
Upload 2 files
Browse files- 2024-07-18-08-15-04.yaml +65 -0
- training_loss.png +0 -0
2024-07-18-08-15-04.yaml
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
top.booster: auto
|
| 2 |
+
top.checkpoint_path: []
|
| 3 |
+
top.finetuning_type: lora
|
| 4 |
+
top.model_name: LLaMA2-7B
|
| 5 |
+
top.quantization_bit: '8'
|
| 6 |
+
top.quantization_method: bitsandbytes
|
| 7 |
+
top.rope_scaling: none
|
| 8 |
+
top.template: default
|
| 9 |
+
top.visual_inputs: false
|
| 10 |
+
train.additional_target: ''
|
| 11 |
+
train.badam_mode: layer
|
| 12 |
+
train.badam_switch_interval: 50
|
| 13 |
+
train.badam_switch_mode: ascending
|
| 14 |
+
train.badam_update_ratio: 0.05
|
| 15 |
+
train.batch_size: 2
|
| 16 |
+
train.compute_type: bf16
|
| 17 |
+
train.create_new_adapter: false
|
| 18 |
+
train.cutoff_len: 1024
|
| 19 |
+
train.dataset:
|
| 20 |
+
- an_data
|
| 21 |
+
train.dataset_dir: data
|
| 22 |
+
train.ds_offload: false
|
| 23 |
+
train.ds_stage: none
|
| 24 |
+
train.freeze_extra_modules: ''
|
| 25 |
+
train.freeze_trainable_layers: 2
|
| 26 |
+
train.freeze_trainable_modules: all
|
| 27 |
+
train.galore_rank: 16
|
| 28 |
+
train.galore_scale: 0.25
|
| 29 |
+
train.galore_target: all
|
| 30 |
+
train.galore_update_interval: 200
|
| 31 |
+
train.gradient_accumulation_steps: 8
|
| 32 |
+
train.learning_rate: 5e-5
|
| 33 |
+
train.logging_steps: 1
|
| 34 |
+
train.lora_alpha: 16
|
| 35 |
+
train.lora_dropout: 0
|
| 36 |
+
train.lora_rank: 8
|
| 37 |
+
train.lora_target: ''
|
| 38 |
+
train.loraplus_lr_ratio: 0
|
| 39 |
+
train.lr_scheduler_type: cosine
|
| 40 |
+
train.max_grad_norm: '1.0'
|
| 41 |
+
train.max_samples: '100000'
|
| 42 |
+
train.neat_packing: false
|
| 43 |
+
train.neftune_alpha: 0
|
| 44 |
+
train.num_train_epochs: '3.0'
|
| 45 |
+
train.optim: adamw_torch
|
| 46 |
+
train.packing: true
|
| 47 |
+
train.ppo_score_norm: false
|
| 48 |
+
train.ppo_whiten_rewards: false
|
| 49 |
+
train.pref_beta: 0.1
|
| 50 |
+
train.pref_ftx: 0
|
| 51 |
+
train.pref_loss: sigmoid
|
| 52 |
+
train.report_to: false
|
| 53 |
+
train.resize_vocab: false
|
| 54 |
+
train.reward_model: null
|
| 55 |
+
train.save_steps: 100
|
| 56 |
+
train.shift_attn: false
|
| 57 |
+
train.training_stage: Pre-Training
|
| 58 |
+
train.use_badam: false
|
| 59 |
+
train.use_dora: false
|
| 60 |
+
train.use_galore: false
|
| 61 |
+
train.use_llama_pro: false
|
| 62 |
+
train.use_pissa: false
|
| 63 |
+
train.use_rslora: false
|
| 64 |
+
train.val_size: 0
|
| 65 |
+
train.warmup_steps: 3
|
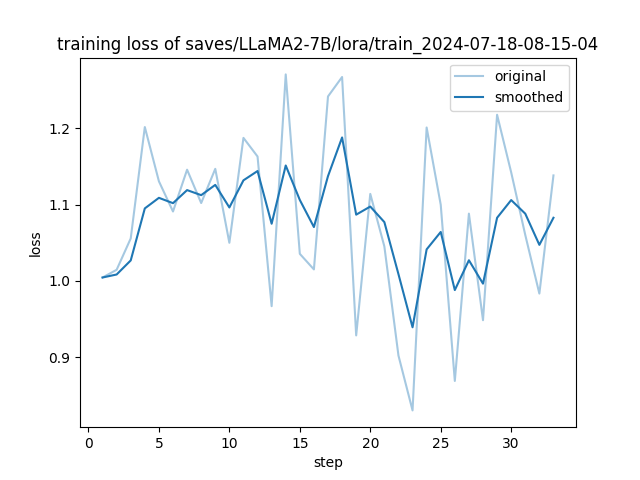
training_loss.png
ADDED
|