

Commit
·
24d9ead
1
Parent(s):
5636730
sherlor
Browse files- README.assets/clip_image002.gif +0 -0
- README.assets/clip_image004.gif +0 -0
- README.assets/clip_image006.gif +0 -0
- README.assets/clip_image008.gif +0 -0
- README.md +101 -0
README.assets/clip_image002.gif
ADDED
|
README.assets/clip_image004.gif
ADDED

|
README.assets/clip_image006.gif
ADDED
|
README.assets/clip_image008.gif
ADDED
|
README.md
CHANGED
|
@@ -1,3 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: gemma
|
| 3 |
---
|
|
|
|
|
|
| 1 |
+
<<<<<<< HEAD
|
| 2 |
+
# Gemma2-9b-chinese-instruct with SFT and DPO
|
| 3 |
+
|
| 4 |
+
## 项目简介
|
| 5 |
+
|
| 6 |
+
Gemma2-9B-Instruct 模型,凭借其庞大的参数规模、卓越的自然语言理解能力以及灵活的指令执行能力,在全球范围内备受瞩目并赢得了高度评价。该模型在广泛的自然语言处理任务中,如文本创作、智能问答、信息摘要等,均展现出了非凡的性能,为人工智能技术的创新与应用奠定了坚实的基础。
|
| 7 |
+
|
| 8 |
+
本项目基于Gemma2-9B-Instruct 模型的强大基础,在llama-factory的训练框架下,精心挑选了百万条高质量的医疗与通用混合中英文数据集进行微调。为了进一步提升模型的表现能力,本项目还引入了直接偏好优化(Direct Preference Optimization, DPO)。
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
#### 模型特点
|
| 13 |
+
|
| 14 |
+
基础模型:基于开源的gemma2-9b-instruct,这是一个经过指令微调的大型语言模型。
|
| 15 |
+
|
| 16 |
+
医疗+中文优化:利用丰富的医疗领域及中文数据集进行微调,显著提升模型在医疗场景及中文处理上的性能。
|
| 17 |
+
|
| 18 |
+
DPO训练:进一步提升语言模型在特定任务或场景下的输出质量,使其更加符合人类的偏好或需求。
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
## 安装与加载
|
| 23 |
+
|
| 24 |
+
克隆本项目到本地:
|
| 25 |
+
|
| 26 |
+
git clone
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
## 模型测评:
|
| 31 |
+
|
| 32 |
+
C-Eval:C-Eval 是一个全面的中文基础模型评估套件。它包含了大量的多项选择题,涵盖了人文、社科、理工以及其他专业四个大方向,包括52个不同的学科和四个难度级别。
|
| 33 |
+
|
| 34 |
+
| C-Eval(0-shot) | Average | Average(hard) | STEM | Social Sciences | Humanities | Other |
|
| 35 |
+
| -------------- | ------- | ------------- | ---- | --------------- | ---------- | ----- |
|
| 36 |
+
| 原模型 | 29.4 | 22.1 | 27.8 | 29.6 | 31.7 | 29.5 |
|
| 37 |
+
| 训练后 | 55.1 | 43 | 53.5 | 64.3 | 50.8 | 53.8 |
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
CMMLU:CMMLU是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。
|
| 42 |
+
|
| 43 |
+
| CMMLU(0-shot) | Average | STEM | Social Sciences | Humanities | Other |
|
| 44 |
+
| ------------- | ------- | ----- | --------------- | ---------- | ----- |
|
| 45 |
+
| 原模型 | 31.88 | 30.34 | 31.74 | 30.49 | 34.57 |
|
| 46 |
+
| 训练后 | 58.45 | 51.68 | 60.51 | 57.89 | 62.23 |
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
## 数据集
|
| 53 |
+
|
| 54 |
+
微调数据集:
|
| 55 |
+
|
| 56 |
+
| | | |
|
| 57 |
+
| ----------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
| 58 |
+
| 中文微调数据集 | llama3 ShareGPT格式中文微调数据集 | https://modelscope.cn/datasets/zhuangxialie/Llama3-Chinese-Dataset/files |
|
| 59 |
+
| code | 数据集包含问题描述和Python语言代码 | https://huggingface.co/datasets/iamtarun/python_code_instructions_18k_alpaca |
|
| 60 |
+
| mathglm | 清华大学算术任务数据集 | https://cloud.tsinghua.edu.cn/d/8d9ee3e52bb54afd9c16/ |
|
| 61 |
+
| sft-20k | 来自于启真医学知识库收集整理的真实医患知识问答数据以及在启真医学知识库的药品文本知识基础上,通过对半结构化数据设置特定的问题模板构造的指令数据 | https://github.com/CMKRG/QiZhenGPT/blob/main/data/train/sft-20k.json |
|
| 62 |
+
| llama_data | Huatuo-Llama-Med-Chinese的微调数据集示例 | https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese/tree/main/data |
|
| 63 |
+
| ChatMed_Consult_Dataset | ChatMed-Dataset是由OpenAI的 GPT-3.5 引擎生成的110,113个医学查询-响应对(中文)的数据集。这些查询是从几个在线医疗咨询网站抓取的,反映了现实世界的医疗需求。响应由 OpenAI 引擎生成。该数据集旨在将医学知识注入中文大语言模型中。 | https://huggingface.co/datasets/michaelwzhu/ChatMed_Consult_Dataset |
|
| 64 |
+
| ChatMed_TCM-v0.2 | 以开源的中医药知识图谱为基础,采用以实体为中心的自指令方法(entity-centric self-instruct),调用ChatGPT得到2.6w+的围绕中医药的指令数据。 | https://huggingface.co/datasets/michaelwzhu/ShenNong_TCM_Dataset |
|
| 65 |
+
| smile-train | 心理健康对话 | https://github.com/qiuhuachuan/smile/tree/main/data |
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
dpo数据集:
|
| 70 |
+
|
| 71 |
+
| | |
|
| 72 |
+
| ----------------- | ---------------------------------------------------------- |
|
| 73 |
+
| DPO-En-Zh-20k | https://huggingface.co/datasets/hiyouga/DPO-En-Zh-20k |
|
| 74 |
+
| orca_dpo_pairs | https://huggingface.co/datasets/Intel/orca_dpo_pairs |
|
| 75 |
+
| Chinese-dpo-pairs | https://huggingface.co/datasets/wenbopan/Chinese-dpo-pairs |
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
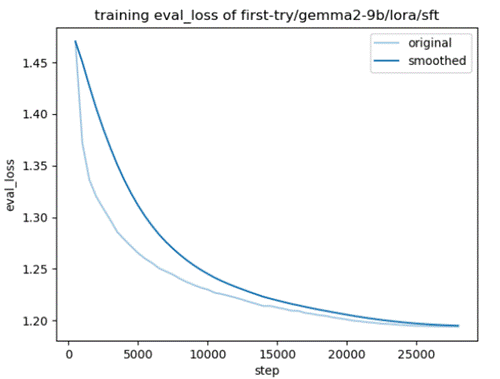
Sft图像:
|
| 80 |
+
|
| 81 |
+

|
| 82 |
+
|
| 83 |
+

|
| 84 |
+
|
| 85 |
+
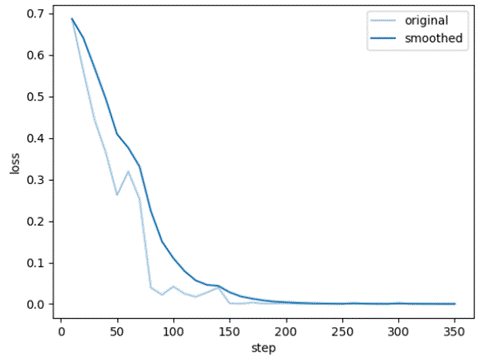
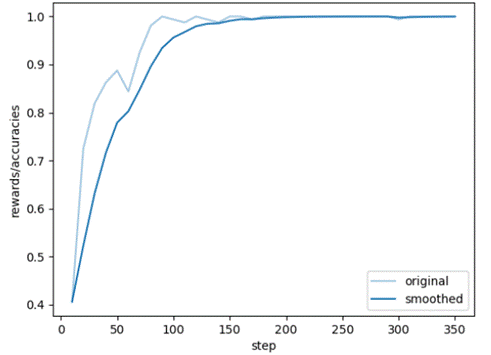
Dpo:
|
| 86 |
+
|
| 87 |
+
Training loss:
|
| 88 |
+
|
| 89 |
+

|
| 90 |
+
|
| 91 |
+
Training rewards:
|
| 92 |
+
|
| 93 |
+

|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
=======
|
| 101 |
---
|
| 102 |
license: gemma
|
| 103 |
---
|
| 104 |
+
>>>>>>> 5246563f1c684f4d658e4d989ab0706efc0e97ef
|