
Commit
•
bc79239
1
Parent(s):
fbf0e61
Upload 14 files
Browse files- .gitattributes +1 -0
- README.md +291 -1
- colbert_linear.pt +3 -0
- config.json +28 -0
- config_sentence_transformers.json +7 -0
- long.jpg +0 -0
- modules.json +20 -0
- pytorch_model.bin +3 -0
- sentence_bert_config.json +4 -0
- sentencepiece.bpe.model +3 -0
- sparse_linear.pt +3 -0
- special_tokens_map.json +51 -0
- tokenizer.json +3 -0
- tokenizer_config.json +20 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,293 @@
|
|
| 1 |
---
|
| 2 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
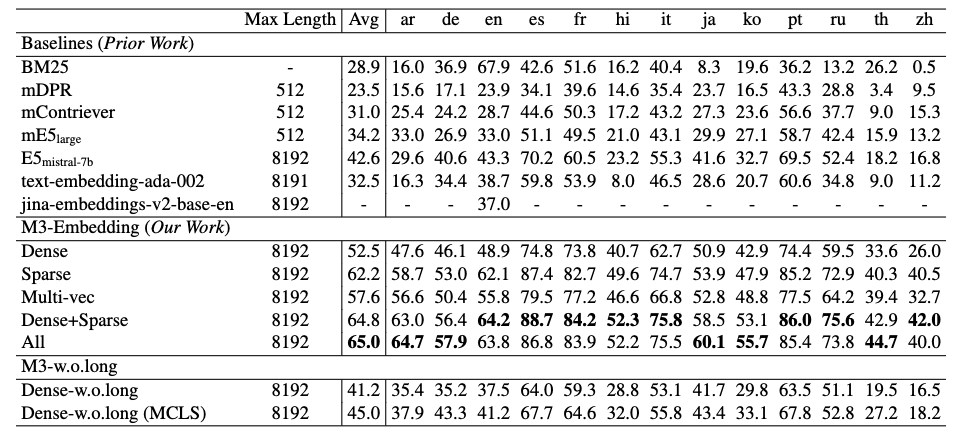
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
pipeline_tag: sentence-similarity
|
| 3 |
+
tags:
|
| 4 |
+
- sentence-transformers
|
| 5 |
+
- feature-extraction
|
| 6 |
+
- sentence-similarity
|
| 7 |
+
license: mit
|
| 8 |
---
|
| 9 |
+
|
| 10 |
+
For more details please refer to our github repo: https://github.com/FlagOpen/FlagEmbedding
|
| 11 |
+
|
| 12 |
+
# BGE-M3 ([paper](https://arxiv.org/pdf/2402.03216.pdf), [code](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3))
|
| 13 |
+
|
| 14 |
+
In this project, we introduce BGE-M3, which is distinguished for its versatility in Multi-Functionality, Multi-Linguality, and Multi-Granularity.
|
| 15 |
+
- Multi-Functionality: It can simultaneously perform the three common retrieval functionalities of embedding model: dense retrieval, multi-vector retrieval, and sparse retrieval.
|
| 16 |
+
- Multi-Linguality: It can support more than 100 working languages.
|
| 17 |
+
- Multi-Granularity: It is able to process inputs of different granularities, spanning from short sentences to long documents of up to 8192 tokens.
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
**Some suggestions for retrieval pipeline in RAG**
|
| 22 |
+
|
| 23 |
+
We recommend to use the following pipeline: hybrid retrieval + re-ranking.
|
| 24 |
+
- Hybrid retrieval leverages the strengths of various methods, offering higher accuracy and stronger generalization capabilities.
|
| 25 |
+
A classic example: using both embedding retrieval and the BM25 algorithm.
|
| 26 |
+
Now, you can try to use BGE-M3, which supports both embedding and sparse retrieval.
|
| 27 |
+
This allows you to obtain token weights (similar to the BM25) without any additional cost when generate dense embeddings.
|
| 28 |
+
To use hybrid retrieval, you can refer to [Vespa](https://github.com/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb
|
| 29 |
+
) and [Milvus](https://github.com/milvus-io/pymilvus/blob/master/examples/hello_hybrid_sparse_dense.py).
|
| 30 |
+
|
| 31 |
+
- As cross-encoder models, re-ranker demonstrates higher accuracy than bi-encoder embedding model.
|
| 32 |
+
Utilizing the re-ranking model (e.g., [bge-reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker), [bge-reranker-v2](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker)) after retrieval can further filter the selected text.
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
## News:
|
| 36 |
+
- 2024/3/20: **Thanks Milvus team!** Now you can use hybrid retrieval of bge-m3 in Milvus: [pymilvus/examples
|
| 37 |
+
/hello_hybrid_sparse_dense.py](https://github.com/milvus-io/pymilvus/blob/master/examples/hello_hybrid_sparse_dense.py).
|
| 38 |
+
- 2024/3/8: **Thanks for the [experimental results](https://towardsdatascience.com/openai-vs-open-source-multilingual-embedding-models-e5ccb7c90f05) from @[Yannael](https://huggingface.co/Yannael). In this benchmark, BGE-M3 achieves top performance in both English and other languages, surpassing models such as OpenAI.**
|
| 39 |
+
- 2024/3/2: Release unified fine-tuning [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/unified_finetune) and [data](https://huggingface.co/datasets/Shitao/bge-m3-data)
|
| 40 |
+
- 2024/2/6: We release the [MLDR](https://huggingface.co/datasets/Shitao/MLDR) (a long document retrieval dataset covering 13 languages) and [evaluation pipeline](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB/MLDR).
|
| 41 |
+
- 2024/2/1: **Thanks for the excellent tool from Vespa.** You can easily use multiple modes of BGE-M3 following this [notebook](https://github.com/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
## Specs
|
| 45 |
+
|
| 46 |
+
- Model
|
| 47 |
+
|
| 48 |
+
| Model Name | Dimension | Sequence Length | Introduction |
|
| 49 |
+
|:----:|:---:|:---:|:---:|
|
| 50 |
+
| [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | 1024 | 8192 | multilingual; unified fine-tuning (dense, sparse, and colbert) from bge-m3-unsupervised|
|
| 51 |
+
| [BAAI/bge-m3-unsupervised](https://huggingface.co/BAAI/bge-m3-unsupervised) | 1024 | 8192 | multilingual; contrastive learning from bge-m3-retromae |
|
| 52 |
+
| [BAAI/bge-m3-retromae](https://huggingface.co/BAAI/bge-m3-retromae) | -- | 8192 | multilingual; extend the max_length of [xlm-roberta](https://huggingface.co/FacebookAI/xlm-roberta-large) to 8192 and further pretrained via [retromae](https://github.com/staoxiao/RetroMAE)|
|
| 53 |
+
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | English model |
|
| 54 |
+
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | English model |
|
| 55 |
+
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | English model |
|
| 56 |
+
|
| 57 |
+
- Data
|
| 58 |
+
|
| 59 |
+
| Dataset | Introduction |
|
| 60 |
+
|:----------------------------------------------------------:|:-------------------------------------------------:|
|
| 61 |
+
| [MLDR](https://huggingface.co/datasets/Shitao/MLDR) | Docuemtn Retrieval Dataset, covering 13 languages |
|
| 62 |
+
| [bge-m3-data](https://huggingface.co/datasets/Shitao/bge-m3-data) | Fine-tuning data used by bge-m3 |
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
## FAQ
|
| 67 |
+
|
| 68 |
+
**1. Introduction for different retrieval methods**
|
| 69 |
+
|
| 70 |
+
- Dense retrieval: map the text into a single embedding, e.g., [DPR](https://arxiv.org/abs/2004.04906), [BGE-v1.5](https://github.com/FlagOpen/FlagEmbedding)
|
| 71 |
+
- Sparse retrieval (lexical matching): a vector of size equal to the vocabulary, with the majority of positions set to zero, calculating a weight only for tokens present in the text. e.g., BM25, [unicoil](https://arxiv.org/pdf/2106.14807.pdf), and [splade](https://arxiv.org/abs/2107.05720)
|
| 72 |
+
- Multi-vector retrieval: use multiple vectors to represent a text, e.g., [ColBERT](https://arxiv.org/abs/2004.12832).
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
**2. How to use BGE-M3 in other projects?**
|
| 76 |
+
|
| 77 |
+
For embedding retrieval, you can employ the BGE-M3 model using the same approach as BGE.
|
| 78 |
+
The only difference is that the BGE-M3 model no longer requires adding instructions to the queries.
|
| 79 |
+
|
| 80 |
+
For hybrid retrieval, you can use [Vespa](https://github.com/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb
|
| 81 |
+
) and [Milvus](https://github.com/milvus-io/pymilvus/blob/master/examples/hello_hybrid_sparse_dense.py).
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
**3. How to fine-tune bge-M3 model?**
|
| 85 |
+
|
| 86 |
+
You can follow the common in this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune)
|
| 87 |
+
to fine-tune the dense embedding.
|
| 88 |
+
|
| 89 |
+
If you want to fine-tune all embedding function of m3 (dense, sparse and colbert), you can refer to the [unified_fine-tuning example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/unified_finetune)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
## Usage
|
| 97 |
+
|
| 98 |
+
Install:
|
| 99 |
+
```
|
| 100 |
+
git clone https://github.com/FlagOpen/FlagEmbedding.git
|
| 101 |
+
cd FlagEmbedding
|
| 102 |
+
pip install -e .
|
| 103 |
+
```
|
| 104 |
+
or:
|
| 105 |
+
```
|
| 106 |
+
pip install -U FlagEmbedding
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
### Generate Embedding for text
|
| 112 |
+
|
| 113 |
+
- Dense Embedding
|
| 114 |
+
```python
|
| 115 |
+
from FlagEmbedding import BGEM3FlagModel
|
| 116 |
+
|
| 117 |
+
model = BGEM3FlagModel('BAAI/bge-m3',
|
| 118 |
+
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
|
| 119 |
+
|
| 120 |
+
sentences_1 = ["What is BGE M3?", "Defination of BM25"]
|
| 121 |
+
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
|
| 122 |
+
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
|
| 123 |
+
|
| 124 |
+
embeddings_1 = model.encode(sentences_1,
|
| 125 |
+
batch_size=12,
|
| 126 |
+
max_length=8192, # If you don't need such a long length, you can set a smaller value to speed up the encoding process.
|
| 127 |
+
)['dense_vecs']
|
| 128 |
+
embeddings_2 = model.encode(sentences_2)['dense_vecs']
|
| 129 |
+
similarity = embeddings_1 @ embeddings_2.T
|
| 130 |
+
print(similarity)
|
| 131 |
+
# [[0.6265, 0.3477], [0.3499, 0.678 ]]
|
| 132 |
+
```
|
| 133 |
+
You also can use sentence-transformers and huggingface transformers to generate dense embeddings.
|
| 134 |
+
Refer to [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding#usage) for details.
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
- Sparse Embedding (Lexical Weight)
|
| 138 |
+
```python
|
| 139 |
+
from FlagEmbedding import BGEM3FlagModel
|
| 140 |
+
|
| 141 |
+
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
|
| 142 |
+
|
| 143 |
+
sentences_1 = ["What is BGE M3?", "Defination of BM25"]
|
| 144 |
+
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
|
| 145 |
+
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
|
| 146 |
+
|
| 147 |
+
output_1 = model.encode(sentences_1, return_dense=True, return_sparse=True, return_colbert_vecs=False)
|
| 148 |
+
output_2 = model.encode(sentences_2, return_dense=True, return_sparse=True, return_colbert_vecs=False)
|
| 149 |
+
|
| 150 |
+
# you can see the weight for each token:
|
| 151 |
+
print(model.convert_id_to_token(output_1['lexical_weights']))
|
| 152 |
+
# [{'What': 0.08356, 'is': 0.0814, 'B': 0.1296, 'GE': 0.252, 'M': 0.1702, '3': 0.2695, '?': 0.04092},
|
| 153 |
+
# {'De': 0.05005, 'fin': 0.1368, 'ation': 0.04498, 'of': 0.0633, 'BM': 0.2515, '25': 0.3335}]
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
# compute the scores via lexical mathcing
|
| 157 |
+
lexical_scores = model.compute_lexical_matching_score(output_1['lexical_weights'][0], output_2['lexical_weights'][0])
|
| 158 |
+
print(lexical_scores)
|
| 159 |
+
# 0.19554901123046875
|
| 160 |
+
|
| 161 |
+
print(model.compute_lexical_matching_score(output_1['lexical_weights'][0], output_1['lexical_weights'][1]))
|
| 162 |
+
# 0.0
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
- Multi-Vector (ColBERT)
|
| 166 |
+
```python
|
| 167 |
+
from FlagEmbedding import BGEM3FlagModel
|
| 168 |
+
|
| 169 |
+
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
|
| 170 |
+
|
| 171 |
+
sentences_1 = ["What is BGE M3?", "Defination of BM25"]
|
| 172 |
+
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
|
| 173 |
+
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
|
| 174 |
+
|
| 175 |
+
output_1 = model.encode(sentences_1, return_dense=True, return_sparse=True, return_colbert_vecs=True)
|
| 176 |
+
output_2 = model.encode(sentences_2, return_dense=True, return_sparse=True, return_colbert_vecs=True)
|
| 177 |
+
|
| 178 |
+
print(model.colbert_score(output_1['colbert_vecs'][0], output_2['colbert_vecs'][0]))
|
| 179 |
+
print(model.colbert_score(output_1['colbert_vecs'][0], output_2['colbert_vecs'][1]))
|
| 180 |
+
# 0.7797
|
| 181 |
+
# 0.4620
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
### Compute score for text pairs
|
| 186 |
+
Input a list of text pairs, you can get the scores computed by different methods.
|
| 187 |
+
```python
|
| 188 |
+
from FlagEmbedding import BGEM3FlagModel
|
| 189 |
+
|
| 190 |
+
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True)
|
| 191 |
+
|
| 192 |
+
sentences_1 = ["What is BGE M3?", "Defination of BM25"]
|
| 193 |
+
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
|
| 194 |
+
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
|
| 195 |
+
|
| 196 |
+
sentence_pairs = [[i,j] for i in sentences_1 for j in sentences_2]
|
| 197 |
+
|
| 198 |
+
print(model.compute_score(sentence_pairs,
|
| 199 |
+
max_passage_length=128, # a smaller max length leads to a lower latency
|
| 200 |
+
weights_for_different_modes=[0.4, 0.2, 0.4])) # weights_for_different_modes(w) is used to do weighted sum: w[0]*dense_score + w[1]*sparse_score + w[2]*colbert_score
|
| 201 |
+
|
| 202 |
+
# {
|
| 203 |
+
# 'colbert': [0.7796499729156494, 0.4621465802192688, 0.4523794651031494, 0.7898575067520142],
|
| 204 |
+
# 'sparse': [0.195556640625, 0.00879669189453125, 0.0, 0.1802978515625],
|
| 205 |
+
# 'dense': [0.6259765625, 0.347412109375, 0.349853515625, 0.67822265625],
|
| 206 |
+
# 'sparse+dense': [0.482503205537796, 0.23454029858112335, 0.2332356721162796, 0.5122477412223816],
|
| 207 |
+
# 'colbert+sparse+dense': [0.6013619303703308, 0.3255828022956848, 0.32089319825172424, 0.6232916116714478]
|
| 208 |
+
# }
|
| 209 |
+
```
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
## Evaluation
|
| 215 |
+
|
| 216 |
+
We provide the evaluation script for [MKQA](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB/MKQA) and [MLDR](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB/MLDR)
|
| 217 |
+
|
| 218 |
+
### Benchmarks from the open-source community
|
| 219 |
+

|
| 220 |
+
The BGE-M3 model emerged as the top performer on this benchmark (OAI is short for OpenAI).
|
| 221 |
+
For more details, please refer to the [article](https://towardsdatascience.com/openai-vs-open-source-multilingual-embedding-models-e5ccb7c90f05) and [Github Repo](https://github.com/Yannael/multilingual-embeddings)
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
### Our results
|
| 225 |
+
- Multilingual (Miracl dataset)
|
| 226 |
+
|
| 227 |
+

|
| 228 |
+
|
| 229 |
+
- Cross-lingual (MKQA dataset)
|
| 230 |
+
|
| 231 |
+

|
| 232 |
+
|
| 233 |
+
- Long Document Retrieval
|
| 234 |
+
- MLDR:
|
| 235 |
+

|
| 236 |
+
Please note that [MLDR](https://huggingface.co/datasets/Shitao/MLDR) is a document retrieval dataset we constructed via LLM,
|
| 237 |
+
covering 13 languages, including test set, validation set, and training set.
|
| 238 |
+
We utilized the training set from MLDR to enhance the model's long document retrieval capabilities.
|
| 239 |
+
Therefore, comparing baselines with `Dense w.o.long`(fine-tuning without long document dataset) is more equitable.
|
| 240 |
+
Additionally, this long document retrieval dataset will be open-sourced to address the current lack of open-source multilingual long text retrieval datasets.
|
| 241 |
+
We believe that this data will be helpful for the open-source community in training document retrieval models.
|
| 242 |
+
|
| 243 |
+
- NarritiveQA:
|
| 244 |
+

|
| 245 |
+
|
| 246 |
+
- Comparison with BM25
|
| 247 |
+
|
| 248 |
+
We utilized Pyserini to implement BM25, and the test results can be reproduced by this [script](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB/MLDR#bm25-baseline).
|
| 249 |
+
We tested BM25 using two different tokenizers:
|
| 250 |
+
one using Lucene Analyzer and the other using the same tokenizer as M3 (i.e., the tokenizer of xlm-roberta).
|
| 251 |
+
The results indicate that BM25 remains a competitive baseline,
|
| 252 |
+
especially in long document retrieval.
|
| 253 |
+
|
| 254 |
+

|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
## Training
|
| 259 |
+
- Self-knowledge Distillation: combining multiple outputs from different
|
| 260 |
+
retrieval modes as reward signal to enhance the performance of single mode(especially for sparse retrieval and multi-vec(colbert) retrival)
|
| 261 |
+
- Efficient Batching: Improve the efficiency when fine-tuning on long text.
|
| 262 |
+
The small-batch strategy is simple but effective, which also can used to fine-tune large embedding model.
|
| 263 |
+
- MCLS: A simple method to improve the performance on long text without fine-tuning.
|
| 264 |
+
If you have no enough resource to fine-tuning model with long text, the method is useful.
|
| 265 |
+
|
| 266 |
+
Refer to our [report](https://arxiv.org/pdf/2402.03216.pdf) for more details.
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
## Acknowledgement
|
| 274 |
+
|
| 275 |
+
Thanks to the authors of open-sourced datasets, including Miracl, MKQA, NarritiveQA, etc.
|
| 276 |
+
Thanks to the open-sourced libraries like [Tevatron](https://github.com/texttron/tevatron), [Pyserini](https://github.com/castorini/pyserini).
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
## Citation
|
| 281 |
+
|
| 282 |
+
If you find this repository useful, please consider giving a star :star: and citation
|
| 283 |
+
|
| 284 |
+
```
|
| 285 |
+
@misc{bge-m3,
|
| 286 |
+
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
|
| 287 |
+
author={Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu},
|
| 288 |
+
year={2024},
|
| 289 |
+
eprint={2402.03216},
|
| 290 |
+
archivePrefix={arXiv},
|
| 291 |
+
primaryClass={cs.CL}
|
| 292 |
+
}
|
| 293 |
+
```
|
colbert_linear.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:19bfbae397c2b7524158c919d0e9b19393c5639d098f0a66932c91ed8f5f9abb
|
| 3 |
+
size 2100674
|
config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"XLMRobertaModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"bos_token_id": 0,
|
| 8 |
+
"classifier_dropout": null,
|
| 9 |
+
"eos_token_id": 2,
|
| 10 |
+
"hidden_act": "gelu",
|
| 11 |
+
"hidden_dropout_prob": 0.1,
|
| 12 |
+
"hidden_size": 1024,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 4096,
|
| 15 |
+
"layer_norm_eps": 1e-05,
|
| 16 |
+
"max_position_embeddings": 258,
|
| 17 |
+
"model_type": "xlm-roberta",
|
| 18 |
+
"num_attention_heads": 16,
|
| 19 |
+
"num_hidden_layers": 24,
|
| 20 |
+
"output_past": true,
|
| 21 |
+
"pad_token_id": 1,
|
| 22 |
+
"position_embedding_type": "absolute",
|
| 23 |
+
"torch_dtype": "float32",
|
| 24 |
+
"transformers_version": "4.33.0",
|
| 25 |
+
"type_vocab_size": 1,
|
| 26 |
+
"use_cache": true,
|
| 27 |
+
"vocab_size": 250002
|
| 28 |
+
}
|
config_sentence_transformers.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"__version__": {
|
| 3 |
+
"sentence_transformers": "2.2.2",
|
| 4 |
+
"transformers": "4.33.0",
|
| 5 |
+
"pytorch": "2.1.2+cu121"
|
| 6 |
+
}
|
| 7 |
+
}
|
long.jpg
ADDED
|
modules.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "0",
|
| 5 |
+
"path": "",
|
| 6 |
+
"type": "sentence_transformers.models.Transformer"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"idx": 1,
|
| 10 |
+
"name": "1",
|
| 11 |
+
"path": "1_Pooling",
|
| 12 |
+
"type": "sentence_transformers.models.Pooling"
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"idx": 2,
|
| 16 |
+
"name": "2",
|
| 17 |
+
"path": "2_Normalize",
|
| 18 |
+
"type": "sentence_transformers.models.Normalize"
|
| 19 |
+
}
|
| 20 |
+
]
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b5e0ce3470abf5ef3831aa1bd5553b486803e83251590ab7ff35a117cf6aad38
|
| 3 |
+
size 2271145830
|
sentence_bert_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"max_seq_length": 256,
|
| 3 |
+
"do_lower_case": false
|
| 4 |
+
}
|
sentencepiece.bpe.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cfc8146abe2a0488e9e2a0c56de7952f7c11ab059eca145a0a727afce0db2865
|
| 3 |
+
size 5069051
|
sparse_linear.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:45c93804d2142b8f6d7ec6914ae23a1eee9c6a1d27d83d908a20d2afb3595ad9
|
| 3 |
+
size 3516
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"cls_token": {
|
| 10 |
+
"content": "<s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"eos_token": {
|
| 17 |
+
"content": "</s>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"mask_token": {
|
| 24 |
+
"content": "<mask>",
|
| 25 |
+
"lstrip": true,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
},
|
| 30 |
+
"pad_token": {
|
| 31 |
+
"content": "<pad>",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false
|
| 36 |
+
},
|
| 37 |
+
"sep_token": {
|
| 38 |
+
"content": "</s>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false
|
| 43 |
+
},
|
| 44 |
+
"unk_token": {
|
| 45 |
+
"content": "<unk>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false
|
| 50 |
+
}
|
| 51 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:21106b6d7dab2952c1d496fb21d5dc9db75c28ed361a05f5020bbba27810dd08
|
| 3 |
+
size 17098108
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<s>",
|
| 3 |
+
"clean_up_tokenization_spaces": true,
|
| 4 |
+
"cls_token": "<s>",
|
| 5 |
+
"eos_token": "</s>",
|
| 6 |
+
"mask_token": {
|
| 7 |
+
"__type": "AddedToken",
|
| 8 |
+
"content": "<mask>",
|
| 9 |
+
"lstrip": true,
|
| 10 |
+
"normalized": true,
|
| 11 |
+
"rstrip": false,
|
| 12 |
+
"single_word": false
|
| 13 |
+
},
|
| 14 |
+
"model_max_length": 8192,
|
| 15 |
+
"pad_token": "<pad>",
|
| 16 |
+
"sep_token": "</s>",
|
| 17 |
+
"sp_model_kwargs": {},
|
| 18 |
+
"tokenizer_class": "XLMRobertaTokenizer",
|
| 19 |
+
"unk_token": "<unk>"
|
| 20 |
+
}
|