

Upload 16 files
Browse files- AllExperimentsSerial.sh +33 -0
- LICENSE +21 -0
- README.md +249 -0
- __init__.py +8 -0
- __main__.py +561 -0
- ai.py +1064 -0
- components.py +951 -0
- convert.py +144 -0
- goals.py +529 -0
- helpers.py +489 -0
- losses.py +60 -0
- media/overview.png +0 -0
- media/resnetTinyFewCombo.png +0 -0
- models.py +120 -0
- requirements.txt +6 -0
- scheduling.py +120 -0
AllExperimentsSerial.sh
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Baseline
|
| 2 |
+
python . -D CIFAR10 -n ResNetTiny -d "LinMix(a=Point(), b=Box(w=Lin(0,0.031373,150,10)), bw=Lin(0,0.5,150,10))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 3 |
+
# InSamp
|
| 4 |
+
python . -D CIFAR10 -n ResNetTiny -d "LinMix(a=Point(), b=InSamp(Lin(0,1,150,10)), bw=Lin(0,0.5, 150,10))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 5 |
+
# InSampLPA
|
| 6 |
+
python . -D CIFAR10 -n ResNetTiny -d "LinMix(a=Point(), b=InSamp(Lin(0,1,150,20), w=Lin(0,0.031373, 150, 20)), bw=Lin(0,0.5, 150, 20))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 7 |
+
# Adv_{1}InSampLPA
|
| 8 |
+
python . -D CIFAR10 -n ResNetTiny -d "LinMix(a=IFGSM(w=Lin(0,0.031373,20,20), k=1), b=InSamp(Lin(0,1,150,10), w=Lin(0,0.031373,150,10)), bw=Lin(0,0.5,150,10))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 9 |
+
# Adv_{3}InSampLPA
|
| 10 |
+
python . -D CIFAR10 -n ResNetTiny -d "LinMix(a=IFGSM(w=Lin(0,0.031373,20,20), k=3), b=InSamp(Lin(0,1,150,10), w=Lin(0,0.031373,150,10)), bw=Lin(0,0.5,150,10))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# Baseline
|
| 14 |
+
python . -D CIFAR10 -n ResNetTiny_FewCombo -d "LinMix(a=Point(), b=Box(w=Lin(0,0.031373,150,10)), bw=Lin(0,0.5,150,10))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 15 |
+
# InSamp
|
| 16 |
+
python . -D CIFAR10 -n ResNetTiny_FewCombo -d "LinMix(a=Point(), b=InSamp(Lin(0,1,150,10)), bw=Lin(0,0.5, 150,10))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 17 |
+
# InSampLPA
|
| 18 |
+
python . -D CIFAR10 -n ResNetTiny_FewCombo -d "LinMix(a=Point(), b=InSamp(Lin(0,1,150,20), w=Lin(0,0.031373, 150, 20)), bw=Lin(0,0.5, 150, 20))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 19 |
+
# Adv_{1}InSampLPA
|
| 20 |
+
python . -D CIFAR10 -n ResNetTiny_FewCombo -d "LinMix(a=IFGSM(w=Lin(0,0.031373,20,20), k=1), b=InSamp(Lin(0,1,150,10), w=Lin(0,0.031373,150,10)), bw=Lin(0,0.5,150,10))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 21 |
+
# Adv_{3}InSampLPA
|
| 22 |
+
python . -D CIFAR10 -n ResNetTiny_FewCombo -d "LinMix(a=IFGSM(w=Lin(0,0.031373,20,20), k=3), b=InSamp(Lin(0,1,150,10), w=Lin(0,0.031373,150,10)), bw=Lin(0,0.5,150,10))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 23 |
+
|
| 24 |
+
# Adv_{1}InSampLPA
|
| 25 |
+
python . -D CIFAR10 -n ResNetTiny_ManyFixed -d "LinMix(a=IFGSM(w=Lin(0,0.031373,20,20), k=1), b=InSamp(Lin(0,1,150,10), w=Lin(0,0.031373,150,10)), bw=Lin(0,0.5,150,10))" --batch-size 50 --width 0.031373 --lr 0.001 --normalize-layer True --clip-norm False --lr-multistep $1
|
| 26 |
+
|
| 27 |
+
# InSamp_{18}
|
| 28 |
+
python . -D CIFAR10 -n SkipNet18 -d "LinMix(a=Point(), b=InSamp(Lin(0,1,200,40)), bw=Lin(0,0.5,200,40))" -t "MI_FGSM(k=20,r=2)" --batch-size 100 --save-freq 2 --width 0.031373 --lr 0.1 --normalize-layer True --clip-norm False --lr-multistep --sgd --custom-schedule "[10,20,250,300,350]" $1
|
| 29 |
+
# Adv_{5}InSamp_{18}
|
| 30 |
+
python . -D CIFAR10 -n SkipNet18 -d "LinMix(a=IFGSM(w=Lin(0,0.031373,20,20)), b=InSamp(Lin(0,1,200,40)), bw=Lin(0,0.5,200,40))" -t "MI_FGSM(k=20,r=2)" --batch-size 100 --width 0.031373 --lr 0.1 --normalize-layer True --clip-norm False --lr-multistep --sgd --custom-schedule "[10,20,250,300,350]" $1
|
| 31 |
+
# InSamp_{18} Combo
|
| 32 |
+
python . -D CIFAR10 -n SkipNet18_Combo -d "LinMix(b=InSamp(Lin(0,1,200,40)), bw=Lin(0,0.5, 200, 40))" --batch-size 100 --width 0.031373 --lr 0.1 --normalize-layer True --clip-norm False --sgd --lr-multistep --custom-schedule "[10,20,250,300,350]" $1
|
| 33 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2018 SRI Lab, ETH Zurich
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
DiffAI v3 <a href="https://www.sri.inf.ethz.ch/"><img width="100" alt="portfolio_view" align="right" src="http://safeai.ethz.ch/img/sri-logo.svg"></a>
|
| 2 |
+
=============================================================================================================
|
| 3 |
+
|
| 4 |
+

|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
DiffAI is a system for training neural networks to be provably robust and for proving that they are robust.
|
| 9 |
+
|
| 10 |
+
Background
|
| 11 |
+
----------
|
| 12 |
+
|
| 13 |
+
By now, it is well known that otherwise working networks can be tricked by clever attacks. For example [Goodfellow et al.](https://arxiv.org/abs/1412.6572) demonstrated a network with high classification accuracy which classified one image of a panda correctly, and a seemingly identical attack picture
|
| 14 |
+
incorrectly. Many defenses against this type of attack have been produced, but very few produce networks for which *provably* verifying the safety of a prediction is feasible.
|
| 15 |
+
|
| 16 |
+
Abstract Interpretation is a technique for verifying properties of programs by soundly overapproximating their behavior. When applied to neural networks, an infinite set (a ball) of possible inputs is passed to an approximating "abstract" network
|
| 17 |
+
to produce a superset of the possible outputs from the actual network. Provided an appropreate representation for these sets, demonstrating that the network classifies everything in the ball correctly becomes a simple task. The method used to represent these sets is the abstract domain, and the specific approximations are the abstract transformers.
|
| 18 |
+
|
| 19 |
+
In DiffAI, the entire abstract interpretation process is programmed using PyTorch so that it is differentiable and can be run on the GPU,
|
| 20 |
+
and a loss function is crafted so that low values correspond to inputs which can be proved safe (robust).
|
| 21 |
+
|
| 22 |
+
Whats New In v3?
|
| 23 |
+
----------------
|
| 24 |
+
|
| 25 |
+
* Abstract Networks: one can now customize the handling of the domains on a per-layer basis.
|
| 26 |
+
* Training DSL: A DSL has been exposed to allow for custom training regimens with complex parameter scheduling.
|
| 27 |
+
* Cross Loss: The box goal now uses the cross entropy style loss by default as suggested by [Gowal et al. 2019](https://arxiv.org/abs/1810.12715)
|
| 28 |
+
* Conversion to Onyx: We can now export to the onyx format, and can export the abstract network itself to onyx (so that one can run abstract analysis or training using tensorflow for example).
|
| 29 |
+
|
| 30 |
+
Requirements
|
| 31 |
+
------------
|
| 32 |
+
|
| 33 |
+
python 3.6.7, and virtualenv, torch 0.4.1.
|
| 34 |
+
|
| 35 |
+
Recommended Setup
|
| 36 |
+
-----------------
|
| 37 |
+
|
| 38 |
+
```
|
| 39 |
+
$ git clone https://github.com/eth-sri/DiffAI.git
|
| 40 |
+
$ cd DiffAI
|
| 41 |
+
$ virtualenv pytorch --python python3.6
|
| 42 |
+
$ source pytorch/bin/activate
|
| 43 |
+
(pytorch) $ pip install -r requirements.txt
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
Note: you need to activate your virtualenv every time you start a new shell.
|
| 47 |
+
|
| 48 |
+
Getting Started
|
| 49 |
+
---------------
|
| 50 |
+
|
| 51 |
+
DiffAI can be run as a standalone program. To see a list of arguments, type
|
| 52 |
+
|
| 53 |
+
```
|
| 54 |
+
(pytorch) $ python . --help
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
At the minimum, DiffAI expects at least one domain to train with and one domain to test with, and a network with which to test. For example, to train with the Box domain, baseline training (Point) and test against the FGSM attack and the ZSwitch domain with a simple feed forward network on the MNIST dataset (default, if none provided), you would type:
|
| 58 |
+
|
| 59 |
+
```
|
| 60 |
+
(pytorch) $ python . -d "Point()" -d "Box()" -t "PGD()" -t "ZSwitch()" -n ffnn
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
Unless otherwise specified by "--out", the output is logged to the folder "out/".
|
| 64 |
+
In the folder corresponding to the experiment that has been run, one can find the saved configuration options in
|
| 65 |
+
"config.txt", and a pickled net which is saved every 10 epochs (provided that testing is set to happen every 10th epoch).
|
| 66 |
+
|
| 67 |
+
To load a saved model, use "--test" as per the example:
|
| 68 |
+
|
| 69 |
+
```
|
| 70 |
+
(pytorch) $ alias test-diffai="python . -d Point --epochs 1 --dont-write --test-freq 1"
|
| 71 |
+
(pytorch) $ test-diffai -t Box --update-test-net-name convBig --test PATHTOSAVED_CONVBIG.pynet --width 0.1 --test-size 500 --test-batch-size 500
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
Note that "--update-test-net-name" will create a new model based on convBig and try to use the weights in the pickled PATHTOSAVED_CONVBIG.pynet to initialize that models weights. This is not always necessary, but is useful when the code for a model changes (in components) but does not effect the number or usage of weight, or when loading a model pickled by a cuda process into a cpu process.
|
| 75 |
+
|
| 76 |
+
The default specification type is the L_infinity Ball specified explicitly by "--spec boxSpec",
|
| 77 |
+
which uses an epsilon specified by "--width"
|
| 78 |
+
|
| 79 |
+
The default specification type is the L_infinity Ball specified explicitly by "--spec boxSpec",
|
| 80 |
+
which uses an epsilon specified by "--width"
|
| 81 |
+
|
| 82 |
+
Abstract Networks
|
| 83 |
+
-----------------
|
| 84 |
+
|
| 85 |
+
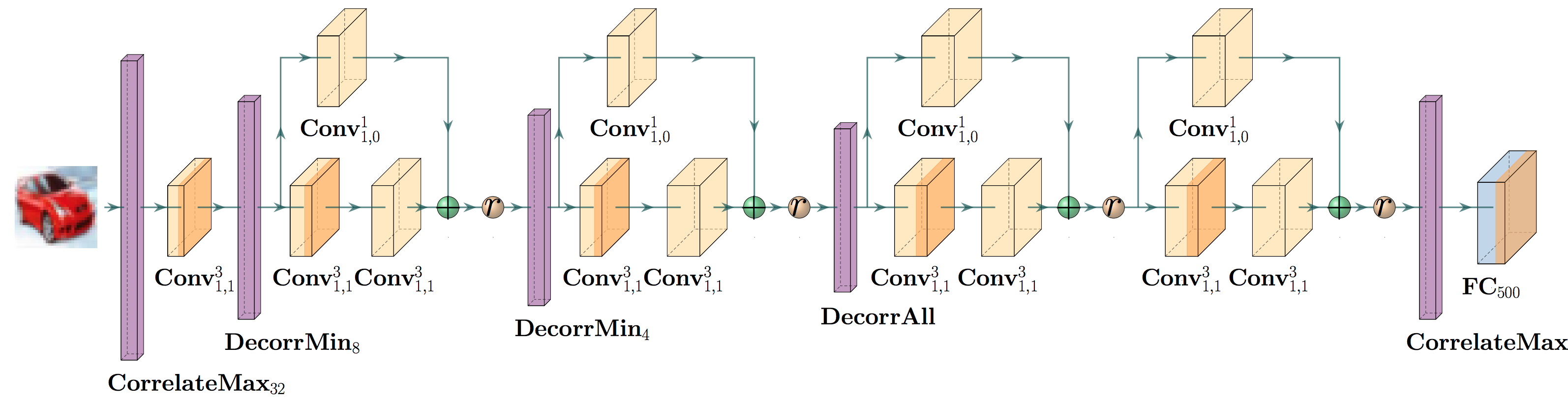
|
| 86 |
+
|
| 87 |
+
A cruical point of DiffAI v3 is that how a network is trained and abstracted should be part of the network description itself. In this release, we provide layers that allow one to alter how the abstraction works,
|
| 88 |
+
in addition to providing a script for converting an abstract network to onyx so that the abstract analysis might be run in tensorflow.
|
| 89 |
+
Below is a list of the abstract layers that we have included.
|
| 90 |
+
|
| 91 |
+
* CorrMaxPool3D
|
| 92 |
+
* CorrMaxPool2D
|
| 93 |
+
* CorrFix
|
| 94 |
+
* CorrMaxK
|
| 95 |
+
* CorrRand
|
| 96 |
+
* DecorrRand
|
| 97 |
+
* DecorrMin
|
| 98 |
+
* DeepLoss
|
| 99 |
+
* ToZono
|
| 100 |
+
* ToHZono
|
| 101 |
+
* Concretize
|
| 102 |
+
* CorrelateAll
|
| 103 |
+
|
| 104 |
+
Training Domain DSL
|
| 105 |
+
-------------------
|
| 106 |
+
|
| 107 |
+
In DiffAI v3, a dsl has been provided to specify arbitrary training domains. In particular, it is now possible to train on combinations of attacks and abstract domains on specifications defined by attacks. Specifying training domains is possible in the command line using ```-d "DOMAIN_INITIALIZATION"```. The possible combinations are the classes listed in domains.py. The same syntax is also supported for testing domains, to allow for testing robustness with different epsilon-sized attacks and specifications.
|
| 108 |
+
|
| 109 |
+
Listed below are a few examples:
|
| 110 |
+
|
| 111 |
+
* ```-t "IFGSM(k=4, w=0.1)" -t "ZNIPS(w=0.3)" ``` Will first test with the PGD attack with an epsilon=w=0.1 and, the number of iterations k=4 and step size set to w/k. It will also test with the zonotope domain using the transformer specified in our [NIPS 2018 paper](https://www.sri.inf.ethz.ch/publications/singh2018effective) with an epsilon=w=0.3.
|
| 112 |
+
|
| 113 |
+
* ```-t "PGD(r=3,k=16,restart=2, w=0.1)"``` tests on points found using PGD with a step size of r*w/k and two restarts, and an attack-generated specification.
|
| 114 |
+
|
| 115 |
+
* ```-d Point()``` is standard non-defensive training.
|
| 116 |
+
|
| 117 |
+
* ```-d "LinMix(a=IFGSM(), b=Box(), aw=1, bw=0.1)"``` trains on points produced by pgd with the default parameters listed in domains.py, and points produced using the box domain. The loss is combined linearly using the weights aw and bw and scaled by 1/(aw + bw). The epsilon used for both is the ambient epsilon specified with "--width".
|
| 118 |
+
|
| 119 |
+
* ```-d "DList((IFGSM(w=0.1),1), (Box(w=0.01),0.1), (Box(w=0.1),0.01))"``` is a generalization of the Mix domain allowing for training with arbitrarily many domains at once weighted by the given values (the resulting loss is scaled by the inverse of the sum of weights).
|
| 120 |
+
|
| 121 |
+
* ```-d "AdvDom(a=IFGSM(), b=Box())"``` trains using the Box domain, but constructs specifications as L∞ balls containing the PGD attack image and the original image "o".
|
| 122 |
+
|
| 123 |
+
* ```-d "BiAdv(a=IFGSM(), b=Box())"``` is similar, but creates specifications between the pgd attack image "a" and "o - (a - o)".
|
| 124 |
+
|
| 125 |
+
One domain we have found particularly useful for training is ```Mix(a=PGD(r=3,k=16,restart=2, w=0.1), b=BiAdv(a=IFGSM(k=5, w=0.05)), bw=0.1)```.
|
| 126 |
+
|
| 127 |
+
While the above domains are all deterministic (up to gpu error and shuffling orders), we have also implemented nondeterministic training domains:
|
| 128 |
+
|
| 129 |
+
* ```-d "Coin(a=IFGSM(), b=Box(), aw=1, bw=0.1)"``` is like Mix, but chooses which domain to train a batch with by the probabilities determined by aw / (aw + bw) and bw / (aw + bw).
|
| 130 |
+
|
| 131 |
+
* ```-d "DProb((IFGSM(w=0.1),1), (Box(w=0.01),0.1), (Box(w=0.1),0.01))"``` is to Coin what DList is to Mix.
|
| 132 |
+
|
| 133 |
+
* ```-d AdvDom(a=IFGSM(), b=DList((PointB(),1), (PointA(), 1), (Box(), 0.2)))``` can be used to share attack images between multiple training types. Here an attack image "m" is found using PGD, then both the original image "o" and the attack image "m" are passed to DList which trains using three different ways: PointA trains with "o", PointB trains with "m", and Box trains on the box produced between them. This can also be used with Mix.
|
| 134 |
+
|
| 135 |
+
* ```-d Normal(w=0.3)``` trains using images sampled from a normal distribution around the provided image using standard deviation w.
|
| 136 |
+
|
| 137 |
+
* ```-d NormalAdv(a=IFGSM(), w=0.3)``` trains using PGD (but this could be an abstract domain) where perturbations are constrained to a box determined by a normal distribution around the original image with standard deviation w.
|
| 138 |
+
|
| 139 |
+
* ```-d InSamp(0.2, w=0.1)``` uses Inclusion sampling as defined in the ArXiv paper.
|
| 140 |
+
|
| 141 |
+
There are more domains implemented than listed here, and of course more interesting combinations are possible. Please look carefully at domains.py for default values and further options.
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
Parameter Scheduling DSL
|
| 145 |
+
------------------------
|
| 146 |
+
|
| 147 |
+
In place of many constants, you can use the following scheduling devices.
|
| 148 |
+
|
| 149 |
+
* ```Lin(s,e,t,i)``` Linearly interpolates between s and e over t epochs, using s for the first i epochs.
|
| 150 |
+
|
| 151 |
+
* ```Until(t,a,b)``` Uses a for the first t epochs, then switches to using b (telling b the current epoch starting from 0 at epoch t).
|
| 152 |
+
|
| 153 |
+
Suggested Training
|
| 154 |
+
------------------
|
| 155 |
+
|
| 156 |
+
```LinMix(a=IFGSM(k=2), b=InSamp(Lin(0,1,150,10)), bw = Lin(0,0.5,150,10))``` is a training goal that appears to work particularly well for CIFAR10 networks.
|
| 157 |
+
|
| 158 |
+
Contents
|
| 159 |
+
--------
|
| 160 |
+
|
| 161 |
+
* components.py: A high level neural network library for composable layers and operations
|
| 162 |
+
* goals.py: The DSL for specifying training losses and domains, and attacks which can be used as a drop in replacement for pytorch tensors in any model built with components from components.py
|
| 163 |
+
* scheduling.py: The DSL for specifying parameter scheduling.
|
| 164 |
+
* models.py: A repository of models to train with which are used in the paper.
|
| 165 |
+
* convert.py: A utility for converting a model with a training or testing domain (goal) into an onyx network. This is useful for exporting DiffAI abstractions to tensorflow.
|
| 166 |
+
* \_\_main\_\_.py: The entry point to run the experiments.
|
| 167 |
+
* helpers.py: Assorted helper functions. Does some monkeypatching, so you might want to be careful importing our library into your project.
|
| 168 |
+
* AllExperimentsSerial.sh: A script which runs the training experiments from the 2019 ArXiv paper from table 4 and 5 and figure 5.
|
| 169 |
+
|
| 170 |
+
Notes
|
| 171 |
+
-----
|
| 172 |
+
|
| 173 |
+
Not all of the datasets listed in the help message are supported. Supported datasets are:
|
| 174 |
+
|
| 175 |
+
* CIFAR10
|
| 176 |
+
* CIFAR100
|
| 177 |
+
* MNIST
|
| 178 |
+
* SVHN
|
| 179 |
+
* FashionMNIST
|
| 180 |
+
|
| 181 |
+
Unsupported datasets will not necessarily throw errors.
|
| 182 |
+
|
| 183 |
+
Reproducing Results
|
| 184 |
+
-------------------
|
| 185 |
+
|
| 186 |
+
[Download Defended Networks](https://www.dropbox.com/sh/66obogmvih79e3k/AACe-tkKGvIK0Z--2tk2alZaa?dl=0)
|
| 187 |
+
|
| 188 |
+
All training runs from the paper can be reproduced as by the following command, in the same order as Table 6 in the appendix.
|
| 189 |
+
|
| 190 |
+
```
|
| 191 |
+
./AllExperimentsSerial.sh "-t MI_FGSM(k=20,r=2) -t HBox --test-size 10000 --test-batch-size 200 --test-freq 400 --save-freq 1 --epochs 420 --out all_experiments --write-first True --test-first False"
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
The training schemes can be written as follows (the names differ slightly from the presentation in the paper):
|
| 195 |
+
|
| 196 |
+
* Baseline: LinMix(a=Point(), b=Box(w=Lin(0,0.031373,150,10)), bw=Lin(0,0.5,150,10))
|
| 197 |
+
* InSamp: LinMix(a=Point(), b=InSamp(Lin(0,1,150,10)), bw=Lin(0,0.5, 150,10))
|
| 198 |
+
* InSampLPA: LinMix(a=Point(), b=InSamp(Lin(0,1,150,20), w=Lin(0,0.031373, 150, 20)), bw=Lin(0,0.5, 150, 20))
|
| 199 |
+
* Adv_{1}ISLPA: LinMix(a=IFGSM(w=Lin(0,0.031373,20,20), k=1), b=InSamp(Lin(0,1,150,10), w=Lin(0,0.031373,150,10)), bw=Lin(0,0.5,150,10))
|
| 200 |
+
* Adv_{3}ISLPA: LinMix(a=IFGSM(w=Lin(0,0.031373,20,20), k=3), b=InSamp(Lin(0,1,150,10), w=Lin(0,0.031373,150,10)), bw=Lin(0,0.5,150,10))
|
| 201 |
+
* Baseline_{18}: LinMix(a=Point(), b=InSamp(Lin(0,1,200,40)), bw=Lin(0,0.5,200,40))
|
| 202 |
+
* InSamp_{18}: LinMix(a=IFGSM(w=Lin(0,0.031373,20,20)), b=InSamp(Lin(0,1,200,40)), bw=Lin(0,0.5,200,40))
|
| 203 |
+
* Adv_{5}IS_{18}: LinMix(b=InSamp(Lin(0,1,200,40)), bw=Lin(0,0.5, 200, 40))
|
| 204 |
+
* BiAdv_L: LinMix(a=IFGSM(k=2), b=BiAdv(a=IFGSM(k=3, w=Lin(0,0.031373, 150, 30)), b=Box()), bw=Lin(0,0.6, 200, 30))
|
| 205 |
+
|
| 206 |
+
To test a saved network as in the paper, use the following command:
|
| 207 |
+
|
| 208 |
+
```
|
| 209 |
+
python . -D CIFAR10 -n ResNetLarge_LargeCombo -d Point --width 0.031373 --normalize-layer True --clip-norm False -t 'MI_FGSM(k=20,r=2)' -t HBox --test-size 10000 --test-batch-size 200 --epochs 1 --test NAMEOFSAVEDNET.pynet
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
About
|
| 213 |
+
-----
|
| 214 |
+
|
| 215 |
+
* DiffAI is now on version 3.0.
|
| 216 |
+
* This repository contains the code used for the experiments in the [2019 ArXiV Paper](https://arxiv.org/abs/1903.12519).
|
| 217 |
+
* To reproduce the experiments from the 2018 ICML paper [Differentiable Abstract Interpretation for Provably Robust Neural Networks](https://files.sri.inf.ethz.ch/website/papers/icml18-diffai.pdf), one must download the source from download the [source code for Version 1.0](https://github.com/eth-sri/diffai/releases/tag/v1.0)
|
| 218 |
+
* Further information and related projects can be found at [the SafeAI Project](http://safeai.ethz.ch/)
|
| 219 |
+
* [High level slides](https://files.sri.inf.ethz.ch/website/slides/mirman2018differentiable.pdf)
|
| 220 |
+
|
| 221 |
+
Citing This Framework
|
| 222 |
+
---------------------
|
| 223 |
+
|
| 224 |
+
```
|
| 225 |
+
@inproceedings{
|
| 226 |
+
title={Differentiable Abstract Interpretation for Provably Robust Neural Networks},
|
| 227 |
+
author={Mirman, Matthew and Gehr, Timon and Vechev, Martin},
|
| 228 |
+
booktitle={International Conference on Machine Learning (ICML)},
|
| 229 |
+
year={2018},
|
| 230 |
+
url={https://www.icml.cc/Conferences/2018/Schedule?showEvent=2477},
|
| 231 |
+
}
|
| 232 |
+
```
|
| 233 |
+
|
| 234 |
+
Contributors
|
| 235 |
+
------------
|
| 236 |
+
|
| 237 |
+
* [Matthew Mirman](https://www.mirman.com) - [email protected]
|
| 238 |
+
* [Gagandeep Singh](https://www.sri.inf.ethz.ch/people/gagandeep) - [email protected]
|
| 239 |
+
* [Timon Gehr](https://www.sri.inf.ethz.ch/tg.php) - [email protected]
|
| 240 |
+
* Marc Fischer - [email protected]
|
| 241 |
+
* [Martin Vechev](https://www.sri.inf.ethz.ch/vechev.php) - [email protected]
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
License and Copyright
|
| 246 |
+
---------------------
|
| 247 |
+
|
| 248 |
+
* Copyright (c) 2018 [Secure, Reliable, and Intelligent Systems Lab (SRI), ETH Zurich](https://www.sri.inf.ethz.ch/)
|
| 249 |
+
* Licensed under the [MIT License](https://opensource.org/licenses/MIT)
|
__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
SCRIPT_DIR = os.path.dirname(os.path.realpath(os.path.join(os.getcwd(), os.path.expanduser(__file__))))
|
| 5 |
+
print(SCRIPT_DIR)
|
| 6 |
+
sys.path.append(SCRIPT_DIR)
|
| 7 |
+
|
| 8 |
+
|
__main__.py
ADDED
|
@@ -0,0 +1,561 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import future
|
| 2 |
+
import builtins
|
| 3 |
+
import past
|
| 4 |
+
import six
|
| 5 |
+
import copy
|
| 6 |
+
|
| 7 |
+
from timeit import default_timer as timer
|
| 8 |
+
from datetime import datetime
|
| 9 |
+
import argparse
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
import torch.optim as optim
|
| 14 |
+
from torchvision import datasets
|
| 15 |
+
from torch.utils.data import Dataset
|
| 16 |
+
import decimal
|
| 17 |
+
import torch.onnx
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
import inspect
|
| 21 |
+
from inspect import getargspec
|
| 22 |
+
import os
|
| 23 |
+
import helpers as h
|
| 24 |
+
from helpers import Timer
|
| 25 |
+
import copy
|
| 26 |
+
import random
|
| 27 |
+
|
| 28 |
+
from components import *
|
| 29 |
+
import models
|
| 30 |
+
|
| 31 |
+
import goals
|
| 32 |
+
import scheduling
|
| 33 |
+
|
| 34 |
+
from goals import *
|
| 35 |
+
from scheduling import *
|
| 36 |
+
|
| 37 |
+
import math
|
| 38 |
+
|
| 39 |
+
import warnings
|
| 40 |
+
from torch.serialization import SourceChangeWarning
|
| 41 |
+
|
| 42 |
+
POINT_DOMAINS = [m for m in h.getMethods(goals) if issubclass(m, goals.Point)]
|
| 43 |
+
SYMETRIC_DOMAINS = [goals.Box] + POINT_DOMAINS
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
datasets.Imagenet12 = None
|
| 47 |
+
|
| 48 |
+
class Top(nn.Module):
|
| 49 |
+
def __init__(self, args, net, ty = Point):
|
| 50 |
+
super(Top, self).__init__()
|
| 51 |
+
self.net = net
|
| 52 |
+
self.ty = ty
|
| 53 |
+
self.w = args.width
|
| 54 |
+
self.global_num = 0
|
| 55 |
+
self.getSpec = getattr(self, args.spec)
|
| 56 |
+
self.sub_batch_size = args.sub_batch_size
|
| 57 |
+
self.curve_width = args.curve_width
|
| 58 |
+
self.regularize = args.regularize
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
self.speedCount = 0
|
| 62 |
+
self.speed = 0.0
|
| 63 |
+
|
| 64 |
+
def addSpeed(self, s):
|
| 65 |
+
self.speed = (s + self.speed * self.speedCount) / (self.speedCount + 1)
|
| 66 |
+
self.speedCount += 1
|
| 67 |
+
|
| 68 |
+
def forward(self, x):
|
| 69 |
+
return self.net(x)
|
| 70 |
+
|
| 71 |
+
def clip_norm(self):
|
| 72 |
+
self.net.clip_norm()
|
| 73 |
+
|
| 74 |
+
def boxSpec(self, x, target, **kargs):
|
| 75 |
+
return [(self.ty.box(x, w = self.w, model=self, target=target, untargeted=True, **kargs).to_dtype(), target)]
|
| 76 |
+
|
| 77 |
+
def curveSpec(self, x, target, **kargs):
|
| 78 |
+
if self.ty.__class__ in SYMETRIC_DOMAINS:
|
| 79 |
+
return self.boxSpec(x,target, **kargs)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
batch_size = x.size()[0]
|
| 83 |
+
|
| 84 |
+
newTargs = [ None for i in range(batch_size) ]
|
| 85 |
+
newSpecs = [ None for i in range(batch_size) ]
|
| 86 |
+
bestSpecs = [ None for i in range(batch_size) ]
|
| 87 |
+
|
| 88 |
+
for i in range(batch_size):
|
| 89 |
+
newTarg = target[i]
|
| 90 |
+
newTargs[i] = newTarg
|
| 91 |
+
newSpec = x[i]
|
| 92 |
+
|
| 93 |
+
best_x = newSpec
|
| 94 |
+
best_dist = float("inf")
|
| 95 |
+
for j in range(batch_size):
|
| 96 |
+
potTarg = target[j]
|
| 97 |
+
potSpec = x[j]
|
| 98 |
+
if (not newTarg.data.equal(potTarg.data)) or i == j:
|
| 99 |
+
continue
|
| 100 |
+
curr_dist = (newSpec - potSpec).norm(1).item() # must experiment with the type of norm here
|
| 101 |
+
if curr_dist <= best_dist:
|
| 102 |
+
best_x = potSpec
|
| 103 |
+
|
| 104 |
+
newSpecs[i] = newSpec
|
| 105 |
+
bestSpecs[i] = best_x
|
| 106 |
+
|
| 107 |
+
new_batch_size = self.sub_batch_size
|
| 108 |
+
batchedTargs = h.chunks(newTargs, new_batch_size)
|
| 109 |
+
batchedSpecs = h.chunks(newSpecs, new_batch_size)
|
| 110 |
+
batchedBest = h.chunks(bestSpecs, new_batch_size)
|
| 111 |
+
|
| 112 |
+
def batch(t,s,b):
|
| 113 |
+
t = h.lten(t)
|
| 114 |
+
s = torch.stack(s)
|
| 115 |
+
b = torch.stack(b)
|
| 116 |
+
|
| 117 |
+
if h.use_cuda:
|
| 118 |
+
t.cuda()
|
| 119 |
+
s.cuda()
|
| 120 |
+
b.cuda()
|
| 121 |
+
|
| 122 |
+
m = self.ty.line(s, b, w = self.curve_width, **kargs)
|
| 123 |
+
return (m , t)
|
| 124 |
+
|
| 125 |
+
return [batch(t,s,b) for t,s,b in zip(batchedTargs, batchedSpecs, batchedBest)]
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def regLoss(self):
|
| 129 |
+
if self.regularize is None or self.regularize <= 0.0:
|
| 130 |
+
return 0
|
| 131 |
+
reg_loss = 0
|
| 132 |
+
r = self.net.regularize(2)
|
| 133 |
+
return self.regularize * r
|
| 134 |
+
|
| 135 |
+
def aiLoss(self, dom, target, **args):
|
| 136 |
+
r = self(dom)
|
| 137 |
+
return self.regLoss() + r.loss(target = target, **args)
|
| 138 |
+
|
| 139 |
+
def printNet(self, f):
|
| 140 |
+
self.net.printNet(f)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
# Training settings
|
| 144 |
+
parser = argparse.ArgumentParser(description='PyTorch DiffAI Example', formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 145 |
+
parser.add_argument('--batch-size', type=int, default=10, metavar='N', help='input batch size for training')
|
| 146 |
+
parser.add_argument('--test-first', type=h.str2bool, nargs='?', const=True, default=True, help='test first')
|
| 147 |
+
parser.add_argument('--test-freq', type=int, default=1, metavar='N', help='number of epochs to skip before testing')
|
| 148 |
+
parser.add_argument('--test-batch-size', type=int, default=10, metavar='N', help='input batch size for testing')
|
| 149 |
+
parser.add_argument('--sub-batch-size', type=int, default=3, metavar='N', help='input batch size for curve specs')
|
| 150 |
+
|
| 151 |
+
parser.add_argument('--custom-schedule', type=str, default="", metavar='net', help='Learning rate scheduling for lr-multistep. Defaults to [200,250,300] for CIFAR10 and [15,25] for everything else.')
|
| 152 |
+
|
| 153 |
+
parser.add_argument('--test', type=str, default=None, metavar='net', help='Saved net to use, in addition to any other nets you specify with -n')
|
| 154 |
+
parser.add_argument('--update-test-net', type=h.str2bool, nargs='?', const=True, default=False, help="should update test net")
|
| 155 |
+
|
| 156 |
+
parser.add_argument('--sgd',type=h.str2bool, nargs='?', const=True, default=False, help="use sgd instead of adam")
|
| 157 |
+
parser.add_argument('--onyx', type=h.str2bool, nargs='?', const=True, default=False, help="should output onyx")
|
| 158 |
+
parser.add_argument('--save-dot-net', type=h.str2bool, nargs='?', const=True, default=False, help="should output in .net")
|
| 159 |
+
parser.add_argument('--update-test-net-name', type=str, choices = h.getMethodNames(models), default=None, help="update test net name")
|
| 160 |
+
|
| 161 |
+
parser.add_argument('--normalize-layer', type=h.str2bool, nargs='?', const=True, default=True, help="should include a training set specific normalization layer")
|
| 162 |
+
parser.add_argument('--clip-norm', type=h.str2bool, nargs='?', const=True, default=False, help="should clip the normal and use normal decomposition for weights")
|
| 163 |
+
|
| 164 |
+
parser.add_argument('--epochs', type=int, default=1000, metavar='N', help='number of epochs to train')
|
| 165 |
+
parser.add_argument('--log-freq', type=int, default=10, metavar='N', help='The frequency with which log statistics are printed')
|
| 166 |
+
parser.add_argument('--save-freq', type=int, default=1, metavar='N', help='The frequency with which nets and images are saved, in terms of number of test passes')
|
| 167 |
+
parser.add_argument('--number-save-images', type=int, default=0, metavar='N', help='The number of images to save. Should be smaller than test-size.')
|
| 168 |
+
|
| 169 |
+
parser.add_argument('--lr', type=float, default=0.001, metavar='LR', help='learning rate')
|
| 170 |
+
parser.add_argument('--lr-multistep', type=h.str2bool, nargs='?', const=True, default=False, help='learning rate multistep scheduling')
|
| 171 |
+
|
| 172 |
+
parser.add_argument('--threshold', type=float, default=-0.01, metavar='TH', help='threshold for lr schedule')
|
| 173 |
+
parser.add_argument('--patience', type=int, default=0, metavar='PT', help='patience for lr schedule')
|
| 174 |
+
parser.add_argument('--factor', type=float, default=0.5, metavar='R', help='reduction multiplier for lr schedule')
|
| 175 |
+
parser.add_argument('--max-norm', type=float, default=10000, metavar='MN', help='the maximum norm allowed in weight distribution')
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
parser.add_argument('--curve-width', type=float, default=None, metavar='CW', help='the width of the curve spec')
|
| 179 |
+
|
| 180 |
+
parser.add_argument('--width', type=float, default=0.01, metavar='CW', help='the width of either the line or box')
|
| 181 |
+
parser.add_argument('--spec', choices = [ x for x in dir(Top) if x[-4:] == "Spec" and len(getargspec(getattr(Top, x)).args) == 3]
|
| 182 |
+
, default="boxSpec", help='picks which spec builder function to use for training')
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed')
|
| 186 |
+
parser.add_argument("--use-schedule", type=h.str2bool, nargs='?',
|
| 187 |
+
const=True, default=False,
|
| 188 |
+
help="activate learning rate schedule")
|
| 189 |
+
|
| 190 |
+
parser.add_argument('-d', '--domain', sub_choices = None, action = h.SubAct
|
| 191 |
+
, default=[], help='picks which abstract goals to use for training', required=True)
|
| 192 |
+
|
| 193 |
+
parser.add_argument('-t', '--test-domain', sub_choices = None, action = h.SubAct
|
| 194 |
+
, default=[], help='picks which abstract goals to use for testing. Examples include ' + str(goals), required=True)
|
| 195 |
+
|
| 196 |
+
parser.add_argument('-n', '--net', choices = h.getMethodNames(models), action = 'append'
|
| 197 |
+
, default=[], help='picks which net to use for training') # one net for now
|
| 198 |
+
|
| 199 |
+
parser.add_argument('-D', '--dataset', choices = [n for (n,k) in inspect.getmembers(datasets, inspect.isclass) if issubclass(k, Dataset)]
|
| 200 |
+
, default="MNIST", help='picks which dataset to use.')
|
| 201 |
+
|
| 202 |
+
parser.add_argument('-o', '--out', default="out", help='picks which net to use for training')
|
| 203 |
+
parser.add_argument('--dont-write', type=h.str2bool, nargs='?', const=True, default=False, help='dont write anywhere if this flag is on')
|
| 204 |
+
parser.add_argument('--write-first', type=h.str2bool, nargs='?', const=True, default=False, help='write the initial net. Useful for comparing algorithms, a pain for testing.')
|
| 205 |
+
parser.add_argument('--test-size', type=int, default=2000, help='number of examples to test with')
|
| 206 |
+
|
| 207 |
+
parser.add_argument('-r', '--regularize', type=float, default=None, help='use regularization')
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
args = parser.parse_args()
|
| 211 |
+
|
| 212 |
+
largest_domain = max([len(h.catStrs(d)) for d in (args.domain)] )
|
| 213 |
+
largest_test_domain = max([len(h.catStrs(d)) for d in (args.test_domain)] )
|
| 214 |
+
|
| 215 |
+
args.log_interval = int(50000 / (args.batch_size * args.log_freq))
|
| 216 |
+
|
| 217 |
+
h.max_c_for_norm = args.max_norm
|
| 218 |
+
|
| 219 |
+
if h.use_cuda:
|
| 220 |
+
torch.cuda.manual_seed(1 + args.seed)
|
| 221 |
+
else:
|
| 222 |
+
torch.manual_seed(args.seed)
|
| 223 |
+
|
| 224 |
+
train_loader = h.loadDataset(args.dataset, args.batch_size, True, False)
|
| 225 |
+
test_loader = h.loadDataset(args.dataset, args.test_batch_size, False, False)
|
| 226 |
+
|
| 227 |
+
input_dims = train_loader.dataset[0][0].size()
|
| 228 |
+
num_classes = int(max(getattr(train_loader.dataset, 'train_labels' if args.dataset != "SVHN" else 'labels'))) + 1
|
| 229 |
+
|
| 230 |
+
print("input_dims: ", input_dims)
|
| 231 |
+
print("Num classes: ", num_classes)
|
| 232 |
+
|
| 233 |
+
vargs = vars(args)
|
| 234 |
+
|
| 235 |
+
total_batches_seen = 0
|
| 236 |
+
|
| 237 |
+
def train(epoch, models):
|
| 238 |
+
global total_batches_seen
|
| 239 |
+
|
| 240 |
+
for model in models:
|
| 241 |
+
model.train()
|
| 242 |
+
|
| 243 |
+
for batch_idx, (data, target) in enumerate(train_loader):
|
| 244 |
+
total_batches_seen += 1
|
| 245 |
+
time = float(total_batches_seen) / len(train_loader)
|
| 246 |
+
if h.use_cuda:
|
| 247 |
+
data, target = data.cuda(), target.cuda()
|
| 248 |
+
|
| 249 |
+
for model in models:
|
| 250 |
+
model.global_num += data.size()[0]
|
| 251 |
+
|
| 252 |
+
timer = Timer("train a sample from " + model.name + " with " + model.ty.name, data.size()[0], False)
|
| 253 |
+
lossy = 0
|
| 254 |
+
with timer:
|
| 255 |
+
for s in model.getSpec(data.to_dtype(),target, time = time):
|
| 256 |
+
model.optimizer.zero_grad()
|
| 257 |
+
loss = model.aiLoss(*s, time = time, **vargs).mean(dim=0)
|
| 258 |
+
lossy += loss.detach().item()
|
| 259 |
+
loss.backward()
|
| 260 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), 1)
|
| 261 |
+
for p in model.parameters():
|
| 262 |
+
if p is not None and torch.isnan(p).any():
|
| 263 |
+
print("Such nan in vals")
|
| 264 |
+
if p is not None and p.grad is not None and torch.isnan(p.grad).any():
|
| 265 |
+
print("Such nan in postmagic")
|
| 266 |
+
stdv = 1 / math.sqrt(h.product(p.data.shape))
|
| 267 |
+
p.grad = torch.where(torch.isnan(p.grad), torch.normal(mean=h.zeros(p.grad.shape), std=stdv), p.grad)
|
| 268 |
+
|
| 269 |
+
model.optimizer.step()
|
| 270 |
+
|
| 271 |
+
for p in model.parameters():
|
| 272 |
+
if p is not None and torch.isnan(p).any():
|
| 273 |
+
print("Such nan in vals after grad")
|
| 274 |
+
stdv = 1 / math.sqrt(h.product(p.data.shape))
|
| 275 |
+
p.data = torch.where(torch.isnan(p.data), torch.normal(mean=h.zeros(p.data.shape), std=stdv), p.data)
|
| 276 |
+
|
| 277 |
+
if args.clip_norm:
|
| 278 |
+
model.clip_norm()
|
| 279 |
+
for p in model.parameters():
|
| 280 |
+
if p is not None and torch.isnan(p).any():
|
| 281 |
+
raise Exception("Such nan in vals after clip")
|
| 282 |
+
|
| 283 |
+
model.addSpeed(timer.getUnitTime())
|
| 284 |
+
|
| 285 |
+
if batch_idx % args.log_interval == 0:
|
| 286 |
+
print(('Train Epoch {:12} {:'+ str(largest_domain) +'}: {:3} [{:7}/{} ({:.0f}%)] \tAvg sec/ex {:1.8f}\tLoss: {:.6f}').format(
|
| 287 |
+
model.name, model.ty.name,
|
| 288 |
+
epoch,
|
| 289 |
+
batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader),
|
| 290 |
+
model.speed,
|
| 291 |
+
lossy))
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
num_tests = 0
|
| 295 |
+
def test(models, epoch, f = None):
|
| 296 |
+
global num_tests
|
| 297 |
+
num_tests += 1
|
| 298 |
+
class MStat:
|
| 299 |
+
def __init__(self, model):
|
| 300 |
+
model.eval()
|
| 301 |
+
self.model = model
|
| 302 |
+
self.correct = 0
|
| 303 |
+
class Stat:
|
| 304 |
+
def __init__(self, d, dnm):
|
| 305 |
+
self.domain = d
|
| 306 |
+
self.name = dnm
|
| 307 |
+
self.width = 0
|
| 308 |
+
self.max_eps = None
|
| 309 |
+
self.safe = 0
|
| 310 |
+
self.proved = 0
|
| 311 |
+
self.time = 0
|
| 312 |
+
self.domains = [ Stat(h.parseValues(d, goals), h.catStrs(d)) for d in args.test_domain ]
|
| 313 |
+
model_stats = [ MStat(m) for m in models ]
|
| 314 |
+
|
| 315 |
+
num_its = 0
|
| 316 |
+
saved_data_target = []
|
| 317 |
+
for data, target in test_loader:
|
| 318 |
+
if num_its >= args.test_size:
|
| 319 |
+
break
|
| 320 |
+
|
| 321 |
+
if num_tests == 1:
|
| 322 |
+
saved_data_target += list(zip(list(data), list(target)))
|
| 323 |
+
|
| 324 |
+
num_its += data.size()[0]
|
| 325 |
+
if h.use_cuda:
|
| 326 |
+
data, target = data.cuda().to_dtype(), target.cuda()
|
| 327 |
+
|
| 328 |
+
for m in model_stats:
|
| 329 |
+
|
| 330 |
+
with torch.no_grad():
|
| 331 |
+
pred = m.model(data).vanillaTensorPart().max(1, keepdim=True)[1] # get the index of the max log-probability
|
| 332 |
+
m.correct += pred.eq(target.data.view_as(pred)).sum()
|
| 333 |
+
|
| 334 |
+
for stat in m.domains:
|
| 335 |
+
timer = Timer(shouldPrint = False)
|
| 336 |
+
with timer:
|
| 337 |
+
def calcData(data, target):
|
| 338 |
+
box = stat.domain.box(data, w = m.model.w, model=m.model, untargeted = True, target=target).to_dtype()
|
| 339 |
+
with torch.no_grad():
|
| 340 |
+
bs = m.model(box)
|
| 341 |
+
org = m.model(data).vanillaTensorPart().max(1,keepdim=True)[1]
|
| 342 |
+
stat.width += bs.diameter().sum().item() # sum up batch loss
|
| 343 |
+
stat.proved += bs.isSafe(org).sum().item()
|
| 344 |
+
stat.safe += bs.isSafe(target).sum().item()
|
| 345 |
+
# stat.max_eps += 0 # TODO: calculate max_eps
|
| 346 |
+
|
| 347 |
+
if m.model.net.neuronCount() < 5000 or stat.domain in SYMETRIC_DOMAINS:
|
| 348 |
+
calcData(data, target)
|
| 349 |
+
else:
|
| 350 |
+
for d,t in zip(data, target):
|
| 351 |
+
calcData(d.unsqueeze(0),t.unsqueeze(0))
|
| 352 |
+
stat.time += timer.getUnitTime()
|
| 353 |
+
|
| 354 |
+
l = num_its # len(test_loader.dataset)
|
| 355 |
+
for m in model_stats:
|
| 356 |
+
if args.lr_multistep:
|
| 357 |
+
m.model.lrschedule.step()
|
| 358 |
+
|
| 359 |
+
pr_corr = float(m.correct) / float(l)
|
| 360 |
+
if args.use_schedule:
|
| 361 |
+
m.model.lrschedule.step(1 - pr_corr)
|
| 362 |
+
|
| 363 |
+
h.printBoth(('Test: {:12} trained with {:'+ str(largest_domain) +'} - Avg sec/ex {:1.12f}, Accuracy: {}/{} ({:3.1f}%)').format(
|
| 364 |
+
m.model.name, m.model.ty.name,
|
| 365 |
+
m.model.speed,
|
| 366 |
+
m.correct, l, 100. * pr_corr), f = f)
|
| 367 |
+
|
| 368 |
+
model_stat_rec = ""
|
| 369 |
+
for stat in m.domains:
|
| 370 |
+
pr_safe = stat.safe / l
|
| 371 |
+
pr_proved = stat.proved / l
|
| 372 |
+
pr_corr_given_proved = pr_safe / pr_proved if pr_proved > 0 else 0.0
|
| 373 |
+
h.printBoth(("\t{:" + str(largest_test_domain)+"} - Width: {:<36.16f} Pr[Proved]={:<1.3f} Pr[Corr and Proved]={:<1.3f} Pr[Corr|Proved]={:<1.3f} {}Time = {:<7.5f}" ).format(
|
| 374 |
+
stat.name,
|
| 375 |
+
stat.width / l,
|
| 376 |
+
pr_proved,
|
| 377 |
+
pr_safe, pr_corr_given_proved,
|
| 378 |
+
"AvgMaxEps: {:1.10f} ".format(stat.max_eps / l) if stat.max_eps is not None else "",
|
| 379 |
+
stat.time), f = f)
|
| 380 |
+
model_stat_rec += "{}_{:1.3f}_{:1.3f}_{:1.3f}__".format(stat.name, pr_proved, pr_safe, pr_corr_given_proved)
|
| 381 |
+
prepedname = m.model.ty.name.replace(" ", "_").replace(",", "").replace("(", "_").replace(")", "_").replace("=", "_")
|
| 382 |
+
net_file = os.path.join(out_dir, m.model.name +"__" +prepedname + "_checkpoint_"+str(epoch)+"_with_{:1.3f}".format(pr_corr))
|
| 383 |
+
|
| 384 |
+
h.printBoth("\tSaving netfile: {}\n".format(net_file + ".pynet"), f = f)
|
| 385 |
+
|
| 386 |
+
if (num_tests % args.save_freq == 1 or args.save_freq == 1) and not args.dont_write and (num_tests > 1 or args.write_first):
|
| 387 |
+
print("Actually Saving")
|
| 388 |
+
torch.save(m.model.net, net_file + ".pynet")
|
| 389 |
+
if args.save_dot_net:
|
| 390 |
+
with h.mopen(args.dont_write, net_file + ".net", "w") as f2:
|
| 391 |
+
m.model.net.printNet(f2)
|
| 392 |
+
f2.close()
|
| 393 |
+
if args.onyx:
|
| 394 |
+
nn = copy.deepcopy(m.model.net)
|
| 395 |
+
nn.remove_norm()
|
| 396 |
+
torch.onnx.export(nn, h.zeros([1] + list(input_dims)), net_file + ".onyx",
|
| 397 |
+
verbose=False, input_names=["actual_input"] + ["param"+str(i) for i in range(len(list(nn.parameters())))], output_names=["output"])
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
if num_tests == 1 and not args.dont_write:
|
| 401 |
+
img_dir = os.path.join(out_dir, "images")
|
| 402 |
+
if not os.path.exists(img_dir):
|
| 403 |
+
os.makedirs(img_dir)
|
| 404 |
+
for img_num,(img,target) in zip(range(args.number_save_images), saved_data_target[:args.number_save_images]):
|
| 405 |
+
sz = ""
|
| 406 |
+
for s in img.size():
|
| 407 |
+
sz += str(s) + "x"
|
| 408 |
+
sz = sz[:-1]
|
| 409 |
+
|
| 410 |
+
img_file = os.path.join(img_dir, args.dataset + "_" + sz + "_"+ str(img_num))
|
| 411 |
+
if img_num == 0:
|
| 412 |
+
print("Saving image to: ", img_file + ".img")
|
| 413 |
+
with open(img_file + ".img", "w") as imgfile:
|
| 414 |
+
flatimg = img.view(h.product(img.size()))
|
| 415 |
+
for t in flatimg.cpu():
|
| 416 |
+
print(decimal.Decimal(float(t)).__format__("f"), file=imgfile)
|
| 417 |
+
with open(img_file + ".class" , "w") as imgfile:
|
| 418 |
+
print(int(target.item()), file=imgfile)
|
| 419 |
+
|
| 420 |
+
def createModel(net, domain, domain_name):
|
| 421 |
+
net_weights, net_create = net
|
| 422 |
+
domain.name = domain_name
|
| 423 |
+
|
| 424 |
+
net = net_create()
|
| 425 |
+
m = {}
|
| 426 |
+
for (k,v) in net_weights.state_dict().items():
|
| 427 |
+
m[k] = v.to_dtype()
|
| 428 |
+
net.load_state_dict(m)
|
| 429 |
+
|
| 430 |
+
model = Top(args, net, domain)
|
| 431 |
+
if args.clip_norm:
|
| 432 |
+
model.clip_norm()
|
| 433 |
+
if h.use_cuda:
|
| 434 |
+
model.cuda()
|
| 435 |
+
if args.sgd:
|
| 436 |
+
model.optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=0.9, weight_decay=5e-4)
|
| 437 |
+
else:
|
| 438 |
+
model.optimizer = optim.Adam(model.parameters(), lr=args.lr)
|
| 439 |
+
|
| 440 |
+
if args.lr_multistep:
|
| 441 |
+
model.lrschedule = optim.lr_scheduler.MultiStepLR(
|
| 442 |
+
model.optimizer,
|
| 443 |
+
gamma = 0.1,
|
| 444 |
+
milestones = eval(args.custom_schedule) if args.custom_schedule != "" else ([200, 250, 300] if args.dataset == "CIFAR10" else [15, 25]))
|
| 445 |
+
else:
|
| 446 |
+
model.lrschedule = optim.lr_scheduler.ReduceLROnPlateau(
|
| 447 |
+
model.optimizer,
|
| 448 |
+
'min',
|
| 449 |
+
patience=args.patience,
|
| 450 |
+
threshold= args.threshold,
|
| 451 |
+
min_lr=0.000001,
|
| 452 |
+
factor=args.factor,
|
| 453 |
+
verbose=True)
|
| 454 |
+
|
| 455 |
+
net.name = net_create.__name__
|
| 456 |
+
model.name = net_create.__name__
|
| 457 |
+
|
| 458 |
+
return model
|
| 459 |
+
|
| 460 |
+
out_dir = os.path.join(args.out, args.dataset, str(args.net)[1:-1].replace(", ","_").replace("'",""),
|
| 461 |
+
args.spec, "width_"+str(args.width), h.file_timestamp() )
|
| 462 |
+
|
| 463 |
+
print("Saving to:", out_dir)
|
| 464 |
+
|
| 465 |
+
if not os.path.exists(out_dir) and not args.dont_write:
|
| 466 |
+
os.makedirs(out_dir)
|
| 467 |
+
|
| 468 |
+
print("Starting Training with:")
|
| 469 |
+
with h.mopen(args.dont_write, os.path.join(out_dir, "config.txt"), "w") as f:
|
| 470 |
+
for k in sorted(vars(args)):
|
| 471 |
+
h.printBoth("\t"+k+": "+str(getattr(args,k)), f = f)
|
| 472 |
+
print("")
|
| 473 |
+
|
| 474 |
+
def buildNet(n):
|
| 475 |
+
n = n(num_classes)
|
| 476 |
+
if args.normalize_layer:
|
| 477 |
+
if args.dataset in ["MNIST"]:
|
| 478 |
+
n = Seq(Normalize([0.1307], [0.3081] ), n)
|
| 479 |
+
elif args.dataset in ["CIFAR10", "CIFAR100"]:
|
| 480 |
+
n = Seq(Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]), n)
|
| 481 |
+
elif args.dataset in ["SVHN"]:
|
| 482 |
+
n = Seq(Normalize([0.5,0.5,0.5], [0.2, 0.2, 0.2]), n)
|
| 483 |
+
elif args.dataset in ["Imagenet12"]:
|
| 484 |
+
n = Seq(Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]), n)
|
| 485 |
+
n = n.infer(input_dims)
|
| 486 |
+
if args.clip_norm:
|
| 487 |
+
n.clip_norm()
|
| 488 |
+
return n
|
| 489 |
+
|
| 490 |
+
if not args.test is None:
|
| 491 |
+
|
| 492 |
+
test_name = None
|
| 493 |
+
|
| 494 |
+
def loadedNet():
|
| 495 |
+
if test_name is not None:
|
| 496 |
+
n = getattr(models,test_name)
|
| 497 |
+
n = buildNet(n)
|
| 498 |
+
if args.clip_norm:
|
| 499 |
+
n.clip_norm()
|
| 500 |
+
return n
|
| 501 |
+
else:
|
| 502 |
+
with warnings.catch_warnings():
|
| 503 |
+
warnings.simplefilter("ignore", SourceChangeWarning)
|
| 504 |
+
return torch.load(args.test)
|
| 505 |
+
|
| 506 |
+
net = loadedNet().double() if h.dtype == torch.float64 else loadedNet().float()
|
| 507 |
+
|
| 508 |
+
|
| 509 |
+
if args.update_test_net_name is not None:
|
| 510 |
+
test_name = args.update_test_net_name
|
| 511 |
+
elif args.update_test_net and '__name__' in dir(net):
|
| 512 |
+
test_name = net.__name__
|
| 513 |
+
|
| 514 |
+
if test_name is not None:
|
| 515 |
+
loadedNet.__name__ = test_name
|
| 516 |
+
|
| 517 |
+
nets = [ (net, loadedNet) ]
|
| 518 |
+
|
| 519 |
+
elif args.net == []:
|
| 520 |
+
raise Exception("Need to specify at least one net with either -n or --test")
|
| 521 |
+
else:
|
| 522 |
+
nets = []
|
| 523 |
+
|
| 524 |
+
for n in args.net:
|
| 525 |
+
m = getattr(models,n)
|
| 526 |
+
net_create = (lambda m: lambda: buildNet(m))(m) # why doesn't python do scoping right? This is a thunk. It is bad.
|
| 527 |
+
net_create.__name__ = n
|
| 528 |
+
net = buildNet(m)
|
| 529 |
+
net.__name__ = n
|
| 530 |
+
nets += [ (net, net_create) ]
|
| 531 |
+
|
| 532 |
+
print("Name: ", net_create.__name__)
|
| 533 |
+
print("Number of Neurons (relus): ", net.neuronCount())
|
| 534 |
+
print("Number of Parameters: ", sum([h.product(s.size()) for s in net.parameters()]))
|
| 535 |
+
print("Depth (relu layers): ", net.depth())
|
| 536 |
+
print()
|
| 537 |
+
net.showNet()
|
| 538 |
+
print()
|
| 539 |
+
|
| 540 |
+
|
| 541 |
+
if args.domain == []:
|
| 542 |
+
models = [ createModel(net, goals.Box(args.width), "Box") for net in nets]
|
| 543 |
+
else:
|
| 544 |
+
models = h.flat([[createModel(net, h.parseValues(d, goals, scheduling), h.catStrs(d)) for net in nets] for d in args.domain])
|
| 545 |
+
|
| 546 |
+
|
| 547 |
+
with h.mopen(args.dont_write, os.path.join(out_dir, "log.txt"), "w") as f:
|
| 548 |
+
startTime = timer()
|
| 549 |
+
for epoch in range(1, args.epochs + 1):
|
| 550 |
+
if f is not None:
|
| 551 |
+
f.flush()
|
| 552 |
+
if (epoch - 1) % args.test_freq == 0 and (epoch > 1 or args.test_first):
|
| 553 |
+
with Timer("test all models before epoch "+str(epoch), 1):
|
| 554 |
+
test(models, epoch, f)
|
| 555 |
+
if f is not None:
|
| 556 |
+
f.flush()
|
| 557 |
+
h.printBoth("Elapsed-Time: {:.2f}s\n".format(timer() - startTime), f = f)
|
| 558 |
+
if args.epochs <= args.test_freq:
|
| 559 |
+
break
|
| 560 |
+
with Timer("train all models in epoch", 1, f = f):
|
| 561 |
+
train(epoch, models)
|
ai.py
ADDED
|
@@ -0,0 +1,1064 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import future
|
| 2 |
+
import builtins
|
| 3 |
+
import past
|
| 4 |
+
import six
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
import torch.optim as optim
|
| 10 |
+
import torch.autograd
|
| 11 |
+
|
| 12 |
+
from functools import reduce
|
| 13 |
+
|
| 14 |
+
try:
|
| 15 |
+
from . import helpers as h
|
| 16 |
+
except:
|
| 17 |
+
import helpers as h
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def catNonNullErrors(op, ref_errs=None): # the way of things is ugly
|
| 22 |
+
def doop(er1, er2):
|
| 23 |
+
erS, erL = (er1, er2)
|
| 24 |
+
sS, sL = (erS.size()[0], erL.size()[0])
|
| 25 |
+
|
| 26 |
+
if sS == sL: # TODO: here we know we used transformers on either side which didnt introduce new error terms (this is a hack for hybrid zonotopes and doesn't work with adaptive error term adding).
|
| 27 |
+
return op(erS,erL)
|
| 28 |
+
|
| 29 |
+
if ref_errs is not None:
|
| 30 |
+
sz = ref_errs.size()[0]
|
| 31 |
+
else:
|
| 32 |
+
sz = min(sS, sL)
|
| 33 |
+
|
| 34 |
+
p1 = op(erS[:sz], erL[:sz])
|
| 35 |
+
erSrem = erS[sz:]
|
| 36 |
+
erLrem = erS[sz:]
|
| 37 |
+
p2 = op(erSrem, h.zeros(erSrem.shape))
|
| 38 |
+
p3 = op(h.zeros(erLrem.shape), erLrem)
|
| 39 |
+
return torch.cat((p1,p2,p3), dim=0)
|
| 40 |
+
return doop
|
| 41 |
+
|
| 42 |
+
def creluBoxy(dom):
|
| 43 |
+
if dom.errors is None:
|
| 44 |
+
if dom.beta is None:
|
| 45 |
+
return dom.new(F.relu(dom.head), None, None)
|
| 46 |
+
er = dom.beta
|
| 47 |
+
mx = F.relu(dom.head + er)
|
| 48 |
+
mn = F.relu(dom.head - er)
|
| 49 |
+
return dom.new((mn + mx) / 2, (mx - mn) / 2 , None)
|
| 50 |
+
|
| 51 |
+
aber = torch.abs(dom.errors)
|
| 52 |
+
|
| 53 |
+
sm = torch.sum(aber, 0)
|
| 54 |
+
|
| 55 |
+
if not dom.beta is None:
|
| 56 |
+
sm += dom.beta
|
| 57 |
+
|
| 58 |
+
mx = dom.head + sm
|
| 59 |
+
mn = dom.head - sm
|
| 60 |
+
|
| 61 |
+
should_box = mn.lt(0) * mx.gt(0)
|
| 62 |
+
gtz = dom.head.gt(0).to_dtype()
|
| 63 |
+
mx /= 2
|
| 64 |
+
newhead = h.ifThenElse(should_box, mx, gtz * dom.head)
|
| 65 |
+
newbeta = h.ifThenElse(should_box, mx, gtz * (dom.beta if not dom.beta is None else 0))
|
| 66 |
+
newerr = (1 - should_box.to_dtype()) * gtz * dom.errors
|
| 67 |
+
|
| 68 |
+
return dom.new(newhead, newbeta , newerr)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def creluBoxySound(dom):
|
| 72 |
+
if dom.errors is None:
|
| 73 |
+
if dom.beta is None:
|
| 74 |
+
return dom.new(F.relu(dom.head), None, None)
|
| 75 |
+
er = dom.beta
|
| 76 |
+
mx = F.relu(dom.head + er)
|
| 77 |
+
mn = F.relu(dom.head - er)
|
| 78 |
+
return dom.new((mn + mx) / 2, (mx - mn) / 2 + 2e-6 , None)
|
| 79 |
+
|
| 80 |
+
aber = torch.abs(dom.errors)
|
| 81 |
+
|
| 82 |
+
sm = torch.sum(aber, 0)
|
| 83 |
+
|
| 84 |
+
if not dom.beta is None:
|
| 85 |
+
sm += dom.beta
|
| 86 |
+
|
| 87 |
+
mx = dom.head + sm
|
| 88 |
+
mn = dom.head - sm
|
| 89 |
+
|
| 90 |
+
should_box = mn.lt(0) * mx.gt(0)
|
| 91 |
+
gtz = dom.head.gt(0).to_dtype()
|
| 92 |
+
mx /= 2
|
| 93 |
+
newhead = h.ifThenElse(should_box, mx, gtz * dom.head)
|
| 94 |
+
newbeta = h.ifThenElse(should_box, mx + 2e-6, gtz * (dom.beta if not dom.beta is None else 0))
|
| 95 |
+
newerr = (1 - should_box.to_dtype()) * gtz * dom.errors
|
| 96 |
+
|
| 97 |
+
return dom.new(newhead, newbeta, newerr)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def creluSwitch(dom):
|
| 101 |
+
if dom.errors is None:
|
| 102 |
+
if dom.beta is None:
|
| 103 |
+
return dom.new(F.relu(dom.head), None, None)
|
| 104 |
+
er = dom.beta
|
| 105 |
+
mx = F.relu(dom.head + er)
|
| 106 |
+
mn = F.relu(dom.head - er)
|
| 107 |
+
return dom.new((mn + mx) / 2, (mx - mn) / 2 , None)
|
| 108 |
+
|
| 109 |
+
aber = torch.abs(dom.errors)
|
| 110 |
+
|
| 111 |
+
sm = torch.sum(aber, 0)
|
| 112 |
+
|
| 113 |
+
if not dom.beta is None:
|
| 114 |
+
sm += dom.beta
|
| 115 |
+
|
| 116 |
+
mn = dom.head - sm
|
| 117 |
+
mx = sm
|
| 118 |
+
mx += dom.head
|
| 119 |
+
|
| 120 |
+
should_box = mn.lt(0) * mx.gt(0)
|
| 121 |
+
gtz = dom.head.gt(0)
|
| 122 |
+
|
| 123 |
+
mn.neg_()
|
| 124 |
+
should_boxer = mn.gt(mx)
|
| 125 |
+
|
| 126 |
+
mn /= 2
|
| 127 |
+
newhead = h.ifThenElse(should_box, h.ifThenElse(should_boxer, mx / 2, dom.head + mn ), gtz.to_dtype() * dom.head)
|
| 128 |
+
zbet = dom.beta if not dom.beta is None else 0
|
| 129 |
+
newbeta = h.ifThenElse(should_box, h.ifThenElse(should_boxer, mx / 2, mn + zbet), gtz.to_dtype() * zbet)
|
| 130 |
+
newerr = h.ifThenElseL(should_box, 1 - should_boxer, gtz).to_dtype() * dom.errors
|
| 131 |
+
|
| 132 |
+
return dom.new(newhead, newbeta , newerr)
|
| 133 |
+
|
| 134 |
+
def creluSmooth(dom):
|
| 135 |
+
if dom.errors is None:
|
| 136 |
+
if dom.beta is None:
|
| 137 |
+
return dom.new(F.relu(dom.head), None, None)
|
| 138 |
+
er = dom.beta
|
| 139 |
+
mx = F.relu(dom.head + er)
|
| 140 |
+
mn = F.relu(dom.head - er)
|
| 141 |
+
return dom.new((mn + mx) / 2, (mx - mn) / 2 , None)
|
| 142 |
+
|
| 143 |
+
aber = torch.abs(dom.errors)
|
| 144 |
+
|
| 145 |
+
sm = torch.sum(aber, 0)
|
| 146 |
+
|
| 147 |
+
if not dom.beta is None:
|
| 148 |
+
sm += dom.beta
|
| 149 |
+
|
| 150 |
+
mn = dom.head - sm
|
| 151 |
+
mx = sm
|
| 152 |
+
mx += dom.head
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
nmn = F.relu(-1 * mn)
|
| 156 |
+
|
| 157 |
+
zbet = (dom.beta if not dom.beta is None else 0)
|
| 158 |
+
newheadS = dom.head + nmn / 2
|
| 159 |
+
newbetaS = zbet + nmn / 2
|
| 160 |
+
newerrS = dom.errors
|
| 161 |
+
|
| 162 |
+
mmx = F.relu(mx)
|
| 163 |
+
|
| 164 |
+
newheadB = mmx / 2
|
| 165 |
+
newbetaB = newheadB
|
| 166 |
+
newerrB = 0
|
| 167 |
+
|
| 168 |
+
eps = 0.0001
|
| 169 |
+
t = nmn / (mmx + nmn + eps) # mn.lt(0).to_dtype() * F.sigmoid(nmn - nmx)
|
| 170 |
+
|
| 171 |
+
shouldnt_zero = mx.gt(0).to_dtype()
|
| 172 |
+
|
| 173 |
+
newhead = shouldnt_zero * ( (1 - t) * newheadS + t * newheadB)
|
| 174 |
+
newbeta = shouldnt_zero * ( (1 - t) * newbetaS + t * newbetaB)
|
| 175 |
+
newerr = shouldnt_zero * ( (1 - t) * newerrS + t * newerrB)
|
| 176 |
+
|
| 177 |
+
return dom.new(newhead, newbeta , newerr)
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def creluNIPS(dom):
|
| 181 |
+
if dom.errors is None:
|
| 182 |
+
if dom.beta is None:
|
| 183 |
+
return dom.new(F.relu(dom.head), None, None)
|
| 184 |
+
er = dom.beta
|
| 185 |
+
mx = F.relu(dom.head + er)
|
| 186 |
+
mn = F.relu(dom.head - er)
|
| 187 |
+
return dom.new((mn + mx) / 2, (mx - mn) / 2 , None)
|
| 188 |
+
|
| 189 |
+
sm = torch.sum(torch.abs(dom.errors), 0)
|
| 190 |
+
|
| 191 |
+
if not dom.beta is None:
|
| 192 |
+
sm += dom.beta
|
| 193 |
+
|
| 194 |
+
mn = dom.head - sm
|
| 195 |
+
mx = dom.head + sm
|
| 196 |
+
|
| 197 |
+
mngz = mn >= 0.0
|
| 198 |
+
|
| 199 |
+
zs = h.zeros(dom.head.shape)
|
| 200 |
+
|
| 201 |
+
diff = mx - mn
|
| 202 |
+
|
| 203 |
+
lam = torch.where((mx > 0) & (diff > 0.0), mx / diff, zs)
|
| 204 |
+
mu = lam * mn * (-0.5)
|
| 205 |
+
|
| 206 |
+
betaz = zs if dom.beta is None else dom.beta
|
| 207 |
+
|
| 208 |
+
newhead = torch.where(mngz, dom.head , lam * dom.head + mu)
|
| 209 |
+
mngz += diff <= 0.0
|
| 210 |
+
newbeta = torch.where(mngz, betaz , lam * betaz + mu ) # mu is always positive on this side
|
| 211 |
+
newerr = torch.where(mngz, dom.errors, lam * dom.errors )
|
| 212 |
+
return dom.new(newhead, newbeta, newerr)
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
class MaxTypes:
|
| 218 |
+
|
| 219 |
+
@staticmethod
|
| 220 |
+
def ub(x):
|
| 221 |
+
return x.ub()
|
| 222 |
+
|
| 223 |
+
@staticmethod
|
| 224 |
+
def only_beta(x):
|
| 225 |
+
return x.beta if x.beta is not None else x.head * 0
|
| 226 |
+
|
| 227 |
+
@staticmethod
|
| 228 |
+
def head_beta(x):
|
| 229 |
+
return MaxTypes.only_beta(x) + x.head
|
| 230 |
+
|
| 231 |
+
class HybridZonotope:
|
| 232 |
+
|
| 233 |
+
def isSafe(self, target):
|
| 234 |
+
od,_ = torch.min(h.preDomRes(self,target).lb(), 1)
|
| 235 |
+
return od.gt(0.0).long()
|
| 236 |
+
|
| 237 |
+
def isPoint(self):
|
| 238 |
+
return False
|
| 239 |
+
|
| 240 |
+
def labels(self):
|
| 241 |
+
target = torch.max(self.ub(), 1)[1]
|
| 242 |
+
l = list(h.preDomRes(self,target).lb()[0])
|
| 243 |
+
return [target.item()] + [ i for i,v in zip(range(len(l)), l) if v <= 0]
|
| 244 |
+
|
| 245 |
+
def relu(self):
|
| 246 |
+
return self.customRelu(self)
|
| 247 |
+
|
| 248 |
+
def __init__(self, head, beta, errors, customRelu = creluBoxy, **kargs):
|
| 249 |
+
self.head = head
|
| 250 |
+
self.errors = errors
|
| 251 |
+
self.beta = beta
|
| 252 |
+
self.customRelu = creluBoxy if customRelu is None else customRelu
|
| 253 |
+
|
| 254 |
+
def new(self, *args, customRelu = None, **kargs):
|
| 255 |
+
return self.__class__(*args, **kargs, customRelu = self.customRelu if customRelu is None else customRelu).checkSizes()
|
| 256 |
+
|
| 257 |
+
def zono_to_hybrid(self, *args, **kargs): # we are already a hybrid zono.
|
| 258 |
+
return self.new(self.head, self.beta, self.errors, **kargs)
|
| 259 |
+
|
| 260 |
+
def hybrid_to_zono(self, *args, correlate=True, customRelu = None, **kargs):
|
| 261 |
+
beta = self.beta
|
| 262 |
+
errors = self.errors
|
| 263 |
+
if correlate and beta is not None:
|
| 264 |
+
batches = beta.shape[0]
|
| 265 |
+
num_elem = h.product(beta.shape[1:])
|
| 266 |
+
ei = h.getEi(batches, num_elem)
|
| 267 |
+
|
| 268 |
+
if len(beta.shape) > 2:
|
| 269 |
+
ei = ei.contiguous().view(num_elem, *beta.shape)
|
| 270 |
+
err = ei * beta
|
| 271 |
+
errors = torch.cat((err, errors), dim=0) if errors is not None else err
|
| 272 |
+
beta = None
|
| 273 |
+
|
| 274 |
+
return Zonotope(self.head, beta, errors if errors is not None else (self.beta * 0).unsqueeze(0) , customRelu = self.customRelu if customRelu is None else None)
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
def abstractApplyLeaf(self, foo, *args, **kargs):
|
| 279 |
+
return getattr(self, foo)(*args, **kargs)
|
| 280 |
+
|
| 281 |
+
def decorrelate(self, cc_indx_batch_err): # keep these errors
|
| 282 |
+
if self.errors is None:
|
| 283 |
+
return self
|
| 284 |
+
|
| 285 |
+
batch_size = self.head.shape[0]
|
| 286 |
+
num_error_terms = self.errors.shape[0]
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
beta = h.zeros(self.head.shape).to_dtype() if self.beta is None else self.beta
|
| 291 |
+
errors = h.zeros([0] + list(self.head.shape)).to_dtype() if self.errors is None else self.errors
|
| 292 |
+
|
| 293 |
+
inds_i = torch.arange(self.head.shape[0], device=h.device).unsqueeze(1).long()
|
| 294 |
+
errors = errors.to_dtype().permute(1,0, *list(range(len(self.errors.shape)))[2:])
|
| 295 |
+
|
| 296 |
+
sm = errors.clone()
|
| 297 |
+
sm[inds_i, cc_indx_batch_err] = 0
|
| 298 |
+
|
| 299 |
+
beta = beta.to_dtype() + sm.abs().sum(dim=1)
|
| 300 |
+
|
| 301 |
+
errors = errors[inds_i, cc_indx_batch_err]
|
| 302 |
+
errors = errors.permute(1,0, *list(range(len(self.errors.shape)))[2:]).contiguous()
|
| 303 |
+
return self.new(self.head, beta, errors)
|
| 304 |
+
|
| 305 |
+
def dummyDecorrelate(self, num_decorrelate):
|
| 306 |
+
if num_decorrelate == 0 or self.errors is None:
|
| 307 |
+
return self
|
| 308 |
+
elif num_decorrelate >= self.errors.shape[0]:
|
| 309 |
+
beta = self.beta
|
| 310 |
+
if self.errors is not None:
|
| 311 |
+
errs = self.errors.abs().sum(dim=0)
|
| 312 |
+
if beta is None:
|
| 313 |
+
beta = errs
|
| 314 |
+
else:
|
| 315 |
+
beta += errs
|
| 316 |
+
return self.new(self.head, beta, None)
|
| 317 |
+
return None
|
| 318 |
+
|
| 319 |
+
def stochasticDecorrelate(self, num_decorrelate, choices = None, num_to_keep=False):
|
| 320 |
+
dummy = self.dummyDecorrelate(num_decorrelate)
|
| 321 |
+
if dummy is not None:
|
| 322 |
+
return dummy
|
| 323 |
+
num_error_terms = self.errors.shape[0]
|
| 324 |
+
batch_size = self.head.shape[0]
|
| 325 |
+
|
| 326 |
+
ucc_mask = h.ones([batch_size, self.errors.shape[0]]).long()
|
| 327 |
+
cc_indx_batch_err = h.cudify(torch.multinomial(ucc_mask.to_dtype(), num_decorrelate if num_to_keep else num_error_terms - num_decorrelate, replacement=False)) if choices is None else choices
|
| 328 |
+
return self.decorrelate(cc_indx_batch_err)
|
| 329 |
+
|
| 330 |
+
def decorrelateMin(self, num_decorrelate, num_to_keep=False):
|
| 331 |
+
dummy = self.dummyDecorrelate(num_decorrelate)
|
| 332 |
+
if dummy is not None:
|
| 333 |
+
return dummy
|
| 334 |
+
|
| 335 |
+
num_error_terms = self.errors.shape[0]
|
| 336 |
+
batch_size = self.head.shape[0]
|
| 337 |
+
|
| 338 |
+
error_sum_b_e = self.errors.abs().view(self.errors.shape[0], batch_size, -1).sum(dim=2).permute(1,0)
|
| 339 |
+
cc_indx_batch_err = error_sum_b_e.topk(num_decorrelate if num_to_keep else num_error_terms - num_decorrelate)[1]
|
| 340 |
+
return self.decorrelate(cc_indx_batch_err)
|
| 341 |
+
|
| 342 |
+
def correlate(self, cc_indx_batch_beta): # given in terms of the flattened matrix.
|
| 343 |
+
num_correlate = h.product(cc_indx_batch_beta.shape[1:])
|
| 344 |
+
|
| 345 |
+
beta = h.zeros(self.head.shape).to_dtype() if self.beta is None else self.beta
|
| 346 |
+
errors = h.zeros([0] + list(self.head.shape)).to_dtype() if self.errors is None else self.errors
|
| 347 |
+
|
| 348 |
+
batch_size = beta.shape[0]
|
| 349 |
+
new_errors = h.zeros([num_correlate] + list(self.head.shape)).to_dtype()
|
| 350 |
+
|
| 351 |
+
inds_i = torch.arange(batch_size, device=h.device).unsqueeze(1).long()
|
| 352 |
+
|
| 353 |
+
nc = torch.arange(num_correlate, device=h.device).unsqueeze(1).long()
|
| 354 |
+
|
| 355 |
+
new_errors = new_errors.permute(1,0, *list(range(len(new_errors.shape)))[2:]).contiguous().view(batch_size, num_correlate, -1)
|
| 356 |
+
new_errors[inds_i, nc.unsqueeze(0).expand([batch_size]+list(nc.shape)).squeeze(2), cc_indx_batch_beta] = beta.view(batch_size,-1)[inds_i, cc_indx_batch_beta]
|
| 357 |
+
|
| 358 |
+
new_errors = new_errors.permute(1,0, *list(range(len(new_errors.shape)))[2:]).contiguous().view(num_correlate, batch_size, *beta.shape[1:])
|
| 359 |
+
errors = torch.cat((errors, new_errors), dim=0)
|
| 360 |
+
|
| 361 |
+
beta.view(batch_size, -1)[inds_i, cc_indx_batch_beta] = 0
|
| 362 |
+
|
| 363 |
+
return self.new(self.head, beta, errors)
|
| 364 |
+
|
| 365 |
+
def stochasticCorrelate(self, num_correlate, choices = None):
|
| 366 |
+
if num_correlate == 0:
|
| 367 |
+
return self
|
| 368 |
+
|
| 369 |
+
domshape = self.head.shape
|
| 370 |
+
batch_size = domshape[0]
|
| 371 |
+
num_pixs = h.product(domshape[1:])
|
| 372 |
+
num_correlate = min(num_correlate, num_pixs)
|
| 373 |
+
ucc_mask = h.ones([batch_size, num_pixs ]).long()
|
| 374 |
+
|
| 375 |
+
cc_indx_batch_beta = h.cudify(torch.multinomial(ucc_mask.to_dtype(), num_correlate, replacement=False)) if choices is None else choices
|
| 376 |
+
return self.correlate(cc_indx_batch_beta)
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
def correlateMaxK(self, num_correlate):
|
| 380 |
+
if num_correlate == 0:
|
| 381 |
+
return self
|
| 382 |
+
|
| 383 |
+
domshape = self.head.shape
|
| 384 |
+
batch_size = domshape[0]
|
| 385 |
+
num_pixs = h.product(domshape[1:])
|
| 386 |
+
num_correlate = min(num_correlate, num_pixs)
|
| 387 |
+
|
| 388 |
+
concrete_max_image = self.ub().view(batch_size, -1)
|
| 389 |
+
|
| 390 |
+
cc_indx_batch_beta = concrete_max_image.topk(num_correlate)[1]
|
| 391 |
+
return self.correlate(cc_indx_batch_beta)
|
| 392 |
+
|
| 393 |
+
def correlateMaxPool(self, *args, max_type = MaxTypes.ub , max_pool = F.max_pool2d, **kargs):
|
| 394 |
+
domshape = self.head.shape
|
| 395 |
+
batch_size = domshape[0]
|
| 396 |
+
num_pixs = h.product(domshape[1:])
|
| 397 |
+
|
| 398 |
+
concrete_max_image = max_type(self)
|
| 399 |
+
|
| 400 |
+
cc_indx_batch_beta = max_pool(concrete_max_image, *args, return_indices=True, **kargs)[1].view(batch_size, -1)
|
| 401 |
+
|
| 402 |
+
return self.correlate(cc_indx_batch_beta)
|
| 403 |
+
|
| 404 |
+
def checkSizes(self):
|
| 405 |
+
if not self.errors is None:
|
| 406 |
+
if not self.errors.size()[1:] == self.head.size():
|
| 407 |
+
raise Exception("Such bad sizes on error:", self.errors.shape, " head:", self.head.shape)
|
| 408 |
+
if torch.isnan(self.errors).any():
|
| 409 |
+
raise Exception("Such nan in errors")
|
| 410 |
+
if not self.beta is None:
|
| 411 |
+
if not self.beta.size() == self.head.size():
|
| 412 |
+
raise Exception("Such bad sizes on beta")
|
| 413 |
+
|
| 414 |
+
if torch.isnan(self.beta).any():
|
| 415 |
+
raise Exception("Such nan in errors")
|
| 416 |
+
if self.beta.lt(0.0).any():
|
| 417 |
+
self.beta = self.beta.abs()
|
| 418 |
+
|
| 419 |
+
return self
|
| 420 |
+
|
| 421 |
+
def __mul__(self, flt):
|
| 422 |
+
return self.new(self.head * flt, None if self.beta is None else self.beta * abs(flt), None if self.errors is None else self.errors * flt)
|
| 423 |
+
|
| 424 |
+
def __truediv__(self, flt):
|
| 425 |
+
flt = 1. / flt
|
| 426 |
+
return self.new(self.head * flt, None if self.beta is None else self.beta * abs(flt), None if self.errors is None else self.errors * flt)
|
| 427 |
+
|
| 428 |
+
def __add__(self, other):
|
| 429 |
+
if isinstance(other, HybridZonotope):
|
| 430 |
+
return self.new(self.head + other.head, h.msum(self.beta, other.beta, lambda a,b: a + b), h.msum(self.errors, other.errors, catNonNullErrors(lambda a,b: a + b)))
|
| 431 |
+
else:
|
| 432 |
+
# other has to be a standard variable or tensor
|
| 433 |
+
return self.new(self.head + other, self.beta, self.errors)
|
| 434 |
+
|
| 435 |
+
def addPar(self, a, b):
|
| 436 |
+
return self.new(a.head + b.head, h.msum(a.beta, b.beta, lambda a,b: a + b), h.msum(a.errors, b.errors, catNonNullErrors(lambda a,b: a + b, self.errors)))
|
| 437 |
+
|
| 438 |
+
def __sub__(self, other):
|
| 439 |
+
if isinstance(other, HybridZonotope):
|
| 440 |
+
return self.new(self.head - other.head
|
| 441 |
+
, h.msum(self.beta, other.beta, lambda a,b: a + b)
|
| 442 |
+
, h.msum(self.errors, None if other.errors is None else -other.errors, catNonNullErrors(lambda a,b: a + b)))
|
| 443 |
+
else:
|
| 444 |
+
# other has to be a standard variable or tensor
|
| 445 |
+
return self.new(self.head - other, self.beta, self.errors)
|
| 446 |
+
|
| 447 |
+
def bmm(self, other):
|
| 448 |
+
hd = self.head.bmm(other)
|
| 449 |
+
bet = None if self.beta is None else self.beta.bmm(other.abs())
|
| 450 |
+
|
| 451 |
+
if self.errors is None:
|
| 452 |
+
er = None
|
| 453 |
+
else:
|
| 454 |
+
er = self.errors.matmul(other)
|
| 455 |
+
return self.new(hd, bet, er)
|
| 456 |
+
|
| 457 |
+
|
| 458 |
+
def getBeta(self):
|
| 459 |
+
return self.head * 0 if self.beta is None else self.beta
|
| 460 |
+
|
| 461 |
+
def getErrors(self):
|
| 462 |
+
return (self.head * 0).unsqueeze(0) if self.beta is None else self.errors
|
| 463 |
+
|
| 464 |
+
def merge(self, other, ref = None): # the vast majority of the time ref should be none here. Not for parallel computation with powerset
|
| 465 |
+
s_beta = self.getBeta() # so that beta is never none
|
| 466 |
+
|
| 467 |
+
sbox_u = self.head + s_beta
|
| 468 |
+
sbox_l = self.head - s_beta
|
| 469 |
+
o_u = other.ub()
|
| 470 |
+
o_l = other.lb()
|
| 471 |
+
o_in_s = (o_u <= sbox_u) & (o_l >= sbox_l)
|
| 472 |
+
|
| 473 |
+
s_err_mx = self.errors.abs().sum(dim=0)
|
| 474 |
+
|
| 475 |
+
if not isinstance(other, HybridZonotope):
|
| 476 |
+
new_head = (self.head + other.center()) / 2
|
| 477 |
+
new_beta = torch.max(sbox_u + s_err_mx,o_u) - new_head
|
| 478 |
+
return self.new(torch.where(o_in_s, self.head, new_head), torch.where(o_in_s, self.beta,new_beta), o_in_s.float() * self.errors)
|
| 479 |
+
|
| 480 |
+
# TODO: could be more efficient if one of these doesn't have beta or errors but thats okay for now.
|
| 481 |
+
s_u = sbox_u + s_err_mx
|
| 482 |
+
s_l = sbox_l - s_err_mx
|
| 483 |
+
|
| 484 |
+
obox_u = o_u - other.head
|
| 485 |
+
obox_l = o_l + other.head
|
| 486 |
+
|
| 487 |
+
s_in_o = (s_u <= obox_u) & (s_l >= obox_l)
|
| 488 |
+
|
| 489 |
+
# TODO: could theoretically still do something better when one is contained partially in the other
|
| 490 |
+
new_head = (self.head + other.center()) / 2
|
| 491 |
+
new_beta = torch.max(sbox_u + self.getErrors().abs().sum(dim=0),o_u) - new_head
|
| 492 |
+
|
| 493 |
+
return self.new(torch.where(o_in_s, self.head, torch.where(s_in_o, other.head, new_head))
|
| 494 |
+
, torch.where(o_in_s, s_beta,torch.where(s_in_o, other.getBeta(), new_beta))
|
| 495 |
+
, h.msum(o_in_s.float() * self.errors, s_in_o.float() * other.errors, catNonNullErrors(lambda a,b: a + b, ref_errs = ref.errors if ref is not None else ref))) # these are both zero otherwise
|
| 496 |
+
|
| 497 |
+
|
| 498 |
+
def conv(self, conv, weight, bias = None, **kargs):
|
| 499 |
+
h = self.errors
|
| 500 |
+
inter = h if h is None else h.view(-1, *h.size()[2:])
|
| 501 |
+
hd = conv(self.head, weight, bias=bias, **kargs)
|
| 502 |
+
res = h if h is None else conv(inter, weight, bias=None, **kargs)
|
| 503 |
+
|
| 504 |
+
return self.new( hd
|
| 505 |
+
, None if self.beta is None else conv(self.beta, weight.abs(), bias = None, **kargs)
|
| 506 |
+
, h if h is None else res.view(h.size()[0], h.size()[1], *res.size()[1:]))
|
| 507 |
+
|
| 508 |
+
|
| 509 |
+
def conv1d(self, *args, **kargs):
|
| 510 |
+
return self.conv(lambda x, *args, **kargs: x.conv1d(*args,**kargs), *args, **kargs)
|
| 511 |
+
|
| 512 |
+
def conv2d(self, *args, **kargs):
|
| 513 |
+
return self.conv(lambda x, *args, **kargs: x.conv2d(*args,**kargs), *args, **kargs)
|
| 514 |
+
|
| 515 |
+
def conv3d(self, *args, **kargs):
|
| 516 |
+
return self.conv(lambda x, *args, **kargs: x.conv3d(*args,**kargs), *args, **kargs)
|
| 517 |
+
|
| 518 |
+
def conv_transpose1d(self, *args, **kargs):
|
| 519 |
+
return self.conv(lambda x, *args, **kargs: x.conv_transpose1d(*args,**kargs), *args, **kargs)
|
| 520 |
+
|
| 521 |
+
def conv_transpose2d(self, *args, **kargs):
|
| 522 |
+
return self.conv(lambda x, *args, **kargs: x.conv_transpose2d(*args,**kargs), *args, **kargs)
|
| 523 |
+
|
| 524 |
+
def conv_transpose3d(self, *args, **kargs):
|
| 525 |
+
return self.conv(lambda x, *args, **kargs: x.conv_transpose3d(*args,**kargs), *args, **kargs)
|
| 526 |
+
|
| 527 |
+
def matmul(self, other):
|
| 528 |
+
return self.new(self.head.matmul(other), None if self.beta is None else self.beta.matmul(other.abs()), None if self.errors is None else self.errors.matmul(other))
|
| 529 |
+
|
| 530 |
+
def unsqueeze(self, i):
|
| 531 |
+
return self.new(self.head.unsqueeze(i), None if self.beta is None else self.beta.unsqueeze(i), None if self.errors is None else self.errors.unsqueeze(i + 1))
|
| 532 |
+
|
| 533 |
+
def squeeze(self, dim):
|
| 534 |
+
return self.new(self.head.squeeze(dim),
|
| 535 |
+
None if self.beta is None else self.beta.squeeze(dim),
|
| 536 |
+
None if self.errors is None else self.errors.squeeze(dim + 1 if dim >= 0 else dim))
|
| 537 |
+
|
| 538 |
+
def double(self):
|
| 539 |
+
return self.new(self.head.double(), self.beta.double() if self.beta is not None else None, self.errors.double() if self.errors is not None else None)
|
| 540 |
+
|
| 541 |
+
def float(self):
|
| 542 |
+
return self.new(self.head.float(), self.beta.float() if self.beta is not None else None, self.errors.float() if self.errors is not None else None)
|
| 543 |
+
|
| 544 |
+
def to_dtype(self):
|
| 545 |
+
return self.new(self.head.to_dtype(), self.beta.to_dtype() if self.beta is not None else None, self.errors.to_dtype() if self.errors is not None else None)
|
| 546 |
+
|
| 547 |
+
def sum(self, dim=1):
|
| 548 |
+
return self.new(torch.sum(self.head,dim=dim), None if self.beta is None else torch.sum(self.beta,dim=dim), None if self.errors is None else torch.sum(self.errors, dim= dim + 1 if dim >= 0 else dim))
|
| 549 |
+
|
| 550 |
+
def view(self,*newshape):
|
| 551 |
+
return self.new(self.head.view(*newshape),
|
| 552 |
+
None if self.beta is None else self.beta.view(*newshape),
|
| 553 |
+
None if self.errors is None else self.errors.view(self.errors.size()[0], *newshape))
|
| 554 |
+
|
| 555 |
+
def gather(self,dim, index):
|
| 556 |
+
return self.new(self.head.gather(dim, index),
|
| 557 |
+
None if self.beta is None else self.beta.gather(dim, index),
|
| 558 |
+
None if self.errors is None else self.errors.gather(dim + 1, index.expand([self.errors.size()[0]] + list(index.size()))))
|
| 559 |
+
|
| 560 |
+
def concretize(self):
|
| 561 |
+
if self.errors is None:
|
| 562 |
+
return self
|
| 563 |
+
|
| 564 |
+
return self.new(self.head, torch.sum(self.concreteErrors().abs(),0), None) # maybe make a box?
|
| 565 |
+
|
| 566 |
+
def cat(self,other, dim=0):
|
| 567 |
+
return self.new(self.head.cat(other.head, dim = dim),
|
| 568 |
+
h.msum(other.beta, self.beta, lambda a,b: a.cat(b, dim = dim)),
|
| 569 |
+
h.msum(self.errors, other.errors, catNonNullErrors(lambda a,b: a.cat(b, dim+1))))
|
| 570 |
+
|
| 571 |
+
|
| 572 |
+
def split(self, split_size, dim = 0):
|
| 573 |
+
heads = list(self.head.split(split_size, dim))
|
| 574 |
+
betas = list(self.beta.split(split_size, dim)) if not self.beta is None else None
|
| 575 |
+
errorss = list(self.errors.split(split_size, dim + 1)) if not self.errors is None else None
|
| 576 |
+
|
| 577 |
+
def makeFromI(i):
|
| 578 |
+
return self.new( heads[i],
|
| 579 |
+
None if betas is None else betas[i],
|
| 580 |
+
None if errorss is None else errorss[i])
|
| 581 |
+
return tuple(makeFromI(i) for i in range(len(heads)))
|
| 582 |
+
|
| 583 |
+
|
| 584 |
+
|
| 585 |
+
def concreteErrors(self):
|
| 586 |
+
if self.beta is None and self.errors is None:
|
| 587 |
+
raise Exception("shouldn't have both beta and errors be none")
|
| 588 |
+
if self.errors is None:
|
| 589 |
+
return self.beta.unsqueeze(0)
|
| 590 |
+
if self.beta is None:
|
| 591 |
+
return self.errors
|
| 592 |
+
return torch.cat([self.beta.unsqueeze(0),self.errors], dim=0)
|
| 593 |
+
|
| 594 |
+
|
| 595 |
+
def applyMonotone(self, foo, *args, **kargs):
|
| 596 |
+
if self.beta is None and self.errors is None:
|
| 597 |
+
return self.new(foo(self.head), None , None)
|
| 598 |
+
|
| 599 |
+
beta = self.concreteErrors().abs().sum(dim=0)
|
| 600 |
+
|
| 601 |
+
tp = foo(self.head + beta, *args, **kargs)
|
| 602 |
+
bt = foo(self.head - beta, *args, **kargs)
|
| 603 |
+
|
| 604 |
+
new_hybrid = self.new((tp + bt) / 2, (tp - bt) / 2 , None)
|
| 605 |
+
|
| 606 |
+
|
| 607 |
+
if self.errors is not None:
|
| 608 |
+
return new_hybrid.correlateMaxK(self.errors.shape[0])
|
| 609 |
+
return new_hybrid
|
| 610 |
+
|
| 611 |
+
def avg_pool2d(self, *args, **kargs):
|
| 612 |
+
nhead = F.avg_pool2d(self.head, *args, **kargs)
|
| 613 |
+
return self.new(nhead,
|
| 614 |
+
None if self.beta is None else F.avg_pool2d(self.beta, *args, **kargs),
|
| 615 |
+
None if self.errors is None else F.avg_pool2d(self.errors.view(-1, *self.head.shape[1:]), *args, **kargs).view(-1,*nhead.shape))
|
| 616 |
+
|
| 617 |
+
def adaptive_avg_pool2d(self, *args, **kargs):
|
| 618 |
+
nhead = F.adaptive_avg_pool2d(self.head, *args, **kargs)
|
| 619 |
+
return self.new(nhead,
|
| 620 |
+
None if self.beta is None else F.adaptive_avg_pool2d(self.beta, *args, **kargs),
|
| 621 |
+
None if self.errors is None else F.adaptive_avg_pool2d(self.errors.view(-1, *self.head.shape[1:]), *args, **kargs).view(-1,*nhead.shape))
|
| 622 |
+
|
| 623 |
+
def elu(self):
|
| 624 |
+
return self.applyMonotone(F.elu)
|
| 625 |
+
|
| 626 |
+
def selu(self):
|
| 627 |
+
return self.applyMonotone(F.selu)
|
| 628 |
+
|
| 629 |
+
def sigm(self):
|
| 630 |
+
return self.applyMonotone(F.sigmoid)
|
| 631 |
+
|
| 632 |
+
def softplus(self):
|
| 633 |
+
if self.errors is None:
|
| 634 |
+
if self.beta is None:
|
| 635 |
+
return self.new(F.softplus(self.head), None , None)
|
| 636 |
+
tp = F.softplus(self.head + self.beta)
|
| 637 |
+
bt = F.softplus(self.head - self.beta)
|
| 638 |
+
return self.new((tp + bt) / 2, (tp - bt) / 2 , None)
|
| 639 |
+
|
| 640 |
+
errors = self.concreteErrors()
|
| 641 |
+
o = h.ones(self.head.size())
|
| 642 |
+
|
| 643 |
+
def sp(hd):
|
| 644 |
+
return F.softplus(hd) # torch.log(o + torch.exp(hd)) # not very stable
|
| 645 |
+
def spp(hd):
|
| 646 |
+
ehd = torch.exp(hd)
|
| 647 |
+
return ehd.div(ehd + o)
|
| 648 |
+
def sppp(hd):
|
| 649 |
+
ehd = torch.exp(hd)
|
| 650 |
+
md = ehd + o
|
| 651 |
+
return ehd.div(md.mul(md))
|
| 652 |
+
|
| 653 |
+
fa = sp(self.head)
|
| 654 |
+
fpa = spp(self.head)
|
| 655 |
+
|
| 656 |
+
a = self.head
|
| 657 |
+
|
| 658 |
+
k = torch.sum(errors.abs(), 0)
|
| 659 |
+
|
| 660 |
+
def evalG(r):
|
| 661 |
+
return r.mul(r).mul(sppp(a + r))
|
| 662 |
+
|
| 663 |
+
m = torch.max(evalG(h.zeros(k.size())), torch.max(evalG(k), evalG(-k)))
|
| 664 |
+
m = h.ifThenElse( a.abs().lt(k), torch.max(m, torch.max(evalG(a), evalG(-a))), m)
|
| 665 |
+
m /= 2
|
| 666 |
+
|
| 667 |
+
return self.new(fa, m if self.beta is None else m + self.beta.mul(fpa), None if self.errors is None else self.errors.mul(fpa))
|
| 668 |
+
|
| 669 |
+
def center(self):
|
| 670 |
+
return self.head
|
| 671 |
+
|
| 672 |
+
def vanillaTensorPart(self):
|
| 673 |
+
return self.head
|
| 674 |
+
|
| 675 |
+
def lb(self):
|
| 676 |
+
return self.head - self.concreteErrors().abs().sum(dim=0)
|
| 677 |
+
|
| 678 |
+
def ub(self):
|
| 679 |
+
return self.head + self.concreteErrors().abs().sum(dim=0)
|
| 680 |
+
|
| 681 |
+
def size(self):
|
| 682 |
+
return self.head.size()
|
| 683 |
+
|
| 684 |
+
def diameter(self):
|
| 685 |
+
abal = torch.abs(self.concreteErrors()).transpose(0,1)
|
| 686 |
+
return abal.sum(1).sum(1) # perimeter
|
| 687 |
+
|
| 688 |
+
def loss(self, target, **args):
|
| 689 |
+
r = -h.preDomRes(self, target).lb()
|
| 690 |
+
return F.softplus(r.max(1)[0])
|
| 691 |
+
|
| 692 |
+
def deep_loss(self, act = F.relu, *args, **kargs):
|
| 693 |
+
batch_size = self.head.shape[0]
|
| 694 |
+
inds = torch.arange(batch_size, device=h.device).unsqueeze(1).long()
|
| 695 |
+
|
| 696 |
+
def dl(l,u):
|
| 697 |
+
ls, lsi = torch.sort(l, dim=1)
|
| 698 |
+
ls_u = u[inds, lsi]
|
| 699 |
+
|
| 700 |
+
def slidingMax(a): # using maxpool
|
| 701 |
+
k = a.shape[1]
|
| 702 |
+
ml = a.min(dim=1)[0].unsqueeze(1)
|
| 703 |
+
|
| 704 |
+
inp = torch.cat((h.zeros([batch_size, k]), a - ml), dim=1)
|
| 705 |
+
mpl = F.max_pool1d(inp.unsqueeze(1) , kernel_size = k, stride=1, padding = 0, return_indices=False).squeeze(1)
|
| 706 |
+
return mpl[:,:-1] + ml
|
| 707 |
+
|
| 708 |
+
return act(slidingMax(ls_u) - ls).sum(dim=1)
|
| 709 |
+
|
| 710 |
+
l = self.lb().view(batch_size, -1)
|
| 711 |
+
u = self.ub().view(batch_size, -1)
|
| 712 |
+
return ( dl(l,u) + dl(-u,-l) ) / (2 * l.shape[1]) # make it easier to regularize against
|
| 713 |
+
|
| 714 |
+
|
| 715 |
+
|
| 716 |
+
class Zonotope(HybridZonotope):
|
| 717 |
+
def applySuper(self, ret):
|
| 718 |
+
batches = ret.head.size()[0]
|
| 719 |
+
num_elem = h.product(ret.head.size()[1:])
|
| 720 |
+
ei = h.getEi(batches, num_elem)
|
| 721 |
+
|
| 722 |
+
if len(ret.head.size()) > 2:
|
| 723 |
+
ei = ei.contiguous().view(num_elem, *ret.head.size())
|
| 724 |
+
|
| 725 |
+
ret.errors = torch.cat( (ret.errors, ei * ret.beta) ) if not ret.beta is None else ret.errors
|
| 726 |
+
ret.beta = None
|
| 727 |
+
return ret.checkSizes()
|
| 728 |
+
|
| 729 |
+
def zono_to_hybrid(self, *args, customRelu = None, **kargs): # we are already a hybrid zono.
|
| 730 |
+
return HybridZonotope(self.head, self.beta, self.errors, customRelu = self.customRelu if customRelu is None else customRelu)
|
| 731 |
+
|
| 732 |
+
def hybrid_to_zono(self, *args, **kargs):
|
| 733 |
+
return self.new(self.head, self.beta, self.errors, **kargs)
|
| 734 |
+
|
| 735 |
+
def applyMonotone(self, *args, **kargs):
|
| 736 |
+
return self.applySuper(super(Zonotope,self).applyMonotone(*args, **kargs))
|
| 737 |
+
|
| 738 |
+
def softplus(self):
|
| 739 |
+
return self.applySuper(super(Zonotope,self).softplus())
|
| 740 |
+
|
| 741 |
+
def relu(self):
|
| 742 |
+
return self.applySuper(super(Zonotope,self).relu())
|
| 743 |
+
|
| 744 |
+
def splitRelu(self, *args, **kargs):
|
| 745 |
+
return [self.applySuper(a) for a in super(Zonotope, self).splitRelu(*args, **kargs)]
|
| 746 |
+
|
| 747 |
+
|
| 748 |
+
def mysign(x):
|
| 749 |
+
e = x.eq(0).to_dtype()
|
| 750 |
+
r = x.sign().to_dtype()
|
| 751 |
+
return r + e
|
| 752 |
+
|
| 753 |
+
def mulIfEq(grad,out,target):
|
| 754 |
+
pred = out.max(1, keepdim=True)[1]
|
| 755 |
+
is_eq = pred.eq(target.view_as(pred)).to_dtype()
|
| 756 |
+
is_eq = is_eq.view([-1] + [1 for _ in grad.size()[1:]]).expand_as(grad)
|
| 757 |
+
return is_eq
|
| 758 |
+
|
| 759 |
+
|
| 760 |
+
def stdLoss(out, target):
|
| 761 |
+
if torch.__version__[0] == "0":
|
| 762 |
+
return F.cross_entropy(out, target, reduce = False)
|
| 763 |
+
else:
|
| 764 |
+
return F.cross_entropy(out, target, reduction='none')
|
| 765 |
+
|
| 766 |
+
|
| 767 |
+
|
| 768 |
+
class ListDomain(object):
|
| 769 |
+
|
| 770 |
+
def __init__(self, al, *args, **kargs):
|
| 771 |
+
self.al = list(al)
|
| 772 |
+
|
| 773 |
+
def new(self, *args, **kargs):
|
| 774 |
+
return self.__class__(*args, **kargs)
|
| 775 |
+
|
| 776 |
+
def isSafe(self,*args,**kargs):
|
| 777 |
+
raise "Domain Not Suitable For Testing"
|
| 778 |
+
|
| 779 |
+
def labels(self):
|
| 780 |
+
raise "Domain Not Suitable For Testing"
|
| 781 |
+
|
| 782 |
+
def isPoint(self):
|
| 783 |
+
return all(a.isPoint() for a in self.al)
|
| 784 |
+
|
| 785 |
+
def __mul__(self, flt):
|
| 786 |
+
return self.new(a.__mul__(flt) for a in self.al)
|
| 787 |
+
|
| 788 |
+
def __truediv__(self, flt):
|
| 789 |
+
return self.new(a.__truediv__(flt) for a in self.al)
|
| 790 |
+
|
| 791 |
+
def __add__(self, other):
|
| 792 |
+
if isinstance(other, ListDomain):
|
| 793 |
+
return self.new(a.__add__(o) for a,o in zip(self.al, other.al))
|
| 794 |
+
else:
|
| 795 |
+
return self.new(a.__add__(other) for a in self.al)
|
| 796 |
+
|
| 797 |
+
def merge(self, other, ref = None):
|
| 798 |
+
if ref is None:
|
| 799 |
+
return self.new(a.merge(o) for a,o in zip(self.al,other.al) )
|
| 800 |
+
return self.new(a.merge(o, ref = r) for a,o,r in zip(self.al,other.al, ref.al))
|
| 801 |
+
|
| 802 |
+
def addPar(self, a, b):
|
| 803 |
+
return self.new(s.addPar(av,bv) for s,av,bv in zip(self.al, a.al, b.al))
|
| 804 |
+
|
| 805 |
+
def __sub__(self, other):
|
| 806 |
+
if isinstance(other, ListDomain):
|
| 807 |
+
return self.new(a.__sub__(o) for a,o in zip(self.al, other.al))
|
| 808 |
+
else:
|
| 809 |
+
return self.new(a.__sub__(other) for a in self.al)
|
| 810 |
+
|
| 811 |
+
def abstractApplyLeaf(self, *args, **kargs):
|
| 812 |
+
return self.new(a.abstractApplyLeaf(*args, **kargs) for a in self.al)
|
| 813 |
+
|
| 814 |
+
def bmm(self, other):
|
| 815 |
+
return self.new(a.bmm(other) for a in self.al)
|
| 816 |
+
|
| 817 |
+
def matmul(self, other):
|
| 818 |
+
return self.new(a.matmul(other) for a in self.al)
|
| 819 |
+
|
| 820 |
+
def conv(self, *args, **kargs):
|
| 821 |
+
return self.new(a.conv(*args, **kargs) for a in self.al)
|
| 822 |
+
|
| 823 |
+
def conv1d(self, *args, **kargs):
|
| 824 |
+
return self.new(a.conv1d(*args, **kargs) for a in self.al)
|
| 825 |
+
|
| 826 |
+
def conv2d(self, *args, **kargs):
|
| 827 |
+
return self.new(a.conv2d(*args, **kargs) for a in self.al)
|
| 828 |
+
|
| 829 |
+
def conv3d(self, *args, **kargs):
|
| 830 |
+
return self.new(a.conv3d(*args, **kargs) for a in self.al)
|
| 831 |
+
|
| 832 |
+
def max_pool2d(self, *args, **kargs):
|
| 833 |
+
return self.new(a.max_pool2d(*args, **kargs) for a in self.al)
|
| 834 |
+
|
| 835 |
+
def avg_pool2d(self, *args, **kargs):
|
| 836 |
+
return self.new(a.avg_pool2d(*args, **kargs) for a in self.al)
|
| 837 |
+
|
| 838 |
+
def adaptive_avg_pool2d(self, *args, **kargs):
|
| 839 |
+
return self.new(a.adaptive_avg_pool2d(*args, **kargs) for a in self.al)
|
| 840 |
+
|
| 841 |
+
def unsqueeze(self, *args, **kargs):
|
| 842 |
+
return self.new(a.unsqueeze(*args, **kargs) for a in self.al)
|
| 843 |
+
|
| 844 |
+
def squeeze(self, *args, **kargs):
|
| 845 |
+
return self.new(a.squeeze(*args, **kargs) for a in self.al)
|
| 846 |
+
|
| 847 |
+
def view(self, *args, **kargs):
|
| 848 |
+
return self.new(a.view(*args, **kargs) for a in self.al)
|
| 849 |
+
|
| 850 |
+
def gather(self, *args, **kargs):
|
| 851 |
+
return self.new(a.gather(*args, **kargs) for a in self.al)
|
| 852 |
+
|
| 853 |
+
def sum(self, *args, **kargs):
|
| 854 |
+
return self.new(a.sum(*args,**kargs) for a in self.al)
|
| 855 |
+
|
| 856 |
+
def double(self):
|
| 857 |
+
return self.new(a.double() for a in self.al)
|
| 858 |
+
|
| 859 |
+
def float(self):
|
| 860 |
+
return self.new(a.float() for a in self.al)
|
| 861 |
+
|
| 862 |
+
def to_dtype(self):
|
| 863 |
+
return self.new(a.to_dtype() for a in self.al)
|
| 864 |
+
|
| 865 |
+
def vanillaTensorPart(self):
|
| 866 |
+
return self.al[0].vanillaTensorPart()
|
| 867 |
+
|
| 868 |
+
def center(self):
|
| 869 |
+
return self.new(a.center() for a in self.al)
|
| 870 |
+
|
| 871 |
+
def ub(self):
|
| 872 |
+
return self.new(a.ub() for a in self.al)
|
| 873 |
+
|
| 874 |
+
def lb(self):
|
| 875 |
+
return self.new(a.lb() for a in self.al)
|
| 876 |
+
|
| 877 |
+
def relu(self):
|
| 878 |
+
return self.new(a.relu() for a in self.al)
|
| 879 |
+
|
| 880 |
+
def splitRelu(self, *args, **kargs):
|
| 881 |
+
return self.new(a.splitRelu(*args, **kargs) for a in self.al)
|
| 882 |
+
|
| 883 |
+
def softplus(self):
|
| 884 |
+
return self.new(a.softplus() for a in self.al)
|
| 885 |
+
|
| 886 |
+
def elu(self):
|
| 887 |
+
return self.new(a.elu() for a in self.al)
|
| 888 |
+
|
| 889 |
+
def selu(self):
|
| 890 |
+
return self.new(a.selu() for a in self.al)
|
| 891 |
+
|
| 892 |
+
def sigm(self):
|
| 893 |
+
return self.new(a.sigm() for a in self.al)
|
| 894 |
+
|
| 895 |
+
def cat(self, other, *args, **kargs):
|
| 896 |
+
return self.new(a.cat(o, *args, **kargs) for a,o in zip(self.al, other.al))
|
| 897 |
+
|
| 898 |
+
|
| 899 |
+
def split(self, *args, **kargs):
|
| 900 |
+
return [self.new(*z) for z in zip(a.split(*args, **kargs) for a in self.al)]
|
| 901 |
+
|
| 902 |
+
def size(self):
|
| 903 |
+
return self.al[0].size()
|
| 904 |
+
|
| 905 |
+
def loss(self, *args, **kargs):
|
| 906 |
+
return sum(a.loss(*args, **kargs) for a in self.al)
|
| 907 |
+
|
| 908 |
+
def deep_loss(self, *args, **kargs):
|
| 909 |
+
return sum(a.deep_loss(*args, **kargs) for a in self.al)
|
| 910 |
+
|
| 911 |
+
def checkSizes(self):
|
| 912 |
+
for a in self.al:
|
| 913 |
+
a.checkSizes()
|
| 914 |
+
return self
|
| 915 |
+
|
| 916 |
+
|
| 917 |
+
class TaggedDomain(object):
|
| 918 |
+
|
| 919 |
+
|
| 920 |
+
def __init__(self, a, tag = None):
|
| 921 |
+
self.tag = tag
|
| 922 |
+
self.a = a
|
| 923 |
+
|
| 924 |
+
def isSafe(self,*args,**kargs):
|
| 925 |
+
return self.a.isSafe(*args, **kargs)
|
| 926 |
+
|
| 927 |
+
def isPoint(self):
|
| 928 |
+
return self.a.isPoint()
|
| 929 |
+
|
| 930 |
+
def labels(self):
|
| 931 |
+
raise "Domain Not Suitable For Testing"
|
| 932 |
+
|
| 933 |
+
def __mul__(self, flt):
|
| 934 |
+
return TaggedDomain(self.a.__mul__(flt), self.tag)
|
| 935 |
+
|
| 936 |
+
def __truediv__(self, flt):
|
| 937 |
+
return TaggedDomain(self.a.__truediv__(flt), self.tag)
|
| 938 |
+
|
| 939 |
+
def __add__(self, other):
|
| 940 |
+
if isinstance(other, TaggedDomain):
|
| 941 |
+
return TaggedDomain(self.a.__add__(other.a), self.tag)
|
| 942 |
+
else:
|
| 943 |
+
return TaggedDomain(self.a.__add__(other), self.tag)
|
| 944 |
+
|
| 945 |
+
def addPar(self, a,b):
|
| 946 |
+
return TaggedDomain(self.a.addPar(a.a, b.a), self.tag)
|
| 947 |
+
|
| 948 |
+
def __sub__(self, other):
|
| 949 |
+
if isinstance(other, TaggedDomain):
|
| 950 |
+
return TaggedDomain(self.a.__sub__(other.a), self.tag)
|
| 951 |
+
else:
|
| 952 |
+
return TaggedDomain(self.a.__sub__(other), self.tag)
|
| 953 |
+
|
| 954 |
+
def bmm(self, other):
|
| 955 |
+
return TaggedDomain(self.a.bmm(other), self.tag)
|
| 956 |
+
|
| 957 |
+
def matmul(self, other):
|
| 958 |
+
return TaggedDomain(self.a.matmul(other), self.tag)
|
| 959 |
+
|
| 960 |
+
def conv(self, *args, **kargs):
|
| 961 |
+
return TaggedDomain(self.a.conv(*args, **kargs) , self.tag)
|
| 962 |
+
|
| 963 |
+
def conv1d(self, *args, **kargs):
|
| 964 |
+
return TaggedDomain(self.a.conv1d(*args, **kargs), self.tag)
|
| 965 |
+
|
| 966 |
+
def conv2d(self, *args, **kargs):
|
| 967 |
+
return TaggedDomain(self.a.conv2d(*args, **kargs), self.tag)
|
| 968 |
+
|
| 969 |
+
def conv3d(self, *args, **kargs):
|
| 970 |
+
return TaggedDomain(self.a.conv3d(*args, **kargs), self.tag)
|
| 971 |
+
|
| 972 |
+
def max_pool2d(self, *args, **kargs):
|
| 973 |
+
return TaggedDomain(self.a.max_pool2d(*args, **kargs), self.tag)
|
| 974 |
+
|
| 975 |
+
def avg_pool2d(self, *args, **kargs):
|
| 976 |
+
return TaggedDomain(self.a.avg_pool2d(*args, **kargs), self.tag)
|
| 977 |
+
|
| 978 |
+
def adaptive_avg_pool2d(self, *args, **kargs):
|
| 979 |
+
return TaggedDomain(self.a.adaptive_avg_pool2d(*args, **kargs), self.tag)
|
| 980 |
+
|
| 981 |
+
|
| 982 |
+
def unsqueeze(self, *args, **kargs):
|
| 983 |
+
return TaggedDomain(self.a.unsqueeze(*args, **kargs), self.tag)
|
| 984 |
+
|
| 985 |
+
def squeeze(self, *args, **kargs):
|
| 986 |
+
return TaggedDomain(self.a.squeeze(*args, **kargs), self.tag)
|
| 987 |
+
|
| 988 |
+
def abstractApplyLeaf(self, *args, **kargs):
|
| 989 |
+
return TaggedDomain(self.a.abstractApplyLeaf(*args, **kargs), self.tag)
|
| 990 |
+
|
| 991 |
+
def view(self, *args, **kargs):
|
| 992 |
+
return TaggedDomain(self.a.view(*args, **kargs), self.tag)
|
| 993 |
+
|
| 994 |
+
def gather(self, *args, **kargs):
|
| 995 |
+
return TaggedDomain(self.a.gather(*args, **kargs), self.tag)
|
| 996 |
+
|
| 997 |
+
def sum(self, *args, **kargs):
|
| 998 |
+
return TaggedDomain(self.a.sum(*args,**kargs), self.tag)
|
| 999 |
+
|
| 1000 |
+
def double(self):
|
| 1001 |
+
return TaggedDomain(self.a.double(), self.tag)
|
| 1002 |
+
|
| 1003 |
+
def float(self):
|
| 1004 |
+
return TaggedDomain(self.a.float(), self.tag)
|
| 1005 |
+
|
| 1006 |
+
def to_dtype(self):
|
| 1007 |
+
return TaggedDomain(self.a.to_dtype(), self.tag)
|
| 1008 |
+
|
| 1009 |
+
def vanillaTensorPart(self):
|
| 1010 |
+
return self.a.vanillaTensorPart()
|
| 1011 |
+
|
| 1012 |
+
def center(self):
|
| 1013 |
+
return TaggedDomain(self.a.center(), self.tag)
|
| 1014 |
+
|
| 1015 |
+
def ub(self):
|
| 1016 |
+
return TaggedDomain(self.a.ub(), self.tag)
|
| 1017 |
+
|
| 1018 |
+
def lb(self):
|
| 1019 |
+
return TaggedDomain(self.a.lb(), self.tag)
|
| 1020 |
+
|
| 1021 |
+
def relu(self):
|
| 1022 |
+
return TaggedDomain(self.a.relu(), self.tag)
|
| 1023 |
+
|
| 1024 |
+
def splitRelu(self, *args, **kargs):
|
| 1025 |
+
return TaggedDomain(self.a.splitRelu(*args, **kargs), self.tag)
|
| 1026 |
+
|
| 1027 |
+
def diameter(self):
|
| 1028 |
+
return self.a.diameter()
|
| 1029 |
+
|
| 1030 |
+
def softplus(self):
|
| 1031 |
+
return TaggedDomain(self.a.softplus(), self.tag)
|
| 1032 |
+
|
| 1033 |
+
def elu(self):
|
| 1034 |
+
return TaggedDomain(self.a.elu(), self.tag)
|
| 1035 |
+
|
| 1036 |
+
def selu(self):
|
| 1037 |
+
return TaggedDomain(self.a.selu(), self.tag)
|
| 1038 |
+
|
| 1039 |
+
def sigm(self):
|
| 1040 |
+
return TaggedDomain(self.a.sigm(), self.tag)
|
| 1041 |
+
|
| 1042 |
+
|
| 1043 |
+
def cat(self, other, *args, **kargs):
|
| 1044 |
+
return TaggedDomain(self.a.cat(other.a, *args, **kargs), self.tag)
|
| 1045 |
+
|
| 1046 |
+
def split(self, *args, **kargs):
|
| 1047 |
+
return [TaggedDomain(z, self.tag) for z in self.a.split(*args, **kargs)]
|
| 1048 |
+
|
| 1049 |
+
def size(self):
|
| 1050 |
+
|
| 1051 |
+
return self.a.size()
|
| 1052 |
+
|
| 1053 |
+
def loss(self, *args, **kargs):
|
| 1054 |
+
return self.tag.loss(self.a, *args, **kargs)
|
| 1055 |
+
|
| 1056 |
+
def deep_loss(self, *args, **kargs):
|
| 1057 |
+
return self.a.deep_loss(*args, **kargs)
|
| 1058 |
+
|
| 1059 |
+
def checkSizes(self):
|
| 1060 |
+
self.a.checkSizes()
|
| 1061 |
+
return self
|
| 1062 |
+
|
| 1063 |
+
def merge(self, other, ref = None):
|
| 1064 |
+
return TaggedDomain(self.a.merge(other.a, ref = None if ref is None else ref.a), self.tag)
|
components.py
ADDED
|
@@ -0,0 +1,951 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
from torch.distributions import multinomial, categorical
|
| 5 |
+
import torch.optim as optim
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
|
| 9 |
+
try:
|
| 10 |
+
from . import helpers as h
|
| 11 |
+
from . import ai
|
| 12 |
+
from . import scheduling as S
|
| 13 |
+
except:
|
| 14 |
+
import helpers as h
|
| 15 |
+
import ai
|
| 16 |
+
import scheduling as S
|
| 17 |
+
|
| 18 |
+
import math
|
| 19 |
+
import abc
|
| 20 |
+
|
| 21 |
+
from torch.nn.modules.conv import _ConvNd
|
| 22 |
+
from enum import Enum
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class InferModule(nn.Module):
|
| 26 |
+
def __init__(self, *args, normal = False, ibp_init = False, **kwargs):
|
| 27 |
+
self.args = args
|
| 28 |
+
self.kwargs = kwargs
|
| 29 |
+
self.infered = False
|
| 30 |
+
self.normal = normal
|
| 31 |
+
self.ibp_init = ibp_init
|
| 32 |
+
|
| 33 |
+
def infer(self, in_shape, global_args = None):
|
| 34 |
+
""" this is really actually stateful. """
|
| 35 |
+
|
| 36 |
+
if self.infered:
|
| 37 |
+
return self
|
| 38 |
+
self.infered = True
|
| 39 |
+
|
| 40 |
+
super(InferModule, self).__init__()
|
| 41 |
+
self.inShape = list(in_shape)
|
| 42 |
+
self.outShape = list(self.init(list(in_shape), *self.args, global_args = global_args, **self.kwargs))
|
| 43 |
+
if self.outShape is None:
|
| 44 |
+
raise "init should set the out_shape"
|
| 45 |
+
|
| 46 |
+
self.reset_parameters()
|
| 47 |
+
return self
|
| 48 |
+
|
| 49 |
+
def reset_parameters(self):
|
| 50 |
+
if not hasattr(self,'weight') or self.weight is None:
|
| 51 |
+
return
|
| 52 |
+
n = h.product(self.weight.size()) / self.outShape[0]
|
| 53 |
+
stdv = 1 / math.sqrt(n)
|
| 54 |
+
|
| 55 |
+
if self.ibp_init:
|
| 56 |
+
torch.nn.init.orthogonal_(self.weight.data)
|
| 57 |
+
elif self.normal:
|
| 58 |
+
self.weight.data.normal_(0, stdv)
|
| 59 |
+
self.weight.data.clamp_(-1, 1)
|
| 60 |
+
else:
|
| 61 |
+
self.weight.data.uniform_(-stdv, stdv)
|
| 62 |
+
|
| 63 |
+
if self.bias is not None:
|
| 64 |
+
if self.ibp_init:
|
| 65 |
+
self.bias.data.zero_()
|
| 66 |
+
elif self.normal:
|
| 67 |
+
self.bias.data.normal_(0, stdv)
|
| 68 |
+
self.bias.data.clamp_(-1, 1)
|
| 69 |
+
else:
|
| 70 |
+
self.bias.data.uniform_(-stdv, stdv)
|
| 71 |
+
|
| 72 |
+
def clip_norm(self):
|
| 73 |
+
if not hasattr(self, "weight"):
|
| 74 |
+
return
|
| 75 |
+
if not hasattr(self,"weight_g"):
|
| 76 |
+
if torch.__version__[0] == "0":
|
| 77 |
+
nn.utils.weight_norm(self, dim=None)
|
| 78 |
+
else:
|
| 79 |
+
nn.utils.weight_norm(self)
|
| 80 |
+
|
| 81 |
+
self.weight_g.data.clamp_(-h.max_c_for_norm, h.max_c_for_norm)
|
| 82 |
+
|
| 83 |
+
if torch.__version__[0] != "0":
|
| 84 |
+
self.weight_v.data.clamp_(-h.max_c_for_norm * 10000,h.max_c_for_norm * 10000)
|
| 85 |
+
if hasattr(self, "bias"):
|
| 86 |
+
self.bias.data.clamp_(-h.max_c_for_norm * 10000, h.max_c_for_norm * 10000)
|
| 87 |
+
|
| 88 |
+
def regularize(self, p):
|
| 89 |
+
reg = 0
|
| 90 |
+
if torch.__version__[0] == "0":
|
| 91 |
+
for param in self.parameters():
|
| 92 |
+
reg += param.norm(p)
|
| 93 |
+
else:
|
| 94 |
+
if hasattr(self, "weight_g"):
|
| 95 |
+
reg += self.weight_g.norm().sum()
|
| 96 |
+
reg += self.weight_v.norm().sum()
|
| 97 |
+
elif hasattr(self, "weight"):
|
| 98 |
+
reg += self.weight.norm().sum()
|
| 99 |
+
|
| 100 |
+
if hasattr(self, "bias"):
|
| 101 |
+
reg += self.bias.view(-1).norm(p=p).sum()
|
| 102 |
+
|
| 103 |
+
return reg
|
| 104 |
+
|
| 105 |
+
def remove_norm(self):
|
| 106 |
+
if hasattr(self,"weight_g"):
|
| 107 |
+
torch.nn.utils.remove_weight_norm(self)
|
| 108 |
+
|
| 109 |
+
def showNet(self, t = ""):
|
| 110 |
+
print(t + self.__class__.__name__)
|
| 111 |
+
|
| 112 |
+
def printNet(self, f):
|
| 113 |
+
print(self.__class__.__name__, file=f)
|
| 114 |
+
|
| 115 |
+
@abc.abstractmethod
|
| 116 |
+
def forward(self, *args, **kargs):
|
| 117 |
+
pass
|
| 118 |
+
|
| 119 |
+
def __call__(self, *args, onyx=False, **kargs):
|
| 120 |
+
if onyx:
|
| 121 |
+
return self.forward(*args, onyx=onyx, **kargs)
|
| 122 |
+
else:
|
| 123 |
+
return super(InferModule, self).__call__(*args, **kargs)
|
| 124 |
+
|
| 125 |
+
@abc.abstractmethod
|
| 126 |
+
def neuronCount(self):
|
| 127 |
+
pass
|
| 128 |
+
|
| 129 |
+
def depth(self):
|
| 130 |
+
return 0
|
| 131 |
+
|
| 132 |
+
def getShapeConv(in_shape, conv_shape, stride = 1, padding = 0):
|
| 133 |
+
inChan, inH, inW = in_shape
|
| 134 |
+
outChan, kH, kW = conv_shape[:3]
|
| 135 |
+
|
| 136 |
+
outH = 1 + int((2 * padding + inH - kH) / stride)
|
| 137 |
+
outW = 1 + int((2 * padding + inW - kW) / stride)
|
| 138 |
+
return (outChan, outH, outW)
|
| 139 |
+
|
| 140 |
+
def getShapeConvTranspose(in_shape, conv_shape, stride = 1, padding = 0, out_padding=0):
|
| 141 |
+
inChan, inH, inW = in_shape
|
| 142 |
+
outChan, kH, kW = conv_shape[:3]
|
| 143 |
+
|
| 144 |
+
outH = (inH - 1 ) * stride - 2 * padding + kH + out_padding
|
| 145 |
+
outW = (inW - 1 ) * stride - 2 * padding + kW + out_padding
|
| 146 |
+
return (outChan, outH, outW)
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
class Linear(InferModule):
|
| 151 |
+
def init(self, in_shape, out_shape, **kargs):
|
| 152 |
+
self.in_neurons = h.product(in_shape)
|
| 153 |
+
if isinstance(out_shape, int):
|
| 154 |
+
out_shape = [out_shape]
|
| 155 |
+
self.out_neurons = h.product(out_shape)
|
| 156 |
+
|
| 157 |
+
self.weight = torch.nn.Parameter(torch.Tensor(self.in_neurons, self.out_neurons))
|
| 158 |
+
self.bias = torch.nn.Parameter(torch.Tensor(self.out_neurons))
|
| 159 |
+
|
| 160 |
+
return out_shape
|
| 161 |
+
|
| 162 |
+
def forward(self, x, **kargs):
|
| 163 |
+
s = x.size()
|
| 164 |
+
x = x.view(s[0], h.product(s[1:]))
|
| 165 |
+
return (x.matmul(self.weight) + self.bias).view(s[0], *self.outShape)
|
| 166 |
+
|
| 167 |
+
def neuronCount(self):
|
| 168 |
+
return 0
|
| 169 |
+
|
| 170 |
+
def showNet(self, t = ""):
|
| 171 |
+
print(t + "Linear out=" + str(self.out_neurons))
|
| 172 |
+
|
| 173 |
+
def printNet(self, f):
|
| 174 |
+
print("Linear(" + str(self.out_neurons) + ")" )
|
| 175 |
+
|
| 176 |
+
print(h.printListsNumpy(list(self.weight.transpose(1,0).data)), file= f)
|
| 177 |
+
print(h.printNumpy(self.bias), file= f)
|
| 178 |
+
|
| 179 |
+
class Activation(InferModule):
|
| 180 |
+
def init(self, in_shape, global_args = None, activation = "ReLU", **kargs):
|
| 181 |
+
self.activation = [ "ReLU","Sigmoid", "Tanh", "Softplus", "ELU", "SELU"].index(activation)
|
| 182 |
+
self.activation_name = activation
|
| 183 |
+
return in_shape
|
| 184 |
+
|
| 185 |
+
def regularize(self, p):
|
| 186 |
+
return 0
|
| 187 |
+
|
| 188 |
+
def forward(self, x, **kargs):
|
| 189 |
+
return [lambda x:x.relu(), lambda x:x.sigmoid(), lambda x:x.tanh(), lambda x:x.softplus(), lambda x:x.elu(), lambda x:x.selu()][self.activation](x)
|
| 190 |
+
|
| 191 |
+
def neuronCount(self):
|
| 192 |
+
return h.product(self.outShape)
|
| 193 |
+
|
| 194 |
+
def depth(self):
|
| 195 |
+
return 1
|
| 196 |
+
|
| 197 |
+
def showNet(self, t = ""):
|
| 198 |
+
print(t + self.activation_name)
|
| 199 |
+
|
| 200 |
+
def printNet(self, f):
|
| 201 |
+
pass
|
| 202 |
+
|
| 203 |
+
class ReLU(Activation):
|
| 204 |
+
pass
|
| 205 |
+
|
| 206 |
+
def activation(*args, batch_norm = False, **kargs):
|
| 207 |
+
a = Activation(*args, **kargs)
|
| 208 |
+
return Seq(BatchNorm(), a) if batch_norm else a
|
| 209 |
+
|
| 210 |
+
class Identity(InferModule): # for feigning model equivelence when removing an op
|
| 211 |
+
def init(self, in_shape, global_args = None, **kargs):
|
| 212 |
+
return in_shape
|
| 213 |
+
|
| 214 |
+
def forward(self, x, **kargs):
|
| 215 |
+
return x
|
| 216 |
+
|
| 217 |
+
def neuronCount(self):
|
| 218 |
+
return 0
|
| 219 |
+
|
| 220 |
+
def printNet(self, f):
|
| 221 |
+
pass
|
| 222 |
+
|
| 223 |
+
def regularize(self, p):
|
| 224 |
+
return 0
|
| 225 |
+
|
| 226 |
+
def showNet(self, *args, **kargs):
|
| 227 |
+
pass
|
| 228 |
+
|
| 229 |
+
class Dropout(InferModule):
|
| 230 |
+
def init(self, in_shape, p=0.5, use_2d = False, alpha_dropout = False, **kargs):
|
| 231 |
+
self.p = S.Const.initConst(p)
|
| 232 |
+
self.use_2d = use_2d
|
| 233 |
+
self.alpha_dropout = alpha_dropout
|
| 234 |
+
return in_shape
|
| 235 |
+
|
| 236 |
+
def forward(self, x, time = 0, **kargs):
|
| 237 |
+
if self.training:
|
| 238 |
+
with torch.no_grad():
|
| 239 |
+
p = self.p.getVal(time = time)
|
| 240 |
+
mask = (F.dropout2d if self.use_2d else F.dropout)(h.ones(x.size()),p=p, training=True)
|
| 241 |
+
if self.alpha_dropout:
|
| 242 |
+
with torch.no_grad():
|
| 243 |
+
keep_prob = 1 - p
|
| 244 |
+
alpha = -1.7580993408473766
|
| 245 |
+
a = math.pow(keep_prob + alpha * alpha * keep_prob * (1 - keep_prob), -0.5)
|
| 246 |
+
b = -a * alpha * (1 - keep_prob)
|
| 247 |
+
mask = mask * a
|
| 248 |
+
return x * mask + b
|
| 249 |
+
else:
|
| 250 |
+
return x * mask
|
| 251 |
+
else:
|
| 252 |
+
return x
|
| 253 |
+
|
| 254 |
+
def neuronCount(self):
|
| 255 |
+
return 0
|
| 256 |
+
|
| 257 |
+
def showNet(self, t = ""):
|
| 258 |
+
print(t + "Dropout p=" + str(self.p))
|
| 259 |
+
|
| 260 |
+
def printNet(self, f):
|
| 261 |
+
print("Dropout(" + str(self.p) + ")" )
|
| 262 |
+
|
| 263 |
+
class PrintActivation(Identity):
|
| 264 |
+
def init(self, in_shape, global_args = None, activation = "ReLU", **kargs):
|
| 265 |
+
self.activation = activation
|
| 266 |
+
return in_shape
|
| 267 |
+
|
| 268 |
+
def printNet(self, f):
|
| 269 |
+
print(self.activation, file = f)
|
| 270 |
+
|
| 271 |
+
class PrintReLU(PrintActivation):
|
| 272 |
+
pass
|
| 273 |
+
|
| 274 |
+
class Conv2D(InferModule):
|
| 275 |
+
|
| 276 |
+
def init(self, in_shape, out_channels, kernel_size, stride = 1, global_args = None, bias=True, padding = 0, activation = "ReLU", **kargs):
|
| 277 |
+
self.prev = in_shape
|
| 278 |
+
self.in_channels = in_shape[0]
|
| 279 |
+
self.out_channels = out_channels
|
| 280 |
+
self.kernel_size = kernel_size
|
| 281 |
+
self.stride = stride
|
| 282 |
+
self.padding = padding
|
| 283 |
+
self.activation = activation
|
| 284 |
+
self.use_softplus = h.default(global_args, 'use_softplus', False)
|
| 285 |
+
|
| 286 |
+
weights_shape = (self.out_channels, self.in_channels, kernel_size, kernel_size)
|
| 287 |
+
self.weight = torch.nn.Parameter(torch.Tensor(*weights_shape))
|
| 288 |
+
if bias:
|
| 289 |
+
self.bias = torch.nn.Parameter(torch.Tensor(weights_shape[0]))
|
| 290 |
+
else:
|
| 291 |
+
self.bias = None # h.zeros(weights_shape[0])
|
| 292 |
+
|
| 293 |
+
outshape = getShapeConv(in_shape, (out_channels, kernel_size, kernel_size), stride, padding)
|
| 294 |
+
return outshape
|
| 295 |
+
|
| 296 |
+
def forward(self, input, **kargs):
|
| 297 |
+
return input.conv2d(self.weight, bias=self.bias, stride=self.stride, padding = self.padding )
|
| 298 |
+
|
| 299 |
+
def printNet(self, f): # only complete if we've forwardt stride=1
|
| 300 |
+
print("Conv2D", file = f)
|
| 301 |
+
sz = list(self.prev)
|
| 302 |
+
print(self.activation + ", filters={}, kernel_size={}, input_shape={}, stride={}, padding={}".format(self.out_channels, [self.kernel_size, self.kernel_size], list(reversed(sz)), [self.stride, self.stride], self.padding ), file = f)
|
| 303 |
+
print(h.printListsNumpy([[list(p) for p in l ] for l in self.weight.permute(2,3,1,0).data]) , file= f)
|
| 304 |
+
print(h.printNumpy(self.bias if self.bias is not None else h.dten(self.out_channels)), file= f)
|
| 305 |
+
|
| 306 |
+
def showNet(self, t = ""):
|
| 307 |
+
sz = list(self.prev)
|
| 308 |
+
print(t + "Conv2D, filters={}, kernel_size={}, input_shape={}, stride={}, padding={}".format(self.out_channels, [self.kernel_size, self.kernel_size], list(reversed(sz)), [self.stride, self.stride], self.padding ))
|
| 309 |
+
|
| 310 |
+
def neuronCount(self):
|
| 311 |
+
return 0
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
class ConvTranspose2D(InferModule):
|
| 315 |
+
|
| 316 |
+
def init(self, in_shape, out_channels, kernel_size, stride = 1, global_args = None, bias=True, padding = 0, out_padding=0, activation = "ReLU", **kargs):
|
| 317 |
+
self.prev = in_shape
|
| 318 |
+
self.in_channels = in_shape[0]
|
| 319 |
+
self.out_channels = out_channels
|
| 320 |
+
self.kernel_size = kernel_size
|
| 321 |
+
self.stride = stride
|
| 322 |
+
self.padding = padding
|
| 323 |
+
self.out_padding = out_padding
|
| 324 |
+
self.activation = activation
|
| 325 |
+
self.use_softplus = h.default(global_args, 'use_softplus', False)
|
| 326 |
+
|
| 327 |
+
weights_shape = (self.in_channels, self.out_channels, kernel_size, kernel_size)
|
| 328 |
+
self.weight = torch.nn.Parameter(torch.Tensor(*weights_shape))
|
| 329 |
+
if bias:
|
| 330 |
+
self.bias = torch.nn.Parameter(torch.Tensor(weights_shape[0]))
|
| 331 |
+
else:
|
| 332 |
+
self.bias = None # h.zeros(weights_shape[0])
|
| 333 |
+
|
| 334 |
+
outshape = getShapeConvTranspose(in_shape, (out_channels, kernel_size, kernel_size), stride, padding, out_padding)
|
| 335 |
+
return outshape
|
| 336 |
+
|
| 337 |
+
def forward(self, input, **kargs):
|
| 338 |
+
return input.conv_transpose2d(self.weight, bias=self.bias, stride=self.stride, padding = self.padding, output_padding=self.out_padding)
|
| 339 |
+
|
| 340 |
+
def printNet(self, f): # only complete if we've forwardt stride=1
|
| 341 |
+
print("ConvTranspose2D", file = f)
|
| 342 |
+
print(self.activation + ", filters={}, kernel_size={}, input_shape={}".format(self.out_channels, list(self.kernel_size), list(self.prev) ), file = f)
|
| 343 |
+
print(h.printListsNumpy([[list(p) for p in l ] for l in self.weight.permute(2,3,1,0).data]) , file= f)
|
| 344 |
+
print(h.printNumpy(self.bias), file= f)
|
| 345 |
+
|
| 346 |
+
def neuronCount(self):
|
| 347 |
+
return 0
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
|
| 351 |
+
class MaxPool2D(InferModule):
|
| 352 |
+
def init(self, in_shape, kernel_size, stride = None, **kargs):
|
| 353 |
+
self.prev = in_shape
|
| 354 |
+
self.kernel_size = kernel_size
|
| 355 |
+
self.stride = kernel_size if stride is None else stride
|
| 356 |
+
return getShapeConv(in_shape, (in_shape[0], kernel_size, kernel_size), stride)
|
| 357 |
+
|
| 358 |
+
def forward(self, x, **kargs):
|
| 359 |
+
return x.max_pool2d(self.kernel_size, self.stride)
|
| 360 |
+
|
| 361 |
+
def printNet(self, f):
|
| 362 |
+
print("MaxPool2D stride={}, kernel_size={}, input_shape={}".format(list(self.stride), list(self.shape[2:]), list(self.prev[1:]+self.prev[:1]) ), file = f)
|
| 363 |
+
|
| 364 |
+
def neuronCount(self):
|
| 365 |
+
return h.product(self.outShape)
|
| 366 |
+
|
| 367 |
+
class AvgPool2D(InferModule):
|
| 368 |
+
def init(self, in_shape, kernel_size, stride = None, **kargs):
|
| 369 |
+
self.prev = in_shape
|
| 370 |
+
self.kernel_size = kernel_size
|
| 371 |
+
self.stride = kernel_size if stride is None else stride
|
| 372 |
+
out_size = getShapeConv(in_shape, (in_shape[0], kernel_size, kernel_size), self.stride, padding = 1)
|
| 373 |
+
return out_size
|
| 374 |
+
|
| 375 |
+
def forward(self, x, **kargs):
|
| 376 |
+
if h.product(x.size()[2:]) == 1:
|
| 377 |
+
return x
|
| 378 |
+
return x.avg_pool2d(kernel_size = self.kernel_size, stride = self.stride, padding = 1)
|
| 379 |
+
|
| 380 |
+
def printNet(self, f):
|
| 381 |
+
print("AvgPool2D stride={}, kernel_size={}, input_shape={}".format(list(self.stride), list(self.shape[2:]), list(self.prev[1:]+self.prev[:1]) ), file = f)
|
| 382 |
+
|
| 383 |
+
def neuronCount(self):
|
| 384 |
+
return h.product(self.outShape)
|
| 385 |
+
|
| 386 |
+
class AdaptiveAvgPool2D(InferModule):
|
| 387 |
+
def init(self, in_shape, out_shape, **kargs):
|
| 388 |
+
self.prev = in_shape
|
| 389 |
+
self.out_shape = list(out_shape)
|
| 390 |
+
return [in_shape[0]] + self.out_shape
|
| 391 |
+
|
| 392 |
+
def forward(self, x, **kargs):
|
| 393 |
+
return x.adaptive_avg_pool2d(self.out_shape)
|
| 394 |
+
|
| 395 |
+
def printNet(self, f):
|
| 396 |
+
print("AdaptiveAvgPool2D out_Shape={} input_shape={}".format(list(self.out_shape), list(self.prev[1:]+self.prev[:1]) ), file = f)
|
| 397 |
+
|
| 398 |
+
def neuronCount(self):
|
| 399 |
+
return h.product(self.outShape)
|
| 400 |
+
|
| 401 |
+
class Normalize(InferModule):
|
| 402 |
+
def init(self, in_shape, mean, std, **kargs):
|
| 403 |
+
self.mean_v = mean
|
| 404 |
+
self.std_v = std
|
| 405 |
+
self.mean = h.dten(mean)
|
| 406 |
+
self.std = 1 / h.dten(std)
|
| 407 |
+
return in_shape
|
| 408 |
+
|
| 409 |
+
def forward(self, x, **kargs):
|
| 410 |
+
mean_ex = self.mean.view(self.mean.shape[0],1,1).expand(*x.size()[1:])
|
| 411 |
+
std_ex = self.std.view(self.std.shape[0],1,1).expand(*x.size()[1:])
|
| 412 |
+
return (x - mean_ex) * std_ex
|
| 413 |
+
|
| 414 |
+
def neuronCount(self):
|
| 415 |
+
return 0
|
| 416 |
+
|
| 417 |
+
def printNet(self, f):
|
| 418 |
+
print("Normalize mean={} std={}".format(self.mean_v, self.std_v), file = f)
|
| 419 |
+
|
| 420 |
+
def showNet(self, t = ""):
|
| 421 |
+
print(t + "Normalize mean={} std={}".format(self.mean_v, self.std_v))
|
| 422 |
+
|
| 423 |
+
class Flatten(InferModule):
|
| 424 |
+
def init(self, in_shape, **kargs):
|
| 425 |
+
return h.product(in_shape)
|
| 426 |
+
|
| 427 |
+
def forward(self, x, **kargs):
|
| 428 |
+
s = x.size()
|
| 429 |
+
return x.view(s[0], h.product(s[1:]))
|
| 430 |
+
|
| 431 |
+
def neuronCount(self):
|
| 432 |
+
return 0
|
| 433 |
+
|
| 434 |
+
class BatchNorm(InferModule):
|
| 435 |
+
def init(self, in_shape, track_running_stats = True, momentum = 0.1, eps=1e-5, **kargs):
|
| 436 |
+
self.gamma = torch.nn.Parameter(torch.Tensor(*in_shape))
|
| 437 |
+
self.beta = torch.nn.Parameter(torch.Tensor(*in_shape))
|
| 438 |
+
self.eps = eps
|
| 439 |
+
self.track_running_stats = track_running_stats
|
| 440 |
+
self.momentum = momentum
|
| 441 |
+
|
| 442 |
+
self.running_mean = None
|
| 443 |
+
self.running_var = None
|
| 444 |
+
|
| 445 |
+
self.num_batches_tracked = 0
|
| 446 |
+
return in_shape
|
| 447 |
+
|
| 448 |
+
def reset_parameters(self):
|
| 449 |
+
self.gamma.data.fill_(1)
|
| 450 |
+
self.beta.data.zero_()
|
| 451 |
+
|
| 452 |
+
def forward(self, x, **kargs):
|
| 453 |
+
exponential_average_factor = 0.0
|
| 454 |
+
if self.training and self.track_running_stats:
|
| 455 |
+
# TODO: if statement only here to tell the jit to skip emitting this when it is None
|
| 456 |
+
if self.num_batches_tracked is not None:
|
| 457 |
+
self.num_batches_tracked += 1
|
| 458 |
+
if self.momentum is None: # use cumulative moving average
|
| 459 |
+
exponential_average_factor = 1.0 / float(self.num_batches_tracked)
|
| 460 |
+
else: # use exponential moving average
|
| 461 |
+
exponential_average_factor = self.momentum
|
| 462 |
+
|
| 463 |
+
new_mean = x.vanillaTensorPart().detach().mean(dim=0)
|
| 464 |
+
new_var = x.vanillaTensorPart().detach().var(dim=0, unbiased=False)
|
| 465 |
+
if torch.isnan(new_var * 0).any():
|
| 466 |
+
return x
|
| 467 |
+
if self.training:
|
| 468 |
+
self.running_mean = (1 - exponential_average_factor) * self.running_mean + exponential_average_factor * new_mean if self.running_mean is not None else new_mean
|
| 469 |
+
if self.running_var is None:
|
| 470 |
+
self.running_var = new_var
|
| 471 |
+
else:
|
| 472 |
+
q = (1 - exponential_average_factor) * self.running_var
|
| 473 |
+
r = exponential_average_factor * new_var
|
| 474 |
+
self.running_var = q + r
|
| 475 |
+
|
| 476 |
+
if self.track_running_stats and self.running_mean is not None and self.running_var is not None:
|
| 477 |
+
new_mean = self.running_mean
|
| 478 |
+
new_var = self.running_var
|
| 479 |
+
|
| 480 |
+
diver = 1 / (new_var + self.eps).sqrt()
|
| 481 |
+
|
| 482 |
+
if torch.isnan(diver).any():
|
| 483 |
+
print("Really shouldn't happen ever")
|
| 484 |
+
return x
|
| 485 |
+
else:
|
| 486 |
+
out = (x - new_mean) * diver * self.gamma + self.beta
|
| 487 |
+
return out
|
| 488 |
+
|
| 489 |
+
def neuronCount(self):
|
| 490 |
+
return 0
|
| 491 |
+
|
| 492 |
+
class Unflatten2d(InferModule):
|
| 493 |
+
def init(self, in_shape, w, **kargs):
|
| 494 |
+
self.w = w
|
| 495 |
+
self.outChan = int(h.product(in_shape) / (w * w))
|
| 496 |
+
|
| 497 |
+
return (self.outChan, self.w, self.w)
|
| 498 |
+
|
| 499 |
+
def forward(self, x, **kargs):
|
| 500 |
+
s = x.size()
|
| 501 |
+
return x.view(s[0], self.outChan, self.w, self.w)
|
| 502 |
+
|
| 503 |
+
def neuronCount(self):
|
| 504 |
+
return 0
|
| 505 |
+
|
| 506 |
+
|
| 507 |
+
class View(InferModule):
|
| 508 |
+
def init(self, in_shape, out_shape, **kargs):
|
| 509 |
+
assert(h.product(in_shape) == h.product(out_shape))
|
| 510 |
+
return out_shape
|
| 511 |
+
|
| 512 |
+
def forward(self, x, **kargs):
|
| 513 |
+
s = x.size()
|
| 514 |
+
return x.view(s[0], *self.outShape)
|
| 515 |
+
|
| 516 |
+
def neuronCount(self):
|
| 517 |
+
return 0
|
| 518 |
+
|
| 519 |
+
class Seq(InferModule):
|
| 520 |
+
def init(self, in_shape, *layers, **kargs):
|
| 521 |
+
self.layers = layers
|
| 522 |
+
self.net = nn.Sequential(*layers)
|
| 523 |
+
self.prev = in_shape
|
| 524 |
+
for s in layers:
|
| 525 |
+
in_shape = s.infer(in_shape, **kargs).outShape
|
| 526 |
+
return in_shape
|
| 527 |
+
|
| 528 |
+
def forward(self, x, **kargs):
|
| 529 |
+
|
| 530 |
+
for l in self.layers:
|
| 531 |
+
x = l(x, **kargs)
|
| 532 |
+
return x
|
| 533 |
+
|
| 534 |
+
def clip_norm(self):
|
| 535 |
+
for l in self.layers:
|
| 536 |
+
l.clip_norm()
|
| 537 |
+
|
| 538 |
+
def regularize(self, p):
|
| 539 |
+
return sum(n.regularize(p) for n in self.layers)
|
| 540 |
+
|
| 541 |
+
def remove_norm(self):
|
| 542 |
+
for l in self.layers:
|
| 543 |
+
l.remove_norm()
|
| 544 |
+
|
| 545 |
+
def printNet(self, f):
|
| 546 |
+
for l in self.layers:
|
| 547 |
+
l.printNet(f)
|
| 548 |
+
|
| 549 |
+
def showNet(self, *args, **kargs):
|
| 550 |
+
for l in self.layers:
|
| 551 |
+
l.showNet(*args, **kargs)
|
| 552 |
+
|
| 553 |
+
def neuronCount(self):
|
| 554 |
+
return sum([l.neuronCount() for l in self.layers ])
|
| 555 |
+
|
| 556 |
+
def depth(self):
|
| 557 |
+
return sum([l.depth() for l in self.layers ])
|
| 558 |
+
|
| 559 |
+
def FFNN(layers, last_lin = False, last_zono = False, **kargs):
|
| 560 |
+
starts = layers
|
| 561 |
+
ends = []
|
| 562 |
+
if last_lin:
|
| 563 |
+
ends = ([CorrelateAll(only_train=False)] if last_zono else []) + [PrintActivation(activation = "Affine"), Linear(layers[-1],**kargs)]
|
| 564 |
+
starts = layers[:-1]
|
| 565 |
+
|
| 566 |
+
return Seq(*([ Seq(PrintActivation(**kargs), Linear(s, **kargs), activation(**kargs)) for s in starts] + ends))
|
| 567 |
+
|
| 568 |
+
def Conv(*args, **kargs):
|
| 569 |
+
return Seq(Conv2D(*args, **kargs), activation(**kargs))
|
| 570 |
+
|
| 571 |
+
def ConvTranspose(*args, **kargs):
|
| 572 |
+
return Seq(ConvTranspose2D(*args, **kargs), activation(**kargs))
|
| 573 |
+
|
| 574 |
+
MP = MaxPool2D
|
| 575 |
+
|
| 576 |
+
def LeNet(conv_layers, ly = [], bias = True, normal=False, **kargs):
|
| 577 |
+
def transfer(tp):
|
| 578 |
+
if isinstance(tp, InferModule):
|
| 579 |
+
return tp
|
| 580 |
+
if isinstance(tp[0], str):
|
| 581 |
+
return MaxPool2D(*tp[1:])
|
| 582 |
+
return Conv(out_channels = tp[0], kernel_size = tp[1], stride = tp[-1] if len(tp) == 4 else 1, bias=bias, normal=normal, **kargs)
|
| 583 |
+
conv = [transfer(s) for s in conv_layers]
|
| 584 |
+
return Seq(*conv, FFNN(ly, **kargs, bias=bias)) if len(ly) > 0 else Seq(*conv)
|
| 585 |
+
|
| 586 |
+
def InvLeNet(ly, w, conv_layers, bias = True, normal=False, **kargs):
|
| 587 |
+
def transfer(tp):
|
| 588 |
+
return ConvTranspose(out_channels = tp[0], kernel_size = tp[1], stride = tp[2], padding = tp[3], out_padding = tp[4], bias=False, normal=normal)
|
| 589 |
+
|
| 590 |
+
return Seq(FFNN(ly, bias=bias), Unflatten2d(w), *[transfer(s) for s in conv_layers])
|
| 591 |
+
|
| 592 |
+
class FromByteImg(InferModule):
|
| 593 |
+
def init(self, in_shape, **kargs):
|
| 594 |
+
return in_shape
|
| 595 |
+
|
| 596 |
+
def forward(self, x, **kargs):
|
| 597 |
+
return x.to_dtype()/ 256.
|
| 598 |
+
|
| 599 |
+
def neuronCount(self):
|
| 600 |
+
return 0
|
| 601 |
+
|
| 602 |
+
class Skip(InferModule):
|
| 603 |
+
def init(self, in_shape, net1, net2, **kargs):
|
| 604 |
+
self.net1 = net1.infer(in_shape, **kargs)
|
| 605 |
+
self.net2 = net2.infer(in_shape, **kargs)
|
| 606 |
+
assert(net1.outShape[1:] == net2.outShape[1:])
|
| 607 |
+
return [ net1.outShape[0] + net2.outShape[0] ] + net1.outShape[1:]
|
| 608 |
+
|
| 609 |
+
def forward(self, x, **kargs):
|
| 610 |
+
r1 = self.net1(x, **kargs)
|
| 611 |
+
r2 = self.net2(x, **kargs)
|
| 612 |
+
return r1.cat(r2, dim=1)
|
| 613 |
+
|
| 614 |
+
def regularize(self, p):
|
| 615 |
+
return self.net1.regularize(p) + self.net2.regularize(p)
|
| 616 |
+
|
| 617 |
+
def clip_norm(self):
|
| 618 |
+
self.net1.clip_norm()
|
| 619 |
+
self.net2.clip_norm()
|
| 620 |
+
|
| 621 |
+
def remove_norm(self):
|
| 622 |
+
self.net1.remove_norm()
|
| 623 |
+
self.net2.remove_norm()
|
| 624 |
+
|
| 625 |
+
def neuronCount(self):
|
| 626 |
+
return self.net1.neuronCount() + self.net2.neuronCount()
|
| 627 |
+
|
| 628 |
+
def printNet(self, f):
|
| 629 |
+
print("SkipNet1", file=f)
|
| 630 |
+
self.net1.printNet(f)
|
| 631 |
+
print("SkipNet2", file=f)
|
| 632 |
+
self.net2.printNet(f)
|
| 633 |
+
print("SkipCat dim=1", file=f)
|
| 634 |
+
|
| 635 |
+
def showNet(self, t = ""):
|
| 636 |
+
print(t+"SkipNet1")
|
| 637 |
+
self.net1.showNet(" "+t)
|
| 638 |
+
print(t+"SkipNet2")
|
| 639 |
+
self.net2.showNet(" "+t)
|
| 640 |
+
print(t+"SkipCat dim=1")
|
| 641 |
+
|
| 642 |
+
class ParSum(InferModule):
|
| 643 |
+
def init(self, in_shape, net1, net2, **kargs):
|
| 644 |
+
self.net1 = net1.infer(in_shape, **kargs)
|
| 645 |
+
self.net2 = net2.infer(in_shape, **kargs)
|
| 646 |
+
assert(net1.outShape == net2.outShape)
|
| 647 |
+
return net1.outShape
|
| 648 |
+
|
| 649 |
+
|
| 650 |
+
|
| 651 |
+
def forward(self, x, **kargs):
|
| 652 |
+
|
| 653 |
+
r1 = self.net1(x, **kargs)
|
| 654 |
+
r2 = self.net2(x, **kargs)
|
| 655 |
+
return x.addPar(r1,r2)
|
| 656 |
+
|
| 657 |
+
def clip_norm(self):
|
| 658 |
+
self.net1.clip_norm()
|
| 659 |
+
self.net2.clip_norm()
|
| 660 |
+
|
| 661 |
+
def remove_norm(self):
|
| 662 |
+
self.net1.remove_norm()
|
| 663 |
+
self.net2.remove_norm()
|
| 664 |
+
|
| 665 |
+
def neuronCount(self):
|
| 666 |
+
return self.net1.neuronCount() + self.net2.neuronCount()
|
| 667 |
+
|
| 668 |
+
def depth(self):
|
| 669 |
+
return max(self.net1.depth(), self.net2.depth())
|
| 670 |
+
|
| 671 |
+
def printNet(self, f):
|
| 672 |
+
print("ParNet1", file=f)
|
| 673 |
+
self.net1.printNet(f)
|
| 674 |
+
print("ParNet2", file=f)
|
| 675 |
+
self.net2.printNet(f)
|
| 676 |
+
print("ParCat dim=1", file=f)
|
| 677 |
+
|
| 678 |
+
def showNet(self, t = ""):
|
| 679 |
+
print(t + "ParNet1")
|
| 680 |
+
self.net1.showNet(" "+t)
|
| 681 |
+
print(t + "ParNet2")
|
| 682 |
+
self.net2.showNet(" "+t)
|
| 683 |
+
print(t + "ParSum")
|
| 684 |
+
|
| 685 |
+
class ToZono(Identity):
|
| 686 |
+
def init(self, in_shape, customRelu = None, only_train = False, **kargs):
|
| 687 |
+
self.customRelu = customRelu
|
| 688 |
+
self.only_train = only_train
|
| 689 |
+
return in_shape
|
| 690 |
+
|
| 691 |
+
def forward(self, x, **kargs):
|
| 692 |
+
return self.abstract_forward(x, **kargs) if self.training or not self.only_train else x
|
| 693 |
+
|
| 694 |
+
def abstract_forward(self, x, **kargs):
|
| 695 |
+
return x.abstractApplyLeaf('hybrid_to_zono', customRelu = self.customRelu)
|
| 696 |
+
|
| 697 |
+
def showNet(self, t = ""):
|
| 698 |
+
print(t + self.__class__.__name__ + " only_train=" + str(self.only_train))
|
| 699 |
+
|
| 700 |
+
class CorrelateAll(ToZono):
|
| 701 |
+
def abstract_forward(self, x, **kargs):
|
| 702 |
+
return x.abstractApplyLeaf('hybrid_to_zono',correlate=True, customRelu = self.customRelu)
|
| 703 |
+
|
| 704 |
+
class ToHZono(ToZono):
|
| 705 |
+
def abstract_forward(self, x, **kargs):
|
| 706 |
+
return x.abstractApplyLeaf('zono_to_hybrid',customRelu = self.customRelu)
|
| 707 |
+
|
| 708 |
+
class Concretize(ToZono):
|
| 709 |
+
def init(self, in_shape, only_train = True, **kargs):
|
| 710 |
+
self.only_train = only_train
|
| 711 |
+
return in_shape
|
| 712 |
+
|
| 713 |
+
def abstract_forward(self, x, **kargs):
|
| 714 |
+
return x.abstractApplyLeaf('concretize')
|
| 715 |
+
|
| 716 |
+
# stochastic correlation
|
| 717 |
+
class CorrRand(Concretize):
|
| 718 |
+
def init(self, in_shape, num_correlate, only_train = True, **kargs):
|
| 719 |
+
self.only_train = only_train
|
| 720 |
+
self.num_correlate = num_correlate
|
| 721 |
+
return in_shape
|
| 722 |
+
|
| 723 |
+
def abstract_forward(self, x):
|
| 724 |
+
return x.abstractApplyLeaf("stochasticCorrelate", self.num_correlate)
|
| 725 |
+
|
| 726 |
+
def showNet(self, t = ""):
|
| 727 |
+
print(t + self.__class__.__name__ + " only_train=" + str(self.only_train) + " num_correlate="+ str(self.num_correlate))
|
| 728 |
+
|
| 729 |
+
class CorrMaxK(CorrRand):
|
| 730 |
+
def abstract_forward(self, x):
|
| 731 |
+
return x.abstractApplyLeaf("correlateMaxK", self.num_correlate)
|
| 732 |
+
|
| 733 |
+
|
| 734 |
+
class CorrMaxPool2D(Concretize):
|
| 735 |
+
def init(self,in_shape, kernel_size, only_train = True, max_type = ai.MaxTypes.head_beta, **kargs):
|
| 736 |
+
self.only_train = only_train
|
| 737 |
+
self.kernel_size = kernel_size
|
| 738 |
+
self.max_type = max_type
|
| 739 |
+
return in_shape
|
| 740 |
+
|
| 741 |
+
def abstract_forward(self, x):
|
| 742 |
+
return x.abstractApplyLeaf("correlateMaxPool", kernel_size = self.kernel_size, stride = self.kernel_size, max_type = self.max_type)
|
| 743 |
+
|
| 744 |
+
def showNet(self, t = ""):
|
| 745 |
+
print(t + self.__class__.__name__ + " only_train=" + str(self.only_train) + " kernel_size="+ str(self.kernel_size) + " max_type=" +str(self.max_type))
|
| 746 |
+
|
| 747 |
+
class CorrMaxPool3D(Concretize):
|
| 748 |
+
def init(self,in_shape, kernel_size, only_train = True, max_type = ai.MaxTypes.only_beta, **kargs):
|
| 749 |
+
self.only_train = only_train
|
| 750 |
+
self.kernel_size = kernel_size
|
| 751 |
+
self.max_type = max_type
|
| 752 |
+
return in_shape
|
| 753 |
+
|
| 754 |
+
def abstract_forward(self, x):
|
| 755 |
+
return x.abstractApplyLeaf("correlateMaxPool", kernel_size = self.kernel_size, stride = self.kernel_size, max_type = self.max_type, max_pool = F.max_pool3d)
|
| 756 |
+
|
| 757 |
+
def showNet(self, t = ""):
|
| 758 |
+
print(t + self.__class__.__name__ + " only_train=" + str(self.only_train) + " kernel_size="+ str(self.kernel_size) + " max_type=" +self.max_type)
|
| 759 |
+
|
| 760 |
+
class CorrFix(Concretize):
|
| 761 |
+
def init(self,in_shape, k, only_train = True, **kargs):
|
| 762 |
+
self.k = k
|
| 763 |
+
self.only_train = only_train
|
| 764 |
+
return in_shape
|
| 765 |
+
|
| 766 |
+
def abstract_forward(self, x):
|
| 767 |
+
sz = x.size()
|
| 768 |
+
"""
|
| 769 |
+
# for more control in the future
|
| 770 |
+
indxs_1 = torch.arange(start = 0, end = sz[1], step = math.ceil(sz[1] / self.dims[1]) )
|
| 771 |
+
indxs_2 = torch.arange(start = 0, end = sz[2], step = math.ceil(sz[2] / self.dims[2]) )
|
| 772 |
+
indxs_3 = torch.arange(start = 0, end = sz[3], step = math.ceil(sz[3] / self.dims[3]) )
|
| 773 |
+
|
| 774 |
+
indxs = torch.stack(torch.meshgrid((indxs_1,indxs_2,indxs_3)), dim=3).view(-1,3)
|
| 775 |
+
"""
|
| 776 |
+
szm = h.product(sz[1:])
|
| 777 |
+
indxs = torch.arange(start = 0, end = szm, step = math.ceil(szm / self.k))
|
| 778 |
+
indxs = indxs.unsqueeze(0).expand(sz[0], indxs.size()[0])
|
| 779 |
+
|
| 780 |
+
|
| 781 |
+
return x.abstractApplyLeaf("correlate", indxs)
|
| 782 |
+
|
| 783 |
+
def showNet(self, t = ""):
|
| 784 |
+
print(t + self.__class__.__name__ + " only_train=" + str(self.only_train) + " k="+ str(self.k))
|
| 785 |
+
|
| 786 |
+
|
| 787 |
+
class DecorrRand(Concretize):
|
| 788 |
+
def init(self, in_shape, num_decorrelate, only_train = True, **kargs):
|
| 789 |
+
self.only_train = only_train
|
| 790 |
+
self.num_decorrelate = num_decorrelate
|
| 791 |
+
return in_shape
|
| 792 |
+
|
| 793 |
+
def abstract_forward(self, x):
|
| 794 |
+
return x.abstractApplyLeaf("stochasticDecorrelate", self.num_decorrelate)
|
| 795 |
+
|
| 796 |
+
class DecorrMin(Concretize):
|
| 797 |
+
def init(self, in_shape, num_decorrelate, only_train = True, num_to_keep = False, **kargs):
|
| 798 |
+
self.only_train = only_train
|
| 799 |
+
self.num_decorrelate = num_decorrelate
|
| 800 |
+
self.num_to_keep = num_to_keep
|
| 801 |
+
return in_shape
|
| 802 |
+
|
| 803 |
+
def abstract_forward(self, x):
|
| 804 |
+
return x.abstractApplyLeaf("decorrelateMin", self.num_decorrelate, num_to_keep = self.num_to_keep)
|
| 805 |
+
|
| 806 |
+
|
| 807 |
+
def showNet(self, t = ""):
|
| 808 |
+
print(t + self.__class__.__name__ + " only_train=" + str(self.only_train) + " k="+ str(self.num_decorrelate) + " num_to_keep=" + str(self.num_to_keep) )
|
| 809 |
+
|
| 810 |
+
class DeepLoss(ToZono):
|
| 811 |
+
def init(self, in_shape, bw = 0.01, act = F.relu, **kargs): # weight must be between 0 and 1
|
| 812 |
+
self.only_train = True
|
| 813 |
+
self.bw = S.Const.initConst(bw)
|
| 814 |
+
self.act = act
|
| 815 |
+
return in_shape
|
| 816 |
+
|
| 817 |
+
def abstract_forward(self, x, **kargs):
|
| 818 |
+
if x.isPoint():
|
| 819 |
+
return x
|
| 820 |
+
return ai.TaggedDomain(x, self.MLoss(self, x))
|
| 821 |
+
|
| 822 |
+
class MLoss():
|
| 823 |
+
def __init__(self, obj, x):
|
| 824 |
+
self.obj = obj
|
| 825 |
+
self.x = x
|
| 826 |
+
|
| 827 |
+
def loss(self, a, *args, lr = 1, time = 0, **kargs):
|
| 828 |
+
bw = self.obj.bw.getVal(time = time)
|
| 829 |
+
pre_loss = a.loss(*args, time = time, **kargs, lr = lr * (1 - bw))
|
| 830 |
+
if bw <= 0.0:
|
| 831 |
+
return pre_loss
|
| 832 |
+
return (1 - bw) * pre_loss + bw * self.x.deep_loss(act = self.obj.act)
|
| 833 |
+
|
| 834 |
+
def showNet(self, t = ""):
|
| 835 |
+
print(t + self.__class__.__name__ + " only_train=" + str(self.only_train) + " bw="+ str(self.bw) + " act=" + str(self.act) )
|
| 836 |
+
|
| 837 |
+
class IdentLoss(DeepLoss):
|
| 838 |
+
def abstract_forward(self, x, **kargs):
|
| 839 |
+
return x
|
| 840 |
+
|
| 841 |
+
def SkipNet(net1, net2, ffnn, **kargs):
|
| 842 |
+
return Seq(Skip(net1,net2), FFNN(ffnn, **kargs))
|
| 843 |
+
|
| 844 |
+
def WideBlock(out_filters, downsample=False, k=3, bias=False, **kargs):
|
| 845 |
+
if not downsample:
|
| 846 |
+
k_first = 3
|
| 847 |
+
skip_stride = 1
|
| 848 |
+
k_skip = 1
|
| 849 |
+
else:
|
| 850 |
+
k_first = 4
|
| 851 |
+
skip_stride = 2
|
| 852 |
+
k_skip = 2
|
| 853 |
+
|
| 854 |
+
# conv2d280(input)
|
| 855 |
+
blockA = Conv2D(out_filters, kernel_size=k_skip, stride=skip_stride, padding=0, bias=bias, normal=True, **kargs)
|
| 856 |
+
|
| 857 |
+
# conv2d282(relu(conv2d278(input)))
|
| 858 |
+
blockB = Seq( Conv(out_filters, kernel_size = k_first, stride = skip_stride, padding = 1, bias=bias, normal=True, **kargs)
|
| 859 |
+
, Conv2D(out_filters, kernel_size = k, stride = 1, padding = 1, bias=bias, normal=True, **kargs))
|
| 860 |
+
return Seq(ParSum(blockA, blockB), activation(**kargs))
|
| 861 |
+
|
| 862 |
+
|
| 863 |
+
|
| 864 |
+
def BasicBlock(in_planes, planes, stride=1, bias = False, skip_net = False, **kargs):
|
| 865 |
+
block = Seq( Conv(planes, kernel_size = 3, stride = stride, padding = 1, bias=bias, normal=True, **kargs)
|
| 866 |
+
, Conv2D(planes, kernel_size = 3, stride = 1, padding = 1, bias=bias, normal=True, **kargs))
|
| 867 |
+
|
| 868 |
+
if stride != 1 or in_planes != planes:
|
| 869 |
+
block = ParSum(block, Conv2D(planes, kernel_size=1, stride=stride, bias=bias, normal=True, **kargs))
|
| 870 |
+
elif not skip_net:
|
| 871 |
+
block = ParSum(block, Identity())
|
| 872 |
+
return Seq(block, activation(**kargs))
|
| 873 |
+
|
| 874 |
+
# https://github.com/kuangliu/pytorch-cifar/blob/master/models/resnet.py
|
| 875 |
+
def ResNet(blocksList, extra = [], bias = False, **kargs):
|
| 876 |
+
|
| 877 |
+
layers = []
|
| 878 |
+
in_planes = 64
|
| 879 |
+
planes = 64
|
| 880 |
+
stride = 0
|
| 881 |
+
for num_blocks in blocksList:
|
| 882 |
+
if stride < 2:
|
| 883 |
+
stride += 1
|
| 884 |
+
|
| 885 |
+
strides = [stride] + [1]*(num_blocks-1)
|
| 886 |
+
for stride in strides:
|
| 887 |
+
layers.append(BasicBlock(in_planes, planes, stride, bias = bias, **kargs))
|
| 888 |
+
in_planes = planes
|
| 889 |
+
planes *= 2
|
| 890 |
+
|
| 891 |
+
print("RESlayers: ", len(layers))
|
| 892 |
+
for e,l in extra:
|
| 893 |
+
layers[l] = Seq(layers[l], e)
|
| 894 |
+
|
| 895 |
+
return Seq(Conv(64, kernel_size=3, stride=1, padding = 1, bias=bias, normal=True, printShape=True),
|
| 896 |
+
*layers)
|
| 897 |
+
|
| 898 |
+
|
| 899 |
+
|
| 900 |
+
def DenseNet(growthRate, depth, reduction, num_classes, bottleneck = True):
|
| 901 |
+
|
| 902 |
+
def Bottleneck(growthRate):
|
| 903 |
+
interChannels = 4*growthRate
|
| 904 |
+
|
| 905 |
+
n = Seq( ReLU(),
|
| 906 |
+
Conv2D(interChannels, kernel_size=1, bias=True, ibp_init = True),
|
| 907 |
+
ReLU(),
|
| 908 |
+
Conv2D(growthRate, kernel_size=3, padding=1, bias=True, ibp_init = True)
|
| 909 |
+
)
|
| 910 |
+
|
| 911 |
+
return Skip(Identity(), n)
|
| 912 |
+
|
| 913 |
+
def SingleLayer(growthRate):
|
| 914 |
+
n = Seq( ReLU(),
|
| 915 |
+
Conv2D(growthRate, kernel_size=3, padding=1, bias=True, ibp_init = True))
|
| 916 |
+
return Skip(Identity(), n)
|
| 917 |
+
|
| 918 |
+
def Transition(nOutChannels):
|
| 919 |
+
return Seq( ReLU(),
|
| 920 |
+
Conv2D(nOutChannels, kernel_size = 1, bias = True, ibp_init = True),
|
| 921 |
+
AvgPool2D(kernel_size=2))
|
| 922 |
+
|
| 923 |
+
def make_dense(growthRate, nDenseBlocks, bottleneck):
|
| 924 |
+
return Seq(*[Bottleneck(growthRate) if bottleneck else SingleLayer(growthRate) for i in range(nDenseBlocks)])
|
| 925 |
+
|
| 926 |
+
nDenseBlocks = (depth-4) // 3
|
| 927 |
+
if bottleneck:
|
| 928 |
+
nDenseBlocks //= 2
|
| 929 |
+
|
| 930 |
+
nChannels = 2*growthRate
|
| 931 |
+
conv1 = Conv2D(nChannels, kernel_size=3, padding=1, bias=True, ibp_init = True)
|
| 932 |
+
dense1 = make_dense(growthRate, nDenseBlocks, bottleneck)
|
| 933 |
+
nChannels += nDenseBlocks * growthRate
|
| 934 |
+
nOutChannels = int(math.floor(nChannels*reduction))
|
| 935 |
+
trans1 = Transition(nOutChannels)
|
| 936 |
+
|
| 937 |
+
nChannels = nOutChannels
|
| 938 |
+
dense2 = make_dense(growthRate, nDenseBlocks, bottleneck)
|
| 939 |
+
nChannels += nDenseBlocks*growthRate
|
| 940 |
+
nOutChannels = int(math.floor(nChannels*reduction))
|
| 941 |
+
trans2 = Transition(nOutChannels)
|
| 942 |
+
|
| 943 |
+
nChannels = nOutChannels
|
| 944 |
+
dense3 = make_dense(growthRate, nDenseBlocks, bottleneck)
|
| 945 |
+
|
| 946 |
+
return Seq(conv1, dense1, trans1, dense2, trans2, dense3,
|
| 947 |
+
ReLU(),
|
| 948 |
+
AvgPool2D(kernel_size=8),
|
| 949 |
+
CorrelateAll(only_train=False, ignore_point = True),
|
| 950 |
+
Linear(num_classes, ibp_init = True))
|
| 951 |
+
|
convert.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import future
|
| 2 |
+
import builtins
|
| 3 |
+
import past
|
| 4 |
+
import six
|
| 5 |
+
|
| 6 |
+
from timeit import default_timer as timer
|
| 7 |
+
from datetime import datetime
|
| 8 |
+
import argparse
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
import torch.optim as optim
|
| 13 |
+
from torchvision import datasets, transforms, utils
|
| 14 |
+
from torch.utils.data import Dataset
|
| 15 |
+
|
| 16 |
+
import inspect
|
| 17 |
+
from inspect import getargspec
|
| 18 |
+
import os
|
| 19 |
+
import helpers as h
|
| 20 |
+
from helpers import Timer
|
| 21 |
+
import copy
|
| 22 |
+
import random
|
| 23 |
+
from itertools import count
|
| 24 |
+
|
| 25 |
+
from components import *
|
| 26 |
+
import models
|
| 27 |
+
|
| 28 |
+
import goals
|
| 29 |
+
from goals import *
|
| 30 |
+
import math
|
| 31 |
+
|
| 32 |
+
from torch.serialization import SourceChangeWarning
|
| 33 |
+
import warnings
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
parser = argparse.ArgumentParser(description='Convert a pickled PyTorch DiffAI net to an abstract onyx net which returns the interval concretization around the final logits. The first dimension of the output is the natural center, the second dimension is the lb, the third is the ub', formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 37 |
+
parser.add_argument('-n', '--net', type=str, default=None, metavar='N', help='Saved and pickled net to use, in pynet format', required=True)
|
| 38 |
+
parser.add_argument('-d', '--domain', type=str, default="Point()", help='picks which abstract goals to use for testing. Uses box. Doesn\'t use time, so don\'t use Lin. Unless point, should specify a width w.')
|
| 39 |
+
parser.add_argument('-b', '--batch-size', type=int, default=1, help='The batch size to export. Not sure this matters.')
|
| 40 |
+
|
| 41 |
+
parser.add_argument('-o', '--out', type=str, default="convert_out/", metavar='F', help='Where to save the net.')
|
| 42 |
+
|
| 43 |
+
parser.add_argument('--update-net', type=h.str2bool, nargs='?', const=True, default=False, help="should update test net")
|
| 44 |
+
parser.add_argument('--net-name', type=str, choices = h.getMethodNames(models), default=None, help="update test net name")
|
| 45 |
+
|
| 46 |
+
parser.add_argument('--save-name', type=str, default=None, help="name to save the net with. Defaults to <domain>___<netfile-.pynet>.onyx")
|
| 47 |
+
|
| 48 |
+
parser.add_argument('-D', '--dataset', choices = [n for (n,k) in inspect.getmembers(datasets, inspect.isclass) if issubclass(k, Dataset)]
|
| 49 |
+
, default="MNIST", help='picks which dataset to use.')
|
| 50 |
+
|
| 51 |
+
parser.add_argument('--map-to-cpu', type=h.str2bool, nargs='?', const=True, default=False, help="map cuda operations in save back to cpu; enables to run on a computer without a GPU")
|
| 52 |
+
|
| 53 |
+
parser.add_argument('--tf-input', type=h.str2bool, nargs='?', const=True, default=False, help="change the shape of the input data from batch-channels-height-width (standard in pytroch) to batch-height-width-channels (standard in tf)")
|
| 54 |
+
|
| 55 |
+
args = parser.parse_args()
|
| 56 |
+
|
| 57 |
+
out_dir = args.out
|
| 58 |
+
|
| 59 |
+
if not os.path.exists(out_dir):
|
| 60 |
+
os.makedirs(out_dir)
|
| 61 |
+
|
| 62 |
+
with warnings.catch_warnings(record=True) as w:
|
| 63 |
+
warnings.simplefilter("always", SourceChangeWarning)
|
| 64 |
+
if args.map_to_cpu:
|
| 65 |
+
net = torch.load(args.net, map_location='cpu')
|
| 66 |
+
else:
|
| 67 |
+
net = torch.load(args.net)
|
| 68 |
+
|
| 69 |
+
net_name = None
|
| 70 |
+
|
| 71 |
+
if args.net_name is not None:
|
| 72 |
+
net_name = args.net_name
|
| 73 |
+
elif args.update_net and 'name' in dir(net):
|
| 74 |
+
net_name = net.name
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def buildNet(n, input_dims, num_classes):
|
| 78 |
+
n = n(num_classes)
|
| 79 |
+
if args.dataset in ["MNIST"]:
|
| 80 |
+
n = Seq(Normalize([0.1307], [0.3081] ), n)
|
| 81 |
+
elif args.dataset in ["CIFAR10", "CIFAR100"]:
|
| 82 |
+
n = Seq(Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]), n)
|
| 83 |
+
elif dataset in ["SVHN"]:
|
| 84 |
+
n = Seq(Normalize([0.5,0.5,0.5], [0.2, 0.2, 0.2]), n)
|
| 85 |
+
elif dataset in ["Imagenet12"]:
|
| 86 |
+
n = Seq(Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]), n)
|
| 87 |
+
|
| 88 |
+
n = n.infer(input_dims)
|
| 89 |
+
n.clip_norm()
|
| 90 |
+
return n
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
if net_name is not None:
|
| 94 |
+
n = getattr(models,net_name)
|
| 95 |
+
n = buildNet(n, net.inShape, net.outShape)
|
| 96 |
+
n.load_state_dict(net.state_dict())
|
| 97 |
+
net = n
|
| 98 |
+
|
| 99 |
+
net = net.to(h.device)
|
| 100 |
+
net.remove_norm()
|
| 101 |
+
|
| 102 |
+
domain = eval(args.domain)
|
| 103 |
+
|
| 104 |
+
if args.save_name is None:
|
| 105 |
+
save_name = h.prepareDomainNameForFile(args.domain) + "___" + os.path.basename(args.net)[:-6] + ".onyx"
|
| 106 |
+
else:
|
| 107 |
+
save_name = args.save_name
|
| 108 |
+
|
| 109 |
+
def abstractNet(inpt):
|
| 110 |
+
if args.tf_input:
|
| 111 |
+
inpt = inpt.permute(0, 3, 1, 2)
|
| 112 |
+
dom = domain.box(inpt, w = None)
|
| 113 |
+
o = net(dom, onyx=True).unsqueeze(1)
|
| 114 |
+
|
| 115 |
+
out = torch.cat([o.vanillaTensorPart(), o.lb().vanillaTensorPart(), o.ub().vanillaTensorPart()], dim=1)
|
| 116 |
+
return out
|
| 117 |
+
|
| 118 |
+
input_shape = [args.batch_size] + list(net.inShape)
|
| 119 |
+
if args.tf_input:
|
| 120 |
+
input_shape = [args.batch_size] + list(net.inShape)[1:] + [net.inShape[0]]
|
| 121 |
+
dummy = h.zeros(input_shape)
|
| 122 |
+
|
| 123 |
+
abstractNet(dummy)
|
| 124 |
+
|
| 125 |
+
class AbstractNet(nn.Module):
|
| 126 |
+
def __init__(self, domain, net, abstractNet):
|
| 127 |
+
super(AbstractNet, self).__init__()
|
| 128 |
+
self.net = net
|
| 129 |
+
self.abstractNet = abstractNet
|
| 130 |
+
if hasattr(domain, "net") and domain.net is not None:
|
| 131 |
+
self.netDom = domain.net
|
| 132 |
+
|
| 133 |
+
def forward(self, inpt):
|
| 134 |
+
return self.abstractNet(inpt)
|
| 135 |
+
|
| 136 |
+
absNet = AbstractNet(domain, net, abstractNet)
|
| 137 |
+
|
| 138 |
+
out_path = os.path.join(out_dir, save_name)
|
| 139 |
+
print("Saving:", out_path)
|
| 140 |
+
|
| 141 |
+
param_list = ["param"+str(i) for i in range(len(list(absNet.parameters())))]
|
| 142 |
+
|
| 143 |
+
torch.onnx.export(absNet, dummy, out_path, verbose=False, input_names=["actual_input"] + param_list, output_names=["output"])
|
| 144 |
+
|
goals.py
ADDED
|
@@ -0,0 +1,529 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import future
|
| 2 |
+
import builtins
|
| 3 |
+
import past
|
| 4 |
+
import six
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
import torch.optim as optim
|
| 10 |
+
import torch.autograd
|
| 11 |
+
import components as comp
|
| 12 |
+
from torch.distributions import multinomial, categorical
|
| 13 |
+
|
| 14 |
+
import math
|
| 15 |
+
import numpy as np
|
| 16 |
+
|
| 17 |
+
try:
|
| 18 |
+
from . import helpers as h
|
| 19 |
+
from . import ai
|
| 20 |
+
from . import scheduling as S
|
| 21 |
+
except:
|
| 22 |
+
import helpers as h
|
| 23 |
+
import ai
|
| 24 |
+
import scheduling as S
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class WrapDom(object):
|
| 29 |
+
def __init__(self, a):
|
| 30 |
+
self.a = eval(a) if type(a) is str else a
|
| 31 |
+
|
| 32 |
+
def box(self, *args, **kargs):
|
| 33 |
+
return self.Domain(self.a.box(*args, **kargs))
|
| 34 |
+
|
| 35 |
+
def boxBetween(self, *args, **kargs):
|
| 36 |
+
return self.Domain(self.a.boxBetween(*args, **kargs))
|
| 37 |
+
|
| 38 |
+
def line(self, *args, **kargs):
|
| 39 |
+
return self.Domain(self.a.line(*args, **kargs))
|
| 40 |
+
|
| 41 |
+
class DList(object):
|
| 42 |
+
Domain = ai.ListDomain
|
| 43 |
+
class MLoss():
|
| 44 |
+
def __init__(self, aw):
|
| 45 |
+
self.aw = aw
|
| 46 |
+
def loss(self, dom, *args, lr = 1, **kargs):
|
| 47 |
+
if self.aw <= 0.0:
|
| 48 |
+
return 0
|
| 49 |
+
return self.aw * dom.loss(*args, lr = lr * self.aw, **kargs)
|
| 50 |
+
|
| 51 |
+
def __init__(self, *al):
|
| 52 |
+
if len(al) == 0:
|
| 53 |
+
al = [("Point()", 1.0), ("Box()", 0.1)]
|
| 54 |
+
|
| 55 |
+
self.al = [(eval(a) if type(a) is str else a, S.Const.initConst(aw)) for a,aw in al]
|
| 56 |
+
|
| 57 |
+
def getDiv(self, **kargs):
|
| 58 |
+
return 1.0 / sum(aw.getVal(**kargs) for _,aw in self.al)
|
| 59 |
+
|
| 60 |
+
def box(self, *args, **kargs):
|
| 61 |
+
m = self.getDiv(**kargs)
|
| 62 |
+
return self.Domain(ai.TaggedDomain(a.box(*args, **kargs), DList.MLoss(aw.getVal(**kargs) * m)) for a,aw in self.al)
|
| 63 |
+
|
| 64 |
+
def boxBetween(self, *args, **kargs):
|
| 65 |
+
|
| 66 |
+
m = self.getDiv(**kargs)
|
| 67 |
+
return self.Domain(ai.TaggedDomain(a.boxBetween(*args, **kargs), DList.MLoss(aw.getVal(**kargs) * m)) for a,aw in self.al)
|
| 68 |
+
|
| 69 |
+
def line(self, *args, **kargs):
|
| 70 |
+
m = self.getDiv(**kargs)
|
| 71 |
+
return self.Domain(ai.TaggedDomain(a.line(*args, **kargs), DList.MLoss(aw.getVal(**kargs) * m)) for a,aw in self.al)
|
| 72 |
+
|
| 73 |
+
def __str__(self):
|
| 74 |
+
return "DList(%s)" % h.sumStr("("+str(a)+","+str(w)+")" for a,w in self.al)
|
| 75 |
+
|
| 76 |
+
class Mix(DList):
|
| 77 |
+
def __init__(self, a="Point()", b="Box()", aw = 1.0, bw = 0.1):
|
| 78 |
+
super(Mix, self).__init__((a,aw), (b,bw))
|
| 79 |
+
|
| 80 |
+
class LinMix(DList):
|
| 81 |
+
def __init__(self, a="Point()", b="Box()", bw = 0.1):
|
| 82 |
+
super(LinMix, self).__init__((a,S.Complement(bw)), (b,bw))
|
| 83 |
+
|
| 84 |
+
class DProb(object):
|
| 85 |
+
def __init__(self, *doms):
|
| 86 |
+
if len(doms) == 0:
|
| 87 |
+
doms = [("Point()", 0.8), ("Box()", 0.2)]
|
| 88 |
+
div = 1.0 / sum(float(aw) for _,aw in doms)
|
| 89 |
+
self.domains = [eval(a) if type(a) is str else a for a,_ in doms]
|
| 90 |
+
self.probs = [ div * float(aw) for _,aw in doms]
|
| 91 |
+
|
| 92 |
+
def chooseDom(self):
|
| 93 |
+
return self.domains[np.random.choice(len(self.domains), p = self.probs)] if len(self.domains) > 1 else self.domains[0]
|
| 94 |
+
|
| 95 |
+
def box(self, *args, **kargs):
|
| 96 |
+
domain = self.chooseDom()
|
| 97 |
+
return domain.box(*args, **kargs)
|
| 98 |
+
|
| 99 |
+
def line(self, *args, **kargs):
|
| 100 |
+
domain = self.chooseDom()
|
| 101 |
+
return domain.line(*args, **kargs)
|
| 102 |
+
|
| 103 |
+
def __str__(self):
|
| 104 |
+
return "DProb(%s)" % h.sumStr("("+str(a)+","+str(w)+")" for a,w in zip(self.domains, self.probs))
|
| 105 |
+
|
| 106 |
+
class Coin(DProb):
|
| 107 |
+
def __init__(self, a="Point()", b="Box()", ap = 0.8, bp = 0.2):
|
| 108 |
+
super(Coin, self).__init__((a,ap), (b,bp))
|
| 109 |
+
|
| 110 |
+
class Point(object):
|
| 111 |
+
Domain = h.dten
|
| 112 |
+
def __init__(self, **kargs):
|
| 113 |
+
pass
|
| 114 |
+
|
| 115 |
+
def box(self, original, *args, **kargs):
|
| 116 |
+
return original
|
| 117 |
+
|
| 118 |
+
def line(self, original, other, *args, **kargs):
|
| 119 |
+
return (original + other) / 2
|
| 120 |
+
|
| 121 |
+
def boxBetween(self, o1, o2, *args, **kargs):
|
| 122 |
+
return (o1 + o2) / 2
|
| 123 |
+
|
| 124 |
+
def __str__(self):
|
| 125 |
+
return "Point()"
|
| 126 |
+
|
| 127 |
+
class PointA(Point):
|
| 128 |
+
def boxBetween(self, o1, o2, *args, **kargs):
|
| 129 |
+
return o1
|
| 130 |
+
|
| 131 |
+
def __str__(self):
|
| 132 |
+
return "PointA()"
|
| 133 |
+
|
| 134 |
+
class PointB(Point):
|
| 135 |
+
def boxBetween(self, o1, o2, *args, **kargs):
|
| 136 |
+
return o2
|
| 137 |
+
|
| 138 |
+
def __str__(self):
|
| 139 |
+
return "PointB()"
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
class NormalPoint(Point):
|
| 143 |
+
def __init__(self, w = None, **kargs):
|
| 144 |
+
self.epsilon = w
|
| 145 |
+
|
| 146 |
+
def box(self, original, w, *args, **kargs):
|
| 147 |
+
""" original = mu = mean, epsilon = variance"""
|
| 148 |
+
if not self.epsilon is None:
|
| 149 |
+
w = self.epsilon
|
| 150 |
+
|
| 151 |
+
inter = torch.randn_like(original, device = h.device) * w
|
| 152 |
+
return original + inter
|
| 153 |
+
|
| 154 |
+
def __str__(self):
|
| 155 |
+
return "NormalPoint(%s)" % ("" if self.epsilon is None else str(self.epsilon))
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
class MI_FGSM(Point):
|
| 160 |
+
|
| 161 |
+
def __init__(self, w = None, r = 20.0, k = 100, mu = 0.8, should_end = True, restart = None, searchable=False,**kargs):
|
| 162 |
+
self.epsilon = S.Const.initConst(w)
|
| 163 |
+
self.k = k
|
| 164 |
+
self.mu = mu
|
| 165 |
+
self.r = float(r)
|
| 166 |
+
self.should_end = should_end
|
| 167 |
+
self.restart = restart
|
| 168 |
+
self.searchable = searchable
|
| 169 |
+
|
| 170 |
+
def box(self, original, model, target = None, untargeted = False, **kargs):
|
| 171 |
+
if target is None:
|
| 172 |
+
untargeted = True
|
| 173 |
+
with torch.no_grad():
|
| 174 |
+
target = model(original).max(1)[1]
|
| 175 |
+
return self.attack(model, original, untargeted, target, **kargs)
|
| 176 |
+
|
| 177 |
+
def boxBetween(self, o1, o2, model, target = None, *args, **kargs):
|
| 178 |
+
return self.attack(model, (o1 - o2).abs() / 2, (o1 + o2) / 2, target, **kargs)
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def attack(self, model, xo, untargeted, target, w, loss_function=ai.stdLoss, **kargs):
|
| 182 |
+
w = self.epsilon.getVal(c = w, **kargs)
|
| 183 |
+
|
| 184 |
+
x = nn.Parameter(xo.clone(), requires_grad=True)
|
| 185 |
+
gradorg = h.zeros(x.shape)
|
| 186 |
+
is_eq = 1
|
| 187 |
+
|
| 188 |
+
w = h.ones(x.shape) * w
|
| 189 |
+
for i in range(self.k):
|
| 190 |
+
if self.restart is not None and i % int(self.k / self.restart) == 0:
|
| 191 |
+
x = is_eq * (torch.rand_like(xo) * w + xo) + (1 - is_eq) * x
|
| 192 |
+
x = nn.Parameter(x, requires_grad = True)
|
| 193 |
+
|
| 194 |
+
model.optimizer.zero_grad()
|
| 195 |
+
|
| 196 |
+
out = model(x).vanillaTensorPart()
|
| 197 |
+
loss = loss_function(out, target)
|
| 198 |
+
|
| 199 |
+
loss.sum().backward(retain_graph=True)
|
| 200 |
+
with torch.no_grad():
|
| 201 |
+
oth = x.grad / torch.norm(x.grad, p=1)
|
| 202 |
+
gradorg *= self.mu
|
| 203 |
+
gradorg += oth
|
| 204 |
+
grad = (self.r * w / self.k) * ai.mysign(gradorg)
|
| 205 |
+
if self.should_end:
|
| 206 |
+
is_eq = ai.mulIfEq(grad, out, target)
|
| 207 |
+
x = (x + grad * is_eq) if untargeted else (x - grad * is_eq)
|
| 208 |
+
|
| 209 |
+
x = xo + torch.min(torch.max(x - xo, -w),w)
|
| 210 |
+
x.requires_grad_()
|
| 211 |
+
|
| 212 |
+
model.optimizer.zero_grad()
|
| 213 |
+
|
| 214 |
+
return x
|
| 215 |
+
|
| 216 |
+
def boxBetween(self, o1, o2, model, target, *args, **kargs):
|
| 217 |
+
raise "Not boxBetween is not yet supported by MI_FGSM"
|
| 218 |
+
|
| 219 |
+
def __str__(self):
|
| 220 |
+
return "MI_FGSM(%s)" % (("" if self.epsilon is None else "w="+str(self.epsilon)+",")
|
| 221 |
+
+ ("" if self.k == 5 else "k="+str(self.k)+",")
|
| 222 |
+
+ ("" if self.r == 5.0 else "r="+str(self.r)+",")
|
| 223 |
+
+ ("" if self.mu == 0.8 else "r="+str(self.mu)+",")
|
| 224 |
+
+ ("" if self.should_end else "should_end=False"))
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
class PGD(MI_FGSM):
|
| 228 |
+
def __init__(self, r = 5.0, k = 5, **kargs):
|
| 229 |
+
super(PGD,self).__init__(r=r, k = k, mu = 0, **kargs)
|
| 230 |
+
|
| 231 |
+
def __str__(self):
|
| 232 |
+
return "PGD(%s)" % (("" if self.epsilon is None else "w="+str(self.epsilon)+",")
|
| 233 |
+
+ ("" if self.k == 5 else "k="+str(self.k)+",")
|
| 234 |
+
+ ("" if self.r == 5.0 else "r="+str(self.r)+",")
|
| 235 |
+
+ ("" if self.should_end else "should_end=False"))
|
| 236 |
+
|
| 237 |
+
class IFGSM(PGD):
|
| 238 |
+
|
| 239 |
+
def __init__(self, k = 5, **kargs):
|
| 240 |
+
super(IFGSM, self).__init__(r = 1, k=k, **kargs)
|
| 241 |
+
|
| 242 |
+
def __str__(self):
|
| 243 |
+
return "IFGSM(%s)" % (("" if self.epsilon is None else "w="+str(self.epsilon)+",")
|
| 244 |
+
+ ("" if self.k == 5 else "k="+str(self.k)+",")
|
| 245 |
+
+ ("" if self.should_end else "should_end=False"))
|
| 246 |
+
|
| 247 |
+
class NormalAdv(Point):
|
| 248 |
+
def __init__(self, a="IFGSM()", w = None):
|
| 249 |
+
self.a = (eval(a) if type(a) is str else a)
|
| 250 |
+
self.epsilon = S.Const.initConst(w)
|
| 251 |
+
|
| 252 |
+
def box(self, original, w, *args, **kargs):
|
| 253 |
+
epsilon = self.epsilon.getVal(c = w, shape = original.shape[:1], **kargs)
|
| 254 |
+
assert (0 <= h.dten(epsilon)).all()
|
| 255 |
+
epsilon = torch.randn(original.size()[0:1], device = h.device)[0] * epsilon
|
| 256 |
+
return self.a.box(original, w = epsilon, *args, **kargs)
|
| 257 |
+
|
| 258 |
+
def __str__(self):
|
| 259 |
+
return "NormalAdv(%s)" % ( str(self.a) + ("" if self.epsilon is None else ",w="+str(self.epsilon)))
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
class InclusionSample(Point):
|
| 263 |
+
def __init__(self, sub, a="Box()", normal = False, w = None, **kargs):
|
| 264 |
+
self.sub = S.Const.initConst(sub) # sub is the fraction of w to use.
|
| 265 |
+
self.w = S.Const.initConst(w)
|
| 266 |
+
self.normal = normal
|
| 267 |
+
self.a = (eval(a) if type(a) is str else a)
|
| 268 |
+
|
| 269 |
+
def box(self, original, w, *args, **kargs):
|
| 270 |
+
w = self.w.getVal(c = w, shape = original.shape[:1], **kargs)
|
| 271 |
+
sub = self.sub.getVal(c = 1, shape = original.shape[:1], **kargs)
|
| 272 |
+
|
| 273 |
+
assert (0 <= h.dten(w)).all()
|
| 274 |
+
assert (h.dten(sub) <= 1).all()
|
| 275 |
+
assert (0 <= h.dten(sub)).all()
|
| 276 |
+
if self.normal:
|
| 277 |
+
inter = torch.randn_like(original, device = h.device)
|
| 278 |
+
else:
|
| 279 |
+
inter = (torch.rand_like(original, device = h.device) * 2 - 1)
|
| 280 |
+
|
| 281 |
+
inter = inter * w * (1 - sub)
|
| 282 |
+
|
| 283 |
+
return self.a.box(original + inter, w = w * sub, *args, **kargs)
|
| 284 |
+
|
| 285 |
+
def boxBetween(self, o1, o2, *args, **kargs):
|
| 286 |
+
w = (o2 - o1).abs()
|
| 287 |
+
return self.box( (o2 + o1)/2 , w = w, *args, **kargs)
|
| 288 |
+
|
| 289 |
+
def __str__(self):
|
| 290 |
+
return "InclusionSample(%s, %s)" % (str(self.sub), str(self.a) + ("" if self.epsilon is None else ",w="+str(self.epsilon)))
|
| 291 |
+
|
| 292 |
+
InSamp = InclusionSample
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
class AdvInclusion(InclusionSample):
|
| 296 |
+
def __init__(self, sub, a="IFGSM()", b="Box()", w = None, **kargs):
|
| 297 |
+
self.sub = S.Const.initConst(sub) # sub is the fraction of w to use.
|
| 298 |
+
self.w = S.Const.initConst(w)
|
| 299 |
+
self.a = (eval(a) if type(a) is str else a)
|
| 300 |
+
self.b = (eval(b) if type(b) is str else b)
|
| 301 |
+
|
| 302 |
+
def box(self, original, w, *args, **kargs):
|
| 303 |
+
w = self.w.getVal(c = w, shape = original.shape, **kargs)
|
| 304 |
+
sub = self.sub.getVal(c = 1, shape = original.shape, **kargs)
|
| 305 |
+
|
| 306 |
+
assert (0 <= h.dten(w)).all()
|
| 307 |
+
assert (h.dten(sub) <= 1).all()
|
| 308 |
+
assert (0 <= h.dten(sub)).all()
|
| 309 |
+
|
| 310 |
+
if h.dten(w).sum().item() <= 0.0:
|
| 311 |
+
inter = original
|
| 312 |
+
else:
|
| 313 |
+
inter = self.a.box(original, w = w * (1 - sub), *args, **kargs)
|
| 314 |
+
|
| 315 |
+
return self.b.box(inter, w = w * sub, *args, **kargs)
|
| 316 |
+
|
| 317 |
+
def __str__(self):
|
| 318 |
+
return "AdvInclusion(%s, %s, %s)" % (str(self.sub), str(self.a), str(self.b) + ("" if self.epsilon is None else ",w="+str(self.epsilon)))
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
class AdvDom(Point):
|
| 322 |
+
def __init__(self, a="IFGSM()", b="Box()"):
|
| 323 |
+
self.a = (eval(a) if type(a) is str else a)
|
| 324 |
+
self.b = (eval(b) if type(b) is str else b)
|
| 325 |
+
|
| 326 |
+
def box(self, original,*args, **kargs):
|
| 327 |
+
adv = self.a.box(original, *args, **kargs)
|
| 328 |
+
return self.b.boxBetween(original, adv.ub(), *args, **kargs)
|
| 329 |
+
|
| 330 |
+
def boxBetween(self, o1, o2, *args, **kargs):
|
| 331 |
+
original = (o1 + o2) / 2
|
| 332 |
+
adv = self.a.boxBetween(o1, o2, *args, **kargs)
|
| 333 |
+
return self.b.boxBetween(original, adv.ub(), *args, **kargs)
|
| 334 |
+
|
| 335 |
+
def __str__(self):
|
| 336 |
+
return "AdvDom(%s)" % (("" if self.width is None else "width="+str(self.width)+",")
|
| 337 |
+
+ str(self.a) + "," + str(self.b))
|
| 338 |
+
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
class BiAdv(AdvDom):
|
| 342 |
+
def box(self, original, **kargs):
|
| 343 |
+
adv = self.a.box(original, **kargs)
|
| 344 |
+
extreme = (adv.ub() - original).abs()
|
| 345 |
+
return self.b.boxBetween(original - extreme, original + extreme, **kargs)
|
| 346 |
+
|
| 347 |
+
def boxBetween(self, o1, o2, *args, **kargs):
|
| 348 |
+
original = (o1 + o2) / 2
|
| 349 |
+
adv = self.a.boxBetween(o1, o2, *args, **kargs)
|
| 350 |
+
extreme = (adv.ub() - original).abs()
|
| 351 |
+
return self.b.boxBetween(original - extreme, original + extreme, *args, **kargs)
|
| 352 |
+
|
| 353 |
+
def __str__(self):
|
| 354 |
+
return "BiAdv" + AdvDom.__str__(self)[6:]
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
class HBox(object):
|
| 358 |
+
Domain = ai.HybridZonotope
|
| 359 |
+
|
| 360 |
+
def domain(self, *args, **kargs):
|
| 361 |
+
return ai.TaggedDomain(self.Domain(*args, **kargs), self)
|
| 362 |
+
|
| 363 |
+
def __init__(self, w = None, tot_weight = 1, width_weight = 0, pow_loss = None, log_loss = False, searchable = True, cross_loss = True, **kargs):
|
| 364 |
+
self.w = S.Const.initConst(w)
|
| 365 |
+
self.tot_weight = S.Const.initConst(tot_weight)
|
| 366 |
+
self.width_weight = S.Const.initConst(width_weight)
|
| 367 |
+
self.pow_loss = pow_loss
|
| 368 |
+
self.searchable = searchable
|
| 369 |
+
self.log_loss = log_loss
|
| 370 |
+
self.cross_loss = cross_loss
|
| 371 |
+
|
| 372 |
+
def __str__(self):
|
| 373 |
+
return "HBox(%s)" % ("" if self.w is None else "w="+str(self.w))
|
| 374 |
+
|
| 375 |
+
def boxBetween(self, o1, o2, *args, **kargs):
|
| 376 |
+
batches = o1.size()[0]
|
| 377 |
+
num_elem = h.product(o1.size()[1:])
|
| 378 |
+
ei = h.getEi(batches, num_elem)
|
| 379 |
+
|
| 380 |
+
if len(o1.size()) > 2:
|
| 381 |
+
ei = ei.contiguous().view(num_elem, *o1.size())
|
| 382 |
+
|
| 383 |
+
return self.domain((o1 + o2) / 2, None, ei * (o2 - o1).abs() / 2).checkSizes()
|
| 384 |
+
|
| 385 |
+
def box(self, original, w, **kargs):
|
| 386 |
+
"""
|
| 387 |
+
This version of it is slow, but keeps correlation down the line.
|
| 388 |
+
"""
|
| 389 |
+
radius = self.w.getVal(c = w, **kargs)
|
| 390 |
+
|
| 391 |
+
batches = original.size()[0]
|
| 392 |
+
num_elem = h.product(original.size()[1:])
|
| 393 |
+
ei = h.getEi(batches,num_elem)
|
| 394 |
+
|
| 395 |
+
if len(original.size()) > 2:
|
| 396 |
+
ei = ei.contiguous().view(num_elem, *original.size())
|
| 397 |
+
|
| 398 |
+
return self.domain(original, None, ei * radius).checkSizes()
|
| 399 |
+
|
| 400 |
+
def line(self, o1, o2, **kargs):
|
| 401 |
+
w = self.w.getVal(c = 0, **kargs)
|
| 402 |
+
|
| 403 |
+
ln = ((o2 - o1) / 2).unsqueeze(0)
|
| 404 |
+
if not w is None and w > 0.0:
|
| 405 |
+
batches = o1.size()[0]
|
| 406 |
+
num_elem = h.product(o1.size()[1:])
|
| 407 |
+
ei = h.getEi(batches,num_elem)
|
| 408 |
+
if len(o1.size()) > 2:
|
| 409 |
+
ei = ei.contiguous().view(num_elem, *o1.size())
|
| 410 |
+
ln = torch.cat([ln, ei * w])
|
| 411 |
+
return self.domain((o1 + o2) / 2, None, ln ).checkSizes()
|
| 412 |
+
|
| 413 |
+
def loss(self, dom, target, *args, **kargs):
|
| 414 |
+
width_weight = self.width_weight.getVal(**kargs)
|
| 415 |
+
tot_weight = self.tot_weight.getVal(**kargs)
|
| 416 |
+
|
| 417 |
+
if self.cross_loss:
|
| 418 |
+
r = dom.ub()
|
| 419 |
+
inds = torch.arange(r.shape[0], device=h.device, dtype=h.ltype)
|
| 420 |
+
r[inds,target] = dom.lb()[inds,target]
|
| 421 |
+
tot = r.loss(target, *args, **kargs)
|
| 422 |
+
else:
|
| 423 |
+
tot = dom.loss(target, *args, **kargs)
|
| 424 |
+
|
| 425 |
+
if self.log_loss:
|
| 426 |
+
tot = (tot + 1).log()
|
| 427 |
+
if self.pow_loss is not None and self.pow_loss > 0 and self.pow_loss != 1:
|
| 428 |
+
tot = tot.pow(self.pow_loss)
|
| 429 |
+
|
| 430 |
+
ls = tot * tot_weight
|
| 431 |
+
if width_weight > 0:
|
| 432 |
+
ls += dom.diameter() * width_weight
|
| 433 |
+
|
| 434 |
+
return ls / (width_weight + tot_weight)
|
| 435 |
+
|
| 436 |
+
class Box(HBox):
|
| 437 |
+
def __str__(self):
|
| 438 |
+
return "Box(%s)" % ("" if self.w is None else "w="+str(self.w))
|
| 439 |
+
|
| 440 |
+
def box(self, original, w, **kargs):
|
| 441 |
+
"""
|
| 442 |
+
This version of it takes advantage of betas being uncorrelated.
|
| 443 |
+
Unfortunately they stay uncorrelated forever.
|
| 444 |
+
Counterintuitively, tests show more accuracy - this is because the other box
|
| 445 |
+
creates lots of 0 errors which get accounted for by the calcultion of the newhead in relu
|
| 446 |
+
which is apparently worse than not accounting for errors.
|
| 447 |
+
"""
|
| 448 |
+
radius = self.w.getVal(c = w, **kargs)
|
| 449 |
+
return self.domain(original, h.ones(original.size()) * radius, None).checkSizes()
|
| 450 |
+
|
| 451 |
+
def line(self, o1, o2, **kargs):
|
| 452 |
+
w = self.w.getVal(c = 0, **kargs)
|
| 453 |
+
return self.domain((o1 + o2) / 2, ((o2 - o1) / 2).abs() + h.ones(o2.size()) * w, None).checkSizes()
|
| 454 |
+
|
| 455 |
+
def boxBetween(self, o1, o2, *args, **kargs):
|
| 456 |
+
return self.line(o1, o2, **kargs)
|
| 457 |
+
|
| 458 |
+
class ZBox(HBox):
|
| 459 |
+
|
| 460 |
+
def __str__(self):
|
| 461 |
+
return "ZBox(%s)" % ("" if self.w is None else "w="+str(self.w))
|
| 462 |
+
|
| 463 |
+
def Domain(self, *args, **kargs):
|
| 464 |
+
return ai.Zonotope(*args, **kargs)
|
| 465 |
+
|
| 466 |
+
class HSwitch(HBox):
|
| 467 |
+
def __str__(self):
|
| 468 |
+
return "HSwitch(%s)" % ("" if self.w is None else "w="+str(self.w))
|
| 469 |
+
|
| 470 |
+
def Domain(self, *args, **kargs):
|
| 471 |
+
return ai.HybridZonotope(*args, customRelu = ai.creluSwitch, **kargs)
|
| 472 |
+
|
| 473 |
+
class ZSwitch(ZBox):
|
| 474 |
+
|
| 475 |
+
def __str__(self):
|
| 476 |
+
return "ZSwitch(%s)" % ("" if self.w is None else "w="+str(self.w))
|
| 477 |
+
def Domain(self, *args, **kargs):
|
| 478 |
+
return ai.Zonotope(*args, customRelu = ai.creluSwitch, **kargs)
|
| 479 |
+
|
| 480 |
+
|
| 481 |
+
class ZNIPS(ZBox):
|
| 482 |
+
|
| 483 |
+
def __str__(self):
|
| 484 |
+
return "ZSwitch(%s)" % ("" if self.w is None else "w="+str(self.w))
|
| 485 |
+
|
| 486 |
+
def Domain(self, *args, **kargs):
|
| 487 |
+
return ai.Zonotope(*args, customRelu = ai.creluNIPS, **kargs)
|
| 488 |
+
|
| 489 |
+
class HSmooth(HBox):
|
| 490 |
+
def __str__(self):
|
| 491 |
+
return "HSmooth(%s)" % ("" if self.w is None else "w="+str(self.w))
|
| 492 |
+
|
| 493 |
+
def Domain(self, *args, **kargs):
|
| 494 |
+
return ai.HybridZonotope(*args, customRelu = ai.creluSmooth, **kargs)
|
| 495 |
+
|
| 496 |
+
class HNIPS(HBox):
|
| 497 |
+
def __str__(self):
|
| 498 |
+
return "HSmooth(%s)" % ("" if self.w is None else "w="+str(self.w))
|
| 499 |
+
|
| 500 |
+
def Domain(self, *args, **kargs):
|
| 501 |
+
return ai.HybridZonotope(*args, customRelu = ai.creluNIPS, **kargs)
|
| 502 |
+
|
| 503 |
+
class ZSmooth(ZBox):
|
| 504 |
+
def __str__(self):
|
| 505 |
+
return "ZSmooth(%s)" % ("" if self.w is None else "w="+str(self.w))
|
| 506 |
+
|
| 507 |
+
def Domain(self, *args, **kargs):
|
| 508 |
+
return ai.Zonotope(*args, customRelu = ai.creluSmooth, **kargs)
|
| 509 |
+
|
| 510 |
+
|
| 511 |
+
|
| 512 |
+
|
| 513 |
+
|
| 514 |
+
# stochastic correlation
|
| 515 |
+
class HRand(WrapDom):
|
| 516 |
+
# domain must be an ai style domain like hybrid zonotope.
|
| 517 |
+
def __init__(self, num_correlated, a = "HSwitch()", **kargs):
|
| 518 |
+
super(HRand, self).__init__(Box())
|
| 519 |
+
self.num_correlated = num_correlated
|
| 520 |
+
self.dom = eval(a) if type(a) is str else a
|
| 521 |
+
|
| 522 |
+
def Domain(self, d):
|
| 523 |
+
with torch.no_grad():
|
| 524 |
+
out = d.abstractApplyLeaf('stochasticCorrelate', self.num_correlated)
|
| 525 |
+
out = self.dom.Domain(out.head, out.beta, out.errors)
|
| 526 |
+
return out
|
| 527 |
+
|
| 528 |
+
def __str__(self):
|
| 529 |
+
return "HRand(%s, domain = %s)" % (str(self.num_correlated), str(self.a))
|
helpers.py
ADDED
|
@@ -0,0 +1,489 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import future
|
| 2 |
+
import builtins
|
| 3 |
+
import past
|
| 4 |
+
import six
|
| 5 |
+
import inspect
|
| 6 |
+
import os
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import torch.optim as optim
|
| 11 |
+
import numpy as np
|
| 12 |
+
import argparse
|
| 13 |
+
import decimal
|
| 14 |
+
import PIL
|
| 15 |
+
from torchvision import datasets, transforms
|
| 16 |
+
from datetime import datetime
|
| 17 |
+
|
| 18 |
+
from forbiddenfruit import curse
|
| 19 |
+
#from torch.autograd import Variable
|
| 20 |
+
|
| 21 |
+
from timeit import default_timer as timer
|
| 22 |
+
|
| 23 |
+
class Timer:
|
| 24 |
+
def __init__(self, activity = None, units = 1, shouldPrint = True, f = None):
|
| 25 |
+
self.activity = activity
|
| 26 |
+
self.units = units
|
| 27 |
+
self.shouldPrint = shouldPrint
|
| 28 |
+
self.f = f
|
| 29 |
+
def __enter__(self):
|
| 30 |
+
self.start = timer()
|
| 31 |
+
return self
|
| 32 |
+
def getUnitTime(self):
|
| 33 |
+
return (self.end - self.start) / self.units
|
| 34 |
+
|
| 35 |
+
def __str__(self):
|
| 36 |
+
return "Avg time to " + self.activity + ": "+str(self.getUnitTime())
|
| 37 |
+
|
| 38 |
+
def __exit__(self, *args):
|
| 39 |
+
self.end = timer()
|
| 40 |
+
if self.shouldPrint:
|
| 41 |
+
printBoth(self, f = self.f)
|
| 42 |
+
|
| 43 |
+
def cudify(x):
|
| 44 |
+
if use_cuda:
|
| 45 |
+
return x.cuda(async=True)
|
| 46 |
+
return x
|
| 47 |
+
|
| 48 |
+
def pyval(a, **kargs):
|
| 49 |
+
return dten([a], **kargs)
|
| 50 |
+
|
| 51 |
+
def ifThenElse(cond, a, b):
|
| 52 |
+
cond = cond.to_dtype()
|
| 53 |
+
return cond * a + (1 - cond) * b
|
| 54 |
+
|
| 55 |
+
def ifThenElseL(cond, a, b):
|
| 56 |
+
return cond * a + (1 - cond) * b
|
| 57 |
+
|
| 58 |
+
def product(it):
|
| 59 |
+
if isinstance(it,int):
|
| 60 |
+
return it
|
| 61 |
+
product = 1
|
| 62 |
+
for x in it:
|
| 63 |
+
if x >= 0:
|
| 64 |
+
product *= x
|
| 65 |
+
return product
|
| 66 |
+
|
| 67 |
+
def getEi(batches, num_elem):
|
| 68 |
+
return eye(num_elem).expand(batches, num_elem,num_elem).permute(1,0,2)
|
| 69 |
+
|
| 70 |
+
def one_hot(batch,d):
|
| 71 |
+
bs = batch.size()[0]
|
| 72 |
+
indexes = [ list(range(bs)), batch]
|
| 73 |
+
values = [ 1 for _ in range(bs) ]
|
| 74 |
+
return cudify(torch.sparse.FloatTensor(ltenCPU(indexes), ftenCPU(values), torch.Size([bs,d])))
|
| 75 |
+
|
| 76 |
+
def seye(n, m = None):
|
| 77 |
+
if m is None:
|
| 78 |
+
m = n
|
| 79 |
+
mn = n if n < m else m
|
| 80 |
+
indexes = [[ i for i in range(mn) ], [ i for i in range(mn) ] ]
|
| 81 |
+
values = [1 for i in range(mn) ]
|
| 82 |
+
return cudify(torch.sparse.ByteTensor(ltenCPU(indexes), dtenCPU(values), torch.Size([n,m])))
|
| 83 |
+
|
| 84 |
+
dtype = torch.float32
|
| 85 |
+
ftype = torch.float32
|
| 86 |
+
ltype = torch.int64
|
| 87 |
+
btype = torch.uint8
|
| 88 |
+
|
| 89 |
+
torch.set_default_dtype(dtype)
|
| 90 |
+
|
| 91 |
+
cpu = torch.device("cpu")
|
| 92 |
+
|
| 93 |
+
cuda_async = True
|
| 94 |
+
|
| 95 |
+
ftenCPU = lambda *args, **kargs: torch.tensor(*args, dtype=ftype, device=cpu, **kargs)
|
| 96 |
+
dtenCPU = lambda *args, **kargs: torch.tensor(*args, dtype=dtype, device=cpu, **kargs)
|
| 97 |
+
ltenCPU = lambda *args, **kargs: torch.tensor(*args, dtype=ltype, device=cpu, **kargs)
|
| 98 |
+
btenCPU = lambda *args, **kargs: torch.tensor(*args, dtype=btype, device=cpu, **kargs)
|
| 99 |
+
|
| 100 |
+
if torch.cuda.is_available() and not 'NOCUDA' in os.environ:
|
| 101 |
+
print("using cuda")
|
| 102 |
+
device = torch.device("cuda")
|
| 103 |
+
ften = lambda *args, **kargs: torch.tensor(*args, dtype=ftype, device=device, **kargs).cuda(non_blocking=cuda_async)
|
| 104 |
+
dten = lambda *args, **kargs: torch.tensor(*args, dtype=dtype, device=device, **kargs).cuda(non_blocking=cuda_async)
|
| 105 |
+
lten = lambda *args, **kargs: torch.tensor(*args, dtype=ltype, device=device, **kargs).cuda(non_blocking=cuda_async)
|
| 106 |
+
bten = lambda *args, **kargs: torch.tensor(*args, dtype=btype, device=device, **kargs).cuda(non_blocking=cuda_async)
|
| 107 |
+
ones = lambda *args, **cargs: torch.ones(*args, **cargs).cuda(non_blocking=cuda_async)
|
| 108 |
+
zeros = lambda *args, **cargs: torch.zeros(*args, **cargs).cuda(non_blocking=cuda_async)
|
| 109 |
+
eye = lambda *args, **cargs: torch.eye(*args, **cargs).cuda(non_blocking=cuda_async)
|
| 110 |
+
use_cuda = True
|
| 111 |
+
print("set up cuda")
|
| 112 |
+
else:
|
| 113 |
+
print("not using cuda")
|
| 114 |
+
ften = ftenCPU
|
| 115 |
+
dten = dtenCPU
|
| 116 |
+
lten = ltenCPU
|
| 117 |
+
bten = btenCPU
|
| 118 |
+
ones = torch.ones
|
| 119 |
+
zeros = torch.zeros
|
| 120 |
+
eye = torch.eye
|
| 121 |
+
use_cuda = False
|
| 122 |
+
device = cpu
|
| 123 |
+
|
| 124 |
+
def smoothmax(x, alpha, dim = 0):
|
| 125 |
+
return x.mul(F.softmax(x * alpha, dim)).sum(dim + 1)
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def str2bool(v):
|
| 129 |
+
if v.lower() in ('yes', 'true', 't', 'y', '1'):
|
| 130 |
+
return True
|
| 131 |
+
elif v.lower() in ('no', 'false', 'f', 'n', '0'):
|
| 132 |
+
return False
|
| 133 |
+
else:
|
| 134 |
+
raise argparse.ArgumentTypeError('Boolean value expected.')
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def flat(lst):
|
| 139 |
+
lst_ = []
|
| 140 |
+
for l in lst:
|
| 141 |
+
lst_ += l
|
| 142 |
+
return lst_
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def printBoth(*st, f = None):
|
| 146 |
+
print(*st)
|
| 147 |
+
if not f is None:
|
| 148 |
+
print(*st, file=f)
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def hasMethod(cl, mt):
|
| 152 |
+
return callable(getattr(cl, mt, None))
|
| 153 |
+
|
| 154 |
+
def getMethodNames(Foo):
|
| 155 |
+
return [func for func in dir(Foo) if callable(getattr(Foo, func)) and not func.startswith("__")]
|
| 156 |
+
|
| 157 |
+
def getMethods(Foo):
|
| 158 |
+
return [getattr(Foo, m) for m in getMethodNames(Foo)]
|
| 159 |
+
|
| 160 |
+
max_c_for_norm = 10000
|
| 161 |
+
|
| 162 |
+
def numel(arr):
|
| 163 |
+
return product(arr.size())
|
| 164 |
+
|
| 165 |
+
def chunks(l, n):
|
| 166 |
+
"""Yield successive n-sized chunks from l."""
|
| 167 |
+
for i in range(0, len(l), n):
|
| 168 |
+
yield l[i:i + n]
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def loadDataset(dataset, batch_size, train, transform = True):
|
| 172 |
+
oargs = {}
|
| 173 |
+
if dataset in ["MNIST", "CIFAR10", "CIFAR100", "FashionMNIST", "PhotoTour"]:
|
| 174 |
+
oargs['train'] = train
|
| 175 |
+
elif dataset in ["STL10", "SVHN"] :
|
| 176 |
+
oargs['split'] = 'train' if train else 'test'
|
| 177 |
+
elif dataset in ["LSUN"]:
|
| 178 |
+
oargs['classes'] = 'train' if train else 'test'
|
| 179 |
+
elif dataset in ["Imagenet12"]:
|
| 180 |
+
pass
|
| 181 |
+
else:
|
| 182 |
+
raise Exception(dataset + " is not yet supported")
|
| 183 |
+
|
| 184 |
+
if dataset in ["MNIST"]:
|
| 185 |
+
transformer = transforms.Compose([ transforms.ToTensor()]
|
| 186 |
+
+ ([transforms.Normalize((0.1307,), (0.3081,))] if transform else []))
|
| 187 |
+
elif dataset in ["CIFAR10", "CIFAR100"]:
|
| 188 |
+
transformer = transforms.Compose(([ #transforms.RandomCrop(32, padding=4),
|
| 189 |
+
transforms.RandomAffine(0, (0.125, 0.125), resample=PIL.Image.BICUBIC) ,
|
| 190 |
+
transforms.RandomHorizontalFlip(),
|
| 191 |
+
#transforms.RandomRotation(15, resample = PIL.Image.BILINEAR)
|
| 192 |
+
] if train else [])
|
| 193 |
+
+ [transforms.ToTensor()]
|
| 194 |
+
+ ([transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))] if transform else []))
|
| 195 |
+
elif dataset in ["SVHN"]:
|
| 196 |
+
transformer = transforms.Compose([
|
| 197 |
+
transforms.RandomHorizontalFlip(),
|
| 198 |
+
transforms.ToTensor(),
|
| 199 |
+
transforms.Normalize((0.5,0.5,0.5), (0.2,0.2,0.2))])
|
| 200 |
+
else:
|
| 201 |
+
transformer = transforms.ToTensor()
|
| 202 |
+
|
| 203 |
+
if dataset in ["Imagenet12"]:
|
| 204 |
+
# https://github.com/facebook/fb.resnet.torch/blob/master/INSTALL.md#download-the-imagenet-dataset
|
| 205 |
+
train_set = datasets.ImageFolder(
|
| 206 |
+
'../data/Imagenet12/train' if train else '../data/Imagenet12/val',
|
| 207 |
+
transforms.Compose([
|
| 208 |
+
transforms.RandomResizedCrop(224),
|
| 209 |
+
transforms.RandomHorizontalFlip(),
|
| 210 |
+
normalize,
|
| 211 |
+
]))
|
| 212 |
+
else:
|
| 213 |
+
train_set = getattr(datasets, dataset)('../data', download=True, transform=transformer, **oargs)
|
| 214 |
+
return torch.utils.data.DataLoader(
|
| 215 |
+
train_set
|
| 216 |
+
, batch_size=batch_size
|
| 217 |
+
, shuffle=True,
|
| 218 |
+
**({'num_workers': 1, 'pin_memory': True} if use_cuda else {}))
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
def variable(Pt):
|
| 222 |
+
class Point:
|
| 223 |
+
def isSafe(self,target):
|
| 224 |
+
pred = self.max(1, keepdim=True)[1] # get the index of the max log-probability
|
| 225 |
+
return pred.eq(target.data.view_as(pred))
|
| 226 |
+
|
| 227 |
+
def isPoint(self):
|
| 228 |
+
return True
|
| 229 |
+
|
| 230 |
+
def labels(self):
|
| 231 |
+
return [self[0].max(1)[1]] # get the index of the max log-probability
|
| 232 |
+
|
| 233 |
+
def softplus(self):
|
| 234 |
+
return F.softplus(self)
|
| 235 |
+
|
| 236 |
+
def elu(self):
|
| 237 |
+
return F.elu(self)
|
| 238 |
+
|
| 239 |
+
def selu(self):
|
| 240 |
+
return F.selu(self)
|
| 241 |
+
|
| 242 |
+
def sigm(self):
|
| 243 |
+
return F.sigmoid(self)
|
| 244 |
+
|
| 245 |
+
def conv3d(self, *args, **kargs):
|
| 246 |
+
return F.conv3d(self, *args, **kargs)
|
| 247 |
+
def conv2d(self, *args, **kargs):
|
| 248 |
+
return F.conv2d(self, *args, **kargs)
|
| 249 |
+
def conv1d(self, *args, **kargs):
|
| 250 |
+
return F.conv1d(self, *args, **kargs)
|
| 251 |
+
|
| 252 |
+
def conv_transpose3d(self, *args, **kargs):
|
| 253 |
+
return F.conv_transpose3d(self, *args, **kargs)
|
| 254 |
+
def conv_transpose2d(self, *args, **kargs):
|
| 255 |
+
return F.conv_transpose2d(self, *args, **kargs)
|
| 256 |
+
def conv_transpose1d(self, *args, **kargs):
|
| 257 |
+
return F.conv_transpose1d(self, *args, **kargs)
|
| 258 |
+
|
| 259 |
+
def max_pool2d(self, *args, **kargs):
|
| 260 |
+
return F.max_pool2d(self, *args, **kargs)
|
| 261 |
+
|
| 262 |
+
def avg_pool2d(self, *args, **kargs):
|
| 263 |
+
return F.avg_pool2d(self, *args, **kargs)
|
| 264 |
+
|
| 265 |
+
def adaptive_avg_pool2d(self, *args, **kargs):
|
| 266 |
+
return F.adaptive_avg_pool2d(self, *args, **kargs)
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
def cat(self, other, dim = 0, **kargs):
|
| 270 |
+
return torch.cat((self, other), dim = dim, **kargs)
|
| 271 |
+
|
| 272 |
+
def addPar(self, a, b):
|
| 273 |
+
return a + b
|
| 274 |
+
|
| 275 |
+
def abstractApplyLeaf(self, foo, *args, **kargs):
|
| 276 |
+
return self
|
| 277 |
+
|
| 278 |
+
def diameter(self):
|
| 279 |
+
return pyval(0)
|
| 280 |
+
|
| 281 |
+
def to_dtype(self):
|
| 282 |
+
return self.type(dtype=dtype, non_blocking=cuda_async)
|
| 283 |
+
|
| 284 |
+
def loss(self, target, **kargs):
|
| 285 |
+
if torch.__version__[0] == "0":
|
| 286 |
+
return F.cross_entropy(self, target, reduce = False)
|
| 287 |
+
else:
|
| 288 |
+
return F.cross_entropy(self, target, reduction='none')
|
| 289 |
+
|
| 290 |
+
def deep_loss(self, *args, **kargs):
|
| 291 |
+
return 0
|
| 292 |
+
|
| 293 |
+
def merge(self, *args, **kargs):
|
| 294 |
+
return self
|
| 295 |
+
|
| 296 |
+
def splitRelu(self, *args, **kargs):
|
| 297 |
+
return self
|
| 298 |
+
|
| 299 |
+
def lb(self):
|
| 300 |
+
return self
|
| 301 |
+
def vanillaTensorPart(self):
|
| 302 |
+
return self
|
| 303 |
+
def center(self):
|
| 304 |
+
return self
|
| 305 |
+
def ub(self):
|
| 306 |
+
return self
|
| 307 |
+
|
| 308 |
+
def cudify(self, cuda_async = True):
|
| 309 |
+
return self.cuda(non_blocking=cuda_async) if use_cuda else self
|
| 310 |
+
|
| 311 |
+
def log_softmax(self, *args, dim = 1, **kargs):
|
| 312 |
+
return F.log_softmax(self, *args,dim = dim, **kargs)
|
| 313 |
+
|
| 314 |
+
if torch.__version__[0] == "0" and torch.__version__ != "0.4.1":
|
| 315 |
+
Point.log_softmax = log_softmax
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
def log_softmax(self, *args, dim = 1, **kargs):
|
| 319 |
+
return F.log_softmax(self, *args,dim = dim, **kargs)
|
| 320 |
+
|
| 321 |
+
if torch.__version__[0] == "0" and torch.__version__ != "0.4.1":
|
| 322 |
+
Point.log_softmax = log_softmax
|
| 323 |
+
|
| 324 |
+
for nm in getMethodNames(Point):
|
| 325 |
+
curse(Pt, nm, getattr(Point, nm))
|
| 326 |
+
|
| 327 |
+
variable(torch.autograd.Variable)
|
| 328 |
+
variable(torch.cuda.DoubleTensor)
|
| 329 |
+
variable(torch.DoubleTensor)
|
| 330 |
+
variable(torch.cuda.FloatTensor)
|
| 331 |
+
variable(torch.FloatTensor)
|
| 332 |
+
variable(torch.ByteTensor)
|
| 333 |
+
variable(torch.Tensor)
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
def default(dic, nm, d):
|
| 337 |
+
if dic is not None and nm in dic:
|
| 338 |
+
return dic[nm]
|
| 339 |
+
return d
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
def softmaxBatchNP(x, epsilon, subtract = False):
|
| 345 |
+
"""Compute softmax values for each sets of scores in x."""
|
| 346 |
+
x = x.astype(np.float64)
|
| 347 |
+
ex = x / epsilon if epsilon is not None else x
|
| 348 |
+
if subtract:
|
| 349 |
+
ex -= ex.max(axis=1)[:,np.newaxis]
|
| 350 |
+
e_x = np.exp(ex)
|
| 351 |
+
sm = (e_x / e_x.sum(axis=1)[:,np.newaxis])
|
| 352 |
+
am = np.argmax(x, axis=1)
|
| 353 |
+
bads = np.logical_not(np.isfinite(sm.sum(axis = 1)))
|
| 354 |
+
|
| 355 |
+
if epsilon is None:
|
| 356 |
+
sm[bads] = 0
|
| 357 |
+
sm[bads, am[bads]] = 1
|
| 358 |
+
else:
|
| 359 |
+
epsilon *= (x.shape[1] - 1) / x.shape[1]
|
| 360 |
+
sm[bads] = epsilon / (x.shape[1] - 1)
|
| 361 |
+
sm[bads, am[bads]] = 1 - epsilon
|
| 362 |
+
|
| 363 |
+
sm /= sm.sum(axis=1)[:,np.newaxis]
|
| 364 |
+
return sm
|
| 365 |
+
|
| 366 |
+
|
| 367 |
+
def cadd(a,b):
|
| 368 |
+
both = a.cat(b)
|
| 369 |
+
a, b = both.split(a.size()[0])
|
| 370 |
+
return a + b
|
| 371 |
+
|
| 372 |
+
def msum(a,b, l):
|
| 373 |
+
if a is None:
|
| 374 |
+
return b
|
| 375 |
+
if b is None:
|
| 376 |
+
return a
|
| 377 |
+
return l(a,b)
|
| 378 |
+
|
| 379 |
+
class SubAct(argparse.Action):
|
| 380 |
+
def __init__(self, sub_choices, *args, **kargs):
|
| 381 |
+
super(SubAct,self).__init__(*args, nargs='+', **kargs)
|
| 382 |
+
self.sub_choices = sub_choices
|
| 383 |
+
self.sub_choices_names = None if sub_choices is None else getMethodNames(sub_choices)
|
| 384 |
+
|
| 385 |
+
def __call__(self, parser, namespace, values, option_string=None):
|
| 386 |
+
if self.sub_choices_names is not None and not values[0] in self.sub_choices_names:
|
| 387 |
+
msg = 'invalid choice: %r (choose from %s)' % (values[0], self.sub_choices_names)
|
| 388 |
+
raise argparse.ArgumentError(self, msg)
|
| 389 |
+
|
| 390 |
+
prev = getattr(namespace, self.dest)
|
| 391 |
+
setattr(namespace, self.dest, prev + [values])
|
| 392 |
+
|
| 393 |
+
def catLists(val):
|
| 394 |
+
if isinstance(val, list):
|
| 395 |
+
v = []
|
| 396 |
+
for i in val:
|
| 397 |
+
v += catLists(i)
|
| 398 |
+
return v
|
| 399 |
+
return [val]
|
| 400 |
+
|
| 401 |
+
def sumStr(val):
|
| 402 |
+
s = ""
|
| 403 |
+
for v in val:
|
| 404 |
+
s += v
|
| 405 |
+
return s
|
| 406 |
+
|
| 407 |
+
def catStrs(val):
|
| 408 |
+
s = val[0]
|
| 409 |
+
if len(val) > 1:
|
| 410 |
+
s += "("
|
| 411 |
+
for v in val[1:2]:
|
| 412 |
+
s += v
|
| 413 |
+
for v in val[2:]:
|
| 414 |
+
s += ", "+v
|
| 415 |
+
if len(val) > 1:
|
| 416 |
+
s += ")"
|
| 417 |
+
return s
|
| 418 |
+
|
| 419 |
+
def printNumpy(x):
|
| 420 |
+
return "[" + sumStr([decimal.Decimal(float(v)).__format__("f") + ", " for v in x.data.cpu().numpy()])[:-2]+"]"
|
| 421 |
+
|
| 422 |
+
def printStrList(x):
|
| 423 |
+
return "[" + sumStr(v + ", " for v in x)[:-2]+"]"
|
| 424 |
+
|
| 425 |
+
def printListsNumpy(val):
|
| 426 |
+
if isinstance(val, list):
|
| 427 |
+
return printStrList(printListsNumpy(v) for v in val)
|
| 428 |
+
return printNumpy(val)
|
| 429 |
+
|
| 430 |
+
def parseValues(values, methods, *others):
|
| 431 |
+
if len(values) == 1 and values[0]:
|
| 432 |
+
x = eval(values[0], dict(pair for l in ([methods] + list(others)) for pair in l.__dict__.items()) )
|
| 433 |
+
|
| 434 |
+
return x() if inspect.isclass(x) else x
|
| 435 |
+
args = []
|
| 436 |
+
kargs = {}
|
| 437 |
+
for arg in values[1:]:
|
| 438 |
+
if '=' in arg:
|
| 439 |
+
k = arg.split('=')[0]
|
| 440 |
+
v = arg[len(k)+1:]
|
| 441 |
+
try:
|
| 442 |
+
kargs[k] = eval(v)
|
| 443 |
+
except:
|
| 444 |
+
kargs[k] = v
|
| 445 |
+
else:
|
| 446 |
+
args += [eval(arg)]
|
| 447 |
+
return getattr(methods, values[0])(*args, **kargs)
|
| 448 |
+
|
| 449 |
+
def preDomRes(outDom, target): # TODO: make faster again by keeping sparse tensors sparse
|
| 450 |
+
t = one_hot(target.long(), outDom.size()[1]).to_dense().to_dtype()
|
| 451 |
+
tmat = t.unsqueeze(2).matmul(t.unsqueeze(1))
|
| 452 |
+
|
| 453 |
+
tl = t.unsqueeze(2).expand(-1, -1, tmat.size()[1])
|
| 454 |
+
|
| 455 |
+
inv_t = eye(tmat.size()[1]).expand(tmat.size()[0], -1, -1)
|
| 456 |
+
inv_t = inv_t - tmat
|
| 457 |
+
|
| 458 |
+
tl = tl.bmm(inv_t)
|
| 459 |
+
|
| 460 |
+
fst = outDom.unsqueeze(1).matmul(tl).squeeze(1)
|
| 461 |
+
snd = outDom.unsqueeze(1).matmul(inv_t).squeeze(1)
|
| 462 |
+
|
| 463 |
+
return (fst - snd) + t
|
| 464 |
+
|
| 465 |
+
def mopen(shouldnt, *args, **kargs):
|
| 466 |
+
if shouldnt:
|
| 467 |
+
import contextlib
|
| 468 |
+
return contextlib.suppress()
|
| 469 |
+
return open(*args, **kargs)
|
| 470 |
+
|
| 471 |
+
def file_timestamp():
|
| 472 |
+
return str(datetime.now()).replace(":","").replace(" ", "")
|
| 473 |
+
|
| 474 |
+
def prepareDomainNameForFile(s):
|
| 475 |
+
return s.replace(" ", "_").replace(",", "").replace("(", "_").replace(")", "_").replace("=", "_")
|
| 476 |
+
|
| 477 |
+
# delimited only
|
| 478 |
+
def callCC(foo):
|
| 479 |
+
class RV(BaseException):
|
| 480 |
+
def __init__(self, v):
|
| 481 |
+
self.v = v
|
| 482 |
+
|
| 483 |
+
def cc(x):
|
| 484 |
+
raise RV(x)
|
| 485 |
+
|
| 486 |
+
try:
|
| 487 |
+
return foo(cc)
|
| 488 |
+
except RV as rv:
|
| 489 |
+
return rv.v
|
losses.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This source file is part of DiffAI
|
| 2 |
+
# Copyright (c) 2018 Secure, Reliable, and Intelligent Systems Lab (SRI), ETH Zurich
|
| 3 |
+
# This software is distributed under the MIT License: https://opensource.org/licenses/MIT
|
| 4 |
+
# SPDX-License-Identifier: MIT
|
| 5 |
+
# For more information see https://github.com/eth-sri/diffai
|
| 6 |
+
|
| 7 |
+
# THE SOFTWARE IS PROVIDED "AS-IS" WITHOUT ANY WARRANTY OF ANY KIND, EITHER
|
| 8 |
+
# EXPRESS, IMPLIED OR STATUTORY, INCLUDING BUT NOT LIMITED TO ANY WARRANTY
|
| 9 |
+
# THAT THE SOFTWARE WILL CONFORM TO SPECIFICATIONS OR BE ERROR-FREE AND ANY
|
| 10 |
+
# IMPLIED WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE,
|
| 11 |
+
# TITLE, OR NON-INFRINGEMENT. IN NO EVENT SHALL ETH ZURICH BE LIABLE FOR ANY
|
| 12 |
+
# DAMAGES, INCLUDING BUT NOT LIMITED TO DIRECT, INDIRECT,
|
| 13 |
+
# SPECIAL OR CONSEQUENTIAL DAMAGES, ARISING OUT OF, RESULTING FROM, OR IN
|
| 14 |
+
# ANY WAY CONNECTED WITH THIS SOFTWARE (WHETHER OR NOT BASED UPON WARRANTY,
|
| 15 |
+
# CONTRACT, TORT OR OTHERWISE).
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
import torch.nn as nn
|
| 19 |
+
import torch.nn.functional as F
|
| 20 |
+
import torch.optim as optim
|
| 21 |
+
|
| 22 |
+
import helpers as h
|
| 23 |
+
import domains
|
| 24 |
+
from domains import *
|
| 25 |
+
import math
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
POINT_DOMAINS = [m for m in h.getMethods(domains) if h.hasMethod(m, "attack")] + [ torch.FloatTensor, torch.Tensor, torch.cuda.FloatTensor ]
|
| 29 |
+
SYMETRIC_DOMAINS = [domains.Box] + POINT_DOMAINS
|
| 30 |
+
|
| 31 |
+
def domRes(outDom, target, **args): # TODO: make faster again by keeping sparse tensors sparse
|
| 32 |
+
t = h.one_hot(target.data.long(), outDom.size()[1]).to_dense()
|
| 33 |
+
tmat = t.unsqueeze(2).matmul(t.unsqueeze(1))
|
| 34 |
+
|
| 35 |
+
tl = t.unsqueeze(2).expand(-1, -1, tmat.size()[1])
|
| 36 |
+
|
| 37 |
+
inv_t = h.eye(tmat.size()[1]).expand(tmat.size()[0], -1, -1)
|
| 38 |
+
inv_t = inv_t - tmat
|
| 39 |
+
|
| 40 |
+
tl = tl.bmm(inv_t)
|
| 41 |
+
|
| 42 |
+
fst = outDom.bmm(tl)
|
| 43 |
+
snd = outDom.bmm(inv_t)
|
| 44 |
+
diff = fst - snd
|
| 45 |
+
return diff.lb() + t
|
| 46 |
+
|
| 47 |
+
def isSafeDom(outDom, target, **args):
|
| 48 |
+
od,_ = torch.min(domRes(outDom, target, **args), 1)
|
| 49 |
+
return od.gt(0.0).long().item()
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def isSafeBox(target, net, inp, eps, dom):
|
| 53 |
+
atarg = target.argmax(1)[0].unsqueeze(0)
|
| 54 |
+
if hasattr(dom, "attack"):
|
| 55 |
+
x = dom.attack(net, eps, inp, target)
|
| 56 |
+
pred = net(x).argmax(1)[0].unsqueeze(0) # get the index of the max log-probability
|
| 57 |
+
return pred.item() == atarg.item()
|
| 58 |
+
else:
|
| 59 |
+
outDom = net(dom.box(inp, eps))
|
| 60 |
+
return isSafeDom(outDom, atarg)
|
media/overview.png
ADDED

|
media/resnetTinyFewCombo.png
ADDED

|
models.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
try:
|
| 2 |
+
from . import components as n
|
| 3 |
+
from . import ai
|
| 4 |
+
from . import scheduling as S
|
| 5 |
+
except:
|
| 6 |
+
import components as n
|
| 7 |
+
import scheduling as S
|
| 8 |
+
import ai
|
| 9 |
+
|
| 10 |
+
############# Previously Known Models. Not guaranteed to have the same performance as previous papers.
|
| 11 |
+
|
| 12 |
+
def FFNN(c, **kargs):
|
| 13 |
+
return n.FFNN([100, 100, 100, 100, 100,c], last_lin = True, last_zono = True, **kargs)
|
| 14 |
+
|
| 15 |
+
def ConvSmall(c, **kargs):
|
| 16 |
+
return n.LeNet([ (16,4,4,2), (32,4,4,2) ], [100,c], last_lin = True, last_zono = True, **kargs)
|
| 17 |
+
|
| 18 |
+
def ConvMed(c, **kargs):
|
| 19 |
+
return n.LeNet([ (16,4,4,2), (32,4,4,2) ], [100,c], padding = 1, last_lin = True, last_zono = True, **kargs)
|
| 20 |
+
|
| 21 |
+
def ConvBig(c, **kargs):
|
| 22 |
+
return n.LeNet([ (32,3,3,1), (32,4,4,2) , (64,3,3,1), (64,4,4,2)], [512, 512,c], padding = 1, last_lin = True, last_zono = True, **kargs)
|
| 23 |
+
|
| 24 |
+
def ConvLargeIBP(c, **kargs):
|
| 25 |
+
return n.LeNet([ (64, 3, 3, 1), (64,3,3,1), (128,3,3,2), (128,3,3,1), (128,3,3,1)], [200,c], padding=1, ibp_init = True, bias = True, last_lin = True, last_zono = True, **kargs)
|
| 26 |
+
|
| 27 |
+
def ResNetWong(c, **kargs):
|
| 28 |
+
return n.Seq(n.Conv(16, 3, padding=1, bias=False), n.WideBlock(16), n.WideBlock(16), n.WideBlock(32, True), n.WideBlock(64, True), n.FFNN([1000, c], ibp_init = True, bias=True, last_lin=True, last_zono = True, **kargs))
|
| 29 |
+
|
| 30 |
+
def TruncatedVGG(c, **kargs):
|
| 31 |
+
return n.LeNet([ (64, 3, 3, 1), (64,3,3,1), (128,3,3,2), (128,3,3,1)], [512,c], padding=1, ibp_init = True, bias = True, last_lin = True, last_zono = True, **kargs)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
############# New Models
|
| 35 |
+
|
| 36 |
+
def ResNetTiny(c, **kargs): # resnetWide also used by mixtrain and scaling provable adversarial defenses
|
| 37 |
+
def wb(c, bias = True, **kargs):
|
| 38 |
+
return n.WideBlock(c, False, bias=bias, ibp_init=True, batch_norm = False, **kargs)
|
| 39 |
+
return n.Seq(n.Conv(16, 3, padding=1, bias=True, ibp_init = True),
|
| 40 |
+
wb(16),
|
| 41 |
+
wb(32),
|
| 42 |
+
wb(32),
|
| 43 |
+
wb(32),
|
| 44 |
+
wb(32),
|
| 45 |
+
n.FFNN([500, c], bias=True, last_lin=True, ibp_init = True, last_zono = True, **kargs))
|
| 46 |
+
|
| 47 |
+
def ResNetTiny_FewCombo(c, **kargs): # resnetWide also used by mixtrain and scaling provable adversarial defenses
|
| 48 |
+
def wb(c, bias = True, **kargs):
|
| 49 |
+
return n.WideBlock(c, False, bias=bias, ibp_init=True, batch_norm = False, **kargs)
|
| 50 |
+
dl = n.DeepLoss
|
| 51 |
+
cmk = n.CorrMaxK
|
| 52 |
+
cm2d = n.CorrMaxPool2D
|
| 53 |
+
cm3d = n.CorrMaxPool3D
|
| 54 |
+
dec = lambda x: n.DecorrMin(x, num_to_keep = True)
|
| 55 |
+
return n.Seq(cmk(32),
|
| 56 |
+
n.Conv(16, 3, padding=1, bias=True, ibp_init = True), dec(8),
|
| 57 |
+
wb(16), dec(4),
|
| 58 |
+
wb(32), n.Concretize(),
|
| 59 |
+
wb(32),
|
| 60 |
+
wb(32),
|
| 61 |
+
wb(32), cmk(10),
|
| 62 |
+
n.FFNN([500, c], bias=True, last_lin=True, ibp_init = True, last_zono = True, **kargs))
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def ResNetTiny_ManyFixed(c, **kargs): # resnetWide also used by mixtrain and scaling provable adversarial defenses
|
| 66 |
+
def wb(c, bias = True, **kargs):
|
| 67 |
+
return n.WideBlock(c, False, bias=bias, ibp_init=True, batch_norm = False, **kargs)
|
| 68 |
+
cmk = n.CorrFix
|
| 69 |
+
dec = lambda x: n.DecorrMin(x, num_to_keep = True)
|
| 70 |
+
return n.Seq(n.CorrMaxK(32),
|
| 71 |
+
n.Conv(16, 3, padding=1, bias=True, ibp_init = True), cmk(16), dec(16),
|
| 72 |
+
wb(16), cmk(8), dec(8),
|
| 73 |
+
wb(32), cmk(8), dec(8),
|
| 74 |
+
wb(32), cmk(4), dec(4),
|
| 75 |
+
wb(32), n.Concretize(),
|
| 76 |
+
wb(32),
|
| 77 |
+
n.FFNN([500, c], bias=True, last_lin=True, ibp_init = True, last_zono = True, **kargs))
|
| 78 |
+
|
| 79 |
+
def SkipNet18(c, **kargs):
|
| 80 |
+
return n.Seq(n.ResNet([2,2,2,2], bias = True, ibp_init = True, skip_net = True), n.FFNN([512, 512, c], bias=True, last_lin=True, last_zono = True, ibp_init = True, **kargs))
|
| 81 |
+
|
| 82 |
+
def SkipNet18_Combo(c, **kargs):
|
| 83 |
+
dl = n.DeepLoss
|
| 84 |
+
cmk = n.CorrFix
|
| 85 |
+
dec = lambda x: n.DecorrMin(x, num_to_keep = True)
|
| 86 |
+
return n.Seq(n.ResNet([2,2,2,2], extra = [ (cmk(20),2),(dec(10),2)
|
| 87 |
+
,(cmk(10),3),(dec(5),3),(dl(S.Until(90, S.Lin(0, 0.2, 50, 40), 0)), 3)
|
| 88 |
+
,(cmk(5),4),(dec(2),4)], bias = True, ibp_init=True, skip_net = True), n.FFNN([512, 512, c], bias=True, last_lin=True, last_zono = True, ibp_init=True, **kargs))
|
| 89 |
+
|
| 90 |
+
def ResNet18(c, **kargs):
|
| 91 |
+
return n.Seq(n.ResNet([2,2,2,2], bias = True, ibp_init = True), n.FFNN([512, 512, c], bias=True, last_lin=True, last_zono = True, ibp_init = True, **kargs))
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def ResNetLarge_LargeCombo(c, **kargs): # resnetWide also used by mixtrain and scaling provable adversarial defenses
|
| 95 |
+
def wb(c, bias = True, **kargs):
|
| 96 |
+
return n.WideBlock(c, False, bias=bias, ibp_init=True, batch_norm = False, **kargs)
|
| 97 |
+
dl = n.DeepLoss
|
| 98 |
+
cmk = n.CorrMaxK
|
| 99 |
+
cm2d = n.CorrMaxPool2D
|
| 100 |
+
cm3d = n.CorrMaxPool3D
|
| 101 |
+
dec = lambda x: n.DecorrMin(x, num_to_keep = True)
|
| 102 |
+
return n.Seq(n.Conv(16, 3, padding=1, bias=True, ibp_init = True), cmk(4),
|
| 103 |
+
wb(16), cmk(4), dec(4),
|
| 104 |
+
wb(32), cmk(4), dec(4),
|
| 105 |
+
wb(32), dl(S.Until(1, 0, S.Lin(0.5, 0, 50, 3))),
|
| 106 |
+
wb(32), cmk(4), dec(4),
|
| 107 |
+
wb(64), cmk(4), dec(2),
|
| 108 |
+
wb(64), dl(S.Until(24, S.Lin(0, 0.1, 20, 4), S.Lin(0.1, 0, 50))),
|
| 109 |
+
wb(64),
|
| 110 |
+
n.FFNN([1000, c], bias=True, last_lin=True, ibp_init = True, **kargs))
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def ResNet34(c, **kargs):
|
| 115 |
+
return n.Seq(n.ResNet([3,4,6,3], bias = True, ibp_init = True), n.FFNN([512, 512, c], bias=True, last_lin=True, last_zono = True, ibp_init = True, **kargs))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def DenseNet100(c, **kwargs):
|
| 119 |
+
return n.DenseNet(growthRate=12, depth=100, reduction=0.5,
|
| 120 |
+
bottleneck=True, num_classes = c)
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
numpy
|
| 2 |
+
six
|
| 3 |
+
future
|
| 4 |
+
forbiddenfruit
|
| 5 |
+
torch==0.4.1
|
| 6 |
+
torchvision==0.2.1
|
scheduling.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import math
|
| 4 |
+
|
| 5 |
+
try:
|
| 6 |
+
from . import helpers as h
|
| 7 |
+
except:
|
| 8 |
+
import helpers as h
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class Const():
|
| 13 |
+
def __init__(self, c):
|
| 14 |
+
self.c = c if c is None else float(c)
|
| 15 |
+
|
| 16 |
+
def getVal(self, c = None, **kargs):
|
| 17 |
+
return self.c if self.c is not None else c
|
| 18 |
+
|
| 19 |
+
def __str__(self):
|
| 20 |
+
return str(self.c)
|
| 21 |
+
|
| 22 |
+
def initConst(x):
|
| 23 |
+
return x if isinstance(x, Const) else Const(x)
|
| 24 |
+
|
| 25 |
+
class Lin(Const):
|
| 26 |
+
def __init__(self, start, end, steps, initial = 0, quant = False):
|
| 27 |
+
self.start = float(start)
|
| 28 |
+
self.end = float(end)
|
| 29 |
+
self.steps = float(steps)
|
| 30 |
+
self.initial = float(initial)
|
| 31 |
+
self.quant = quant
|
| 32 |
+
|
| 33 |
+
def getVal(self, time = 0, **kargs):
|
| 34 |
+
if self.quant:
|
| 35 |
+
time = math.floor(time)
|
| 36 |
+
return (self.end - self.start) * max(0,min(1, float(time - self.initial) / self.steps)) + self.start
|
| 37 |
+
|
| 38 |
+
def __str__(self):
|
| 39 |
+
return "Lin(%s,%s,%s,%s, quant=%s)".format(str(self.start), str(self.end), str(self.steps), str(self.initial), str(self.quant))
|
| 40 |
+
|
| 41 |
+
class Until(Const):
|
| 42 |
+
def __init__(self, thresh, a, b):
|
| 43 |
+
self.a = Const.initConst(a)
|
| 44 |
+
self.b = Const.initConst(b)
|
| 45 |
+
self.thresh = thresh
|
| 46 |
+
|
| 47 |
+
def getVal(self, *args, time = 0, **kargs):
|
| 48 |
+
return self.a.getVal(*args, time = time, **kargs) if time < self.thresh else self.b.getVal(*args, time = time - self.thresh, **kargs)
|
| 49 |
+
|
| 50 |
+
def __str__(self):
|
| 51 |
+
return "Until(%s, %s, %s)" % (str(self.thresh), str(self.a), str(self.b))
|
| 52 |
+
|
| 53 |
+
class Scale(Const): # use with mix when aw = 1, and 0 <= c < 1
|
| 54 |
+
def __init__(self, c):
|
| 55 |
+
self.c = Const.initConst(c)
|
| 56 |
+
|
| 57 |
+
def getVal(self, *args, **kargs):
|
| 58 |
+
c = self.c.getVal(*args, **kargs)
|
| 59 |
+
if c == 0:
|
| 60 |
+
return 0
|
| 61 |
+
assert c >= 0
|
| 62 |
+
assert c < 1
|
| 63 |
+
return c / (1 - c)
|
| 64 |
+
|
| 65 |
+
def __str__(self):
|
| 66 |
+
return "Scale(%s)" % str(self.c)
|
| 67 |
+
|
| 68 |
+
def MixLin(*args, **kargs):
|
| 69 |
+
return Scale(Lin(*args, **kargs))
|
| 70 |
+
|
| 71 |
+
class Normal(Const):
|
| 72 |
+
def __init__(self, c):
|
| 73 |
+
self.c = Const.initConst(c)
|
| 74 |
+
|
| 75 |
+
def getVal(self, *args, shape = [1], **kargs):
|
| 76 |
+
c = self.c.getVal(*args, shape = shape, **kargs)
|
| 77 |
+
return torch.randn(shape, device = h.device).abs() * c
|
| 78 |
+
|
| 79 |
+
def __str__(self):
|
| 80 |
+
return "Normal(%s)" % str(self.c)
|
| 81 |
+
|
| 82 |
+
class Clip(Const):
|
| 83 |
+
def __init__(self, c, l, u):
|
| 84 |
+
self.c = Const.initConst(c)
|
| 85 |
+
self.l = Const.initConst(l)
|
| 86 |
+
self.u = Const.initConst(u)
|
| 87 |
+
|
| 88 |
+
def getVal(self, *args, **kargs):
|
| 89 |
+
c = self.c.getVal(*args, **kargs)
|
| 90 |
+
l = self.l.getVal(*args, **kargs)
|
| 91 |
+
u = self.u.getVal(*args, **kargs)
|
| 92 |
+
if isinstance(c, float):
|
| 93 |
+
return min(max(c,l),u)
|
| 94 |
+
else:
|
| 95 |
+
return c.clamp(l,u)
|
| 96 |
+
|
| 97 |
+
def __str__(self):
|
| 98 |
+
return "Clip(%s, %s, %s)" % (str(self.c), str(self.l), str(self.u))
|
| 99 |
+
|
| 100 |
+
class Fun(Const):
|
| 101 |
+
def __init__(self, foo):
|
| 102 |
+
self.foo = foo
|
| 103 |
+
def getVal(self, *args, **kargs):
|
| 104 |
+
return self.foo(*args, **kargs)
|
| 105 |
+
|
| 106 |
+
def __str__(self):
|
| 107 |
+
return "Fun(...)"
|
| 108 |
+
|
| 109 |
+
class Complement(Const): # use with mix when aw = 1, and 0 <= c < 1
|
| 110 |
+
def __init__(self, c):
|
| 111 |
+
self.c = Const.initConst(c)
|
| 112 |
+
|
| 113 |
+
def getVal(self, *args, **kargs):
|
| 114 |
+
c = self.c.getVal(*args, **kargs)
|
| 115 |
+
assert c >= 0
|
| 116 |
+
assert c <= 1
|
| 117 |
+
return 1 - c
|
| 118 |
+
|
| 119 |
+
def __str__(self):
|
| 120 |
+
return "Complement(%s)" % str(self.c)
|