
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,17 +1,17 @@
|
|
| 1 |
-
---
|
| 2 |
-
license:
|
| 3 |
-
task_categories:
|
| 4 |
-
- zero-shot-classification
|
| 5 |
-
- text-classification
|
| 6 |
-
- feature-extraction
|
| 7 |
-
language:
|
| 8 |
-
- en
|
| 9 |
-
tags:
|
| 10 |
-
- climate
|
| 11 |
-
pretty_name: ClimateX
|
| 12 |
-
size_categories:
|
| 13 |
-
- 1K<n<10K
|
| 14 |
-
---
|
| 15 |
|
| 16 |
# ClimateX: Expert Confidence in Climate Statements
|
| 17 |
_What do LLMs know about climate? Let's find out!_
|
|
@@ -28,7 +28,7 @@ The authors of the United Nations International Panel on Climate Change (IPCC) r
|
|
| 28 |
|
| 29 |
Our dataset leverages this distinctive and consistent approach to labelling uncertainty across topics, disciplines, and report chapters, to help NLP and climate communication researchers evaluate how well LLMs can assess human expert confidence in a set of climate science statements from the IPCC reports.
|
| 30 |
|
| 31 |
-

|
| 34 |
|
|
@@ -42,11 +42,7 @@ From the full 8094 labeled sentences, we further selected **300 statements to fo
|
|
| 42 |
- Making the breakdown between source reports representative of the number of statements from each report;
|
| 43 |
- Making sure the test set contains at least 5 sentences from each class and from each source, to ensure our results are statistically robust.
|
| 44 |
|
| 45 |
-
Then, we manually reviewed and cleaned each sentence in the test set to provide for a fairer assessment of model capacity.
|
| 46 |
-
- We removed 26 extraneous references to figures, call-outs, boxes, footnotes, or subscript typos (`CO 2');
|
| 47 |
-
- We split 19 compound statements with conflicting confidence sub-labels, and removed 6 extraneous mid-sentence labels of the same category as the end-of-sentence label;
|
| 48 |
-
- We added light context to 23 sentences, and replaced 5 sentences by others when they were meaningless outside of a longer paragraph;
|
| 49 |
-
- We removed qualifiers at the beginning of 29 sentences to avoid biasing classification (e.g. 'But...', 'In summary...', 'However...').
|
| 50 |
|
| 51 |
**The remaining 7794 sentences not allocated to the test split form our train split.**
|
| 52 |
|
|
@@ -54,14 +50,4 @@ Of note: while the IPCC report uses a 5 levels scale for confidence, almost no `
|
|
| 54 |
|
| 55 |
## Code Download
|
| 56 |
|
| 57 |
-
The code to reproduce dataset collection and our LLM benchmarking experiments is [released on GitHub](https://github.com/rlacombe/
|
| 58 |
-
|
| 59 |
-
## Paper
|
| 60 |
-
|
| 61 |
-
We use this dataset to evaluate how recent LLMs fare at classifying the scientific confidence associated with each statement in a statistically representative, carefully constructed test split of the dataset.
|
| 62 |
-
|
| 63 |
-
We show that `gpt3.5-turbo` and `gpt4` assess the correct confidence level with reasonable accuracy even in the zero-shot setting; but that, along with other language models we tested, they consistently overstate the certainty level associated with low and medium confidence labels. Models generally perform better on reports before their knowledge cutoff, and demonstrate intuitive classifications on a baseline of non-climate statements. However, we caution it is still not fully clear why these models perform well, and whether they may also pick up on linguistic cues within the climate statements and not just prior exposure to climate knowledge and/or IPCC reports.
|
| 64 |
-
|
| 65 |
-
Our results have implications for climate communications and the use of generative language models in knowledge retrieval systems. We hope the ClimateX dataset provides the NLP and climate sciences communities with a valuable tool with which to evaluate and improve model performance in this critical domain of human knowledge.
|
| 66 |
-
|
| 67 |
-
Pre-print upcomping.
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: cc-by-4.0
|
| 3 |
+
task_categories:
|
| 4 |
+
- zero-shot-classification
|
| 5 |
+
- text-classification
|
| 6 |
+
- feature-extraction
|
| 7 |
+
language:
|
| 8 |
+
- en
|
| 9 |
+
tags:
|
| 10 |
+
- climate
|
| 11 |
+
pretty_name: ClimateX Expert Confidence in Climate Statements dataset
|
| 12 |
+
size_categories:
|
| 13 |
+
- 1K<n<10K
|
| 14 |
+
---
|
| 15 |
|
| 16 |
# ClimateX: Expert Confidence in Climate Statements
|
| 17 |
_What do LLMs know about climate? Let's find out!_
|
|
|
|
| 28 |
|
| 29 |
Our dataset leverages this distinctive and consistent approach to labelling uncertainty across topics, disciplines, and report chapters, to help NLP and climate communication researchers evaluate how well LLMs can assess human expert confidence in a set of climate science statements from the IPCC reports.
|
| 30 |
|
| 31 |
+
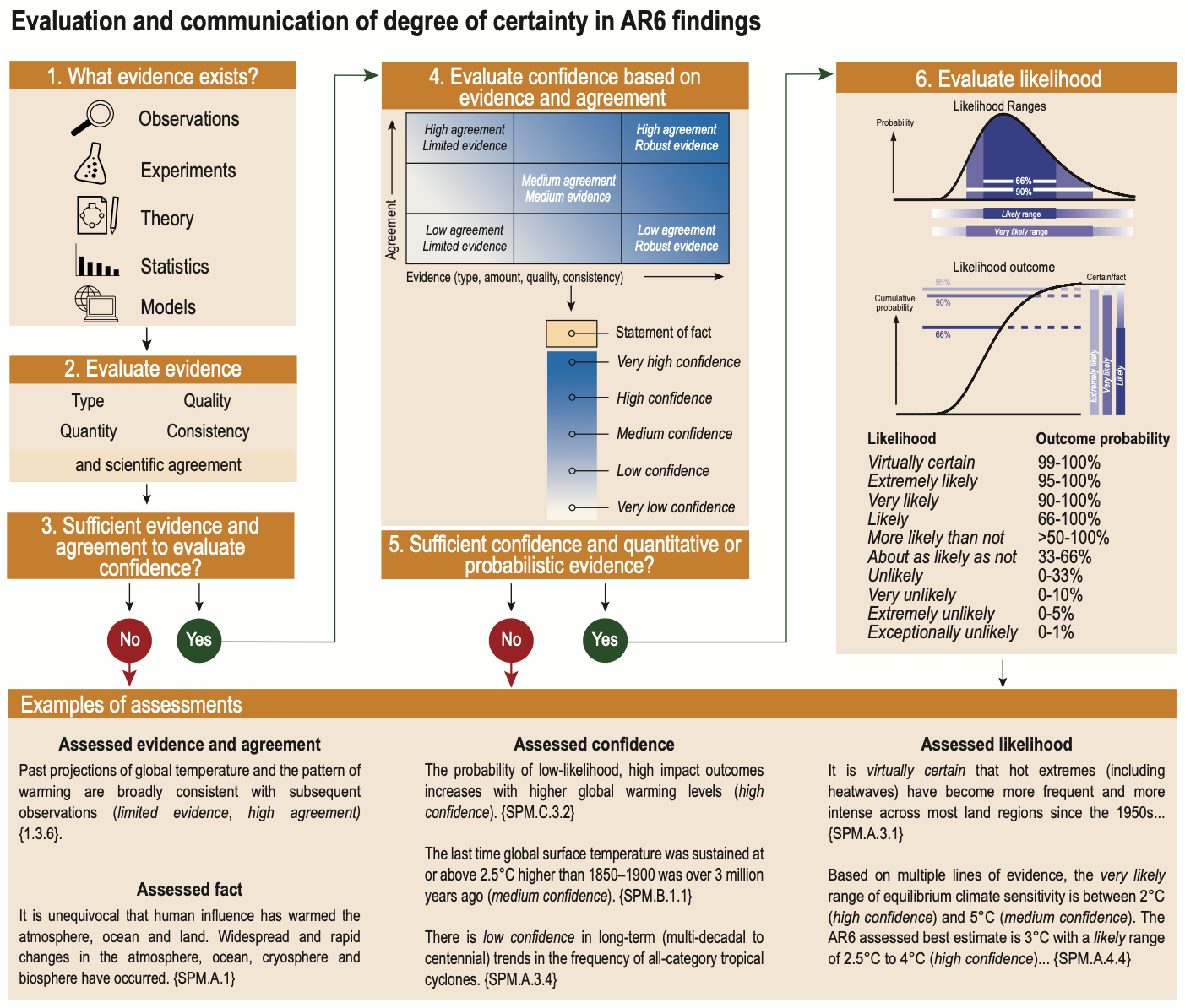
|
| 32 |
|
| 33 |
Source: [IPCC AR6 Working Group I report](https://www.ipcc.ch/report/ar6/wg1/)
|
| 34 |
|
|
|
|
| 42 |
- Making the breakdown between source reports representative of the number of statements from each report;
|
| 43 |
- Making sure the test set contains at least 5 sentences from each class and from each source, to ensure our results are statistically robust.
|
| 44 |
|
| 45 |
+
Then, we manually reviewed and cleaned each sentence in the test set to provide for a fairer assessment of model capacity. We then progamatically cleaned up the train set (removing references and extraneous confidence labels, and explaining acronyms)
|
|
|
|
|
|
|
|
|
|
|
|
|
| 46 |
|
| 47 |
**The remaining 7794 sentences not allocated to the test split form our train split.**
|
| 48 |
|
|
|
|
| 50 |
|
| 51 |
## Code Download
|
| 52 |
|
| 53 |
+
The code to reproduce dataset collection and our LLM benchmarking experiments is [released on GitHub](https://github.com/rlacombe/ClimateX).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|