"""
|
| 202 |
+
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
|
| 203 |
+
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
| 204 |
+
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
| 205 |
+
# and should be between [0, 1]
|
| 206 |
+
|
| 207 |
+
accepts_eta = "eta" in set(
|
| 208 |
+
inspect.signature(self.scheduler.step).parameters.keys()
|
| 209 |
+
)
|
| 210 |
+
extra_step_kwargs = {}
|
| 211 |
+
if accepts_eta:
|
| 212 |
+
extra_step_kwargs["eta"] = eta
|
| 213 |
+
|
| 214 |
+
# check if the scheduler accepts generator
|
| 215 |
+
accepts_generator = "generator" in set(
|
| 216 |
+
inspect.signature(self.scheduler.step).parameters.keys()
|
| 217 |
+
)
|
| 218 |
+
if accepts_generator:
|
| 219 |
+
extra_step_kwargs["generator"] = generator
|
| 220 |
+
return extra_step_kwargs
|
| 221 |
+
|
| 222 |
+
def decode_latents(self, latents):
|
| 223 |
+
"""
|
| 224 |
+
Decode the latents to produce a video.
|
| 225 |
+
|
| 226 |
+
Parameters:
|
| 227 |
+
latents (torch.Tensor): The latents to be decoded.
|
| 228 |
+
|
| 229 |
+
Returns:
|
| 230 |
+
video (torch.Tensor): The decoded video.
|
| 231 |
+
video_length (int): The length of the video in frames.
|
| 232 |
+
"""
|
| 233 |
+
video_length = latents.shape[2]
|
| 234 |
+
latents = 1 / 0.18215 * latents
|
| 235 |
+
latents = rearrange(latents, "b c f h w -> (b f) c h w")
|
| 236 |
+
# video = self.vae.decode(latents).sample
|
| 237 |
+
video = []
|
| 238 |
+
for frame_idx in tqdm(range(latents.shape[0])):
|
| 239 |
+
video.append(self.vae.decode(
|
| 240 |
+
latents[frame_idx: frame_idx + 1]).sample)
|
| 241 |
+
video = torch.cat(video)
|
| 242 |
+
video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
|
| 243 |
+
video = (video / 2 + 0.5).clamp(0, 1)
|
| 244 |
+
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
|
| 245 |
+
video = video.cpu().float().numpy()
|
| 246 |
+
return video
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
@torch.no_grad()
|
| 250 |
+
def __call__(
|
| 251 |
+
self,
|
| 252 |
+
ref_image,
|
| 253 |
+
face_emb,
|
| 254 |
+
audio_tensor,
|
| 255 |
+
face_mask,
|
| 256 |
+
pixel_values_full_mask,
|
| 257 |
+
pixel_values_face_mask,
|
| 258 |
+
pixel_values_lip_mask,
|
| 259 |
+
width,
|
| 260 |
+
height,
|
| 261 |
+
video_length,
|
| 262 |
+
num_inference_steps,
|
| 263 |
+
guidance_scale,
|
| 264 |
+
num_images_per_prompt=1,
|
| 265 |
+
eta: float = 0.0,
|
| 266 |
+
motion_scale: Optional[List[torch.Tensor]] = None,
|
| 267 |
+
generator: Optional[Union[torch.Generator,
|
| 268 |
+
List[torch.Generator]]] = None,
|
| 269 |
+
output_type: Optional[str] = "tensor",
|
| 270 |
+
return_dict: bool = True,
|
| 271 |
+
callback: Optional[Callable[[
|
| 272 |
+
int, int, torch.FloatTensor], None]] = None,
|
| 273 |
+
callback_steps: Optional[int] = 1,
|
| 274 |
+
**kwargs,
|
| 275 |
+
):
|
| 276 |
+
# Default height and width to unet
|
| 277 |
+
height = height or self.unet.config.sample_size * self.vae_scale_factor
|
| 278 |
+
width = width or self.unet.config.sample_size * self.vae_scale_factor
|
| 279 |
+
|
| 280 |
+
device = self._execution_device
|
| 281 |
+
|
| 282 |
+
do_classifier_free_guidance = guidance_scale > 1.0
|
| 283 |
+
|
| 284 |
+
# Prepare timesteps
|
| 285 |
+
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
| 286 |
+
timesteps = self.scheduler.timesteps
|
| 287 |
+
|
| 288 |
+
batch_size = 1
|
| 289 |
+
|
| 290 |
+
# prepare clip image embeddings
|
| 291 |
+
clip_image_embeds = face_emb
|
| 292 |
+
clip_image_embeds = clip_image_embeds.to(self.image_proj.device, self.image_proj.dtype)
|
| 293 |
+
|
| 294 |
+
encoder_hidden_states = self.image_proj(clip_image_embeds)
|
| 295 |
+
uncond_encoder_hidden_states = self.image_proj(torch.zeros_like(clip_image_embeds))
|
| 296 |
+
|
| 297 |
+
if do_classifier_free_guidance:
|
| 298 |
+
encoder_hidden_states = torch.cat([uncond_encoder_hidden_states, encoder_hidden_states], dim=0)
|
| 299 |
+
|
| 300 |
+
reference_control_writer = ReferenceAttentionControl(
|
| 301 |
+
self.reference_unet,
|
| 302 |
+
do_classifier_free_guidance=do_classifier_free_guidance,
|
| 303 |
+
mode="write",
|
| 304 |
+
batch_size=batch_size,
|
| 305 |
+
fusion_blocks="full",
|
| 306 |
+
)
|
| 307 |
+
reference_control_reader = ReferenceAttentionControl(
|
| 308 |
+
self.denoising_unet,
|
| 309 |
+
do_classifier_free_guidance=do_classifier_free_guidance,
|
| 310 |
+
mode="read",
|
| 311 |
+
batch_size=batch_size,
|
| 312 |
+
fusion_blocks="full",
|
| 313 |
+
)
|
| 314 |
+
|
| 315 |
+
num_channels_latents = self.denoising_unet.in_channels
|
| 316 |
+
|
| 317 |
+
latents = self.prepare_latents(
|
| 318 |
+
batch_size * num_images_per_prompt,
|
| 319 |
+
num_channels_latents,
|
| 320 |
+
width,
|
| 321 |
+
height,
|
| 322 |
+
video_length,
|
| 323 |
+
clip_image_embeds.dtype,
|
| 324 |
+
device,
|
| 325 |
+
generator,
|
| 326 |
+
)
|
| 327 |
+
|
| 328 |
+
# Prepare extra step kwargs.
|
| 329 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 330 |
+
|
| 331 |
+
# Prepare ref image latents
|
| 332 |
+
ref_image_tensor = rearrange(ref_image, "b f c h w -> (b f) c h w")
|
| 333 |
+
ref_image_tensor = self.ref_image_processor.preprocess(ref_image_tensor, height=height, width=width) # (bs, c, width, height)
|
| 334 |
+
ref_image_tensor = ref_image_tensor.to(dtype=self.vae.dtype, device=self.vae.device)
|
| 335 |
+
ref_image_latents = self.vae.encode(ref_image_tensor).latent_dist.mean
|
| 336 |
+
ref_image_latents = ref_image_latents * 0.18215 # (b, 4, h, w)
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
face_mask = face_mask.unsqueeze(1).to(dtype=self.face_locator.dtype, device=self.face_locator.device) # (bs, f, c, H, W)
|
| 340 |
+
face_mask = repeat(face_mask, "b f c h w -> b (repeat f) c h w", repeat=video_length)
|
| 341 |
+
face_mask = face_mask.transpose(1, 2) # (bs, c, f, H, W)
|
| 342 |
+
face_mask = self.face_locator(face_mask)
|
| 343 |
+
face_mask = torch.cat([torch.zeros_like(face_mask), face_mask], dim=0) if do_classifier_free_guidance else face_mask
|
| 344 |
+
|
| 345 |
+
pixel_values_full_mask = (
|
| 346 |
+
[torch.cat([mask] * 2) for mask in pixel_values_full_mask]
|
| 347 |
+
if do_classifier_free_guidance
|
| 348 |
+
else pixel_values_full_mask
|
| 349 |
+
)
|
| 350 |
+
pixel_values_face_mask = (
|
| 351 |
+
[torch.cat([mask] * 2) for mask in pixel_values_face_mask]
|
| 352 |
+
if do_classifier_free_guidance
|
| 353 |
+
else pixel_values_face_mask
|
| 354 |
+
)
|
| 355 |
+
pixel_values_lip_mask = (
|
| 356 |
+
[torch.cat([mask] * 2) for mask in pixel_values_lip_mask]
|
| 357 |
+
if do_classifier_free_guidance
|
| 358 |
+
else pixel_values_lip_mask
|
| 359 |
+
)
|
| 360 |
+
pixel_values_face_mask_ = []
|
| 361 |
+
for mask in pixel_values_face_mask:
|
| 362 |
+
pixel_values_face_mask_.append(
|
| 363 |
+
mask.to(device=self.denoising_unet.device, dtype=self.denoising_unet.dtype))
|
| 364 |
+
pixel_values_face_mask = pixel_values_face_mask_
|
| 365 |
+
pixel_values_lip_mask_ = []
|
| 366 |
+
for mask in pixel_values_lip_mask:
|
| 367 |
+
pixel_values_lip_mask_.append(
|
| 368 |
+
mask.to(device=self.denoising_unet.device, dtype=self.denoising_unet.dtype))
|
| 369 |
+
pixel_values_lip_mask = pixel_values_lip_mask_
|
| 370 |
+
pixel_values_full_mask_ = []
|
| 371 |
+
for mask in pixel_values_full_mask:
|
| 372 |
+
pixel_values_full_mask_.append(
|
| 373 |
+
mask.to(device=self.denoising_unet.device, dtype=self.denoising_unet.dtype))
|
| 374 |
+
pixel_values_full_mask = pixel_values_full_mask_
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
uncond_audio_tensor = torch.zeros_like(audio_tensor)
|
| 378 |
+
audio_tensor = torch.cat([uncond_audio_tensor, audio_tensor], dim=0)
|
| 379 |
+
audio_tensor = audio_tensor.to(dtype=self.denoising_unet.dtype, device=self.denoising_unet.device)
|
| 380 |
+
|
| 381 |
+
# denoising loop
|
| 382 |
+
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
| 383 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 384 |
+
for i, t in enumerate(timesteps):
|
| 385 |
+
# Forward reference image
|
| 386 |
+
if i == 0:
|
| 387 |
+
self.reference_unet(
|
| 388 |
+
ref_image_latents.repeat(
|
| 389 |
+
(2 if do_classifier_free_guidance else 1), 1, 1, 1
|
| 390 |
+
),
|
| 391 |
+
torch.zeros_like(t),
|
| 392 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 393 |
+
return_dict=False,
|
| 394 |
+
)
|
| 395 |
+
reference_control_reader.update(reference_control_writer)
|
| 396 |
+
|
| 397 |
+
# expand the latents if we are doing classifier free guidance
|
| 398 |
+
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
| 399 |
+
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
| 400 |
+
|
| 401 |
+
noise_pred = self.denoising_unet(
|
| 402 |
+
latent_model_input,
|
| 403 |
+
t,
|
| 404 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 405 |
+
mask_cond_fea=face_mask,
|
| 406 |
+
full_mask=pixel_values_full_mask,
|
| 407 |
+
face_mask=pixel_values_face_mask,
|
| 408 |
+
lip_mask=pixel_values_lip_mask,
|
| 409 |
+
audio_embedding=audio_tensor,
|
| 410 |
+
motion_scale=motion_scale,
|
| 411 |
+
return_dict=False,
|
| 412 |
+
)[0]
|
| 413 |
+
|
| 414 |
+
# perform guidance
|
| 415 |
+
if do_classifier_free_guidance:
|
| 416 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 417 |
+
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
| 418 |
+
|
| 419 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 420 |
+
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
| 421 |
+
|
| 422 |
+
# call the callback, if provided
|
| 423 |
+
if i == len(timesteps) - 1 or (i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0:
|
| 424 |
+
progress_bar.update()
|
| 425 |
+
if callback is not None and i % callback_steps == 0:
|
| 426 |
+
step_idx = i // getattr(self.scheduler, "order", 1)
|
| 427 |
+
callback(step_idx, t, latents)
|
| 428 |
+
|
| 429 |
+
reference_control_reader.clear()
|
| 430 |
+
reference_control_writer.clear()
|
| 431 |
+
|
| 432 |
+
# Post-processing
|
| 433 |
+
images = self.decode_latents(latents) # (b, c, f, h, w)
|
| 434 |
+
|
| 435 |
+
# Convert to tensor
|
| 436 |
+
if output_type == "tensor":
|
| 437 |
+
images = torch.from_numpy(images)
|
| 438 |
+
|
| 439 |
+
if not return_dict:
|
| 440 |
+
return images
|
| 441 |
+
|
| 442 |
+
return FaceAnimatePipelineOutput(videos=images)
|
hallo/animate/face_animate_static.py
ADDED
|
@@ -0,0 +1,481 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
"""
|
| 3 |
+
This module is responsible for handling the animation of faces using a combination of deep learning models and image processing techniques.
|
| 4 |
+
It provides a pipeline to generate realistic face animations by incorporating user-provided conditions such as facial expressions and environments.
|
| 5 |
+
The module utilizes various schedulers and utilities to optimize the animation process and ensure efficient performance.
|
| 6 |
+
|
| 7 |
+
Functions and Classes:
|
| 8 |
+
- StaticPipelineOutput: A class that represents the output of the animation pipeline, c
|
| 9 |
+
ontaining properties and methods related to the generated images.
|
| 10 |
+
- prepare_latents: A function that prepares the initial noise for the animation process,
|
| 11 |
+
scaling it according to the scheduler's requirements.
|
| 12 |
+
- prepare_condition: A function that processes the user-provided conditions
|
| 13 |
+
(e.g., facial expressions) and prepares them for use in the animation pipeline.
|
| 14 |
+
- decode_latents: A function that decodes the latent representations of the face animations into
|
| 15 |
+
their corresponding image formats.
|
| 16 |
+
- prepare_extra_step_kwargs: A function that prepares additional parameters for each step of
|
| 17 |
+
the animation process, such as the generator and eta values.
|
| 18 |
+
|
| 19 |
+
Dependencies:
|
| 20 |
+
- numpy: A library for numerical computing.
|
| 21 |
+
- torch: A machine learning library based on PyTorch.
|
| 22 |
+
- diffusers: A library for image-to-image diffusion models.
|
| 23 |
+
- transformers: A library for pre-trained transformer models.
|
| 24 |
+
|
| 25 |
+
Usage:
|
| 26 |
+
- To create an instance of the animation pipeline, provide the necessary components such as
|
| 27 |
+
the VAE, reference UNET, denoising UNET, face locator, and image processor.
|
| 28 |
+
- Use the pipeline's methods to prepare the latents, conditions, and extra step arguments as
|
| 29 |
+
required for the animation process.
|
| 30 |
+
- Generate the face animations by decoding the latents and processing the conditions.
|
| 31 |
+
|
| 32 |
+
Note:
|
| 33 |
+
- The module is designed to work with the diffusers library, which is based on
|
| 34 |
+
the paper "Diffusion Models for Image-to-Image Translation" (https://arxiv.org/abs/2102.02765).
|
| 35 |
+
- The face animations generated by this module should be used for entertainment purposes
|
| 36 |
+
only and should respect the rights and privacy of the individuals involved.
|
| 37 |
+
"""
|
| 38 |
+
import inspect
|
| 39 |
+
from dataclasses import dataclass
|
| 40 |
+
from typing import Callable, List, Optional, Union
|
| 41 |
+
|
| 42 |
+
import numpy as np
|
| 43 |
+
import torch
|
| 44 |
+
from diffusers import DiffusionPipeline
|
| 45 |
+
from diffusers.image_processor import VaeImageProcessor
|
| 46 |
+
from diffusers.schedulers import (DDIMScheduler, DPMSolverMultistepScheduler,
|
| 47 |
+
EulerAncestralDiscreteScheduler,
|
| 48 |
+
EulerDiscreteScheduler, LMSDiscreteScheduler,
|
| 49 |
+
PNDMScheduler)
|
| 50 |
+
from diffusers.utils import BaseOutput, is_accelerate_available
|
| 51 |
+
from diffusers.utils.torch_utils import randn_tensor
|
| 52 |
+
from einops import rearrange
|
| 53 |
+
from tqdm import tqdm
|
| 54 |
+
from transformers import CLIPImageProcessor
|
| 55 |
+
|
| 56 |
+
from hallo.models.mutual_self_attention import ReferenceAttentionControl
|
| 57 |
+
|
| 58 |
+
if is_accelerate_available():
|
| 59 |
+
from accelerate import cpu_offload
|
| 60 |
+
else:
|
| 61 |
+
raise ImportError("Please install accelerate via `pip install accelerate`")
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
@dataclass
|
| 65 |
+
class StaticPipelineOutput(BaseOutput):
|
| 66 |
+
"""
|
| 67 |
+
StaticPipelineOutput is a class that represents the output of the static pipeline.
|
| 68 |
+
It contains the images generated by the pipeline as a union of torch.Tensor and np.ndarray.
|
| 69 |
+
|
| 70 |
+
Attributes:
|
| 71 |
+
images (Union[torch.Tensor, np.ndarray]): The generated images.
|
| 72 |
+
"""
|
| 73 |
+
images: Union[torch.Tensor, np.ndarray]
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class StaticPipeline(DiffusionPipeline):
|
| 77 |
+
"""
|
| 78 |
+
StaticPipelineOutput is a class that represents the output of the static pipeline.
|
| 79 |
+
It contains the images generated by the pipeline as a union of torch.Tensor and np.ndarray.
|
| 80 |
+
|
| 81 |
+
Attributes:
|
| 82 |
+
images (Union[torch.Tensor, np.ndarray]): The generated images.
|
| 83 |
+
"""
|
| 84 |
+
_optional_components = []
|
| 85 |
+
|
| 86 |
+
def __init__(
|
| 87 |
+
self,
|
| 88 |
+
vae,
|
| 89 |
+
reference_unet,
|
| 90 |
+
denoising_unet,
|
| 91 |
+
face_locator,
|
| 92 |
+
imageproj,
|
| 93 |
+
scheduler: Union[
|
| 94 |
+
DDIMScheduler,
|
| 95 |
+
PNDMScheduler,
|
| 96 |
+
LMSDiscreteScheduler,
|
| 97 |
+
EulerDiscreteScheduler,
|
| 98 |
+
EulerAncestralDiscreteScheduler,
|
| 99 |
+
DPMSolverMultistepScheduler,
|
| 100 |
+
],
|
| 101 |
+
):
|
| 102 |
+
super().__init__()
|
| 103 |
+
|
| 104 |
+
self.register_modules(
|
| 105 |
+
vae=vae,
|
| 106 |
+
reference_unet=reference_unet,
|
| 107 |
+
denoising_unet=denoising_unet,
|
| 108 |
+
face_locator=face_locator,
|
| 109 |
+
scheduler=scheduler,
|
| 110 |
+
imageproj=imageproj,
|
| 111 |
+
)
|
| 112 |
+
self.vae_scale_factor = 2 ** (
|
| 113 |
+
len(self.vae.config.block_out_channels) - 1)
|
| 114 |
+
self.clip_image_processor = CLIPImageProcessor()
|
| 115 |
+
self.ref_image_processor = VaeImageProcessor(
|
| 116 |
+
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True
|
| 117 |
+
)
|
| 118 |
+
self.cond_image_processor = VaeImageProcessor(
|
| 119 |
+
vae_scale_factor=self.vae_scale_factor,
|
| 120 |
+
do_convert_rgb=True,
|
| 121 |
+
do_normalize=False,
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
def enable_vae_slicing(self):
|
| 125 |
+
"""
|
| 126 |
+
Enable VAE slicing.
|
| 127 |
+
|
| 128 |
+
This method enables slicing for the VAE model, which can help improve the performance of decoding latents when working with large images.
|
| 129 |
+
"""
|
| 130 |
+
self.vae.enable_slicing()
|
| 131 |
+
|
| 132 |
+
def disable_vae_slicing(self):
|
| 133 |
+
"""
|
| 134 |
+
Disable vae slicing.
|
| 135 |
+
|
| 136 |
+
This function disables the vae slicing for the StaticPipeline object.
|
| 137 |
+
It calls the `disable_slicing()` method of the vae model.
|
| 138 |
+
This is useful when you want to use the entire vae model for decoding latents
|
| 139 |
+
instead of slicing it for better performance.
|
| 140 |
+
"""
|
| 141 |
+
self.vae.disable_slicing()
|
| 142 |
+
|
| 143 |
+
def enable_sequential_cpu_offload(self, gpu_id=0):
|
| 144 |
+
"""
|
| 145 |
+
Offloads selected models to the GPU for increased performance.
|
| 146 |
+
|
| 147 |
+
Args:
|
| 148 |
+
gpu_id (int, optional): The ID of the GPU to offload models to. Defaults to 0.
|
| 149 |
+
"""
|
| 150 |
+
device = torch.device(f"cuda:{gpu_id}")
|
| 151 |
+
|
| 152 |
+
for cpu_offloaded_model in [self.unet, self.text_encoder, self.vae]:
|
| 153 |
+
if cpu_offloaded_model is not None:
|
| 154 |
+
cpu_offload(cpu_offloaded_model, device)
|
| 155 |
+
|
| 156 |
+
@property
|
| 157 |
+
def _execution_device(self):
|
| 158 |
+
if self.device != torch.device("meta") or not hasattr(self.unet, "_hf_hook"):
|
| 159 |
+
return self.device
|
| 160 |
+
for module in self.unet.modules():
|
| 161 |
+
if (
|
| 162 |
+
hasattr(module, "_hf_hook")
|
| 163 |
+
and hasattr(module._hf_hook, "execution_device")
|
| 164 |
+
and module._hf_hook.execution_device is not None
|
| 165 |
+
):
|
| 166 |
+
return torch.device(module._hf_hook.execution_device)
|
| 167 |
+
return self.device
|
| 168 |
+
|
| 169 |
+
def decode_latents(self, latents):
|
| 170 |
+
"""
|
| 171 |
+
Decode the given latents to video frames.
|
| 172 |
+
|
| 173 |
+
Parameters:
|
| 174 |
+
latents (torch.Tensor): The latents to be decoded. Shape: (batch_size, num_channels_latents, video_length, height, width).
|
| 175 |
+
|
| 176 |
+
Returns:
|
| 177 |
+
video (torch.Tensor): The decoded video frames. Shape: (batch_size, num_channels_latents, video_length, height, width).
|
| 178 |
+
"""
|
| 179 |
+
video_length = latents.shape[2]
|
| 180 |
+
latents = 1 / 0.18215 * latents
|
| 181 |
+
latents = rearrange(latents, "b c f h w -> (b f) c h w")
|
| 182 |
+
# video = self.vae.decode(latents).sample
|
| 183 |
+
video = []
|
| 184 |
+
for frame_idx in tqdm(range(latents.shape[0])):
|
| 185 |
+
video.append(self.vae.decode(
|
| 186 |
+
latents[frame_idx: frame_idx + 1]).sample)
|
| 187 |
+
video = torch.cat(video)
|
| 188 |
+
video = rearrange(video, "(b f) c h w -> b c f h w", f=video_length)
|
| 189 |
+
video = (video / 2 + 0.5).clamp(0, 1)
|
| 190 |
+
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
|
| 191 |
+
video = video.cpu().float().numpy()
|
| 192 |
+
return video
|
| 193 |
+
|
| 194 |
+
def prepare_extra_step_kwargs(self, generator, eta):
|
| 195 |
+
"""
|
| 196 |
+
Prepare extra keyword arguments for the scheduler step.
|
| 197 |
+
|
| 198 |
+
Since not all schedulers have the same signature, this function helps to create a consistent interface for the scheduler.
|
| 199 |
+
|
| 200 |
+
Args:
|
| 201 |
+
generator (Optional[torch.Generator]): A random number generator for reproducibility.
|
| 202 |
+
eta (float): The eta parameter used with the DDIMScheduler. It should be between 0 and 1.
|
| 203 |
+
|
| 204 |
+
Returns:
|
| 205 |
+
dict: A dictionary containing the extra keyword arguments for the scheduler step.
|
| 206 |
+
"""
|
| 207 |
+
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
| 208 |
+
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
| 209 |
+
# and should be between [0, 1]
|
| 210 |
+
|
| 211 |
+
accepts_eta = "eta" in set(
|
| 212 |
+
inspect.signature(self.scheduler.step).parameters.keys()
|
| 213 |
+
)
|
| 214 |
+
extra_step_kwargs = {}
|
| 215 |
+
if accepts_eta:
|
| 216 |
+
extra_step_kwargs["eta"] = eta
|
| 217 |
+
|
| 218 |
+
# check if the scheduler accepts generator
|
| 219 |
+
accepts_generator = "generator" in set(
|
| 220 |
+
inspect.signature(self.scheduler.step).parameters.keys()
|
| 221 |
+
)
|
| 222 |
+
if accepts_generator:
|
| 223 |
+
extra_step_kwargs["generator"] = generator
|
| 224 |
+
return extra_step_kwargs
|
| 225 |
+
|
| 226 |
+
def prepare_latents(
|
| 227 |
+
self,
|
| 228 |
+
batch_size,
|
| 229 |
+
num_channels_latents,
|
| 230 |
+
width,
|
| 231 |
+
height,
|
| 232 |
+
dtype,
|
| 233 |
+
device,
|
| 234 |
+
generator,
|
| 235 |
+
latents=None,
|
| 236 |
+
):
|
| 237 |
+
"""
|
| 238 |
+
Prepares the initial latents for the diffusion pipeline.
|
| 239 |
+
|
| 240 |
+
Args:
|
| 241 |
+
batch_size (int): The number of images to generate in one forward pass.
|
| 242 |
+
num_channels_latents (int): The number of channels in the latents tensor.
|
| 243 |
+
width (int): The width of the latents tensor.
|
| 244 |
+
height (int): The height of the latents tensor.
|
| 245 |
+
dtype (torch.dtype): The data type of the latents tensor.
|
| 246 |
+
device (torch.device): The device to place the latents tensor on.
|
| 247 |
+
generator (Optional[torch.Generator], optional): A random number generator
|
| 248 |
+
for reproducibility. Defaults to None.
|
| 249 |
+
latents (Optional[torch.Tensor], optional): Pre-computed latents to use as
|
| 250 |
+
initial conditions for the diffusion process. Defaults to None.
|
| 251 |
+
|
| 252 |
+
Returns:
|
| 253 |
+
torch.Tensor: The prepared latents tensor.
|
| 254 |
+
"""
|
| 255 |
+
shape = (
|
| 256 |
+
batch_size,
|
| 257 |
+
num_channels_latents,
|
| 258 |
+
height // self.vae_scale_factor,
|
| 259 |
+
width // self.vae_scale_factor,
|
| 260 |
+
)
|
| 261 |
+
if isinstance(generator, list) and len(generator) != batch_size:
|
| 262 |
+
raise ValueError(
|
| 263 |
+
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
| 264 |
+
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
if latents is None:
|
| 268 |
+
latents = randn_tensor(
|
| 269 |
+
shape, generator=generator, device=device, dtype=dtype
|
| 270 |
+
)
|
| 271 |
+
else:
|
| 272 |
+
latents = latents.to(device)
|
| 273 |
+
|
| 274 |
+
# scale the initial noise by the standard deviation required by the scheduler
|
| 275 |
+
latents = latents * self.scheduler.init_noise_sigma
|
| 276 |
+
return latents
|
| 277 |
+
|
| 278 |
+
def prepare_condition(
|
| 279 |
+
self,
|
| 280 |
+
cond_image,
|
| 281 |
+
width,
|
| 282 |
+
height,
|
| 283 |
+
device,
|
| 284 |
+
dtype,
|
| 285 |
+
do_classififer_free_guidance=False,
|
| 286 |
+
):
|
| 287 |
+
"""
|
| 288 |
+
Prepares the condition for the face animation pipeline.
|
| 289 |
+
|
| 290 |
+
Args:
|
| 291 |
+
cond_image (torch.Tensor): The conditional image tensor.
|
| 292 |
+
width (int): The width of the output image.
|
| 293 |
+
height (int): The height of the output image.
|
| 294 |
+
device (torch.device): The device to run the pipeline on.
|
| 295 |
+
dtype (torch.dtype): The data type of the tensor.
|
| 296 |
+
do_classififer_free_guidance (bool, optional): Whether to use classifier-free guidance or not. Defaults to False.
|
| 297 |
+
|
| 298 |
+
Returns:
|
| 299 |
+
Tuple[torch.Tensor, torch.Tensor]: A tuple of processed condition and mask tensors.
|
| 300 |
+
"""
|
| 301 |
+
image = self.cond_image_processor.preprocess(
|
| 302 |
+
cond_image, height=height, width=width
|
| 303 |
+
).to(dtype=torch.float32)
|
| 304 |
+
|
| 305 |
+
image = image.to(device=device, dtype=dtype)
|
| 306 |
+
|
| 307 |
+
if do_classififer_free_guidance:
|
| 308 |
+
image = torch.cat([image] * 2)
|
| 309 |
+
|
| 310 |
+
return image
|
| 311 |
+
|
| 312 |
+
@torch.no_grad()
|
| 313 |
+
def __call__(
|
| 314 |
+
self,
|
| 315 |
+
ref_image,
|
| 316 |
+
face_mask,
|
| 317 |
+
width,
|
| 318 |
+
height,
|
| 319 |
+
num_inference_steps,
|
| 320 |
+
guidance_scale,
|
| 321 |
+
face_embedding,
|
| 322 |
+
num_images_per_prompt=1,
|
| 323 |
+
eta: float = 0.0,
|
| 324 |
+
generator: Optional[Union[torch.Generator,
|
| 325 |
+
List[torch.Generator]]] = None,
|
| 326 |
+
output_type: Optional[str] = "tensor",
|
| 327 |
+
return_dict: bool = True,
|
| 328 |
+
callback: Optional[Callable[[
|
| 329 |
+
int, int, torch.FloatTensor], None]] = None,
|
| 330 |
+
callback_steps: Optional[int] = 1,
|
| 331 |
+
**kwargs,
|
| 332 |
+
):
|
| 333 |
+
# Default height and width to unet
|
| 334 |
+
height = height or self.unet.config.sample_size * self.vae_scale_factor
|
| 335 |
+
width = width or self.unet.config.sample_size * self.vae_scale_factor
|
| 336 |
+
|
| 337 |
+
device = self._execution_device
|
| 338 |
+
|
| 339 |
+
do_classifier_free_guidance = guidance_scale > 1.0
|
| 340 |
+
|
| 341 |
+
# Prepare timesteps
|
| 342 |
+
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
| 343 |
+
timesteps = self.scheduler.timesteps
|
| 344 |
+
|
| 345 |
+
batch_size = 1
|
| 346 |
+
|
| 347 |
+
image_prompt_embeds = self.imageproj(face_embedding)
|
| 348 |
+
uncond_image_prompt_embeds = self.imageproj(
|
| 349 |
+
torch.zeros_like(face_embedding))
|
| 350 |
+
|
| 351 |
+
if do_classifier_free_guidance:
|
| 352 |
+
image_prompt_embeds = torch.cat(
|
| 353 |
+
[uncond_image_prompt_embeds, image_prompt_embeds], dim=0
|
| 354 |
+
)
|
| 355 |
+
|
| 356 |
+
reference_control_writer = ReferenceAttentionControl(
|
| 357 |
+
self.reference_unet,
|
| 358 |
+
do_classifier_free_guidance=do_classifier_free_guidance,
|
| 359 |
+
mode="write",
|
| 360 |
+
batch_size=batch_size,
|
| 361 |
+
fusion_blocks="full",
|
| 362 |
+
)
|
| 363 |
+
reference_control_reader = ReferenceAttentionControl(
|
| 364 |
+
self.denoising_unet,
|
| 365 |
+
do_classifier_free_guidance=do_classifier_free_guidance,
|
| 366 |
+
mode="read",
|
| 367 |
+
batch_size=batch_size,
|
| 368 |
+
fusion_blocks="full",
|
| 369 |
+
)
|
| 370 |
+
|
| 371 |
+
num_channels_latents = self.denoising_unet.in_channels
|
| 372 |
+
latents = self.prepare_latents(
|
| 373 |
+
batch_size * num_images_per_prompt,
|
| 374 |
+
num_channels_latents,
|
| 375 |
+
width,
|
| 376 |
+
height,
|
| 377 |
+
face_embedding.dtype,
|
| 378 |
+
device,
|
| 379 |
+
generator,
|
| 380 |
+
)
|
| 381 |
+
latents = latents.unsqueeze(2) # (bs, c, 1, h', w')
|
| 382 |
+
# latents_dtype = latents.dtype
|
| 383 |
+
|
| 384 |
+
# Prepare extra step kwargs.
|
| 385 |
+
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
| 386 |
+
|
| 387 |
+
# Prepare ref image latents
|
| 388 |
+
ref_image_tensor = self.ref_image_processor.preprocess(
|
| 389 |
+
ref_image, height=height, width=width
|
| 390 |
+
) # (bs, c, width, height)
|
| 391 |
+
ref_image_tensor = ref_image_tensor.to(
|
| 392 |
+
dtype=self.vae.dtype, device=self.vae.device
|
| 393 |
+
)
|
| 394 |
+
ref_image_latents = self.vae.encode(ref_image_tensor).latent_dist.mean
|
| 395 |
+
ref_image_latents = ref_image_latents * 0.18215 # (b, 4, h, w)
|
| 396 |
+
|
| 397 |
+
# Prepare face mask image
|
| 398 |
+
face_mask_tensor = self.cond_image_processor.preprocess(
|
| 399 |
+
face_mask, height=height, width=width
|
| 400 |
+
)
|
| 401 |
+
face_mask_tensor = face_mask_tensor.unsqueeze(2) # (bs, c, 1, h, w)
|
| 402 |
+
face_mask_tensor = face_mask_tensor.to(
|
| 403 |
+
device=device, dtype=self.face_locator.dtype
|
| 404 |
+
)
|
| 405 |
+
mask_fea = self.face_locator(face_mask_tensor)
|
| 406 |
+
mask_fea = (
|
| 407 |
+
torch.cat(
|
| 408 |
+
[mask_fea] * 2) if do_classifier_free_guidance else mask_fea
|
| 409 |
+
)
|
| 410 |
+
|
| 411 |
+
# denoising loop
|
| 412 |
+
num_warmup_steps = len(timesteps) - \
|
| 413 |
+
num_inference_steps * self.scheduler.order
|
| 414 |
+
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
| 415 |
+
for i, t in enumerate(timesteps):
|
| 416 |
+
# 1. Forward reference image
|
| 417 |
+
if i == 0:
|
| 418 |
+
self.reference_unet(
|
| 419 |
+
ref_image_latents.repeat(
|
| 420 |
+
(2 if do_classifier_free_guidance else 1), 1, 1, 1
|
| 421 |
+
),
|
| 422 |
+
torch.zeros_like(t),
|
| 423 |
+
encoder_hidden_states=image_prompt_embeds,
|
| 424 |
+
return_dict=False,
|
| 425 |
+
)
|
| 426 |
+
|
| 427 |
+
# 2. Update reference unet feature into denosing net
|
| 428 |
+
reference_control_reader.update(reference_control_writer)
|
| 429 |
+
|
| 430 |
+
# 3.1 expand the latents if we are doing classifier free guidance
|
| 431 |
+
latent_model_input = (
|
| 432 |
+
torch.cat(
|
| 433 |
+
[latents] * 2) if do_classifier_free_guidance else latents
|
| 434 |
+
)
|
| 435 |
+
latent_model_input = self.scheduler.scale_model_input(
|
| 436 |
+
latent_model_input, t
|
| 437 |
+
)
|
| 438 |
+
|
| 439 |
+
noise_pred = self.denoising_unet(
|
| 440 |
+
latent_model_input,
|
| 441 |
+
t,
|
| 442 |
+
encoder_hidden_states=image_prompt_embeds,
|
| 443 |
+
mask_cond_fea=mask_fea,
|
| 444 |
+
return_dict=False,
|
| 445 |
+
)[0]
|
| 446 |
+
|
| 447 |
+
# perform guidance
|
| 448 |
+
if do_classifier_free_guidance:
|
| 449 |
+
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
| 450 |
+
noise_pred = noise_pred_uncond + guidance_scale * (
|
| 451 |
+
noise_pred_text - noise_pred_uncond
|
| 452 |
+
)
|
| 453 |
+
|
| 454 |
+
# compute the previous noisy sample x_t -> x_t-1
|
| 455 |
+
latents = self.scheduler.step(
|
| 456 |
+
noise_pred, t, latents, **extra_step_kwargs, return_dict=False
|
| 457 |
+
)[0]
|
| 458 |
+
|
| 459 |
+
# call the callback, if provided
|
| 460 |
+
if i == len(timesteps) - 1 or (
|
| 461 |
+
(i + 1) > num_warmup_steps and (i +
|
| 462 |
+
1) % self.scheduler.order == 0
|
| 463 |
+
):
|
| 464 |
+
progress_bar.update()
|
| 465 |
+
if callback is not None and i % callback_steps == 0:
|
| 466 |
+
step_idx = i // getattr(self.scheduler, "order", 1)
|
| 467 |
+
callback(step_idx, t, latents)
|
| 468 |
+
reference_control_reader.clear()
|
| 469 |
+
reference_control_writer.clear()
|
| 470 |
+
|
| 471 |
+
# Post-processing
|
| 472 |
+
image = self.decode_latents(latents) # (b, c, 1, h, w)
|
| 473 |
+
|
| 474 |
+
# Convert to tensor
|
| 475 |
+
if output_type == "tensor":
|
| 476 |
+
image = torch.from_numpy(image)
|
| 477 |
+
|
| 478 |
+
if not return_dict:
|
| 479 |
+
return image
|
| 480 |
+
|
| 481 |
+
return StaticPipelineOutput(images=image)
|
hallo/datasets/__init__.py
ADDED
|
File without changes
|
hallo/datasets/audio_processor.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=C0301
|
| 2 |
+
'''
|
| 3 |
+
This module contains the AudioProcessor class and related functions for processing audio data.
|
| 4 |
+
It utilizes various libraries and models to perform tasks such as preprocessing, feature extraction,
|
| 5 |
+
and audio separation. The class is initialized with configuration parameters and can process
|
| 6 |
+
audio files using the provided models.
|
| 7 |
+
'''
|
| 8 |
+
import math
|
| 9 |
+
import os
|
| 10 |
+
|
| 11 |
+
import librosa
|
| 12 |
+
import numpy as np
|
| 13 |
+
import torch
|
| 14 |
+
from audio_separator.separator import Separator
|
| 15 |
+
from einops import rearrange
|
| 16 |
+
from transformers import Wav2Vec2FeatureExtractor
|
| 17 |
+
|
| 18 |
+
from hallo.models.wav2vec import Wav2VecModel
|
| 19 |
+
from hallo.utils.util import resample_audio
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class AudioProcessor:
|
| 23 |
+
"""
|
| 24 |
+
AudioProcessor is a class that handles the processing of audio files.
|
| 25 |
+
It takes care of preprocessing the audio files, extracting features
|
| 26 |
+
using wav2vec models, and separating audio signals if needed.
|
| 27 |
+
|
| 28 |
+
:param sample_rate: Sampling rate of the audio file
|
| 29 |
+
:param fps: Frames per second for the extracted features
|
| 30 |
+
:param wav2vec_model_path: Path to the wav2vec model
|
| 31 |
+
:param only_last_features: Whether to only use the last features
|
| 32 |
+
:param audio_separator_model_path: Path to the audio separator model
|
| 33 |
+
:param audio_separator_model_name: Name of the audio separator model
|
| 34 |
+
:param cache_dir: Directory to cache the intermediate results
|
| 35 |
+
:param device: Device to run the processing on
|
| 36 |
+
"""
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
sample_rate,
|
| 40 |
+
fps,
|
| 41 |
+
wav2vec_model_path,
|
| 42 |
+
only_last_features,
|
| 43 |
+
audio_separator_model_path:str=None,
|
| 44 |
+
audio_separator_model_name:str=None,
|
| 45 |
+
cache_dir:str='',
|
| 46 |
+
device="cuda:0",
|
| 47 |
+
) -> None:
|
| 48 |
+
self.sample_rate = sample_rate
|
| 49 |
+
self.fps = fps
|
| 50 |
+
self.device = device
|
| 51 |
+
|
| 52 |
+
self.audio_encoder = Wav2VecModel.from_pretrained(wav2vec_model_path, local_files_only=True).to(device=device)
|
| 53 |
+
self.audio_encoder.feature_extractor._freeze_parameters()
|
| 54 |
+
self.only_last_features = only_last_features
|
| 55 |
+
|
| 56 |
+
if audio_separator_model_name is not None:
|
| 57 |
+
try:
|
| 58 |
+
os.makedirs(cache_dir, exist_ok=True)
|
| 59 |
+
except OSError as _:
|
| 60 |
+
print("Fail to create the output cache dir.")
|
| 61 |
+
self.audio_separator = Separator(
|
| 62 |
+
output_dir=cache_dir,
|
| 63 |
+
output_single_stem="vocals",
|
| 64 |
+
model_file_dir=audio_separator_model_path,
|
| 65 |
+
)
|
| 66 |
+
self.audio_separator.load_model(audio_separator_model_name)
|
| 67 |
+
assert self.audio_separator.model_instance is not None, "Fail to load audio separate model."
|
| 68 |
+
else:
|
| 69 |
+
self.audio_separator=None
|
| 70 |
+
print("Use audio directly without vocals seperator.")
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
self.wav2vec_feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(wav2vec_model_path, local_files_only=True)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def preprocess(self, wav_file: str):
|
| 77 |
+
"""
|
| 78 |
+
Preprocess a WAV audio file by separating the vocals from the background and resampling it to a 16 kHz sample rate.
|
| 79 |
+
The separated vocal track is then converted into wav2vec2 for further processing or analysis.
|
| 80 |
+
|
| 81 |
+
Args:
|
| 82 |
+
wav_file (str): The path to the WAV file to be processed. This file should be accessible and in WAV format.
|
| 83 |
+
|
| 84 |
+
Raises:
|
| 85 |
+
RuntimeError: Raises an exception if the WAV file cannot be processed. This could be due to issues
|
| 86 |
+
such as file not found, unsupported file format, or errors during the audio processing steps.
|
| 87 |
+
|
| 88 |
+
Returns:
|
| 89 |
+
torch.tensor: Returns an audio embedding as a torch.tensor
|
| 90 |
+
"""
|
| 91 |
+
if self.audio_separator is not None:
|
| 92 |
+
# 1. separate vocals
|
| 93 |
+
# TODO: process in memory
|
| 94 |
+
outputs = self.audio_separator.separate(wav_file)
|
| 95 |
+
if len(outputs) <= 0:
|
| 96 |
+
raise RuntimeError("Audio separate failed.")
|
| 97 |
+
|
| 98 |
+
vocal_audio_file = outputs[0]
|
| 99 |
+
vocal_audio_name, _ = os.path.splitext(vocal_audio_file)
|
| 100 |
+
vocal_audio_file = os.path.join(self.audio_separator.output_dir, vocal_audio_file)
|
| 101 |
+
vocal_audio_file = resample_audio(vocal_audio_file, os.path.join(self.audio_separator.output_dir, f"{vocal_audio_name}-16k.wav"), self.sample_rate)
|
| 102 |
+
else:
|
| 103 |
+
vocal_audio_file=wav_file
|
| 104 |
+
|
| 105 |
+
# 2. extract wav2vec features
|
| 106 |
+
speech_array, sampling_rate = librosa.load(vocal_audio_file, sr=self.sample_rate)
|
| 107 |
+
audio_feature = np.squeeze(self.wav2vec_feature_extractor(speech_array, sampling_rate=sampling_rate).input_values)
|
| 108 |
+
seq_len = math.ceil(len(audio_feature) / self.sample_rate * self.fps)
|
| 109 |
+
|
| 110 |
+
audio_feature = torch.from_numpy(audio_feature).float().to(device=self.device)
|
| 111 |
+
audio_feature = audio_feature.unsqueeze(0)
|
| 112 |
+
|
| 113 |
+
with torch.no_grad():
|
| 114 |
+
embeddings = self.audio_encoder(audio_feature, seq_len=seq_len, output_hidden_states=True)
|
| 115 |
+
assert len(embeddings) > 0, "Fail to extract audio embedding"
|
| 116 |
+
if self.only_last_features:
|
| 117 |
+
audio_emb = embeddings.last_hidden_state.squeeze()
|
| 118 |
+
else:
|
| 119 |
+
audio_emb = torch.stack(embeddings.hidden_states[1:], dim=1).squeeze(0)
|
| 120 |
+
audio_emb = rearrange(audio_emb, "b s d -> s b d")
|
| 121 |
+
|
| 122 |
+
audio_emb = audio_emb.cpu().detach()
|
| 123 |
+
|
| 124 |
+
return audio_emb
|
| 125 |
+
|
| 126 |
+
def get_embedding(self, wav_file: str):
|
| 127 |
+
"""preprocess wav audio file convert to embeddings
|
| 128 |
+
|
| 129 |
+
Args:
|
| 130 |
+
wav_file (str): The path to the WAV file to be processed. This file should be accessible and in WAV format.
|
| 131 |
+
|
| 132 |
+
Returns:
|
| 133 |
+
torch.tensor: Returns an audio embedding as a torch.tensor
|
| 134 |
+
"""
|
| 135 |
+
speech_array, sampling_rate = librosa.load(
|
| 136 |
+
wav_file, sr=self.sample_rate)
|
| 137 |
+
assert sampling_rate == 16000, "The audio sample rate must be 16000"
|
| 138 |
+
audio_feature = np.squeeze(self.wav2vec_feature_extractor(
|
| 139 |
+
speech_array, sampling_rate=sampling_rate).input_values)
|
| 140 |
+
seq_len = math.ceil(len(audio_feature) / self.sample_rate * self.fps)
|
| 141 |
+
|
| 142 |
+
audio_feature = torch.from_numpy(
|
| 143 |
+
audio_feature).float().to(device=self.device)
|
| 144 |
+
audio_feature = audio_feature.unsqueeze(0)
|
| 145 |
+
|
| 146 |
+
with torch.no_grad():
|
| 147 |
+
embeddings = self.audio_encoder(
|
| 148 |
+
audio_feature, seq_len=seq_len, output_hidden_states=True)
|
| 149 |
+
assert len(embeddings) > 0, "Fail to extract audio embedding"
|
| 150 |
+
|
| 151 |
+
if self.only_last_features:
|
| 152 |
+
audio_emb = embeddings.last_hidden_state.squeeze()
|
| 153 |
+
else:
|
| 154 |
+
audio_emb = torch.stack(
|
| 155 |
+
embeddings.hidden_states[1:], dim=1).squeeze(0)
|
| 156 |
+
audio_emb = rearrange(audio_emb, "b s d -> s b d")
|
| 157 |
+
|
| 158 |
+
audio_emb = audio_emb.cpu().detach()
|
| 159 |
+
|
| 160 |
+
return audio_emb
|
| 161 |
+
|
| 162 |
+
def close(self):
|
| 163 |
+
"""
|
| 164 |
+
TODO: to be implemented
|
| 165 |
+
"""
|
| 166 |
+
return self
|
| 167 |
+
|
| 168 |
+
def __enter__(self):
|
| 169 |
+
return self
|
| 170 |
+
|
| 171 |
+
def __exit__(self, _exc_type, _exc_val, _exc_tb):
|
| 172 |
+
self.close()
|
hallo/datasets/image_processor.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This module is responsible for processing images, particularly for face-related tasks.
|
| 3 |
+
It uses various libraries such as OpenCV, NumPy, and InsightFace to perform tasks like
|
| 4 |
+
face detection, augmentation, and mask rendering. The ImageProcessor class encapsulates
|
| 5 |
+
the functionality for these operations.
|
| 6 |
+
"""
|
| 7 |
+
import os
|
| 8 |
+
from typing import List
|
| 9 |
+
|
| 10 |
+
import cv2
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
from insightface.app import FaceAnalysis
|
| 14 |
+
from PIL import Image
|
| 15 |
+
from torchvision import transforms
|
| 16 |
+
|
| 17 |
+
from ..utils.util import get_mask
|
| 18 |
+
|
| 19 |
+
MEAN = 0.5
|
| 20 |
+
STD = 0.5
|
| 21 |
+
|
| 22 |
+
class ImageProcessor:
|
| 23 |
+
"""
|
| 24 |
+
ImageProcessor is a class responsible for processing images, particularly for face-related tasks.
|
| 25 |
+
It takes in an image and performs various operations such as augmentation, face detection,
|
| 26 |
+
face embedding extraction, and rendering a face mask. The processed images are then used for
|
| 27 |
+
further analysis or recognition purposes.
|
| 28 |
+
|
| 29 |
+
Attributes:
|
| 30 |
+
img_size (int): The size of the image to be processed.
|
| 31 |
+
face_analysis_model_path (str): The path to the face analysis model.
|
| 32 |
+
|
| 33 |
+
Methods:
|
| 34 |
+
preprocess(source_image_path, cache_dir):
|
| 35 |
+
Preprocesses the input image by performing augmentation, face detection,
|
| 36 |
+
face embedding extraction, and rendering a face mask.
|
| 37 |
+
|
| 38 |
+
close():
|
| 39 |
+
Closes the ImageProcessor and releases any resources being used.
|
| 40 |
+
|
| 41 |
+
_augmentation(images, transform, state=None):
|
| 42 |
+
Applies image augmentation to the input images using the given transform and state.
|
| 43 |
+
|
| 44 |
+
__enter__():
|
| 45 |
+
Enters a runtime context and returns the ImageProcessor object.
|
| 46 |
+
|
| 47 |
+
__exit__(_exc_type, _exc_val, _exc_tb):
|
| 48 |
+
Exits a runtime context and handles any exceptions that occurred during the processing.
|
| 49 |
+
"""
|
| 50 |
+
def __init__(self, img_size, face_analysis_model_path) -> None:
|
| 51 |
+
self.img_size = img_size
|
| 52 |
+
|
| 53 |
+
self.pixel_transform = transforms.Compose(
|
| 54 |
+
[
|
| 55 |
+
transforms.Resize(self.img_size),
|
| 56 |
+
transforms.ToTensor(),
|
| 57 |
+
transforms.Normalize([MEAN], [STD]),
|
| 58 |
+
]
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
self.cond_transform = transforms.Compose(
|
| 62 |
+
[
|
| 63 |
+
transforms.Resize(self.img_size),
|
| 64 |
+
transforms.ToTensor(),
|
| 65 |
+
]
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
self.attn_transform_64 = transforms.Compose(
|
| 69 |
+
[
|
| 70 |
+
transforms.Resize(
|
| 71 |
+
(self.img_size[0] // 8, self.img_size[0] // 8)),
|
| 72 |
+
transforms.ToTensor(),
|
| 73 |
+
]
|
| 74 |
+
)
|
| 75 |
+
self.attn_transform_32 = transforms.Compose(
|
| 76 |
+
[
|
| 77 |
+
transforms.Resize(
|
| 78 |
+
(self.img_size[0] // 16, self.img_size[0] // 16)),
|
| 79 |
+
transforms.ToTensor(),
|
| 80 |
+
]
|
| 81 |
+
)
|
| 82 |
+
self.attn_transform_16 = transforms.Compose(
|
| 83 |
+
[
|
| 84 |
+
transforms.Resize(
|
| 85 |
+
(self.img_size[0] // 32, self.img_size[0] // 32)),
|
| 86 |
+
transforms.ToTensor(),
|
| 87 |
+
]
|
| 88 |
+
)
|
| 89 |
+
self.attn_transform_8 = transforms.Compose(
|
| 90 |
+
[
|
| 91 |
+
transforms.Resize(
|
| 92 |
+
(self.img_size[0] // 64, self.img_size[0] // 64)),
|
| 93 |
+
transforms.ToTensor(),
|
| 94 |
+
]
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
self.face_analysis = FaceAnalysis(
|
| 98 |
+
name="",
|
| 99 |
+
root=face_analysis_model_path,
|
| 100 |
+
providers=["CUDAExecutionProvider", "CPUExecutionProvider"],
|
| 101 |
+
)
|
| 102 |
+
self.face_analysis.prepare(ctx_id=0, det_size=(640, 640))
|
| 103 |
+
|
| 104 |
+
def preprocess(self, source_image_path: str, cache_dir: str, face_region_ratio: float):
|
| 105 |
+
"""
|
| 106 |
+
Apply preprocessing to the source image to prepare for face analysis.
|
| 107 |
+
|
| 108 |
+
Parameters:
|
| 109 |
+
source_image_path (str): The path to the source image.
|
| 110 |
+
cache_dir (str): The directory to cache intermediate results.
|
| 111 |
+
|
| 112 |
+
Returns:
|
| 113 |
+
None
|
| 114 |
+
"""
|
| 115 |
+
source_image = Image.open(source_image_path)
|
| 116 |
+
ref_image_pil = source_image.convert("RGB")
|
| 117 |
+
# 1. image augmentation
|
| 118 |
+
pixel_values_ref_img = self._augmentation(ref_image_pil, self.pixel_transform)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
# 2.1 detect face
|
| 122 |
+
faces = self.face_analysis.get(cv2.cvtColor(np.array(ref_image_pil.copy()), cv2.COLOR_RGB2BGR))
|
| 123 |
+
# use max size face
|
| 124 |
+
face = sorted(faces, key=lambda x: (x["bbox"][2] - x["bbox"][0]) * (x["bbox"][3] - x["bbox"][1]))[-1]
|
| 125 |
+
|
| 126 |
+
# 2.2 face embedding
|
| 127 |
+
face_emb = face["embedding"]
|
| 128 |
+
|
| 129 |
+
# 2.3 render face mask
|
| 130 |
+
get_mask(source_image_path, cache_dir, face_region_ratio)
|
| 131 |
+
file_name = os.path.basename(source_image_path).split(".")[0]
|
| 132 |
+
face_mask_pil = Image.open(
|
| 133 |
+
os.path.join(cache_dir, f"{file_name}_face_mask.png")).convert("RGB")
|
| 134 |
+
|
| 135 |
+
face_mask = self._augmentation(face_mask_pil, self.cond_transform)
|
| 136 |
+
|
| 137 |
+
# 2.4 detect and expand lip, face mask
|
| 138 |
+
sep_background_mask = Image.open(
|
| 139 |
+
os.path.join(cache_dir, f"{file_name}_sep_background.png"))
|
| 140 |
+
sep_face_mask = Image.open(
|
| 141 |
+
os.path.join(cache_dir, f"{file_name}_sep_face.png"))
|
| 142 |
+
sep_lip_mask = Image.open(
|
| 143 |
+
os.path.join(cache_dir, f"{file_name}_sep_lip.png"))
|
| 144 |
+
|
| 145 |
+
pixel_values_face_mask = [
|
| 146 |
+
self._augmentation(sep_face_mask, self.attn_transform_64),
|
| 147 |
+
self._augmentation(sep_face_mask, self.attn_transform_32),
|
| 148 |
+
self._augmentation(sep_face_mask, self.attn_transform_16),
|
| 149 |
+
self._augmentation(sep_face_mask, self.attn_transform_8),
|
| 150 |
+
]
|
| 151 |
+
pixel_values_lip_mask = [
|
| 152 |
+
self._augmentation(sep_lip_mask, self.attn_transform_64),
|
| 153 |
+
self._augmentation(sep_lip_mask, self.attn_transform_32),
|
| 154 |
+
self._augmentation(sep_lip_mask, self.attn_transform_16),
|
| 155 |
+
self._augmentation(sep_lip_mask, self.attn_transform_8),
|
| 156 |
+
]
|
| 157 |
+
pixel_values_full_mask = [
|
| 158 |
+
self._augmentation(sep_background_mask, self.attn_transform_64),
|
| 159 |
+
self._augmentation(sep_background_mask, self.attn_transform_32),
|
| 160 |
+
self._augmentation(sep_background_mask, self.attn_transform_16),
|
| 161 |
+
self._augmentation(sep_background_mask, self.attn_transform_8),
|
| 162 |
+
]
|
| 163 |
+
|
| 164 |
+
pixel_values_full_mask = [mask.view(1, -1)
|
| 165 |
+
for mask in pixel_values_full_mask]
|
| 166 |
+
pixel_values_face_mask = [mask.view(1, -1)
|
| 167 |
+
for mask in pixel_values_face_mask]
|
| 168 |
+
pixel_values_lip_mask = [mask.view(1, -1)
|
| 169 |
+
for mask in pixel_values_lip_mask]
|
| 170 |
+
|
| 171 |
+
return pixel_values_ref_img, face_mask, face_emb, pixel_values_full_mask, pixel_values_face_mask, pixel_values_lip_mask
|
| 172 |
+
|
| 173 |
+
def close(self):
|
| 174 |
+
"""
|
| 175 |
+
Closes the ImageProcessor and releases any resources held by the FaceAnalysis instance.
|
| 176 |
+
|
| 177 |
+
Args:
|
| 178 |
+
self: The ImageProcessor instance.
|
| 179 |
+
|
| 180 |
+
Returns:
|
| 181 |
+
None.
|
| 182 |
+
"""
|
| 183 |
+
for _, model in self.face_analysis.models.items():
|
| 184 |
+
if hasattr(model, "Dispose"):
|
| 185 |
+
model.Dispose()
|
| 186 |
+
|
| 187 |
+
def _augmentation(self, images, transform, state=None):
|
| 188 |
+
if state is not None:
|
| 189 |
+
torch.set_rng_state(state)
|
| 190 |
+
if isinstance(images, List):
|
| 191 |
+
transformed_images = [transform(img) for img in images]
|
| 192 |
+
ret_tensor = torch.stack(transformed_images, dim=0) # (f, c, h, w)
|
| 193 |
+
else:
|
| 194 |
+
ret_tensor = transform(images) # (c, h, w)
|
| 195 |
+
return ret_tensor
|
| 196 |
+
|
| 197 |
+
def __enter__(self):
|
| 198 |
+
return self
|
| 199 |
+
|
| 200 |
+
def __exit__(self, _exc_type, _exc_val, _exc_tb):
|
| 201 |
+
self.close()
|
hallo/datasets/mask_image.py
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
"""
|
| 3 |
+
This module contains the code for a dataset class called FaceMaskDataset, which is used to process and
|
| 4 |
+
load image data related to face masks. The dataset class inherits from the PyTorch Dataset class and
|
| 5 |
+
provides methods for data augmentation, getting items from the dataset, and determining the length of the
|
| 6 |
+
dataset. The module also includes imports for necessary libraries such as json, random, pathlib, torch,
|
| 7 |
+
PIL, and transformers.
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import json
|
| 11 |
+
import random
|
| 12 |
+
from pathlib import Path
|
| 13 |
+
|
| 14 |
+
import torch
|
| 15 |
+
from PIL import Image
|
| 16 |
+
from torch.utils.data import Dataset
|
| 17 |
+
from torchvision import transforms
|
| 18 |
+
from transformers import CLIPImageProcessor
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class FaceMaskDataset(Dataset):
|
| 22 |
+
"""
|
| 23 |
+
FaceMaskDataset is a custom dataset for face mask images.
|
| 24 |
+
|
| 25 |
+
Args:
|
| 26 |
+
img_size (int): The size of the input images.
|
| 27 |
+
drop_ratio (float, optional): The ratio of dropped pixels during data augmentation. Defaults to 0.1.
|
| 28 |
+
data_meta_paths (list, optional): The paths to the metadata files containing image paths and labels. Defaults to ["./data/HDTF_meta.json"].
|
| 29 |
+
sample_margin (int, optional): The margin for sampling regions in the image. Defaults to 30.
|
| 30 |
+
|
| 31 |
+
Attributes:
|
| 32 |
+
img_size (int): The size of the input images.
|
| 33 |
+
drop_ratio (float): The ratio of dropped pixels during data augmentation.
|
| 34 |
+
data_meta_paths (list): The paths to the metadata files containing image paths and labels.
|
| 35 |
+
sample_margin (int): The margin for sampling regions in the image.
|
| 36 |
+
processor (CLIPImageProcessor): The image processor for preprocessing images.
|
| 37 |
+
transform (transforms.Compose): The image augmentation transform.
|
| 38 |
+
"""
|
| 39 |
+
|
| 40 |
+
def __init__(
|
| 41 |
+
self,
|
| 42 |
+
img_size,
|
| 43 |
+
drop_ratio=0.1,
|
| 44 |
+
data_meta_paths=None,
|
| 45 |
+
sample_margin=30,
|
| 46 |
+
):
|
| 47 |
+
super().__init__()
|
| 48 |
+
|
| 49 |
+
self.img_size = img_size
|
| 50 |
+
self.sample_margin = sample_margin
|
| 51 |
+
|
| 52 |
+
vid_meta = []
|
| 53 |
+
for data_meta_path in data_meta_paths:
|
| 54 |
+
with open(data_meta_path, "r", encoding="utf-8") as f:
|
| 55 |
+
vid_meta.extend(json.load(f))
|
| 56 |
+
self.vid_meta = vid_meta
|
| 57 |
+
self.length = len(self.vid_meta)
|
| 58 |
+
|
| 59 |
+
self.clip_image_processor = CLIPImageProcessor()
|
| 60 |
+
|
| 61 |
+
self.transform = transforms.Compose(
|
| 62 |
+
[
|
| 63 |
+
transforms.Resize(self.img_size),
|
| 64 |
+
transforms.ToTensor(),
|
| 65 |
+
transforms.Normalize([0.5], [0.5]),
|
| 66 |
+
]
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
self.cond_transform = transforms.Compose(
|
| 70 |
+
[
|
| 71 |
+
transforms.Resize(self.img_size),
|
| 72 |
+
transforms.ToTensor(),
|
| 73 |
+
]
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
self.drop_ratio = drop_ratio
|
| 77 |
+
|
| 78 |
+
def augmentation(self, image, transform, state=None):
|
| 79 |
+
"""
|
| 80 |
+
Apply data augmentation to the input image.
|
| 81 |
+
|
| 82 |
+
Args:
|
| 83 |
+
image (PIL.Image): The input image.
|
| 84 |
+
transform (torchvision.transforms.Compose): The data augmentation transforms.
|
| 85 |
+
state (dict, optional): The random state for reproducibility. Defaults to None.
|
| 86 |
+
|
| 87 |
+
Returns:
|
| 88 |
+
PIL.Image: The augmented image.
|
| 89 |
+
"""
|
| 90 |
+
if state is not None:
|
| 91 |
+
torch.set_rng_state(state)
|
| 92 |
+
return transform(image)
|
| 93 |
+
|
| 94 |
+
def __getitem__(self, index):
|
| 95 |
+
video_meta = self.vid_meta[index]
|
| 96 |
+
video_path = video_meta["image_path"]
|
| 97 |
+
mask_path = video_meta["mask_path"]
|
| 98 |
+
face_emb_path = video_meta["face_emb"]
|
| 99 |
+
|
| 100 |
+
video_frames = sorted(Path(video_path).iterdir())
|
| 101 |
+
video_length = len(video_frames)
|
| 102 |
+
|
| 103 |
+
margin = min(self.sample_margin, video_length)
|
| 104 |
+
|
| 105 |
+
ref_img_idx = random.randint(0, video_length - 1)
|
| 106 |
+
if ref_img_idx + margin < video_length:
|
| 107 |
+
tgt_img_idx = random.randint(
|
| 108 |
+
ref_img_idx + margin, video_length - 1)
|
| 109 |
+
elif ref_img_idx - margin > 0:
|
| 110 |
+
tgt_img_idx = random.randint(0, ref_img_idx - margin)
|
| 111 |
+
else:
|
| 112 |
+
tgt_img_idx = random.randint(0, video_length - 1)
|
| 113 |
+
|
| 114 |
+
ref_img_pil = Image.open(video_frames[ref_img_idx])
|
| 115 |
+
tgt_img_pil = Image.open(video_frames[tgt_img_idx])
|
| 116 |
+
|
| 117 |
+
tgt_mask_pil = Image.open(mask_path)
|
| 118 |
+
|
| 119 |
+
assert ref_img_pil is not None, "Fail to load reference image."
|
| 120 |
+
assert tgt_img_pil is not None, "Fail to load target image."
|
| 121 |
+
assert tgt_mask_pil is not None, "Fail to load target mask."
|
| 122 |
+
|
| 123 |
+
state = torch.get_rng_state()
|
| 124 |
+
tgt_img = self.augmentation(tgt_img_pil, self.transform, state)
|
| 125 |
+
tgt_mask_img = self.augmentation(
|
| 126 |
+
tgt_mask_pil, self.cond_transform, state)
|
| 127 |
+
tgt_mask_img = tgt_mask_img.repeat(3, 1, 1)
|
| 128 |
+
ref_img_vae = self.augmentation(
|
| 129 |
+
ref_img_pil, self.transform, state)
|
| 130 |
+
face_emb = torch.load(face_emb_path)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
sample = {
|
| 134 |
+
"video_dir": video_path,
|
| 135 |
+
"img": tgt_img,
|
| 136 |
+
"tgt_mask": tgt_mask_img,
|
| 137 |
+
"ref_img": ref_img_vae,
|
| 138 |
+
"face_emb": face_emb,
|
| 139 |
+
}
|
| 140 |
+
|
| 141 |
+
return sample
|
| 142 |
+
|
| 143 |
+
def __len__(self):
|
| 144 |
+
return len(self.vid_meta)
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
if __name__ == "__main__":
|
| 148 |
+
data = FaceMaskDataset(img_size=(512, 512))
|
| 149 |
+
train_dataloader = torch.utils.data.DataLoader(
|
| 150 |
+
data, batch_size=4, shuffle=True, num_workers=1
|
| 151 |
+
)
|
| 152 |
+
for step, batch in enumerate(train_dataloader):
|
| 153 |
+
print(batch["tgt_mask"].shape)
|
| 154 |
+
break
|
hallo/datasets/talk_video.py
ADDED
|
@@ -0,0 +1,312 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
"""
|
| 3 |
+
talking_video_dataset.py
|
| 4 |
+
|
| 5 |
+
This module defines the TalkingVideoDataset class, a custom PyTorch dataset
|
| 6 |
+
for handling talking video data. The dataset uses video files, masks, and
|
| 7 |
+
embeddings to prepare data for tasks such as video generation and
|
| 8 |
+
speech-driven video animation.
|
| 9 |
+
|
| 10 |
+
Classes:
|
| 11 |
+
TalkingVideoDataset
|
| 12 |
+
|
| 13 |
+
Dependencies:
|
| 14 |
+
json
|
| 15 |
+
random
|
| 16 |
+
torch
|
| 17 |
+
decord.VideoReader, decord.cpu
|
| 18 |
+
PIL.Image
|
| 19 |
+
torch.utils.data.Dataset
|
| 20 |
+
torchvision.transforms
|
| 21 |
+
|
| 22 |
+
Example:
|
| 23 |
+
from talking_video_dataset import TalkingVideoDataset
|
| 24 |
+
from torch.utils.data import DataLoader
|
| 25 |
+
|
| 26 |
+
# Example configuration for the Wav2Vec model
|
| 27 |
+
class Wav2VecConfig:
|
| 28 |
+
def __init__(self, audio_type, model_scale, features):
|
| 29 |
+
self.audio_type = audio_type
|
| 30 |
+
self.model_scale = model_scale
|
| 31 |
+
self.features = features
|
| 32 |
+
|
| 33 |
+
wav2vec_cfg = Wav2VecConfig(audio_type="wav2vec2", model_scale="base", features="feature")
|
| 34 |
+
|
| 35 |
+
# Initialize dataset
|
| 36 |
+
dataset = TalkingVideoDataset(
|
| 37 |
+
img_size=(512, 512),
|
| 38 |
+
sample_rate=16000,
|
| 39 |
+
audio_margin=2,
|
| 40 |
+
n_motion_frames=0,
|
| 41 |
+
n_sample_frames=16,
|
| 42 |
+
data_meta_paths=["path/to/meta1.json", "path/to/meta2.json"],
|
| 43 |
+
wav2vec_cfg=wav2vec_cfg,
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
# Initialize dataloader
|
| 47 |
+
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
|
| 48 |
+
|
| 49 |
+
# Fetch one batch of data
|
| 50 |
+
batch = next(iter(dataloader))
|
| 51 |
+
print(batch["pixel_values_vid"].shape) # Example output: (4, 16, 3, 512, 512)
|
| 52 |
+
|
| 53 |
+
The TalkingVideoDataset class provides methods for loading video frames, masks,
|
| 54 |
+
audio embeddings, and other relevant data, applying transformations, and preparing
|
| 55 |
+
the data for training and evaluation in a deep learning pipeline.
|
| 56 |
+
|
| 57 |
+
Attributes:
|
| 58 |
+
img_size (tuple): The dimensions to resize the video frames to.
|
| 59 |
+
sample_rate (int): The audio sample rate.
|
| 60 |
+
audio_margin (int): The margin for audio sampling.
|
| 61 |
+
n_motion_frames (int): The number of motion frames.
|
| 62 |
+
n_sample_frames (int): The number of sample frames.
|
| 63 |
+
data_meta_paths (list): List of paths to the JSON metadata files.
|
| 64 |
+
wav2vec_cfg (object): Configuration for the Wav2Vec model.
|
| 65 |
+
|
| 66 |
+
Methods:
|
| 67 |
+
augmentation(images, transform, state=None): Apply transformation to input images.
|
| 68 |
+
__getitem__(index): Get a sample from the dataset at the specified index.
|
| 69 |
+
__len__(): Return the length of the dataset.
|
| 70 |
+
"""
|
| 71 |
+
|
| 72 |
+
import json
|
| 73 |
+
import random
|
| 74 |
+
from typing import List
|
| 75 |
+
|
| 76 |
+
import torch
|
| 77 |
+
from decord import VideoReader, cpu
|
| 78 |
+
from PIL import Image
|
| 79 |
+
from torch.utils.data import Dataset
|
| 80 |
+
from torchvision import transforms
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
class TalkingVideoDataset(Dataset):
|
| 84 |
+
"""
|
| 85 |
+
A dataset class for processing talking video data.
|
| 86 |
+
|
| 87 |
+
Args:
|
| 88 |
+
img_size (tuple, optional): The size of the output images. Defaults to (512, 512).
|
| 89 |
+
sample_rate (int, optional): The sample rate of the audio data. Defaults to 16000.
|
| 90 |
+
audio_margin (int, optional): The margin for the audio data. Defaults to 2.
|
| 91 |
+
n_motion_frames (int, optional): The number of motion frames. Defaults to 0.
|
| 92 |
+
n_sample_frames (int, optional): The number of sample frames. Defaults to 16.
|
| 93 |
+
data_meta_paths (list, optional): The paths to the data metadata. Defaults to None.
|
| 94 |
+
wav2vec_cfg (dict, optional): The configuration for the wav2vec model. Defaults to None.
|
| 95 |
+
|
| 96 |
+
Attributes:
|
| 97 |
+
img_size (tuple): The size of the output images.
|
| 98 |
+
sample_rate (int): The sample rate of the audio data.
|
| 99 |
+
audio_margin (int): The margin for the audio data.
|
| 100 |
+
n_motion_frames (int): The number of motion frames.
|
| 101 |
+
n_sample_frames (int): The number of sample frames.
|
| 102 |
+
data_meta_paths (list): The paths to the data metadata.
|
| 103 |
+
wav2vec_cfg (dict): The configuration for the wav2vec model.
|
| 104 |
+
"""
|
| 105 |
+
|
| 106 |
+
def __init__(
|
| 107 |
+
self,
|
| 108 |
+
img_size=(512, 512),
|
| 109 |
+
sample_rate=16000,
|
| 110 |
+
audio_margin=2,
|
| 111 |
+
n_motion_frames=0,
|
| 112 |
+
n_sample_frames=16,
|
| 113 |
+
data_meta_paths=None,
|
| 114 |
+
wav2vec_cfg=None,
|
| 115 |
+
):
|
| 116 |
+
super().__init__()
|
| 117 |
+
self.sample_rate = sample_rate
|
| 118 |
+
self.img_size = img_size
|
| 119 |
+
self.audio_margin = audio_margin
|
| 120 |
+
self.n_motion_frames = n_motion_frames
|
| 121 |
+
self.n_sample_frames = n_sample_frames
|
| 122 |
+
self.audio_type = wav2vec_cfg.audio_type
|
| 123 |
+
self.audio_model = wav2vec_cfg.model_scale
|
| 124 |
+
self.audio_features = wav2vec_cfg.features
|
| 125 |
+
|
| 126 |
+
vid_meta = []
|
| 127 |
+
for data_meta_path in data_meta_paths:
|
| 128 |
+
with open(data_meta_path, "r", encoding="utf-8") as f:
|
| 129 |
+
vid_meta.extend(json.load(f))
|
| 130 |
+
self.vid_meta = vid_meta
|
| 131 |
+
self.length = len(self.vid_meta)
|
| 132 |
+
self.pixel_transform = transforms.Compose(
|
| 133 |
+
[
|
| 134 |
+
transforms.Resize(self.img_size),
|
| 135 |
+
transforms.ToTensor(),
|
| 136 |
+
transforms.Normalize([0.5], [0.5]),
|
| 137 |
+
]
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
self.cond_transform = transforms.Compose(
|
| 141 |
+
[
|
| 142 |
+
transforms.Resize(self.img_size),
|
| 143 |
+
transforms.ToTensor(),
|
| 144 |
+
]
|
| 145 |
+
)
|
| 146 |
+
self.attn_transform_64 = transforms.Compose(
|
| 147 |
+
[
|
| 148 |
+
transforms.Resize((64,64)),
|
| 149 |
+
transforms.ToTensor(),
|
| 150 |
+
]
|
| 151 |
+
)
|
| 152 |
+
self.attn_transform_32 = transforms.Compose(
|
| 153 |
+
[
|
| 154 |
+
transforms.Resize((32, 32)),
|
| 155 |
+
transforms.ToTensor(),
|
| 156 |
+
]
|
| 157 |
+
)
|
| 158 |
+
self.attn_transform_16 = transforms.Compose(
|
| 159 |
+
[
|
| 160 |
+
transforms.Resize((16, 16)),
|
| 161 |
+
transforms.ToTensor(),
|
| 162 |
+
]
|
| 163 |
+
)
|
| 164 |
+
self.attn_transform_8 = transforms.Compose(
|
| 165 |
+
[
|
| 166 |
+
transforms.Resize((8, 8)),
|
| 167 |
+
transforms.ToTensor(),
|
| 168 |
+
]
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
def augmentation(self, images, transform, state=None):
|
| 172 |
+
"""
|
| 173 |
+
Apply the given transformation to the input images.
|
| 174 |
+
|
| 175 |
+
Args:
|
| 176 |
+
images (List[PIL.Image] or PIL.Image): The input images to be transformed.
|
| 177 |
+
transform (torchvision.transforms.Compose): The transformation to be applied to the images.
|
| 178 |
+
state (torch.ByteTensor, optional): The state of the random number generator.
|
| 179 |
+
If provided, it will set the RNG state to this value before applying the transformation. Defaults to None.
|
| 180 |
+
|
| 181 |
+
Returns:
|
| 182 |
+
torch.Tensor: The transformed images as a tensor.
|
| 183 |
+
If the input was a list of images, the tensor will have shape (f, c, h, w),
|
| 184 |
+
where f is the number of images, c is the number of channels, h is the height, and w is the width.
|
| 185 |
+
If the input was a single image, the tensor will have shape (c, h, w),
|
| 186 |
+
where c is the number of channels, h is the height, and w is the width.
|
| 187 |
+
"""
|
| 188 |
+
if state is not None:
|
| 189 |
+
torch.set_rng_state(state)
|
| 190 |
+
if isinstance(images, List):
|
| 191 |
+
transformed_images = [transform(img) for img in images]
|
| 192 |
+
ret_tensor = torch.stack(transformed_images, dim=0) # (f, c, h, w)
|
| 193 |
+
else:
|
| 194 |
+
ret_tensor = transform(images) # (c, h, w)
|
| 195 |
+
return ret_tensor
|
| 196 |
+
|
| 197 |
+
def __getitem__(self, index):
|
| 198 |
+
video_meta = self.vid_meta[index]
|
| 199 |
+
video_path = video_meta["video_path"]
|
| 200 |
+
mask_path = video_meta["mask_path"]
|
| 201 |
+
lip_mask_union_path = video_meta.get("sep_mask_lip", None)
|
| 202 |
+
face_mask_union_path = video_meta.get("sep_mask_face", None)
|
| 203 |
+
full_mask_union_path = video_meta.get("sep_mask_border", None)
|
| 204 |
+
face_emb_path = video_meta["face_emb_path"]
|
| 205 |
+
audio_emb_path = video_meta[
|
| 206 |
+
f"{self.audio_type}_emb_{self.audio_model}_{self.audio_features}"
|
| 207 |
+
]
|
| 208 |
+
tgt_mask_pil = Image.open(mask_path)
|
| 209 |
+
video_frames = VideoReader(video_path, ctx=cpu(0))
|
| 210 |
+
assert tgt_mask_pil is not None, "Fail to load target mask."
|
| 211 |
+
assert (video_frames is not None and len(video_frames) > 0), "Fail to load video frames."
|
| 212 |
+
video_length = len(video_frames)
|
| 213 |
+
|
| 214 |
+
assert (
|
| 215 |
+
video_length
|
| 216 |
+
> self.n_sample_frames + self.n_motion_frames + 2 * self.audio_margin
|
| 217 |
+
)
|
| 218 |
+
start_idx = random.randint(
|
| 219 |
+
self.n_motion_frames,
|
| 220 |
+
video_length - self.n_sample_frames - self.audio_margin - 1,
|
| 221 |
+
)
|
| 222 |
+
|
| 223 |
+
videos = video_frames[start_idx : start_idx + self.n_sample_frames]
|
| 224 |
+
|
| 225 |
+
frame_list = [
|
| 226 |
+
Image.fromarray(video).convert("RGB") for video in videos.asnumpy()
|
| 227 |
+
]
|
| 228 |
+
|
| 229 |
+
face_masks_list = [Image.open(face_mask_union_path)] * self.n_sample_frames
|
| 230 |
+
lip_masks_list = [Image.open(lip_mask_union_path)] * self.n_sample_frames
|
| 231 |
+
full_masks_list = [Image.open(full_mask_union_path)] * self.n_sample_frames
|
| 232 |
+
assert face_masks_list[0] is not None, "Fail to load face mask."
|
| 233 |
+
assert lip_masks_list[0] is not None, "Fail to load lip mask."
|
| 234 |
+
assert full_masks_list[0] is not None, "Fail to load full mask."
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
face_emb = torch.load(face_emb_path)
|
| 238 |
+
audio_emb = torch.load(audio_emb_path)
|
| 239 |
+
indices = (
|
| 240 |
+
torch.arange(2 * self.audio_margin + 1) - self.audio_margin
|
| 241 |
+
) # Generates [-2, -1, 0, 1, 2]
|
| 242 |
+
center_indices = torch.arange(
|
| 243 |
+
start_idx,
|
| 244 |
+
start_idx + self.n_sample_frames,
|
| 245 |
+
).unsqueeze(1) + indices.unsqueeze(0)
|
| 246 |
+
audio_tensor = audio_emb[center_indices]
|
| 247 |
+
|
| 248 |
+
ref_img_idx = random.randint(
|
| 249 |
+
self.n_motion_frames,
|
| 250 |
+
video_length - self.n_sample_frames - self.audio_margin - 1,
|
| 251 |
+
)
|
| 252 |
+
ref_img = video_frames[ref_img_idx].asnumpy()
|
| 253 |
+
ref_img = Image.fromarray(ref_img)
|
| 254 |
+
|
| 255 |
+
if self.n_motion_frames > 0:
|
| 256 |
+
motions = video_frames[start_idx - self.n_motion_frames : start_idx]
|
| 257 |
+
motion_list = [
|
| 258 |
+
Image.fromarray(motion).convert("RGB") for motion in motions.asnumpy()
|
| 259 |
+
]
|
| 260 |
+
|
| 261 |
+
# transform
|
| 262 |
+
state = torch.get_rng_state()
|
| 263 |
+
pixel_values_vid = self.augmentation(frame_list, self.pixel_transform, state)
|
| 264 |
+
|
| 265 |
+
pixel_values_mask = self.augmentation(tgt_mask_pil, self.cond_transform, state)
|
| 266 |
+
pixel_values_mask = pixel_values_mask.repeat(3, 1, 1)
|
| 267 |
+
|
| 268 |
+
pixel_values_face_mask = [
|
| 269 |
+
self.augmentation(face_masks_list, self.attn_transform_64, state),
|
| 270 |
+
self.augmentation(face_masks_list, self.attn_transform_32, state),
|
| 271 |
+
self.augmentation(face_masks_list, self.attn_transform_16, state),
|
| 272 |
+
self.augmentation(face_masks_list, self.attn_transform_8, state),
|
| 273 |
+
]
|
| 274 |
+
pixel_values_lip_mask = [
|
| 275 |
+
self.augmentation(lip_masks_list, self.attn_transform_64, state),
|
| 276 |
+
self.augmentation(lip_masks_list, self.attn_transform_32, state),
|
| 277 |
+
self.augmentation(lip_masks_list, self.attn_transform_16, state),
|
| 278 |
+
self.augmentation(lip_masks_list, self.attn_transform_8, state),
|
| 279 |
+
]
|
| 280 |
+
pixel_values_full_mask = [
|
| 281 |
+
self.augmentation(full_masks_list, self.attn_transform_64, state),
|
| 282 |
+
self.augmentation(full_masks_list, self.attn_transform_32, state),
|
| 283 |
+
self.augmentation(full_masks_list, self.attn_transform_16, state),
|
| 284 |
+
self.augmentation(full_masks_list, self.attn_transform_8, state),
|
| 285 |
+
]
|
| 286 |
+
|
| 287 |
+
pixel_values_ref_img = self.augmentation(ref_img, self.pixel_transform, state)
|
| 288 |
+
pixel_values_ref_img = pixel_values_ref_img.unsqueeze(0)
|
| 289 |
+
if self.n_motion_frames > 0:
|
| 290 |
+
pixel_values_motion = self.augmentation(
|
| 291 |
+
motion_list, self.pixel_transform, state
|
| 292 |
+
)
|
| 293 |
+
pixel_values_ref_img = torch.cat(
|
| 294 |
+
[pixel_values_ref_img, pixel_values_motion], dim=0
|
| 295 |
+
)
|
| 296 |
+
|
| 297 |
+
sample = {
|
| 298 |
+
"video_dir": video_path,
|
| 299 |
+
"pixel_values_vid": pixel_values_vid,
|
| 300 |
+
"pixel_values_mask": pixel_values_mask,
|
| 301 |
+
"pixel_values_face_mask": pixel_values_face_mask,
|
| 302 |
+
"pixel_values_lip_mask": pixel_values_lip_mask,
|
| 303 |
+
"pixel_values_full_mask": pixel_values_full_mask,
|
| 304 |
+
"audio_tensor": audio_tensor,
|
| 305 |
+
"pixel_values_ref_img": pixel_values_ref_img,
|
| 306 |
+
"face_emb": face_emb,
|
| 307 |
+
}
|
| 308 |
+
|
| 309 |
+
return sample
|
| 310 |
+
|
| 311 |
+
def __len__(self):
|
| 312 |
+
return len(self.vid_meta)
|
hallo/models/__init__.py
ADDED
|
File without changes
|
hallo/models/attention.py
ADDED
|
@@ -0,0 +1,921 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
# pylint: disable=C0303
|
| 3 |
+
|
| 4 |
+
"""
|
| 5 |
+
This module contains various transformer blocks for different applications, such as BasicTransformerBlock,
|
| 6 |
+
TemporalBasicTransformerBlock, and AudioTemporalBasicTransformerBlock. These blocks are used in various models,
|
| 7 |
+
such as GLIGEN, UNet, and others. The transformer blocks implement self-attention, cross-attention, feed-forward
|
| 8 |
+
networks, and other related functions.
|
| 9 |
+
|
| 10 |
+
Functions and classes included in this module are:
|
| 11 |
+
- BasicTransformerBlock: A basic transformer block with self-attention, cross-attention, and feed-forward layers.
|
| 12 |
+
- TemporalBasicTransformerBlock: A transformer block with additional temporal attention mechanisms for video data.
|
| 13 |
+
- AudioTemporalBasicTransformerBlock: A transformer block with additional audio-specific mechanisms for audio data.
|
| 14 |
+
- zero_module: A function to zero out the parameters of a given module.
|
| 15 |
+
|
| 16 |
+
For more information on each specific class and function, please refer to the respective docstrings.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
from typing import Any, Dict, List, Optional
|
| 20 |
+
|
| 21 |
+
import torch
|
| 22 |
+
from diffusers.models.attention import (AdaLayerNorm, AdaLayerNormZero,
|
| 23 |
+
Attention, FeedForward)
|
| 24 |
+
from diffusers.models.embeddings import SinusoidalPositionalEmbedding
|
| 25 |
+
from einops import rearrange
|
| 26 |
+
from torch import nn
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class GatedSelfAttentionDense(nn.Module):
|
| 30 |
+
"""
|
| 31 |
+
A gated self-attention dense layer that combines visual features and object features.
|
| 32 |
+
|
| 33 |
+
Parameters:
|
| 34 |
+
query_dim (`int`): The number of channels in the query.
|
| 35 |
+
context_dim (`int`): The number of channels in the context.
|
| 36 |
+
n_heads (`int`): The number of heads to use for attention.
|
| 37 |
+
d_head (`int`): The number of channels in each head.
|
| 38 |
+
"""
|
| 39 |
+
|
| 40 |
+
def __init__(self, query_dim: int, context_dim: int, n_heads: int, d_head: int):
|
| 41 |
+
super().__init__()
|
| 42 |
+
|
| 43 |
+
# we need a linear projection since we need cat visual feature and obj feature
|
| 44 |
+
self.linear = nn.Linear(context_dim, query_dim)
|
| 45 |
+
|
| 46 |
+
self.attn = Attention(query_dim=query_dim, heads=n_heads, dim_head=d_head)
|
| 47 |
+
self.ff = FeedForward(query_dim, activation_fn="geglu")
|
| 48 |
+
|
| 49 |
+
self.norm1 = nn.LayerNorm(query_dim)
|
| 50 |
+
self.norm2 = nn.LayerNorm(query_dim)
|
| 51 |
+
|
| 52 |
+
self.register_parameter("alpha_attn", nn.Parameter(torch.tensor(0.0)))
|
| 53 |
+
self.register_parameter("alpha_dense", nn.Parameter(torch.tensor(0.0)))
|
| 54 |
+
|
| 55 |
+
self.enabled = True
|
| 56 |
+
|
| 57 |
+
def forward(self, x: torch.Tensor, objs: torch.Tensor) -> torch.Tensor:
|
| 58 |
+
"""
|
| 59 |
+
Apply the Gated Self-Attention mechanism to the input tensor `x` and object tensor `objs`.
|
| 60 |
+
|
| 61 |
+
Args:
|
| 62 |
+
x (torch.Tensor): The input tensor.
|
| 63 |
+
objs (torch.Tensor): The object tensor.
|
| 64 |
+
|
| 65 |
+
Returns:
|
| 66 |
+
torch.Tensor: The output tensor after applying Gated Self-Attention.
|
| 67 |
+
"""
|
| 68 |
+
if not self.enabled:
|
| 69 |
+
return x
|
| 70 |
+
|
| 71 |
+
n_visual = x.shape[1]
|
| 72 |
+
objs = self.linear(objs)
|
| 73 |
+
|
| 74 |
+
x = x + self.alpha_attn.tanh() * self.attn(self.norm1(torch.cat([x, objs], dim=1)))[:, :n_visual, :]
|
| 75 |
+
x = x + self.alpha_dense.tanh() * self.ff(self.norm2(x))
|
| 76 |
+
|
| 77 |
+
return x
|
| 78 |
+
|
| 79 |
+
class BasicTransformerBlock(nn.Module):
|
| 80 |
+
r"""
|
| 81 |
+
A basic Transformer block.
|
| 82 |
+
|
| 83 |
+
Parameters:
|
| 84 |
+
dim (`int`): The number of channels in the input and output.
|
| 85 |
+
num_attention_heads (`int`): The number of heads to use for multi-head attention.
|
| 86 |
+
attention_head_dim (`int`): The number of channels in each head.
|
| 87 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 88 |
+
cross_attention_dim (`int`, *optional*): The size of the encoder_hidden_states vector for cross attention.
|
| 89 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
|
| 90 |
+
num_embeds_ada_norm (:
|
| 91 |
+
obj: `int`, *optional*): The number of diffusion steps used during training. See `Transformer2DModel`.
|
| 92 |
+
attention_bias (:
|
| 93 |
+
obj: `bool`, *optional*, defaults to `False`): Configure if the attentions should contain a bias parameter.
|
| 94 |
+
only_cross_attention (`bool`, *optional*):
|
| 95 |
+
Whether to use only cross-attention layers. In this case two cross attention layers are used.
|
| 96 |
+
double_self_attention (`bool`, *optional*):
|
| 97 |
+
Whether to use two self-attention layers. In this case no cross attention layers are used.
|
| 98 |
+
upcast_attention (`bool`, *optional*):
|
| 99 |
+
Whether to upcast the attention computation to float32. This is useful for mixed precision training.
|
| 100 |
+
norm_elementwise_affine (`bool`, *optional*, defaults to `True`):
|
| 101 |
+
Whether to use learnable elementwise affine parameters for normalization.
|
| 102 |
+
norm_type (`str`, *optional*, defaults to `"layer_norm"`):
|
| 103 |
+
The normalization layer to use. Can be `"layer_norm"`, `"ada_norm"` or `"ada_norm_zero"`.
|
| 104 |
+
final_dropout (`bool` *optional*, defaults to False):
|
| 105 |
+
Whether to apply a final dropout after the last feed-forward layer.
|
| 106 |
+
attention_type (`str`, *optional*, defaults to `"default"`):
|
| 107 |
+
The type of attention to use. Can be `"default"` or `"gated"` or `"gated-text-image"`.
|
| 108 |
+
positional_embeddings (`str`, *optional*, defaults to `None`):
|
| 109 |
+
The type of positional embeddings to apply to.
|
| 110 |
+
num_positional_embeddings (`int`, *optional*, defaults to `None`):
|
| 111 |
+
The maximum number of positional embeddings to apply.
|
| 112 |
+
"""
|
| 113 |
+
|
| 114 |
+
def __init__(
|
| 115 |
+
self,
|
| 116 |
+
dim: int,
|
| 117 |
+
num_attention_heads: int,
|
| 118 |
+
attention_head_dim: int,
|
| 119 |
+
dropout=0.0,
|
| 120 |
+
cross_attention_dim: Optional[int] = None,
|
| 121 |
+
activation_fn: str = "geglu",
|
| 122 |
+
num_embeds_ada_norm: Optional[int] = None,
|
| 123 |
+
attention_bias: bool = False,
|
| 124 |
+
only_cross_attention: bool = False,
|
| 125 |
+
double_self_attention: bool = False,
|
| 126 |
+
upcast_attention: bool = False,
|
| 127 |
+
norm_elementwise_affine: bool = True,
|
| 128 |
+
# 'layer_norm', 'ada_norm', 'ada_norm_zero', 'ada_norm_single'
|
| 129 |
+
norm_type: str = "layer_norm",
|
| 130 |
+
norm_eps: float = 1e-5,
|
| 131 |
+
final_dropout: bool = False,
|
| 132 |
+
attention_type: str = "default",
|
| 133 |
+
positional_embeddings: Optional[str] = None,
|
| 134 |
+
num_positional_embeddings: Optional[int] = None,
|
| 135 |
+
):
|
| 136 |
+
super().__init__()
|
| 137 |
+
self.only_cross_attention = only_cross_attention
|
| 138 |
+
|
| 139 |
+
self.use_ada_layer_norm_zero = (
|
| 140 |
+
num_embeds_ada_norm is not None
|
| 141 |
+
) and norm_type == "ada_norm_zero"
|
| 142 |
+
self.use_ada_layer_norm = (
|
| 143 |
+
num_embeds_ada_norm is not None
|
| 144 |
+
) and norm_type == "ada_norm"
|
| 145 |
+
self.use_ada_layer_norm_single = norm_type == "ada_norm_single"
|
| 146 |
+
self.use_layer_norm = norm_type == "layer_norm"
|
| 147 |
+
|
| 148 |
+
if norm_type in ("ada_norm", "ada_norm_zero") and num_embeds_ada_norm is None:
|
| 149 |
+
raise ValueError(
|
| 150 |
+
f"`norm_type` is set to {norm_type}, but `num_embeds_ada_norm` is not defined. Please make sure to"
|
| 151 |
+
f" define `num_embeds_ada_norm` if setting `norm_type` to {norm_type}."
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
if positional_embeddings and (num_positional_embeddings is None):
|
| 155 |
+
raise ValueError(
|
| 156 |
+
"If `positional_embedding` type is defined, `num_positition_embeddings` must also be defined."
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
if positional_embeddings == "sinusoidal":
|
| 160 |
+
self.pos_embed = SinusoidalPositionalEmbedding(
|
| 161 |
+
dim, max_seq_length=num_positional_embeddings
|
| 162 |
+
)
|
| 163 |
+
else:
|
| 164 |
+
self.pos_embed = None
|
| 165 |
+
|
| 166 |
+
# Define 3 blocks. Each block has its own normalization layer.
|
| 167 |
+
# 1. Self-Attn
|
| 168 |
+
if self.use_ada_layer_norm:
|
| 169 |
+
self.norm1 = AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 170 |
+
elif self.use_ada_layer_norm_zero:
|
| 171 |
+
self.norm1 = AdaLayerNormZero(dim, num_embeds_ada_norm)
|
| 172 |
+
else:
|
| 173 |
+
self.norm1 = nn.LayerNorm(
|
| 174 |
+
dim, elementwise_affine=norm_elementwise_affine, eps=norm_eps
|
| 175 |
+
)
|
| 176 |
+
|
| 177 |
+
self.attn1 = Attention(
|
| 178 |
+
query_dim=dim,
|
| 179 |
+
heads=num_attention_heads,
|
| 180 |
+
dim_head=attention_head_dim,
|
| 181 |
+
dropout=dropout,
|
| 182 |
+
bias=attention_bias,
|
| 183 |
+
cross_attention_dim=cross_attention_dim if only_cross_attention else None,
|
| 184 |
+
upcast_attention=upcast_attention,
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
# 2. Cross-Attn
|
| 188 |
+
if cross_attention_dim is not None or double_self_attention:
|
| 189 |
+
# We currently only use AdaLayerNormZero for self attention where there will only be one attention block.
|
| 190 |
+
# I.e. the number of returned modulation chunks from AdaLayerZero would not make sense if returned during
|
| 191 |
+
# the second cross attention block.
|
| 192 |
+
self.norm2 = (
|
| 193 |
+
AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 194 |
+
if self.use_ada_layer_norm
|
| 195 |
+
else nn.LayerNorm(
|
| 196 |
+
dim, elementwise_affine=norm_elementwise_affine, eps=norm_eps
|
| 197 |
+
)
|
| 198 |
+
)
|
| 199 |
+
self.attn2 = Attention(
|
| 200 |
+
query_dim=dim,
|
| 201 |
+
cross_attention_dim=(
|
| 202 |
+
cross_attention_dim if not double_self_attention else None
|
| 203 |
+
),
|
| 204 |
+
heads=num_attention_heads,
|
| 205 |
+
dim_head=attention_head_dim,
|
| 206 |
+
dropout=dropout,
|
| 207 |
+
bias=attention_bias,
|
| 208 |
+
upcast_attention=upcast_attention,
|
| 209 |
+
) # is self-attn if encoder_hidden_states is none
|
| 210 |
+
else:
|
| 211 |
+
self.norm2 = None
|
| 212 |
+
self.attn2 = None
|
| 213 |
+
|
| 214 |
+
# 3. Feed-forward
|
| 215 |
+
if not self.use_ada_layer_norm_single:
|
| 216 |
+
self.norm3 = nn.LayerNorm(
|
| 217 |
+
dim, elementwise_affine=norm_elementwise_affine, eps=norm_eps
|
| 218 |
+
)
|
| 219 |
+
|
| 220 |
+
self.ff = FeedForward(
|
| 221 |
+
dim,
|
| 222 |
+
dropout=dropout,
|
| 223 |
+
activation_fn=activation_fn,
|
| 224 |
+
final_dropout=final_dropout,
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
# 4. Fuser
|
| 228 |
+
if attention_type in {"gated", "gated-text-image"}: # Updated line
|
| 229 |
+
self.fuser = GatedSelfAttentionDense(
|
| 230 |
+
dim, cross_attention_dim, num_attention_heads, attention_head_dim
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
# 5. Scale-shift for PixArt-Alpha.
|
| 234 |
+
if self.use_ada_layer_norm_single:
|
| 235 |
+
self.scale_shift_table = nn.Parameter(
|
| 236 |
+
torch.randn(6, dim) / dim**0.5)
|
| 237 |
+
|
| 238 |
+
# let chunk size default to None
|
| 239 |
+
self._chunk_size = None
|
| 240 |
+
self._chunk_dim = 0
|
| 241 |
+
|
| 242 |
+
def set_chunk_feed_forward(self, chunk_size: Optional[int], dim: int = 0):
|
| 243 |
+
"""
|
| 244 |
+
Sets the chunk size for feed-forward processing in the transformer block.
|
| 245 |
+
|
| 246 |
+
Args:
|
| 247 |
+
chunk_size (Optional[int]): The size of the chunks to process in feed-forward layers.
|
| 248 |
+
If None, the chunk size is set to the maximum possible value.
|
| 249 |
+
dim (int, optional): The dimension along which to split the input tensor into chunks. Defaults to 0.
|
| 250 |
+
|
| 251 |
+
Returns:
|
| 252 |
+
None.
|
| 253 |
+
"""
|
| 254 |
+
self._chunk_size = chunk_size
|
| 255 |
+
self._chunk_dim = dim
|
| 256 |
+
|
| 257 |
+
def forward(
|
| 258 |
+
self,
|
| 259 |
+
hidden_states: torch.FloatTensor,
|
| 260 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 261 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 262 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 263 |
+
timestep: Optional[torch.LongTensor] = None,
|
| 264 |
+
cross_attention_kwargs: Dict[str, Any] = None,
|
| 265 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 266 |
+
) -> torch.FloatTensor:
|
| 267 |
+
"""
|
| 268 |
+
This function defines the forward pass of the BasicTransformerBlock.
|
| 269 |
+
|
| 270 |
+
Args:
|
| 271 |
+
self (BasicTransformerBlock):
|
| 272 |
+
An instance of the BasicTransformerBlock class.
|
| 273 |
+
hidden_states (torch.FloatTensor):
|
| 274 |
+
A tensor containing the hidden states.
|
| 275 |
+
attention_mask (Optional[torch.FloatTensor], optional):
|
| 276 |
+
A tensor containing the attention mask. Defaults to None.
|
| 277 |
+
encoder_hidden_states (Optional[torch.FloatTensor], optional):
|
| 278 |
+
A tensor containing the encoder hidden states. Defaults to None.
|
| 279 |
+
encoder_attention_mask (Optional[torch.FloatTensor], optional):
|
| 280 |
+
A tensor containing the encoder attention mask. Defaults to None.
|
| 281 |
+
timestep (Optional[torch.LongTensor], optional):
|
| 282 |
+
A tensor containing the timesteps. Defaults to None.
|
| 283 |
+
cross_attention_kwargs (Dict[str, Any], optional):
|
| 284 |
+
Additional cross-attention arguments. Defaults to None.
|
| 285 |
+
class_labels (Optional[torch.LongTensor], optional):
|
| 286 |
+
A tensor containing the class labels. Defaults to None.
|
| 287 |
+
|
| 288 |
+
Returns:
|
| 289 |
+
torch.FloatTensor:
|
| 290 |
+
A tensor containing the transformed hidden states.
|
| 291 |
+
"""
|
| 292 |
+
# Notice that normalization is always applied before the real computation in the following blocks.
|
| 293 |
+
# 0. Self-Attention
|
| 294 |
+
batch_size = hidden_states.shape[0]
|
| 295 |
+
|
| 296 |
+
gate_msa = None
|
| 297 |
+
scale_mlp = None
|
| 298 |
+
shift_mlp = None
|
| 299 |
+
gate_mlp = None
|
| 300 |
+
if self.use_ada_layer_norm:
|
| 301 |
+
norm_hidden_states = self.norm1(hidden_states, timestep)
|
| 302 |
+
elif self.use_ada_layer_norm_zero:
|
| 303 |
+
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(
|
| 304 |
+
hidden_states, timestep, class_labels, hidden_dtype=hidden_states.dtype
|
| 305 |
+
)
|
| 306 |
+
elif self.use_layer_norm:
|
| 307 |
+
norm_hidden_states = self.norm1(hidden_states)
|
| 308 |
+
elif self.use_ada_layer_norm_single:
|
| 309 |
+
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = (
|
| 310 |
+
self.scale_shift_table[None] +
|
| 311 |
+
timestep.reshape(batch_size, 6, -1)
|
| 312 |
+
).chunk(6, dim=1)
|
| 313 |
+
norm_hidden_states = self.norm1(hidden_states)
|
| 314 |
+
norm_hidden_states = norm_hidden_states * \
|
| 315 |
+
(1 + scale_msa) + shift_msa
|
| 316 |
+
norm_hidden_states = norm_hidden_states.squeeze(1)
|
| 317 |
+
else:
|
| 318 |
+
raise ValueError("Incorrect norm used")
|
| 319 |
+
|
| 320 |
+
if self.pos_embed is not None:
|
| 321 |
+
norm_hidden_states = self.pos_embed(norm_hidden_states)
|
| 322 |
+
|
| 323 |
+
# 1. Retrieve lora scale.
|
| 324 |
+
lora_scale = (
|
| 325 |
+
cross_attention_kwargs.get("scale", 1.0)
|
| 326 |
+
if cross_attention_kwargs is not None
|
| 327 |
+
else 1.0
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
# 2. Prepare GLIGEN inputs
|
| 331 |
+
cross_attention_kwargs = (
|
| 332 |
+
cross_attention_kwargs.copy() if cross_attention_kwargs is not None else {}
|
| 333 |
+
)
|
| 334 |
+
gligen_kwargs = cross_attention_kwargs.pop("gligen", None)
|
| 335 |
+
|
| 336 |
+
attn_output = self.attn1(
|
| 337 |
+
norm_hidden_states,
|
| 338 |
+
encoder_hidden_states=(
|
| 339 |
+
encoder_hidden_states if self.only_cross_attention else None
|
| 340 |
+
),
|
| 341 |
+
attention_mask=attention_mask,
|
| 342 |
+
**cross_attention_kwargs,
|
| 343 |
+
)
|
| 344 |
+
if self.use_ada_layer_norm_zero:
|
| 345 |
+
attn_output = gate_msa.unsqueeze(1) * attn_output
|
| 346 |
+
elif self.use_ada_layer_norm_single:
|
| 347 |
+
attn_output = gate_msa * attn_output
|
| 348 |
+
|
| 349 |
+
hidden_states = attn_output + hidden_states
|
| 350 |
+
if hidden_states.ndim == 4:
|
| 351 |
+
hidden_states = hidden_states.squeeze(1)
|
| 352 |
+
|
| 353 |
+
# 2.5 GLIGEN Control
|
| 354 |
+
if gligen_kwargs is not None:
|
| 355 |
+
hidden_states = self.fuser(hidden_states, gligen_kwargs["objs"])
|
| 356 |
+
|
| 357 |
+
# 3. Cross-Attention
|
| 358 |
+
if self.attn2 is not None:
|
| 359 |
+
if self.use_ada_layer_norm:
|
| 360 |
+
norm_hidden_states = self.norm2(hidden_states, timestep)
|
| 361 |
+
elif self.use_ada_layer_norm_zero or self.use_layer_norm:
|
| 362 |
+
norm_hidden_states = self.norm2(hidden_states)
|
| 363 |
+
elif self.use_ada_layer_norm_single:
|
| 364 |
+
# For PixArt norm2 isn't applied here:
|
| 365 |
+
# https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L70C1-L76C103
|
| 366 |
+
norm_hidden_states = hidden_states
|
| 367 |
+
else:
|
| 368 |
+
raise ValueError("Incorrect norm")
|
| 369 |
+
|
| 370 |
+
if self.pos_embed is not None and self.use_ada_layer_norm_single is False:
|
| 371 |
+
norm_hidden_states = self.pos_embed(norm_hidden_states)
|
| 372 |
+
|
| 373 |
+
attn_output = self.attn2(
|
| 374 |
+
norm_hidden_states,
|
| 375 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 376 |
+
attention_mask=encoder_attention_mask,
|
| 377 |
+
**cross_attention_kwargs,
|
| 378 |
+
)
|
| 379 |
+
hidden_states = attn_output + hidden_states
|
| 380 |
+
|
| 381 |
+
# 4. Feed-forward
|
| 382 |
+
if not self.use_ada_layer_norm_single:
|
| 383 |
+
norm_hidden_states = self.norm3(hidden_states)
|
| 384 |
+
|
| 385 |
+
if self.use_ada_layer_norm_zero:
|
| 386 |
+
norm_hidden_states = (
|
| 387 |
+
norm_hidden_states *
|
| 388 |
+
(1 + scale_mlp[:, None]) + shift_mlp[:, None]
|
| 389 |
+
)
|
| 390 |
+
|
| 391 |
+
if self.use_ada_layer_norm_single:
|
| 392 |
+
norm_hidden_states = self.norm2(hidden_states)
|
| 393 |
+
norm_hidden_states = norm_hidden_states * \
|
| 394 |
+
(1 + scale_mlp) + shift_mlp
|
| 395 |
+
|
| 396 |
+
ff_output = self.ff(norm_hidden_states, scale=lora_scale)
|
| 397 |
+
|
| 398 |
+
if self.use_ada_layer_norm_zero:
|
| 399 |
+
ff_output = gate_mlp.unsqueeze(1) * ff_output
|
| 400 |
+
elif self.use_ada_layer_norm_single:
|
| 401 |
+
ff_output = gate_mlp * ff_output
|
| 402 |
+
|
| 403 |
+
hidden_states = ff_output + hidden_states
|
| 404 |
+
if hidden_states.ndim == 4:
|
| 405 |
+
hidden_states = hidden_states.squeeze(1)
|
| 406 |
+
|
| 407 |
+
return hidden_states
|
| 408 |
+
|
| 409 |
+
|
| 410 |
+
class TemporalBasicTransformerBlock(nn.Module):
|
| 411 |
+
"""
|
| 412 |
+
A PyTorch module that extends the BasicTransformerBlock to include temporal attention mechanisms.
|
| 413 |
+
This class is particularly useful for video-related tasks where capturing temporal information within the sequence of frames is necessary.
|
| 414 |
+
|
| 415 |
+
Attributes:
|
| 416 |
+
dim (int): The dimension of the input and output embeddings.
|
| 417 |
+
num_attention_heads (int): The number of attention heads in the multi-head self-attention mechanism.
|
| 418 |
+
attention_head_dim (int): The dimension of each attention head.
|
| 419 |
+
dropout (float): The dropout probability for the attention scores.
|
| 420 |
+
cross_attention_dim (Optional[int]): The dimension of the cross-attention mechanism.
|
| 421 |
+
activation_fn (str): The activation function used in the feed-forward layer.
|
| 422 |
+
num_embeds_ada_norm (Optional[int]): The number of embeddings for adaptive normalization.
|
| 423 |
+
attention_bias (bool): If True, uses bias in the attention mechanism.
|
| 424 |
+
only_cross_attention (bool): If True, only uses cross-attention.
|
| 425 |
+
upcast_attention (bool): If True, upcasts the attention mechanism for better performance.
|
| 426 |
+
unet_use_cross_frame_attention (Optional[bool]): If True, uses cross-frame attention in the UNet model.
|
| 427 |
+
unet_use_temporal_attention (Optional[bool]): If True, uses temporal attention in the UNet model.
|
| 428 |
+
"""
|
| 429 |
+
def __init__(
|
| 430 |
+
self,
|
| 431 |
+
dim: int,
|
| 432 |
+
num_attention_heads: int,
|
| 433 |
+
attention_head_dim: int,
|
| 434 |
+
dropout=0.0,
|
| 435 |
+
cross_attention_dim: Optional[int] = None,
|
| 436 |
+
activation_fn: str = "geglu",
|
| 437 |
+
num_embeds_ada_norm: Optional[int] = None,
|
| 438 |
+
attention_bias: bool = False,
|
| 439 |
+
only_cross_attention: bool = False,
|
| 440 |
+
upcast_attention: bool = False,
|
| 441 |
+
unet_use_cross_frame_attention=None,
|
| 442 |
+
unet_use_temporal_attention=None,
|
| 443 |
+
):
|
| 444 |
+
"""
|
| 445 |
+
The TemporalBasicTransformerBlock class is a PyTorch module that extends the BasicTransformerBlock to include temporal attention mechanisms.
|
| 446 |
+
This is particularly useful for video-related tasks, where the model needs to capture the temporal information within the sequence of frames.
|
| 447 |
+
The block consists of self-attention, cross-attention, feed-forward, and temporal attention mechanisms.
|
| 448 |
+
|
| 449 |
+
dim (int): The dimension of the input and output embeddings.
|
| 450 |
+
num_attention_heads (int): The number of attention heads in the multi-head self-attention mechanism.
|
| 451 |
+
attention_head_dim (int): The dimension of each attention head.
|
| 452 |
+
dropout (float, optional): The dropout probability for the attention scores. Defaults to 0.0.
|
| 453 |
+
cross_attention_dim (int, optional): The dimension of the cross-attention mechanism. Defaults to None.
|
| 454 |
+
activation_fn (str, optional): The activation function used in the feed-forward layer. Defaults to "geglu".
|
| 455 |
+
num_embeds_ada_norm (int, optional): The number of embeddings for adaptive normalization. Defaults to None.
|
| 456 |
+
attention_bias (bool, optional): If True, uses bias in the attention mechanism. Defaults to False.
|
| 457 |
+
only_cross_attention (bool, optional): If True, only uses cross-attention. Defaults to False.
|
| 458 |
+
upcast_attention (bool, optional): If True, upcasts the attention mechanism for better performance. Defaults to False.
|
| 459 |
+
unet_use_cross_frame_attention (bool, optional): If True, uses cross-frame attention in the UNet model. Defaults to None.
|
| 460 |
+
unet_use_temporal_attention (bool, optional): If True, uses temporal attention in the UNet model. Defaults to None.
|
| 461 |
+
|
| 462 |
+
Forward method:
|
| 463 |
+
hidden_states (torch.FloatTensor): The input hidden states.
|
| 464 |
+
encoder_hidden_states (torch.FloatTensor, optional): The encoder hidden states. Defaults to None.
|
| 465 |
+
timestep (torch.LongTensor, optional): The current timestep for the transformer model. Defaults to None.
|
| 466 |
+
attention_mask (torch.FloatTensor, optional): The attention mask for the self-attention mechanism. Defaults to None.
|
| 467 |
+
video_length (int, optional): The length of the video sequence. Defaults to None.
|
| 468 |
+
|
| 469 |
+
Returns:
|
| 470 |
+
torch.FloatTensor: The output hidden states after passing through the TemporalBasicTransformerBlock.
|
| 471 |
+
"""
|
| 472 |
+
super().__init__()
|
| 473 |
+
self.only_cross_attention = only_cross_attention
|
| 474 |
+
self.use_ada_layer_norm = num_embeds_ada_norm is not None
|
| 475 |
+
self.unet_use_cross_frame_attention = unet_use_cross_frame_attention
|
| 476 |
+
self.unet_use_temporal_attention = unet_use_temporal_attention
|
| 477 |
+
|
| 478 |
+
# SC-Attn
|
| 479 |
+
self.attn1 = Attention(
|
| 480 |
+
query_dim=dim,
|
| 481 |
+
heads=num_attention_heads,
|
| 482 |
+
dim_head=attention_head_dim,
|
| 483 |
+
dropout=dropout,
|
| 484 |
+
bias=attention_bias,
|
| 485 |
+
upcast_attention=upcast_attention,
|
| 486 |
+
)
|
| 487 |
+
self.norm1 = (
|
| 488 |
+
AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 489 |
+
if self.use_ada_layer_norm
|
| 490 |
+
else nn.LayerNorm(dim)
|
| 491 |
+
)
|
| 492 |
+
|
| 493 |
+
# Cross-Attn
|
| 494 |
+
if cross_attention_dim is not None:
|
| 495 |
+
self.attn2 = Attention(
|
| 496 |
+
query_dim=dim,
|
| 497 |
+
cross_attention_dim=cross_attention_dim,
|
| 498 |
+
heads=num_attention_heads,
|
| 499 |
+
dim_head=attention_head_dim,
|
| 500 |
+
dropout=dropout,
|
| 501 |
+
bias=attention_bias,
|
| 502 |
+
upcast_attention=upcast_attention,
|
| 503 |
+
)
|
| 504 |
+
else:
|
| 505 |
+
self.attn2 = None
|
| 506 |
+
|
| 507 |
+
if cross_attention_dim is not None:
|
| 508 |
+
self.norm2 = (
|
| 509 |
+
AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 510 |
+
if self.use_ada_layer_norm
|
| 511 |
+
else nn.LayerNorm(dim)
|
| 512 |
+
)
|
| 513 |
+
else:
|
| 514 |
+
self.norm2 = None
|
| 515 |
+
|
| 516 |
+
# Feed-forward
|
| 517 |
+
self.ff = FeedForward(dim, dropout=dropout,
|
| 518 |
+
activation_fn=activation_fn)
|
| 519 |
+
self.norm3 = nn.LayerNorm(dim)
|
| 520 |
+
self.use_ada_layer_norm_zero = False
|
| 521 |
+
|
| 522 |
+
# Temp-Attn
|
| 523 |
+
# assert unet_use_temporal_attention is not None
|
| 524 |
+
if unet_use_temporal_attention is None:
|
| 525 |
+
unet_use_temporal_attention = False
|
| 526 |
+
if unet_use_temporal_attention:
|
| 527 |
+
self.attn_temp = Attention(
|
| 528 |
+
query_dim=dim,
|
| 529 |
+
heads=num_attention_heads,
|
| 530 |
+
dim_head=attention_head_dim,
|
| 531 |
+
dropout=dropout,
|
| 532 |
+
bias=attention_bias,
|
| 533 |
+
upcast_attention=upcast_attention,
|
| 534 |
+
)
|
| 535 |
+
nn.init.zeros_(self.attn_temp.to_out[0].weight.data)
|
| 536 |
+
self.norm_temp = (
|
| 537 |
+
AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 538 |
+
if self.use_ada_layer_norm
|
| 539 |
+
else nn.LayerNorm(dim)
|
| 540 |
+
)
|
| 541 |
+
|
| 542 |
+
def forward(
|
| 543 |
+
self,
|
| 544 |
+
hidden_states,
|
| 545 |
+
encoder_hidden_states=None,
|
| 546 |
+
timestep=None,
|
| 547 |
+
attention_mask=None,
|
| 548 |
+
video_length=None,
|
| 549 |
+
):
|
| 550 |
+
"""
|
| 551 |
+
Forward pass for the TemporalBasicTransformerBlock.
|
| 552 |
+
|
| 553 |
+
Args:
|
| 554 |
+
hidden_states (torch.FloatTensor): The input hidden states with shape (batch_size, seq_len, dim).
|
| 555 |
+
encoder_hidden_states (torch.FloatTensor, optional): The encoder hidden states with shape (batch_size, src_seq_len, dim).
|
| 556 |
+
timestep (torch.LongTensor, optional): The timestep for the transformer block.
|
| 557 |
+
attention_mask (torch.FloatTensor, optional): The attention mask with shape (batch_size, seq_len, seq_len).
|
| 558 |
+
video_length (int, optional): The length of the video sequence.
|
| 559 |
+
|
| 560 |
+
Returns:
|
| 561 |
+
torch.FloatTensor: The output tensor after passing through the transformer block with shape (batch_size, seq_len, dim).
|
| 562 |
+
"""
|
| 563 |
+
norm_hidden_states = (
|
| 564 |
+
self.norm1(hidden_states, timestep)
|
| 565 |
+
if self.use_ada_layer_norm
|
| 566 |
+
else self.norm1(hidden_states)
|
| 567 |
+
)
|
| 568 |
+
|
| 569 |
+
if self.unet_use_cross_frame_attention:
|
| 570 |
+
hidden_states = (
|
| 571 |
+
self.attn1(
|
| 572 |
+
norm_hidden_states,
|
| 573 |
+
attention_mask=attention_mask,
|
| 574 |
+
video_length=video_length,
|
| 575 |
+
)
|
| 576 |
+
+ hidden_states
|
| 577 |
+
)
|
| 578 |
+
else:
|
| 579 |
+
hidden_states = (
|
| 580 |
+
self.attn1(norm_hidden_states, attention_mask=attention_mask)
|
| 581 |
+
+ hidden_states
|
| 582 |
+
)
|
| 583 |
+
|
| 584 |
+
if self.attn2 is not None:
|
| 585 |
+
# Cross-Attention
|
| 586 |
+
norm_hidden_states = (
|
| 587 |
+
self.norm2(hidden_states, timestep)
|
| 588 |
+
if self.use_ada_layer_norm
|
| 589 |
+
else self.norm2(hidden_states)
|
| 590 |
+
)
|
| 591 |
+
hidden_states = (
|
| 592 |
+
self.attn2(
|
| 593 |
+
norm_hidden_states,
|
| 594 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 595 |
+
attention_mask=attention_mask,
|
| 596 |
+
)
|
| 597 |
+
+ hidden_states
|
| 598 |
+
)
|
| 599 |
+
|
| 600 |
+
# Feed-forward
|
| 601 |
+
hidden_states = self.ff(self.norm3(hidden_states)) + hidden_states
|
| 602 |
+
|
| 603 |
+
# Temporal-Attention
|
| 604 |
+
if self.unet_use_temporal_attention:
|
| 605 |
+
d = hidden_states.shape[1]
|
| 606 |
+
hidden_states = rearrange(
|
| 607 |
+
hidden_states, "(b f) d c -> (b d) f c", f=video_length
|
| 608 |
+
)
|
| 609 |
+
norm_hidden_states = (
|
| 610 |
+
self.norm_temp(hidden_states, timestep)
|
| 611 |
+
if self.use_ada_layer_norm
|
| 612 |
+
else self.norm_temp(hidden_states)
|
| 613 |
+
)
|
| 614 |
+
hidden_states = self.attn_temp(norm_hidden_states) + hidden_states
|
| 615 |
+
hidden_states = rearrange(
|
| 616 |
+
hidden_states, "(b d) f c -> (b f) d c", d=d)
|
| 617 |
+
|
| 618 |
+
return hidden_states
|
| 619 |
+
|
| 620 |
+
|
| 621 |
+
class AudioTemporalBasicTransformerBlock(nn.Module):
|
| 622 |
+
"""
|
| 623 |
+
A PyTorch module designed to handle audio data within a transformer framework, including temporal attention mechanisms.
|
| 624 |
+
|
| 625 |
+
Attributes:
|
| 626 |
+
dim (int): The dimension of the input and output embeddings.
|
| 627 |
+
num_attention_heads (int): The number of attention heads.
|
| 628 |
+
attention_head_dim (int): The dimension of each attention head.
|
| 629 |
+
dropout (float): The dropout probability.
|
| 630 |
+
cross_attention_dim (Optional[int]): The dimension of the cross-attention mechanism.
|
| 631 |
+
activation_fn (str): The activation function for the feed-forward network.
|
| 632 |
+
num_embeds_ada_norm (Optional[int]): The number of embeddings for adaptive normalization.
|
| 633 |
+
attention_bias (bool): If True, uses bias in the attention mechanism.
|
| 634 |
+
only_cross_attention (bool): If True, only uses cross-attention.
|
| 635 |
+
upcast_attention (bool): If True, upcasts the attention mechanism to float32.
|
| 636 |
+
unet_use_cross_frame_attention (Optional[bool]): If True, uses cross-frame attention in UNet.
|
| 637 |
+
unet_use_temporal_attention (Optional[bool]): If True, uses temporal attention in UNet.
|
| 638 |
+
depth (int): The depth of the transformer block.
|
| 639 |
+
unet_block_name (Optional[str]): The name of the UNet block.
|
| 640 |
+
stack_enable_blocks_name (Optional[List[str]]): The list of enabled blocks in the stack.
|
| 641 |
+
stack_enable_blocks_depth (Optional[List[int]]): The list of depths for the enabled blocks in the stack.
|
| 642 |
+
"""
|
| 643 |
+
def __init__(
|
| 644 |
+
self,
|
| 645 |
+
dim: int,
|
| 646 |
+
num_attention_heads: int,
|
| 647 |
+
attention_head_dim: int,
|
| 648 |
+
dropout=0.0,
|
| 649 |
+
cross_attention_dim: Optional[int] = None,
|
| 650 |
+
activation_fn: str = "geglu",
|
| 651 |
+
num_embeds_ada_norm: Optional[int] = None,
|
| 652 |
+
attention_bias: bool = False,
|
| 653 |
+
only_cross_attention: bool = False,
|
| 654 |
+
upcast_attention: bool = False,
|
| 655 |
+
unet_use_cross_frame_attention=None,
|
| 656 |
+
unet_use_temporal_attention=None,
|
| 657 |
+
depth=0,
|
| 658 |
+
unet_block_name=None,
|
| 659 |
+
stack_enable_blocks_name: Optional[List[str]] = None,
|
| 660 |
+
stack_enable_blocks_depth: Optional[List[int]] = None,
|
| 661 |
+
):
|
| 662 |
+
"""
|
| 663 |
+
Initializes the AudioTemporalBasicTransformerBlock module.
|
| 664 |
+
|
| 665 |
+
Args:
|
| 666 |
+
dim (int): The dimension of the input and output embeddings.
|
| 667 |
+
num_attention_heads (int): The number of attention heads in the multi-head self-attention mechanism.
|
| 668 |
+
attention_head_dim (int): The dimension of each attention head.
|
| 669 |
+
dropout (float, optional): The dropout probability for the attention mechanism. Defaults to 0.0.
|
| 670 |
+
cross_attention_dim (Optional[int], optional): The dimension of the cross-attention mechanism. Defaults to None.
|
| 671 |
+
activation_fn (str, optional): The activation function to be used in the feed-forward network. Defaults to "geglu".
|
| 672 |
+
num_embeds_ada_norm (Optional[int], optional): The number of embeddings for adaptive normalization. Defaults to None.
|
| 673 |
+
attention_bias (bool, optional): If True, uses bias in the attention mechanism. Defaults to False.
|
| 674 |
+
only_cross_attention (bool, optional): If True, only uses cross-attention. Defaults to False.
|
| 675 |
+
upcast_attention (bool, optional): If True, upcasts the attention mechanism to float32. Defaults to False.
|
| 676 |
+
unet_use_cross_frame_attention (Optional[bool], optional): If True, uses cross-frame attention in UNet. Defaults to None.
|
| 677 |
+
unet_use_temporal_attention (Optional[bool], optional): If True, uses temporal attention in UNet. Defaults to None.
|
| 678 |
+
depth (int, optional): The depth of the transformer block. Defaults to 0.
|
| 679 |
+
unet_block_name (Optional[str], optional): The name of the UNet block. Defaults to None.
|
| 680 |
+
stack_enable_blocks_name (Optional[List[str]], optional): The list of enabled blocks in the stack. Defaults to None.
|
| 681 |
+
stack_enable_blocks_depth (Optional[List[int]], optional): The list of depths for the enabled blocks in the stack. Defaults to None.
|
| 682 |
+
"""
|
| 683 |
+
super().__init__()
|
| 684 |
+
self.only_cross_attention = only_cross_attention
|
| 685 |
+
self.use_ada_layer_norm = num_embeds_ada_norm is not None
|
| 686 |
+
self.unet_use_cross_frame_attention = unet_use_cross_frame_attention
|
| 687 |
+
self.unet_use_temporal_attention = unet_use_temporal_attention
|
| 688 |
+
self.unet_block_name = unet_block_name
|
| 689 |
+
self.depth = depth
|
| 690 |
+
|
| 691 |
+
zero_conv_full = nn.Conv2d(
|
| 692 |
+
dim, dim, kernel_size=1)
|
| 693 |
+
self.zero_conv_full = zero_module(zero_conv_full)
|
| 694 |
+
|
| 695 |
+
zero_conv_face = nn.Conv2d(
|
| 696 |
+
dim, dim, kernel_size=1)
|
| 697 |
+
self.zero_conv_face = zero_module(zero_conv_face)
|
| 698 |
+
|
| 699 |
+
zero_conv_lip = nn.Conv2d(
|
| 700 |
+
dim, dim, kernel_size=1)
|
| 701 |
+
self.zero_conv_lip = zero_module(zero_conv_lip)
|
| 702 |
+
# SC-Attn
|
| 703 |
+
self.attn1 = Attention(
|
| 704 |
+
query_dim=dim,
|
| 705 |
+
heads=num_attention_heads,
|
| 706 |
+
dim_head=attention_head_dim,
|
| 707 |
+
dropout=dropout,
|
| 708 |
+
bias=attention_bias,
|
| 709 |
+
upcast_attention=upcast_attention,
|
| 710 |
+
)
|
| 711 |
+
self.norm1 = (
|
| 712 |
+
AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 713 |
+
if self.use_ada_layer_norm
|
| 714 |
+
else nn.LayerNorm(dim)
|
| 715 |
+
)
|
| 716 |
+
|
| 717 |
+
# Cross-Attn
|
| 718 |
+
if cross_attention_dim is not None:
|
| 719 |
+
if (stack_enable_blocks_name is not None and
|
| 720 |
+
stack_enable_blocks_depth is not None and
|
| 721 |
+
self.unet_block_name in stack_enable_blocks_name and
|
| 722 |
+
self.depth in stack_enable_blocks_depth):
|
| 723 |
+
self.attn2_0 = Attention(
|
| 724 |
+
query_dim=dim,
|
| 725 |
+
cross_attention_dim=cross_attention_dim,
|
| 726 |
+
heads=num_attention_heads,
|
| 727 |
+
dim_head=attention_head_dim,
|
| 728 |
+
dropout=dropout,
|
| 729 |
+
bias=attention_bias,
|
| 730 |
+
upcast_attention=upcast_attention,
|
| 731 |
+
)
|
| 732 |
+
self.attn2_1 = Attention(
|
| 733 |
+
query_dim=dim,
|
| 734 |
+
cross_attention_dim=cross_attention_dim,
|
| 735 |
+
heads=num_attention_heads,
|
| 736 |
+
dim_head=attention_head_dim,
|
| 737 |
+
dropout=dropout,
|
| 738 |
+
bias=attention_bias,
|
| 739 |
+
upcast_attention=upcast_attention,
|
| 740 |
+
)
|
| 741 |
+
self.attn2_2 = Attention(
|
| 742 |
+
query_dim=dim,
|
| 743 |
+
cross_attention_dim=cross_attention_dim,
|
| 744 |
+
heads=num_attention_heads,
|
| 745 |
+
dim_head=attention_head_dim,
|
| 746 |
+
dropout=dropout,
|
| 747 |
+
bias=attention_bias,
|
| 748 |
+
upcast_attention=upcast_attention,
|
| 749 |
+
)
|
| 750 |
+
self.attn2 = None
|
| 751 |
+
|
| 752 |
+
else:
|
| 753 |
+
self.attn2 = Attention(
|
| 754 |
+
query_dim=dim,
|
| 755 |
+
cross_attention_dim=cross_attention_dim,
|
| 756 |
+
heads=num_attention_heads,
|
| 757 |
+
dim_head=attention_head_dim,
|
| 758 |
+
dropout=dropout,
|
| 759 |
+
bias=attention_bias,
|
| 760 |
+
upcast_attention=upcast_attention,
|
| 761 |
+
)
|
| 762 |
+
self.attn2_0=None
|
| 763 |
+
else:
|
| 764 |
+
self.attn2 = None
|
| 765 |
+
self.attn2_0 = None
|
| 766 |
+
|
| 767 |
+
if cross_attention_dim is not None:
|
| 768 |
+
self.norm2 = (
|
| 769 |
+
AdaLayerNorm(dim, num_embeds_ada_norm)
|
| 770 |
+
if self.use_ada_layer_norm
|
| 771 |
+
else nn.LayerNorm(dim)
|
| 772 |
+
)
|
| 773 |
+
else:
|
| 774 |
+
self.norm2 = None
|
| 775 |
+
|
| 776 |
+
# Feed-forward
|
| 777 |
+
self.ff = FeedForward(dim, dropout=dropout,
|
| 778 |
+
activation_fn=activation_fn)
|
| 779 |
+
self.norm3 = nn.LayerNorm(dim)
|
| 780 |
+
self.use_ada_layer_norm_zero = False
|
| 781 |
+
|
| 782 |
+
|
| 783 |
+
|
| 784 |
+
def forward(
|
| 785 |
+
self,
|
| 786 |
+
hidden_states,
|
| 787 |
+
encoder_hidden_states=None,
|
| 788 |
+
timestep=None,
|
| 789 |
+
attention_mask=None,
|
| 790 |
+
full_mask=None,
|
| 791 |
+
face_mask=None,
|
| 792 |
+
lip_mask=None,
|
| 793 |
+
motion_scale=None,
|
| 794 |
+
video_length=None,
|
| 795 |
+
):
|
| 796 |
+
"""
|
| 797 |
+
Forward pass for the AudioTemporalBasicTransformerBlock.
|
| 798 |
+
|
| 799 |
+
Args:
|
| 800 |
+
hidden_states (torch.FloatTensor): The input hidden states.
|
| 801 |
+
encoder_hidden_states (torch.FloatTensor, optional): The encoder hidden states. Defaults to None.
|
| 802 |
+
timestep (torch.LongTensor, optional): The timestep for the transformer block. Defaults to None.
|
| 803 |
+
attention_mask (torch.FloatTensor, optional): The attention mask. Defaults to None.
|
| 804 |
+
full_mask (torch.FloatTensor, optional): The full mask. Defaults to None.
|
| 805 |
+
face_mask (torch.FloatTensor, optional): The face mask. Defaults to None.
|
| 806 |
+
lip_mask (torch.FloatTensor, optional): The lip mask. Defaults to None.
|
| 807 |
+
video_length (int, optional): The length of the video. Defaults to None.
|
| 808 |
+
|
| 809 |
+
Returns:
|
| 810 |
+
torch.FloatTensor: The output tensor after passing through the AudioTemporalBasicTransformerBlock.
|
| 811 |
+
"""
|
| 812 |
+
norm_hidden_states = (
|
| 813 |
+
self.norm1(hidden_states, timestep)
|
| 814 |
+
if self.use_ada_layer_norm
|
| 815 |
+
else self.norm1(hidden_states)
|
| 816 |
+
)
|
| 817 |
+
|
| 818 |
+
if self.unet_use_cross_frame_attention:
|
| 819 |
+
hidden_states = (
|
| 820 |
+
self.attn1(
|
| 821 |
+
norm_hidden_states,
|
| 822 |
+
attention_mask=attention_mask,
|
| 823 |
+
video_length=video_length,
|
| 824 |
+
)
|
| 825 |
+
+ hidden_states
|
| 826 |
+
)
|
| 827 |
+
else:
|
| 828 |
+
hidden_states = (
|
| 829 |
+
self.attn1(norm_hidden_states, attention_mask=attention_mask)
|
| 830 |
+
+ hidden_states
|
| 831 |
+
)
|
| 832 |
+
|
| 833 |
+
if self.attn2 is not None:
|
| 834 |
+
# Cross-Attention
|
| 835 |
+
norm_hidden_states = (
|
| 836 |
+
self.norm2(hidden_states, timestep)
|
| 837 |
+
if self.use_ada_layer_norm
|
| 838 |
+
else self.norm2(hidden_states)
|
| 839 |
+
)
|
| 840 |
+
hidden_states = self.attn2(
|
| 841 |
+
norm_hidden_states,
|
| 842 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 843 |
+
attention_mask=attention_mask,
|
| 844 |
+
) + hidden_states
|
| 845 |
+
|
| 846 |
+
elif self.attn2_0 is not None:
|
| 847 |
+
norm_hidden_states = (
|
| 848 |
+
self.norm2(hidden_states, timestep)
|
| 849 |
+
if self.use_ada_layer_norm
|
| 850 |
+
else self.norm2(hidden_states)
|
| 851 |
+
)
|
| 852 |
+
|
| 853 |
+
level = self.depth
|
| 854 |
+
full_hidden_states = (
|
| 855 |
+
self.attn2_0(
|
| 856 |
+
norm_hidden_states,
|
| 857 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 858 |
+
attention_mask=attention_mask,
|
| 859 |
+
) * full_mask[level][:, :, None]
|
| 860 |
+
)
|
| 861 |
+
bz, sz, c = full_hidden_states.shape
|
| 862 |
+
sz_sqrt = int(sz ** 0.5)
|
| 863 |
+
full_hidden_states = full_hidden_states.reshape(
|
| 864 |
+
bz, sz_sqrt, sz_sqrt, c).permute(0, 3, 1, 2)
|
| 865 |
+
full_hidden_states = self.zero_conv_full(full_hidden_states).permute(0, 2, 3, 1).reshape(bz, -1, c)
|
| 866 |
+
|
| 867 |
+
face_hidden_state = (
|
| 868 |
+
self.attn2_1(
|
| 869 |
+
norm_hidden_states,
|
| 870 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 871 |
+
attention_mask=attention_mask,
|
| 872 |
+
) * face_mask[level][:, :, None]
|
| 873 |
+
)
|
| 874 |
+
face_hidden_state = face_hidden_state.reshape(
|
| 875 |
+
bz, sz_sqrt, sz_sqrt, c).permute(0, 3, 1, 2)
|
| 876 |
+
face_hidden_state = self.zero_conv_face(
|
| 877 |
+
face_hidden_state).permute(0, 2, 3, 1).reshape(bz, -1, c)
|
| 878 |
+
|
| 879 |
+
lip_hidden_state = (
|
| 880 |
+
self.attn2_2(
|
| 881 |
+
norm_hidden_states,
|
| 882 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 883 |
+
attention_mask=attention_mask,
|
| 884 |
+
) * lip_mask[level][:, :, None]
|
| 885 |
+
|
| 886 |
+
) # [32, 4096, 320]
|
| 887 |
+
lip_hidden_state = lip_hidden_state.reshape(
|
| 888 |
+
bz, sz_sqrt, sz_sqrt, c).permute(0, 3, 1, 2)
|
| 889 |
+
lip_hidden_state = self.zero_conv_lip(
|
| 890 |
+
lip_hidden_state).permute(0, 2, 3, 1).reshape(bz, -1, c)
|
| 891 |
+
|
| 892 |
+
if motion_scale is not None:
|
| 893 |
+
hidden_states = (
|
| 894 |
+
motion_scale[0] * full_hidden_states +
|
| 895 |
+
motion_scale[1] * face_hidden_state +
|
| 896 |
+
motion_scale[2] * lip_hidden_state + hidden_states
|
| 897 |
+
)
|
| 898 |
+
else:
|
| 899 |
+
hidden_states = (
|
| 900 |
+
full_hidden_states +
|
| 901 |
+
face_hidden_state +
|
| 902 |
+
lip_hidden_state + hidden_states
|
| 903 |
+
)
|
| 904 |
+
# Feed-forward
|
| 905 |
+
hidden_states = self.ff(self.norm3(hidden_states)) + hidden_states
|
| 906 |
+
|
| 907 |
+
return hidden_states
|
| 908 |
+
|
| 909 |
+
def zero_module(module):
|
| 910 |
+
"""
|
| 911 |
+
Zeroes out the parameters of a given module.
|
| 912 |
+
|
| 913 |
+
Args:
|
| 914 |
+
module (nn.Module): The module whose parameters need to be zeroed out.
|
| 915 |
+
|
| 916 |
+
Returns:
|
| 917 |
+
None.
|
| 918 |
+
"""
|
| 919 |
+
for p in module.parameters():
|
| 920 |
+
nn.init.zeros_(p)
|
| 921 |
+
return module
|
hallo/models/audio_proj.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This module provides the implementation of an Audio Projection Model, which is designed for
|
| 3 |
+
audio processing tasks. The model takes audio embeddings as input and outputs context tokens
|
| 4 |
+
that can be used for various downstream applications, such as audio analysis or synthesis.
|
| 5 |
+
|
| 6 |
+
The AudioProjModel class is based on the ModelMixin class from the diffusers library, which
|
| 7 |
+
provides a foundation for building custom models. This implementation includes multiple linear
|
| 8 |
+
layers with ReLU activation functions and a LayerNorm for normalization.
|
| 9 |
+
|
| 10 |
+
Key Features:
|
| 11 |
+
- Audio embedding input with flexible sequence length and block structure.
|
| 12 |
+
- Multiple linear layers for feature transformation.
|
| 13 |
+
- ReLU activation for non-linear transformation.
|
| 14 |
+
- LayerNorm for stabilizing and speeding up training.
|
| 15 |
+
- Rearrangement of input embeddings to match the model's expected input shape.
|
| 16 |
+
- Customizable number of blocks, channels, and context tokens for adaptability.
|
| 17 |
+
|
| 18 |
+
The module is structured to be easily integrated into larger systems or used as a standalone
|
| 19 |
+
component for audio feature extraction and processing.
|
| 20 |
+
|
| 21 |
+
Classes:
|
| 22 |
+
- AudioProjModel: A class representing the audio projection model with configurable parameters.
|
| 23 |
+
|
| 24 |
+
Functions:
|
| 25 |
+
- (none)
|
| 26 |
+
|
| 27 |
+
Dependencies:
|
| 28 |
+
- torch: For tensor operations and neural network components.
|
| 29 |
+
- diffusers: For the ModelMixin base class.
|
| 30 |
+
- einops: For tensor rearrangement operations.
|
| 31 |
+
|
| 32 |
+
"""
|
| 33 |
+
|
| 34 |
+
import torch
|
| 35 |
+
from diffusers import ModelMixin
|
| 36 |
+
from einops import rearrange
|
| 37 |
+
from torch import nn
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class AudioProjModel(ModelMixin):
|
| 41 |
+
"""Audio Projection Model
|
| 42 |
+
|
| 43 |
+
This class defines an audio projection model that takes audio embeddings as input
|
| 44 |
+
and produces context tokens as output. The model is based on the ModelMixin class
|
| 45 |
+
and consists of multiple linear layers and activation functions. It can be used
|
| 46 |
+
for various audio processing tasks.
|
| 47 |
+
|
| 48 |
+
Attributes:
|
| 49 |
+
seq_len (int): The length of the audio sequence.
|
| 50 |
+
blocks (int): The number of blocks in the audio projection model.
|
| 51 |
+
channels (int): The number of channels in the audio projection model.
|
| 52 |
+
intermediate_dim (int): The intermediate dimension of the model.
|
| 53 |
+
context_tokens (int): The number of context tokens in the output.
|
| 54 |
+
output_dim (int): The output dimension of the context tokens.
|
| 55 |
+
|
| 56 |
+
Methods:
|
| 57 |
+
__init__(self, seq_len=5, blocks=12, channels=768, intermediate_dim=512, context_tokens=32, output_dim=768):
|
| 58 |
+
Initializes the AudioProjModel with the given parameters.
|
| 59 |
+
forward(self, audio_embeds):
|
| 60 |
+
Defines the forward pass for the AudioProjModel.
|
| 61 |
+
Parameters:
|
| 62 |
+
audio_embeds (torch.Tensor): The input audio embeddings with shape (batch_size, video_length, blocks, channels).
|
| 63 |
+
Returns:
|
| 64 |
+
context_tokens (torch.Tensor): The output context tokens with shape (batch_size, video_length, context_tokens, output_dim).
|
| 65 |
+
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
def __init__(
|
| 69 |
+
self,
|
| 70 |
+
seq_len=5,
|
| 71 |
+
blocks=12, # add a new parameter blocks
|
| 72 |
+
channels=768, # add a new parameter channels
|
| 73 |
+
intermediate_dim=512,
|
| 74 |
+
output_dim=768,
|
| 75 |
+
context_tokens=32,
|
| 76 |
+
):
|
| 77 |
+
super().__init__()
|
| 78 |
+
|
| 79 |
+
self.seq_len = seq_len
|
| 80 |
+
self.blocks = blocks
|
| 81 |
+
self.channels = channels
|
| 82 |
+
self.input_dim = (
|
| 83 |
+
seq_len * blocks * channels
|
| 84 |
+
) # update input_dim to be the product of blocks and channels.
|
| 85 |
+
self.intermediate_dim = intermediate_dim
|
| 86 |
+
self.context_tokens = context_tokens
|
| 87 |
+
self.output_dim = output_dim
|
| 88 |
+
|
| 89 |
+
# define multiple linear layers
|
| 90 |
+
self.proj1 = nn.Linear(self.input_dim, intermediate_dim)
|
| 91 |
+
self.proj2 = nn.Linear(intermediate_dim, intermediate_dim)
|
| 92 |
+
self.proj3 = nn.Linear(intermediate_dim, context_tokens * output_dim)
|
| 93 |
+
|
| 94 |
+
self.norm = nn.LayerNorm(output_dim)
|
| 95 |
+
|
| 96 |
+
def forward(self, audio_embeds):
|
| 97 |
+
"""
|
| 98 |
+
Defines the forward pass for the AudioProjModel.
|
| 99 |
+
|
| 100 |
+
Parameters:
|
| 101 |
+
audio_embeds (torch.Tensor): The input audio embeddings with shape (batch_size, video_length, blocks, channels).
|
| 102 |
+
|
| 103 |
+
Returns:
|
| 104 |
+
context_tokens (torch.Tensor): The output context tokens with shape (batch_size, video_length, context_tokens, output_dim).
|
| 105 |
+
"""
|
| 106 |
+
# merge
|
| 107 |
+
video_length = audio_embeds.shape[1]
|
| 108 |
+
audio_embeds = rearrange(audio_embeds, "bz f w b c -> (bz f) w b c")
|
| 109 |
+
batch_size, window_size, blocks, channels = audio_embeds.shape
|
| 110 |
+
audio_embeds = audio_embeds.view(batch_size, window_size * blocks * channels)
|
| 111 |
+
|
| 112 |
+
audio_embeds = torch.relu(self.proj1(audio_embeds))
|
| 113 |
+
audio_embeds = torch.relu(self.proj2(audio_embeds))
|
| 114 |
+
|
| 115 |
+
context_tokens = self.proj3(audio_embeds).reshape(
|
| 116 |
+
batch_size, self.context_tokens, self.output_dim
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
context_tokens = self.norm(context_tokens)
|
| 120 |
+
context_tokens = rearrange(
|
| 121 |
+
context_tokens, "(bz f) m c -> bz f m c", f=video_length
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
return context_tokens
|
hallo/models/face_locator.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This module implements the FaceLocator class, which is a neural network model designed to
|
| 3 |
+
locate and extract facial features from input images or tensors. It uses a series of
|
| 4 |
+
convolutional layers to progressively downsample and refine the facial feature map.
|
| 5 |
+
|
| 6 |
+
The FaceLocator class is part of a larger system that may involve facial recognition or
|
| 7 |
+
similar tasks where precise location and extraction of facial features are required.
|
| 8 |
+
|
| 9 |
+
Attributes:
|
| 10 |
+
conditioning_embedding_channels (int): The number of channels in the output embedding.
|
| 11 |
+
conditioning_channels (int): The number of input channels for the conditioning tensor.
|
| 12 |
+
block_out_channels (Tuple[int]): A tuple of integers representing the output channels
|
| 13 |
+
for each block in the model.
|
| 14 |
+
|
| 15 |
+
The model uses the following components:
|
| 16 |
+
- InflatedConv3d: A convolutional layer that inflates the input to increase the depth.
|
| 17 |
+
- zero_module: A utility function that may set certain parameters to zero for regularization
|
| 18 |
+
or other purposes.
|
| 19 |
+
|
| 20 |
+
The forward method of the FaceLocator class takes a conditioning tensor as input and
|
| 21 |
+
produces an embedding tensor as output, which can be used for further processing or analysis.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
from typing import Tuple
|
| 25 |
+
|
| 26 |
+
import torch.nn.functional as F
|
| 27 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 28 |
+
from torch import nn
|
| 29 |
+
|
| 30 |
+
from .motion_module import zero_module
|
| 31 |
+
from .resnet import InflatedConv3d
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class FaceLocator(ModelMixin):
|
| 35 |
+
"""
|
| 36 |
+
The FaceLocator class is a neural network model designed to process and extract facial
|
| 37 |
+
features from an input tensor. It consists of a series of convolutional layers that
|
| 38 |
+
progressively downsample the input while increasing the depth of the feature map.
|
| 39 |
+
|
| 40 |
+
The model is built using InflatedConv3d layers, which are designed to inflate the
|
| 41 |
+
feature channels, allowing for more complex feature extraction. The final output is a
|
| 42 |
+
conditioning embedding that can be used for various tasks such as facial recognition or
|
| 43 |
+
feature-based image manipulation.
|
| 44 |
+
|
| 45 |
+
Parameters:
|
| 46 |
+
conditioning_embedding_channels (int): The number of channels in the output embedding.
|
| 47 |
+
conditioning_channels (int, optional): The number of input channels for the conditioning tensor. Default is 3.
|
| 48 |
+
block_out_channels (Tuple[int], optional): A tuple of integers representing the output channels
|
| 49 |
+
for each block in the model. The default is (16, 32, 64, 128), which defines the
|
| 50 |
+
progression of the network's depth.
|
| 51 |
+
|
| 52 |
+
Attributes:
|
| 53 |
+
conv_in (InflatedConv3d): The initial convolutional layer that starts the feature extraction process.
|
| 54 |
+
blocks (ModuleList[InflatedConv3d]): A list of convolutional layers that form the core of the model.
|
| 55 |
+
conv_out (InflatedConv3d): The final convolutional layer that produces the output embedding.
|
| 56 |
+
|
| 57 |
+
The forward method applies the convolutional layers to the input conditioning tensor and
|
| 58 |
+
returns the resulting embedding tensor.
|
| 59 |
+
"""
|
| 60 |
+
def __init__(
|
| 61 |
+
self,
|
| 62 |
+
conditioning_embedding_channels: int,
|
| 63 |
+
conditioning_channels: int = 3,
|
| 64 |
+
block_out_channels: Tuple[int] = (16, 32, 64, 128),
|
| 65 |
+
):
|
| 66 |
+
super().__init__()
|
| 67 |
+
self.conv_in = InflatedConv3d(
|
| 68 |
+
conditioning_channels, block_out_channels[0], kernel_size=3, padding=1
|
| 69 |
+
)
|
| 70 |
+
|
| 71 |
+
self.blocks = nn.ModuleList([])
|
| 72 |
+
|
| 73 |
+
for i in range(len(block_out_channels) - 1):
|
| 74 |
+
channel_in = block_out_channels[i]
|
| 75 |
+
channel_out = block_out_channels[i + 1]
|
| 76 |
+
self.blocks.append(
|
| 77 |
+
InflatedConv3d(channel_in, channel_in, kernel_size=3, padding=1)
|
| 78 |
+
)
|
| 79 |
+
self.blocks.append(
|
| 80 |
+
InflatedConv3d(
|
| 81 |
+
channel_in, channel_out, kernel_size=3, padding=1, stride=2
|
| 82 |
+
)
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
self.conv_out = zero_module(
|
| 86 |
+
InflatedConv3d(
|
| 87 |
+
block_out_channels[-1],
|
| 88 |
+
conditioning_embedding_channels,
|
| 89 |
+
kernel_size=3,
|
| 90 |
+
padding=1,
|
| 91 |
+
)
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
def forward(self, conditioning):
|
| 95 |
+
"""
|
| 96 |
+
Forward pass of the FaceLocator model.
|
| 97 |
+
|
| 98 |
+
Args:
|
| 99 |
+
conditioning (Tensor): The input conditioning tensor.
|
| 100 |
+
|
| 101 |
+
Returns:
|
| 102 |
+
Tensor: The output embedding tensor.
|
| 103 |
+
"""
|
| 104 |
+
embedding = self.conv_in(conditioning)
|
| 105 |
+
embedding = F.silu(embedding)
|
| 106 |
+
|
| 107 |
+
for block in self.blocks:
|
| 108 |
+
embedding = block(embedding)
|
| 109 |
+
embedding = F.silu(embedding)
|
| 110 |
+
|
| 111 |
+
embedding = self.conv_out(embedding)
|
| 112 |
+
|
| 113 |
+
return embedding
|
hallo/models/image_proj.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
image_proj_model.py
|
| 3 |
+
|
| 4 |
+
This module defines the ImageProjModel class, which is responsible for
|
| 5 |
+
projecting image embeddings into a different dimensional space. The model
|
| 6 |
+
leverages a linear transformation followed by a layer normalization to
|
| 7 |
+
reshape and normalize the input image embeddings for further processing in
|
| 8 |
+
cross-attention mechanisms or other downstream tasks.
|
| 9 |
+
|
| 10 |
+
Classes:
|
| 11 |
+
ImageProjModel
|
| 12 |
+
|
| 13 |
+
Dependencies:
|
| 14 |
+
torch
|
| 15 |
+
diffusers.ModelMixin
|
| 16 |
+
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
from diffusers import ModelMixin
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class ImageProjModel(ModelMixin):
|
| 24 |
+
"""
|
| 25 |
+
ImageProjModel is a class that projects image embeddings into a different
|
| 26 |
+
dimensional space. It inherits from ModelMixin, providing additional functionalities
|
| 27 |
+
specific to image projection.
|
| 28 |
+
|
| 29 |
+
Attributes:
|
| 30 |
+
cross_attention_dim (int): The dimension of the cross attention.
|
| 31 |
+
clip_embeddings_dim (int): The dimension of the CLIP embeddings.
|
| 32 |
+
clip_extra_context_tokens (int): The number of extra context tokens in CLIP.
|
| 33 |
+
|
| 34 |
+
Methods:
|
| 35 |
+
forward(image_embeds): Forward pass of the ImageProjModel, which takes in image
|
| 36 |
+
embeddings and returns the projected tokens.
|
| 37 |
+
|
| 38 |
+
"""
|
| 39 |
+
|
| 40 |
+
def __init__(
|
| 41 |
+
self,
|
| 42 |
+
cross_attention_dim=1024,
|
| 43 |
+
clip_embeddings_dim=1024,
|
| 44 |
+
clip_extra_context_tokens=4,
|
| 45 |
+
):
|
| 46 |
+
super().__init__()
|
| 47 |
+
|
| 48 |
+
self.generator = None
|
| 49 |
+
self.cross_attention_dim = cross_attention_dim
|
| 50 |
+
self.clip_extra_context_tokens = clip_extra_context_tokens
|
| 51 |
+
self.proj = torch.nn.Linear(
|
| 52 |
+
clip_embeddings_dim, self.clip_extra_context_tokens * cross_attention_dim
|
| 53 |
+
)
|
| 54 |
+
self.norm = torch.nn.LayerNorm(cross_attention_dim)
|
| 55 |
+
|
| 56 |
+
def forward(self, image_embeds):
|
| 57 |
+
"""
|
| 58 |
+
Forward pass of the ImageProjModel, which takes in image embeddings and returns the
|
| 59 |
+
projected tokens after reshaping and normalization.
|
| 60 |
+
|
| 61 |
+
Args:
|
| 62 |
+
image_embeds (torch.Tensor): The input image embeddings, with shape
|
| 63 |
+
batch_size x num_image_tokens x clip_embeddings_dim.
|
| 64 |
+
|
| 65 |
+
Returns:
|
| 66 |
+
clip_extra_context_tokens (torch.Tensor): The projected tokens after reshaping
|
| 67 |
+
and normalization, with shape batch_size x (clip_extra_context_tokens *
|
| 68 |
+
cross_attention_dim).
|
| 69 |
+
|
| 70 |
+
"""
|
| 71 |
+
embeds = image_embeds
|
| 72 |
+
clip_extra_context_tokens = self.proj(embeds).reshape(
|
| 73 |
+
-1, self.clip_extra_context_tokens, self.cross_attention_dim
|
| 74 |
+
)
|
| 75 |
+
clip_extra_context_tokens = self.norm(clip_extra_context_tokens)
|
| 76 |
+
return clip_extra_context_tokens
|
hallo/models/motion_module.py
ADDED
|
@@ -0,0 +1,608 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
# pylint: disable=W0613
|
| 3 |
+
# pylint: disable=W0221
|
| 4 |
+
|
| 5 |
+
"""
|
| 6 |
+
temporal_transformers.py
|
| 7 |
+
|
| 8 |
+
This module provides classes and functions for implementing Temporal Transformers
|
| 9 |
+
in PyTorch, designed for handling video data and temporal sequences within transformer-based models.
|
| 10 |
+
|
| 11 |
+
Functions:
|
| 12 |
+
zero_module(module)
|
| 13 |
+
Zero out the parameters of a module and return it.
|
| 14 |
+
|
| 15 |
+
Classes:
|
| 16 |
+
TemporalTransformer3DModelOutput(BaseOutput)
|
| 17 |
+
Dataclass for storing the output of TemporalTransformer3DModel.
|
| 18 |
+
|
| 19 |
+
VanillaTemporalModule(nn.Module)
|
| 20 |
+
A Vanilla Temporal Module class for handling temporal data.
|
| 21 |
+
|
| 22 |
+
TemporalTransformer3DModel(nn.Module)
|
| 23 |
+
A Temporal Transformer 3D Model class for transforming temporal data.
|
| 24 |
+
|
| 25 |
+
TemporalTransformerBlock(nn.Module)
|
| 26 |
+
A Temporal Transformer Block class for building the transformer architecture.
|
| 27 |
+
|
| 28 |
+
PositionalEncoding(nn.Module)
|
| 29 |
+
A Positional Encoding module for transformers to encode positional information.
|
| 30 |
+
|
| 31 |
+
Dependencies:
|
| 32 |
+
math
|
| 33 |
+
dataclasses.dataclass
|
| 34 |
+
typing (Callable, Optional)
|
| 35 |
+
torch
|
| 36 |
+
diffusers (FeedForward, Attention, AttnProcessor)
|
| 37 |
+
diffusers.utils (BaseOutput)
|
| 38 |
+
diffusers.utils.import_utils (is_xformers_available)
|
| 39 |
+
einops (rearrange, repeat)
|
| 40 |
+
torch.nn
|
| 41 |
+
xformers
|
| 42 |
+
xformers.ops
|
| 43 |
+
|
| 44 |
+
Example Usage:
|
| 45 |
+
>>> motion_module = get_motion_module(in_channels=512, motion_module_type="Vanilla", motion_module_kwargs={})
|
| 46 |
+
>>> output = motion_module(input_tensor, temb, encoder_hidden_states)
|
| 47 |
+
|
| 48 |
+
This module is designed to facilitate the creation, training, and inference of transformer models
|
| 49 |
+
that operate on temporal data, such as videos or time-series. It includes mechanisms for applying temporal attention,
|
| 50 |
+
managing positional encoding, and integrating with external libraries for efficient attention operations.
|
| 51 |
+
"""
|
| 52 |
+
|
| 53 |
+
# This code is copied from https://github.com/guoyww/AnimateDiff.
|
| 54 |
+
|
| 55 |
+
import math
|
| 56 |
+
|
| 57 |
+
import torch
|
| 58 |
+
import xformers
|
| 59 |
+
import xformers.ops
|
| 60 |
+
from diffusers.models.attention import FeedForward
|
| 61 |
+
from diffusers.models.attention_processor import Attention, AttnProcessor
|
| 62 |
+
from diffusers.utils import BaseOutput
|
| 63 |
+
from diffusers.utils.import_utils import is_xformers_available
|
| 64 |
+
from einops import rearrange, repeat
|
| 65 |
+
from torch import nn
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def zero_module(module):
|
| 69 |
+
"""
|
| 70 |
+
Zero out the parameters of a module and return it.
|
| 71 |
+
|
| 72 |
+
Args:
|
| 73 |
+
- module: A PyTorch module to zero out its parameters.
|
| 74 |
+
|
| 75 |
+
Returns:
|
| 76 |
+
A zeroed out PyTorch module.
|
| 77 |
+
"""
|
| 78 |
+
for p in module.parameters():
|
| 79 |
+
p.detach().zero_()
|
| 80 |
+
return module
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
class TemporalTransformer3DModelOutput(BaseOutput):
|
| 84 |
+
"""
|
| 85 |
+
Output class for the TemporalTransformer3DModel.
|
| 86 |
+
|
| 87 |
+
Attributes:
|
| 88 |
+
sample (torch.FloatTensor): The output sample tensor from the model.
|
| 89 |
+
"""
|
| 90 |
+
sample: torch.FloatTensor
|
| 91 |
+
|
| 92 |
+
def get_sample_shape(self):
|
| 93 |
+
"""
|
| 94 |
+
Returns the shape of the sample tensor.
|
| 95 |
+
|
| 96 |
+
Returns:
|
| 97 |
+
Tuple: The shape of the sample tensor.
|
| 98 |
+
"""
|
| 99 |
+
return self.sample.shape
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def get_motion_module(in_channels, motion_module_type: str, motion_module_kwargs: dict):
|
| 103 |
+
"""
|
| 104 |
+
This function returns a motion module based on the given type and parameters.
|
| 105 |
+
|
| 106 |
+
Args:
|
| 107 |
+
- in_channels (int): The number of input channels for the motion module.
|
| 108 |
+
- motion_module_type (str): The type of motion module to create. Currently, only "Vanilla" is supported.
|
| 109 |
+
- motion_module_kwargs (dict): Additional keyword arguments to pass to the motion module constructor.
|
| 110 |
+
|
| 111 |
+
Returns:
|
| 112 |
+
VanillaTemporalModule: The created motion module.
|
| 113 |
+
|
| 114 |
+
Raises:
|
| 115 |
+
ValueError: If an unsupported motion_module_type is provided.
|
| 116 |
+
"""
|
| 117 |
+
if motion_module_type == "Vanilla":
|
| 118 |
+
return VanillaTemporalModule(
|
| 119 |
+
in_channels=in_channels,
|
| 120 |
+
**motion_module_kwargs,
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
raise ValueError
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
class VanillaTemporalModule(nn.Module):
|
| 127 |
+
"""
|
| 128 |
+
A Vanilla Temporal Module class.
|
| 129 |
+
|
| 130 |
+
Args:
|
| 131 |
+
- in_channels (int): The number of input channels for the motion module.
|
| 132 |
+
- num_attention_heads (int): Number of attention heads.
|
| 133 |
+
- num_transformer_block (int): Number of transformer blocks.
|
| 134 |
+
- attention_block_types (tuple): Types of attention blocks.
|
| 135 |
+
- cross_frame_attention_mode: Mode for cross-frame attention.
|
| 136 |
+
- temporal_position_encoding (bool): Flag for temporal position encoding.
|
| 137 |
+
- temporal_position_encoding_max_len (int): Maximum length for temporal position encoding.
|
| 138 |
+
- temporal_attention_dim_div (int): Divisor for temporal attention dimension.
|
| 139 |
+
- zero_initialize (bool): Flag for zero initialization.
|
| 140 |
+
"""
|
| 141 |
+
|
| 142 |
+
def __init__(
|
| 143 |
+
self,
|
| 144 |
+
in_channels,
|
| 145 |
+
num_attention_heads=8,
|
| 146 |
+
num_transformer_block=2,
|
| 147 |
+
attention_block_types=("Temporal_Self", "Temporal_Self"),
|
| 148 |
+
cross_frame_attention_mode=None,
|
| 149 |
+
temporal_position_encoding=False,
|
| 150 |
+
temporal_position_encoding_max_len=24,
|
| 151 |
+
temporal_attention_dim_div=1,
|
| 152 |
+
zero_initialize=True,
|
| 153 |
+
):
|
| 154 |
+
super().__init__()
|
| 155 |
+
|
| 156 |
+
self.temporal_transformer = TemporalTransformer3DModel(
|
| 157 |
+
in_channels=in_channels,
|
| 158 |
+
num_attention_heads=num_attention_heads,
|
| 159 |
+
attention_head_dim=in_channels
|
| 160 |
+
// num_attention_heads
|
| 161 |
+
// temporal_attention_dim_div,
|
| 162 |
+
num_layers=num_transformer_block,
|
| 163 |
+
attention_block_types=attention_block_types,
|
| 164 |
+
cross_frame_attention_mode=cross_frame_attention_mode,
|
| 165 |
+
temporal_position_encoding=temporal_position_encoding,
|
| 166 |
+
temporal_position_encoding_max_len=temporal_position_encoding_max_len,
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
if zero_initialize:
|
| 170 |
+
self.temporal_transformer.proj_out = zero_module(
|
| 171 |
+
self.temporal_transformer.proj_out
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
def forward(
|
| 175 |
+
self,
|
| 176 |
+
input_tensor,
|
| 177 |
+
encoder_hidden_states,
|
| 178 |
+
attention_mask=None,
|
| 179 |
+
):
|
| 180 |
+
"""
|
| 181 |
+
Forward pass of the TemporalTransformer3DModel.
|
| 182 |
+
|
| 183 |
+
Args:
|
| 184 |
+
hidden_states (torch.Tensor): The hidden states of the model.
|
| 185 |
+
encoder_hidden_states (torch.Tensor, optional): The hidden states of the encoder.
|
| 186 |
+
attention_mask (torch.Tensor, optional): The attention mask.
|
| 187 |
+
|
| 188 |
+
Returns:
|
| 189 |
+
torch.Tensor: The output tensor after the forward pass.
|
| 190 |
+
"""
|
| 191 |
+
hidden_states = input_tensor
|
| 192 |
+
hidden_states = self.temporal_transformer(
|
| 193 |
+
hidden_states, encoder_hidden_states
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
output = hidden_states
|
| 197 |
+
return output
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
class TemporalTransformer3DModel(nn.Module):
|
| 201 |
+
"""
|
| 202 |
+
A Temporal Transformer 3D Model class.
|
| 203 |
+
|
| 204 |
+
Args:
|
| 205 |
+
- in_channels (int): The number of input channels.
|
| 206 |
+
- num_attention_heads (int): Number of attention heads.
|
| 207 |
+
- attention_head_dim (int): Dimension of attention heads.
|
| 208 |
+
- num_layers (int): Number of transformer layers.
|
| 209 |
+
- attention_block_types (tuple): Types of attention blocks.
|
| 210 |
+
- dropout (float): Dropout rate.
|
| 211 |
+
- norm_num_groups (int): Number of groups for normalization.
|
| 212 |
+
- cross_attention_dim (int): Dimension for cross-attention.
|
| 213 |
+
- activation_fn (str): Activation function.
|
| 214 |
+
- attention_bias (bool): Flag for attention bias.
|
| 215 |
+
- upcast_attention (bool): Flag for upcast attention.
|
| 216 |
+
- cross_frame_attention_mode: Mode for cross-frame attention.
|
| 217 |
+
- temporal_position_encoding (bool): Flag for temporal position encoding.
|
| 218 |
+
- temporal_position_encoding_max_len (int): Maximum length for temporal position encoding.
|
| 219 |
+
"""
|
| 220 |
+
def __init__(
|
| 221 |
+
self,
|
| 222 |
+
in_channels,
|
| 223 |
+
num_attention_heads,
|
| 224 |
+
attention_head_dim,
|
| 225 |
+
num_layers,
|
| 226 |
+
attention_block_types=(
|
| 227 |
+
"Temporal_Self",
|
| 228 |
+
"Temporal_Self",
|
| 229 |
+
),
|
| 230 |
+
dropout=0.0,
|
| 231 |
+
norm_num_groups=32,
|
| 232 |
+
cross_attention_dim=768,
|
| 233 |
+
activation_fn="geglu",
|
| 234 |
+
attention_bias=False,
|
| 235 |
+
upcast_attention=False,
|
| 236 |
+
cross_frame_attention_mode=None,
|
| 237 |
+
temporal_position_encoding=False,
|
| 238 |
+
temporal_position_encoding_max_len=24,
|
| 239 |
+
):
|
| 240 |
+
super().__init__()
|
| 241 |
+
|
| 242 |
+
inner_dim = num_attention_heads * attention_head_dim
|
| 243 |
+
|
| 244 |
+
self.norm = torch.nn.GroupNorm(
|
| 245 |
+
num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True
|
| 246 |
+
)
|
| 247 |
+
self.proj_in = nn.Linear(in_channels, inner_dim)
|
| 248 |
+
|
| 249 |
+
self.transformer_blocks = nn.ModuleList(
|
| 250 |
+
[
|
| 251 |
+
TemporalTransformerBlock(
|
| 252 |
+
dim=inner_dim,
|
| 253 |
+
num_attention_heads=num_attention_heads,
|
| 254 |
+
attention_head_dim=attention_head_dim,
|
| 255 |
+
attention_block_types=attention_block_types,
|
| 256 |
+
dropout=dropout,
|
| 257 |
+
cross_attention_dim=cross_attention_dim,
|
| 258 |
+
activation_fn=activation_fn,
|
| 259 |
+
attention_bias=attention_bias,
|
| 260 |
+
upcast_attention=upcast_attention,
|
| 261 |
+
cross_frame_attention_mode=cross_frame_attention_mode,
|
| 262 |
+
temporal_position_encoding=temporal_position_encoding,
|
| 263 |
+
temporal_position_encoding_max_len=temporal_position_encoding_max_len,
|
| 264 |
+
)
|
| 265 |
+
for d in range(num_layers)
|
| 266 |
+
]
|
| 267 |
+
)
|
| 268 |
+
self.proj_out = nn.Linear(inner_dim, in_channels)
|
| 269 |
+
|
| 270 |
+
def forward(self, hidden_states, encoder_hidden_states=None):
|
| 271 |
+
"""
|
| 272 |
+
Forward pass for the TemporalTransformer3DModel.
|
| 273 |
+
|
| 274 |
+
Args:
|
| 275 |
+
hidden_states (torch.Tensor): The input hidden states with shape (batch_size, sequence_length, in_channels).
|
| 276 |
+
encoder_hidden_states (torch.Tensor, optional): The encoder hidden states with shape (batch_size, encoder_sequence_length, in_channels).
|
| 277 |
+
|
| 278 |
+
Returns:
|
| 279 |
+
torch.Tensor: The output hidden states with shape (batch_size, sequence_length, in_channels).
|
| 280 |
+
"""
|
| 281 |
+
assert (
|
| 282 |
+
hidden_states.dim() == 5
|
| 283 |
+
), f"Expected hidden_states to have ndim=5, but got ndim={hidden_states.dim()}."
|
| 284 |
+
video_length = hidden_states.shape[2]
|
| 285 |
+
hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
|
| 286 |
+
|
| 287 |
+
batch, _, height, weight = hidden_states.shape
|
| 288 |
+
residual = hidden_states
|
| 289 |
+
|
| 290 |
+
hidden_states = self.norm(hidden_states)
|
| 291 |
+
inner_dim = hidden_states.shape[1]
|
| 292 |
+
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(
|
| 293 |
+
batch, height * weight, inner_dim
|
| 294 |
+
)
|
| 295 |
+
hidden_states = self.proj_in(hidden_states)
|
| 296 |
+
|
| 297 |
+
# Transformer Blocks
|
| 298 |
+
for block in self.transformer_blocks:
|
| 299 |
+
hidden_states = block(
|
| 300 |
+
hidden_states,
|
| 301 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 302 |
+
video_length=video_length,
|
| 303 |
+
)
|
| 304 |
+
|
| 305 |
+
# output
|
| 306 |
+
hidden_states = self.proj_out(hidden_states)
|
| 307 |
+
hidden_states = (
|
| 308 |
+
hidden_states.reshape(batch, height, weight, inner_dim)
|
| 309 |
+
.permute(0, 3, 1, 2)
|
| 310 |
+
.contiguous()
|
| 311 |
+
)
|
| 312 |
+
|
| 313 |
+
output = hidden_states + residual
|
| 314 |
+
output = rearrange(output, "(b f) c h w -> b c f h w", f=video_length)
|
| 315 |
+
|
| 316 |
+
return output
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
class TemporalTransformerBlock(nn.Module):
|
| 320 |
+
"""
|
| 321 |
+
A Temporal Transformer Block class.
|
| 322 |
+
|
| 323 |
+
Args:
|
| 324 |
+
- dim (int): Dimension of the block.
|
| 325 |
+
- num_attention_heads (int): Number of attention heads.
|
| 326 |
+
- attention_head_dim (int): Dimension of attention heads.
|
| 327 |
+
- attention_block_types (tuple): Types of attention blocks.
|
| 328 |
+
- dropout (float): Dropout rate.
|
| 329 |
+
- cross_attention_dim (int): Dimension for cross-attention.
|
| 330 |
+
- activation_fn (str): Activation function.
|
| 331 |
+
- attention_bias (bool): Flag for attention bias.
|
| 332 |
+
- upcast_attention (bool): Flag for upcast attention.
|
| 333 |
+
- cross_frame_attention_mode: Mode for cross-frame attention.
|
| 334 |
+
- temporal_position_encoding (bool): Flag for temporal position encoding.
|
| 335 |
+
- temporal_position_encoding_max_len (int): Maximum length for temporal position encoding.
|
| 336 |
+
"""
|
| 337 |
+
def __init__(
|
| 338 |
+
self,
|
| 339 |
+
dim,
|
| 340 |
+
num_attention_heads,
|
| 341 |
+
attention_head_dim,
|
| 342 |
+
attention_block_types=(
|
| 343 |
+
"Temporal_Self",
|
| 344 |
+
"Temporal_Self",
|
| 345 |
+
),
|
| 346 |
+
dropout=0.0,
|
| 347 |
+
cross_attention_dim=768,
|
| 348 |
+
activation_fn="geglu",
|
| 349 |
+
attention_bias=False,
|
| 350 |
+
upcast_attention=False,
|
| 351 |
+
cross_frame_attention_mode=None,
|
| 352 |
+
temporal_position_encoding=False,
|
| 353 |
+
temporal_position_encoding_max_len=24,
|
| 354 |
+
):
|
| 355 |
+
super().__init__()
|
| 356 |
+
|
| 357 |
+
attention_blocks = []
|
| 358 |
+
norms = []
|
| 359 |
+
|
| 360 |
+
for block_name in attention_block_types:
|
| 361 |
+
attention_blocks.append(
|
| 362 |
+
VersatileAttention(
|
| 363 |
+
attention_mode=block_name.split("_", maxsplit=1)[0],
|
| 364 |
+
cross_attention_dim=cross_attention_dim
|
| 365 |
+
if block_name.endswith("_Cross")
|
| 366 |
+
else None,
|
| 367 |
+
query_dim=dim,
|
| 368 |
+
heads=num_attention_heads,
|
| 369 |
+
dim_head=attention_head_dim,
|
| 370 |
+
dropout=dropout,
|
| 371 |
+
bias=attention_bias,
|
| 372 |
+
upcast_attention=upcast_attention,
|
| 373 |
+
cross_frame_attention_mode=cross_frame_attention_mode,
|
| 374 |
+
temporal_position_encoding=temporal_position_encoding,
|
| 375 |
+
temporal_position_encoding_max_len=temporal_position_encoding_max_len,
|
| 376 |
+
)
|
| 377 |
+
)
|
| 378 |
+
norms.append(nn.LayerNorm(dim))
|
| 379 |
+
|
| 380 |
+
self.attention_blocks = nn.ModuleList(attention_blocks)
|
| 381 |
+
self.norms = nn.ModuleList(norms)
|
| 382 |
+
|
| 383 |
+
self.ff = FeedForward(dim, dropout=dropout,
|
| 384 |
+
activation_fn=activation_fn)
|
| 385 |
+
self.ff_norm = nn.LayerNorm(dim)
|
| 386 |
+
|
| 387 |
+
def forward(
|
| 388 |
+
self,
|
| 389 |
+
hidden_states,
|
| 390 |
+
encoder_hidden_states=None,
|
| 391 |
+
video_length=None,
|
| 392 |
+
):
|
| 393 |
+
"""
|
| 394 |
+
Forward pass for the TemporalTransformerBlock.
|
| 395 |
+
|
| 396 |
+
Args:
|
| 397 |
+
hidden_states (torch.Tensor): The input hidden states with shape
|
| 398 |
+
(batch_size, video_length, in_channels).
|
| 399 |
+
encoder_hidden_states (torch.Tensor, optional): The encoder hidden states
|
| 400 |
+
with shape (batch_size, encoder_length, in_channels).
|
| 401 |
+
video_length (int, optional): The length of the video.
|
| 402 |
+
|
| 403 |
+
Returns:
|
| 404 |
+
torch.Tensor: The output hidden states with shape
|
| 405 |
+
(batch_size, video_length, in_channels).
|
| 406 |
+
"""
|
| 407 |
+
for attention_block, norm in zip(self.attention_blocks, self.norms):
|
| 408 |
+
norm_hidden_states = norm(hidden_states)
|
| 409 |
+
hidden_states = (
|
| 410 |
+
attention_block(
|
| 411 |
+
norm_hidden_states,
|
| 412 |
+
encoder_hidden_states=encoder_hidden_states
|
| 413 |
+
if attention_block.is_cross_attention
|
| 414 |
+
else None,
|
| 415 |
+
video_length=video_length,
|
| 416 |
+
)
|
| 417 |
+
+ hidden_states
|
| 418 |
+
)
|
| 419 |
+
|
| 420 |
+
hidden_states = self.ff(self.ff_norm(hidden_states)) + hidden_states
|
| 421 |
+
|
| 422 |
+
output = hidden_states
|
| 423 |
+
return output
|
| 424 |
+
|
| 425 |
+
|
| 426 |
+
class PositionalEncoding(nn.Module):
|
| 427 |
+
"""
|
| 428 |
+
Positional Encoding module for transformers.
|
| 429 |
+
|
| 430 |
+
Args:
|
| 431 |
+
- d_model (int): Model dimension.
|
| 432 |
+
- dropout (float): Dropout rate.
|
| 433 |
+
- max_len (int): Maximum length for positional encoding.
|
| 434 |
+
"""
|
| 435 |
+
def __init__(self, d_model, dropout=0.0, max_len=24):
|
| 436 |
+
super().__init__()
|
| 437 |
+
self.dropout = nn.Dropout(p=dropout)
|
| 438 |
+
position = torch.arange(max_len).unsqueeze(1)
|
| 439 |
+
div_term = torch.exp(
|
| 440 |
+
torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)
|
| 441 |
+
)
|
| 442 |
+
pe = torch.zeros(1, max_len, d_model)
|
| 443 |
+
pe[0, :, 0::2] = torch.sin(position * div_term)
|
| 444 |
+
pe[0, :, 1::2] = torch.cos(position * div_term)
|
| 445 |
+
self.register_buffer("pe", pe)
|
| 446 |
+
|
| 447 |
+
def forward(self, x):
|
| 448 |
+
"""
|
| 449 |
+
Forward pass of the PositionalEncoding module.
|
| 450 |
+
|
| 451 |
+
This method takes an input tensor `x` and adds the positional encoding to it. The positional encoding is
|
| 452 |
+
generated based on the input tensor's shape and is added to the input tensor element-wise.
|
| 453 |
+
|
| 454 |
+
Args:
|
| 455 |
+
x (torch.Tensor): The input tensor to be positionally encoded.
|
| 456 |
+
|
| 457 |
+
Returns:
|
| 458 |
+
torch.Tensor: The positionally encoded tensor.
|
| 459 |
+
"""
|
| 460 |
+
x = x + self.pe[:, : x.size(1)]
|
| 461 |
+
return self.dropout(x)
|
| 462 |
+
|
| 463 |
+
|
| 464 |
+
class VersatileAttention(Attention):
|
| 465 |
+
"""
|
| 466 |
+
Versatile Attention class.
|
| 467 |
+
|
| 468 |
+
Args:
|
| 469 |
+
- attention_mode: Attention mode.
|
| 470 |
+
- temporal_position_encoding (bool): Flag for temporal position encoding.
|
| 471 |
+
- temporal_position_encoding_max_len (int): Maximum length for temporal position encoding.
|
| 472 |
+
"""
|
| 473 |
+
def __init__(
|
| 474 |
+
self,
|
| 475 |
+
*args,
|
| 476 |
+
attention_mode=None,
|
| 477 |
+
cross_frame_attention_mode=None,
|
| 478 |
+
temporal_position_encoding=False,
|
| 479 |
+
temporal_position_encoding_max_len=24,
|
| 480 |
+
**kwargs,
|
| 481 |
+
):
|
| 482 |
+
super().__init__(*args, **kwargs)
|
| 483 |
+
assert attention_mode == "Temporal"
|
| 484 |
+
|
| 485 |
+
self.attention_mode = attention_mode
|
| 486 |
+
self.is_cross_attention = kwargs.get("cross_attention_dim") is not None
|
| 487 |
+
|
| 488 |
+
self.pos_encoder = (
|
| 489 |
+
PositionalEncoding(
|
| 490 |
+
kwargs["query_dim"],
|
| 491 |
+
dropout=0.0,
|
| 492 |
+
max_len=temporal_position_encoding_max_len,
|
| 493 |
+
)
|
| 494 |
+
if (temporal_position_encoding and attention_mode == "Temporal")
|
| 495 |
+
else None
|
| 496 |
+
)
|
| 497 |
+
|
| 498 |
+
def extra_repr(self):
|
| 499 |
+
"""
|
| 500 |
+
Returns a string representation of the module with information about the attention mode and whether it is cross-attention.
|
| 501 |
+
|
| 502 |
+
Returns:
|
| 503 |
+
str: A string representation of the module.
|
| 504 |
+
"""
|
| 505 |
+
return f"(Module Info) Attention_Mode: {self.attention_mode}, Is_Cross_Attention: {self.is_cross_attention}"
|
| 506 |
+
|
| 507 |
+
def set_use_memory_efficient_attention_xformers(
|
| 508 |
+
self,
|
| 509 |
+
use_memory_efficient_attention_xformers: bool,
|
| 510 |
+
):
|
| 511 |
+
"""
|
| 512 |
+
Sets the use of memory-efficient attention xformers for the VersatileAttention class.
|
| 513 |
+
|
| 514 |
+
Args:
|
| 515 |
+
use_memory_efficient_attention_xformers (bool): A boolean flag indicating whether to use memory-efficient attention xformers or not.
|
| 516 |
+
|
| 517 |
+
Returns:
|
| 518 |
+
None
|
| 519 |
+
|
| 520 |
+
"""
|
| 521 |
+
if use_memory_efficient_attention_xformers:
|
| 522 |
+
if not is_xformers_available():
|
| 523 |
+
raise ModuleNotFoundError(
|
| 524 |
+
(
|
| 525 |
+
"Refer to https://github.com/facebookresearch/xformers for more information on how to install"
|
| 526 |
+
" xformers"
|
| 527 |
+
),
|
| 528 |
+
name="xformers",
|
| 529 |
+
)
|
| 530 |
+
|
| 531 |
+
if not torch.cuda.is_available():
|
| 532 |
+
raise ValueError(
|
| 533 |
+
"torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is"
|
| 534 |
+
" only available for GPU "
|
| 535 |
+
)
|
| 536 |
+
|
| 537 |
+
try:
|
| 538 |
+
# Make sure we can run the memory efficient attention
|
| 539 |
+
_ = xformers.ops.memory_efficient_attention(
|
| 540 |
+
torch.randn((1, 2, 40), device="cuda"),
|
| 541 |
+
torch.randn((1, 2, 40), device="cuda"),
|
| 542 |
+
torch.randn((1, 2, 40), device="cuda"),
|
| 543 |
+
)
|
| 544 |
+
except Exception as e:
|
| 545 |
+
raise e
|
| 546 |
+
processor = AttnProcessor()
|
| 547 |
+
else:
|
| 548 |
+
processor = AttnProcessor()
|
| 549 |
+
|
| 550 |
+
self.set_processor(processor)
|
| 551 |
+
|
| 552 |
+
def forward(
|
| 553 |
+
self,
|
| 554 |
+
hidden_states,
|
| 555 |
+
encoder_hidden_states=None,
|
| 556 |
+
attention_mask=None,
|
| 557 |
+
video_length=None,
|
| 558 |
+
**cross_attention_kwargs,
|
| 559 |
+
):
|
| 560 |
+
"""
|
| 561 |
+
Args:
|
| 562 |
+
hidden_states (`torch.Tensor`):
|
| 563 |
+
The hidden states to be passed through the model.
|
| 564 |
+
encoder_hidden_states (`torch.Tensor`, optional):
|
| 565 |
+
The encoder hidden states to be passed through the model.
|
| 566 |
+
attention_mask (`torch.Tensor`, optional):
|
| 567 |
+
The attention mask to be used in the model.
|
| 568 |
+
video_length (`int`, optional):
|
| 569 |
+
The length of the video.
|
| 570 |
+
cross_attention_kwargs (`dict`, optional):
|
| 571 |
+
Additional keyword arguments to be used for cross-attention.
|
| 572 |
+
|
| 573 |
+
Returns:
|
| 574 |
+
`torch.Tensor`:
|
| 575 |
+
The output tensor after passing through the model.
|
| 576 |
+
|
| 577 |
+
"""
|
| 578 |
+
if self.attention_mode == "Temporal":
|
| 579 |
+
d = hidden_states.shape[1] # d means HxW
|
| 580 |
+
hidden_states = rearrange(
|
| 581 |
+
hidden_states, "(b f) d c -> (b d) f c", f=video_length
|
| 582 |
+
)
|
| 583 |
+
|
| 584 |
+
if self.pos_encoder is not None:
|
| 585 |
+
hidden_states = self.pos_encoder(hidden_states)
|
| 586 |
+
|
| 587 |
+
encoder_hidden_states = (
|
| 588 |
+
repeat(encoder_hidden_states, "b n c -> (b d) n c", d=d)
|
| 589 |
+
if encoder_hidden_states is not None
|
| 590 |
+
else encoder_hidden_states
|
| 591 |
+
)
|
| 592 |
+
|
| 593 |
+
else:
|
| 594 |
+
raise NotImplementedError
|
| 595 |
+
|
| 596 |
+
hidden_states = self.processor(
|
| 597 |
+
self,
|
| 598 |
+
hidden_states,
|
| 599 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 600 |
+
attention_mask=attention_mask,
|
| 601 |
+
**cross_attention_kwargs,
|
| 602 |
+
)
|
| 603 |
+
|
| 604 |
+
if self.attention_mode == "Temporal":
|
| 605 |
+
hidden_states = rearrange(
|
| 606 |
+
hidden_states, "(b d) f c -> (b f) d c", d=d)
|
| 607 |
+
|
| 608 |
+
return hidden_states
|
hallo/models/mutual_self_attention.py
ADDED
|
@@ -0,0 +1,496 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=E1120
|
| 2 |
+
"""
|
| 3 |
+
This module contains the implementation of mutual self-attention,
|
| 4 |
+
which is a type of attention mechanism used in deep learning models.
|
| 5 |
+
The module includes several classes and functions related to attention mechanisms,
|
| 6 |
+
such as BasicTransformerBlock and TemporalBasicTransformerBlock.
|
| 7 |
+
The main purpose of this module is to provide a comprehensive attention mechanism for various tasks in deep learning,
|
| 8 |
+
such as image and video processing, natural language processing, and so on.
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
from typing import Any, Dict, Optional
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
from einops import rearrange
|
| 15 |
+
|
| 16 |
+
from .attention import BasicTransformerBlock, TemporalBasicTransformerBlock
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def torch_dfs(model: torch.nn.Module):
|
| 20 |
+
"""
|
| 21 |
+
Perform a depth-first search (DFS) traversal on a PyTorch model's neural network architecture.
|
| 22 |
+
|
| 23 |
+
This function recursively traverses all the children modules of a given PyTorch model and returns a list
|
| 24 |
+
containing all the modules in the model's architecture. The DFS approach starts with the input model and
|
| 25 |
+
explores its children modules depth-wise before backtracking and exploring other branches.
|
| 26 |
+
|
| 27 |
+
Args:
|
| 28 |
+
model (torch.nn.Module): The root module of the neural network to traverse.
|
| 29 |
+
|
| 30 |
+
Returns:
|
| 31 |
+
list: A list of all the modules in the model's architecture.
|
| 32 |
+
"""
|
| 33 |
+
result = [model]
|
| 34 |
+
for child in model.children():
|
| 35 |
+
result += torch_dfs(child)
|
| 36 |
+
return result
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class ReferenceAttentionControl:
|
| 40 |
+
"""
|
| 41 |
+
This class is used to control the reference attention mechanism in a neural network model.
|
| 42 |
+
It is responsible for managing the guidance and fusion blocks, and modifying the self-attention
|
| 43 |
+
and group normalization mechanisms. The class also provides methods for registering reference hooks
|
| 44 |
+
and updating/clearing the internal state of the attention control object.
|
| 45 |
+
|
| 46 |
+
Attributes:
|
| 47 |
+
unet: The UNet model associated with this attention control object.
|
| 48 |
+
mode: The operating mode of the attention control object, either 'write' or 'read'.
|
| 49 |
+
do_classifier_free_guidance: Whether to use classifier-free guidance in the attention mechanism.
|
| 50 |
+
attention_auto_machine_weight: The weight assigned to the attention auto-machine.
|
| 51 |
+
gn_auto_machine_weight: The weight assigned to the group normalization auto-machine.
|
| 52 |
+
style_fidelity: The style fidelity parameter for the attention mechanism.
|
| 53 |
+
reference_attn: Whether to use reference attention in the model.
|
| 54 |
+
reference_adain: Whether to use reference AdaIN in the model.
|
| 55 |
+
fusion_blocks: The type of fusion blocks to use in the model ('midup', 'late', or 'nofusion').
|
| 56 |
+
batch_size: The batch size used for processing video frames.
|
| 57 |
+
|
| 58 |
+
Methods:
|
| 59 |
+
register_reference_hooks: Registers the reference hooks for the attention control object.
|
| 60 |
+
hacked_basic_transformer_inner_forward: The modified inner forward method for the basic transformer block.
|
| 61 |
+
update: Updates the internal state of the attention control object using the provided writer and dtype.
|
| 62 |
+
clear: Clears the internal state of the attention control object.
|
| 63 |
+
"""
|
| 64 |
+
def __init__(
|
| 65 |
+
self,
|
| 66 |
+
unet,
|
| 67 |
+
mode="write",
|
| 68 |
+
do_classifier_free_guidance=False,
|
| 69 |
+
attention_auto_machine_weight=float("inf"),
|
| 70 |
+
gn_auto_machine_weight=1.0,
|
| 71 |
+
style_fidelity=1.0,
|
| 72 |
+
reference_attn=True,
|
| 73 |
+
reference_adain=False,
|
| 74 |
+
fusion_blocks="midup",
|
| 75 |
+
batch_size=1,
|
| 76 |
+
) -> None:
|
| 77 |
+
"""
|
| 78 |
+
Initializes the ReferenceAttentionControl class.
|
| 79 |
+
|
| 80 |
+
Args:
|
| 81 |
+
unet (torch.nn.Module): The UNet model.
|
| 82 |
+
mode (str, optional): The mode of operation. Defaults to "write".
|
| 83 |
+
do_classifier_free_guidance (bool, optional): Whether to do classifier-free guidance. Defaults to False.
|
| 84 |
+
attention_auto_machine_weight (float, optional): The weight for attention auto-machine. Defaults to infinity.
|
| 85 |
+
gn_auto_machine_weight (float, optional): The weight for group-norm auto-machine. Defaults to 1.0.
|
| 86 |
+
style_fidelity (float, optional): The style fidelity. Defaults to 1.0.
|
| 87 |
+
reference_attn (bool, optional): Whether to use reference attention. Defaults to True.
|
| 88 |
+
reference_adain (bool, optional): Whether to use reference AdaIN. Defaults to False.
|
| 89 |
+
fusion_blocks (str, optional): The fusion blocks to use. Defaults to "midup".
|
| 90 |
+
batch_size (int, optional): The batch size. Defaults to 1.
|
| 91 |
+
|
| 92 |
+
Raises:
|
| 93 |
+
ValueError: If the mode is not recognized.
|
| 94 |
+
ValueError: If the fusion blocks are not recognized.
|
| 95 |
+
"""
|
| 96 |
+
# 10. Modify self attention and group norm
|
| 97 |
+
self.unet = unet
|
| 98 |
+
assert mode in ["read", "write"]
|
| 99 |
+
assert fusion_blocks in ["midup", "full"]
|
| 100 |
+
self.reference_attn = reference_attn
|
| 101 |
+
self.reference_adain = reference_adain
|
| 102 |
+
self.fusion_blocks = fusion_blocks
|
| 103 |
+
self.register_reference_hooks(
|
| 104 |
+
mode,
|
| 105 |
+
do_classifier_free_guidance,
|
| 106 |
+
attention_auto_machine_weight,
|
| 107 |
+
gn_auto_machine_weight,
|
| 108 |
+
style_fidelity,
|
| 109 |
+
reference_attn,
|
| 110 |
+
reference_adain,
|
| 111 |
+
fusion_blocks,
|
| 112 |
+
batch_size=batch_size,
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
def register_reference_hooks(
|
| 116 |
+
self,
|
| 117 |
+
mode,
|
| 118 |
+
do_classifier_free_guidance,
|
| 119 |
+
_attention_auto_machine_weight,
|
| 120 |
+
_gn_auto_machine_weight,
|
| 121 |
+
_style_fidelity,
|
| 122 |
+
_reference_attn,
|
| 123 |
+
_reference_adain,
|
| 124 |
+
_dtype=torch.float16,
|
| 125 |
+
batch_size=1,
|
| 126 |
+
num_images_per_prompt=1,
|
| 127 |
+
device=torch.device("cpu"),
|
| 128 |
+
_fusion_blocks="midup",
|
| 129 |
+
):
|
| 130 |
+
"""
|
| 131 |
+
Registers reference hooks for the model.
|
| 132 |
+
|
| 133 |
+
This function is responsible for registering reference hooks in the model,
|
| 134 |
+
which are used to modify the attention mechanism and group normalization layers.
|
| 135 |
+
It takes various parameters as input, such as mode,
|
| 136 |
+
do_classifier_free_guidance, _attention_auto_machine_weight, _gn_auto_machine_weight, _style_fidelity,
|
| 137 |
+
_reference_attn, _reference_adain, _dtype, batch_size, num_images_per_prompt, device, and _fusion_blocks.
|
| 138 |
+
|
| 139 |
+
Args:
|
| 140 |
+
self: Reference to the instance of the class.
|
| 141 |
+
mode: The mode of operation for the reference hooks.
|
| 142 |
+
do_classifier_free_guidance: A boolean flag indicating whether to use classifier-free guidance.
|
| 143 |
+
_attention_auto_machine_weight: The weight for the attention auto-machine.
|
| 144 |
+
_gn_auto_machine_weight: The weight for the group normalization auto-machine.
|
| 145 |
+
_style_fidelity: The style fidelity for the reference hooks.
|
| 146 |
+
_reference_attn: A boolean flag indicating whether to use reference attention.
|
| 147 |
+
_reference_adain: A boolean flag indicating whether to use reference AdaIN.
|
| 148 |
+
_dtype: The data type for the reference hooks.
|
| 149 |
+
batch_size: The batch size for the reference hooks.
|
| 150 |
+
num_images_per_prompt: The number of images per prompt for the reference hooks.
|
| 151 |
+
device: The device for the reference hooks.
|
| 152 |
+
_fusion_blocks: The fusion blocks for the reference hooks.
|
| 153 |
+
|
| 154 |
+
Returns:
|
| 155 |
+
None
|
| 156 |
+
"""
|
| 157 |
+
MODE = mode
|
| 158 |
+
if do_classifier_free_guidance:
|
| 159 |
+
uc_mask = (
|
| 160 |
+
torch.Tensor(
|
| 161 |
+
[1] * batch_size * num_images_per_prompt * 16
|
| 162 |
+
+ [0] * batch_size * num_images_per_prompt * 16
|
| 163 |
+
)
|
| 164 |
+
.to(device)
|
| 165 |
+
.bool()
|
| 166 |
+
)
|
| 167 |
+
else:
|
| 168 |
+
uc_mask = (
|
| 169 |
+
torch.Tensor([0] * batch_size * num_images_per_prompt * 2)
|
| 170 |
+
.to(device)
|
| 171 |
+
.bool()
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
def hacked_basic_transformer_inner_forward(
|
| 175 |
+
self,
|
| 176 |
+
hidden_states: torch.FloatTensor,
|
| 177 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 178 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 179 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 180 |
+
timestep: Optional[torch.LongTensor] = None,
|
| 181 |
+
cross_attention_kwargs: Dict[str, Any] = None,
|
| 182 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 183 |
+
video_length=None,
|
| 184 |
+
):
|
| 185 |
+
gate_msa = None
|
| 186 |
+
shift_mlp = None
|
| 187 |
+
scale_mlp = None
|
| 188 |
+
gate_mlp = None
|
| 189 |
+
|
| 190 |
+
if self.use_ada_layer_norm: # False
|
| 191 |
+
norm_hidden_states = self.norm1(hidden_states, timestep)
|
| 192 |
+
elif self.use_ada_layer_norm_zero:
|
| 193 |
+
(
|
| 194 |
+
norm_hidden_states,
|
| 195 |
+
gate_msa,
|
| 196 |
+
shift_mlp,
|
| 197 |
+
scale_mlp,
|
| 198 |
+
gate_mlp,
|
| 199 |
+
) = self.norm1(
|
| 200 |
+
hidden_states,
|
| 201 |
+
timestep,
|
| 202 |
+
class_labels,
|
| 203 |
+
hidden_dtype=hidden_states.dtype,
|
| 204 |
+
)
|
| 205 |
+
else:
|
| 206 |
+
norm_hidden_states = self.norm1(hidden_states)
|
| 207 |
+
|
| 208 |
+
# 1. Self-Attention
|
| 209 |
+
# self.only_cross_attention = False
|
| 210 |
+
cross_attention_kwargs = (
|
| 211 |
+
cross_attention_kwargs if cross_attention_kwargs is not None else {}
|
| 212 |
+
)
|
| 213 |
+
if self.only_cross_attention:
|
| 214 |
+
attn_output = self.attn1(
|
| 215 |
+
norm_hidden_states,
|
| 216 |
+
encoder_hidden_states=(
|
| 217 |
+
encoder_hidden_states if self.only_cross_attention else None
|
| 218 |
+
),
|
| 219 |
+
attention_mask=attention_mask,
|
| 220 |
+
**cross_attention_kwargs,
|
| 221 |
+
)
|
| 222 |
+
else:
|
| 223 |
+
if MODE == "write":
|
| 224 |
+
self.bank.append(norm_hidden_states.clone())
|
| 225 |
+
attn_output = self.attn1(
|
| 226 |
+
norm_hidden_states,
|
| 227 |
+
encoder_hidden_states=(
|
| 228 |
+
encoder_hidden_states if self.only_cross_attention else None
|
| 229 |
+
),
|
| 230 |
+
attention_mask=attention_mask,
|
| 231 |
+
**cross_attention_kwargs,
|
| 232 |
+
)
|
| 233 |
+
if MODE == "read":
|
| 234 |
+
|
| 235 |
+
bank_fea = [
|
| 236 |
+
rearrange(
|
| 237 |
+
rearrange(
|
| 238 |
+
d,
|
| 239 |
+
"(b s) l c -> b s l c",
|
| 240 |
+
b=norm_hidden_states.shape[0] // video_length,
|
| 241 |
+
)[:, 0, :, :]
|
| 242 |
+
# .unsqueeze(1)
|
| 243 |
+
.repeat(1, video_length, 1, 1),
|
| 244 |
+
"b t l c -> (b t) l c",
|
| 245 |
+
)
|
| 246 |
+
for d in self.bank
|
| 247 |
+
]
|
| 248 |
+
motion_frames_fea = [rearrange(
|
| 249 |
+
d,
|
| 250 |
+
"(b s) l c -> b s l c",
|
| 251 |
+
b=norm_hidden_states.shape[0] // video_length,
|
| 252 |
+
)[:, 1:, :, :] for d in self.bank]
|
| 253 |
+
modify_norm_hidden_states = torch.cat(
|
| 254 |
+
[norm_hidden_states] + bank_fea, dim=1
|
| 255 |
+
)
|
| 256 |
+
hidden_states_uc = (
|
| 257 |
+
self.attn1(
|
| 258 |
+
norm_hidden_states,
|
| 259 |
+
encoder_hidden_states=modify_norm_hidden_states,
|
| 260 |
+
attention_mask=attention_mask,
|
| 261 |
+
)
|
| 262 |
+
+ hidden_states
|
| 263 |
+
)
|
| 264 |
+
if do_classifier_free_guidance:
|
| 265 |
+
hidden_states_c = hidden_states_uc.clone()
|
| 266 |
+
_uc_mask = uc_mask.clone()
|
| 267 |
+
if hidden_states.shape[0] != _uc_mask.shape[0]:
|
| 268 |
+
_uc_mask = (
|
| 269 |
+
torch.Tensor(
|
| 270 |
+
[1] * (hidden_states.shape[0] // 2)
|
| 271 |
+
+ [0] * (hidden_states.shape[0] // 2)
|
| 272 |
+
)
|
| 273 |
+
.to(device)
|
| 274 |
+
.bool()
|
| 275 |
+
)
|
| 276 |
+
hidden_states_c[_uc_mask] = (
|
| 277 |
+
self.attn1(
|
| 278 |
+
norm_hidden_states[_uc_mask],
|
| 279 |
+
encoder_hidden_states=norm_hidden_states[_uc_mask],
|
| 280 |
+
attention_mask=attention_mask,
|
| 281 |
+
)
|
| 282 |
+
+ hidden_states[_uc_mask]
|
| 283 |
+
)
|
| 284 |
+
hidden_states = hidden_states_c.clone()
|
| 285 |
+
else:
|
| 286 |
+
hidden_states = hidden_states_uc
|
| 287 |
+
|
| 288 |
+
# self.bank.clear()
|
| 289 |
+
if self.attn2 is not None:
|
| 290 |
+
# Cross-Attention
|
| 291 |
+
norm_hidden_states = (
|
| 292 |
+
self.norm2(hidden_states, timestep)
|
| 293 |
+
if self.use_ada_layer_norm
|
| 294 |
+
else self.norm2(hidden_states)
|
| 295 |
+
)
|
| 296 |
+
hidden_states = (
|
| 297 |
+
self.attn2(
|
| 298 |
+
norm_hidden_states,
|
| 299 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 300 |
+
attention_mask=attention_mask,
|
| 301 |
+
)
|
| 302 |
+
+ hidden_states
|
| 303 |
+
)
|
| 304 |
+
|
| 305 |
+
# Feed-forward
|
| 306 |
+
hidden_states = self.ff(self.norm3(
|
| 307 |
+
hidden_states)) + hidden_states
|
| 308 |
+
|
| 309 |
+
# Temporal-Attention
|
| 310 |
+
if self.unet_use_temporal_attention:
|
| 311 |
+
d = hidden_states.shape[1]
|
| 312 |
+
hidden_states = rearrange(
|
| 313 |
+
hidden_states, "(b f) d c -> (b d) f c", f=video_length
|
| 314 |
+
)
|
| 315 |
+
norm_hidden_states = (
|
| 316 |
+
self.norm_temp(hidden_states, timestep)
|
| 317 |
+
if self.use_ada_layer_norm
|
| 318 |
+
else self.norm_temp(hidden_states)
|
| 319 |
+
)
|
| 320 |
+
hidden_states = (
|
| 321 |
+
self.attn_temp(norm_hidden_states) + hidden_states
|
| 322 |
+
)
|
| 323 |
+
hidden_states = rearrange(
|
| 324 |
+
hidden_states, "(b d) f c -> (b f) d c", d=d
|
| 325 |
+
)
|
| 326 |
+
|
| 327 |
+
return hidden_states, motion_frames_fea
|
| 328 |
+
|
| 329 |
+
if self.use_ada_layer_norm_zero:
|
| 330 |
+
attn_output = gate_msa.unsqueeze(1) * attn_output
|
| 331 |
+
hidden_states = attn_output + hidden_states
|
| 332 |
+
|
| 333 |
+
if self.attn2 is not None:
|
| 334 |
+
norm_hidden_states = (
|
| 335 |
+
self.norm2(hidden_states, timestep)
|
| 336 |
+
if self.use_ada_layer_norm
|
| 337 |
+
else self.norm2(hidden_states)
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
# 2. Cross-Attention
|
| 341 |
+
tmp = norm_hidden_states.shape[0] // encoder_hidden_states.shape[0]
|
| 342 |
+
attn_output = self.attn2(
|
| 343 |
+
norm_hidden_states,
|
| 344 |
+
# TODO: repeat这个地方需要斟酌一下
|
| 345 |
+
encoder_hidden_states=encoder_hidden_states.repeat(
|
| 346 |
+
tmp, 1, 1),
|
| 347 |
+
attention_mask=encoder_attention_mask,
|
| 348 |
+
**cross_attention_kwargs,
|
| 349 |
+
)
|
| 350 |
+
hidden_states = attn_output + hidden_states
|
| 351 |
+
|
| 352 |
+
# 3. Feed-forward
|
| 353 |
+
norm_hidden_states = self.norm3(hidden_states)
|
| 354 |
+
|
| 355 |
+
if self.use_ada_layer_norm_zero:
|
| 356 |
+
norm_hidden_states = (
|
| 357 |
+
norm_hidden_states *
|
| 358 |
+
(1 + scale_mlp[:, None]) + shift_mlp[:, None]
|
| 359 |
+
)
|
| 360 |
+
|
| 361 |
+
ff_output = self.ff(norm_hidden_states)
|
| 362 |
+
|
| 363 |
+
if self.use_ada_layer_norm_zero:
|
| 364 |
+
ff_output = gate_mlp.unsqueeze(1) * ff_output
|
| 365 |
+
|
| 366 |
+
hidden_states = ff_output + hidden_states
|
| 367 |
+
|
| 368 |
+
return hidden_states
|
| 369 |
+
|
| 370 |
+
if self.reference_attn:
|
| 371 |
+
if self.fusion_blocks == "midup":
|
| 372 |
+
attn_modules = [
|
| 373 |
+
module
|
| 374 |
+
for module in (
|
| 375 |
+
torch_dfs(self.unet.mid_block) +
|
| 376 |
+
torch_dfs(self.unet.up_blocks)
|
| 377 |
+
)
|
| 378 |
+
if isinstance(module, (BasicTransformerBlock, TemporalBasicTransformerBlock))
|
| 379 |
+
]
|
| 380 |
+
elif self.fusion_blocks == "full":
|
| 381 |
+
attn_modules = [
|
| 382 |
+
module
|
| 383 |
+
for module in torch_dfs(self.unet)
|
| 384 |
+
if isinstance(module, (BasicTransformerBlock, TemporalBasicTransformerBlock))
|
| 385 |
+
]
|
| 386 |
+
attn_modules = sorted(
|
| 387 |
+
attn_modules, key=lambda x: -x.norm1.normalized_shape[0]
|
| 388 |
+
)
|
| 389 |
+
|
| 390 |
+
for i, module in enumerate(attn_modules):
|
| 391 |
+
module._original_inner_forward = module.forward
|
| 392 |
+
if isinstance(module, BasicTransformerBlock):
|
| 393 |
+
module.forward = hacked_basic_transformer_inner_forward.__get__(
|
| 394 |
+
module,
|
| 395 |
+
BasicTransformerBlock)
|
| 396 |
+
if isinstance(module, TemporalBasicTransformerBlock):
|
| 397 |
+
module.forward = hacked_basic_transformer_inner_forward.__get__(
|
| 398 |
+
module,
|
| 399 |
+
TemporalBasicTransformerBlock)
|
| 400 |
+
|
| 401 |
+
module.bank = []
|
| 402 |
+
module.attn_weight = float(i) / float(len(attn_modules))
|
| 403 |
+
|
| 404 |
+
def update(self, writer, dtype=torch.float16):
|
| 405 |
+
"""
|
| 406 |
+
Update the model's parameters.
|
| 407 |
+
|
| 408 |
+
Args:
|
| 409 |
+
writer (torch.nn.Module): The model's writer object.
|
| 410 |
+
dtype (torch.dtype, optional): The data type to be used for the update. Defaults to torch.float16.
|
| 411 |
+
|
| 412 |
+
Returns:
|
| 413 |
+
None.
|
| 414 |
+
"""
|
| 415 |
+
if self.reference_attn:
|
| 416 |
+
if self.fusion_blocks == "midup":
|
| 417 |
+
reader_attn_modules = [
|
| 418 |
+
module
|
| 419 |
+
for module in (
|
| 420 |
+
torch_dfs(self.unet.mid_block) +
|
| 421 |
+
torch_dfs(self.unet.up_blocks)
|
| 422 |
+
)
|
| 423 |
+
if isinstance(module, TemporalBasicTransformerBlock)
|
| 424 |
+
]
|
| 425 |
+
writer_attn_modules = [
|
| 426 |
+
module
|
| 427 |
+
for module in (
|
| 428 |
+
torch_dfs(writer.unet.mid_block)
|
| 429 |
+
+ torch_dfs(writer.unet.up_blocks)
|
| 430 |
+
)
|
| 431 |
+
if isinstance(module, BasicTransformerBlock)
|
| 432 |
+
]
|
| 433 |
+
elif self.fusion_blocks == "full":
|
| 434 |
+
reader_attn_modules = [
|
| 435 |
+
module
|
| 436 |
+
for module in torch_dfs(self.unet)
|
| 437 |
+
if isinstance(module, TemporalBasicTransformerBlock)
|
| 438 |
+
]
|
| 439 |
+
writer_attn_modules = [
|
| 440 |
+
module
|
| 441 |
+
for module in torch_dfs(writer.unet)
|
| 442 |
+
if isinstance(module, BasicTransformerBlock)
|
| 443 |
+
]
|
| 444 |
+
|
| 445 |
+
assert len(reader_attn_modules) == len(writer_attn_modules)
|
| 446 |
+
reader_attn_modules = sorted(
|
| 447 |
+
reader_attn_modules, key=lambda x: -x.norm1.normalized_shape[0]
|
| 448 |
+
)
|
| 449 |
+
writer_attn_modules = sorted(
|
| 450 |
+
writer_attn_modules, key=lambda x: -x.norm1.normalized_shape[0]
|
| 451 |
+
)
|
| 452 |
+
for r, w in zip(reader_attn_modules, writer_attn_modules):
|
| 453 |
+
r.bank = [v.clone().to(dtype) for v in w.bank]
|
| 454 |
+
|
| 455 |
+
|
| 456 |
+
def clear(self):
|
| 457 |
+
"""
|
| 458 |
+
Clears the attention bank of all reader attention modules.
|
| 459 |
+
|
| 460 |
+
This method is used when the `reference_attn` attribute is set to `True`.
|
| 461 |
+
It clears the attention bank of all reader attention modules inside the UNet
|
| 462 |
+
model based on the selected `fusion_blocks` mode.
|
| 463 |
+
|
| 464 |
+
If `fusion_blocks` is set to "midup", it searches for reader attention modules
|
| 465 |
+
in both the mid block and up blocks of the UNet model. If `fusion_blocks` is set
|
| 466 |
+
to "full", it searches for reader attention modules in the entire UNet model.
|
| 467 |
+
|
| 468 |
+
It sorts the reader attention modules by the number of neurons in their
|
| 469 |
+
`norm1.normalized_shape[0]` attribute in descending order. This sorting ensures
|
| 470 |
+
that the modules with more neurons are cleared first.
|
| 471 |
+
|
| 472 |
+
Finally, it iterates through the sorted list of reader attention modules and
|
| 473 |
+
calls the `clear()` method on each module's `bank` attribute to clear the
|
| 474 |
+
attention bank.
|
| 475 |
+
"""
|
| 476 |
+
if self.reference_attn:
|
| 477 |
+
if self.fusion_blocks == "midup":
|
| 478 |
+
reader_attn_modules = [
|
| 479 |
+
module
|
| 480 |
+
for module in (
|
| 481 |
+
torch_dfs(self.unet.mid_block) +
|
| 482 |
+
torch_dfs(self.unet.up_blocks)
|
| 483 |
+
)
|
| 484 |
+
if isinstance(module, (BasicTransformerBlock, TemporalBasicTransformerBlock))
|
| 485 |
+
]
|
| 486 |
+
elif self.fusion_blocks == "full":
|
| 487 |
+
reader_attn_modules = [
|
| 488 |
+
module
|
| 489 |
+
for module in torch_dfs(self.unet)
|
| 490 |
+
if isinstance(module, (BasicTransformerBlock, TemporalBasicTransformerBlock))
|
| 491 |
+
]
|
| 492 |
+
reader_attn_modules = sorted(
|
| 493 |
+
reader_attn_modules, key=lambda x: -x.norm1.normalized_shape[0]
|
| 494 |
+
)
|
| 495 |
+
for r in reader_attn_modules:
|
| 496 |
+
r.bank.clear()
|
hallo/models/resnet.py
ADDED
|
@@ -0,0 +1,435 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=E1120
|
| 2 |
+
# pylint: disable=E1102
|
| 3 |
+
# pylint: disable=W0237
|
| 4 |
+
|
| 5 |
+
# src/models/resnet.py
|
| 6 |
+
|
| 7 |
+
"""
|
| 8 |
+
This module defines various components used in the ResNet model, such as InflatedConv3D, InflatedGroupNorm,
|
| 9 |
+
Upsample3D, Downsample3D, ResnetBlock3D, and Mish activation function. These components are used to construct
|
| 10 |
+
a deep neural network model for image classification or other computer vision tasks.
|
| 11 |
+
|
| 12 |
+
Classes:
|
| 13 |
+
- InflatedConv3d: An inflated 3D convolutional layer, inheriting from nn.Conv2d.
|
| 14 |
+
- InflatedGroupNorm: An inflated group normalization layer, inheriting from nn.GroupNorm.
|
| 15 |
+
- Upsample3D: A 3D upsampling module, used to increase the resolution of the input tensor.
|
| 16 |
+
- Downsample3D: A 3D downsampling module, used to decrease the resolution of the input tensor.
|
| 17 |
+
- ResnetBlock3D: A 3D residual block, commonly used in ResNet architectures.
|
| 18 |
+
- Mish: A Mish activation function, which is a smooth, non-monotonic activation function.
|
| 19 |
+
|
| 20 |
+
To use this module, simply import the classes and functions you need and follow the instructions provided in
|
| 21 |
+
the respective class and function docstrings.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
import torch
|
| 25 |
+
import torch.nn.functional as F
|
| 26 |
+
from einops import rearrange
|
| 27 |
+
from torch import nn
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class InflatedConv3d(nn.Conv2d):
|
| 31 |
+
"""
|
| 32 |
+
InflatedConv3d is a class that inherits from torch.nn.Conv2d and overrides the forward method.
|
| 33 |
+
|
| 34 |
+
This class is used to perform 3D convolution on input tensor x. It is a specialized type of convolutional layer
|
| 35 |
+
commonly used in deep learning models for computer vision tasks. The main difference between a regular Conv2d and
|
| 36 |
+
InflatedConv3d is that InflatedConv3d is designed to handle 3D input tensors, which are typically the result of
|
| 37 |
+
inflating 2D convolutional layers to 3D for use in 3D deep learning tasks.
|
| 38 |
+
|
| 39 |
+
Attributes:
|
| 40 |
+
Same as torch.nn.Conv2d.
|
| 41 |
+
|
| 42 |
+
Methods:
|
| 43 |
+
forward(self, x):
|
| 44 |
+
Performs 3D convolution on the input tensor x using the InflatedConv3d layer.
|
| 45 |
+
|
| 46 |
+
Example:
|
| 47 |
+
conv_layer = InflatedConv3d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1)
|
| 48 |
+
output = conv_layer(input_tensor)
|
| 49 |
+
"""
|
| 50 |
+
def forward(self, x):
|
| 51 |
+
"""
|
| 52 |
+
Forward pass of the InflatedConv3d layer.
|
| 53 |
+
|
| 54 |
+
Args:
|
| 55 |
+
x (torch.Tensor): Input tensor to the layer.
|
| 56 |
+
|
| 57 |
+
Returns:
|
| 58 |
+
torch.Tensor: Output tensor after applying the InflatedConv3d layer.
|
| 59 |
+
"""
|
| 60 |
+
video_length = x.shape[2]
|
| 61 |
+
|
| 62 |
+
x = rearrange(x, "b c f h w -> (b f) c h w")
|
| 63 |
+
x = super().forward(x)
|
| 64 |
+
x = rearrange(x, "(b f) c h w -> b c f h w", f=video_length)
|
| 65 |
+
|
| 66 |
+
return x
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class InflatedGroupNorm(nn.GroupNorm):
|
| 70 |
+
"""
|
| 71 |
+
InflatedGroupNorm is a custom class that inherits from torch.nn.GroupNorm.
|
| 72 |
+
It is used to apply group normalization to 3D tensors.
|
| 73 |
+
|
| 74 |
+
Args:
|
| 75 |
+
num_groups (int): The number of groups to divide the channels into.
|
| 76 |
+
num_channels (int): The number of channels in the input tensor.
|
| 77 |
+
eps (float, optional): A small constant to add to the variance to avoid division by zero. Defaults to 1e-5.
|
| 78 |
+
affine (bool, optional): If True, the module has learnable affine parameters. Defaults to True.
|
| 79 |
+
|
| 80 |
+
Attributes:
|
| 81 |
+
weight (torch.Tensor): The learnable weight tensor for scale.
|
| 82 |
+
bias (torch.Tensor): The learnable bias tensor for shift.
|
| 83 |
+
|
| 84 |
+
Forward method:
|
| 85 |
+
x (torch.Tensor): Input tensor to be normalized.
|
| 86 |
+
return (torch.Tensor): Normalized tensor.
|
| 87 |
+
"""
|
| 88 |
+
def forward(self, x):
|
| 89 |
+
"""
|
| 90 |
+
Performs a forward pass through the CustomClassName.
|
| 91 |
+
|
| 92 |
+
:param x: Input tensor of shape (batch_size, channels, video_length, height, width).
|
| 93 |
+
:return: Output tensor of shape (batch_size, channels, video_length, height, width).
|
| 94 |
+
"""
|
| 95 |
+
video_length = x.shape[2]
|
| 96 |
+
|
| 97 |
+
x = rearrange(x, "b c f h w -> (b f) c h w")
|
| 98 |
+
x = super().forward(x)
|
| 99 |
+
x = rearrange(x, "(b f) c h w -> b c f h w", f=video_length)
|
| 100 |
+
|
| 101 |
+
return x
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
class Upsample3D(nn.Module):
|
| 105 |
+
"""
|
| 106 |
+
Upsample3D is a PyTorch module that upsamples a 3D tensor.
|
| 107 |
+
|
| 108 |
+
Args:
|
| 109 |
+
channels (int): The number of channels in the input tensor.
|
| 110 |
+
use_conv (bool): Whether to use a convolutional layer for upsampling.
|
| 111 |
+
use_conv_transpose (bool): Whether to use a transposed convolutional layer for upsampling.
|
| 112 |
+
out_channels (int): The number of channels in the output tensor.
|
| 113 |
+
name (str): The name of the convolutional layer.
|
| 114 |
+
"""
|
| 115 |
+
def __init__(
|
| 116 |
+
self,
|
| 117 |
+
channels,
|
| 118 |
+
use_conv=False,
|
| 119 |
+
use_conv_transpose=False,
|
| 120 |
+
out_channels=None,
|
| 121 |
+
name="conv",
|
| 122 |
+
):
|
| 123 |
+
super().__init__()
|
| 124 |
+
self.channels = channels
|
| 125 |
+
self.out_channels = out_channels or channels
|
| 126 |
+
self.use_conv = use_conv
|
| 127 |
+
self.use_conv_transpose = use_conv_transpose
|
| 128 |
+
self.name = name
|
| 129 |
+
|
| 130 |
+
if use_conv_transpose:
|
| 131 |
+
raise NotImplementedError
|
| 132 |
+
if use_conv:
|
| 133 |
+
self.conv = InflatedConv3d(self.channels, self.out_channels, 3, padding=1)
|
| 134 |
+
|
| 135 |
+
def forward(self, hidden_states, output_size=None):
|
| 136 |
+
"""
|
| 137 |
+
Forward pass of the Upsample3D class.
|
| 138 |
+
|
| 139 |
+
Args:
|
| 140 |
+
hidden_states (torch.Tensor): Input tensor to be upsampled.
|
| 141 |
+
output_size (tuple, optional): Desired output size of the upsampled tensor.
|
| 142 |
+
|
| 143 |
+
Returns:
|
| 144 |
+
torch.Tensor: Upsampled tensor.
|
| 145 |
+
|
| 146 |
+
Raises:
|
| 147 |
+
AssertionError: If the number of channels in the input tensor does not match the expected channels.
|
| 148 |
+
"""
|
| 149 |
+
assert hidden_states.shape[1] == self.channels
|
| 150 |
+
|
| 151 |
+
if self.use_conv_transpose:
|
| 152 |
+
raise NotImplementedError
|
| 153 |
+
|
| 154 |
+
# Cast to float32 to as 'upsample_nearest2d_out_frame' op does not support bfloat16
|
| 155 |
+
dtype = hidden_states.dtype
|
| 156 |
+
if dtype == torch.bfloat16:
|
| 157 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 158 |
+
|
| 159 |
+
# upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
|
| 160 |
+
if hidden_states.shape[0] >= 64:
|
| 161 |
+
hidden_states = hidden_states.contiguous()
|
| 162 |
+
|
| 163 |
+
# if `output_size` is passed we force the interpolation output
|
| 164 |
+
# size and do not make use of `scale_factor=2`
|
| 165 |
+
if output_size is None:
|
| 166 |
+
hidden_states = F.interpolate(
|
| 167 |
+
hidden_states, scale_factor=[1.0, 2.0, 2.0], mode="nearest"
|
| 168 |
+
)
|
| 169 |
+
else:
|
| 170 |
+
hidden_states = F.interpolate(
|
| 171 |
+
hidden_states, size=output_size, mode="nearest"
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
# If the input is bfloat16, we cast back to bfloat16
|
| 175 |
+
if dtype == torch.bfloat16:
|
| 176 |
+
hidden_states = hidden_states.to(dtype)
|
| 177 |
+
|
| 178 |
+
# if self.use_conv:
|
| 179 |
+
# if self.name == "conv":
|
| 180 |
+
# hidden_states = self.conv(hidden_states)
|
| 181 |
+
# else:
|
| 182 |
+
# hidden_states = self.Conv2d_0(hidden_states)
|
| 183 |
+
hidden_states = self.conv(hidden_states)
|
| 184 |
+
|
| 185 |
+
return hidden_states
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
class Downsample3D(nn.Module):
|
| 189 |
+
"""
|
| 190 |
+
The Downsample3D class is a PyTorch module for downsampling a 3D tensor, which is used to
|
| 191 |
+
reduce the spatial resolution of feature maps, commonly in the encoder part of a neural network.
|
| 192 |
+
|
| 193 |
+
Attributes:
|
| 194 |
+
channels (int): Number of input channels.
|
| 195 |
+
use_conv (bool): Flag to use a convolutional layer for downsampling.
|
| 196 |
+
out_channels (int, optional): Number of output channels. Defaults to input channels if None.
|
| 197 |
+
padding (int): Padding added to the input.
|
| 198 |
+
name (str): Name of the convolutional layer used for downsampling.
|
| 199 |
+
|
| 200 |
+
Methods:
|
| 201 |
+
forward(self, hidden_states):
|
| 202 |
+
Downsamples the input tensor hidden_states and returns the downsampled tensor.
|
| 203 |
+
"""
|
| 204 |
+
def __init__(
|
| 205 |
+
self, channels, use_conv=False, out_channels=None, padding=1, name="conv"
|
| 206 |
+
):
|
| 207 |
+
"""
|
| 208 |
+
Downsamples the given input in the 3D space.
|
| 209 |
+
|
| 210 |
+
Args:
|
| 211 |
+
channels: The number of input channels.
|
| 212 |
+
use_conv: Whether to use a convolutional layer for downsampling.
|
| 213 |
+
out_channels: The number of output channels. If None, the input channels are used.
|
| 214 |
+
padding: The amount of padding to be added to the input.
|
| 215 |
+
name: The name of the convolutional layer.
|
| 216 |
+
"""
|
| 217 |
+
super().__init__()
|
| 218 |
+
self.channels = channels
|
| 219 |
+
self.out_channels = out_channels or channels
|
| 220 |
+
self.use_conv = use_conv
|
| 221 |
+
self.padding = padding
|
| 222 |
+
stride = 2
|
| 223 |
+
self.name = name
|
| 224 |
+
|
| 225 |
+
if use_conv:
|
| 226 |
+
self.conv = InflatedConv3d(
|
| 227 |
+
self.channels, self.out_channels, 3, stride=stride, padding=padding
|
| 228 |
+
)
|
| 229 |
+
else:
|
| 230 |
+
raise NotImplementedError
|
| 231 |
+
|
| 232 |
+
def forward(self, hidden_states):
|
| 233 |
+
"""
|
| 234 |
+
Forward pass for the Downsample3D class.
|
| 235 |
+
|
| 236 |
+
Args:
|
| 237 |
+
hidden_states (torch.Tensor): Input tensor to be downsampled.
|
| 238 |
+
|
| 239 |
+
Returns:
|
| 240 |
+
torch.Tensor: Downsampled tensor.
|
| 241 |
+
|
| 242 |
+
Raises:
|
| 243 |
+
AssertionError: If the number of channels in the input tensor does not match the expected channels.
|
| 244 |
+
"""
|
| 245 |
+
assert hidden_states.shape[1] == self.channels
|
| 246 |
+
if self.use_conv and self.padding == 0:
|
| 247 |
+
raise NotImplementedError
|
| 248 |
+
|
| 249 |
+
assert hidden_states.shape[1] == self.channels
|
| 250 |
+
hidden_states = self.conv(hidden_states)
|
| 251 |
+
|
| 252 |
+
return hidden_states
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
class ResnetBlock3D(nn.Module):
|
| 256 |
+
"""
|
| 257 |
+
The ResnetBlock3D class defines a 3D residual block, a common building block in ResNet
|
| 258 |
+
architectures for both image and video modeling tasks.
|
| 259 |
+
|
| 260 |
+
Attributes:
|
| 261 |
+
in_channels (int): Number of input channels.
|
| 262 |
+
out_channels (int, optional): Number of output channels, defaults to in_channels if None.
|
| 263 |
+
conv_shortcut (bool): Flag to use a convolutional shortcut.
|
| 264 |
+
dropout (float): Dropout rate.
|
| 265 |
+
temb_channels (int): Number of channels in the time embedding tensor.
|
| 266 |
+
groups (int): Number of groups for the group normalization layers.
|
| 267 |
+
eps (float): Epsilon value for group normalization.
|
| 268 |
+
non_linearity (str): Type of nonlinearity to apply after convolutions.
|
| 269 |
+
time_embedding_norm (str): Type of normalization for the time embedding.
|
| 270 |
+
output_scale_factor (float): Scaling factor for the output tensor.
|
| 271 |
+
use_in_shortcut (bool): Flag to include the input tensor in the shortcut connection.
|
| 272 |
+
use_inflated_groupnorm (bool): Flag to use inflated group normalization layers.
|
| 273 |
+
|
| 274 |
+
Methods:
|
| 275 |
+
forward(self, input_tensor, temb):
|
| 276 |
+
Passes the input tensor and time embedding through the residual block and
|
| 277 |
+
returns the output tensor.
|
| 278 |
+
"""
|
| 279 |
+
def __init__(
|
| 280 |
+
self,
|
| 281 |
+
*,
|
| 282 |
+
in_channels,
|
| 283 |
+
out_channels=None,
|
| 284 |
+
conv_shortcut=False,
|
| 285 |
+
dropout=0.0,
|
| 286 |
+
temb_channels=512,
|
| 287 |
+
groups=32,
|
| 288 |
+
groups_out=None,
|
| 289 |
+
pre_norm=True,
|
| 290 |
+
eps=1e-6,
|
| 291 |
+
non_linearity="swish",
|
| 292 |
+
time_embedding_norm="default",
|
| 293 |
+
output_scale_factor=1.0,
|
| 294 |
+
use_in_shortcut=None,
|
| 295 |
+
use_inflated_groupnorm=None,
|
| 296 |
+
):
|
| 297 |
+
super().__init__()
|
| 298 |
+
self.pre_norm = pre_norm
|
| 299 |
+
self.pre_norm = True
|
| 300 |
+
self.in_channels = in_channels
|
| 301 |
+
out_channels = in_channels if out_channels is None else out_channels
|
| 302 |
+
self.out_channels = out_channels
|
| 303 |
+
self.use_conv_shortcut = conv_shortcut
|
| 304 |
+
self.time_embedding_norm = time_embedding_norm
|
| 305 |
+
self.output_scale_factor = output_scale_factor
|
| 306 |
+
|
| 307 |
+
if groups_out is None:
|
| 308 |
+
groups_out = groups
|
| 309 |
+
|
| 310 |
+
assert use_inflated_groupnorm is not None
|
| 311 |
+
if use_inflated_groupnorm:
|
| 312 |
+
self.norm1 = InflatedGroupNorm(
|
| 313 |
+
num_groups=groups, num_channels=in_channels, eps=eps, affine=True
|
| 314 |
+
)
|
| 315 |
+
else:
|
| 316 |
+
self.norm1 = torch.nn.GroupNorm(
|
| 317 |
+
num_groups=groups, num_channels=in_channels, eps=eps, affine=True
|
| 318 |
+
)
|
| 319 |
+
|
| 320 |
+
self.conv1 = InflatedConv3d(
|
| 321 |
+
in_channels, out_channels, kernel_size=3, stride=1, padding=1
|
| 322 |
+
)
|
| 323 |
+
|
| 324 |
+
if temb_channels is not None:
|
| 325 |
+
if self.time_embedding_norm == "default":
|
| 326 |
+
time_emb_proj_out_channels = out_channels
|
| 327 |
+
elif self.time_embedding_norm == "scale_shift":
|
| 328 |
+
time_emb_proj_out_channels = out_channels * 2
|
| 329 |
+
else:
|
| 330 |
+
raise ValueError(
|
| 331 |
+
f"unknown time_embedding_norm : {self.time_embedding_norm} "
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
self.time_emb_proj = torch.nn.Linear(
|
| 335 |
+
temb_channels, time_emb_proj_out_channels
|
| 336 |
+
)
|
| 337 |
+
else:
|
| 338 |
+
self.time_emb_proj = None
|
| 339 |
+
|
| 340 |
+
if use_inflated_groupnorm:
|
| 341 |
+
self.norm2 = InflatedGroupNorm(
|
| 342 |
+
num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True
|
| 343 |
+
)
|
| 344 |
+
else:
|
| 345 |
+
self.norm2 = torch.nn.GroupNorm(
|
| 346 |
+
num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True
|
| 347 |
+
)
|
| 348 |
+
self.dropout = torch.nn.Dropout(dropout)
|
| 349 |
+
self.conv2 = InflatedConv3d(
|
| 350 |
+
out_channels, out_channels, kernel_size=3, stride=1, padding=1
|
| 351 |
+
)
|
| 352 |
+
|
| 353 |
+
if non_linearity == "swish":
|
| 354 |
+
self.nonlinearity = F.silu()
|
| 355 |
+
elif non_linearity == "mish":
|
| 356 |
+
self.nonlinearity = Mish()
|
| 357 |
+
elif non_linearity == "silu":
|
| 358 |
+
self.nonlinearity = nn.SiLU()
|
| 359 |
+
|
| 360 |
+
self.use_in_shortcut = (
|
| 361 |
+
self.in_channels != self.out_channels
|
| 362 |
+
if use_in_shortcut is None
|
| 363 |
+
else use_in_shortcut
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
self.conv_shortcut = None
|
| 367 |
+
if self.use_in_shortcut:
|
| 368 |
+
self.conv_shortcut = InflatedConv3d(
|
| 369 |
+
in_channels, out_channels, kernel_size=1, stride=1, padding=0
|
| 370 |
+
)
|
| 371 |
+
|
| 372 |
+
def forward(self, input_tensor, temb):
|
| 373 |
+
"""
|
| 374 |
+
Forward pass for the ResnetBlock3D class.
|
| 375 |
+
|
| 376 |
+
Args:
|
| 377 |
+
input_tensor (torch.Tensor): Input tensor to the ResnetBlock3D layer.
|
| 378 |
+
temb (torch.Tensor): Token embedding tensor.
|
| 379 |
+
|
| 380 |
+
Returns:
|
| 381 |
+
torch.Tensor: Output tensor after passing through the ResnetBlock3D layer.
|
| 382 |
+
"""
|
| 383 |
+
hidden_states = input_tensor
|
| 384 |
+
|
| 385 |
+
hidden_states = self.norm1(hidden_states)
|
| 386 |
+
hidden_states = self.nonlinearity(hidden_states)
|
| 387 |
+
|
| 388 |
+
hidden_states = self.conv1(hidden_states)
|
| 389 |
+
|
| 390 |
+
if temb is not None:
|
| 391 |
+
temb = self.time_emb_proj(self.nonlinearity(temb))[:, :, None, None, None]
|
| 392 |
+
|
| 393 |
+
if temb is not None and self.time_embedding_norm == "default":
|
| 394 |
+
hidden_states = hidden_states + temb
|
| 395 |
+
|
| 396 |
+
hidden_states = self.norm2(hidden_states)
|
| 397 |
+
|
| 398 |
+
if temb is not None and self.time_embedding_norm == "scale_shift":
|
| 399 |
+
scale, shift = torch.chunk(temb, 2, dim=1)
|
| 400 |
+
hidden_states = hidden_states * (1 + scale) + shift
|
| 401 |
+
|
| 402 |
+
hidden_states = self.nonlinearity(hidden_states)
|
| 403 |
+
|
| 404 |
+
hidden_states = self.dropout(hidden_states)
|
| 405 |
+
hidden_states = self.conv2(hidden_states)
|
| 406 |
+
|
| 407 |
+
if self.conv_shortcut is not None:
|
| 408 |
+
input_tensor = self.conv_shortcut(input_tensor)
|
| 409 |
+
|
| 410 |
+
output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
|
| 411 |
+
|
| 412 |
+
return output_tensor
|
| 413 |
+
|
| 414 |
+
|
| 415 |
+
class Mish(torch.nn.Module):
|
| 416 |
+
"""
|
| 417 |
+
The Mish class implements the Mish activation function, a smooth, non-monotonic function
|
| 418 |
+
that can be used in neural networks as an alternative to traditional activation functions like ReLU.
|
| 419 |
+
|
| 420 |
+
Methods:
|
| 421 |
+
forward(self, hidden_states):
|
| 422 |
+
Applies the Mish activation function to the input tensor hidden_states and
|
| 423 |
+
returns the resulting tensor.
|
| 424 |
+
"""
|
| 425 |
+
def forward(self, hidden_states):
|
| 426 |
+
"""
|
| 427 |
+
Mish activation function.
|
| 428 |
+
|
| 429 |
+
Args:
|
| 430 |
+
hidden_states (torch.Tensor): The input tensor to apply the Mish activation function to.
|
| 431 |
+
|
| 432 |
+
Returns:
|
| 433 |
+
hidden_states (torch.Tensor): The output tensor after applying the Mish activation function.
|
| 434 |
+
"""
|
| 435 |
+
return hidden_states * torch.tanh(torch.nn.functional.softplus(hidden_states))
|
hallo/models/transformer_2d.py
ADDED
|
@@ -0,0 +1,431 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=E1101
|
| 2 |
+
# src/models/transformer_2d.py
|
| 3 |
+
|
| 4 |
+
"""
|
| 5 |
+
This module defines the Transformer2DModel, a PyTorch model that extends ModelMixin and ConfigMixin. It includes
|
| 6 |
+
methods for gradient checkpointing, forward propagation, and various utility functions. The model is designed for
|
| 7 |
+
2D image-related tasks and uses LoRa (Low-Rank All-Attention) compatible layers for efficient attention computation.
|
| 8 |
+
|
| 9 |
+
The file includes the following import statements:
|
| 10 |
+
|
| 11 |
+
- From dataclasses import dataclass
|
| 12 |
+
- From typing import Any, Dict, Optional
|
| 13 |
+
- Import torch
|
| 14 |
+
- From diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 15 |
+
- From diffusers.models.lora import LoRACompatibleConv, LoRACompatibleLinear
|
| 16 |
+
- From diffusers.models.modeling_utils import ModelMixin
|
| 17 |
+
- From diffusers.models.normalization import AdaLayerNormSingle
|
| 18 |
+
- From diffusers.utils import (USE_PEFT_BACKEND, BaseOutput, deprecate,
|
| 19 |
+
is_torch_version)
|
| 20 |
+
- From torch import nn
|
| 21 |
+
- From .attention import BasicTransformerBlock
|
| 22 |
+
|
| 23 |
+
The file also includes the following classes and functions:
|
| 24 |
+
|
| 25 |
+
- Transformer2DModel: A model class that extends ModelMixin and ConfigMixin. It includes methods for gradient
|
| 26 |
+
checkpointing, forward propagation, and various utility functions.
|
| 27 |
+
- _set_gradient_checkpointing: A utility function to set gradient checkpointing for a given module.
|
| 28 |
+
- forward: The forward propagation method for the Transformer2DModel.
|
| 29 |
+
|
| 30 |
+
To use this module, you can import the Transformer2DModel class and create an instance of the model with the desired
|
| 31 |
+
configuration. Then, you can use the forward method to pass input tensors through the model and get the output tensors.
|
| 32 |
+
"""
|
| 33 |
+
|
| 34 |
+
from dataclasses import dataclass
|
| 35 |
+
from typing import Any, Dict, Optional
|
| 36 |
+
|
| 37 |
+
import torch
|
| 38 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 39 |
+
# from diffusers.models.embeddings import CaptionProjection
|
| 40 |
+
from diffusers.models.lora import LoRACompatibleConv, LoRACompatibleLinear
|
| 41 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 42 |
+
from diffusers.models.normalization import AdaLayerNormSingle
|
| 43 |
+
from diffusers.utils import (USE_PEFT_BACKEND, BaseOutput, deprecate,
|
| 44 |
+
is_torch_version)
|
| 45 |
+
from torch import nn
|
| 46 |
+
|
| 47 |
+
from .attention import BasicTransformerBlock
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
@dataclass
|
| 51 |
+
class Transformer2DModelOutput(BaseOutput):
|
| 52 |
+
"""
|
| 53 |
+
The output of [`Transformer2DModel`].
|
| 54 |
+
|
| 55 |
+
Args:
|
| 56 |
+
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`
|
| 57 |
+
or `(batch size, num_vector_embeds - 1, num_latent_pixels)` if [`Transformer2DModel`] is discrete):
|
| 58 |
+
The hidden states output conditioned on the `encoder_hidden_states` input. If discrete, returns probability
|
| 59 |
+
distributions for the unnoised latent pixels.
|
| 60 |
+
"""
|
| 61 |
+
|
| 62 |
+
sample: torch.FloatTensor
|
| 63 |
+
ref_feature: torch.FloatTensor
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
class Transformer2DModel(ModelMixin, ConfigMixin):
|
| 67 |
+
"""
|
| 68 |
+
A 2D Transformer model for image-like data.
|
| 69 |
+
|
| 70 |
+
Parameters:
|
| 71 |
+
num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
|
| 72 |
+
attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
|
| 73 |
+
in_channels (`int`, *optional*):
|
| 74 |
+
The number of channels in the input and output (specify if the input is **continuous**).
|
| 75 |
+
num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
|
| 76 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 77 |
+
cross_attention_dim (`int`, *optional*): The number of `encoder_hidden_states` dimensions to use.
|
| 78 |
+
sample_size (`int`, *optional*): The width of the latent images (specify if the input is **discrete**).
|
| 79 |
+
This is fixed during training since it is used to learn a number of position embeddings.
|
| 80 |
+
num_vector_embeds (`int`, *optional*):
|
| 81 |
+
The number of classes of the vector embeddings of the latent pixels (specify if the input is **discrete**).
|
| 82 |
+
Includes the class for the masked latent pixel.
|
| 83 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to use in feed-forward.
|
| 84 |
+
num_embeds_ada_norm ( `int`, *optional*):
|
| 85 |
+
The number of diffusion steps used during training. Pass if at least one of the norm_layers is
|
| 86 |
+
`AdaLayerNorm`. This is fixed during training since it is used to learn a number of embeddings that are
|
| 87 |
+
added to the hidden states.
|
| 88 |
+
|
| 89 |
+
During inference, you can denoise for up to but not more steps than `num_embeds_ada_norm`.
|
| 90 |
+
attention_bias (`bool`, *optional*):
|
| 91 |
+
Configure if the `TransformerBlocks` attention should contain a bias parameter.
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
_supports_gradient_checkpointing = True
|
| 95 |
+
|
| 96 |
+
@register_to_config
|
| 97 |
+
def __init__(
|
| 98 |
+
self,
|
| 99 |
+
num_attention_heads: int = 16,
|
| 100 |
+
attention_head_dim: int = 88,
|
| 101 |
+
in_channels: Optional[int] = None,
|
| 102 |
+
out_channels: Optional[int] = None,
|
| 103 |
+
num_layers: int = 1,
|
| 104 |
+
dropout: float = 0.0,
|
| 105 |
+
norm_num_groups: int = 32,
|
| 106 |
+
cross_attention_dim: Optional[int] = None,
|
| 107 |
+
attention_bias: bool = False,
|
| 108 |
+
num_vector_embeds: Optional[int] = None,
|
| 109 |
+
patch_size: Optional[int] = None,
|
| 110 |
+
activation_fn: str = "geglu",
|
| 111 |
+
num_embeds_ada_norm: Optional[int] = None,
|
| 112 |
+
use_linear_projection: bool = False,
|
| 113 |
+
only_cross_attention: bool = False,
|
| 114 |
+
double_self_attention: bool = False,
|
| 115 |
+
upcast_attention: bool = False,
|
| 116 |
+
norm_type: str = "layer_norm",
|
| 117 |
+
norm_elementwise_affine: bool = True,
|
| 118 |
+
norm_eps: float = 1e-5,
|
| 119 |
+
attention_type: str = "default",
|
| 120 |
+
):
|
| 121 |
+
super().__init__()
|
| 122 |
+
self.use_linear_projection = use_linear_projection
|
| 123 |
+
self.num_attention_heads = num_attention_heads
|
| 124 |
+
self.attention_head_dim = attention_head_dim
|
| 125 |
+
inner_dim = num_attention_heads * attention_head_dim
|
| 126 |
+
|
| 127 |
+
conv_cls = nn.Conv2d if USE_PEFT_BACKEND else LoRACompatibleConv
|
| 128 |
+
linear_cls = nn.Linear if USE_PEFT_BACKEND else LoRACompatibleLinear
|
| 129 |
+
|
| 130 |
+
# 1. Transformer2DModel can process both standard continuous images of
|
| 131 |
+
# shape `(batch_size, num_channels, width, height)` as well as quantized image embeddings of
|
| 132 |
+
# shape `(batch_size, num_image_vectors)`
|
| 133 |
+
# Define whether input is continuous or discrete depending on configuration
|
| 134 |
+
self.is_input_continuous = (in_channels is not None) and (patch_size is None)
|
| 135 |
+
self.is_input_vectorized = num_vector_embeds is not None
|
| 136 |
+
self.is_input_patches = in_channels is not None and patch_size is not None
|
| 137 |
+
|
| 138 |
+
if norm_type == "layer_norm" and num_embeds_ada_norm is not None:
|
| 139 |
+
deprecation_message = (
|
| 140 |
+
f"The configuration file of this model: {self.__class__} is outdated. `norm_type` is either not set or"
|
| 141 |
+
" incorrectly set to `'layer_norm'`.Make sure to set `norm_type` to `'ada_norm'` in the config."
|
| 142 |
+
" Please make sure to update the config accordingly as leaving `norm_type` might led to incorrect"
|
| 143 |
+
" results in future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it"
|
| 144 |
+
" would be very nice if you could open a Pull request for the `transformer/config.json` file"
|
| 145 |
+
)
|
| 146 |
+
deprecate(
|
| 147 |
+
"norm_type!=num_embeds_ada_norm",
|
| 148 |
+
"1.0.0",
|
| 149 |
+
deprecation_message,
|
| 150 |
+
standard_warn=False,
|
| 151 |
+
)
|
| 152 |
+
norm_type = "ada_norm"
|
| 153 |
+
|
| 154 |
+
if self.is_input_continuous and self.is_input_vectorized:
|
| 155 |
+
raise ValueError(
|
| 156 |
+
f"Cannot define both `in_channels`: {in_channels} and `num_vector_embeds`: {num_vector_embeds}. Make"
|
| 157 |
+
" sure that either `in_channels` or `num_vector_embeds` is None."
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
if self.is_input_vectorized and self.is_input_patches:
|
| 161 |
+
raise ValueError(
|
| 162 |
+
f"Cannot define both `num_vector_embeds`: {num_vector_embeds} and `patch_size`: {patch_size}. Make"
|
| 163 |
+
" sure that either `num_vector_embeds` or `num_patches` is None."
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
if (
|
| 167 |
+
not self.is_input_continuous
|
| 168 |
+
and not self.is_input_vectorized
|
| 169 |
+
and not self.is_input_patches
|
| 170 |
+
):
|
| 171 |
+
raise ValueError(
|
| 172 |
+
f"Has to define `in_channels`: {in_channels}, `num_vector_embeds`: {num_vector_embeds}, or patch_size:"
|
| 173 |
+
f" {patch_size}. Make sure that `in_channels`, `num_vector_embeds` or `num_patches` is not None."
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
# 2. Define input layers
|
| 177 |
+
self.in_channels = in_channels
|
| 178 |
+
|
| 179 |
+
self.norm = torch.nn.GroupNorm(
|
| 180 |
+
num_groups=norm_num_groups,
|
| 181 |
+
num_channels=in_channels,
|
| 182 |
+
eps=1e-6,
|
| 183 |
+
affine=True,
|
| 184 |
+
)
|
| 185 |
+
if use_linear_projection:
|
| 186 |
+
self.proj_in = linear_cls(in_channels, inner_dim)
|
| 187 |
+
else:
|
| 188 |
+
self.proj_in = conv_cls(
|
| 189 |
+
in_channels, inner_dim, kernel_size=1, stride=1, padding=0
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
# 3. Define transformers blocks
|
| 193 |
+
self.transformer_blocks = nn.ModuleList(
|
| 194 |
+
[
|
| 195 |
+
BasicTransformerBlock(
|
| 196 |
+
inner_dim,
|
| 197 |
+
num_attention_heads,
|
| 198 |
+
attention_head_dim,
|
| 199 |
+
dropout=dropout,
|
| 200 |
+
cross_attention_dim=cross_attention_dim,
|
| 201 |
+
activation_fn=activation_fn,
|
| 202 |
+
num_embeds_ada_norm=num_embeds_ada_norm,
|
| 203 |
+
attention_bias=attention_bias,
|
| 204 |
+
only_cross_attention=only_cross_attention,
|
| 205 |
+
double_self_attention=double_self_attention,
|
| 206 |
+
upcast_attention=upcast_attention,
|
| 207 |
+
norm_type=norm_type,
|
| 208 |
+
norm_elementwise_affine=norm_elementwise_affine,
|
| 209 |
+
norm_eps=norm_eps,
|
| 210 |
+
attention_type=attention_type,
|
| 211 |
+
)
|
| 212 |
+
for d in range(num_layers)
|
| 213 |
+
]
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
# 4. Define output layers
|
| 217 |
+
self.out_channels = in_channels if out_channels is None else out_channels
|
| 218 |
+
# TODO: should use out_channels for continuous projections
|
| 219 |
+
if use_linear_projection:
|
| 220 |
+
self.proj_out = linear_cls(inner_dim, in_channels)
|
| 221 |
+
else:
|
| 222 |
+
self.proj_out = conv_cls(
|
| 223 |
+
inner_dim, in_channels, kernel_size=1, stride=1, padding=0
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
# 5. PixArt-Alpha blocks.
|
| 227 |
+
self.adaln_single = None
|
| 228 |
+
self.use_additional_conditions = False
|
| 229 |
+
if norm_type == "ada_norm_single":
|
| 230 |
+
self.use_additional_conditions = self.config.sample_size == 128
|
| 231 |
+
# TODO(Sayak, PVP) clean this, for now we use sample size to determine whether to use
|
| 232 |
+
# additional conditions until we find better name
|
| 233 |
+
self.adaln_single = AdaLayerNormSingle(
|
| 234 |
+
inner_dim, use_additional_conditions=self.use_additional_conditions
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
self.caption_projection = None
|
| 238 |
+
|
| 239 |
+
self.gradient_checkpointing = False
|
| 240 |
+
|
| 241 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 242 |
+
if hasattr(module, "gradient_checkpointing"):
|
| 243 |
+
module.gradient_checkpointing = value
|
| 244 |
+
|
| 245 |
+
def forward(
|
| 246 |
+
self,
|
| 247 |
+
hidden_states: torch.Tensor,
|
| 248 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 249 |
+
timestep: Optional[torch.LongTensor] = None,
|
| 250 |
+
_added_cond_kwargs: Dict[str, torch.Tensor] = None,
|
| 251 |
+
class_labels: Optional[torch.LongTensor] = None,
|
| 252 |
+
cross_attention_kwargs: Dict[str, Any] = None,
|
| 253 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 254 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 255 |
+
return_dict: bool = True,
|
| 256 |
+
):
|
| 257 |
+
"""
|
| 258 |
+
The [`Transformer2DModel`] forward method.
|
| 259 |
+
|
| 260 |
+
Args:
|
| 261 |
+
hidden_states (`torch.LongTensor` of shape `(batch size, num latent pixels)` if discrete,
|
| 262 |
+
`torch.FloatTensor` of shape `(batch size, channel, height, width)` if continuous):
|
| 263 |
+
Input `hidden_states`.
|
| 264 |
+
encoder_hidden_states ( `torch.FloatTensor` of shape `(batch size, sequence len, embed dims)`, *optional*):
|
| 265 |
+
Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
|
| 266 |
+
self-attention.
|
| 267 |
+
timestep ( `torch.LongTensor`, *optional*):
|
| 268 |
+
Used to indicate denoising step. Optional timestep to be applied as an embedding in `AdaLayerNorm`.
|
| 269 |
+
class_labels ( `torch.LongTensor` of shape `(batch size, num classes)`, *optional*):
|
| 270 |
+
Used to indicate class labels conditioning. Optional class labels to be applied as an embedding in
|
| 271 |
+
`AdaLayerZeroNorm`.
|
| 272 |
+
cross_attention_kwargs ( `Dict[str, Any]`, *optional*):
|
| 273 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 274 |
+
`self.processor` in
|
| 275 |
+
[diffusers.models.attention_processor]
|
| 276 |
+
(https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 277 |
+
attention_mask ( `torch.Tensor`, *optional*):
|
| 278 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 279 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 280 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 281 |
+
encoder_attention_mask ( `torch.Tensor`, *optional*):
|
| 282 |
+
Cross-attention mask applied to `encoder_hidden_states`. Two formats supported:
|
| 283 |
+
|
| 284 |
+
* Mask `(batch, sequence_length)` True = keep, False = discard.
|
| 285 |
+
* Bias `(batch, 1, sequence_length)` 0 = keep, -10000 = discard.
|
| 286 |
+
|
| 287 |
+
If `ndim == 2`: will be interpreted as a mask, then converted into a bias consistent with the format
|
| 288 |
+
above. This bias will be added to the cross-attention scores.
|
| 289 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 290 |
+
Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
|
| 291 |
+
tuple.
|
| 292 |
+
|
| 293 |
+
Returns:
|
| 294 |
+
If `return_dict` is True, an [`~models.transformer_2d.Transformer2DModelOutput`] is returned, otherwise a
|
| 295 |
+
`tuple` where the first element is the sample tensor.
|
| 296 |
+
"""
|
| 297 |
+
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension.
|
| 298 |
+
# we may have done this conversion already, e.g. if we came here via UNet2DConditionModel#forward.
|
| 299 |
+
# we can tell by counting dims; if ndim == 2: it's a mask rather than a bias.
|
| 300 |
+
# expects mask of shape:
|
| 301 |
+
# [batch, key_tokens]
|
| 302 |
+
# adds singleton query_tokens dimension:
|
| 303 |
+
# [batch, 1, key_tokens]
|
| 304 |
+
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
| 305 |
+
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
| 306 |
+
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
| 307 |
+
if attention_mask is not None and attention_mask.ndim == 2:
|
| 308 |
+
# assume that mask is expressed as:
|
| 309 |
+
# (1 = keep, 0 = discard)
|
| 310 |
+
# convert mask into a bias that can be added to attention scores:
|
| 311 |
+
# (keep = +0, discard = -10000.0)
|
| 312 |
+
attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0
|
| 313 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 314 |
+
|
| 315 |
+
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
| 316 |
+
if encoder_attention_mask is not None and encoder_attention_mask.ndim == 2:
|
| 317 |
+
encoder_attention_mask = (
|
| 318 |
+
1 - encoder_attention_mask.to(hidden_states.dtype)
|
| 319 |
+
) * -10000.0
|
| 320 |
+
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
| 321 |
+
|
| 322 |
+
# Retrieve lora scale.
|
| 323 |
+
lora_scale = (
|
| 324 |
+
cross_attention_kwargs.get("scale", 1.0)
|
| 325 |
+
if cross_attention_kwargs is not None
|
| 326 |
+
else 1.0
|
| 327 |
+
)
|
| 328 |
+
|
| 329 |
+
# 1. Input
|
| 330 |
+
batch, _, height, width = hidden_states.shape
|
| 331 |
+
residual = hidden_states
|
| 332 |
+
|
| 333 |
+
hidden_states = self.norm(hidden_states)
|
| 334 |
+
if not self.use_linear_projection:
|
| 335 |
+
hidden_states = (
|
| 336 |
+
self.proj_in(hidden_states, scale=lora_scale)
|
| 337 |
+
if not USE_PEFT_BACKEND
|
| 338 |
+
else self.proj_in(hidden_states)
|
| 339 |
+
)
|
| 340 |
+
inner_dim = hidden_states.shape[1]
|
| 341 |
+
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(
|
| 342 |
+
batch, height * width, inner_dim
|
| 343 |
+
)
|
| 344 |
+
else:
|
| 345 |
+
inner_dim = hidden_states.shape[1]
|
| 346 |
+
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(
|
| 347 |
+
batch, height * width, inner_dim
|
| 348 |
+
)
|
| 349 |
+
hidden_states = (
|
| 350 |
+
self.proj_in(hidden_states, scale=lora_scale)
|
| 351 |
+
if not USE_PEFT_BACKEND
|
| 352 |
+
else self.proj_in(hidden_states)
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
# 2. Blocks
|
| 356 |
+
if self.caption_projection is not None:
|
| 357 |
+
batch_size = hidden_states.shape[0]
|
| 358 |
+
encoder_hidden_states = self.caption_projection(encoder_hidden_states)
|
| 359 |
+
encoder_hidden_states = encoder_hidden_states.view(
|
| 360 |
+
batch_size, -1, hidden_states.shape[-1]
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
ref_feature = hidden_states.reshape(batch, height, width, inner_dim)
|
| 364 |
+
for block in self.transformer_blocks:
|
| 365 |
+
if self.training and self.gradient_checkpointing:
|
| 366 |
+
|
| 367 |
+
def create_custom_forward(module, return_dict=None):
|
| 368 |
+
def custom_forward(*inputs):
|
| 369 |
+
if return_dict is not None:
|
| 370 |
+
return module(*inputs, return_dict=return_dict)
|
| 371 |
+
|
| 372 |
+
return module(*inputs)
|
| 373 |
+
|
| 374 |
+
return custom_forward
|
| 375 |
+
|
| 376 |
+
ckpt_kwargs: Dict[str, Any] = (
|
| 377 |
+
{"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 378 |
+
)
|
| 379 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 380 |
+
create_custom_forward(block),
|
| 381 |
+
hidden_states,
|
| 382 |
+
attention_mask,
|
| 383 |
+
encoder_hidden_states,
|
| 384 |
+
encoder_attention_mask,
|
| 385 |
+
timestep,
|
| 386 |
+
cross_attention_kwargs,
|
| 387 |
+
class_labels,
|
| 388 |
+
**ckpt_kwargs,
|
| 389 |
+
)
|
| 390 |
+
else:
|
| 391 |
+
hidden_states = block(
|
| 392 |
+
hidden_states, # shape [5, 4096, 320]
|
| 393 |
+
attention_mask=attention_mask,
|
| 394 |
+
encoder_hidden_states=encoder_hidden_states, # shape [1,4,768]
|
| 395 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 396 |
+
timestep=timestep,
|
| 397 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 398 |
+
class_labels=class_labels,
|
| 399 |
+
)
|
| 400 |
+
|
| 401 |
+
# 3. Output
|
| 402 |
+
output = None
|
| 403 |
+
if self.is_input_continuous:
|
| 404 |
+
if not self.use_linear_projection:
|
| 405 |
+
hidden_states = (
|
| 406 |
+
hidden_states.reshape(batch, height, width, inner_dim)
|
| 407 |
+
.permute(0, 3, 1, 2)
|
| 408 |
+
.contiguous()
|
| 409 |
+
)
|
| 410 |
+
hidden_states = (
|
| 411 |
+
self.proj_out(hidden_states, scale=lora_scale)
|
| 412 |
+
if not USE_PEFT_BACKEND
|
| 413 |
+
else self.proj_out(hidden_states)
|
| 414 |
+
)
|
| 415 |
+
else:
|
| 416 |
+
hidden_states = (
|
| 417 |
+
self.proj_out(hidden_states, scale=lora_scale)
|
| 418 |
+
if not USE_PEFT_BACKEND
|
| 419 |
+
else self.proj_out(hidden_states)
|
| 420 |
+
)
|
| 421 |
+
hidden_states = (
|
| 422 |
+
hidden_states.reshape(batch, height, width, inner_dim)
|
| 423 |
+
.permute(0, 3, 1, 2)
|
| 424 |
+
.contiguous()
|
| 425 |
+
)
|
| 426 |
+
|
| 427 |
+
output = hidden_states + residual
|
| 428 |
+
if not return_dict:
|
| 429 |
+
return (output, ref_feature)
|
| 430 |
+
|
| 431 |
+
return Transformer2DModelOutput(sample=output, ref_feature=ref_feature)
|
hallo/models/transformer_3d.py
ADDED
|
@@ -0,0 +1,257 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
"""
|
| 3 |
+
This module implements the Transformer3DModel, a PyTorch model designed for processing
|
| 4 |
+
3D data such as videos. It extends ModelMixin and ConfigMixin to provide a transformer
|
| 5 |
+
model with support for gradient checkpointing and various types of attention mechanisms.
|
| 6 |
+
The model can be configured with different parameters such as the number of attention heads,
|
| 7 |
+
attention head dimension, and the number of layers. It also supports the use of audio modules
|
| 8 |
+
for enhanced feature extraction from video data.
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
from dataclasses import dataclass
|
| 12 |
+
from typing import Optional
|
| 13 |
+
|
| 14 |
+
import torch
|
| 15 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 16 |
+
from diffusers.models import ModelMixin
|
| 17 |
+
from diffusers.utils import BaseOutput
|
| 18 |
+
from einops import rearrange, repeat
|
| 19 |
+
from torch import nn
|
| 20 |
+
|
| 21 |
+
from .attention import (AudioTemporalBasicTransformerBlock,
|
| 22 |
+
TemporalBasicTransformerBlock)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
@dataclass
|
| 26 |
+
class Transformer3DModelOutput(BaseOutput):
|
| 27 |
+
"""
|
| 28 |
+
The output of the [`Transformer3DModel`].
|
| 29 |
+
|
| 30 |
+
Attributes:
|
| 31 |
+
sample (`torch.FloatTensor`):
|
| 32 |
+
The output tensor from the transformer model, which is the result of processing the input
|
| 33 |
+
hidden states through the transformer blocks and any subsequent layers.
|
| 34 |
+
"""
|
| 35 |
+
sample: torch.FloatTensor
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class Transformer3DModel(ModelMixin, ConfigMixin):
|
| 39 |
+
"""
|
| 40 |
+
Transformer3DModel is a PyTorch model that extends `ModelMixin` and `ConfigMixin` to create a 3D transformer model.
|
| 41 |
+
It implements the forward pass for processing input hidden states, encoder hidden states, and various types of attention masks.
|
| 42 |
+
The model supports gradient checkpointing, which can be enabled by calling the `enable_gradient_checkpointing()` method.
|
| 43 |
+
"""
|
| 44 |
+
_supports_gradient_checkpointing = True
|
| 45 |
+
|
| 46 |
+
@register_to_config
|
| 47 |
+
def __init__(
|
| 48 |
+
self,
|
| 49 |
+
num_attention_heads: int = 16,
|
| 50 |
+
attention_head_dim: int = 88,
|
| 51 |
+
in_channels: Optional[int] = None,
|
| 52 |
+
num_layers: int = 1,
|
| 53 |
+
dropout: float = 0.0,
|
| 54 |
+
norm_num_groups: int = 32,
|
| 55 |
+
cross_attention_dim: Optional[int] = None,
|
| 56 |
+
attention_bias: bool = False,
|
| 57 |
+
activation_fn: str = "geglu",
|
| 58 |
+
num_embeds_ada_norm: Optional[int] = None,
|
| 59 |
+
use_linear_projection: bool = False,
|
| 60 |
+
only_cross_attention: bool = False,
|
| 61 |
+
upcast_attention: bool = False,
|
| 62 |
+
unet_use_cross_frame_attention=None,
|
| 63 |
+
unet_use_temporal_attention=None,
|
| 64 |
+
use_audio_module=False,
|
| 65 |
+
depth=0,
|
| 66 |
+
unet_block_name=None,
|
| 67 |
+
stack_enable_blocks_name = None,
|
| 68 |
+
stack_enable_blocks_depth = None,
|
| 69 |
+
):
|
| 70 |
+
super().__init__()
|
| 71 |
+
self.use_linear_projection = use_linear_projection
|
| 72 |
+
self.num_attention_heads = num_attention_heads
|
| 73 |
+
self.attention_head_dim = attention_head_dim
|
| 74 |
+
inner_dim = num_attention_heads * attention_head_dim
|
| 75 |
+
self.use_audio_module = use_audio_module
|
| 76 |
+
# Define input layers
|
| 77 |
+
self.in_channels = in_channels
|
| 78 |
+
|
| 79 |
+
self.norm = torch.nn.GroupNorm(
|
| 80 |
+
num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True
|
| 81 |
+
)
|
| 82 |
+
if use_linear_projection:
|
| 83 |
+
self.proj_in = nn.Linear(in_channels, inner_dim)
|
| 84 |
+
else:
|
| 85 |
+
self.proj_in = nn.Conv2d(
|
| 86 |
+
in_channels, inner_dim, kernel_size=1, stride=1, padding=0
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
if use_audio_module:
|
| 90 |
+
self.transformer_blocks = nn.ModuleList(
|
| 91 |
+
[
|
| 92 |
+
AudioTemporalBasicTransformerBlock(
|
| 93 |
+
inner_dim,
|
| 94 |
+
num_attention_heads,
|
| 95 |
+
attention_head_dim,
|
| 96 |
+
dropout=dropout,
|
| 97 |
+
cross_attention_dim=cross_attention_dim,
|
| 98 |
+
activation_fn=activation_fn,
|
| 99 |
+
num_embeds_ada_norm=num_embeds_ada_norm,
|
| 100 |
+
attention_bias=attention_bias,
|
| 101 |
+
only_cross_attention=only_cross_attention,
|
| 102 |
+
upcast_attention=upcast_attention,
|
| 103 |
+
unet_use_cross_frame_attention=unet_use_cross_frame_attention,
|
| 104 |
+
unet_use_temporal_attention=unet_use_temporal_attention,
|
| 105 |
+
depth=depth,
|
| 106 |
+
unet_block_name=unet_block_name,
|
| 107 |
+
stack_enable_blocks_name=stack_enable_blocks_name,
|
| 108 |
+
stack_enable_blocks_depth=stack_enable_blocks_depth,
|
| 109 |
+
)
|
| 110 |
+
for d in range(num_layers)
|
| 111 |
+
]
|
| 112 |
+
)
|
| 113 |
+
else:
|
| 114 |
+
# Define transformers blocks
|
| 115 |
+
self.transformer_blocks = nn.ModuleList(
|
| 116 |
+
[
|
| 117 |
+
TemporalBasicTransformerBlock(
|
| 118 |
+
inner_dim,
|
| 119 |
+
num_attention_heads,
|
| 120 |
+
attention_head_dim,
|
| 121 |
+
dropout=dropout,
|
| 122 |
+
cross_attention_dim=cross_attention_dim,
|
| 123 |
+
activation_fn=activation_fn,
|
| 124 |
+
num_embeds_ada_norm=num_embeds_ada_norm,
|
| 125 |
+
attention_bias=attention_bias,
|
| 126 |
+
only_cross_attention=only_cross_attention,
|
| 127 |
+
upcast_attention=upcast_attention,
|
| 128 |
+
)
|
| 129 |
+
for d in range(num_layers)
|
| 130 |
+
]
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
# 4. Define output layers
|
| 134 |
+
if use_linear_projection:
|
| 135 |
+
self.proj_out = nn.Linear(in_channels, inner_dim)
|
| 136 |
+
else:
|
| 137 |
+
self.proj_out = nn.Conv2d(
|
| 138 |
+
inner_dim, in_channels, kernel_size=1, stride=1, padding=0
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
self.gradient_checkpointing = False
|
| 142 |
+
|
| 143 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 144 |
+
if hasattr(module, "gradient_checkpointing"):
|
| 145 |
+
module.gradient_checkpointing = value
|
| 146 |
+
|
| 147 |
+
def forward(
|
| 148 |
+
self,
|
| 149 |
+
hidden_states,
|
| 150 |
+
encoder_hidden_states=None,
|
| 151 |
+
attention_mask=None,
|
| 152 |
+
full_mask=None,
|
| 153 |
+
face_mask=None,
|
| 154 |
+
lip_mask=None,
|
| 155 |
+
motion_scale=None,
|
| 156 |
+
timestep=None,
|
| 157 |
+
return_dict: bool = True,
|
| 158 |
+
):
|
| 159 |
+
"""
|
| 160 |
+
Forward pass for the Transformer3DModel.
|
| 161 |
+
|
| 162 |
+
Args:
|
| 163 |
+
hidden_states (torch.Tensor): The input hidden states.
|
| 164 |
+
encoder_hidden_states (torch.Tensor, optional): The input encoder hidden states.
|
| 165 |
+
attention_mask (torch.Tensor, optional): The attention mask.
|
| 166 |
+
full_mask (torch.Tensor, optional): The full mask.
|
| 167 |
+
face_mask (torch.Tensor, optional): The face mask.
|
| 168 |
+
lip_mask (torch.Tensor, optional): The lip mask.
|
| 169 |
+
timestep (int, optional): The current timestep.
|
| 170 |
+
return_dict (bool, optional): Whether to return a dictionary or a tuple.
|
| 171 |
+
|
| 172 |
+
Returns:
|
| 173 |
+
output (Union[Tuple, BaseOutput]): The output of the Transformer3DModel.
|
| 174 |
+
"""
|
| 175 |
+
# Input
|
| 176 |
+
assert (
|
| 177 |
+
hidden_states.dim() == 5
|
| 178 |
+
), f"Expected hidden_states to have ndim=5, but got ndim={hidden_states.dim()}."
|
| 179 |
+
video_length = hidden_states.shape[2]
|
| 180 |
+
hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
|
| 181 |
+
|
| 182 |
+
# TODO
|
| 183 |
+
if self.use_audio_module:
|
| 184 |
+
encoder_hidden_states = rearrange(
|
| 185 |
+
encoder_hidden_states,
|
| 186 |
+
"bs f margin dim -> (bs f) margin dim",
|
| 187 |
+
)
|
| 188 |
+
else:
|
| 189 |
+
if encoder_hidden_states.shape[0] != hidden_states.shape[0]:
|
| 190 |
+
encoder_hidden_states = repeat(
|
| 191 |
+
encoder_hidden_states, "b n c -> (b f) n c", f=video_length
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
batch, _, height, weight = hidden_states.shape
|
| 195 |
+
residual = hidden_states
|
| 196 |
+
|
| 197 |
+
hidden_states = self.norm(hidden_states)
|
| 198 |
+
if not self.use_linear_projection:
|
| 199 |
+
hidden_states = self.proj_in(hidden_states)
|
| 200 |
+
inner_dim = hidden_states.shape[1]
|
| 201 |
+
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(
|
| 202 |
+
batch, height * weight, inner_dim
|
| 203 |
+
)
|
| 204 |
+
else:
|
| 205 |
+
inner_dim = hidden_states.shape[1]
|
| 206 |
+
hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(
|
| 207 |
+
batch, height * weight, inner_dim
|
| 208 |
+
)
|
| 209 |
+
hidden_states = self.proj_in(hidden_states)
|
| 210 |
+
|
| 211 |
+
# Blocks
|
| 212 |
+
motion_frames = []
|
| 213 |
+
for _, block in enumerate(self.transformer_blocks):
|
| 214 |
+
if isinstance(block, TemporalBasicTransformerBlock):
|
| 215 |
+
hidden_states, motion_frame_fea = block(
|
| 216 |
+
hidden_states,
|
| 217 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 218 |
+
timestep=timestep,
|
| 219 |
+
video_length=video_length,
|
| 220 |
+
)
|
| 221 |
+
motion_frames.append(motion_frame_fea)
|
| 222 |
+
else:
|
| 223 |
+
hidden_states = block(
|
| 224 |
+
hidden_states, # shape [2, 4096, 320]
|
| 225 |
+
encoder_hidden_states=encoder_hidden_states, # shape [2, 20, 640]
|
| 226 |
+
attention_mask=attention_mask,
|
| 227 |
+
full_mask=full_mask,
|
| 228 |
+
face_mask=face_mask,
|
| 229 |
+
lip_mask=lip_mask,
|
| 230 |
+
timestep=timestep,
|
| 231 |
+
video_length=video_length,
|
| 232 |
+
motion_scale=motion_scale,
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
# Output
|
| 236 |
+
if not self.use_linear_projection:
|
| 237 |
+
hidden_states = (
|
| 238 |
+
hidden_states.reshape(batch, height, weight, inner_dim)
|
| 239 |
+
.permute(0, 3, 1, 2)
|
| 240 |
+
.contiguous()
|
| 241 |
+
)
|
| 242 |
+
hidden_states = self.proj_out(hidden_states)
|
| 243 |
+
else:
|
| 244 |
+
hidden_states = self.proj_out(hidden_states)
|
| 245 |
+
hidden_states = (
|
| 246 |
+
hidden_states.reshape(batch, height, weight, inner_dim)
|
| 247 |
+
.permute(0, 3, 1, 2)
|
| 248 |
+
.contiguous()
|
| 249 |
+
)
|
| 250 |
+
|
| 251 |
+
output = hidden_states + residual
|
| 252 |
+
|
| 253 |
+
output = rearrange(output, "(b f) c h w -> b c f h w", f=video_length)
|
| 254 |
+
if not return_dict:
|
| 255 |
+
return (output, motion_frames)
|
| 256 |
+
|
| 257 |
+
return Transformer3DModelOutput(sample=output)
|
hallo/models/unet_2d_blocks.py
ADDED
|
@@ -0,0 +1,1343 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
# pylint: disable=W1203
|
| 3 |
+
|
| 4 |
+
"""
|
| 5 |
+
This file defines the 2D blocks for the UNet model in a PyTorch implementation.
|
| 6 |
+
The UNet model is a popular architecture for image segmentation tasks,
|
| 7 |
+
which consists of an encoder, a decoder, and a skip connection mechanism.
|
| 8 |
+
The 2D blocks in this file include various types of layers, such as ResNet blocks,
|
| 9 |
+
Transformer blocks, and cross-attention blocks,
|
| 10 |
+
which are used to build the encoder and decoder parts of the UNet model.
|
| 11 |
+
The AutoencoderTinyBlock class is a simple autoencoder block for tiny models,
|
| 12 |
+
and the UNetMidBlock2D and CrossAttnDownBlock2D, DownBlock2D, CrossAttnUpBlock2D,
|
| 13 |
+
and UpBlock2D classes are used for the middle and decoder parts of the UNet model.
|
| 14 |
+
The classes and functions in this file provide a flexible and modular way
|
| 15 |
+
to construct the UNet model for different image segmentation tasks.
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
from typing import Any, Dict, Optional, Tuple, Union
|
| 19 |
+
|
| 20 |
+
import torch
|
| 21 |
+
from diffusers.models.activations import get_activation
|
| 22 |
+
from diffusers.models.attention_processor import Attention
|
| 23 |
+
from diffusers.models.resnet import Downsample2D, ResnetBlock2D, Upsample2D
|
| 24 |
+
from diffusers.models.transformers.dual_transformer_2d import \
|
| 25 |
+
DualTransformer2DModel
|
| 26 |
+
from diffusers.utils import is_torch_version, logging
|
| 27 |
+
from diffusers.utils.torch_utils import apply_freeu
|
| 28 |
+
from torch import nn
|
| 29 |
+
|
| 30 |
+
from .transformer_2d import Transformer2DModel
|
| 31 |
+
|
| 32 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def get_down_block(
|
| 36 |
+
down_block_type: str,
|
| 37 |
+
num_layers: int,
|
| 38 |
+
in_channels: int,
|
| 39 |
+
out_channels: int,
|
| 40 |
+
temb_channels: int,
|
| 41 |
+
add_downsample: bool,
|
| 42 |
+
resnet_eps: float,
|
| 43 |
+
resnet_act_fn: str,
|
| 44 |
+
transformer_layers_per_block: int = 1,
|
| 45 |
+
num_attention_heads: Optional[int] = None,
|
| 46 |
+
resnet_groups: Optional[int] = None,
|
| 47 |
+
cross_attention_dim: Optional[int] = None,
|
| 48 |
+
downsample_padding: Optional[int] = None,
|
| 49 |
+
dual_cross_attention: bool = False,
|
| 50 |
+
use_linear_projection: bool = False,
|
| 51 |
+
only_cross_attention: bool = False,
|
| 52 |
+
upcast_attention: bool = False,
|
| 53 |
+
resnet_time_scale_shift: str = "default",
|
| 54 |
+
attention_type: str = "default",
|
| 55 |
+
attention_head_dim: Optional[int] = None,
|
| 56 |
+
dropout: float = 0.0,
|
| 57 |
+
):
|
| 58 |
+
""" This function creates and returns a UpBlock2D or CrossAttnUpBlock2D object based on the given up_block_type.
|
| 59 |
+
|
| 60 |
+
Args:
|
| 61 |
+
up_block_type (str): The type of up block to create. Must be either "UpBlock2D" or "CrossAttnUpBlock2D".
|
| 62 |
+
num_layers (int): The number of layers in the ResNet block.
|
| 63 |
+
in_channels (int): The number of input channels.
|
| 64 |
+
out_channels (int): The number of output channels.
|
| 65 |
+
prev_output_channel (int): The number of channels in the previous output.
|
| 66 |
+
temb_channels (int): The number of channels in the token embedding.
|
| 67 |
+
add_upsample (bool): Whether to add an upsample layer after the ResNet block. Defaults to True.
|
| 68 |
+
resnet_eps (float): The epsilon value for the ResNet block. Defaults to 1e-6.
|
| 69 |
+
resnet_act_fn (str): The activation function to use in the ResNet block. Defaults to "swish".
|
| 70 |
+
resnet_groups (int): The number of groups in the ResNet block. Defaults to 32.
|
| 71 |
+
resnet_pre_norm (bool): Whether to use pre-normalization in the ResNet block. Defaults to True.
|
| 72 |
+
output_scale_factor (float): The scale factor to apply to the output. Defaults to 1.0.
|
| 73 |
+
|
| 74 |
+
Returns:
|
| 75 |
+
nn.Module: The created UpBlock2D or CrossAttnUpBlock2D object.
|
| 76 |
+
"""
|
| 77 |
+
# If attn head dim is not defined, we default it to the number of heads
|
| 78 |
+
if attention_head_dim is None:
|
| 79 |
+
logger.warning("It is recommended to provide `attention_head_dim` when calling `get_down_block`.")
|
| 80 |
+
logger.warning(f"Defaulting `attention_head_dim` to {num_attention_heads}.")
|
| 81 |
+
attention_head_dim = num_attention_heads
|
| 82 |
+
|
| 83 |
+
down_block_type = (
|
| 84 |
+
down_block_type[7:]
|
| 85 |
+
if down_block_type.startswith("UNetRes")
|
| 86 |
+
else down_block_type
|
| 87 |
+
)
|
| 88 |
+
if down_block_type == "DownBlock2D":
|
| 89 |
+
return DownBlock2D(
|
| 90 |
+
num_layers=num_layers,
|
| 91 |
+
in_channels=in_channels,
|
| 92 |
+
out_channels=out_channels,
|
| 93 |
+
temb_channels=temb_channels,
|
| 94 |
+
dropout=dropout,
|
| 95 |
+
add_downsample=add_downsample,
|
| 96 |
+
resnet_eps=resnet_eps,
|
| 97 |
+
resnet_act_fn=resnet_act_fn,
|
| 98 |
+
resnet_groups=resnet_groups,
|
| 99 |
+
downsample_padding=downsample_padding,
|
| 100 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
if down_block_type == "CrossAttnDownBlock2D":
|
| 104 |
+
if cross_attention_dim is None:
|
| 105 |
+
raise ValueError(
|
| 106 |
+
"cross_attention_dim must be specified for CrossAttnDownBlock2D"
|
| 107 |
+
)
|
| 108 |
+
return CrossAttnDownBlock2D(
|
| 109 |
+
num_layers=num_layers,
|
| 110 |
+
transformer_layers_per_block=transformer_layers_per_block,
|
| 111 |
+
in_channels=in_channels,
|
| 112 |
+
out_channels=out_channels,
|
| 113 |
+
temb_channels=temb_channels,
|
| 114 |
+
dropout=dropout,
|
| 115 |
+
add_downsample=add_downsample,
|
| 116 |
+
resnet_eps=resnet_eps,
|
| 117 |
+
resnet_act_fn=resnet_act_fn,
|
| 118 |
+
resnet_groups=resnet_groups,
|
| 119 |
+
downsample_padding=downsample_padding,
|
| 120 |
+
cross_attention_dim=cross_attention_dim,
|
| 121 |
+
num_attention_heads=num_attention_heads,
|
| 122 |
+
dual_cross_attention=dual_cross_attention,
|
| 123 |
+
use_linear_projection=use_linear_projection,
|
| 124 |
+
only_cross_attention=only_cross_attention,
|
| 125 |
+
upcast_attention=upcast_attention,
|
| 126 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 127 |
+
attention_type=attention_type,
|
| 128 |
+
)
|
| 129 |
+
raise ValueError(f"{down_block_type} does not exist.")
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def get_up_block(
|
| 133 |
+
up_block_type: str,
|
| 134 |
+
num_layers: int,
|
| 135 |
+
in_channels: int,
|
| 136 |
+
out_channels: int,
|
| 137 |
+
prev_output_channel: int,
|
| 138 |
+
temb_channels: int,
|
| 139 |
+
add_upsample: bool,
|
| 140 |
+
resnet_eps: float,
|
| 141 |
+
resnet_act_fn: str,
|
| 142 |
+
resolution_idx: Optional[int] = None,
|
| 143 |
+
transformer_layers_per_block: int = 1,
|
| 144 |
+
num_attention_heads: Optional[int] = None,
|
| 145 |
+
resnet_groups: Optional[int] = None,
|
| 146 |
+
cross_attention_dim: Optional[int] = None,
|
| 147 |
+
dual_cross_attention: bool = False,
|
| 148 |
+
use_linear_projection: bool = False,
|
| 149 |
+
only_cross_attention: bool = False,
|
| 150 |
+
upcast_attention: bool = False,
|
| 151 |
+
resnet_time_scale_shift: str = "default",
|
| 152 |
+
attention_type: str = "default",
|
| 153 |
+
attention_head_dim: Optional[int] = None,
|
| 154 |
+
dropout: float = 0.0,
|
| 155 |
+
) -> nn.Module:
|
| 156 |
+
""" This function ...
|
| 157 |
+
Args:
|
| 158 |
+
Returns:
|
| 159 |
+
"""
|
| 160 |
+
# If attn head dim is not defined, we default it to the number of heads
|
| 161 |
+
if attention_head_dim is None:
|
| 162 |
+
logger.warning("It is recommended to provide `attention_head_dim` when calling `get_up_block`.")
|
| 163 |
+
logger.warning(f"Defaulting `attention_head_dim` to {num_attention_heads}.")
|
| 164 |
+
attention_head_dim = num_attention_heads
|
| 165 |
+
|
| 166 |
+
up_block_type = (
|
| 167 |
+
up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
|
| 168 |
+
)
|
| 169 |
+
if up_block_type == "UpBlock2D":
|
| 170 |
+
return UpBlock2D(
|
| 171 |
+
num_layers=num_layers,
|
| 172 |
+
in_channels=in_channels,
|
| 173 |
+
out_channels=out_channels,
|
| 174 |
+
prev_output_channel=prev_output_channel,
|
| 175 |
+
temb_channels=temb_channels,
|
| 176 |
+
resolution_idx=resolution_idx,
|
| 177 |
+
dropout=dropout,
|
| 178 |
+
add_upsample=add_upsample,
|
| 179 |
+
resnet_eps=resnet_eps,
|
| 180 |
+
resnet_act_fn=resnet_act_fn,
|
| 181 |
+
resnet_groups=resnet_groups,
|
| 182 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 183 |
+
)
|
| 184 |
+
if up_block_type == "CrossAttnUpBlock2D":
|
| 185 |
+
if cross_attention_dim is None:
|
| 186 |
+
raise ValueError(
|
| 187 |
+
"cross_attention_dim must be specified for CrossAttnUpBlock2D"
|
| 188 |
+
)
|
| 189 |
+
return CrossAttnUpBlock2D(
|
| 190 |
+
num_layers=num_layers,
|
| 191 |
+
transformer_layers_per_block=transformer_layers_per_block,
|
| 192 |
+
in_channels=in_channels,
|
| 193 |
+
out_channels=out_channels,
|
| 194 |
+
prev_output_channel=prev_output_channel,
|
| 195 |
+
temb_channels=temb_channels,
|
| 196 |
+
resolution_idx=resolution_idx,
|
| 197 |
+
dropout=dropout,
|
| 198 |
+
add_upsample=add_upsample,
|
| 199 |
+
resnet_eps=resnet_eps,
|
| 200 |
+
resnet_act_fn=resnet_act_fn,
|
| 201 |
+
resnet_groups=resnet_groups,
|
| 202 |
+
cross_attention_dim=cross_attention_dim,
|
| 203 |
+
num_attention_heads=num_attention_heads,
|
| 204 |
+
dual_cross_attention=dual_cross_attention,
|
| 205 |
+
use_linear_projection=use_linear_projection,
|
| 206 |
+
only_cross_attention=only_cross_attention,
|
| 207 |
+
upcast_attention=upcast_attention,
|
| 208 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 209 |
+
attention_type=attention_type,
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
raise ValueError(f"{up_block_type} does not exist.")
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
class AutoencoderTinyBlock(nn.Module):
|
| 216 |
+
"""
|
| 217 |
+
Tiny Autoencoder block used in [`AutoencoderTiny`]. It is a mini residual module consisting of plain conv + ReLU
|
| 218 |
+
blocks.
|
| 219 |
+
|
| 220 |
+
Args:
|
| 221 |
+
in_channels (`int`): The number of input channels.
|
| 222 |
+
out_channels (`int`): The number of output channels.
|
| 223 |
+
act_fn (`str`):
|
| 224 |
+
` The activation function to use. Supported values are `"swish"`, `"mish"`, `"gelu"`, and `"relu"`.
|
| 225 |
+
|
| 226 |
+
Returns:
|
| 227 |
+
`torch.FloatTensor`: A tensor with the same shape as the input tensor, but with the number of channels equal to
|
| 228 |
+
`out_channels`.
|
| 229 |
+
"""
|
| 230 |
+
|
| 231 |
+
def __init__(self, in_channels: int, out_channels: int, act_fn: str):
|
| 232 |
+
super().__init__()
|
| 233 |
+
act_fn = get_activation(act_fn)
|
| 234 |
+
self.conv = nn.Sequential(
|
| 235 |
+
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
|
| 236 |
+
act_fn,
|
| 237 |
+
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
|
| 238 |
+
act_fn,
|
| 239 |
+
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
|
| 240 |
+
)
|
| 241 |
+
self.skip = (
|
| 242 |
+
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
|
| 243 |
+
if in_channels != out_channels
|
| 244 |
+
else nn.Identity()
|
| 245 |
+
)
|
| 246 |
+
self.fuse = nn.ReLU()
|
| 247 |
+
|
| 248 |
+
def forward(self, x: torch.FloatTensor) -> torch.FloatTensor:
|
| 249 |
+
"""
|
| 250 |
+
Forward pass of the AutoencoderTinyBlock class.
|
| 251 |
+
|
| 252 |
+
Parameters:
|
| 253 |
+
x (torch.FloatTensor): The input tensor to the AutoencoderTinyBlock.
|
| 254 |
+
|
| 255 |
+
Returns:
|
| 256 |
+
torch.FloatTensor: The output tensor after passing through the AutoencoderTinyBlock.
|
| 257 |
+
"""
|
| 258 |
+
return self.fuse(self.conv(x) + self.skip(x))
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
class UNetMidBlock2D(nn.Module):
|
| 262 |
+
"""
|
| 263 |
+
A 2D UNet mid-block [`UNetMidBlock2D`] with multiple residual blocks and optional attention blocks.
|
| 264 |
+
|
| 265 |
+
Args:
|
| 266 |
+
in_channels (`int`): The number of input channels.
|
| 267 |
+
temb_channels (`int`): The number of temporal embedding channels.
|
| 268 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout rate.
|
| 269 |
+
num_layers (`int`, *optional*, defaults to 1): The number of residual blocks.
|
| 270 |
+
resnet_eps (`float`, *optional*, 1e-6 ): The epsilon value for the resnet blocks.
|
| 271 |
+
resnet_time_scale_shift (`str`, *optional*, defaults to `default`):
|
| 272 |
+
The type of normalization to apply to the time embeddings. This can help to improve the performance of the
|
| 273 |
+
model on tasks with long-range temporal dependencies.
|
| 274 |
+
resnet_act_fn (`str`, *optional*, defaults to `swish`): The activation function for the resnet blocks.
|
| 275 |
+
resnet_groups (`int`, *optional*, defaults to 32):
|
| 276 |
+
The number of groups to use in the group normalization layers of the resnet blocks.
|
| 277 |
+
attn_groups (`Optional[int]`, *optional*, defaults to None): The number of groups for the attention blocks.
|
| 278 |
+
resnet_pre_norm (`bool`, *optional*, defaults to `True`):
|
| 279 |
+
Whether to use pre-normalization for the resnet blocks.
|
| 280 |
+
add_attention (`bool`, *optional*, defaults to `True`): Whether to add attention blocks.
|
| 281 |
+
attention_head_dim (`int`, *optional*, defaults to 1):
|
| 282 |
+
Dimension of a single attention head. The number of attention heads is determined based on this value and
|
| 283 |
+
the number of input channels.
|
| 284 |
+
output_scale_factor (`float`, *optional*, defaults to 1.0): The output scale factor.
|
| 285 |
+
|
| 286 |
+
Returns:
|
| 287 |
+
`torch.FloatTensor`: The output of the last residual block, which is a tensor of shape `(batch_size,
|
| 288 |
+
in_channels, height, width)`.
|
| 289 |
+
|
| 290 |
+
"""
|
| 291 |
+
|
| 292 |
+
def __init__(
|
| 293 |
+
self,
|
| 294 |
+
in_channels: int,
|
| 295 |
+
temb_channels: int,
|
| 296 |
+
dropout: float = 0.0,
|
| 297 |
+
num_layers: int = 1,
|
| 298 |
+
resnet_eps: float = 1e-6,
|
| 299 |
+
resnet_time_scale_shift: str = "default", # default, spatial
|
| 300 |
+
resnet_act_fn: str = "swish",
|
| 301 |
+
resnet_groups: int = 32,
|
| 302 |
+
attn_groups: Optional[int] = None,
|
| 303 |
+
resnet_pre_norm: bool = True,
|
| 304 |
+
add_attention: bool = True,
|
| 305 |
+
attention_head_dim: int = 1,
|
| 306 |
+
output_scale_factor: float = 1.0,
|
| 307 |
+
):
|
| 308 |
+
super().__init__()
|
| 309 |
+
resnet_groups = (
|
| 310 |
+
resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
|
| 311 |
+
)
|
| 312 |
+
self.add_attention = add_attention
|
| 313 |
+
|
| 314 |
+
if attn_groups is None:
|
| 315 |
+
attn_groups = (
|
| 316 |
+
resnet_groups if resnet_time_scale_shift == "default" else None
|
| 317 |
+
)
|
| 318 |
+
|
| 319 |
+
# there is always at least one resnet
|
| 320 |
+
resnets = [
|
| 321 |
+
ResnetBlock2D(
|
| 322 |
+
in_channels=in_channels,
|
| 323 |
+
out_channels=in_channels,
|
| 324 |
+
temb_channels=temb_channels,
|
| 325 |
+
eps=resnet_eps,
|
| 326 |
+
groups=resnet_groups,
|
| 327 |
+
dropout=dropout,
|
| 328 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 329 |
+
non_linearity=resnet_act_fn,
|
| 330 |
+
output_scale_factor=output_scale_factor,
|
| 331 |
+
pre_norm=resnet_pre_norm,
|
| 332 |
+
)
|
| 333 |
+
]
|
| 334 |
+
attentions = []
|
| 335 |
+
|
| 336 |
+
if attention_head_dim is None:
|
| 337 |
+
logger.warning(
|
| 338 |
+
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {in_channels}."
|
| 339 |
+
)
|
| 340 |
+
attention_head_dim = in_channels
|
| 341 |
+
|
| 342 |
+
for _ in range(num_layers):
|
| 343 |
+
if self.add_attention:
|
| 344 |
+
attentions.append(
|
| 345 |
+
Attention(
|
| 346 |
+
in_channels,
|
| 347 |
+
heads=in_channels // attention_head_dim,
|
| 348 |
+
dim_head=attention_head_dim,
|
| 349 |
+
rescale_output_factor=output_scale_factor,
|
| 350 |
+
eps=resnet_eps,
|
| 351 |
+
norm_num_groups=attn_groups,
|
| 352 |
+
spatial_norm_dim=(
|
| 353 |
+
temb_channels
|
| 354 |
+
if resnet_time_scale_shift == "spatial"
|
| 355 |
+
else None
|
| 356 |
+
),
|
| 357 |
+
residual_connection=True,
|
| 358 |
+
bias=True,
|
| 359 |
+
upcast_softmax=True,
|
| 360 |
+
_from_deprecated_attn_block=True,
|
| 361 |
+
)
|
| 362 |
+
)
|
| 363 |
+
else:
|
| 364 |
+
attentions.append(None)
|
| 365 |
+
|
| 366 |
+
resnets.append(
|
| 367 |
+
ResnetBlock2D(
|
| 368 |
+
in_channels=in_channels,
|
| 369 |
+
out_channels=in_channels,
|
| 370 |
+
temb_channels=temb_channels,
|
| 371 |
+
eps=resnet_eps,
|
| 372 |
+
groups=resnet_groups,
|
| 373 |
+
dropout=dropout,
|
| 374 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 375 |
+
non_linearity=resnet_act_fn,
|
| 376 |
+
output_scale_factor=output_scale_factor,
|
| 377 |
+
pre_norm=resnet_pre_norm,
|
| 378 |
+
)
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
self.attentions = nn.ModuleList(attentions)
|
| 382 |
+
self.resnets = nn.ModuleList(resnets)
|
| 383 |
+
|
| 384 |
+
def forward(
|
| 385 |
+
self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None
|
| 386 |
+
) -> torch.FloatTensor:
|
| 387 |
+
"""
|
| 388 |
+
Forward pass of the UNetMidBlock2D class.
|
| 389 |
+
|
| 390 |
+
Args:
|
| 391 |
+
hidden_states (torch.FloatTensor): The input tensor to the UNetMidBlock2D.
|
| 392 |
+
temb (Optional[torch.FloatTensor], optional): The token embedding tensor. Defaults to None.
|
| 393 |
+
|
| 394 |
+
Returns:
|
| 395 |
+
torch.FloatTensor: The output tensor after passing through the UNetMidBlock2D.
|
| 396 |
+
"""
|
| 397 |
+
# Your implementation here
|
| 398 |
+
hidden_states = self.resnets[0](hidden_states, temb)
|
| 399 |
+
for attn, resnet in zip(self.attentions, self.resnets[1:]):
|
| 400 |
+
if attn is not None:
|
| 401 |
+
hidden_states = attn(hidden_states, temb=temb)
|
| 402 |
+
hidden_states = resnet(hidden_states, temb)
|
| 403 |
+
|
| 404 |
+
return hidden_states
|
| 405 |
+
|
| 406 |
+
|
| 407 |
+
class UNetMidBlock2DCrossAttn(nn.Module):
|
| 408 |
+
"""
|
| 409 |
+
UNetMidBlock2DCrossAttn is a class that represents a mid-block 2D UNet with cross-attention.
|
| 410 |
+
|
| 411 |
+
This block is responsible for processing the input tensor with a series of residual blocks,
|
| 412 |
+
and applying cross-attention mechanism to attend to the global information in the encoder.
|
| 413 |
+
|
| 414 |
+
Args:
|
| 415 |
+
in_channels (int): The number of input channels.
|
| 416 |
+
temb_channels (int): The number of channels for the token embedding.
|
| 417 |
+
dropout (float, optional): The dropout rate. Defaults to 0.0.
|
| 418 |
+
num_layers (int, optional): The number of layers in the residual blocks. Defaults to 1.
|
| 419 |
+
resnet_eps (float, optional): The epsilon value for the residual blocks. Defaults to 1e-6.
|
| 420 |
+
resnet_time_scale_shift (str, optional): The time scale shift type for the residual blocks. Defaults to "default".
|
| 421 |
+
resnet_act_fn (str, optional): The activation function for the residual blocks. Defaults to "swish".
|
| 422 |
+
resnet_groups (int, optional): The number of groups for the residual blocks. Defaults to 32.
|
| 423 |
+
resnet_pre_norm (bool, optional): Whether to apply pre-normalization for the residual blocks. Defaults to True.
|
| 424 |
+
num_attention_heads (int, optional): The number of attention heads for cross-attention. Defaults to 1.
|
| 425 |
+
cross_attention_dim (int, optional): The dimension of the cross-attention. Defaults to 1280.
|
| 426 |
+
output_scale_factor (float, optional): The scale factor for the output tensor. Defaults to 1.0.
|
| 427 |
+
"""
|
| 428 |
+
def __init__(
|
| 429 |
+
self,
|
| 430 |
+
in_channels: int,
|
| 431 |
+
temb_channels: int,
|
| 432 |
+
dropout: float = 0.0,
|
| 433 |
+
num_layers: int = 1,
|
| 434 |
+
transformer_layers_per_block: Union[int, Tuple[int]] = 1,
|
| 435 |
+
resnet_eps: float = 1e-6,
|
| 436 |
+
resnet_time_scale_shift: str = "default",
|
| 437 |
+
resnet_act_fn: str = "swish",
|
| 438 |
+
resnet_groups: int = 32,
|
| 439 |
+
resnet_pre_norm: bool = True,
|
| 440 |
+
num_attention_heads: int = 1,
|
| 441 |
+
output_scale_factor: float = 1.0,
|
| 442 |
+
cross_attention_dim: int = 1280,
|
| 443 |
+
dual_cross_attention: bool = False,
|
| 444 |
+
use_linear_projection: bool = False,
|
| 445 |
+
upcast_attention: bool = False,
|
| 446 |
+
attention_type: str = "default",
|
| 447 |
+
):
|
| 448 |
+
super().__init__()
|
| 449 |
+
|
| 450 |
+
self.has_cross_attention = True
|
| 451 |
+
self.num_attention_heads = num_attention_heads
|
| 452 |
+
resnet_groups = (
|
| 453 |
+
resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
|
| 454 |
+
)
|
| 455 |
+
|
| 456 |
+
# support for variable transformer layers per block
|
| 457 |
+
if isinstance(transformer_layers_per_block, int):
|
| 458 |
+
transformer_layers_per_block = [transformer_layers_per_block] * num_layers
|
| 459 |
+
|
| 460 |
+
# there is always at least one resnet
|
| 461 |
+
resnets = [
|
| 462 |
+
ResnetBlock2D(
|
| 463 |
+
in_channels=in_channels,
|
| 464 |
+
out_channels=in_channels,
|
| 465 |
+
temb_channels=temb_channels,
|
| 466 |
+
eps=resnet_eps,
|
| 467 |
+
groups=resnet_groups,
|
| 468 |
+
dropout=dropout,
|
| 469 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 470 |
+
non_linearity=resnet_act_fn,
|
| 471 |
+
output_scale_factor=output_scale_factor,
|
| 472 |
+
pre_norm=resnet_pre_norm,
|
| 473 |
+
)
|
| 474 |
+
]
|
| 475 |
+
attentions = []
|
| 476 |
+
|
| 477 |
+
for i in range(num_layers):
|
| 478 |
+
if not dual_cross_attention:
|
| 479 |
+
attentions.append(
|
| 480 |
+
Transformer2DModel(
|
| 481 |
+
num_attention_heads,
|
| 482 |
+
in_channels // num_attention_heads,
|
| 483 |
+
in_channels=in_channels,
|
| 484 |
+
num_layers=transformer_layers_per_block[i],
|
| 485 |
+
cross_attention_dim=cross_attention_dim,
|
| 486 |
+
norm_num_groups=resnet_groups,
|
| 487 |
+
use_linear_projection=use_linear_projection,
|
| 488 |
+
upcast_attention=upcast_attention,
|
| 489 |
+
attention_type=attention_type,
|
| 490 |
+
)
|
| 491 |
+
)
|
| 492 |
+
else:
|
| 493 |
+
attentions.append(
|
| 494 |
+
DualTransformer2DModel(
|
| 495 |
+
num_attention_heads,
|
| 496 |
+
in_channels // num_attention_heads,
|
| 497 |
+
in_channels=in_channels,
|
| 498 |
+
num_layers=1,
|
| 499 |
+
cross_attention_dim=cross_attention_dim,
|
| 500 |
+
norm_num_groups=resnet_groups,
|
| 501 |
+
)
|
| 502 |
+
)
|
| 503 |
+
resnets.append(
|
| 504 |
+
ResnetBlock2D(
|
| 505 |
+
in_channels=in_channels,
|
| 506 |
+
out_channels=in_channels,
|
| 507 |
+
temb_channels=temb_channels,
|
| 508 |
+
eps=resnet_eps,
|
| 509 |
+
groups=resnet_groups,
|
| 510 |
+
dropout=dropout,
|
| 511 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 512 |
+
non_linearity=resnet_act_fn,
|
| 513 |
+
output_scale_factor=output_scale_factor,
|
| 514 |
+
pre_norm=resnet_pre_norm,
|
| 515 |
+
)
|
| 516 |
+
)
|
| 517 |
+
|
| 518 |
+
self.attentions = nn.ModuleList(attentions)
|
| 519 |
+
self.resnets = nn.ModuleList(resnets)
|
| 520 |
+
|
| 521 |
+
self.gradient_checkpointing = False
|
| 522 |
+
|
| 523 |
+
def forward(
|
| 524 |
+
self,
|
| 525 |
+
hidden_states: torch.FloatTensor,
|
| 526 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 527 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 528 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 529 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 530 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 531 |
+
) -> torch.FloatTensor:
|
| 532 |
+
"""
|
| 533 |
+
Forward pass for the UNetMidBlock2DCrossAttn class.
|
| 534 |
+
|
| 535 |
+
Args:
|
| 536 |
+
hidden_states (torch.FloatTensor): The input hidden states tensor.
|
| 537 |
+
temb (Optional[torch.FloatTensor], optional): The optional tensor for time embeddings.
|
| 538 |
+
encoder_hidden_states (Optional[torch.FloatTensor], optional): The optional encoder hidden states tensor.
|
| 539 |
+
attention_mask (Optional[torch.FloatTensor], optional): The optional attention mask tensor.
|
| 540 |
+
cross_attention_kwargs (Optional[Dict[str, Any]], optional): The optional cross-attention kwargs tensor.
|
| 541 |
+
encoder_attention_mask (Optional[torch.FloatTensor], optional): The optional encoder attention mask tensor.
|
| 542 |
+
|
| 543 |
+
Returns:
|
| 544 |
+
torch.FloatTensor: The output tensor after passing through the UNetMidBlock2DCrossAttn layers.
|
| 545 |
+
"""
|
| 546 |
+
lora_scale = (
|
| 547 |
+
cross_attention_kwargs.get("scale", 1.0)
|
| 548 |
+
if cross_attention_kwargs is not None
|
| 549 |
+
else 1.0
|
| 550 |
+
)
|
| 551 |
+
hidden_states = self.resnets[0](hidden_states, temb, scale=lora_scale)
|
| 552 |
+
for attn, resnet in zip(self.attentions, self.resnets[1:]):
|
| 553 |
+
if self.training and self.gradient_checkpointing:
|
| 554 |
+
|
| 555 |
+
def create_custom_forward(module, return_dict=None):
|
| 556 |
+
def custom_forward(*inputs):
|
| 557 |
+
if return_dict is not None:
|
| 558 |
+
return module(*inputs, return_dict=return_dict)
|
| 559 |
+
|
| 560 |
+
return module(*inputs)
|
| 561 |
+
|
| 562 |
+
return custom_forward
|
| 563 |
+
|
| 564 |
+
ckpt_kwargs: Dict[str, Any] = (
|
| 565 |
+
{"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 566 |
+
)
|
| 567 |
+
hidden_states, _ref_feature = attn(
|
| 568 |
+
hidden_states,
|
| 569 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 570 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 571 |
+
attention_mask=attention_mask,
|
| 572 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 573 |
+
return_dict=False,
|
| 574 |
+
)
|
| 575 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 576 |
+
create_custom_forward(resnet),
|
| 577 |
+
hidden_states,
|
| 578 |
+
temb,
|
| 579 |
+
**ckpt_kwargs,
|
| 580 |
+
)
|
| 581 |
+
else:
|
| 582 |
+
hidden_states, _ref_feature = attn(
|
| 583 |
+
hidden_states,
|
| 584 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 585 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 586 |
+
attention_mask=attention_mask,
|
| 587 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 588 |
+
return_dict=False,
|
| 589 |
+
)
|
| 590 |
+
hidden_states = resnet(hidden_states, temb, scale=lora_scale)
|
| 591 |
+
|
| 592 |
+
return hidden_states
|
| 593 |
+
|
| 594 |
+
|
| 595 |
+
class CrossAttnDownBlock2D(nn.Module):
|
| 596 |
+
"""
|
| 597 |
+
CrossAttnDownBlock2D is a class that represents a 2D cross-attention downsampling block.
|
| 598 |
+
|
| 599 |
+
This block is used in the UNet model and consists of a series of ResNet blocks and Transformer layers.
|
| 600 |
+
It takes input hidden states, a tensor embedding, and optional encoder hidden states, attention mask,
|
| 601 |
+
and cross-attention kwargs. The block performs a series of operations including downsampling, cross-attention,
|
| 602 |
+
and residual connections.
|
| 603 |
+
|
| 604 |
+
Attributes:
|
| 605 |
+
in_channels (int): The number of input channels.
|
| 606 |
+
out_channels (int): The number of output channels.
|
| 607 |
+
temb_channels (int): The number of tensor embedding channels.
|
| 608 |
+
dropout (float): The dropout rate.
|
| 609 |
+
num_layers (int): The number of ResNet layers.
|
| 610 |
+
transformer_layers_per_block (Union[int, Tuple[int]]): The number of Transformer layers per block.
|
| 611 |
+
resnet_eps (float): The ResNet epsilon value.
|
| 612 |
+
resnet_time_scale_shift (str): The ResNet time scale shift type.
|
| 613 |
+
resnet_act_fn (str): The ResNet activation function.
|
| 614 |
+
resnet_groups (int): The ResNet group size.
|
| 615 |
+
resnet_pre_norm (bool): Whether to use ResNet pre-normalization.
|
| 616 |
+
num_attention_heads (int): The number of attention heads.
|
| 617 |
+
cross_attention_dim (int): The cross-attention dimension.
|
| 618 |
+
output_scale_factor (float): The output scale factor.
|
| 619 |
+
downsample_padding (int): The downsampling padding.
|
| 620 |
+
add_downsample (bool): Whether to add downsampling.
|
| 621 |
+
dual_cross_attention (bool): Whether to use dual cross-attention.
|
| 622 |
+
use_linear_projection (bool): Whether to use linear projection.
|
| 623 |
+
only_cross_attention (bool): Whether to use only cross-attention.
|
| 624 |
+
upcast_attention (bool): Whether to upcast attention.
|
| 625 |
+
attention_type (str): The attention type.
|
| 626 |
+
"""
|
| 627 |
+
def __init__(
|
| 628 |
+
self,
|
| 629 |
+
in_channels: int,
|
| 630 |
+
out_channels: int,
|
| 631 |
+
temb_channels: int,
|
| 632 |
+
dropout: float = 0.0,
|
| 633 |
+
num_layers: int = 1,
|
| 634 |
+
transformer_layers_per_block: Union[int, Tuple[int]] = 1,
|
| 635 |
+
resnet_eps: float = 1e-6,
|
| 636 |
+
resnet_time_scale_shift: str = "default",
|
| 637 |
+
resnet_act_fn: str = "swish",
|
| 638 |
+
resnet_groups: int = 32,
|
| 639 |
+
resnet_pre_norm: bool = True,
|
| 640 |
+
num_attention_heads: int = 1,
|
| 641 |
+
cross_attention_dim: int = 1280,
|
| 642 |
+
output_scale_factor: float = 1.0,
|
| 643 |
+
downsample_padding: int = 1,
|
| 644 |
+
add_downsample: bool = True,
|
| 645 |
+
dual_cross_attention: bool = False,
|
| 646 |
+
use_linear_projection: bool = False,
|
| 647 |
+
only_cross_attention: bool = False,
|
| 648 |
+
upcast_attention: bool = False,
|
| 649 |
+
attention_type: str = "default",
|
| 650 |
+
):
|
| 651 |
+
super().__init__()
|
| 652 |
+
resnets = []
|
| 653 |
+
attentions = []
|
| 654 |
+
|
| 655 |
+
self.has_cross_attention = True
|
| 656 |
+
self.num_attention_heads = num_attention_heads
|
| 657 |
+
if isinstance(transformer_layers_per_block, int):
|
| 658 |
+
transformer_layers_per_block = [transformer_layers_per_block] * num_layers
|
| 659 |
+
|
| 660 |
+
for i in range(num_layers):
|
| 661 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 662 |
+
resnets.append(
|
| 663 |
+
ResnetBlock2D(
|
| 664 |
+
in_channels=in_channels,
|
| 665 |
+
out_channels=out_channels,
|
| 666 |
+
temb_channels=temb_channels,
|
| 667 |
+
eps=resnet_eps,
|
| 668 |
+
groups=resnet_groups,
|
| 669 |
+
dropout=dropout,
|
| 670 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 671 |
+
non_linearity=resnet_act_fn,
|
| 672 |
+
output_scale_factor=output_scale_factor,
|
| 673 |
+
pre_norm=resnet_pre_norm,
|
| 674 |
+
)
|
| 675 |
+
)
|
| 676 |
+
if not dual_cross_attention:
|
| 677 |
+
attentions.append(
|
| 678 |
+
Transformer2DModel(
|
| 679 |
+
num_attention_heads,
|
| 680 |
+
out_channels // num_attention_heads,
|
| 681 |
+
in_channels=out_channels,
|
| 682 |
+
num_layers=transformer_layers_per_block[i],
|
| 683 |
+
cross_attention_dim=cross_attention_dim,
|
| 684 |
+
norm_num_groups=resnet_groups,
|
| 685 |
+
use_linear_projection=use_linear_projection,
|
| 686 |
+
only_cross_attention=only_cross_attention,
|
| 687 |
+
upcast_attention=upcast_attention,
|
| 688 |
+
attention_type=attention_type,
|
| 689 |
+
)
|
| 690 |
+
)
|
| 691 |
+
else:
|
| 692 |
+
attentions.append(
|
| 693 |
+
DualTransformer2DModel(
|
| 694 |
+
num_attention_heads,
|
| 695 |
+
out_channels // num_attention_heads,
|
| 696 |
+
in_channels=out_channels,
|
| 697 |
+
num_layers=1,
|
| 698 |
+
cross_attention_dim=cross_attention_dim,
|
| 699 |
+
norm_num_groups=resnet_groups,
|
| 700 |
+
)
|
| 701 |
+
)
|
| 702 |
+
self.attentions = nn.ModuleList(attentions)
|
| 703 |
+
self.resnets = nn.ModuleList(resnets)
|
| 704 |
+
|
| 705 |
+
if add_downsample:
|
| 706 |
+
self.downsamplers = nn.ModuleList(
|
| 707 |
+
[
|
| 708 |
+
Downsample2D(
|
| 709 |
+
out_channels,
|
| 710 |
+
use_conv=True,
|
| 711 |
+
out_channels=out_channels,
|
| 712 |
+
padding=downsample_padding,
|
| 713 |
+
name="op",
|
| 714 |
+
)
|
| 715 |
+
]
|
| 716 |
+
)
|
| 717 |
+
else:
|
| 718 |
+
self.downsamplers = None
|
| 719 |
+
|
| 720 |
+
self.gradient_checkpointing = False
|
| 721 |
+
|
| 722 |
+
def forward(
|
| 723 |
+
self,
|
| 724 |
+
hidden_states: torch.FloatTensor,
|
| 725 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 726 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 727 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 728 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 729 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 730 |
+
additional_residuals: Optional[torch.FloatTensor] = None,
|
| 731 |
+
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
|
| 732 |
+
"""
|
| 733 |
+
Forward pass for the CrossAttnDownBlock2D class.
|
| 734 |
+
|
| 735 |
+
Args:
|
| 736 |
+
hidden_states (torch.FloatTensor): The input hidden states.
|
| 737 |
+
temb (Optional[torch.FloatTensor], optional): The token embeddings. Defaults to None.
|
| 738 |
+
encoder_hidden_states (Optional[torch.FloatTensor], optional): The encoder hidden states. Defaults to None.
|
| 739 |
+
attention_mask (Optional[torch.FloatTensor], optional): The attention mask. Defaults to None.
|
| 740 |
+
cross_attention_kwargs (Optional[Dict[str, Any]], optional): The cross-attention kwargs. Defaults to None.
|
| 741 |
+
encoder_attention_mask (Optional[torch.FloatTensor], optional): The encoder attention mask. Defaults to None.
|
| 742 |
+
additional_residuals (Optional[torch.FloatTensor], optional): The additional residuals. Defaults to None.
|
| 743 |
+
|
| 744 |
+
Returns:
|
| 745 |
+
Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]: The output hidden states and residuals.
|
| 746 |
+
"""
|
| 747 |
+
output_states = ()
|
| 748 |
+
|
| 749 |
+
lora_scale = (
|
| 750 |
+
cross_attention_kwargs.get("scale", 1.0)
|
| 751 |
+
if cross_attention_kwargs is not None
|
| 752 |
+
else 1.0
|
| 753 |
+
)
|
| 754 |
+
|
| 755 |
+
blocks = list(zip(self.resnets, self.attentions))
|
| 756 |
+
|
| 757 |
+
for i, (resnet, attn) in enumerate(blocks):
|
| 758 |
+
if self.training and self.gradient_checkpointing:
|
| 759 |
+
|
| 760 |
+
def create_custom_forward(module, return_dict=None):
|
| 761 |
+
def custom_forward(*inputs):
|
| 762 |
+
if return_dict is not None:
|
| 763 |
+
return module(*inputs, return_dict=return_dict)
|
| 764 |
+
|
| 765 |
+
return module(*inputs)
|
| 766 |
+
|
| 767 |
+
return custom_forward
|
| 768 |
+
|
| 769 |
+
ckpt_kwargs: Dict[str, Any] = (
|
| 770 |
+
{"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 771 |
+
)
|
| 772 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 773 |
+
create_custom_forward(resnet),
|
| 774 |
+
hidden_states,
|
| 775 |
+
temb,
|
| 776 |
+
**ckpt_kwargs,
|
| 777 |
+
)
|
| 778 |
+
hidden_states, _ref_feature = attn(
|
| 779 |
+
hidden_states,
|
| 780 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 781 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 782 |
+
attention_mask=attention_mask,
|
| 783 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 784 |
+
return_dict=False,
|
| 785 |
+
)
|
| 786 |
+
else:
|
| 787 |
+
hidden_states = resnet(hidden_states, temb, scale=lora_scale)
|
| 788 |
+
hidden_states, _ref_feature = attn(
|
| 789 |
+
hidden_states,
|
| 790 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 791 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 792 |
+
attention_mask=attention_mask,
|
| 793 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 794 |
+
return_dict=False,
|
| 795 |
+
)
|
| 796 |
+
|
| 797 |
+
# apply additional residuals to the output of the last pair of resnet and attention blocks
|
| 798 |
+
if i == len(blocks) - 1 and additional_residuals is not None:
|
| 799 |
+
hidden_states = hidden_states + additional_residuals
|
| 800 |
+
|
| 801 |
+
output_states = output_states + (hidden_states,)
|
| 802 |
+
|
| 803 |
+
if self.downsamplers is not None:
|
| 804 |
+
for downsampler in self.downsamplers:
|
| 805 |
+
hidden_states = downsampler(hidden_states, scale=lora_scale)
|
| 806 |
+
|
| 807 |
+
output_states = output_states + (hidden_states,)
|
| 808 |
+
|
| 809 |
+
return hidden_states, output_states
|
| 810 |
+
|
| 811 |
+
|
| 812 |
+
class DownBlock2D(nn.Module):
|
| 813 |
+
"""
|
| 814 |
+
DownBlock2D is a class that represents a 2D downsampling block in a neural network.
|
| 815 |
+
|
| 816 |
+
It takes the following parameters:
|
| 817 |
+
- in_channels (int): The number of input channels in the block.
|
| 818 |
+
- out_channels (int): The number of output channels in the block.
|
| 819 |
+
- temb_channels (int): The number of channels in the token embedding.
|
| 820 |
+
- dropout (float): The dropout rate for the block.
|
| 821 |
+
- num_layers (int): The number of layers in the block.
|
| 822 |
+
- resnet_eps (float): The epsilon value for the ResNet layer.
|
| 823 |
+
- resnet_time_scale_shift (str): The type of activation function for the ResNet layer.
|
| 824 |
+
- resnet_act_fn (str): The activation function for the ResNet layer.
|
| 825 |
+
- resnet_groups (int): The number of groups in the ResNet layer.
|
| 826 |
+
- resnet_pre_norm (bool): Whether to apply layer normalization before the ResNet layer.
|
| 827 |
+
- output_scale_factor (float): The scale factor for the output.
|
| 828 |
+
- add_downsample (bool): Whether to add a downsampling layer.
|
| 829 |
+
- downsample_padding (int): The padding value for the downsampling layer.
|
| 830 |
+
|
| 831 |
+
The DownBlock2D class inherits from the nn.Module class and defines the following methods:
|
| 832 |
+
- __init__: Initializes the DownBlock2D class with the given parameters.
|
| 833 |
+
- forward: Forward pass of the DownBlock2D class.
|
| 834 |
+
|
| 835 |
+
The forward method takes the following parameters:
|
| 836 |
+
- hidden_states (torch.FloatTensor): The input tensor to the block.
|
| 837 |
+
- temb (Optional[torch.FloatTensor]): The token embedding tensor.
|
| 838 |
+
- scale (float): The scale factor for the input tensor.
|
| 839 |
+
|
| 840 |
+
The forward method returns a tuple containing the output tensor and a tuple of hidden states.
|
| 841 |
+
"""
|
| 842 |
+
def __init__(
|
| 843 |
+
self,
|
| 844 |
+
in_channels: int,
|
| 845 |
+
out_channels: int,
|
| 846 |
+
temb_channels: int,
|
| 847 |
+
dropout: float = 0.0,
|
| 848 |
+
num_layers: int = 1,
|
| 849 |
+
resnet_eps: float = 1e-6,
|
| 850 |
+
resnet_time_scale_shift: str = "default",
|
| 851 |
+
resnet_act_fn: str = "swish",
|
| 852 |
+
resnet_groups: int = 32,
|
| 853 |
+
resnet_pre_norm: bool = True,
|
| 854 |
+
output_scale_factor: float = 1.0,
|
| 855 |
+
add_downsample: bool = True,
|
| 856 |
+
downsample_padding: int = 1,
|
| 857 |
+
):
|
| 858 |
+
super().__init__()
|
| 859 |
+
resnets = []
|
| 860 |
+
|
| 861 |
+
for i in range(num_layers):
|
| 862 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 863 |
+
resnets.append(
|
| 864 |
+
ResnetBlock2D(
|
| 865 |
+
in_channels=in_channels,
|
| 866 |
+
out_channels=out_channels,
|
| 867 |
+
temb_channels=temb_channels,
|
| 868 |
+
eps=resnet_eps,
|
| 869 |
+
groups=resnet_groups,
|
| 870 |
+
dropout=dropout,
|
| 871 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 872 |
+
non_linearity=resnet_act_fn,
|
| 873 |
+
output_scale_factor=output_scale_factor,
|
| 874 |
+
pre_norm=resnet_pre_norm,
|
| 875 |
+
)
|
| 876 |
+
)
|
| 877 |
+
|
| 878 |
+
self.resnets = nn.ModuleList(resnets)
|
| 879 |
+
|
| 880 |
+
if add_downsample:
|
| 881 |
+
self.downsamplers = nn.ModuleList(
|
| 882 |
+
[
|
| 883 |
+
Downsample2D(
|
| 884 |
+
out_channels,
|
| 885 |
+
use_conv=True,
|
| 886 |
+
out_channels=out_channels,
|
| 887 |
+
padding=downsample_padding,
|
| 888 |
+
name="op",
|
| 889 |
+
)
|
| 890 |
+
]
|
| 891 |
+
)
|
| 892 |
+
else:
|
| 893 |
+
self.downsamplers = None
|
| 894 |
+
|
| 895 |
+
self.gradient_checkpointing = False
|
| 896 |
+
|
| 897 |
+
def forward(
|
| 898 |
+
self,
|
| 899 |
+
hidden_states: torch.FloatTensor,
|
| 900 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 901 |
+
scale: float = 1.0,
|
| 902 |
+
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
|
| 903 |
+
"""
|
| 904 |
+
Forward pass of the DownBlock2D class.
|
| 905 |
+
|
| 906 |
+
Args:
|
| 907 |
+
hidden_states (torch.FloatTensor): The input tensor to the DownBlock2D layer.
|
| 908 |
+
temb (Optional[torch.FloatTensor], optional): The token embedding tensor. Defaults to None.
|
| 909 |
+
scale (float, optional): The scale factor for the input tensor. Defaults to 1.0.
|
| 910 |
+
|
| 911 |
+
Returns:
|
| 912 |
+
Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]: The output tensor and any additional hidden states.
|
| 913 |
+
"""
|
| 914 |
+
output_states = ()
|
| 915 |
+
|
| 916 |
+
for resnet in self.resnets:
|
| 917 |
+
if self.training and self.gradient_checkpointing:
|
| 918 |
+
|
| 919 |
+
def create_custom_forward(module):
|
| 920 |
+
def custom_forward(*inputs):
|
| 921 |
+
return module(*inputs)
|
| 922 |
+
|
| 923 |
+
return custom_forward
|
| 924 |
+
|
| 925 |
+
if is_torch_version(">=", "1.11.0"):
|
| 926 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 927 |
+
create_custom_forward(resnet),
|
| 928 |
+
hidden_states,
|
| 929 |
+
temb,
|
| 930 |
+
use_reentrant=False,
|
| 931 |
+
)
|
| 932 |
+
else:
|
| 933 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 934 |
+
create_custom_forward(resnet), hidden_states, temb
|
| 935 |
+
)
|
| 936 |
+
else:
|
| 937 |
+
hidden_states = resnet(hidden_states, temb, scale=scale)
|
| 938 |
+
|
| 939 |
+
output_states = output_states + (hidden_states,)
|
| 940 |
+
|
| 941 |
+
if self.downsamplers is not None:
|
| 942 |
+
for downsampler in self.downsamplers:
|
| 943 |
+
hidden_states = downsampler(hidden_states, scale=scale)
|
| 944 |
+
|
| 945 |
+
output_states = output_states + (hidden_states,)
|
| 946 |
+
|
| 947 |
+
return hidden_states, output_states
|
| 948 |
+
|
| 949 |
+
|
| 950 |
+
class CrossAttnUpBlock2D(nn.Module):
|
| 951 |
+
"""
|
| 952 |
+
CrossAttnUpBlock2D is a class that represents a cross-attention UpBlock in a 2D UNet architecture.
|
| 953 |
+
|
| 954 |
+
This block is responsible for upsampling the input tensor and performing cross-attention with the encoder's hidden states.
|
| 955 |
+
|
| 956 |
+
Args:
|
| 957 |
+
in_channels (int): The number of input channels in the tensor.
|
| 958 |
+
out_channels (int): The number of output channels in the tensor.
|
| 959 |
+
prev_output_channel (int): The number of channels in the previous output tensor.
|
| 960 |
+
temb_channels (int): The number of channels in the token embedding tensor.
|
| 961 |
+
resolution_idx (Optional[int]): The index of the resolution in the model.
|
| 962 |
+
dropout (float): The dropout rate for the layer.
|
| 963 |
+
num_layers (int): The number of layers in the ResNet block.
|
| 964 |
+
transformer_layers_per_block (Union[int, Tuple[int]]): The number of transformer layers per block.
|
| 965 |
+
resnet_eps (float): The epsilon value for the ResNet layer.
|
| 966 |
+
resnet_time_scale_shift (str): The type of time scale shift to be applied in the ResNet layer.
|
| 967 |
+
resnet_act_fn (str): The activation function to be used in the ResNet layer.
|
| 968 |
+
resnet_groups (int): The number of groups in the ResNet layer.
|
| 969 |
+
resnet_pre_norm (bool): Whether to use pre-normalization in the ResNet layer.
|
| 970 |
+
num_attention_heads (int): The number of attention heads in the cross-attention layer.
|
| 971 |
+
cross_attention_dim (int): The dimension of the cross-attention layer.
|
| 972 |
+
output_scale_factor (float): The scale factor for the output tensor.
|
| 973 |
+
add_upsample (bool): Whether to add upsampling to the block.
|
| 974 |
+
dual_cross_attention (bool): Whether to use dual cross-attention.
|
| 975 |
+
use_linear_projection (bool): Whether to use linear projection in the cross-attention layer.
|
| 976 |
+
only_cross_attention (bool): Whether to only use cross-attention and no self-attention.
|
| 977 |
+
upcast_attention (bool): Whether to upcast the attention weights.
|
| 978 |
+
attention_type (str): The type of attention to be used in the cross-attention layer.
|
| 979 |
+
|
| 980 |
+
Attributes:
|
| 981 |
+
up_block (nn.Module): The UpBlock module responsible for upsampling the input tensor.
|
| 982 |
+
cross_attn (nn.Module): The cross-attention module that performs attention between
|
| 983 |
+
the decoder's hidden states and the encoder's hidden states.
|
| 984 |
+
resnet_blocks (nn.ModuleList): A list of ResNet blocks that make up the ResNet portion of the block.
|
| 985 |
+
"""
|
| 986 |
+
|
| 987 |
+
def __init__(
|
| 988 |
+
self,
|
| 989 |
+
in_channels: int,
|
| 990 |
+
out_channels: int,
|
| 991 |
+
prev_output_channel: int,
|
| 992 |
+
temb_channels: int,
|
| 993 |
+
resolution_idx: Optional[int] = None,
|
| 994 |
+
dropout: float = 0.0,
|
| 995 |
+
num_layers: int = 1,
|
| 996 |
+
transformer_layers_per_block: Union[int, Tuple[int]] = 1,
|
| 997 |
+
resnet_eps: float = 1e-6,
|
| 998 |
+
resnet_time_scale_shift: str = "default",
|
| 999 |
+
resnet_act_fn: str = "swish",
|
| 1000 |
+
resnet_groups: int = 32,
|
| 1001 |
+
resnet_pre_norm: bool = True,
|
| 1002 |
+
num_attention_heads: int = 1,
|
| 1003 |
+
cross_attention_dim: int = 1280,
|
| 1004 |
+
output_scale_factor: float = 1.0,
|
| 1005 |
+
add_upsample: bool = True,
|
| 1006 |
+
dual_cross_attention: bool = False,
|
| 1007 |
+
use_linear_projection: bool = False,
|
| 1008 |
+
only_cross_attention: bool = False,
|
| 1009 |
+
upcast_attention: bool = False,
|
| 1010 |
+
attention_type: str = "default",
|
| 1011 |
+
):
|
| 1012 |
+
super().__init__()
|
| 1013 |
+
resnets = []
|
| 1014 |
+
attentions = []
|
| 1015 |
+
|
| 1016 |
+
self.has_cross_attention = True
|
| 1017 |
+
self.num_attention_heads = num_attention_heads
|
| 1018 |
+
|
| 1019 |
+
if isinstance(transformer_layers_per_block, int):
|
| 1020 |
+
transformer_layers_per_block = [transformer_layers_per_block] * num_layers
|
| 1021 |
+
|
| 1022 |
+
for i in range(num_layers):
|
| 1023 |
+
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
|
| 1024 |
+
resnet_in_channels = prev_output_channel if i == 0 else out_channels
|
| 1025 |
+
|
| 1026 |
+
resnets.append(
|
| 1027 |
+
ResnetBlock2D(
|
| 1028 |
+
in_channels=resnet_in_channels + res_skip_channels,
|
| 1029 |
+
out_channels=out_channels,
|
| 1030 |
+
temb_channels=temb_channels,
|
| 1031 |
+
eps=resnet_eps,
|
| 1032 |
+
groups=resnet_groups,
|
| 1033 |
+
dropout=dropout,
|
| 1034 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 1035 |
+
non_linearity=resnet_act_fn,
|
| 1036 |
+
output_scale_factor=output_scale_factor,
|
| 1037 |
+
pre_norm=resnet_pre_norm,
|
| 1038 |
+
)
|
| 1039 |
+
)
|
| 1040 |
+
if not dual_cross_attention:
|
| 1041 |
+
attentions.append(
|
| 1042 |
+
Transformer2DModel(
|
| 1043 |
+
num_attention_heads,
|
| 1044 |
+
out_channels // num_attention_heads,
|
| 1045 |
+
in_channels=out_channels,
|
| 1046 |
+
num_layers=transformer_layers_per_block[i],
|
| 1047 |
+
cross_attention_dim=cross_attention_dim,
|
| 1048 |
+
norm_num_groups=resnet_groups,
|
| 1049 |
+
use_linear_projection=use_linear_projection,
|
| 1050 |
+
only_cross_attention=only_cross_attention,
|
| 1051 |
+
upcast_attention=upcast_attention,
|
| 1052 |
+
attention_type=attention_type,
|
| 1053 |
+
)
|
| 1054 |
+
)
|
| 1055 |
+
else:
|
| 1056 |
+
attentions.append(
|
| 1057 |
+
DualTransformer2DModel(
|
| 1058 |
+
num_attention_heads,
|
| 1059 |
+
out_channels // num_attention_heads,
|
| 1060 |
+
in_channels=out_channels,
|
| 1061 |
+
num_layers=1,
|
| 1062 |
+
cross_attention_dim=cross_attention_dim,
|
| 1063 |
+
norm_num_groups=resnet_groups,
|
| 1064 |
+
)
|
| 1065 |
+
)
|
| 1066 |
+
self.attentions = nn.ModuleList(attentions)
|
| 1067 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1068 |
+
|
| 1069 |
+
if add_upsample:
|
| 1070 |
+
self.upsamplers = nn.ModuleList(
|
| 1071 |
+
[Upsample2D(out_channels, use_conv=True, out_channels=out_channels)]
|
| 1072 |
+
)
|
| 1073 |
+
else:
|
| 1074 |
+
self.upsamplers = None
|
| 1075 |
+
|
| 1076 |
+
self.gradient_checkpointing = False
|
| 1077 |
+
self.resolution_idx = resolution_idx
|
| 1078 |
+
|
| 1079 |
+
def forward(
|
| 1080 |
+
self,
|
| 1081 |
+
hidden_states: torch.FloatTensor,
|
| 1082 |
+
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
|
| 1083 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 1084 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 1085 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 1086 |
+
upsample_size: Optional[int] = None,
|
| 1087 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1088 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 1089 |
+
) -> torch.FloatTensor:
|
| 1090 |
+
"""
|
| 1091 |
+
Forward pass for the CrossAttnUpBlock2D class.
|
| 1092 |
+
|
| 1093 |
+
Args:
|
| 1094 |
+
self (CrossAttnUpBlock2D): An instance of the CrossAttnUpBlock2D class.
|
| 1095 |
+
hidden_states (torch.FloatTensor): The input hidden states tensor.
|
| 1096 |
+
res_hidden_states_tuple (Tuple[torch.FloatTensor, ...]): A tuple of residual hidden states tensors.
|
| 1097 |
+
temb (Optional[torch.FloatTensor], optional): The token embeddings tensor. Defaults to None.
|
| 1098 |
+
encoder_hidden_states (Optional[torch.FloatTensor], optional): The encoder hidden states tensor. Defaults to None.
|
| 1099 |
+
cross_attention_kwargs (Optional[Dict[str, Any]], optional): Additional keyword arguments for cross attention. Defaults to None.
|
| 1100 |
+
upsample_size (Optional[int], optional): The upsample size. Defaults to None.
|
| 1101 |
+
attention_mask (Optional[torch.FloatTensor], optional): The attention mask tensor. Defaults to None.
|
| 1102 |
+
encoder_attention_mask (Optional[torch.FloatTensor], optional): The encoder attention mask tensor. Defaults to None.
|
| 1103 |
+
|
| 1104 |
+
Returns:
|
| 1105 |
+
torch.FloatTensor: The output tensor after passing through the block.
|
| 1106 |
+
"""
|
| 1107 |
+
lora_scale = (
|
| 1108 |
+
cross_attention_kwargs.get("scale", 1.0)
|
| 1109 |
+
if cross_attention_kwargs is not None
|
| 1110 |
+
else 1.0
|
| 1111 |
+
)
|
| 1112 |
+
is_freeu_enabled = (
|
| 1113 |
+
getattr(self, "s1", None)
|
| 1114 |
+
and getattr(self, "s2", None)
|
| 1115 |
+
and getattr(self, "b1", None)
|
| 1116 |
+
and getattr(self, "b2", None)
|
| 1117 |
+
)
|
| 1118 |
+
|
| 1119 |
+
for resnet, attn in zip(self.resnets, self.attentions):
|
| 1120 |
+
# pop res hidden states
|
| 1121 |
+
res_hidden_states = res_hidden_states_tuple[-1]
|
| 1122 |
+
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
|
| 1123 |
+
|
| 1124 |
+
# FreeU: Only operate on the first two stages
|
| 1125 |
+
if is_freeu_enabled:
|
| 1126 |
+
hidden_states, res_hidden_states = apply_freeu(
|
| 1127 |
+
self.resolution_idx,
|
| 1128 |
+
hidden_states,
|
| 1129 |
+
res_hidden_states,
|
| 1130 |
+
s1=self.s1,
|
| 1131 |
+
s2=self.s2,
|
| 1132 |
+
b1=self.b1,
|
| 1133 |
+
b2=self.b2,
|
| 1134 |
+
)
|
| 1135 |
+
|
| 1136 |
+
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
|
| 1137 |
+
|
| 1138 |
+
if self.training and self.gradient_checkpointing:
|
| 1139 |
+
|
| 1140 |
+
def create_custom_forward(module, return_dict=None):
|
| 1141 |
+
def custom_forward(*inputs):
|
| 1142 |
+
if return_dict is not None:
|
| 1143 |
+
return module(*inputs, return_dict=return_dict)
|
| 1144 |
+
|
| 1145 |
+
return module(*inputs)
|
| 1146 |
+
|
| 1147 |
+
return custom_forward
|
| 1148 |
+
|
| 1149 |
+
ckpt_kwargs: Dict[str, Any] = (
|
| 1150 |
+
{"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
|
| 1151 |
+
)
|
| 1152 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1153 |
+
create_custom_forward(resnet),
|
| 1154 |
+
hidden_states,
|
| 1155 |
+
temb,
|
| 1156 |
+
**ckpt_kwargs,
|
| 1157 |
+
)
|
| 1158 |
+
hidden_states, _ref_feature = attn(
|
| 1159 |
+
hidden_states,
|
| 1160 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1161 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1162 |
+
attention_mask=attention_mask,
|
| 1163 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1164 |
+
return_dict=False,
|
| 1165 |
+
)
|
| 1166 |
+
else:
|
| 1167 |
+
hidden_states = resnet(hidden_states, temb, scale=lora_scale)
|
| 1168 |
+
hidden_states, _ref_feature = attn(
|
| 1169 |
+
hidden_states,
|
| 1170 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1171 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1172 |
+
attention_mask=attention_mask,
|
| 1173 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1174 |
+
return_dict=False,
|
| 1175 |
+
)
|
| 1176 |
+
|
| 1177 |
+
if self.upsamplers is not None:
|
| 1178 |
+
for upsampler in self.upsamplers:
|
| 1179 |
+
hidden_states = upsampler(
|
| 1180 |
+
hidden_states, upsample_size, scale=lora_scale
|
| 1181 |
+
)
|
| 1182 |
+
|
| 1183 |
+
return hidden_states
|
| 1184 |
+
|
| 1185 |
+
|
| 1186 |
+
class UpBlock2D(nn.Module):
|
| 1187 |
+
"""
|
| 1188 |
+
UpBlock2D is a class that represents a 2D upsampling block in a neural network.
|
| 1189 |
+
|
| 1190 |
+
This block is used for upsampling the input tensor by a factor of 2 in both dimensions.
|
| 1191 |
+
It takes the previous output channel, input channels, and output channels as input
|
| 1192 |
+
and applies a series of convolutional layers, batch normalization, and activation
|
| 1193 |
+
functions to produce the upsampled tensor.
|
| 1194 |
+
|
| 1195 |
+
Args:
|
| 1196 |
+
in_channels (int): The number of input channels in the tensor.
|
| 1197 |
+
prev_output_channel (int): The number of channels in the previous output tensor.
|
| 1198 |
+
out_channels (int): The number of output channels in the tensor.
|
| 1199 |
+
temb_channels (int): The number of channels in the time embedding tensor.
|
| 1200 |
+
resolution_idx (Optional[int], optional): The index of the resolution in the sequence of resolutions. Defaults to None.
|
| 1201 |
+
dropout (float, optional): The dropout rate to be applied to the convolutional layers. Defaults to 0.0.
|
| 1202 |
+
num_layers (int, optional): The number of convolutional layers in the block. Defaults to 1.
|
| 1203 |
+
resnet_eps (float, optional): The epsilon value used in the batch normalization layer. Defaults to 1e-6.
|
| 1204 |
+
resnet_time_scale_shift (str, optional): The type of activation function to be applied after the convolutional layers. Defaults to "default".
|
| 1205 |
+
resnet_act_fn (str, optional): The activation function to be applied after the batch normalization layer. Defaults to "swish".
|
| 1206 |
+
resnet_groups (int, optional): The number of groups in the group normalization layer. Defaults to 32.
|
| 1207 |
+
resnet_pre_norm (bool, optional): A flag indicating whether to apply layer normalization before the activation function. Defaults to True.
|
| 1208 |
+
output_scale_factor (float, optional): The scale factor to be applied to the output tensor. Defaults to 1.0.
|
| 1209 |
+
add_upsample (bool, optional): A flag indicating whether to add an upsampling layer to the block. Defaults to True.
|
| 1210 |
+
|
| 1211 |
+
Attributes:
|
| 1212 |
+
layers (nn.ModuleList): A list of nn.Module objects representing the convolutional layers in the block.
|
| 1213 |
+
upsample (nn.Module): The upsampling layer in the block, if add_upsample is True.
|
| 1214 |
+
|
| 1215 |
+
"""
|
| 1216 |
+
|
| 1217 |
+
def __init__(
|
| 1218 |
+
self,
|
| 1219 |
+
in_channels: int,
|
| 1220 |
+
prev_output_channel: int,
|
| 1221 |
+
out_channels: int,
|
| 1222 |
+
temb_channels: int,
|
| 1223 |
+
resolution_idx: Optional[int] = None,
|
| 1224 |
+
dropout: float = 0.0,
|
| 1225 |
+
num_layers: int = 1,
|
| 1226 |
+
resnet_eps: float = 1e-6,
|
| 1227 |
+
resnet_time_scale_shift: str = "default",
|
| 1228 |
+
resnet_act_fn: str = "swish",
|
| 1229 |
+
resnet_groups: int = 32,
|
| 1230 |
+
resnet_pre_norm: bool = True,
|
| 1231 |
+
output_scale_factor: float = 1.0,
|
| 1232 |
+
add_upsample: bool = True,
|
| 1233 |
+
):
|
| 1234 |
+
super().__init__()
|
| 1235 |
+
resnets = []
|
| 1236 |
+
|
| 1237 |
+
for i in range(num_layers):
|
| 1238 |
+
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
|
| 1239 |
+
resnet_in_channels = prev_output_channel if i == 0 else out_channels
|
| 1240 |
+
|
| 1241 |
+
resnets.append(
|
| 1242 |
+
ResnetBlock2D(
|
| 1243 |
+
in_channels=resnet_in_channels + res_skip_channels,
|
| 1244 |
+
out_channels=out_channels,
|
| 1245 |
+
temb_channels=temb_channels,
|
| 1246 |
+
eps=resnet_eps,
|
| 1247 |
+
groups=resnet_groups,
|
| 1248 |
+
dropout=dropout,
|
| 1249 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 1250 |
+
non_linearity=resnet_act_fn,
|
| 1251 |
+
output_scale_factor=output_scale_factor,
|
| 1252 |
+
pre_norm=resnet_pre_norm,
|
| 1253 |
+
)
|
| 1254 |
+
)
|
| 1255 |
+
|
| 1256 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1257 |
+
|
| 1258 |
+
if add_upsample:
|
| 1259 |
+
self.upsamplers = nn.ModuleList(
|
| 1260 |
+
[Upsample2D(out_channels, use_conv=True, out_channels=out_channels)]
|
| 1261 |
+
)
|
| 1262 |
+
else:
|
| 1263 |
+
self.upsamplers = None
|
| 1264 |
+
|
| 1265 |
+
self.gradient_checkpointing = False
|
| 1266 |
+
self.resolution_idx = resolution_idx
|
| 1267 |
+
|
| 1268 |
+
def forward(
|
| 1269 |
+
self,
|
| 1270 |
+
hidden_states: torch.FloatTensor,
|
| 1271 |
+
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
|
| 1272 |
+
temb: Optional[torch.FloatTensor] = None,
|
| 1273 |
+
upsample_size: Optional[int] = None,
|
| 1274 |
+
scale: float = 1.0,
|
| 1275 |
+
) -> torch.FloatTensor:
|
| 1276 |
+
|
| 1277 |
+
"""
|
| 1278 |
+
Forward pass for the UpBlock2D class.
|
| 1279 |
+
|
| 1280 |
+
Args:
|
| 1281 |
+
self (UpBlock2D): An instance of the UpBlock2D class.
|
| 1282 |
+
hidden_states (torch.FloatTensor): The input tensor to the block.
|
| 1283 |
+
res_hidden_states_tuple (Tuple[torch.FloatTensor, ...]): A tuple of residual hidden states.
|
| 1284 |
+
temb (Optional[torch.FloatTensor], optional): The token embeddings. Defaults to None.
|
| 1285 |
+
upsample_size (Optional[int], optional): The size to upsample the input tensor to. Defaults to None.
|
| 1286 |
+
scale (float, optional): The scale factor to apply to the input tensor. Defaults to 1.0.
|
| 1287 |
+
|
| 1288 |
+
Returns:
|
| 1289 |
+
torch.FloatTensor: The output tensor after passing through the block.
|
| 1290 |
+
"""
|
| 1291 |
+
is_freeu_enabled = (
|
| 1292 |
+
getattr(self, "s1", None)
|
| 1293 |
+
and getattr(self, "s2", None)
|
| 1294 |
+
and getattr(self, "b1", None)
|
| 1295 |
+
and getattr(self, "b2", None)
|
| 1296 |
+
)
|
| 1297 |
+
|
| 1298 |
+
for resnet in self.resnets:
|
| 1299 |
+
# pop res hidden states
|
| 1300 |
+
res_hidden_states = res_hidden_states_tuple[-1]
|
| 1301 |
+
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
|
| 1302 |
+
|
| 1303 |
+
# FreeU: Only operate on the first two stages
|
| 1304 |
+
if is_freeu_enabled:
|
| 1305 |
+
hidden_states, res_hidden_states = apply_freeu(
|
| 1306 |
+
self.resolution_idx,
|
| 1307 |
+
hidden_states,
|
| 1308 |
+
res_hidden_states,
|
| 1309 |
+
s1=self.s1,
|
| 1310 |
+
s2=self.s2,
|
| 1311 |
+
b1=self.b1,
|
| 1312 |
+
b2=self.b2,
|
| 1313 |
+
)
|
| 1314 |
+
|
| 1315 |
+
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
|
| 1316 |
+
|
| 1317 |
+
if self.training and self.gradient_checkpointing:
|
| 1318 |
+
|
| 1319 |
+
def create_custom_forward(module):
|
| 1320 |
+
def custom_forward(*inputs):
|
| 1321 |
+
return module(*inputs)
|
| 1322 |
+
|
| 1323 |
+
return custom_forward
|
| 1324 |
+
|
| 1325 |
+
if is_torch_version(">=", "1.11.0"):
|
| 1326 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1327 |
+
create_custom_forward(resnet),
|
| 1328 |
+
hidden_states,
|
| 1329 |
+
temb,
|
| 1330 |
+
use_reentrant=False,
|
| 1331 |
+
)
|
| 1332 |
+
else:
|
| 1333 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1334 |
+
create_custom_forward(resnet), hidden_states, temb
|
| 1335 |
+
)
|
| 1336 |
+
else:
|
| 1337 |
+
hidden_states = resnet(hidden_states, temb, scale=scale)
|
| 1338 |
+
|
| 1339 |
+
if self.upsamplers is not None:
|
| 1340 |
+
for upsampler in self.upsamplers:
|
| 1341 |
+
hidden_states = upsampler(hidden_states, upsample_size, scale=scale)
|
| 1342 |
+
|
| 1343 |
+
return hidden_states
|
hallo/models/unet_2d_condition.py
ADDED
|
@@ -0,0 +1,1432 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
# pylint: disable=E1101
|
| 3 |
+
# pylint: disable=W1203
|
| 4 |
+
|
| 5 |
+
"""
|
| 6 |
+
This module implements the `UNet2DConditionModel`,
|
| 7 |
+
a variant of the 2D U-Net architecture designed for conditional image generation tasks.
|
| 8 |
+
The model is capable of taking a noisy input sample and conditioning it based on additional information such as class labels,
|
| 9 |
+
time steps, and encoder hidden states to produce a denoised output.
|
| 10 |
+
|
| 11 |
+
The `UNet2DConditionModel` leverages various components such as time embeddings,
|
| 12 |
+
class embeddings, and cross-attention mechanisms to integrate the conditioning information effectively.
|
| 13 |
+
It is built upon several sub-blocks including down-blocks, a middle block, and up-blocks,
|
| 14 |
+
each responsible for different stages of the U-Net's downsampling and upsampling process.
|
| 15 |
+
|
| 16 |
+
Key Features:
|
| 17 |
+
- Support for multiple types of down and up blocks, including those with cross-attention capabilities.
|
| 18 |
+
- Flexible configuration of the model's layers, including the number of layers per block and the output channels for each block.
|
| 19 |
+
- Integration of time embeddings and class embeddings to condition the model's output on additional information.
|
| 20 |
+
- Implementation of cross-attention to leverage encoder hidden states for conditional generation.
|
| 21 |
+
- The model supports gradient checkpointing to reduce memory usage during training.
|
| 22 |
+
|
| 23 |
+
The module also includes utility functions and classes such as `UNet2DConditionOutput` for structured output
|
| 24 |
+
and `load_change_cross_attention_dim` for loading and modifying pre-trained models.
|
| 25 |
+
|
| 26 |
+
Example Usage:
|
| 27 |
+
>>> import torch
|
| 28 |
+
>>> from unet_2d_condition_model import UNet2DConditionModel
|
| 29 |
+
>>> model = UNet2DConditionModel(
|
| 30 |
+
... sample_size=(64, 64),
|
| 31 |
+
... in_channels=3,
|
| 32 |
+
... out_channels=3,
|
| 33 |
+
... encoder_hid_dim=512,
|
| 34 |
+
... cross_attention_dim=1024,
|
| 35 |
+
... )
|
| 36 |
+
>>> # Prepare input tensors
|
| 37 |
+
>>> sample = torch.randn(1, 3, 64, 64)
|
| 38 |
+
>>> timestep = 0
|
| 39 |
+
>>> encoder_hidden_states = torch.randn(1, 14, 512)
|
| 40 |
+
>>> # Forward pass through the model
|
| 41 |
+
>>> output = model(sample, timestep, encoder_hidden_states)
|
| 42 |
+
|
| 43 |
+
This module is part of a larger ecosystem of diffusion models and can be used for various conditional image generation tasks.
|
| 44 |
+
"""
|
| 45 |
+
|
| 46 |
+
from dataclasses import dataclass
|
| 47 |
+
from os import PathLike
|
| 48 |
+
from pathlib import Path
|
| 49 |
+
from typing import Any, Dict, List, Optional, Tuple, Union
|
| 50 |
+
|
| 51 |
+
import torch
|
| 52 |
+
import torch.utils.checkpoint
|
| 53 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 54 |
+
from diffusers.loaders import UNet2DConditionLoadersMixin
|
| 55 |
+
from diffusers.models.activations import get_activation
|
| 56 |
+
from diffusers.models.attention_processor import (
|
| 57 |
+
ADDED_KV_ATTENTION_PROCESSORS, CROSS_ATTENTION_PROCESSORS,
|
| 58 |
+
AttentionProcessor, AttnAddedKVProcessor, AttnProcessor)
|
| 59 |
+
from diffusers.models.embeddings import (GaussianFourierProjection,
|
| 60 |
+
GLIGENTextBoundingboxProjection,
|
| 61 |
+
ImageHintTimeEmbedding,
|
| 62 |
+
ImageProjection, ImageTimeEmbedding,
|
| 63 |
+
TextImageProjection,
|
| 64 |
+
TextImageTimeEmbedding,
|
| 65 |
+
TextTimeEmbedding, TimestepEmbedding,
|
| 66 |
+
Timesteps)
|
| 67 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 68 |
+
from diffusers.utils import (SAFETENSORS_WEIGHTS_NAME, USE_PEFT_BACKEND,
|
| 69 |
+
WEIGHTS_NAME, BaseOutput, deprecate, logging,
|
| 70 |
+
scale_lora_layers, unscale_lora_layers)
|
| 71 |
+
from safetensors.torch import load_file
|
| 72 |
+
from torch import nn
|
| 73 |
+
|
| 74 |
+
from .unet_2d_blocks import (UNetMidBlock2D, UNetMidBlock2DCrossAttn,
|
| 75 |
+
get_down_block, get_up_block)
|
| 76 |
+
|
| 77 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 78 |
+
|
| 79 |
+
@dataclass
|
| 80 |
+
class UNet2DConditionOutput(BaseOutput):
|
| 81 |
+
"""
|
| 82 |
+
The output of [`UNet2DConditionModel`].
|
| 83 |
+
|
| 84 |
+
Args:
|
| 85 |
+
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 86 |
+
The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
|
| 87 |
+
"""
|
| 88 |
+
|
| 89 |
+
sample: torch.FloatTensor = None
|
| 90 |
+
ref_features: Tuple[torch.FloatTensor] = None
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
|
| 94 |
+
r"""
|
| 95 |
+
A conditional 2D UNet model that takes a noisy sample, conditional state, and a timestep and returns a sample
|
| 96 |
+
shaped output.
|
| 97 |
+
|
| 98 |
+
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
|
| 99 |
+
for all models (such as downloading or saving).
|
| 100 |
+
|
| 101 |
+
Parameters:
|
| 102 |
+
sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
|
| 103 |
+
Height and width of input/output sample.
|
| 104 |
+
in_channels (`int`, *optional*, defaults to 4): Number of channels in the input sample.
|
| 105 |
+
out_channels (`int`, *optional*, defaults to 4): Number of channels in the output.
|
| 106 |
+
center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
|
| 107 |
+
flip_sin_to_cos (`bool`, *optional*, defaults to `False`):
|
| 108 |
+
Whether to flip the sin to cos in the time embedding.
|
| 109 |
+
freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
|
| 110 |
+
down_block_types (`Tuple[str]`, *optional*, defaults to
|
| 111 |
+
`("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
|
| 112 |
+
The tuple of downsample blocks to use.
|
| 113 |
+
mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
|
| 114 |
+
Block type for middle of UNet, it can be one of `UNetMidBlock2DCrossAttn`, `UNetMidBlock2D`, or
|
| 115 |
+
`UNetMidBlock2DSimpleCrossAttn`. If `None`, the mid block layer is skipped.
|
| 116 |
+
up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D")`):
|
| 117 |
+
The tuple of upsample blocks to use.
|
| 118 |
+
only_cross_attention(`bool` or `Tuple[bool]`, *optional*, default to `False`):
|
| 119 |
+
Whether to include self-attention in the basic transformer blocks, see
|
| 120 |
+
[`~models.attention.BasicTransformerBlock`].
|
| 121 |
+
block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
|
| 122 |
+
The tuple of output channels for each block.
|
| 123 |
+
layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
|
| 124 |
+
downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
|
| 125 |
+
mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
|
| 126 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 127 |
+
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
| 128 |
+
norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
|
| 129 |
+
If `None`, normalization and activation layers is skipped in post-processing.
|
| 130 |
+
norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
|
| 131 |
+
cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
|
| 132 |
+
The dimension of the cross attention features.
|
| 133 |
+
transformer_layers_per_block (`int`, `Tuple[int]`, or `Tuple[Tuple]` , *optional*, defaults to 1):
|
| 134 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
|
| 135 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 136 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 137 |
+
reverse_transformer_layers_per_block : (`Tuple[Tuple]`, *optional*, defaults to None):
|
| 138 |
+
The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`], in the upsampling
|
| 139 |
+
blocks of the U-Net. Only relevant if `transformer_layers_per_block` is of type `Tuple[Tuple]` and for
|
| 140 |
+
[`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
|
| 141 |
+
[`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
|
| 142 |
+
encoder_hid_dim (`int`, *optional*, defaults to None):
|
| 143 |
+
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
| 144 |
+
dimension to `cross_attention_dim`.
|
| 145 |
+
encoder_hid_dim_type (`str`, *optional*, defaults to `None`):
|
| 146 |
+
If given, the `encoder_hidden_states` and potentially other embeddings are down-projected to text
|
| 147 |
+
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
| 148 |
+
attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
|
| 149 |
+
num_attention_heads (`int`, *optional*):
|
| 150 |
+
The number of attention heads. If not defined, defaults to `attention_head_dim`
|
| 151 |
+
resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
|
| 152 |
+
for ResNet blocks (see [`~models.resnet.ResnetBlock2D`]). Choose from `default` or `scale_shift`.
|
| 153 |
+
class_embed_type (`str`, *optional*, defaults to `None`):
|
| 154 |
+
The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
|
| 155 |
+
`"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
|
| 156 |
+
addition_embed_type (`str`, *optional*, defaults to `None`):
|
| 157 |
+
Configures an optional embedding which will be summed with the time embeddings. Choose from `None` or
|
| 158 |
+
"text". "text" will use the `TextTimeEmbedding` layer.
|
| 159 |
+
addition_time_embed_dim: (`int`, *optional*, defaults to `None`):
|
| 160 |
+
Dimension for the timestep embeddings.
|
| 161 |
+
num_class_embeds (`int`, *optional*, defaults to `None`):
|
| 162 |
+
Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
|
| 163 |
+
class conditioning with `class_embed_type` equal to `None`.
|
| 164 |
+
time_embedding_type (`str`, *optional*, defaults to `positional`):
|
| 165 |
+
The type of position embedding to use for timesteps. Choose from `positional` or `fourier`.
|
| 166 |
+
time_embedding_dim (`int`, *optional*, defaults to `None`):
|
| 167 |
+
An optional override for the dimension of the projected time embedding.
|
| 168 |
+
time_embedding_act_fn (`str`, *optional*, defaults to `None`):
|
| 169 |
+
Optional activation function to use only once on the time embeddings before they are passed to the rest of
|
| 170 |
+
the UNet. Choose from `silu`, `mish`, `gelu`, and `swish`.
|
| 171 |
+
timestep_post_act (`str`, *optional*, defaults to `None`):
|
| 172 |
+
The second activation function to use in timestep embedding. Choose from `silu`, `mish` and `gelu`.
|
| 173 |
+
time_cond_proj_dim (`int`, *optional*, defaults to `None`):
|
| 174 |
+
The dimension of `cond_proj` layer in the timestep embedding.
|
| 175 |
+
conv_in_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_in` layer. conv_out_kernel (`int`,
|
| 176 |
+
*optional*, default to `3`): The kernel size of `conv_out` layer. projection_class_embeddings_input_dim (`int`,
|
| 177 |
+
*optional*): The dimension of the `class_labels` input when
|
| 178 |
+
`class_embed_type="projection"`. Required when `class_embed_type="projection"`.
|
| 179 |
+
class_embeddings_concat (`bool`, *optional*, defaults to `False`): Whether to concatenate the time
|
| 180 |
+
embeddings with the class embeddings.
|
| 181 |
+
mid_block_only_cross_attention (`bool`, *optional*, defaults to `None`):
|
| 182 |
+
Whether to use cross attention with the mid block when using the `UNetMidBlock2DSimpleCrossAttn`. If
|
| 183 |
+
`only_cross_attention` is given as a single boolean and `mid_block_only_cross_attention` is `None`, the
|
| 184 |
+
`only_cross_attention` value is used as the value for `mid_block_only_cross_attention`. Default to `False`
|
| 185 |
+
otherwise.
|
| 186 |
+
"""
|
| 187 |
+
|
| 188 |
+
_supports_gradient_checkpointing = True
|
| 189 |
+
|
| 190 |
+
@register_to_config
|
| 191 |
+
def __init__(
|
| 192 |
+
self,
|
| 193 |
+
sample_size: Optional[int] = None,
|
| 194 |
+
in_channels: int = 4,
|
| 195 |
+
_out_channels: int = 4,
|
| 196 |
+
_center_input_sample: bool = False,
|
| 197 |
+
flip_sin_to_cos: bool = True,
|
| 198 |
+
freq_shift: int = 0,
|
| 199 |
+
down_block_types: Tuple[str] = (
|
| 200 |
+
"CrossAttnDownBlock2D",
|
| 201 |
+
"CrossAttnDownBlock2D",
|
| 202 |
+
"CrossAttnDownBlock2D",
|
| 203 |
+
"DownBlock2D",
|
| 204 |
+
),
|
| 205 |
+
mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
|
| 206 |
+
up_block_types: Tuple[str] = (
|
| 207 |
+
"UpBlock2D",
|
| 208 |
+
"CrossAttnUpBlock2D",
|
| 209 |
+
"CrossAttnUpBlock2D",
|
| 210 |
+
"CrossAttnUpBlock2D",
|
| 211 |
+
),
|
| 212 |
+
only_cross_attention: Union[bool, Tuple[bool]] = False,
|
| 213 |
+
block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
|
| 214 |
+
layers_per_block: Union[int, Tuple[int]] = 2,
|
| 215 |
+
downsample_padding: int = 1,
|
| 216 |
+
mid_block_scale_factor: float = 1,
|
| 217 |
+
dropout: float = 0.0,
|
| 218 |
+
act_fn: str = "silu",
|
| 219 |
+
norm_num_groups: Optional[int] = 32,
|
| 220 |
+
norm_eps: float = 1e-5,
|
| 221 |
+
cross_attention_dim: Union[int, Tuple[int]] = 1280,
|
| 222 |
+
transformer_layers_per_block: Union[int, Tuple[int], Tuple[Tuple]] = 1,
|
| 223 |
+
reverse_transformer_layers_per_block: Optional[Tuple[Tuple[int]]] = None,
|
| 224 |
+
encoder_hid_dim: Optional[int] = None,
|
| 225 |
+
encoder_hid_dim_type: Optional[str] = None,
|
| 226 |
+
attention_head_dim: Union[int, Tuple[int]] = 8,
|
| 227 |
+
num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
|
| 228 |
+
dual_cross_attention: bool = False,
|
| 229 |
+
use_linear_projection: bool = False,
|
| 230 |
+
class_embed_type: Optional[str] = None,
|
| 231 |
+
addition_embed_type: Optional[str] = None,
|
| 232 |
+
addition_time_embed_dim: Optional[int] = None,
|
| 233 |
+
num_class_embeds: Optional[int] = None,
|
| 234 |
+
upcast_attention: bool = False,
|
| 235 |
+
resnet_time_scale_shift: str = "default",
|
| 236 |
+
time_embedding_type: str = "positional",
|
| 237 |
+
time_embedding_dim: Optional[int] = None,
|
| 238 |
+
time_embedding_act_fn: Optional[str] = None,
|
| 239 |
+
timestep_post_act: Optional[str] = None,
|
| 240 |
+
time_cond_proj_dim: Optional[int] = None,
|
| 241 |
+
conv_in_kernel: int = 3,
|
| 242 |
+
projection_class_embeddings_input_dim: Optional[int] = None,
|
| 243 |
+
attention_type: str = "default",
|
| 244 |
+
class_embeddings_concat: bool = False,
|
| 245 |
+
mid_block_only_cross_attention: Optional[bool] = None,
|
| 246 |
+
addition_embed_type_num_heads=64,
|
| 247 |
+
_landmark_net=False,
|
| 248 |
+
):
|
| 249 |
+
super().__init__()
|
| 250 |
+
|
| 251 |
+
self.sample_size = sample_size
|
| 252 |
+
|
| 253 |
+
if num_attention_heads is not None:
|
| 254 |
+
raise ValueError(
|
| 255 |
+
"At the moment it is not possible to define the number of attention heads via `num_attention_heads`"
|
| 256 |
+
"because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131."
|
| 257 |
+
"Passing `num_attention_heads` will only be supported in diffusers v0.19."
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
# If `num_attention_heads` is not defined (which is the case for most models)
|
| 261 |
+
# it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
|
| 262 |
+
# The reason for this behavior is to correct for incorrectly named variables that were introduced
|
| 263 |
+
# when this library was created. The incorrect naming was only discovered much later in
|
| 264 |
+
# https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
|
| 265 |
+
# Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
|
| 266 |
+
# which is why we correct for the naming here.
|
| 267 |
+
num_attention_heads = num_attention_heads or attention_head_dim
|
| 268 |
+
|
| 269 |
+
# Check inputs
|
| 270 |
+
if len(down_block_types) != len(up_block_types):
|
| 271 |
+
raise ValueError(
|
| 272 |
+
"Must provide the same number of `down_block_types` as `up_block_types`."
|
| 273 |
+
f"`down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
|
| 274 |
+
)
|
| 275 |
+
|
| 276 |
+
if len(block_out_channels) != len(down_block_types):
|
| 277 |
+
raise ValueError(
|
| 278 |
+
"Must provide the same number of `block_out_channels` as `down_block_types`."
|
| 279 |
+
f"`block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
if not isinstance(only_cross_attention, bool) and len(
|
| 283 |
+
only_cross_attention
|
| 284 |
+
) != len(down_block_types):
|
| 285 |
+
raise ValueError(
|
| 286 |
+
"Must provide the same number of `only_cross_attention` as `down_block_types`."
|
| 287 |
+
f"`only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
|
| 288 |
+
)
|
| 289 |
+
|
| 290 |
+
if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(
|
| 291 |
+
down_block_types
|
| 292 |
+
):
|
| 293 |
+
raise ValueError(
|
| 294 |
+
"Must provide the same number of `num_attention_heads` as `down_block_types`."
|
| 295 |
+
f"`num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
|
| 296 |
+
)
|
| 297 |
+
|
| 298 |
+
if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(
|
| 299 |
+
down_block_types
|
| 300 |
+
):
|
| 301 |
+
raise ValueError(
|
| 302 |
+
"Must provide the same number of `attention_head_dim` as `down_block_types`."
|
| 303 |
+
f"`attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
|
| 304 |
+
)
|
| 305 |
+
|
| 306 |
+
if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(
|
| 307 |
+
down_block_types
|
| 308 |
+
):
|
| 309 |
+
raise ValueError(
|
| 310 |
+
"Must provide the same number of `cross_attention_dim` as `down_block_types`."
|
| 311 |
+
f"`cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
|
| 312 |
+
)
|
| 313 |
+
|
| 314 |
+
if not isinstance(layers_per_block, int) and len(layers_per_block) != len(
|
| 315 |
+
down_block_types
|
| 316 |
+
):
|
| 317 |
+
raise ValueError(
|
| 318 |
+
"Must provide the same number of `layers_per_block` as `down_block_types`."
|
| 319 |
+
f"`layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
|
| 320 |
+
)
|
| 321 |
+
if (
|
| 322 |
+
isinstance(transformer_layers_per_block, list)
|
| 323 |
+
and reverse_transformer_layers_per_block is None
|
| 324 |
+
):
|
| 325 |
+
for layer_number_per_block in transformer_layers_per_block:
|
| 326 |
+
if isinstance(layer_number_per_block, list):
|
| 327 |
+
raise ValueError(
|
| 328 |
+
"Must provide 'reverse_transformer_layers_per_block` if using asymmetrical UNet."
|
| 329 |
+
)
|
| 330 |
+
|
| 331 |
+
# input
|
| 332 |
+
conv_in_padding = (conv_in_kernel - 1) // 2
|
| 333 |
+
self.conv_in = nn.Conv2d(
|
| 334 |
+
in_channels,
|
| 335 |
+
block_out_channels[0],
|
| 336 |
+
kernel_size=conv_in_kernel,
|
| 337 |
+
padding=conv_in_padding,
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
# time
|
| 341 |
+
if time_embedding_type == "fourier":
|
| 342 |
+
time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
|
| 343 |
+
if time_embed_dim % 2 != 0:
|
| 344 |
+
raise ValueError(
|
| 345 |
+
f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}."
|
| 346 |
+
)
|
| 347 |
+
self.time_proj = GaussianFourierProjection(
|
| 348 |
+
time_embed_dim // 2,
|
| 349 |
+
set_W_to_weight=False,
|
| 350 |
+
log=False,
|
| 351 |
+
flip_sin_to_cos=flip_sin_to_cos,
|
| 352 |
+
)
|
| 353 |
+
timestep_input_dim = time_embed_dim
|
| 354 |
+
elif time_embedding_type == "positional":
|
| 355 |
+
time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
|
| 356 |
+
|
| 357 |
+
self.time_proj = Timesteps(
|
| 358 |
+
block_out_channels[0], flip_sin_to_cos, freq_shift
|
| 359 |
+
)
|
| 360 |
+
timestep_input_dim = block_out_channels[0]
|
| 361 |
+
else:
|
| 362 |
+
raise ValueError(
|
| 363 |
+
f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
self.time_embedding = TimestepEmbedding(
|
| 367 |
+
timestep_input_dim,
|
| 368 |
+
time_embed_dim,
|
| 369 |
+
act_fn=act_fn,
|
| 370 |
+
post_act_fn=timestep_post_act,
|
| 371 |
+
cond_proj_dim=time_cond_proj_dim,
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
| 375 |
+
encoder_hid_dim_type = "text_proj"
|
| 376 |
+
self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
|
| 377 |
+
logger.info(
|
| 378 |
+
"encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined."
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
| 382 |
+
raise ValueError(
|
| 383 |
+
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
| 384 |
+
)
|
| 385 |
+
|
| 386 |
+
if encoder_hid_dim_type == "text_proj":
|
| 387 |
+
self.encoder_hid_proj = nn.Linear(
|
| 388 |
+
encoder_hid_dim, cross_attention_dim)
|
| 389 |
+
elif encoder_hid_dim_type == "text_image_proj":
|
| 390 |
+
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 391 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 392 |
+
# case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
|
| 393 |
+
self.encoder_hid_proj = TextImageProjection(
|
| 394 |
+
text_embed_dim=encoder_hid_dim,
|
| 395 |
+
image_embed_dim=cross_attention_dim,
|
| 396 |
+
cross_attention_dim=cross_attention_dim,
|
| 397 |
+
)
|
| 398 |
+
elif encoder_hid_dim_type == "image_proj":
|
| 399 |
+
# Kandinsky 2.2
|
| 400 |
+
self.encoder_hid_proj = ImageProjection(
|
| 401 |
+
image_embed_dim=encoder_hid_dim,
|
| 402 |
+
cross_attention_dim=cross_attention_dim,
|
| 403 |
+
)
|
| 404 |
+
elif encoder_hid_dim_type is not None:
|
| 405 |
+
raise ValueError(
|
| 406 |
+
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
| 407 |
+
)
|
| 408 |
+
else:
|
| 409 |
+
self.encoder_hid_proj = None
|
| 410 |
+
|
| 411 |
+
# class embedding
|
| 412 |
+
if class_embed_type is None and num_class_embeds is not None:
|
| 413 |
+
self.class_embedding = nn.Embedding(
|
| 414 |
+
num_class_embeds, time_embed_dim)
|
| 415 |
+
elif class_embed_type == "timestep":
|
| 416 |
+
self.class_embedding = TimestepEmbedding(
|
| 417 |
+
timestep_input_dim, time_embed_dim, act_fn=act_fn
|
| 418 |
+
)
|
| 419 |
+
elif class_embed_type == "identity":
|
| 420 |
+
self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
|
| 421 |
+
elif class_embed_type == "projection":
|
| 422 |
+
if projection_class_embeddings_input_dim is None:
|
| 423 |
+
raise ValueError(
|
| 424 |
+
"`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
|
| 425 |
+
)
|
| 426 |
+
# The projection `class_embed_type` is the same as the timestep `class_embed_type` except
|
| 427 |
+
# 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
|
| 428 |
+
# 2. it projects from an arbitrary input dimension.
|
| 429 |
+
#
|
| 430 |
+
# Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
|
| 431 |
+
# When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
|
| 432 |
+
# As a result, `TimestepEmbedding` can be passed arbitrary vectors.
|
| 433 |
+
self.class_embedding = TimestepEmbedding(
|
| 434 |
+
projection_class_embeddings_input_dim, time_embed_dim
|
| 435 |
+
)
|
| 436 |
+
elif class_embed_type == "simple_projection":
|
| 437 |
+
if projection_class_embeddings_input_dim is None:
|
| 438 |
+
raise ValueError(
|
| 439 |
+
"`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
|
| 440 |
+
)
|
| 441 |
+
self.class_embedding = nn.Linear(
|
| 442 |
+
projection_class_embeddings_input_dim, time_embed_dim
|
| 443 |
+
)
|
| 444 |
+
else:
|
| 445 |
+
self.class_embedding = None
|
| 446 |
+
|
| 447 |
+
if addition_embed_type == "text":
|
| 448 |
+
if encoder_hid_dim is not None:
|
| 449 |
+
text_time_embedding_from_dim = encoder_hid_dim
|
| 450 |
+
else:
|
| 451 |
+
text_time_embedding_from_dim = cross_attention_dim
|
| 452 |
+
|
| 453 |
+
self.add_embedding = TextTimeEmbedding(
|
| 454 |
+
text_time_embedding_from_dim,
|
| 455 |
+
time_embed_dim,
|
| 456 |
+
num_heads=addition_embed_type_num_heads,
|
| 457 |
+
)
|
| 458 |
+
elif addition_embed_type == "text_image":
|
| 459 |
+
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
| 460 |
+
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
| 461 |
+
# case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
|
| 462 |
+
self.add_embedding = TextImageTimeEmbedding(
|
| 463 |
+
text_embed_dim=cross_attention_dim,
|
| 464 |
+
image_embed_dim=cross_attention_dim,
|
| 465 |
+
time_embed_dim=time_embed_dim,
|
| 466 |
+
)
|
| 467 |
+
elif addition_embed_type == "text_time":
|
| 468 |
+
self.add_time_proj = Timesteps(
|
| 469 |
+
addition_time_embed_dim, flip_sin_to_cos, freq_shift
|
| 470 |
+
)
|
| 471 |
+
self.add_embedding = TimestepEmbedding(
|
| 472 |
+
projection_class_embeddings_input_dim, time_embed_dim
|
| 473 |
+
)
|
| 474 |
+
elif addition_embed_type == "image":
|
| 475 |
+
# Kandinsky 2.2
|
| 476 |
+
self.add_embedding = ImageTimeEmbedding(
|
| 477 |
+
image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim
|
| 478 |
+
)
|
| 479 |
+
elif addition_embed_type == "image_hint":
|
| 480 |
+
# Kandinsky 2.2 ControlNet
|
| 481 |
+
self.add_embedding = ImageHintTimeEmbedding(
|
| 482 |
+
image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim
|
| 483 |
+
)
|
| 484 |
+
elif addition_embed_type is not None:
|
| 485 |
+
raise ValueError(
|
| 486 |
+
f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'."
|
| 487 |
+
)
|
| 488 |
+
|
| 489 |
+
if time_embedding_act_fn is None:
|
| 490 |
+
self.time_embed_act = None
|
| 491 |
+
else:
|
| 492 |
+
self.time_embed_act = get_activation(time_embedding_act_fn)
|
| 493 |
+
|
| 494 |
+
self.down_blocks = nn.ModuleList([])
|
| 495 |
+
self.up_blocks = nn.ModuleList([])
|
| 496 |
+
|
| 497 |
+
if isinstance(only_cross_attention, bool):
|
| 498 |
+
if mid_block_only_cross_attention is None:
|
| 499 |
+
mid_block_only_cross_attention = only_cross_attention
|
| 500 |
+
|
| 501 |
+
only_cross_attention = [
|
| 502 |
+
only_cross_attention] * len(down_block_types)
|
| 503 |
+
|
| 504 |
+
if mid_block_only_cross_attention is None:
|
| 505 |
+
mid_block_only_cross_attention = False
|
| 506 |
+
|
| 507 |
+
if isinstance(num_attention_heads, int):
|
| 508 |
+
num_attention_heads = (num_attention_heads,) * \
|
| 509 |
+
len(down_block_types)
|
| 510 |
+
|
| 511 |
+
if isinstance(attention_head_dim, int):
|
| 512 |
+
attention_head_dim = (attention_head_dim,) * len(down_block_types)
|
| 513 |
+
|
| 514 |
+
if isinstance(cross_attention_dim, int):
|
| 515 |
+
cross_attention_dim = (cross_attention_dim,) * \
|
| 516 |
+
len(down_block_types)
|
| 517 |
+
|
| 518 |
+
if isinstance(layers_per_block, int):
|
| 519 |
+
layers_per_block = [layers_per_block] * len(down_block_types)
|
| 520 |
+
|
| 521 |
+
if isinstance(transformer_layers_per_block, int):
|
| 522 |
+
transformer_layers_per_block = [transformer_layers_per_block] * len(
|
| 523 |
+
down_block_types
|
| 524 |
+
)
|
| 525 |
+
|
| 526 |
+
if class_embeddings_concat:
|
| 527 |
+
# The time embeddings are concatenated with the class embeddings. The dimension of the
|
| 528 |
+
# time embeddings passed to the down, middle, and up blocks is twice the dimension of the
|
| 529 |
+
# regular time embeddings
|
| 530 |
+
blocks_time_embed_dim = time_embed_dim * 2
|
| 531 |
+
else:
|
| 532 |
+
blocks_time_embed_dim = time_embed_dim
|
| 533 |
+
|
| 534 |
+
# down
|
| 535 |
+
output_channel = block_out_channels[0]
|
| 536 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 537 |
+
input_channel = output_channel
|
| 538 |
+
output_channel = block_out_channels[i]
|
| 539 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 540 |
+
|
| 541 |
+
down_block = get_down_block(
|
| 542 |
+
down_block_type,
|
| 543 |
+
num_layers=layers_per_block[i],
|
| 544 |
+
transformer_layers_per_block=transformer_layers_per_block[i],
|
| 545 |
+
in_channels=input_channel,
|
| 546 |
+
out_channels=output_channel,
|
| 547 |
+
temb_channels=blocks_time_embed_dim,
|
| 548 |
+
add_downsample=not is_final_block,
|
| 549 |
+
resnet_eps=norm_eps,
|
| 550 |
+
resnet_act_fn=act_fn,
|
| 551 |
+
resnet_groups=norm_num_groups,
|
| 552 |
+
cross_attention_dim=cross_attention_dim[i],
|
| 553 |
+
num_attention_heads=num_attention_heads[i],
|
| 554 |
+
downsample_padding=downsample_padding,
|
| 555 |
+
dual_cross_attention=dual_cross_attention,
|
| 556 |
+
use_linear_projection=use_linear_projection,
|
| 557 |
+
only_cross_attention=only_cross_attention[i],
|
| 558 |
+
upcast_attention=upcast_attention,
|
| 559 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 560 |
+
attention_type=attention_type,
|
| 561 |
+
attention_head_dim=(
|
| 562 |
+
attention_head_dim[i]
|
| 563 |
+
if attention_head_dim[i] is not None
|
| 564 |
+
else output_channel
|
| 565 |
+
),
|
| 566 |
+
dropout=dropout,
|
| 567 |
+
)
|
| 568 |
+
self.down_blocks.append(down_block)
|
| 569 |
+
|
| 570 |
+
# mid
|
| 571 |
+
if mid_block_type == "UNetMidBlock2DCrossAttn":
|
| 572 |
+
self.mid_block = UNetMidBlock2DCrossAttn(
|
| 573 |
+
transformer_layers_per_block=transformer_layers_per_block[-1],
|
| 574 |
+
in_channels=block_out_channels[-1],
|
| 575 |
+
temb_channels=blocks_time_embed_dim,
|
| 576 |
+
dropout=dropout,
|
| 577 |
+
resnet_eps=norm_eps,
|
| 578 |
+
resnet_act_fn=act_fn,
|
| 579 |
+
output_scale_factor=mid_block_scale_factor,
|
| 580 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 581 |
+
cross_attention_dim=cross_attention_dim[-1],
|
| 582 |
+
num_attention_heads=num_attention_heads[-1],
|
| 583 |
+
resnet_groups=norm_num_groups,
|
| 584 |
+
dual_cross_attention=dual_cross_attention,
|
| 585 |
+
use_linear_projection=use_linear_projection,
|
| 586 |
+
upcast_attention=upcast_attention,
|
| 587 |
+
attention_type=attention_type,
|
| 588 |
+
)
|
| 589 |
+
elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
|
| 590 |
+
raise NotImplementedError(
|
| 591 |
+
f"Unsupport mid_block_type: {mid_block_type}")
|
| 592 |
+
elif mid_block_type == "UNetMidBlock2D":
|
| 593 |
+
self.mid_block = UNetMidBlock2D(
|
| 594 |
+
in_channels=block_out_channels[-1],
|
| 595 |
+
temb_channels=blocks_time_embed_dim,
|
| 596 |
+
dropout=dropout,
|
| 597 |
+
num_layers=0,
|
| 598 |
+
resnet_eps=norm_eps,
|
| 599 |
+
resnet_act_fn=act_fn,
|
| 600 |
+
output_scale_factor=mid_block_scale_factor,
|
| 601 |
+
resnet_groups=norm_num_groups,
|
| 602 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 603 |
+
add_attention=False,
|
| 604 |
+
)
|
| 605 |
+
elif mid_block_type is None:
|
| 606 |
+
self.mid_block = None
|
| 607 |
+
else:
|
| 608 |
+
raise ValueError(f"unknown mid_block_type : {mid_block_type}")
|
| 609 |
+
|
| 610 |
+
# count how many layers upsample the images
|
| 611 |
+
self.num_upsamplers = 0
|
| 612 |
+
|
| 613 |
+
# up
|
| 614 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 615 |
+
reversed_num_attention_heads = list(reversed(num_attention_heads))
|
| 616 |
+
reversed_layers_per_block = list(reversed(layers_per_block))
|
| 617 |
+
reversed_cross_attention_dim = list(reversed(cross_attention_dim))
|
| 618 |
+
reversed_transformer_layers_per_block = (
|
| 619 |
+
list(reversed(transformer_layers_per_block))
|
| 620 |
+
if reverse_transformer_layers_per_block is None
|
| 621 |
+
else reverse_transformer_layers_per_block
|
| 622 |
+
)
|
| 623 |
+
only_cross_attention = list(reversed(only_cross_attention))
|
| 624 |
+
|
| 625 |
+
output_channel = reversed_block_out_channels[0]
|
| 626 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 627 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 628 |
+
|
| 629 |
+
prev_output_channel = output_channel
|
| 630 |
+
output_channel = reversed_block_out_channels[i]
|
| 631 |
+
input_channel = reversed_block_out_channels[
|
| 632 |
+
min(i + 1, len(block_out_channels) - 1)
|
| 633 |
+
]
|
| 634 |
+
|
| 635 |
+
# add upsample block for all BUT final layer
|
| 636 |
+
if not is_final_block:
|
| 637 |
+
add_upsample = True
|
| 638 |
+
self.num_upsamplers += 1
|
| 639 |
+
else:
|
| 640 |
+
add_upsample = False
|
| 641 |
+
|
| 642 |
+
up_block = get_up_block(
|
| 643 |
+
up_block_type,
|
| 644 |
+
num_layers=reversed_layers_per_block[i] + 1,
|
| 645 |
+
transformer_layers_per_block=reversed_transformer_layers_per_block[i],
|
| 646 |
+
in_channels=input_channel,
|
| 647 |
+
out_channels=output_channel,
|
| 648 |
+
prev_output_channel=prev_output_channel,
|
| 649 |
+
temb_channels=blocks_time_embed_dim,
|
| 650 |
+
add_upsample=add_upsample,
|
| 651 |
+
resnet_eps=norm_eps,
|
| 652 |
+
resnet_act_fn=act_fn,
|
| 653 |
+
resolution_idx=i,
|
| 654 |
+
resnet_groups=norm_num_groups,
|
| 655 |
+
cross_attention_dim=reversed_cross_attention_dim[i],
|
| 656 |
+
num_attention_heads=reversed_num_attention_heads[i],
|
| 657 |
+
dual_cross_attention=dual_cross_attention,
|
| 658 |
+
use_linear_projection=use_linear_projection,
|
| 659 |
+
only_cross_attention=only_cross_attention[i],
|
| 660 |
+
upcast_attention=upcast_attention,
|
| 661 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 662 |
+
attention_type=attention_type,
|
| 663 |
+
attention_head_dim=(
|
| 664 |
+
attention_head_dim[i]
|
| 665 |
+
if attention_head_dim[i] is not None
|
| 666 |
+
else output_channel
|
| 667 |
+
),
|
| 668 |
+
dropout=dropout,
|
| 669 |
+
)
|
| 670 |
+
self.up_blocks.append(up_block)
|
| 671 |
+
prev_output_channel = output_channel
|
| 672 |
+
|
| 673 |
+
# out
|
| 674 |
+
if norm_num_groups is not None:
|
| 675 |
+
self.conv_norm_out = nn.GroupNorm(
|
| 676 |
+
num_channels=block_out_channels[0],
|
| 677 |
+
num_groups=norm_num_groups,
|
| 678 |
+
eps=norm_eps,
|
| 679 |
+
)
|
| 680 |
+
|
| 681 |
+
self.conv_act = get_activation(act_fn)
|
| 682 |
+
|
| 683 |
+
else:
|
| 684 |
+
self.conv_norm_out = None
|
| 685 |
+
self.conv_act = None
|
| 686 |
+
self.conv_norm_out = None
|
| 687 |
+
|
| 688 |
+
if attention_type in ["gated", "gated-text-image"]:
|
| 689 |
+
positive_len = 768
|
| 690 |
+
if isinstance(cross_attention_dim, int):
|
| 691 |
+
positive_len = cross_attention_dim
|
| 692 |
+
elif isinstance(cross_attention_dim, (tuple, list)):
|
| 693 |
+
positive_len = cross_attention_dim[0]
|
| 694 |
+
|
| 695 |
+
feature_type = "text-only" if attention_type == "gated" else "text-image"
|
| 696 |
+
self.position_net = GLIGENTextBoundingboxProjection(
|
| 697 |
+
positive_len=positive_len,
|
| 698 |
+
out_dim=cross_attention_dim,
|
| 699 |
+
feature_type=feature_type,
|
| 700 |
+
)
|
| 701 |
+
|
| 702 |
+
@property
|
| 703 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 704 |
+
r"""
|
| 705 |
+
Returns:
|
| 706 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 707 |
+
indexed by its weight name.
|
| 708 |
+
"""
|
| 709 |
+
# set recursively
|
| 710 |
+
processors = {}
|
| 711 |
+
|
| 712 |
+
def fn_recursive_add_processors(
|
| 713 |
+
name: str,
|
| 714 |
+
module: torch.nn.Module,
|
| 715 |
+
processors: Dict[str, AttentionProcessor],
|
| 716 |
+
):
|
| 717 |
+
if hasattr(module, "get_processor"):
|
| 718 |
+
processors[f"{name}.processor"] = module.get_processor(
|
| 719 |
+
return_deprecated_lora=True
|
| 720 |
+
)
|
| 721 |
+
|
| 722 |
+
for sub_name, child in module.named_children():
|
| 723 |
+
fn_recursive_add_processors(
|
| 724 |
+
f"{name}.{sub_name}", child, processors)
|
| 725 |
+
|
| 726 |
+
return processors
|
| 727 |
+
|
| 728 |
+
for name, module in self.named_children():
|
| 729 |
+
fn_recursive_add_processors(name, module, processors)
|
| 730 |
+
|
| 731 |
+
return processors
|
| 732 |
+
|
| 733 |
+
def set_attn_processor(
|
| 734 |
+
self,
|
| 735 |
+
processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]],
|
| 736 |
+
_remove_lora=False,
|
| 737 |
+
):
|
| 738 |
+
r"""
|
| 739 |
+
Sets the attention processor to use to compute attention.
|
| 740 |
+
|
| 741 |
+
Parameters:
|
| 742 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 743 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 744 |
+
for **all** `Attention` layers.
|
| 745 |
+
|
| 746 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 747 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 748 |
+
|
| 749 |
+
"""
|
| 750 |
+
count = len(self.attn_processors.keys())
|
| 751 |
+
|
| 752 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 753 |
+
raise ValueError(
|
| 754 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 755 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 756 |
+
)
|
| 757 |
+
|
| 758 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 759 |
+
if hasattr(module, "set_processor"):
|
| 760 |
+
if not isinstance(processor, dict):
|
| 761 |
+
module.set_processor(processor, _remove_lora=_remove_lora)
|
| 762 |
+
else:
|
| 763 |
+
module.set_processor(
|
| 764 |
+
processor.pop(f"{name}.processor"), _remove_lora=_remove_lora
|
| 765 |
+
)
|
| 766 |
+
|
| 767 |
+
for sub_name, child in module.named_children():
|
| 768 |
+
fn_recursive_attn_processor(
|
| 769 |
+
f"{name}.{sub_name}", child, processor)
|
| 770 |
+
|
| 771 |
+
for name, module in self.named_children():
|
| 772 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 773 |
+
|
| 774 |
+
def set_default_attn_processor(self):
|
| 775 |
+
"""
|
| 776 |
+
Disables custom attention processors and sets the default attention implementation.
|
| 777 |
+
"""
|
| 778 |
+
if all(
|
| 779 |
+
proc.__class__ in ADDED_KV_ATTENTION_PROCESSORS
|
| 780 |
+
for proc in self.attn_processors.values()
|
| 781 |
+
):
|
| 782 |
+
processor = AttnAddedKVProcessor()
|
| 783 |
+
elif all(
|
| 784 |
+
proc.__class__ in CROSS_ATTENTION_PROCESSORS
|
| 785 |
+
for proc in self.attn_processors.values()
|
| 786 |
+
):
|
| 787 |
+
processor = AttnProcessor()
|
| 788 |
+
else:
|
| 789 |
+
raise ValueError(
|
| 790 |
+
f"Cannot call `set_default_attn_processor` when attention processors are of type {next(iter(self.attn_processors.values()))}"
|
| 791 |
+
)
|
| 792 |
+
|
| 793 |
+
self.set_attn_processor(processor, _remove_lora=True)
|
| 794 |
+
|
| 795 |
+
def set_attention_slice(self, slice_size):
|
| 796 |
+
r"""
|
| 797 |
+
Enable sliced attention computation.
|
| 798 |
+
|
| 799 |
+
When this option is enabled, the attention module splits the input tensor in slices to compute attention in
|
| 800 |
+
several steps. This is useful for saving some memory in exchange for a small decrease in speed.
|
| 801 |
+
|
| 802 |
+
Args:
|
| 803 |
+
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
|
| 804 |
+
When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
|
| 805 |
+
`"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
|
| 806 |
+
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
|
| 807 |
+
must be a multiple of `slice_size`.
|
| 808 |
+
"""
|
| 809 |
+
sliceable_head_dims = []
|
| 810 |
+
|
| 811 |
+
def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
|
| 812 |
+
if hasattr(module, "set_attention_slice"):
|
| 813 |
+
sliceable_head_dims.append(module.sliceable_head_dim)
|
| 814 |
+
|
| 815 |
+
for child in module.children():
|
| 816 |
+
fn_recursive_retrieve_sliceable_dims(child)
|
| 817 |
+
|
| 818 |
+
# retrieve number of attention layers
|
| 819 |
+
for module in self.children():
|
| 820 |
+
fn_recursive_retrieve_sliceable_dims(module)
|
| 821 |
+
|
| 822 |
+
num_sliceable_layers = len(sliceable_head_dims)
|
| 823 |
+
|
| 824 |
+
if slice_size == "auto":
|
| 825 |
+
# half the attention head size is usually a good trade-off between
|
| 826 |
+
# speed and memory
|
| 827 |
+
slice_size = [dim // 2 for dim in sliceable_head_dims]
|
| 828 |
+
elif slice_size == "max":
|
| 829 |
+
# make smallest slice possible
|
| 830 |
+
slice_size = num_sliceable_layers * [1]
|
| 831 |
+
|
| 832 |
+
slice_size = (
|
| 833 |
+
num_sliceable_layers * [slice_size]
|
| 834 |
+
if not isinstance(slice_size, list)
|
| 835 |
+
else slice_size
|
| 836 |
+
)
|
| 837 |
+
|
| 838 |
+
if len(slice_size) != len(sliceable_head_dims):
|
| 839 |
+
raise ValueError(
|
| 840 |
+
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
|
| 841 |
+
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
|
| 842 |
+
)
|
| 843 |
+
|
| 844 |
+
for i, size in enumerate(slice_size):
|
| 845 |
+
dim = sliceable_head_dims[i]
|
| 846 |
+
if size is not None and size > dim:
|
| 847 |
+
raise ValueError(
|
| 848 |
+
f"size {size} has to be smaller or equal to {dim}.")
|
| 849 |
+
|
| 850 |
+
# Recursively walk through all the children.
|
| 851 |
+
# Any children which exposes the set_attention_slice method
|
| 852 |
+
# gets the message
|
| 853 |
+
def fn_recursive_set_attention_slice(
|
| 854 |
+
module: torch.nn.Module, slice_size: List[int]
|
| 855 |
+
):
|
| 856 |
+
if hasattr(module, "set_attention_slice"):
|
| 857 |
+
module.set_attention_slice(slice_size.pop())
|
| 858 |
+
|
| 859 |
+
for child in module.children():
|
| 860 |
+
fn_recursive_set_attention_slice(child, slice_size)
|
| 861 |
+
|
| 862 |
+
reversed_slice_size = list(reversed(slice_size))
|
| 863 |
+
for module in self.children():
|
| 864 |
+
fn_recursive_set_attention_slice(module, reversed_slice_size)
|
| 865 |
+
|
| 866 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 867 |
+
if hasattr(module, "gradient_checkpointing"):
|
| 868 |
+
module.gradient_checkpointing = value
|
| 869 |
+
|
| 870 |
+
def enable_freeu(self, s1, s2, b1, b2):
|
| 871 |
+
r"""Enables the FreeU mechanism from https://arxiv.org/abs/2309.11497.
|
| 872 |
+
|
| 873 |
+
The suffixes after the scaling factors represent the stage blocks where they are being applied.
|
| 874 |
+
|
| 875 |
+
Please refer to the [official repository](https://github.com/ChenyangSi/FreeU) for combinations of values that
|
| 876 |
+
are known to work well for different pipelines such as Stable Diffusion v1, v2, and Stable Diffusion XL.
|
| 877 |
+
|
| 878 |
+
Args:
|
| 879 |
+
s1 (`float`):
|
| 880 |
+
Scaling factor for stage 1 to attenuate the contributions of the skip features. This is done to
|
| 881 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 882 |
+
s2 (`float`):
|
| 883 |
+
Scaling factor for stage 2 to attenuate the contributions of the skip features. This is done to
|
| 884 |
+
mitigate the "oversmoothing effect" in the enhanced denoising process.
|
| 885 |
+
b1 (`float`): Scaling factor for stage 1 to amplify the contributions of backbone features.
|
| 886 |
+
b2 (`float`): Scaling factor for stage 2 to amplify the contributions of backbone features.
|
| 887 |
+
"""
|
| 888 |
+
for _, upsample_block in enumerate(self.up_blocks):
|
| 889 |
+
setattr(upsample_block, "s1", s1)
|
| 890 |
+
setattr(upsample_block, "s2", s2)
|
| 891 |
+
setattr(upsample_block, "b1", b1)
|
| 892 |
+
setattr(upsample_block, "b2", b2)
|
| 893 |
+
|
| 894 |
+
def disable_freeu(self):
|
| 895 |
+
"""Disables the FreeU mechanism."""
|
| 896 |
+
freeu_keys = {"s1", "s2", "b1", "b2"}
|
| 897 |
+
for _, upsample_block in enumerate(self.up_blocks):
|
| 898 |
+
for k in freeu_keys:
|
| 899 |
+
if (
|
| 900 |
+
hasattr(upsample_block, k)
|
| 901 |
+
or getattr(upsample_block, k, None) is not None
|
| 902 |
+
):
|
| 903 |
+
setattr(upsample_block, k, None)
|
| 904 |
+
|
| 905 |
+
def forward(
|
| 906 |
+
self,
|
| 907 |
+
sample: torch.FloatTensor,
|
| 908 |
+
timestep: Union[torch.Tensor, float, int],
|
| 909 |
+
encoder_hidden_states: torch.Tensor,
|
| 910 |
+
cond_tensor: torch.FloatTensor=None,
|
| 911 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 912 |
+
timestep_cond: Optional[torch.Tensor] = None,
|
| 913 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 914 |
+
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
| 915 |
+
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
| 916 |
+
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 917 |
+
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
| 918 |
+
down_intrablock_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 919 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 920 |
+
return_dict: bool = True,
|
| 921 |
+
post_process: bool = False,
|
| 922 |
+
) -> Union[UNet2DConditionOutput, Tuple]:
|
| 923 |
+
r"""
|
| 924 |
+
The [`UNet2DConditionModel`] forward method.
|
| 925 |
+
|
| 926 |
+
Args:
|
| 927 |
+
sample (`torch.FloatTensor`):
|
| 928 |
+
The noisy input tensor with the following shape `(batch, channel, height, width)`.
|
| 929 |
+
timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
|
| 930 |
+
encoder_hidden_states (`torch.FloatTensor`):
|
| 931 |
+
The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
|
| 932 |
+
class_labels (`torch.Tensor`, *optional*, defaults to `None`):
|
| 933 |
+
Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
|
| 934 |
+
timestep_cond: (`torch.Tensor`, *optional*, defaults to `None`):
|
| 935 |
+
Conditional embeddings for timestep. If provided, the embeddings will be summed with the samples passed
|
| 936 |
+
through the `self.time_embedding` layer to obtain the timestep embeddings.
|
| 937 |
+
attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
|
| 938 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 939 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 940 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 941 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 942 |
+
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
| 943 |
+
`self.processor` in
|
| 944 |
+
[diffusers.models.attention_processor]
|
| 945 |
+
(https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
| 946 |
+
added_cond_kwargs: (`dict`, *optional*):
|
| 947 |
+
A kwargs dictionary containing additional embeddings that if specified are added to the embeddings that
|
| 948 |
+
are passed along to the UNet blocks.
|
| 949 |
+
down_block_additional_residuals: (`tuple` of `torch.Tensor`, *optional*):
|
| 950 |
+
A tuple of tensors that if specified are added to the residuals of down unet blocks.
|
| 951 |
+
mid_block_additional_residual: (`torch.Tensor`, *optional*):
|
| 952 |
+
A tensor that if specified is added to the residual of the middle unet block.
|
| 953 |
+
encoder_attention_mask (`torch.Tensor`):
|
| 954 |
+
A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
|
| 955 |
+
`True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
|
| 956 |
+
which adds large negative values to the attention scores corresponding to "discard" tokens.
|
| 957 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 958 |
+
Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
|
| 959 |
+
tuple.
|
| 960 |
+
cross_attention_kwargs (`dict`, *optional*):
|
| 961 |
+
A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
|
| 962 |
+
added_cond_kwargs: (`dict`, *optional*):
|
| 963 |
+
A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
|
| 964 |
+
are passed along to the UNet blocks.
|
| 965 |
+
down_block_additional_residuals (`tuple` of `torch.Tensor`, *optional*):
|
| 966 |
+
additional residuals to be added to UNet long skip connections from down blocks to up blocks for
|
| 967 |
+
example from ControlNet side model(s)
|
| 968 |
+
mid_block_additional_residual (`torch.Tensor`, *optional*):
|
| 969 |
+
additional residual to be added to UNet mid block output, for example from ControlNet side model
|
| 970 |
+
down_intrablock_additional_residuals (`tuple` of `torch.Tensor`, *optional*):
|
| 971 |
+
additional residuals to be added within UNet down blocks, for example from T2I-Adapter side model(s)
|
| 972 |
+
|
| 973 |
+
Returns:
|
| 974 |
+
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
| 975 |
+
If `return_dict` is True, an [`~models.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
|
| 976 |
+
a `tuple` is returned where the first element is the sample tensor.
|
| 977 |
+
"""
|
| 978 |
+
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
| 979 |
+
# The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
|
| 980 |
+
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
| 981 |
+
# on the fly if necessary.
|
| 982 |
+
default_overall_up_factor = 2**self.num_upsamplers
|
| 983 |
+
|
| 984 |
+
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
| 985 |
+
forward_upsample_size = False
|
| 986 |
+
upsample_size = None
|
| 987 |
+
|
| 988 |
+
for dim in sample.shape[-2:]:
|
| 989 |
+
if dim % default_overall_up_factor != 0:
|
| 990 |
+
# Forward upsample size to force interpolation output size.
|
| 991 |
+
forward_upsample_size = True
|
| 992 |
+
break
|
| 993 |
+
|
| 994 |
+
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension
|
| 995 |
+
# expects mask of shape:
|
| 996 |
+
# [batch, key_tokens]
|
| 997 |
+
# adds singleton query_tokens dimension:
|
| 998 |
+
# [batch, 1, key_tokens]
|
| 999 |
+
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
| 1000 |
+
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
| 1001 |
+
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
| 1002 |
+
if attention_mask is not None:
|
| 1003 |
+
# assume that mask is expressed as:
|
| 1004 |
+
# (1 = keep, 0 = discard)
|
| 1005 |
+
# convert mask into a bias that can be added to attention scores:
|
| 1006 |
+
# (keep = +0, discard = -10000.0)
|
| 1007 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 1008 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 1009 |
+
|
| 1010 |
+
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
| 1011 |
+
if encoder_attention_mask is not None:
|
| 1012 |
+
encoder_attention_mask = (
|
| 1013 |
+
1 - encoder_attention_mask.to(sample.dtype)
|
| 1014 |
+
) * -10000.0
|
| 1015 |
+
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
| 1016 |
+
|
| 1017 |
+
# 0. center input if necessary
|
| 1018 |
+
if self.config.center_input_sample:
|
| 1019 |
+
sample = 2 * sample - 1.0
|
| 1020 |
+
|
| 1021 |
+
# 1. time
|
| 1022 |
+
timesteps = timestep
|
| 1023 |
+
if not torch.is_tensor(timesteps):
|
| 1024 |
+
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
| 1025 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 1026 |
+
is_mps = sample.device.type == "mps"
|
| 1027 |
+
if isinstance(timestep, float):
|
| 1028 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 1029 |
+
else:
|
| 1030 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 1031 |
+
timesteps = torch.tensor(
|
| 1032 |
+
[timesteps], dtype=dtype, device=sample.device)
|
| 1033 |
+
elif len(timesteps.shape) == 0:
|
| 1034 |
+
timesteps = timesteps[None].to(sample.device)
|
| 1035 |
+
|
| 1036 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 1037 |
+
timesteps = timesteps.expand(sample.shape[0])
|
| 1038 |
+
|
| 1039 |
+
t_emb = self.time_proj(timesteps)
|
| 1040 |
+
|
| 1041 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 1042 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 1043 |
+
# there might be better ways to encapsulate this.
|
| 1044 |
+
t_emb = t_emb.to(dtype=sample.dtype)
|
| 1045 |
+
|
| 1046 |
+
emb = self.time_embedding(t_emb, timestep_cond)
|
| 1047 |
+
aug_emb = None
|
| 1048 |
+
|
| 1049 |
+
if self.class_embedding is not None:
|
| 1050 |
+
if class_labels is None:
|
| 1051 |
+
raise ValueError(
|
| 1052 |
+
"class_labels should be provided when num_class_embeds > 0"
|
| 1053 |
+
)
|
| 1054 |
+
|
| 1055 |
+
if self.config.class_embed_type == "timestep":
|
| 1056 |
+
class_labels = self.time_proj(class_labels)
|
| 1057 |
+
|
| 1058 |
+
# `Timesteps` does not contain any weights and will always return f32 tensors
|
| 1059 |
+
# there might be better ways to encapsulate this.
|
| 1060 |
+
class_labels = class_labels.to(dtype=sample.dtype)
|
| 1061 |
+
|
| 1062 |
+
class_emb = self.class_embedding(
|
| 1063 |
+
class_labels).to(dtype=sample.dtype)
|
| 1064 |
+
|
| 1065 |
+
if self.config.class_embeddings_concat:
|
| 1066 |
+
emb = torch.cat([emb, class_emb], dim=-1)
|
| 1067 |
+
else:
|
| 1068 |
+
emb = emb + class_emb
|
| 1069 |
+
|
| 1070 |
+
if self.config.addition_embed_type == "text":
|
| 1071 |
+
aug_emb = self.add_embedding(encoder_hidden_states)
|
| 1072 |
+
elif self.config.addition_embed_type == "text_image":
|
| 1073 |
+
# Kandinsky 2.1 - style
|
| 1074 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1075 |
+
raise ValueError(
|
| 1076 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image'"
|
| 1077 |
+
"which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 1078 |
+
)
|
| 1079 |
+
|
| 1080 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 1081 |
+
text_embs = added_cond_kwargs.get(
|
| 1082 |
+
"text_embeds", encoder_hidden_states)
|
| 1083 |
+
aug_emb = self.add_embedding(text_embs, image_embs)
|
| 1084 |
+
elif self.config.addition_embed_type == "text_time":
|
| 1085 |
+
# SDXL - style
|
| 1086 |
+
if "text_embeds" not in added_cond_kwargs:
|
| 1087 |
+
raise ValueError(
|
| 1088 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time'"
|
| 1089 |
+
"which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
|
| 1090 |
+
)
|
| 1091 |
+
text_embeds = added_cond_kwargs.get("text_embeds")
|
| 1092 |
+
if "time_ids" not in added_cond_kwargs:
|
| 1093 |
+
raise ValueError(
|
| 1094 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'text_time'"
|
| 1095 |
+
"which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
|
| 1096 |
+
)
|
| 1097 |
+
time_ids = added_cond_kwargs.get("time_ids")
|
| 1098 |
+
time_embeds = self.add_time_proj(time_ids.flatten())
|
| 1099 |
+
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
|
| 1100 |
+
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
|
| 1101 |
+
add_embeds = add_embeds.to(emb.dtype)
|
| 1102 |
+
aug_emb = self.add_embedding(add_embeds)
|
| 1103 |
+
elif self.config.addition_embed_type == "image":
|
| 1104 |
+
# Kandinsky 2.2 - style
|
| 1105 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1106 |
+
raise ValueError(
|
| 1107 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image'"
|
| 1108 |
+
"which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
| 1109 |
+
)
|
| 1110 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 1111 |
+
aug_emb = self.add_embedding(image_embs)
|
| 1112 |
+
elif self.config.addition_embed_type == "image_hint":
|
| 1113 |
+
# Kandinsky 2.2 - style
|
| 1114 |
+
if (
|
| 1115 |
+
"image_embeds" not in added_cond_kwargs
|
| 1116 |
+
or "hint" not in added_cond_kwargs
|
| 1117 |
+
):
|
| 1118 |
+
raise ValueError(
|
| 1119 |
+
f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint'"
|
| 1120 |
+
"which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
|
| 1121 |
+
)
|
| 1122 |
+
image_embs = added_cond_kwargs.get("image_embeds")
|
| 1123 |
+
hint = added_cond_kwargs.get("hint")
|
| 1124 |
+
aug_emb, hint = self.add_embedding(image_embs, hint)
|
| 1125 |
+
sample = torch.cat([sample, hint], dim=1)
|
| 1126 |
+
|
| 1127 |
+
emb = emb + aug_emb if aug_emb is not None else emb
|
| 1128 |
+
|
| 1129 |
+
if self.time_embed_act is not None:
|
| 1130 |
+
emb = self.time_embed_act(emb)
|
| 1131 |
+
|
| 1132 |
+
if (
|
| 1133 |
+
self.encoder_hid_proj is not None
|
| 1134 |
+
and self.config.encoder_hid_dim_type == "text_proj"
|
| 1135 |
+
):
|
| 1136 |
+
encoder_hidden_states = self.encoder_hid_proj(
|
| 1137 |
+
encoder_hidden_states)
|
| 1138 |
+
elif (
|
| 1139 |
+
self.encoder_hid_proj is not None
|
| 1140 |
+
and self.config.encoder_hid_dim_type == "text_image_proj"
|
| 1141 |
+
):
|
| 1142 |
+
# Kadinsky 2.1 - style
|
| 1143 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1144 |
+
raise ValueError(
|
| 1145 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj'"
|
| 1146 |
+
"which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1147 |
+
)
|
| 1148 |
+
|
| 1149 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1150 |
+
encoder_hidden_states = self.encoder_hid_proj(
|
| 1151 |
+
encoder_hidden_states, image_embeds
|
| 1152 |
+
)
|
| 1153 |
+
elif (
|
| 1154 |
+
self.encoder_hid_proj is not None
|
| 1155 |
+
and self.config.encoder_hid_dim_type == "image_proj"
|
| 1156 |
+
):
|
| 1157 |
+
# Kandinsky 2.2 - style
|
| 1158 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1159 |
+
raise ValueError(
|
| 1160 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj'"
|
| 1161 |
+
"which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1162 |
+
)
|
| 1163 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1164 |
+
encoder_hidden_states = self.encoder_hid_proj(image_embeds)
|
| 1165 |
+
elif (
|
| 1166 |
+
self.encoder_hid_proj is not None
|
| 1167 |
+
and self.config.encoder_hid_dim_type == "ip_image_proj"
|
| 1168 |
+
):
|
| 1169 |
+
if "image_embeds" not in added_cond_kwargs:
|
| 1170 |
+
raise ValueError(
|
| 1171 |
+
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'ip_image_proj'"
|
| 1172 |
+
"which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
| 1173 |
+
)
|
| 1174 |
+
image_embeds = added_cond_kwargs.get("image_embeds")
|
| 1175 |
+
image_embeds = self.encoder_hid_proj(image_embeds).to(
|
| 1176 |
+
encoder_hidden_states.dtype
|
| 1177 |
+
)
|
| 1178 |
+
encoder_hidden_states = torch.cat(
|
| 1179 |
+
[encoder_hidden_states, image_embeds], dim=1
|
| 1180 |
+
)
|
| 1181 |
+
|
| 1182 |
+
# 2. pre-process
|
| 1183 |
+
sample = self.conv_in(sample)
|
| 1184 |
+
if cond_tensor is not None:
|
| 1185 |
+
sample = sample + cond_tensor
|
| 1186 |
+
|
| 1187 |
+
# 2.5 GLIGEN position net
|
| 1188 |
+
if (
|
| 1189 |
+
cross_attention_kwargs is not None
|
| 1190 |
+
and cross_attention_kwargs.get("gligen", None) is not None
|
| 1191 |
+
):
|
| 1192 |
+
cross_attention_kwargs = cross_attention_kwargs.copy()
|
| 1193 |
+
gligen_args = cross_attention_kwargs.pop("gligen")
|
| 1194 |
+
cross_attention_kwargs["gligen"] = {
|
| 1195 |
+
"objs": self.position_net(**gligen_args)
|
| 1196 |
+
}
|
| 1197 |
+
|
| 1198 |
+
# 3. down
|
| 1199 |
+
lora_scale = (
|
| 1200 |
+
cross_attention_kwargs.get("scale", 1.0)
|
| 1201 |
+
if cross_attention_kwargs is not None
|
| 1202 |
+
else 1.0
|
| 1203 |
+
)
|
| 1204 |
+
if USE_PEFT_BACKEND:
|
| 1205 |
+
# weight the lora layers by setting `lora_scale` for each PEFT layer
|
| 1206 |
+
scale_lora_layers(self, lora_scale)
|
| 1207 |
+
|
| 1208 |
+
is_controlnet = (
|
| 1209 |
+
mid_block_additional_residual is not None
|
| 1210 |
+
and down_block_additional_residuals is not None
|
| 1211 |
+
)
|
| 1212 |
+
# using new arg down_intrablock_additional_residuals for T2I-Adapters, to distinguish from controlnets
|
| 1213 |
+
is_adapter = down_intrablock_additional_residuals is not None
|
| 1214 |
+
# maintain backward compatibility for legacy usage, where
|
| 1215 |
+
# T2I-Adapter and ControlNet both use down_block_additional_residuals arg
|
| 1216 |
+
# but can only use one or the other
|
| 1217 |
+
if (
|
| 1218 |
+
not is_adapter
|
| 1219 |
+
and mid_block_additional_residual is None
|
| 1220 |
+
and down_block_additional_residuals is not None
|
| 1221 |
+
):
|
| 1222 |
+
deprecate(
|
| 1223 |
+
"T2I should not use down_block_additional_residuals",
|
| 1224 |
+
"1.3.0",
|
| 1225 |
+
"Passing intrablock residual connections with `down_block_additional_residuals` is deprecated \
|
| 1226 |
+
and will be removed in diffusers 1.3.0. `down_block_additional_residuals` should only be used \
|
| 1227 |
+
for ControlNet. Please make sure use `down_intrablock_additional_residuals` instead. ",
|
| 1228 |
+
standard_warn=False,
|
| 1229 |
+
)
|
| 1230 |
+
down_intrablock_additional_residuals = down_block_additional_residuals
|
| 1231 |
+
is_adapter = True
|
| 1232 |
+
|
| 1233 |
+
down_block_res_samples = (sample,)
|
| 1234 |
+
for downsample_block in self.down_blocks:
|
| 1235 |
+
if (
|
| 1236 |
+
hasattr(downsample_block, "has_cross_attention")
|
| 1237 |
+
and downsample_block.has_cross_attention
|
| 1238 |
+
):
|
| 1239 |
+
# For t2i-adapter CrossAttnDownBlock2D
|
| 1240 |
+
additional_residuals = {}
|
| 1241 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 1242 |
+
additional_residuals["additional_residuals"] = (
|
| 1243 |
+
down_intrablock_additional_residuals.pop(0)
|
| 1244 |
+
)
|
| 1245 |
+
|
| 1246 |
+
sample, res_samples = downsample_block(
|
| 1247 |
+
hidden_states=sample,
|
| 1248 |
+
temb=emb,
|
| 1249 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1250 |
+
attention_mask=attention_mask,
|
| 1251 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1252 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1253 |
+
**additional_residuals,
|
| 1254 |
+
)
|
| 1255 |
+
else:
|
| 1256 |
+
sample, res_samples = downsample_block(
|
| 1257 |
+
hidden_states=sample, temb=emb, scale=lora_scale
|
| 1258 |
+
)
|
| 1259 |
+
if is_adapter and len(down_intrablock_additional_residuals) > 0:
|
| 1260 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 1261 |
+
|
| 1262 |
+
down_block_res_samples += res_samples
|
| 1263 |
+
|
| 1264 |
+
if is_controlnet:
|
| 1265 |
+
new_down_block_res_samples = ()
|
| 1266 |
+
|
| 1267 |
+
for down_block_res_sample, down_block_additional_residual in zip(
|
| 1268 |
+
down_block_res_samples, down_block_additional_residuals
|
| 1269 |
+
):
|
| 1270 |
+
down_block_res_sample = (
|
| 1271 |
+
down_block_res_sample + down_block_additional_residual
|
| 1272 |
+
)
|
| 1273 |
+
new_down_block_res_samples = new_down_block_res_samples + (
|
| 1274 |
+
down_block_res_sample,
|
| 1275 |
+
)
|
| 1276 |
+
|
| 1277 |
+
down_block_res_samples = new_down_block_res_samples
|
| 1278 |
+
|
| 1279 |
+
# 4. mid
|
| 1280 |
+
if self.mid_block is not None:
|
| 1281 |
+
if (
|
| 1282 |
+
hasattr(self.mid_block, "has_cross_attention")
|
| 1283 |
+
and self.mid_block.has_cross_attention
|
| 1284 |
+
):
|
| 1285 |
+
sample = self.mid_block(
|
| 1286 |
+
sample,
|
| 1287 |
+
emb,
|
| 1288 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1289 |
+
attention_mask=attention_mask,
|
| 1290 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1291 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1292 |
+
)
|
| 1293 |
+
else:
|
| 1294 |
+
sample = self.mid_block(sample, emb)
|
| 1295 |
+
|
| 1296 |
+
# To support T2I-Adapter-XL
|
| 1297 |
+
if (
|
| 1298 |
+
is_adapter
|
| 1299 |
+
and len(down_intrablock_additional_residuals) > 0
|
| 1300 |
+
and sample.shape == down_intrablock_additional_residuals[0].shape
|
| 1301 |
+
):
|
| 1302 |
+
sample += down_intrablock_additional_residuals.pop(0)
|
| 1303 |
+
|
| 1304 |
+
if is_controlnet:
|
| 1305 |
+
sample = sample + mid_block_additional_residual
|
| 1306 |
+
|
| 1307 |
+
# 5. up
|
| 1308 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 1309 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 1310 |
+
|
| 1311 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets):]
|
| 1312 |
+
down_block_res_samples = down_block_res_samples[
|
| 1313 |
+
: -len(upsample_block.resnets)
|
| 1314 |
+
]
|
| 1315 |
+
|
| 1316 |
+
# if we have not reached the final block and need to forward the
|
| 1317 |
+
# upsample size, we do it here
|
| 1318 |
+
if not is_final_block and forward_upsample_size:
|
| 1319 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 1320 |
+
|
| 1321 |
+
if (
|
| 1322 |
+
hasattr(upsample_block, "has_cross_attention")
|
| 1323 |
+
and upsample_block.has_cross_attention
|
| 1324 |
+
):
|
| 1325 |
+
sample = upsample_block(
|
| 1326 |
+
hidden_states=sample,
|
| 1327 |
+
temb=emb,
|
| 1328 |
+
res_hidden_states_tuple=res_samples,
|
| 1329 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1330 |
+
cross_attention_kwargs=cross_attention_kwargs,
|
| 1331 |
+
upsample_size=upsample_size,
|
| 1332 |
+
attention_mask=attention_mask,
|
| 1333 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1334 |
+
)
|
| 1335 |
+
else:
|
| 1336 |
+
sample = upsample_block(
|
| 1337 |
+
hidden_states=sample,
|
| 1338 |
+
temb=emb,
|
| 1339 |
+
res_hidden_states_tuple=res_samples,
|
| 1340 |
+
upsample_size=upsample_size,
|
| 1341 |
+
scale=lora_scale,
|
| 1342 |
+
)
|
| 1343 |
+
|
| 1344 |
+
# 6. post-process
|
| 1345 |
+
if post_process:
|
| 1346 |
+
if self.conv_norm_out:
|
| 1347 |
+
sample = self.conv_norm_out(sample)
|
| 1348 |
+
sample = self.conv_act(sample)
|
| 1349 |
+
sample = self.conv_out(sample)
|
| 1350 |
+
|
| 1351 |
+
if USE_PEFT_BACKEND:
|
| 1352 |
+
# remove `lora_scale` from each PEFT layer
|
| 1353 |
+
unscale_lora_layers(self, lora_scale)
|
| 1354 |
+
|
| 1355 |
+
if not return_dict:
|
| 1356 |
+
return (sample,)
|
| 1357 |
+
|
| 1358 |
+
return UNet2DConditionOutput(sample=sample)
|
| 1359 |
+
|
| 1360 |
+
@classmethod
|
| 1361 |
+
def load_change_cross_attention_dim(
|
| 1362 |
+
cls,
|
| 1363 |
+
pretrained_model_path: PathLike,
|
| 1364 |
+
subfolder=None,
|
| 1365 |
+
# unet_additional_kwargs=None,
|
| 1366 |
+
):
|
| 1367 |
+
"""
|
| 1368 |
+
Load or change the cross-attention dimension of a pre-trained model.
|
| 1369 |
+
|
| 1370 |
+
Parameters:
|
| 1371 |
+
pretrained_model_name_or_path (:class:`~typing.Union[str, :class:`~pathlib.Path`]`):
|
| 1372 |
+
The identifier of the pre-trained model or the path to the local folder containing the model.
|
| 1373 |
+
force_download (:class:`~bool`):
|
| 1374 |
+
If True, re-download the model even if it is already cached.
|
| 1375 |
+
resume_download (:class:`~bool`):
|
| 1376 |
+
If True, resume the download of the model if partially downloaded.
|
| 1377 |
+
proxies (:class:`~dict`):
|
| 1378 |
+
A dictionary of proxy servers to use for downloading the model.
|
| 1379 |
+
cache_dir (:class:`~Optional[str]`):
|
| 1380 |
+
The path to the cache directory for storing downloaded models.
|
| 1381 |
+
use_auth_token (:class:`~bool`):
|
| 1382 |
+
If True, use the authentication token for private models.
|
| 1383 |
+
revision (:class:`~str`):
|
| 1384 |
+
The specific model version to use.
|
| 1385 |
+
use_safetensors (:class:`~bool`):
|
| 1386 |
+
If True, use the SafeTensors format for loading the model weights.
|
| 1387 |
+
**kwargs (:class:`~dict`):
|
| 1388 |
+
Additional keyword arguments passed to the model.
|
| 1389 |
+
|
| 1390 |
+
"""
|
| 1391 |
+
pretrained_model_path = Path(pretrained_model_path)
|
| 1392 |
+
if subfolder is not None:
|
| 1393 |
+
pretrained_model_path = pretrained_model_path.joinpath(subfolder)
|
| 1394 |
+
config_file = pretrained_model_path / "config.json"
|
| 1395 |
+
if not (config_file.exists() and config_file.is_file()):
|
| 1396 |
+
raise RuntimeError(
|
| 1397 |
+
f"{config_file} does not exist or is not a file")
|
| 1398 |
+
|
| 1399 |
+
unet_config = cls.load_config(config_file)
|
| 1400 |
+
unet_config["cross_attention_dim"] = 1024
|
| 1401 |
+
|
| 1402 |
+
model = cls.from_config(unet_config)
|
| 1403 |
+
# load the vanilla weights
|
| 1404 |
+
if pretrained_model_path.joinpath(SAFETENSORS_WEIGHTS_NAME).exists():
|
| 1405 |
+
logger.debug(
|
| 1406 |
+
f"loading safeTensors weights from {pretrained_model_path} ..."
|
| 1407 |
+
)
|
| 1408 |
+
state_dict = load_file(
|
| 1409 |
+
pretrained_model_path.joinpath(SAFETENSORS_WEIGHTS_NAME), device="cpu"
|
| 1410 |
+
)
|
| 1411 |
+
|
| 1412 |
+
elif pretrained_model_path.joinpath(WEIGHTS_NAME).exists():
|
| 1413 |
+
logger.debug(f"loading weights from {pretrained_model_path} ...")
|
| 1414 |
+
state_dict = torch.load(
|
| 1415 |
+
pretrained_model_path.joinpath(WEIGHTS_NAME),
|
| 1416 |
+
map_location="cpu",
|
| 1417 |
+
weights_only=True,
|
| 1418 |
+
)
|
| 1419 |
+
else:
|
| 1420 |
+
raise FileNotFoundError(
|
| 1421 |
+
f"no weights file found in {pretrained_model_path}")
|
| 1422 |
+
|
| 1423 |
+
model_state_dict = model.state_dict()
|
| 1424 |
+
for k in state_dict:
|
| 1425 |
+
if k in model_state_dict:
|
| 1426 |
+
if state_dict[k].shape != model_state_dict[k].shape:
|
| 1427 |
+
state_dict[k] = model_state_dict[k]
|
| 1428 |
+
# load the weights into the model
|
| 1429 |
+
m, u = model.load_state_dict(state_dict, strict=False)
|
| 1430 |
+
print(m, u)
|
| 1431 |
+
|
| 1432 |
+
return model
|
hallo/models/unet_3d.py
ADDED
|
@@ -0,0 +1,839 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
# pylint: disable=E1101
|
| 3 |
+
# pylint: disable=R0402
|
| 4 |
+
# pylint: disable=W1203
|
| 5 |
+
|
| 6 |
+
"""
|
| 7 |
+
This is the main file for the UNet3DConditionModel, which defines the UNet3D model architecture.
|
| 8 |
+
|
| 9 |
+
The UNet3D model is a 3D convolutional neural network designed for image segmentation and
|
| 10 |
+
other computer vision tasks. It consists of an encoder, a decoder, and skip connections between
|
| 11 |
+
the corresponding layers of the encoder and decoder. The model can handle 3D data and
|
| 12 |
+
performs well on tasks such as image segmentation, object detection, and video analysis.
|
| 13 |
+
|
| 14 |
+
This file contains the necessary imports, the main UNet3DConditionModel class, and its
|
| 15 |
+
methods for setting attention slice, setting gradient checkpointing, setting attention
|
| 16 |
+
processor, and the forward method for model inference.
|
| 17 |
+
|
| 18 |
+
The module provides a comprehensive solution for 3D image segmentation tasks and can be
|
| 19 |
+
easily extended for other computer vision tasks as well.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
from collections import OrderedDict
|
| 23 |
+
from dataclasses import dataclass
|
| 24 |
+
from os import PathLike
|
| 25 |
+
from pathlib import Path
|
| 26 |
+
from typing import Dict, List, Optional, Tuple, Union
|
| 27 |
+
|
| 28 |
+
import torch
|
| 29 |
+
import torch.nn as nn
|
| 30 |
+
import torch.utils.checkpoint
|
| 31 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 32 |
+
from diffusers.models.attention_processor import AttentionProcessor
|
| 33 |
+
from diffusers.models.embeddings import TimestepEmbedding, Timesteps
|
| 34 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 35 |
+
from diffusers.utils import (SAFETENSORS_WEIGHTS_NAME, WEIGHTS_NAME,
|
| 36 |
+
BaseOutput, logging)
|
| 37 |
+
from safetensors.torch import load_file
|
| 38 |
+
|
| 39 |
+
from .resnet import InflatedConv3d, InflatedGroupNorm
|
| 40 |
+
from .unet_3d_blocks import (UNetMidBlock3DCrossAttn, get_down_block,
|
| 41 |
+
get_up_block)
|
| 42 |
+
|
| 43 |
+
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
@dataclass
|
| 47 |
+
class UNet3DConditionOutput(BaseOutput):
|
| 48 |
+
"""
|
| 49 |
+
Data class that serves as the output of the UNet3DConditionModel.
|
| 50 |
+
|
| 51 |
+
Attributes:
|
| 52 |
+
sample (`torch.FloatTensor`):
|
| 53 |
+
A tensor representing the processed sample. The shape and nature of this tensor will depend on the
|
| 54 |
+
specific configuration of the model and the input data.
|
| 55 |
+
"""
|
| 56 |
+
sample: torch.FloatTensor
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
class UNet3DConditionModel(ModelMixin, ConfigMixin):
|
| 60 |
+
"""
|
| 61 |
+
A 3D UNet model designed to handle conditional image and video generation tasks. This model is particularly
|
| 62 |
+
suited for tasks that require the generation of 3D data, such as volumetric medical imaging or 3D video
|
| 63 |
+
generation, while incorporating additional conditioning information.
|
| 64 |
+
|
| 65 |
+
The model consists of an encoder-decoder structure with skip connections. It utilizes a series of downsampling
|
| 66 |
+
and upsampling blocks, with a middle block for further processing. Each block can be customized with different
|
| 67 |
+
types of layers and attention mechanisms.
|
| 68 |
+
|
| 69 |
+
Parameters:
|
| 70 |
+
sample_size (`int`, optional): The size of the input sample.
|
| 71 |
+
in_channels (`int`, defaults to 8): The number of input channels.
|
| 72 |
+
out_channels (`int`, defaults to 8): The number of output channels.
|
| 73 |
+
center_input_sample (`bool`, defaults to False): Whether to center the input sample.
|
| 74 |
+
flip_sin_to_cos (`bool`, defaults to True): Whether to flip the sine to cosine in the time embedding.
|
| 75 |
+
freq_shift (`int`, defaults to 0): The frequency shift for the time embedding.
|
| 76 |
+
down_block_types (`Tuple[str]`): A tuple of strings specifying the types of downsampling blocks.
|
| 77 |
+
mid_block_type (`str`): The type of middle block.
|
| 78 |
+
up_block_types (`Tuple[str]`): A tuple of strings specifying the types of upsampling blocks.
|
| 79 |
+
only_cross_attention (`Union[bool, Tuple[bool]]`): Whether to use only cross-attention.
|
| 80 |
+
block_out_channels (`Tuple[int]`): A tuple of integers specifying the output channels for each block.
|
| 81 |
+
layers_per_block (`int`, defaults to 2): The number of layers per block.
|
| 82 |
+
downsample_padding (`int`, defaults to 1): The padding used in downsampling.
|
| 83 |
+
mid_block_scale_factor (`float`, defaults to 1): The scale factor for the middle block.
|
| 84 |
+
act_fn (`str`, defaults to 'silu'): The activation function to be used.
|
| 85 |
+
norm_num_groups (`int`, defaults to 32): The number of groups for normalization.
|
| 86 |
+
norm_eps (`float`, defaults to 1e-5): The epsilon for normalization.
|
| 87 |
+
cross_attention_dim (`int`, defaults to 1280): The dimension for cross-attention.
|
| 88 |
+
attention_head_dim (`Union[int, Tuple[int]]`): The dimension for attention heads.
|
| 89 |
+
dual_cross_attention (`bool`, defaults to False): Whether to use dual cross-attention.
|
| 90 |
+
use_linear_projection (`bool`, defaults to False): Whether to use linear projection.
|
| 91 |
+
class_embed_type (`str`, optional): The type of class embedding.
|
| 92 |
+
num_class_embeds (`int`, optional): The number of class embeddings.
|
| 93 |
+
upcast_attention (`bool`, defaults to False): Whether to upcast attention.
|
| 94 |
+
resnet_time_scale_shift (`str`, defaults to 'default'): The time scale shift for the ResNet.
|
| 95 |
+
use_inflated_groupnorm (`bool`, defaults to False): Whether to use inflated group normalization.
|
| 96 |
+
use_motion_module (`bool`, defaults to False): Whether to use a motion module.
|
| 97 |
+
motion_module_resolutions (`Tuple[int]`): A tuple of resolutions for the motion module.
|
| 98 |
+
motion_module_mid_block (`bool`, defaults to False): Whether to use a motion module in the middle block.
|
| 99 |
+
motion_module_decoder_only (`bool`, defaults to False): Whether to use the motion module only in the decoder.
|
| 100 |
+
motion_module_type (`str`, optional): The type of motion module.
|
| 101 |
+
motion_module_kwargs (`dict`): Keyword arguments for the motion module.
|
| 102 |
+
unet_use_cross_frame_attention (`bool`, optional): Whether to use cross-frame attention in the UNet.
|
| 103 |
+
unet_use_temporal_attention (`bool`, optional): Whether to use temporal attention in the UNet.
|
| 104 |
+
use_audio_module (`bool`, defaults to False): Whether to use an audio module.
|
| 105 |
+
audio_attention_dim (`int`, defaults to 768): The dimension for audio attention.
|
| 106 |
+
|
| 107 |
+
The model supports various features such as gradient checkpointing, attention processors, and sliced attention
|
| 108 |
+
computation, making it flexible and efficient for different computational requirements and use cases.
|
| 109 |
+
|
| 110 |
+
The forward method of the model accepts a sample, timestep, and encoder hidden states as input, and it returns
|
| 111 |
+
the processed sample as output. The method also supports additional conditioning information such as class
|
| 112 |
+
labels, audio embeddings, and masks for specialized tasks.
|
| 113 |
+
|
| 114 |
+
The from_pretrained_2d class method allows loading a pre-trained 2D UNet model and adapting it for 3D tasks by
|
| 115 |
+
incorporating motion modules and other 3D specific features.
|
| 116 |
+
"""
|
| 117 |
+
|
| 118 |
+
_supports_gradient_checkpointing = True
|
| 119 |
+
|
| 120 |
+
@register_to_config
|
| 121 |
+
def __init__(
|
| 122 |
+
self,
|
| 123 |
+
sample_size: Optional[int] = None,
|
| 124 |
+
in_channels: int = 8,
|
| 125 |
+
out_channels: int = 8,
|
| 126 |
+
flip_sin_to_cos: bool = True,
|
| 127 |
+
freq_shift: int = 0,
|
| 128 |
+
down_block_types: Tuple[str] = (
|
| 129 |
+
"CrossAttnDownBlock3D",
|
| 130 |
+
"CrossAttnDownBlock3D",
|
| 131 |
+
"CrossAttnDownBlock3D",
|
| 132 |
+
"DownBlock3D",
|
| 133 |
+
),
|
| 134 |
+
mid_block_type: str = "UNetMidBlock3DCrossAttn",
|
| 135 |
+
up_block_types: Tuple[str] = (
|
| 136 |
+
"UpBlock3D",
|
| 137 |
+
"CrossAttnUpBlock3D",
|
| 138 |
+
"CrossAttnUpBlock3D",
|
| 139 |
+
"CrossAttnUpBlock3D",
|
| 140 |
+
),
|
| 141 |
+
only_cross_attention: Union[bool, Tuple[bool]] = False,
|
| 142 |
+
block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
|
| 143 |
+
layers_per_block: int = 2,
|
| 144 |
+
downsample_padding: int = 1,
|
| 145 |
+
mid_block_scale_factor: float = 1,
|
| 146 |
+
act_fn: str = "silu",
|
| 147 |
+
norm_num_groups: int = 32,
|
| 148 |
+
norm_eps: float = 1e-5,
|
| 149 |
+
cross_attention_dim: int = 1280,
|
| 150 |
+
attention_head_dim: Union[int, Tuple[int]] = 8,
|
| 151 |
+
dual_cross_attention: bool = False,
|
| 152 |
+
use_linear_projection: bool = False,
|
| 153 |
+
class_embed_type: Optional[str] = None,
|
| 154 |
+
num_class_embeds: Optional[int] = None,
|
| 155 |
+
upcast_attention: bool = False,
|
| 156 |
+
resnet_time_scale_shift: str = "default",
|
| 157 |
+
use_inflated_groupnorm=False,
|
| 158 |
+
# Additional
|
| 159 |
+
use_motion_module=False,
|
| 160 |
+
motion_module_resolutions=(1, 2, 4, 8),
|
| 161 |
+
motion_module_mid_block=False,
|
| 162 |
+
motion_module_decoder_only=False,
|
| 163 |
+
motion_module_type=None,
|
| 164 |
+
motion_module_kwargs=None,
|
| 165 |
+
unet_use_cross_frame_attention=None,
|
| 166 |
+
unet_use_temporal_attention=None,
|
| 167 |
+
# audio
|
| 168 |
+
use_audio_module=False,
|
| 169 |
+
audio_attention_dim=768,
|
| 170 |
+
stack_enable_blocks_name=None,
|
| 171 |
+
stack_enable_blocks_depth=None,
|
| 172 |
+
):
|
| 173 |
+
super().__init__()
|
| 174 |
+
|
| 175 |
+
self.sample_size = sample_size
|
| 176 |
+
time_embed_dim = block_out_channels[0] * 4
|
| 177 |
+
|
| 178 |
+
# input
|
| 179 |
+
self.conv_in = InflatedConv3d(
|
| 180 |
+
in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1)
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
# time
|
| 184 |
+
self.time_proj = Timesteps(
|
| 185 |
+
block_out_channels[0], flip_sin_to_cos, freq_shift)
|
| 186 |
+
timestep_input_dim = block_out_channels[0]
|
| 187 |
+
|
| 188 |
+
self.time_embedding = TimestepEmbedding(
|
| 189 |
+
timestep_input_dim, time_embed_dim)
|
| 190 |
+
|
| 191 |
+
# class embedding
|
| 192 |
+
if class_embed_type is None and num_class_embeds is not None:
|
| 193 |
+
self.class_embedding = nn.Embedding(
|
| 194 |
+
num_class_embeds, time_embed_dim)
|
| 195 |
+
elif class_embed_type == "timestep":
|
| 196 |
+
self.class_embedding = TimestepEmbedding(
|
| 197 |
+
timestep_input_dim, time_embed_dim)
|
| 198 |
+
elif class_embed_type == "identity":
|
| 199 |
+
self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
|
| 200 |
+
else:
|
| 201 |
+
self.class_embedding = None
|
| 202 |
+
|
| 203 |
+
self.down_blocks = nn.ModuleList([])
|
| 204 |
+
self.mid_block = None
|
| 205 |
+
self.up_blocks = nn.ModuleList([])
|
| 206 |
+
|
| 207 |
+
if isinstance(only_cross_attention, bool):
|
| 208 |
+
only_cross_attention = [
|
| 209 |
+
only_cross_attention] * len(down_block_types)
|
| 210 |
+
|
| 211 |
+
if isinstance(attention_head_dim, int):
|
| 212 |
+
attention_head_dim = (attention_head_dim,) * len(down_block_types)
|
| 213 |
+
|
| 214 |
+
# down
|
| 215 |
+
output_channel = block_out_channels[0]
|
| 216 |
+
for i, down_block_type in enumerate(down_block_types):
|
| 217 |
+
res = 2**i
|
| 218 |
+
input_channel = output_channel
|
| 219 |
+
output_channel = block_out_channels[i]
|
| 220 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 221 |
+
|
| 222 |
+
down_block = get_down_block(
|
| 223 |
+
down_block_type,
|
| 224 |
+
num_layers=layers_per_block,
|
| 225 |
+
in_channels=input_channel,
|
| 226 |
+
out_channels=output_channel,
|
| 227 |
+
temb_channels=time_embed_dim,
|
| 228 |
+
add_downsample=not is_final_block,
|
| 229 |
+
resnet_eps=norm_eps,
|
| 230 |
+
resnet_act_fn=act_fn,
|
| 231 |
+
resnet_groups=norm_num_groups,
|
| 232 |
+
cross_attention_dim=cross_attention_dim,
|
| 233 |
+
attn_num_head_channels=attention_head_dim[i],
|
| 234 |
+
downsample_padding=downsample_padding,
|
| 235 |
+
dual_cross_attention=dual_cross_attention,
|
| 236 |
+
use_linear_projection=use_linear_projection,
|
| 237 |
+
only_cross_attention=only_cross_attention[i],
|
| 238 |
+
upcast_attention=upcast_attention,
|
| 239 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 240 |
+
unet_use_cross_frame_attention=unet_use_cross_frame_attention,
|
| 241 |
+
unet_use_temporal_attention=unet_use_temporal_attention,
|
| 242 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 243 |
+
use_motion_module=use_motion_module
|
| 244 |
+
and (res in motion_module_resolutions)
|
| 245 |
+
and (not motion_module_decoder_only),
|
| 246 |
+
motion_module_type=motion_module_type,
|
| 247 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 248 |
+
use_audio_module=use_audio_module,
|
| 249 |
+
audio_attention_dim=audio_attention_dim,
|
| 250 |
+
depth=i,
|
| 251 |
+
stack_enable_blocks_name=stack_enable_blocks_name,
|
| 252 |
+
stack_enable_blocks_depth=stack_enable_blocks_depth,
|
| 253 |
+
)
|
| 254 |
+
self.down_blocks.append(down_block)
|
| 255 |
+
|
| 256 |
+
# mid
|
| 257 |
+
if mid_block_type == "UNetMidBlock3DCrossAttn":
|
| 258 |
+
self.mid_block = UNetMidBlock3DCrossAttn(
|
| 259 |
+
in_channels=block_out_channels[-1],
|
| 260 |
+
temb_channels=time_embed_dim,
|
| 261 |
+
resnet_eps=norm_eps,
|
| 262 |
+
resnet_act_fn=act_fn,
|
| 263 |
+
output_scale_factor=mid_block_scale_factor,
|
| 264 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 265 |
+
cross_attention_dim=cross_attention_dim,
|
| 266 |
+
attn_num_head_channels=attention_head_dim[-1],
|
| 267 |
+
resnet_groups=norm_num_groups,
|
| 268 |
+
dual_cross_attention=dual_cross_attention,
|
| 269 |
+
use_linear_projection=use_linear_projection,
|
| 270 |
+
upcast_attention=upcast_attention,
|
| 271 |
+
unet_use_cross_frame_attention=unet_use_cross_frame_attention,
|
| 272 |
+
unet_use_temporal_attention=unet_use_temporal_attention,
|
| 273 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 274 |
+
use_motion_module=use_motion_module and motion_module_mid_block,
|
| 275 |
+
motion_module_type=motion_module_type,
|
| 276 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 277 |
+
use_audio_module=use_audio_module,
|
| 278 |
+
audio_attention_dim=audio_attention_dim,
|
| 279 |
+
depth=3,
|
| 280 |
+
stack_enable_blocks_name=stack_enable_blocks_name,
|
| 281 |
+
stack_enable_blocks_depth=stack_enable_blocks_depth,
|
| 282 |
+
)
|
| 283 |
+
else:
|
| 284 |
+
raise ValueError(f"unknown mid_block_type : {mid_block_type}")
|
| 285 |
+
|
| 286 |
+
# count how many layers upsample the videos
|
| 287 |
+
self.num_upsamplers = 0
|
| 288 |
+
|
| 289 |
+
# up
|
| 290 |
+
reversed_block_out_channels = list(reversed(block_out_channels))
|
| 291 |
+
reversed_attention_head_dim = list(reversed(attention_head_dim))
|
| 292 |
+
only_cross_attention = list(reversed(only_cross_attention))
|
| 293 |
+
output_channel = reversed_block_out_channels[0]
|
| 294 |
+
for i, up_block_type in enumerate(up_block_types):
|
| 295 |
+
res = 2 ** (3 - i)
|
| 296 |
+
is_final_block = i == len(block_out_channels) - 1
|
| 297 |
+
|
| 298 |
+
prev_output_channel = output_channel
|
| 299 |
+
output_channel = reversed_block_out_channels[i]
|
| 300 |
+
input_channel = reversed_block_out_channels[
|
| 301 |
+
min(i + 1, len(block_out_channels) - 1)
|
| 302 |
+
]
|
| 303 |
+
|
| 304 |
+
# add upsample block for all BUT final layer
|
| 305 |
+
if not is_final_block:
|
| 306 |
+
add_upsample = True
|
| 307 |
+
self.num_upsamplers += 1
|
| 308 |
+
else:
|
| 309 |
+
add_upsample = False
|
| 310 |
+
|
| 311 |
+
up_block = get_up_block(
|
| 312 |
+
up_block_type,
|
| 313 |
+
num_layers=layers_per_block + 1,
|
| 314 |
+
in_channels=input_channel,
|
| 315 |
+
out_channels=output_channel,
|
| 316 |
+
prev_output_channel=prev_output_channel,
|
| 317 |
+
temb_channels=time_embed_dim,
|
| 318 |
+
add_upsample=add_upsample,
|
| 319 |
+
resnet_eps=norm_eps,
|
| 320 |
+
resnet_act_fn=act_fn,
|
| 321 |
+
resnet_groups=norm_num_groups,
|
| 322 |
+
cross_attention_dim=cross_attention_dim,
|
| 323 |
+
attn_num_head_channels=reversed_attention_head_dim[i],
|
| 324 |
+
dual_cross_attention=dual_cross_attention,
|
| 325 |
+
use_linear_projection=use_linear_projection,
|
| 326 |
+
only_cross_attention=only_cross_attention[i],
|
| 327 |
+
upcast_attention=upcast_attention,
|
| 328 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 329 |
+
unet_use_cross_frame_attention=unet_use_cross_frame_attention,
|
| 330 |
+
unet_use_temporal_attention=unet_use_temporal_attention,
|
| 331 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 332 |
+
use_motion_module=use_motion_module
|
| 333 |
+
and (res in motion_module_resolutions),
|
| 334 |
+
motion_module_type=motion_module_type,
|
| 335 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 336 |
+
use_audio_module=use_audio_module,
|
| 337 |
+
audio_attention_dim=audio_attention_dim,
|
| 338 |
+
depth=3-i,
|
| 339 |
+
stack_enable_blocks_name=stack_enable_blocks_name,
|
| 340 |
+
stack_enable_blocks_depth=stack_enable_blocks_depth,
|
| 341 |
+
)
|
| 342 |
+
self.up_blocks.append(up_block)
|
| 343 |
+
prev_output_channel = output_channel
|
| 344 |
+
|
| 345 |
+
# out
|
| 346 |
+
if use_inflated_groupnorm:
|
| 347 |
+
self.conv_norm_out = InflatedGroupNorm(
|
| 348 |
+
num_channels=block_out_channels[0],
|
| 349 |
+
num_groups=norm_num_groups,
|
| 350 |
+
eps=norm_eps,
|
| 351 |
+
)
|
| 352 |
+
else:
|
| 353 |
+
self.conv_norm_out = nn.GroupNorm(
|
| 354 |
+
num_channels=block_out_channels[0],
|
| 355 |
+
num_groups=norm_num_groups,
|
| 356 |
+
eps=norm_eps,
|
| 357 |
+
)
|
| 358 |
+
self.conv_act = nn.SiLU()
|
| 359 |
+
self.conv_out = InflatedConv3d(
|
| 360 |
+
block_out_channels[0], out_channels, kernel_size=3, padding=1
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
@property
|
| 364 |
+
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.attn_processors
|
| 365 |
+
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
| 366 |
+
r"""
|
| 367 |
+
Returns:
|
| 368 |
+
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
| 369 |
+
indexed by its weight name.
|
| 370 |
+
"""
|
| 371 |
+
# set recursively
|
| 372 |
+
processors = {}
|
| 373 |
+
|
| 374 |
+
def fn_recursive_add_processors(
|
| 375 |
+
name: str,
|
| 376 |
+
module: torch.nn.Module,
|
| 377 |
+
processors: Dict[str, AttentionProcessor],
|
| 378 |
+
):
|
| 379 |
+
if hasattr(module, "set_processor"):
|
| 380 |
+
processors[f"{name}.processor"] = module.processor
|
| 381 |
+
|
| 382 |
+
for sub_name, child in module.named_children():
|
| 383 |
+
if "temporal_transformer" not in sub_name:
|
| 384 |
+
fn_recursive_add_processors(
|
| 385 |
+
f"{name}.{sub_name}", child, processors)
|
| 386 |
+
|
| 387 |
+
return processors
|
| 388 |
+
|
| 389 |
+
for name, module in self.named_children():
|
| 390 |
+
if "temporal_transformer" not in name:
|
| 391 |
+
fn_recursive_add_processors(name, module, processors)
|
| 392 |
+
|
| 393 |
+
return processors
|
| 394 |
+
|
| 395 |
+
def set_attention_slice(self, slice_size):
|
| 396 |
+
r"""
|
| 397 |
+
Enable sliced attention computation.
|
| 398 |
+
|
| 399 |
+
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
|
| 400 |
+
in several steps. This is useful to save some memory in exchange for a small speed decrease.
|
| 401 |
+
|
| 402 |
+
Args:
|
| 403 |
+
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
|
| 404 |
+
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
|
| 405 |
+
`"max"`, maxium amount of memory will be saved by running only one slice at a time. If a number is
|
| 406 |
+
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
|
| 407 |
+
must be a multiple of `slice_size`.
|
| 408 |
+
"""
|
| 409 |
+
sliceable_head_dims = []
|
| 410 |
+
|
| 411 |
+
def fn_recursive_retrieve_slicable_dims(module: torch.nn.Module):
|
| 412 |
+
if hasattr(module, "set_attention_slice"):
|
| 413 |
+
sliceable_head_dims.append(module.sliceable_head_dim)
|
| 414 |
+
|
| 415 |
+
for child in module.children():
|
| 416 |
+
fn_recursive_retrieve_slicable_dims(child)
|
| 417 |
+
|
| 418 |
+
# retrieve number of attention layers
|
| 419 |
+
for module in self.children():
|
| 420 |
+
fn_recursive_retrieve_slicable_dims(module)
|
| 421 |
+
|
| 422 |
+
num_slicable_layers = len(sliceable_head_dims)
|
| 423 |
+
|
| 424 |
+
if slice_size == "auto":
|
| 425 |
+
# half the attention head size is usually a good trade-off between
|
| 426 |
+
# speed and memory
|
| 427 |
+
slice_size = [dim // 2 for dim in sliceable_head_dims]
|
| 428 |
+
elif slice_size == "max":
|
| 429 |
+
# make smallest slice possible
|
| 430 |
+
slice_size = num_slicable_layers * [1]
|
| 431 |
+
|
| 432 |
+
slice_size = (
|
| 433 |
+
num_slicable_layers * [slice_size]
|
| 434 |
+
if not isinstance(slice_size, list)
|
| 435 |
+
else slice_size
|
| 436 |
+
)
|
| 437 |
+
|
| 438 |
+
if len(slice_size) != len(sliceable_head_dims):
|
| 439 |
+
raise ValueError(
|
| 440 |
+
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
|
| 441 |
+
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
|
| 442 |
+
)
|
| 443 |
+
|
| 444 |
+
for i, size in enumerate(slice_size):
|
| 445 |
+
dim = sliceable_head_dims[i]
|
| 446 |
+
if size is not None and size > dim:
|
| 447 |
+
raise ValueError(
|
| 448 |
+
f"size {size} has to be smaller or equal to {dim}.")
|
| 449 |
+
|
| 450 |
+
# Recursively walk through all the children.
|
| 451 |
+
# Any children which exposes the set_attention_slice method
|
| 452 |
+
# gets the message
|
| 453 |
+
def fn_recursive_set_attention_slice(
|
| 454 |
+
module: torch.nn.Module, slice_size: List[int]
|
| 455 |
+
):
|
| 456 |
+
if hasattr(module, "set_attention_slice"):
|
| 457 |
+
module.set_attention_slice(slice_size.pop())
|
| 458 |
+
|
| 459 |
+
for child in module.children():
|
| 460 |
+
fn_recursive_set_attention_slice(child, slice_size)
|
| 461 |
+
|
| 462 |
+
reversed_slice_size = list(reversed(slice_size))
|
| 463 |
+
for module in self.children():
|
| 464 |
+
fn_recursive_set_attention_slice(module, reversed_slice_size)
|
| 465 |
+
|
| 466 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 467 |
+
if hasattr(module, "gradient_checkpointing"):
|
| 468 |
+
module.gradient_checkpointing = value
|
| 469 |
+
|
| 470 |
+
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attn_processor
|
| 471 |
+
def set_attn_processor(
|
| 472 |
+
self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]
|
| 473 |
+
):
|
| 474 |
+
r"""
|
| 475 |
+
Sets the attention processor to use to compute attention.
|
| 476 |
+
|
| 477 |
+
Parameters:
|
| 478 |
+
processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
|
| 479 |
+
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
| 480 |
+
for **all** `Attention` layers.
|
| 481 |
+
|
| 482 |
+
If `processor` is a dict, the key needs to define the path to the corresponding cross attention
|
| 483 |
+
processor. This is strongly recommended when setting trainable attention processors.
|
| 484 |
+
|
| 485 |
+
"""
|
| 486 |
+
count = len(self.attn_processors.keys())
|
| 487 |
+
|
| 488 |
+
if isinstance(processor, dict) and len(processor) != count:
|
| 489 |
+
raise ValueError(
|
| 490 |
+
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
| 491 |
+
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
| 492 |
+
)
|
| 493 |
+
|
| 494 |
+
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
| 495 |
+
if hasattr(module, "set_processor"):
|
| 496 |
+
if not isinstance(processor, dict):
|
| 497 |
+
module.set_processor(processor)
|
| 498 |
+
else:
|
| 499 |
+
module.set_processor(processor.pop(f"{name}.processor"))
|
| 500 |
+
|
| 501 |
+
for sub_name, child in module.named_children():
|
| 502 |
+
if "temporal_transformer" not in sub_name:
|
| 503 |
+
fn_recursive_attn_processor(
|
| 504 |
+
f"{name}.{sub_name}", child, processor)
|
| 505 |
+
|
| 506 |
+
for name, module in self.named_children():
|
| 507 |
+
if "temporal_transformer" not in name:
|
| 508 |
+
fn_recursive_attn_processor(name, module, processor)
|
| 509 |
+
|
| 510 |
+
def forward(
|
| 511 |
+
self,
|
| 512 |
+
sample: torch.FloatTensor,
|
| 513 |
+
timestep: Union[torch.Tensor, float, int],
|
| 514 |
+
encoder_hidden_states: torch.Tensor,
|
| 515 |
+
audio_embedding: Optional[torch.Tensor] = None,
|
| 516 |
+
class_labels: Optional[torch.Tensor] = None,
|
| 517 |
+
mask_cond_fea: Optional[torch.Tensor] = None,
|
| 518 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 519 |
+
full_mask: Optional[torch.Tensor] = None,
|
| 520 |
+
face_mask: Optional[torch.Tensor] = None,
|
| 521 |
+
lip_mask: Optional[torch.Tensor] = None,
|
| 522 |
+
motion_scale: Optional[torch.Tensor] = None,
|
| 523 |
+
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
| 524 |
+
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
| 525 |
+
return_dict: bool = True,
|
| 526 |
+
# start: bool = False,
|
| 527 |
+
) -> Union[UNet3DConditionOutput, Tuple]:
|
| 528 |
+
r"""
|
| 529 |
+
Args:
|
| 530 |
+
sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
|
| 531 |
+
timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps
|
| 532 |
+
encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states
|
| 533 |
+
return_dict (`bool`, *optional*, defaults to `True`):
|
| 534 |
+
Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
|
| 535 |
+
|
| 536 |
+
Returns:
|
| 537 |
+
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
| 538 |
+
[`~models.unet_2d_condition.UNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`. When
|
| 539 |
+
returning a tuple, the first element is the sample tensor.
|
| 540 |
+
"""
|
| 541 |
+
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
| 542 |
+
# The overall upsampling factor is equal to 2 ** (# num of upsampling layears).
|
| 543 |
+
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
| 544 |
+
# on the fly if necessary.
|
| 545 |
+
default_overall_up_factor = 2**self.num_upsamplers
|
| 546 |
+
|
| 547 |
+
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
| 548 |
+
forward_upsample_size = False
|
| 549 |
+
upsample_size = None
|
| 550 |
+
|
| 551 |
+
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
| 552 |
+
logger.info(
|
| 553 |
+
"Forward upsample size to force interpolation output size.")
|
| 554 |
+
forward_upsample_size = True
|
| 555 |
+
|
| 556 |
+
# prepare attention_mask
|
| 557 |
+
if attention_mask is not None:
|
| 558 |
+
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
| 559 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 560 |
+
|
| 561 |
+
# center input if necessary
|
| 562 |
+
if self.config.center_input_sample:
|
| 563 |
+
sample = 2 * sample - 1.0
|
| 564 |
+
|
| 565 |
+
# time
|
| 566 |
+
timesteps = timestep
|
| 567 |
+
if not torch.is_tensor(timesteps):
|
| 568 |
+
# This would be a good case for the `match` statement (Python 3.10+)
|
| 569 |
+
is_mps = sample.device.type == "mps"
|
| 570 |
+
if isinstance(timestep, float):
|
| 571 |
+
dtype = torch.float32 if is_mps else torch.float64
|
| 572 |
+
else:
|
| 573 |
+
dtype = torch.int32 if is_mps else torch.int64
|
| 574 |
+
timesteps = torch.tensor(
|
| 575 |
+
[timesteps], dtype=dtype, device=sample.device)
|
| 576 |
+
elif len(timesteps.shape) == 0:
|
| 577 |
+
timesteps = timesteps[None].to(sample.device)
|
| 578 |
+
|
| 579 |
+
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
| 580 |
+
timesteps = timesteps.expand(sample.shape[0])
|
| 581 |
+
|
| 582 |
+
t_emb = self.time_proj(timesteps)
|
| 583 |
+
|
| 584 |
+
# timesteps does not contain any weights and will always return f32 tensors
|
| 585 |
+
# but time_embedding might actually be running in fp16. so we need to cast here.
|
| 586 |
+
# there might be better ways to encapsulate this.
|
| 587 |
+
t_emb = t_emb.to(dtype=self.dtype)
|
| 588 |
+
emb = self.time_embedding(t_emb)
|
| 589 |
+
|
| 590 |
+
if self.class_embedding is not None:
|
| 591 |
+
if class_labels is None:
|
| 592 |
+
raise ValueError(
|
| 593 |
+
"class_labels should be provided when num_class_embeds > 0"
|
| 594 |
+
)
|
| 595 |
+
|
| 596 |
+
if self.config.class_embed_type == "timestep":
|
| 597 |
+
class_labels = self.time_proj(class_labels)
|
| 598 |
+
|
| 599 |
+
class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
|
| 600 |
+
emb = emb + class_emb
|
| 601 |
+
|
| 602 |
+
# pre-process
|
| 603 |
+
sample = self.conv_in(sample)
|
| 604 |
+
if mask_cond_fea is not None:
|
| 605 |
+
sample = sample + mask_cond_fea
|
| 606 |
+
|
| 607 |
+
# down
|
| 608 |
+
down_block_res_samples = (sample,)
|
| 609 |
+
for downsample_block in self.down_blocks:
|
| 610 |
+
if (
|
| 611 |
+
hasattr(downsample_block, "has_cross_attention")
|
| 612 |
+
and downsample_block.has_cross_attention
|
| 613 |
+
):
|
| 614 |
+
sample, res_samples = downsample_block(
|
| 615 |
+
hidden_states=sample,
|
| 616 |
+
temb=emb,
|
| 617 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 618 |
+
attention_mask=attention_mask,
|
| 619 |
+
full_mask=full_mask,
|
| 620 |
+
face_mask=face_mask,
|
| 621 |
+
lip_mask=lip_mask,
|
| 622 |
+
audio_embedding=audio_embedding,
|
| 623 |
+
motion_scale=motion_scale,
|
| 624 |
+
)
|
| 625 |
+
# print("")
|
| 626 |
+
else:
|
| 627 |
+
sample, res_samples = downsample_block(
|
| 628 |
+
hidden_states=sample,
|
| 629 |
+
temb=emb,
|
| 630 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 631 |
+
# audio_embedding=audio_embedding,
|
| 632 |
+
)
|
| 633 |
+
# print("")
|
| 634 |
+
|
| 635 |
+
down_block_res_samples += res_samples
|
| 636 |
+
|
| 637 |
+
if down_block_additional_residuals is not None:
|
| 638 |
+
new_down_block_res_samples = ()
|
| 639 |
+
|
| 640 |
+
for down_block_res_sample, down_block_additional_residual in zip(
|
| 641 |
+
down_block_res_samples, down_block_additional_residuals
|
| 642 |
+
):
|
| 643 |
+
down_block_res_sample = (
|
| 644 |
+
down_block_res_sample + down_block_additional_residual
|
| 645 |
+
)
|
| 646 |
+
new_down_block_res_samples += (down_block_res_sample,)
|
| 647 |
+
|
| 648 |
+
down_block_res_samples = new_down_block_res_samples
|
| 649 |
+
|
| 650 |
+
# mid
|
| 651 |
+
sample = self.mid_block(
|
| 652 |
+
sample,
|
| 653 |
+
emb,
|
| 654 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 655 |
+
attention_mask=attention_mask,
|
| 656 |
+
full_mask=full_mask,
|
| 657 |
+
face_mask=face_mask,
|
| 658 |
+
lip_mask=lip_mask,
|
| 659 |
+
audio_embedding=audio_embedding,
|
| 660 |
+
motion_scale=motion_scale,
|
| 661 |
+
)
|
| 662 |
+
|
| 663 |
+
if mid_block_additional_residual is not None:
|
| 664 |
+
sample = sample + mid_block_additional_residual
|
| 665 |
+
|
| 666 |
+
# up
|
| 667 |
+
for i, upsample_block in enumerate(self.up_blocks):
|
| 668 |
+
is_final_block = i == len(self.up_blocks) - 1
|
| 669 |
+
|
| 670 |
+
res_samples = down_block_res_samples[-len(upsample_block.resnets):]
|
| 671 |
+
down_block_res_samples = down_block_res_samples[
|
| 672 |
+
: -len(upsample_block.resnets)
|
| 673 |
+
]
|
| 674 |
+
|
| 675 |
+
# if we have not reached the final block and need to forward the
|
| 676 |
+
# upsample size, we do it here
|
| 677 |
+
if not is_final_block and forward_upsample_size:
|
| 678 |
+
upsample_size = down_block_res_samples[-1].shape[2:]
|
| 679 |
+
|
| 680 |
+
if (
|
| 681 |
+
hasattr(upsample_block, "has_cross_attention")
|
| 682 |
+
and upsample_block.has_cross_attention
|
| 683 |
+
):
|
| 684 |
+
sample = upsample_block(
|
| 685 |
+
hidden_states=sample,
|
| 686 |
+
temb=emb,
|
| 687 |
+
res_hidden_states_tuple=res_samples,
|
| 688 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 689 |
+
upsample_size=upsample_size,
|
| 690 |
+
attention_mask=attention_mask,
|
| 691 |
+
full_mask=full_mask,
|
| 692 |
+
face_mask=face_mask,
|
| 693 |
+
lip_mask=lip_mask,
|
| 694 |
+
audio_embedding=audio_embedding,
|
| 695 |
+
motion_scale=motion_scale,
|
| 696 |
+
)
|
| 697 |
+
else:
|
| 698 |
+
sample = upsample_block(
|
| 699 |
+
hidden_states=sample,
|
| 700 |
+
temb=emb,
|
| 701 |
+
res_hidden_states_tuple=res_samples,
|
| 702 |
+
upsample_size=upsample_size,
|
| 703 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 704 |
+
# audio_embedding=audio_embedding,
|
| 705 |
+
)
|
| 706 |
+
|
| 707 |
+
# post-process
|
| 708 |
+
sample = self.conv_norm_out(sample)
|
| 709 |
+
sample = self.conv_act(sample)
|
| 710 |
+
sample = self.conv_out(sample)
|
| 711 |
+
|
| 712 |
+
if not return_dict:
|
| 713 |
+
return (sample,)
|
| 714 |
+
|
| 715 |
+
return UNet3DConditionOutput(sample=sample)
|
| 716 |
+
|
| 717 |
+
@classmethod
|
| 718 |
+
def from_pretrained_2d(
|
| 719 |
+
cls,
|
| 720 |
+
pretrained_model_path: PathLike,
|
| 721 |
+
motion_module_path: PathLike,
|
| 722 |
+
subfolder=None,
|
| 723 |
+
unet_additional_kwargs=None,
|
| 724 |
+
mm_zero_proj_out=False,
|
| 725 |
+
use_landmark=True,
|
| 726 |
+
):
|
| 727 |
+
"""
|
| 728 |
+
Load a pre-trained 2D UNet model from a given directory.
|
| 729 |
+
|
| 730 |
+
Parameters:
|
| 731 |
+
pretrained_model_path (`str` or `PathLike`):
|
| 732 |
+
Path to the directory containing a pre-trained 2D UNet model.
|
| 733 |
+
dtype (`torch.dtype`, *optional*):
|
| 734 |
+
The data type of the loaded model. If not provided, the default data type is used.
|
| 735 |
+
device (`torch.device`, *optional*):
|
| 736 |
+
The device on which the loaded model will be placed. If not provided, the default device is used.
|
| 737 |
+
**kwargs (`Any`):
|
| 738 |
+
Additional keyword arguments passed to the model.
|
| 739 |
+
|
| 740 |
+
Returns:
|
| 741 |
+
`UNet3DConditionModel`:
|
| 742 |
+
The loaded 2D UNet model.
|
| 743 |
+
"""
|
| 744 |
+
pretrained_model_path = Path(pretrained_model_path)
|
| 745 |
+
motion_module_path = Path(motion_module_path)
|
| 746 |
+
if subfolder is not None:
|
| 747 |
+
pretrained_model_path = pretrained_model_path.joinpath(subfolder)
|
| 748 |
+
logger.info(
|
| 749 |
+
f"loaded temporal unet's pretrained weights from {pretrained_model_path} ..."
|
| 750 |
+
)
|
| 751 |
+
|
| 752 |
+
config_file = pretrained_model_path / "config.json"
|
| 753 |
+
if not (config_file.exists() and config_file.is_file()):
|
| 754 |
+
raise RuntimeError(
|
| 755 |
+
f"{config_file} does not exist or is not a file")
|
| 756 |
+
|
| 757 |
+
unet_config = cls.load_config(config_file)
|
| 758 |
+
unet_config["_class_name"] = cls.__name__
|
| 759 |
+
unet_config["down_block_types"] = [
|
| 760 |
+
"CrossAttnDownBlock3D",
|
| 761 |
+
"CrossAttnDownBlock3D",
|
| 762 |
+
"CrossAttnDownBlock3D",
|
| 763 |
+
"DownBlock3D",
|
| 764 |
+
]
|
| 765 |
+
unet_config["up_block_types"] = [
|
| 766 |
+
"UpBlock3D",
|
| 767 |
+
"CrossAttnUpBlock3D",
|
| 768 |
+
"CrossAttnUpBlock3D",
|
| 769 |
+
"CrossAttnUpBlock3D",
|
| 770 |
+
]
|
| 771 |
+
unet_config["mid_block_type"] = "UNetMidBlock3DCrossAttn"
|
| 772 |
+
if use_landmark:
|
| 773 |
+
unet_config["in_channels"] = 8
|
| 774 |
+
unet_config["out_channels"] = 8
|
| 775 |
+
|
| 776 |
+
model = cls.from_config(unet_config, **unet_additional_kwargs)
|
| 777 |
+
# load the vanilla weights
|
| 778 |
+
if pretrained_model_path.joinpath(SAFETENSORS_WEIGHTS_NAME).exists():
|
| 779 |
+
logger.debug(
|
| 780 |
+
f"loading safeTensors weights from {pretrained_model_path} ..."
|
| 781 |
+
)
|
| 782 |
+
state_dict = load_file(
|
| 783 |
+
pretrained_model_path.joinpath(SAFETENSORS_WEIGHTS_NAME), device="cpu"
|
| 784 |
+
)
|
| 785 |
+
|
| 786 |
+
elif pretrained_model_path.joinpath(WEIGHTS_NAME).exists():
|
| 787 |
+
logger.debug(f"loading weights from {pretrained_model_path} ...")
|
| 788 |
+
state_dict = torch.load(
|
| 789 |
+
pretrained_model_path.joinpath(WEIGHTS_NAME),
|
| 790 |
+
map_location="cpu",
|
| 791 |
+
weights_only=True,
|
| 792 |
+
)
|
| 793 |
+
else:
|
| 794 |
+
raise FileNotFoundError(
|
| 795 |
+
f"no weights file found in {pretrained_model_path}")
|
| 796 |
+
|
| 797 |
+
# load the motion module weights
|
| 798 |
+
if motion_module_path.exists() and motion_module_path.is_file():
|
| 799 |
+
if motion_module_path.suffix.lower() in [".pth", ".pt", ".ckpt"]:
|
| 800 |
+
print(
|
| 801 |
+
f"Load motion module params from {motion_module_path}")
|
| 802 |
+
motion_state_dict = torch.load(
|
| 803 |
+
motion_module_path, map_location="cpu", weights_only=True
|
| 804 |
+
)
|
| 805 |
+
elif motion_module_path.suffix.lower() == ".safetensors":
|
| 806 |
+
motion_state_dict = load_file(motion_module_path, device="cpu")
|
| 807 |
+
else:
|
| 808 |
+
raise RuntimeError(
|
| 809 |
+
f"unknown file format for motion module weights: {motion_module_path.suffix}"
|
| 810 |
+
)
|
| 811 |
+
if mm_zero_proj_out:
|
| 812 |
+
logger.info(
|
| 813 |
+
"Zero initialize proj_out layers in motion module...")
|
| 814 |
+
new_motion_state_dict = OrderedDict()
|
| 815 |
+
for k in motion_state_dict:
|
| 816 |
+
if "proj_out" in k:
|
| 817 |
+
continue
|
| 818 |
+
new_motion_state_dict[k] = motion_state_dict[k]
|
| 819 |
+
motion_state_dict = new_motion_state_dict
|
| 820 |
+
|
| 821 |
+
# merge the state dicts
|
| 822 |
+
state_dict.update(motion_state_dict)
|
| 823 |
+
|
| 824 |
+
model_state_dict = model.state_dict()
|
| 825 |
+
for k in state_dict:
|
| 826 |
+
if k in model_state_dict:
|
| 827 |
+
if state_dict[k].shape != model_state_dict[k].shape:
|
| 828 |
+
state_dict[k] = model_state_dict[k]
|
| 829 |
+
# load the weights into the model
|
| 830 |
+
m, u = model.load_state_dict(state_dict, strict=False)
|
| 831 |
+
logger.debug(
|
| 832 |
+
f"### missing keys: {len(m)}; \n### unexpected keys: {len(u)};")
|
| 833 |
+
|
| 834 |
+
params = [
|
| 835 |
+
p.numel() if "temporal" in n else 0 for n, p in model.named_parameters()
|
| 836 |
+
]
|
| 837 |
+
logger.info(f"Loaded {sum(params) / 1e6}M-parameter motion module")
|
| 838 |
+
|
| 839 |
+
return model
|
hallo/models/unet_3d_blocks.py
ADDED
|
@@ -0,0 +1,1401 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0801
|
| 2 |
+
# src/models/unet_3d_blocks.py
|
| 3 |
+
|
| 4 |
+
"""
|
| 5 |
+
This module defines various 3D UNet blocks used in the video model.
|
| 6 |
+
|
| 7 |
+
The blocks include:
|
| 8 |
+
- UNetMidBlock3DCrossAttn: The middle block of the UNet with cross attention.
|
| 9 |
+
- CrossAttnDownBlock3D: The downsampling block with cross attention.
|
| 10 |
+
- DownBlock3D: The standard downsampling block without cross attention.
|
| 11 |
+
- CrossAttnUpBlock3D: The upsampling block with cross attention.
|
| 12 |
+
- UpBlock3D: The standard upsampling block without cross attention.
|
| 13 |
+
|
| 14 |
+
These blocks are used to construct the 3D UNet architecture for video-related tasks.
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
from einops import rearrange
|
| 19 |
+
from torch import nn
|
| 20 |
+
|
| 21 |
+
from .motion_module import get_motion_module
|
| 22 |
+
from .resnet import Downsample3D, ResnetBlock3D, Upsample3D
|
| 23 |
+
from .transformer_3d import Transformer3DModel
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def get_down_block(
|
| 27 |
+
down_block_type,
|
| 28 |
+
num_layers,
|
| 29 |
+
in_channels,
|
| 30 |
+
out_channels,
|
| 31 |
+
temb_channels,
|
| 32 |
+
add_downsample,
|
| 33 |
+
resnet_eps,
|
| 34 |
+
resnet_act_fn,
|
| 35 |
+
attn_num_head_channels,
|
| 36 |
+
resnet_groups=None,
|
| 37 |
+
cross_attention_dim=None,
|
| 38 |
+
audio_attention_dim=None,
|
| 39 |
+
downsample_padding=None,
|
| 40 |
+
dual_cross_attention=False,
|
| 41 |
+
use_linear_projection=False,
|
| 42 |
+
only_cross_attention=False,
|
| 43 |
+
upcast_attention=False,
|
| 44 |
+
resnet_time_scale_shift="default",
|
| 45 |
+
unet_use_cross_frame_attention=None,
|
| 46 |
+
unet_use_temporal_attention=None,
|
| 47 |
+
use_inflated_groupnorm=None,
|
| 48 |
+
use_motion_module=None,
|
| 49 |
+
motion_module_type=None,
|
| 50 |
+
motion_module_kwargs=None,
|
| 51 |
+
use_audio_module=None,
|
| 52 |
+
depth=0,
|
| 53 |
+
stack_enable_blocks_name=None,
|
| 54 |
+
stack_enable_blocks_depth=None,
|
| 55 |
+
):
|
| 56 |
+
"""
|
| 57 |
+
Factory function to instantiate a down-block module for the 3D UNet architecture.
|
| 58 |
+
|
| 59 |
+
Down blocks are used in the downsampling part of the U-Net to reduce the spatial dimensions
|
| 60 |
+
of the feature maps while increasing the depth. This function can create blocks with or without
|
| 61 |
+
cross attention based on the specified parameters.
|
| 62 |
+
|
| 63 |
+
Parameters:
|
| 64 |
+
- down_block_type (str): The type of down block to instantiate.
|
| 65 |
+
- num_layers (int): The number of layers in the block.
|
| 66 |
+
- in_channels (int): The number of input channels.
|
| 67 |
+
- out_channels (int): The number of output channels.
|
| 68 |
+
- temb_channels (int): The number of token embedding channels.
|
| 69 |
+
- add_downsample (bool): Flag to add a downsampling layer.
|
| 70 |
+
- resnet_eps (float): Epsilon for residual block stability.
|
| 71 |
+
- resnet_act_fn (callable): Activation function for the residual block.
|
| 72 |
+
- ... (remaining parameters): Additional parameters for configuring the block.
|
| 73 |
+
|
| 74 |
+
Returns:
|
| 75 |
+
- nn.Module: An instance of a down-sampling block module.
|
| 76 |
+
"""
|
| 77 |
+
down_block_type = (
|
| 78 |
+
down_block_type[7:]
|
| 79 |
+
if down_block_type.startswith("UNetRes")
|
| 80 |
+
else down_block_type
|
| 81 |
+
)
|
| 82 |
+
if down_block_type == "DownBlock3D":
|
| 83 |
+
return DownBlock3D(
|
| 84 |
+
num_layers=num_layers,
|
| 85 |
+
in_channels=in_channels,
|
| 86 |
+
out_channels=out_channels,
|
| 87 |
+
temb_channels=temb_channels,
|
| 88 |
+
add_downsample=add_downsample,
|
| 89 |
+
resnet_eps=resnet_eps,
|
| 90 |
+
resnet_act_fn=resnet_act_fn,
|
| 91 |
+
resnet_groups=resnet_groups,
|
| 92 |
+
downsample_padding=downsample_padding,
|
| 93 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 94 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 95 |
+
use_motion_module=use_motion_module,
|
| 96 |
+
motion_module_type=motion_module_type,
|
| 97 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
if down_block_type == "CrossAttnDownBlock3D":
|
| 101 |
+
if cross_attention_dim is None:
|
| 102 |
+
raise ValueError(
|
| 103 |
+
"cross_attention_dim must be specified for CrossAttnDownBlock3D"
|
| 104 |
+
)
|
| 105 |
+
return CrossAttnDownBlock3D(
|
| 106 |
+
num_layers=num_layers,
|
| 107 |
+
in_channels=in_channels,
|
| 108 |
+
out_channels=out_channels,
|
| 109 |
+
temb_channels=temb_channels,
|
| 110 |
+
add_downsample=add_downsample,
|
| 111 |
+
resnet_eps=resnet_eps,
|
| 112 |
+
resnet_act_fn=resnet_act_fn,
|
| 113 |
+
resnet_groups=resnet_groups,
|
| 114 |
+
downsample_padding=downsample_padding,
|
| 115 |
+
cross_attention_dim=cross_attention_dim,
|
| 116 |
+
audio_attention_dim=audio_attention_dim,
|
| 117 |
+
attn_num_head_channels=attn_num_head_channels,
|
| 118 |
+
dual_cross_attention=dual_cross_attention,
|
| 119 |
+
use_linear_projection=use_linear_projection,
|
| 120 |
+
only_cross_attention=only_cross_attention,
|
| 121 |
+
upcast_attention=upcast_attention,
|
| 122 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 123 |
+
unet_use_cross_frame_attention=unet_use_cross_frame_attention,
|
| 124 |
+
unet_use_temporal_attention=unet_use_temporal_attention,
|
| 125 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 126 |
+
use_motion_module=use_motion_module,
|
| 127 |
+
motion_module_type=motion_module_type,
|
| 128 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 129 |
+
use_audio_module=use_audio_module,
|
| 130 |
+
depth=depth,
|
| 131 |
+
stack_enable_blocks_name=stack_enable_blocks_name,
|
| 132 |
+
stack_enable_blocks_depth=stack_enable_blocks_depth,
|
| 133 |
+
)
|
| 134 |
+
raise ValueError(f"{down_block_type} does not exist.")
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def get_up_block(
|
| 138 |
+
up_block_type,
|
| 139 |
+
num_layers,
|
| 140 |
+
in_channels,
|
| 141 |
+
out_channels,
|
| 142 |
+
prev_output_channel,
|
| 143 |
+
temb_channels,
|
| 144 |
+
add_upsample,
|
| 145 |
+
resnet_eps,
|
| 146 |
+
resnet_act_fn,
|
| 147 |
+
attn_num_head_channels,
|
| 148 |
+
resnet_groups=None,
|
| 149 |
+
cross_attention_dim=None,
|
| 150 |
+
audio_attention_dim=None,
|
| 151 |
+
dual_cross_attention=False,
|
| 152 |
+
use_linear_projection=False,
|
| 153 |
+
only_cross_attention=False,
|
| 154 |
+
upcast_attention=False,
|
| 155 |
+
resnet_time_scale_shift="default",
|
| 156 |
+
unet_use_cross_frame_attention=None,
|
| 157 |
+
unet_use_temporal_attention=None,
|
| 158 |
+
use_inflated_groupnorm=None,
|
| 159 |
+
use_motion_module=None,
|
| 160 |
+
motion_module_type=None,
|
| 161 |
+
motion_module_kwargs=None,
|
| 162 |
+
use_audio_module=None,
|
| 163 |
+
depth=0,
|
| 164 |
+
stack_enable_blocks_name=None,
|
| 165 |
+
stack_enable_blocks_depth=None,
|
| 166 |
+
):
|
| 167 |
+
"""
|
| 168 |
+
Factory function to instantiate an up-block module for the 3D UNet architecture.
|
| 169 |
+
|
| 170 |
+
Up blocks are used in the upsampling part of the U-Net to increase the spatial dimensions
|
| 171 |
+
of the feature maps while decreasing the depth. This function can create blocks with or without
|
| 172 |
+
cross attention based on the specified parameters.
|
| 173 |
+
|
| 174 |
+
Parameters:
|
| 175 |
+
- up_block_type (str): The type of up block to instantiate.
|
| 176 |
+
- num_layers (int): The number of layers in the block.
|
| 177 |
+
- in_channels (int): The number of input channels.
|
| 178 |
+
- out_channels (int): The number of output channels.
|
| 179 |
+
- prev_output_channel (int): The number of channels from the previous layer's output.
|
| 180 |
+
- temb_channels (int): The number of token embedding channels.
|
| 181 |
+
- add_upsample (bool): Flag to add an upsampling layer.
|
| 182 |
+
- resnet_eps (float): Epsilon for residual block stability.
|
| 183 |
+
- resnet_act_fn (callable): Activation function for the residual block.
|
| 184 |
+
- ... (remaining parameters): Additional parameters for configuring the block.
|
| 185 |
+
|
| 186 |
+
Returns:
|
| 187 |
+
- nn.Module: An instance of an up-sampling block module.
|
| 188 |
+
"""
|
| 189 |
+
up_block_type = (
|
| 190 |
+
up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
|
| 191 |
+
)
|
| 192 |
+
if up_block_type == "UpBlock3D":
|
| 193 |
+
return UpBlock3D(
|
| 194 |
+
num_layers=num_layers,
|
| 195 |
+
in_channels=in_channels,
|
| 196 |
+
out_channels=out_channels,
|
| 197 |
+
prev_output_channel=prev_output_channel,
|
| 198 |
+
temb_channels=temb_channels,
|
| 199 |
+
add_upsample=add_upsample,
|
| 200 |
+
resnet_eps=resnet_eps,
|
| 201 |
+
resnet_act_fn=resnet_act_fn,
|
| 202 |
+
resnet_groups=resnet_groups,
|
| 203 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 204 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 205 |
+
use_motion_module=use_motion_module,
|
| 206 |
+
motion_module_type=motion_module_type,
|
| 207 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
if up_block_type == "CrossAttnUpBlock3D":
|
| 211 |
+
if cross_attention_dim is None:
|
| 212 |
+
raise ValueError(
|
| 213 |
+
"cross_attention_dim must be specified for CrossAttnUpBlock3D"
|
| 214 |
+
)
|
| 215 |
+
return CrossAttnUpBlock3D(
|
| 216 |
+
num_layers=num_layers,
|
| 217 |
+
in_channels=in_channels,
|
| 218 |
+
out_channels=out_channels,
|
| 219 |
+
prev_output_channel=prev_output_channel,
|
| 220 |
+
temb_channels=temb_channels,
|
| 221 |
+
add_upsample=add_upsample,
|
| 222 |
+
resnet_eps=resnet_eps,
|
| 223 |
+
resnet_act_fn=resnet_act_fn,
|
| 224 |
+
resnet_groups=resnet_groups,
|
| 225 |
+
cross_attention_dim=cross_attention_dim,
|
| 226 |
+
audio_attention_dim=audio_attention_dim,
|
| 227 |
+
attn_num_head_channels=attn_num_head_channels,
|
| 228 |
+
dual_cross_attention=dual_cross_attention,
|
| 229 |
+
use_linear_projection=use_linear_projection,
|
| 230 |
+
only_cross_attention=only_cross_attention,
|
| 231 |
+
upcast_attention=upcast_attention,
|
| 232 |
+
resnet_time_scale_shift=resnet_time_scale_shift,
|
| 233 |
+
unet_use_cross_frame_attention=unet_use_cross_frame_attention,
|
| 234 |
+
unet_use_temporal_attention=unet_use_temporal_attention,
|
| 235 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 236 |
+
use_motion_module=use_motion_module,
|
| 237 |
+
motion_module_type=motion_module_type,
|
| 238 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 239 |
+
use_audio_module=use_audio_module,
|
| 240 |
+
depth=depth,
|
| 241 |
+
stack_enable_blocks_name=stack_enable_blocks_name,
|
| 242 |
+
stack_enable_blocks_depth=stack_enable_blocks_depth,
|
| 243 |
+
)
|
| 244 |
+
raise ValueError(f"{up_block_type} does not exist.")
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class UNetMidBlock3DCrossAttn(nn.Module):
|
| 248 |
+
"""
|
| 249 |
+
A 3D UNet middle block with cross attention mechanism. This block is part of the U-Net architecture
|
| 250 |
+
and is used for feature extraction in the middle of the downsampling path.
|
| 251 |
+
|
| 252 |
+
Parameters:
|
| 253 |
+
- in_channels (int): Number of input channels.
|
| 254 |
+
- temb_channels (int): Number of token embedding channels.
|
| 255 |
+
- dropout (float): Dropout rate.
|
| 256 |
+
- num_layers (int): Number of layers in the block.
|
| 257 |
+
- resnet_eps (float): Epsilon for residual block.
|
| 258 |
+
- resnet_time_scale_shift (str): Time scale shift for time embedding normalization.
|
| 259 |
+
- resnet_act_fn (str): Activation function for the residual block.
|
| 260 |
+
- resnet_groups (int): Number of groups for the convolutions in the residual block.
|
| 261 |
+
- resnet_pre_norm (bool): Whether to use pre-normalization in the residual block.
|
| 262 |
+
- attn_num_head_channels (int): Number of attention heads.
|
| 263 |
+
- cross_attention_dim (int): Dimensionality of the cross attention layers.
|
| 264 |
+
- audio_attention_dim (int): Dimensionality of the audio attention layers.
|
| 265 |
+
- dual_cross_attention (bool): Whether to use dual cross attention.
|
| 266 |
+
- use_linear_projection (bool): Whether to use linear projection in attention.
|
| 267 |
+
- upcast_attention (bool): Whether to upcast attention to the original input dimension.
|
| 268 |
+
- unet_use_cross_frame_attention (bool): Whether to use cross frame attention in U-Net.
|
| 269 |
+
- unet_use_temporal_attention (bool): Whether to use temporal attention in U-Net.
|
| 270 |
+
- use_inflated_groupnorm (bool): Whether to use inflated group normalization.
|
| 271 |
+
- use_motion_module (bool): Whether to use motion module.
|
| 272 |
+
- motion_module_type (str): Type of motion module.
|
| 273 |
+
- motion_module_kwargs (dict): Keyword arguments for the motion module.
|
| 274 |
+
- use_audio_module (bool): Whether to use audio module.
|
| 275 |
+
- depth (int): Depth of the block in the network.
|
| 276 |
+
- stack_enable_blocks_name (str): Name of the stack enable blocks.
|
| 277 |
+
- stack_enable_blocks_depth (int): Depth of the stack enable blocks.
|
| 278 |
+
|
| 279 |
+
Forward method:
|
| 280 |
+
The forward method applies the residual blocks, cross attention, and optional motion and audio modules
|
| 281 |
+
to the input hidden states. It returns the transformed hidden states.
|
| 282 |
+
"""
|
| 283 |
+
def __init__(
|
| 284 |
+
self,
|
| 285 |
+
in_channels: int,
|
| 286 |
+
temb_channels: int,
|
| 287 |
+
dropout: float = 0.0,
|
| 288 |
+
num_layers: int = 1,
|
| 289 |
+
resnet_eps: float = 1e-6,
|
| 290 |
+
resnet_time_scale_shift: str = "default",
|
| 291 |
+
resnet_act_fn: str = "swish",
|
| 292 |
+
resnet_groups: int = 32,
|
| 293 |
+
resnet_pre_norm: bool = True,
|
| 294 |
+
attn_num_head_channels=1,
|
| 295 |
+
output_scale_factor=1.0,
|
| 296 |
+
cross_attention_dim=1280,
|
| 297 |
+
audio_attention_dim=1024,
|
| 298 |
+
dual_cross_attention=False,
|
| 299 |
+
use_linear_projection=False,
|
| 300 |
+
upcast_attention=False,
|
| 301 |
+
unet_use_cross_frame_attention=None,
|
| 302 |
+
unet_use_temporal_attention=None,
|
| 303 |
+
use_inflated_groupnorm=None,
|
| 304 |
+
use_motion_module=None,
|
| 305 |
+
motion_module_type=None,
|
| 306 |
+
motion_module_kwargs=None,
|
| 307 |
+
use_audio_module=None,
|
| 308 |
+
depth=0,
|
| 309 |
+
stack_enable_blocks_name=None,
|
| 310 |
+
stack_enable_blocks_depth=None,
|
| 311 |
+
):
|
| 312 |
+
super().__init__()
|
| 313 |
+
|
| 314 |
+
self.has_cross_attention = True
|
| 315 |
+
self.attn_num_head_channels = attn_num_head_channels
|
| 316 |
+
resnet_groups = (
|
| 317 |
+
resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
|
| 318 |
+
)
|
| 319 |
+
|
| 320 |
+
# there is always at least one resnet
|
| 321 |
+
resnets = [
|
| 322 |
+
ResnetBlock3D(
|
| 323 |
+
in_channels=in_channels,
|
| 324 |
+
out_channels=in_channels,
|
| 325 |
+
temb_channels=temb_channels,
|
| 326 |
+
eps=resnet_eps,
|
| 327 |
+
groups=resnet_groups,
|
| 328 |
+
dropout=dropout,
|
| 329 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 330 |
+
non_linearity=resnet_act_fn,
|
| 331 |
+
output_scale_factor=output_scale_factor,
|
| 332 |
+
pre_norm=resnet_pre_norm,
|
| 333 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 334 |
+
)
|
| 335 |
+
]
|
| 336 |
+
attentions = []
|
| 337 |
+
motion_modules = []
|
| 338 |
+
audio_modules = []
|
| 339 |
+
|
| 340 |
+
for _ in range(num_layers):
|
| 341 |
+
if dual_cross_attention:
|
| 342 |
+
raise NotImplementedError
|
| 343 |
+
attentions.append(
|
| 344 |
+
Transformer3DModel(
|
| 345 |
+
attn_num_head_channels,
|
| 346 |
+
in_channels // attn_num_head_channels,
|
| 347 |
+
in_channels=in_channels,
|
| 348 |
+
num_layers=1,
|
| 349 |
+
cross_attention_dim=cross_attention_dim,
|
| 350 |
+
norm_num_groups=resnet_groups,
|
| 351 |
+
use_linear_projection=use_linear_projection,
|
| 352 |
+
upcast_attention=upcast_attention,
|
| 353 |
+
unet_use_cross_frame_attention=unet_use_cross_frame_attention,
|
| 354 |
+
unet_use_temporal_attention=unet_use_temporal_attention,
|
| 355 |
+
)
|
| 356 |
+
)
|
| 357 |
+
audio_modules.append(
|
| 358 |
+
Transformer3DModel(
|
| 359 |
+
attn_num_head_channels,
|
| 360 |
+
in_channels // attn_num_head_channels,
|
| 361 |
+
in_channels=in_channels,
|
| 362 |
+
num_layers=1,
|
| 363 |
+
cross_attention_dim=audio_attention_dim,
|
| 364 |
+
norm_num_groups=resnet_groups,
|
| 365 |
+
use_linear_projection=use_linear_projection,
|
| 366 |
+
upcast_attention=upcast_attention,
|
| 367 |
+
use_audio_module=use_audio_module,
|
| 368 |
+
depth=depth,
|
| 369 |
+
unet_block_name="mid",
|
| 370 |
+
stack_enable_blocks_name=stack_enable_blocks_name,
|
| 371 |
+
stack_enable_blocks_depth=stack_enable_blocks_depth,
|
| 372 |
+
)
|
| 373 |
+
if use_audio_module
|
| 374 |
+
else None
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
+
motion_modules.append(
|
| 378 |
+
get_motion_module(
|
| 379 |
+
in_channels=in_channels,
|
| 380 |
+
motion_module_type=motion_module_type,
|
| 381 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 382 |
+
)
|
| 383 |
+
if use_motion_module
|
| 384 |
+
else None
|
| 385 |
+
)
|
| 386 |
+
resnets.append(
|
| 387 |
+
ResnetBlock3D(
|
| 388 |
+
in_channels=in_channels,
|
| 389 |
+
out_channels=in_channels,
|
| 390 |
+
temb_channels=temb_channels,
|
| 391 |
+
eps=resnet_eps,
|
| 392 |
+
groups=resnet_groups,
|
| 393 |
+
dropout=dropout,
|
| 394 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 395 |
+
non_linearity=resnet_act_fn,
|
| 396 |
+
output_scale_factor=output_scale_factor,
|
| 397 |
+
pre_norm=resnet_pre_norm,
|
| 398 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 399 |
+
)
|
| 400 |
+
)
|
| 401 |
+
|
| 402 |
+
self.attentions = nn.ModuleList(attentions)
|
| 403 |
+
self.resnets = nn.ModuleList(resnets)
|
| 404 |
+
self.audio_modules = nn.ModuleList(audio_modules)
|
| 405 |
+
self.motion_modules = nn.ModuleList(motion_modules)
|
| 406 |
+
|
| 407 |
+
def forward(
|
| 408 |
+
self,
|
| 409 |
+
hidden_states,
|
| 410 |
+
temb=None,
|
| 411 |
+
encoder_hidden_states=None,
|
| 412 |
+
attention_mask=None,
|
| 413 |
+
full_mask=None,
|
| 414 |
+
face_mask=None,
|
| 415 |
+
lip_mask=None,
|
| 416 |
+
audio_embedding=None,
|
| 417 |
+
motion_scale=None,
|
| 418 |
+
):
|
| 419 |
+
"""
|
| 420 |
+
Forward pass for the UNetMidBlock3DCrossAttn class.
|
| 421 |
+
|
| 422 |
+
Args:
|
| 423 |
+
self (UNetMidBlock3DCrossAttn): An instance of the UNetMidBlock3DCrossAttn class.
|
| 424 |
+
hidden_states (Tensor): The input hidden states tensor.
|
| 425 |
+
temb (Tensor, optional): The input temporal embedding tensor. Defaults to None.
|
| 426 |
+
encoder_hidden_states (Tensor, optional): The encoder hidden states tensor. Defaults to None.
|
| 427 |
+
attention_mask (Tensor, optional): The attention mask tensor. Defaults to None.
|
| 428 |
+
full_mask (Tensor, optional): The full mask tensor. Defaults to None.
|
| 429 |
+
face_mask (Tensor, optional): The face mask tensor. Defaults to None.
|
| 430 |
+
lip_mask (Tensor, optional): The lip mask tensor. Defaults to None.
|
| 431 |
+
audio_embedding (Tensor, optional): The audio embedding tensor. Defaults to None.
|
| 432 |
+
|
| 433 |
+
Returns:
|
| 434 |
+
Tensor: The output tensor after passing through the UNetMidBlock3DCrossAttn layers.
|
| 435 |
+
"""
|
| 436 |
+
hidden_states = self.resnets[0](hidden_states, temb)
|
| 437 |
+
for attn, resnet, audio_module, motion_module in zip(
|
| 438 |
+
self.attentions, self.resnets[1:], self.audio_modules, self.motion_modules
|
| 439 |
+
):
|
| 440 |
+
hidden_states, motion_frame = attn(
|
| 441 |
+
hidden_states,
|
| 442 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 443 |
+
return_dict=False,
|
| 444 |
+
) # .sample
|
| 445 |
+
if len(motion_frame[0]) > 0:
|
| 446 |
+
# if motion_frame[0][0].numel() > 0:
|
| 447 |
+
motion_frames = motion_frame[0][0]
|
| 448 |
+
motion_frames = rearrange(
|
| 449 |
+
motion_frames,
|
| 450 |
+
"b f (d1 d2) c -> b c f d1 d2",
|
| 451 |
+
d1=hidden_states.size(-1),
|
| 452 |
+
)
|
| 453 |
+
|
| 454 |
+
else:
|
| 455 |
+
motion_frames = torch.zeros(
|
| 456 |
+
hidden_states.shape[0],
|
| 457 |
+
hidden_states.shape[1],
|
| 458 |
+
4,
|
| 459 |
+
hidden_states.shape[3],
|
| 460 |
+
hidden_states.shape[4],
|
| 461 |
+
)
|
| 462 |
+
|
| 463 |
+
n_motion_frames = motion_frames.size(2)
|
| 464 |
+
if audio_module is not None:
|
| 465 |
+
hidden_states = (
|
| 466 |
+
audio_module(
|
| 467 |
+
hidden_states,
|
| 468 |
+
encoder_hidden_states=audio_embedding,
|
| 469 |
+
attention_mask=attention_mask,
|
| 470 |
+
full_mask=full_mask,
|
| 471 |
+
face_mask=face_mask,
|
| 472 |
+
lip_mask=lip_mask,
|
| 473 |
+
motion_scale=motion_scale,
|
| 474 |
+
return_dict=False,
|
| 475 |
+
)
|
| 476 |
+
)[0] # .sample
|
| 477 |
+
if motion_module is not None:
|
| 478 |
+
motion_frames = motion_frames.to(
|
| 479 |
+
device=hidden_states.device, dtype=hidden_states.dtype
|
| 480 |
+
)
|
| 481 |
+
|
| 482 |
+
_hidden_states = (
|
| 483 |
+
torch.cat([motion_frames, hidden_states], dim=2)
|
| 484 |
+
if n_motion_frames > 0
|
| 485 |
+
else hidden_states
|
| 486 |
+
)
|
| 487 |
+
hidden_states = motion_module(
|
| 488 |
+
_hidden_states, encoder_hidden_states=encoder_hidden_states
|
| 489 |
+
)
|
| 490 |
+
hidden_states = hidden_states[:, :, n_motion_frames:]
|
| 491 |
+
|
| 492 |
+
hidden_states = resnet(hidden_states, temb)
|
| 493 |
+
|
| 494 |
+
return hidden_states
|
| 495 |
+
|
| 496 |
+
|
| 497 |
+
class CrossAttnDownBlock3D(nn.Module):
|
| 498 |
+
"""
|
| 499 |
+
A 3D downsampling block with cross attention for the U-Net architecture.
|
| 500 |
+
|
| 501 |
+
Parameters:
|
| 502 |
+
- (same as above, refer to the constructor for details)
|
| 503 |
+
|
| 504 |
+
Forward method:
|
| 505 |
+
The forward method downsamples the input hidden states using residual blocks and cross attention.
|
| 506 |
+
It also applies optional motion and audio modules. The method supports gradient checkpointing
|
| 507 |
+
to save memory during training.
|
| 508 |
+
"""
|
| 509 |
+
def __init__(
|
| 510 |
+
self,
|
| 511 |
+
in_channels: int,
|
| 512 |
+
out_channels: int,
|
| 513 |
+
temb_channels: int,
|
| 514 |
+
dropout: float = 0.0,
|
| 515 |
+
num_layers: int = 1,
|
| 516 |
+
resnet_eps: float = 1e-6,
|
| 517 |
+
resnet_time_scale_shift: str = "default",
|
| 518 |
+
resnet_act_fn: str = "swish",
|
| 519 |
+
resnet_groups: int = 32,
|
| 520 |
+
resnet_pre_norm: bool = True,
|
| 521 |
+
attn_num_head_channels=1,
|
| 522 |
+
cross_attention_dim=1280,
|
| 523 |
+
audio_attention_dim=1024,
|
| 524 |
+
output_scale_factor=1.0,
|
| 525 |
+
downsample_padding=1,
|
| 526 |
+
add_downsample=True,
|
| 527 |
+
dual_cross_attention=False,
|
| 528 |
+
use_linear_projection=False,
|
| 529 |
+
only_cross_attention=False,
|
| 530 |
+
upcast_attention=False,
|
| 531 |
+
unet_use_cross_frame_attention=None,
|
| 532 |
+
unet_use_temporal_attention=None,
|
| 533 |
+
use_inflated_groupnorm=None,
|
| 534 |
+
use_motion_module=None,
|
| 535 |
+
motion_module_type=None,
|
| 536 |
+
motion_module_kwargs=None,
|
| 537 |
+
use_audio_module=None,
|
| 538 |
+
depth=0,
|
| 539 |
+
stack_enable_blocks_name=None,
|
| 540 |
+
stack_enable_blocks_depth=None,
|
| 541 |
+
):
|
| 542 |
+
super().__init__()
|
| 543 |
+
resnets = []
|
| 544 |
+
attentions = []
|
| 545 |
+
audio_modules = []
|
| 546 |
+
motion_modules = []
|
| 547 |
+
|
| 548 |
+
self.has_cross_attention = True
|
| 549 |
+
self.attn_num_head_channels = attn_num_head_channels
|
| 550 |
+
|
| 551 |
+
for i in range(num_layers):
|
| 552 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 553 |
+
resnets.append(
|
| 554 |
+
ResnetBlock3D(
|
| 555 |
+
in_channels=in_channels,
|
| 556 |
+
out_channels=out_channels,
|
| 557 |
+
temb_channels=temb_channels,
|
| 558 |
+
eps=resnet_eps,
|
| 559 |
+
groups=resnet_groups,
|
| 560 |
+
dropout=dropout,
|
| 561 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 562 |
+
non_linearity=resnet_act_fn,
|
| 563 |
+
output_scale_factor=output_scale_factor,
|
| 564 |
+
pre_norm=resnet_pre_norm,
|
| 565 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 566 |
+
)
|
| 567 |
+
)
|
| 568 |
+
if dual_cross_attention:
|
| 569 |
+
raise NotImplementedError
|
| 570 |
+
attentions.append(
|
| 571 |
+
Transformer3DModel(
|
| 572 |
+
attn_num_head_channels,
|
| 573 |
+
out_channels // attn_num_head_channels,
|
| 574 |
+
in_channels=out_channels,
|
| 575 |
+
num_layers=1,
|
| 576 |
+
cross_attention_dim=cross_attention_dim,
|
| 577 |
+
norm_num_groups=resnet_groups,
|
| 578 |
+
use_linear_projection=use_linear_projection,
|
| 579 |
+
only_cross_attention=only_cross_attention,
|
| 580 |
+
upcast_attention=upcast_attention,
|
| 581 |
+
unet_use_cross_frame_attention=unet_use_cross_frame_attention,
|
| 582 |
+
unet_use_temporal_attention=unet_use_temporal_attention,
|
| 583 |
+
)
|
| 584 |
+
)
|
| 585 |
+
# TODO:检查维度
|
| 586 |
+
audio_modules.append(
|
| 587 |
+
Transformer3DModel(
|
| 588 |
+
attn_num_head_channels,
|
| 589 |
+
in_channels // attn_num_head_channels,
|
| 590 |
+
in_channels=out_channels,
|
| 591 |
+
num_layers=1,
|
| 592 |
+
cross_attention_dim=audio_attention_dim,
|
| 593 |
+
norm_num_groups=resnet_groups,
|
| 594 |
+
use_linear_projection=use_linear_projection,
|
| 595 |
+
only_cross_attention=only_cross_attention,
|
| 596 |
+
upcast_attention=upcast_attention,
|
| 597 |
+
use_audio_module=use_audio_module,
|
| 598 |
+
depth=depth,
|
| 599 |
+
unet_block_name="down",
|
| 600 |
+
stack_enable_blocks_name=stack_enable_blocks_name,
|
| 601 |
+
stack_enable_blocks_depth=stack_enable_blocks_depth,
|
| 602 |
+
)
|
| 603 |
+
if use_audio_module
|
| 604 |
+
else None
|
| 605 |
+
)
|
| 606 |
+
motion_modules.append(
|
| 607 |
+
get_motion_module(
|
| 608 |
+
in_channels=out_channels,
|
| 609 |
+
motion_module_type=motion_module_type,
|
| 610 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 611 |
+
)
|
| 612 |
+
if use_motion_module
|
| 613 |
+
else None
|
| 614 |
+
)
|
| 615 |
+
|
| 616 |
+
self.attentions = nn.ModuleList(attentions)
|
| 617 |
+
self.resnets = nn.ModuleList(resnets)
|
| 618 |
+
self.audio_modules = nn.ModuleList(audio_modules)
|
| 619 |
+
self.motion_modules = nn.ModuleList(motion_modules)
|
| 620 |
+
|
| 621 |
+
if add_downsample:
|
| 622 |
+
self.downsamplers = nn.ModuleList(
|
| 623 |
+
[
|
| 624 |
+
Downsample3D(
|
| 625 |
+
out_channels,
|
| 626 |
+
use_conv=True,
|
| 627 |
+
out_channels=out_channels,
|
| 628 |
+
padding=downsample_padding,
|
| 629 |
+
name="op",
|
| 630 |
+
)
|
| 631 |
+
]
|
| 632 |
+
)
|
| 633 |
+
else:
|
| 634 |
+
self.downsamplers = None
|
| 635 |
+
|
| 636 |
+
self.gradient_checkpointing = False
|
| 637 |
+
|
| 638 |
+
def forward(
|
| 639 |
+
self,
|
| 640 |
+
hidden_states,
|
| 641 |
+
temb=None,
|
| 642 |
+
encoder_hidden_states=None,
|
| 643 |
+
attention_mask=None,
|
| 644 |
+
full_mask=None,
|
| 645 |
+
face_mask=None,
|
| 646 |
+
lip_mask=None,
|
| 647 |
+
audio_embedding=None,
|
| 648 |
+
motion_scale=None,
|
| 649 |
+
):
|
| 650 |
+
"""
|
| 651 |
+
Defines the forward pass for the CrossAttnDownBlock3D class.
|
| 652 |
+
|
| 653 |
+
Parameters:
|
| 654 |
+
- hidden_states : torch.Tensor
|
| 655 |
+
The input tensor to the block.
|
| 656 |
+
temb : torch.Tensor, optional
|
| 657 |
+
The token embeddings from the previous block.
|
| 658 |
+
encoder_hidden_states : torch.Tensor, optional
|
| 659 |
+
The hidden states from the encoder.
|
| 660 |
+
attention_mask : torch.Tensor, optional
|
| 661 |
+
The attention mask for the cross-attention mechanism.
|
| 662 |
+
full_mask : torch.Tensor, optional
|
| 663 |
+
The full mask for the cross-attention mechanism.
|
| 664 |
+
face_mask : torch.Tensor, optional
|
| 665 |
+
The face mask for the cross-attention mechanism.
|
| 666 |
+
lip_mask : torch.Tensor, optional
|
| 667 |
+
The lip mask for the cross-attention mechanism.
|
| 668 |
+
audio_embedding : torch.Tensor, optional
|
| 669 |
+
The audio embedding for the cross-attention mechanism.
|
| 670 |
+
|
| 671 |
+
Returns:
|
| 672 |
+
-- torch.Tensor
|
| 673 |
+
The output tensor from the block.
|
| 674 |
+
"""
|
| 675 |
+
output_states = ()
|
| 676 |
+
|
| 677 |
+
for _, (resnet, attn, audio_module, motion_module) in enumerate(
|
| 678 |
+
zip(self.resnets, self.attentions, self.audio_modules, self.motion_modules)
|
| 679 |
+
):
|
| 680 |
+
# self.gradient_checkpointing = False
|
| 681 |
+
if self.training and self.gradient_checkpointing:
|
| 682 |
+
|
| 683 |
+
def create_custom_forward(module, return_dict=None):
|
| 684 |
+
def custom_forward(*inputs):
|
| 685 |
+
if return_dict is not None:
|
| 686 |
+
return module(*inputs, return_dict=return_dict)
|
| 687 |
+
|
| 688 |
+
return module(*inputs)
|
| 689 |
+
|
| 690 |
+
return custom_forward
|
| 691 |
+
|
| 692 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 693 |
+
create_custom_forward(resnet), hidden_states, temb
|
| 694 |
+
)
|
| 695 |
+
|
| 696 |
+
motion_frames = []
|
| 697 |
+
hidden_states, motion_frame = torch.utils.checkpoint.checkpoint(
|
| 698 |
+
create_custom_forward(attn, return_dict=False),
|
| 699 |
+
hidden_states,
|
| 700 |
+
encoder_hidden_states,
|
| 701 |
+
)
|
| 702 |
+
if len(motion_frame[0]) > 0:
|
| 703 |
+
motion_frames = motion_frame[0][0]
|
| 704 |
+
# motion_frames = torch.cat(motion_frames, dim=0)
|
| 705 |
+
motion_frames = rearrange(
|
| 706 |
+
motion_frames,
|
| 707 |
+
"b f (d1 d2) c -> b c f d1 d2",
|
| 708 |
+
d1=hidden_states.size(-1),
|
| 709 |
+
)
|
| 710 |
+
|
| 711 |
+
else:
|
| 712 |
+
motion_frames = torch.zeros(
|
| 713 |
+
hidden_states.shape[0],
|
| 714 |
+
hidden_states.shape[1],
|
| 715 |
+
4,
|
| 716 |
+
hidden_states.shape[3],
|
| 717 |
+
hidden_states.shape[4],
|
| 718 |
+
)
|
| 719 |
+
|
| 720 |
+
n_motion_frames = motion_frames.size(2)
|
| 721 |
+
|
| 722 |
+
if audio_module is not None:
|
| 723 |
+
# audio_embedding = audio_embedding
|
| 724 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 725 |
+
create_custom_forward(audio_module, return_dict=False),
|
| 726 |
+
hidden_states,
|
| 727 |
+
audio_embedding,
|
| 728 |
+
attention_mask,
|
| 729 |
+
full_mask,
|
| 730 |
+
face_mask,
|
| 731 |
+
lip_mask,
|
| 732 |
+
motion_scale,
|
| 733 |
+
)[0]
|
| 734 |
+
|
| 735 |
+
# add motion module
|
| 736 |
+
if motion_module is not None:
|
| 737 |
+
motion_frames = motion_frames.to(
|
| 738 |
+
device=hidden_states.device, dtype=hidden_states.dtype
|
| 739 |
+
)
|
| 740 |
+
_hidden_states = torch.cat(
|
| 741 |
+
[motion_frames, hidden_states], dim=2
|
| 742 |
+
) # if n_motion_frames > 0 else hidden_states
|
| 743 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 744 |
+
create_custom_forward(motion_module),
|
| 745 |
+
_hidden_states,
|
| 746 |
+
encoder_hidden_states,
|
| 747 |
+
)
|
| 748 |
+
hidden_states = hidden_states[:, :, n_motion_frames:]
|
| 749 |
+
|
| 750 |
+
else:
|
| 751 |
+
hidden_states = resnet(hidden_states, temb)
|
| 752 |
+
hidden_states = attn(
|
| 753 |
+
hidden_states,
|
| 754 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 755 |
+
).sample
|
| 756 |
+
if audio_module is not None:
|
| 757 |
+
hidden_states = audio_module(
|
| 758 |
+
hidden_states,
|
| 759 |
+
audio_embedding,
|
| 760 |
+
attention_mask=attention_mask,
|
| 761 |
+
full_mask=full_mask,
|
| 762 |
+
face_mask=face_mask,
|
| 763 |
+
lip_mask=lip_mask,
|
| 764 |
+
return_dict=False,
|
| 765 |
+
)[0]
|
| 766 |
+
# add motion module
|
| 767 |
+
if motion_module is not None:
|
| 768 |
+
hidden_states = motion_module(
|
| 769 |
+
hidden_states, encoder_hidden_states=encoder_hidden_states
|
| 770 |
+
)
|
| 771 |
+
|
| 772 |
+
output_states += (hidden_states,)
|
| 773 |
+
|
| 774 |
+
if self.downsamplers is not None:
|
| 775 |
+
for downsampler in self.downsamplers:
|
| 776 |
+
hidden_states = downsampler(hidden_states)
|
| 777 |
+
|
| 778 |
+
output_states += (hidden_states,)
|
| 779 |
+
|
| 780 |
+
return hidden_states, output_states
|
| 781 |
+
|
| 782 |
+
|
| 783 |
+
class DownBlock3D(nn.Module):
|
| 784 |
+
"""
|
| 785 |
+
A 3D downsampling block for the U-Net architecture. This block performs downsampling operations
|
| 786 |
+
using residual blocks and an optional motion module.
|
| 787 |
+
|
| 788 |
+
Parameters:
|
| 789 |
+
- in_channels (int): Number of input channels.
|
| 790 |
+
- out_channels (int): Number of output channels.
|
| 791 |
+
- temb_channels (int): Number of token embedding channels.
|
| 792 |
+
- dropout (float): Dropout rate for the block.
|
| 793 |
+
- num_layers (int): Number of layers in the block.
|
| 794 |
+
- resnet_eps (float): Epsilon for residual block stability.
|
| 795 |
+
- resnet_time_scale_shift (str): Time scale shift for the residual block's time embedding.
|
| 796 |
+
- resnet_act_fn (str): Activation function used in the residual block.
|
| 797 |
+
- resnet_groups (int): Number of groups for the convolutions in the residual block.
|
| 798 |
+
- resnet_pre_norm (bool): Whether to use pre-normalization in the residual block.
|
| 799 |
+
- output_scale_factor (float): Scaling factor for the block's output.
|
| 800 |
+
- add_downsample (bool): Whether to add a downsampling layer.
|
| 801 |
+
- downsample_padding (int): Padding for the downsampling layer.
|
| 802 |
+
- use_inflated_groupnorm (bool): Whether to use inflated group normalization.
|
| 803 |
+
- use_motion_module (bool): Whether to include a motion module.
|
| 804 |
+
- motion_module_type (str): Type of motion module to use.
|
| 805 |
+
- motion_module_kwargs (dict): Keyword arguments for the motion module.
|
| 806 |
+
|
| 807 |
+
Forward method:
|
| 808 |
+
The forward method processes the input hidden states through the residual blocks and optional
|
| 809 |
+
motion modules, followed by an optional downsampling step. It supports gradient checkpointing
|
| 810 |
+
during training to reduce memory usage.
|
| 811 |
+
"""
|
| 812 |
+
def __init__(
|
| 813 |
+
self,
|
| 814 |
+
in_channels: int,
|
| 815 |
+
out_channels: int,
|
| 816 |
+
temb_channels: int,
|
| 817 |
+
dropout: float = 0.0,
|
| 818 |
+
num_layers: int = 1,
|
| 819 |
+
resnet_eps: float = 1e-6,
|
| 820 |
+
resnet_time_scale_shift: str = "default",
|
| 821 |
+
resnet_act_fn: str = "swish",
|
| 822 |
+
resnet_groups: int = 32,
|
| 823 |
+
resnet_pre_norm: bool = True,
|
| 824 |
+
output_scale_factor=1.0,
|
| 825 |
+
add_downsample=True,
|
| 826 |
+
downsample_padding=1,
|
| 827 |
+
use_inflated_groupnorm=None,
|
| 828 |
+
use_motion_module=None,
|
| 829 |
+
motion_module_type=None,
|
| 830 |
+
motion_module_kwargs=None,
|
| 831 |
+
):
|
| 832 |
+
super().__init__()
|
| 833 |
+
resnets = []
|
| 834 |
+
motion_modules = []
|
| 835 |
+
|
| 836 |
+
# use_motion_module = False
|
| 837 |
+
for i in range(num_layers):
|
| 838 |
+
in_channels = in_channels if i == 0 else out_channels
|
| 839 |
+
resnets.append(
|
| 840 |
+
ResnetBlock3D(
|
| 841 |
+
in_channels=in_channels,
|
| 842 |
+
out_channels=out_channels,
|
| 843 |
+
temb_channels=temb_channels,
|
| 844 |
+
eps=resnet_eps,
|
| 845 |
+
groups=resnet_groups,
|
| 846 |
+
dropout=dropout,
|
| 847 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 848 |
+
non_linearity=resnet_act_fn,
|
| 849 |
+
output_scale_factor=output_scale_factor,
|
| 850 |
+
pre_norm=resnet_pre_norm,
|
| 851 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 852 |
+
)
|
| 853 |
+
)
|
| 854 |
+
motion_modules.append(
|
| 855 |
+
get_motion_module(
|
| 856 |
+
in_channels=out_channels,
|
| 857 |
+
motion_module_type=motion_module_type,
|
| 858 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 859 |
+
)
|
| 860 |
+
if use_motion_module
|
| 861 |
+
else None
|
| 862 |
+
)
|
| 863 |
+
|
| 864 |
+
self.resnets = nn.ModuleList(resnets)
|
| 865 |
+
self.motion_modules = nn.ModuleList(motion_modules)
|
| 866 |
+
|
| 867 |
+
if add_downsample:
|
| 868 |
+
self.downsamplers = nn.ModuleList(
|
| 869 |
+
[
|
| 870 |
+
Downsample3D(
|
| 871 |
+
out_channels,
|
| 872 |
+
use_conv=True,
|
| 873 |
+
out_channels=out_channels,
|
| 874 |
+
padding=downsample_padding,
|
| 875 |
+
name="op",
|
| 876 |
+
)
|
| 877 |
+
]
|
| 878 |
+
)
|
| 879 |
+
else:
|
| 880 |
+
self.downsamplers = None
|
| 881 |
+
|
| 882 |
+
self.gradient_checkpointing = False
|
| 883 |
+
|
| 884 |
+
def forward(
|
| 885 |
+
self,
|
| 886 |
+
hidden_states,
|
| 887 |
+
temb=None,
|
| 888 |
+
encoder_hidden_states=None,
|
| 889 |
+
):
|
| 890 |
+
"""
|
| 891 |
+
forward method for the DownBlock3D class.
|
| 892 |
+
|
| 893 |
+
Args:
|
| 894 |
+
hidden_states (Tensor): The input tensor to the DownBlock3D layer.
|
| 895 |
+
temb (Tensor, optional): The token embeddings, if using transformer.
|
| 896 |
+
encoder_hidden_states (Tensor, optional): The hidden states from the encoder.
|
| 897 |
+
|
| 898 |
+
Returns:
|
| 899 |
+
Tensor: The output tensor after passing through the DownBlock3D layer.
|
| 900 |
+
"""
|
| 901 |
+
output_states = ()
|
| 902 |
+
|
| 903 |
+
for resnet, motion_module in zip(self.resnets, self.motion_modules):
|
| 904 |
+
# print(f"DownBlock3D {self.gradient_checkpointing = }")
|
| 905 |
+
if self.training and self.gradient_checkpointing:
|
| 906 |
+
|
| 907 |
+
def create_custom_forward(module):
|
| 908 |
+
def custom_forward(*inputs):
|
| 909 |
+
return module(*inputs)
|
| 910 |
+
|
| 911 |
+
return custom_forward
|
| 912 |
+
|
| 913 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 914 |
+
create_custom_forward(resnet), hidden_states, temb
|
| 915 |
+
)
|
| 916 |
+
|
| 917 |
+
else:
|
| 918 |
+
hidden_states = resnet(hidden_states, temb)
|
| 919 |
+
|
| 920 |
+
# add motion module
|
| 921 |
+
hidden_states = (
|
| 922 |
+
motion_module(
|
| 923 |
+
hidden_states, encoder_hidden_states=encoder_hidden_states
|
| 924 |
+
)
|
| 925 |
+
if motion_module is not None
|
| 926 |
+
else hidden_states
|
| 927 |
+
)
|
| 928 |
+
|
| 929 |
+
output_states += (hidden_states,)
|
| 930 |
+
|
| 931 |
+
if self.downsamplers is not None:
|
| 932 |
+
for downsampler in self.downsamplers:
|
| 933 |
+
hidden_states = downsampler(hidden_states)
|
| 934 |
+
|
| 935 |
+
output_states += (hidden_states,)
|
| 936 |
+
|
| 937 |
+
return hidden_states, output_states
|
| 938 |
+
|
| 939 |
+
|
| 940 |
+
class CrossAttnUpBlock3D(nn.Module):
|
| 941 |
+
"""
|
| 942 |
+
Standard 3D downsampling block for the U-Net architecture. This block performs downsampling
|
| 943 |
+
operations in the U-Net using residual blocks and an optional motion module.
|
| 944 |
+
|
| 945 |
+
Parameters:
|
| 946 |
+
- in_channels (int): Number of input channels.
|
| 947 |
+
- out_channels (int): Number of output channels.
|
| 948 |
+
- temb_channels (int): Number of channels for the temporal embedding.
|
| 949 |
+
- dropout (float): Dropout rate for the block.
|
| 950 |
+
- num_layers (int): Number of layers in the block.
|
| 951 |
+
- resnet_eps (float): Epsilon for residual block stability.
|
| 952 |
+
- resnet_time_scale_shift (str): Time scale shift for the residual block's time embedding.
|
| 953 |
+
- resnet_act_fn (str): Activation function used in the residual block.
|
| 954 |
+
- resnet_groups (int): Number of groups for the convolutions in the residual block.
|
| 955 |
+
- resnet_pre_norm (bool): Whether to use pre-normalization in the residual block.
|
| 956 |
+
- output_scale_factor (float): Scaling factor for the block's output.
|
| 957 |
+
- add_downsample (bool): Whether to add a downsampling layer.
|
| 958 |
+
- downsample_padding (int): Padding for the downsampling layer.
|
| 959 |
+
- use_inflated_groupnorm (bool): Whether to use inflated group normalization.
|
| 960 |
+
- use_motion_module (bool): Whether to include a motion module.
|
| 961 |
+
- motion_module_type (str): Type of motion module to use.
|
| 962 |
+
- motion_module_kwargs (dict): Keyword arguments for the motion module.
|
| 963 |
+
|
| 964 |
+
Forward method:
|
| 965 |
+
The forward method processes the input hidden states through the residual blocks and optional
|
| 966 |
+
motion modules, followed by an optional downsampling step. It supports gradient checkpointing
|
| 967 |
+
during training to reduce memory usage.
|
| 968 |
+
"""
|
| 969 |
+
def __init__(
|
| 970 |
+
self,
|
| 971 |
+
in_channels: int,
|
| 972 |
+
out_channels: int,
|
| 973 |
+
prev_output_channel: int,
|
| 974 |
+
temb_channels: int,
|
| 975 |
+
dropout: float = 0.0,
|
| 976 |
+
num_layers: int = 1,
|
| 977 |
+
resnet_eps: float = 1e-6,
|
| 978 |
+
resnet_time_scale_shift: str = "default",
|
| 979 |
+
resnet_act_fn: str = "swish",
|
| 980 |
+
resnet_groups: int = 32,
|
| 981 |
+
resnet_pre_norm: bool = True,
|
| 982 |
+
attn_num_head_channels=1,
|
| 983 |
+
cross_attention_dim=1280,
|
| 984 |
+
audio_attention_dim=1024,
|
| 985 |
+
output_scale_factor=1.0,
|
| 986 |
+
add_upsample=True,
|
| 987 |
+
dual_cross_attention=False,
|
| 988 |
+
use_linear_projection=False,
|
| 989 |
+
only_cross_attention=False,
|
| 990 |
+
upcast_attention=False,
|
| 991 |
+
unet_use_cross_frame_attention=None,
|
| 992 |
+
unet_use_temporal_attention=None,
|
| 993 |
+
use_motion_module=None,
|
| 994 |
+
use_inflated_groupnorm=None,
|
| 995 |
+
motion_module_type=None,
|
| 996 |
+
motion_module_kwargs=None,
|
| 997 |
+
use_audio_module=None,
|
| 998 |
+
depth=0,
|
| 999 |
+
stack_enable_blocks_name=None,
|
| 1000 |
+
stack_enable_blocks_depth=None,
|
| 1001 |
+
):
|
| 1002 |
+
super().__init__()
|
| 1003 |
+
resnets = []
|
| 1004 |
+
attentions = []
|
| 1005 |
+
audio_modules = []
|
| 1006 |
+
motion_modules = []
|
| 1007 |
+
|
| 1008 |
+
self.has_cross_attention = True
|
| 1009 |
+
self.attn_num_head_channels = attn_num_head_channels
|
| 1010 |
+
|
| 1011 |
+
for i in range(num_layers):
|
| 1012 |
+
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
|
| 1013 |
+
resnet_in_channels = prev_output_channel if i == 0 else out_channels
|
| 1014 |
+
|
| 1015 |
+
resnets.append(
|
| 1016 |
+
ResnetBlock3D(
|
| 1017 |
+
in_channels=resnet_in_channels + res_skip_channels,
|
| 1018 |
+
out_channels=out_channels,
|
| 1019 |
+
temb_channels=temb_channels,
|
| 1020 |
+
eps=resnet_eps,
|
| 1021 |
+
groups=resnet_groups,
|
| 1022 |
+
dropout=dropout,
|
| 1023 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 1024 |
+
non_linearity=resnet_act_fn,
|
| 1025 |
+
output_scale_factor=output_scale_factor,
|
| 1026 |
+
pre_norm=resnet_pre_norm,
|
| 1027 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 1028 |
+
)
|
| 1029 |
+
)
|
| 1030 |
+
|
| 1031 |
+
if dual_cross_attention:
|
| 1032 |
+
raise NotImplementedError
|
| 1033 |
+
attentions.append(
|
| 1034 |
+
Transformer3DModel(
|
| 1035 |
+
attn_num_head_channels,
|
| 1036 |
+
out_channels // attn_num_head_channels,
|
| 1037 |
+
in_channels=out_channels,
|
| 1038 |
+
num_layers=1,
|
| 1039 |
+
cross_attention_dim=cross_attention_dim,
|
| 1040 |
+
norm_num_groups=resnet_groups,
|
| 1041 |
+
use_linear_projection=use_linear_projection,
|
| 1042 |
+
only_cross_attention=only_cross_attention,
|
| 1043 |
+
upcast_attention=upcast_attention,
|
| 1044 |
+
unet_use_cross_frame_attention=unet_use_cross_frame_attention,
|
| 1045 |
+
unet_use_temporal_attention=unet_use_temporal_attention,
|
| 1046 |
+
)
|
| 1047 |
+
)
|
| 1048 |
+
audio_modules.append(
|
| 1049 |
+
Transformer3DModel(
|
| 1050 |
+
attn_num_head_channels,
|
| 1051 |
+
in_channels // attn_num_head_channels,
|
| 1052 |
+
in_channels=out_channels,
|
| 1053 |
+
num_layers=1,
|
| 1054 |
+
cross_attention_dim=audio_attention_dim,
|
| 1055 |
+
norm_num_groups=resnet_groups,
|
| 1056 |
+
use_linear_projection=use_linear_projection,
|
| 1057 |
+
only_cross_attention=only_cross_attention,
|
| 1058 |
+
upcast_attention=upcast_attention,
|
| 1059 |
+
use_audio_module=use_audio_module,
|
| 1060 |
+
depth=depth,
|
| 1061 |
+
unet_block_name="up",
|
| 1062 |
+
stack_enable_blocks_name=stack_enable_blocks_name,
|
| 1063 |
+
stack_enable_blocks_depth=stack_enable_blocks_depth,
|
| 1064 |
+
)
|
| 1065 |
+
if use_audio_module
|
| 1066 |
+
else None
|
| 1067 |
+
)
|
| 1068 |
+
motion_modules.append(
|
| 1069 |
+
get_motion_module(
|
| 1070 |
+
in_channels=out_channels,
|
| 1071 |
+
motion_module_type=motion_module_type,
|
| 1072 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 1073 |
+
)
|
| 1074 |
+
if use_motion_module
|
| 1075 |
+
else None
|
| 1076 |
+
)
|
| 1077 |
+
|
| 1078 |
+
self.attentions = nn.ModuleList(attentions)
|
| 1079 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1080 |
+
self.audio_modules = nn.ModuleList(audio_modules)
|
| 1081 |
+
self.motion_modules = nn.ModuleList(motion_modules)
|
| 1082 |
+
|
| 1083 |
+
if add_upsample:
|
| 1084 |
+
self.upsamplers = nn.ModuleList(
|
| 1085 |
+
[Upsample3D(out_channels, use_conv=True, out_channels=out_channels)]
|
| 1086 |
+
)
|
| 1087 |
+
else:
|
| 1088 |
+
self.upsamplers = None
|
| 1089 |
+
|
| 1090 |
+
self.gradient_checkpointing = False
|
| 1091 |
+
|
| 1092 |
+
def forward(
|
| 1093 |
+
self,
|
| 1094 |
+
hidden_states,
|
| 1095 |
+
res_hidden_states_tuple,
|
| 1096 |
+
temb=None,
|
| 1097 |
+
encoder_hidden_states=None,
|
| 1098 |
+
upsample_size=None,
|
| 1099 |
+
attention_mask=None,
|
| 1100 |
+
full_mask=None,
|
| 1101 |
+
face_mask=None,
|
| 1102 |
+
lip_mask=None,
|
| 1103 |
+
audio_embedding=None,
|
| 1104 |
+
motion_scale=None,
|
| 1105 |
+
):
|
| 1106 |
+
"""
|
| 1107 |
+
Forward pass for the CrossAttnUpBlock3D class.
|
| 1108 |
+
|
| 1109 |
+
Args:
|
| 1110 |
+
self (CrossAttnUpBlock3D): An instance of the CrossAttnUpBlock3D class.
|
| 1111 |
+
hidden_states (Tensor): The input hidden states tensor.
|
| 1112 |
+
res_hidden_states_tuple (Tuple[Tensor]): A tuple of residual hidden states tensors.
|
| 1113 |
+
temb (Tensor, optional): The token embeddings tensor. Defaults to None.
|
| 1114 |
+
encoder_hidden_states (Tensor, optional): The encoder hidden states tensor. Defaults to None.
|
| 1115 |
+
upsample_size (int, optional): The upsample size. Defaults to None.
|
| 1116 |
+
attention_mask (Tensor, optional): The attention mask tensor. Defaults to None.
|
| 1117 |
+
full_mask (Tensor, optional): The full mask tensor. Defaults to None.
|
| 1118 |
+
face_mask (Tensor, optional): The face mask tensor. Defaults to None.
|
| 1119 |
+
lip_mask (Tensor, optional): The lip mask tensor. Defaults to None.
|
| 1120 |
+
audio_embedding (Tensor, optional): The audio embedding tensor. Defaults to None.
|
| 1121 |
+
|
| 1122 |
+
Returns:
|
| 1123 |
+
Tensor: The output tensor after passing through the CrossAttnUpBlock3D.
|
| 1124 |
+
"""
|
| 1125 |
+
for _, (resnet, attn, audio_module, motion_module) in enumerate(
|
| 1126 |
+
zip(self.resnets, self.attentions, self.audio_modules, self.motion_modules)
|
| 1127 |
+
):
|
| 1128 |
+
# pop res hidden states
|
| 1129 |
+
res_hidden_states = res_hidden_states_tuple[-1]
|
| 1130 |
+
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
|
| 1131 |
+
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
|
| 1132 |
+
|
| 1133 |
+
if self.training and self.gradient_checkpointing:
|
| 1134 |
+
|
| 1135 |
+
def create_custom_forward(module, return_dict=None):
|
| 1136 |
+
def custom_forward(*inputs):
|
| 1137 |
+
if return_dict is not None:
|
| 1138 |
+
return module(*inputs, return_dict=return_dict)
|
| 1139 |
+
|
| 1140 |
+
return module(*inputs)
|
| 1141 |
+
|
| 1142 |
+
return custom_forward
|
| 1143 |
+
|
| 1144 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1145 |
+
create_custom_forward(resnet), hidden_states, temb
|
| 1146 |
+
)
|
| 1147 |
+
|
| 1148 |
+
motion_frames = []
|
| 1149 |
+
hidden_states, motion_frame = torch.utils.checkpoint.checkpoint(
|
| 1150 |
+
create_custom_forward(attn, return_dict=False),
|
| 1151 |
+
hidden_states,
|
| 1152 |
+
encoder_hidden_states,
|
| 1153 |
+
)
|
| 1154 |
+
if len(motion_frame[0]) > 0:
|
| 1155 |
+
motion_frames = motion_frame[0][0]
|
| 1156 |
+
# motion_frames = torch.cat(motion_frames, dim=0)
|
| 1157 |
+
motion_frames = rearrange(
|
| 1158 |
+
motion_frames,
|
| 1159 |
+
"b f (d1 d2) c -> b c f d1 d2",
|
| 1160 |
+
d1=hidden_states.size(-1),
|
| 1161 |
+
)
|
| 1162 |
+
else:
|
| 1163 |
+
motion_frames = torch.zeros(
|
| 1164 |
+
hidden_states.shape[0],
|
| 1165 |
+
hidden_states.shape[1],
|
| 1166 |
+
4,
|
| 1167 |
+
hidden_states.shape[3],
|
| 1168 |
+
hidden_states.shape[4],
|
| 1169 |
+
)
|
| 1170 |
+
|
| 1171 |
+
n_motion_frames = motion_frames.size(2)
|
| 1172 |
+
|
| 1173 |
+
if audio_module is not None:
|
| 1174 |
+
# audio_embedding = audio_embedding
|
| 1175 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1176 |
+
create_custom_forward(audio_module, return_dict=False),
|
| 1177 |
+
hidden_states,
|
| 1178 |
+
audio_embedding,
|
| 1179 |
+
attention_mask,
|
| 1180 |
+
full_mask,
|
| 1181 |
+
face_mask,
|
| 1182 |
+
lip_mask,
|
| 1183 |
+
motion_scale,
|
| 1184 |
+
)[0]
|
| 1185 |
+
|
| 1186 |
+
# add motion module
|
| 1187 |
+
if motion_module is not None:
|
| 1188 |
+
motion_frames = motion_frames.to(
|
| 1189 |
+
device=hidden_states.device, dtype=hidden_states.dtype
|
| 1190 |
+
)
|
| 1191 |
+
|
| 1192 |
+
_hidden_states = (
|
| 1193 |
+
torch.cat([motion_frames, hidden_states], dim=2)
|
| 1194 |
+
if n_motion_frames > 0
|
| 1195 |
+
else hidden_states
|
| 1196 |
+
)
|
| 1197 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1198 |
+
create_custom_forward(motion_module),
|
| 1199 |
+
_hidden_states,
|
| 1200 |
+
encoder_hidden_states,
|
| 1201 |
+
)
|
| 1202 |
+
hidden_states = hidden_states[:, :, n_motion_frames:]
|
| 1203 |
+
else:
|
| 1204 |
+
hidden_states = resnet(hidden_states, temb)
|
| 1205 |
+
hidden_states = attn(
|
| 1206 |
+
hidden_states,
|
| 1207 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1208 |
+
).sample
|
| 1209 |
+
|
| 1210 |
+
if audio_module is not None:
|
| 1211 |
+
|
| 1212 |
+
hidden_states = (
|
| 1213 |
+
audio_module(
|
| 1214 |
+
hidden_states,
|
| 1215 |
+
encoder_hidden_states=audio_embedding,
|
| 1216 |
+
attention_mask=attention_mask,
|
| 1217 |
+
full_mask=full_mask,
|
| 1218 |
+
face_mask=face_mask,
|
| 1219 |
+
lip_mask=lip_mask,
|
| 1220 |
+
)
|
| 1221 |
+
).sample
|
| 1222 |
+
# add motion module
|
| 1223 |
+
hidden_states = (
|
| 1224 |
+
motion_module(
|
| 1225 |
+
hidden_states, encoder_hidden_states=encoder_hidden_states
|
| 1226 |
+
)
|
| 1227 |
+
if motion_module is not None
|
| 1228 |
+
else hidden_states
|
| 1229 |
+
)
|
| 1230 |
+
|
| 1231 |
+
if self.upsamplers is not None:
|
| 1232 |
+
for upsampler in self.upsamplers:
|
| 1233 |
+
hidden_states = upsampler(hidden_states, upsample_size)
|
| 1234 |
+
|
| 1235 |
+
return hidden_states
|
| 1236 |
+
|
| 1237 |
+
|
| 1238 |
+
class UpBlock3D(nn.Module):
|
| 1239 |
+
"""
|
| 1240 |
+
3D upsampling block with cross attention for the U-Net architecture. This block performs
|
| 1241 |
+
upsampling operations and incorporates cross attention mechanisms, which allow the model to
|
| 1242 |
+
focus on different parts of the input when upscaling.
|
| 1243 |
+
|
| 1244 |
+
Parameters:
|
| 1245 |
+
- in_channels (int): Number of input channels.
|
| 1246 |
+
- out_channels (int): Number of output channels.
|
| 1247 |
+
- prev_output_channel (int): Number of channels from the previous layer's output.
|
| 1248 |
+
- temb_channels (int): Number of channels for the temporal embedding.
|
| 1249 |
+
- dropout (float): Dropout rate for the block.
|
| 1250 |
+
- num_layers (int): Number of layers in the block.
|
| 1251 |
+
- resnet_eps (float): Epsilon for residual block stability.
|
| 1252 |
+
- resnet_time_scale_shift (str): Time scale shift for the residual block's time embedding.
|
| 1253 |
+
- resnet_act_fn (str): Activation function used in the residual block.
|
| 1254 |
+
- resnet_groups (int): Number of groups for the convolutions in the residual block.
|
| 1255 |
+
- resnet_pre_norm (bool): Whether to use pre-normalization in the residual block.
|
| 1256 |
+
- attn_num_head_channels (int): Number of attention heads for the cross attention mechanism.
|
| 1257 |
+
- cross_attention_dim (int): Dimensionality of the cross attention layers.
|
| 1258 |
+
- audio_attention_dim (int): Dimensionality of the audio attention layers.
|
| 1259 |
+
- output_scale_factor (float): Scaling factor for the block's output.
|
| 1260 |
+
- add_upsample (bool): Whether to add an upsampling layer.
|
| 1261 |
+
- dual_cross_attention (bool): Whether to use dual cross attention (not implemented).
|
| 1262 |
+
- use_linear_projection (bool): Whether to use linear projection in the cross attention.
|
| 1263 |
+
- only_cross_attention (bool): Whether to use only cross attention (no self-attention).
|
| 1264 |
+
- upcast_attention (bool): Whether to upcast attention to the original input dimension.
|
| 1265 |
+
- unet_use_cross_frame_attention (bool): Whether to use cross frame attention in U-Net.
|
| 1266 |
+
- unet_use_temporal_attention (bool): Whether to use temporal attention in U-Net.
|
| 1267 |
+
- use_motion_module (bool): Whether to include a motion module.
|
| 1268 |
+
- use_inflated_groupnorm (bool): Whether to use inflated group normalization.
|
| 1269 |
+
- motion_module_type (str): Type of motion module to use.
|
| 1270 |
+
- motion_module_kwargs (dict): Keyword arguments for the motion module.
|
| 1271 |
+
- use_audio_module (bool): Whether to include an audio module.
|
| 1272 |
+
- depth (int): Depth of the block in the network.
|
| 1273 |
+
- stack_enable_blocks_name (str): Name of the stack enable blocks.
|
| 1274 |
+
- stack_enable_blocks_depth (int): Depth of the stack enable blocks.
|
| 1275 |
+
|
| 1276 |
+
Forward method:
|
| 1277 |
+
The forward method upsamples the input hidden states and residual hidden states, processes
|
| 1278 |
+
them through the residual and cross attention blocks, and optional motion and audio modules.
|
| 1279 |
+
It supports gradient checkpointing during training.
|
| 1280 |
+
"""
|
| 1281 |
+
def __init__(
|
| 1282 |
+
self,
|
| 1283 |
+
in_channels: int,
|
| 1284 |
+
prev_output_channel: int,
|
| 1285 |
+
out_channels: int,
|
| 1286 |
+
temb_channels: int,
|
| 1287 |
+
dropout: float = 0.0,
|
| 1288 |
+
num_layers: int = 1,
|
| 1289 |
+
resnet_eps: float = 1e-6,
|
| 1290 |
+
resnet_time_scale_shift: str = "default",
|
| 1291 |
+
resnet_act_fn: str = "swish",
|
| 1292 |
+
resnet_groups: int = 32,
|
| 1293 |
+
resnet_pre_norm: bool = True,
|
| 1294 |
+
output_scale_factor=1.0,
|
| 1295 |
+
add_upsample=True,
|
| 1296 |
+
use_inflated_groupnorm=None,
|
| 1297 |
+
use_motion_module=None,
|
| 1298 |
+
motion_module_type=None,
|
| 1299 |
+
motion_module_kwargs=None,
|
| 1300 |
+
):
|
| 1301 |
+
super().__init__()
|
| 1302 |
+
resnets = []
|
| 1303 |
+
motion_modules = []
|
| 1304 |
+
|
| 1305 |
+
# use_motion_module = False
|
| 1306 |
+
for i in range(num_layers):
|
| 1307 |
+
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
|
| 1308 |
+
resnet_in_channels = prev_output_channel if i == 0 else out_channels
|
| 1309 |
+
|
| 1310 |
+
resnets.append(
|
| 1311 |
+
ResnetBlock3D(
|
| 1312 |
+
in_channels=resnet_in_channels + res_skip_channels,
|
| 1313 |
+
out_channels=out_channels,
|
| 1314 |
+
temb_channels=temb_channels,
|
| 1315 |
+
eps=resnet_eps,
|
| 1316 |
+
groups=resnet_groups,
|
| 1317 |
+
dropout=dropout,
|
| 1318 |
+
time_embedding_norm=resnet_time_scale_shift,
|
| 1319 |
+
non_linearity=resnet_act_fn,
|
| 1320 |
+
output_scale_factor=output_scale_factor,
|
| 1321 |
+
pre_norm=resnet_pre_norm,
|
| 1322 |
+
use_inflated_groupnorm=use_inflated_groupnorm,
|
| 1323 |
+
)
|
| 1324 |
+
)
|
| 1325 |
+
motion_modules.append(
|
| 1326 |
+
get_motion_module(
|
| 1327 |
+
in_channels=out_channels,
|
| 1328 |
+
motion_module_type=motion_module_type,
|
| 1329 |
+
motion_module_kwargs=motion_module_kwargs,
|
| 1330 |
+
)
|
| 1331 |
+
if use_motion_module
|
| 1332 |
+
else None
|
| 1333 |
+
)
|
| 1334 |
+
|
| 1335 |
+
self.resnets = nn.ModuleList(resnets)
|
| 1336 |
+
self.motion_modules = nn.ModuleList(motion_modules)
|
| 1337 |
+
|
| 1338 |
+
if add_upsample:
|
| 1339 |
+
self.upsamplers = nn.ModuleList(
|
| 1340 |
+
[Upsample3D(out_channels, use_conv=True, out_channels=out_channels)]
|
| 1341 |
+
)
|
| 1342 |
+
else:
|
| 1343 |
+
self.upsamplers = None
|
| 1344 |
+
|
| 1345 |
+
self.gradient_checkpointing = False
|
| 1346 |
+
|
| 1347 |
+
def forward(
|
| 1348 |
+
self,
|
| 1349 |
+
hidden_states,
|
| 1350 |
+
res_hidden_states_tuple,
|
| 1351 |
+
temb=None,
|
| 1352 |
+
upsample_size=None,
|
| 1353 |
+
encoder_hidden_states=None,
|
| 1354 |
+
):
|
| 1355 |
+
"""
|
| 1356 |
+
Forward pass for the UpBlock3D class.
|
| 1357 |
+
|
| 1358 |
+
Args:
|
| 1359 |
+
self (UpBlock3D): An instance of the UpBlock3D class.
|
| 1360 |
+
hidden_states (Tensor): The input hidden states tensor.
|
| 1361 |
+
res_hidden_states_tuple (Tuple[Tensor]): A tuple of residual hidden states tensors.
|
| 1362 |
+
temb (Tensor, optional): The token embeddings tensor. Defaults to None.
|
| 1363 |
+
upsample_size (int, optional): The upsample size. Defaults to None.
|
| 1364 |
+
encoder_hidden_states (Tensor, optional): The encoder hidden states tensor. Defaults to None.
|
| 1365 |
+
|
| 1366 |
+
Returns:
|
| 1367 |
+
Tensor: The output tensor after passing through the UpBlock3D layers.
|
| 1368 |
+
"""
|
| 1369 |
+
for resnet, motion_module in zip(self.resnets, self.motion_modules):
|
| 1370 |
+
# pop res hidden states
|
| 1371 |
+
res_hidden_states = res_hidden_states_tuple[-1]
|
| 1372 |
+
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
|
| 1373 |
+
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
|
| 1374 |
+
|
| 1375 |
+
# print(f"UpBlock3D {self.gradient_checkpointing = }")
|
| 1376 |
+
if self.training and self.gradient_checkpointing:
|
| 1377 |
+
|
| 1378 |
+
def create_custom_forward(module):
|
| 1379 |
+
def custom_forward(*inputs):
|
| 1380 |
+
return module(*inputs)
|
| 1381 |
+
|
| 1382 |
+
return custom_forward
|
| 1383 |
+
|
| 1384 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 1385 |
+
create_custom_forward(resnet), hidden_states, temb
|
| 1386 |
+
)
|
| 1387 |
+
else:
|
| 1388 |
+
hidden_states = resnet(hidden_states, temb)
|
| 1389 |
+
hidden_states = (
|
| 1390 |
+
motion_module(
|
| 1391 |
+
hidden_states, encoder_hidden_states=encoder_hidden_states
|
| 1392 |
+
)
|
| 1393 |
+
if motion_module is not None
|
| 1394 |
+
else hidden_states
|
| 1395 |
+
)
|
| 1396 |
+
|
| 1397 |
+
if self.upsamplers is not None:
|
| 1398 |
+
for upsampler in self.upsamplers:
|
| 1399 |
+
hidden_states = upsampler(hidden_states, upsample_size)
|
| 1400 |
+
|
| 1401 |
+
return hidden_states
|
hallo/models/wav2vec.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=R0901
|
| 2 |
+
# src/models/wav2vec.py
|
| 3 |
+
|
| 4 |
+
"""
|
| 5 |
+
This module defines the Wav2Vec model, which is a pre-trained model for speech recognition and understanding.
|
| 6 |
+
It inherits from the Wav2Vec2Model class in the transformers library and provides additional functionalities
|
| 7 |
+
such as feature extraction and encoding.
|
| 8 |
+
|
| 9 |
+
Classes:
|
| 10 |
+
Wav2VecModel: Inherits from Wav2Vec2Model and adds additional methods for feature extraction and encoding.
|
| 11 |
+
|
| 12 |
+
Functions:
|
| 13 |
+
linear_interpolation: Interpolates the features based on the sequence length.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
import torch.nn.functional as F
|
| 17 |
+
from transformers import Wav2Vec2Model
|
| 18 |
+
from transformers.modeling_outputs import BaseModelOutput
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class Wav2VecModel(Wav2Vec2Model):
|
| 22 |
+
"""
|
| 23 |
+
Wav2VecModel is a custom model class that extends the Wav2Vec2Model class from the transformers library.
|
| 24 |
+
It inherits all the functionality of the Wav2Vec2Model and adds additional methods for feature extraction and encoding.
|
| 25 |
+
...
|
| 26 |
+
|
| 27 |
+
Attributes:
|
| 28 |
+
base_model (Wav2Vec2Model): The base Wav2Vec2Model object.
|
| 29 |
+
|
| 30 |
+
Methods:
|
| 31 |
+
forward(input_values, seq_len, attention_mask=None, mask_time_indices=None
|
| 32 |
+
, output_attentions=None, output_hidden_states=None, return_dict=None):
|
| 33 |
+
Forward pass of the Wav2VecModel.
|
| 34 |
+
It takes input_values, seq_len, and other optional parameters as input and returns the output of the base model.
|
| 35 |
+
|
| 36 |
+
feature_extract(input_values, seq_len):
|
| 37 |
+
Extracts features from the input_values using the base model.
|
| 38 |
+
|
| 39 |
+
encode(extract_features, attention_mask=None, mask_time_indices=None, output_attentions=None, output_hidden_states=None, return_dict=None):
|
| 40 |
+
Encodes the extracted features using the base model and returns the encoded features.
|
| 41 |
+
"""
|
| 42 |
+
def forward(
|
| 43 |
+
self,
|
| 44 |
+
input_values,
|
| 45 |
+
seq_len,
|
| 46 |
+
attention_mask=None,
|
| 47 |
+
mask_time_indices=None,
|
| 48 |
+
output_attentions=None,
|
| 49 |
+
output_hidden_states=None,
|
| 50 |
+
return_dict=None,
|
| 51 |
+
):
|
| 52 |
+
"""
|
| 53 |
+
Forward pass of the Wav2Vec model.
|
| 54 |
+
|
| 55 |
+
Args:
|
| 56 |
+
self: The instance of the model.
|
| 57 |
+
input_values: The input values (waveform) to the model.
|
| 58 |
+
seq_len: The sequence length of the input values.
|
| 59 |
+
attention_mask: Attention mask to be used for the model.
|
| 60 |
+
mask_time_indices: Mask indices to be used for the model.
|
| 61 |
+
output_attentions: If set to True, returns attentions.
|
| 62 |
+
output_hidden_states: If set to True, returns hidden states.
|
| 63 |
+
return_dict: If set to True, returns a BaseModelOutput instead of a tuple.
|
| 64 |
+
|
| 65 |
+
Returns:
|
| 66 |
+
The output of the Wav2Vec model.
|
| 67 |
+
"""
|
| 68 |
+
self.config.output_attentions = True
|
| 69 |
+
|
| 70 |
+
output_hidden_states = (
|
| 71 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 72 |
+
)
|
| 73 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 74 |
+
|
| 75 |
+
extract_features = self.feature_extractor(input_values)
|
| 76 |
+
extract_features = extract_features.transpose(1, 2)
|
| 77 |
+
extract_features = linear_interpolation(extract_features, seq_len=seq_len)
|
| 78 |
+
|
| 79 |
+
if attention_mask is not None:
|
| 80 |
+
# compute reduced attention_mask corresponding to feature vectors
|
| 81 |
+
attention_mask = self._get_feature_vector_attention_mask(
|
| 82 |
+
extract_features.shape[1], attention_mask, add_adapter=False
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
hidden_states, extract_features = self.feature_projection(extract_features)
|
| 86 |
+
hidden_states = self._mask_hidden_states(
|
| 87 |
+
hidden_states, mask_time_indices=mask_time_indices, attention_mask=attention_mask
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
encoder_outputs = self.encoder(
|
| 91 |
+
hidden_states,
|
| 92 |
+
attention_mask=attention_mask,
|
| 93 |
+
output_attentions=output_attentions,
|
| 94 |
+
output_hidden_states=output_hidden_states,
|
| 95 |
+
return_dict=return_dict,
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
hidden_states = encoder_outputs[0]
|
| 99 |
+
|
| 100 |
+
if self.adapter is not None:
|
| 101 |
+
hidden_states = self.adapter(hidden_states)
|
| 102 |
+
|
| 103 |
+
if not return_dict:
|
| 104 |
+
return (hidden_states, ) + encoder_outputs[1:]
|
| 105 |
+
return BaseModelOutput(
|
| 106 |
+
last_hidden_state=hidden_states,
|
| 107 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 108 |
+
attentions=encoder_outputs.attentions,
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def feature_extract(
|
| 113 |
+
self,
|
| 114 |
+
input_values,
|
| 115 |
+
seq_len,
|
| 116 |
+
):
|
| 117 |
+
"""
|
| 118 |
+
Extracts features from the input values and returns the extracted features.
|
| 119 |
+
|
| 120 |
+
Parameters:
|
| 121 |
+
input_values (torch.Tensor): The input values to be processed.
|
| 122 |
+
seq_len (torch.Tensor): The sequence lengths of the input values.
|
| 123 |
+
|
| 124 |
+
Returns:
|
| 125 |
+
extracted_features (torch.Tensor): The extracted features from the input values.
|
| 126 |
+
"""
|
| 127 |
+
extract_features = self.feature_extractor(input_values)
|
| 128 |
+
extract_features = extract_features.transpose(1, 2)
|
| 129 |
+
extract_features = linear_interpolation(extract_features, seq_len=seq_len)
|
| 130 |
+
|
| 131 |
+
return extract_features
|
| 132 |
+
|
| 133 |
+
def encode(
|
| 134 |
+
self,
|
| 135 |
+
extract_features,
|
| 136 |
+
attention_mask=None,
|
| 137 |
+
mask_time_indices=None,
|
| 138 |
+
output_attentions=None,
|
| 139 |
+
output_hidden_states=None,
|
| 140 |
+
return_dict=None,
|
| 141 |
+
):
|
| 142 |
+
"""
|
| 143 |
+
Encodes the input features into the output space.
|
| 144 |
+
|
| 145 |
+
Args:
|
| 146 |
+
extract_features (torch.Tensor): The extracted features from the audio signal.
|
| 147 |
+
attention_mask (torch.Tensor, optional): Attention mask to be used for padding.
|
| 148 |
+
mask_time_indices (torch.Tensor, optional): Masked indices for the time dimension.
|
| 149 |
+
output_attentions (bool, optional): If set to True, returns the attention weights.
|
| 150 |
+
output_hidden_states (bool, optional): If set to True, returns all hidden states.
|
| 151 |
+
return_dict (bool, optional): If set to True, returns a BaseModelOutput instead of the tuple.
|
| 152 |
+
|
| 153 |
+
Returns:
|
| 154 |
+
The encoded output features.
|
| 155 |
+
"""
|
| 156 |
+
self.config.output_attentions = True
|
| 157 |
+
|
| 158 |
+
output_hidden_states = (
|
| 159 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 160 |
+
)
|
| 161 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 162 |
+
|
| 163 |
+
if attention_mask is not None:
|
| 164 |
+
# compute reduced attention_mask corresponding to feature vectors
|
| 165 |
+
attention_mask = self._get_feature_vector_attention_mask(
|
| 166 |
+
extract_features.shape[1], attention_mask, add_adapter=False
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
hidden_states, extract_features = self.feature_projection(extract_features)
|
| 170 |
+
hidden_states = self._mask_hidden_states(
|
| 171 |
+
hidden_states, mask_time_indices=mask_time_indices, attention_mask=attention_mask
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
encoder_outputs = self.encoder(
|
| 175 |
+
hidden_states,
|
| 176 |
+
attention_mask=attention_mask,
|
| 177 |
+
output_attentions=output_attentions,
|
| 178 |
+
output_hidden_states=output_hidden_states,
|
| 179 |
+
return_dict=return_dict,
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
hidden_states = encoder_outputs[0]
|
| 183 |
+
|
| 184 |
+
if self.adapter is not None:
|
| 185 |
+
hidden_states = self.adapter(hidden_states)
|
| 186 |
+
|
| 187 |
+
if not return_dict:
|
| 188 |
+
return (hidden_states, ) + encoder_outputs[1:]
|
| 189 |
+
return BaseModelOutput(
|
| 190 |
+
last_hidden_state=hidden_states,
|
| 191 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 192 |
+
attentions=encoder_outputs.attentions,
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def linear_interpolation(features, seq_len):
|
| 197 |
+
"""
|
| 198 |
+
Transpose the features to interpolate linearly.
|
| 199 |
+
|
| 200 |
+
Args:
|
| 201 |
+
features (torch.Tensor): The extracted features to be interpolated.
|
| 202 |
+
seq_len (torch.Tensor): The sequence lengths of the features.
|
| 203 |
+
|
| 204 |
+
Returns:
|
| 205 |
+
torch.Tensor: The interpolated features.
|
| 206 |
+
"""
|
| 207 |
+
features = features.transpose(1, 2)
|
| 208 |
+
output_features = F.interpolate(features, size=seq_len, align_corners=True, mode='linear')
|
| 209 |
+
return output_features.transpose(1, 2)
|
hallo/utils/__init__.py
ADDED
|
File without changes
|
hallo/utils/util.py
ADDED
|
@@ -0,0 +1,616 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=C0116
|
| 2 |
+
# pylint: disable=W0718
|
| 3 |
+
# pylint: disable=R1732
|
| 4 |
+
"""
|
| 5 |
+
utils.py
|
| 6 |
+
|
| 7 |
+
This module provides utility functions for various tasks such as setting random seeds,
|
| 8 |
+
importing modules from files, managing checkpoint files, and saving video files from
|
| 9 |
+
sequences of PIL images.
|
| 10 |
+
|
| 11 |
+
Functions:
|
| 12 |
+
seed_everything(seed)
|
| 13 |
+
import_filename(filename)
|
| 14 |
+
delete_additional_ckpt(base_path, num_keep)
|
| 15 |
+
save_videos_from_pil(pil_images, path, fps=8)
|
| 16 |
+
|
| 17 |
+
Dependencies:
|
| 18 |
+
importlib
|
| 19 |
+
os
|
| 20 |
+
os.path as osp
|
| 21 |
+
random
|
| 22 |
+
shutil
|
| 23 |
+
sys
|
| 24 |
+
pathlib.Path
|
| 25 |
+
av
|
| 26 |
+
cv2
|
| 27 |
+
mediapipe as mp
|
| 28 |
+
numpy as np
|
| 29 |
+
torch
|
| 30 |
+
torchvision
|
| 31 |
+
einops.rearrange
|
| 32 |
+
moviepy.editor.AudioFileClip, VideoClip
|
| 33 |
+
PIL.Image
|
| 34 |
+
|
| 35 |
+
Examples:
|
| 36 |
+
seed_everything(42)
|
| 37 |
+
imported_module = import_filename('path/to/your/module.py')
|
| 38 |
+
delete_additional_ckpt('path/to/checkpoints', 1)
|
| 39 |
+
save_videos_from_pil(pil_images, 'output/video.mp4', fps=12)
|
| 40 |
+
|
| 41 |
+
The functions in this module ensure reproducibility of experiments by seeding random number
|
| 42 |
+
generators, allow dynamic importing of modules, manage checkpoint files by deleting extra ones,
|
| 43 |
+
and provide a way to save sequences of images as video files.
|
| 44 |
+
|
| 45 |
+
Function Details:
|
| 46 |
+
seed_everything(seed)
|
| 47 |
+
Seeds all random number generators to ensure reproducibility.
|
| 48 |
+
|
| 49 |
+
import_filename(filename)
|
| 50 |
+
Imports a module from a given file location.
|
| 51 |
+
|
| 52 |
+
delete_additional_ckpt(base_path, num_keep)
|
| 53 |
+
Deletes additional checkpoint files in the given directory.
|
| 54 |
+
|
| 55 |
+
save_videos_from_pil(pil_images, path, fps=8)
|
| 56 |
+
Saves a sequence of images as a video using the Pillow library.
|
| 57 |
+
|
| 58 |
+
Attributes:
|
| 59 |
+
_ (str): Placeholder for static type checking
|
| 60 |
+
"""
|
| 61 |
+
|
| 62 |
+
import importlib
|
| 63 |
+
import os
|
| 64 |
+
import os.path as osp
|
| 65 |
+
import random
|
| 66 |
+
import shutil
|
| 67 |
+
import subprocess
|
| 68 |
+
import sys
|
| 69 |
+
from pathlib import Path
|
| 70 |
+
|
| 71 |
+
import av
|
| 72 |
+
import cv2
|
| 73 |
+
import mediapipe as mp
|
| 74 |
+
import numpy as np
|
| 75 |
+
import torch
|
| 76 |
+
import torchvision
|
| 77 |
+
from einops import rearrange
|
| 78 |
+
from moviepy.editor import AudioFileClip, VideoClip
|
| 79 |
+
from PIL import Image
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def seed_everything(seed):
|
| 83 |
+
"""
|
| 84 |
+
Seeds all random number generators to ensure reproducibility.
|
| 85 |
+
|
| 86 |
+
Args:
|
| 87 |
+
seed (int): The seed value to set for all random number generators.
|
| 88 |
+
"""
|
| 89 |
+
torch.manual_seed(seed)
|
| 90 |
+
torch.cuda.manual_seed_all(seed)
|
| 91 |
+
np.random.seed(seed % (2**32))
|
| 92 |
+
random.seed(seed)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def import_filename(filename):
|
| 96 |
+
"""
|
| 97 |
+
Import a module from a given file location.
|
| 98 |
+
|
| 99 |
+
Args:
|
| 100 |
+
filename (str): The path to the file containing the module to be imported.
|
| 101 |
+
|
| 102 |
+
Returns:
|
| 103 |
+
module: The imported module.
|
| 104 |
+
|
| 105 |
+
Raises:
|
| 106 |
+
ImportError: If the module cannot be imported.
|
| 107 |
+
|
| 108 |
+
Example:
|
| 109 |
+
>>> imported_module = import_filename('path/to/your/module.py')
|
| 110 |
+
"""
|
| 111 |
+
spec = importlib.util.spec_from_file_location("mymodule", filename)
|
| 112 |
+
module = importlib.util.module_from_spec(spec)
|
| 113 |
+
sys.modules[spec.name] = module
|
| 114 |
+
spec.loader.exec_module(module)
|
| 115 |
+
return module
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def delete_additional_ckpt(base_path, num_keep):
|
| 119 |
+
"""
|
| 120 |
+
Deletes additional checkpoint files in the given directory.
|
| 121 |
+
|
| 122 |
+
Args:
|
| 123 |
+
base_path (str): The path to the directory containing the checkpoint files.
|
| 124 |
+
num_keep (int): The number of most recent checkpoint files to keep.
|
| 125 |
+
|
| 126 |
+
Returns:
|
| 127 |
+
None
|
| 128 |
+
|
| 129 |
+
Raises:
|
| 130 |
+
FileNotFoundError: If the base_path does not exist.
|
| 131 |
+
|
| 132 |
+
Example:
|
| 133 |
+
>>> delete_additional_ckpt('path/to/checkpoints', 1)
|
| 134 |
+
# This will delete all but the most recent checkpoint file in 'path/to/checkpoints'.
|
| 135 |
+
"""
|
| 136 |
+
dirs = []
|
| 137 |
+
for d in os.listdir(base_path):
|
| 138 |
+
if d.startswith("checkpoint-"):
|
| 139 |
+
dirs.append(d)
|
| 140 |
+
num_tot = len(dirs)
|
| 141 |
+
if num_tot <= num_keep:
|
| 142 |
+
return
|
| 143 |
+
# ensure ckpt is sorted and delete the ealier!
|
| 144 |
+
del_dirs = sorted(dirs, key=lambda x: int(
|
| 145 |
+
x.split("-")[-1]))[: num_tot - num_keep]
|
| 146 |
+
for d in del_dirs:
|
| 147 |
+
path_to_dir = osp.join(base_path, d)
|
| 148 |
+
if osp.exists(path_to_dir):
|
| 149 |
+
shutil.rmtree(path_to_dir)
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def save_videos_from_pil(pil_images, path, fps=8):
|
| 153 |
+
"""
|
| 154 |
+
Save a sequence of images as a video using the Pillow library.
|
| 155 |
+
|
| 156 |
+
Args:
|
| 157 |
+
pil_images (List[PIL.Image]): A list of PIL.Image objects representing the frames of the video.
|
| 158 |
+
path (str): The output file path for the video.
|
| 159 |
+
fps (int, optional): The frames per second rate of the video. Defaults to 8.
|
| 160 |
+
|
| 161 |
+
Returns:
|
| 162 |
+
None
|
| 163 |
+
|
| 164 |
+
Raises:
|
| 165 |
+
ValueError: If the save format is not supported.
|
| 166 |
+
|
| 167 |
+
This function takes a list of PIL.Image objects and saves them as a video file with a specified frame rate.
|
| 168 |
+
The output file format is determined by the file extension of the provided path. Supported formats include
|
| 169 |
+
.mp4, .avi, and .mkv. The function uses the Pillow library to handle the image processing and video
|
| 170 |
+
creation.
|
| 171 |
+
"""
|
| 172 |
+
save_fmt = Path(path).suffix
|
| 173 |
+
os.makedirs(os.path.dirname(path), exist_ok=True)
|
| 174 |
+
width, height = pil_images[0].size
|
| 175 |
+
|
| 176 |
+
if save_fmt == ".mp4":
|
| 177 |
+
codec = "libx264"
|
| 178 |
+
container = av.open(path, "w")
|
| 179 |
+
stream = container.add_stream(codec, rate=fps)
|
| 180 |
+
|
| 181 |
+
stream.width = width
|
| 182 |
+
stream.height = height
|
| 183 |
+
|
| 184 |
+
for pil_image in pil_images:
|
| 185 |
+
# pil_image = Image.fromarray(image_arr).convert("RGB")
|
| 186 |
+
av_frame = av.VideoFrame.from_image(pil_image)
|
| 187 |
+
container.mux(stream.encode(av_frame))
|
| 188 |
+
container.mux(stream.encode())
|
| 189 |
+
container.close()
|
| 190 |
+
|
| 191 |
+
elif save_fmt == ".gif":
|
| 192 |
+
pil_images[0].save(
|
| 193 |
+
fp=path,
|
| 194 |
+
format="GIF",
|
| 195 |
+
append_images=pil_images[1:],
|
| 196 |
+
save_all=True,
|
| 197 |
+
duration=(1 / fps * 1000),
|
| 198 |
+
loop=0,
|
| 199 |
+
)
|
| 200 |
+
else:
|
| 201 |
+
raise ValueError("Unsupported file type. Use .mp4 or .gif.")
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
def save_videos_grid(videos: torch.Tensor, path: str, rescale=False, n_rows=6, fps=8):
|
| 205 |
+
"""
|
| 206 |
+
Save a grid of videos as an animation or video.
|
| 207 |
+
|
| 208 |
+
Args:
|
| 209 |
+
videos (torch.Tensor): A tensor of shape (batch_size, channels, time, height, width)
|
| 210 |
+
containing the videos to save.
|
| 211 |
+
path (str): The path to save the video grid. Supported formats are .mp4, .avi, and .gif.
|
| 212 |
+
rescale (bool, optional): If True, rescale the video to the original resolution.
|
| 213 |
+
Defaults to False.
|
| 214 |
+
n_rows (int, optional): The number of rows in the video grid. Defaults to 6.
|
| 215 |
+
fps (int, optional): The frame rate of the saved video. Defaults to 8.
|
| 216 |
+
|
| 217 |
+
Raises:
|
| 218 |
+
ValueError: If the video format is not supported.
|
| 219 |
+
|
| 220 |
+
Returns:
|
| 221 |
+
None
|
| 222 |
+
"""
|
| 223 |
+
videos = rearrange(videos, "b c t h w -> t b c h w")
|
| 224 |
+
# height, width = videos.shape[-2:]
|
| 225 |
+
outputs = []
|
| 226 |
+
|
| 227 |
+
for x in videos:
|
| 228 |
+
x = torchvision.utils.make_grid(x, nrow=n_rows) # (c h w)
|
| 229 |
+
x = x.transpose(0, 1).transpose(1, 2).squeeze(-1) # (h w c)
|
| 230 |
+
if rescale:
|
| 231 |
+
x = (x + 1.0) / 2.0 # -1,1 -> 0,1
|
| 232 |
+
x = (x * 255).numpy().astype(np.uint8)
|
| 233 |
+
x = Image.fromarray(x)
|
| 234 |
+
|
| 235 |
+
outputs.append(x)
|
| 236 |
+
|
| 237 |
+
os.makedirs(os.path.dirname(path), exist_ok=True)
|
| 238 |
+
|
| 239 |
+
save_videos_from_pil(outputs, path, fps)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
def read_frames(video_path):
|
| 243 |
+
"""
|
| 244 |
+
Reads video frames from a given video file.
|
| 245 |
+
|
| 246 |
+
Args:
|
| 247 |
+
video_path (str): The path to the video file.
|
| 248 |
+
|
| 249 |
+
Returns:
|
| 250 |
+
container (av.container.InputContainer): The input container object
|
| 251 |
+
containing the video stream.
|
| 252 |
+
|
| 253 |
+
Raises:
|
| 254 |
+
FileNotFoundError: If the video file is not found.
|
| 255 |
+
RuntimeError: If there is an error in reading the video stream.
|
| 256 |
+
|
| 257 |
+
The function reads the video frames from the specified video file using the
|
| 258 |
+
Python AV library (av). It returns an input container object that contains
|
| 259 |
+
the video stream. If the video file is not found, it raises a FileNotFoundError,
|
| 260 |
+
and if there is an error in reading the video stream, it raises a RuntimeError.
|
| 261 |
+
"""
|
| 262 |
+
container = av.open(video_path)
|
| 263 |
+
|
| 264 |
+
video_stream = next(s for s in container.streams if s.type == "video")
|
| 265 |
+
frames = []
|
| 266 |
+
for packet in container.demux(video_stream):
|
| 267 |
+
for frame in packet.decode():
|
| 268 |
+
image = Image.frombytes(
|
| 269 |
+
"RGB",
|
| 270 |
+
(frame.width, frame.height),
|
| 271 |
+
frame.to_rgb().to_ndarray(),
|
| 272 |
+
)
|
| 273 |
+
frames.append(image)
|
| 274 |
+
|
| 275 |
+
return frames
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
def get_fps(video_path):
|
| 279 |
+
"""
|
| 280 |
+
Get the frame rate (FPS) of a video file.
|
| 281 |
+
|
| 282 |
+
Args:
|
| 283 |
+
video_path (str): The path to the video file.
|
| 284 |
+
|
| 285 |
+
Returns:
|
| 286 |
+
int: The frame rate (FPS) of the video file.
|
| 287 |
+
"""
|
| 288 |
+
container = av.open(video_path)
|
| 289 |
+
video_stream = next(s for s in container.streams if s.type == "video")
|
| 290 |
+
fps = video_stream.average_rate
|
| 291 |
+
container.close()
|
| 292 |
+
return fps
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
def tensor_to_video(tensor, output_video_file, audio_source, fps=25):
|
| 296 |
+
"""
|
| 297 |
+
Converts a Tensor with shape [c, f, h, w] into a video and adds an audio track from the specified audio file.
|
| 298 |
+
|
| 299 |
+
Args:
|
| 300 |
+
tensor (Tensor): The Tensor to be converted, shaped [c, f, h, w].
|
| 301 |
+
output_video_file (str): The file path where the output video will be saved.
|
| 302 |
+
audio_source (str): The path to the audio file (WAV file) that contains the audio track to be added.
|
| 303 |
+
fps (int): The frame rate of the output video. Default is 25 fps.
|
| 304 |
+
"""
|
| 305 |
+
tensor = tensor.permute(1, 2, 3, 0).cpu(
|
| 306 |
+
).numpy() # convert to [f, h, w, c]
|
| 307 |
+
tensor = np.clip(tensor * 255, 0, 255).astype(
|
| 308 |
+
np.uint8
|
| 309 |
+
) # to [0, 255]
|
| 310 |
+
|
| 311 |
+
def make_frame(t):
|
| 312 |
+
# get index
|
| 313 |
+
frame_index = min(int(t * fps), tensor.shape[0] - 1)
|
| 314 |
+
return tensor[frame_index]
|
| 315 |
+
new_video_clip = VideoClip(make_frame, duration=tensor.shape[0] / fps)
|
| 316 |
+
audio_clip = AudioFileClip(audio_source).subclip(0, tensor.shape[0] / fps)
|
| 317 |
+
new_video_clip = new_video_clip.set_audio(audio_clip)
|
| 318 |
+
new_video_clip.write_videofile(output_video_file, fps=fps)
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
silhouette_ids = [
|
| 322 |
+
10, 338, 297, 332, 284, 251, 389, 356, 454, 323, 361, 288,
|
| 323 |
+
397, 365, 379, 378, 400, 377, 152, 148, 176, 149, 150, 136,
|
| 324 |
+
172, 58, 132, 93, 234, 127, 162, 21, 54, 103, 67, 109
|
| 325 |
+
]
|
| 326 |
+
lip_ids = [61, 185, 40, 39, 37, 0, 267, 269, 270, 409, 291,
|
| 327 |
+
146, 91, 181, 84, 17, 314, 405, 321, 375]
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
def compute_face_landmarks(detection_result, h, w):
|
| 331 |
+
"""
|
| 332 |
+
Compute face landmarks from a detection result.
|
| 333 |
+
|
| 334 |
+
Args:
|
| 335 |
+
detection_result (mediapipe.solutions.face_mesh.FaceMesh): The detection result containing face landmarks.
|
| 336 |
+
h (int): The height of the video frame.
|
| 337 |
+
w (int): The width of the video frame.
|
| 338 |
+
|
| 339 |
+
Returns:
|
| 340 |
+
face_landmarks_list (list): A list of face landmarks.
|
| 341 |
+
"""
|
| 342 |
+
face_landmarks_list = detection_result.face_landmarks
|
| 343 |
+
if len(face_landmarks_list) != 1:
|
| 344 |
+
print("#face is invalid:", len(face_landmarks_list))
|
| 345 |
+
return []
|
| 346 |
+
return [[p.x * w, p.y * h] for p in face_landmarks_list[0]]
|
| 347 |
+
|
| 348 |
+
|
| 349 |
+
def get_landmark(file):
|
| 350 |
+
"""
|
| 351 |
+
This function takes a file as input and returns the facial landmarks detected in the file.
|
| 352 |
+
|
| 353 |
+
Args:
|
| 354 |
+
file (str): The path to the file containing the video or image to be processed.
|
| 355 |
+
|
| 356 |
+
Returns:
|
| 357 |
+
Tuple[List[float], List[float]]: A tuple containing two lists of floats representing the x and y coordinates of the facial landmarks.
|
| 358 |
+
"""
|
| 359 |
+
model_path = "pretrained_models/face_analysis/models/face_landmarker_v2_with_blendshapes.task"
|
| 360 |
+
BaseOptions = mp.tasks.BaseOptions
|
| 361 |
+
FaceLandmarker = mp.tasks.vision.FaceLandmarker
|
| 362 |
+
FaceLandmarkerOptions = mp.tasks.vision.FaceLandmarkerOptions
|
| 363 |
+
VisionRunningMode = mp.tasks.vision.RunningMode
|
| 364 |
+
# Create a face landmarker instance with the video mode:
|
| 365 |
+
options = FaceLandmarkerOptions(
|
| 366 |
+
base_options=BaseOptions(model_asset_path=model_path),
|
| 367 |
+
running_mode=VisionRunningMode.IMAGE,
|
| 368 |
+
)
|
| 369 |
+
|
| 370 |
+
with FaceLandmarker.create_from_options(options) as landmarker:
|
| 371 |
+
image = mp.Image.create_from_file(str(file))
|
| 372 |
+
height, width = image.height, image.width
|
| 373 |
+
face_landmarker_result = landmarker.detect(image)
|
| 374 |
+
face_landmark = compute_face_landmarks(
|
| 375 |
+
face_landmarker_result, height, width)
|
| 376 |
+
|
| 377 |
+
return np.array(face_landmark), height, width
|
| 378 |
+
|
| 379 |
+
|
| 380 |
+
def get_lip_mask(landmarks, height, width, out_path):
|
| 381 |
+
"""
|
| 382 |
+
Extracts the lip region from the given landmarks and saves it as an image.
|
| 383 |
+
|
| 384 |
+
Parameters:
|
| 385 |
+
landmarks (numpy.ndarray): Array of facial landmarks.
|
| 386 |
+
height (int): Height of the output lip mask image.
|
| 387 |
+
width (int): Width of the output lip mask image.
|
| 388 |
+
out_path (pathlib.Path): Path to save the lip mask image.
|
| 389 |
+
"""
|
| 390 |
+
lip_landmarks = np.take(landmarks, lip_ids, 0)
|
| 391 |
+
min_xy_lip = np.round(np.min(lip_landmarks, 0))
|
| 392 |
+
max_xy_lip = np.round(np.max(lip_landmarks, 0))
|
| 393 |
+
min_xy_lip[0], max_xy_lip[0], min_xy_lip[1], max_xy_lip[1] = expand_region(
|
| 394 |
+
[min_xy_lip[0], max_xy_lip[0], min_xy_lip[1], max_xy_lip[1]], width, height, 2.0)
|
| 395 |
+
lip_mask = np.zeros((height, width), dtype=np.uint8)
|
| 396 |
+
lip_mask[round(min_xy_lip[1]):round(max_xy_lip[1]),
|
| 397 |
+
round(min_xy_lip[0]):round(max_xy_lip[0])] = 255
|
| 398 |
+
cv2.imwrite(str(out_path), lip_mask)
|
| 399 |
+
|
| 400 |
+
|
| 401 |
+
def get_face_mask(landmarks, height, width, out_path, expand_ratio):
|
| 402 |
+
"""
|
| 403 |
+
Generate a face mask based on the given landmarks.
|
| 404 |
+
|
| 405 |
+
Args:
|
| 406 |
+
landmarks (numpy.ndarray): The landmarks of the face.
|
| 407 |
+
height (int): The height of the output face mask image.
|
| 408 |
+
width (int): The width of the output face mask image.
|
| 409 |
+
out_path (pathlib.Path): The path to save the face mask image.
|
| 410 |
+
|
| 411 |
+
Returns:
|
| 412 |
+
None. The face mask image is saved at the specified path.
|
| 413 |
+
"""
|
| 414 |
+
face_landmarks = np.take(landmarks, silhouette_ids, 0)
|
| 415 |
+
min_xy_face = np.round(np.min(face_landmarks, 0))
|
| 416 |
+
max_xy_face = np.round(np.max(face_landmarks, 0))
|
| 417 |
+
min_xy_face[0], max_xy_face[0], min_xy_face[1], max_xy_face[1] = expand_region(
|
| 418 |
+
[min_xy_face[0], max_xy_face[0], min_xy_face[1], max_xy_face[1]], width, height, expand_ratio)
|
| 419 |
+
face_mask = np.zeros((height, width), dtype=np.uint8)
|
| 420 |
+
face_mask[round(min_xy_face[1]):round(max_xy_face[1]),
|
| 421 |
+
round(min_xy_face[0]):round(max_xy_face[0])] = 255
|
| 422 |
+
cv2.imwrite(str(out_path), face_mask)
|
| 423 |
+
|
| 424 |
+
|
| 425 |
+
def get_mask(file, cache_dir, face_expand_raio):
|
| 426 |
+
"""
|
| 427 |
+
Generate a face mask based on the given landmarks and save it to the specified cache directory.
|
| 428 |
+
|
| 429 |
+
Args:
|
| 430 |
+
file (str): The path to the file containing the landmarks.
|
| 431 |
+
cache_dir (str): The directory to save the generated face mask.
|
| 432 |
+
|
| 433 |
+
Returns:
|
| 434 |
+
None
|
| 435 |
+
"""
|
| 436 |
+
landmarks, height, width = get_landmark(file)
|
| 437 |
+
file_name = os.path.basename(file).split(".")[0]
|
| 438 |
+
get_lip_mask(landmarks, height, width, os.path.join(
|
| 439 |
+
cache_dir, f"{file_name}_lip_mask.png"))
|
| 440 |
+
get_face_mask(landmarks, height, width, os.path.join(
|
| 441 |
+
cache_dir, f"{file_name}_face_mask.png"), face_expand_raio)
|
| 442 |
+
get_blur_mask(os.path.join(
|
| 443 |
+
cache_dir, f"{file_name}_face_mask.png"), os.path.join(
|
| 444 |
+
cache_dir, f"{file_name}_face_mask_blur.png"), kernel_size=(51, 51))
|
| 445 |
+
get_blur_mask(os.path.join(
|
| 446 |
+
cache_dir, f"{file_name}_lip_mask.png"), os.path.join(
|
| 447 |
+
cache_dir, f"{file_name}_sep_lip.png"), kernel_size=(31, 31))
|
| 448 |
+
get_background_mask(os.path.join(
|
| 449 |
+
cache_dir, f"{file_name}_face_mask_blur.png"), os.path.join(
|
| 450 |
+
cache_dir, f"{file_name}_sep_background.png"))
|
| 451 |
+
get_sep_face_mask(os.path.join(
|
| 452 |
+
cache_dir, f"{file_name}_face_mask_blur.png"), os.path.join(
|
| 453 |
+
cache_dir, f"{file_name}_sep_lip.png"), os.path.join(
|
| 454 |
+
cache_dir, f"{file_name}_sep_face.png"))
|
| 455 |
+
|
| 456 |
+
|
| 457 |
+
def expand_region(region, image_w, image_h, expand_ratio=1.0):
|
| 458 |
+
"""
|
| 459 |
+
Expand the given region by a specified ratio.
|
| 460 |
+
Args:
|
| 461 |
+
region (tuple): A tuple containing the coordinates (min_x, max_x, min_y, max_y) of the region.
|
| 462 |
+
image_w (int): The width of the image.
|
| 463 |
+
image_h (int): The height of the image.
|
| 464 |
+
expand_ratio (float, optional): The ratio by which the region should be expanded. Defaults to 1.0.
|
| 465 |
+
|
| 466 |
+
Returns:
|
| 467 |
+
tuple: A tuple containing the expanded coordinates (min_x, max_x, min_y, max_y) of the region.
|
| 468 |
+
"""
|
| 469 |
+
|
| 470 |
+
min_x, max_x, min_y, max_y = region
|
| 471 |
+
mid_x = (max_x + min_x) // 2
|
| 472 |
+
side_len_x = (max_x - min_x) * expand_ratio
|
| 473 |
+
mid_y = (max_y + min_y) // 2
|
| 474 |
+
side_len_y = (max_y - min_y) * expand_ratio
|
| 475 |
+
min_x = mid_x - side_len_x // 2
|
| 476 |
+
max_x = mid_x + side_len_x // 2
|
| 477 |
+
min_y = mid_y - side_len_y // 2
|
| 478 |
+
max_y = mid_y + side_len_y // 2
|
| 479 |
+
if min_x < 0:
|
| 480 |
+
max_x -= min_x
|
| 481 |
+
min_x = 0
|
| 482 |
+
if max_x > image_w:
|
| 483 |
+
min_x -= max_x - image_w
|
| 484 |
+
max_x = image_w
|
| 485 |
+
if min_y < 0:
|
| 486 |
+
max_y -= min_y
|
| 487 |
+
min_y = 0
|
| 488 |
+
if max_y > image_h:
|
| 489 |
+
min_y -= max_y - image_h
|
| 490 |
+
max_y = image_h
|
| 491 |
+
|
| 492 |
+
return round(min_x), round(max_x), round(min_y), round(max_y)
|
| 493 |
+
|
| 494 |
+
|
| 495 |
+
def get_blur_mask(file_path, output_file_path, resize_dim=(64, 64), kernel_size=(101, 101)):
|
| 496 |
+
"""
|
| 497 |
+
Read, resize, blur, normalize, and save an image.
|
| 498 |
+
|
| 499 |
+
Parameters:
|
| 500 |
+
file_path (str): Path to the input image file.
|
| 501 |
+
output_dir (str): Path to the output directory to save blurred images.
|
| 502 |
+
resize_dim (tuple): Dimensions to resize the images to.
|
| 503 |
+
kernel_size (tuple): Size of the kernel to use for Gaussian blur.
|
| 504 |
+
"""
|
| 505 |
+
# Read the mask image
|
| 506 |
+
mask = cv2.imread(file_path, cv2.IMREAD_GRAYSCALE)
|
| 507 |
+
|
| 508 |
+
# Check if the image is loaded successfully
|
| 509 |
+
if mask is not None:
|
| 510 |
+
# Resize the mask image
|
| 511 |
+
resized_mask = cv2.resize(mask, resize_dim)
|
| 512 |
+
# Apply Gaussian blur to the resized mask image
|
| 513 |
+
blurred_mask = cv2.GaussianBlur(resized_mask, kernel_size, 0)
|
| 514 |
+
# Normalize the blurred image
|
| 515 |
+
normalized_mask = cv2.normalize(
|
| 516 |
+
blurred_mask, None, 0, 255, cv2.NORM_MINMAX)
|
| 517 |
+
# Save the normalized mask image
|
| 518 |
+
cv2.imwrite(output_file_path, normalized_mask)
|
| 519 |
+
return f"Processed, normalized, and saved: {output_file_path}"
|
| 520 |
+
return f"Failed to load image: {file_path}"
|
| 521 |
+
|
| 522 |
+
|
| 523 |
+
def get_background_mask(file_path, output_file_path):
|
| 524 |
+
"""
|
| 525 |
+
Read an image, invert its values, and save the result.
|
| 526 |
+
|
| 527 |
+
Parameters:
|
| 528 |
+
file_path (str): Path to the input image file.
|
| 529 |
+
output_dir (str): Path to the output directory to save the inverted image.
|
| 530 |
+
"""
|
| 531 |
+
# Read the image
|
| 532 |
+
image = cv2.imread(file_path, cv2.IMREAD_GRAYSCALE)
|
| 533 |
+
|
| 534 |
+
if image is None:
|
| 535 |
+
print(f"Failed to load image: {file_path}")
|
| 536 |
+
return
|
| 537 |
+
|
| 538 |
+
# Invert the image
|
| 539 |
+
inverted_image = 1.0 - (
|
| 540 |
+
image / 255.0
|
| 541 |
+
) # Assuming the image values are in [0, 255] range
|
| 542 |
+
# Convert back to uint8
|
| 543 |
+
inverted_image = (inverted_image * 255).astype(np.uint8)
|
| 544 |
+
|
| 545 |
+
# Save the inverted image
|
| 546 |
+
cv2.imwrite(output_file_path, inverted_image)
|
| 547 |
+
print(f"Processed and saved: {output_file_path}")
|
| 548 |
+
|
| 549 |
+
|
| 550 |
+
def get_sep_face_mask(file_path1, file_path2, output_file_path):
|
| 551 |
+
"""
|
| 552 |
+
Read two images, subtract the second one from the first, and save the result.
|
| 553 |
+
|
| 554 |
+
Parameters:
|
| 555 |
+
output_dir (str): Path to the output directory to save the subtracted image.
|
| 556 |
+
"""
|
| 557 |
+
|
| 558 |
+
# Read the images
|
| 559 |
+
mask1 = cv2.imread(file_path1, cv2.IMREAD_GRAYSCALE)
|
| 560 |
+
mask2 = cv2.imread(file_path2, cv2.IMREAD_GRAYSCALE)
|
| 561 |
+
|
| 562 |
+
if mask1 is None or mask2 is None:
|
| 563 |
+
print(f"Failed to load images: {file_path1}")
|
| 564 |
+
return
|
| 565 |
+
|
| 566 |
+
# Ensure the images are the same size
|
| 567 |
+
if mask1.shape != mask2.shape:
|
| 568 |
+
print(
|
| 569 |
+
f"Image shapes do not match for {file_path1}: {mask1.shape} vs {mask2.shape}"
|
| 570 |
+
)
|
| 571 |
+
return
|
| 572 |
+
|
| 573 |
+
# Subtract the second mask from the first
|
| 574 |
+
result_mask = cv2.subtract(mask1, mask2)
|
| 575 |
+
|
| 576 |
+
# Save the result mask image
|
| 577 |
+
cv2.imwrite(output_file_path, result_mask)
|
| 578 |
+
print(f"Processed and saved: {output_file_path}")
|
| 579 |
+
|
| 580 |
+
def resample_audio(input_audio_file: str, output_audio_file: str, sample_rate: int):
|
| 581 |
+
p = subprocess.Popen([
|
| 582 |
+
"ffmpeg", "-y", "-v", "error", "-i", input_audio_file, "-ar", str(sample_rate), output_audio_file
|
| 583 |
+
])
|
| 584 |
+
ret = p.wait()
|
| 585 |
+
assert ret == 0, "Resample audio failed!"
|
| 586 |
+
return output_audio_file
|
| 587 |
+
|
| 588 |
+
def get_face_region(image_path: str, detector):
|
| 589 |
+
try:
|
| 590 |
+
image = cv2.imread(image_path)
|
| 591 |
+
if image is None:
|
| 592 |
+
print(f"Failed to open image: {image_path}. Skipping...")
|
| 593 |
+
return None, None
|
| 594 |
+
|
| 595 |
+
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=image)
|
| 596 |
+
detection_result = detector.detect(mp_image)
|
| 597 |
+
|
| 598 |
+
# Adjust mask creation for the three-channel image
|
| 599 |
+
mask = np.zeros_like(image, dtype=np.uint8)
|
| 600 |
+
|
| 601 |
+
for detection in detection_result.detections:
|
| 602 |
+
bbox = detection.bounding_box
|
| 603 |
+
start_point = (int(bbox.origin_x), int(bbox.origin_y))
|
| 604 |
+
end_point = (int(bbox.origin_x + bbox.width),
|
| 605 |
+
int(bbox.origin_y + bbox.height))
|
| 606 |
+
cv2.rectangle(mask, start_point, end_point,
|
| 607 |
+
(255, 255, 255), thickness=-1)
|
| 608 |
+
|
| 609 |
+
save_path = image_path.replace("images", "face_masks")
|
| 610 |
+
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
| 611 |
+
cv2.imwrite(save_path, mask)
|
| 612 |
+
# print(f"Processed and saved {save_path}")
|
| 613 |
+
return image_path, mask
|
| 614 |
+
except Exception as e:
|
| 615 |
+
print(f"Error processing image {image_path}: {e}")
|
| 616 |
+
return None, None
|
requirements.txt
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate==0.28.0
|
| 2 |
+
audio-separator==0.17.2
|
| 3 |
+
av==12.1.0
|
| 4 |
+
bitsandbytes==0.43.1
|
| 5 |
+
decord==0.6.0
|
| 6 |
+
diffusers==0.27.2
|
| 7 |
+
einops==0.8.0
|
| 8 |
+
insightface==0.7.3
|
| 9 |
+
librosa==0.10.2.post1
|
| 10 |
+
mediapipe[vision]==0.10.14
|
| 11 |
+
mlflow==2.13.1
|
| 12 |
+
moviepy==1.0.3
|
| 13 |
+
numpy==1.26.4
|
| 14 |
+
omegaconf==2.3.0
|
| 15 |
+
onnx2torch==1.5.14
|
| 16 |
+
onnx==1.16.1
|
| 17 |
+
onnxruntime==1.18.0
|
| 18 |
+
opencv-contrib-python==4.9.0.80
|
| 19 |
+
opencv-python-headless==4.9.0.80
|
| 20 |
+
opencv-python==4.9.0.80
|
| 21 |
+
pillow==10.3.0
|
| 22 |
+
setuptools==70.0.0
|
| 23 |
+
torch==2.2.2
|
| 24 |
+
torchvision==0.17.2
|
| 25 |
+
tqdm==4.66.4
|
| 26 |
+
transformers==4.39.2
|
| 27 |
+
xformers==0.0.25.post1
|
| 28 |
+
isort==5.13.2
|
| 29 |
+
pylint==3.2.2
|
| 30 |
+
pre-commit==3.7.1
|
scripts/inference.py
ADDED
|
@@ -0,0 +1,372 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# pylint: disable=E1101
|
| 2 |
+
# scripts/inference.py
|
| 3 |
+
|
| 4 |
+
"""
|
| 5 |
+
This script contains the main inference pipeline for processing audio and image inputs to generate a video output.
|
| 6 |
+
|
| 7 |
+
The script imports necessary packages and classes, defines a neural network model,
|
| 8 |
+
and contains functions for processing audio embeddings and performing inference.
|
| 9 |
+
|
| 10 |
+
The main inference process is outlined in the following steps:
|
| 11 |
+
1. Initialize the configuration.
|
| 12 |
+
2. Set up runtime variables.
|
| 13 |
+
3. Prepare the input data for inference (source image, face mask, and face embeddings).
|
| 14 |
+
4. Process the audio embeddings.
|
| 15 |
+
5. Build and freeze the model and scheduler.
|
| 16 |
+
6. Run the inference loop and save the result.
|
| 17 |
+
|
| 18 |
+
Usage:
|
| 19 |
+
This script can be run from the command line with the following arguments:
|
| 20 |
+
- audio_path: Path to the audio file.
|
| 21 |
+
- image_path: Path to the source image.
|
| 22 |
+
- face_mask_path: Path to the face mask image.
|
| 23 |
+
- face_emb_path: Path to the face embeddings file.
|
| 24 |
+
- output_path: Path to save the output video.
|
| 25 |
+
|
| 26 |
+
Example:
|
| 27 |
+
python scripts/inference.py --audio_path audio.wav --image_path image.jpg
|
| 28 |
+
--face_mask_path face_mask.png --face_emb_path face_emb.pt --output_path output.mp4
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
import argparse
|
| 32 |
+
import os
|
| 33 |
+
|
| 34 |
+
import torch
|
| 35 |
+
from diffusers import AutoencoderKL, DDIMScheduler
|
| 36 |
+
from omegaconf import OmegaConf
|
| 37 |
+
from torch import nn
|
| 38 |
+
|
| 39 |
+
from hallo.animate.face_animate import FaceAnimatePipeline
|
| 40 |
+
from hallo.datasets.audio_processor import AudioProcessor
|
| 41 |
+
from hallo.datasets.image_processor import ImageProcessor
|
| 42 |
+
from hallo.models.audio_proj import AudioProjModel
|
| 43 |
+
from hallo.models.face_locator import FaceLocator
|
| 44 |
+
from hallo.models.image_proj import ImageProjModel
|
| 45 |
+
from hallo.models.unet_2d_condition import UNet2DConditionModel
|
| 46 |
+
from hallo.models.unet_3d import UNet3DConditionModel
|
| 47 |
+
from hallo.utils.util import tensor_to_video
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class Net(nn.Module):
|
| 51 |
+
"""
|
| 52 |
+
The Net class combines all the necessary modules for the inference process.
|
| 53 |
+
|
| 54 |
+
Args:
|
| 55 |
+
reference_unet (UNet2DConditionModel): The UNet2DConditionModel used as a reference for inference.
|
| 56 |
+
denoising_unet (UNet3DConditionModel): The UNet3DConditionModel used for denoising the input audio.
|
| 57 |
+
face_locator (FaceLocator): The FaceLocator model used to locate the face in the input image.
|
| 58 |
+
imageproj (nn.Module): The ImageProjector model used to project the source image onto the face.
|
| 59 |
+
audioproj (nn.Module): The AudioProjector model used to project the audio embeddings onto the face.
|
| 60 |
+
"""
|
| 61 |
+
def __init__(
|
| 62 |
+
self,
|
| 63 |
+
reference_unet: UNet2DConditionModel,
|
| 64 |
+
denoising_unet: UNet3DConditionModel,
|
| 65 |
+
face_locator: FaceLocator,
|
| 66 |
+
imageproj,
|
| 67 |
+
audioproj,
|
| 68 |
+
):
|
| 69 |
+
super().__init__()
|
| 70 |
+
self.reference_unet = reference_unet
|
| 71 |
+
self.denoising_unet = denoising_unet
|
| 72 |
+
self.face_locator = face_locator
|
| 73 |
+
self.imageproj = imageproj
|
| 74 |
+
self.audioproj = audioproj
|
| 75 |
+
|
| 76 |
+
def forward(self,):
|
| 77 |
+
"""
|
| 78 |
+
empty function to override abstract function of nn Module
|
| 79 |
+
"""
|
| 80 |
+
|
| 81 |
+
def get_modules(self):
|
| 82 |
+
"""
|
| 83 |
+
Simple method to avoid too-few-public-methods pylint error
|
| 84 |
+
"""
|
| 85 |
+
return {
|
| 86 |
+
"reference_unet": self.reference_unet,
|
| 87 |
+
"denoising_unet": self.denoising_unet,
|
| 88 |
+
"face_locator": self.face_locator,
|
| 89 |
+
"imageproj": self.imageproj,
|
| 90 |
+
"audioproj": self.audioproj,
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def process_audio_emb(audio_emb):
|
| 95 |
+
"""
|
| 96 |
+
Process the audio embedding to concatenate with other tensors.
|
| 97 |
+
|
| 98 |
+
Parameters:
|
| 99 |
+
audio_emb (torch.Tensor): The audio embedding tensor to process.
|
| 100 |
+
|
| 101 |
+
Returns:
|
| 102 |
+
concatenated_tensors (List[torch.Tensor]): The concatenated tensor list.
|
| 103 |
+
"""
|
| 104 |
+
concatenated_tensors = []
|
| 105 |
+
|
| 106 |
+
for i in range(audio_emb.shape[0]):
|
| 107 |
+
vectors_to_concat = [
|
| 108 |
+
audio_emb[max(min(i + j, audio_emb.shape[0]-1), 0)]for j in range(-2, 3)]
|
| 109 |
+
concatenated_tensors.append(torch.stack(vectors_to_concat, dim=0))
|
| 110 |
+
|
| 111 |
+
audio_emb = torch.stack(concatenated_tensors, dim=0)
|
| 112 |
+
|
| 113 |
+
return audio_emb
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def inference_process(args: argparse.Namespace):
|
| 118 |
+
"""
|
| 119 |
+
Perform inference processing.
|
| 120 |
+
|
| 121 |
+
Args:
|
| 122 |
+
args (argparse.Namespace): Command-line arguments.
|
| 123 |
+
|
| 124 |
+
This function initializes the configuration for the inference process. It sets up the necessary
|
| 125 |
+
modules and variables to prepare for the upcoming inference steps.
|
| 126 |
+
"""
|
| 127 |
+
# 1. init config
|
| 128 |
+
config = OmegaConf.load(args.config)
|
| 129 |
+
config = OmegaConf.merge(config, vars(args))
|
| 130 |
+
source_image_path = config.source_image
|
| 131 |
+
driving_audio_path = config.driving_audio
|
| 132 |
+
save_path = config.save_path
|
| 133 |
+
if not os.path.exists(save_path):
|
| 134 |
+
os.makedirs(save_path)
|
| 135 |
+
motion_scale = [config.pose_weight, config.face_weight, config.lip_weight]
|
| 136 |
+
if args.checkpoint is not None:
|
| 137 |
+
config.audio_ckpt_dir = args.checkpoint
|
| 138 |
+
# 2. runtime variables
|
| 139 |
+
device = torch.device(
|
| 140 |
+
"cuda") if torch.cuda.is_available() else torch.device("cpu")
|
| 141 |
+
if config.weight_dtype == "fp16":
|
| 142 |
+
weight_dtype = torch.float16
|
| 143 |
+
elif config.weight_dtype == "bf16":
|
| 144 |
+
weight_dtype = torch.bfloat16
|
| 145 |
+
elif config.weight_dtype == "fp32":
|
| 146 |
+
weight_dtype = torch.float32
|
| 147 |
+
else:
|
| 148 |
+
weight_dtype = torch.float32
|
| 149 |
+
|
| 150 |
+
# 3. prepare inference data
|
| 151 |
+
# 3.1 prepare source image, face mask, face embeddings
|
| 152 |
+
img_size = (config.data.source_image.width,
|
| 153 |
+
config.data.source_image.height)
|
| 154 |
+
clip_length = config.data.n_sample_frames
|
| 155 |
+
face_analysis_model_path = config.face_analysis.model_path
|
| 156 |
+
with ImageProcessor(img_size, face_analysis_model_path) as image_processor:
|
| 157 |
+
source_image_pixels, \
|
| 158 |
+
source_image_face_region, \
|
| 159 |
+
source_image_face_emb, \
|
| 160 |
+
source_image_full_mask, \
|
| 161 |
+
source_image_face_mask, \
|
| 162 |
+
source_image_lip_mask = image_processor.preprocess(
|
| 163 |
+
source_image_path, save_path, config.face_expand_ratio)
|
| 164 |
+
|
| 165 |
+
# 3.2 prepare audio embeddings
|
| 166 |
+
sample_rate = config.data.driving_audio.sample_rate
|
| 167 |
+
assert sample_rate == 16000, "audio sample rate must be 16000"
|
| 168 |
+
fps = config.data.export_video.fps
|
| 169 |
+
wav2vec_model_path = config.wav2vec.model_path
|
| 170 |
+
wav2vec_only_last_features = config.wav2vec.features == "last"
|
| 171 |
+
audio_separator_model_file = config.audio_separator.model_path
|
| 172 |
+
with AudioProcessor(
|
| 173 |
+
sample_rate,
|
| 174 |
+
fps,
|
| 175 |
+
wav2vec_model_path,
|
| 176 |
+
wav2vec_only_last_features,
|
| 177 |
+
os.path.dirname(audio_separator_model_file),
|
| 178 |
+
os.path.basename(audio_separator_model_file),
|
| 179 |
+
os.path.join(save_path, "audio_preprocess")
|
| 180 |
+
) as audio_processor:
|
| 181 |
+
audio_emb = audio_processor.preprocess(driving_audio_path)
|
| 182 |
+
|
| 183 |
+
# 4. build modules
|
| 184 |
+
sched_kwargs = OmegaConf.to_container(config.noise_scheduler_kwargs)
|
| 185 |
+
if config.enable_zero_snr:
|
| 186 |
+
sched_kwargs.update(
|
| 187 |
+
rescale_betas_zero_snr=True,
|
| 188 |
+
timestep_spacing="trailing",
|
| 189 |
+
prediction_type="v_prediction",
|
| 190 |
+
)
|
| 191 |
+
val_noise_scheduler = DDIMScheduler(**sched_kwargs)
|
| 192 |
+
sched_kwargs.update({"beta_schedule": "scaled_linear"})
|
| 193 |
+
|
| 194 |
+
vae = AutoencoderKL.from_pretrained(config.vae.model_path)
|
| 195 |
+
reference_unet = UNet2DConditionModel.from_pretrained(
|
| 196 |
+
config.base_model_path, subfolder="unet")
|
| 197 |
+
denoising_unet = UNet3DConditionModel.from_pretrained_2d(
|
| 198 |
+
config.base_model_path,
|
| 199 |
+
config.motion_module_path,
|
| 200 |
+
subfolder="unet",
|
| 201 |
+
unet_additional_kwargs=OmegaConf.to_container(
|
| 202 |
+
config.unet_additional_kwargs),
|
| 203 |
+
use_landmark=False,
|
| 204 |
+
)
|
| 205 |
+
face_locator = FaceLocator(conditioning_embedding_channels=320)
|
| 206 |
+
image_proj = ImageProjModel(
|
| 207 |
+
cross_attention_dim=denoising_unet.config.cross_attention_dim,
|
| 208 |
+
clip_embeddings_dim=512,
|
| 209 |
+
clip_extra_context_tokens=4,
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
audio_proj = AudioProjModel(
|
| 213 |
+
seq_len=5,
|
| 214 |
+
blocks=12, # use 12 layers' hidden states of wav2vec
|
| 215 |
+
channels=768, # audio embedding channel
|
| 216 |
+
intermediate_dim=512,
|
| 217 |
+
output_dim=768,
|
| 218 |
+
context_tokens=32,
|
| 219 |
+
).to(device=device, dtype=weight_dtype)
|
| 220 |
+
|
| 221 |
+
audio_ckpt_dir = config.audio_ckpt_dir
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
# Freeze
|
| 225 |
+
vae.requires_grad_(False)
|
| 226 |
+
image_proj.requires_grad_(False)
|
| 227 |
+
reference_unet.requires_grad_(False)
|
| 228 |
+
denoising_unet.requires_grad_(False)
|
| 229 |
+
face_locator.requires_grad_(False)
|
| 230 |
+
audio_proj.requires_grad_(False)
|
| 231 |
+
|
| 232 |
+
reference_unet.enable_gradient_checkpointing()
|
| 233 |
+
denoising_unet.enable_gradient_checkpointing()
|
| 234 |
+
|
| 235 |
+
net = Net(
|
| 236 |
+
reference_unet,
|
| 237 |
+
denoising_unet,
|
| 238 |
+
face_locator,
|
| 239 |
+
image_proj,
|
| 240 |
+
audio_proj,
|
| 241 |
+
)
|
| 242 |
+
|
| 243 |
+
m,u = net.load_state_dict(
|
| 244 |
+
torch.load(
|
| 245 |
+
os.path.join(audio_ckpt_dir, "net.pth"),
|
| 246 |
+
map_location="cpu",
|
| 247 |
+
),
|
| 248 |
+
)
|
| 249 |
+
assert len(m) == 0 and len(u) == 0, "Fail to load correct checkpoint."
|
| 250 |
+
print("loaded weight from ", os.path.join(audio_ckpt_dir, "net.pth"))
|
| 251 |
+
|
| 252 |
+
# 5. inference
|
| 253 |
+
pipeline = FaceAnimatePipeline(
|
| 254 |
+
vae=vae,
|
| 255 |
+
reference_unet=net.reference_unet,
|
| 256 |
+
denoising_unet=net.denoising_unet,
|
| 257 |
+
face_locator=net.face_locator,
|
| 258 |
+
scheduler=val_noise_scheduler,
|
| 259 |
+
image_proj=net.imageproj,
|
| 260 |
+
)
|
| 261 |
+
pipeline.to(device=device, dtype=weight_dtype)
|
| 262 |
+
|
| 263 |
+
audio_emb = process_audio_emb(audio_emb)
|
| 264 |
+
|
| 265 |
+
source_image_pixels = source_image_pixels.unsqueeze(0)
|
| 266 |
+
source_image_face_region = source_image_face_region.unsqueeze(0)
|
| 267 |
+
source_image_face_emb = source_image_face_emb.reshape(1, -1)
|
| 268 |
+
source_image_face_emb = torch.tensor(source_image_face_emb)
|
| 269 |
+
|
| 270 |
+
source_image_full_mask = [
|
| 271 |
+
(mask.repeat(clip_length, 1))
|
| 272 |
+
for mask in source_image_full_mask
|
| 273 |
+
]
|
| 274 |
+
source_image_face_mask = [
|
| 275 |
+
(mask.repeat(clip_length, 1))
|
| 276 |
+
for mask in source_image_face_mask
|
| 277 |
+
]
|
| 278 |
+
source_image_lip_mask = [
|
| 279 |
+
(mask.repeat(clip_length, 1))
|
| 280 |
+
for mask in source_image_lip_mask
|
| 281 |
+
]
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
times = audio_emb.shape[0] // clip_length
|
| 285 |
+
|
| 286 |
+
tensor_result = []
|
| 287 |
+
|
| 288 |
+
generator = torch.manual_seed(42)
|
| 289 |
+
|
| 290 |
+
for t in range(times):
|
| 291 |
+
|
| 292 |
+
if len(tensor_result) == 0:
|
| 293 |
+
# The first iteration
|
| 294 |
+
motion_zeros = source_image_pixels.repeat(
|
| 295 |
+
config.data.n_motion_frames, 1, 1, 1)
|
| 296 |
+
motion_zeros = motion_zeros.to(
|
| 297 |
+
dtype=source_image_pixels.dtype, device=source_image_pixels.device)
|
| 298 |
+
pixel_values_ref_img = torch.cat(
|
| 299 |
+
[source_image_pixels, motion_zeros], dim=0) # concat the ref image and the first motion frames
|
| 300 |
+
else:
|
| 301 |
+
motion_frames = tensor_result[-1][0]
|
| 302 |
+
motion_frames = motion_frames.permute(1, 0, 2, 3)
|
| 303 |
+
motion_frames = motion_frames[0-config.data.n_motion_frames:]
|
| 304 |
+
motion_frames = motion_frames * 2.0 - 1.0
|
| 305 |
+
motion_frames = motion_frames.to(
|
| 306 |
+
dtype=source_image_pixels.dtype, device=source_image_pixels.device)
|
| 307 |
+
pixel_values_ref_img = torch.cat(
|
| 308 |
+
[source_image_pixels, motion_frames], dim=0) # concat the ref image and the motion frames
|
| 309 |
+
|
| 310 |
+
pixel_values_ref_img = pixel_values_ref_img.unsqueeze(0)
|
| 311 |
+
|
| 312 |
+
audio_tensor = audio_emb[
|
| 313 |
+
t * clip_length: min((t + 1) * clip_length, audio_emb.shape[0])
|
| 314 |
+
]
|
| 315 |
+
audio_tensor = audio_tensor.unsqueeze(0)
|
| 316 |
+
audio_tensor = audio_tensor.to(
|
| 317 |
+
device=net.audioproj.device, dtype=net.audioproj.dtype)
|
| 318 |
+
audio_tensor = net.audioproj(audio_tensor)
|
| 319 |
+
|
| 320 |
+
pipeline_output = pipeline(
|
| 321 |
+
ref_image=pixel_values_ref_img,
|
| 322 |
+
audio_tensor=audio_tensor,
|
| 323 |
+
face_emb=source_image_face_emb,
|
| 324 |
+
face_mask=source_image_face_region,
|
| 325 |
+
pixel_values_full_mask=source_image_full_mask,
|
| 326 |
+
pixel_values_face_mask=source_image_face_mask,
|
| 327 |
+
pixel_values_lip_mask=source_image_lip_mask,
|
| 328 |
+
width=img_size[0],
|
| 329 |
+
height=img_size[1],
|
| 330 |
+
video_length=clip_length,
|
| 331 |
+
num_inference_steps=config.inference_steps,
|
| 332 |
+
guidance_scale=config.cfg_scale,
|
| 333 |
+
generator=generator,
|
| 334 |
+
motion_scale=motion_scale,
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
tensor_result.append(pipeline_output.videos)
|
| 338 |
+
|
| 339 |
+
tensor_result = torch.cat(tensor_result, dim=2)
|
| 340 |
+
tensor_result = tensor_result.squeeze(0)
|
| 341 |
+
|
| 342 |
+
output_file = config.output
|
| 343 |
+
# save the result after all iteration
|
| 344 |
+
tensor_to_video(tensor_result, output_file, driving_audio_path)
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
if __name__ == "__main__":
|
| 348 |
+
parser = argparse.ArgumentParser()
|
| 349 |
+
|
| 350 |
+
parser.add_argument(
|
| 351 |
+
"-c", "--config", default="configs/inference/default.yaml")
|
| 352 |
+
parser.add_argument("--source_image", type=str, required=False,
|
| 353 |
+
help="source image", default="test_data/source_images/6.jpg")
|
| 354 |
+
parser.add_argument("--driving_audio", type=str, required=False,
|
| 355 |
+
help="driving audio", default="test_data/driving_audios/singing/sing_4.wav")
|
| 356 |
+
parser.add_argument(
|
| 357 |
+
"--output", type=str, help="output video file name", default=".cache/output.mp4")
|
| 358 |
+
parser.add_argument(
|
| 359 |
+
"--pose_weight", type=float, help="weight of pose", default=1.0)
|
| 360 |
+
parser.add_argument(
|
| 361 |
+
"--face_weight", type=float, help="weight of face", default=1.0)
|
| 362 |
+
parser.add_argument(
|
| 363 |
+
"--lip_weight", type=float, help="weight of lip", default=1.0)
|
| 364 |
+
parser.add_argument(
|
| 365 |
+
"--face_expand_ratio", type=float, help="face region", default=1.2)
|
| 366 |
+
parser.add_argument(
|
| 367 |
+
"--checkpoint", type=str, help="which checkpoint", default=None)
|
| 368 |
+
|
| 369 |
+
|
| 370 |
+
command_line_args = parser.parse_args()
|
| 371 |
+
|
| 372 |
+
inference_process(command_line_args)
|
setup.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
setup.py
|
| 3 |
+
----
|
| 4 |
+
This is the main setup file for the hallo face animation project. It defines the package
|
| 5 |
+
metadata, required dependencies, and provides the entry point for installing the package.
|
| 6 |
+
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
# -*- coding: utf-8 -*-
|
| 10 |
+
from setuptools import setup
|
| 11 |
+
|
| 12 |
+
packages = \
|
| 13 |
+
['hallo', 'hallo.datasets', 'hallo.models', 'hallo.animate', 'hallo.utils']
|
| 14 |
+
|
| 15 |
+
package_data = \
|
| 16 |
+
{'': ['*']}
|
| 17 |
+
|
| 18 |
+
install_requires = \
|
| 19 |
+
['accelerate==0.28.0',
|
| 20 |
+
'audio-separator>=0.17.2,<0.18.0',
|
| 21 |
+
'av==12.1.0',
|
| 22 |
+
'bitsandbytes==0.43.1',
|
| 23 |
+
'decord==0.6.0',
|
| 24 |
+
'diffusers==0.27.2',
|
| 25 |
+
'einops>=0.8.0,<0.9.0',
|
| 26 |
+
'insightface>=0.7.3,<0.8.0',
|
| 27 |
+
'mediapipe[vision]>=0.10.14,<0.11.0',
|
| 28 |
+
'mlflow==2.13.1',
|
| 29 |
+
'moviepy>=1.0.3,<2.0.0',
|
| 30 |
+
'omegaconf>=2.3.0,<3.0.0',
|
| 31 |
+
'opencv-python>=4.9.0.80,<5.0.0.0',
|
| 32 |
+
'pillow>=10.3.0,<11.0.0',
|
| 33 |
+
'torch==2.2.2',
|
| 34 |
+
'torchvision==0.17.2',
|
| 35 |
+
'transformers==4.39.2',
|
| 36 |
+
'xformers==0.0.25.post1']
|
| 37 |
+
|
| 38 |
+
setup_kwargs = {
|
| 39 |
+
'name': 'anna',
|
| 40 |
+
'version': '0.1.0',
|
| 41 |
+
'description': '',
|
| 42 |
+
'long_description': '# Anna face animation',
|
| 43 |
+
'author': 'Your Name',
|
| 44 |
+
'author_email': '[email protected]',
|
| 45 |
+
'maintainer': 'None',
|
| 46 |
+
'maintainer_email': 'None',
|
| 47 |
+
'url': 'None',
|
| 48 |
+
'packages': packages,
|
| 49 |
+
'package_data': package_data,
|
| 50 |
+
'install_requires': install_requires,
|
| 51 |
+
'python_requires': '>=3.10,<4.0',
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
setup(**setup_kwargs)
|