
figures commit from lixin4sky
Browse files- .DS_Store +0 -0
- README.md +102 -0
- figures/.DS_Store +0 -0
- figures/figure_1_the_pipeline_of_ProGraph_benchmark_construction.jpg +0 -0
- figures/figure_2_the_pipeline_of_LLM4Graph_dataset_construction_and_corresponding_model_enhancement.jpg +0 -0
- figures/figure_4_the_pass rate_and_accuracy_of_open-source_models_withe_instruction_tuning.jpg +0 -0
- figures/figure_6_compilation_error_statistics_for_open-source_models.jpg +0 -0
.DS_Store
CHANGED
|
Binary files a/.DS_Store and b/.DS_Store differ
|
|
|
README.md
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
license: mit
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
metrics:
|
| 5 |
+
- accuracy
|
| 6 |
+
- pass rate
|
| 7 |
+
base_model:
|
| 8 |
+
- meta-llama/Meta-Llama-3-8B-Instruct
|
| 9 |
+
- deepseek-ai/deepseek-coder-7b-instruct-v1.5
|
| 10 |
+
library_name: transformers, alignment-handbook
|
| 11 |
+
pipeline_tag: question-answering
|
| 12 |
+
|
| 13 |
+
### 1. Introduction of this repository
|
| 14 |
+
|
| 15 |
+
Official Repository of "Can Large Language Models Analyze Graphs like Professionals? A Benchmark, Datasets and Models". NeurIPS 2024
|
| 16 |
+
|
| 17 |
+
- **Paper Link:** (https://arxiv.org/abs/2409.19667/)
|
| 18 |
+
- **GitHub Repository:** (https://github.com/BUPT-GAMMA/ProGraph)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
### 2. Pipelines and Experimental Results
|
| 22 |
+
|
| 23 |
+
#### The pipeline of ProGraph benchmark construction
|
| 24 |
+
|
| 25 |
+
<img width="1000px" alt="" src="https://huggingface.co/spaces/lixin4sky/ProGraph/blob/main/figure_1_the_pipeline_of_ProGraph_benchmark_construction.jpg">
|
| 26 |
+
|
| 27 |
+
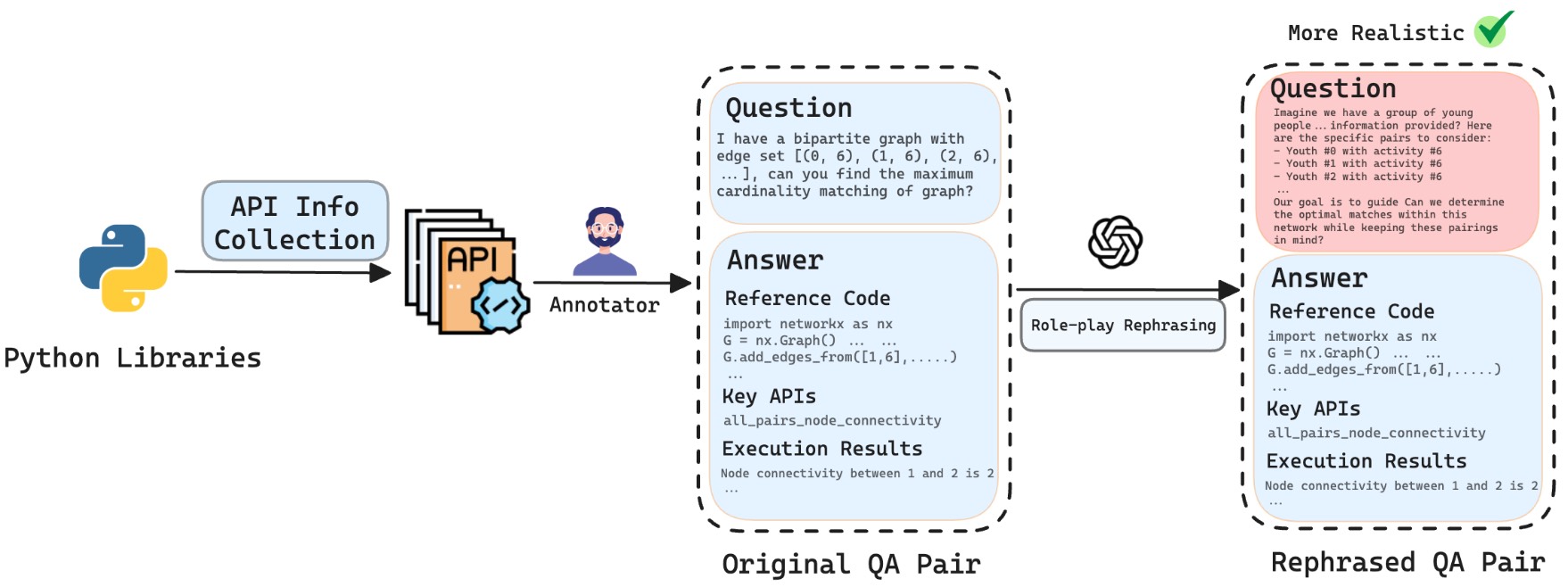
#### The pipeline of LLM4Graph dataset construction and corresponding model enhancement.
|
| 28 |
+
Code datasets. We construct two code datasets in the form of QA pairs. The questions in both datasets are the same, but the answers differ. In the simpler dataset, each answer only contains Python code. Inspired by Chain of Thought (CoT) [55], each answer in the more complex dataset additionally includes relevant APIs and their documents as prefixes. This modification can facilitate open-source models to utilize document information more effectively. We name the above code datasets as Code (QA) and Doc+Code (QA), respectively. Unlike the hand-crafted benchmark, problems in the code datasets are automatically generated and each contains only one key API.
|
| 29 |
+
|
| 30 |
+
<img width="1000px" alt="" src="https://huggingface.co/spaces/lixin4sky/ProGraph/blob/main/figure_2_the_pipeline_of_LLM4Graph_dataset_construction_and_corresponding_model_enhancement.jpg">
|
| 31 |
+
|
| 32 |
+
#### The pass rate (left) and accuracy (right) of open-source models with instruction tuning.
|
| 33 |
+
|
| 34 |
+
<img width="1000px" alt="" src="https://huggingface.co/spaces/lixin4sky/ProGraph/blob/main/figure_4_the_pass%20rate_and_accuracy_of_open-source_models_withe_instruction_tuning.jpg">
|
| 35 |
+
|
| 36 |
+
#### Compilation error statistics for open source models.
|
| 37 |
+
|
| 38 |
+
<img width="1000px" alt="" src="https://huggingface.co/spaces/lixin4sky/ProGraph/blob/main/figure_6_compilation_error_statistics_for_open-source_models.jpg">
|
| 39 |
+
|
| 40 |
+
#### Performance (%) of open-source models regarding different question types.
|
| 41 |
+
|
| 42 |
+
| Model | Method | True/False | | Drawing | | Calculation | | Hybrid | |
|
| 43 |
+
| --- | --- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
|
| 44 |
+
| | | Pass Rate | Accuracy | Pass Rate | Accuracy | Pass Rate | Accuracy | Pass Rate | Accuracy |
|
| 45 |
+
| Llama 3 | No Fine-tune | 43.6 | 33.3 | 28.3 | 10.0 | 15.6 | 12.5 | 26.8 | 8.3 |
|
| 46 |
+
| | Code Only | 82.1 | 71.8 | 59.2 | 42.0 | 34.4 | 31.3 | 60.7 | **43.6** |
|
| 47 |
+
| | Code+RAG 3 | **84.6** | 44.0 | 56.9 | 29.0 | 50.0 | 37.5 | 66.1 | 37.2 |
|
| 48 |
+
| | Code+RAG 5 | 66.7 | 36.8 | 53.5 | 25.4 | 37.5 | 28.1 | 60.7 | 36.3 |
|
| 49 |
+
| | Code+RAG 7 | 66.7 | 37.2 | 50.9 | 24.4 | 50.0 | 35.9 | 64.3 | 39.3 |
|
| 50 |
+
| | Doc+Code | 82.1 | **73.1** | 64.4 | 43.7 | 40.6 | 31.8 | **67.9** | 41.3 |
|
| 51 |
+
| Deepseek Coder | No Fine-tune | 66.7 | 41.5 | 47.8 | 22.1 | **53.1** | 39.4 | 46.4 | 18.2 |
|
| 52 |
+
| | Code Only | 71.8 | 61.5 | 60.0 | 41.1 | 50.0 | **45.3** | 62.5 | 42.1 |
|
| 53 |
+
| | Code+RAG 3 | 71.8 | 48.3 | 57.7 | 32.2 | **53.1** | **45.3** | 44.6 | 22.8 |
|
| 54 |
+
| | Code+RAG 5 | 71.8 | 53.9 | 50.7 | 29.3 | 40.6 | 34.4 | 39.3 | 28.6 |
|
| 55 |
+
| | Code+RAG 7 | 74.4 | 54.7 | 50.4 | 28.7 | 37.5 | 34.4 | 48.2 | 31.4 |
|
| 56 |
+
| | Doc+Code | 79.5 | 68.0 | **66.2** | **46.0** | 37.5 | 34.4 | 66.1 | 42.3 |
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
### 3. How to Use
|
| 60 |
+
Here give some examples of how to use our models.
|
| 61 |
+
#### Chat Model Inference
|
| 62 |
+
```python
|
| 63 |
+
import torch
|
| 64 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM, StoppingCriteria, StoppingCriteriaList
|
| 65 |
+
from peft import PeftModel
|
| 66 |
+
|
| 67 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 68 |
+
|
| 69 |
+
model_name_or_path = 'deepseek-ai/deepseek-coder-7b-instruct-v1.5'
|
| 70 |
+
# You can use Llama-3-8B by 'meta-llama/Meta-Llama-3-8B-Instruct'.
|
| 71 |
+
# You can also use your local path.
|
| 72 |
+
peft_model_path = 'https://huggingface.co/lixin4sky/ProGraph/tree/main/deepseek-code-only'
|
| 73 |
+
# Or other models in the repository.
|
| 74 |
+
|
| 75 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
|
| 76 |
+
model = AutoModelForCausalLM.from_pretrained(model_name_or_path).to(device)
|
| 77 |
+
peft_model = PeftModel.from_pretrained(model, peft_model_path).to(device)
|
| 78 |
+
|
| 79 |
+
input_text = '' # the question.
|
| 80 |
+
|
| 81 |
+
message = [
|
| 82 |
+
{"role": "user", "content": f"{input_text}"},
|
| 83 |
+
]
|
| 84 |
+
|
| 85 |
+
input_ids = tokenizer.apply_chat_template(conversation=message,
|
| 86 |
+
tokenize=True,
|
| 87 |
+
add_generation_prompt=False,
|
| 88 |
+
return_tensors='pt')
|
| 89 |
+
|
| 90 |
+
input_ids = input_ids.to("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 91 |
+
with torch.inference_mode():
|
| 92 |
+
output_ids = model.generate(input_ids=input_ids[:, :-3], max_new_tokens=4096, do_sample=False, pad_token_id=2)
|
| 93 |
+
response = tokenizer.batch_decode(output_ids.detach().cpu().numpy(), skip_special_tokens = True)
|
| 94 |
+
|
| 95 |
+
print(response)
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
You can find more tutorials in our GitHub repository: (https://github.com/BUPT-GAMMA/ProGraph)
|
| 99 |
+
|
| 100 |
+
### 4. Next Level
|
| 101 |
+
- **GraphTeam:** (https://arxiv.org/abs/2410.18032)
|
| 102 |
+
- **Github Repository:** (https://github.com/BUPT-GAMMA/GraphTeam)
|
figures/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
figures/figure_1_the_pipeline_of_ProGraph_benchmark_construction.jpg
ADDED
|
figures/figure_2_the_pipeline_of_LLM4Graph_dataset_construction_and_corresponding_model_enhancement.jpg
ADDED

|
figures/figure_4_the_pass rate_and_accuracy_of_open-source_models_withe_instruction_tuning.jpg
ADDED

|
figures/figure_6_compilation_error_statistics_for_open-source_models.jpg
ADDED

|