
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,342 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: llama3
|
| 3 |
+
library_name: transformers
|
| 4 |
+
pipeline_tag: text-generation
|
| 5 |
+
base_model: meta-llama/Meta-Llama-3-70B
|
| 6 |
+
language:
|
| 7 |
+
- zh
|
| 8 |
+
- en
|
| 9 |
+
tags:
|
| 10 |
+
- zhtw
|
| 11 |
+
widget:
|
| 12 |
+
- text: >-
|
| 13 |
+
A chat between a curious user and an artificial intelligence assistant.
|
| 14 |
+
The assistant gives helpful, detailed, and polite answers to the user's
|
| 15 |
+
questions. USER: 你好,請問你可以幫我寫一封推薦信嗎? ASSISTANT:
|
| 16 |
+
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
# 量化模型:AWQ by Troy Chuang
|
| 20 |
+
* 此模型由 [Llama-3-Taiwan-8B-Instruct](https://huggingface.co/yentinglin/Llama-3-Taiwan-8B-Instruct) 以 [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 量化,使用default 4 bit。
|
| 21 |
+
* 請注意:此模型經量化後精度流失,將稍微降低模型效能,但換來更快的推理速度。
|
| 22 |
+
* 以下為 Llama-3-Taiwan-8B-Instruct 的 Model Card。
|
| 23 |
+
|
| 24 |
+
<img src="https://cdn-uploads.huggingface.co/production/uploads/5df9c78eda6d0311fd3d541f/vlfv5sHbt4hBxb3YwULlU.png" alt="Taiwan LLM Logo" width="600" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
|
| 25 |
+
|
| 26 |
+
# 🚀 [Demo Site](https://twllm.com/)
|
| 27 |
+
|
| 28 |
+
Try out Llama-3-Taiwan interactively at [twllm.com](https://twllm.com/)
|
| 29 |
+
|
| 30 |
+
# ⚔️ [Chatbot Arena](https://arena.twllm.com/)
|
| 31 |
+
|
| 32 |
+
Participate in the exciting [Chatbot Arena](https://arena.twllm.com/) and compete against other chatbots!
|
| 33 |
+
|
| 34 |
+
🚀 We're excited to introduce Llama-3-Taiwan-70B! Llama-3-Taiwan-70B is a 70B parameter model finetuned on a large corpus of Traditional Mandarin and English data using the Llama-3 architecture. It demonstrates state-of-the-art performance on various Traditional Mandarin NLP benchmarks.
|
| 35 |
+
|
| 36 |
+
The model was trained with [NVIDIA NeMo™ Framework](https://www.nvidia.com/en-us/ai-data-science/generative-ai/nemo-framework/) using the NVIDIA Taipei-1 built with [NVIDIA DGX H100](https://www.nvidia.com/en-us/data-center/dgx-h100/) systems.
|
| 37 |
+
|
| 38 |
+
The compute and data for training Llama-3-Taiwan-70B was generously sponsored by [Chang Gung Memorial Hospital](https://www.cgmh.org.tw/eng), [Chang Chun Group](https://www.ccp.com.tw/ccpweb.nsf/homepage?openagent), [Legalsign.ai](https://legalsign.ai/), [NVIDIA](https://www.nvidia.com/zh-tw/), [Pegatron](https://www.pegatroncorp.com/), [TechOrange](https://buzzorange.com/techorange/), and [Unimicron](https://www.unimicron.com/) (in alphabetical order).
|
| 39 |
+
|
| 40 |
+
We would like to acknowledge the [contributions](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc1#contributions) of our data provider, team members and advisors in the development of this model, including [shasha77](https://www.youtube.com/@shasha77) for high-quality YouTube scripts and study materials, [Taiwan AI Labs](https://ailabs.tw/) for providing local media content, [Ubitus K.K.](https://ubitus.net/zh/) for offering gaming content, Professor Yun-Nung (Vivian) Chen for her guidance and advisement, Wei-Lin Chen for leading our pretraining data pipeline, Tzu-Han Lin for synthetic data generation, Chang-Sheng Kao for enhancing our synthetic data quality, and Kang-Chieh Chen for cleaning instruction-following data.
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# Model Summary
|
| 44 |
+
|
| 45 |
+
Llama-3-Taiwan-70B is a large language model finetuned for Traditional Mandarin and English users. It has strong capabilities in language understanding, generation, reasoning, and multi-turn dialogue. Key features include:
|
| 46 |
+
|
| 47 |
+
- 70B parameters
|
| 48 |
+
- Languages: Traditional Mandarin (zh-tw), English (en)
|
| 49 |
+
- Finetuned on High-quality Traditional Mandarin and English corpus covering general knowledge as well as industrial knowledge in legal, manufacturing, medical, and electronics domains
|
| 50 |
+
- 8K context length
|
| 51 |
+
- Open model released under the Llama-3 license
|
| 52 |
+
|
| 53 |
+
# Training Details
|
| 54 |
+
|
| 55 |
+
- Training Framework: [NVIDIA NeMo](https://www.nvidia.com/zh-tw/ai-data-science/products/nemo/), [NVIDIA NeMo Megatron](https://docs.nvidia.com/nemo-framework/user-guide/latest/nemotoolkit/nlp/megatron.html)
|
| 56 |
+
- Inference Framework: [NVIDIA TensorRT-LLM](https://github.com/NVIDIA/TensorRT-LLM)
|
| 57 |
+
- Base model: [Llama-3 70B](https://llama.meta.com/llama3/)
|
| 58 |
+
- Hardware: [NVIDIA DGX H100](https://www.nvidia.com/zh-tw/data-center/dgx-h100/) on Taipei-1
|
| 59 |
+
- Context length: 8K tokens ([128k version](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-128k))
|
| 60 |
+
- Batch size: 2M tokens per step
|
| 61 |
+
|
| 62 |
+
# Evaluation
|
| 63 |
+
|
| 64 |
+
Checkout [Open TW LLM Leaderboard](https://huggingface.co/spaces/yentinglin/open-tw-llm-leaderboard) for full and updated list.
|
| 65 |
+
|
| 66 |
+
| Model | [TMLU](https://arxiv.org/pdf/2403.20180) | Taiwan Truthful QA | [Legal Eval](https://huggingface.co/datasets/lianghsun/tw-legal-benchmark-v1) | [TW MT-Bench](https://huggingface.co/datasets/MediaTek-Research/TCEval-v2) | Long context | Function Calling | [TMMLU+](https://github.com/iKala/ievals) |
|
| 67 |
+
|---------------------------------------------------------------------------------|--------------|---------------|--------------------|--------------|--------------|-----------------|-----------|
|
| 68 |
+
| | 學科知識 | 台灣在地化測試 | 台灣法律考題 | 中文多輪對答 | 長文本支援 | 函數呼叫 | |
|
| 69 |
+
| [**yentinglin/Llama-3-Taiwan-70B-Instruct**](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct) | **74.76%** | 80.95% | 68.42% | 7.54 | [128k version](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-128k) | ✅ | 67.53% |
|
| 70 |
+
| [**yentinglin/Llama-3-Taiwan-70B-Instruct-DPO**](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-DPO) | 74.60% | **81.75%** | **70.33%** | - | - | ✅ | - |
|
| 71 |
+
| [**yentinglin/Llama-3-Taiwan-70B-Instruct-128k**](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct) | 73.01% | 80.16% | 63.64% | - | - | ✅ | - |
|
| 72 |
+
| [**yentinglin/Llama-3-Taiwan-8B-Instruct**](https://huggingface.co/yentinglin/Llama-3-Taiwan-8B-Instruct) | 59.50% | 61.11% | 53.11% | 7.21 | [128k version](https://huggingface.co/yentinglin/Llama-3-Taiwan-8B-Instruct-128k) | ✅ | 52.28% |
|
| 73 |
+
| [**yentinglin/Llama-3-Taiwan-8B-Instruct-DPO**](https://huggingface.co/yentinglin/Llama-3-Taiwan-8B-Instruct-DPO) | 59.88% | 59.52% | 52.63% | - | - | ✅ | - |
|
| 74 |
+
| [**yentinglin/Llama-3-Taiwan-8B-Instruct-128k**](https://huggingface.co/yentinglin/Llama-3-Taiwan-8B-Instruct-128k) | - | - | - | - | - | ✅ | - |
|
| 75 |
+
| [Claude-3-Opus](https://www.anthropic.com/api) | [73.59% (5-shot)](https://arxiv.org/pdf/2403.20180) | [69.84%](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc3/tree/main/opus-Taiwan-Truthful-QA) | [60.29%](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc3/tree/main/opus) | - | 200k | ✅ | - |
|
| 76 |
+
| [GPT4-o](https://platform.openai.com/docs/api-reference/chat/create) | [65.56% (0-shot), 69.88% (5-shot)](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc3/tree/main/4o-tmlu) | [76.98%](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc3/tree/main/4o-Taiwan-Truthful-QA) | [53.59%](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc3/tree/main/4o) | - | 128k | ✅ | - |
|
| 77 |
+
| [GPT4-turbo](https://platform.openai.com/docs/api-reference/chat/create) | [70.42% (5-shot)](https://arxiv.org/pdf/2403.20180) | - | - | - | 128k | ✅ | 60.34%^ |
|
| 78 |
+
| [Gemini-Pro](https://ai.google.dev/gemini-api/docs) | [61.40% (5-shot)](https://arxiv.org/pdf/2403.20180) | - | - | - | 1000k | ✅ | 49.92%^ |
|
| 79 |
+
| [GPT-3.5-turbo-1106](https://platform.openai.com/docs/api-reference/chat/create) | [49.37% (5-shot)](https://arxiv.org/pdf/2403.20180) | - | - | 7.1 | 128k | ✅ | 41.76%^ |
|
| 80 |
+
| [Qwen1.5-110B-Chat](https://huggingface.co/Qwen/Qwen1.5-110B-Chat) | **75.69%** | 66.67% | 49.28% | - | 32k | ✅ | 65.81% |
|
| 81 |
+
| [Yi-34B-Chat](https://huggingface.co/01-ai/Yi-34B-Chat) | 73.59% | 71.43% | 55.02% | 6.9 | 200k | ✅ | 64.10% |
|
| 82 |
+
| [Meta-Llama-3-70B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct) | 70.95% | 65.08% | 52.63% | - | 8k | ✅ | 62.75% |
|
| 83 |
+
| [Mixtral-8x22B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1) | 55.57% | 52.38% | 44.98% | - | 64k | ✅ | 52.16% |
|
| 84 |
+
| [Breexe-8x7B-Instruct-v0_1](https://huggingface.co/MediaTek-Research/Breexe-8x7B-Instruct-v0_1) | - | - | - | 7.2 | 8k | ❓ | 48.92% |
|
| 85 |
+
| [c4ai-command-r-plus](https://huggingface.co/CohereForAI/c4ai-command-r-plus) | 62.87% | 64.29% | 34.45% | - | 128k | ✅ | 49.75% |
|
| 86 |
+
| [Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) | 55.81% | 46.83% | 35.89% | - | 8k | ✅ | 43.38% |
|
| 87 |
+
| [Breeze-7B-Instruct-v1_0](https://huggingface.co/MediaTek-Research/Breeze-7B-Instruct-v1_0) | 55.57% | 52.38% | 39.23% | 6.0 | 32k | ❓ | 41.77% |
|
| 88 |
+
| [Llama3-TAIDE-LX-8B-Chat-Alpha1](https://huggingface.co/taide/Llama3-TAIDE-LX-8B-Chat-Alpha1) | 47.30% | 50.79% | 37.80% | - | 8k | ❓ | 39.03% |
|
| 89 |
+
| [Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) | 40.97% | 37.30% | 27.27% | - | 4k | ❓ | 33.02% |
|
| 90 |
+
|
| 91 |
+
Numbers are 0-shot by default.
|
| 92 |
+
|
| 93 |
+
[Eval implementation](https://github.com/adamlin120/lm-evaluation-harness)
|
| 94 |
+
|
| 95 |
+
^ taken the closet matching numbers from original dataset.
|
| 96 |
+
|
| 97 |
+
## Needle in a Haystack Evaluation
|
| 98 |
+
|
| 99 |
+
The "Needle in a 出師表" evaluation tests the model's ability to locate and recall important information embedded within a large body of text, using the classic Chinese text 《出師表》 by 諸葛亮.
|
| 100 |
+
|
| 101 |
+
To run the evaluation, use the [script](https://github.com/adamlin120/needle-haystack/tree/main).
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
# TW MT-Bench Score
|
| 105 |
+
|
| 106 |
+
- Average Score: 7.5375
|
| 107 |
+
- Maximum Score: 10
|
| 108 |
+
- Minimum Score: 1
|
| 109 |
+
- Median Score: 9.0
|
| 110 |
+
- Standard Deviation: 3.0349783771882133
|
| 111 |
+
- Total Number of Scores: 160
|
| 112 |
+
- [Model resopnse](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc1/blob/main/Llama-3-Taiwan.jsonl)
|
| 113 |
+
- [GPT-4 Eval](https://huggingface.co/yentinglin/Llama-3-Taiwan-70B-Instruct-rc1/blob/main/gpt-4_single.jsonl)
|
| 114 |
+
- [Code fork from `mtkresearch/TCEval` with bug fixing](https://github.com/adamlin120/TCEval)
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
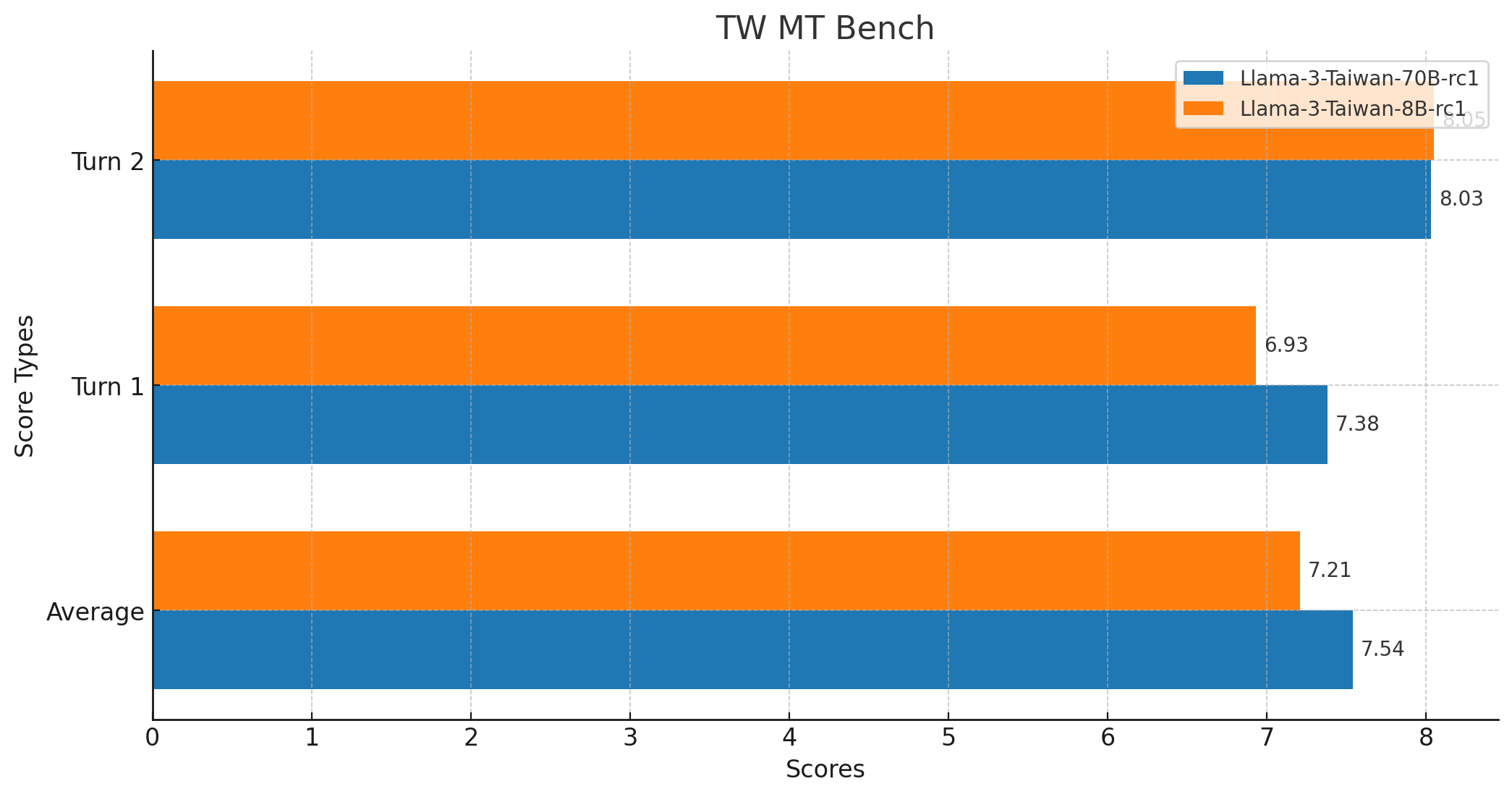
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
# Use Cases
|
| 121 |
+
|
| 122 |
+
Llama-3-Taiwan-70B can be applied to a wide variety of NLP tasks in Traditional Chinese and English, including:
|
| 123 |
+
|
| 124 |
+
<details>
|
| 125 |
+
<summary>1. 多輪對話</summary>
|
| 126 |
+
|
| 127 |
+
<pre>
|
| 128 |
+
System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project.
|
| 129 |
+
|
| 130 |
+
User: 嗨,你好!
|
| 131 |
+
|
| 132 |
+
Assistant: 你好!我今天可以如何協助你?
|
| 133 |
+
|
| 134 |
+
User: 就想聊天而已....
|
| 135 |
+
|
| 136 |
+
Assistant: 當然,我很樂意和你聊天!有什麼特別想談論的嗎?
|
| 137 |
+
</pre>
|
| 138 |
+
|
| 139 |
+
</details>
|
| 140 |
+
|
| 141 |
+
<details>
|
| 142 |
+
<summary>2. RAG(檢索增強生成)</summary>
|
| 143 |
+
|
| 144 |
+
Demo: 可以打開 `Search Web` on [twllm.com](https://twllm.com/)
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+

|
| 148 |
+
|
| 149 |
+
|
| 150 |
+

|
| 151 |
+
|
| 152 |
+
<pre>
|
| 153 |
+
System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project.
|
| 154 |
+
|
| 155 |
+
User: 明天台大天氣如何?
|
| 156 |
+
|
| 157 |
+
Assistant: 根據天氣預報,明天台大天氣為陣雨。低溫 24°C。10 到 15 公里/小時 的 東 風 。降雨機率為 40%。
|
| 158 |
+
</pre>
|
| 159 |
+
|
| 160 |
+
</details>
|
| 161 |
+
|
| 162 |
+
<details>
|
| 163 |
+
<summary>3. 格式化輸出, 語言理解, 實體識別, 函數調用</summary>
|
| 164 |
+
|
| 165 |
+
If you are interested in function-calling, I strongly recommend [using constrained decoding](https://huggingface.co/docs/text-generation-inference/basic_tutorials/using_guidance) to turn on `json mode`.
|
| 166 |
+
|
| 167 |
+
Example from HW7 in `INTRODUCTION TO GENERATIVE AI 2024 SPRING` from `HUNG-YI LEE (李宏毅)`
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+

|
| 171 |
+
|
| 172 |
+
<pre>
|
| 173 |
+
System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project.
|
| 174 |
+
|
| 175 |
+
User: 您是電影評論分析師,負責情緒分析。
|
| 176 |
+
分析每個被評論的句子,評估句子中每個字和標點符號的重要性,
|
| 177 |
+
並且將結果使用 tuple 的結構列出。
|
| 178 |
+
tuple 值的範圍介於 -1 (負向) 到 1 (正向) 之間,
|
| 179 |
+
然後,將評論分類為正向 (1) 或負向 (-1)。
|
| 180 |
+
這些需要被評論的句子,包含在 <review> 標籤中間。
|
| 181 |
+
|
| 182 |
+
輸出範例:
|
| 183 |
+
[(<單字或標點符號>, <float importance>), ...]
|
| 184 |
+
<int classification>
|
| 185 |
+
<review> 根據外媒報導,宏都拉斯在去年3月與台灣斷交,並轉往與中國建交之後,卻遲遲等不到中國的金援,談好要進口宏都拉斯的白蝦也拖延許久,甚至還將白蝦價格殺價至過往與台灣交易的半價,再加上墨西哥同時也中斷了與宏國的白蝦貿易,對當地蝦農可說是雪上加霜。 <review>
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
Assistant: [('根據', 0.2), ('外媒', 0.1), ('報導', -0.1), (',', 0.05), ('宏都拉斯', -0.3), ('在去年3月與台灣斷交, ', -0.5), ('並轉往與中國建交之後, ', -0.4), ('卻遲遲等不到中國的金援, ', -1),
|
| 189 |
+
('談好要進口宏都拉斯的白蝦也拖延許久, ', -1),
|
| 190 |
+
(',甚至還將白蝦價格殺價至過往與台灣交易的半價,再加上墨西哥同時也中斷了與宏國的白蝦貿易,對當地蝦農可說是雪上加霜。 ',-1)]
|
| 191 |
+
-1
|
| 192 |
+
|
| 193 |
+
</pre>
|
| 194 |
+
</details>
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
# Get Started
|
| 201 |
+
|
| 202 |
+
*Caveat: System message should always be set.*
|
| 203 |
+
|
| 204 |
+
## Hugging Face Transformers library
|
| 205 |
+
You can use Llama-3-Taiwan-70B with the Hugging Face Transformers library:
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
```python
|
| 209 |
+
import torch
|
| 210 |
+
from transformers import pipeline, StoppingCriteria
|
| 211 |
+
|
| 212 |
+
# Define a custom stopping criteria class
|
| 213 |
+
class EosListStoppingCriteria(StoppingCriteria):
|
| 214 |
+
def __init__(self, eos_sequence=[128256]):
|
| 215 |
+
self.eos_sequence = eos_sequence
|
| 216 |
+
|
| 217 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 218 |
+
last_ids = input_ids[:, -len(self.eos_sequence):].tolist()
|
| 219 |
+
return self.eos_sequence in last_ids
|
| 220 |
+
|
| 221 |
+
# Initialize the model with automatic device mapping
|
| 222 |
+
llm = pipeline("text-generation", model="yentinglin/Llama-3-Taiwan-70B-Instruct-rc1", device_map="auto")
|
| 223 |
+
tokenizer = llm.tokenizer
|
| 224 |
+
|
| 225 |
+
# Define a conversation example
|
| 226 |
+
chat = [
|
| 227 |
+
{"role": "system", "content": "You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project."},
|
| 228 |
+
{"role": "user", "content": "你好,請問你可以完成什麼任務?"},
|
| 229 |
+
{"role": "assistant", "content": "你好,我可以幫助您解決各種問題、提供資訊並協助完成多種任務。例如:回答技術問題、提供建議、翻譯文字、尋找資料或協助您安排行程等。請告訴我如何能幫助您。"},
|
| 230 |
+
{"role": "user", "content": "太棒了!"}
|
| 231 |
+
]
|
| 232 |
+
flatten_chat_for_generation = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
|
| 233 |
+
"""
|
| 234 |
+
<|im_start|>user
|
| 235 |
+
You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project.<|im_end|>
|
| 236 |
+
<|im_start|>user
|
| 237 |
+
你好,請問你可以完成什麼任務?<|im_end|>
|
| 238 |
+
<|im_start|>assistant
|
| 239 |
+
你好,我可以幫助您解決各種問題、提供資訊和協助您完成許多不同的任務。例如:回答技術問題、提供建議、翻譯文字、尋找資料或協助您安排行程等。請告訴我如何能幫助您。<|im_end|>
|
| 240 |
+
<|im_start|>user
|
| 241 |
+
太棒了!<|im_end|>
|
| 242 |
+
<|im_start|>assistant
|
| 243 |
+
|
| 244 |
+
"""
|
| 245 |
+
|
| 246 |
+
# Generate a response using the custom stopping criteria
|
| 247 |
+
output = llm(flatten_chat_for_generation, return_full_text=False, max_new_tokens=128, top_p=0.9, temperature=0.7, stopping_criteria=[EosListStoppingCriteria([tokenizer.eos_token_id])])
|
| 248 |
+
print(output[0]['generated_text'])
|
| 249 |
+
"謝謝!很高興能夠為您服務。如果有任何其他需要協助的地方,請隨時與我聯繫。我會盡最大努力為您提供所需的支援。"
|
| 250 |
+
```
|
| 251 |
+
|
| 252 |
+
## vLLM
|
| 253 |
+
|
| 254 |
+
Start the server
|
| 255 |
+
```bash
|
| 256 |
+
export NUM_GPUS=4
|
| 257 |
+
export PORT=8000
|
| 258 |
+
|
| 259 |
+
docker run \
|
| 260 |
+
-e HF_TOKEN=$HF_TOKEN \
|
| 261 |
+
--gpus '"device=0,1,2,3"' \
|
| 262 |
+
-v ~/.cache/huggingface:/root/.cache/huggingface \
|
| 263 |
+
-p "${PORT}:8000" \
|
| 264 |
+
--ipc=host \
|
| 265 |
+
vllm/vllm-openai:v0.4.0.post1 \
|
| 266 |
+
--model "yentinglin/Llama-3-Taiwan-70B-Instruct-rc1" \
|
| 267 |
+
-tp "${NUM_GPUS}"
|
| 268 |
+
```
|
| 269 |
+
|
| 270 |
+
Sample client code, or you can use anything OpenAI-API compatible clients
|
| 271 |
+
|
| 272 |
+
```python
|
| 273 |
+
# pip install "openai>=1.0.0"
|
| 274 |
+
from openai import OpenAI
|
| 275 |
+
# Set OpenAI's API key and API base to use vLLM's API server.
|
| 276 |
+
openai_api_key = "EMPTY"
|
| 277 |
+
openai_api_base = "http://localhost:8000/v1"
|
| 278 |
+
|
| 279 |
+
client = OpenAI(
|
| 280 |
+
api_key=openai_api_key,
|
| 281 |
+
base_url=openai_api_base,
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
chat_response = client.chat.completions.create(
|
| 285 |
+
model="yentinglin/Llama-3-Taiwan-70B-Instruct-rc1",
|
| 286 |
+
messages=[
|
| 287 |
+
{"role": "system", "content": "You are a helpful assistant."},
|
| 288 |
+
{"role": "user", "content": "Tell me a joke."},
|
| 289 |
+
]
|
| 290 |
+
)
|
| 291 |
+
print("Chat response:", chat_response)
|
| 292 |
+
```
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
Enjoy exploring the capabilities of Llama-3-Taiwan-70B! We look forward to seeing what you create with this powerful open-source model. If you have any questions or feedback, please let us know.
|
| 296 |
+
|
| 297 |
+
# Contributions
|
| 298 |
+
- [**Professor Yun-Nung (Vivian) Chen**](https://www.csie.ntu.edu.tw/~yvchen/), for her guidance and advisement throughout the project.
|
| 299 |
+
- [**Wei-Lin Chen**](mailto:[email protected]), for leading our pretraining data pipeline.
|
| 300 |
+
- [**Tzu-Han Lin**](mailto:[email protected]), for synthetic data generation.
|
| 301 |
+
- [**Chang-Sheng Kao**](mailto:[email protected]), for enhancing our synthetic data quality.
|
| 302 |
+
- [**Kang-Chieh Chen**](mailto:[email protected]), for cleaning instruction-following data.
|
| 303 |
+
- [**Min-Yi Chen**](mailto:[email protected]) and [**Shao-Heng Hsu**](mailto:[email protected]), for collecting chemical engineering data and benchmarks.
|
| 304 |
+
- Chung-Yao Ma, Jonathan Guo and Kai-Chun Chang, for collecting manufacturing and electrical engineering data and benchmarks, and project progress management
|
| 305 |
+
|
| 306 |
+
# Citation
|
| 307 |
+
```
|
| 308 |
+
@article{DBLP:journals/corr/abs-2311-17487,
|
| 309 |
+
author = {Yen{-}Ting Lin and
|
| 310 |
+
Yun{-}Nung Chen},
|
| 311 |
+
title = {Taiwan {LLM:} Bridging the Linguistic Divide with a Culturally Aligned
|
| 312 |
+
Language Model},
|
| 313 |
+
journal = {CoRR},
|
| 314 |
+
volume = {abs/2311.17487},
|
| 315 |
+
year = {2023},
|
| 316 |
+
url = {https://doi.org/10.48550/arXiv.2311.17487},
|
| 317 |
+
doi = {10.48550/ARXIV.2311.17487},
|
| 318 |
+
eprinttype = {arXiv},
|
| 319 |
+
eprint = {2311.17487},
|
| 320 |
+
timestamp = {Tue, 05 Dec 2023 14:40:42 +0100},
|
| 321 |
+
biburl = {https://dblp.org/rec/journals/corr/abs-2311-17487.bib},
|
| 322 |
+
bibsource = {dblp computer science bibliography, https://dblp.org}
|
| 323 |
+
}
|
| 324 |
+
@article{DBLP:journals/corr/abs-2403-20180,
|
| 325 |
+
author = {Po{-}Heng Chen and
|
| 326 |
+
Sijia Cheng and
|
| 327 |
+
Wei{-}Lin Chen and
|
| 328 |
+
Yen{-}Ting Lin and
|
| 329 |
+
Yun{-}Nung Chen},
|
| 330 |
+
title = {Measuring Taiwanese Mandarin Language Understanding},
|
| 331 |
+
journal = {CoRR},
|
| 332 |
+
volume = {abs/2403.20180},
|
| 333 |
+
year = {2024},
|
| 334 |
+
url = {https://doi.org/10.48550/arXiv.2403.20180},
|
| 335 |
+
doi = {10.48550/ARXIV.2403.20180},
|
| 336 |
+
eprinttype = {arXiv},
|
| 337 |
+
eprint = {2403.20180},
|
| 338 |
+
timestamp = {Wed, 10 Apr 2024 17:37:45 +0200},
|
| 339 |
+
biburl = {https://dblp.org/rec/journals/corr/abs-2403-20180.bib},
|
| 340 |
+
bibsource = {dblp computer science bibliography, https://dblp.org}
|
| 341 |
+
}
|
| 342 |
+
```
|