Post
771
🔥 🔥 Releasing our new paper on AI safety alignment -- Safety Arithmetic: A Framework for Test-time Safety Alignment of Language Models by Steering Parameters and Activations 🎯 with Sayan Layek, Somnath Banerjee and Soujanya Poria.
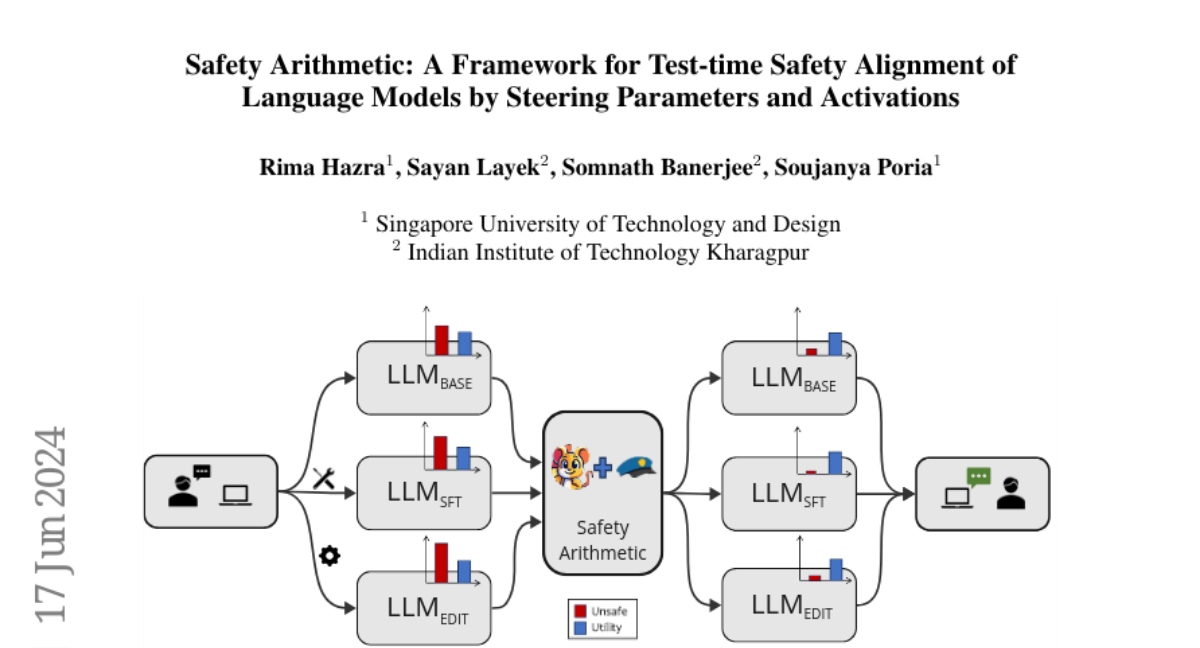
👉 We propose Safety Arithmetic, a training-free framework enhancing LLM safety across different scenarios: Base models, Supervised fine-tuned models (SFT), and Edited models. Safety Arithmetic involves Harm Direction Removal (HDR) to avoid harmful content and Safety Alignment to promote safe responses.
👉 Paper: https://arxiv.org/abs/2406.11801v1
👉 Code: https://github.com/declare-lab/safety-arithmetic
👉 We propose Safety Arithmetic, a training-free framework enhancing LLM safety across different scenarios: Base models, Supervised fine-tuned models (SFT), and Edited models. Safety Arithmetic involves Harm Direction Removal (HDR) to avoid harmful content and Safety Alignment to promote safe responses.
👉 Paper: https://arxiv.org/abs/2406.11801v1
👉 Code: https://github.com/declare-lab/safety-arithmetic