
File size: 10,593 Bytes
f647f77 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 |
#!/usr/bin/env python
from __future__ import annotations
import argparse
import functools
import os
import pathlib
import sys
from typing import Callable
if os.environ.get('SYSTEM') == 'spaces':
os.system("sed -i '10,17d' DualStyleGAN/model/stylegan/op/fused_act.py")
os.system("sed -i '10,17d' DualStyleGAN/model/stylegan/op/upfirdn2d.py")
sys.path.insert(0, 'DualStyleGAN')
import dlib
import gradio as gr
import huggingface_hub
import numpy as np
import PIL.Image
import torch
import torch.nn as nn
import torchvision.transforms as T
from model.dualstylegan import DualStyleGAN
from model.encoder.align_all_parallel import align_face
from model.encoder.psp import pSp
ORIGINAL_REPO_URL = 'https://github.com/williamyang1991/DualStyleGAN'
TITLE = 'williamyang1991/DualStyleGAN'
DESCRIPTION = f"""This is a demo for {ORIGINAL_REPO_URL}.

You can select style images for each style type from the tables below.
The style image index should be in the following range:
(cartoon: 0-316, caricature: 0-198, anime: 0-173, arcane: 0-99, comic: 0-100, pixar: 0-121, slamdunk: 0-119)
"""
ARTICLE = """## Style images
Note that the style images here for Arcane, comic, Pixar, and Slamdunk are the reconstructed ones, not the original ones due to copyright issues.
### Cartoon

### Caricature

### Anime

### Arcane

### Comic

### Pixar

### Slamdunk
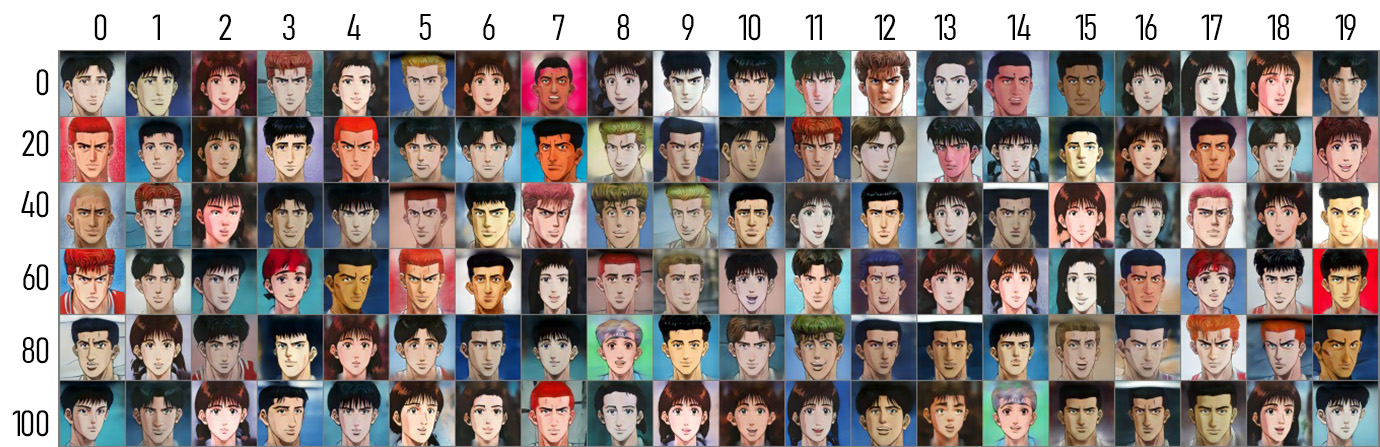
"""
TOKEN = os.environ['TOKEN']
MODEL_REPO = 'hysts/DualStyleGAN'
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument('--device', type=str, default='cpu')
parser.add_argument('--theme', type=str)
parser.add_argument('--live', action='store_true')
parser.add_argument('--share', action='store_true')
parser.add_argument('--port', type=int)
parser.add_argument('--disable-queue',
dest='enable_queue',
action='store_false')
parser.add_argument('--allow-flagging', type=str, default='never')
parser.add_argument('--allow-screenshot', action='store_true')
return parser.parse_args()
def load_encoder(device: torch.device) -> nn.Module:
ckpt_path = huggingface_hub.hf_hub_download(MODEL_REPO,
'models/encoder.pt',
use_auth_token=TOKEN)
ckpt = torch.load(ckpt_path, map_location='cpu')
opts = ckpt['opts']
opts['device'] = device.type
opts['checkpoint_path'] = ckpt_path
opts = argparse.Namespace(**opts)
model = pSp(opts)
model.to(device)
model.eval()
return model
def load_generator(style_type: str, device: torch.device) -> nn.Module:
model = DualStyleGAN(1024, 512, 8, 2, res_index=6)
ckpt_path = huggingface_hub.hf_hub_download(
MODEL_REPO, f'models/{style_type}/generator.pt', use_auth_token=TOKEN)
ckpt = torch.load(ckpt_path, map_location='cpu')
model.load_state_dict(ckpt['g_ema'])
model.to(device)
model.eval()
return model
def load_exstylecode(style_type: str) -> dict[str, np.ndarray]:
if style_type in ['cartoon', 'caricature', 'anime']:
filename = 'refined_exstyle_code.npy'
else:
filename = 'exstyle_code.npy'
path = huggingface_hub.hf_hub_download(MODEL_REPO,
f'models/{style_type}/{filename}',
use_auth_token=TOKEN)
exstyles = np.load(path, allow_pickle=True).item()
return exstyles
def create_transform() -> Callable:
transform = T.Compose([
T.Resize(256),
T.CenterCrop(256),
T.ToTensor(),
T.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
])
return transform
def create_dlib_landmark_model():
path = huggingface_hub.hf_hub_download(
'hysts/dlib_face_landmark_model',
'shape_predictor_68_face_landmarks.dat',
use_auth_token=TOKEN)
return dlib.shape_predictor(path)
def denormalize(tensor: torch.Tensor) -> torch.Tensor:
return torch.clamp((tensor + 1) / 2 * 255, 0, 255).to(torch.uint8)
def postprocess(tensor: torch.Tensor) -> PIL.Image.Image:
tensor = denormalize(tensor)
image = tensor.cpu().numpy().transpose(1, 2, 0)
return PIL.Image.fromarray(image)
@torch.inference_mode()
def run(
image,
style_type: str,
style_id: float,
structure_weight: float,
color_weight: float,
dlib_landmark_model,
encoder: nn.Module,
generator_dict: dict[str, nn.Module],
exstyle_dict: dict[str, dict[str, np.ndarray]],
transform: Callable,
device: torch.device,
) -> tuple[PIL.Image.Image, PIL.Image.Image, PIL.Image.Image, PIL.Image.Image,
PIL.Image.Image]:
generator = generator_dict[style_type]
exstyles = exstyle_dict[style_type]
style_id = int(style_id)
style_id = min(max(0, style_id), len(exstyles) - 1)
stylename = list(exstyles.keys())[style_id]
image = align_face(filepath=image.name, predictor=dlib_landmark_model)
input_data = transform(image).unsqueeze(0).to(device)
img_rec, instyle = encoder(input_data,
randomize_noise=False,
return_latents=True,
z_plus_latent=True,
return_z_plus_latent=True,
resize=False)
img_rec = torch.clamp(img_rec.detach(), -1, 1)
latent = torch.tensor(exstyles[stylename]).repeat(2, 1, 1).to(device)
# latent[0] for both color and structrue transfer and latent[1] for only structrue transfer
latent[1, 7:18] = instyle[0, 7:18]
exstyle = generator.generator.style(
latent.reshape(latent.shape[0] * latent.shape[1],
latent.shape[2])).reshape(latent.shape)
img_gen, _ = generator([instyle.repeat(2, 1, 1)],
exstyle,
z_plus_latent=True,
truncation=0.7,
truncation_latent=0,
use_res=True,
interp_weights=[structure_weight] * 7 +
[color_weight] * 11)
img_gen = torch.clamp(img_gen.detach(), -1, 1)
# deactivate color-related layers by setting w_c = 0
img_gen2, _ = generator([instyle],
exstyle[0:1],
z_plus_latent=True,
truncation=0.7,
truncation_latent=0,
use_res=True,
interp_weights=[structure_weight] * 7 + [0] * 11)
img_gen2 = torch.clamp(img_gen2.detach(), -1, 1)
img_rec = postprocess(img_rec[0])
img_gen0 = postprocess(img_gen[0])
img_gen1 = postprocess(img_gen[1])
img_gen2 = postprocess(img_gen2[0])
return image, img_rec, img_gen0, img_gen1, img_gen2
def main():
gr.close_all()
args = parse_args()
device = torch.device(args.device)
style_types = [
'cartoon',
'caricature',
'anime',
'arcane',
'comic',
'pixar',
'slamdunk',
]
generator_dict = {
style_type: load_generator(style_type, device)
for style_type in style_types
}
exstyle_dict = {
style_type: load_exstylecode(style_type)
for style_type in style_types
}
dlib_landmark_model = create_dlib_landmark_model()
encoder = load_encoder(device)
transform = create_transform()
func = functools.partial(run,
dlib_landmark_model=dlib_landmark_model,
encoder=encoder,
generator_dict=generator_dict,
exstyle_dict=exstyle_dict,
transform=transform,
device=device)
func = functools.update_wrapper(func, run)
image_paths = sorted(pathlib.Path('images').glob('*.jpg'))
examples = [[path.as_posix(), 'cartoon', 26, 0.6, 1.0]
for path in image_paths]
gr.Interface(
func,
[
gr.inputs.Image(type='file', label='Input Image'),
gr.inputs.Radio(
style_types,
type='value',
default='cartoon',
label='Style Type',
),
gr.inputs.Number(default=26, label='Style Image Index'),
gr.inputs.Slider(
0, 1, step=0.1, default=0.6, label='Structure Weight'),
gr.inputs.Slider(0, 1, step=0.1, default=1.0,
label='Color Weight'),
],
[
gr.outputs.Image(type='pil', label='Aligned Face'),
gr.outputs.Image(type='pil', label='Reconstructed'),
gr.outputs.Image(type='pil',
label='Result 1 (Color and structure transfer)'),
gr.outputs.Image(type='pil',
label='Result 2 (Structure transfer only)'),
gr.outputs.Image(
type='pil',
label='Result 3 (Color-related layers deactivated)'),
],
examples=examples,
theme=args.theme,
title=TITLE,
description=DESCRIPTION,
article=ARTICLE,
allow_screenshot=args.allow_screenshot,
allow_flagging=args.allow_flagging,
live=args.live,
).launch(
enable_queue=args.enable_queue,
server_port=args.port,
share=args.share,
)
if __name__ == '__main__':
main()
|