
Анастасия
commited on
Commit
•
019c64d
1
Parent(s):
536d618
project_streamlit_app
Browse files- .gitattributes +1 -0
- __init__.py +0 -0
- images/.DS_Store +0 -0
- images/classes.png +0 -0
- images/classification_report.png +0 -0
- images/kino.png +0 -0
- images/toxy.png +0 -0
- main.py +38 -0
- model/.DS_Store +0 -0
- model/__pycache__/bert.cpython-310.pyc +0 -0
- model/__pycache__/ltsm_att.cpython-310.pyc +0 -0
- model/__pycache__/ml.cpython-310.pyc +0 -0
- model/__pycache__/rnn.cpython-310.pyc +0 -0
- model/bert.py +29 -0
- model/embedding_matrix.pt +3 -0
- model/logistic_regression_weights.pkl +3 -0
- model/lr_weights.pkl +3 -0
- model/lstm_att_weight.pt +3 -0
- model/ltsm_att.py +99 -0
- model/ml.py +36 -0
- model/rubert_tiny_toxicity_tokenizer_weights.pt/special_tokens_map.json +3 -0
- model/rubert_tiny_toxicity_tokenizer_weights.pt/tokenizer.json +3 -0
- model/rubert_tiny_toxicity_tokenizer_weights.pt/tokenizer_config.json +3 -0
- model/rubert_tiny_toxicity_tokenizer_weights.pt/vocab.txt +0 -0
- model/rubert_tiny_toxicity_weights.pt +3 -0
- model/tf-idf.pkl +3 -0
- model/word2vec_for_ltsm.model +3 -0
- model/word_dict.json +3 -0
- pages/.DS_Store +0 -0
- pages/01_🎞️_Kinootzovik.py +38 -0
- pages/02_🤖_Toxicity.py +56 -0
- pages/03_🔥_Results.py +69 -0
- pages/__init__.py +0 -0
- pages/__pycache__/__init__.cpython-310.pyc +0 -0
- requirements.txt +221 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.json filter=lfs diff=lfs merge=lfs -text
|
__init__.py
ADDED
|
File without changes
|
images/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
images/classes.png
ADDED
|
images/classification_report.png
ADDED
|
images/kino.png
ADDED

|
images/toxy.png
ADDED

|
main.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
|
| 3 |
+
st.write("""
|
| 4 |
+
\n ## Классификация отзывов на фильм 📽️
|
| 5 |
+
\n ## Оценка степени токсичности пользовательского сообщения 🌶️
|
| 6 |
+
|
| 7 |
+
""")
|
| 8 |
+
|
| 9 |
+
# \n ## Генерация текста GPT-моделью по пользовательскому prompt 🕹️
|
| 10 |
+
|
| 11 |
+
st.write("### *<span style='color:red'>LSTM Team</span>*", unsafe_allow_html=True)
|
| 12 |
+
|
| 13 |
+
st.write("""
|
| 14 |
+
### Состав команды:
|
| 15 |
+
\n1. ##### Анастасия 👩🏻💻
|
| 16 |
+
\n2. ##### Алексей 👨🏻💻
|
| 17 |
+
\n3. ##### Тигран 👨🏻💻
|
| 18 |
+
""")
|
| 19 |
+
|
| 20 |
+
st.write("""
|
| 21 |
+
### Проекты:
|
| 22 |
+
""")
|
| 23 |
+
|
| 24 |
+
st.write("""
|
| 25 |
+
#### 1. Необходимо построить модель классификации введенного пользователем отзыва. Результаты предсказаний класса вывести тремя моделями.
|
| 26 |
+
\n ##### Задача по моделям:
|
| 27 |
+
\n- Классический ML-алгоритм, обученный на BagOfWords/TF-IDF представлении
|
| 28 |
+
\n- RNN или LSTM модель (предпочтительно использовать вариант с attention)
|
| 29 |
+
\n- BERT-based
|
| 30 |
+
|
| 31 |
+
\n #### 2. Оценка степени токсичности пользовательского сообщения
|
| 32 |
+
\n ##### Задачи:
|
| 33 |
+
\n- Решить с помощью модели rubert-tiny-toxicity
|
| 34 |
+
|
| 35 |
+
""")
|
| 36 |
+
# \n ### 3. Генерация текста GPT-моделью по пользовательскому prompt
|
| 37 |
+
# \n ##### Задачи:
|
| 38 |
+
# \n- Пользователь может регулировать длину выдаваемой последовательности, Число генераций, Температуру или top-k/p
|
model/.DS_Store
ADDED
|
Binary file (8.2 kB). View file
|
|
|
model/__pycache__/bert.cpython-310.pyc
ADDED
|
Binary file (1.54 kB). View file
|
|
|
model/__pycache__/ltsm_att.cpython-310.pyc
ADDED
|
Binary file (3.92 kB). View file
|
|
|
model/__pycache__/ml.cpython-310.pyc
ADDED
|
Binary file (1.25 kB). View file
|
|
|
model/__pycache__/rnn.cpython-310.pyc
ADDED
|
Binary file (5.89 kB). View file
|
|
|
model/bert.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import streamlit as st
|
| 3 |
+
from transformers import AutoTokenizer, AutoModel
|
| 4 |
+
from sklearn.linear_model import LogisticRegression
|
| 5 |
+
import joblib
|
| 6 |
+
from time import time
|
| 7 |
+
|
| 8 |
+
dict = {0: 'Нейтральный', 1: 'Положительный', 2: 'Отрицательный'}
|
| 9 |
+
def preprocess_bert(text):
|
| 10 |
+
start_time = time()
|
| 11 |
+
tokenizer = AutoTokenizer.from_pretrained("cointegrated/rubert-tiny2")
|
| 12 |
+
model = AutoModel.from_pretrained("cointegrated/rubert-tiny2")
|
| 13 |
+
t = tokenizer(text, padding=True, truncation=True, return_tensors='pt')
|
| 14 |
+
with torch.no_grad():
|
| 15 |
+
model_output = model(**{k: v.to(model.device) for k, v in t.items()})
|
| 16 |
+
embeddings = model_output.last_hidden_state[:, 0, :]
|
| 17 |
+
embeddings = torch.nn.functional.normalize(embeddings)
|
| 18 |
+
embeddings = embeddings.detach().cpu().numpy()
|
| 19 |
+
|
| 20 |
+
lr = LogisticRegression()
|
| 21 |
+
lr = joblib.load('model/lr_weights.pkl')
|
| 22 |
+
# with open('model/lr_weights.pkl', 'rb') as f:
|
| 23 |
+
# lr = pickle.load(f)
|
| 24 |
+
predicted_label = lr.predict(embeddings)
|
| 25 |
+
predicted_label_text = dict[predicted_label[0]]
|
| 26 |
+
end_time = time()
|
| 27 |
+
|
| 28 |
+
inference_time = end_time - start_time
|
| 29 |
+
return f"***{predicted_label_text}***, время предсказания: ***{inference_time:.4f} сек***."
|
model/embedding_matrix.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0b8025aae0f6b8a31730a4cdb9095a51e33a4a1f8657a326e898e7c8f3e67007
|
| 3 |
+
size 278827972
|
model/logistic_regression_weights.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:12241487451736eb9e5305e4ce317ee3c76d12be8498cecbb5c33ebeab995036
|
| 3 |
+
size 120750
|
model/lr_weights.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:46e799a83602c0ee314840d648ce76b41c9ee18e6f03058f50df62a35a868650
|
| 3 |
+
size 8367
|
model/lstm_att_weight.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6983922dd858d31e89d5e55e8e02f6a812e013b13202f5042bdc7026ba5134db
|
| 3 |
+
size 139823799
|
model/ltsm_att.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import numpy as np
|
| 3 |
+
from gensim.models import Word2Vec
|
| 4 |
+
import torch
|
| 5 |
+
from torch.utils.data import DataLoader, TensorDataset
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torchutils as tu
|
| 9 |
+
from torchmetrics import Accuracy
|
| 10 |
+
from torchmetrics.functional import f1_score
|
| 11 |
+
from string import punctuation
|
| 12 |
+
import time
|
| 13 |
+
|
| 14 |
+
with open('model/word_dict.json', 'r') as fp:
|
| 15 |
+
vocab_to_int = json.load(fp)
|
| 16 |
+
|
| 17 |
+
wv = Word2Vec.load("model/word2vec_for_ltsm.model")
|
| 18 |
+
VOCAB_SIZE = len(vocab_to_int)+1
|
| 19 |
+
HIDDEN_SIZE = 128
|
| 20 |
+
SEQ_LEN = 128
|
| 21 |
+
DEVICE='cpu'
|
| 22 |
+
EMBEDDING_DIM = 128
|
| 23 |
+
|
| 24 |
+
embedding_matrix = torch.load('model/embedding_matrix.pt')
|
| 25 |
+
embedding_layer = torch.nn.Embedding.from_pretrained(torch.FloatTensor(embedding_matrix))
|
| 26 |
+
|
| 27 |
+
class ConcatAttention(nn.Module):
|
| 28 |
+
def __init__(
|
| 29 |
+
self,
|
| 30 |
+
hidden_size: torch.Tensor = HIDDEN_SIZE
|
| 31 |
+
) -> None:
|
| 32 |
+
|
| 33 |
+
super().__init__()
|
| 34 |
+
self.hidden_size = hidden_size
|
| 35 |
+
self.linear = nn.Linear(hidden_size, hidden_size)
|
| 36 |
+
self.align = nn.Linear(hidden_size * 2, hidden_size)
|
| 37 |
+
self.tanh = nn.Tanh()
|
| 38 |
+
|
| 39 |
+
def forward(
|
| 40 |
+
self,
|
| 41 |
+
lstm_outputs: torch.Tensor, # BATCH_SIZE x SEQ_LEN x HIDDEN_SIZE
|
| 42 |
+
final_hidden: torch.Tensor # BATCH_SIZE x HIDDEN_SIZE
|
| 43 |
+
) -> tuple[torch.Tensor]:
|
| 44 |
+
|
| 45 |
+
att_weights = self.linear(lstm_outputs)
|
| 46 |
+
att_weights = torch.bmm(att_weights, final_hidden.unsqueeze(2))
|
| 47 |
+
att_weights = F.softmax(att_weights.squeeze(2), dim=1)
|
| 48 |
+
|
| 49 |
+
cntxt = torch.bmm(lstm_outputs.transpose(1, 2), att_weights.unsqueeze(2))
|
| 50 |
+
concatted = torch.cat((cntxt, final_hidden.unsqueeze(2)), dim=1)
|
| 51 |
+
att_hidden = self.tanh(self.align(concatted.squeeze(-1)))
|
| 52 |
+
|
| 53 |
+
return att_hidden, att_weights
|
| 54 |
+
|
| 55 |
+
class LSTMConcatAttention(nn.Module):
|
| 56 |
+
def __init__(self) -> None:
|
| 57 |
+
super().__init__()
|
| 58 |
+
|
| 59 |
+
self.embedding = embedding_layer
|
| 60 |
+
self.lstm = nn.LSTM(EMBEDDING_DIM, HIDDEN_SIZE, batch_first=True)
|
| 61 |
+
self.attn = ConcatAttention(HIDDEN_SIZE)
|
| 62 |
+
self.clf = nn.Sequential(
|
| 63 |
+
nn.Linear(HIDDEN_SIZE, 128),
|
| 64 |
+
nn.Dropout(),
|
| 65 |
+
nn.Tanh(),
|
| 66 |
+
nn.Linear(128, 3)
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
def forward(self, x):
|
| 70 |
+
embeddings = self.embedding(x)
|
| 71 |
+
outputs, (h_n, _) = self.lstm(embeddings)
|
| 72 |
+
att_hidden, att_weights = self.attn(outputs, h_n.squeeze(0))
|
| 73 |
+
out = self.clf(att_hidden)
|
| 74 |
+
return out, att_weights
|
| 75 |
+
|
| 76 |
+
model_concat = LSTMConcatAttention()
|
| 77 |
+
model_concat.load_state_dict(torch.load('model/lstm_att_weight.pt', map_location='cpu'))
|
| 78 |
+
model_concat.eval()
|
| 79 |
+
|
| 80 |
+
def pred(text):
|
| 81 |
+
start_time = time.time()
|
| 82 |
+
text = text.lower()
|
| 83 |
+
text = ''.join([c for c in text if c not in punctuation])
|
| 84 |
+
text = [vocab_to_int[word] for word in text.split() if vocab_to_int.get(word)]
|
| 85 |
+
if len(text) <= 128:
|
| 86 |
+
zeros = list(np.zeros(128 - len(text)))
|
| 87 |
+
text = zeros + text
|
| 88 |
+
else:
|
| 89 |
+
text = text[: 128]
|
| 90 |
+
text = torch.Tensor(text)
|
| 91 |
+
text = text.unsqueeze(0)
|
| 92 |
+
text = text.type(torch.LongTensor)
|
| 93 |
+
# print(text.shape)
|
| 94 |
+
pred = model_concat(text)[0].argmax(1)
|
| 95 |
+
labels = {0: 'Негативный', 1:'Позитивный', 2:'Нейтральный'}
|
| 96 |
+
end_time = time.time()
|
| 97 |
+
inference_time = end_time - start_time
|
| 98 |
+
# return labels[pred.item()], inference_time
|
| 99 |
+
return f"***{labels[pred.item()]}***, время предсказания: ***{inference_time:.4f} сек***."
|
model/ml.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import numpy as np
|
| 3 |
+
import joblib
|
| 4 |
+
import time
|
| 5 |
+
from sklearn.feature_extraction.text import TfidfVectorizer
|
| 6 |
+
from sklearn.linear_model import LogisticRegression
|
| 7 |
+
import time
|
| 8 |
+
import pandas as pd
|
| 9 |
+
import joblib
|
| 10 |
+
|
| 11 |
+
model_ml = LogisticRegression()
|
| 12 |
+
vectorizer = joblib.load("model/tf-idf.pkl")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def preprocess(text):
|
| 16 |
+
# Убедитесь, что text - это список
|
| 17 |
+
if isinstance(text, str):
|
| 18 |
+
text = [text]
|
| 19 |
+
# Преобразуйте текст
|
| 20 |
+
text = vectorizer.transform(text)
|
| 21 |
+
return text
|
| 22 |
+
|
| 23 |
+
model = model_ml
|
| 24 |
+
model = joblib.load("model/logistic_regression_weights.pkl")
|
| 25 |
+
|
| 26 |
+
def predict(text):
|
| 27 |
+
start_time = time.time()
|
| 28 |
+
text = preprocess(text)
|
| 29 |
+
predicted_label = model.predict(text)
|
| 30 |
+
dict = {'Bad': 'Отрицательный', 'Neutral': 'Нейтральный', 'Good': 'Положительный'}
|
| 31 |
+
predicted_label_text = dict[predicted_label[0]]
|
| 32 |
+
end_time = time.time()
|
| 33 |
+
|
| 34 |
+
inference_time = end_time - start_time
|
| 35 |
+
|
| 36 |
+
return f"***{predicted_label_text}***, время предсказания: ***{inference_time:.4f} сек***."
|
model/rubert_tiny_toxicity_tokenizer_weights.pt/special_tokens_map.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b6d346be366a7d1d48332dbc9fdf3bf8960b5d879522b7799ddba59e76237ee3
|
| 3 |
+
size 125
|
model/rubert_tiny_toxicity_tokenizer_weights.pt/tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:064a132db204e46351abb4c3acb9da22fc4a837390be3b87877e79212e10dffa
|
| 3 |
+
size 705727
|
model/rubert_tiny_toxicity_tokenizer_weights.pt/tokenizer_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7160a114cff6faf66cd441ceaaf0dd32964ecd8c4933679247b596cd1a7125b3
|
| 3 |
+
size 1343
|
model/rubert_tiny_toxicity_tokenizer_weights.pt/vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model/rubert_tiny_toxicity_weights.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d7e02ce2bbd1611e3eb07ba3735710fb81b8dcf120223e987897f0d87c0525f5
|
| 3 |
+
size 47165548
|
model/tf-idf.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a13623e7dcb541282d1c3807bcc21ec7fa2e3c551d91bc557a6977e069c9eef9
|
| 3 |
+
size 1539730
|
model/word2vec_for_ltsm.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c8f7fdcfe5bb9b680626007980139e21fe3dec2408c1ee0e34c96ba5af1b7259
|
| 3 |
+
size 2182195
|
model/word_dict.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9cc11db4510ff54d488abaae9613aa1dd3e976dc2db3c334a1a915cfdfc52f1f
|
| 3 |
+
size 17951147
|
pages/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
pages/01_🎞️_Kinootzovik.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
from model.bert import preprocess_bert
|
| 4 |
+
from model.ml import predict
|
| 5 |
+
# from model.rnn import pred
|
| 6 |
+
from model.ltsm_att import pred
|
| 7 |
+
|
| 8 |
+
"""
|
| 9 |
+
## Классификация киноотзывов
|
| 10 |
+
"""
|
| 11 |
+
st.image('images/kino.png')
|
| 12 |
+
|
| 13 |
+
st.sidebar.header('Панель инструментов :gear:')
|
| 14 |
+
|
| 15 |
+
text = st.text_area('Поле для ввода отзыва', height=300)
|
| 16 |
+
|
| 17 |
+
with st.sidebar:
|
| 18 |
+
choice_model = st.radio('Выберите модель:', options=['ML-TFIDF', 'RuBert', 'LSTM(attention)'])
|
| 19 |
+
|
| 20 |
+
if choice_model == 'RuBert':
|
| 21 |
+
if text:
|
| 22 |
+
st.write(preprocess_bert(text))
|
| 23 |
+
|
| 24 |
+
if choice_model == 'ML-TFIDF':
|
| 25 |
+
if text:
|
| 26 |
+
st.write(predict(text))
|
| 27 |
+
|
| 28 |
+
if choice_model == 'LSTM(attention)':
|
| 29 |
+
if text:
|
| 30 |
+
st.write(pred(text))
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
data = pd.DataFrame({'Модель': ['ML-TFIDF-LogReg', 'RNN', 'RuBert-tiny2-LogReg'], 'F1-macro': [0.65, 0.57, 0.62]})
|
| 34 |
+
# Вывод таблицы
|
| 35 |
+
checkbox = st.sidebar.checkbox("Таблица f1-macro")
|
| 36 |
+
if checkbox:
|
| 37 |
+
st.write("<h1 style='text-align: center; font-size: 20pt;'>Оценка качества моделей по метрике f1-macro</h1>", unsafe_allow_html=True)
|
| 38 |
+
st.table(data)
|
pages/02_🤖_Toxicity.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification
|
| 3 |
+
import streamlit as st
|
| 4 |
+
import pandas as pd
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
model_checkpoint = 'cointegrated/rubert-tiny-toxicity'
|
| 8 |
+
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
|
| 9 |
+
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint)
|
| 10 |
+
if torch.cuda.is_available():
|
| 11 |
+
model.cuda()
|
| 12 |
+
|
| 13 |
+
# Сохранение весов модели
|
| 14 |
+
model_weights_filename = "model/rubert_tiny_toxicity_weights.pt"
|
| 15 |
+
torch.save(model.state_dict(), model_weights_filename)
|
| 16 |
+
|
| 17 |
+
# Сохранение весов токенизатора
|
| 18 |
+
tokenizer_weights_filename = "model/rubert_tiny_toxicity_tokenizer_weights.pt"
|
| 19 |
+
tokenizer.save_pretrained(tokenizer_weights_filename)
|
| 20 |
+
|
| 21 |
+
def text2toxicity(text, aggregate=False):
|
| 22 |
+
""" Calculate toxicity of a text (if aggregate=True) or a vector of toxicity aspects (if aggregate=False)"""
|
| 23 |
+
with torch.no_grad():
|
| 24 |
+
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True).to(model.device)
|
| 25 |
+
proba = torch.sigmoid(model(**inputs).logits).cpu().numpy()
|
| 26 |
+
if isinstance(text, str):
|
| 27 |
+
proba = proba[0]
|
| 28 |
+
if aggregate:
|
| 29 |
+
return 1 - proba.T[0] * (1 - proba.T[-1])
|
| 30 |
+
return proba
|
| 31 |
+
|
| 32 |
+
"""
|
| 33 |
+
## Оценка степени токсичности сообщения
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
st.image('images/toxy.png')
|
| 37 |
+
|
| 38 |
+
# Ввод предложения от пользователя
|
| 39 |
+
input_text = st.text_area("Введите предложение:", height=100)
|
| 40 |
+
|
| 41 |
+
# Обработка входных данных через модель
|
| 42 |
+
if input_text:
|
| 43 |
+
# Вывод результатов
|
| 44 |
+
my_dict = {
|
| 45 |
+
'Не токсичный': (text2toxicity(input_text, False))[0],
|
| 46 |
+
'Оскорбление': (text2toxicity(input_text, False))[1],
|
| 47 |
+
'Непристойность': (text2toxicity(input_text, False))[2],
|
| 48 |
+
'Угроза': (text2toxicity(input_text, False))[3],
|
| 49 |
+
'Опасный': (text2toxicity(input_text, False))[4]
|
| 50 |
+
}
|
| 51 |
+
# my_dict['index'] = 'your_index_value'
|
| 52 |
+
# st.write({text2toxicity(input_text, False)[0]: 'non-toxic'})
|
| 53 |
+
|
| 54 |
+
df = pd.DataFrame(my_dict, index=['вероятности'])
|
| 55 |
+
st.dataframe(df)
|
| 56 |
+
st.write(f'Вероятность токсичного комментария {text2toxicity(input_text, True)}')
|
pages/03_🔥_Results.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from PIL import Image
|
| 3 |
+
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
|
| 6 |
+
st.write("""
|
| 7 |
+
## 📝 Итоги.
|
| 8 |
+
""")
|
| 9 |
+
"""
|
| 10 |
+
### 1. Классификация киноотзывов
|
| 11 |
+
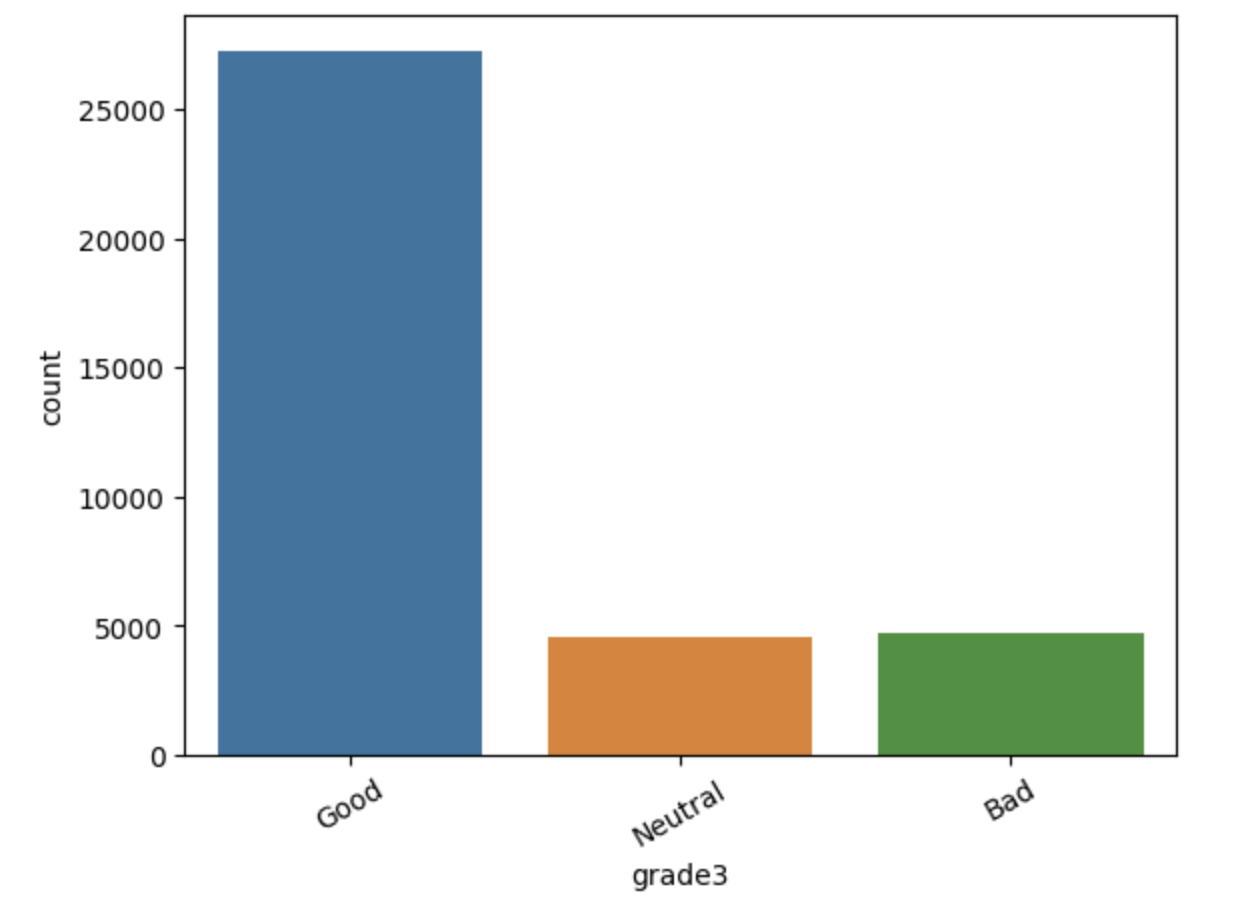
Датасет для обучения оказался крайне несбалансированным, отзывы разделены на три класса: Нейтральный, \
|
| 12 |
+
Положительный, Отрицательный
|
| 13 |
+
"""
|
| 14 |
+
st.image('images/classes.png')
|
| 15 |
+
'''
|
| 16 |
+
\n Датасет был поделен на три выборки:
|
| 17 |
+
'''
|
| 18 |
+
st.text('Тренировочный сет - 21954 отзывов')
|
| 19 |
+
st.text('Валидационный сет - 8782 отзывов')
|
| 20 |
+
st.text('Тестовый сет - 5855 отзывов')
|
| 21 |
+
|
| 22 |
+
"""
|
| 23 |
+
##### 1. Rubert-tiny2, модель-классификатор: LogisticRegression
|
| 24 |
+
"""
|
| 25 |
+
"""
|
| 26 |
+
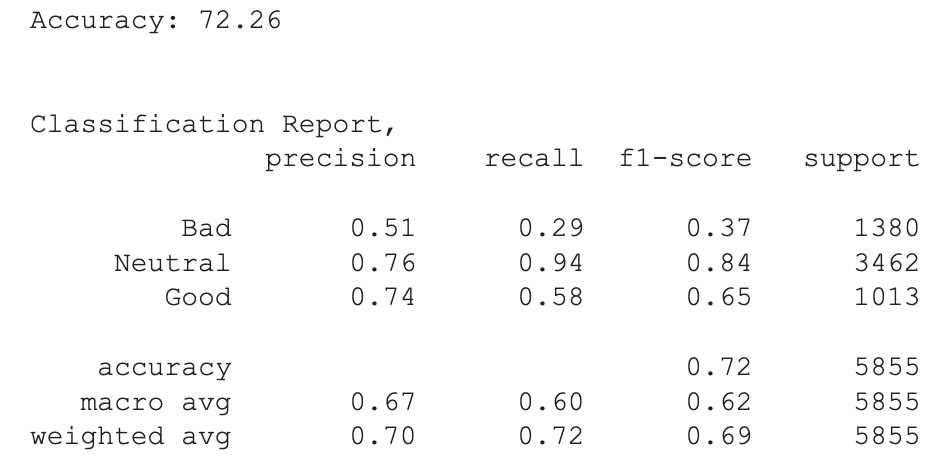
Была проведена балансировка классов в тренировочном наборе методом Oversampling(RandomOverSampler). На скорость обучения повлияла \
|
| 27 |
+
максимальная длина твита после токенизации в train, MAX_LEN = 4548, она была ограничена 1024 в виду возможностей производительности \
|
| 28 |
+
системы. Классификатором была выбрана LogisticRegression, также исходя из скорости обучения.
|
| 29 |
+
\n ##### Classification Report:
|
| 30 |
+
"""
|
| 31 |
+
st.image('images/classification_report.png')
|
| 32 |
+
|
| 33 |
+
"""
|
| 34 |
+
Метрика качества f1-macro показала наилучший результат 0.62
|
| 35 |
+
"""
|
| 36 |
+
|
| 37 |
+
"""
|
| 38 |
+
##### 2. ML-алгоритм, обученный на TF-IDF представлении, модель-классификатор: LogisticRegression
|
| 39 |
+
"""
|
| 40 |
+
|
| 41 |
+
"""
|
| 42 |
+
Прежде всего для этого алгоритма был проведена предобработки текста, а именно очистка текста от лишних символов, \
|
| 43 |
+
лемматизация текста, затем, была проведена балансировка классов в тренировочном наборе методом Oversampling(SMOTE). \
|
| 44 |
+
Для TfidfVectorizer был указан параметр max_features=5000, т.е. было выбрано максимальное количество признаков \
|
| 45 |
+
(слов или термов), которые были учтены при создании матрицы TF-IDF. Классификатором была выбрана LogisticRegression, \
|
| 46 |
+
исходя из скорости обучения.
|
| 47 |
+
\n Метрика качества f1-macro показала наилучший результат 0.65
|
| 48 |
+
"""
|
| 49 |
+
|
| 50 |
+
"""
|
| 51 |
+
##### 3. Модель на основе LTSM
|
| 52 |
+
"""
|
| 53 |
+
|
| 54 |
+
"""
|
| 55 |
+
Предобработка текста осуществлялась аналогичным с предыдущими моделями способом, для обеспечения сравнимых результатов \
|
| 56 |
+
Векторизация текста проводилась с помощью Word2Vec, встроенного в модель. Модель обрабатывала текст через \
|
| 57 |
+
LTSM слои, были выбраны значения hidden_size 128, embedding_dim 128. В модели также применялся механизм \
|
| 58 |
+
Attention. Классификация производилась внутри модели полносвязными слоями.
|
| 59 |
+
\n Метрика качества f1-macro в конце обучения составила 0.57
|
| 60 |
+
"""
|
| 61 |
+
"""
|
| 62 |
+
### 2. Оценка степени токсичности пользовательского сообщения
|
| 63 |
+
Задача была решена с помощью модели [rubert-tiny-toxicity](https://huggingface.co/cointegrated/rubert-tiny-toxicity), \
|
| 64 |
+
доработанной для классификации токсичности и неуместности коротких неофициальных текстов на русском языке, \
|
| 65 |
+
таких как комментарии в социальных сетях.
|
| 66 |
+
\n Датасет: 14412 сообщений из соцсетей, разделенных на два класса: токсичные и не токсичные. Токсичные \
|
| 67 |
+
преимущественно наполнены оскорбительной и нецензурной лексикой.
|
| 68 |
+
"""
|
| 69 |
+
|
pages/__init__.py
ADDED
|
File without changes
|
pages/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (203 Bytes). View file
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
absl-py==2.0.0
|
| 2 |
+
aiofiles==23.1.0
|
| 3 |
+
aiogram==3.1.1
|
| 4 |
+
aiohttp==3.8.6
|
| 5 |
+
aiosignal==1.3.1
|
| 6 |
+
altair==5.1.2
|
| 7 |
+
annotated-types==0.6.0
|
| 8 |
+
anyio==4.0.0
|
| 9 |
+
appdirs==1.4.4
|
| 10 |
+
appnope==0.1.3
|
| 11 |
+
argon2-cffi==23.1.0
|
| 12 |
+
argon2-cffi-bindings==21.2.0
|
| 13 |
+
arrow==1.3.0
|
| 14 |
+
asttokens==2.4.1
|
| 15 |
+
astunparse==1.6.3
|
| 16 |
+
async-lru==2.0.4
|
| 17 |
+
async-timeout==4.0.3
|
| 18 |
+
attrs==23.1.0
|
| 19 |
+
Babel==2.13.1
|
| 20 |
+
beautifulsoup4==4.12.2
|
| 21 |
+
black==23.11.0
|
| 22 |
+
bleach==6.1.0
|
| 23 |
+
blinker==1.7.0
|
| 24 |
+
cachetools==5.3.2
|
| 25 |
+
certifi==2023.7.22
|
| 26 |
+
cffi==1.16.0
|
| 27 |
+
charset-normalizer==3.3.2
|
| 28 |
+
click==8.1.7
|
| 29 |
+
comm==0.2.0
|
| 30 |
+
contourpy==1.2.0
|
| 31 |
+
cycler==0.12.1
|
| 32 |
+
debugpy==1.8.0
|
| 33 |
+
decorator==5.1.1
|
| 34 |
+
defusedxml==0.7.1
|
| 35 |
+
exceptiongroup==1.1.3
|
| 36 |
+
executing==2.0.1
|
| 37 |
+
fastjsonschema==2.19.0
|
| 38 |
+
filelock==3.13.1
|
| 39 |
+
flatbuffers==23.5.26
|
| 40 |
+
fonttools==4.44.0
|
| 41 |
+
fqdn==1.5.1
|
| 42 |
+
frozendict==2.3.8
|
| 43 |
+
frozenlist==1.4.0
|
| 44 |
+
fsspec==2023.10.0
|
| 45 |
+
gast==0.5.4
|
| 46 |
+
gensim==4.3.2
|
| 47 |
+
gitdb==4.0.11
|
| 48 |
+
GitPython==3.1.40
|
| 49 |
+
google-auth==2.25.1
|
| 50 |
+
google-auth-oauthlib==1.1.0
|
| 51 |
+
google-pasta==0.2.0
|
| 52 |
+
grpcio==1.59.3
|
| 53 |
+
h5py==3.10.0
|
| 54 |
+
html5lib==1.1
|
| 55 |
+
huggingface-hub==0.19.4
|
| 56 |
+
idna==3.4
|
| 57 |
+
imageio==2.31.6
|
| 58 |
+
importlib-metadata==6.8.0
|
| 59 |
+
ipykernel==6.26.0
|
| 60 |
+
ipython==8.17.2
|
| 61 |
+
ipywidgets==8.1.1
|
| 62 |
+
isoduration==20.11.0
|
| 63 |
+
jedi==0.19.1
|
| 64 |
+
Jinja2==3.1.2
|
| 65 |
+
joblib==1.3.2
|
| 66 |
+
json5==0.9.14
|
| 67 |
+
jsonpointer==2.4
|
| 68 |
+
jsonschema==4.19.2
|
| 69 |
+
jsonschema-specifications==2023.7.1
|
| 70 |
+
jupyter==1.0.0
|
| 71 |
+
jupyter-console==6.6.3
|
| 72 |
+
jupyter-events==0.9.0
|
| 73 |
+
jupyter-lsp==2.2.0
|
| 74 |
+
jupyter_client==8.6.0
|
| 75 |
+
jupyter_core==5.5.0
|
| 76 |
+
jupyter_server==2.10.1
|
| 77 |
+
jupyter_server_terminals==0.4.4
|
| 78 |
+
jupyterlab==4.0.9
|
| 79 |
+
jupyterlab-pygments==0.2.2
|
| 80 |
+
jupyterlab-widgets==3.0.9
|
| 81 |
+
jupyterlab_code_formatter==2.2.1
|
| 82 |
+
jupyterlab_commands==0.4.0
|
| 83 |
+
jupyterlab_server==2.25.2
|
| 84 |
+
keras==2.15.0
|
| 85 |
+
kiwisolver==1.4.5
|
| 86 |
+
lazy_loader==0.3
|
| 87 |
+
libclang==16.0.6
|
| 88 |
+
lightning-utilities==0.10.0
|
| 89 |
+
lxml==4.9.3
|
| 90 |
+
magic-filter==1.0.12
|
| 91 |
+
Markdown==3.5.1
|
| 92 |
+
markdown-it-py==3.0.0
|
| 93 |
+
MarkupSafe==2.1.3
|
| 94 |
+
matplotlib==3.8.1
|
| 95 |
+
matplotlib-inline==0.1.6
|
| 96 |
+
mdurl==0.1.2
|
| 97 |
+
mistune==3.0.2
|
| 98 |
+
ml-dtypes==0.2.0
|
| 99 |
+
mplcyberpunk==0.7.0
|
| 100 |
+
mpmath==1.3.0
|
| 101 |
+
multidict==6.0.4
|
| 102 |
+
multitasking==0.0.11
|
| 103 |
+
mypy-extensions==1.0.0
|
| 104 |
+
nbclient==0.9.0
|
| 105 |
+
nbconvert==7.11.0
|
| 106 |
+
nbformat==5.9.2
|
| 107 |
+
nest-asyncio==1.5.8
|
| 108 |
+
networkx==3.2.1
|
| 109 |
+
nltk==3.8.1
|
| 110 |
+
notebook==7.0.6
|
| 111 |
+
notebook_shim==0.2.3
|
| 112 |
+
numpy==1.26.1
|
| 113 |
+
oauthlib==3.2.2
|
| 114 |
+
opencv-contrib-python==4.8.1.78
|
| 115 |
+
opencv-python==4.8.1.78
|
| 116 |
+
opt-einsum==3.3.0
|
| 117 |
+
overrides==7.4.0
|
| 118 |
+
packaging==23.2
|
| 119 |
+
pandas==2.1.2
|
| 120 |
+
pandocfilters==1.5.0
|
| 121 |
+
parso==0.8.3
|
| 122 |
+
pathspec==0.11.2
|
| 123 |
+
patsy==0.5.3
|
| 124 |
+
peewee==3.17.0
|
| 125 |
+
pexpect==4.8.0
|
| 126 |
+
Pillow==10.0.1
|
| 127 |
+
platformdirs==4.0.0
|
| 128 |
+
plotly==5.18.0
|
| 129 |
+
plotly-express==0.4.1
|
| 130 |
+
prometheus-client==0.18.0
|
| 131 |
+
prompt-toolkit==3.0.41
|
| 132 |
+
protobuf==4.23.4
|
| 133 |
+
psutil==5.9.6
|
| 134 |
+
ptyprocess==0.7.0
|
| 135 |
+
pure-eval==0.2.2
|
| 136 |
+
py-cpuinfo==9.0.0
|
| 137 |
+
pyarrow==14.0.0
|
| 138 |
+
pyasn1==0.5.1
|
| 139 |
+
pyasn1-modules==0.3.0
|
| 140 |
+
pycparser==2.21
|
| 141 |
+
pydantic==2.3.0
|
| 142 |
+
pydantic_core==2.6.3
|
| 143 |
+
pydeck==0.8.1b0
|
| 144 |
+
Pygments==2.16.1
|
| 145 |
+
pyparsing==3.1.1
|
| 146 |
+
python-dateutil==2.8.2
|
| 147 |
+
python-json-logger==2.0.7
|
| 148 |
+
pytz==2023.3.post1
|
| 149 |
+
PyYAML==6.0.1
|
| 150 |
+
pyzmq==25.1.1
|
| 151 |
+
qtconsole==5.5.1
|
| 152 |
+
QtPy==2.4.1
|
| 153 |
+
referencing==0.30.2
|
| 154 |
+
regex==2023.10.3
|
| 155 |
+
requests==2.31.0
|
| 156 |
+
requests-oauthlib==1.3.1
|
| 157 |
+
rfc3339-validator==0.1.4
|
| 158 |
+
rfc3986-validator==0.1.1
|
| 159 |
+
rich==13.6.0
|
| 160 |
+
rpds-py==0.10.6
|
| 161 |
+
rsa==4.9
|
| 162 |
+
safetensors==0.4.1
|
| 163 |
+
scikit-image==0.22.0
|
| 164 |
+
scikit-learn==1.3.2
|
| 165 |
+
scipy==1.11.3
|
| 166 |
+
seaborn==0.13.0
|
| 167 |
+
Send2Trash==1.8.2
|
| 168 |
+
shortcuts==0.11.0
|
| 169 |
+
six==1.16.0
|
| 170 |
+
smart-open==6.4.0
|
| 171 |
+
smmap==5.0.1
|
| 172 |
+
sniffio==1.3.0
|
| 173 |
+
soupsieve==2.5
|
| 174 |
+
stack-data==0.6.3
|
| 175 |
+
statsmodels==0.14.0
|
| 176 |
+
streamlit==1.28.1
|
| 177 |
+
sympy==1.12
|
| 178 |
+
tenacity==8.2.3
|
| 179 |
+
tensorboard==2.15.1
|
| 180 |
+
tensorboard-data-server==0.7.2
|
| 181 |
+
tensorflow==2.15.0
|
| 182 |
+
tensorflow-estimator==2.15.0
|
| 183 |
+
tensorflow-io-gcs-filesystem==0.34.0
|
| 184 |
+
tensorflow-macos==2.15.0
|
| 185 |
+
termcolor==2.4.0
|
| 186 |
+
terminado==0.18.0
|
| 187 |
+
thop==0.1.1.post2209072238
|
| 188 |
+
threadpoolctl==3.2.0
|
| 189 |
+
tifffile==2023.9.26
|
| 190 |
+
tinycss2==1.2.1
|
| 191 |
+
tokenizers==0.15.0
|
| 192 |
+
toml==0.10.2
|
| 193 |
+
tomli==2.0.1
|
| 194 |
+
toolz==0.12.0
|
| 195 |
+
torch==2.1.1
|
| 196 |
+
torchmetrics==1.2.1
|
| 197 |
+
torchutils==0.0.4
|
| 198 |
+
torchview==0.2.6
|
| 199 |
+
torchvision==0.16.1
|
| 200 |
+
tornado==6.3.3
|
| 201 |
+
tqdm==4.66.1
|
| 202 |
+
traitlets==5.13.0
|
| 203 |
+
transformers==4.35.2
|
| 204 |
+
types-python-dateutil==2.8.19.14
|
| 205 |
+
typing_extensions==4.7.1
|
| 206 |
+
tzdata==2023.3
|
| 207 |
+
tzlocal==5.2
|
| 208 |
+
ultralytics==8.0.216
|
| 209 |
+
uri-template==1.3.0
|
| 210 |
+
urllib3==2.0.7
|
| 211 |
+
validators==0.22.0
|
| 212 |
+
wcwidth==0.2.10
|
| 213 |
+
webcolors==1.13
|
| 214 |
+
webencodings==0.5.1
|
| 215 |
+
websocket-client==1.6.4
|
| 216 |
+
Werkzeug==3.0.1
|
| 217 |
+
widgetsnbextension==4.0.9
|
| 218 |
+
wrapt==1.14.1
|
| 219 |
+
yarl==1.9.2
|
| 220 |
+
yfinance==0.2.31
|
| 221 |
+
zipp==3.17.0
|