Spaces:
Paused

Paused
new files
Browse files- .gitattributes +0 -35
- BuildingAChainlitApp.md +111 -0
- Dockerfile +11 -0
- README.md +112 -5
- __pycache__/app.cpython-311.pyc +0 -0
- aimakerspace/__init__.py +0 -0
- aimakerspace/__pycache__/__init__.cpython-311.pyc +0 -0
- aimakerspace/__pycache__/text_utils.cpython-311.pyc +0 -0
- aimakerspace/__pycache__/vectordatabase.cpython-311.pyc +0 -0
- aimakerspace/openai_utils/__init__.py +0 -0
- aimakerspace/openai_utils/__pycache__/__init__.cpython-311.pyc +0 -0
- aimakerspace/openai_utils/__pycache__/chatmodel.cpython-311.pyc +0 -0
- aimakerspace/openai_utils/__pycache__/embedding.cpython-311.pyc +0 -0
- aimakerspace/openai_utils/__pycache__/prompts.cpython-311.pyc +0 -0
- aimakerspace/openai_utils/chatmodel.py +45 -0
- aimakerspace/openai_utils/embedding.py +59 -0
- aimakerspace/openai_utils/prompts.py +78 -0
- aimakerspace/text_utils.py +77 -0
- aimakerspace/vectordatabase.py +81 -0
- app.py +122 -0
- chainlit.md +3 -0
- images/docchain_img.png +0 -0
- paul_graham_essays.txt +0 -0
- requirements.txt +3 -0
.gitattributes
DELETED
|
@@ -1,35 +0,0 @@
|
|
| 1 |
-
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
-
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
-
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
-
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
-
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
-
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
-
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
-
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
-
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
-
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
BuildingAChainlitApp.md
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Building a Chainlit App
|
| 2 |
+
|
| 3 |
+
What if we want to take our Week 1 Day 2 assignment - [Pythonic RAG](https://github.com/AI-Maker-Space/AIE4/tree/main/Week%201/Day%202) - and bring it out of the notebook?
|
| 4 |
+
|
| 5 |
+
Well - we'll cover exactly that here!
|
| 6 |
+
|
| 7 |
+
## Anatomy of a Chainlit Application
|
| 8 |
+
|
| 9 |
+
[Chainlit](https://docs.chainlit.io/get-started/overview) is a Python package similar to Streamlit that lets users write a backend and a front end in a single (or multiple) Python file(s). It is mainly used for prototyping LLM-based Chat Style Applications - though it is used in production in some settings with 1,000,000s of MAUs (Monthly Active Users).
|
| 10 |
+
|
| 11 |
+
The primary method of customizing and interacting with the Chainlit UI is through a few critical [decorators](https://blog.hubspot.com/website/decorators-in-python).
|
| 12 |
+
|
| 13 |
+
> NOTE: Simply put, the decorators (in Chainlit) are just ways we can "plug-in" to the functionality in Chainlit.
|
| 14 |
+
|
| 15 |
+
We'll be concerning ourselves with three main scopes:
|
| 16 |
+
|
| 17 |
+
1. On application start - when we start the Chainlit application with a command like `chainlit run app.py`
|
| 18 |
+
2. On chat start - when a chat session starts (a user opens the web browser to the address hosting the application)
|
| 19 |
+
3. On message - when the users sends a message through the input text box in the Chainlit UI
|
| 20 |
+
|
| 21 |
+
Let's dig into each scope and see what we're doing!
|
| 22 |
+
|
| 23 |
+
## On Application Start:
|
| 24 |
+
|
| 25 |
+
The first thing you'll notice is that we have the traditional "wall of imports" this is to ensure we have everything we need to run our application.
|
| 26 |
+
|
| 27 |
+
```python
|
| 28 |
+
import os
|
| 29 |
+
from typing import List
|
| 30 |
+
from chainlit.types import AskFileResponse
|
| 31 |
+
from aimakerspace.text_utils import CharacterTextSplitter, TextFileLoader
|
| 32 |
+
from aimakerspace.openai_utils.prompts import (
|
| 33 |
+
UserRolePrompt,
|
| 34 |
+
SystemRolePrompt,
|
| 35 |
+
AssistantRolePrompt,
|
| 36 |
+
)
|
| 37 |
+
from aimakerspace.openai_utils.embedding import EmbeddingModel
|
| 38 |
+
from aimakerspace.vectordatabase import VectorDatabase
|
| 39 |
+
from aimakerspace.openai_utils.chatmodel import ChatOpenAI
|
| 40 |
+
import chainlit as cl
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
Next up, we have some prompt templates. As all sessions will use the same prompt templates without modification, and we don't need these templates to be specific per template - we can set them up here - at the application scope.
|
| 44 |
+
|
| 45 |
+
```python
|
| 46 |
+
system_template = """\
|
| 47 |
+
Use the following context to answer a users question. If you cannot find the answer in the context, say you don't know the answer."""
|
| 48 |
+
system_role_prompt = SystemRolePrompt(system_template)
|
| 49 |
+
|
| 50 |
+
user_prompt_template = """\
|
| 51 |
+
Context:
|
| 52 |
+
{context}
|
| 53 |
+
|
| 54 |
+
Question:
|
| 55 |
+
{question}
|
| 56 |
+
"""
|
| 57 |
+
user_role_prompt = UserRolePrompt(user_prompt_template)
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
> NOTE: You'll notice that these are the exact same prompt templates we used from the Pythonic RAG Notebook in Week 1 Day 2!
|
| 61 |
+
|
| 62 |
+
Following that - we can create the Python Class definition for our RAG pipeline - or *chain*, as we'll refer to it in the rest of this walkthrough.
|
| 63 |
+
|
| 64 |
+
Let's look at the definition first:
|
| 65 |
+
|
| 66 |
+
```python
|
| 67 |
+
class RetrievalAugmentedQAPipeline:
|
| 68 |
+
def __init__(self, llm: ChatOpenAI(), vector_db_retriever: VectorDatabase) -> None:
|
| 69 |
+
self.llm = llm
|
| 70 |
+
self.vector_db_retriever = vector_db_retriever
|
| 71 |
+
|
| 72 |
+
async def arun_pipeline(self, user_query: str):
|
| 73 |
+
### RETRIEVAL
|
| 74 |
+
context_list = self.vector_db_retriever.search_by_text(user_query, k=4)
|
| 75 |
+
|
| 76 |
+
context_prompt = ""
|
| 77 |
+
for context in context_list:
|
| 78 |
+
context_prompt += context[0] + "\n"
|
| 79 |
+
|
| 80 |
+
### AUGMENTED
|
| 81 |
+
formatted_system_prompt = system_role_prompt.create_message()
|
| 82 |
+
|
| 83 |
+
formatted_user_prompt = user_role_prompt.create_message(question=user_query, context=context_prompt)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
### GENERATION
|
| 87 |
+
async def generate_response():
|
| 88 |
+
async for chunk in self.llm.astream([formatted_system_prompt, formatted_user_prompt]):
|
| 89 |
+
yield chunk
|
| 90 |
+
|
| 91 |
+
return {"response": generate_response(), "context": context_list}
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
Notice a few things:
|
| 95 |
+
|
| 96 |
+
1. We have modified this `RetrievalAugmentedQAPipeline` from the initial notebook to support streaming.
|
| 97 |
+
2. In essence, our pipeline is *chaining* a few events together:
|
| 98 |
+
1. We take our user query, and chain it into our Vector Database to collect related chunks
|
| 99 |
+
2. We take those contexts and our user's questions and chain them into the prompt templates
|
| 100 |
+
3. We take that prompt template and chain it into our LLM call
|
| 101 |
+
4. We chain the response of the LLM call to the user
|
| 102 |
+
3. We are using a lot of `async` again!
|
| 103 |
+
|
| 104 |
+
#### QUESTION #1:
|
| 105 |
+
|
| 106 |
+
Why do we want to support streaming? What about streaming is important, or useful?
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
|
Dockerfile
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.9
|
| 2 |
+
RUN useradd -m -u 1000 user
|
| 3 |
+
USER user
|
| 4 |
+
ENV HOME=/home/user \
|
| 5 |
+
PATH=/home/user/.local/bin:$PATH
|
| 6 |
+
WORKDIR $HOME/app
|
| 7 |
+
COPY --chown=user . $HOME/app
|
| 8 |
+
COPY ./requirements.txt ~/app/requirements.txt
|
| 9 |
+
RUN pip install -r requirements.txt
|
| 10 |
+
COPY . .
|
| 11 |
+
CMD ["chainlit", "run", "app.py", "--port", "7860"]
|
README.md
CHANGED
|
@@ -1,11 +1,118 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: docker
|
| 7 |
pinned: false
|
| 8 |
license: apache-2.0
|
| 9 |
---
|
| 10 |
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: DeployPythonicRAG
|
| 3 |
+
emoji: 📉
|
| 4 |
+
colorFrom: blue
|
| 5 |
+
colorTo: purple
|
| 6 |
sdk: docker
|
| 7 |
pinned: false
|
| 8 |
license: apache-2.0
|
| 9 |
---
|
| 10 |
|
| 11 |
+
# Deploying Pythonic Chat With Your Text File Application
|
| 12 |
+
|
| 13 |
+
In today's breakout rooms, we will be following the processed that you saw during the challenge - for reference, the instructions for that are available [here](https://github.com/AI-Maker-Space/Beyond-ChatGPT/tree/main).
|
| 14 |
+
|
| 15 |
+
Today, we will repeat the same process - but powered by our Pythonic RAG implementation we created last week.
|
| 16 |
+
|
| 17 |
+
You'll notice a few differences in the `app.py` logic - as well as a few changes to the `aimakerspace` package to get things working smoothly with Chainlit.
|
| 18 |
+
|
| 19 |
+
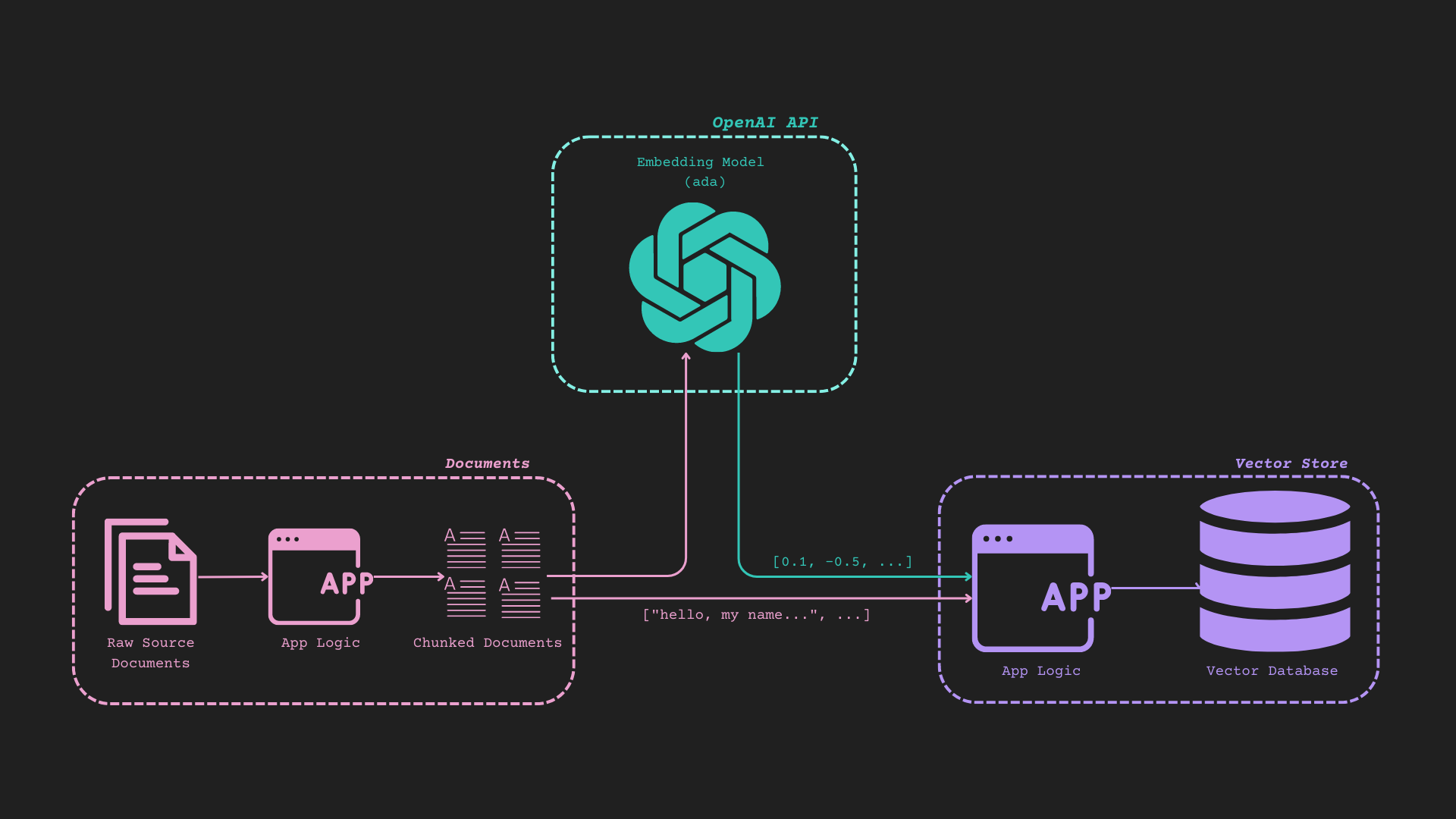
## Reference Diagram (It's Busy, but it works)
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
## Deploying the Application to Hugging Face Space
|
| 24 |
+
|
| 25 |
+
Due to the way the repository is created - it should be straightforward to deploy this to a Hugging Face Space!
|
| 26 |
+
|
| 27 |
+
> NOTE: If you wish to go through the local deployments using `chainlit run app.py` and Docker - please feel free to do so!
|
| 28 |
+
|
| 29 |
+
<details>
|
| 30 |
+
<summary>Creating a Hugging Face Space</summary>
|
| 31 |
+
|
| 32 |
+
1. Navigate to the `Spaces` tab.
|
| 33 |
+
|
| 34 |
+

|
| 35 |
+
|
| 36 |
+
2. Click on `Create new Space`
|
| 37 |
+
|
| 38 |
+

|
| 39 |
+
|
| 40 |
+
3. Create the Space by providing values in the form. Make sure you've selected "Docker" as your Space SDK.
|
| 41 |
+
|
| 42 |
+

|
| 43 |
+
|
| 44 |
+
</details>
|
| 45 |
+
|
| 46 |
+
<details>
|
| 47 |
+
<summary>Adding this Repository to the Newly Created Space</summary>
|
| 48 |
+
|
| 49 |
+
1. Collect the SSH address from the newly created Space.
|
| 50 |
+
|
| 51 |
+

|
| 52 |
+
|
| 53 |
+
> NOTE: The address is the component that starts with `[email protected]:spaces/`.
|
| 54 |
+
|
| 55 |
+
2. Use the command:
|
| 56 |
+
|
| 57 |
+
```bash
|
| 58 |
+
git remote add hf HF_SPACE_SSH_ADDRESS_HERE
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
3. Use the command:
|
| 62 |
+
|
| 63 |
+
```bash
|
| 64 |
+
git pull hf main --no-rebase --allow-unrelated-histories -X ours
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
4. Use the command:
|
| 68 |
+
|
| 69 |
+
```bash
|
| 70 |
+
git add .
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
5. Use the command:
|
| 74 |
+
|
| 75 |
+
```bash
|
| 76 |
+
git commit -m "Deploying Pythonic RAG"
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
6. Use the command:
|
| 80 |
+
|
| 81 |
+
```bash
|
| 82 |
+
git push hf main
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
7. The Space should automatically build as soon as the push is completed!
|
| 86 |
+
|
| 87 |
+
> NOTE: The build will fail before you complete the following steps!
|
| 88 |
+
|
| 89 |
+
</details>
|
| 90 |
+
|
| 91 |
+
<details>
|
| 92 |
+
<summary>Adding OpenAI Secrets to the Space</summary>
|
| 93 |
+
|
| 94 |
+
1. Navigate to your Space settings.
|
| 95 |
+
|
| 96 |
+

|
| 97 |
+
|
| 98 |
+
2. Navigate to `Variables and secrets` on the Settings page and click `New secret`:
|
| 99 |
+
|
| 100 |
+

|
| 101 |
+
|
| 102 |
+
3. In the `Name` field - input `OPENAI_API_KEY` in the `Value (private)` field, put your OpenAI API Key.
|
| 103 |
+
|
| 104 |
+

|
| 105 |
+
|
| 106 |
+
4. The Space will begin rebuilding!
|
| 107 |
+
|
| 108 |
+
</details>
|
| 109 |
+
|
| 110 |
+
## 🎉
|
| 111 |
+
|
| 112 |
+
You just deployed Pythonic RAG!
|
| 113 |
+
|
| 114 |
+
Try uploading a text file and asking some questions!
|
| 115 |
+
|
| 116 |
+
## 🚧CHALLENGE MODE 🚧
|
| 117 |
+
|
| 118 |
+
For more of a challenge, please reference [Building a Chainlit App](./BuildingAChainlitApp.md)!
|
__pycache__/app.cpython-311.pyc
ADDED
|
Binary file (6.64 kB). View file
|
|
|
aimakerspace/__init__.py
ADDED
|
File without changes
|
aimakerspace/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (188 Bytes). View file
|
|
|
aimakerspace/__pycache__/text_utils.cpython-311.pyc
ADDED
|
Binary file (5.43 kB). View file
|
|
|
aimakerspace/__pycache__/vectordatabase.cpython-311.pyc
ADDED
|
Binary file (5.71 kB). View file
|
|
|
aimakerspace/openai_utils/__init__.py
ADDED
|
File without changes
|
aimakerspace/openai_utils/__pycache__/__init__.cpython-311.pyc
ADDED
|
Binary file (201 Bytes). View file
|
|
|
aimakerspace/openai_utils/__pycache__/chatmodel.cpython-311.pyc
ADDED
|
Binary file (2.51 kB). View file
|
|
|
aimakerspace/openai_utils/__pycache__/embedding.cpython-311.pyc
ADDED
|
Binary file (4.13 kB). View file
|
|
|
aimakerspace/openai_utils/__pycache__/prompts.cpython-311.pyc
ADDED
|
Binary file (5.52 kB). View file
|
|
|
aimakerspace/openai_utils/chatmodel.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from openai import OpenAI, AsyncOpenAI
|
| 2 |
+
from dotenv import load_dotenv
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
load_dotenv()
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class ChatOpenAI:
|
| 9 |
+
def __init__(self, model_name: str = "gpt-4o-mini"):
|
| 10 |
+
self.model_name = model_name
|
| 11 |
+
self.openai_api_key = os.getenv("OPENAI_API_KEY")
|
| 12 |
+
if self.openai_api_key is None:
|
| 13 |
+
raise ValueError("OPENAI_API_KEY is not set")
|
| 14 |
+
|
| 15 |
+
def run(self, messages, text_only: bool = True, **kwargs):
|
| 16 |
+
if not isinstance(messages, list):
|
| 17 |
+
raise ValueError("messages must be a list")
|
| 18 |
+
|
| 19 |
+
client = OpenAI()
|
| 20 |
+
response = client.chat.completions.create(
|
| 21 |
+
model=self.model_name, messages=messages, **kwargs
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
if text_only:
|
| 25 |
+
return response.choices[0].message.content
|
| 26 |
+
|
| 27 |
+
return response
|
| 28 |
+
|
| 29 |
+
async def astream(self, messages, **kwargs):
|
| 30 |
+
if not isinstance(messages, list):
|
| 31 |
+
raise ValueError("messages must be a list")
|
| 32 |
+
|
| 33 |
+
client = AsyncOpenAI()
|
| 34 |
+
|
| 35 |
+
stream = await client.chat.completions.create(
|
| 36 |
+
model=self.model_name,
|
| 37 |
+
messages=messages,
|
| 38 |
+
stream=True,
|
| 39 |
+
**kwargs
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
async for chunk in stream:
|
| 43 |
+
content = chunk.choices[0].delta.content
|
| 44 |
+
if content is not None:
|
| 45 |
+
yield content
|
aimakerspace/openai_utils/embedding.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dotenv import load_dotenv
|
| 2 |
+
from openai import AsyncOpenAI, OpenAI
|
| 3 |
+
import openai
|
| 4 |
+
from typing import List
|
| 5 |
+
import os
|
| 6 |
+
import asyncio
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class EmbeddingModel:
|
| 10 |
+
def __init__(self, embeddings_model_name: str = "text-embedding-3-small"):
|
| 11 |
+
load_dotenv()
|
| 12 |
+
self.openai_api_key = os.getenv("OPENAI_API_KEY")
|
| 13 |
+
self.async_client = AsyncOpenAI()
|
| 14 |
+
self.client = OpenAI()
|
| 15 |
+
|
| 16 |
+
if self.openai_api_key is None:
|
| 17 |
+
raise ValueError(
|
| 18 |
+
"OPENAI_API_KEY environment variable is not set. Please set it to your OpenAI API key."
|
| 19 |
+
)
|
| 20 |
+
openai.api_key = self.openai_api_key
|
| 21 |
+
self.embeddings_model_name = embeddings_model_name
|
| 22 |
+
|
| 23 |
+
async def async_get_embeddings(self, list_of_text: List[str]) -> List[List[float]]:
|
| 24 |
+
embedding_response = await self.async_client.embeddings.create(
|
| 25 |
+
input=list_of_text, model=self.embeddings_model_name
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
return [embeddings.embedding for embeddings in embedding_response.data]
|
| 29 |
+
|
| 30 |
+
async def async_get_embedding(self, text: str) -> List[float]:
|
| 31 |
+
embedding = await self.async_client.embeddings.create(
|
| 32 |
+
input=text, model=self.embeddings_model_name
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
return embedding.data[0].embedding
|
| 36 |
+
|
| 37 |
+
def get_embeddings(self, list_of_text: List[str]) -> List[List[float]]:
|
| 38 |
+
embedding_response = self.client.embeddings.create(
|
| 39 |
+
input=list_of_text, model=self.embeddings_model_name
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
return [embeddings.embedding for embeddings in embedding_response.data]
|
| 43 |
+
|
| 44 |
+
def get_embedding(self, text: str) -> List[float]:
|
| 45 |
+
embedding = self.client.embeddings.create(
|
| 46 |
+
input=text, model=self.embeddings_model_name
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
return embedding.data[0].embedding
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
if __name__ == "__main__":
|
| 53 |
+
embedding_model = EmbeddingModel()
|
| 54 |
+
print(asyncio.run(embedding_model.async_get_embedding("Hello, world!")))
|
| 55 |
+
print(
|
| 56 |
+
asyncio.run(
|
| 57 |
+
embedding_model.async_get_embeddings(["Hello, world!", "Goodbye, world!"])
|
| 58 |
+
)
|
| 59 |
+
)
|
aimakerspace/openai_utils/prompts.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class BasePrompt:
|
| 5 |
+
def __init__(self, prompt):
|
| 6 |
+
"""
|
| 7 |
+
Initializes the BasePrompt object with a prompt template.
|
| 8 |
+
|
| 9 |
+
:param prompt: A string that can contain placeholders within curly braces
|
| 10 |
+
"""
|
| 11 |
+
self.prompt = prompt
|
| 12 |
+
self._pattern = re.compile(r"\{([^}]+)\}")
|
| 13 |
+
|
| 14 |
+
def format_prompt(self, **kwargs):
|
| 15 |
+
"""
|
| 16 |
+
Formats the prompt string using the keyword arguments provided.
|
| 17 |
+
|
| 18 |
+
:param kwargs: The values to substitute into the prompt string
|
| 19 |
+
:return: The formatted prompt string
|
| 20 |
+
"""
|
| 21 |
+
matches = self._pattern.findall(self.prompt)
|
| 22 |
+
return self.prompt.format(**{match: kwargs.get(match, "") for match in matches})
|
| 23 |
+
|
| 24 |
+
def get_input_variables(self):
|
| 25 |
+
"""
|
| 26 |
+
Gets the list of input variable names from the prompt string.
|
| 27 |
+
|
| 28 |
+
:return: List of input variable names
|
| 29 |
+
"""
|
| 30 |
+
return self._pattern.findall(self.prompt)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class RolePrompt(BasePrompt):
|
| 34 |
+
def __init__(self, prompt, role: str):
|
| 35 |
+
"""
|
| 36 |
+
Initializes the RolePrompt object with a prompt template and a role.
|
| 37 |
+
|
| 38 |
+
:param prompt: A string that can contain placeholders within curly braces
|
| 39 |
+
:param role: The role for the message ('system', 'user', or 'assistant')
|
| 40 |
+
"""
|
| 41 |
+
super().__init__(prompt)
|
| 42 |
+
self.role = role
|
| 43 |
+
|
| 44 |
+
def create_message(self, format=True, **kwargs):
|
| 45 |
+
"""
|
| 46 |
+
Creates a message dictionary with a role and a formatted message.
|
| 47 |
+
|
| 48 |
+
:param kwargs: The values to substitute into the prompt string
|
| 49 |
+
:return: Dictionary containing the role and the formatted message
|
| 50 |
+
"""
|
| 51 |
+
if format:
|
| 52 |
+
return {"role": self.role, "content": self.format_prompt(**kwargs)}
|
| 53 |
+
|
| 54 |
+
return {"role": self.role, "content": self.prompt}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class SystemRolePrompt(RolePrompt):
|
| 58 |
+
def __init__(self, prompt: str):
|
| 59 |
+
super().__init__(prompt, "system")
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class UserRolePrompt(RolePrompt):
|
| 63 |
+
def __init__(self, prompt: str):
|
| 64 |
+
super().__init__(prompt, "user")
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class AssistantRolePrompt(RolePrompt):
|
| 68 |
+
def __init__(self, prompt: str):
|
| 69 |
+
super().__init__(prompt, "assistant")
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
if __name__ == "__main__":
|
| 73 |
+
prompt = BasePrompt("Hello {name}, you are {age} years old")
|
| 74 |
+
print(prompt.format_prompt(name="John", age=30))
|
| 75 |
+
|
| 76 |
+
prompt = SystemRolePrompt("Hello {name}, you are {age} years old")
|
| 77 |
+
print(prompt.create_message(name="John", age=30))
|
| 78 |
+
print(prompt.get_input_variables())
|
aimakerspace/text_utils.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class TextFileLoader:
|
| 6 |
+
def __init__(self, path: str, encoding: str = "utf-8"):
|
| 7 |
+
self.documents = []
|
| 8 |
+
self.path = path
|
| 9 |
+
self.encoding = encoding
|
| 10 |
+
|
| 11 |
+
def load(self):
|
| 12 |
+
if os.path.isdir(self.path):
|
| 13 |
+
self.load_directory()
|
| 14 |
+
elif os.path.isfile(self.path) and self.path.endswith(".txt"):
|
| 15 |
+
self.load_file()
|
| 16 |
+
else:
|
| 17 |
+
raise ValueError(
|
| 18 |
+
"Provided path is neither a valid directory nor a .txt file."
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
def load_file(self):
|
| 22 |
+
with open(self.path, "r", encoding=self.encoding) as f:
|
| 23 |
+
self.documents.append(f.read())
|
| 24 |
+
|
| 25 |
+
def load_directory(self):
|
| 26 |
+
for root, _, files in os.walk(self.path):
|
| 27 |
+
for file in files:
|
| 28 |
+
if file.endswith(".txt"):
|
| 29 |
+
with open(
|
| 30 |
+
os.path.join(root, file), "r", encoding=self.encoding
|
| 31 |
+
) as f:
|
| 32 |
+
self.documents.append(f.read())
|
| 33 |
+
|
| 34 |
+
def load_documents(self):
|
| 35 |
+
self.load()
|
| 36 |
+
return self.documents
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class CharacterTextSplitter:
|
| 40 |
+
def __init__(
|
| 41 |
+
self,
|
| 42 |
+
chunk_size: int = 1000,
|
| 43 |
+
chunk_overlap: int = 200,
|
| 44 |
+
):
|
| 45 |
+
assert (
|
| 46 |
+
chunk_size > chunk_overlap
|
| 47 |
+
), "Chunk size must be greater than chunk overlap"
|
| 48 |
+
|
| 49 |
+
self.chunk_size = chunk_size
|
| 50 |
+
self.chunk_overlap = chunk_overlap
|
| 51 |
+
|
| 52 |
+
def split(self, text: str) -> List[str]:
|
| 53 |
+
chunks = []
|
| 54 |
+
for i in range(0, len(text), self.chunk_size - self.chunk_overlap):
|
| 55 |
+
chunks.append(text[i : i + self.chunk_size])
|
| 56 |
+
return chunks
|
| 57 |
+
|
| 58 |
+
def split_texts(self, texts: List[str]) -> List[str]:
|
| 59 |
+
chunks = []
|
| 60 |
+
for text in texts:
|
| 61 |
+
chunks.extend(self.split(text))
|
| 62 |
+
return chunks
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
if __name__ == "__main__":
|
| 66 |
+
loader = TextFileLoader("data/KingLear.txt")
|
| 67 |
+
loader.load()
|
| 68 |
+
splitter = CharacterTextSplitter()
|
| 69 |
+
chunks = splitter.split_texts(loader.documents)
|
| 70 |
+
print(len(chunks))
|
| 71 |
+
print(chunks[0])
|
| 72 |
+
print("--------")
|
| 73 |
+
print(chunks[1])
|
| 74 |
+
print("--------")
|
| 75 |
+
print(chunks[-2])
|
| 76 |
+
print("--------")
|
| 77 |
+
print(chunks[-1])
|
aimakerspace/vectordatabase.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from collections import defaultdict
|
| 3 |
+
from typing import List, Tuple, Callable
|
| 4 |
+
from aimakerspace.openai_utils.embedding import EmbeddingModel
|
| 5 |
+
import asyncio
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def cosine_similarity(vector_a: np.array, vector_b: np.array) -> float:
|
| 9 |
+
"""Computes the cosine similarity between two vectors."""
|
| 10 |
+
dot_product = np.dot(vector_a, vector_b)
|
| 11 |
+
norm_a = np.linalg.norm(vector_a)
|
| 12 |
+
norm_b = np.linalg.norm(vector_b)
|
| 13 |
+
return dot_product / (norm_a * norm_b)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class VectorDatabase:
|
| 17 |
+
def __init__(self, embedding_model: EmbeddingModel = None):
|
| 18 |
+
self.vectors = defaultdict(np.array)
|
| 19 |
+
self.embedding_model = embedding_model or EmbeddingModel()
|
| 20 |
+
|
| 21 |
+
def insert(self, key: str, vector: np.array) -> None:
|
| 22 |
+
self.vectors[key] = vector
|
| 23 |
+
|
| 24 |
+
def search(
|
| 25 |
+
self,
|
| 26 |
+
query_vector: np.array,
|
| 27 |
+
k: int,
|
| 28 |
+
distance_measure: Callable = cosine_similarity,
|
| 29 |
+
) -> List[Tuple[str, float]]:
|
| 30 |
+
scores = [
|
| 31 |
+
(key, distance_measure(query_vector, vector))
|
| 32 |
+
for key, vector in self.vectors.items()
|
| 33 |
+
]
|
| 34 |
+
return sorted(scores, key=lambda x: x[1], reverse=True)[:k]
|
| 35 |
+
|
| 36 |
+
def search_by_text(
|
| 37 |
+
self,
|
| 38 |
+
query_text: str,
|
| 39 |
+
k: int,
|
| 40 |
+
distance_measure: Callable = cosine_similarity,
|
| 41 |
+
return_as_text: bool = False,
|
| 42 |
+
) -> List[Tuple[str, float]]:
|
| 43 |
+
query_vector = self.embedding_model.get_embedding(query_text)
|
| 44 |
+
results = self.search(query_vector, k, distance_measure)
|
| 45 |
+
return [result[0] for result in results] if return_as_text else results
|
| 46 |
+
|
| 47 |
+
def retrieve_from_key(self, key: str) -> np.array:
|
| 48 |
+
return self.vectors.get(key, None)
|
| 49 |
+
|
| 50 |
+
async def abuild_from_list(self, list_of_text: List[str]) -> "VectorDatabase":
|
| 51 |
+
embeddings = await self.embedding_model.async_get_embeddings(list_of_text)
|
| 52 |
+
for text, embedding in zip(list_of_text, embeddings):
|
| 53 |
+
self.insert(text, np.array(embedding))
|
| 54 |
+
return self
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
if __name__ == "__main__":
|
| 58 |
+
list_of_text = [
|
| 59 |
+
"I like to eat broccoli and bananas.",
|
| 60 |
+
"I ate a banana and spinach smoothie for breakfast.",
|
| 61 |
+
"Chinchillas and kittens are cute.",
|
| 62 |
+
"My sister adopted a kitten yesterday.",
|
| 63 |
+
"Look at this cute hamster munching on a piece of broccoli.",
|
| 64 |
+
]
|
| 65 |
+
|
| 66 |
+
vector_db = VectorDatabase()
|
| 67 |
+
vector_db = asyncio.run(vector_db.abuild_from_list(list_of_text))
|
| 68 |
+
k = 2
|
| 69 |
+
|
| 70 |
+
searched_vector = vector_db.search_by_text("I think fruit is awesome!", k=k)
|
| 71 |
+
print(f"Closest {k} vector(s):", searched_vector)
|
| 72 |
+
|
| 73 |
+
retrieved_vector = vector_db.retrieve_from_key(
|
| 74 |
+
"I like to eat broccoli and bananas."
|
| 75 |
+
)
|
| 76 |
+
print("Retrieved vector:", retrieved_vector)
|
| 77 |
+
|
| 78 |
+
relevant_texts = vector_db.search_by_text(
|
| 79 |
+
"I think fruit is awesome!", k=k, return_as_text=True
|
| 80 |
+
)
|
| 81 |
+
print(f"Closest {k} text(s):", relevant_texts)
|
app.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import List
|
| 3 |
+
from chainlit.types import AskFileResponse
|
| 4 |
+
from aimakerspace.text_utils import CharacterTextSplitter, TextFileLoader
|
| 5 |
+
from aimakerspace.openai_utils.prompts import (
|
| 6 |
+
UserRolePrompt,
|
| 7 |
+
SystemRolePrompt,
|
| 8 |
+
AssistantRolePrompt,
|
| 9 |
+
)
|
| 10 |
+
from aimakerspace.openai_utils.embedding import EmbeddingModel
|
| 11 |
+
from aimakerspace.vectordatabase import VectorDatabase
|
| 12 |
+
from aimakerspace.openai_utils.chatmodel import ChatOpenAI
|
| 13 |
+
import chainlit as cl
|
| 14 |
+
|
| 15 |
+
system_template = """\
|
| 16 |
+
Use the following context to answer a users question. If you cannot find the answer in the context, say you don't know the answer."""
|
| 17 |
+
system_role_prompt = SystemRolePrompt(system_template)
|
| 18 |
+
|
| 19 |
+
user_prompt_template = """\
|
| 20 |
+
Context:
|
| 21 |
+
{context}
|
| 22 |
+
|
| 23 |
+
Question:
|
| 24 |
+
{question}
|
| 25 |
+
"""
|
| 26 |
+
user_role_prompt = UserRolePrompt(user_prompt_template)
|
| 27 |
+
|
| 28 |
+
class RetrievalAugmentedQAPipeline:
|
| 29 |
+
def __init__(self, llm: ChatOpenAI(), vector_db_retriever: VectorDatabase) -> None:
|
| 30 |
+
self.llm = llm
|
| 31 |
+
self.vector_db_retriever = vector_db_retriever
|
| 32 |
+
|
| 33 |
+
async def arun_pipeline(self, user_query: str):
|
| 34 |
+
context_list = self.vector_db_retriever.search_by_text(user_query, k=4)
|
| 35 |
+
|
| 36 |
+
context_prompt = ""
|
| 37 |
+
for context in context_list:
|
| 38 |
+
context_prompt += context[0] + "\n"
|
| 39 |
+
|
| 40 |
+
formatted_system_prompt = system_role_prompt.create_message()
|
| 41 |
+
|
| 42 |
+
formatted_user_prompt = user_role_prompt.create_message(question=user_query, context=context_prompt)
|
| 43 |
+
|
| 44 |
+
async def generate_response():
|
| 45 |
+
async for chunk in self.llm.astream([formatted_system_prompt, formatted_user_prompt]):
|
| 46 |
+
yield chunk
|
| 47 |
+
|
| 48 |
+
return {"response": generate_response(), "context": context_list}
|
| 49 |
+
|
| 50 |
+
text_splitter = CharacterTextSplitter()
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def process_text_file(file: AskFileResponse):
|
| 54 |
+
import tempfile
|
| 55 |
+
|
| 56 |
+
with tempfile.NamedTemporaryFile(mode="w", delete=False, suffix=".txt") as temp_file:
|
| 57 |
+
temp_file_path = temp_file.name
|
| 58 |
+
|
| 59 |
+
with open(temp_file_path, "wb") as f:
|
| 60 |
+
f.write(file.content)
|
| 61 |
+
|
| 62 |
+
text_loader = TextFileLoader(temp_file_path)
|
| 63 |
+
documents = text_loader.load_documents()
|
| 64 |
+
texts = text_splitter.split_texts(documents)
|
| 65 |
+
return texts
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
@cl.on_chat_start
|
| 69 |
+
async def on_chat_start():
|
| 70 |
+
files = None
|
| 71 |
+
|
| 72 |
+
# Wait for the user to upload a file
|
| 73 |
+
while files == None:
|
| 74 |
+
files = await cl.AskFileMessage(
|
| 75 |
+
content="Please upload a Text File file to begin!",
|
| 76 |
+
accept=["text/plain"],
|
| 77 |
+
max_size_mb=2,
|
| 78 |
+
timeout=180,
|
| 79 |
+
).send()
|
| 80 |
+
|
| 81 |
+
file = files[0]
|
| 82 |
+
|
| 83 |
+
msg = cl.Message(
|
| 84 |
+
content=f"Processing `{file.name}`...", disable_human_feedback=True
|
| 85 |
+
)
|
| 86 |
+
await msg.send()
|
| 87 |
+
|
| 88 |
+
# load the file
|
| 89 |
+
texts = process_text_file(file)
|
| 90 |
+
|
| 91 |
+
print(f"Processing {len(texts)} text chunks")
|
| 92 |
+
|
| 93 |
+
# Create a dict vector store
|
| 94 |
+
vector_db = VectorDatabase()
|
| 95 |
+
vector_db = await vector_db.abuild_from_list(texts)
|
| 96 |
+
|
| 97 |
+
chat_openai = ChatOpenAI()
|
| 98 |
+
|
| 99 |
+
# Create a chain
|
| 100 |
+
retrieval_augmented_qa_pipeline = RetrievalAugmentedQAPipeline(
|
| 101 |
+
vector_db_retriever=vector_db,
|
| 102 |
+
llm=chat_openai
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
# Let the user know that the system is ready
|
| 106 |
+
msg.content = f"Processing `{file.name}` done. You can now ask questions!"
|
| 107 |
+
await msg.update()
|
| 108 |
+
|
| 109 |
+
cl.user_session.set("chain", retrieval_augmented_qa_pipeline)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
@cl.on_message
|
| 113 |
+
async def main(message):
|
| 114 |
+
chain = cl.user_session.get("chain")
|
| 115 |
+
|
| 116 |
+
msg = cl.Message(content="")
|
| 117 |
+
result = await chain.arun_pipeline(message.content)
|
| 118 |
+
|
| 119 |
+
async for stream_resp in result["response"]:
|
| 120 |
+
await msg.stream_token(stream_resp)
|
| 121 |
+
|
| 122 |
+
await msg.send()
|
chainlit.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Welcome to Chat with Your Text File
|
| 2 |
+
|
| 3 |
+
With this application, you can chat with an uploaded text file that is smaller than 2MB!
|
images/docchain_img.png
ADDED
|
paul_graham_essays.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
chainlit==0.7.700
|
| 3 |
+
openai
|