---
license: apache-2.0
pipeline_tag: text-to-image
tags:
- stable diffusion
- ip adapter
---
# IP Composition Adapter
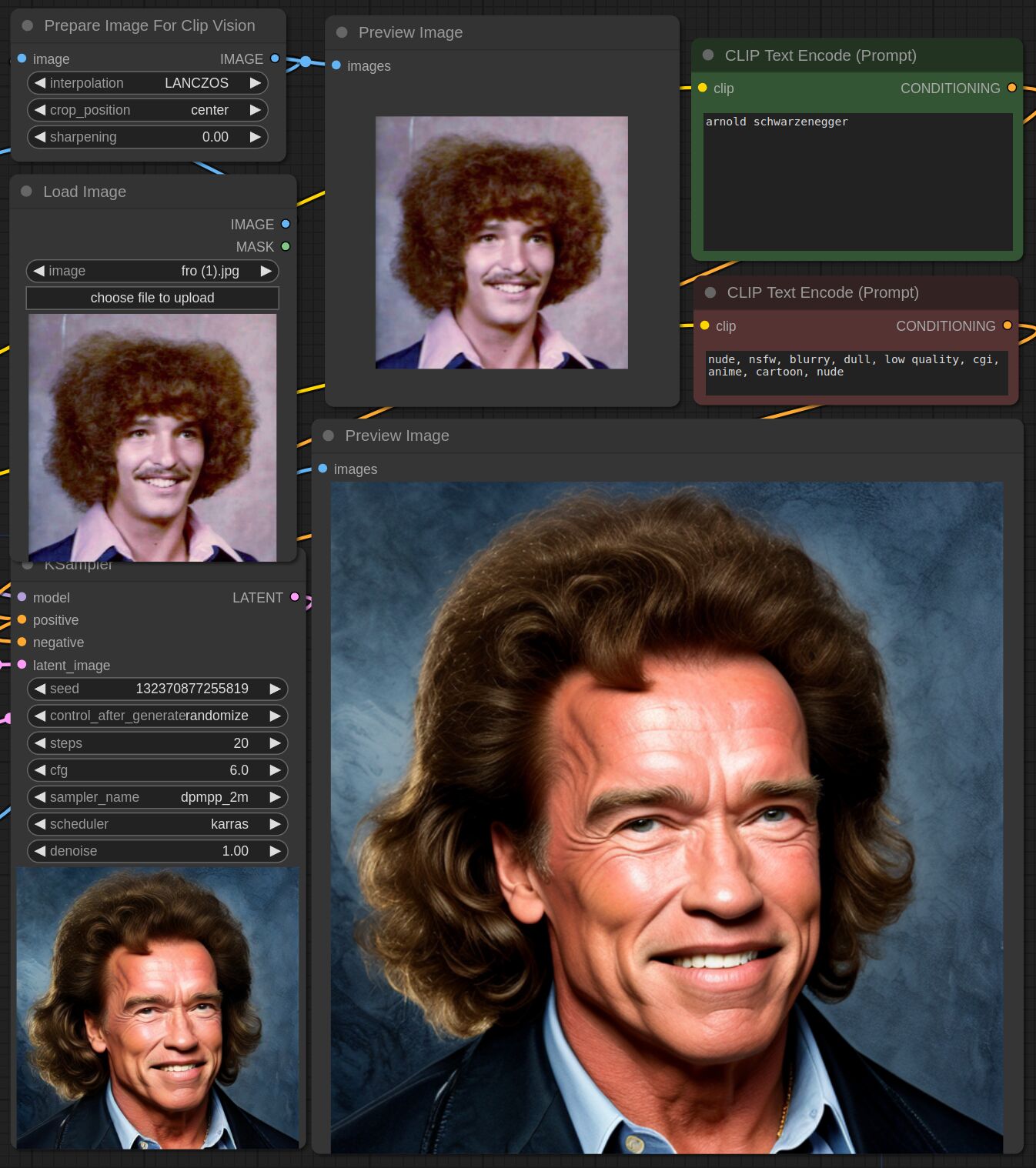
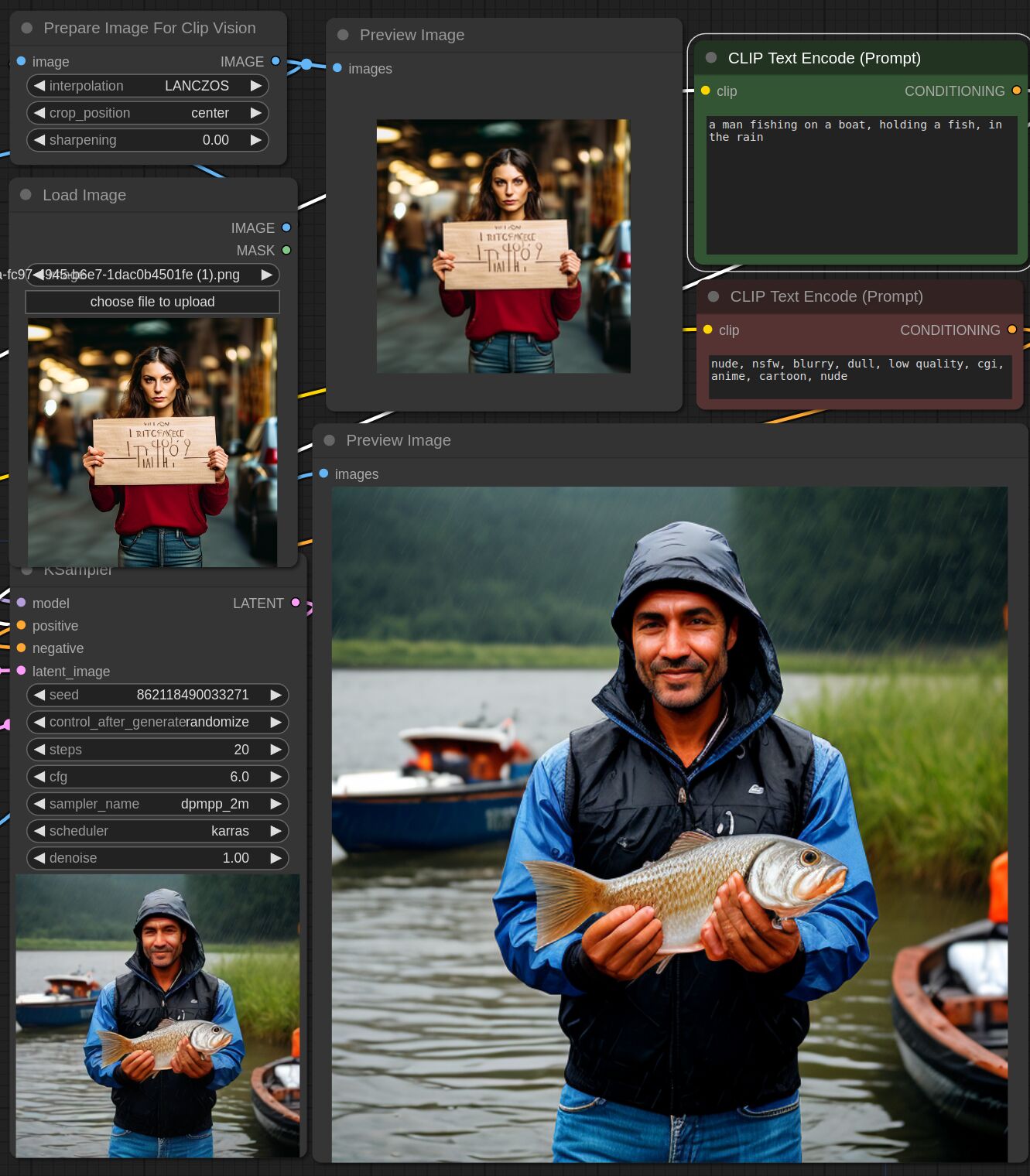
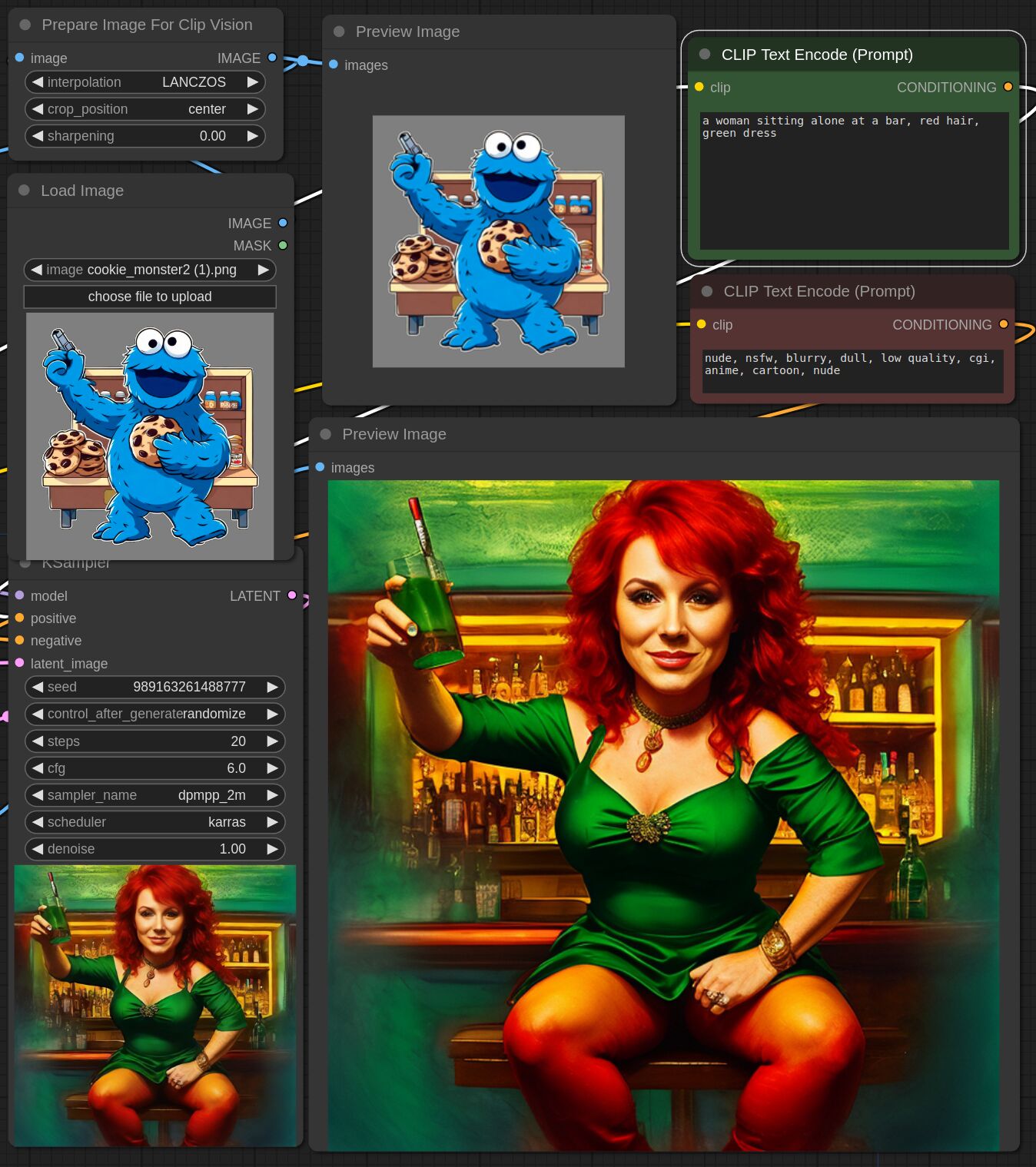
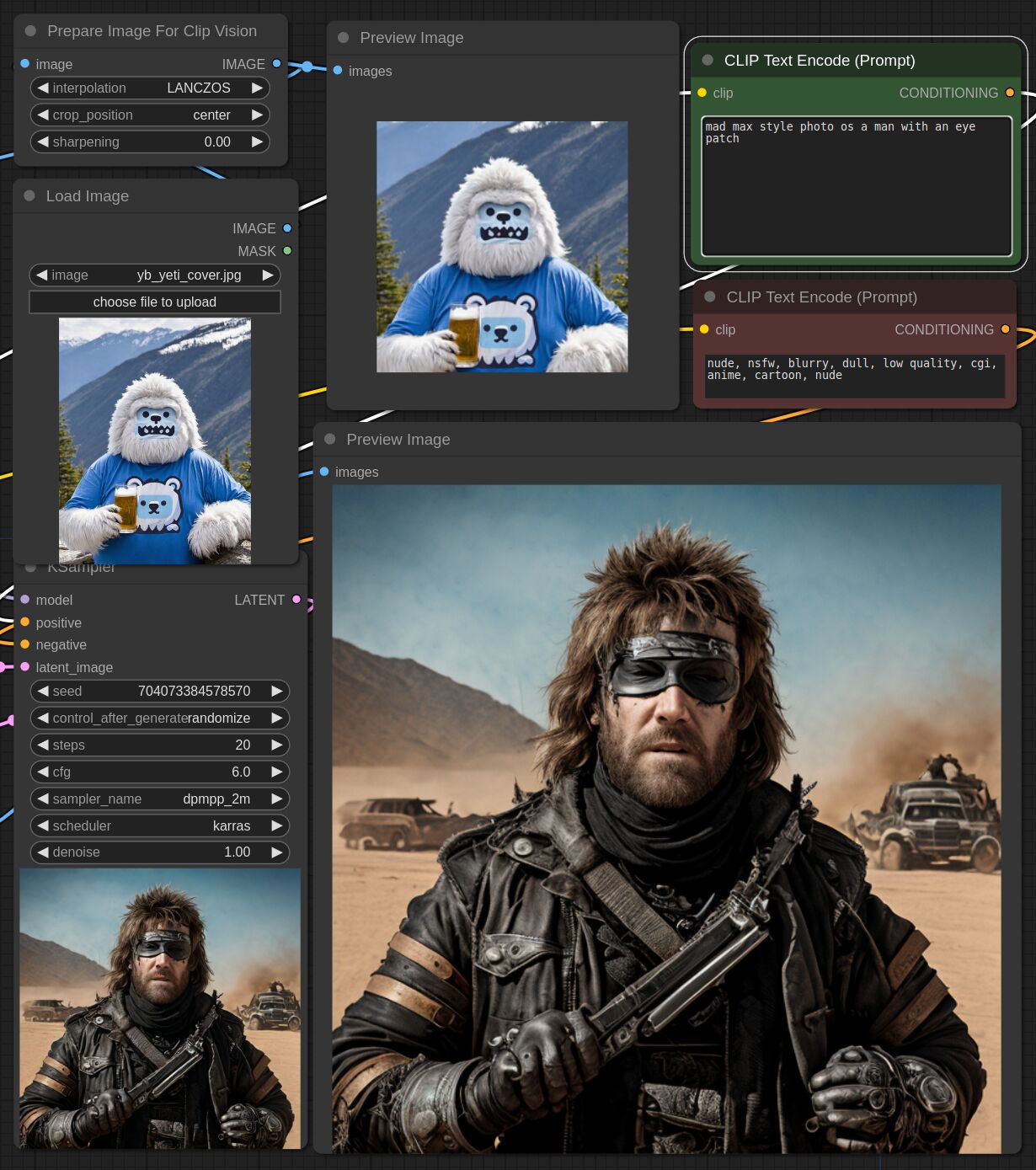
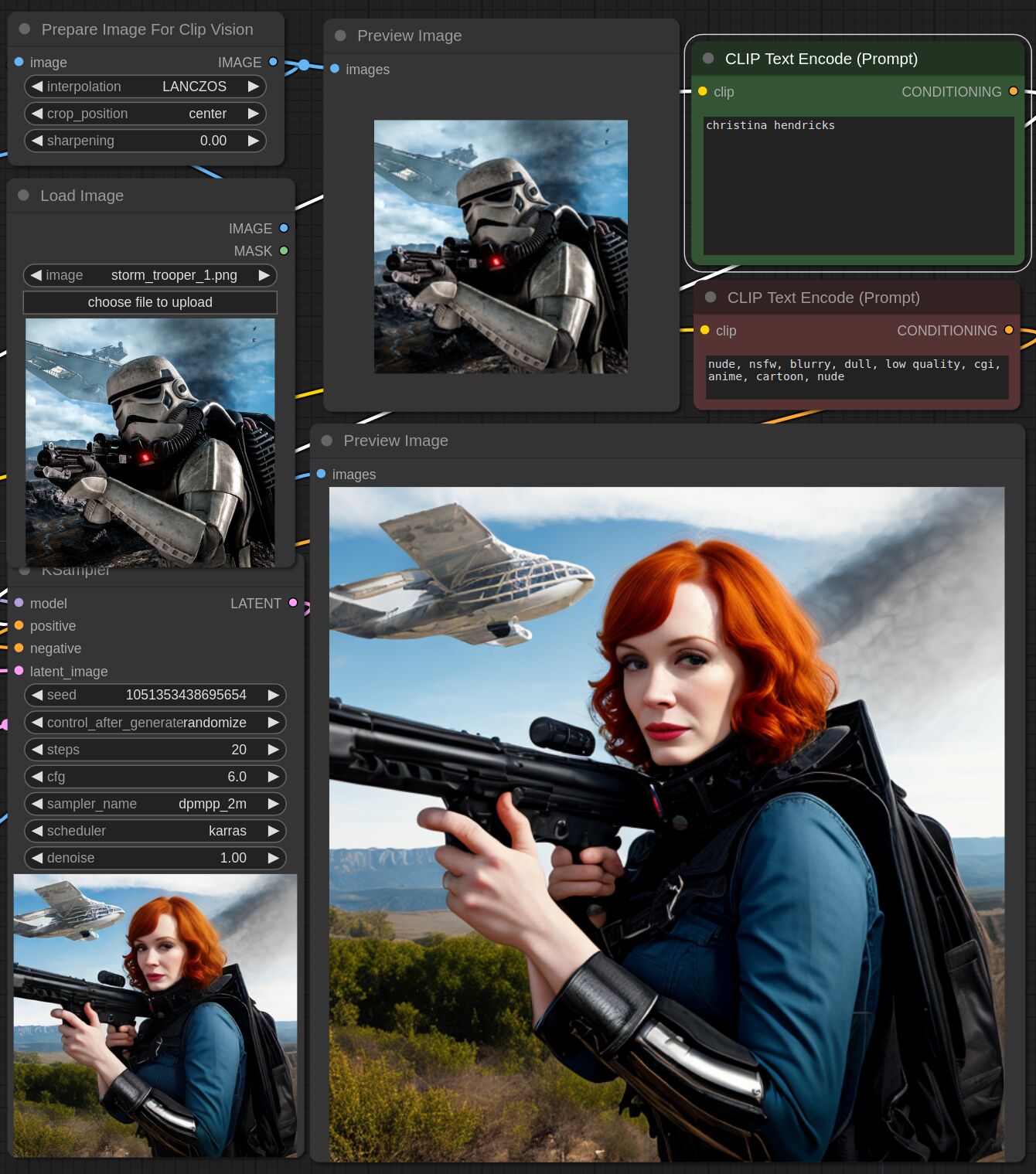
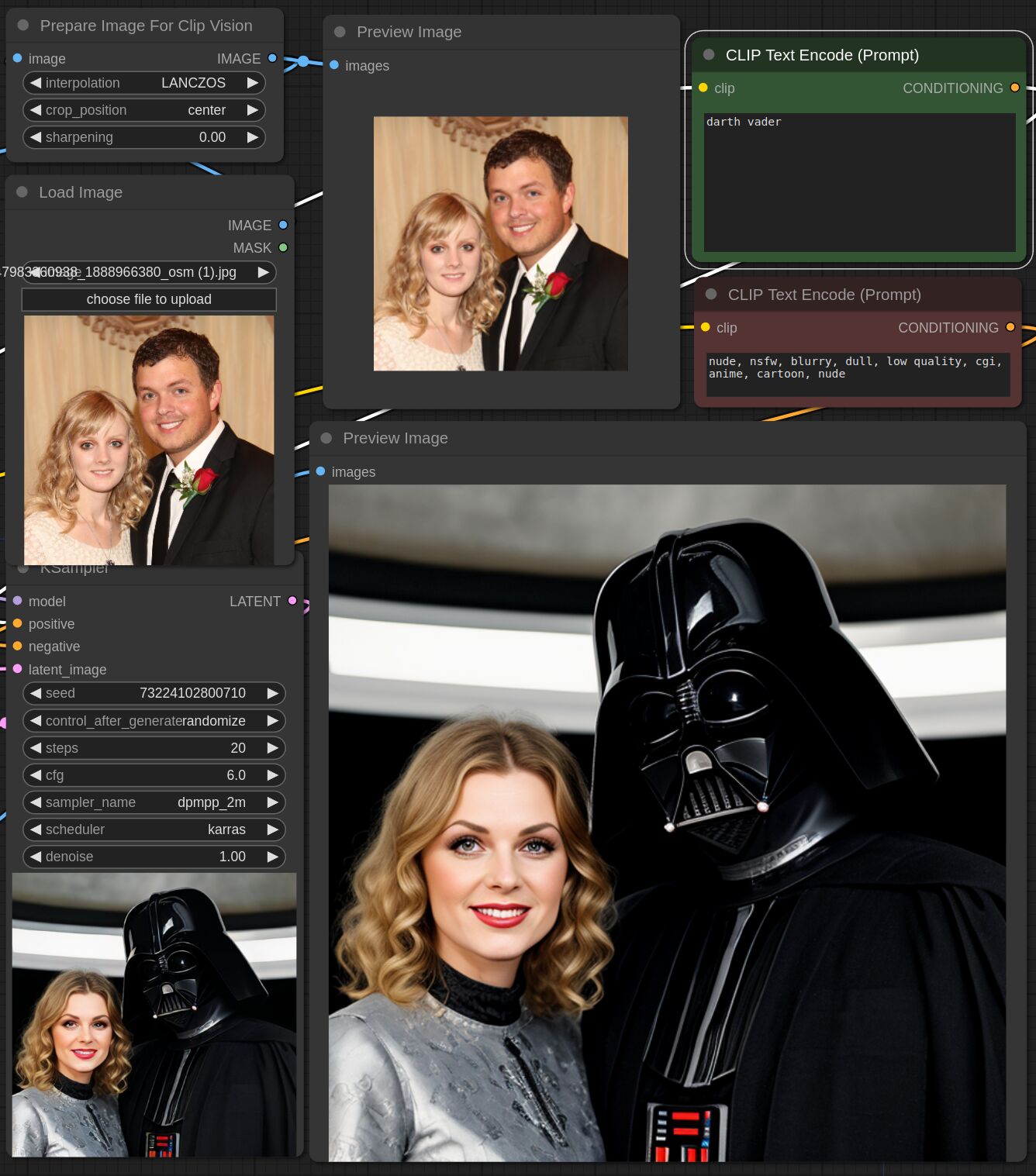
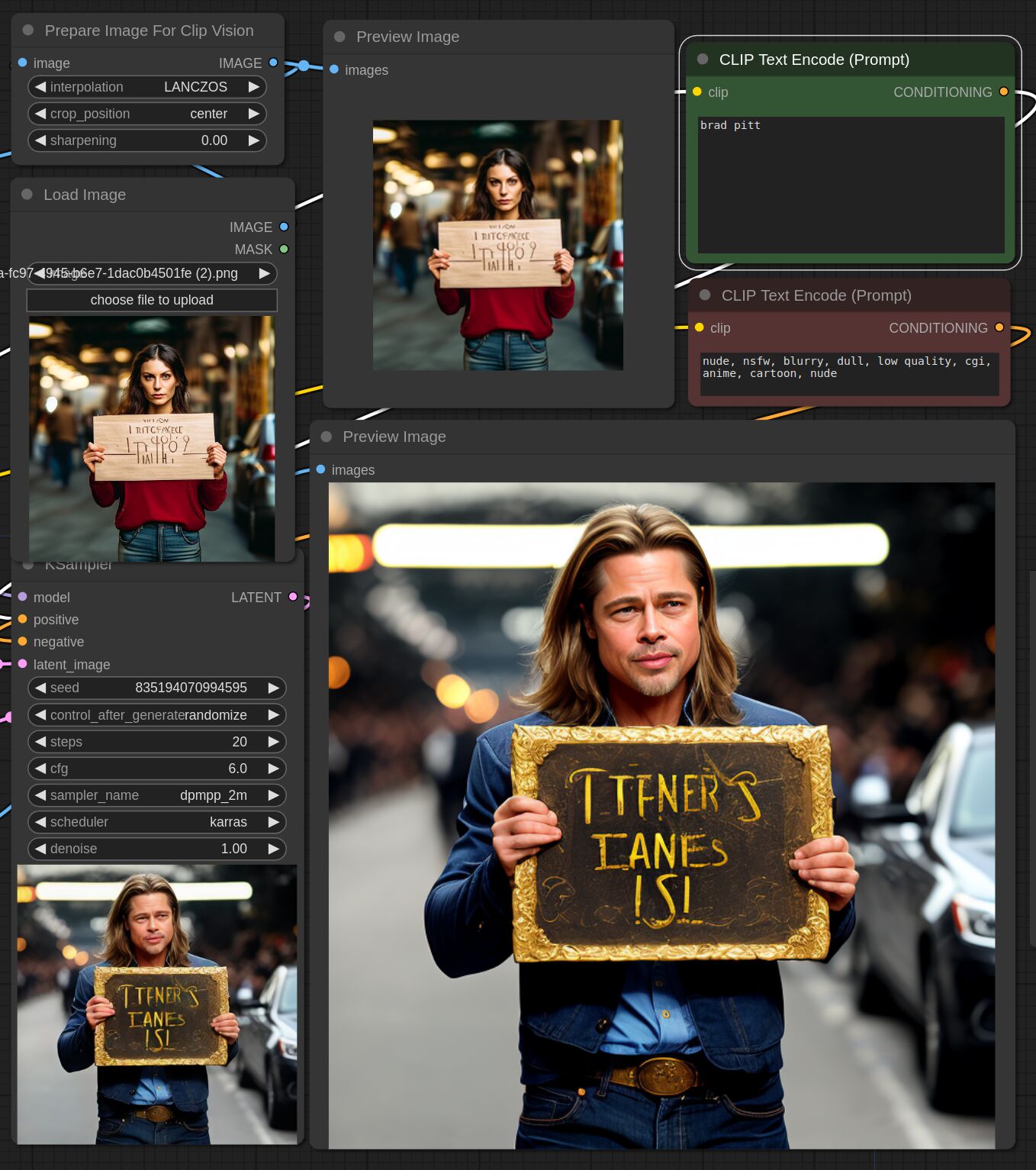
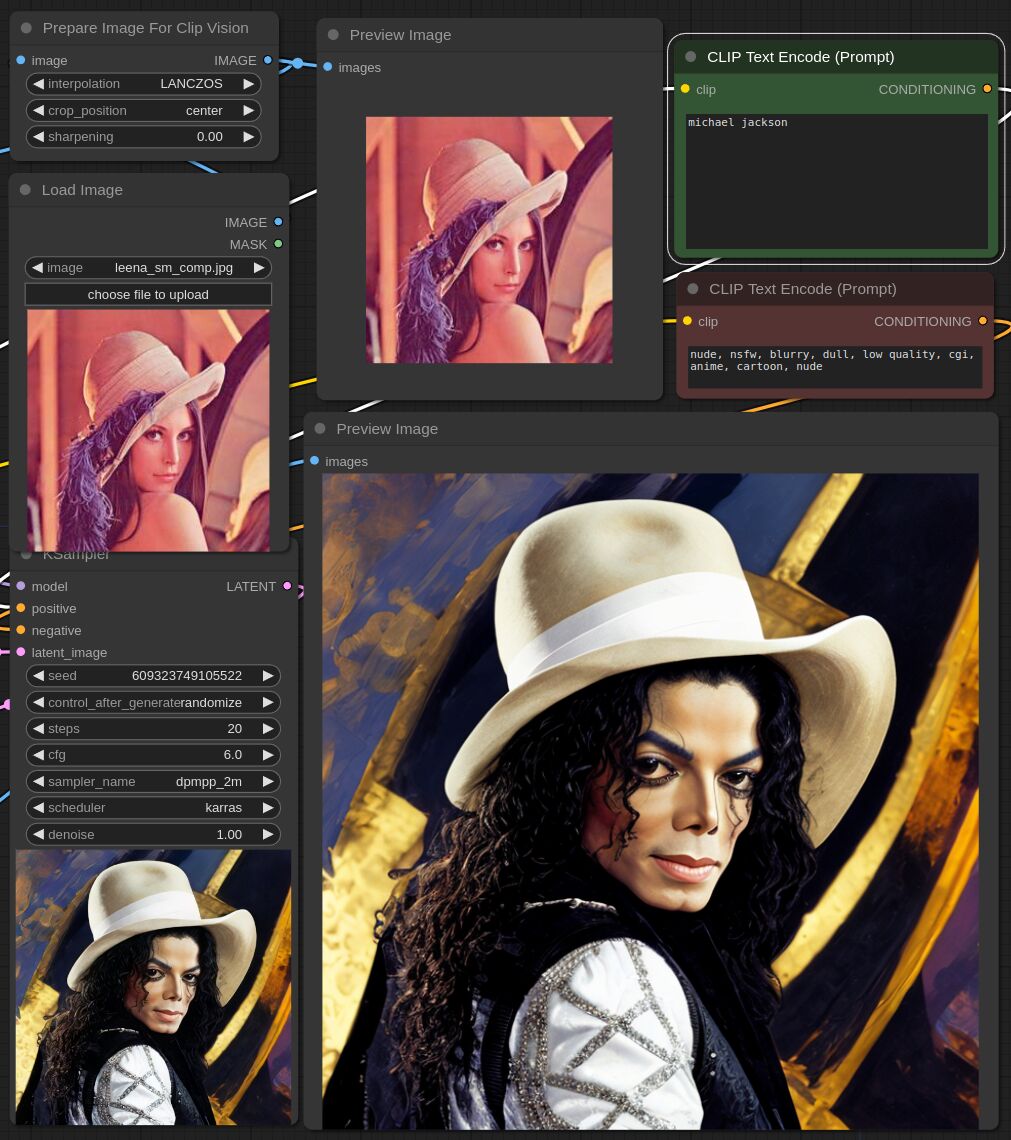
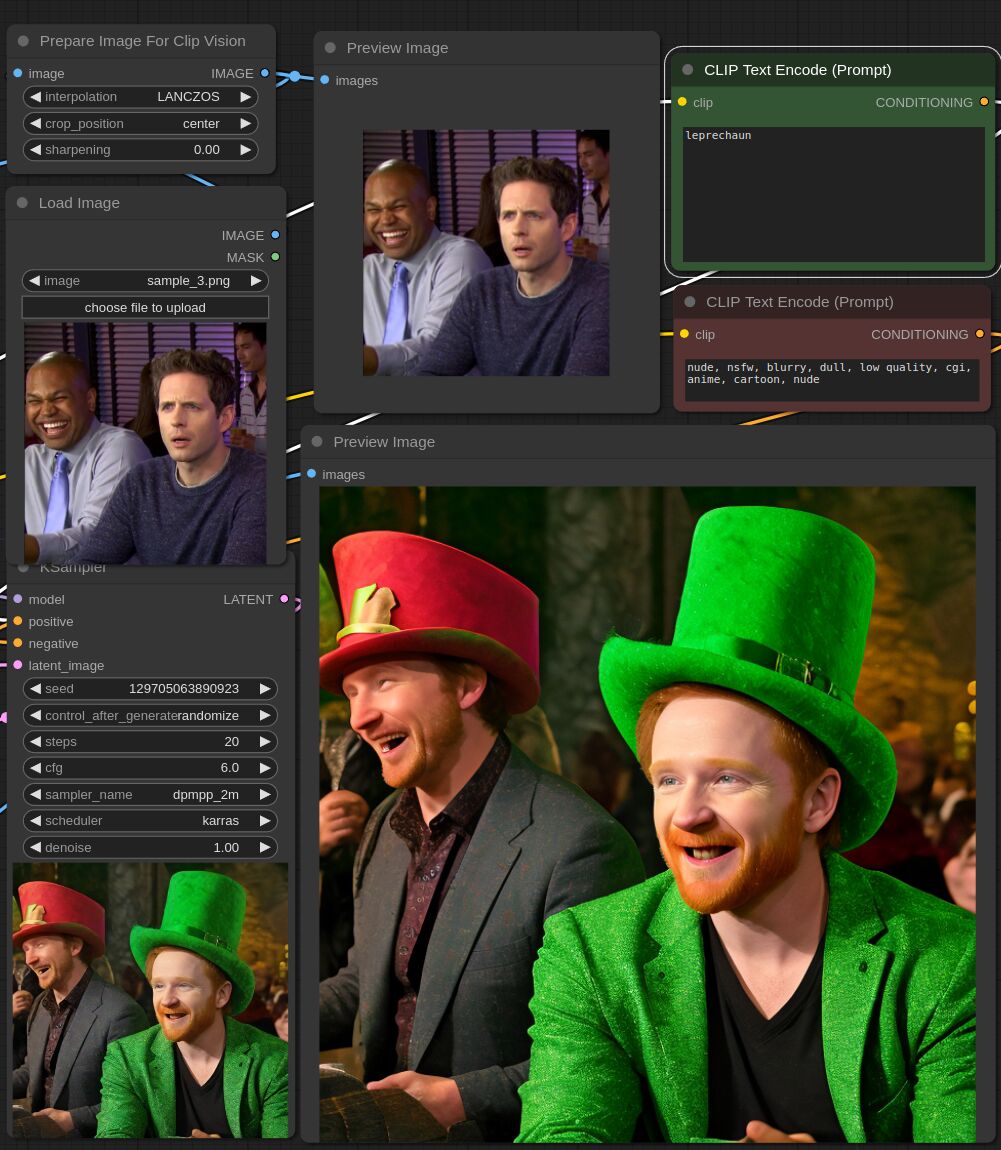
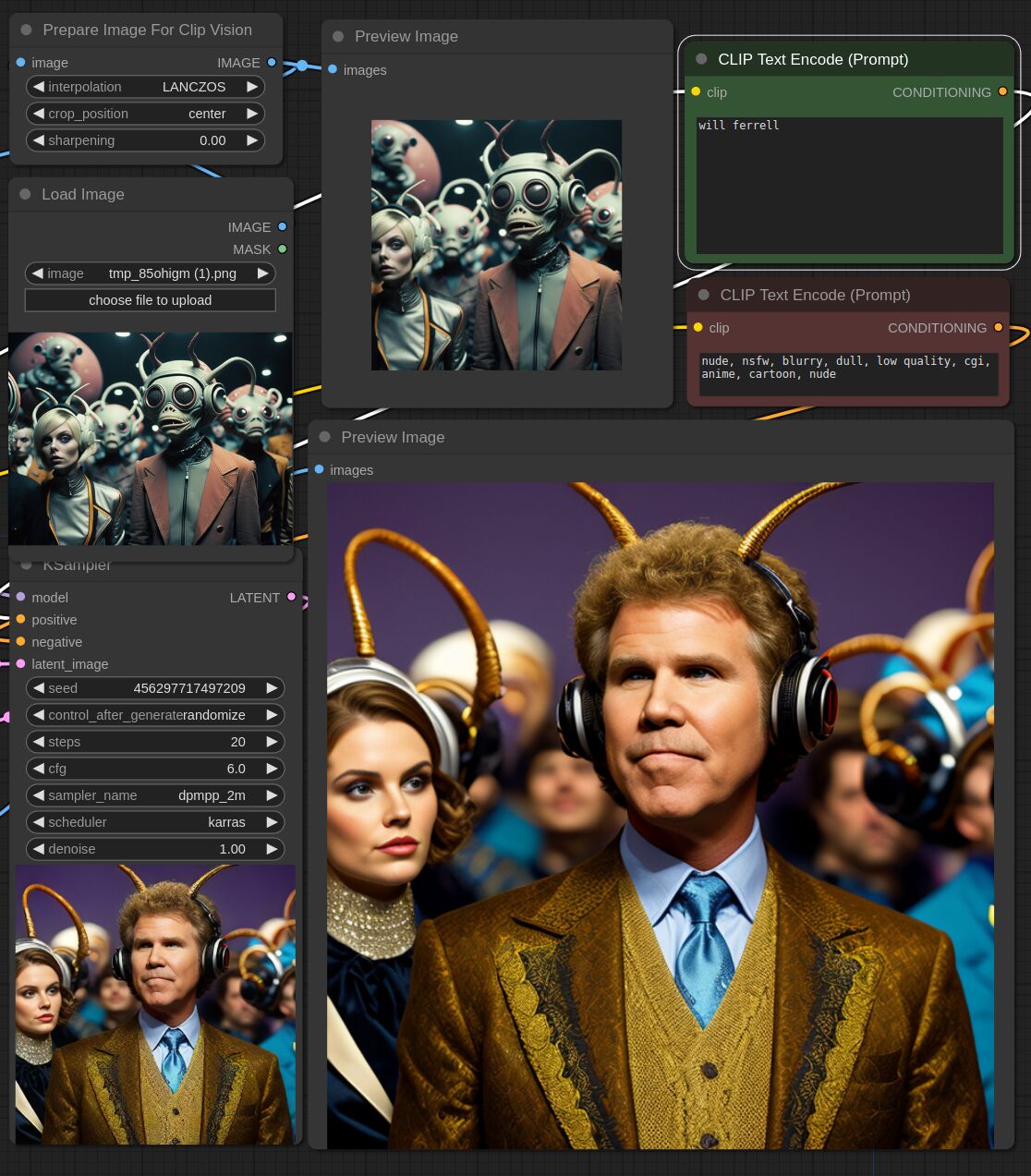
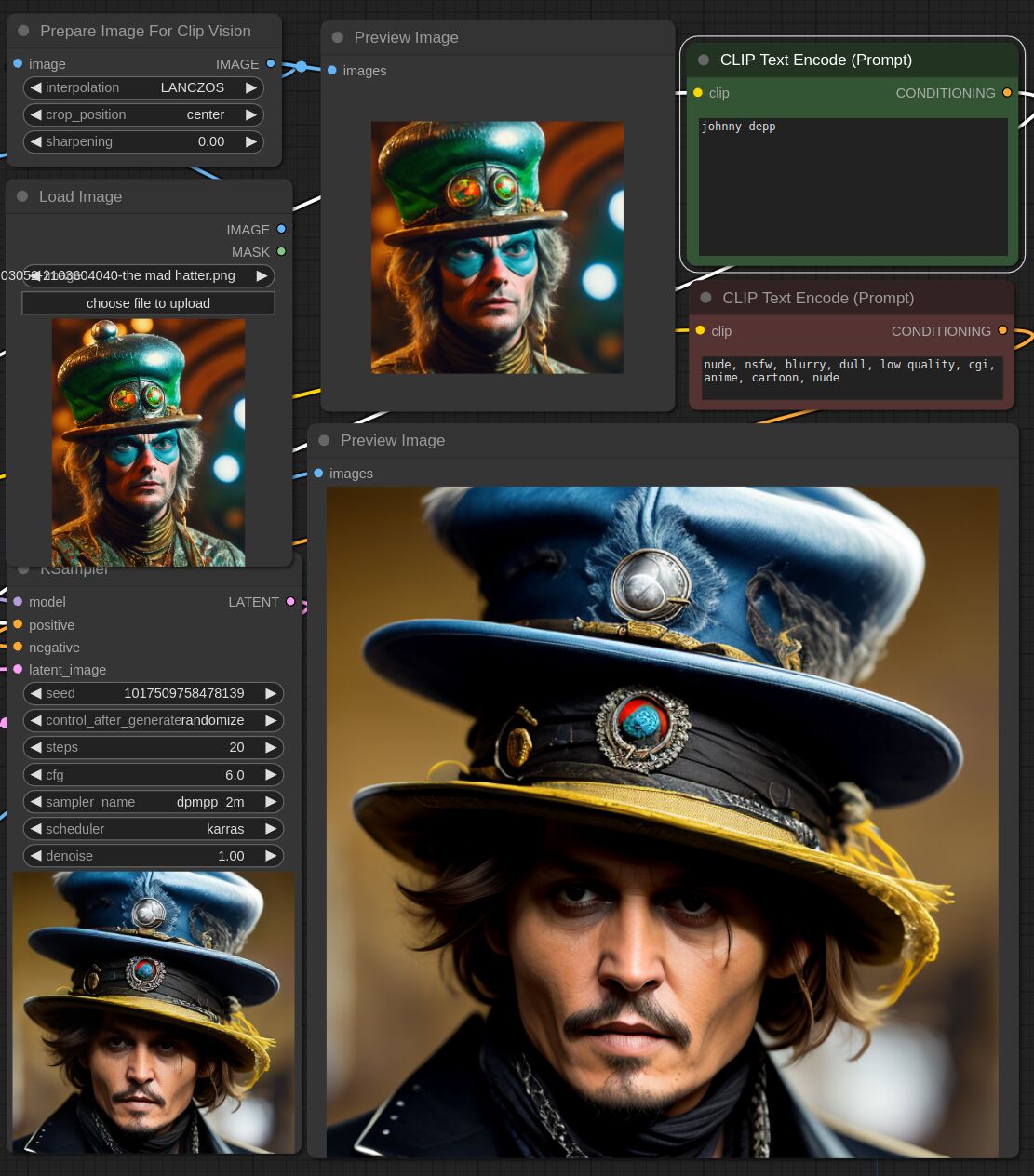
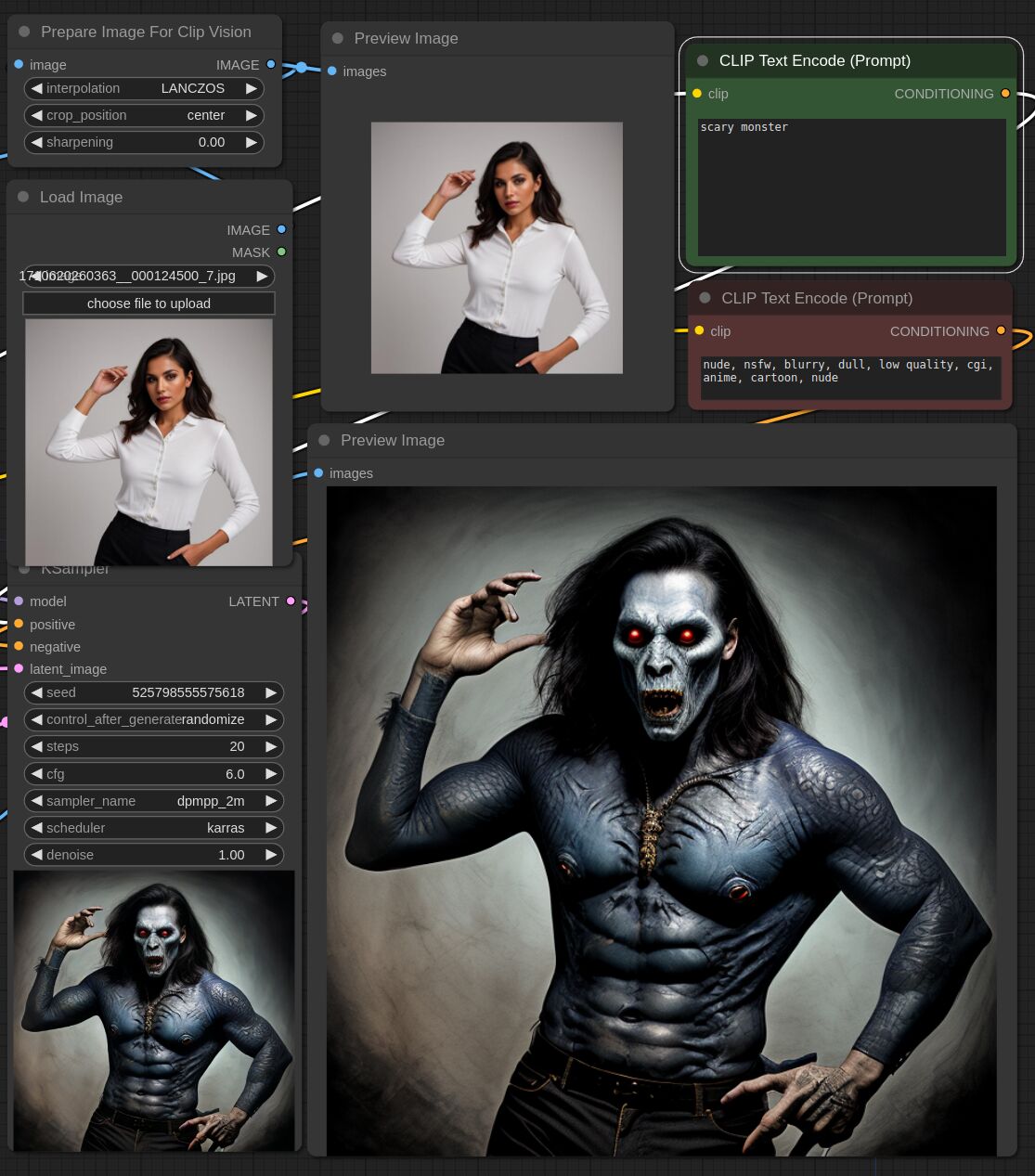
This adapter for Stable Diffusion 1.5 is designed to inject the general composition of an image into the model while mostly ignoring the style and content. Meaning a portrait of a person waving their left hand will result in an image of a completely different person waving with their left hand.
### SDXL
SDXL variant is cooking. Follow me on here or [Twitter](https://twitter.com/ostrisai) for updates when it is avaliable.
### Thanks
I want to give a special thanks to [POM](https://huggingface.co./peteromallet) with [BANODOCO](https://huggingface.co./BANODOCO). This was their idea, I just trained it. Full credit goes to them.
## Usage
Use just like other IP+ adapters from [h94/IP-Adapter](https://huggingface.co./h94/IP-Adapter) for SD 1.5. Use the same CLIP vision encoder ([CLIP-H](https://huggingface.co./h94/IP-Adapter/tree/main/models/image_encoder))
### How is it different from control nets?
Control nets are more rigid. A control net will spatially align an image to nearly perfectly match the control image. The composition adapter allows the control to be more flexible.
## Examples