---
license: apache-2.0
language:
- en
pipeline_tag: text-generation
library_name: transformers
tags:
- nlp
- llm
- mllm
---
# CrystalChat-7B-Web2Code: a fully-reproducible vision large language model based on CrystalChat-7B LLM for webpage code generation
## Model Description
CrystalChat-7B based multi-modal large language model (MLLM) mimics the training recipe used for Vicuna-7B based [LLaVa-v1.5](https://huggingface.co./docs/transformers/main/model_doc/llava). CrystalChat-7B based MLLMs models are entirely transparent, having open-sourced all materials, including code, data, model checkpoint, intermediate results, and more at [TODO: Add paper link](). CrystalChat-7B-Web2Code MLLM is specialized in webpage images-to-html code generation.
### About CrystalChat-7B-Web2Code:
* 7 billion parameter LLM
* CLIP ViT-L/14-336px vision encoder
* Languages: English
* Models Released: CrystalChat-7B-Web2Code
* Trained in 2 stages
* License: ?
Crystal-based models were developed as a collaboration between [MBZUAI](https://mbzuai.ac.ae/institute-of-foundation-models/), [Petuum](https://www.petuum.com/), and [LLM360](https://www.llm360.ai/)????.
## Evaluation
General Evaluation Metrics for MLLMs. MME serves as an extensive evaluative benchmark,
aiming to assess perceptual and cognitive capability of MLLMs within 14 sub-tasks. Additionally, we also evaluate the performance of our models on text-oriented visual question answering tasks employing a diverse set of benchmark datasets including ScienceQA and TextVQA. Furthermore, we assess our models’ ability toward anti-hallucination through POPE.
| LLM Backbone | MME-P | MME-C | POPE | SciQA | TextVQA |
|-----------------------------------|---------|--------|-------|--------|---------|
| CrystalCoder-7B | 1359.83 | 238.92 | 86.182 | 64.15 | 50.39 |
| CrystalChat-7B | 1456.53 | **308.21** | 86.96 | 67.77 | **57.84** |
| Vicuna-7B | **1481.12** | 302.85 | **87.174** | **67.97** | 56.49 |
*Table 1: Comparison of different LLM backbones on visual language understanding benchmarks. All models are instruction-tuned on the general domain data (i.e. LLaVA)*
TODO: Add general and code evaluations once jason confirms
## Data and Training Details
### Pretrain Data
LLaVA Visual Instruct Pretrain LCS-558K is a filtered subset of the LAION, CC, and SBU datasets, featuring a more balanced distribution of concept coverage. The file includes multimodal synthesized conversations generated from image-caption pairs by incorporating randomly selected instructions such as "Describe this image." It is used for pretraining in LLaVA, with the raw CC-3M caption serving as the default answer.
### Finetune Data
The finetuning data contains the following:
#### LLaVa Finetuning Data
The dataset chosen was created by LLaVA with academic-task-oriented VQA data mixture and data from ShareGPT. LLaVA Visual Instruct 150K is a dataset of GPT-generated multimodal instruction-following data. It is designed for visual instruction tuning and aims to develop large multimodal models with capabilities akin to GPT-4 in both vision and language.
| Data | Size | Response formatting prompts |
|---------------|------|--------------------------------------------------------------------------|
| LLaVA [36] | 158K | – |
| ShareGPT [46] | 40K | – |
| VQAv2 [19] | 83K | Answer the question using a single word or phrase. |
| GQA [21] | 72K | Answer the question using a single word or phrase. |
| OKVQA [41] | 9K | Answer the question using a single word or phrase. |
| OCRVQA [42] | 80K | Answer the question using a single word or phrase. |
| A-OKVQA [45] | 66K | Answer with the option’s letter from the given choices directly. |
| TextCaps [47] | 22K | Provide a one-sentence caption for the provided image. |
| RefCOCO [24, 40] | 48K | Note: randomly choose between the two formats. Provide a short description for this region. |
| VG [25] | 86K | Provide the bounding box coordinate of the region this sentence describes. |
| **Total** | **665K** | |
*Table 2. Instruction-following Data Mixture of LLaVA-1.5.*
#### Web2Code Data
The Web2Code instruction tuning dataset was released in [Web2Code: A Large-scale Webpage-to-Code Dataset
and Evaluation Framework for Multimodal LLMs](TODO: Add link). The dataset construction and instruction generation process involves four key components:
DWCG: We created new webpage image-code pair data DWCG by generating high-quality HTML webpage-code pairs following the CodeAlpaca prompt using GPT-3.5 and converting them into instruction-following data.
DWCGR: We refined existing webpage code generation data by transforming existing datasets, including WebSight and Pix2Code, into an instruction-following data format similar to LLaVA data, so they can be used as instruction-following data to train MLLMs.
DWU: We created new text question-answer pair data by generating a new question-answer pair dataset utilizing our new GPT-3.5 generated data for webpage understanding.
DWUR: We refined the WebSRC question-answer data to improve its quality using GPT-4.
### Code Datasets
| Dataset | DWCG (ours) | DWCGR (ours) |
|---------|-------------|-------------------|
| **Instruction** | ✓ | ✓ |
| **Source** | Synthetic | Synthetic |
| **Size** | 60K | 824.7K |
| **Avg Length (tokens)** | 471.8±162.3 | 652.85±157.0 |
| **Avg Tag Count** | 28.1±10.6 | 35.3±9.0 |
| **Avg DOM Depth** | 5.3±1.0 | 6.5±1.0 |
| **Avg Unique Tags** | 13.6±2.7 | 13.5±2.5 |
*Table 3. DWCG is a newly generated GPT-3.5-based dataset, while DWCGR is the refined dataset that utilizes WebSight and Pix2Code datasets*
### Webpage Understanding Datasets
| Dataset | DWU | DWUR |
|---------------|---------|-----------------|
| **Instruction** | ✓ | ✓ |
| **Size** | 243.5K | 51.5K |
*Table 4. Distribution of DWU and DWUR datasets. Both datasets include high-quality question-answer pairs for webpage understanding.*
#TODO: check if this is needed, if yes, replace with corresponding for code model
## Stage 2 - Finetuning
| Checkpoints | |
| ----------- | ----------- |
| [CrystalChat](https://huggingface.co./qazimbhat1/my-model-repo3/tree/main) |
| [CrystalCoder](https://huggingface.co./qazimbhat1/Crystal-based-MLLM-7B/tree/Crystal-coder-7B) |
## Stage 1 - Pretraining
| Checkpoints | |
| ----------- | ----------- |
| [CrystalChat](https://huggingface.co./qazimbhat1/Crystal-based-MLLM-7B/tree/Crystal-based-MLLM-7B-pretrain) |
| [CrystalCoder](https://huggingface.co./qazimbhat1/Crystal-based-MLLM-7B/tree/Crystal-coder-7B-pretrain) |
[to find all branches: git branch -a]
## Examples
TODO: Add image as sample example
Example 1:
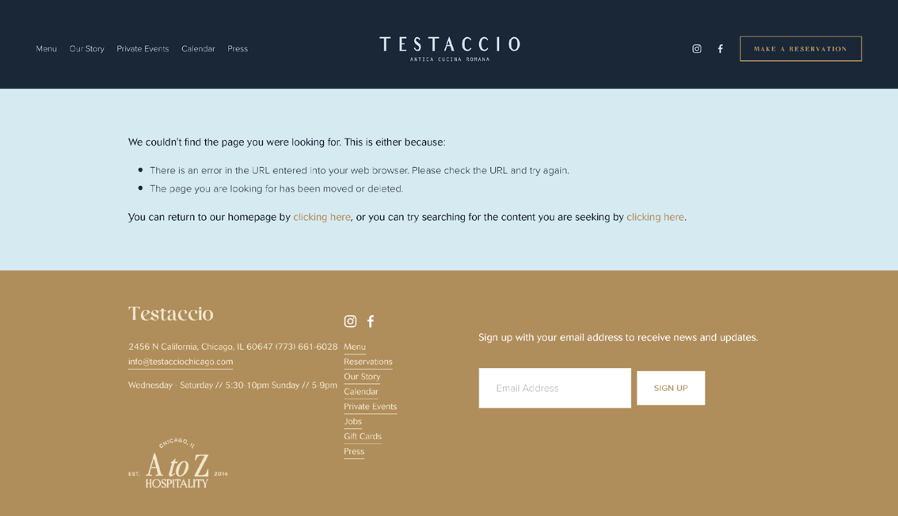 *Image 1. Original Input Image.*
*Image 1. Original Input Image.*
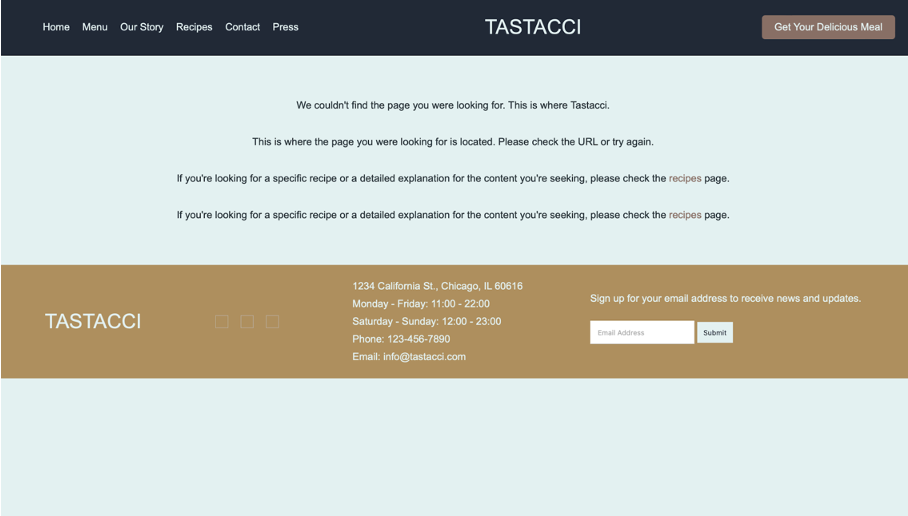 *Image 2. CrystalChat-7B-Web2Code model output.*
Example 2:
*Image 2. CrystalChat-7B-Web2Code model output.*
Example 2:
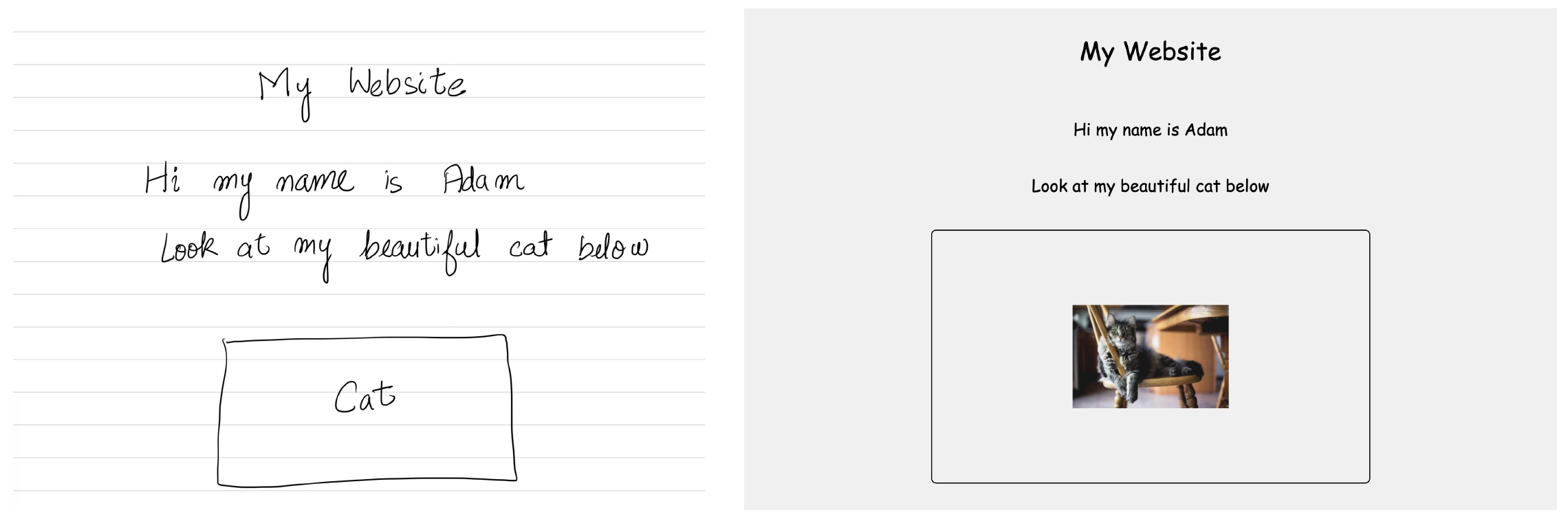 *Image 3. Hand-drawn webpage input to CrystalChat-7B-Web2Code generated output.*
## Loading Crystal
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"LLM360/CrystalChat-7B-MLLM",
padding_side="right",
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"LLM360/CrystalChat-7B-MLLM",
trust_remote_code=True,
torch_dtype=torch.float16,
device_map='auto',
low_cpu_mem_usage=True
)
```
## LLM-360
LLM-360 is an open research lab enabling community-owned AGI through open-source large model research and development.
Crystal-based Models enables community-owned AGI by creating standards and tools to advance the bleeding edge of LLM capability and empower knowledge transfer, research, and development.
We believe in a future where artificial general intelligence (AGI) is created by the community, for the community. Through an open ecosystem of equitable computational resources, high-quality data, and flowing technical knowledge, we can ensure ethical AGI development and universal access for all innovators.
[Visit us](https://www.llm360.ai/)
## Citation
**BibTeX:**
```bibtex
@article{
title={},
author={},
year={},
}
```
*Image 3. Hand-drawn webpage input to CrystalChat-7B-Web2Code generated output.*
## Loading Crystal
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"LLM360/CrystalChat-7B-MLLM",
padding_side="right",
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"LLM360/CrystalChat-7B-MLLM",
trust_remote_code=True,
torch_dtype=torch.float16,
device_map='auto',
low_cpu_mem_usage=True
)
```
## LLM-360
LLM-360 is an open research lab enabling community-owned AGI through open-source large model research and development.
Crystal-based Models enables community-owned AGI by creating standards and tools to advance the bleeding edge of LLM capability and empower knowledge transfer, research, and development.
We believe in a future where artificial general intelligence (AGI) is created by the community, for the community. Through an open ecosystem of equitable computational resources, high-quality data, and flowing technical knowledge, we can ensure ethical AGI development and universal access for all innovators.
[Visit us](https://www.llm360.ai/)
## Citation
**BibTeX:**
```bibtex
@article{
title={},
author={},
year={},
}
```